/
















































































































































































































































































































































































































































































































































































































































































































































































































Автор: Крёнке Д.
Теги: компьютерные технологии информационные машины машины для обработки данных программирование базы данных
ISBN: 5-94723-275-8
Год: 2003




Текст
ТЕОРИ* РАКТИКА
ПОСТРОЕНИЯ
□
8-Е ИЗДАНИЕ
Д КРЕНКЕ
DATABASE
PROCESSING
Eighth Edition
David M. Kroenke
Prentice Hall PTR
Upper Saddle River, New Jersey 07458
www.phptr.com
PH
PTR
KARCCMKR COmPUTER SCIENCE
Д.КРЁНКЕ
ТЕОРИЯ И ПРАКТИКА
ПОСТРОЕНИЯ
БАЗ ДАННЫХ
8-Е ИЗДАНИЕ
Е^ППТЕР'
Москва - Санкт-Петербург ■ Нижний Новгород * Воронеж
Ростов-на-Дону ■ Екатеринбург ■ Самара.
Киев ■ Харьков - Минск
2003
ББК 32.973.233я7
УДК 681.31.016(075)
К79
К79 Теория и практика построения баз данных. 8-е изд. / Д. Крёнке. — СПб.:
Питер, 2003. — 800 с: ил. — (Серия «Классика computer science»).
ISBN 5-94723-275-8
В книге, написанной в форме учебного пособия для студентов, специализирующихся в области
информационных технологии, освещается широкий круг теоретических и практических вопросов,
связанных с разработкой и использованием баз данных.
К особенностям восьмого издания книги относится, в частности, появление материала,
посвященного новым технологиям публикации баз данных (XML) и обработки баз данных масштаба
предприятия (ODBC, ASP, JDBC, JSP).
Книгу отличает продуманность структуры, живой и доступный язык изложения, а также
большое количество примеров, моделирующих типичные ситуации из практики делового мира
ББК 32.973.233я7
УДК 681.31.016(075)
Информация, содержащаяся в данной книге, получена из источников, рассматриваемых издательством как надежные. Тем не
менее, имея в виду возможные человеческие или технические ошибки, издательство не может гарантировать абсолютную
точность и полноту приводимых сведений и не несет ответственности за возможные ошибки, связанные с использованием книги.
©2002, 2000, 1998, 1995 and 1992 by Pearsen Education, Inc.
ISBN 0-13-064839-6 (англ.) © Перевод на русский язык, ЗАО Издательский дом «Питер», 2003
ISBN 5-94723-275-8 © Издание на русском языке, оформление, ЗАО Издательский дом «Питер», 2003
Краткое содержание
Предисловие 18
Часть I. Введение
Глава 1. Введение в базы данных 24
Глава 2. Введение в разработку баз данных 52
Часть И. Моделирование данных
Глава 3. Модель «сущность—связь» 82
Глава 4. Семантическая объектная модель 118
Часть Ш. Проектирование баз данных
Глава 5. Реляционная модель и нормализация 166
Глава 6. Проектирование баз данных в рамках модели «сущность—связь» . . 206
Глава 7. Проектирование баз данных в рамках семантической
объектной модели 245
Часть IV. Построение реляционных баз данных
Глава 8. Основы построения реляционных баз данных 274
Глава 9. Язык SQL 304
Глава 10. Проектирование приложений баз данных 330
Часть V. Обработка многопользовательских баз данных
Глава 11. Многопользовательские базы данных 378
Глава 12. Работа с базами данных в Oracle 422
Глава 13. Работа с базами данных в SQL Server 2000 467
Часть VI. Обработка организационных баз данных
Глава 14. Сети, многоуровневые архитектуры и XML 516
Глава 15. ODBC, OLE DB, ADO и ASP 559
Глава 16. JDBC, Java Server Pages и MySQL 606
Глава 17. Совместное использование данных предприятия 645
Часть УН, Работа с объектно-ориентированными базами данных
Глава 18. Объектно-ориентированные базы данных 692
Приложение А. Структуры данных 729
Приложение Б. Создание семантических объектных моделей
в программе Tabledesigner 756
Алфавитный указатель 785
Содержание
Предисловие 18
Особенности настоящего издания 19
Последовательный обзор глав книги 20
Благодарности 21
От издательства 22
Часть I. Введение
Глава 1. Введение в базы данных 24
Четыре примера применения баз данных 24
Малярная фирма Мэри Ричарде 25
Бюро проката музыкальных инструментов Treble Clef Music 28
Бюро лицензирования и регистрации 30
Туристический информационный центр 30
Сравнение четырех типов баз данных 32
Отношения между прикладными программами и СУБД 33
Системы обработки файлов 35
Разделенные и изолированные данные 35
Дублирование данных 36
Зависимость прикладных программ от форматов файлов 36
Несовместимость файлов 37
Трудность представления данных в удобном для пользователя виде 37
Системы обработки баз данных 37
Данные интегрированы 38
Меньшее количество дублирующихся данных 38
Независимость программ от данных 38
Представление данных в удобном для пользователя виде 38
Определение термина «база данных» 39
Самодокументированность 39
База данных — это собрание интегрированных записей 39
База данных является моделью модели 40
История баз данных 41
Организационный контекст 41
Реляционная модель 42
Коммерческие СУБД для микрокомпьютеров 43
Содержание 7
Клиент-серверные приложения баз данных 44
Базы данных с использованием интернет-технологий 45
Распределенные базы данных 46
Объектно-ориентированные СУБД 47
Резюме 47
Вопросы группы I 49
Проекты 50
Вопросы к проекту FiredUp 50
Глава 2. Введение в разработку баз данных 52
База данных 52
Данные пользователя 52
Метаданные 54
Индексы 55
Метаданные приложений 57
СУБД 57
Подсистема средств проектирования 57
Подсистема обработки 58
Ядро СУБД 58
Создание базы данных 59
Пример схемы базы данных 59
Создание таблиц 61
Определение связей 61
Компоненты приложения 63
Формы 63
Запросы 66
Отчеты 68
Меню 69
Прикладные программы 70
Процесс разработки базы данных 72
Общие стратегии 72
Моделирование данных 73
Резюме 76
Вопросы I группы 77
Вопросы II группы 78
Вопросы к проекту FiredUp 79
Часть 11- Моделирование данных
Глава 3. Модель «сущность—связь» 82
Элементы модели «сущность—связь» 82
Сущности 82
Атрибуты 83
Идентификаторы 84
8 Содержание
Связи 84
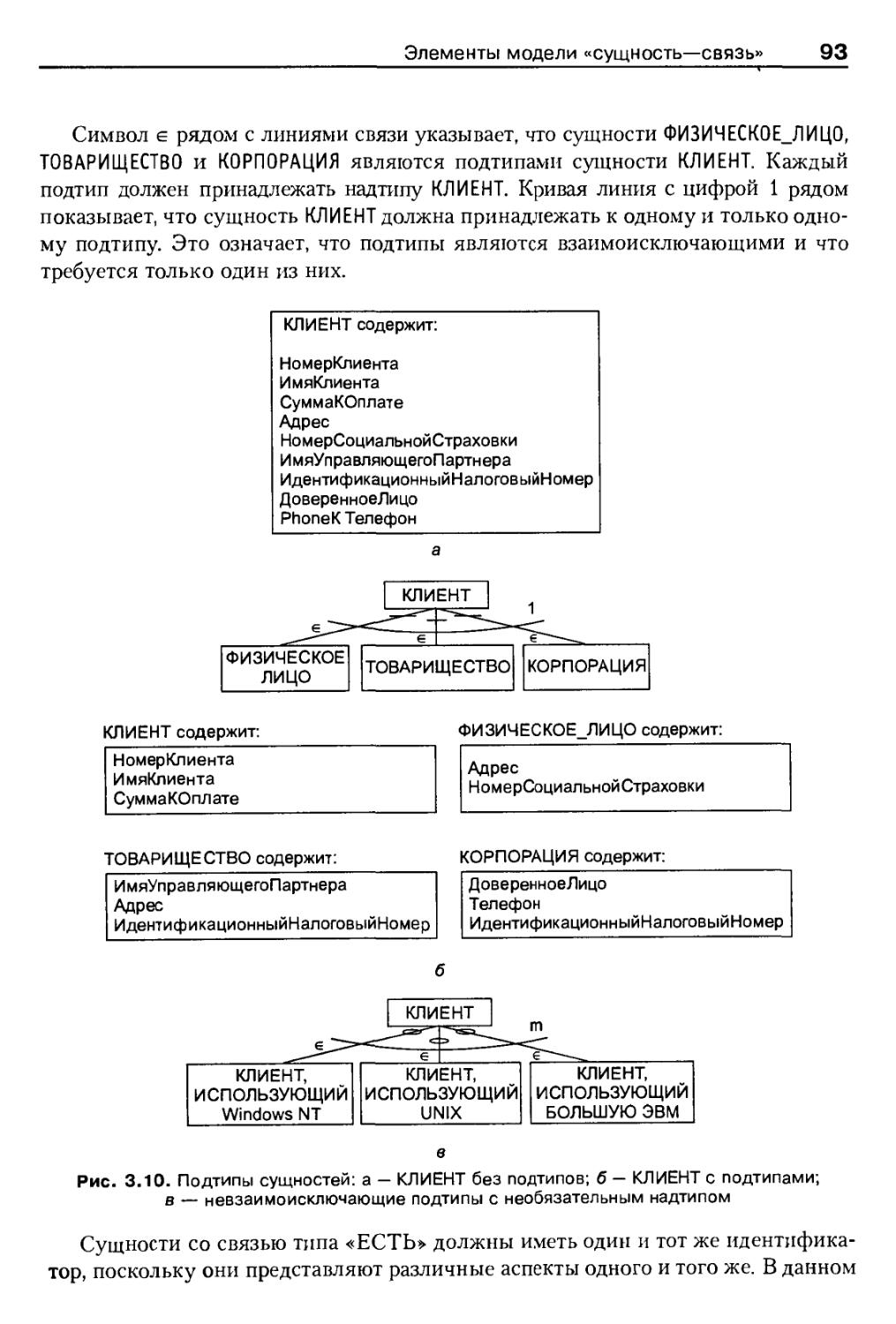
Подтипы сущностей 92
Пример ER-диаграммы 94
Документирование делового регламента 95
Модель «сущность— связь» и CASE-средства 96
Диаграммы «сущность— связь» в стиле UML 96
Сущности и связи в UML • 97
Конструкции ООП, введенные языком UML 99
Роль UML в базах данных на сегодняшний день 101
Примеры 102
Пример 1: танцевальный клуб Джефферсона 102
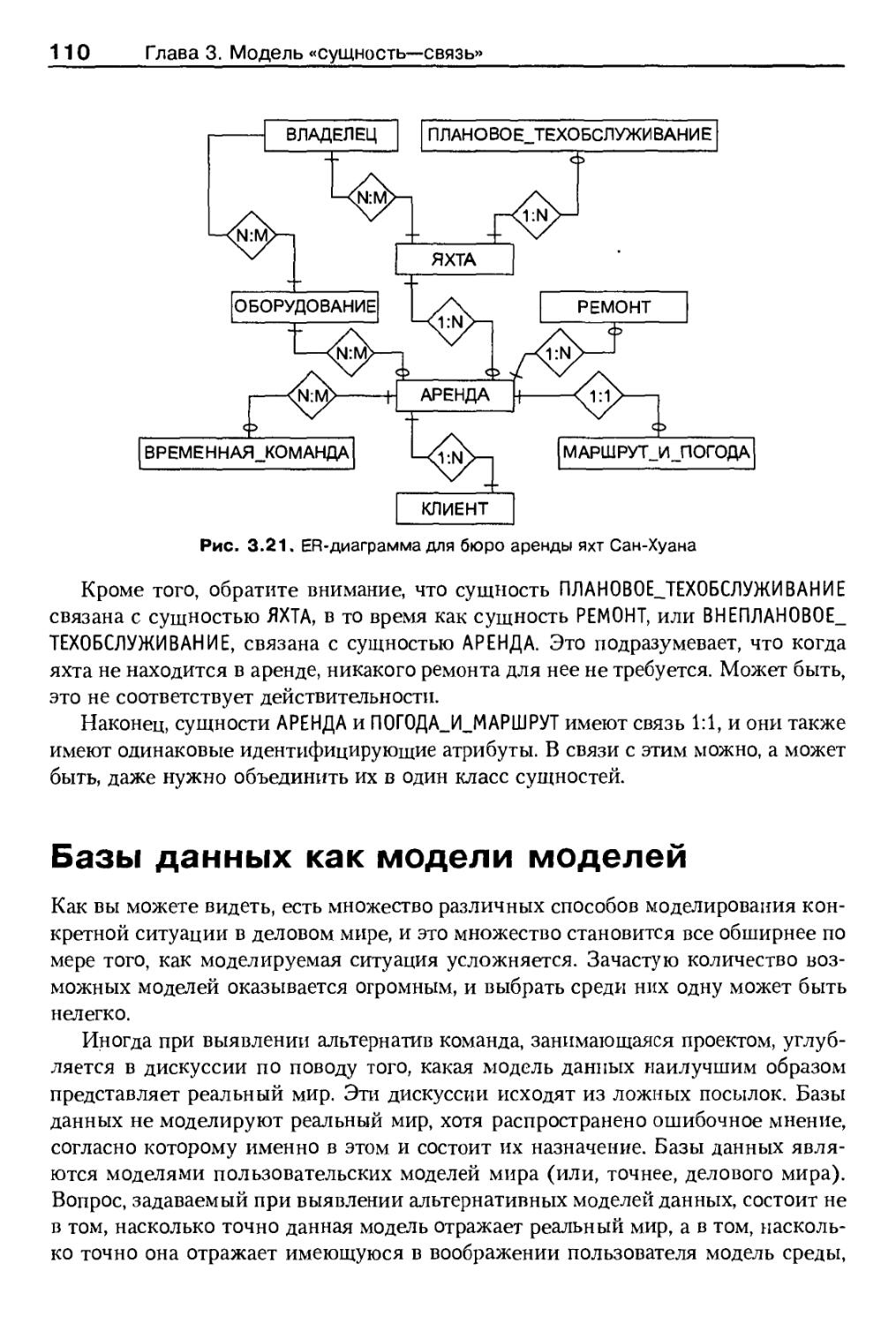
Пример 2: бюро проката парусных яхт Сан-Хуана 107
Базы данных как модели моделей 110
Резюме 111
Вопросы группы I 112
Вопросы группы II 114
Проекты 114
Вопросы к проекту FiredUp 116
Глава 4. Семантическая объектная модель 118
Семантические объекты 119
Определение семантических объектов 119
Атрибуты 120
Объектные идентификаторы 124
Домены атрибутов 125
Представления семантических объектов 125
Создание семантических объектных моделей данных 127
Пример: база данных администрации университета Highline 127
Спецификация объектов 133
Типы объектов 137
Простые объекты 138
Композитные объекты 138
Составные объекты 141
Гибридные объекты 144
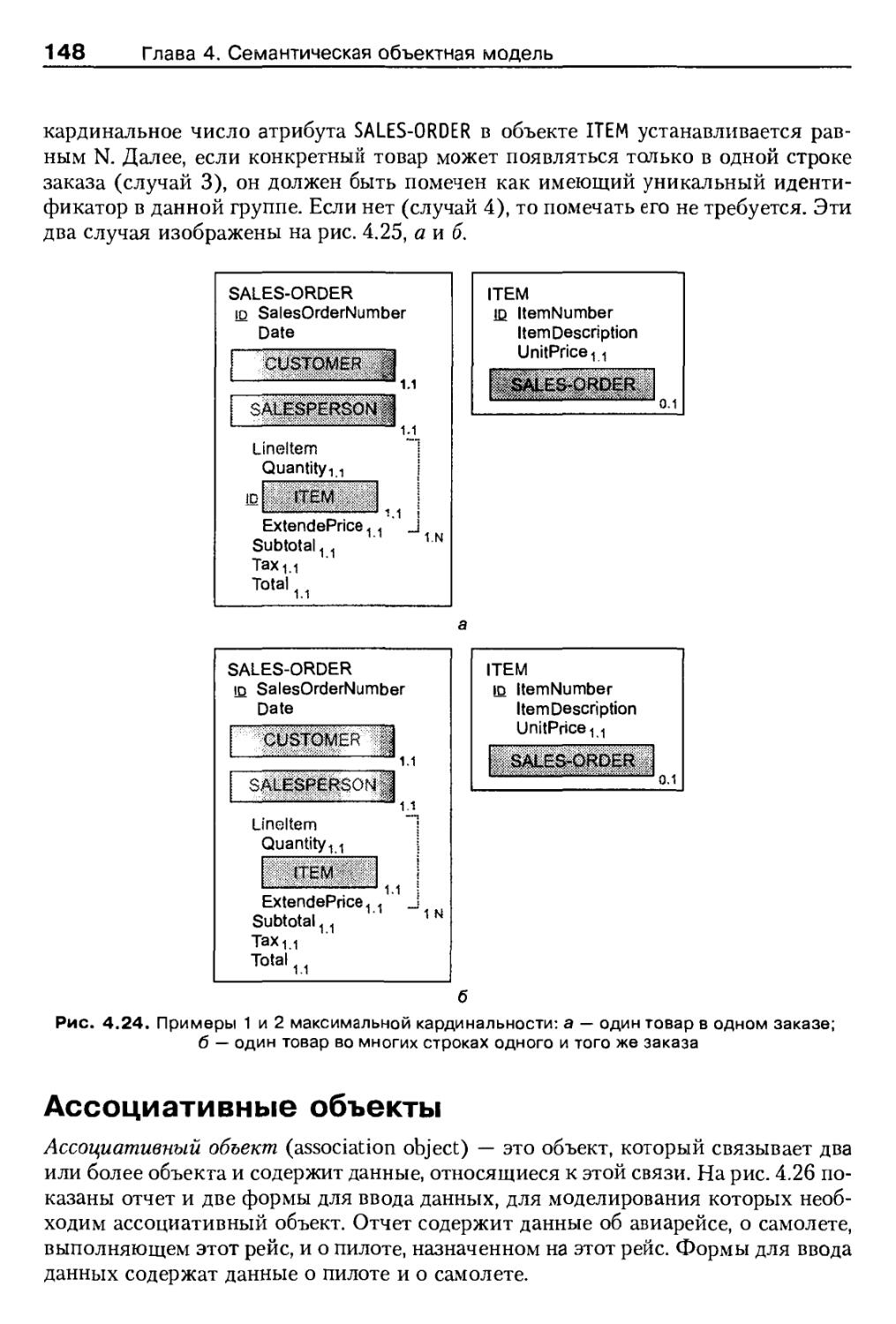
Ассоциативные объекты 148
Объекты вида родитель/подтип 151
Объекты вида архетип/версия 154
Сравнение семантической объектной модели и модели «сущность—связь» . . . 156
Резюме 159
Вопросы группы I 160
Вопросы группы И 162
Проекты 162
Вопросы к проекту FiredUp 163
Содержание 9
Часть 111. Проектирование баз данных
Глава 5. Реляционная модель и нормализация 166
Реляционная модель 166
Функциональные зависимости 168
Ключи 169
Функциональные зависимости, ключи и уникальность 171
Нормализация 172
Аномалии модификации 172
Суть нормализации 174
Классы отношений 175
Нормальные формы от первой до пятой 176
Вторая нормальная форма (2НФ) 176
Третья нормальная форма (ЗНФ) 177
Нормальная форма Бойса-Кодда (НФБК) 178
Четвертая нормальная форма (4НФ) 180
Пятая нормальная форма (5НФ) 183
Доменно-ключевая нормальная форма (ДКНФ) 183
Определение 184
Первый пример до мен но-ключе вой нормальной формы 185
Второй пример доменно-ключевой нормальной формы 186
Третий пример доменно-ключевой нормальной формы 188
Синтез отношений 190
Атрибутивная связь «один к одному» 191
Атрибутивная связь «многие к одному» 193
Атрибутивная связь «многие ко многим» 194
Многозначные зависимости: часть вторая 195
Оптимизация 196
Денормализация 196
Преднамеренная избыточность 198
Резюме 199
Вопросы I группы 200
Вопросы II группы 202
Вопросы к проекту FiredUp 204
Глава 6. Проектирование баз данных в рамках
модели «сущность—связь» 206
Преобразование моделей «сущность—связь» в реляционные конструкции . . . 206
Представление сущностей с помощью реляционной модели 206
Представление связей типа «ИМЕЕТ» 211
Представление тернарных связей и связей высших порядков 221
Представление связей типа «ЕСТЬ» (подтипов) 225
Пример проекта 226
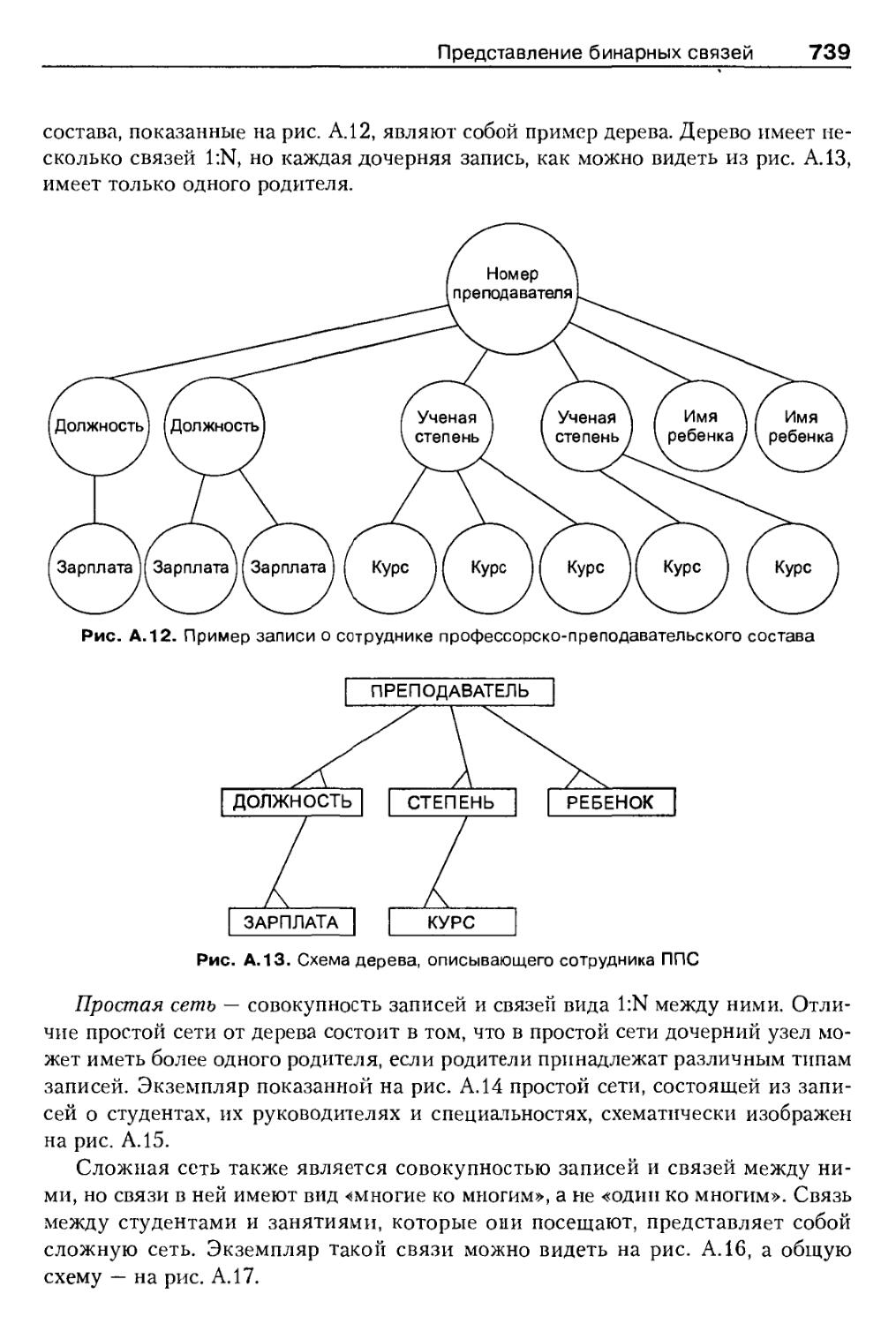
Деревья, сети и списки материалов 228
Деревья 229
Простые сети 231
10 Содержание
Сложные сети 231
Списки материалов 232
Суррогатные ключи 234
Пустые значения 238
Резюме 239
Вопросы I группы 240
Вопросы И группы 243
Проекты 243
Вопросы к проекту FiredUp 243
Глава 7. Проектирование баз данных в рамках
семантической объектной модели 245
Преобразования семантических объектов в реляционные конструкции 245
Простые объекты 245
Композитные объекты 246
Составные объекты 249
Представление составных объектов со связью 1:1 249
Представление связей «один ко многим» и «многие к одному» 250
Представление связей «многие ко многим» 252
Гибридные объекты 253
Ассоциативные объекты 257
Объекты вида родитель/подтип 258
Объекты вида архетип/версия 261
Примеры объектов 262
Подписной абонемент 263
Описание продукта 264
Акт о нарушении правил дорожного движения 266
Резюме 268
Вопросы I группы 269
Вопросы II группы 270
Проекты 272
Вопросы к проекту FiredUp 272
Часть IV. Построение реляционных баз данных
Глава 8. Основы построения реляционных баз данных . . 274
Описание реляционных данных 274
Обзор терминологии 274
Реализация реляционной базы данных 277
Манипулирование реляционными данными 281
Категории языков манипулирования реляционными данными 281
Интерфейсы языков манипулирования данными 283
Реляционная алгебра 287
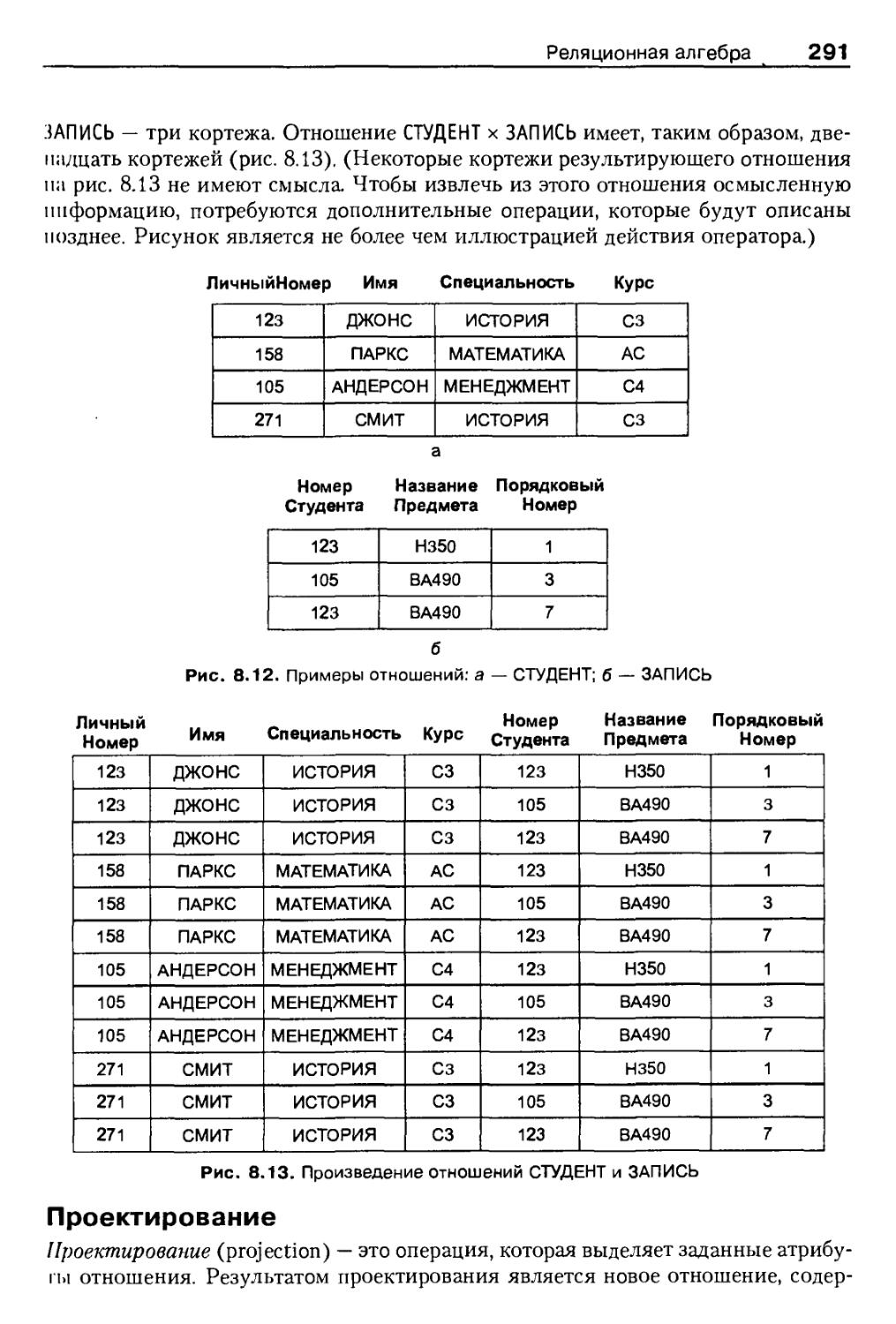
Реляционные операторы 287
Выражение запросов в терминах реляционной алгебры 295
Содержание 11
Резюме 300
Вопросы I группы 301
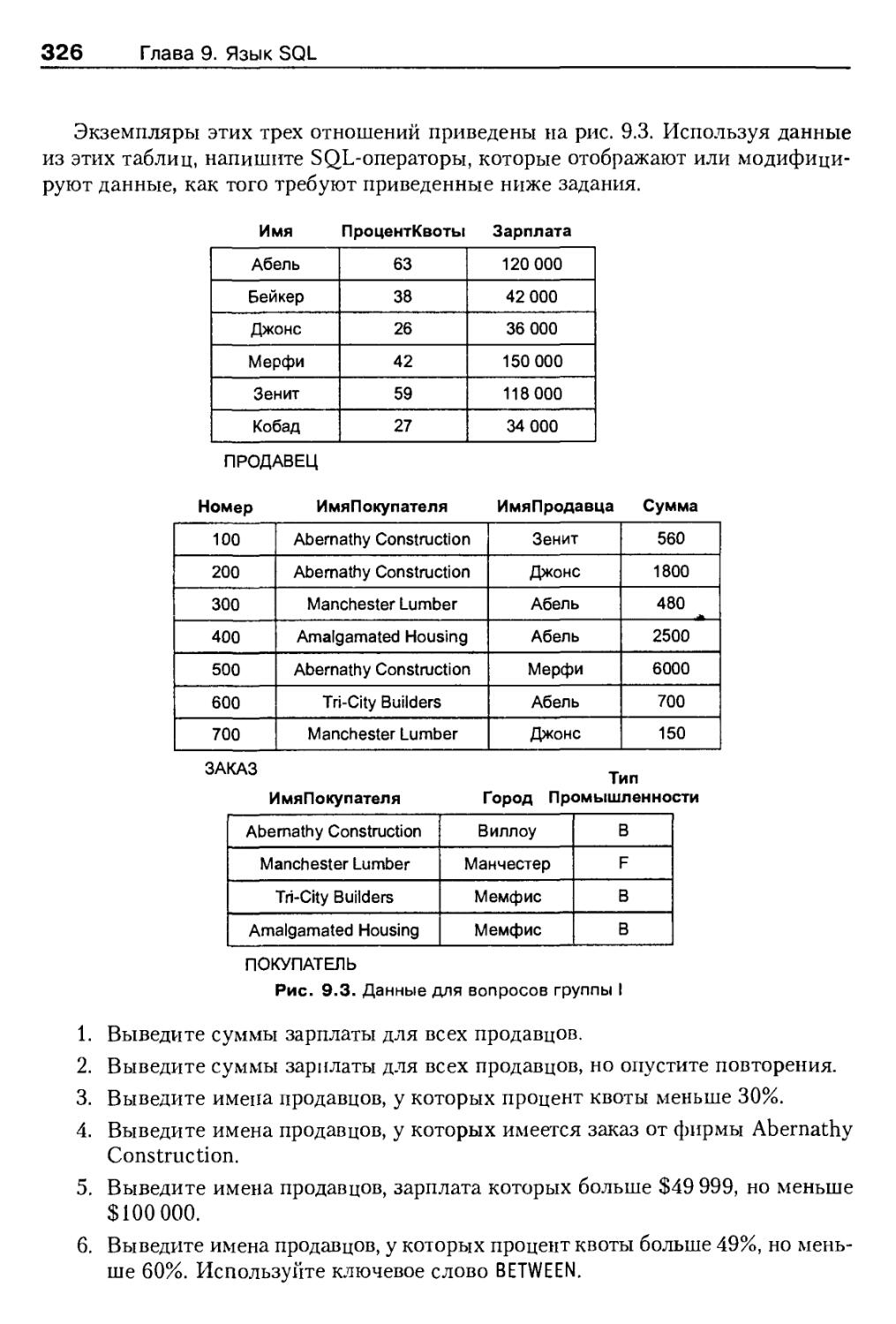
Глава 9. Язык SQL 304
Запрос одиночной таблицы 305
Проектирование в SQL 307
Выборка в SQL 308
Сортировка 311
Встроенные функции SQL 312
Встроенные функции и группировка 313
Запрос нескольких таблиц 315
Вложенные запросы 315
Соединение с помощью SQL 317
Сравнение вложенного запроса и соединения 319
Внешнее соединение 320
Операторы EXISTS и NOT EXISTS 321
Изменение данных 323
Вставка данных 323
Удаление данных 324
Модификация данных 324
Резюме 325
Вопросы I группы 325
Вопросы II группы 328
Вопросы к проекту FiredUp 328
Глава 10. Проектирование приложений баз данных . . . 330
Функции приложения базы данных 330
Пример приложения: галерея View Ridge 332
Требования к приложению 332
Проектирование базы данных 333
Создание, чтение, обновление и удаление экземпляров представлений .... 336
Чтение экземпляров представлений 338
Создание новых экземпляров представлений 339
Обновление экземпляров представлений 342
Удаление экземпляров представлений 343
Проектирование форм 344
Структура формы должна отражать структуру представления 345
Семантика данных должна быть графически очевидна 346
Структура формы должна побуждать к правильным действиям 347
Формы в среде графического интерфейса пользователя 348
Передвижение курсора и единообразная семантика клавиш 351
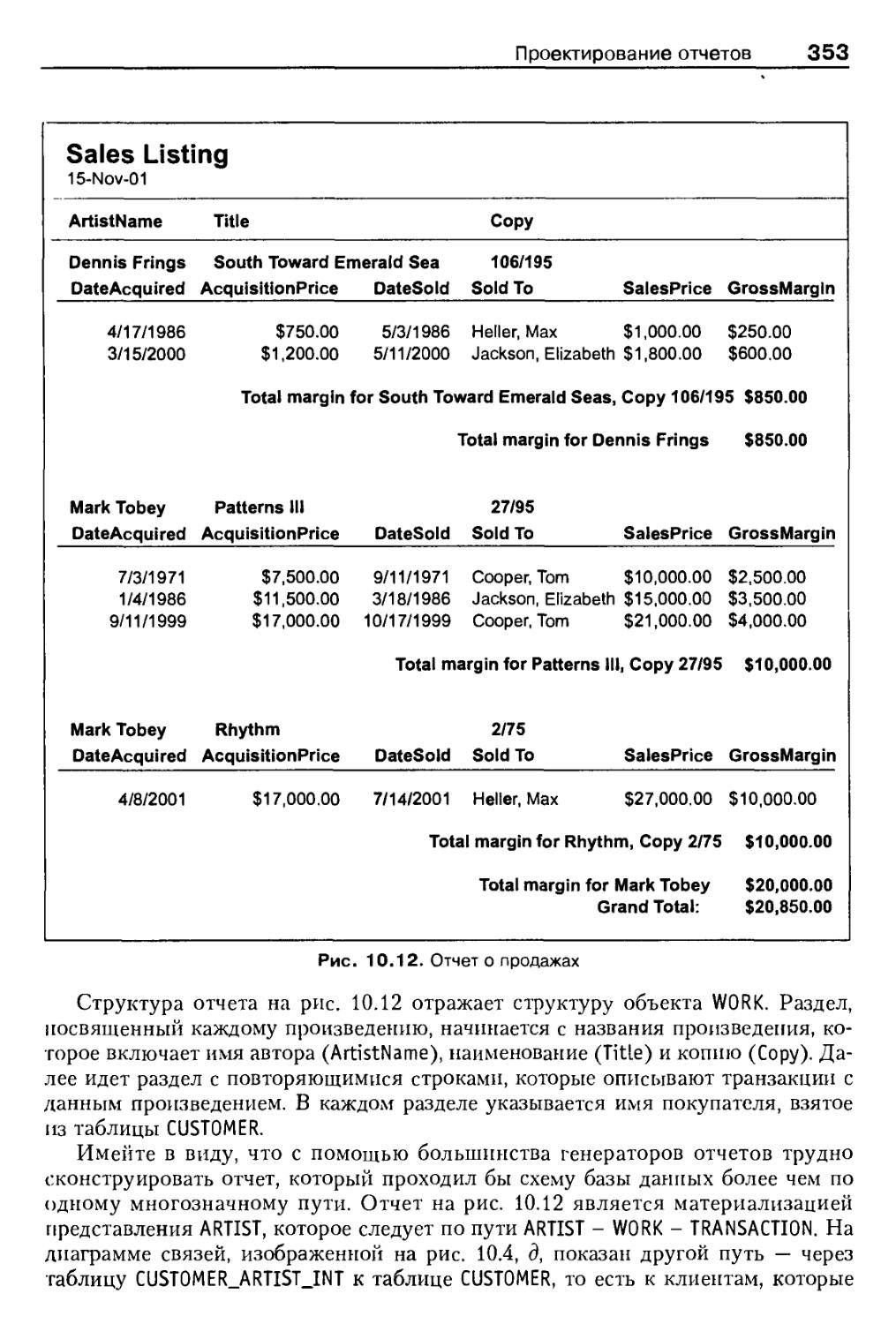
Проектирование отчетов 352
Структура отчета 352
Подразумеваемые объекты 354
Реализация ограничений 356
Ограничения доменов 357
12 Содержание
Ограничения уникальности 359
Ограничения связей 359
Ограничения делового регламента 366
Безопасность и контроль 366
Безопасность 367
Контроль 368
Логика приложения 370
Резюме 370
Вопросы I группы 372
Вопросы I! группы 374
Проекты 375
Вопросы к проекту FiredUp 375
Часть V. Обработка многопользовательских баз данных
Глава 11. Многопользовательские базы данных .... 378
Администрирование баз данных 379
Управление структурой базы данных 380
Управление параллельной обработкой 382
Необходимость в атомарных транзакциях 382
Блокировка ресурсов 387
Оптимистическая и пессимистическая блокировка 390
Объявление характеристик блокировки 393
Согласованные транзакции 394
Уровень изоляции транзакции 395
Безопасность базы данных 398
Права и обязанности по обработке 399
Обеспечение безопасности средствами СУБД 400
Обеспечение безопасности средствами приложения 406
Восстановление базы данных 407
Восстановление путем повторной обработки . 408
Восстановление через откат-накат 409
Управление СУБД 412
Поддержание репозитория данных 413
Резюме 415
Вопросы I группы 417
Вопросы II группы 419
Проекты 420
Вопросы к проекту FiredUp 420
Глава 12. Работа с базами данных в Oracle 422
Установка Oracle 423
Создание базы данных Oracle 423
Работа с SQL Plus 424
Создание таблиц 428
Создание связей 433
Содержание 13
Создание индексов 435
Изменение структуры таблицы 435
Контрольные ограничения 436
Использование оператора ALTER TABLE с контрольными ограничениями . . 437
Представления 437
Логика приложения 440
Обработка файлов PL/SQL 440
Хранимые процедуры 440
Триггеры 448
Словарь данных 452
Управление параллельной обработкой 453
Уровень изоляции «завершенное чтение» 455
Уровень изоляции «сериализуемость» 455
Уровень изоляции «только чтение» 456
Дополнительные замечания о блокировках 456
Oracle и безопасность 457
Резервное копирование и восстановление в Oracle 457
Средства восстановления Oracle 457
Типы сбоев 458
Вопросы, не затронутые в данной главе 460
Резюме 460
Вопросы I группы 462
Проекты 465
Вопросы к проекту FiredUp 465
Глава 13. Работа с базами данных в SQL Server 2000 . . 467
Установка SQL Server 2000 467
Создание базы данных SQL Server 468
Создание таблиц 469
Определение связей 479
Представления 482
Индексы 485
Логика приложения 486
Хранимые запросы 487
Хранимые процедуры 488
Триггеры 495
Управление параллельной обработкой 499
Уровень изоляции транзакции 500
Поведение курсора 501
Блокировочные подсказки 502
Безопасность 503
Резервное копирование и восстановление 503
Типы резервных копий 504
Модели восстановления SQL Server 505
Восстановление базы данных 506
План обслуживания базы данных 507
14 Содержание
Вопросы, не затронутые в этой главе 507
Резюме 508
Вопросы I группы 510
Проекты 512
Вопросы к проекту FiredUp 513
Часть VI. Обработка организационных баз данных
Глава 14. Сети, многоуровневые архитектуры и XML . . 516
Разновидности сетевого окружения 516
Интернет 516
Интрасети 517
Беспроводной доступ в сети 518
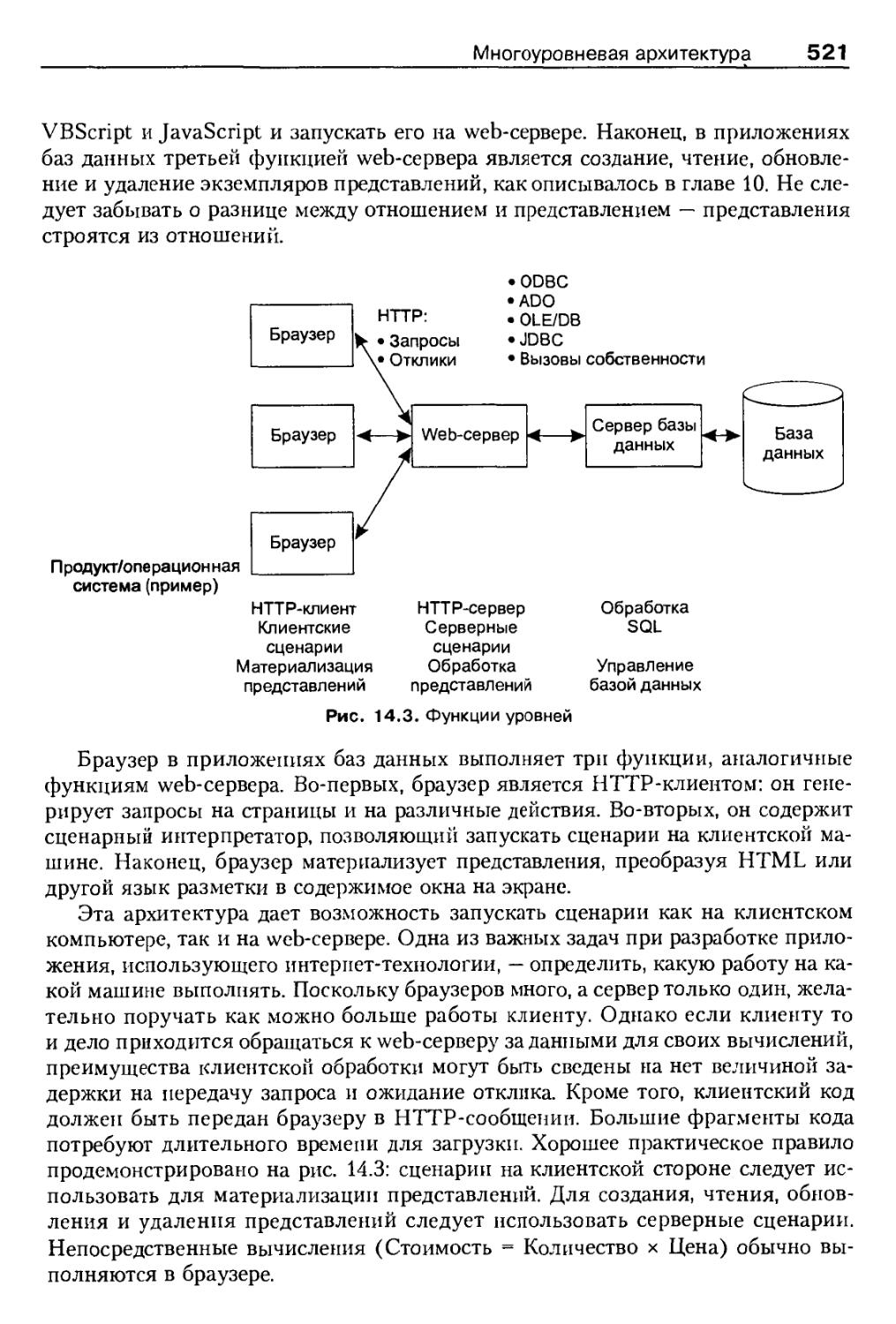
Многоуровневая архитектура 519
Web-сервер под управлением Windows 2000 522
Web-сервер под управлением Unix и Linux 523
Многоуровневая обработка 524
Языки разметки и DHTML 526
Стандарты языков разметки 526
Проблемы, связанные с HTML 527
DHTML 528
XML —расширяемый язык разметки 530
XML как язык разметки 530
XML-документ и DTD 531
Материализация ХМL-документов 533
Терминология и стандарты ХМL 538
XML Schema 540
Протокол WAP 548
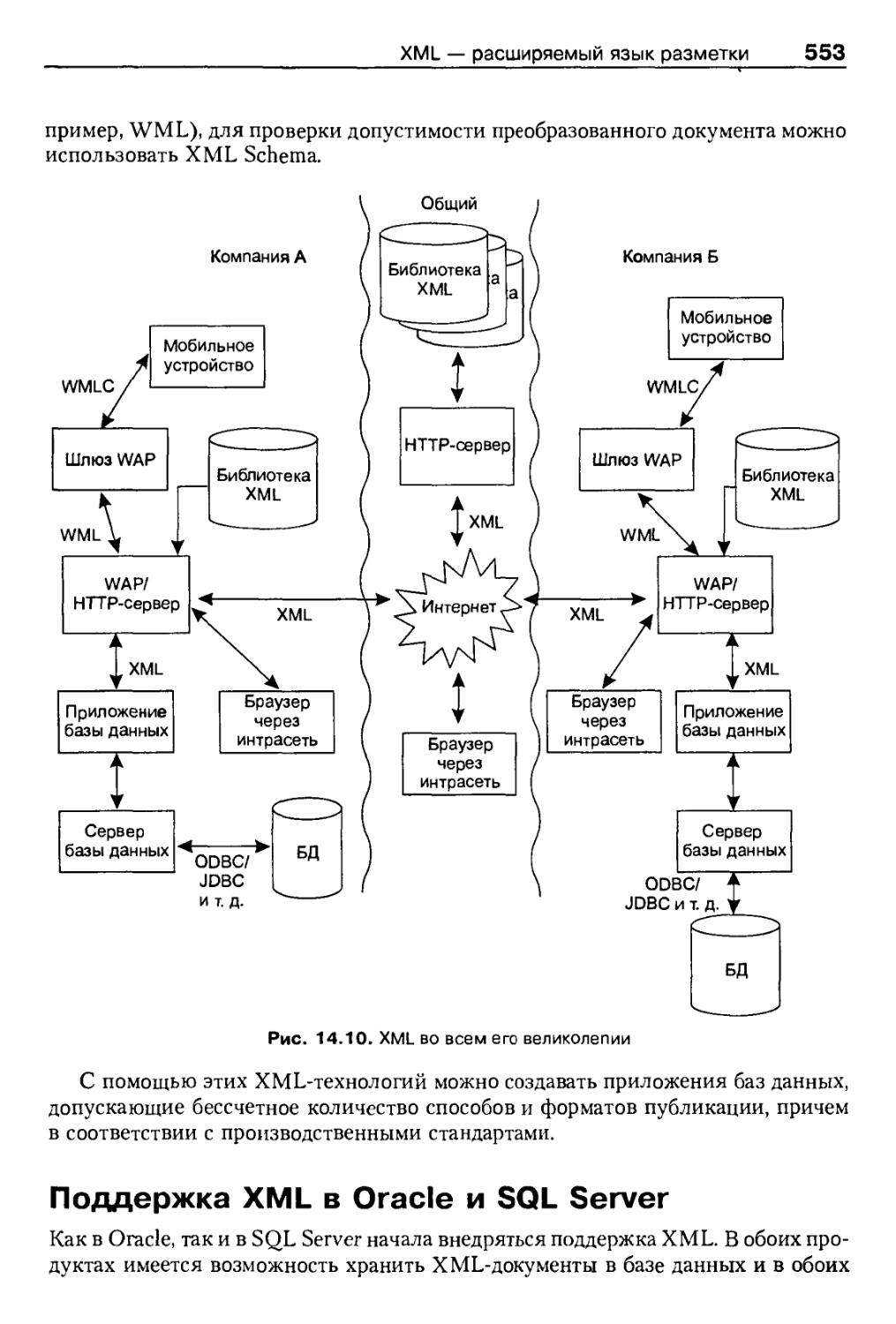
Значение XML для приложений баз данных 549
Пример применения XML в электронной коммерции 552
Поддержка XML в Oracle и SQL Server 553
Резюме 554
Вопросы I группы 556
Вопросы II группы 557
Вопросы к проекту FiredUp 558
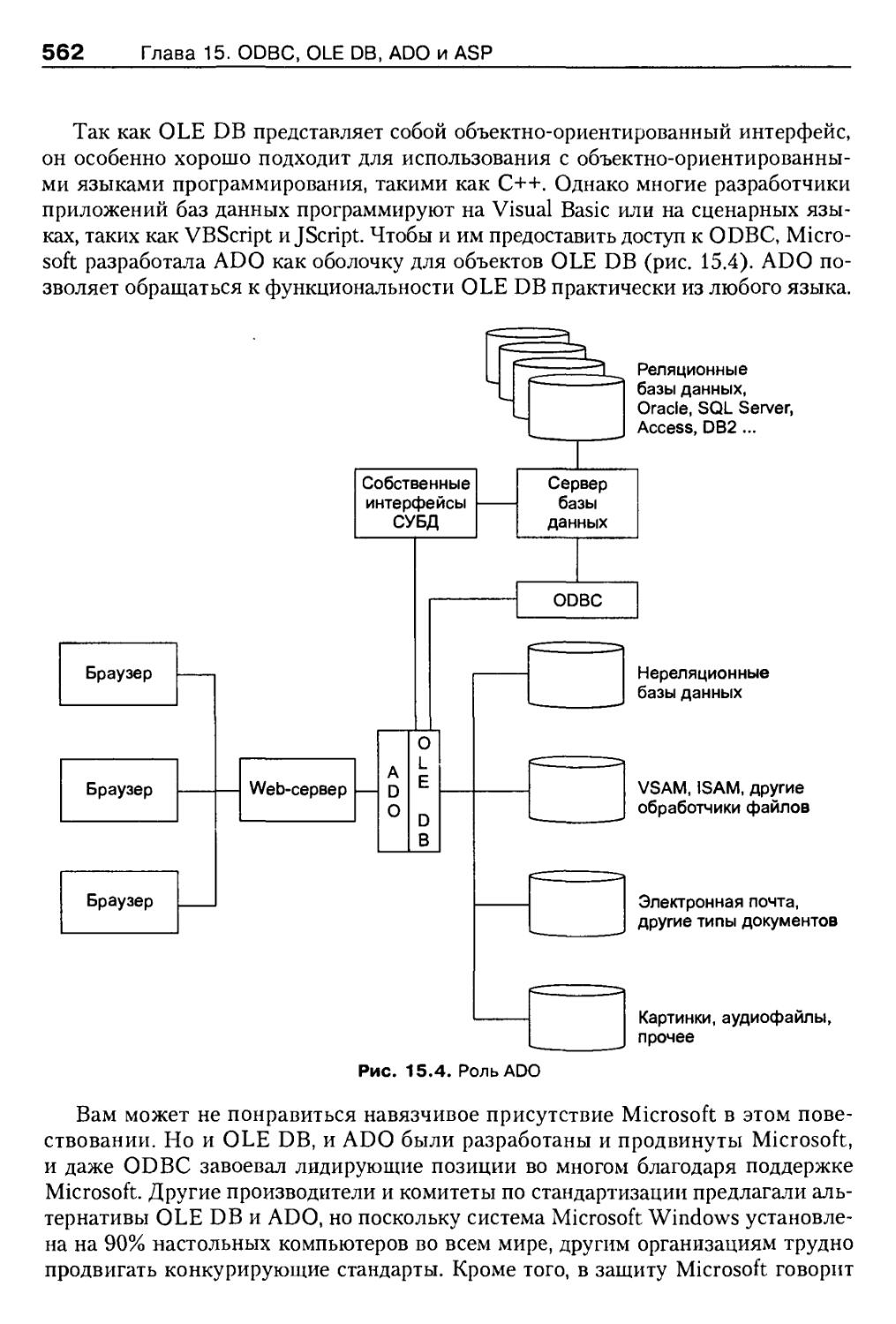
Глава 15- ODBC, OLE DB, ADO и ASP 559
Окружение web-сервера 559
Стандарт ODBC 563
Архитектура ODBC 563
Уровни соответствия 565
Задание имени источника данных ODBC 567
OLEDB 568
Цели создания OLE DB 571
Основные конструкции OLE DB 572
Содержание 15
ADO 574
Вызов ADO из ASP-страниц 574
Объектная модель ADO 575
Примеры использования ADO 580
Пример 1 — чтение таблицы 581
Пример 2 — чтение таблицы обобщенным способом 584
Пример 3 — чтение любой таблицы 586
Пример 4 — обновление таблицы 591
Пример 5 — вызов хранимой процедуры 595
Резюме 601
Вопросы I группы 602
Вопросы II группы 604
Вопросы к проекту FjredUp 605
Глава 16. JDBC, Java Server Pages и MySQL 606
JDBC 606
Типы драйверов 607
Использование JDBC 608
Примеры использования JDBC . . . 611
Java Server Pages 618
JSP-страницы и сервлеты 618
Apache Tomcat 619
Настройка Tomcat для обработки JSP 619
Примеры JSP-страниц 620
MySQL 632
Ограничения MySQL 633
Работа с MySQL 634
Настройка разрешений на доступ для JDBC 636
Управление параллельной обработкой 637
Резервное копирование и восстановление 639
Заключительное слово о MySQL 639
Резюме 639
Вопросы I группы 641
Вопросы II группы 643
Проекты 643
Вопросы к проекту FiredUp 644
Глава 17. Совместное использование
данных предприятия 645
Архитектуры организационных систем обработки данных 645
Системы удаленной обработки 646
Клиент-серверные системы 647
Системы совместного использования файлов 648
Системы обработки распределенных баз данных 650
Загрузка данных 655
Компания Universal Equipment 655
16 Содержание
Процесс загрузки 657
Потенциальные проблемы при обработке загруженных баз данных 658
Оперативная аналитическая обработка данных (OLAP) 660
Информационные хранилища 669
Компоненты информационного хранилища 670
Требования к информационному хранилищу 671
Проблемы разработки и эксплуатации информационных хранилищ .... 672
Информационные лавки 677
Администрирование данных 678
Потребность в администрировании данных 679
Проблемы администрирования данных 679
Задачи отдела администрирования данных 681
Резюме 684
Вопросы I группы 687
Вопросы II группы 690
Часть VII, Работа с объектно-ориентированными базами данных
Глава 18. Объектно-ориентированные базы данных . . . 692
Введение в объектно-ориентированное программирование 693
Терминология ООП 693
Пример ООП 695
Постоянное хранение объектов 699
Постоянное хранение объектов в традиционной файловой системе .... 701
Постоянное хранение объектов с помощью СУБД 701
Постоянное хранение объектов с использованием ООСУБД 703
Постоянное хранение объектов в Oracle 704
Типы объектов и коллекции 705
Объекты Oracle 710
Стандарты ООСУБД 714
SQL3 714
ODMG-93 721
Резюме 725
Вопросы I группы 726
Вопросы II группы 728
Приложение А. Структуры данных 729
Плоские файлы 729
Обработка плоских файлов в различном порядке 729
Замечание по поводу адресации записей 730
Упорядочение с помощью связных списков 731
Упорядочение с помощью индексов 734
Бинарные деревья 735
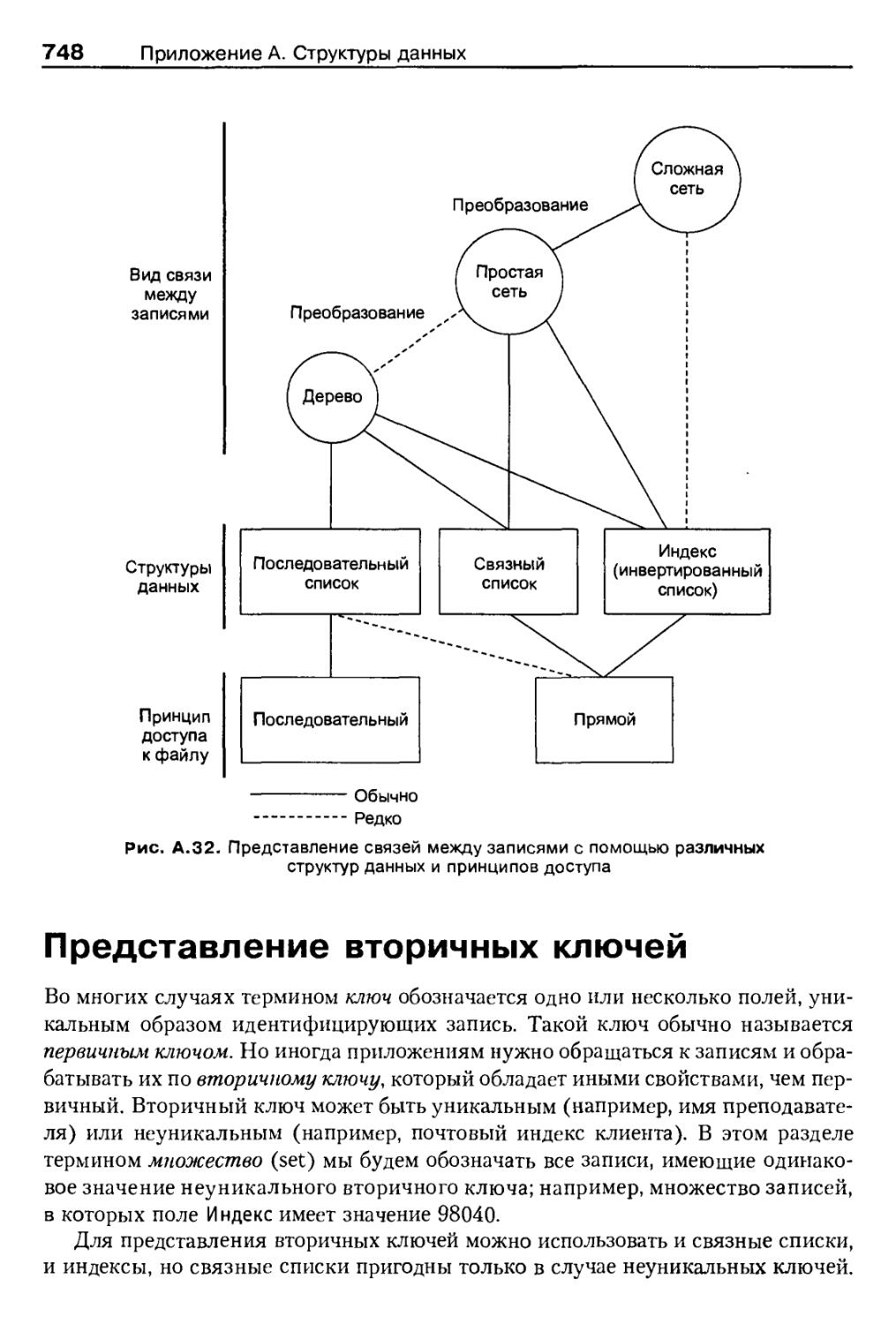
Резюме по структурам данных 737
Представление бинарных связей 738
Обзор видов связей между записями 738
Содержание 17
Представление деревьев 740
Представление простых сетей 743
Представление сложных сетей 745
Представление вторичных ключей 748
Представление вторичных ключей с помощью связных списков 749
Представление вторичных ключей с помощью индексов 750
Резюме 753
Вопросы! группы 754
Вопросы II группы 755
Приложение Б. Создание семантических объектных
моделей в программе Tabledesigner 756
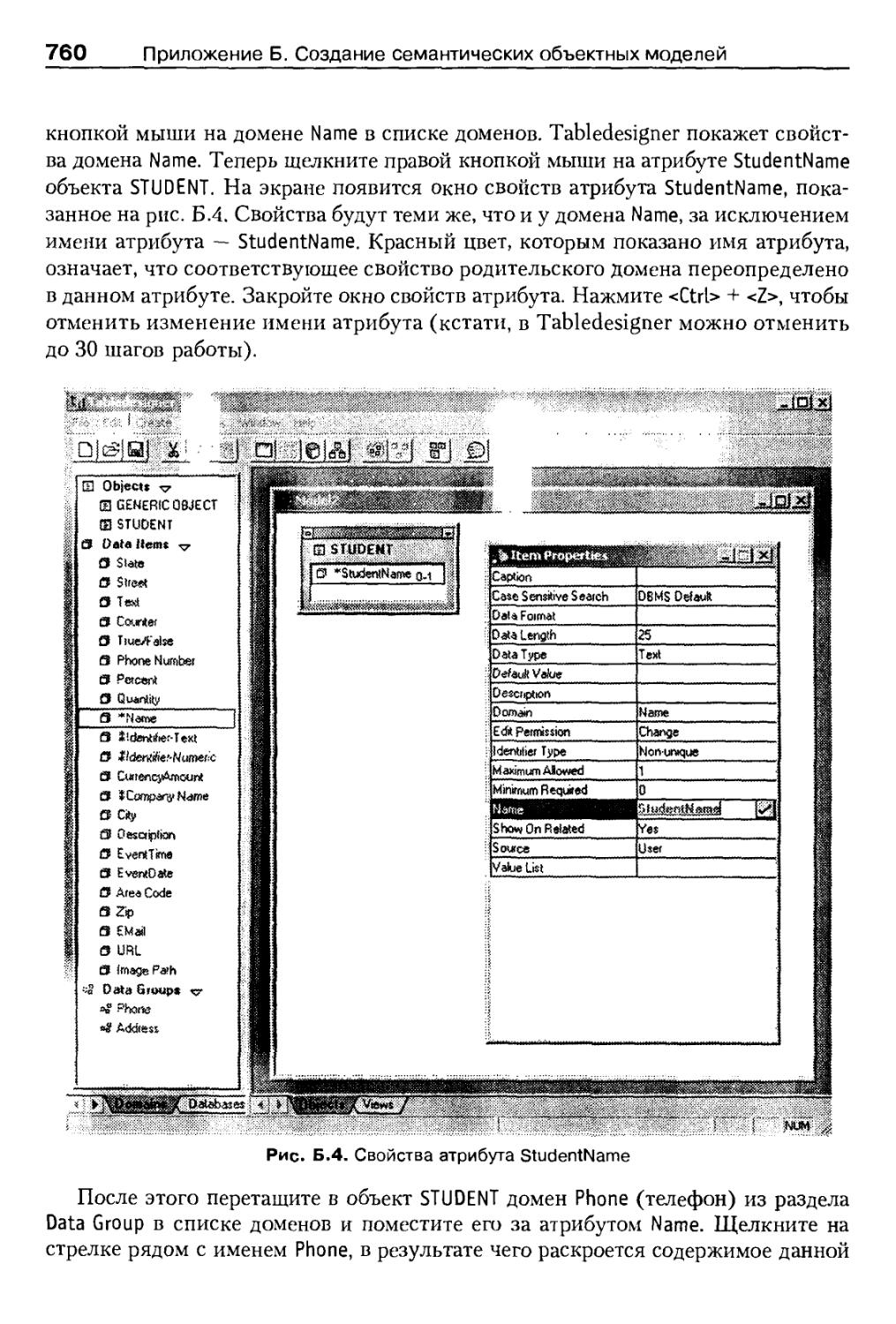
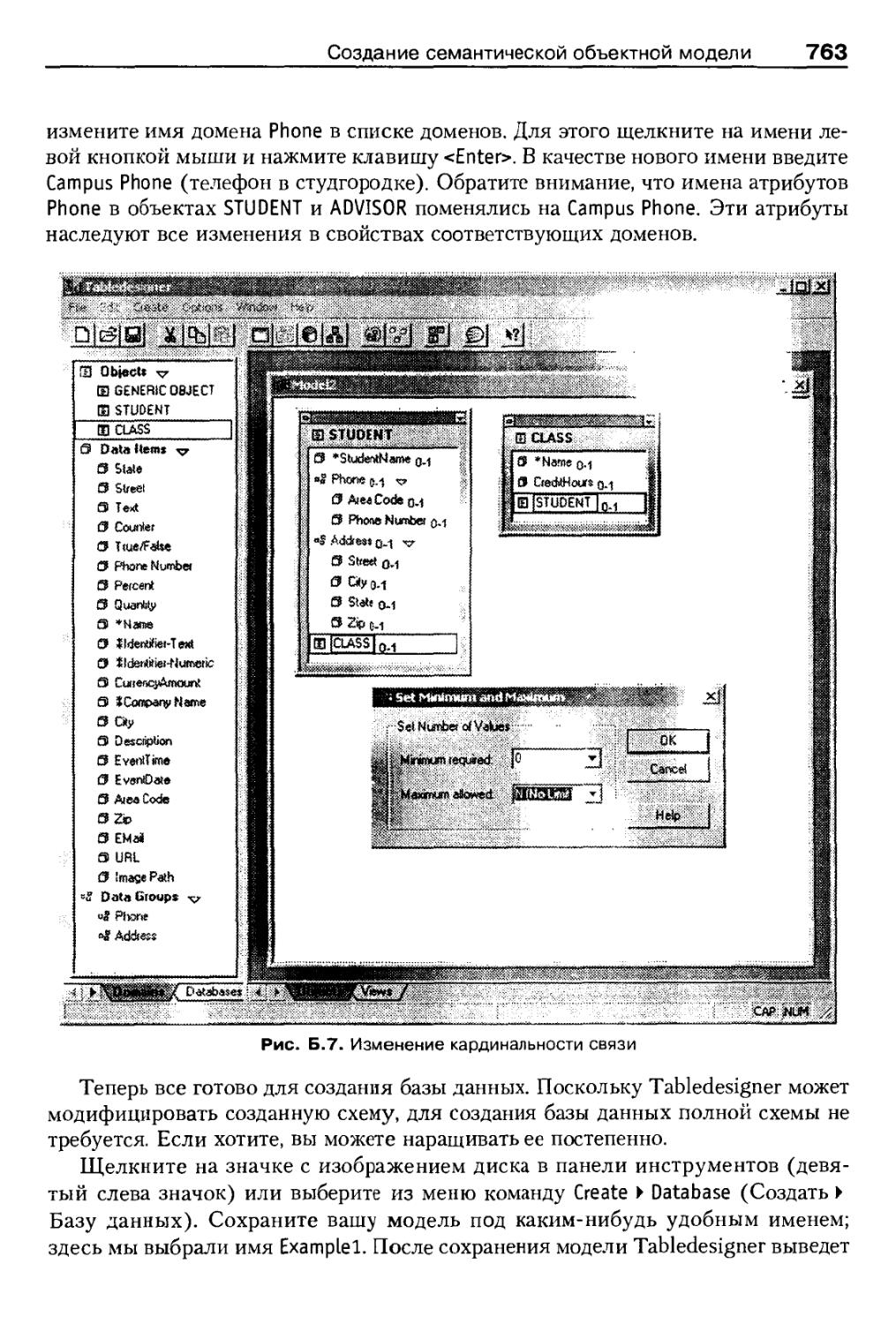
Создание семантической объектной модели 758
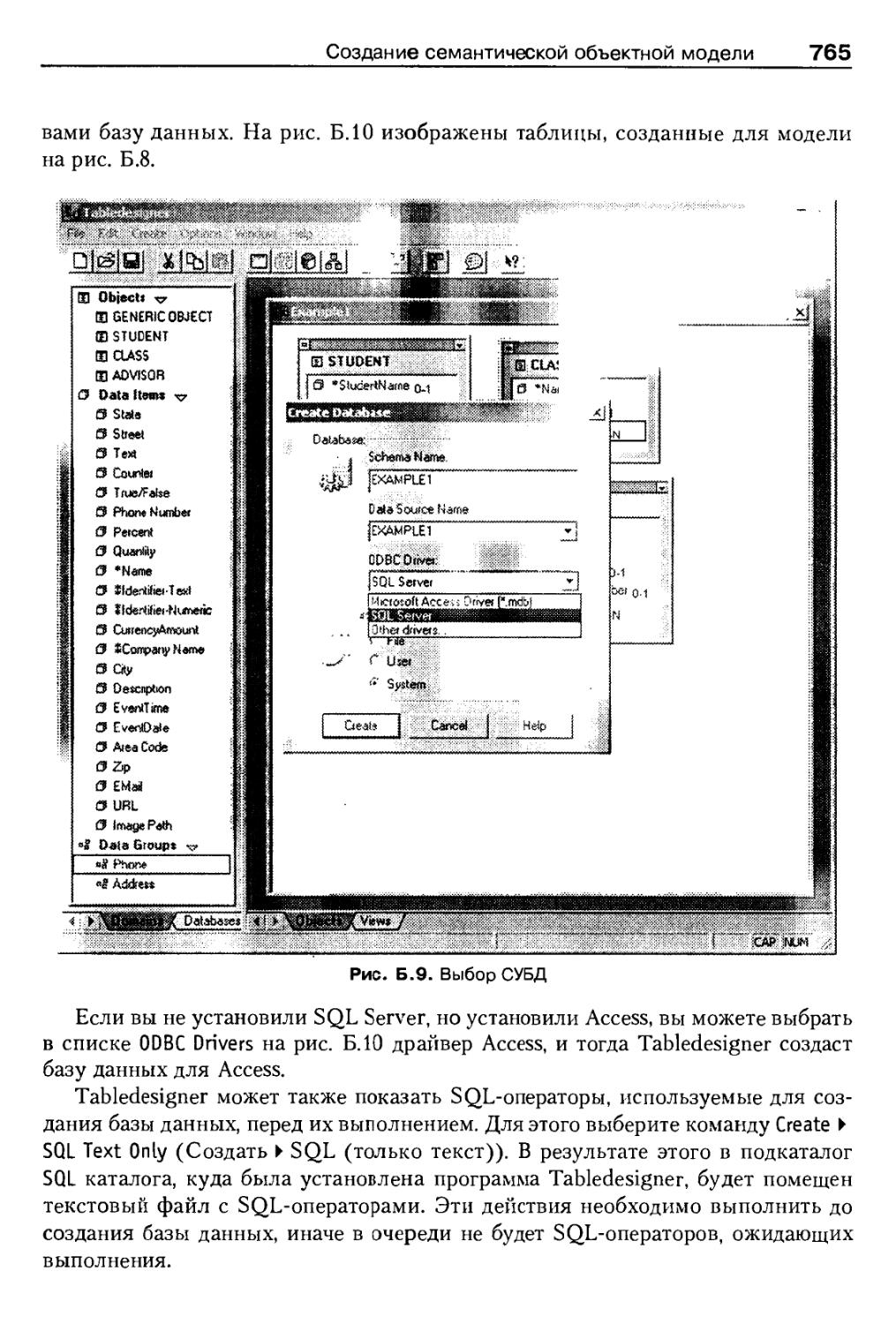
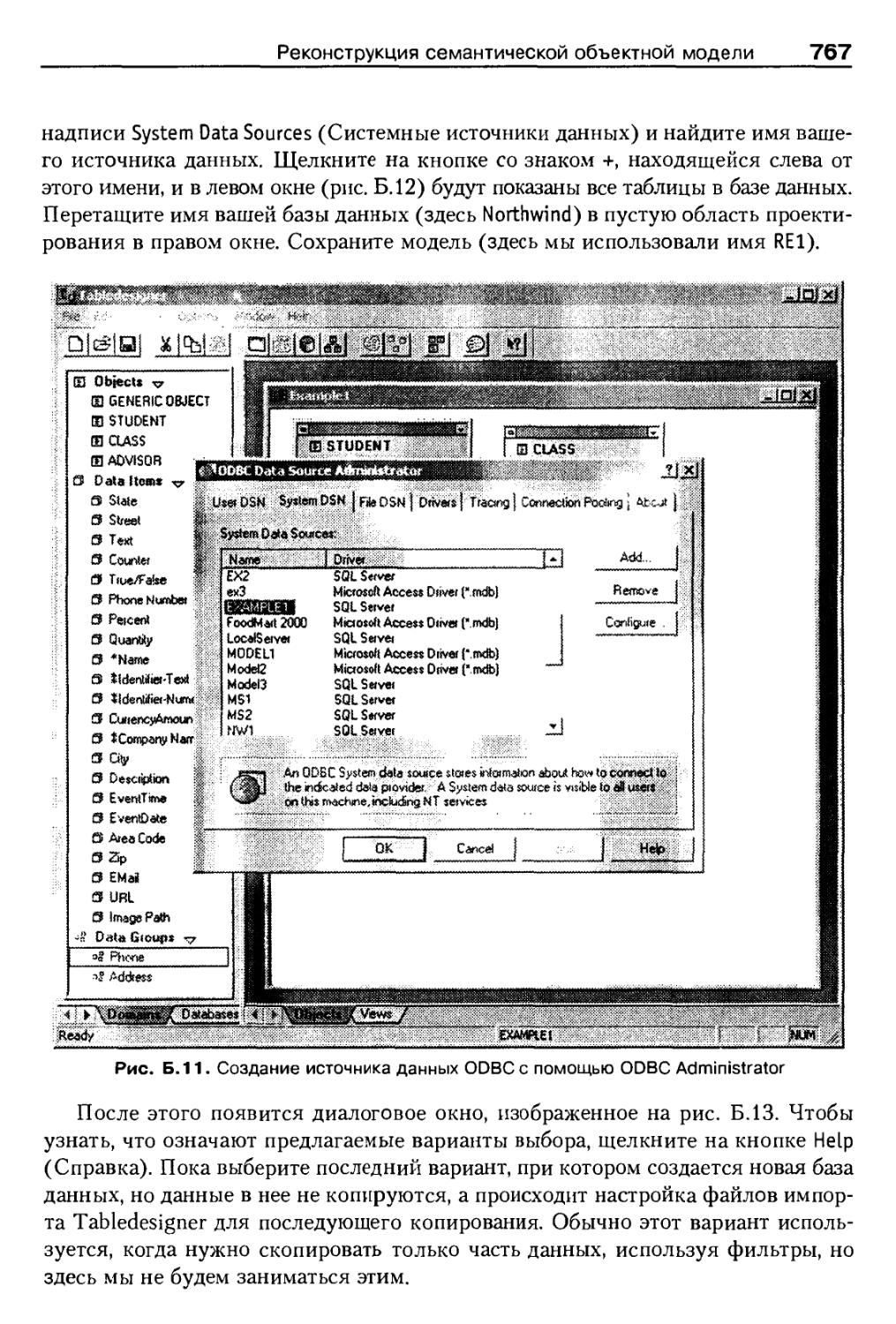
Реконструкция семантической объектной модели по имеющейся базе данных . . 766
Публикация базы данных в Web 775
Следующие шаги 783
Упражнения 783
Алфавитный указатель 785
Предисловие
По словам Алена Гринспена (Alan Greenspan), главы Федеральной резервной
системы США, внедрение информационных технологий сделало возможным
беспрецедентный прирост эффективности в экономике. Хотя главная заслуга в этом
традиционно приписывается сети Интернет, жизненно важную роль за кулисами
процесса играют технологии баз данных. В конце концов, Интернет — всего лишь
коммуникационная система; значительная часть его ценности определяется
информацией и данными, передаваемыми от базы данных к пользователю и в
обратном направлении.
Новости о происходящих то и дело банкротствах в электронном бизнесе могут
заставить студентов задуматься о том, не снизится ли в связи с этим ценность
упомянутых технологий. Однако нет ничего более далекого от истины, чем
подобное предположение. Лу Гестнер (Lou Gestner), глава корпорации IBM, несколько
лет назад высказал идею, что реальная выгода от использования Интернета и
связанных с этим технологий появится только после того, как эти технологии
возьмет на вооружение традиционная, корпоративная Америка — предприятия так
называемой «старой» экономики. Главные перспективы для технологий баз
данных (и для будущих специалистов в этой области) лежат в применении этих
технологий во всех сферах бизнеса и разновидностях экономической деятельности.
Все вышесказанное означает, что нет более подходящего момента для
изучения теории баз данных, чем теперь. От персональных баз данных, хранящихся на
настольных компьютерах, до больших баз данных для многих организаций,
разбросанных по всему миру по множеству компьютеров, — важность всех видов баз
данных в качестве экономических активов непрерывно растет. Маркетинг,
торговля, производство, финансы, бухгалтерский учет, менеджмент и, разумеется,
все экономические дисциплины используют базы данных для повышения
эффективности соответствующих видов деятельности.
Далее, после бурного всплеска развития новых технологий и видов продукции,
произошедшего в последние годы, стали ясны ключевые элементы успешного
управления базой данных в современных условиях. Знание концепций
моделирования данных и принципов организации баз данных по-прежнему является
определяющим фактором; в той же мере, что и ранее, сохраняют свою важность
реляционная модель и SQL. Возросло значение администрирования баз данных,
и особенно технологий, поддерживающих управление многопользовательскими
базами данных, поскольку все базы данных, где применяются новые технологии,
являются многопользовательскими.
Особенности настоящего издания 19
Что касается публикации баз данных, то победителями в конкурентной
борьбе между разнообразными технологиями оказались технологии web-публикации,
в частности, трехуровневая и многоуровневая архитектуры, XML, ASP (Active
Server Pages) и JSP (Java Server Pages). В сочетании с ними свое значение
сохраняют и ODBC с OLE DB, и JDBC.
Говоря коротко, технология баз данных оказывается сегодня важной как
никогда, и основные технологии, которые необходимо осваивать в этой связи,
стали яснее, чем когда бы то ни было за последние пять лет.
Особенности настоящего издания
В соответствии со сделанными выше замечаниями, вторая половина книги была
полностью переписана. Почти весь материал в главах с 11 по 16 является новым.
Основные задачи администрирования баз данных рассмотрены в главе 11, а затем
проиллюстрированы для Oracle в главе 12 и для SQL Server в главе 13. В главе 14
приведен обзор основных технологий публикаций баз данных в Web, после
чего в главе 15 дана иллюстрация этих технологий для ODBC, OLE DB, IIS и ASP,
а в главе 16 — для JDBC, JSP и MySQL. Глава 17 содержит информацию по
поводу OLAP, а глава 18 знакомит читателя с новыми объектно-реляционными
конструкциями в Oracle.
Рассмотреть все эти темы в течение одного семестра представляется
затруднительным, и, по моему мнению, следует серьезно подумать о том, чтобы
посвятить курсу теории баз данных целый год. Между тем, если у вас есть только один
семестр и времени не хватает, это издание подготовлено с тем расчетом, чтобы
позволить выбрать один из трех наборов альтернативных технологий.
В частности, в книге дается описание двух моделей данных: модели
«сущность—связь» и модели семантических объектов. Если времени мало, стоит
изучить первую из них как намного более популярную. Аналогичным образом, для
изучения многопользовательских баз данных можете выбрать либо Oracle (глава
12), либо SQL Server (глава 13) — все зависит от того, что требуется от молодых
специалистов в вашем регионе. Наконец, касаясь вопросов веб-публикации, если
ваш курс ограничен по времени, выберите либо IIS, ASP и ODBC (глава 15),
либо Java, JDBC и JSP (глава 16). Последовательность изложения ни в коей
мере не пострадает, если вы выберете один вариант в каждой из трех
предлагаемых пар. Разумеется, если время не является для вас проблемой, стоит уделить
внимание всем перечисленным темам.
Концепция Вариант 1 Вариант 2
Моделирование данных Модель «сущность—связь» Модель семантических объектов
Главы 3 и 6 Главы 4 и 7
Многопользовательские Oracle SQL Server
СУБД Глава 13 Глава 14
web-публикация IIS, ASP, ODBC Java, JDBC, JSP
Глава 15 Глава 16
20 Предисловие
В это издание включены также новые серии упражнений, которые можно
найти в конце каждой главы. Речь в них идет о небольшой компании,
занимающейся продвижением, продажей, производством и обслуживанием походных
горелок. Цель этих упражнений — дать студентам возможность применить знания,
почерпнутые из каждой главы, для решения небольшой реальной задачи,
требующей, однако, известного напряжения.
Последовательный обзор глав книги
Настоящий текст состоит из семи частей. Часть I представляет собой введение
в теорию баз данных. В главе 1 приводятся примеры использования баз данных,
вводятся основные термины и кратко излагается история вопроса. В главе 2
описывается процесс разработки простой базы данных и приложения с
использованием Microsoft Access 2002.
Во второй части книги рассматриваются вопросы моделирования данных.
Глава 3 знакомит читателя с моделью «сущность—связь» и демонстрирует, каким
образом эта модель была интегрирована с UML — унифицированным языком
моделирования. В главе 4 описывается модель семантических объектов —
альтернативный модели «сущность—связь» способ моделирования данных.
Принципам организации баз данных посвящена часть III. В главе 5 рассматривается
реляционная модель и нормализация. Далее в главе б с помощью идей, развитых
в главах 3 и 5, модели «сущность—связь» трансформируются в конкретные
варианты организации реляционной базы данных. В главе 7 описывается процесс
преобразования моделей семантических объектов в конкретные структуры
реляционных баз данных, для чего используются идеи, изложенные в главах 4 и 5.
Следующая часть книги посвящена основам реализации баз данных. Глава 8
является обзорной, в главе 9 описывается процедурный язык SQL, а в главе 10
рассматриваются структура и функции приложений реляционных баз данных.
Часть V посвящена управлению многопользовательской базой данных. В главе 11
рассматривается администрирование баз данных и обсуждаются важнейшие
вопросы функционирования многопользовательских баз данных, включая
управление конкуренцией, безопасность, резервное копирование и восстановление.
Идеи, изложенные в главе 11, иллюстрируются затем для Oracle в главе 12 и для
SQL Server в главе 13. Помимо того, глава 12 демонстрирует использование SQL
для определения данных.
Вопросам публикации баз данных в Web посвящена часть VI. В главе 14
излагаются основы сетевой обработки, многоуровневая архитектура и XML. В главе 15
описывается практическое применение этих концепции на базе технологии
Microsoft с использованием ODBC, OLE, IIS и ASP. В главе 16 также реализуются
идеи главы 14, но уже на базе Java, для чего используется JDBC, JSP и MySQL.
Обсуждаемые концепции иллюстрируются примером с использованием Linux
и Apache Tomcat. Глава 17 обращается к проблемам администрирования данных
и знакомит читателя с технологией OLAP.
Благодарности 21
Часть VII состоит всего из одной главы, которая посвящена работе с
объектно-ориентированными базами данных. Новым в этой главе является описание
объектно-реляционных возможностей Oracle. Приложение А содержит краткий
обзор структур данных, а приложение Б демонстрирует использование
программы Tabledesigner — средства, позволяющего разрабатывать модели
семантических объектов и преобразовывать их в реальные структуры баз данных и
ASP-страницы.
Благодарности
Серьезными изменениями, которые претерпела вторая половина настоящего
издания, я обязан конструктивным и полезным дискуссиям с моим редактором,
Бобом Хораном (Bob Horan), а также исключительно ценным и вдумчивым
отзывам, поступившим от следующих людей:
+ Джек Беккер (Jack Becker), Университет Северного Техаса
+ Уильям Д. Берг (William D. Burg), Университет Алабамы в Бирмингеме
+ Бхушан Капур (Bhushan Kapoor), Калифорнийский государственный
университет — Фуллертон
+ Дональд Р. Москейто (Donald R. Moscato), Иона Колледж
+ Нэнси Л. Руссо (Nancy L. Russo), Университет Северного Иллинойса
+ Бехруз Сагафи (Behrooz Saghafi), Чикагский государственный университет
+ Джозеф Л. Сессум (Joseph L. Sessum), Государственный университет Кен-
несо
+ Ашраф Ширани (Ashraf Shirani), Государственный университет Сан-Хосе
♦ Людвиг Слуски (Ludwig Slusky), Калифорнийский государственный
университет — Лос-Анджелес.
Кроме того, Марти Мюррей (Marty Murray) из Общественного колледжа
Портленда вдохновил меня на разработку материала по Oracle для главы 12 и
оказал в этом неоценимую помощь. Идеей включить в главу 16 материал,
посвященный JSP и MySQL, я обязан Уорнеру Скайереру (Warner Schyerer) из корпорации
SoundDev, Сиэтл. Спасибо также Джуд Столлер (Jude Stoller) из корпорации
SoundDev, которая предоставила отзыв на этот материал. Я особенно благодарю
Криса Уилкенса (Chris Wilkens) из SafariDog.com, который помог мне настроить
Linux, Apache и Tomcat.
Спасибо Oracle и Microsoft за предоставление студенческих версий своих
продуктов. Также спасибо Торстену Ганцу (Thorsten Ganz), президенту Cool-
strategy.com, который предоставил программу Tabledesigner студентам,
использующим в обучении эту книгу, и Кендзи Каваи (Kenji Kawai), продолжающему
играть решающую роль в разработке продуктов, базирующихся на модели
семантических объектов. Отдельное спасибо Кайл Хэныон (Kyle Hannon) из Prentice-
Hall, занимавшейся обработкой текста и различных вспомогательных компонен-
22 Предисловие
тов и обеспечившей их успешную сборку, а также Ванессе Наттри (Vanessa
Nuttry) из Prentice-Hall, умело управлявшей производственным процессом.
Наконец, я благодарю Линду (Lynda) за ее любовь, поддержку и воодушевление.
Теория баз данных — захватывающая область, которая развивалась pi
эволюционировала в течение более чем тридцати лет. Я верю в то, что это ее развитие
продолжится еще как минимум столько же времени, и желаю вам успехов в
исследовании многочисленных возможностей, открывающихся перед вами!
Дэвид Крёнке (David Kroenke)
Сиэтл, штат Вашингтон
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу электронной
почты comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
Все исходные тексты, приведенные в книге, вы можете найти по адресу
http://www.piter.com/download.
На web-сайте издательства http://www.piter.com вы найдете подробную
информацию о наших книгах.
Часть I
Введение
Часть I книги, состоящая из двух глав, посвящена знакомству с базами данных.
В главе 1 описаны четыре типичных варианта применения баз данных и
рассмотрены преимущества баз данных над использовавшимися ранее системами
обработки файлов. Кроме того, в ней определен термин база данных и кратко
изложена история вопроса. В главе 2 описаны элементы базы данных и дан обзор
функций системы управления базами данных (СУБД). В качестве заключения
к вводной части книги в главе 2 перечислены задачи, которые приходится решать
в процессе разработки базы данных и ее приложений.
Часть I дает представление о назначении баз данных и природе их
компонентов и приложений. Цель этой части — заложить необходимые основы для
подробного изучения концепций и технологий баз данных, представленных в
последующих главах.
Глава 1
Введение в базы данных
Базы данных всегда были важной темой при изучении информационных систем.
Но именно в последние годы, благодаря бурному развитию Интернета и
связанному с этим технологическому прорыву, знание технологии баз данных стало одним
из наиболее популярных путей к карьере. Технология баз данных позволяет
сделать интернет-приложение чем-то большим, чем просто средство для публикации
брошюр, что было характерно для ранних приложений. В то же время интернет-
технологии обеспечивают стандартизированный и доступный способ доставки
содержимого базы данных пользователям. Ни одно из этих новых обстоятельств
не отменяет необходимости в классических приложениях баз данных, которые
были незаменимы в бизнесе до появления Интернета, — они лишь усиливают
важность знаний о базах данных.
Многие студенты находят этот предмет интересным и увлекательным, хотя
порой он может быть трудным. Проектирование и разработка баз данных
требуют одновременно и искусства, и инженерных навыков. Понимание требований
пользователя и воплощение этих требований в эффективной логической
структуре базы данных является искусством. Преобразование логической структуры
в физическую базу данных с функционально завершенными,
высокопроизводительными приложениями представляет собой инженерную задачу. Оба эти
аспекта сулят множество трудных и увлекательных интеллектуальных головоломок.
Из-за крайне высокой востребованности технологии баз данных навыки и
знания, полученные вами в процессе изучения этого курса, будут иметь огромный
спрос. Цель этой книги — заложить в вас твердые знания основ технологии баз
данных, чтобы вы могли начать успешную карьеру в этой области, если таков
будет ваш выбор.
Четыре примера применения баз данных
Задача базы данных состоит в том, чтобы помочь людям в учете различного рода
вещей. В классических приложениях баз данных ведется учет заказов, клиентов,
выполненных работ, сотрудников, телефонных звонков и многих других вещей,
представляющих интерес для предпринимателя. В последнее время технология
баз данных используется в Интернете не только для этих традиционных нужд, но
и для новых приложений, к которым относится, например, реклама, настроенная
Четыре примера применения баз данных 25
на характеристики потребителей, и отслеживание предпочтений клиентов при
просмотре веб-страниц и покупке товаров. Такие базы данных, наряду с
традиционными числовыми данными — именами, датами и номерами телефонов, включают
в себя картинки, а также аудио- и видеоинформацию. Следующие четыре примера
иллюстрируют применение технологии баз данных в широком спектре областей.
Малярная фирма Мэри Ричарде
Мэри Ричарде — профессиональный маляр, владеет и управляет небольшой
компанией, состоящей из нее самой, еще одного профессионального маляра и, когда
это необходимо, наемных работников. Мэри занимается этим бизнесом уже 10 лет
и приобрела за это время репутацию высококвалифицированного маляра,
работающего за умеренную плату. Большую часть заказов она получает от
постоянных клиентов, нанимающих ее для покраски домов, а также от их знакомых.
Кроме того, некоторое количество заказов Мэри получает от строительных
подрядчиков и профессиональных дизайнеров интерьера.
Клиенты помнят Мэри намного лучше, чем она их. Порою она бывает смущена,
когда клиент звонит ей и говорит что-нибудь такое: «Здравствуйте, Мэри, это Джон
Мэплз. Вы красили мой дом три года назад». При этом звонящий подразумевает,
что Мэри вспомнит его и работу, которую она для него сделала; но если учесть, что
Мэри красит более 50 домов в год, для нее это будет затруднительно. Ситуация
становится еще хуже, когда клиент заявляет: «Моей соседке понравилось, как вы
покрасили наш дом, и она хочет, чтобы вы и у нее сделали что-нибудь вроде этого».
Чтобы несколько разгрузить свою память и лучше организовать учет
деятельности фирмы, Мэри наняла консультанта для разработки базы данных, которую
она могла бы хранить на своем персональном компьютере. В базе данных
должны храниться записи о клиентах, заказах и поставщиках клиентов,
представленные в форме таблиц (рис. 1.1).
Записью и получением данных из этих таблиц занимается специальная
программа, называемая системой управления базой данных (database management
system), или СУБД (DBMS). К сожалению, эти данные, будучи представлены
в форме таблиц, не слишком полезны для Мэри. Ей скорее хотелось бы знать,
как клиенты и заказы связаны друг с другом, — например, какие работы были
выполнены ею для конкретного клиента или какие клиенты были направлены
к ней конкретным человеком.
Чтобы предоставить Мэри такую возможность, консультант создал
прикладную программу (application program), которая обрабатывает формы (forms) для
ввода данных и формирует отчеты (reports). Рассмотрим пример,
представленный на рис. 1.2. В изображенную здесь форму Мэри вводит личные данные
клиента — имя, телефон и адрес. Далее она вводит сведения о работах, выполненных
для клиента, и указывает, кто направил этого клиента к ней. Эти данные
могут быть затем отражены в отчете, пример которого показан на рис. 1.3. Другие
функции этой базы данных включают оценку стоимости заказа, учет
поставщиков клиентов и создание наклеек с адресом для рекламных буклетов, которые
Мэри время от времени рассылает.
26 Глава 1. Введение в базы данных
Рие Edit View Insert Tods Window fctelp
D & •..,.: ЧХ ■ -; Ф • ' -'■ ' •
Ǥ
3-
1 SOURCEJOI
*M&
Name
PhoneNumbei
1 Valley Designs
2 Aspen Construction
3 Mary Engers Design
(Auto Number)
(303) 549-8879
РОЭ) 776-8899
(303) 767-7783
l<fij Create table in Design view
Efj Create table by using wcard
|Ц] Create table by entering data
Щ CUSTOMER
'job-
Ш SOURCE
Record: .Н1.«.|Г
l » 1>Ф«1оГ з
CUSTOMERJOjCustorner Name
Street
2 Wu, Jason
3 Maples. Marilyn
4 Jackson, Chris
■ - i (AutoNumber)
|P««<1: Hi'* П l" ► JHJt+tdF 3
123 E Elm Denver
2518 S Link Lane Denver
4700 Lafayette Eoulder
City [State] -Zip I PhoneNuwber | SOURCE JO
CO 80210-7786 (303) 555-0089
CO 80243- "(303) 777-6898
CO 81237-3484 _ (54Э) 388-1243
/
I*
Re
JOBJD |
t
2
3
4
5
(AutoNumber)
cord: .niVi!
JobDate | Description
3/3/2000 Pamt extenor in 794 White
7/7/2000 Paint dining room and kitchen
3/15/2001 Prep and paint upstairs bath
4/3/2O01 Pamt exterior doors in 633 Red
7/14/2001 Prep and paint interior wood trim
3 JL±±U±±J <f 5
| AmountBiHed j
$2.750 00
$1.778 00
$550 00
$885 00
$1.299 00
$0 00
AmountPaid
$2.750 00
$1,778 00
$550 00
$885 00
$1.299 00
$0 00
CUSTOMERJD!
2}
2}
2j
. . 4!
3j
d!
^ХТ^Лл-.^1
:i^ii*<^%i8&< ЛЛадйСкЛ >■■■ •■>
^JGliU
Рис. 1.1. Таблицы данных для малярной фирмы Мэри Ричарде
-lolxi
Customer ]^Vu, Jason
Phone
Street
Ciiv
State
JOB
|l303) 555-0089
J123E Elm
jDenver
{ССГ; Zip
Г80210-7786
I Record; И 1 < f Г
► |n|n»Iof 3
Referral Source
j^p'e'n Constr.K'i.jn j[]
Phone 1|303'|'"'Г6-38Ээ
JobDate
►
*
j 3/3^2000
| 7/7/2ШЩ:
|3/15/2001::
I
Record, .h !„*„J f
Description
I Pamt exterior in 7Э4 White
1 Paint dtnmg room and kitchen
jPiep and paint upstairs bath
1
1 „»,.1..M.I>*1 of 3
ArnountBrBed
j ilTSCTf
j $1 778 '"["*
| $55и~~Г
I ~r
AmountPaiJ
42.750
$1.778
i550
to
*i
zl
Рис. 1.2. Пример формы для ввода данных для малярной фирмы Мэри Ричарде
Четыре примера применения баз данных 27
tomer Job History I
шты.
' ;:~- в :х:'
Ш§ШШЩ}Ш Ш^лоо% ' Зо« jetup » ^ЩЩт
1 Customer Job History
t CustomerName Wu. Jason
1 PhoneNumber (SOS) 555-008
JobDate Description
3/Э/2000 Paint e*enor in 794 Whte
7/7/2000 Paint cinng room and kitchen
ЗЛ 5/2001 Prep and paint ipstairs b<*h
Total
CustomerName Afaples, Marilyn
PhoneNumber (303) 777-689
JobDate Description
7f\ 4/2001 Prep and pent interior vwod trim
T.tal
CustomerName Jackson, Chris
PhoneNumber (549) SS8-124
| JobDate Description
4/3/2001 Paint e*enor doors n 633 Red
T.tal
Grand ТоШ
„*^>^^
Thursday, March 01,2001
Щ.
AmountBiUed AmountPcad
$2,750 $2,750
*1,77B $1,778
$550 $550
$5,07S $5,07*
AmountBiUed AmountPtad
$1,299 $1.299
$1,299 $1,299
AmountBiUed AmountPcad
$865 $885
«885 Ш5
| 7£rf£|| /^gi|
**««****^
2]
,s^^^s^^:^
^i J
jjpascPant Shop Pro f &M**' Wcrw* • Dat=»
9 Customer Job Hist...
ним "У-Ш
Рис. 1.3. Пример отчета для малярной фирмы Мэри Ричарде
Прикладная программа и СУБД обрабатывают заполненную форму и
переписывают данные из нее в таблицы, подобные изображенным на рис. 1.1.
Аналогичным образом прикладная программа и СУБД извлекают данные из этих
таблиц для создания отчетов, таких как представленные на рис. 1.3.
Еще раз вернувшись к рис. 1.1, обратите внимание, что строки таблицы
содержат перекрестные ссылки и поэтому оказываются связанными друг с
другом. Для каждой работы (JOB) указан номер клиента (CUST0MERJD), заказавшего
эту работу, и для каждого клиента (CUSTOMER) указан номер поставщика клиента
(S0URCE_ID), то есть человека, направившего этого клиента к Мэри. Эти ссылки
используются для объединения данных в формы и отчеты.
Как вы можете догадаться, Мэри вряд ли имеет представление о том, как
проектировать таблицы, создавать их с помощью СУБД и разрабатывать
прикладную программу для создания форм и отчетов. Но ваших знаний технологии баз
данных к моменту окончания этого курса должно хватить для того, чтобы суметь
разработать такую базу данных и прикладную программу для работы с ней. Вы
должны будете также уметь проектировать таблицы и манипулировать ими для
создания довольно сложных форм и отчетов.
28 Глава 1. Введение в базы данных
Бюро проката музыкальных инструментов
Treble Clef Music
База данных Мэри Ричарде называется однопользовательской (single-user),
поскольку в каждый конкретный момент времени к ней обращается только один
пользователь. В некоторых случаях такое ограничение неприемлемо: иногда
требуется, чтобы одновременно к базе данных могли обращаться несколько человек
с различных компьютеров. Такие многопользовательские (multi-user) базы
данных являются более сложными, поскольку СУБД и прикладные программы
должны заботиться о том, чтобы действия одного пользователя не
противоречили действиям другого.
Бюро проката Treble Clef Music использует базу данных для учета сдаваемых
в аренду музыкальных инструментов. Для этого требуется
многопользовательская база данных, поскольку в периоды наплыва клиентов выдачей
музыкальных инструментов могут одновременно заниматься несколько служащих. Кроме
того, менеджер также должен иметь доступ к базе данных, чтобы определить
момент, когда необходимо будет заказать большее количество определенных
инструментов. При этом менеджер не хочет мешать процессу выдачи
инструментов.
Бюро Treble Clef Music имеет локальную сеть, соединяющую несколько
персональных компьютеров с сервером, на котором находится база данных (рис. 1.4).
У каждого из служащих есть доступ к прикладной программе, позволяющей
работать с тремя видами форм. Форма CUSTOMER (рис. 1.5, а) содержит
информацию о клиенте, форма RENTAL AGREEMENT (рис. 1.5, б) представляет договор
аренды и используется для учета выдачи и возврата инструментов, а форма
INSTRUMENT (рис. 1.5, в) содержит сведения об инструменте и историю его аренды.
Сервер
базы данных
Локальная сеть
Компьютер Компьютеры
менеджера клерков
Рис. 1.4. Локальная сеть бюро проката Treble Clef Music
Четыре примера применения баз данных 29
-tnlxfc
ТгеМЩШЩ Music — Customer Form
Customer Nams
Homophone
WorkPhrjne
Street
C*y ...
Stale
INVOICES
I Mary & Fred Jackson
j|703) 4437788 ;.;
\{Г03) 443-44821
1200 Seventeenth Ave
HieKandtia
~Zi* |0223-4"5567 '
ChMien
+
Л
|7 erherine
jj ay main a
1 _
Recofd- и j. < j |
1 J.
JnvoiceNurnba ItwoiceOate
► j—~~ 100037' l'i'u/16/гОО*"
$37
1 » JHJ»»t or 2
i »1"М* г
IJdM P F.ffWffW.JMili^^
-inf*?!
Treble Clef Music — Rental Agreement Form |
hr
J Re
l
nvoiceN'jmfrei j 100097 ....
nvoceDate {' 0/1 £Л?0СЛ j ^
WoiKRione j^Q?] 443-4432
HomePhcne j'"'"/*) 40 ""88
Rental Items
j SwiaWurnbei. Ca>eQO«y D$»eOut DdteRetumed МопЙЛуРее
►
| R*
cord
-
Г 478930^ jB «at cia^ei ' ' 1 UJ/lb/t-JU1 j" " j " %\7C&
556788 ^j jiiandaid vrohn ! ЮЧб'ЛЮ' | ' ; J S2725"
! Uf 1 1 " " !
|§^^§Pjrf3
гасяишЕ=сэиг Tol3l M4-,
Ml 111 ! _iJ_Hii*Jof 2
I iijiijil ишшшшщшшшшт
Treble Clef Music —
ГЙ
[Re
•i#
••Cat
aINurobiM j 478390
tgory |B tla> ;i3rmet
DICES
;..; tnyoiceN umber h\oie<-;Date
HF
te
1 Re
cord
j 100087 рОЛб;?001"|
;р:;Х:^Ш--:-''- "' • ::
Instrument Data Form
MortNyFee j 11 ?
F.er.»ed> j lo
Total
144 75
.-IQJXIJ
-
j 1 j
cord- и! *.l! i v.l»'i>*l of i
l<| >:}| l.:= ► |H.>»l0f 3
Г
Рис. 1.5. Формы, используемые бюро Treble Clef: a — информация о покупателе;
б — договор аренды; а — сведения об инструменте
30 Глава 1. Введение в базы данных
Чтобы уяснить проблемы, которые необходимо преодолеть в
многопользовательской базе данных, представьте себе, что произойдет, если два клиента
одновременно попытаются взять напрокат один и тот же кларнет си бемоль. СУБД
и прикладная программа должны каким-то образом обнаружить эту ситуацию
и сообщить служащим, что им следует выбрать другой инструмент.
Бюро лицензирования и регистрации
Рассмотрим теперь еще более обширное приложение технологии баз данных —
государственное бюро регистрации автомобилей и выдачи водительских прав.
В него входят 52 центра, где принимаются экзамены по вождению и
осуществляется выдача и продление прав, а также 37 офисов, занимающихся регистрацией
транспортных средств.
Персонал этих офисов использует в своей работе базу данных. Прежде чем
конкретному лицу будут выданы или продлены права, в базе данных
просматриваются сведения об этом лице на предмет наличия нарушений правил дорожного
движения, ДТП или задержаний. На основе этих данных принимается решение,
могут ли права быть продлены, и если да, то будут ли в них какие-либо
ограничения. Аналогичным образом, персонал в отделе регистрации автомобилей
обращается к базе данных, чтобы определить, был ли автомобиль зарегистрирован
ранее, а если был, то на чье имя, и нет ли каких-либо из ряда вон выходящих
причин, по которым в регистрации следует отказать.
У этой базы данных сотни пользователей, включая не только персонал,
занимающийся регистрацией и выдачей прав, но и служащих финансового
управления, а также сотрудников правоохранительных органов. Неудивительно, что база
является большой и сложной и имеет более 40 таблиц, причем некоторые из них
содержат сотни тысяч строк данных.
Большие организационные базы данных, подобные только что рассмотренной
нами, были первыми приложениями технологии баз данных. Подобные системы
находятся в эксплуатации уже в течение 20 или 30 лет и за этот период
неоднократно модифицировались в соответствии с менявшимися требованиями времени.
Существуют организационные базы данных, предназначенные для ведения счетов
в банках и других финансовых институтах, учета готовой продукции и
комплектующих иа складах больших предприятий, обработки медицинской
документации в госпиталях и страховых компаниях, а также для правительственных нужд.
Сегодня многие организации модифицируют прикладные программы своих
баз данных, чтобы дать клиентам возможность обращаться к этим данным и
даже вносить в них изменения через Интернет. Если вы работаете на большую
организацию, то вас вполне могут подключить к подобному проекту.
Туристический информационный центр
Калверт-Айленд — это прекрасный, но малоизвестный остров на западном
побережье Канады. Для продвижения острова на мировой туристический рынок
Совет по коммерции Калверт-Айленда разработал сайт, преследующий три цели:
Четыре примера применения баз данных 31
♦ рекламу природных условий Калверт-Айленда, а также мест отдыха и
развлечений;
♦ запись имен и адресов посетителей сайта для последующей рассылки пм
рекламной информации;
♦ прием запросов на бронирование мест в гостиницах, аренду коттеджей
и туристическое обслуживание, а также направление этих запросов
соответствующим фирмам.
Для поддержки этого сайта используются две базы данных. Первая из них —
рекламная — содержит данные, фотографии, видеоклипы и звуковые фрагменты,
дающие представление о природе Калверт-Айленда, возможностях острова в
сфере отдыха и развлечений и происходящих событиях. У этой базы данных есть
два типа пользователей. Обычные пользователи имеют доступ к ней только для
чтения. Пользуясь стандартными браузерами, эти пользователи могут
исследовать сайт в поисках интересующих их сведений об острове. В этом им помогает
прикладная программа, извлекающая данные и мультимедийные элементы из
рекламной базы данных (рис. 1.6).
: -5 ШШШ^^ШШтШШ^ШШШШШШ^Ш^ШШШ^Ш^ШШШШ^^Ш:
'•• ffai =. £*::;:' $W'V'.£© •';: favqifc**:';' |^dp; *f
ь^ШЬивЯ
^й*&'::;.•*:.•. '$.?<r#&iy^ :.;'$tap ^ RefreshJr-Heme'-' i ' Search ;• Fe«^*«''';Misl'o^':.'; Channel .•>: Mscter
j-Addew |£] ЬНр.//1(жаЬ*(УсаЫУ1-а1т«.а$р 3 . i LWw!
Calvert Island Reservation Centre Application I View/Edit ^J
Facility:: Activity Center
Things to Once you've arrived at Calvert Island» you can choose among many vaned
do: activities.
d
0Й::|ЩП::*< 'й'- l*%ltttiJr*^Z<X*:
Ш
Рис. 1.6. Web-страница туристического информационного центра Калверт-Айленда
32 Глава 1. Введение в базы данных
Другой тип пользователей рекламной базы данных — это сотрудники Совета
по коммерции, осуществляющие поддержку сайта. Сотрудники могут добавлять,
изменять и удалять данные и мультимедийные файлы из базы данных, по мере
того как сменяется реклама, фирмы присоединяются к программе и покидают ее,
а также удовлетворяются пожелания пользователей.
Кроме рекламной базы данных, прикладные программы сайта обращаются
к базе данных клиентов. В ней хранятся сведения, предоставляемые посетителями
сайта при заполнении анкеты и при запросе на бронирование или обслуживание.
Сюда относятся имя клиента, почтовый и электронный адреса, интересы,
предпочтения и предмет запроса. Когда посетитель вводит запрос, прикладная
программа пересылает его по электронной почте соответствующей фирме. Время от
времени фирмам рассылаются сводки всех запросов, поступивших за
определенный период, для контроля за их выполнением и других управленческих целей.
Есть три основных аспекта, отличающих базу данных острова Калверт-Айленд
от рассмотренных нами ранее приложений. Во-первых, рекламная база данных
в значительной своей части содержит не только структурированные данные, такие
как имена и адреса фирм, но также неструктурированные потоки битов в
мультимедийных файлах. Во-вторых, прикладная программа доставляет информацию
пользователю посредством стандартного браузера. Вид форм, которые
используются в малярной фирме Мэри Ричарде, бюро проката музыкальных инструментов
и бюро лицензирования и регистрации, определяется проектировщиком и
изменяется только при модификации приложения. То, в каком виде формы
предстают перед пользователями базы данных Калверт-Айленда, определяется ие
только приложением, но и маркой, версией и локальными настройками их браузеров.
Третья характеристика, отличающая базу данных Калверт-Айленда, — это
применение стандартной web-ориентированной технологии для передачи данных
между браузером, приложением и базой данных. При этом используются протокол
передачи гипертекста (HTTP), динамический язык разметки гипертекстовых
документов (DHTML) и расширяемый язык разметки (XML). Использование этих
стандартов означает, что доступ к этому приложению может получить любой
пользователь, имеющий браузер. Предварительной установки какого-либо
программного обеспечения не требуется. Следовательно, возможности для использования
этого приложения практически не ограничены. В главах 14-16 мы обсудим роль,
которую играют HTTP, DHTML и XML в работе с базами данных, в которых:
♦ присутствуют как структурированные, так и мультимедийные данные;
♦ формы и отчеты отображаются с помощью стандартного браузера;
♦ для передачи данных применяются стандарты Интернета — HTTP, DHTML
и XML.
Сравнение четырех типов баз данных
Приведенные примеры демонстрируют возможные варианты использования
технологии баз данных. Есть сотни тысяч баз данных, похожих на ту, что имеется
в малярной фирме Мэри Ричарде, — однопользовательские базы данных с относи-
Отношения между прикладными программами и СУБД 33
тельно небольшим количеством данных, скажем, менее 10 Мбайт. Формы и
отчеты для этих баз данных имеют обычно довольно простой вид.
У других баз данных, подобных той, что используется в бюро проката Treble
Clef Music, несколько пользователей, но общее их количество обычно не
превышает 20-30 человек. Они содержат умеренное количество данных — например,
50 или 100 Мбайт. Формы и отчеты должны быть достаточно сложными, чтобы
поддерживать несколько различных деловых функций.
Самые большие размеры у баз данных, подобных той, что мы рассматривали
для случая бюро регистрации автомобилей, — у них сотни пользователей и
триллионы байтов данных. Для работы с этими базами данных используется
множество различных приложений, у каждого из которых свои собственные формы
и отчеты. Наконец, некоторые базы данных применяют интернет-технологии
и обрабатывают как символьные, так и мультимедийные данные — изображения,
звуки, анимацию, видео и т. п. Сравнительные характеристики перечисленных
типов баз данных приведены в табл. 1.1.
Прочтя книгу, вы сможете проектировать и реализовывать базы данных
наподобие тех, что используются в малярной фирме Мэри Ричарде и в бюро проката
Treble Clef Music. Возможно, вы будете еще не в состоянии создавать такие
большие и сложные базы данных, как та, что используется в бюро регистрации
транспортных средств, но, тем не менее, сможете быть полезным членом команды по
разработке и созданию такой базы данных. Вы также сможете создавать
небольшие или средних размеров базы данных, использующие интернет-технологии.
Таблица 1.1. Характеристики различных типов баз данных
Тип Пример Типичное количество Типичный размер
одновременно базы данных
работающих
пользователей
Персональная Малярная фирма Мэри 1
Ричарде
Коллективная Бюро проката музыкальных < 25
инструментов Treble
Clef Music
Организационная Бюро лицензирования Сотни-тысячи
и регистрации автомобилей
Сетевая Туристический Сотни-тысячи
(Интернет) информационный центр
Калверт-Айленда
Отношения между прикладными
программами и СУБД
Все предыдущие примеры и, разумеется, все приложения технологии баз данных
имеют общую структуру, показанную на рис. 1.7, — пользователь
взаимодействует с прикладной программой, которая, в свою очередь, взаимодействует с СУБД,
обращающейся к данным в базе.
< 1 о Мбайт
< 100 Мбайт
> 1 Тбайт
Любой
34 Глава 1. Введение в базы данных
Когда-то граница между прикладной программой и СУБД была четко
определена. Приложения писались на языках третьего поколения, таких как COBOL,
и обращались к СУБД за услугами по обработке данных. Фактически, так дело
обстоит до сих пор, чаще всего в базах данных, располагающихся на больших ЭВМ.
I
<—Н
Приложение,
обрабатывающее
данные клиентов
Пользователь
I
Приложение,
обрабатывающее
информацию
о прокате
Пользователь
№
<—►
Другие
приложения
Пользователи
Рис. 1.7. Отношения между пользователями, приложениями
базы данных, СУБД и базой данных
Сегодня, однако, возможности и функции многих коммерческих СУБД
расширились настолько, что СУБД могут самостоятельно выполнять значительную
часть функций, ранее находившихся в ведении прикладных программ.
Например, в большинстве коммерческих СУБД есть генераторы отчетов и форм,
которые можно встраивать в приложения. Этот факт важен для нас по двум
причинам. Во-первых, хотя основной объем этого текста посвящен проектированию
и разработке баз данных, мы часто будем уделять внимание проектированию и
разработке приложений. В конце концов, ни одному пользователю не нужна база
данных как таковая. Пользователям скорее нужны формы, отчеты и запросы по
их данным.
Во-вторых, время от времени вы будете замечать, что материал этого курса
в чем-то пересекается с материалом курса системного программирования,
поскольку разработка эффективных приложений баз данных требует многих
навыков из тех, что вы приобрели или приобретете в ходе изучения курса системного
программирования. И наоборот, в большинство современных курсов системного
программирования входит такая тема, как проектирование баз данных. Различие
между двумя курсами заключается в расстановке акцентов: здесь мы делаем
упор на проектирование, построение и обработку базы данных, а в курсе
системного программирования — на разработку информационных систем, большинство
из которых использует технологию баз данных.
Системы обработки файлов 35
Системы обработки файлов
Лучший способ уяснить общую природу и свойства современных баз данных —
рассмотреть характеристики систем, существовавших до появления технологии
баз данных. При эксплуатации такого рода систем возникал ряд проблем,
которые технология баз данных помогла решить.
В первых деловых информационных системах группы записей хранились в
отдельных файлах; такие системы назывались системами обработки файлов (file-
processing systems). На рис. 1.8 приведены в качестве примера две системы
обработки файлов, которые можно было бы использовать в бюро проката Treble
Clef Music. Одна система обрабатывает данные клиентов, а другая —
информацию о прокате.
Хотя системы обработки файлов являются огромным усовершенствованием по
сравнению с ведением записей вручную, у них есть значительные ограничения:
♦ данные разделены и изолированы;
♦ значительная часть данных дублируется;
♦ прикладные программы зависят от форматов файлов;
♦ зачастую файлы несовместимы друг с другом;
♦ представление данных в виде, удобном для пользователя, оказывается
затруднительным.
Приложение,
обрабатывающее
данные клиентов
Файл
клентов
Пользователь
файла клиентов
Пользователь
файла клиентов
Приложение,
обрабатывающее
информацию
о прокате
Файл
проката
Рис. 1.8. Две системы обработки файлов
Разделенные и изолированные данные
Служащие бюро Treble Clef Music должны ассоциировать клиентов с
инструментами, которые те берут в аренду. Для системы, изображенной на рис. 1.8, нужно
каким-то образом извлечь данные из файлов клиентов и проката и
скомбинировать их в третий файл. В системах обработки файлов это вызовет сложности.
Во-первых, системные аналитики и программисты должны определить, какие
части каждого из файлов для этого требуются, а затем решить, как файлы
должны относиться друг к другу; наконец, они должны скоординировать обработку
36 Глава 1. Введение в базы данных
файлов таким образом, чтобы извлечение данных происходило корректно. Даже
для двух файлов эта задача довольно сложна, а вообразите себе, что необходимо
скоординировать 10 или более файлов!
Дублирование данных
В примере с бюро проката Treble Clef Music часто возникает ситуация, когда имя
клиента, его адрес и другие данные записываются несколько раз. А именно, эти
данные записываются один раз в файл клиентов, а затем каждый раз, когда с
данным клиентом заключается договор аренды, — в файл проката. То, что при этом
впустую тратится дисковое пространство, — еще не самая большая проблема;
главная проблема, возникающая при дублировании данных, касается
целостности данных (data integrity).
Совокупность данных обладает целостностью, если данные в ней логически
согласованы. Когда данные дублируются, это зачастую нарушает их целостность.
Например, если клиент сменит фамилию или адрес, то все файлы, содержащие
эти данные, необходимо будет обновить, но существует опасность, что
обновлены будут не все файлы, и между ними появятся несоответствия. В случае
Treble Clef Music может оказаться, что в разных записях в файле проката
клиент имеет разные адреса.
Проблемы целостности данных являются серьезными. Если данные
противоречат друг другу, это приведет к несогласованным результатам и
неопределенности. Если отчет одного приложения не согласуется с отчетом другого приложения,
то кто сможет сказать, какой из них является правильным? Когда результаты не
согласованы, достоверность хранимых данных и даже само функционирование
административной информационной системы ставятся под сомнение.
Зависимость прикладных программ
от форматов файлов
При обработке файлов прикладные программы зависят от форматов файлов.
Обычно в системах обработки файлов физические форматы файлов и записей
являются частью кода приложения. В языке COBOL, например, форматы файлов
записываются в разделе DATA DIVISION. Проблема заключается в том, что при внесении
изменений в форматы файлов приходится также менять и прикладные программы.
Например, если в записи о клиенте поле почтового индекса будет расширено
с пяти цифр до девяти, все программы, работающие с этой записью, необходимо
будет модифицировать, даже если они не используют это поле. Поскольку файл
клиентов может обрабатываться двадцатью программами, такое изменение
означает, что программист должен обнаружить все затронутые программы, внести
в них изменения и затем заново протестировать их; все это требует
значительных временных затрат и является дополнительным источником ошибок. Кроме
того, требовать от программистов модификации программ, не использующих то
поле, формат которого изменился, — значит просто бросать деньги на ветер.
Системы обработки баз данных 37
Несовместимость файлов
Одним из следствий зависимости прикладных программ от форматов файлов
является то, что сами форматы файлов зависят от языка или средства, используемого
для их генерации. Так, формат файла, созданного программой на языке COBOL,
отличается от формата файла, созданного программой на Visual Basic, который,
в свою очередь, отличается от формата файла, созданного программой на C++.
В результате, оперативно комбинировать или сравнивать файлы оказывается
невозможно. Пусть, например, в файле под названием FILE-A хранятся данные
о клиенте, содержащие поле Номер_Клиента, а в файле под названием FILE-B
хранятся данные об аренде, также содержащие поле Номер_Клиента. Пусть нам
требуется скомбинировать записи, у которых значение этого поля одинаково. Если
FILE-A обрабатывается программой на Visual Basic, a FILE-B обрабатывается
программой на C++, то прежде чем мы сможем комбинировать записи из них, нам
придется преобразовать оба файла к некоторому общему формату. Это требует
времени, а иногда вызывает затруднения. С увеличением количества
комбинируемых файлов растет и число таких проблем.
Трудность представления данных в удобном
для пользователя виде
В системе обработки файлов нелегко представить данные в естественном для
пользователя виде. Пользователи хотят видеть данные об аренде в формате,
аналогичном изображенному на рис. 1.5, б. Но для того чтобы вывести данные в
таком виде, необходимо извлечь данные из нескольких файлов, скомбинировать их
и представить вместе. Причина возникшего затруднения в том, что в системах
обработки файлов связи между записями не представлены в явной форме и не
обрабатываются. Поскольку система обработки файлов не может быстро определить,
какие клиенты взяли напрокат какие инструменты, то создание отчета,
демонстрирующего, например, предпочтения клиента, представляется крайне трудной
задачей.
Системы обработки баз данных
Технология баз данных была разработана для того, чтобы преодолеть
ограничения, свойственные системам обработки файлов. Чтобы понять, каким образом
это было сделано, сравните систему обработки файлов (см. рис. 1.8) с системой
обработки базы данных (database processing system) (см. рис. 1.7). Программы
обработки файлов обращаются непосредственно к файлам данных. В отличие от
них, программы обработки баз данных для доступа к данным вызывают СУБД.
Это отличие важно тем, что оно упрощает прикладное программирование:
программистам больше не нужно задумываться о том, как физически организовано
хранение данных, и они могут смело сконцентрироваться на вопросах,
представляющих важность для пользователя, а не для компьютерной системы.
38 Глава 1. Введение в базы данных
Данные интегрированы
В системе базы данных все данные хранятся в едином месте, называемом базой
данных. Прикладная программа может попросить СУБД обратиться к данным
о клиентах или о продажах, или к тем и другим. Если нужны данные обоих типов,
программист задает только способ комбинирования данных, а СУБД выполняет
все необходимые для этого операции. Таким образом, в задачи программиста не
входит написание программ для объединения данных, что требовалось для
системы на рис. 1.8.
Меньшее количество дублирующихся данных
В базе данных дублирование данных минимально. Например, для базы данных
бюро Treble Clef Music номер, имя и адрес клиента записываются только один
раз. Когда эти данные потребуются, СУБД может получить их, а для их
модификации необходимо будет только одно обновление. Поскольку данные хранятся
в одном месте, проблемы их целостности стоят не так остро: вероятность
разночтений между несколькими копиями одного и того же элемента данных снижается.
Независимость программ от данных
База данных уменьшает зависимость программ от форматов файлов. Все
форматы записей хранятся в самой базе данных (вместе с данными), и обращение к
данным производит СУБД, а не прикладные программы. В отличие от программ
обработки файлов, в прикладные программы базы данных не требуется включать
формат всех файлов и записей, которые они обрабатывают. Прикладные
программы должны содержать лишь описание (длину и тип) каждого элемента
данных, который требуется им в базе данных. СУБД преобразует элементы данных
в записи и выполняет другие подобные преобразования.
Независимость программ от форматов данных минимизирует влияние
изменения формата данных на прикладные программы. Изменения формата вводятся
в СУБД, а та, в свою очередь, обновляет информацию о структуре базы данных.
По большей части прикладные программы не осведомлены о смене формата. Это
также означает, что при добавлении, изменении или удалении каких-либо
элементов данных из базы данных модификации требуют только те программы,
которые непосредственно используют эти данные. Для приложений, состоящих из
множества программ, это может дать существенную экономию времени.
Представление данных в удобном
для пользователя виде
Как вы неоднократно обнаружите на всем протяжении данной книги, технология
баз данных дает возможность непосредственно представить объекты,
существующие в мире пользователя. Формы, подобные изображенным на рис. 1.5, легко по-
Определение термина «база данных» 39
лучить на основании информации из базы данных, поскольку сведения о связях
между записями также хранятся в базе данных.
Определение термина «база данных»
Термин база данных (database) страдает от обилия различных интерпретаций. Он
использовался для обозначения чего угодно — от обычной картотеки до многих
томов данных, которые правительство собирает о своих гражданах. В этой книге
мы будем использовать данный термин в конкретном значении: база данных —
это самодокументированное собрание интегрированных записей. Важно понять
обе части этого определения.
Самодокументированность
База данных является самодокументированпой (self-describing): она содержит,
в дополнение к исходным данным пользователя, описание собственной
структуры. Это описание называется словарем данных (data dictionary), каталогом
данных (data directory) или метаданными (metadata).
В этом смысле база данных напоминает библиотеку, которую можно
представить как самодокументированный набор книг. Кроме книг в библиотеке имеется
каталог с их описанием. Точно так же словарь данных (являющийся частью базы
данных, подобно тому, как каталог является частью библиотеки) описывает
данные, содержащиеся в базе данных.
Почему самодокументированность является столь важной характеристикой
базы данных? Во-первых, она обусловливает независимость программ от
данных. Иначе говоря, она дает возможность определить структуру и содержимое
базы данных путем обращения к самой базе данных. Нам не придется делать
предположения о том, что содержит база данных, а также отпадет необходимость
как-либо внешне документировать формат записей и файлов (как это делается
в системах обработки файлов).
Во-вторых, если мы изменим структуру данных в базе (например, добавим
новые элементы данных к существующей записи), то эти изменения мы внесем
только в словарь данных. Лишь небольшую часть программ необходимо будет
изменить (если таковые вообще будут). В большинстве случаев модификации
потребуют только те программы, которые непосредственно обрабатывают
элементы данных, претерпевшие изменения.
База данных — это собрание
интегрированных записей
Стандартная иерархия данных выглядит следующим образом: биты
объединяются в байты, или символы; символы группируются в поля; из полей формируются
записи; записи организуются в файлы (рис. 1.9, а). Есть соблазн последовать
40 Глава 1. Введение в базы данных
этому образцу и сказать, что файлы объединяются в базу данных. Хотя это
утверждение будет верным, оно, тем не менее, отразит суть недостаточно полно.
В базе данных действительно содержатся файлы данных пользователя,
однако ими все не исчерпывается. Как уже упоминалось ранее, в разделе метаданных
база данных содержит описание самой себя. Кроме того, база данных содержит
индексы (indexes), которые представляют связи между данными, а также служат
для повышения производительности приложений базы данных. Наконец,
зачастую база данных содержит данные о приложениях, использующих эту базу
данных. Структура форм для ввода данных и отчетов иногда является частью базы
данных. Эту последнюю категорию данных мы называем метадапиъши
приложений (application metadata). Таким образом, база данных содержит четыре типа
данных, представленных на рис. 1.9, б: файлы данных пользователя, метаданные,
индексы и метаданные приложений.
Биты
Байты, 1
или символы Г*
Поля
Записи
Файлы
Биты
Байты,
или символы
Поля
Записи
Файлы "
+
Метаданные
+
Индексы
+
Метаданные
приложения^
Рис. 1.9. Иерархия элементов данных: a — в системах обработки файлов
иб-в системах баз данных
База данных является моделью модели
База данных представляет собой модель. Возникает соблазн сказать, что база
данных — это модель реальности или некоторой части реальности, относящейся
к бизнесу. Однако это неверно. База данных не моделирует реальность или какую-
либо ее часть, но является моделью пользовательской модели (user model).
Например, база данных Мэри Ричарде представляет собой модель того, как Мэри
видит свой бизнес. С ее точки зрения, ее бизнес состоит из клиентов, работ и
поставщиков клиентов. Поэтому в ее базе данных представлены факты, касающиеся
этих объектов. Имена и адреса клиентов, описание и временные рамки
производимых работ, имена поставщиков клиентов — все это данные, являющиеся
важными для ведения бизнеса в представлении Мэри.
Базы данных различаются по уровню детализации. Некоторые их них просты
и примитивны. Список клиентов и сумм, которые они должны заплатить, — вот
История баз данных 41
приблизительное представление модели, существующей в голове Мэри. Более
детализированное представление включает виды работ, имена поставщиков
клиентов и путь, проделанный до места проведения каждой из работ. Очень
подробное представление может включать вид и количество использованной краски,
требуемое количество малярных кистей и количество часов, ушедшее на каждую
фазу работ — измерения, окраску дерева и стен, зачистку и т. п.
Степень детализации, которая должна присутствовать в базе данных, зависит
от того, какого рода информация необходима. Ясно, что чем больше требуется
информации, тем более подробной должна быть база данных. Выбор
подходящей степени детализации является важной частью работы по проектированию
базы данных. Как вы обнаружите, основополагающим критерием здесь является
уровень детализации, имеющийся в голове пользователя.
База данных представляет собой динамическую модель, поскольку бизнес
имеет свойство меняться: люди приходят и уходят, продукты появляются и
устаревают, деньги зарабатываются и тратятся. По мере этих изменений данные,
представляющие бизнес, также должны меняться. В противном случае они будут
устаревать и представлять бизнес неадекватно.
Транзакции (transactions) являются представлением событий. Когда
происходят какие-то события, с базой данных должны быть выполнены
соответствующие транзакции. Для этого кто-либо (например, оператор ввода данных,
продавец или кассир в банке) запускает программу обработки транзакций и вводит
данные для транзакций. Программа затем вызывает СУБД для внесения
изменений в базу данных. Обычно программа обработки транзакций выдает на дисплей
или распечатывает на бумаге отчет — например, подтверждение заказа или чек.
История баз данных
Базы данных изначально использовались в больших корпорациях и крупных
организациях как основа для больших систем обработки транзакций. В качестве
примера можно привести бюро лицензирования и регистрации транспортных
средств, рассмотренное нами выше. Позднее, по мере того как популярность
завоевывали микрокомпьютеры, технология баз данных также мигрировала в этом
направлении и стала использоваться для однопользовательских, персональных
приложений, подобных тому, которым пользуется Мэри Ричарде. Затем, когда
микрокомпьютеры начали объединять в рабочие группы, технология баз данных
была модифицирована с учетом этой тенденции, примером чего может служить
бюро проката Treble Clef. Наконец, в настоящее время базы данных
используются в приложениях для Интернета и интрасетей.
Организационный контекст
Исходное предназначение технологии базы данных заключалось в том, чтобы
преодолеть трудности с системами обработки файлов, речь о которых шла ранее
в этой главе. В середине 1960-х годов большие корпорации накапливали данные
42 Глава 1. Введение в базы данных
в системах обработки файлов с феноменальной скоростью, но работать с этими
данными становилось все сложнее, и все более затруднительной оказывалась
разработка новых систем. Более того, менеджеры хотели иметь возможность
соотносить данные из одной файловой системы с данными из другой системы.
Ограничения файловой обработки препятствовали простой интеграции
данных. Технология баз данных, однако, выполнила обещание решить эти
проблемы, и крупные компании начали разрабатывать организационные базы данных.
В этих базах данных централизованно хранились и обрабатывались данные о
заказах, товарах и счетах предприятия. Эти приложения представляли собой
главным образом системы обработки транзакций организационного масштаба.
На первых порах, когда технология была еще несовершенной, приложения
баз данных были сложны в разработке и выдавали много ошибок. Даже успешно
работающие приложения были медленными и ненадежными: аппаратное
обеспечение того времени было не в состоянии быстро справиться с объемом
выполняемых транзакций, разработчики еще не изобрели более эффективные способы
хранения и извлечения данных, а программисты еще не освоили работу с базами
данных, и иногда их программы работали некорректно.
Обнаружен был и еще один недостаток баз данных — их уязвимость. Если
произойдет сбой в системе обработки файлов, из строя выйдет только одно
конкретное приложение. Если же сбой случится в базе данных, то выйдут из строя
все ее приложения.
Постепенно ситуация улучшилась. Разработчики аппаратного и программного
обеспечения научились создавать системы, достаточно мощные, чтобы
поддерживать большое количество параллельно работающих пользователей, и достаточно
быстродействующие, чтобы справляться с требуемым объемом транзакций.
Были разработаны новые способы контроля, защиты и резервного копирования баз
данных. Усовершенствовались стандартные процедуры обработки данных, а
программисты научились писать более эффективный и легкий для поддержания код.
К середине 1970-х базы данных были в состоянии эффективно и надежно
обрабатывать организационные приложения. Многие из этих приложений
используются до сих пор, более чем через 25 лет после их создания!
Реляционная модель
В 1970 г. Э. Ф. Кодд (Е. F. Codcl) опубликовал свою эпохальную статью1, в
которой он применил концепции раздела математики, называемого реляционной
алгеброй, к проблеме хранения больших объемов данных. Статья Кодда положила
начало движению в сфере проектирования баз данных, которое привело
несколько лет спустя к созданию реляционной модели базы данных (relational database
model). Эта модель представляет собой определенный способ структурирования
и обработки базы данных, и мы будем подробно обсуждать ее в главе 5, а также
в главах 9-14.
Е. Е. Codd, «A Relational Model of Data for Large Shared Databanks», Communications of the ACM,
06.1970, с 377-387.
История баз данных 43
Преимущество реляционной модели заключается в способе хранения данных,
который минимизирует их дублирование и исключает определенные типы
ошибок обработки, возникающие при других способах хранения данных. Данные
хранятся в виде таблиц со столбцами и строками, как показано на рис. 1.1.
Согласно реляционной модели, не все виды таблиц одинаково приемлемы.
С помощью процесса, называемого нормализацией (normalization),
нежелательная таблица может быть преобразована в две или более приемлемых. Более
подробно о процессе нормализации вы узнаете из главы 5.
Другое преимущество реляционной модели состоит в том, что в столбцах
содержатся данные, связывающие одну строку с другой. Например, на рис. 1.1
столбец CUSTOMER_JD в таблице JOB связан со столбцом CUSTOMER_ID в таблице
CUSTOMER. Это делает связи между строками видимыми для пользователя.
Поначалу считалось, что реляционная модель позволит пользователям
извлекать информацию из баз данных без помощи профессионалов MIS
(административно-информационной системы). Доля истины в этом есть, так как таблицы
представляют собой простые и интуитивно понятные конструкции. Кроме того,
поскольку связи хранятся вместе с данными, пользователи могут при
необходимости комбинировать нужные строки. Например, чтобы получить запись о
конкретном договоре аренды, пользователь базы данных бюро проката Treble Clef
Music мог бы скомбинировать строку таблицы CUSTOMER со строками таблицы
RENTAL
Оказалось, что этот процесс слишком сложен для большинства
пользователей. По этой причине ожидания, что реляционная модель предоставит
пригодный для неспециалистов способ доступа к базам данных, не оправдались.
Оглядываясь назад, можно резюмировать: ключевым преимуществом реляционной
модели оказалось то, что она дает специалистам (таким, как вы!) стандартный
способ структурирования и обработки баз данных.
Коммерческие СУБД для микрокомпьютеров
В 1979 г. небольшая компания под названием Ashton-Tate представила новый
программный продукт для микрокомпьютеров, dBase II, и назвала его
реляционной СУБД. Применяя чрезвычайно успешную рыночную тактику, Ashton-Tate
почти бесплатно распространила более 100 000 копий своего продукта среди
покупателей новых в то время микрокомпьютеров Osborne. Многие из тех, кто
приобрел эти компьютеры, были пионерами микрокомпьютерной индустрии. Они
начали создавать приложения для микрокомпьютеров с использованием dBase,
и число dBase-приложений быстро росло. В результате Ashton-Tate стала одной
из первых крупных корпораций в индустрии микрокомпьютеров. Позднее она
была приобретена компанией Borland, которая в настоящее время продает
продукты линии dBase.
Успех этого продукта, однако, вызвал неразбериху и путаницу в мире баз
данных. Проблема была в следующем: в соответствии с определением, которое стало
преобладать в конце 70-х годов, продукт под названием dBase II вообще не
являлся СУБД, а тем более реляционной. Фактически это был язык программиро-
44 Глава 1. Введение в базы данных
вания с расширенными возможностями для обработки файлов. Системы,
разработанные на базе dBase II, гораздо более напоминали то, что изображено на рис. 1,8,
чем то, что на рис. 1.7. Около миллиона пользователей dBase II были уверены,
что используют реляционную СУБД, хотя в действительности это было не так.
Таким образом, термины система управления базами данных (database
management system) и реляционная база данных (relational database) в начале бума
микрокомпьютеров использовались достаточно произвольно. Большинство тех, кто
работал с базами данных на микрокомпьютерах, на самом деле занимались
обработкой файлов и не получали тех преимуществ, которые характерны для баз
данных (хотя они и не замечали этого). Сегодня, когда рынок микрокомпьютеров
стал более зрелым и искушенным, ситуация стала иной. dBase IV и
последующие продукты линии dBase, такие как FoxPro, являются по-настоящему
реляционными СУБД.
Хотя продукты dBase действительно были первым ориентированным на
микрокомпьютеры приложением технологии баз данных, примерно в это же время
другие производители начали переносить свои продукты с больших ЭВМ на
микрокомпьютеры. В качестве примеров коммерческих СУБД, перенесенных на
микрокомпьютеры, можно упомянуть Oracle, Focus и Ingress. Они
действительно являются СУБД, и многие также согласятся с тем, что они действительно
реляционные.
Одним из следствий переноса технологии баз данных на микрокомпьютеры
явилось резкое улучшение пользовательского интерфейса СУБД. Пользователи
микрокомпьютеров не стали бы мириться с неуклюжим и неудобным
интерфейсом, который характерен для СУБД, работающих на больших ЭВМ. Таким
образом, с разработкой коммерческих СУБД, ориентированных на микрокомпьютеры,
интерфейс этих программ стал удобнее в использовании. Это стало возможным
потому, что микрокомпьютерные СУБД работают на приспособленных под эти
задачи компьютерах, а также потому, что больше вычислительных ресурсов стало
доступно для обработки пользовательского интерфейса. Сегодняшние СУБД
богаты возможностями, надежны и имеют графический пользовательский интерфейс.
Сочетание микрокомпьютеров, реляционной модели и значительно
улучшенного пользовательского интерфейса позволило перенести технологию баз
данных из контекста организации в контекст персональных компьютеров. Когда это
произошло, число мест, где используется технология баз данных, увеличилось на
порядки. В 1980 г. в США было около 10 000 мест, где использовались СУБД,
сегодня же их более 40 миллионов!
Клиент-серверные приложения баз данных
В середине - конце 1980-х годов конечные пользователи начали объединять свои
компьютеры в локальные сети (local area networks, LAN), Эти сети сделали
возможной передачу данных между компьютерами с невиданными до тех пор
скоростями. Первые приложения этой технологии обеспечивали совместное
использование периферийных устройств, таких как быстродействующие дисковые
накопители большой емкости, дорогие принтеры и плоттеры, и осуществляли связь
История баз данных 45
между компьютерами посредством электронной почты. В перспективе, однако,
пользователи хотели совместно использовать свои базы данных, что привело к
развитию многопользовательских приложений баз данных для локальных сетей.
Многопользовательская архитектура, применяемая в локальных сетях,
значительно отличается от многопользовательской архитектуры, применявшейся на
больших ЭВМ (mainframe). В случае последних в обработке приложения базы
данных участвовал только один процессор, а в локальных сетях для этого могут
использоваться несколько процессоров. Поскольку эта ситуация, помимо
очевидной выгоды (большая производительность), влечет за собой и новые трудности
(координация действий независимых процессоров), возник новый стиль
многопользовательской обработки баз данных, называемый клиент-серверной
архитектурой баз данных (client-server database architecture).
Не все базы данных в локальных сетях используют клиент-серверную
архитектуру. Более простой, но менее устойчивый режим обработки баз данных
называется архитектурой с совместным использованием файлов (file-sharing architecture).
Компания, подобная Treble Clef Music, могла бы, скорее всего, использовать
любую из этих двух архитектур, поскольку она представляет собой небольшую
организацию с умеренными требованиями к обработке. Однако для рабочих
групп большего размера потребуется клиент-серверная архитектура. Эти
подходы будут подробно описываться и обсуждаться в главе 17.
Базы данных с использованием
интернет-технологий
Как было показано на примере туристического информационного центра Кал-
верт-Айленда, технология баз данных применяется в настоящее время в
сочетании с технологией публикации данных в Web. Эта же технология используется и
для публикации приложений в корпоративных и организационных интрасетях.
Некоторые эксперты полагают, что в будущем все приложения баз данных будут
доставляться пользователям при помощи браузеров и связанных с этим
интернет-технологий — даже персональные базы данных, которые «публикуются» для
одного человека.
Существует две категории приложений, использующих интернет-технологии.
Первая категория включает в себя чистые web-приложения баз данных, как это
было в случае с островом Калверт-Айленд. Вторая категория — традиционные
персональные, коллективные и организационные базы данных, которые не
публикуются в Интернете, но используют браузеры и технологии, подобные DHTML
и XML. Поскольку называть последнюю категорию интернет-базами данных
было бы некорректно, в этой книге обе категории объединены под термином базы
данных с использованием интернет-технологий.
Эта категория находится сегодня на переднем крае технологии баз данных.
Как вы узнаете из главы 14, язык XML исключительно хорошо отвечает
потребностям приложений баз данных и служит основой для многих новых продуктов
и услуг в этой сфере.
46 Глава 1. Введение в базы данных
Распределенные базы данных
Прежде чем мы завершим этот исторический обзор, необходимо обсудить два
аспекта технологии баз данных, которые теоретически представляют важность, но
еще не получили широкого применения. Этими аспектами являются
распределенные и объектно-ориентированные базы данных. Мы обсудим их более
подробно в главах 17 и 18 соответственно.
Организационные базы данных решают проблемы, характерные для систем
обработки файлов, и обеспечивают более целостную обработку данных
организации. Персональные и коллективные базы данных переносят технологию баз
данных еще ближе к пользователям, так как управляются локально.
Распределенные базы данных (distributed databases) сочетают в себе эти два типа,
позволяя объединять между собой персональные, коллективные и организационные
базы данных в целостные, но распределенные системы. Как таковые, они
теоретически обеспечивают более гибкие варианты доступа к данным и их обработки,
но в то же время ставят проблемы, многие из которых не решены до сих пор.
Сущность распределенных баз данных заключается в том, что все данные
организации распылены между многими компьютерами — микрокомпьютерами,
серверами локальных сетей и большими ЭВМ, которые взаимодействуют между
собой в процессе обработки базы данных. Цель этих систем в том, чтобы у
каждого пользователя возникало ощущение, что он — единственный пользователь
данных организации, и чтобы при этом обеспечивались такие же согласованность,
точность и быстродействие, какие были бы, если бы этой распределенной базой
данных больше никто не пользовался.
Среди наиболее актуальных проблем распределенных баз данных можно
упомянуть проблемы безопасности и контроля. Обеспечить доступ к базе данных
для столь большого количества пользователей (а конкурирующих пользователей
могут быть сотни) и проконтролировать, какие действия они выполняют с
распределенной базой данных, — это непростые задачи.
Координация и синхронизация обработки могут вызывать затруднения. Если
одна группа пользователей загружает и обновляет часть базы данных, а затем
передает модифицированные данные обратно на большую ЭВМ, то как может
система в это же время предотвратить попытку другого пользователя использовать
старую версию данных, находящуюся в настоящий момент на большой ЭВМ?
Представьте себе, что в этот процесс вовлечено огромное количество файлов,
сотни пользователей и множество различного компьютерного оборудования.
Если переход от организационных баз данных к персональным и затем к
коллективным происходил достаточно легко, то трудности, стоящие перед
проектировщиками и разработчиками распределенных СУБД, монументальны. По
правде говоря, даже при том, что работа над распределенными системами баз данных
ведется вот уже более 25 лет, значительные проблемы все еще остаются.
Корпорация Microsoft разработала архитектуру распределенной обработки данных
и набор поддерживающих ее продуктов под названием Microsoft Transaction
Server (MTS) и сейчас занимается ее построением. Хотя MTS является
многообещающим проектом и среди всех компаний именно у Microsoft имеются ресурсы
Резюме 47
для разработки и продвижения на рынок подобной системы, до сих пор остается
неясным, действительно ли распределенные базы данных смогут удовлетворить
каждодневные потребности организаций в сфере обработки данных. Более
подробную информацию по этой теме вы найдете в главе 15, в той ее части, где
идет обсуждение OLE DB.
Объектно-ориентированные СУБД
В конце 1980-х годов началось использование нового стиля программирования под
названием объектно-ориентированное программирование (object-oriented
programming), или ООП (OOP), который, как будет объяснено в главе 18, имел
существенно иную ориентацию, чем традиционное программирование. Если говорить
вкратце, то структуры данных, которые обрабатываются в ООП, являются
значительно более сложными, чем те структуры, с которыми приходится иметь дело
в традиционных языках программирования. Кроме того, сложно обеспечить
хранение этих структур с помощью существующих коммерческих СУБД. Как
следствие возникает новая категория СУБД — объектно-ориентированные СУБД
(object oriented DBMS), предназначенные для хранения и обработки структур
данных ООП.
По множеству причин ООП еще не получило широкого применения в
деловых информационных системах. Во-первых, оно является сложным в
использовании, а разработка приложений ООП стоит очень дорого. Во-вторых, у
большинства организаций миллионы или миллиарды байтов данных организованы
в реляционные базы данных, и они не желают брать на себя риск и расходы,
связанные с преобразованием этих баз данных в формат
объектно-ориентированных СУБД. Наконец, большинство объектно-ориентированных СУБД были
разработаны для поддержки инженерных приложений, и они просто не обладают
возможностями и функциями, подходящими или быстро адаптируемыми для
нужд деловых приложений.
Следовательно, в обозримом будущем объектно-ориентированные СУБД,
скорее всего, не будут широко использоваться в приложениях коммерческих
информационных систем. Мы обсудим ООП, объектно-ориентированные базы данных
и принадлежащий Oracle Corporation гибрид под названием объектно-реляционные
базы данных (object-relational databases) в главе 18, но в основном этот рассказ
будет посвящен реляционной модели, поскольку она связана с технологиями,
которые вы наверняка будете использовать в течение первых пяти лет вашей карьеры.
Резюме
Базы данных — один из наиболее важных курсов, связанных с
информационными системами. Навыки и знания, приобретаемые в ходе изучения этого курса,
пользуются большим спросом не только для традиционных приложений, но
также для приложений, использующих интернет-технологию в открытых и
закрытых сетях.
48 Глава 1. Введение в базы данных
Технология баз данных используется во множестве приложений. Некоторые
из них предназначены для единственного пользователя с единственным
компьютером, другие используются рабочими группами в количестве 20-30 человек
через локальную сеть, третьи служат сотням пользователей и содержат
триллионы байтов данных. В последнее время технология баз данных применяется
в сочетании с интернет-технологией для поддержки мультимедийных
приложений в открытых и закрытых сетях.
Компонентами приложения базы данных являются сама база данных, система
управления базой данных (СУБД) и прикладные программы. Иногда
прикладные программы действуют полностью независимо от СУБД, а иногда
значительная часть функциональности приложения обеспечивается за счет возможностей
и функций СУБД.
Системы обработки файлов хранят данные в отдельных файлах, каждый из
которых содержит свой тип данных. Эти системы имеют несколько ограничений.
Данные, хранимые в отдельных файлах, трудно комбинировать, поскольку они
зачастую дублируются в разных файлах, что приводит к нарушениям
целостности данных. Прикладные программы зависят от форматов файлов, что вызывает
проблемы при обслуживании: когда форматы меняются, файлы становятся
несовместимыми, и требуется их преобразовывать. Трудно также представить
данные в удобном для пользователя виде.
Системы обработки баз данных были разработаны для того, чтобы
преодолеть эти ограничения. В базе данных СУБД служит интерфейсом между
прикладными программами и базой данных. Данные интегрированы, и они не
дублируются столь часто. Изменение физических форматов файлов затрагивает
только СУБД. Если элементы данных изменяются, добавляются или удаляются,
лишь немногие из прикладных программ требуют модификации. Технология баз
данных упрощает представление данных в удобном для пользователя виде.
База данных — это самодокументированное собрание интегрированных
записей. Она является самодокументированной, так как содержит описание самой
себя в словаре данных. Словарь данных известен также как каталог данных, или
метаданные. База данных является собранием интегрированных записей,
поскольку связи между записями также хранятся в базе данных. Такая
организация позволяет СУБД конструировать даже весьма сложные объекты, комбинируя
данные на основании хранимых связей. Связи часто хранятся как избыточные
данные. Таким образом, три составляющие базы данных — это данные
приложений, словарь данных и избыточные данные.
Технология баз данных развивалась в несколько стадий. Ранние базы данных
фокусировались на обработке транзакций с данными организации. Затем
появление реляционной модели и микрокомпьютеров привело к созданию
персональных приложений баз данных. С появлением локальных сетей началась
разработка коллективных баз данных с клиент-серверной архитектурой. Сегодня
традиционные приложения баз данных доставляются пользователю с помощью
интернет-технологий. Важными направлениями в отрасли баз данных являются
распределенные и объектно-ориентированные базы данных. Сегодня, однако, ни
одно из этих двух направлений не стало коммерчески успешным и не получило
широкого применения в деловых приложениях.
Вопросы группы I 49
Вопросы группы I
1. В чем состоит важность изучения баз данных?
2. Опишите сущность и характеристики приложений однопользовательских
баз данных, применяемых отдельными пользователями, такими как Мэри
Ричарде.
3. Опишите сущность и характеристики приложений коллективных баз
данных, используемых рабочими группами, такими как бюро проката Treble
Clef Music.
4. Опишите сущность и характеристики приложений баз данных,
используемых такими организациями, как Государственное бюро выдачи
водительских прав и регистрации транспортных средств.
5. Опишите сущность и характеристики приложений баз данных,
используемых такими организациями, как туристический информационный центр
острова Калверт-Айленд.
6. Объясните сущность и функции каждого компонента на рис. 1.7.
7. Как со временем меняются взаимоотношения между прикладными
программами и СУБД?
8. Перечислите ограничения систем обработки файлов, как они описаны в этой
главе.
9. Объясните, каким образом технология баз данных преодолевает
ограничения, перечисленные вами в ответе на вопрос 8.
10. Определите термин база данных.
11. Что такое метаданные? Что такое индексы? Что такое метаданные
приложений?
12. Объясните, почему база данных является моделью. Опишите различие
между моделью реальности и моделью пользовательской модели реальности.
Почему важно это различие?
13. Дайте пример приложения персональной базы данных, отличный от
приведенного в этой главе.
14. Дайте пример приложения коллективной базы данных, отличный от
приведенного в этой главе.
15. Дайте пример приложения базы данных для большой организации,
отличный от приведенного в этой главе.
16. Перечислите недостатки, которыми обладали ранние приложения
организационных баз данных.
17. Каковы два основных преимущества реляционной модели?
18. Опишите вехи развития микрокомпьютерных СУБД.
19. Что было основным фактором, давшим толчок развитию приложений
коллективных баз данных?
50 Глава 1. Введение в базы данных
20. Чем клиент-серверная архитектура отличается от многопользовательской
архитектуры, применявшейся на больших ЭВМ?
21. В чем состоит различие между интернет-приложением базы данных и
приложением базы данных, использующим интернет-технологию?
22. Дайте общую характеристику распределенной обработки данных.
Перечислите некоторые наиболее серьезные проблемы, которые предстоит
решить.
23. Сформулируйте цель объектно-ориентированной базы данных. Почему
такие базы данных не получили большего распространения в
приложениях информационных систем?
Проекты
1. Зайдите на сайт какого-нибудь производителя компьютеров, например Dell
(www.dell.com). С помощью этого сайта определите, какую модель ноутбука
вы могли бы порекомендовать за сумму до $2500. Как вы думаете, сколько
баз данных используется для поддержки этого сайта — одна или несколько?
Какими возможностями и функциями данный сайт, по вашему мнению,
в наибольшей степени обязан технологии баз данных, если иметь в виду
определение базы данных и преимущества обработки баз данных?
2. Зайдите на сайт какой-нибудь книготорговой компании, например Amazon
(www.amazon.com). Найдите с помощью этого сайта наиболее свежую из
опубликованных автобиографий Уильяма Вордсворта (William
Wordsworth). Как вы думаете, сколько баз данных используется для поддержки
этого сайта — одна или несколько? Какими возможностями и функциями
данный сайт, по вашему мнению, в наибольшей степени обязан
технологии баз данных, если иметь в виду определение базы данных и
преимущества обработки баз данных?
Вопросы к проекту FiredUp
FiredUp, Inc. — небольшая компания, владельцами которой являются Керт и Джу-
ли Роубэрдс. Эта компания, находящаяся в Брисбэйне, Австралия, производит
и продает легкие походные горелки под названием FireNow. Керт, работавший
раньше аэрокосмическим инженером, изобрел и запатентовал сопло, которое не
дает огню в горелке погаснуть даже при очень сильном ветре — до 90 миль в час.
Джули, промышленный дизайнер по образованию, разработала элегантную
складную конструкцию, которая имеет небольшой вес и габариты, проста в установке
и весьма устойчива. Семья Роубэрдс производит горелки в своем гараже и
продает клиентам напрямую, принимая заказы через Интернет, по факсу и по почте.
Вопросы к проекту FiredUp 51
Владельцы FiredUp хотели бы отслеживать проданные горелки на тот случай,
если им понадобится войти в контакт с покупателями относительно дефектов
в изделиях и по другим вопросам, связанным с качеством изделий. Они также
думают, что смогут использовать список покупателей для рекламы других
изделий, если когда-нибудь разработают что-либо еще.
1. Как вы думаете, подойдет ли база данных FiredUp для хранения данных
о проданных горелках и их покупателях? Опишите условия, при которых,
по вашему мнению, база данных будет подходящим средством, а при
каких — неподходящим. Сформулируйте, при каких условиях им подойдет
персональная база данных. При каких условиях им может понадобиться
коллективная база данных? Интернет-база данных?
2. Решите ту же задачу применительно к регистрации кофейных автоматов,
продаваемых компанией Starbucks. Пусть, например, Starbucks хочет иметь
возможность хранить сведения о клиентах, которые приобрели в
магазинах этой компании автоматы для продажи кофе «эспрессо». Как
изменятся ответы па вопросы первого пункта?
Глава 2
Введение в разработку
баз данных
В этой главе в общих чертах рассматривается процесс разработки базы данных
и ее приложений. Мы начнем с описания элементов базы данных и обсуждения
характерных особенностей и функций СУБД. Далее мы проиллюстрируем процесс
создания базы данных и приложения для работы с ней. В заключение мы обсудим
популярные стратегии разработки баз данных. Цель этой главы состоит в том,
чтобы заложить основу для детального описания этой технологии, которое
последует в дальнейших главах.
База данных
На рис. 2.1 показаны основные компоненты системы базы данных. Базу данных
обрабатывает СУБД, которая используется разработчиками и пользователями,
обращающимися к СУБД напрямую или косвенно, через прикладные
программы. Данный раздел посвящен базе данных, а СУБД и прикладные программы
обсуждаются в следующих разделах.
Как вам уже известно из главы 1, база данных состоит из четырех основных
элементов: данных пользователя, метаданных, индексов и метаданных приложений.
Данные пользователя
Сегодня большинство баз данных представляют данные пользователя в виде
отношений (relations). Формальное определение термина отношение мы дадим
в главе 5. На данный же момент будем рассматривать отношение как таблицу
данных. Столбцы таблицы содержат поля, или атрибуты, а строки содержат
записи о конкретных объектах делового мира.
Не все отношения являются одинаково желательными; некоторые отношения
структурированы лучше, чем другие. В главе 5 описан процесс, называемый
нормализацией (normalization), с помощью которого получаются хорошо
структурированные отношения. Чтобы получить представление о разнице между плохо
и хорошо структурированными отношениями, рассмотрим отношение R1 (ИмяСту-
База данных 53
дента, ТелефонСтудента, ИмяРуководителя, ТелефонРуководителя),
содержащее имена и телефоны студентов и их руководителей:
ИмяСтудента
ТлфСтудента
ИмяРуковод
Тлфруковод
Бейкер, Рекс
Чарлз, Мэри
Джонсон, Бет
Скотт, Гленн
Зилог, Фрита
232-8897
232-0099
232-4487
232-4444
232-5588
Парке
Парке
Джонс
Парке
Джонс
236-0098
236-0098
236-0110
236-0098
236-0110
База
данных
База данных содержит
Данные пользователей
Метаданные
Индексы
Метаданные приложений
С
У
Б
Д
Средства проектирования
Средство для создания
таблиц
Средство для создания
формул
Средство для создания
запросов
Средство для создания
отчетов
Подсистема обработки
Процессор форм
Процессор запросов
Генератор отчетов
Средства обработки,
реализованные
на процедурных языках
Разработчик
Прикладные
программы
СУБД
Рис. 2-1. Компоненты системы базы
данных
Недостаток этого отношения состоит в том, что оно содержит данные,
принадлежащие двум различным темам — студентам и руководителям. Такая
структура отношения порождает определенные проблемы при его обновлении.
Например, если у руководителя по фамилии Парке изменится номер телефона,
необходимо будет изменить три строки данных. По этой причине было бы лучше
представить данные в виде двух отношений. Первое из них, R2 (ИмяСтудента,
ТелефонСтудента, ИмяРуководителя), будет содержать имя и телефон студента и
фамилию его руководителя:
ИмяСтудентв
ТлфСтудента
ИмяРуковод
Бейкер, Рекс
Чарлз, Мзри
232-8897
232-0099
Парке
Парке
продолжение&
54 Глава 2. Введение в разработку баз данных
ИмяСтудента ТлфСтудента ИмяРуковод
Джонсон, Бет 232-4487 Джонс
Скотт, Гленн 232-4444 Парке
Зилог, Фрита 232-5588 Джонс
Второе отношение, R3 (ИмяРуководителя, ТелефонРуководителя), будет содержать
фамилию и телефон руководителя:
ИмяРуковод ТлфРуковод
Парке 236-0098
Джонс 236-0110
Теперь, если у руководителя изменится номер телефона, необходимо будет
изменить только одну строку в отношении R3. Разумеется, чтобы сформировать
отчет, в котором были бы представлены имена студентов вместе с именами их
руководителей, нужно будет объединить строки этих двух таблиц. Оказывается,
однако, что гораздо лучше хранить отношения раздельно и объединять их при
составлении отчета, чем хранить их в виде одной комбинированной таблицы.
Метаданные
Как было указано в главе 1, база данных является самодокументированной, то
есть одной из ее составляющих является описание собственной структуры. Это
описание называется метаданными (metadata). Так как СУБД предназначены
для хранения таблиц и манипуляции ими, большинство из них хранят
метаданные в форме таблиц, иногда называемых системными таблицами (system tables).
В табл. 2.1 представлены два примера хранения метаданных в системных
таблицах. В таблице SysTables перечислены все таблицы, имеющиеся в базе данных,
и для каждой таблицы указаны количество столбцов и имена одного или
нескольких столбцов, служащих первичным ключом. Такой столбец или набор
столбцов является уникальным идентификатором строки. В таблице SysColumns
перечислены столбцы, имеющиеся в каждой таблице, а также тип данных и
ширина каждого столбца. Эти две таблицы представляют собой типичные образцы
системных таблиц; в других подобных таблицах хранятся списки индексов,
ключей, хранимых процедур и т. п.
Таблица 2.1. Примеры метаданных
Таблица SysTables
Имя таблицы Число столбцов Первичный ключ
Студент 4 НомерСтудента
Руководитель 3 ИмяРуководителя
Дисциплина 3 НомерДисциплины
УчебныйПлан 3 {НомерСтудента, НомерДисциплины}
База данных 55
Таблица SysColumns
Имя столбца
НомерСтудента
Имя
фамилия
Специальность
ИмяРуководителя
Телефон
Кафедра
НомерДисциплины
Название
КоличествоЧасов
НомерСтудента
НомерДисциплины
Курс
Имя таблицы
Студент
Студент
Студент
Студент
Руководитель
Руководитель
Руководитель
Дисциплина
Дисциплина
Дисциплина
УчебныйПлан
УчебныйПлан
УчебныйПлан
Тип данных
Integer
Text
Text
Text
Text
Text
Text
Integer
Text
Decimal
Integer
Integer
Text
Длина
4
20
30
10
25
12
15
4
10
4
4
4
2
Хранение метаданных в таблицах не только эффективно для СУБД, но и
удобно для разработчиков, поскольку для запроса метаданных они могут
использовать те же самые средства, что и для запроса пользовательских данных. В главе 9
мы обсудим язык под названием SQL, который используется для запроса и
обновления таблиц метаданных и пользовательских данных.
В качестве возможного примера использования SQL представьте, что вы
разработали базу данных с 15 таблицами и 200 столбцами. Вы помните, что
некоторые столбцы имеют тип данных currency, но не можете вспомнить, какие именно.
С помощью SQL можно обратиться к таблице SysColumns и по ней определить,
какие столбцы имеют указанный тип данных.
Индексы
Третий тип данных, которые хранятся в базе данных, призван улучшить ее
производительность и доступность. Эти данные, называемые иногда избыточпъши
данными (overhead data), состоят главным образом из индексов (indexes), хотя
в ряде случаев используются и другие структуры данных, такие как связанные
списки (индексы и связанные списки обсуждаются в приложении А).
В табл. 2.2 приведены данные о студентах и два индекса к ней. Чтобы
уяснить, какая может быть польза от индексов, представьте себе, что данные в
таблице СТУДЕНТ расположены в порядке возрастания значения поля НомерСтудента,
а пользователь хотел бы создать из этих данных отчет, отсортированный по по*
лю Фамилия. Для этого можно было бы извлечь все данные из таблицы и
отсортировать, но, если размеры таблицы не слишком малы, этот процесс может
занять много времени. В качестве альтернативы можно создать индекс Фамилия,
приведенный в табл. 2.2. Записи в этом индексе отсортированы по полю Фамилия,
Длины приведены в байтах или, что то же самое, в символах (для текстовых данных).
56 Глава 2. Введение в разработку баз данных
поэтому достаточно считать записи из индекса в порядке следования, чтобы
затем получать данные из таблицы СТУДЕНТ, отсортированные в нужном порядке.
Таблица 2.2. Примеры индексов
Таблица СТУДЕНТ
НомерСтудента Имя
100 Джеймс
200 Мэри
300 Бет
400 Элдридж
500 Крис
600 Джон
700 Майкл
Фамилия
Бейкер
Абернати
Джексон
Джонсон
Тафт
Сматерс
Джонсон
Специальность
Бухгалтерский учет
Информационные системы
Бухгалтерский учет
Маркетинг
Бухгалтерский учет
Информационные системы
Бухгалтерский учет
Индекс Фамилия
Фамилия
Абернати
Бейкер
Джонсон
Джонсон
Сматерс
Тафт
НомерСтудента
200
100
300
400, 700
600
500
Индекс Специальность
Специальность
Бухгалтерский учет
Информационные системы
Маркетинг
НомерСтудента
100, 300,500, 700
200,600
400
Теперь представьте, что требуется получить данные о студентах,
отсортированные по полю Специальность. Опять-таки, можно извлечь эти данные из
таблицы СТУДЕНТ и отсортировать, а можно создать индекс Специальность и
использовать его, как показано выше.
Индексы используются не только для сортировки, но и для быстрого доступа
к данным. Пусть, например, пользователю нужны сведения только о тех
студентах, чьей специальностью являются информационные системы. Без индекса
пришлось бы проводить поиск по всей таблице. Имея же индекс, можно найти в нем
соответствующую запись и использовать ее для нахождения нужных строк в
таблице. На самом деле, если количество строк невелико, как в таблице СТУДЕНТ,
индексы не нужны, но представьте себе таблицу, которая содержит 10 000 или
20 000 строк. В этом случае сортировка или поиск по всей таблице работали бы
слишком медленно.
Индексы удобны для сортировки и поиска, но за их использование
приходится платить свою цену. Каждый раз, когда обновляется строка в таблице СТУДЕНТ,
СУБД 57
индексы также необходимо обновлять. Это не обязательно плохо — это означает
только, что индексы не даются даром и поэтому должны использоваться только
в тех случаях, когда это действительно оправдано.
Метаданные приложений
Четвертый и последний тип информации в базе данных — это метаданные
приложений (application metadata), которые описывают структуру и формат
пользовательских форм, отчетов, запросов и других компонентов приложений. Не все
СУБД поддерживают компоненты приложений, а из тех СУБД, где такая
возможность предусмотрена, не все хранят структуру этих компонентов в виде
метаданных приложений в базе данных. Однако большинство современных СУБД
хранят эту информацию в базе данных. Вообще говоря, ни разработчики баз
данных, ни пользователи не обращаются к метаданным приложений напрямую,
а пользуются соответствующими средствами, которые предоставляет СУБД.
СУБД
СУБД значительно различаются по своим характеристикам и функциям.
Первые продукты такого рода были разработаны для больших ЭВМ в конце 1960-х
годов и были весьма примитивны. С тех пор СУБД постоянно
совершенствовались, а функции их расширялись. Усовершенствования касались не только
обработки баз данных: СУБД также снабжались функциями, упрощающими создание
приложений баз данных.
В этой главе для иллюстрации возможностей СУБД мы будем
использовать Microsoft Access 2002. Это обусловлено тем, что Access 2002 обладает
всеми типичными характеристиками и функциями современной СУБД. Однако
Access 2002 не является единственной СУБД такого рода, и наш выбор ни в коей
мере не предполагает какого-либо предпочтения перед другими подобными
продуктами, например Lotus Approach.
Как видно из рис. 2.1, характеристики и функции СУБД можно разделить на
три подсистемы: подсистему средств проектирования, подсистему средств
обработки и ядро СУБД.
Подсистема средств проектирования
Подсистема средств проектирования (design tools subsystem) представляет
собой набор инструментов, упрощающих проектирование и реализацию баз данных
и их приложений. Как правило, этот набор включает в себя средства для создания
таблиц, форм, запросов и отчетов. В СУБД имеются также языки
программирования и интерфейсы для них. Например, в Access есть два языка: макроязык, не
требующий глубокого знания программирования, и версия языка BASIC под
названием Visual Basic.
58 Глава 2. Введение в разработку баз данных
Подсистема обработки
Подсистема обработки (run-time subsystem)1 занимается обработкой
компонентов приложения, созданных с помощью средств проектирования. Например,
в Access 2002 имеется компонент, материализующий формы и связывающий
элементы форм с данными таблиц. Представьте себе форму с текстовым полем, где
отображается значение столбца НомерСтудента из таблицы СТУДЕНТ. В процессе
работы приложения при открытии формы процессор форм (form processor)
извлекает значение поля НомерСтудента из текущей строки таблицы и отображает
его в форме. Все это делается автоматически — ни пользователю, ни
разработчику не требуется ничего делать, если имеется готовая форма. Другие процессоры
подсистемы обработки предназначены для выполнения запросов и вывода
отчетов. Кроме того, в подсистеме обработки имеется компонент, обрабатывающий
запросы прикладных программ на чтение и запись данных в базу.
Хотя это не показано на рис. 2.1, СУБД должны также предоставлять
интерфейс для стандартных языков программирования, таких как C++ и Java.
Дальнейшую информацию об этом вы получите из глав 15 и 16.
Ядро СУБД
Третий компонент СУБД — это ее ядро (DBMS engine), которое выполняет
функцию посредника между подсистемой средств проектирования и обработки
и данными. Ядро СУБД получает запросы от двух других компонентов,
выраженные в терминах таблиц, строк и столбцов, и преобразует эти запросы в команды
операционной системы, выполняющие запись и чтение данных с физического
носителя.
Кроме того, ядро СУБД участвует в управлении транзакциями, блокировке,
резервном копировании и восстановлении. Как будет показано в главе 11,
действия с базой данных должны выполняться как единое целое. Например, при
обработке заказа изменения в таблицах КЛИЕНТ, ЗАКАЗ и СКЛАД должны
производиться согласованно: либо выполняются все, либо не выполняется ни одно. Ядро
СУБД помогает координировать действия, с тем чтобы либо выполнялись все
действия в группе, либо не выполнялись ни одного.
Microsoft предоставляет два различных ядра для Access 2002: Jet Engine и SQL
Server. Ядро Jet Engine используется для небольших персональных и
коллективных баз данных. Ядро SQL Server, представляющее собой независимый продукт
Microsoft, предназначено для крупных баз данных уровня отдела и небольших
В английском языке подсистема обработки обозначается термином ?rin-time subsystem. He следует
путать его с похожим термином run-time product, который имеет несколько другое значение. Этим
термином некоторые производители обозначают урезанный вариант комплектации СУБД, куда
входят подсистема обработки н ядро, но не входит подсистема средств проектирования. Такой
вариант позволяет лишь запускать готовое приложение. Назначение таких продуктов в том, чтобы
снизить стоимость приложения для конечного пользователя. Обычно СУБД без подсистемы средств
разработки стоит намного дешевле, чем полноценная СУБД, а иногда и вовсе бесплатна.
Следовательно, полную версию продукта покупает только разработчик, а конечные пользователи покупают
сокращенную версию.
Создание базы данных 59
или среднего размера организационных баз данных. Когда вы создаете базу
данных с помощью встроенных в Access 2002 средств генерации таблиц (такие базы
данных хранятся вместе с suffix.mdb), вы используете Jet Engine. Создавая
проект Access 2002 (с suffix.adp), вы тем самым создаете прикладной интерфейс для
ядра SQL Server.
Создание базы данных
Схема базы данных (database scheme) определяет структуру базы данных, ее
таблиц, связей и доменов, а также деловой регламент. Схема базы данных — это
проект, основа, на которой строятся база данных и ее приложения.
Пример схемы базы данных
Чтобы уяснить себе, что такое схема базы данных и зачем она нужна, рассмотрим
пример. Колледж Highline — небольшой колледж свободных искусств на
Среднем Западе США. Отдел студенческого досуга колледжа финансирует локальные
спортивные секции, но испытывает проблемы с учетом спортивного инвентаря,
выданного капитанам различных команд. Схема базы данных для системы учета
спортинвентаря будет содержать следующие компоненты.
Таблицы
База данных имеет две таблицы1: CAPTAIN (CaptainName, Phone,Street City, State, ZIP),
содержащую сведения о капитанах, и ITEM (Quantity, Description, Dateln, DateOut),
содержащую данные об инвентаре. Здесь перед скобками даны имена таблиц, а в
скобках указываются имена столбцов.
Ни CaptainName (имя капитана), ни Description (описание) не обязаны быть
уникальными, поскольку вполне может быть два капитана по имени Мэри Смит,
и уж наверняка имеется много инвентаря под названием «футбольные мячи».
Чтобы обеспечить однозначную идентификацию каждой строки (важность этого
будет объяснена в последующих главах), мы добавим в каждую из этих таблиц
столбец с уникальным номером, как показано ниже:
CAPTAIN(CAPTAIN_ID, CaptainName, Phone, Street, City, State, ZIP)
ITEM(ITEMJD, Quantity, Description, Dateln, DateOut)
Связи
Две представленные здесь таблицы имеют следующие связи: одна строка
таблицы CAPTAIN связана с несколькими строками таблицы ITEM, но одна строка
таблицы ITEM связана с одной и только одной строкой таблицы CAPTAIN. Такая связь
обозначается 1:N и произносится «один kN» или «один ко многим». Обозначение
Как будет показано в главах 3-7, наиболее важной и сложной задачей при разработке баз данных
является проектирование структуры таблиц. Начав этот пример с уже готовых таблиц, мы опустили
большую часть проекта.
60 Глава 2. Введение в разработку баз данных
1:N следует понимать так, что одна строка в первой таблице связана с
несколькими строками во второй таблице.
По тем обозначениям таблиц, которые даны выше, невозможно сказать, какая
строка таблицы CAPTAIN связана с какими строками таблицы ITEM. Поэтому,
чтобы обозначить их связь, мы добавим в таблицу ITEM столбец CAPTAIN_ID. Полная
структура двух таблиц выглядит следующим образом:
CAPTAIN(CAPTAIN_ID, CaptainName, Phone, Street, City,*State, ZIP)
ITEM(ITEM_ID, Quantity, Description, Dateln, DateOut, CAPTAIN JD)
При такой структуре легко определить, какому капитану был выдан данный
инвентарь. Например, чтобы узнать, кому был выдан инвентарь за номером 1234,
в соответствующей строке таблицы ITEM мы найдем значение CAPTAIN JD. По
этому номеру мы сможем определить имя и номер телефона данного капитана.
Домены
Домен1 (domain) — это множество значений, которые может принимать
столбец. Рассмотрим домены для столбцов таблицы ITEM. Предположим, что ITEMJD
и Quantity (количество) — целые числа, Description — текст с максимальной
длиной 25 символов, Dateln и DateOut (даты выдачи и возврата) имеют тип «дата»,
a CAPTAINJD также является целым числом. Кроме задания физического
формата, нам также необходимо решить, будут ли какие-либо из доменов уникальными
для данной таблицы. В нашем примере мы хотим, чтобы столбец ITEMJD был
уникальным, поэтому необходимо указать это в определении домена. Поскольку
капитану может быть выдано более одной единицы инвентаря, столбец CAPTAIN^
ID не является уникальным для таблицы ITEM.
Необходимо также задать домены для столбцов таблицы CAPTAIN. CAPTAIN JD
является целым числом, а все остальные столбцы — это текстовые поля
различной длины. CAPTAIN JD должен быть уникальным для таблицы CAPTAIN.
Деловой регламент
Последний элемент схемы базы данных — это деловой регламент (business rules),
представляющий собой ограничения на возможные действия пользователя,
которые необходимо отразить в базе данных и ее приложениях. Примером делового
регламента для колледжа Highline может служить следующий набор правил:
1. Чтобы капитан мог получить на руки какой-либо инвентарь, у него
должен быть местный телефон.
2. Ни за одним капитаном не должно числиться более семи футбольных
мячей.
3. По окончании каждого семестра капитаны обязаны возвратить весь
инвентарь в течение пяти дней.
4. Капитан не может получить на руки новый инвентарь, если у него имеется
задолженность по ранее взятому инвентарю.
Это определение значительно упрощено, с тем чтобы сконцентрироваться на компонентах системы
базы данных. Более полное обсуждение доменов происходит в главе 4.
Создание базы данных 61
Деловой регламент является важной частью схемы, поскольку он задает
такие ограничения на возможные значения данных, которые должны выполняться
в любом случае, независимо от того, каким образом изменения достигают ядра
СУБД. Не важно, что является источником запроса на изменение данных —
пользователь формы, запрос на обновление/чтение или прикладная программа:
СУБД должна позаботиться о том, чтобы эти изменения не нарушили никаких
правил.
К сожалению, реализация делового регламента осуществляется в различных
СУБД по-разному. В Access 2002 некоторые правила могут задаваться в схеме и
выполняться автоматически. В таких продуктах, как SQL Server и Oracle, деловой
регламент реализуется с помощью так называемых хранимых процедур (stored
procedures). В некоторых случаях СУБД оказывается неспособной реализовать
выполнение требуемых правил, и их приходится закладывать в прикладные
программы. Мы обсудим эту тему более подробно в главе 10.
Создание таблиц
Следующим шагом после разработки схемы базы данных является создание
таблиц. Для этого используются специализированные средства, предоставляемые
СУБД. На рис. 2.4 показан вид окна, используемого Microsoft Access при создании
таблицы ITEM. Имя каждого столбца создаваемой таблицы указывается в столбце
Field Name (Имя поля), а тип данных задастся в столбце Data Type (Тип данных).
В столбце Description (Описание), не обязательном к заполнению, даются описания
столбцов таблицы и комментарии. Дополнительные данные по каждому
столбцу — количество символов, формат, заголовок и прочее — указываются в полях
ввода группы Field Properties (Свойства поля), расположенной в нижней части окна.
На рис. 2.2 фокус ввода находится на столбце ITEMJD. Обратите внимание,
что свойство Indexed (Индексируется) в нижней части окна установлено в значение
Yes (No Duplicates), что означает, что для столбца ITEMJD должен быть создан
индекс из уникальных значений. Таблица CAPTAIN создается аналогичным образом.
Определение связей
Связь между таблицами CAPTAIN и ITEM имеет вид 1:N, что изображается на схеме
путем помещения ключа таблицы CAPTAIN в таблицу ITEM. Столбец, играющий ту
же роль, что и столбец CAPTAINJD в таблице ITEM, называется иногда внешним
ключом (foreign key), поскольку он является ключом таблицы, внешней по
отношению к той таблице, в которой он находится. При создании форм, запросов и
отчетов СУБД может оказать большую помощь разработчику, если она знает, что
столбец CAPTAIN_ID в таблице ITEM является внешним ключом таблицы CAPTAIN.
В различных СУБД статус внешнего ключа объявляется по-разному. В Microsoft
Access для этого рисуется связь между ключом и внешним ключом, как показано
на рис. 2.3. Столбец CAPTAINJD основной таблицы (CAPTAIN) соответствует
столбцу CAPTAIN JD в связанной с ней таблице (ITEM).
62 Глава 2. Введение в разработку баз данных
•»inixj
ITEMJD|
Quantity
Description
DateOut
Datejn
captain" id
AutoNumber
Number
Text
Date/Time
Date/Time
Number
Surrogate key
Quantity checked out
Descntion of item
: Date checked out
Date checked in
■ Foreign key for i ;N relationship to CAPTAIN
ШЩШЙЩШ^: ;
General J Lookup |
FieMSte*1
ЫеЦ-Шв*
Format:.!■■■■
Captibnl -;
inde^cf:;:;
^У1111Ш11111111111':
t:rg Integer
Ircrement
res i^fic Z'Lplicates'
\Afieldnaiflfr.canbeup to
| ertcN^&ersfong,
i ^uding; spaces. Press
Г Fl fcf-h^p .on ftefc}
Рис. 2.2. Создание таблицы в Microsoft Access 2002
1,11-1
з
ТаЫе/Queryt
J CAPTAIN
I CAPTAIN JD
1
1
Related Table/Query:
jJlTEM
jj CAPTAIN JD
d
й
Лснп Type,,
'Г* EnforceR.ef eventsintegrity-
Relationship Tyoe:J:y!$pe-To-Man>
Рис. 2.З. Объявление связи в Microsoft Access 2002
Одним из преимуществ объявления связи для СУБД является то, что
когда данные из столбцов двух таблиц считываются в форму, запрос или отчет,
СУБД знает, как связаны строки этих таблиц. Хотя эту связь можно указать
для каждой конкретной формы, запроса или отчета, однократное объявление
экономит время и снижает вероятность ошибок. На прочие элементы в окне Edit
Relationship (Редактировать связь) мы пока не будем обращать внимания: о них
Компоненты приложения 63
вы узнаете в ходе дальнейшего изложения. Когда определены таблицы, столбцы
и связи, следующим шагом является построение компонентов приложения.
Компоненты приложения
Приложение базы данных состоит из форм, запросов, отчетов, меню и
прикладных программ. Как показано на рис. 2.1, формы, запросы и отчеты можно
создавать с помощью средств, поставляемых в комплекте с СУБД. Прикладные
программы должны быть написаны либо на входном языке СУБД, либо на одном из
стандартных языков и затем посредством СУБД соединены с базой данных.
Формы
На рис. 2.4 изображены три различных представления данных, содержащихся
в таблицах CAPTAIN и ITEM. На рис. 2.4, а данные представлены в табличном
формате. Щелкнув мышью на знаке «плюс», имеющемся в начале каждой строки,
пользователь может увидеть записи из таблицы ITEM, связанные с конкретной
строкой таблицы CAPTAIN. Это было проделано во второй строке для капитана с
фамилией Abernathy. Обратите внимание, что со строкой Abernathy связаны две
строки таблицы ITEM.
На рис. 2.4, б показан второй вид представления — в виде формы для ввода
данных (data entry form). В этой форме в каждый момент времени отображаются
данные для одного капитана. Неопытные пользователи, скорее всего, найдут это
представление более простым в использовании, чем табличный формат.
К странице регистрации капитанов, показанной на рис. 2.4, е, можно
обращаться через Интернет или университетскую интрасеть, используя браузер
Microsoft Internet Explorer. Для этого страница должна храниться на web-сервере,
подобном Internet Information Server. Дальнейшую информацию об этом вы
получите из глав 14-16. На данный момент следует просто знать, что такие формы
можно создавать с помощью средств, входящих в состав Access 2002.
Табличное представление автоматически генерируется Access 2002 для каждой
таблицы, определенной в схеме базы данных. Формы для ввода данных, однако,
должны создаваться с помощью генераторов форм. На рис. 2.5 показан один из
способов создания такой формы. В качестве источника данных для новой формы
заявлена таблица CAPTAIN (не показана на рисунке). Access выводит окно,
называемое списком полей (field list), в котором перечислены все столбцы таблицы CAPTAIN.
На рисунке пользователь перетащил (drag-n-drop) поле CaptainName из списка
полей в форму. В ответ на это Access создал метку с названием CaptainName и
поле ввода, куда будут вводиться значения CaptainName. Теперь поле ввода
привязано (bound) к столбцу CaptainName таблицы CAPTAIN. Другие столбцы
таблицы привязываются аналогичным образом; столбцы таблицы ITEM привязываются
к форме с помощью средства, называемого субформой (subform). В Access
имеется также мастер форм, позволяющий создавать формы наподобие той, что
изображена на рис. 2.4, б.
64 Глава 2. Введение в разработку баз данных
|jji^LUj.',"iHiiiyyiii.. шшшшшшштштшшштт
f5
■. J CeptainN^^^vi^l^^Pftcfhe-^^jP^-*-" ■ :\>'$1&ШШ&*Р'->.ь
+
Miyamoto, Mary '398 232 1770 McGilvra Hall #544
Abernathy, Mary Jayne 223 768 3378 777 East Fiftieth
~¥
Qga;ntity ■•; |;:;:У||::-.:-.Description-: | ■ ^DateOirt^ |
14 Soccer Shirts 3/22/2001
5.Soccer Balls 3/22/2001
o;
+ Jackson, Stephen ; 331.442.1454 300 East Centerview Apt 21
cor
d: _
«1 #1 i $*A+W*]tf.3-x^£}>
Iflfjf |1|1^Ш|11|Ь| *|!
j,-. City -<ШШ1Жгр li
Campus
Chicago
Datefn
6/3/2001
6/3/2001
Evanston
ML ";323398
ML ^22343 ■;
6
НЭ Captain СЬесклЛ;Рй!1^;:П::--й:^Щ=ЙЩ||^ЩШ|
►
Re
Ca
Ph
ptainName JAbernathy, Mary Jayne
one J223 768 337
ITEM
Quantify Description
►
cprc
j" 14 j Soccer Shirts
j 5 )Soccer Balis ~ "
If r-jiz
cord: И I <..] j "_: Г ► Mn-j of 2
1; Hj < 11 2 ► ]HJ»*j of 3 .
ЙЩйй?:8!:Ш:й^'::й?:^.' '■ y''
Street
City
State
|"7Ea>rFiNeihJ
r:,:ago
fr 2p rs:
DateGui Dataln Л
"]3/22>200l"j 6/3/2001
*]3/22/2C0T'] Б/3/2007 -J
"1 1 J
.„Jq.jxlj
зэе i
!
.,
в
ы^тшшвш^ш^ш^^^^^^^^^^^т^. ^m*i\
CaptainNaw.
Phone:
Street:
C*y:
State:
Zip'.
Captain Registration Page 1
|3ackson, Steohen 1!
|зЗМ42.1 1
1300 East Centerview Apt 22 j j
j Evanston
nr— !
122343 '
ч captain2 of 3 ;|j|i ■ ■ v'►;£>!;>■ ■ ►* ^|Ш|$-||;'^^:;':Щ^ j!
Рис. 2.4. Представление данных из таблиц CAPTAIN и ITEM: a — табличный формат;
б — форма для ввода данных; в — форма для ввода данных в браузере
Ни в одной из представленных форм не отображаются столбцы CAPTAIN_ID
и ITEM__ID. Эти идентификаторы скрыты от пользователя. Но СУБД
автоматически присваивает им новые значения, когда пользователь создает новые строки
в таблицах CAPTAIN или ITEM. Так, когда пользователь открывает пустую фор-
Компоненты приложения 65
му, СУБД автоматически создает новую строку в таблице CAPTAIN и присваивает
значение столбцу CAPTAINJD этой строки. Каждый раз, когда пользователь
создает для капитана новую строку в таблице ITEM, СУБД присваивает значение
столбцу ITEM_ID этой строки, а в столбец CAPTAINJD новой строки помещает
текущее значение CAPTAIN_ID. Обратимся вновь к рис. 2.2. Для столбца ITEMJD был
заявлен тип данных AutoNumber (Автонумерация). Это предписывает Access
автоматически присваивать ITEM_ID новые значения всякий раз, когда
создаются новые строки в таблице ITEM. При создании таблицы CAPTAIN (не показана на
рисунке) аналогичный вариант был выбран и для CAPTAIN_ID. Заметьте, однако,
что для столбца CAPTAIN_ID в таблице ITEM автоматическая нумерация не
задается. Это обусловлено тем, что новое значение CAPTAINJD присваивается при
добавлении строки в таблицу CAPTAIN; это значение затем копируется в поле
CAPTAINJD таблицы ITEM, когда строка этой таблицы привязывается к
определенному капитану.
File gdJt_. View':.. Insert Format Tools Window Hdp .:.■■■...'
CaptamNarre - ' Tahoma -8 В 1 U Щ: Ж ^1 &* ~ A * .$ -■ :'"""U c=> ▼ J
Make cliject visible? NUM A
Рис. 2.5. Создание формы в Microsoft Access 2002
Почему же эти идентификаторы скрыты от пользователей? Дело в том, что
для пользователей они не имеют смысла. Колледж Highline не присваивает
идентификаторы капитанам или выдаваемому на руки инвентарю (в противном
случае, если бы пользователи как-то работали с этими идентификаторами, их
66 Глава 2. Введение в разработку баз данных
необходимо было бы сделать видимыми). Идентификаторы введены здесь
только для того, чтобы каждая строка однозначно определялась Access,
следовательно, пользователям нет нужды их видеть. Такие идентификаторы называются
суррогатными ключами (surrogate keys).
Запросы
Время от времени пользователям нужно запрашивать (query) данные из базы,
чтобы отвечать на вопросы, идентифицировать проблемы или обнаруживать
определенные ситуации. Представьте себе, например, что один из пользователей
хочет знать, имеется ли по состоянию на начало осеннего семестра 2001 г. какой-
либо инвентарь, выданный до 1 сентября 2001 г., но еще не возвращенный назад.
Если да, то пользователь хочет знать вид и количество такого инвентаря, а также
имена капитанов, у которых он находится.
Существует множество способов реализации такого запроса. Один из
способов — обратиться к помощи языка запросов (SQL), который описывается в
главе 9. Другой способ заключается в том, чтобы использовать запрос по образцу
(query by example, QBE). На рис. 2.6 показан процесс создания запроса по
образцу в Microsoft Access. Пользователь помещает в окно запросов имена таблиц, из
которых предстоит запрашивать данные. Это уже проделано в верхней части
формы, изображенной на рис. 2.6. Поскольку связь между CAPTAIN и ITEM уже
определена для Access (см. рис. 2.3), то Access знает, что две эти таблицы
связаны через CAPTAINLID, как показывает линия на рис. 2.6 между двумя
прямоугольниками, символизирующими таблицы.
Б Microsoft Access -IQuery t vSelfctt Омегу}
£jfp File Edit V«w insert Query Ipols )$Щ**к-\$№'
fii- ! <fa z ai - 5F> ©:W-::<5L
CAPTAINJD
CaptainName
Phone
Street
City
State
,Zip
4
\
ПЕМ_Ю
Quantity
Description
lOateOut
Dateln
CAPTAIN JD
1
J
Field I CaptainName
TatAe'
So*1:'
Criteria:
Quantity
ITEM
Description
a
<#9/t/2O0t*|
lLL
Й
id
Рис. 2.6. Создание запроса в Microsoft Access 2002
Компоненты приложения 67
Далее указывается, какие столбцы данных следует возвращать в запросе.
В Access это делается путем перетаскивания имен столбцов из прямоугольников,
символизирующих таблицы, в ячейки в нижней части формы. На рис. 2.8 в запрос
помещены столбцы CaptainName, Phone, Quantity, Description, DateOut и Dateln. После
этого в строке Criteria (Критерии) указываются критерии запроса. Критерии
сейчас заключаются в том, что данные должны датироваться числами,
предшествующими (<) 1 сентября 2001 г. (9/1/2001 в американских обозначениях). Знак
«#» в форме — это символ, который окружает даты в Access. Кроме того,
значение Dateln должно быть равно нулю (Is Null); это означает, что для Dateln
значение не задано. Результат этого запроса приведен на рис. 2.7. Обратите внимание,
что весь показанный здесь инвентарь был выдан до 1 сентября 2001 г., что и
требовалось в определении запроса.
В Access и большинстве других СУБД запросы можно хранить как часть
приложения, так что впоследствии при необходимости они могут быть
выполнены повторно. Кроме того, запросы могут быть параметризованными, то есть
построенными так, чтобы значения параметров для них можно было
задавать прямо перед выполнением. Например, можно параметризовать запрос,
изображенный на рис. 2.6, так, чтобы пользователь вводил значение DateOut
непосредственно перед выполнением запроса. В результате будет показан весь
инвентарь, выданный на руки до указанной даты, но до сих пор не
возвращенный.
Третий тин запроса, более легкий для пользователей, называется запросом
из формы (query by form). В этом случае пользователь вводит критерии запроса
в форму для ввода данных и нажимает кнопку поиска. СУБД находит все данные,
соответствующие заданным критериям. В нашем случае в форме на рис. 2.4
пользователь ввел бы <#9/1/2001# в поле DateOut и Is Null в поле Dateln. после
чего нажал бы кнопку QueryByForm (Запрос по форме). СУБД нашла бы записи для
всех капитанов, отвечающие указанным критериям запроса. Запрос по форме
является более новым и современным способом запроса данных, чем запрос по
образцу, и, скорее всего, заменит его во многих приложениях.
Рис. 2.7. Результат запроса, приведенного на рис. 2.6
68 Глава 2. Введение в разработку баз данных
Отчеты
Отчет (report) — это форматированное отображение информации из базы
данных. Отчет на рис. 2.8 содержит по одному разделу на каждого капитана
команды, и в каждом таком разделе приведен список инвентаря, выданного на руки
данному капитану. Например, инвентарь, выданный капитану по имени Мэри
Миямото (Mary Miyamoto), показан в первом разделе отчета.
Captain Equipment Report
vf ■*■?>•;+; <?y+x,:i*:-5?fS!'JS >$&&&'<^'.*\,?:&$&'!Х Ik?.
j CaptainName Miyamoto, Mary
\ Phone 398.2311770
DateOut Quantity Description Dateln
4/1/2001 1 Coaches Manual
4/1/2001 7 Soccer Balls 6/10/2001
4/10/2001 25 Blue Soccer Shirts 6/10/2001
j CaptainName Abernalhy, MaryJayne
\ Phone 223.768.3378
DateOut Quantity Description Dateln
3/22/2001 5 Soccer Balls 6/3/2001
3/22/2001 14 Soccer Shirts 6/3/2001
Рис. 2.8. Пример отчета для колледжа Highline
Разработка отчета напоминает разработку формы для ввода данных, хотя в
некоторых случаях разработать отчет легче, поскольку он используется только для
отображения данных. Иногда отчеты строить труднее, так как зачастую они
имеют более сложную структуру, чем формы.
На рис. 2.9 показан процесс разработки отчета, изображенного на рис. 2.8,
в Microsoft Access. Перед вами образец полосного генератора отчетов (banded
report writer), который называется так потому, что отчет делится на разделы,
или полосы (bands). Как видно из рисунка, в отчете имеется полоса заголовков
(header band), полоса содержимого (detail band) и полоса колонтитулов (footer
band). Полоса заголовка отчета (report header) содержит название отчета, а в
полосе колонтитулов отображается время, когда отчет был напечатан, номер
страницы и общее число страниц. Заголовок страницы (page header) пуст, а
заголовок CAPTAIN J D содержит персональные данные капитана и метки для раздела
содержимого. В разделе содержимого отображается инвентарь, выданный
капитану.
Компоненты приложения 69
Ы Microsoft Access - [Captain Equipment R«mm* : Reporfl
:S.Fte .gtft ..-View Insert Fgrmat Tods Wjndow Мф
; Report - • ' .
# П:
д eg1 ..> Э с - 3 -
Sf
u\
■f Repe»t Heady
Captain Equipment Report
4 Pagie Header
«CAPTAIN Г0 Header
Phone \:?honi? ' J-
D4teOuil.Quartfity Description
«РеЫ
Dti&IX
СчгЧ-'-Л JS.QUWIMt [riC-^I.Qn
«Page Foot a
*F Repot r Fax*
"Azp '; jkfftqp/A )(и/ ' 4 #»5«У i
!ГГ
*td
Design View
Рис. 2.9. Разработка отчета в Microsoft Access 2002
Недостаток этого отчета в том, что два поля с датами оказываются
разделенными. Отчет выглядел бы лучше, если бы мы поместили поле DateOut между
полями Description и Dateln. Это делается путем элементарного перетаскивания
меток и текстовых полей, и именно таковы типичные изменения, которые
делаются с помощью подобных инструментов.
Вообще говоря, отчеты могут иметь много разделов. В более сложном
примере, таком как распределение студентов по курсам, отчет мог бы быть
сгруппирован по таблицам КОЛЛЕДЖ, КАФЕДРА, ДИСЦИПЛИНА и СТУДЕНТ. В этом случае он
имел бы три полосы заголовков и строку содержимого.
Меню
Меню (menus) предназначены для того, чтобы сделать компоненты приложения
более доступными для конечного пользователя, а также для контроля действий
пользователя. На рис. 2.8 показан пример меню для колледжа Highline. В полосе,
находящейся в верхней части формы, изображены пункты меню верхнего уровня:
File (Файл), Forms (Формы), Queries (Запросы), Reports (Отчеты) и Help (Помощь).
Подчеркнутые буквы представляют «горячие» клавиши (hotkeys). Если
удерживать клавишу <Alt>, нажимая при этом клавишу с подчеркнутой буквой,
откроется соответствующее подменю.
На рис. 2.10 пользователь нажал клавиши <Alt> + <5>. Выбранное подменю
состоит из следующих пунктов: Select All Records (Выбрать все записи), Select by Name
(Выбрать по имени) и Select by Phone (Выбрать по номеру телефона). В свою
очередь, каждый из этих пунктов можно выбрать с помощью «горячих» клавиш,
нажимая <ALt> и нужную клавишу. Меню делают приложение более доступным
70 Глава 2. Введение в разработку баз данных
для пользователя, показывая существующие варианты выбора и помогая выбрать
желаемое действие. Меню могут также использоваться для управления доступом
пользователей к формам, отчетам и программам. Некоторые приложения
пользуются этим, динамически изменяя меню после того, как пользователь
зарегистрируется (sign on).
Прикладные программы
Последний компонент приложения базы данных — это прикладные программы
(application programs). Как мы уже упоминали ранее, такие программы могут
быть написаны на входном языке СУБД или на стандартном языке, работа
которого с СУБД обеспечивается через специальный программный интерфейс. Здесь
мы будем пользоваться Microsoft Visual Basic в сочетании с Access 2002.
* Htshime хтшштшшш щшштт
шш
■ №:
РШШ::';|:|0|^^ Нф£!
шшшшшшт
Рис. 2.10. Пример меню
ЁШШШШШШШМШШШШ
>^тт
ii
\
<F-Defce* -У:
Ш Text Вон: Description
■jDescnption
^[CaptamName
ЩХ1
•{phone
Before Update . . ,' r'.: '*
J
Afte/ Update ,
\\\Ш:' '\ЩшШЩЩР1 ..OnCtoty . .
♦ F о* m Header
:-Ш11Щ^1Ц^^;':.Ъ«С!«А№-
# Detail '■..'.-
±L
|lT£M_IDJQuanWy jbescnption
351
On Undo« ! ;'i . . . .
On Change. <
On Enter.
On Exit> . . ; . . ,
On Got Focus ... ,
On lost Focus .....
On dick,
Or, 0Ы Click
*J
1
[Event,Procedure]| rlr, J -—I
zi
-p.
Рис. 2.11. Перехват события в форме Captain Checkout Form
Пусть деловой регламент колледжа Highline содержит правило, гласящее, что
капитаны, которые не живут в общежитии, не могут получать на руки руковод-
Компоненты приложения 71
ство тренера. Мы не знаем, чем обусловлено такое правило, — возможно,
руководство тренера содержит секретные инструкции, которые дают Highline
преимущество в соревнованиях, и колледж хочет контролировать, кому выдается это
руководство. А может быть, руководства дорогие, и студентам, живущим в
общежитии, легче предъявить счет в случае потери. Какой бы ни была причина, Highline
хочет, чтобы приложение базы данных обеспечивало выполнение этого правила.
Есть много способов сделать это. Один из способов, показанный на рис. 2.11, —
перехват события, заключающегося в изменении текстового поля Description
(Описание) в субформе Item (Инвентарь) формы Captain Checkout Form, и
обеспечение соблюдения указанного правила всякий раз, когда описание
меняется. На рис. 2.9 разработчик открыл окно свойств для текстового поля Description
и указал, что в случае изменения содержимого поля (On Change) следует перейти
к процедуре обработки события (Event Procedure). После этого Access открыл окно
для ввода процедуры, изображенное на рис. 2.12.
£fe £dt View Insert Debug Run Tools Add-!ns Window £ф/
■ Jafxj
0^4
► и тЫ Ы&ЪЯ'(-Щй$Ы-р:,
•Зй $& acwzmain (ACWZMAIM)
Б-|£ IH2DB1(CH2DB1)
В -'Ч Microsoft Access Class Obje._i-
Ш fwthJTEMSubfam
iL
J Description Textbox
^'Alphabetic fciigitaiHJs v
^d
[ColumnWtdth
kortrobource
CootroiTipText
ControlType
pecimaJPtaces
beFauKValue
pisplaywhen
enabled
[EnterKev6ehavior
|дшаши
:2310
iDescfiptnn
;109
io
0
jTrue
'False
| Desertion
-1
J
■Ш
шшммшишм
-»j;. Ichange
«s
||«UisJj<fi
~3
^civate Sub Description Change О
If Forma'[Captain Checkout Form]'City.Value <> "Campus" Then
If InStr(Description.Text, "Coaches Manual") > 0 Then
Beep
MsgBox ("Off campus coaches cannot checkout coaches manual")
Description.Text - ""
End If
1
Рис. 2.12. Код Visual Basic, реализующий положение делового регламента
Разработчик написал фрагмент кода на Visual Basic, который будет
запускаться при изменении описания. Сначала процедура определяет ситуацию, когда
значение поля City (Город) не равно строке «Campus» («Общежитие»). В этом
случае вызывается функция InStr, проверяющая, содержится ли в поле описания
инвентаря (Description.Text) строка «Coac2hes Manual» («Руководство Тренера»).
Если да, то генерируется звуковой сигнал и выдается предупреждающее
сообщение, а поле Description очищается.
Этот код запускается всякий раз, когда пользователь изменяет значение
текстового поля Description. Есть и другие, более эффективные способы выполнения
этого правила, но здесь нашей целью было показать, как код приложения может
быть связан с формами базы данных.
72 Глава 2. Введение в разработку баз данных
Разумеется, можно также написать код, работающий независимо от
каких-либо форм или отчетов. Можно написать программы, читающие и обновляющие
данные в базе точно так же, как это делается с файлами других типов. Примеры
подобных программ вы увидите далее в этой книге, в частности в главе 15, где
мы продемонстрируем использование Microsoft ADO для чтения и обновления
данных на web-сервере, и в главе 16, где будет показано использование Java для
той же цели.
Процесс разработки базы данных
Многие тома были посвящены разработке информационных систем вообще и
приложений баз данных в частности, поэтому здесь нам нет нужды сколько-нибудь
глубоко обсуждать процессы системной разработки. В завершение этой главы
мы лишь кратко рассмотрим процессы, используемые для разработки баз данных
и их приложений.
Общие стратегии
База данных — это модель пользовательской модели деловой активности.
Поэтому, для того чтобы построить эффективную базу данных и ее приложения,
команда разработчиков должна ясно представить себе пользовательскую модель.
Для этого команда строит модель данных, идентифицирующую объекты, которые
должны храниться в базе данных, и определяет их структуру и связи между
ними. Это понимание должно быть достигнуто на ранней стадии процесса
разработки путем опроса пользователей и составления технического задания (statement of
requirements). Большинство таких технических заданий включают
использование прототипов (prototypes) — шаблонных баз данных и приложений,
представляющих различные аспекты создаваемой системы.
Есть две общих стратегии разработки баз данных: сверху вниз и снизу вверх.
Разработка сверху вниз (top-down database development) идет от общего к
частному. Она начинается с изучения стратегических целей организации, способов,
при помощи которых эти цели могут быть достигнуты, требований к
информации, которые должны быть удовлетворены для достижения этих целей, и систем,
необходимых для предоставления такой информации. Результатом такого
исследования является абстрактная модель данных.
Отталкиваясь от этой общей модели, команда разработчиков двигается «вниз»,
к все более и более подробным описаниям и моделям. Модели промежуточного
уровня также постоянно детализируются, пока не воплотятся в конкретные базы
данных и их приложения. Одно или более из этих приложений берется затем
в разработку. В конце концов вся высокоуровневая модель данных
трансформируется в низкоуровневые модели, после чего реализуются все указанные
системы, базы данных и приложения.
Процесс разработки базы данных 73
При разработке снизу вверх (bottom-up database development) уровень
абстракции меняется в обратном направлении: исходным пунктом является
необходимость в конкретной системе. Способ выбора первой системы варьируется от
организации к организации. В одних организациях приложение выбирается
правлением, в других пользователи могут выбирать его самостоятельно, в
третьих побеждает мнение того, кто в администрации громче всех кричит.
Так или иначе, для разработки выбирается конкретная система. Команда
разработчиков затем составляет техническое задание, рассматривая выходы и
входы существующих компьютерных систем, анализируя формы и отчеты,
используемые в существующих системах с ручной записью, и опрашивая пользователей
с целью определения их потребностей в новых отчетах, формах и запросах, а
также других требований. Исходя из этого всего, команда программистов
разрабатывает информационную систему. Если система включает в себя базу данных,
команда на основании технического задания строит модель данных, а имея
модель данных, она проектирует и реализует базу данных. Когда создание данной
системы завершается, запускаются другие проекты, целью которых является
построение дополнительных информационных систем.
Сторонники разработки сверху вниз утверждают, что этот подход имеет
преимущество перед разработкой снизу вверх, поскольку модели данных (и
соответствующие им системы) строятся с глобальной перспективой. Они считают,
что такие системы гораздо лучше взаимодействуют между собой, являются
более согласованными и требуют намного меньше переделок.
Сторонники разработки снизу вверх говорят, что такой подход работает
быстрее и сопряжен с меньшим риском. Они утверждают, что моделирование
сверху вниз выливается в большое количество трудновыполнимых исследований
и что процесс планирования часто заходит в тупик. Хотя моделирование снизу
вверх не обязательно имеет своим результатом оптимальный набор систем, тем
не менее, с его помощью можно быстро создать работающую систему. Такие
системы начинают давать прибыль гораздо быстрее, чем системы, смоделированные
сверху вниз, и это более чем компенсирует любые переделки и модификации,
которые придется сделать, чтобы настроить систему на глобальную перспективу.
В этой книге описываются средства и способы, которые можно
использовать при любом стиле системной разработки. Например, хотя и модель
«сущность—связь» (глава 3), и семантическая объектная модель (глава 4) работают
при разработке как сверху вниз, так и снизу вверх, модель «сущность—связь»
более эффективна при разработке сверху вниз, а семантическая объектная
модель — при разработке снизу вверх.
Моделирование данных
Как уже говорилось, наиболее важная цель на стадии разработки технического
задания — это создание модели данных пользователя (user data model), или
моделирование данных (data modeling). Как бы это ни делалось — сверху вниз или
74 Глава 2. Введение в разработку баз данных
снизу вверх, — это включает в себя опрос пользователей, документирование
требований и построение модели данных и прототипов на основе этих требований.
Такая модель показывает, какие объекты должны храниться в базе данных, и
определяет их структуру и связи между ними.
Рассмотрим, например, рис. 2.13, а — список заказов, выполненных
продавцом за определенный период времени. Чтобы приложение базы данных могло
выдать такой отчет, база данных должна содержать информацию,
представленную в этом отчете, поэтому разработчики базы данных должны исследовать этот
отчет и на его основании определить, какие данные должны храниться в базе.
В нашем случае должны быть данные о продавцах (имя и регион) и данные о
заказах (компания, дата заказа и количество товара).
Разработка баз данных осложняется тем, что требований может быть
несколько и они обычно перекрываются. Отчет на рис. 2.13, б также содержит
данные о продавцах, но вместо заказов в нем перечислены комиссионные. Глядя
на этот отчет, мы можем предположить, что существуют различные типы заказов
и для каждого из них определен свой процент комиссионных.
Список заказов
03 октября 2001
Имя
Kevin Dougherty
Mary В. Wu
продавца
Регион
Западный
Западный
НазваниеКомпании
Cabo Controls
Ajax Electric
American Maxell
ДатаЗаказа
9/12/2001
9/17/2001
9/24/2001
Общая сумма:
Сумма
$2,349,83
$2,349,88
$23,445,00
$17,339,44
$40,784,44
$43,134,32
Отчет о комиссионных продавца
03 октября 2001
Имя МестныйНомер ДатаВыпискиЧека ТипКомиссионных СуммаКомиссионных
I Kevin Dougherty 232-9988
MaryB.Wu 232*9987
9/30/2001
9/30/2001
9/30/2001
xz
с
A
Общая сумма:
$487,38
$487,38
$237,44
$1,785,39
$2,022,83
$2,510,21
Рис. 2.13. Примеры двух связанных отчетов: а — отчет о продажах
и б — отчет о комиссионных
Процесс разработки базы данных 75
Заказы, перечисленные в отчете на рис. 2.13, 6, каким-то образом связаны с
заказами, перечисленными на рис. 2.13, д, но каким именно, остается не слишком
ясным. Команда разработчиков должна определить эти связи, делая выводы из
отчетов и форм, интервьюируя пользователей, используя собственные знания по
данному вопросу и другие источники.
Моделирование данных как делание выводов
Когда пользователи говорят, что им нужны формы и отчеты с определенными
данными и структурами, это подразумевает, что у них в голове имеется некая
модель, представляющая вещи в их мире. Однако пользователи могут быть не
в состоянии точно описать эту модель. Если бы разработчик спросил типичного
пользователя: «Как вы себе представляете структуру модели данных,
касающихся продавцов?», то мир пользователя выглядел бы по меньшей мере загадочным,
поскольку большинство пользователей не мыслят такими категориями.
Вместо того чтобы задавать подобные вопросы, разработчики должны из
высказываний пользователя о формах и отчетах делать выводы о структуре
и связях объектов, которые должны храниться в базе данных. Затем разработчики
воплощают эти выводы в модели данных, которая трансформируется в проект
базы данных, который, в свою очередь, реализуется при помощи СУБД. Затем
конструируются приложения, генерирующие отчеты и формы для
пользователей.
Таким образом, построение модели данных — это процесс делания
предположений. Отчеты и формы напоминают тени на стене. Пользователи могут описать
тени, но не могут описать формы тел, отбрасывающих эти тени. Поэтому
разработчикам приходится делать предположения, решать обратную задачу, и
реконструировать из этих теней структуры и связи.
Этот процесс является, к сожалению, в большей степени искусством, чем
наукой. Можно изучить все средства и способы моделирования данных
(фактически эти средства и способы являются предметом разговора в следующих двух
главах), но их использование представляет собой искусство, которое требует
опыта, направляемого интуицией.
Качество модели является важным аспектом. Если документированная
модель данных адекватно отображает модель данных, присутствующую в
воображении пользователя, есть отличный шанс, что разработанные на ее основании
приложения будут отвечать потребностям пользователей. Если же
пользовательская модель данных отображена в документированной модели
неадекватно, то приложение вряд ли приблизится к тому, что действительно нужно
пользователям.
Моделирование в многопользовательских системах
Процесс моделирования данных еще больше усложняется в
многопользовательских коллективных и организационных базах данных, поскольку различные
пользователи могут представлять себе различные модели данных. Эти модели
76 Глава 2. Введение в разработку баз данных
могут оказаться несогласованными, хотя в большинстве случаев несоответствия
между ними могут быть устранены. Например, пользователи могут употреблять
один и тот же термин для разных вещей или различные термины для одной и той
же вещи.
Но иногда имеющиеся различия не дают возможности согласованного
решения. В таких случаях разработчик базы данных должен документировать эти
различия и помочь пользователям разрешить их, а это, как правило, означает,
что некоторым людям придется изменить свой взгляд на мир.
Недоразумения по поводу термина «модель»
В следующих двух главах представлены два альтернативных средства для
построения моделей данных: модель «сущность—связь» и семантическая
объектная модель. Обе модели представляют собой структуры для описания и
документирования требований пользователя к данным. Чтобы избежать недоразумений,
обратите внимание на различное использование термина модель. Команда
разработчиков анализирует требования и строит пользовательскую модель данных, или
модель требований к данным (requirements data model). Эта модель является
представлением требований пользователя к структуре и связям объектов,
которые должны храниться в базе данных. Для создания пользовательской модели
данных команда разработчиков использует средства, которые называются моделью
«сущность—связь» и семантической объектной моделью. Эти средства состоят из
языковых и изобразительных стандартов для представления пользовательской
модели данных. Их роль в разработке баз данных подобна той роли, которую
выполняют алгоритмы и псевдокод в программировании.
Резюме
Компонентами системы базы данных являются база данных, СУБД и
прикладные программы, с которыми работают как пользователи, так и разработчики.
База данных состоит из данных, метаданных, индексов и метаданных приложения.
Большинство современных баз данных представляют данные в виде отношений,
или таблиц, хотя не все отношения одинаково желательны. Нежелательные
отношения могут быть преобразованы в два или более желательных с помощью
процесса, называемого нормализацией. Метаданные часто хранятся в специальных
таблицах, которые называются системными таблицами.
Характеристики и функции СУБД можно сгруппировать в три подсистемы.
С помощью подсистемы средств проектирования определяется структура базы
данных, приложений и их компонентов. Функцией подсистемы обработки
является материализация форм, отчетов и запросов путем чтения или записи данных
в базу. Ядро СУБД является посредником между двумя другими
подсистемами и операционной системой. Она принимает запросы, выраженные в
терминах таблиц, строк и столбцов, и преобразует их в запросы на физическое чтение
и запись.
Вопросы I группы 77
Схема — это описание структуры базы данных. Она включает в себя описание
таблиц, связей и доменов, а также деловой регламент. Строки одной таблицы
могут быть связаны со строками других таблиц. В этой главе проиллюстрирована
связь вида 1:N между двумя таблицами; как вы увидите из следующей главы,
есть и другие типы связей.
Домен — это множество значений, которые может иметь столбец. Мы должны
указывать домен для каждого столбца каждой таблицы.
Наконец, деловой регламент — это ограничения на виды деловой активности,
которые должны быть отражены в базе данных и ее приложениях.
Для создания табличных структур, определения связей и создания форм,
запросов, отчетов и меню используются средства, предоставляемые СУБД. СУБД
также включают в себя средства для взаимодействия с прикладными
программами, написанными либо на входном языке СУБД, либо на стандартных языках,
таких как Java.
Поскольку база данных является моделью пользовательской модели деловой
активности, разработка базы данных начинается с изучения и записи этой
модели. Иногда она выражается в форме прототипов будущего приложения или
компонентов приложения.
Два общих стиля разработки таковы: разработка сверху вниз, которая идет от
общего к частному, и разработка снизу вверх, которая идет от частного к
общему. В первом случае приложения разрабатываются с глобальной перспективой,
зато во втором случае разработка идет быстрее. Иногда используется
комбинация этих двух подходов.
Модели данных конструируются путем делания выводов из высказываний
пользователя. Собираются формы, отчеты и запросы, и на их основании
разработчики делают вывод о структурах, существующих в воображении
пользователей. Это необходимо, поскольку большинство пользователей не способны
непосредственно описать свои модели данных. Моделирование данных может быть
особенно затруднительным в многопользовательских приложениях, где
представления различных пользователей могут противоречить друг другу, и ни один
пользователь не может представить себе всю картину деловой активности.
Термин модель данных используется двояко: он может означать как модель
пользовательских представлений о данных, так и средства, используемые для
описания этих представлений.
Вопросы I группы
1. Назовите основные компоненты системы базы данных и кратко поясните
функцию каждого из них.
2. Приведите пример отношения (отличный от представленного в этой
главе), обновление которого может быть сопряжено с проблемами. В качестве
образца используйте отношение R1.
78 Глава 2. Введение в разработку баз данных
3. Преобразуйте отношение из вашего ответа на вопрос 2 в два или более
отношения, для которых проблем при обновлении не возникнет. В качестве
образца используйте отношения R2 и R3.
4. Поясните роль, которую играют метаданные и системные таблицы.
5. Какова функция индексов? В каких случаях их применение оправдано
и чем приходится за них платить?
6. Какова функция метаданных приложения? В чем их отличие от
метаданных?
7. Дайте описание характеристик и функций подсистемы средств
разработки СУБД.
8. Дайте описание характеристик и функций подсистемы обработки СУБД.
9. Дайте описание характеристик и функций ядра СУБД.
10. Что такое схема базы данных? Перечислите ее компоненты.
11. Как представляются связи в проекте реляционной базы данных?
Приведите пример двух таблиц, имеющих связь вида 1:N, и объясните, каким
образом эта связь отражается на данных.
12. Что такое домены и зачем они нужны?
13. Что такое деловой регламент? Приведите пример делового регламента для
отношений из вашего ответа на вопрос 11.
14. Что такое внешний ключ? Какой столбец (или столбцы) отношений из
вашего ответа на вопрос 11 является внешним ключом?
15. Опишите назначение форм, отчетов, запросов и меню.
16. Поясните разницу между запросом по образцу и запросом по форме.
17. Какова первая важнейшая задача при разработке базы данных и ее
приложений?
18. Какую роль играют прототипы?
19. Опишите процесс разработки базы данных сверху вниз. Каковы его
преимущества и недостатки?
20. Опишите процесс разработки базы данных снизу вверх. Каковы его
преимущества и недостатки?
21. Дайте два различных толкования термина модель данных.
Вопросы II группы
22. Реализуйте базу данных с отношениями CAPTAIN и ITEM в любой СУБД,
к которой у вас есть доступ. Используйте средства, предлагаемые данной
СУБД, для ввода данных в каждое из этих двух отношений. С помощью
средств, предоставляемых СУБД, создайте и обработайте запрос, который
показывает список инвентаря, выданного на руки до 1 сентября 2001 г., но
Вопросы к проекту FiredUp 79
еще не возвращенного. Распечатайте для такого инвентаря имя капитана,
его номер телефона, а также количество и описание.
23. Поговорите с профессиональным разработчиком приложений баз данных
и выясните, какой процесс он использует для разработки баз данных.
Разработка ли это сверху вниз, снизу вверх или какая-то другая стратегия?
Как этот разработчик строит модели данных и какие средства он для этого
использует? Каковы главные проблемы, возникающие при разработке базы
данных?
24. Проанализируйте утверждение: «База данных — это модель
пользовательской модели реальности». В чем его отличие от утверждения «База
данных — это модель реальности»? Представьте себе, что у двоих
разработчиков возник спор по поводу модели данных, и один из них заявляет: «Моя
модель лучше представляет реальность». Что этот разработчик
подразумевает в действительности? Какие отличия могут возникнуть, если
разработчик более склонен верить первому утверждению, чем второму?
Вопросы к проекту FiredUp
Рассмотрим ситуацию с компанией FiredUp, с которой вы познакомились в
первой главе. С каждой горелкой покупатель получает бланк регистрации продукта,
содержащий следующие данные: имя покупателя, почтовый адрес (улица, дом,
квартира, город, штат, почтовый индекс, страна), адрес электронный почты,
телефон, дата покупки и серийный номер.
Предположим, что FiredUp решает создать персональную базу данных со
следующими таблицами: КЛИЕНТ (Имя, Улица, Дом, Квартира, Город, Штат, ПочтовыйИн-
декс, Страна, ЭлектронныйАдрес, Телефон) и ПОКУПКА (ДатаПокупки, СерийныйНомер).
1. Создайте таблицу с данными, структура которой будет соответствовать
таблице КЛИЕНТ. В таблице должно быть по меньшей мере четыре
строки. (Для ответа на вопросы 1-7 достаточно ввести данные в текстовом
редакторе.)
2. Какой из столбцов таблицы КЛИЕНТ можно использовать для однозначной
идентификации строки в таблице? Такой столбец иногда называется
первичным ключом, как вы позже узнаете из этой книги.
3. Создайте таблицу с данными, структура которой будет соответствовать
таблице ПОКУПКА. В таблице должно быть по меньшей мере четыре строки.
4. Какой из столбцов таблицы ПОКУПКА можно использовать в качестве
первичного ключа для этой таблицы?
5. Имея определенные выше таблицы, невозможно связать конкретного
покупателя с его горелкой. Один из способов сделать это — добавить столбец
СерийныйНомер из таблицы ПОКУПКА в таблицу КЛИЕНТ. После этого
таблица КЛИЕНТ будет выглядеть следующим образом: КЛИЕНТ (Имя, Улица, Дом,
Квартира, Город, Штат, ПочтовыйИндекс, Страна, ЭлектронныйАдрес, Телефон).
80 Глава 2. Введение в разработку баз данных
Скопируйте данные из таблицы КЛИЕНТ и добавьте к ним столбец Серий-
ныйНомер. Назовите получившуюся таблицу КЛИЕНТ1.
6. Связь двух таблиц можно представить и по-другому: поместить столбец
ЭлектронныйАдрес из таблицы КЛИЕНТ в таблицу ПОКУПКА. После этого
таблица ПОКУПКА будет выглядеть следующим образом: ПОКУПКА (ДатаПо-
купки, СерийныйНомер, ЭлектронныйАдрес). Скопируйте данные из таблицы
ПОКУПКА и добавьте к ним столбец ЭлектронныйАдрес из таблицы КЛИЕНТ.
Назовите получившуюся таблицу П0КУПКА1.
7. Теперь у вас имеются три возможные структуры: КЛИЕНТ1 + П0КУПКА,
КЛИЕНТ+П0КУПКА1 и КЛИЕНТ1+П0КУПКА1. При каких условиях вы могли
бы рекомендовать первую структуру? Вторую структуру?
8. При каких условиях вы могли бы порекомендовать третью структуру?
Часть II
Моделирование данных
Моделирование данных — это процесс создания логического представления
структуры базы данных. Правильно сконструированная модель данных должна
поддерживать все пользовательские представления данных. Моделирование данных
является наиболее важной задачей при разработке эффективных приложений баз
данных. Если база данных будет неверно отражать пользовательское
представление данных, то пользователи найдут ее приложения неудобными, неполными
и не оправдывающими ожиданий. Моделирование данных — основа для всей
последующей работы при разработке баз данных и их приложений.
Часть II описывает два различных подхода к моделированию данных. В главе 3
рассматривается модель «сущность—связь» (entity-relationship model), имеющая
значительное количество сторонников среди профессиональных разработчиков
баз данных. В главе 4 описывается семантическая объектная модель, которая
обладает меньшим числом приверженцев, однако некоторые считают ее более
богатой и простой в использовании, чем модель «сущность—связь».
Эти модели представляют собой языки для описания структуры данных и их
связей в представлении пользователей. Моделирование данных отражает
логическую структуру данных, так же как блок-схемы алгоритмов отражают
логическую структуру программы.
Глава 3
Модель «сущность—связь»
Эта глава описывает и иллюстрирует использование модели «сущность—связь»
(entity-relationship model), введенной Питером Ченом (Peter Chen) в 1976 г1.
В этой статье Чен заложил основу модели, которая с тех пор расширялась и
модифицировалась самим Ченом и многими другими2. Кроме того, модель
«сущность—связь» вошла в состав множества CASE-инструментов, которые также
внесли свой вклад в ее эволюцию. На сегодняшний день не существует единого
общепринятого стандарта для модели «сущность—связь», зато есть набор общих
конструкций, которые лежат в основе большинства вариантов этой модели.
Описанию этих общих конструкций и демонстрации их применения и посвящена
данная глава. Символы, применяемые для графического представления модели
«сущность—связь», весьма различны. Мы обсудим не только традиционные
символы, но и символы языка UML (Unified Model Language, унифицированный
язык моделирования) — средства проектирования, завоевывающего все
большую популярность среди программистов ООП и включающего в себя модель
«сущность—связь».
Элементы модели «сущность—связь»
Ключевыми элементами модели «сущность—связь» являются сущности,
атрибуты, идентификаторы и связи. Рассмотрим каждый из них по очереди.
Сущности
Сущность (entity) — это некоторый объект, идентифицируемый в рабочей
среде пользователя, нечто такое, за чем пользователь хотел бы наблюдать.
Примерами сущностей могут служить СОТРУДНИК Мэри Доу, КЛИЕНТ 12345, ЗАКАЗ 1000,
ПРОДАВЕЦ Джон Смит или ПРОДУКТ А4200. Сущности одного и того же типа
группируются в классы сущностей (entity classes). Так, класс сущностей СОТРУДНИК
1 P. P. Chen, «The Entity-Relationship Model — Towards a Unified View of Data», ACM Transactions on
Database Systems, январь 1976, с. 9-36.
2 Thomas A. Bruce, Designing Quality Databases with IDEF1X Information Modeh (New York: Dorset House
Publishing, 1992).
Элементы модели «сущность—связь» 83
является совокупностью всех сущностей СОТРУДНИК. В тексте книги классы
сущностей обозначаются заглавными буквами.
Важно уяснить разницу между классом сущностей и экземпляром сущности.
Класс сущностей — это совокупность сущностей, и описывается он структурой
или форматом сущностей, составляющих этот класс. Экземпляр сущности (entity
instance) представляет конкретную сущность, такую как КЛИЕНТ 12345; он
описывается значениями атрибутов данной сущности. Обычно класс сущностей
содержит множество экземпляров сущности. Например, класс КЛИЕНТ содержит
множество экземпляров — по одному на каждого клиента, для которого имеется
запись в базе данных. Пример класса сущностей и двух экземпляров сущности
показан на рис. 3.1.
КЛИЕНТ
сущность содержит:
НомерКлиента
ИмяКлиента
Адрес
Город
Штат
Почтовый Индекс
ИмяДоверенногоЛица
НомерТелефона
Два экземпляра сущности КЛИЕНТ:
12345
Ajax Manufacturing
123 Elm St
Memphis
TN
32455
P. Schwartz
223-5567
67890
Jefferson Dance Club|
345-10th Avenue
Boston
MA
01234
Frita Bellingsley
210-8896
Рис. З.1. КЛИЕНТ: пример сущности
Атрибуты
У сущностей есть атрибуты (attributes), или, как их иногда называют, свойства
(properties), которые описывают характеристики сущности. Примерами
атрибутов могут служить Имя Сотрудника, ДатаНайма и КодКвалификации. В тексте этой
книги атрибуты обозначаются как прописными, так и строчными буквами. В
модели «сущность—связь» предполагается, что все экземпляры данного класса
сущностей имеют одинаковые атрибуты.
Исходное определение модели «сущность—связь» включает в себя
композитные атрибуты (composite attributes) и многозначные атрибуты (multi-valued
attributes). В качестве примера композитного атрибута можно привести атрибут
Адрес, состоящий из группы атрибутов {Улица, Город, Штат, Индекс}. Примером
многозначного атрибута может служить атрибут ИмяДоверенногоЛица сущности
КЛИЕНТ, который может содержать имена нескольких доверенных лиц данного
клиента. Атрибут может быть одновременно и композитным, и многозначным —
84 Глава 3. Модель «сущность—связь»
например композитный атрибут Телефон, состоящий из группы атрибутов {Код-
Региона, МестныйНомер}, может быть многозначным, что позволит иметь в базе
данных несколько телефонных номеров одного и того же лица. В большинстве
реализаций модели «сущность—связь» однозначные композитные атрибуты
игнорируются, и требуется, чтобы многозначные атрибуты (будь они составные
или нет) преобразовывались в сущности, как будет показано ниже.
Идентификаторы
Экземпляры сущностей имеют идентификаторы (identifiers) — атрибуты, с
помощью которых эти экземпляры именуются, или идентифицируются. Например,
экземпляры сущностей класса СОТРУДНИК могут идентифицироваться по
атрибутам НомерСоциальнойСтраховки, ТабельныйНомерСотрудника или ИмяСотрудника.
Такие атрибуты, как Зарплата или ДатаНайма, вряд ли могут служить
идентификаторами экземпляров сущностей класса СОТРУДНИК, поскольку обычно эти атрибуты
не используются для однозначного указания на конкретного сотрудника.
Подобно этому, сущности класса КЛИЕНТ могут идентифицироваться по атрибутам
НомерКлиента или ИмяКлиента, а сущности класса ЗАКАЗ могут
идентифицироваться по атрибуту НомерЗаказа.
Идентификатор экземпляра сущности состоит из одного или более атрибутов
сущности. Идентификатор может быть уникальным (unique) либо неуникальным
(nonunique). Если идентификатор является уникальным, его значение будет
указывать на один и только один экземпляр сущности. Если идентификатор
является неуникальным, его значение будет указывать на некоторое множество
экземпляров. ТабельныйНомерСотрудника является, скорее всего, уникальным
идентификатором, а ИмяСотрудника — неуникальным (например, может быть
несколько сотрудников по имени Джон Смит).
Идентификаторы, состоящие из нескольких атрибутов, называются
композитными идентификаторами (composite identifiers). Примерами могут служить
совокупности вида {КодРегиона, МестныйНомер}, {НазваниеПроекта, НазваниеЗадачи}
и {Имя, Фамилия, ДобавочныйНомерТелефона}.
Связи
Взаимоотношения сущностей выражаются связями (relationships). Модель
«сущность—связь» включает в себя классы связей и экземпляры связей1. Классы
связей (relationship classes) — это взаимоотношения между классами сущностей,
а экземпляры связи (relationship instances) — взаимоотношения между
экземплярами сущностей. У связей могут быть атрибуты.
Класс связей может затрагивать несколько классов сущностей. Число классов
сущностей, участвующих в связи, называется степенью связи (relationship degree).
Изображенная на рис. 3.2, а связь ПРОДАВЕЦ-ЗАКАЗ имеет степень 2, поскольку
Для краткости мы будем иногда опускать слово экземпляр в тех случаях, когда из контекста будет
очевидно, что подразумевается именно экземпляр сущности, а не класс сущностей.
Элементы модели «сущность—связь» 85
в ней участвуют два класса сущностей: ПРОДАВЕЦ и ЗАКАЗ. Связь РОДИТЕЛЬ на
рис. 3.2, б имеет степень 3, так как в ней участвуют три класса сущностей: МАТЬ,
ОТЕЦ и РЕБЕНОК. Связи степени 2 весьма распространены, их часто называют еще
бинарными связями (binary relationships).
ПРОДАВЕЦ
ПРОДАВЕЦ-ЗАКАЗ
ЗАКАЗ
а б
Рис. 3.2. Различные степени связей: а — связь степени 2; б — связь степени 3
Три типа бинарных связей
На рис. 3.3 показаны три типа бинарных связей. В связи 1:1 («один к одному»)
одиночный экземпляр сущности одного типа связан с одиночным
экземпляром сущности другого типа. На рис. 3.3, а связь СЛУЖЕБНЫЙ_АВТОМОБИЛЬ
связывает одиночную сущность класса СОТРУДНИК с одиночной сущностью класса
АВТОМОБИЛЬ. В соответствии с этой диаграммой, ни за одним сотрудником не
закреплено более одного автомобиля, и ни один автомобиль не закреплен более чем
за одним сотрудником.
СОТРУДНИК
м>
АВТОМОБИЛЬ
СЛУЖЕБНЫИ-АВТОМОБИЛЬ
а
ОБЩЕЖИТИЕ
СТУДЕНТ
ОБЩЕЖИТИЕ-ЖИЛЕЦ
б
СТУДЕНТ
КЛУБ
СТУДЕНТ-КЛУБ
СТУДЕНТ
ОБЩЕЖИТИЕ 1Щ№ЩУ^ СТУДЕНТ
IT-
КЛУБ
Рис. 3.3. Три типа бинарных связей: а — бинарная связь 1:1; б ~ бинарная связь 1:14;
в — бинарная связь N:M; г — представление связи с помощью разветвлений
На рис. 3.3, б изображен второй тип связи, 1:N («один к N» или «один ко
многим»). В этой связи, которая называется ОБЩЕЖИТИЕ-ЖИЛЕЦ, единичный
экземпляр сущности класса ОБЩЕЖИТИЕ связан со многими экземплярами сущно-
86 Глава 3. Модель «сущность—связь»
сти класса СТУДЕНТ. В соответствии с этим рисунком, в общежитии проживает
много студентов, но каждый студент живет только в одном общежитии.
Позиция, в которой стоят 1 и N, имеет значение. Единица стоит на той
стороне связи, где располагается ОБЩЕЖИТИЕ, а N стоит на той стороне связи, где
располагается СТУДЕНТ. Если бы 1 и N располагались наоборот, и связь записывалась
бы как N:l, получилось бы, что в общежитии живет один студент, причем
каждый студент живет в нескольких общежитиях. Это, разумеется, не так.
На рис. 3.3, в показан третий тип бинарной связи, N:M (читается «N к М» или
«многие ко многим»). Эта связь называется СТУДЕНТ-КЛУБ, и она связывает
экземпляры сущностей класса СТУДЕНТ с экземплярами сущностей класса КЛУБ.
Один студент может быть членом нескольких клубов, а в одном клубе может
состоять много студентов.
Числа внутри ромба, символизирующего связь, обозначают максимальное
количество сущностей на каждой стороне связи. Эти ограничения называются
максимальными кардинальными числами, а совокупность из двух таких
ограничений для обеих сторон связи называется максимальной кардинальностью (maximum
cardinality) связи. Например, о связи, изображенной на рис. 3.3, б, говорят, что
она обладает максимальной кардинальностью 1:N. Кардинальные числа могут
иметь и другие значения, а не только 1 и N. Например, связь между сущностями
БАСКЕТБОЛЬНАЯ_КОМАНДА и ИГРОК может иметь кардинальность 1:5, что говорит
нам о том, что в баскетбольной команде может быть не более пяти игроков.
Связи трех типов, представленных на рис. 3.3, называются иногда связями
типа «ИМЕЕТ», или связями обладания (HAS-A relationships). Такой термин
используется потому, что одна сущность имеет (has) связь с другой сущностью.
Например: сотрудник имеет автомобиль, студент имеет общежитие, клуб имеет
студентов.
Диаграммы «сущность—связь»
Схемы, изображенные на рис. 3.3, называются диаграммами «сущность—связь»,
или ER-диаграммами (entity-relationship diagrams, ER-diagrams). Такие
диаграммы стандартизированы, но не слишком жестко. В соответствии с этим
стандартом, классы сущностей обозначаются прямоугольниками, связи обозначаются
ромбами, а максимальное кардинальное число каждой связи указывается внутри
ромба1. Имя сущности указывается внутри прямоугольника, а имя связи
указывается рядом с ромбом.
ОБЩЕЖИТИЕ
C1:N
СТУДЕНТ
ОБЩЕЖИТИЕ-СТУДЕНТ
Рис. 3.4. Связь с указанной минимальной кардинальностью
Описываемые здесь графические символы, которые берут начало в этой модели, не являются
лучшим способом отображения модели в системе с графическим интерфейсом пользователя, подобной
Macintosh или Microsoft Windows. Фактически модель «сущность—связь» была разработана задолго
до того, как какая-либо система графического интерфейса приобрела популярность. Символы
языка UML, которые будут представлены позже в этой главе, легче использовать в графической среде.
Элементы модели «сущность—связ^» 87
Хотя в некоторых ER-диаграммах имя связи указывается внутри ромба,
получающаяся при этом диаграмма может выглядеть ужасно, поскольку ромбы
приходится делать большого размера и вне масштаба, чтобы в них поместилось
имя связи. Чтобы избежать этого, имена связей иногда пишут над ромбом. Когда
имя помещается внутрь или поверх ромба, кардинальность связи изображается
с помощью разветвлений на линиях, соединяющих сущность (или сущности)
с множественной стороной связи. На рис. 3.3, г показаны связи ОБЩЕЖИТИЕ-
ЖИЛЕЦ и СТУДЕНТ-КЛУБ с такими разветвлениями.
Как мы уже говорили, максимальная кардинальность показывает максимальное
число сущностей, которые могут участвовать в связи. Каково же минимальное
число таких сущностей, приведенные диаграммы не сообщают. Например, рис. 3.3, б
показывает, что студент может проживать максимум в одном общежитии, однако
из него не ясно, обязан ли студент проживать в каком-либо общежитии.
Для указания минимальной кардинальности (minimum cardinality) существует
несколько способов. Один из них, продемонстрированный на рис. 3.4, заключается
в следующем: чтобы показать, что сущность обязана участвовать в связи, на линию
связи помещают перпендикулярную черту, а чтобы показать, что сущность может
(но не обязана) участвовать в связи, на линию связи помещают овал.
Соответственно, рис. 3.4 показывает, что сущность ОБЩЕЖИТИЕ должна быть связана как
минимум с одной сущностью СТУДЕНТ, однако сущность СТУДЕНТ не обязана иметь
связь с сущностью ОБЩЕЖИТИЕ. Полный набор накладываемых на связь
ограничений состоит в том, что ОБЩЕЖИТИЕ имеет минимальное кардинальное число,
равное единице, и максимальное кардинальное число, равное «многим» сущностям
СТУДЕНТ. СТУДЕНТ имеет минимальное кардинальное число, равное нулю, и
максимальное кардинальное число, равное одному экземпляру сущности ОБЩЕЖИТИЕ.
Может существовать связь между сущностями одного и того же класса.
Например, для сущностей класса СТУДЕНТ может быть определена связь С0СЕД_
П0_К0МНАТЕ. Такая связь показана на рис. 3.5, я, а на рис. 3.5, б изображены
экземпляры сущностей, охваченных этой связью. Связи между сущностями
одного и того же класса называются иногда рекурсивными связями (recursive
relationships).
Изображение атрибутов в диаграммах
«сущность—связь»
В некоторых версиях ER-диаграмм атрибуты обозначаются эллипсами,
соединенными с сущностью или связью, которой они принадлежат. На рис. 3.6, а показаны
сущности ОБЩЕЖИТИЕ и СТУДЕНТ и связь ОБЩЕЖИТИЕ-ЖИЛЕЦ с принадлежащими
им атрибутами. Как видно из рисунка, сущность ОБЩЕЖИТИЕ имеет атрибуты
НазваниеОбщежития, Местоположение и КоличествоКомнат, а сущность СТУДЕНТ
имеет атрибуты НомерСтудента, ИмяСтудента и Курс. Связь ОБЩЕЖИТИЕ-ЖИЛЕЦ имеет
атрибут Плата, который показывает внесенную студентом плату за проживание
в конкретном общежитии.
Если сущность имеет много атрибутов, такое их перечисление в ER-диаграмме
может сделать ее чересчур громоздкой и трудной для восприятия. В подобных случаях
88 Глава 3. Модель «сущность—связь»
список атрибутов сущностей дается отдельно, как показано на рис. 3.6, б. Многие
CASE-средства показывают такие атрибуты в раскрывающихся окнах.
СТУДЕНТ
^
1:N)
СОСЕД-ПО-КОМНАТЕ
Рис. 3.5. Рекурсивная связь
НомерСтудента '
[ Местоположение\)
(ЯазваниеОбщежития)
ОБЩЕЖИТИЕ-
ЖИЛЕЦ
ОБЩЕЖИТИЕ
КоличествоКомнат
СТУДЕНТ
ОБЩЕЖИТИЕ-
ЖИЛЕЦ
ОБЩЕЖИТИЕ
СТУДЕНТ
ОБЩЕЖИТИЕ содержит СТУДЕНТ содержит
НазваниеОбщежития
Местоположение
КоличествоКомнат
НомерСтудента
ИмяСтудента
Курс
ОБЩЕЖИТИЕ-ЖИЛЕЦ содержит
Плата
Рис. 3.6. Изображение свойств на диаграммах «сущность—связь»
а — указание на диаграмме; б — отдельное перечисление
Элементы модели «сущность—связь» 89
Слабые сущности
В модели «сущность—связь» определен особый тип сущности, называемый
слабой сущностью (weak entity). К слабым сущностям относятся такие сущности,
которые могут существовать в базе данных только в том случае, если в ней
присутствует сущность некоторого другого типа. Сущность, не являющаяся слабой,
называется сильной сущностью (strong entity).
Чтобы разобраться в том, что такое слабые сущности, рассмотрим базу данных
отдела кадров с классами сущностей СОТРУДНИК и ПОДЧИНЕННЫЙ. Предположим,
что, в соответствии с деловым регламентом, экземпляр сущности СОТРУДНИК может
существовать, не будучи связанным ни с одной сущностью класса ПОДЧИНЕННЫЙ,
но сущность ПОДЧИНЕННЫЙ не может существовать вне связи с какой-либо
сущностью класса СОТРУДНИК. Тогда сущность ПОДЧИНЕННЫЙ является слабой.
Это означает, что данные о сущности ПОДЧИНЕННЫЙ могут появиться в базе
данных только в том случае, если эта сущность имеет связь с какой-либо сущностью
класса СОТРУДНИК.
СОТРУДНИК
1:N>ej ПОДЧИНЕННЫЙ!
ДОМ
КВАРТИРА
Идентификатор: Идентификатор:
НазваниеДома {НазваниеДома
НомерКвартиры}
6
Рис. 3.7. Слабые сущности: а — пример слабой сущности;
б — пример идентификационно-зависимой сущности
Как показано на рис. 3.7, б, слабые сущности обозначаются
прямоугольниками со скругленными углами. Кроме того, связь, от которой зависит
существование сущности, обозначается ромбом со скругленными углами. В качестве
альтернативы, в некоторых ER-диаграммах (не показано здесь) прямоугольники для
слабых сущностей рисуются двойной линией, а связи, от которых зависит
существование этих сущностей, изображаются двойными ромбами.
В модели «сущность—связь» имеется особый тип слабых сущностей,
называемый идентификационно-зависимыми сущностями (ID-dependent entities). Это
такие сущности, идентификаторы которых содержат идентификатор другой
сущности. Рассмотрим сущности ДОМ и КВАРТИРА. Пусть идентификатором
сущности ДОМ является атрибут НазваниеДома, а идентификатором сущности КВАРТИРА
является композитный идентификатор {НазваниеДома, НомерКвартиры}.
Поскольку идентификатор сущности КВАРТИРА содержит в себе идентификатор
сущности ДОМ (НазваниеДома), то сущность КВАРТИРА является
идентификационно-зависимой от сущности ДОМ. Сравните рис. 3.7, б с рис. 3.7, а. По-другому можно
представить это так, что, как логически, так и физически, квартира не может
существовать, если не существует соответствующего здания.
90 Глава 3. Модель «сущность—связь»
Идентификационно-зависимые сущности встречаются часто. Еще одним
примером может служить сущность ВЕРСИЯ в связи с сущностью ПРОДУКТ, где
ПРОДУКТ — это некоторый программный продукт, а ВЕРСИЯ — номер его версии.
Идентификатором продукта является атрибут НазваниеПродукта, а
идентификатором версии является совокупность {НазваниеПродукта, НомерВерсии}. Третий
пример — это сущность ИЗДАНИЕ в связи с сущностью У.ЧЕБНИК.
Идентификатором сущности УЧЕБНИК является атрибут Заглавие, а идентификатором издания
является совокупность {Заглавие, ПорядковыйНомерИздания}.
К сожалению, в определении термина слабая сущность есть скрытая
неоднозначность, и она по-разному интерпретируется различными проектировщиками
баз данных (а также различными авторами книг). Эта неоднозначность
заключается в следующем: в строгом смысле, слабая сущность определяется как любая
сущность, чье присутствие в базе данных зависит от другой сущности; тогда
любая сущность, участвующая в связи минимальной кардинальности 1 с другой
сущностью, является слабой. Таким образом, рассматривая базу данных
образовательного учреждения, можно заключить следующее: если у студента должен
быть руководитель, то сущность СТУДЕНТ является слабой, поскольку она не
может быть записана в базу данных без связи с какой-либо сущностью класса
РУКОВОДИТЕЛЬ. Это толкование, однако, кажется некоторым людям слишком
широким. Студент физически не зависит от руководителя (в отличие от случая
с квартирой и домом), как не зависит от него и логически (что бы по этому
поводу ни думали студент и руководитель!), поэтому сущность СТУДЕНТ должна
считаться сильной сущностью.
Чтобы избежать подобных ситуаций, некоторые интерпретируют определение
слабой сущности более ограниченно. Чтобы сущность можно было отнести к
разряду слабых, она должна логически зависеть от другой сущности. Согласно
данному определению, сущности ПОДЧИНЕННЫЙ и КВАРТИРА должны считаться
слабыми, а сущность СТУДЕНТ — нет. Подчиненный не был бы подчиненным, если бы
не находился в подчинении у кого-то, а квартира не может существовать без
здания, в котором она могла бы располагаться. Студент же может логически
существовать и без руководителя, даже если деловой регламент этого не допускает.
Чтобы проиллюстрировать эту интерпретацию, рассмотрим несколько
примеров. Пусть модель данных включает в себя связь между сущностями ЗАКАЗ
и АГЕНТ (рис. 3.8, а). Хотя можно сказать, что для каждого заказа должен быть
указан агент, в действительности это не обязательно (заказ может быть, к
примеру, продажей за наличные, при которой имя агента не записывается).
Следовательно, минимальное кардинальное число, равное 1, проистекает из делового
регламента, а не из логической необходимости. Таким образом, сущность ЗАКАЗ,
хотя и требует наличия сущности АГЕНТ, не зависит от существования последней,
поэтому ЗАКАЗ следует рассматривать как сильную сущность.
Теперь рассмотрим связь между сущностями ПАЦИЕНТ и РЕЦЕПТ,
изображенную на рис. 3.8, б. Здесь рецепт не может логически существовать без пациента.
Следовательно, помимо того, что минимальное кардинальное число сущности
РЕЦЕПТ равно 1, эта сущность также зависит от существования сущности ПАЦИЕНТ.
Отсюда следует, что РЕЦЕПТ — это слабая сущность. Наконец, рассмотрим сущность
Элементы модели «сущность—связь» 91
НАЗНАЧЕНИЕ, изображенную на рис. 3.8, в. Идентификатор этой сущности
содержит идентификатор сущности ПРОЕКТ. Здесь, кроме того, что сущность НАЗНАЧЕНИЕ
имеет минимальную кардинальность 1 и зависит от существования сущности
ПРОЕКТ, она является еще и идентификационно-зависимой от последней,
поскольку ее ключ содержит ключ сущности ПРОЕКТ. Таким образом, сущность
НАЗНАЧЕНИЕ является слабой.
АГЕНТ
РЕЦЕПТ
ПРОЕКТ
Идентификатор:
НазваниеПроекта
Рис. 3.8. Примеры обязательных сущностей
В этой книге мы определяем слабые сущности как логически зависящие от
существования другой сущности. Следовательно, не все сущности, имеющие
минимальную кардинальность 1 в связи с другой сущностью, являются слабыми.
Только логически зависимые сущности квалифицируются нами как слабые. Это
определение также подразумевает, что слабыми являются все
идентификационно-зависимые сущности. Кроме того, любая слабая сущность имеет
минимальное кардинальное число 1 в связи с сущностью, от которой зависит, но
произвольно взятая сущность с минимальным кардинальным числом, равным 1, не
обязательно должна быть слабой1.
Представление многозначных атрибутов при помощи
слабых сущностей
Многозначные атрибуты представляются в модели «сущность—связь» путем
создания новой слабой сущности и построения связи вида «один ко многим».
В качестве примера на рис. 3.9, а изображено представление многозначного
атрибута ДоверенноеЛицо сущности КЛИЕНТ. Создается новая сущность под с именем
Д0ВЕРЕНН0Е_ЛИЦ0 с единственным атрибутом ДоверенноеЛицо. Связь между
сущностями Д0ВЕРЕНН0Е_ЛИЦ0 и КЛИЕНТ имеет вид «один ко многим». Созданная
таким образом сущность должна быть слабой, поскольку она логически зависит
от сущности, имеющей многозначный атрибут.
Здесь не упоминаются случаи, когда минимальная кардинальность оказывается больше единицы.
Логика аналогична, но сущность теперь зависит от набора сущностей.
ЗАКАЗ
ПАЦИЕНТ
а
б
( НАЗНАЧЕНИЕ }fl-<ft:1
Идентификатор:
{НазваниеПроекта,
Название задачи}
92 Глава 3. Модель «сущность—связь»
На рис. 3.9, б изображено представление многозначного составного атрибута
Адрес. Новая слабая сущность АДРЕС содержит всю совокупность атрибутов, а
именно атрибуты Улица, Город, Штат и ПочтовыйИндекс.
имя_доверенного_лица)
ИМЯ_ДОВЕРЕННОГО_ЛИЦА содержит:
ИмяДоверенногоЛица
АДРЕС J
АДРЕС содержит:
Улица
Город
Штат
Индекс
Рис. 3.9. Представление многозначных атрибутов с помощью слабых сущностей
Подтипы сущностей
Некоторые сущности имеют необязательные наборы атрибутов; эти сущности
часто представляются с помощью подтипов (subtypes)1. Рассмотрим, например,
сущность КЛИЕНТ с атрибутами НомерКлиента, ИмяКлиента и СуммаКОплате.
Предположим, что клиент может быть физическим лицом, товариществом или корпорацией
и что необходимо указывать некоторую дополнительную информацию,
зависящую от типа клиента. Пусть эта информация имеет следующее содержание:
ФИЗИЧЕСКОЕ_ЛИЦО: Адрес, НомерСоциальнойСтраховки
ТОВАРИЩЕСТВО: ИмяУправляющегоПартнера, Адрес, ИдентификационныйНалоговый-
Номер
КОРПОРАЦИЯ: КонтактноеЛицо, Телефон, ИдентификационныйНалоговыйНомер
Одна из возможностей — отнести все эти атрибуты к сущности КЛИЕНТ, как
показано на рис. 3.10, а. В этом случае, однако, некоторые атрибуты будут
неприменимы. Например, такой атрибут, как имя управляющего партнера, не имеет
смысла для индивидуального или корпоративного клиента, и таким образом, он
не может иметь какого-либо значения.
В модели, более близкой к реальной ситуации, вместо этого будет определено три
подтипа сущностей, как показано на рис. 3.10, 6. Здесь сущности ФИЗИЧЕСКОЕ_
ЛИЦО, ТОВАРИЩЕСТВО и КОРПОРАЦИЯ изображены как подтипы сущности КЛИЕНТ.
Последняя, в свою очередь, является надтипом (supertype) для сущностей
ФИЗИЧЕСКОЕ.ЛИЦО, ТОВАРИЩЕСТВО и КОРПОРАЦИЯ.
Подтипы были добавлены в модель «сущность—связь» после публикации оригинальной статьи Че-
на, и они являются частью того, что называется расширенной моделью ^сущность—связь*.
КЛИЕНТ
КЛИЕНТ содержит:
НомерКлиента
ИмяКлиента
прочие атрибуты...
КЛИЕНТ
КЛИЕНТ содержит:
НомерКлиента
ИмяКлиента
прочие атрибуты...
1:N
:1:N
Элементы модели «сущность—связь»
93
Символ е рядом с линиями связи указывает, что сущности ФИЗИЧЕСКОЕ_ЛИЦО,
ТОВАРИЩЕСТВО и КОРПОРАЦИЯ являются подтипами сущности КЛИЕНТ. Каждый
подтип должен принадлежать надтипу КЛИЕНТ. Кривая линия с цифрой 1 рядом
показывает, что сущность КЛИЕНТ должна принадлежать к одному и только
одному подтипу. Это означает, что подтипы являются взаимоисключающими и что
требуется только один из них.
КЛИЕНТ содержит:
НомерКлиента
ИмяКлиента
СуммаКОплате
Адрес
НомерСоциальнойСтраховки
ИмяУправляющегоПартнера
ИдентификационныйНалоговыйНомер
ДоверенноеЛицо
PhoneK Телефон
КЛИЕНТ содержит:
НомерКлиента
ИмяКлиента
СуммаКОплате
ФИЗИЧЕСКОЕ_ЛИЦО содержит:
Адрес
НомерСоциальнойСтраховки
ТОВАРИЩЕСТВО содержит:
ИмяУправляющегоПартнера
Адрес
ИдентификационныйНалоговыйНомер
КОРПОРАЦИЯ содержит:
ДоверенноеЛицо
Телефон
ИдентификационныйНалоговыйНомер
КЛИЕНТ,
ИСПОЛЬЗУЮЩИЙ
Windows NT
КЛИЕНТ,
ИСПОЛЬЗУЮЩИЙ]
UNIX
КЛИЕНТ,
ИСПОЛЬЗУЮЩИЙ
БОЛЬШУЮ ЭВМ
Рис. 3.10. Подтипы сущностей: а — КЛИЕНТ без подтипов; б — КЛИЕНТ с подтипами;
в — невзаимоисключающие подтипы с необязательным надтипом
Сущности со связью типа «ЕСТЬ» должны иметь один и тот же
идентификатор, поскольку они представляют различные аспекты одного и того же. В данном
94 Глава 3. Модель «сущность—связь»
случае таким идентификатором является НомерКлиента. Сравните эту ситуацию
со связью типа «ИМЕЕТ», показанной на рис. 3.3, где сущности представляют
различные вещи.
Иерархии генерализации имеют специальную характеристику, называемую
наследованием (inheritance), которая означает, что подтипы классов сущностей
наследуют атрибуты от надтипа. Сущность ТОВАРИЩЕСТВО, к примеру, наследует
атрибуты ИмяКлиента и СуммаКОплате от сущности КЛИЕНТ.
Причины, по которым подтипы используются в моделировании данных,
отличаются от причин, по которым они используются в объектно-ориентированном
программировании. Фактически, в модели данных они применяются с
единственной целью: избежать ситуаций, при которых некоторые атрибуты должны иметь
нулевые значения. Например, на рис. 3.10, я, если атрибуту НомерСоциальнойСтра-
ховки присвоено значение, то остальные четыре атрибута должны быть равны
нулю. Эта ситуация наиболее ярко проявляется в медицинских приложениях:
представьте себе, например, что пациенту мужского пола задается вопрос о
количестве беременностей. Нулевые значения более детально обсуждаются в главе 6.
Пример ER-диаграммы
На рис. 3.11 показан пример ER-диаграммы, содержащей все элементы модели
«сущность—связь», о которых шла речь до сих пор. Она изображает сущности
и связи для инженерной консалтинговой компании, которая занимается
анализом строительства и состояния домов и других зданий и сооружений.
СОТРУДНИК
ЗАКРЕПЛЕННЫЙ_ГРУЗОВИК
ГРУЗОВИК
ИНЖЕНЕР
ИСПОЛНИТЕЛЬ_РАБОТЫ \n
ИНЖЕНЕР-КВАЛИФИКАЦИЯ
1:N)
РАБОТА
ИНЖЕНЕР-
СЕРТИФИКАЦИЯ
м/ КЛИЕНТ-РАБОТА /мХ
м/ / N > ВИД-СЕРТИФИКАТА
СЕРТИФИКАТ
КЕМ_ПРИВЕДЕН
Рис. 3.11. Пример диаграммы «сущность—связь»
На диаграмме есть класс сущностей, представляющий сотрудников компании.
Поскольку некоторые сотрудники являются инженерами, сущность СОТРУДНИК
Элементы модели «сущность—связь» 95
связана с сущностью ИНЖЕНЕР как подтип. Каждый инженер должен быть
сотрудником; сущность ИНЖЕНЕР имеет связь 1:1 с сущностью ГРУЗОВИК; каждый
грузовик должен быть закреплен за каким-то инженером, но не у всех
инженеров есть грузовики.
Инженеры выполняют работы (сущность РАБОТА) для клиентов (сущность
КЛИЕНТ). Инженер может не выполнять никаких работ (иначе говоря, выполнять
ноль работ) или выполнять много работ, но каждая отдельно взятая работа
может выполняться только одним конкретным инженером. Для одного и того же
клиента может выполняться много различных работ, и один и тот же вид работы
может выполняться для множества клиентов. Клиент должен оплатить как
минимум одну работу, но различные виды работ существуют независимо от клиентов.
Связь КЛИЕНТ-РАБОТА имеет атрибут Плата, который показывает сумму,
уплаченную конкретным клиентом за конкретную работу. (Прочие атрибуты сущностей
и связей не показаны на этой диаграмме.)
Иногда одни клиенты приводят других, что показывается с помощью
рекурсивной связи КЕМ_ПРИВЕДЕН. Клиент может привести одного или нескольких
других клиентов. Клиент не обязан быть приведен другим клиентом, но каждого
клиента может привести только один клиент.
Сущность СЕРТИФИКАЦИЯ_ИНЖЕНЕРА показывает, что данный инженер получил
образование и прошел тестирование, требуемое для получения конкретного
сертификата. Инженер может иметь сертификаты (сущность СЕРТИФИКАТ).
Существование сущности СЕРТИФИКАЦИЯ_ИНЖЕНЕРА зависит от сущности ИНЖЕНЕР
через связь ИНЖЕНЕР-КВАЛИФИКАЦИЯ. СЕРТИФИКАТ - это сущность, описывающая
конкретный сертификат.
Документирование делового регламента
В главе 2 в качестве элементов схемы базы данных были введены таблицы, связи,
домены и деловой регламент. Первые три элемента присутствуют в модели
«сущность—связь» или логически выводятся из нее, но деловой регламент в этой
модели никак не упомянут. Таким образом, правила, составляющие деловой
регламент, иногда добавляются к ER-модели на стадии моделирования данных.
ER-модель разрабатывается исходя из анализа требований,
сформулированных пользователями. В процессе этого анализа часто возникает вопрос о
деловом регламенте, и, разумеется, системные аналитики должны взять себе за
правило спрашивать о нем пользователей.
Рассмотрим сущности ГРУЗОВИК и ИНЖЕНЕР на рис. 3.11. Имеются ли в
деловом регламенте правила, касающиеся того, за кем может быть закреплен
грузовик? Если имеющегося количества грузовиков недостаточно для того, чтобы
закрепить грузовик за каждым инженером, то какие правила будут определять то,
кому достанется грузовик? Быть может, приложение базы данных должно
назначать грузовики в пользование тем инженерам, в графике которых стоит
наибольшее количество работ в течение определенного периода времени или
наибольшее количество работ вне офиса; возможны и другие варианты.
Другой пример — распределение работ между инженерами. Могут
существовать правила, определяющие то, каким набором сертификатов должен обладать
96 Глава 3. Модель «сущность—связь»
инженер, чтобы быть допущенным к выполнению определенных видов работ.
К примеру, может быть, что для инспектирования многоквартирного дома
инженер должен иметь лицензию профессионального инженера. Даже если закона,
предписывающего такой порядок, не существует в природе, данное правило
может быть продиктовано политикой компании.
Выполнение правил делового регламента может (но не обязано)
обеспечиваться средствами СУБД, а может быть организовано в прикладной программе.
Иногда деловой регламент формулируется в виде процедур, которым должны
следовать пользователи приложения базы данных. На данный момент способ,
с помощью которого организуется выполнение правил делового регламента, не
имеет значения. Важно документировать эти правила, чтобы они стали частью
системных требований.
Модель «сущность—связь» и CASE-средства
Разработка моделей данных в рамках модели «сущность—связь» значительно
упростилась в последние годы, поскольку теперь инструменты для построения
ER-диаграмм входят в состав многих популярных CASE-средств. К таким
продуктам относятся, в частности, IEW, IEF, DEFT, ER-WIN и Visio. Эти продукты
также объединяют сущности с отношениями, с помощью которых эти сущности
представлены в базе данных, что может облегчить администрирование,
управление и обслуживание базы данных.
Мы не предполагаем работать с CASE-средствами в рамках данной книги.
Но если в вашем университете имеется такое средство, всеми способами
используйте его для создания ER-диаграмм при выполнении назначенных вам
упражнений. ER-диаграммы, созданные с помощью CASE-средств, обычно имеют более
красивый вид, и их гораздо легче изменять и адаптировать.
Диаграммы «сущность—связь» в стиле UML
Унифицированный язык моделирования (UML) — это набор структур и методик
для моделирования и проектирования объектно-ориентированных программ
(ООП) и приложений. UML — это одновременно и методология разработки
систем ООП, и набор инструментов для разработки таких систем. UML получил
известность стараниями группы OMG (Object Management Group) —
организации, которая занимается разработкой ООП-моделей, технологии и стандартов
с 1980-х годов. Этот язык стал также находить широкое применение в среде
профессионалов ООП. На UML базируются инструменты для
объектно-ориентированного проектирования, разработанные компанией Rational Systems.
Будучи методологией разработки приложений, UML является предметом
курса системной разработки и поэтому представляет для нас лишь
ограниченный интерес. Вам могут, однако, встретиться диаграммы «сущность—связь»,
выполненные в стиле UML, поэтому представление об этом стиле следует иметь.
Диаграммы «сущность—связь» в стиле UML 97
Нужно просто осознать, что когда дело касается проектирования баз данных,
обращение с этими диаграммами происходит точно так же, как и с традиционными
ER-диаграммами.
Сущности и связи в UML
На рис. 3.12 приведено UML-представление структур, изображенных на рис. 3.3.
Каждая сущность представлена классом сущностей, который изображен в виде
прямоугольника с тремя сегментами. В верхнем сегменте указано имя сущности
и другие данные, о которых мы будем говорить далее. Во втором сегменте
перечислены имена атрибутов сущности, а в третьем описаны ограничения и методы
(программные процедуры), относящиеся к данной сущности.
СОТРУДНИК
НомерСотрудника
Имя
Должность
Телефон
КодКвалификации
Ограничения и методы
перечисляются здесь
СЛУЖЕБНЫЙ_АВТОМОБИЛЬ
0..1 1..1
АВТОМОБИЛЬ
НомерЛицензии
VINHoMep
Производитель
Модель
ГодВы пуска
Ограничения и методы
перечисляются здесь
а
ОБЩЕЖИТИЕ
Название
МестныйАдрес
КоличествоМест
Телефон
Ограничения и методы
перечисляются здесь
ОБЩЕЖИТИЕ-ЖИЛЕЦ
1..1 0..*
СТУДЕНТ
НомерСтудента
ИмяСтудента
Телефон
Группа
Комната
Ограничения и методы
перечисляются здесь
б
СТУДЕНТ
НомерСтудента
ИмяСтудента
| Телефон
Группа
Комната
Ограничения и методы
перечисляются здесь
СТУДЕНТ-КЛУБ
0..* 0..*
КЛУБ
НомерКлуба
КодИсточникаФинансирования
Описание
Президент
Телефон Президента
Ограничения и методы
перечисляются здесь
в
Рис. 3.12. Представления различных типов связей в UML: a — связь 1:1;
б — связь 1 :N; a — связь N:M
98 Глава 3. Модель «сущность—связь»
Связи показаны линиями, соединяющими две сущности. Кардинальность
представлена в формате х..у, где х — это необходимый минимум, а у —
допустимый максимум. Так, 0..1 означает, что наличие данной сущности необязательно,
а максимально допустимое количество — одна. Звездочка представляет
неограниченное количество. Например, запись 1..* означает, что требуется одна сущность,
а допускается неограниченное количество. Найдите на-рис. 3.12, а> б примеры
связей с максимальной кардинальностью 1:1, 1:N и N:M.
Представление слабых сущностей
На рис. 3.13 изображено UML-представление слабых сущностей. На линии связи
рядом с родителем слабой сущности (то есть рядом с сущностью, от которой
зависит слабая сущность) помещается закрашенный ромб. На рис. 3.13, а сущность
РЕЦЕПТ является слабой сущностью, а сущность ПАЦИЕНТ — ее родителем. Все
слабые сущности имеют родителя, поэтому их кардинальность в связи с родителем
всегда 1..1. Исходя из этого, кардинальность на родительской стороне
обозначается просто как 1.
ПАЦИЕНТ
Имя
Телефон
Страховая Компа н ия
НомерСтраховки
Идентификатор: Имя
Методы
ПАЦЕНТ-РЕЦЕПТ
<не идентифицирующая>
ж1 0..*
w
РЕЦЕПТ
Дата
Но мер Рецепта
Врач
Лекарство
Дозировка
Идентификатор: НомерРецепта
Методы
а
ПРОЕКТ
НазваниеПроекта
Дата Начала
ДатаЗавершения
КодИсточникаФинансирования
Идентификатор: НазваниеПроекта
Методы
ПРОЕКТ-НАЗНАЧЕНИЕ
<идентифици рующая>
1..1 0..*
НАЗНАЧЕНИЕ
НазваниеЗадачи
НачалоРаботы
Предполаг аемоеКоличествоЧасов
ДействительноеКоличествоЧасов
Имя Сотрудника
Ограничения и методы
перечисляются здесь
б
Рис. 3.13. Представление слабых сущностей в UML: а — слабая сущность, не являющаяся
идентификационно-зависимой; б — идентификационно-зависимая слабая сущность
На рис. 3.13, а показана слабая сущность, не являющаяся идентификационно-
зависимой. Это обозначается выражением <non-identifying> (не
идентифицирующая) на связи ПАЦИЕНТ-РЕЦЕПТ. На рис. 3.13, б изображена идентификационно-
зависимая слабая сущность. На это указывает ярлык <identifying>
(идентифицирующая).
Диаграммы «сущность—связь» в стиле UML 99
Представление подтипов
Способ представления подтипов в UML показан на рис. 3.14. На этом рисунке
допустимыми подтипами сущности КЛИЕНТ являются ФИЗИЧЕСКОЕ_ЛИЦО,
ТОВАРИЩЕСТВО и КОРПОРАЦИЯ. В соответствии с рисунком, каждый клиент может иметь
один, два или все три указанных подтипа. Для данной ситуации это не имеет
смысла: клиент должен быть одного и только одного типа. Текущая версия UML
не предоставляет способов для документирования взаимоисключаемости.
Можно, однако, добавить в диаграмму соответствующее обозначение.
КЛИЕНТ
НомерКлиента
ИмяКлиента
СуммаКОплате
Идентификатор: НомерКлиента
Методы
Т Тип Клиента
ФИЗИЧЕСКОЕ_ЛИЦО КОРПОРАЦИЯ
Адрес ДоверенноеЛицо
НомерСоциальнойСтраховки Телефон
ИдентификационныйНалоговыйНомер
Методы Методы
ТОВАРИЩЕСТВО
ИмяУправляющегоПартнера
Адрес
ИдентификационныйНалоговыйНомер
| Методы
Рис. 3.14. Представление подтипов в UML
На рис. 3.15 представлена UML-версия диаграммы «сущность—связь»,
показанной ранее на рис. 3.11. Поскольку связь между сущностями РАБОТА и КЛИЕНТ
имеет атрибут Плата, для несения этого атрибута выделена специальная
сущность РАБОТА_ДЛЯ_КЛИЕНТА. Такова стандартная практика при использовании
средств UML. Обратите также внимание на представление рекурсивной связи
КЕМЛРИВЕДЕН.
Конструкции ООП, введенные языком UML
Так как UML является объектно-ориентированной технологией, к классам
сущностей UML были добавлены некоторые конструкции ООП. Здесь мы только
коснемся этих идей, а развитие им дадим в главе 18. Во-первых, классы всех
сущностей, которые должны храниться в базе данных, помечаются стереотипом
100
Глава 3. Модель «сущность—связь»
«Persistent» (устойчивый). Это означает, что существование данных должно
продолжаться даже после того, как будет разрушен объект, их обрабатывавший.
Проще говоря, это значит, что класс сущности должен храниться в базе данных.
СОТРУДНИК
ЗАКРЕПЛЕННЫИ_ГРУЗОВИК ТипСотрудника
I
ГРУЗОВИК
i КЛИЕНТ-
РАБОТА
Плата
0..*
КЛИЕН
КЛИЕНТ
0..1 1..1
ИСПОЛНИТЕЛЬ^
0..* 1.1
РАБОТА-КР
T-KP
ИНЖЕНЕР
АБОТЫ
0..*
РАБОТА
п л
и.л
0..*
КЕМ_ПРИВЕДЕН
♦1 °'Ч
ИНЖЕНЕР- I
КВАЛИФИКАЦИЯ
ИНЖЕНЕР-
СЕРТИФИКАЦИЯ
ВИД_СЕРТИФИКАТА
0..*
| СЕРТИФИКАТ |
Рис. 3.15. UML-версия диаграммы «сущность—связь» с рис. 3.11
Далее, UML допускает назначение атрибутов классам сущностей. Атрибуты
класса (class attributes) отличаются от атрибутов сущностей тем, что они
принадлежат всему классу сущностей данного типа. Так, на рис. 3.16 атрибут Число-
Пациентов сущности ПАЦИЕНТ является атрибутом всей совокупности сущностей
этого типа, имеющихся в базе данных. ИсточникПоступления — это атрибут,
документирующий источник поступления всех пациентов, присутствующих в базе
данных.
Как вы позже узнаете, в рамках реляционной модели такие атрибуты
классов просто негде хранить. Вместо того чтобы хранить атрибуты вроде
ЧислоПациентов в базе данных, они иногда вычисляются на этапе выполнения программы.
В других случаях для хранения этих атрибутов выделяется специальный класс
сущностей. Для класса сущностей ПАЦИЕНТ, изображенного на рис. 3.16,
можно создать новую сущность под названием ИСТ0ЧНИК_П0СТУШ1ЕНИЯ_ПАЦИЕНТА,
имеющую атрибуты ЧислоПациентов и ИсточникПоступления. В таком случае все
сущности класса ПАЦИЕНТ будут связаны с сущностью ИСТ0ЧНИК_П0СТУПЛЕНИЯ_
ПАЦИЕНТА.
Диаграммы «сущность—связь» в стиле UML 101
«Перманентный»
ПАЦИЕНТ
#ЧислоПациентов
#ИсточникПоступления
#НомерПациента
#Имя
#Телефон
#СтраховаяКомпания
| #НомерСтраховки
+Первичный ключ: НомерПациента
+ПолучитьИмя(): Имя
+ВвестиИмя(): Имя
+ПолучитьРецепт(перечислитель)
+RemovePrescripton()
ПАЦИЕНТ-РЕЦЕПТ
<не идентифицирующая>
▼
«Перманентный»
РЕЦЕПТ
... атрибутов класса
...список атрибутов
. .. список методов
Рис. 3.16. Представление классов сущностей в UML с помощью конструкций ООП
Третьей новой особенностью является то, что UML использует
объектно-ориентированную нотацию для обозначения видимости атрибутов и методов.
Атрибуты, именам которых предшествует знак «+», являются открытыми, атрибуты
со знаком «#» являются защищенными, а со знаком «-» — закрытыми. На рис. 3.16
атрибут Имя сущности ПАЦИЕНТ является защищенным.
Эти термины имеют корни в объектно-ориентированном программировании.
Открытым (public) называется такой атрибут, который может читаться и
изменяться любым методом любого объекта. Термин защищенный (protected)
означает, что атрибут или метод доступен только для методов данного класса и его
подклассов, а термин закрытый (private) указывает на то, что соответствующий
атрибут или метод доступен только для методов данного класса.
Наконец, в UML задаются ограничения и методы, для чего служит третий
сегмент прямоугольника, изображающего класс сущностей. На рис. 3.16 на
значение атрибута НомерПациента налагается ограничение первичного ключа. Это
означает просто, что НомерПациента является уникальным идентификатором.
Кроме того, рис. 3.16 указывает, что должны быть созданы следующие методы:
ПолучитьИмя() — для открытого доступа к атрибуту Имя (обратите внимание на
знак «+» перед ПолучитьИмя(), ВвестиИмя() — для установки значения этого
атрибута, и ПолучитьРецепт() — для перебора совокупности сущностей класса РЕЦЕПТ,
связанных с данной сущностью ПАЦИЕНТ.
Роль UML в базах данных на сегодняшний день
Идеи, которые иллюстрирует рис. 3.16, представляются довольно туманными в том,
что касается применимости объектного мышления к построению и
функционированию баз данных. Такая объектно-ориентированная йотация не согласуется с
обычаями и процедурами, принятыми в коммерческих базах данных сегодняшнего
дня. Понятие о том, что атрибут сущности может быть скрыт внутри объекта, не
имеет смысла, если только база данных не обрабатывается исключительно
объектно-ориентированными программами; но даже если так, эти программы должны
102 Глава 3. Модель «сущность—связь»
обрабатывать данные в соответствии с этой политикой. За исключением
специализированных объектно-ориентированных СУБД (ООСУБД) и их приложений,
так никогда не делается.
Напротив, большинство коммерческих СУБД позволяют всем видам программ
обращаться к базе данных и обрабатывать любые данные, в отношении которых
у этих программ имеются соответствующие полномочия. Более того, с такими
средствами, как генератор запросов в Microsoft Access 2002 (см. рис. 2.6), просто
не существует способов ограничить доступ к значениям атрибутов отдельного
объекта.
Итак, все сводится к необходимости знания о том, как интерпретировать
диаграммы «сущность—связь», выполненные в стиле UML. Они точно так же
пригодны для проектирования баз данных, как и традиционные ER-диаграммы.
Однако на текущий момент объектно-ориентированная нотация, которая в них
вводится, имеет весьма ограниченную практическую ценность. Дальнейшую
информацию по этой теме вы найдете в главе 18.
Примеры
Лучший способ приобрести навыки работы с любым средством для
моделирования — изучать примеры и использовать это средство для создания своих
собственных моделей. В оставшейся части этой главы описаны два примера, которые
помогут вам справиться с вашей первой задачей. Проработав эти примеры,
займитесь решением задач, приведенных в конце главы.
Пример 1: танцевальный клуб Джефферсона
Танцевальный клуб Джефферсона производит обучение танцам и предлагает
индивидуальные и групповые занятия. Плата составляет $45 в час с человека или
пары при индивидуальных занятиях и $6 в час с человека при групповых
занятиях. Индивидуальные занятия проводятся на протяжении всего дня, с полудня
до 22 часов, шесть дней в неделю. Групповые занятия проводятся по вечерам.
В танцевальнОхМ клубе работают два вида инструкторов: постоянные и
приходящие. Постоянные инструкторы еженедельно получают фиксированную
зарплату, а приходящие получают установленную сумму либо за вечер, либо за
работу с конкретным классом.
Кроме занятий, танцевальный клуб Джефферсона два раза в неделю
организует танцевальные вечеринки с музыкальными записями. Входная плата
составляет $5 с человека. Танцевальный вечер в пятницу пользуется большей
популярностью и собирает в среднем около 80 человек; воскресный вечер собирает
около 30 посетителей. Цель этих танцевальных вечеров — предоставить
ученикам место для практики. Еда и напитки не предусматриваются.
Танцевальный клуб хотел бы разработать информационную систему, которая
позволяла бы вести учет проведенных занятий и учеников. Помимо того,
менеджеры клуба хотели бы знать количество и типы занятий, проведенных каждым
Примеры 103
инструктором, а также иметь возможность подсчитать среднюю стоимость
занятия у каждого инструктора.
Сущности
Лучше всего начать построение модели «сущность—связь» с определения
потенциальных сущностей. В документах или беседах сущности обычно
представляются существительными (места, люди, концепции, события, оборудование и т. п.).
Исследовав предыдущий пример на предмет важных словосочетаний,
относящихся к информационной системе, мы получим следующий список:
+ индивидуальное занятие;
+ групповое занятие;
+ инструктор;
+ постоянный инструктор;
+ приходящий инструктор;
+ вечер танцев;
+ клиент.
Ясно, что словосочетания индивидуальное занятие и групповое занятие имеют
между собой нечто общее, как и словосочетания постоянный инструктор и
приходящий инструктор. Одним из возможных решений будет определить сущность
под названием ЗАНЯТИЕ с подтипами ИНДИВИДУАЛЬНОЕ_ЗАНЯТИЕ и ГРУППОВОЕ^
ЗАНЯТИЕ, а также сущность ИНСТРУКТОР с подтипами ПОСТОЯННЫЙ_ИНСТРУКТОР и
ПРИХОДЯ ЩИ Й_И НСТРУКТОР. Кроме этих сущностей, в модели будут
присутствовать сущности ВЕЧЕРЛАНЦЕВ и КЛИЕНТ.
Как было отмечено в главе 2, в моделировании данных есть столько же от
искусства, сколько от науки. Решение, описанное только что, является лишь одним
из возможных. Второе решение состоит в том, чтобы исключить сущности ЗАНЯТИЕ
и ИНСТРУКТОР из списка, приведенного в предыдущем абзаце, и удалить все
подтипы. Третье возможное решение — это исключить сущность ЗАНЯТИЕ
(поскольку занятие нигде не упоминается само по себе как словосочетание), но оставить
сущность ИНСТРУКТОР и ее подтипы. В данном случае мы выберем третий
вариант, так как он представляется наиболее подходящим с точки зрения
имеющейся у нас информации. Таким образом, список сущностей будет выглядеть
следующим образом: ИНДИВИДУАЛЬНОЕ_ЗАНЯТИЕ, ГРУППОВОЕ_ЗАНЯТИЕ, ИНСТРУКТОР,
ПОСТОЯННЫЙ_ИНСТРУКТОР, ПРИХОДЯЩИЙ_ИНСТРУКТОР, ВЕЧЕРЛАНЦЕВ и КЛИЕНТ.
Чтобы сделать правильный выбор среди этих альтернатив, необходимо
проанализировать требования и выяснить, каким образом данные требования
отразятся на структуре системы. Иногда полезно рассмотреть атрибуты сущностей.
Если, например, сущность ЗАНЯТИЕ не имеет никаких атрибутов, кроме
идентификатора, то вводить такую сущность нет необходимости.
Связи
Начнем стого, что сущность ИНСТРУКТОР имеет два подтипа: П0СТ0ЯННЫЙ_ИНС-
ТРУКТОР и ПРИХОДЯЩИЙ_ИНСТРУКТОР. Любой инструктор должен быть либо
постоянным, либо приходящим, значит, подтипы являются взаимоисключающими.
104 Глава 3. Модель «сущность—связь
Далее рассмотрим связи между сущностями ИНСТРУКТОР и ИНДИВИДУАЛЬН0Е_
ЗАНЯТИЕ или ГРУППОВОЕ_ЗАНЯТИЕ. Инструктор может проводить много
индивидуальных занятий и, как правило, индивидуальное занятие проводится одним
инструктором. Но в ходе дальнейшего разговора с менеджерами
танцевального клуба выясняется, что для продвинутых танцоров, особенно тех, кто
готовится к соревнованиям, к индивидуальным занятиям иногда привлекается два
инструктора. Поэтому связь между сущностями ИНСТРУКТОР и ИНДИВИДУАЛЬНОЕ^.
ЗАНЯТИЕ должна иметь тип «один ко многим». По поводу групповых занятий мы,
однако, будем полагать, что каждое из них ведет только один инструктор. Связи,
описанные нами только что, изображены на рис. 3.17.
Клиенты могут посещать как индивидуальные, так и групповые занятия.
Иногда индивидуальное занятие проводится с одним человеком, а иногда — с парой.
Есть два способа моделирования этой ситуации. Можно определить сущность
ПАРА как имеющую связь 1:2 с сущностью КЛИЕНТ, а можно допустить, что обе
сущности, КЛИЕНТ и ПАРА, могут иметь связь с сущностью ИНДИВИДУАЛЬНОЕ^.
ЗАНЯТИЕ. Мы предполагаем, что пары не посещают групповые занятия, а если и
посещают, то этот факт не настолько важен, чтобы записывать его в базу данных.
Эта альтернатива показана на рис. 3.18, а.
Существование сущности ИНДИВИДУАЛЬНОЕ_ЗАНЯТИЕ зависит от сущностей
КЛИЕНТ и ПАРА. То есть занятие не может существовать, если оно не проводится
с каким-либо клиентом или парой. Число 1 рядом с горизонтальной линией,
проведенной на рисунке под сущностями КЛИЕНТ и ПАРА, показывает, что в
индивидуальном занятии должны участвовать как минимум один клиент или одна
пара, что разумно, поскольку индивидуальное занятие зависит от них.
ИНДИВИДУАЛЬНОЕ_ЗАНЯТИЕ
ГРУППОВОЕ ЗАНЯТИЕ
Ч)\ у^
ИНСТРУКТОР
ПОСТОЯННЫЙ_ИНСТРУКТОР ПРИХОДЯЩИЙ_ИНСТРУКТОР
Рис. 3.17. Исходная ER-диаграмма для танцевального клуба Джефферсона
Альтернатива заключается в том, чтобы не вводить пары, а указать тип связи
между сущностями КЛИЕНТ и ИНДИВИДУАЛЬНОЕ_ЗАНЯТИЕ как «многие ко многим».
Если быть более точным, эта связь должна иметь тип «один или два ко многим»,
как показано на рис. 3.18, б. Хотя эта модель является не такой подробной, как
модель на рис. 3.18, <я, ее может быть вполне достаточно для нужд танцевального
клуба Джефферсона.
Осталось рассмотреть возможные связи сущности ВЕЧЕР_ТАНЦЕВ с другими
сущностями. Вечера танцев посещают как инструкторы, так и клиенты, и разработ-
Примеры 105
чики должны решить, важно ли показывать эти связи в структуре базы данных.
Действительно ли для танцевального клуба важно знать, какие клиенты посетили
какие танцевальные вечера? Так ли уж хотят менеджеры клуба вести запись
посетителей в компьютерную информационную систему при входе в танцзал? И
захочется ли посетителям, чтобы эти данные записывались? Скорее всего, эти связи
не принадлежат к числу тех, которые требуется или следует хранить в базе данных.
КЛИЕНТ И <2:1
И ПАРА
Гиндивидуальное_занятие"
(N:My
ГРУППОВОЕ ЗАНЯТИЕ
И КЛИЕНТ г^
[индивидуальное_занятие]
групповое занятие
Рис. 3.18. Способы представления клиента: а — с сущностью ПАРА; б— без сущности ПАРА
Иначе обстоит дело со связью между сущностями ВЕЧЕР__ТАНЦЕВ и ИНСТРУКТОР.
Хозяин клуба любит, когда на танцевальных вечерах присутствуют несколько
клубных инструкторов. В связи с этим требованием правление клуба
составило расписание посещения вечеров инструкторами. Составление и запись этого
расписания требуют, чтобы в базе данных присутствовала связь ВЕЧЕР_ТАНЦЕВ-
ИНСТРУКТОР, которая имеет тип «многие ко многим».
Окончательный вид ER-диаграммы для танцевального
клуба Джефферсона
На рис. 3.19 показан окончательный вид ER-диаграммы для модели, описанной
в этом разделе. Мы не стали приводить на ней имена связей: хотя это сделало бы
диаграмму более правильной по форме, при имеющихся у нас данных указание
имен связей мало что прибавило бы.
Существование сущности ИНДИВИДУАЛЬНОЕ_ЗАНЯТИЕ зависит от сущности
КЛИЕНТ, а ГРУППОВОЕ_ЗАНЯТИЕ — нет, потому что расписание групповых занятий
106 Глава 3. Модель «сущность—связь»
составляется задолго до того, как на них записывается какой-либо клиент, и эти
занятия будут проводиться даже в том случае, если ни один клиент не придет.
Для индивидуальных занятий, однако, дело обстоит не так — они назначаются
только по запросу клиента. Обратите также внимание, что в этой модели не
представлены пары.
КЛИЕНТ
[ индивидуал ьное.занятие]
ГРУППОВОЕ ЗАНЯТИЕ
ИНСТРУКТОР
N:M>
ВЕЧЕР_ТАНЦЕВ
ПОСТОЯННЫЙ_ИНСТРУКТОР ПРИХОДЯЩИЙ_ИНСТРУКТОР
Рис. 3.19. Окончательный вид ER-диаграммы для танцевального клуба Джефферсона
Разработав модель, подобную этой, следует проверить, насколько она точна
и полна по отношению к требованиям пользователей. Обычно это делается с
помощью самих пользователей.
Проверка созданной ER-модели данных
Ошибки проще и дешевле исправлять на ранних стадиях процесса разработки
базы данных, чем на поздних. Например, изменение максимального
кардинального числа связи с 1:N на N:M на стадии моделирования данных сводится просто
к внесению соответствующего исправления в ER-диаграмму. Но когда база
данных уже разработана и наполнена данными и написаны прикладные программы
для ее обработки, такое изменение потребует значительной переделки, возможно,
даже недель труда. Поэтому важно определить, какая модель данных требуется,
прежде чем начинать ее воплощать.
Один из способов сделать это — рассмотреть ER-модель в контексте того,
на какого рода запросы может ответить база данных со структурой,
описываемой данной моделью. Взгляните, к примеру, на диаграмму, изображенную на
рис. 3.19. На какие вопросы может дать ответ база данных, реализованная на
основе данного проекта?
+ Какие и кем были проведены индивидуальные занятия?
+ Какие клиенты посещали индивидуальные занятия у Джека?
+ Кто является постоянным инструктором клуба?
+ Какие инструкторы должны прийти на танцевальный вечер в пятницу?
Примеры 107
При проверке модели данных вы можете формулировать такие вопросы и
задавать их пользователям, которых затем можно попросить составить свой
список вопросов. Они могут задавать вопросы, касающиеся структуры базы
данных, чтобы проверить ее соответствие поставленным требованиям. Например,
представьте, что пользователи спрашивают, какие клиенты посетили вечер танцев
в прошлую пятницу. Разработчики модели данных, изображенной на рис. 3.19,
должны прийти к заключению, что их структура неверна, поскольку на
поставленный вопрос с помощью данной ER-модели ответить невозможно. Если
требуется ответ на этот вопрос, необходимо ввести связь между сущностями КЛИЕНТ
и ВЕЧЕР.ТАНЦЕВ.
Очевидно, что посредством такого неформального и нечетко
структурированного процесса невозможно доказать, что структура является правильной. Тем не
менее, это прагматичный метод, пригодный для определения потенциальной
правильности структуры. И даже такой метод все же лучше, чем отсутствие
проверки вообще!
Пример 2: бюро проката парусных яхт Сан-Хуана
Бюро проката яхт Сан-Хуана — это посредническая фирма, занимающаяся
прокатом парусных яхт. Яхты не являются собственностью фирмы — она сдает их
от имени владельцев, которые хотят получать доход от своих яхт, когда не
пользуются ими. За свои услуги фирма Сан-Хуана берет плату. Фирма
специализируется на яхтах, которые могут использоваться для многодневных или
недельных походов: самая маленькая из яхт имеет длину 28 футов, а самая
большая — 51 фут.
Каждая яхта полностью экипирована на момент сдачи в аренду. Большая
часть оборудования предоставляется владельцами, но некоторое
оборудование добавляется фирмой. Оборудование, предоставляемое владельцами, включает
в себя предметы, закрепленные на яхте, то есть радиостанции, компасы,
глубиномеры и прочий инструмент, плиты и холодильники. Есть и другое оборудование,
предоставляемое владельцами, но не являющееся частью яхты. Это могут быть
паруса, лини, якоря, спасательные шлюпки, спасательные жилеты, а также то,
что находится в каютах: блюда, столовое серебро, кухонные принадлежности,
постельные принадлежности и т. д. Фирма Сан-Хуана предоставляет также
расходуемый инвентарь и припасы — карты, навигационные книги, таблицы приливов
и течений, мыло, полотенца для посуды, туалетную бумагу и тому подобные
предметы.
Важной составляющей обязанностей фирмы Сан-Хуана является учет
оборудования, имеющегося на яхтах. Многое оборудование является дорогим, а
некоторое, в частности то, которое не закреплено на яхте, может легко потеряться
или быть украдено. В течение срока проката яхты ответственными за
оборудование являются клиенты.
Фирма Сан-Хуана ведет подробный учет клиентов и истории проката яхт.
Это требуется не только для маркетинговых целей, но и для того, чтобы иметь
108 Глава 3. Модель «сущность—связь»
записи о путешествиях клиентов. Некоторые маршруты и погодные условия
более опасны, чем другие, поэтому фирма желает знать об опыте своих клиентов.
По большей части фирма занимается прокатом только яхт, то есть капитан
или команда не предоставляется. В некоторых случаях, однако, клиенты
заказывают услуги капитана или каких-либо других членов команды, и тогда фирма
нанимает соответствующий персонал на договорной основе.
Яхты часто требуют обслуживания. Контракты, заключенные фирмой Сан-
Хуана с владельцами лодок, требуют от фирмы ведения тщательной записи всех
операций по обслуживанию и связанных с этим расходов, включая обычные
операции, такие как мойка или замена масла, а также внеплановые ремонты. Иногда
ремонт может потребоваться во время рейса. Например, у яхты может отказать
двигатель, когда она будет находиться далеко от доков Сан-Хуана. В этом случае
клиенты вызывают по радио диспетчера фирмы, который определяет наиболее
подходящее место для проведения ремонта и направляет персонал оттуда на
аварийную яхту. Чтобы принимать все эти решения, диспетчерам требуется
информация об имеющихся ремонтных доках, а также сведения о качестве и стоимости
предыдущих ремонтов.
Прежде чем продолжить чтение, постарайтесь составить диаграмму
«сущность—связь» для этого случая самостоятельно. Проанализируйте
приведенный выше текст и найдите в нем существительные, которые, на ваш взгляд,
являются важными для проекта. После этого определите возможные связи
между сущностями. Наконец, перечислите возможные атрибуты каждой сущности
и связи.
Сущности
Модель данных, требуемая для бюро аренды Сан-Хуана, более сложна, чем
модель для танцевального клуба Джефферсона. Потенциальные сущности
показаны на рис. 3.20, а.
Рассмотрим сначала сущности, относящиеся к оборудованию. Есть много
различных типов оборудования, и это наводит нас на мысль о введении
подтипов. Однако спросим себя: почему фирму Сан-Хуана должно интересовать
оборудование? Фирме вовсе не нужно знать характеристики каждого предмета —
например, длину цепи каждого якоря. В задачи фирмы скорее входит учет
элементов оборудования и их типов, чтобы можно было определить, что из
оборудования потеряно или повреждено. Таким образом, для данного случая мы отнесем
все типы оборудования к одной сущности — ОБОРУДОВАНИЕ.
Принадлежность оборудования указывается путем введения связи между
сущностями ОБОРУДОВАНИЕ и ВЛАДЕЛЕЦ. Если фирма Сан-Хуана может быть
экземпляром сущности ВЛАДЕЛЕЦ, то все оборудование, являющееся собственностью
фирмы, может быть отнесено к этой сущности. Аналогичным образохМ, исходя из
описанной ситуации, представляется безосновательным разделение
оборудования на закрепленное и не закрепленное на яхте. Точный список может быть
составлен и без такого разделения. Окончательный список сущностей приведен на
рис. 3.20, б.
Примеры 109
АРЕНДА
ЯХТА
КЛИЕНТ
ВЛАДЕЛЕЦ
ОБОРУДОВАНИЕ
ОБОРУДОВАНИЕ.ВЛАДЕЛЬЦА
ЗАКРЕПЛЕННОЕ_ОБОРУДОВАНИЕ_ВЛАДЕЛЬЦА
НЕЗАКРЕПЛЕННОЕ_ОБОРУДОВАНИЕ_ВЛАД ЕЛЬЦА
СОБСТВЕННОЕ_ОБОРУДОВАНИЕ_ФИРМЫ
МАРШРУТ_И_ПОГОДА
РЕЙС
ВРЕМЕННАЯ_КОМАНДА
ПЛАНОВОЕ_ТЕХОБСЛУЖИВАНИЕ
ВНЕПЛАНОВОЕ_ТЕХОБСЛУЖИВАНИЕ
РЕМОНТ
РЕМОНТНЫЙДОК
а
Возможные сущности для бюро аренды Сан-Хуана
АРЕНДА, или РЕЙС (синонимы)
ЯХТА
КЛИЕНТ
ВЛАДЕЛЕЦ
ОБОРУДОВАНИЕ
МАРШРУТ_И_ПОГОДА
ВРЕМЕННАЯ_КОМАНДА
ПЛАНОВОЕ_ТЕХОБСЛУЖИВАНИЕ
РЕМОНТ, или ВНЕПЛАНОВОЕ_ТЕХОБСЛУЖИВАНИЕ (синонимы)
РЕМОНТНЫЙЛОК
б
Окончательный список сущностей
Рис. 3.20. Сущности для бюро аренды яхт Сан-Хуана
Обратите внимание, что АРЕНДА и РЕЙС являются синонимами: они относятся
к одной и той же транзакции. Мы приводим здесь оба имени, чтобы можно было
соотнести их с описанием ситуации.
Возможно, что сущности ПЛАН0В0Е__ТЕХ06СЛУЖИВАНИЕ и ВНЕПЛАНОВОЕЛХ-
ОБСЛУЖИВАНИЕ следует объединить. Один из способов определить, необходимо
это или нет, — проанализировать атрибуты обеих сущностей. Если они
одинаковы, то два класса сущностей могут быть объединены. Заметьте также, что
сущности РЕМОНТ и ВНЕПЛАН0В0Е_ТЕХ06СЛУЖИВАНИЕ определены как синонимы.
Связи
На рис. 3.21 изображена диаграмма «сущность—связь» для бюро аренды Сан-
Хуана. По большей части представленные на этой диаграмме связи являются
очевидными, но связь между сущностями ОБОРУДОВАНИЕ и АРЕНДА может быть
предметом спора. Можно было бы сказать, что определенная часть оборудования
должна быть отнесена к яхте (сущность ЯХТА), а не к аренде, или что часть
оборудования (а именно оборудование, которое закреплено на яхте) следует отнести
к яхте, а оставшуюся часть — к аренде. Эти изменения представляют собой
возможные альтернативы для структуры, показанной на рис. 3.21.
110 Глава 3. Модель «сущность—связь»
ВЛАДЕЛЕЦ ПЛАНОВ0Е_ТЕХ0БСЛУЖИВАНИЕ
Рис. 3.21. ER-диаграмма для бюро аренды яхт Сан-Хуана
Кроме того, обратите внимание, что сущность ПЛАНОВОЕ_ТЕХОБСЛУЖИВАНИЕ
связана с сущностью ЯХТА, в то время как сущность РЕМОНТ, или ВНЕПЛАНОВОЕ.
ТЕХОБСЛУЖИВАНИЕ, связана с сущностью АРЕНДА. Это подразумевает, что когда
яхта не находится в аренде, никакого ремонта для нее не требуется. Может быть,
это не соответствует действительности.
Наконец, сущности АРЕНДА и ПОГОДА_И_МАРШРУТ имеют связь 1:1, и они также
имеют одинаковые идентифицирующие атрибуты. В связи с этим можно, а может
быть, даже нужно объединить их в один класс сущностей.
Базы данных как модели моделей
Как вы можете видеть, есть множество различных способов моделирования
конкретной ситуации в деловом мире, и это множество становится все обширнее по
мере того, как моделируемая ситуация усложняется. Зачастую количество
возможных моделей оказывается огромным, и выбрать среди них одну может быть
нелегко.
Иногда при выявлении альтернатив команда, занимающаяся проектом,
углубляется в дискуссии по поводу того, какая модель данных наилучшим образом
представляет реальный мир. Эти дискуссии исходят из ложных посылок. Базы
данных не моделируют реальный мир, хотя распространено ошибочное мнение,
согласно которому именно в этом и состоит их назначение. Базы данных
являются моделями пользовательских моделей мира (или, точнее, делового мира).
Вопрос, задаваемый при выявлении альтернативных моделей данных, состоит не
в том, насколько точно данная модель отражает реальный мир, а в том,
насколько точно она отражает имеющуюся в воображении пользователя модель среды,
Резюме 111
которая его окружает. Цель заключается в том, чтобы разработать структуру,
которая будет соответствовать представлениям пользователей.
Иммануил Кант и другие философы могли бы возразить, что людям не дано
построить модель того, что существует на самом деле, и заявили бы, что суть
вещей навсегда останется тайной для человечества1. Распространяя эту
аргументацию на компьютерные системы, Виноград (Winograd) и Флоре (Flores)
высказали идею, что в обществах индивидуумы конструируют системы символов,
которые позволяют им успешно действовать в мире. Последовательность
символов не является моделью бесконечности реального мира, а скорее представляет
собой просто социальную систему, позволяющую пользователям успешно
координировать свои действия; ничего более по этому поводу сказать нельзя2.
Таким образом, компьютерные системы должны моделировать и представлять
взаимоотношения между своими пользователями. Они не моделируют ничего,
кроме системы символов и связей. Поэтому научитесь задавать себе следующие
вопросы: «Насколько точно данная модель отражает восприятие пользователей
и имеющуюся в их воображении модель мира? Поможет ли эта модель
пользователям согласованно и успешно взаимодействовать друг с другом и с
клиентами?» Для аналитика бессмысленно заявлять, что его модель является лучшим
представлением реальности. Суть в том, чтобы разработать модель, которая
адекватно отражает модель деловой среды в представлении пользователя.
Резюме
Модель «сущность—связь» была разработана Питером Ченом. В этой модели
определяются сущности — идентифицируемые объекты, представляющие важность для
пользователя. Все сущности данного типа образуют класс сущностей. Отдельная
сущность называется экземпляром. Сущности имеют атрибуты, которые
описывают их характеристики; один или несколько атрибутов определяют сущность.
Связи отражают взаимоотношения между сущностями. В ER-модели связи
определяются явным образом; у каждой связи есть имя; существуют также
классы связей и экземпляры связей. У связей могут быть атрибуты.
Степень связи — это число сущностей, которые в ней участвуют. Большинство
связей являются бинарными. Имеется три типа бинарных связей: 1:1, 1:N и N:M.
На диаграммах «сущность—связь» сущности изображаются
прямоугольниками, а связи — ромбами. Максимальное кардинальное число связи указывается
внутри ромба. Минимальное кардинальное число указывается с помощью
перпендикулярной черты или овала. Связи, соединяющие сущности одного класса,
1 «Мы не можем, разумеется, за пределами всего возможного опыта составить определенное
представление о том, какими являются веши сами по себе. И все же не в нашей власти совершенно
устраниться от их исследования; ибо опыт никогда не удовлетворяет рассудок полностью, но, отвечая
на вопросы, отсылает нас вес дальше и дальше назад и оставляет нас неудовлетворенными
относительно полного решения» (Иммануил Кант. Пролегомены к любой будущей метафизике).
2 Terry Winograd and F. Flores, Understanding Computers and Cognition (Reading, MA: Addison-Wesley,
1986).
112 Глава 3. Модель «сущность—связь»
называются рекурсивными. Атрибуты могут быть показаны на ER-диаграмме
в эллипсах или в отдельной таблице.
Слабая сущность — это сущность, существование которой зависит от другой
сущности; сущность, не являющаяся слабой, называется сильной сущностью.
Слабые сущности изображаются с помощью прямоугольников со скругленными
углами. Далее в этой книге мы определяем слабую сущность как сущность,
логически зависящую от другой сущности. Сущность может иметь минимальное
кардинальное число 1 в связи с другой сущностью, но при этом не быть слабой.
Многозначные атрибуты представляются с помощью слабых сущностей.
Некоторые сущности имеют подтипы, которые определяют подмножества
подобных сущностей. Подтипы наследуют атрибуты от своего родителя, или надти-
па. Связи типа «ИМЕЕТ» соединяют сущности разных типов, и идентификаторы
у этих сущностей различны. Связи типа «ЕСТЬ» — это связи подтипов с их
родителями, и идентификаторы у сущностей, участвующих в такой связи, одинаковы.
Разработав модель данных, необходимо определить деловой регламент,
который будет накладывать ограничения на возможные действия с сущностями.
Каждая сущность в модели должна быть проанализирована на предмет
возможного добавления, изменения и удаления данных. Удаления, в частности,
зачастую являются источником важных ограничений на обработку.
Сформулированные правила делового регламента необходимо документировать в модели данных.
Модель «сущность—связь» является важной частью многих CASE-продук-
тов. Эти продукты предоставляют средства для конструирования и хранения
ER-диаграмм. Некоторые из CASE-инструментов объединяют конструкции ER-
модели с данными репозитория CASE. Унифицированный язык моделирования
(UML) вводит новый стиль построения диаграмм «сущность—связь». Вам
следует иметь представление о диаграммах, выполненных в этом стиле; однако
нужно понимать, что при проектировании базы данных не существует
фундаментальных различий между традиционным стилем и UML-стилем.
Завершив создание ER-модели, следует ее испытать. Один из способов это
сделать — составить перечень вопросов, на которые можно ответить с помощью
разработанной модели данных. Далее этот перечень показывается пользователям,
которым предлагают подумать насчет дополнительных вопросов. Затем
проверяется способность ER-модели ответить на эти дополнительные вопросы.
Базы данных моделируют не реальный мир, а модель делового мира,
присутствующую в воображении пользователя. Правильным критерием для оценки
модели данных является то, насколько эта модель соответствует пользовательской
модели. Спор о том, какая модель наилучшим образом отражает реальный мир,
не имеет смысла.
Вопросы группы I
1. Дайте определение сущности и приведите пример.
2. Поясните разницу между классом сущностей и экземпляром сущности.
3. Дайте определение атрибута и приведите примеры атрибутов для
сущности, описанной вами в ответе на вопрос 1.
Вопросы группы I 113
4. Объясните, что такое композитный атрибут, и приведите пример.
5. Какой из атрибутов, приведенных вами в ответе на вопрос 3,
идентифицирует сущность?
6. Дайте определение связи и приведите пример.
7. Объясните, в чем разница между классом связей и экземпляром связи.
8. Дайте определение степени связи. Приведите пример связи со степенью
больше 2, отличный от того, который дан в тексте.
9. Перечислите три типа бинарных связей и приведите примеры. Нарисуйте
ER-диаграмму для каждого типа.
10. Дайте определения терминов максимальное кардинальное число и
минимальное кардинальное число, максимальная кардинальность и минимальная
кардинальность.
11. Назовите и нарисуйте символы, используемые в диаграммах «сущность-
связь» для изображения: (а) сущности; (б) связи; (в) слабой сущности и ее
связи; (г) рекурсивной связи; (д) сущности подтипа.
12. Приведите пример ER-диаграммы для сущностей ОТДЕЛ и СОТРУДНИК,
имеющих связь 1:N. Сделайте допущение, что в отделе может и не быть
сотрудников, но каждый сотрудник должен работать в каком-либо отделе.
13. Приведите пример рекурсивной связи и изобразите его на ER-диаграмме.
14. Приведите примеры атрибутов для сущностей ОТДЕЛ и СОТРУДНИК (из
ответа на вопрос 12) и изобразите их на ER-диграмме. Используйте для
этого символы UML-стиля.
15. Дайте определение термина слабая сущность и приведите пример,
отличный от того, который дан в тексте.
16. Поясните, в чем состоит неоднозначность в определении термина слабая
сущность. Как этот термин интерпретируется в книге? Приведите
примеры, отличные от тех, которые даны в тексте.
17. Дайте определение термина идентификационно-зависимая сущность и
приведите пример, отличный от того, который дан в тексте.
18. Продемонстрируйте использование слабой сущности для представления
многозначного атрибута Квалификация сущности СОТРУДНИК. Укажите
минимальное и максимальное кардинальное число на обеих сторонах связи.
Используйте традиционные символы.
19. Продемонстрируйте использование слабой сущности для представления
многозначного составного атрибута Телефон, состоящего из однозначных
атрибутов КодРегиона и НомерТелефона. Пусть при этом атрибут Телефон
принадлежит сущности ПРОДАВЕЦ. Укажите минимальное и
максимальное кардинальное число на обеих сторонах связи. Используйте символы
UML-стиля.
20. Опишите, что такое подтипы сущностей, и приведите пример, отличный
от того, который дан в тексте.
114 Глава 3. Модель «сущность—связь»
21. Объясните значение термина наследование и покажите, как он относится
к вашему ответу на вопрос 20.
22. Поясните разницу между связью типа «ИМЕЕТ» и связью типа «ЕСТЬ»
и приведите пример для каждой связи.
23. Как документируется деловой регламент в модели «сущность—связь»?
24. Объясните, почему важно проверять модель данных после ее создания.
Опишите один из способов проверки модели данных и объясните, как с
помощью этого способа можно проверить модель, изображенную на рис. 3.21.
Вопросы группы II
25. Модифицируйте ER-диаграмму на рис. 3.19, включив в нее сущность
ЗАНЯТИЕ. Пусть сущности ИНДИВИДУАЛЬНОЕ_ЗАНЯТИЕ и ГРУППОВОЕ^ЗАНЯТИЕ
будут подтипами сущности ЗАНЯТИЕ. Измените связи, где это необходимо.
Используйте традиционные символы.
26. Модифицируйте ER-диаграмму на рис. 3.19, исключив из нее сущность
ИНСТРУКТОР. Измените связи, где это необходимо. Используйте символы
UML-стиля.
27. Какие из моделей на рис. 3.19 и из вашего ответа на вопросы 25 и 26 вы
предпочитаете? Объясните причину вашего предпочтения.
28. Модифицируйте ER-диаграмму на рис. 3.21, включив в нее подтипы
оборудования. При этом допустите, что оборудование, находящееся в
собственности бюро аренды Сан-Хуана, относится к сущности АРЕНДА, а прочее
оборудование относится к сущности ЯХТА. Для оборудования,
относящегося к яхте, смоделируйте различие между тем оборудованием, которое
закреплено, и тем, которое не закреплено на яхте. Каков выигрыш от такой
усложненной модели?
Проекты
Разработайте ER-диаграмму для базы данных Городского жилищного
агентства — некоммерческой организации, выступающей за создание жилья для
малообеспеченных граждан и улучшение его качества. Агентство работает в одном из
крупных городов Среднего Запада, включая пригороды, с общим количеством
населения около 2,2 миллионов человек.
Агентство ведет учет местоположения, занятости и состояния жилья для лиц
с низкими доходами на 11 переписных участках города и его пригородов. В
пределах этих участков имеется около 250 зданий, где предоставляется жилье
малообеспеченным гражданам. В среднем в каждом здании имеется 25 квартир и
других единиц жилья.
Агентство хранит информацию по каждому переписному участку —
географические границы, типичные доходы населения, имена выборных лиц, основные
Проекты 115
предприятия, главных инвесторов важнейших объектов данного района, а также
прочие демографические и экономические данные. Хранится также
ограниченное количество информации о криминальной обстановке. Для каждого
здания агентство хранит следующую информацию: наименование, адрес, размер, имя
и адрес владельца, имя и адрес должника по закладной, данные о ремонте и
реконструкции, а также наличие приспособлений, облегчающих жизнь
инвалидов. Кроме того, агентство хранит список всех единиц жилья в здании, включая
тип, площадь, число спален, число ванных комнат, наличие кухни и столовой,
местоположение внутри здания и различные примечания. Агентство хотело бы
иметь данные о среднем числе жильцов на квадратный метр для каждой
единицы жилья, но на сегодняшний день не имеет возможностей для сбора и хранения
такого рода данных. Тем не менее, агентство хранит информацию о том,
является ли конкретная единица жилья занятой.
Столичное агентство жилья служит в качестве информационной палаты и
предлагает три основных вида услуг. Во-первых, оно ведет работу с политиками,
лоббистами и адвокатскими группами в поддержку закона, который бы поощрял
развитие жилья для малообеспеченных через налоговые льготы, выделение
предпочтительных зон развития и другие законодательные стимулы. Для этого
агентство предоставляет информацию о жилье для граждан с низким доходом
руководству штата, округа и города. Во-вторых, посредством выступлений, семинаров,
выставок на съездах и другой PR-деятельности официальные лица агентства
прилагают усилия к повышению осознания обществом потребности в жилье для
малообеспеченных людей. Наконец, агентство предоставляет информацию о таком
жилье другим агентствам, работающим с малообеспеченными и бездомными.
1. Зайдите на сайт производителя компьютеров, например Dell (www.dell.com).
Пользуясь средствами сайта, определите, какой ноутбук вы могли бы
приобрести для пользователя с бюджетом $10000. Занимаясь выяснением
этого вопроса, подумайте о том, какой структурой может обладать база данных
по компьютерным системам и подсистемам, используемая для поддержки
данного сайта.
Разработайте ER-диаграмму для базы данных по компьютерным системам
и подсистемам для этого сайта. Изобразите на ней все сущности и связи,
причем у сущности должно быть минимум два атрибута. Укажите
минимальное и максимальное кардинальное число для обеих сторон каждой
связи. Возможными сущностями являются БА30ВАЯ_К0НФИГУРАЦИЯ, 0БЪЕМ_
ПАМЯТИ, ВИДЕОКАРТА и ПРИНТЕР. (Разумеется, в реальности возможных
сущностей гораздо больше.) Введите какие-нибудь многозначные атрибуты, как
показано в тексте. Используйте подтипы, где это имеет смысл. Чтобы проект
не оказался чрезмерно велик, ограничьтесь тем, что требуется для человека,
который точно решил купить компьютер, но еще не выбрал, какой именно.
2. Зайдите на сайт виртуального книжного магазина, например Amazon (www.
amazon.com). Пользуясь средствами сайта, найдите три лучших книги по
XML для человека, который только начал изучать этот предмет.
Занимаясь выяснением данного вопроса, подумайте о том, какой может быть
структура базы данных по книгам, авторам, предметам и родственным темам.
116 Глава 3. Модель «сущность—связь»
Разработайте ER-диаграмму для базы данных этого сайта. Изобразите на ней
все сущности и связи, причем каждая сущность должна иметь не меньше двух-
трех атрибутов. Укажите минимальное и максимальное кардинальное число
для обеих сторон каждой связи. Возможными сущностями являются ЗАГОЛОВОК,
АВТОР, ИЗДАТЕЛЬ, ЭКЗЕМПЛЯР и ТЕМА. (Разумеется, в реальности возможных
сущностей гораздо больше.) Введите какие-нибудь многозначные атрибуты, как
показано в тексте. Используйте подтипы, где это имеет смысл. Чтобы проект не
слишком разрастался, предположим, что учет нужен только для книг. Далее
ограничьтесь потребностями человека, который точно решил купить книгу, но
еще не выбрал, какую. Не рассматривайте заказ клиента, выполнение заказа,
заказ на поставку и другие подобные деловые операции.
Вопросы к проекту FiredUp
Рассмотрим ситуацию, обсуждаемую в конце глав 1 и 2. Предположим, что фирма
FiredUp разработала линию из трех горелок: FiredNow, FiredAlways и FiredAt-
Camp. Предположим далее, что фирма продает запасные части для каждого
типа горелок, а также производит их ремонт. В одних случаях ремонт является
бесплатным, поскольку выполняется в течение гарантийного срока, в других
случаях взимается только стоимость деталей, в третьих взимается стоимость
деталей и работы. Фирма FiredUp желает вести учет всех этих данных. Когда
владельцев фирмы спросили о подробностях, они составили следующий список:
КЛИЕНТ: Имя, Улица, Дом, Квартира, Город, Штат, Индекс, Страна, ЭлектронныйАд-
рес, Телефон
ГОРЕЛКА: СерийныйНомер, Тип, ДатаИзготовления, ИнициалыПроверяющего
СЧЕТ-ФАКТУРА: НомерСчета, Дата, Клиент (со списком проданных товаров и
указанием их стоимости), Сумма
РЕМОНТ: НомерРемонта, Клиент, Горелка, Описание (со списком деталей,
использованных при ремонте, и указанием их стоимости, если таковая взимается), Сумма
ДЕТАЛЬ: Номер, Описание, Стоимость, ПродажнаяЦена
1. Создайте диаграмму «сущность—связь» для базы данных фирмы FiredUp.
Задайте на свое усмотрение минимальную и максимальную кардинальность
для связей между сущностями. Дайте объяснение каждому
кардинальному числу. Используйте слабые сущности там, где считаете это нужным. Не
используйте подтипы. Укажите идентификационно-зависимые сущности,
если таковые имеются.
2. Модифицируйте ER-диаграмму из вашего ответа на вопрос 1, представив
сущности СЧЕТ-ФАКТУРА и РЕМОНТ соответствующими подтипами. При
каких условиях эта структура окажется лучше, чем предыдущая?
3. Предположим, что фирма FiredUp хочет записывать домашний и
мобильный телефон, факс и несколько адресов электронной почты своих
клиентов. Модифицируйте свою ER-диаграмму, введя множественные значения
атрибутов Телефон и ЭлектронныйАдрес.
Вопросы к проекту FiredUp, 117
4. Предположим, что фирма FiredUp разрабатывает различные версии одной
и той же горелки, то есть FiredNow Version 1, FiredNow Version 2 и т. д.
Модифицируйте необходимым образом вашу ER-диаграмму из ответа на
вопрос 1, чтобы учесть эту ситуацию.
5. Когда пользователей спрашивают о том, какие данные они хотели бы
отслеживать, они не всегда помнят все, что им нужно. Пользуясь своими
знаниями об операциях малого предприятия, составьте список сущностей,
которые они могли забыть. Покажите потенциальные связи между этими
сущностями на ER-диаграмме. Что бы вы сказали по поводу
необходимости каких-либо из этих дополнительных данных для FiredUp?
Глава 4
Семантическая объектная
модель
В этой главе обсуждается семантическая объектная модель (semantic object
model), которая, так же как и модель «сущность—связь», описанная в главе 3,
используется для моделирования данных. Как показано на рис. 4.1, команда
разработчиков опрашивает пользователей, анализирует предоставленные ими отчеты,
формы и запросы и на их основе строит пользовательскую модель данных. Эта
модель данных в дальнейшем воплощается в структуре базы данных.
Конкретная форма модели данных зависит от конструкций, используемых для
ее построения. Если используется модель «сущность—связь», конструируемая
модель будет содержать сущности, связи и т. п. В случае использования
семантической объектной модели конструируемая модель будет содержать семантические
объекты и связанные с ними конструкции, которые описываются в данной главе.
Модель «сущность—связь» и семантическая объектная модель подобны двум
различным линзам, сквозь которые смотрят разработчики баз данных при
изучении и документировании пользовательских данных. Обе линзы действуют, и обе
они в конечном счете воплощаются в определенной структуре базы данных.
Однако, поскольку эти линзы не одинаковы и создают разные изображения,
структура баз данных, полученных с их помощью, может несколько различаться.
Разрабатывая базу данных, вы должны решить, какой подход применять, так же как
фотографу приходится решать, какую использовать линзу. Каждый подход
имеет свои сильные и слабые стороны, которые мы обсудим в конце этой главы.
Семантическая объектная модель была впервые представлена в третьем
издании этой книги в 1988 г. Она основана на концепциях, разработанных и
опубликованных Коддом, Хаммером и Мак-Леодом1. Семантическая объектная модель —
это модель данных. Ее не следует путать с объектно-ориентированной
обработкой баз данных, о которой пойдет речь в главе 18. Вы узнаете, чем цели, свойства
и конструкции семантической объектной модели отличаются от
объектно-ориентированных баз данных.
Е. F. Codd, «Extending the Relational Model to Capture More Meaning», ACM Transactions on Database
Systems, декабрь 1976, с. 397-424; Michael Hammer and Dennis McLeod, «Database Description
with SDM: A Semantic Database Model», ACM Transactions on Database Systems, сентябрь 1981,
с. 351-386.
Семантические объекту 119
Модель «сущность—связь»
ч
\
\
{)
W
w\
Сущности
и связи
-*
Представление
пользовательских данных
w
W
Семантические
объекты
-+
Структура
базы данных
Структура
базы данных
Пользовательские отчеты,\
формы, запросы N
Семантическая объектная модель
Рис. 4.1. Использование различных моделей при разработке баз данных
Семантические объекты
Задача приложения базы данных состоит в том, чтобы предоставлять формы,
отчеты и запросы, с помощью которых пользователи могли бы отслеживать
сущности или объекты, представляющие интерес для их деятельности. Целью ранних
стадий разработки базы данных является определение того, какие вещи должны
быть представлены в базе данных, задание характеристик этих вещей и
установление связи между ними.
В главе 3 мы называли эти вещи сущностями. В этой главе мы будем их
называть семантическими объектами (semantic objects), а иногда просто объектами.
Слово семантический означает «смысловой», и семантический объект — это
объект, который в определенной степени моделирует смысл пользовательских дан-
пых. Семантические объекты моделируют восприятие пользователя более точно,
чем модель «сущность—связь». Мы используем со словом объект прилагательное
семантический, чтобы отличать объекты, о которых идет речь в этой главе, от
объектов, которыми оперируют объектно-ориентированные языки программирования.
Определение семантических объектов
Сущности и объекты в некоторых отношениях схожи, но у них есть и различия.
Мы начнем со сходства. Семантический объект — это представление некоторой
вещи, идентифицируемой в рабочей среде пользователя. Если выражаться более
формально, семантический объект — это именованная совокупность атрибутов,
которая в достаточной степени описывает отдельный феномен.
120 Глава 4. Семантическая объектная модель
Подобно сущностям, семантические объекты группируются в классы. У
объектного класса есть имя, которое отличает его от других классов и соответствует
именам вещей, представляемых этим классом. Так, в базе данных, содержащей
информацию о студентах, имеется объектный класс под названием СТУДЕНТ.
Обратите внимание, что имена объектных классов, как и имена классов сущностей,
пишутся заглавными буквами. Отдельный семантический объект представляет
собой экземпляр класса. Например, Уильям Джонс является экземпляром класса
СТУДЕНТ, а Бухгалтерия является экземпляром класса ОТДЕЛ.
Подобно сущностям, объект имеет набор атрибутов. Каждый атрибут
описывает одну из характеристик представляемого феномена. Например, объект СТУДЕНТ
может иметь атрибуты Имя, Домашний Адрес, МестныйАдрес, ДатаРождения, ДатаОкон-
чанияШколы и Специальность. Этот набор атрибутов также является достаточным
описанием (sufficient description), то есть он описывает все характеристики,
необходимые пользователям для работы. Как было указано нами в конце главы 3,
каждая вещь в мире имеет бесконечное множество характеристик, и мы не в
состоянии представить всю их совокупность. Вместо этого мы представляем только те
из них, которые требуются для удовлетворения информационных потребностей
пользователей в той степени, чтобы они могли успешно выполнять свои
функции. Достаточность описания означает также, что объекты являются
самодостаточными. Например, все требуемые данные о покупателе содержатся в объекте
КЛИЕНТ, так что нам нигде больше не требуется искать, чтобы найти эти данные.
Объекты представляют отдельные феномены (distinct identity), то есть в
восприятии пользователей они являются чем-то независимым и самостоятельным,
что требует учета. Феномены — это сущности, информация о которых
необходима. Чтобы лучше уяснить значение термина отделысый феномен, вспомните,
что существует разница между объектами и экземплярами объектов. КЛИЕНТ —
это имя объекта, а КЛИЕНТ 12345 — имя экземпляра объекта. Когда мы говорим,
что объект представляет отдельный феномен, мы имеем в виду, что пользователи
считают каждый экземпляр объекта уникальным и имеющим самостоятельное
значение.
Наконец, стоит отметить, что феномены, представляемые объектами, могут
существовать физически, как, например, объекты класса СОТРУДНИК, а могут и не
существовать, как объекты класса ЗАКАЗ. Заказ как таковой является моделью
контрактного соглашения о предоставлении определенных товаров или услуг
в установленном порядке и на известных условиях. Он является не физическим
предметом, а представлением соглашения. Таким образом, чтобы нечто могло
считаться объектом, ему не обязательно существовать физически — нужно лишь,
чтобы это нечто имело самостоятельное значение в представлении пользователей.
Атрибуты
Семантические объекты имеют атрибуты, описывающие их характеристики. Есть
три типа атрибутов. Простые атрибуты (simple attributes) состоят из одного
элемента. Примерами могут быть атрибуты ДатаНайма, НомерНакладной и Итоговая-
СуммаПродаж. Групповые атрибуты (group attributes) являют собой совокупности
других атрибутов. В качестве примера можно привести атрибут Адрес, состоящий
Семантические объекты 121
из атрибутов {Улица, Город, Штат, Индекс}. Еще один пример — атрибут ПолноеИмя,
включающий в себя атрибуты {Имя, Отчество, Фамилия}. Семантические объектные
атрибуты (semantic object attributes) — это атрибуты, которые устанавливают
связь между двумя семантическими объектами.
Чтобы лучше понять эти определения, взгляните на рис. 4.2, а, который
представляет собой пример семантической объектной диаграммы (semantic object
diagram), или просто объектной диаграммы (object diagram). Такие диаграммы
используются командами разработчиков для описания и визуального
представления структуры объектов. Объекты изображаются в вертикально
ориентированных прямоугольниках. Имя объекта указывается вверху, а атрибуты
записываются по порядку после имени объекта.
Объект КАФЕДРА содержит пример каждого из трех типов атрибутов.
Атрибуты НазваниеКафедры, НомерТелефона и НомерФакса являются простыми:
каждый из них представляет один элемент данных. МестныйАдрес — групповой
атрибут, состоящий из простых атрибутов Корпус и НомерОфиса. Наконец, КОЛЛЕДЖ,
ПРЕПОДАВАТЕЛЬ и СТУДЕНТ — это семантические объектные атрибуты, то есть эти
объекты связаны с объектом КАФЕДРА и логически содержатся в нем.
Смысл этих объектных атрибутов, или объектных ссылок (object links), как их
иногда называют, состоит в том, что когда пользователь думает об определенной
кафедре, он имеет в виду не только название кафедры, локальный адрес, номер
телефона и номер факса этой кафедры, но также колледж, в котором она
находится, профессоров, преподающих на ней, и студентов, занимающихся на ней.
Поскольку КОЛЛЕДЖ, ПРЕПОДАВАТЕЛЬ и СТУДЕНТ также являются объектами,
полная модель данных содержит диаграммы и для них. Объект КОЛЛЕДЖ несет в себе
атрибуты колледжа, объект ПРЕПОДАВАТЕЛЬ — атрибуты членов профессорско-
преподавательского состава, а объект СТУДЕНТ содержит атрибуты студентов.
КАФЕДРА
/о НазваниеКафедр
МестныйАдрес™
Корпус
НомерОфиса _
НомерТелефона
НомерФакса
ы
|-Д-Щсвд9Щ|?;*|
[.ПРЕПОДАЕ^ЛЬ;]
| V сШейЩй]
КАФЕДРА
ю НазваниеКафедры
МестныйАдрес ~
Корпус i.-i
НомерОфиса i.i_
J 0.1
НомерТелефона 1 N
I
НомерФакса 0N
|к Щ|||1[:: "1
|РРЕГ||||||||ЛЬ ]
Ц с^И1|ИмИ11:::
1.1
1 N '
1.N
Рис. 4.2. Диаграмма объекта КАФЕДРА: а — объект КАФЕДРА;
б — объект КАФЕДРА с кардинальными числами
122 Глава 4. Семантическая объектная модель
Кардинальное число атрибута
Каждый атрибут семантического объекта имеет максимальное и минимальное
кардинальные числа. Минимальное кардинальное число показывает количество
экземпляров атрибута, которые должны существовать, чтобы объект был
допустимым. Обычно это число равно 0 или 1. Если оно равно 0, атрибут не обязан
иметь значение, а если 1, то атрибут обязан иметь значение. Хотя это и необычно,
минимальное кардинальное число иногда может быть больше единицы.
Например, атрибут Игрок в объекте под названием БАСКЕТБОЛЫНАЯ_КОМАНДА может
иметь минимальное кардинальное число, равное 5, поскольку таково наименьшее
число игроков, требуемое для создания баскетбольной команды.
Максимальное кардинальное число показывает максимальное количество
экземпляров атрибута, которое может иметь объект. Обычно оно равно 1 или N.
Если оно равно 1, атрибут может иметь не более одного экземпляра; если оно
равно N, атрибут может иметь много экземпляров, и предельное количество не
задано. Иногда максимальное кардинальное число равно определенному числу,
например 5, — это означает, что объект может иметь не более пяти экземпляров
атрибута. Например, атрибут ИГРОК в объекте БАСКЕТБОЛЬНАЯ_КОМАНДА может
иметь максимальное кардинальное число, равное 15, и это будет означать, что
в состав команды может быть включено не более 15 игроков.
Кардинальность изображается в виде нижнего индекса атрибута в
формате N.M, где N — минимальное кардинальное число, а М — максимальное.
На рис. 4.2, б минимальное кардинальное число для атрибута НазваниеКафедры
равно 1, и максимальное также 1; таким образом, требуется ровно один
экземпляр этого атрибута. Кардинальность атрибута НомерТелефона равна 1.N, то есть
кафедра обязана иметь минимум один номер телефона, но в принципе номеров
у нее может быть много. Кардинальность 0.1 у атрибута НомерФакса означает, что
кафедра может не иметь факса, а может и иметь, но только один.
Кардинальные числа групп и атрибутов групп, как правило, невелики.
Возьмем атрибут МестныйАдрес. Его кардинальность 0.1, то есть кафедра не обязана
иметь адрес, но если имеет, то только один. Теперь рассмотрим простые
атрибуты, из которых состоит атрибут МестныйАдрес. Как Корпус, так и НомерОфиса
имеют кардинальность 1.1. Вы можете удивиться, каким образом получается, что
группа может быть необязательной, если атрибуты, составляющие эту группу,
являются обязательными. Дело в том, что кардинальные числа действуют только
между атрибутом и его контейнером (группой, содержащей этот атрибут).
Минимальное кардинальное число атрибута МестныйАдрес показывает, что этот
атрибут не обязан иметь значение, то есть кафедра не обязана иметь адрес. А
минимальные кардинальные числа атрибутов Корпус и НомерОфиса показывают, что
эти атрибуты должны существовать в атрибуте МестныйАдрес. Таким образом,
группа МестныйАдрес не обязана существовать, но если уж она существует, то
составляющие ее атрибуты Корпус и НомерОфиса должны иметь значения.
Экземпляры объектов
Объектные диаграммы для кафедры, показанные на рис. 4.2, представляют собой
просто формат, общую структуру, которую можно отнести к любой кафедре. На
рис. 4.3 представлен экземпляр объекта КАФЕДРА. Здесь указаны значения каждо-
Семантические объекты 123
го атрибута конкретной кафедры. Кафедра имеет название «Информационные
системы» и расположена в офисе № 213 корпуса социальных наук. Обратите
внимание, что атрибут НомерТелефона имеет три значения: в офисе кафедры
информационных систем имеется три телефонные линии. Другие кафедры могут иметь
меньшее или большее количество телефонов, но у каждой кафедры есть по
крайней мере один телефон.
Информационные систен
Корпус социальных наук
213
491-0099
491-1182
491-0098
493-0100
Й|йлЬедж БизнёЩ
Рис. 4.3. Экземпляр объекта КАФЕДРА с рис. 4.2
Далее, имеется один экземпляр атрибута КОЛЛЕДЖ, со значением Колледж
Бизнеса, и множество экземпляров объектных атрибутов ПРЕПОДАВАТЕЛЬ и СТУДЕНТ.
Каждый из этих объектных атрибутов является полноценным объектом и имеет
все атрибуты, определенные для объекта данного типа. Чтобы не усложнять
диаграмму, мы указали на ней только имена экземпляров объектных атрибутов.
Объектная диаграмма — это картина восприятия пользователем объекта в
рабочей среде. Таким образом, в воображении пользователя объект КАФЕДРА
содержит все эти данные. Кафедра логически содержит данные о колледже, к
которому она принадлежит, а также о профессорах и студентах, относящихся к этой
кафедре.
Парные атрибуты
В семантической объектной модели нет однонаправленных связей между
объектами. Если один объект содержит в себе другой объект, то этот другой будет,
в свою очередь, содержать в себе первый. Например, если объект КАФЕДРА
содержит в себе объектный атрибут КОЛЛЕДЖ, то и объект КОЛЛЕДЖ будет содержать
соответствующий объектный атрибут КАФЕДРА. Эти объектные атрибуты
называются иногда парными атрибутами (paired attributes), так как они всегда
появляются по два.
Почему объектные атрибуты должны быть парными? Ответ заключается в том
способе, каким человеческие существа представляют себе связи между объектами.
1Ы
НазваниеКафедры
МестныйАдрес
НомерТелефона
НомерФакса
КОЛЛЕДЖ
ПРЕПОДАВАТЕЛЬ
СТУДЕНТ
124 Глава 4. Семантическая объектная модель
Если объект А имеет связь с объектом Б, то объект Б будет иметь связь с
объектом А. По крайней мере, Б связан с А как «вещь, которая связана с Б». Если этот
аргумент кажется неочевидным, попробуйте вообразить однонаправленную связь
между объектами. Это сделать невозможно.
Объектные идентификаторы
Объектный идентификатор (object identifier) — это один или несколько
объектных атрибутов, с помощью которых пользователи идентифицируют экземпляры
объектов. Такие идентификаторы представляют собой потенциальные имена
семантического объекта. Для объекта КЛИЕНТ возможными идентификаторами
являются НомерКлиента и ИмяКлиента. Каждый из этих идентификаторов является
атрибутом, рассматриваемым пользователями в качестве допустимого имени для
экземпляров объектного класса КЛИЕНТ. Сравните эти идентификаторы с
атрибутами ДатаПервогоЗаказа, КурсАкций или ЧислоСотрудников. Такие атрибуты не
являются идентификаторами, потому что пользователи не думают о них как об
именах экземпляров объектов класса КЛИЕНТ.
Групповой идентификатор (group identifier) — это идентификатор,
содержащий более одного атрибута. Примерами могут служить идентификаторы {Имя,
Фамилия}, {Имя, НомерТелефона} и {Штат, НомерЛицензии}.
Объектные идентификаторы могут быть уникальными или неуникальными,
в зависимости от того, как пользователи представляют себе свои данные.
Например, НомерСчета является уникальным идентификатором обьекта ЗАКАЗ, но Имя-
Студента не является уникальным идентификатором объекта СТУДЕНТ. Может быть
два студента по имени, к примеру, Мэри Смит. В таком случае пользователи
будут идентифицировать с помощью атрибута ИмяСтудента группу из одного или
более студентов и затем, если необходимо, использовать значения других
атрибутов для указания конкретного члена этого множества.
В семантических объектных диаграммах объектные идентификаторы
обозначаются с помощью букв ID перед атрибутом. Если идентификатор является
уникальным, эти буквы подчеркнуты. На рис. 4.2, бу например, атрибут НазваниеКа-
федры является уникальным идентификатором объекта КАФЕДРА.
Обычно, если атрибут должен использоваться в качестве идентификатора, он
обязан иметь значение. Кроме того, как правило, для данного объекта имеется не
более одного идентифицирующего атрибута. Поэтому в большинстве случаев
кардинальность атрибута-идентификатора равна 1.1, и это значение мы
используем по умолчанию.
Есть, однако, относительно небольшое число случаев, когда кардинальность
идентификатора отличается от 1.1. Рассмотрим, например, атрибут Псевдоним
семантического объекта ЧЕЛОВЕК. Человек не обязан иметь псевдоним, однако
может иметь и несколько. Следовательно, кардинальность этого атрибута равна O.N.
Указание нижних индексов всех атрибутов загромождает семантическую
объектную диаграмму. Для упрощения мы предположим, что кардинальность
простых идентифицирующих атрибутов равна 1.1, а прочих идентифицирующих
атрибутов — 0.1. Если кардинальность простого атрибута имеет другое значение,
Семантические объекты 125
мы укажем ее на диаграмме. В противном случае нижние индексы простых
атрибутов будут опускаться.
Домены атрибутов
Домен (domain) атрибута — это описание множества его значений.
Характеристики домена зависят от типа атрибута. Домен простого атрибута состоит из
физического и семантического описания. Физическое описание (physical description)
показывает тип данных (например, число или строка), длину данных и другие
ограничения (например, требование, чтобы первый символ был буквой или чтобы
значение не превышало 9999.99). Семантическое описание (semantic description)
указывает функцию, или назначение данного атрибута; оно отличает этот
атрибут от других атрибутов с тем же физическим описанием.
Например, домен атрибута НазваниеКафедры может быть определен как
«набор строк длиной до 7 символов, представляющих наименования кафедр
университета Higliline». Фраза «набор строк длиной до 7 символов» представляет собой
физическое описание домена, а «...представляющих имена кафедр университета
Highline» — семантическое описание. Семантическое описание отличает строки
из семи символов, представляющие названия кафедр, от строк такой же длины,
которые представляют, скажем, названия учебных дисциплин, корпусов или
какие-то еще атрибуты.
В некоторых случаях физическое описание домена простого атрибута
представляет собой нумерованный список — набор отдельных значений атрибутов.
Доменом атрибута ЦветДетали может быть, например, нумерованный список
{«Синий», «Желтый», «Красный»}.
Домен группового атрибута также имеет физическое и семантическое
описание. Физическое описание — это список всех атрибутов в группе в порядке их
следования. Семантическое описание — это описание функции, или назначения,
данной группы. Так, физическим описанием домена МестныйАдрес (см. рис. 4.2)
является список {Корпус, НомерОфиса}; семантическим описанием является фраза
«местоположение офиса в университете Highline».
Домен объектного атрибута — это набор экземпляров объектов данного типа.
На рис. 4.2, например, доменом объектного атрибута ПРЕПОДАВАТЕЛЬ является
совокупность всех экземпляров объектов класса ПРЕПОДАВАТЕЛЬ, представленных
в базе данных. Доменом объекта КОЛЛЕДЖ является совокупность всех объектов
класса КОЛЛЕДЖ, представленных в базе данных. В определенном смысле, домен
атрибута — это динамически нумерованный список, который содержит все
экземпляры объектов данного типа.
Представления семантических объектов
Пользователи имеют доступ к значениям объектных атрибутов через
приложения базы данных, которые предоставляют формы для ввода данных, отчеты и
запросы. В большинстве случаев такие формы, отчеты и запросы не требуют
доступа ко всем атрибутам объекта. Например, на рис. 4.4. показаны представления
126 Глава 4. Семантическая объектная модель
объекта КАФЕДРА для двух различных приложений. Некоторые атрибуты объекта
КАФЕДРА (например, НазваниеКафедры) являются видимыми в обоих
представлениях. Другие атрибуты видимы только в одном из представлений. Например,
атрибут СТУДЕНТ является видимым только в представлении СписокСтудентов, а
атрибут ПРЕПОДАВАТЕЛЬ виден только в представлении Персонал.
Часть объекта, видимая для конкретного приложения, называется
представлением семантического объекта (semantic object view), или просто
представлением (view). Представление состоит из имени объекта и списка всех атрибутов,
видимых в этом представлении.
Представления используются двояким образом. Когда вы разрабатываете
базу данных, вы можете использовать их для разработки модели данных.
Взгляните снова на рис. 4.1. Как можно видеть, при разработке модели данных
разработчики базы данных и приложений двигаются в обратном направлении. То есть
они начинают с форм, отчетов и запросов, которые пользователи объявляют
необходимыми, и двигаются назад, к структуре базы данных. Для этого комарща
выбирает требуемую форму, отчет или запрос и определяет, какое представление
должно существовать, чтобы можно было создать такую форму, отчет или
запрос. Затем команда переходит к следующей форме, отчету или запросу и делает
то же самое. Далее получившиеся два представлершя объединяются. Описанный
процесс повторяется до тех пор, пока структура базы данных не будет полностью
сформирована.
Второй аспект использования представлений возникает, когда структура
базы данных уже создана. В этом случае представления создаются для поддержки
новых форм, отчетов и запросов на основе существующей структуры базы
данных. Примеры этого второго подхода приведены в части IV, где обсуждаются
SQL Server и Oracle.
КАФЕДРА
ю НазваниеКафедры у
МестныйАдрес
Корпус^.,
НомерОфиса1.1_
НомерТелефона 1 N
НомерФакса 0 N
|| коЩедж
ШРЕПОдаВАТЕЛЬ
ЬШ. ._.■ " J--J L
Шетдант. ,ш
^.^■■...,:—•••••■'•;■■■ i •;:;:i:;:;:f;:^i
Представление СписокСтудентов
— НазваниеКафедры
•СТУДЕНТ:;
к Представление Персонал
\ НазваниеКафедры
ЛЩПОДАШЕПЬ
Рис. 4.4. Два представления семантического объекта
КАФЕДРА— СписокСтудентов и Персонал
Создание семантических объектных моделей данных 127
Создание семантических объектных
моделей данных
В этом разделе иллюстрируется процесс разработки семантических объектов,
в ходе которого разработчики анализируют интерфейс приложения (формы,
отчеты, запросы) и двигаются в обратном направлении, получая из этой
информации структуру объектов. Например, чтобы смоделировать структуру объекта
КАФЕДРА, мы сначала собираем все отчеты, формы и запросы, связанные с
кафедрой. Исходя из них, мы определяем объект КАФЕДРА, который позволяет
конструировать эти отчеты, формы и запросы.
Однако для абсолютно нового приложения в распоряжении разработчиков
иет компьютерных отчетов, форм и запросов, которые можно было бы изучать.
В этой ситуации разработчики начинают с определения того, какие объекты
пользователи хотят отслеживать. Затем путем опроса пользователей команда
выясняет, какие объектные атрибуты являются важными. На основе этой
информации могут быть созданы прототипы форм и отчетов, с помощью которых модель
данных будет далее уточняться.
Пример: база данных администрации
университета Highline
Предположим, что администрация университета Highline желает вести учет дан-
пых по кафедрам, факультетам и специальностям студентов. Предположим,
далее, что приложение должно генерировать четыре типа отчетов (рис. 4.5,4.7,4.9
и 4.11). Наша цель — изучить эти отчеты и, используя инженерный анализ,
определить, какие объекты и атрибуты должны храниться в базе данных.
Объект КОЛЛЕДЖ
Отчет, изображенный на рис. 4.5, содержит информацию о колледже, а именно
о Колледже бизнеса. Данный отчет — это только один частный пример.
Университет Highline имеет подобные отчеты и о других колледжах, в частности о
Колледже искусств и наук и колледже социальных наук. Создавая модель данных,
важно собрать достаточное количество примеров, чтобы на их основе можно
было построить образец отчета о колледже. Здесь мы предположим, что отчет на
рис. 4.5 является типичным.
Исследуя отчет, мы найдем данные, специфичные для данного колледжа
(название, имя декана, номер телефона и местный адрес, а также сведения о каждой
из кафедр колледжа. Это наводит на мысль о том, что база данных может
содержать объекты КОЛЛЕДЖ и КАФЕДРА, а также связь между ними.
Эти предварительные заключения отражены в объектных диаграммах на
рис. 4.6. Обратите внимание, что мы не указали кардинальность простых
атрибутов, у которых она равна 0.1.
128 Глава 4. Семантическая объектная модель
Телефон: 232-1187
Кафедра
Бухгалтерский учет
Финансы
Информационные
системы
Менеджмент
Производство
Колледж Бизнеса
Мэри Джефферсон, декан
Заведующий
Джексон, Сеймур П.
Хью Тень, Сьюзен
Браммер, Натаниэль Д.
Татл, Кристин А.
Барнс, Джек Т.
Местный адрес:
Корпус бизнеса, комната 100
Телефон
232-1841
232-1414
236-0011
236-9988
236-1184
Всего студентов
318
211
247
184
212
Рис. 4.5. Пример отчета о колледже
КОЛЛЕДЖ
ю НазваниеКолледжа
ИмяДекана
НомерТелефона
МестныйАдрес
Корпус 1.1
НомерОфиса 11
0.1
:зй4«вЖ:
КАФЕДРА
ю НазваниеКафедры
Заведующий
НомерТелефона
ВсегоСтудентов
, кдашадж
Рис. 4.6. Первая версия объектов КОЛЛЕДЖ и КАФЕДРА
Кардинальность атрибута КАФЕДРА объекта КОЛЛЕДЖ равна 1.N — это
означает, что колледж должен иметь как минимум одну кафедру и кафедр может быть
много. Это минимальное кардинальное число не может быть выведено из отчета
на рис. 4.5. Чтобы его получить, пользователям был задан вопрос о том, может
ли существовать колледж без кафедр, и их ответ был отрицательным.
Также обратите внимание, что структура объекта КАФЕДРА выведена на
основе данных, представленных на рис. 4.5. Поскольку объектные атрибуты всегда
являются парными, объект КОЛЛЕДЖ показан внутри объекта КАФЕДРА, хотя,
строго говоря, этот факт нельзя получить из анализа рис. 4.5. Как и в ситуации
с атрибутом КАФЕДРА объекта КОЛЛЕДЖ, пользователей попросили определить
кардинальность атрибута КОЛЛЕДЖ. Она равна 1.1, что означает, что кафедра
может быть связана с одним и только одним колледжем.
По ходу изложения мы интерпретировали отчет на рис. 4.5 таким образом,
что группы повторяющихся данных относятся к объекту КАФЕДРА как к
независимому объекту. Фактически наличие таких групп часто является сигналом
о том, что существует некий другой объект. Однако это не всегда так.
Повторяющаяся группа может быть также групповым атрибутом, у которого оказалось
несколько значений.
Создание семантических объектных моделей данныу 129
Вас, возможно, интересует, как различить эти два типа повторяющихся
данных — те, которые представляют объект, и те, которые представляют группу.
Какого-либо твердого и четкого правила на этот счет не существует, поскольку
ответ зависит от того, как пользователи представляют себе свой мир.
Следовательно, наилучшим выходом будет спросить самих пользователей о семантике
их данных. Спросите, являются ли эти повторяющиеся группы данных частью
колледжа, или они относятся к чему-то еще — чему-то самостоятельному. В первом
случае они составляют групповой атрибут, во втором — семантический объект.
Посмотрите также другие отчеты (или формы, или запросы). Имеются ли у
пользователей отчеты по кафедрам? Если да, то предположение о том, что кафедра
может быть представлена семантическим объектом, подтвердится. На самом деле
персонал университета Highline работает с двумя видами отчетов по кафедрам.
Этот факт еще более укрепляет нас в мысли о том, что следует ввести объект под
названием КАФЕДРА.
Далее, группы атрибутов, представляющие независимый объект, обычно
содержат явный идентифицирующий атрибут или несколько атрибутов.
Автомобили имеют номер или номер лицензии, продукты имеют учетный номер или
штрих-код (SKU). Заказы также имеют учетные номера. Однако группа
атрибутов {ДатаИзмерения, ДавлениеВШине} не имеет явного идентификатора. Когда вы
спросите пользователя об идентификаторе этой группы, он в ответ спросит вас
что-нибудь вроде: «Давление в шине чего?». Это будет давление в шине
легкового автомобиля или грузовика или трейлера, или какого-либо еще
транспортного средства. Следовательно, такая группа представляет собой групповой
атрибут некоторого другого объекта — объекта, который является ответом на вопрос
«чего?».
Объект КАФЕДРА
Отчет, представленный на рис. 4.7, содержит информацию о кафедрах, а также
список работающих на них преподавателей. Обратите внимание, что этот отчет
содержит местный адрес кафедры. Поскольку эти данные не присутствуют в
версии объекта КАФЕДРА, изображенной на рис. 4.6, их необходимо добавить к
объекту, как показано на рис. 4.8. Такое уточнение является типичным для процесса
моделирования данных. То есть структура семантических объектов постоянно
уточняется по мере того, как идентифицируются и анализируются новые отчеты,
формы и запросы.
Объект ПРЕПОДАВАТЕЛЬ
Отчет на рис. 4.7 не только указывает на необходимость введения объекта
КАФЕДРА, но и наводит на мысль, что для представления данных о профессоре
может понадобиться еще один объект. Соответственно, в модель добавлен объект
ПРЕПОДАВАТЕЛЬ, как показано на рис. 4.8. Идентификатор объекта
ПРЕПОДАВАТЕЛЬ, которым является атрибут ИмяПреподавателя, не является уникальным; на
:ж) указывает тот факт, что буквы ID на рис. 4.8 не подчеркнуты.
130 Глава 4. Семантическая объектная модель
Кафедра информационных систем
Колледж бизнеса
Заведующий: Браммер, Натаниэль Д.
Телефон: 236-0011
МестныйАдрес: Корпус социальных наук, комната 213
Преподаватель
Джонс, Пол Д.
Парке, Мэри Б.
By, Элизабет
Офис
Телефон
Корпус социальных наук, комната 219 232-7713
Корпус социальных наук, комната 308 232-5791
Корпус социальных наук, комната 232 232-9112
Рис. 4.7. Пример отчета о кафедре
В соответствии с объектными диаграммами на рис. 4.8, на каждой кафедре
должен быть как минимум один преподаватель, причем на одной кафедре
преподавателей гложет быть несколько, но каждый преподаватель должен работать на
одной и только на одной кафедре. Таким образом, согласно этой модели, работа
по совместительству запрещена. Это ограничение является частью делового
регламента, который должен определяться из опросов пользователей.
На рис. 4.9 показан второй отчет о кафедре. В нем представлена информация
о кафедре и о студентах, специальность которых имеет отношение к этой
кафедре. Ситуация, когда об одном объекте имеется два отчета, типична; эти отчеты
просто документируют различные представления одной и той же вещи. Более
того, существование второго отчета укрепляет нашу уверенность в том, что
кафедра является объектом в понимании пользователей.
Объект СТУДЕНТ
Отчет на рис. 4.9 содержит данные о студентах, профилирующая специальность
которых относится к области деятельности данной кафедры, что подразумевает,
что студенты также являются объектами. Поэтому объект КАФЕДРА должен также
содержать объекты СТУДЕНТ и ПРЕПОДАВАТЕЛЬ, как показано на рис. 4.10.
КАФЕДРА
/о НазваниеКафедры
Заведующий
НомерТелефона
ВсегоСтудентов
МестныйАдрес
Корпус 1.1
НомерОфиса л л
'~J о.
1|щ;щл^||1;
||||пЩДЩЩ1]||
ПРЕПОДАВАТЕЛЬ
ю ИмяПреподавателя
МестныйАдрес
Корпуси
НомерОфиса 1 л
0.1
НомерТелвфона
Рис. 4.8. Уточненный объект КАФЕДРА и новый объект ПРЕПОДАВАТЕЛЬ
Создание семантических объектных моделей данных 131
Список студентов
Кафедра информационных систем
Заведующий: Браммер, Натаниэль Д. Телефон: 236-0011
Имя студента Номер студента Телефон
Джексон, Робин Д. 12345 237-8713
Линкольн, Фред Дж. 48127 237-8713
Мэдисон, Дженис А. 37512 237-8713
Рис. 4.9. Второй пример отчета о кафедре
Объект СТУДЕНТ на рис. 4.10 имеет атрибуты ИмяСтудента, НомерСтудента и Но-
мерТелефона — атрибуты, перечисленные в отчете на рис. 4.9. Обратите
внимание, что и ИмяСтудента, и НомерСтудента являются идентификаторами. Имена
студентов не являются уникальными, а номера уникальны.
На рис. 4.11 представлен другой пример отчета о студентах —
письмо-приглашение, которое университет рассылает поступившим в него студентам. Даже
несмотря на то, что это письмо, оно все же является отчетом; вероятно, оно было
создано в текстовом редакторе с помощью мастера стандартных писем.
Те элементы данных в письме, которые должны храниться в базе данных,
напечатаны жирным шрифтом. Кроме данных, относящихся к студенту, письмо
также содержит данные о профильной кафедре студента и о его руководителе.
Поскольку руководитель является преподавателем, это письмо подтверждает
потребность в отдельном объекте под названием ПРЕПОДАВАТЕЛЬ. Уточненные
диаграммы объектов ПРЕПОДАВАТЕЛЬ и СТУДЕНТ представлены на рис. 4.12. Глядя на
объект СТУДЕНТ, можно видеть, что как КАФЕДРА, так и ПРЕПОДАВАТЕЛЬ имеют
единственное значение (их максимальное кардинальное число равно 1).
Следовательно, студент этого университета имеет максимум одну профильную
кафедру и одного руководителя, причем имеет обязательно.
Объект СТУДЕНТ на рис. 4.12 соответствует данным, изображенным на рис. 4.11.
Может, однако, оказаться, что студент имеет более одной специальности, и тогда
атрибуты КАФЕДРА и ПРЕПОДАВАТЕЛЬ будут многозначными. Этот факт не может
быть выявлен из единственного стандартного письма, которое было
представлено, поэтому требуется проанализировать другие письма и провести
дополнительные опросы, чтобы определить, разрешено ли иметь несколько профилирующих
специальностей. Здесь мы предполагаем, что такая специальность может быть
только одна.
Имя студента дается сначала в формате Имя Фамилия в верхней строчке
письма, а затем в формате Фамилия в приветствии. Если указание имен в этом
формате является обязательным, то одного атрибута ИмяСтудента (на рис. 4.10)
будет недостаточно, и необходимо будет ввести группу {Имя, Фамилия}. Это
сделано на рис. 4.12. Заметьте также, что и имя руководителя дается в формате
{Имя, Фамилия}, что означает, что имя профессора должно быть также разделено
па два атрибута.
132 Глава 4. Семантическая объектная модель
КАФЕДРА
/о НазваниеКафедры
Заведующий
НомерТелефона
ВсегоСтудентов
МестныйАдрес
Корпус 1.1
НомерОфиса 11
-* 0.1
колледж т
ПРЕПОДАВАТЕЛ
|ОТУДЕНТ
1.N
СТУДЕНТ
ю Имя Студента
/о НомерСтудента
НомерТелефона
кн
Рис. 4.10. Уточненный объект КАФЕДРА и новый объект СТУДЕНТ
Мистеру Фреду Парксу
123, Эльм-Стрит
Лос-Анджелес, Калифорния 98002
Уважаемый мистер Парке,
рад сообщить, что вы приняты на кафедру бухгалтерского учета
университета Highline, начиная с осеннего семестра 2000 года.
Кафедра бухгалтерского учета находится по адресу: корпус
бизнеса, комната 210.
Вашим руководителем назначена профессор Элизабет Джонсон,
ее номер телефона 232-8740, офис расположен в корпусе бизнеса,
комната 227. Просьба назначить встречу с руководителем сразу
по прибытию в университетский городок.
Поздравляю, и добро пожаловать в университет Highline!
Искренне ваш,
Ян П. Сматерс,
Президент
Рис. 4.11. Письмо-приглашение
Кроме того, из письма видно, что именам в адресах и приветствиях должно
предшествовать обращение «Мистер» или «Мисс». Чтобы обеспечить такую
возможность, к объекту СТУДЕНТ следует добавить еще один атрибут, и на основании
данного атрибута выбирать титул. Другая возможность — хранить в базе данных
сам титул. Преимущество этого подхода в том, что он позволяет хранить и другие
титулы, помимо «Мистер» и «Мисс», — например, «Доктор».
В текущей версии модели данных иных титулов, кроме «Мистер» и «Мисс»,
не требуется. Однако вполне вероятна ситуация, при которой дополнительные
Создание семантических объектных моделей данных 133
обращения могут понадобиться; следовательно, второй вариант более надежен, и
поэтому к объекту СТУДЕНТ на рис. 4.12 добавлен атрибут Обращение.
ПРЕПОДАВАТЕЛЬ -
ю Имя Преподавателя
Имя 0i1
Фамилия лл
МестныйАдрес
Корпус 1.1
НомерОфиса и
НомерТелефона
шщ^т
;;г|||ЩЗД"||§
1.1
1.N
СТУДЕНТ
ю Имя Студента
Имя01
Фамилия 1Л
ю НомерСтудента
НомерТелефона
ДомашнийАдрес ~\
Улица01
Город и
Штат и
Индекс лл
Обращение
Дата Поступления
ЩЩЩ?ШЩ
щшсшШ^Ш!!
Рис. 4.12. Уточненные объекты ПРЕПОДАВАТЕЛЬ и СТУДЕНТ
Опять-таки, эти изменения иллюстрируют итеративную природу
моделирования данных. Имеющиеся решения часто приходится пересматривать и
корректировать вновь и вновь. Это не означает, что процесс проектирования идет
с ошибками; фактически, такие итерации являются обычными и ожидаемыми.
Спецификация объектов
На рис. 4.13 показан окончательный вариант объектных диаграмм для базы
данных университета Highline. Внесено несколько дополнительных изменений:
атрибуты ИмяДекана и Председатель смоделированы в формате {Имя, Фамилия},
чтобы все имена имели одинаковый формат. Далее, чтобы увеличить точность
модели, атрибут ПРЕПОДАВАТЕЛЬ объекта СТУДЕНТ был переименован — теперь он
называется РУКОВОДИТЕЛЬ. Экземпляр объекта ПРЕПОДАВАТЕЛЬ, связанный через
:>тот атрибут с экземпляром объекта СТУДЕНТ, это не просто кто-то из
преподавателей данного студента, а совершенно конкретный преподаватель, который является
руководителем данного студента, и термин руководитель является более точным,
чем термин преподаватель.
Домен этого атрибута не меняется. Атрибут РУКОВОДИТЕЛЬ имеет домен
ПРЕПОДАВАТЕЛЬ, такой же домен и у атрибута ПРЕПОДАВАТЕЛЬ. Он по-прежнему
указывает на экземпляры семантического объекта ПРЕПОДАВАТЕЛЬ. Смена имени — это
лишь уточнение роли, которую домен ПРЕПОДАВАТЕЛЬ играет в семантических
объектах СТУДЕНТ. Аналогичное изменение было сделано и в объекте ПРЕПОДАВАТЕЛЬ:
атрибут СТУДЕНТ был переименован и называется теперь РУКОВОДИМЫЙ_СТУДЕНТ,
но этот атрибут по-прежнему связан с объектами из домена СТУДЕНТ.
134 Глава 4. Семантическая объектная модель
КОЛЛЕДЖ
/о НазваниеКолледжа
ИмяДекана
Имя о.1
Фамилия лл -
НомерТелефона
МестныйАдрес
Корпус 1.1
НомерОфисаи
1.1
0.1
?.$■•$%■
КАФЕДРА
/о Назван иеКафедры
Заведующий
Имя о.1
Фамилия лл
НомерТелефона
ВсегоСтудентов -
МестныйАдрес
Корпус 11
НомерОфиса л 1
Ш1Щ^ЖЯ
шшшшшш
1.1
ПРЕПОДАВАТЕЛЬ -
ю ИмяПреподавагеля
Имя 01
Фамилия 1t1
МестныйАдрес
Корпус 1.1
HoMepOqf)nca 1.1
НомерТелефона
Ш^Ш$й;Ш
1.1
. $1Ш1В11Ш1
СТУДЕНТ
id ИмяСтудента
Имя01
Фамилия^
ю НомерСтудента
НомерТелефона
Домашний Адрес
Улица ол
Город, 1
Штат111
Индекс1л
Обращение
ДатаПоступления
;;г кафедра V
1.1
^консультант-;
Рис. 4.13. Полный набор семантических объектных диаграмм
В табл. 4.1 и 4.2 представлена спецификация модели данных. Семантические
объекты и атрибуты определены в спецификации семантических объектов, а
домены определены в спецификации доменов. Первая таблица является
альтернативным представлением информации в семантических объектных диаграммах,
и ее интерпретация очевидна.
Вторая таблица, таблица доменов, содержит такую информацию о доменах,
которая не может быть получена из семантических объектных диаграмм. Как
было указано ранее, домен имеет как семантическое, так и физическое описание.
Семантическое описание каждого объекта дается в столбце Описание, а
физическое описание дается в столбце Спецификация. Содержание столбца Описание
говорит само за себя.
Создание семантических объектных моделей данных 135
Таблица 4.1. Спецификации семантических объектов для базы данных
университета Highline
Имя объекта Имя свойства Мин. Макс. Статус Имя домена
кард. кард, идент.
КОЛЛЕДЖ
КАФЕДРА
ПРЕПОДАВАТЕЛЬ
СТУДЕНТ
Назван иеКолледжа
ИмяДекана
Имя
Фамилия
Телефон
МестныйАдрес
Корпус
НомерОфиса
КАФЕДРА
НазваниеКафедры
Заведующий
Имя
Фамилия
Телефон
ВсегоСтудентов
МестныйАдрес
Корпус
НомерОфиса
КОЛЛЕДЖ
ПРЕПОДАВАТЕЛЬ
СТУДЕНТ
ИмяПреподавателя
Имя
Фамилия
МестныйАдрес
Корпус
НомерОфиса
Телефон
КАФЕДРА
РУКОВОДИМЫЙ
СТУДЕНТ
ИмяСтудента
Имя
Фамилия
НомерСтудента
Телефон
ДомашнийАдрес
Обращение
ДатаПоступления
КАФЕДРА
РУКОВОДИТЕЛЬ
1
1
0
1
0
0
1
1
1
1
1
0
1
0
0
0
1
1
1
1
1
1
0
1
0
1
1
0
1
1
1
0
1
1
0
1
0
0
1
1
N
N
N
N
Ю
Ю
ID
ID
Ю
НазваниеКолледжа
ИмяЧеловека
Имя
Фамилия
Телефон
МестныйАдрес
Корпус
НомерОфиса
КАФЕДРА
Назван иеКафедры
ИмяЧеловека
Имя
Фамилия
Телефон
ЧислоСтудентов
МестныйАдрес
Корпус
НомерОфиса
КОЛЛЕДЖ
ПРЕПОДАВАТЕЛЬ
СТУДЕНТ
ИмяЧеловека
Имя
Фамилия
МестныйАдрес
Корпус
НомерОфиса
Телефон
КАФЕДРА
СТУДЕНТ
ИмяЧеловека
Имя
Фамилия
НомерСтудента
Телефон
Адрес
Обращение
Квартал ьнаяДата
КАФЕДРА
РУКОВОДИТЕЛЬ
136 Глава 4. Семантическая объектная модель
Таблица 4.2. Спецификация доменов для базы данных университета Highline
Имя домена
Адрес
Корпус
Местный Ад рее
Город
КОЛЛЕДЖ
НазваниеКолледжа
КАФЕДРА
НазваниеКафедры
Имя
Фамилия
Тип
Групповой
Простой
Групповой
Простой
Семантический
объект
Простой
Семантический
объект
Простой
Простой
Простой
Семантическое
описание
Адрес в США
Название корпуса
в университете
Адрес в университете
Название города
Один из колледжей
университета Highline
Официальное название
колледжа университета
Highline
Учебная кафедра
университета
Официальное название
учебной кафедры
университета
Часть группы
ИмяЧеловека,
представляющая имя
Часть группы
Физическое
описание
Улица
Город
Штат
Индекс
Text 20
Корпус
НомерОфиса
Text 25
См. спецификацию
семантических объектов
Text 25
См. спецификацию
семантических объектов
Text 25
Text 20
Text 30
ЧислоСтудентов
НомерОфиса
ИмяЧеловека
Телефон
ПРЕПОДАВАТЕЛЬ
Квартал ьнаяДата
Формула
Простой
Групповой
Простой
Семантический
объект
Простой
ИмяЧеловека,
представляющая
фамилию
Число студентов
на данной кафедре
Номер офиса
в университете
Имя и фамилия
администратора,
преподавателя или
студента
Номер телефона с кодом
региона
Имя постоянного члена
профессорско-
преподавательского
состава Highline
Учебная четверть и год
Integer; значение
в интервале {0-999},
формат 999
Text 4
Имя
Фамилия
Text 4
См. спецификацию
семантических
объектов
Text 3; значения {q01},
где q = один из
символов {«О», «3», «В»,
«Л»}, а 01 — десятичное
число от 00 до 99
Типы объектов 137
Имя домена
Штат
Улица
СТУДЕНТ
НомерСтудента
Обращение
Индекс
Тип
Простой
Простой
Семантический
объект
Простой
Простой
Простой
Семантическое
описание
Двухбук венная
аббревиатура штата
Название улицы
Лицо, принятое
в университет Highline
Идентификатор,
присвоенный
студенту, принятому
в университет Highline
Обращение человека
(для использования
в обращениях)
Девятизначный индекс
Физическое
описание
Text 2
Text 30
См. спецификацию
семантических объектов
Integer; интервал —
{10000-99999},
формат 99999
Text 6, значения
{«Мистер», «Мисс»}
Text 10, формат
99999-9999
Спецификация доменов включает в себя физическое описание и в некоторых
случаях множество значений и формат. Домен НомерСтудента определен,
например, как целое число, принимающее значения между 10000 и 99999 в формате
с пятью десятичными цифрами. (В данной таблице цифра 9 в описании формата
означает десятичную цифру.) Другие домены описаны аналогичным образом.
Домен Обращение является примером домена-перечисления, значениями
которого являются «Мистер» и «Мисс». Физическое описание группового домена
состоит из списка доменов, входящих в группу. Физическое описание домена
семантического объекта — это просто ссылка на описание семантического объекта.
Домен атрибута ВсегоСтудентов являет собой пример четвертого типа
домена — формулы (formula domain). Формулы представляют атрибуты,
вычисленные на основе других значений. Домен ЧислоСтудентов — это число объектов типа
СТУДЕНТ, связанных с данным объектом типа КАФЕДРА. Мы не будем описывать
здесь способы, с помощью которых это вычисление описывается в определении
домена. На данном этапе для нас важно только указать потребность в формуле
и ее спецификацию.
Типы объектов
В этом разделе описываются и демонстрируются семь типов объектов. Для
каждого типа объектов мы исследуем отчет или форму и покажем, как их можно
представить с помощью данного объекта. Далее, в главе 7, мы трансформируем
каждый из этих типов в соответствующую структуру базы данных.
В данном разделе используются три новых термина. Однозначный атрибут
(single-value attribute) — это атрибут с максимальным кардинальным числом 1.
Многозначный атрибут (multi-value attribute) — это атрибут, имеющий
максимальное кардинальное число больше 1. Необъектный атрибут (non-object attribute) —
это простой или групповой атрибут.
138 Глава 4. Семантическая объектная модель
Простые объекты
Простой объект (simple object) — это семантический объект, имеющий только
однозначные, простые или групповые атрибуты. Пример такого объекта показан на
рис. 4.14. В левой части этого рисунка представлены два экземпляра отчета под
названием Ярлык для оборудования. Такие ярлыки, наклеиваемые на офисное
оборудование, помогают вести его учет. Их можно рассматривать как отчеты.
На рис. 4.14, б изображен простой объект ОБОРУДОВАНИЕ, с помощью которого
моделируется ярлык для оборудования. Атрибуты объекта включают в себя то,
что указано на ярлыке: ИнвентарныйНомер, Описание, ДатаПриобретения и Стоимость.
Обратите внимание, что ни один из этих атрибутов не является многозначным,
как ни один из них не является и объектным. Следовательно, объект ОБОРУДОВАНИЕ
является простым объектом.
ЯРЛЫК ОБОРУДОВАНИЯ:
ИнвентарныйНомер: 100 Описание: Стол
ДатаПриобретения: 2/27/2000 Стоимость: $350.00
ЯРЛЫК ОБОРУДОВАНИЯ:
ИнвентарныйНомер: 100
ДатаПриобретения: 3/1/0200
Описание: Лампа
Стоимость: $39.95
ОБОРУДОВАНИЕ
ю ИнвентарныйНомер
Описание
ДатаПриобретения
Стой мость
Рис. 4.14. Пример простого объекта: а — отчеты, основанные на простом объекте;
б - простой объект ОБОРУДОВАНИЕ
Композитные объекты
Композитный объект (composite object) — это семантический объект,
содержащий один или несколько многозначных, простых или групповых атрибутов, но не
имеющий объектных атрибутов. Счет за услуги гостиницы, изображенный на
рис. 4.15, а, демонстрирует потребность в композитном объекте. Этот счет
содержит данные, относящиеся к счету в целом: НомерСчета, ДатаПрибытия, ИмяКлиента
и СуммаКОплате. Кроме того, в нем имеется повторяющаяся группа атрибутов,
которая описывает предоставленные клиенту услуги. Каждая группа включает в
себя атрибуты ДатаОказанияУслуги, ОписаниеУслуги и Стоимость.
На рис. 4.15, б показана диаграмма объекта СЧЕТ_ИЗ_0ТЕЛЯ. Атрибут Строка-
Расходов — это групповой атрибут, имеющий максимальное кардинальное число
N, что означает, что группа {ДатаОказанияУслуги, ОписаниеУслуги и Стоимость}
может появляться многократно в одном и том же экземпляре семантического
объекта СЧЕТ_ИЗ_0ТЕЛЯ.
Строка расходов не моделируется как самостоятельный семантический
объект, а вводится как атрибут объекта СЧЕТ_ИЗ_0ТЕЛЯ. Такая организация
оправдана тем, что гостиница не рассматривает каждую строку расходов в счете клиента
как нечто отдельное, и строки расходов не имеют собственных идентификаторов.
Служащие не вводят данные в строку расходов иначе как в контексте счета. Сна-
Типы объектов 139
чала служащий вводит данные для счета № 1234, а затем, в контексте данного
счета, вводит суммы. Бывает и так, что служащий берет уже существующий счет
и вносит в него дополнительные расходы.
Номер счета:
Имя клиента.
10/12/2001
10/12/2001
10/12/2001
10/12/2001
10/13/2001
I 10/13/2001
10/13/2001
ОТЕЛЬ GRANDVIEW
Си Блафс, Калифорния
1234 Дата
Мэри Джонс
Номер
Еда
Телефон
Налог
Номер
Еда
Телефон
Сумма к оплате
прибытия: 10/12/2001
$99.00
$ 37.55
$ 2.50
$ 15.00
$99.00
$ 47.90
$15.00
$315.95
а ^ б
Рис. 4.15. Пример композитного объекта: а — отчет, основанный на композитном объекте;
б — композитный объект СЧЕТ_ИЗ_ОТЕЛЯ
Минимальное кардинальное число атрибута СтрокаРасходов равно 0, что
означает, что объект СЧЕТ_ИЗ_0ТЕЛЯ может существовать без единой строки расходов.
Это позволяет открывать счет в тот момент, когда клиент вселяется в гостиницу,
и до того, как появятся какие-либо расходы. Если бы минимальное
кардинальное число равнялось 1, то нельзя было бы открыть счет, прежде чем будет
начислена хотя бы одна сумма. Решение об этом должно приниматься в свете
имеющегося делового регламента. Политика отеля может заключаться в том, чтобы не
открывать счет, пока не будут начислены какие-либо расходы. В таком случае
минимальное кардинальное число атрибута СтрокаРасходов должно равняться 1.
Композитный объект может иметь более одного многозначного атрибута.
На рис. 4.16, а показан счет за услуги гостиницы, в котором имя клиента и
стоимость услуг представлены многозначными атрибутами. Каждая из этих групп
независима от другой. Например, второе имя в группе ИмяКлиента не связано
логически со второй строкой расходов.
На рис. 4.16, б представлена объектная диаграмма для счета, показанного
на рис. 4.16, а. Атрибут ИмяКлиента показан как многозначный. Он не помещен
и скобку СтрокаРасходов, поскольку повторения имен не имеют ничего общего
с повторениями услуг. Они независимы, как мы только что отметили.
И простые, и групповые атрибуты могут быть многозначными. На рис. 4.16, а,
например, ИмяКлиента является простым многозначным атрибутом. Одного этого
достаточно, чтобы объект можно было назвать композитным.
Многозначные атрибуты могут также быть вложенными. Представьте себе,
к примеру, что требуется вести учет отдельных видов расходов в рамках одной
строки. В форме на рис. 4.17, а расходы подразделяются на виды. Например, еда
СЧЕТ_ИЗ_ОТЕЛЯ
/о НомерСчета
ДатаПрибытия
ю ИмяКлиента
СтрокаРасходов 1
ДатаОказанияУслуги 11
Описание Услуги 1 л
Стоимость 11
~*0.N
СуммаКОплате 1 л
140 Глава 4. Семантическая объектная модель
делится на завтрак, обед и ужин. Объектная диаграмма с такими вложенными
атрибутами, представленная на рис. 4.17, б, показывает, что оплата любых услуг
может быть разделена на составляющие.
1 Номер счета
1имя клиента
10/12/2001
10/12/2001
! 10/12/2001
10/12/2001
10/13/2001
10/13/2001
| 10/13/2001
ОТЕЛЬ GRANDVIEW
Си Блафс, Калифорния
1234
Мэри Джонс
Фред Джонс
Сэлли Джонс
Номер
Еда
Телефон
Налог
Номер
Еда
Телефон
Дата
Сумма к оплате
прибытия: 10/12/2001
$ 99.00
$ 37.55
$ 2.50
$15.00
$99.00
$47.90
$15.00
$315.95
СЧЕТ_ИЗ_ОТЕЛЯ
ю НомерСчета
ДатаПрибытия
ю ИмяКлиента
Строка Расходов
ДатаОказанияУслуги 11
ОписаниеУслуги 1<1
Стоимость 1.,
СуммаКОплате 1.,
0.N
Рис. 4.16. Композитный объект с двумя группами: а — объект СЧЕТ_ИЗ_ОТЕЛЯ
многозначным именем клиента; б — объект СЧЕТ_ИЗ_ОТЕЛЯ с двумя
многозначными группами
Номер счета:
Имя клиента:
10/12/2001
10/12/2001
10/12/2001
I 10/12/2001
10/13/2001
10/13/2001
10/13/2001
ОТЕЛЬ GRANDVIEW
Си Блафс, Калифорния
1234 Дата прибытия: 10/12/2001
Мэри Джонс
Номер
Еда о ~
Завтрак
Обед
Телефон
Налог
Номер
Еда
Завтрак
Закуски
Обед
Телефон
Сумма к оплате
-^^ а
$99.00
$ 15.25
$ 22.30
$ 37.50
$ 2.50
$ 15.00 ,
$ 99.00
$ 15.25
$ 5.50
$ 22.30
$ 47.90
$ 15.00
$315.95
СЧЕТ_ИЗ_ОТЕЛЯ
ю НомерСчета
ДатаПрибытия
ю ИмяКлиента
Строка Расходов
ДатаОказанияУслуги 1
ОписаниеУслуги
ПодвидУслуги Г1
СтоимостьПодвида
1.1.
СтоимостьУслуги 11
СуммаКОплате Г1<
Рис. 4.17. Композитный объект с вложенными группами: а — объект СЧЕТ_ИЗ_ОТЕЛЯ
с разновидностями услуг; б — объект СЧЕТ_ИЗ_ОТЕЛЯ с вложенными
многозначными группами
Типы объектов 141
Для закрепления повторим, что композитный объект — это объект, имеющий
один или несколько простых или групповых атрибутов. Объектных атрибутов
он не содержит.
Составные объекты
Составной объект (compound object) имеет минимум один объектный атрибут.
На рис. 4.18, а показаны две различные формы для ввода данных. Одна из них
используется автомобильным парком компании для учета имеющихся
транспортных средств. Во вторую форму вводятся данные о сотрудниках. Согласно этим
формам, конкретное транспортное средство закрепляется не более чем за одним
сотрудником, и за конкретным сотрудником может быть закреплено не более
одного автомобиля.
Мы не можем определить из этих форм, должен ли каждый автомобиль
закрепляться за каким-либо сотрудником и должен ли каждый сотрудник иметь
автомобиль. Чтобы получить эту информацию, нам пришлось бы спросить об
этом пользователей, работающих в автопарке или в отделе кадров. Предположим,
мы выяснили, что сотрудник не обязан иметь транспортное средство, но каждое
транспортное средство должно быть закреплено за каким-либо сотрудником.
На рис. 4.18, б представлены диаграммы для объектов СОТРУДНИК и ТРАНС-
П0РТН0Е_СРЕДСТВ0. Объект СОТРУДНИК содержит в качестве одного из атрибутов
объект ТРАНСПОРТНОЕ_СРЕДСТВО, а ТРАНСПОРТНОЕ_СРЕДСТВО, в свою очередь,
содержит в качестве одного из атрибутов объект СОТРУДНИК. Поскольку и СОТРУДНИК,
и ТРАНСП0РТНОЕ_СРЕДСТВО имеют объектные атрибуты, оба они являются
составными объектами. Более того, так как ни один из атрибутов не является
многозначным, связь между объектами СОТРУДНИК и ТРАНСПОРТНОЕ_СРЕДСТВО имеет
вид «один к одному» — 1:1.
На рис. 4.18, а формы ДАННЫЕ СОТРУДНИКА и ДАННЫЕ ТРАНСПОРТНОГО СРЕДСТВА
включают одна другую. То есть в форме ДАННЫЕ ТРАНСПОРТНОГО СРЕДСТВА
имеется поле «Закреплено за сотрудником», а в форме ДАННЫЕ СОТРУДНИКА имеется
поле «Закреплен автомобиль». Но это не всегда так: иногда связь может казаться
однонаправленной. Рассмотрим отчет и форму на рис. 4.19, б, в которых
описываются два объекта: DORMITORY (общежитие) и STUDENT (студент). Из отчета DORMITORY
OCCUPANCY REPORT (занятость общежития) мы можем видеть, что в представлении
пользователей общежитие имеет атрибуты, относящиеся как к самому
общежитию — название общежития, имя ответственного жильца, телефон (Dormitory,
Resident Assistant, Phone), так и к проживающим в нем студентам — имя
студента, номер студента, группа (Student name, Student Number, Class).
С другой стороны, форма с данными о студенте (Student Data Form) на рис. 4.19, а
содержит информацию, касающуюся исключительно самого студента, — никаких
данных об общежитии в этой форме не имеется. (Местный адрес может быть
адресом общежития, но даже если и так, этот факт явно недостаточно важен,
чтобы документировать его в форме. При разработке базы данных возможность
этого следует выяснить в ходе опроса пользователей. Здесь мы предположим,
что форма Student Data Form не содержит информации об общежитии.)
142 Глава 4. Семантическая объектная модель
ДАННЫЕ ТРАНСПОРТНОГО СРЕДСТВА ,
Номер лицензии
Производитель
Серийный номер
Тип | Год выпуска | Цвет
Закреплен за сотрудником
РАБОЧИЕ ДАННЫЕ СОТРУДНИКА !
Имя сотрудника
Почтовый ящик
Код оплаты
Код
квалификации
Дата приема
на работу
Номер сотрудника
Отдел | Телефон ,
Закреплен автомобиль
СОТРУДНИК
ю ИмяСотрудника
Ш НомерСотрудника
ПочтовыйЯщик
Отдел
Телефон
КодОплаты
КодКвалификации
Дата Найма
ТРАНСПОРТНО^СРЕДСТВО
ГРАНСПОРТНОЕ_СРЕДСТВО
ю Имя Препода вате ля
Ш НомерЛицензии
СерийныйНомер ,
Производитель
Тип ,
Год выпуска
Цвет
... СОТРУДНИК
1.1
Рис. 4.18. Составные объекты со связью вида 1:1 между свойствами: а — примеры форм
для ввода данных об автомобиле и сотруднике; б — составные объекты СОТРУДНИК
и ТРАНСПОРТНОЕ.СРЕДСТВО
Как мы уже отметили ранее, объектные атрибуты всегда появляются парами.
Даже если формы, отчеты и запросы демонстрируют только одну сторону связи,
у связи всегда имеется две стороны. Связь можно сравнить с мостом,
соединяющим два острова: мост соприкасается с обоими островами, и двигаться по нему
можно в обоих направлениях, даже если по обычаю или закону этот мост
является однонаправленным.
Если не удается найти ни одной формы или отчета, документирующего одну
из сторон связи, команда разработчиков должна спросить пользователей о
кардинальных числах этой связи. В этом случае команде требуется выяснить,
сколько общежитий может быть у студента и должен ли студент быть прикреплен
к общежитию. Здесь мы допустим, что ответы на этот вопрос были следующими:
студент может быть прикреплен максимум к одному общежитию, но может и не
быть прикрепленным ни к одному. Так, на рис. 4.19, б объект DORMITORY
содержит многозначный объектный атрибут STUDENT, а объект STUDENT имеет
однозначный объектный атрибут DORMITORY. Таким образом, связь между объектами
DORMITORY и STUDENT имеет вид «один ко многим», или 1:N.
Ти п ы о бъе ktqb 143
DORMITORY OCCUPANCY REPORT i
Dormitory
Jngersol!
Student name
Adams, Elizabeth
Baker, Rex
Baker, Brydie
I Charles, Stewart
Scott Sally
Taylor, Lynne
Resident Assistant
Sarah and Allen French
Student Number
710
104
744
319
447
810
Phone |
3-5567
Class
SO
FR
JN
SO
SO
FR
Щ Student Data fotm
iiil
DORMITORY
Ш DormName
Ю ResidentName
Phone
| ' STUDENT"><';':
I.N
STUDENT
id StudentName
id. StudentNumber
Major
Adviser
Class
HighScool
PriorCollege
Cam pus Address
CampusPhone
V DORMITORY
0.1
Рис. 4.19. Составные объекты со связью вида 1:N между свойствами: а — примеры форм
для ввода данных об общежитии и студенте; б — составные объекты DORMITORY и STUDENT
Еще один пример составных объектов показан на рис. 4.20, а. Из
представленных здесь форм мы можем заключить, что одна книга может быть
написана несколькими авторами (форма Book Stock Data, содержащая данные об
имеющихся в наличии книгах) и что один автор может написать много книг (форма
Books In Stock, By Author, содержащая данные об имеющихся в наличии книгах,
144 Глава 4. Семантическая объектная модель
отсортированных по авторам). Так, на рис. 4.20 объект BOOK (книга) содержит
многозначный объектный атрибут AUTHOR (автор), а объект AUTHOR имеет
многозначный объектный атрибут BOOK. Следовательно, связь между объектами
BOOK и AUTHOR имеет вид «многие ко многим», или N:M. Более того, книга
обязана иметь автора, а автор, чтобы считаться таковым, должен написать
минимум одну книгу. Поэтому оба эти объекта имеют минимальное кардинальное
число 1.
S3 воок Stock Data
I
зоок
id Title
;?AuffloRf-;/i:
id ISBN
Publisher
Copyringht Date
IN
AUTHOR
id AuthorName
AuthorDates
||J; BOOK
1 N I
Рис. 4.20. Составные объекты со связью вида N:M между свойствами: а — примеры
форм для ввода данных книжного магазина; б — объекты BOOK и AUTHOR
На рис. 4.21 изображены все четыре типа составных объектов. Вообще
говоря, объект А может содержать максимум один или много объектов Б.
Аналогично, объект Б может содержать один или много объектов Б. Мы будем
использовать эту таблицу при обсуждении структуры базы данных в главе 7.
Гибридные объекты
Гибридные объекты (hybrid objects) — это комбинации композитных и составных
объектов. В частности, гибридный объект — это семантический объект, имеющий
минимум один многозначный групповой атрибут, в состав которого входит
объектный атрибут.
На рис. 4.22, а изображена вторая версия отчета о занятости общежития,
представленного на рис. 4.20, я. Различие заключается в том, что третий столбец
Типы объектов 145
данных студента содержит атрибут Rent (плата за проживание) вместо атрибута
Class (группа). Эта разница является существенной, поскольку плата за
проживание в общежитии является атрибутом не студента, а общежития, и относится
к комбинации объектов STUDENT и DORMITORY.
Объект 1 может содержать
Один
Много
Один
1:1
М:1
Много
1:N
M:N
Объект 2
может
содержать
Рис. 4.21. Четыре типа составных объектов
DORMITORY OCCUPANCY REPORT
Dormitory
Ingersoll
Student name
Adams, Elizabeth
Baker, Rex
Baker, Brydie
Charles, Stewart
Scott, Sally
Taylor, Lynne
Resident Assistant
Sarah and Allen French
Student Number
710
104
744
319
447
810
Phone
3-5567
Rent
$175.00 i
$225.00
$175.00
$ 135.00 I
$ 225.00
$175.00
DORMITORY
Ш DormName
ResidentName
Phone
StudentRent
ШШЯШШШЯ I
Rent
0.1
I
STUDENT
id StudentName
Ш StudentNumber
Щ)ОВМГТОЯУ :ff
0.1
DORMITORv.
id DormName
ResidentName
Phone
$ТЦ||||1Т
Rent
0.1
STUDENT
id StudentName
id StudentNumber
Г
DORMITORY.:
Рис. 4.22. Гибридный объект DORMITORY: a — отчет об общежитии со свойством Плата;
б — правильный вид объектов DORMITORY и STUDENT; в — неправильный вид объектов
DORMITORY и STUDENT
146 Глава 4. Семантическая объектная модель
На рис. 4.22, б показана объектная диаграмма, моделирующая эту форму.
Объект DDRMITORY содержит многозначную группу, включающую в себя
объектный атрибут STUDENT и необъектный атрибут Rent. Это означает, что атрибуты
Rent и STUDENT являются спаренными в контексте объекта DORMITORY.
Рассмотрим теперь альтернативный вариант объекта DORMITORY,
представленный на рис. 4.22, е. Это неправильная модель отчета, изображенного на рис. 4.22, а,
так как она показывает, что атрибуты Rent и STUDENT являются многозначными
независимо друг от друга, что неверно, потому что эти атрибуты являются
многозначными как пара.
На рис. 4.23, а изображена форма, основанная на другом гибридном
объекте. Эта форма под названием Sales Order Form (заказ на покупку) содержит
данные о заказе (Sales Order Number, Date, Subtotal, Tax, Total), данные о покупателе
(CUSTOMER) и продавце (SALESPERSON), а также многозначную группу,
содержащую данные о заказанных товарах. Кроме того, в этой многозначной группе
представлены данные о товаре — ITEM (Item Number, Description и Unit Price).
На рис. 4.23, 6 показан семантический объект SALES-ORDER (заказ). Он
содержит необъектные атрибуты SatesOrderNumber (номер заказа), Date (дата), Subtotal
(промежуточный итог), Tax (налог) и Total (итог). Кроме того, он содержит
объектные атрибуты CUSTOMER и SALESPERSON, а также многозначную группу,
представляющую каждую позицию заказа. Группа содержит необъектные атрибуты Quantity
(количество) и Extended Price (цена с надбавкой) и объектный атрибут ITEM.
Объектные диаграммы на рис. 4.23, б неоднозначны в одном аспекте, который
может быть важен или не важен, в зависимости от приложения. Согласно
объектной диаграмме, товар может быть связан более чем с одним заказом. Но поскольку
многозначная группа Lineltem инкапсулирована (вложена) в объект SALES-ORDER,
из этой диаграммы не ясно, может ли конкретный вид товара появляться один
раз или многократно в одном и том же объекте SALES-ORDER.
В общем, есть четыре интерпретации максимального кардинального числа
для спаренных атрибутов гибридного объекта SALES-ORDER:
1. Конкретный товар может появляться только в одном заказе и только в
одной строке данного заказа.
2. Конкретный товар может появляться только в одном заказе, но во многих
его строках.
3. Конкретный товар может появляться во многих заказах, но в каждом
заказе — только в одной строке.
4. Конкретный товар может появляться во многих заказах, а в рамках
заказа — во многих строках.
Когда важно различать эти случаи, нужно использовать следующую запись:
в случаях 1 и 2 максимальное кардинальное число гибридного объектного
атрибута следует установить равным 1. Так, для данного примера максимальное
кардинальное число атрибута SALES-ORDER объекта ITEM установлено равным 1. Если
конкретный товар может появляться только в одной строке заказа (случай 1), он
должен быть помечен как имеющий уникальный идентификатор в данной
группе. Если нет (случай 2), то помечать его не требуется. Эти два случая
изображены на рис. 4.24, а и б.
Типы объектов 147
S3 CatbonRwer Furniture Sales G tder Form
f^j^^^l^ffv-ili^Si^
Date 25-Sep-C4
ШШШ' Carbon R 'ver с
d
^ ::гз4
;|Щге '^щШшк
'•:'■■ ■?$■'' '•'..':.?%■'&:>''.*''
';'■' S atoei^i.Hfe£:;
W
"Dods":-
--d
Salesperson Code
1 g-i 1
: :j Quanli^H foero ЙышЬ« j:-.
'• Pfttfrription
j UnifPflte:
78 .Executive Desk
79 Conference Table
80 Side Chair
SALES-ORDER
ID SalesOrderNumber
Date
.::.£ШТО№И;
ШШМ$РШ80Н$
Lineltem
Quantity-^
ШШй
ExtendePrice л
1.1
Subtotal
Tax 1И
Total л л
1.1
IN
ITEM
ID ItemNumber
Item Description
UnitPrice1 1
|SALE^gDEgi
O.N
CUSTOMER
id CustomerName
Address
City
State
Zip
Phone
BjSALES-ORD^e
SALESPERSON i
jp SalesPersonName
SalesPersonCode
>;::$НМ$Щ*Ш'<-
O.N
Рис. 4.23. Гибридный объект SALES-ORDER и связанные с ним объекты:
а — форма заказа; б — объекты, моделирующие форму заказа
В случаях 3 и 4 максимальное кардинальное число гибридного объектного
атрибута устанавливается равным N. Так, для данного примера максимальное
148 Глава 4. Семантическая объектная модель
кардинальное число атрибута SALES-ORDER в объекте ITEM устанавливается
равным N. Далее, если конкретный товар может появляться только в одной строке
заказа (случай 3), он должен быть помечен как имеющий уникальный
идентификатор в данной группе. Если нет (случай 4), то помечать его не требуется. Эти
два случая изображены на рис. 4.25, а и б.
SALES-ORDER
ю SalesOrderNumber
Date
CUSTOMER
SALESPERSON! 1
Lineltem
Quantity т.-,
:§TEM
ExtendePrice л
Subtotal
TaXi.i
Total л л
1.1
ITEM
Ш ItemNumber
Item Description
UnitPrice11
0.1
SALES-ORDER
id SalesOrderNumber
Date
CUSTOMER
II
1.1
SALESjPEBSONi
Lineltem
Quantity r1
"■:ШШ
ExtendePrice
Subtotal
Tax!.!
Total 4 4
1.1 -'
1 N
1.1
ITEM
ID ItemNumber
Item Description
UnitPrice1 л
^тшщщ^
0.1
Рис. 4.24. Примеры 1 и 2 максимальной кардинальности: а — один товар в одном заказе;
б — один товар во многих строках одного и того же заказа
Ассоциативные объекты
Ассоциативный объект (association object) — это объект, который связывает два
или более объекта и содержит данные, относящиеся к этой связи. На рис. 4.26
показаны отчет и две формы для ввода данных, для моделирования которых
необходим ассоциативный объект. Отчет содержит данные об авиарейсе, о самолете,
выполняющем этот рейс, и о пилоте, назначенном на этот рейс. Формы для ввода
данных содержат данные о пилоте и о самолете.
Типы объектов 149
На рис. 4.27 объект FLIGHT (авиарейс) — это ассоциативный объект, который
связывает объекты AIRPLANE (самолет) и PILOT (пилот) и хранит данные об их
связи. Объект FILGHT содержит в себе по одному объектному атрибуту AIRPLANE
и PILOT, но объекты AIRPLANE и PILOT содержат множество объектных атрибутов
FLIGHT. Такого рода связь двух или более объектов возникает часто, особенно в
приложениях, где требуется назначить друг другу две вещи или более. В качестве
других примеров можно привести объект РАБОТА, связывающий объекты АРХИТЕКТОР
и КЛИЕНТ, объект ЗАДАЧА, связывающий объекты СОТРУДНИК и ПРОЕКТ, и объект
ЗАКАЗ, связывающий объекты ПОСТАВЩИК и УСЛУГА.
В примере, показанном на рис. 4.26, ассоциативный объект FLIGHT имеет
собственный идентификатор, группу {FlightNumber, Date} (номер рейса, дата). Часто
ассоциативные объекты не имеют собственных идентификаторов, и тогда
идентификатор представляет собой комбинацию идентификаторов объектов, которые
связаны в ассоциативном объекте.
SALES-ORDER
ю SalesOrderNumber
Date
§ОЩ^ЩШ:
р&А1£8Й|^&М-
1.1
1.1
Linellem
Quantity^
~:;пШ?\'
ExtendePrice
Subtotal
1.1
1.1
1.N
Taxt1
Total л
i.i
ITEM
jq ItemNumber
ItemDescription
UnitPrice1>1
№ES-QFffii
J0.N
SALES-ORDER
jq SalesOrderNumber
Date
Ш-^ЩшщЩ
||gfttESFER$QN;
Linellem
Quantity^ t
ITE&&
ExtendePrice
Subtotal
Tax ^
Total A A
1.1
1.1
1.1
ITEM
jq ItemNumber
ItemDescription
UnitPricei^
'O.N
Рис. 4.25. Примеры 3 и 4 максимальной кардинальности: а — один товар в одной строке
многих заказов; б — один товар во многих строках многих заказов
150 Глава 4. Семантическая объектная модель
FLY CHEAP INTERNATIONAL
Flight Planning Data Report
FLIGHT NUMBER
ORIGINATING CITY
FUEL ON TAKEOFF
WEIGHT ON TAKEOFF
FC-17 DATE 7/30/2001
Seattle DESTINATION Hong Kong
AIRPLANE
Tail Number
Type
Capacity
PILOT
Name
FI-ID
Flight Hours
N1234FI
747-SP
148
Micheel Nilson
32887
18,348
Рис. 4.26. Пример ассоциативного объекта: отчеты и формы
Чтобы лучше понять это, рассмотрим рис. 4.28, а, на котором изображен
отчет о назначении архитекторов на проект. Хотя само назначение не имеет явного
идентификатора, в действительности идентификатором является комбинация
Типы объектов 151
{НазваниеПроекта, ИмяАрхитектора}. Эти атрибуты, однако, принадлежат объектам
ПРОЕКТ и АРХИТЕКТОР соответственно, а не объекту НАЗНАЧЕНИЕ.
Идентификатором назначения является, таким образом, комбинация идентификаторов вещей,
которые назначаются друг другу.
FLIGHT
id FlightiD j
FlightNumber !
Date J
OriginatingCity
Destination
FueOnTakeOff
WeightOnTakeOff
I AIRPLANE -'Щ
-3^4
Рис. 4.27. Объекты FLIGHT, PILOT и AIRPLANE
На рис. 4.28, б показаны объектные диаграммы для этого случая. И ПРОЕКТ,
и АРХИТЕКТОР являются объектными атрибутами объекта НАЗНАЧЕНИЕ, а группа
{ПРОЕКТ, АРХИТЕКТОР} является идентификатором объекта НАЗНАЧЕНИЕ. Это
означает, что комбинация экземпляра объекта ПРОЕКТ и экземпляра объекта АРХИТЕКТОР
идентифицирует конкретное назначение.
Обратите внимание, что идентификатор НомерНазначения на рис. 4.28, б не
является уникальным; тем самым указывается, что архитектор может быть
назначен на один и тот же проект несколько раз. Если это не так, идентификатор
должен быть объявлен уникальным. Далее, если сотрудник может быть назначен
на один и тот же проект более одного раза и если по какой-то причине важно
иметь уникальный идентификатор для назначения, к группе следует добавить
атрибут даты или какой-нибудь еще атрибут, указывающий время (неделя,
квартал и т. д.).
Объекты вида родитель/подтип
Чтобы понять, что представляют собой объекты вида родитель/подтип (parent/
subtype objects), рассмотрим объект СОТРУДНИК на рис. 4.29, а. Некоторые
атрибуты объекта СОТРУДНИК относятся ко всем сотрудникам, а некоторые — только
к тем сотрудникам, которые являются менеджерами. Объект на рис. 4.29, а не
слишком точно отражает действительность, поскольку атрибуты, свойственные
менеджерам, не подходят для сотрудников, не являющихся менеджерами.
Более удачная модель показана на рис. 4.29, б. Здесь объект СОТРУДНИК
содержит объект подтипа МЕНЕДЖЕР. Все атрибуты, относящиеся к менеджерам, перене-
AIRPLANE
ip_ TallNumber
Manufacturer
Type
TotalAirframeHours
TatalEngineHours
EngHoursPastOH
CurrentCapacity
RangeAsConfig
TUQHT
J0.N
.
PILOT 1
ю FCI-ID
Name
SpocialSecurity Number 1
Street
City
State i
Zip
Phone
EmergPhone
DateOfLastCheckOut
Hours
DateOfLastPhysical
Ш^МшШШш
O.N
152 Глава 4. Семантическая объектная модель
сены в объект МЕНЕДЖЕР. Сотрудники, не являющиеся менеджерами, имеют один
экземпляр объекта СОТРУДНИК и ни одного экземпляра объекта МЕНЕДЖЕР.
Сотрудники-менеджеры имеют по одному экземпляру объектов СОТРУДНИК и МЕНЕДЖЕР.
В этом примере объект СОТРУДНИК называется родительским объектом (parent
object), или объектом надтипа (supertype object), а объект МЕНЕДЖЕР называется
объектом подтипа (subtype object).
Отчет о назначении на проект
Название проекта Дом Абернати
Менеджер проекта Дж. Смит
Начало проекта 11/11/1999
Окончание проекта
Архитектор
Телефон
Номер офиса
Б. Джексон
232-8878
J-1133
Начало работы по назначению 12/15/2001
Окончание работы по назначению 3/15/2002
HoursK Максимальное количество часов в бюджете 345
Максимальная стоимость труда $ 27,500
Максимальная стоимость материалов $ 17,500
НАЗНАЧЕНИЕ
ю НомерНазначения
ПРОЕКТ
'1.1!
АРХИТЕКТОР
111
НачалоНазначения
КонецНазначения
МаксимумЧасов
МаксСтоимостьТруда
МаксСтоимостьМатериалов
ПРОЕКТ
ю НазваниеПроекта
МенеджерПроекта
НачалоПроекта
ОкончаниеПроекта
ШЗЩШЩЙ!
АРХИТЕКТОР
ю ИмяАрхитектора
Телефон
НомерОфиса
НАЗНАЧЕНИИ
1.N
Рис. 4.28. Ассоциативный объект НАЗНАЧЕНИЕ: а — пример отчета о назначении;
б — объект НАЗНАЧЕНИЕ с семантическим объектным идентификатором
Первым атрибутом подтипа является родительский объект, обозначенный
индексом Р. Указание родительского атрибута является обязательным всегда.
Идентификаторы у подтипа те же, что и у родителя. На рис. 4.29 атрибуты Номер-
Сотрудника и ИмяСотрудника являются идентификаторами как объекта СОТРУДНИК,
так и объекта МЕНЕДЖЕР.
Атрибуты подтипа показываются с помощью индексов 0.ST или 1.ST. Первая
цифра (0 или 1) — это минимальное кардинальное число подтипа. Если оно
равно 0, подтип является необязательным, а если 1, то подтип является
обязательным. (Обязательный подтип не имеет смысла для этого примера, но необ-
Типы объектов 153
ходимость в нем появится в последующих, более сложных случаях.) Буквы ST
(subtype — подтип) указывают на то, что атрибут является подтипом, или
атрибутом типа «ЕСТЬ».
Объекты вида родитель/подтип обладают важной характеристикой,
называемой наследованием. Подтип приобретает, или наследует, все атрибуты своего
родителя, и поэтому объект МЕНЕДЖЕР наследует все атрибуты объекта СОТРУДНИК.
Вдобавок родитель приобретает все атрибуты своих подтипов, и сотрудник,
являющийся менеджером, приобретает все атрибуты менеджера.
Семантический объект может содержать более одного атрибута подтипа. На
рис, 4,30 показан второй вариант объекта СОТРУДНИК, который имеет два атрибута
подтипа — МЕНЕДЖЕР и ПРОГРАММИСТ. Поскольку оба этих атрибута являются
необязательными, объект СОТРУДНИК может иметь, один или оба эти подтипа или не
иметь ни одного. Это означает, что некоторые сотрудники не являются ни
менеджерами, ни программистами, некоторые являются менеджерами, но не являются
программистами, некоторые являются программистами, но не являются
менеджерами, а некоторые одновременно являются программистами и менеджерами.
СОТРУДНИК
id НомерСотрудника 11
id ИмяСотрудника tЛ
ДатаНайма
Зарплата
ДолжностьМенеджера
УровеньМенеджмента
НачисленнаяПремия
ВыплаченнаяПремия
Данные сотрудника
Данные менеджера
СОТРУДНИК
ю НомерСотрудника
ю ИмяСотрудника
ДатаНайма
Зарплата
МЕНЕДЖЕР
o.sr
МЕНЕДЖЕР
£',' СОТРУДНИК
Stai «23 р
ДолжностьМенеджера
УровеньМенеджмента
НачисленнаяПремия
ВыплаченнаяПремия
Рис. 4.29. Необходимость введения подтипа МЕНЕДЖЕР: а — объект СОТРУДНИК
без подтипа; б - объект СОТРУДНИК с подтипом МЕНЕДЖЕР
Иногда подтипы исключают друг друга. То есть транспортное средство может
быть легковым автомобилем или грузовиком, но не тем и другим одновременно.
Клиент может быть индивидуальным клиентом, товариществом или
корпорацией, но только одним из этих трех типов. Когда подтипы исключают друг друга,
они помещаются в группу подтипов, и группе присваивается индекс в формате
X.Y.Z. X — это минимальное кардинальное число, равное 0 или 1, в зависимости
154 Глава 4. Семантическая объектная модель
от того, является ли группа подтипов обязательной. Y и Z указывают количество
атрибутов в группе, которым разрешается иметь значение. Y — минимальное
количество, Z — максимальное.
На рис. 4.31, а три типа клиентов изображены как группа подтипов. Индекс
группы, 0.1.1, означает, что подтип не требуется, но если он существует, в группе
должен существовать минимум один и максимум один*подтип (иначе говоря,
ровно один). Заметьте, что каждый из подтипов имеет индекс 0.ST, то есть все
они являются необязательными, как и должно быть. Если бы все они были
обязательными, максимальное количество атрибутов было бы 3, а не 1. Эта запись
достаточно надежна, чтобы предусмотреть ситуации, когда обязательными
являются три из пяти или семь из десяти подтипов.
СОТРУДНИК
Ш НомерСотрудника
ю ИмяСотрудника
ДатаНайма
Зарплата
1^'МЕИей^Це1
ШОГЙШШТ
0ST
0.ST
МЕНЕДЖЕР
11 7Ь6ТрэднМ?:;|
Должность Менеджера
УровеньМенеджмента
НачисленнаяПремия
ВыплаченнаяПремия
ПРОГРАММИСТ
1ШШШШШЙШШ
Язык o.n
ОперационнаяСистема 0 N
Рис» 4.30. Объект СОТРУДНИК с двумя подтипами
Можно смоделировать и более сложные ограничения, если ввести вложенные
подтипы. Группа подтипов на рис. 4.31, б моделирует ситуацию, когда
корпорация может быть либо налогооблагаемой, либо не налогооблагаемой. Если
корпорация не является налогооблагаемой, это должна быть либо правительственная
организация, либо школа. В этом примере показано только несколько
необъектных атрибутов. В реальности, если бы требовалась такая сложная структура,
в ней, скорее всего, было бы больше атрибутов.
Объекты вида архетип/версия
Последний тип объектов — это объекты вида архетип/версия (archetype/version
objects). Объект-архетип (archetype object) — это семантический объект,
порождающий другие семантические объекты, которые представляют версии (version
objects), выпуски или издания архетипа. Например, на рис. 4.32 объект-архетип
УЧЕБНИК порождает объекты-версии ИЗДАНИЕ. Согласно этой модели, атрибуты
Название, Автор и Издательство принадлежат объекту УЧЕБНИК, а атрибуты Поряд-
ковыйНомерИздания, ДатаВыхода и КоличествоСтраниц — объекту ИЗДАНИЕ.
Типы объектов 155
КЛИЕНТ
ю НомерКлиента
ИмяКлиента
Телефон
$тЩ£Щ&КтЩ.
•ТОВДШЩЕСТВд;.;
0.ST :
o.st ;
ШЬ* ■'.■":..';.v.i..:.6... •■■■ :•:.• ::; ;*ш
O.ST
0/1.1
ФИЗИЧЕСК0Е_ЛИЦО
>"^-клиЁйт:
НомерСоциальнойСтраховки
СовокупнаяСтоимость
ТОВАРИЩЕСТВО
;gg|№^EHfv
НалоговыйНомер
УправляющийПартнер
КОРПОРАЦИЯ
Р
НалоговыйНомер
Баланс
ИмяДоверенногоЛица
ТелефонДо вере иного Лица
ФИЗИЧЕСКОЕ_ЛИЦО
•:КЯШШ
НалоговыйНомер
Баланс
ИмяДоверенногоЛица
Тел ефон Доверен но гоЛ и ца
:тлШ)0&пмштт^юр(2
0.ST
нЕвдо(адш
OS Г
0.1.1
ПРАВИТЕЛЬСТВЕННОЕ АГЕНТСТВО
Н^НЯИИ^^К^сШ
ФедеральныйНомер
НАЛОГООБЛАГАЕМАЯ КОРП
|||||||||1||||
НалоговаяСтавка
НЕНАЛОГООБЛАГАЕМАЯ_КОРП
шшшшшшш?
НомерОсвобожд
р
эния
;пЩитШьственноЩ
^^^^^^^^^^^' ";Ш111|1111
0.ST
0.ST
0.1
ШКОЛА
ИЕнЭДрэШ^
ШкольныйОкруг
Рис. 4.31. Взаимоисключающие (а) и вложенные (б) подтипы
Идентификационная группа объекта ИЗДАНИЕ состоит из двух частей: УЧЕБНИК
и ПорядковыйНомерИздания. Это типичный образец идентификатора
объекта-версии. Одна часть идентификатора содержит объект-архетип, а вторая часть — это
простой атрибут, идентифицирующий версию архетипа. На рис. 4.33 изображен
еще один пример объектов вида архетип/версия.
156 Глава 4. Семантическая объектная модель
УЧЕБНИК
Ш ISBN
Название
Автор
Издательство
• ИЗДАНИЕ •
l.N
ИЗДАНИЕ
ю Идентификатор Издания
-^ЁБНИКЖЙ
ПорядковыйНомерИздания
ДатаВыхода -
Количество Страниц
1.1
Рис. 4.32. Пример объекта вида архетип/версия
ИЗДАНИЕ
ю I Название
Адрес
Улица
Город
Штат
Индекс
КоличествоЭтажей
КВАРТИРА
1.N
КВАРТИРА
ID ИдентификаторКвартиры
;издеди:ш
НомерКвартиры 1А
КоличествоКомнат
Площадь
1.1
Рис. 4.33. Еще один пример объекта вида архетип/версия
Сравнение семантической объектной
модели и модели «сущность—связь»
Модель «сущность—связь» и семантическая объектная модель имеют как сходства,
так и различия. Они похожи тем, что обе являются инструментами для уяснения
и документирования структуры пользовательских данных. Обе они имеют своей
целью моделирование структуры вещей в мире пользователей и связей между ними.
Принципиальное различие между двумя моделями заключается в ориентации.
Модель «сущность—связь» в качестве базовой концепции рассматривает
концепцию сущности. Сущности и их связи выступают, если хотите, как атомы модели
данных. Эти атомы могут быть организованы в структуры, которые модель
«сущность—связь» называет пользовательскими представлениями (user views).
Пользовательские представления — это комбинации сущностей, строение которых
напоминает строение семантических объектов.
Базовое понятие семантической объектной модели — семантический объект.
Набор семантических объектов в модели данных — это карта структуры вещей,
которые пользователи считают существенными. Эти объекты являются атомами
мира пользователей и представляют собой наименьшие различимые единицы,
которыми пользователи желают оперировать. Они могут разбиваться на более
мелкие части внутри СУБД (или в приложении), но эти более мелкие части не
представляют интереса для пользователей.
С точки зрения семантической объектной модели, сущности, в том виде как
они определены в модели «сущность—связь», не существуют. Они являются
лишь фрагментами, кусками реальных сущностей. Фактически, единственные
Сравнение семантической объектной модели 157
сущности, которые имеют смысл для пользователей, — это семантические
объекты. По-другому можно выразить это, сказав, что семантические объекты
являются семантически самодостаточными, или семантически завершенными.
Рассмотрим пример. На рис. 4.34 представлены четыре семантических объекта: ЗАКАЗ,
КЛИЕНТ, ПРОДАВЕЦ и ТОВАР. Когда пользователь говорит: «Покажите мне заказ
№ 2000», он имеет в виду, что следует показать объект ЗАКАЗ так, как он
смоделирован на рис. 4.34. Сюда входят, среди прочего, данные о покупателе.
Поскольку информация о покупателе является частью заказа, объект ЗАКАЗ содержит
объект КЛИЕНТ.
ЗАКАЗ
Ш НомерЗаказа
Дата
V-4WEHT
jjg -ЙРСЩАВЕЦ
СтрокаЗаказа
Количество
1.1
Стоимость
Промежуточный Итог]
Налог 1.1
Итог
КЛИЕНТ
ID НомерКлиента
ИмяКлиента
Адрес
Улица
Город
Штат
Индекс.
ЗАКЩЙШ
ПРОДАВЕЦ
Ш ИмяПродавца
КодПродавца
Ш£ШШШШШ
ТОВАР
I id НомерТовара
Название
Описание
:-;:';: заШ||1|1
0.N
Рис. 4.34. Объект ЗАКАЗ и связанные с ним семантические объекты
КЛИЕНТ
ПРОДАВЕЦ
ЗАКАЗ
1:N)
(СТР0КА_ЗАКАЗА
ТОВАР
Рис. 4.35. Модель «сущность—связь» для объекта ЗАКАЗ и КЛИЕНТ
158 Глава 4. Семантическая объектная модель
На рис. 4.35 изображена модель «сущность—связь» для тех же данных,
которая содержит сущности ЗАКАЗ, КЛИЕНТ, ПРОДАВЕЦ, ТОВАР и СКЛАД. Сущность
ЗАКАЗ имеет атрибуты НомерЗаказа, Дата, ПромежуточныйИтог, Налог и Итог.
Теперь, если пользователь попросит: «Покажите мне заказ № 2000», он будет
разочарован и, скорее всего, задаст вопрос: «А где же остальные данные?» То есть
сущность ЗАКАЗ не соответствует пользовательскому представлению о заказе
как об отдельном феномене. Эта сущность является лишь частью реального
заказа.
В то же время, когда пользователь (возможно, даже тот же самый) попросит:
«Покажите мне покупателя № 12345», он будет иметь в виду, что следует
показать все данные, которые на рис. 4.34 относятся к покупателю, включая имя
клиента, все составляющие адреса и все заказы этого покупателя. Сущность КЛИЕНТ
на рис. 4.35 имеет только атрибуты ИмяКлиента, Улица, Город, Штат и Индекс. Если
бы пользователю, который попросил: «Покажите мне покупателя ABC»,
предоставили только эти данные, он был бы снова разочарован: «Нет, это только часть
того, что мне нужно».
С точки зрения семантической объектной модели, в сущностях, как они
представлены в модели «сущность—связь», нет необходимости. Семантические
объекты можно сразу преобразовывать в структуру базы данных, никак не
рассматривая ER-сущности. Они являют собой, так сказать, недостроенные дома,
воздвигнутые в процессе ухода от парадигмы компьютерных структур данных
к парадигме пользователей.
Еще одно отличие состоит в том, что семантические объекты содержат в
себе больше метаданных, чем сущности. В семантической объектной модели на
рис. 4.34 отражено то, что НомерКлиента является уникальным идентификатором
в представлении пользователей. Он может использоваться или не
использоваться в качестве идентификатора в соответствующей таблице, но данный факт не
существенд ля модели данных. Мы также можем видеть, что НомерКлиента
является для пользователей неуникальным идентификатором. Более того,
семантическая объектная диаграмма указывает на тот факт, что существует семантическая
группа атрибутов под названием Адрес. Эта группа содержит другие атрибуты,
составляющие вместе адрес. Существование этой группы станет для нас важным
при разработке форм и отчетов. Наконец, семантическая объектная диаграмма
показывает, что конкретный ТОВАР может быть включен более чем в один ЗАКАЗ,
но в каждом заказе этот товар может появиться только в одной строке. Этот
факт невозможно указать на диаграмме «сущность—связь».
Решите в конечном счете, какой из рисунков — 4.34 или 4.35 — дает вам
лучшее представление о том, что должно содержаться в базе данных. Многие находят,
что рамки, очерченные вокруг семантических объектов, и скобки, заключающие
в себе групповые атрибуты, помогают более четко представить общую картину
модели данных.
Резюме 159
Резюме
Как модель «сущность—связь», так и семантическая объектная модель
используются для интерпретации требований пользователей и моделирования
пользовательских данных. Эти модели похожи на линзы, сквозь которые смотрят
разработчики, изучая и документируя пользовательские данные. Обе они в конечном
счете воплощаются в структуру базы данных.
Семантический объект — это именованная совокупность атрибутов, которая
в достаточной степени определяет отдельный феномен. Семантические
объекты группируются в классы, и как у классов, так и у экземпляров семантических
объектов есть имена. Например, именем класса является СОТРУДНИК, а именем
экземпляра этого класса — СОТРУДНИК 2000.
Атрибуты описывают характеристики представляемых феноменов. Набор
атрибутов является достаточным, если он отражает все характеристики, которые
требуются пользователям для выполнения их работы. Объекты представляют
отдельные феномены — вещи и явления, которые рассматриваются
пользователями как независимые и самостоятельные. Отдельные феномены,
представляемые объектами, могут существовать или не существовать физически — в самом
деле, ведь они могут сами по себе быть представлением чего-то, как, например,
контракт.
Объектные атрибуты могут быть простыми элементами данных, группами
или другими семантическими объектами. Объектные диаграммы визуально
представляют структуру объектов. Имена объектов пишутся заглавными буквами
в верхней части диаграммы. Необъектные атрибуты записываются строчными
буквами, а группы атрибутов заключаются в скобки.
Все атрибуты имеют минимальное кардинальное число, показывающее,
сколько экземпляров атрибута должно существовать, чтобы объект был допустимым.
Они также имеют максимальное кардинальное число, которое показывает
максимально допустимое количество экземпляров атрибута. Кардинальность
записывается в формате N.M, где N — это минимальное кардинальное число, а М —
максимальное кардинальное число. Чтобы не загромождать объектную
диаграмму, кардинальность 0.1 у простого атрибута не указывается. Но для групповых
и объектных атрибутов кардинальность указывается всегда.
Объектные атрибуты всегда возникают парами. Если один объект имеет связь
с другим, этот второй объект должен иметь связь с первым. Объектные
идентификаторы — это атрибуты, которые служат, в представлении пользователей, для
различения объектов. Идентификаторы могут быть уникальными либо
неуникальными. Атрибут любого типа может быть идентификатором.
Идентификаторы обозначаются буквами ID перед именем атрибута. Если атрибут является
уникальным, то буквы ID подчеркиваются. Кардинальность идентификатора
равна обычно 1.1.
Домен атрибута — это совокупность всех возможных значений этого
атрибута. Домены имеют физическое и семантическое описание. Существует три типа
доменов: простой, групповой и семантический объект.
160 Глава 4. Семантическая объектная модель
Приложения оперируют объектами через пользовательские представления.
Представление объекта состоит из имени объекта и всех атрибутов, видимых из
данного представления. Разработка представления и объекта зачастую
представляет собой итеративный процесс.
Процесс разработки набора объектных диаграмм является итеративным.
Сначала анализируются отчеты или формы, на их основе разрабатывается исходный
набор объектов, а затем изучаются другие отчеты и формы, исходя из которых
вводятся новые объекты и уточняются имеющиеся. Этот процесс продолжается
до тех пор, пока не будут исследованы все отчеты и формы.
Существует семь типов объектов. Простые объекты не имеют многозначных
и объектных атрибутов. Композитные объекты имеют многозначные атрибуты,
но не имеют объектных атрибутов. Составные объекты содержат объектные
атрибуты, а гибридные объекты сочетают в себе композитные и составные
объекты. Ассоциативные объекты связывают два или более других объектов. Объекты
подтипов представляют разновидности объектов. Наконец, объекты вида
архетип/версия используются для моделирования объектов, содержащих базовые
данные и множественные их вариации, или версии.
Модель «сущность—связь» в качестве базовых элементов рассматривает
сущности, в то время как семантическая объектная модель рассматривает в качестве
базовых элементов семантические объекты. Кроме того, семантическая
объектная модель содержит больше информации о значении данных, чем модель
«сущность—связь».
Вопросы группы I
1. Объясните, почему модель «сущность—связь» и семантическая объектная
модель похожи на линзы.
2. Дайте определение семантического объекта.
3. Объясните разницу между именем класса объекта и именем экземпляра
объекта. Приведите примеры для обоих случаев.
4. Что требуется для того, чтобы набор атрибутов был достаточным описанием?
5. Объясните, что понимается под словосочетанием отдельный феномен в
определении семантического объекта.
6. Объясните, почему отдельная строка заказа не является семантическим
объектом.
7. Назовите три типа атрибутов.
8. Приведите примеры атрибутов следующих типов:
1) простой однозначный атрибут;
2) групповой однозначный атрибут;
3) простой многозначный атрибут;
4) групповой многозначный атрибут;
Вопросы группы 1 161
5) простой объектный атрибут;
6) многозначный объектный атрибут.
9. Что такое минимальное кардинальное число? Как оно используется? Какие
типы атрибутов имеют минимальное кардинальное число?
10. Что такое максимальное кардинальное число? Как оно используется?
Какие типы атрибутов имеют максимальное кардинальное число?
11. Что такое парные атрибуты? Для чего они нужны?
12. Что такое идентификатор объекта? Приведите пример простого и
группового атрибута, идентифицирующего объект.
13. Дайте определение домена атрибута. Какие бывают типы доменов
атрибутов? Почему необходимо семантическое описание?
14. Что такое представление семантического объекта? Приведите пример
объекта и двух его представлений, отличный от того, который дан в тексте.
15. Приведите пример простого объекта, отличный от того, который дан в этой
главе.
16. Приведите три примера композитных объектов, отличные от тех, которые
приведены в этой главе. У одного объекта должен быть ровно один
простой многозначный атрибут, другой объект должен иметь две
независимых многозначных группы, а третий объект должен содержать вложенные
многозначные группы.
17. Приведите примеры четырех наборов составных объектов, отличные от
тех, которые даны в тексте. Один набор должен иметь связь 1:1, другой —
1:N, третий — М:1, и четвертый — M:N.
18. Приведите пример гибридного объекта, отличный от того, который дан
в этой главе.
19. Приведите пример одного ассоциированного и двух составных объектов,
отличный от тех примеров, которые даны в этой главе.
20. Приведите пример объекта надтипа с тремя объектами подтипов,
отличный от того, который дан в тексте.
21. Приведите примеры объектов вида архетип/версия, отличный от
приведенных в этой главе.
22. Укажите сходства модели «сущность—связь» и семантической объектной
модели.
23. Укажите основные различия между моделью «сущность—связь» и
семантической объектной моделью.
24. Объясните, почему сущности, как они определены в модели «сущность-
связь», не существуют в действительности.
25. Покажите, как модель «сущность—связь» и семантическая объектная
модель будут интерпретировать данные, содержащиеся в форме SALES-ORDER
на рис. 4.23, а, и укажите основные различия.
162 Глава 4. Семантическая объектная модель
Вопросы группы II
26. Модифицируйте семантическую объектную диаграмму на рис. 4.13, введя
в нее объекты ГРУППА, ПРЕДМЕТЫ_НА_ВЫБОР и ЗАПИСЬ. Предположим, что
ЗАПИСЬ — это ассоциативный объект, связывающий студента с предметом.
27. Модифицируйте семантическую объектную диаграмму на рис. 4.13, введя
в нее объект КОМИТЕТ. Допустим, что один преподаватель может быть
назначен в несколько комитетов и что комитет включает в себя много
преподавателей. Создайте объект ЗАСЕДАНИЯ — объект вида архетип/версия,
представляющий заседания комитета.
28. Измените свой ответ на вопрос 27, введя объект ЗАСЕДАЙ ИЕ как
многозначную группу внутри объекта КОМИТЕТ. Является ли эта модель более
удачной, чем предыдущая? Обоснуйте свой ответ.
Проекты
1. Разработайте семантическую объектную модель для Столичного агентства
жилья из проекта 1 в конце главы 3.
2. Зайдите на сайт какого-нибудь производителя компьютеров, например
Dell (www.deU.com). Пользуясь средствами сайта, определите, какой
ноутбук вы могли бы приобрести для пользователя с бюджетом $10 000.
Занимаясь выяснением этого вопроса, подумайте о том, какой структурой
может обладать база данных по компьютерным системам и подсистемам,
используемая для поддержки данного сайта.
Разработайте семантическую объектную модель для базы данных по
компьютерным системам и подсистемам для этого сайта. Возможными объектами
являются БА30ВАЯ_К0НФИГУРАЦИЯ, 0БЪЕМ_ПАМЯТИ, ВИДЕОКАРТА и ПРИНТЕР.
Покажите связи между объектами и наделите каждый объект минимум
двумя-тремя атрибутами. Укажите тип каждого семантического объекта.
Чтобы проект не оказался чрезмерно велик, ограничьтесь тем, что
требуется для человека, который точно решил купить компьютер, но еще не
выбрал, какой именно.
3. Зайдите на сайт виртуального книжного магазина, такого как Amazon (www.
amazon.com). Пользуясь средствами сайта, найдите три лучших книги по
XML для человека, который только начал изучать этот предмет.
Занимаясь выяснением данного вопроса, подумайте о том, какой может быть
структура базы данных по книгам, авторам, предметам и родственным
темам.
Разработайте семантическую объектную модель для базы данных этого сайта.
Возможными объектами являются ЗАГОЛОВОК, АВТОР, ИЗДАТЕЛЬ и ТЕМА.
Покажите связи между объектами и наделите каждый объект минимум двумя-тремя
атрибутами. Укажите тип каждого семантического объекта. Чтобы проект не
слишком разрастался, предположим, что учет нужен только для книг. Далее
Вопросы к проекту FiredUp 163
ограничьтесь потребностями человека, который точно решил купить книгу, но
еще не выбрал, какую. Не рассматривайте заказ клиента, выполнение заказа,
заказ на поставку и другие подобные деловые операции.
Вопросы к проекту FiredUp
Рассмотрим ситуацию, обсуждаемую в конце глав 1 и 2. Предположим, что фирма
FiredUp разработала линию из трех горелок: FiredNow, FiredAlways и FiredAtCamp.
Предположим далее, что фирма продает запасные части для каждого типа
горелок, а также производит их ремонт. В одних случаях ремонт является
бесплатным, поскольку выполняется в течение гарантийного срока, в других случаях
взимается только стоимость деталей, в третьих взимается стоимость деталей и работы.
Фирма FiredUp желает вести учет всех этих данных. Когда владельцев фирмы
спросили о подробностях, они составили следующий список:
КЛИЕНТ: Имя, Улица, Дом, Квартира, Город, Штат, Индекс, Страна, ЭлектронныйАд-
рес, Телефон
ГОРЕЛКА: СерийныйНомер, Тип, ДатаИзготовления, ИнициалыПроверяющего
СЧЕТ-ФАКТУРА: НомерСчета, Дата, Клиент (со списком проданных товаров и
указанием их стоимости), Сумма
РЕМОНТ: НомерРемонта, Клиент, Горелка, Описание (со списком деталей,
использованных при ремонте, и указанием их стоимости, если таковая взимается), Сумма
ДЕТАЛЬ: Номер, Описание, Стоимость, Цена
1. Создайте набор семантических объектов для базы данных фирмы FiredUp.
Задайте на свое усмотрение минимальное и максимальное кардинальные
числа для всех атрибутов. Обоснуйте каждое кардинальное число.
Используйте столько типов семантических объектов, сколько считаете нужным,
но не используйте подтипы. (Эта задача окажется проще, если вы
загрузите Tabledesigner — средство для рисования семантических объектных
диаграмм, которое описано в приложении Б. Используйте это средство для
определения семантических объектов и распечатки отчетов об объектах,
которые вы будете сдавать преподавателю. Однако прежде чем делать это,
ознакомьтесь с приложением Б и посоветуйтесь с преподавателем.)
2. Модифицируйте объектные диаграммы из вашего ответа на вопрос 1,
представив объекты СЧЕТ-ФАКТУРА и РЕМОНТ в виде подтипов. При каких
условиях эта структура окажется лучше, чем предыдущая?
3. Предположим, что фирма FiredUp хочет записывать домашний и
мобильный телефон, факс и несколько адресов электронной почты своих
пользователей. Модифицируйте ответы на предыдущие вопросы, введя
множественные значения атрибутов Телефон и ЭлектронныйАдрес.
4. Предположим, что фирма FiredUp разрабатывает различные версии одной
и той же горелки, то есть FiredNow V.l, FiredNow V.2 и т. д.
Модифицируйте необходимым образом свой ответ на вопрос 1, чтобы учесть эту
ситуацию.
164 Глава 4. Семантическая объектная модель
5. Когда пользователей спрашивают о том, какие данные они хотели бы
отслеживать, они не всегда помнят все, что им нужно. Пользуясь своими
знаниями об операциях малого предприятия, составьте список
семантических объектов, которые они могли забыть. Не забудьте указать связи
между объектами. Что бы вы сказали по поводу необходимости каких-либо из
этих дополнительных данных для FiredUp?
6. Если вы ответили на вопросы к проекту FiredUp в конце главы 3, сравните
модель «сущность—связь», разработанную для предыдущей главы, с
семантической объектной моделью, разработанной вами только что. Какую из
моделей вы предпочтете? Какая из моделей, как вам кажется, будет более
понятной для сотрудников FiredUp?
Часть III
Проектирование баз данных
Часть III книги посвящена вопросам проектирования баз данных. Глава 5
знакомит читателя с реляционной моделью и нормализацией. Важность реляционной
модели состоит в том, что она является стандартом, в терминах которого
выражена структура большинства баз данных; кроме того, на этой модели основано
большинство современных СУБД. Нормализация важна тем, что она позволяет
проверить качество реляционной структуры.
В главе 6 на основе материала, изложенного в главе 5, рассматривается
процесс преобразования модели «сущность—связь» в независимую от СУБД
реляционную структуру. Глава 7 описывает создание подобной структуры, исходя из
семантической объектной модели данных.
Глава 5
Реляционная модель
и нормализация
Реляционная модель важна по двум причинам. Во-первых, поскольку
конструкции реляционной модели имеют широкий и общий характер, она позволяет
описывать структуры баз данных независимым от СУБД образом. Во-вторых,
реляционная модель является основой почти всех СУБД. Таким образом, понимание
принципов этой модели существенно.
В этой главе даются основы реляционной модели (relational model) и
объясняются фундаментальные принципы нормализации (normalization). Мы начнем
с того факта, что не все отношения одинаковы: некоторые из них более
предпочтительны, чем другие. Нормализация — это процесс преобразования отношения,
имеющего некоторые недостатки, в отношение, которое этих недостатков не
имеет. Что еще более важно, нормализацию можно использовать как критерий для
определения желательности и правильности отношений. Вопрос о том, что такое
хорошо структурированное отношение, был предметом многочисленных
теоретических исследований. Термин нормализация обязан своим появлением одному
из пионеров технологии баз данных, Э. Ф. Кодду (Е. F. Codd), который
определил различные нормальные формы (normal forms) отношений. В этой главе мы
обсудим нормализацию, включая результаты теорем, важных и полезных для
разработчиков баз данных. Доказательства этих теорем и формальное, более
тщательное исследование данного вопроса можно найти в работе Дейта и Ульмана
(C.J. Date и J. D. Ullman)1.
Реляционная модель
Отношение (relation) — это двумерная таблица. Каждая строка в таблице
содержит данные, относящиеся к некоторой вещи или какой-то ее части. Каждый
столбец таблицы описывает какой-либо атрибут этой вещи. Иногда строки
называются кортежами (tuples), а столбцы — атрибутами (attributes).
C.J. Date, Ли Introduction to Database Systems, Sixth Edition (Reading, MA: Addison-Wesley, 1994); и
J. D. Ullman and Jennifer Widom, A First Course in Database Systems (Upper Saddle River, NJ: Prentice
Hall, 1997).
Реляционная модель 167
Термины отношение, кортеж и атрибут пришли из реляционной
математики, которая является теоретическим источником этой модели. Профессионалы
MIS предпочитают употреблять аналогичные термины файл (file), запись (record)
и поле (field), а большинство пользователей находят более удобными термины
таблица (table), строка (row) и столбец (column). Все эти термины сведены в
таблицу на рис. 5.1.
Реляционная
модель
Программист Пользователь
Отношение
Кортеж (строка)
Атрибут
Файл
Запись
Поле
Таблица
Строка
Столбец
Рис. 5.1. Эквивалентная терминология реляционной модели
Чтобы таблица была отношением, она должна удовлетворять определенным
ограничениям1. Во-первых, значения в ячейках таблицы должны быть
одиночными — ни повторяющиеся группы, ни массивы не допускаются2. Все записи
и столбце должны быть одного типа. Например, если третий столбец первой
строки таблицы содержит номер сотрудника, то и во всех остальных строках таблицы
третий столбец также должен содержать номер сотрудника. Каждый столбец
имеет уникальное имя; порядок столбцов в таблице несуществен. Наконец, в
отношении не может быть двух одинаковых строк, и порядок строк не имеет значения.
На рис. 5.2 представлен пример отношения. Отношение имеет семь строк,
в каждой из которых четыре столбца. Если бы мы расположили столбцы в ином
порядке (скажем, поместив ТабельныйНомер в крайний левый столбец) или
переставили бы строки (например, по возрастанию значения столбца Возраст), мы
получили бы эквивалентное отношение.
Атрибут 1 Атрибут 2 Атрибут 3 Атрибут 4
Имя Возраст Пол ТабельныйНомер
Кортеж 1
Кортеж 2
Кортеж 7
Андерсон
Деккер
Гловер
Джексон
Мур
Наката
Смит
21
22
22
21
19
20
19
Ж
М
М
Ж
м
ж
м
010110
010100
101000
201100
111100
111101
111111
Рис. 5.2. Отношение СОТРУДНИК
1 Е. F. Codd, «A relational Model of Data for Large Shared Databanks», Communications of the ЛСМ, июнь
1970, с. 377-387.
2 Это не означает, что значения должны быть фиксированной длины. Текстовое поле с записью
переменной длины, например, является вполне допустимым значением. Однако ячейка может
содержать лишь одно такое значение.
168 Глава 5. Реляционная модель и нормализация
Рисунок 5.2 представляет отдельный экземпляр отношения. Обобщенный
формат отношения — СОТРУДНИК (Имя, Возраст, Пол, ТабельныйНомер) — называется
структурой отношения, и именно это большинство людей имеет в виду,
используя термин отношение.
Чтобы понять, что такое нормализация, мы должны определить два важных
термина: функциональная зависимость и ключ.
Функциональные зависимости
Функциональная зависимость (functional dependency) — это связь между
атрибутами. Предположим, что если мы знаем значение одного атрибута, то можем
вычислить (или найти) значение другого атрибута. Например, если нам известен
номер счета клиента, то мы можем определить состояние его счета. В таком
случае мы можем сказать, что атрибут СостояниеСчетаКлиента функционально зависит
от атрибута НомерСчетаКлиента.
Говоря более общим языком, атрибут Y функционально зависит от атрибута X,
если значение X определяет значение Y. Другими словами, если нам известно
значение X, мы можем определить значение Y.
Уравнения выражают функциональные зависимости. Например, если мы
знаем цену и количество приобретенного товара, мы можем определить стоимость
покупки по следующей формуле:
Стоимость = Цена х Количество
В этом случае мы могли бы сказать, что атрибут Стоимость функционально
зависит от атрибутов Цена и Количество.
Функциональные зависимости между атрибутами в отношении обычно не
выражаются уравнениями. Пусть, например, каждому студенту присвоен
уникальный идентификационный номер, и у каждого студента есть одна и только
одна специальность. Имея номер студента, мы можем узнать его специальность,
поэтому атрибут Специальность функционально зависит от атрибута НомерСтудента.
Или рассмотрим компьютеры в вычислительной лаборатории. Каждый
компьютер имеет конкретный размер основной памяти, поэтому атрибут ОбъемПамяти
функционально зависит от атрибута СерийныйНомерКомпьютера.
В отличие от случая с уравнением, такие функциональные зависимости
нельзя разрешить при помощи арифметики; вместо этого они хранятся в базе
данных. Фактически, можно утверждать, что базу данных стоит иметь только ради
хранения и выдачи функциональных зависимостей.
Функциональные зависимости обозначаются следующим образом:
НомерСтудента > Специальность
СерийныйНомерКомпьютера > ОбъемПамяти
Первое выражение читается так: «атрибут НомерСтудента функционально
определяет атрибут Специальность», «атрибут НомерСтудента определяет атрибут
Специальность» или «атрибут Специальность зависит от атрибута НомерСтудента».
Атрибуты по правую сторону от стрелки называются детерминантами (determinants).
Как уже говорилось, если номер студента определяет специальность, то
каждому номеру студента соответствует только одна специальность. Между тем, од-
Реляционная модель 169
ной и той же специальности может соответствовать более одного номера
студента. Пусть студент под номером 123 специализируется на бухгалтерском учете.
Тогда для любого отношения, где присутствуют столбцы НомерСтудента и
Специальность, выполнится условие: если НомерСтудента = 123, то Специальность = Бух-
галтерскийУчет. Обратное, однако, неверно: если Специальность = БухгалтерскийУчет,
то атрибут НомерСтудента может принимать различные значения, так как на
бухгалтерском учете может специализироваться много студентов. Следовательно, мы
можем сказать, что связь атрибутов НомерСтудента и Специальность имеет вид N:l.
В общем случае можно утверждать, что если А определяет В, связь между
значениями А и В имеет вид N:l.
В функциональные зависимости могут быть вовлечены группы атрибутов.
Рассмотрим отношение ОЦЕНКИ (НомерСтудента, Дисциплина, Оценка). Комбинация
номера студента и дисциплины определяет оценку. Такая функциональная
зависимость записывается следующим образом:
(НомерСтудента, Дисциплина) > Оценка
Заметьте, что для определения оценки требуется как номер студента, так и
дисциплина. Мы не можем разделить эту функциональную зависимость, поскольку
ни номер студента, ни дисциплина не определяют оценку сами по себе.
Обратите внимание на следующее различие. Если X > (Y, Z), то X > Y и X > Z.
Например, если НомерСтудента > (ИмяСтудента, Специальность), то НомерСтудента >
ИмяСтудента и НомерСтудента > Специальность. Но если (X, Y) >Z, то в общем случае
неверно, что X > Y или X > Z. Следовательно, если (НомерСтудента, Дисциплина) >
Оценка, то ни номер студента, ни дисциплина как таковые оценку не определяют.
Ключи
Ключ (key) — это группа из одного или более атрибутов, которая уникальным
образом идентифицирует строку. Рассмотрим отношение СЕКЦИЯ (рис. 5.3),
имеющее атрибуты НомерСтудента, Секция и Плата. Строка этого отношения содержит
информацию о том, что студент посещает определенную секцию за определенную
плату. Предположим, что студент одновременно не может посещать более одной
секции. В этом случае значение атрибута НомерСтудента идентифицирует
единственную строку, поэтому данный атрибут является ключом.
СЕКЦИЯ (НомерСтудента, Секция, Плата)
Ключ: НомерСтудента
Sample Data
НомерСтудента Секция Плата
100
150
175
200
Лыжи
Плавание
Сквош
Плавание
200
50
50
50 I
Рис. 5.3. Отношение СЕКЦИЯ
170 Глава 5. Реляционная модель и нормализация
Ключи могут также составляться из нескольких атрибутов. Например, если
студентам разрешено одновременно посещать более одной секции, то один и тот
же номер студента может появиться в разных строках таблицы, поэтому атрибут
НомерСтудента не будет уникальным образом определять строку. Для этого
потребуется какое-то сочетание атрибутов; возможно, это будет комбинация
(НомерСтудента, Секция).
Попутно отметим, что в предыдущем абзаце затронут тонкий, но весьма
важный аспект. Являются ли атрибуты ключами и являются ли они функционально
зависимыми — это определяется не абстрактным набором правил, а моделями,
присутствующими в воображении пользователей, а также деловым регламентом
организации, использующей базу данных. Что в приведенном выше примере
является ключом — НомерСтудента, комбинация (НомерСтудента, Секция) или какое-
то еще сочетание атрибутов, — целиком и полностью определяется тем, как
представляют себе ситуацию люди, работающие в организации, которая использует
базу данных. Ответы на эти вопросы мы должны получить от пользователей.
По ходу дальнейшего изложения имейте в виду, что все наши предположения
о функциональных зависимостях, ключах, ограничениях и тому подобных вещах
определяются моделями в воображении пользователей.
Допустим, в ходе опроса пользователей мы выяснили, что студентам
разрешено одновременно быть записанными в несколько спортивных секций. Эта
ситуация отражена в отношении СЕКЦИИ (рис. 5.4). Как мы отметили,
НомерСтудента не является ключом этого отношения. В самом деле, студент с номером 100
посещает секцию гольфа и секцию лыж, и атрибут НомерСтудента со
значением 100 появляется в двух различных строках. Фактически, для этого отношения
ни один атрибут сам по себе не является ключом, то есть ключ должен состоять
из двух или более атрибутов.
НомерСтудента Секция Плата
100
100
150
175
175
200
200
Лыжи
Гольф
Плавание
Сквош
Плавание
Плавание
Гольф
200
65
50
50
50
50
65
Рис. 5.4. Отношение СЕКЦИИ
Рассмотрим, какие комбинации из двух атрибутов возможны для данной
таблицы. Таких комбинаций имеется три: (НомерСтудента, Секция), (НомерСтудента,
Плата) и (Секция, Плата). Является ли какая-либо из этих комбинаций ключом?
Чтобы быть ключом, группа атрибутов должна уникальным образом
идентифицировать строку. Опять-таки, ответы на подобные вопросы мы должны получить
от пользователей. Наше решение не должно основываться на выборочных дан-
Реляционная модели 171
ных, подобных тем, которые приведены на рис. 5.4, или на наших собственных
предположениях.
Допустим, поговорив с пользователями, мы пришли к выводу, что плата за
абонемент в различных секциях может совпадать. Поскольку это так,
комбинация (НомерСтудента, Плата) не может уникальным образом определить строку.
Например, студент с номером 100 может посещать две различных секции,
каждая из которых стоит $200. Это означает, что комбинация (100, $200) возникла
бы в таблице дважды, поэтому такая комбинация не может быть ключом.
Может ли быть ключом сочетание (Секция, Плата)? Может ли комбинация
(Лыжи, $200) уникальным образом определить строку? Нет, не может, поскольку
секцию лыж может посещать много студентов. А как насчет сочетания (Номер-
Студента, Секция)? Имея те сведения, которые мы получили от пользователей,
можно ли сказать, что комбинация значения атрибутов НомерСтудента и Секция
уникальным образом определяет строку таблицы? Да, можно, пока от нас не
требуется вести записи об истории посещения секций студентом. Иными словами,
должна ли эта таблица содержать сведения только о тех секциях, которые
студент посещает на данный момент, или же в ней должны быть записи о секциях,
которые студент посещал ранее?
И снова, чтобы ответить на этот вопрос, мы должны обратиться к
пользователям. Предположим, мы выяснили, что необходимо хранить сведения только
о посещаемых в настоящий момент секциях. Тогда комбинация (НомерСтудента,
Секция) может уникальным образом определить строку отношения и,
следовательно, эта комбинация является ключом данного отношения. Если бы
пользователи указали, что должны также храниться записи о секциях, которые
посещались в прошлом, то отношение на рис. 5.3 имело бы дублирующиеся строки.
Поскольку это недопустимо по определению отношения, нам пришлось бы
добавить другие атрибуты, например атрибут Дата.
Это приводит нас к важному заключению. Каждое отношение имеет
минимум один ключ. Это утверждение должно быть верным, поскольку ни одно
отношение не может иметь одинаковых строк, и, следовательно, в крайнем случае
ключ будет состоять из всех атрибутов отношения.
Функциональные зависимости, ключи
и уникальность
У многих студентов возникает путаница с понятиями функиональной
зависимости, ключа и уникальности. Чтобы избежать этой путаницы, уясните себе
следующее: детерминант функциональной зависимости может в отношении быть
уникальным или неуникальным. Если нам известно, что А определяет В и что А
и В находятся в одном и том же отношении, мы все равно не знаем, является ли А
уникальным в этом отношении. Мы знаем только то, что А определяет В.
Например, в отношении СЕКЦИИ атрибут Секция функционально определяет
атрибут Плата, но название конкретной секции может, тем не менее,
фигурировать в нескольких строках отношения. Функциональная зависимость говорит
172 Глава 5. Реляционная модель и нормализация
только о том, что везде, где атрибуту Секция сопутствует атрибут Плата,
конкретному значению атрибута Секция всегда соответствует одно и то же значение
атрибута Плата. То есть абонемент в секцию лыж всегда стоит $200, независимо от
того, сколько раз секция лыж фигурирует в таблице.
В отличие от детерминантов, ключи всегда являются уникальными. Ключ
функционально определяет целую строку. Если бы значения ключей
дублировались, дублировался бы и весь кортеж. Но это недопустимо, поскольку по
определению строки в отношении должны быть уникальными. Таким образом, когда
мы говорим, что атрибут (или комбинация атрибутов) является ключом, мы
знаем, что этот атрибут или комбинация будут уникальными. Например, если
сочетание (НомерСтудента, Секция) является ключом, то сочетание (100, Лыжи) может
появиться в таблице только один раз.
Чтобы проверить, как вы усвоили эти понятия, попытайтесь объяснить,
почему в отношении СЕКЦИЯ (см. рис. 5.3) НомерСтудента является и детерминантом,
и ключом, а Секция является только детерминантом, но не ключом. (Имейте в
виду, что отношение на рис. 5.3 отражает политику, когда студентам не
разрешается одновременно посещать более одной секции.)
Нормализация
К сожалению, не все отношения одинаково желательны. Таблица, отвечающая
минимальному определению отношения, может иметь неэффективную или
неподходящую структуру. Для некоторых отношений изменение данных может
привести к нежелательным последствиям, называемым аномалиями
модификации (modification anomalies). Аномалии могут быть устранены путем разбиения
исходного отношения на два или более новых отношения. В большинстве случаев
переопределенные, или нормализованные, отношения являются более
предпочтительными.
Аномалии модификации
Рассмотрим опять отношение СЕКЦИЯ на рис. 5.3. Если мы удалим строку, где
записаны данные о студенте с номером 100, мы потеряем не только информацию о том,
что студент с номером 100 является лыжником, но и тот факт, что абонемент в
секцию лыж стоит $200. Это называется аномалией удаления (deletion anomaly) —
то есть, удаляя факты, относящиеся к одной сущности (студент с номером 100
является лыжником), мы непроизвольно удаляем факты, относящиеся к другой
сущности (плата за абонемент в секцию лыж составляет $200). Выполнив одну
операцию удаления, мы теряем информацию о двух сущностях.
На примере того же самого отношения можно продемонстрировать аномалию
вставки (insertion anomaly). Предположим, мы хотим записать в базу данных тот
факт, что абонемент в секцию подводного плавания стоит $175, однако мы не
можем ввести эти данные в отношение СЕКЦИЯ, пока хотя бы один студент не
запишется в секцию подводного плавания. Это ограничение выглядит глупо.
Нормализация 173
Почему для того, чтобы указать стоимость абонемента, требуется ждать, когда
кто-нибудь запишется в секцию? Это ограничение называется аномалией
вставки. Суть его в том, что мы не можем записать в таблицу некоторый факт об
одной сущности, не указав дополнительно некоторый факт о другой сущности.
Отношение в табл. 5.3 может быть использовано в некоторых приложениях,
но оно имеет явные проблемы. Мы можем устранить как аномалию удаления,
так и аномалию вставки, разделив отношение СЕКЦИЯ на два отношения, каждое
из которых будет содержать информацию на определенную тему. Например, в
одно отношение мы поместим атрибуты НомерСтудента и Секция (назовем это
отношение СТУДЕНТ-СЕКЦИЯ), а в другое — атрибуты Секция и Плата (назовем это
отношение СЕКЦИЯ-ПЛАТА). Эти два отношения с данными из нашего примера
изображены на рис. 5.5.
СЕКЦИЯ (НомерСтудента, Секция, Плата) СЕКЦИЯ-ПЛАТА (Секция, Плата)
Ключ: НомерСтудента Ключ: Секция
НомерСтудента Секция Секция Плата
100
150
175
200
Лыжи
Плавание
Сквош
Плавание
Лыжи
Плавание
Сквош
200
50
50
Рис. 5.5. Разбиение отношения СЕКЦИЯ на два отношения
Теперь, если мы удалим запись о студенте с номером 100 из таблицы СТУДЕНТ-
СЕКЦИЯ, мы уже не потеряем тот факт, что абонемент в секцию лыж стоит $200.
Более того, мы можем добавить в таблицу СЕКЦИЯ-ПЛАТА секцию подводного
плавания с указанием стоимости абонемента, не дожидаясь, пока кто-либо
запишется в эту секцию. Таким образом, аномалии удаления и вставки устранены.
Разбиение одного отношения на два имеет, однако, один недостаток.
Предположим, что студент хочет записаться в несуществующую секцию. Например,
студент с номером 250 хочет записаться в секцию ракетбола. Мы можем вставить
соответствующую строку в отношение СТУДЕНТ-СЕКЦИЯ (строка будет содержать
запись (250, Ракетбол)), но следует ли это делать? Стоит ли разрешать студенту
записываться в секцию, которая отсутствует в отношении СЕКЦИЯ-ПЛАТА? Друпши
словами, должна ли система каким-либо образом препятствовать добавлению строк
в таблицу СТУДЕНТ-СЕКЦИЯ, если название соответствующей секции отсутствует
в таблице СЕКЦИЯ-ПЛАТА? Ответ на этот вопрос содержится в требованиях
пользователей. Если такое действие должно быть запрещено, данное ограничение (а это не
что иное, как статья делового регламента) необходимо внести в схему базы данных.
Позже, на стадии реализации, выполнение этого ограничения будет возложено
иа СУБД, если используемая СУБД предоставляет такую возможность. Если нет,
то соблюдение ограничения должно обеспечиваться прикладными программами.
Допустим, пользователи указывают, что секции могут существовать и до
того, как кто-либо в них запишется, однако студент не может записаться в
секцию, для которой не указан размер платы за абонемент (то есть в секцию, данные
174 Глава 5. Реляционная модель и нормализация
о которой отсутствуют в таблице СЕКЦИЯ-ПЛАТА). При проектировании базы
данных мы можем задокументировать это ограничение любым из следующих
способов: «множество значений атрибута Секция в таблице СТУДЕНТ-СЕКЦИЯ является
подмножеством множества значений атрибута Секция в таблице СЕКЦИЯ-ПЛАТА»,
«СТУДЕНТ-СЕКЦИЯ [Секция] является подмножеством СЕКЦИЯ-ПЛАТА [Секция]» либо
«СТУДЕНТ-СЕКЦИЯ [Секция] с СЕКЦИЯ-ПЛАТА [Секция]».
Квадратные скобки в этой записи обозначают столбец данных, извлекаемый
иэ отношения. Смысл этих выражений в том, что атрибут Секция в отношении
СТУДЕНТ-СЕКЦИЯ может принимать только те значения, которые имеет атрибут
Секция в отношении СЕКЦИЯ-ПЛАТА. Это означает также, что прежде чем ввести
название какой-то секции в отношение СТУДЕНТ-СЕКЦИЯ, мы должны проверить,
что такое название уже существует в отношении СЕКЦИЯ-ПЛАТА. Ограничения,
подобные этому, называются ограничениями ссылочной целостности (referential
integrity constraints), или ограничениями целостности по внешнему ключу
(interrelation constraints).
Суть нормализации
Аномалии, присутствующие в отношении на рис. 5.3, можно интуитивно описать
следующим образом: проблемы возникают из-за того, что отношение СЕКЦИЯ
содержит факты, относящиеся к двум различным темам.
1. Кто из студентов какую секцию посещает.
2. Какова плата за абонемент в каждой из секций.
Когда мы добавляем новую строку, нам приходится добавлять информацию,
затрагивающую две различные темы; точно так же, когда мы удаляем строку, мы
вынуждены удалять данные, относящиеся сразу к двум темам.
Помните, что учительница родного языка и литературы говорила вам, что
абзац должен иметь только одну тему? Если абзац содержал более одной темы, вас
учили разбивать его на два или более абзаца таким образом, чтобы каждый из
получившихся абзацев содержал ровно одну тему. Аналогичные высказывания
справедливы и для отношений. Каждое нормализованное отношение имеет од-
ну-единственную тему. Любое отношение, содержащее две или более темы,
следует разбить на два или более отношения, каждое из которых будет содержать
одну тему. Этот процесс составляет суть нормализации. Когда мы обнаруживаем
отношение с аномалиями модификации, мы устраняем эти аномалии, разбивая
отношение на два или более новых отношения, каждое из которых содержит
факты, относящиеся к одной теме.
Однако не стоит забывать, что всякий раз, когда мы разбиваем отношение,
мы, возможно, порождаем ограничение ссылочной целостности. Поэтому
следует обязательно проверять наличие таких ограничений каждый раз при
разбиении отношения на два или более новых.
В оставшейся части этой главы вам предстоит узнать несколько правил,
относящихся к нормализации. Все эти правила представляют собой частные случаи
только что описанного процесса.
Нормализация 175
Классы отношений
Отношения можно классифицировать по типам аномалий модификации,
которым они подвержены. В 1970-х годах теоретики реляционных баз данных
постепенно сокращали количество этих типов. Кто-то находил аномалию,
классифицировал ее и думал, как предотвратить ее возникновение. Каждый раз, когда это
происходило, критерии построения отношений совершенствовались. Эти классы
отношений и способы предотвращения аномалий называются нормальными
формами (normal forms). В зависимости от своей структуры, отношение может быть
в первой, во второй или в какой-либо другой нормальной форме.
В своей работе, последовавшей за эпохальной статьей 1970 г., Кодд и другие
определили первую, вторую и третью нормальные формы (1НФ, 2НФ и ЗНФ).
Позднее была введена нормальная форма Бойса-Кодда (НФБК), а затем были
определены четвертая и пятая нормальные формы. Как показывает рис. 5.6, эти
нормальные формы являются вложенными. То есть отношение во второй
нормальной форме является также отношением в первой нормальной форме, а
отношение в 5НФ (пятая нормальная форма) находится одновременно в 4НФ,
НФБК, ЗНФ, 2НФ и 1НФ.
Первая нормальная форма (1НФ)
Вторая нормальная форма (2НФ)
Третья нормальная форма (ЗНФ)
Нормальная форма Бойса-Кодда (НФБК)
Четвертая нормальная форма (4НФ)
Пятая нормальная форма (5НФ)
*Доменно-ключевая нормальная форма (ДКНФ) ^~ "~"
Рис. 5.6. Взаимосвязь нормальных форм
Эти нормальные формы помогали, но у них было и серьезное ограничение.
Не было теории, гарантирующей, что какая-либо из этих форм устранит все
аномалии: каждая форма могла устранить только определенные их виды. Эта
ситуация разрешилась в 1981 г., когда Р. Фагин (R. Fagin) ввел новую нормальную
форму, которую он назвал домеино-ключевой нормальной формой, или ДКНФ
(domain/key normal form, DK/NF). В своей важной статье Фагин показал, что
отношение в ДКНФ свободно от всех аномалий модификации, независимо от их
типа1. Он также показал, что любое отношение, свободное от аномалий
модификации, должно находиться в ДКНФ.
До введения ДКНФ теоретикам реляционных баз данных приходилось
продолжать поиск все новых и новых аномалий и нормальных форм.
Доказательство Фагина упростило ситуацию. Если мы можем привести отношение к ДКНФ,
1 R. Fagin, «A Normal Form for Relational Databases That Is Based On Domains and Keys», Л CM Transactions
on Database Systems, сентябрь 1981, с. 387-415.
176 Глава 5. Реляционная модель и нормализация
мы можем быть уверены, что в нем не будет аномалий модификации. Вся
загвоздка в том, как привести отношение к ДКНФ,
Нормальные формы от первой до пятой
О любой таблице данных, удовлетворяющей определению отношения, говорят,
что она находится в первой нормальной форме (first normal form, INF).
Вспомните, что для того, чтобы таблица была отношением, должно выполняться
следующее: ячейки таблицы должны содержать одиночные значения и в качестве
значений не допускаются ни повторяющиеся группы, ни массивы. Все записи в одном
столбце (атрибуте) должны иметь один и тот же тип. Каждый столбец должен
иметь уникальное имя, но порядок следования столбцов в таблице несуществен.
Наконец, в таблице не может быть двух одинаковых строк, и порядок следования
строк несуществен.
Отношение на рис. 5.4 находится в первой нормальной форме. Как мы
видели, однако, отношения в первой нормальной форме могут иметь аномалии
модификации. Чтобы устранить эти аномалии, мы разбиваем отношение на два или
более новых отношения. Когда мы делаем это, новые отношения оказываются
в некоторой другой нормальной форме, а в какой именно, зависит от того, какие
аномалии мы устранили, а также от того, каким аномалиям подвержены
получившиеся отношения.
Вторая нормальная форма (2НФ)
Чтобы понять, что такое вторая нормальная форма, рассмотрим отношение СЕКЦИИ
на рис, 5,4, Это отношение имеет аномалии модификации, подобные тем, которые
мы рассматривали ранее. Если мы удалим строку с данными о студенте с
номером 175, мы потеряем тот факт, что абонемент в секцию сквоша стоит $50. Кроме
того, мы не можем ввести информацию о секции, пока в эту секцию не запишется
хотя бы один студент. Таким образом, это отношение подвержено как аномалии
удаления, так и аномалии вставки.
Проблема с этим отношением состоит в том, что оно содержит зависимость,
затрагивающую только часть ключа. Ключом является комбинация (НомерСтуден-
та, Секция), но отношение содержит зависимость Секция > Плата. Детерминант этой
зависимости (Секция) представляет собой лишь часть ключа (НомерСтудента,
Секция). В этом случае мы можем сказать, что атрибут Плата частично зависит от
ключа таблицы. Аномалий модификации не было бы, если бы Плата зависела от
всего ключа. Чтобы устранить эти аномалии, мы должны разделить отношение
на два отношения.
Данный пример приводит нас к определению второй нормальной формы
(second normal form, 2NF): отношение находится во второй нормальной форме,
если все его неключевые атрибуты зависят от всего ключа. В соответствии с этим
определением, если отношение имеет в качестве ключа одиночный атрибут, то
оно автоматически находится во второй нормальной форме. Поскольку ключ
является одиночным атрибутом, то по умолчанию каждый неключевой атрибут за-
Нормальные формы от первой до пятой, 177
нисит от всего ключа, и частичных зависимостей быть не может. Таким образом,
вторая нормальная форма представляет интерес только для тех отношений,
которые имеют композитные ключи.
Отношение СЕКЦИИ может быть разбито на два отношения во второй
нормальной форме. Это те самые отношения, которые изображены на рис. 5.5, а именно
СТУДЕНТ-СЕКЦИЯ и СЕКЦИЯ-ПЛАТА. Мы знаем, что новые отношения находятся во
пторой нормальной форме, поскольку оба они имеют в качестве ключей
одиночные атрибуты.
Третья нормальная форма (ЗНФ)
Отношения во второй нормальной форме также могут иметь аномалии.
Рассмотрим отношение ПРОЖИВАНИЕ на рис. 5.7, а. Ключом здесь является НомерСтудента,
и имеются функциональные зависимости НомерСтудента > Общежитие и
Общежитие > Плата. Эти зависимости возникают потому, что каждый студент живет
только в одном общежитии, и каждое общежитие взимает со всех проживающих в нем
студентов одинаковую плату. Например, каждый живущий в общежитии Рэн-
дольф-Холл платит $3200 за квартал.
ПРОЖИВАНИЕ (НомерСтудента, Общежитие, Плата)
Ключ: НомерСтудента
Функциональные зависимости:Общежитие -» Плата
НомерСтудента -» Общежитие -» Плата
НомерСтудента Общежитие Плата
100
150
200
250
300
Рэндольф
Ингерсол
Рэндольф
Питкин
Рэндольф
3200
3100
3200
3100
3200
а
СТУДЕНТ-ПРОЖИВАНИЕ ОБЩЕЖИТИЕ-ПЛАТА
(НомерСтудента, Общежитие) (Общежитие, Плата)
Ключ: НомерСтудента Ключ: Общежитие
НомерСтудента Общежитие Общежитие Плата
Рэндольф
Ингерсол
Рэндольф
Питкин
Рэндольф
3200
3100
3200
3100
3200
100
150
200
250
300
Рэндольф
Ингерсол
Рэндольф
Питкин
Рэндольф
б
Рис. 5.7. Устранение транзитивной зависимости: а — отношение с транзитивной
зависимостью; б — два отношения, не имеющих транзитивных зависимостей
178 Глава 5. Реляционная модель и нормализация
Поскольку НомерСтудента определяет атрибут Общежитие, а Общежитие
определяет атрибут Плата, то косвенным образом НомерСтудента > Плата. Такая структура
функциональных зависимостей называется транзитивной зависимостью (transitive
dependence), поскольку атрибут НомерСтудента определяет атрибут Плата через
атрибут Общежитие.
Ключом отношения ПРОЖИВАНИЕ является НомерСтудента, который является
одиночным атрибутом, и, следовательно, отношение находится во второй
нормальной форме (и Общежитие, и Плата определяются атрибутом НомерСтудента).
Несмотря на это, отношение ПРОЖИВАНИЕ имеет аномалии, обусловленные
транзитивной зависимостью.
Что произойдет, если мы удалим вторую строку отношения на рис. 5.7, а?
Мы потеряем не только тот факт, что студент № 150 живет в Ингерсолл-Холле,
но и тот факт, что проживание в этом общежитии стоит $3100. Это аномалия
удаления. А как мы можем записать тот факт, что плата за проживание в Кэр-
ригг-Холле составляет $3500? Никак, пока туда не решит вселиться хотя бы
один студент. Это аномалия вставки.
Чтобы удалить аномалии из отношения во второй нормальной форме,
необходимо устранить транзитивную зависимость, что приводит нас к
определению третьей нормальной формы (third normail form, 3NF): отношение
находится в третьей нормальной форме, если оно находится во второй нормальной
форме и не имеет транзитивных зависимостей.
Отношение ПРОЖИВАНИЕ можно разделить на два отношения в третьей
нормальной форме. На рис. 5.7, б мы видим два отношения, получившиеся в
результате этой операции: СТУДЕНТ-ПРОЖИВАНИЕ (НомерСтудента, Общежитие) и ОБЩЕЖИТИЕ-
ПЛАТА (Общежитие, Плата).
Отношение СЕКЦИЯ на рис. 5.3 также содержит транзитивную зависимость.
В этом отношении НомерСтудента определяет атрибут Секция, а Секция определяет
атрибут Плата. Поэтому отношение СЕКЦИЯ не находится в третьей нормальной
форме. Разбиение данного отношения на отношения СТУДЕНТ-СЕКЦИЯ
(НомерСтудента, Секция) и СЕКЦИЯ-ПЛАТА (Секция, Плата) устраняет аномалии.
Нормальная форма Бойса-Кодда (НФБК)
К сожалению, даже отношения в третьей нормальной форме могут иметь
аномалии. Рассмотрим отношение КОНСУЛЬТАНТ (рис. 5.8, а). Пусть требования к этому
отношению таковы:
1. Студент может иметь одну или несколько специальностей.
2. Консультантами по одному и тому же предмету могут быть несколько
преподавателей.
3. Каждый преподаватель может быть консультантом только по одной
специальности.
Будем также предполагать, что у преподавателей не может быть одинаковых
фамилий.
Нормальные формы от первой до пятой , 179
КОНСУЛЬТАНТ (НомерСтудента, Специальность, Преподаватель)
Ключ (первичный): (НомерСтудента, Специальность)
Ключ (вторичный): (НомерСтудента, Преподаватель)
Функциональные
зависимости: Преподаватель -» Специальность
НомерСтудента Специальность Преподаватель
100
I 150
200
250
300
300
Математика
Психология
Математика
Математика
Рэндольф
Психология
Кош и
Юнг
Риман
Коши
Перле
Риман
а
СТУДЕНТ-КОНСУЛЬТАНТ КОНСУЛЬТАНТ-ПРЕДМЕТ
(НомерСтудента, Преподаватель)
Ключ: НомерСтудента, Преподаватель Ключ: Преподаватель
НомерСтудента Преподаватель Консультант Предмет
100
150
200
250
300
300
Коши
Юнг
Риман •
Коши
Перле
Риман
Коши
Юнг
Риман
Перле
Математика
Психология
Математика
Психология
б
Рис. 5.8. Нормальная форма Бойса-Кодда: а — отношение, находящееся в ЗНФ,
но не в НФБК; б — два отношения, находящиеся в НФБК
Поскольку студенты могут специализироваться в нескольких областях,
атрибут НомерСтудента не определяет атрибут Специальность. Более того, так как
студент может иметь несколько консультантов, НомерСтудента не определяет и
атрибут Преподаватель. Таким образом, НомерСтудента сам по себе не может быть
ключом.
Комбинация (НомерСтудента, Специальность) определяет атрибут Преподаватель,
а комбинация (НомерСтудента, Преподаватель) определяет атрибут Специальность.
Следовательно, любая из этих комбинаций может быть ключом. Два или более
атрибута или группы атрибутов, которые могут быть ключом, называются
ключами-кандидатами (candidate keys). Тот из ключей-кандидатов, который
выбирается в качестве ключа, называется первичиъш ключом (primary key).
Кроме ключей-кандидатов, есть еще одна функциональная зависимость,
которую следует рассмотреть: атрибут Преподаватель определяет атрибут Специальность
(любой из преподавателей является консультантом только по одному предмету;
следовательно, зная имя преподавателя, мы можем определить специальность).
Таким образом, Преподаватель является детерминантом.
180 Глава 5. Реляционная модель и нормализация
По определению, отношение КОНСУЛЬТАНТ находится в первой нормальной
форме. Оно также находится во второй нормальной форме, поскольку не имеет
неключевых атрибутов (каждый из атрибутов является частью минимум одного
ключа). Наконец, это отношение находится в третьей нормальной форме, так как
не имеет транзитивных зависимостей. Тем не менее, несмотря на все это,
отношение имеет аномалии модификации.
Пусть студент с номером 300 отчисляется из университета. Если мы удалим
строку с информацией о студенте с номером 300, мы потеряем тот факт, что
Перле является консультантом по психологии. Это аномалия удаления. Далее,
как мы можем записать в базу тот факт, что Кейнс является консультантом по
экономике? Никак, пока не появится хотя бы один студент,
специализирующийся на экономике. Это аномалия удаления.
Ситуации, подобные только что описанной, приводят нас к определению
нормальной формы Бойса-Кодда (Boyce-Codd normal form, BK/NF): отношение
находится в НФБК, если каждый детерминант является ключом-кандидатом.
Отношение КОНСУЛЬТАНТ не находится в НФБК, поскольку детерминант Преподаватель
не является ключом-кандидатом.
Как и в других примерах, отношение КОНСУЛЬТАНТ можно разбить на два
отношения, не имеющие аномалий. Например, отношения СТУДЕНТ-КОНСУЛЬТАНТ
(НомерСтудента, Преподаватель) и КОНСУЛЬТАНТ-ПРЕДМЕТ (Преподаватель, Специальность)
не имеют аномалий.
Отношения в НФБК не имеют аномалий, относящихся к функциональным
зависимостям, и некогда казалось, что вопрос с аномалиями модификации на
этом исчерпан. Однако вскоре обнаружилось, что аномалии могут быть
обусловлены и иными причинами, нежели функциональные зависимости.
Четвертая нормальная форма (4НФ)
Рассмотрим отношение СТУДЕНТ на рис. 5.9, которое отображает связи между
студентами, специальностями и секциями. Предположим, что студенты могут
иметь несколько специальностей и заниматься в нескольких различных секциях.
В таком случае единственным ключом является комбинация (НомерСтудента,
Специальность, Секция). Например, студентка с номером 100 специализируется на
музыке и бухгалтерском учете и, кроме того, посещает секции плавания и
тенниса, а студент с номером 150 специализируется только на математике и
занимается бегом.
Какова связь между атрибутами НомерСтудента и Специальность? Это не
функциональная зависимость, поскольку у студента может быть несколько
специальностей. Одному и тому же значению атрибута НомерСтудента может
соответствовать много значений атрибута Специальность. Помимо того, одному и тому же
значению атрибута НомерСтудента может соответствовать много значений
атрибута Секция.
Такая зависимость атрибутов называется многозначной зависимостью (multi-
value dependency). Многозначные зависимости приводят к аномалиям
модификации. Для начала обратите внимание на избыточность данных на рис. 5.9.
Нормальные формы от первой до пятой, 181
Студентке с номером 100 посвящено четыре записи, в каждой из которых указана
одна из ее специализаций и одна из посещаемых ею секций. Если бы те же
данные хранились в меньшем количестве строк (скажем, было бы две строки — одна
для музыки и плавания, а другая для бухгалтерского учета и тенниса), это
дезориентировало бы пользователей. Получалось бы, что студентка с номером 100
плавает только тогда, когда специализируется на музыке, а в теннис играет только
тогда, когда специализируется на бухгалтерском учете. Но такая интерпретация
нелогична. Специальности и секции совеершенно независимы друг от друга.
Поэтому, чтобы избежать таких неверных заключений, мы храним все сочетания
специальностей и секций.
СТУДЕНТ (НомерСтудента, Специальность, Секция)
Ключ: (НомерСтудента, Специальность, Секция)
Многозначные
зависимости: НомерСтудента -» -> Специальность
НомерСтудента -» -» Секция
НомерСтудента Специальность Секция
| 100
100
100
100
150
Музыка
Бухгалтерский учет
Музыка
Бухгалтерский учет
Математика
Плавание
Плавание
Теннис
Теннис
Оздоровительный бег
Рис. 5.9. Отношение с многозначными зависимостями
Допустим, что студентка с номером 100 решила записаться в секцию лыж,
и поэтому мы добавляем в таблицу строку [100, Музыка, Лыжи], как показано на
рис. 5.10, а. В данный момент из отношения можно сделать вывод, что
студентка 100 занимается лыжами только как музыкант, но не как бухгалтер. Чтобы
данные имели согласованный характер, мы должны добавить столько строк,
сколько имеется специальностей, и в каждой из них указать секцию лыж. Таким
образом, мы должны добавить строку [100, Бухгалтерский учет, Лыжи], как
показано на рис. 5.10, б. Это аномалия обновления: требуется слишком много
модификаций, чтобы внести одно простое изменение.
Вообще говоря, многозначная зависимость существует, когда отношение
имеет минимум три атрибута, причем два из них являются многозначными, а их
значения зависят только от третьего атрибута. Другими словами, в отношении
R (А, В, С) существует многозначная зависимость, если А многозначным образом
определяет В и С, а сами В и С не зависят друг от друга. Как мы видели из
предыдущего примера, НомерСтудента многозначно определяет атрибуты Специальность
и Секция, но сами Специальность и Секция не зависят друг от друга.
Вернемся вновь к рис. 5.9. Обратите внимание на то, как обозначаются
многозначные зависимости: НомерСтудента » Специальность и НомерСтудента » Секция.
Это читается следующим образом: «атрибут НомерСтудента многозначно
определяет атрибут Специальность» и «атрибут НомерСтудента многозначно определяет
182 Глава 5. Реляционная модель и нормализация
атрибут Секция». Данное отношение находится в НФБК (2НФ — поскольку его
ключом является совокупность всех атрибутов, ЗНФ — так как отсутствуют
транзитивные зависимости, и НФБК — поскольку нет неключевых
детерминантов). Однако, как мы убедились, оно имеет аномалии: если студент берет
дополнительную специальность, мы должны добавить в отношение столько строк,
в скольких секциях данный студент занимается, и в каждой из этих строк
указать новую специальность. То же самое справедливо и для случая, когда студент
записывается в новую секцию. Если студент отказывается от одной из
специальностей, мы должны удалить все строки, где указана данная специальность. Если
студент занимается в четырех секциях, то название специальности будет
содержаться в четырех строках, и все эти строки необходимо будет удалить.
СТУДЕНТ (НомерСтудента, Специальность, Секция)
Ключ: (НомерСтудента, Специальность, Секция)
НомерСтудента Специальность Секция
100
100
100
100
100
150
Музыка
Музыка
Бухгалтерский учет
Музыка
Бухгалтерский учет
Математика
Лыжи
Плавание
Плавание
Теннис
Теннис
Оздоровительный бег
а
НомерСтудента Специальность Секция
100
100
100
| 100
100
100
150
Музыка
Бухгалтерский учет
Музыка
Бухгалтерский учет
Музыка
Бухгалтерский учет
Математика
Лыжи
Лыжи
Плавание
Плавание
Теннис
Теннис
Оздоровительный бег
б
Рис. 5.10. Отношение СТУДЕНТ с аномалиями вставки: а — вставка одной строки;
б — вставка нескольких строк
Чтобы устранить эти аномалии, мы должны избавиться от многозначной
зависимости. Мы сделаем это, создав два отношения, в каждом из которых будут
храниться данные только по одному многозначному атрибуту. Результирующие
отношения не будут иметь аномалий. Это отношения СТУДЕНТ-СПЕЦИАЛЬНОСТЬ
(НомерСтудента, Специальность) и СТУДЕНТ-СЕКЦИЯ (НомерСтудента, Секция),
приведенные на рис. 5.11.
Доменно-ключевая нормальная форма (ДКНФ) , 183
СТУДЕНТ-СПЕЦИАЛЬНОСТЬ СТУДЕНТ-СЕКЦИЯ
(НомерСтудента, Специальность) (НомерСтудента, Секция)
Ключ: (НомерСтудента, Специальность) Ключ: (НомерСтудента, Секция)
НомерСтудента Специальность НомерСтудента Секция
100
100
150
Музыка
Бухгалтерский учет
Математика
100
100
100
150
Лыжи
Плавание
Теннис
Оздоровительный бег
Рис. 5.11. Устранение многозначной зависимости
Исходя из сделанных нами наблюдений, мы определим четвертую
нормальную форму (fourth normal form, 4NF) следующим образом: отношение находится
в четвертой нормальной форме, если оно находится в НФБК и не имеет много-
мшчных зависимостей. После обсуждения доменно-ключевой нормальной
формы (далее в этой главе) мы вернемся к описанию многозначных зависимостей,
по уже в другом, более интуитивном ключе.
Пятая нормальная форма (5НФ)
Пятая нормальная форма (fifth normal form, 5NF) связана с зависимостями,
которые имеют несколько неопределенный характер. Речь здесь идет об отношениях,
которые можно разделить на несколько более мелких отношений, как мы это
делали выше, но затем невозможно восстановить. Условия, при которых возникает
:)та ситуация, не имеют ясной, интуитивной интерпретации. Нам неизвестно,
каковы следствия таких зависимостей; мы не знаем даже, есть ли у них
какие-либо практические следствия. За более подробной информацией о пятой
нормальной форме обращайтесь к работе Дэйта, которая цитировалась ранее в этой главе.
Доменно-ключевая нормальная
форма (ДКНФ)
Все описанные выше нормальные формы были выделены исследователями,
выявившими аномалии у некоторых отношений, которые находились в нормальной
форме более низкого порядка: обнаружение аномалий модификации у
отношений во второй нормальной форме привело к определению третьей нормальной
формы и т. д. Хотя каждая нормальная форма решала часть проблем, найденных
у предыдущей нормальной формы, никто не мог сказать, какие проблемы еще не
пыявлены. Каждый такой шаг являлся прогрессом на пути к представлению об
оптимальной структуре базы данных, однако никто не мог гарантировать, что не
будет обнаружено еще каких-либо аномалий. В этом разделе мы рассмотрим
нормальную форму, которая будет свободна от аномалий любого типа. Когда мы
приводим отношения к этой форме, мы знаем, что в этом случае даже скрытые
аномалии, связанные с пятой нормальной формой, возникнуть не могут.
184 Глава 5. Реляционная модель и нормализация
В 1981 г. Фагин опубликовал важную статью, в которой он определил домен-
но-ключевую нормальную форму (domain/key normal form, DKNF)1. Он показал,
что отношение в ДКНФ не имеет аномалий модификации и, более того, любое
отношение, не имеющее аномалий модификации, должно находиться в ДКНФ.
Это открытие положило конец введению нормальных форм, и теперь в
нормальных формах более высокого порядка нет необходимости* — по крайней мере, для
устранения аномалий модификации.
Столь же важно и то, что определение доменно-ключевой нормальной
формы затрагивает только понятия домена и ключа — понятия фундаментальные
и близкие сердцу специалистов в области баз данных. Они непосредственно
поддерживаются существующими СУБД (или, по крайней мере, могут
поддерживаться). В каком-то смысле, работа Фагина формализовала и обосновала то,
во что многие специалисты верили интуитивно, но были не в состоянии точно
описать.
Определение
Понятие ДКНФ весьма просто: отношение находится в доменно-ключевой
нормальной форме, если каждое ограничение, накладываемое на это отношение,
является логическим следствием определения доменов и ключей. Рассмотрим
важные термины, фигурирующие в этом определении: ограничение, ключ и домен.
Термин ограничение (constraint) имеет в данном определении намеренно
широкое толкование. Фагин определяет ограничение как любое правило,
регулирующее возможные статические значения атрибутов и достаточно точное для
того, чтобы можно было установить, выполняется оно или нет. Правила
редактирования, ограничения взаимоотношений и структуры отношений,
функциональные зависимости и многозначные зависимости являются примерами таких
ограничений. Фагин явным образом исключает отсюда ограничения,
относящиеся к изменениям значений данных, или ограничения, зависящие от времени.
Например, правило «Зарплата продавца за текущий период не может быть
меньше, чем за предыдущий период» не подпадает под определение ограничения,
которое дал Фагин. За исключением ограничений, зависящих от времени,
определение Фагина является широким и охватывает много случаев.
Ключ (key) — это уникальный идентификатор кортежа, как мы его уже
определили. Третий важный термин в определении ДКНФ — домен (domain). В
главе 4 говорилось, что домен — это описание допустимых значений атрибута. Он
состоит из двух частей: физического описания и семантического, или
логического, описания. Физическое описание — это множество значений, которые может
принимать атрибут, а логическое описание — это смысл данного атрибута.
Доказательство Фагина относится к обеим частям.
Говоря неформально, отношение находится в ДКНФ, если выполнение
ограничений на домены и ключи приводит к выполнению всех ограничений. Более
того, поскольку отношения в ДКНФ не могут иметь аномалий модификации,
1 R. Fagin, «A Normal Form for Relational Databases That Is Based On Domains and Keys», ACM Transactions
on Database Systems, сентябрь 1981, с. 387-415.
Доменно-ключевая нормальная форма (ДКНФ) 185
СУБД может предотвратить возникновение этих аномалий, реализуя
выполнение ограничений на домены и ключи.
К сожалению, пока не известен ни один алгоритм преобразования отношения
к доменно-ключевой нормальной форме; неизвестно даже, какие отношения
могут быть приведены к ДКНФ. Нахождение и создание отношений в ДКНФ
является более искусством, чем наукой.
Несмотря на все это, при практическом проектировании баз данных ДКНФ
служит в высшей степени полезным ориентиром. Если мы сможем вводить
отношения таким образом, что все налагаемые на них ограничения являются
логическими следствиями доменов и ключей, то в таких отношениях не будет
аномалий модификации. Во многих случаях этот критерий может быть соблюден. Если
же выполнить его не представляется возможным, необходимые ограничения
должны быть встроены в логику прикладных программ, которые обрабатывают
базу данных. Более подробно мы узнаем об этом далее в этой главе и в главе 10.
Следующие три примера иллюстрируют доменно-ключевую нормальную
форму.
Первый пример доменно-ключевой
нормальной формы
Рассмотрим отношение СТУДЕНТ на рис 5.12, имеющее атрибуты НомерСтудента,
Курс, Общежитие и Плата. Здесь Плата — это сумма, которую студент платит за
проживание в общежитии.
СТУДЕНТ (НомерСтудента, Курс, Общежитие, Плата)
Ключ: НомерСтудента
Ограничения: Общежитие -> Плата
НомерСтудента не должен начинаться с цифры 1
Рис. 5.12. Первый пример ДКНФ
НомерСтудента функционально определяет остальные три атрибута, поэтому
НомерСтудента является ключом. Допустим, мы также знаем, что, согласно
требованиям пользователей, Общежитие > Плата и НомерСтудента не должен
начинаться с 1. Если нам удастся представить эти требования в качестве логических
следствий определения доменов и ключей, то мы сможем быть уверены, в
соответствии с теоремой Фагина, что аномалий модификации не возникнет. В данном
примере это будет легко сделать.
Чтобы реализовать ограничение, указывающее, что номера студентов не долж-
пы начинаться с 1, мы просто включим это требование в определение домена
атрибута НомерСтудента (рис 5.13). Соблюдение ограничения домена
гарантирует, что данное требование будет выполнено.
Далее нам требуется сделать функциональную зависимость Общежитие > Плата
логическим следствием ключей. Если бы атрибут Общежитие был ключевым, за-
иисимость Общежитие > Плата была бы логическим следствием ключа. Поэтому
186 Глава 5. Реляционная модель и нормализация
встает вопрос о том, как сделать Общежитие ключом. Атрибут Общежитие не
может быть ключом в отношении СТУДЕНТ, так как в одном и том же
общежитии живет более одного студента, зато он может быть ключом своего
собственного отношения. Таким образом, мы можем ввести отношение ОБЩЕЖИТИЕ-ПЛАТА
с атрибутами Общежитие и Плата. Общежитие является ключом этого отношения.
Введя это новое отношение, мы можем удалить атрибут Плата из отношения
СТУДЕНТ. Окончательные определения доменов и отношений для этого примера
представлены на рис. 5.13.
Определения доменов
НомерСтудента CDDD, где С десятичная цифра, не равная 1;
D десятичная цифра
Курс {'СГ.'Сг'.'СЗ'.'С^.'АС'}
Общежитие CHAR (4)
Плата DEC (4)
Определения отношений и ключей
СТУДЕНТ (НомерСтудента, Курс, Общежитие)
Ключ: НомерСтудента
ОБЩЕЖИТИЕ-ПЛАТА (Общежитие, Плата)
Ключ: Общежитие
Рис. 5.13. Определения доменов и ключей для первого примера ДКНФ
Этот же результат мы получили, преобразовав отношение из 2НФ в ЗНФ для
удаления транзитивных зависимостей. В этом случае, однако, процесс был
проще, а результат является более надежным. Процесс был проще потому, что нам
не требовалось знать, что мы устраняем транзитивную зависимость. Все, что нам
было нужно — это найти действенные способы превращения всех ограничений
в логические следствия определений доменов и ключей. Результат является более
надежным потому, что при преобразовании отношения в третью нормальную
форму мы знали только то, что количество аномалий в нем стало меньше по
сравнению со второй нормальной формой. Приведя отношение к ДКНФ, мы
точно знаем, что получившиеся отношения не будут иметь никаких аномалий
модификации.
Второй пример доменно-ключевой
нормальной формы
Следующий, более сложный пример затрагивает отношение, приведенное на
рис. 5.14. Отношение ПРЕПОДАВАТЕЛЬ содержит данные о преподавателях,
предметах, которые они ведут, и студентах, которыми они руководят. Атрибуты Номер-
Сотрудника и ИмяСотрудника (имя члена профессорско-преподавательского
состава) однозначно определяют преподавателя. НомерСтудента однозначно определяет
студента, однако ИмяСтудента не обязательно определяет НомерСтудента.
Преподаватель может вести несколько предметов и быть руководителем у нескольких
Доменно-ключевая нормальная форма (ДКНФ) 187
студентов, но каждым студентом руководит только один преподаватель. Номер-
Сотрудника начинается с единицы, а НомерСтудента не может с нее начинаться.
ПРЕПОДАВАТЕЛЬ (НомерСотрудника, Имя Сотрудника,
Предмет, НомерСтудента, ИмяСтудента)
Ключ: (НомерСотрудника, Предмет, НомерСтудента)
Ограничения: НомерСотрудника -> ИмяСотрудника
ИмяСотрудника -> НомерСотрудника
НомерСотрудника -> -> Предмет | ИмяСтудента
ИмяСотрудника -> -> Предмет | ИмяСтудента
НомерСтудента -> НомерСотрудника
НомерСтудента -> ИмяСотрудника
НомерСтудента -> ИмяСтудента
НомерСотрудника должен начинаться с 1;
НомерСтудента не должен начинаться с 1
Рис. 5.14. Второй пример ДКНФ
Эти высказывания могут быть более точно сформулированы с помощью
функциональных и многозначных зависимостей, представленных на рис. 5.14.
НомерСотрудника и ИмяСотрудника функционально определяют друг друга (в
сущности, они эквивалентны). НомерСотрудника и ИмяСотрудника многозначно
определяют Предмет и НомерСтудента. НомерСтудента функционально определяет Номер-
Сотрудника и ИмяСотрудника. НомерСтудента определяет ИмяСтудента.
В более сложных примерах, таких как этот, полезно рассмотреть ДКНФ в
более интуитивном свете. Вспомните, что суть нормализации заключается в том,
что каждое отношение должно иметь одну тему. Если рассмотреть отношение
ПРЕПОДАВАТЕЛЬ с этой точки зрения, в нем присутствует три темы. Первая
тема — это соответствие между атрибутами НомерСотрудника и ИмяСотрудника,
вторая тема — предметы, которые ведет преподаватель, а третья —
идентификационный номер, имя и руководитель данного студента.
На рис. 5.15 представлены три отношения, отражающие эти темы. Отношение
ППС (профессорско-преподавательский состав) выражает эквивалентность
атрибутов НомерСотрудника и ИмяСотрудника. НомерСотрудника является ключом, а Имя-
Сотрудника является альтернативным ключом, что означает, что оба атрибута
уникальны для этого отношения. Поскольку оба они являются ключевыми,
функциональные зависимости НомерСотрудника > ИмяСотрудника и ИмяСотрудника >
НомерСотрудника представляют собой логические следствия ключей.
Отношение ПОДГОТОВКА отражает соответствие между преподавателями и
предметами; в нем указаны предметы, которые может вести каждый из
преподавателей. Ключом является комбинация (ИмяСотрудника, Предмет). Оба атрибута
являются необходимыми для ключа, потому что один преподаватель может вести
несколько предметов, а один и тот же предмет может вестись несколькими
преподавателями. Наконец, в отношении СТУДЕНТ для каждого номера студента
указано имя этого студента и его руководителя. Заметьте, что каждое из этих
отношений имеет единственную тему. Эти отношения выражают все ограничения,
фигурирующие на рис. 5.14, в виде логических следствий определений доменов
188 Глава 5. Реляционная модель и нормализация
и ключей. Поэтому данные отношения находятся в доменно-ключевой
нормальной форме.
Обратите внимание, что отделение темы ПОДГОТОВКА от темы СТУДЕНТ
устранило многозначные зависимости. Когда мы рассматривали четвертую
нормальную форму, мы обнаружили, что для того, чтобы устранить многозначные
зависимости, необходимо разнести многозначные атрибуты в различные отношения.
Используемый нами здесь подход состоит в разбиении отношения с
несколькими темами на несколько отношений, каждое из которых содержит одну тему.
Тем самым мы устанили многозначную зависимость. Фактически, оба подхода
привели нас к одинаковому решению.
Определения доменов
НомерСотрудника CDDD, где С=1; D — десятичная цифра
ИмяСотрудника CHAR (30)
НомерСтудента CDDD, где С — десятичная цифра, неравная 1;
D — десятичная цифра
ИмяСтудента CHAR (30)
Определения отношений и ключей
ППС (НомерСотрудника, ИмяСотрудника)
Ключ (первичный): НомерСотрудника
Ключ (кандидат)'.ИмяСотрудника
ПОДГОТОВКА (ИмяСотрудника, Предмет)
Ключ: (ИмяСотрудника, Предмет)
СТУДЕНТ (НомерСтудента, Курс, Общежитие)
Ключ: НомерСтудента
Рис. 5.15. Определение доменов и ключей для второго примера ДКНФ
Третий пример доменно-ключевой
нормальной формы
В следующем примере рассматривается ситуация, которая не охватывается ни
одной из нормальных форм, но часто возникает на практике. Это ситуация, когда
отношение имеет ограничение на значения данных в строке, не являющееся ни
функциональной, ни многозначной зависимостью.
Рассмотрим ограничения, имеющиеся в отношении СТУДЕНТ-РУКОВОДИТЕЛЬ на
рис. 5.16. Это отношение содержит информацию о студенте и его руководителе.
Атрибут НомерСтудента определяет атрибуты ИмяСтудента, НомерСотрудника, Имя-
Сотрудника и СотрудникАспирантуры, поэтому он является ключом. Атрибуты
НомерСотрудника и ИмяСотрудника однозначно определяют члена
профессорско-преподавательского состава и взаимно эквивалентны, как и в предыдущем примере.
И НомерСотрудника, и ИмяСотрудника определяют атрибут СотрудникАспирантуры.
Наконец, новым типом ограничения является то, что руководителями
аспирантов могут быть только сотрудники аспирантуры.
Доменно-ключевая нормальная форма (ДКНФ) 189
СТУДЕНТ-РУКОВОДИТЕЛЬ (НомерСтудента, ИмяСтудента,
НомерСотрудника, СотрудникАспирентуры)
Ключ: НомерСтуденте
Ограничения: НомерСотрудника -» ИмяСотрудника
ИмяСотрудника -» НомерСотрудника
НомерСотрудника и ИмяСотрудника -* СотрудникАспирантуры
Только сотрудники аспирантуры могут быть руководителями аспирантов
НомерСотрудника начинается с 1
НомерСтудента не должен начинаться с 1
НомерСтудента для аспиранта начинается с 9
СотрудникАспирантуры = Г1 для сотрудников аспирантуры,
[О для остальных сотрудников}
Рис. 5.16. Третий пример ДКНФ
Ограничения доменов заключаются в том, что НомерСтудента не должен
начинаться с 1, для аспирантов НомерСтудента должен начинаться с 9, НомерСотрудника
должен начинаться с 1, а атрибут СотрудникАспирантуры должен быть равен 1 для
сотрудников аспирантуры и 0 для всех остальных сотрудников. При таком
определении доменов требование, чтобы аспирантами руководили только
сотрудники аспирантуры, может быть представлено как ограничение на значения строки.
В частности, если атрибут НомерСтудента начинается с 9, то атрибут
СотрудникАспирантуры должен быть равен 1.
Чтобы привести это отношение к ДКНФ, мы поступим так же, как в
предыдущем примере. Каковы основные темы отношения СТУДЕНТ-РУКОВОДИТЕЛЬ? Одна
из тем — это профессорско-преподавательский состав; к ней относятся атрибуты
НомерСотрудника, ИмяСотрудника и СотрудникАспирантуры. Вынесем эти атрибуты
и отношение ППС. Поскольку атрибуты НомерСотрудника и ИмяСотрудника
определяют атрибут СотрудникАспирантуры, любой из этих атрибутов может быть
ключом, и это отношение находится в ДКНФ (рис. 5.17).
Теперь рассмотрим данные, относящиеся к студентам и их руководителям.
На первый взгляд может показаться, что здесь имеется только одна тема, а
именно руководство, однако из требования о том, чтобы аспирантами руководили
только сотрудники аспирантуры, следует иное. На самом деле, здесь есть две
темы: руководство аспирантами и руководство студентами. В связи с этим на
рис. 5.17 мы имеем два отношения: РУКОВОДИТЕЛЬ-АСПИРАНТ, содержащее
информацию об аспирантах, и РУКОВОДИТЕЛЬ-СТУДЕНТ, содержащее информацию о
студентах. Посмотрим, каковы будут определения доменов: Номер Аспиранта
начинается с 9; ИмяСотрудникаАспирантуры — это ИмяСотрудника из строки отношения
ППС с атрибутом СотрудникАспирантуры, равным 1; наконец, НомерСтудента не
должен начинаться с 1 или 9. Все ограничения, фигурирующие на рис. 5.16, следуют
из определения ключей и доменов на рис. 5.17. Поэтому данные отношения
находятся в ДКНФ и не имеют аномалий модификации.
В качестве подведения итога обсуждения нормальных форм в таблице на
рис. 5.18 перечислены все нормальные формы и даны их определяющие
характеристики.
190 Глава 5. Реляционная модель и нормализация
Определения доменов
НомерСотрудника CDDD, где С=1; D десятичная цифра
ИмяСотрудника CHAR (30)
Сотрудник Аспирантуры [0,1]
НомерСтудента CDDD, где С — десятичная цифра, С * 1; С ф 9
D десятичная цифра
НомерАспиранта CDDD, где С — десятичная цифра, С = 9;
D — десятичная цифра
ИмяСтудента CHAR (30)
Дополнительное определение доменов
ИмяСотрудникаАсп
{ИмяСотрудника из таблицы ППС, для которого
СотрудникАспирантуры = 1}
Определения отношений и ключей
ППС (НомерСотрудника, ИмяСотрудника)
Ключ: НомерСотрудника или ИмяСотрудника
РУКОВОДИТЕЛЬ-АСПИРАНТ (НомерАспиранта, ИмяСтудента, ИмяСотрудникаАсп)
Ключ: НомерАспиранта
РУКОВОДИТЕЛЬ-СТУДЕНТ (НомерСтудента, ИмяСтудента, ИмяСотрудника)
Ключ: НомерСтудента
Рис. 5.17. Определение доменов и ключей для третьего примера
Форма
1НФ
2НФ
ЗНФ
НФБ
4НФ
5НФ
ДКНФ
Определяющая характеристика
Любое отношение
Каждый из неключевых атрибутов зависит
от всего ключа целиком
Нет транзитивных зависимостей
Каждый детерминант является ключом-кандидатом
Отсутствуют многозначные зависимости
Не описывается здесь
Все ограничения на отношение являются
логическими следствиями определений
доменов и ключей
Рис. 5.18. Нормальные формы
Синтез отношений
В предыдущем разделе мы подходили к проектированию реляционных схем с
аналитических позиций. Вопрос, задававшийся нами, был таков: пусть у нас имеется
некоторое отношение, в хорошей ли форме оно находится? Имеет ли оно
аномалии модификации? В данном разделе мы подойдем к проектированию
реляционных структур, исходя из синтетической перспективы. Вопрос в этом случае
звучит так: если у нас имеется набор атрибутов с определенными функциональными
зависимостями, какие отношения следует из них формировать?
Синтез отношений 191
Прежде всего, отметим, что два атрибута (скажем, А и В) могут иметь связь
трех видов:
1. Они могут определять друг друга: А>ВиВ>А. В этом случае А и В имеют
атрибутивную связь «один к одному».
2. Один из них может определять другой: А > В или В > А. В этом случае А и В
имеют атрибутивную связь «многие к одному».
3. Они могут быть функционально не связаны: А не > В и В не > А. В этом
случае А и В имеют атрибутивную связь «многие ко многим».
Атрибутивная связь «один к одному»
Если А определяет В, а В определяет А, значения атрибутов имеют связь «один
к одному» (one-to-one relationship). Это должно быть так, поскольку если А
определяет В, то между А и В должна быть связь «многие к одному». Между тем,
справедливо и другое утверждение: если В определяет А, то между В и А должна быть
ошзь «один к одному». Чтобы оба утверждения были справедливы
одновременно, связь между А и В должна в действительности иметь вид «один к одному» (что
является частным случаем связи «многие к одному»), а связь между В и А в
реальности также имеет вид «один к одному». Поэтому в данном случае наличествует
с вязь «один к одному».
Этот случай иллюстрируется атрибутами НомерСотрудника и ИмяСотрудника
н предыдущем разделе, посвященном доменно-ключевой нормальной форме.
Каждый из этих атрибутов однозначно определяет сотрудника факультета.
Следовательно, каждому значению атрибута НомерСотрудника соответствует ровно
одно значение атрибута ИмяСотрудника, и наоборот.
Относительно примера с атрибутами НомерСотрудника и ИмяСотрудника можно
высказать три эквивалентных утверждения:
+ Если два атрибута функционально определяют друг друга, между их
значениями имеется связь «один к одному».
+ Если два атрибута однозначно определяют одну и ту же вещь (сущность
или объект), между их значениями имеется связь «один к одному».
+ Если два атрибута имеют связь «один к одному», они функционально
определяют друг друга.
При создании базы данных с атрибутами, имеющими связь «один к
одному», эти два атрибута должны появляться вместе минимум в одном отношении.
Другие атрибуты, которые функционально определяются данными атрибутами
(атрибут, который функционально определяется одним из них, функционально
определяется и другим), могут также находиться в этом отношении.
Рассмотрим отношение ППС (НомерСотрудника, ИмяСотрудника, СотрудникАспи-
рантуры) из третьего примера в предыдущем разделе. НомерСотрудника и
ИмяСотрудника функционально определяют друг друга. Атрибут СотрудникАспирантуры
также может появиться в отношении, поскольку он определяется атрибутами
192 Глава 5. Реляционная модель и нормализация
НомерСотрудника и ИмяСотрудника. Атрибуты, которые не определяются
функционально данными атрибутами, не могут появляться с ними в одном отношении.
Рассмотрим отношения ППС и ПОДГОТОВКА из примера № 2, в котором и Номер-
Сотрудника, и ИмяСотрудника присутствуют в отношении ППС, но Предмет (из
отношения ПОДГОТОВКА) там появиться не может. Атрибут Предмет может иметь
различные значения для сотрудника факультета, поэтому Предмет не зависит от
атрибутов НомерСотрудника или ИмяСотрудника. Если бы мы добавили атрибут
Предмет в отношение ППС, ключом этого отношения обязательно должно было бы
быть сочетание (НомерСотрудника, Предмет) либо (ИмяСотрудника, Предмет). В этом
случае, однако, отношение ППС не было бы в ДКНФ, потому что зависимости
между атрибутами НомерСотрудника и ИмяСотрудника не были бы логическими
следствиями ни одного из возможных ключей.
Эти выражения собраны в первом столбце табл. 5.1, а правила определения
записей приведены во врезке. Если А и 3 имеют связь 1:1, они могут находиться
в одном отношении R. А определяет В, а В определяет А. Ключом отношения может
быть либо А, либо В. Новый атрибут С может быть добавлен в отношение R, если
один из атрибутов А и В функционально определяет С.
Таблица 5.1. Три типа связей атрибутов
Определение
отношения*
Зависимости
Ключ
Правило добавления
атрибутов
Тип связи между атрибутами
Один к
R(A,B)
А->В
В-»А
Либо А,
одному
либо В
Либо А, либо В -> С
Многие
S(C,D)
C->D
D->C
С
С->Е
к одному
Многие ко многим
T(E,F)
E-»F
F->E
(E,F)
(E,F)->G
* Буквы, используемые в определениях этих отношений, соответствуют буквам во врезке,
расположенной далее.
Атрибуты, имеющие связь «один к одному», должны присутствовать
вместе по меньшей мере в одном отношении, чтобы они могли быть
эквивалентными (например, НомерСотрудника, равный 198, относится к профессору Харту).
В общем случае, однако, нежелательно, чтобы эти атрибуты появлялись вместе
более чем в одном отношении, поскольку это приведет к ненужному
дублированию данных. Часто один из этих атрибутов или оба они появляются в других
отношениях. В примере №2 атрибут ИмяСотрудника появляется и в отношении
ПОДГОТОВКА, и в отношении СТУДЕНТ. В принципе можно было бы поместить Имя-
Сотрудника в отношение ПОДГОТОВКА, а НомерСотрудника — в отношение СТУДЕНТ,
но это, вообще говоря, порочная практика: когда атрибуты спарены подобным
образом, из них следует выбрать один, который будет представлять эту пару
во всех других отношениях. Во втором примере для этой цели выбран атрибут
ИмяСотрудника.
Синтез отношений 193
ПРАВИЛА ПОСТРОЕНИЯ ОТНОШЕНИЙ
Связь «один к одному»
♦ Атрибуты, имеющие связь «один к одному», должны фигурировать вместе по крайней
мере в одном отношении. Пусть отношение носит имя R, а его атрибуты — А и В.
♦ Либо А, либо В должен быть ключом отношения R.
♦ Если некоторый атрибут функционально определяется атрибутом А или В, он может быть
добавлен в отношение R.
♦ Атрибут, не определяемый функционально атрибутами А или В, не может быть добавлен
в отношение R
♦ Атрибуты А и В должны находиться вместе в отношении R и более ни в каком другом
отношении.
♦ Для представления пары (А, В) в отношениях, отличных от R, должен последовательно
использоваться один из атрибутов, А или В.
Связь «многие к одному»
♦ Атрибуты, имеющие связь «многие к одному», могут находиться вместе в одном
отношении. Пускай в отношении S атрибут С определяет атрибут D.
♦ Атрибут С должен быть ключом отношения S.
♦ Если некоторый атрибут определяется атрибутом С, он может быть добавлен в
отношение S.
♦ Атрибут, не определяемый функционально атрибутом С, не может быть добавлен в
отношение S.
Связь «многие ко многим»
♦ Атрибуты, имеющие связь «многие ко многим», могут сосуществовать в одном
отношении. Пускай в отношении Т имеются два таких атрибута, Е и F.
♦ Ключом отношения Т должна быть комбинация (Е, F).
♦ Если некоторый атрибут определяется сочетанием атрибутов (Е, F), он может быть
добавлен в отношение Т.
♦ Атрибут, не определяемый функционально сочетанием атрибутов (Е, F), не может быть
добавлен в отношение Т.
♦ Если добавление нового атрибута G расширяет ключ отношения до (Е, F, G), это
значит, что тема отношения изменилась. Либо атрибут G логически не принадлежит
отношению Т, либо следует выбрать другое имя для отношения в соответствии с
поменявшейся темой.
Атрибутивная связь «многие к одному»
Гели атрибут А определяет В, но В не определяет А, то между их значениями
имеется связь «многие к одному» (many-to-one relationship). В отношении РУКОВОДИТЕЛЬ
из примера № 2 НомерСтудента определяет НомерСотрудника. Отдельно взятый
преподаватель может быть руководителем у многих студентов, однако каждым
студентом руководит только один преподаватель. Поэтому здесь имеется связь
«многие к одному».
Чтобы отношение находилось в ДКНФ, все ограничения должны быть
следствиями ключей, и поэтому каждый детерминант должен быть ключом. Если
атрибуты А, В и С находятся в одном отношении, и А определяет В, то атрибут А
должен быть ключом (имея в виду, что он определяет также и С). Если же
атрибут С определяется сочетанием (А, В), тогда сочетание (А, В) должно быть
ключом. В последнем случае никакой другой функциональной зависимости
(например, А > В) не допускается.
194 Глава 5. Реляционная модель и нормализация
Применить эти утверждения к проектированию баз данных вы можете
следующим образом: если в создаваемом отношении А определяет В, то добавлять
в это отношение можно только те атрибуты, которые определяются атрибутом А.
Допустим, например, что вы поместили в отношение под названием СТУДЕНТ
атрибуты НомерСтудента и Общежитие. В это отношение вы можете добавлять
любые другие атрибуты, которые определяются атрибутом НомерСтудента,
например ИмяСтудента. Но если атрибут Плата определяется атрибутом Общежитие, его
нельзя добавить в данное отношение. Атрибут Плата может быть добавлен только
в том случае, если НомерСтудента > Плата.
Эти утверждения приведены в среднем столбце табл. 5.1. Если С и D имеют
связь N:l, они могут находиться вместе в отношении S. С будет определять D, но D
не будет определять С. Ключом отношения S будет атрибут С. Другой атрибут, Е,
может быть добавлен в отношение S, только если С определяет Е.
Атрибутивная связь «многие ко многим»
Если А не определяет В, а В не определяет А, то между значениями этих атрибутов
имеется связь «многие ко многим» (many-to-many relationship). В примере № 2
атрибуты ИмяСотрудника и Предмет имеют связь «многие ко многим». Один
преподаватель ведет много предметов, а один и тот же предмет ведется многими
преподавателями. В связи «многие ко многим» оба атрибута должны быть ключами
отношения. Например, ключом отношения ПОДГОТОВКА из примера № 2 является
комбинация (ИмяСотрудника, Предмет).
При построении отношений, у которых ключами являются несколько
атрибутов, можно добавлять новые атрибуты, которые функционально зависят от всего
ключа. Атрибут КоличествоЧасов функционально зависит от каждого из
атрибутов в сочетании (ИмяСотрудника, Предмет) и поэтому может быть добавлен в
отношение. Атрибут Должность в данное отношение добавить нельзя, потому что он
зависит только от атрибута ИмяСотрудника, но не от атрибута Предмет. Если
требуется хранить атрибут Должность в базе данных, его следует добавить в
отношение, содержащее информацию о профессорско-преподавательском составе, а ие
о подготовке.
Эти высказывания приведены в правом столбце табл. 5.1. Если атрибуты Е
и F имеют связь M:N, то Е не определяет F, a F не определяет Е. Оба эти атрибута
можно поместить в отношение Т, и в этом случае ключом отношения Т будет
комбинация (Е, F). Новый атрибут G может быть добавлен в отношение Т, если
он определяется обоими атрибутами из сочетания (Е, F). Атрибут G нельзя
добавить в отношение Т, если он определяется только одним из атрибутов в
комбинации (Е, F).
Рассмотрим аналогичный пример. Предположим, мы хотим добавить в
отношение ПОДГОТОВКА атрибут НомерАудитории. Определяется ли НомерАудитории
ключом отношения ПОДГОТОВКА комбинацией (ИмяСотрудника, Предмет)? Скорее
всего нет, поскольку преподаватель может вести один и тот же предмет в
различных аудиториях.
Синтез отношений 195
Сочетание (ИмяСотрудника, Предмет) и атрибут НомерАудитории имеют связь
M:N. Раз это так, можно применить правила, приведенные в табл. 5.1, но здесь
роль Е будет играть сочетание (ИмяСотрудника, Предмет), а роль F — атрибут Номер-
Аудитории. Теперь мы можем построить новое отношение Т с атрибутами Имя-
Сотрудника, Предмет и НомерАудитории. Ключом этого отношения будет
комбинация (ИмяСотрудника, Предмет, НомерАудитории). В этой ситуации получается, что
мы создали новое отношение с новой темой. Рассмотрим отношение Т,
содержащее сведения об именах преподавателей, предметах и номерах аудиторий. Темой
этого отношения больше не является ПОДГОТОВКА; скорее эту тему можно было
бы сформулировать так: КТО-ЧТО-И-ГДЕ-ПРЕПОДАЕТ.
Изменение темы может быть как уместным, так и неуместным. Если
НомерАудитории является значимым атрибутом, тема действительно должна быть
изменена. В этом случае отношение ПОДГОТОВКА не подходит, и более уместной
является тема КТО-ЧТО-И-ГДЕ-ПРЕПОДАЕТ.
С другой стороны, в зависимости от требований пользователей, отношение
ПОДГОТОВКА может быть пригодным в том виде, в каком оно есть. В таком случае,
если атрибут НомерАудитории все же должен храниться в базе данных, его
следует поместить в другое отношение — например, СЕКЦИЯ-НОМЕР, ПРЕДМЕТ-СЕКЦИЯ
или что-нибудь наподобие этого.
Многозначные зависимости: часть вторая
Изложенные выше соображения, касающиеся атрибутивной связи «многие ко
многим», могут сделать концепцию многозначных зависимостей более простой
для понимания. Проблема с отношением СТУДЕНТ (НомерСтудента, Специальность,
Секция) на рис. 5.9 состоит в том, что в нем имеется две различных связи вида
«многие ко многим»: одна между атрибутами НомерСтудента и Специальность, а
другая — между атрибутами НомерСтудента и Секция. Ясно, что специализации
студента не имеют никакого отношения к секциям, в которых он занимается. Однако
если обе связи присутствуют в одном отношении, возникает впечатление, что
между этими атрибутами существует какая-то взаимосвязь.
Атрибуты Специальность и Секция независимы, и никакой проблемы не
возникло бы, если бы студент мог специализироваться только в одной области и
заниматься только в одной секции. Тогда НомерСтудента функционально определял
бы атрибуты Специальность и Секция, и отношение находилось бы в ДКНФ. В этом
случае связь каждого из этих атрибутов с атрибутом НомерСтудента имела бы вид
«многие к одному».
Другой способ представить себе возникающее затруднение состоит в
исследовании ключа (НомерСтудента, Специальность, Секция). Поскольку в отношении
СТУДЕНТ имеются связи вида «многие ко многим», ключ должен содержать в себе
каждый из атрибутов. Теперь спросим себя: а какую тему представляет данный
ключ? Мы можем сказать, что это комбинация специальности студента и
посещаемых им секций. Но такая комбинация не одна, их множество. Одна
строка этого отношения описывает только часть комбинации, и чтобы получить
196 Глава 5. Реляционная модель и нормализация
всю картину, нам нужны все строки, содержащие информацию о конкретном
студенте. Вообще говоря, строка отношения должна содержать все данные,
описывающие отдельный экземпляр темы данного отношения. Например, строка
Покупатель должна содержать все нужные нам данные о конкретном покупателе.
Рассмотрим отношение ПОДГОТОВКА из примера № 2 в разделе, посвященном
доменно-ключевой нормальной форме. Ключом этого отношения является
комбинация (ИмяСотрудника, Предмет). Тема состоит в том, что конкретный
преподаватель имеет подготовку, достаточную для ведения определенного предмета.
Нам нужна только одна строка этого отношения, чтобы получить всю требуемую
информацию о комбинации данного профессора и данного предмета (в отношение
могут входить такие атрибуты, как КоличествоЧасов, СредняяОценкаКурса и т. д.).
Глядя на другие строки, мы не получим никакой дополнительной информации
на эту тему.
Как вы знаете, решение проблемы многозначных зависимостей заключается
в том, чтобы разбить исходное отношение на два новых, каждое из которых будет
иметь только одну тему. В отношении СТУДЕНТ-СПЕЦИАЛЬНОСТЬ представлены
комбинации студентов и специальностей. Все, что мы знаем о каждой из таких
комбинаций, содержится в одной строке, и мы не получим какой-либо
дополнительной информации о данной комбинации, исследуя другие строки.
Оптимизация
В этой главе мы исследовали концепцию нормализации и продемонстрировали,
как создавать таблицы в доменно-ключевой нормальной форме.
Использовавшийся нами метод пригоден для большинства случаев, однако иногда результат
нормализации не стоит затраченных усилий. В последнем разделе главы мы
рассмотрим две ситуации, в которых это может случиться.
Денормализация
Как уже говорилось, нормализованные отношения свободны от аномалий
модификации, и по этой причине они являются более предпочтительными, чем
ненормализованные отношения. Но если судить с других позиций, иногда
нормализация не стоит того, чтобы ее проводить.
Рассмотрим отношение КЛИЕНТ (НомерКлиента, ИмяКлиента, Город- Штат, Индекс),
где ключом является НомерКлиента. Это отношение не находится в ДКНФ,
поскольку в нем имеется функциональная зависимость Индекс > (Город, Штат),
которая не следует из ключа — атрибута НомерКлиента. Следовательно, мы имеем
ограничение, не являющееся следствием определения ключей.
Данное отношение может быть преобразовано в два отношения следующего
вида: КЛИЕНТ (НомерКлиента, ИмяКлиента, Индекс), где ключом является
НомерКлиента, и ИНДЕКСЫ (Индекс, Город, Штат), где ключом является Индекс. Эти два отно-
Оптимизация 197
шения находятся в доменно-ключевой нормальной форме, но они, скорее всего,
не представляют собой более удачного решения по сравнению с исходной
таблицей. Возможно, что ненормализованная таблица лучше, поскольку ее будет легче
обрабатывать, а неудобства, связанные с дублированием данных о городе и
штате, не столь существенны.
В качестве второго примера рассмотрим отношение КОЛЛЕДЖ (НазваниеКол-
леджа, Декан, ЗаместительДекана). Эта таблица не находится в доменно-ключевой
нормальной форме, так как ограничение НазваниеКолледжа > Декан не является
логическим следствием ключа таблицы.
Отношение КОЛЛЕДЖ можно нормализовать, разбив его на два отношения:
ДЕКАН (НазваниеКолледжа, Декан) и ЗАМДЕКАНА (НазваниеКолледжа,
ЗаместительДекана). Однако теперь, когда приложению базы данных нужно будет получить
данные о колледже, ему придется прочитать минимум две, а возможно, и все четыре
строки данных. В качестве альтернативы можно поместить всех трех
заместителей декана в таблицу КОЛЛЕДЖ, выделив для каждого индивидуальный атрибут.
Получившаяся таблица имела бы следующий вид: К0ЛЛЕДЖ1 (НазваниеКолледжа,
Декан, ЗаместительДекана!, ЗаместительДекана2, ЗаместительДеканаЗ).
Отношение К0ЛЛЕДЖ1 находится в ДКНФ, поскольку все его атрибуты
функционально зависят от ключа НазваниеКолледжа. Однако здесь что-то потеряно.
Для того чтобы увидеть, что именно мы потеряли, предположим, что мы хотим
узнать названия колледжей, в которых есть заместитель декана по имени Мэри
Абернати. Для этого нам придется искать данное имя в каждом из трех столбцов
ЗаместительДекана. Наш запрос будет выглядеть примерно следующим образом:
SELECT НазваниеКолледжа
FROM К0ЛЛЕДЖ1
WHERE ЗаместительДекана1 = 'Мэри Абернати* OR
ЗаместительДекана2 = 'Мэри Абернати' OR
ЗаместительДеканаЗ = 'Мэри Абернати"
Используя нормализованный вариант с таблицей ЗАМДЕКАНА, нам пришлось
бы написать только:
SELECT НазваниеКолледжа
FROM ЗАМДЕКАНА
WHERE ЗаместительДекана = 'Мэри Абернати'
В этом примере даны три возможных решения, у каждого из которых есть
свои преимущества и недостатки. Выбор среди этих решений — это искусство: не
существует твердого и быстрого правила, указывающего, какой из вариантов
является наилучшим. Выбор зависит от характеристик приложений, использующих
;>ту базу данных.
В общем, иногда отношения намеренно оставляют в ненормализованном виде
либо нормализуют, а затем денормализуют. Зачастую это длается для
повышения производительности. Всегда, когда необходимо комбинировать данные из
двух различных таблиц, СУБД должна выполнять дополнительную работу. В
большинстве случаев для этого требуется как минимум две операции чтения вместо
одной.
198 Глава 5. Реляционная модель и нормализация
Преднамеренная избыточность
Одним из преимуществ нормализованных отношений является то, что в них
минимизируется дублирование данных (только значения ключей появляются более
чем в одном отношении). Но в целях повышения производительности иногда
уместным является умышленное дублирование данных. Рассмотрим, например,
приложение, обрабатывающее заказы, которое обращается к таблице ТОВАР,
имеющей следующие столбцы:
НомерТовара
НаименованиеТовара
ЦветТовара
ОписаниеТовара
ФотографияТовара
КоличествоВНаличии
ЗаказанноеКоличество
СтандартнаяЦена
СтандартнаяСтоимость
ИмяПокупателя
Предположим, что атрибут НомерТовара является ключом и что таблица
находится в ДКНФ. Предположим также, что атрибут ОписаниеТовара — это
потенциально длинное текстовое поле, а ФотографияТовара — это столбец двоичных
данных длиной минимум 256 Кбайт.
Приложению, обрабатывающему заказы, необходимо будет обратиться к этой
таблице, чтобы получить значения атрибутов НазваниеТовара, ЦветТовара,
СтандартнаяЦена и КоличествоВНаличии. Допустим, что приложению не требуется
ОписаниеТовара или ФотографияТовара. В зависимости от характеристик используемой
СУБД, возможно, что присутствие этих двух больших столбцов значительно
замедлит обработку. В этой ситуации проектировщики базы данных могут решить
продублировать некоторые данные во второй таблице, которая будет содержать
только ту информацию, которая требуется для обработки заказа. К примеру, они
могут создать таблицу под названием ЗАКАЗ_ТОВАРА (НомерТовара, Наименование-
Товара, ЦветТовара, СтандартнаяЦена, КоличествоВНаличии), которая будет
использоваться только приложением, обрабатывающим заказы.
В этом случае проектировщики создают потенциальный источник серьезных
проблем с целостностью данных. Им придется разработать процедуры как
программного, так и ручного контроля, чтобы гарантировать, что таких проблем не
возникнет. Поэтому к подобному решению они прибегнут только в том случае,
если, по их мнению, повышение производительности окупит расходы, связанные
с дополнительным контролем, и риск возникновения проблем с целостностью
данных.
Еще одна причина для введения преднамеренной избыточности — это
создание таблиц, предназначенных исключительно для создания отчетов и поддержки
принятия решений. Дальнейшее обсуждение этого вопроса последует в главе 17.
Резюце 199
Резюме
Реляционная модель важна по двум причинам: во-первых, с ее помощью можно
описывать структуры баз данных независимым от СУБД образом, а во-вторых,
эта модель лежит в основе значительной части современных СУБД. Критерием
правильности и желательности отношений может служить нормализация.
Отношение — это двумерная таблица, в ячейках которой записаны
одиночные значения. Все значения в одном столбце принадлежат к одному и тому же
типу; каждый столбец имеет уникальное имя; порядок следования столбцов
несуществен. Столбцы называются также атрибутами. В отношении не может
быть двух одинаковых строк, а порядок следования строк несуществен. Строки
называются также кортежами. Термины таблица, файл и отношение являются
синонимами; то же самое можно сказать о терминах столбец, поле и атрибут;
термины строка, запись и кортеж также синонимичны.
Функциональная зависимость — это связь между атрибутами. Y
функционально зависит от X, если значение X определяет значение Y. Детерминантом
называется группа из одного или нескольких атрибутов, находящаяся с левой
стороны функциональной зависимости. Например, если X определяет Y, то X
является детерминантом. Ключ — это группа из одного или нескольких атрибутов,
которая однозначно определяет кортеж. Каждое отношение имеет минимум
один ключ; поскольку каждая строка уникальна, в самом крайнем случае
ключом является совокупность всех атрибутов отношения. Хотя ключ всегда
уникален, детерминант функциональной зависимости может таковым и не быть.
Являются ли атрибуты ключами и являются ли они функционально зависимыми —
это определяется не абстрактным набором правил, а тем смыслом, который
вкладывают пользователи в эти атрибуты.
В некоторых отношениях в результате обновления данных возникают
нежелательные последствия, называемые аномалиями модификации. Аномалия
удаления — это ситуация, когда удаление одной строки из отношения вызывает
потерю информации о двух или более фактах. Аномалией вставки называется
ситуация, когда реляционная структура вынуждает добавлять информацию
одновременно о двух фактах. Аномалии могут быть устранены путем разбиения
исходного отношения на два.
Существует много типов аномалий модификации. Отношения можно
классифицировать по типам аномалий, которые ими ликвидируются. Типы, на которые
подразделяются отношения в рамках этой классификации, называются
нормальными формами.
По определению каждое отношение находится в первой нормальной форме.
Отношение находится во второй нормальной форме, если каждый из его
неключевых атрибутов зависит от всего ключа. Отношение находится в третьей
нормальной форме, если оно находится во второй нормальной форме и не имеет
транзитивных зависимостей. Отношение находится в нормальной форме Бойса-
Кодда, если каждый его детерминант является ключом-кандидатом. Отношение
находится в четвертой нормальной форме, если оно находится в нормальной
форме Бойса-Кодда и не имеет многозначных зависимостей. Определение пятой
200 Глава 5. Реляционная модель и нормализация
нормальной формы не имеет интуитивной интерпретации, и поэтому мы его не
приводили.
Отношение находится в доменно-ключевой нормальной форме, если каждое
ограничение, накладываемое на отношение, является логическим следствием
определения доменов и ключей. Под ограничением здесь понимается любое
условие, определяющее возможные статические значения атрибутов, истинность
которого может быть проверена. Домены, как они определены нами, имеют
физическую и семантическую составляющие. В контексте ДКНФ, однако, под доменом
подразумевается только физическое описание.
Неформальная интерпретация ДКНФ заключается в том, что каждое
отношение должно иметь только одну тему. Например, в отношении может содержаться
информация о профессорах или о студентах, но не о тех и других одновременно.
Нормализация — это процесс анализа отношений. Отношения можно также
строить синтетическим путем, рассматривая связи между атрибутами. Если два
атрибута функционально определяют друг друга, между ними имеется связь
вида «один к одному». Если один из двух атрибутов функционально определяет
второй, между этими атрибутами имеется связь «многие к одному». Если ни
один из двух атрибутов не определяет другой, между этими атрибутами имеется
связь «многие ко многим». Эти факты, приведенные в табл. 5.1, можно
использовать при создании отношений.
В некоторых случаях нормализация нежелательна. Всякий раз, когда
исходная таблица разбивается на две или более новых, возникают ограничения
ссылочной целостности. Если расходы на дополнительную обработку двух таблиц
и обеспечение ссылочной целостности превышают выгоду от устранения
аномалий модификации, нормализация не рекомендуется. Вдобавок в некоторых
случаях создание повторяющихся столбцов предпочтительнее обычных способов
нормализации, а в других случаях для повышения производительности вводится
преднамеренная избыточность.
Вопросы I группы
1. Какие ограничения должны быть наложены на таблицу, чтобы она могла
считаться отношением?
2. Определите следующие термины: отношение, кортеж, атрибут, файл,
запись, таблица, строка, столбец.
3. Дайте определение термина функциональная зависимость. Приведите
пример двух атрибутов, имеющих функциональную зависимость, и двух
атрибутов, не имеющих функциональной зависимости.
4. Если атрибут НомерСтудента функционально определяет атрибут Секция,
означает ли это, что в отношении может быть только одно значение
атрибута НомерСтудента? Обоснуйте свой ответ.
5. Дайте определение термина детерминант.
6. Приведите пример отношения с функциональной зависимостью, в
которой детерминант состоит из двух или более атрибутов.
Вопросы 1 группы 201
7. Дайте определение термина ключ.
8. Если атрибут НомерСтудента является ключом отношения, является ли он
детерминантом? Может ли конкретное значение этого атрибута появиться
в отношении более одного раза?
9. Что такое аномалия удаления? Приведите пример, отличный от того,
который дан в тексте.
10. Что такое аномалия вставки? Приведите пример, отличный от того,
который дан в тексте.
11. Объясните, как соотносятся между собой первая, вторая, третья
нормальные формы, нормальная форма Бойса-Кодда, четвертая, пятая и доменно-
ключевая нормальные формы.
12. Дайте определение термина вторая нормальная форма. Приведите пример
отношения, которое находится в первой нормальной форме, но не
находится во второй нормальной форме. Преобразуйте это отношение в
отношения, находящиеся во второй нормальной форме.
13. Дайте определение термина третья нормальная форма. Приведите
пример отношения, которое находится во второй нормальной форме, но не
находится в третьей нормальной форме. Преобразуйте это отношение в
отношения, находящиеся в третьей нормальной форме.
14. Дайте определение термина нормальная форма Бойса-Кодда. Приведите
пример отношения, которое находится в ЗНФ, но не находится в НФБК.
Преобразуйте это отношение в отношения, находящиеся в НФБК.
15. Дайте определение термина многозначная зависимость. Приведите
пример.
16. Почему многозначные зависимости не являются проблемой в отношениях,
имеющих только два атрибута?
17. Дайте определение термина четвертая нормальная форма. Приведите
пример отношения, которое находится в НФБК, но не находится в 4НФ.
Преобразуйте это отношение в отношения, находящиеся в 4НФ.
18. Дайте определение термина доменно-ключевая нормальная форма. Почему
эта форма важна?
19. Преобразуйте следующее отношение к ДКНФ. Сделайте и
сформулируйте соотвествующие предположения о функциональных зависимостях и
доменах.
ОБОРУДОВАНИЕ (Производитель, Модель, ДатаПриобретения, ИмяПокупателя,
Телефон Покупателя, МестоположениеЗавода, Город- Штат, Индекс)
20. Преобразуйте следующее отношение в ДКНФ. Сделайте и
сформулируйте соотвествующие предположения о функциональных зависимостях и
доменах.
СЧЕТ (Номер, ИмяПокупателя, НомерПокупателя, АдресПокупателя, НомерТова-
ра, ЦенаТовара, КоличествоТовара, НомерПродавца, ИмяПродавца, Промежуточ-
ныйИтог, Налог, ВсегоКОплате)
202 Глава 5. Реляционная модель и нормализация
21. Снова ответьте на вопрос 20, но теперь добавьте атрибут НалоговыйСтатус-
Покупателя (0, если покупатель не освобожден от налога, и 1, если
освобожден). Добавьте также ограничение, что налог не должен включаться в счет,
если НалоговыйСтатусПокупателя равен 1.
22. Приведите пример (отличный от того, который дан в тексте) ситуации,
в которой, как вы считаете, нормализацию производить не стоило бы.
Изобразите отношения и обоснуйте свое решение.
23. Укажите две ситуации, п которых проектировщики базы данных могут
преднамеренно прибегнуть к дублированию данных. Каков риск,
связанный с подобными решениями?
Вопросы II группы
24. Рассмотрим следующее отношение (табл. 5.2):
Таблица 5.2. Отношение ПРОЕКТ
НомерПроекта ИмяСотрудника ЗарплатаСотрудника
100А Джонс 64 000
100А Смит 51 000
100В Смит 51 000
200А Джонс 64 000
200В Джонс 64 000
200С Парке 28 000
200С Смит 51 000
200D Парке 28 000
ПРОЕКТ (НазваниеПроекта, ИмяСотрудника, ЗарплатаСотрудника)
Здесь НазваниеПроекта — это название рабочего проекта, ИмяСотрудника —
имя сотрудника, работающего в рамках данного проекта, а
ЗарплатаСотрудника — заработная плата данного сотрудника.
Если предположить, что представленные здесь данные выявляют все
имеющиеся функциональные зависимости и ограничения, какое из следующих
утверждений будет верным?
НазваниеПроекта > ИмяСотрудника
НазваниеПроекта > ЗарплатаСотрудника
(НазваниеПроекта, ИмяСотрудника) > ЗарплатаСотрудника
ИмяСотрудника > ЗарплатаСотрудника
ЗарплатаСотрудника > НазваниеПроекта
ЗарплатаСотрудника > (НазваниеПроекта, ИмяСотрудника)
Ответьте на следующие вопросы:
1) Что является ключом отношения ПРОЕКТ?
2) Все ли неключевые атрибуты (если таковые есть) зависят от всего
ключа целиком?
Вопросы II группы 203
3) В какой нормальной форме находится отношение ПРОЕКТ?
4) Опишите две аномалии модификации, характерные для отношения ПРОЕКТ.
5) Является ли атрибут НазваниеПроекта детерминантом?
6) Является ли атрибут ИмяСотрудника детерминантом?
7) Является ли детерминантом сочетание (НазваниеПроекта, ИмяСотрудника)?
8) Является ли детерминантом ЗарплатаСотрудника?
9) Содержит ли это отношение транзитивную зависимость? Если да, то
какую?
10) Переделайте это отношение так, чтобы устранить аномалии модификации.
25. Рассмотрим следующее отношение (табл. 5.3):
Таблица 5.3. Отношение ПРОЕКТ-ЧАСЫ
ИмяСотрудника НомерПроекта НомерЗадачи Телефон ВсегоЧасов
Дон
Дон
Дон
Дон
Пэм
Пэм
Пэм
100А
100 А
200В
200 В
100А
200А
200 D
В-1
Р-1
В-1
р-1
С-1
С-1
С-1
12345
12345
12345
12345
67890
67890
67890
12
12
12
12
26
26
26
ПРОЕКТ-ЧАСЫ (ИмяСотрудника, НазваниеПроекта, НазваниеЗадачи, Телефон,
ВсегоЧасов)
Здесь НазваниеЗадачи — это название стандартной рабочей задачи,
Телефон — номер телефона сотрудника, а ВсегоЧасов — количество часов,
отработанных сотрудником в рамках данного проекта.
Если предположить, что представленные здесь данные выявляют все
имеющиеся функциональные зависимости и ограничения, какое из следующих
утверждений будет верным?
ИмяСотрудника > НазваниеПроекта
ИмяСотрудника » НазваниеПроекта
ИмяСотрудника > НазваниеЗадачи
ИмяСотрудника » НазваниеЗадачи
ИмяСотрудника > Телефон
ИмяСотрудника > ВсегоЧасов
(ИмяСотрудника, НазваниеПроекта) > ВсегоЧасов
(ИмяСотрудника, Телефон) > НазваниеЗадачи
НазваниеПроекта > НазваниеЗадачи
НазваниеЗадачи > НазваниеПроекта
Ответьте на следующие вопросы:
1) Перечислите все детерминанты.
2) Содержит ли данное отношение транзитивную зависимость? Если да,
то какую?
204 Глава 5. Реляционная модель и нормализация
3) Содержит ли данное отношение многозначную зависимость? Если да,
то какие атрибуты не связаны между собой?
4) Опишите аномалию удаления, которая имеется в этом отношении.
5) Сколько тем содержит данное отношение?
6) Переделайте отношение так, чтобы устранить аномалии модификации.
Сколько отношений у вас получилось? Сколько тем содержит каждое
из новых отношений?
7) Рассмотрим приведенные ниже определения отношений, доменов и
ключей.
Определения доменов:
ИмяСотрудникаСНА1*(20)
НомерТелефонаОЕС(5)
НаименованиеОборудованияСНАР(Ю)
МестоположениеСНАИ(7)
doHMOCTbCURRENCY
flaiaYYMMDD
ВремяННММ, где 00 <= НН <- 23
00 <= ММ <= 59
Отношения, ключи и ограничения:
СОТРУДНИК (ИмяСотрудника, НомерТелефона)
Ключ:ИмяСотрудника
Ограничения:ИмяСотрудника > НомерТелефона
ОБОРУДОВАНИЕ (НаименованиеОборудования, Местоположение, Стоимость)
Ключ:Наименование06орудования
Ограничения:Наименование06орудования > Местоположение
НаименованиеОборудования > Стоимость
СЕАНС (Дата, Время, НаименованиеОборудования, ИмяСотрудника)
Ключ(Дата, Время, НаименованиеОборудования)
Ограничения:(Дата, Время, НаименованиеОборудования) >
ИмяСотрудника
26. Модифицируйте определения так, чтобы добавить следующее ограничение:
сотрудник не может записаться более чем на один сеанс работы с
оборудованием.
27. Определим в качестве ночного времени часы между 21.00 и 05.00.
Добавьте атрибут ТипСотрудника, значение которого равно 1, если сотрудник
работает в ночное время. Измените определения таким образом, чтобы ввести
условие, что только сотрудники, работающие ночью, могут записываться
на ночные сеансы.
Вопросы к проекту FiredUp
Фирма FiredUp наняла команду проектировщиков, разработавших для базы
данных фирмы приведенные ниже отношения (вообще-то эту команду следовало бы
уволить!). База данных должна содержать информацию о проданных горелках,
Вопросы к проекту Fired Up 205
выполненном ремонте и клиентах. Чтобы ознакомиться с потребностями фирмы,
обратитесь к проектам в конце глав 1-3. Для каждого из представленных ниже
отношений укажите ключи-кандидаты, функциональные зависимости и
многозначные зависимости (если таковые присутствуют). Если ответ не очевиден,
приведите обоснование этого. В какой нормальной форме находится каждое из
отношений, если иметь в виду указанные вами ключи и другие элементы?
Преобразуйте каждое из отношений в два или более новых отношения, находящихся
и доменно-ключевой нормальной форме. Укажите первичный ключ каждой
таблицы, ключи-кандидаты и внешние ключи, а также сформулируйте ограничения
ссылочной целостности, если они имеются.
Отвечая на эти вопросы, исходите из следующих предположений:
+ Тип и версия горелки определяют емкость бака.
+ Горелка может ремонтироваться много раз, но не более одного раза в день.
+ На каждый произведенный ремонт выписывается отдельный счет.
+ Горелка может быть зарегистрирована на различных пользователей, но не
одновременно.
+ Горелка состоит из многих деталей, и каждая деталь может использоваться
во многих горелках. Таким образом, фирма FiredUp ведет записи о
различных типах деталей (например, клапан форсунки), но не об отдельных
деталях (клапан форсунки номер 41734, изготовленный 12 декабря 2001 г.).
Ниже следует список отношений.
ПР0ДУКТ1 (СерийныйНомер, Тип, НомерВерсии, ЕмкостьБака, ДатаИзготовления, Ини-
циалыИнспектора)
ПР0ДУКТ2 (СерийныйНомер, Тип, ЕмкостьБака, ДатаРемонта, НомерСчетаЗаРемонт,
СтоимостьРемонта)
РБМ0НТ1 (НомерСчетаЗаРемонт, ДатаРемонта, СтоимостьРемонта, ИмяВыполнявшего-
Ремонт, Телефон ВыполнявшегоРемонт)
РЕМ0НТ2 (НомерСчетаЗаРемонт, ДатаРемонта, СтоимостьРемонта, ИмяВыполнявшего-
Ремонт, ТелефонВыполнявшегоРемонт, СерийныйНомер, Тип, ЕмкостьБака)
РБМОНТЗ (ДатаРемонта, СтоимостьРемонта, СерийныйНомер, ДатаИзготовления)
ГОРЕЛ КА1 (СерийныйНомер, НомерСчетаЗаРемонт, НомерДетали)
ГОРЕЛКА2 (СерийныйНомер, НомерСчетаЗаРемонт, РегистрационныйНомерВладельца)
Предположим, что нужно записывать владельца горелки, даже если она
никогда не ремонтировалась.
Исходя из сделанных предположений, приведенных выше отношений и
содержащихся в них атрибутов, а также из ваших знаний о малом бизнесе, постройте
для фирмы FiredUp набор отношений в доменно-ключевой нормальной форме.
Укажите первичные ключи и внешние ключи, а также сформулируйте
ограничения целостности по внешнему ключу.
Глава 6
Проектирование баз данных
в рамках модели
«сущность—связь»
В главе 3 мы обсуждали модель «сущность—связь», а в главе 5 — реляционную
модель и нормализацию. В настоящей главе мы свяжем эти два предмета и
покажем, как требования пользователей, выраженные в терминах модели
«сущность—связь», преобразуются в реляционные конструкции. Эти конструкции не
зависят от конкретной СУБД.
Глава 6 состоит из трех разделов. В первом разделе мы изложим методики
преобразования моделей «сущность—связь» в реляционные конструкции. Как
вы увидите, важную роль в этом процессе играет нормализация. Второй раздел
посвящен применению этих методик для преобразования четырех структур,
часто возникающих в приложениях баз данных. В заключительном разделе главы
обсуждаются суррогатные ключи и пустые значения.
Преобразование моделей
«сущность—связь» в реляционные
конструкции
Согласно модели «сущность—связь», вещи, учет которых хотят вести
пользователи, представляются сущностями, а взаимоотношения между этими сущностями
представляются явно определенными связями. В данном разделе описывается,
как эти сущности и связи преобразуются в элементы реляционной модели.
Представление сущностей с помощью
реляционной модели
Представление сущностей средствами реляционной модели имеет
прямолинейный характер. Начнем с того, что введем для каждой сущности свое отношение.
Именем отношения будет имя сущности, а атрибутами отношения — атрибуты
Преобразование моделей «сущность—связь» 207
сущности. Далее рассмотрим каждое из отношений в свете критериев
нормализации, описанных в главе 5. При этом может (но не обязана) возникнуть
необходимость в модификации первоначальной структуры.
Сущность КЛИЕНТ содержит:
НомерКлиента
ИмяКлиента
Адрес
Город
Штат
Индекс
ИмяДоверенногоЛица
НомерТелефона
а
КЛИЕНТ (НомерКлиента. ИмяКлиента, Адрес, Город, Штат,
Индекс, ИмяДоверенногоЛица, НомерТелефона)
6
Рис. 6.1. Представление сущности с помощью отношения: а — сущность КЛИЕНТ;
б — отношение, представляющее сущность КЛИЕНТ
На рис. 6.1, а изображена сущность КЛИЕНТ, взятая из рис. 3.1. Она имеет
следующие атрибуты: НомерКлиента, ИмяКлиента, Адрес, Город, Штат, Индекс и Телефон.
Определим для этой сущности отношение, а атрибуты сущности сделаем его
столбцами. Если из модели данных нам известно, какой атрибут
идентифицирует сущность, то данный атрибут станет ключом отношения. В противном случае,
чтобы определить, какой атрибут или набор атрибутов может идентифицировать
сущность, мы должны спросить пользователей или как-то иначе
проанализировать требования. Здесь мы предполагаем, что ключом является НомерКлиента.
На этом рисунке, как и на следующих за ним, ключи отношения подчеркнуты.
Роль нормализации
На этапе формулировки требований единственное условие состояло в том, чтобы
сущность была важна для пользователя. Не предпринималось никаких попыток
определить, удовлетворяет ли сущность критериям нормализации, описанным
и главе 5. Теперь отношение, введенное для сущности, следует проанализировать
в свете критериев нормализации.
Рассмотрим, например, отношение КЛИЕНТ на рис. 6.1, б. Находится ли оно
и доменно-ключевой нормальной форме (ДКНФ)? Чтобы это выяснить, нам
необходимо знать, какие ограничения существуют относительно него. Без
исчерпывающего описания требований мы не будем знать все ограничения (например,
нее ограничения доменов). Но некоторые требования мы можем определить,
исходя только из имен атрибутов и наших знаний о природе бизнеса.
Во-первых, НомерКлиента определяет все остальные атрибуты, поскольку
уникальные значения атрибутов ИмяКлиента, Адрес, Город, Штат, Индекс,
ИмяДоверенногоЛица и Телефон могут быть определены по заданному значению атрибута
208 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
НомерКлиента. Есть, однако, и другие ограничения, проистекающие из других
функциональных зависимостей. Индекс определяет Город и Штат, а
ИмяДоверенногоЛица определяет НомерТелефона. Чтобы создать набор отношений в ДКНФ, мы
должны представить эти дополнительные функциональные зависимости как
логические следствия доменов и ключей, и это мы можем сделать, введя три
отношения, показанные на рис. 6.2. Заметьте, что ключом отношения КЛИЕНТ является
НомерКлиента, ключом отношения ТАБЛИЦА_ИНДЕКСОВ является Индекс, а ключом
отношения КОНТАКТ является ИмяДоверенногоЛица. Также обратите внимание на
ограничения ссылочной целостности.
Отношения, изображенные на рис. 6.2, находятся в ДКНФ и будут лишены
аномалий модификации. То есть, чтобы добавить новые индексы и новых
доверенных лиц, нам не придется добавлять нового клиента. Кроме того, при
удалении последнего клиента с данным индексом мы не потеряем информацию о том,
какие город и штат соответствуют этому значению индекса. Однако, как мы
указали в конце главы 5, большинство профессионалов сочли бы этот дизайн
выхолощенным: вынесение атрибутов Индекс, Город и Штат в отдельную таблицу
затрудняет работу с конструкцией в целом. Следовательно, более удачным решением
было бы оставить атрибуты Индекс, Город и Штат в отношении КЛИЕНТ.
КЛИЕНТ (НомерКлиента. Адрес, Индекс, ИмяДоверенногоЛица)
ТАБЛИЦА_ИНДЕКСОВ (Индекс, Город, Штат)
КОНТАКТ (ИмяДоверенногоЛица. НомерТелефона)
Ограничения ссылочной целостности:
Значение атрибута Индекс в отношении КЛИЕНТ должно существовать среди значений
атрибута Индекс в отношении ТАБЛИЦА_ИНДЕКСОВ
Значение атрибута ИмяДоверенногоЛица в отношении КЛИЕНТ должно
существовать среди значений атрибута ИмяДоверенногоЛица в отношении КОНТАКТ
Рис. 6.2. Представление сущности КЛИЕНТ с помощью отношений
в доменно-ключевой нормальной форме
Что можно сказать по поводу отношения КОНТАКТ? Если связь между
доверенным лицом и компанией имеет вид 1:1, то вынесение контактной
информации в отдельную таблицу мало что дает. В этом случае отношение на рис. 6.1, б
приемлемо. Если же указанная связь не однозначна, то отношение КОНТАКТ
следует представить как отдельную сущность, надлежащим образом связанную
с сущностью КЛИЕНТ (эта связь может иметь вид N:l или 1:N), и соответственно
модифицировать ER-модель.
В других примерах ДКНФ является наиболее предпочтительной формой.
Рассмотрим сущность КОМИССИОННЫЕ_ПРОДАВЦА на рис. 6.3, а. Если мы
попытаемся представить эту сущность в виде одного отношения, как показано на
рис. 6.3, б, результатом явится беспорядочное нагромождение атрибутов с
многочисленными потенциальными аномалиями модификации.
Данное отношение явно содержит более одной темы, а именно оно содержит
тему служащих, тему продаж за определенный период и тему комиссионных, вы-
Преобразование моделей «сущность—связь» 209
плачиваемых служащим. Отношения в ДКНФ, представляющие эту сущность,
изображены на рис. 6.3, в. Интуитивно ясно, что это решение является более
удачным, чем то, которое показано на рис. 6.3, б: оно более прямолинейно и
лучше подходит в данной ситуации.
Сущность КОМИССИОННЫЕ содержит:
НомерПродааца
ИмяПродавца
Телефон
НомерЧека
ДатаВыпискиЧека
Период
СуммаПродаж
СуммаКомиссионных
БюджетнаяКатегория
а
КОМИССИОННЫЕ (НомерПродавца, ИмяПродавца, Телефон,
НомерЧека. ДатаВыпискиЧека, Период, СуммаПродаж,
СуммаКомиссионных, БюджетнаяКатегория)
Функциональные зависимости:
Атрибут НомерЧека является ключом
Атрибут НомерПродавца определяет атрибуты ИмяПродавца,
Телефон и БюджетнаяКатегория
Комбинация (НомерПродавца, Период) определяет атрибуты
СуммаПродаж, СуммаКомиссионных
6
ПРОДАВЕЦ (НомерПродавца. ИмяПродавца, Телефон, БюджетнаяКатегория)
ПРОДАЖИ (НомерПродавца. Период. СуммаПродаж, СуммаКомиссионных)
КОМИССИОННЫЙ_ЧЕК (НомерЧека. ДатаВыпискиЧека, НомерПродавца, Период)
Ограничения ссылочной целостности:
Значение атрибута НомерПродавца в отношении ПРОДАЖИ
должно существовать среди значений атрибута НомерПродавца
в отношении ПРОДАВЕЦ
Сочетание (НомерПродавца, Период) в отношении КОМИССИОННЫЙ__ЧЕК должно
существовать среди значений сочетания (НомерПродавца, Период) в отношении
ПРОДАЖИ
в
Рис. 6.3. Нормализованная сущность: а - сущность КОМИССИОННЫЕ_ПРОДАВЦА;
б — представление сущности КОМИССИОННЫЕ_ПРОДАВЦА в виде одного отношения;
а — представление сущности КОМИССИОННЫЕ_ПРОДАВЦА в виде отношений
в доменно-ключевой нормальной форме
Подводя итог нашего изложения на данный момент, можно сказать
следующее: чтобы преобразовать сущность в реляционную конструкцию, сначала
следует построить отношение, в качестве столбцов которого выступают атрибуты
сущности. Затем это отношение нужно проанализировать в свете критериев
нормализации. Во многих случаях реляционную структуру можно улучшить,
разработав набор отношений, находящихся в ДКНФ.
210 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
Тем не менее, отношения в ДКНФ не всегда являются самыми предпочти-,
тельными. Если отношения запутаны и с ними сложно работать, более удачным
может оказаться решение, не основанное на ДКНФ. Производительность также
может иметь значение. Обращение к двум рши трем отношениям для получения
необходимых данных о клиенте может отнимать чересчур много времени.
Независимо от того, каким будет наше решение относительно нормализации,
мы должны исследовать каждое из отношений сущности применительно к
критериям нормализации. То есть, если мы собираемся «согрешить», следует
принять на этот счет взвешенное и обдуманное решение. Попутно мы определим
типы аномалий модификации, которым подвержены исследуемые отношения.
Представление слабых сущностей
Слабые сущности требуют особого подхода при создании реляционной
структуры. Вспомните, что существование слабой сущности зависит от некоторой другой
сущности. Если слабая сущность является экзистенциально-зависимой, но не
идентификационно-зависимой, ее можно преобразовать в реляционную
конструкцию с помощью приемов, описанных в предыдущем разделе.
Экзистенциальная зависимость должна быть встроена в реляционную конструкцию таким
образом, чтобы приложение не могло создать слабую сущность без ее родителя
(сущности, от которой данная сущность зависит). Более того, деловой регламент
необходимо дополнить положением, согласно которому при удалении родителя
слабая сущность также удаляется. Эти правила должны быть описаны в
реляционной структуре.
Данная ситуация выглядит несколько по-иному, если слабая сущность
является также идентификационно-зависимой. На рис. 6.4, а СТР0КА_РАСХ0Д0В
является идентификационно-зависимой сущностью. Эта сущность слабая,
поскольку ее логическое существование зависит от сущности СЧЕТ, и
идентификационно-зависимая, поскольку ее идентификатор содержит идентификатор
сущности СЧЕТ.
При создании отношения для идентификационно-зависимой сущности мы
обязаны поместить в него ключ как самой сущности, так и ее родителя. Посмотрим,
например, что получилось бы, если бы мы просто ввели отношение для сущности
СТР0КА_РАСХ0Д0В и не включили в него ключ сущности СЧЕТ. Такое отношение
показано на рис. 6.4, б. Что является ключом этого отношения? Поскольку
сущность СТР0КА_РАСХ0Д0В является идентификационно-зависимой, у нее нет
полноценного ключа, и фактически, это отношение вполне может иметь
повторяющиеся строки. (Такое может случиться, если в двух заказах указано одно и то же
количество определенного товара в одной и той же строке.)
Таким образом, если имеется идентификационно-зависимая сущность, в
отношение для этой сущности необходимо добавить ключ родительского
отношения, и этот дополнительный атрибут становится частью ключа слабой сущности.
На рис. 6.4, в мы добавили в отношение СТР0КА_РАСХ0Д0В атрибут НомерСчета —
ключ отношения СЧЕТ. Ключом отношения СТР0КА_РАСХ0Д0В является
комбинация {НомерСчета, НомерСтроки}.
Преобразование моделей «сущность—связь» 211
СЧЕТ
СТРОКА_РАСХОДОВ
СТРОКА_РАСХОДОВ (НомерСтроки. Количество, НомерТовара,
Описание, Цена, Стоимость)
б
СТРОКА_РАСХОДОВ (НомерСчета. НомерСтроки. Количество, НомерТовара,
Описание, цена, Стоимость)
в
Рис. 6.4. Реляционное представление слабой сущности: а — пример слабой сущности;
б — отношение, представляющее сущность СТРОКА_РАСХОДОВ, с неправильным ключом;
а — отношение, представляющее сущность СТРОКА_РАСХОДОВ, с правильным ключом
Представление связей типа «ИМЕЕТ»
В модели «сущность—связь» есть две разновидности связей: связь типа «ИМЕЕТ»,
характерная для сущностей, принадлежащих к разным логическим типам, и связь
типа «ЕСТЬ», возникающая между сущностями, которые являются подтипами
одного и того же логического типа. В этом разделе мы рассмотрим связи типа
«ИМЕЕТ»; к связям типа «ЕСТЬ» мы обратимся позже. Существует три вида
связей типа «ЕСТЬ»: «один к одному», «один ко многим» и «многие ко многим».
Представление связи «один к одному»
Простейшая форма бинарной связи — это связь «один к одному» (1:1), при
которой сущность одного типа связана не более чем с одной сущностью другого типа.
В примере с сущностями СОТРУДНИК и АВТОМОБИЛЬ такая связь отражает
ситуацию, когда за сотрудником может быть закреплено не более одного автомобиля,
а автомобиль может быть выделен не более чем одному сотруднику. ER-диаграм-
ма для этого случая изображена на рис. 6.5.
Представление связи 1:1 с помощью реляционной модели осуществляется
просто. Сначала каждая сущность представляется в виде отношения, а затем
ключ одного из отношений помещается в другое. На рис. 6.6, а ключ отношения
СОТРУДНИК помещается в отношение АВТОМОБИЛЬ, а на рис. 6.6, б ключ
отношения АВТОМОБИЛЬ помещается в отношение СОТРУДНИК.
Когда ключ одного отношения помещается в другое отношение, он
называется внешним ключом (foreign key). На рис. 6.6, а Ном ер Сотрудника является
внешним ключом отношения АВТОМОБИЛЬ, а на рис. 6.6, б НомерЛицензии — внешний
ключ отношения СОТРУДНИК. На этом рисунке внешние ключи выделены
куренном, но иногда их подчеркивают пунктирной линией. Бывает и так, что внешние
ключи вообще никак специально не выделяются. В тех местах данного текста,
где потенциально может возникнуть путаница, мы будем выделять внешние
ключи курсивом, но в большинстве случаев они не будут обозначаться явно.
При связи 1:1 можно взять ключ любой из таблиц и поместить его в качестве
внешнего ключа в другую таблицу. На рис. 6.6, а в таблицу СОТРУДНИК помещен
ипешний ключ НомерЛицензии. При такой структуре мы можем двигаться от
212 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
таблицы СОТРУДНИК к таблице АВТОМОБИЛЬ или в обратном направлении. В
первом случае нам известен сотрудник, и мы хотим узнать, какой автомобиль
закреплен за этим сотрудником. Чтобы получить данные о сотруднике, мы находим
в таблице СОТРУДНИК строку с этой информацией по значению атрибута Номер-
Сотрудника. Из найденной строки мы берем НомерЛицензии автомобиля,
закрепленного за данным сотрудником. По номеру лицензии мы находим информацию
об автомобиле в таблице АВТОМОБИЛЬ.
СОТРУДНИК <f1:1> АВТОМОБИЛЬ
Рис. 6.5. Пример связи 1:1
СОТРУДНИК (Номер Сотрудника. ИмяСотрудника, Телефон,... НомерЛицензии)
АВТОМОБИЛЬ (НомерЛицензии. СерийныйНомер, Цвет, Производитель, Модель,...)
Ограничения ссылочной целостности:
Значение атрибута НомерЛицензии в отношении СОТРУДНИК должно
существовать среди значений атрибута НомерЛицензии в отношении АВТОМОБИЛЬ
а
СОТРУДНИК (НомерСотрудника. ИмяСотрудника, Телефон,...)
АВТОМОБИЛЬ (НомерЛицензии. СерийныйНомер, Цвет, Производитель, Модель,....
Номер Сотрудника)
Ограничения ссылочной целостности:
Значение атрибута НомерСотрудника в отношении АВТОМОБИЛЬ должно
существовать среди значений атрибута НомерСотрудника в отношении СОТРУДНИК
6
Рис. 6.6. Возможные варианты представления связи 1:1: а — помещение ключа
отношения АВТОМОБИЛЬ в отношение СОТРУДНИК; б — помещение ключа
отношения СОТРУДНИК в отношение АВТОМОБИЛЬ
Теперь рассмотрим движение в противоположном направлении. Допустим,
у нас имеется автомобиль, и мы хотим выяснить, за кем он закреплен. Используя
структуру, изображенную на рис. 6.6, я, мы обращаемся к таблице СОТРУДНИК
и ищем в ней строку, которая содержит заданный номер лицензии. Данные о
сотруднике, за которым закреплен этот автомобиль, находятся в этой строке.
Аналогичные действия предпринимаются для движения в двух направлениях
при альтернативной структуре, в которой внешний ключ НомерСотрудника
помещается в таблицу АВТОМОБИЛЬ. Двигаясь от сотрудника к автомобилю, мы
обращаемся напрямую к отношению АВТОМОБИЛЬ и ищем в нем строку с заданным
значением атрибута НомерСотрудника. Двигаясь от автомобиля к сотруднику, мы
ищем в отношении АВТОМОБИЛЬ строку с заданным значением атрибута
НомерЛицензии. Из этой строки мы извлекаем НомерСотрудника и по нему находим данные
о сотруднике в таблице СОТРУДНИК. Под термином поиск здесь подразумевается
нахождение строки по значению одного из столбцов. Позднее, когда мы будем
обсуждать модели конкретных СУБД, мы покажем, как это делается.
Преобразование моделей «сущность—связь» 213
Хотя две структуры, изображенные на рис. 6.6, эквивалентны по сути, они
могут различаться по производительности. Например, если запросы в одном
направлении осуществляются чаще, чем в другом, мы можем отдать предпочтение
какой-либо одной из этих структур. Кроме того, если СУБД осуществляет поиск
по первичным ключам гораздо быстрее, чем по внешним ключам, одна из этих
структур также может оказаться более предпочтительной.
«Подозрительные» связи 1:1
I la рис. 6.7 показана еще одна связь 1:1, в которой каждый сотрудник имеет
определенный разряд тарифной сетки и каждый разряд тарифной сетки
соответствует какому-либо сотруднику. Перпендикулярные черточки указывают на то, что
связь между сущностями СОТРУДНИК и РАЗРЯД носит в обоих направлениях
обязательный характер. Когда связь имеет вид 1:1 и является обязательной в обоих
направлениях, то с высокой вероятностью указанные записи отражают различные
аспекты одной и той же сущности, особенно если обе сущности имеют
одинаковый ключ, как показано на рис. 6.7. В таком случае, вообще говоря, записи
следует объединить в одно отношение. Приучитесь относиться с подозрением к
подобным обязательным связям 1:1.
СОТРУДНИК
;1:1.
РАЗРЯД
Рис. 6.7. Подозрительная связь вида 1:1
Тем не менее, разделение сущности на два отношения в некоторых случаях
может быть оправдано. Одно из возможных оснований — это производительность.
Допустим, например, что данные о разряде тарифной сетки имеют значительную
длину и используются гораздо менее часто, чем прочие данные о сотрудниках.
В этих условиях может быть оправдано вынесение этих данных в отдельную
таблицу РАЗРЯД, чтобы более часто встречающиеся запросы, которые касаются
другой информации о сотрудниках, могли обрабатываться быстрее.
Другое основание для разделения одной логической сущности на две — это
более высокий уровень безопасности. Если СУБД не поддерживает безопасность
на уровне элементов данных, может возникнуть потребность отделить данные
о тарифных разрядах от прочей информации, чтобы предотвратить
несанкционированный доступ к этим данным. Создание отдельной таблицы РАЗРЯД
может быть желательно также в том случае, если предполагается записывать
;)ту таблицу на дисковые носители, доступные для определенной категории
пользователей.
Не стоит делать из этой дискуссии вывод, что все связи 1:1 можно ставить
под сомнение: подозрительными являются только те из них, которые
описывают различные аспекты одной и той же сущности. Например, обязательная
связь 1:1 между сущностями СОТРУДНИК и АВТОМОБИЛЬ вполне допустима,
поскольку участвующие в ней отношения описывают логически совершенно
разные вещи.
214 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
Представление связей «один ко многим»
Второй тип бинарных связей — это связь «один ко многим» (1:N), при которой
сущность одного типа может быть связана с несколькими сущностями другого
типа. На рис. 6.8 изображена диаграмма связи «один ко многим» между
преподавателями и студентами. В этой связи один преподаватель связан со многими
студентами, у которых он является руководителем. Как указывалось в главе 3, овал
означает, что связь между сущностями ПРЕПОДАВАТЕЛЬ и СТУДЕНТ имеет
необязательный характер; другими словами, ПРЕПОДАВАТЕЛЬ может и не руководить ни
одним студентом. Перпендикулярная черта на другом конце линии связи
означает, что каждой строке в отношении СТУДЕНТ должна соответствовать строка в
отношении ПРЕПОДАВАТЕЛЬ.
К отношениям, между которыми имеется связь 1:N, иногда применяются
термины родитель (parent) и потомок (child). Родитель — это отношение на
унарной стороне связи (с кардинальным числом 1), а потомок — это отношение на
множественной стороне связи (с кардинальным числом N). На рис. 6.8, а
сущность ПРЕПОДАВАТЕЛЬ является родителем, а сущность СТУДЕНТ — потомком.
На рис. 6.8 показаны еще две связи «один ко многим». На рис. 6.8, б
сущности ОБЩЕЖИТИЕ соответствует много сущностей СТУДЕНТ, но любой сущности
СТУДЕНТ соответствует только одна сущность ОБЩЕЖИТИЕ. Далее, в общежитии
может не числиться ни одного студента, а от студента не требуется жить в
общежитии.
На рис. 6.8, в сущность КЛИЕНТ связана со многими сущностями ВСТРЕЧА,
но каждой сущности ВСТРЕЧА соответствует только одна сущность КЛИЕНТ. Более
того, с клиентом может не быть назначено ни одной встречи, но каждая встреча
должна быть назначена с каким-либо клиентом.
Связи 1:N представляются простым и прямолинейным образом. Сначала
каждая сущность представляется в виде отношения, затем ключ отношения,
представляющего родительскую сущность, помещается в отношение, представляющее
дочернюю сущность. Так, чтобы представить связь РУКОВОДСТВО, изображенную
на рис. 6.8, а} мы помещаем ключ отношения ПРЕПОДАВАТЕЛЬ — ИмяПреподавате-
ля — в отношение СТУДЕНТ, как показано на рис. 6.9.
ПРЕПОДАВАТЕЛЬ
ОБЩЕЖИТИЕ
КЛИЕНТ
^ <1:N>-e-
а
-0-^:N>-b
б
4 ОЮ-0-
СТУДЕНТ
СТУДЕНТ
ВСТРЕЧА
Рис. 6.8. Пример связей «один ко многим»: а — связь «необязательно — обязательно»;
б — связь «необязательно — необязательно»; а — связь 1:N со слабой сущностью
Преобразование моделей «сущность—связь» 215
Рисунок 6.9 являет собой пример того, что иногда называется диаграммой
структуры данных (data structure diagram). В такой диаграмме отношения
показываются в виде прямоугольников, между которыми прочерчены линии связи;
ключевые атрибуты в них выделены подчеркиванием. Вилка, расположенная на
линии связи, указывает на множественность связи.
ПРЕПОДАВАТЕЛЬ
ИмяПреподавателя Телефон Кафедра
L СТУДЕНТ
НомерСтудента ИмяСтудента МестныйАдрее \ИмяПреподавателя
Ограничение ссылочной целостности:
Значение атрибута ИмяПреподавателя в отношении СТУДЕНТ
должно существовать среди значений атрибута ИмяПреподавателя
в отношении ПРЕПОДАВАТЕЛЬ
Рис. 6.9. Реляционное представление сущностей ПРОФЕССОР и СТУДЕНТ из рис. 6.8, а
Вилка на том конце линии связи на рис. 6.9, где располагается отношение
СТУДЕНТ, означает, что каждой строке в отношении ПРЕПОДАВАТЕЛЬ может соответ-
гтиовать много строк в отношении СТУДЕНТ. Отсутствие вилки на противоположном
конце говорит о том, что каждым студентом может руководить максимум один
преподаватель. Как и в ER-диаграммах, для обозначения обязательных связей
используется перпендикулярная черта, а необязательные связи обозначаются овалами.
Обратите внимание: благодаря тому, что ИмяПреподавателя хранится в качест-
ио внешнего ключа в отношении СТУДЕНТ, мы можем обрабатывать связь между
ними в обоих направлениях. Имея НомерСтудента, мы можем найти
соответствующую строку в отношении СТУДЕНТ и извлечь из нее имя руководителя данного
студента. Чтобы получить остальные данные о профессоре, мы используем имя
преподавателя, полученное нами из отношения СТУДЕНТ, для нахождения
соответствующей строки в таблице ПРЕПОДАВАТЕЛЬ. Чтобы определить имена всех
студентов, которыми руководит данный преподаватель, мы найдем в отношении СТУДЕНТ
псе строки, в которых в столбце ИмяПреподавателя значится имя данного
преподавателя. Из этих строк мы извлечем информацию о студентах.
Сравните эту ситуацию с ситуацией, когда необходимо было представлять
связи 1:1. В обоих случаях мы помещаем ключ одного отношения в качестве
внешнего ключа в другое отношение. Однако в связи 1:1 не имеет значения,
ключ какого из двух отношений выбирается в качестве внешнего ключа. В
случае со связью 1:N это не так. Ключ родительского отношения должен помещаться
и дочернее отношение.
Чтобы лучше уяснить этот момент, посмотрим, что произойдет, если мы
поместим ключ потомка в родительское отношение — то есть поместим НомерСтудента
в отношение ПРЕПОДАВАТЕЛЬ. Поскольку атрибуты в отношении могут иметь
только одно значение, каждая запись в таблице ПРЕПОДАВАТЕЛЬ может вместить
информацию только об одном студенте. Следовательно, с помощью такой структуры
нельзя представить множественную сторону связи 1:N. Поэтому, чтобы
представить связь 1:N, мы должны поместить ключ родительского отношения в дочернее.
216 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
На рис. 6.10 представлены сущности КЛИЕНТ и ВСТРЕЧА. Каждую из этих
сущностей мы представили в виде одного отношения. ВСТРЕЧА — это идентификационно -
зависимая слабая сущность, поэтому она имеет композитный ключ, состоящий
из ключа сущности, от которой она зависит, и как минимум одного собственного
атрибута. Здесь ключом является сочетание (НомерКлиента, Дата, Время). Чтобы
представить связь 1:N, в обычном случае мы бы добавили ключ родителя в
дочернее отношение. В данной ситуации, однако, ключ родителя (НомерКлиента)
уже является частью дочернего отношения, поэтому добавлять его не требуется.
КЛИЕНТ
| НомерКлиента | ИмяКлиента | Адрес
Город 1 Штат | Индекс ]
ВСТРЕЧА
^
1 НомерКлиента | Дата | Время
Плата |
Ограничение ссылочной целостности:
Значение атрибута НомерКлиента в отношении ВСТРЕЧА
должно существовать среди значений атрибута
НомерКлиента в отношении КЛИЕНТ
Рис. 6.10. Реляционное представление слабой сущности из рис. 6.8, в
Представление связей «многие ко многим»
Третий и последний тип бинарных связей — это связи «многие ко многим» (M:N),
в которых сущности одного типа соответствует много сущностей второго типа,
и сущности второго типа соответствует много сущностей первого типа.
На рис. 6.11 изображена ER-диаграмма связи вида «многие ко многим»
между студентами и предметами. Сущности СТУДЕНТ может соответствовать много
сущностей ПРЕДМЕТ, и сущности ПРЕДМЕТ может соответствовать много
сущностей СТУДЕНТ. Обратите внимание, что обе сущности, участвующие в связи,
являются необязательными: студент не обязан записываться на какой-либо предмет,
а предмет может не преподаваться ни одному студенту. На рис. 6.11, б
приведены данные для этого примера.
Связи «многие ко многим» не могут быть напрямую представлены с помощью
отношений, как это было со связями вида «один к одному» и «один ко многим».
Чтобы понять, почему это так, попытайтесь использовать ту стратегию, что мы
применяли для связей 1:1 и 1:N — поместить ключ одного отношения в другое
отношение в качестве внешнего ключа. Сначала введите для каждой
сущности свое отношение; назовите эти отношения СТУДЕНТ и ПРЕДМЕТ. Теперь
попробуйте поместить ключ отношения СТУДЕНТ (скажем, НомерСтудента) в отношение
ПРЕДМЕТ. Поскольку в ячейках отношения недопустимы множественные
значения, в каждой строке есть место только для одного значения атрибута
НомерСтудента, поэтому мы не можем связать более одного студента с каждым предметом.
Та же самая проблема возникнет, если мы попытаемся поместить ключ
отношения ПРЕДМЕТ (скажем, НомерПредмета) в отношение СТУДЕНТ. Мы сможем
указать идентификатор первого предмета, на который записан данный студент, но
для остальных предметов места уже не останется.
Преобразование моделей «сущность—связь», 217
СТУДЕНТ
ПРЕДМЕТ
СТУДЕНТ 100
СТУДЕНТ 200
СТУДЕНТ 300
ПРЕДМЕТ 10
ПРЕДМЕТ 20
ПРЕДМЕТ 30
ПРЕДМЕТ 40
Рис. 6.11. Пример связи M:N: a — ER-диаграмма связи между сущностями СТУДЕНТ
и ПРЕДМЕТ; б — данные для связи между сущностями СТУДЕНТ и ПРЕДМЕТ
На рис. 6.12 показана другая (и неправильная) стратегия. Здесь мы поместили
в отношение ПРЕДМЕТ по одной строке на каждого студента, который посещает
данный предмет, поэтому в нем имеется две строки для предмета 10 и две строки
для предмета 30. Проблема с этой схемой состоит в том, что мы дублируем
данные о предметах, тем самым порождая аномалии модификации. Если, например,
изменится расписание занятий по предмету 10, потребуется изменить много
строк. Рассмотрим также аномалии вставки и удаления: как мы можем добавить
новый предмет, пока на него не записался ни один студент? И что произойдет,
если студент с номером 300 откажется от предмета 40? Очевидно, что такая
стратегия неработоспособна.
НомерСтудента Прочие данные студента
100
100
300
СТУДЕНТ
НомерПредмета ЧасыЗанятий Прочие данные о предмете НомерПредмета
100
100
300
100
300
10:00 МЩ||;
10:00MWEI;&
3:00 ТН
3:00 ТЫф£
8;Q0 MW#
чаШ = 1
ffr.
100
200
200
300
300
ПРЕДМЕТ
Рис. 6.12. Неправильное представление связи M:N
218 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
Решение этой проблемы состоит в том, чтобы создать третье отношение,
представляющее связь как таковую. На рис. 6.13, а изображено отношение СТУДЕНТ-
ПРЕДМЕТ. Подобные отношения называются отношениями пересечтия (intersection
relations), поскольку каждая строка такого отношения хранит данные о связи
конкретного студента с конкретным классом. Обратите внимание, что каждой
линии связи между сущностями СТУДЕНТ и ПРЕДМЕТ на рис. 6.11, б соответствует
одна строка в отношении пересечения на рис. 6.13, б.
СТУДЕНТ (НомерСтудента. ИмяСтудента)
ПРЕДМЕТ (НомерПредмета. НазваниеПредмета)
СТУДЕНТ-ПРЕДМЕТ (НомерСтудента. НомерПредмета)
Ограничения ссылочной целостности:
Значение атрибута НомерПредмета в отношении СТУДЕНТ-ПРЕДМЕТ
должно существовать среди значений атрибута НомерПредмета в отношении ПРЕДМЕТ
Значение атрибута НомерСтудента в отношении СТУДЕНТ-ПРЕДМЕТ
должно существовать среди значений атрибута НомерСтудента в отношении СТУДЕНТ
1 100
200
300
Джонс, Мэри
Паркер, Фред
By, Джейсон
V
\х
\
100
200
200
300
300
10
10
30
30
40
10
20
30
40
Бухгалтерский учет!
Финансы
Маркетинг
Базы данных
Рис. 6.13. Представление связи M:N: a — отношения, необходимые для представления
связи между сущностями СТУДЕНТ и ПРЕДМЕТ; б — данные для связи между
сущностями СТУДЕНТ и ПРЕДМЕТ
Диаграммы структуры данных для связи СТУДЕНТ-ПРЕДМЕТ представлены на
рис. 6.14. Связь между отношениями ПРЕДМЕТ и СТУДЕНТ-ПРЕДМЕТ имеет вид 1:N,
так же как и связь между отношениями СТУДЕНТ и СТУДЕНТ-ПРЕДМЕТ. По сути,
мы осуществили декомпозицию связи вида M:N на две связи 1:N. Ключом
отношения СТУДЕНТ-ПРЕДМЕТ является совокупность ключей обоих его родителей:
(НомерСтудента, НомерПредмета). Ключом отношения пересечения всегда является
комбинация родительских ключей. Заметьте также, что оба родительских
отношения являются обязательными. Родитель должен существовать для каждого
ключевого значения в отношении пересечения.
СТУДЕНТ
НомерСтудента и мя Студента
СТУДЕНТ-ПРЕДМЕТ
ПРЕДМЕТ
НомерПредмета |имяПредмете
Номер Студента НомерПредмета
Рис. 6.14. Диаграмма структуры данных для связи между сущностями СТУДЕНТ и ПРЕДМЕТ
Преобразование моделей «сущность—связь»
219
Представление рекурсивных связей
Рекурсивная связь (recursive relationship) — это связь между сущностями одного
п того же класса. У рекурсивных связей нет фундаментальных отличий от других
спязей типа «ИМЕЕТ», и они могут быть представлены теми же способами. Как
и нерекурсивных связей типа «ИМЕЕТ», рекурсивных связей существует три
разновидности: 1:1, 1:N и M:N; на рис. 6.15 приведен пример каждой из этих
разновидностей.
СПОНСОР
Г^1
ЧЕЛОВЕК
а
'-КС
ТО-ЛЕЧИ"
х:УП
гс
ВРАЧ
КЕМ-ПРИВЕДЕН
КЛИЕНТ |
6
Я
Рис. 6.15. Примеры рекурсивной связи: а — рекурсивная связь 1:1;
б — рекурсивная связь 1:N; в — рекурсивная связь N:M
Рассмотрим сначала отношение СПОНСОР на рис. 6.15, а. При связи 1:1 один
человек может финансировать другого, и каждый человек финансируется не
более чем одним человеком. На рис. 6.16, а приведены данные для этого примера.
Для представления рекурсивной связи 1:1 мы применим подход, почти
идентичный тому, который использовался для обычных связей 1:1: мы можем
поместить ключ финансируемого лица в строку спонсора либо поместить ключ
спонсора в строку финансируемого лица. На рис. 6.16, б приведен первый вариант,
а па рис. 6.16, в — второй. Оба варианта работают, поэтому выбор определяется
из соображений производительности.
Данный способ идентичен тому, который применялся для нерекурсивных
связей 1:1, за тем исключением, что родительская и дочерняя строки находятся
и одном и том же отношении. Можно представить себе данный процесс
следующим образом: вообразим, что связь существует между двумя разными
отношениями, определим, что является ключом, и объединим два отношения в одно.
Чтобы проиллюстрировать это, рассмотрим связь КЕМ-ПРИВЕДЕН на рис. 6.15, б.
Это связь 1;N, как показывают данные на рис. 6.17, а. Когда эти данные
помещаются в отношение, одна из строк представляет человека, который приводит
клиентов, а другие строки представляют клиентов, приведенных данным
человеком. Строка человека, приводящего клиентов, играет роль родительской строки,
а те строки, на которые она ссылается, играют роли дочерних строк. Как и для
всех связей вида 1:N, ключ родителя мы вставляем в потомок. На рис. 6.17, б
мы помещаем номер человека, приводящего клиентов, в строки всех клиентов,
приведенных этим человеком.
220 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
Человек
s- Джонс
^ Смит
ч^. Парке
/- Миртл
^►Пайнс
Отношение ЧЕЛ0ВЕК1
Человек ФинансируемоеЛицо
Джонс
Смит
Парке
| Миртл
Пайнс
Смит
Парке
null
Пайнс
null
Ограничение ссылочной целостности:
Значение атрибута ФинансируемоеЛицо должно существовать
среди значений атрибута Человек
6
Отношение ЧЕЛ0ВЕК2
Человек Спонсор
Джонс
Смит
Парке
Миртл
Пайнс
null
Джонс
Смит
null
Миртл
Ограничение ссылочной целостности:
Значение атрибута Спонсор должно существовать
среди значений атрибута Человек
Рис. 6.16. Пример рекурсивной связи 1:1: а — данные для рекурсивной связи 1:1;
6 — первый вариант представления рекурсивной связи 1:1; в — второй вариант
представления рекурсивной связи 1:1
Рассмотрим теперь рекурсивные связи M:N. Связь У-КОГО-ЛЕЧИТСЯ на рис. 6.15, в
представляет ситуацию, в которой врачи лечат друг друга. Данные для этого
примера приведены на рис. 6.18, а. Как и для других связей M:N, нам необходимо
создать таблицу пересечения, в которой будут показаны связанные между собой
пары строк. В первом столбце находится имя того, кто лечит, а во втором — имя
того, кто лечится. Эта структура изображена на рис. 6.18, б.
Рекурсивные связи, таким образом, представляются точно так же, как и
другие виды связей. Однако строки таблиц могут при этом играть две различные
роли. Одни являются родительскими, другие — дочерними. Если некоторый ключ
Преобразование моделей «сущность—связь» 221
предполагается сделать родительским, и строка не имеет родителя, ее значение
будет пустым. Если некоторый ключ предполагается сделать дочерним, и строка
не имеет потомка, ее значение также будет пустым.
Клиент номер
100
300
400
Привел следующих клиентов
200,400
500
600,700
НомерКлиента
100
200
300
400
500
600
700
ДанныеКлиента
КемПриведен
null
100
null
100
300
400
400
Ограничение ссылочной целостности;
Значение атрибута КемПриведен должно существовать
среди значений атрибута НомерКлиента
Рис. 6.17. Пример рекурсивной связи 1:14: а — данные для связи КЕМ-ПРИВЕДЕН;
б — представление рекурсивной связи 1:N с помощью отношений
Представление тернарных связей и связей
высших порядков
Тернарные связи (ternary relationship) представляются с применением подходов,
описанных выше, но зачастую есть особые соображения, которые необходимо
документировать в виде положений делового регламента. Рассмотрим, например,
сущности ЗАКАЗ, КЛИЕНТ и СЛУЖАЩИЙ. В большинстве случаев мы можем
относиться к этой тернарной связи как к двум бинарным.
Допустим, что заказ всегда делается одним покупателем, но один и тот же
покупатель может делать много заказов. Следовательно, бинарная связь между
сущностями ЗАКАЗ и КЛИЕНТ имеет вид N:l. Аналогичным образом,
предположим, что заказ может выполняться только одним служащим, но один и тот же
служащий может выполнять много заказов. Исходя из этого, бинарная связь
между сущностями ЗАКАЗ и СЛУЖАЩИЙ также имеет вид N:l.
Обе эти связи могут быть представлены с использованием вышеописанных
подходов. Первую связь мы представим, поместив ключ отношения КЛИЕНТ в
отношение ЗАКАЗ, а вторую — поместив в это же отношение ключ отношения
СЛУЖАЩИЙ. Таким образом, мы создали тернарную связь между сущностями
ЗАКАЗ, КЛИЕНТ и СЛУЖАЩИЙ в виде двух отдельных бинарных связей.
222 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
Лечащий врач
Джонс
Парке
Смит
Абернати
Франклин
Пациент
Смит
Абернати
Джонс
Франклин
а
Отношение ВРАЧ
Имя Прочие атрибуты
Джонс
Парке
Смит
Абернати
О'Лири
Франклин
Отношени(
Человек
Джонс
Парке
Смит
Абернати
Парке
Франклин
Джонс
э ЛЕЧЕНИЕ_ПРСЧ
Спонсор
Смит
Смит
Абернати
Джонс |
Франклин
Абернати
Абернати
Огранимения ссылочной целостности:
Значение атрибута Врач в отношении ЛЕЧЕНИЕ_ПРСЧ должно
существовать среди значений атрибута Имя в отношении ВРАЧ
Значение атрибута Пациент в отношении ЛЕЧЕНИЕ_ПРСЧ должно
существовать среди значений атрибута Имя в отношении ВРАЧ
6
Рис. 6.18. Пример рекурсивной связи M:N: a — данные для связи У-КОГО-ЛЕЧИТСЯ;
6 — представление рекурсивной связи M:N с помощью отношений
Предположим, однако, что деловой регламент содержит положение, согласно
которому каждый покупатель может размещать заказы только у конкретного
служащего. В этом случае тернарная связь ЗАКАЗ:КЛИЕНТ;СЛУЖАЩИЙ
ограничивается дополнительной бинарной связью вида N:l между сущностями КЛИЕНТ
и СЛУЖАЩИЙ. Чтобы представить данное ограничение, нам необходимо добавить
ключ отношения СЛУЖАЩИЙ в отношение КЛИЕНТ. Получившиеся три отношения
будут выглядеть следующим образом:
Преобразование моделей «сущность—связь» 223
ЗАКАЗ (НомерЗаказа, неключевые атрибуты данных, НомерКлиента, НомерСлужащего)
ПОКУПАТЕЛЬ (НомерКлиента, неключевые атрибуты данных, НомерСлужащего)
КЛЕРК (НомерСлужащего, неключевые атрибуты данных)
Ограничение, устанавливающее, что конкретному клиенту может звонить
только конкретный служащий, означает, что только определенные значения
атрибутов НомерКлиента и НомерСлужащего могут совместно существовать в
отношении ЗАКАЗ. К сожалению, нет способа выразить это ограничение в
терминах реляционной модели. Однако оно должно быть документировано в проекте,
а реализация его должна обеспечиваться хранимыми процедурами или
прикладными программами (рис. 6.19).
Таблица ПРОДАВЕЦ
НомерПродавиа
10
20
30
Прочие неключевые
данные
Таблица КЛИЕНТ
НомерКлиента
ЮоО
2000
3000
Прочие неключевые
данные
НомерПродавца
10
20
30
— Бинарное ограничение «ДОЛЖНО БЫТЬ»
Таблица ЗАКАЗ
НомерЗаказа
100
200
l 300
400
500
Прочие неключевые
данные
НомерПродавца
10
20
10
30
НомерКлиента
1000
2000
1000
3000
2000
Здесь разрешено только значение 20 —
Рис. 6.19. Бинарное ограничение «ДОЛЖНО БЫТЬ»
Кроме того, существуют такие типы бинарных ограничений как «НЕ ДОЛЖНО
БЫТЬ» и «ДОЛЖНО ВКЛЮЧАТЬ». Ограничение «НЕ ДОЛЖНО БЫТЬ» -
:>то бинарная связь, указывающая комбинации, которые не допустимы в
тернарной связи. Например, на тернарную связь РЕЦЕПТ:ЛЕКАРСТВ0:П0КУПАТЕЛЬ может
быть наложено ограничение в виде таблицы АЛЛЕРГИЯ, где указаны лекарства,
которые покупателю не разрешается принимать (рис. 6.20).
224 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
Таблица ЛЕКАРСТВО
Номер-Лекарства
10
20
30
45
70
90
Прочие неключевые I
данные |
Таблица АЛЛЕРГИЯ
НомерКлиента
1000
1000
2000
2000
3000
| 3000
3000
L^
НомерЛекарства
10
20
20
45
30
45
70
Прочие неключевые
данные
— Бинарное ограничение «НЕ ДОЛЖНО БЫТЬ»'
Таблица РЕЦЕПТ
НомерРеиепта
100
200
300
400
500
Прочие неключевые
данные
НомерЛекарства
45
10
70
20
НомерКлиента
1000
2000
1000
3000
2000
Здесь не могут появиться значения 20 или 45 -
Рис. 6.20. бинарное ограничение «НЕ ДОЛЖНО БЫТЬ»
Ограничение «ДОЛЖНО ВКЛЮЧАТЬ» — это бинарная связь, указывающая
все комбинации, которые должны присутствовать в тернарной связи.
Рассмотрим, например, связь АВТ0М0БИЛЬ:РЕМ0НТ:РАБ0ТА. Пускай ремонт включает в
себя определенное количество работ, каждая из которых должна быть выполнена,
чтобы ремонт был успешным. В этом случае, если выполняется ремонт
автомобиля, то все работы в рамках этого ремонта должны появиться в качестве строк
отношения АВТОМОБИЛЬ-РЕМОНТ (рис. 6.21).
Преобразование моделей «сущность—связь», 225
Таблица РЕМОНТ
НомерРемонта
10
20
30
45
Прочие неключевые |
данные '
Таблица РАБОТА
НомерРаботы
1001
1002
1003
2001
2002
3001
| 4001а
Прочие не ключевые
данные
НомерРемонта
10
10
10
20
20
30
40
Бинарное ограничение «ДОЛЖНО БЫТЬ»
Таблица АВТОМОБИЛЬ-РЕМОНТ
НомерСчета
100
200
300
400
500
НомерРемонте
10
10
10
20
20
НомерКлиента
1001
1002
1003
2001
Прочие неключевые
данные
Здесь должно появиться 2002 —
Рис. 6.21. Бинарное ограничение «ДОЛЖНО ВКЛЮЧАТЬ»
Ни один из трех типов бинарных ограничений, описанных здесь, не может
быть представлен в терминах реляционной модели. Все связи должны
представляться в виде комбинаций бинарных связей. Однако ограничения должны быть
документированы в проекте базы данных.
Представление связей типа «ЕСТЬ» (подтипов)
Стратегия представления подтипов, или связей типа «ЕСТЬ», несколько
отличается от стратегии, используемой для связей типа «ИМЕЕТ». Рассмотрим в
качестве примера сущность КЛИЕНТ с атрибутами НомерКлиента, ИмяКлиента и Сумма-
226 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
КОплате. Допустим, что есть три подтипа сущности КЛИЕНТ: ФИЗИЧЕСКОЕ_ЛИЦО,
ТОВАРИЩЕСТВО и КОРПОРАЦИЯ, имеющие следующие атрибуты:
ФИЗИЧЕСКОЕ_ЛИЦО: Адрес, НомерСоциалынойСтраховки
ТОВАРИЩЕСТВО: ИмяУправляющегоПартнера, Адрес, ИНН
КОРПОРАЦИЯ: ДоверенноеЛицо, Телефон, ИНН
Чтобы представить эту структуру с помощью отношений, мы введем одно
отношение для надтипа (КЛИЕНТ) и по одному отношению для каждого подтипа.
Затем мы похместим каждый из атрибутов надтипа в отношение, которое
представляет надтип, а каждый из атрибутов подтипов — в отношения,
представляющие подтипы. На этом этапе отношения подтипов не имеют ключей. Чтобы
создать ключ, мы добавим к каждому из подтипов ключ надтипа — НомерКлиента.
Окончательный список отношений выглядит следующим образом:
КЛИЕНТ (НомерКлиента, ИмяКлиента, СуммаКОплате)
ФИЗИЧЕСКОЕ-ЛИЦО (НомерКлиента, Адрес, НомерСоциальнойСтраховки)
ТОВАРИЩЕСТВО (НомерКлиента, ИмяУправляющегоПартнера, Адрес, ИНН)
КОРПОРАЦИЯ (НомерКлиента, ДоверенноеЛицо, Телефон, ИНН)
Обратите внимание, что при такой структуре связь между строкой отношения
КЛИЕНТ и строкой одного из подтипов имеет вид 1:1. Ни один клиент не имеет
более одной строки в отношении подтипа, и каждому подтипу однозначно
соответствует одна из строк надтипа. В зависимости от ограничений, накладываемых
приложением, возможна ситуация, когда строке отношения КЛИЕНТ будет
соответствовать несколько строк, каждая из которых будет принадлежать
отдельному подтипу. Но ни одной строке отношения КЛИЕНТ не может соответствовать
более одной строки в одном и том же отношении подтипа.
Может случиться так, что у одного или нескольких подтипов будут
собственные ключи. Например, приложение может запрашивать атрибут НомерКорпора-
тивногоКлиента, который отличается от атрибута НомерКлиента. В этом случае
ключом отношения КОРПОРАЦИЯ является НомерКорпоративногоКлиента. Поскольку
связь между сущностями КЛИЕНТ и КОРПОРАЦИЯ имеет вид 1:1, ее можно
установить, поместив ключ одного из отношений в другое. В большинстве случаев
более удачным решением считается помещение ключа отношения надтипа в ключ
отношения подтипа. В этой ситуации отношение КОРПОРАЦИЯ будет иметь
следующую структуру:
КОРПОРАЦИЯ (НомерКорпоративногоКлиента, НомерКлиента, ДоверенноеЛицо,
Телефон, ИНН)
Пример проекта
Рисунок 6.22 — это копия ER-диаграммы, первоначально приведенной в главе 3
на рис. 3.9. Он содержит все основные элементы, используемые в ER-диаграммах.
Чтобы представить эту диаграмму с помощью отношений, мы сначала для каждой
сущности создадим соответствующее отношение. В приведенной ниже таблице
указаны ключи всех созданных нами отношений.
Пример проекту 227
Отношение Ключ
СОТРУДНИК НомерСотрудника
ИНЖЕНЕР НомерСотрудника
ГРУЗОВИК НомерЛицензии
РАБОТА НомерСчета
КЛИЕНТ НомерКлиента
КЛИЕНТ-РАБОТА (НомерСчета, НомерКлиента)
ИНЖЕНЕР-СЕРТИФИКАТ (НомерСотрудника, НазваниеСертификата)
СЕРТИФИКАТ НазваниеСертификата
На следующем шаге мы проверим каждое из этих отношений на соответствие
критериям нормализации. Пример не говорит нам, какие атрибуты должны быть
представлены, поэтому мы не можем определить ограничения. Мы
предположим, что эти отношения находятся в ДКНФ, хотя в реальности справедливость
этого предположения нужно было бы проверить, исходя из перечня атрибутов
и ограничений. На данный момент мы сконцентрируемся на представлении
связей. Отношения и их ключевые атрибуты (в том числе внешние ключи)
перечислены на рис. 6.22, б.
Связь между отношениями СОТРУДНИК и ИНЖЕНЕР уже представлена, так как
эти отношения имеют один и тот же ключ, НомерСотрудника. ИНЖЕНЕР и ГРУЗОВИК
имеют связь 1:1, поэтому представить эту связь можно, поместив ключ одного из
этих отношений в другое. Поскольку грузовик должен закрепляться за
сотрудником, пустых значений не возникнет, если мы поместим атрибут
НомерСотрудника в отношение ГРУЗОВИК; именно так мы и поступим.
Для представления связи между отношениями ИНЖЕНЕР и РАБОТА, имеющей
вид 1:N, мы поместим ключ отношения ИНЖЕНЕР (являющегося родителем) в
отношение РАБОТА (являющееся потомком). Связь между отношениями РАБОТА
и КЛИЕНТ имеет вид M:N, поэтому мы должны создать отношение пересечения.
Так как данная связь и*меет атрибут (Плата), мы добавим этот атрибут в
отношение пересечения КЛИЕНТ-РАБОТА. Чтобы представить рекурсивную связь КЕМ-
ПРИВЕДЕН, имеющую вид 1:N, мы добавим к отношению КЛИЕНТ атрибут Кем-
Приведен. Как вы правильно догадались, имя КемПриведен подразумевает, что
в отношение помещается ключ родителя (клиента, приводящего других клиентов).
Поскольку отношение ИНЖЕНЕР-СЕРТИФИКАТ является
идентификационно-зависимым от отношения ИНЖЕНЕР, мы знаем, что атрибут НомерСотрудника должен
быть частью ключа; таким образом, мы имеем композитный ключ
(НомерСотрудника, НазваниеСертификата). Связь зависимости имеет вид 1:N и будет
обеспечиваться посредством атрибута НомерСотрудника. Наконец, связь между
отношениями СЕРТИФИКАТ и ИНЖЕНЕР-СЕРТИФИКАТ имеет вид 1:N, поэтому нормальным
решением было бы поместить ключ отношения СЕРТИФИКАТ (родителя) в
отношение ИНЖЕНЕР-СЕРТИФИКАТ. Но этот ключ уже является частью отношения, так
что указанное действие выполнять не нужно.
Изучите этот пример, чтобы убедиться, что вы понимаете различные типы
связей и выражение их в терминах отношений. Все элементы модели
«сущность—связь» присутствуют на рис. 6.20. По поводу ограничений ссылочной
целостности обратитесь к вопросу 6.40.
228 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
ЗАКРЕПЛ
КЛИЕ
0..1
ГРУЗОВИК
КЛИЕНТ-
РАБОТА
НТ-КР
0..*
КЛИЕНТ
ЕННЫЙ_ГРУЗОВИК
1..1
СОТРУДНИК
А
| ТипСотрудника -
ИНЖЕНЕР
ИСПОЛНИТЕЛЬ РАБОТЫ
о..* Li_
0..*
^ИНЖЕНЕР-КВАЛИФИКАЦИЯ
ф. .. .
1
1..1
РАБОТА
РАБОТА-КР l '
0./
ИНЖЕНЕР-
СЕРТИФИКАТ
ВИД_СЕРТИФИКАТА
0..1
0..*
0..*
СЕРТИФИКАТ
КЕМ_ПРИВЕДЕН
СОТРУДНИК (НомерСотрудника. прочие неключевые атрибуты отношения СОТРУДНИК...)
ИНЖЕНЕР (НомерСотрудника. прочие неключевые атрибуты отношения ИНЖЕНЕР...)
ГРУЗОВИК (НомерЛицензии. прочие неключевые атрибуты отношения ГРУЗОВИК,
НомерСотрудника)
РАБОТА (НомерСчета. прочие неключевые атрибуты отношения РАБОТА, НомерСотрудника)
КЛИЕНТ (НомерКлиента. прочие неключевые атрибуты отношения КЛИЕНТ, КемПриаеден)
КЛИЕНТ-РАБОТА (НомерСчета. НомерКлиента. Плата)
ИНЖЕНЕР-СЕРТИФИКАТ (НомерСотрудника. НазваниеСертификата.
прочие неключевые атрибуты отношения ИНЖЕНЕР-СЕРТИФИКАТ)
СЕРТИФИКАТ (НазваниеСертификата. прочие неключевые атрибуты отношения СЕРТИФИКАТ)
б
Рис. 6.22. Реляционное представление ER-диаграммы для данного примера:
а — ER-диаграмма из главы 3; б — отношения, представляющие эту ER-диаграмму
Деревья, сети и списки материалов
Хотя ни модель «сущность—связь», ни семантическая объектная модель не
делают никаких предположений относительно структуры связей между сущностями,
некоторые шаблоны возникают настолько часто, что им были присвоены специ-
Деревья, сети и списки материалов 229
альные имена. К этим шаблонам относятся деревья, простые сети, сложные сети
и списки материалов. Мы опишем суть этих шаблонов здесь, в контексте модели
«сущность—связь».
Деревья
Дерево (tree), или иерархия (hierarchy), как его иногда называют, — это структура
данных, элементы которой имеют друг с другом связь «один ко многим». Каждый
элемент имеет максимум одного родителя. На рис. 6.23 изображен пример дерева.
В соответствии с общепринятой терминологией, каждый элемент называется
узлом (node), а связи между элементами называются ветвями (branches). Узел,
располагающийся на вершине дерева, называется корием (root). Между прочим, это
довольно своеобразная метафора: у настоящих деревьев корни обычно находятся
внизу! На рис. 6.23 узел 1 является корнем дерева.
Рис. 6.23. Пример дерева
Каждый узел дерева, за исключением корня, имеет родителя (parent) — узел,
расположенный непосредственно над данным узлом и связанный с ним. Так,
узел 2 является родителем узла 5, узел 4 является родителем узла 8 и т. д. Как
уже говорилось выше, деревья отличаются от других структур данных тем, что
каждый узел имеет максимум одного родителя. Мы говорим «максимум одного
родителя», поскольку у корня родителей нет.
Узлы, расположенные непосредственно под данным узлом и связанные с ним,
называются потомками (children) этого узла, или дочерними узлами. Вообще
говоря, не существует ограничений на количество потомков, которое может иметь
узел. Узел 2 имеет два потомка — узлы 5 и 6; узел 3 не имеет потомков; узел 4
имеет три потомка — узлы 7, 8 и 9. Узлы, имеющие одного родителя,
называются близнецами (twins), или братьями (siblings). Например, узлы 5 и 6 являются
близнецами, или братьями.
На рис. 6.24 изображено дерево сущностей, в котором вы можете увидеть
несколько связей «один ко многим» между сущностями в системе университета.
Колледжи состоят из множества кафедр, на которых, в свою очередь, работают
множество преподавателей и административных работников. Наконец, нрепода-
матели руководят множеством студентов, которые получают множество оценок.
В этой структуре имеется шесть типов сущностей, но все связи имеют вид 1:N.
Чтобы представить дерево сущностей, используя реляционную модель, мы
просто применим понятия, описанные в предыдущих разделах этой главы. Сна-
230 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
чала мы преобразуем каждую сущность в отношение. Затем проанализируем
созданные отношения согласно критериям нормализации и, если потребуется,
разобьем исходные отношения на более мелкие. Связь 1:N мы будем представлять,
помещая ключ родительского отношения в дочернее. На рис. 6.24, б изображена
диаграмма структуры данных, соответствующая дереву на рис. 6.24, а.
Итак, дерево, или иерархия — это совокупность записей, организованная
таким образом, что все связи в ней имеют вид 1:N. Все записи имеют ровно одного
родителя, кроме корня, который родителей не имеет. Иерархия может быть
представлена в виде набора отношений с помощью описанных ранее методов.
Иерархии распространены в бизнесе, особенно в производственных приложениях.
| ПРЕПОДАВАТЕЛЬ |
\
| СТУДЕНТ |
\
1 ОЦЕНКА |
АДМИНИСТРАЦИЯ
Рис. 6.24. Представление дерева с помощью отношений: а — дерево сущностей;
б — представление дерева сущностей в виде отношений
Деревья, сети и списки материалов 231
Простые сети
Простая сеть (simple network) также представляет собой структуру данных,
имеющую связи «один ко многим». Однако в простой сети элементы могут иметь
более одного родителя, если родители принадлежат к различным типам.
Например, в простой сети, представленной на рис. 6.25, каждая сущность СТУДЕНТ имеет
дна родителя: сущности РУКОВОДИТЕЛЬ и СПЕЦИАЛЬНОСТЬ. Структура данных, изо-
Г>раженная на рис. 6.25, не является деревом, поскольку сущности класса СТУДЕНТ
имеют более одного родителя.
На рис. 6.26, а показана общая структура этой простой сети. Обратите
внимание, что все связи имеют вид «один ко многим», но сущность СТУДЕНТ имеет два
родителя. На этом рисунке родительские записи помещены вверху, а дочерние
располагаются под ними. Такое расположение удобно, но не обязательно. Вам
могут встретиться простые сети, где родители изображены рядом с потомками
или под ними. Распознать в этих структурах простые сети можно по тому
признаку, что один тип записи фигурирует в качестве дочернего в двух (или более)
связях «один ко многим».
РУКОВОДИТЕЛЬ СПЕЦИАЛЬНОСТЬ
ГрЛ [ Р2 | | рз I ГсТоо] Гс2оо]
Рис. 6.25. Пример простой сети
Чтобы представить простую сеть сущностей с помощью реляционной модели,
нужно следовать процедурам, описанным ранее. Сначала мы преобразуем
каждую сущность в отношение и, при необходимости, нормализуем созданные
отношения. Затем представляем каждую из связей 1:N, помещая ключ родительского
отношения в дочернее. Результат этого процесса для сети, изображенной на
рис. 6.26, а, показан на рис. 6.26, б.
Сложные сети
Сложная сеть (complex network) — это структура данных, среди связей
которой имеется по меньшей мере одна связь «многие ко многим». Сложная сеть на
рис. 6.27, а иллюстрирует связи между счетами, строками заказа, товарами и
поставщиками. Две из трех связей имеют вид 1:N, а третья — M:N. Поскольку
имеется как минимум одна связь «многие ко многим», эта структура называется
сложной сетью.
Как отмечалось выше, связи M:N не имеют прямого представления в
реляционной модели. Следовательно, прежде чем эту структуру можно будет
представить в реляционной форме, мы должны ввести отношение пересечения. На
рис. 6.27, б отношением пересечения является отношение ДЕТАЛЬ-ПОСТАВЩИК.
232
Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
Н РУКОВОДИТЕЛЬ
СПЕЦИАЛЬНОСТЬ
СТУДЕНТ
Рис. 6.26. Представление простой сети с помощью отношений:
а — простая сеть, сконструированная из сущностей;
б — представление данной простой сети в виде отношений
СЧЕТ
1:N)
СТРОКА ЗАКАЗА
ДЕТАЛЬ
(N:M>
ПОСТАВЩИК
СЧЕТ
ДЕТАЛЬ
ПОСТАВЩИК
НомерПоставшика
ДЕТАЛЬ-ПОСТАВЩИК
НомерДетали] НомерПоставшика
Рис. 6.27. Представление сложной сети с помощью отношений:
а — сложная сеть, сконструированная из сущностей;
б — представление этой сложной сети в виде отношений
Списки материалов
Список материалов (bill of materials) — специальная структура данных, которая
часто появляется в производственных приложениях. Фактически, такие структуры
дали главный импульс развитию технологии баз данных в начале 1960-х годов.
На рис. 6.28 представлен пример списка материалов, в котором показаны
части, составляющие изделие. Если подходить с точки зрения конкретного
продукта, эта структура данных является иерархией. Но поскольку одна и та же деталь
Деревья, сети и списки материалов 233
может использоваться более чем в одном изделии, эта структура на самом деле
представляет собой сеть. Например, деталь АВС100 имеет два предка: продукт А
и продукт В.
Рис. 6.28. Пример списка материалов
Список материалов может быть представлен с помощью отношений
несколькими способами. Наиболее распространенный из них — представление его в
виде рекурсивной связи M:N. Деталь (или изделие, или блок, или подблок и т. д.)
содержит много элементов. В то же время, может быть много элементов, которые
содержат данный элемент. На рис. 6.29, а показана общая структура
рекурсивной связи M:N, а на рис. 6.29, б изображен экземпляр отношения пересечения,
созданного для представления данного списка материалов.
ЭЛЕМЕНТ
ВходитВСостав Содержит
НомерЭлемента Прочие данные об элементе...
Содержит
ВходитВСостав
Содержит
Ограничения ссылочной целостности:
Значение атрибута ВходитВСостав
в отношен и и ЭЛЕМЕНТ-СВЯЗЬ должно
существовать среди значений атрибута
НомерЭлемента в отношении ЭЛЕМЕНТ
Значение атрибута Содержит
в отношении ЭЛЕМЕНТ-СВЯЗЬ должно
существовать среди значений атрибута
НомерЭлемента в отношении ЭЛЕМЕНТ
а
А
А
В
В
АВС100
АВС100
; АВС200
АВС200
АВС600
АВС600
АВС600
SUB1
SUB1
АВС100
АВС200
АВС100
АВС600
Р1
Р2
SUB1
Р4
Р1
РЗ
Р4
АВС100
Р2
Обратите внимание,
что элемент А
содержит
элемент АВС100,
а элемент АВС100
входит в состав
элемента А
Рис. 6.29. Представление списка материалов с помощью отношений:
а — отношения, представляющие список материалов; б — данные
для отношения пересечения ЭЛЕМЕНТ-СВЯЗЬ
234 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
Прежде чем завершить эту главу, мы должны обсудить два важных вопроса:
суррогатные ключи и пустые значения.
Суррогатные ключи
Суррогатный ключ (surrogate key) — это предоставляемый системой уникальный
идентификатор, используемый в качестве первичного ключа отношения.
Значения суррогатного ключа не имеют смысла для пользователей, поэтому в формах
и отчетах они обычно скрываются. СУБД не позволит изменить значение
суррогатного ключа.
Есть две причины для использования суррогатных ключей: одна
прагматическая, другая философская. Рассмотрим вначале прагматическую причину.
Прагматическая причина
Допустим, имеется связь M:N между следующими двумя таблицами:
МОЛЛЮСК (НазваниеМоллюска, Размер, Цвет, Описание)
ПЛЯЖ (НазваниеПляжа, Тип, НаправлениеВолны, СредняяТемператураВоды)
Связь между этими таблицами имеет вид M:N, поскольку моллюсков
можно найти на многих пляжах, и на одном и том же пляже можно найти много
разных типов моллюсков. Предположим, что названия моллюсков — это
текстовые данные вроде Cyrtopleura costata, и моделируются они физическим
доменом TEXT (50). Далее допустим, что названия пляжей также имеют текстовый
формат, например Уидби-Айленд, Криссент-Бич, Ист-Энд, и моделируются
они физическим доменом TEXT (75). Ясно, что индексы, которые необходимо
будет создать из этих столбцов для обеспечения уникальности, будут довольно
длинными. (Информацию о таком использовании индексов вы найдете в
приложении А.)
Более серьезная проблема, однако, касается таблицы пересечения, которая
будет представлять связь M:N. В этой таблице будет два столбца
(НазваниеМоллюска, НазваниеПляжа), домены которых определены как TEXT (50) и ТЕХТ(75)
соответственно. Данные и индексы этой таблицы пересечения будут непомерно
объемными! Например, если база данных по моллюскам содержит 1000 видов,
представителей которых можно найти в среднем на 100 пляжах, таблица
пересечения будет содержать 100 000 строк, в каждой из которых будет по 125
символов. Последней каплей будет то, что все эти данные дублируют
НазваниеМоллюска в таблице МОЛЛЮСК и НазваниеПляжа в таблице ПЛЯЖ.
Затраты на хранение и обработку этих индексов могут быть значительно
снижены, если определить суррогатный ключ в таблицах МОЛЛЮСК и ПЛЯЖ. Для
этого в таблицы МОЛЛЮСК и ПЛЯЖ нужно добавить новые столбцы: скажем, Но-
мерМоллюска и НомерПляжа соответственно. Эти столбцы СУБД определяет как
тип AutoNumber (или что-нибудь в этом роде, в зависимости от используемой
СУБД). Когда столбец определяется таким образом, то всякий раз, когда СУБД
создает новую строку, она генерирует новое, уникальное значение для этого
столбца новой строки.
Деревья, сети и списки материалов 235
С использованием суррогатного ключа наши таблицы будут иметь
следующий вид:
МОЛЛЮСК (НомерМоллюска, НазваниеМоллюска, Размер, Цвет, Описание)
ПЛЯЖ (НомерПляжа, НазваниеПляжа, Тип, НаправлениеВолны, СредняяТемпература-
Воды)
МОЛЛЮСК-ПЛЯЖ (НомерМоллюска, НомерПляжа)
Генерируемые значения суррогатных ключей представляют собой обычно
32-битные целые числа или что-нибудь подобное. Такие значения компактны, их
легко индексировать; введение суррогатных ключей приводит не только к
значительному снижению занимаемого файлового пространства, но и к повышению
быстродействия.
Итак, по прагматическим причинам всегда, когда таблица имеет первичный
ключ, являющийся длинным текстом, или композитный ключ, содержащий
длинные текстовые элементы, стоит подумать об использовании суррогатных ключей.
Философская причина
Философская причина использования суррогатных ключей состоит в том, что
они служат для поддержания идентичности сущности. Когда пользователь
записывает строку в таблицу, эта строка является представлением чего-то. Это что-то
должно существовать, пока пользователь не удалит его. Существование этого
чего-то не должно зависеть от присутствия или отсутствия определенных значений
данных. Поскольку суррогатные ключи не могут быть изменены пользователем
и поскольку они являются гарантированно уникальными, они представляют
идентичность строки (или сущности).
Чтобы прояснить этот момент, рассмотрим две таблицы на рис. 6.30, а,
которые используют в качестве ключей данные, а не суррогатные ключи. Между
отношениями РУКОВОДИТЕЛЬ и СТУДЕНТ существует связь вида 1:N. Эта связь
обеспечивается внешним ключом ИмяРуководителя в отношении СТУДЕНТ. Теперь
предположим, что профессор Сэшнс хочет поменять фамилию на Джонсон.
Допустим, что такое изменение разрешено, и допустим также, что наше
приложение достаточно умно для того, чтобы распространить это изменение через
внешний ключ таким образом, что в столбце ИмяРуководителя таблицы СТУДЕНТ
все значения с фамилией Сэшнс заменяются на Джонсон. Данные будут
выглядеть, как показано на рис. 6.30, б.
И вот мы наблюдаем путаницу. Мы перегрузили фамилию Джонсон, так что
теперь невозможно определить, какими студентами руководит профессор
Джонсон с кафедры бухгалтерского учета, а какими — профессор Джонсон с кафедры
нрава. Хуже того, эта неразбериха является артефактом нашего проекта, а не
следствием каких-либо проблем в среде пользователей.
(Лирическое отступление: вам может прийти в голову, что проблема
заключается в том, что атрибут ИмяРуководителя не был определен как уникальный.
Такое определение, разумеется, предотвратило бы возникновение хаоса, однако
сразу напрашивается вопрос: а кто мы такие, разработчики базы данных, чтобы
определять, что руководители не могут иметь одинаковых имен? Если семантика
236 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
рассматриваемой задачи допускает, что разные руководители могут иметь одно
и то же имя, то мы не имеем права конструировать базу данных, которая не
допускает дублирования имен. Ограничивать поведение пользователей в угоду базе
данных — это плохой замысел.)
Рассмотрим ту же ситуацию с суррогатными ключами. На рис. 6.31, а
изображены данные перед изменением имени, а на рис. 6.31-, б — после изменения.
Ключи не перепутываются, поскольку для представления связи используются
суррогатные ключи.
Отношение РУКОВОДИТЕЛЬ
Имя Отдел
Джонсон
Элдридж
Сэшнс
Бухгалтерский учет
Право
Право
Отношение СТУДЕНТ
Имя Специальность ИмяРуководителя
Франклин
Джефферсон
Вашингтон
Линкольн
Право
Бухгалтерский учет
Право
Право
Элдридж
Джонсон
Сэшнс
Сэшнс
а
Отношение РУКОВОДИТЕЛЬ
Имя Отдел
Джонсон
Элдридж
Джонсон
Бухгалтерский учет
Право
Право
Отношение СТУДЕНТ
Имя Специальность ИмяРуководителя
Франклин
Джефферсон
Вашингтон
Линкольн
Право
Бухгалтерский учет
Право
Право
Элдридж
Джонсон
Джонсон
Джонсон
б
Рис. 6.30. Пример ситуации с перепутыванием ключей: а — отношения
СТУДЕНТ и РУКОВОДИТЕЛЬ без суррогатных ключей, до изменения;
б — те же отношения после изменения
Есть множество других способов выразить понятие о том, что суррогатные
ключи защищают идентификацию. Мир объектно-ориентированного
программирования приводит (другими способами) тот же самый аргумент для объектов
Деревья, сети и списки материалоэ 237
ООП. Все аргументы сводятся к тому, что если идентификатор строки
неизменен на протяжении всего времени существования строки, идентификация этой
строки сможет производиться всегда.
Отношение РУКОВОДИТЕЛЬ
НомерРуководителя Имя Отдел
1
2
3
Джонсон
Элдридж
Сэшнс
Бухгалтерский учет
Право
Право
Отношение СТУДЕНТ
НомерСтудента Имя Специальность НомерРуководителя
20
21
22
23
Франклин
Джефферсон
Вашингтон
Линкольн
Право
Бухгалтерский учет
Право
Право
2
1
3
3
а
Отношение РУКОВОДИТЕЛЬ
НомерРуководителя Имя Отдел
1
2
3
Джонсон
Элдридж
Джонсон
Бухгалтерский учет
Право
Право
Отношение СТУДЕНТ
НомерСтудента Имя Специальность НомерРуководителя
20
21
22
23
Франклин
Джефферсон
Вашингтон
Линкольн
Право
Бухгалтерский учет
Право
Право
2
1
3
3
б
Рис. 6.31. Пример ситуации, когда благодаря использованию суррогатных ключей
перепутывание ключей невозможно: а — отношения СТУДЕНТ и РУКОВОДИТЕЛЬ
до изменения; б — те же отношения после изменения
Это преимущество, однако, имеет свою цену. В структуре на рис. 6.30, а вы
можете посмотреть на строку отношения СТУДЕНТ и сразу сказать, кто является
руководителем данного студента. Имея в роли ключей данные, вам не нужно
выполнять поиск в таблице РУКОВОДИТЕЛЬ, чтобы найти имя руководителя за
данным номером, как это приходится делать со структурой на рис. 6.31, б. Кроме
того, если база данных обменивается информацией с другими базами, которые
используют данные в качестве ключей, применение суррогатных ключей может
привести к проблемам.
238 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
Так использовать суррогатные ключи или нет?
Каков же итог дискуссии? Мнения экспертов расходятся. Никто не оспаривает
прагматических причин для их использования, но некоторые считают, что
применение суррогатных ключей должно быть ограничено теми случаями, где они
необходимы, подобно примеру с моллюсками. Другие возражают, что суррогатные
ключи должны использоваться везде и что данные вообще не следует
использовать в качестве ключей.
Сам я использую суррогатные ключи почти всегда. Я не решаюсь вводить
суррогатные ключи в таблицах, имеющих в качестве естественного ключа легко
индексируемые данные, — например в таблице ПРОДУКТ, содержащей столбец
НомерПродукта с уникальными целыми значениями. Иногда я также не ввожу
суррогатные ключи в таблицах, которые регулярно используются для обмена
данными с другими базами данных.
Эта политика означает, что в некоторых базах данных, разработанных мною,
присутствует смесь информационных и суррогатных ключей. Мне это не
нравится, и это может приводить к недоразумениям. До некоторой степени
количество недоразумений можно уменьшить, используя четкую схему именования
столбцов с суррогатными ключами. Я обычно использую для этих столбцов
имена вроде ИмяТаблицы1д или ИмяТаблицы_ЪУ,.
Обсудите эту тему с вашим преподавателем — у него определенно будут
другие идеи и мнения. Данное решение относится к сфере искусства и должно, по
моему мнению, приниматься индивидуально для каждой таблицы.
Пустые значения
Атрибут имеет пустое значение (null value), если его значение не задано.
Проблема с пустыми значениями состоит в том, что они допускают множество
толкований. Пустое значение может означать, что: а) значение атрибута неизвестно; б)
атрибут неприменим; в) значение атрибута равно нулю. Рассмотрим, например,
атрибут ДатаСмерти в отношении КЛИЕНТ. Что означает пустое значение этого
атрибута? Возможно, пользователи не знают, жив клиент или нет; возможно,
клиент является корпоративным и данный атрибут к нему неприменим; наконец,
возможно, что клиент является физическим лицом и он жив.
Есть несколько способов устранения этой неоднозначности. Первый способ
заключается в том, чтобы не допускать ее. Определите атрибут как
обязательный. Это работает отлично, если в представлении пользователей атрибут
действительно является обязательным. Однако пользователей может раздражать
необходимость указывать, например, значение атрибута ЛюбимыйЦветПокупателя,
если этот атрибут не представляет важности для их работы.
В главе 3 мы узнали способ избежать появления пустых значений там, где
атрибут является неприменимым, — введение подтипов. Введение сущностей
ПАЦИЕНТ-МУЖЧИНА и ПАЦИЕНТ-ЖЕНЩИНА в качестве подтипов сущности ПАЦИЕНТ
избавит пациента мужского пола от необходимости указывать количество
беременностей, а пациентов женского пола — от вопросов о состоянии предстатель-
Резюме 239
ной железы, например. Однако это решение является дорогим — в том смысле,
что оно требует введения двух новых таблиц, и чтобы получить данные обо всех
пациентах, понадобится соединять эти таблицы.
Еще одно решение заключается в том, чтобы определить каждый атрибут с
начальным значением, распознаваемым как пустое. Текстовому атрибуту,
например, может быть присвоено начальное значение (не определено). Далее
пользователи могут присвоить ему значение (не подходит) в случае неприменимости
данного значения. Данный подход будет более эффективен, если такие варианты
выбора будут появляться в раскрывающихся списках (см. главу 10). Хотя данное
решение работает для текстовых атрибутов, проблема с числовыми, логическими
и другими нетекстовыми атрибутами остается. Разумеется, выйти из положения
можно, моделируя эти атрибуты в виде текста, чтобы можно было ввести
значения типа (не определено) и (не подходит). Но в этом случае вам придется писать
собственную процедуру редактирования, которая гарантирует, что в таблицу
будут вводиться правильные числа или даты. Вам также придется программным
путем преобразовывать эти данные к соответствующему типу, прежде чем
производить над ними арифметические операции.
Иногда лучшее решение — не делать ничего с пустыми значениями. Если
пользователи могут смириться с неоднозначностью или если решение требует
больше затрат, чем приносит выгоды, просто документируйте факт
существования проблемы. Обратитесь также к главе 9, где вы найдете информацию о
последствиях, вызываемых наличием пустых значений при выполнении операций
соединения.
Резюме
Для преобразования модели «сущность—связь» каждую сущность в модели
нужно представить отношением. Атрибуты сущности при этом станут атрибутами
отношения. Созданное отношение следует проанализировать на предмет
необходимости нормализации и, если потребуется, разбить на два или более новых
отношения.
В модели «сущность—связь» существует три вида бинарных связей типа
«ИМЕЕТ»: 1:1, 1:N и N:M. Чтобы представить связь 1:1, мы помещаем ключ
одного отношения в другое отношение. Иногда отношения «один к одному»
указывают на то, что два отношения принадлежат одной сущности и их следует
объединить в одно отношение.
Чтобы представить связь 1:N, мы помещаем ключ родительского отношения
в дочернее отношение. Наконец, чтобы представить связь M:N, мы создаем
отношение пересечения, содержащее ключи двух других отношений.
Рекурсивные связи — это связи, в которых участвуют сущности одного и того
же класса. Есть три типа рекурсивных связей: 1:1, 1:N и N:M. Эти типы
представляются так же, как и в случае нерекурсивных связей. Для связей 1:1 и 1:N мы
помещаем внешний ключ в отношение, которое представляет сущность. Для
представления рекурсивных связей N:M мы создаем отношение пересечения.
240 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
Тернарные связи и связи высших порядков могут быть представлены в виде
комбинаций бинарных связей. Однако в этом случае все бинарные ограничения,
налагаемые на тернарную связь, также должны быть представлены в проекте.
Поскольку такие ограничения невозможно реализовать в реляционной
структуре, их необходимо документировать как положения делового регламента.
Имеется три типа таких ограничений: «ДОЛЖНО БЫТЬ», «НЕ ДОЛЖНО БЫТЬ»
и «ДОЛЖНО ВКЛЮЧАТЬ».
Сущности надтипов и подтипов (связи типа «ЕСТЬ») также представляются
в виде отношений. Вводится одно отношение для сущности надтипа и по одному
отношению — для каждой сущности подтипа. Обычно ключи отношений
совпадают и связи между строками определяются с помощью этих ключей. Если же
ключи не совпадают, можно поместить ключ отношения надтипа в отношение
подтипа, или наоборот. Чаще всего ключ отношения надтипа помещается в
отношение подтипа.
Комбинации бинарных связей могут формировать три типа более сложных
структур. Дерево — это совокупность типов записей, в которой каждая запись
имеет ровно одного родителя, за исключением корня, у которого нет родителя.
В простой сети записи могут иметь нескольких родителей, но все родители
должны быть различных типов. В сложной сети записи могут иметь нескольких
родителей одного и того же типа. Иначе говоря, в сложной сети по меньшей мере
одна из бинарных связей имеет вид M:N.
Список материалов — структура данных, часто возникающая в
производственных приложениях. Такие структуры могут быть представлены рекурсивными
связями M:N.
Суррогатные ключи — это предоставляемые системой уникальные
идентификаторы, используемые в качестве первичных ключей отношений. Они
используются по прагматическим причинам — чтобы уменьшить размер ключа и повысить
быстродействие. Есть также и более философские причины для их
использования: они поддерживают идентификацию сущности. Вообще говоря, применение
таких ключей рекомендуется.
Пустое значение — это не заданное значение атрибута. Такие значения
допускают неоднозначное толкование. Они могут означать, что значение атрибута
неизвестно, атрибут неприменим или же его значение равно нулю. Предотвратить
появление пустых значений можно, оформляя значения атрибутов как
обязательные, используя подтипы или присваивая начальные значения. Пустые значения
можно также игнорировать, если возникающая неоднозначность не вызывает
трудностей у пользователей.
Вопросы I группы
1. Объясните, как сущности ER-модели преобразовываются в отношения.
2. Почему необходимо проверять отношения, введенные для представления
сущностей, на предмет необходимости нормализации? При каких условиях
отношения должны быть модифицированы, если они не находятся в ДКНФ?
При каких условиях отношения не следует модифицировать?
Вопросы I группы, 241
3. Объясните, чем представление слабых сущностей отличается от
представления сильных сущностей.
4. Перечислите три типа бинарных связей и приведите пример каждого типа.
Не используйте примеры, которые даны в тексте.
5. Определите термин внешний ключ и приведите пример.
6. Укажите два способа преобразования в реляционную структуру связи 1:1
для вашего ответа на вопрос 4. Используйте диаграммы структуры данных.
7. Для вашего ответа на вопрос 6 опишите метод получения данных об одной
из сущностей по известному ключу другой. Опишите метод получения
данных о второй сущности по известному ключу первой. Дайте ответ для
обеих альтернатив из ответа на вопрос 6.
8. Почему некоторые связи вида 1:1 рассматриваются как подозрительные?
При каких условиях отношения, между которыми имеется связь вида 1:1,
должны комбинироваться в одно отношение?
9. Дайте определения терминов родитель и потомок и приведите примеры.
10. Покажите, как преобразовать в реляционную структуру связь 1:N из
вашего ответа на вопрос 4. Используйте диаграмму структуры данных.
11. Для вашего ответа на вопрос 10 опишите метод получения данных обо
всех потомках по имеющемуся ключу предка. Опишите метод получения
данных о предке по имеющемуся ключу потомка.
12. Для связи вида 1:N объясните, почему необходимо помещать ключ
родительского отношения в дочернее, а не наоборот.
13. Приведите примеры бинарных связей 1:N, отличные от тех, которые
приведены в тексте, для следующих разновидностей связей:
1) связь «необязательно—необязательно»;
2) связь «необязательно—обязательно»;
3) связь «обязательно—необязательно»;
4) связь «обязательно—обязательно».
Проиллюстрируйте ваши ответы, используя диаграммы структуры данных.
14. Покажите, как преобразовать в реляционную структуру связь N:M из
вашего ответа на вопрос 4. Используйте диаграмму структуры данных.
15. Для вашего ответа на вопрос 14 опишите метод получения данных о
потомке одной сущности по имеющемуся ключу другой. Опишите также
метод получения данных о потомке второй сущности по имеющемуся ключу
первой.
16. Почему невозможно преобразовать в отношения связи N:M, используя
ту же стратегию, что и для связей 1:N?
17. Объясните значение термина отношение пересечения.
18. Дайте определения трех типов рекурсивных бинарных связей и приведите
пример каждого типа.
242 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
19. Покажите, как представить в виде отношений рекурсивную связь 1:1 из
вашего ответа на вопрос 18. В чем здесь заключается отличие от
представления нерекурсивных связей 1:1?
20. Покажите, как представить в виде отношений рекурсивную связь 1:N из
вашего ответа на вопрос 18. В чем здесь отличие от представления
нерекурсивных связей 1:N?
21. Покажите, как представить в виде отношений рекурсивную связь M:N из
вашего ответа на вопрос 18. В чем здесь отличие от представления
нерекурсивных связей M:N?
22. Объясните, как используются бинарные связи для представления
тернарной связи в виде реляционной структуры. Приведите пример, отличный
от того, который дан в тексте.
23. Для вашего ответа на вопрос 22 определите бинарное ограничение,
налагаемое на тернарную связь. Объясните, как представить это ограничение.
В связи с тем, что ограничение не может быть реализовано в реляционной
модели, что следует сделать?
24. Приведите примеры бинарных ограничений типа «НЕ ДОЛЖНО БЫТЬ»
и «ДОЛЖНО ВКЛЮЧАТЬ», отличные от тех, которые даны в тексте.
25. Приведите пример надтипа с двумя или более подтипами и покажите, как
представить их с помощью отношений.
26. Дайте определения терминов дерево, простая сеть и сложная сеть.
27. Приведите пример древовидной структуры, отличный от того, который
дан в тексте, и покажите, как представить эту структуру с помощью
отношений.
28. Приведите пример простой сети, отличный от того, который дан в тексте,
и покажите, как представить эту структуру с помощью отношений.
29. Приведите пример сложной сети, отличный от того, который дан в тексте,
и покажите, как представить эту структуру с помощью отношений.
30. Что такое список материалов? Приведите пример, отличный от того,
который дан в тексте, и покажите, как представить ваш пример с помощью
отношений.
31. Определите термин суррогатный ключ и опишите две причины, по
которым суррогатные ключи следует использовать.
32. Опишите ситуацию (отличную от той, которая приведена в тексте), в
которой имеются очевидные прагматические причины для использования
суррогатных ключей.
33. Поясните смысл высказывания: «Суррогатные ключи служат для
поддержания идентичности сущности». Почему это важно?
34. Каковы три возможные интерпретации пустых значений?
35. Опишите три различных способа избежать появления пустых значений.
36. В каких случаях пустые значения не являются проблемой?
Вопросы к проекту FiredUp 243
Вопросы II группы
37. Преобразуйте диаграмму «сущность—связь» для танцевального клуба Джеф-
ферсона (см. рис. 3.19) в отношения. Представьте ваш ответ в виде
диаграммы структуры данных и укажите ограничения ссылочной целостности.
38. Преобразуйте диаграмму «сущность—связь» для бюро аренды яхт Сан-
Хуана (см. рис. 3.21) в отношения. Представьте ваш ответ в виде
диаграммы структуры данных и укажите ограничения ссылочной целостности.
39. Некоторые из отношений на рис. 6.19, 6.20 и 6.21 не находятся в ДКНФ.
Покажите эти отношения на рисунках и объясните, почему они не
находятся в ДКНФ. В какой нормальной форме находятся эти отношения?
Чем можно обосновать такое решение? Как еще приложение базы данных
может реализовывать бинарные ограничения?
40. Сформулируйте все ограничения ссылочной целостности для отношений
на рис. 6.22, б.
Проекты
1. Завершите проект 1 в конце главы 3, если вы еще не сделали этого.
Преобразуйте вашу ER-диаграмму в набор отношений. Если какие-либо из
отношений не находятся в ДКНФ, обоснуйте ваше решение создать
ненормализованные отношения.
2. Завершите проект 2 в конце главы 3, если вы еще не сделали этого.
Преобразуйте вашу ER-диаграмму в набор отношений. Если какие-либо из
отношений не находятся в ДКНФ, обоснуйте ваше решение создать
ненормализованные отношения.
3. Завершите проект 3 в конце главы 3, если вы еще не сделали этого.
Преобразуйте вашу ER-диаграмму в набор отношений. Если какие-либо из
отношений не находятся в ДКНФ, обоснуйте ваше решение создать
ненормализованные отношения.
Вопросы к проекту FiredUp
Если вы еще этого не сделали, создайте диаграммы «сущность—связь» для
вопросов 1 и 2 проекта FiredUp в конце главы 3.
1. Преобразуйте диаграмму «сущность—связь» из вопроса 1 проекта FiredUp
в набор отношений, находящихся в доменно-ключевой нормальной форме.
Для каждого отношения укажите первичный ключ, ключи-кандидаты,
если таковые имеются, и внешние ключи. Сформулируйте все ограничения
ссылочной целостности. Если потребуется, сделайте необходимые
предположения о семантике реализуемого приложения и дайте обоснование этих
предположений.
244 Глава 6. Проектирование баз данных в рамках модели «сущность—связь»
2. Модифицируйте ваш ответ на вопрос 1, введя в него ненормализованные
отношения, если вы считаете, что использование таких отношений
оправданно. Обоснуйте введение каждого из ненормализованных отношений.
Если потребуется, сделайте необходимые предположения о семантике
реализуемого приложения и дайте обоснование этих предположений.
3. Преобразуйте диаграмму «сущность—связь» из ответа на вопрос 3 проекта
FiredUp в конце главы 3 в набор отношений, предпочтительно в доменно-
ключевой нормальной форме. Если какие-либо из ваших отношений не
находятся в доменно-ключевой нормальной форме, объясните почему.
Для каждого отношения укажите первичный ключ, ключи-кандидаты,
если таковые имеются, и внешние ключи. Сформулируйте все ограничения
ссылочной целостности.
4. Модифицируйте ваш ответ на вопрос 3, приведенный выше, предположив,
что номер домашнего телефона, факса и мобильного телефона должны
быть представлены отдельными однозначными атрибутами. Является ли
эта структура более удачной, чем предыдущая? Обоснуйте свой ответ.
Глава 7
Проектирование баз данных
в рамках семантической
объектной модели
В этой главе обсуждается преобразование семантических объектных моделей в
реляционные конструкции. Сначала мы опишем процедуру преобразования
каждого из семи распространенных типов семантических объектов. Затем
проиллюстрируем моделирование и реляционное представление семантических объектов на
примере нескольких объектов реального мира. Поскольку лучшим способом
изучить данный вопрос является самостоятельная проработка примеров, вам
настоятельно рекомендуется реализовать проекты, представленные в конце этой главы.
Преобразования семантических объектов
в реляционные конструкции
В главе 4 введена семантическая объектная модель данных и определено семь
типов семантических объектов. В данном разделе мы опишем методы
преобразования каждого из этих семи типов объектов в отношения. При работе с
семантическими объектами возникновение проблем нормализации менее вероятно, чем при
работе с моделями «сущность—связь», поскольку определение семантических
объектов обычно разделяет семантические темы на групповые атрибуты или
объекты. Таким образом, когда объект преобразуется в отношения, последние
обычно либо находятся в ДКНФ, либо весьма близки к этой форме.
Простые объекты
На рис. 7.1 показано преобразование простого объекта в отношение. Вспомните,
что простой объект не имеет многозначных атрибутов и объектных атрибутов.
Следовательно, он может быть представлен в базе данных одним отношением.
На рис. 7.1, а приведен пример простого объекта ОБОРУДОВАНИЕ, который может
быть представлен в виде одного отношения, как показано на рис. 7.1, б. Каждый
246 Глава 7. Проектирование баз данных в рамках объектной модели
атрибут объекта вводится как атрибут отношения, а идентифицирующий
атрибут, ИнвентарныйНомер, становится ключевым атрибутом отношения, на что
указывает подчеркивание этого атрибута на рис. 7.1, б.
ОБОРУДОВАНИЕ
ID ИнвентарныйНомер
Описание
ДатаПриобретения
Стоимость
а
ОБОРУДОВАНИЕ (ИнвентарныйНомер. Описание, ДатаПриобретения, Стоимость)
б
Рис. 7.1. Реляционное представление простого объекта: а — диаграмма объекта
ОБОРУДОВАНИЕ; б - отношение ОБОРУДОВАНИЕ
Общая схема преобразования простых объектов в отношения показана на
рис. 7.2. Объект ОБЪЕКИ трансформируется в отношение 01. Экземпляры
объекта ОБЪЕКП идентифицирует атрибут А1; он становится ключом отношения 01.
Неключевые данные обозначены на этом и последующих рисунках многоточием.
Поскольку ключ — это атрибут, однозначно идентифицирующий строку
таблицы, только уникальные идентификаторы (обозначенные подчеркнутыми
буквами ID) могут быть преобразованы в ключи. Если у объекта нет уникального
идентификатора, то такой идентификатор необходимо создать, объединив
существующие атрибуты или введя суррогатный ключ.
ОБЪЕКТ
1Q А1
w
w
R1
А1
Рис. 7.2. Общая схема преобразования простого объекта в отношение
Композитные объекты
Композитным объектом называется объект, имеющий один или несколько простых
или групповых многозначных атрибутов, но не имеющий объектных атрибутов.
На рис. 7.3, а приведен пример композитного объекта — СЧЕТ_ИЗ_ГОСТИНИЦЫ. Для
представления этого объекта создано два отношения: одно — для базового объекта
СЧЕТ_ИЗ_ГОСТИНИЦЫ, а другое — для повторяющегося группового атрибута Плата-
ЗаДень. Получившаяся структура показана на рис. 7.3, б.
Атрибут НомерСчета в отношении ПЛАТА_ЗА_ДЕНЬ подчеркнут, так как он
является частью ключа, и выделен курсивом, поскольку он одновременно является
внешним ключом (ключом отношения СЧЕТ__ИЗ_ГОСТИНИЦЫ). Атрибут ДатаНачис-
ления подчеркнут потому, что он является ключом отношения ПЛАТА_ЗА_ДЕНЬ,
но не выделен курсивом, поскольку не является внешним ключом.
Преобразования семантических объектов в реляционные конструкции 247
В общем случае при преобразовании композитных объектов вводится одно
отношение для объекта как такового и по одному отношению на каждый
многозначный атрибут. На рис. 7.4, а объект ОБЪЕКИ содержит две группы
многозначных атрибутов, каждая из которых представлена отношением в структуре
базы данных. Ключ каждой из этих таблиц представляет собой сочетание
идентификатора объекта и идентификатора группы. Так, представлением объекта
ОБЪЕКИ является отношение 01 с ключом А1, отношение 02 с ключом (А1, П)
и отношение 03 с ключом (А1, Г2).
СЧЕТ_ИЗ_ГОСТИНИЦЫ
НомерСчета
ДатаВселения
ИмяКлиента
ВсегоКО плате
ПлатзЗаДемь _
Ш ДатаНачисления
ПлатаЗаНомер
ПлатаЗаЕду
ПлатаЗаТелефон
ПрочиеУслуги
Налог
0.N
а
СЧЕТ_ИЗ_ГОСТИНИЦЫ (НомерСчета. ДатаВселения, ИмяКлиента, ВсегоКОплате)
ПЛАТА_ЗА_ДЕНЬ (НомерСчета. ДатаНачисления. ПлатаЗаНомер, ПлатаЗаЕду,
ПлатаЗаТелефон, ПрочиеУслуги, Налог)
Ограничение ссылочной целостности:
Значение атрибута НомерСчета в отношении ПЛАТА_ЗА_ДЕНЬ должно существовать
среди значений атрибута НомерСчета в отношении СЧЕТ_ИЗ_ГОСТИНИЦЫ
б
Рис. 7.3. Реляционное представление композитного объекта: а — диаграмма объекта СЧЕТ_
ИЗ_ГОСТИНИЦЫ; б - реляционное представление объекта СЧЕТ_ИЗ_ГОСТИНИЦЫ
Минимальное кардинальное число связи в направлении от объекта к группе
задается минимальным кардинальным числом группового атрибута. На рис. 7.4, а
минимальное кардинальное число первой группы Группа1 равно 1, а группы
Группа2 — 0. Эти кардинальные числа показаны на диаграмме структуры данных
и виде перпендикулярной черты (в 02) и овала (в 03). Минимальное
кардинальное число связи по направлению от группы к объекту по умолчанию всегда
равно 1, поскольку группа не может существовать, если не существует объекта,
который должен содержать эту группу. Эти минимальные кардинальные числа
показаны перпендикулярными чертами на линиях связи, ведущих к 01.
Как указано в главе 4, группы могут быть вложенными. На рис. 7.4, б показан
объект, в котором одна группа вложена в другую. В такой ситуации отношение,
представляющее вложенную группу, подчиняется отношению, представляющему
внешнюю группу. На рис. 7.4, б отношение 03 подчинено отношению 02. Ключом
248 Глава 7. Проектирование баз данных в рамках объектной модели
отношения 03 является ключ отношения 02, (А1, Г1) в сочетании с
идентификатором второй группы, Г2; таким образом, ключом отношения 03 является
комбинация (А1, П, Г2).
ОБЪЕКП
Ю А1
fovnna 1 -*
ie n
| f&vnna 2 -
j 10Г2
I.N
O.N
Al
п
Al
£2
Ограничения ссылочной целостности:
Значение атрибута А1 в отношении 02 должно существовать среди
значений атрибута А1 в отношении 01
Значение атрибута А1 в отношении 03 должно существовать среди
значений атрибута А1 в отношении 01
а
ОБЪЕКП
ID A1
Группа 1
ID П
Группа 2
ШГ2
ON
1.N
С
С
01
All
12
61
п
)3
А1
п |
ч
ч
Г2
Рис,
Ограничения ссылочной целостности:
Значение атрибута А1 в отношении 02 должно существовать среди
значений атрибута А1 в отношении 01
Значение комбинации (А1, П) в отношении 03 должно существовать среди
значений комбинации (А1, П) в отношении 02
б
7.4. Общая схема преобразования композитных объектов: а — композитные объекты
с раздельными группами; б — композитные объекты в вложенными группами
Убедитесь, что вы понимаете, почему ключи на рис. 7.4, б построены именно
таким образом. Также обратите внимание, что некоторые атрибуты подчеркнуты
Преобразования семантических объектов в реляционные конструкции^ 249
п выделены курсивом, а некоторые просто подчеркнуты, так как первые
являются и локальными, и внешними ключами, а вторые — только локальными ключами.
Составные объекты
Реляционное представление составных объектов напоминает реляционное
представление сущностей. Фактически, составные объекты и сущности имеют много
сходных черт.
Как мы говорили в главе 4, объект ОБЪЕКП может содержать один или много
экземпляров объекта 0БЪЕКТ2, и наоборот, объект 0БЪЕКТ2 может содержать
один или много экземпляров объекта ОБЪЕКП. Это приводит к возникновению
показанных на рис. 7.5 связей между объектами.
Все эти связи сводятся к некоторому варианту связи «один к одному», «один
ко многим» или «многие ко многим». В частности, связь в направлении от
объекта ОБЪЕКП к объекту 0БЪЕКТ2 может иметь вид 1:1, 1:N или N:M, в то время
как связь в направлении от объекта 0БЪЕКТ2 к объекту ОБЪЕКП может иметь
вид 1:1, 1:М или M:N. Любая из этих связей представляется одним из трех
возможных типов.
Объект 1 может содержать
Один
Много
Один
1:1
М:1
Много
1:N
M:N
Рис. 7.5. Четыре типа составных объектов
Представление составных объектов со связью 1:1
Рассмотрим связь между членом спортивного клуба (ЧЛЕН_КЛУБА) и шкафчиком
м раздевалке (ШКАФЧИК). Каждый шкафчик закрепляется за одним членом
спортивного клуба, и за каждым членом этого клуба может быть закреплен один и
только один шкафчик. На рис. 7.6, а представлены объектные диаграммы. Чтобы
представить эти объекты с помощью отношений, мы для каждого объекта введем
отношение, а затем, как и в случае связи 1:1 между сущностями, поместим ключ
одного из отношений в другое. В данном случае мы можем поместить ключ
отношения ШКАФЧИК в отношение ЧЛЕН_КЛУБА или ключ отношения ЧЛЕН_КЛУБА
is отношение ШКАФЧИК. На рис. 7.6, б изображен случай, когда ключ отношения
ШКАФЧИК помещен в отношение ЧЛЕН_КЛУБА. Обратите внимание, что атрибут
НомерШкафчика в отношении ШКАФЧИК подчеркнут, так как здесь он является
ключом, а в отношении ЧЛЕН_КЛУБА — выделен курсивом, поскольку для данного
отношения он является внешним ключом.
В общем случае при связи 1:1 между объектами ОБЪЕКП и 0БЪЕКТ2 мы
вводим по одному отношению для каждого объекта: 01 и 02 соответственно. Затем
мы помещаем ключ одного из отношений (А1 или А2) в другое отношение, как
показано на рис. 77.
250 Глава 7. Проектирование баз данных в рамках объектной модели
ЧЛЕН_КЛУБА
щЛичныйНомер
Имя
Адрес
Город
Штат
Индекс
цу щю^чщ ^gj
Ш* 1
I
иКАФЧИК
1Q НомерШкафчика
Тип
Код
Расположение
ШШШШШ^-
0.1
ЧЛЕН_КЛУБА (ЛичныйНомер. Имя, Адрес, Город, Штат, Индекс, НомерШкафчика)
ШКАФЧИК(
Ограничение ссылочной целостности:
Значение атрибута НомерШкафчика в отношении ЧЛЕН_КЛУБА должно существовать
среди значений атрибута НомерШкафчика в отношении ШКАФЧИК
б
Рис. 7.6. Пример реляционного представления составных объектов со связью вида 1:1:
а — пример составных объектов со связью 1:1; б — реляционное представление этих объектов
ОБЪЕКП
!Р_ А1
ОБЪЕКТ^
1.1
01
М
02
6l[
А2
I
0БЪЕКТ2
IP. A2
ЬвувёгЩ
0.1
02
А2
А1
Ограничение ссылочной целостности:
Значение атрибута А2 в отношении 01
должно существовать среди значений
атрибута А2 в отношении 02
Ограничение ссылочной целостности:
Значение атрибута А1 в отношении 02
должно существовать среди значений
атрибута А1 в отношении 01
Рис. 7.7. Общая схема преобразования составных объектов со связью 1:1
Представление связей «один ко многим»
и «многие к одному»
Теперь рассмотрим связи 1:N и N:l. На рис. 7.8, а приведен пример связи 1:N
между объектами ОБОРУДОВАНИЕ и РЕМОНТ. Элемент оборудования может ремонти-
Преобразования семантических объектов в реляционные конструкции 251
роиаться много раз, но конкретный ремонт может относиться только к одному
элементу оборудования.
Объекты на рис. 7.8, а представлены отношениями на рис. 7.8, б. Обратите
шншание, что ключ родителя (объект на унарной стороне связи) помещается
и дочернее отношение (объект на множественной стороне связи).
ОБОРУДОВАНИЕ
ю СерийныйНомер
Тип
Модель
ДатаПриобретения
Стоимость
Место
РЕМОНТ \
РЕМОНТ
Ш НомерСчета
Дата
Описание
Стоимость
щтущшищ 1t
ОБОРУДОВАНИЕ (СерийныйНомер. Тип, Модель, ДатаПриобретения, Стоимость, Место)
РЕМОНТ (НомерСчета. Дата, Описание, Стоимость, СерийныйНомер)
Ограничение ссылочной целостности:
Значение атрибута СерийныйНомер в отношении РЕМОНТ должно
существовать среди значений атрибута СерийныйНомер
в отношении ОБОРУДОВАНИЕ
б
Рис. 7.8. Реляционное представление составных объектов со связью 1:N:
а — пример составных объектов со связью 1:N; б — их реляционное представление
На рис. 7.9 показана общая схема преобразования составных объектов со
связью 1:N. Объект ОБЪЕКИ содержит много объектов 0БЪЕКТ2, а объект 0БЪЕКТ2
содержит только один объект ОБЪЕКИ. Чтобы представить эту структуру с
помощью отношений, мы вводим по одному отношению для каждого из объектов
и помещаем ключ родителя в потомок. Например, на рис. 7.9 атрибут А1
помещается в отношение 02.
Если бы объект 0БЪЕКТ2 содержал много объектов ОБЪЕКИ, а объект ОБЪЕКИ —
только один объект 0БЪЕКТ2, мы бы использовали ту же стратегию, только
отношения 01 и 02 поменялись бы ролями. То есть мы поместили бы атрибут А2 в
отношение 01.
Минимальные кардинальные числа в обоих случаях определяются
минимальными кардинальными числами объектных атрибутов. На рис. 7.9 объект ОБЪЕКИ
требует наличия по крайней мере одного объекта 0БЪЕКТ2, но 0БЪЕКТ2 не требует
обязательного наличия объекта ОБЪЕКИ. Кардинальные числа показаны на
диаграмме структуры данных в виде овала на той стороне связи, где располагается
01, и перпендикулярной черты на той стороне связи, где располагается 02. Эти
лначения приведены просто для примера: один из объектов или оба могли бы
иметь кардинальное число 0, 1 или какое-либо другое.
252 Глава 7. Проектирование баз данных в рамках объектной модели
ОБЪЕКЛ
Ш А1
;;:ОбШю*2;-
1 N
01
0БЪЕКТ2
1Q А2
$обыщ$:
0.1
I
0
м|
2 L
А2
А1
Ограничение ссылочной целостности:
Значение атрибута А1 в отношении 02 должно существовать
среди значений атрибута А1 в отношении 01
Рис. 7.9. Общая схема преобразования составных объектов со связью 1:N
Представление связей «многие ко многим»
Наконец, рассмотрим связи M:N. Как и в случае связей M:N между сущностями, мы
определяем три отношения: по одному отношению для каждого из объектов плюс
отношение пересечения. Отношение пересечения представляет связь двух объектов
и состоит из ключей обоих своих родителей. На рис. 7.10, а показана связь M:N
между объектами КНИГА и АВТОР. На рис. 7.10, б изображены три отношения,
представляющие эти объекты: КНИГА, АВТОР и КНИГА-АВТОР-ПСЧ (отношение пересечения).
Обратите внимание, что отношение КНИГА-АВТОР-ПСЧ не содержит иеключевых
данных. Оба атрибута — НомерВКаталоге и НомерСоциальнойСтраховки — подчеркнуты
и выделены курсивом, поскольку они являются и локальными, и внешними ключами.
В общем случае, если два объекта имеют связь вида M:N, мы вводим три
отношения: 01 для объекта 0БЪЕКТ1, 02 для объекта 0БЪЕКТ2 и 03 — отношение
пересечения. Общая схема показана на рис. 7.11. Заметьте, что атрибутами
отношения 03 являются только А1 и А2. В случае составных объектов со связью M:N
отношение 03 никогда не содержит неключевых данных. Важность этого
замечания станет ясна, когда мы сравним связи M:N в составных объектах со связями
этого вида в ассоциативных объектах.
Что касается минимального кардинального числа, то родители отношения
пересечения являются обязательными. Минимальные кардинальные числа связей
в направлении к отношению пересечения определяются минимальными
кардинальными числами связей между объектами. На рис. 7.11, например, строка в
отношении 01 требует наличия строки в отношении 03, поскольку минимальное
кардинальное число объекта ОБЪЕКЛ в объекте 0БЪЕКТ2 равно 1. Однако строка
в отношении 02 не требует наличия строки в отношении 03, поскольку
минимальное кардинальное число объекта ОБЪЕКТ! в объекте 0БЪЕКТ2 равно 0.
Преобразования семантических объектов в реляционные конструкции 253
КНИГА
Ш НомерВ Каталоге
Заголовок
НомерДляВызова
:ДВТОР;?:|Щ1ы
АВТОР
Ш НомерСоциальнойСтраховки
Имя
Телефон
КНИГА (НомерВКаталоге. Заголовок, НомерДляВызова)
АВТОР (НомерСоциальнойСтраховки. Имя, Телефон)
КНИГА-АВТОР-ПСЧ (НомерВКаталоге. НомерСоциальнойСтраховки)
Ограничения ссылочной целостности:
Значение атрибута НомерВКаталоге в отношении КНИГА-АВТОР-ПСЧ должно
существовать среди значений атрибута НомерВКаталоге в отношении КНИГА
Значение атрибута НомерСоциальнойСтраховки в отношении КНИГА-АВТОР-ПСЧ должно
существовать среди значений атрибута НомерСоциальнойСтраховки в отношении АВТОР
б
Рис. 7.10. Реляционное представление составных объектов со связью M:N:
а — объекты КНИГА и АВТОР; б — их реляционное представление
ОБЪЕКП
Ш А1
ШШЩ-
1
.N
0БЪЕКТ2
Ш А2
ЙИИЙЕКТ1:-
11
01
I
02
А1
03
Ч
V А
AZ
М
/
А2
•*
Ограничения ссылочной целостности:
Значение атрибута А1 в отношении 03 должно существовать
среди значений атрибута А1 в отношении 01
Значение атрибута А2 в отношении 03 должно существовать
среди значений атрибута А2 в отношении 02
Рис. 7.11. Общая схема преобразования составных объектов со связью M:N в отношения
Гибридные объекты
Гибридные объекты могут преобразовываться в реляционные конструкции с
помощью комбинации методов, применяемых для композитных и составных объектов.
254 Глава 7. Проектирование баз данных в рамках объектной модели
На рис. 7.12, а показан гибридный объект ЗАКАЗ и связанные с ним объекты. Чтобы
представить данный объект с помощью отношений, мы вводим одно отношение
для самого объекта и по одному отношению для содержащихся в нем объектов
ПОКУПАТЕЛЬ и СЛУЖАЩИЙ. Затем, как в случае композитного объекта, мы вводим
отношение для многозначной группы, которой является СтрокаЗаказа. Поскольку
эта группа содержит другой объект, ТОВАР, мы вводим.отношение и для этого
объекта. Все связи «один ко многим» представляются путем помещения ключа
родителя в дочернее отношение, как показано на рис. 7.12, б.
Пример на рис. 7.12 обманчиво прост. Как отмечалось в главе 4, на самом деле
есть четыре разновидности гибридных объектов. Эти разновидности приведены
в табл. 7.1.
Таблица 7.1. Четыре случая кардинальности гибридного объекта
Случай Описание Пример
1 ОБЪЕКТ2 связан с одним экземпляром Объект ТОВАР связан с одним
ОБЪЕКТ1 и может появиться только объектом ЗАКАЗ и может появиться
в одном экземпляре группы, только в одной строке этого заказа
принадлежащей этому объекту
2 ОБЪЕКТ2 связан с одним экземпляром Объект ТОВАР связан с одним
ОБЪЕКЛ и может появиться в нескольких объектом ЗАКАЗ и может появиться
экземплярах группы, принадлежащей в нескольких строках этого заказа
этому объекту
3 ОБЪЕКТ2 может быть связан связан Объект ТОВАР связан с несколькими
с несколькими экземплярами ОБЪЕКТ1 объектами ЗАКАЗ, но в каждом
и может появиться только в одном из заказов может появиться только
экземпляре группы, принадлежащей в одной строке
этому объекту
4 ОБЪЕКТ2 может быть связан связан Объект ТОВАР связан с несколькими
с несколькими экземплярами ОБЪЕКЛ объектами ЗАКАЗ и может
и может появиться в нескольких экземплярах появиться в нескольких строках
группы, принадлежащей этому объекту каждого из заказов
Случаи 3 и 4 встречаются чаще, чем случаи 1 и 2, поэтому их мы рассмотрим
в первую очередь. Объект ОБЪЕКЛ на рис. 7.13 содержит две группы: Tpynnal
иллюстрирует случай 3, а Группа2 — случай 4.
Группа1 имеет максимальное кардинальное число N, что означает, что ОБЪЕКЛ
может содержать много экземпляров группы Группа1. Кроме того, поскольку
0БЪЕКТ2 помечен как уникальный идентификатор, конкретный экземпляр
объекта 0БЪЕКТ2 может появляться только в одном из экземпляров группы Группа1,
содержащейся в объекте ОБЪЕКЛ. Таким образом, ОБЪЕКЛ действует как
идентификатор группы Группа1 в объекте ОБЪЕКЛ.
(Этот случай иллюстрируется объектом ЗАКАЗ на рис. 7.12. Объект ТОВАР
является идентификатором группы СтрокаЗаказа, поэтому данный товар может
появиться только в одной строке конкретного заказа. Но один и тот же товар может
фигурировать в различных заказах.)
Рассмотрим реляционное представление группы Группа1 на рис. 7.13.
Отношение 01 представляет ОБЪЕКЛ, а отношение 02 представляет 0БЪЕКТ2. Кроме того,
для группы Группа! было создано третье отношение, 0-Г1. Связь между 01 и 0-Г1
Преобразования семантических объектов в реляционные конструкции 255
имеет вид 1:N, поэтому мы помещаем ключ отношения 02 (атрибут А2) в
отношение 0-Г1. Поскольку объект 0БЪЕКТ2 может появляться с конкретным значением
атрибута ОБЪЕКИ только один раз, комбинация (Al, A2) в отношении 0-Г1
является уникальной и может быть сделана ключом данного отношения.
ЗАКАЗ
Ш НомерЗаказа
Дата
Шр^ЕЛЬ'Й
:ШйШйий -|
СтрокаЗаказа
Количество
ШВВИНЯ
Стоимость
ПромежуточныйИ
Налог11
Итог1.1
1.1
1.1
1.1
Т0Г1.1
1.N
ТОВАР
1Й КодТовара
ОписаниеТовара
1 Цена 1,1
jiff заЩ- i
о.и
ПОКУПАТЕЛЬ
ю ИмяПокупателя
Адрес
Город
Штат
Индекс
id Телефон
:ШКАЗ
И 0.N
СЛУЖАЩИЙ
JD ИмяСлужащего
КодСлужащего 1.,
.ЗАКАЗ
ЗАКАЗ (НомерЗаказа, Дета, Промежуточный Итог, Налог, Итог, Телефон,
ИмяСлужа щего)
ПОКУПАТЕЛЬ (ИмяПокупателя. Адрес, Город, Штет, Индекс, Телефон)
СЛУЖАЩИЙ (ИмяСлужашего. КодСлужащего)
СТРОКА_ЗАКАЗА (НомарЗаказа. КодТовара. Количество, Стоимость)
ТОВАР (КодТовара. ОписаниеТовара, Цена)
Ограничения ссылочной целостности:
Значение атрибута ИмяСлужащего в отношении ЗАКАЗ должно существовать
среди значений атрибута ИмяСлужащего в отношении СЛУЖАЩИЙ
Значение атрибута Телефон в отношении ЗАКАЗ должно существовать
среди значений атрибута Телефон в отношении ПОКУПАТЕЛЬ
Значение атрибута НомерЗаказа в отношении СТРОКА_ЗАКАЗА должно существовать
среди значений атрибута НомерЗаказа в отношении ЗАКАЗ
Значение атрибута КодТовара в отношении CTPOKAJ3AKA3A должно существовать
среди значений атрибуте КодТовера в отношении ЗАКАЗ
б
Рис. 7.12. Пример реляционного представления гибридных объектов: а — пример гибридного
объекта; б — реляционное представление объекта ЗАКАЗ и связанных с ним объектов
256 Глава 7. Проектирование баз данных в рамках объектной модели
ОБЪЕКП
1 1Q А1
Группа 1
Ш
Пэу
IQ
jiiife^?!
1
ппа 2
||||ЁКТЗ:
.1
1.N
Q.N
02
01
0БЪЕКТ2
!D_ A2
\figti&Ctti
(
А
3.11
- Случай 4
03
А2
А1
A3
М
А2
А1
Г2
A3
Офаничения ссылочной целостности:
Значение атрибута А1 в отношении 0-Г1 должно существовать
среди значений атрибута А1 в отношении 01
Значение атрибута А2 в отношении 0-Г1 должно существовать
среди значений атрибута А2 в отношении 02
Значение атрибута А1 в отношении 0-Г2 должно существовать
среди значений атрибута А1 в отношении 01
Значение атрибута A3 в отношении 0-Г2 должно существовать
среди значений атрибута A3 в отношении 03
Рис. 7.13. Общая схема преобразования гибридных объектов в отношения
Теперь рассмотрим группу Группа2. Объект ОБЪЕКТЗ не определяет группу
Группа2, поэтому он может появляться в различных экземплярах этой группы
внутри одного экземпляра объекта ОБЪЕКП. (Объект ЗАКАЗ на рис. 7.12 был бы
подобен ОБЪЕКТЗ, если бы объектный атрибут ТОВАР не был уникальным
идентификатором в группе СтрокаЗаказа. Это означало бы, что конкретный товар может
фигурировать много раз в одном и том же заказе.) Так как объект ОБЪЕКТЗ не
является идентификатором группы Группа2, мы предполагаем, что
идентификатором является какой-то другой атрибут, Г2.
На рис. 7.13 показано созданное нами для объекта ОБЪЕКТЗ отношение 03, а
также отношение 0-Г2, представляющее группу Группа2. Связь между 01 и 0-Г2 имеет
вид 1:N, поэтому мы помещаем ключ отношения 01 (атрибут А1) в отношение 0-Г2.
Связь между 03 и 0-Г2 имеет вид 1:N, поэтому мы помещаем ключ отношения 03
(атрибут A3) в отношение 0-Г2.
Теперь, однако, в отличие от случая с группой rpynnal, комбинация (А1, A3)
не может быть ключом 0-Г2, поскольку атрибут A3 может быть спарен с данным
Преобразования семантических объектов в реляционные конструкции- 257
атрибутом А1 много раз. То есть комбинация (А1, A3) не является уникальной
и 0-Г2, поэтому ключом этого отношения должна быть комбинация (А1, Г2).
Случай 1 аналогичен случаю 3, с тем только ограничением, что объект 0БЪЕКТ2
может быть связан только с одним экземпляром объекта 0БЪЕКТ1. Отношения,
изображенные на рис. 7.13, годятся и здесь, но мы должны добавить ключ
отношения 01 (атрибут А1) в отношение 02 и установить ограничение, состоящее в том,
что комбинация (Al, A2) в отношении 0-Г1 должна совпадать с комбинацией
(Al, A2) в отношении 02.
Случай 2 аналогичен случаю 4, но с тем ограничением, что объект ОБЪЕКТЗ
может быть связан только с одним экземпляром объекта ОБЪЕКИ. Опять-таки,
отношения на рис. 7.13 остаются годными и для этого случая, но мы должны
добавить ключ отношения 01 (атрибут А1) в отношение 03 и установить
следующее ограничение: комбинация (А1, A3) в отношении 0-Г2 является
подмножеством комбинации (А1, A3) в отношении 03 (см. вопросы 3 и 8 в конце главы.)
Ассоциативные объекты
Ассоциативный объект — это объект, который связывает два других объекта. Он
представляет собой частных! случай составного объекта, возникающий чаще
всего в ситуациях, связанных с каким-либо назначением. На рис. 7.14, а изображен
объект РЕЙС, который связывает объекты САМОЛЕТ и ПИЛОТ. Для представления
ассоциативного объекта мы определяем отношение для каждого из трех
объектов, а затем представляем связи между ними, используя одну из стратегий,
описанных выше. На рис. 7.14, б, например, изображены три отношения: одно
определено для объекта САМОЛЕТ, одно для объекта ПИЛОТ и одно для объекта РЕЙС.
Связи между объектом РЕЙС и каждым из объектов САМОЛЕТ и ПИЛОТ имеют вид
1:N; чтобы представить эти связи, мы помещаем ключ родителя в дочернее
отношение. В данном случае мы помещаем ключи отношений САМОЛЕТ и ПИЛОТ в
отношение РЕЙС.
Отношение РЕЙС имеет свой собственный ключ. Хотя оно содержит внешние
ключи, эти ключи являются всего лишь атрибутами и не входят в ключ
отношения. Однако это не всегда так. Если бы отношение РЕЙС не имело собственного
ключа, его ключом была бы комбинация внешних ключей объектов, которые оно
связывает. В данном случае это была бы комбинация {ХвостовойНомер, НомерПи-
лота, Дата}.
В общем случае при преобразовании ассоциативных объектов в
реляционные конструкции мы определяем по одному отношению на каждый объект,
участвующий в связи. На рис. 7.15 объект ОБЪЕКТЗ связывает объекты ОБЪЕКИ
и 0БЪЕКТ2. Для этих объектов мы определяем отношения 01, 02 и 03, как
показано на рисунке. Ключи обоих родительских отношений, 01 и 02, фигурируют
в качестве внешних ключей в отношении 03, представляющем ассоциативный
объект. Если бы ассоциативный объект не имел уникального
идентифицирующего атрибута, для создания уникального идентификатора использовалась бы
комбинация атрибутов отношений 01 и 02.
258 Глава 7. Проектирование баз данных в рамках объектной модели
САМОЛЕТ
!£ ХвостовойНомер
Тип
Налет
ШЙ&9&
пилот
1Q НомерП илота
Имя
Телефон
ШШШШШб
!Ej°N
РЕЙС
1Q Идентификатор Рейса
НомерРейса 1 л
Дата 1.1
АэропортОтправления 1
АэропортНазначения
ЯШ?с&:-
Шйр
и
САМОЛЕТ (ХвостовойНомер. Тип, Налет)
ПИЛОТ (НомерПилота. Имя, Телефон)
РЕЙС (НомерРейсе. Дата, АэропортОтправления, АэропортНазначения,
ХаостовойНомер, НомерПилота)
Ограничения ссылочной целостности:
Значение атрибута ХвостовойНомер в отношении РЕЙС должно существовать
среди знечений атрибута ХвостовойНомер в отношении САМОЛЕТ
Значение атрибута НомерПилота в отношении РЕЙС должно существовать
среди значений атрибута НомерПилота в отношении ПИЛОТ
б
Рис. 7.14. Пример реляционного представления ассоциативного объекта и связанных
с ним объектов: а — ассоциативный объект РЕЙС и связанные с ним объекты;
б — реляционное представление объектов САМОЛЕТ, ПИЛОТ и РЕЙС
Обратите внимание на различие между ассоциативным отношением на
рис. 7.15 и отношением пересечения на рис. 7.11. Принципиальная разница
состоит в том, что в ассоциативной таблице хранятся данные, представляющие
некоторый аспект комбинации объектов; отношение же пересечения не
содержит данных и существует лишь для того, чтобы указать, какие объекты связаны
друг с другом.
Объекты вида родитель/подтип
Представление объектов вида родитель/подтип (родитель носит еще
название надтипа) аналогично представлению сущностей с подтипами. Мы вводим
одно отношение для родительского объекта и по одному отношению для
каждого объекта подтипа. Ключом каждого из этих отношений является ключ
родителя.
П реобразования семантических объектов в реляционные конструкции * 259
ОБЪЕКТ2
ю А2
Цбъектй
3.N
ОБЪЕКТЗ
1Q A3
tltbEKflf
ОВЪ£КТ2
1 1
01
I
02
м
о;
N, У
A3
А1
А2
А2
Ограничения ссылочной целостности:
Значение атрибута А1 в отношении 03 должно существовать
среди значений атрибута А1 в отношении 01
Значение атрибута А2 в отношении 03 должно существовать
среди значений атрибута А2 в отношении 02
Рис. 7.15. Общая схема преобразования ассоциативных объектов в отношения
На рис. 7.16, а представлен родительский объект ЧЕЛОВЕК, который имеет два
изаимоисключающих подтипа, СТУДЕНТ и ПРЕПОДАВАТЕЛЬ. На рис. 7.16, а
показано реляционное представление этих трех объектов. Каждый объект
представляется таблицей, и ключ у всех трех таблиц один и тот же.
Отношения на рис. 7.16, б ставят перед нами следующую проблему. Чтобы
определить, к какому из двух типов относится конкретный человек,
прикладной программе придется выполнить поиск и в таблице СТУДЕНТ, и в таблице
ПРЕПОДАВАТЕЛЬ. Если соответствующая запись будет обнаружена в таблице
СТУДЕНТ, значит, человек является студентом; если в таблице ПРЕПОДАВАТЕЛЬ —
.шачит, человек является преподавателем. Такой способ определения носит
косвенный характер и, скорее всего, будет работать медленно, а если человек не
принадлежит ни к одному из этих типов (что возможно), то две таблицы будут
просканированы понапрасну. Из-за этой проблемы в родительскую таблицу
иногда помещается атрибут, указывающий тип.
На рис. 7.16, в показаны две разновидности указателя типа. В первом
варианте, который представлен в отношении ЧЕЛ0ВЕК1, тип объекта хранит атрибут
Тип Человека. Возможными значениями этого атрибута являются строки «СТУДЕНТ»,
«ПРОФЕССОР» или «ДРУГОЙ». Приложение может прочесть значение этого
атрибута и таким образом определить, принадлежит ли человек к одному из подтипов,
п если да, то к какому.
Второй вариант представлен в отношении ЧЕЛ0ВЕК2, имеющем два дополни-
|сльных атрибута: ТипСтудент и ТипПрофессор. Каждый из атрибутов является
260 Глава 7. Проектирование баз данных в рамках объектной модели
булевой переменной с допустимыми значениями «истина» и «ложь».
Обратите внимание, что если человек может принадлежать только к одному из
возможных типов (как здесь), то когда одно из этих значений истинно, другое должно
быть ложно.
ЧЕЛОВЕК
\й НомерСоциальнойСтраховки
ИмяЧеловека
Телефон
llilili^Eiii
О ST
|ll|ipA8|ii||;
ПИЛОТ
ie
ЧЕЛОВЕК^
Дата Рожден и я
СреднийБалл
р
ПРЕПОДАВАТЕЛЬ
1Q
ЧЕЛОВЕК
Звание
Кафедра
р
ЧЕЛОВЕК (НомерСоциальнойСтраховки. ИмяЧеловека, Телефон)
СТУДЕНТ (НомерСоциальнойСтраховки. ДатаРождения, СреднийБалл)
ПРЕПОДАВАТЕЛЬ (НомерСоциальнойСтраховки. Звание, Кафедра)
Ограничения ссылочной целостности:
Значение атрибута НомерСоциальнойСтраховки в отношении СТУДЕНТ должно
существовать среди значений атрибута НомерСоциальнойСтраховки
в отношении ЧЕЛОВЕК
Значение атрибута НомерСоциальнойСтраховки в отношении ПРЕПОДАВАТЕЛЬ должно
существовать среди значений атрибута НомерСоциальнойСтраховки
в отношении ЧЕЛОВЕК
ЧЕЛОВЕК1 (НомерСоциальнойСтраховки. ИмяЧеловека, Телефон, ТипЧеловека)
ЧЕЛОВЕК2 (НомерСоциальнойСтраховки. ИмяЧеловека, Телефон, ТипСтудент,
Тип Преподаватель)
в
Рис. 7.16. Пример реляционного представления объектов вида родитель/подтип:
а - родительский объект ЧЕЛОВЕК и объекты-подтипы СТУДЕНТ и ПРЕПОДАВАТЕЛЬ;
б — реляционное представление родителя и подтипов; а — альтернативный
вариант реляционного представления
Вообще говоря, вариант, представленный в отношении ЧЕЛ0ВЕК1, более
предпочтителен в том случае, когда подтипы являются взаимоисключающими.
Вариант, приведенный в отношении ЧЕЛ0ВЕК2, больше подходит в ситуациях, когда
подтипы не исключают друг друга.
Общая схема представления подтипов показана на рис. 7.17. Одно
отношение создается для родителя и по одному — для каждого из подтипов. Ключом
всех отношений является идентификатор родителя. Все связи между родителем
и подтипами имеют вид 1:1. Обратите внимание на длинную черту,
пересекающую линии связи, и на кардинальность группы подтипов. Кардинальность 0.1.1
Преобразования семантических объектов в реляционные конструкции t 261
пшорит о том, что ни один из подтипов не является обязательным, но если он
присутствует, допустим максимум один подтип.
ОБЪЕКП
1С А1
ПОДТИПУ
0.ST
||ПЩТИП^|
O.ST
ПОДТИП1
,ОеЪЁКТ1::
р
03
М
А2
Ограничения ссылочной целостности:
Значение атрибута А1 в отношении 02 должно существовать среди
значений атрибута А1 в отношении 01
Значение атрибута А1 в отношении 03 должно существовать среди
значений атрибута А1 в отношении 02
Рис. 7.17. Общая схема преобразования объектов вида родитель/подтип в отношения
(Вспомните, что кардинальность группы записывается в формате r.m.n, где
i • булево значение, определяющее, является ли группа подтипов необходимой,
ш -- минимальное количество подтипов, которые должны иметь значение внутри
i рунпы, an — максимальное количество подтипов, могущих иметь значение в
группе. Поэтому, например, в группе из пяти подтипов кардинальность 1.2.4 указывает
пи то, что группа является необходимой, по крайней мере два атрибута в ней
должны иметь значение и значение в ней могут иметь максимум четыре атрибута.)
Объекты вида архетип/версия
()бьекты вида архетип/версия — это объекты, моделирующие различные итерации,
иерсни или экземпляры основного объекта. Объекты на рис. 7.18, а моделируют
программные продукты, которые существуют в различных версиях. Примерами
подобных продуктов являются Microsoft Internet Explorer и Netscape Navigator.
Примерами версий являются Access 2000 и Access 2002.
Реляционное представление объектов ПРОДУКТ и ВЕРСИЯ показано на рис. 7.18, б.
Одно отношение введено для объекта ПРОДУКТ и одно — для объекта ВЕРСИЯ.
Ключом объекта ВЕРСИЯ является комбинация ключа объекта ПРОДУКТ и
локального ключа (НомерВерсии) объекта ВЕРСИЯ.
262 Глава 7. Проектирование баз данных в рамках объектной модели
ПРОДУКТ
1й Название
Описание
Сум маПродажП родукта
щщроутшт
пилот
iq ИдентификаторВерсии
ЩШ>ШШШ
НомерВерсии
ДатаВыхода
СуммаП родажЭерси и
it
ПРОДУКТ (Название. Описание, Сум маПродажП родукта)
ВЕРСИЯ (Название. НомерВерсии, ДатаВыхода, СуммаПродажВерсии)
Ограничение ссылочной целостности:
Значение атрибута Название в отношении ВЕРСИЯ должно существовать
среди значений атрибута Название в отношении ПРОДУКТ
б
Рис. 7.18. Пример реляционного представления объектов вида архетип/версия:
а — объект-архетип ПРОДУКТ и объект ВЕРСИЯ; б — их реляционное представление
ОБЪЕКЛ
1Q А1
^ШШШ
с
.N
ОБЪЕКТ2
ю Объект2Ю
>оеЩЩ|
А? 1
•1_
Л
01
|М| ~
02 \
М
А2
ч
Ограничения ссылочной целостности:
Значение атрибута А1 в отношении 02 должно существовать
среди значений атрибута А1 в отношении 01
Рис. 7.19. Общая схема преобразования объектов вида архетип/версия в отношения
На рис. 7.19 показана общая схема преобразования объектов вида
архетип/версия в отношения. Атрибут А1 отношения 02 является и локальным, и внешним
ключом, а атрибут А2 является только локальным ключом.
Примеры объектов
Чтобы на практике применить описанные понятия, рассмотрим несколько объектов,
взятых из реального бизнеса. Примеры расположены по возрастанию уровня
сложности. Мы будем моделировать каждый объект и представлять его с помощью отно-
Примеры объектов 263
топни, используя методы, описанные в этой главе. Ограничения ссылочной
целостности для этих объектов вы сформулируете в ответах на вопросы 7.20, 7.21 и 7.22.
Подписной абонемент
I la рис. 7.20, а показан подписной абонемент на журнал. Этот абонемент может
быть представлен по крайней мере двумя объектными структурами. Если
издатели журнала Fine Woodworking рассматривают подписчика как атрибут подписки,
то подписка может быть смоделирована простым объектом, который
представляется одним отношением, как показано на рис, 7.20, б.
Fine
Wood
iTmWorking
То subscribe
□ 1 year (6 issues) for just $18 С 20% off the newsstand price.
(Outside the U.S. $21/year.CU.S. funds, please)
□ 2 years (12 issues) for just $34 С save 24%
(Outside the U.S. $40/2 yearsCU.S. funds, please)
Name
Address
City ,
State
Zip
D My payment is enclosed. D Please bill me.
Please start my subscription with □ current issue D next issue.
SUBSCRIPTION
ie SubNumber
Start Date
EndDate
AmtDue
Name
Address
City
State
Zip
PayCode
SUBSCRIPTION
SubNumber StartDate EndDate AmtDue Name Address
City | State [ Zip | PayCode
Рис. 7.20. Альтернативные представления подписки: а — бланк подписки;
б — подписка, смоделированная в виде одного объекта
264 Глава 7. Проектирование баз данных в рамках объектной модели
Если данная компания издает только один журнал и больше никаких
публикаций не планирует, структура на рис. 7.20, б будет работать. Если же компания
выпускает несколько различных изданий и клиент может подписаться более
чем на одно из них, то данные о клиенте будут дублироваться для каждого
издания, на которое этот клиент подписывается. Это будет не только пустой тратой
файлового пространства издателя, но и источником раздражения для клиента,
поскольку если он сменит адрес, то будет вынужден подтвердить изменение
адреса для каждого выписываемого им издания данного издательства.
Если компания выпускает или планирует выпускать несколько изданий,
более удачным решением будет смоделировать подписчика в виде отдельного
объекта, как показано на рис. 7.21. Объект CUSTOMER (клиент) является составным
объектом со связью 1:N и представлен на этом рисунке отношениями.
CUSTOMER
iq CustomerNumber
id Name
Address
City
State
Zip
SUBSCRIPTION
iq SubNumber
StartDate
End Date
AmtDue
PayCode
lillllllljl
CUSTOMER
CustomerNumber
SUBSCRIPTION
Name Address City State Zip
SubNumber StartDate EndDate AmtDue PayCode CustomerNumber
Рис. 7.21. Подписка, смоделированная в виде двух объектов
Описание продукта
На рис. 7.22, а показано описание популярного готового продукта в упаковке. В то
время как на рис. 7.20, а представлена старая форма без данных, на рис. 7.22, а
изображен конкретный экземпляр отчета с данными о рисовых хлопьях. Данный
формат используется во всех отчетах о хлопьях фирмы Kellogg.
На рис. 7.22, б показан композитный объект, который может лежать в основе
этого отчета. Мы говорим «может», поскольку существует много различных
способов представления данного объекта. Кроме того, в ходе дальнейшего
исследования мы можем обнаружить другие объекты, существование которых, если
исходить из одного этого отчета, не очевидно. Например, рекомендация
министерства сельского хозяйства США может быть самостоятельным семантическим
объектом.
Примеры объектовч 265
RICE
KRISPIES
NUTRITION INFORMATION
SERVING SIZE: 1GZ (28 4 g, ABOUT 1 CUP)
SERVINGS PER PACKAGE. 1Э
CALORIES
PROTEIN
CARBOHYDRATE
FAT
CHOLESTEROL
SODIUM
POTASSIUM
PERCENTAGE OF U.S.
cent/u.
110
2g
2$ g
Og
0 mg
290 mg
35 mg
«TTHIftCUP
VfTWNSAtO
аиыуск
150*
eg
3ig
og*
Omg*
360mg
240mg
RECOMMENDED
DAILY ALLOWANCES (U.S. ROA)
PROTEIN
VITAMIN A
VITAMIN С
THIAMIN
RIBOFLAVIN
NIACIN
CALCIUM
IRON
VITAMIN D
VITAMIN в.
FOLIC ACIO
PHOSPHORUS
MAGNESIUM
ZINC
COPPER
2
25
25
35
35
35
♦ .
10
10
35
35
4
2
?
2
Ю
30
2S
40
45
35
15
10
25
35
35
15
6
6
4
•WHOLE MILK SUPPLIES AN AOOITIONAl Э0
CALORIES. 4 a FAT. ANO IS mo CMOLESTEAOL.
* 'CONTAINS LESS THAN 24 OFTHE U S ЯОА OF
THIS NUTRIENT
INGREDIENTS RICE. SUGAR SALT.
CORN SYRUP. MALT FLAVORING.
VITAMINS ANO IRON: ViTAMiN С (SODIUM
ASCORBATE AND ASCORBIC ACID)
NIACINAMIDE. IRON. VITAMIN в, (PY.
RIOOXINE HYDROCHLORIDE) VlTAMlNA
(PALMITATE). VITAMIN B, (RIBOFLAVIN).
VITAMIN 6, (THIAMIN HYDROCHLORIDE).
FOLIC ACID. AND VITAMIN D.
TO KEEP THIS CEREAL FRESH. BHT
HAS BEEN ADDED TO THE
PACKAGING.
CEREAL-PRODUCCT
ID Name
ServingSize
NumberServings
Nutrient
jrj NutrientName
CerealOnlyAmt
WithMilkAmt
USDARecDailyAllow
ID VitaminName
CerealOnlyPercent
WithMilkPercent
Ingredient 1-N
Vitamin Iron 1-N
7.N
I.N
Рис. 7.22. Представление отчета о выпускаемых хлопьях: а — отчет о продукте;
б — диаграмма объекта CEREAL-PRODUCT
Для иллюстративных целей мы делаем различные предположения о группах
Nutrient (пищевая ценность) и USDARecDailyAllow (рекомендованная министерством
сельского хозяйства ежедневная норма). Объект CEREAL-PRODUCT (хлопья)
предполагает, что каждый элемент группы Nutrient — калории, белки, углеводы, жиры,
холестерин, натрий и калий — является необходимым в каждом экземпляре
данного объекта. Мы, однако, не предполагаем этого для группы USDARecDailyAllow,
поскольку должен существовать только один экземпляр этой группы.
Отчет на рис. 7.22, а имеет много интерпретаций и может моделироваться
несколькими различными способами. При разработке реального проекта важно
собрать как можно больше отчетов о других выпускаемых хлопьях, их составе
и пищевой ценности. В результате анализа этих документов данный
семантический объект, скорее всего, будет дополнен какими-то новыми структурами.
266 Глава 7. Проектирование баз данных в рамках объектной модели
На рис. 7.23 показано реляционное представление объекта CEREAL-PRODUCT.
Минимальное кардинальное число 7 указывается рядом с перпендикулярной
чертой на линии связи, обозначающей обязательную связь. Внешние ключи
были размещены так, как описывалось ранее для композитных объектов.
NUTRIENT
Name
NutrientNeme
CerealOnlyAmt
-
CEREAL-PRODUCT
Name
/
"7
WithMilkAmt
INGREDIENT
i Name
Ingredient
ServingSize ServingsPerPackage
USDA-RDA
Name
VitaminName
\
^^ VIT-IRON
Name
Vitaminlron
CerealOnlyPercent
WithMilkPercent |
Рис. 7.23. Реляционное представление объекта CEREAL-PRODUCT
Акт о нарушении правил дорожного движения
На рис. 7.24, а изображен бланк акта о нарушении правил дорожного движения,
используехМЫЙ в штате Вашингтон. Разработчик этого бланка дал нам важные
подсказки относительно объектов, лежащих в основе этого бланка. Обратите
внимание на то, что бланк разделен на разделы с закругленными углами,
означающими, что эти разделы относятся к разным объектам. Кроме того, некоторые группы
атрибутов имеют названия, что указывает нам на необходимость введения
групповых атрибутов.
На рис. 7.24, б изображен один из вариантов моделирования объектов, лежащих
в основе акта о нарушении правил дорожного движения. Хотя мы не можем быть
уверены в этом, изучив всего одну форму, есть определенные признаки, по которым
можно сделать вывод, что водитель, транспортное средство и офицер дорожной
полиции являются независимыми объектами. Во-первых, данные, относящиеся
к каждому из них, находятся в разных секциях бланка. Но более важно то, что
каждый раздел содержит поля, которые несомненно являются идентифицирующими
атрибутами чего-то еще, помимо уведомления об исправлении (CORRECTION-NOTICE).
Например, комбинация {DriversLicense, State} (водительская лицензия, штат)
идентифицирует водителя; VehicLeLicense (лицензия транспортного средства), State
(штат) и VIN (идентификационный номер транспортного средства)
идентифицируют зарегистрированный автомобиль; наконец, PersonnelNumber (личный номер)
идентифицирует офицера дорожной полиции. Эти ключевые поля определенно
Примеры объектов, 267
являются детерминантами, поэтому для каждого из них был введен свой объект.
Реляционное представление этих диаграмм показано на рис. 7.25,
CORRECTION-NOTICE
ID Number
DRIVER
VEHICLE
OFFICER,'
Violation Date
Month
Day
Year
Time
District
Detach
Location
Distance
Direction
City
Highway
Violation 1N
Action Required
1.1
"l
1.1
WASHINGTON STATE PATROL CORRECTION NOTICE
Г
Кгоеккя
. DiunzC M
5053 $$ Aw SB
MecerlsbuuL »™, Wo, г£*х?ВО<Ю\
□RIVERS LICENSE
. 00000
a
bwthdate Г нот] wot eyes!
W*jf\2/27\K\ €\1€5 BL
. , . r~J&
HKXES LICENSE I STATE COLOR YEAR ] M«iK£ I TYPEA
AAAOOO Wa\ Щ Sm& \ 900}
I I I I I I I II I t i I I I I
^VIOLATION DATE WST
mo 11 ж 7 ъ*200Гж* 935\ Z
| LOCATION _
\^17^E
Ш
Енмжскмж, on SR410
Writing text wkiU driving
^OFFICERS
^850)
I CORRECT VIOLATIONS) IMMEDIATELY Я
it
a
DRIVER
ю Name -
Last
First
Initial __
Address 11
City
State
ZipCode
id License
DriversLicense
State
Sex
Birthdate
Height
Weight
Eyes
1 1
CORRECTION-NOTICE
VEHICLE
id License
VehicleLicense
State
Color
Year
Make
Type
Ш VIN
Registered Owner
Address
1ШВШШ1ш-но*Ш
1.N
OFFICER
Name
ID Personnel umber
.*6DRRECTIQN-NOTICE
Рис. 7.24. Уведомление об исправлении нарушения: а — образец бланка;
6 — диаграмма объекта CORRECTION-NOTICE
268 Глава 7. Проектирование баз данных в рамках объектной модели
DRIVER
| Last
Rrsl
1 Initial
Ajdress
CORRECTION-NOTICE
[Number [Month
Date
VIOLATION^
Violation
Number
VEHICLE
License 1
State 1
City 1 State
ZipCode]
pYea
ir Time
District
PriversLicense
State
Sex
DFFICER
Name
PersonnelNumber
Datach Distance Direction
Birthdate
Height
Weight Eyes
City | Highway | ActionRequired
DrwersUcense
State
PersonnelNumber VIN
r V
CD
Color
Yea
IT
[маке
Type j
VIN |
RegisteredOwner
Address
Рис. 7.25. Реляционное представление объекта CORRECTION-NOTICE
Резюме
Способ преобразования семантических объектов в отношения зависит от типа
объекта. Простые объекты представляются одним отношением. Необъектные
атрибуты выступают в качестве атрибутов этого отношения.
Для представления композитных объектов требуется два или более
отношений. Одно из отношений содержит однозначные атрибуты объекта. Остальные
отношения содержат простые или групповые многозначные атрибуты, для
каждого из которых создается одно отношение. Ключ отношения, представляющего
многозначный атрибут, — это всегда композитный ключ, который состоит из
ключа объекта и идентификатора композитной группы, имеющейся в этом объекте.
Для представления составного объекта требуется по крайней мере два
объекта. Каждое отношение имеет свой собственный ключ, отличающийся от других.
Есть четыре типа составных объектов, различающихся по видам связи — «один
к одному», «один ко многим», «многие к одному» и «многие ко многим». Чтобы
представить эти типы, необходимо создать соответствующие внешние ключи.
Для связей «один к одному» ключ любой из таблиц можно поместить в
качестве внешнего ключа в другую таблицу. Для связей «одни ко многим» и «многие
к одному» ключ родительского отношения помещается в дочернее отношение.
Наконец, для связей «многие ко многим» создается таблица пересечения, в
которую помещаются ключи обоих отношений.
Гибридные объекты представляются путем создания таблицы для
многозначного группового атрибута композитного объекта и помещения в эту таблицу
ключа отношения, представляющего некомпозитный объект. Четыре примера
гибридных объектов представлены в табл. 7.1.
Для представления ассоциативных объектов требуется по крайней мере три
отношения — по одному на каждый из объектов, участвующих в связи. Каждое
отношение имеет свой собственный ключ, а отношение, представляющее
ассоциативный объект, содержит в качестве внешних ключей ключи двух других объектов.
Вопросы I группы, 269
Объекты вида родитель/подтип представляются одним отношением для
базового объекта и одним отношением для каждого из подтипов. Как правило, ключ
у всех отношений один и тот же. Иногда в родительское отношение помещается
идентифицирующий атрибут, который указывает тип объекта.
Для объектов вида архетип/версия создается одно отношение,
представляющее архетип, и одно отношение, представляющее версию. Ключ отношения,
представляющего версию, всегда содержит ключ архетипа.
Вопросы I группы
1. Приведите пример простого объекта, отличный от того, который дан в
тексте. Покажите, как представить этот объект с помощью отношения.
2. Приведите пример композитного объекта, отличный от того, который дан
в тексте. Покажите, как представить этот объект с помощью отношений.
3. Приведите пример составного объекта со связью вида 1:1, отличный от
того, который дан в тексте. Покажите, как представить этот объект с
помощью отношений.
4. Приведите пример составного объекта со связью вида 1:N, отличный от
того, который дан в тексте. Покажите, как представить этот объект с
помощью отношений.
5. Приведите пример составного объекта со связью вида М:1, отличный от
того, который дан в тексте. Покажите, как представить этот объект с
помощью отношений.
6. Приведите пример составного объекта со связью вида M:N, отличный от
того, который дан в тексте. Покажите, как представить этот объект с
помощью отношений.
7. Приведите пример гибридного объекта первого рода (см. табл. 7.1).
Покажите, как представить этот объект с помощью отношений.
8. Приведите пример гибридного объекта второго рода (см. табл. 7.1).
Покажите, как представить этот объект с помощью отношений.
9. Приведите пример ассоциативного объекта и связанных с ним объектов,
отличный от того, который дан в тексте. Покажите, как представить эти
объекты с помощью отношений. Пусть при этом ассоциативный объект
имеет свой собственный идентификатор.
10. Сделайте то же самое, что и в ответе на вопрос 9, но в предположении, что
ассоциативный объект не имеет собственного идентификатора.
11. Приведите пример родительского объекта, имеющего по крайней мере два
взаимоисключающих подтипа. Покажите, как представить эти объекты
с помощью отношений. Используйте атрибут, указывающий тип объекта.
12. Приведите пример родительского объекта, имеющего по крайней мере два
подтипа, не являющихся взаимоисключающими. Покажите, как
представить эти объекты с помощью отношений. Используйте атрибут,
указывающий тип объекта.
270 Глава 7. Проектирование баз данных в рамках объектной модели
13. Найдите в вашем университете бланк, который может быть адекватно
смоделирован в виде простого объекта. Покажите, как представить этот
объект с помощью отношений.
14. Найдите в вашем университете бланк, который может быть адекватно
смоделирован в виде композитного объекта. Покажите, как представить этот
объект с помощью отношений.
15. Найдите в вашем университете бланк, который может быть адекватно
смоделирован в виде составного объекта одного из типов. Покажите, как
представить эти объекты с помощью отношений.
16. Найдите в вашем университете бланк, который может быть адекватно
смоделирован в виде гибридного объекта. Классифицируйте этот объект в
соответствии с табл. 7.1. Покажите, как представить эти объекты с помощью
отношений.
17. Найдите в вашем университете бланк, который может быть адекватно
смоделирован в виде ассоциативного объекта и связанных с ним объектов.
Покажите, как представить эти объекты с похмощью отношений.
18. Найдите в вашем университете бланк, который может быть адекватно
смоделирован в виде объектов вида родитель/подтип. Покажите, как
представить эти объекты с помощью отношений.
19. Найдите в вашем университете бланк, который может быть адекватно
смоделирован в виде объектов вида архетип/версия. Покажите, как
представить эти объекты с помощью отношений.
20. Какие ограничения ссылочной целостности (если они есть) должны быть
указаны для структур, изображенных на рис. 7.20, б и 7.21?
21. Какие ограничения ссылочной целостности (если они есть) должны быть
указаны для структуры, изображенной на рис. 7.23?
22. Какие ограничения ссылочной целостности (если они есть) должны быть
указаны для структуры, изображенной на рис. 7.25?
23. Пусть объект 01 имеет связь вида 1:N с объектом 02, а объект 02 имеет
связь вида 1:N с объектом 03. Пусть при этохМ объект 02 является
обязательным в объекте 01, а объект 03 является необязательным в 01. Есть ли
разница между ограничением ссылочной целостности, налагаемым на связь
между 01 и 02, и ограничением ссылочной целостности, налагаемым на
связь между 01 и 03? Если есть, то какая?
Вопросы II группы
24. Приведите пример каждого из четырех случаев гибридных объектов,
приведенных в правом столбце табл. 7.1. Покажите, как ваши примеры будут
представляться в виде отношений.
25. Модифицируйте рис. 7.22, б и 7.23 так, чтобы учесть в них отчеты,
изображенные на рис. 7.26.
Вопросы II группыч 271
FDA REPORT #6272
Date: 06/30/2001
Issuer: Kellogg's Corporation
Report Title: Product Summary by Ingredient
Corn
Corn syrup
Malt
Wheat
Corn Flakes
Krispix
Nutrigrain (Corn)
Rice Krispies
Frosted Flakes
Sugar Pops
Rice Krispies
Sugar Smacks
Sugar Smacks
Nutrigrain (Wheat)
SUPPLIERS LIST
Date: 06/30/2001
Ingredient
Corn
Wheat
Barley
Supplier
Wilson
J. Perkins
Pollack
McKay
Adams
Kroner
Schmidt
Wilson
Pollack
Price I
2.80 |
2.72
2.83 ]
2.80 I
1.19
1.19
1.22
0.85
0.84
Рис. 7.26. Отчеты для вопроса 25
West Side Story
Based on a conception of Jerome Robbins
Book by ARTHUR LAURENTS
Music by LEONARD BERNSTEIN
Lyrics by STEPHEN SONDHEIM
v:: Entire Onginal Production Directed
and Choreographed by JEROME ROBBINS
Originally produced on Broadway by Robet E. Griffith and Harold S. Prince
by arrangement wittt Roger L. Stevens
Orchestration by Leonard Bernstein with Sid Ramm and Irwin KDStal
HIGHLIGHTS FROM THE COMPLETE RECORDING
Maria KIRI ТЕ KANAWA
Tony JOSE CARRERAS
Anita TATIANA TROYANOS
Riff KURT OLLMAN
and MARILYN HORNE singing TSomewhereY
Louise Edeikan Diesel Marty Nelson
Consuele Stella Zambaiis Baby John . .. Stephen Bogardus
Fenclsea Angelina Reaux A-reb Peter Thorn
Action David Livingston Snowboy Todd Lester
.Richard Harrell
Jet Song
(Riff. Action. Baby John. A-rab. Chorus)
Something's Coming
(Tony)
Maria
(Tony)
Tonight
(Maria, Tony)
America
(Anita. RDsalia. Chorus)
Cool
(Riff. Chorus)
One Hand, One Heart
(Tony. Mana)
Tonight (Ensemble)
(Entire Cesi)
1 Feel Pretty
(Mana. Chorus)
Somewhere
(A Girl)
Gee OFIcer Krupke
13-131
[2*331
[2-561
[5271
[4"47]
[4-37]
15-38]
|3'40]
[3'22]
[2'34]
14-18]
(Ас'юп. Snowboy. Diesel. A-rab, Baby John. Chorus)
A Boy Like That
(Anita, Maria]
1 Have a Love
(Maria. Arnta)
Taunting Scene
(Orchestra)
Finale
(Mana Tony)
[2-051
[3'301
[Г21]
[2-401
Рис. 7.27. Отчет для вопроса 26
26. Руководствуясь внешним видом коробки для компакт-диска, показанной
на рис 7.27, выполните следующее.
1) Нарисуйте диаграммы для объектов ARTIST (исполнитель), R0LE (роль)
и S0NG (песня).
2) Укажите, какие связи имеются между объектами. К каким типам
принадлежат эти объекты (простые, композитные и т. д.)?
3) Для каждого объекта, участвующего в связи, укажите, является ли он
обязательным или необязательным.
4) Преобразуйте объектные диаграммы в диаграммы отношений.
272 Глава 7. Проектирование баз данных в рамках объектной модели
Каков ключ каждого из отношений? Какие внешние ключи присутствуют в
отношениях?
Проекты
1. Завершите проект 1 в конце главы 4, если вы еще этого не сделали.
Преобразуйте вашу семантическую объектную модель в набор отношений. Если
какие-либо из получившихся отношений не находятся в ДКНФ, объясните,
почему вы сделали выбор в пользу ненормализованных отношений.
2. Завершите проект 2 в конце главы 4, если вы еще этого не сделали.
Преобразуйте вашу семантическую объектную модель в набор отношений. Если
какие-либо из получившихся отношений не находятся в ДКНФ, объясните,
почему вы сделали выбор в пользу ненормализованных отношений.
3. Завершите проект 3 в конце главы 4, если вы еще этого не сделали.
Преобразуйте вашу семантическую объектную модель в набор отношений. Если
какие-либо из получившихся отношений не находятся в ДКНФ, объясните,
почему вы сделали выбор в пользу ненормализованных отношений.
Вопросы к проекту FiredUp
Создайте семантические объекты для вопросов 1 и 3 в проекте FiredUp в конце
главы 4, если вы еще этого не сделали.
1. Преобразуйте структуру семантических объектов из ответа на вопрос 1
в конце главы 4 в набор отношений, находящихся в доменно-ключевой
нормальной форме. Для каждого отношения укажите первичный ключ,
ключи-кандидаты, если таковые имеются, и внешние ключи. Укажите все
ограничения ссылочной целостности. Если потребуется, сделайте
необходимые предположения о семантике реализуемого приложения и дайте
обоснование этих предположений.
2. Модифицируйте ваш ответ на вопрос 1, введя в него ненормализованные
отношения, если вы считаете, что использование таких отношений
оправданно. Обоснуйте введение каждого из ненормализованных отношений.
Если потребуется, сделайте необходимые предположения о семантике
реализуемого приложения и дайте их обоснование.
3. Преобразуйте семантическую объектную диаграмму из ответа на вопрос 3
в конце главы 3 в набор отношений, предпочтительно в
доменно-ключевой нормальной форме. Если какие-либо из ваших отношений не
находятся в доменно-ключевой нормальной форме, объясните почему. Для каждого
отношения укажите первичный ключ, ключи-кандидаты, если таковые
имеются, и внешние ключи. Укажите все ограничения ссылочной целостности.
Модифицируйте ваш ответ на вопрос 3, приведенный выше, предположив, что
номера домашнего телефона, факса и мобильного телефона должны быть
представлены отдельными однозначными атрибутами. Является ли эта структура
более удачной, чем предыдущая? Обоснуйте свой ответ.
Часть IV
Построение реляционных
баз данных
И четвертой части книги, состоящей из трех глав, рассматривается построение
баз данных на основе реляционной модели. Глава 8 посвящена операциям над
реляционными данными. Открывается глава обзором существующих типов языков
манипулирования реляционными данными. Далее описываются основные опера-
горы реляционной алгебры и приводятся примеры их использования.
В главе 9 описывается SQL — язык структурированных запросов. Этот язык
рекомендован Американским национальным институтом стандартов (ANSI) в
качестве стандартного языка для манипулирования реляционными базами данных;
кроме того, он является основным языком ^манипулирования данными в
коммерческих СУБД. Завершает четвертую часть книги глава 10, где обсуждается
разработка приложений баз данных.
Глава 8
Основы построения
реляционных баз данных
Эта глава даст вам основные представления о построении реляционных баз
данных. Вначале мы рассмотрим способы описания реляционных данных,
познакомимся с реляционной терминологией и выясним, как структура базы данных
описывается для СУБД. Далее мы обратимся к распределению пространства на
физических носителях и созданию информационной части базы данных.
Оставшаяся часть главы посвящена манипулированию реляционными данными: в ней
рассматриваются четыре типа языков манипулирования реляционными
данными (DML), три общих режима интерфейса между языками манипулирования
данными и СУБД, основные операторы реляционной алгебры и примеры
запросов, выраженных в терминах реляционной алгебры.
Описание реляционных данных
В процессе построения реляционной базы данных должны быть решены
несколько задач. Во-первых, необходимо описать структуру базы данных для СУБД. Для
этого разработчик использует язык описания данных или какой-либо
эквивалентный способ описания структуры (например, графическое отображение). Затем
база данных записывается на тот или иной физический носитель и заполняется
данными. В этом разделе мы рассмотрим каждую из этих задач, но сначала
познакомимся с реляционной терминологией.
Обзор терминологии
Как указывалось в главе 5, отношение — это таблица, обладающая
определенными свойствами.
1. Записи в отношении могут иметь только одиночные значения;
множественные значения не допускаются. Следовательно, на пересечении строки
и столбца находится только одно значение.
2. Все записи в одном столбце имеют один и тот же тип. Например, один
столбец может содержать имена покупателей, а другой — их даты рожде-
Описание реляционных данных ^ 275
Имя
Райли
Мерфи
i Краевски
Тинг
Диксон
Абель
Дата
рождения
19.01.1946
28.12.1981
21.10.1973
23.05.1938
15.04.1987
19.06.1957
Пол
Ж
м
ж
ж
м
м
Номер
счета
147
289
533
681
704
193
Лечащий i
врач
Ли
Сингх
Леви
Спок
Леви
Сингх
ния. Каждый столбец имеет уникальное имя, и порядок следования
столбцов несуществен. Столбцы отношения носят название атрибутов.
Каждый атрибут имеет свой домен, который представляет собой физическое
и логическое описание множества допустимых значений.
3. В отношении не может быть двух одинаковых строк, и порядок
следования строк несуществен (рис. 8.1). Строки отношения называются также
кортежами.
Столбец 1 Столбец 2 Столбец 3 Столбец 4 Столбец 5
(или атрибут 1)
Строка 1
(или кортеж 1)
Строка 2
Строка 3
Строка 4
Строка 5
Строка 6
Рис. 8.1. Отдельный экземпляр реляционной структуры PATIENT
Рисунок 8.1 являет собой пример, или отдельный экземпляр, реляционной
структуры, содержащей сведения о пациенте клиники. Обобщенный формат,
PATIENT (Name, BirthDate, Gender, AccountNumber, Physician) — это структура
отношения; именно ее большинство людей имеют в виду под термином отношение.
(Вспомните из главы 5, что подчеркиванием выделяется атрибут, являющийся
ключом отношения.) Если мы добавим в структуру отношения ограничение на
возможные значения данных, мы получим реляционную схему (relational schema).
Все эти термины приведены в табл. 8.1.
Недоразумения относительно термина «ключ»
Термин ключ зачастую является источником недоразумений, так как он имеет
различные значения на стадиях проектирования и реализации. В процессе
проектирования под ключом понимается один или несколько столбцов, однозначно
определяющих строку отношения. Как мы знаем из главы 5, каждое отношение
имеет хотя бы один ключ, поскольку каждая строка является уникальной; в
предельном случае ключ представляет собой комбинацию всех столбцов отношения.
Обычно ключ состоит из одного-двух столбцов.
На стадии реализации термин ключ используется в другом значении. В
большинстве реляционных СУБД ключом называется столбец, на базе которого
СУБД формирует индекс и другие структуры данных. Это делается для того,
чтобы обеспечить быстрый доступ к значениям из данного столбца. Эти ключи
не обязаны быть уникальными, и зачастую они действительно таковыми не
являются. Они создаются только для повышения быстродействия. (Информацию
о таких структурах данных вы найдете в приложении А.)
276 Глава 8. Основы построения реляционных баз данных
Рассмотрим, например, отношение ЗАКАЗ (НомерЗаказа, ДатаЗаказа, НомерКли-
ента, Количество). С точки зрения проектирования, ключом этого отношения
является НомерЗаказа, так как выделение жирным шрифтом означает, что данный
атрибут однозначно определяет строку отношения. С точки зрения реализации,
ключом может быть любой из четырех столбцов данного отношения. Это может
быть, например, атрибут ДатаЗаказа. В таком случае СУБД создаст структуру
данных, обеспечивающую быстрый доступ к данным из отношения ЗАКАЗ по
значению даты заказа. Скорее всего, конкретному значению атрибута ДатаЗаказа
будет соответствовать много строк. В данном смысле определение атрибута в
качестве ключа не говорит ничего о его уникальности.
Иногда, чтобы различать два значения слова ключ, употребляются термины
логический ключ (logical key) и физический ключ (physical key). Логический ключ —
это уникальный идентификатор, а физический ключ — это столбец, для которого
с целью увеличения быстродействия создан индекс или другая структура данных.
Таблица 8.1. Обзор реляционной терминологии
Термин Значение
Отношение (таблица, файл) Двумерная таблица
Атрибут (столбец, поле, Столбец отношения
элемент данных)
Кортеж (строка, запись) Строка отношения
Домен Физическое и логическое описание множества допустимых
значений
Реляционная структура Формат отношения
Вхождение Реляционная структура с данными
Реляционная схема Реляционная структура плюс ограничения
Ключ Группа из одного или нескольких атрибутов, которая
однозначно идентифицирует кортеж в отношении
Логический ключ То же, что и ключ
Физический ключ (индекс) Группа из одного или нескольких атрибутов, для которой
существует специальная структура данных, ускоряющая
считывание данных по значениям этих атрибутов
и обеспечивающая быстрый последовательный доступ
Индексы
Поскольку физический ключ обычно является индексом, некоторые оставляют
за термином ключ значение логического ключа, а за термином индекс — значение
физического ключа. В данной книге мы именно так и будем поступать: термин
ключ мы будем использовать в значении «логический ключ», а термин индекс —
в значении «физический ключ».
В пользу создания индексов есть три соображения. Одно из них состоит в том,
чтобы обеспечить ускоренный доступ к строкам по значению индексируемого
атрибута. Другое заключается в упрощении сортировки строк по этому
атрибуту. Например, в отношении ЗАКАЗ в качестве ключа может быть определен
атрибут ДатаЗаказа, в результате чего отчеты, в которых заказы отсортированы по
дате, будут генерироваться быстрее.
Описание реляционных данных, 277
Третья цель построения индексов — обеспечение уникальности. Индексы не
обязаны быть уникальными, но когда разработчик хочет, чтобы какой-то столбец
был уникальным, СУБД создает для этого столбца индекс. В большинстве
реляционных СУБД столбец или группу столбцов можно сделать уникальными, если
при определении столбца в таблице указать ключевое слово UNIQUE.
Реализация реляционной базы данных
И этой книге для описания структуры базы данных мы используем реляционную
модель. Поэтому от проектирования базы данных мы можем непосредственно
переходить к ее реализации. Нам нет нужды как-либо преобразовывать структуру
па стадии реализации: все, что требуется сделать, — это описать существующую
реляционную структуру для СУБД.
При реализации баз данных с использованием СУБД, основанных не на
реляционной модели, дело обстоит иначе. Например, реализуя базу данных на основе
модели DL/I, мы должны преобразовать реляционную структуру в
иерархическую, а затем описать для СУБД преобразованную структуру.
Описание структуры базы данных для СУБД
Есть несколько способов, с помощью которых структура базы данных
описывается для СУБД. Эти способы зависят от того, какая конкретно СУБД используется.
В некоторых продуктах создается текстовый файл, который описывает структуру
базы данных. Язык, используемый для определения такой структуры, иногда
называется языком определения данных (data definition language, DDL). В текстовом
DDL-файле перечислены названия таблиц базы данных, указаны названия
столбцов этих таблиц и описано их содержимое, определены индексы, а также описаны
другие структуры (ограничения, меры безопасности). В листинге 8.1 с помощью
типичного языка определения данных описана простая реляционная база данных
для гипотетической СУБД. Более реалистичные примеры с использованием
стандарта под названием SQL приведены в главах 12 и 13.
Листинг 8.1. Пример текстового DDL-файла определения данных
CREATE SCHEMA PHYSICIAN
CREATE SCHEMA PHYSICIAN
CREATE TABLE PATIENT
(Name CHARACTER VARYING (35) NOT NULL.
Date Of Birth DATE/TIME,
Gender CHARACTER VARYING (10),
AccountNumber INTEGER NOT NULL.
PhysicianNameJKl CHARACTER VARYING (35) NOT NULL.
PRIMARY KEY (AccountNumber ),
продолжение &
278 Глава 8. Основы построения реляционных баз данных
Листинг 8.1 (продолжение)
FOREIGN KEY (PhysicianNameJKl)
REFERENCES PHYSICIAN
)
CREATE TABLE PHYSICIAN
(PhysicianName CHARACTER VARYING (35) NOT NULL,
AreaCode CHARACTER VARYING (3).
LocalNumber CHARACTER VARYING (8) NOT NULL,
PRIMARY KEY (PhysicianName)
)
Некоторые СУБД не требуют, чтобы структура базы данных была определена
с помощью DDL в текстовом формате. Наиболее распространенная
альтернатива — это графический способ задания структуры базы данных. Например,
в Access 2002 разработчику дается графическая структура в виде списка, в
соответствующих местах которой нужно ввести имена таблиц и столбцов. Пример
этого мы видели в главе 2 (см. рис. 2.2).
Вообще говоря, графические средства описания данных распространены
в СУБД, предназначенных для работы на персональных компьютерах. На
серверах и больших ЭВМ применяются как графические, так и текстовые средства.
Например, в Oracle и SQL Server для определения данных могут применяться
оба способа. На рис. 8.2 представлена общая схема процесса описания данных
для СУБД.
Текстовый файл
с операторами
DDL
Пользователь/
Данные
о структуре
базы данных
ИЛИ
Подсистема
средств
проектирования
базы данных
Метаданные
Индексы
Метаданные
приложений
Метаданные
пользователя
База данных
Графическое
средство проектирования
Рис. 8.2. Процесс описания данных для СУБД
Описание реляционных данных 279
При любом способе определения структуры данных разработчик должен дать
название каждой таблице, определить столбцы для этой таблицы и описать
физический формат данных в каждом столбце (скажем, TEXT 10). Кроме того, в
зависимости от возможностей используемой СУБД, разработчик может указать
ограничения, которые должны реализовываться СУБД. Значения столбцов могут
определяться, например, как NOT NULL (не пустой) или UNIQUE (уникальный).
Некоторые продукты позволяют также устанавливать ограничения на возможные
.шачения (атрибут Часть может принимать значения, меньшие 10 000, а атрибут
Цвет может принимать одно из значений [4Красный','Зеленый7Синий']). Наконец,
могут быть введены ограничения целостности по внешнему ключу. Приведем
пример такого ограничения: «Значение атрибута НомерОтдела в таблице СОТРУДНИК
должно быть равно значению атрибута НомерОтдела в таблице ОТДЕЛ».
Во многих СУБД разработчик может также устанавливать пароли и
использовать другие средства контроля и безопасности. Как будет показано в главе 11,
существует множество различных стратегий обеспечения безопасности. В одних
стратегиях объектами контроля являются структуры данных (например, таблица
защищается паролем), в других — пользователи (обладатель пароля X может
читать и обновлять таблицы Т1 и Т2).
Распределение пространства на физических носителях
Кроме определения структуры базы данных, разработчик должен выделить место
для базы данных на физическом носителе. И вновь конкретные действия зависят
от того, какая именно СУБД используется. В случае персональной базы данных
исе, что требуется сделать, — это присвоить базе данных каталог на диске и дать
ей имя. После этого СУБД автоматически выделит пространство для хранения
данных.
Другие СУБД, в особенности предназначенные для серверов и больших ЭВМ,
требуют больших усилий. Чтобы повысить быстродействие и улучшить контроль,
необходимо тщательно спроектировать распределение информации в базе дан-
пых по дискам и каналам. Например, в зависимости от специфики обработки
приложений, может оказаться, что определенные таблицы лучше размещать на
одном и том же диске. И наоборот, может быть важно, чтобы определенные
таблицы не находились на одном и том же диске.
Рассмотрим, например, объект-заказ, скомпонованный из таблиц ЗАКАЗ, СТРОКА^
ЗАКАЗА и ТОВАР. Предположим, что при обработке заказа приложение считывает
одну строку из таблицы ЗАКАЗ, несколько строк из таблицы СТРОКА_ЗАКАЗА и по
одной строке из таблицы ТОВАР для каждой строки из таблицы CTP0KAJJAKA3A.
Далее, строки из таблицы СТРОКА_ЗАКАЗА, относящиеся к одному и тому же
заказу, обычно сгруппированы вместе, а строки в таблице ТОВАР не сгруппированы
никак. Эту ситуацию иллюстрирует рис. 8.3.
Теперь представим, что организация параллельно обрабатывает множество
заказов и что у нее есть два диска: один большого объема и быстродействующий,
а другой — меньшего объема и более медленный. Разработчик должен
определить наилучшее место для хранения данных. Возможно, производительность
улучшится, если таблица ТОВАР будет храниться на большом диске с быстрым
280 Глава 8. Основы построения реляционных баз данных
доступом, а таблицы СТРОКА_ЗАКАЗА и ЗАКАЗ — на диске меньшего размера и
быстродействия. А может быть, производительность будет выше, если поместить
данные из таблиц ЗАКАЗ и СТРОКА_ЗАКАЗА за предыдущие месяцы на более
медленный диск, а за текущий месяц — на более быстрый.
Таблица ЗАКАЗ Таблица СТРОКА_ЗАКАЗА Таблица ТОВАР
Номер Номер Номер Номер Код Описание
Заказа Заказа Строки Строки Товара Товара
100
200
300
К
100
100
100
200
200
300
300
300
300
300
1
2
3
1
2
1
2
3
4
5
10
70
50
50
10
60
10
50
20
30
\
10
20
30
40
50
60
70
А
В
С
D
Е
F
G
Обратите внимание: для любого заказа соответствующие строки в таблице
СТРОКА_ЗАКАЗА находятся рядом, а в таблице ТОВАР разбросаны
по разным местам
Рис. 8.3. Данные для трех таблиц, представляющих заказ
Мы не можем ответить на эти вопросы здесь, поскольку ответ зависит от объема
данных, характеристик СУБД и операционной системы, размера и
быстродействия дисков и каналов, а также от требований приложений, использующих эту базу
данных. Смысл состоит в том, что все эти факторы необходимо принимать во
внимание при выделении пространства для базы данных на физическом носителе.
Кроме местоположения и объема пространства для данных пользователя,
разработчику, возможно, потребуется также указать, должно ли это пространство
увеличиваться по мере необходимости, и если да, то на какую величину. Как правило,
величина такого приращения указывается либо в виде фиксированного значения,
либо в виде процентов от первоначального объема занимаемого пространства.
При создании базы данных разработчику понадобится выделить файловое
пространство для журналов базы данных. О ведении журналов вы узнаете в
главах 11 — 13; на данном этапе вам просто следует знать, что СУБД ведет журнал
изменений в базе данных, который потом, в случае необходимости, можно
использовать для восстановления базы. Файловое пространство для журналов
выделяется на этапе создания базы данных.
Составление плана обслуживания базы данных
План обслуживания (maintenance plan) базы данных — это расписание процедур,
которые необходимо выполнять на регулярной основе. Эти процедуры включают
в себя резервное копирование базы данных, сброс содержимого журнала базы
Манипулирование реляционными данными 281
данных в архивные файлы, проверка на наличие нарушений ссылочной
целостности, оптимизация дискового пространства для данных пользователя и индексов
и т. д. К этим вопросам мы также обратимся в главе 11, но имейте в виду, что план
обслуживания базы данных должен составляться в процессе ее создания или
вскоре после него.
Заполнение базы данных информацией
Когда база данных описана и для ее хранения выделено пространство на
физическом носителе, можно начинать заполнение базы данных информацией. То,
каким путем это делается, зависит от требования приложений и возможностей
СУБД. В лучшем случае все данные уже находятся в формате, воспринимаемом
компьютером, а в СУБД имеются возможности и средства, позволяющие
упростить импорт данных с магнитных носителей. В худшем случае все данные
должны вводиться вручную через клавиатуру с помощью прикладных программ,
созданных разработчиками «с нуля». Большинство ситуаций, где необходимо
конвертирование данных, находятся в промежутке между этими двумя крайними
случаями.
Когда данные введены, необходимо проверить их корректность. Такая
проверка утомительна и требует больших трудозатрат, однако она весьма важна.
Зачастую, особенно в больших базах данных, есть смысл в написании специальных
программ для проверки данных. Преимущества от использования этих программ
вполне окупят время и деньги, затраченные командой разработчиков на их
создание. Такие программы занимаются тем, что подсчитывают количество строк
в различных категориях, вычисляют контрольные суммы, выполняют проверки
допустимости значений данных и другие процедуры контроля.
Манипулирование реляционными
данными
Мы обсудили проектирование реляционных баз данных и способы, при помощи
которых структура базы данных описывается для СУБД. До сих пор, говоря об
операциях с отношениями, мы рассуждали в обобщенной и интуитивной манере.
Такая манера хороша, пока речь идет о проекте, но для реализации приложений
нам нужен четкий и непротиворечивый язык, выражающий логику обработки.
Такие языки носят название языков манипулирования данными (data manipulation
languages, DML).
Категории языков манипулирования
реляционными данными
На сегодняшний день предложено четыре стратегии манипулирования
реляционными данными. Первая из стратегий, реляционная алгебра (relational algebra),
определяет операторы, действующие на отношения (они подобны операторам
282 Глава 8. Основы построения реляционных баз данных
высшей алгебры +, - и т. д.). Эти операторы позволяют манипулировать
отношениями для достижения желаемого результата. Но реляционная алгебра трудна
в использовании, отчасти потому, что она является процедурной. Это значит, что
при использовании реляционной алгебры мы должны знать не только то, что мы
делаем, но и то, как это делается.
Реляционная алгебра не используется в коммерческих системах обработки
баз данных. Хотя ни одна коммерчески успешная СУБД не включает в себя
инструментарий реляционной алгебры, мы будем обсуждать ее здесь, поскольку
это поможет яснее представить себе манипулирование реляционными данными
и заложит основу для изучения SQL.
Реляционное исчисление (relational calculus) — вторая стратегия
манипулирования реляционными данными. Реляционное исчисление не является
процедурным; оно представляет собой язык, выражающий то, что мы хотим сделать, без
указания на то, как этого достичь. Вспомните переменную интегрирования в
интегральном исчислении: эта переменная принимает значения из того диапазона,
по которому происходит интегрирование. В реляционном исчислении есть
подобная переменная. В кортежио-реляционном исчислении областью значений
этой переменной являются кортежи отношения, а в доменно-реляционном
исчислении — значения домена. В основе реляционного исчисления лежит область
математики, называемая исчислением предикатов.
Если вы не собираетесь становиться теоретиком реляционной технологии,
вам, скорее всего, не понадобится изучать реляционное исчисление. Оно никогда
не используется в коммерческих системах обработки баз данных, и в его
изучении для наших целей нет необходимости. Таким образом, мы не будем
обсуждать его в этой книге.
Хотя реляционное исчисление трудно для понимания и использования, его
непроцедурный характер является преимуществом. Поэтому разработчики СУБД
начали поиск других непроцедурных стратегий, который привел к появлению
третьей и четвертой категорий языков манипулирования реляционными данными.
Языки, ориентированные на преобразования (transform-oriented languages), —
это класс непроцедурных языков, которые преобразуют входные данные,
имеющие вид отношений, в результат, представляющий собой одно отношение. В этих
языках имеются простые в использовании структуры, позволяющие указать
действия, которые необходимо совершить с предоставленными данными. SQUARE,
SEQUEL и SQL — это примеры языков, ориентированных на преобразования.
Язык SQL будет подробно изучаться нами в главах 9, 12 и 13.
Четвертая категория языков манипулирования реляционными данными — это
графические языки. К этой категории относятся запрос по образцу (Query-by-
Example) и запрос из формы (Query-by-Form). В числе продуктов,
поддерживающих эту категорию, можно упомянуть Approach (фирмы Lotus) и Access.
Пользователю выдается графическое представление одного отношения или более.
Представление может иметь вид формы для ввода данных, электронной таблицы
или какой-либо другой структуры. СУБД преобразует представление в
соответствующее отношение и формирует запросы (скорее всего, на SQL) от лица
пользователя. После этого пользователи инициируют выполнение операторов DML,
Манипулирование реляционными данными 283
по они об этом не знают. Четыре категории языков манипулирования
реляционными данными:
+ реляционная алгебра;
+ реляционное исчисление;
+ языки, ориентированные на преобразования (например, SQL);
+ запрос по образцу, запрос из формы.
Интерфейсы языков манипулирования данными
И этом разделе мы рассмотрим четыре вида интерфейсов, с помощью которых
осуществляется манипулирование информацией в базе данных.
Манипулирование данными посредством форм
В большинстве реляционных СУБД имеются средства для создания форм.
Некоторые формы генерируются автоматически при определении таблицы, другие
должны создаваться разработчиком. Помощь в этом процессе может оказать
интеллектуальный ассистент, присутствующий, например, в Access. Форма может
иметь вид таблицы (электронной таблицы), в которой одновременно
показываются несколько строк отношения. Есть и другой вид форм, где каждая строка
отношения представляется отдельно. На рис. 8.4 и 8.5 приведены примеры обоих
типов форм для таблицы PATIENT с рис. 8Л. Большинство продуктов обеспечивают
некоторую гибкость в обработке форм и отчетов. Например, строки для обработки
могут выбираться по значениям столбцов и могут быть отсортированы. Таблица
на рис. 8.4 отсортирована по значению поля AccountNumber.
Abel
Murphy
Krajewski
Ting
Dixon
1
"1
1/19/46= F 147. Lee
6/19/57rM 193 Singh
" 12/28/81 :'M 289 Singh "
16/21/73; F 533: Levy
5/23/38rF ! 661Spock
4/15/87rM 704 Levy
Рис. 8.4. Пример табличной экранной формы
т patient
МЫ$$
ШйЙ!^
ШШШ
533 £Л
Рис. 8.5. Пример однострочной экранной формы
284 Глава 8. Основы построения реляционных баз данных
Многие формы, генерируемые по умолчанию, содержат в себе данные только
из одного отношения. Если нужно получить данные из двух или более
отношений, тогда, как правило, нужно создавать специальные формы с помощью средств
СУБД. Такие средства позволяют создавать как многотабличные, так и
многострочные формы. Поскольку использование этих средств сильно зависит от
конкретной СУБД, мы не будем рассматривать их далее.
Интерфейс языка запросов и обновлений
Второй тип интерфейса к базе данных — это язык запросов и обновлений (query/
update language), или просто язык запросов (query language). (Хотя большинство
такого рода языков позволяют выполнять как запрос, так и обновление данных,
их чаще всего называют языками запросов.) В этом случае пользователь вводит
команды, которые указывают, какие действия необходимо произвести над базой
данных. СУБД расшифровывает эти команды и выполняет предписанные
действия. Рисунок 8.6 показывает, какие программы участвуют в обработке запроса.
Пользователь *
Или
Пользователь *
Графический
интерфейс
Операторы запроса
Обработчик
запросов
<—*>
Ядро СУБД
Операторы
запроса
Данные
Рис. 8.6. Программы, участвующие в обработке запроса
Команды
СУБД
Важнейшим из всех языков запросов является SQL. Чтобы дать вам
представление о языках запросов, рассмотрим следующий SQL-оператор, который
обрабатывает отношение PATIENT, показанное на рис. 8.1:
SELECT Name. DateOfBirth
FROM PATIENT
WHERE Physician = 'Levy'
Этот оператор извлекает из отношения PATIENT все строки, в которых атрибут
Physician имеет значение 'Levy'. Значения атрибутов Name и DateOfBirth из этих
строк он затем помещает во вторую таблицу.
Хранимые процедуры
Со временем пользователи и разработчики баз данных обнаружили, что
некоторые последовательности команд SQL приходится выполнять регулярно.
Единственное, что при этом меняется, — это значения, указываемые в предложении
WHERE. Например, при ежемесячном начислении платежей выполняются одни
и те же SQL-операторы, но с различной датой закрытия. Чтобы учесть эту
потребность, производители СУБД ввели так называемые хранимые процедуры (stored
Манипулирование реляционными данными 285
procedures). Такая процедура представляет собой набор SQL-операторов,
который хранится в файле и может быть запущен на выполнение одной командой.
Параметры, указываемые в предложении WHERE и т. д., могут передаваться при
вызове процедуры. Примером может служить следующее:
DO BILLING ST0RED_PR0CEDURE FOR BILLDATE = "9/1/2000"
Эта строка запускает хранимую процедуру под названием BILLING со
значением параметра BILLDATE, равным "9/1/2000".
По мере накопления разработчиками опыта выявилась одна проблема. SQL
создавался как подъязык данных, и при этом не делалось попыток наделить его
всеми элементами полноценного языка программирования. Однако некоторые
из этих элементов были необходимы для написания хранимых процедур, и
производители СУБД создали расширенные версии SQL, включив в них
дополнительные возможности. Один такой язык, PL/SQL, был разработан для Oracle,
а еще один, под названием TRANSACT-SQL, — для SQL Server. Более подробно
об этих языках вы узнаете из глав 12 и 13.
Специальный тип хранимой процедуры — триггер (trigger) — вызывается
СУБД при выполнении заданного условия. Например, в приложении,
обрабатывающем заказы, разработчик должен создать триггер, который запускается в тех
случаях, когда количество товара на складе оказывается ниже заданного предела
(то есть пора заказывать товар у оптового поставщика). Более подробно о
хранимых процедурах вы узнаете из глав 12 и 13.
Интерфейс прикладных программ
Четвертый тип интерфейса доступа к данным — это доступ через прикладные
программы, написанные на таких языках программирования, как COBOL, BASIC,
Perl, Pascal и C++. Кроме того, некоторые прикладные программы пишутся на
встроенных в используемые СУБД языках. Из таких языков программирования
наибольшей известностью пользуется dBASE.
Есть два стиля интерфейса между прикладными программами и СУБД.
Первый из них характеризуется тем, что прикладные программы вызывают
подпрограммы из библиотеки функций, поставляемой в комплекте с СУБД. Например,
чтобы считать строку из таблицы, прикладная программа вызывает функцию
чтения СУБД и передает ей параметры, которые указывают нужную таблицу,
требуемые столбцы, критерии выбора строки и т. п.
В некоторых случаях вместо вызовов функций используется
объектно-ориентированный синтаксис. В приведенном ниже коде Access объектный указатель db
устанавливается на открытую в данный момент базу данных, а объектный
указатель rs ссылается на строки таблицы PATIENT:
set db = currentdbO
set rs = db.OpenRecordsetrPATIENT")
С помощью последнего указателя можно обращаться к свойствам
открытого набора записей и запускать его методы. Например, с помощью свойства
286 Глава 8. Основы построения реляционных баз данных
rs.AllowDeletions можно определить, могут ли быть удалены записи из набора
записей PATIENT. Метод MoveFirst перемещает курсор на первую строку.
Второй, более старый тип интерфейса используется иногда в СУБД,
предназначенных для больших ЭВМ и серверов. Здесь производителем СУБД
определен набор высокоуровневых команд доступа к данным. Эти команды, которые
относятся к обработке базы данных и не являются частью какого-либо
стандартного языка, встраиваются в код прикладной программы.
Прикладная программа со встроенными командами передается на
предварительный компилятор, входящий в комплект СУБД. Он транслирует операторы
доступа к данным в корректные вызовы функций и определяет области данных,
которые будут совместно использоваться прикладными программами и СУБД.
Предварительный компилятор также вставляет в программу код,
поддерживающий доступ к этим областям данных. Обработанная таким образом программа
передается на языковой компилятор. На рис. 8.7 показано взаимодействие
программ в этом процессе.
Программа
со встроенными
операторами DML
W
W
Предварительный
компилятор
СУБД запросов
^
Г
Программа
с операторами DML,
транслированными в вызовы
функций со встроенными
операторами DML
Компилятор
языка
Стандартная
объектная
программа
Рис. 8.7. Обработка программы со встроенными операторами SQL
Помимо использования в обработке запросов, SQL применяется в качестве
языка доступа к данным в прикладных программах. В этом режиме операторы
SQL встраиваются в программы и транслируются в вызовы функций
предварительным компилятором. Тем самым уменьшается количество времени и денег,
требуемое на обучение персонала, поскольку один и тот же язык может использоваться
как для запросов, так и для доступа к данным в прикладных программах.
Необходимо, однако, преодолеть одно неудобство. Язык SQL ориентирован на
преобразования: он принимает на входе одно или несколько отношений, манипулирует ими
и выдает на выходе результирующее отношение. Таким образом, за один прием
обрабатывается одно отношение. Почти все прикладные программы
ориентированы на работу со строками (записями), то есть они считывают одну строку,
обрабатывают ее, считывают следующую строку и т. д. Программы, следовательно,
обрабатывают по одной строке за прием. В результате имеется несоответствие
Реляционная алгебра 287
и базовой ориентации SQL и языков, на которых пишутся прикладные
программы. Чтобы компенсировать это несоответствие, прикладные программы
предполагают, что результаты выполнения SQL-операторов являются файлами. Чтобы
проиллюстрировать это, предположим, что в прикладную программу встроен
приведенный ниже SQL-оператор (тот, который мы уже рассматривали ранее):
SELECT Name, DateOfBirth
FROM PATIENT
WHERE Physician = 'Levy'
Результатом этих операторов является таблица с двумя столбцами и N
строками. Для обработки результатов этого запроса пишется прикладная программа,
которая предполагает, что на выходе эти операторы выдают файл с N записями.
Приложение открывает этот запрос, обрабатывает первую строку, следующую
строку и так далее, пока не будет обработана последняя строка. Логика здесь та
же, что и при обработке файла с последовательным доступом. Примеры таких
прикладных программ вы увидите в главах 12, 13, 15 и 16. На данный момент
просто знайте, что есть несоответствие между базовой ориентацией SQL
(отношения) и языком программирования (строка, или запись) и что это
несоответствие необходимо корректировать, когда прикладные программы обращаются к
реляционной базе данных посредством SQL.
Реляционная алгебра
Реляционная алгебра похожа на алгебру, которую вы учили в старших классах
школы, но с одним важным отличием. В школьной алгебре переменные
представляли числа, и операторы +, -, х и / оперировали численными величинами. В
реляционной алгебре переменные — это отношения: операторы действуют на
отношения, и результатом их действия являются новые отношения. Например, операция
объединения комбинирует кортежи одного отношения с кортежами другого
отношения, в результате чего получается третье отношение. Реляционная алгебра
является замкнутой, то есть результаты одной или более реляционных операций
всегда представляют собой отношение.
Отношения — это множества. Кортежи отношения можно рассматривать как
элементы множества, следовательно, те операции, которые определены для
множеств, могут выполняться и над отношениями. Сначала мы продемонстрируем
четыре таких оператора из теории множеств, а затем обсудим другие операторы,
специфичные для реляционной алгебры. Но прежде мы рассмотрим примеры
отношений, которые будут использоваться нами на протяжении этой и
следующей глав.
Реляционные операторы
На рис. 8.8 показано шесть отношений и определения их атрибутов и доменов.
Обратите внимание, что атрибут НазваниеПредмета фигурирует в нескольких
288 Глава 8. Основы построен^.РеляЦИОНН
™ й1/т НазваниеПредмета в отношении ЗАНЯТИЯ ино
отношениях. В связи с этим атриоу * "
гда обозначается как ЗАНЯТИЯ.НазваниеПредмета.
1.ТРЕТЬЕКУРСНИК(ЩНо^.Имя^
2. ПОЧЕТНЫЙ СТУДЕНТ (tieWB- "™ИалЬн0Сть Kvdc^
3. СТУДЕНТ тйчныйНомеС Имя' £"^Гя дГи'ои^
I. пАпПсИ(£1^
Атрибут
Номер
ТРЕТЬЕКУРСНИКАМ*
Специальность
ЛичныйНомер 1(ГМмо
ПОЧЕТНЫЙ_СТУДЕНТ^мя
Интересы
ЛичныйНомер
СТУДЕНТ.Имя
Специальность
Курс
ЗАНЯТИЯ.НазваниеПредмета
Время
Аудитория
НомерСтудента опмРта
ЗАПИСЬ.НазваниеПреДмета
ПорядковыйНомер
НомерСот рудника
ППС.Имя
Кафедра
Домен
Ида нтификато ры Людей
ИменаЛюдей
НазванияПредметов
ИдентификаторыЛюдай
ИменаЛюдей
НазванияПредметов
ИдентификаторыЛюдей
ИменаЛюдей
НазванияПредметов
НомераКурсов
НазванияПредметов
ЧасыЗанятий
Аудитории
ИдентификаторыЛюдей
НазванияП редматов
ПорядковыеНомера
ИдентификаторыЛюдей
ИменаЛюдей
НазванияПредметов
Имя домена
ИдентификаторыЛюдей
ИменаЛюдей
НазванияПредметов
НомераКурсов
НазванияПредметов
ЧасыЗанятий
Аудитории
ПорядковыеНомера
формат
DecimalK(3)
CharK(8) (нереалистично,
н0 удобно для нашего примера)
CharK(10)
Значение из множества
г.С1,|,С2,,,СЗ,,,С4,1,АС']
CharK(lO)
charK(5), формат: DDDHH, где DK —значение
и3 множества [ТТ.'В'.'С'Ч', "Я', Г],
1^К — десятичное число от 1 до 12
charK(5), формат: BBRRR, где ВВК —
ко/Д корпуса, a RRRK— номер аудитории
десятичное число от 0 до 100
Рис. 8.8. Примеры отношений и доменов: а - определения отношений;
б - домены атрибутов; в - определения доменов
Реляционная алгебра 289
В ходе дальнейшего изложения символьные значения приводятся в
одинарных кавычках, а те символы, которые не заключены в кавычки, относятся к
именам. Так, 'АУДИТОРИЯ' и Аудитория отличаются тем, что 'АУДИТОРИЯ' — это
значение, а Аудитория — это, например, имя домена. Что касается числовых данных, то
числа, не заключенные в кавычки, представляют собой числовые данные, а числа
и кавычках — строки. То есть 123 — это число, а '123' — это строка, составленная
из символов Т, '2' и '3'.
Объединение
Объединение (union) двух отношений — это комбинирование кортежей одного
отношения с кортежами другого отношения, в результате чего получается третье
отношение. Порядок, в котором кортежи следуют в результирующем отношении,
несуществен, но повторяющиеся строки должны быть удалены. Объединение
отношений А и В обозначается А + В.
Чтобы данная операция имела смысл, отношения должны быть совместимы
по объединению (union compatible), то есть оба отношения должны иметь
одинаковое количество атрибутов, и атрибуты в соответствующих столбцах должны
принадлежать одному и тому же домену. Если, например, третий атрибут одного
из отношений принадлежит домену Аудитории, то третий атрибут второго
отношения также должен принадлежать этому домену.
На рис. 8.8 отношения ТРЕТЬЕКУРСНИК и ПОЧЕТНЫЙ_СТУДЕНТ совместимы по
объединению, поскольку оба они имеют по три атрибута, и соответствующие
атрибуты принадлежат одному и тому же домену. Атрибуты ТРЕТЬЕКУРСНИК.СтНомер и
ПОЧЕТНЫЙ_СТУДЕНТ.Номер принадлежат домену ИдентификаторыЛюдей; атрибуты
ТРЕТЬЕКУРСНИК.Имя и ПОЧЕТНЫЙ_СТУДЕНТ.Имя принадлежат домену ИменаЛюдей;
атрибуты ТРЕТЬЕКУРСНИК.Специальность и ПОЧЕТНЫЙ_СТУДЕНТ.Интересы
принадлежат домену НазванияПредметов. Отношения ТРЕТЬЕКУРСНИК и ЗАНЯТИЯ имеют по
три атрибута, но они несовместимы по объединению (union incompatible),
поскольку их атрибуты происходят из разных доменов.
На рис. 8.9 показано объединение отношений ТРЕТЬЕКУРСНИК и ПОЧЕТНЫЙ.
СТУДЕНТ. Обратите внимание, что кортеж [123, ДЖОНС, ИСТОРИЯ], который
фигурирует в обоих отношениях, не дублируется в объединении.
Разность
Разность (difference) двух отношений — это отношение, содержащее все кортежи,
которые присутствуют в первом отношении, но не присутствуют во втором.
Отношения должны быть совместимы по объединению. Разность отношений
ТРЕТЬЕКУРСНИК и ПОЧЕТНЫЙ_СТУДЕНТ показана на рис. 8.10. Как и в арифметике,
при вычитании порядок следования аргументов имеет значение, так что А - В
не равняется В - А.
Пересечение
Пересечение (intersection) двух отношений — это отношение, содержащее
кортежи, которые присутствуют и в первом, и во втором отношении. Отношения
290 Глава 8. Основы построения реляционных баз данных
должны быть совместимы по объединению. На рис. 8.11 пересечение отношений
ТРЕТЬЕКУРСНИК и ПОЧЕТНЫЙ_СТУДЕНТ содержит всего один кортеж [123, ДЖОНС,
ИСТОРИЯ], поскольку это единственный кортеж, который присутствует в обоих
отношениях.
СтНомер
Имя Специальность
123
158
271
ДЖОНС
ПАРКС
СМИТ
ИСТОРИЯ
МАТЕМАТИКА
ИСТОРИЯ
а
Номер Имя Интересы
105
123
АНДЕРСОН
ДЖОНС
МЕНЕДЖМЕНТ
ИСТОРИЯ
б
,, ,_ Специальность
Номер Имя или Интересь1
123
158
271
105
ДЖОНС
ПАРКС
СМИТ
АНДЕРСОН
ИСТОРИЯ
МАТЕМАТИКА
ИСТОРИЯ
МЕНЕДЖМЕНТ
Рис. 8.9. Отношения ТРЕТЬЕКУРСНИК и ПОЧЕТНЫЙ_СТУДЕНТ и их объединение:
а — пример отношения ТРЕТЬЕКУРСНИК; б — пример отношения ПОЧЕТНЫЙ_СТУДЕНТ;
в — объединение отношений ТРЕТЬЕКУРСНИК и ПОЧЕГНЫЙ_СТУДЕНТ
СтНомер
Имя Специальность
158
! 271
ПАРКС
СМИТ
МАТЕМАТИКА
ИСТОРИЯ
Рис. 8.10. Разность отношений ТРЕТЬЕКУРСНИК и ПОЧЕТНЫЙ_СТУДЕНТ
,, _. Специальность
Номер Имя или Интересы
123
ДЖОНС
ИСТОРИЯ
Рис. 8.11. Пересечение отношений ТРЕТЬЕКУРСНИК и ПОЧЕТНЫЙ_СТУДЕНТ
Произведение
Произведение (product) двух отношений (иногда его называют декартовым
произведением (Cartesian product)) — это попарная конкатенация всех строк одного
отношения со всеми строками другого. Произведение отношения А, имеющего m кортежей,
и отношения В, имеющего п кортежей, имеет m x n кортежей. Произведение
обозначается А х В. На рис. 8.12 отношение СТУДЕНТ имеет четыре кортежа, а отношение
Реляционная алгебра 291
ЗАПИСЬ — три кортежа. Отношение СТУДЕНТ х ЗАПИСЬ имеет, таким образом,
двенадцать кортежей (рис. 8.13). (Некоторые кортежи результирующего отношения
па рис. 8.13 не имеют смысла Чтобы извлечь из этого отношения осмысленную
информацию, потребуются дополнительные операции, которые будут описаны
позднее. Рисунок является не более чем иллюстрацией действия оператора.)
ЛичныйНомер Имя Специальность Курс
123
158
105
271
ДЖОНС
ПАРКС
АНДЕРСОН
СМИТ
ИСТОРИЯ
МАТЕМАТИКА
МЕНЕДЖМЕНТ
ИСТОРИЯ
сз
АС
С4
сз
Номер Название Порядковый
Студента Предмета Номер
123
105
123
Н350
ВА490
ВА490
1
3
7
Рис. 8.12. Примеры отношений: а — СТУДЕНТ; б — ЗАПИСЬ
Личный
Номер
123
123
123
158
158
158
105
105
105
271
271
271
Имя
ДЖОНС
ДЖОНС
ДЖОНС
ПАРКС
ПАРКС
ПАРКС
АНДЕРСОН
АНДЕРСОН
АНДЕРСОН
СМИТ
СМИТ
СМИТ
Специальность
ИСТОРИЯ
ИСТОРИЯ
ИСТОРИЯ
МАТЕМАТИКА
МАТЕМАТИКА
МАТЕМАТИКА
МЕНЕДЖМЕНТ
МЕНЕДЖМЕНТ
МЕНЕДЖМЕНТ
ИСТОРИЯ
ИСТОРИЯ
ИСТОРИЯ
Курс
СЗ
СЗ
сз
АС
АС
АС
С4
С4
С4
СЗ
СЗ
СЗ
Номер
Студента
123
105
123
123
105
123
123
105
123
123
105
123
Название
Предмета
Н350
ВА490
ВА490
Н350
ВА490
ВА490
Н350
ВА490
ВА490
Н350
ВА490
ВА490
Порядковый
Номер
1
3
7
1
3
7
1
3
7
1
3
7
Рис. 8.13. Произведение отношений СТУДЕНТ и ЗАПИСЬ
Проектирование
Проектирование (projection) — это операция, которая выделяет заданные
атрибуты отношения. Результатом проектирования является новое отношение, содер-
292 Глава 8. Основы построения реляционных баз данных
жащее выбранные атрибуты; иными словами, при проектировании из исходного
отношения выбирается некоторое множество столбцов. В качестве примера
рассмотрим отношение СТУДЕНТ из рис. 8.12, а. На рис. 8.14, а показана проекция
этого отношения на атрибуты Имя и Специальность, которая обозначена СТУДЕНТ
[Имя, Специальность]. На рис. 8.14, б показана проекция этого отношения на
атрибуты Специальность и Курс, обозначенная СТУДЕНТ [Специальность, Курс].
Обратите внимание, что хотя отношение СТУДЕНТ имеет четыре кортежа,
проекция СТУДЕНТ [Специальность, Курс] имеет только три. Один кортеж был
исключен, поскольку после выполнения операции проектирования кортеж [ИСТОРИЯ, С1]
оказался в результирующем отношении в двух экземплярах. Так как результат
проектирования является отношением, а отношение не может иметь одинаковых
кортежей, избыточный кортеж был исключен.
Проекцию можно также использовать для изменения порядка следования
атрибутов в отношении. Например, проекция СТУДЕНТ [Курс, Специальность, Имя,
ЛичныйНомер] меняет порядок атрибутов в отношении СТУДЕНТ на обратный
(исходный порядок представлен на рис. 8.11). Иногда эта возможность позволяет
сделать два отношения совместимыми по объединению.
Имя Специальность Специальность Курс
ДЖОНС
ПАРКС
АНДЕРСОН
СМИТ
ИСТОРИЯ
МАТЕМАТИКА
МЕНЕДЖМЕНТ
ИСТОРИЯ
ИСТОРИЯ
МАТЕМАТИКА
МЕНЕДЖМЕНТ
сз
А4
С4
а б
Рис. 8.14. Проекции отношения СТУДЕНТ: а — СТУДЕНТ [Имя, Специальность];
б — СТУДЕНТ [Специальность, Курс]
Выборка
В то время как оператор проектирования выделяет вертикальное подмножество
(столбцы) отношения, оператор выборки (selection) выделяет горизонтальное
подмножество (строки). Проектирование указывает, какие атрибуты должны быть
в новом отношении, а выборка указывает, какие строки должны в нем
присутствовать. Обозначается выборка путем указания имени отношения, за которым следует
ключевое слово WHERE («где»), за которым, в свою очередь, идет условие,
накладываемое на атрибуты. На рис. 8.15, а представлена выборка СТУДЕНТ WHERE
Специальность = 'МАТЕМАТИКА', а на рис. 8.15, б - СТУДЕНТ WHERE Курс = Т1'.
Соединение
Операция соединения (join) представляет собой комбинацию произведения,
выборки и (возможно) проектирования. Соединение двух отношений А и В
происходит следующим образом. Сначала формируется произведение Ах В. Затем
делается выборка, при которой исключаются некоторые кортежи (критерии отбора
указываются в операторе соединения). После этого путем проектирования могут
быть (при необходимости) исключены некоторые атрибуты.
Реляционная алгебра 293
Личный
Номер
Имя Специальность Курс
158
ПАРКС
МАТЕМАТИКА
АС
а
Личный
Номер Имя Специальность Курс
123
158
ДЖОНС
СМИТ
ИСТОРИЯ
ИСТОРИЯ
сз
сз
Рис. 8.15. Примеры выборки: а — СТУДЕНТ WHERE Специальность = 'МАТЕМАТИКА';
б — СТУДЕНТ WHERE Курс = 'С1'
Рассмотрим отношения СТУДЕНТ и ЗАПИСЬ, показанные на рис. 8.12.
Предположим, мы хотим знать имя и номер каждого студента. Чтобы получить эти
данные, нам нужно соединить кортежи отношения СТУДЕНТ с соответствующими
кортежами отношения ЗАПИСЬ на основании атрибута НомерСтудента. Такое
соединение мы обозначаем как СТУДЕНТ JOIN (ЛичныйНомер = НомерСтудента) ЗАПИСЬ .
Эта запись означает: «Соединить кортеж отношения СТУДЕНТ с кортежем
отношения ЗАПИСЬ, если значение атрибута ЛичныйНомер в отношении СТУДЕНТ
равняется значению атрибута НомерСтудента в отношении ЗАПИСЬ».
Чтобы построить это соединение, мы сначала находим произведение
отношений СТУДЕНТ и ЗАПИСЬ — результат этой операции представлен на рис. 8.13. Затем
мы выбираем те кортежи произведения, где значение атрибута ЛичныйНомер из
отношения СТУДЕНТ равно значению атрибута НомерСтудента из отношения ЗАПИСЬ
(таких кортежей только три). Результат этой операции изображен на рис. 8.16, а.
Заметьте, что у нас имеется два идентичных атрибута: СТУДЕНТ.ЛичныйНомер
п ЗАПИСЬ.НомерСтудента. Один из них является лишним, и мы его исключаем
путем проектирования (в данном случае мы выбираем ЗАПИСЬ.НомерСтудента).
Результатом является отношение на рис. 8.16, б. Соединение на рис. 8.16, а
называется эквивалентным соединением (equijoin), а соединение на рис. 8.16, б —
естественным соединением (natural join). Если не указано иного, то когда
говорят о соединении, подразумевается естественное соединение.
Поскольку построение произведения двух больших отношений является
длительной операцией, алгоритм, который использует СУБД для соединения двух
отношений, отличается от того, который описан здесь. Результат, однако,
остается тем же самым.
Можно выполнять соединение и по другим условиям, а не только по равенству.
\\ качестве примеров можно привести соединения СТУДЕНТ JOIN (ЛичныйНомер*
НомерСтудента) ЗАПИСЬ или СТУДЕНТ JOIN (ЛичныйНомер < НомерСотрудника) ППС.
Результатом последнего соединения явится набор кортежей, в котором номера
студентов меньше, чем номера сотрудников. Такая операция может иметь смысл,
если, скажем, идентификаторы присваиваются людям в хронологическом
порядке. В результирующем отношении будут представлены пары
студент—преподаватель, в которых студент появился в учебном заведении раньше, чем преподаватель.
294 Глава 8. Основы построения реляционных баз данных
Личный
Номер
Имя
_ Номер Название Порядковый
Специальность Курс студента Предмета Номер
123
123
105
ДЖОНС
ДЖОНС
АНДЕРСОН
ИСТОРИЯ
ИСТОРИЯ
МЕНЕДЖМЕНТ
сз
сз
С4
123
123
105
Н350
ВА490
ВА490
1
7
3
Личный
Номер
Имя Специальность Курс
Название
Предмета
Порядковый
Номер
123
123
105
ДЖОНС
ДЖОНС
АНДЕРСОН
ИСТОРИЯ
ИСТОРИЯ
МЕНЕДЖМЕНТ
СЗ
сз
С4
Н350
ВА490
ВА490
1
7
3
Личный
Номер
Имя
_ Номер Название Порядковый
Специальность Курс студента Предмета Номер
123
123
123
105
271
ДЖОНС
ДЖОНС
ПАРКС
АНДЕРСОН
СМИТ
ИСТОРИЯ
ИСТОРИЯ
МАТЕМАТИКА
МЕНЕДЖМЕНТ
ИСТОРИЯ
СЗ
СЗ
АС
С4
СЗ
123
123
Null
105
Null
Н350
ВА490
Null
ВА490
Null
1
7
Null
3
Null
Рис. 8.16. Примеры
соединение; б —
соединения отношений СТУДЕНТ и ЗАПИСЬ: а — эквивалентное
■ естественное соединение; в — левое внешнее соединение
Есть одно важное ограничение на условия соединения: атрибуты, входящие
в условие, должны относиться к одному и тому же домену, поэтому соединение
вида СТУДЕНТ JOIN (Специальность = НазваниеПредмета) ЗАНЯТИЯ противоречит
логике. Даже при том, что значения атрибутов Специальность и НазваниеПредмета
имеют тип Char (10), они относятся к разным доменам. С семантической точки
зрения такого рода соединение не имеет смысла. (К сожалению, многие
реляционные СУБД допускают такие соединения.)
Внешнее соединение
Операция соединения приведет к отношению, в котором перечислены студенты
и предметы, на которые они записаны. Студенты, не записанные ни на один из
предметов, не будут представлены в результатах. Если мы хотим включить в
результирующее отношение всех студентов, можно использовать внешнее
соединение (outer join). Так, в результате операции левого внешнего соединения (left outer
join), имеющей вид СТУДЕНТ LEFT OUTER JOIN (ЛичныйНомер=НомерСтудента) ЗАПИСЬ,
получится отношение, в котором будут присутствовать все строки из отношения
СТУДЕНТ. Данное отношение представлено на рис. 8.16, в. В нем фигурирует студент
Смит, хотя этот студент не записан ни на один из предметов. Ключевое слово LEFT
(левый) указывает, что в результате должны быть представлены все строки из
Реляционная алгебра 295
отношения, находящегося по левую сторону от оператора соединения (в нашем
случае это отношение СТУДЕНТ). Операция правого внешнего соединения (right
outer join), имеющая вид СТУДЕНТ RIGHT OUTER JOIN (ЛичныйНомер = НомерСтудента)
ЗАПИСЬ, приведет к отношению, в котором будут присутствовать все строки из
таблицы, находящейся справа от оператора соединения, — а именно таблицы
ЗАПИСЬ. Внешнее соединение удобно использовать при работе со связями, в
которых минимальное кардинальное число равняется нулю с одной или с обеих
сторон. Иногда, когда во избежание неоднозначности требуется указать, какой
именно тип соединения имеется в виду, вместо термина соединение используется
термин внутреннее соединение (inner join).
Выражение запросов в терминах
реляционной алгебры
В табл. 8.2 перечислены все основные операции реляционной алгебры,
описанные выше. Из них стандартными операциями теории множеств являются
объединение (+), вычитание (-), пересечение и произведение. Операция выборки
выделяет из отношения определенные кортежи (строки) в соответствии с
условиями, наложенными на значения атрибутов. Операция проектирования
выделяет из отношения атрибуты (столбцы) по заданным именам. Наконец, операция
соединения конкатенирует кортежи двух отношений в соответствии с условием,
наложенным на значения атрибутов.
Таблица 8.2. Операции реляционной алгебры
Тип
Формат
Пример
Операции над
множествам
Выборка
Проекция
Соединение
Внутреннее
соединение
Внешнее
соединение
+, -, пересечение,
перемножение
отношение WHERE (условие)
отношение [список атрибутов]
отношение1 JOIN (условие)
отношение 2
То же, что и соединение
отношение1 LEFT OUTER JOIN
(условие) отношение 2
СТУДЕНТ [Имя] - ТРЕТЬЕКУРСНИК [Имя]
ЗАНЯТИЯ WHERE НазваниеПредмета = 'А'
СТУДЕНТ [Имя, Специальность]
СТУДЕНТ JOIN
(ЛичныйНомер=НомерСтудента) ЗАПИСЬ
СТУДЕНТ LEFT OUTER JOIN
(ЛичныйНомер=НомерСтудента) ЗАПИСЬ
СТУДЕНТ LEFT OUTER JOIN
(ЛичныйНомер=НомерСтудента) ЗАПИСЬ
отношение1 RIGHT OUTER JOIN
(условие) отношение 2
Теперь посмотрим, как с помощью реляционных операторов можно
формулировать запросы. Воспользуемся для этого отношениями СТУДЕНТ, ЗАНЯТИЯ
и ЗАПИСЬ, показанными на рис. 8.12. Данные для примера представлены на
рис. 8.17. Наша цель состоит в том, чтобы продемонстрировать различные операции
296 Глава 8. Основы построения реляционных баз данных
с отношениями. Хотя вы, скорее всего, не будете использовать реляционную
алгебру при работе с коммерческими продуктами, эти примеры помогут вам
понять, каким образом можно манипулировать отношениями.
Имя Специальность Курс
100
150
200
250
300
350
400
450
ДЖОНС
ПАРКС
БЕЙКЕР
ГЛАСС
БЕЙКЕР
РАССЕЛ
РАЙ
ДЖОНС
ИСТОРИЯ
БУХГАЛТЕРСКИЙ
УЧЕТ
МАТЕМАТИКА
ИСТОРИЯ
БУХГАЛТЕРСКИЙ
УЧЕТ
МАТЕМАТИКА
БУХГАЛТЕРСКИЙ
УЧЕТ
ИСТОРИЯ
*АС '
С2
АС
С4
С4
СЗ
С1
С4
а
Номер Название Порядковый
Студента Предмета Номер
100
150
200
200
300
400
400
400
, 450
BD445
ВА200
BD445
CS250
CS150
ВА200
BF410
CS250
ВА200
1
1 I
2 ,
1
1
2
1
2
3
6
Название
Предмета Время Аудитория
ВА200
BD445
BF410
CS150
CS250
П-Я9
ПСЯЗ
ПСЯ8
ПСЯЗ
ПСЯ1
SC110
SC213
SC213
ЕА304
ЕВ210
в
Рис. В.17. Данные для отношений, определенных на рис. 8.11: а — отношение СТУДЕНТ;
б — отношение ЗАПИСЬ; в — отношение ЗАНЯТИЯ
Реляционная алгебра 297
1. Вывести имена всех студентов.
СТУДЕНТ [Имя]
Эта строка проектирует отношение СТУДЕНТ на атрибут Имя. Результатом
, является следующая таблица:
джонс
ПАРКС
БЕЙКЕР
ГЛАСС
РАССЕЛ
РАЙ
Повторяющиеся имена могут быть опущены. Хотя имена Джонс и Бейкер
фигурируют в отношении СТУДЕНТ дважды, повторения были исключены,
поскольку результат проектирования представляет собой отношение, а
отношение не может содержать одинаковые кортежи.
Вывести имена студентов, записанных хотя бы на один предмет.
ЗАПИСЬ [НомерСтудента]
Этот запрос похож на первый, но здесь оператор проектирования
действует на отношение ЗАПИСЬ. Результатом является следующая таблица:
| 100 |
| 150 |
| 200 |
| 300 |
| 400 |
| 450 |
Как и в предыдущем примере, одинаковые строки были удалены.
Вывести номера студентов, не записанных ни на один предмет.
СТУДЕНТ [ЛичныйНомер] - ЗАПИСЬ [НомерСтудента]
Это выражение представляет собой разность между проекциями двух
отношений: проекция СТУДЕНТ [ЛичныйНомер] содержит номера всех
студентов, а проекция ЗАПИСЬ [НомерСтудента] содержит номера студентов,
записанных на какие-либо предметы. Их разность — это номера студентов, не
записанных ни на один предмет. Результатом является следующая таблица:
250
350
298 Глава 8. Основы построения реляционных баз данных
4. Вывести номера студентов, записанных на предмет 'BD445'.
ЗАПИСЬ WHERE НазваниеПредмета = 'BD445' [НомерСтудента]
Это выражение выделяет соответствующие кортежи и затем проектирует
их на атрибут НомерСтудента. Результатом является следующая таблица:
| 250 |
| 350
5. Вывести имена студентов, записанных на предмет 'BD445'.
СТУДЕНТ JOIN (ЛичныйНомер - НомерСтудента) ЗАПИСЬ WHERE НазваниеПредмета =
'BD445' [СТУДЕНТ.Имя]
Чтобы дать ответ на этот запрос, требуются данные из обеих таблиц —
и СТУДЕНТ, и ЗАПИСЬ. В частности, из таблицы СТУДЕНТ берутся имена
студентов, а условие «записан на предмет BD445» проверяется по таблице
ЗАПИСЬ. Поскольку необходимы оба отношения, их нужно соединить. К
результату соединения таблиц СТУДЕНТ и ЗАПИСЬ применяется операция
выборки, за которой следует проектирование на имена студентов. Результатом
является следующая таблица:
джонс
БЕЙКЕР
Как уже отмечалось ранее, у двух или более отношений, входящих в
выражение, могут оказаться атрибуты с одинаковыми именами. Поэтому для
определенности перед именем атрибута может указываться имя
отношения. Так, в нашем примере делается проекция на атрибут СТУДЕНТ.Имя.
В данном случае префикс служит лишь для демонстрации, поскольку в
рассматриваемое выражение не входят какие-либо другие отношения,
имеющие атрибут Имя. Однако когда имена атрибутов повторяются (например,
атрибут НазваниеПредмета имеется в отношениях ЗАПИСЬ и ЗАНЯТИЯ), запись
с префиксом оказывается необходимой. Рассмотрим следующую задачу.
6. Вывести названия предметов, на которые записан студент Парке, и
расписание занятий по этим предметам.
Чтобы ответить на этот вопрос, мы должны свести воедино данные из трех
отношений. Из таблицы СТУДЕНТ мы возьмем учетный номер студента Пар-
кса, из таблицы ЗАПИСЬ — предметы, на которые записан этот студент, а из
таблицы ЗАНЯТИЯ — расписание занятий по этим предметам.
СТУДЕНТ WHERE Имя = 'ПАРКС JOIN (ЛичныйНомер « НомерСтудента) ЗАПИСЬ JOIN
(ЗАПИСЬ.НазваниеПредмета = ЗАНЯТИЯ.НазваниеПредмета) ЗАНЯТИЯ
[ЗАНЯТИЯ.НазваниеПредмета. Время]
Это выражение выделяет кортеж студента по фамилии Парке из
отношения СТУДЕНТ и соединяет его с соответствующими кортежами отношения
ЗАПИСЬ. Результат соединяется с соответствующими кортежами отноше-
Реляционная алгебра 299
ния ЗАНЯТИЯ. Наконец, берется проекция, которая выделяет названия
предметов и время проведения занятий. Результат имеет следующий вид:
ВА200
ВА20О
Есть другие способы представления этого запроса, эквивалентные этому.
Один из них выглядит так:
СТУДЕНТ JOIN (ЛичныйНомер - НомерСтудента) ЗАПИСЬ JOIN
(ЗАПИСЬ.НазваниеПредмета - ЗАНЯТИЯ.НазваниеПредмета) PFYZNBZ WHERE
Имя - 'ПАРКС [ЗАНЯТИЯ.Название, Время]
Это выражение отличается от первого тем, что выборка данных о студенте
с фамилией Парке не выполняется до тех пор, пока не будут выполнены
все соединения. Если предположить, что компьютер будет выполнять
операции именно в таком порядке, это выражение будет вычисляться медленнее,
чем предыдущее, так как придется соединять большее количество кортежей.
Такие различия являются большим недостатком реляционной алгебры.
С точки зрения пользователя, эквивалентные запросы должны занимать
одинаковое количество времени (и, следовательно, стоить одинаково).
Представьте себе недоумение пользователя, если один и тот же запрос в одной
форме стоит $1.17, а в другой — $4 436. Для неискушенного пользователя
такая разница в стоимости будет представляться просто чьей-то прихотью.
7. Для всех студентов (включая тех, кто не записан ни на один предмет)
вывести номера курсов, на которых они учатся, и аудиторий, в которых они
занимаются.
Поскольку результат должен содержать данные обо всех студентах, в
данном запросе необходимо использовать внешнее соединение. Синтаксис
прямолинеен:
СТУДЕНТ LEFT OUTER JOIN (ЛичныйНомер = НомерСтудента) ЗАПИСЬ (ЗАПИСЬ.
НазваниеПредмета - ЗАНЯТИЯ.НазваниеПредмета) JOIN ЗАНЯТИЯ [Курс. Аудитория]
В результирующей таблице помшю прочего указано, на каких курсах
учатся студенты Гласе и Рассел, не записанные ни на один предмет:
АС
С2
АС
С4
С4
1 СЗ
С1
С1
С1
С4
SC213
SC110
ЕВ210
Null
ЕА304
Null
SC110
SC213
ЕВ210
SC110
300 Глава 8. Основы построения реляционных баз данных
Резюме
При построении реляционной базы данных требуется решить несколько задач.
Во-первых, необходимо описать структуру базы данных для СУБД. Затем нужно
выделить файловое пространство и заполнить базу данных информацией.
В реляционной модели данные представляются и обрабатываются в форме
таблиц, называемых отношениями. Столбцы таблиц называются атрибутами,
а строки — кортежами. Термины таблица, столбец и строка, а также термины
файл, поле и запись являются синонимами терминов отношение, атрибут и
кортеж соответственно.
Использование термина ключ может привести к неоднозначности, так как на
стадии проектирования и реализации он употребляется в различных значениях.
На стадии проектирования этим термином обозначается логический ключ, то есть
один или несколько атрибутов, однозначно интерпретирующих строку. На
стадии реализации этим термином обозначается физический ключ, то есть
структура данных, используемая для повышения производительности. Логический ключ
может быть, а может и не быть физическим ключом; физический ключ также
может, но не обязан быть логическим ключом. В этой книге под словом ключ мы
подразумеваем логический ключ, а под словом индекс — физический ключ.
Поскольку для описания структуры базы данных мы используем
реляционную модель, нам нет необходимости осуществлять какие-либо преобразования
на стадии реализации. Мы просто описываем имеющуюся структуру для СУБД.
Есть два способа сделать это: представить описание в виде текстового
DDL-файла или воспользоваться графическими средствами описания данных. В обоих
случаях для СУБД описываются таблицы, столбцы, индексы, ограничения,
пароли и другие элементы управления.
Помимо описания структуры базы данных, разработчики должны выделить
для базы данных пространство на физическом носителе. В
многопользовательских системах это может быть важно для эффективной работы СУБД. Наконец,
база данных заполняется информацией, для чего используются средства,
предоставляемые производителем СУБД, или программы, разработанные
производителем, или и то и другое.
Есть четыре категории языков манипулирования данными: реляционная
алгебра, реляционное исчисление, языки, ориентированные на преобразования, и
запросы по образцу. Реляционная алгебра состоит из набора реляционных
операторов, с помощью которых можно манипулировать отношениями для получения
желаемого результата. Реляционная алгебра является процедурной. Языки,
ориентированные на преобразования, предоставляют непроцедурные способы для
преобразования набора отношений в желаемый результат. Наиболее
распространенный пример — это язык SQL.
Существует три способа доступа к реляционной базе данных. Один из них
состоит в том, чтобы использовать средства для генерации форм и отчетов,
предоставляемые СУБД. Второй способ — использовать язык запросов и
преобразований; наиболее популярным языком такого рода является SQL. Третий способ
предполагает доступ через прикладные программы.
Прикладные программы могут взаимодействовать с СУБД через вызовы
функций, а также с помощью методов объектов или специальных команд базы
Вопросы 1 группы 301
длимых, транслируемых предварительным компилятором. Реляционная модель
и|мкаптирована на обработку одного отношения за один прием, но большинство
тыков программирования обрабатывают за один прием только одну строку.
Необходимо предусмотреть какие-то способы компенсации этого несоответствия.
Назначение реляционной алгебры состоит в том, чтобы манипулировать
отношениями для получения желаемого результата. Она включает в себя
следующие операторы: объединение, разность, пересечение, произведение, проекция,
иыборка, (внутреннее) соединение и внешнее соединение.
Вопросы I группы
1. Назовите и опишите три задачи, которые необходимо решить при
построении реляционной базы данных.
2. Определите термины отношение, атрибут, кортеж и домен.
3. Объясните, как используются термины таблица, столбец, строка, файл,
поле и запись.
4. Объясните, в чем различие между отношением и схемой отношения
(реляционной схемой).
5. Дайте определения терминов ключ, индекс, логический ключ и физический ключ.
6. Назовите три причины для использования индексов.
7. При каких условиях необходимо преобразовывать структуру базы данных
на стадии реализации?
8. Объясните термин язык определения данных. Какой цели он служит?
9. Как еще можно описать структуру базы данных, кроме как в текстовом
файле?
10. Какие аспекты структуры базы данных должны быть описаны для СУБД?
11. Приведите пример (отличный от данного в тексте), когда выделение
пространства для базы данных на физическом носителе представляет важность.
12. Опишите наилучшую и наихудшую ситуации при заполнении базы данных
информацией.
13. Перечислите и кратко охарактеризуйте четыре категории языков
манипулирования реляционными данными (DML).
14. Объясните, как можно манипулировать реляционными данными
посредством форм.
15. Объясните роль языков запросов в манипулировании реляционными
данными. Чем хранимые запросы отличаются от прикладных программ? Зачем
они используются?
16. Опишите два стиля интерфейса между прикладными программами и базой
данных. Укажите роль предварительного компилятора.
17. Объясните, в чем состоит несоответствие между ориентацией SQL и
большинства языков программирования. Каким образом это несоответствие
исправляется?
302 Глава 8. Основы построения реляционных баз данных
18. Чем отличается реляционная алгебра от школьной алгебры?
19. Почему реляционная алгебра является замкнутой?
20. Определите термин совместимость по объединению. Приведите в качестве
примера два отношения, которые совместимы по объединению, и два
отношения, которые несовместимы по объединению.
В вопросах 21-23 идет речь о следующих двух отношениях:
КОМПАНИЯ (Название, ЧислоСотрудников, ОбъемПродаж)
ПРОИЗВОДИТЕЛИ (Название, КоличествоЛюдей, Доход)
21. Приведите пример объединения этих двух отношений.
22. Приведите пример разности этих двух отношений.
23. Приведите пример пересечения этих двух отношений.
В вопросах 24-28 имеются в виду следующие три отношения:
ПРОДАВЕЦ (Имя, Зарплата)
ЗАКАЗ (Номер, ИмяПокупателя, ИмяПродавца, Сумма)
ПОКУПАТЕЛЬ (Имя, Город, ТипПромышленности)
Имя
Номер
ЗАКАЗ
Зарплата
Абель
Бейкер
Джонс
Мерфи
Зенит
Кобад
120 000
42 000
36 000
150 000
118 000
34 000
ПРОДАВЕЦ
ИмяПокупателя
ИмяПродавца Сумма
100
200
300
400
500
600
700
Abernathy Construction
Abernathy Construction
Manchester Lumber
Amalgamated Housing
Abernathy Construction
Tri-City Builders
Manchester Lumber
Зенит
Джонс
Абель
Абель
Мерфи
Абель
Джонс
560
1800
480
2500
6000
700
100
ИмяПокупателя
Тип
Город Промышленности
Abernathy Construction
Manchester Lumber
Tri-City Builders
Amalgamated Housing
Виллоу
Манчестер
Мемфис
Мемфис
В
F
В
В
ПОКУПАТЕЛЬ
Рис. 8.18. Данные для вопросов 24^28
Вопросы 1 группы 303
24. Приведите пример произведения отношений ПРОДАВЕЦ и ЗАКАЗ.
25. Приведите примеры следующих проекций:
ПРОДАВЕЦ [Имя, Зарплата]
ПРОДАВЕЦ [Зарплата]
При каких условиях в проекции ПРОДАВЕЦ [Зарплата] будет меньше строк,
чем в отношении ПРОДАВЕЦ?
26. Приведите пример выборки из отношения ПРОДАВЕЦ по атрибуту Имя, по
атрибуту Зарплата и по атрибутам Имя и Зарплата одновременно.
27. Приведите пример эквивалентного соединения и натурального соединения
отношений ПРОДАВЕЦ и ЗАКАЗ, где атрибут Имя из отношения ПРОДАВЕЦ
равен атрибуту ИмяПродавца из отношения ЗАКАЗ.
28. Напишите выражения реляционной алгебры, выводящие:
1) имена всех продавцов;
2) имена всех продавцов, для которых имеется строка ЗАКАЗ;
3) имена всех продавцов, не имеющих строки ЗАКАЗ;
4) имена продавцов, имеющих заказ от фирмы Abernathy Construction;
5) зарплаты продавцов, имеющих заказ от фирмы Abernathy Construction;
6) названия городов, в которых проживают покупатели, сделавшие заказ
у продавца по фамилии Джонс;
7) имена всех продавцов с именами покупателей, сделавших у них заказ.
Включите в ответ имена продавцов, у которых нет заказов.
Глава 9
Язык SQL
SQL, или язык структурированных запросов, — на сегодняшний день наиболее
важный из языков манипулирования реляционными данными. Он рекомендован
Американским национальным институтом стандартов (ANSI) в качестве
стандартного языка манипулирования реляционными базами данных и используется
как язык доступа к данным многими коммерческими СУБД, включая DB2,
SQL/DS, Oracle, INGRES, SYBASE, SQL Server, dBase for Windows, Paradox,
Microsoft Access и многие другие. Благодаря своей популярности SQL стал
стандартным языком для обмена ршформацией между компьютерами. Поскольку
существует версия SQL, которая может работать почти на любом компьютере
и операционной системе, компьютерные системы способны обмениваться
данными, передавая друг другу запросы и ответы на языке SQL.
Разработка SQL начиналась в середине 70-х годов в исследовательскохм
центре IBM в Сан-Хосе, и изначально язык носил название SEQUEL. Было
выпущено несколько версий SEQUEL, и в 1980 г. продукт был переименован в SQL.
С тех пор, помимо IBM, многие производители присоединились к разработке
программных продуктов для SQL. Институт ANSI взял на себя работу по
поддержке SQL и периодически публикует обновленные версии стандарта SQL.
В этой главе обсуждается ядро SQL в том виде, как оно описано в стандарте
ANSI 1992 г., который часто обозначают как SQL921. Последняя версия
стандарта, SQL3, содержит расширения языка для объектно-ориентированного
программирования. Эта версия обсуждается в главе 18.
Конструкции и выражения в конкретной реализации SQL (например, в Oracle
или SQL Server) могут немного отличаться от ANSI-стандарта. Частично это
обусловлено тем, что многие ком*мерческие СУБД были разработаны до того,
как появилось соглашение о стандарте, а также тем, что производители
закладывали в свои продукты дополнительные возможности с целью получить
преимущество в конкурентной борьбе. Исходя из рыночной перспективы, одной лишь
поддержки стандарта ANSI порою считалось недостаточно для обеспечения
привлекательности продукта.
Команды языка SQL могут использоваться интерактивно как язык запросов,
а также могут быть встроены в прикладные программы. Таким образом, SQL не
является языком программирования (как, например, COBOL); он скорее
представляет собой подъязык данных (data sublanguage) или язык доступа к данным
(data access language), встраиваемый в другие языки.
International Standards Organization Publication ISO/1EC 9075: 1992, Database Language SQL
Запрос одиночной таблицы ч 305
В этой главе представлены интерактивные операторы SQL, которые, будучи
встроенными в прикладные программы, требуют настройки и модификации
(см. главы 12 и 13). Здесь рассматриваются только операторы манипулирования
данными, а операторы определения данных обсуждаются в главах 12 и 13.
SQL — это язык, ориентированный на преобразования, который принимает
на входе одно или несколько отношений и выдает на выходе одно отношение.
Результат каждого SQL-запроса представляет собой отношение; даже если
результатом является отдельное число, это число считается отношением, у
которого одна строка и один столбец. Таким образом, подобно реляционной алгебре,
язык SQL является замкнутым.
Запрос одиночной таблицы
В этом разделе мы рассмотрим возможности, которые имеются в SQL для
запроса одиночной таблицы. Позже в этой главе мы обсудим многотабличные запросы
и операторы обновления. По традиции зарезервированные слова SQL, такие как
SELECT и FROM, пишутся заглавными буквами. Кроме того, для операторов SQL
обычно используется многострочная запись, как показано в этой главе.
Компиляторы языка SQL, однако, не требуют ни заглавных букв, ни многострочной
записи. Эти соглашения служат лишь для того, чтобы обеспечить большую ясность
для людей, читающих программы на SQL.
1. ТРЕТЬЕКУРСНИК (СтНомер. Имя, Специальность)
2. ПОЧЁТНЫЙ_СТУДЕНТ (Номер. Имя, Интересы)
3. СТУДЕНТ (ЛичныйНомер. Имя, Специальность, Курс)
4. ЗАНЯТИЯ (НазваниеПредмета. Время, Аудитория)
5. ЗАПИСЬ (НомерСтудента. НазваниеПредмета. Порядковый Номер)
6. ППС (НомерСотрудника. ИмяСотрудника, Кафедра)
Атрибут
1 номер
ТРЕТЬЕКУРСНИК.Имя
Специальность
2 ЛичныйНомер
ПОЧЕТНЫЙ_СТУДЕНТИмя
Интересы
3 ЛичныйНомер
СТУДЕНТИмя
Специальность
Курс
4 ЗАНЯТИЯ.НазваниеПредмета
Время
Аудитория
5 НомерСтудента
ЗАПИСЬ. НазваниеПредмета
ПорядковыйНомер
6 НомерСотрудника
ППСИмя
Кафедра
Домен
ИдентификаторыЛюдей
ИменаЛюдей
НазванияПредметов
ИдентификаторыЛюдей
ИменаЛюдей
НазванияПредметов
ИдентификаторыЛюдей
ИменаЛюдей
НазванияПредметов
НомераКурсов
НазванияПредметов
ЧасыЗанятий
Аудитории
ИдентификаторыЛюдей
НазванияПредметов
Порядковые Номера
ИдентификаторыЛюдей
ИменаЛюдей
НазванияПредметов
Рис. 9.1. Отношения, используемые в примерах применения SQL
306 Глава 9. Язык SQL
Мы будем пользоваться теми же самыми шестью отношениями, на примере
которых мы иллюстрировали реляционную алгебру в главе 8. Структура этих
отношений изображена на рис. 9.1, а данные для примера приведены на рис. 9.2.
Личный
Номер
Имя
Специальность Курс
100
150
200
[ 250
300
| 350
400
| 450
ДЖОНС
ПАРКС
БЕЙКЕР
ГЛАСС
БЕЙКЕР
РАССЕЛ
РАЙ
ДЖОНС
ИСТОРИЯ
БУХГАЛТЕРСКИЙ
УЧЕТ
МАТЕМАТИКА
ИСТОРИЯ
БУХГАЛТЕРСКИЙ
УЧЕТ
МАТЕМАТИКА
БУХГАЛТЕРСКИЙ
УЧЕТ
ИСТОРИЯ
АС |
С2
АС
С4
С4
СЗ
С1
С4
Номер
Студента
100
150
200
200
300
400
400
| 400
| 450
Название
Предмета
BD445
ВА200
BD445
CS250
CS150
ВА200
BF410
CS250
ВА200
Порядковый
Номер
1 |
1 |
2 J
1
1 |
2
1
2
3
Название
Предмета
б
Время
Аудитория
ВА200
BD445
i BF410
| CS150
| CS250
П-Я9
ПСЯЗ
ПСЯ8
ПСЯЗ
ПСЯ1
SC110 !
SC213
SC213
ЕА304
ЕВ210
Рис. 9.2. Данные для примеров применения SQL: a — отношение СТУДЕНТ;
б — отношение ЗАПИСЬ; а — отношение ЗАНЯТИЯ
Запрос одиночной таблицы 307
Проектирование в SQL
Чтобы выполнить проектирование с помощью SQL, мы указываем имя
отношения, проекция которого берется, и перечисляем требуемые столбцы. При
использовании стандартного синтаксиса SQL проекция СТУДЕНТ [ЛичныйНомер, Имя,
Специальность] выглядит следующим образом:
SELECT ЛичныйНомер, Имя, Специальность
FROM СТУДЕНТ
Операторы SELECT и FROM являются обязательными; столбцы, которые нужно
получить, перечисляются после оператора SELECT, а имя таблицы, проекция
которой берется, указывается после оператора FROM. Результат проектирования для
данных из рис. 9.2 выглядит следующим образом:
Имя Специальность
| 100
150
| 200
I 250
300
I 350
: 400
( 450
ДЖОНС
ПАРКС
БЕЙКЕР
ГЛАСС
БЕЙКЕР
РАССЕЛ
РАЙ
ДЖОНС
ИСТОРИЯ
БУХГАЛТЕРСКИЙ
УЧЕТ
МАТЕМАТИКА
ИСТОРИЯ
БУХГАЛТЕРСКИЙ
УЧЕТ
МАТЕМАТИКА
БУХГАЛТЕРСКИЙ
УЧЕТ
ИСТОРИЯ
Не путайте оператор SELECT с оператором выборки (selection) в реляционной
алгебре. С помощью оператора SELECT можно выполнять определенные в
реляционной алгебре операции проектирования и выборки, а также некоторые другие
действия. Выборка же — это операция реляционной алгебры, заключающаяся
в получении некоторого подмножества строк из таблицы.
Рассмотрим другой пример:
SELECT Специальность
FROM СТУДЕНТ
Результатом будет таблица, показанная на следующей странице.
Как можно видеть, данная таблица содержит одинаковые строки, и,
следовательно, в строгом смысле она не является отношением. На самом деле, SQL
не удаляет повторяющиеся строки автоматически, поскольку для этого может
потребоваться много времени, а во многих случаях это нежелательно или
ненужно.
308 Глава 9. Язык SQL
ИСТОРИЯ
БУХГАЛТЕРСКИЙ
УЧЕТ
МАТЕМАТИКА
история
БУХГАЛТЕРСКИЙ
УЧЕТ
МАТЕМАТИКА
БУХГАЛТЕРСКИЙ
УЧЕТ
ИСТОРИЯ
Если дублирующиеся строки должны быть удалены, нужно указать ключевое
слово DISTINCT, как показано ниже:
SELECT DISTINCT Специальность
FROM СТУДЕНТ
Результатом этой операции явится отношение:
история
БУХГАЛТЕРСКИЙ
УЧЕТ
МАТЕМАТИКА
Выборка в SQL
Операция выборки реляционной алгебры также выполняется с помощью
команды SELECT. Примером может служить следующее:
SELECT ЛичныйНомер. Имя. Специальность. Курс
FROM СТУДЕНТ
WHERE Специальность = 'МАТЕМАТИКА'
В выражении SELECT указаны имена всех столбцов таблицы. FROM определяет
таблицу, из которой производится выборка, а новая фраза WHERE задает условия
для выборки. Формат SELECT...FROM...WHERE — это фундаментальная структура
операторов SQL. Следующая запись является эквивалентной формой
предыдущего запроса:
SELECT*
FROM СТУДЕНТ
WHERE Специальность = 'МАТЕМАТИКА'
Звездочка (*) означает, что предстоит получить все столбцы таблицы.
Результатом обоих этих запросов будет таблица:
Запрос одиночной таблицы 309
250
350
БЕЙКЕР
РАССЕЛ
МАТЕМАТИКА
МАТЕМАТИКА
АС
СЗ
Выборку и проектирование можно объединить:
SELECT Имя. Курс
FROM СТУДЕНТ
WHERE Специальность = 'МАТЕМАТИКА'
Результатом будет:
БЕЙКЕР
РАССЕЛ
АС
СЗ
В предложении WHERE можно указать несколько условий. Например, выражение
SELECT Имя. Курс
FROM СТУДЕНТ
WHERE Специальность = 'МАТЕМАТИКА' AND Курс
приведет к следующей таблице:
'АС
БЕЙКЕР
АС
Условия в предложении WHERE могут относиться к множеству значений. Для
этого можно использовать операторы IN и NOT IN. Рассмотрим выражение
SELECT Имя
FROM СТУДЕНТ
WHERE Специальность IN ['МАТЕМАТИКА'
'БУХГАЛТЕРСКИЙ УЧЕТ']
Обратите внимание, что в скобках можно указывать несколько значений. Это
выражение означает следующее: «Отобразить имена студентов,
специализирующихся на математике или бухгалтерском учете». Результатом будет таблица:
ПАРКС
БЕЙКЕР
БЕЙКЕР
РАССЕЛ
РАИ
Выражение
SELECT Имя
FROM СТУДЕНТ
WHERE Специальность NOT IN ['МАТЕМАТИКА'
'БУХГАЛТЕРСКИЙ УЧЕТ']
310 Глава 9. Язык SQL
представляет имена студентов, которые специализируются в любых областях,
кроме математики и бухгалтерского учета. Результатом будет таблица:
джонс
ГЛАСС
ДЖОНС
Выражение Специальность IN означает, что столбец Специализация может
содержать любые из перечисленных значений. Это эквивалентно логическому
оператору ИЛИ. Выражение Специальность NOT IN означает, чтс значение в
соответствующем столбце не должно равняться ни одному из перечисленных
значений.
В предложениях WHERE можно также указывать диапазоны и шаблоны.
Диапазоны задаются с помощью оператора BETWEEN. Например, оператор
SELECT Имя. Специальность
FROM СТУДЕНТ
WHERE ЛичныйНомер BETWEEN 200 AND 300
даст следующий результат:
БЕЙКЕР
ГЛАСС
БЕЙКЕР
МАТЕМАТИКА
ИСТОРИЯ
БУХГАЛТЕРСКИЙ
УЧЕТ
Это выражение эквивалентно записи:
SELECT Имя. Специальность
FROM СТУДЕНТ
WHERE ЛичныйНомер >= 200 AND ЛичныйНомер <= 300
Таким образом, при использовании оператора BETWEEN граничные значения
(здесь это 200 и 300) включаются в выбранный диапазон.
Оператор LIKE используется в SQL-выражениях для выборки по шаблону.
Символ 'J (подчеркивание) представляет произвольный одиночный символ.
Символ '%' (процент) представляет последовательность из одного или более
произвольных символов. Так, результатом выражения
SELECT Имя. Курс
FROM СТУДЕНТ
WHERE Курс LIKE 'CJ
является отношение, имеющее два столбца — Имя и Курс, где Курс состоит из
двух символов, первым из которых является 'С:
Запрос одиночной таблицы 311
ПАРКС
ГЛАСС
БЕЙКЕР
РАССЕЛЛ
РАЙ
ДЖОНС
С2
С4
С4 |
сз
С1
С4
Следующее выражение позволяет найти студентов, чьи имена
оканчиваются на 'С:
SELECT Имя
FROM СТУДЕНТ
WHERE Имя LIKE '%C
Результатом будет:
джонс
ПАРКС
ГЛАСС
ДЖОНС
(В Microsoft Access используется иной набор джокеров, чем в стандарте ANSI.
Вместо символа подчеркивания используется символ '?', а вместо символа
процента — символ '*'.)
Наконец, оператор IS NULL предназначен для поиска пустых (или
отсутствующих) значений. Выражение
SKLECT Имя
f ROM СТУДЕНТ
WHERE Курс IS NULL
даст имена студентов, у которых отсутствует значение в столбце Курс. Из данных,
приведенных на рис. 9.2, можно видеть, что запись о курсе имеется у всех студен-
гон, поэтому результатом данного выражения будет отношение, не содержащее
ми одной строки.
Сортировка
Строки результирующего отношения могут быть отсортированы по значениям
одного или нескольких столбцов с помощью оператора ORDER BY. Рассмотрим
следующий пример:
SELECT Имя, Специальность. Курс
FROM СТУДЕНТ
312 Глава 9. Язык SQL
WHERE Специальность = 'БУХГАЛТЕРСКИЙ УЧЕТ'
ORDER BY Имя
Этот запрос перечислит в алфавитном порядке студентов,
специализирующихся на бухгалтерском учете. Результат имеет следующий вид:
БЕЙКЕР
ПАРКС
РАЙ
БУХГАЛТЕРСКИЙ
УЧЕТ
БУХГАЛТЕРСКИЙ
УЧЕТ
БУХГАЛТЕРСКИЙ
УЧЕТ
С4
С2
С1
Для сортировки можно выбрать более одного столбца. В этом случае первый
из указанных столбцов будет главным полем, по которому будет производиться
сортировка, следующий столбец будет следующим по старшинству полем, и т. д.
Можно объявить сортировку столбцов как по возрастанию (ключевое слово ASC),
так и по убыванию (ключевое слово DESC). В качестве примера рассмотрим
следующий оператор:
SELECT Имя, Специальность, Курс
FROM СТУДЕНТ
WHERE Курс IN ['С1\ 'С2\ 'С4']
ORDER BY Имя ASC, Курс DESC
Результатом будет таблица:
БЕЙКЕР
ПАРКС
РАЙ
ГЛАСС
ДЖОНС
БУХГАЛТЕРСКИЙ
УЧЕТ
БУХГАЛТЕРСКИЙ
УЧЕТ
БУХГАЛТЕРСКИЙ
УЧЕТ
ИСТОРИЯ
ИСТОРИЯ
С4
С2
С1
С4
С4
Ключевые слова ORDER BY могут комбинироваться с любыми операторами SELECT.
Встроенные функции SQL
В SQL предусмотрено пять встроенных функций (built-in functions): COUNT, SUM,
AVG, MAX и MIN1. Функции COUNT и SUM различны, хотя обе они выполняют
подсчет. Функция COUNT вычисляет количество строк в таблице, a SUM подсчитывает
Иногда встроенные функции называют также агрегированными функциями (aggregate functions),
чтобы отличать их от встроенных функций языков программирования, таких как SUBSTRING.
Запрос одиночной таблицы, 313
количество числовых столбцов. Функции AVG, МАХ и MIN также работают с
числовыми столбцами: AVG вычисляет среднее значение, а МАХ и MIN находят
соответственно максимальное и минимальное значение столбца в таблице.
Выражение
SELECT C0UNT(*)
FROM СТУДЕНТ
подсчитывает количество строк в таблице СТУДЕНТ и отображает его в таблице,
имеющей одну строку и один столбец:
| 8 |
Рассмотрим выражения
SELECT COUNT (Специальность)
FROM СТУДЕНТ
и
SELECT COUNT (DISTINCT Специальность)
FROM СТУДЕНТ
Первое выражение подсчитывает общее количество специальностей в таблице,
включая повторения, а второе — количество различных специальностей.
Результаты имеют следующий вид:
8
и
3
За исключением операторов с ключевым словом GROUP BY, которое
рассмотрено ниже, встроенные функции в операторе SELECT не могут перемежаться с
именами столбцов. Таким образом, запись вида
SELECT Имя, COUNT (*)
недопустима.
Встроенные функции можно использовать для запроса результата, как в
приведенных выше примерах. В большинстве реализаций SQL и в стандарте ANSI
SQL встроенные функции не могут фигурировать в предложении WHERE.
Встроенные функции и группировка
Для большей практичности встроенные функции можно применять к группам
строк внутри таблицы. Такие группы формируются путем сбора (в логическом,
314 Глава 9. Язык SQL
а не в физическом смысле) строк, имеющих одинаковое значение заданного
столбца. Например, студентов можно группировать по специальностям — то есть
для каждого значения атрибута Специальность будет сформирована своя группа.
На рис. 9.2 можно выделить три группы студентов: одна специализируется на
истории, другая — на бухгалтерском учете, а третья — на математике.
Ключевое слово GROUP BY инструктирует СУБД группировать те строки,
которые имеют одинаковое значение заданного столбца. Рассмотрим выражение
SELECT Имя, C0UNK*)
FROM СТУДЕНТ
GROUP BY Специальность
Результатом будет отношение:
ИСТОРИЯ
БУХГАЛТЕРСКИЙ
УЧЕТ
МАТЕМАТИКА
3
3
2
Строки таблицы СТУДЕНТ логически сгруппированы по значению атрибута
Специальность, а функция COUNT суммирует количество строк в каждой группе.
Результат представляет собой таблицу из двух столбцов: названия
специальности и количества студентов с этой специальностью. Для подгрупп в операторе
SELECT могут быть указаны как столбцы, так и встроенные функции.
В некоторых случаях возникает потребность рассматривать не все группы.
Например, мы сформировали группы студентов, имеющих одинаковую
специальность, и теперь хотим рассматривать только те из них, количество студентов
в которых больше двух. Чтобы указать нужное нам подмножество групп, мы
можем воспользоваться SQL-предложением HAVING.
Следующие операторы SQL выдают перечень предметов, на которых
специализируется более двух студентов, а также количество студентов, занимающихся
по каждой из этих специализаций:
SELECT Специальность, COUNT (*)
FROM СТУДЕНТ
GROUP BY Специальность
HAVING COUNT (*) > 2
Здесь составляются группы из студентов, имеющих одинаковую
специальность, затем выбираются те из них, в составе которых имеется более двух
студентов (прочие группы игнорируются.) На выходе выдаются название специальности
и число студентов в каждой из выбранных групп. Результат имеет следующий
вид:
ИСТОРИЯ
БУХГАЛТЕРСКИЙ
УЧЕТ
3
3
Запрос нескольких таблиц 315
Для еще большей общности могут быть также добавлены предложения WHERE.
Однако это может привести к неоднозначности. Рассмотрим выражение
SELECT Специальность. МАХ (ЛичныйНомер)
FROM СТУДЕНТ
WHERE Курс = 'С4'
GROUP BY Специальность
HAVING COUNT (*) > 1
Результат будет зависеть от того, когда будет применяться условие в
предложении WHERE — до или после условия в предложении HAVING. Чтобы устранить
эту неопределенность, стандарт SQL устанавливает правило, согласно которому
предложения WHERE должны применяться в первую очередь. Соответственно,
н приведенном операторе порядок выполнения операций таков: выбираются
студенты четвертого курса; формируются группы; из групп выбираются те, которые
удовлетворяют условию предложения HAVING; выводятся результаты. В данном
случае результат выглядит так:
ИСТОРИЯ
450
(Этот запрос допустим не во всех реализациях SQL. В некоторых
реализациях единственные атрибуты, которые могут фигурировать во фразе SELECT запроса
с предложением GROUP BY, — это атрибуты из фразы GROUP BY и встроенные
функции от этих атрибутов. Таким образом, в данном запросе допустимыми
будут только атрибут Специальность и встроенные функции от этого атрибута.)
Запрос нескольких таблиц
В этом разделе мы распространим наше обсуждение языка SQL на операции с
двумя и более таблицами. Для иллюстрации этих команд будут использоваться
таблицы СТУДЕНТ, ЗАНЯТИЯ и ЗАПИСЬ.
Вложенные запросы
Предположим, мы хотим знать имена студентов, записанных на предмет под
шифром BD445. Если нам известно, что на этот предмет записаны студенты с
номерами 100 и 200, то правильные результаты выдаст следующий запрос:
SELECT Имя
FROM СТУДЕНТ
WHERE ЛичныйНомер IN [100, 200]
Обычно мы не знаем номеров студентов, записанных на какой-то предмет,
по у нас есть возможность их определить. Рассмотрим выражение
SELECT НомерСтудента
316 Глава 9. Язык SQL
FROM ЗАПИСЬ
WHERE НазваниеПредмета = 'BD445'
Результатом операции будет таблица:
100
200
Вот те номера студентов, которые нам требовались. Комбинируя последние
два запроса, мы получаем следующее:
SELECT Имя
FROM СТУДЕНТ
WHERE ЛичныйНомер IN
(SELECT НомерСтудента
FROM ЗАПИСЬ
WHERE НазваниеПредмета = 'BD445')
Второе предложение SELECT, которое называется вложенным запросом (subquery),
заключено в круглые скобки.
Эти выражения оказывается проще понять, если читать их снизу вверх.
Последние три оператора выдают номера студентов, записанных на предмет BD445,
а первые три оператора выдают имена выбранных студентов. Результат запроса
таков:
джонс
БЕЙКЕР
Чтобы данная операция была семантически корректной, СТУДЕНТ.ЛичныйНомер
и ЗАПИСЬ.НомерСтудента должны иметь один и тот же домен.
Вложенные запросы могут состоять из трех или даже большего количества
таблиц. Предположим, например, что мы хотим узнать имена студентов, в
расписании у которых стоят занятия по понедельникам, средам и пятницам с 3 часов
(они обозначены в наших данных как 'ПСЯЗ'). Прежде всего 4нам нужны
названия предметов, занятия по которым начинаются в это время:
SELECT ЗАНЯТИЯ.НазваниеПредмета
FROM ЗАНЯТИЯ
WHERE Время = 'ПСЯЗ'
(Поскольку мы имеем дело с тремя различными таблицами, мы указываем
имена столбцов вместе с именами таблиц, чтобы избежать недоразумений и
неоднозначности. Так, ЗАНЯТИЯ.НазваниеПредмета обозначает столбец
НазваниеПредмета в отношении ЗАНЯТИЯ.)
Далее мы определяем личные номера студентов, записанных на эти
предметы, с помощью следующего выражения:
Запрос нескольких таблиц 317
SELECT ЗАПИСЬ.НомерСтудента
FROM ЗАПИСЬ
WHERE ЗАПИСЬ.НазваниеПредмета IN
(SELECT ЗАНЯТИЯ.НазваниеПредмета
FROM ЗАНЯТИЯ
WHERE Время = 'ПСЯЗ')
Это даст результат:
100
200
300
то есть номера студентов, занимающихся в указанное нами время. Чтобы
получить имена этих студентов, мы используем следующее выражение:
SELECT СТУДЕНТ.Имя
FROM СТУДЕНТ
WHERE СТУДЕНТ.ЛичныйНомер IN
SELECT ЗАПИСЬ.НомерСтудента
FROM ЗАПИСЬ
WHERE ЗАПИСЬ.НазваниеПредмета IN
(SELECT ЗАНЯТИЯ.НазваниеПредмета
FROM ЗАНЯТИЯ
WHERE ЗАНЯТИЯ.Время = 'ПСЯЗ')
Результатом будет:
ДЖОНС
БЕЙКЕР
БЕЙКЕР
Эта стратегия работает хорошо, пока атрибуты, входящие в ответ, происходят
из одной и той же таблицы. Если же результат содержит информацию из двух
или более таблиц, перед нами встает проблема. Предположим, к примеру, что мы
хотим узнать имена студентов и названия предметов, на которые они записаны.
То есть нам нужны атрибуты ЛичныйНомер, ИмяСтудента и НазваниеПредмета. В этом
случае результаты происходят из двух различных таблиц (СТУДЕНТ и ЗАПИСЬ),
и стратегия вложенных запросов не работает.
Соединение с помощью SQL
Чтобы получить атрибуты ЛичныйНомер, Имя и НазваниеПредмета для каждого
студента, мы должны соединить таблицу СТУДЕНТ с таблицей ЗАПИСЬ. Это делается
следующими операторами:
318 Глава 9. Язык SQL
SELECT СТУДЕНТ.ЛичныйНомер, СТУДЕНТ.Имя. ЗАПИСЬ.НазваниеПредмета
FROM СТУДЕНТ. ЗАПИСЬ
WHERE СТУДЕНТ.ЛичныйНомер = ЗАПИСЬ.НомерСтудента
Вспомните, что соединение — это комбинация трех операций: умножения,
затем выборки и наконец (обычно) — проекции. В этом выражении оператор FROM
производит перемножение отношений СТУДЕНТ и ЗАПИСЬ, а оператор WHERE
производит выборку. Значение выражения звучит так: «Выбрать из произведения
отношений СТУДЕНТ и ЗАПИСЬ те строки, в которых значение атрибута
ЛичныйНомер из отношения СТУДЕНТ равно значению атрибута НомерСтудента в отношении
ЗАПИСЬ». Наконец, после выборки берется проекция на номер студента, имя и
название предмета. Результат имеет следующий вид:
100
, 150
200
200
300
400
400
400
450
ДЖОНС
ПАРКС
БЕЙКЕР
БЕЙКЕР
БЕЙКЕР
РАЙ
РАЙ
РАЙ
ДЖОНС
BD445
ВА200
BD445
CS250
CS150
ВА200
BF410
CS250
ВА200
Предложение WHERE может содержать и другие квалификаторы помимо тех,
которые непосредственно требуются для соединения. Например,
SELECT СТУДЕНТ.ЛичныйНомер. ЗАПИСЬ.НазваниеПредмета
FROM СТУДЕНТ. ЗАПИСЬ
WHERE СТУДЕНТ.ЛичныйНомер = ЗАПИСЬ.НомерСтудента
AND СТУДЕНТ.Имя = 'РАЙ'
AND ЗАПИСЬ.ПорядковыйНомер = 1
Здесь дополнительные квалификаторы — это условия СТУДЕНТ.Имя = ТАЙ'
и ЗАПИСЬ.ПорядковыйНомер = 1. Это выражение будет иметь своим результатом
список учетных номеров всех студентов по имени Рай, кто записался первым на
какой-либо предмет, и список соответствующих предметов.
400
BF410
Когда требуются данные более чем из двух таблиц, мы можем использовать
аналогичную стратегию. В следующем примере соединяются три таблицы:
SELECT СТУДЕНТ.ЛичныйНомер. ЗАНЯТИЯ.НазваниеПредмета, ЗАНЯТИЯ.Время,
ЗАПИСЬ.ПорядковыйНомер
Запрос нескольких таблиц 319
FROM СТУДЕНТ. ЗАПИСЬ. ПРЕДМЕТ
WHERE СТУДЕНТ.ЛичныйНомер = ЗАПИСЬ.НомерСтудента
AND ЗАПИСЬ.НазваниеПредмета - ЗАНЯТИЯ.НазваниеПредмета
AND СТУДЕНТ.Имя = 'БЕЙКЕР'
Результатом этой операции будет:
200
200
300
BD445
CS250
CS150
ПСЯЗ
ПСЯ12
ПСЯЗ
2
1
1
Сравнение вложенного запроса и соединения
Соединение может использоваться в качестве альтернативы множеству
вложенных запросов. Например, мы использовали вложенный запрос для нахождения
студентов, записанных на предмет BD445. Для представления этого запроса мы
также можем использовать соединение:
SELECT СТУДЕНТ.Имя
FROM СТУДЕНТ. ЗАПИСЬ
WHERE СТУДЕНТ.ЛичныйНомер - ЗАПИСЬ.НомерСтудента
AND ЗАПИСЬ.НазваниеПредмета - 'BD445*
Подобным же образом вопрос «Каковы имена студентов, занимающихся по
понедельникам, средам и пятницам в 3 часа?» может быть представлен в виде
запроса
SELECT СТУДЕНТ.Имя
FROM СТУДЕНТ. ЗАПИСЬ. ЗАНЯТИЯ
WHERE СТУДЕНТ.ЛичныйНомер = ЗАПИСЬ.НомерСтудента
AND ЗАПИСЬ.НазваниеПредмета - ЗАНЯТИЯ.НазваниеПредмета
AND ЗАНЯТИЯ.Время = 'ПСЯЗ'
Хотя выражения с соединением во многих случаях могут составить
альтернативу вложенным запросам, они не способны заменить их в любой ситуации.
Например, вложенные запросы со служебными словами EXISTS и NOT EXISTS
(обсуждаются ниже) нельзя представить с помощью соединений.
Не все соединения можно заменить вложенным запросом. Когда используется
соединение, отображаемые столбцы могут относиться к любой из соединяемых
таблиц, а вложенный запрос способен отобразить столбцы только той таблицы,
которая указана в выражении FROM первого оператора SELECT. Предположим,
например, что мы хотим определить названия курсов, на которые записаны
студенты. Мы можем выразить это в виде вложенного запроса:
SELECT DISTINCT НазваниеПредмета
FROM ЗАПИСЬ
320 Глава 9. Язык SQL
WHERE НомерСтудента IN
(SELECT ЛичныйНомер
FROM СТУДЕНТ
WHERE Курс NOT = 'AC')
или в виде соединения:
SELECT DISTINCT НазваниеПредмета
FROM ЗАПИСЬ. СТУДЕНТ
WHERE ЗАПИСЬ.НомерСтудента - СТУДЕНТ.ЛичныйНомер
AND Курс NOT = 'AC
Но если мы хотим знать и названия предметов, и номера курсов, на которых
учатся студенты, мы должны использовать соединение. Вложенный запрос не
подойдет, поскольку требуемые результаты происходят из разных таблиц, а
именно названия предметов хранятся в таблице ЗАПИСЬ, а имена студентов — в
таблице СТУДЕНТ. Правильный ответ выдаст следующий запрос:
SELECT DISTINCT ЗАПИСЬ.НазваниеПредмета. СТУДЕНТ.Курс
FROM ЗАПИСЬ. СТУДЕНТ
WHERE ЗАПИСЬ.НомерСтудента = СТУДЕНТ.ЛичныйНомер
AND СТУДЕНТ.Курс NOT = 'AC
Результат имеет следующий вид:
ВА200
CS150
ВА200
BF410
CS250
| ВА200
С2 |
С4
С1
С1
С1
С4
Внешнее соединение
Стандарт ANSI SQL не поддерживает операцию внешнего соединения. Однако
эта операция поддерживается многими СУБД. Здесь мы продемонстрируем
использование одной из них.
Предположим, нам нужен список студентов и названия предметов, на которые
они записаны. Допустим, кроме того, что мы хотим получить сведения обо всех
студентах, включая даже тех, кто не записан ни на один из предметов. В Microsoft
Access этот результат можно получить с помощью следующего выражения:
SELECT Имя. НазваниеПредмета
FROM СТУДЕНТ LEFT JOIN ЗАПИСЬ
ON ЛичныйНомер = НомерСтудента;
Операторы EXISTS и NOT EXISTS 321
Результатом будет:
ДЖОНС
ПАРКС
БЕЙКЕР
БЕЙКЕР
ГЛАСС
БЕЙКЕР
РАССЕЛ
РАЙ
РАЙ
РАЙ
ДЖОНС
BD445
ВА200
BD445
CS250
Null
CS150
Null
ВА200
BF410
CS250 j
ВА200
Обратите внимание на различия между Access SQL и записью, принятой в
стандарте ANSI. Условия соединения задаются с помощью ключевого слова ON. Кроме
того, все выражения SQL заканчиваются точкой с запятой.
Операторы EXISTS и NOT EXISTS
EXISTS и NOT EXISTS («существует» и «не существует») — логические операторы,
принимающие значение «истина» или «ложь», в зависимости от наличия или
отсутствия строк, удовлетворяющих заданным условиям. Пусть, например, мы
хотим узнать номера студентов, записанных более чем на один предмет:
SELECT DISTINCT НомерСтудента
FROM ЗАПИСЬ А
WHERE EXISTS
(SELECT*
FROM ЗАПИСЬ В
WHERE А.НомерСтудента = В.НомерСтудента
AND А.НазваниеПредмета NOT = В.НазваниеПредмета)
В этом примере как основной, так и вложенный запросы относятся к таблице
ЗАПИСЬ. Во избежание неоднозначности этим двум вариантам использования
таблицы ЗАПИСЬ присвоены различные имена. В первом операторе FROM таблице
ЗАПИСЬ присвоено временное произвольное имя А, а во втором операторе FROM —
другое временное произвольное имя В.
Выражение во вложенном запросе означает следующее: следует найти две
строки в таблице ЗАПИСЬ, имеющие один и тот же номер студента, но различные
названия предметов. (Это означает, что студент записан более чем на один
предмет.) Если такие две строки существуют, то оператор EXISTS будет иметь логиче-
322 Глава 9. Язык SQL
ское значение «истина»; в этом случае номер данного студента будет
присутствовать в ответе. В противном случае оператор EXISTS будет иметь логическое значение
«ложь», и номер данного студента в результате фигурировать не будет.
Можно рассматривать этот запрос и по-другому: представим себе две
отдельные и идентичные копии таблицы ЗАПИСЬ. Назовем одну из копий А, а другую В.
Будем сравнивать каждую строку А с каждой строкой В. Сначала рассмотрим
первую строку А и первую строку В. Поскольку эти две строки идентичны, то
и номер студента, и название предмета в них совпадают, поэтому атрибут Номер-
Студента из данной строки не попадет в ответ.
Теперь рассмотрим первую строку А и вторую строку В. Если номер студента
один и тот же, а названия предметов различаются, данный номер студента будет
отображен в результатах. В сущности, мы сравниваем первую строку таблицы
ЗАПИСЬ со второй строкой этой же таблицы. В данных, представленных на рис. 9.2,
ни номер студента, ни название предмета не совпадают.
Далее мы продолжаем сравнивать первую строку А с каждой строкой В. Если
выполняются заданные нами условия, мы выводим номер студента. Когда будут
пройдены все строки таблицы В, мы перейдем ко второй строке таблицы А и будем
сравнивать ее с каждой строкой таблицы В (на самом деле, когда мы
рассматриваем n-ю строку таблицы А, то в таблице В необходимо рассмотреть только
строки, номера которых больше п).
Результатом этого запроса будет:
200
400
Чтобы продемонстрировать использование ключевого слова NOT EXISTS ,
предположим, что мы хотим узнать имена студентов, которые записаны на все
предметы. По-другому это можно выразить так: нам нужны имена таких студентов,
для которых не существует предметов, на которые они не были бы записаны. Это
делается с помощью следующего запроса:
SELECT СТУДЕНТ.Имя
FROM СТУДЕНТ
WHERE NOT EXISTS
(SELECT*
FROM ЗАПИСЬ
WHERE NOT EXISTS
(SELECT*
FROM ЗАНЯТИЯ
WHERE ЗАНЯТИЯ.НазваниеПредмета = ЗАПИСЬ.НазваниеПредмета
AND ЗАПИСЬ.НомерСтудента = СТУДЕНТ.ЛичныйНомер))
Этот запрос состоит из трех частей. В нижней части ведется поиск предметов,
на которые записан студент. Средняя часть определяет, есть ли такие предметы,
на которые студент не записан. Если нет, то студент записан на все предметы,
и его имя отображается в результатах.
Изменение данных 323
Этот запрос может оказаться сложным для понимания. Если у вас есть
проблемы с этим, используйте данные, представленные на рис. 9.2, и следуйте
инструкциям. Для этих данных ответ состоит в том, что нет ни одного студента, который
был бы записан на все предметы. Вы можете попытаться изменить данные таким
образом, чтобы какой-либо студент был записан на все предметы. Еще один
способ уяснить себе суть этого запроса — попробовать представить его в другом виде,
без применения ключевого слова NOT EXISTS. Проблемы, с которыми вы при этом
столкнетесь, помогут вам понять, почему оператор NOT EXISTS необходим.
Изменение данных
В SQL предусмотрены средства для изменения данных в таблицах путем вставки
новых строк, удаления строк и модификации значений в существующих строках.
SQL позволяет также менять структуру данных, хотя мы не будем затрагивать
.)ту тему до глав 12 и 13.
Вставка данных
Строки можно вставлять в таблицы по одной или группами. Чтобы вставить одну
строку, мы пишем следующее:
INSERT INTO ЗАПИСЬ
VALUES (400. "BD445\ 44)
После ключевого слова INSERT INTO указывается имя таблицы, а после
ключевого слова VALUES — вставляемые значения.
Если мы знаем не все данные (например, нам неизвестно значение атрибута
Позиция), можно поступить следующим образом:
INSERT INTO ЗАПИСЬ
(НомерСтудента. НазваниеПредмета)
VALUES (400. 'BD445*. 44)
Атрибут ПорядковыйНомер может быть добавлен позже. Обратите внимание,
что в результате этого запроса поле Позиция в новой строке будет иметь нулевое
значение.
Можно также копировать группы строк из одной таблицы в другую. Пусть,
например, нам нужно заполнить таблицу ТРЕТЬЕКУРСНИК, показанную на рис. 9.1.
INSERT INTO ТРЕТЬЕКУРСНИК
VALUES
(SELECT ЛичныйНомер. Имя, Специальность
FROM СТУДЕНТ
WHERE Курс = 'СЗ")
Вложенный оператор SELECT, как и все выражения SELECT, описанные в
предыдущих двух разделах, позволяет указывать строки для копирования. Это
свойство предоставляет весьма широкие возможности.
324 Глава 9. Язык SQL
Удаление данных
Как и в случае вставки, строки можно удалять по одной или группами.
Следующий пример удаляет строку с данными о студенте 100:
DELETE FROM СТУДЕНТ
WHERE СТУДЕНТ.ЛичныйНомер = 100
Обратите внимание, что если студент 100 записан на какие-либо предметы,
это удаление вызовет нарушение целостности, поскольку для строк таблицы
ЗАПИСЬ, в которых НомерСтудента = 100, не будет соответствующей строки в
таблице СТУДЕНТ.
Каким образом можно удалить группу строк, показывают следующие два
примера. В них из таблицы ЗАПИСЬ удаляется информация о предметах, на
которые записаны студенты, специализирующиеся на бухгалтерском учете, а из
таблицы СТУДЕНТ удаляются данные обо всех таких студентах:
DELETE FROM ЗАПИСЬ
WHERE ЗАПИСЬ.НомерСтудента IN
(SELECT СТУДЕНТ.ЛичныйНомер
FRDM СТУДЕНТ
WHERE СТУДЕНТ.Специальность = 'Бухгалтерский учет")
DELETE FRDM СТУДЕНТ
WHERE СТУДЕНТ.Специальность = 'Бухгалтерский учет'
Порядок выполнения этих операций имеет значение: если бы он был
обратным, ни одна строка из таблицы ЗАПИСЬ не была бы удалена, потому что
соответствующие строки из таблицы СТУДЕНТ оказались бы уже удаленными.
Модификация данных
Строки можно также модифицировать — по одной или группами. Для изменения
значения столбца предназначены ключевые слова UPDATE и SET. После SET
указывается имя столбца, значение в котором требуется изменить, а затем новое
значение либо способ его вычисления. Рассмотрим два примера:
UPDATE ЗАПИСЬ
SET ПорядковыйНомер = 44
WHERE НомерСтудента = 400
и
UPDATE ЗАПИСЬ
SET ПорядковыйНомер = МАХ(ПорядковыйНомер) + 1
WHERE НомерСтудента = 400
Во втором операторе UPDATE значение столбца вычисляется с помощью
встроенной функции МАХ. Некоторые реализации SQL, однако, могут не допускать
использования встроенных функций в качестве аргумента команды SET.
Вопросы I группы 325
Для демонстрации массовых обновлений предположим, что название предмета
поменялось с BD445 на BD564. В этом случае, чтобы предотвратить проблемы с
целостностью, должны быть изменены как таблица ЗАПИСЬ, так и таблица ПРЕДМЕТ.
UPDATE ЗАПИСЬ
SET НазваниеПредмета = 'BD564'
WHERE НазваниеПредмета = 'BD445'
UPDATE ЗАНЯТИЯ
SET НазваниеПредмета = 'BD564'
WHERE НазваниеПредмета = *BD445'
Помните, что массовые обновления могут представлять большую опасность.
Пользователю дается огромная власть, которая при правильном ее
использовании позволяет быстро выполнить насущную задачу, а если ею распорядиться
немирно, может привести к серьезным проблемам.
Резюме
SQL — это наиболее важный на сегодняшний день язык манипулирования
реляционными данными. Он превратился в стандартный язык для обмена информацией
между компьютерами, и популярность его продолжает расти. Операторы SQL,
действующие на отдельную таблицу, — это операторы SELECT, SELECT с
предложением WHERE, SELECT с предложением GROUP BY и SELECT с предложениями GROUP
BY и HAVING. В SQL также имеются встроенные функции COUNT, SUM, AVG, МАХ и MIN.
Операции с двумя и более таблицами выполняются с помощью вложенных
запросов, соединений и операторов EXISTS и NOT EXISTS. Вложенные запросы и
соединения часто выполняют одни и те же операции, но не являются полностью
взаимозаменяемыми. Для вложенных запросов требуется, чтобы запрашиваемые
атрибуты происходили из одной и той же таблицы, а в случае соединений это не
обязательно. С другой стороны, существуют типы запросов, которые можно
реализовать с помощью вложенных запросов и операторов EXISTS и NOT EXISTS, но
невозможно с помощью соединений.
Операторы SQL для модификации данных включают команды INSERT, DELETE
и UPDATE, которые предназначены соответственно для вставки, удаления и
изменения значений данных.
В этой главе мы представили базовые команды SQL в стандартной форме,
а в главах 13, 14 и 16 мы будем использовать эти команды для обработки базы
данных с помощью коммерческих СУБД.
Вопросы I группы
В вопросах этой группы речь идет о следующих отношениях:
ПРОДАВЕЦ (Имя, ПроцентКвоты, Зарплата)
ЗАКАЗ (Номер, ИмяПокупателя, ИмяПродавца, Сумма)
ПОКУПАТЕЛЬ (Имя, Город, ТипПромышленности)
326 Глава 9. Язык SQL
Экземпляры этих трех отношений приведены на рис. 9.3. Используя данные
из этих таблиц, напишите SQL-операторы, которые отображают или
модифицируют данные, как того требуют приведенные ниже задания.
Имя
Абель
Бейкер
Джонс
Мерфи
Зенит
Кобад
ПроцентКвоты
63
38
26
42
59
27
Зарплата
120 000
42 000
36 000
150 000
118 000
34 000
ПРОДАВЕЦ
Номер
100
200
300
400
500
I 600
700
ИмяПокупателя
Abernathy Construction
Abernathy Construction
Manchester Lumber
Amalgamated Housing
Abernathy Construction
Tri-City Builders
Manchester Lumber
ИмяПродавца
Зенит
Джонс
Абель
Абель
Мерфи
Абель
Джонс
Сумма
560
1800
480
2500
6000
700
150
ЗАКАЗ
ИмяПокупателя
Тип
Город Промышленности
Abernathy Construction
Manchester Lumber
Tri-City Builders
Amalgamated Housing
Виллоу
Манчестер
Мемфис
Мемфис
В
F
в !
в
ПОКУПАТЕЛЬ
Рис. 9.3. Данные для вопросов группы I
1. Выведите суммы зарплаты для всех продавцов.
2. Выведите суммы зарплаты для всех продавцов, но опустите повторения.
3. Выведите имена продавцов, у которых процент квоты меньше 30%.
4. Выведите имена продавцов, у которых имеется заказ от фирмы Abernathy
Construction.
5. Выведите имена продавцов, зарплата которых больше $49 999, но меньше
$100 000.
6. Выведите имена продавцов, у которых процент квоты больше 49%, но
меньше 60%. Используйте ключевое слово BETWEEN.
Вопросы I группы 327
7. Выведите имена продавцов, у которых процент квоты больше 49%, но
меньше 60%. Используйте ключевое слово LIKE.
8. Выведите имена покупателей, живущих в городе, название которого
оканчивается на «С».
9. Выведите имена и зарплаты продавцов, у которых нет заказа от фирмы
Abernathy Construction, в порядке возрастания заработной платы.
10. Подсчитайте количество заказов.
11. Подсчитайте количество различных покупателей, имеющих какой-либо
заказ.
12. Вычислите средний процент квоты для продавцов.
13. Выведите имя продавца, у которого наибольший процент квоты.
14. Подсчитайте количество заказов у каждого продавца.
15. Подсчитайте количество заказов у каждого продавца, учитывая только те
заказы, в которых Сумма превышает 500.
16. Выведите имена и проценты квоты для продавцов, имеющих заказ от
фирмы Abernathy Construction, в порядке убывания процента квоты
(используйте вложенный запрос).
17. Выведите имена и проценты квоты для продавцов, имеющих заказ от
фирмы Abernathy Construction, в порядке убывания процента квоты
(используйте соединение).
18. Выведите процент квоты для продавцов, имеющих заказ от покупателей
из Мемфиса (используйте вложенный запрос).
19. Выведите процент квоты для продавцов, имеющих заказ от покупателей
из Мемфиса (используйте соединение).
20. Выведите тип промышленности и имена продавцов для всех заказов от
компаний, находящихся в Мемфисе.
21. Выведите имена продавцов вместе с именами покупателей, сделавших
заказы у этих продавцов. Включите в ответ имена продавцов, у которых нет
заказов. Используйте запись, принятую в Microsoft Access.
22. Выведите имена продавцов, имеющих два заказа и более.
23. Выведите имена продавцов и проценты квоты для тех из них, которые
имеют два заказа и более.
24. Выведите имена и возраст продавцов, имеющих заказы от всех покупателей.
25. Напишите SQL-оператор, вставляющий новую строку в таблицу ПОКУПАТЕЛЬ.
26. Напишите SQL-онератор, вставляющий новое имя и возраст в отношение
ПРОДАВЕЦ (предполагается, что заработная плата не определена).
27. Напишите SQL-оператор, вставляющий строки в новую таблицу
ПЕРЕДОВИК (Имя, Зарплата), для включения в которую продавец должен иметь
заработную плату не меньше $100 000.
28. Напишите SQL-оператор, удаляющий информацию о покупателе Abernathy
Construction.
328 Глава 9. Язык SQL
29. Напишите SQL-оператор, удаляющий информацию обо всех заказах от
Abernathy Construction.
30. Напишите SQL-оператор, изменяющий зарплату продавца по фамилии
Джонс на $45 000.
31. Напишите SQL-оператор, увеличивающий зарплату всех продавцов на 10%.
32. Предположим, что продавец Джонс поменял фамилию на Парке.
Напишите SQL-операторы, выполняющие необходимые изменения.
Вопросы II группы
33. Установите Microsoft Access и откройте базу данных Northwind.
Используя средство Query Design/SQL View, напишите SQL-операторы для
перечисленных ниже запросов и запустите их.
1) Перечислите все столбцы поставщиков.
2) Выведите атрибут CompanyName для поставщиков, у которых этот
атрибут начинается с «New».
3) Перечислите столбцы всех продуктов от поставщиков, атрибут Company-
Name которых начинается с «New». Приведите ответы, использующие
как вложенный запрос, так и соединение.
4) Выведите атрибуты ReorderLevel и Count для всех продуктов.
5) Выведите атрибуты ReorderLevel и Count для всех продуктов, у которых
ReorderLevel превышает 1.
6) Выведите атрибуты ReorderLevel и Count для всех продуктов, у которых
ReorderLevel превышает 1, от поставщиков, атрибут CompanyName
которых начинается с «New».
Вопросы к проекту FiredUp
Предположим, что фирма FiredUp создала базу данных со следующими таблицами:
ПОКУПАТЕЛЬ (ПокупательСК, Имя, Телефон, ЭлектронныйАдрес)
ГОРЕЛКА (СерийныйНомер, Тип, Версия, ДатаИзготовления)
РЕГИСТРАЦИЯ (ПокупательСК, Серийный_Номер, Дата)
РЕМОНТ (НомерСчета, СерийныйНомер, Дата, Описание, Стоимость, ПокупательСК)
Напишите SQL-операторы, выполняющие приведенные ниже задания. Пусть
даты имеют формат ммддгггг.
1. Выведите все данные из всех четырех таблиц.
2. Выведите список версий всех горелок.
3. Выведите список версий всех горелок типа «FiredNow».
4. Выведите серийный номер и дату регистрации для продуктов,
зарегистрированных в 2000 году.
Вопросы к проекту FiredUft 329
5. Выведите серийный номер и дату регистрации для продуктов,
зарегистрированных в феврале. Используйте джокер «_».
6. Выведите серийный номер и дату регистрации для продуктов,
зарегистрированных в феврале. Используйте джокер «%».
7. Выведите список имен и адресов электронной почты покупателей, у
которых есть электронная почта.
8. Выведите список имен покупателей, не имеющих электронной почты;
отсортируйте результаты в обратном алфавитном порядке.
9. Определите максимальную стоимость ремонта горелки.
10. Определите среднюю стоимость ремонта горелки.
11. Определите количество всех горелок.
12. Определите количество горелок каждого типа и выведите тип и количество.
13. Выведите имена и адреса электронной почты всех покупателей, для
которых производился ремонт горелки на сумму более $50. Используйте
вложенный запрос.
14. Выведите имена и адреса электронной почты всех покупателей, на
которых зарегистрирована горелка типа «FiredNow». Используйте вложенный
запрос.
15. Выведите имена и адреса электронной почты всех покупателей, для
которых производился ремонт горелки на сумму более $50. Используйте
соединение.
16. Выведите имена и адреса электронной почты всех покупателей, на
которых зарегистрирована горелка типа «FiredNow». Используйте соединение.
17. Выведите имена покупателей, адреса электронной почты и даты
регистрации для всех покупателей, зарегистрированных в FiredUp.
18. Выведите имена и адреса электронной почты покупателей, имеющих
зарегистрированную горелку, но не сдававших пи одной горелки в ремонт.
19. Выведите имена и адреса электронной почты покупателей, имеющих
зарегистрированную горелку, но не сдававших данную горелку в ремонт.
Глава 10
Проектирование
приложений баз данных
Эта глава познакомит вас с фундаментальными принципами проектирования
приложений баз данных. Сначала мы рассмотрим, какие функции выполняет
приложение базы данных. Каждую из этих функций мы обсудим более подробно
на примере приложения базы данных картинной галереи. Идеи, представленные
в этой главе, применимы в большей степени к приложениям баз данных,
предназначенным для использования в традиционных средах, например Windows.
В главах 14-16 эти идеи получат развитие в отношении приложений,
использующих технологию Интернет.
Прежде чем мы начнем, необходимо сделать одно пояснение, касающееся
терминологии. На заре технологии баз данных было легко указать границу между
СУБД и приложением: приложения были отдельными программами, которые
вызывали СУБД. Сегодня, в особенности с появлением СУБД для настольных
компьютеров, подобных Microsoft Access, эта граница стала несколько размытой.
Чтобы избежать неоднозначности в этой главе, мы будем считать, что все
формы, отчеты, меню, равно как и любой программный код, содержащийся в них,
входят в приложение базы данных. Автономные программы, вызывающие СУБД,
также являются частью приложения. Все структуры, правила и ограничения,
касающиеся таблицы, а также определения связей относятся к ведению СУБД
и входят в состав базы данных. К примеру, относительно правила, касающегося
столбца таблицы и записанного в ее определении, считается, что оно реализуется
СУБД. Если то же самое правило относится к форме, то считается, что оно
реализуется приложением базы данных. По ходу дальнейшего изложения вы
осознаете важность такого различения.
Функции приложения базы данных
В списке перечислены функции приложения базы данных. Первая функция
заключается в обработке представлений данных. Есть четыре основных функции
обработки: создание, чтение, обновление и удаление. Они иногда обозначаются
Функции приложения базы данных, 331
аббревиатурой CRUD (от английского «create, read, update, delete») — это
создание, чтение, обновление и удаление представлений данных.
+ Создание, чтение, обновление и удаление представлений.
+ Форматирование (или материализация) представлений:
♦ форм;
♦ отчетов;
♦ межпроцессных представлений;
♦ OLAP-кубов;
♦ прочих представлений.
+ Реализация ограничений:
♦ доменов;
♦ уникальности;
♦ связей;
♦ делового регламента.
+ Обеспечение механизмов безопасности и контроля.
4- Реализация логики обработки информации.
Представление приложения — это нечто большее, чем просто строка таблицы
или результат выполнения SQL-оператора. Часто конструкция представления
приложения требует двух или более SQL-операторов, как вы увидите из
следующего раздела.
Вторая функция приложения — это форматирование (formatting), или
материализация (materialization), обрабатываемых представлений. Обратите внимание,
что данные (представление) и внешний вид этих данных (формат или
материализация) — не одно и то же. Одно и то же представление имеет, как правило,
много различных форматов. Различие между данными и формой особенно
важно для приложений, использующих интернет-технологии.
Есть несколько типов материализации представлений. Формы и отчеты —
два наиболее распространенных из них. Существуют, однако, и другие важные
типы. Межпроцессовая материализация (interprocess materialization)
используется для пересылки представления от одного сервера или приложения другому.
Формат таких материализации определяется стандартным интерфейсом
(например, Microsoft COM) или протоколом (например, XML), с которыми вы
познакомитесь в главе 14. Хороший пример использования дайной разновидности
материализации — электронный обмен данными. Другие тршы материализации
имеют более специализированный характер. О кубах и их роли в оперативной
аналитической обработке данных (OLAP) вы узнаете из главы 17. Естественный
язык также представляет собой один из типов материализации.
Третья функция приложения базы данных — реализация, ограничений. В
частности, это могут быть структурные ограничения: соответствие значений элементов
данных спецификациям домена, обеспечение уникальности и реализация
ограничений ссылочной целостности. К прочим ограничениям относятся положения
332 Глава 10. Проектирование приложений баз данных
делового регламента, например такое: «Продавец не имеет права ничего
продавать покупателю, чей адрес находится вне пределов региона ответственности
этого продавца».
Четвертая функция приложения базы данных — обеспечение механизмов
безопасности и контроля. Чтобы повысить уровень безопасности, обеспечиваемый
именами пользователей и паролями, приложение работает во взаимодействии
с операционной системой и СУБД. Меню и подобные им конструкции
накладывают ограничения на то, какие действия и в какой момент могут предпринимать
пользователи.
Последняя функция приложения базы данных — реализация логики
обработки информации. Рассмотрим, например, приложение, реализующее процедуру
ввода заказов. Когда покупатель заказывает пять экземпляров книги,
приложение должно уменьшить количество экземпляров этой книги на складе на пять
штук. Если количества экземпляров на складе недостаточно для выполнения
заказа или это количество меньше заданной величины, требуется предпринять
некоторое другое действие (например, заказать книги у оптового поставщика).
Последние две функции рассматриваются подробно в рамках курса
системного программирования, поэтому в этой книге им будет уделено меньше всего
внимания. Сосредоточимся на первых трех функциях, поскольку они специфичны
для приложений баз данных.
Прежде чем мы начнем изучать эти функции более подробно, рассмотрим
требования, которые галерея View Ridge предъявляет к базе данных и ее
приложению.
Пример приложения: галерея View Ridge
Галерея View Ridge — это небольшая галерея, которая продает современные
произведения искусства, включая литографии, оригинальную живопись и
фотографии. Все литографии и фотографии подписаны и пронумерованы, и цена
большей части произведений находится в пределах от $1000 до $25 000. View Ridge
занимается продажей уже в течение 27 лет. У галереи есть бессменный владелец,
три продавца и два рабочих, которые изготавливают рамы, развешивают работы
в галерее и готовят их к отправке клиенту.
Галерея View Ridge проводит дни открытых дверей и другие мероприятия
для привлечения клиентов. Произведения искусства выставляются также в
офисах местных компаний, ресторанах и других общественных местах. View Ridge
является собственником всех продаваемых произведений; комиссионной
торговлей галерея не занимается.
Требования к приложению
Требования к приложению базы данных View Ridge приведены на рис. 10.1.
Во-первых, владелец и продавцы хотят вести учет клиентов и их интересов в
области искусства. Продавцам необходимо знать, кого извещать о поступлении
Пример приложения: галерея View Ridge, 333
новой работы, и организовывать персональное общение с клиентами в устной
1! письменной форме.
Учет клиентов и отслеживание их интересов в области изобразительного искусства
Учет произведений, приобретаемых клиентами в галерее
Учет произведений, приобретаемых галереей
Выдача списка художников и произведений, когда-либо появлявшихся в галерее
Выдача сведений о продаваемости произведений заданного художника
Отображение на web-странице списка выставленных на продажу произведений
Выдача списка отчетов о продуктах (для бухгалтера галереи)
Рис. 10.1. Перечень требований к приложению базы данных галереи View Ridge
Кроме того, в базе данных должна храниться информация о произведениях,
приобретенных каждым из клиентов, чтобы продавцы могли уделять больше
времени наиболее активным клиентам. Иногда записи о приобретениях
используются для определения местонахождения работ, поскольку время от времени
галерея выкупает редкие произведения для перепродажи. В приложении базы
данных должна быть также предусмотрена форма для регистрации новых работ,
приобретаемых галереей.
Галерея View Ridge желает, чтобы приложение базы данных выдавало
список всех произведений, которые когда-либо появлялись в галерее, и их авторов.
Владелец хотел бы также иметь возможность определять, насколько быстро
продаются произведения каждого из художников и какова их максимальная
цена. Приложение должно отображать список работ, имеющихся в наличии,
на web-странице, к которой потенциальные клиенты могли бы обращаться через
Интернет. Наконец, желательно, чтобы база данных генерировала отчеты, что
уменьшило бы нагрузку на бухгалтера, работающего в галерее не на полную
ставку.
Проектирование базы данных
На рис. 10.2 и 10.3 показана структура объектов, которые должны присутствовать
в базе данных галереи. Объекты CUSTOMER (клиент) и ARTIST (художник) являют-
ся составными объектами, а объект WORK (произведение) является гибридным
объектом, уникальным идентификатором которого служит группа {ARTIST, Title,
Сору} (художник, название, копия). Многозначная группа Transaction
(транзакция) отражает приобретение и продажу работ галереей. Многозначность этой
группы обусловлена тем, что одна и та же работа может пройти через галерею
несколько раз (из-за обмена и выкупа работ). Объект WORK является гибридным
потому, что он содержит объектный атрибут CUSTOMER в многозначной группе
Transaction.
334 Глава 10. Проектирование приложений баз данных
CUSTOMER
ю Name
Phone
Area Code
LocalNumber
Address
Street
City
State
Zip
0.1
||||-;r-VyoRK--
iill&RTiST-;.:
O.N
G.N
WORK
loWorklDGroup
ШЁЙШ
Title
Copy
Description
Transaction
Ш DateAcquired
AcquisitionPrice
PurchaseDate
li.i
ЩШШвШЙИ
SalesPrice
ARTIST
id Name
Nationality
Dates
BirthDate
DeceasedDate
^m^^-iu
. ^хейЕк-^З
-
0.1
O.N
O.N
Name, AreaCode, LocalNumber, Street, City, State, Zip)
WORK (ArtistName. Title. Copy. Description)
TRANSACTION (ArtistName. Title, Copy, DateAcquired. AcquisitionPrice,
PurchaseDate, CustNumber, SalesPrice)
ARTIST (ArtistName. Nationality, Birthdate, DeceasedDate)
CUSTOMER_ARTISTJNT (CustNumber. ArtistName)
Рис. 10.2. Структура базы данных галереи View Ridge: a — семантические объекты;
б — ER-диаграмма; в — реляционная структура
Как уже упоминалось, галерея хочет отслеживать интересы клиентов. В
частности, она желает знать, работами каких художников интересуется каждый из
клиентов, а также то, какие клиенты интересуются работами данного
художника. Выполнение этих требований обеспечивается путем помещения
многозначного атрибута ARTIST в объект CUSTOMER и многозначного атрибута CUSTOMER
Пример приложения: галерея View Ridge 335
и объект ARTIST. Диаграмма «сущность—связь» для базы данных галереи
изображена на рис. 10.2, б.
CUSTOMER (CustomerlD. Name, AreaCode, LocalNumber, Street, City, State, Zip)
WORK (WorkjD, ArtistlD, Title, Copy, Description)
TRANSACTION (TransactionlD. WorkID, DateAcquired, AcquisitionPrice,
PurchaseDate, CustomerlD, SalesPrice)
ARTIST (ArtistlD. ArtistName, Nationality, Birthdate, DeceasedDate)
CUSTOMER_ARTIST_INT (CustomerlD. ArtistlD)
Ограничения ссылочной целостности:
Значение атрибута ArtistlD в отношении WORK должно существовать
среди значений атрибута ArtistlD в отношении ARTIST
Значение атрибута WorkID в отношении TRANSACTION должно существовать
среди значений атрибута WorkID в отношении WORK
Значение атрибута CustomerlD в отношении TRANSACTION должно существовать
среди значений атрибута CustomerlD в отношении CUSTOMER
Значение атрибута CustomerlD в отношении CUSTOMER_ARTIST_INT должно
существовать среди значений атрибута CustomerlD в отношении CUSTOMER
Значение атрибута ArtistlD в отношении CUSTOMER_ARTIST_INT должно существовать
среди значений атрибута ArtistlD в отношении ARTIST
б
рис. 10.3. Структура базы данных галереи View Ridge: a — реляционная
структура с суррогатными ключами; б — диаграмма связей в Access
336 Глава 10. Проектирование приложений баз данных
Реляционное представление объектов галереи View Ridge показано на
рис. 10.2, в. Поскольку объект CUSTOMER не имеет уникального идентификатора,
такой идентификатор нужно создать, чтобы использовать его в дальнейшем
в качестве ключа. Здесь мы добавили идентификационный номер покупателя,
CustNumber. Максимальное кардинальное число групп Phone (телефон) и Address
(адрес) равно 1, так что атрибуты из этих групп могут быть помещены в таблицу
CUSTOMER. Фактически эти группы не представлены в таблице в качестве групп,
а информация, содержащаяся в них, используется на более позднем этапе —
при создании форм.
Ключ таблицы WORK состоит из ключа таблицы ARTIST и атрибутов Title
(название) и Сору (копия). Единственный неключевой атрибут отношения WORK —
это атрибут Description (описание). Так как атрибут Transaction является
многозначным, для него необходимо создать таблицу. Ключом этой таблицы будет
ключ объекта, в котором она содержится (ArtistName, Title, Copy), плюс ключ
группы (DateAcquired — дата приобретения). Заметьте также, что атрибут CustNumber
фигурирует как внешний ключ в таблице TRANSACTION.
Объект ARTIST представлен одной таблицей, и в качестве ключа этой таблицы
можно использовать атрибут ArtistName (имя художника), поскольку имена
авторов моделируются как уникальные. Для представления связи M:N между
таблицами CUSTOMER и ARTIST должна быть создана таблица пересечения CUSTOMER,.
ARTISTJNT.
Принимая во внимание большое количество текстовых ключей и, в
частности, большой композитный ключ таблицы TRANSACTION, можно существенно
усовершенствовать реляционную структуру, заменив информационные ключи
суррогатными. Такая модификация структуры показана на рис. 10.3, а. Имена
суррогатных ключей образованы путем присоедршения суффикса ID к имени
таблицы.
Структура на рис. 10.3, а является более удачной, поскольку в ней
дублируется меньшее количество данных. Столбцы ArtistName, Title и Сору нет нужды
копировать в таблицу Transaction. Так как с одной и той же работой может
выполняться большое количество транзакций, экономия может оказаться
внушительной. На рис. 10.3, б представлена диаграмма «сущность—связь» для
структуры с суррогатными ключами.
Создание, чтение, обновление и удаление
экземпляров представлений
Представление (view) — это структурированный список элементов данных из
сущностей или семантических объектов, определенных в модели данных. Экземпляр
представления (view instance) — это представление, заполненное данными из
конкретного экземпляра сущности или семантического объекта. На рис. 10.4, а
изображен пример представления для базы данных галереи, структура которой
показана на рис. 10.2 и 10.3. Это представление содержит данные о клиенте, его
Создание, чтение, обновление и удаление экземпляров представлений ^ 337
флпзакциях и интересах. В этом представлении для каждого клиента
потенциально имеется много транзакций, и каждая из транзакций относится к одной
работе. Для одного и того же клиента может быть указано множество имен
художников (это те художники, работами которых клиент интересуется).
CUSTOMER.Name
CUSTOMER.AreaCode
CUSTOMER.LocalNumber
TRANSACTION.PurchaseDate
TRANSACTION.SalesPrice .. .
WORK.ARTIST.Name
WORK.Title
WORK.Copy
ARTIST.Name. ..
a
Jackson, Elizabeth
206
284-6783
7/15/94
4,300
2/5/99
2,500
11/22/97
17,850
Juan Miro
Mark Tobey
Dennis Frings
Mark Tobey
Lithograph One
10/75
Juan Miro
Poster 14
5/250
Juan Miro
Awakening Child
1/1
б
Рис. 10.4. Представление CUSTOMER: a — структурированный
список атрибутов; б — данные для примера
Обратите внимание, что атрибут Artist.Name появляется в этом представлении
дважды. В первом случае это имя художника, работу которого приобрел клиент.
Во втором случае это имя художника, произведениями которого данный клиент
338 Глава 10. Проектирование приложений баз данных
интересуется. В примере на рис. 10.4, б клиент приобрел работы художников
Тоби и Миро, но кроме этих авторов он также интересуется работами художника
по имени Деннис Фрингс. Поэтому фамилии Tobey и Miro появляются в
представлении по два раза: в первый раз как значения атрибута WORK.ARTIST.Name,
а во второй раз как значения атрибута ARTIST.Name.
Напомним, что представление — это структурированный список атрибутов.
Поскольку он является структурированным, атрибуты могут фигурировать в
представлении неоднократно. Обратите внимание, кроме того, что представление
является только списком значений элементов данных. Оно может быть
форматировано или материализовано множеством различных способов: в виде формы,
отчета или какого-нибудь другого типа материализации.
Теперь посмотрим, что можно делать с представлением. Начнем с чтения.
Чтение экземпляров представлений
Чтобы прочитать существующее представление, приложение должно запустить
один или несколько SQL-операторов, считывающих значения элементов
данных, и поместить результаты в структуру представления. Данные представления
Customer на рис. 10.4 были получены путем следования по схеме базы данных
двумя путями: один — через таблицу TRANSACTION, а другой — через таблицу
CUSTOMER_ARTIST_INT. Структура SQL-операторов такова, что один оператор
позволяет проследовать через схему только одним путем. Таким образом, данное
представление потребует отдельного SQL-оператора для каждого пути. Для
первого пути необходимые данные о клиенте по имени Mary Jackson можно
получить с помощью следующего оператора:
SELECTCUSTOMER.CustomerlD, CUSTOMER.Name. CUSTOMER.AreaCode,
CUSTOMER. Local Number. ARTISLName. WORK. Title.
WORK. Copy.TRANSACTION.PurchaseDate. TRANSACTION.SalesPrice
FR0MCUST0MER. TRANSACTION. WORK, ARTIST
WHERECUSTOMET.CustomerlD = TRANSACTION.CustomerlD
ANDWORK.WorkID = TRANSATION.Work ID
AND ARTIST.ArtistID = WORK.ArtistID
ANDCUSTOMER.Name - 'Jackson. Mary'
Проанализируйте этот оператор, глядя на диаграмму связей на рис. 10.3, а.
Чтобы получить данные по всем трем связям вверху диаграммы, необходимо
выполнить три соединения.
В контексте разработки приложений результат выполнения
SQL-оператора называется иногда набором записей (recordset). Согласно терминологии
Microsoft, этот термин означает отношение в ООП-оболочке. Набор записей
имеет методы и свойства. В качестве примера метода можно назвать метод Open,
примером свойства является свойство CursorType. Более подробно вы узнаете об
этом из главы 14.
Создание, чтение, обновление и удаление экземпляров представлений , 339
Чтобы узнать, работы каких авторов интересуют клиента, требуется второй
SQL-оператор, который следует через таблицу CUSTOMER__ARTIST_INT. Оператор
имеет следующий вид:
'.I LECTCUSTOMER. Customer ID, ARTIST.Name
I ROMCUSTOMER. CUSTOMER_ARTIST-INT. ARTIST
WlirRECUSTOMER. Customer ID = CUSTOM ER_ARTIST_INT. Customer ID
ANDCUSTOMER_ARTIST_INT.ArtistID = ARTIST.ArtistID
ANDCUSTOMER.Name = 'Jackson. Mary'
Поскольку атрибут CUSTOMER.Name не является уникальным, возможно, что
дна набора записей, полученные с помощью приведенных SQL-операторов, будут
содержать данные более чем об одном клиенте. Следовательно, в приложении
должен быть код, проверяющий значения атрибута CustomerlD в наборах записей
и связывающий между собой правильные строки.
После запуска приложение обладает всеми данными, необходимыми для
построения одного или нескольких экземпляров представления, изображенного на
рис. 10.2 и 10.3. То, как конкретно это делается, зависит от используемого языка.
И языке COBOL данные будут помещены в структуры, определенные в разделе
Data Division. В Visual Basic данные могут быть помещены в структуру или
несколько массивов. В C++ и Java данные помещаются в объекты. Здесь мы не
интересуемся этими вопросами. Цель скорее в том, чтобы вы почувствовали, каким
образом приложение должно запускать один или несколько SQL-операторов для
заполнения структуры данных представления. Пример на языке Java будет
приведен в главе 16.
Создание новых экземпляров представлений
Чтобы создать новый экземпляр представления, приложение должно сначала
получить новые данные и связи. Это чаще всего делается с помощью формы
для ввода данных, но приложения получают также данные от других программ
и иными путями. В любом случае, после того как приложение получает новые
.шачения данных, оно запускает SQL-операторы, сохраняющие эти значения в базе
данных.
Рассмотрим представление New Customer на рис. 10.5. Это представление
используется каждый раз, когда новый клиент приобретает у галереи
произведение. Оно содержит данные о клиенте, о транзакции и интересах этого клиента.
От представления, изображенного на рис. 10.4, данное представление отличается
гем, что в нем содержится больше данных о клиенте, а также тем, что оно
допускает только одну транзакцию. Однако атрибут ARTIST.Name может иметь
несколько значений, отражающих интересы нового клиента.
Пусть новые данные для этого представления находятся в программной
структуре под названием NewCust Предположим далее, что мы можем обращаться к
значениям в структуре, указывая префикс NewCust перед именами элементов
структуры. Так, NewCust.CUSTOMER.Name соответствует атрибуту Name таблицы CUSTOMER
it структуре NewCust
340 Глава 10. Проектирование приложений баз данных
CUSTOMER.Name
CUSTOMER.AreaCode
CUSTOMER.LocalNumber
CUSTOMER.Address
CUSTOMER.City 1
CUSTOMER.State
CUSTOMER.Zip
TRANSACTION.DateAcquired
TRANSACTION.AcquisitionPrice
TRANSACTION.PurchaseDate
TRANSACTlON.SalesPrice
WORK.ARTIST.Name
WORK.Title
WORK.Copy
ARTIST.Name ...
Рис. 10.5. Представление New Customer
Чтобы записать это представление в базу данных, мы должны сохранить
данные нового клиента в таблице CUSTOMER, сохранить данные новой транзакции
в таблице TRANSACTION и создать строку в таблице пересечения CUSTOMER_ARTIST_
INT для каждого из художников, работами которых интересуется клиент.
Данные клиента будут записаны следующим SQL-оператором:
INSERT INTO CUSTOMER
(CUSTOMER.Name.
CUSTOMER.AreaCode.
CUSTOMER.LocalNumber.
CUSTOMER.Address.
CUSTOMER.City,
CUSTOMER.State.
CUSTOMER.Zip)
VALUES(NewCust.CUSTOMER.Name
NewCust.CUSTOMER.AreaCode,
NewCust.CUSTOMER.Local Number,
NewCust.CUSTOMER.Address.
NewCust.CUSTOMER.City.
NewCust.CUSTOMER.State.
NewCust.CUSTOMER.Zip)
Допустим, что при создании новой строки СУБД присваивает суррогатному
ключу CUSTOMER.CustomerlD значение. Это значение потребуется нам для того,
чтобы завершить создание нового экземпляра представления, и один из способов
его получить — запустить следующий SQL-оператор:
Создание, чтение, обновление и удаление экземпляров представлений ч 341
SLLECT CUSTOMER.Customer ID. CUSTOMER.AreaCode. CUSTOMER.Local Number
I ROM CUSTOMER
WHERE CUSTOMER.Name - NewCust.CUSTOMER.Name
Поскольку атрибут CUSTOMER.Name не является уникальным, в наборе записей
может оказаться более одной строки. В этом случае нужно будет найти
правильную строку по номеру телефона. Предположим, что при необходимости это было
сделано, и под именем NewCust.CUSTOMER.CustomerlD в программную структуру
Г)ыло записано правильное значение.
Для сохранения данных о транзакции также будет использоваться
оператор INSERT. Однако при этом надо будет указать значения внешних ключей
TRANSACTION.WorkID и TRANSACTION.CustomerlD. Мы уже показали, как получить
значение атрибута CustomerlD, и теперь осталось только получить значение
атрибута WorkID. Эту задачу выполнит следующий SQL-оператор:
SELECT WORK.WorkID
FROM WORK, ARTIST
WHERE WORK.ArtistID = ARTIST.ArtistID
AND ARTIST.Name = NewCust.WORK.ARTIST.Name
AND WORK.Title - NewCust.WORK.Title
AND WORK.Copy = NewCust.WORK.Copy
Пусть возвращенное значение суррогатного ключа сохранено под именем
NewCust.WORK.WorklD.
Для добавления новой строки в таблицу TRANSACTION можно запустить
следующий SQL-оператор:
INSERT INTO TRANSACTION
(TRANSACTION.WorkID,
TRANSACTION.DateAcquired.
TRANSACTION.AcquisitionPrice,
TRANSACTION.PurchaseDate,
TRANSACTION.CustomerlD.
TRANSACTION.SalesPrice)
VALUES
(NewCust.TRANSACTION.WorkID.
NewCust.TRANSACTION.DateAcqui red.
NewCust.TRANSACTION.AcquisitionPrice.
NewCust.TRANSACTION.PurchaseDate.
NewCust.TRANSACTION.CustomerlD,
NewCust.TRANSACTION.Sal esPrice)
Теперь осталось только создать строки в таблице пересечения CUSTOMER_ARTIST_
INT. Для этого нам нужно получить атрибут ArtistID каждого художника,
работами которого интересуется клиент, и затем создать новую строку в таблице
пересечения. Эту логику иллюстрирует следующий фрагмент псевдокода:
For eachNewCust.ARTIST.Name
SELECT ARTIST.ArtistID
342 Глава 10. Проектирование приложений баз данных
FROMARTIST
WHEREARTIST.Name = NewCust.ARTIST. Name
INSERTINTO CUSTOMER_ARTIST-INT
(CustomerlD. ArtistID)
VALUESCNewCust.CUSTOMER.CustomerlD.
ARTIST.ArtistID)
NextNewCust.ARTIST.Name
Теперь представление New Customer сохранено в базе данных. Разумеется,
полная реализация включает в себя перехват и обработку ошибок, возвращенных
СУБД. Например, в приложении должны быть предусмотрены процедуры на
случай, когда запрошенного произведения или художника нет в базе данных.
Обновление экземпляров представлений
Третье фундаментальное действие, производимое над представлениями, — это
обновление. При обновлении представления возможны три типа изменений.
Первый тип — это изменение значения, например, когда у клиента меняется
номер телефона. Второй тип — изменение связи. Примером может служить случай,
когда клиент перестает интересоваться работами какого-либо художника. Третий
тип обновления подразумевает добавление одной или нескольких новых строк;
в нашем случае это происходит, когда клиент совершает покупку.
Обновления первого типа можно производить с помощью SQL-операторов
UPDATE. Пусть, например, в программе имеется структура под названием UpdateCust,
и эта структура состоит из элементов CustomerlD, AreaCode (код региона) и Local-
Number (местный номер). Новые значения элементам этой структуры присвоит
следующий SQL-оператор:
UPDATECUSTOMER
SETCUSTOMER.AreaCode = UpdateCust.AreaCode
CUSTOMER.Local Number = UpdateCust.Local Number
WHERECUSTOMER.CustomerlD = UpdateCustomer.Customer ID
Изменения в связях производятся столь же элементарно. Если связь имеет
вид «один ко многим», то требуется просто присвоить новое значение
внешнему ключу. Пусть, например, связь между таблицами ОТДЕЛ и СОТРУДНИК имеет
вид 1:N. Тогда НомерОтдела (или другой ключ) будет храниться как внешний
ключ в таблице СОТРУДНИК. Чтобы перевести сотрудника в другой отдел,
приложению потребуется только поменять значение атрибута НомерОтдела на другое.
Если связь имеет вид «многие ко многим», то необходимо модифицировать
внешний ключ в таблице пересечения. Например в галерее, если покупатель
перестал интересоваться Марком Тоби, а заинтересовался Деннисом Фрингсом,
нужно изменить соответствующую строку в таблице пересечения, чтобы она
указывала не на Марка Тоби, а на Денниса Фрингса.
Предположим, что в переменной UpdateCust.CustomerlD хранится
идентификатор покупателя, в переменной UpdateCust.OldArtistID хранится идентификатор
строки Марка Тоби в таблице ARTIST, а в переменной UpdateCust.NewArtistID xpa-
Создание, чтение, обновление и удаление экземпляров представлений 343
пится идентификатор строки Денниса Фрингса в таблице ARTIST. Необходимые
изменения произведет следующий оператор:
UPDATE CUSTOMER_ARTISTJNT
SET CUSTOMER_ARTIST_INT. Artist ID = UpdateCust.NewArtistID
WHERE CUSTOMER_ARTIST_INT. CustomerlD = UpdateCust. Customer ID
ANDCUSTOMER_ARTIST_INT.ArtistID = UpdateCust. 01 dArtist ID
В связи вида «многие ко многим» можно также удалить связь (connection), не
заменяя ее новой, или создать новую связь, не удаляя старой. Чтобы удалить
снизь, нужно просто удалить соответствующую строку в таблице пересечения.
Чтобы создать связь, нужно добавить строку в таблицу пересечения.
Третий тип обновления требует добавления новой строки в одну или
несколько таблиц. Если, например, существующий клиент делает новое приобретение,
то необходимо будет создать новую строку в таблице TRANSACTION. Это можно
сделать так же, как это делалось при создании нового экземпляра представления.
Удаление экземпляров представлений
Удаление экземпляра представления предполагает удаление из таблиц тех строк,
из которых это представление состоит. Сложность состоит в том, чтобы
определить, сколько строк нужно удалять. Предположим, например, что галерея хочет
удалить данные о покупательнице по имени Мэри Джонс. Ясно, что нужно
удалить строку «Jones, Mary» из таблицы CUSTOMER. Кроме того, необходимо удалить
нее строки из таблицы пересечения CUSTOMER_ARTIST_INT, относящиеся к этой
покупательнице. Но что делать со строками в таблице TRANSACTION? Эта таблица
содержит атрибут CustomerlD, и если строка дайной покупательницы будет удалена,
все строки в таблице TRANSACTION, где указан ее идентификатор, будут содержать
неверные данные.
Ответ на подобные вопросы определяется исходя из модели данных. В ER-
модели все слабые сущности удаляются, если удаляется сущность, от которой
они зависят. В противном случае никаких дополнительных удалений не произ-
нодится. В семантической объектной модели удаляются все данные,
содержащиеся в объекте (объект может содержать много таблиц, если у него есть
многозначные атрибуты), но никакие данные о другом объекте не удаляются. Помимо
:>тих правил, имеется еще одно: удаление не допускается, если оно вызовет
нарушение кардинальности связи. Мы коснемся этой темы здесь и рассмотрим ее
более подробно позднее в этой главе.
Обратимся к модели на рис. 10.2 и 10.3. Когда удаляется информация о
клиенте, то наряду со всеми строками в таблице CUSTOMER_ARTIST_INT,
относящимися к этому клиенту, удаляется также строка в таблице CUSTOMER. Данные из
таблицы TRANSACTION не удаляются, поскольку она находится в другом объекте —
WORK. Обратите внимание, однако, что минимальное кардинальное число
объекта CUSTOMER в объекте TRANSACTION равно 1. Следовательно, если данный
покупатель связан с транзакцией, то объект CUSTOMER в этой связи является
необходимым, и удаление не допускается.
344 Глава 10. Проектирование приложений баз данных
Некоторые СУБД поддерживают удаление зависимых строк, обычно
называемое каскадным удалением (cascading delete). На рис. 10.6 показано
диалоговое окно редактирования связи в Access. Обратите внимание, что флажок Cascade
Delete Related Records (Каскадное удаление связанных записей) установлен. Это
означает, что при удалении строки из таблицы WORK Access автоматически
удаляет все связанные с ней строки в таблице TRANSACTION. -
Customer©
Мате
Sfoeet
С*у
State
Zip
AreaCode
юеаШпЬег
"*"*\
•
\ »
\ "■ ,
\
\
\
sections)
Acquired
ъ&югРг'ке
^seDate
ттегЮ
•Pri«
ID
Tftte
Copy
ArtistlD
Description
- ionafty
hdate
.eesedOate
imeftuwi
%риш t&Wq
work
^TRANSACTION
JliWorWD
Рис. 10.6. Включение каскадных удалений
Как говорилось выше, кардинальность связи играет важную роль в
определении того, должны ли удаляться строки представления. Мы обратимся к этой
теме позже в этой главе, рассматривая реализацию ограничений.
В этом разделе был приведен обзор действий, которые должны быть
предприняты при создании, чтении, обновлении и удалении экземпляров представлений.
Некоторые из описанных здесь действий могут выполняться СУБД
автоматически. Например, в Access имеются мастеры, с помощью которых можно создать
форму, содержащую данные клиента и один из путей — либо к транзакциям
данного покупателя, либо к его интересам. Пользователи этой формы могут
создавать, читать, обновлять и удалять экземпляры представления Customer и данные
по одному из путей. Однако мастер Access не способен сгенерировать форму,
которая поддерживала бы оба пути в представлении Customer на рис. 10.2 и 10.3.
Для этого разработчику придется написать соответствующий программный код.
Проектирование форм
Как показывает рис. 10.1, вторая основная функция приложения базы данных
состоит в том, чтобы генерировать материализации представлений. В этой главе мы
рассмотрим материализации в виде отчетов и форм. В главе 14 мы рассмотрим
Проектирование форм 345
межпроцессные материализации с использованием XML, а в главе 17 мы
рассмотрим материализации в OLAP-кубах.
Форма (form) — это экранный объект, используемый для ввода и редактиро-
иания данных. Формы, доступные только для чтения, могут также
использоваться в качестве отчетов, но в большинстве случаев, когда разработчики говорят
о формах, они имеют в виду формы, с помощью которых редактируются и
вводятся данные.
Некоторые формы просты в использовании и дают при вводе только
небольшое количество ошибок. Другие кажутся неудобными и запутанными, и при
работе с ними сложно не допускать ошибки. В этом разделе мы рассмотрим
несколько принципов создания хороших форм.
Структура формы должна отражать
структуру представления
Прежде всего, чтобы форма оставляла впечатление естественности и с ней было
легко работать, ее структура должна отражать структуру представления, которое
она материализует. Взгляните на форму, показанную на рис. 10.7, являющуюся
материализацией представления Customer, изображенного на рис. 10.4, а.
\-Шл:шЩ^ш^щ^^ШШШЩ?^ш^^^Шй
llffilf
Vfew Biclge (ЩЩ;£и|тотёг Рмг^Й1Я^^^^^^Ш
jJockson, Elizabeth
S'ttaot-'. J"123 4<h Avenue
C^:;': :•: js*a«te
State' |v/A Zip |'*лтй/7
iBieiSiilllil
Г"
►
Re
M*KT<^^V .•'■':•'■'•■'■
km W^';};-.:;..-::;,; •;;••:
РчШ$св*ф..:;.-:.
11||||§
ij.jj.;.!.:.'.'r^t; .^ j
i:-':..V::4«:M
■ ■ "~П
"i" " :'.': ' XL<. \
ж* "UN
к.%Щ
4
Г REACTION
PwchaseD*»*.""
:'-5ЛЛй» JU
И|м*кТоЬе/
Re
ITusnMtra
| <^№Mifo
1
*ь ilLJ
'" r-J juhogf-aph One
jj jPoster H ~~
~"^] |Aimik«^C№
-ЦШ"
} ''■■ » 1 »i !»♦! or' з
jm/7s' '
ртШ
— рт»
— t
| ?ЛУ94 j *
| гът f~~
| "ТШ>97 ]
, ^p-
socio
$2,500
$17.850
J
SHUT
1 > \Н\>*\"М ■
zl
Рис. 10.7. Материализация представления Customer (рис. 10.4, a) в виде формы
Структура этой формы отражает представление Customer. Первый раздел
формы содержит основные сведения о клиенте — имя, телефон и адрес. Во втором
346 Глава 10. Проектирование приложений баз данных
разделе приведена информация об интересах клиента. Наконец, в третьем
разделе перечислены произведения, приобретенные данным клиентом. Пользователи
находят эту форму удобной в использовании, потому что способ группировки
атрибутов отражает их понимание структуры данных клиента.
Вообще говоря, при проектировании формы все данные, принадлежащие
одному отношению, должны располагаться рядом, в одном разделе формы. Если
предположить, что база данных находится в доменно-ключевой нормальной
форме, каждое отношение должно характеризоваться своей темой, и
пользователи должны ожидать, что найдут все данные, относящиеся к этой теме, в одном
месте. Так, в приведенной на рисунке форме есть три раздела: клиент, его
интересы и транзакции.
Из этого правила есть одно исключение: атрибуты базового отношения
представления (здесь — отношение CUSTOMER) не всегда помещают по соседству друг
с другом. Предположим, например, что в таблице CUSTOMER есть простой атрибут
с именем TotalPurchases (общая сумма покупок). Если бы мы следовали
указанному правилу, мы бы поместили атрибут TotalPurchases в первом разделе формы.
Но с точки зрения пользователей, более целесообразно было бы поместить этот
атрибут в конце формы, после списка всех покупок.
Форма на рис. 10.7 не является единственной приемлемой формой этого
представления. Раздел транзакций, к примеру, можно разместить перед разделом
интересов клиента. Сведения о клиенте можно расположить так, чтобы их вид был
больше похож на горизонтальный. Атрибуты CustomerName, AreaCode и LocalNumber
можно было бы поместить в один столбец, a Street, City, State и Zip (улица, город,
штат, почтовый индекс) — в другой. Все эти альтернативы позволяют в
структуре формы отразить структуру объектов, лежащих в ее основе.
Семантика данных должна быть
графически очевидна
Еще одна характеристика хорошо спроектированной формы заключается в том,
что семантика данных является графически очевидной. Рассмотрим раздел
основных сведений о покупателе в форме Customer на рис. 10.7. Обратите внимание
на прямоугольники, которыми ограничены поля AreaCode и LocalNumber, а также
поля Street, City, State и Zip.
Чтобы понять, для чего это сделано, обратимся вновь к рис. 10.3, а.
Семантический объект CUSTOMER имеет групповые атрибуты Phone (телефон) и Address
(адрес). Так как оба этих атрибута имеют максимальное кардинальное число 1,
они не являются обязательными с точки зрения реляционной структуры.
Фактически, они не фигурируют в отношениях на рис. 10.2, в или 10.3, а.
Единственная их задача состоит в том, чтобы семантически связывать друг с другом
атрибуты AreaCode и LocalNumber, а также атрибуты Street, City, State и Zip.
Назначение прямоугольников в форме Customer Purchase Form — придать этим
связям графическую наглядность. Для большинства пользователей такое решение
удобно. Зная, что телефонный номер состоит из кода региона и местного номера,
они находят тесную графическую связь между этими атрибутами весьма логичной.
Проектирование форм 347
Структура формы должна побуждать
к правильным действиям
Структура формы должна облегчать выполнение правильных действий и
затруднять выполнение ошибочных. Например, поле State в форме на рис. 10.7 имеет
маленькие размеры. Очевидно, при этом ожидается, что пользователь введет
только двухбуквенную аббревиатуру штата. Но более удачным будет такое
решение, при котором можно будет ввести только два символа, а наилучший выход
состоит в том, чтобы представить штаты в раскрывающемся списке и дать пользо-
нателю возможность выбирать только из этого списка.
На рис. 10.7 некоторые поля имеют белый цвет, а некоторые серый. Формы
и этом приложении спроектированы так, что пользователи могут вводить данные
шлько в белые поля; элементы данных, расположенные в серых полях, не могут
быть изменены в форме. Так, пользователь не имеет возможности вводить
данные в поля Сору или Title раздела Transaction. Вместо этого, чтобы выбрать или
изменить название работы, пользователь щелкает мышью на комбинированном
списке в столбне Artist. Когда пользователь щелкает мышью на стрелке,
отображается перечень произведений в раскрывающемся списке, как показано на
рис. 10.8. Если пользователь хочет обновить пли удалить данные о произведении
или художнике, он должен использовать другую форму.
■ ^^^^^^^ЩШ^^Ш^^^^Ш^^^&^^^^
щшш
View Ridg^&aitery OiStdfrierWrcbase Form
Customer Name
pT".
{Jackson. Ehzobelh
'one;-
'- «Code-
-OcflJMumb* 17S4S733
'lit*** j 123--«h Avenue
(Seattle
IVv'A ; &p
1*5114-88?:
Aihsl;. |f!*«; e$t»
JMwkTab^F.'
идол Мяо;:;;
jPebfo Ptcesso
►! "
JL.Z.
Z:: ;
Z :
Л
T"
U*«r*i«L£]J
ч
Ftfte
PwchaseDate
$:ШР«с*
|M«feTobey 3 рйо^ЖГ
|iu$nM*o jj jPasterH
W.300
$2,50>J
$17.850
,ШРу,,;:--:;;
'250
ит:.
тт.
zl
№*.}:
Л)
Рис. 10.8. Использование раскрывающегося списка
Такое решение обусловлено тем, что когда пользователи вводят новые
транзакции для клиентов, они должны добавлять данные, касающиеся только транз-
348 Глава 10. Проектирование приложений баз данных
акций, а именно PurchaseDate (дата продажи) и SalesPrice (цена продажи). Если
позволить им изменять данные в таблицах ARTIST и WORK, это откроет двери для
возможных непреднамеренных или ошибочных изменений; кроме того, чтобы
продать работу, такие изменения данных и не нужны.
Подобным же образом организована форма Artists Interests (интерес к
художникам). Пользователи могут выбирать значения только из предоставленного
списка. Этот случай, однако, не столь однозначен, как предыдущий.
Возможно, продавцы хотели бы иметь возможность зарегистрировать интерес клиента
к произведениям определенного художника, даже если этот художник не
представлен в базе данных галереи. В этом случае форму следовало бы изменить,
чтобы пользователи могли добавлять авторов в список. Решение,
представленное на рис. 10.7, может быть обусловлено тем, что владелец галереи хочет
регистрировать интерес клиентов только к тем художникам, работы которых
представлены в галерее на настоящий момент или будут представлены в будущем. Таким
образом, ему нужен контроль над тем, какие имена могут появляться.
Формы в среде графического интерфейса
пользователя
Графический интерфейс пользователя предоставляет ряд возможностей, которые
могут значительно упростить работу пользователей с приложениями баз данных.
Раскрывающиеся списки
Раскрывающийся список (drop-down list box) — это элемент управления
графического интерфейса, представляющий собой список альтернатив, из которых может
выбирать пользователь. Специальное свойство этого элемента управления
определяет, является ли данный список фиксированным или пользователи могут
добавлять в него новые значения. На рис. 10.9 представлена новая версия формы
Customer Purchase Form, где пользователи имеют возможность добавлять имена
художников, отсутствующих в списке. Этот процесс сводится к тому, что
приложение добавляет новую строку в таблицу ARTIST. Разумеется, чтобы это работало,
обязательным атрибутом может быть только ArtistName. Если будут определены
еще какие-либо обязательные поля, СУБД откажется вставлять новую строку.
Раскрывающиеся списки имеют несколько преимуществ перед полями ввода. Во-
первых, людям легче распознать что-либо, чем воспроизвести. Например, в
форме на рис. 10.8 легче выбрать имя художника из списка, чем вспомнить всех
художников, имеющихся в базе данных. Кроме того, распознать имя проще, чем
правильно его написать. Наконец, если список настроен так, что отображает
только те значения, которые имеются в базе данных, это предотвращает попадание
в базу данных неочевидных ошибок, связанных со случайным нажатием
клавиш пользователем. К сожалению, «Juan Miro» (с одним пробелом между п и М)
и «JuanMiro» (с двумя пробелами между пиМ) будут восприниматься СУБД как
два различных автора. Фиксированные раскрывающиеся списки избавят от
появления таких ошибок.
Проектирование форм 349
■ iinmiili.i iiniiViiiMi.iili iiniiinn-iii ■■ iii»»ii>iniiiii ,,i, , < 1' ««i.ij.iVi':».«!>.*^ >« yj ':■.!>.' ■■■ j j jO'.'''.? '> |.''.' j ■ ''I'l '.f! ■ 'J !>.U OX'V'' — '—■■■■'»i;i;iW
\ i>> ackson, Elizabeth
\
f
; -ait-
j _
I i -.. Hie Cc^igf;;^
<kt&*$ zJ\Р^^Щ^ШЖ
Щ0~3;- {РО^'Й^^Й^ЙЙ
tn Mgo Щ "■ [Аю&спЦ> СШ ■ :•;:■■•'•
ШШЯШЙЩ
ЩЩрШ"^-
':"•-'""■•'•'• |i>i",m""v'
f УаъАаЩ^
j ISs^f*""
j WZ№?"\
'ыж~У^Ш
$2.500 Щ?*
tf 7.850 '':V
ilLJ) ~~ЩЩ"of 2
Рис. 10.9. Раскрывающийся список, позволяющий вводить новые значения
Переключатели и группы
Переключатель (option button) или миогопозициоиный переключатель (radio
button) — это экранный орган управления, позволяющий выбирать одно
условие или состояние из нескольких возможных. Предположим, что галерея решила
вести учет налогового статуса своих покупателей. Пусть этот статус может иметь
два значения — Taxable (облагается налогом) и Nontaxable (не облагается
налогом), и эти значения являются взаимоисключающими. Для сбора этих данных
можно использовать группу переключателей, подобную группе Tax Status
(Налоговый статус) на рис. 10.10. По логике работы этой группы, если
пользователь выбирает статус Taxable, выбор значения Nontaxable автоматически
отменяется. Если пользователь выбирает статус Nontaxable, автоматически отменяется
статус Taxable.
Полученные из формы данные прикладная программа должна сохранить в
столбце таблицы, который представляет вариант, выбранный пользователем. В
данном примере этот столбец носит название TaxStatus (Налоговый статус). Есть два
способа хранения данных, вводимых с помощью переключателя. Первый способ
заключается в том, чтобы записывать данные в виде целого числа в диапазоне
количества кнопок. В нашем случае это будет число 1 или 2. Второй способ —
записывать данные в виде текста, описывающего выбранный вариант. Здесь
возможными вариантами являются «Да» или «Нет».
pabto Picasso
РПмУ
Dennis Fnngs
Jecbtfr» Pofeck
Juan M«o
Lawrence Kearw
Mark Г obey
РаЫо Picasso
Setodore D*8
350 Глава 10. Проектирование приложений баз данных
|Щ^»|^
*Ш*1.
;ai!ery Customer Put ' е Format-
Я
#::::$Ss&:
Name
jt23;4U^
аШ. <гц*«зи : .
it
El
ЯТ«Ь^^Щ|;:|:
!ит)^1хШ*Ш
Ш&к&^йШ
&щф$п^Х?и„
:::|:;i-:;J2:^.j
■ :•'•' Л Щ
J^lf]
\: ::H-;;:.:.:i::l;.;:.:::: %:- J£ • .:
Z7|
TRANSACTION
• };эд*::| ■; ;Д|ё ■... • • ..- ШШШ&
>
шш<т z$ ЩШШ^ЩЩщ
$&ji$toj.: _j ^^шШгА^Ш'Ш-.
'^Ш<>: л} ЩЩЩЩХЩШ-
ШШШЫ1 ущШшь'У
. • Со^-.
$~\:р]Щ§
ТВ'РШЙ;
—,|Щ
"Щ37
^i'F^dwse^te'j' >;:
^Ну1""; 7715/94 •;■•["""
Щ 'Vs&t f~~
%| иШэ?:\
;»Г "Г
..Safe^iice
$4,30С
J2.50P
Г7.35С
:::-^
.V .!; ^
• w-J
d
Рис. 10.10. Использование групп переключателей
d
£&■*&&$&
Флажки
Флажки (check boxes) похожи на переключатели, однако варианты выбора в
группе флажков не являются взаимоисключающими: можно выбрать более одного
варианта. Пусть, например, галерея хочет хранить в базе данных информацию
о том, какие виды изобразительного искусства интересуют покупателей.
Возможными видами являются литография, живопись маслом, живопись пастелью и
фотография; в форме CUSTOMER на рис. 10.11 они представлены в виде группы
флажков Interest Area(s) (Область интересов). Пользователь делает выбор,
устанавливая соответствующие флажки.
На рис. 10.11 обратите внимание на затененные флажки Pastels и Ceramics. Это
говорит о том, что соответствующие элементы данных имеют пустые значения.
Пользователи могут интерпретировать это так, что данный покупатель интересуется
литографиями и фотографиями и не интересуется масляной живописью. О том,
интересуется ли этот покупатель пастелью и керамикой, информация
отсутствует. (Пустые значения обсуждаются в главе 6.) Если важно отслеживать нулевой
статус, структура базы данных должна предусматривать три значения для каждого
флажка: установлен, сброшен и не определен (null). Это касается и переключателей.
Web-формы
Формы, отображаемые в браузерах, также представляют собой формы
графического интерфейса, и все сказанное выше относится и к ним. Однако у web-форм
есть одно свойство, которое отсутствует у форм Windows: гиперссылки. Такие
Проектирование форм 351
ссылки особенно полезны для материализации ссылок на другие семантические
объекты или сильные сущности. Например, в форме на рис. 10.7 ссылки на
интересы клиента можно заменить гиперссылками. Когда пользователь щелкает мышью
па такой ссылке, открывается форма ARTIST с соответствующими данными. То же
самое можно сделать и со ссылками на произведения.
(з-щци
шщиш^^вш^мшш
шш
¥ШЩ
т
^^щшйш^^^^шюияв^^яшрр
Customer Name
^Nwnb«r p£4 57£ j
State JWA~ Zip ] 331 i'9-8877"
. tfiAfi$ACT>GN
|Jackson Elizabeth
r \bfe
Atf# fN#**&
■"
i
£
Й'вфТ«й«^'''' jE~^-j
*чз*Мко л !
f^bte'Kwo '"''li. J
De^T&gs" 7jL s
' JL
К L^U-Л^ JJ~" ^" » j
jftBCcc* HJ..* If
!•■ V
ArtKdt
►
*
рИ^кТс^йу"
риагГм»о
риагГМяо
i
T*te^V
~3 jUho£*&h Crte
3 pS«t,i,ГГ"',''',~JaJJ',''
y 1 [Awakei^Cbid
~3 |
1 JLliilid ** з
■..с^::;Щ
рЩ£Т
ш"щ [55ЖТ-
— р—
~~~ 1
РиФюф&е
\ 77&V Г
[ '"""l/b.^9 pJ
] П/22/Э7 Р
1 г-
V'JWwWs*^.-
$4.300
$2.500
$17,850
^
i
i
|
1
-J
d
JiLJI iJLii«ii±Jrf2
Рис. 10.11. Использование флажков
Передвижение курсора и единообразная
семантика клавиш
При разработке форм также заслуживает внимания вопрос о работе курсора.
Курсор должен передвигаться по форме легко и естественно. Это обычно
означает, что движение курсора отражает логическую последовательность действий
конечного пользователя по мере того как он читает документы с исходными данными.
Если предполагается, что данные будут вводиться в форму в процессе разговора
по телефону, курсор должен отслеживать направление разговора. В этом случае
следует выбирать такой закон движения курсора, который покупатель находит
естественным и правильным.
То, как двигается курсор, особенно важно в момент возникновения
исключительной ситуации и после нее. Предположим, что при работе с формой,
изображенной на рис. 10.7, была допущена ошибка — например, введен
неправильный код штата. Форма должна обрабатываться так, чтобы курсор передвигался
в то место, которое напрашивается логически. Например, приложение может
352 Глава 10. Проектирование приложений баз данных
вывести список допустимых значений штатов и поместить курсор в некоторую
логичную позицию — например, на первый штат, аббревиатура которого
начинается с первой буквы, введенной пользователем. Когда штат выбран, курсор
должен переместиться обратно к полю Zip — следующему по логике обработки
полю формы.
Действие специальных клавиш, таких как ESC и функциональные клавиши,
должно быть согласованным и единообразным. Если клавиша ESC применяется
для выхода из форм, используйте ее исключительно для этой цели и ни для
какой другой (кроме тех действий, которые логически эквивалентны выходу из
формы). Действие клавиш должно быть согласованным во всем приложении.
Так, если клавиша ESC используется для выхода из одной формы, она должна
использоваться для выхода из всех форм. Если сочетание клавиш <Ctrl> + <D>
используется для удаления данных в одной форме, то следует использовать его
для удаления данных и во всех прочих формах. В противном случае стереотипы
действий, сформированные в одном месте приложения, приходится
пересматривать в другом месте приложения. Это неэкономно, раздражает и
дезориентирует пользователей и, наконец, приводит к ошибкам. Хотя сказанное здесь может
казаться само собой разумеющимся, как раз внимание к таким деталям и делает
форму простой и удобной в использовании.
Проектирование отчетов
Проектирование отчетов (reports) весьма широко обсуждается в текстах,
посвященных разработке приложений, — даже в большей степени, чем проектирование
форм. Мы не станем повторять или даже пытаться обобщать в данном разделе
содержание этих дискуссий, а рассмотрим вместо этого несколько принципов,
которые непосредственно касаются понятия отчета как материализации
представления базы данных.
Структура отчета
Принципы проектирования хороших отчетов аналогичны принципам
проектирования хороших форм. Как и в случае форм, структура отчета должна
отражать структуру лежащего в его основе представления. Это означает, что данные
из одной таблицы должны быть, вообще говоря, размещены друг рядом с другом,
в одном разделе отчета. Как и для форм, из этого правила имеется
исключение: базовое отношение данного представления (например, отношение CUSTOMER
для представления Customer) в отчете может быть разбито на части. Группы
атрибутов, такие как Phone, должны также помещаться вместе и каким-то образом
различаться.
На рис. 10.12 показан пример отчета для галереи View Ridge, в котором
приведены данные по каждому произведению искусства и по транзакциям,
осуществленным с этими произведениями, вычислена общая прибыль по каждой работе
и каждому автору, а также итоговая прибыль.
Проектирование отчетов 353
Sales Listing
15-Nov-01
ArtistName
Dennis Frings
Date Acquired
4/17/1986
3/15/2000
Mark Tobey
I DateAcquired
! 7/3/1971
I 1/4/1986
9/11/1999
Mark Tobey
DateAcquired
4/8/2001
Title
Copy
South Toward Emerald Sea 106/195
AcquisitionPrice
$750.00
$1.200.00
DateSold Sold To SalesPrice
5/3/1986 Heller, Max $1.000.00
5/11/2000 Jackson, Elizabeth $1,800.00
GrossMargin
$250.00
$600.00
Total margin for South Toward Emerald Seas, Copy 106/195 $850.00
Patterns III
AcquisitionPrice
$7,500.00
$11,500.00
$17.000.00
Rhythm
AcquisitionPrice
$17,000.00
Total margin for Dennis Frings
27/95
DateSold Sold To SalesPrice
9/11/1971 Cooper, Tom $10,000.00
3/18/1986 Jackson, Elizabeth $15.000.00
10/17/1999 Cooper. Tom $21,000.00
Total margin for Patterns III, Copy 27/95
2/75
DateSold Sold To SalesPrice
7/14/2001 Heller, Max $27,000.00
Total margin for Rhythm, Copy 2/75
Total margin for Mark Tobey
Grand Total:
$850.00
GrossMargin
$2.500.00
$3.500.00
$4,000.00
$10,000.00
GrossMargin
$10.000.00
$10,000.00
$20,000.00
$20,850.00
Рис. 10.12. Отчет о продажах
Структура отчета на рис. 10.12 отражает структуру объекта WORK. Раздел,
посвященный каждому произведению, начинается с названия произведения,
которое включает имя автора (ArtistName), наименование (Title) и копию (Сору).
Далее идет раздел с повторяющимися строками, которые описывают транзакции с
данным произведением. В каждом разделе указывается имя покупателя, взятое
из таблицы CUSTOMER.
Имейте в виду, что с помощью большинства генераторов отчетов трудно
сконструировать отчет, который проходил бы схему базы данных более чем по
одному многозначному пути. Отчет на рис. 10.12 является материализацией
представления ARTIST, которое следует по пути ARTIST - WORK - TRANSACTION. На
диаграмме связей, изображенной на рис. 10.4, д, показан другой путь — через
таблицу CUST0MER_ARTIST_INT к таблице CUSTOMER, то есть к клиентам, которые
354 Глава 10. Проектирование приложений баз данных
интересуются работами данного художника. В большинстве генераторов отчетов
будет трудно построить такой отчет, который показывал бы оба этих пути.
В отчетах зачастую фигурируют вычисленные значения атрибутов, которые
не входят в соответствующее представление и не хранятся в базе данных. В
отчете на рис. 10.12 таких атрибутов четыре — Gross Margin (прибыль от транзакции),
Total Margin by Work (прибыль от произведения), Total Margin by Artist (прибыль от
художника) и Grand Total (суммарная прибыль). Значения всех этих атрибутов
вычисляются «на лету», в момент создания отчета.
Хотя эти вычисленные значения можно было бы хранить в базе данных, в
действительности это редко имеет смысл, потому что значения, на основе которых
они вычислялись, могут измениться. Если, к примеру, пользователь изменит
значение атрибута SalesPrice для некоторой транзакции и не вычислит
повторно суммарную прибыль и все итоги, зависящие от этого атрибута, то хранимые
в базе данных значения окажутся неверными. Однако осуществление всех
вычислений, необходимых при обновлении, может вызвать недопустимо
медленную обработку. Следовательно, подобного рода итоги лучше всего, как правило,
вычислять «на лету». Формулы для вычисления таких итогов рассматриваются,
таким образом, как часть материализации отчета, а не представления, лежащего
в его основе.
Подразумеваемые объекты
Рассмотрим запрос «Вывести всех авторов, отсортированных по итоговой
прибыли». На первый взгляд может показаться, что здесь запрашивается отчет об
объекте ARTIST. Однако слова «...отсортированных по...» указывают, что необходимо
рассматривать более одного такого объекта. Фактически, запрос относится не
к объекту ARTIST, а к объекту, который можно обозначить как «множество всех
объектов ARTIST». В отчете на рис. 10.12 приведены данные по множеству авторов,
и в действительности этот отчет основан па объекте «множество всех объектов
ARTIST», а не на объекте ARTIST.
Человеческий разум так быстро переходит от объекта А к объекту
«множество всех объектов А», что мы, как правило, даже не чувствуем, что произошло
какое-то изменение. Однако при разработке приложений баз данных важно
отслеживать этот сдвиг, поскольку, когда он происходит, приложение должно вести
себя иначе. Рассмотрим три способа, которыми сортировка может изменить
природу базового объекта: (1) сортировка по объектному идентификатору; (2)
сортировка по неидентифицирующим, необъектным столбцам; (3) сортировка по
атрибутам, входящим в состав объектных атрибутов.
Сортировка по объектному идентификатору
Если данные в отчете должны быть отсортированы по значению атрибута,
являющегося идентификатором объекта, подлинным запрашиваемым объектом
является совокупность таких объектов. Так, отчет об объекте ARTIST, данные в котором
отсортированы по значению атрибута ArtistName, является на самом деле отчетом
об объекте «множество всех объектов ARTIST». Для большинства генераторов от-
Проектирование отчетов 355
четов, входящих в состав СУБД, составить отчет об объекте «множество всех X»
пе сложнее, чем составить отчет об объекте X. Тем не менее, важно знать, что
произошло изменение типа объекта.
Сортировка по неидентифицирующим, необъектным
столбцам
Когда пользователю нужен отчет, данные в котором отсортированы по атрибуту,
который не является идентификатором объекта, реальный объект,
присутствующий в воображении пользователей, имеет, скорее всего, совершенно другой тип.
Пусть, например, пользователю нужен отчет об авторах, отсортированный по
атрибуту Nationality (национальность). Такой отчет является на самом деле
материализацией объекта NATIONALITY, а не объекта ARTIST. Аналогичным образом,
если пользователь запрашивает отчет о покупателях, отсортированный по атрибуту
AreaCode, на самом деле базовым объектом для отчета является объект под
названием PHONE-REGION (региональный телефонный префикс) или нечто подобное.
На рис. 10.13 представлен пример объекта PHONE-REGION.
PHONE-REGION
id AreaCode
Рис. 10.13. Объект PHONE-REGION
Такие объекты, как NATIONALITY и PHONE-REGION, являются подразумеваемыми
объектами (implied objects), то есть их существование следует из того факта, что
пользователь запрашивает подобного рода отчет. Если для пользователя нечто
имеет смысл в качестве переменной сортировки, то это нечто должно быть в
воображении пользователя объектом, вне зависимости от того, смоделирован этот
объект в базе данных или нет.
Сортировка по атрибутам, входящим в состав
объектных атрибутов
Третий возможный способ сортировки отчетов — сортировка по атрибутам,
содержащимся в объектных атрибутах. Например, пользователь может запросить
отчет о произведениях, отсортированный по дате рождения художника. Объект
ARTIST является объектным атрибутом объекта WORK, a BirthDate (дата
рождения) — это атрибут, содержащийся в объекте ARTIST. В этом случае пользователь
на самом деле запрашивает отчет о подразумеваемом объекте (называемом,
скажем, TIME (время) или ARTISTIC PERIOD (период в искусстве)), который содержит
много объектов ARTIST, каждый из которых, в свою очередь, включает много
объектов WORK, представленных в галерее.
Понимание того, как меняется тип объекта, может упростить задачу
разработки отчета. Если действовать так, как будто базовым объектом является WORK,
логика отчета будет запутанной. Если в качестве базового объекта принимается
WORK, то необходимо создать материализации для всех объектов WORK, включающие
356 Глава 10. Проектирование приложений баз данных
атрибуты ARTIST и BirthDate. Если же в основу отчета положить подразумеваемый
объект, содержащий объект ARTIST, который, в свою очередь, содержит объект
WORK, то можно создать объекты ARTIST, отсортированные по атрибуту BirthDate
и объектным атрибутам WORK, которые можно трактовать как многозначные
строки в каждом из объектов ARTIST.
Реализация ограничений
В соответствии с рис. 10.1, третьей основной функцией приложения базы данных
является реализация ограничений. Во многих случаях СУБД способна
реализовать ограничения лучше, чем приложение, поэтому данная функция не
является функцией одних только прикладных программ. Наша задача, однако, состоит
в том, чтобы описать типы ограничений и способы их реализации независимо от
того, каким путем они будут реализовываться — через прикладную программу
или через СУБД.
Первая причина, по которой СУБД часто является более подходящим
кандидатом на реализацию ограничений, чем прикладная программа, заключается
в том, что СУБД — это центр, через который обязательно проходят все изменения
в данных. Независимо от того, что является источником изменения (форма,
другая программа, импорт большого объема данных), СУБД имеет возможность
проверить и в случае необходимости отвергнуть данное изменение. Далее,
определенные правила (одним из таких правил является уникальность) могут
потребовать проверки всех строк в таблице, а СУБД лучше приспособлена к
выполнению таких операций, чем приложение. Кроме того, если правило реализуется
СУБД, то его достаточно будет запрограммировать единожды. Если же правило
реализуется приложением, то для каждого нового приложения его придется
программировать заново. Это неэкономно и порождает опасность несогласованной
реализации правил прикладными программами.
Следует, тем не менее, отметить, что не все СУБД обладают возможностями
и функциями, необходимыми для реализации ограничений. Вдобавок, порою
намного сложнее написать и установить код, реализующий ограничение, с
помощью инструментов, предлагаемых СУБД, чем встроить такой код в
прикладную программу. Более того, в некоторых архитектурах (в частности, в Microsoft
Transaction Server) обработка оказывается более эффективной, если с сервера
данных снимается бремя проверки ограничений. Пользователю определенной
формы, например, может быть запрещено предпринимать некоторые действия
или вводить определенные данные. В этом случае с реализацией ограничения
лучше справится приложение.
Ваша цель должна быть в том, чтобы понять, какие существуют типы
ограничений и какими способами они реализуются. Если можно, реализуйте их с
помощью СУБД; в противном случае реализуйте их в приложении. Сейчас мы
рассмотрим четыре типа ограничений: ограничения доменов, ограничения уникальности,
ограничения ссылочной целостности и положения делового регламента.
Реализация ограничений 357
Ограничения доменов
Вспомните из главы 4, что домен — это множество значений, которые может при-
ипмать атрибут. Определения доменов содержат семантический компонент (имя
художника) и физический компонент (Text 25, алфавитные символы). В общем
случае невозможно реализовать ограничение на семантический компонент с
помощью автоматизированного процесса. Мы еще не находимся на такой стадии
развития компьютерной индустрии, чтобы автоматизированные процессы могли
определять, что ЗМ — это название компании, а не имя художника. Поэтому
сегодня нас главным образом интересует реализация физической части определения
домена.
Ограничения доменов проистекают из модели данных, как описывалось в
главе 4. Степень конкретизации ограничений доменов может варьироваться в
широких пределах. В базе данных галереи View Ridge атрибут ARTIST.Name может
быть произвольным набором из 25 пли менее текстовых символов. Домен
атрибута Сору определен более конкретно. Формат, используемый галереей, имеет
вид nn/mm, где пп — это номер данной копир!, a mm — общее количество
существующих копий. Так, 5/100 обозначает пятую копию из ста существующих.
Ясно, что значение типа 105/100 не имеет смысла. Поэтому следует
предусмотреть код, проверяющий корректность данных, чтобы гарантировать соблюдение
формата.
На рис. 10.14 приведен пример ограничения домена в Access. Ограничение
состоит в том, что дата покупки (атрибут PurchaseDate) должна быть меньше или
равна системной дате компьютера иа момент ввода информации о покупке.
Обратите внимание на строку, обозначенную Validation Rule (Правило проверки).
Правило задается выражением «<« Now()». Если пользователь попытается ввести
данные, которые нарушают это правило, появится сообщение, содержащее
текст, который введен в следующей строке (Validation Text — Текст сообщения).
Па рис. 10.15 показано, что произойдет, если пользователь попытается ввести
дату 10/15/99, когда системная дата компьютера меньше, чем 10/15/99. Введенные
данные Access отвергает.
Еще один тип ограничений — это обязательность значения. Строго говоря,
требование, чтобы значение было задано, представляет собой скорее
ограничение таблицы, чем ограничение домена. Домен — это множество значений; вопрос
о том, обязательно данное значение или нет, возникает тогда, когда домен
появляется в таблице.
В модели данных должно быть указано, является ли атрибут обязательным.
В семантической объектной модели, если минимальное кардинальное число
атрибута равно 1, то этот атрибут является обязательным. Единственное, что
требуется, чтобы реализовать это ограничение в Access, — установить свойство
Required (Обязательный) данного столбца в значение Yes (Да). На рис. 10.16 это
сделано для атрибута Name в определении таблицы ARTIST. В других СУБД, как
вы увидите позже, используются другие способы.
358 Глава 10. Проектирование приложений баз данных
ШШЩ&*-'-*Ш£\
ИЙВДйШВДЙВДЩТОд ~ Д]7iif IIIif• ojmj
^ю-\гг'т:^шШШ-
mm
AutcNumber
System generated surrogate tey
Date/Tme Date the wa k was purchased
Cun-ency Amour* paid f 05 rhe work
Date/Time.'' Date the work was sold
Number ID or Customer purchasing the «ork
Currency Price of work
Number IDofwork
4^Жк1Л1СБЩШ§
5 <; Purchase Ddte - Enter Today's De
^
Рис. 10.14. Создание ограничения домена в Acces
Ш2-
llift
В
J&ft^Kb'
■:■:■:■:• .-.-:■■■ :У : -У <:^^^вН^^вШ^ШШШЩ^ШЩЛШ
§§»
«ill
^ey?JFM|^ ущ!
Customer Name ; Ijackson. Elizabeth
Phorv? У _.''.УУ; • "Щ
LOC4#^*E«b«' : j284 PS?
S*ttwT У^'гЗ-'^ЬА'/е-гк.е ;!;|
£fy У,-; jSeaHit
J Vt'' П> <Х-\'-\-,Ц^&Ь. j, :;
j\*<k irtf«t*$t$ ■'^Ш-Й-У
!!►
;1
!:S:
Ш
Mfc Tobey ■ да^л
JlMOT M*0 ■ ■ ,::;:;;Ш-;-У ■■:':-!«
^ЫоЖйоУ-.l""'.""'-" ^
ЗвГШ.РйПО^ . Л
¥
*■; —-;'zj
iir i
i:V:j ;;Vs^e$l?te;«
j . ^л'сс*- ^ С^^гя :~'"|ife:;t:.. ] " 7/iv*t]—; кзио
iij
-£.
j j 17^u*•' ^ j^eT*r:«*i Г-Г'.ШЙШ'- Г^'^ггл?:] $i/.850 ^
; rz?7«7'" Ti pv^Tu "7/..; :■.. рЩ$&.':'.' 1 ...*/s/1iS1I \ ""i^ffir
iill i ii^ifiiigiP)
o.'ivss (
1
i
_1j
11Ш:ШШШ:§1
||ШЩ|В
Рис. 10.15. Результат нарушения пр^ила проверки
Реализация ограничений 359
Рис. 10.16. Определение атрибута Name таблицы ARTIST в качестве обязательного и уникального
Ограничения обязательности важны потому, что они предотвращают
появление пустых значений. Еще один способ это сделать — определить начальное
значение, которое СУБД будет присваивать столбцу при создании строки. В Access
ото делается путем записи значения или выражения в свойство Default Value
(Значение по умолчанию). См. рис. 10.16 и обсуждение пулевых значений в главе 6.
Ограничения уникальности
Уникальность — второй тип ограничений. Как уже отмечалось, ограничения
этого типа лучше реализуются СУБД, поскольку она способна создавать структуры
данных, позволяющие проводить проверку уникальности весьма быстро. В
приложении А описано, как для этой цели можно использовать индексы.
На рис. 10.16 показано определение в Access атрибута Name таблицы ARTIST
в качестве уникального. Обратите внимание, что свойство Indexed
(Индексируемый) установлено в значение Yes (No Duplicates) (Да, без повторений). При таких
установках Access гарантирует, что ни из одного источника в базу данных не
будут введены одинаковые имена художников.
Ограничения связей
Есть два типа ограничений связей: ограничения ссылочной целостности (referential
integrity constraints) и ограничения кардинальности связи (relationship cardinality
360 Глава 10. Проектирование приложений баз данных
constraints). Ограничениями ссылочной целостности называются ограничения
на значения внешнего ключа. Это те ограничения, которые возникают, например,
при нормализации, когда одно отношение разбивается на два новых, и которые
появляются между сильными и слабыми сущностями. Ограничения
кардинальности связи обусловлены значениями минимальной и максимальной
кардинальности связи. Рассмотрим оба этих типа ограничении.
Ограничения ссылочной целостности
Все ограничения ссылочной целостности являются ограничениями на значения
внешнего ключа. Рассмотрим сначала ограничение ссылочной целостности на
рис. 10.3, а: значение атрибута ArtistID в таблице WORK должно существовать
среди значений одноименного атрибута в таблице ARTIST. Атрибут ArtistID является
внешним ключом в таблице WORK, и ограничение означает, что его значение
должно соответствовать одному из значений атрибута ArtistID в таблице ARTIST,
как объяснялось ранее.
Пока все приложения запрограммированы правильно, пока все транзакции
обрабатываются корректно и пока никто из пользователей случайно не удалит
художника, не удалив связанные с ним произведения (а из-за второго
ограничения — и связанные с ним транзакции, а из-за третьего ограничения — и
связанных с ним покупателей), — в общем, пока все идет хорошо, никаких нарушений
целостности по внешнему ключу не произойдет. В конце концов, изначально
база данных не имеет проблем с целостностью, а чтобы эти проблемы возникли,
сначала их надо вызвать.
Разумеется, здесь мы рассчитываем слишком на многое. Ошибки случаются.
Поэтому в СУБД предусмотрена возможность определить и реализовать такие
ограничения средствами самой СУБД. Это значит, что СУБД не позволит
выполнить операцию вставки, удаления или модификации значения внешнего
ключа, которая приведет к нарушению ограничения целостности по внешнему
ключу. Например, заглянем немного вперед и посмотрим на рис. 10.20, где
установленный флажок Enforce Referential Integrity (Реализовывать ссылочную
целостность) предписывает Access реализовывать следующее ограничение: значение
атрибута EmpLoyeeName в таблице EMPL0YEE_PhoneNumber должно существовать
среди значений атрибута Name в таблице EMPLOYEE.
Подобные возможности существуют во всех СУБД. Кроме того, в серверных
СУБД, таких как ORACLE и SQL Server, имеются утилиты, периодически
запуская которые, можно гарантировать, что в базу данных не проникнут
нарушения ссылочной целостности, обусловленные частично завершенными
транзакциями, импортированными данными и другими чудесами Вселенной. Запуск
этих утилит обычно входит в план обслуживания базы данных (см. главу 11).
Ограничения кардинальности связи
Ограничения кардинальности связи проистекают из кардинальных чисел
связанных объектных атрибутов. Например, на рис. 10.3, а связь с объектом CUSTOMER
в группе WORK.Transaction имеет кардинальность 1.1; следовательно, группа
Transaction должна иметь связь с объектом CUSTOMER.
Реализация ограничений 361
Вообще такие ограничения имеют два источника: ненулевое минимальное
кардинальное число и максимальное кардинальное число, не равное 1 или N.
'Гак, кардинальности 1.1, l.N, 2.N приведут к возникновению ограничений
кардинальности, как и кардинальности 0.3, 1.4 и 2.4. За одним исключением, эти
транзакции должны реализовываться в коде приложения.
Исключением является кардинальность 1.1 на стороне потомка в связи 1:N.
13 этом случае ограничение можно реализовать, сделав внешний ключ
обязательным. Так, ограничение кардинальности 1.1 на объект CUSTOMER в группе
WORK.Transaction можно реализовать, сделав атрибут CustomerlD обязательным
it таблице TRANSACTION.
Во всех прочих случаях разработчик базы данных должен написать код,
реализующий ограничения кардинальности. Этот код можно поместить в хранимые
процедуры, которые будут вызываться СУБД при внесении изменений в связи,
либо в прикладные программы, либо в обработчики определенных событий в
формах, например BeforeUpdate (обсуждается ниже).
Чтобы упростить обсуждение, мы будем рассматривать только
ограничения 1.1 и l.N. Логика этих двух примеров непосредственно распространяется
и на прочие ограничения.
На рис. 10.17 представлена связь между отношениями СПЕЦИАЛЬНОСТЬ и СТУДЕНТ.
В соответствии с рис. 10.17, а, специальность должна быть связана по крайней
мере с одним студентом, а каждый студент должен иметь ровно одну
специальность. Когда пользователи обновляют любое из этих отношений, должен
вызваться код реализации ограничений. На рис. 10.17, б, например, если пользователь
попытается удалить строку студента 400, код реализации ограничений должен
отклонить этот запрос. Если бы этот запрос был разрешен, для строки в таблице
ФИНАНСЫ не нашлось бы дочерней строки, и ограничение обязательности было
бы нарушено. Подобным же образом, невозможно добавить новую строку в
таблицу СПЕЦИАЛЬНОСТЬ (например «БИОЛОГИЯ»), пока не появится студент,
специализирующийся на этом предмете.
MAJOR
STUDENT
а
ФИНАНСЫ
СТ400
Рис. 10.17. Пример ограничения вида «обязательно-обязательно»:
а — структура связи; б — данные для примера
362 Глава 10. Проектирование приложений баз данных
Строка, у которой отсутствует заявленный обязательный родитель или
потомок, называется иногда фрагментом (fragment), а дочерние строки, не имеющие
заявленного обязательного родителя, иногда называют зависшими записями.
Одна из функций прикладной программы — предотвращать появление фрагментов
и зависших записей.
Способ предотвращения появления фрагментов зависит от типа ограничения.
На рис. 10.18 приведены примеры четырех возможных ограничений на связи вида
1:N: «обязательно-обязательно» (О-О), «обязательно-необязательно» (О-Н),
«необязательно-обязательно» (Н-О) и «необязательно-необязательно» (Н-Н).
Эти ограничения показаны только для связей вида «один ко многим», но эти же
четыре типа сохраняются и для других типов связей.
СЧЕТ_ИЗ_/ОСТИНИЦЫ ПРЕПОДАВАТЕЛЬ
ПЛАТА_ЗА_ДЕНЬ
СТУДЕНТ
КЛУБ
СТУДЕНТ
ПРОЕКТ
СОТРУДНИК
Рис. 10.18. Пример четырех типов ограничений связи: а — «обязательно-обязательно»
(О—О); б — «обязательно-необязательно» (О-Н); в — «необязательно-
обязательно» (Н-О); г — «необязательно-необязательно» (Н-Н)
Нарушения ограничений могут происходить при всяком изменении значений
ключевых атрибутов. Например, если на рис. 10.17, б изменить специализацию
студента 300, поменяв «БУХГАЛТЕРСКИЙ УЧЕТ» иа «ФИНАНСЫ», студент будет
переведен на кафедру финансов. Хотя при этом меняется родитель, это не вызывает
нарушения ограничения.
Такое нарушение произойдет, однако, если поменять специализацию
студента 400 на «БУХГАЛТЕРСКИЙ УЧЕТ». После этого окажется, что ни один студент не
специализируется на предмете «ФИНАНСЫ», и таким образом будет нарушено
ограничение «О-О» между таблицами СПЕЦИАЛЬНОСТЬ и СТУДЕНТ.
В табл. 10.1 и 10.2 представлен свод правил, позволяющих предотвратить
появление фрагментов для каждого из указанных типов ограничений. В табл. 10.1
приведены правила, касающиеся действий с родительской строкой, а в табл. 10.2 —
с дочерней строкой. Как видно из этих таблиц, возможных действий имеется
три: вставить новые строки, модифицировать ключевые данные и удалить
строки. В этих таблицах перечислены правила для связей вида «один ко многим»;
правила для связей вида «один к одному» аналогичны.
Реализация ограничений
363
Таблица 10.1. Условия допустимости изменений в родительских записях
Тип связи
0-0
0-Н
Н-0
Н-Н
Вставка
Создать как
минимум одного
потомка
ОК
Добавить нового
потомка ИЛИ
соответствующий
потомок уже
существует
ОК
Обновление (ключа)
Изменить соответствующие
ключи у всех потомков
Изменить соответствующие
ключи у всех потомков
Изменить ключ как минимуму
одного потомка ИЛИ
соответствующий потомок уже
существует
ОК
Удаление
Удалить всех потомков
ИЛИ переназначить
всех потомков
Удалить всех потомков
ИЛИ переназначить
всех потомков
ОК
ОК
Таблица 10.2. Условия допустимости изменений в дочерних записях
Тип связи
0-0
О-Н
Н-0
Н-Н
Вставка
Родитель
существует ИЛИ
создать родителя
Родитель
существует ИЛИ
создать родителя
ОК
ОК
Обновление (ключа)
Родитель с новым значением
существует (или создать его)
И брат существует
Родитель с новым значением
существует ИЛИ создать
родителя
Брат существует
ОК
Удаление
Брат существует
ОК
Брат существует
ОК
Ограничения на обновление родительских строк
Первая строка в табл. 10.1 относится к ограничениям «О-О». Новую роднтель-
гкую строку можно вставить только в том случае, если в то же самое время
создается по крайней мере одна дочерняя строка, что можно сделать, либо вставив
новую дочернюю строку, либо взяв ее от другого родителя (однако последнее
действие может само по себе вызвать нарушение ограничения).
Изменение ключа родителя разрешается в связи «О-О» только в том случае,
если при этом изменяются значения соответствующего внешнего ключа в
дочерних строках. (Можно переназначить всех потомков другому родителю и затем
создать для родителя хотя бы одного нового потомка, но так поступают редко.)
Так, изменение атрибута Счет-Фактура в отношении СЧЕТ_ЗА_ГОСТИНИЦУ
разрешается, если значение этого атрибута будет также изменено в соответствующих
строках таблицы ПЛАТА_ЗА_ДЕНЬ. Обратите внимание, что при использовании
суррогатных ключей это действие никогда не произойдет.
Наконец, родитель в связи «О-О» может быть удален только тогда, когда
будут удалены или переназначены все его потомки.
Что касается ограничений «О-Н», родительские строки можно добавлять
без ограничений, поскольку родитель не обязан иметь потомка. Для связи на
рис. 10.18, б в отношение ПРЕПОДАВАТЕЛЬ новую строку можно добавить без
364 Глава 10. Проектирование приложений баз данных
каких-либо ограничений. Но изменение ключа родителя разрешено лишь в том
случае, если соответствующие значения в дочерних строках также будут
изменены. Если у отношения ПРЕПОДАВАТЕЛЬ в связи на рис. 10.18, б изменится ключ,
то значение атрибута Руководитель у всех студентов, руководимых данным
профессором, нужно тоже изменить.
Наконец, в связи с ограничением «О-Н» родительская строка может быть
удалена, только если все потомки будут удалены или переназначены. Для связи
ПРЕПОДАВАТЕЛЬ-СТУДЕНТ придется, возможно, переназначить все строки.
В ограничениях «Н-О» родитель может быть вставлен только в том случае,
если в это же время добавляется по меньшей мере один потомок или если
соответствующий потомок уже существует. Для связи «Н-О» между таблицами
СТУДЕНТ и КЛУБ на рис. 10.18, в новый клуб можно добавить, только если создать
соответствующую строку в таблице СТУДЕНТ (либо добавив нового студента, либо
изменив значение атрибута Клуб у существующего студента). Кроме того,
подходящий студент может уже существовать.
Аналогичным образом, ключ родителя в связи «Н-О» может быть изменен,
только если будет создан новый потомок или если подходящая дочерняя строка
уже существует. То есть «Секция лыж» может начать называться «Секцией
подводного плавания», только если хотя бы один лыжник хочет заняться
подводным плаванием или какой-то студент уже занимается этим видом спорта.
Ограничения на удаление родительских строк в связи «Н-О» отсутствуют.
Последний тип ограничений связи, «Н-Н», показан на рис. 10.18, г. В такой
связи отсутствуют какие-либо ограничения на любой тип обновления строк.
Строки отношений ПРОЕКТ и СОТРУДНИК могут модифицироваться так, как это
необходимо.
Ограничения на обновление дочерних строк
Правила, предотвращающие появление фрагментов при обновлении дочерних
строк, представлены на рис. 10.19, би аналогичны правилам на рис. 10.19, а. Одно
заметное различие состоит в том, что в некоторых случаях дочерние строки могут
модифицироваться или удаляться, если у них имеются братья. Например, в
ограничении «О-О» дочерняя строка может быть удалена, пока у нее существуют
братья (последний ребенок никогда не покидает дом!). Для ограничения «О-О»
на рис. 10.18, а строка отношения ПЛАТА_ЗА_ДЕНЬ может быть удалена, пока
кроме нее остается хотя бы одна строка.
За исключением того, что относится к братьям, правила, предотвращающие
появление фрагментов при обработке дочерних строк, подобны правилам,
сформулированным для предков. Убедитесь, что вы понимаете каждое из
высказываний в табл. 10.2.
Использование СУБД для реализации
ограничений кардинальности
Имея в виду сказанное выше, полезно рассмотреть ограничения в табл. 10.1 и 10.2
в контексте средств определения связей в СУБД Access. Предположим, что в базе
Реализация ограничение 365
данных имеется объект EMPLOYEE (сотрудник) с многозначным атрибутом Phone
Number (номер телефона). Чтобы показать значение средних столбцов табл. 10.1
и 10.2, примем, что в качестве ключа EMPLOYEE используется не суррогатный
ключ, а атрибут EMPLOYEE.Name.
На рис. 10.19 показано окно определения связи для этого примера.
Установленный флажок Enforce Referential Integrity (Реализовывать ссылочную
целостность) указывает на то, что Access не позволит создать новую строку в таблице
ЕМ PL0YEE_PhoneN umber, если соответствующее значение атрибута Employee Name
отсутствует в таблице EMPLOYEE. В этом состоит суть ссылочной целостности —
как описывалось выше. Второй установленный флажок, Cascade Update Related
Fields (Каскадное обновление связанных полей), означает, что если в таблице
EMPLOYEE меняется имя сотрудника, то это изменение будет распространено на
все связанные с ним строки в таблице EMPLOYEE_PhoneNumber. Это реализует
правила в средних столбцах табл. 10.1 и 10.2. (Опять-таки, в этом не было бы
необходимости, если бы использовались суррогатные ключи.)
ъ 11! х: ©^ сь
жш
I
Name
j Employ eeNarne
' Phone Nufnfcwr
[abfe/Qwy.
EMFIOVEE
P^daurf Tsb^jery:.
▼ {EMPLOYEE J>hor.e Nunj^
„tJ EmpioyeeNdtne ?_*_
Г7 ёг^ф№#егШ irtoaprr/
P C$Ka«tefj)c^«Reid^Fiekj5
P Ca$c^Qfk*»R&$e4fi*zci>te
Relationship Tv?*
Ог^-То-НэПу
'"■-*Ш\
OK.-^fffJ
Сдпс^Щг|:'у|
jo;>Type., J .
Рис. 10.19. Свойства связи в Access
Последний установленный флажок, Cascade Delete Related Records (Каскадное
удаление связанных записей), означает, что когда удаляется строка из таблицы
EMPLOYEE, все связанные с ней строки в таблице EMPL0YEE_PhoneNumber также
удаляются. Это аналогично описанной ранее ситуации при удалении
экземпляров представлений.
366 Глава 10. Проектирование приложений баз данных
Эта возможность Access относится к правилам во втором и третьем столбцах
табл. 10.1 и в первом и втором столбцах табл. 10.2. Она не затрагивает правила
в первом столбце табл. 10.1 или в третьем столбце табл. 10.2. Эти правила
должны быть реализованы в хранимых процедурах или в приложении.
Ограничения делового регламента
Ограничения делового регламента (business rule constraints) определяются
логикой и требованиями конкретного приложения. Они проистекают из процедур
и политики, существующих в организации, которая будет использовать
приложение баз данных. Примерами положений делового регламента могут служить
следующие правила.
+ Сумма комиссионных продавца не может превышать 50% общего объема
пула комиссионных.
+ Заказ не будет оформляться, если суммарная стоимость заказываемых
товаров меньше чем $200.
+ Для избранных покупателей расходы по пересылке не учитываются.
+ Продавцы не могут оформлять заказы для себя.
+ Чтобы быть менеджером по продаже, сотрудник должен прежде всего
быть продавцом.
Поскольку деловой регламент зависит от приложения, в СУБД не
предусмотрено никаких общих возможностей для их реализации. Вместо этого в СУБД
предоставлена возможность вставки кода перед наиболее важными событиями
и после них. На рис. 10.20 представлен перечень событий, которые могут
перехватываться формами в Access. На этом рисунке разработчик находится в процессе
добавления логики обработки события Before Insert (перед вставкой). Логика
может принимать одну из нескольких форм: процедура обработки события на
входном языке Access, Visual Basic или каком-либо другом языке
программирования либо макрокоманда Access. Для процедуры обработки события или
макрокоманды доступны все данные, содержащиеся в форме и в базе данных. Таким
образом, с помощью перехвата событий можно реализовать любое из правил,
перечисленных в приведенном выше списке.
В серверных СУБД, таких как Oracle и SQL Server, используются
аналогичные способы. Логика может быть встроена в триггеры — хранимые процедуры,
которые вызываются при наступлении событий в базе данных. События,
доступные для перехвата, подобны тем, что перечислены на рис. 10.20.
Безопасность и контроль
Четвертая основная функция приложения базы данных из перечисленных на
рис. 10.1 — обеспечение механизмов безопасности и контроля. Цель состоит в том,
чтобы создавать приложения, в которых соответствующие действия могли бы
совершать только пользователи с достаточными полномочиями и в подходящее время.
Безопасность и контроль 367
Рис. 10.20. События, доступные для перехвата формами Access
Безопасность
Большинство СУБД обеспечивают безопасность на уровне имени пользователя
п пароля. При получении пользователем учетной записи может быть ограничен
его доступ к определенным формам, отчетам, таблицам и даже столбцам таблиц.
Все это полезно, и в этом имеется смысл. Однако это не помогает ограничить
доступ пользователя к определенным экземплярам данных.
Например, в приложении базы данных кадрового отдела каждый сотрудник
должен иметь привилегии для просмотра только своей собственной записи.
Определенным сотрудникам кадрового отдела должно быть предоставлено право
просматривать некоторые данные обо всех сотрудниках, а старший менеджер по
кадрам должен иметь возможность просматривать все данные обо всех сотрудниках.
Ограничение доступа к определенным формам и отчетам здесь не поможет.
Каждому сотруднику необходимо просматривать форму Employee; ограничение
368 Глава 10. Проектирование приложений баз данных
должно состоять в том, что сотрудник может видеть только те данные в этой
форме, которые относятся лично к нему (за указанными исключениями). Иногда
вам могут встретиться термины горизонтальная безопасность (horizontal security)
и вертикальная безопасность (vertical security). Чтобы понять их, представим
себе таблицу. Вертикальная безопасность будет ограничивать доступ к
определенным столбцам, но все строки будут видны. Горизонтальная безопасность
будет ограничивать доступ к определенным строкам, но при этом видны будут
все столбцы.
Приложения, которые ограничивают доступ к определенным формам,
отчетам, таблицам и столбцам, обеспечивают вертикальную безопасность.
Приложения, которые ограничивают доступ к определенного рода данным в формах,
отчетах, таблицах или столбцах, обеспечивают горизонтальную безопасность. Имена
пользователя и пароли можно непосредственно использовать для обеспечения
вертикальной безопасности. Горизонтальная безопасность требует от
разработчиков написания программного кода.
Например, чтобы обеспечить горизонтальную безопасность в приложении
базы данных кадрового отдела, приложение будет получать имя пользователя от
системы безопасности СУБД и ограничивать доступ пользователя к базе только
теми строками, которые содержат данное имя либо связаны со строками,
содержащими данное имя, через соединения. Один из способов это сделать —
указывать имя пользователя как аргумент предложения WHERE в SQL-операторах.
Поскольку каждая ситуация требует индивидуального подхода, большего мы
сказать не можем. Просто имейте в виду, что когда говорится, что СУБД
поддерживает безопасность, это чаще всего означает только поддержку вертикальной
безопасности с помощью имен пользователей и паролей.
Контроль
Большинство приложений управляют действиями пользователя посредством
меню. На рис. 10.21, а показана система меню для приложения «дографического»
периода, а па рис. 10.21, б показана та же самая система меню, но в приложении
с графическим интерфейсом пользователя.
Меню на рис. 10.21 являются статическими. Более эффективное управление
можно обеспечить путем динамического изменения содержимого меню, когда
меняется контекст пользователя. Меню такого типа вы можете видеть в Access,
когда панель инструментов меняется в зависимости от того, с чем вы
работаете—с генератором таблиц, форм или отчетов. Разработчики приложения базы
данных могут использовать подобную стратегию для изменения содержимого
меню в зависимости от формы или отчета, который просматривает пользователь,
и даже в зависимости от действия, которое пользователь предпринимает в ходе
заполнения формы. Используя Access, разработчик может менять
содержимое меню, перехватывая события, подобные тем, что перечислены па рис. 10.20,
и динамически модифицировать его структуру.
Безопасность и контроль , 369
VIEW RIDGE GALLERY
— 1. Process CUSTOMER Data
2. Process ARTIST Data
3. Process ART WORK Data
Press <F1> for HELP; <ESC> to EXIT
-► VIEW RIDGE GALLERY
CUSTOMER Processing Menu
— 1. Find CUSTOMER Data
2. Add a New CUSTOMER
3. Print CUSTOMER List
Press <F1> for HELP; <ESC> to EXIT
VIEW RIDGE GALLERY
Find CUSTOMER Menu
1. Find by CUSTOMER Name
2. Find by CUSTOMER Number
Press <F1> for HELP; <ESC> to EXIT
ШШ
||Щ1Ш111)|Шс1' faf m
\ШШЬШ
Рис. 10.21. Иерархия меню для галереи View Ridge: a — без использования графического
интерфейса; б — с использованием графического интерфейса
Особый вид управления необходим для транзакций. В главе 11 вы узнаете
о способах управления многопользовательской обработкой, которые
предотвращают нежелательные побочные эффекты от действий одного пользователя на
действия другого пользователя. Ключевым элементом управления многопользо-
иательской обработкой является указание границ, в которых действия должны
иыполняться как единое целое. Такие границы иногда называются рамками
транзакции (transaction boundaries). Например, последовательность SQL-операторов
370 Глава 10. Проектирование приложений баз данных
для создания представления, которая приведена в начале этой главы, должна
выполняться как единое целое, как одна транзакция.
Мы не будем предвосхищать изложение, которое последует в главе 11, однако
скажем, что указание рамок транзакции является задачей приложения. Как
правило, приложение делает это, выполняя перед началом единицы обработки
оператор BEGIN TRANSACTION, а по окончании - оператор END TRANSACTION.
Установка рамок транзакции не вызывает затруднений, если
пользовательские представления хорошо спроектированы. Приложение выполняет оператор
BEGIN TRANSACTION в начале представления и END TRANSACTION в конце
представления. Оставшуюся часть этой дискуссии мы отложим до главы 12.
Логика приложения
Последняя указанная на рис. 10.1 функция приложения базы данных —
реализация логики приложения (application logic). Эта тема подробно обсуждается в
курсе системной разработки, поэтому мы не уделим ей здесь много внимания.
Потребность в реализации логики приложения вытекает из системных
требований. В системе ввода заказов логика приложения определяет то, как берегся
товар со склада, что делать при недостаточном количестве товара иа складе, как
организовывать отложенный заказ и т. п. В приложении базы данных, которое
базируется на формах (например, приложение галереи View Ridge), выполнение
кода, реализующего эту логику, приурочивается к событиям наподобие
перечисленных на рис. 10.20.
В других приложениях баз данных, где формы материализуются самим
приложением, а не СУБД (распространенная ситуация на больших ЭВМ),
приложение обрабатывает данные способом, аналогичным тому, который применяется
при обработке файлов. Логика встраивается в приложение в тех его местах, где
происходит обмен данными с СУБД. Некоторые прикладные программы
получают данные от других программ; в этом случае логика обработки также
встраивается в приложение.
Таким образом, способ, которым логика обработки реализуется в
приложениях баз данных, зависит как от логики, так и от самой среды. В каждом виде
приложений этот способ свой, будь то приложения для настольных компьютеров,
клиент-серверных систем, больших ЭВМ или приложения, использующие
интернет-технологии. Вы познакомились с тем, как перехватываются события в
приложениях для настольных компьютеров. Прочие способы будут рассмотрены нами
в последующих главах.
Резюме
Приложение базы данных имеет пять основных функций: (1) создание, чтение,
обновление и удаление представлений; (2) материализация, или форматирование
представлении; (3) реализация ограничений; (4) обеспечение механизмов
безопасности и управления; (5) реализация логики приложения.
Резюме, 371
Представление — это структурированный список элементов данных из
сущностей или семантических объектов. Экземпляр представления — это
представление, заполненное данными. Поскольку представления структурированы,
отдельно взятый элемент данных может фигурировать в представлении неоднократно.
Для чтения представления запускается один или несколько SQL-операторов,
получающих данные. Если представление включает два или более пути следования
но связям в схеме, потребуется более одного SQL-оператора. Набор записей —
:>то отношение, заключенное в оболочку ООП.
Создание представления требует добавления одной или более строк в таблицы
и, возможно, создания или изменения значений внешних ключей с целью
установления связей. Есть три возможных типа обновления: изменение существующих
данных, изменение связей и создание новых строк для многозначных атрибутов.
Удаление представления требует удаления одной или более строк и настройки
ипешних ключей. Трудность при удалении заключается в том, чтобы знать,
сколько и чего удалять. Слабые сущности должны удаляться, если удаляется сущность,
от которой они зависят. Многозначные атрибуты, входящие в состав
семантического объекта, должны также удаляться. В некоторых СУБД можно назначать
связям режим каскадного удаления, при котором СУБД будет автоматически
удалять соответствующие зависимые строки.
Форма — это экранный объект, предназначенный для ввода и
редактирования данных. Принципы проектирования форм таковы: структура формы должна
отражать структуру представления, семантика данных должна быть графически
очевидной и структура формы должна побуждать к правильным действиям. Для
повышения удобства работы с формой можно использовать раскрывающиеся
списки, переключатели и флажки.
Отчеты также должны проектироваться так, чтобы их структура отражала
структуру материализуемого ими представления. Сортировка данных в отчете
зачастую подразумевает существование других объектов. В большинстве
генераторов отчетов оказывается трудным сконструировать отчет, который следовал
Пы более чем по одному многозначному пути в схеме. В отчетах часто
встречаются вычисленные атрибуты; обычно хранение этих атрибутов в базе данных не
оправданно.
Ограничения могут реализовываться либо СУБД, либо прикладной
программой. В большинстве случаев лучше по возможности поручать их реализацию
СУБД, поскольку СУБД является центром, через который обязательно
проходят все изменения данных. В некоторых случаях, однако, СУБД не имеет средств
для реализации ограничений, и такие ограничения должны реализовываться
приложением. Ограничения домена реализуют физическую часть определения
ломена. Еще один тип ограничений — это обязательные значения. Определение
значения в качестве обязательного предотвращает появление нулевых значений,
не имеющих однозначной трактовки. Ограничения уникальности лучше всего
реализуются СУБД; это обычно делается путем построения индексов.
Есть два типа ограничений связи: ограничения ссылочной целостности и
ограничения кардинальности. Ограничения ссылочной целостности реализуются
лучше всего. Ограничения кардинальности возникают, когда минимальное карди-
372 Глава 10, Проектирование приложений баз данных
нальное число не равно нулю или максимальное кардинальное число не равно 1
или N. За исключением случая кардинальности 1,1 на стороне потомка в связях
1:N, такие ограничения должны реализовываться в коде приложения.
Правила для реализации ограничений для связей 1:N приведены в табл. 10.1 и 10,2.
Ограничения делового регламента реализуются приложением в коде,
вызываемом при перехвате событий, в триггерах или прикладных программах.
Большинство СУБД обеспечивают безопасность на уровне имени пользователя
и пароля. Таким образом можно обеспечить вертикальную безопасность;
горизонтальная безопасность должна обеспечиваться в коде приложения. Большинство
приложений обеспечивают управление посредством меню. Оптимальное
управление имеет место тогда, когда меню меняется при изменении контекста
пользователя. Прикладные программы играют важную роль для определения рамок
транзакции. Логика приложения воплощается в коде, который вызывается при перехвате
событий и другими способами, которые будут описаны в последующих главах.
Вопросы I группы
1. Перечислите пять основных функций приложения базы данных.
2. Перечислите функции обработки представлений данных.
3. Дайте определение термина представление, как он используется в этой главе.
4. Что такое экземпляр представления?
5. Объясните, чем представление отличается от материализации.
6. Может ли атрибут появляться в представлении более одного раза? Почему?
7. При каких условиях можно прочитать представление с помощью одного
SQL-оператора?
8. При каких условиях чтение представления потребует более одного SQL-
оператора?
9. Покажите два пути, имеющиеся в представлении Customer на рис, 10.4.
10. Дайте определение термина набор записей.
11. Опишите в общих словах, что требуется сделать для создания нового
представления,
12. Как создаются связи при создании нового представления?
13. Какой прием можно использовать, чтобы получить значение суррогатного
ключа при вставке новых строк в таблицу?
14. Перечислите три типа изменений, которые могут произойти при
обновлении экземпляра представления,
15. Объясните, как изменяются связи 1:N и N:M.
16. В чем состоит основная трудность при написании кода, удаляющего
экземпляр представления?
17. Как с помощью модели «сущность—связь» определить, сколько и чего нужно
удалять?
Вопросы I группы , 373
18. Как с помощью семантической модели определить, сколько и чего нужно
удалять?
19. Что такое каскадное удаление и в чем его важность?
20. Поясните смысл высказывания: «Структура формы должна отражать
структуру представления».
21. Каким образом следует проектировать формы, чтобы семантика данных
была графически очевидной?
22. Каким образом следует проектировать формы, чтобы их структура
побуждала к правильным действиям?
23. Объясните, какова роль раскрывающихся списков, переключателей и
флажков при проектировании форм.
24. Какие существуют ограничения при материализации представлений в
виде отчетов?
25. Объясните, почему вычисляемые значения, которые встречаются в
отчетах, как правило, не следует хранить в базе данных.
26. Объясните, каким образом запрос отчета об объектах, отсортированных по
некоторому значению, меняет базовый объект отчета,
27. Почему реализацию ограничений обычно следует поручать СУБД, а не
конкретной форме, отчету или прикладной программе?
28. Почему иногда ограничения реализуются в прикладных программах?
29. Приведите пример ограничения домена и объясните, как оно может быть
реализовано в Access.
30. Объясните, какого рода неопределенность возникает в случае наличия
пустых значений атрибутов. Укажите два способа, позволяющих
предотвратить появление таких значений,
31. Почему реализацию ограничений уникальности следует, как правило,
поручать СУБД?
32. Укажите два источника ограничений кардинальности,
33. Назовите два типа ограничений связи.
34. Каков наилучший способ реализации ограничений целостности по
внешнему ключу?
35. Как можно реализовать ограничение кардинальности 1,1 на стороне
потомка в связи 1:N?
36. Дайте определения терминов фрагмент и зависшая запись.
37. Обоснуйте значения в первом столбце табл. 10.1.
38. Объясните, почему средний столбец табл. 10,1 не нужен при
использовании суррогатных ключей,
39. Обоснуйте значения в третьем столбце табл. 10.1.
40. Обоснуйте значения в первом столбце табл. 10,2,
41. Обоснуйте значения в третьем столбце табл. 10.2.
374 Глава 10. Проектирование приложений баз данных
42. Объясните, почему ограничения в первом столбце табл. 10.1 и в третьем
столбце табл. 10.2 не реализованы в окне редактирования связи Access,
изображенном на рис. 10.19.
43. Приведите пример ограничения делового регламента, которое можно было
бы применить к модели данных из рис. 10.2 и 10.3. Объясните, как можно
было бы реализовать это ограничение с помощью перехвата событий.
44. Дайте определения терминов горизонтальная безопасность и
вертикальная безопасность.
45. Какой тип безопасности обеспечивают имя пользователя и пароль?
46. Какой тип безопасности должен обеспечиваться в коде приложения?
47. Объясните, в чем преимущество динамических меню над статическими.
48. Как логика приложения связана с базой данных при использовании Access?
Вопросы II группы
Вопросы 49-51 относятся к изображенному ниже представлению Artist, в основе
которого лежит модель данных из рис. 10.2 и 10.3.
ARTIST.Name
ARTIST.Nationality
TRANSACTION.PurchaseDate
TRANSACTION.SalesPrice
CUSTOMER.Name
CUSTOMER.Phone.AreaCode
CUSTOMER.Phone.Loca1 Number
CUSTOMER.Name...
Многоточием обозначены структуры, которые могут повторяться.
49. Напишите SQL-операторы для чтения экземпляра данного представления,
содержащего данные о художнике Марке Тоби.
50. Напишите SQL-операторы, создающие новый экземпляр данного
представления. Сделайте это в предположении, что у вас есть данные
художника, одна транзакция и много имен клиентов для второго экземпляра
CUSTOMER.Name. Пусть эти данные записаны в структуре под названием
NewArtist. Используйте синтаксис, аналогичный приведенному в тексте.
51. Напишите SQL-операторы, обновляющие это представление следующим
образом:
1) Поменяйте написание имени художника Марка Тоби с «Mark Tobey» па
«Mark Toby».
2) Создайте новую транзакцию для этого художника. Предположим, что
все необходимые данные о транзакции, произведениях и покупателях
хранятся в структуре под названием NewTrans.
Вопросы к проекту FiredUp t 375
3) Добавьте новых покупателей, которые интересуются работами данного
художника. Предположим, что данные о них хранятся в коллекции, к
которой вы можете обращаться с помощью команды For Each NewCust.Name.
4) Напишите SQL-операторы, удаляющие строку художника Марка Тоби
и связанные с ней строки в таблицах TRANSACTION и WORK.
Проекты
1. С помощью Access создайте базу данных, структура которой показана на
рис. 10.2 и 10.3. Создайте форму для описанного выше (вопрос 49)
представления Artist Обоснуйте структуру формы, руководствуясь принципами,
описанными в этой главе. Подсказка: для создания одной из вложенных
форм вы можете использовать мастер Access, но вторую вам придется
добавить вручную. Создав вложенные формы, добавьте вручную
комбинированные списки.
2. Завершите проект 1 в конце главы 3 или 4, если вы еще не сделали этого.
1) Перечислите три представления, три формы и три отчета, которые, как
вы считаете, понадобятся для данного приложения, и укажите, каково
назначение каждого из элементов.
2) Изобразите структуру раскрывающегося меню для этого приложения
(с использованием графического интерфейса пользователя). На основе
вашей модели разработайте одну из форм для ввода свойств жилого
объекта. Укажите, какой орган управления (текстовое поле,
раскрывающийся список) используется для каждого из полей. Обоснуйте структуру
вашей формы, руководствуясь принципами, описанными в этой главе.
Вопросы к проекту FiredUp
Прочтите задание к проекту FiredUp в конце главы 9. Отвечая на приведенные
ниже вопросы, используйте четыре определенные там таблицы.
1. Сконструируйте следующие представления (за образец возьмите рис. 10.4):
1) Постройте представление, начинающееся с таблицы ГОРЕЛКА и
содержащее все данные из всех таблиц. Назовите это представление Г0РЕЛКА_ПР.
2) Постройте представление, начинающееся с таблицы КЛИЕНТ и
содержащее все данные из всех таблиц. Назовите это представление КЛИЕНТ_ПР.
3) Постройте представление, начинающееся с таблицы РЕГИСТРАЦИЯ и
содержащее все таблицы, кроме таблицы РЕМ0НТ_Г0РЕЛКИ. Назовите это
представление РЕГИСТРАЦИЯ_ПР.
4) Постройте представление, начинающееся с таблицы РЕМ0НТ_Г0РЕЛКИ
и содержащее все данные из всех таблиц. Назовите это представление
РЕМ0НТ_Г0РЕЛКИ_ПР.
376 Глава 10. Проектирование приложений баз данных
2. Напишите SQL-операторы, обрабатывающие представления, как указано
ниже. В качестве образца используйте SQL-оператор, начинающийся в
разделе «Чтение экземпляров представлений» данной главы.
1) Напишите SQL-операторы, необходимые для чтения представления
Г0РЕЛКА_ПР. Начните с некоторого серийного номера.
2) Напишите SQL-операторы, необходимые для создания нового
экземпляра представления РЕГИСТРАЦИЯ_ПР, в предположении, что
необходимые данные о горелке уже имеются в базе данных, а данные о
покупателе — нет.
3) Напишите SQL-операторы, необходимые для построения нового
экземпляра представления РЕМ0НТ_Г0РЕЛКИ_ПР, в предположении, что
необходимые данные о горелке уже имеются в базе данных, а данные о
покупателе — нет. Зарегистрируйте горелку в процессе записи информации
о ремонте.
4) Напишите SQL-операторы, удаляющие все записи о конкретной
горелке. Используйте представление Г0РЕЛКА_ПР.
Часть V
Обработка
многопользовательских
баз данных
В части V данной книги рассматриваются вопросы обработки
многопользовательских баз данных и различные подходы к этому в двух наиболее популярных СУБД.
Глава 11 посвящена администрированию и основным приемам обработки
многопользовательских баз данных. Следующие две главы демонстрируют воплощение
этих идей с использованием Oracle 8i (глава 12) и SQL Server 2000 (глава 13).
Глава 11
Многопользовательские
базы данных
Многопользовательские базы данных, являясь весьма ценным инструментом для
организаций, в то же время вызывают ряд трудностей. Во-первых, они сложны
в проектировании и разработке, поскольку предполагают наличие множества
перекрывающихся пользовательских представлений. Кроме того, требования со
временем меняются, а изменение требований обусловливает необходимость
изменений в структуре базы данных. Такие структурные изменения должны тщательно
планироваться и контролироваться, чтобы изменение, сделанное для одной
группы, не вызвало проблем в другой. Вдобавок при параллельной обработке
запросов от нескольких пользователей необходимо принимать специальные меры,
чтобы действия одного пользователя не оказывали непредусмотренного влияния
на действия другого пользователя. Как вы увидите, это весьма важная и сложная
тема.
В больших организациях должны быть определены права и обязанности по
обработке. Что происходит, например, когда сотрудник покидает фирму? Когда
его записи можно удалить? Для обработки информации по выплате заработной
платы — по окончании последнего оплаченного периода. Для квартальной
отчетности — в конце квартала. Для подсчета налоговых отчислений — в конце года.
И так далее. Ясно, что ни один отдел не может в одностороннем порядке
определить, когда можно удалять данные. Аналогичные рассуждения справедливы
относительно вставки новых данных и изменения существующих. Эти и другие
соображения указывают на необходимость разработки системы безопасности,
которая позволит выполнять только строго определенные действия в строго
определенное время и только пользователям, имеющим для этого достаточные
полномочия.
Базы данных стали ключевым компонентом функционирования организаций
и даже основной составляющей их стоимости. К сожалению, базы данных не
застрахованы от сбоев и крушений. Следовательно, жизненно необходимы
эффективные планы, методики и процедуры резервного копирования и
восстановления.
Наконец, со временем потребуются изменения в самой СУБД с целью
повышения производительности, внедрения новых возможностей и версий программ-
Администрирование баз данных 379
пого обеспечения и учета модификаций в операционной системе, под
управлением которой она работает. Все это требует хорошего руководства.
Для решения этих задач в большинстве организаций были созданы отделы
администрирования баз данных. Сначала мы рассмотрим, что входит в их
функции, а затем опишем методики, процедуры п программное обеспечение,
используемые для выполнения этих функций. В следующих двух главах мы обсудим
II продемонстрируем в действии средства администрирования баз данных,
имеющиеся в СУБД Oracle 8i и SQL Server 2000.
Администрирование баз данных
И промышленности используются два термина: администрирование данных (data
administration) и администрирование базы данных (database administration). В од-
ппх случаях эти термины считаются синонимичными, а в других они имеют
разные значения. В данной книге под администрированием базы данных мы будем
понимать функцию, относящуюся к конкретной базе данных, включая ее
приложения. Настоящая глава посвящена администрированию баз данных.
Администрирование данных обсуждается в главе 17.
Базы данных значительно различаются по своему размеру и широте охвата —
от персональных однопользовательских баз данных до больших межорганизаци-
опных баз данных, таких как система предварительного заказа авиабилетов. Все
они нуждаются в администрировании, хотя задачи, которые в этой связи
предстоит решать, различны по степени сложности. Например, пользователи
персональных баз данных выполняют простые процедуры резервного копирования
данных и хранят для документирования минимальное количество записей. В этом
случае пользователь базы данных одновременно выполняет функции ее
администратора, хотя, возможно, и не подозревает об этом.
В приложениях многопользовательских баз данных администрирование
становится как более важной, так и более сложной задачей. Поэтому данная задача
иыделяется формально. В некоторых приложениях эта функция поручается
одному или двум сотрудникам, работающим на неполную ставку. В случае
больших баз данных, использующих Интернет или интрасеть, администрирование
зачастую оказывается слишком затратной по времени и разноплановой задачей,
чтобы можно было поручить ее одному сотруднику, даже работающему полный
рабочий день. Поддержание базы данных с десятками или сотнями
пользователей требует значительных временных затрат, наряду с техническими знаниями
и дипломатическими навыками, и обычно осуществляется специальным отделом.
Менеджера этого отдела часто называют администратором базы данных.
В общую компетенцию отдела администрирования базы данных входит
упрощение разработки и использования базы данных. Обычно это означает
поддержание баланса между противоречащими друг другу установками — на защиту
базы данных и на максимизацию ее доступности и выгод от ее использования.
Отдел администрирования базы данных отвечает за разработку,
функционирование и обслуживание базы данных и ее приложений. Перечень конкретных
380 Глава 11. Многопользовательские базы данных
функций приведен на рис. 11.1. Каждую из этих функций мы рассмотрим в
последующих разделах.
> Управление структурой базы данных
> Управление параллельной обработкой
> Распределение прав и обязанностей по обработке
> Обеспечение безопасности базы данных
> Восстановление базы данных
> Управление СУБД
> Поддержание репозитория данных
Рис. 11.1. Функции администратора базы данных
Управление структурой базы данных
Управление структурой базы данных включает участие в первоначальном
проектировании и реализации базы данных, а также руководство и контроль в
процессе внесения в нее изменений. В идеальном случае отдел администрирования
привлекается к работе на ранней стадии разработки базы данных и ее приложений
и принимает участие в изучении требований, оценке альтернатив, включая то,
какую СУБД предпочтительнее использовать, и разработке структуры базы
данных. Для больших организационных приложений администратор базы данных —
это обычно менеджер, который руководит работой технически ориентированного
персонала по проектированию базы данных.
Как говорилось в главе 8, при создании базы данных приходится решать
несколько задач. Прежде всего, создается база данных и выделяется место на
физическом носителе под саму базу и ее журналы. Затем создаются таблицы,
индексы, хранимые процедуры и триггеры. Примеры этого вы увидите в следующих
двух главах. Когда структуры базы данных сформированы, база заполняется
информацией. В большинстве СУБД предусмотрены утилиты для записи больших
объемов данных.
Конфигурирование
После того как база данных и ее приложения будут реализованы, неизбежно будут
меняться требования. Это может быть обусловлено новыми потребностями,
изменениями в бизнес-окружении, сменой политики и т. д. Когда изменение
требований вызывает необходимость изменения структуры базы данных, следует
действовать с большой осторожностью, потому что структурные изменения редко
затрагивают только одно приложение.
Следовательно, эффективное администрирование базы данных должно
включать в себя процедуры и политику, с помощью которых пользователи могли бы
регистрировать свои потребности в изменениях, а все сообщество пользователей базы
данных имело бы возможность обсуждать эффект от этих изменений, чтобы
затем можно было принять глобальное решение о том, стоит ли их воплощать.
Администрирование баз данных 381
Из-за больших размеров и сложности базы данных и ее приложений
изменения иногда приводят к неожиданным результатам. Поэтому администратор базы
данных должен быть готов к тому, что базу данных придется восстанавливать,
и должен иметь достаточное количество информации для диагностики и
устранения проблемы, вызвавшей сбой. База данных наиболее подвержена сбоям
после внесения изменений в ее структуру.
Документирование
В обязанности администратора по управлению структурой базы данных входит
также ведение документации. Исключительно важно знать, какие модификации
были произведены, когда и каким образом. Изменение в структуре базы данных
может повлечь за собой ошибку, которая не будет проявляться в течение шести
месяцев; при отсутствии должного документирования изменений диагностика
такой проблемы становится почти невозможной. Могут потребоваться десятки
повторных прогонов, чтобы выявить момент, когда начали появляться первые
симптомы, и по этой причине важно также вести запись тестовых процедур и
прогонов, сделанных для проверки произведенной модификации. Если
используются стандартизированные тестовые процедуры, тестовые формы и методы ведения
записей, запись тестовых результатов не должна занимать много времени.
Хотя ведение документации — процесс утомительный и бесконечный,
затраченные на него усилия окупаются, когда приходит беда и документация
оказывается тем, без чего невозможно решить серьезную (и дорогостоящую)
проблему. В настоящее время появляется много продуктов, облегчающих бремя
ведения документации. Многие CASE-средства, например, можно использовать
для документирования логической структуры базы данных. Для
отслеживания изменений можно использовать программы контроля версий. Словари
данных обеспечивают составление отчетов и применение других средств для чтения
и интерпретации структуры информации в базе данных.
Другая причина для тщательного документирования изменений в структуре
базы данных состоит в том, чтобы должным образом использовать исторические
данные. Если, например, маркетологи захотят проанализировать данные о
продажах трехлетней давности, находившиеся в архивах в течение двух лет, им
необходимо будет знать, какова была структура базы данных перед тем, как данные
были отправлены в архив. В ответе на этот вопрос могут помочь записи,
отражающие изменения в структуре базы данных. Аналогичная ситуация возникает,
когда для восстановления поврежденной базы данных приходится использовать
резервную копию шестимесячной давности (хотя такого происходить не должно,
иногда это случается). Резервную копию можно использовать для
реконструкции базы данных до того состояния, в котором она находилась на момент снятия
этой копии. Затем можно в хронологическом порядке выполнить транзакции
и произвести структурные изменения, чтобы восстановить базу данных до ее
текущего состояния. В списке приведен перечень обязанностей администратора по
управлению структурой базы данных.
Участие в разработке базы данных и приложений
+ Помощь на стадии определения требований и оценки альтернатив.
+ Активная роль в проектировании и создании базы данных.
382 Глава 11. Многопользовательские базы данных
Помощь в изменении структуры базы данных
+ Поиск решений во взаимодействии с пользователями.
+ Оценка того, как планируемое изменение отразится на каждом пользователе.
+ Организация форума по вопросам конфигурирования.
+ Готовность к устранению проблем, возникающих после внесения изменений.
+ Ведение документации.
Управление параллельной обработкой
Меры по управлению параллельной обработкой нацелены на предотвращение
непредусмотренного влияния действий одного пользователя на действия другого.
Иногда цель состоит в том, чтобы в условиях параллельной обработки
пользователь получил тот же результат, как и в случае, если бы он был единственным
пользователем. В других случаях подразумевается, что действия различных
пользователей будут влиять друг на друга, но ожидаемым образом.
Например, пользователь, который ввел свой заказ в компьютерную систему,
должен получить один и тот же результат независимо от того, сколько еще есть
пользователей кроме него — ни одного или сотни. С другой стороны,
пользователь, запрашивающий отчет о состоянии склада на самый последний момент,
возможно, захочет получить информацию о незавершенных изменениях,
начатых другими пользователями, даже если существует риск, что эти изменения
впоследствии будут отменены.
К сожалению, не существует способа управления параллельной обработкой,
который бы одинаково хорошо подходил для всех ситуаций. Все эти способы
предполагают некоторый компромисс. Например, пользователь может весьма
жестко управлять параллельной обработкой, заблокировав всю базу данных, но
пока будут обрабатываться данные для этого пользователя, ни один другой
пользователь не сможет ничего сделать. Такая защита надежна, но дорога. Как вы
увидите, существуют и другие меры, которые труднее запрограммировать или
реализовать, зато они повышают производительность. Есть также меры,
максимизирующие производительность при низком уровне управления параллельной
обработкой. При проектировании многопользовательских баз данных вам
придется делать выбор среди этих компромиссов.
Необходимость в атомарных транзакциях
В большинстве приложений баз данных работа пользователей организована в
форме транзакций (transactions), известных также как логические единицы работы
(logical units of work, LUW). Транзакция — это последовательность действий с базой
данных, в которой либо все действия выполняются успешно, либо не выполняется
ни одно из них (в последнем случае база данных остается без изменений). Такая
транзакция иногда называется атомарной (atomic), поскольку она выполняется
как единое целое.
Управление параллельной обработкой 383
Рассмотрим следующую последовательность действий с базой данных,
которые могут потребоваться при регистрации нового заказа.
1. Изменить запись данного покупателя, увеличив сумму к оплате.
2. Изменить запись продавца, увеличив сумму комиссионных.
3. Вставить в базу данных запись о новом заказе.
Предположим, что на последнем шаге нас постигла неудача — например, из-
за недостатка файлового пространства. Представьте себе недоразумение,
которое возникло бы, если бы выполнены были только первые два действия, но
не третье. Покупателю был бы выставлен счет за заказ, который он не получал,
а продавец получил бы комиссионные за товар, который он не отправлял
покупателю. Ясно, что эти три действия должны выполняться как единое целое: либо
псе сразу, либо ни одного.
На рис. 11.2 и 11.3 приведено сравнение результатов этих действий в виде
последовательности независимых шагов (рис. 11.2) и в виде атомарной транзакции
(рис. 11.3). Обратите внимание, что когда терпит неудачу одно из действий,
составляющих атомарную транзакцию, то изменений в базе данных не
производится. Также обратите внимание, что для указания рамок транзакции прикладная
программа должна дать команды на начало транзакции (Start Transaction),
сохранение транзакции (Commit Transaction) и откат транзакции (Rollback Transaction).
Конкретная форма этих команд различается в разных СУБД.
Параллельная обработка транзакций
Когда в одно и то же время происходит обработка двух транзакций с базой данных,
:>ти транзакции называются параллельными транзакциями (concurrent transactions).
Хотя у пользователей может создаваться впечатление, что их транзакции
обрабатываются одновременно, это не может быть так, ибо процессор машины,
обрабатывающей базу данных, способен выполнять только одну инструкцию в каждый
момент времени. Обычно транзакции выполняются попеременно, то есть
операционная система переключает процессор между несколькими задачами, так что
на заданный промежуток времени выполняется некоторая часть каждой из них.
Это переключение между задачами происходит столь быстро, что два человека,
сидящие бок о бок перед двумя компьютерами, обрабатывающими одну и ту же
Пазу данных, могут подумать, что их транзакции выполняются одновременно;
и реальности же их транзакции перемежаются.
На рис. 11.4 показаны две параллельные транзакции. Транзакция
пользователя А считывает элемент 100, изменяет его и записывает обратно в базу данных.
Транзакция пользователя В выполняет те же самые действия, но с элементом 200.
Процессор обрабатывает транзакцию пользователя А, пока не произойдет
прерывание ввода-вывода или какая-либо иная задержка пользователя А. Тогда
процессор переключается на пользователя В и обрабатывает его транзакцию
до прихода прерывания, после чего операционная система передает управление
обратно транзакции первого пользователя. Пользователям обработка кажется
одновременной, но на самом деле она попеременная, или параллельная.
Лействие
После
КЛИЕНТ
Номер Номер
клиента заказа
Описание Стоимость
123 I
I 1000
400 бейсбольных
мячей
$2400
ПРОДАВЕЦ
Имя СуммаПродаж
ДЖОНС $3200
ЗАКАЗЫ
Номер
1000
i 2000
3000
4000
5000
6000
7000
♦ПЕРЕПОЛНЕНИЕ*
СТАРТ
1. Добавить данные
о новом заказе
в таблицу КЛИЕНТ.
2. Добавить данные
о новом заказе
в таблицу ПРОДАВЕЦ.
3. Добавить новый заказ
в таблицу ЗАКАЗ.
t
СТОП
КЛИЕНТ
Номер Номер
клиента заказа
Описание Стоимость
123
123
I
1000
8000
400 бейсбольных
мячей
250 баскетбольных
мячей
$2400
$6500
ПРОДАВЕЦ
Имя СуммаПродаж
| ДЖОНС |
$9700 | •" | "• |
ЗАКАЗЫ
Номер
заказа
1000
2000
3000
4000
5000
6000
7000
'ПЕРЕПОЛНЕНИЕ*
Рис. 11.2. Успешное выполнение только двух действий из трех приводит к аномалиям
По
КЛИЕНТ
Номер Номер
клиента заказа
Описание Стоимость
123 I
I 1000
400 бейсбольных
мячей
$2400
ПРОДАВЕЦ
Имя СуммаПродаж
ДЖОНС $3200
ЗАКАЗЫ
Номер
заказа
1000
2000
3000
4000
5000
6000
7000
ПЕРЕПОЛНЕНИЕ*
Рис. 11.3. Никаких изменений
Транзакция
После
Начать транзакцию.
Добавить данные
в таблицу КЛИЕНТ.
Добавить данные
в таблицу ПРОДАВЕЦ.
Добавить данные
в таблицу ЗАКАЗ.
Если нет ошибок,
сохранить транзакцию,
иначе — отменить
транзакцию.
КЛИЕНТ
Номер Номер
клиента заказа
Описание Стоимость
123
1000
400 бейсбольных
мячей
$2400
ПРОДАВЕЦ
Имя СуммаПродаж
| ДЖОНС |
$3200 | •" | •" |
ЗАКАЗЫ
Номер
заказа
1000
2000
3000
4000
5000
6000
7000
ПЕРЕПОЛНЕНИЕ*
ie производится, поскольку вся транзакция завершается неудачно
386 Глава 11. Многопользовательские базы данных
Проблема потерянного обновления
Параллельная обработка, изображенная на рис. 11.4, не вызывает проблем,
поскольку пользователи обрабатывают различные данные. Но предположим,
что оба пользователя хотят обратиться к элементу 100. Например, пользователь А
хочет заказать пять единиц товара 100, а пользователь В — три единицы этого
же товара.
Пользователь А
Пользователь В
1. Считать элемент 100.
2. Изменить элемент 100.
3. Записать элемент 100.
1. Считать элемент 100.
2. Изменить элемент 100.
3. Записать элемент 100.
Порядок обработки на сервере базы данных
1. Считать элемент 100 для А.
2. Считать элемент 200 для В.
3. Изменить элемент 100 для А.
4. Записать элемент 100 для А.
5. Изменить элемент 200 для В.
6. Записать элемент 200 для В.
Рис. 11.4. Пример параллельной обработки запросов двух пользователей
Рисунок 11.5 иллюстрирует возникающую проблему. Пользователь А
считывает запись о товаре 100 в свою рабочую область. В соответствии с этой записью
в наличии имеется 10 единиц товара. Затем пользователь В читает запись о
товаре 100 в свою рабочую область. Опять-таки, согласно этой записи в наличии
имеется 10 единиц товара. Теперь пользователь А берет пять единиц товара,
уменьшает количество единиц товара в своей рабочей области до пяти и обновляет
запись для товара 100. После этого пользователь В берет три единицы товара,
уменьшает количество товара в своей рабочей области до семи единиц и
записывает это количество в базу данных. Теперь база данных ошибочно
показывает, что в наличии имеется семь единиц товара 100. Итак: мы начали с 10 единиц
в наличии, пользователь А взял пять, пользователь В взял три, а база данных
показывает, что осталось семь. Ясно, что это не так.
Данные обоих пользователей были верными на момент считывания. Но когда
пользователь В считывал запись, у пользователя А уже была ее копия, которую
он вот-вот собирался изменить. Эта ситуация носит название проблемы
потерянного обновления (lost update problem), или проблемы параллельного
обновления (concurrent update problem). Существует другая, схожая проблема,
называемая проблемой несогласованного чтения (inconsistent read problem). В этом случае
пользователь А читает данные, которые были обработаны некоторым фрагментом
Управление параллельной обработкой 387
транзакции пользователя В. Как следствие у пользователя А оказываются
ошибочные данные.
Одно из средств против несогласоваиностей, вызванных параллельной
обработкой, состоит в том, чтобы не давать нескольким приложениям получать
копни одной и той же записи, когда предполагается скорое изменение данной
записи. Это средство называется блокировкой ресурсов (resource locking).
Пользователь А Пользователь В
1. Считать элемент 100 И- Считать элемент 100
(пусть количество элементов равно 10). (пусть количество элементов равно 10).
2. Уменьшить количество элементов на 5. 2. Уменьшить количество элементов на 3.
3. Записать элемент 100. 3. Записать элемент 100.
Порядок обработки на сервере базы данных
1. Считать элемент 100 (для А).
2. Считать элемент 100 (для В).
3. Установить количество элементов равным 5 (для А).
4. Записать элемент 100 для А.
5. Установить количество элементов равным 7 (для В).
6. Записать элемент 100 для В.
Обратите внимание: изменение и запись
на шагах 3 и 4 оказываются потерянными
Рис. 11.5. Проблема потерянного обновления
Блокировка ресурсов
Один из способов предотвратить проблемы при параллельной обработке —
запретить совместное использование ресурсов путем блокировки данных, которые
считываются для обновления. На рис. 11.6 изображен порядок обработки при
использовании команды lock. Из-за блокировки транзакция пользователя В должна
ждать, пока пользователь А не закончит работу с данными по товару 100. При
такой стратегии пользователь В сможет прочесть запись о товаре 100 только после
того, как пользователь А завершит ее модификацию. В этом случае
результирующее количество единиц товара в базе данных будет равно двум, как и должно
быть. (Было десять, А взял пять, В взял три, осталось два.)
Терминология блокировки
Блокировки могут налагаться либо автоматически, по инициативе СУБД, либо
командой, которая передается СУБД прикладной программой или запросом
пользователя. Блокировки, налагаемые СУБД, называются неявными блокиров-
388 Глава 11. Многопользовательские базы данных
ками (implicit locks), а блокировки, налагаемые по команде, — явными
блокировками (explicit locks).
В предыдущем примере блокировки налагались на строки данных. Однако не все
блокировки налагаются на этом уровне. Некоторые СУБД предусматривают
блокировку на уровне страницы, другие — на уровне таблицы, а третьи — на уровне
базы данных. Размер блокируемого ресурса называется глубиной детализации
блокировки (lock granularity). При большой глубине детализации СУБД легче
справляется с администрированием блокировки, но такие блокировки часто
являются причиной конфликтов. Блокировки с маленькой глубиной
детализации сложно администрировать (СУБД приходится отслеживать и проверять
гораздо больше деталей), но конфликты при этом менее часты.
Пользователь А
Пользователь В
1. Заблокировать элемент 100.
2. Считать элемент 100.
3. Уменьшить количество элементов на 5.
4. Записать элемент 100.
1. Заблокировать элемент 100.
2. Считать элемент 100.
3. Уменьшить количество элементов нв 3.
4. Записать элемент 100.
Порядок обработки на сервере базы данных
НС
Транзакция А
4.
■6.
7.
8.
9.
10.
11.
Заблокировать элемент 100 для А.
Считать элемент 100 для А.
Заблокировать элемент 100 для В -»
неудача -> В переводится в состояние ожидания
Установить количество элементов равным 5 для А.
Записать элемент 100 для А,
Снять блокировку А с элемента 100.
Заблокировать элемент 100 для В.
Считать элемент 100 для В.
Установить количество элементов равным 2 для В.
Записать элемент 100 для В.
Снять блокировку В с элемента 100. J
Транзакция В
Рис. 11.6. Параллельная обработка с явными блокировками
Блокировки различаются также по типу. При монопольной блокировке
(exclusive lock) блокируются все виды доступа к элементу. Ни одна другая
транзакция не может читать или изменять данные. Коллективная блокировка (shared
lock) блокирует элемент от изменения, но не от чтения. То есть другие
транзакции могут свободно читать данный элемент, если они не пытаются
изменить его.
Управление параллельной обработкой 389
Сериализуемые транзакции
Когда две или более транзакции обрабатываются параллельно, их результаты,
сохраняемые в базе данных, должны быть логически согласованы с результатами,
которые получились бы, если бы данные транзакции обрабатывались
каким-нибудь последовательным способом. Такая схема обработки параллельных
транзакций называется сериализуемой (serializable).
Сериализуемость может быть достигнута несколькими способами. Один из
способов — обработка транзакций с использованием двухфаз}юй блокировки
(two-phase locking). При этой стратегии транзакциям позволяется налагать
блокировки по мере необходимости, но как только первая блокировка снимается,
данная транзакция уже не может наложить никаких других блокировок. Таким
образом, транзакции имеют фазу нарастания (growing phase), на которой
блокировки налагаются, и фазу сжатия (shrinking phase), на которой блокировки
снимаются.
В ряде СУБД используется особая разновидность двухфазной блокировки,
13 этом случае блокировки налагаются на всем протяжении транзакции, но ни
одна блокировка не освобождается, пока не будет выдана команда COMMIT
(сохранение) или ROLLBACK (откат, возврат к предыдущему состоянию). Эта
стратегия имеет более ограничительный характер, чем требуется для двухфазной
блокировки, зато ее легче реализовать.
Вообще говоря, рамки транзакции должны соответствовать определениям
представления базы данных, которое она обрабатывает. В двухфазной стратегии
строки каждого отношения в представлении блокируются по мерс
необходимости. Изменения производятся, но информация не записывается в базу данных,
пока представление не будет полностью обработано. После этого изменения
сохраняются в базе данных, и все блокировки снимаются.
Рассмотрим приложение для ввода заказов, содержащее объект
ЗАКАЗ-ПОКУПАТЕЛЬ, который построен из данных таблиц ПОКУПАТЕЛЬ, ПРОДАВЕЦ и ЗАКАЗ.
Чтобы гарантировать, что база данных не пострадает от аномалий, вызванных
параллельной обработкой, транзакция ввода заказа налагает блокировки на
таблицы ПОКУПАТЕЛЬ, ПРОДАВЕЦ и ЗАКАЗ по мере необходимости, производит все
необходимые изменения в базе данных, а затем снимает блокировки.
Взаимная блокировка
Решая одну проблему, блокировка способна вызвать другую. Посмотрим, что
может произойти, когда два пользователя хотят заказать две единицы товара.
Предположим, что пользователь А хочет заказать бумагу, и если он сможет достать
бумагу, то хочет заказать и карандаши. Теперь предположим, что пользователь В
хочет заказать карандаши, а если удастся достать карандаши, то он закажет еще
и бумагу. Возможный порядок обработки показан на рис. 11.7.
На этом рисунке пользователи А и В оказываются в ситуации, которая носит
название взаимной блокировки (deadlock), или «смертельного объятия» (deadly
embrace). Каждый из них ожидает освобождения ресурса, заблокированного дру-
390 Глава 11. Многопользовательские базы данных
гим пользователем. Есть два распространенных способа решения этой проблемы:
не допускать возникновения взаимных блокировок либо позволять им
возникать, а затем распутывать их.
Предотвратить возникновение взаимной блокировки можно несколькими
способами. Первый из них — заставлять пользователей блокировать все
требуемые ресурсы сразу. Если бы, например, пользователь А.па рисунке с самого
начала заблокировал и карандаши, и бумагу, взаимная блокировка не возникла бы.
Второй способ предотвратить взаимную блокировку — потребовать от всех
прикладных программ блокировать ресурсы в одном и том же порядке. Даже если не
все приложения будут налагать блокировки таким образом, вероятность
возникновения взаимной блокировки снизится хотя бы для тех приложений, которые
используют данную стратегию. Эту философию можно распространить на
организационные стандарты программирования следующим образом: «Всегда, когда
происходит обработка строк из таблиц в связи родитель-потомок, блокируй
сначала родителя, затем потомка». Это, по крайней мере, снизит вероятность
взаимной блокировки, а может и вовсе исключить ее.
Пользователь А
Пользователь В
1. Заблокировать бумагу.
2. Взять бумагу.
3. Заблокировать карандаши.
1. Заблокировать карандаши.
2. Взять карандаши.
3. Заблокировать бумагу.
Порядок обработки на сервере базы данных
1. Заблокировать бумагу для А.
2. Заблокировать карандаши для В.
3. Обработать запрос А, обновить данные о бумаге.
4. Обработать запрос В, обновить данные о карандашах.
5. Перевести А в состояние ожидания (карандашей).
6. Перевести В в состояние ожидания (бумаги).
**Блокировка**
Рис. 11.7. Взаимная блокировка
Почти в каждой СУБД имеются алгоритмы обнаружения взаимной
блокировки. Когда происходит взаимная блокировка, обычное решение состоит в том,
чтобы отменить одну из транзакции, тем самым удалив из базы данных
произведенные ею изменения. Варианты того, как это сделать в Oracle и SQL Server, вы
увидите в главах 12 и 13.
Оптимистическая и пессимистическая блокировки
Блокировки могут налагаться двумя основными стилями. При
оптимистической блокировке (optimistic locking) делается предположение, что конфликта
Управление параллельной обработкой 391
не произойдет. Данные считываются, транзакция обрабатывается, производятся
обновления, а после этого делается проверка, не возник лн конфликт. Если
мет, транзакция завершается. Если да, транзакция повторяется до тех пор, пока
не сможет успешно завершиться. При пессимистической блокировке (pessimistic
locking) предполагается, что конфликт обязательно произойдет. Сначала
налагаются блокировки, затем обрабатывается транзакция, а после этого
блокировки снимаются.
В листинге 11.1 приведен пример каждого из стилей наложения блокировок
для транзакции, которая уменьшает количество карандашей в таблице ПРОДУКТ
на пять штук. При оптимистической блокировке сначала данные считываются,
и текущее количество карандашей сохраняется в переменной СтароеКоличество.
Затем обрабатывается транзакция и в предположении, что все прошло успешно,
налагается блокировка на таблицу ПРОДУКТ. Эта блокировка может затрагивать
только строку карандашей, но возможно, глубина детализации будет и большей.
В любом случае, запускается SQL-оператор, обновляющий строку карандашей,
с условием WHERE Количество = СтароеКоличество. Если никакая другая транзакция
не изменила атрибут Количество в строке карандашей, тогда результат оператора
UPDATE будет успешным. Если какая-то другая транзакция изменила значения
атрибута Количество в строке карандашей, выполнение оператора UPDATE будет
неудачным, и транзакцию придется повторить.
Листинг 11.1. Сравнение оптимистической и пессимистической блокировок
Оптимистическая блокировка:
SELECT ПРОДУКТ.Название, ПРОДУКТ.Колимеетво
FROM ПРОДУКТ
WHERE ПРОДУКТ.Название^'Карандаш'
СтароеКоличество = ПРОДУКТ.Количество
Set НовоеКоличество = ПРОДУКТ.Количество - 5
{обработка транзакции - если НовоеКоличество < 0, генерируется исключение и т. д.
Если все в порядке:}
LOCK ПРОДУКТ {с определенной глубиной детализации}
UPDATE ПРОДУКТ
SET ПРОДУКТ.Количество = НовоеКоличество
WHERE ПРОДУКТ.Название = 'Карандаш'
AND ПРОДУКТ.Количество = СтароеКоличество
UNLOCK ПРОДУКТ
{проверяем, было ли обновление успешным:
если нет, повторяем транзакцию}
продолжение *Р
392 Глава 11. Многопользовательские базы данных
Листинг 11.1 (продолжение)
Пессимистическая блокировка:
LOCK ПРОДУКТ {с определенной глубиной детализации}
SELECT ПРОДУКТ.Название. ПРОДУКТ.Количество
FROM ПРОДУКТ
WHERE ПРОДУКТ.Название='Карандаш'
Set НовоеКоличество = ПРОДУКТ.Количество - 5
{обработка транзакции - если НовоеКоличество < 0, генерируется исключение и т. д.
Если все в порядке:}
UPDATE ПРОДУКТ
SET ПРОДУКТ.Количество = НовоеКоличество
WHERE ПРОДУКТ.Название - 'Карандаш'
UNLOCK ПРОДУКТ
{проверка на успешность обновления не требуется}
В случае пессимистической блокировки еще до начала работы на таблицу
ПРОДУКТ налагается блокировка (с некоторой глубиной детализации). Затем счи-
тываются значения, обрабатывается транзакция, выполняется оператор UPDATE
и таблица ПРОДУКТ разблокируется.
Преимущество оптимистической блокировки состоит в том, что она
налагается только после обработки транзакции. Таким образом, блокировка
удерживается в течение более короткого времени, чем при пессимистической стратегии.
Если транзакция является сложной или клиент — медлительным (например,
имеются задержки при передаче, клиент занят другой работой, пользователь
уходит попить кофе или выключает компьютер, не выйдя из браузера),
блокировка будет удерживаться в течение значительно меньшего промежутка
времени. Это преимущество будет еще более важно, если глубина детализации
блокировки велика — скажем, вся таблица ПРОДУКТ.
Недостаток оптимистической блокировки заключается в том, что если со
строкой карандашей происходит много активных действий, транзакцию,
возможно, придется повторить многократно. Таким образом, транзакции, которые
связаны с большой активностью по отношению к конкретной строке (например,
покупка популярного товара), плохо приспособлены для оптимистической
блокировки.
Вообще говоря, Интернет — место дикое и непредсказуемое, и пользователи
часто предпринимают неожиданные действия вроде прерывания транзакций на
середине. Поэтому, если только полюователи Интернета не были предварительно
отобраны (например, путем записи в план интерактивных покупок),
оптимистическая блокировка являет собой более удачный выбор. В интрасетях, однако,
принять решение сложнее. Возможно, оптимистическая блокировка и здесь ока-
Управление параллельной обработкой 393
жстся предпочтительнее, если нет какой-либо характеристики приложения,
которая вызывала бы значительную активность по отношению к отдельным
строкам, или если требования приложения почему-либо делают повторную
обработку транзакций особенно нежелательной.
Объявление характеристик блокировки
Как вы можете видеть, управление параллельной обработкой — предмет
сложный; некоторые решения о типах и стратегиях блокировок должны приниматься
методом проб и ошибок. По этой и другим причинам прикладные программы
базы данных обычно не налагают явных блокировок. Вместо этого они
указывают рамки транзакций, а затем объявляют, какой тип поведения им хотелось бы
наблюдать у СУБД. Таким образом, если поведение при блокировке нужно
изменить, то нет необходимости переписывать приложение, чтобы налагать
блокировки в других его местах. Вместо этого просто меняются объявления
характеристик блокировки.
В листинге 11.2 показана транзакция с карандашами, в которой рамки
транзакции указаны с помощью операторов BEGIN TRANSACTION, COMMIT TRANSACTION
и ROLLBACK TRANSACTION. Рамки транзакции — это та информация, которая
жизненно необходима СУБД, чтобы реализовывать различные стратегии блокировки.
Если разработчик объявит теперь (через системный параметр или каким-либо
другим способом), что ему нужна оптимистическая блокировка, СУБД неявным
образом наложит блокировки, соответствующие этой стратегии, в правильном
месте. Если после этого разработчик сменит тактику и запросит
пессимистическую блокировку, СУБД неявно наложит свои блокировки в другом месте.
Листинг 11.2. Обозначение рамок транзакции
BEGIN TRANSACTION:
SELECT ПРОДУКТ.Название, ПРОДУКТ.Количество
FROM ПРОДУКТ
WHERE ПРОДУКТ.Название^'Карандаш"
СтароеКоличество = ПРОДУКТ.Количество
Set НовоеКоличество = ПРОДУКТ.Количество - 5
(обработка части транзакции - если НовоеКоличество < 0. генерируется
исключение, и т. д.}
LOCK ПРОДУКТ {с определенной глубиной детализации}
UPDATE ПРОДУКТ
SET ПРОДУКТ.Количество - НовоеКоличество
WHERE ПРОДУКТ.Название = 'Карандаш'
продолжение^
394 Глава 11. Многопользовательские базы данных
Листинг 11.2 (продолжение)
{продолжение обработки транзакции}...
IF транзакция выполнена успешно THEN
CDMMIT TRANSACTION
ELSE
ROLLBACK TRANSACTION
END IF
Далее выполняются другие действия, не входящие в эту транзакцию...
Согласованные транзакции
Иногда встречается аббревиатура ACID, относящаяся к транзакциям. Она
расшифровывается так: «atomicity, consistency, isolation, durability», что в переводе
с английского означает «атомарность, согласованность, изолированность и
устойчивость». Таким образом, ACID-транзакция — это транзакция, обладающая
всеми перечисленными свойствами. Как вы только что узнали, атомарная
транзакция — это такая транзакция, в которой либо выполняются все содержащиеся
в ней действия с базой данных, либо не выполняется ни одно из них. Устойчивая
транзакция — это транзакция, в которой все сохраненные изменения остаются
в базе данных. СУБД не будет удалять эти изменения даже в случае ошибки. Если
транзакция устойчивая, СУБД при необходимости предоставит возможность для
восстановления изменений, произведенных всеми записанными действиями.
Однако термины согласованная и изолированная не являются столь же
определенными, как термины атомарная и устойчивая. Рассмотрим следующий
обновляющий SQL-оператор:
UPDATE КЛИЕНТ
SET КодРегиона = '425'
WHERE Индекс = '98050'
Предположим, что в таблице КЛИЕНТ имеется 500 000 строк, и в 500 из них
атрибут Индекс имеет значение «98050». Чтобы найти все эти 500 строк, СУБД
потребуется некоторое время. Будет ли на протяжении этого времени разрешено
другим транзакциям обновлять поля КодРегиона и Индекс таблицы КЛИЕНТ? Если
SQL-оператор является согласованным, такие обновления будут запрещены.
Обновление будет применено к набору строк в том виде, в каком они существовали
в момент запуска SQL-оператора. Такая согласованность называется
согласованностью на уровне оператора (statement level consistency).
Теперь рассмотрим транзакцию, которая содержит два оператора
обновления:
BEGIN TRANSACTION
UPDATE КЛИЕНТ
SET КодРегиона - '425'
Управление параллельной обработкой 395
WHERE Индекс = '98050"
{прочие действия этой транзакции}
UPDATE КЛИЕНТ
SET Скидка = 0.05
WHERE КодРегиона = '425'
{прочие действия этой транзакции}
COMMIT TRANSACTION
Что в данном контексте означает термин согласованность!
Согласованность на уровне оператора означает, что каждый из операторов независимо
обрабатывает согласованные строки, но в интервале между двумя операторами
указанные строки могут изменяться другими пользователями. Согласованность
на уровне транзакции (transaction level consistency) означает, что все строки,
затронутые любым из SQL-операторов, защищены от изменений на протяжении
всей транзакции. Обратите внимание, однако, что при некоторых реализациях
согласованности транзакция не будет видеть свои же собственные изменения.
В данном примере второй оператор не будет видеть строк, измененных первым
оператором.
Таким образом, когда вы слышите термин согласованность, следует выяснить,
какой тип согласованности имеется в виду. Следует также знать и о ловушке,
которую может содержать в себе согласованность на уровне транзакции.
Еще более сложной является ситуация с термином изолированность.
Рассмотрим его в следующем разделе.
Уровень изоляции транзакции
Блокировки предотвращают потерю изменений при параллельной обработке.
Тем не менее, существует ряд проблем, которые они предотвратить не в
состоянии. Одной из таких проблем является «грязное» чтение (dirty read) — чтение
транзакцией записи, которая изменена, но еще не записана в базе данных. Это
может произойти, например, когда одна транзакция считывает строку, измененную
другой незавершенной транзакцией, а эта другая транзакция впоследствии
отменяется.
Невоспроизводимое чтение (nonrepeatable reads) — это ситуация, когда при
повторном чтении данных, уже считанных ранее, транзакция обнаруживает
модификации или удаления, вызванные другой завершенной транзакцией.
Наконец, фантомное чтение (phantom reads) — это ситуация, когда при повторном
чтении данных транзакция обнаруживает новые строки, вставленные другой
завершенной транзакцией после предыдущего чтения.
В стандарте SQL 1992 г. определены четыре уровня изоляции транзакций
(transaction isolation levels), которые определяют допустимость перечисленных выше
проблем. Цель состоит в том, чтобы разработчик прикладной программы мог
указать желаемый уровень изоляции, а СУБД осуществляла бы управление
блокировками в соответствии с этим указанием.
396 Глава 11. Многопользовательские базы данных
Как можно видеть на рис. 11.8, уровень изоляции под названием
«незавершенное чтение» (read uncommitted) допускает «грязное» чтение,
невоспроизводимое чтение и фантомное чтение. Уровень изоляции «завершенное чтение»
(read committed) предотвращает «грязное» чтение. Уровень изоляции
«воспроизводимое чтение» (repeatable reads) предотвращает «грязное» чтение и
невоспроизводимое чтение. Уровень изоляции «сериализуемость» (serializable) не
допускает возникновения ни одной из этих трех проблем.
Тип
проблемы
«Грязное» чтение
Невоспроизводимое
чтение
Фантомное
чтение
Уровень изоляции
Незавершенное
чтение
Возможно
Возможно
Возможно
Завершенное
чтение
Невозможно
Возможно
Возможно
Воспроизводимое
чтение
Невозможно
Невозможно
Возможно
Сериализуемость
Невозможно
Невозможно
Невозможно
Рис. 11.8. Уровни изоляции
Вообще говоря, чем большие ограничения предусматривает уровень
изоляции, тем меньше пропускная способность базы данных, хотя многое зависит от
нагрузки и от того, как написаны прикладные программы. Кроме того, не всеми
СУБД поддерживаются все четыре уровня изоляции. Могут также различаться
способы поддержки и бремя, которое они возлагают на программиста. О том, как
уровни изоляции поддерживаются в Oracle и SQL Server, вы узнаете из
следующих двух глав.
Тип курсора
Курсор — это указатель на набор строк. Обычно курсоры определяются с
помощью операторов SELECT. Например, оператор
DECLARECURSOR TransCursor AS
SELECT*
FROMTRANSACTION
WHEREPurchasePrice > '10000'
определяет курсор под названием TransCursor, действующий на наборе строк,
указанном в операторе SELECT. Когда прикладная программа открывает курсор
и считывает первую строку, о курсоре говорят, что он «указывает на первую
строку».
Транзакция может открывать несколько курсоров — как последовательно, так
и одновременно. Кроме того, на одной и той же таблице можно открыть два и
более курсора; это можно сделать как на самой таблице, так и на ее
SQL-представлении. Поскольку курсоры потребляют значительное количество памяти, то
открытие нескольких курсоров, к примеру, для тысячи параллельных транзакций,
может оказаться накладным в отношении памяти и процессорного времени.
Один из способов снизить потребление ресурсов при работе с курсорами —
Управление параллельной обработкой 397
использовать курсоры с ограниченными возможностями в случаях, когда полно-
функциональный курсор не требуется.
В табл. 11.1 перечислены четыре типа курсоров, используемых в среде
Windows 2000. (В других системах типы курсоров аналогичны.) Простейший тип
курсора — последовательный (forward only cursor). Он позволяет
приложению передвигаться по набору строк только вперед. Изменения,
произведенные другими курсорами в данной транзакции, а также другими транзакциями,
будут видны только в том случае, если затронутые ими строки находятся
впереди курсора.
Таблица 11.1. Типы курсоров
Тип курсора
Описание
Свойства
Последовательный
Статический
Ключевой
Динамический
Приложение может
перебирать набор записей
только в одном
направлении — вперед
Приложение видит данные
в том состоянии, в каком
они были на момент
открытия курсора
При открытии курсора
для каждой строки набора
записей сохраняется
значение первичного ключа.
Обращаясь к строке,
приложение использует
этот ключ для получения
текущего значения строки
Приложение видит любые
изменения, вызванные
любым источником
Изменения, производимые другими
курсорами в данной транзакции или
другими транзакциями, будут видимы
только в том случае, если они
затрагивают строки, находящиеся
перед курсором
Изменения, производимые данным
курсором, являются видимыми.
Изменения, инициированные
другими источниками, не видны.
Перемещение курсора возможно
в обоих направлениях
Обновления, вызванные любым
источником, являются видимыми.
Вставки из других источников не видны
(в наборе записей для них не имеется
ключей). Строки, вставляемые данным
курсором, добавляются в конец набора
записей. Изменения, вызванные любым
источником, являются видимыми.
Изменения в порядке строк не видны.
Если выставлен уровень изоляции
«незавершенное чтение»
(то есть допускается «грязное» чтение),
то несохраненные обновления
и удаления являются видимыми;
в противном случае видны только
сохраненные обновления и удаления
Все вставки, обновления, удаления
и изменения в порядке записей являются
видимыми. Если выставлен уровень
изоляции «незавершенное чтение»
(то есть допускается «грязное» чтение),
то несохраненные изменения являются
видимыми. В противном случае видны
тоько сохраненные изменения
Остальные три типа курсоров называются двунаправленными курсорами
(scrollable cursors), поскольку приложение может передвигаться по набору записей
398 Глава 11. Многопользовательские базы данных
как вперед, так и назад. Статический курсор (static cursor) обрабатывает
«снимок» отношения, сделанный в момент открытия курсора. Изменения, сделанные
таким курсором, являются видимыми для самого курсора; изменения из любых
других источников являются невидимыми.
Ключевые курсоры (keyset cursors) соединяют в себе некоторые свойства
статических и динамических курсоров. При открытии такого курсора для каждой
строки в наборе записей сохраняется значение первичного ключа. Когда
приложение устанавливает курсор на некоторую строку, СУБД по ключу считывает
текущее значение этой строки. Если приложение собирается обновить строку,
которая была удалена другим курсором в этой же транзакции либо другой
транзакцией, СУБД создает новую строку со старым значением ключа и помещает
в нее обновленные значения (если, конечно, заполнены все требуемые поля).
Новые строки, вставленные другими курсорами данной транзакции или другими
транзакциями, невидимы для ключевого курсора. Данный курсор видит лишь
сохраненные обновления и удаления, если только уровень изоляции транзакции
не допускает «грязное» чтение.
Динамический курсор (dynamic cursor) — это полнофункциональцый курсор.
Все вставки, обновления, удаления и изменения в порядке строк являются
видимыми для динамического курсора. Как и в случае ключевых курсоров, если
уровень изоляции транзакции не допускает «грязное» чтение, курсор может видеть
только сохраненные изменения.
Количество потребляемых ресурсов и необходимый объем обработки зависит
от типа курсора. В общем случае, че*м ниже находится тип курсора в табл. 11.1,
тем выше расходы. Поэтому, чтобы увеличить производительность СУБД,
разработчик приложения должен создавать курсоры, имеющие ровно столько
возможностей, сколько требуется для выполнения поставленной задачи. Также
весьма важно представлять, каким образом курсоры реализуются в конкретной
СУБД и где они размещаются — на сервере или на клиенте. Иногда бывает
выгоднее иметь динамический курсор на клиенте, чем статический — на сервере.
Никакого общего правила сформулировать невозможно, поскольку
производительность зависит от способа реализации курсора в СУБД и требований приложения.
Предостережение: если вы не укажете уровень изоляции транзакции или тип
курсора, СУБД будет использовать уровень или тип, предусмотренный по
умолчанию. Заданные по умолчанию параметры могут идеально подходить для
вашего приложения, а могут оказаться и совершенно непригодными. Таким образом,
хотя эти вопросы можно игнорировать, последствий избежать все равно не
удастся. Изучите возможности вашей СУБД и используйте их рационально.
Безопасность базы данных
Защита безопасности базы данных заключается в том, что право выполнять
некоторые действия дается только определенным пользователям и в определенное
Безопасность базы данных 399
нремя. Эта цель труднодостижима, и чтобы хоть в какой-то степени к ней
приблизиться, команда разработчиков базы данных должна на стадии определения
требований к проекту установить для всех пользователей права и обязанности по
обработке (processing rights and responsibilities). Реализация этих требований
безопасности может обеспечиваться соответствующими возможностями СУБД,
л при их недостаточности — логикой прикладных программ.
Права и обязанности по обработке
Рассмотрим для примера потребности галереи View Ridge, описанной в главе 10.
У базы данных галереи есть три типа пользователей: продавцы, менеджеры и
системные администраторы. Продавцы могут регистрировать новых покупателей
и вводить данные транзакций, изменять данные покупателей и запрашивать
любые данные. Они не могут ни вводить данные о новом художнике или
произведении, ни удалять данные.
Менеджеры имеют все права, которые предоставлены продавцам, но помимо
того им разрешено вводить данные о новых художниках и произведениях, а
также модифицировать данные транзакций. Хотя менеджеры имеют право удалять
данные, в данном приложении им не дается таких полномочий. Это сделано для
того, чтобы исключить возможность случайной потери данных.
Системному администратору предоставлен неограниченный доступ к
данным. Он может создавать, обновлять, читать и удалять любую информацию из
базы данных. Администратор может также предоставлять права по обработке
другим пользователям и менять структуру элементов базы данных — таблиц,
индексов, хранимых процедур и т. п. Полномочия всех пользователей базы данных
галереи View Ridge перечислены в табл. 11.2.
Таблица 11.2. Права и обязанности по обработке в галерее View Ridge
Customer Transaction Work Artist
Продавцы
Менеджеры
Системный
администратор
Вставка,
Изменение,
Запрос
Вставка,
Изменение,
Запрос
Вставка,
Изменение,
Запрос,
Удаление,
Выделение прав,
Модификация,
Структуры
Вставка,
Запрос
Вставка,
Изменение,
Запрос
Вставка,
Изменение,
Запрос,
Удаление,
Выделение прав,
Модификация,
Структуры
Запрос
Вставка,
Изменение,
Запрос
Вставка,
Изменение,
Запрос,
Удаление,
Выделение прав,
Модификация,
Структуры
Запрос
Вставка,
Изменение,
Запрос
Вставка,
Изменение,
Запрос,
Удаление,
Выделение прав,
Модификация,
Структуры
400 Глава 11. Многопользовательские базы данных
В этой таблице полномочия даются не индивидуальным пользователям, а
различным типам, или группам пользователей (user groups). Это является обычным,
но не обязательным. Можно было бы указать, например, что пользователь по
имени Бенджамин Франклин имеет определенные права по.обработке. Обратите
также внимание, что при работе с группами необходимо иметь какой-то способ
распределения пользователей по группам. Когда в систему входит пользователь
по имени Мэри Смит, должен быть некоторый способ, позволяющий определить,
к какой группе или группам относится данный пользователь. Мы обсудим это
подробнее в следующем разделе.
По ходу изложения мы использовали фразу «права и обязанности по
обработке». Эта фраза подразумевает, что любое право влечет за собой некоторую
обязанность. Если, например, системный администратор удаляет данные
транзакций, он отвечает за то, чтобы эти удаления не оказали неблагоприятного
воздействия на функционирование галереи, целостность данных ее бухгалтерии и т. д.
Обязанности по обработке не могут выполняться СУБД или приложениями
базы данных. Эти обязанности возлагаются на пользователей и разъясняются им
при обучении работе с системой. Данная тема относится к курсу системной
разработки, и мы не будем здесь в нее углубляться. Повторим лишь, что любые
права всегда сопровождаются обязанностями. Эти обязанности должны
документироваться и выполняться.
В соответствии с рис. 11.1, в задачи администратора базы данных входит
управление правами и обязанностями по обработке. Это подразумевает, что
права и обязанности могут меняться с течением времени. В ходе работы с базой
данных, по мере внесения изменений в приложения и в структуру СУБД возникает
потребность во введении новых или изменении существующих прав и
обязанностей. Администратор базы данных играет ведущую роль в обсуждении и
реализации таких изменений.
Когда права по обработке определены, необходимо их реализовать. Эта
задача может быть возложена на различные элементы: операционную систему, сеть,
web-сервер, СУБД или приложение. В последующих двух разделах мы
рассмотрим реализацию прав по обработке средствами СУБД и приложения. Описание
остальных возможностей выходит за рамки данной книги.
Обеспечение безопасности средствами СУБД
Терминология, возможности и функции безопасности СУБД варьируются от
продукта к продукту. В принципе, во всех СУБД существует возможность
ограничить выполнение определенных действий определенным временем и кругом
пользователей. Общая модель безопасности СУБД представлена на рис. 11.9.
Пользователю может быть назначена одна или несколько ролей, а роль может
принадлежать одному или многим пользователям. Как пользователи, так и роли
могут иметь много различных полномочий. С каждым объектом (в широком
Безопасность базы данных 401
смысле этого слова) связаны определенные полномочия. Каждое полномочие
относится к одному пользователю или группе и одному объекту.
Когда пользователь входит в систему базы данных, СУБД ограничивает его
действия полномочиями, определенными индивидуально для данного
пользователя, а также для роли, назначенной данному пользователю. Определить,
является ли пользователь тем, за кого он себя выдает, — задача, вообще говоря,
сложная. Во всех коммерческих СУБД используется тот или иной вариант
парольной защиты, даже при том, что такой метод обеспечения безопасности можно
легко обойти, если пользователи небрежно относятся к своим личным
идентификаторам.
Пользователь
Ричард Энт
Элеанор By
Джеймс Джонсон
Роль
Бухгалтерия может обновлять таблицу CUSTOMER
Элеанор By может запускать приложение MonthEnd
Джеймс Джонсон может менять все таблицы
Полномочие
Объект
Таблица
Представление
Процедура
Приложение
Бухгалтерия
Кассиры
Менеджеры
Неизвестная публика
Рис. 11.9. Модель безопасности СУБД
Как правило, пользователи самостоятельно вводят свое имя и пароль, а в
некоторых приложениях имя пользователя и пароль вводятся системой от лица
пользователя. Например, Windows 2000 может непосредственно передать имя
пользователя и пароль для входа в систему СУБД SQL Server. В других
случаях имя пользователя и пароль предоставляются прикладной программой.
В интернет-приложениях обычно определяется группа под названием вроде
«Unknown Public» (неизвестная публика), и в эту группу записываются
анонимные пользователи, входящие в систему. Таким образом, компании типа Dell
Computer избегают необходимости вводить каждого пользователя в систему под
собственным именем и паролем.
Модели систем безопасности, используемые в Oracle и SQL Server,
изображены на рис. 11.10, 11.11, 11.12 и 11.13. Как вы можете видеть, обе они
представляют собой варианты общей модели, показанной на рис. 11.9. В соответствии с
моделью Oracle на рис. 11.10, я, у каждого пользователя есть профиль, который
указывает, какие системные ресурсы может задействовать данный пользователь.
Пример определения профиля показан на рис. 11.10, б. Пользователю может
быть назначено много ролей, и одна и та же роль может быть назначена многим
пользователям. Каждый пользователь или роль имеет множество привилегий.
402 Глава 11. Многопользовательские базы данных
Есть два вида привилегий. Объектные привилегии определяют действия,
которые могут быть предприняты по отношению к объектам базы данных —
таблицам, представлениям и индексам. Системные привилегии определяют
возможные действия с использованием команд Oracle.
Профиль
Пользователь
Роль
Привилегия
Объект Система
■Маме: IUNKNOWNUSERS
Reads/Session.
Reads/Call:
Private S6A:
Compose Limit-
;J6000
jiooo
|30
I1
b
J10QO
j Default
(Default
(Default
Э
zl
zl
■ ■■ ^
zl
, 'zl
zl
zl
zl
KBytes
Service Unite
Create
Cancel
Slll|$3i
JM
Рис. 11.10. Безопасность в Oracle: a — модель безопасности Oracle;
б — определение профиля
Безопасность базы данных % 403
Пример такой системы безопасности представлен на рис. 11.11.
Пользователю DK даны роли CONNECT (соединение) и RESOURCE (ресурс). Просматривая
список дальше, мы обнаружим, что с ролью CONNECT связаны такие системные
привилегии, как ALTER SESSION (смена сессии), CREATE CLUSTER (создание кластера)
и другие, включая CREATE TABLE (создание таблицы). Взглянув еще ниже, мы
увидим, что пользователю ОКбыл присвоен профиль DEFAULT («по умолчанию»).
LJ ofacie7.word * [ |
Ы О Users | ]|
5 g $ DBSNMP
1 ^ '• DK
I . ; В -О Roles Granted j
1 ! i ft V CONNECT ['\U
I I : ж ^RESOURCE ЩЯ
j '* -Q System Privileges Granted iHlj
a : £3 Object Privileges Granted .4*3 jl
1 * в DKROENKE :|J|
1. * g SCOTT €;]]
1: * 8 SYS 1;1
j; tt--t SYSTEM ||
I j 8 -V CONNECT Щ
| f i £3 Roles Gtanted Й-| II
I) : В -О jSystem Privileges Grantee) £:].|]
|M ! "51 ALTER SESSION ЦП
|M fl CREATE CLUSTER Й
|1 I ! ' |l CREATE DATABASE UNK :H|
I { I . fl. CREATE SEQUENCE &Ц
|| | й CREATE SESSION Й
I! i ■ ■■ fl CREATE SYNONYM rf
I j ! fjl CREATE TABLE #
\\ \ i ■ Jl CREATE VIEW Я
II = * О Object Privileges Granted ?: ]|
1 j * « DBA /r
J I 9 - W EXPJULLJ)ATABASE f.';
I j m <® IMP_FULL_DATABASE
| j * <® RESOURCE
1 ( & W SNMPAGENT
I a-O Profiles
I f ©DEFAULT
I В О Users Assigned —"I
1 | DBSNMP
1 -■• DK
I ; § DKROENKE
j I § SYS Л]}
Рис. 11.11. Безопасность в Oracle: профили и роли пользователей
Схема безопасности SQL Server показана на рис. 11.12, я. Учетная запись (имя
пользователя и пароль, используемые при входе в SQL Server или в Windows)
может быть ассоциирована с одной или более комбинацией база данных/пользо-
404 Глава 11. Многопользовательские базы данных
ватель. Например, на рис. 11.12, б учетной записи Lynda в домене DBGRV101
разрешен доступ к базе данных ViewRidgel с именем пользователя Lynda, к базе
данных ViewRidge2 с именем пользователя Lynda и к базе данных ViewRidge3 с именем
пользователя LyndaSpecialAccount. Как можно видеть из рис. 11.12, а> с данной
комбинацией база данных/пользователь может быть связано несколько
учетных записей.
Учетная запись
V
Пользователь
базы данных
Роль
Полномочие
Таблица,
представление,
хранимая процедура,
функция
SQL s<*ve* 1одиШЩШ^ШШШШШШ1Ш1
Genial |1^Вйо1е«11^^^^Щщ|ИШ11^И-:
й
Pefmil j D atabase |j Uset: ■
,ViewRidge2 Lynda
fe?; Ш ViewRidge3 LyndaSpecialAccount
G Ш master
D Ш model
D atabase totesfor VievvRidge.1': '/".-
Permit in Database Role
f£ db_denydatareader
f£ db_denydatawriter
^ fj[ Salesperson
* £ Manager
OK
СапоШ!
Help
Рис. 11.12. Безопасность в SQL Server: a — модель безопасности SQL Server;
б — пример учетной записи
Безопасность базы данных
405
co^Awweb»*, mi цфлю» lues, $^;$до;* до**ю<4
o«A5$er<ie^i*.'...;-. •
ши^г
%
'o)*c<.' ".::-: •
"i ШЗН1Ш
Г; ArtFofS^eBy
""3 CUSTOMER
"'1 CUSTOMER-
- " CUSTOMER!.
■ jpwny
.dbo
dbo
dbo
dbo
• ; select
ИШйёШ
■ИГ
йГ
ЙГ
*f
(NiEM
^iiii
• L'J
&
. #
UPDAtS-;
&УШШ
o
#
«f
G
■|Q|UT| EXEC СЯ' ^
i #
: # _j
! О
"3 CteaieCutt dbo
"J Cu*tomeHn$e»l dbo
* Expenavetoti. dbo
ШШШШЩ
^.&^ЩЩ^ШШ>:.'
■''Action- '.x«w/..'i«>ls.';.'; j <J= ** ; ©^
■Р«ф*тй#яЬ«нПоь
\ db_$eci*ityadm)n
. db_ddladrran
) db_beckupope»at«
' db_da*a»e«te*
.'. db_da**wilet
db_denydat*eade«
db_denydataw(itat
/ SatetPereon
/ Man*g«
%;:
;ВШ8
аарь^щ:::.-.:.'
it orty.ubjj^-iwtfi pwrnaion* tot <hu user..;
(№|к('
Tin ршнв
Cc AitFoiSaleBy
Ш CUSTOMER
Ш CUSTOMER
AT CUSTOMERI
%} CrealeCutt
^ Custcmwjnsert
AT E xperoiveAih
■Own** ■:
dbo
dbo
dbo
dbo
dbo
dbo
T.
SELECT ::!*NSERT
с с?.
n ; a
a { b
•[3"Vb
{
. . П T D
;UPBftfE
D
D
П
D
. . P...
VfDELETE -D<EC
П
: h :
! : CI
: a
• С; ^
■DBi ['*.}
*>": :;
• ::
Рис. 11.13. Безопасность в SQL Server: a — пример роли; б — пример пользователя
На рис. 11.13, а показаны полномочия роли Manager (менеджер) в базе
данных ViewRidgel. Роль может быть назначена одному или многим пользователям,
а в данном случае — только одному пользователю, Lynda. Полномочия роли
Manager обозначены зелеными галочками в диалоговом окне Permissions (Пол-
406 Глава 11. Многопользовательские базы данных
номочия). EXEC обозначает возможность запускать хранимые процедуры, a DRI —
возможность создавать, изменять или удалять декларативные ограничения
ссылочной целостности, такие как «CustomerlD в таблице CUSTOMER-ARTIST-INT
должно быть подмножеством CustomerlD в таблице CUSTOMER». EXEC
относится только к хранимым процедурам, a DRI — только к таблицам и
представлениям.
Данная комбинация база данных/пользователь имеет все полномочия ролей,
которые ей назначены, а также все индивидуальные полномочия,
принадлежащие этому пользователю. Рисунок 11.13, б показывает, что пользователю View-
Ridgel/Lynda назначены роли Salesperson и Manager, и данный пользователь будет
обладать всеми полномочиями этих ролей. Кроме того, ему даны полномочия
создавать, модифицировать и удалять декларативные ограничения ссылочной
целостности, относящиеся к таблицам ARTIST, CUSTOMER и CUSTOMER-ARTIST-INT
(на рисунке часть имени этой таблицы отсечена).
Обеспечение безопасности средствами
приложения
Хотя такие СУБД, как Oracle или SQL Server, предоставляют значительные
возможности по обеспечению безопасности, эти возможности по своей натуре
являются весьма общими. Если приложению требуются специфические меры
безопасности, например «пользователь не может просматривать строки таблицы или
соединения таблиц, имя сотрудника в которых отличается от его собственного»,
то СУБД будет бессильна это сделать. В таких случаях система безопасности
должна быть дополнена функциями, реализованными в самом приложении.
Например, как вы узнаете из главы 14, безопасность интернет-приложений
часто обеспечивается компьютером, на котором расположен web-сервср.
Обеспечение безопасности сервером означает, что важные для безопасности данные не
должны передаваться по сети.
Чтобы лучше понять это, представим себе приложение, в котором при
нажатии пользователем определенной кнопки на странице браузера web-серверу, а
затем и СУБД посылается следующий запрос:
SELECT *
FROM СОТРУДНИК
Этот оператор, разумеется, возвратит все строки таблицы СОТРУДНИК. Если же
требования безопасности приложения ограничивают доступ сотрудников к
данным только их личной информацией, то web-сервер может добавить к этому
запросу предложение WHERE, как показано ниже:
SELECT *
FROM СОТРУДНИК
WHERE СОТРУДНИК.Имя = •^ЗЕЗБГОМвИняСотрудниказО*^
Восстановление базы данных 407
Как вы узнаете из глав 15 и 16, такое выражение заставит web-сервер указать
и предложении WHERE имя данного сотрудника. Для пользователя, вошедшего
и систему под именем Бенджамин Франклин, результирующий SQL-оператор будет
иыглядеть следующим образом:
SELECT *
FROM СОТРУДНИК
WHERE СОТРУДНИК.Имя = 'Бенджамин Франклин"
Поскольку имя вставляется программой, работающей на web-сервере,
пользователь браузера не знает, что это происходит, а если бы даже и знал, то не смог
бы вмешаться в этот процесс.
Такая обработка может производиться на web-сервере, как только что было
показано, а может выполняться и самими прикладными программами, либо
встраиваться в хранимые процедуры или триггеры и запускаться СУБД при
необходимости.
Эту идею можно развить, организовав хранение информации, относящейся
к безопасности, в специализированной базе данных, доступ к которой могут
осуществлять web-сервер или хранимые процедуры и триггеры. Каждому
идентификатору пользователя в такой базе данных может быть сопоставлен перечень
значений, которые должны вставляться в предложение WHERE при запрашивании
пользователем данных. Предположим, сотрудники отдела кадров могут
запрашивать из базы данных не только свою личную информацию. Чтобы организовать
такой доступ, можно записать в специализированную базу данных
соответствующие предикаты для предложения WHERE, которые будут считываться прикладной
программой и в нужный момент присоединяться к SQL-операторам SELECT.
Есть много других способов расширения возможностей СУБД по обеспечению
безопасности за счет приложения. Однако в первую очередь следует
задействовать систему безопасности СУБД. Только если ее функций оказывается
недостаточно, стоит дополнять их за счет прикладных программ. Чем ниже уровень, на
котором идет обеспечение безопасности, тем меньше возможностей для
несанкционированного вторжения. Кроме того, система безопасности СУБД работает
быстрее, ее использование приводит к меньшим затратам и, возможно, дает
лучшие результаты, чем разработка собственной системы.
Восстановление базы данных
Компьютерные системы порою дают сбои. Причин тому множество: поломки
аппаратного обеспечения, дефекты в программах, неточности в описаниях ручных
процедур и ошибочные человеческие действия. Все перечисленные виды ошибок
могут возникать и возникают в приложениях баз данных. Поскольку база данных
совместно используется множеством людей и зачастую является ключевым
элементом функционирования организации, важно как можно быстрее ее восстановить.
408 Глава 11. Многопользовательские базы данных
Это ставит перед нами несколько задач. Во-первых, с точки зрения бизнеса,
работа должна продолжаться. Например, выполнение заказов, осуществление
финансовых транзакций и составление упаковочных листов должно быть
организовано вручную. Позже, когда приложение базы данных вновь заработает,
можно будет ввести новые данные. Во-вторых, персонал, ответственный за
компьютерную систему, должен восстановить ее как можно быстрее и привести как
можно ближе к тому состоянию, которое было до сбоя. В-третьих, пользователи
должны знать, что требуется сделать, когда система вновь начнет
функционировать. Возможно, придется повторно ввести какие-то данные, и пользователям
нужно знать, насколько далеко им следует возвращаться назад.
Когда происходит сбой, невозможно просто устранить проблему и
продолжать обработку. Если даже при этом не были потеряны никакие данные (для
чего необходимо, чтобы все виды памяти были энергонезависимыми, —
совершенно нереалистичное предположение), то синхронизация и планирование
обработки слишком сложны, чтобы состояние системы можно было
воспроизвести в точности. Чтобы продолжить работу точно с того места, где она была
прервана, операционной системе потребовалось бы громадное количество
избыточных данных и времени на их обработку. Невозможно прокрутить время назад
и вернуть все электроны в те же конфигурации, в которых они находились на
момент возникновения ошибки. Возможны два подхода к восстановлению базы
данных: повторная обработка и откат-накат.
Восстановление путем повторной обработки
Поскольку обработка не может быть возобновлена точно с того места, где она
была прервана, следующая возможность — отойти назад до некоторой известной
точки и возобновить обработку с нее. Простейший способ такого
восстановления — это периодически делать копию базы данных (называемую снимком базы
данных (database save)) и хранить записи обо всех транзакциях, которые были
выполнены со времени последнего копирования. Затем при возникновении сбоя
персонал может восстановить базу данных по ее снимку и заново произвести все
транзакции.
К сожалению, эта простая стратегия, как правило, нереализуема. Во-первых,
повторное выполнение транзакций занимает столько же времени, сколько оно
заняло до возникновения ошибки. Если компьютер имеет напряженный график
работы, система может так никогда и не «догнать» свое исходное состояние.
Во-вторых, при параллельной обработке транзакций события происходят
асинхронно. Небольшие вариации в действиях человека — например, когда
пользователь чуть медленнее вставляет дискету или читает сообщение электронной
почты, прежде чем ответить на запрос приложения, — могут изменить порядок
обработки параллельных транзакций. Поэтому может случиться, что хотя
изначально последний билет на данный рейс достался клиенту А, при повторной
обработке его получит клиент В. В связи с этим повторная обработка обычно
не является реально осуществимой формой восстановления от сбоев в системах
параллельной обработки.
Восстановление базы данных 409
Восстановление через откат-накат
Второй подход к восстановлению заключается в том, чтобы периодически делать
копии (снимки) базы данных и вести журнал всех изменений, произведенных
транзакциями в базе данных со времени последнего копирования. В этом случае,
когда происходит сбой, можно использовать один из двух методов. При первом
методе, который называется накатом (rollforward), база данных восстанавливается
до сохраненного состояния, после чего выполняются все правильные транзакции.
(Мы не обрабатываем транзакции повторно, поскольку прикладные программы
не участвуют в процессе восстановления. Все, что мы делаем — это производим
изменения в базе данных согласно записям в журнале.)
Второй метод называется откатом (rollback). При этом методе мы отменяем
изменения, произведенные в базе данных ошибочными или частично
выполненными транзакциями. Затем повторно запускаются правильные транзакции,
которые выполнялись в момент возникновения сбоя.
Оба эти метода требуют ведения журнала (log) результатов транзакций. Этот
журнал содержит записи изменений, произведенных с данными, в
хронологическом порядке. Прежде чем транзакция будет выполнена, ее необходимо записать
в журнал. Тогда, если крах системы произойдет в интервале между записью
транзакции в журнал и выполнением ее, то в худшем случае у нас будет иметься
запись о невыполненной транзакции. Если, напротив, транзакции сначала
выполняются, а затем уже записываются в журнал, то возможен нежелательный
вариант, когда изменения в базе данных произведены, но запись об этих
изменениях отсутствует. В такой ситуации неискушенный пользователь может повторно
ввести транзакцию, которая уже выполнена.
В случае сбоя журнал используется как для отмены, так и для повторного
выполнения транзакций (рис. 11.14). Чтобы была возможна отмена транзакций,
журнал должен содержать копию каждой записи (или страницы) базы данных,
сделанную перед ее изменением. Такие записи называются исходными образами
(before-images). Отмена транзакции производится путем последовательной
записи в базу данных исходных образов всех произведенных ею изменений.
Чтобы было возможно повторное выполнение транзакций, журнал должен
содержать копию каждой записи (или страницы) базы данных, сделанную после ее
изменения. Такие записи называются конечными образами (after-images).
Транзакция выполняется повторно путем последовательной записи в базу данных
конечных образов всех произведенных ею изменений. Пример фрагмента журнала
транзакций представлен на рис. 11.15, я.
В этом примере каждая транзакция имеет уникальное имя для целей
идентификации. Все образы каждой транзакции связаны между собой указателями. Один
указатель указывает на предыдущее изменение, сделанное данной транзакцией
(обратный указатель), а другой — на следующее изменение, сделанное данной
транзакцией (прямой указатель). Нуль в поле указателя означает конец списка.
Подсистема восстановления СУБД использует эти указатели для нахождения
всех записей, относящихся к данной транзакции. На рис. 11.15, б приведен
пример связи между записями в журнале.
410 Глава 11. Многопользовательские базы данных
База данных
с изменениями
Исходные образы
-►(Отмена)-
А
База данных
без изменений
База данных
без изменений
(снимок)
Конечные образы
т
База данных
без изменений
Рис. 11.14. Откат и накат транзакций: а — отмена изменений в базе данных (откат);
б — повторное выполнение изменений в базе данных (накат)
Идентификатор транзакции Тип операции
Указатель назад Объект
Указатель вперед Исходный образ
Время Конечный образ
Относительный
номер записи
1
2
3
4
5
6
7
8
9
10
ОТ1
ОТ1
ОТ2
ОТ1
ОТ1
СИ
ОТ1
ОТ2
СТ1
СТ1
0
1
0
2
4
0
5
3
6
9
2
4
8
5
7
9
0
0
10
0
11
11
11
11
11
11
11
11
11
11
42
43
46
47
47
48
49
50
51
51
СТАРТ
ИЗМЕНИТЬ
СТАРТ
ИЗМЕНИТЬ
ВСТАВИТЬ
СТАРТ
СОХРАНИТЬ
СОХРАНИТЬ
ИЗМЕНИТЬ
СОХРАНИТЬ
КЛИЕНТ 100
ПРОДАВЕЦ АА
ЗАКАЗ 11
ПРОДАВЕЦ ВВ
(старое значение)
(старое значение)
(старое значение)
(новое значение)
(новое значение)
(значение)
(новое значение)
Рис. 11.15. Журнал транзакций: а — элементы данных, содержащиеся в записи журнала
транзакций; б — пример журнала с тремя транзакциями
Восстановление базы данных 411
Остальные элементы данных журнала — это время выполнения действия, тип
операции (START обозначает начало транзакции, COMMIT завершает
транзакцию, снимая все наложенные ею блокировки), объект, над которым
производилось действие (например, тип и идентификатор записи), а также исходные и
конечные образы.
Принять данные о заказе от браузера.
Считать данные из таблиц КЛИЕНТ и ПРОДАВЕЦ.
Внести изменения в считанные записи. -ч
Записать обновленные данные в таблицу КЛИЕНТ. } „
Записать обновленные данные в таблицу ПРОДАВЕЦ. Г (Деиствия записаны
Добавить новую строку в таблицу ЗАКАЗ. J B жУРнал)
*** КРАХ СИСТЕМЫ***
Исходные образы
записей в таблицах
КЛИЕНТ
и ПРОДАВЕЦ
База данных
с измененными
таблицами КЛИЕНТ,
ПРОДАВЕЦ и ЗАКАЗ
Процессор восстановления
(применяет к базе данных исходные
образы записей в таблицах
КЛИЕНТ и ПРОДАВЕЦ и удаляет новую
запись из таблицы ЗАКАЗ)
База данных,
из которой удалена
неудачная
транзакция
Рис. 11.16. Пример стратегии восстановления: а — транзакция, добавляющая новый заказ;
б — процесс удаления данных о заказе
Если есть журнал с исходными и конечными образами, то отмена и повторное
выполнение транзакций происходит элементарно (но мы все равно опишем этот
процесс). На рис. 11.16, чтобы отменить транзакцию, программа восстановления
просто заменяет каждую измененную запись ее исходным образом. Когда все
исходные образы будут восстановлены, транзакция будет отменена. Чтобы
повторно выполнить транзакцию, программа восстановления начинает с версии базы
412 Глава 11. Многопользовательские базы данных
данных, существовавшей на момент начала данной транзакции, и записывает
в базу все конечные образы. Как уже говорилось, это действие подразумевает,
что имеется снимок базы данных с более ранней ее версией.
Восстановление базы данных до ее последнего снимка и повторное
выполнение всех транзакций может потребовать значительного времени. Чтобы
уменьшить задержку, в СУБД иногда используются контрольные точки. Контрольная
точка (checkpoint) — это точка синхронизации между базой данных и журналом
транзакций. Для вставки контрольной точки СУБД отклоняет новые запросы,
завершает обработку текущих запросов и сбрасывает свои буферы на диск.
Затем СУБД ждет, пока операционная система не сообщит, что все текущие
операции записи на диск и в журнал успешно выполнены. Теперь база данных и
журнал синхронизированы. После этого в журнале делается запись о контрольной
точке. Позже база данных может быть восстановлена с контрольной точки, при
этом нужно будет записать конечные образы только тех транзакций, которые
начались после контрольной точки.
Вставка контрольной точки — недорогая операция, и можно выполнять три
или четыре (а можно и больше) таких операции в час. Таким образом, для
восстановления потребуется не более 15-20 минут работы. Большинство СУБД
вставляют контрольные точки автоматически, делая человеческое
вмешательство ненужным.
Конкретные примеры приемов резервного копирования и восстановления
в Oracle и SQL Server вы увидите в следующих двух главах. На данный момент
вам нужно просто понимать основные идеи и сознавать, что обеспечение
разработки адекватных планов резервного копирования и восстановления, а также
создание снимков и журналов базы данных являются обязанностью
администратора базы данных.
Управление СУБД
Кроме управления работой с данными и структурой базы данных, администратор
обязан управлять самой СУБД. Он должен собирать и анализировать статистику
производительности системы и идентифицировать области, чреватые
возникновением проблем. Вспомните, что база данных обслуживает множество
пользовательских групп. Администратор базы данных должен рассматривать все жалобы
на медленный отклик системы, неточность данных, сложность в использовании
и т. п. Если требуются какие-то изменения, администратор должен составить план
этих изменений и реализовать их.
Администратор должен периодически осуществлять мониторинг
пользовательской активности при работе с базой данных. Отчеты могут содержать
информацию о том, какие пользователи были наиболее активны, какие файлы и,
возможно, элементы данных использовались, какие методы доступа были при
этом задействованы. Также в отчетах может присутствовать информация о типах
и частоте возникновения ошибок. Администратор анализирует эту информацию
с целью определить, нужны ли какие-либо изменения в структуре базы данных
Поддержание репозитория данных 413
для повышения производительности или упрощения работы пользователей.
Если такие изменения необходимы, администратор обеспечивает их реализацию.
Администратор базы данных должен анализировать текущую статистику
производительности базы данных и активности пользователей. При
обнаружении каких-либо проблем с производительностью (в ходе анализа отчета или по
жалобе пользователя) администратор должен определить, требуется ли
модификация структуры базы данных или системы. Примерами возможных
структурных модификаций являются введение новых ключей, чистка данных, удаление
ключей и установление новых связей между объектами.
Когда производитель используемой СУБД объявляет о новых возможностях
продукта, администратор базы данных должен рассмотреть их в свете потребностей
сообщества пользователей. Если он решит внедрить эти новые возможности,
разработчиков следует уведомить об этом и обучить их использованию.
Соответственно, помимо управления структурой базы данных администратор должен
осуществлять управление и контроль над изменениями в СУБД.
В обязанности администратора базы данных могут входить и другие
изменения в системе; какие именно — это зависит от используемой СУБД и другого
программного и аппаратного обеспечения. Например, изменения в
операционной системе или web-сервере могут повлечь за собой необходимость
модификации некоторых возможностей, функций или параметров СУБД. Поэтому
администратор базы данных должен также настраивать СУБД для совместной работы
с другим используемым программным обеспечением.
Первоначальный выбор параметров СУБД (таких как уровень изоляции
транзакций) происходит в момент, когда еще мало известно о том, как система будет
работать в конкретном пользовательском окружении. Следовательно, опыт
работы с системой и результаты анализа ее производительности могут указать на
необходимость изменений. Даже если производительность кажется приемлемой,
возможно, администратор базы данных захочет исследовать, как изменение ее
параметров будет влиять на производительность. Этот процесс называется
настройкой (tuning), или оптимизацией (optimizing), системы. В списке приведен
перечень обязанностей администратора базы данных по управлению СУБД.
♦ Подготовка отчетов о работе базы данных.
+ Рассмотрение жалоб пользователей на работу системы.
♦ Оценка необходимости изменений в структуре базы данных или приложений.
♦ Модификация структуры базы данных.
♦ Оценка и внедрение новых возможностей и функций СУБД.
♦ Настройка СУБД.
Поддержание репозитория данных
Представьте себе большое и активное интернет-приложение базы данных,
подобное тем, что используются компаниями, занимающимися электронной
коммерцией, — например, продажей музыки в сети Интернет. Информацию для такой
414 Глава 11. Многопользовательские базы данных
системы могут предоставлять несколько различных баз данных, десятки web-
страниц и сотни, если не тысячи, пользователей.
Предположим, что компания, использующая это приложение, желает
расширить ассортимент предлагаемых товаров, включив в него спортивные товары.
Высшее руководство компании может попросить администратора базы данных
оценить время и другие ресурсы, необходимые для того, чтобы настроить базу
данных на поддержку новой линии продуктов.
Чтобы администратор базы данных смог ответить на этот запрос, ему
потребуются подробные метаданные, описывающие базу данных, ее приложения
и компоненты этих приложений, пользователей и их права и привилегии, а также
другие элементы системы. Часть этих метаданных хранится в системных
таблицах базы данных, но одной только этой части будет недостаточно, чтобы
ответить на вопросы, задаваемые высшим руководством. Администратору базы
данных требуются дополнительные данные об объектах СОМ и ActiveX, сценарных
процедурах и функциях, ASP-страницах, таблицах стилей, определениях типов
документов и т. п. Кроме того, хотя механизмы безопасности СУБД
обеспечивают документирование данных о пользователях, группах и привилегиях, они
делают это в высокоструктурированной и зачастую неудобной форме.
По этим причинам многие организации разрабатывают и поддерживают репо-
зитории данных (data repositories), которые представляют собой коллекции
метаданных, описывающих базу данных, ее приложения, web-страницы,
пользователей и другие компоненты приложений. Репозиторий может быть виртуальным
в том смысле, что составляющие его метаданные собраны из различных
источников, в числе которых может быть СУБД, программное обеспечение
контроля версий, библиотеки кода, средства генерации и редактирования web-страниц
и т. д. Репозиторий данных также может быть интегрированным продуктом,
который поставляется производителем CASE-средств или другими компаниями,
например Microsoft или Oracle.
В любом из этих случаев администратор базы данных должен задуматься о
построении репозитория данных задолго до того, как высшее руководство начнет
задавать вопросы. На самом деле репозиторий должен строиться при разработке
системы, и его следует рассматривать как важную составляющую часть системы.
В противном случае администратор базы данных будет «вечно догоняющим»,
пытаясь поддерживать существующие приложения, адаптировать их к новым
потребностям и каким-то образом собирать метаданные для репозитория.
Лучший вид репозиториев — это активные репозиторий (active repositories).
Они формируются в процессе разработки системы за счет того, что при создании
компонентов системы автоматически создаются метаданные. Менее желательным,
но все же эффективным вариантом являются пассивные репозиторий (passive
repositories): заполнение таких репозиториев и создание метаданных для них
происходит вручную.
Интернет создал невиданные возможности для расширения клиентской базы
и увеличения продаж и рентабельности в бизнесе. Базы данных и
приложения, используемые компаниями в своей работе, составляют ключевой элемент
этого успеха. К сожалению, найдутся такие организации, росту которых будет
Резюме 415
препятствовать неспособность наращивать свои приложения или адаптировать
их к меняющимся потребностям. Зачастую построить новую систему
оказывается проще, чем адаптировать уже существующую; определенно, построение новой
системы, которая интегрировалась бы со старой, в то же время заменяя ее, может
быть весьма сложной задачей.
Резюме
Многопользовательские базы данных ставят перед организациями, создающими
и использующими их, сложные задачи, и в большинстве организаций в этой
связи учреждена должность администратора базы данных, который призван
обеспечить решение этих проблем. В этой книге термином администратор базы данных
обозначается человек или группа людей, ответственные за конкретную базу
данных. Администратор данных выполняет аналогичные функции, но они относятся
ко всей совокупности информационных активов организации.
Администрирование данных обсуждается в главе 17. Основные функции администратора базы
данных перечислены на рис. 11.1.
Администратор базы данных занимается первоначальной разработкой
структур базы данных и обеспечивает управление их конфигурацией по мере
возникновения потребностей в изменениях. Важной функцией администратора базы
данных является подробное документирование структуры и изменений в ней.
Управление параллельной обработкой имеет своей целью предотвращение
непредусмотренного влияния действий одного пользователя на действия
другого. Не существует какой-либо одной техники управления параллельной
обработкой, которая годилась бы на все случаи жизни. Приходится находить
компромисс между уровнем защищенности и пропускной способностью базы данных.
Транзакция, или логическая единица обработки, — это последовательность
действий с базой данных, в которой либо выполняются все действия, либо не
выполняется ни одно. Действия параллельных транзакций выполняются на сервере
базы данных попеременно. В некоторых случаях при отсутствии управления
параллельными транзакциями может произойти потеря обновлений. Еще одна
проблема, возникающая при параллельной обработке, — несогласованное чтение.
Во избежание проблем, связанных с параллельной обработкой, элементы базы
данных блокируются. Неявные блокировки налагаются СУБД, явные блокировки
налагаются прикладными программами. Размер блокируемого ресурса
называется глубиной детализации блокировки. Монопольная блокировка предотвращает
чтение заблокированного ресурса любым другим пользователем; коллективная
блокировка позволяет другим пользователям читать заблокированный ресурс,
но не позволяет обновлять его.
Две параллельные транзакции, результаты выполнения которых совпадают
с теми результатами, которые получились бы, если бы эти транзакции
выполнялись отдельно, называются сериализуемыми транзакциями. Одной из схем
достижения сериализуемости является двухфазная блокировка, при которой
блокировки налагаются на фазе нарастания и снимаются на фазе сжатия. Особым
416 Глава 11. Многопользовательские базы данных
случаем двухфазной блокировки является стратегия, при которой блокировки
налагаются на протяжении всей транзакции, но не снимаются, пока транзакция
не будет завершена.
Взаимная блокировка, или «смертельное объятие», возникает, когда каждая
из двух транзакций ожидает доступа к ресурсу, заблокированному другой
транзакцией. Предотвратить взаимную блокировку можно, обязав транзакции
налагать блокировки одновременно; если же взаимная блокировка произошла, то
единственный способ снять ее — это прервать одну из транзакций (и отменить
частично выполненную работу). При оптимистической блокировке
предполагается, что конфликта между транзакциями не возникнет, а если таковой все-таки
возникает, то система обрабатывает его последствия. При пессимистической
блокировке предполагается, что конфликт произойдет, и для его
предотвращения заблаговременно принимаются меры. В общем случае оптимистическая
блокировка является более предпочтительной для приложений, работающих с
Интернетом, и для многих интрасетевых приложений.
Большинство прикладных программ не налагает блокировки явным образом.
Вместо этого они помечают рамки транзакции с помощью операторов BEGIN,
COMMIT и ROLLBACK и указывают, какая стратегия управления параллельной
обработки им требуется. СУБД самостоятельно налагает блокировки в
соответствии с тем, какого поведения требует приложение.
ACID-транзакция — это транзакция, являющаяся атомарной, согласованной,
изолированной и устойчивой. Устойчивость означает, что изменения в базе
данных являются постоянными. Согласованность может быть на уровне оператора
или на уровне транзакции. Транзакция, характеризующаяся согласованностью
на уровне транзакции, может не видеть своих собственных результатов. В стандарте
SQL 1992 г. определены четыре уровня изоляции транзакций: «незавершенное
чтение», «завершенное чтение», «воспроизводимое чтение» и «сериализуемость».
Характеристики каждого из этих уровней изоляции приведены на рис. 11.8.
Курсор — это указатель на набор записей. Наиболее распространены четыре
типа курсоров: последовательный, статический, ключевой и динамический.
Разработчики должны выбирать уровни изоляции и типы курсоров, которые
подходят для конкретного приложения и СУБД.
Задача системы безопасности базы данных состоит в том, чтобы
определенные действия могли предприниматься только определенными пользователями
и в определенное время. Чтобы разработать эффективную систему безопасности
базы данных, необходимо определить для всех пользователей права и
обязанности по обработке.
СУБД предоставляют некоторые возможности по обеспечению безопасности.
Большинство из них включают объявление пользователей, групп, защищаемых
объектов и полномочий или привилегий по доступу к этим объектам. Почти во
всех СУБД используется та или иная разновидность идентификации по имени
пользователя и паролю. Возможности СУБД по обеспечению безопасности
могут быть дополнены функциями, реализованными в прикладных программах.
В случае сбоя системы база данных должна быть как можно скорее
восстановлена к работоспособному состоянию. Транзакции, которые выполнялись
в момент возникновения сбоя, должны быть повторно сохранены в базе данных
Вопросы I группы 417
или обработаны. Хотя в некоторых случаях восстановление можно осуществить
путем повторной обработки, почти всегда предпочтительнее использовать
журналы и откат-накат. Для уменьшения количества работы, необходимой для
восстановления после сбоя, можно устанавливать контрольные точки.
В дополнение к перечисленным выше задачам, администратор базы данных
управляет самой СУБД, измеряя производительность приложений базы данных
и определяя необходимость изменений в структуре базы данных или настройки
производительности СУБД. Администратор также обеспечивает ознакомление
с новыми возможностями СУБД и внедрение их при необходимости. Наконец,
администратор базы данных ответствен за поддержание репозитория данных.
Вопросы I группы
1. Кратко опишите пять проблем, которые возникают перед организациями,
создающими и использующими многопользовательские базы данных.
2. Поясните разницу между администратором базы данных и
администратором данных.
3. Перечислите семь важных задач, стоящих перед администратором базы
данных.
4. Перечислите обязанности администратора базы данных по управлению
структурой базы данных.
5. Что такое контроль конфигурации? Почему он необходим?
6. Поясните значение слова непредусмотренный во фразе «действия одного
пользователя не оказывают непредусмотренного влияния на действия
другого пользователя».
7. Объясните, какого рода компромисс возникает при управлении
параллельной обработкой.
8. Дайте определение атомарной транзакции и объясните, почему важна
атомарность.
9. Поясните, в чем разница между параллельными транзакциями и
одновременными транзакциями. Сколько процессоров требуется для
одновременной обработки транзакций?
10. Приведите пример потери обновления, отличный от приведенного в тексте.
11. Объясните, чем явная блокировка отличается от неявной.
12. Что такое глубина детализации блокировки?
13. Объясните, в чем разница между монопольной и коллективной блокировкой,
14. Что такое двухфазная блокировка?
15. Как связано снятие всех блокировок в конце транзакции с двухфазной
блокировкой?
16. Как в общем случае следует определять рамки транзакции?
418 Глава 11. Многопользовательские базы данных
17. Что такое монопольная блокировка? Как ее можно избежать? Как можно
устранить ее, когда она возникает?
18. Объясните, чем оптимистическая блокировка отличается от
пессимистической.
19. Объясните, в чем преимущества подхода, при котором обозначаются
рамки транзакций и объявляются характеристики блокировок, а само
наложение блокировок поручается СУБД.
20. Объясните, как используются операторы BEGIN, COMMIT и ROLLBACK TRANSACTION.
21. Расшифруйте термин АСЮ-трапзакция.
22. Объясните, что такое согласованность на уровне оператора.
23. Объясните, что такое согласованность на уровне транзакции. Каким
нежелательным свойством она характеризуется?
24. В чем цель выделения различных уровней изоляции транзакций?
25. Опишите уровень изоляции «незавершенное чтение». Приведите пример
его использования.
26. Опишите уровень изоляции «завершенное чтение». Приведите пример его
использования.
27. Опишите уровень изоляции «воспроизводимое чтение». Приведите
пример его использования.
28. Опишите уровень изоляции «сериал изу ем ость». Приведите пример его
использования.
29. Дайте определение термина курсор.
30. Объясните, почему транзакция может иметь много курсоров. Иначе
говоря, каким образом транзакция может иметь на данной таблице более
одного курсора?
31. В чем преимущество использования различных типов курсоров?
32. Опишите последовательные курсоры. Приведите пример их использования.
33. Опишите статические курсоры. Приведите пример их использования.
34. Опишите ключевые курсоры. Приведите пример их использования.
35. Опишите динамические курсоры. Приведите пример их использования.
36. Что произойдет, если вы не объявите СУБД уровень изоляции транзакции
и тип курсора? Плохо это или хорошо?
37. Объясните, почему необходимо определять права и обязанности по
обработке. Каким образом выполняются эти обязанности?
38. Объясните, как связаны между собой пользователи, группы, полномочия и
объекты в системе безопасности типичной базы данных.
39. Укажите преимущества и недостатки обеспечения безопасности
средствами СУБД.
40. Укажите преимущества и недостатки обеспечения безопасности
средствами приложения.
Вопросы II группы, 419
41. Объясните, как можно восстановить базу данных путем повторной
обработки. Почему этот метод в общем случае не реализуем на практике?
42. Дайте определение терминам откат и накат.
43. Почему важно делать запись в журнале, перед тем как производить
изменения в базе данных?
44. Опишите процесс отката. При каких условиях он должен использоваться?
45. Опишите процесс наката. При каких условиях он должен использоваться?
46. В чем преимущества частой расстановки контрольных точек в базе
данных?
47. Перечислите обязанности администратора базы данных по управлению
СУБД.
48. Что такое репозиторий данных? Что такое пассивный репозиторий?
Активный репозиторий?
49. Объясните, в чем важность репозитория данных. Что может произойти,
если его не будет?
Вопросы II группы
50. Зайдите на сайт www.microsoft.com и поищите на нем информацию об уровнях
изоляции транзакций и типах курсоров. На данном этапе не обращайте
внимания на информацию об RDS, ADO, ODBC и OLE DB, а
сконцентрируйтесь на возможностях и функциях SQL Server. Сравните возможности
этой СУБД с тем, что описано в тексте данной главы.
51. Зайдите на сайт www.oracle.com и поищите на нем информацию об уровнях
изоляции транзакций и типах курсоров. На данном этапе не обращайте
внимания на информацию об ODBC и сконцентрируйтесь на
возможностях и функциях Oracle. Сравните возможности этой СУБД с тем, что
описано в тексте данной главы.
52. Опишите преимущества и недостатки системы безопасности, опирающейся на
имя пользователя и пароль. Какого рода небрежность могут проявить
пользователи по отношению к своей идентификационной информации? Как эта
небрежность может угрожать безопасности базы данных? Какие шаги
необходимо предпринять, чтобы снизить риск возникновения подобных проблем?
53. Поищите в Интернете информацию о CASE-средствах, которые
предоставляют возможность создания репозиториев, и о специализированных
инструментах для построения репозиториев. Выберите наилучшее, по вашему
мнению, средство и перечислите его основные функции и возможности.
Объясните, как эти функции и возможности могут помочь
администратору базы данных компании, которая занимается электронной коммерцией
и хочет расширить ассортимент своих товаров.
420 Глава 11. Многопользовательские базы данных
Проекты
Рассмотрим представление Customer на рис. 10.4.
1. Предположим, что вы разрабатываете приложение, создающее новые
экземпляры этого представления. Какой уровень изоляции транзакций вы
бы использовали? Назовите курсоры, которые будут в этом
представлении, и укажите, какой тип вы рекомендуете для каждого из них.
2. Предположим, что вы разрабатываете приложение, модифицирующее
значения (только значения, но не связи) в этом представлении. Какой
уровень изоляции транзакций вы бы использовали? Назовите курсоры,
которые будут в этом представлении, и укажите, какой тип вы рекомендуете
для каждого из них.
3. Предположим, что вы разрабатываете приложение, модифицирующее
значения и связи в этом представлении. Как изменится ваш ответ на вопрос 2?
4. Предположим, что вы разрабатываете приложение, удаляющее
информацию о неактивных покупателях (покупателях, которые ни разу не
приобретали произведения искусства). Какой уровень изоляции транзакций вы
бы использовали? Назовите курсоры, которые будут в этом
представлении, и укажите, какой тип вы рекомендуете для каждого из них.
Вопросы к проекту FiredUp
1. Предположим, что фирма FiredUp Inc. наняла вас в качестве консультанта
для разработки базы данных с четырьмя таблицами, описанными в конце
главы 9. Допустим, что персонал FiredUp составляют два владельца,
администратор офиса, техник по ремонту и два работника, занимающихся сборкой.
Администратор офиса обрабатывает все регистрационные формы. Техник
по ремонту вводит все данные о ремонте, а сборщики вводят данные о
горелках, которые они изготовили. Подготовьте записку длиной 3-5 страниц,
адресованную менеджерам FiredUp, которая затрагивает следующие вопросы.
1) Потребность в администрировании базы данных в FiredUp.
2) Ваши рекомендации по поводу того, кто мог бы служить в качестве
администратора базы данных. Будем считать, что фирма FiredUp имеет
недостаточно большие размеры для того, чтобы позволить себе нанять
администратора базы данных на полную ставку.
3) Руководствуясь рис. 11.1, опишите, в чем будет заключаться
деятельность администратора базы данных в FiredUp. Как энергичный
консультант, имейте в виду, что вы можете рекомендовать себя для
выполнения некоторых функций администратора базы данных.
2. Для сотрудников, описанных в вопросе 1, определите пользователей, группы
и полномочия относительно данных из четырех таблиц, описанных в конце
главы 9. В качестве образца используйте схему обеспечения безопасности,
показанную на рис. 11.9. Опять-таки, не забудьте включить себя.
Вопросы к проекту FiredUp 421
3. Рассмотрим представления РЕГИСТРАЦИЯ.ПР и РЕМОНТ_ГОРЕЛКИ_ЛР,
определенные в конце главы 10.
1) Приведите пример «грязного» чтения, невоспроизводимого чтения и
фантомного чтения при обработке представления РЕГИСТРАЦИЯ_ПР.
2) Какие меры по управлению параллельной обработкой, с вашей точки
зрения, подойдут для транзакции, которая обновляет представление
РЕГИСТРАЦИЯ_ПР? Какие меры по управлению параллельной
обработкой, с вашей точки зрения, подойдут для транзакции, которая удаляет
данные из представления РЕГИСТРАЦИЯ_ПР? Укажите предположения,
которые вы делаете.
3) Ответьте на вопрос 2, имея теперь в виду представление ПОКУПАТЕЛЬ.
ПР. Дайте обоснование отличий от ответа на вопрос 2.
4) Какой уровень изоляции вы использовали бы для транзакции, которая
распечатывает отчет обо всех ремонтах горелок за некоторый период?
Какой тип курсора вы бы использовали?
Глава 12
Работа с базами данных
в Oracle
Oracle — мощная и устойчивая СУБД, работающая под управлением различных
операционных систем, включая Windows 98, Windows 2000, несколько вариантов
Unix, ряд операционных систем для больших ЭВМ и Linux. Она является самой
популярной СУБД в мире и имеет длительную историю разработки и
использования. Значительная часть технологии Oracle открыта для разработчика, что
обеспечивает большую гибкость при ее конфигурировании и настройке.
Однако все это означает, что Oracle может быть непростой в установке, и для
работы с ней необходимо многому научиться. О том, насколько широки
горизонты мира Oracle, можно судить по толщине одной из наиболее популярных книг
по этой СУБД: она насчитывает более 1300 страниц и, тем не менее, не
охватывает всех аспектов. Более того, методики, которые работают в версии Oracle,
предназначенной для одной операционной системы, могут потребовать
модификации в версии для другой операционной системы. С Oracle вам придется
запастись терпением и не рассчитывать на то, что вы овладеете этим предметом
за одну ночь.
Существует много конфигураций программного пакета Oracle. Во-первых, есть
две различные версии ядра СУБД Oracle: для индивидуального использования
(Personal Oracle) и для организаций (Enterprise Oracle). Кроме того, имеется
программа для разработки форм и отчетов (Forms and Reports), программа Oracle
Designer и множество средств для публикации баз данных Oracle в Web.
Добавьте к этому необходимость работы в различных операционных системах и
поддержки нескольких сетевых протоколов, и вы поймете, почему Oracle
представляет такую сложность в изучении.
Oracle SQL Plus — это утилита для обработки запросов на языке SQL и
создания таких компонентов, как хранимые процедуры и триггеры. Данная утилита
неизменно присутствует во всех вариантах конфигурации продукта. Поэтому на
ней мы в основном и сконцентрируем наше внимание. С помощью SQL Plus
можно передавать Oracle команды на языках SQL и PL/SQL. PL/SQL — это
язык, расширяющий возможности SQL за счет включения в него конструкций,
характерных для языков программирования. Мы будем использовать PL/SQL
Создание базы данных Oracle 423
для создания таблиц, ограничений, связей, представлений, хранимых процедур
и триггеров.
В этой главе будет использоваться пример с базой данных галереи View Ridge
из главы 10, а последовательность изложения материала будет в общих чертах
повторять ход дискуссии об администрировании баз данных в главе 11.
Установка Oracle
Если в приобретенную вами версию книги входит диск с Oracle, установите ее
сейчас. По мере нашего продвижения повторяйте действия, описанные в тексте.
У вас должно быть две версии Oracle Personal Edition: для Windows 98 и для
Windows 2000. Установите версию, соответствующую вашей операционной
системе. Не пытайтесь устанавливать программы Oracle Designer или Forms and
Reports. Они не понадобятся вам при изучении данной главы, и их может
оказаться непросто установить и сконфигурировать. Работы вам хватит и с
базовыми компонентами Oracle.
Создание базы данных Oracle
Есть три способа создать базу данных Oracle: посредством мастера Oracle
Configuration Assistant, с помощью предоставляемых Oracle специальных процедур
создания баз данных и с помощью SQL-команды CREATE DATABASE. Первый способ
гораздо проще всех остальных, так что им вам и следует воспользоваться.
Мастер Database Conficuration Assistant можно найти в одной из папок,
созданных при установке Oracle. В зависимости от того, какую операционную систему
вы используете, его можно найти в меню Пуск ► Программы ► 0racle-0raHome81 ►
Database Administration или в каком-либо подобном месте. Названия папок и
меню у вас могут отличаться; в этом случае мастер следует искать внутри меню
Пуск ► Программы.
При запуске мастера Database Configuration Assistant вы увидите картинку,
изображенную на рис. 12.1. Щелкните мышью на команде Create a database (Создать
базу данных) и выберите вариант установки Typical (Типичная); укажите, что
следует скопировать существующие файлы базы данных с компакт-диска, и выберите
имя для вашей базы данных. В этой главе базе данных дано имя VR1. Нажмите
Finish (Готово), и мастер создаст базу данных.
По умолчанию Oracle создаст в вашей базе данных три учетных записи:
INTERNAL с паролем ORACLE, SYS с паролем CHANGEJ)N_INSTALL и SYSTEM с паролем
MANAGER. (Имена учетных записей и пароли нечувствительны к регистру
символов.)
Oracle создаст стандартные файлы для ваших данных и журналов операций.
Разработчику предоставлена большая свобода в том, как и где создавать эти
файлы, но здесь мы не будем касаться этих вопросов. Вы сможете разобраться
в этом самостоятельно, когда изучите основы Oracle.
424 Глава 12. Работа с базами данных в Oracle
Oracle Database еооШШШШШШШв
QSlfti-
Рис. 12.1. Создание базы данных Oracle
Работа с SQL Plus
Чтобы запустить SQL Plus, найдите значок этой программы в меню Пуск ►
Программы и щелкните на нем. Войдите в свою базу данных с учетной записи SYSTEM,
введя имя базы данных в поле Host String (Имя базы данных), как показано на
рис. 12.2. (Процедура может отличаться, если вы используете версию Oracle,
настроенную кем-то другим. В этом случае следует обратиться к администратору
базы данных.) Нажмите ОК, и вы должны будете увидеть окно, подобное
изображенному на рис. 12.3.
LT'Tf 'ГГм^ДшИДИ
User Name:
Password:
:¥ Host String:
HI
1111
щщяШшш&шшш'ь-'^
JSYSTEM
JVRIJ
OK
Cancel
|
Рис. 12.2. Вход в базу данных с учетной записи Oracle
Среди множества функций SQL Plus есть и функция текстового редактора.
Работа с Oracle будет проще, если вы узнаете немного об этом редакторе.
Во-первых, когда вы вводите что-то с клавиатуры в SQL Plus, вводимые вами символы
помещаются в буфер. При нажатии клавиши Enter SQL Plus сохраняет то, что
Создание базы данных Oracle
425
иы ввели, в виде строки в буфере и переходит на новую строку, но не завершает
оператор и не пытается его выполнить.
& Oracle SQt*Plu«
Pile' ШЩ Se^;.s:J$^^^|^^^^^r40^?^^^'^ 3&''
jSQL*Plus: Release 8.1.5.0.0 - Production on Wed Nou 29 08:19:05 2088 HJ!
|(c) Copyright 1999 Oracle Corporation. All rights reserued.
Connected to:
0racle8i personal Edition Release 8.1.5.0.0 - Production
With the Partitioning and Java options
JPL/SQL Release 8.1.5.8.0 - Production
|SQL> |
Рис. 12.3. Приглашение SQL Plus
Буфер SQL Plus
На рис. 12.4 пользователь ввел SQL-оператор из двух строк. При необходимости
пользователь может ввести большее количество строк. Когда пользователь
вводит точку с запятой и нажимает Enter, SQL Plus отмечает конец оператора и
выполняет его. Попробуйте это сделать, но не обращайте внимания на результаты —
ими мы займемся позже.
£ Grade «}t*Pfus
SQL*Plus: Release 8.1.5.0.0 - Production on Wed Nou 29 08:47:26 2000
(c) Copyright 1999 Oracle Corporation. All rights reserued.
Connected to:
Oracleei Personal Edition Release 8.1.5.0.0 - Production
With the partitioning and Java options
PL/SQL Release 8.1.5.0.0 - Production
;SQL> SELECT Table_Name
:j 2 FROM USER_Tfi8LES
I 3
i
Рис. 12.4. Многострочный буфер SQL Plus
426 Глава 12. Работа с базами данных в Oracle
Чтобы увидеть содержимое буфера, введите команду LIST, как показано на
рис. 12.5. Строка, помеченная звездочкой, — в данном случае строка 3 —
является текущей строкой. Чтобы сделать текущей другую строку, введите LIST и номер
строки, например LIST 1. Теперь текущей является первая строка.
:|table_name
llREPCAT$_RESOLUTlON_STftTISTICS
;;REPCAT$_RESOL_STATS_CONTROL
:REPCAT$_RUNTIME_PARHS
REPCAT$_SNAPGROUP
:|HEPCAT$_TEMPLATE_OBJECTS
!!REPCAT$_TEMPLATE_PARMS
i;REPCAT$_TEMPLATE SITES
HREPCAT$_USER_AUTHORIZATIONS
:REPCAT$_USER_PARM_UALUES
:SQLPLUS_PRODUCT_PROFILE
:T1
TRANSACTION
WORK
j55 rows selected.
|JSQL> LIST
jj 1 SELECT Table_Nane
2 FROH USERJTABLES
I: 3*
!SQL> |
Рис. 12.5. Использование команды LIST
Чтобы изменить содержимое текущей строки, введите команду change /строка1/
строка2/, где строка1 — это последовательность символов, которую вы хотите
заменить, а строка2 — последовательность символов, на которую производится
замена. На рис. 12.6 пользователь ввел:
change /Table_Name/*/
Это выражение заменяет строку «Table_Name» на строку «*».
Теперь, когда пользователь введет команду list, в первой строке буфера вместо
выражения SELECT Table_Name появится выражение SELECT *. Чтобы увидеть весь
оператор, снова введите LIST. Введите символ косой черты (/), затем нажмите
Enter, и оператор, находящийся в буфере, будет выполнен.
Прежде чем продолжить, отметим, что в Oracle команды, имена столбцов,
таблиц и представлений, а также прочие элементы базы данных не
чувствительны к регистру. LIST — это то же самое, что и list, как показывает рис. 12.6.
Единственный случай, когда регистр имеет значение, — внутри кавычек в строковых
выражениях. Так, выражения
SELECT * from ARTIST
•'•••:"•. ''JtiJ'i.4'
select * FROM artist
Создание базы данных Oracle 427
идентичны. Но выражения
SELECT * FROM ARTIST WHERE Name = 'Miго'
I!
SELECT * FROM ARTIST WHERE Name = 'MIRO'
являются различными. Регистр играет роль внутри кавычек, которые
используются для данных.
SQL>
1
2
3*
SQL>
1*
SQL>
1*
SQL>
1
2
3*
SQL>
LIST
SELECT Table Name
FROM USER TABLES
LIST1
SELECT Table_Name
change /Table_Name/V
SELECT *
list
SELECT*
FROM USER TABLES
I
Рис. 12.6. Изменение содержимого строки в буфере
Есть также разница между точкой с запятой (;) и косой чертой (/). Точка с
запятой является символом конца оператора, а косая черта предписывает Oracle
выполнить операторы, находящиеся в буфере. Если имеется только один оператор,
и отсутствует неопределенность по поводу того, что требуется сделать, Oracle будет
интерпретировать точку с запятой и косую черту одинаково. Так, в выражении
Select * from USERJABLES:
точка с запятой одновременно служит символом конца оператора и заставляет
Oracle выполнить этот оператор. Введите вместо нее символ косой черты, и
оператор будет выполнен снова.
Использование внешнего текстового редактора
Возможностей встроенного текстового редактора SQL Plus вполне хватает для
внесения небольших изменений, но при редактировании длинных выражений, таких
как хранимые процедуры, он становится неудобным. В связи с этим в SQL Plus
предусмотрена возможность работы с внешним текстовым редактором. Чтобы
настроить SQL Plus для работы с внешним редактором, необходимо прежде всего
создать папку для ваших файлов и указать на нее SQL Plus.
Для этого сначала выйдите из SQL Plus, введя команду exit на приглашение
SQb>. Теперь создайте папку для ваших файлов Oracle — например, C:\MyDirectory\
OracleCode. Найдите на вашем компьютере значок SQL Plus, щелкните на нем правой
428 Глава 12. Работа с базами данных в Oracle
клавишей мыши, чтобы открыть диалог Properties (Свойства), и введите имя
созданной вами папки в текстовое поле Start In (Начинать в...). Нажмите ОК и вновь
запустите SQL Plus.
В оконном меню SQL Plus выберите команду Edit ► Editor ► Define Editor (Правка ►
Редактор ► Задать редактор). Здесь вы можете ввести имя вашего текстового
редактора. По умолчанию предлагается выбрать Notepad (Блокнот); для наших
целей его будет достаточно, поэтому нажмите ОК.
Теперь Notepad выбран в качестве редактора по умолчанию для SQL Plus, и
ваша папка определена для него как рабочая. С этого момента, получив с клавиатуры
команду Edit, SQL Plus будет вызывать Notepad (или другой текстовый редактор,
выбранный вами). Теперь вы можете создавать, сохранять и редактировать файлы
во вновь созданной папке. В качестве примера заново введите операторы:
SELECT Table Jame
FROM USERJABLES:
После появления результатов введите команду Edit SQL Plus вызовет Notepad,
загрузив в него содержимое буфера. Сохраните данный файл под именем EXl.txt,
выбрав в меню редактора команду Save As (Сохранить как...). Закройте Notepad,
и вы вернетесь в SQL Plus. Чтобы отредактировать созданный только что файл,
введите Edit EXl.txt, и этот файл откроется в вашем текстовом редакторе. Когда
вы выйдете из редактора и возвратитесь в SQL Plus, файл будет помещен в буфер
SQL Plus. Чтобы выполнить содержимое буфера, введите символ косой черты (/).
Кстати, по умолчанию для файлов в SQL Plus используется расширение .sql.
Если вы назовете файл EXl.sql, то можно ввести просто Edit EX1, и SQL Plus
добавит расширение за вас.
Будучи вооружены этими знаниями SQL Plus, мы теперь можем исследовать
некоторые характеристики Oracle. В следующем разделе мы будем использовать
пример с галереей View Ridge, описанный в главе 10, и создадим для него схему
базы данных с суррогатными ключами, показанную на рис. 10.3, г.
Создание таблиц
Базовый синтаксис SQL-оператора CREATETABLE показан в листинге 12.1: за
выражением CREATE TABLE следует имя таблицы, а затем список имен типов и свойств
столбцов, заключенный в скобки. Оператор заканчивается точкой с запятой, как
и все SQL-операторы Oracle.
Листинг 12.1. Создание таблиц CUSTOMER, ARTIST и CUSTOMER_ARTISTJNT
CREATE TABLE CUSTOMED
CustomerID int NOT NULL.
Name varchar(25) NOT NULL.
Street varchar(30) NULL.
City varchar(35) NULL,
State varchar(2) NULL.
Zip varchar(5) NULL.
Area_Code varchar(3) NULL.
Phone_Number varchar(8) NULL);
Создание базы данных Oracle 429
ALTER TABLE CUSTOMER
ADD CONSTRAINT CustomerPK PRIMARY KEY ( CustomerlD );
CREATE INDEX CustomerNamelndex ON CUSTOMER(Name):
CREATE TABLE ARTIST(
ArtiStID int PRIMARY KEY.
Name varchar(25) NOT NULL.
Nationality varchar(30) NULL.
Birthdate date NULL.
DeceasedDate date NULL);
CREATE UNIQUE INDEX ArtistNamelndex ON ARTlST(Name);
CREATE TABLE CUSTOMERJ\RTIST_INT(
ArtiStID int NOT NULL.
CustomerlD int NOT NULL);
ALTER TABLE CUSTOMER)_ARTIST_INT
ADD CONSTRAINT CustomerArtistPK PRIMARY KEY ( ArtistID, CustomerlD );
В листинге 12.1 показаны два способа создания первичного ключа. Структура
таблицы CUSTOMER создается без первичного ключа, а первичный ключ
определяется с помощью оператора ALTER TABLE, следующего за оператором создания
таблицы. Ограничению первичного ключа здесь дано имя CustomerPK. Второй способ
создания первичного ключа состоит в том, что в операторе CREATE TABLE для
соответствующего столбца указывается свойство PRIMARY KEY. В листинге 12.1 это
сделано для таблицы ARTIST. (В данной главе текст, который вы вводите в
редакторе, изображается на рисунке как обычный текст. Вид экрана SQL Plus
показывается в прямоугольнике, как на рис. 12.6.)
Если таблица имеет композитный первичный ключ, то можно использовать
только первый метод, поскольку синтаксис оператора CREATE TABLE позволяет
указывать свойство PRIMARY KEY только для одного столбца. Так, первичный ключ
для таблицы CUSTOMER_ARTIST_INT', являющийся композитным, должен быть
определен с помощью оператора ALTER TABLE, как показано в листинге 12.1.
Откройте Notepad и введите изображенный здесь текст. Сохраните его в файле
под именем Createl.sql. Теперь запустите SQL Plus и введите команду
Start Createl
на приглашение SQL>. (Если вы использовали расширение, отличное от .sql, вы
должны указать его явно, например Start Createl.txt.)
SQL Plus откроет файл Createl.sql и поместит содержащиеся в нем
SQL-операторы в буфер, но выполнять их не будет, пока вы не введете символ косой
черты (/). Только после этого ваши таблицы будут созданы.
В Oracle вместо дефиса следует использовать символ подчеркивания.
430 Глава 12. Работа с базами данных в Oracle
Если потребовалось что-то изменить, наберите
Edit Createl
и файл откроется в текстовом редакторе. Сделайте необходимые изменения,
сохраните их и выйдите из редактора. SQL Plus поместит исправленные операторы
в буфер. Чтобы запустить их, введите косую черту.
Если вы хотите, чтобы ваши операторы автоматически запускались по
прочтении файла, поместите за последним оператором символ косой черты. Когда
вы введете команду Start имя_файла, содержащиеся в файле операторы будут
выполнены автоматически.
Увидеть структуру таблицы можно с помощью команды DESCRIPTION или DESC.
Введите команду DESC CUSTOMER, и SQL Plus отобразит структуру таблицы
CUSTOMER. Ваши таблицы должны выглядеть так, как показано на рис. 12.7.
Обратите внимание, что стандартный тип данных SQL varchar изменен на varchar2:
Oracle предпочитает такое имя. Кроме того, суррогатные ключи, которым был
присвоен стандартный тип int, поменяли свой тип на number(38) — число длиной
38 байт. Список некоторых наиболее часто используемых типов данных Oracle
приведен в табл. 12.1.
SQL> desc customer;
Name
CUSTOMERID
NAME
STREET
CITY
STATE
i ZIP
AREA_CODE
PHONE_NUMBER
1 SQL> desc artist
Name
ARTISTID
NAME
NATIONALITY
BIRTHDATE
DECEASEDDATE
SQL> desc customer_artistjnt;
Name
ARTISTID
CUSTOMERID
Null?
NOT NULL
NOT NULL
Null?
NOT NULL
NOT NULL
Null?
NOT NULL
NOT NULL
Type
NUMBER{38)
VARCHAR2(25)
VARCHAR2<30)
VARCHAR2{35)
VARCHAR2(2)
VARCHAR2{5)
VARCHAR2{3)
VARCHAR2{8)
Type
NUMBER{38) |
VARCHAR2(25)
VARCHAR2{30)
DATE
DATE
Type
NUMBER{38)
NUMBER{38)
Рис. 12.7. Использование команды DESCRIBE (DESC)
Создание базы данных Oracle 431
Таблица 12.1. Наиболее часто используемые типы данных Oracle
Тип данных Описание
BLOB Большой двоичный объект, Может быть длиной до 4 Гбайт
CHAR{n) Текстовое поле фиксированной длины п. Максимум 2000 символов
DATE Поле длиной 7 байт, содержащее дату и время
INT Целое число длиной 38 знаков
NUMBER{n,d) Число длиной п с d знаками после запятой
VARCHAR(n) Текстовое поле переменной длины до п символов. Максимальное значение
или
VARCHAR2(n)
п = 4000
Создание суррогатных ключей с помощью
последовательностей
Последовательность (sequence) — это объект, который генерирует серию
последовательных уникальных чисел. Последовательности чаще всего используются
для генерации значений суррогатных ключей. Следующий оператор определяет
последовательность под названием CustID, которая начинается с 1000 и
увеличивается на 1 при каждом использовании:
Create Sequence CustID Increment by 1 start with 100;
Для нас являются важными два метода последовательностей. Метод NextVal
выдает следующее значение в последовательности, а метод CurrVal выдает
текущее значение в последовательности. Так, CustID.NextVal выдает следующее
значение в последовательности CustID. С помощью последовательности вы можете
вставить строку в таблицу CUSTOMER, как показано ниже:
INSERT INTO CUSTOMER
(CustomerlD, Name. Area_Code. Phone_Number)
VALUES
(CustID.NextVal. 'Mary Jones'. '350'. '555-1234'):
Этот оператор создаст в таблице CUSTOMER строку, где столбцу CustomerlD
будет присвоено следующее значение в последовательности CustID. Выполнив
этот оператор, вы можете считать только что созданную строку с помощью
метода CurrVal:
SELECT *
FROM CUSTOMER
WHERE CustomerlD = CustID.CurrVal:
Здесь метод CustID.CurrVal возвращает текущее значение в
последовательности, то есть только что использованное значение.
К сожалению, использование последовательностей не гарантирует
корректности значений суррогатных ключей. Во-первых, любой разработчик может
использовать существующую последовательность для произвольных целей. Если
последовательность используется для каких-либо иных целей, нежели генерация
432 Глава 12. Работа с базами данных в Oracle
суррогатных ключей, некоторые значения в ней будут пропущены. Вторая, более
серьезная проблема заключается в том, что в схеме нет ничего, что запрещало бы
выполнить вставку без использования последовательности. Так, Oracle примет
без возражений оператор
INSERT INTO CUSTOMER
(CustomerlD. Name, Area_Code, Phone_Number)
VALUES
(350. 'Mary Jones', '350'. -555-1234');
Возможно, что выполнение этого оператора приведет к появлению
одинаковых значений сурогатного ключа. В этом случае Oracle не позволит выполнить
вставку, поскольку атрибут CustomerlD определен как первичный ключ. Но даже
если и так, все равно может возникнуть потребность в коде, который бы
обрабатывал это исключение. Наконец, есть вероятность, что кто-то случайно
использует не ту последовательность для вставки в таблицу. Несмотря на возможность
таких проблем, последовательности представляют собой лучший способ работы
с суррогатными ключами в Oracle.
Приведенные ниже последовательности будут использоваться нами в базе
данных галереи View Ridge. Создайте их с помощью SQL Plus.
Create Sequence CustID Increment by 1 start with 1000;
Create Sequence Artist ID Increment by 1 start with 1;
Create Sequence Work ID Increment by 1 start with 500;
Create Sequence TransID Increment by 1 start with 100:
Ввод данных
Теперь с помощью этих последовательностей мы можем заполнять таблицы
данными. В листинге 12.2 показан созданный в Notepad файл, состоящий из
последовательности операторов INSERT. Создайте такой файл в своем текстовом
редакторе, поместите в конце символ косой черты и сохраните файл под именем ACIns.sql.
Введите
Start AC Ins:
и операторы, содержащиеся в ACIns, будут выполнены. Ваши данные должны
выглядеть так, как показано на рис, 12.8.
Листинг 12.2. Вставка данных в таблицы ARTIST и CUSTOMER
INSERT INTO ARTIST (ArtistID, Name. Nationality) Values
(ArtistlD.NextVal, 'Tobey'. 'US');
INSERT INTO ARTIST (ArtistID, Name, Nationality) Values
(ArtistlD.NextVal. 'Miro'. 'Spanish');
INSERT INTO ARTIST (ArtistID. Name, Nationality) Values
(ArtistlD.NextVal, 'Fnngs'. 'US');
INSERT INTO ARTIST (ArtistID, Name, Nationality) Values
(ArtistlD.NextVal. 'Foster'. 'English');
INSERT INTO ARTIST (ArtistID, Name. Nationality) Values
(ArtistlD.NextVal. 'van Vronkin'. 'US');
Создание базы данных Oracle 433
INSERT INTO CUSTOMER (CustomerlD. Name. Area_Code, Phonejumber) Values
(CustlD.NextVal, 'Jeffrey Janes'. '206'. '555-1234');
INSERT INTO CUSTOMER (CustomerlD, Name. Area_Code. Phonejumber) Values
(CustlD.NextVal, 'David Smith'. '206'. '555-4434'):
INSERT INTO CUSTOMER (CustomerlD. Name. Area_Code. Phonejumber) Values
(CustlD.NextVal. 'Tiffany Twilight', '360', '555-1040');
SQL> SELECT ArtistID, Name, Nationality FROM ARTIST;
ARTISTID NAME
2 Miro
3 Frings
4 Foster
5 van Vronkin
j 1 Tobey
SQL> SELECT CustomerlD, Name, Area_Code
CUSTOMERID NAME
1001 David Smith
1002 Tiffany Twilight
1000 Jeffrey Janes
NATIONALITY
Spanish
US
English
US !
US
Phone_Num ber FROM CUSTOMER;
ARE PHONEJSIU
206 555-4434
360 555-1040
206 555-1234
Рис. 12.8. Таблицы ARTIST и CUSTOMER после вставки
Операторы DROP и ALTER
С помощью оператора DROP можно удалять различные структуры из базы
данных. Например, операторы
DROP TABLE MYTABLE;
DROP SEQUENCE MySequence;
удалят из базы данных таблицу MYTABLE и последовательность MySequence,
соответственно. Все данные из таблицы MYTABLE будут потеряны.
С помощью оператора DROP можно также удалить столбец из таблицы, как
показано ниже:
ALTER TABLE MYTABLE DROP COLUMN MyColumn;
Другие примеры использования операторов DROP и ALTER вы увидите в ходе
дальнейшего обсуждения.
Создание связей
В Oracle связи создаются путем введения ограничений целостности по
внешнему ключу. Например, следующие SQL-операторы определяют связь между
434 Глава 12. Работа с базами данных в Oracle
таблицами CUSTOMER и CUSTOMER_ARTISTJNT и между таблицами ARTIST и CUSTOMER^
ARTISTJNT:
ALTER TABLE CUSTOMER_ARTISTJNT ADD CONSTRAINT ArtistlntFK
FOREIGN KEY(ArtiStlD) REFERENCES ARTIST ON DELETE CASCADE;
ALTER TABLE CUSTOMER_ARTIST_INT ADD CONSTRAINT CustomerlntFK
FOREIGN KEY(CustomerlD) REFERENCES CUSTOMER ON DELETE CASCADE;
Ограничениям даны имена ArtistlntFK и CustomerlntFK. Эти имена не играют
особой роли для Oracle и могут выбираться разработчиком. Обратите внимание,
что для родительской таблицы указан только столбец, являющийся внешним
ключом. Oracle предполагает, что внешний ключ будет связан с первичным
ключом родительской таблицы, поэтому указывать столбец первичного ключа нет
необходимости. Фраза ON DELETE CASCADE указывает на то, что при удалении
строк из родительской таблицы соответствующие строки дочерних таблиц
должны быть также удалены. Слово cascade (каскад) используется здесь потому, что
удаление идет каскадом от родительской таблицы к дочерней.
Введите эти операторы в редактор SQL Plus и заполните несколько строк
таблицы пересечения. Теперь, если вы удалите данные о покупателе или
художнике, соответствующие строки в таблице пересечения будут также удалены.
В листинге 12.3 показаны операторы, создающие таблицы WORK и TRANSACTION.
Обратите внимание, что в определениях ограничений по внешнему ключу
отсутствует фраза ON DELETE CASCADE. Так, ограничение ArtistFK сделает невозможным
удаление тех строк в таблице ARTIST, которые имеют дочерние строки в таблице
WORK. Ограничения WorkFK и CustomerFK функционируют сходным образом.
Листинг 12.3. Создание таблиц WORK и TRANSACTION
CREATE TABLE WORK {
Work ID int PRIMARY KEY.
Description varchar(lOOO) NULL.
Title varchar(25) NOT NULL.
Copy varchar(8) NOT NULL.
ArtistID int NOT NULL);
ALTER TABLE WORK ADD CONSTRAINT ArtistFK
FOREIGN KEY (ArtistID) REFERENCES ARTIST;
CREATE TABLE TRANSACTION (
TransactionID int PRIMARY KEY.
DateAcquired date NOT NULL.
AcquisitionPrice number(7.2) NULL,
PurchaseDate date NULL.
SalesPrice number(7.2) NULL.
CustomerID int NULL.
WorkID int NOT NULL);
ALTER TABLE TRANSACTION ADD CONSTRAINT WorkFK
FOREIGN KEY (WorkID) REFERENCES WORK;
Создание базы данных Oracle 435
ALTER TABLE TRANSACTION ADD CONSTRAINT CustomerFK
FOREIGN KEY (CustomerlD) REFERENCES CUSTOMER;
Оператор ALTER можно также использовать для удаления ограничения. Оператор
ALTER TABLE MYTABLE DROP CONSTRAINT MyConstraint
удалит ограничение MyConstraint из таблицы МуТаЫе.
Запись number(7,2) в листинге 12.3 обозначает число с семью цифрами, две из
которых находятся справа от десятичной точки. Запись number(7) означает целое
число из семи цифр.
Создание индексов
Индексы создаются для обеспечения уникальности столбцов, упрощения
сортировки и реализации быстрого получения данных по значениям столбцов.
Столбцы, которые часто фигурируют в условиях равенства в предложениях WHERE,
являются хорошими кандидатами на создание индекса. Условия равенства могут
относиться к одной таблице или же к соединению. Эти два случая представлены
в следующих примерах:
SELECT *
FROM MYTABLE
WHERE Columnl = 100;
и
SELECT *
FROM MYTABLE1. MYTABLE2
WHERE MYTABLE1.Columnl = MYTABLE2.Column2;
Если подобные операторы выполняются часто, то столбцы Columnl и Column2
являются хорошими кандидатами на создание индексов.
Следующий оператор создает индекс по столбцу Name таблицы CUSTOMER:
CREATE INDEX CustNameldx ON CUSTOMER(Name);
Индексу дано имя CustNameldx. И здесь имя не играет особой роли для Oracle.
Чтобы создать уникальный индекс, перед ключевым словом INDEX вставьте
ключевое слово UNIQUE. Например, чтобы гарантировать, что ни одно произведение
не будет записано дважды в таблицу WORK, мы можем создать уникальный
индекс по столбцам (Title, Copy, ArtistID), как показано ниже:
CREATE UNIQUE INDEX WorkUniquelndex ON WORK(Title, Copy. ArtistID);
Изменение структуры таблицы
После создания таблицы ее структуру можно изменять с помощью оператора
ALTER TABLE. Будьте, однако, осторожны с этим оператором, поскольку при его
использовании возможна потеря данных.
436 Глава 12. Работа с базами данных в Oracle
Добавление или удаление столбца осуществляется элементарно:
ALTER TABLE MYTABLE ADD CI NUMBER(4);
ALTER TABLE MYTABLE DRDP CDLUMN CI;
Первый оператор добавляет столбец с именем С1 и присваивает ему тип числа
длиной четыре символа. Второй оператор удаляет только что созданный столбец.
Обратите внимание, что при создании столбца ключевое слово COLUMN опускается.
При запуске этих команд вы получите короткое сообщение: «Table altered»
(таблица изменена). Чтобы убедиться, что желаемые изменения действительно были
произведены, просмотрите структуру таблицы с помощью оператора DESCRIBE.
Ограничения на модификацию столбцов таблиц
Столбец можно удалить в любой момент. При этом, однако, все данные из этого
столбца будут потеряны. Также в любой момент можно добавить пустой (NULL)
столбец.
Чтобы добавить непустой (NOT NULL) столбец, сначала создайте его в таблице
как пустой, заполните все его строки данными, а затем объявите его непустым
(NOT NULL) с помощью предложения MODIFY. Предположим, например, что вы
добавили столбец С1 в таблицу Т1. После того как этот столбец будет заполнен в
каждой строчке таблицы Т1, можно запустить следующий оператор:
ALTER TABLE Tl MODIFY CI NOT NULL;
Теперь столбец CI будет обязательно требовать присвоения значения.
При модификации столбца вы можете увеличивать количество символов в
текстовых столбцах и количество цифр в числовых столбцах. Вы можете также
свободно увеличивать или уменьшать количество цифр после десятичной
точки. Если данный столбец имеет во всех строках нулевые значения, вы можете
уменьшать длину текстовых и числовых данных, а также менять тип данных
столбца.
Контрольные ограничения
Контрольные ограничения (check constraints) — это условия, налагаемые на
возможные значения столбцов. Контрольные ограничения должны формулироваться
так, чтобы результат их проверки принимал значение «истина» или «ложь» и
чтобы для их вычисления использовались только константы и значения из текущей
строки таблицы, на которой определено данное ограничение. Контрольные
ограничения не могут содержать вложенных запросов и последовательностей, а также
не могут ссылаться на функцию SysDate.
Контрольные ограничения могут создаваться вместе с таблицей или
добавляться позднее. Примером первого случая является оператор
CREATE TABLE MYTABLE(
Name VARCHAR(SO) NOT NULL,
State CHAR(2) NULL CHECK(State IN (*CA\ 'CO', 'NY'))):
Создание базы данных Oracle 437
При таком определении единственно возможными значениями для столбца
State являются «СА», «СО» и «NY».
Примером контрольного ограничения, добавляемого с помощью оператора
ALTER, может служить следующее выражение:
ALTER TABLE TRANSACTION ADD CONSTRAINT DateCheck CHECK(DateAcquired <= PurchaseDate);
Чтобы это ограничение работало, оба столбца — DateAcquired и PurchaseDate —
должны находиться в таблице TRANSACTION.
Оператор ALTER TABLE позволяет также снимать ограничения:
ALTER TABLE TRANSACTION OROP CONSTRAINT DateCheck;
Использование оператора ALTER TABLE
с контрольными ограничениями
С помощью только что рассмотренного нами приема можно модифицировать
таблицу ARTIST. В листинге 12.1 мы установили для столбцов BirthDate (дата
рождения) и Deceased Date (дата смерти) тип данных Date. Допустим, что
пользователям базы данных не нужно, чтобы в этих столбцах хранилась полная дата, а
нужен только год рождения или смерти художника. Предположим также, что из
представленных в галерее художников нет ни одного, кто бы родился или умер
ранее 1400 года или позже 2100 года.
Так как мы еще не записывали никаких данных в эти столбцы, оба они имеют
пустые значения, что позволяет нам менять тип данных, не удаляя сами
столбцы. Для этого нужно ввести в SQL Plus такие команды:
ALTER TABLE ARTIST MODIFY BirthDate Number(4);
ALTER TABLE ARTIST M00IFY OeceasedDate Number(4);
Следующие два оператора устанавливают пределы значений столбцов BirthDate
и DeceasedDate:
ALTER TABLE ARTIST ADD CONSTRAINT BDLimit CHECK (BirthDate BETWEEN 1400 ANO 2100);
ALTER TABLE ARTIST ADD CONSTRAINT DOLimit CHECK (DeceasedDate BETWEEN 1400 AND 2100):
Рассмотрим следующие команды обновления:
UPDATE ARTIST SET BirthDate = 1870 WHERE Name = 'Miro';
UPOATE ARTIST SET BirthOate = 1270 WHERE Name = 'Tobey';
Первое обновление пройдет успешно, а второе нарушит ограничение и
поэтому не будет выполнено. Попробуйте запустить эти операторы и посмотрите,
каковы будут результаты.
Представления
Как говорилось в главе 10, представления в SQL отличаются от того, что мы
называли представлениями базы данных. Представление в SQL — это результат
438 Глава 12. Работа с базами данных в Oracle
SQL-выражения, состоящего из операторов выборки, проектирования и
соединения. Например, если соединить строки таблиц ARTIST, WORK и TRANS, выбрать из
этих строк определенные столбцы и применить к результирующему отношению
предложение WHERE, то в результате получится некоторое представление.
Важное ограничение SQL-представлений состоит в том, что они могут
содержать не более одного многозначного пути. К примеру, представление базы
данных, изображенное на рис. 10.4, которое одновременно содержит данные из
таблиц CUSTOMER, TRANS и CUSTOMER_ARTIST_INT, невозможно реализовать в виде
SQL-представления. Мы вернемся к этой теме позже, в главе 14, когда будем
обсуждать XML.
Несмотря на это ограничение, SQL-представления полезны. Во-первых, они
позволяют обеспечить более гибкую защиту таблиц. Это делается следующим
образом: создается представление, содержащее все столбцы таблицы, но
пользователям этого представления даются иные полномочия, чем пользователям самой
таблицы или других ее представлений. Во-вторых, с помощью представлений
можно ограничивать доступ к определенным столбцам или строкам. Например,
можно создать представление таблицы СОТРУДНИК, в котором будет
отсутствовать столбец Зарплата, а также будут опущены все данные об администрации.
Третье, для чего могут использоваться представления, — это соединение таблиц.
Идея заключается в том, чтобы пользователю не приходилось самому выполнять
соединение, а достаточно было бы просто запросить соответствующее
представление. При этом структура таблицы оказывается скрытой от пользователей, что
иногда бывает желательно.
Создание представлений
На рис. 12.9 показан процесс создания и использования простого представления.
Здесь определено представление VI, состоящее из единственного столбца —
столбца Name из таблицы CUSTOMER. Когда пользователь выбирает все столбцы
представления (с помощью клавиши *), результат содержит только столбец Name.
Ни один из прочих столбцов таблицы CUSTOMER пользователю не показывается,
поскольку они не входят в данное представление.
Более сложное представление показано в листинге 12.4. Это представление
соединяет три таблицы и затем налагает условие на столбцы Acquisition Price и
CustomerlD. Представления, подобные этому, называют иногда представлениями
соединения Q'oin views), поскольку они базируются на соединениях. Обратите
внимание, что оператор Select на рис. 12.10 не содержит ни соединения, ни
предложения WHERE. Соответствующие операции выполняются «за кулисами», при
построении представления.
Листинг 12.4. Создание представления
CREATE VIEW ExpensiveArt AS
SELECT Name, Copy. Title
FROM ARTIST. WORK, TRANSACTION
WHERE ARTIST.Artist ID - WORK.ArtistID AND
WORK.WorkID = TRANSACTION.Work ID AND
AcquisitionPrice > 10000 AND
CustomerlD IS NULL;
Создание базы данных Oracle 439
SQL> CREATE VIEW V1 AS
2 SELECT Name
3 FROM CUSTOMER;
View created.
SQL> SELECT* FROM V1;
NAME
David Smith
Tiffany Twilight
Jeffrey Janes
Рис. 12.9. Создание представления
SQL> select * from expensiveart;
NAME COPY
Tobey 4/40
| Tobey 4/40
Miro 79/122
TITLE
Mystic Fabric
Mystic Fabric
Mi Vida
Рис. 12.10. Выборка из представления
Вообще говоря, представления, основанные на одной таблице, допускают
обновление данных. Если это почему-либо нежелательно, вы можете создать
представление только для чтения, добавив выражение WITH READ ONLY в конец
определения представления. Так, выражение
CREATE VIEW VI AS
SELECT *
FROM ARTIST
WITH READ ONLY;
создаст представление, доступное только для чтения.
Иногда для обновления данных в представлении можно использовать SQL-
оператор UPDATE, но это возможно только в особых обстоятельствах и только
в том случае, если изменение затрагивает только одну таблицу.
В общем же случае оператор UPDATE не может использоваться для
обновления данных в представлении. Для этих целей вам потребуется написать
специальный триггер, называемый замещающим триггером (триггер INSTEAD OF). Мы
будем рассматривать такие триггеры в следующем разделе.
440 Глава 12. Работа с базами данных в Oracle
Логика приложения
Есть много способов обработки баз данных Oracle из приложений. Один из
способов заключается в том, чтобы создавать приложения на C++, С#, Java,
Visual Basic или каком-либо другом языке программирования и вызывать из них
программы Oracle. Как говорилось в главе 8, для этого можно воспользоваться
кодовыми библиотеками Oracle или задействовать промышленные стандарты
ODBC или JDBC. Примеры последнего подхода будут продемонстрированы
в главах 15 и 16.
Другой способ обработки баз данных Oracle состоит в написании процедур на
PL/SQL. Эти процедуры можно хранить в виде файлов, запускаемых по команде
START в SQL Plus, в виде хранимых процедур в базе данных, а также в виде
триггеров, которые вызываются при наступлении определенных событий.
Рассмотрим каждый из этих вариантов.
Обработка файлов PL/SQL
Если пользователь базы данных имеет доступ к SQL Plus, он может сохранить
операторы PL/SQL в файле и запускать их напрямую командой START. Файл,
содержащий оператор
SELECT *
FROM ExpensiveArt;
/
можно сохранить под именем ToSelLsql. Пользователь откроет SQL Plus и введет
команду
Start ToSell;
В результате будут выведены данные из представления ExpensiveArt.
В реальности большинство пользователей в деловом мире не имеет доступа
к SQL Plus, а если бы и имели, то вряд ли работа с этой программой пришлась
бы им по вкусу. Однако этот стиль обработки используется администраторами
и разработчиками баз данных для автоматизации рутинных задач
администрирования.
Хранимые процедуры
Хранимая процедура — это программа на языке PL/SQL или Java, которая
хранится в базе данных. Хранимые процедуры могут иметь параметры, вызывать
другие процедуры и функции, возвращать значения и генерировать исключения.
Хранимые процедуры могут вызываться удаленно. Примеры вызова хранимых
процедур с использованием интернет-технологии вы увидите в главах 15 и 16.
Здесь мы рассмотрим два примера хранимых процедур.
Логика приложения 441
Хранимая процедура Customerjnsert
Галерее View Ridge требуется возможность добавлять в базу данных новых
клиентов и записывать информацию о художниках, работами которых клиенты
интересуются. В частности, нужно записывать имя и телефоны клиента, а также
ассоциировать его со всеми художниками выбранной национальности.
В листинге 12.5 показана хранимая процедура, выполняющая эту задачу.
Процедура, которая называется Customer_Insert, принимает четыре параметра:
newname (имя нового клиента), newareacode (код региона), newphone (телефон)
и artistnationality (национальность художника). Ключевое слово IN указывает
на то, что все эти параметры являются входными. Выходные параметры
(которых у этой процедуры нет) обозначаются ключевым словом OUT, а параметры,
играющие роль и входных, и выходных, — сочетанием IN OUT. Обратите
внимание, что для параметра указывается тип данных, но не длина. Oracle определит
длину из контекста.
Листинг 12.5. Процедура Customerjnsert
CREATE OR REPLACE PROCEDURE Customerjnsert
(
newname IN char,
newareacode IN char,
newphone IN char,
artistnationality IN char
)
AS
rowcount integer(4):
CURSOR artistcursor IS
SELECT ArtistID
FROM ARTIST
WHERE Nationality=artistnationality
BEGIN
SELECT Count (*) INTO rowcount
FROM CUSTOMER
WHERE Name=newname AND Area_Code5newareacode AND Phone_Number = newphone;
IF rowcount > 0 THEN
BEGIN
DBMS_OUTPUT.PUT_LINE ('Клиент уже есть в базе данных - никаких действий
не предпринято');
RETURN;
END;
END IF;
продолжение •&
442 Глава 12. Работа с базами данных в Oracle
Листинг 12.5 (продолжение)
INSERT INTO CUSTOMER
(CustomerlD. Name. Area_Code. Phone_Number)
VALUES
(CustlD.NextVal, newname. newareacode, newphone):
FOR artist IN artistcursor
LOOP
INSERT INTO CUSTOMER_ARTISTJNT
(CustomerlD, ArtistID)
VALUES
(CustlD.CurrVal, artist.ArtistID);
END LOOP;
DBMS_OUTPUT.PUT_LINE (' Новый клиент успешно добавлен в базу ');
END;
/
Раздел объявления переменных следует за ключевым словом AS. Оператор
SELECT определяет переменную-курсор (cursor variable) с именем artistcursor. Этот
курсор выделяет из таблицы ARTIST для обработки строки всех художников
заданной национальности.
В первом разделе процедуры выполняется проверка, нет ли уже в базе инфор:
мации о данном клиенте. В этом случае никакия действия не предпринимаются,
а пользователю с помощью пакета Oracle DBMSJDUTPUT выводится
соответствующее сообщение.
Прежде чем мы продолжим обсуждение этой процедуры, обратите внимание,
что пользователь получит это сообщение только в том случае, если процедура
будет вызвана из SQL Plus. В случае вызова процедуры иным путем, например
с помощью браузера через Интернет, пользователь не увидит этого сообщения.
Чтобы сообщить пользователю об ошибке, разработчик должен воспользоваться
выходным параметром или сгенерировать исключение. Эти вопросы, однако,
выходят за рамки настоящей дискуссии. Синтаксис для вывода строки и значения
переменной, хотя это не показано в листинге 12.5, имеет вид DBMS_.OUTPUT.PUT_
LINECcTpoKay/переменная).
Кроме того, чтобы такие сообщения стали видимыми, следует выполнить
команду
Set serveroutput on;
Если при работе в SQL Plus вы не видите сообщений, выводимых вашими
процедурами, скорее всего, вы не выполнили этот оператор.
Оставшаяся часть процедуры в листинге 12.5 вставляет данные о новом
клиенте и затем перебирает всех художников выбранной национальности.
Обратите внимание на использование специальной конструкции PL/SQL FOR artist IN
artistcursor. Эта конструкция выполняет несколько задач. Прежде всего, она
открывает курсор и считывает первую строку. Затем она последовательно
обрабатывает все строки под курсором и по окончании обработки передает управление
следующему оператору после FOR. Заметьте также, что обращение к столбцу
Логика приложения 443
ArtistID текущей строки происходит с использованием синтаксиса artist.ArtistID,
где artist — это имя переменной цикла FOR, а не курсора.
После того как процедура написана, ее необходимо скомпилировать и
сохранить в базе данных. Наберите текст процедуры в редакторе и сохраните его под
именем, скажем, SP_CI.sql. Если в последней строке файла вы поместите косую
черту, то процедура будет скомпилирована и сохранена в базе данных
автоматически после ввода команды
Start SP_CI
Если вы что-то ввели неправильно, у вас могут возникнуть ошибки
компиляции. К сожалению, SQL Plus не покажет вам эти ошибки автоматически, а выдаст
сообщение: «Warning: Procedure created with compilation errors» («Предупреждение:
при компиляции процедуры обнаружены ошибки»). Чтобы увидеть ошибки,
введите команду
Show errors:
Если синтаксических ошибок не было, вы получите сообщение «Procedure
created» («Процедура создана»). Теперь вы можете вызывать эту процедуру с
помощью команд EXECUTE или EXEC:
Exec Customer JnsertCSelma Warning'. '206'. '555-0099", 'US');
Если возникнут ошибки на этапе выполнения процедуры, номера строк в
отчете об ошибках не будут совпадать с номерами строк, которые вы можете видеть
в своем текстовом редакторе. Вы можете настроить SQL Plus так, чтобы
выводимые номера строк соответствовали вашим, но этот процесс слишком сложен,
чтобы описывать его здесь. С теми простыми процедурами, которые мы будем
рассматривать, можно обойтись и без этого. Главное, имейте в виду, что номера
строк могут не совпадать.
Хранимая процедура NewCustomerWithTransaction
В главе 10 были описаны процедуры на языке SQL для создания, чтения,
модификации и удаления представления базы данных, изображенного на рис. 10.4.
Хранимая процедура, реализующая процесс создания этого представления,
показана в листинге 12.6.
Листинг 12.6. Процедура NewCustomerWithTransaction
CREATE OR REPLACE PROCEDURE NewCustomerWithTransaction
(
newname IN char,
newareacode IN char,
newphone IN char.
artistname IN char.
worktitle IN char,
workcopy IN char,
price IN number
)
продолжение^
444 Глава 12. Работа с базами данных в Oracle
Листинг 12.6 (продолжение)
AS
rowcount integer (2) ;
tid int;
aid int:
CURSOR transcursor IS
SELECT TransactionID, ARTIST.ArtistID
FROM ARTIST. WORK. TRANSACTION
WHERE Name=artistname AND Title-worktitle AND Copy=workcopy AND
TRANSACTION.Customer ID IS NULL AND
ARTIST.ArtistID - WORK.ArtistID AND
WORK.WorkID = TRANSACTION.WorkID;
BEGIN
/* Клиент уже есть в базе данных? */
SELECT Count (*) INTO rowcount
FROM CUSTOMER
WHERE Name=newname AND Area_Code=newareacode AND Phone_Number = newphone
IF rowcount > 0 THEN
BEGIN
DBMSJ)UTPUT.PIIT_LINE ('Customer Already Exists -- No Action Taken1);
RETURN;
END;
END IF;
/* Клиента нет в базе данных, добавляем нового клиента */
INSERT INTO CUSTOMER
(CustomerlD. Name. Area_Code, Phone_Number)
VALUES
(CustlD.NextVal, newname. newareacode, newphone);
/* Ищем одну и только одну свободную строку в таблице TRANSACTION. */
rowcount :5 0;
FOR trans In transcursor
LDOP
tid := trans.TransactionID;
aid := trans.ArtistID;
rowcount := rowcount + 1;
END LOOP;
IF rowcount > 1 Then
BEGIN
/* Слишком много свободных строк -- выдаем сообщение об ошибке,
отменяем изменения и выходим из процедуры */
ROLLBACK;
DBMS_OUTPUT.PUT_LINE (' Неверные данные в таблицах
ARTIST/WORK/TRANSACTION -- никаких действий не предпринято ');
Логика приложения 445
RETURN;
END;
END IF;
IF rowcount 5 0 Then
BEGIN
/* Нет ни одной свободной строки -- выдаем сообщение об ошибке,
отменяем изменения и выходим из процедуры */
RDLLBACK;
DBMS—OUTPUT.PUT_LINE (' Ни одной свободной строки в таблице
TRANSACTION -- никаких действий не предпринято ');
RETURN;
END;
END IF;
/* Есть ровно одна строка -- используем ее. Идентификатор транзакции,
полученный из transcursor. находится в переменной tid */
DBMS_OUTPUT.PUT_LINE (tid);
UPDATE TRANSACTION
SET CustomerlD = CustlD.Currval. Salesprice = price, PurchaseDate »
SysDate
WHERE Transactions = tid;
DBMS_QUTPUT.PUT_UNE (' Клиент добавлен в базу данных, данные транзакций
обновлены ');
/* Теперь регистрируем интерес данного клиента к данному художнику */
/* Используем идентификатор художника, находящийся в переменной aid, и
текущее значение последовательности CurrVal */
INSERT INTO CUSTQMER_ARTIST_INT (ArtistlD. CustomerlD)
VALUES (aid, CustlD.CurrVal);
END;
/
Логика этой процедуры, носящей имя NewCustomerWithTransaction, такова.
Сначала создаются данные нового клиента, и в таблице TRANSACTION, где
регистрируются купленные произведения, ведется поиск строк, в которых столбец CustomerlD
имеет пустое значение. Этот поиск ведется по соединению таблиц ARTIST, WORK
и TRANSACTION, так как имя художника (Name) хранится в таблице ARTIST, а
название произведения (Title) и номер копии (Сору) хранятся в таблице WORK. Если
найдена ровно одна такая строка, в ней обновляются столбцы CustomerlD
(идентификатор клиента), SalesPrice (цена продажи) и PurchaseDate (дата приобретения).
Затем добавляется запись в таблицу пересечения, чтобы зарегистрировать
интерес клиента к данному художнику. В противном случае, если число найденных
строк больше или меньше 1, никаких изменений в базе данных не производится.
Параметры процедуры NewCustomerWithTransaction содержат информацию о
клиенте и приобретенном произведении. В процедуре объявлены несколько
переменных и курсор. Курсор определен на соединении таблиц ARTIST, WORK и TRANSACTION.
Он выделяет столбцы TransactionID и ARTIST.ArtistID из строк, содержащих
данные об искомом художнике и произведении и имеющих нулевое значение
столбца CustomerlD.
446 Глава 12. Работа с базами данных в Oracle
Прежде всего процедура выполняет проверку, нет ли уже в базе данных
информации о данном клиенте. Если нет, данные нового клиента добавляются в
базу. В PL/SQL нет оператора BEGIN TRANSACTION1 — первое действие с базой
данных автоматически начинает транзакцию. Здесь новая транзакция начнется при
добавлении данных о покупателе.
Обратите также внимание, что комментарии заключены между скобками
вида /* и */. Такие комментарии могут состоять из нескольких строк, и если вы
начнете комментарий с символов /*, но забудете завершить его символами */, то
вся ваша программа будет воспринята как комментарий.
После того как данные о новом покупателе добавлены в базу, обрабатывается
курсор TransCursor. Переменная rowcount используется для подсчета строк, в
переменную tid записывается значение TransactionID, а в переменную aid — значение
ArtistlD. Заметьте, что оператор присваивания в Oracle выглядит так: «:=».
Например, tid :* trans.transactionID обозначает, что в переменную tid записывается
значение trans.TransactionID.
В соответствии с логикой процедуры, если найдена одна и только одна
строка, удовлетворяющая критериям, то в переменных tid и aid будут содержаться
значения, нужные нам для успешного завершения транзакции. Если же таких
строк не найдено или найдено более одной, то транзакция будет прервана, и ни
tid, ни aid не будут использованы.
Для подсчета строк мы могли бы использовать выражение Count(*), и затем,
если Count(*) = 1, запустить другой оператор, который бы получал нужные нам
значения aid и tid. При той логике, которая реализована в листинге 12.6,
необходимость во втором SQL-операторе отпадает.
Если число строк RowCount больше единицы или равно нулю, то выдается
сообщение об ошибке и выполняется откат транзакции, отменяющий вставку
данных в таблицу CUSTOMER. Если RowCount равно 1, обновляется соответствующая
строка в таблице TRANSACTION. Обратите внимание на использование функции
SysDate, с помощью которой записывается текущая дата. Наконец, в таблицу
пересечения добавляется строка с информацией о покупателе и авторе купленного
произведения (aid).
Эта хранимая процедура может быть вызвана командой наподобие
Exec NewCustomerWithTransaction('Susan WiT. '206'. "555-1000". 'Miro', 'Mi V1da'.
'79/122'. '65000'):
Следующие два оператора отображают данные после обновления:
SELECT CUSTOMER.Name. Copy. Title. ARTIST.Name
FROM CUSTOMER. TRANSACTION. WORK. ARTIST
WHERE CUSTOMER.CustomerID = TRANSACTION.CustomerlD AND
TRANSACTION.WorkID = WQRK.WorkID AND
WORK.ArtistlD = ARTIST.ArtistlD:
Будьте внимательны! Слово TRANSACTION используется здесь в двух значениях: как имя одной
из таблиц в базе данных галереи View Ridge и как английское слово, обозначающее транзакцию —
группу операторов, выполняемых как единое целое. Конкретное значение ясно из контекста, ио
имейте в виду, что возможна путаница.
Логика приложения 447
и
SELECT CUSTOMER.Name. ARTIST.Name
FROM CUSTOMER. CUSTOMER_ARTIST_INT, ARTIST
WHERE CUSTOMER. Customer ID = CUSTOMER_ARTIST_INT.CustomerID
AND
ARTIST. Artist ID = CUSTQMER_ARTISTJNT.ArtistID;
Обратите внимание, что требуется два SQL-оператора, поскольку это
представление базы данных имеет два многозначных пути. Оно не может быть
представлено одним SQL-оператором (или SQL-представлением).
Результаты этих запросов показаны на рис. 12.11. Данные покупательницы
по имени Сьюзен By (Susan Wu) корректным образом записаны в таблицы
TRANSACTION и CUSTOMERJ\RTISTJNT.
SQL> SELECT CUSTOMER.Name, Copy, Title, ARTIST.Name
2 FROM CUSTOMER, TRANSACTION, WORK, ARTIST
3 WHERE CUSTOMER.CustomerlD = TRANSACTION.CustomerlD AND |
4 TRANSACTION.WorkID = WORK.WorklD AND
, 5 WORK.ArtistlD =
NAME
Tiffany Twilight
David Smith
Jeffrey Janes
Tiffany Twilight
Susan Wu
ARTISTArtistlD;
COPY
4/40
4/40
5/40
79/122
79/122
SQL> SELECT CUSTOMER.Name, ARTISTName
TITLE
Mystic Fabric
Mystic Fabric
Mystic Fabric
Mi Vida
Mi Vida
2 FROM CUSTOMER, CUSTOMER_ARTIST_INT, ARTIST
NAME
Tobey
Tobey
Tobey
Miro
Miro
3 WHERE CUSTOMER-CustomerlD = CUSTOMER_ARTISTJNT.CustomeriD
4 AND
5 ARTlST.ArtistlD
NAME
Susan Wu
Fred Smathers
Selma Warning
Fred Smathers
Selma Warning
Fred Smathers
Selma Warning
7 rows selected.
= CUSTOMER_ARTISTJNTArtistlD;
NAME
Miro
Frings
Frings
van Vronkin
van Vronkin
Tobey
Tobey
Рис. 12.11. Данные после добавления нового клиента
448 Глава 12. Работа с базами данных в Oracle
Триггеры
Триггеры в Oracle — это процедуры на языке Java или SQL, которые вызываются
при выполнении определенных действий с базой данных. Oracle поддерживает
несколько типов триггеров: одни запускаются командами SQL, создающими в
базе данных новые структуры, например таблицы, другие запускаются единожды
на уровне таблицы, когда происходит изменение строк таблицы, третьи
запускаются по одному разу для каждой измененной строки. Последние называются
строчными триггерами (row triggers); их мы и будем рассматривать здесь. Oracle
поддерживает три вида триггеров: предваряющие (триггеры BEFORE),
завершающие (триггеры AFTER) и замещающие (триггеры INSTEAD OF).
Рассмотрим примеры каждого из этих типов.
Пример предваряющего триггера
В листинге 12.7 показан предваряющий триггер, который используется для
задания значения строки перед обновлением. Чтобы использовать этот триггер,
создайте сначала в таблице TRANSACTION новый столбец под именем AskingPrice. Это
можно сделать командой
ALTER TABLE TRANSACTION ADD Askingprice Number(7,2);
В листинге 12.7 триггер New_Price определен фразой Before Insert or Update of
AcquisitionPrice ON TRANSACTION. Эта фраза, являясь правильной, содержит
неопределенность. Она означает «ПЕРЕД (любой) вставкой в транзакции или ПЕРЕД
обновлением AcquisitionPrice в транзакции запустить триггер». Таким образом,
триггер будет запущен при любой вставке или при обновлении столбца
AcquisitionPrice. Обновления других столбцов не вызовут запуска триггера.
Листинг 12.7. Предваряющий триггер New_Price
CREATE DR REPLACE TRIGGER New_Price
BEFDRE INSERT OR UPDATE of AcquisitionPrice DN TRANSACTION
FDR EACH ROW
/* Устанавливаем новое значение AskingPrice перед вставкой или обновлением */
BEGIN
:new.AskingPrice := :new.AcquisitionPrice * 2:
END;
Фраза FOR EACH ROW (для каждой строки) указывает, что данный триггер
является строчным. Логика его работы проста: новое значение AskingPrice
вычисляется как удвоенное новое значение AcquisitionPrice.
Префикс :new доступен только для триггеров. Он обозначает новое значение
столбца в команде INSERT или UPDATE. Так, :new.AcquisitionPrice обозначает новое
Логика приложения 449
значение Acquisition Price (заданное пользователем). Для обновлений и удалений
существует также префикс :old, обозначающий значение столбца до выполнения
команды UPDATE или DELETE.
Введите текст триггера в текстовом редакторе и сохраните его в файле под
названием Trigl.sql. Затем в SQL Plus введите команду Start Trigl, и триггер ском-
пилируется. Если не будет ошибок компиляции, триггер будет сохранен в базе
данных и станет активным. Обновите столбец Acquisition Price и затем выберите
строки, которые вы обновили. Значение столбца Asking Price будет задано триггером.
Если у вас будут ошибки компиляции, вы сможете их увидеть, введя команду
Show Errors, как это делалось ранее с хранимыми процедурами.
Пример завершающего триггера
В листинге 12.8 показан пример завершающего триггера. Логика его такова: View
Ridge определяет произведение, предназначенное для продажи, как любое
произведение, имеющее строку в таблице TRANSACTION с пустым значением CustomerlD.
Задача этого триггера — гарантировать, что такая строка в таблице TRANSACTION будет
существовать, когда в базу данных будет записываться произведение. Этот триггер,
запускаемый при создании строки в таблице WORK, проверяет таблицу TRANSACTION
и не производит никаких действий, если находит в ней подходящую строку.
Листинг 12.8. Завершающий триггер On_Work_lnsert
CREATE DR REPLACE TRIGGER DnJIORKJnsert
AFTER INSERT ON WDRK
FOR EACH RDW
DECLARE
rowcount integer(2);
BEGIN
/* Считаем доступные строки */
SELECT Count (*) INTD rowcount
FROM TRANSACTION
WHERE CustomerlD IS NULL AND WorkID5:new.WorkID:
IF rowcount > 0 Then /* Строка существует, ничего не предпринимаем */
DBMSJDUTPUT.PUTJJNE (Подходящая строка в таблице TRANSACTION
существует -- никаких действий не предпринято.');
RETURN;
ELSE /* Нужно добавить новую строку */
INSERT INTD TRANSACTION (TransactionlD. DateAcquired. WorkID)
VALUES (TransID.NextVal. SysDate, :new.WorkID);
END IF;
END;
/
450 Глава 12. Работа с базами данных в Oracle
Логика работы триггера элементарна. Он подсчитывает количество
подходящих строк, и если это количество больше нуля, то ничего не предпринимается;
если оно равно нулю, в таблице TRANSACTION создается новая строка с
соответствующими данными. Обратите внимание на то, как префикс :new используется
в части VALUES оператора INSERT.
Пример замещающего триггера
Замещающие триггеры используются для обновления представлений.
Рассмотрим представление, определенное в листинге 12.9. Оно соединяет в себе четыре
таблицы и, как представление соединения, не может быть обновлено без помощи
соответствующего триггера.
Листинг 12.9. Определение представления CustomerPurchases
CREATE VIEW CustomerPurchases AS
SELECT CUSTOMER.Name CustName, Copy, Title, ARTIST.Name ArtistName
FROM CUSTOMER. TRANSACTION, WORK, ARTIST
WHERE CUSTOMER.CustomerlD =- TRANSACTION.Customer ID AND
TRANSACTION.Work ID = WORK.WorkID AND
WORK.Art1st ID = ARTIST.ArtistID;
SQL> SELECT -
CUSTNAME
Tiffany Twilight
David Smith
Jeffrey Janes
Tiffany Twilight
Susan Wu
FROM CustomerPurchases;
COPY
4/40
4/40
5/40
79/122
79/122
TITLE
Mystic Fabric
Mystic Fabric
Mystic Fabric
Mi Vida
Mi Vida
ARTISTNAME
Tobey
Tobey
Tobey
Miro
Miro
Рис. 12.12. Данные CustomerPurchases
Обратите внимание на фразу SELECT в определении этого представления. Она
задает синонимы для столбцов CUSTOMER.Name (синоним CustName) и ARTIST.Name
(синоним ArtistName). Если бы это не было сделано, в представлении оказалось
бы два столбца с именем Name, а такое недопустимо. Рисунок 12.12 показывает,
как используются синонимы при обработке этого представления. В качестве
заголовков столбцов фигурируют CUSTNAME и ARTISTNAME.
Исследуйте данные на рис. 12.12; подумайте, что должно произойти, когда
пользователь попытается обновить столбец Title. Название «Mystic Fabric»
фигурирует в трех строках, но в таблице WORK имеется только две строки с таким
названием. Что должна сделать Oracle, когда пользователь обновит столбец Title?
Должна ли она обновить строки в таблице WORK, на которой основано это
представление? Или она должна создать в таблице WORK новые строки и связать их со
строками данного представления? А может, необходимо сделать что-то другое?
Логика приложения 451
11евозможно написать для СУБД обобщенный код, который бы корректно
обрабатывал каждую возможную ситуацию.
Замещающие триггеры позволяют разработчику задать действия, которые
необходимо предпринять при попытке обновить представление в конкретном
приложении. В листинге 12.10 показан пример такого триггера, который обрабатывает
обновления столбца Title представления CustomerPurchases. Поскольку
замещающие триггеры, в отличие от предваряющих, не могут содержать фразу UPDATE OF,
мы должны написать код, определяющий, был ли изменен столбец Title.
Листинг 12.10. Замещающий триггер TitleJJpdate
CREATE OR REPLACE TRIGGER TitleJJpdate
INSTEAD OF UPDATE ON CustomerPurchases
FOR EACH ROW
BEGIN
/* Ничего не делаем, кроме случая, когда обновляется столбец Title */
IF :new.Title 5 :old.Title THEN
RETURN;
END IF;
UPDATE WORK
SET Title = :new.Title
WHERE Title = :old.Title;
END;
Если пользователь обновляет столбец Title, то соответствующее изменение
вносится в таблицу WORK. Обратите внимание, что запуск триггера происходит
при обновлении представления CustomerPurchases, но само обновление
производится в таблице WORK — одной из таблиц, на которой базируется это
представление. Как раз для таких действий и предназначаются замещающие триггеры.
Этот триггер может приводить к неожиданным результатам. Если
пользователь введет:
UPDATE CustomerPurchases SET Title = 'aa\ Copy = '1/3' WHERE Title = *bb';
то будет произведено обновление столбца Title, но ничего не произойдет со
столбцом Сору. Лучше было бы выдать пользователю сообщение, предупреждающее
о таком эффекте.
Обработка исключений
В нашем изложении опущена тема обработки исключений в PL/SQL. Это
заслуживает сожаления, ибо обработка исключений важна и полезна. Дело в том, что
эта тема является слишком обширной, чтобы обсуждать ее здесь. Однако если вы
в будущем собираетесь программировать на PL/SQL, обязательно изучите этот
важный вопрос. Обработка исключений может использоваться в любых видах
452 Глава 12. Работа с базами данных в Oracle
процедур на PL/SQL, но особо она полезна в предваряющих и замещающих
триггерах для отмены незафиксированных обновлений. Исключения необходимы
потому, что в Oracle откат транзакции невозможно произвести в теле триггера.
Вместо этого можно использовать исключения для генерации предупреждений
и сообщений об ошибках. Исключения также дают Oracle больше информации
о том, что делает триггер.
Например, триггер, изображенный в листинге 12.10, имеет странную
особенность. Если вы введете
UPDATE Customer-Purchases SET Copy = '5/5' WHERE Title = 'Mystic Fabric';
триггер не обновит ни одной строки. Однако Oracle сообщит, что все строки
представления, имеющие в столбце Title название «Mystic Fabric», были обновлены.
Это было обусловлено тем, что триггеру были переданы все строки, и Oracle не
знала, какая из их вызвала обновление, а какая нет. Если же вы включите в этот
триггер код, генерирующий исключение, Oracle будет знать, что строка не была
обновлена, и выдаст правильное количество обновленных строк.
Словарь данных
Oracle поддерживает исчерпывающий словарь метаданных. Этот словарь
описывает структуру таблиц, последовательностей, представлений, индексов,
ограничений, хранимых процедур и многого другого. Он также содержит исходные тексты
процедур, функций и триггеров. И это еще не все.
В таблице DICT словаря метаданных содержатся данные, описывающие сам
словарь. Вы можете запрашивать данные из этой таблицы, чтобы узнать больше
о содержимом словаря данных, но имейте в виду, что она имеет большие
размеры. Например, если вы запросите имена всех таблиц словаря данных, вам будет
возвращено более 800 строк.
Предположим, вы хотите узнать, какие таблицы с информацией о
пользовательских и системных таблицах имеются в словаре данных. В этом вам поможет
следующий запрос:
SELECT Table_Name, Contents
FROM DICT
WHERE Table_Name LIKE ('STABLES*');
Будет возвращено около двадцати пяти строк. Одна из таблиц будет
называться USE ROTABLES. Чтобы увидеть столбцы этой таблицы, введите
DESC USERJABLES;
Вы можете использовать эту стратегию для получения из словаря
метаданных информации об интересующих вас объектах и структурах. В табл. 12.2
перечислены многие из представлений и указано их назначение. Таблицы USER_
SOURCE и USERJTRIGGERS полезны, когда требуется узнать, исходные тексты каких
процедур и триггеров хранятся в настоящий момент в базе данных.
Управление параллельной обработкой 453
Таблица 12.2. Некоторые полезные таблицы из словаря данных Oracle
Имя таблицы Содержимое
DICT Метаданные, описывающие словарь данных
USER_CATALOG Список таблиц, представлений, последовательностей и других
структур, принадлежащих пользователю
USERJTABLES Структуры таблиц пользователя
USER_TAB_COLUMNS Потомок таблицы USER_JABL.ES. Содержит данные о столбцах
таблиц. Синонимом является COLS
USERJVIEWS Пользовательские представления
USER_CONSTRAINTS Пользовательские ограничения
USER_CONS_COLUMNS Потомок таблицы USER_CONSTRAINTS. Содержит столбцы,
на которые наложены ограничения
USER_TRIGGERS Метаданные, описывающие триггеры. Запрашивайте столбцы
Trigger_Name, Trigger_Type и Trigger_Event. Предупреждение:
Trigger_Body в действительности не содержит исходного кода
триггера.
USER_SOURCE Чтобы получить текст процедуры MYTRIGGER, введите
SELECT Text
FROM USER_SOURCE
WHERE Name=iMYTRIGGER'
AND
Type='PROCEDURE'
На данном этапе вы обладаете достаточным знанием SQL, чтобы
самостоятельно исследовать словарь метаданных. Имейте в виду, что Oracle записывает
все имена в верхнем регистре. Если вы ищете триггер On_Customer_Insert, вам
следует искать имя ON_CUSTOMER_INSERT.
Управление параллельной обработкой
Oracle поддерживает три различных уровня изоляции транзакций и вдобавок
позволяет приложениям налагать блокировки явным образом. Явное наложение
блокировок, однако, не рекомендуется, поскольку оно может войти в конфликт
со стратегией блокировки, применяемой Oracle по умолчанию, и, кроме того,
увеличивает вероятность взаимной блокировки транзакций.
Прежде чем мы будем обсуждать уровни изоляции транзакций, необходимо
кратко рассмотреть то, как Oracle обрабатывает изменения в базе данных. Oracle
ведет учет числа изменений в системе (System Change Number, SCN), которое
представляет собой значение масштаба базы данных, увеличивающееся на
единицу всякий раз, когда в базе данных производится изменение. Когда изменяется
строка, текущее значение SCN сохраняется вместе со строкой. Одновременно
исходный образ строки помещается в сегмент отката (rollback segment) — буфер,
поддерживаемый Oracle для выполнения отката и записи транзакций в журнал.
Исходный образ включает в себя значение SCN, которое было записано в строке
до изменения. Завершив обновление, Oracle увеличивает SCN.
454 Глава 12. Работа с базами данных в Oracle
Допустим, приложение выдает SQL-оператор вида
UPDATE MYTABLE
SET MyColumnl = 'Новое_Значение'
WHERE MyColumn2 - 'Что-нибудь':
Сначала записывается значение SCN, имевшее место .в момент запуска
оператора. Назовем это значение SCN оператора. При обработке запроса, в данном
случае при поиске строк, в которых MyColumn2 = 'Что-нибудь', Oracle выберет
только те строки, которые содержат завершенные изменения с SCN, меньшим или
равным SCN оператора. Если Oracle находит строку с завершенным изменением,
SCN которой превышает SCN оператора, она ищет в сегменте отката версию этой
строки с завершенным изменением, SCN которой меньше, чем SCN оператора.
При таком способе обработки SQL-операторы всегда считывают
согласованный набор значений — те значения, которые были записаны до или в момент
запуска оператора. Как вы увидите, эта стратегия иногда применяется и к
транзакциям. В этом случае все операторы в транзакции считывают строки, SCN которых
не превышает значение SCN, имевшее место на момент начала транзакции.
Обратите внимание, что Oracle считывает только завершенные изменения.
Следовательно, «грязное» чтение невозможно.
Oracle поддерживает три уровня изоляции транзакций: «завершенное чтение»,
«сериализуемость» и «только чтение» (read only). Первые два уровня изоляции
определены в стандарте ANSI 1992 г., а уровень «только чтение» является
уникальным для Oracle. В табл. 12.3 приведена характеристика этих уровней
изоляции.
Таблица 12.3. Варианты управления параллельной обработкой в Oracle
Уровень изоляции Описание
Завершенное чтение Уровень изоляции, используемый Oracle по умолчанию. «Грязное»
чтение невозможно, но повторное чтение может дать различные
результаты. Возможно возникновение фантомов.
Каждый оператор считывает согласованные данные. Когда
налагается блокировка на обновление, операторы откатываются
и запускаются вновь по необходимости. Взаимная блокировка
обнаруживается, и один из операторов, вызвавших ее, откатывается
Сериализуемость «Грязное» чтение невозможно. Повторное чтение дает один
и тот же результат, фантомы невозможны.
Все операторы в транзакции считывают согласованные данные.
Ошибка «Cannot Serialize» («Невозможно сериализовать») возникает,
когда транзакция пытается обновить или удалить строку
с завершенным изменением, которое произошло после начала
транзакции. Кроме того, эта ошибка возникает, когда транзакции
или операторы, налагающие блокировку, фиксируют свои
изменения, а также когда транзакция откатывается вследствие
взаимной блокировки. Обработку исключения «Cannot Serialize»
необходимо производить в прикладных программах
Только чтение Все операторы считывают согласованные данные. Невозможны
вставка, обновление или удаление
Явные блокировки Не рекомендуются
Управление параллельной обработкой 455
Уровень изоляции «завершенное чтение»
Вспомните из главы И, что при уровне изоляции «завершенное чтение»
«грязное» чтение невозможно, однако чтение может быть невоспроизводимым, и могут
возникать фантомы. «Завершенное чтение» — это уровень изоляции транзакций,
применяемый в Oracle по умолчанию, поскольку Oracle никогда не считывает не-
сохраненные изменения.
При уровне изоляции «завершенное чтение» каждый оператор по
отдельности согласован, но два различных оператора в одной и той же транзакции могут
считать несогласованные данные. Это то же самое, что согласованность на
уровне оператора, как она определена в предыдущей главе. Если требуется
согласованность на уровне транзакции, необходимо использовать уровень
«сериализуемость». Однако не смешивайте согласованность на уровне оператора с проблемой
потери обновления. В Oracle потерянные обновления невозможны, так как она
никогда не читает «грязные» данные.
Из-за того, как Oracle использует SCN, ей не требуется налагать блокировки
при чтении. Но перед тем как изменить или удалить строку, Oracle наложит на
нее монопольную блокировку. Если другая транзакция наложила монопольную
блокировку на данную строку, оператор будет ждать. Если наложившая
блокировку транзакция откатывается, изменение или удаление выполняется.
Если наложившая блокировку транзакция сохраняется в базе данных, то
оператору передается новое значение SCN, и сам оператор (а не транзакция)
откатывается и запускается заново. Когда происходит откат оператора, изменения,
уже произведенные этим оператором, отменяются с помощью сегментов отката.
Вследствие использования монопольных блокировок могут возникать
ситуации взаимной блокировки. Когда такое происходит, Oracle обнаруживает
взаимную блокировку с помошью графа ожидания (wait-for graph) и производит откат
одного из вызвавших конфликт операторов.
Уровень изоляции «сериализуемость»
Как вы узнали из главы И, при уровне изоляции «сериализуемость» «грязное»
чтение невозможно, чтение всегда является воспроизводимым, и фантомы
возникать не могут. Oracle поддерживает этот уровень изоляции, но для его работы
необходимо участие прикладной программы.
Чтобы изменить уровень изоляции транзакции внутри самой транзакции,
используйте команду Set Следующий оператор установит уровень изоляции
«сериализуемость» на время выполнения транзакции:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
Чтобы изменить уровень изоляции для всех транзакций в сессии,
воспользуйтесь командой ALTER:
ALTER SESSIONS SET ISOLATIONJ.EVEL SERIALIZABLE:
Когда установлен уровень изоляции «сериализуемость», Oracle сохраняет
значение SCN в момент запуска транзакции. Назовем это значение SCN транзакции.
456 Глава 12. Работа с базами данных в Oracle
Пока транзакция выполняется, Oracle считывает только те зафиксированные
изменения, для которых значение SCN не преышает SCN транзакции.
Следовательно, чтение всегда являтся воспроизводимым, а фантомы невозможны.
Пока транзакция не пытается обновить или удалить какую-либо строку с
завершенным изменением, SCN которой больше SCN транзакции, обработка
транзакции будет идти своим чередом. Если же транзакция попытается обновить или
удалить такую строку, Oracle выдаст ошибку «Cannot Serialize». Здесь должна
сыграть свою роль прикладная программа. Она может зафиксировать
сделанные изменения, выполнить откат всей транзакции или предпринять какое-то
другое действие- Любая программа, выполняемая с уровнем изоляции «сериали-
зуемость», должна содержать такую обработку исключений.
Кроме того, когда транзакция, выполняемая при уровне изоляции «сериали-
зуемость», пытается обновить или удалить строку, на которую другой
транзакцией или оператором наложена монопольная блокировка, транзакция ждет.
Если происходит откат транзакции или оператора, наложившего блокировку,
обработка транзакции может быть продолжена. Если же наложившая блокировку
транзакция сохраняется, Oracle выдает ошибку «Cannot Serialize», и приложение
должно обработать это исключение.
Подобным же образом, если произошел откат сериализуемой транзакции
вследствие взаимной блокировки, также произойдет ошибка «Cannot Serialize».
Уровень изоляции «только чтение»
При этом уровне изоляции транзакция считывает только те строки с
завершенными изменениями, для которых значение SCN меньше или равно SCN
транзакции. Если транзакция обнаруживает строки с завершенными изменениями, в
которых значение SCN превышает SCN транзакции, Oracle обратится к сегментам
отката и реконструирует строку в том виде, как она была до начала транзакции.
На этом уровне изоляции запрещены вставка, обновление и удаление.
Дополнительные замечания о блокировках
Приложение может налагать блокировки явным образом, используя форму SELECT
FOR UPDATE оператора SELECT. Это не рекомендуется делать, пока вы не узнаете о
блокировках в Oracle гораздо больше, чем описано здесь.
Oracle использует разнообразные типы внутренних блокировок для
обеспечения описанных здесь уровней изоляции. Существует, например, коллективная
блокировка строки, а также несколько типов табличных блокировок. Есть и
другие блокировки, используемые Oracle для своих нужд. Вы можете узнать больше
об этих блокировках в документации по Oracle.
Чттобы снизить вероятность конфликта блокировок, Oracle не не дает
возможности распространять блокировки с одного уровня на другой. Строчные
блокировки остаются строчными, даже если их насчитываются сотни на сотнях
строк таблицы. Эта стратегия отличается от стратегии SQL Server, как вы
узнаете из следующей главы. Oracle Corporation заявляет, что нерасширение блокиро-
Резервное копирование и восстановление в Oracle 457
»ок является преимуществом, и возможно, что это так, особенно если учитывать
архитектуру блокировок Oracle в целом.
Oracle и безопасность
Как описывалось в главе 11, для добавления пользователя в базу данных
администратор базы данных создает учетную запись с именем пользователя и паролем.
Каждому пользователю присваивается профиль — характеристика предельных
объемов системных ресурсов, которые могут быть выделены данному
пользователю. Сюда входит лимит совокупного процессорного времени, предоставляемого
в течение одного сеанса или за один вызов Oracle, и другие подобные ограничения.
В Oracle имеются системные и объектные привилегии. Системные
привилегии — это права на выполнение общих задач, таких как SELECT ANY TABLE и UPDATE
ANY TABLE. Объектные привилегии относятся к действиям с определенными
элементами базы данных — таблицами, представлениями и последовательностями.
Для предоставления привилегий другому пользователю можно использовать
оператор GRANT.
Роль в Oracle — это совокупность привилегий и других ролей. Одна и та же
роль может быть присвоена многим пользователям, и один и тот же
пользователь может иметь множество ролей. Примером роли в базе данных галереи
View Ridge может служить MANAGER. Эта роль наделяется всеми системными
и объектными привилегиями, необходимыми для выполнения менеджерских
функций в галерее. Учетные записи пользователя с данной ролью
присваиваются ряду сотрудников галереи View Ridge.
Более подробную информацию о безопасности в Oracle вы можете получить,
поискав там документацию по темам пользователь, роли и привилегии.
Резервное копирование и восстановление
в Oracle
В Oracle имеется превосходный набор средств и служебных программ для
резервного копирования и восстановления. Они обладают большой гибкостью, что
позволяет применять их для самых разных типов баз данных — от небольших
коллективных, копирование которых может осуществляться ночью, в нерабочее
время, до огромных межорганизационных, которые функционируют круглые
сутки без выходных и не должны ни на минуту прекращать работу.
Средства восстановления Oracle
Oracle поддерживает три типа файлов, важных для резервного копирования и
восстановления. Файлы данных (datafiles) содержат данные пользователя и системную
информацию. Из-за способа, применимого Oracle для сброса буферов данных на
458 Глава 12. Работа с базами данных в Oracle
диск, в произвольный момент времени файлы данных могут содержать как
сохраненные, так и несохраненные изменения. Разумеется, обработка транзакций в Oracle
происходит таким образом, что несохраненные изменения в конечном счете либо
сохраняются в базе данных, либо удаляются, но в «снимке» файлов данных, взятом
в любой отдельный момент времени, несохраненные изменения будут
присутствовать. Таким образом, при остановке Oracle или выполнении определенных видов
резервного копирования необходимо производить «чистку» файлов данных, чтобы
в них оставались только сохраненные изменения.
Файлы отката (ReDo files) содержат журналы изменений базы данных; они
представляют собой резервные копии сегментов отката, используемых при
параллельной обработке транзакций. Контрольные файлы (control files) — это
небольшие файлы, в которых перечисляются имена, местоположение и описание
содержимого различных файлов, используемых Oracle. Контрольные файлы
часто обновляются, и они должны быть доступны для Oracle, чтобы база данных
могла функционировать.
Есть два типа файлов отката. Текущие, или онлайновые, файлы отката (online
ReDo files) хранятся на диске и содержат сегменты отката от недавних
изменений в базе данных. Архивные, или оффлайновые, файлы отката (offline ReDo files) —
это резервные копии текущих файлов отката. Они хранятся отдельно от текущих
файлов отката и не обязательно на дисковом накопителе. Oracle может работать
в одном из двух режимов: ARCHIVELOG и N0ARCHIVEL0G. В режиме ARCHIVELOG при
заполнении текущих файлов отката их содержимое копируется в архивные
файлы отката.
Контрольные файлы и текущие файлы отката настолько важны, что Oracle
рекомендует хранить две активные копии каждого из них. Этот процесс
называется в терминологии Oracle мультиплексированием (multiplexing).
Типы сбоев
Техника восстановления в Oracle зависит от типа возникшего сбоя. В случае сбоя
приложения (application failure), произошедшего, например, из-за ошибки в
логике приложения, Oracle просто выполняет откат несохраненных изменений,
сделанных данным приложением, используя для этого сегменты отката в
оперативной памяти и текущие файлы отката.
Другие типы сбоев подразумевают более сложный процесс восстановления.
Сбой экземпляра (instance failure) — это сбой в самой Oracle, произошедший из-
за ошибки операционной системы или аппаратного обеспечения компьютера.
Сбой носителя (media failure) происходит, когда Oracle оказывается не в
состоянии произвести запись в физический файл. Причина может заключаться в том,
что имеется повреждение головки диска или другая дисковая ошибка, что
нужное устройство не включено в сеть или что файл испорчен.
Восстановление после сбоя экземпляра
Когда Oracle перезапускается после сбоя экземпляра, она в первую очередь
просматривает контрольный файл, чтобы определить, где находятся все остальные
Резервное копирование и восстановление в Oracle 459
файлы. Затем она обрабатывает файлы данных, используя информацию из
текущих файлов отката. При этом выполняются (накатываются) все изменения,
зарегистрированные в файлах отката, но не сохраненные в файлах данных на момент
возникновения сбоя. В ходе этого процесса сегменты отката заполняются
записями транзакций из файла отката.
По завершении наката файлы данных могут содержать несохраненные
изменения. Эти изменения могли присутствовать в файлах данных в момент сбоя
экземпляра, а могли появиться в результате наката. Так или иначе, Oracle удаляет
эти изменения, используя сегменты отката, созданные в ходе выполнения
наката. Чтобы незавершенным транзакциям не приходилось дожидаться отката, все
сохраненные транзакции помечаются как мертвые (DEAD). Если новая
транзакция оказывается заблокированной изменением, которое произведено мертвой
транзакцией, диспетчер блокировок снимает блокировки, удерживаемые
мертвой транзакцией.
При восстановлении после сбоя экземпляра архивные файлы отката не
используются. Следовательно, восстановление после сбоя экземпляра может быть
произведено как в режиме ARCHIVELOG, так и в режиме N0ARCHIVEL0G.
Восстановление после сбоя носителя
Для восстановления после сбоя носителя используется резервная копия базы
данных. Если база данных работала в режиме N0ARCHIVEL0G, то ничего больше сделать
нельзя. Архивные файлы отката будут бесполезны, поскольку они будут
содержать записи изменений, сделанных значительно позже, чем была сделана
резервная копия. Организация должна найти какой-то другой способ восстановления
данных. (Между прочим, начинать думать о таких вещах нуждо гораздо раньше!)
Если Oracle работала в режиме ARCHIVELOG, то в архиве после сбоя будут
содержаться копии текущих файлов отката. В этом случае база данных
восстанавливается из резервной копии, а затем с помощью архивных файлов отката
производится накат. По завершении наката изменения, сделанные несохраненными
транзакциями, отменяются путем описанного выше процесса отката.
Существует два вида резервных копий. Согласованная резервная копия
(consistent backup) — это такая резервная копия, в которой из файлов данных
удалены все несохраненные изменения. Для создания такой копии работа базы
данных должна быть приостановлена, все буферы должны быть сброшены на диск,
а изменения, произведенные несохраненными транзакциями, должны быть
удалены. Ясно, что этот вид резервного копирования неприемлем для баз данных,
функционирующих в режиме 24x7.
Несогласованная резервная копия (inconsistent backup) может содержать
несохраненные изменения. Такого рода резервное копирование производится Oracle
«на лету», в ходе обработки базы данных. Чтобы восстановить базу данных из
несогласованной резервной копии, сначала эта копия делается согласованной.
Для этого на основании записей из архивных журналов записываются или
отменяются все транзакции, которые выполнялись в момент, когда делалась
резервная копия. Несогласованную резервную копию можно сделать не со всей базы
данных, а лишь с ее части. Так, в приложении, работающем в режиме 24x7, каждую
460 Глава 12. Работа с базами данных в Oracle
ночь можно копировать одну седьмую часть базы данных. В результате за
неделю будет сделана резервная копия всей базы данных.
Менеджер восстановления Oracle (Oracle Recovery Manager, RMAN) — это
служебная программа, предназначенная для создания резервных копий и
восстановления базы данных. RMAN позволяет создать специальную базу данных
восстановления, содержащую информацию об архивных» файлах и операциях по
восстановлению. Однако описание этой программы выходит за рамки нашего
изложения.
Вопросы, не затронутые в данной главе
Есть несколько важных аспектов Oracle, которые не обсуждались нами в этой
главе. Во-первых, Oracle поддерживает объектно-ориентированные структуры,
которые разработчики могут использовать для создания собственных
абстрактных типов данных. С помощью Oracle можно также создавать и обрабатывать
базы данных, представляющие собой гибриды традиционных и объектных баз
данных. Такие гибриды называются объектно-реляционными базами данных (object-
relational databases); их мы будем обсуждать в главе 18.
Далее следует отметить, что версия Oracle для предприятий (Enterprise Oracle)
поддерживает обработку распределенных баз данных, которые хранятся более
чем на одном компьютере. Этот вопрос будет обсуждаться в главе 17. Помимо
этого, есть еще несколько служебных программ Oracle, которые не были нами
упомянуты. Например, Oracle Loader — это утилита для ввода больших объемов
информации в базу данных Oracle. Другие утилиты предназначены для
измерения и оптимизации производительности Oracle.
Тем не менее, наиболее важные аспекты и вопросы, связанные с Oracle,
нашли свое отражение в этой главе. Если вы разобрались с представленными здесь
базовыми концепциями, то у вас уже есть многое для того, чтобы стать
успешным разработчиком баз данных в СУБД Oracle.
Резюме
Oracle — мощная и устойчивая СУБД, работающая под управлением множества
операционных систем и содержащая в себе много различных продуктов. В этой
главе описана работа с программой SQL Plus, с помощью которой можно
создавать и обрабатывать процедуры на языках SQL и PL/SQL во всех версиях Oracle.
PL/SQL — это язык, расширяющий возможности SQL за счет добавления в него
конструкций, специфичных для языков программирования.
Создать базу данных в Oracle можно с помощью мастера Database Configuration
Assistant, с помощью предоставляемых Oracle специализированных процедур или
с помощью SQL-команды CREATE DATABASE. Мастер Database Configuration Assistant
создает стандартную базу данных и файлы журналов. SQL Plus содержит
текстовый редактор с ограниченными возможностями, который хранит текущий опера-
Резюме 461
гор в многострочном буфере. SQL Plus можно настроить на работу с внешним
текстовым редактором, таким как Notepad.
Для создания таблиц в Oracle служит SQL-команда CREATE TABLE. В тексте
команды указывается имя создаваемой таблицы, а за ним в скобках — имена, типы
данных и свойства столбцов. Работу с суррогатными ключами в Oracle можно
организовать с помощью последовательностей. Объекты-последовательности
имеют метод NextVal, возвращающий следующее значение в последовательности, и
метод CurrVal, возвращающий текущее значение в последовательности. К сожалению,
реализация суррогатных ключей с помощью последовательностей не
гарантирует того, что таблица будет иметь допустимые значения суррогатных ключей.
Таблицы (и данные в них) удаляются из базы данных командой DROP. Столбцы
таблиц могут быть удалены командой ALTER TABLE. Связи определяются путем
введения ограничений внешнего ключа, для чего используется команда ALTER
TABLE ... ADD COINSTRAINT .... Можно инициировать удаление строк в таблицах
с зависимыми ключами при удалении строк в родительских таблицах, для чего
служит фраза ON DELETE CASCADE в определении связи.
Индексы создаются для обеспечения уникальности и возможности быстрого
получения данных по значениям столбцов. Индексы создаются командой CREATE
INDEX. Добавлять, изменять или удалять столбцы из таблицы можно с помощью
команды ALTER. Контрольные ограничения — это ограничения, налагаемые на
возможные значения столбцов. Условия в таких ограничениях должны должны
формулироваться так, чтобы результат их проверки принимал значение
«истина» или «ложь» и чтобы для их вычисления использовались только константы
и значения из текущей строки таблицы, на которой определено ограничение.
Добавление и снятие ограничения производится командой ALTER TABLE.
SQL-представление — это результат выполнения SQL-выражения SELECT,
использующего выборку, проектирование и соединение. Такие представления могут
иметь максимум один многозначный путь. Представления создаются с помощью
команды CREATE VIEW. Представления соединения создаются с помощью
соединения и, как правило, не могут обновляться командами INSERT, UPDATE и DELETE.
Однако для их обновления можно использовать замещающие (INSTEAD-OF)
триггеры.
Последовательности операторов PL/SQL могут сохраняться в файлах и
обрабатываться с помощью SQL Plus. Они могут также записываться в базу данных
в виде хранимых процедур и вызываться из других программ на PL/SQL или из
прикладных программ. Примеры хранимых процедур изображены в листингах 12.5
и 12.6. В Oracle также имеются триггеры — программы на PL/SQL или Java,
которые вызываются при наступлении определенного события в базе данных.
Примеры предваряющих, завершающих и замещающих триггеров приведены в
листингах 12.17, 12.8 и 12.9 соответственно.
Oracle поддерживает словарь метаданных. Сами метаданные хранятся в
таблице DICT. Запросив информацию из этой таблицы, можно ознакомиться с
содержимым словаря.
Oracle поддерживает три уровня изоляции транзакций: завершенное чтение,
сериализуемость и только чтение. Из-за того, как обрабатываются значения SCN,
«грязное» чтение в Oracle невозможно. При использовании уровня изоляции
462 Глава 12. Работа с базами данных в Oracle
«сериализуемость» прикладная программа должна обрабатывать ошибку «Cannot
serialize» («Невозможно сериализовать»). Приложения могут налагать
блокировки явным образом, используя команду SELECT FOR UPDATE, но это не рекомендуется.
С помощью Oracle администратор определяет пользователей и привилегии.
Роль — это группа привилегий и других ролей. Одному и тому же пользователю
может быть дано множество ролей, и одна и та же роль может быть дана
множеству пользователей.
В процессе резервного копирования и восстановления в Oracle используются
три типа файлов: файлы данных, текущие и архивные файлы отката и контрольные
файлы. При работе в режиме ARCHIVELOG Oracle записывает в журнал все изменения,
произведенные в базе данных. В случае сбоя приложения или экземпляра Oracle
может восстановить базу данных без использования архивного файла журнала.
Однако для восстановления после сбоя носителя архивные файлы необходимы.
Резервные копии могут быть согласованными и несогласованными.
Несогласованную копию мождно сделать согласованной, обработав архивный файл журнала.
Вопросы I группы
1. Опишите общие характеристики Oracle и состав пакета программ Oracle.
Объясните, почему эти характеристики определяют значительную
сложность освоения продукта.
2. Что такое SQL Plus и в чем заключаются его функции?
3. Назовите три способа создания базы данных Oracle. Какой способ
является наиболее простым?
4. Объясните, как изменить содержимое строки в буфере SQL Plus.
Предположим, что в буфере находится три оператора, текущим является
третий оператор, а вам необходимо поменять второй оператор с CustID=1000
на CustomerID=1000.
5. Как настроить рабочую папку для SQL Plus?
6. Постройте SQL-оператор, создающий таблицу Т1 со столбцами Cl, C2 и СЗ.
Пусть С1 является суррогатным ключом. Пусть также С2 содержит текст
длиной 50 символов, а СЗ содержит дату.
7. Напишите оператор, создающий последовательность, которая начинается
с 50 и имеет инкремент 2 (то есть каждый элемент на 2 больше
предыдущего). Назовите эту последовательность TISeq.
8. Покажите, как вставить строку в таблицу Т1 (вопрос 6), используя
последовательность, созданную в ответе на вопрос 7.
9. Напишите SQL-оператор, запрашивающий строку, созданную в ответе на
вопрос 8.
10. Опишите проблемы, которые связаны с использованием
последовательностей для столбцов, являющихся суррогатными ключами.
И. Напишите SQL-операторы, удаляющие таблицу Т1 и последовательность
TISeq.
Вопросы 1 группы 463
12. Напишите SQL-операторы, удаляющие столбец СЗ таблицы Т1,
13. Напишите SQL-операторы, создающие связь между таблицами Т2 и ТЗ,
Пусть ТЗ имеет столбец FK1, являющийся внешним ключом и связанный
с Т2, и пусть удаления в Т2 должны вызывать удаления в ТЗ,
14. Ответьте на вопрос 13, но не вызывайте удаления в ТЗ.
15. Покажите, как удалить связь с помощью SQL.
16. Напишите SQL-операторы, создающие уникальный индекс по столбцам С2
и СЗ таблицы Т1.
17. В каких случаях следует использовать индексы?
18. Напишите SQL-операторы, добавляющие в таблицу Т1 новый столбец С4.
Пусть этот столбец содержит значения типа Currency, и максимальное
значение равно $1 000 000.
19. При каких условиях можно удалить столбец из существующей таблицы?
20. При каких условиях можно добавить столбец к существующей таблице?
21. Покажите, как добавить непустой столбец к существующей таблице.
22. При каких условиях можно изменить ширину текстового или числового
столбца?
23. При каких условиях можно изменить тип данных столбца?
24. Покажите, как добавить ограничение, указывающее, что значение столбца
С4 таблицы Т1 не может быть меньше 1000.
25. Покажите, как добавить ограничение, указывающее, что столбец С4
таблицы Т1 не может быть меньше столбца С5 таблицы Т1.
26. Для базы данных галереи View Ridge, описанной в этой главе, постройте
представление, содержащее имя клиента (Name), город (City) и штат (State),
в котором он проживает. Назовите это представление CustView.
27. Для базы данных галереи View Ridge, описанной в этой главе, постройте
представление, содержащее имя клиента и имена авторов всех работ,
приобретенных данным клиентом.
28. Для базы данных галереи View Ridge, описанной в этой главе, постройте
представление, содержащее имя клиента и имена всех художников,
работами которых интересуется данный клиент. Поясните, в чем разница
между этим представлением и представлением из вопроса 27,
29. Можно ли объединить представления из вопросов 27 и 28 в одно
представление? Почему?
30. Как обновить представление соединения с помощью Oracle?
31. Создайте файл с последовательностью операторов PL/SQL, которая
описывает структуру таблиц CUSTOMER, ARTIST, WORK, TRANSACTION и CUSTOMER.
ARTISTJNT. Дайте файлу имя VRTabs.sql и покажите, как запустить этот файл
на выполнение из SQL Plus.
32. Что означают ключевые слова IN, OUT и IN OUT в процедуре на PL/SQL?
464 Глава 12. Работа с базами данных в Oracle
33. Что нужно сделать, чтобы можно было увидеть сообщения, выводимые с
помощью пакета DBMSJ3UTPUT? Какие ограничения существуют на такой вывод?
34. Объясните, как работает оператор PL/SQL FOR переменная IN имя_курсора.
35. Какой оператор используется для вывода сообщений об ошибках при
компиляции триггеров и хранимых процедур?
36. Каков синтаксис оператора BEGIN TRANSACTION в PL/SQL? Как запускается
транзакция?
37. Как используются переменные tid и aid в хранимой процедуре в
листинге 12.6, если в таблице TRANSACTION не обнаружено подходящих строк? Как
они используются в случае, если в таблице TRANSACTION найдена ровно
одна подходящая строка?
38. Объясните, в чем состоит назначение предварительных, завершающих и
замещающих триггеров.
39. Каким образом в теле триггера, запущенного обновлением столбца, можно
получить значение, которое столбец имел до обновления? Каким образом
в коде триггера можно получить значение, которое будет присвоено столбцу?
40. Объясните, почему для представлений соединения нужны замещающие
триггеры.
41. Объясните что произойдет, если удалить оператор IF в триггере на
листинге 12.10.
42. Напишите SQL-оператор, который получает из словаря данных имена
таблиц, содержащих информацию о триггерах.
43. Какие три уровня изоляции транзакций поддерживаются Oracle?
44. Объясните, как число изменений в системе используется Oracle для
считывания данных в том состоянии, в каком они были в определенный
момент времени.
45. В каком случае в Oracle возможно «грязное» чтение?
46. Объясните, как Oracle обрабатывает конфликтующие блокировки, когда
транзакция выполняется в режиме завершенного чтения.
47. Напишите SQL-оператор, задающий уровень изоляции «сериализуемость»
на весь сеанс.
48. Что происходит, когда транзакция, выполняемая в режиме сериализуемо-
сти, пытается обновить данные, которые уже обновлены другой
транзакцией? Пусть (1) SCN меньше, чем SCN транзакции; (2) SCN больше, чем
SCN транзакции.
49. Сформулируйте три условия, при которых транзакция может получить
исключение «Cannot serialize».
50. Объясните, как Oracle обрабатывает уровень изоляции «сериализуемость».
51. Объясните, как связаны пользователи, роли и привилегии в контексте
безопасности Oracle.
52. Какие три типа файлов важны для резервного копирования и
восстановления в Oracle?
Вопросы к проекту FiredUp 465
53. В чем разница между текущими и архивными файлами отката? Как
используется каждый из этих типов файлов?
54. Что означает термин мультиплексирование в контексте резервного
копирования восстановления баз данных в Oracle?
55. Объясните, как в Oracle происходит восстановление после сбоя приложения.
56. Что такое сбой экземпляра и как Oracle восстанавливается после него?
57. Что такое сбой носителя и как Oracle восстанавливается после него?
Проекты
Чтобы реализовать представленные ниже проекты, создайте средствами Oracle
базу данных для галереи View Ridge, как описано в этой главе. Рассмотрим
представление базы данных под названием Artist, введенное в вопросах группы II в
конце главы 10.
1. Напишите процедуру на PL/SQL, считывающую из представления
таблицу ARTIST. Отобразите на экране полученные данные. Пусть имя
художника служит в качестве входного параметра.
2. Напишите процедуру на PL/SQL, считывающую из представления
таблицы ARTIST, TRANSACTION и CUSTOMER. Отобразите на экране полученные
данные средствами пакета DBMS_0UTPUT. Пусть имя художника служит в
качестве входного параметра.
3. Напишите процедуру на PL/SQL, считывающую все таблицы из
представления. Отобразите на экране полученные данные средствами пакета DBMS_
OUTPUT. Пусть имя художника служит в качестве входного параметра.
4. Напишите процедуру на PL/SQL, которая ассоциирует с художником
заинтересованность нового клиента. Пусть имя художника и имя клиента
будут входными параметрами. Если имя покупателя не уникально,
выведите сообщение об ошибке. Прежде чем вставлять новую строку,
проведите проверку на уникальность в таблице CUSTOMER_ARTIST_INT. Выведите
сообщение об ошибке, если обнаружится дублирование.
5. Напишите замещающий триггер, который запускается при вставке новой
строки и обновлении столбца Nationality в таблице ARTIST. Если новое
значение равно «British», замените его на «English».
Вопросы к проекту FiredUp
Создайте с помощью Oracle базу данных со следующими четырьмя таблицами1:
КЛИЕНТ (НомерКлиента, Имя, Телефон, ЭлектронныйАдрес)
} При реализации этой части проекта следует иметь в виду, что Oracle воспринимает символы
кириллицы в идентификаторах как ошибки, поэтому имена таблиц и столбцов следует вводить
символами латинского алфавита. Мы оставляем здесь кириллическое написание, чтобы сохранить
единообразие в рамках проекта. — Прим. перев.
466 Глава 12. Работа с базами данных в Oracle
ГОРЕЛКА (СерийныйНомер, Тип, Версия, ДатаВыпуска)
РЕГИСТРАЦИЯ (НомерКлиента, СерийныйНомер, ДатаРегистрации)
РЕМОНТ-ГОРЕЛКИ (НомерСчетаЗаРемонт, СерийныйНомер, ДатаРемонта, Описание,
Стоимость, НомерКлиента)
Пусть первичные ключи таблиц КЛИЕНТ, ГОРЕЛКА и РЕМОНТ-ГОРЕЛКИ являются
суррогатными ключами. Создайте для них последовательности. Создайте связи,
реализующие следующие ограничения ссылочной целостности:
♦ НомерКлиента в таблице РЕГИСТРАЦИЯ является подмножеством
НомерКлиента в таблице КЛИЕНТ;
♦ СерийныйНомер в таблице РЕГИСТРАЦИЯ является подмножеством
СерийныйНомер в таблице ГОРЕЛКА;
♦ СерийныйНомер в таблице РЕМОНТ-ГОРЕЛКИ является подмножеством
СерийныйНомер в таблице ГОРЕЛКА;
♦ НомерКлиента в таблице РЕМОНТ-ГОРЕЛКИ является подмножеством Номер-
Клиента в таблице КЛИЕНТ.
Не включайте каскадные удаления.
1. Заполните ваши таблицы данными и отобразите их на экране.
2. Создайте хранимую процедуру для регистрации горелки. Процедура
получает в качестве входных параметров имя, телефон, адрес электронной
почты клиента и серийный номер горелки. Если данный клиент уже имеется
в базе данных (имя, телефон и электронный адрес совпадают), записывайте
его НомерКлиента в таблицу РЕГИСТРАЦИЯ. В противном случае создайте
для этого клиента новую строку в таблице КЛИЕНТ. Будем предполагать,
что горелка с заданным серийным номером уже существует в базе данных.
Если это не так, выведите сообщение об ошибке и отмените изменения,
сделанные в таблице КЛИЕНТ. Написав процедуру, протестируйте ее.
3. Создайте хранимую процедуру для регистрации ремонта горелки.
Процедура получает в качестве входных параметров имя, телефон и адрес
электронной почты клиента, серийный номер горелки, описание и стоимость
ремонта. Будем предполагать, что заданный серийный номер существует;
если это не так, выведите сообщение об ошибке и не производите в базе
данных никаких изменений. Используйте существующую строку в
таблице КЛИЕНТ, если имя, телефон и электронный адрес совпадают; в
противном случае создайте новую строку в таблице КЛИЕНТ. Предположим, что
строка в таблице РЕМОНТ-ГОРЕЛКИ должна быть создана. Зарегистрируйте
горелку, если необходимо.
4. Создайте представление, содержащее все данные, которые имеются в FiredUp
на заданного покупателя. Назовите это представление ДанныеКлиента. Это
представление должно соединять данные из таблиц КЛИЕНТ, РЕГИСТРАЦИЯ,
ГОРЕЛКА и РЕМОНТ-ГОРЕЛКИ. Напишите хранимую процедуру,
принимающую в качестве аргумента имя клиента и выводящую всю информацию по
данному клиенту.
Глава 13
Работа с базами данных
в SQL Server 2000
Эта глава описывает основные возможности и функции Microsoft SQL Server 2000.
Для иллюстрации используется пример с галереей View Ridge из главы 10, а
структура изложения повторяет ход обсуждения задач администрирования баз данных
в главе 11. Направленность и охват изложения остаются примерно такими же,
каковы они были в предыдущей главе, посвященной Oracle. Благодаря тому что
язык SQL стандартизирован Американским национальным институтом
стандартов (ANSI), почти все, что вы узнали об обработке баз данных с помощью SQL
в Oracle, будет справедливо и для SQL Server. Поэтому мы сконцентрируемся
в большей мере на средствах графического проектирования, имеющихся в SQL
Server, чем на операторах SQL.
SQL Server — большой и сложный продукт. В рамках этой главы мы сможем
рассмотреть его лишь поверхностно. Цель заключается в том, чтобы подготовить
вас к использованию SQL Server в ваших собственных проектах и дать
необходимые основы, которые позволят вам продолжить изучение этого продукта
самостоятельно или в других курсах.
Установка SQL Server 2000
Если у вас есть диск с SQL Server, стоит установить программу сейчас. Для
работы SQL Server 2000 требуется Windows NT с пакетом обновлений Service Pack 5
или новее, Windows 2000 Professional, Windows 2000 Server, Windows 2000 Advanced
Server или Windows 2000 Datacenter Server. Кроме того, требуется как минимум
64 Мбайт оперативной памяти и около 250 Мбайт дискового пространства
(можно меньше, но для наших целей это не рекомендуется).
Чтобы установить SQL Server, войдите в систему на вашем компьютере с
администраторскими правами и вставьте компакт-диск. Программа установки
должна запуститься автоматически. Если этого не происходит, щелкните на
файле autorun.exe в корневом каталоге CD. Далее щелкните на SQL Server Components
(Компоненты SQL Server), а затем на команде Install Database Server (Установить
468 Глава 13. Работа с базами данных в SQL Server 2000
сервер баз данных). Оставшаяся часть процесса установки представляет собой
обычную установку программы в среде Windows.
Установив программное обеспечение, вы можете начать работу с SQL Server,
выбрав в меню Пуск ► Программы группу Microsoft SQL Server, а в ней — программу
Enterprise Manager. Запустив эту программу, найдите на левой панели значок
Microsoft SQL Servers. Щелкните на символе «+», чтобы развернуть его, затем
точно так же откройте группу SQL Server Group. Под именем этой группы вы
увидите значок с именем вашего компьютера, за которым будет следовать (Windows
NT). Щелкните на символе «+» рядом с этим значком. После этого окно
программы должно будет принять вид, изображенный на рис. 13.1. На этом рисунке
видно имя компьютера, с которого была получена эта копия экрана, а именно
DBGRV101.
*Ю Consote;jtoe$Mi^
шт
>\
'1 Console Root
Щ Microsoft SQL Servers
JDBGRV101 (Windows NT)
SrGO Databases
Ctl-Gj Data Transformation Services
Ш Q Management
Ш £j Replication
ф-ffel Security
Ш-{£3 Support Services
Ш ЁЗ Meta Data Services
DBGRV101
(Windows NT)
Рис. 13.1. Enterprise Manager
Создание базы данных SQL Server
Чтобы создать новую базу данных, щелкните на папке Databases (Базы данных)
и выберите New Database (Новая база данных). Введите имя вашей базы данных
(здесь ViewRidgel) в поле Name (Имя), как показано на рис. 13.2.
По умолчанию SQL Server создаст один файл данных и один файл журнала
для каждой базы данных. Вы можете создать несколько файлов данных и
журналов и ассоциировать определенные таблицы и журналы с определенными
файлами и группами файлов. Однако все это выходит за рамки нашего изложения.
Если вы хотите узнать об этом больше, щелкните правой кнопкой мыши на
папке Databases и выберите Help (Помощь). Чтобы найти информацию по этой теме,
в левой панели окна Help введите в поле-Search Text (Найти текст) строку «file
groups».
Создание базы данных SQL Server 469
На данном этапе примите все параметры файлов, которые SQL Server предлагает
по умолчанию. Увидеть эти параметры можно во вкладках Data Files (Файлы
данных) и Transaction Log (Журнал транзакций).
шШШШИ
•ИШШЗйё!^15. ^ ""•' ?э№_*'.'*'' B)S|1l
■i^il|eii^LlfM'H
|G3 Console Root
U Microsoft SQL Servers
Q-4@| SQL Server Group
В fjfc DBGRV101 (Windows NT
"+' CJ Data Transformatior
* _J Management
* I Replication
* ~J Security
- _J Support Services
* _j Meta Data Services
< SOL Server GrouD•.;•:",* -'
GeneM^|.t)ele FAm ] Tian&a&qk Log j
| Ж.1:^^ jViewRidgel.
Ш
•.' Name
Database.
Statu*.
Ovw^er:;
Dale «aated
5i2«.:- :•••'.-v.
Bac^t^-v.;.";':,vs:--v •
MaintjBh'aoce
Maintenance о'л;
ОэЙаЙОП палг,е
Ш
Cancel
Help
Рис. 13.2. Создание базы данных SQL Server
Создав базу данных, откройте папку Databases, а в ней — папку с именем
вашей базы данных. Затем щелкните на значке Tables (Таблицы). Окно программы
должно после этого выглядеть подобно рис. 13.3, только у вас еще не будет
никаких пользовательских таблиц. Все таблицы, перечисленные у вас на правой
панели, — это системные таблицы, используемые SQL Server для управления базой
данных. Кстати, dbo обозначает database owner — «владелец базы данных». Если
вы установили SQL Server и создали эту базу данных, владельцем являетесь вы.
Создание таблиц
Есть два способа создания и модификации таблиц (и вообще большинства
структур SQL Server 2000). Первый способ — применять SQL-операторы CREATE или
ALTER, как мы делали в Oracle в предыдущей главе. Второй способ —
использовать графические возможности SQL Server. Поскольку графический способ
отличается от того, что мы описывали выше, в большинстве случаев в этой главе мы
будем пользоваться именно им. Однако имейте в виду, что создавать структуры
базы данных программным путем можно только с помощью операторов SQL.
470 Глава 13. Работа с базами данных в SQL Server 2000
«its Console ftoot\Microsoft:!5Qt:ierVer«\S(^ ^ШШШШЯ!
'Action $e* look
f> «* \ШЩХ&\Х.&Щ\'Ё1\
т.
ОЙЙ
free],
; imti.-.m
[••■"1 Console Root
В fjU Microsoft SQL Servers
В 1§| SQL Server Group
В Щ> DBGRV101 (Windows NT)
Kill) Databases
'; {*i-^ master
i \$-Щ m°del
: ЙЧЦ msdb
I Ш- (I Northwind
-jjhi
Щ-Щ pubs
Щ-Щ tempdb
B-@ ViewRidgel
1 -s£j Diagrams
rSlili
; 6V Views
J Stored Procedures
j Users
_ f Roles
■bi Rules
; ;■ Щ Defaults
I ; & User Defined Data Types
; Cs User Defined Functions
fe"H*l Data Transformation Services
Ф ЩИ Management
Ш Cl3 Replication
Й £j Security
1+i'Q Support Services
Wl C-l M^ta Data Services
Name-;>,.
LSwner
LlXEL.
_ CUSTOMER . dbo
|Э CUSTOMER-ARTIST-INT dbo
Qdtproperties dbo
H syscolumns dbo
jUJsyscomments dbo
Hsysdepends dbo
IIHI sysfilegroups dbo
pH sysfiles dbo
plsysfilesl dbo
[ЁО sysforeignkeys dbo
Bsysfulltextcatalogs dbo
\W\ sysf ulltextnotify dbo
psysindexes dbo
Щ sysindexkeys dbo
\Ш sysmembers dbo
psysobjects dbo
lllsyspernnissions dbo
)W\ sysproperties dbo
Ш1 sysprotects dbo
J Ш sysref erences dbo
ijl^systypes dbo
fliU sysusers dbo
|Щ] TRANS dbo
fewORK dbo
User
User
System
System
System
System
System
System
System
System
System
System
System
System
System
System
System
System
System
System
System
System
User
User
у-ж
Рис. 13.3. Список таблиц в базе данных
Создание таблиц с помощью оператора CREATE
На рис. 13.4 показан типичный SQL-оператор CREATE TABLE. Как описано в
предыдущей главе, такие операторы всегда начинаются с ключевых слов CREATE TABLE,
за которыми следует имя новой таблицы. Далее идет список столбцов
таблицы, заключенный в скобки. Для каждого столбца указывается имя, тип данных
и свойства, если они есть. Описания столбцов разделяются запятыми, но после
последнего столбца запятая не ставится.
Таблица, создаваемая оператором на рис. 13.4, называется CUST и содержит
четыре столбца: CustomerlD, Name, AreaCode и LocalNumber. Столбец CustomerlD имеет
целый тип (int) и является первичным ключом таблицы. Столбец Name содержит
строковые данные (тип char) и имеет длину 50 символов. Столбец Name считается
NOT NULL, что означает, что пустые значения для этого столбца не допускаются.
Если свойство NULL или NOT NULL не указано, по умолчанию предполагается NULL.
Имя столбца Name заключено в квадратные скобки: [Name]. Это необходимо
потому, что Name является зарезервированным словом SQL Server. Если не поместить
Создание базы данных SQL Server 471
его в скобки, SQL Server будет пытаться интерпретировать его как имя одной из
своих конструкций. Таким образом, всякий раз, когда вы собираетесь
использовать ключевое слово SQL Server в качестве пользовательского идентификатора,
заключайте его в скобки. Если вы не уверены, является ли данное слово
зарезервированным, на всякий случай все равно заключите его в скобки. Вреда от этого
не будет.
тш!/$Ш?*
\Ш
Щ SQt Омегу Analyzer
File £dit Query' r^ools Window-' Help ):^ШШШШ№ШШШ^^^Ш^^^Ш^^^Ш-
id - c& Н.Ш1:с ЧШ;^ Л1':^в
ШШШ
«"Query - DBGRV101 деё««аМаё*:£ВДШШ*М^
Ш&Ш&
■.-.CREATE Table CUST
'; 1. Customer ID
i [Name]
AreaCode
LocalNumber
int
char i50)
char {5}
DEFAULT
CHECK
PRIMARY KEY,
NOT BUi;!.,
(206)
(AreaCode IK
■212'>J,
The command(sj completed successfully.
Connections;. 1.
INUM
Рис. 13.4. Создание таблицы с помощью SQL в окне Query Analyzer
Для столбца AreaCode в этом примере установлено значение по умолчанию,
равное (206). Далее, контрольное ограничение (CHECK) допускает присваивание
столбцу AreaCode только тех значений, которые указаны в списке. Кроме того,
данный столбец может иметь пустое значение. Столбец LocalNumber определен
как char(8), и поскольку свойство NULL или NOT NULL для него не указано, он
будет наделен свойством по умолчанию, то есть NULL.
Есть несколько способов передать оператор CREATE на выполнение SQL Server.
Простейший из них — использовать анализатор запросов Query Analyzer. Для
этого в главном меню Enterprise Manager выберите команду Tools
(Инструменты) и в открывшемся меню выберите SQL Query Analyzer, как показано на
рис. 13.5. Введите оператор CREATE TABLE в окне анализатора запросов и
щелкните на синей галочке, расположенной на панели инструментов. Если ваш оператор
содержит синтаксические ошибки, отчет о них будет представлен ниже, в окне
под текстом оператора. Исправив ошибки, щелкните на зеленой стрелке — и
таблица будет создана.
Чтобы убедиться, что таблица на самом деле была создана, вернитесь в окно
Enterprise Manager, щелкните правой кнопкой мыши на значке Tables и
выберите Refresh (Обновить). Новая таблица должна появиться в списке таблиц в
правой панели. Щелкните правой кнопкой мыши на новой таблице и выберите
472 Глава 13. Работа с базами данных в SQL Server 2000
Design Table (Проектировать таблицу). Вы увидите окно, подобное
изображенному на рис. 13.6. Обратите внимание, что для столбца AreaCode действительно
выбрано значение по умолчанию (206) и что столбцы AreaCode и LocalNumber могут
иметь пустые значения. Кроме того, первичным ключом таблицы является
столбец CustomerlD, на что указывает символ ключа слева от имени этого столбца.
Ъ console поо^\1^^щш^:^^^шшшшшшшшшшт
'&*«^!$И"
Тгйр
Z",l Console Root :
fj Microsoft S;
B^jJsQLSe!'
В Щ} ОВс
й-р::
i S-'
i №
i Ы
; т
:> Ы
! й-1
Tpols J£|if# 1'В: OS \Ж '
> 'к" Data Tran^oVm^bipn Services
'%■.Job Scheduling;«v'.:.
|'-::. Replication ./:;'Д:\
щв.са
■мшшшшт&т.
I ..-SQL Profiler
Щ Generate .^ЦЗсфс...
l||;r^eb^e:Wdihtenanc^ fanner...
11Ш;':;''^--':х;:Л":-: ::-:"
|:;J Ji?i|an^ga.SQL Seryer Mesisageisg •.
illtlfpnL'iv::-И..'
!■ fc] Rules
I-Ш Defaults
User Defined Data Types
J5s User Defined Functions
Й- ЩЦ Data Transformation Services
Й;Й Management
ЕйЩЦ Replication
Ej3-di Security
ШШ Support Services
Ш-Ш Meta Data Services
HER
W-ARTIST-
jrties
Inns
. jnents
"|nds
roups
f
jgnkeys
. txtcatalogs
ixtnotify
;|<es
: frkeys
fibers
TNT
ЁЗ sysobjects
Щ syspermissions
Ш sysproperties
Hsysprotects
:@sysreferences
;|@systypes
'Iflsvsusers
Щ] TRANS
|E]work
^«•*]Щ*йй*^*??^;Н::
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
dbo
User
User
System
System
System
System
System
System
System
System
System
System
System
System
System
System
System
System
System
System
System
System
User
User
Ш
Рис. 13.5. Вызов Query Analyzer
Окно создания таблиц в графическом режиме
Второй способ создать таблицу напоминает то, как это делается в Microsoft
Access. В Enterprise Manager щелкните правой кнопкой мыши на значке Tables
и выберите команду New Table (Новая таблица). Перед вами возникнет пустая
форма, в которую вы можете ввести имена (Column Name) и типы данных (Data
Туре) столбцов новой таблицы. Для некоторых типов данных (например, char) вы
можете задать длину, для других же (таких, как int) длина однозначно
определяется типом данных.
Создание базы данных SQL Server 473
& 2:Design ТаЬ1ё;Щ^Ш||;|ШИ|Ш1Ш
ШШ
у ^1Ш^ШЩШЖЙ1^л
• Column Name; :i
•DataType: [length | AllowШ&
Customer ID
Name
AreaCode
LocalNumber
;int
char
char
char
4
50
5
8
CplurQn§j-.
0е5сйЙЩ|;
Default Value
Z06)
. 1% ;
Formula
Cdiauon
<database default >
■
Рис. 13.6. Таблица SQL Server, созданная с помощью SQL на рис. 13.4
На рис. 13.7 столбец ArtistID является суррогатным ключом. Чтобы заставить
SQL Server автоматически присваивать значения этому столбцу, для его
свойства Identity (Идентификатор) задано значение Yes. Начальное значение задается
полем Identity Seed (Начальное значение идентификатора), а приращение,
которое получает суррогатный ключ при добавлении новой строки, указывается
в поле Identity Increment (Приращение идентификатора). В нашем случае отсчет
ArtistID начнется с 1 и будет увеличиваться на 1. Только один столбец таблицы
может быть идентификатором. В SQL Server нет объектов, подобных
последовательностям в Oracle.
Чтобы сделать столбец ArtistID ключом таблицы, щелкните в любом месте
строки с именем этого столбца, чтобы выделить ее, а затем щелкните на символе
ключа на панели инструментов окна создания таблиц. Чтобы создать
композитный ключ, выделите все столбцы, составляющие ключ, и щелкните на символе
ключа.
Стандартные типы данных SQL Server 2000 перечислены в табл. 13.1. При
определении столбца можно выбирать любой из этих типов.
474 Глава 13. Работа с базами данных в SQL Server 2000
ш ^Design Table ЗДТШЩШШШШШ
ШШ:
iGdiimri Namie+i
SrbstlD
ArtistName
Nationality
Birthdate
C'eceaseddate
•Datatype;..;:]Length г Aflow №§s
: int
:char
jcnar
iYear(smaliint)
4
50 '
25
jYear(smallint) 12
•
•
•
^lai.xi
"I
>3£
Рис. 13.7. Создание таблицы с помощью средств графического проектирования
Таблица 13.1. Стандартные типы данных SQL Server
Тип данных Описание
Binary Массив двоичных данных, длина от 0 до 8000 байт
Char Массив символьных данных, длина от 0 до 8000 байт
Datetime Дата и время длиной 8 байт. Диапазон: от 1 января 1753 г.
до 31 декабря 9999 г., с точностью до трех сотых секунды
Decimal Десятичное число, можно задавать точность и масштаб.
Диапазон: от -10А38 + 1 до 10А38 - 1
Float Число с плавающей точкой длиной 8 байт. Диапазон значений:
от -1.79Е+308 до 1.79Е+308
Image Массив двоичных данных переменной длины. Максимальная длина
2147483647 байт
Int 4-байтовое целое число. Диапазон значений: от -2147483648 до
+2147483647
Money Денежная сумма, длина 8 байт. Диапазон: от -922337203685477.5808
до +922337203685477.5807
Numeric To же, что и Decimal
Real 4-байтовое число с плавающей точкой. Диапазон значений: от -3.40Е+38
до +3.40Е+38
Smalldatetime Дата и время длиной 4 байта. Диапазон: от 1 января 1900 г. до 6 июня
2079 г., с точностью до одной минуты
Smallint 2-байтовое целое число. Диапазон: от -32768 до 32767
Создание базы данных SQL Server 475
Тип данных Описание
Small money Денежная сумма, длина 4 байта. Диапазон: от -214748.3648 до
+214748.3647, с точностью до одной десятитысячной денежной единицы
Text Текст переменной длины, максимальная длина 2147483647 символов
Tinyint 1 -байтовое целое. Диапазон: от 0 до 255
Varchar Массив символьных данных переменной длины, длина от 0 до 8000 байт
Пользовательские типы данных
SQL Server 2000 поддерживает пользовательские типы данных (user-defined data
types) — важное средство, которое можно использовать для представления
доменов. Представьте, например, что в приложении View Ridge домены столбцов
Birth Date и Deceased Date представляют собой не полную дату, а только четыре
цифры года.
Чтобы реализовать это в SQL Server 2000, можно ввести специальный
пользовательский тип данных. В Enterprise Manager щелкните правой кнопкой мыши
на значке User-Defined Data Types (Пользовательские типы данных) и выберите
команду New User-Defined Data Type (Новый пользовательский тип данных).
Появится диалоговое окно, подобное изображенному на рис. 13.8. Введите имя нового
типа данных в поле Name: и выберите для него тип данных из числа стандартных
типов. Здесь введен тип данных Year, определенный как smallint.
User-Defined Oaka Type Preperfcie* 'ЯНН
1^'.б(йЙ^|
Шок
Cancel
£L ""*
Data type:
Length
Alow NULLr
Rule:
Default.
JYea,
| smallint
|(none]
: j(none)
t.
Kelp
Рис. 13.8. Определение пользовательского типа данных
После этого новый тип данных появится в раскрывающемся списке,
который вызывается щелчком на столбце Data Types, — как если бы этот тип
принадлежал к числу стандартных. На рис. 13.7 тип Year выбран для столбцов Birthdate
и Deceaseddate.
Пользовательские типы данных еще более полезны в сочетании с правилами.
476 Глава 13. Работа с базами данных в SQL Server 2000
Правила
Правила (rules) — это декларативные выражения, ограничивающие возможные
значения данных. Общий формат для них таков: @имя_переменной <формулиров-
ка_правила>. На рис. 13.9 показан процесс создания правила @year BETWEEN 1400
AND 2100. В качестве формулировки правила можно использовать любое
предикатное выражение SQL (из числа тех, что могут использоваться в предложении
WHERE). Имя переменной несущественно. Создать новое правило можно,
щелкнув правой клавишей мыши на значке Rules (Правила) и выбрав команду New Rule
(Новое правило).
щ
т№№.%а*т^№шштттштшшш
j^-.^i* i
&
^ca'^Fi^le
: >г»£Г?Ч'Ш.Ч 400 >Л* 2100
j< j ■:.■■ . рщ$щщ^р
Шт1^
;?№W®
■ш
!*'.::••:.•.• . •:
• ВЫШуыр
Cancel
Nan*
'^^Ш^ШШ
Ш Srate
i^Year
iDateT.ype
char
smallint
>BHd 'FutaeGnfr ]
llliHMJ.l^JJL^^^J
& ■ Q .
■ ■ QK:|;^ j ' ^^j^^j^M^H
:**■■
Рис. 13.9. Создание правила и связывание его с пользовательским типом данных
Одно особенно полезное выражение выглядит так: ©переменная IN (список
значений). Например, выражение ©State IN (ТА','OR','W A', 'AZ') ограничивает диапазон
значений столбца или пользовательского типа данных приведенным в скобках
списком.
Правило на рис. 13.9 привязано к пользовательскому типу данных Year. Как
следствие оно будет ограничивать диапазон возможных значений всех столбцов,
имеющих тип данных Year.
Правила служат той же цели, что и предложения CHECK (контрольные
ограничения) в операторах CREATE и ALTER; в SQL Server можно пользоваться и тем
и другим. Контрольные ограничения являются частью ANSI-стандарта SQL
1992 г., и поэтому некоторые организации предпочитают использовать именно
их. Преимущество же правил в том, что их можно определить в графическом
режиме.
Создание базы данных SQL Server 477
Изменение структуры таблицы
Менять структуру таблицы можно также несколькими способами. Во-первых, это
можно сделать с помощью SQL-оператора ALTER, как в предыдущей главе.
Во-вторых, можно использовать ту же форму, что и при создании таблиц (см. рис. 13.6
и 13.7). На рис. 13.10 показано несколько операторов ALTER, меняющих структуру
таблицы CUST. Первый из них увеличивает длину столбца Name до 100 символов.
■ Г ALTER TABLE CUST ^J
.1] ALTER COLUMN Name char ПОО) NOT NULL j
:| j Salter table cust
;|| '/: ADD Customers i nee ffis.r NULL
M::|-:ALTER TABLE CUST
|;i|l|| DROP COLUHW LocalNuntber
№§5 ALTER TABLE CUST
ЩШ ADD LocalNunriber char (2 5) HULL ~H
Ш -^ • -г-- : ' ,,„• Xtf
!|J(0 row(s) affected) If
i Ы „„__„ 'j?- .--■■—J лГ И
:| Д,^аФ ЯР Messages j vjl
!Шь|Ёё^Йо£<в.О) jQ^OTGiyviTO^ In'd, Col32 ''Mi
Рис. 13.10. Изменение структуры таблицы с помощью операторов ALTER
Второй оператор ALTER создает новый столбец, CustomerSince, и присваивает ему
тип данных Year. Следующие два оператора демонстрируют альтернативный способ
увеличения длины столбца. Один оператор удаляет столбец, а второй вновь
создает его, но уже с другой длиной. В отличие от первого случая, однако, данные будут
потеряны, поскольку столбец физически удаляется, прежде чем будет воссоздан.
Такие изменения можно произвести и в окне проектирования таблиц, как
показано на рис. 13.11. Надо просто открыть это окно и изменить необходимым
образом столбцы, типы данных и длины. SQL Server предупредит вас, если вы
попытаетесь сделать недопустимые изменения.
SQL Server позволяет уменьшать длину типов char, varchar и им подобных, даже
если данные таких типов содержатся в каких-нибудь столбцах. При этом, однако,
данные усекаются. В результате могут появиться одинаковые значения,
нарушающие ограничения уникальности, вследствие чего изменения будут отклонены,
что может привести к неразберихе, Таким образом, подобное укорочение следует
выполнять с осторожностью.
478 Глава 13. Работа с базами данных в SQL Server 2000
£*2:0esmn ТЖШШШНИ
у т^!т^ШШМШШ^ШШШ'.ШШ1
►я
®!^^^Ш1111^ШШ1П^§Ш5^ш1
fustomerlD
Name
AreaCode
CustomerSince
LocalNumber
int
char
char
Year (smallint)
char
4
too
5
2
25
•
V
•
:;Cctonrvs 1
:■:::•: r>£:'v-
■ C«&rfotfon
De(£|tValue
>ЫШ\
■ ' ##V' \ •
Idenj&y.
'■*&Ш?Г.1
■:: ■■■■<•.■
Formula
I; \*Y
.':■':■:::
■:J:;ip
■■ \$i
:;no
■ H
: %'k>
::""::: ::s:S.'
;;•?:-..
||,,:j:d
?Ш1Щ
SSII-
Рис. 13.11. Результат выполнения операторов ALTER на рис. 13.10
То же самое относится к возможности изменить тип данных столбца: вы можете
это сделать, даже если в столбце имеются данные, но будьте осторожны, так как
данные могут быть потеряны. Если текстовое поле AreaCode, содержащее только
числовые данные, превратить в целое число, это не приведет ни к каким
проблемам. Но если проделать ту же операцию с текстовым полем Name, потеря данных
неизбежна.
Создание таблиц для примеров
Если вы повторяете действия, описываемые в этой главе, со своей копией SQL
Server, то сейчас вам следует создать пять таблиц, показанных на рис. 10.3, г.
Можете удалить таблицу CUST — она не понадобится нам в дальнейшем. Для
этого щелкните правой кнопкой мыши на имени таблицы в списке таблиц и
выберите команду Delete (Удалить).
Таблице TRANSACTION дайте имя TRANS. Слово TRANSACTION имеет настолько
особенный смысл для SQL Server, что ни одна хранимая процедура не будет
работать с таблицей, названной таким именем, даже если вы заключите его в
скобки. Так что жизнь будет проще, если вы назовете таблицу TRANS.
Определите для всех таблиц суррогатные ключи. Как и в предыдущей главе,
для каждого идентификатора задайте свое начальное значение. Для таблицы
Создание базы данных SQL Server 479
ARTIST задайте начальное значение 1, для CUSTOMER — 1000, для WORK — 500, а для
TRANS — 100. Приращение во всех случаях оставьте равным 1. Обозначьте ключ
каждой из таблиц, выделив соответствующий столбец или столбцы и щелкнув
на символе ключа.
Как и в Oracle, если вы создаете таблицы с помощью SQL-операторов, то при
создании таблицы CUST0MER_ARTIST_INT не присваивайте ни одному ее столбцу
свойство PRIMARY KEY. Вместо этого после выполнения оператора CREATE TABLE
создайте ограничение первичного ключа:
CONSTRAINT pk_constraint PRIMARY KEY (CustomerlD, ArtistID)
Этот оператор установит композитный ключ (CustomerlD, ArtistID) с именем
pk_constraint. Разумеется, имя для ограничения вы можете выбрать на свое
усмотрение.
Определение связей
Связи, как и другие структуры, можно создавать двумя способами: либо
определяя внешние ключи в операторах ALTER TABLE, либо рисуя связи на диаграмме
базы данных. С первым способом мы познакомились в предыдущей главе, поэтому
сейчас будем работать с диаграммой базы данных.
Щелкните правой клавишей мыши на значке Diagrams (Диаграммы) и
выберите команду New Database Diagram (Новая диаграмма базы данных). Запустится
мастер, который проведет вас через процесс добавления таблиц в диаграмму.
Поместите на диаграмму все пять таблиц с рис. 10.3, г.
Для создания связи перетащите первичный ключ из одной таблицы во
внешний ключ другой таблицы, с которой вы хотите установить связь. Например,
чтобы связать таблицы ARTIST и CUSTOMER_ARTIST_INT, нажмите левую кнопку
мыши, когда курсор будет находиться на столбце ArtistID в таблице ARTIST и,
удерживая кнопку нажатой, переместите курсор мыши на столбец ArtistID
таблицы CUST0MER_ARTIST_INT, после чего отпустите кнопку. Тем самым будет создана
связь, и на экране появится диалоговое окно, изображенное на рис. 13.12.
Обратите внимание, что SQL Server предлагает для связи имя по умолчанию и
показывает столбцы, служащие первичным и внешним ключом. Все это вы можете
принять как есть, а вот расположенные ниже флажки, устанавливающие режим
обеспечения ссылочной целостности, заслуживают более внимательного
отношения к себе.
Обеспечение ссылочной целостности
Вспомните, что ограничения ссылочной целостности касаются присутствия
ключевых значений в родительской и дочерних таблицах. В частности, такие
ограничения гарантируют, что ключевое значение дочерней таблицы присутствует
в связанной с ней родительской таблице. Примером может служить следующее
ограничение: всякое значение ArtistID в таблице CUSTOMER_ARTIST_INT должно
существовать среди значений ArtistID в таблице ARTIST.
480 Глава 13. Работа с базами данных в SQL Server 2000
-J
т able* | Columns ReUuonshfc* j lftdexe$/£eys j Check Cw$*r»rte j
Table name: j a>STQWER-ARTIST~lNT
Selected relationship: [со FKjZUSTOMER ARTIST -INT.ARTIST ^
.New | beiete I
ftelata$Np name. .j^r j:ustOMER-ARTIST-INT_ARTIST]
Pnroary tey fcabte Foreign key table.
ftRttST
ArtistID
^P^:*RM^b
jj ArtistID
I
P. 0»ckexisting data maeatJoO;. ■..
P En(=orw'reletl6r«Np'% »Й aticl'UPDATEs
Г Cascade Update Related Fields'
fC? Cascade Delete Related Reoord$
Close
Help
Рис. 13.12. Определение свойств связи
Первый флажок на рис. 13.12 включает проверку ссылочной целостности
существующих данных. Поскольку мы создаем новую базу данных, для нас он
не играет роли. Но если бы мы создавали связь с уже существующими данными
и хотели бы с помощью SQL Server провести в них поиск нарушений ссылочной
целостности, мы бы установили этот флажок. При сброшенном флажке SQL
Server применяет ограничения только к новым и модифицируемым данным.
Если база данных имеет большие размеры, то вам, скорее всего, не захочется
проверять с помощью SQL Server ссылочную целостность существующих
данных, так как этот процесс может оказаться весьма длительным. Кроме того, не
следует устанавливать этот флажок, если вы не знаете, как устранять те
нарушения, которые могут обнаружиться. Вы можете и не знать, как исправить связь
в существующих данных.
Следующий флажок, Enforce relationship for replication (Поддерживать связь при
репликации), относится к распределенной обработке, и пока что мы не будем его
обсуждать.
Третий флажок, Enforce relationship for INSERTS and UPDATES (Поддерживать связь
при вставках и обновлениях), имеет существенное значение для наших текущих
целей. Когда этот флажок сброшен, SQL Server игнорирует связи при
обновлениях и удалениях. Так, если мы сбросим этот флажок, то после удаления строки
из таблицы ARTIST в таблице CUSTOMER_ARTISTJNT могут остаться строки с несу-
Создание базы данных SQL Server 481
шествующими значениями ArtistlD. Такое нежелательно, поэтому этот флажок
следует установить.
Теперь, если мы не установим ни один из двух расположенных ниже
флажков, SQL Server просто запретит любое обновление или вставку, которые
нарушают данное ограничение ссылочной целостности. Чуть позже мы выгодно
воспользуемся этим.
В связи, которую мы создаем, участвует таблица пересечения. Если удаляется
строка из таблицы ARTIST, нам нужно, чтобы соответствующие строки в таблице
пересечения также удалялись. Следовательно, мы устанавливаем флажок Cascade
Delete Related Records (Каскадное удаление связанных записей). Тем самым мы
предписываем SQL Server при удалении строки из таблицы ARTIST удалять все
связанные с ней строки в таблице пересечения. Это вызывает то же действие, что
и SQL-предложение ON DELETE CASCADE, описанное в главе 12.
В нашей структуре используются суррогатные ключи, и, следовательно,
изменение значений ключей невозможно. Поэтому нам нет нужды беспокоиться о
каскадном обновлении связанных записей (флажок Cascade Update Related Records).
Значения ключей обновляться не могут.
Аналогичным образом можно определить связь между таблицами CUSTOMER
и CUSTOMER_ARTIST_INT. Установите для нее флажки Enforce relationship for INSERTS
and UPDATES и Cascade Delete Related Records.
Теперь рассмотрим связи между таблицами ARTIST и WORK, WORK и TRANS, а
также CUSTOMER и TRANS. Ни для одной из этих связей не нужны каскадные
удаления. Вместо этого следует запретить любые удаления, которые могут вызвать
нарушение ссылочной целостности. Если, например, кто-нибудь попытается
удалить строку в таблице WORK, у которой имеется дочерняя строка в таблице TRANS,
не следует допускать такого удаления. Для этого в диалоговом окне свойств
связи (Properties ► Relationships) установите флажок Enforce relationship for INSERTS and
UPDATES, но не устанавливайте флажок Cascade Delete Related Records. Все связи,
имеющиеся в нашей базе данных, перечислены в табл. 13.2.
Таблица 13.2. Реализация ограничений ссылочной целостности
в базе данных View Ridge
Связь Поддержание Каскадное
связи при вставках удаление
и обновлениях связанных записей
Между CUSTOMER и TRANS Да Нет
Между CUSTOMER и CUSTOMER_ARTISTJNT Да Да
Между ARTIST и WORK Да Нет
Между WORK и TRANS Да Нет
Между ARTIST и CUSTOMER_ARTIST_lNT Да Да
Когда связи настроены таким образом, то, например, единственный способ
удалить из таблицы ARTIST запись о каком-нибудь художнике — это сначала
удалить из таблицы TRANS записи обо всех транзакциях с работами данного
художника, затем удалить из таблицы WORK записи обо всех работах данного
художника и лишь после этого удалить соответствующую строку из таблицы ARTIST.
482 Глава 13. Работа с базами данных в SQL Server 2000
Окончательный вид диаграммы связей изображен на рис. 13.13. Свойства
любой связи можно определить, щелкнув правой кнопкой мыши на линии,
представляющей эту связь.
Рис. 13.13. Схема базы данных View Ridge
Представления
Если вы еще не прочли раздел главы 12, посвященный представлениям, сделайте
это. Приведенные там общие замечания справедливы и для представлений,
созданных в SQL Server.
Создание представлений
Создавать представления можно с помощью операторов SQL или с помощью
графических средств проектирования SQL Server. Эти два способа показаны в
таблицах на рис. 13.14 и 13.15 соответственно.
Представление, определенное на этих рисунках, называется ExpensiveArtist-
Work. Оно соединяет данные из таблиц ARTIST, WORK и TRANS и затем выбирает
строки, в которых значение столбца AcquisitionPrice превышает 10 000, Из
созданного таким образом представления пользователь может получить данные с
помощью следующего SQL-оператора:
SELECT*
FROMExpensiveArtistWork
Пользователю не придется выполнять соединение таблиц, на которых
основывается это представление; более того, ему даже не нужно будет знать о том,
что такое соединение было произведено.
Заметьте, кстати, что на рис. 13,14 перед именем каждой таблицы указан
префикс dbo. Причина этого состоит в следующем. По умолчанию имени каждой
Создание базы данных SQL Server 483
таблицы предшествует имя пользователя. Если в ссылке на таблицу имя
пользователя отсутствует, SQL Server автоматически присоединяет к ссылке имя
пользователя, который инициирует запрос. Так, если пользователь John,
зарегистрированный в SQL Server, ссылается на таблицу CUST, SQL Server будет искать
таблицу с именем John.CUST. Но если тот же самый John ссылается на таблицу
dbo.CUST, SQL Server будет искать таблицу с именем dbo.CUST, а не John.CUST.
1 CREATE VIEW ExpensiveArtistUork
If SELECT dbo,ARTIST.ArtistName: dbo.[WORK] .Title; dbo.[WORK] .Copy,
II dbo.TRANS.AcquisitionPrice
If FP.OH dbo -ARTIST INNER JO.R;
I dbo. [WORK] ON dbo, ARTIST, Art ist ID «■ dbo , [WORK] .ArtiatID
j j INNER J0.1N
j dbo.TRANS ON dbo,[WORK].WorklD - dbo,TRANS,UorkID
1} WHERE dbo.TRANS,AcquisitionPrice > 10000
j [The command(s) completed successfully.
j ^ ■ ДЮШШ!=У^* Qfl^lllf I ■ ":";" ■:jl|||:;|::: МЩШ--1- ' ■:1111111Ш1:1:3::^ ••• 1
llllliillllllllllll::.Шllilllll;'.,;:,, Ы&& ^Ш£йlllllEl- .■;Ш-;|СрППесЬоП$;: 1,, . . -; '" |||:$|$||Ц?.[% ' :''/4 j
Рис. 13.14. Создание представления с помощью SQL
В операторе CREATE VIEW на рис. 13.14 префикс dbo добавлен ко всем ссылкам на
таблицы, так что этот оператор доступен и для других пользователей помимо dbo.
Для пользователя dbo все эти префиксы являются излишними, поскольку они
в любом случае были бы добавлены SQL Server . Но когда данный оператор
запускает пользователь John, присутствие префикса dbo гарантирует, что SQL Server
будет обращаться к таблицам, владельцем которых является dbo, а не сам John.
Поскольку к имени представления ExpensiveArtistWork имя пользователя не
присоединено, то в результате запроса, инициированного dbo, будет создано
представление с именем dbo.ExpensiveArtistWork. Если этот же запрос инициирует
пользователь John, то будет создано представление с именем John.ExpensiveArtWork.
Это будут два разных представления. Данные в них будут одинаковы, так как
они основываются на одних и тех же таблицах, но тем не менее, представлений
будет два, и имена их будут различны.
Чтобы создать представление с помощью графических средств, в Enterprise
Manager щелкните правой кнопкой мыши на значке Views (Представления) и
выберите команду New View (Новое представление). Затем щелкните правой кнопкой
мыши на пустой верхней панели и выберите команду Add Table (Добавить
таблицу). Чтобы создать представление, изображенное на рис. 13.15, добавьте таблицы
ARTIST, WORK и TRANS. Поставьте галочки напротив имен столбцов ArtistName, Title,
М*£
484 Глава 13. Работа с базами данных в SQL Server 2000
Сору и AcquisitionPrice. В третьей панели напротив AcquisitionPrice в столбце Criteria
(Критерии) укажите критерий >10000. После того как вы это сделаете, SQL Server
покажет код соответствующего SQL-запроса в четвертой панели. Щелкните на
красном восклицательном знаке в панели инструментов, и SQL Server заполнит
представление вашими данными, как показано в последней панели на рис. 13.15.
Рис. 13.15. Создание представления с помощью графических средств проектирования
Обновляемые представления
Одни представления можно использовать для обновления данных, а другие —
нет. Указать условия, которые делают представление обновляемым, трудно.
Вообще говоря, любое представление, основывающееся на одной таблице, может
быть использовано для обновления и удаления, если оно не содержит
встроенных функций (например, COUNT или МАХ) и вычисляемых столбцов в
предложении SELECT. Такое представление допускает и вставку данных, если оно включает
в себя все ненулевые столбцы таблицы. В противном случае вставка невозможна.
Представления, основывающиеся на соединениях, более сложны. В SQL Server
представление, имеющее более одной таблицы в предложении FROM, не может
использоваться для удаления. Многотабличные представления допускают
вставку и обновление, если эти операции производятся только над одной из таблиц,
входящих в представление, и опять-таки в предположении, что представление не
имеет встроенных функций или производных столбцов в предложении SELECT.
Создание базы данных SQL Server 485
Наконец, представления, которые иначе невозможно обновить, можно сделать
обновляемыми, если создать замещающий триггер для операции обновления.
Такой триггер представляет собой процедуру, написанную на TRANSACT-SQL,
которая выполняет операции вставки, обновления или удаления вместо SQL
Server. Мы рассмотрим это более подробно, когда будем обсуждать триггеры.
Индексы
Индексы, как уже говорилось, — это специальные структуры данных,
создаваемые для повышения производительности базы данных (см. приложение А).
SQL Server автоматически создает индексы по всем первичным и внешним
ключам. Разработчик может также с помощью SQL Server создавать индексы и по
другим столбцам, которые часто фигурируют в предложениях WHERE или
используются для сортировки данных при последовательной обработке таблицы для
запросов и отчетов.
Чтобы создать индекс, щелкните правой кнопкой мыши на таблице,
содержащей столбец, который вы хотите индексировать, выберите All Tasks (Все задачи),
затем выберите Manage Indexes (Управление индексами). Откроется диалоговое
окно, изображенное в левой части рис. 13.16. Щелкните на кнопке New...
(Новый...), и перед вами появится диалоговое окно, изображенное в правой части
рис. 13.16. На этом рисунке разработчик создает индекс по столбцу Zip таблицы
CUSTOMER. Индекс, который называется CUSTOMER_Zip_Index, должен быть
заполнен на 80% и отнесен к группе файлов PRIMARY. Перегрузка оставляет
пространство в индексе открытым для вставок на всех уровнях, исключая самый нижний.
Заполнение характеризует объем пустого пространства, оставляемого на нижнем
уровне индекса. За дальнейшей информацией об этих параметрах обращайтесь
к приложению А и к документации на SQL Server.
ШШЩЩр:;'
*J
Select {Ьв*ЫаЬа*е aftd.i&te k*¥№>№*W)a-&if&i&a d*rie
|U V.ewRidgel
jlfJHdbo] [CUSTOMER]
Г Incbjde^rtwftdWec»*
^CUSTOMER
ttyyfck:
ШШЯЕШШЖ
Яух$$м
•gp! ;:;-.ueate«^ibdex'ofl:^idSoiPUS10MHRj in database f^wwRidgel \
К Pad index
!"': -:f*~ Unique v-as^^, Г* ■•■■.v.-f.-ri-:
-&■£V;:--. • *'\'>.:- * щ$ья>
t^'bik i& ««compute *»*№*» (not fecwnmertfJedjE '<*%
>!;'^.:Р&дЮЦГ
j PRIMARY
W&x&v.
Рис. 13.16. Создание индекса в графическом режиме
:'Щ
486 Глава 13. Работа с базами данных в SQL Server 2000
В последнем диалоговом окне щелкните на кнопке Edit SQL... (Редактировать
SQL...), и вы увидите диалоговое окно, изображенное на рис. 13.17. Оно будет
содержать текст SQL-оператора, введя который в окне анализатора запросов,
можно было бы создать тот же самый индекс.
Edit Transatt-SQl Script *• DBGKVim
[CREATE
INDEX (CUSTOMER AJnctoflON l*o] [CUSTOMER] ЦВД cte*C)
IWITH
PAD INDEX
JILLFACTOB*80
ON [PRIMARY]
л( ' iTn Г'нм|'У| ;,:M^nl..:.mii;:l:iniiil-|lli:i'n i ■■ ft fl ■*.&! V =" 4 ' i'ljiZJ
:fw ^f-fcri£&^
Рис. 13.17. SQL-код, создающий индекс
SQL Server поддерживает два вида индексов: кластеризованные и не
кластеризованные. В кластеризованном индексе данные хранятся на нижнем уровне
и в том же порядке, что и сам индекс. В некластеризованном индексе нижний
уровень не содержит данных, но содержит указатели на данные. Поскольку
строки могут быть отсортированы только в одном физическом порядке за один раз,
для каждой таблицы допускается только один кластеризованный индекс.
Кластеризованные индексы обеспечивают более быстрое получение данных, чем
^кластеризованные. Обычно они оказываются быстрее и при обновлении, но не в том
случае, когда много обновлений происходит в одном и том же месте в
середине отношения. За дальнейшей информацией обращайтесь к документации на
SQL Server.
Логика приложения
Существует много способов обработки баз данных SQL Server. Вы уже видели,
как с помощью анализатора запросов Query Analyzer можно запускать на
выполнение SQL-операторы. До сих пор мы пользовались этим только для создания
Логика приложения 487
структур базы данных, но таким образом можно выполнять SQL-операторы
любого типа. Далее, обработка структур и содержимого базы данных возможна с
помощью прикладных программ на таких языках, как Visual Basic, Java, C# или C++,
с использованием для доступа к данным технологий Active Data Objects, ODBC
или JDBC. Примеры реализации этого подхода для обработки данных через
Интернет будут продемонстрированы в главе 15.
Третий способ доступа к базе данных заключается в написании процедур на
языке TRANSACT-SQL. Этот язык расширяет базовые возможности SQL,
добавляя в него элементы программирования — параметры, переменные,
условные операторы IF, циклы WHILE и т. п. TRANSACT-SQL играет ту же роль для
SQL Server, что и PL/SQL — для Oracle.
Программы, написанные на TRANSACT-SQL, можно передавать на
выполнение СУБД через Query Analyzer, хранимые процедуры или триггеры. В данном
разделе мы рассмотрим каждый из этих способов. Процедуры на TRANSACT-
SQL можно также вызывать из web-сценариев, как вы узнаете из главы 15.
Хранимые запросы
Представим себе, что каждый понедельник утром менеджер View Ridge хочет
получать список всех произведений, предлагаемых к продаже галереей в настоящее
время. Один из способов сделать это — написать SQL-запрос, показанный на
рис. 13.18. Этот запрос возвращает атрибуты ArtistName, Title и Сору каждой
картины, для которой столбец CustomerlD в таблице WORK равен нулю (то есть каждой
непроданной картины).
^^^1:,..:.:....,.аШ
i||j||;.£dit: Query Tools V^^^je^!
И':- C£ У £1
Ш^1Ш^9^^^^^Шо yiewii*1." ±J ШШ ШййШ,;
'::':'-'•'• ^'Ч:^:'Й^:'.^:?ЙУ:^'
' Query - DBC»V*01.YiewRii|«ct^e{»¥l«\J^
1^Уф«&Ц;;кШ£й^^
,,::,: JMJffl
|SEL,£CT dbo. ARTIST. Arc lstNaroe, dbo . [UORK] .Title . dbo . [WORK] .Copy
|FROH dbo.[WORK] IMNKR JOIN
dbo. TRANS ON dbo. [UORKJ -UorklD •■• dbo . TRANS , Work ID
INNER .?OIM
dbo.ARTIST ON dbo.[UORK] >ArtistID " dbo.ARTIST.ArtistID
JWHERE <dbo. TRANS. С us tower ID IS HULL1.
|ORDER BY dbo,ARTIST.ArtistName dbo,[WORK].Title, dbo.[UORK].Copy
ijj'
"3
£Ш&А»ъЙап«:-
1ШЙ
Ш&РУ,
gll!;:Mark Tobey
ЩрМаск Tobey
ЩЩМагк Tobey
Mystic Fabric
HystiC Fabric
Northwest by Night
.4/40
5/40
7/18
|^§-йЩрР Message}'
J
ЩЩ;^^Ш1^^^^^^Щ^^Щ1^Щ^^щШт Б1|Щ1Яо^ "и
^f|||;;:i|:onnecttof*s.; Z-..';.
W
Рис. 13.18. Пример хранимого запроса
488 Глава 13. Работа с базами данных в SQL Server 2000
Чтобы каждую неделю не писать этот запрос заново, менеджер может
написать его один раз и сохранить в файле. Затем пользователь запускает программу
SQL Query Analyzer, открывает файл запроса и запускает его на выполнение.
Однако для этого требуется, чтобы пользователи имели доступ к SQL Query
Analyzer, что маловероятно, особенно если работа происходит не на том
компьютере, который управляет базой данных. Кроме того, описанные действия
слишком сложны для пользователей. Предпочтительнее вариант с прикладной
программой, выполняющей запрос и сообщающей пользователю результаты в более
дружественной манере.
Тем не менее, этот стиль обработки часто используется администраторами баз
данных. Они разрабатывают на TRANSACT-SQL процедуры, выполняющие
многие рутинные задачи администрирования. Эти процедуры сохраняются в файлах
и затем используются при необходимости.
Хранимые процедуры
Другой подход к обработке баз данных SQL Server заключается в создании
процедур на TRANSACT-SQL и хранении их на компьютерах пользователей или в базе
данных. Эти — так называемые хранимые — процедуры могут вызываться по
именам, и им можно передавать параметры. Например, оператор
InsertARTIST @ArtistName='Matisse'
вызывает хранимую процедуру InsertARTIST и передает ей параметр @ArtistName со
значением «Matisse». Такие процедуры могут быть сколь угодно сложными: они
могут обрабатывать несколько баз данных, вызывать другие хранимые
процедуры и функции и т. д.
С приходом Интернета все более распространенным становится вариант, когда
хранимые процедуры держатся в базе данных, а не распространяются по
компьютерам пользователей. Web-сервер и браузер вызывают хранимые процедуры и
передают параметры по HTTP-соединению, установленному с помощью Active Data
Objects или СОМ. Мы продемонстрируем этот подход позже, в главе 15.
Здесь же мы будем писать хранимые процедуры в SQL Server и тестировать
их с помощью программы SQL Query Analyzer. Это делается для большей
наглядности. В реальности хранимые процедуры вызывались бы прикладной
программой по локальной сети или Интернету, а не с помощью SQL Query Analyzer.
Хранимая процедура Customer J nsert
В листинге 13.1 изображена хранимая процедура, которая сохраняет в базе
данных информацию о новом клиенте и связывает этого клиента со всеми
художниками заданной национальности. (Логика этой процедуры точно такая же, как
и процедуры Customer_Insert в предыдущей главе.) Процедура имеет четыре входных
параметра: @NewName, @NewAreaCode, ©NewPhone и ©Nationality. Как вы можете
видеть, параметры и переменные в TRANSACT-SQL предваряются символом @.
Первые три параметра — это данные нового клиента, а четвертый параметр
представляет собой национальности художников, которыми интересуется новый клиент.
Логика приложения 489
Листинг 13.1. Хранимая процедура Customerjnsert
CREATE PROCEDURE Customer Insert
@NewName
@NewAreaCode
@NewPhone
(^Nationality
AS
DECLARE @Count
DECLARE @Aid as
DECLARE @Cid as
char(50).
char (5)
char (8),
char(25)
as smallint
int
int
Проверяем, нет ли данного клиента в базе данных */
SELECT @Count - Count (*)
FROM dbo.CUSTOMER
WHERE [Name]=@NewName AND AreaCode=@NewAreaCode AND LocalNumber=@NewPhone
IF (BCount > 0
BEGIN
PRINT 'Клиент уже есть в базе данных -- никаких действий не предпринято
RETURN
END
/* Добавляем нового клиента */
INSERT INTO dbo.CUSTOMER
([Name]. AreaCode Local Number)
VALUES
(PNewName, @NewAreaCode. @NewPhone)
/* Получаем новое значение суррогатного ключа */
Select @Cid = CustomerlD
FROM dbo.CUSTOMER
WHERE [Name]=@NewName AND AreaCode=@NewAreaCode AND LocalNumber=@NewPhone
/* Теперь создаем запись в таблице пересечения для каждого художника
соответствующей национальности */
DECLARE Artist_Cursor CURSOR FOR
SELECT ArtistID
FROM dbo.ARTIST
WHERE Nationality=@Nationality
/* Обрабатываем каждого художника указанной национальности */
OPEN Aitist^Cursor
FETCH NEXT FROM Artistjlursor INTO @Aid
WHILE @(aFETCH_STATUS = 0
BEGIN
INSERT INTO dbo.[CUSTOMER-ARTIST-INT]
(ArtistID. CustomerlD)
продолжение^
490 Глава 13. Работа с базами данных в SQL Server 2000
Листинг 13.1 (продолжение)
VALUES (©Aid @Cid)
FETCH NEXT FROM Artist_CurSor INTO @Aid
END
CLOSE Artist_Cursor
DEALLOCATE Artist^Cursor
GO
Первая задача, которую выполняет данная хранимая процедура, — проверить,
нет ли записи об этом клиенте в базе данных. Если count в первом операторе
SELECT оказывается больше 0, это значит, что строка для этого клиента уже
существует. В этом случае никаких действий не предпринимается, хранимая
процедура выводит сообщение об ошибке и завершает свою работу. Это сообщение об
ошибке, между прочим, будет видимым в Query Analyzer, но в общем случае не
будет видимым для прикладных программ, вызывающих данную процедуру.
Передать сообщение об ошибке пользователю через прикладную программу можно
с помощью параметра или каким-нибудь другим способом. Этот вопрос мы
рассмотрим в последующих главах.
Далее процедура вставляет новые данные в таблицу dbo.CUSTOMER и
считывает новое значение CustomerlD в переменную @Cid.
Чтобы создать соответствующие строки в таблице пересечения,
открывается курсор с помощью SQL-оператора, который возвращает все строки из
таблицы ARTIST, в которых значение столбца Nationality равно значению параметра
©Nationality. Затем происходит обработка курсора в цикле LOOP, в ходе которой
в таблицу пересечения CUSTOM ER_ARTIST_INT вставляются новые строки.
Оператор FETCH передвигает курсор на следующую строку.
На рис. 13.19 показано, как с помощью этой хранимой процедуры, вызываемой
из SQL Query Analyzer, добавить в базу данных нового клиента, интересующегося
художниками из США. Процедуре передаются параметры, значения которых
выделены красным цветом. На рис. 13,20 показано состояние данных в базе после
выполнения хранимой процедуры. В таблицу CUSTOMER был добавлен покупатель
Линда Джонсон (Lynda Johnson) с идентификатором CustomerlD, равным 1038.
Обратите внимание, что имеется три художника из США и что для каждого из
них в таблицу CUSTOM ER_ARTIST_JNT была вставлена строка с CustomerID=1038.
Для создания хранимой процедуры щелкните правой кнопкой мыши на
значке Stored Procedures (Хранимые процедуры) и выберите команду New Stored Procedure
(Новая хранимая процедура). Чтобы изменить существующую хранимую
процедуру, щелкните правой кнопкой мыши на ее названии в списке процедур и
выберите пункт Properties (Свойства).
Хранимая процедура NewCustomerWithTransaction
Хранимая процедура, создающая представление NewCustomer, показана в
листинге 13.2. Эта процедура принимает семь параметров, содержащих данные о новом
клиенте и сделанном им приобретении.
Логика приложения
491
1 Query ~ ШШШМе^Мж1№Ш№«Мт
Customer_Insert SNewName -'Lynda Johnson' , ^j
GNewAreaCode -'206'/
SNewPhone ~l553-1808r,
QNationality «'US*
ihWw111ftnrriW Vitfiin.r.iiiViiitfilifii-inJ-.fr.fr.Vi. ftиiiI fi! f№riViiTiVi ir
ШШШШШ2]
(1 row(s) affected)
(1 row(s) affected)
(1 row(s) affected)
(1 row(s) affected)
JJJ"
Рис. 13.19. Вызов процедуры Customerjnsert из окна Query Analyzer
щг^л^Т^^Шттм^^Ш^^^^^^^^^^
f в? Ш' в is ж!!р"Т^Щ^(1Ш^ оШШ'
]/
Ш
Fdstomerib {Name ■ ■' '-:>4lAreaCod$ >:••;.->• |tsea№AM№"-
1000 Jeffrey Janes 206 100
1001 David Smith .425 50
1015 Tiffany Twilight 206 555-1000
1033 Fred Smathers -206 555-1234
1034 Mary Beth Frederic. 206 555-1000
1036 Selma Warning ;206 555-1234
1037 Susan Wu[ =206 -555-1234
1038 .Lynda Johnson ;206 555-1000
;щШ&. •• • * Ш^фШЩ^ШШ^- . :>:.:■■ -::..V ■':.
; ■■•• ц
-1*
.<!
■<1
• :<fi
:<{\
:<N
<<\\
:'<tl
:<м
■JJ!
'■:-A\
Щ\-'**Ш ззкШУ'-
CustomerlD
lArtistID
1015
1015
1033
1034
1034
1034
1036
1037'
1033
1033
1033
5
•8
14 '
;5
.8
И
:14
:14
5
-infx]
[»
tz
LiaL
j
'■(■^«ei'M »_Qt
Art»tK>
3
4
5
6
8
14
aliii|
шФ^Ш*
lArtfefeNamfev-
Miro
Kandmsky
Fnngs
Klee
. David Moos
j Mark Tqbey
ШЙ1Ж^^1Ш:
r^i foatiot^tV;-^J: ■•:•' • i SrthGlatd::::>:'
1 Spanish 1370
1 Russian 1854
:US 1700
i German 1900
!US <NULL>
[US <NUU>
тш/^тщ^^^^^-
fDeceaseddat*':-. •;•■
1950
1900
1300
<NULL>
<NULL>
<NULL>
-гзтг ЩМЖ
ШЗ
«ИВй
Рис. 13.20. Результаты вызова хранимой процедуры из рис. 13.19
492 Глава 13. Работа с базами данных в SQL Server 2000
Листинг 13.2. Хранимая процедура NewCustomerWithTransaction
CREATE PROCEDURE NewCustomerWithTransaction
@NewName char(50), @NewAreaCode char (3). @NewPhone char (8).
@ArtistName char(50). (BWorkTitle char(50). @WorkCopy char(10).
@Price small money
AS
DECLARE (BCount as smallint
DECLARE @Aid as int
DECLARE @Cid as int
DECLARE @Wid as int
DECLARE (BTid as int
SELECT (BCoLint=CoLint (*)
FROM dbo.CUSTOMER
WHERE [Name]=@NewName AND AreaCode=@NewAreaCode AND Local Number«@NewPhone
IF(BCoLint > 0
BEGIN PRINT ' Клиент уже есть в базе данных -- никаких действий не
предпринято '
RETURN
END
BEGIN TRANSACTION /* Начинаем транзакцию; если не можем ее выполнить -- делаем
откат всех изменений */
INSERT INTO dbo.CUSTOMER
([Name], AreaCode, Local Number)
VALUES (@NewName, @NewAreaCode, @NewPhone)
Select @Cid = CustomerlD
FROM dbo.CUSTOMER
WHERE [Name]=@NewName AND AreaCode=@NewAreaCode AND Local Nurnber^NewPhone
SELECT ©Aid = Artist ID
FROM dbo.ARTIST
WHERE ArtistName=(BArtistNarne
If @Aid IS NULL /* Неправильный идентификатор художника */
BEGIN
Print' Неправильный идентификатор художника '
ROLLBACK
RETURN
END
SELECT (BWid = Work ID
FROM dbo.[WORK]
WHERE ArtistID = @Aid AND Title - GWorkTitle AND Copy - GWorkCopy
lf@Wid IS NULL /* Неправильный идентификатор произведения */
Логика приложения 493
BEGIN
Print 'Неправильный идентификатор произведения1
ROLLBACK
RETURN
END
SELECT (BTid=TransactionID
FROM dbo.[TRANS]
WHERE WorklDHBWid AND SalesPrice IS NULL
If @Tid IS NULL /* Неправильный идентификатор транзакции */
BEGIN
Print ' Неправильный идентификатор транзакции '
ROLLBACK
RETURN
END
UPDATE dbo.[TRANS] /* Все в порядке, обновляем строку в таблице TRANS */
SET PurchaseDade = GETDATEO. SalesPrice = @Price, CustomerlD = (Kid
WHERE TransactionID=(3Tid
INSERT INTO dbo.[CUSTOMER-ARTIST-INT] /* Регистрируем интерес клиента к данному
художнику */
(CustomerlD. ArtistID)
Values ((BCid, @Aid)
COMMIT
GO
Первое, что нужно сделать, — это проверить, не существует ли уже этот клиент
в базе данных; если да, процедура завершает работу с сообщением об ошибке.
Если этого клиента нет в базе данных, процедура начинает транзакцию.
Вспомните из главы 11, что транзакции гарантируют атомарность действий,
выполняемых с базой данных: либо выполняются все обновления, либо не
выполняется ни одного. Итак, начинается транзакция, и в таблицу CUSTOMER вставляется
строка для нового клиента. Далее считывается новое значение CustomerlD, как
показано выше. Затем процедура проверяет допустимость значений ArtistID, WorkID
и TransactionlD. Если хотя бы одно из них является некорректным, происходит
откат транзакции.
Если все перечисленные значения правильны, оператор UPDATE обновляет
столбцы PurchaseDate, Price и CustomerlD в соответствующей строке таблицы TRANS.
В столбец PurchaseDate записывается системная дата (с помощью системной
функции GETDATEO), в столбец SalesPrice — значение параметра @Рп'се, а в
столбец CustomerlD — значение переменной @Cid. Наконец, добавляется строка в
таблицу CUST0MER_ARTISTJNT, чтобы зарегистрировать интерес клиента к данному
художнику. Если до этого момента все идет нормально, транзакция сохраняется.
На рис. 13.21 показан вызов этой процедуры с тестовыми данными, а на
рис. 13.22 изображены результаты вызова в базе данных. Новому клиенту был
присвоен идентификатор CustomerlD, равный 1040, и этот идентификатор был записан
494 Глава 13. Работа с базами данных в SQL Server 2000
в столбец внешнего ключа CustomerlD таблицы TRANS, как и требовалось.
Соответствующим образом были установлены значения столбцов PurchaseDate и SalesPrice.
Обратите внимание на новую строку в таблице пересечения, которая отражает
интерес клиента под номером 1040 к художнику под номером 14.
и Query ~ DeGRVIOI.Vfei^ido^l^DBGRVlOlSAdfl^M*^ifi^MiiiiMM
тх-ггй.
Ш±ЮШ
NevCustornerlJithTransaction
GNewName -'fconaid G. Gray* ,
@NewAreaCode ^M2 5»;
@NewPhone =•'555-123*» .
QArtistNaxne * ! Heirfc Tobey» ; QtforkTitle »»Kyatic Fabr*^, BWorkCopy ~'5/4Q',
GPrice -49750
ШШШЖ*тШ*ЧЖЪЖ
(1 row(s) affected)
(1 row(s) affected)
(1 row(s) affected)
Zi
Рис. 13.21. Вызов процедуры NewCustomerWithTransaction из окна Query Analyzer
Aw-
яШ
Щх
цш
i'pfc
■ШШ&Ш
1000
1001
1015
1033
1034
1036
1037
1038
1040
Шю& Я Ш^М&ШШй".
Jeffrey Janes 206
David Smith 425
Tiffany Twilight 206
Fred Smathers 206
Mary Beth Frederic 206
5e*ma Warrwtg 206
Susan Wu 206
Lynda Johnson 206
Donald G. Gray 425
й'й^'йаШййлёг'1.-
100
50
555-1000
555-1234
555-1000
555-1234
555-1234
555-1000
555-1234
■ ,Tj
J
/B
ШШШ
ЩШ^ШВмШШШШ:-
1015
1015
103Э
^1034
1034
1034
1036
1037
1038 '
10Э5
1038
1040
Ш11Н Ш hi ш IJ53 .'
■мттт^тШ
"3!
:^,^Д.;.^|
$Шх$Щ$$8Ш«
ш
й
WertJ»
505
506
507
525
""' • Гаг*Ь*££> '
14
3
14
14
"iTftfe":. '■ ."
MvsticFabnc
Mi Vida
Slow Embers
Mystic Fabric
..teapv
4/40
73/122
55'?7
5/4",
'>5.-ipr ЮГ?. ,:.:..:•.:•:■:': /JiV. ^+1.
: ■ rr f ^he only privately he"jj
- - : :*ck, but very beautiK7?
• \-ju-> ___ ■:>:;
сf damage, but great «пг ^ *
^ш
rt5*M»irvTaWe^RAN^»nVi«^^«e^«»*e«lVi«^
л
■f
*
&J
>l^2. Ш Bi
Tf апуасйопЮ..
100
101
121
122
124
ш|Шш#^'^н
. \№гШ.ШШ-' 1 Date Acq wed'
505 2/27/1974
505 7/17/1989
52S 11/17/1430
505 2/27/1999
50"? op/2001
ъ.ШШ:..:.
.-. itequstfonPo*?
8750
28900
4500
8000
13700
,g|:: ;
\т&Ш&<&в-.'
л/18/1974
10/14/1989
i 1/21/2000
2/15/2000
<4!L>
...:.'!!Г.":1.'.'..-.
' ]5atesPneeV- .::■;•
13500
46700
49750
17500
<NUIL>
■:■-:-:■{ CustomerlD
1015
1001
;1040
:i036
■ <NULL>
JAs^rtgPrK» :.:.:..;.:■;!;■;{
17500 ;
зеьоо
90or;
1*000 1
3"4-:o
J
Рис. 13.22. Результаты вызова хранимой процедуры из рис. 13.21
Логика приложения 495
Триггеры
Триггеры представляют собой хранимые процедуры, вызываемые при
выполнении заданной команды — вставки, обновления или удаления. Завершающие
триггеры выполняются после обработки соответствующей команды, а замещающие
триггеры — вместо оператора, который привел к вызову триггера. Завершающие
триггеры запускаются после выполнения всех каскадных обновлений и удалений.
Предваряющие триггеры в SQL Server не поддерживаются, в отличие от Oracle.
Триггер NewJPrice
В листинге 13.3 показан триггер, с помощью которого вычисляется значение
столбца NewPrice. Вид оператора CREATE TRIGGER показывает, что триггер должен
вызываться при вставках и обновлениях в таблице TRANS. Первым делом код
триггера определяет, затрагивает ли изменение (здесь под изменением
понимается вставка или обновление) столбец AcquisitionPrice. Если нет, триггер завершает
свою работу.
Листинг 13.3. Триггер New_Price
CREATE TRIGGER New_Price ON [dbo].[TRANS]
FOR INSERT.UPDATE
AS
DECLARE (BNewPrice as smallmoney
DECLARE (Bid as int
IF NOT UPDATE (AcquisitionPrice) RETURN /* Интерес представляют только новые
значения или изменения атрибута AcquisitionPrice */
SELECT @NewPrice - AcquisitionPrice. @id » TransactionID FROM inserted
Set (BNewPrice @NewPrice * 2 /* Здесь можно было бы использовать функцию,
вычисляющую изменение цены по более сложному закону */
/* Обратите внимание: выполнение следующих операторов приведет к рекурсивному
вызову данного триггера. Он сразу завершит свою работу, поскольку это обновление
не затрагивает атрибут AcquisitionPrice. */
UPDATE dbo.TRANS
SET AskingPrice = @NewPrice
WHERE TiansactionID - (Bid
Если же вставка или обновление затрагивает столбец AcquisitionPrice,
стоящий далее оператор SELECT возвращает новое значение AcquisitionPrice и значение
TransactionID. Данный оператор работает с псевдотаблицей, которая
поддерживается SQL Server. Эта таблица называется inserted и содержит все вставленные
или измененные данные. Есть еще одна подобная таблица (не используемая
здесь), которая называется deleted и содержит данные, существовавшие до опера-
496 Глава 13. Работа с базами данных в SQL Server 2000
ции удаления. Таблицы inserted и deleted доступны только в коде триггера. Они
сходны по своей функции с префиксами :new и :old, используемыми в Oracle,
Далее триггер вычисляет новую цену в переменной ©Price. Полученное
значение затем записывается в столбец AskingPrice обновляемой строки. Как
говорится в комментарии, обновление таблицы TRANS в этом триггере приведет к
повторному, рекурсивному его срабатыванию. Однако при втором запуске триггера
обновление не будет затрагивать столбец AcquisitionPrice, поэтому второй
экземпляр триггера завершит свою работу, не производя второго обновления.
Это, кстати, довольно затратный способ реализации для такой простой
формулы. Лучшим решением было бы определить формулу обновления как
свойство столбца AskingPrice в определении таблицы TRANS. Однако если бы
вычисление AskingPrice производилось более сложным способом либо если бы для этого
требовалось обращение к другим таблицам или даже другим базам данных, то
такой триггер был бы необходим.
Триггер On_WORKJnsert
В листинге 13.4 изображен более типичный способ использования триггера. Как
уже говорилось в главе 10, одно и то же произведение искусства может быть
продано галереей несколько раз. Но поскольку мы используем суррогатные ключи,
то каждый раз при регистрации произведения в базе данных информация о нем
будет помещаться в новую строку, что создаст впечатление, будто это какое-то
другое произведение. Чтобы предотвратить такую ситуацию, мы напишем
триггер 0n_W0RK_Insert, который будет проверять, не было ли это произведение
зарегистрировано в базе данных когда-либо ранее. Если да, то вновь созданная строка
будет удалена из таблицы WORK и вместо нее будет использоваться старая.
Листинг 13.4. Триггер On_WORKJnsert
CREATE TRIGGER 0n_W0RK_Insert ON dbo.[W0RK] FOR INSERT
AS
DECLARE ©NewWorkID as int
DECLARE ©Count as small int
DECLARE @Aid as int
DECLARE ©Title as char (50)
DECLARE ©Copy as char (10)
SELECT ^NewWorkID = WorkID, @Aid = ArtistlD. ©Title = Title, @Copy = Copy
FROM Inserted /* Эта псевдотаблица, содержащая вставленные данные, является
доступной для триггеров */
SELECT ©Count = Count (*)
FROM ViewRidgel.dbo.[W0RK]
WHERE ArtistlD - ©Aid AND Title = ©Title AND Copy = ©Copy
IF ©Count > 2 /* Ошибка: для данного произведения было доступно 2 строки
ДО вставки */
Логика приложение 497
BEGIN
ROLLBACK
Print ' Ошибка в таблице WORK: для данного произведения доступно более
одной строки '
RETURN
END
IF @Count = 2 /* Означает, что одна строка была доступна до вставки. Отменяем
вставку и используем сущеетвующую строку. */
BEGIN
ROLLBACK
SELECT @NewWorkID = WorkID /* Получаем значение столбца WorkID из
существующей строки */
FROM ViewRidgel.dbo.[WORK]
WHERE ArtistID = @Aid AND Title - ©Title AND Copy - ©Copy
END
SELECT ©Count = Count(*)/* Проверяем наличие доступных строк в таблице TRANS */
FROM ViewRidgel.dbo.TRANS
WHERE ©NewWorklD - WorkID AND CustomerlD IS NULL
IF ©Count > 0 RETURN /* Имеется одна строка */
INSERT INTO ViewRidgel.dbo.TRANS
(WorkID. DateAcquired)
VALUES (©NewWorklD. GETDATEO)
Кроме того, галерее требуется, чтобы для каждого произведения,
выставленного на продажу, имелась строка в таблице TRANS с нулевым значением
CustomerlD. Если данная работа никогда прежде не выставлялась в галерее,
нужно создать новую запись в таблице TRANS и связать ее с новой строкой таблицы
WORK. Если работа ранее уже появлялась в галерее, но для нее нет строки в
таблице TRANS с нулевым значением CustomerlD, такую строку следует создать. Если
такая строка уже имеется (это значит, что работа ни разу не была продана),
ничего предпринимать не требуется.
Первая задача процедуры — получить данные нового произведения из
псевдотаблицы inserted. Затем с помощью оператора SELECT подсчитывается
количество строк в таблице WORK, имеющих такие же значения атрибутов ArtistID, Title
и Сору. Если это количество больше двух, значит, ранее произошла ошибка. Строк
с такими данными должно быть максимум две — та, которая была изначально,
и новая. Если таких строк больше двух, триггер производит откат транзакции,
выводит сообщение об ошибке и завершает работу.
Есть обнаружено ровно две строки, это означает, что данная работа уже
выставлялась в галерее ранее, и триггер отменяет транзакцию, удаляя только что
добавленную в таблицу WORK строку. Между прочим, в результате отката этой
транзакции удаляются и те изменения, которые привели к срабатыванию триггера.
498 Глава 13. Работа с базами данных в SQL Server 2000
Выполнив откат, триггер получает значение WorkID другой строки, содержащей
данные этого произведения.
Теперь WorkID указывает либо на старую строку, если произведение уже
выставлялось в галерее ранее, либо на новую строку, если произведение появляется
в галерее впервые.
Единственное, что осталось сделать, — определить, имеется ли для этого
произведения строка в таблице TRANS с нулевым значением CustomerlD. Если такая
строка есть, то ничего предпринимать не требуется. В противном случае в
таблицу TRANS необходимо вставить новую строку.
На рис. 13.23 в базу данных View Ridge добавляются два произведения.
Первое из них никогда ранее не выставлялось в галерее, а второе уже успело
побывать в ее стенах. На рис. 13.24 показаны таблицы WORK и TRANS после
выполнения обеих вставок. Для работы «Northwest by Night» в таблицу WORK была
добавлена строка, а для копии № 5 работы «Mystic Fabric» — нет, потому что
запись о ней уже имеется в базе данных. (Мы знаем это потому, что с ней связана
строка в таблице TRANS с TransactionID=131.)
Щ[1 row(s) affected)
Ш If
|j(l row(s) affected) ;||||
ч =fe 1
i|(l row(s) affected) jpljj
:| Щ Ц 1 ]
i| I
ii|(l row(s) affected) il ]
I ijli
10-фк&{Щ^• ■ мЩ&!ШШу. й/ .'•" ЖШ -SB-., J';:f:,.: Ш:.,:..-..'.J
Рис. 13.23. Операции вставки, приводящие к вызову триггера в листинге 13.4
В таблицу TRANS были добавлены две строки; внешние ключи были
установлены на правильные строки таблицы WORK. Обратите внимание также, что
функция GETDATEQ записывает в столбец DateAcquired не только дату, но и время.
Управление параллельной обработкой 499
Остальные значения в столбце DateAcquired явно были заданы вручную,
поскольку в них отсутствует время.
101 505 7/17/1989 28900 10/14/1989 46700 1001 38600
121 525 11/17/1989 4500 11/21/2000 49750 1040 9000
122 505 2/27/1999 8000 3/15/2000 17500 1036 16000
124 505 4/7/2001 18700 <WJLL> <NULL> <NULL> 37400
129 ' ,530 11/21/2000 l:54;00PM <NULL> <WJLL> <NULL> <NULL> <NULL>
130 S25 11/21/2000 1 54:00 PM <NULL> <WJLL> <NULL> <NULL> <NULL>
Рис. 13.24. Результат вставок из рис. 13.23
Представление, которое иным способом обновить невозможно, можно
сделать обновляемым, определив для него замещающий триггер. В этом случае SQL
Server не будет пытаться выполнить операцию вставки, обновления или
удаления, а вместо этого вызовет триггер. Это требуется потому, что производитель
СУБД не в состоянии написать универсальный код, выполняющий, к
примеру, вставку в экземпляр произвольного представления. Зная же конкретное
приложение, можно написать код, делающий это для представлений
определенного вида.
В этом разделе вы познакомились с основными функциями хранимых
процедур и триггеров. Многое еще предстоит узнать, однако приведенных здесь основ
должно быть достаточно для начала. Из главы 15 вы узнаете, как вызывать
хранимые процедуры с использованием интернет-технологий.
Управление параллельной обработкой
SQL Server 2000 предоставляет исчерпывающий набор возможностей для
управления параллельной обработкой. Количество вариантов выбора велико, и
итоговое поведение определяется взаимодействием трех факторов: уровня
изоляции транзакции, характеристик курсора и блокировочных подсказок, заданных
в предложении SELECT. Блокировочное поведение зависит также от того, обра-
500 Глава 13. Работа с базами данных в SQL Server 2000
батывается ли курсор как часть транзакции, является ли оператор SELECT частью
курсора, и как подаются команды на обновление — из транзакции или
независимо.
В этом разделе мы обсудим только основы. За дальнейшей информацией
обращайтесь к документации по SQL Server 2000.
В SQL Server блокировки не налагаются напрямую. Вместо этого
разработчик указывает требуемую стратегию управления параллельной обработкой, и SQL
Server самостоятельно определяет, где налагать блокировки. Блокировки
налагаются на строки, страницы, ключи, индексы, таблицы и даже на всю базу данных.
SQL Server определяет необходимый уровень блокировки и может повышать или
понижать его в ходе обработки. Также SQL Server определяет, когда налагать
блокировку и когда снимать ее, в зависимости от предпочтений,
сформулированных разработчиком.
Уровень изоляции транзакции
В табл. 13.3 представлены возможности управления параллельной обработкой.
Самый обширный из них по количеству настроек — уровень изоляции
транзакции. Возможные уровни изоляции перечислены в порядке возрастания
ограничений в первой строке таблицы. Это те самые четыре уровня, которые вы
изучали в главе 11 и которые определены в стандарте SQL-92. Обратите внимание,
что в SQL Server можно разрешить «грязное» чтение, если установить уровень
изоляции READ UNCOMMITTED («незавершенное чтение»). По умолчанию
установлен уровень изоляции READ COMMITTED («завершенное чтение»).
Таблица 13.3. Варианты управления параллельной обработкой в SQL Server
Тип
Охват
Варианты
Уровень изоляции
транзакции
Характеристики
курсора
Блокировочные
подсказки
Соединение —
все транзакции
Курсор
SELECT
READ UNCOMMITTED
READ COMMITTED
REPEATABLE READ
SERIALIZABLE
READJ3NLY
OPTIMISTIC
SCROLL_LOCK
READCOMMITTED
READUNCOMMITTED
REPEATABLEREAD
SERIALIZABLE
NOLOCK
HOLDLOCK и другие...
Управление параллельной обработкой 501
Следующим по возрастанию ограничений уровнем изоляции является REPEATABLE
READ («воспроизводимое чтение»), при котором SQL Server налагает и
удерживает блокировки всех строк, считываемых данной транзакцией. Это означает, что
другие пользователи не могут изменить или удалить строку, которая была
считана транзакцией, пока транзакция не будет зафиксирована или прервана.
Повторное чтение курсора может, однако, привести к появлению фантомов.
Наиболее жестким уровнем изоляции является SERIALIZABLE («сериализуе-
мость»). При нем SQL Server налагает блокировку на диапазон строк, считанных
данной транзакцией. Тем самым гарантируется, что считанные данные не будут
изменены или удалены и что в заблокированном диапазоне не будут вставлены
новые строки, которые вызвали бы фантомное чтение. Обеспечение этого уровня
изоляции обходится дороже всего, и его следует использовать только в тех
случаях, когда он абсолютно необходим.
В качестве примера можно привести следующий SQL-оператор, который
устанавливает уровень изоляции REPEATABLE READ:
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
Этот оператор можно вставить в любое место, где допускается применение
TRANSACT-SQL, но до выполнения каких-либо действий с базой данных.
Поведение курсора
Второй способ объявления блокировочных предпочтений — задание поведения
курсора (cursor concurrency). Возможны три варианта: только чтение (READ_0NLY),
оптимистическая блокировка (OPTIMISTIC) и пессимистическая блокировка (в SQL
Server обозначается SCR0LL_L0CK). Как говорилось в главе 11, при
оптимистической стратегии блокировки никаких блокировок не налагается, пока
пользователь не обновит данные. После этого, если ранее считанные данные были
изменены, обновление отклоняется. Разумеется, прикладная программа должна указать,
что нужно делать, когда происходит отказ в обновлении.
SCR0LL_L0CK представляет собой вариант пессимистической блокировки. В этом
случае при считывании любой строки на нее налагается блокировка обновления.
Если курсор открывается из транзакции, блокировка удерживается до тех пор,
пока транзакция не будет зафиксирована или отменена. Если курсор
открывается вне транзакции, блокировка снимается при чтении следующей строки.
Вспомните из главы 11, что одна блокировка обновления может воспрепятствовать
другой блокировке обновления, но не коллективной блокировке. Таким образом,
в других соединениях эта строка может читаться при коллективной блокировке.
Поведение курсора по умолчанию зависит от типа курсора (см. главу 11). Для
статических и последовательных курсоров это только чтение, а для
динамических и ключевых — оптимистическая блокировка.
502 Глава 13. Работа с базами данных в SQL Server 2000
Поведение курсора задается с помощью оператора DECLARE CURSOR. В качестве
примера приведем следующий оператор, который объявляет динамический
курсор с пессимистической блокировкой, распространяющийся на все строки
таблицы TRANS:
DECLARE MY_CURS0R CURSOR DYNAMIC SCR0LL_L0CKS
FOR
SELECT *
FROM TRANS
Блокировочные подсказки
Дальнейшее изменение блокировочного поведения возможно с помощью
блокировочных подсказок (locking hints) в параметре WITH предложения FROM
оператора SELECT. В табл. 13.3 перечислены некоторые из блокировочных подсказок,
возможных в SQL Server. Первые четыре подсказки переопределяют уровень
изоляции транзакции, а две другие влияют на тип налагаемой блокировки.
Рассмотрим следующие операторы:
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
DECLARE MY_CURS0R CURSOR DYNAMIC SCR0LLJ.0CKS
FOR
SELECT *
FROM TRANS WITH READ UNCOMMITTED NOLOCK
Без блокировочных подсказок курсор MY_CURS0R имел бы уровень изоляции
REPEATABLE READ и блокировал бы обновление всех считанных строк. Эти
блокировки удерживались бы до тех пор, пока транзакция не была бы сохранена.
Благодаря блокировочным подсказкам этому курсору присваивается уровень
изоляции READ UNCOMMITTED. Кроме того, параметр NOLOCK изменяет тип курсора
с DYNAMIC на READ_0NLY.
Рассмотрим другой пример:
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
DECLARE MY_CURS0R CURSOR DYNAMIC SCR0LLJ.0CKS
FOR
SELECT *
FROM TRANS WITH HOLDLOCK
Эта блокировочная подсказка заставит SQL Server удерживать блокировку
обновления всех считанных строк, пока транзакция не будет сохранена. В
результате уровень изоляции транзакции вместо REPEATABLE READ станет SERIALIZABLE.
Вообще говоря, начинающим не рекомендуется пользоваться
блокировочными подсказками. Пока вы не стали экспертом по этому вопросу, задавайте
уровень изоляции и характеристику курсора так, как это принято делать.
Резервное копирование и восстановление 503
Безопасность
Вопросы безопасности в SQL Server рассматривались в главе И, и мы не будем
повторять обсуждение здесь. Напомним, что комбинация из имени пользователя
и пароля — это удостоверение, используемое при входе в SQL Server или в
Windows 2000 (с последующей передачей его SQL Server). Такая комбинация
связывается с одной или несколькими комбинациями база данных/пользователь. Роль —
это принадлежность к именованной группе пользователей, обладающих
одинаковым уровнем доступа к базе данных. Примером могут служить роли Продавец
и Менеджер. Пользователи могут вообще не иметь ролей или иметь много ролей;
кроме того, пользователи обладают полномочиями. Роль может не принадлежать
ни одному пользователю, а может принадлежать многим; ролям также
присваиваются полномочия.
Полномочия, связанные с определенной комбинацией имени пользователя
и пароля, включают в себя все полномочия пользователя, которому
принадлежит данная комбинация, а также все полномочия всех ролей, назначенных
данному пользователю. Пользователю может быть дано полномочие на присвоение
полномочий другим пользователям с помощью оператора GRANT.
Резервное копирование и восстановление
Когда вы создаете базу данных SQL Server, генерируются файлы данных и
журналов. Как объяснено в главе И, следует периодически делать резервные копии
этих файлов. Это позволит впоследствии восстановить базу данных после сбоя,
скопировав ее из ранее сделанного снимка и воспроизведя изменения,
зафиксированные в журнале.
Чтобы восстановить базу данных, SQL Server берет ранее сделанную
резервную копию и на нее накладывает конечные образы из журнала. Когда
достигается конец журнала, изменения, вызванные незафиксированными транзакциями,
отменяются.
Можно также обрабатывать журнал до определенного момента времени или
до метки транзакции. Например, выполнение оператора
BEGIN TRANSACTION NewCust WITH MARK
приведет к тому, что при каждом запуске этой транзакции в журнале будет
ставиться метка транзакции с именем NewCust. В этом случае можно будет
восстановить журнал до точки, находящейся непосредственно до или после самой
первой метки NewCust либо первой такой метки после определенного момента
времени. Затем с помощью восстановленного журнала можно будет
восстановить базу данных. Следует, однако, иметь в виду, что такие метки расходуют
место в журнале, поэтому их не стоит использовать без достаточного основания.
504 Глава 13. Работа с базами данных в SQL Server 2000
Типы резервных копий
SQL Server поддерживает несколько типов резервных копий. Чтобы увидеть их,
откройте Enterprise Manager, откройте папку Databases и правой кнопкой мыши
щелкните на имени базы данных. Выберите пункт All Tasks (Все задачи), затем
Backup Database (Создать резервную копию базы данных). Появится диалоговое
окно, изображенное на рис. 13.25. Теперь вы можете создать резервную копию
базы данных (полную или дифференциальную), журнала транзакций или
отдельных файлов и групп файлов.
:';:Ща1И!ёф-:' Г" eA'Ridge! backup
Рис. 13.25. Диалоговое окно создания резервной копии
Как следует из названия, полная резервная копия (complete backup) — это
копия всей базы данных. Дифференциальная резервная копия (differential backup)
представляет собой копию изменений, произведенных в базе данных с того
момента, как была сделана последняя полная копия. Это значит, что прежде чем
делать первую дифференциальную копию, необходимо сделать полную копию.
Поскольку дифференциальные копии делаются быстрее, их можно делать чаще, тем
самым снижая вероятность потери данных. С другой стороны, с помощью
полных копий, хотя они и требуют более продолжительного времени для снятия,
восстанавливать базу данных несколько проще, как вы увидите далее.
Журнал транзакций также нужно периодически копировать, чтобы
гарантировать сохранность его содержимого. Кроме того, журнал транзакций необ-
Резервное копирование и восстановление 505
ходимо скопировать перед тем, как использовать его для восстановления базы
данных.
Резервные копии можно делать на диске или на магнитной ленте. По
возможности их следует делать на иных устройствах, чем те, где хранится действующая
база данных с журналами. Использование для этих целей съемных устройств
позволяет хранить резервные копии в месте, физически удаленном от центра
обработки данных. Это важно для восстановления после разрушений, вызванных
стихийными бедствиями — наводнениями, ураганами и т. п.
Модели восстановления SQL Server
SQL Server предусматривает три модели восстановления (recovery models):
простую, полную и выборочную. Задать модель восстановления можно, щелкнув
правой кнопкой мыши на имени базы данных в Enterprise Manager и выбрав
Properties (Свойства). Модель восстановления задается во вкладке Options
(Параметры). Пример изображен на рис. 13.26.
VtewRJtfqel Properties
|;Шй^^|;:р^арав!&] т»ал?а^й^|':?Й?й(^^УЙ?^* j Рмп&аот •
jFull
iBulk-Loqqn
Г~ Restrict access
<"
■ Read о--
Reco*e*y
Moos''
Sprigs
Г AN SIMULA deim^ES^.
.:,:; p $ ^^&!ШШт..
|T:Aute shrink
P Use quoted, identifier
ifa:'5ie n.T'ips'it'ii'V i*,el;:
OK
Cancel
*}■
Help>;||
Рис. 13.26. Параметры модели восстановления
При простой модели восстановления (simple recovery) журнал не ведется.
Единственный способ восстановить в этом случае базу данных — это
активировать последнюю резервную копию. Изменения, сделанные после снятия этой
копии, будут потеряны. Простую модель восстановления можно использовать для
506 Глава 13. Работа с базами данных в SQL Server 2000
базы данных, содержимое которой никогда не меняется, — например, для базы
данных закрытого кладбища, содержащей имена покойных и сведения о
расположении их могил. Это может быть также база данных, используемая для
анализа в режиме «только чтение» информации, поступившей из какой-то другой
транзакционной базы данных.
При полной модели восстановления (full recovery) в журнал заносятся все
изменения, произведенные в базе данных, а при выборочной модели (bulk-logged
recovery) — все, кроме тех, которые приводят к появлению в журнале записей
больших размеров. Сюда относятся изменения в объемных текстовых и
графических элементах данных, действия наподобие CREATE INDEX и некоторые другие
операции с большим объемом данных. Организация может использовать
выборочный режим восстановления, если для нее важно экономить место в журналах
и если данные, которые используются в указанных выше операциях,
сохраняются каким-либо еще образом.
Восстановление базы данных
Если есть должным образом сделанные резервные копии базы данных и
журналов, восстановление базы данных производится элементарно. Первым делом
следует восстановить текущий журнал, чтобы сделать доступными изменения,
записанные в самом последнем журнале. После этого щелкните правой кнопкой
мыши на имени базы данных в Enterprise Manager, выберите пункт All Tasks и
затем Restore Database (Восстановить базу данных). Появится диалоговое окно,
изображенное на рис. 13.27.
В этом примере база данных ViewRidgel восстанавливается под именем ViewRidge3.
Менять имя базы данных не обязательно. Здесь замысел состоит в том, чтобы
восстановить базу данных под другим именем, проверить ее, удалить то, что
осталось от старой базы, а затем переименовать восстановленную базу данных
в ViewRidgel.
База данных восстанавливается до состояния на 24 ноября 2000 года, 14:08:24.
Если бы мы оставили пустым поле First Backup to Restore (Начальная резервная
копия), то база данных восстанавливалась бы до конца журнала. При нажатии
кнопки 0К (Готово) SQL Server начнет восстановление, в ходе которого он будет
извещать администратора о динамике процесса и его завершении.
(Замечу между прочим, что восстанавливать базу данных мне пришлось
потому, что я случайно инициировал следующее обновление:
UPDATE WORK
SET Сору='99/2000'
На самом же деле я хотел написать
UPDATE WORK
SET Copy-'99/2000'
WHERE WorkID=530
Вопросы, не затронутые в этой главе 507
Restore database
*ii
^4|1рЩЙ!г;!:Г;
Р$ЙЩ^фйаЬв;е
Fie*to*$££
iP^ebsie
«egpougfsor.il
5Й|»ЙЙ^^Й1я^№К." ■ 3idge1
F*0^^jy$$&$i;';.:;-J: _ 3/20001:48:20 PM -ViewRidgel backup
Г ft$* in ftte restae: "• '.'■ j
Restore-
■2
jtype
@
; Backup SetOdte
11/20/20001:4...
11/20/20001:4...
ЦШ?'
jfl^itoie'Ftdm
12... CAProgram..
79Kb CAProgram..
1
Фаскир$еШате
ViewRidgel backup
ViewRidgel backup
"1
jj-
-J
OK
Cancel
Help
Рис. 13.27. Восстановление базы данных до состояния на определенный момент времени
Эту ошибку я сделал чуть позже 14:30, поэтому я восстановил базу до более
раннего момента, но такого, что изменения, которые я хотел сохранить, тогда
уже были внесены.)
План обслуживания базы данных
С целью решения различных задач, среди которых упрощение создания
резервных копий базы данных и журналов, вы можете создать план обслуживания
(maintenance plan) базы данных. Для этой цели в SQL Server существует
специальный мастер. Чтобы его вызвать, щелкните правой кнопкой мыши на имени
базы данных, выберите пункт All Tasks и затем Maintenance Plan (План
обслуживания). Этот мастер поможет вам в организации выполнения различных задач по
расписанию. Эти задачи включают в себя реорганизацию индексов и другие
связанные с этим действия. Однако важно здесь то, что вы можете организовать
автоматическое резервное копирование данных и журналов по расписанию.
Вопросы, не затронутые в этой главе
Есть несколько важных вопросов, связанных с SQL Server, которые не были
затронуты в этой главе. Во-первых, в SQL Server имеются утилиты для измерения
производительности базы данных. Администратор базы данных может использо-
508 Глава 13. Работа с базами данных в SQL Server 2000
вать эти утилиты при настройке базы данных. Еще одна возможность, не
описанная здесь, — это соединение Access с SQL Server. Информацию по этой теме
можно найти в документации на Access.
В SQL Server имеются средства для поддержки распределенной обработки баз
данных, которая в SQL Server называется репликацией (replication). Эти средства
используют модель распределенной обработки «публикация-подписка»,
которую мы будем рассматривать в главе 17. Тема распределенной обработки
данных, хотя и важна сама по себе, тем не менее выходит за рамки данной книги.
Microsoft предоставляет сервер OLE DB иод названием Distributed Transaction
Manager (диспетчер распределенных транзакций), который координирует
распределенные транзакции. Java поддерживает технологию под названием
Enterprise Java Beans, служащую тем же целям. Мы коснемся этих вопросов в
главах 15 и 16.
Наконец, в SQL Server имеются средства для обработки представлений баз
данных в форме XML-документов. Язык XML будет подробно обсуждаться
нами в следующей главе.
Резюме
SQL Server 2000 может устанавливаться на компьютерах под управлением
Windows NT и Windows 2000. Есть два способа создания таблиц, представлений,
индексов и других структур базы данных. Первый способ — использовать средства
графического проектирования, подобные имеющимся в Access. Второй способ
состоит в написании SQL-операторов, создающих эти структуры, и передаче их на
выполнение SQL Server с помощью программы SQL Query Analyzer. Типы
данных SQL Server перечислены в табл. 13.3.
SQL Server поддерживает пользовательские типы данных, которые
позволяют реализовать домены. Эти типы можно использовать для определения
столбцов как в средствах графического проектирования, так и в SQL-операторах. Для
столбцов и пользовательских типов данных можно задавать правила. В случае
пользовательского типа правило реализуется для всех столбцов, имеющих
заданный тип.
Структуру таблицы можно менять с помощью графических средств или SQL-
оператора ALTER TABLE. Связи можно создавать путем рисования их на
диаграммах базы данных или определения внешних ключей в SQL-операторах.
Связи имегсгг ряд свойств (диалог Properties), относящихся к обеспечению
ссылочной целостности. Если установлен флажок Enforce Relationship, SQL Server
не допустит появления в дочерних таблицах значений внешних ключей, не
соответствующих первичным ключам родительских таблиц. Поддерживаются
каскадные обновления и удаления. Если в структуре базы данных используются
суррогатные ключи, в каскадных обновлениях нет необходимости.
SQL Server поддерживает SQL-представления. Одни представления можно
использовать для обновления данных, другие — нет. Любое представление, ос-
Резюме 509
новывающееся на одной таблице, является обновляемым, если оно не включает
в себя встроенные функции или производные столбцы. Чтобы представление
допускало вставку, в нем должны присутствовать все ненулевые столбцы.
Представление, содержащее данные более чем из одной таблицы, не может
использоваться для удаления. Многотабличные представления допускают вставку
и обновление, если эти операции затрагивают только одну таблицу из
имеющихся в представлении. Представление, которое другим способом обновить
невозможно, можно сделать обновляемым, определив для него замещающий
триггер.
Индексы — это специальные структуры данных, используемые для
повышения производительности базы данных. SQL Server автоматически создает
индекс по всем первичным и внешним ключам. Дополнительные индексы
создаются с помощью оператора CREATE INDEX или графического средства Manage
Index. SQL Server поддерживает кластеризованные и некластеризованные
индексы.
SQL Server имеет входной язык под названием TRANSACT-SQL, в котором,
помимо базовых SQL-операторов, предусмотрены программные конструкции —
параметры, переменные и логические структуры (IF, WHILE и т. д.). Реализация
логики приложения в SQL Server возможна тремя способами: посредством
процедур на TRANSACT-SQL и хранимых запросов, которые вызываются с
помощью программы SQL Query Analyzer, посредством хранимых процедур, которые
вызываются из прикладных программ или через SQL Query Analyzer, и
посредством триггеров, которые вызываются SQL Server при выполнении
определенных действий с базой данных.
Хранимые процедуры могут находиться на компьютерах пользователей или
в базе данных и вызываться из прикладных программ. Последнее более
характерно для интернет-приложений, как вы узнаете из главы 15. Хранимая процедура,
записывающая в базу данных информацию о новом клиенте и его приобретении,
показана в листинге 13.2. Примеры триггеров вставки и обновления приведены
на рис. 13.21 и 13.22.
Поведение SQL Server при управлении параллельной обработкой
определяется тремя факторами: уровнем изоляции транзакции, поведением курсора
и блокировочными подсказками, данными пользователем в предложении SELECT.
Эти факторы представлены в табл. 13.3. Поведение также меняется в
зависимости от того, каким образом происходят изменения — в контексте транзакций,
в контексте курсоров или независимо. Имея блокировочные предпочтения,
указанные разработчиком, SQL Server самостоятельно налагает блокировки.
Блокировки могут налагаться с различной глубиной детализации, которая в ходе
обработки может быть увеличена или уменьшена.
SQL Server поддерживает создание резервных копий журналов, а также
полных и дифференциальных резервных копий базы данных. Предусмотрены три
модели восстановления: простая, полная и выборочная. При простой модели
журнал не ведется и записи из журнала не обрабатываются. При полной модели
510 Глава 13. Работа с базами данных в SQL Server 2000
все операции, выполняемые с базой данных, заносятся в журнал и затем
воспроизводятся при восстановлении. В случае выборочной модели при ведении
журнала опускаются определенные виды транзакций, для записи которых требуется
много места.
Вопросы I группы
1. Установите SQL Server 2000 и создайте базу данных под названием MEDIA
(мои картинки). Для размеров, имен и местоположения файлов оставьте
параметры, задаваемые по умолчанию.
2. Напишите SQL-оператор, создающий таблицу под названием PICTURE
(слайд) со столбцами Name (название), Description (описание), DateTaken
(дата съемки) и FileName (имя файла). Пусть Name имеет тип char(20),
Description — varchar(200), DateTaken — smalldate, a FileName — char(45). Кроме
того, пусть атрибуты Name и DateTaken являются обязательными.
Используйте Name в качестве первичного ключа. Задайте для столбца Description
по умолчанию значение «(None)».
3. С помощью SQL Query Analyzer выполните оператор из вопроса 2 и
создайте в базе данных MEDIA таблицу PICTURE.
4. Откройте базу данных MEDIA в Enterprise Manager и откройте окно
проектирования базы данных для таблицы PICTURE. В этом окне добавьте в
таблицу столбец-идентификатор PicturelD, задав для него начальное значение
300 и приращение 25. Поменяйте первичный ключ с Name на PicturelD.
5. С помощью графического средства проектирования таблиц задайте
значение по умолчанию для столбца DateTaken равным системной дате.
6. Создайте пользовательский тип данных под названием Subject (тема),
определив его как char(30). Добавьте в таблицу PICTURE столбец Topic (тема),
имеющий тип Subject.
7. Создайте правило под названием Valid_Subjects (допустимые темы),
определяющее следующее множество значений: {'Home', 'Office', family', 'Recreation',
'Sports', 'Pets'} (дом, работа, семья, отдых, спорт, животные). Привяжите это
правило к пользовательскому типу данных Subject.
8. Напишите операторы ALTER, выполняющие следующие действия:
1. Изменение длины столбца Name до 50 символов.
2. Удаление столбца DateTaken.
3. Добавление столбца TakenBy (кто снимал), имеющего тип char(40).
9. Передайте операторы, созданные вами в ответе на вопрос 8, на
выполнение SQL Server с помощью SQL Query Analyzer. После этого откройте
окно проектирования таблиц и убедитесь, что изменения произведены
должным образом.
Вопросы I группы 511
10. Создайте таблицу SLIDE-SHOW (презентация), имеющую столбцы ShowID
(номер презентации), Name (название), Description (описание), Purpose (цель).
Пусть ShowID будет суррогатным ключом. Задайте тип данных для
столбцов name и Description так, как считаете нужным. Для столбца Purpose
укажите тип данных Subject. Используйте SQL-оператор CREATE или средство
графического проектирования таблиц.
11. Создайте таблицу SHOW-PICTURE-INT, представляющую собой пересечение
таблиц PICTURE и SLIDE-SHOW.
12. Создайте необходимые связи между таблицами PICTURE и SHOW-PICTURE-
INT, а также между таблицами SLIDE-SHOW и SHOW-PICTURE-INT. Установите
режим обеспечения ссылочной целостности таким образом, чтобы
запретить удаление из таблицы SLIDE-SHDW строк, имеющих связанные с ними
строки в таблице SHOW-PICTURE-INT. Обеспечьте также каскадные удаления
при удалении строки из таблицы PICTURE.
13. Объясните, как установить свойство Cascade Update для связей из во*
проса 12.
14. Напишите SQL-оператор, создающий представление PopularShows
(популярные презентации), содержащее столбцы SLIDE-SHOW,Name и PICTURE.
Name всех презентаций, у которых столбец Purpose имеет значение «Ноте»
или «Pets». Запустите этот оператор на выполнение с помощью SQL Query
Analyzer.
15. Откройте средство для проектирования представлений и убедитесь, что
представление PopularShows было спроектировано правильно.
Модифицируйте это представление, добавив в него столбцы Description и FileName.
16. Может ли SQL-оператор DELETE использоваться с представлением Popular-
Shows? Почему?
17. При каких условиях представление PopularShows допускает вставку и
модификацию?
18. Создайте индекс по столбцу Purpose. Воспользуйтесь для этого средством
графического проектирования Manage Index.
19. Для чего используется переменная @Count в листинге 13.1?
20. Зачем нужен оператор SELECT, который начинается с SELECT @Cid?
21. Объясните, как бы вы изменили хранимую процедуру в листинге 13.1,
чтобы связать клиента со всеми художниками, которые (а) родились до
1900 года или (б) имеют нулевое значение атрибута BirthDate.
22. Объясните, в чем назначение транзакции в листинге 13.2.
23. Что произойдет, если хранимой процедуре в листинге 13.2 будет передано
неправильное значение атрибута Сору?
24. Объясните, почему триггер в листинге 13.3 является рекурсивным. Что
остановит рекурсию?
512 Глава 13. Работа с базами данных в SQL Server 2000
25. Объясните, почему в листинге 13.4 значение @Count, большее 2, означает,
что еще до вызова триггера 0nJ/V0RK_Insert произошла ошибка.
26. Что произойдет при выполнении оператора ROLLBACK в листинге 13.4?
27. Каковы три основных фактора, определяющие блокировочное поведение
SQL Server?
28. Раскройте смысл каждого из четырех уровней изоляции транзакции,
перечисленных в табл. 13.3.
29. Раскройте смысл каждого из трех типов поведения курсора,
перечисленных в табл. 13.3.
30. В чем назначение блокировочных подсказок?
31. Чем полная резервная копия отличается от дифференциальной? В каких
случаях рекомендуется делать полные резервные копии, а в каких —
дифференциальные?
32. Объясните разницу между простой, полной и выборочной моделями
восстановления. Для каждой модели опишите условия, при которых вы ее
выбрали бы.
33. Когда необходимо восстановление к состоянию на определенный момент
времени?
Проекты
Для следующих проектов создайте базу данных View Ridge с помощью SQL
Server, как описано в этой главе. Рассмотрим представление Artist View, о
котором шла речь в вопросах группы II в конце главы 10.
1. Напишите на TRANS ACT-SQL процедуру, считывающую ту часть
представления, которая относится к таблице ARTIST. Отобразите полученные
данные в Query Analyzer, как показано в этой главе. Пусть имя художника
будет входным параметром процедуры.
2. Напишите на TRANSACT-SQL процедуру, считывающую ту часть
представления, которая включает данные из таблиц ARTIST, TRANSACTION и CUSTOMER
(клиентов берите только тех, для которых имеются транзакции).
Отобразите полученные данные в Query Analyzer, как показано в этой главе. Пусть
имя художника будет входным параметром процедуры.
3. Напишите на TRANSACT-SQL процедуру, считывающую данные из всех
таблиц, содержащихся в представлении. Отобразите полученные данные
в Query Analyzer, как показано в этой главе. Пусть имя художника будет
входным параметром процедуры.
4. Напишите на TRANSACT-SQL процедуру, регистрирующую интерес
клиента к определенному художнику. Пусть имя художника и имя клиента
будут входными параметрами. Если имя клиента не уникально, выведите
Вопросы к проекту RredUp 513
сообщение об ошибке. Прежде чем вставлять новую строку, проверьте, нет
ли одинаковых строк в таблице CUST0MER_ARTISTJNT. Выведите
сообщение об ошибке, если такие строки обнаружатся.
5. Напишите завершающий триггер, который контролировал бы вставку в
таблицу ARTIST и другие ее модификации. Если в ходе этих операций столбцу
Nationality присваивается значение «British», поменяйте его на «English».
Вопросы к проекту FiredUp
С помощью SQL Server создайте базу данных со следующими таблицами:
КЛИЕНТ (НомерКлиента, Имя, Телефон, ЭлектронныйАдрес)
ГОРЕЛКА (СерийныйНомер, Тип, Версия, ДатаВыпуска)
РЕГИСТРАЦИЯ (НомерКлиента, СерийныйНомер, ДатаРегистрации)
РЕМОНТ-ГОРЕЛКИ (НомерСчетаЗаРемонт, СерийныйНомер, ДатаРемонта, Описание,
Стоимость, НомерКлиента)
Пусть первичные ключи таблиц КЛИЕНТ, ГОРЕЛКА и РЕМОНТ-ГОРЕЛКИ являются
суррогатными ключами. Создайте связи, которые обеспечивали бы выполнение
следующих ограничений ссылочной целостности:
+ НомерКлиента в таблице РЕГИСТРАЦИЯ является подмножеством
НомерКлиента в таблице КЛИЕНТ;
+ СерийныйНомер в таблице РЕГИСТРАЦИЯ является подмножеством
СерийныйНомер в таблице ГОРЕЛКА;
+ СерийныйНомер в таблице РЕМОНТ-ГОРЕЛКИ является подмножеством
СерийныйНомер в таблице ГОРЕЛКА;
+ НомерКлиента в таблице РЕМОНТ-ГОРЕЛКИ является подмножеством Номер-
Клиента в таблице КЛИЕНТ.
Не включайте каскадные удаления.
1. Заполните таблицы данными и выведите их на экран.
2. Создайте хранимую процедуру, которая регистрировала бы горелку. В
качестве входных параметров процедура должна принимать имя, телефон
и адрес электронной почты клиента, а также серийный номер горелки. Если
запись о данном клиенте уже имеется в базе данных (имя, телефон и
электронный адрес совпадают), используйте для регистрации его
НомерКлиента. Будем предполагать, что горелка с данным серийным номером уже
занесена в базу данных. Если это не так, выведите сообщение об ошибке
и отмените изменения, произведенные в таблице КЛИЕНТ. Протестируйте
написанную процедуру.
3. Создайте хранимую процедуру, которая записывала бы информацию о
ремонте горелки. В качестве входных параметров процедура должна
принимать имя, телефон и адрес электронной почты клиента, серийный номер
514 Глава 13. Работа с базами данных в SQL Server 2000
горелки, описание ремонта и его стоимость. Действуйте в предположении,
что заданный серийный номер существует; если нет, выведите сообщение
об ошибке и не производите в базе данных никаких изменений. Если
запись о данном клиенте уже имеется в базе данных (имя, телефон и
электронный адрес совпадают), используйте существующую строку в таблице
КЛИЕНТ, если нет — создайте новую. В таблицу РЕМОНТ-ГОРЕЛКИ должна
быть внесена новая запись. Если необходимо, зарегистрируйте горелку.
4. Создайте представление, содержащее всю информацию об указанном
клиенте, которой обладает FiredUp. Назовите это представление ДанныеКлиен-
та. Это представление должно соединять в себе данные из таблиц КЛИЕНТ,
РЕГИСТРАЦИЯ, ГОРЕЛКА и РЕМОНТ-ГОРЕЛКИ. Напишите хранимую процедуру,
принимающую в качестве аргумента имя клиента и выводящую все
данные этого клиента.
Часть VI
Обработка организационных
баз данных
Часть VI книги посвящена технологиям публикации pi использования
организационных баз данных. В главах 14-16 рассматривается обработка баз данных
с использованием интернет-технологий. Речь идет о технологиях, первоначально
разработанных для Интернета, но в настоящий момент применяемых также в
закрытых интрасетях. В главе 14 излагаются основы — разновидности сетевого
окружения, трехуровневые и многоуровневые архитектуры и XML. Глава 15
иллюстрирует использование технологий Microsoft (OLE DB, ADO и Active Server
Pages) для публикации приложений баз данных. В главе 16 демонстрируется
решение тех же задач с помощью JDBC, Java и Java Server Pages. Завершается
часть VI книги главой 17, в которой обсуждаются другие виды архитектур
организационных баз данных, OLAP-приложения и администрирование данных.
Многие из описываемых в этой главе технологий быстро развиваются.
Информацию о них вы можете найти на следующих сайтах: новые технологии
Oracle — www.oracle,com, новые технологии Microsoft — www.microsoft.com,
последние новости XML и связанных с ним технологий — www.w3.org, последние
новости Java-технологий — www.sun.com/java. Эти сайты можно рассматривать
скорее как отправные точки поиска; вам стоит также самостоятельно поискать
информацию в Web, так как постоянно возникают новые сайты, посвященные
этой тематике.
Глава 14
Сети, многоуровневые
архитектуры и XML
С возникновением Интернета начали появляться технологии, которые сегодня
используются для публикации баз данных как в Интернете, так и в закрытых ин-
трасетях. Мы начнем с краткого обзора разновидностей сетевого окружения,
затем опишем многоуровневые архитектуры, наиболее часто используемые в
приложениях баз данных. Далее мы рассмотрим роль HTML и DHTML, а завершим
главу обсуждением XML. Как вы узнаете, наиболее важным для обработки баз
данных является язык XML Schema.
Разновидности сетевого окружения
Сеть (network) — это совокупность компьютеров, общающихся между собой
посредством стандартизированного протокола. Некоторые сети являются
открытыми (public) — ими может пользоваться любой, заплатив провайдеру,
предоставляющему доступ (или, как студенты, присоединившись к организации, уже
оплатившей доступ). Другие сети являются закрытыми (private). Доступ к ним
могут получить только уполномоченные на это лица. Наиболее популярной
открытой сетью является Интернет; именно с него мы и начнем.
Интернет
Интернет (Internet) представляет собой открытую сеть, состоящую из
компьютеров, которые общаются между собой посредством коммуникационного
протокола под названием TCP/IP (Transmission Control Program/Internet Protocol,
Программа управления передачей/Интернет-протокол). Эта сеть была создана
Агентством перспективных исследований (Advanced Research Projects Agency, ARPA)
вооруженных сил США в 1960-х годах. Изначально она называлась ARPANET
и соединяла крупные вычислительные центры военных ведомств, университетов
и исследовательских институтов. Со временем к этой сети присоединялось все
больше и больше организаций, и постепенно интерес к ней стали проявлять
коммерчески ориентированные организации, не связанные с научными
исследованиями. Сегодня эта сеть известна под названием Интернет.
Разновидности сетевого окружения 517
В 1989 г. Тим Бернерс-Ли (Tim Berners-Lee) из Европейской лаборатории
ядерной физики (CERN) начал работу над проектом, который позволил бы
исследователям делиться результатами своей работы с помощью Интернета. Этот
проект привел к разработке HTTP (hypertext transfer protocol) — протокола
передачи гипертекста, основанного на протоколе TCP/IP и обеспечивающего
совместное использование документов со встроенными ссылками на другие
документы в сетях TCP/IP.
С точки зрения приложений баз данных, заслуживают внимания две
особенности протокола HTTP. Во-первых, этот протокол ориентирован на запрос (request-
oriented). HTTP-сервер ждет, пока не придет запрос, а по приходе запроса
выполняет некоторые действия и затем, возможно, генерирует отклик. В отличие от
традиционных приложений информационных управляющих систем, он не ведет
статистики и никаким другим способом не отслеживает активность приложений.
Во-вторых, HTTP-приложения являются бесстатусиыми (stateless), то есть
у них нет состояния. Получив запрос, HTTP-сервер обрабатывает его, а затем
«забывает» о клиенте, который прислал этот запрос. Попыток продолжить сеанс
или обмен данными с определенным клиентом не предпринимается. Отсутствие
состояния не является помехой для web-приложений, доставляющих клиенту
статическое содержимое — рекламу и т. п.
Однако для приложений баз данных отсутствие состояния представляет
неудобство, ведь они ведут обработку транзакций, а это может подразумевать
многократный обмен данными между клиентом и сервером. Следовательно,
необходимо каким-то образом дополнить HTTP, чтобы приложения баз данных имели
способ поддерживать свое состояние. Несколько лет назад web-приложения
вынуждены были для этого самостоятельно заниматься определенной
алгоритмической «гимнастикой». Сегодня механизмы поддержания состояния
предоставляются IIS в сочетании с ASP и сервлетами Java в сочетании с JSP.
Интрасети
Термин иитрасеть (intranet) имеет несколько различных толкований. Чаще всего
этим термином обозначается закрытая локальная (LAN) или глобальная (WAN)
сеть, использующая TCP/IP, HTML и технологию браузеров на клиентских
компьютерах и технологию web-серверов на серверных машинах. Иногда данный
термин используется для обозначения любой закрытой локальной или
глобальной сети, в которой имеются клиенты и серверы.
Есть две характеристики интрасетей, которые отличают их от Интернета. Во-
первых, интрасети являются закрытыми. Они либо вообще не соединены с
открытой сетью, либо соединены с ней через брандмауэр (firewall) — компьютер,
выступающий в качестве защитного шлюза. Брандмауэры фильтруют трафик
между интрасетью pi Интернетом и отслеживают его источник и приемник. Одни
брандмауэры действуют таким образом, что пропускают только определенные
виды трафика, другие, наоборот, запрещают определенные виды трафика, третьи
работают в обоих режимах.
518 Глава 14. Сети, многоуровневые архитектуры и XML
Поскольку интрасети являются закрытыми, о безопасности в них приходится
заботиться меньше. Это не означает, что безопасности вообще не требуется уделять
внимания; смысл в том, что меры безопасности могут быть не столь
изощренными. В большинстве случаев компьютеры в интрасети являются известными
и поддерживаются организацией, которая владеет данной сетью и обслуживает
ее. Несанкционированный доступ и нарушения безопасности в такой сети легче
выявить и предотвратить, чем в открытой сети.
Вторая основная отличительная характеристика интрасети — скорость
передачи данных. В интрасетях она велика: многие интрасети имеют скорость
порядка 100 000 Кбит/с (тысяч бит в секунду). Сравните это с 56 Кбит/с — типичной
скоростью, на которой работают пользователи, соединяющиеся с Интернетом
при помощи модема. Даже те из пользователей, кто перешел на DSL и другие
специализированные модемные технологии, работают на скоростях, не
превышающих 500 Кбит/с. Таким образом, при проектировании
интернет-приложения необходимо привести требования приложения к скорости передачи данных
в соответствие с возможностями пользователей.
Благодаря этой разнице в скорости в интрасетевых приложениях можно
использовать большие растровые рисунки, звуковые файлы и анимацию. Что
касается мира баз данных, то здесь более важной является возможность передавать
на клиентские компьютеры результаты запросов, содержащие большие объемы
данных. Кроме того, высокая скорость позволяет загружать на клиентские
машины программные файлы большого размера. Это означает, как вы узнаете
позже, что в интрасети клиент может выполнять больший объем действий по
обработке приложения, чем в Интернете.
Беспроводной доступ в сети
Пользователи мобильных телефонов, наладонных компьютеров и других
мобильных устройств хотят иметь доступ в Интернет и в организационные интрасети по
беспроводной технологии. Поскольку мобильные устройства имеют
ограниченный размер экрана, уменьшенную клавиатуру и сокращенный объем памяти,
стандартные протоколы, подобные HTML и XML, не подходят для
использования на таких устройствах. Для установления международного стандарта доступа
в сеть с мобильных устройств был разработан протокол WAP (Wireless Application
Protocol, протокол для мобильных приложений). Кроме того, для отображения
web-страниц на мобильных устройствах был разработан вариант XML под
названием WML (Wireless Markup Language, язык разметки для мобильных устройств).
На рис. 14.1 показано использование всех трех типов сетей для управления
контактной информацией. Секретарше здесь нужен доступ к именам и
телефонам контактных лиц из офиса, из дома и с мобильного телефона, когда она
находится в пути. База данных с контактной информацией может находиться в ее
офисе, дома или у провайдера. Секретарше не важно, где конкретно находится
база данных: все, что она хочет, — это иметь доступ к единому источнику
контактной информации в любое время. Дальнейшее обсуждение WML и WAP
последует позже, после того как мы рассмотрим XML.
Многоуровневая архитектура 519
\
Беспроводной
Интернет
В дороге
В офисе
Рис. 14.1. Потребность в доступе к данным по сети из любой точки
Многоуровневая архитектура
На рис. 14.2 изображена трехуровневая архитектура (three-level architecture),
используемая во многих приложениях баз данных, применяющих
интернет-технологии. На этом и трех следующих рисунках будет много аббревиатур. Не
беспокойтесь, если вы еще не знакомы с этими терминами. Серверы (IIS) и языки
разметки (DHTML) мы рассмотрим после того, как обсудим общую архитектуру.
Стандарты баз данных (ODBC) будут описываться в главах 15 и 16.
На рис. 14.2 показаны три уровня, или три типа процессоров. Если
перечислять слева направо, это сервер базы данных, web-сервер и браузер или
клиентский компьютер. Как показано, каждый из этих уровней может работать под
управлением своей операционной системы. В этом примере сервер базы данных
работает под управлением Unix, web-сервер — под управлением Windows 2000,
а браузеры — под управлением операционной системы Macintosh. Это только
пример. Скорее всего, на уровне браузеров будет наблюдаться смесь из Windows 98,
Unix, Macintosh и Windows 2000. Web-сервер и сервер базы данных могут
работать под Unix или Windows 2000,
520 Глава 14. Сети, многоуровневые архитектуры и XML
Продукт/операционная
система (пример)
Nel
Браузер
Браузер
Браузер
scape Navigj
Macintosh
• Web-страница
W- • Клиентский код • SQL
\» Данные • Relations
\
t
/
Web-сервер
^ w
•^ w
Сервер базы
•данных
<-►
/
ator, Microsoft IIS, Oracle,
Windows 2000 Unix
F^ ^1
База
данных
Рис. 14.2. Трехуровневая архитектура
Продукты, показанные в качестве примеров на рис. 14.2, включают Oracle
на сервере базы данных, Microsoft Internet Information Server (IIS) на
web-сервере и браузер Netscape Navigator на клиентских компьютерах. Опять-таки,
это всего лишь пример. На сервере базы данных может работать любая СУБД
от Access до DB2. Распространенными web-серверами являются IIS, Netscape
Server и Apache. Наиболее популярными браузерами являются Netscape Navigator
и Microsoft Internet Explorer.
Как показано на рисунке, через интерфейс между web-сервером и сервером
базы данных передаются SQL-операторы и реляционные данные. Через
интерфейс между web-сервером и браузером передаются web-страницы, клиентский код
и данные. Мы еще будем много говорить о каждом из этих интерфейсов в этой
и последующих трех главах.
Функции описанных трех уровней перечислены на рис. 14.3. Назначение
сервера базы данных — нести на себе СУБД, которая выполняет SQL-операторы и
осуществляет управление базой данных. Здесь СУБД действует в традиционной роли,
заключающейся в манипулировании данными. Возможности прикладных средств,
которые вы видели в Access, в данном случае не задействуются. СУБД на сервере
базы данных на рис. 14.3 не создает форм, отчетов или меню, а выполняет
исключительно функции ядра — прием SQL-запросов и обработку строк в таблицах,
как описывалось в предыдущих двух главах.
На рис. 14.3 показаны стандарты и интерфейсы прикладных программ, которые
используются при передаче данных между сервером базы данных и
web-сервером. ODBC, OLE DB и ADO будут рассматриваться нами в главе 15, a JDBC —
в главе 16. В данный момент следует смотреть на эти стандарты просто как на
способ передачи SQL-кода и отношений между web-сервером и сервером базы
данных.
Web-сервер (web server) выполняет три основные функции. Во-первых, это
HTTP-сервер: он обрабатывает протокол HTTP, принимая запросы и генерируя
отклики в формате HTTP. Во-вторых, на web-сервере располагаются сценарный
интерпретатор (scripting engine), что позволяет разработчикам писать код на
Многоуровневая архитектура 521
VBScript и JavaScript и запускать его на web-сервере. Наконец, в приложениях
баз данных третьей функцией web-сервера является создание, чтение,
обновление и удаление экземпляров представлений, как описывалось в главе 10. Не
следует забывать о разнице между отношением и представлением — представления
строятся из отношений.
Браузер
HTTP:
• Запросы
,• Отклики
• ODBC
•ADO
• OLE/DB
• JDBC
• Вызовы собственности
Браузер ч—>\ Web-сервер
Сервер базы
данных
<-►
База
данных
Продукт/операционная
система (пример)
Браузер
HTTP-клиент HTTP-сервер
Клиентские Серверные
сценарии сценарии
Материализация Обработка
представлений представлений
Рис. 14.3. Функции уровней
Обработка
SQL
Управление
базой данных
Браузер в приложениях баз данных выполняет три функции, аналогичные
функциям web-сервера. Во-первых, браузер является HTTP-клиентом: он
генерирует запросы на страницы и на различные действия. Во-вторых, он содержит
сценарный интерпретатор, позволяющий запускать сценарии на клиентской
машине. Наконец, браузер материализует представления, преобразуя HTML или
другой язык разметки в содержимое окна на экране.
Эта архитектура дает возможность запускать сценарии как на клиентском
компьютере, так и на web-сервере. Одна из важных задач при разработке
приложения, использующего интернет-технологии, — определить, какую работу на
какой машине выполнять. Поскольку браузеров много, а сервер только один,
желательно поручать как можно больше работы клиенту. Однако если клиенту то
и дело приходится обращаться к web-серверу заданными для своих вычислений,
преимущества клиентской обработки могут быть сведены на нет величиной
задержки на передачу запроса и ожидание отклика. Кроме того, клиентский код
должен быть передан браузеру в HTTP-сообщении. Большие фрагменты кода
потребуют длительного времени для загрузки. Хорошее практическое правило
продемонстрировано на рис. 14.3: сценарии на клиентской стороне следует
использовать для материализации представлений. Для создания, чтения,
обновления и удаления представлений следует использовать серверные сценарии.
Непосредственные вычисления (Стоимость = Количество х Цена) обычно
выполняются в браузере.
522 Глава 14. Сети, многоуровневые архитектуры и XML
Web-сервер под управлением Windows 2000
На рис. 14.4 изображены стандарты и языки, обычно используемые, когда web-
сервер работает под управлением операционной системы Windows 2000. В этом
случае роль HTTP-сервера почти всегда будет играть IIS, поскольку эта система
является частью Windows. IIS предоставляет интерфейс под названием ISAPI
(Internet Server Application Program Interface, интерфейс прикладных программ
Интернет-сервера), с помощью которого другие программы могут перехватывать
и обрабатывать HTTP-сообщения. Одной из таких программ является ASP (Active
Server Processor, обработчик активных серверных страниц), Он обрабатывает все
web-страницы с расширением .asp. Когда IIS получает такую страницу, она
посылает ее ASP через интерфейс ISAPI. ASP обрабатывает страницу и генерирует
отклик, который передается IIS через ISAPI и далее посылается клиенту.
- Обработка на клиенте с помощью
• JavaScript
• VBScript
• байт-кода Java
• элементов управления ActiveX
г- Обработка на сервере с помощью
• ASP и
• JavaScript
• VBScript
•Perl
• элементов управления ActiveX
• специально разработанной
программы на Java или C++
Браузер
IIS
ASP
Специально
разработанная
программа
Windows 2000 (NT Server)
Сервер
базы данных
Рис. 14,4
HTML
DHTML
XML
. Стандарты
Web-сервер
• ODBC
• ADO
• OLE/DB
• Вызовы собственных
интерфейсов СУБД
и языки, наиболее часто используемые на серверах
под управлением ПО Microsoft
ASP содержит сценарные интерпретаторы, поэтому ASP-страницы могут
содержать операторы JavaScript, VBScript, Perl и других сценарных языков. ASP
выполнит эти операторы при обработке страницы. Кроме того, в страницу могут
быть встроены элементы управления ActiveX (ActiveX controls), и они также
будут вызываться при обработке страницы.
ASP — не единственная программа, которая может использовать интерфейс
ISAPI. Разработчики программ на языках C++ и Java могут создавать собственные
программы для обработки HTTP-сообщений, вместо того чтобы работать с ASP.
Многоуровневая архитектура 523
При использовании web-сервера Microsoft в качестве стандарта доступа к
данным будет, скорее всего, использоваться ODBC, ADO или OLE DB, поскольку
эти стандарты поддерживаются и пропагандируются Microsoft.
Web-сервер под управлением Unix и Linux
На web-серверах, работающих под управлением Unix или Linux (рис. 14.5), в
качестве HTTP-сервера используется не IIS, a Apache, Netscape Web Server и
подобные им продукты. Apache — наиболее популярный в мире web-сервер, отчасти
благодаря тому, что он является бесплатным. Информацию об Apache вы можете
найти на сайте www.apache.org.
Обработка на клиенте с помощью
• JavaScript
• апплетов и байт-кода Java
Р Обработка на сервере
с помощью
• сервлетов Java
• JSP (и Java)
• Perl или другого
сценарного языка
• специально разработанной
программы на Java или C++
Браузер
• HTML
• DHTML
•XML
Apache
или Netscape
Server
CGI
ISAPI
или NSAPIK
Apache Tomcat
(обработчик
сервлетов и JSP)
Специально
разработанная
программа
CGI-сценарии,
Perl, PHP
ASP
Специально
разработанная
программа
JSP
Сервлеты
Java
Unix (Linux)
Сервер
базы данных
Web-сервер
• JDBC
• Вызовы собственных
интерфейсов СУБД
• ODBC
Рис. 14.5. Стандарты и языки, наиболее часто используемые
на серверах под управлением Unix
В прошлом приложения, занимающиеся обработкой HTTP-запросов на Apache
и подобных ему серверах, широко использовали интерфейс под названием CGI
(Common Gateway Interface, общий шлюзовый интерфейс). Он обладал тем
недостатком, что для каждого пользователя в память загружалась одна копия
программы-обработчика. Если 100 пользователей обращались к одному и тому же
сценарию, то в память загружались 100 копий сценария. Такая ситуация
недопустима при той рабочей нагрузке, которая существует на коммерческих сайтах.
Как вы узнаете из главы 16, это не единственная проблема, связанная с CGI.
524 Глава 14. Сети, многоуровневые архитектуры и XML
На сегодняшний день для обработки приложений баз данных чаще всего
используются сервлеты Java (Java servlets) или JSP (Java Server Pages), или и то
и другое вместе. Эти технологии требуют наличия программного обеспечения,
реализующего спецификации сервлетов Java или Java Server Pages. Базовый
сервер Apache этого не делает, но при содействии организации Apache был
разработан продукт под названием Apache Tomcat, в котором эти спецификации
реализованы. Tomcat, подобно Apache, является бесплатным (www.jakarta.tomcat.org).
Tomcat можно запустить как автономный web-сервер для тестирования
приложения, а для высокопроизводительных web-приложений можно настроить его на
работу вместе с Apache. Еще один бесплатный продукт, который можно
использовать отдельно для тестирования сервлетов и JSP-страниц, — это JavaServer
Web Development Kit. Есть и другие продукты с похожими характеристиками.
Поищите в Web информацию по Java Servlet 2.2 и JavaServer Pages 1.1. Мы будем
подробно обсуждать использование этих продуктов в главе 16.
Следует заметить, что между технологиями ASP и JSP есть существенная
разница. В ASP вы можете использовать любой поддерживаемый сценарный
язык, например VBScript или JavaScript, однако напрямую вставлять код на C++
или Java в ASP-страницу нельзя. В отличие от этого, в JSP весь код пишется на
Java; даже если вы пишете всего лишь маленькие фрагменты кода, эти
фрагменты состоят из операторов Java.
Apache и другие Unix-серверы также поддерживают ISAPI, и существуют
версии ASP, которые могут работать с этими продуктами. Конечно, если в ASP-
страницах используются элементы управления ActiveX и другие компоненты
Microsoft, они не будут работать правильно (или вообще не будут работать).
Серверы Netscape предоставляют свой собственный интерфейс — NSAPI,
выполняющий аналогичные ISAPI функции.
При обращении к базам данных из программ на Java чаще всего
используется технология JDBC, Существуют также мосты от JDBC к ODBC, облегчающие
для программ на Java использование драйверов ODBC. Кроме того, СУБД могут
вызываться с помощью кодовых библиотек. Ни ADO, ни OLE DB не
реализованы на платформе Unix.
Ранее мы упомянули, что HTTP является протоколом без состояния, имея
в виду, что сервер обрабатывает запрос и затем забывает о том, кто его присылал.
Бесстатусная обработка неприемлема для большинства приложений баз данных,
поэтому возможность отслеживать состояние сеанса была добавлена в IIS для
Windows 2000, а также в Tomcat и подобные ему обработчики сервлетов в мире
Unix/Linux. Как это сделано, вы увидите из следующих двух глав.
Многоуровневая обработка
В некоторых приложениях трехуровневая архитектура возлагает непомерно
большое бремя на web-сервер. Вспомните, что web-сервер не только работает как
HTTP-сервер, который может отвечать на тысячи запросов, но еще и управляет
соединениями с сервером базы данных, генерирует и передает SQL-запросы,
формирует из результатов запросов представления, реализует логику приложения
Многоуровневая архитектура 525
и обеспечивает соблюдение делового регламента. И после всего этого он еще
генерирует отклик пользователю, работающему с браузером.
При такой нагрузке web-сервер может стать элементом, ограничивающим
производительность. Одно из решений этой проблемы состоит в распределении
нагрузки между большим количеством, возможно даже сотнями, серверов.
Однако это решение может, в свою очередь, привести к ряду других проблем,
поскольку для его воплощения требуется, чтобы на каждом из web-серверов были
установлены все программы, необходимые для выполнения вышеописанных
функций. Это может стать для администратора настоящей головной болью. Другое
решение — использовать web-сервер (или серверы) только для обработки HTTP-
запросов и откликов, а обработку представлений, делового регламента и т. п.
возложить на другие серверы. Это решение изображено на рис. 14.6, а, где
обработка представлений и реализация делового регламента производится
различными компьютерами.
Браузер
\
Web-сервер
<4г+>
Обработчик
представлений
Обработчик
делового
регламента
а
Обработчик
распределенной
базы данных
предприятия
Сервер
базы данных
БД
Обработчик
службы
сообщений
Рис. 14.6. Примеры многоуровневой архитектуры: а — использование нескольких
процессоров для обработки представлений и делового регламента; б — использование
нескольких процессоров для распределенной обработки
Еще одна проблема из этой серил возникает, когда обработка одной
транзакции распределена между множеством компьютеров. Предположим, что в
системе, изображенной на рис. 14.6, б, информация о заказе находится в базе данных
526 Глава 14. Сети, многоуровневые архитектуры и XML
DB1, а информация о пользователе — в базе данных DB2. Предположим далее,
что для нормальной обработки заказа обновления необходимо произвести в
обеих базах данных и что прежде, чем заказ будет принят к выполнению,
необходимо отправить сообщение на производство и получить добро. Решение,
показанное на рис. 14.6, б, состоит в том, чтобы поручить одному серверу обработку
распределенных транзакций, а другим — обработку баз данных и сообщений.
Ясно, что существует много возможностей. По мере того как организации
будут набирать опыт в электронной коммерции, вероятно возникновение новых
шаблонов многоуровневой обработки. На данном этапе вам просто следует
уяснить, что обработка баз данных с использованием интернет-технологий не
сводится к трем уровням, и на каждом уровне может быть множество серверов,
среди которых распределена нагрузка.
Языки разметки и DHTML
Языки разметки (markup languages) служат для определения внешнего вида и
поведения web-страницы. Как уже отмечалось, первым таким языком, завоевавшим
доминирующее положение в Web, стал HTML, являющийся подмножеством
более мощного и сложного языка под названием SGML. В этом разделе мы
рассмотрим два языка разметки — динамический HTML (DHTML) и XML. По уровню
сложности эти языки занимают промежуточное положение между HTML и SGML.
Но прежде чем углубляться в рассмотрение этих языков, обсудим сначала
исторический контекст, в котором происходило развитие web-стандартов.
Стандарты языков разметки
HTML изначально имел необычайный успех, потому что он дал толчок к развитию
сотен тысяч сайтов и сделал общение в Web реальностью для широкой
компьютерной общественности. Со временем, однако, стали выявляться значительные
недостатки первоначальной версии HTML, особенно в том, что касалось
разработки web-приложений баз данных. В ходе работы над преодолением этих
недостатков выросло понимание необходимости появления стандартов. В противном
случае каждый производитель вносил бы свои собственные усовершенствования,
и вскоре получилось бы так, что определенные страницы могли бы
обрабатываться только определенными браузерами, а это свело бы на нет одно из наиболее
важных преимуществ Web.
Поэтому начиная с 1994 г. Всемирный web-консорциум (World Wide Web
Consortium, W3C) стал пропагандировать стандарты для HTML и других
языков разметки. Эти стандарты приобрели большую значимость. Посетите сайт
консорциума под адресу www.w3.org. Там вы найдете полезную информацию,
учебные пособия, продвигаемые (или рекомендуемые) стандарты и те
стандарты, которые еще находятся в процессе развития.
Роль и значение стандартов будет для вас более ясны, если вы поймете, какие
чувства питают к стандартам производители программного обеспечения. Это од-
Языки разметки и DHTML 527
новременно и любовь, и ненависть. С одной стороны, производители любят
стандарты, поскольку те обеспечивают порядок на рынке и определяют основной набор
возможностей, который должны иметь продукты. С другой стороны,
производители их ненавидят, поскольку стандарты могут обесценить возможности,
функции и технологии, в которые могли быть вложены значительные инвестиции.
Стандарты являются для производителей палкой о двух концах еще и в
другом смысле. Если разработанный продукт будет строго соответствовать
стандарту и не более того, то у покупателей не будет оснований отдать ему
предпочтение перед продуктами конкурентов. Но если производитель добавит в продукт
новые возможности и функции, его будут критиковать за то, что он не следует
стандарту. Например, Microsoft разработала язык DHTML, который поддерживал
стандарт W3C под названием HTML 4.O. Однако в язык были также добавлены
функции, выходящие за рамки этого стандарта. В зависимости от ситуации, эти
возможности могут быть прекрасными, поскольку они расширяют
функциональность, или ужасными, поскольку они работают адекватно не во всех браузерах.
По этой причине нестандартные возможности добавляются в продукт таким
образом, чтобы другие продукты, не поддерживающие эти возможности,
справлялись с этим более или менее элегантно. Например, схема документа будет
динамически разворачиваться и сворачиваться в браузерах, поддерживающих
данную функцию, а в тех браузерах, где она не поддерживается, схема будет всегда
изображаться в развернутом виде.
Проблемы, связанные с HTML
Исходная версия HTML обладала рядом недостатков. Во-первых, содержимое,
разметка и формат страницы были перемешаны между собой — определение
содержимого было невозможно отделить от разметки и формата. Это означало, что
если вы хотите представить одно и то же содержимое несколькими способами,
вам придется создать две копии этого содержимого, каждую со своей разметкой
и своим форматом. Для приложений баз данных это означало также, что данные
и материализация представления были сложным образом перемешаны.
Другой недостаток заключался в отсутствии возможности определить
стили. Было невозможно, например, сделать так, чтобы все заголовки выводились
шрифтом определенной гарнитуры, размера и начертания. Соответственно, если
бы разработчик захотел поменять формат всех заголовков первого уровня, ему
пришлось бы найти все такие заголовки на странице (или на сайте) и изменить
формат каждого из них по отдельности. Таким образом, нужна была возможность
определить стиль заданного элемента формата.
Третьим слабым местом оригинального HTML было то, что к элементам web-
страиицы нельзя было обращаться из сценариев и других программ. Например,
не было возможности обращаться из сценария к элементу, представляющему
заголовок страницы, чтобы динамически менять его внешний вид или
расположение. Невозможно также было написать код, реагирующий на события Windows,
такие как передвижение мыши и щелчки ее кнопками. Следовательно, чтобы
изменить структуру или внешний вид страницы, браузер должен был заново
528 Глава 14. Сети, многоуровневые архитектуры и XML
обратиться к серверу и получить с него целиком новую страницу. Такие
круговые путешествия были медленными и неэкономными.
Наконец, и это для нас важнее всего, в HTML не было конструкций,
упрощающих кэширование и манипуляцию данными на клиенте. Всякий раз, когда
браузеру нужно было вывести дополнительные данные, он был вынужден
обращаться к серверу. В связи со всеми перечисленными обстоятельствами,
Всемирный Web-консорциум разработал для HTML стандарт под названием HTML 4.0,
в котором были введены возможности и функции, нацеленные на преодоление
этих и других недостатков.
DHTML
DHTML — это реализация стандарта HTML 4.0, разработанная Microsoft. Она
включает в себя все, что входит в стандарт, плюс дополнительные возможности
и функции. DHTML поддерживается браузером Microsoft Internet Explorer 4.0
и более поздних версий, а также IIS 4.0 и выше. Netscape Navigator поддерживает
только ту часть DHTML, которая относится к HTML 4.0; остальные
возможности DHTML, выходящие за рамки данного стандарта, им не поддерживаются.
Следовательно, используя DHTML, необходимо следить за тем, чтобы
оставаться в пределах HTML 4.0, если пользователи создаваемого приложения работают
с браузерами, отличными от Internet Explorer.
DHTML обладает несколькими ключевыми характеристиками, которые
преодолевают недостатки ранних версий HTML. Во-первых, DHTML
предоставляет объектную модель под названием DOM (Document Object Model,
объектная модель документов). В этой модели все элементы страницы представляются
в виде объектов. Этими объектами можно манипулировать из сценариев,
изменяя их атрибуты и вызывая принадлежащие им методы. Так, схема документа
может сначала показываться в свернутой форме, а затем разворачиваться, когда
пользователь щелкает на ней мышью.
Благодаря DOM содержимое страницы, разметку и формат можно менять
программно, не обновляя страницу с сервера. Это не только экономит время, но
и избавляет пользователей от раздражающего мелькания и перезагрузки всей
страницы при каждом изменении заголовка. Теперь обновляется только та часть
текста, в которой произошли изменения.
Еще одна ключевая особенность HTML 4.0 и DHTML — это поддержка
каскадных таблиц стилей (CSS, Cascade Style Sheets). Они позволяют задавать
формат для различных типов элементов страницы. Например, следующий DHTML-
код устанавливает цвет фона и текста для заголовков первого и второго уровней:
<STYLE TYPE="text/class">
<!-
HI {font-familyrLucida; font-style:normal; color;black}
HI {font-family:Lucida: font-style:normal: color:greenj
->
</STYLE>
Языки разметки и DHTML 529
Когда в документе обнаруживается заголовок первого или второго уровня, он
будет выглядеть так, как это определено в элементе STYLE. Так, в следующем
примере заголовок второго уровня «Это пример» будет выведен шрифтом Lucida
зеленого цвета нормального начертания:
<Н2>
Это пример
</Н2>
В данном примере оба стиля были определены для стандартных HTML-тегов
HI и Н2. Разработчик может также вводить свои собственные теги и определять
для них стили.
В DHTML возможна ситуация, когда элемент имеет два несовместимых
стиля. Например, в таблице стилей может быть задан определенный формат для
всех абзацев, но конкретный параграф на конкретной странице может быть
помечен другим стилем. В данном случае стиль параграфа будет иметь приоритет
над стилем, указанным в таблице стилей. Общее правило таково: используются
те стилевые метки, которые ближе к содержимому. Благодаря этой
характеристике такие таблицы стилей и называются каскадными.
Таблицы стилей могут находиться в самой странице или быть получены
извне, из других документов, содержащих определения стилей. Таким образом,
в DHTML содержимое и материализация могут быть разделены.
Таблицы стилей в сочетании DOM позволяют изменять web-страницы, не
обновляя их с сервера. Например, стиль заголовков второго уровня может
меняться, когда курсор мыши находится на заголовке первого уровня; возможны и
более сложные изменения.
Параллельно с DHTML Microsoft разработала набор элементов управления
ActiveX под названием Remote Data Services (RDS, служба удаленной обработки
данных). С помощью этих элементов управления разработчик может кэшировать
информацию из базы данных на клиентской машине, отображать ее, принимать
изменения и отправлять модифицированную информацию обратно на сервер
как обновление в базе данных.
В реальности, однако, RDS годится только для тех представлений, которые
состоят из одной таблицы. Обновление более сложных представлений может
потребовать выполнения двух, трех или более SQL-операторов, как вы знаете из
предыдущей главы. Такого рода многотабличные обноааения невозможны в RDS.
Для этих целей используется ADO.
Как таковая, служба RDS не слишком важна для нас — важна
предоставляемая DHTML возможность динамически изменять структуру web-страницы.
Например, с помощью DHTML можно запросить представление из базы данных,
программным способом определить количество и имена столбцов в
представлении и динамически сконфигурировать web-страшщу, чтобы отобразить эти
данные.
DHTML и HTML 4.0 исправляют многие дефекты исходного HTML, однако
сохраняют ту же фундаментальную структуру и характер. Теперь мы обратимся
к спецификации, коренным образом отличающейся от HTML.
530 Глава 14. Сети, многоуровневые архитектуры и XML
XML — расширяемый язык разметки
Появление XML (extensible Markup Language, расширяемый язык разметки)
является одним из наиболее важных событий в мире информационных систем за
последние десять лет. Во-первых, XML предоставляет расширяемый стандарт
материализации документов на web-страницах. Во-вторых, XML приобрел
немаловажное значение для обмена данными; в особенности он удобен для передачи
представлений баз данных. Кроме того, XML прост — по крайней мере, просты
его базовые структуры, поэтому он используется для представления многих
типов стандартизированного текста. Например, файлы конфигурации Tomcat,
обработчика сервлетов Java для Apache, имеют формат XML.
XML используется в настоящее время в качестве стандарта для удаленного
вызова процедур. Пока не появился протокол SOAP (Simple Object Access Protocol,
простой протокол доступа к объектам), в борьбе за право быть стандартом для
этих целей соперничали DCOM и CORBA. SOAP представляет собой всего лишь
способ передачи по HTTP вызовов процедур, представленных в виде небольших
XML-документов. Вне всякого сомнения, в будущем для XML найдется еще
много применений.
XML — это обширная тема, заслуживающая отдельной книги. Здесь же мы
будем вынуждены сосредоточиться на использовании XML для материализации
web-страниц и передачи представлений базы данных. Великолепные материалы
по этой тематике можно найти на сайтах www.w3.org и www.xml.org. Вы можете
дать своей карьере стремительный взлет, если изучите все возможное, что
касается XML.
XML как язык разметки
В качестве языка разметки XML имеет значительные преимущества перед HTML
и DHTML. Этому есть несколько причин. Во-первых, авторы языка XML
обеспечили четкое разделение между структурой документа, его содержимым и
материализацией. В XML предусмотрены средства для определения каждой из этих
трех составляющих, и природа этих средств такова, что они не могут
смешиваться, как это было в HTML.
Кроме того, хотя XML стандартизирован, этот стандарт может расширяться
разработчиками, как следует из названия. В XML вы не ограничены
фиксированным набором элементов вроде <TITLE>, <H1> и <?>: вы можете определять свои
собственные элементы.
Одной из проблем HTML и DHTML является то, что они предоставляют
слишком большую свободу. Рассмотрим следующий HTML-код:
<@060>1п2>3дравствуй. мир!</h2>
Тег <h2> можно использовать для обозначения заголовка второго уровня
в структуре документа. Однако его можно использовать и для того, чтобы просто
XML — расширяемый язык разметки 531
вывести слова «Здравствуй, мир!» определенным стилем. Из-за этой
характеристики мы не можем положиться на теги в деле определения истинной структуры
HTML-страницы. Использование тегов имеет слишком произвольный характер:
<h2> может означать заголовок, а может не означать ничего.
Как вы увидите, в XML структура документа формально определена. Если
мы находим тег <street>, мы знаем точно, где этот тег расположен и как он
соотносится с другими тегами в структуре документа. Таким образом, о
XML-документах говорят, что они в точности передают семантику содержащихся в них
данных.
ХМL-документ и DTD
В листинге 14.1 показан пример XML-документа. Обратите внимание, что
документ имеет два раздела. В первом разделе определяется структура документа;
этот раздел называется определением типа документа, или DTD (Document Type
Declaration). Второй раздел содержит собственно данные.
Листинг 14.1. Пример XML-документа
<!DDCTYPE customer [
<!ELEMENT customer (name. address)>
<!ELEMENT name (firstname. lastname)>
<!ELEMENT firstname (#PCDATA)>
<!ELEMENT lastname (#PCDATA)>
<!ELEMENT address (street*, city, state. zip)>
<!ELEMENT street (#PCDATA)>
<!ELEMENT city (#PCDATA)>
<!ELEMENT state (#PCDATA)>
<!ELEMENT zip (#PCDATA)>
]>
<customer>
<name>
<firstname>MichelIe</firstname>
<]astname>Correl1i </lastname>
</name>
<address>
<street>1824 East 7th Avenue</street>
<street>Suite 700</street>
<city>Memphis</city>
<state>TN</state>
<zip>32123-7788</zip>
</address>
</customer>
DTD начинается с ключевого слова D0CTYPE, за которым следует имя типа
документа — customer. Далее идет описание содержимого документа customer.
В нем есть две группы: name и address. Группа name состоит из двух элементов —
firstname и Lastname. Эти элементы определены как #PCDATA, то есть строки
532 Глава 14. Сети, многоуровневые архитектуры и XML
символьных данных. Ниже описывается элемент address, состоящий из четырех
элементов: street, city, state и zip. Каждый из этих элементов также определен
как символьные данные. Знак + после имени элемента street указывает на то,
что этот элемент обязан иметь минимум одно значение, но может иметь
несколько значений.
Экземпляр данных типа customer, показанный в листинге 14.1, соответствует
DTD, поэтому данный документ называет XML-докумептом, допустимым по
типу (type-valid XML document). Если бы он не соответствовал DTD, он назывался
бы недопустимым по типу документом (not-type valid XML document).
Недопустимые по типу документы могут, тем не менее, быть абсолютно правильными
с точки зрения XML: они просто не являются допустимыми экземплярами
своего типа. Например, если бы документ в листинге 14.1 содержал два элемента
city, он был бы по-прежнему правильным с точки зрения XML, но
недопустимым по типу.
Хотя DTD почти всегда желательны, они не являются обязательными в XML-
документах. Документ, не имеющий DTD, по определению является
недопустимым по типу, поскольку не существует типа, относительно которого можно было
бы проверить его допустимость.
Раздел DTD не обязательно должен содержаться в самом документе. В
листинге 14.2 показан документ типа customer, в котором DTD загружается с URL
http://www.somewhere.com/dtds/customer.dtd. Преимущество внешнего хранения
DTD в том, что можно проверять допустимость множества документов
относительно одного и того же DTD.
Листинг 14.2, XML-документ с внешним DTD
<!D0CTYPE customer SYSTEM "http://www.somewhere.com/dtds/customer.dtd>
<customer>
<name>
<firstname>Mi chelle</fi rstname>
<l astname>CorrelIi </1a stname>
</name>
<address>
<street>1824 East 7th Avenue</street>
<street>Suite 700</street>
<ci ty>Memphi s</city>
<state>TN</state>
<zip>32123-7788</zip>
</address>
</customer>
Создатель DTD может определять любые элементы по своему желанию.
Следовательно, ХМL-документы могут расширяться, но расширяться
стандартизированным и контролируемым способом. Как вы увидите позже, DTD являет
собой довольно удобный способ описания представлений баз данных.
XML — расширяемый язык разметки 533
Материализация XML-документов
В XML-докумеите в листинге 14.1 определены структура и содержимое. Однако
ничто в документе не указывает на то, как его следует материализовать.
Разработчики XML обеспечили четкое разделение структуры, содержимого и формата.
Для материализации XML-документа существует два средства: каскадные
таблицы стилей и XSLT. Рассмотрим эти средства.
Материализация XML посредством каскадных
таблиц стилей
Каскадные таблицы стилей, или CSS, рассматривались нами в разделе,
посвященном DHTML. В XML-документах они используются аналогичным образом.
То есть для тегов определяются стили и применяются к ним в каскадном
порядке. Рассмотрим следующее определение стиля для документа в листинге 14.1:
<STYLE TYPE="text/class">
<!-
customer {font-fami lyiLucida; font-style.-normal; color:black}
name {font-fami ]y:Lucida: font-style:norma]; colorgreen}
lastname {font-family:Lucida; font-style:normal: coloured}
->
</STYLE>
Согласно этому определению, цветом по умолчанию для отображения
документа типа customer является черный. Но для элементов типа name цвет изменен
с черного на зеленый, а для элементов типа Lastname — с зеленого на красный.
Таким образом, стили располагаются друг над другом каскадом.
На сегодняшний день не существует стандартного соглашения относительно
того, где должны находиться такие определения стилей. Их можно поместить
в документ, а можно вынести во внешний файл, оставив в документе ссылку на
этот файл. В различных продуктах они реализуются по-разному.
Материализация XML посредством XSLT
Второй способ материализации XML предполагает использование XSLT (extensible
Style Language for Transformations, расширяемый язык стилей для
преобразований). XSLT — это мощный и надежный язык преобразований. Его можно
использовать для материализации XML-документов в DHTML или HTML, а также для
множества других целей. Одно из популярных применений для XSLT —
трансформация XML-документа в одном формате в XML-документ в другом формате.
Например, с помощью XSLT компания может преобразовать накладную,
представляющую собой ХМL-документ в некотором внутреннем формате, в
эквивалентный XML-документ в формате клиента. Есть много возможностей и
функций XSLT, которые мы не будем здесь описывать. Информацию о них вы можете
найти на сайте www.w3.org.
Язык XSLT является, во-первых, декларативным, а во-вторых,
преобразовательным. Декларативным он является потому, что вместо указания процедуры
534 Глава 14. Сети, многоуровневые архитектуры и XML
материализации элементов документа вы создаете набор правил, которые
определяют, как будет материализоваться документ. Преобразовательным же он
является потому, что с его помощью документ, задаваемый на входе, преобразуется
в другой документ.
В листинге 14.3 показан документ типа customerlist с данными о двух
клиентах. Он имеет DTD и является допустимым по типу. Оператор, следующий за
DTD, вызывает таблицу стилей XSLT под названием CustomerList.xsL, которая
показана в листинге 14.4. Результат обработки этого XML-документа показан
в листинге 14.5 и на рис. 14.7.
** * Q 2 $ "; '2| Search (ЗУ Favorites '3Hs^1# •
'fejDone" ' V :\---. ■ \ ^ЩComputer
Рис. 14.7. Материализация в браузере
Листинг 14.3. XML-документ customerlist
<?xml version='1.0,?>
<!DDCTYPE customerlist [
<!ELEMENT customerlist (customer+)>
<!ELEMENT customer (name, address) >
<!ELEMENT name (firstname. lastname)>
<! ELEMENT firstname (#PCDATA)>
<! ELEMENT lastname (#PCDATA)>
<!ELEMENT address (street*, city, state. zip)>
<!ELEMENT street (#PCDATA)>
<!ELEMENT city (#PCDATA)>
<!ELEMENT state (#PCDATA)>
XML — расширяемый язык разметки 535
<!ELEMENT zip (#PCDATA)>
]>
<?xml .-stylesheet type="text/xsl" href~"CustomerList.xsr?>
<customerlist>
<customer>
<name>
<firstname>Mi chel1e</fi rstnarne>
<lastname>Correlli</lastname>
</name>
<address>
<street>1824 East 7th Avenue</street>
<street>Suite 700</street>
<city>Memphis</city>
<state>TN</state>
<zip>32123-7788</zip>
</address>
</customer>
<customer>
<name>
<fi rstname>Lynda</firstname>
<lastname>Jaynes</fastname>
</name>
<address>
<street>2 Elm Street</street>
<city>New York City</city>
<state>NY</state>
<zip>02123-7445</zip>
</address>
</customer>
</customerlist>
Листинг 14.4. Пример XSL-документа
<?xml version="1.0"?>
<HTML xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<B0DY STYLE="font-family:Arial. helvetica, sans-serif: font-size:14pt;
background-color:teal">
<xsl :for-each select="customerlist/customer">
<DIV STYLE="background-color:purple: color:white: padding:4px">
<SPAN STYLE="font-weight:bold: color:white">
<xsl:value-of select="name/lastname'7></SPAN>
- <xsl :value-of select="name/firstname,7>
</DIV>
<xsl:for-each select="address/street">
<DIV STYLE="margin-left:20px; margin-bottom:lem; font-size:10pt:
продолжение^*
536 Глава 14. Сети, многоуровневые архитектуры и XML
Листинг 14.4 (продолжение)
font-style:bold: color:blue">
<xsl:value-of select="node()'7>
<DIV>
<xsl:for-each>
<DIV STYLE="margin-left:20px: margin-bottom:lem: font-size:12pt;
font-style:bold"><xsl :value-of select=,,address/city'7>.
<xsl :value-of select=,,address/zip'7>
</DIV>
<DIV STYLE^"margin-left:20px; margin-bottom:lem: font-size: 14pt: color:red">
<xsl:value-of select="address/zip'7>
</DIV>
<xsl:for-each>
</body>
</HTML>
Листинг 14.5. Материализация посредством XSLT
<HTML xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<B0DY STYLE="font-family:Arial. helvetica, sans-serif: font-size: 14pt:
background-color: teal">
<DIV STYLE="background-color:brown; color:white: padding:4px">
<SPAN STYLE="font-weight:bold: color: white">Correlli</SPAN>
- Michelle
</DIV>
<DIV STYLE-"margin-left:20px; margin-bottom:lem: font-size: lOpt; font-style: bold:
color:yellow">
1824 East 7th Avenue
</DIV>
<DIV STYLE="margin-left:20px: margin-bottom: lem: font-size: IDpt: font-style: bold:
color:yellow">
Suite 700
</DIV>
<DIV STYLE="margin-left:20px; margin-bottom:lem: font-size: 12pt: font-style: bold">
Memphis, IN
</DIV>
<DIV STYLE="margin-left:20px: margin-bottom: lem: font-size: 14pt: color:blue">
32123-7788
</DIV>
<DIV STYLE="background-color: brown: color:white: padding:4px">
<SPAN STYLE="font-weight:bold: color:white">Jaynes</SPAN>
- Lynda
</DIV>
<DIV STYLE="margin-left:20px; margin-bottom: lem; font-size: IDpt: font-style: bold:
color:yellow">
2 Elm Street
</DIV>
XML — расширяемый язык разметки 537
<DIV STYLE="margin-left:20px; margin-bottom:lem: font-size: 12pt: font-style:
bold" >
New York City. NY
</DIV>
<DIV STYLE="margin-left:20px; margin-bottom: lem: font-size: 14pt: color:btue">
02123-7445
</DIV>
</80DY>
</HTML>
Данная таблица стилей использует возможности браузера Microsoft Internet
Explorer 5.0, имеющего встроенный обработчик XSLT, к которому можно
обращаться из таблицы. В листинге 14.4, например, все элементы, которые
начинаются с <xsl:, вызывают XSLT-обработчик Internet Explorer 5.0.
Таблица стилей XSL имеет структуру вида {шаблон, действие). Идея состоит
в том, что XSLT-обработчик ищет в документе вхождения некоторого элемента,
и когда такой элемент найден, предпринимает заданное действие. Так, первый
оператор xsl
<xsl:for-each se1ect="customerlist/customer7>
инициирует поиск в документе элемента, обозначенного как customerlist. Когда
такой элемент обнаруживается, начинается поиск элемента, обозначенного как
customer (он должен находиться внутри элемента customerlist). Если
соответствующий элемент будет найден, будут выполнены действия, указанные в цикле,
завершающемся оператором </xsl:for-each> (третий снизу оператор в таблице стилен).
В этом цикле каждому элементу внутри элемента customer, который, в свою
очередь, содержится внутри элемента customerlist, присваивается стиль.
Обратите внимание на внутренний цикл for-each, который нужен на тот случай, если
элементов street окажется несколько.
XSLT-обработчики являются контекстно-ориентированными: каждый
оператор выполняется в контексте найденного соответствия шаблону поиска. Так,
оператор
<xslivalue-of selecta"name/]astname"/>
действует в контексте вхождения шаблона customerlist/customer, найденного в
документе. Нет необходимости писать
<xsl:select="customer]ist/customer/name/lastname'7>
поскольку контекст customerlist/customer уже задан. На самом деле, если бы
оператор select был записан таким образом, то ничего не было бы найдено.
Аналогичным образом, поиск <xsl:select="lastname"/> ничего бы не обнаружил, поскольку
lastname появляется только в контексте customerlist/customer/name, но не в
контексте customerlist/customer.
Эта ориентация на контекст объясняет необходимость в операторе
<xsl:value-of se1ect="node()7>
538 Глава 14. Сети, многоуровневые архитектуры и XML
(в середине таблицы стилей). Этот оператор находится в контексте customerlist/
customer/address/street Таким образом, текущим узлом (node) является элемент
street, и данное выражение предписывает выдать значение этого элемента.
Обратите также внимание на то, что таблицей стилей было произведено
небольшое преобразование. В исходном документе элемент lastname следовал за firstname,
а в выходном потоке они расположены в обратном порядке» Код HTML,
генерируемый синтаксическим анализатором XSLT в Internet Explorer, показан в
листинге 14.5. На нем видно, как правила преобразования, заданные в XSL-докумен-
те, соблюдались для документа, изображенного в листинге 14.3. Материализация
HTML, как она выглядит в окне браузера, показана на рис. 14.7.
Microsoft постоянно обновляет синтаксический анализатор XSLT в Internet
Explorer по мере развития стандарта. Анализатор, с помощью которого был
получен листинг 14.5 и рис. 14.7, датируется октябрем 2000 года. Информацию
о реализации XSLT в более новых версиях Internet Explorer можно найти на
сайте Microsoft.
Терминология и стандарты XML
По мере вашего знакомства с XML вам будет встречаться все большее количество
аббревиатур. Основные из них перечислены в табл. 14.1. Стандарты,
документацию и некоторые учебные материалы по этой тематике можно найти на сайтах
www.w3.org и www.xmLorg.
Таблица 14.1
Стандарт Описание
XML Расширяемый язык разметки. Язык разметки документов, который
положил начало развитию следующего:
XSL — Расширяемый язык стилей. Вначале это был способ преобразования
первоначальное XML в потенциально весьма сложные стили. Разделен на две части:
значение XSLT — для преобразования структуры документа, и XSL-FO —
для форматирования документов сложными стилями
XSL — Таблица стилей XSLT. Документ, содержащий пары вида {шаблон,
современное действие} и другие данные, используемые при трансформации
значение XML-документа
XSLT Программа (или процесс), которая применяет таблицы стилей XSLT
к XML-документу, в результате чего на выходе получается
преобразованный XML-документ
XSL-FO Расширяемый язык стилей для форматирования объектов. Часть
оригинального XSL, оставшаяся после отделения XSLT. Очень большой
и сложный стандарт для изощренного форматирования, до сих пор
находящийся в стадии развития
Xpath Подъязык XSLT, используемый для идентификации частей XML-документа,
подлежащих преобразованию. Может также использоваться для
вычислений и строковых манипуляций
XPointer Стандарт связывания документов между собой. XPointer содержит
многие элементы XPath
SAX Простой интерфейс прикладных программ для XML. Событийный
синтаксический анализатор, который уведомляет программу
при обнаружении элементов XML в ходе анализа документа
XML — расширяемый язык разметки 539
Стандарт Описание
DOM Объектная модель документов. Интерфейс прикладных программ,
представляющий XML-документ в виде дерева. Каждый узел дерева
представляет фрагмент XML-документа. Программы могут напрямую
обращаться к узлу DOM-представления и манипулировать им
XQL Стандарт для представления SQL-запросов в виде XML-документов.
В структуре запроса используются элементы XPath, а результат
представляется в XML-формате. Данный стандарт находится в процессе
развития и обещает стать важным в будущем
XML Пространства имен XML — стандарт именования определяемых собраний.
Namespaces X:Name интерпретируется как элемент Name, определенный
в пространстве имен X. Y:Name интерпретируется как элемент Name,
определенный в пространстве имен Y. Полезен для предотвращения
конфликтов имен
XML Schema Удовлетворяющий стандарту XML язык, который позволяет задавать
требования к структуре ХМL-документа. Расширяет и заменяет DTD.
Находится в процессе развития и обещает быть исключительно
важным для обработки баз данных
Как показывает табл. 14.1, аббревиатура XSL имела два различных
значения. Изначально это был способ преобразования XML-документов в
потенциально весьма сложные форматы, подобные тем, что используются
коммерческими принтерами. В 1999 г. Всемирный Web-консорциум решил разделить XSL
на две части: спецификацию XSLT, предназначенную для преобразования
документов, и спецификацию XSL-FO (formatting objects — форматирование
объектов), предназначенную для сложного форматирования. Сегодня термин XSL
как таковой относится к таблицам стилей, подобным той, что показана в
листинге 14.4.
XPath — это стандарт для обращения к элементам в документах. В
листинге 14.4 в выражениях вроде <xsL:value-of-select="name/lastname"> используется
стандарт XPath для указания на конкретный элемент документа. XPath
включает в себя концепции из другого стандарта, XPointer, цель разработки которого
состояла в том, чтобы предоставить способ, с помощью которого один документ
мог бы ссылаться на элементы других документов.
SAX и DOM представляют собой различные методы синтаксического
анализа XML-документов. Процесс синтаксического анализа (parsing) включает в себя
чтение документа, разбиение его на компоненты и выполнение определенных
действий, исходя из результатов разбиения — например, сохранение компонентов
в базе данных. Синтаксические анализаторы XML могут также проверять
допустимость документов по отношению к DTD или Schema (см. следующий раздел).
В случае использования интерфейса SAX XSLT-процессор (или другая
программа, занимающаяся обработкой XML-документов) вызывает
удовлетворяющий стандарту SAX синтаксический анализатор и передает ему имя документа,
который предстоит анализировать. SAX-анализатор обрабатывает документ и
вызывает объекты XSLT-процессора при обнаружении определенных структур.
Интерфейс DOM функционирует на основании другой парадигмы.
Синтаксический анализатор, удовлетворяющий стандарту DOM, обрабатывает весь
XML-документ и создает его древообразное представление. XSLT-процессор
540 Глава 14. Сети, многоуровневые архитектуры и XML
может затем вызвать DOM-аиализатор для получения определенных элементов
с помощью XPath или аналогичной схемы именования. DOM требует, чтобы
весь документ был обработай за один прием, и в случае очень больших документов
может потребоваться чрезмерно большое количество памяти. В такой ситуации
более подходящим выбором является SAX. С другой стороны, если необходимо,
чтобы все содержимое документа было доступно одновременно, то
единственным вариантом является DOM.
XQL — это находящийся в стадии разработки стандарт для представления
запросов в виде XML-документов. Например, с его помощью можно представить
SQL-оператор в виде XML. Этот стандарт может стать важным в будущем.
Последние два стандарта в табл. 14.1 имеют большое значение для
профессионалов в области баз данных, поскольку среди их особенностей есть упрощение
представления доменов. Стандарт XML Namespaces предоставляет способ для
объявления и использования групп определений. Предположим, например, что один
разработчик определяет элемент Instrument в контексте музыки (то есть
музыкальный инструмент). Такой элемент может иметь атрибуты Manufacturer
(производитель), Model (модель) и Material (материал). Второй разработчик определяет элемент
с таким же именем, Instrument, но в контексте электроники (то есть прибор). Этот
элемент может иметь атрибуты Manufacturer, Model и Voltage (напряжение).
Неоднозначностей можно избежать, определив для каждого из этих
элементов свое пространство имен (namespace). Введем пространство Music, в котором
атрибуты Manufacturer, Model и Material будут определяться в соответствии с
музыкальной спецификой. Введем также пространство Electronics с
соответствующими данной области определениями атрибутов Manufacturer, Model и Voltage.
Без поддержки пространств имен вероятно возникновение конфликтных
ситуаций. Элемент Model в XML-документе может иметь значение как Violin
(скрипка), так и Voltage Regulator (регулятор напряжения). Но если мы сошлемся на него
как на Music:Model в DTD или Schema, никакой неопределенности не возникнет.
В листинге 14.4 мы использовали пространство имен. Выражение <HTMLxmlns:
xsl="http..." определяет пространство имен под названием xsl. Далее в документе
выражения, подобные xsl:value-of select, используют это пространство имен и
указывают, что выражение value-of определено в пространстве имен xsl.
Чтобы более полно представить себе важность пространств имен, рассмотрим
стандарт XML Schema. Этому стандарту посвящен следующий раздел.
XML Schema
XML Schema — это стандарт на предъявление ограничений к XML-документу.
XML Schema играет роль, аналогичную DTD, но совершенствует и расширяет его
спецификацию. Этот стандарт еще новый и находится в постоянном изменении,
а синтаксические анализаторы, способные проверять допустимость
XML-документов по отношению к XML Schema, еще только разрабатываются. На момент
написания этой книги на сайте Microsoft имелась бета-версия анализатора XML Schema
XML — расширяемый язык разметки 541
для IE 5.0, Возможно, когда вы будете читать эту книгу, данная программа уже
будет полноценным продуктом. Есть и другие производители, включая Oracle,
разработавшие синтаксические анализаторы XML с проверкой допустимости
относительно XML Schema. Последнюю информацию об этом можно найти в Web.
Синтаксис, используемый в данном разделе, соответствует спецификации XML
Schema, датируемой октябрем 2000 года.
Как упоминалось прежде, документ, соответствующий DTD, называется
допустимым по типу. Аналогичным образом, документ, соответствующий XML Schema,
называется допустимым по схеме. XML-документ может быть абсолютно
правильно сформированным, ио не быть допустимым ни по типу, ни по схеме.
Наиболее важным усовершенствованием в XML Schema по сравнению с DTD
является то, что XML-схемы сами по себе являются XML-документами. В
отличие от DTD, имеющих свой собственный синтаксис, для XML Schema можно
использовать тот же самый синтаксис, что и для XML. Это означает, что вы можете
применять анализатор с проверкой допустимости по схеме для проверки
создаваемых вами схем. (Здесь явно просматривается классическая проблема курицы
и яйца. Схема, являющаяся прародителем всех остальных XML-схем, находится
на сайте www.w3.org; она должна быть написана в формате DTD, но ни одна ее
наследница уже не обязана делать этого.)
Концепции XML Schema
В табл. 14.2 приведены важные выражения XML Schema и их использование
на примере XML-документа. В XML Schema есть два типа элементов: простые
и сложные. (Эти термины используются точно в том же смысле, что и в
семантической объектной модели в главе 4.) Простой элемент состоит из одного
значения-содержимого. Элементы price и purchaseDate в табл. 14.2 являются простыми.
Таблица 14.2. Пример XML Schema
Schema Definition
Example Document Fragment
<element name="price" type="dt:decimar/>
<element name="purchaseDate" type="dt:date'7>
<complex Type name="Address"/>
<sequence>
<element name="street" type="dt:string"
maxoccurs="37>
<element name="mai1Stop" type="dt:string"
minoccurs="0'V>
<element name="city" type="dt:string7>
<element name="state" type="dt:string'7>
<element name="zip" type="dt:string'7>
</sequence>
<attribute name="datel_astChanged" typ="dt:date,7>
</complexType>
<price>27.50</price>
<purchaseDate>2001-12-
10</purchaseDate>
<Address datel_astChanged="2001-
12-14">
<street> 1824 Highland
Ave</street>
<street>Suite 400</street>
<city>Seattle</city>
<state>WA</state>
<zip>98119</zip>
</Address>
продолжение^
542 Глава 14. Сети, многоуровневые архитектуры и XML
Таблица 14.2 (продолжение)
Schema Definition Example Document Fragment
<schema targetNamespace <?xml version="1.0"?>
xmlns=,,http://www.kumquat.com/xnaldocs/dtd1,, <customerView
xmlns="http://www.kumquat.com/xmldocs/dtd1" xmlns="http://www.kumquat.com/
xmldocs/dtd1">
xm!ns:dt=,,http://www.w3.org/2000/10/XMLSchemaM>
<element name=McustomerView"> <part>1234=</part>
<color>red</color>
<element name="parf type="partType7>
<element name="part" type="partType"/> </customerView>
<element name="color" type="dt.string7>
</element>
</schema>
Элементы имеют тип, который указывает домен содержимого элемента. Здесь
элемент price происходит из домена dtdecimal. Это означает, что множество
значений элемента price ограничено определением decimal в пространстве имен dt.
Подобным же образом тип (домен) элемента purchaseDate задан определением date
в пространстве имен dt. Вскоре мы вернемся к пространствам имен. Пока что их
можно рассматривать как ссылку на место, где находятся определения типов.
В третьей строке табл. 14.2 показан элемент complexType. Он называется Address
и состоит из последовательности элементов {street, mailStop, city, state, zip}. По
умолчанию в XML Schema элементы имеют кардинальность 1.1, то есть элементы
обязаны иметь значение, и притом не более одного. Изменить это можно с помощью
атрибутов minoccurs и maxoccurs. В элементе Address, например, элемент street может
иметь до трех вхождений (maxoccurs="3"), а элемент mailStop является
необязательным (minoccurs="0"). Неограниченное число вхождений определяется путем
установки атрибута maxoccurs в значение «unbounded».
Сложные типы могут иметь атрибуты. Этим атрибутам могут присваиваться
значения в XML-документе. Атрибуты отличаются от содержимого элемента
тем, что предназначены для хранения метаданных о самом элементе, а не
значения содержимого. В качестве типичного примера атрибута можно привести
атрибут units (единицы измерения) элемента quantity (количество) или атрибут
country (страна) элемента address (адрес). В табл. 14.2 элемент Address имеет один
атрибут под названием dateLastChanged. Этот атрибут в приведенном примере
документа установлен в значение «2001-12-10».
Пространства имен XML
Пространства имен XML (XML Namespaces) — один из наиболее запутанных
аспектов спецификации XML Schema. Причина этого частично состоит в том, что
они преднамеренно были определены как можно более общим образом.
Рассмотрим операторы в элементе, расположенном в последней строке в
табл. 14.2. Первое выражение с помощью ключевого слова targetNamespace опре-
XML — расширяемый язык разметки 543
деляет целевое пространство имен (target namespace). Тем самым указывается
пространство имен, создаваемое схемой. Целевое пространство имен — это
набор определений, являющихся результатом текущей схемы; это пространство
имен будет использоваться для проверки других XML-документов. Выражение
targetNamespace xmlns="http://www.kumquat.com/xmldocs/dtdl" сообщает
синтаксическому анализатору, что эту схему следует использовать для создания
пространства имен "http://www.kumquat.com/xmldocs/dtdl". На это имя могут в дальнейшем
ссылаться документы, основанные на данной схеме. Пример тому можно видеть
в документе customerView, во втором столбце последней строки в табл. 14.2.
Кроме целевого пространства имен каждый XML-документ может, хотя и не
обязан, иметь одно пространство имен по умолчанию (default namespace) и много
помеченных пространств имен (labeled namespaces). Эти пространства имен
используются синтаксическим анализатором, пока он интерпретирует XML-схему
в процессе создания целевого пространства имен. Пространство имен по
умолчанию указывается с помощью ключевого слова xmlns=, за которым в кавычках
следует имя этого пространства. Помеченное пространство имен указывается
ключевым словом xmlns, за которым следует двоеточие, имя метки, знак равенства
и имя пространства имен в скобках. Так, xmlns;aviation="http://www.abc.com/dtd"
создает помеченное пространство имен под названием aviation и дает ему имя
"http://www.abc.com/dtd".
В табл. 14.2 оператор xmlns="http://www.kumquat.com/xmldocs/dtdl"
определяет пространство имен по умолчанию. Если не указано иное, синтаксический
анализатор будет использовать пространство имен по умолчанию при
интерпретации содержимого схемы. Обратите внимание, что в этом случае целевое
пространство имен и пространство имен по умолчанию задают один и тот же путь —
"http://www.kumquat.com/xmldocs/dtdl". Это говорит синтаксическому
анализатору о том, что нужно искать в текущей схеме определения всех непомеченных
элементов. Между прочим, эти два пространства имен не обязаны совпадать —
целевое пространство имен и пространство имен по умолчанию могут быть
различными.
В последней строке табл. 14.2 пространство имен по умолчанию используется
для определения элемента part. Он имеет тип «partType», без метки. Поскольку
для типа partType метка отсутствует, синтаксический анализатор будет искать его
определение где-то в текущей схеме.
Третий оператор, начинающийся с xmlnsrdt, присваивает помеченному
пространству имен dt имя "http://www.w3.org/2000/10/XMLSchema". Это имя
указывает на пространство имен, содержащее определения стандартных типов
XML-элементов. (Их список можно увидеть по адресу www.w3.org.) Пространство имен
используется далее в схеме, где элементу color присваивается тип «dt.String».
Такое выражение предписывает синтаксическому анализатору обратиться к
пространству имен, обозначенному меткой dt, и найти в нем определение типа String.
В следующих разделах вы увидите более удачные примеры использования
множественных пространств имен.
Теперь начинается самая хитрая часть. Пространства имен, которые мы
использовали, выглядят как URI — уникальные идентификаторы ресурсов. Однако
544 Глава 14. Сети, многоуровневые архитектуры и XML
этого не требуется. Единственное требование состоит в том, чтобы имена
пространств имен были уникальными везде, где может использоваться XML Schema.
Если бы мы знали, что никто другой не будет никогда использовать
идентификатор BOAT, мы могли бы определить пространство имен с меткой, например, sailing
посредством выражения xmlns:sailing»"BOAT". Однако это слово вряд ли будет
уникальным.
URI используются в качестве идентификаторов пространств имен потому,
что их можно выбрать уникальными в мировом масштабе. Например,
идентификатор //www.prenhaLLcom/databaseprocessing8e/Chapterl4/Figurel4-l3/dtdw
является полноценным всемирно уникальным идентификатором. Кто-то еще мог бы,
конечно, использовать его в качестве идентификатора пространства имен, но
издательство Prentice Hall имело бы право возражать против этого, как в случае,
если бы кто-нибудь без разрешения издательства использовал торговую марку
Prentice Hall.
На этом хитрая часть еще не заканчивается: в спецификации Всемирного
Web-консорциума нет такого требования, чтобы схема действительно находилась
по указанному URI. Таким образом, URI используется только для присвоения
уникального идентификатора пространству имен и более ни для чего.
Местоположение реальных документов, содержащих определения пространств имен,
может быть сообщено синтаксическому анализатору каким-нибудь другим путем —
например, это могут быть параметры, передаваемые анализатору при запуске.
Спецификация не указывает, как это должно происходить.
Тем не менее, имейте в виду, что в конкретных реализациях XML Schema
имена пространств имен могут указывать на реальное местоположение
необходимых документов. Если так, то это является выбором разработчика:
стандарт допускает и другие механизмы. Короче говоря, хотя имена пространств
имен и выглядят как URI, это не обязательно. От них требуется только
уникальность.
Использование множественных пространств имен
для преодоления неоднозначности доменов
Ранее, при обсуждении стандартов и терминологии XML, мы столкнулись с
проблемой, которая возникает, когда одно и то же слово обозначает различные вещи.
Предположим, например, что разработчик XML-схемы хочет определить
элемент musicallnstrument, состоящий из элементов {source, model, comment}, и
элемент electricalDevice, состоящий из элементов {source, model, comment}.
Составляющие элемента musicallnstrument и элемента electricalDevice имеют
одинаковые имена, но их домены различны. Значениями элемента source в элементах
musicallnstrument могут быть только компании, производящие музыкальные
инструменты, а в элементах electricalDevice — компании, производящие электронное
оборудование. Элемент comment предполагает еще большие различия. В
элементах musicallnstrument это материал, из которого изготовлен инструмент, — сплав,
серебро, медь и т. д., а в electricalDevice это напряжение, на которое рассчитано
электронное устройство.
XML — расширяемый язык разметки 545
В табл. 14.3 иллюстрируется использование множественных пространств
имен для разрешения неоднозначности имен элементов. Определены два
помеченных пространства имен: music и electronic. В пространстве имен music эти элементы
определяются способом, присущим миру музыки, а в пространстве имен electronic —
способом, присущим миру электроники. Сложный тип musicallnstrument
включает в себя элементы source, model и comment, как вы и могли ожидать. Этим
элементам, однако, присвоены типы из пространства имен music: элемент source имеет
тип musicimanufacturer, элемент model — тип musicmodel, а элемент comment — тип
musicimaterial
Таблица 14.3. Пример использования XML Schema с несколькими
пространствами имен
Schema Definition
Example Document
<schema targetNamespace <?xml version=*\0"?>
xmlns=http://www. mycompany.com/orders/dtd <equipment
xmlns=http://www. mycompany.com/orders/dtd xmlns="http://www. mycompany.com/
xmlns:dt=http://www.w3.org/2000/10/XMLSchema orders/dtd>
xmlns:music=http://www. musiccompany.com/xml/dtd
xmlns:electronic=Mhttp://www.electrica!company.com/
xml/dtd">
<complexType name="equipmentM>
<complexType name="musicalinstrument"
maxoccurs= "unbounded">
<sequence>
<element name^'source" type =
"music: man ufacturer"/>
<element name="model" type ="music:model7>
<e!ement name="comment" type ="music.materiar
mlnoccurs="07>
</sequence>
</complexType>
<complexType name="electronicDeviceY>
<sequence>
<element name=Msource" type =
"electronic: man uf acturer'7>
<element name="moder type ="electronic:modeT/>
<element name="comment" type =
,,electronic:voltage'7>
</sequence>
</complexType>
</comp!exType>
<musicallnstrument>
<source>Yamaha</source>
<model>Standard
Flute</model>
<comment>Silver</comment>
</musicallnstrument>
<musicallnstrument>
<source>Yamaha</source>
<model>Piano</mode!>
</musicallnstrument>
<electricalDevice>
<source>Hewlett-
Packard</source>
<model>HP-2780Z</model>
<comment> 12</comment>
< /e lectrical Device >
</equipment>
</schema>
546 Глава 14. Сети, многоуровневые архитектуры и XML
Сходная ситуация наблюдается для электронного устройства. Его элементы
определены типами electromcmanufacturer, electroiric:modelH electron!cvoltage.
Стандарт XML Schema предоставляет много способов ограничить домен
определения типа. Можно потребовать, чтобы элементы имели определенные
значения, находились в определенном диапазоне чисел, были константами, имели
значения по умолчанию и т. д. Так, возможные значения элемента manufacturer
в пространстве имен music могут быть ограничены через определение типа
набором {Yamaha, Steinway, Horner}, и тогда только эти значения будут разрешенными.
Аналогичные приемы можно использовать и для всех остальных элементов. Эти
приемы находятся вне рамок нашего изложения; информацию о них можно
найти на сайте www.w3.org.
В табл. 14.3 проиллюстрировано еще несколько идей. Имея в виду изложенное
выше, вы должны быть в состоянии объяснить, почему приведенный здесь
документ, который является действительным по схеме, может, тем не менее, иметь
элемент musicallnstrument без элемента material, и почему в нем может быть два
элемента musicallnstrument. Кроме того, вы должны быть способны ответить на
вопрос, почему этот документ не был бы действительным по схеме, будь в нем
два элемента electricalDevice.
Комментарий редактора американского издания
Описанное выше имеет огромное значение для обработки баз данных.
Возможности XML Schema обеспечивают стандартизированное, расширяемое и
международное решение проблемы, являвшейся бичом баз данных со времени их
изобретения, — реализации ограничений доменов. До сих пор единственным способом
реализовать эти ограничения было написание кода приложения, хранимых
процедур или триггеров. Этот код, однако, служил единственной цели, и его
приходилось переписывать каждый раз, когда менялся домен — например, когда новая
компания начинала производить музыкальные инструменты. XML Schema
позволяет написать код один раз — а именно в программе, проверяющей
допустимость XML-документов по отношению к их схемам, и затем домены
определяются как данные, расширяемым и стандартизированным способом. Когда домен
изменяется, нужно только обновить список допустимых значений. Отпадает
необходимость в высококвалифицированных, дорогих, а главное живых (и поэтому
склонных к ошибкам) программистах.
Должно пройти несколько лет, пока будут разработаны продукты,
реализующие этот стандарт, и еще несколько лет, чтобы компании научились ими
пользоваться (здесь-то и появитесь вы!). Но рано или поздно XML Schema или
что-то очень близкое к этому стандарту получит весьма широкое применение,
поскольку это может коренным образом упростить разработку и поддержание
приложений.
XML-схема для галереи View Ridge
В табл. 14.4 показана XML-схема для представления Customer галереи View Ridge,
взятого с рис. 10.4. В начале схемы определен элемент nameOfArtist; это сделано
так, что его можно использовать дважды в теле представления custView.
XML — расширяемый язык разметки 547
Таблица 14.4. XML-схема для представления CustomerView базы данных ViewRidge
Schema Definition
Example Document
<schema targetNamespace
xmlns="http://www.viewridge.com/customer"
xmlns="http://www.viewridge.com/customer"
xmlns:dt="http://www.w3.org/2000/10/XMLSchema">
<element name="nameOfArtist" type="dt.string7>
<complexType name="custView" maxoccurs="unbounded">
<sequence>
<complexType name="customer">
<sequence>
<element name="name" type ="dt:string'7>
<element name=4,areaCode" type ="dt:string"
minoccurs="0"/>
<element name="localNumber" type ="dt:string7>
<complexType name="transaction"
maxoccurs="unbounded">
<sequence>
<element name="purchaseDate" type="dt:date7>
<element name="salesPrice" type=udt:decimar/>
<complexType name="work'*>
<sequence>
<element name="artistName"
type="name0fArtist7>
<eiement name="workTitle" type="dt:string7>
<element name="workCopy" type="dt:string"
minoccurs="0">
</sequence>
</complexType>
</sequence>
</complexType>
<complexType name="artistlnteresr
maxoccurs="unbounded7>
<element name=artistName type="nameOfArtist7>
</complexType>
</sequence>
</complexType>
</sequence>
</complexType>
<?xml version="1.0"?>
<custView
xmlns="http://www.viewridge.com/
customer" >
<customer>
<name>Jackson,
Elizabeth</name>
<areaCode>206</areaCode>
<localNumber>989-
4344</localNumber>
<transaction>
<purchaseDate>2002-12-
10</purchaseDate>
<salesPrice>4300.00</salesPrice>
<work>
<artistName>Juan
Miro</artistName>
<wor kTitle >Poste r </workTitle >
<workCopy > 14/8=</workCopy >
</work>
</transaction>
<artistlnterest>
<artistName>Juan
Miro</artistName>
<artistName>Mark
Tobey</artistName >
<artistName>Dennis
Frings</artistName>
</artistlnterest>
</customer>
</customerview>
Этот пример демонстрирует полезность такой установки, когда целевое
пространство имен и пространство имен по умолчанию совпадают. Когда
синтаксический анализатор обнаруживает имя nameOfArtist, он заносит его в целевое про-
548 Глава 14. Сети, многоуровневые архитектуры и XML
странство имен. Следовательно, когда обрабатываются два элемента artistName,
имеющие тип nameOfArtist и не имеющие никакой метки (вроде dt), синтаксический
анализатор обращается к пространству имен по умолчанию и ищет nameOfArtist
там. Он его обязательно найдет, поскольку целевое пространство имен и
пространство имен по умолчанию совпадают.
Подобное определение типа элемента избавляет от многих ошибок, так как
если его нужно изменить, это требуется сделать лишь в одном месте, и это
изменение распространяется на все элементы, определенные этим типом. Кроме того,
определения могут быть длинными, и определение многократно используемых
атрибутов в одном месте экономит время.
Этот пример не показывает всей мощи языка XML Schema. Например, домен
workCopy имеет вид ппп/ттт, где пит — положительные целые числа,
причем ппп должно быть меньше ттт. Этот сложный домен может быть определен
в синтаксисе XML Schema, и после этого соответствующее ограничение будет
реализовываться синтаксическим анализатором. Аналогичные замечания
справедливы для ограничений на areaCode, localNumber, purchaseDate и salesPrice.
Протокол WAP
Протокол WAP (Wireless Application Protocol, протокол для мобильных устройств)
был создан для того, чтобы упростить использование интернет-технологий на
мобильных устройствах, таких как сотовые телефоны и наладонные компьютеры.
Ранее в этой главе мы привели типичный пример WAP-приложения. В этом
разделе мы рассмотрим сущность WAP.
На рис. 14.8 показаны основные компоненты WAP-системы. WAP-сервер —
это HTTP-сервер, который преобразует стандартный web-протокол XML в WML
(Wireless Markup Language) — язык разметки для мобильных устройств. WML
является подмножеством XML, следовательно, WML-документы можно проверять
на допустимость по отношению к DTD или XML-схемам. Кроме того, для
преобразования XML-документов в WML с целью обработки их на мобильных
устройствах можно использовать XSLT. XSLT также применяется для преобразования
WML-отклика мобильных устройств в стандартный XML. Стандарт WML
включает в себя сценарный язык WML Script, являющийся вариантом JavaScript.
Как показано на рис. 14.8, WML преобразуется web-шлюзом в сжатую форму,
называемую WMLC. Эта сжатая форма похожа на скомпилированную
программу, так как представляет собой гораздо меньшую по размеру бинарную версию
WML-документа. Целью сжатия является сужение диапазона частот,
необходимого для передачи WML-документа.
На сегодняшний день размер экрана и возможности клавиатуры мобильных
устройств недостаточны для того, чтобы поддерживать полноценные браузеры.
В них используются микробраузеры (microbrowsers) — сверхтонкие приложения,
обрабатывающие WML.
XML-документ при преобразовании в WML разбивается на разделы,
достаточно компактные для того, чтобы их могли отображать микробраузеры на мобильных
устройствах. Эти разделы называются картами (card), а набор карт носит
название колоды (deck). Обычно вся колода передается на мобильное устройство за
один прием. Отображение карт на дисплее происходит по одной. Ссылки на от-
ХМL — расширяемый язык разметки 549
дельные карты записываются в формате идентификатор_колоды#идентификатор_кар-
ты. Карты из текущей колоды доступны непосредственно с мобильного устройства,
а для считывания карт из других колод необходимо обратиться к WAP-серверу.
Интернет-браузер
Мобильное
устройство
WMLC
Шлюз WAP
WML
WAP- или
HTTP-сервер
Микро-браузер <■
WML-колоды и карты
с использованием WMLKScript
Преобразование
> WML^XML
через XSLT
Рис. 14.8. Использование протокола WAP
WAP не требует использования XML. В мобильных приложениях можно
использовать и HTML. Преимущество XML состоит в том, что WML-доку-
мент можно проверить на допустимость и что для преобразований между WML
и XML можно использовать XSLT.
Значение XML для приложений баз данных
XML, вероятно, представляет собой наиболее важный качественный скачок
для приложений баз данных со времен изобретения реляционной модели. Об
этом позволяют говорить ключевые характеристики XML, перечисленные на
рис. 14.9.
> Стандартизированный способ представления доменов.
> Стандартизированный способ описания представлений баз данных.
> Четкое разделение структуры, содержимого и материализации.
> Возможность проверки допустимости документов.
> Международные стандарты типов документов.
Рис. 14.9. Характеристики XML, представляющие важность для приложений баз данных
Во-первых, XML Schema предоставляет стандартизированный способ
представления доменов. Во-вторых, XML дает стандартные способы описания
структуры представлений баз данных. Благодаря этому любое приложение, способное
обрабатывать DTD или XML-схему, может корректным образом
интерпретировать произвольное представление базы данных.
550 Глава 14. Сети, многоуровневые архитектуры и XML
Рассмотрим XML-схему представления Customer базы данных галереи View
Ridge в табл. 14.4. До появления XML для того, чтобы две программы могли
обмениваться этим представлением, для них необходимо было бы определить
специальный протокол, с помощью которого описывалась бы структура
представления. При использовании XML им нужно лишь интерпретировать XML-схему
в табл. 14.4; никакого предварительного соглашения или протокола не требуется.
В прошлом за неимением стандартного способа описания представлений баз
данных разработчики использовали для этой цели SQL. Но, как вы знаете из
главы 10, SQL не может использоваться для представлений, содержащих более
одного многозначного пути через схему. Представление в табл. 14.4 имеет два
многозначных пути: один через Transaction, а другой через Artist. Следовательно,
требуется несколько SQL-операторов, однако стандартного способа указать, как
они должны соединяться, не существует. XML преодолевает этот недостаток.
Третье крупное преимущество XML — четкое разделение между структурой,
содержимым и материализацией. Структура документа может храниться в
одном месте в виде DTD или XML-схемы, а все документы, основывающиеся на
этой структуре, могут содержать ссылки на нее. Например, компания Boeing
может выложить на один из своих сайтов XML-схему бланка заказа авиационных
компонентов, и все покупатели запасных частей для самолетов смогут
использовать эту схему для заказов.
Компании, покупающие компоненты у Boeing, могут разработать свои
собственные приложения, которые будут выписывать заказы, удовлетворяющие этой
схеме. Способ, при помощи которого создается документ-заказ, будет полностью
скрыт от Boeing и кого бы то ни было еще. Это может быть приложение базы
данных, а может быть текстовый редактор — способ создания документа
неизвестен и не играет роли.
Более того, Boeing может разработать много различных таблиц стилей XSL
для материализации этого документа: одну — для отдела приема заказов, другую —
для производственного отдела, третью — для бухгалтерии, четвертую — для
отдела маркетинга. Может также быть специальная таблица стилей для клиентов.
Клиенты компании Boeing могут также создавать свои собственные таблицы
стилей, основанные на этой схеме. Таким образом, каждый может
материализовать содержимое стандартного документа-заказа любым подходящим способом.
Четвертой важной характеристикой XML является проверка допустимости
документов. В случае с той же компанией Boeing клиент при выписке заказа
может проверить его допустимость относительно DTD или XML-схемы. Так он
сможет быть уверенным, что отправляет компании только допустимые по типу и
схеме заказы. Аналогичным образом, при приеме заказов на сайтах Boeing может
автоматически проверяться их допустимость относительно DTD или XML-схемы.
Это даст гарантию, что приняты будут только допустимые по типу и схеме заказы.
Такую проверку допустимости можно организовать и без помощи XML, но это
гораздо сложнее. Компании Boeing пришлось бы написать для этого специальную
программу и разослать ее всем клиентам и отделам, которым необходимо
проводить проверку допустимости. При этом для каждого типа документа понадобилась
бы своя собственная программа. Используя стандарт XML, фирме достаточно
XML — расширяемый язык разметки 551
лишь поместить DTD или схемы в доступное место, и все заинтересованные
стороны смогут проверять допустимость своих документов различных типов.
Последнее важное преимущество XML заключается в том, что
производственные группы могут разрабатывать DTD и XML-схемы индустриального
масштаба. Организация под названием OASIS (Organization for the Advancement of
Structured Information Standards, Организация развития стандартов
структурированной информации) служит как бы расчетной палатой для публикации
стандартов XML Schema. Она ведет реестр XML.ORG, в котором перечислены
опубликованные схемы и имеется поисковая машина для нахождения схем по
заданной тематике. В табл. 14.5 перечислены некоторые из ныне существующих
стандартов.
Таблица 14,5. Индустриальные стандарты XML
Отрасль производства Примеры стандартов
Бухгалтерский учет
Архитектура и
строительство
Автомобильная
промышленность
Банковское дело
Электронный обмен
данными
Кадровые ресурсы
American Institute of Certified Public Accountants (AICPA):
Extensible Reporting Markup Language (XFRML) [Первая
страница OASIS
Open Applications Group (OAG)
Architecture, Engineering and Construction XML Working Group
(aecXML Working Group)
ConSource.com: Construction Manufacturing and Distribution
Extensible Markup Language (cmdXML)
Automotive Industry Action Group (AlAG)
Global Automedia
MSR: Standards for information interchange in the engineering
process (MEDOC)
The Society of Automotive Engineers (SAE): XML for the
Automotive Industry — SAE J2008 [Первая страница OASIS]
Bankikng Industry Technology Secretariat (BITS): [Первая
страница OASIS]
Financial Services Technology Consortium (FSTC): Bank Internet
Payment System (BIPS) [Первая страница OASIS]
Open Applications Group, Inc (OAG)
Data Interchange Standards Association (DISA): [Первая
страница OASIS]
EEMA EDI/EC Work Group [Первая страница OASIS]
European Committee for Standartization / Information Society
Standartization System (CEN/ISSS; The European XML/EDI Pilot
Project [Первая страница OASIS])
XML/EDI Group [Первая страница OASIS]
DataMain: Human Resources Markup Language
HR-XML Consortium [Первая страница OASIS]: JobPosting,
CandidateProfile, Resume
Open Applications Group (OAG): Open Applications Group
Interface Specification (OASIS) [Первая страница OASIS]
Tapestry.Net: JOB markup language (JOB)
Open Applications Group, Inc (OAG)
продолжение^
552 Глава 14. Сети, многоуровневые архитектуры и XML
Таблица 14.5 (продолжение)
Отрасль производства Примеры стандартов
Страхование ♦ ACORD: Property and Casualty [Первая страница OASIS],
Life (XMLife) [Первая страница OASIS]
♦ Lexica: iLingo
Недвижимость ♦ OpenMLS: Real Estate Listing Management System (OpenMLS)
[Первая страница OASIS]
♦ Real Estate standards Working Group (RETS): Real Estate
Transaction Standard [Первая страница OASIS]
Программное ♦ IBM: [Первая страница OASIS]
обеспечение + Flashl/ne.com: Software Component Documentation DTD
♦ Flashline.com:
♦ INRIA: Koala Bean Markup Language (KBML) [Первая страница
OASIS]
♦ Marimba и Microsoft: Open Software Description Format (OSD)
[Первая страница OASIS]
♦ Object Management Group: [Первая страница OASIS]
Автоматическое ♦ Internet Engineering task Force (IETF): Simple Workflow Access
управление Protocol (SWAP) [Первая страница OASIS]
технологическим + Workflow Management Coalition (MfMC): Wf-XML [Первая
процессом страница OASIS]
Пример применения XML в электронной
коммерции
Рисунок 14.10 демонстрирует роль XML в совместном использовании
документов из базы данных в приложении электронной коммерции (которая
обозначается еще В2В, Business to business). Находящаяся слева компания А (например,
Boeing) использует одно или несколько приложений базы данных для создания
XML-документов. Эти приложения обращаются к XML-схемам, чтобы
определить требуемую структуру представления. Как показывает рисунок, эти
документы находятся на локальных сайтах, в публичных библиотеках схем и в
библиотеках схем компании Б (например, одного из поставщиков Boeing).
Созданные документы передаются на web-сервер. Далее они передаются на
WAP- или HTTP-серверы. Разумеется, нет такого требования, чтобы документы
были доступны с мобильных устройств, — эта возможность показана здесь просто
для иллюстрации. Сгенерированные XML-документы, содержащие
представление базы данных, могут быть отправлены на внутренние серверы компании А
для внутреннего использования, опубликованы на общедоступных web-серверах,
поддерживаемых компанией А или какой-либо другой компанией или могут
быть переданы на сервер, контролируемый компанией Б.
На любой стадии XML-документ может быть проверен на допустимость
относительно соответствующей XML-схемы, чтобы убедиться, что ничего не было
потеряно. Более того, на любой стадии документ с помощью XSLT может быть
преобразован в другой XML-формат, в WML, в голос, в формат, воспринимаемый
производственными машинами, например роботами, и в любой другой формат.
Если документ будет преобразован в формат, являющийся XML-форматом (на-
XML — расширяемый язык разметки 553
пример, WML), для проверки допустимости преобразованного документа можно
использовать XML Schema.
Рис. 14.10. XML во всем его великолепии
С помощью этих XML-технологий можно создавать приложения баз данных,
допускающие бессчетное количество способов и форматов публикации, причем
в соответствии с производственными стандартами.
Поддержка XML в Oracle и SQL Server
Как в Oracle, так и в SQL Server начала внедряться поддержка XML. В обоих
продуктах имеется возможность хранить X ML-доку менты в базе данных и в обоих
554 Глава 14. Сети, многоуровневые архитектуры и XML
есть DOM-ориентированные синтаксические анализаторы для обработки XML-
документов. Эти анализаторы позволяют программам извлекать поля базы
данных из XML-документов и хранить их в виде столбцов таблиц.
Кроме того, оба продукта поддерживают стандарт XPath, позволяющий вести
поиск XML-документов. В обоих продуктах предусмотрена возможность
материализовать результаты SQL-запросов в виде ХМ L-доку ментов. Оба продукта
позволяют обрабатывать XML-документы и формы, созданные базой данных,
с помощью интернет-технологий. Oracle использует для этой цели страницы
XSQL, которые можно встраивать в JSP-страницы (об этом речь пойдет в
главе 16). SQL Server использует ADO и ASP-страницы (обсуждаются в следующей
главе).
Поддержка XML в коммерческих СУБД еще явно находится на ранней,
формирующейся стадии. Интеграция между конструкциями баз данных и XML
является несколько неудобной. Но поддержка этих возможностей обязательно будет
улучшена в следующих версиях продуктов. Данная тема находится на переднем
крае коммерческих технологий обработки баз данных, и будет интересно
увидеть, как это все разовьется в будущем. Оставайтесь на связи!
Резюме
Компьютерная сеть — это совокупность компьютеров, которые общаются между
собой с использованием стандартизированного протокола. Открытые сети
доступны любому, кто внесет установленную плату; чтобы стать пользователем
закрытой сети, нужно предварительно получить разрешение на доступ к ней.
Интернет — это открытая компьютерная сеть, основывающаяся на протоколе
TCP/IP. Она начиналась как военный исследовательский проект, известный под
названием ARPANET.
В 1989 г. Тимом Бернерсом-Ли из института CERN был разработан протокол
передачи гипертекста — HTTP. Протокол HTTP ориентирован на запрос и не
имеет состояния.
Интрасеть — это частная локальная или глобальная сеть использующая TCP/IP,
HTML и браузеры. Интрасети либо не подключены к сети Интернет, либо
подключены к ней через брандмауэр. Интрасети имеют производительность, на
порядки превышающую производительность Интернета. Беспроводной доступ к
сетям возможен с сотовых телефонов и других мобильных устройств при
помощи протокола WAP.
Приложения баз данных, использующие интернет-технологии, чаще всего
имеют трех- или многоуровневую архитектуру. Трехуровневая архитектура
состоит из сервера базы данных, web-сервера и клиентских компьютеров. Каждый
из этих уровней может использовать свою операционную систему и продукты
различных производителей. Назначение сервера базы данных состоит в том,
чтобы нести на себе СУБД, которая обрабатывает запросы и предоставляет услуги
многопользовательской базы данных. Web-сервер — это HTTP-сервер, на
котором работает интерпретатор сценарных языков и который позволяет приложе-
Резюме 555
нию базы данных создавать, читать, обновлять и удалять представления.
Клиентская машина действует в роли HTTP-клиента, на котором также работает
интерпретатор сценарных языков и который материализует представления базы
данных.
Распространенными web-серверами являются Microsoft IIS, Apache и Netscape
Web Server. В сочетании с IIS на Windows-серверах часто используется
технология ASP, а на Unix-серверах — сервлеты Java и JSP.
Для языков разметки важную роль играют стандарты, благодаря которым
web-страницы могут обрабатываться любыми браузерами. Всемирный
Web-консорциум публикует стандарты и управляет процессом их разработки.
Коммерческие продукты расширяют стандарты, но прр* этом они создают проблемы для
пользователей продуктов, которые не поддерживают эти расширения. Стандарт
HTML 4.0 был разработан для устранения проблем, присутствовавших в рашшх
версиях HTML. Разработанный Microsoft язык DHTML (динамический HTML)
реализует и расширяет HTML 4.O. Для приложений баз данных важны три
возможности DHTML: объектная модель документов (DOM), каскадные таблицы
стилей (CSS) и служба удаленной обработки данных (RDS) — набор элементов
управления ActiveX, которые обеспечивают кэширование и материализацию
данных на клиентской машине без обращения к серверу.
XML — это язык разметки, разработанный для обеспечения четкого разделения
между структурой документа, его содержимым и материализацией. Он может
расширяться, но стандартизированным способом. Структура документа задается
определением типов (DTD) или XML-схемой. XML-документы,
соответствующие своим DTD, называются допустимыми по типу. Материализация XML-
документов может осуществляться с помощью CSS или XSLT (расширяемого
языка стилей для преобразований). XSLT представляет собой декларативный,
ориентированный на преобразование язык для манипулирования документами.
С помощью XSLT можно преобразовать XML-документ в HTML или в другой
XML-документ, имеющий иную структуру.
Перечень важных XML-стандартов приведен в табл. 14.1. XML Schema —
это стандарт для предъявления ограничений к XML-документам; XML-документы,
соответствующие своей схеме, называются допустимыми по схеме. XML Schema
имеет преимущества перед DTD во многих отношениях. Во-первых, XML-схемы
являются сами по себе XML-документами, которые могут быть проверены.
Кроме того, XML-схемы предоставляют обобщенный и расширяемый способ
реализации доменов через использование пространств имен XML.
WML — это XML-стандарт для обработки XML-документов с
использованием микробраузеров на мобильных устройствах. XML-страницы при
использовании WML делятся на разделы, называемые картами. Полный набор WML-карт
называется колодой. В WML имеется сценарный язык WMLScript, являющийся
вариантом ECMAScript.
XML чрезвычайно важен для приложений баз данных, поскольку
предоставляет стандартизированный способ выражения структуры представлений баз
данных, четко разделяет структуру, содержимое и материализацию документа,
обеспечивает стандартизированную проверку допустимости документов и позволяет
556 Глава 14. Сети, многоуровневые архитектуры и XML
промышленным группам разрабатывать полезные стандарты индустриального
масштаба для описания структуры представлений баз данных. Поддержка XML
имеется как в Oracle, так и в SQL Server.
Вопросы I группы
1. Дайте определения терминам сеть, открытая сеть и закрытая сеть.
2. Дайте определение термину Интернет.
3. Что такое TCP/IP и в чем его назначение?
4. Объясните, что имеется в виду, когда говорят, что протокол HTTP
является ориентированным на запрос и не имеет состояния.
5. Как называется протокол, предназначенный для поддержки доступа в сети
с мобильных устройств?
6. Назовите каждый из уровней в трехуровневой архитектуре и опишите его
роль.
7. Объясните, как трехуровневая архитектура обеспечивает взаимодействие
различных операционных систем и web-продуктов.
8. Объясните функции каждого из компонентов web-сервера на рис. 14.4.
9. Покажите два возможных варианта использования дополнительных
уровней в многоуровневой архитектуре.
10. В чем состоит важность стандартов для языков разметки?
11. Что такое W3C и почему он важен?
12. Почему производители с одной стороны любят стандарты, а с другой
стороны — ненавидят их?
13. Перечислите недостатки ранних версий HTML.
14. В чем различие между HTML 4.0 и DHTML?
15. Объясните, в чем состоит важность объектной модели документов (DOM).
16. Что такое каскадные таблицы стилей? В чем их важность?
17. Что такое RDS? Какова роль этой технологии?
18. Объясните, что такое XML и в чем его преимущества перед HTML и DHTML
19. Объясните смысл утверждения «HTML предоставляет слишком много
свободы».
20. Что такое DTD и в чем состоит его назначение?
21. Дайте определения терминов документ, действительный по типу, и
документу недействительный по типу.
22. Объясните, как CSS используется в XML-документах.
23. Что такое XSLT? Для чего он нужен?
24. Почему XSLT является декларативным? Почему он является
преобразовательным?
Вопросы II группы 557
25. Объясните, в чем важность контекста при работе с XSLT.
26. Опишите различия между DOM и SAX.
27. Какие два типа элементов возможны в XML Schema? Приведите пример
каждого типа.
28. Объясните разницу между содержимым элемента и его атрибутами.
29. Что такое целевое пространство имен и в чем его назначение?
30. Что такое пространство имен по умолчанию и как оно используется?
31. Почему удобно давать целевому пространству имен и пространству имен
по умолчанию один и тот же идентификатор?
32. Приведите пример помеченного пространства имен.
33. Объясните, как с помощью пространств имен разрешить неоднозначность
имен элементов.
34. Почему идентификаторы пространств имен выглядят как интернет-адреса?
Требует ли стандарт XML Schema, чтобы XML-схемы располагались по
этим адресам?
35. Что такое WAP, WML, WML Script, колода и карта?
36. В чем заключается важность XML для приложений базы данных?
37. Почему SQL не является эффективным способом определения структуры
представления базы данных?
Вопросы II группы
38. Посетите сайт www.w3.org и выясните, какой стандарт рекомендуется в
настоящее время для HTML. Как он отличается от того стандарта, который
описан в этой главе? Разрабатывается ли какой-нибудь новый стандарт
для HTML? Если да, то какой и какие возможности он будет иметь?
39. Посетите сайт www.w3.org и выясните, какой стандарт рекомендуется в
настоящее время для XSLT. Как он отличается от того стандарта, который
описан в этой главе для Internet Explorer 5.0? Какие стандарты XSLT
находятся в разработке?
40. Посетите сайт www.w3.org и выясните, какой стандарт рекомендуется в
настоящее время для XML Schema. Чем он отличается от стандарта,
описанного в этой главе?
41. Посетите сайт Microsoft или Oracle и исследуйте поддерживаемые ими
продукты и технологию, реализующие стандарт XML Schema. Как эти
продукты отличаются от описанных в этой главе?
42. Посетите сайт www.xml.org, зайдите в реестр и найдите стандарт,
относящийся к интересующей вас области. Опишите назначение этого стандарта.
Насколько полезен, по вашему мнению, будет этот стандарт?
43. Посетите www.wapforum.org и определите рекомендуемый в настоящее время
стандарт WAP. Как он отличается от того, который описан в этой главе?
558 Глава 14. Сети, многоуровневые архитектуры и XML
Вопросы к проекту FiredUp
Чета Роубэрдс решает, что их клиенты должны иметь возможность
зарегистрировать свою горелку через Интернет. Они не знают, как это сделать, поэтому
нанимают вас в качестве консультанта.
Предположим, что они решили, что лучше завести'собственный сайт, чем
пользоваться услугами сервисного бюро.
1. Стоит ли FiredUp разрабатывать собственный сайт? В чем преимущества
и недостатки такого решения?
2. Рассмотрите трехуровневую архитектуру в свете потребностей FiredUp.
Каковы могут быть функции каждого из уровней?
3. Какую операционную систему вы рекомендовали бы для web-сервера
FiredUp — Windows 2000 или Linux? Объясните преимущества и недостатки
каждой системы.
4. Какой продукт вы рекомендовали бы для сервера базы данных FiredUp —
Access, Oracle или SQL Server? Обоснуйте свое предпочтение.
5. Желательно ли для FiredUp располагать web-сервер и сервер базы данных
на одном компьютере? В чем состоят преимущества и недостатки этого
подхода?
6. Создайте DTD для XML и пример регистрационного документа. Будем
предполагать наличие в базе данных следующих таблиц:
КЛИЕНТ (НомерКлиента, Имя, Телефон, ЭлектронныйАдрес)
ГОРЕЛКА (СерийныйНомер, Тип, Версия, ДатаВыпуска)
РЕГИСТРАЦИЯ (НомерКлиента, СерийныйНомер, ДатаРегистрации)
РЕМ0НТ_Г0РЕЛКИ (НомерСчетаЗаРемонт, СерийныйНомер, ДатаРемонта, Описание,
Стоимость, НомерКлиента)
7. Создайте XML-схему для регистрационного документа.
Глава 15
ODBC, OLE DB, ADO и ASP
В этой главе рассматриваются стандартные интерфейсы для доступа к серверам
баз данных. ODBC (Open Database Connectivity standard, открытый стандарт
совместимости баз данных) был разработан в начале 1990-х годов с целью
предоставить независимый от СУБД способ обработки информации из реляционных
баз данных. В середине 1990-х годов компания Microsoft представила OLE DB —
объектно-ориентированный интерфейс, имеющий функциональность сервера
данных. Как вы узнаете, OLE DB был разработан не только для реляционных баз
данных, но и для многих других типов источников данных. Будучи СОМ-интер-
фейсом, OLE DB непосредственно доступен из C++, С# и Java, но недоступен из
Visual Basic и сценарных языков. Поэтому компания Microsoft разработала ADO
(Active Data Objects) — набор объектов, позволяющий использовать OLE DB из
любых языков программирования, включая Visual Basic, VBScript и JScript.
Прежде чем рассматривать эти стандарты, составим представление о том,
какое окружение имеет web-сервер в приложениях баз данных, использующих
интернет-технологии.
Окружение web-сервера
Окружение, в котором находятся современные приложения баз данных,
использующие интернет-технологии, весьма многообразно и сложно по составу. Как
показывает рис. 15.1, типичный web-сервер должен публиковать приложения,
содержащие данные из множества различных источников. Пока что мы
рассматривали только реляционные базы данных, однако, как вы можете видеть из этого
рисунка, существуют и другие типы источников данных.
Рассмотрим, с какими проблемами сталкивается разработчик web-серверных
приложений при интеграции данных из различных источников. В качестве таких
источников могут выступать база данных Oracle, база данных DB2 для больших
ЭВМ, нереляционная база данных IMS, системы обработки файлов VSAM и ISAM,
папки электронной почты и т. д. Каждый из этих продуктов имеет свой
собственный программный интерфейс, который разработчик должен выучить. Кроме
того, каждый из этих продуктов меняется, и со временем будут добавлены новые
возможности и функции, что еще больше усложнит задачу разработчика.
560 Глава 15. ODBC, OLE DB, ADO и ASP
Браузер
Браузер
Браузер
Web-сервер
Э_
Реляционные
базы данных,
Oracle, SQL Server,
Access, DB2,...
Нереляционные
базы данных
VSAM, ISAM, другие
обработчики файлов
Электронная почта,
другие типы документов
Картинки, аудиофайлы,
прочее
Рис. 15.1. Потребности интернет-приложения
Стандарт ODBC был разработан для решения той части данной проблемы,
которая относится к реляционным базам данных и источникам данных,
имеющим табличную организацию, например электронным таблицам. Как
показано на рис. 15.2, ODBC является интерфейсом между web-сервером (или другим
пользователем базы данных) и сервером базы данных. Он представляет собой
набор стандартов, позволяющих, кроме прочего, запускать на выполнение SQL-
операторы и возвращать результаты и сообщения об ошибках. Из рисунка
можно видеть, что разработчики могут обращаться к серверам данных через
«родные» интерфейсы, если таковы их предпочтения (иногда это делается для
увеличения производительности), но когда работы слишком много, а время и желание
изучать множество библиотек собственных интерфейсов СУБД отсутствуют, то
вместо них можно пользоваться ODBC.
Стандарт ODBC имел большой успех, поскольку чрезвычайно упростил
некоторые задачи, связанные с разработкой баз данных. Как вы узнаете, у него
есть существенный недостаток, для преодоления которого Microsoft разработала
стандарт OLE DB. На рис. 15.3 представлены отношения между OLE DB, ODBC
и другими типами источников данных. OLE DB предоставляет
объектно-ориентированный интерфейс к источникам данных почти любого типа.
Производители СУБД могут заключать фрагменты «родных» библиотек в объекты OLE DB,
благодаря чему функции этих библиотек становятся доступными через
интерфейс OLE DB. Кроме того, OLE DB можно использовать как интерфейс к
источникам данных ODBC. Наконец, в OLE DB предусмотрена поддержка и
нереляционных источников данных.
Окружение web-сервера 561
Собственные
интерфейсы
СУБД
Реляционные
базы данных,
Oracle, SQL Server,
Access, DB2 ...
Нереляционные
базы данных
VSAM, ISAM, другие
обработчики файлов
Электронная почта,
другие типы документов
Картинки, аудиофайлы,
прочее
Рис. 15.2. Роль стандарта ODBC
Собственные
интерфейсы
СУБД
Реляционные
базы данных,
Oracle, SQL Server,
Access, DB2...
Нереляционные
базы данных
VSAM, ISAM, другие
обработчики файлов
Электронная почта,
другие типы документов
Картинки, аудиофайлы,
прочее
Рис. 15.3. Роль OLE DB
562 Глава 15. ODBC, OLE DB, ADO и ASP
Так как OLE DB представляет собой объектно-ориентированный интерфейс,
он особенно хорошо подходит для использования с
объектно-ориентированными языками программирования, такими как C++. Однако многие разработчики
приложений баз данных программируют на Visual Basic или на сценарных
языках, таких как VBScript и JScript. Чтобы и им предоставить доступ к ODBC,
Microsoft разработала ADO как оболочку для объектов OLE DB (рис. 15.4). ADO
позволяет обращаться к функциональности OLE DB практически из любого языка.
?г^
Реляционные
базы данных,
Oracle, SQL Server,
Access, DB2 ...
Собственные
интерфейсы
СУБД
Браузер
Браузер
Браузер
А
Web-сервер |—| D
О
Сервер
базы
данных
ODBC
Нереляционные
базы данных
VSAM, ISAM, другие
обработчики файлов
Электронная почта,
другие типы документов
Картинки, аудиофайлы,
прочее
Рис. 15.4. Роль ADO
Вам может не понравиться навязчивое присутствие Microsoft в этом
повествовании. Но и OLE DB, и ADO были разработаны и продвинуты Microsoft,
и даже ODBC завоевал лидирующие позиции во многом благодаря поддержке
Microsoft. Другие производители и комитеты по стандартизации предлагали
альтернативы OLE DB и ADO, но поскольку система Microsoft Windows
установлена на 90% настольных компьютеров во всем мире, другим организациям трудно
продвигать конкурирующие стандарты. Кроме того, в защиту Microsoft говорит
Стандарт ODBC 563
то, что OLE DB и ADO отлично выполняют свои функции. Они облегчают труд
разработчика баз данных, и, возможно, они одержали бы победу даже в равной
конкурентной борьбе.
Однако наши цели имеют более земной характер. Изучение ADO необходимо
вам для того, чтобы вы могли создавать качественные приложения баз данных
с использованием интернет-технологий. С этих позиций мы и будем подробно
рассматривать каждый из этих стандартов.
Стандарт ODBC
Стандарт ODBC — это интерфейс, с помощью которого прикладные программы
могут обращаться к SQL-базам данных и обрабатывать их независимым от СУБД
способом. Это означает, к примеру, что приложение, которое использует
интерфейс ODBC, может обрабатывать базу данных Oracle, SYBASE, INFORMIX
и любую другую базу данных, совместимую с ODBC, без каких-либо изменений
в программном коде. Цель состоит в том, чтобы дать разработчику
возможность создать одно приложение, способное обращаться к базам данных,
поддерживаемым различными СУБД, без необходимости его менять или даже
перекомпилировать.
Стандарт ODBC был разработан комитетом производственных экспертов,
сформированным из членов комитетов Х/Ореп и SQL Access Group. Было
предложено несколько стандартов, но победителем оказался ODBC, в
основном потому, что он реализован Microsoft и является важной составной частью
Windows. Изначально интерес Microsoft к поддержке этого стандарта был
обусловлен желанием обеспечить в продуктах, подобных Excel, возможность
обращения к различным СУБД без перекомпиляции. Разумеется, с тех пор как
стандарт OLE DB был внедрен, интересы Microsoft изменились.
ODBC важен для систем баз данных, использующих интернет-технологии,
потому что теоретически можно разработать приложение, которое будет
обрабатывать базы данных, поддерживаемые различными СУБД. Мы говорим
«теоретически», поскольку продукты соответствуют стандарту в различной степени.
К счастью, комитет ODBC предвидел то, что в уровне поддержки стандарта
будут различия, и принял некоторые меры на этот случай, как вы узнаете позже.
Архитектура ODBC
На рис. 15.5 показаны компоненты стандарта ODBC. Прикладная программа,
диспетчер драйвера и драйверы СУБД находятся на том компьютере, где
располагается web-сервер. Диспетчеры посылают запросы источникам данных,
которые находятся на сервере базы данных. Согласно стандарту, источник
данных (data source) — это база данных, поддерживающая ее СУБД, операционная
система и сетевая платформа. Источник данных ODBC может быть
реляционной базой данных, файловым сервером, например BTrieve, и даже электронной
таблицей.
564 Глава 15. ODBC, OLE DB, ADO и ASP
Web-сервер
Серверы базы данных
Приложение
Диспетчер
драйверов
Драйвер СУБД-
Драйвер СУБД2
Драйвер СУБДз
СУБД,
СУБД5
СУБДз
БД
Ji'-:-
БД
_ _.
БД
Приложение может обрабатывать базу данных с помощью любой из трех СУБД
Рис. 15.5. Архитектура ODBC
Приложение инициирует запросы на создание соединения с источником
данных, на выполнение SQL-операторов и получение результатов, на обработку
ошибок и на начало, фиксацию и откат транзакций. ODBC предоставляет
стандартный способ для выполнения каждого из этих запросов и определяет
стандартный набор кодов ошибок и сообщений.
Диспетчер драйвера (driver manager) служит в качестве посредника между
приложениями и драйверами СУБД. Когда приложение запрашивает
соединение, драйвер определяет тип СУБД, которая обрабатывает заданный источник
данных ODBC, и загружает этот драйвер в память (если он еще не загружен).
Диспетчер драйвера также обрабатывает определенные запросы на
инициализацию и проверяет допустимость формата и порядка запросов к ODBC,
которые он получает от приложения. Диспетчер драйвера предоставляется Microsoft
и входит в состав Windows.
Драйвер (driver) обрабатывает запросы к ODBC и передает конкретные
SQL-операторы на выполнение заданному источнику данных. Для каждого типа
источника данных имеется свой драйвер. Например, есть драйверы для DB2,
Oracle, Access и всех других продуктов, производители которых решили
поддерживать стандарт ODBC. Драйверы поставляются производителями СУБД
и независимыми компаниями.
Драйвер отвечает за то, чтобы стандартные команды ODBC выполнялись
корректно. В некоторых случаях, если сам источник данных не соответствует
стандарту SQL, драйверу приходится выполнять значительную работу, чтобы
восполнить недостаток функциональности источника данных. В других
случаях, когда источник данных имеет полномасштабную поддержку SQL, драйвер
только передает запрос на обработку источнику данных. Драйвер также
преобразует коды ошибок источника данных и сообщения в стандартные коды и
сообщения ODBC.
ODBC определяет два типа драйверов: одноуровневые и многоуровневые. ОЭ-
ноуровпевый драйвер (single-tier driver) занимается как обработкой вызовов ODBC,
так и выполнением SQL-операторов. Пример одноуровневого драйвера
изображен на рис. 15.6, а. В этом примере данные хранятся в файлах Xbase (формат,
используемый FoxPro, dBase и другими продуктами). Поскольку диспетчеры
Стандарт ODBC 565
файлов Xbase не поддерживают SQL, преобразование SQL-запроса в команды
манипуляции файлами Xbase и обратное преобразование результатов в SQL
возлагается на драйвер.
Web-сервер
Компьютер
сервера данных
Приложение
Диспетчер
драйверов
Одноуровневый
драйвер
БД
Команды
файлового
ввода-вывода Данных
Web-сервер
Приложение
Диспетчер
драйверов
Драйвер
СУБД
Команды
SQL
СУБД
Компьютер сервера
базы данных
БД
Файлы базы
данных
Рис. 15.6. Типы драйверов ODBC: а — одноуровневый драйвер; б — многоуровневый драйвер
Многоуровневый драйвер (multi-tier driver) занимается только обработкой
вызовов ODBC, a SQL-запросы передает на выполнение серверу базы данных. Он
может переформатировать SQL-запрос, чтобы тот соответствовал диалекту
конкретного источника данных, но выполнение запроса не входит в его функции.
Пример использования многоуровневого драйвера показан на рис. 15.6, б.
Уровни соответствия
Перед создателями стандарта ODBC стояла дилемма. Если они зададут стандарт
на минимальный уровень совместимости, поддержать этот стандарт будут в
состоянии многие производители. Однако при этом стандарт будет представлять
только малую долю всей мощи и выразительности, которыми обладают ODBC
и SQL. С другой стороны, если стандарт будет предписывать очень высокий
уровень совместимости, то лишь немногие производители смогут поддерживать
его, а это лишит его ценности. Чтобы справиться с этой дилеммой, комитет по
разработке ODBC принял мудрое решение — определить уровни соответствия
стандарту. Уровни соответствия определяются по отношению к SQL и по
отношению к ODBC.
Уровень соответствия ODBC
Уровень соответствия ODBC (ODBC conformance level) описывает то, какие
возможности и функции доступны через интерфейс прикладных программ (API)
драйвера. Интерфейс прикладных программ драйвера — это набор функций,
566 Глава 15. ODBC, OLE DB, ADO и ASP
которые может вызывать приложение для обращения за услугами источника
данных. В списке приведено описание трех уровней соответствия ODBC,
описанных в стандарте. На практике почти все драйверы обеспечивают по крайней мере
первый уровень соответствия, поэтому базовый уровень не представляет особого
интереса.
Базовый уровень (Core API)
+ Соединение с источниками данных.
+ Подготовка и выполнение SQL-операторов.
+ Получение данных из набора результатов.
+ Фиксация или откат транзакций.
+ Получение информации об ошибках.
Первый уровень (Level 1 API)
+ Соответствие ODBC на базовом уровне.
+ Соединение с источниками данных, содержащих информацию,
специфичную для драйвера.
+ Отправка и прием частичных результатов.
♦ Получение информации из каталога.
+ Получение информации о параметрах, возможностях и функциях драйвера.
Второй уровень (Level 2 API)
+ Соответствие ODBC на базовом и первом уровнях.
+ Обзор возможных соединений и источников данных.
+ Получение «родной» формы SQL.
+ Вызов библиотеки преобразований.
+ Обработка двунаправленных курсоров.
Приложение может вызвать драйвер, чтобы определить, какой уровень
соответствия ODBC он предоставляет. Если приложение требует такого уровня
соответствия, который не обеспечивается драйвером, оно может корректно
прервать сеанс и выдать пользователю соответствующее сообщение. Можно
написать приложение так, чтобы оно использовало функции более высокого
уровня соответствия, если они доступны, а если нет, реализовывало их
самостоятельно.
Например, драйверы второго уровня должны предоставлять
двунаправленный курсор. Приложение можно запрограммировать так, чтобы оно
использовало курсоры, если они доступны, а если нет, реализовывало бы отсутствующую
функцию собственными средствами, используя предложения WHERE с сильными
ограничениями. Это гарантирует, что за один прием приложению будет
возвращаться лишь небольшое количество строк, которые будут обрабатываться с
помощью курсора, поддерживаемого самим приложением. Во втором случае
производительность, скорее всего, будет ниже, зато, по крайней мере, приложение
будет способно успешно выполнить задачу.
Стандарт ОРВр 567
Уровни соответствия SQL
Уровни соответствия SQL (SQL conformance levels) описывают то, какие SQL-
операторы, выражения и типы данных может обрабатывать драйвер. Как
показано в списке, определены три уровня соответствия. Возможности минимального
синтаксиса SQL весьма ограничены, и большинство драйверов поддерживают по
крайней мере базовый синтаксис.
Минимальный синтаксис (minimum SQL grammar)
♦ CREATE TABLE, DROP TABLE.
+ Простой оператор SELECT (без вложенных запросов).
♦ INSERT, UPDATE, DELETE.
♦ Простые выражения (А > В + С).
♦ Типы данных CHAR, VARCHAR, LONGCHAR.
Базовый синтаксис (core SQL grammar)
+ Минимальный синтаксис.
♦ ALTER TABLE, CREATE INDEX, DROP INDEX.
♦ CREATE VIEW, DROP VIEW.
♦ GRANT, REVOKE.
+ Полный синтаксис оператора SELECT (включая вложенные запросы).
♦ Встроенные функции: SUM, COUNT, MAX, MIN, AVG.
Расширенный синтаксис (extended SQL grammar)
+ Базовый синтаксис.
+ Внешние соединения.
♦ UPDATE и DELETE с использованием позиции курсора.
♦ Скалярные функции: SUBSTRING, ABS.
+ Переменные для даты, времени и временная метка.
+ Пакетная обработка SQL-операторов.
♦ Хранимые процедуры.
Как и в случае с уровнями соответствия ODBC, приложение может вызвать
драйвер, чтобы определить, какой уровень соответствия SQL он поддерживает.
Имея эту информацию, приложение может затем определить, какие
SQL-операторы можно передавать на выполнение драйверу. Если необходимо, приложение
может прервать сеанс или использовать альтернативные, менее мощные способы
получения данных.
Задание имени источника данных ODBC
Источник данных — это структура данных ODBC, идентифицирующая базу
данных, и СУБД, которая ее обрабатывает. Источники данных могут также
идентифицировать другие типы данных — электронные таблицы, другие хранилища
данных, не являющиеся базами данных, но нас они здесь не интересуют.
568 Глава 15. ODBC, OLE DB, ADO и ASP
Есть три типа источников данных: файловые, системные и пользовательские.
Файловый источник данных (file data source) — это файл, который может
совместно использоваться пользователями базы данных. Единственное требование
состоит в том, чтобы пользователи имели один и тот же драйвер ODBC и
одинаковый уровень доступа к базе данных. Файловый источник данных может
распространяться среди потенциальных пользователей посредством
электронной почты или другими способами. Системный источник данных (system data
source) — это источник данных, являющийся локальным для отдельного
компьютера. Системный источник данных может использовать операционная система
и любой пользователь этой системы (обладающий соответствующими
полномочиями). Пользовательский источник данных (user data source) доступен только
для того пользователя, который его создал.
Вообще говоря, для web-приложений наилучшим вариантом является
создание системного источника данных на web-сервере. Пользователи обращаются
к web-серверу посредством браузеров, а web-сервер через системный источник
данных устанавливает соединение с СУБД и базой данных.
На рис. 15.7 показан процесс создания системного источника данных с
помощью Администратора источников данных ODBC (ODBC Data Source Administrator
Service), который можно найти на Панели управления (Control Panel) Windows.
На рис. 15.7, а пользователь выбирает драйвер для базы данных Oracle. Обратите
внимание, что есть два таких драйвера: один предоставлен Microsoft, а другой —
Oracle. Эти драйверы могут иметь различные возможности, и пользователю
следует обратиться к документации на каждый из них, чтобы определить, какой из
них лучше подходит для его приложения. На рисунке показаны также драйверы
для Paradox, текстовых файлов и Visual FoxPro.
На рис. 15.7, б пользователь выбирает базу данных. В данном случае это
VR1 — база данных Oracle, созданная в главе 12. Источник данных для работы
с этой базой назван ViewRidgeOracle. Мы будем использовать его далее в этой
главе. Кроме того, мы будем использовать файловый источник данных под
названием ViewRidgeSS для работы с базой данных SQL Server, созданной в главе 13.
OLE DB
OLE DB — это то, на чем основывается доступ к данным в мире Microsoft. В связи
с этим важно понять фундаментальные идеи OLE DB, даже если вы будете
работать только с ADO-интерфейсами, занимающими более высокий уровень. В этом
разделе мы изложим основные принципы работы OLE DB.
OLE DB является реализацией разработанного Microsoft объектного стандарта
OLE. OLE-объекты являются СОМ-объектами и поддерживают все требуемые
для таких объектов интерфейсы. В сущности, OLE DB разбивает всю
совокупность возможностей и функций СУБД на отдельные фрагменты — СОМ-объек-
ты с узкой специализацией. Одни объекты выполняют запросы, другие
производят обновления, третьи создают структурные элементы базы данных — таблицы,
индексы и представления, четвертые занимаются управлением транзакциями —
например, устанавливают оптимистическую блокировку.
OLE DB 569
«Ш1ШШШШ1ШШШ
ШтШ Sjetern 0S*rf ffed§N f Omm f Tracing | Cewecfon Poofi>g j About J ''
^9PoU^SoMr«««
ШНШШШ
Naroe
| Privet
ElCQCMdtffc Mcrosdf Access Driver (* mdb)
LocalS er ver S Q L S er ver
ViewRidgeAccess Microsoft Access Driver (" mob)
ViewRidgeDSN Driver do Microsoft Access (Vmdb)
ViewRidgeOracle Oracle ODBC Dover
ViewRidgeSS SQL Server
An 0ШС System data source «wwiflfamj
*hefofea*ed data provider, ASjfctenxfefca
<kp» th* firachhe, hcbdirts fcf T ««vice*/ ..
. • . , V-/ </.'
it- —
OK
Cancel, j
Sefect a «fewer *qr *Фн?Ь you v*ar* to $e1 up 2 rfafta a
двии
ДЯ^^
PlIIPJ™' ' 1 {Ни;;;
ГГ"""11*ш**4 jHU;*?
I L*^P^Y?U Hv:: й
I E^J^*^..l ЩШ11
1 Liil^j • ^B:o- ?
ШШ
***** _.._
Microsoft ODBC (or Oiacle
Microsoft Paradox Driver (' db)
Microsoft Paiadox-Treiber (" db ]
Microsoft Text Driver (* Ы1; H.csv)
Microsoft Text-Treiber (Mxt; ■ csv]
Microsoft Visual FoxPio Driver
Microsoft Visual FoxPro-Treibei
Ощ^ШЩЩш
SQLServer
. fvif
2.
4
4
4
4.
6-i '
Bll
B. •
2f—<
Finish
tanaei
Oracle» 0ШШЩ5Ш
Qata Source Name ViewRidgeOracle
л Data Source to the Oracle DatabaseVR1
- Oat«.SourGetV
UssrtD:
^•'•;-v;-^jf
СопгаЫ to database^ Read офгор<&::; Т*
PiWe^Cotlttjt;:'; :..':;;;-'::::В "8^:[lF
• Appfeab6ttOp*fora7::f:f^ '
Enable. F $0^. .f/:\ ^.^.C6unfe}l0
W^rotwcj Options
TraniteiSo«tJption«"
Ш
:^M
Рис. 15.7. Создание системного источника данных: а — выбор драйвера;
б — выбор базы данных
Это свойство OLE DB позволяет преодолеть крупный недостаток ODBC.
Чтобы продукт мог считаться соответствующим стандарту ODBC,
производитель должен создать драйвер почти для всех функций СУБД. Это сложная
задача, требующая значительных начальных вложений. Используя же OLE DB,
производитель СУБД может реализовывать их функции в продукте частями.
Можно, к примеру, реализовать только обработчик запросов, создать для него
570 Глава 15. ODBC, OLE DB, ADO и ASP
интерфейс OLE DB, и в результате продукт будет доступен для клиентов,
использующих ADO. Позже производитель может добавить другие объекты и
интерфейсы OLE DB, расширяющие функциональность продукта.
Поскольку данная книга не подразумевает знакомства читателей с объектно-
ориентированным программированием, то прежде чем двигаться дальше, нам
следует определить некоторые понятия. В частности, это понятия абстракции,
метода, свойства и коллекции. Абстракция (abstraction) — это обобщение чего-то.
Интерфейсы ODBC являются обобщениями «родных» методов доступа к СУБД.
Когда мы создаем абстракцию чего-либо, мы теряем детали, но получаем
возможность работать с более широким диапазоном типов.
Например, набор записей (recordset) является абстракцией отношения. В данной
абстракции набор записей определен как объект, имеющий ряд характеристик,
которые присущи всем отношениям. Например, каждый набор записей содержит
множество столбцов, которые в абстракции называются полями. Назначение
абстракции состоит в том, чтобы передать все существенные черты и отбросить
детали, не представляющие важности для тех, кто пользуется этой абстракцией. Так,
отношения в Oracle могут иметь некоторое свойство, которым не обладает набор
записей; то же самое может быть справедливо и для отношений в SQL Server,
AS/400, DB2 и других СУБД. Эти уникальные характеристики будут потеряны
в абстракции, но если абстракция является удачной, никто не будет возражать.
Теперь переместимся на один уровень вверх. Набор строк (rowset) является
в OLE DB абстракцией набора записей. Зачем же понадобилось в OLE DB
определять еще одну абстракцию? Дело в том, что OLE DB обращается к источникам
данных, которые не являются таблицами, но имеют некоторые из характеристик,
присущих таблицам. Рассмотрим совокупность всех адресов электронной почты,
содержащихся в вашей адресной книге. Можно ли назвать эту совокупность
отношением? Нет, но у нее есть определенные характеристики, свойственные
отношениям. Каждый адрес электронной почты представляет собой
семантически взаимосвязанную группу элементов данных. Подобно строкам таблицы, они
упорядочены: есть первый адрес, второй, третий и т. д. Но в отличие от строк
отношения, они не принадлежат к одному и тому же типу. Некоторые из них
являются адресами людей, а некоторые — адресами списков рассылки. Таким
образом, ни одно действие с набором записей, критичное к тому, чтобы все
элементы набора имели одинаковый тип, не может быть выполнено на наборе строк.
Двигаясь от общего к частному, OLE DB определяет набор свойств и признаков
набора строк. Более того, OLE DB определяет набор записей как подтип набора
строк. Наборы записей обладают всеми свойствами и признаками,
свойственными наборам строк, плюс еще некоторыми характеристиками, которые яиляются
уникальными для наборов записей.
Абстракции распространены и весьма полезны. Вы можете услышать об
абстракциях управления транзакциями, абстракциях запросов, абстракциях
интерфейсов. Это просто означает, что некоторые характеристики набора вещей
определены формально как тип.
Объект в объектно-ориентированном программировании — это абстракция,
определяемая своими свойствами и методами. Например, объект,
представляющий набор строк, имеет свойство AUowEdit, свойство RecordsetType и свойство EOF.
OLE DB 571
Эти свойства (properties) представляют характеристики абстракции набора
записей. Объект характеризуется также действиями, которые он способен
выполнять. Эти действия называются методами (methods). Набор записей имеет такие
методы, как Open, MoveFirst, MoveNext и Close.
Строго говоря, определение абстракции объекта называется объектным
классом (object class), или просто классом. Объектом же называется экземпляр
объектного класса, например конкретный набор записей. Все объекты одного класса
имеют одни и те же методы и свойства, но значения этих свойств различны у
разных объектов.
Остался последний термин, которому предстоит дать определение, а именно
коллекция. Коллекция (collection) — это объект, содержащий группу других
объектов. К примеру, набор записей содержит группу объектов, называемых полями
(fields). Коллекция имеет свойства и методы. Одно из свойств всех коллекций
называется Count. Это свойство описывает количество объектов в коллекции.
Так, recordset.Fields.Count представляет количество полей в коллекции. В ADO
и OLE DB имена коллекций образуются как форма множественного числа от
имен объектов, в них содержащихся. Например, имеется коллекция Fields,
состоящая из объектов Field, коллекция Errors, состоящая из объектов Error, коллекция
Parameters, состоящая из объектов Parameter, и т. д. Важным методом коллекций
является метод iterator, который осуществляет перебор элементов коллекции или
идентифицирует их каким-либо иным образом.
Если вас испугали определения, не отчаивайтесь. Практическое
использование этих понятий вы увидите в конце этой главы.
Цели создания OLE DB
Основные цели, преследовавшиеся при создании OLE DB, перечислены в списке.
Во-первых, как уже говорилось, OLE DB разбивает функциональность СУБД на
объектные кусочки. Это разделение обеспечивает большую гибкость как для
потребителей данных (data consumers) — пользователей функциональности OLE DB,
так и для поставщиков данных (data providers) — производителей продуктов,
которые предоставляют доступ к функциональности OLE DB. Потребители данных
имеют дело только с теми объектами и функциями, которые им нужны;
мобильное устройство для чтения базы данных может иметь весьма малые габариты.
В отличие от случая с ODBC, поставщикам данных требуется реализовать только
некоторый фрагмент функциональности СУБД. Это разделение означает также,
что поставщики данных могут предоставлять доступ к возможностям и
функциям СУБД через множество различных интерфейсов.
1. Создание объектных интерфейсов для элементов функциональности СУБД —
запрос, обновление, управление транзакциями.
2. Увеличение гибкости:
♦ дать потребителям данных возможность использовать только те
объекты, которые им нужны;
♦ дать поставщикам данных возможность открывать доступ к элементам
функциональности СУБД;
572 Глава 15. ODBC, OLE DB, ADO и ASP
♦ обеспечить возможность доступа к функциональности с помощью
множества различных интерфейсов;
♦ сделать эти интерфейсы стандартизированными и расширяемыми.
3. Создание объектных интерфейсов для любых типов данных: реляционных
баз данных (через ODBC или собственные интерфейсы СУБД),
нереляционных баз данных, систем обработки файлов (VSAM и др.), электронной
почты и многого другого.
4. Реализация такой стратегии, при которой данные не должны
преобразовываться в другие форматы или перемещаться из того места, где они
находятся.
Последнее утверждение требует пояснений. Объектный интерфейс
представляет собой как бы упакованный набор объектов. Интерфейс (interface ) — это
набор объектов плюс свойства и методы, доступ к которым они предоставляют.
Объект не обязан открывать в интерфейсе все свои свойства и методы. Так, в
интерфейсе запроса набор записей будет поддерживать только чтение, а в
интерфейсе обновления — создание, обновление и удаление.
То, как объект поддерживает интерфейс, называется реализацией
(implementation) интерфейса. Реализация полностью скрыта от пользователя. Фактически,
разработчики объекта вольны менять ее, когда захотят. Однако если им
вздумается изменить интерфейс, то заслуженное презрение со стороны пользователей
будет им обеспечено!
OLE DB определяет стандартизированные интерфейсы. Однако поставщики
данных свободны в том, чтобы добавлять интерфейсы в дополнение к базовым
стандартам. Такая расширяемость имеет первостепенное значение для
достижения следующей цели — предоставить объектный интерфейс для любых типов
данных. Реляционные базы данных могут обрабатываться с помощью объектов
OLE DB, использующих ODBC или собственные драйверы СУБД. В OLE DB
предусмотрена поддержка и других типов данных, как указано выше.
Побочным следствием этих целевых установок является то, что данные не
нужно ни преобразовывать из одного формата в другой, ни перемещать из
одного источника данных в другой. Web-сервер на рис. 15.1 может использовать
OLE DB для обработки данных в любом из форматов прямо в том месте, где эти
данные находятся. Это означает, что транзакции могут затрагивать
множество источников данных и быть распределенными по различным компьютерам.
Для этого в OLE DB предусмотрено средство под названием MTS (Microsoft
Transaction Server, сервер транзакций Microsoft), но его обсуждение выходит за
рамки данной книги.
Основные конструкции OLE DB
Как показывает следующий список, в OLE DB имеется два типа поставщиков
услуг. Поставщики табличных данных (table data providers) представляют свои
данные через наборы строк. Примерами являются СУБД, электронные таблицы
и обработчики файлов ISAM, подобные dBase и FoxPro. Кроме того, в виде набо-
OLE DB 573
ров строк могут быть представлены и другие типы данных, например сообщения
электронной почты. Поставщики табличных данных приносят данные
определенного типа в мир OLE DB.
+ Поставщик табличных данных
♦ Предоставляет доступ к данным через наборы строк.
♦ Примеры: СУБД, электронные таблицы, системы ISAM, электронная
почта.
♦ Поставщик услуг
♦ Не имеет своих данных.
♦ Преобразует данные с помощью интерфейсов OLE DB.
♦ Является одновременно и потребителем, и поставщиком данных.
♦ Примеры: обработчик запросов, генератор XML-документов.
Поставщик услуг (service provider) занимается преобразованием данных.
Поставщики услуг принимают данные OLE DB от поставщика табличных данных
и некоторым образом их преобразуют. Поставщики услуг являются и
потребителями данных (исходных), и поставщиками данных (преобразованных). В
качестве примера поставщика услуг можно привести службу, которая получает данные
от реляционной СУБД и преобразует их в XML-документы.
Объект, называемый набором строк (rowset), играет фундаментальную роль
в OLE DB: набор строк эквивалентен тому, что мы называли курсором в главе 11,
и эти два термина фактически синонимичны. В списке перечислены основные
интерфейсы, поддерживаемые набором строк. Интерфейс IRowSet предоставляет
методы для последовательного передвижения по набору строк только в прямом
направлении. Когда вы объявляете последовательный курсор в OLE DB, вы
вызываете интерфейс IRowSet. Интерфейс IAccessor используется для связывания
программных переменных с полями набора строк. При использовании ADO этот
интерфейс в значительной степени скрыт, потому что он используется
сценарным ядром в своей работе. Но если вы работаете с библиотеками типов в VB, вы
можете использовать методы этого интерфейса.
♦ IRowSet
Методы для последовательного перебора строк.
+ IAccessor
Методы для установления связей между набором строк и переменными
программы-клиента.
♦ IColumnsInfo
Методы для получения информации о столбцах набора строк.
+ Прочие интерфейсы
Двунаправленные курсоры.
Создание, обновление и удаление строк.
Прямой доступ к конкретным строкам (закладки).
Явные блокировки.
И так далее...
574 Глава 15. ODBC, OLE DB, ADO и ASP
Интерфейс IColumnsInfo имеет методы для получения информации о столбцах
набора строк. Мы будем использовать этот интерфейс в двух примерах
применения ADO в конце этой главы. IRowSet, IAccessor и IColumnsInfo являются
базовыми интерфейсами набора строк. Другие интерфейсы предназначены для более
сложных операций — манипуляций с двунаправленными курсорами,
обновления, прямого доступа к конкретным строкам, явных блокировок и многого
другого.
Рассмотрим зти интерфейсы в контексте двух наборов строк — один из них
взят из обычного отношения, а другой содержит коллекцию адресов
электронной почты. Первые три интерфейса могут быть непосредственно использованы
с обоими наборами строк. Функции и возможности последних трех
интерфейсов, скорее всего, будут различаться для этих двух наборов, а некоторые из них
могут быть вообще не определены для какого-то из наборов. Последнее
замечание: наборы строк могут содержать указатели на объекты, так что с их помощью
можно создавать весьма сложные структуры.
ADO
ADO (Active Data Objects) — зто простая объектная модель, которую могут
использовать потребители данных для обработки любых данных OLE DB. К ней
можно обращаться из сценарных языков, таких как JScript и VBScript, а также из
Visual Basic, Java, С# и C++. Microsoft постановила, что ADO заменит все
остальные методы доступа к данным, поэтому изучение этой технологии важно не
только для приложений баз данных, применяющих интернет-технологии, но и для
любых приложений, использующих для работы с данными продукты Microsoft.
Благодаря абстракциям OLE DB и объектной структуре объектная модель
ADO и ее интерфейсы остаются одними и теми же независимо от типа
обрабатываемых данных. Таким образом, разработчик, изучающий ADO в применении
к обработке реляционных баз данных, сможет использовать эти знания и для
обработки папки с сообщениями электронной почты. Характеристики ADO
перечислены в следующем списке.
+ Простая объектная модель для потребителей данных OLE DB.
♦ Может использоваться из VBScript, JScript, Visual Basic, Java, C#, C++.
+ Единый стандарт Microsoft для доступа к данным.
+ Объекты доступа к данным остаются одними и теми же для всех типов
данных OLE DB.
Вызов ADO из ASP-страниц
В этой главе мы будем вызывать ADO на web-сервере, используя ASP-страни-
цы. Такие страницы содержат смесь DHTML (или XML) и программных
конструкций на языках VBScript или JavaScript. В этой главе мы будем использо-
ADO 575
вать VBScript. ASP-страницы можно писать в любом текстовом редакторе, но
легче их писать в редакторе FrontPage и подобных ему продуктах для создания
web-страниц.
IIS (Internet Information Server, информационный сервер Интернета) —
это web-сервер, встроенный в операционные системы Windows 2000 Professional
и Windows NT. Как уже говорилось в главе 14, ASP является ISAPI-расшире-
нием IIS. С практической точки зрения зто означает, что всякий раз, когда IIS
получает файл с расширением .asp, она посылает этот файл программе ASP для
обработки.
Все операторы языков программирования, заключенные между символами
<% и %>, будут обрабатываться на компьютере web-сервера. Остальные
операторы будут переданы на выполнение браузеру пользователя. Весь код, который мы
будем писать в этой главе, будет обрабатываться на web-сервере.
Для вызова ASP-страниц поместите их в какую-нибудь папку, например
C:\MyDirectory. Затем откройте IIS и создайте виртуальную папку, указывающую
на ту папку, в которую вы поместили ваши ASP-страницы. Это можно сделать,
щелкнув правой кнопкой мыши на значке Default Web Site (Сайт по умолчанию)
в окне Internet Information Server. Выберите команду New ► Virtual Directory
(Создать ► Виртуальная папка), в результате чего запустится мастер, который
предложит вам дать имя виртуальной папке и указать реальную папку (здесь
C:\MyDirectory), в которой будут находиться ваши ASP-страницы. На третьей
панели мастера выберите Read (Чтение) и Run Scripts (Выполнять сценарии). Для
примеров в этой главе мы будем использовать виртуальную папку с именем
ViewRidgeExamplel.
Нет необходимости в том, чтобы СУБД и web-сервер находились на одной и той
же машине. Когда вы задаете имя источника данных ODBC, вы можете выбрать
базу данных, которая находится на другом компьютере и доступна с компьютера
web-сервера. Это будет проще, если другой компьютер работает под
управлением Windows, но можно сделать зто и для других операционных систем. Ничто,
разумеется, не запрещает web-серверу и СУБД находиться на одной машине.
Объектная модель ADO
Объектная модель ADO, показанная на рис. 15.8, является надстройкой к
объектной модели OLE DB. Соединение (объект Connection) — зто первый объект ADO,
который необходимо создать и который является основой для всех остальных. Из
соединения разработчик может создать один или несколько наборов записей
(объект RecordSet) и одну или несколько команд (объект Command). Все ошибки,
которые генерируются в процессе создания любого из этих объектов и работы
с ним, ADO будет помещать в специальную коллекцию Errors.
Каждый объект RecordSet имеет коллекцию полей (Fields); каждое поле
(объект Field) в этой коллекции соответствует столбцу в наборе записей. Кроме того,
каждая команда имеет коллекцию параметров (Parameters), элементы которой
представляют переданные команде параметры.
576 Глава 15. ODBC, OLE DB, ADO и ASP
Connection
□ Объект
Record Set
|Ц Коллекция
!!1111Ш1ЙИ|!Й-:=
Command
Field
ЩЩЩШШЩМ"№
mmi&rormm
Parameter
error
Рис. 15.8. Объектная модель ADO
Объект Connection
Следующие операторы VBScript, запущенные из web-страницы, создают
объект-соединение Connection. После их выполнения переменная objConn будет указывать
на объект, связанный с источником данных ODBC под названием ViewRidgeSS:
<%
Di objConn
Set objConn = Server.CreateObject CADODB.Connection")
objConn.IsolationLevel = adXactReadCommitted * используем ADOVBS
objConn.Open "ViewRidgeSS". "sa" ' открываем соединение
%>
В этом фрагменте кода оператор Server.CreateObject вызывает метод CreateObject
ASP-объекта Server. Тип объекта, здесь ADODB.Connection, передается в качестве
параметра. После выполнения этого оператора переменная objConn указывает на
новый объект Connection. Далее для этого соединения устанавливается уровень
изоляции с помощью константы из файла ADOVBS. Данный файл можно сделать
доступным для сценария с помощью следующего оператора:
<!--#include virtual = "ViewRidgeExamplel/ADOVBS.inc-->"
Этот оператор должен быть в ASP-файле, но вне скобок <%...%>. Чтобы он
сработал, вы должны скопировать файл ADOVBS.inc в свой каталог (найдите файл
с помощью команды Search (Найти) в главном меню Windows). Также следует
поменять имя виртуальной папки, если оно у вас отличается от ViewRidgeExamplel.
Имена и значения важных констант ADOVBS перечислены в табл. 15.1.
Использование имен констант вместо их значений делает ваш код более
удобочитаемым. Это также облегчает адаптацию кода, если Microsoft вдруг изменит смысл
этих значений (что маловероятно, но все-таки возможно).
ADO 577
Таблица 15.1. Константы ADO
Уровень изоляции
«Грязное» чтение
Завершенное чтение
Воспроизводимое чтение
Сериализуемость
Тип курсора
Последовательный
Ключевой
Динамический
Статический
Тип блокировки
Имя константы
adXactReadUncomnnitted
adXactReadConnnnitted
adXactRepeatabieRead
adXactSerializable
Имя константы
adOpenForwardOnly
adOpenKeyset
adOpenDynamic
adOpenStatic
Имя константы
Значение
256
4096
65536
1048576
Значение
0
1
2
3
Значение
Только чтение adLockReadOnly 1
Пессимистическая блокировка adLockPessimistic 2
Оптимистическая блокировка adLockOptimistic 3
Оптимистическая блокировка ad Batch Optimistic 4
с массовыми обновлениями
Последний оператор открывает источник данных ODBC, вызывая метод Open
объекта Connection. Ему в качестве параметра передается имя пользователя sa.
Если бы требовался пароль, он был бы следующим параметром. Понятно, что
безопасность здесь никудышная, хотя все не так плохо, как кажется на первый
взгляд, поскольку код будет выполняться на web-сервере и никогда не будет
пересылаться по сети. Тем не менее, лучше было бы запрашивать имя
пользователя и пароль непосредственно на этапе выполнения. Этот вопрос, однако, не
связан напрямую с обработкой баз данных, и мы не будем углубляться в его
обсуждение.
Итак, мы установили соединение с СУБД через источник данных ODBC, и база
данных открыта. С помощью указателя objConn можно обращаться ко всем
остальным методам объекта Connection (см. рис. 15.8), включая методы создания и
использования объектов RecordSet и Command. Кроме того, через этот указатель
можно работать с коллекцией Errors.
Объект RecordSet
Имея соединение с открытой базой данных, создадим объект RecordSet (здесь и далее
символы <% и %> будут опускаться, но все приведенные ниже примеры должны
помещаться между ними, иначе код не будет выполняться на web-сервере):
Dim objRecord, varSql
varSQL = "SELECT * FROM ARTIST"
Set objRecordSet - Server.CreateObject CADODB.RecordSet")
objRecordSet.CursorType = adOpenStatic
objRecordSet.LockType = adLockReadOnly
objRecordSet.Open varSql, objConn
578 Глава 15. ODBC, OLE DB, ADO и ASP
Тип курсора (свойство CursorType) и тип блокировки (свойство LockType)
могут также передаваться в качестве параметров методу open, как показано здесь:
Dim objRecord, varSql
varSQL = "SELECT * FROM ARTIST"
Set objRecordSet - Server.CreateObject ("ADODB.RecordSet")
objRecordSet.Open varSql. objConn. adOpenStatic. adLockReadOnly
Так или иначе, эти операторы приводят к выполнению SQL-оператора,
записанного в переменной varSql, с использованием курсора, являющегося
статическим и предназначенного только для чтения. Все столбцы таблицы ARTIST будут
представлены полями в наборе записей. Если бы в операторе SELECT были
указаны только два столбца, например SELECT ArtistID, Nationality FROM ARTIST, тогда
только эти два столбца были бы включены в качестве полей в набор записей.
Между прочим, в SQL Server, если имя таблицы имеет пробелы или другие
необычные символы либо является зарезервированным словом SQL, оно
заключается в квадратные скобки. Однако Oracle не воспринимает имена таблиц в
квадратных скобках: вместо этого нестандартные имена следует заключать в
кавычки. Таким образом, если в вашей базе данных есть такие таблицы, вам придется
писать различный код в зависимости от того, чью базу данных вы используете —
Oracle или SQL Server.
Коллекция Fields
При создании набора записей создается экземпляр коллекции Fields. Работать с этой
коллекцией позволяет следующий код:
Dim varl. varNumCols, objField
varNumCols = objRecordSet.Fields.Count
For varl = 0 to varNumCols - 1
Set objField = objRecordSet.Fields(varl)
4 теперь objField.Name содержит имя поля.
' a objField.Value содержит его значение
' здесь можно выполнять с ними некоторые действия
Next
Во втором операторе в переменную varNumCols записывается количество
столбцов в наборе записей, для чего считывается значение свойства Count коллекции
Fields. Затем идет цикл, в котором перебираются элементы коллекции. Свойство
Fields(O) указывает на первый столбец набора строк, поэтому переменная цикла
пробегает значения от 0 до Count -1.
С самим объектами-полями в этом примере никаких действий не
производится. В реальном приложении имя поля можно определить с помощью свойства
objField.Name, а значение поля — с помощью свойства objField.Value. В следующих
примерах вы увидите, как это делается.
Коллекция Errors
Всякий раз, когда происходит ошибка, ADO создает экземпляр коллекции Errors.
Это должна быть именно коллекция, поскольку один оператор ADO может вы-
ADO 579
звать несколько ошибок. Эту коллекцию можно обрабатывать тем же способом,
что и коллекции Fields:
Dim varl, varErrorCount. objError
On Error Resume Next
varErrorCount = objConn.Errors.Count
If varErrorCount > 0 Then
For varl = 0 to varNumCols - 1
Set objError = objConn.Errors(varl)
теперь objError.Description содержит
описание ошибки
Next
End If
В цикле объектному указателю objError присваиваются значения objConn.
Errors(varl). Обратите внимание, что эта коллекция принадлежит соединению
(objConn), а не набору записей (objRecordSet). Свойство Description объекта Error
можно использовать для возвращения пользователю сообщения об ошибке.
К сожалению, VBScript имеет очень ограниченные возможности для
обработки ошибок. Код проверки ошибок (начинающийся с On Error Resume Next)
необходимо помещать после каждого оператора ADO, который может вызвать ошибку.
Так как это может вызвать нежелательное увеличение объема кода, лучше было
бы написать функцию обработки ошибок и вызывать ее после каждого вызова
объекта ADO.
Объект Command
ADO-объект Command используется для запуска запросов и хранимых процедур,
находящихся в базе данных. Коллекция Parameters объекта Command
предназначена для передачи параметров. Предположим, например, что в базе данных,
соединение с которой мы установили в objConn, имеется хранимая процедура FindArtist,
принимающая один параметр — национальность художников, данные о
которых нужно предоставить. Следующий код вызывает эту процедуру с параметром
«Spanish» и создает набор записей objRs, в который помещаются результаты ее
выполнения:
Dim objCommand. objParam. objRs
' Создаем объект Command, соединяем его с objConn и задаем его формат
Set objCommand - Server.CreateobjectC'ADODB.command")
Set objCommand.ActiveConnection = objConn
objCommand.CommandText - "{call FindArtist (?)}"
задаем значение параметра
Set objParam- objCommand.CreateParameter ("Nationality", adChar, adParamlnput. 25)
objCommand.parameters.Apend objParam
580 Глава 15, ODBC, OLE DB, ADO и ASP
objParam.Value = "Spanish"
' запускаем хранимую процедуру
Set objRs = objCommand.Execute
В этом примере сначала создается объект типа ADODB.command, затем для него
указывается активное соединение — objConn. Далее в сбойстве CommandText
задается формат вызова хранимой процедуры. Это свойство используется для
указания имени хранимой процедуры и количества ее параметров. Параметр
обозначается знаком вопроса. Если бы было три параметра, текст команды был
бы {call FindArtist (?,?,?}.
Далее создается объект Parameter. Константы adChar и adParamlnput взяты из
ADOVBS и указывают на то, что параметр имеет тип char и что он является для
процедуры входным. Максимальная длина параметра установлена равной 25
символам. Создав параметр, его необходимо присоединить к команде, для чего
служит метод Append. Наконец, с помощью метода Execute происходит вызов
хранимой процедуры. Итак, мы создали набор записей objRs, содержащий результаты
выполнения хранимой процедуры.
Примеры использования ADO
Следующие пять примеров показывают, как вызывать ADO из VBScript с
помощью ASP. Упор в них делается на использование ADO, а не на график, внешний
вид или последовательность действий. Если вы хотите, чтобы ваше приложение
выглядело и вело себя лучше, вы должны быть способны соответствующим
образом модифицировать эти примеры. Сейчас вам следует просто научиться
использовать ADO.
Все эти примеры работают с базой данных View Ridge. В некоторых из них
мы соединяемся с источником данных ViewRidgeSS — базой данных SQL Server,
в других мы используем ViewRidgeOracle — базу данных Oracle. В последнем
примере требуется изменить всего один оператор, чтобы переключиться с SQL Server
на Oracle! Это удивительно, и это как раз то, на что надеялись разработчики
спецификации ODBC.
Как вы знаете из предыдущей главы, протокол HTTP не имеет состояния.
ASP-процессор, тем не менее, будет поддерживать состояние транзакции. Для
каждой транзакции он хранит набор сеансовых переменных. В этих примерах
мы будем использовать сеансовые переменные для сохранения соединений.
Оператор
Set SessionCabc") = "Wowzers"
создает сеансовую переменную с именем «abc» и присваивает ей строковое
значение «Wowzers». Более осмысленные примеры последуют далее.
Чтобы запустить любую из этих ASP-страниц, откройте браузер и введите
http://local host/ViewRidgeExamplel/^J)a^a. asp
Примеры использования ADO 581
Здесь имя_файла — это имя ASP-страницы. Если вы запускаете ASP-страницу
не с того компьютера, где работает IIS, а с какого-то другого, вместо «localhost»
следует ввести адрес вашего сервера.
Пример 1 — чтение таблицы
В листинге 15.1 показана ASP-страница, которая отображает содержимое
таблицы ARTIST.
Листинг 15.1. Artist.asp
<HTML>
<HEAD>
<МЕТА HTTP-EQUIV="Content-Type" CDNTENT="text/html ;charset=windows-1252">
<TlTLE>Artist</TlTLE>
</HEAD>
<!--#include vi rtual="ViewRidgeExamplel/adovbs.inc"-->
<B0DY>
<%
Dim objConn. objRecordSet. varSql
If I$Object(Session("_conn")) Then 'если соединение уже установлено.
' используем его
Set objConn - Session("_conn")
Else
Set objConn = Server.CreateObjectCADODB.connection")
' устанавливаем соединение
objConn.open "ViewRidgeSS", "sa" ' открываем файл ODBC SQL Server
' как пользователь sa, без пароля
objConn. IsolationLevel = adXactReadCommitted ' избегаем «грязного»
' чтения
Set Session("_conn") = objConn
End If
Set objRecordSet=Server.CreateObjectCADODB.Recordset") "создаем объект
' recordset
varSql = "SELECT ArtistName. Nationality FROM ARTIST" 'настраиваем
' SQL-команду
objRecordSet.Open varSql. objConn. adOpenStatic, adLockReadOnly
'курсор статический, обновление не требуется
<TABLE B0RDER= 1 BGC0L0R=#ffffff CELLSPACING=5><F0NT FACE="Arial"
COLOR=#000000><CAPTION><B>ARTIST</B></CAPTION></FONT>
<THEAD>
<TR>
продолжение &
582 Глава 15. ODBC, OLE DB, ADO и ASP
Листинг 15.1 {продолжение)
<TH BGCOLOR=#c0c0c0 BORDERCOLOR-#000000><FONT SIZE=2 FACE="Arial"
COLOR=#000000>Name</FONT></TH>
<TH BGCOLOR=#c0c0c0 BORDERCOLOR=#000000 ><F0NT SIZE=2 FACE="Arial"
COLOR=#W00000>Nati onali ty</F0NT></TH>
</TR>
</THEAD>
<TB0DY>
<%
On Error Resume Next
objRecordSet.MoveFirst
do while Not objRecordSet.eof
%>
<TR VALIGN=TOP>
<T0 BORDERCOLOR=#c0c0c0 ><F0NT SIZE=2 FACE="Arial"
COLOR=#000000><^=Server.HTMLEncode(objRecordSet(MArtistName"))^><BR></FONT></TD>
<TD BORDERCOLOR=#c0c0c0><FONT SIZE=2 FACE="Arial"
COLOR=#000000><^=Server.HTMLEncode(objRecordSet("Nationality"))^><BR></FONT></TD)
>
</TR>
<%
End If
Next*>
<TR>
obj Reco rdSet.MoveNext
loop*>
</TB0DY>
<TF00T></TF00T>
</TABLE>
</B0DY>
</HTML>
Начинается страница со стандартного HTML. Первый раздел серверного
кода создает объект Connection, а затем объект RecordSet, содержащий результаты
выполнения следующего SQL-оператора:
SELECTArtistName. Nationality
FROMARTIST
Поскольку соединения используют большое количество ресурсов, как в
смысле времени, требуемого на их создание, так и в смысле количества потребляемой
ими памяти, объект Connection в этом примере сохраняется в сеансовой
переменной _сопп. В первый раз, когда пользователь вызовет ASP-страницу, соедине-
Примеры использования ADO 583
ние еще не будет существовать. В этом случае результатом вызова функции
IsObject("_conn") будет значение false, так как переменная _сопп еще не указывает
ни на какой объект. Код, следующий за оператором Else, создает объект Connection.
Далее создается объект RecordSet для оператора SELECT в переменной varSql.
Следующий раздел ASP-страницы содержит HTML-код, предназначенный
для браузера. За ним следует несколько фрагментов серверного сценарного кода,
перемешанного с HTML. Оператор On Error Resume Next отменяет обработку
ошибок сценарным ядром ASP, предписывая продолжать выполнение сценария.
Хорошая ASP-страница в этом случае обеспечила бы обработку ошибок.
Последняя часть страницы просто создает HTML-код и вставляет в него
полученные значения. Цикл objRecordSet.MoveFirst...MoveNext представляет
стандартную логику последовательной обработки файла.
Результат выполнения этой ASP-страницы показан на рис. 15.9. В этой
странице и в породившем ее ASP-файле нет ничего впечатляющего, за исключением
следующего обстоятельства: если бы эта страница находилась в Интернете, ее
могли бы видеть более 250 миллионов человек во всем мире! При этом им не
понадобилось бы никакого программного обеспечения, кроме того, что уже
установлено на их компьютерах.
•| : ;Miro Spanish
|j • ;Kandinsky Russian
i| ; prings US
I ; jKlee German
| JDavid Moos л US
if -MarkTobey HjS
j| :Henri Matisse' French ;
Рис. 15.9. Результат выполнения ASP-страницы Artist.asp
584 Глава 15. ODBC, OLE DB, ADO и ASP
Пример 2 — чтение таблицы обобщенным
способом
В первом примере объекты, составляющие объектную модель ADO,
использовались по минимуму. Мы можем расширить этот пример за счет использования
коллекции Fields. Предположим, мы хотим задавать имя таблицы в качестве
параметра, а на выходе получать содержимое всех столбцов этой таблицы, за
исключением суррогатного ключа.
ASP-страница, показанная в листинге 15.2, выполнит эту задачу, с той
оговоркой, что имя таблицы будет задаваться в переменной varTableName. В следующем
примере будет показано, как организовать ввод имени таблицы с использованием
средств обработки форм HTML.
Листинг 15.2, CustomerOracle.asp
<HTML>
<HEAD>
<МЕТА HTTP-EQUIV="Content-Type" CONTENT="text/html;charset=windows-1252">
<TITLE>Table Display Page</TITLE>
</HEAD>
<B0DY>
<!--#include virtual="ViewRidgeExamplei/adovbs.inc"-->
<%
Dim objConn. objRecordSet, objField
Dim varNumCols, varl, varSql
Dim varTableName. varKeyName
varTablename = "CUSTOMER"
varKeyName = "CUSTOMERID"
If IsObject(Session("_conn")) Then ' если соединение уже установлено.
' используем его
Set objConn = Session("_conn")
Else
Set objConn = Server.CreateObjectCADODB.connection") ' устанавливаем
' соединение
'открываем ODBC-файл Oracle из-под учетной записи system с паролем manager
objConn.open "ViewRidgeOracle". "system", "manager"
objConn.IsolationLevel = adXactReadCommitted ' избегаем «грязного» чтения
Set Session("_conn") = objConn
End If
Set objRecordSet = Server.CreateObjectCADODB.Recordset")
varSQL = "SELECT * FROM " & varTableName
objRecordSet.Open varSql. objConn ' тип курсора и тип блокировки
' не поддерживаются драйвером Oracle
<TABLE B0RDER=1 BGCDLOR=#ffffff CELLSPACIKG=5><F0NT FACE="Arial" COLOR = #000000>
<CAPTI0N><B><£varTableName2> (in Dracle database) </B></CAPTlOH></FDNT>
Примеры использования ADO 585
<THEAD>
<TR>
<%
varNumCols - objRecordSet.Fields.Count
For varl = 0 to varNumCols - 1
Set objField = objRecordSet.Fields(varl)
If objField.Name <> varKeyName Then ' опускаем суррогатный ключ % >
<TH BGCOLOR=#c0c0c0 BORDERCOLOR=#000000 ><F0NT SIZE=2 FACE="Arial"
COLOR=#00000><S=objField. Name *></F0NT></TH>
<%
End If
NextS>
</TR>
</THEAD>
<TB0DY>
<%
On Error Resume Next
objRecordSet.MoveFirsC
do while Not objRecordSet.eof
%>
<TR VALIGN=TOP>
<%
varNumCols * objRecordSet.Fields.Count
For varl » 0 to varNumCols - 1
Set objField = objRecordSet.Fields(varl)
If objField.Name <> varKeyName Then ' опускаем суррогатный ключ %>
<TD BORDECOLOR=#c0c0c0 ><F0NT SIZE - 2 FACE="Arial"
COLOR=#000000><^=Server.HTMLEncode (objField.Value i*><BR></FONT></TD>
<%
End If
Next*>
</TR>
<%
objRecordSet.MoveNext
loop£>
</TB0DY>
<TF00T></TFDDT>
</TABLE>
</B0DY>
</HTML>
Первая часть серверного сценария имеет ту же самую функцию, что и в
листинге 15.1. Единственное различие состоит в том, что обращение происходит
к источнику данных Oracle.
Переменная varSql задается с помощью переменной varTableName. Амперсанд
(&) — оператор, соединяющий две строки. Результатом этого выражения
является следующая строка:
SELECT * FROM CUSTOMER
586 Глава 15. ODBC, OLE DB, ADO и ASP
Заметьте также, что имя таблицы включено в заголовок HTML-таблицы с
помощью кода <CAPTION><B><%=varTableName%></Bx/CAPTION>. Код между
символами % приведет к тому, что в заголовок HTML-таблицы будет вставлено
значение переменной varTableName.
Следующий фрагмент серверного сценария обрабатывает коллекцию Fields.
Переменной varNumCols присваивается значение свойства Count коллекции Fields,
и затем элементы коллекции перебираются в цикле. Обратите внимание,
каким образом HTML разбросан в серверном коде (или серверный код разбросан
в HTML — как вам больше нравится). Ранее в переменную varKeyName было
записано имя суррогатного ключа, и цикл проверяет, не совпадает ли имя текущего
столбца с именем суррогатного ключа. Если нет, генерируется HTML-код,
создающий заголовок таблицы. Аналогичный цикл используется на следующей
странице для заполнения таблицы значениями из набора записей.
Преимущество этой страницы заключается в том, что она может обрабатывать
любую таблицу, а не только какую-то конкретную. Фактически, если использовать
введенную ранее терминологию, мы можем сказать, что страница в листинге 15.2
является абстракцией страницы из листинга 15.1. Результаты обработки этой
страницы показаны на рис. 15.10. Столбец CUST0MERID не показан, как мы и ожидали.
":-"-fSS
ЗИ able Display Page- f^*^i^^Ш^ШШШ^Ш
ля
Ш&&&
) http;/^ocalhost/V«wRidgeExamplel/cu5tomeroracle.asp
ЗйШКШ^Я
CUSTOMER (in Oracle database)
David Smith j
Tiffany Twilight :
Fred Smathers •
Selma Warning:
Jeffrey Janes
Susan Wu
ШШЙ ОТ МЮ&ЙЖ КйрийВПЙМ!
.............. ,... ^. .
Ч 360
.! ' 212
''•]"' ' 206
206 ""
1 V '206
555-4434 , j
J555-1040 j
:555-1212 !|
I555-0099
|555-1234
555-1000 !
~i i
ЗМ1Ш
I^Sffi^vS
Рис. 15.10. Результат обработки ASP-страницы CustomerOracle.asp
Пример 3 — чтение любой таблицы
На рис. 15.11, а показана форма для ввода данных, куда клиент может ввести имя
таблицы, которую следует отобразить. (Более удачным было бы решение, при
котором клиенту выдавался бы раскрывающийся список с возможными
вариантами выбора, но это уводит нас от обсуждения ADO.) Пользователь ввел в форму
имя artist Предположим теперь, что когда пользователь щелкает мышью на кнопке
Примеры использования ADO 587
Show Table (Показать таблицу), форма должна запустить сценарий на сервере,
который отобразит содержимое таблицы ARTIST в том же сеансе браузера.
Допустим также, что суррогатный ключ отображать не нужно. Желаемые результаты
показаны на рис. 15.11, б.
,^С$Щ
Щ Table .Display f own ~ ШШШШШШШ&ШШт
1 Address |?fhttp^^ 7 Г З-''"-^^Jt^^T ^
"3
Table Display Selection Form
nterTabltNamt:
jartistl
IhowTsbfe I Щ
* ..."■ J ;vXAtt
108ns
|g local btranefc
Щ Table Display Р^^\^^№^Ш^--ШШшШ^^^
^SlJSl
•4*B*fc * «* • ф Ш df i ^Search Ш****'*** фНЛогу \ & Щ * |j
Address j^] http-//localhost/ViewRidgeExamp!el/GeneralTable.ajp
~j*] '&*& :j Links
••I:
View Another Table
ARTIST Cm SQL Server Database)
•Miro _^Spanish _ J870 _j1950 __j
170ЙГ '|^дЩ"™ Vj
1900* i !
::z:jz:;;:z^
Kandinsky jRussian
:F rings TUS
.Klee jGerman
David Moos *US
Mark Tobey JUS
Henri MatjssefFranch
[*O0one
Рис. 15.11. Отображение содержимого произвольной таблицы:
а — форма для ввода имени таблицы; б — вид таблицы
588 Глава 15. ODBC, OLE DB, ADO и ASP
Для выполнения этой задачи требуются две ASP-страницы. Первая,
показанная в листинге 15.3, представляет собой HTML-страницу, содержащую тег FORM:
<F0RM METHOD="post" ACTION='*GeneralTable.asp">
Этот тег определяет на странице раздел формы; данный раздел будет
содержать вводимые данные. В данной форме вводится только, один элемент данных —
имя таблицы. Метод post — это HTML-процесс, посредством которого данные из
формы (в нашем случае имя таблицы artist) передаются ASP-серверу и
помещаются в объект под названием Form. Альтернативным методом является get, при
котором значения данных передаются в качестве параметров. Это различие здесь
для нас не слишком важно. Вторым параметром тега FORM является ACTION,
значение которого — строка «GeneralTable.asp». Этот параметр предписывает IIS по
получении отклика от формы передать файл GeneralTable.asp на обработку ASP-
процессору. Значения из формы будут помещены в объект Form.
Листинг 15.3. Код, выводящий содержимое произвольной
таблицы ViewRidgeTables.asp
<HTNL>
<HEAD>
<МЕТА HTTP-EQUIV="Content-Type" CONTENT-"text/html;charset=windows-1252">
<TITLE>Table Display Form</TlTLE>
</HEAD>
<B0DY>
<F0RM METHOD="post" ACTION="GeneralTable.asp">
<P><STR0NG><F0NT color=purple face="" size=5> : Snbsp: Table Display
Selection Form</F0NT></STR0NG>
<P></P>
<P> </P>
<P><F0NT style="BACKGROUND-COLOR: #ffffff"><FONT color=forestgreen face=""
styl^"BACKGROUND-COLOR: #ffffff">Enter
TableName:</FONT>  :  :</FONT></P>
<P></P>
<P><F0NT styles"BACKGROUND-COLOR: #ffffffff></F0NT> <INPUT id-textl
name=textl></P>
<P><F0NT style-'BACKGROUND-COLOR: #ffffff">
<INPUT id=subinitl name=submitl type=submit value="Show table"
>  :
<INPUT id=resetl name-reset! type=reset value-="Reset Values"></F0NT></P>
</F0RM>
</B0DY>
</HTML>
Примеры использования ADO 589
Листинг 15-4. Код, выводящий содержимое произвольной
таблицы GeneralTable.asp
<HTML>
<HEAD>
<МЕТА HTTP-EQUIV="Content-Type" CONTENT="text/html :charset=windows-1252">
<TlTLE>Table Display Page</TITLE>
</HEAD>
<B0DY>
<!--#include virtual = "ViewRedgeExamplel/adovbs.inc"
<%
Dim objConn. objRecordSet, objField
Dim varNumCols. varl. varSql
Dim varTableName, varRecordSetName, varKeyName
Dim varTableNameFirst, varTableNameRest
varTablename = Request. Form ("text!")
' Формируем имя ключа как имя таблицы в нижнем регистре с заглавной первой
' буквой + символы ID,
varTableNameFirst = UCase(Left(varTableName, D)
varTableNameRest - LCase(Right(varTableName. Len(varTableName)-D)
varKeyName = varTableNameFirst & varTableNameRest &"ID"
varRecordSetName = "jrsj' & varTableName ' используем для сохранения указателя
' на набор записей
If IsObject(Session("_conn")) Then
Set objConn = Session("_conn")
Else
Set objConn = Server.CreateObjectCADODB.connection")
objConn.IsolationLevel = adXactReadCommitted ' избегаем «грязного» чтения
objConn.open "ViewRidgeSS". "sa"
Set Session("_conn") = objConn
End If
If IsObject(Session(varRecordSetName)) Then
Set objRecordSet = Session(varRecordSetName) ' используем сохраненный набор
' записей, если зто возможно
objRecordSet.Requery
Else
varSql = "SELECT * FROM " & "[" & varTableHame & "]" ' Заключаем имя таблицы
' в скобки, если оно
' содержит пробелы и т. п.
Set objRecordSet = Server.CreateObjectCADODB.Recordset")
' В следующем операторе обратите внимание на использование типов курсора
' и блокировок а л
г продолжением
590 Глава 15. ODBC, OLE DB, ADO и ASP
Листинг 15.4 (продолжение)
objRecordSet.Open varSql. objConn. adOpenDynamic. adLockOptimistic
' разрешаем обновление
Set Session(varRecordsetHame) = objRecordSet
End If
%>
<@060>TABLE B0RDER=1 BGCOLOR«#ffffff CELLSPACING=0><FONT FACE-MAr1ar
COLOR«#000000>
<CAPTI0N><B><2KJCase (varTableName) *> (in SQL Server
Database)</B></CAPTION></FONT>
<THEAD>
<TR>
<%
varNumCols - objRecordSet.Fields.Count
For varl = 0 to varNumCols - 1
Set objField = objRecordSet.Fields (varl)
If objField.Name о varKeyName Then %>
<TH BGCOLOR=#cOcOcO BORDERCOLOR=#00000 ><FONT SIZE-2 FACE=,,AriaV
C0L0R=#000000><2hobj Field.Name*></FONT></TH>
<%
End If
NextS>
</TR>
</THEAD>
<TBODY>
<%
On Error Resume Next
obj Recordset.MoveF i rst
do while Not objRecordSet.eof
%>
<TR VALIGN=TOP>
<%
varNumCols = objRecordSet.Fields.Count
For varl = 0 to varNumCols - 1
Set objField = objRecordSet.Fields(varl)
If objField.Name <> varKeyName Then %>
<TD BORDERCOLOR=#cOcOcO ><FONT SIZE=2 FACE-''АпаГ
COLOR=#000000><S=Server.HTMLEncode (objField.Value) S><BR></FOHT></TD>
<%
End If
NexU>
</TR>
<%
obj RecordSet.MoveNext
Примеры использования ADO 591
loop£>
<BR><BR><A HREF="ViewRidgeTables.asp">View Another Table</A>
</TB0DY>
<TF00T></TF00T>
</TABLE>
</B0DY>
</HTML>
Остальная часть страницы представляет собой стандартный HTML.
Обратите внимание, что полю для ввода текста присвоено имя textl.
В листинге 15.4 показана ASP-страница GeneralTable.asp, которая
вызывается, когда ASP-процессору приходит отклик от страницы с формой,
изображенной в листинге 15.3. Первый выполняемый сценарный оператор имеет
следующий вид:
varTableName - Request.Form("textl")
Request.Form — это имя объекта, который содержит значения, посланные
браузером. В этом случае textl будет содержать значение «artist».
Эта версия GeneraLTabLe обрабатывает базу данных View Ridge для SQL Server.
Имена суррогатных ключей в SQL Server представлены в виде ArtistID, а не
ARTISTID. Поскольку сравнения строк в VBScript чувствительны к регистру букв,
нам нужно убедиться, что переменная varKeyName содержит имя суррогатного
ключа в требуемом формате. Пользователь мог ввести ARTIST, artist, Artist или,
скажем, aRtlsT, поэтому мы не можем просто присоединить буквы ID к
введенному имени таблицы. Три оператора, начинающиеся с varKeyNameFirst,
используют функции UCase и LCase для придания правильного формата значению
varKeyName.
Оставшаяся часть этой страницы имеет тот же вид, что и на странице Customer,
asp, показанной в листинге 15.2. Снова обратите внимание, что в переменную
varKeyName будет записано имя суррогатного ключа ArtistID, значения которого
мы не хотим выводить.
Пример 4 — обновление таблицы
Во всех трех предыдущих примерах рассматривается чтение данных. Следующий
пример демонстрирует обновление данных в таблице средствами ADO путем
вставки новой строки. На рис. 15.12, а показана форма, в которую вводится имя и
национальность художника. Эта страница аналогична ViewRidgeTabLes.asp, только
в ней имеется два поля ввода вместо одного. Когда пользователь нажимает кнопку
Save New Artist (Зарегистрировать нового художника), запись о художнике
добавляется в базу данных, и если результат является успешным, выводится страница,
представленная на рис. 15.12, б. Ссылка See New List (Просмотр обновленного
списка) вызывает страницу Artist-asp, которая выводит содержимое таблицы
ARTIST с новой строкой, как показано на рис. 15.13.
592 Глава 15. ODBC, OLE DB, ADO и ASP
*lNew. ARTIST Entry fwm 4*ШШ£ШШШШтЩШШЩШ
fife Ed* View.. Pavaues Tods.'' Ни?'.:
«*idii
AddTWS J4*j ^tp://localhost/ViewRidgeExample1/NewArtlst.asp 31. ^Gc Jnks /
New Artist Data Form
AjftirrtName: |Marc Chagall
Nationality feenchj
S<M? New Arts &j|jj ^p|(&t^ftlues;:':j
jCtone
"Sf
|Тге«*Йгале£ ч'' : 'A
Ц Add ARTIST example * ^»oso№ Ш#Щ:Ш|ШЩ1111|^ШР^
N Rfe EdK.'Vfew F*wr*es Tool* . Hefc
ш*&?*м*к
l5 £^i^J
jj Address Щ http://localhost/ViewRidgeExamplel/AddArtist.ASP
Data has been added. Thank you!
See New List
Рис. 15.12. Добавление данных в таблицу ARTIST: a — форма для ввода данных;
б — страница сообщения об успешной вставке
Тексты соответствующих ASP-страниц приведены в листингах 15.5 и 15.6.
Первая страница представляет собой форму для ввода данных с двумя полями,
в одно из которых вводится имя художника (поле Name), а в другое — его
национальность (поле Nation), Когда пользователь нажимает кнопку Submit
(Подтвердить), эти данные посылаются обратно IIS, которая, в свою очередь, передает их
вместе со страницей AddArtistasp ASP-обработчику.
Примеры использования ADtO 593
.Miro ;Spanish
;J Kandinsky Russian
11 Fnngs US
|| ^Wee iGerman
1 David Moos :US
j !магк tobey ■ ;US
I] . Henri Matisse- [French
| • |Marc Chagall: jFrench
Рис. 5.13. Вид таблицы ARTIST
Листинг 15.5. Вставка данных с помощью NewArtist.asp
<HTML>
<HEAD>
<МЕТА HTTP-EQUIV-"Content-Type" CONTENT-"text/html ;charset-windows-1252">
<TITLE>New ARTIST Entry Form</TITLE>
</HEAD>
<B0DY>
<F0RM METHOD-"post" ACTION="AddArtist.ASP">
<P><STR0NG><F0NT color=purple face="" size=5> New Artist Data
Form</FQNT></STRDNG>
<P></P>
<P> </P>
<P><F0NT style="BACKGROUND-COLOR: #ffffff"><FONT color=forestgreen face=""
style=,rBACKGROUND-COLOR: #ffffff>Arti st
Name:</F0NT>  :  : :
<INPUT id-text 1 name=Name style="HEIGHT: 22px; WIDTH: 164px"></F0NT></P>
<P><F0NT color=forestgreen face=""
Style="BACKGROUND-COLOR:
#ffffff ">Nationality:&ntasp;  :  :  :  :
<INPUT id=text2 name=Nation style="HEIGHT: 22px; WIDTH: 167px"></F0NT></P>
продолжение^
594 Глава 15. ODBC, OLE DB, ADO и ASP
Листинг 15.5 (продолжение)
<P> </P>
<P><F0NT style-"BACKGROUND-COLOR: #ffffff">
<INPUT id=submitl name=submitl type=submit value="Save New
Artist">  :
<INPUT id=resetl name=resetl type=reset value="Reset Values"></FONT></P>
</F0RM>
</B0DY>
</HTML>
Листинг 15.6. Вставка данных с помощью AddArtist.asp
<HTML>
<HEAD>
<META HTTP-EQUIV="Content-Type" CONTENT«"text/html :charset=windows-1252,,>
<TITLE>Add ARTIST Example</TITLE>
</HEAD>
<B0DY>
<!--#include virtual="ViewRidgeExample/adovbs.inc"-->
<%
Dim objConn, objRecordSet. objField
Dim varNumCols. varl. varSql
Set objConn = Server.CreateObject ("ADODB.connection")
objConn.open "ViewRidgeSS". "sa" ' открываем как пользователь sa
objConn.IsolationLevel = adXactReadCommitted ' избегаем «грязного» чтения
varSql = "SELECT * FROM [ARTIST]"
Set objRecordSet = Server.CreateObject ("ADOOB.Recordset" )
' В следующем операторе обратите внимание на использование типов курсора
' и блокировок
objRecordSet.Open varSql. objConn. adOpenDynamic. adLockOptimistic
objRecordSet.AddNew
objRecordSet ("ArtistName") - Request.Form ("Name")
objRecordSet ("Nationality") = Request.Form ("Nation")
objRecordSet.Update
On Error Resume Next
varErrorCount - objConn.Errors.Count
If varErrorCount > 0 Then
For varl = 0 to varErrorCount - 1
Response.Write "<BR><I>" & objConn.Errors {varl).Description & "</I><BR>"
Next
End If
objRecordSet.CI os
objConn.Close
Примеры использования ADO 595
Response.Write "<BR>Data has been added. Thank you!<BR>"
Response. Write "<A HREF=M& &"artist -asp" & & ">See New List</A>"
%>
<BR><BR>
</B0DY>
</HTML>
Страница AddArtist.asp (показана в листинге 15.6) создает объекты Connection
и Recordset. При этом не делается попыток сохранить указатели на эти объекты
в сеансовых переменных. (Предполагается, что за один сеанс будет добавлен
только один художник, поэтому сохранение не потребуется.) Если указатели
все-таки нужно сохранить, это можно сделать по аналогии с предыдущими примерами.
Основная отличительная особенность данной страницы заключается в
следующих операторах:
objRecordSet.AddNew
objRecordSet("Name")=Request.Form("Name")
objRecordSetC Nat ionality")=Request.Form(' 'Nation")
objRecordSet.Update
Первый оператор создает новую строку в объекте objRecordSet. Затем в нее
записываются значения полей Name и Nationality, считанные из формы. Обратите
внимание, что имена столбцов не обязаны совпадать с именами полей формы.
Здесь второй столбец называется Nationality, а значение поля формы — Nation.
Вызов функции objRecordSet.Update производит обновление базы данных.
Обратите внимание на код обработки ошибок, который выводит сообщения об
ошибках с помощью оператора Response.Wnte (этот метод принадлежит встроенному
ASP-объекту Response). Завершается страница двумя вызовами этого же метода,
первый из которых отправляет пользователю подтверждающее сообщение, а
второй создает ссылку на страницу Artist.asp, перейдя по которой, пользователь
может увидеть таблицу с новыми данными.
Пример 5 — вызов хранимой процедуры
Мы создали две версии хранимой процедуры Customer_Insert: одну для Oracle,
другую для SQL Server (в главах 12 и 13 соответственно). В обоих случаях
хранимая процедура принимает в качестве параметров имя нового клиента, код
региона, местный номер телефона и национальность художников, работами
которых интересуется данный клиент. Процедура создает новую запись в таблице
CUSTOMER it добавляет соответствующие строки в таблицу пересечений.
Чтобы вызвать хранимую процедуру из ASP-страшщы, мы создадим web-
форму (рис. 15.14), в которую будут вводиться данные клиента. Когда пользователь
нажмет кнопку Add Customer (Добавить клиента), будет вызвана ASP-страница,
которая, в свою очередь, вызовет хранимую процедуру, передав ей данные из
формы. Чтобы пользователь мог убедиться, что данные были добавлены корректно,
ASP-страница затем запросит представление, соединяющее имена клиентов с
именами и национальностями художников. Результат представлен на рис. 15.15.
596 Глава 15. ODBC, OLE DB, ADO и ASP
2 Table Display form - Microsoft Ш1&^£ц$Ш$$Ш
j \ Ne Edit" •'• View ' flworftes'■ Took ' Help ''
11 Address j|j] http7/localhost/ViewRidgeExamplel/NewCustomerOracle.asp ^3 ^^ I ftJnks ;
View Ridge Gallery
New Customer Form
Наше
Phone 1555-3345
Richard Baxendale
206
Naaonaatv of Artists JUS|
Add Customer. J Resgt.Yaluag , j
Ш&**"'
|Loeai intranet
I
Рис. 15.14. Форма для ввода данных о клиенте
■Ц Customer Update Display Nge *МШШ&ШШШШ$ШШ1
■ -rite s)t - View'' Favorites, ntoote Hefc, •
*Mm
|bidcJros^j#3 http://localho5t/ViewRidgeExamplel/CustomerIn5ertOracle.ASP 3 fffe..
!' '^.eaefc. -f* * 5$> O'tSljj.^seatch G&j Favorites. ф^Щеу^ф j
~m
Customers and Interests After Update
COSTNAME
Fred Smathers
Fred Smalhers
Fred Smalhers
F rings
van Vronkin
Tobey
US
US
:.us
.Richard Baxendale Fnngs . US
"Richard Baxendale van Vronkin J US
Richard Baxendale "Tobey . US
Selma Warning Fnngs j US
Selma Warning van Vronkin^J US
Selma Warning Tobey i;US
•Susan Wu Miro ! Spanish
f$j^pone
rr
H<x^wy««e.t-
Рис. 15,15. Вид соединения таблиц CUSTOMER и ARTIST
Примеры использования ADO 597
В листинге 15.7 показан код формы для ввода данных. Полям ввода даны
имена textl-text4. Когда пользователь нажимает кнопку Add Customer, данные из
формы передаются указанной в операторе FORM METHOD ASP-странице Customer-
InsertOracle (листинг 15.8).
Листинг 15.7. Вызов хранимой процедуры с помощью NewCustomerOracle.asp
<HTML>
<HEAD>
<МЕТА HTTP-EQUIV-'Tontent-Type" CONTENT="text/html ;charset=windows-1252">
<TlTLE>Table Display Form</TlTLE>
</HEAD>
<B0DY>
<F0RM METHOD="post" ACTION-'XustomerlnsertOracle.ASP'^
<P><STR0NG><F0WT color=purple face="" size=5>  : View Ridge
Gallery</FONT></STRONG>
<P> , Ssnbsp; <strong><font co1or="purple" face size="5"> New
Customer Form</font></strong><P><font style="background-color : #ffffff"
co1or-"forestgreen" face> : Snbsp; Snbsp;
Name: Snbsp; Snbsp; </font><F0NT style="BACKGROUND-COLOR:
#ffffff"> Snbsp: Snbsp; Snbsp: Snbsp; Snbsp; Snbsp; Snbsp; Snbsp; Snbsp;
 : &nbs p: Snbsp; Snbsp: Snbsp: Snbsp; Snbsp; Snbsp; Snbsp; Snbsp: Snbsp:
 : Snbsp:
</FONT><INPUT id=textl name=textl></P>
<P> <font style="background-color: #ffffff" color="forestgreen"
face> : Snbsp;  :AreaCode<font style="background-co"lor :
#ffffff">: : Snbsp; Snbsp ;</font> Snbsp; Snbsp: Snbsp; Snbsp;
  : : Snbsp; Snbsp: Snbsp; Snbsp;  :  :  : Snbsp; Snbsp;
</font><INPUT id=text2 name=text2 size="6"></P>
<P><font style="background-color: #ffffffM color="forestgreen" face>
 : Snbsp:
Phone: Snbsp; Snbsp; Snbsp; Snbsp; Snbsp; Snbsp; Snbsp; Snbsp; Snbsp: Snbsp;
 :  : Snbsp: Snbsp: Snbsp;  : Snbsp; Snbsp: Snbsp;
Snbsp; Snbsp;
</font><INPUT id=text3 name-text3
sizee"20"> Snbsp; Snbsp: Snbsp: Snbsp: Snbsp: </P>
<P> Snbsp: Snbsp: <font style="background-co]or : #ffffff"
color="forestgreen" face>Nationality
of Artists: Snbsp; Snbsp; </font> Snbsp; <INPUT id*text4 name-text4
sizee"17"></p>
продолжение &
598 Глава 15. ODBC, OLE DB, ADO и ASP
Листинг 15.7 {продолжение)
<P> :<FONT styIe="BACKGROUND-COLOR: #ffffff">
</F0NT> <F0NT style="BACKGROUND
COLOR: #ffffff">
<INPUT id=submitl name=submitl type=submit value^'Add Customer" > :
 :
<INPUT id=resetl name=resetl type=reset value="Reset Values"></FONT></P>
</F0RM>
</B0DY>
</HTML>
Листинг 15.8. Вызов хранимой процедуры с помощью CustomerlnsertOracle.asp
<HTML>
<HEAD>
<МЕТА HTTP-EQUlV="Content-Type" CONTENT^'text/html ;charset=windows-1252">
<TITLE>Customer Update Display Page</TITLE>
</HEAD>
<B0DY>
<P><STR0NG><F0NT color=purple face="" size=5> : Customers and Interests
After
Update</FONT></STRONG>
<!"#include virtual="ViewRidgeExamplei/adovbs.inc"-->
<%
Dim objConn. objCommand, objparam. oRs
Dim objRecordSet, obj Field
Dim varl. varSql. varNumCols. varValue
If IsObject(Session(" conn")) Then
Set objConn » Session("_conn") ' используем текущий сеанс, если это возможно
Else
Set objConn = Server.CreateObjectC'ADODB. connection")
' хранимая процедура установит свой собственный уровень изоляции
objConn.open "ViewRidgeOracle". "system", "manager" ' используем зто
' для обновления
' через Oracle
'objConn.open "ViewRidgeSS". "sa" ' а это можно было бы использовать
' для обновления через SQL Server
Set Session("__conn") « objConn
End If
Set objCommand = Server.CreateObjectC'ADODB.Command") ' создаем объект command
Set objCommand. ActiveConnection - objConn ' устанавливаем соединение
' для объекта command
objConmand.CormiandText=H{call Customer_Insert (?, ?, ?. ?)}" ' готовим вызов
1 хранимой процедуры
Примеры использования ADO 599
' Присваиваем необходимые значения четырем параметрам
Set objParam * objCommand.CreateParameterC'NewName". adChar, adParamlnput, 50)
objCommand. Parameters. Append objParam
objParam. Value = Request. Form("textl")
Set objParam * objCommand.CreateParameterCAreaCode". adChar, adParamlnput, 5)
objCormiand. Parameters. Append objParam
objParam. Value = Request.Form("text2")
Set objParam = objCommand. Create ParameteK'PhoneNumber". adChar,
adParamlnput. 8)
objCommand. Parameters. Append
objParam objParam. Value = Request.Form("text3")
Set objParam = objCommand.CreateParameterf'Nationality". adChar,
adParamlnpul. 25)
objCommand. Parameters.Append objParam
objParam. Value - Request.Form("text4")
' Вызываем хранимую процедуру
Set oRs = objCommand.Execute
' now read the data from a view having both CUSTOMER and ARTIST
varSql = "SELECT * FROM CUSTOMERINTERESTS" ' используем соединение через
' таблицу пересечений
Set objRecordSet - Server.CreateObjectCADODB. Recordset")
objRecordSet.Open varSql. objConn
%>
<TABLE BORDERS BGC0L0R=#ffffff CELLSPACING-5><F0NT FACE="Arialn
COLOR-#000000><CAPTION><B><CUSTOMERS AND INTERESTS</B></CAPTION></FONT>
<THEAD>
<TR>
<%
varNumCols « objRecordSet.Fields.Count
For varl = 0 to varNumCols - 1
Set objField - objRecordSet.Fields(varl)
%>
<TH BGCOL0R=#c0c0c0 B0RDERC0L0R =#000000 ><FONT SIZE-2 FACE="Ar1al"
C0L0R=#000000><S=objFi eld.Name*></FONT></TH>
<%
</TR>
</THEAD>
<TB0DY>
<%
On Error Resume Next
objRecordSet.MoveFi rst
продолжение &
600 Глава 15. ODBC, OLE DB, ADO и ASP
Листинг 15.8 (продолжение)
do while Not objRecordSet.eof
%>
<TR VALIGN=TOP>
<%
varNumCols - objRecordSet.Fields.Count
For varl = 0 to varNumCols - 1
Set objField - objRecordSet.Fields(varl)
If objRecordSet.Fields(varl).Type = adNumeric then
varValue=CDbl(objField.Value)
varValue = convert(char, varValue)
else
varValue=Server.HTMLEncode(objField.Value)
End If
%>
<TD BORDERCOLOR=#cOcOcO ><FONT SIZE=2 FACE-"Ariar
COLOR=#000000><^(varValue)^><BR></FONTx/TD>
<%
varValue=""
NextS>
</TR>
<%
objRecordSet.MoveNext
1оорЯ>
</TBDDY>
<TFOOT></TFOOT>
</TABLE>
</BODY>
</HTML>
Эта страница ищет сохраненный объект Connection и, если не находит
такового, создает новое соединение, как показано в предыдущих примерах. Затем
она создает команду objCommand и связывает ее с соединением objConn. После
этого задается шаблон вызова хранимой процедуры Customer_Insert строкой
«CommandText="{call Customer_Insert(?, ?, ?, ?)}». Четыре знака вопроса указывают
на то, что процедуре будет передано четыре параметра. Далее создаются
параметры и присоединяются к объекту-команде. В конце происходит запуск
команды, что приводит к вызову хранимой процедуры. Уровень изоляции транзакции
и свойства курсора не задаются, так как хранимая процедура установит их
самостоятельно.
После выполнения команды создается набор записей, содержащий все
столбцы представления CUSTOMERINTERESTS, и данные из него отображаются в браузере
так же, как показано в предыдущих примерах.
В обеих базах данных — как Oracle, так и SQL Server — представление
CUSTOMERINTERESTS было определено как соединение таблиц CUSTOMER и ARTIST
через таблицу пересечения. Для Oracle использовался следующий синтаксис:
Резюме 601
CREATE VIEW CUSTOMERINTERESTS AS
SELECT CUSTOMER.NAME CUSTNAME. ARTIST.NAME ARTISTNAME, ARTIST.NATIONALITY
FROM CUSTOMER, CUSTOMER_ARTIST_INT. ARTIST
WHERE CUSTOMER. CUSTOMER ID - CUSTOMER_ARTIST_INT.CUSTOMERID AND ARTIST. ARTISTID -
CUSTOMER_ARTIST_INT.ARTISTID
ORDER BY CUSTNAME
Эта страница интересна тем, что единственное различие между приведенной
здесь версией для Oracle и версией для SQL Server заключается в имени
источника данных ODBC, имени учетной записи и пароле. Обратите внимание на
строку комментария под оператором objConn.Open: все особенности конкретных
СУБД содержатся в хранимых процедурах, и разработчику ASP-страницы
ничего не нужно знать о них.
Эти примеры дают представление об использовании ADO. Лучший способ
узнать об этом больше — написать несколько страниц самостоятельно. В данной
главе описаны все основные методики, которые вам потребуются. Вам пришлось
немало потрудиться, чтобы дойти до этого места, и если вы понимаете
достаточно для того, чтобы написать собственную ASP-страницу, то вас можно
поздравить — вы многого достигли с первой главы!
Резюме
Приложения баз данных, использующие интернет-технологии, находятся в
богатом и сложном по составу окружении. Кроме реляционных баз данных,
существуют также нереляционные базы данных, системы обработки файлов, подобные
VSAM, электронная почта и другие типы данных — изображения, звуковые
файлы и т. д. Для облегчения труда прикладных программистов был разработан ряд
стандартов. Стандарт ODBC предназначен для работы с реляционными базами
данных, а стандарт OLE DB позволяет работать как с реляционными, так и с
нереляционными базами данных. С целью обеспечения более легкого доступа к
функциональности OLE DB для программистов, не знакомых с ООП, был разработан
стандарт ADO.
ODBC, или открытый стандарт взаимодействия баз данных,
предоставляет интерфейс, с помощью которого программы на web-сервере могут обращаться
к реляционным источникам данных и обрабатывать данные из них независимым
от СУБД способом. Стандарт ODBC был разработан производственным
комитетом и реализован многими производителями, в том числе Microsoft. ODBC
включает в себя прикладные программы, диспетчер драйвера, драйвер СУБД
и компоненты источника данных. Существует два типа драйверов:
одноуровневые и многоуровневые. Есть также три типа источников данных: файловые,
системные и пользовательские. Системные источники данных рекомендуются
для web-серверов. При определении системного источника данных необходимо
указать тип драйвера и идентификатор используемой базы данных.
OLE DB — это то, на чем основан доступ к данным в мире Microsoft. Данный
стандарт реализует спецификации Microsoft OLE и СОМ и доступен объектно-
602 Глава 15. ODBC, OLE DB, ADO и ASP
ориентированным программам через данные интерфейсы. OLE DB разбивает
возможности и функции СУБД на объекты, что упрощает для производителей
реализацию функциональности по частям. Ключевыми терминами являются
абстракция, метод, свойство и коллекция. Набор строк является абстракцией
набора записей, который, в свою очередь, является абстракцией отношения. Объекты
имеют свойства, описывающие их характеристики, и методы — действия,
которые они могут выполнять. Коллекция — это объект, содержащий группу
других объектов. Цели OLE DB перечислены в списке. Интерфейс — это объект,
предоставляющий доступ к некоторому множеству свойств и методов набора
объектов. Различные интерфейсы могут предоставлять доступ к разным методам
и свойствам одного и того же набора объектов. Реализация — это способ
выполнения задач объектом. Реализация скрыта от внешнего мира, и ее можно изменять,
не затрагивая пользователей объектов. Интерфейс не должен меняться никогда.
Поставщики табличных данных представляют данные в виде наборов строк.
Поставщики услуг преобразуют данные в другую форму; такие поставщики
одновременно являются и потребителями данных. Набор строк эквивалентен
курсору. Основными интерфейсами набора строк являются интерфейсы IRowSet,
IAccessor и IColumnsInfo. Есть и другие интерфейсы, предоставляющие различные
дополнительные возможности.
Объект Connection устанавливает соединение с поставщиком данных и
источником данных. Соединения имеют режим изоляции. После того как соединение
установлено, с его помощью можно создавать наборы записей (объект RecordSet)
и команды (объект Command). Объект RecordSet представляет курсор и имеет
свойства CursorType и LockType. Наборы записей можно создавать с помощью SQL-
операторов. Для индивидуальной обработки полей набора записей используется
коллекция Fields объекта RecordSet.
Коллекция Errors содержит сообщения об ошибках, произошедших в
результате выполнения операции ADO. Объект Command используется для запуска
параметризованных запросов или хранимых процедур. Введенные данные можно
пересылать ASP-странице на обработку посредством HTML-тега FORM.
Обновления в таблицах производятся с помощью метода Update объекта RecordSet.
Вопросы I группы
1. Объясните, в чем состоит сложность окружения, в котором находятся web-
серверы.
2. Какова связь между ODBC, OLE DB и ADO?
3. Объясните, чем автор оправдывает уделение столь большого внимания
стандартам Microsoft. Согласны ли вы с ним?
4. Перечислите компоненты стандарта ODBC.
5. Какую роль играет диспетчер драйвера? Кто его предоставляет?
6. Какую роль играет драйвер СУБД? Кто его предоставляет?
7. Что такое одноуровневый драйвер?
Вопросы I группы 603
8. Что такое многоуровневый драйвер?
9. Есть ли что-нибудь общее в том, как термин уровень используется по
отношению к архитектуре компьютерных систем (трехуровневая архитектура)
и в ODBC?
10. Какова роль уровней соответствия?
11. Дайте краткую характеристику трех уровней соответствия интерфейса
прикладных программ ODBC.
12. Дайте краткую характеристику трех уровней соответствия грамматики SQL.
13. Объясните разницу между тремя типами источников данных.
14. Какой тип источника данных рекомендуется для web-серверов?
15. Какие два действия необходимо выполнить при настройке имени
источника данных ODBC?
16. Каково назначение OLE DB?
17. Какой недостаток ODBC преодолевается в OLE DB?
18. Определите термин абстракция и объясните, как он относится к OLE DB.
19. Приведите пример абстракции с набором строк.
20. Что такое свойства и методы объекта?
21. В чем разница между объектным классом и объектом?
22. Какую роль играют потребители и поставщики данных?
23. Что такое интерфейс?
24. В чем разница между интерфейсом и реализацией?
25. Объясните, почему реализация может меняться, а интерфейс не должен
меняться никогда.
26. Перечислите цели OLE DB.
27. Что такое MTS и каковы его функции?
28. Чем отличается поставщик табличных данных от поставщика услуг? Какой
из них занимается преобразованием данных OLE DB в XML-документы?
29. В чем разница между набором строк и курсором в контексте OLE DB?
30. Какие языки можно использовать с ADO?
31. Перечислите объекты, составляющие объектную модель ADO, и укажите
их взаимосвязи.
32. Какова функция объекта Connection?
33. Напишите фрагмент кода на Visual Basic, создающий объект Connection.
34. Какова функция объекта RecordSet?
35. Напишите фрагмент кода на Visual Basic, создающий объект RecordSet.
36. Что содержится в коллекции Fields? Приведите пример ситуации, в
которой вы использовали бы зту коллекцию.
37. Напишите фрагмент кода на Visual Basic, обрабатывающий коллекцию Fields.
604 Глава 15. ODBC, OLE DB, ADO и ASP
38. Что содержится в коллекции Errors? Приведите пример ситуации, в
которой вы использовали бы эту коллекцию.
39. Напишите фрагмент кода на Visual Basic, обрабатывающий коллекцию Errors.
40. Каково назначение объекта Command?
41. Напишите фрагмент кода на Visual Basic, который запускал бы
параметризованный хранимый запрос с двумя параметрами, А и В.
42. Объясните назначение тегов <% и %> в ASP-страницах.
43. Объясните назначение переменной _сопп в листинге 15.1.
44. Для чего нужен код, создающий переменную varKeyName в листинге 15.4?
45. Объясните назначение параметра ACTION тега FORM в листинге 15.3.
46. Объясните, что произойдет, если будет выполнен следующий оператор
в ASP-странице в листинге 15.4:
varTableName = Request.Form("text1")
47. Напишите фрагмент кода на Visual Basic, добавляющий новую запись в
набор записей objMyRecordSet. Пусть имеется два поля, А и В, со значениями
«AValue» и «BValue» соответственно.
48. Какой цели служит оператор Response.Write?
Вопросы II группы
49. Корпорация Microsoft прилагает много усилий для продвижения
стандартов OLE DB и ADO. Однако она не получает непосредственной
прибыли от этих стандартов. IIS поставляется бесплатно в составе Windows NT
и Windows 2000. На сайте Microsoft имеется множество статей в помощь
разработчикам, и все это находится в свободном доступе. Как вы думаете,
почему Microsoft это делает? Какая цель преследуется?
50. В тексте ASP-страницы в листинге 15.6 устанавливается динамический тип
курсора. Какое воздействие это окажет на обработку этой страницы и
страниц Customer.asp и Artist.asp? Как, по вашему мнению, должны быть заданы
уровень изоляции, тип курсора и тип блокировки в приложении,
включающем все эти страницы?
51. Объясните, как следует изменить ASP-страницу в листинге 15.1, чтобы
она работала с источником данных ViewRidgeOracle. Объясните, как следует
изменить ASP-страницу в листинге 15.2, чтобы она работала с источником
данных ViewRidgeSS. Хотя простота таких изменений представляет интерес
с технологической точки зрения, является ли эта возможность сколько-
нибудь важной в мире коммерции?
52. Если вы установили Oracle, запустите с помощью браузера ASP-страницу
в листинге 15.2. Теперь откройте SQL Plus и удалите две строки из таблицы
CUSTOMER с помощью SQL-оператора DELETE. Снова запустите
ASP-страницу в браузере. Объясните полученные результаты.
Вопросы к проекту FiredUp 605
53. Если вы установили SQL Server, запустите с помощью браузера ASP-стра-
ницу в листинге 15.1. Теперь откройте SQL Query Analyzer и удалите две
строки из таблицы CUSTOMER с помощью SQL-оператора DELETE. Снова
запустите ASP-страницу в браузере. Объясните полученные результаты.
Если вы ответили на вопрос 52, объясните различия в результатах, если
таковые были.
Вопросы к проекту FiredUp
Создайте базу данных YourFired с помощью Oracle или SQL Server, если вы еще не
сделали этого. Следуйте указаниям в конце главы 12 или 13 соответственно.
1. Создайте ASP-страницу, отображающую таблицу ГОРЕЛКА.
2. Создайте ASP-страницу, отображающую любую таблицу в базе данных
FiredUp. За образец возьмите листинги 15.3 и 15.4.
3. Создайте ASP-страницу, позволяющую ввести данные новой горелки.
Обоснуйте ваш выбор уровня изоляции курсора.
4. Создайте ASP-страницу, позволяющую клиенту зарегистрировать свою
горелку. Обоснуйте ваш выбор уровня изоляции курсора.
5. Создайте хранимую процедуру, позволяющую ввести данные о ремонте
горелки.
6. Создайте ASP-страницу, вызывающую хранимую процедуру, которая была
создана в предыдущем вопросе. За образец возьмите листинги 15.7 и 15.8.
Глава 16
JDBC, Java Server Pages
и MySQL
В этой главе обсуждаются альтернативы технологиям и продуктам Microsoft —
OLE DB, ADO и IIS. В частности, мы будем рассматривать JDBC, Java Server
Pages (JSP) с использованием Apache/Tomcat и СУБД под названием MySQL.
В разработке этих продуктов большую роль сыграло движение open source, и все
они имеют открытые исходные тексты. Фактически, для разработки всех примеров
этой главы использовалось только программное обеспечение с открытыми текстами.
Но наличие открытых исходных текстов не является обязательным для
использования JDBC: эту технологию можно применять также в Windows 2000
и других операционных системах для работы с SQL Server, Oracle и другими
распространенными СУБД. JSP-страницы и Apache/Tomcat тоже могут работать
под Windows 2000. Однако все примеры этой главы были разработаны и
проверены с использованием Linux.
Как вы можете догадаться, единственное требование при использовании JDBC
состоит в том, что программы должны быть написаны на Java. Данная книга не
предполагает знакомства читателя с программированием на Java, и нет
необходимости понимать каждую строчку кода: целью должно быть понимание сути
и возможностей представленных здесь технологий. Если вы уже программируете
на Java, приведенные примеры должны побудить вас к созданию примеров более
сложных и реалистичных. В любом случае, по прочтении этой главы вы будете
способны сравнить возможности ODBC, ADO и ASP с JDBC и JSP.
JDBC
Для начала заметим, что, несмотря на утверждения многих источников, JDBC не
означает Java Database Connectivity. По утверждению компании Sun, изобретателя
Java, JDBC — это вообще не аббревиатура, а просто JDBC. Остается только
догадываться, какие правовые или личностные конфликты стоят за этим утверждением.
Драйверы JDBC существуют почти для всех мыслимых СУБД.
Корпорация Sun поддерживает каталог этих драйверов на своем сайте по адресу httpr/
java.sun.com/products/jdbc. Некоторые драйверы являются бесплатными, и
почти у всех есть ознакомительные версии, которые можно свободно использовать
JDBC 607
в течение ограниченного периода времени. Драйверы JDBC, взятые при
подготовке этой главы, — это драйверы MySQL с открытыми исходными текстами,
разработанные Марком Мэтьюсом (Mark Mathews). Их можно загрузить по
адресу http://worldserver.com/mm.mysql.
Чтобы вы не приобрели вредные привычки, прежде чем продолжить,
исправим одну потенциальную ошибку. Название СУБД MySQL произносится «май
эс-кью-эл», а не «май сиквел». Вряд ли это важно, но если вы хотите произвести
впечатление, всегда говорите «май эс-кью-эл».
Типы драйверов
Sun определяет четыре типа драйверов. Драйверы первого типа представляют
собой мост от JDBC к ODBC. Они обеспечивают интерфейс между Java и
обычными драйверами ODBC. Большинство драйверов ODBC написано на С или C++.
По причинам, которые не важны для нас здесь, между Java и C/C++ существует
определенная несовместимость. Драйверы JDBC-ODBC устраняют эту
несовместимость и позволяют обращаться к источникам данных ODBC из Java.
Поскольку использование ODBC было описано нами в предыдущей главе, первый тип
драйверов мы далее рассматривать не будем.
Драйверы типов 2-4 написаны полностью на Java и отличаются только
способом соединения с СУБД. Драйверы типа 2 соединяются с СУБД через «родные»
интерфейсы — например, обращаются к Oracle с использованием стандартного
(не ODBC) программного интерфейса Oracle. Драйверы типов 3 и 4
предназначены для использования в сетях связи. Драйвер типа 3 транслирует вызовы
JDBC в независимый от СУБД сетевой протокол. Этот протокол затем
преобразуется в сетевой протокол конкретной СУБД. Драйвер типа 4 транслирует
вызовы JDBC в сетевой протокол конкретной СУБД.
Чтобы понять различия между драйверами типов 2-4, нужно сначала понять
различия между сервлетом (servlet) и апплетом (applet). Как вы, возможно,
знаете, язык Java разрабатывался как переносимый. Чтобы удовлетворить
требованию переносимости, Java-программы компилируются не в конкретный
машинный язык, а в машинно-независимый байт-код. Sun, Microsoft и другие
компании разработали интерпретаторы байт-кода для каждой платформы (Intel 386,
Alpha и т. д.). Эти интерпретаторы называются виртуальными машинами Java
(Java virtual machines).
Для выполнения скомпилированной Java программы машинно-независимый
байт-код интерпретируется виртуальной машиной. Оборотная сторона
заключается в том, что интерпретация байт-кода добавляет промежуточный шаг и,
следовательно, такие программы не могут выполняться так же быстро, как программы,
компилируемые непосредственно в машинный код. В зависимости от нагрузки
приложения это может вызывать неудобства или нет.
Апплет — это программа в байт-коде Java, выполняемая на компьютере
пользователя приложения. Байт-код апплета посылается пользователю по HTTP и
вызывается с пользовательской машины также с помощью HTTP.
Интерпретация байт-кода производится виртуальной машиной, которая обычно является
608 Глава 16. JDBC, Java Server Pages и MySQL
частью браузера. По причине переносимости один и ют же байт-код может быть
отправлен на компьютер под управлением Windows, Unix или MacOS.
Сервлет — это Java-программа, вызываемая по HTTP на web-сервере. Она
отвечает на запросы от браузеров пользователей. Сервлеты интерпретируются
и выполняются виртуальной машиной Java, работающей на web-сервере.
Поскольку драйверы типов 3 и 4 работают с сетевыми протоколами, их можно
использовать в коде апплетов и сервлетов. Драйверы типа 2 могут
использоваться только в ситуации, когда Java-программа и СУБД находятся на одной и той
же машине или когда в СУБД имеется специальная программа,
занимающаяся связью между компьютером, на котором работает Java-программа, и
компьютером, на котором располагается СУБД.
Таким образом, если ваша программа должна соединяться с базой данных из
апплета (двухуровневая архитектура), можно использовать только драйверы
типов 3 и 4. При этом, если ваша СУБД имеет драйвер типа 4, используйте его,
поскольку он будет работать быстрее, чем драйвер типа 3.
В трехуровневой или многоуровневой архитектуре, если web-сервер и СУБД
работают на одной и той же машине, можно использовать драйвер любого из
трех типов. Если же они находятся на разных машинах, то безо всяких
трудностей могут быть использованы драйверы типов 3 и 4. Подойдет также и драйвер
типа 2, если в СУБД имеются средства, обеспечивающие связь между
web-сервером и СУБД. Характеристики типов драйверов JDBC приведены в табл. 16.1.
Таблица 16.1- Типы драйверов JDBC
Тип драйвера Характеристики
1 Мост ODBC/JDBC Предоставляет Java-интерфейс к драйверу ODBC.
Позволяет работать с источниками данных ODBC на Java
2 Java-интерфейс к собственной библиотеке функций СУБД. Java-программа
и СУБД должны находиться на одной машине, в противном случае СУБД
должна сама заботиться о связи между двумя компьютерами
3 Java-интерфейс к независимому от СУБД сетевому протоколу. Может
использоваться для сервлетов и апплетов
4 Java-интерфейс к сетевому протоколу конкретной СУБД. Может
использоваться для сервлетов и апплетов
Использование JDBC
В отличие от ODBC, в JDBC нет отдельной программы, специально
предназначенной для создания источника данных. Создание соединения происходит в Java-
коде через драйвер JDBC. Алгоритм использования драйвера JDBC имеет
следующий вид.
1. Загрузить драйвер.
2. Установить соединение с базой данных.
3. Создать оператор.
4. Выполнить некоторые действия с созданным оператором.
Как вы увидите, имя СУБД и базы данных указываются на шаге 2.
JDBC 609
Загрузка драйвера
Чтобы загрузить драйвер, необходимо сначала достать библиотеку драйвера и
установить ее в каталог. Этот каталог обязательно должен быть указан в
определении переменной окружения CLASSPATH компилятора и виртуальной машины Java.
Есть несколько способов загрузить драйвер в программу; наиболее надежным
является следующий:
Class.forName(string).newInstance();
Значение строкового параметра зависит от используемого драйвера. Для
драйверов MM MySQL строка загрузки выглядит так:
Class.forName("org.gjt.mm.mysql.Dri ver").newlnstance();
Этот метод будет генерировать исключение, поэтому следует заключить его
вызов в блок tryrcatch. (Если вы не являетесь Java-программистом, не
отчаивайтесь — просто поймите, что эти операторы делают классы JDBC доступными для
программы.)
Установление соединения с базой данных
Следующим этапом после загрузки драйвера является создание объекта,
представляющего соединение с вашей базой данных. Формат таков:
Connection conn = DriverManager.getConnection(string);
Класс DriverManager входит в библиотеку JDBC, которую вы загрузили на
первом шаге. Он играет ту же роль, что и диспетчер драйвера ODBC.
Драйверы JDBC регистрируются в этом классе. На одной машине может быть
зарегистрировано несколько драйверов. При вызове метода DriverManager.getConnection
диспетчер просматривает свой список драйверов и выбирает из него первый
подходящий драйвер. Таким образом, если ваше соединение способно
обрабатывать несколько драйверов, вы можете получить не тот драйвер, который
ожидаете.
Строковый параметр, передаваемый методу getConnection, состоит из трех
частей, разделенных двоеточиями. Первой частью всегда является строка jdbc,
вторая часть — это ключевое слово, идентифицирующее используемую СУБД,
а третья — URL базы данных, которую предстоит обрабатывать, с
необязательными параметрами наподобие имени пользователя и пароля.
Следующий оператор установит соединение с базой данных MySQL под
названием vrl от имени пользователя dkl с паролем sesame:
Connection conn =
DriverManager. getConnectionC jdbc: mysql ://1oca1host/vrl?user=dkl&password=sesame")
Содержимое второй и третьей части этой строки зависит от драйвера JDBC.
На самом деле некоторые драйверы требуют задавать имя пользователя и
пароль как отдельные параметры. Чтобы определиться в этом вопросе, обратитесь
к документации драйвера.
610 Глава 16. JDBC, Java Server Pages и MySQL
Между прочим, большая часть этой технологии имеет корни в мире Unix. Unix
чувствительна к регистру букв, и почти во всем, что вы вводите здесь, регистр
также имеет значение. Например, jdbc и JDBC — это не одно и то же. Набирайте
все в том же регистре, в каком показано здесь. Из этого правила есть несколько
исключений, но они не стоят упоминания или запоминания. Просто набирайте
все так, как показано здесь.
Метод getConnection также будет генерировать исключение, поэтому его
вызов тоже следует поместить внутрь блока tryxatch.
Создание оператора
Следующий шаг — это создание объекта Statement. Процедура напоминает то, что
мы делали в предыдущей главе для создания объекта Command. Синтаксис таков:
Statement stmt = conn.createStatementO;
Никаких параметров этому методу не передается.
Сейчас вы увидите, как можно обрабатывать созданный оператор.
Обработка операторов
Методы объекта Statement стандартизированы в спецификации JDBC. Драйвер
сможет выполнить любой из приведенных операторов (и еще много других).
За подробной информацией обращайтесь к документации драйвера. В наших
примерах мы будем использовать методы executeQuery и executeUpdate:
ResultSet rs * stmt.executeQuery(querystring);
int result = stmt.executeUpdate(updatestring);
Первый оператор возвращает набор результатов, который можно
использовать точно так же, как мы использовали курсоры в предыдущих главах. Второй
оператор возвращает целое число, которое показывает количество обновленных
строк. В качестве конкретных примеров можно привести следующее:
ResultSet rs = stmt.executeQuery("SELECT * FROM CUSTOMER");
и
int result = stmt.executeUpdate("UPDATE ARTIST SET Nationality WHERE Name='Foster"*);
Обратите внимание, что внутри двойных кавычек во избежание
недоразумений используются одиночные.
Для получения запрошенных строк можно перебрать набор результатов,
возвращенных методом executeQuery. Количество и имена столбцов можно получить
с помощью метода getMetaData. Его синтаксис следующий:
ResultSetMetaDate rsMeta = rs.getMetaDataO;
Теперь, как вы увидите из следующих примеров, можно вызывать методы
getColumnCount и getColumnName объекта rsMeta, которые возвращают
соответственно количество и имена столбцов.
JDBC 611
Готовые и вызываемые операторы
Компилированные запросы и хранимые процедуры можно вызывать с помощью
готовых операторов (prepared statements) и вызываемых операторов (callable
statements). Они используются подобно объекту Command, о котором шла речь
в главе 15. Поскольку ни компилированные запросы, ни хранимые процедуры не
поддерживаются MySQL, в примерах этой главы использовать их мы не будем.
Продемонстрируем, тем не менее, использование вызываемых операторов.
Допустим, мы работаем с базой данных View Ridge в версии для Oracle, созданной
в главе 12, и нам нужно вызвать хранимую процедуру Customerlnsert. Будем
предполагать, что объект conn содержит установленное соединение с базой данных
View Ridge для Oracle:
CallableStatement cs = conn.prepareCall("{call CustomerInsert(?, ?, ?, ?)}");
cs.setStringd. "Mary Johnson");
cs.setString(2. "212");
cs.setStringO. "555-1234");
cs.setString(4, "US");
cs.executeO;
Эта последовательность, вызывающая хранимую процедуру Customerlnsert с
приведенными данными, очень похожа на ту, которая использовалась для ODBC
в предыдущей главе. Можно также получать значения, возвращаемые
процедурами, но этот вопрос выходит за рамки нашего обсуждения. Дальнейшую
информацию вы найдете по адресу http://java.sun.com/products/jdk/l.l/docs/guide/jdbc.
На рис. 16.1 изображены все компоненты JDBС. Приложение создает объекты
Connection, Statement, ResultSetH ResultSetMetaData. Вызовы методов этих объектов
перенаправляются через диспетчер драйвера (объект DriverManager)
соответствующему драйверу, а тот выполняет предписанные действия со своей базой данных.
Обратите внимание, что база данных Oracle на этом рисунке может
обрабатываться либо через мост JDBC-ODBC, либо с помощью чистого JDBC-драйвера.
Примеры использования JDBC
В листингах 16.1 и 16.2 показаны два примера использования драйверов JDBC
mm.mysql с СУБД MySQL Обратите внимание, что обе эти программы
импортируют java.sqL*. Также обратите внимание, что драйверы JDBC не импортируются, а
загружаются. Если вы попытаетесь их импортировать, результатом будет неразбериха.
Во всех этих примерах используется база данных View Ridge, изображенная на
рис. 10.3, г. Она содержит следующие таблицы:
CUSTOMER (CustomerlD, Name, AreaCode, PhoneNumber, Street City, State, Zip)
ARTIST (ArtistID, Name, Nationality, BirthDate, DeceasedDate)
CUSTOMER_ARTIST_INT (CustomerlD, ArtistID)
WORK (WorkID, Description, Title, Copy, ArtistID);
TRANSACTION (TransactionID, DateAcquired, PurchasePrice, SalesPrice, CustomerlD, WorkID)
Связи и ограничения ссылочной целостности описаны в главе 10.
612 Глава 16. JDBC, Java Server Pages и MySQL
Connection
Statement
ResultSet
CallableStatement
PreparedStatement
ResultSetMetaData
Приложение
Диспетчер
драйверов
Драйвер MySQL
База данных
MySQL
Драйвер Oracle
Мост JDBC-ODBC
Драйвер ODBC
База данных
Oracle
База данных
SQL Server
База данных
Oracle
Рис. 16.1. Компоненты JDBC
Класс GeneralTable
В листинге 16.1 показан Java-класс GeneralTable. Он принимает один параметр — имя
таблицы из базы данных MySQL под названием vrl. MySQL чувствительна к
регистру, и имена всех таблиц в базе данных пишутся заглавными буквами.
Следовательно, программа должна преобразовать введенное имя таблицы к верхнему регистру.
Листинг 16.1. Класс GeneralTable
import java.io,*;
import java.sql.*;
public class GeneralTable {
/** Программа на Java, выводящая содержимое любой таблицы
* При вызове передается один параметр -- имя таблицы,
* которое автоматически преобразуется к верхнему регистру
*/
public static void main (String [] args)
{ if (args.length <1) {
System.out.println ("Предоставленных данных недостаточно." return;
}
String varTableName = args[0];
JDBC 613
varTableName = varTableName.tollpperCase 0;
System, out. println ("Выводится таблица" + varTableName) ;
try {
// Загрузка классов MySQL JDBC от Марка Мэтьюса
// mm.mysql. jdbc-1.2c
Class. forName ("org.gjt.mm.mysql.Driver"), newlnstance () ;
// Строка соединения указывает на локальную базу данных MySQL,
// пользователь dkl
String connString = "jdbc:mysql: //localhost/vrl?user=dki";
System.out.println ("Попытка установления соединения с " + connString)
Connection conn = DriverManager .getConnection(connString) ;
// Получаем набор результатов
Statement stmt = conn.createStatement () ;
String varSQL = "SELECT * FROM " + varTableName:
ResultSet rs = stmt.executeQuery(varSQL) ;
// Получаем метаданные, описывающие только что открытый набор
// результатов
ResultSetMetaData rsMeta = rs.getMetaData О;
// Выводим имена столбцов в виде строк
String varColNames = "";
int varCol Count s rsMeta.getColumnCount 0;
for (int col =1; col <= varColCount; col++) {
varColNames s varColNames + rsMeta.getColumnName(col) +" ";
System.out.pri ntln(varColNames);
// Выводим значения столбцов
while (rs.nextO) {
for (int col = 1; col <= varColCount; col++) {
System.out.print{rs.getString(col) + " "}:
}
System.out.println ();
}
// Очистка
rs.close ();
stmt.closeO;
conn.closeO;
catch (Exception e) {
e.printStackTraceO
614 Глава 16. JDBC, Java Server Pages и MySQL
Данный пример является прямым приложением только что описанных нами
идей. Класс GeneralTable имеет общедоступный метод, не возвращающий
значений (в этом и состоит значение слов public и void). Программа проверяет наличие
хотя бы одного параметра, записывает переданное ей имя таблицы в переменную
varTableName и приводит это имя к верхнему регистру. Затем она обрабатывает
базу данных в блоке try с помощью драйверов JDBC. Блок try используется
потому, что многие методы генерируют исключения. Эти исключения будут
перехвачены в блоке catch.
В этих примерах оставлена стандартная обработка исключений. Если вы
программируете на Java, то, скорее всего, знаете много способов улучшить
обработку исключений по сравнению с тем, что показано здесь. Однако сейчас нас
интересуют базы данных.
Если вы не знакомы с программированием на Java, просто представьте, что
все операторы, помещенные внутрь блока try, который обозначается «try{...}>>, —
это то, что происходит при нормальной работе. Все операторы, помещенные
внутрь блока catch, который обозначается «catch{...}>>, — это то, что происходит,
когда возникает ошибка. Кроме того, по аналогии с SQL, в Java многострочные
комментарии начинаются с «/*» и заканчиваются на «*/». Однострочный
комментарий начинается с «//»,
Драйверы mm,mysql загружаются, как описано выше, а затем создаются
соединение (объект conn) и оператор (объект stmt). Имя базы данных — vrl, имя
пользователя — dkl. Пароль отсутствует. (Чтобы это работало, в MySQL нужно
определить пользователя с именем dkl и наделить его полномочиями обращаться к базе
данных vrl без пароля. Эти действия мы обсудим в последнем разделе главы,)
Для набора результатов rs создается объект rsMeta, содержащий метаданные.
Из него считываются имена столбцов и затем выводятся в виде одной длинной
строки (varColumnNames). После этого набор результатов перебирается, и каждая
его строка выводится на экран. Результат выглядит не слишком красиво, но, по
крайней мере, принцип ясен и все работает.
Типичный результат работы программы выглядит следующим образом:
Showing Table ARTIST
Trying connection with jdbc.mysql://local host/vrl?user=dkl
Name Nationality Birthdate DeceasedDate ArtistID
Miro Spanish null null 1
Tobey US null null 2
Van Vronken US null null 3
Matisse French null null 4
Как и говорилось, выглядит это не очень красиво.
Класс Customerlnsert
В листинге 16.2 показана вторая Java-программа, которая обновляет базу данных
vrl. Эта программа реализует логику процедуры Customerlnsert, описанную в
главах 10, 12, 13 и 15. (Вы еще не устали от этой процедуры? Что ж, по крайней мере,
логика вам знакома!)
JDBC 615
Листинг 16.2. Класс Customerlnsert
import java.io.*;
import java.sql.*;
public class Customerlnsert {
/** Реализация на Java процедуры Customerlnsert для галереи View Ridge.
* Процедура принимает в качестве параметров имя клиента (CustomerName),
* его код региона (AreaCode). номер телефона (Local Number) и
национальность
* художников, которые его интересуют (Nationality). Добавляет нового
клиента,
* если его еще нет в базе данных, и затем ассоциирует данного клиента со
всеми
* художниками указанной национальности, добавляя соответствующие строки
* в таблицу пересечений.
*/
public static void main (String [] args) {
if (args.length < 4) {
System.out.println ("Предоставленных данных недостаточно");
return;
String varName = args[0];
String varAreaCode = args[l];
String varLocalNumber = args [2];
String varNationality = args[3];
insertData (varName, varAreaCode. varLocalNumber, varNationality) ;
}
public static void insertData (String varName.
String varAreaCode,
String varLocalNumber,
String varNationality) {
System.out.println ("Добавляется строка для" + varName);
try {
// Загрузка класса драйвера JDBC от Марка Мэтьюса
// mm.mysql.jdbc-1.2с
Class. forNameCorg.gjt. mm. mysql. Driver") -newInstanceO ;
// соединяемся с базой данных vrl как пользователь dkl. без пароля
String connString = "jdbc:mysql:/Vlocalhost/1' + "vrl" + "?user=dkl":
продолжение^
616 Глава 16. JDBC, Java Server Pages и MySQL
Листинг 16.2 {продолжение)
System.out.printIn ("Попытка установления соединения с " + connString);
Connection conn = DriverManager.getConnection(connString);
// Соединение установлено. Далее идет проверка на дублирование данных.
Statement stmt = conn.createStatement О ;
String varSQL = "SELECT Name ";
String varWhere = "FROM CUSTOMER WHERE Name= ,и;
varWhere = varWhere + varName + "' AND AreaCode = '";
varWhere = varWhere + varAreaCode + "' AND PhoneNumber -
varWhere = varWhere + varLocalNumber + ;
varSQL = varSQL + varWhere;
ResultSet rs = stmt .executeOuery (varSQL) ;
while (rs .next О ) {
// Имеются дублирующиеся данные
System, out .println
("Указанный пользователь уже имеется 8 базе. Изменений не произведено.");
rs. close О ;
stmt, close О ;
conn, close () ;
return;
}
// Можно добавлять новые данные
varSQL = "INSERT INTO CUSTOMER (Name. AreaCode, PhoneNumber)";
varSQL = varSQL + " VALUES ('" + varName + "' . ,и;
varSQL = varSQL + varAreaCode + " \ '";
varSQL = varSQL + varLocal Number + ■■'у/'
int result = stmt.executeUpdate (varSQL);
if (result == 0) {
System.out.println ("Ошибка при вставке");
rs.close () ;
stmt.close () :
conn.close () ;
return;
}
// Обновление прошло успешно; теперь нужно добавить строки в таблицу
// пересечений. Для этого получаем идентификатор нового клиента
varSQL = "SELECT CustomerlD" + varWhere;
rs = stmt.executeQuery(varSQL) ;
String varCid ="";
while (rs.next ()) {
varCid = rs.getString(l) ;
if (varCid == "0" ) {
System.out.printlnC'He удается найти идентификатор нового клиента") ;
rs.closeO ;
JDBC 617
stmt.closeO ;
conn.closedO ;
return;
}
}
// Теперь добавляем строки в таблицу пересечений
varSQL = "SELECT ArtistID FROM ARTIST WHERE Nationality = '" + varNationality
String varlnsertStart = "INSERT INTO CUSTOMER_ARTIST_INT (CustomerlD.
ArtistID) VALUES ("
->+ varCid +", ;
String varlnsertEnd = ")";
rs = stmt.executeQuery (varSQL) ;
System.out.println("Добавляются записи в таблицу пересечений для клиента" "+
varCid) ;
while (rs.next О ) {
result * stmt.executeUpdate (varlnsertStart + rs.getStringd ) +
varlnsertEnd) ;
}
// Очистка
rs. closeO :
stmt. closeO ;
conn. closeO ;
}
catch (Exception e) {
e.prtntStackTraceO ;
Как вы помните, эта процедура имеет четыре параметра: имя нового клиента,
код региона, местный номер телефона и национальность всех художников,
работами которых интересуется данный клиент. Эти параметры принимаются
процедурой main и передаются методу InsertData. В принципе, метод InsertData здесь не
нужен: мы могли бы вместить все в один метод, как в предыдущем примере.
Отдельный метод создается потому, что в следующем разделе мы будем
преобразовывать его в класс Java bean. Это преобразование будет легче выполнить, если
данный метод будет выделен.
Сначала метод InsertData загружает драйверы и создает строку соединения
с базой данных vrl для пользователя dkl. Затем он производит проверку на
предмет присутствия записи о данном клиенте в базе данных, запрашивая из vrl
строки с заданным именем, кодом региона и номером телефона. Если такая строка
находится, выводится сообщение, и набор строк, оператор и соединение
закрываются. В противном случае в таблицу CUSTOMER вставляется новая строка.
Столбец CustomerlD, являющийся суррогатным ключом таблицы CUSTOMER,
определен в базе данных ключевым словом AUTO_INCREMENT. Таким образом,
значение этого столбца задавать не требуется: СУБД MySQL задаст его сама.
618 Глава 16. JDBC, Java Server Pages и MySQL
Если вставка оказалась успешной, переменная result не должна равняться нулю;
если это не так, значит, во время обновления произошла ошибка. В этом случае
выводится предупреждающее сообщение и все объекты очищаются. Если ошибок
не произошло, значение CustomerlD считывается из базы данных, а затем в таблицу
CUSTOMER_ARTIST_INT вставляются строки. Логика здесь весьма напоминает
логику хранимой процедуры CustomerlnsertB версии для Oracle и SQL Server.
На этом этапе переменная result не проверяется на нулевое значение; в более
совершенной версии этой программы такая проверка производилась бы. А если
вы программируете на Java, то знаете, что все выводы сообщений об ошибках
и очистку объектов нужно выполнять с помощью исключений. Здесь мы
опустим обсуждение этих вопросов и сосредоточимся на том, что непосредственно
связано с базами данных.
Теперь, после краткого введения в JDBC, мы обсудим использование этой
технологии в Java Server Pages.
Java Server Pages
Java Server Pages (JSP) — это продукт, предоставляющий возможность создания
динамических web-страниц с помощью HTML, XML и языка программирования
Java. Java Server Pages внешне очень походит на Active Server Pages, но это
сходство обманчиво, поскольку в основе этого продукта лежит совсем другая
технология. JSP и ASP схожи в том, что в обоих случаях HTML смешивается с
программным кодом. Но в ASP программирование ограничено сценарными языками,
подобными VBScript или JScript, а в JSP программирование осуществляется на
Java и только на Java. Таким образом, разработчик web-страниц получает в свое
распоряжение всю мощь полноценного объектно-ориентированного языка
программирования.
Поскольку Java является машинно-независимым языком, JSP-страницы также
машинно-независимы. Используя JSP, вы не ограничены рамками Windows 2000
и IIS. Одну и ту же JSP-страницу можно запустить на сервере под управлением
Linux, Windows и других операционных систем.
Официальную спецификацию JSP можно найти по адресу http://java.sun.com/
products/jsp.
JSP-страницы и сервлеты
JSP-страницы преобразуются в стандартный язык Java и затем компилируются
как обычные Java-программы. В частности, они преобразуются в сервлеты Java,
то есть в подклассы класса HttpServlet. Таким образом, код JSP-страницы имеет
доступ к объектам, представляющим HTTP-запросы и их результаты, к их
методам и другим функциям HTTP.
Поскольку JSP-страницы преобразуются в подклассы сервлетов, в них не
требуется создавать полноценные Java-классы или методы. Вы можете просто
вставлять фрагменты Java-кода там, где пожелаете, а при синтаксическом анали-
Java Server Pages 619
зе страницы они будут корректным образом помещены в подкласс сервлета. Так,
например, следующий фрагмент будет отлично работать в JSP-странице без
всякого дополнительного Java-кода:
<% String раг^уМате="карнавал":
partyName = partyName.toUpperCaseO;
out.println ("Приходите на наш " + partyName); %>
В результате обработки этой части JSP-страницы в окне браузера появится
надпись «Приходите на наш КАРНАВАЛ». Кстати, обратите внимание, что Java-код
помещается между «<%» и «%>», как и код на VBScript или JScript в ASP-стра-
ницах.
Чтобы использовать JSP-страницы, web-сервер должен поддерживать
спецификации Java servlet 2.1 + и Java Server Pages 1.0+. Список серверов,
поддерживающих эти спецификации, вы можете найти по адресу http://java.sun.com/products/
servlet/industry.htmL Есть по крайней мере пять-шесть подходящих вариантов. В
оставшейся части главы мы будем использовать для этих целей сервер Apache
Tomcat.
Apache Tomcat
По состоянию на декабрь 2000 года web-сервер Apache не поддерживает сервле-
ты. Однако фонд Apache и корпорация Sun выступили совместными спонсорами
проекта Jakarta, в рамках которого был создан обработчик сервлетов под
названием Apache Tomcat. Исходные тексты и двоичный вариант Tomcat можно найти
на сайте проекта Jakarta по адресу http://jakarta.apache.org.
Tomcat представляет собой обработчик сервлетов, который может работать
в связке с Apache или как автономный web-сервер. Возможности Tomcat как web-
сервера ограничены, поэтому в автономном режиме он обычно используется
только для тестирования сервлетов и JSP-страниц. В коммерческих
приложениях Tomcat следует использовать совместно с Apache.
Если Tomcat и Apache работают отдельно на одном web-сервере, они
должны использовать разные порты. По умолчанию для web-сервера предназначен
порт 80, и обычно Apache использует именно этот порт. При использовании
Tomcat в автономном режиме для него обычно выделяется порт 8080, хотя номер
порта, разумеется, можно изменить,
В приведенных ниже примерах Tomcat использует порт 8080. Эти примеры
запуск&тась в закрытой интрасети, где машине, на которой работал Tomcat, был
присвоен IP-адрес Ю.О.О.З.Таким образом, чтобы вызвать страницу somepage.jsp,
в поле адреса браузера нужно ввести строку http://10.0.0.3:8080/somepage.jsp.
Настройка Tomcat для обработки JSP
При установке Tomcat для него будет создана структура каталогов, куда
необходимо поместить библиотеки классов и web-страницы. Для Tomcat версии 3.1
библиотеки классов следует помещать в каталог install-dir/lib, a JSP-страницы —
620 Глава 16. JDBC, Java Server Pages и MySQL
в каталог install-dir/webapps/ROOT/WEB-INF/classes, где install-dir — это каталог,
в который устанавливается Tomcat. В Linux утилита RPM по умолчанию
устанавливает Tomcat в каталог /usr/Local/jakarta-tomcat. Соответственно,
библиотеки классов в этом случае нужно поместить в каталог /usr/Local/jakarta-tomcat/
lib, a JSP-страницы — в каталог/usr/local/jakarta-tomcat/webapps/ROOT/WEB-INF/
classes. Если вы устанавливаете Tomcat в другой операционной системе или вообще
устанавливаете другой обработчик сервлетов, стоит обратиться к документации.
Устанавливая файлы классов в подкаталог lib, нужно иметь в виду маленький
нюанс: Tomcat создает свой CLASSPATH при запуске. Поэтому после того, как вы
установите новый файл класса в каталог lib, вы должны остановить и
перезапустить Tomcat, чтобы он смог увидеть этот файл. Если же вы просто скопируете
новый файл в подкаталог lib без перезапуска Tomcat, вы получите исключение
Class not found (класс не найден). (Поверьте мне, я знаю это...)
Все приведенные ниже JSP-страницы используют драйверы MySQL mm.mysql.
Чтобы работа с этими драйверами стала возможной, необходимо поместить в
подкаталог lib библиотеку класса соответствующего драйвера. Для примеров этой
главы использовалась библиотека mm_uncomp.jar.
На рис. 16.2 изображена схема процесса компиляции JSP-страниц. Получив
запрос на обработку JSP-страницы, Tomcat (или другой обработчик сервлетов)
находит скомпилированную версию этой страницы и проверяет, является ли
данная версия текущей. Для этого он ищет иекомпилированную версию
страницы с более поздней датой и временем, чем скомпилированная страница. Если
страница не является текущей (нашлась более поздняя скомпилированная
страница), производится синтаксический анализ новой страницы, после чего она
преобразуется в исходный Java-файл, который затем компилируется.
Полученный сервлет загружается и выполняется. Если же скомпилированная JSP-стра-
ница оказывается текущей, то она загружается в память и выполняется. Если
JSP-страница уже находится в памяти, обработчик просто выполняет ее.
(Между прочим, у такой автоматической компиляции есть один недостаток:
если вы сделаете синтаксические ошибки и забудете протестировать свои
страницы, то первый пользователь, обратившийся к этим страницам, получит
сообщение об ошибках компиляции.)
В отличие от CGI-файлов и некоторых других web-серверных программ,
одновременно в памяти находится не более одной JSP-страницы. Более того,
страницы выполняются одним из потоков Tomcat, а не независимым процессом. Это
означает, что для выполнения JSP-страницы требуется гораздо меньше памяти
и процессорного времени, чем для выполнения сравнимого по
функциональности CGI-сценария.
Примеры JSP-страниц
В этом разделе описываются две простые JSP-страницы. Первая страница
представляет собой JSP-версию класса GeneralTable, показанного в листинге 16.1.
Вторая реализует логику работы метода insertData (листинг 16.2) в классе Java bean,
который затем вызывается из другой JSP-страницы.
Java Server Pages 621
Запрос JSP-страницы
Разбор
JSP-страницы
и создание
исходного
Java-файла
Компилировать
исходный
Java-файл
Загрузить JSP-сервлет
Запустить JSP-сервлет
т
Отклик JSP-страницы
Рис. 16.2. Процесс компиляции JSP-страницы
GeneralTable.jsp
В листинге 16.3 изображена JSP-страница, выводящая содержимое любой таблицы
из базы данных MySQL под названием vrl. Эта страница по своему формату и
логике работы очень напоминает страницу GeneralTable.asp в листинге рис. 15.4.
Предполагается, что пользователь передает странице имя таблицы в качестве параметра.
Листинг 16.3. Страница GeneralTable.jsp
<!D0CTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<!-- Example of Oatabase Access from a JSP Page -->
<£@ page import="java.sql .*" %>
<HTML>
<HEAD>
<TlTLE>Table Display Using JDBC and MySQL</TITLE>
<META NAME="author" CONTENT="David Kroenke">
<META NAME-"keywords"
CONTENT="JSP, JDBC. Database Access">
продолжение^
622 Глава 16. JDBC, Java Server Pages и MySQL
Листинг 16.3 (продолжение)
<META NAME="description"
CONTENT="An example of displaying a table using JSP.">
<LIHK REL=STYLESHEET HREF="JSP-Styles.css" TYPE="text/css">
</HEAD>
<B0DY>
<H2>Database Access Example</H2>
<%, String varTableName= request.getparameter ("Table") ;
varTableName = varTableName.toUpperCaseO ; %>
<H3>Showing Data from MySQL Database vrl</H3>
<%
try {
// Загрузка драйверов JDBC Марка Мэтьюса
Class.forName ("org.gjt.mm.mysql.Driver").newlnstance() ;
// Устанавливаем соединение с базой данных vrl как пользователь dkl
String connString = "jdbc:mysql://localhost/" + "vrl" + "?user=dkl";
Connection conn « DriverManager.getConnection(connString) ;
// Получаем rs и rsMeta для оператора SELECT
Statement stmt = conn.createStatement О ;
String varSQL = "SELECT * FROM " + varTableName;
ResultSet rs = stmt.executeQuery (varSQL) ;
Result SetMetaData rsMeta = rs.getMetaData О ;
<TABLE BORDERS BGC0L0R=#ffffff CELLSPACING=5><F0HT FACE-"Arial" COLOR-#000000
><CAPTION><B><*=varTableName ^></B></CAPTI0N></F0NT>
<THEADx*
String varColNames ="";
int varColCount = rsMeta.getColumnCount О ;
for (int col =1; col <- varColCountO; col++) {
*xTH BGCOLOR=#c0c0c0 BORDERCOLOR=#000000 ><F0NT SIZE=2 FACE ="Anal"
COLOR=#000000
><^rsMeta.getColumnName(col)^x/FONT> : </TH>
<% }%>
</TR>
</THEAD>
<TB0DYx*
while [rs.next 0) {
2><TR VALlGN-TOPx*
for (int col = 1; col <= varColCount; col++) {
X><TD BORDERCOLOR~#C0C0C0 xFONT SIZE-2 FACE="Arial" COLOR=#000000
x*=rs .getStringCcol )*xBRx/FONTx/TD>
<% }
}
II II Очистка
rs. closeO ;
Java Server Pages 623
Stmt. closeO ;
conn. closeO ;
}
catch (ClassMotFoundException e) {
out.println("Driver Exception " + e) ;
}*>
</TR>
</TB0DY>
<TF00T</TF00T>
</TABLE>
</B0DY>
</HTML>
На рис. 16.3 показаны результаты вызова этой страницы из браузера Internet
Explorer на компьютере под управлением Windows 2000. Сама страница
обрабатывалась Tomcat на компьютере под управлением Linux. Обратите внимание на
вызов порта 8080: в коммерческой системе Tomcat работал бы вместе с Apache на
заданном по умолчанию порте 80, и указывать номер порта не требовалось бы.
3§таЫеО*Ы<*у ийп«Ф^;ШШШ§ШШШш
$j$dj*fc |Ё http://10 0.0 3:8080/(3enetatTable.)sp?Table=ARTl5T ]£j Ч^"' -*** *'
Database Access Example
Showing Data from MySQL Database vr1
ARTIST
J
t Ыатё: ЦШШпз
Miro Spanish
Tobey US
van Vronken US
Matisse French
ttyj [вШйаЩ \£>ежтваШе
null null
null null
null null
null null
iMW«
1
2 :
;3 I
4
-il
Рис. 16.3. Результат вызова страницы GeneralTable
В листинге 16.3 весь Java-код выделен красным цветом. Первая строка
вызывает каталог страниц, загружая библиотеку java.sql. Затем с помощью метода
getParameter HTTP-объекта request считывается параметр, содержащий имя таб-
624 Глава 16. JDBC, Java Server Pages и MySQL
лицы. Полученная строка преобразуется в строку верхнего регистра. Далее
загружаются классы JDBC, как это делалось в листинге 16.1, и создается соединение
с базой данных vrl для пользователя dkl. Остальной код тот же, что и в
листинге 16.2, — он просто разбросан среди операторов HTML, используемых для
вывода результатов.
Опять-таки, эта страница кажется обманчиво похожей на свою ASP-версию,
GeneralTable.asp, приведенную в главе 15. Разница заключается не только в том,
что вместо ADO и ODBC используется JDBC. Более важно то, что эта страница
будет скомпилирована в Java-программу, а следовательно, станет переносимой
и заработает быстрее.
CustomerlnsertUsingBean.jsp
Поскольку в JSP-страницах используется Java, разработчик имеет в своем
распоряжении всю мощь полноценного объектно-ориентированного языка
программирования. Это означает, что JSP-страницы могут вызывать предварительно
скомпилированные объекты. Это важно и полезно по множеству причин. Во-первых,
это отделяет друг от друга задачи написания программной логики и генерации
HTML-кода. Таким образом, в организации работа над этими двумя существенно
различными задачами может быть поручена двум разным группам. Во-вторых,
это позволяет реализовывать логику в независимых модулях с возможностью их
повторного использования, а также обеспечивает многие другие преимущества,
связанные с инкапсуляцией. Наконец, это уменьшает сложность поддержания сайта.
(Если вы не являетесь Java-программистом, можете пропустить следующий
абзац. Что касается классов Java bean — просто вообразите себе Java-класс с
примерным поведением, который не стыдно показать мамочке.)
Говоря простым языком, класс Java bean — это класс, обладающий тремя
свойствами. Во-первых, у него нет открытых (public) переменных. Во-вторых,
обращение ко всем постоянно хранимым значениям происходит с помощью
методов с названиями вида getxxxn setxxx. Например, значение туУаШесчитывается
с помощью метода getmyValue() и задается с помощью метода setmyValue().
В-третьих, класс Java bean должен либо не иметь конструктора вообще, либо иметь один
явно определенный конструктор без аргументов.
В листинге 16.4 показан класс Java bean под названием CustomerlnsertUsingBean.
Этот класс имеет метод, реализующий логику работы процедуры Customerlnsert
базы данных галереи View Ridge (да, это опять она! Но в последний раз). Этот
класс имеет четыре постоянно хранимых значения: newName, newAreaCode, new-
LocalNumber и newNationality. Для каждого из этих значений определены два
метода доступа — getXXX и setXXX. У класса нет ни открытых постоянно хранимых
значений, ни конструктора. Следовательно, класс CustomerlnsertUsingBean
удовлетворяет определению класса Java bean.
Листинг 16.4. Класс CustomerlnsertBean
import java.io.*;
import java.sql.*;
public class CustomerlnsertBean {
Java Server Pages 625
/** Класс Java bean для процедуры Customerlnsert базы данных View Ridge.
* Доступ к постоянным значениям осуществляется с помощью
* методов getxxx и setxxx.
*
* Процедура добавляет нового клиента, если его еще нет в базе данных,
* а затем ассоциирует его со всеми художниками выбранной национальности.
* вставляя соответствующие строки в таблицу пересечений.
*/
private String newName = "unknown";
private String newAreaCode = "":
private String newLocalNumber = "";
private String newNationality = "";
public String getnewNameO {
return (newName) ;
}
public void setnewName (String newName) {
if (newName != null) {
this.newName = newName;
} else {
this.newName = "unknown";
}
}
public String getnewAreaCode О {
return (newAreaCode) ;
}
public void setnewAreaCode (String newAreaCode) {
if (newAreaCode !=null) {
this.newAreaCode = newAreaCode;
} else {
this.newName = "" ;
public String getnewLocalNumber О {
return (newLocalNumber) ;
}
public void setnewLocalNumber (String newLocalNumber) {
if (newLocalNumber != null) {
this. newLocalNumber = newLocalNumber;
} else {
this.newName = "";
}
}
продолжение^
626 Глава 16. JDBC, Java Server Pages и MySQL
Листинг 16.4 [продолжение)
public String getnewNationality О {
return (newNationality) ;
}
public void setnewNationality (String newNationality) {.
if (newNationality != null) {
this.newNationality = newNationality;
} else {
this.newName = "";
}
}
public String InsertDataO {
try {
// Загрузка драйверов JDBC Марка Мэтьюса
// mm.mysql.jdbc-1.2c
Class.forName ("org.gjt.mm.mysql.Driver") .newlnstance О ;
// Устанавливаем соединение с базой данных vrl как пользователь dkl.
// без пароля
String connString = "jdbcimysql://localhost/" + "vrl" + "?user=dkl";
Connection conn = DriverManager.getConnection(connString) ;
// Соединение установлено. Далее идет проверка на дублирование данных.
Statement stmt = conn.createStatement ( ) ;
String varSQL - "SELECT Name ";
String varWhere = "FROM CUSTOMER WHERE Name- '";
varWhere = varWhere + newName + "' AND AreaCode e '" ;
varWhere = varWhere + newAreaCode + '" AND PhoneNumber = '";
varWhere = varWhere + newLocal Number + ;
varSQL = varSQL + varWhere;
ResultSet rs = stmt.executeQuery (varSQL) ;
while (rs.next 0) {
// Имеются дублирующиеся данные.
rs.closeO ;
stmt.closeO ;
conn.closeO ;
return ("Данные дублируются - никаких действий не предпринято ");
}
// Все в порядке, теперь можно добавлять новые данные
varSQL = "INSERT INTO CUSTOMER (Name, AreaCode. PhoneNumber} ";
varSQL = varSQL + " VALUES ('" + newName + "'. '";
varSQL = varSQL + newAreaCode + "', '";
varSQL = varSQL + newLocal Number + ,")" ;
int result - stmt.executeUpdate (varSQL);
Java Server Pages 627
if (result == 0) {
// Ошибка при вставке
rs.closeO ;
stmt.closet) ;
conn.close() ;
return ("Ошибка при вставке");
}
// Обновление прошло успешно; теперь нужно добавить строки в таблицу пересечений.
// Для этого получаем идентификатор нового клиенга
varSQL - "SELECT CustomerID " + varWhere;
rs = stmt.executeQuery (varSQL) ;
String varCid ="";
while (rs.next О ) {
varCid = rs.getString(l) ;
if (varCid == "0" ) {
// He удалось получить идентификатор нового клиента
rs.closeO ;
stmt.closeO ;
conn.closeO ;
return ("He удается найти нового клиента после вставки");
}
}
// Теперь добавляем строки в таблицу пересечений
varSQL « "SELECT Artist ID FROM ARTIST WHERE Nationality = '"
+ newNationality + ;
String varlnsertStart = "INSERT INTO CUST0MER_ARTIST_INT
(CustomerlD, ArtistID} VALUES
->(" + varCid +". ";
String varlnsertEnd = ")";
rs = stmt.executeQuery (varSQL);
while (rs.nextO) {
result = stmt.executeUpdate
(varlnsertStart + rs.getString(l) + varlnsertEnd);
}
// Очистка
rs.closeO ;
stmt.closeO ;
conn.closeO ;
return ("Success") ;
}
catch (Exception e) {
return ("Exception: " + e ):
}
628 Глава 16. JDBC, Java Server Pages и MySQL
Процедура обновления реализована в методе под названием InsertData. Этот
метод идентичен методу InsertData в листинге 16.2.
На рис. 16.4 показана форма, в которую вводятся данные нового клиента.
HTML-страница для этой формы изображена в листинге 16.5. Обратите
внимание, что тег FORM ACTION имеет значение CustomerlnsertUsingBean.jsp. Также
обратите внимание, что текстовым полям даны имена newName, newAreCode,
newLocalNumber и newNationality. Это имеет значение, потому что при нажатии
кнопки Add Customer (Добавить клиента) странице CustomerlnsertUsingBean.jsp
передаются параметры, содержащие эти имена. Как вы увидите, JSP может
осуществлять привязку входных параметров к одноименным свойствам объекта,
если это потребуется.
ЦГаЫе Х^Ш^.ЩШШШШШШШЯШШ^Ш.
Шё§Ш:1ШШ!Н -*.i.Q.l .?>?
Acfctess|Й http://10.о!0.3:8080/MewCustomer.htm S:3^> "'llEnta; '
View Ridge Gallery
New Customer Form
Bob Horan
AreaCvde- 809
555-3345
In&&on*Htv '>: .Artist?. French
^0ШШЩгщУс\ Fles^^Ligs^|
1Ш 'Oone;:
4
■i
Рис. 16.4. Вид в окне браузера формы New Customer
Листинг 16.5. HTML-код формы New Customer
<HTML>
<HEAD>
<META HTTP-EQUlV="Content-Type" CONTENT=,rtext/htnir>
<TITLE>Table Display Form</TITLE>
<LINK REL-STYLESHEET HREF=MJSP-Styles.css" TYPE^'text/CSS'^
Java Server Pages 629
</HEAD>
<BODY>
<FORM METHOO="post" ACTION="CustomerInsertUsingBean.jsp">
<P><STRONG><FONT color=purple face="" size=5> :  : View Ridge
Gallery</FONT></STRONG>
<P>  :<strong><font co"lor="purple" face size="4"> New
Customer Form</font></strong><P><font sty]e="background-color: #FDF5FC"
color="forestgreen" face>
Name:  : </font><F0NT style=MBACKGR0UND-COLOR: #FDF5EC"> :
 : &nbs p;
 :  :  :  :  :  :
</FONT><INPUT id=newName name=newName></P>
<P> <font style="background-col or: #FDF5EC" color="forestgreen"
face>  :   ;AreaCode<font style="backgroLind-co]or ;
#FDF5E6">: </font>  :  :
 : &n bsp;  :  :  :  :
</font><INPUT id=newAreaCode name=newAreaCode size="6"></P>
<P><font style="background-color: #FDF5EC" color="forestgreen"
face> :
Phone:  :  
 :  :  :  
 :  :  
 
 
 
 :  :  :
  ;  :  :  :
</fontxINPUT id=newLoca!Number name=newLocalNumber Size="20">
 : </P>
<P> :  : <font style="background-color : #FDF5EC"
color"forestgreen" face>Nationality
of Artists:  : </font> <INPUT id=newNationality
name=newNationa]ity size="17"></P>
<P> :<FONT sty!e="BACKGROUND-COLOR: #FDF5EC">
 :  : </F0NT>  : <F0NT sty!e=MBACKGROUND-
COLOR: #FDF5EC">
<IN'PUT id="submitl name=submit] type=subrait value="Add Customer" >  :
 :
<INPUT id=resetl name=resetl type=reset va1ue="Reset Va"lues"></FONT></P>
</F0RM>
</B0DY>
</HTML>
630 Глава 16. JDBC, Java Server Pages и MySQL
Код JSP-страницы CustomerlnsertUsingBean.jsp приведен в листинге 16.6.
Важную роль в этой странице играют два оператора:
<jsp:useBean id="insert" class""CustomerlnsertBean"^
и
<jsp:setProperty name="insert" property="*'7>
Первый оператор дает компилятору JSP команду загрузить класс Customerlnsert-
Bean и связать его с именем insert. Чтобы это работало в Tomcat 3.1, в каталоге
install-dir/webapps/ROOT/WEB-INF/classes, где install-dir — это каталог, в котором
установлен Tomcat, должна находиться скомпилированная версия класса Java bean под
названием CustomerlnsertBean.class. При стандартной установке с помощью
утилиты RPM это будет каталог usr/LocaL/jakarta-tomcat/webapps/ROOT/WEB-INF/classes.
Листинг 16.6. Страница CustomerlnsertUsingBean.jsp
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<!--
Example of Database Access from a JSP Page
<%$ page import="java.sql.*" %>
<HTML>
<HEAD>
<TITLE>Updating Using a Java Bean</TITLE>
<META NAME="author" C0NTENT="David Kroenke">
<META NAME="keywords"
C0NTENT="JSP. JDSC. Database Access">
<META NAME= "description"
C0NTENT="An example of invoking a bean and displaying results.">
<LINK REL=STYLESHEET HREF="JSP-Styles.css" TYPE="text/css">
</HEAD>
<B0DY>
<H2>Database Update Using JDBC from a Java Bean</H2>
<H3>Processing the View Ridge Customer Insert for MySQL Database vrl</H3>
<jsp:useBean id="insert" class="CustomerInsertBean" /> <jsp-.setProperty
name=Minsert" property»"*" />
<%
II Свойства класса были установлены предыдущим оператором,
// теперь вызываем класс, чтобы выполнить вставку
String result=insert.InsertData() ;
if (result != "Success") {
// Выводим сообщение об ошибке и завершаем процедуру
out. printin( "Ошибка" + result};
return;
}
// Данные успешно добавлены в базу. Выводим таблицу пересечений
try {
// Загрузка драйверов JDBC Марка Мэтьюса
//
Java Server Pages 631
Class.forNameC'org.gjt.mm.mysql.Driver") . newlnatance 0 ;
String connString - "jdbcrmysql://localhost/" + "vrl" + "?user=dkl";
Connection conn = DriverManager.getConnection (connString) ;
// Соединяем таблицы CUSTOMER и ARTIST через таблицу пересечений
// Обратите внимание на использование синонимов для CUSTOMER.Name
// и ARTIST.Name
Statement stmt = conn.createStatamentO ;
String varSQL - "SELECT CUSTOMER.Name Customer. ARTIST.4Name Artist,
Nationality ";
VarSQL - varSOL + "FROM CUSTOMER, CUSTOMER_ARTIST_INT. ARTIST ";
varSQL - varSQL + "WHERE CUSTOMER.CustomerID = CUSTOMERJ\RTIST_INT.CustomerID
AND ";
varSQL = varSQL + "ARTIST.ArtistID = CUSTOMER ARTIST INT.ArtistID";
ResultSet rs = stmt.executeQuery(varSQL) ;
ResultSetMetaData rsMeta = rs.getMetaDataO :
<TABLE B0RDER=1 BGC0L0R=#ffffff CELLSPACING=5><F0OT FACE="Arial" COLOR=#000000>
<CAPTION><B>Customers and Interests</B></CAPTION></FONT>
<THEAD>
<TRx*
String varColNames ="";
int varCol Count = rsMeta.getColunnCountO ;
for (int col =1; col <= varColCount: col++) {
*><TH BGCOLOR=#c0c0c0 BORDERCOLOR=#000000 ><F0NT SIZE=2 FACE ="АпаГ
COLOR=#000000
>X=rsMeta.getColumnName(col)X></FONT> </TH>
<% )%>
</TR>
</THEAD>
<TB0DY><*
while (rs.next 0) {
*><TR VALIGN=TOP><*
for (int col = 1; col <= varColCount: col++) { %>
<TD BORDERCOLOR=#C0C0C0 ><FONT SIZE=2 FACE="Arial" COLOR=#000000
><£=rs.getString(col) *><BR></FONT></TD><£
=rs.getStri ng(col)2><BR></F0NT></TD><*
}
}
// Очистка
rs.closeO;
stmt.closeO:
}
catch (ClassNotFoundException e) {
out.println ("Drinver Exception " + e);
}*>
</TR>
продолжение &
632 Глава 16. JDBC, Java Server Pages и MySQL
Листинг 16.6 (продолжение)
</TBODY>
<TFOOT></TFDOT>
</TABLE>
</BODY>
</HTML>
Второй оператор предписывает синтаксическому анализатору JSP
устанавливать свойства класса с использованием входных параметров формы. Символ «*»
сигнализирует о том, что все свойства должны быть привязаны к одноименным
параметрам. Этот короткий оператор заменяет собой следующую
последовательность операторов:
<jsp:setProperty name="insert"
property="newValue"
value='<Я= request,getParameter CnewName")%>'/>
<jsp:setProperty name="insert"
property="newAreaCode"
val ue='<%= request.getParameter("newAreaCode")%>'/>
<jsp:setProperty name="insert"
property="newLocalNumber"
value='<^= request.getParameterГnewLocalNumber")%>'/>
<jsp:setProperty name="insert"
property="newNational ity"
value='<^= request. getParameter ("newNational ity")&>'/>
Разумеется, можно использовать обе версии. На самом деле длинную версию
использовать необходимо, если имена параметров формы отличаются от имен
свойств объекта.
В листинге 16.6 метод InsertData вызывается при помощи следующей строки:
String result=insert.InsertData();
Если метод возвращает значение, отличное от Success, выводится
сообщение об ошибке. В противном случае на экран выводится соединение таблиц
CUSTOMER, CUSTOMER_ARTIST_INIT и ARTIST аналогично тому, как это делается в
листинге 16.1. Результат изображен на рис. 16.5.
Это было очень краткое введение в разработку JSP-страниц. Многие вопросы
остались за рамками нашего изложения. Подробнее о сервлетах и Java Server
Pages можно прочитать в специальной литературе.
MySQL
MySQL — это свободно распространяемая СУБД с открытыми исходными
текстами, работающая под управлением Unix, Linux и Windows. Исходные тесты и
бинарные файлы MySQL можно загрузить с сайта MySQL по адресу http://www.mysql.com.
Примеры этой главы запускались в MySQL для Linux, но они будут работать
и в других операционных системах.
MySQL 633
Database Update Using JDBC from a Java Bean
I Processing the View Ridge Customer Insert for MySQL Database vii
I Customers and Interests
Selma Warning Tobey : US f
Selma Warning van Vronken US щ
Fred Smathers Tobey .US ; ;::
Fred Smathers van Vronken US J ;:
Susan Wu ; Tobey . US i :
Susan Wu ; jvan Vronken.,US J
Taylor Johnson. .Tobey ; ;US j
Taylor Johnson; |van Vronken||US ;
CJ Mossberg . 'Matisse ' French ;
i Wilma Greene |Miro ■ Spanish
1 Bob Horan iMattsse French : j ■
г ZZIZZZZZZ. ...., щ
Рис. 16.5. Результат вызова страницы CustomerlnsertUsingBean.jsp
По состоянию на декабрь 2000 года плата за лицензию на установку MySQL
не предусматривалась, кроме случаев встраивания ее в в коммерческое
приложение. Более подробная информация содержится в лицензионном соглашении,
которое можно найти на сайте MySQL.
В MySQL отсутствуют многие возможности, которые можно найти в
коммерческих СУБД, подобных Oracle с SQL Server, и если у вас есть доступ к одному
из этих продуктов, стоит использовать их. Если же вы работаете с малым
бюджетом или хотите принять участие в движении open source, MySQL может быть
хорошим выбором. В среде Linux/Unix MySQL не только дешевле, чем Oracle
и другие коммерческие продукты, но и легче в установке. В настоящее время
есть несколько хороших книг, способных послужить руководством по MySQL.
Это может показаться забавным, но по причине своих ограниченных
возможностей в сфере управления транзакциями и протоколирования MySQL показывает
очень высокое быстродействие в приложениях, целиком ориентированных на
запрос. Есть интернет-компании, которые для поддержки своих баз данных
используют Oracle, но для публикации на web-серверах загружают их в MySQL.
Ограничения MySQL
MySQL версий 3.x не поддерживает представления, хранимые процедуры и
триггеры. Все это, однако, включено в список задач на будущее, поэтому стоит
634 Глава 16. JDBC, Java Server Pages и MySQL
просмотреть последнюю документацию на предмет того, не появились ли какие-то
из этих функций в более новых версиях продукта.
Второй момент касается ограничений внешнего ключа (ссылочной
целостности). Хотя эти ограничения воспринимаются MySQL при синтаксическом
анализе как допустимые конструкции, никаких действий в связи с ними не
предпринимается. Это означает, например, что выражение ON CASCADE DELETE в ограничении
внешнего ключа не будет воспринято как ошибка, однако каскадные удаления,
вопреки ожиданиям, производиться не будут. Если обратиться к примеру с
галереей View Ridge, то синтаксический анализатор MySQL легко пропустит
следующее ограничение:
ALTER TABLE CUSTOMER_ARTIST_INT ADD CONSTRAINT CustomerIntFK FOREIGN
KEY(CustomerlD) REFERENCES CUSTOMER ON DELETE CASCADE;
Но после удаления строки из таблицы CUSTOMER каскадных удалений не будет,
и придется выполнить их вручную.
Работа с MySQL
Чтобы запустить MySQL из командной строки, введите
MySQL -u имя_пользователя -р
Введите действующее имя пользователя. После этого вам будет предложено
ввести пароль. Если вы используете учетную запись, которая не имеет пароля,
вы можете набрать
MySQL -и имя_пользователя
Чтобы увидеть, какие имеются базы данных, введите
Show databases;
Обратите внимание, что команды MySQL завершаются точкой с запятой.
Кроме того, команды MySQL нечувствительны к регистру, но в именах
пользовательских конструкций (таблиц, столбцов и т. д.) регистр имеет значение.
Работа с существующей базой данных
Для работы с одной из уже существующих баз данных введите
Use имя_базы_данных;
Например, для работы с базой данных vrl следует набрать
Use vrl;
Чтобы узнать, какие таблицы имеются в базе данных, введите
Show tables;
Метаданные таблиц выводятся с помощью команды describe, например
Describe CUSTOMER;
MySQL 635
Теперь можно вводить любые стандартные операторы SQL. Операторы SELECT,
UPDATE, INSERT pi DELETE будут работать так, как и ожидается.
Создание новой базы данных
Чтобы создать новую базу данных, войдите в MySQL с той учетной записи,
которую вы хотите сделать владельцем новой базы. Затем введите
Create Database имя_новой_базы_данных;
Например, чтобы создать базу данных с именем vr2, следует ввести
Create database vr2;
Создав пустую базу данных, можно формировать ее структуру с помощью SQL-
операторов CREATE, как мы делали ранее. В листинге 16.7 показана
последовательность операторов, создающая структуру базы данных View Ridge. Всем суррогатным
ключам дано свойство AUTOJNCREMENT. Этот тип данных представляет собой
поддерживаемую MySQL последовательность, которая начинается с единицы и
увеличивается с шагом один. Обратите внимание, что MySQL поддерживает тип данных
Year. Этот тип данных, являющийся четырехзначным целым числом, используется
для столбцов BirthDate и DeceasedDate таблицы ARTIST. Обратите внимание и на то,
что ограничения внешнего ключа отсутствуют. Как уже говорилось выше, MySQL
воспримет их как допустимые конструкции, но ничего не будет с ними делать.
Листинг 16.7. SQL-операторы для создания базы данных View Ridge в MySQL
CREATE TABLE CUSTOMER (
CustomerlD int AUTOJNCREMENT PRIMARY КЕУ.
Name varchar(25) NULL.
Street varchar (30) NULL.
City varchar(35) NULL.
State varchar(2) NULL.
Zip varchar(9) NULL.
AreaCode varchar(3) NULL.
PhoneNumber varchar (8) NULL) ;
CREATE INDEX CUSTOMER_Name_IDX ON CUSTOMER (Name) ;
CREATE TABLE ARTIST (
ArtistID int AUTOJNCREMENT PRIMARY KEY.
Name varchar(25) NOT NULL.
Nationality varchar(30) NULL.
Birthdate year NULL.
DeceasedDate year NULL);
CREATE UNIQUE INDEX ARTIST_Name_IDX ON ARTIST(Name);
CREATE TABLE W0RK(
Work ID int AUTOJNCREMENT PRIMARY KEY.
Description text NULL,
продолжение^
636 Глава 16. JDBC, Java Server Pages и MySQL
Листинг 16.7 {продолжение)
Title varchar(25) NOT NULL.
Copy varchar(8) NOT NULL.
ArtistID int NOT NULL);
CREATE UNIQUE INDEX WORK_ID_IDX ON WORK (Title. Copy. ArtistID);
CREATE TABLE CUSTOMER_ARTIST_INT (
ArtistID int NOT NULL.
Customer-ID int NOT NULL):
ALTER TABLE CUSTOMER_ARTlST_INT
ADD
CONSTRAINT CUST ARTIST PK PRIMARY KEY ( ArtistID. CustomerlD );
CREATE TABLE TRANSACTION (
TransactionID int AUTOJNCREMENT PRIMARY KEY.
DateAcqulred date NOT NULL,
AcquisitionPrice decimal(7.2) NULL.
PurchaseDate date NULL.
SalesPrice decimal(7.2) NULL.
CustomerlD int NULL.
Work ID int NOT NULL);
В листинге 16.7 создается уникальный индекс по столбцам (Title, Copy, ArtistID)
таблицы WORK. Этот уникальный индекс предотвращает вставку в базу данных
повторяющихся записей о произведениях. Это означает, что действия,
выполняемые приведенными ранее Java-программами для предупреждения таких
ситуаций, оказываются ненужными. Они не приносят никакого вреда, разве что чуть-
чуть снижают производительность. Тем не менее, как сказано в главе 10, всегда
лучше по возможности обеспечивать выполнение ограничений целостности в базе
данных.
Показанные здесь операторы можно вводить в MySQL вручную. Но если эти
операторы записаны у вас в файле, их можно импортировать в MySQL.
Предположим, последовательность операторов, показанных в листинге 16.7, содержится
в файле под именем VRSQL.txt. Чтобы ее выполнить, введите в командной строке
оболочки shell (не MySQL!) следующую команду:
mysql --user=dkl --password=sesame < VRSQL.txt
В результате запустится MySQL для пользователя dkl с паролем sesame и
будут выполнены содержащиеся в файле операторы.
Настройка разрешений на доступ для JDBC
Если вы понимаете ограничения MySQL, работа с этой СУБД не представляет
трудностей. Операторы SQL выполняются в точности так, как и следует ожидать.
Есть, однако, одна маленькая особенность, о которой следует знать. Соединения
MySQL 637
с JDBC обрабатываются не так, как все остальные пользовательские соединения.
Чтобы понять, что в связи с этим следует делать, рассмотрим сначала словарь
данных MySQL.
MySQL хранит метаданные в базе данных mysql. Особый интерес
представляют в ней две таблицы: user и db. Чтобы увидеть содержащиеся в них метаданные,
откройте базу данных mysql и введите команду describe с именами этих таблиц.
Для просмотра списка пользователей и их компьютеров введите на приглашение
mysql следующее:
Use mysql;
SELECT Host, User FROM user;
Для просмотра списка пользователей, их компьютеров и баз данных,
доступных для них, введите
SELECT Host, User. Db FROM db;
В качестве имени компьютера обычно фигурирует строка localhost, имя
компьютера, на котором работает MySQL, и имена других компьютеров. Значение %
означает, что данный пользователь может устанавливать соединение с любого
компьютера.
Исходя из этого, логично предположить, что программы JDBC, работающие
на той же машине, что и MySQL, в качестве имени компьютера будут иметь
localhost. Однако это не так. Дело в том, что для MySQL localhost обозначает
соединение через сокет, тогда как в JDBC соединение устанавливается по
протоколу TCP/IP. Таким образом, если вы хотите установить соединение с помощью
JDBC, простейшим (но наименее безопасным) методом будет предоставить
требуемой учетной записи доступ к базе данных с любой машины. Это делает
следующий оператор:
GRANT ALL ON vrl.* TO dkKa'X IDENTIFIED BY "sesame";
Этот оператор предоставляет полномочия доступа ко всем таблицам базы
данных vrl пользователю учетной записи dkl с паролем sesame. Символ процента
(%) означает, что dkl может устанавливать соединение с любого компьютера.
Для большей безопасности его следует заменить конкретным IP-адресом.
Выполнив этот оператор, запросите из таблицы db столбцы User, Host и Db,
чтобы удостовериться, что ваш пользователь в качестве имени компьютера имеет %.
Если это так, то вы можете соединяться с этой базой данных с помощью JDBC.
Управление параллельной обработкой
MySQL имеет ограниченную поддержку управления параллельной обработкой.
В версии 3.0 отсутствует поддержка транзакций, соответственно, уровень
изоляции транзакции тоже установить невозможно. Отсутствует также возможность
отката транзакций. Приложения должны выполнять откат самостоятельно при
необходимости.
638 Глава 16. JDBC, Java Server Pages и MySQL
MySQL использует блокировки чтения и записи на уровне таблицы. При
выполнении оператора SELECT MySQL налагает блокировки чтения на все таблицы,
указанные в операторе. Такая блокировка не даст другим сеансам произвести
запись в эти таблицы, но чтению препятствовать не будет. При выполнении
операторов INSERT, UPDATE и DELETE MySQL налагает блокировки записи на все
затронутые ими таблицы. Такая блокировка не позволит другим сеансам ни читать,
ни записывать данные. Результатом этой блокировочной стратегии является
согласованность данных, считываемых и обновляемых отдельно взятым
оператором. Таким образом, все операции чтения и записи данных происходят правильно.
Компенсировать отсутствие транзакций можно, отмечая предполагаемые
рамки транзакций командами LOCK TABLES/UNLOCK TABLES. Так, последовательность
операторов
LOCK TABLES Tl. Т2, ТЗ WRITE;
UPDATE TABLE Tl SET Coll-"xzy" WHERE Coll^'abc";
UPDATE TABLE T2
UPDATE TABLE T3
... прочие действия этой транзакции с таблицами Tl. T2. ТЗ
UNLOCK TABLES;
не позволит другим пользователям выполнить запись или чтение данных из
таблиц Tl, Т2 и ТЗ, пока идет обработка транзакции. Все обновления между
операторами LOCK и UNLOCK являются атомарными, поскольку выполняются до снятия
какой-либо блокировки.
К сожалению, при таком использовании блокировок для других
пользователей заблокированных таблиц работа остановится. Пока выполняется
транзакция, ни один пользователь не сможет читать или записывать данные в таблицы
Tl, Т2 и ТЗ. На период блокировки MySQL превратится в однопользовательскую
систему по отношению к этим трем таблицам. Это, скорее всего, будет серьезной
проблемой, если.транзакции являются длительными и если приложение
производит много обновлений.
В любом сеансе все таблицы должны блокироваться одновременно. Если
требуется блокировка с более широким охватом, сеанс должен снять имеющиеся
блокировки и заново наложить блокировки на большее число таблиц. Таким
образом, ни у одного сеанса не может быть более одного активного оператора LOCK
TABLES одновременно. Как вы помните из главы 11, эта стратегия исключает
вероятность возникновения взаимной блокировки.
«Грязное» чтение может быть возможно или нет в зависимости от того, как
написано приложение. В MySQL не предусмотрен откат, поэтому, если
приложение не выполняет откат самостоятельно, «грязное» чтение возможно. Если
же приложение способно выполнять откат и если действия, откат которых
требуется произвести, расположены между операторами LOCK TABLES и UNLOCK TABLES,
«грязное» чтение невозможно. Однако, как уже говорилось, такая стратегия
может привести к неприемлемо низкой пропускной способности. Наконец, если
приложение делает откат, но не использует операторы LOCK и UNLOCK, то
«грязное» чтение возможно.
Резюме 639
Резервное копирование и восстановление
Возможности MySQL в сфере резервного копирования и восстановления
ограничены. В MySQL есть утилита для сохранения базы данных и отдельных таблиц из
нее. В некоторых случаях, однако, более быстрым и столь же простым методом
является сохранение файлов базы данных на резервных носителях с помощью
команд копирования операционной системы.
MySQL ведет журнал выполняемых действий. Но этот журнал состоит из
команд и выполняемой работы, а не из исходных и конечных образов. Для
восстановления базы данных копируется более ранняя версия базы и к ней
применяются команды, записанные в журнале. Массовые изменения записываются
в виде команд: в журнале указывается только имя файла, явившегося
источником изменений. Отдельные изменения не регистрируются.
Кстати, если вы восстанавливаете базу данных после ввода ошибочного
оператора, например
DROP TABLE CUSTOMER;
не забудьте перед повторной обработкой журнала удалить из него этот оператор
DROP. В противном случае он будет выполнен диспетчером журнала, и вы
вернетесь туда, откуда пришли, — к отсутствующей таблице CUSTOMER.
Заключительное слово о MySQL
Насколько можно судить по этому разделу, система MySQL лишена многих
возможностей и функций, имеющихся в современных СУБД. Может возникнуть
вопрос, зачем же она вообще нужна. Дело в том, что, как сказано выше, эта СУБД
распространяется свободно и имеет открытые исходные тексты. Если вы хотите
принять участие в проекте open source в области СУБД, MySQL будет хорошим
выбором. Кроме того, MySQL проста и даже приятна в использовании.
Имеющиеся в ней возможности и функции реализованы хорошо. Создается
впечатление, что сообщество разработчиков MySQL предпочитает делать немного, но
качественно. Работать с таким продуктом — одно удовольствие.
Резюме
JDBC — это альтернатива ODBC и ADO, обеспечивающая доступ к базам данных
для программ, написанных на Java. Драйверы JDBC существуют почти для
каждой мыслимой СУБД. Корпорация Sun определила четыре типа драйверов.
Драйверы типа 1 обеспечивают мост между Java и ODBC. Драйверы типов 2-4
написаны целиком на Java. Драйверы типа 2 в связи между компьютерами полагаются
на возможности СУБД, если таковые имеются. Драйверы типа 3 транслируют
вызовы JDBC в независимый от СУБД сетевой протокол. Драйверы типа 4
преобразуют вызовы JDBC в сетевой протокол конкретной СУБД.
Апплет — это скомпилированная в байт-код программа на Java, которая
передается браузеру по HTTP и вызывается с помощью этого же протокола. Сервлет —
640 Глава 16. JDBC, Java Server Pages и MySQL
это Java-программа, работающая на сервере и отвечающая на HTTP-запросы.
Драйверы типов 3 и 4 могут использоваться как для апплетов, так и для сервле-
тов. Драйверы типа 2 могут использоваться только в сервлетах, и только если
СУБД и web-сервер находятся на одной машине, или если СУБД
самостоятельно обеспечивает связь между web-сервером и сервером базы данных.
Алгоритм использования JDBC состоит из четырех шагов: (1) загрузить
драйвер; (2) установить соединение с базой данных; (3) создать оператор; (4)
выполнить оператор. Библиотеки классов драйвера должны быть в CLASSPATH
компилятора и виртуальной машины Java. Они загружаются в
Java-программу с помощью метода forName. Соединение устанавливается с помощью метода
getConnection объекта DriverManager. Строка соединения состоит из символов jdbc:,
за которыми следует имя драйвера и URL базы данных.
Операторы создаются с помощью метода createStatement объекта Connection.
Выполнение операторов производится методами executeQuery и executeUpdate
объекта Statement. Объекты ResultSetMetaData создаются при помощи метода getMetaData
объекта ResultSet JDBC позволяет выполнять скомпилированные запросы и
хранимые процедуры с использованием объектов PreparedStatement и CallableStatement.
Технология Java Server Pages QSP) позволяет создавать динамические web-
страницы с использованием HTML, XML и Java. JSP-страницы предоставляют
в распоряжение разработчика всю мощь полноценного
объектно-ориентированного языка программирования. Ни VBScript, ни JavaScript в JSP использоваться
не могут. JSP-страницы компилируются в машинно-независимый байт-код.
JSP-страницы компилируются в виде подклассов класса HttpServlet.
Следовательно, в JSP-страницу можно помещать как законченные Java-программы, так
и фрагменты Java-кода. Чтобы работа с JSP-страницами была возможна,
web-сервер должен реализовывать спецификации Java Servlet 2.1+ и Java Server Pages 1.0+.
Apache Tomcat, свободно распространяемый продукт с открытыми исходными
текстами от проекта Jakarta, поддерживает эти спецификации. Tomcat может
работать в связке с Apache или как автономный тестовый web-сервер.
При использовании Tomcat (или любого другого обработчика JSP) драйверы
JDBC и JSP-страницы должны помещаться в специальные каталоги. То же
самое относится и к классам Java bean, используемым JSP-страницами. Получив
запрос на обработку JSP-страницы, Tomcat сначала убеждается, что
используется самая новая версия страницы. Если обнаруживается более поздняя
скомпилированная версия страницы, Tomcat автоматически производит ее
синтаксический анализ и компиляцию. В памяти одновременно находится максимум одна
копия JSP-страницы, и запросы на обработку JSP-страниц выполняются
отдельным потоком обработчика сервлетов, а не отдельным процессом. Если требуется,
Java-код в JSP-странице может вызывать скомпилированный класс Java bean.
MySQL — это свободно распространяемая СУБД с открытыми текстами,
работающая под управлением Unix, Linux и Windows. Платить за лицензию на ее
установку не требуется. MySQL может обеспечить весьма быструю обработку
запросов, но она не поддерживает представления, хранимые процедуры и
триггеры. Ограничения ссылочной целостности могут быть определены, но они не
будут реализовываться MySQL. MySQL поддерживает словарь данных в базе
данных с именем mysql. Для определения полномочий пользователей можно запросить
Вопросы I группы 641
таблицы user и db из этой базы данных. Для обращения к MySQL через JDBC
учетной записи пользователя должен быть предоставлен доступ к базе данных либо
с любого компьютера, либо с IP-адреса, представляющего локальный компьютер.
MySQL предоставляет ограниченные возможности для управления
параллельной обработкой. Транзакции не поддерживаются, поэтому нет операторов COMMIT
и ROLLBACK и невозможно установить уровень изоляции. MySQL налагает
блокировки на уровне таблицы. Коллективная блокировка чтения налагается при
выполнении операторов SELECT, а при записи налагается монопольная блокировка.
Блокировка на уровне таблиц может привести к снижению пропускной
способности. Операторы, которые должны выполняться в рамках транзакции, можно
окружать командами LOCK TABLES и UNLOCK TABLES. Взаимная блокировка
предотвращается за счет того, что одновременно может быть активен только один
оператор LOCK TABLES. «Грязное» чтение возможно, если некоторые приложения
производят откат выполняемых действий, но не блокируют таблицы на время
выполнения этих действий.
Возможности MySQL в сфере резервного копирования и восстановления
также ограничены. В MySQL имеется утилита, которая дополняет программы
копирования операционной системы. MySQL ведет журнал выполненных команд.
Этот журнал не содержит исходных и конечных образов, и в него не
записываются результаты массовых обновлений или удалений. Хотя MySQL имеет
множество ограничений MySQL, она проста в использовании, а те возможности
и функции, которые в ней реализованы, реализованы качественно.
Вопросы I группы
1. Что необходимо для использования JDBC?
2. Как расшифровывается JDBC?
3. Какие четыре типа драйверов есть в JDBC?
4. Объясните назначение драйверов JDBC типа 1.
5. Объясните назначение драйверов JDBC типов 2-4.
6. Дайте определения терминов апплет и сервлет.
7. Объясните, как в Java достигается переносимость.
8. Перечислите четыре шага, из которых состоит работа с драйвером JDBC.
9. Напишите оператор Java, загружающий драйверы mm.mysql,
использованные в этой главе.
10. Напишите Java-оператор, устанавливающий соединение с базой данных
с помощью драйверов mm.mysql. Пусть база данных называется CustData,
имя пользователя — Lew, пароль — Secret
11. Напишите оператор Java, создающий объект Statement (набор результатов).
12. Напишите оператор Java, создающий объект ResultSet, содержащий
столбцы Name и Nationality таблицы ARTIST, используя созданный ранее объект
Statement с именем $.
642 Глава 16. JDBC, Java Server Pages и MySQL
13. Напишите Java-оператор, перебирающий набор результатов s, созданный
в ответе на вопрос 12.
14. Напишите Java-оператор, выполняющий обновление, при котором
национальность художника по фамилии Jones меняется на French. Используйте
созданный ранее набор результатов s.
15. Как в вопросе 14 можно определить, успешным ли было обновление?
16. Напишите Java-оператор, который создает объект, содержащий
метаданные набора результатов, созданного в ответе на вопрос 12.
17. Напишите последовательность Java-операторов, необходимую для вызова
хранимой процедуры CustomerJDelete. Будем предполагать, что процедура
имеет три текстовых параметра: имя клиента, код региона и номер телефона.
Пусть параметры процедуры имеют значения Mary Orange, 206 и 555-1234.
18. Каково назначение Java Server Pages?
19. Опишите различия между ASP- и JSP-страницами.
20. Объясните, как достигается переносимость JSP-страниц.
21. Почему в JSP-страницы можно включать маленькие фрагменты
Java-кода? Почему для этого не требуется писать законченные Java-программы?
22. Для чего предназначен Tomcat?
23. Какие действия следует предпринять при стандартной установке Tomcat,
прежде чем использовать JSP-страницы, которые загружают классы JDBC?
24. Что нужно сделать при подключении к Tomcat новых библиотек классов,
чтобы эти библиотеки появились в CLASSPATH?
25. Опишите процесс компиляции и выполнения JSP-страниц. Можно ли
использовать устаревшую страницу? Обоснуйте свой ответ.
26. Почему JSP-страницы предпочтительнее CGI-сценариев?
27. Каким требованиям должен удовлетворять Java-класс, чтобы быть
классом Java bean?
28. Напишите директиву jsp, загружающую класс Java bean с именем Customer-
DeleteBean. Дайте загруженному классу идентификатор custdeL
29. Напишите директиву jsp, присваивающую свойству Propl класса Java bean
значение параметра формы Ра га ml.
30. Почему лучше давать свойствам объекта и параметрам формы
одинаковые имена? Напишите директиву jsp, связывающую свойства и параметры
в этом случае.
31. В чем разница между вызовом класса Java bean из Java-программы и из
Java-кода JSP-страницы?
32. При каких условиях вы стали бы использовать MySQL?
33. С каким типом работы отлично справляется MySQL?
34. Перечислите основные ограничения MySQL.
35. Как MySQL обрабатывает ограничения ссылочной целостности?
Проекты 643
36. Какой SQL-оператор используется в MySQL для создания новой таблицы?
37. Что нужно иметь в виду, устанавливая соединение с MySQL с помощью
JDBC?
38. Напишите команду MySQL, дающую пользователю с именем Lew
полномочия на доступ к любой таблице базы данных CustData. Пусть паролем
будет Secret.
39. Опишите имеющиеся в MySQL возможности управления транзакциями.
40. Как MySQL использует блокировки чтения?
41. Как MySQL использует блокировки записи?
42. На каком уровне MySQL налагает блокировки? Каковы преимущества
и недостатки такого подхода?
43. Покажите, как приложение может обеспечить атомарность транзакций
с использованием операторов LOCK TABLES и UNLOCK TABLES.
44. В чем заключается недостаток стратегии, описанной вами в ответе на
вопрос 43?
45. Почему взаимная блокировка в MySQL невозможна?
46. При каких условиях в MySQL возможно «грязное» чтение?
47. Опишите имеющиеся в MySQL возможности для резервного копирования.
48. Каковы ограничения протоколирования в MySQL?
49. Согласно доводам автора, почему стоит использовать MySQL?
Вопросы II группы
50. Сравните между собой ASP и JSP. Укажите сильные и слабые стороны
каждой технологии. При каких условиях вы отдали бы предпочтение одной
технологии перед другой? Насколько важна переносимость для
web-серверов? Насколько большим недостатком является зависимость от Microsoft?
Некоторые говорят, что выбор в пользу той или другой технологии
является скорее вопросом личных предпочтений и ценностей, нежели чего-то
другого. Согласны ли вы с этим?
51. Перепишите класс Java bean, показанный в листинге 16.4, чтобы он
использовал исключения, а не возвращал значение result. Модифицируйте JSP-
страницу, чтобы она корректно обрабатывала этот класс. Чем
получившийся класс лучше исходного?
Проекты
1. Напишите Java-программу, использующую MySQL и драйверы mm.mysql,
которыми мы пользовались в этой главе. Ваша программа должна
реализовать логику работы хранимой процедуры CustomerlnsertWothTransaction,
644 Глава 16. JDBC, Java Server Pages и MySQL
описанной в варианте для Oracle в главе 12 и в варианте для SQL Server
в главе 13. Сделайте так, чтобы программа выводила те же результаты, что
показаны в представлении CustomerPurchasesView. Запустите вашу
программу в автономном режиме.
2. Преобразуйте программу, написанную вами для проекта 1, в класс Java bean.
Напишите JSP-страницу, вызывающую этот класс.
3. Найдите драйвер ODBC для Oracle и напишите Java-программу,
устанавливающую соединение с версией базы данных View Ridge для Oracle и
выводящую содержимое любой таблицы этой базы данных. Напишите Java-
программу, вызывающую хранимую процедуру Customerlnsert. Для вызова
используйте JDBC-объект CallableStatement.
4. Преобразуйте программу, написанную вами для проекта 3, в класс Java
bean. Напишите JSP-страницу, вызывающую этот класс.
5. Найдите драйвер ODBC для SQL Server и напишите Java-программу,
устанавливающую соединение с версией базы данных View Ridge для SQL Server
и выводящую содержимое любой таблицы этой базы данных. Напишите
Java-программу, вызывающую хранимую процедуру Customerlnsert. Для
вызова используйте JDBC-объект CallableStatement.
6. Преобразуйте программу, написанную вами для проекта 5, в класс Java bean.
Напишите JSP-страницу, вызывающую этот класс.
Вопросы к проекту FiredUp
Создайте базу данных FiredUp в MySQL или Oracle. В MySQL вы не сможете
задавать ограничения ссылочной целостности; в остальном следуйте указаниям,
приведенным в конце главы 12 или 13.
1. Напишите JSP-страницу, выводящую таблицу ГОРЕЛКА.
2. Напишите JSP-страницу, выводящую содержимое любой таблицы базы
данных FiredUp. За образец возьмите листинг 16.1.
3. Напишите JSP-страницу, позволяющую ввести данные о новой горелке.
Для вставки используйте класс Java bean. За образец возьмите листинги
16.4 и 16.5.
4. Напишите JSP-страницу, позволяющую клиентам регистрировать свои
горелки.
5. Создайте класс Java bean, реализующий процедуру ввода данных о
ремонте горелки.
6. Напишите JSP-страницу, вызывающую класс Java bean, созданный в
вопросе 5. За образец возьмите листинги 16.4 и 16.5.
Глава 17
Совместное использование
данных предприятия
В предыдущих главах этой книги описывалась работа с базами данных в
контексте персональных компьютеров и интернет-технологий с использованием
трехуровневой и многоуровневой архитектуры. Но на предприятиях
используются также другие, более старые типы систем. Поскольку вам, возможно, придется
с ними столкнуться, в первой части этой главы мы кратко рассмотрим
характеристики трех типов таких систем. Четвертый тип систем, который постепенно
начинает использоваться в коммерческих приложениях, — это системы
распределенной обработки баз данных, которые мы также будем обсуждать здесь. И Oracle,
и SQL Server поддерживают распределенную обработку баз данных.
Данные являются важным активом организации — активом, который можно
использовать не только для упрощения работы, но и для управления,
планирования, прогнозирования, стратегического анализа и т. п. К сожалению, во многих
организациях, наряду с несомненным положительным эффектом от
использования баз данных, имеется сознание того, что в сфере анализа, планирования
и других составляющих управления предприятием базы данных используются
неэффективно. В этой главе обсуждаются вопросы, представляющие важность
для увеличения отдачи от средств, инвестированных в данные какого-либо
предприятия, — загрузка централизованных данных, оперативная аналитическая
обработка данных (OLAP), хранилища данных и администрирование данных.
Архитектуры организационных систем
обработки данных
Для обработки данных в масштабе предприятия используются несколько
различных архитектур. В прошлом наиболее распространены были системы удаленной
обработки данных. Но по мере того как микрокомпьютеры стали появляться в
офисах и выросла их мощь в качестве серверов данных, возникли новые архитектуры
многопользовательских систем обработки данных. В этом разделе мы обсудим
системы удаленной обработки данных, клиент-серверные системы, системы
совместного использования файлов и системы обработки распределенных баз данных.
646 Глава 17. Совместное использование данных предприятия
Системы удаленной обработки
Классическим методом поддержки многопользовательской базы данных
является удаленная обработка (teleprocessing), при которой используется один
компьютер и один процессор. Вся обработка производится этим единственным
компьютером.
На рис. 17.1 показана типичная система удаленной обработки (teleprocessing
system). Пользователи работают с неинтеллектуальными («глупыми»)
терминалами (или с микрокомпьютерами, эмулирующими такие терминалы), которые
передают сообщения о транзакциях и данные центральному компьютеру. Часть
операционной системы, отвечающая за управление связью, принимает
сообщения и данные и передает их соответствующим прикладным программам.
Программы обращаются к СУБД, а СУБД выполняет операции с базой данных,
используя ту часть операционной системы, которая отвечает за обработку данных.
Когда транзакция завершается, подсистема управления связью возвращает
результаты пользователям, сидящим у терминалов.
На рис. 17.1 показаны п пользователей, транзакции которых обрабатывают
три различные прикладные программы. Поскольку на стороне пользователя
интеллектуальные устройства присутствуют в ограниченной степени (имеются
в виду, естественно, терминалы), все команды форматирования вывода должны
генерироваться процессором центрального компьютера и передаваться по линии
связи. Это означает, что пользовательский интерфейс имеет текстовую
ориентацию и примитивен по своей сути. Системы, подобные этой, называются
системами удаленной обработки, поскольку связь между всеми входами и выходами
осуществляется через находящийся на расстоянии центральный компьютер,
ведущий обработку.
Терминал
пользователя 1 w
Терминал ^^
пользователя 2 ^" ►
1
Терминал /
пппьзорателя п /
осУс
ПП1
ПП2
ППп
СУБД
ОСуд
^ W
^ W
БД
Communications Lines
Компьютер удаленной обработки
ОСук = часть операционной системы, отвечающая
за управление коммуникацией
ПП
• прикладная программа
ОСуд = часть операционной системы, отвечающая
за управление данными
Рис. 17.1. Связи между программами в системе удаленной обработки данных
Архитектуры организационных систем обработки данных 647
Исторически системы удаленной обработки были наиболее
распространенной альтернативой многопользовательским системам баз данных. Но по мере
уменьшения соотношения цены и производительности для компьютеров и, в
частности, с появлением персональных компьютеров, они были вытеснены другими
системами, состоящими более чем из одного компьютера.
Клиент-серверные системы
На рис. 17.2 изображена схема одной из таких систем, которая носит название
клиент-серверной системы (client-server system). В отличие от системы
удаленной обработки, в которой имеется только один компьютер, клиент-серверная
система состоит из множества компьютеров, объединенных в сеть. Одни
компьютеры, называемые клиентами (clients), занимаются обработкой прикладных
программ. Другие компьютеры, называемые серверами (servers), занимаются
обработкой базы данных.
Пользователь 1 < ►
ПП1
ПП2
ОСс
Клиентский компьютер 1
Пользователь 2 «< м ПП2 ОССЕТЬ
Клиентский компьютер 2
Пользователь п <-
ПП2
ППЗ
ОСс
Локальная или глобальная сеть
ОСс
СУБД
ОСу
БД
Компьютер сервера базы данных
ОССЕТЬ = часть операционной системы,
Клиентский компьютер п
ОС
уд
отвечающая за сетевую коммуникацию
= часть операционной системы, отвечающая
за управление данными
Рис. 17.2. Клиент-серверная архитектура
На рис. 17.2 показан пример, в котором каждый из п пользователей имеет
свой клиентский компьютер, обрабатывающий приложения, — пользователь
Userl обрабатывает на компьютере Clientl приложения API и АР2, пользователь
User2 обрабатывает приложение АР2 на компьютере Client2, а пользователь UserN
обрабатывает приложения АР2 и АРЗ на компьютере ClientN. Второй компьютер —
это сервер базы данных.
Тип компьютеров может быть совершенно разным. Теоретически, в роли
клиентских компьютеров могут выступать большие ЭВМ или микрокомпьютеры.
648 Глава 17. Совместное использование данных предприятия
Однако из соображений стоимости функции клиентов почти всегда выполняют
микрокомпьютеры. Точно так же в роли сервера может выступать компьютер
любого типа, но по экономическим причинам функции сервера чаще всего
выполняет микрокомпьютер. Клиенты и серверы соединяются в локальную (LAN)
или глобальную (WAN) сеть.
Хотя редко случается, чтобы в качестве клиентских-машин использовалось
что-либо иное, кроме микрокомпьютеров, роль сервера иногда выполняется
большой ЭВМ, особенно когда сервер должен иметь большую вычислительную
мощность или когда из соображений безопасности и для большего контроля за
базой данных размещение ее на микрокомпьютере представляется неуместным.
Система на рис. 17.2 имеет один сервер, хотя это не всегда так. Различные
серверы могут обрабатывать различные базы данных или предоставлять
клиентам другие услуги. Например, в фирме, занимающейся инженерными
разработками, один сервер может обрабатывать базу данных, а на другом могут работать
системы автоматического проектирования.
Если обработкой базы данных занимаются несколько серверов, то чтобы
такая система могла считаться клиент-серверной, каждый из серверов должен
обрабатывать свою базу данных. Если же два сервера обрабатывают одну базу
данных, такая система уже не может претендовать на название
клиент-серверной, а назвать ее следует системой распределенной обработки базы данных.
Системы совместного использования файлов
Вторая многопользовательская архитектура представлена на рис. 17.3. В этой
архитектуре, которая носит название архитектуры с совместным использованием
файлов (file-sharing), на пользовательских компьютерах находятся не только
прикладные программы, но и СУБД. В этом случае сервер является файловым
сервером, а не сервером базы данных. Почти во всех системах с совместным
использованием файлов применяются локальные сети из микрокомпьютеров.
Архитектура с совместным использованием файлов была разработана до
клиент-серверной архитектуры и во многих отношениях является более
примитивной. При совместном использовании файлов СУБД каждого пользовательского
компьютера посылает запросы на обработку файлов подсистеме обработки
данных операционной системы файлового сервера. Это означает, что при такой
архитектуре трафик в локальной сети гораздо больше, чем при клиент-серверной
архитектуре.
Рассмотрим, например, запрос, возвращающий столбцы Name и Address всех
строк таблицы CUSTOMER, где столбец Zip имеет значение 98033. В
клиент-серверной системе прикладная программа послала бы следующую SQL-команду:
SELECT NAME, ADDRESS
FROM CUSTOMER
WHERE ZIP=98033
Сервер возвратил бы столбцы Name и Address всех строк, удовлетворяющих
критерию отбора.
Архитектуры организационных систем обработки данных 649
Пользователь 1 < ►
ПП1
ПП2
СУБД
ОСс
Клиентский компьютер 1
Пользователь 2 М-
ПП2
СУБД
ОСс
Клиентский компьютер 2
Пользователь п <-
ПП2
ППп
СУБД
ОСс
Локальная сеть
ОСс
ОСу
БД
Компьютер файлового сервера
Клиентский компьютер п
ОСсеть = часть операционной системы,
отвечающая за сетевую коммуникацию
ОСуд = часть операционной системы,
отвечающая за управление данными
Рис. 17.3. Архитектура с совместным использованием файлов
В системе с совместным использованием файлов СУБД находится на
локальном компьютере, поэтому программы на файловом сервере не способны
обработать SQL-запрос. Подобная обработка должна происходить на пользовательском
компьютере, поэтому СУБД вынуждена запрашивать у файлового сервера всю
таблицу CUSTOMER целиком. Если эта таблица имеет индексы или другие
связанные с ней избыточные данные, они также должны быть переданы клиенту. Ясно,
что при совместном использовании файлов по локальной сети передаются
гораздо большие объемы данных.
Из-за этих проблем системы с совместным использованием файлов редко
используются для обработки больших объемов данных, которая ориентирована на
транзакции. Слишком много данных необходимо блокировать и передавать для
выполнения каждой транзакции, и производительность такой архитектуры
оказывается слишком низкой. Однако для этой архитектуры все же есть одно
применение: запрос данных, загруженных из базы. Если одному или нескольким
пользователям требуется доступ к большим фрагментам базы данных для
составления отчетов или ответов на запросы, то, возможно, имеет смысл поставить
сервер, загружающий большие порции данных. При этом загруженные данные
не обновляются и не возвращаются в базу данных. Примеры обработки
загруженных данных мы будем рассматривать далее в этой главе.
Системы с совместным использованием файлов имеют также приложения, не
связанные с базами данных. В качестве примера можно привести системы, где
требуется хранить большие файлы (звук, графику и анимацию) на
высокоскоростных дисках большого объема. С помощью таких систем организуется также
совместное использование дорогих принтеров, плоттеров и другого
периферийного оборудования.
650 Глава 17, Совместное использование данных предприятия
Системы обработки распределенных баз данных
Четвертая альтернатива (рис. 17.4) — это системы обработки распределенных
баз данных, в которых база данных распределена по множеству компьютеров.
На рис. 17.4 база данных (или часть ее) хранится на всех п компьютерах. Как
показано на рисунке, компьютеры 1, 2 и п обрабатывают и приложения, и базу
данных, а компьютер 3 обрабатывает только базу данных.
Сеть
Пользователь 1 <—►
Пользователь 2 Ч—>■
Пользователь 3 ^—►
Компьютер п
ОССЕть = часть операционной системы,
отвечающая за сетевую коммуникацию
ОСуд = часть операционной системы,
отвечающая за управление данными
СУРБД = система управления
распределенными базами данных
Рис. 17.4. Архитектура распределенной базы данных
Пунктирная линия, которой обведены файлы, означает, что база данных
включает в себя все сегменты, хранящиеся на всех п компьютерах. Эти компью-
Архитектуры организационных систем обработки данных 651
теры могут физически размещаться в одном помещении, а могут — в разных
концах планеты.
Распределенная обработка и обработка
распределенных баз данных
Обратимся снова к рис. 17.1, 17.2, 17.3 и 17.4. Система с совместным
использованием файлов, клиент-серверная система и система обработки распределенных
баз данных имеют одно важное отличие от системы удаленной обработки данных:
всех них для обработки приложений или СУБД используется более одного
компьютера. Соответственно, большинство сказало бы, что все эти три архитектуры
являются примерами распределенных систем (distributed systems), поскольку
обработка приложения распределена по нескольким компьютерам.
Обратите внимание, однако, что сама база данных является распределенной
только в архитектуре на рис. 17.4. Ни в клиент-серверной системе, ни в системе
с совместным использованием файлов база данных не распределена по множеству
компьютеров. Следовательно, большинство не причислило бы клиент-серверную
архитектуру и архитектуру с совместным использованием файлов к системам
распределенных баз данных (distributed database systems).
Типы распределенных баз данных
Есть несколько типов распределенных баз данных. Взгляните сначала на рис. 17.5, я,
на котором изображена нераспределенная база данных, состоящая из четырех
частей — W, X, Y и Z. Все эти четыре сегмента расположены в одном и том же месте,
и дублирование данных отсутствует.
Теперь рассмотрим распределенные базы данных, изображенные на рис. 17.5, 6-г.
На рис. 17.5, б изображен первый тип распределенной базы данных, где база
данных расположена на двух компьютерах — сегменты W и X хранятся на
компьютере 1, а сегменты Y и Z — на компьютере 2. На рис. 17.5, в вся база данных
продублирована (реплицирована) на двух компьютерах. Наконец, на рис. 17.5, г база
данных разделена, а ее сегмент Y продублирован.
По отношению к разделению баз данных иногда употребляются два
термина. Вертикальиьш разделом (vertical partition), или вертикальным фрагментом
(vertical fragment), называется таблица, разделенная на две или более
совокупности столбцов. Например, таблица R (С1, С2, СЗ, С4) может быть разделена на два
вертикальных фрагмента: Р1 (С1, С2) и Р2 (СЗ, С4). В зависимости от приложения и
от причины, по которой производится разделение, ключ отношения R, скорее
всего, будет помещен в отношение Р2, которое примет вид Р2 (С1, СЗ, С4).
Горизонтальный раздел (horizontal partition), или горизонтальный фрагмент (horizontal
fragment), — это фрагмент таблицы, представляющий собой совокупность строк.
Например, если первые 1000 строк отношения R помещаются в отношение R1
(С1, С2, СЗ, С4), а оставшиеся строки помещаются в отношение R2 (С1, С2, СЗ, С4), то
отношения R1 и R2 образуют два горизонтальных фрагмента. Иногда база данных
разбивается и на горизонтальные, и на вертикальные разделы, и результат
такого разделения называется смегианньш разделом (mixed partition).
652 Глава 17. Совместное использование данных предприятия
ПП1
СУБД/ОС
^ -
W
F~ -^l
w
X
Г У
Z
Автономный компьютер
Линия Ч
связи
^—
^
ПП1
СУБД/ОС
Компьютер 1
ПП2
СУБД/ОС
^
«-
i
i
W
W
1
1
1
1
1
1
1
1
1
Компьютер 2
W
БД1
БД2_
БД
Линия
связи И
Линия
связи
и
ПП1
ПП2
СУБД/ОС
^
^
w
^
_ W _
_ X _
У
Z
Компьютер 1
БД (копия 1)
L
ПП1
ПП2
СУБД/ОС
^ W
^ ^
F" "^
w
X _
У
Z
Компьютер 2
БД (копия 2)
ПП1
СУБД/ОС
i
i
•^ ►
i
i
W
X
У
Компьютер 1
ПП2
СУБД/ОС
ВД1
У
Z
Компьютер 2
БД2
Рис. 17.5. Типы распределенных баз данных: а — неразделенная, нереплицированная;
б — разделенная, нереплицированная; в — неразделенная, реллицированная;
г — разделенная, реллицированная
Сравнение различных типов распределенных
баз данных
Сравнение баз данных с различной степенью распределения приведено на рис. 17.6.
Четыре типа баз данных расположены на рисунке слева направо по возрастанию
степени разделения. Нераспределенная база данных находится в крайней левой
точке отрезка оси сравнения, а распределенная и реллицированная база
данных — в крайней правой. Разделы хранятся на двух или более компьютерах, а
неразделенная база данных целиком дублируется на двух или более компьютерах.
Характеристики этих альтернатив тоже указаны на рис. 17.6. Слева направо
возрастают параллелизм, независимость, гибкость и доступность, однако при этом
повышаются стоимость, сложность, трудность в управлении и риск
несанкционированного доступа.
Архитектуры организационных систем обработки данных 653
Единая . Континуум Распределенные
база данных базы данных
• •— » •
Единые Разделенные Неразделенные Разделенные
неразделенные нереллицированные реплицированные реплицированные
нереплицированные
-
-
-
-
+
+
+
Рис. 17.6.
Возрастание параллелизма
Возрастание независимости
Повышение гибкости
Повышение доступности
Увеличение стоимости/сложности
Возрастание трудности в управлении
^
w
W
За*
+
+
+
+
-
-
Повышение риска для безопасности системы -
Характеристика баз данных по степени распределения
Одно из этих преимуществ имеет особенное значение для бизнеса. Варианты,
расположенные справа на рис. 17.6, обладают большей гибкостью и,
следовательно, могут быть лучше приспособлены под конкретную организационную
структуру и бизнес-процессы. Например, компанию-производителя с высокой
степенью децентрализации, в которой менеджерам-технологам предоставлена
большая свобода в планировании, не сможет удовлетворить информационная
система, изображенная на рис. 17.5, я, поскольку структура этой системы войдет
в конфликт со структурой компании. Таким образом, альтернативы,
расположенные в правой части рисунка, в большей степени подходят этой организации,
чем те, которые находятся слева.
Наибольшим недостатком распределения является сложность управления
и обусловленная этим потенциальная опасность потери целостности данных.
Рассмотрим архитектуру базы данных на рис. 17.5, г. Пользователь, сидящий за
компьютером 1, может читать и обновлять элемент данных раздела Y,
расположенный на компьютере 1, одновременно с тем, как этот же элемент раздела Y,
расположенный на компьютере 2, будет читаться и обновляться пользователем,
сидящим за компьютером 2.
Методы распределенной обработки
В разных СУБД применяются различные способы распределенной обработки.
В Oracle и SQL Server поддержка распределенной обработки осуществляется
сходным образом, но одни и те же вещи называются по-разному, и наоборот —
разные вещи имеют одинаковые названия. У других производителей также
имеется своя терминология. Здесь мы сосредоточимся на основных идеях.
Простейшим способом обработки распределенной базы данных является
загрузка данных только для чтения. В этом случае обновлением всех данных в базе
654 Глава 17. Совместное использование данных предприятия
занимается только один компьютер, но копии данных только для чтения могут
посылаться на множество (возможно, тысячи) компьютеров. В Oracle такие
копии, предназначенные только для чтения, называются материализованными
представлениями (materialized views). В SQL Server эти копии называются
моментальными снимками (snapshots). Этот тип распределенной обработки мы
будем рассматривать в следующем разделе.
При более сложном способе распределенной обработки запросы на
обновление данных могут приходить со множества компьютеров, но на обработку они
передаются одному специализированному компьютеру. Например, компьютер А
может быть определен как единственный компьютер, который может обновлять
таблицу СОТРУДНИК (и основанные на ней представления), а компьютер Б может
быть определен как единственный компьютер, которому разрешено обновлять
таблицу КЛИЕНТ (и ее представления). Время от времени обновления должны
передаваться обратно на все компьютеры в распределенной сети, и базы данных
должны синхронизироваться.
Наиболее сложный способ заключается в том, чтобы разрешить
множественное обновление одних и тех же данных в различных местах. В этом случае могут
возникнуть три вида конфликтов распределенных обновлений (distributed update
conflicts). Во-первых, может быть нарушена уникальность. В базе данных галереи
View Ridge два разных компьютера могут создать в таблице ROW строку с
одинаковыми значениями столбцов Copy, Title и ArtistlD. Другая возможность напоминает
проблему потерянного обновления: на двух компьютерах может обновляться одна
и та же строка. Третий конфликт возникает в ситуации, когда на одном
компьютере обновляется строка, удаленная на другом компьютере.
Для разрешения конфликтов обновлений выделяется специальный
компьютер. Он следит за всеми обновлениями, и возникающие конфликты разрешаются
либо собственными средствами СУБД, либо приложениями, подобно тому как
это делается в триггерах. В самых крайних случаях делается запись о конфликте
в журнале, и он разрешается вручную. Последний способ не рекомендуется,
поскольку до устранения конфликта множество строк в работающих базах данных
могут зависнуть в неопределенном положении, что приведет к неприемлемому
снижению пропускной способности информационной системы предприятия.
Ни один из этих способов не решает проблемы обеспечения атомарности
транзакций в распределенной базе данных. Эта проблема становится особенно
важной, если имеется вероятность конфликтов обновлений. В какой момент
работу с базой данных можно считать выполненной? Если во время разрешения
конфликта распределенных обновлений должен произойти откат обновлений,
то потенциально возможно, что распределенная транзакция не будет выполнена
в течение нескольких часов или даже суток. Ясно, что такая задержка неприемлема.
Если оставить в стороне конфликты распределенных обновлений, остается
еще один сложный вопрос — координация распределенных транзакций. Чтобы
транзакция была атомарной, ни одно обновление в распределенной транзакции
не должно быть сохранено, пока не будут сохранены все действия транзакции.
Это означает, что каждый компьютер должен записать свои обновления
условно и ожидать от диспетчера распределенных транзакций уведомления о том, что
действия всех остальных компьютеров также записаны. Для этой цели использу-
Загрузка данных 655
ется алгоритм, называемый двухфазной фиксацией (two-phase commit). У
компании Microsoft имеется служба OLE под названием Distributed Transaction Service
(служба распределенных транзакций), или DTSy реализующая двухфазную
фиксацию. Б мире Java для этого используется технология Enterprise Java Beans.
Рассмотрение этих продуктов и технологий выходит за рамки нашего
изложения, но об их существовании знать следует. Дополнительную информацию по
этой теме можно получить, выполнив поиск по ключевому слову replication
(репликация) в документации по Oracle и SQL Server.
Загрузка данных
С появлением мощных персональных компьютеров стала возможной загрузка
больших объемов данных предприятия на компьютеры пользователей и отделов
для локальной обработки. Пользователи могут запрашивать эти данные с
помощью локальных СУБД, а также импортировать их в электронные таблицы,
программы финансового анализа, графические и другие программы.
Вообще говоря, загруженные данные могут использоваться только для
запросов и составления отчетов. Их нельзя обновить, так как после их извлечения из
действующей базы данных контроль параллельной обработки этих данных не
ведется. Чтобы лучше понять трудности, связанные с обработкой загруженных
данных, рассмотрим типичный пример.
Компания Universal Equipment
Компания Universal Equipment производит и продает тяжелые машины для
строительной промышленности. Продукция компании включает бульдозеры,
грейдеры, погрузчики и буровые установки. Каждый вид продукции находится
в ведении одного из менеджеров по продукции в отделе маркетинга, который
отвечает за планирование, рекламу, маркетинговую поддержку, разработку
рекламных материалов и т. д. Каждому менеджеру выделен набор из двух или трех
родственных продуктов.
Реклама является самой крупной статьей расходов менеджеров по
продукции, поэтому им необходимо измерять эффективность размещаемой рекламы.
В каждом рекламном объявлении компании Universal Equipment имеется
почтовая карточка для запроса информации. На каждой карточке напечатан номер,
уникальный для каждого вида объявления, по которому можно установить,
благодаря какому из объявлений произошла данная покупка. Чтобы упростить
отслеживание стимулированных рекламой покупок, отдел маркетинга
разработал микрокомпьютерное приложение базы данных, которую могут использовать
менеджеры по продукции.
На рис. 17.7, а изображены семантические объекты, фигурирующие в этом
приложении. Объект ОБЪЯВЛЕНИЕ соответствует рекламному объявлению; объект
ВИД_ОБЪЯВЛЕНИЯ представляет вид конкретного объявления в конкретной
публикации; объект ПРОДУКТ — конкретный продукт, например бульдозер. Объект
656 Глава 17. Совместное использование данных предприятия
ПРОДУКТ содержит две повторяющиеся группы — Квота и Продажи. Эти группы
являются многозначными, поскольку доля продаж определяется ежеквартально, а
продажи — еженедельно.
Это представление объекта ПРОДУКТ является весьма простым. Реальный
объект такого рода имеет больше атрибутов. Но поскольку остальные данные в этом
приложении не требуются, мы не стали их показывать. Структура базы данных,
состоящей из этих объектов, изображена на рис. 17.7, б.
ОБЪЯВЛЕНИЕ
ш Название
Агентство
ДатаСоздания
||||^ОБЪЯВЛЕНИЙ:
|||§1РОДукт ;';;;■]
0 N
ВИД^ОБЪЯВЛЕНИЯ
Ш НомерОбъявления
Издание
Дата
.ОБЪЯВЛЕНИЕ
1.1
СТИМУЛИРОВАННАЯ^йКУПД
| ПРОДУКТ
Ш Квота
Название -п
ДатаКвоты
Объем Квоты -,
Продажи
ДатаПериодаПродаж
Объем Продаж
: ОБЪЯВЛЕНИЕ
G.N
0.1
СТИМУЛИРОВАННА^УПОКУПК^
0.N
СТИМУЛИРОВАННАЯ_ПОКУПКА
ш НомерСтПокупки ~]
ТелефонКлиента j
Дата J 1 1
ИмяКлиеита
| ПРОДУКТ |
:.1
I ВИД^)БЪЯВЛЕНЙЯ
L ""* л ,AWkl i i
ВИД^ОБЪЯВЛЕНИЯ
КВОТА
ПРОДАЖИ
СТИМУЛИРОВАННАЯ ПОКУПКА
Рис. 17.7. Объекты и отношения маркетинговой базы данных Universal Equipment: a — объекты,
с которыми работают менеджеры; б — реляционные структуры, реализующие эти объекты
Загрузка данных 657
Процесс загрузки
Менеджерам по продукции выделены персональные компьютеры, соединенные
с другими компьютерами через локальную сеть отдела маркетинга компании
Universal Equipment. Для получения данных о продажах и стимулированных
рекламой покупках компьютеры обращаются к файловому серверу, который
выполняет роль шлюза на пути к большой ЭВМ компании Universal Equipment
(компьютеру, занимающемуся обработкой транзакций). Архитектура системы подобна
изображенной на рис. 17.8.
Компьютер 1
Загруженная
БД
Компьютер 2
Загруженная
БД
Компьютер N
Локальная сеть
Загруженная
БД
Компьютер-шлюз
(файловый сервер)
Большая ЭВМ
(центральный компьютер
удаленной обработки)
Загруженная
БД
БД удаленной
обработки
Терминал
удаленной
обработки
Терминал
удаленной
обработки
Терминал
удаленной
обработки
Терминал
удаленной
обработки
Рис. 17.8. Совместное использование загруженных данных со шлюзом в роли файлового сервера
Каждый понедельник ответственный пользователь отдела маркетинга
запускает программу, разработанную отделом информационных систем управ-
658 Глава 17. Совместное использование данных предприятия
ления Universal Equipment, которая обновляет таблицы ПРОДАЖИ, КВОТА и
СТИМУЛ ИРОВАННАЯ_ПОКУПКА базы данных файлового сервера с помощью информации,
полученной из главной базы данных компании. Эта программа добавляет
данные за последнюю неделю и делает необходимые исправления. При этом
импортируются данные о продажах всех родственных продуктов, чтобы менеджеры по
продукции могли провести сравнительный анализ. После загрузки данных на
файловый сервер любой менеджер по продукции может получить с этого сервера
интересующие его данные. Благодаря мерам безопасности менеджеры по
продукции не могут получить данные, доступ к которым им не разрешен.
Потенциальные проблемы при обработке
загруженных баз данных
Загрузка данных приближает данные к пользователю и увеличивает пользу от
них. Однако, к сожалению, она сопряжена с трудностью обеспечения
координации, согласованности и контроля доступа, а также с опасностью компьютерных
преступлений.
Координация
Рассмотрим проблему координации на примере таблиц СГИМУЛИРОВАННАЯ_ПОКУПКА
и ВИД_ОБЪЯВЛЕНИЯ. Таблица СТИМУЛИРОВАННАЯ_ПОКУПКА обновляется данными
с большой ЭВМ (информация о стимулированных рекламой покупках вводится
продавцами и записывается в главный компьютер). Но таблица ВИД_ОБЪЯВЛЕНИЯ
обновляется «локально» ответственным пользователем отдела маркетинга,
который получает данные из отчетов, подготовленных менеджером по рекламе и
рекламным агентством.
Данная ситуация может вызвать проблемы, когда объявление размещается
в первый раз в новом выпуске или публикации. Например, благодаря объявлению
могут произойти покупки, информация о которых будет записана в базу данных
главного компьютера прежде, чем данные о виде объявления будут сохранены на
файловом сервере. Позже при загрузке информации с главного компьютера
программа импорта отклонит данные об этих покупках, так как они нарушат
ограничение, согласно которому каждая строка таблицы СТИМУЛИРОВАННАЯ_ПОКУПКА
должна иметь родителя в таблице ВИД_ОБЪЯВЛЕНИЯ. Таким образом,
локальное обновление и загрузка должны тщательно координироваться: ответственный
пользователь должен добавлять данные в таблицу ВИД_ОБЪЯВЛЕНИЯ перед
импортом данных с главного компьютера. Аналогичные проблемы с координацией
могут возникнуть при обновлении данных в таблицах КВОТА и ПРОДАЖИ.
Согласованность
Вторая проблема, связанная с загрузкой данных, относится к согласованности.
Предполагается, что менеджеры по продукции не будут изменять полученные
данные о долях и продажах. Но что произойдет, если менеджер изменит данные?
В этом случае вероятна ситуация, когда данные в его базе не будут согласованы
Загрузка данных 659
с данными в базах предприятия, файлового сервера и, возможно, других
менеджеров по продукции. Отчеты, составленные этим менеджером, будут расходиться
с другими отчетами. А если несколько менеджеров изменят свои данные,
возможно появление большого количества несогласованных данных.
Ясно, что эта ситуация наводит на мысль о необходимости строгого контроля.
База данных должна быть спроектирована таким образом, чтобы данные в ней
нельзя было изменить. Если это невозможно (например, СУБД для
персонального компьютера не позволяет наложить такое ограничение, а стоимость
написания соответствующей прикладной программы непозволительно высока), то
решение этой проблемы — в обучении. Менеджеры по продукции должны знать
о проблемах, которые возникнут в случае изменения ими данных, и им
необходимо указать, что так делать не следует.
Контроль доступа
Третья проблема заключается в контроле доступа. Когда данные передаются на
несколько компьютерных систем, контролировать доступ становится сложнее.
Например, в компании Universal Equipment данные о квотах и продажах могут
быть конфиденциальными. Вице-президент отдела продаж не хотел бы, чтобы
продавцы узнавали о квотах продаж на предстоящий период до ежегодного
собрания отдела продаж. Но если эти данные есть в базах 15 менеджеров по
продукции, трудно гарантировать, что они будут сохранены в тайне до нужного момента.
Более того, файловый сервер получает все данные о квотах и продажах,
которые предполагается загружать таким способом, чтобы менеджер по продукции
получал только данные по продуктам, находящимся в его ведении. Однако у
менеджеров по продажам силен дух соперничества, и они, возможно, захотят
получить данные о продуктах друг друга. Если сделать эти данные доступными на
файловом сервере отдела маркетинга, это может привести к проблемам
управленческого характера.
Компьютерные преступления
Четвертая проблема — больший риск компьютерных преступлений — тесно
связана с контролем доступа. Контроль доступа направлен на предотвращение
нежелательной, но законной деятельности, тогда как к компьютерным преступлениям
относятся незаконные деяния. Данные на главном компьютере предприятия
могут представлять большую ценность. Например, данные о квотах и продажах
компании Universal Equipment очень интересуют конкурирующие компании.
Когда происходит массовая загрузка данных на файловый сервер и затем иа
один или несколько персональных компьютеров, предотвращение нелегального
копирование становится трудной задачей. Спрятать дискету или компакт-диск
очень легко, к тому же иногда сотрудники имеют возможность обращаться к
рабочим компьютерам по удаленному соединению. В этих ситуациях обнаружить
или предотвратить копирование данных практически невозможно. Один только
риск компьютерных преступлений может на практике заставить отказаться от
мысли о разработке подобной системы, даже если в остальных отношениях это
660 Глава 17. Совместное использование данных предприятия
было бы великолепным решением. Потенциальные проблемы загруженных баз
данных перечислены в следующем списке.
Координация
+ Загруженные данные должны удовлетворять ограничениям базы данных.
+ Локальные обновления должны быть координированы с загрузкой.
Согласованность
+ В общем случае загруженные данные не должны обновляться.
+ В приложениях должны быть предусмотрены специальные меры для
предотвращения обновления.
+ Пользователи должны быть осведомлены о возможных проблемах.
Контроль доступа
+ Данные могут быть реплицированы на нескольких компьютерах.
+ Процедуры контроля доступа к данным являются более сложными.
Потенциальная опасность компьютерных преступлений
+ Нелегальное копирование трудно предотвратить.
♦ Дискеты и нелегальный доступ по сети легко скрыть.
♦ Риск компьютерных преступлений может заставить отказаться от
разработки приложений, работающих с загруженными данными.
Использование web-сервера для публикации
загруженных данных
На рис. 17.9 показан один из способов использования web-сервера для публикации
загруженных данных. Шлюз и сервер базы данных изображены здесь на одном
компьютере, однако их можно разместить и отдельно — шлюз на одном
компьютере, а сервер на другом. Для получения загруженных данных web-сервер
обращается к серверу базы данных. Затем данные выводятся на браузеры пользователей.
Оперативная аналитическая обработка
данных (OLAP)
В последние годы появился новый способ представления информации под
названием оперативная аналитическая обработка данных (on-line analytic processing),
или OLAP. В OLAP данные представляются в системе координат с п осями,
например с двумя (в рамках таблицы) или тремя (в рамках куба (cube)). Поскольку
OLAP не накладывает ограничений на количество осей, используется термин
гиперкуб (hypercube). Этот термин означает отображение с неограниченным
числом осей. Чаще всего применяется термин куб OLAP (OLAP cube).
Рассмотрим пример отношения, показанный в табл. 17.1. В нем приведены
данные по односемейным домам и кондоминиумам в Калифорнии и Неваде. Как
можно видеть, запрашиваемая цена и цена продажи указаны как для
существующих, так и для строящихся домов.
Оперативная аналитическая обработка данных (OLAP) 661
£
Рабочая
база данных
Файлы,
извлеченные
из базы данных
Большая ЭВМ
Шлюз и сервер
базы данных
Рис. 17.9. Обработка загруженных данных на web-сервере
Таблица 17.1. Отношение, представляющее исходные данные для OLAP-куба
Категория
Новый
Существующий
Существующий
Новый
Существующий
Существующий
Новый
Существующий
Существующий
Тип
Односемейный
Кондоминиум
Односемейный
Кондоминиум
Односемейный
Односемейный
Односемейный
Кондоминиум
Кондоминиум
Город
Сан-
Франциско
Лос-
Анджелес
Элько
Сан-Диего
Парадайз
Лас-Вегас
Сан-
Франциско
Лос-
Анджелес
Лас-Вегас
Штат
Калифорния
Калифорния
Невада
Калифорния
Калифорния
Невада
Калифорния
Калифорния
Невада
Дата
01.01.
2000
05.03.
2001
17.07.
2001
22.12.
2000
19.11.
2001
19.01.
2001
01.01.
2000
05.03.
2001
19.06.
2001
Цена
продажи
679,000
327,989
105,675
375,000
425,000
317,000
679,000
327,989
297,000
Запрашиваемая
цена
685,000
350,000
125,000
375,000
449,000
325,000
685,000
350,000
305,000
продолжение^
662 Глава 17. Совместное использование данных предприятия
Таблица 17.1 (продолжение)
Категория Тип Город
Существую- Односемейный Лос-
щий Анджел ее
Новый Кондоминиум Лос-
Анджелес
И т. д.
Штат
Калифорния
Калифорния
Дата
01.04.
2000
05.08.
2001
Цена
продажи
579,000
321,000
Запрашиваемая
цена
625,000
320,000
Терминология О LAP
Куб OLAP для этих данных показан в табл. 17.2. Данные откладываются по двум
осям (axes), которыми являются строки и столбцы. На каждой оси может быть
показано одно или несколько измерений (dimension). В табл. 17.2 по оси строк
показано измерение Дата, а по оси столбцов — измерения Категория и Место. Когда на
одной оси показываются два или более измерения, то приводятся все возможные
комбинации данных одного измерения с данными другого. Так, например, данные
о существующих и строящихся домах приведены по каждому месту. Ячейки куба
представляют меры (measures) куба, или отображаемые данные. В этом кубе мерой
является средняя цена продажи. Могут быть и другие меры — например,
запрашиваемая цена или даже разница между ценой продажи и запрашиваемой ценой.
Таблица 17.2. Пример OLAP-куба
Средняя
2000 К1
К2
КЗ
К4
2001 К1
К2
КЗ
К4
цена продажи односемейных домов (в тыс. долл.)
Янв
Фев
Map
Существующие дома
Калифорния
Сан-
Лос-
Сан-
Франциско Анджелес Диего
408
419
427
433
437
435
452
450
432
437
436
441
465
438
477
431
437
439
454
467
444
437
452
455
375
382
380
382
380
377
368
381
373
368
388
355
Невада
179
180
195
188
190
193
198
187
188
190
196
198
Новые дома
Калифорния
Сан-
Франциско
418
429
426
437
438
432
450
457
436
444
447
499
Лос-
Анджелес
468
437
471
437
439
434
457
464
446
432
455
455
Сан-
Диего
371
382
387
380
382
370
367
388
371
363
385
355
Невада
190
185
198
193
190
198
197
191
201
196
199
202
Обратите внимание, что все данные в табл. 17.2 относятся к односемейным
домам. Данных о кондоминиумах этот куб не содержит. На самом деле таких кубов
два: один с данными по односемейным домам, а другой — с данными по
кондоминиумам. Эти кубы удобно мысленно располагать один за другим, как показано
на рис. 17.10. При таком взгляде эти два куба представляются в виде слоев данных,
Оперативная аналитическая обработка данных (OLAP) 663
и действительно, измерения, остающиеся в кубе постоянными, называются слоями
(slices). Таким образом, в приведенном примере куб расслоен по измерению Тип.
Куб кондоминиумов
Куб
односемейных
домов
Потенциально много слоев
Рис. 17.10. Слои OLAP-куба
Возможные значения данных в измерении называются членами (members).
Измерение Тип состоит из членов {Односемейный дом, Кондоминиум}, а измерение
Категория — из членов {Новый, Существующий}. В этом кубе членами измерения
Штат являются значения {Калифорния, Невада}, но при рассмотрении
недвижимости на всей территории Соединенных Штатов измерение Штат может иметь
50 членов. Иногда измерение содержит очень большое количество членов —
представьте себе, например, все комбинации {Штат, Город}. Наконец, в некоторых
случаях члены являются вычисляемыми. Хорошими примерами являются дата
и время. Имея дату, мы можем вычислить члены Месяц, Квартал, Год и Век.
Последним важным термином OLAP является уровень (level). Уровень
измерения — это его позиция в иерархии. Рассмотрим, например, измерение Дата.
У него есть уровни Год, Квартал и Месяц. Уровнями измерения Место являются
Город и Штат. Терминология OLAP приведена в табл. 17.3.
Таблица 17.3. Терминология OLAP
Термин
Описание
Пример на рис. 17.12
Ось
Измерение
Уровень
Член
Мера
Слой
Координата гиперкуба
Свойство данных, которое
откладывается по оси
(Иерархическое)
подмножество измерения
Элемент данных в измерении
Исходные данные для куба
Измерение или мера,
являющиеся постоянными
в пределах отображения
Строки, столбцы
Время, Тип жилья, Место
{Калифорния, Невада}
{Сан-Франциско, Лос-Анджелес, Прочие}
{К1, К2, КЗ, К4}
{Новый, Существующий}
{Янв, фев, Map}
Цена продажи, Запрашиваемая цена
Тип жилья (все приведенные данные —
для односемейных домов; для кондоминиумов
существует еще один куб)
664 Глава 17. Совместное использование данных предприятия
Определения куба и представления
Терминология OLAP находится в постоянном изменении, и на настоящий момент
она не однозначна в одном важном отношении. Термин куб используется для
описания как семантической структуры, так и ее материализации. Куб, показанный
в табл. 17.2, является лишь одним представлением, или материализацией,
семантической структуры, имеющей определенные измерения, уровни и меры. Мы могли
бы создать другой куб с этими даниьми, поменяв места*ми строки и столбцы, и
третий куб, где изхмерение Место находилось бы сверху, а под каждым его членом
располагались столбцы Строящееся и Существующее. Поэтому при чтении документов
OLAP важно понимать, в каком значении используется слово куб.
Чтобы проиллюстрировать это, рассмотрим определение куба в листингах 17.1
и 17.2. Используемый здесь синтаксис основан на документации Microsoft OLE
DB для OLAP, но сходные конструкции используются и другими
производителями. Оператор Create Cube определяет четыре измерения и два уровня логической
структуры. Измерения Время и Место имеют уровни, а измерения КатегорияЖилья
и ТипЖилья — нет. Хотя это здесь не показано, измерение может иметь более одного
набора уровней. В этом случае для измерения определяется две или более иерархии.
Листинг 17.1. Использование расширенного SQL: описание данных OLAP
CREATE CUBE КубПродажЖилья (
DIMENSION Время TYPE TIME.
LEVEL Год TYPE YEAR,
LEVEL Квартал TYPE QUARTER.
LEVEL Месяц TYPE MONTH.
DIMENSION Место,
LEVEL США TYPE ALL,
LEVEL Штат,
LEVEL Город,
DIMENSION КатегорияЖилья.
DIMENSION ТипЖилья.
MEASURE ЦенаПродаж,
FUNCTION СРЕДНЕЕ
MEASURE ЗапрашиваемаяЦена.
FUNCTION СРЕДНЕЕ
)
Листинг 17.2. Пример многомерного оператора SELECT
SELECT CR0SSJ0IN ({Существующие дома, Новые дома}. {Калифорния.Children.
Невада})
ON COLUMNS,
{1998.Kl.Children, 1998.K2. 1998.КЗ. 1998.K4.
1999.Kl.Children. 1999.K2. 1999.КЗ. 1999.K4}
ON ROWS
FROM КубПродажЖилья
WHERE (ЦенаПродажи, ТипЖилья = 'Односемейный')
Структура в листингах 17.1 и 17.2 — это определение способа интерпретации,
или осмысления данных о жилье. Она не является представлением данных. Для
Оперативная аналитическая обработка данных (OLAP) 665
определения представления, или материализации, для потребностей OLAP был
расширен синтаксис SQL. В листинге 17.1 показаны операторы OLAP SQL,
создающие материализацию куба, показанного в табл. 17.1. Единственное, что
может смущать в этом операторе, — термин CR0SSJOIN. Результатом выполнения
оператора CR0SSJ0IN ({А, В}, {1, 2}) является следующее отображение:
А
1 2
В
1 2
Выполнение оператора CR0SSJ0IN ({1, 2}, {А, В}) приводит к отображению
1
А В
2
А В
Если несколько развить эту идею, можно составить оператор CR0SSJ0IN
({Существующее жилье, Строящееся жилье}, {Калифорния.Children, Невада}), результатом
которого будет
Существующие дома
Калифорния
Сан- Лос-
Франциско Анджелес
Новые дома
Невада Калифорния Невада
Сан- Сан- Лос- Сан-
Диего Франциско Анджелес Диего
Единственное добавление к последнему оператору — выражение Калифорния.
Children, которое означает, что нужно провести разбиение по всем потомкам
члена Калифорния для всех уровней куба.
SQL-оператор в листинге 17.2 содержит выражения ON COLUMNS и ON ROWS.
Тем самым объяшшются оси, по которым будут откладываться измерения.
Обратите также внимание, что для задания слоев представления используется
предложение WHERE. В соответствии с рисунком, показываться должны только
продажная цена и тип жилья для односемейного дома. Заметьте, что расслоение может
осуществляться как по измерению, так и по мере.
Структуры схемы OLAP
Все данные из примера в табл. 17.1 и 17.2 взяты из одной таблицы. Такая
ситуация нетипична: обычно данные по крайней мере нескольких измерений хранятся
не в той таблице, что содержит меры. На рис. 17.11 показан пример табличной
структуры OLAP для базы данных галереи View Ridge. Данные измерений,
например SalesPrice, хранятся в таблице TRANS, а данные о прочих измерениях хранятся
в родительских таблицах, соединенных с таблицей TRANS через внешние ключи.
Куб, основанный на данных, представленных на рис. 17.11, а, может иметь
измерения CUSTOMER, ART_DEALER, SALESPERSON и WORK. Данные членов этих
измерений будут считываться из соответствующих таблиц. Структура, изображенная на
рис. 17.11, я, столь распространена, что ей было дано специальное название —
схема «звезда» (star schema), которое отражает принцип расположения таблиц
с данными измерений вокруг таблицы с данными мер.
666 Глава 17. Совместное использование данных предприятия
IcustdM^W
ilf1
ш
шш
CustomerlD
Name
AreaCode
LocalNumber
Street
City
State
Zip
j
... .v . . . . :
iilfjJDEALER;;
ЩЩ
ArtDealerlD
CompanyName
City
State
Country
шШЩ
Ю
PurchaseDate
SalesPrice
CustomerlD
AskngPrice
SalespersonID
ArtDealerlD
IS fwoTkllT
вРШ
pi
ь
Ш
ArtistID
Title
Copy
Description
-Щ
*
jj
1
1
PurchaseDate
SalesPrice
CustomerlD
AskingPrice
SalespersonID
ArtDealerlD
w
1 *
a
SALESCT^ON И
Li
liii
21111
1
i
[JjArtDealerlD
CompanyName
City
Ш 5tate
Country
^RE.:*--
GenrelD
Genre \
Description |
Era |
•:•:••••:•:•:•x•:<•:•:•:•:.:.>:<•x»^^»:•y•:<<<.^:•:•ч^y•w^'V^^x^«S
Рис. 17.11. Типы схем OLAP: a — пример схемы «звезда»; б — пример схемы «снежинка»
Оперативная аналитическая обработка данных (OLAP) 667
Обратите внимание, что на этом рисунке отсутствует атрибут имени
художника (ARTIST.Name). Чтобы добавить этот атрибут, OLAP-проектировщик может
соединить столбец ARTIST.Name с таблицей WORK через ключ ArtistlD. Но в этом
случае таблица WORK не будет находиться в доменно-ключевой нормальной
форме, в результате чего возникнет дублирование данных.
Альтернатива хранению таких соединений изображена на рис. 17.11, б. Здесь
таблица ARTIST не соединяется с таблицей WORK, а хранится в нормализованной
форме. Добавлена также другая таблица, GENRE (жанр). Такая структура также
возникает регулярно, и ей было дано название схема «снежинка» (snowflake schema).
Разница между структурами, имеющими форму звезды и снежинки, заключается
в том, что в структуре типа «звезда» каждая таблица с данными измерения
непосредственно связана с таблицей, где хранятся значения мер. Эти таблицы могут
(но не обязаны) быть нормализованными. Структура типа «снежинка» может
иметь несколько уровней таблиц, и каждая таблица в ней нормализована.
Выбор между этими двумя структурами зависит от объема и природы
данных, а также от нагрузки OLAP. В общем случае схема «звезда» требует
большего количества памяти, но она быстрее в обработке. Схема «снежинка»
обрабатывается медленнее, зато требует меньше памяти.
Способы хранения данных OLAP (ROLAP, MOLAP и HOLAP)
ROLAP, MOLAP и HOLAP представляют собой различные способы хранения
данных OLAP. В сущности, вопрос заключается в следующем: что позволит
достичь максимальной производительности — внедрение средств OLAP в
реляционные СУБД, использование специализированных автономных средств или и то
и другое одновременно?
Сторонники ROLAP (реляционной OLAP) заявляют, что СУБД с
расширенными возможностями, включающими предварительную обработку определенных
запросов и некоторые другие функции, могут служить вполне адекватными
средствами хранения данных OLAP. Сторонники MOLAP (многомерной OLAP)
считают, что хотя СУБД хорошо подходят для обработки транзакций, выполнения
запросов и создания отчетов, требования OLAP к обработке данных настолько
специфичны, что ни одна СУБД не может достичь в этой сфере приемлемой
производительности. Сторонники третьего пути, HOLAP (гибридной OLAP),
считают, что и СУБД, и специализированные OLAP-процессоры могут успешно
использоваться для этих целей, и каждая из составляющих имеет свою роль.
Microsoft использует эти термины более узко в контексте средств
оперативной аналитической обработки СУБД SQL Server. Для Microsoft термин ROLAP
означает, что хранение исходных данных и заранее вычисленных агрегации
данных происходит в базе данных SQL Server. При MOLAP данные, структура куба
и заранее вычисленные агрегации данных хранятся в специализированной
многомерной структуре данных. При HOLAP данные остаются в реляционной базе
данных, но агрегации данных хранятся в многомерной структуре.
MOLAP дает максимальную производительность, но и требует больше всего
памяти. ROLAP требует меньше памяти, но работает медленней. ROLAP
предназначена для больших баз данных, информация из которых запрашивается редко.
668 Глава 17. Совместное использование данных предприятия
В способе HOLAP высокоуровневая обработка дает большую
производительность, но при исследовании мелких деталей быстродействие снижается.
На рис. 17.12 показана архитектура OLAP, заявленная Microsoft для
применения в SQL Server 7.0 и Office 2000. Это гибридная архитектура, которая
включает OLAP-обработку на центральных серверах данных, web-сервере и клиентских
компьютерах. Организационные базы данных обрабатываются центральными
серверами данных, показанными на диаграмме справа. Доступ к результатам этой
обработки предоставляется через главную службу таблиц (Pivot Table Service)
на web-сервере или локальном компьютере. Кроме того, на web-сервере или на
локальном компьютере могут храниться локальные версии данных OLAP.
Хранилище
MOLAP
~7\
Хранилище
ROLAP
Хранилище
ROLAP
Клиентский компьютер
Рис. 17.12. Архитектура OL^P Microsoft
У этой архитектуры есть несколько ключевых элементов. Во-первых, это
главная служба таблиц, которая представляет собой OLAP-процессор, доступ-
Информационные хранилища 669
ный в виде службы NT и Windows 2000. Эта служба работает и в других версиях
Windows, где используется Office 2000. Фактически, главная служба таблиц
вызывается всякий раз, когда в Access создаются страницы доступа к данным.
Еще чаще она используется Excel.
Доступ к главной службе таблиц осуществляется через расширение OLE DB,
которое называется OLE DB для OLAP. Это расширение построено на базе
технологии OLE DB, рассматривавшейся в главе 15; в сущности, оно расширяет
понятие набора строк, включая в него не только наборы записей, но и наборы данных,
являющиеся абстракциями кубов. Расширение ADO для обработки OLE DB для
OLAP называется ADO MD (многомерная ADO). В ADO MD объекты Connection
и Command могут открывать наборы данных и обрабатывать их динамически
подобно тому, как это делалось для наборов записей в главе 15. Данные могут как
считываться, так и записываться.
Эта архитектура в максимально возможной степени приближает OLAP к
клиенту, поскольку вычислительные требования OLAP могут быть огромны. Это не
представляет трудностей при обработке локальных данных, но для создания кубов,
требующих загрузки данных с центрального сервера предприятия, может
понадобиться передача значительных объемов данных. Возможно, это окажется
неосуществимым. Определенно, такие системы нужно будет настраивать по мере
накопления опыта.
Как указано на рис. 17.12, OLAP-обработке могут подвергаться
централизованные, загруженные или локальные данные. По мере того как организации
передают все большее количество своих данных в распоряжение пользователей,
возрастают проблемы с управлением данными. Возможным решением этих проблем
являются информационные хранилища, обсуждаемые в следующем разделе.
Информационные хранилища
Загрузка данных действительно приближает их к пользователю, тем самым
повышая их эффективность. Управление одним или двумя компьютерами,
осуществляющими загрузку, не представляет трудностей. Однако если каждый отдел пожелает
иметь свой источник загруженных данных, возникновение управленческих проблем
неизбежно. В связи с этим у организаций возникла потребность в
стандартизированной службе, обеспечивающей перемещение данных к пользователю и
увеличение их полезности. Такая служба носит название информационного хранилища.
Информационное хранилище (data warehouse) — это место хранения данных
предприятия, предназначенное для упрощения принятия управленческих
решений. Информационное хранилище включает в себя не только данные, но также
инструменты, процедуры, обучение, персонал и другие ресурсы, облегчающие
доступ к данным и делающие его более осмысленным для лиц, принимающих
решения. Назначение информационного хранилища состоит в увеличении
ценности информационных активов предприятия.
Как показано на рис. 17.13, роль информационного хранилища заключается
в том, чтобы хранить выдержки из рабочих данных и выдавать их пользователям
в удобном формате. Это могут быть как выдержки из базы данных и файлов, так
670 Глава 17, Совместное использование данных предприятия
и отсканированные образы документов, записи, фотографии и другие нечисловые
данные. Информационное хранилище служит для хранения, комбинирования,
агрегирования, преобразования и доставки данных пользователям с помощью
средств анализа и принятия решений, таких как OLAP.
Браузеры
Информационное
хранилище
Выдержки
из данных
Web-сервер
F ,'Д
\ <;1
I . ||
Сервер отдела
Пользовательские
компьютеры
Пол ьзовательские
компьютеры
Рис. 17.13. Информационное хранилище
Компоненты информационного хранилища
Компоненты информационного хранилища перечислены в следующем списке. Как
уже говорилось, источником данных для информационного хранилища служит
рабочая база данных. Следовательно, в информационном хранилище должны
быть средства для извлечения и хранения данных. Но сами эти данные
бесполезны без соответствующих метаданных, описывающих природу, происхождение,
формат данных, ограничения на их использование и другие свойства, влияющие
на использование данных.
+ Средства извлечения данных.
+ Выдержки из данных.
+ Метаданные, описывающие содержимое информационного хранилища.
♦ СУБД и OLAP-серверы информационного хранилища.
Информационные хранилища 671
+ Средства управления данными информационного хранилища.
+ Программы доставки данных.
+ Аналитические программы для конечных пользователей.
+ Курсы обучения пользователей и учебные материалы.
+ Консультанты информационного хранилища.
Потенциально информационное хранилище содержит миллиарды байтов
данных во множестве различных форматов. Соответственно, для хранения и
обработки данных ему необходимы собственные СУБД и сервер OLAP. Для этой
цели можно использовать разные СУБД и OLAP-продукты, и их возможности
и функции могут быть расширены путем разработки дополнительного
программного обеспечения, обеспечивающего переформатирование, агрегирование,
интеграцию и передачу данных от одного процессора информационного хранилища
другому. Кроме того, могут потребоваться программы для хранения и обработки
нечисловых данных, например графики и анимации.
Поскольку назначение информационного хранилища в том, чтобы сделать
данные организации более доступньши, в нем должны быть средства не только для
доставки данных пользователям, но и для передачи данных для анализа, ответов
на запросы, составления отчетов, а также оперативной аналитической обработки
с определяемыми пользователем принципами группировки и разгруппирования.
Информационное хранилище предоставляет важный, но сложный набор
ресурсов и услуг. Поэтому в нем должны быть предусмотрены курсы обучения
персонала, учебные пособия, интерактивные справочные утилиты и другие
подобные продукты, облегчающие использование ресурсов информационного
хранилища. Наконец, информационное хранилище должно иметь
квалифицированный персонал, предоставляющий консультационные услуги.
Требования к информационному хранилищу
Требования к информационному хранилищу отличаются от требований к
обычному приложению базы данных. Прежде всего, в типичном приложении базы данных
структура отчетов и запросов стандартизирована: содержащиеся в них данные
могут меняться со времене*\г, но структура их остается прежней. В отличие от
этого, пользователям информационного хранилища часто нужно менять
структуру запросов и отчетов.
Рассмотрим пример. Допустим, компания определяет зоны ответственности
продавцов по географическому принципу — скажем, на каждый штат или
провинцию Северной Америки имеется свой продавец. Теперь предположим, что
пользователь информационного хранилища хочет узнать, как изменятся
размеры комиссионных, если вместо географического распределения персонала
продавцам будут назначаться конкретные клиенты. Чтобы сравнить эти
альтернативы, нужно сгруппировать продажи по компаниям и по штатам. Структура
запросов и отчетов, которые понадобятся для этой цели, будет различаться.
Еще одно различие состоит в том, что пользователи хотят самостоятельно
задавать принцип группировки данных. Например, пользователю, который хочет
исследовать эффект от различных маркетинговых кампаний, в одном случае может
672 Глава 17. Совместное использование данных предприятия
потребоваться группировка продаж по цвету упаковки, в другом — по
маркетинговой программе, в третьем — по цвету упаковки для каждой из маркетинговых
программ, а в четвертом — по маркетинговым программам для каждого цвета
упаковки. В каждом отчете аналитику важны одни и те же данные, ему просто
нужно по-разному их разбивать и группировать.
Пользователи информационного хранилища хотят самостоятельно задавать
параметры не только группировки, но и разгруппирования, или
параметрического разбиения (drill down), данных. Пусть, например, на экране представлены
данные о совокупных продажах за определенный год. Пользователь может захотеть,
чтобы одним щелчком на данных можно было разбить их на продажи по месяцам,
а следующим щелчком — на продажи по месяцам и продуктам или по регионам,
продуктам и месяцам. Хотя можно написать приложение базы данных, которое
обеспечивало бы такую возможность для фиксированного набора параметров
разбиения, чаще всего эти параметры зависят от пользователя и задачи. В
действительности, некоторые пользователи и сами не знают, какое разбиение данных им
нужно, пока не увидят данные и не попробуют различные типы разбиения.
Следовательно, средства параметрического разбиения данных должны быть гибкими.
Еще одним общим требованием является графическое отображение
результатов. Пользователи хотят видеть результаты географического разбиения данных
в соответствующей форме — например, продажи, сгруппированные по штатам
и провинциям, должны быть показаны на фоне карты Северной Америки, а
перераспределение сотрудников по офисам должно быть представлено на диаграмме
офисного пространства. Опять-таки, эти требования выполнить труднее,
поскольку они зависят от конкретного пользователя и конкретной задачи.
Наконец, многим пользователям информационных хранилищ нужна
возможность импортировать данные из них в специализированные программы. Например,
финансовым аналитикам хочется импортировать данные в электронные таблицы
и программы финансового анализа. Менеджерам портфеля заказов нужно
импортировать данные в программы управления портфелем заказов, а инженерам
буровых установок — в программы сейсмического анализа. Все это обычно
означает, что данные из информационного хранилища должны форматироваться
определенными способами. Список требований к информационному хранилищу
приведен в следующем списке.
+ Запросы и отчеты с переменной структурой.
+ Группировка данных по произвольным критериям.
+ Параметрическое разбиение данных по произвольным критериям.
+ Графический вывод.
+ Интеграция со специализированными программами.
Проблемы разработки и эксплуатации
информационных хранилищ
До сих пор мы идеализировали информационные хранилища, в результате чего
о них могло возникнуть впечатление как о панацее для принятия управленческих
решений. На деле же реализация описанных нами возможностей является весьма
Информационные хранилища 673
сложной задачей. В этой связи существует несколько важных проблем, которые
предстоит решить.
Несогласованность данных
Если информационное хранилище предоставляет недостоверные данные, то ясно,
что такое хранилище является бесполезным, если не вредным. Дело заключается
не только в качестве данных, которые информационное хранилище извлекает из
своих источников. Информация из источника данных может быть достоверной
на момент извлечения, но при объединении хмежду собой данных, не
согласованных по времени или типу (домену), можно нечаянно внести ошибки.
Рассмотрим пример извлеченных данных, представленный в табл. 17.4 и 17.5.
Одна таблица представляет собой выдержку из данных о заказах, а вторая —
выдержку из данных о выписанных продавцам премиальных. Предположим,
пользователь информационного хранилища хочет исследовать связь между
эффективностью работы продавца и его премиальными. Как может показаться на
первый взгляд, все, что для этого нужно сделать — это сложить суммы заказов
каждого продавца и сравнить итоговый результат с суммой его премиальных.
Эту задачу может выполнить следующий SQL-код:
SELECT ИмяПродавца. Бшп(СуммаЗаказа). СуммаПремиальных
FROM ЗАКАЗ. ПРЕМИЯ
WHERE ЗАКАЗ.НомерПродавца = ПРЕМИЯ.НомерПродавца
GROUP BY ЗАКАЗ.НомерПродавца
(Попутно заметим, что типичный пользователь информационного
хранилища, скорее всего, не знает SQL в объеме, достаточном для написания такого кода,
поэтому должен найтись кто-то, кто сделает это за него, или должна быть какая-
то программа, которая сгенерирует его автоматически через графический
интерфейс запроса.)
Таблица 17.4. ЗАКАЗ
НомерПродавца НомерЗаказа СуммаЗаказа
ТОО 1000 $12,000
200 1200 $17,000
100 1400 $13,500
300 1600 $11,335
Таблица 17.5. ПРЕМИЯ
НомерПродавца ИмяПродавца СуммаПремиальных
100 Мэри Смит $3,000
200 Фред Джонсон $2,500
300 Лаура Джексон $3,250
Будем считать, что данные были достоверными на момент извлечения, и
предположим, что они были получены из двух различных информационных систем —
системы обработки заказов и системы учета заработной платы сотрудников.
674 Глава 17. Совместное использование данных предприятия
Поскольку данные извлекались из разных информационных систем, то
неизвестно, согласованы ли они между собой по времени. Возможно, данные о
заказах были достоверными по состоянию на последнюю пятницу месяца, а данные
о премиальных — на последний день месяца. В данных нет ничего, что указывало
бы на это различие, а в реальности о нем может никто и не знать. Однако оно
может оказать существенное влияние на результаты анализа.
Кроме времени, различаться может также тип данных (домен). Рассмотрим
табл. 17.6 и 17.7 и предположим, что требуется составить отчет о совокупных
продажах по каждому региону. Для этого потребуется следующий SQL-код:
$Е1_ЕСТТорговаяЗона, 5ит(СовокупныеПродажи)
FROMPETHOH. ПРОДАВЕЦ
WHEREPErHOH.ТорговаяЗона = ПРОДАВЕЦ. ТорговаяЗона
GROUP ВУРЕГИОН
Для приведенных на рисунке данных результатом запроса будет таблица с
тремя строками, по одной на каждую из торговых зон NW, NE и СО. Поскольку ни
зона SE, ни зона SW не указаны в таблице РЕГИОН, они не появились в соединении,
и продажи из этих зон не будут учтены в результате. Скорее всего, в намерения
пользователя входило нечто другое.
Таблица 17.6. ПРОДАВЕЦ
НомерПродавца Регион Год СовокупныеПродажи
Джонсон
By
О'Коннор
^бернати
Лопес
Джонсон
By
О'Коннор
Абернати
Лопес
SO
NW
NE
SE
SW
SO
NW
NE
SO
SO
2000
2000
2000
2000
2000
2001
2001
2001
2001
2001
$175,988
$223,445
$337,665
$276,889
$334,557
$225,988
$276,445
$389,737
$362,768
$419,334
Таблица 17.7. РЕГИОН
ТорговаяЗона Менеджер
NW Аллен
NE Брэндлманн
SO Кьюррид
В реальности дело обстояло так: в период между 2000 pi 2001 годами
компания внесла изменения в карту торговых зон, объединив зоны SE и SW в одну зону
S0. Соответственно, в строку S0 результата запроса следовало добавить суммы
продаж всех продавцов из зон SE и SW. Если выразить это в терминах теории баз
данных, домены атрибутов ТорговаяЗона и Регион различаются. Домен атрибута
Информационные хранилища 675
ТорговаяЗона — это множество торговых зон на настоящий момент, а домен
атрибута Регион — название торговой зоны, в которой была произведена продажа, на
момент этой продажи.
Для небольших объемов данных, как в табл. 17.4, 17.5, 17.6 и 17.7, эти
проблемы имеют очевидный характер. Но когда таблицы содержат тысячи строк данных,
такое несоответствие может ускользнуть от внимания аналитика, и
принимаемые решения будет основываться на недостоверных данных.
Для решения этой проблемы должны создаваться метаданные, описывающие
временные характеристики и домены исходных данных. Эти метаданные должны
быть легко доступными для пользователей информационного хранилища, а
пользователей необходимо научить уделять серьезное внимание этим вопросам.
Интеграция средств
Еще она серьезная проблема, связанная с информационными хранилищами,
касается интеграции разнообразных средств, необходимых пользователям для
работы. Парадигмы различных продуктов и категорий продуктов, как правило,
различаются. СУБД оперируют таблицами, средства OLAP — кубами,
программы обработки электронных таблиц — электронными таблицами, пакеты
финансового планирования — планами и т. д. В результате пользовательские
интерфейсы этих продуктов оказываются непохожими. Обучение пользователей
работе с несколькими продуктами, принадлежащими к различным категориям, может
потребовать существенных затрат, и зачастую у самих пользователей на это нет
ни времени, ни желания.
Еще более серьезную проблему представляет экспорт и импорт данных
между продуктами из различных категорий. Рассмотрим электронную таблицу. В ней
содержатся данные по трем различным темам: отделы, менеджеры и сотрудники.
Номер-
Сотрудника
1000
2000
3000
4000
Имя-
Сотрудника
ву
О'Коннор
Абернати
Лопес
Номер-
Отдела
10
20
10
20
Менеджер
Мерфи
Джоплин
Мерфи
Джоплин
Телефон-
Менеджера
232-1000
244-7788
232-1000
244-7788
Код-
Отдела
А47
D87
А47
D87
Чтобы импортировать эту таблицу в нормализованном виде в базу данных,
каждую тему нужно будет вынести в отдельные таблицы: СОТРУДНИК (Но-
мерСотрудника, ИмяСотрудника, НомерОтдела), ОТДЕЛ (НомерОтдела, КодОт-
дела, Менеджер), МЕНЕДЖЕР (Менеджер, ТелефонМенеджера). Если
нормализацию не проводить, результатом будет значительное дублирование данных, как
описано в главе 5. Однако обычный пользователь базы данных, во-первых, не
поймет, для чего требуется нормализация, а во-вторых, не будет знать, как ее
выполнить.
Наконец, при совместном использовании продуктов от разных
производителей зачастую трудно выявить источник возникающих проблем. Например,
производитель продукта, из которого экспортируются данные, может считать,
676 Глава 17. Совместное использование данных предприятия
что в некорректном экспорте-импорте виновата программа, осуществляющая
импорт, а производитель этой программы может заявлять прямо
противоположное. Поскольку у производителей нет ни опыта эксплуатации продуктов друг
друга, ни желания способствовать использованию чужих решений, техническая
поддержка может превратиться в кошмар.
Отсутствие средств управления данными
информационного хранилища
Хотя есть множество продуктов и средств, предназначенных для извлечения
информации из источников данных, и множество ориентированных на конечного
пользователя средств анализа данных и создания запросов и отчетов, на настоящий
момент наблюдается отсутствие средств управления самим информационным
хранилищем. Если бы информационное хранилище состояло только из
выдержек из реляционных баз данных, а проблемы различия временных характеристик
и доменов могли быть разрешены путем обучения и четкого определения
процедур, задача управления ресурсами информационного хранилища была бы под силу
коммерческим СУБД. В большинстве случаев, однако, это не так.
Большая часть информационных хранилищ содержит выдержки не только из
баз данных, но также из файлов, электронных таблиц, изображений и внешних
источников данных. Поэтому управлять ресурсами информационного
хранилища средствами одной только коммерческой СУБД невозможно, и организации,
создающие информационное хранилище, вынуждены разрабатывать собственное
программное обеспечение. Обычно ядром такого программного обеспечения
является СУБД, а штатный персонал информационного хранилища осуществляет
реализацию дополнительных возможностей и функций, необходимых для
управления ресурсами хранилища.
Другая, сходная проблема касается управления метаданными. Лишь в
немногих СУБД возможности словарей данных отвечают потребностям
информационного хранилища в сфере управления метаданными. Как уже говорилось,
пользователям необходимо знать не только то, что содержится в информационном
хранилище, но и происхождение данных, их временные характеристики, домены,
предположения, сделанные при извлечении данных, и т. д. Персоналу
информационного хранилища необходимо разрабатывать собственное программное
обеспечение управления метаданными, дополняющее возможности СУБД и других
средств управления словарями данных.
Разработка программного обеспечения управления данными является
сложным и дорогостоящим делом. Созданное программное обеспечение должно
поддерживаться. Производители программ извлечения и анализа данных постоянно
совершенствуют свои продукты, и для поддержки новых интерфейсов придется
вносить изменения в собственное программное обеспечение. Более того, будут
меняться и требования пользователей, что приведет к необходимости создания
новых программ, которые нужно будет затем интегрировать в программное
обеспечение управления информационным хранилищем.
Информационные хранилища 677
Особый характер требований
Информационные хранилища предназначены для поддержки принятия
управленческих решений. В то время как значительная часть принимаемых
управленческих решений имеет стандартный и повторяющийся характер, многие решения
имеют особенную природу. Вопросы о том, следует ли объединить торговые зоны
и склады, продавать определенную линию продуктов, внедрить новые стратегии
интернет-продаж и маркетинга, не относятся к числу стандартных и
возникающих регулярно.
Компьютерные системы, подобно системам бюрократическим,
неповоротливы и дороги в настройке, и наиболее эффективно они работают, когда
потребности отвечают определенному шаблону. Поэтому эти системы отлично
выполняют такие задачи, как ввод заказов и бронирование мест. Сложнее разработать
систему, которая бы оперативно приспосабливалась к нестандартному
изменению требований и нужд. Таким образом, информационные хранилища успешнее
всего работают в приложениях, где изменение требований следует
определенному шаблону. Если новое требование сходно по структуре с предыдущим,
например «консолидация серверной торговой зоны будет похожа на консолидацию
южной торговой зоны», то информационное хранилище сможет быстро
приспособиться к этому требованию. Если же нет, понадобятся значительные затраты
времени, средств и усилий.
Информационные лавки
В связи с описанными выше неудобствами некоторые организации решили
ограничить область охвата информационных хранилищ, чтобы взамен получить
большую управляемость. Информационная лавка (data mart) — это то же
информационное хранилище, но с более узкой направленностью. Информационные
лавки могут быть ориентированы на определенный тип входных данных,
конкретную бизнес-функцию, отдельную организационную единицу или некоторую
географическую область.
Ограничение содержимого информационной лавки определенным типом
данных (например, базы данных и электронные таблицы) облегчает управление
информационным хранилищем и потенциально позволяет использовать для этих
целей обычную коммерческую СУБД. К тому же, метаданные в этом случае
имеют более простую структуру, и их легче поддерживать.
В информационной лавке, ориентированной на выполнение конкретной
бизнес-функции, может быть множество типов данных и метаданных, требующих
поддержания, но все эти данные служат одному и тому же типу пользователей.
Средства управления информационным хранилищем и выдачи данных
пользователям могут быть разработаны с учетом предпочтений рыночных аналитиков.
Наконец, информационная лавка, ограниченная отдельной организационной
единицей или географической областью, может иметь много различных типов
входных данных и пользователей, но количество обрабатываемых в ней данных
оказывается меньшим, чем для всей компании. Меньше будет и запросов на
678 Глава 17. Совместное использование данных предприятия
обслуживание, поэтому ресурсы информационного хранилища могут быть
выделены меньшему числу пользователей.
На рис. 17.14 показаны зоны охвата различных вариантов совместного
использования данных, рассматривавшихся в этой главе. Загрузка данных — самая
узкая по направленности и наиболее простая альтернатива. Данные
извлекаются из работающих систем и доставляются определенным пользователям для
конкретных целей. Загружаемые данные предоставляются регулярно, поэтому
структура приложения фиксирована, пользователи хорошо обучены, а
возникновение таких проблем, как несогласованность по времени и домену, маловероятно,
поскольку пользователи приобретают опыт, работая с одними и теми же
данными. На другом полюсе находится информационное хранилище,
предоставляющее множество различных типов данных и услуг как в обычном порядке, так
и по запросам особого характера. Информационные лавки находятся
посередине. По мере движения слева направо по диаграмме альтернативы становятся
более мощными, но при этом более дорогостоящими и сложными в реализации.
Загрузка
данных
Информационные лавки
Конкретный тип Конкретная Конкретная
входных данных бизнес- организационная
функция единица
или географическая
область
Информационное
хранилище ,
Проще Сложнее
Рис. 17.14. Варианты совместного использования данных предприятия по степени сложности
Администрирование данных
Данные организации являются таким же ресурсом, как и производственные
помещения, оборудование и финансовые активы. Сбор данных требует больших затрат
времени и средств, а применение полученной информации не ограничивается
только производственной деятельностью. Информация, полученная в результате
анализа данных, может быть использована для оценки работы персонала,
качества продукции и эффективности маркетинговых программ, а также для
определения тенденций в покупательских предпочтениях, поведении и т. д. С ее помощью
можно моделировать эффект от изменения продуктов, стратегий продаж и
торговых зон. Список возможных применений столь велик, что в реальности данные
зачастую служат средством достижения и удержания преимущества компании
в конкурентной борьбе. К сожалению, однако, пока данные находятся в рабочих
базах данных, полезность их ограничена.
Ввиду потенциальной ценности данных как одного из видов
организационных ресурсов, на многих предприятиях были созданы отделы администрирова-
Администрирование данных 679
ния данных (data administration). В задачи этих отделов входит не только охрана
и защита данных, но и обеспечение их эффективного использования.
В каком-то смысле администратор данных (data administrator) выполняет
в отношении данных ту же функцию, что ревизор — в отношении денежных
средств. Ревизор отвечает не только за то, чтобы финансовые активы были
надежно защищены и правильно учтены, но также за то, чтобы они эффективно
использовались. Если хранить деньги предприятия где-нибудь в подвале, они, конечно,
будут защищены, но не будут эффективно использоваться. Деньги следует
инвестировать таким образом, чтобы они служили достижению целей организации.
Аналогичным образом, в администрировании данных одной только защиты
данных недостаточно. Нужно также стремиться к повышению эффективности
использования организационных данных.
Потребность в администрировании данных
Чтобы понять, для чего нужно администрирование данных, рассмотрим аналогию
с университетской библиотекой. Обычно университетская библиотека содержит
сотни тысяч книг, журналов, правительственных отчетов и т. д., но от них нет
никакого проку, если они просто стоят на полках. Чтобы книги и журналы приносили
пользу, необходимо, чтобы ими могли воспользоваться люди, которые в них
нуждаются.
Ясно, что библиотека должна иметь какое-то описание своего содержимого,
чтобы потенциальные читатели могли узнать, что имеется в наличии. На первый
взгляд, решение выглядит тривиально — например, создать карточный каталог.
Но это потребует большой работы. Как должны идентифицироваться единицы
хранения? Как они должны описываться? Есть и фундаментальный вопрос —
что вообще такое единица хранения? Каким образом можно обеспечить
сосуществование различных способов идентификации (ISBN, десятичная система Дьюи,
номер правительственного отчета)? Как помочь людям найти материалы, о
существовании которых они и не подозревают?
Есть и другие сложности. Предположим, университет настолько велик, что
имеет несколько библиотек. Как в этом случае следует организовать работу с
собраниями, чтобы они представляли собой единый ресурс? Более того, на некоторых
кафедрах могут быть собственные библиотеки. Следует ли включать их в
университетскую библиотечную систему? У многих преподавателей имеются
обширные личные библиотеки. Должны ли они быть частью системы?
Проблемы администрирования данных
Описанная выше аналогия с библиотекой недостаточно глубока, поскольку
администрирование данных организации является значительно более сложной
задачей, чем администрирование библиотеки. Прежде всего, в принципе не ясно, что
представляет собой «единица хранения». Библиотеки содержат книги, периодику
и т. п., но данные организации поступают в огромном множестве форматов. Это
могут быть традиционные записи, но есть еще документы, электронные таблицы,
графики и иллюстрации, чертежи, аудио- и видеофайлы. Как это все должно
680 Глава 17. Совместное использование данных предприятия
описываться? Каковы основные категории организационных данных? Эти
вопросы представляют важность, поскольку ответы на них определяют способ
организации, каталогизации, защиты, оценки и управления данными.
В большинстве организаций для одних и тех же вещей существует множество
названий. Например, номер телефона может называться НомерТелефона, Телефон,
ТелефонныйНомер, ТелефонСотрудника и ТелефонОтдела. Какие из этих названий
являются более предпочтительными? Когда графический дизайнер разрабатывает
форму с номером телефона, какое обозначение он должен использовать? Когда
программист пишет программу, какое имя он должен дать переменной,
содержащей номер телефона? Когда пользователь запрашивает код региона клиента при
анализе покупательских тенденций, какое имя он должен указать в запросе?
Есть также много способов представления элемента данных. Номер телефона
может быть представлен 10-значным целым числом, текстовым полем из 10
символов, текстовым полем из 13 символов в формате (ппп)ппп-пппп} текстовым
полем из 12 символов в формате ппп-ппп-пппп или в других форматах. Какой из
них следует выбрать? Какой следует сделать стандартным, если потребуется?
И все же такие различия между данными организации и материалами
библиотеки — ничто по сравнению со следующим: люди должны иметь возможность
изменять данные организации.
Что было бы, если бы люди, беря книги в библиотеке, принимались в них
писать, вырывать страницы, вставлять новые, а потом возвращали бы их на полки?
Или еще хуже: представьте, что некто берет в библиотеке три книги, вносит во
все три какие-то изменения и возвращает обратно, заявляя библиотекарю: «Вы
должны либо изменить все три книги, либо не изменять ни одной».
Поскольку данные организации являются совместно используемыми
ресурсами, на права и обязанности по обработке должны быть наложены ограничения.
Например, когда сотрудник покидает компанию, его записи нельзя удалять
сразу же: они должны поддерживаться в течение нескольких лет для
управленческой отчетности и расчета налоговых отчислений. Следовательно, ни один отдел
ие может самостоятельно удалить информацию из базы данных только на том
основании, что сотрудник в нем больше не числится. Отдел администрирования
должен помочь в определении прав и обязанностей пользователей по обработке.
Эта роль аналогична роли администратора базы данных, описанной в главе 11,
однако в том случае зона ответственности ограничивалась отдельной базой
данных; здесь же такой зоной является вся организация.
В дополнение ко всем этим техническим проблемам существуют также
проблемы организационного порядка. Например, права на доступ к данным могут
быть источником власти в организации, следовательно, изменения в этих правах
могут означать перераспределение полномочий власти. Таким образом, за
администрированием данных стоят всевозможные политические вопросы. Их обсуждение
выходит за рамки настоящего изложения, но от этого они не становятся менее
важными. Проблемы администрирования данных перечислены в следующем списке.
♦ Существует множество типов данных.
♦ Базовые категории данных не очевидны.
♦ Одни и те же данные могут называться по-разному.
Администрирование данных 681
♦ Одни и те же данные могут иметь много описаний и форматов.
♦ Данные изменяются, зачастую параллельно.
♦ Политические и организационные вопросы усложняют решение рабочих
вопросов.
Задачи отдела администрирования данных
Описанные выше проблемы усложняют администрирование данных. Чтобы
защитить данные организации и одновременно увеличить выгоду от них, отдел
администрирования данных должен выполнять несколько задач. Их можно
разделить на несколько категорий.
Связи с общественностью
+ Информировать сотрудников организации о существовании такой
функции, как администрирование данных.
♦ Объяснять причину существования стандартов, политики и руководящих
принципов.
+ Представлять в положительном свете услуги, оказываемые отделом
администрирования данных.
Стандарты организации данных
♦ Устанавливать стандартные способы описания элементов данных.
Стандарты включают название, определение, описание, ограничения на
обработку и т. д.
♦ Назначать распорядителей данных.
Политика в отношении данных
+ Устанавливать политику организации в отношении данных. Примеры:
безопасность, назначение распорядителей данных, распределение.
Форум для разрешения конфликтов
♦ Устанавливать процедуры извещения о конфликтах.
♦ Обеспечивать возможность заслушивания всех точек зрения.
♦ Иметь полномочия на принятие решений, направленных на разрешение
конфликтов.
Возврат средств, инвестированных организацией в данные
♦ Привлекать внимание к стоимости инвестиций в данные организации.
♦ Исследовать новые методы и технологии.
♦ Следовать упреждающей стратегии информационного управления.
Связи с общественностью
В первую очередь, отдел администрирования данных отвечает за осведомленность
организации о собственном существовании и за предоставление своих услуг
остальной части организации. Сотрудники должны знать, что существует
администрирование данных, что оно включает определенную политику, стандарты и руководящие
682 Глава 17. Совместное использование данных предприятия
принципы, касающиеся данных организации и строящиеся по определенным
правилам; они должны понимать, почему необходимо уважать и соблюдать эти
правила, руководящие принципы и ограничения.
Администрирование данных должно быть сервисом, и именно так его
должны воспринимать пользователи. Таким образом, мероприятия по
администрированию данных должны представляться организации в-позитивном свете, как
нужная и полезная услуга. Сотрудники должны верить, что они могут что-то
приобрести, участвуя в этих мероприятиях. В противном случае пользователи
будут видеть для себя в этой функции одни сплошные затраты и никакой
выгоды, и она будет игнорироваться.
Стандарты организации данных
Для эффективной работы с данными предприятия необходима их четкая
организация. Если бы каждый отдел или сотрудник мог по-своему определять понятие
элемента данных или способ его именования или описания, возник бы хаос.
Невозможно было бы даже составить опись данных, не говоря уже о том, чтобы
работать с ними. Соответственно, многие организации пришли к выводу, что
важные элементы данных должны описываться стандартизированным образом.
Например, отдел администрирования данных может решить, что каждому
элементу данных, представляющему важность для организации, будут присвоены
стандартное имя, определение, описание, набор ограничений на обработку и т. п.
Когда эта структура задана, возникает следующий вопрос: кто будет
устанавливать эти стандартные описания? Например, кто будет определять стандартное
имя или стандартные ограничения на обработку?
Во многих организациях отдел администрирования данных не разрабатывает
стандартные описания. Вместо этого для каждого элемента данных назначается
так называемый распорядитель данных (data proponent) — отдел или другая
организационная единица, ответственная за работу с этим элементом. В
обязанности распорядителя входит разработка и поддержание официальных определений
организации, касающихся назначенного ему элемента данных. Хотя отдел
администрирования данных может быть распорядителем каких-то элементов данных,
большинство распорядителей относится к другим отделам.
Встречается термин владелец данных (data owner), который обычно
используется в том же значении, что и введенный выше термин распорядитель данных.
Мы будем избегать использования здесь этого термина, поскольку он в какой-то
степени предполагает право собственности, что в действительности не имеет
места. И с юридической, и с практической точки зрения организация
является единственным владельцем своих данных. Хотя некоторые пользователи или
группы пользователей имеют обоснованное право претендовать на большую
свободу распоряжения определенными данными, чем другие, эти группы не
являются владельцами данных. Поэтому мы отдаем предпочтение термину
распорядитель данных.
Итак, в основе администрирования данных лежит система стандартов
организации данных. Отдел администрирования данных отвечает за работу с
пользователями и менеджерами для установления работоспособной системы стандартов,
Администрирование данных 683
которая должны быть документирована и представлена организации некоторым
эффективным способом. Кроме того, должны быть разработаны процедуры
оценки степени соблюдения стандартов сотрудниками.
Политика в отношении данных
Еще одна группа функций отдела администрирования данных касается политики
в отношении данных. Чтобы показать необходимость существования такой
политики, рассмотрим сначала вопрос безопасности данных. У каждой организации
имеются конфиденциальные данные, и отдел администрирования данных
отвечает за разработку системы безопасности для их защиты. При этом необходимо
ответить на вопросы: какие схемы обеспечения безопасности данных должны быть
применены? Нужна ли организации многоуровневая система безопасности,
подобная той, что существует в военных организациях, или достаточно будет более
простой системы? Политика безопасности должна также определять то, какие
требования будут предъявляться к людям, имеющим доступ к конфиденциальным
данным, и какие договоры они должны будут для этого подписывать. Следует ли
допускать копирование конфиденциальных данных? Как должно проводиться
обучение сотрудников мерам по безопасности данных? Что следует
предпринимать при нарушении установленных процедур безопасности?
Второй тип политики в отношении данных касается распорядителен данных
и прав на обработку. Что значит быть распорядителем данных? Какие права
имеет распорядитель по сравнению с другими группами? Кто выбирает
распорядителя данных и как это можно изменить?
Третий тип политики в отношении данных затрагивает распределение
данных — например, должны ли официальные данные распределяться по множеству
компьютеров, и если да, то какой из экземпляров этих данных будет считаться
официальным (если таковой будет). Какие виды обработки должны быть
разрешены по отношению к распределенным данным? Должны ли данные, которые
были распределены, возвращаться в официальное хранилище? Если да, какие
процедуры проверки необходимо к ним применять перед их принятием?
Форум для разрешения конфликтов
относительно данных
Чтобы данные организации использовались эффективно, доступ к ним должен
быть коллективным, но природа людей такова, что они не любят делиться.
Соответственно, организация должна быть готова к разрешению споров, касающихся
распорядителей данных, ограничений на обработку и других вопросов.
Первое, за что в этой связи отвечает отдел администрирования данных, —
заведение процедур извещения о конфликтах. Когда у одного пользователя или
группы пользователей возникает конфликт с другим пользователем или группой,
сторонам необходим четкий порядок извещения об имеющем место конфликте.
После признания конфликта всем сторонам, вовлеченным в него, должна быть
обеспечена возможность представить свою точку зрения в рамках установленных
процедур. Персонал отдела администрирования данных, возможно, при участии
распорядителей затронутых конфликтом данных, должен разрешить конфликт.
684 Глава 17. Совместное использование данных предприятия
Данный сценарий предполагает, что организация дает отделу
администрирования данных полномочия выносить и исполнять решения по возникающим
конфликтам.
Отдел администрирования данных организует форум по разрешению
конфликтов, работающий в масштабе всей организации. В задачи отдела
администрирования базы данных также входит организация такого форума, но
относящегося к конкретной базе данных.
Увеличение отдачи от инвестиций в данные
предприятия
Последняя функция отдела администрирования данных — увеличение отдачи от
инвестиций в данные предприятия. В рамках этой функции отдел
администрирования может задаваться такими вопросами: с максимальной ли эффективностью
используются ресурсы данных организации? Можно ли получить большую
отдачу? Если нет, то почему? Стоит ли все это понесенных затрат? Данная функция
включает в себя все остальные — связи с общественностью, установление
стандартов и политики, разрешение конфликтов и т. д. Иногда эта функция
предполагает также исследование новых способов хранения, обработки и представления
данных, новых методов, технологий и т. п.
Успешное выполнение этой роли требует упреждающей стратегии
информационного управления. Интерес представляют вопросы о том, можно ли использовать
информацию для улучшения положения на рынке, повышения
конкурентоспособности и увеличения собственного капитала компании. Отдел
администрирования данных должен работать в тесном сотрудничестве с отделами планирования
и развития предприятия, чтобы предвидеть новые требования к информации,
а не просто реагировать на них.
Наконец, данные необходимо сделать доступными для потенциальных
пользователей. Доступность означает не просто техническую возможность получения
данных для опытного персонала с высокой мотивацией, а предоставление
пользователям данных удобным для них способом и в форматах, которые
непосредственно применимы к выполняемой ими работе.
Резюме
Классической архитектурой обработки многопользовательских баз данных
является удаленная обработка. При ней пользователи работают с «глупыми»
терминалами или персональными компьютерами, их эмулирующими. Программа
управления коммуникациями, прикладные программы, СУБД и операционная система
работают на едином центральном компьютере. Поскольку вся обработка
производится единственным компьютером, пользовательский интерфейс систем
удаленной обработки обычно прост и примитивен.
Клиент-серверная система состоит из компьютеров, объединенных в сеть,
чаще всего локальную (LAN). Почти во всех случаях компьютеры
пользователей, называемые клиентами, являются персональными компьютерами, и в боль-
Резюме 685
шинстве случаев в роли сервера также выступает персональный компьютер, хотя
для этой цели может использоваться и большая ЭВМ. Прикладные программы
работают на клиентском компьютере, а СУБД и часть операционной системы,
отвечающая за обработку данных, находятся на сервере.
Системы с совместным использованием файлов также состоят из
компьютеров, объединенных в сеть, и, подобно клиент-серверной архитектуре, сеть
обычно является локальной, а компьютеры — персональными. Основное
различие между системами с совместным использованием файлов и
клиент-серверными системами состоит в том, что серверный компьютер предоставляет меньшее
количество услуг компьютерам пользователей. Сервер, который в данном случае
называется файловым сервером (file server), а не сервером базы данных (database
server), предоставляет доступ к файлам и другим ресурсам. Следовательно, как
СУБД, так и прикладные программы должны быть установлены на
пользовательских компьютерах.
В системе распределенной обработки базы данных одну и ту же базу данных
обрабатывает множество компьютеров. Есть несколько типов распределенных баз
данных: разделенная и нереплицированная, неразделенная и реплицированная
и разделенная и реплицированная. В общем случае, чем больше степень
разделения и репликации, тем больше гибкость, независимость и надежность. С другой
стороны, возрастают временные затраты и увеличивается сложность управления
и обеспечения безопасности.
Существует три способа обработки распределенных баз данных: загрузка
данных только для чтения, выделение специализированного компьютера для
обновления базы данных и обновление данных множеством компьютеров. При
распределенном обновлении возникает три типа конфликтов: потеря уникальности,
потеря обновлений из-за параллельных транзакций и обновление стертых
данных. Если удаление допускается более чем на одном компьютере, эти проблемы
необходимо решать.
Координация распределенных атомарных транзакций сложна и требует
двухфазного сохранения. Для решения этих проблем предназначены такие
технологии, как OLE Distributed Transaction Server и Enterprise Java Beans.
С появлением мощных персональных компьютеров стала возможна загрузка
значительных объемов данных предприятия на компьютеры пользователей для
локальной обработки. Пользователи могут запрашивать загруженные данные
и составлять на их основе отчеты, используя установленные на своих
машинах СУБД. В большинстве случаев пользователям не разрешается обновлять
и возвращать данные, поскольку это может привести к потере целостности
данных. Даже если загружаемые данные не обновляются и не возвращаются, могут
возникать проблемы координации данных, согласованности, контроля доступа
и компьютерной преступности. Для публикации загруженных данных можно
использовать web-сервер.
Оперативная аналитическая обработка данных (OLAP) — это новый
способ представления информации. Данные изображаются в кубах, имеющих оси,
измерения, меры, слои и уровни. Оси описывают физическую структуру
представления — строки и столбцы. Измерения — это характеристики данных, откла-
686 Глава 17, Совместное использование данных предприятия
дываемые вдоль осей. Меры — это отображаемые значения данных. Слоями
называются атрибуты куба (измерения или меры), которые должны оставаться
постоянными в представлении. Уровень — это атрибут измерения, описывающий
его положение в иерархии.
Термин куб относится как к семантической структуре, используемой для
интерпретации данных, так и к конкретной материализации данных в такой
семантической структуре. В листинге 17.1 показан один из способов определения
структуры, а в листинге 17.2 — один из способов определения материализации
структуры куба.
ROLAP (реляционная OLAP), MOLAP (многомерная OLAP) и HOLAP
(гибридная OLAP) представляют собой три разновидности оперативной
аналитической обработки данных. Сторонники ROLAP говорят, что реляционной СУБД
с некоторыми расширениями достаточно для удовлетворения вычислительных
требований OLAP, сторонники MOLAP возражают, что для этих целей
необходим специализированный многомерный процессор, а сторонники HOLAP
заявляют, что нужно использовать и то и другое.
Компания Microsoft создала расширения OLE DB и ADO для OLAP. OLE DB
для OLAP включает объект, называемый набором данных; объектная модель
ADO MD содержит новые объекты, позволяющие обрабатывать наборы данных
так же, как и наборы записей. В Office 2000 и Windows 2000 была добавлена
Главная служба таблиц. Архитектура Microsoft переносит значительную часть
OLAP-обработки на клиентские компьютеры; будет ли это приемлемо для
обработки данных на серверах предприятий, пока неизвестно.
Информационное хранилище — это хранилище данных предприятия,
предназначенное для упрощения принятия управленческих решений. В
информационном хранилище содержатся выдержки из рабочих баз данных, файлы,
изображения, записи, фотографии, внешние данные и другая информация.
Информационное хранилище предоставляет доступ к этим данным в формате, удобном
для пользователей.
Компонентами информационного хранилища являются средства извлечения
данных, выдержки данных, метаданные, одна или несколько СУБД,
разработанное на предприятии программное обеспечение для управления данными,
программы доставки данных, аналитические средства, курсы обучения
пользователей и консультирующий персонал. Типичные требования к информационному
хранилищу включают создание запросов и отчетов с переменной структурой,
группировку данных по задаваемым пользователем критериям, параметрическое
разбиение данных, графическое отображение результатов и интеграцию со
специализированными программами.
В ходе создания и эксплуатации информационных хранилищ приходится
решать несколько важных проблем. Прежде всего, при объединении данных из
различных источников результат может содержать несогласованности из-за
различия временных характеристик и доменов исходных данных. Далее, в
информационном хранилище, как правило, имеется большое количество
прикладных программ, относящихся к разным областям. Пользовательские интерфейсы
этих программ могут значительно различаться, экспорт и импорт данных между
Вопросы 1 группы 687
ними может осуществляться некорректно, а получить техническую поддержку
может быть трудно.
Еще одна проблема — отсутствие средств управления самим
информационным хранилищем. Организация может быть вынуждена самостоятельно
разрабатывать программное обеспечение для управления нереляционными данными
и поддержания соответствующих метаданных. Разработка такого программного
обеспечения является сложной и дорогостоящей. Наконец, многие запросы к
информационному хранилищу имеют необычную природу; такие запросы трудно
выполнить. В связи с этим многие организации разработали информационные
хранилища с ограниченной областью охвата, называемые информационными
лавками.
Данные являются важнейшим активом организации, который обеспечивает
поддержку как деловых операций, так и принятия управленческих решений.
Задача отдела администрирования данных состоит не только в охране и защите
информационных активов, но и в обеспечении их эффективного использования.
Одной из наиболее важных функций отдела администрирования данных
является документирование содержимого информационных активов организации. Это
сложная задача, поскольку данные хранятся во множестве различных форматов
и разбросаны по всей организации. Отдел администрирования данных должен
помогать в установлении организационных стандартов на имена и форматы
элементов данных, а также в определении прав и обязанностей по обработке.
Наконец, поскольку данные представляют собой один из видов ресурсов, пользование
ими может быть источником власти, поэтому отдел администрирования данных
должен иметь дело с организационными и политическими вопросами.
Специфические функции отдела администрирования данных включают
продвижение его услуг, выработку стандартов организации данных и назначение
распорядителей данных, выработку правильной политики в отношении данных
и создание форума для разрешения конфликтов. Все эти функции
направлены на то, чтобы увеличить отдачу от инвестиции в информационные активы
предприятия.
Вопросы I группы
1. Перечислите архитектуры, используемые для обработки
многопользовательских баз данных.
2. Нарисуйте архитектуру системы удаленной обработки. Укажите, какие
компьютеры и программы входят в ее состав, и объясните, на каком
компьютере работает каждая из программ.
3. Почему пользовательский интерфейс приложений удаленной обработки
обычно ориентирован на текст и примитивен?
4. Нарисуйте архитектуру клиент-серверной системы. Укажите, какие
компьютеры и программы входят в ее состав, и объясните, на каком компьютере
работает каждая из программ.
688 Глава 17. Совместное использование данных предприятия
5. Какие типы компьютеров используются в клиент-серверных системах?
6. Сколько серверов имеет клиент-серверная система? Каковы ограничения,
касающиеся серверов?
7. Нарисуйте архитектуру системы с совместным использованием файлов.
Укажите, какие компьютеры и программы входят в ее состав, и объясните,
на каком компьютере работает каждая из программ.
8. Объясните, чем будет отличаться обработка следующего SQL-запроса в
клиент-серверной системе и системе с совместным использованием файлов:
SELECT ИмяСтудента, НазваниеПредмета
FROM СТУДЕНТ, УСПЕВАЕМОСТЬ
WHERE СТУДЕНТ.НомерСтудента = УСПЕВАЕМОСТЬ.НомерСтудента
AND УСПЕВАЕМОСТЬ.Оценка = '5'
Будем предполагать, что база данных имеет две таблицы:
СТУДЕНТ (НомерСтудента, ИмяСтудента, ТелефонСтудента)
УСПЕВАЕМОСТЬ (НомерПредмета, НомерСтудента, Оценка)
9. Объясните, почему системы с совместным использованием файлов редко
используются в приложениях, обрабатывающих транзакции с большими
объемами данных.
10. Дайте определения терминов разделение и репликация в контексте
приложений распределенных баз данных.
11. Объясните разницу между вертикальным и горизонтальным фрагментами.
12. Объясните, чем различаются четыре типа баз данных на рис. 17.6.
13. Перечислите и опишите три способа обработки распределенной базы данных.
14. Опишите три типа конфликтов, возникающих при распределенном
обновлении.
15. Каково назначение двухфазного сохранения?
16. Опишите в общих чертах проблему координации обработки загруженных
баз данных.
17. Опишите в общих чертах проблему согласованности при обработке
загруженных баз данных.
18. Опишите в общих чертах проблему контроля доступа при обработке
загруженных баз данных.
19. Почему при обработке загруженных баз данных существует повышенный
риск компьютерных преступлений?
20. Нарисуйте компоненты системы, использующей web-сервер для
публикации данных.
21. Что такое куб О LAP? Приведите пример, отличный от показанного в
табл. 17.2.
22. Объясните разницу между осью и измерением в OLAP.
23. Что такое мера куба OLAP?
Вопросы I группы 689
24. Что означает термин слой по отношению к кубу OLAP?
25. Что такое член измерения? Приведите примеры для измерений Время
и Место.
26. Объясните использование уровней в табл. 17.2.
27. В чем заключается неоднозначность термина куб?
28. Каким будет результат выражения CROSSJOIN ({Мэри, Линда}, {Парусный спорт,
Лыжи})? А выражения CROSSJOIN ({Парусный спорт, Лыжи}, {Мэри, Линда})?
29. Напишите SQL-оператор SELECT, создающий куб, аналогичный
приведенному в табл. 17.2, но в котором строки pi столбцы меняются местами, а
измерение Место представлено перед измерением Категория (если читать слева
направо).
30. Объясните разницу между схемами «снежинка» и «звезда».
31. Что такое ROLAP, MOLAP и HOLAP?
32. Опираясь на обсуждение в этой книге, объясните, как стандарт OLE был
расширен для OLAP?
33. Как расшифровывается ADO MD и каковы его функции?
34. Дайте определение термина информационное хранилище.
35. Сравните работу с информационным хранилищем и обработку
загруженных данных.
36. Перечислите и опишите компоненты информационного хранилища.
37. Объясните, что означает изменение структуры запроса или отчета и в чем
его отличие от изменения данных в запросе или отчете.
38. Приведите пример (отличный от данного в книге), когда пользователю
необходимо сгруппировать данные.
39. Приведите пример (отличный от данного в книге), когда пользователю
требуется параметрическое разбиение данных.
40. Укажите два источника несогласованности данных и приведите пример
каждого из них, отличный от приведенного в книге.
41. Опишите проблемы, возникающие при использовании средств, имеющих
различные парадигмы и лицензированных различными производителями.
42. Объясните, почему приходится самостоятельно разрабатывать
программное обеспечение для информационного хранилища.
43. Почему особый характер запросов к информационному хранилищу
представляет трудности?
44. Что такое информационные лавки и почему компании их разрабатывают?
45. Перечислите и кратко опишите три типа информационных лавок.
46. Объясните, почему данные являются важным активом организации.
47. Приведите несколько примеров использования данных, помимо
поддержки функционирования системы.
690 Глава 17. Совместное использование данных предприятия
48. В чем работа администратора данных схожа с работой ревизора?
49. Кратко обоснуйте потребность предприятий в администрировании данных.
50. Перечислите и кратко опишите проблемы администрирования данных.
51. Опишите функцию маркетинга в администрировании данных.
52. Какую роль играет администрирование данных па отношению к
стандартам организации данных?
53. Определите термин распорядитель данных.
54. В чем разница между распорядителем данных и владельцем данных?
55. Опишите роль администрирования данных в выработке политики по
отношению к данным.
56. Объясните, что включает в себя создание форума для разрешения
конфликтов.
57. Каким образом администрирование данных может помочь повысить
отдачу от инвестиций в данные организации?
Вопросы II группы
58. Рассмотрим компанию, у которой есть национальный менеджер по
продажам и 15 региональных продавцов. Еженедельно продавцы загружают
данные о продажах с главного компьютера и на их основе обновляют свои
прогнозы продаж на следующий месяц. После этого они соединяются по
модему с базой данных сервера и сохраняют в ней свои прогнозы. Затем
менеджер объединяет эти данные в прогноз масштаба всей компании.
Какие проблемы, вопросы и сложности могут возникнуть в этой
ситуации (если иметь в виду координацию, согласованность, контроль доступа
и компьютерные преступления)?
59. Рассмотрите данные, которыми обладает ваш колледж или университет.
Как вам кажется, эффективно ли ваше образовательное учреждение
использует свои информационные активы? Каким образом вы можете
определить, что информационные ресурсы используются не только для
поддержки функционирования системы? Опишите, как, по вашему мнению,
ваш колледж или университет мог бы использовать свои
информационные ресурсы в следующих областях:
♦ Набор студентов.
♦ Сбор средств.
♦ Планирование программ.
♦ Студенческие дела.
♦ Дела выпускников.
♦ Другие области.
Часть VII
Работа с объектно-
ориентированными
базами данных
Часть VII книги состоит из одной главы, в которой рассматриваются объектно-
ориентированное программирование и объектные СУБД. Она содержит краткое
введение в объектно-ориентированное программирование и обсуждение
объектно-реляционной СУБД Oracle, объектного расширения SQL под названием
SQL3 и стандарта объектного управления данными под названием ODMG-93.
Эта часть дополняет материал по OLE DB, ADO и JDBC, приведенный в
главах 15 и 16. В тех главах были изложены практические вопросы использования
объектных интерфейсов для обращения к базам данных, а здесь представлен
концептуальный взгляд на цели и задачи объектно-ориентированных баз данных.
Глава 18
Объектно-ориентированные
базы данных
В этой главе рассматриваются вопросы постоянного хранения объектов,
реализованных на таких языках программирования, как Java, С # и C++. Как вы
знаете, в реляционных базах данных информация хранится в форме таблиц, строк
и столбцов. Реляционные базы данных, как таковые, не слишком хорошо
приспособлены для хранения объектов, поскольку объекты могут содержать сложные
структуры данных, а также указатели на другие объекты. Кроме того, у объектов
есть исполняемые функции, называемые методами, поэтому, чтобы объект можно
было перевести в постоянную форму, необходимо предусмотреть какой-то способ
хранения методов.
Специализированные СУБД, носящие название объектно-ориентированные
СУБД, или ООСУБД (Object-Oriented DBMS, OODBMS), были разработаны
в начале 1990-х годов для обеспечения постоянного хранения объектов. Эти
продукты не имели коммерческого успеха, так как требовали преобразования
существующих данных в формат ООСУБД. Организации отказываются делать такое
преобразование, поскольку оно является весьма дорогостоящим и выигрыш от
него не покрывает понесенных затрат.
Однако объектно-ориентированное программирование в настоящий момент
переживает взлет, и потребность в постоянном хранении объектов никуда не
исчезла. В связи с этим производители традиционных СУБД стали расширять
возможности своих продуктов, чтобы наряду с обычным хранением
реляционных данных обеспечить постоянное хранение объектов. Такие продукты
получили название объектно-реляционных СУБД (object-relational DBMS), и они,
вероятно, будут находить все более широкое применение в будущем. В
частности, средства моделирования и хранения объектов разработаны компанией
Oracle.
Поскольку мы не предполагаем, что вы владеете объектно-ориентированным
программированием, эта глава начинается с обсуждения основных терминов
и идей ООП. После этого мы рассмотрим различные способы реализации
постоянного хранения объектов и продемонстрируем, как постоянное хранение
реализовано в Oracle. В конце мы затронем два важных объектных стандарта — SQL3
и ODMG-93.
Введение в объектно-ориентированное программирование 693
Введение в объектно-ориентированное
программирование
Объектно-ориентированное программирование, или ООП (object-oriented
programming, OOP), представляет собой способ проектирования и написания программ.
ООП существенно отличается от традиционного программирования, поскольку
оно влечет за собой новое видение программных структур. В ООП программа не
представляется в виде последовательности инструкций, а рассматривается как
набор структур данных, содержащих как элементы данных, так и программные
инструкции.
Разницу между традиционным программированием и ООП можно
представить и по-другому: традиционное программирование структурируется вокруг
логики в первую очередь и данных — во вторую, а ООП — в первую очередь
вокруг данных и во вторую — вокруг логики. Например, для разработки
традиционной программы создания заказа нужно сначала представить ее логику в виде
блок-схемы алгоритма или псевдокода. Обрабатываемые данные
документируются при этом как часть логики.
Разрабатывая объектно-ориентированную программу создания заказа, мы
сначала должны выявить объекты, участвующие в этом процессе, — например ЗАКАЗ,
ПРОДАВЕЦ, ТОВАР и КЛИЕНТ. Затем следует спроектировать эти объекты в виде
элементов данных и программ, открытых для доступа друг другу. После этого нужно
описать поведение объектов в виде блок-схемы алгоритма или псевдокода.
Терминология ООП
Объект ООП — это инкапсулированная структура (encapsulated structure),
имеющая атрибуты (attributes) и методы (methods). Термин инкапсулированная
структура означает, что объект является самодостаточным: програм*\ш, внешние по
отношению к объекту, ничего не знают о его структуре, и такое знание им не
требуется. «Внешний вид» объекта называется его интерфейсом (interface). Интерфейс
состоит из тех атрибутов и методов, которые являются видимыми для внешнего мира.
Инкапсулированное внутреннее строение объекта называется его реализацией
(implementation). Атрибуты1 объектов ООП организуются в определенную структуру.
Методы объектов ООП представляют собой последовательности инструкций,
выполняемых объектом. Например, у объекта может быть метод, отображающий
данный объект, метод, создающий данный объект, и метод, изменяющий данный
объект. Рассмотрим метод, изменяющий объект КЛИЕНТ. Этот метод, входящий
в состав объекта, является программой; программа содержит инструкции,
которые получают данные от пользователя или из других источников.
Вместо термина атрибуты иногда используется термин свойства. В частности, это имеет место
в стандарте ODMG-93, где термин атрибут используется в более узком смысле, как вы увидите
позже. Сталкиваясь с терминами класс, тип, свойство и атрибут, уделяйте внимание контексту,
поскольку разные авторы используют эти термины немного по-разному. Здесь мы будем употреблять
эти термины в соответствии с обсуждаемой темой.
694 Глава 18. Объектно-ориентированные базы данных
Объекты взаимодействуют, вызывая методы друг друга. Метод Изменить
объекта КЛИЕНТ, например, вызывает методы других объектов для получения
данных, изменения собственного содержимого и запроса услуг. Вызываемые
методы, в свою очередь, могут вызывать другие методы и т. д. Поскольку все объекты
являются инкапсулированными, ни один объект не может знать структуру
другого объекта и не нуждается в таком знании. Это упрощает структуру
приложения и способствует эффективному взаимодействию отдельных объектов.
Многие объекты имеют общие методы. Чтобы уменьшить количество
одинакового кода, объекты создаются как подклассы более общих классов. Объект 01,
являющийся подклассом другого объекта, 02, наследует (inherit) все атрибуты
и методы 02. Например, приложение может иметь общий класс СОТРУДНИК,
имеющий два подкласса, ПРОДАВЕЦ и ИНЖЕНЕР. Методы, являющиеся общими для всех
трех классов, например ПолучитьНомерТелефона, помещаются в класс СОТРУДНИК.
Подклассы ПРОДАВЕЦ и ИНЖЕНЕР наследуют эти методы. Следовательно, когда
программа вызывает метод ПолучитьНомерТелефона класса ПРОДАВЕЦ или ИНЖЕНЕР,
в реальности вызывается метод ПолучитьНомерТелефона класса СОТРУДНИК. Если
требования приложения таковы, что сведения о номерах телефонов инженеров
должны получаться иным путем, чем о номерах телефонов прочих сотрудников,
то класс ИНЖЕНЕР будет иметь собственную версию метода
ПолучитьНомерТелефона. Эта собственная версия будет использоваться при вызове программой метода
ПолучитьНомерТелефона объекта ИНЖЕНЕР. Такая характеристика называется
полиморфизмом (polymorphism).
В ООП часто используются несколько терминов. Логическая структура
объекта — его имя, атрибуты и методы — называется объектным классом (object class).
Группа объектных классов называется библиотекой классов (class library).
Экземпляры классов называются экземплярами объектов (object instances), или просто
объектами (objects).
Объекты создаются путем вызова конструкторов (constructors) — программ,
получающих оперативную память для объекта и формирующих структуры,
необходимые для создания экземпляра объекта. Деструкторы (destructors) объектов —
это программы, уничтожающие объекты pi освобождающие занимаемую ими
память. Объекты могут быть временными (transient) или постоянными (persistent).
Временный объект существует только в оперативной памяти компьютера во
время выполнения программы. Когда программа завершается, объект прекращает
свое существование. Постоянный объект — это объект, записанный на
физический носитель, например диск. Постоянный объект существует вне пределов
программы и может быть считан в оперативную память с физического носителя.
Целью О О СУ БД является обеспечение постоянного хранения объектов. У
объектов имеются как данные, так и методы; следовательно, ООСУБД, в отличие
от традиционной СУБД, должна хранить и данные, ц программы. Поскольку
каждый объект данного класса имеет один и тот же набор методов, методы
сохраняются только один раз — как методы класса. В отличие от методов,
значения элементов данных являются уникальными для экземпляра объекта, поэтому
данные каждого экземпляра объекта должны храниться отдельно. Эту мысль
иллюстрирует рис. 18.1. На самом деле немногие ООСУБД в настоящий момент
Пример ООП
695
обеспечивают постоянное хранение методов, но, вероятно, в будущем эта ситуащш
изменится.
Объектный класс КЛИЕНТ
Данные клиента 100
Методы
объекта
КЛИЕНТ
Данные клиента 200
Данные клиента 9000
Набор методов является единым для всех экземпляров одного класса
Данные каждого экземпляра объекта хранятся отдельно
Рис. 18.1. Пример объекта КЛИЕНТ
Пример ООП
В табл. 18.1 ив листинге 18.1 показан фрагмент объектно-ориентированного
интерфейса и пример метода. Чтобы не углубляться в детали, не имеющие значения
для настоящего изложения, код написан в обобщенной форме, соответствующей
принципам объектно-ориентированного программирования, а не какому-либо
реальному языку программирования. Эту форму следует рассматривать как нечто
вроде псевдокода для объектной программы.
Таблица 18.1. Объекты, методы и атрибуты
Объект
Методы
Атрибуты
СОТРУДНИК
Создать
Сохранить
Уничтожить
Номер (R)
Имя (R)
ПРОДАВЕЦ
(подкласс класса
СОТРУДНИК)
Создать
Сохранить
Уничтожить
Назначить (ЗАКАЗ, Индекс)
ВсегоКомиссионных (R)
ВсегоЗаказов (RW)
КЛИЕНТ
Создать
Сохранить
Уничтожить
Назначить (ЗАКАЗ)
Найти
Имя (R)
Телефон (R)
Индекс (R)
ТекущийБаланс (RW)
продолжение&
696 Глава 18. Объектно-ориентированные базы данных
Таблица 18.1 {продолжение)
Объект
Методы
Атрибуты
ТОВАР
Создать Номер (R)
Сохранить Название (R)
Уничтожить Описание (R)
Найти (Номер) Цена (R)
Взять (ЗАКАЗ, Количество)
Положить (ЗАКАЗ, Количество)
Найти
ЗАКАЗ
Создать
Сохранить
Уничтожить
Распечатать
Номер(R)
Дата (R)
Сумма(R)
ИмяКлиента (R)
ИмяПродавца (R)
Листинг 18.1. Фрагмент объектно-ориентированной программы
ЗАКАЗ!Создать method
Dim _Клиент as object. ^Продавец as object. _Товар as object
Dim СуммаЗаказа as Currency. ДатаЗаказа as Date. НомерЗаказа as Number
Dim СтрокаЗаказа as Structure
[
НомерТовара as Number.
НазваниеТовара as Text(25),
КоличествоТовара as Count.
ОтложенноеКоличество as Count,
Стоимость as Currency
]
{Получаем имя клиента из некоторого источника}
Set _Клиент = КЛИЕНТШайти (ИмяКлиента)
If _Клиент = Nothing then
Set _Клиент = КЛИЕНТ!Создать (ИмяКлиента)
End If
_Клиент!Назначить(Ме)
Set _Продавец = ПРОДАВЕЦЖазначить (Me. _Клиент,Индекс)
{Получаем из некоторого источника код и количество единиц
первого товара в заказе}
Me.СуммаЗаказа = О
While Not НомерТовара.EOF
Me.СтрокаЗаказа!Создать
Me.СтрокаЗаказа.НомерТовара = НомерТовара
Set _Товар = ТОВАР!Найти (НомерТовара)
{обрабатываем ошибку, если такого товара не существует}
Me.СтрокаЗаказа.НазваниеТовара = _Товар.Название
Me.СтрокаЗаказа.Количество = Т0ВАР!Взять (Количество)
Пример ООП 697
If Me.СтрокаЗаказа.Количество <> Количество Then
Me. СтрокаЗаказа.ОтложенноеКоличество = Количество
Me.СтрокаЗаказа.Количество
End If
Me.СтрокаЗаказа.Стоимость = СтрокаЗаказа.Количество * ТОВАР,Цена
Ме.СуммаЗаказа = Ме.СуммаЗаказа + Me.СтрокаЗаказа.Стоимость
_Товар!Сохранить
Me.СтрокаЗаказа!Сохранить
{Получаем из некоторого источника код и количество единиц следующего
товара. Предполагаем, что источник устанавливает переменную EOF в
значение true, когда все строки заказа обработаны,}
While End
^Продавец.СуммаПродаж = _Продазец.СуммаПродаж + Ме.СуммаЗаказа
_Клиент.ТекущийБаланс = _Клиент.ТекущийБаланс + Ме.СуммаЗаказа
_Продавец1Сохранить
_Клиент!Сохранить
ME .'Сохранить
End ЗАКАЗ!Сохранить
В табл. 18.1 показан фрагмент интерфейса нескольких объектов, используемых
в приложении обработки заказов. Каждый объект имеет набор методов и
атрибутов, открываемых им для доступа извне. Каждый объект имеет конструктор (метод
Создать) и деструктор (метод Уничтожить). У некоторых методов есть параметры:
например, метод Присвоить объекта ПРОДАВЕЦ принимает в качестве параметров
указатель на объект ЗАКАЗ и значение атрибута Индекс. Атрибуты, помеченные
буквой (R), могут только считываться, но не изменяться; атрибуты, помеченные
буквами (RW), могут и считываться, и записываться.
Обозначения в листинге 18.1 требуют пояснений. Во-вторых, в фигурные
скобки заключаются комментарии. Они используются здесь для описания
функций программного кода, который должен присутствовать в реальной программе,
но опущен в данном примере для краткости или в силу ненужности для данного
рассмотрения. Оператор Dim используется для объявления переменных и их
типов, как в языке Basic. Тип данных СтрокаЗаказа объявлен как структура,
состоящая из элементов данных, перечисленных в квадратных скобках.
Восклицательный знак служит разделителем между именем объекта и именем одного из его
методов. Так, КЛИЕНЛНайти обозначает метод Найти объекта КЛИЕНТ. Точка
используется в качестве разделителя между именем объекта и именем одного из
его атрибутов. Так, _Клиент.Индекс обозначает атрибут Индекс объекта, на
который указывает переменная _Клиент.
В листинге 18.1 используются два особых ключевых слова. Ключевое слово
Nothing является указателем на объект, представляющий пустое значение. На
рисунке выражение
If _Клиент = Nothing
обозначает: «сравнить значение объектной переменной ^Клиент с указателем на
пустой объект». Ключевое слово Me — это указатель на объект, код которого
698 Глава 18. Объектно-ориентированные базы данных
выполняется в данный момент. Код, приведенный в листинге 18.1, будет
выполняться экземпляром объекта ЗАКАЗ, поскольку это код метода данного объекта.
Соответственно, Me здесь указывает на конкретный экземпляр объекта ЗАКАЗ,
выполняющий этот код.
Метод ЗАКАЗ!Создать начинает свою работу с получения имени клиента,
делающего заказ; как конкретно происходит получение этих данных (например, из
поля ввода в форме), для нас сейчас не важно. Затем вызывается метод Найти
объекта КЛИЕНТ, который ищет в базе данных клиента с заданным именем и
возвращает указатель на найденный объект. Подробности выполнения этого поиска
скрыты внутри метода КЛИЕНТ!Найти, и мы не знаем, как делается выборка, что
происходит при обнаружении более одного клиента с заданным именем и т. д.
В результате выполнения этой операции переменной Клиент присваивается
значение указателя на экземпляр объекта КЛИЕНТ или специальное значение
Nothing, то есть указатель на пустой объект. Если Клиент указывает на пустой
объект, то с помощью метода КЛИЕНТ!Создать создается новый объект КЛИЕНТ,
и указатель на этот объект записывается в переменную Клиент. Как можно
видеть, логика работы метода предполагает, что метод КЛИЕНЛСоздать
действительно возвращает указатель на экземпляр объекта КЛИЕНТ. В реальности в этом
месте следовало бы снова выполнить проверку на пустое значение
переменной Клиент, но для краткости в остальной части программы такая проверка
опускается.
У объекта КЛИЕНТ имеется открытый для внешнего доступа метод Назначить,
с помощью которого заказ назначается определенному клиенту. Из-за
инкапсуляции мы не знаем, что делает метод Назначить, но мы вызываем его и
передаем ему значение Me — указатель на текущий объект. Фактически, метод
Назначить здесь является примером того, что называется обратным вызовом (callback).
Объект ЗАКАЗ в методе Создать передает указатель на себя объекту КЛИЕНТ, в
результате чего клиент может отслеживать свои заказы. Это делается, в
частности, для того, чтобы объект КЛИЕНТ перед своим уничтожением мог вызвать все
связанные с ним объекты ЗАКАЗ. Таким образом, объекты ЗАКАЗ смогут
уничтожить указатель на объект КЛИЕНТ, когда этот указатель станет
недействительным. Обратные вызовы имеют также много других применений. Далее метод
ЗАКАЗ!Создать записывает в переменную Продавец указатель на объект ПРОДАВЕЦ.
Этому методу передается почтовый индекс клиента (атрибут Индекс), и это
подсказывает нам, что индекс имеет какое-то отношение к распределению
клиентов между продавцами. Опять-таки, из-за инкапсуляции мы не знаем,
как это делается. Так как методология приложения скрыта, способ
распределения клиентов между продавцами в объекте ПРОДАВЕЦ может быть изменен,
но это никак не повлияет на логику этой или какой-либо другой программы.
Таким образом, если метод ПРОДАВЕЦЖазначить будет назначать клиентов
продавцам в соответствии с фазами Луны, ни одну строку кода листинга 18.1 менять
не потребуется!
Следующий раздел кода заполняет строки заказа. Обратите внимание, что
локальные элементы данных адресуются с помощью ключевого слова Me. (На са-
Постоянное хранение объектов 699
мом деле, в большинстве объектно-ориентированных языков программирования
Me подразумевается и не является обязательным; здесь мы помещаем его для
ясности.) В начале каждого повторения цикла While с помощью метода СтрокаЗака-
за!Создать выделяется память для следующей строки заказа.
Метод ТОВАРШзять забирает товары со склада. Обратите внимание: логика
работы метода предполагает, что если число единиц товара на складе меньше, чем
заказанное количество единиц товара, то недостающее количество должно быть
оформлено как отложенный заказ. Также обратите внимание, что измененный
объект ТОВАР сохраняется после обработки каждой строки заказа. Кроме того,
в отличие от объектов КЛИЕНТ и ПРОДАВЕЦ, объектам ТОВАР не передается
указатель для обратного вызова. Это означает, что объекты ТОВАР не знают, с какими
объектами ЗАКАЗ они связаны. Понятно, что в данном приложении для объектов
ТОВАР несущественно, в каких заказах они фигурируют.
Цикл продолжается, пока все требуемые товары не будут перечислены в
заказе. После этого обновляются итоговые суммы в объектах ПРОДАВЕЦ и КЛИЕНТ, и
оба эти объекта сохраняются вместе с Me.
Фрагмент кода, приведенного в листинге 18.1, представляет собой
типичный пример объектно-ориентированной программы и выявляет несколько
важных вопросов, имеющих значение для объектно-ориентированных систем баз
данных. Один из этих вопросов таков: каким образом объекты делаются
постоянными?
Постоянное хранение объектов
На рис. 18.2 изображены структуры данных, существующие после создания
заказа. Объект ЗАКАЗ содержит базовые данные заказа, такие как ЗАКАЗ.Номер,
ЗАКАЗ.Дата, ЗАКАЗ.Сумма, а также повторяющуюся группу строк заказа, имеющих
такие атрибуты, как НомерТовара, НазваниеТовара, Количество, ОтложенноеКоличест-
во и Стоимость. Кроме того, базовые данные заказа включают указатели на
объекты КЛИЕНТ и ПРОДАВЕЦ, с которыми связан этот заказ, а также указатели на
каждый из объектов ТОВАР, фигурирующий в строке заказа. Эти указатели являются
частью данных объекта ЗАКАЗ. Чтобы сделать этот объект постоянным,
необходимо сохранить все эти данные. Кроме того, нужно сохранить каждый из объектов
КЛИЕНТ, ПРОДАВЕЦ и ТОВАР, хотя их структурам неизвестна. В объектах КЛИЕНТ
и ПРОДАВЕЦ сохраняется также указатель на объект ЗАКАЗ в результате обратных
вызовов, сделанных в методах [Назначить.
Эти указатели вызывают особенные трудности. В большинстве
объектно-ориентированных языков программирования указатели являют собой ту или иную
форму адреса в памяти. Такие адреса действительны только в период
выполнения программы; при повторном ее запуске адреса объектов уже другие.
Следовательно, сохраняя объект, необходимо преобразовать указатели на объекты в
памяти в постоянные уникальные идентификаторы, которые будут действительны
в течение всего времени существования объекта, независимо от того, находится
700 Глава 18. Объектно-ориентированные базы данных
ли он в памяти. Процесс преобразования постоянных идентификаторов в адреса
в памяти называется настройкой по адресам (swizzling).
СТРОКА ЗАКАЗА
Номер товара Название товара Количество Отложенное количество Стоимость L
Объект ЗАКАЗ
Рис. 18.2. Пример структуры данных объекта
Наконец, вспомните, что объект определяется как значения данных плюс
методы. Таким образом, чтобы сделать объект постоянным, необходимо сохранить
и методы, и данные экземпляров объектов. Но в отличие от элементов данных,
методы каждого объекта данного класса остаются одними и теми же, поэтому
методы требуется сохранить лишь однажды — для всех экземпляров данного
объектного класса. Действия, которые необходимо выполнить для обеспечения
постоянного хранения объектов, перечислены на рис. 18.3.
• Сохранить данные экземпляра объекта
• Преобразовать указатели на объекты, находящиеся в оперативной памяти,
в постоянные уникальные идентификаторы (настройка по адресам)
• Сохранить методы объектного класса
Рис. 18.3. Действия, которые необходимо выполнить для обеспечения
постоянного хранения объекта
Постоянное хранение объектов может осуществляться с помощью
традиционной файловой системы, реляционной СУБД или объектно-ориентированной
СУБД. Рассмотрим каждый из этих- способов.
Постоянное хранение объектов 701
Постоянное хранение объектов в традиционной
файловой системе
Объекты можно хранить в традиционной файловой системе, но это возлагает на
плечи программиста тяжелое бремя. Рассмотрим данные на рис. 18.2.
Разработчику может прийти в голову мысль создать один файл для методов всех объектов
и второй файл для данных всех объектов. Для этого необходимо будет
разработать обобщенную структуру данных, которая позволит записывать методы и данные
в файлы и считывать их оттуда при необходимости. В табл. 18.2 показан пример
файла, в котором хранятся элементы данных. (Для хранения методов необходимо
создать еще один подобный файл.)
Таблица 18.2. Хранение данных объекта в файле фиксированной длины
НомерЗаписи КодЗаписи Содержимое Ссылка
1 ЗАКАЗ Данные заказа 100 4
2 ПРОДАВЕЦ Данные продавца Джонса null
3 КЛИЕНТ Данные клиента Ю000 null
4 СТРОКА_ЗАКАЗА Данные строки заказа 100 5
5 СТРОКА_ЗАКАЗА Данные строки заказа 100 null
Для работы с таким файлом программист должен будет написать метод,
который будет записывать и считывать содержащиеся в нем данные объектов, находить
объекты по запросу, организовывать неиспользуемое файловое пространство и т. д.
Далее разработчику придется разработать и реализовать алгоритмы настройки
по адресам и обратной операции. Кроме того, существует еще проблема
начальной загрузки. Ведь все методы хранятся в файлах, включая методы,
выполняющие сохранение и чтение методов. Как должен загружаться метод, который
считывает первый метод?
Все эти трудности были преодолены еще много лет назад в файловых
подсистемах операционных систем. Но в этом-то все и дело: такое программирование
медленно, утомительно, рискованно и трудно, и оно уже было выполнено в
традиционных системах обработки файлов. Зачем проделывать все то же самое еще раз?
Из-за этих проблем хранение объектов в традиционных файловых системах
имеет смысл лишь тогда, когда приложение имеет несколько простых объектов,
структура которых не меняется. Немногие бизнес-приложения удовлетворяют
этому критерию.
Постоянное хранение объектов с помощью СУБД
Другой подход к постоянному хранению объектов заключается в использовании
коммерческих реляционных СУБД. При этом подходе бремя, ложащееся на
плечи программиста, оказывается меньше, чем при использовании традиционной
обработки файлов, поскольку основные задачи управления файлами — размещение
702 Глава 18. Объектно-ориентированные базы данных
записей, индексирование, управление файловым пространством и т. д. — берет на
себя СУБД. Программисту остается определить реляционные структуры для
представления объектов и написать код, выполняющий посредническую функцию
между программой и СУБД при чтении-записи объектов и настройке по адресам.
Далее приведены таблицы, необходимые для хранения объектов ЗАКАЗ, СТР0КА_
ЗАКАЗА, КЛИЕНТ, ПРОДАВЕЦ и ТОВАР. Мы уже встречали эту структуру ранее.
Единственный новый элемент в ней — это таблица, где хранятся методы объектов; она
имеет текстовое поле большой длины, в котором и хранится код методов.
СОТРУДНИК (Номер, Имя, ...)
ПРОДАВЕЦ (Номер, ВсегоКохМиссионных, СуммаПродаж, ...)
КЛИЕНТ (Имя, Телефон, Индекс, ТекущийБаланс, ...)
ТОВАР (Номер, Название, Описание, Цена, ...)
ЗАКАЗ (Номер, Дата, Сумма, ПРОДАВЕЦЛомер, КЛИЕНТ.Имя, ...)
СТРОКА_ЗАКАЗА (ЗАКАЗЛомер, ТОВАРЛомер, НазваниеТовара, Количе-
ствоТовара, ОтложенноеКоличество, Стоимость, ...)
МЕТОДЫ (ИмяОбъекта, Имя Метода, КодМетода)
В реляционных базах данных связи представляются через внешние ключи.
Это означает, что программист должен реализовать некоторый способ
постоянного хранения связей с помощью внешних ключей. Наиболее распространенный
способ — обеспечить в конструкторе объекта создание уникального
идентификатора. Этот идентификатор может храниться в базовой таблице объекта и
показываться объектОхМ как свойство только для чтения. Объекты, которым требуется
ссылка на этот объект, могут хранить у себя значение этого идентификатора.
Такая стратегия создает одну проблему: когда объект уничтожается, он должен
уведомить об этом все объекты, имеющие ссылку на него, чтобы они могли
удалить эту ссылку и предпринять другие необходимые действия. Это одна из
причин, по которой используются обратные вызовы, как в листинге 18.1.
Объектно-ориентированное мышление хоронит саму концепцию связи. Так,
например, когда объект ЗАКАЗ устанавливает связь с объектом ПРОДАВЕЦ, он
интересуется только своей стороной этой связи. Если объект ЗАКАЗ захочет
установить связь с несколькими объектами ПРОДАВЕЦ, он сможет это сделать. Объект
ЗАКАЗ не знает, со сколькими объектами ЗАКАЗ имеет связь объект ПРОДАВЕЦ. Это
знание скрыто в объекте ПРОДАВЕЦ и не является частью логики объекта ЗАКАЗ.
Эта характеристика может быть как преимуществом, так и недостатком, в
зависимости от того, как на это смотреть. Предположим, что один заказ могут
обрабатывать несколько продавцов, и у одного продавца может быть много
заказов. Выражаясь языком баз данных, объекты ЗАКАЗ и ПРОДАВЕЦ имеют связь M:N.
В этом случае в реляционной базе данных создается таблица пересечения,
содержащая идентификаторы объектов ЗАКАЗ и ПРОДАВЕЦ, связанных между собой.
В объектном мире продавец знает, что у него есть много заказов, а заказ
«знает», что его обрабатывают много продавцов, однако они не знают этого друг
о друге. Следовательно, структуры данных, в которых хранятся связи, будут
разделены. В объекте ЗАКАЗ будет место для хранения множества ссылок на объекты
ПРОДАВЕЦ, а в объекте ПРОДАВЕЦ будет место для хранения множества ссылок на
объект ЗАКАЗ. Эти наборы ссылок будут изолированы друг от друга.
Постоянное хранение объектов 703
Имеет ли это значение? Нет, пока нет ошибок в обработке объектов, но есть
такой риск, поскольку ссылки на объекты хотя и разделены, но не независимы.
Если заказ 1000 связан с продавцом А, то, по определению, продавец А связан
с заказом 1000. В мире реляционных СУБД., поскольку связь представляется
строкой в таблице пересечения, удаление строки с одной стороны автоматически
приводит к удалению соответствующей строки с другой стороны. Однако в мире
объектов может случиться так, что связь будет удалена только с одной стороны
и не будет удалена с другой. Так, заказ 1000 может быть связан с продавцом А,
но продавец А может и не быть связанным с заказом 1000. Очевидно, что это
ошибка и что такого не следует допускать, но такая ситуация может возникнуть,
если определение связей происходит исключительно с
объектно-ориентированной точки зрения.
При использовании реляционной СУБД для постоянного хранения объектов
объем работы для программиста оказывается меньше, чем при использовании
традиционных файловых структур. Однако остается необходимость
преобразовывать объекты в реляционные конструкции, писать запросы на SQL (или
другом языке), считывать и записывать объекты с помощью СУБД и производить
настройку по адресам. Для выполнения этих задач были разработаны объектно-
ориентированные СУБД.
Постоянное хранение объектов
с использованием ООСУБД
Третий способ постоянного хранения объектов — использование
объектно-ориентированных СУБД. Такие продукты специально приспособлены для
постоянного храпения объектов и, следовательно, сводят к минимуму труд прикладных
программистов.
ООСУБД изначально интегрирована с объектно-ориентированным языком
программирования. Таким образом, в код приложения не нужно встраивать
никаких дополнительных структур типа SQL. В примере на рис. 18.2, возможно,
методы Сохранить фактически предоставляются ООСУБД. Следовательно,
вызывая метод Сохранить, программист обращается к ООСУБД.
Кроме того, в состав ООСУБД входит компилятор (или ООСУБД входят
в состав компилятора — все зависит от точки зрения), который обрабатывает
исходный текст и автоматически создает в объектной базе данных структуры для
храпения объектов. Соответственно, в отличие от реляционных СУБД или
систем обработки файлов, программист не должен преобразовывать объекты в
реляционные или файловые структуры — ООСУБД делает это автоматически.
Наконец, поскольку ООСУБД специально предназначены для постоянного
хранения объектов, в них обеспечивается та или иная форма настройки по
адресам. Таким образом, для кода, подобного показанному в листинге 18.1, этой
проблемы не будет. Объект получает ссылку на другой объект, и эта ссылка всегда
является действительной. Если ссылка принимает другие формы, программа не
знает об этом.
704 Глава 18. Объектно-ориентированные базы данных
Это приводит нас к характеристике ООСУБД, которая называется
одноуровневой памятью. В некоторых ООСУБД программе (а следовательно, и
программисту) не нужно знать, находится объект в памяти или нет. Если заказ 1000 имеет
связь с продавцом А, заказ 1000 может смело использовать доступные свойства
продавца А, не проверяя, загружены ли эти данные в память, не выполняя чтения
и не посылая SQL-запрос. Если объект продавца А находится в памяти, ООСУБД
создает ссылку, а если нет, ООСУБД загружает объект в память и затем создает
на него ссылку.
В табл. 18.3 сравнивается объем работ, которую приходится проделать
программисту при каждом из трех способов постоянного хранения объектов.
Очевидно, что ООСУБД предоставляет программисту ООП существенные
преимущества. Почему же тогда эти продукты не используются повсюду? Этому вопросу
посвящен следующий раздел.
Таблица 18.3. Сравнение различных способов постоянного хранения объектов
по требуемому объему работы
ООСУБД
Реляционные СУБД
Традиционные системы обработки файлов
Вызов
специального
метода
ООСУБД
♦
♦
♦
♦
Преобразование
адресов объектов
в памяти в постоянные
идентификаторы
и наоборот (настройка
по адресам)
Создание реляционных
структур данных
Написание процедуры
на SQL (или на другом
языке)
Встраивание SQL
в программу
♦
♦
♦
♦
♦
♦
Преобразование адресов объектов
в памяти в постоянные идентификаторы
и наоборот (настройка по адресам)
Создание реляционных структур данных
Написание процедуры сохранения объекта
в постоянной форме
Вызов процедуры сохранения объекта
в постоянной форме
Преобразование объектов в файловую
структуру и наоборот
Нахождение объектов по требованию
Управление дисковым пространством
Другие задачи по управлению файлами
Постоянное хранение объектов в Oracle
Компания Oracle расширила возможности своих СУБД, включив в них
поддержку объектного моделирования и постоянного хранения объектов. Как уже
говорилось, такие базы данных иногда называются объектно-реляционными базами
данных.
По ходу чтения подумайте над тем, каким образом Oracle удалось соединить
объектно-ориентированное мышление с реляционной моделью. Даже если в
некоторых отношениях этот гибрид довольно неуклюж, он позволяет организациям
постепенно мигрировать от реляционного способа хранения данных к
объектному. Как уже упоминалось, чистые объектно-ориентированные СУБД,
требовавшие резкой смены парадигм, были отвергнуты. Во многих отношениях Oracle
выполнила блестящую работу, обеспечив поддержку текущей клиентской базы
и, в то же время, распространив возможности продукта в объектном мире.
Постоянное хранение объектов в Oracle 705
Настоящее изложение основывается на 8-й версии Oracle. Эти возможности
и функции, несомненно, будут совершенствоваться и расширяться, так что стоит
просмотреть документацию на более новые версии Oracle, чтобы узнать о
последних достижениях Oracle в области храпения объектов.
Типы объектов и коллекции
Для постоянного хранения объекта в Oracle нужно сначала создать тип,
представляющий этот объект. Этот тип может далее использоваться в отношении
любым из четырех возможных способов. В простейшем случае столбцового объекта
(column object) объектный тип используется для определения столбца таблицы.
В остальных трех случаях создается коллекция объектов одного из трех типов:
массивы переменной длины (variable length arrays), вложенные таблицы (nested
tables) и объекты-строки (row objects). Рассмотрим каждый из этих типов.
Столбцовые объекты
Следующий оператор определяет объектный тип obj_Apartment, описывающий
квартиру:
CREATE TYPE obj_Apartment AS OBJECT (
BuildingName VARCHAR2C25).
ApartmentNumber CHAR(4).
NumberBedrooms NUMBER)
/
Этот тип имеет три столбца (название здания, номер квартиры и число
спальных комнат), использующих встроенные типы данных Oracle. (Вспомните, что
косая черта командует SQL Plus выполнить только что введенный оператор.
С этого момента мы будем опускать косую черту в конце всех примеров.)
Следующий оператор CREATE определяет столбцовый объект с именем Location
(место жительства), имеющий объектный тип obj_Apartment:
CREATE TABLE PERSON (
NameVARCHAR (50),
Locati onobj_Apartment)
Данные из этой таблицы об имени и месте проживания людей можно
запрашивать и обрабатывать так же, как данные из всякого другого отношения. Однако
синтаксис операторов INSERT и UPDATE несколько отличается. Следующий
оператор выполняет вставку строки в таблицу PERSON:
INSERT INTO PERSON (Name. Location) VALUES CSelma Whitbread", obj_
ApartmentCEastlake', '206'. 2)):
Обратите внимание на то, как используется имя типа данных в предложении
VALUES. Следующий оператор выполняет обновление строки:
UPDATE PERSON
SET Location=obj_ApartmentСEastlake'. '412'. 3)
WHERE Name='Selma Whitbread';
706 Глава 18. Объектно-ориентированные базы данных
И снова обратите внимание на использование имени типа данных. На рис. 18.4
показан результат запроса из этой таблицы.
SQL> SELECT * FROM PERSON;
NAME
LOCATION(BUILDINGNAME, APARTMENTNUMBER,
Lynda Janes
OBJ_APARTMENT('Eastlake', '206 ', 2)
Selma Whitbread
OBJ_flPflRTMENT('Eastlake', '444 \ 3)
NUMBERBEDROOMS)
a
SQL> SELECT * FROM BUILDING1;
BUILDINGID NAME
UNITS(APARTMENTNUMBER, NUMBERBEDROQMS)
1 Eastlake
APARTMENT_LIST1(APT_UNITri00 ', 1), APT_UNIT('200
2 Westuiew
APARTMENT_LIST1(APT_UNIT(Mei \ 1), APT_UNIT( "201
', 2), APT_UNIT(*3O0
'• 2), APT_UNITC301
'. D)
'. D)
б
JSQL> SELECT * FROM BUILDING2;
BUILDINGID NAME
UNITS(APARTMENTNUMBER, NUMBERBEDROOMS)
1 Eastlake
APAOTHENTa_LIST2(APT_UNIT(l180 ',1), APT_UNIT( a288
2 Westuiew
flPflRTMENT_LIST2(flPT_UMIT(-181 ', 1). APT_UNIT('2D1
•. 2), APT_UNITC380
\ 2). APTJJNIT("3D1
', 1>>
'. D) !
e
SQL> SELECT * FROM APARTMENTS;
BUILDINGNAME APAR NUMBERBEDROOMS
Westuiew 333 2
Westuiew 235 2
г
Рис. 18.4. Работа оператора SELECT с объектными структурами: а — выборка столбцового
объекта; б — выборка массива переменной длины; а — выборка вложенной таблицы;
г — выборка строчного объекта
Массивы переменной длины
Массивы переменной длины — это один из способов создания коллекций
объектных типов. Чтобы понять, как используются такие массивы, предположим,
Постоянное хранение объектов в Oracle 707
что нам нужно создать таблицу с данными о многоквартирном доме. В ней
должно быть значение суррогатного ключа, название здания и перечень квартир
в здании.
Для этого сначала создадим объект для квартиры, а затем запишем его в
массив переменной длины, как показано в следующем фрагменте:
CREATE TYPE AptJJnit AS OBJECT (
ApartmentNumber char(5),
NumberBedrooms int);
CREATE TYPE APARTMENT_LIST1 AS VARRAY(50) OF APTJJnit
Здесь тип APARTMENT_LIST1 может иметь до 50 элементов типа Apt_l)rnt.
Следующий оператор создаст таблицу с информацией о домах,
использующую этот массив переменной длины:
CREATE TABLE BUILDING1 (
BuildinglD NUMBER.
NameVARCHAR2(50)
UnitsAPARTMENT_LISTl):
Теперь, чтобы вставить данные в таблицу, мы должны использовать имена
массива и его элементов, как показано здесь:
INSERT INTO BUILDING1 (BuildinglD. Name, Units) VALUES
(1. 'Eastlake',
APARTMENT_LISTKApt_Unit('100\ 1),
(AptJJmt('200\ 2),
(AptJJnit('300\ 1)));
Считывать значения всех столбцов можно с помощью обычного оператора
SELECT, но только если в предложении WHERE нет ссылок на элементы AptJJnit.
На рис. 18.4, б показаны результаты оператора SELECT * для всех строк.
Если же вы хотите получить значения AptJJnit или использовать его
значения в предложении WHERE, вы должны будете вывернуть этот запрос наизнанку,
как показано ниже:
SELECT ApartmentNumber
FROM TABLE (
SELECT UNITS
FROM BUILDING1
WHERE Name='Eastlake")
WHERE ApartmentNumber>100;
Этот запрос делает выборку атрибута ApartmentNumber из объекта UNITS,
являющегося массивом переменной длины. Таблица BUILDING обрабатывается как
во вложенном запросе. Результатом будет таблица, содержащая столбец
ApartmentNumber и две строки — 200 и 300.
В Oracle версии 8 нельзя обновить или удалить отдельные строки в массиве
переменной длины с помощью оператора UPDATE или DELETE. Вместо этого необ-
708 Глава 18. Объектно-ориентированные базы данных
ходимо написать процедуру на PL/SQL, перебирающую массив. Если вы хотите
использовать для этой цели оператор UPDATE или DELETE, вам нужно создать
вложенную таблицу, как описывается в следующем разделе.
Вложенные таблицы
Вложенные таблицы определяются почти так же, как и массивы переменной
длины. Разница между ними заключается в том, что данные массива переменной
длины хранятся в таблице, в которой они определены, а данные вложенных
таблиц — в отдельной таблице. Создать таблицу BUILDING с помощью вложенных
таблиц можно посредством следующего оператора:
CREATE TYPE APARTMENT_LIST2 AS TABLE OF AptJJmt;
/
CREATE TABLE BUILDING2 (
BuildingID NUMBER,
Name VARCHAR2(50),
Units APARTMENTJJST2)
NESTED TABLE Units STORE AS UNITSJABLE;
Единственное отличие от синтаксиса определения массивов переменной
длины состоит в том, что вложенной таблице должно быть дано имя. Здесь таблица
названа UNITS_TABLE.
На рис. 18.4, в показан результат выборки SELECT * всех строк таблицы
BUILDING2; обратите внимание, что он идентичен результату для примера с
массивом переменной длины. Операторы вставки и запроса, используемые со
вложенными таблицами, идентичны тем, которые используются для массивов
переменной длины:
INSERT INTO BUILDING2 (BuildingID, Name. Units) VALUES
(1, 'Eastlake',
APARTMENT_LIST2 (Apt_Umt( '100'. 1),
(Apt_Unit('200'. 2),
(Apt_Unit('300'. 1)));
и
SELECT ApartmentNumber
FROM TABLE (
SELECT UNITS
FROM BUILDING2
WHERE Name='Eastlake")
WHERE ApartmentNumber>100:
Однако, как было обещано, вы можете обновлять и удалять элементы
вложенной таблицы:
UPDATE TABLE (
SELECT Units
Постоянное хранение объектов в Oracle 709
FROM BUILDING2
WHERE Name='Eastlake')
SET NumberBedrooms=5
WHERE ApartmentNumber>100;
и
DELETE FROM TABLE (
SELECT Units
FROM BUILDING2
WHERE Name='Eastlake')
WHERE ApartmentNumber=100;
Как можно видеть, массивы переменной длины и вложенные таблицы весьма
похожи между собой, но у них есть и различия. Во-первых, как уже говорилось,
операторы UPDATE и DELETE работают только со вложенными таблицами. Кроме
того, массивы переменной длины ограничены максимальным размером, а
вложенные таблицы — нет. К тому же, Oracle хранит массивы переменной длины
вместе с таблицей, а данные вложенных таблиц — отдельно. Наконец, в массиве
переменной длины поддерживается определенный порядок строк, а во
вложенной таблице порядок строк может меняться по мере того, как в нее добавляются
новые строки.
Строчные объекты
Строчные объекты представляют собой четвертый способ использования
объектных типов в таблицах. Таблица строчных объектов — это просто таблица,
содержащая только объекты. Для нашего примера определим объект-квартиру obj_
Apartment, как прежде:
CREATE TYPE ob]_Apartment AS OBJECT (
BuildingName VARCHAR2(25).
ApartmentNumber char(4).
NumberBedrooms NUMBER);
Следующий оператор создаст таблицу с объектами obj_Apartment:
INSERT INTO APARTMENTS (BuildingName, ApartmentNumber, NumberBedrooms)
VALUES CWestview', '333', 2)
Следующий оператор произведет обновление строки в таблице APARTMENTS:
UPDATE apartments
SET NumberBedrooms = 5
WHERE ApartmentNumber = '100';
Наконец, удаление строки выполнит следующий оператор:
DELETE FROM APARTMENTS
WHERE ApartmentNumber='100';
710 Глава 18. Объектно-ориентированные базы данных
Объекты Oracle
Ранее было показано, как определяются объектные типы и как их можно
использовать в качестве элементов таблиц. При таких способах хранения объектов
объектная структура накладывается на отношения, а результирующие отношения
могут обрабатываться с помощью различных вариаций SQL. Но Oracle
предлагает и другой вариант — наложение реляционных структур на объекты. Для
обработки этих структур SQL непригоден. Эти структуры представляют собой
объекты, хранящиеся в базе данных, но манипуляции с ними должны выполняться
объектно-ориентированными программами.
Определение объектного типа
В листинге 18.2 показаны определения объектных типов Oracle для системы
обработки заказов, изображенной на рис. 18.2. Как показано ранее, структура
объектов и пользовательские типы данных определяются с помощью оператора CREATE
TYPE. Первые два типа, определенные на рисунке, — это пользовательский тип
obj_ADDRESS (адрес) и массив переменной длины под названием obj_PHONE_LIST
(список телефонов), имеющий максимальную длину 5. Эти два типа могут
использоваться в операторах CREATE TYPE AS OBJECT точно так же, как используются
типы данных при создании таблиц.
Листинг 18.2. Описание объектов в Oracle
CREATE TYPE obj ADDRESS AS OBJECT (
Street VARCHAR2(50)
City VARCHAR2(50)
State VARCHAR2(2)
Zip VARCHAR2U0)
Country VARCHAR2(15)
)
/
CREATE TYPE obj_PHONE_LIST AS VARRAY(5) OF VARCHAR2(12)
/
CREATE TYPE obj_SALESPERSON AS OBJECT (
SalespersonlD NUMBER,
Name VARCHAR2(50),
Address obj_ADDRESS.
PhoneNums obj_PHONE_LIST
)
/
CREATE TYPE obj_CUSTOMER AS OBJECT (
CustomerlD NUMBER,
Name VARCHAR2(50),
Address obj_ADDRESS,
PhoneNums obj PHONEJ.IST
Постоянное хранение объектов в Oracle 711
CREATE TYPE objJTEM
/
CREATE TYPE obj_LINEITEM AS OBJECT (
ItemNumber NUMBER,
ItemRef REF objJTEM,
Quantity NUMBER,
QuantityBackOrdered NUMBER.
ExtendedPrice NUMBER
)
/
CREATE TYPE tist_LINEITEM AS TABLE OF obj_LINEITEM
/
CREATE TYPE objJTEM AS OBJECT (
ItemNumber NUMBER,
ItemName VARCHAR2(25).
Price NUMBER
)
/
CREATE TYPE obj_0RDER AS OBJECT (
OrderNumber NUMBER.
OrderDate DATE.
Lineltems Iist_LINEITEM,
Shi pToAddress obj_ADDRESS,
Customer REF obj__CUSTOMER.
Salesperson REF obj_ SALESPERSON,
MEMBER FUNCTION total Items RERURN NUMBER
)
Далее в листинге 18.2 определены типы obj_SALESPERSON (продавец) и obj_
CUSTOMER (клиент). В обоих из них задействованы пользовательские типы obj_
ADDRESS и obj_PHONE_LIST. Такое использование означает, что каждый из
объектов obj_SALESPERSON и obj_CUSTOMER имеет атрибуты Street (улица), City (город),
State (штат), Zip (Индекс) и Country (Страна). Каждый из них имеет также массив
переменной длины, содержащий номера телефонов.
Следующий оператор CREATE TYPE является пустым; он нужен для того, чтобы
сообщить синтаксическому анализатору типов Oracle, что далее последует
определение объекта objJTEM (товар). Этот оператор позволяет использовать в
определении типа obj_LINEITEM (строка заказа) символ obj_ITEM, хотя последний еще
не был определен.
Определение типа obj_LINEITEM включает атрибуты ItemNumber (номер
товара), Quantity (количество), QuantityBackordered (отложенное количество)
и ExtendedPrice (цена с налогом), как показано на рис. 18.2. Однако помимо этого
оно включает ссылочный атрибут. Этот атрибут, представляющий собой ссылку
на товар и названный ItemRef, определен как REFobj_JTEM. Такая запись означает,
что данный атрибут содержит предоставляемое системой значение указателя на
712 Глава 18. Объектно-ориентированные базы данных
конкретный экземпляр объекта ITEM. Этот указатель будет действителен вне
зависимости от того, находится ли объект, на который он указывает, в
оперативной памяти или на диске. Если требуется настройка по адресам, Oracle выполнит
ее автоматически.
Разумеется, прикладная программа должна присвоить ItemRef значение. Одним
из способов сделать это является использование следующего SQL-оператора:
INSERT INTO ItemRef
SELECT REF(itemPtr) FROM objjTEM itemPtr
WHERE itemPtr.ItemNumber=10000;
Здесь предполагается, что только один элемент имеет значение ItemNumber,
равное 10 000.
Вы может спросить, в чем разница между типами данных REF и внешними
ключами. Во-первых, значения REF скрыты от пользователей и не имеют для
них смысла. Таким образом, как и для суррогатных ключей, для таких ссылок не
требуется каскадная модификация. Но если экземпляр obj_lTEM, на который
указывает ссылка, будет удален, значение этой ссылки окажется
недействительным. Программа должна проверить ссылку на допустимость, прежде чем
пользоваться ею.
Во-вторых, такие ссылки указывают на объекты, а не на строки таблиц.
Объект, на который указывает ссылка, может сам иметь сложную структуру данных
и, кроме того, иметь методы. Oracle предоставляет также библиотеку классов,
которая упрощает манипулирование такими ссылками. Последним различием
является то, что такие ссылки являются однонаправленными. Объект obj_ITEM,
на который указывает ссылка, может, но не обязан иметь обратный указатель на
объект obj_LINEITEM — например, в данном примере указатель назад отсутствует.
Это означает, что мы можем двигаться от obj_LINEITEM к obj_ITEM, но не наоборот.
В следующем операторе определяется объект list_LINEITEM как таблица,
состоящая из объектов obj_LINElTEM. Это напоминает приведенное ранее
определение АРАRTMENT_LIST2. Последним определен объект objJDRDER (заказ). В отличие
от BUILDING2, определенного как таблица, objJDRDER определяется как объект.
Поскольку он является объектом, атрибут Lineltems вложенной таблицы,
указывающий на тип list_LINEITEM, не обязан иметь вложенную таблицу.
Рассматривая листинг 18.2, имейте в виду, что мы определяем элементы
данных объекта, а не реляционные таблицы или что-нибудь им подобное.
Структуры данных этого объекта будут обрабатываться только методами объекта.
В последнем разделе определяется интерфейс методов объекта. Здесь
интерфейс имеет только один метод, под названием totalltems (всего товаров), который
возвращает одиночное значение типа NUMBER. В более реалистичном примере
было бы определено много методов.
Определение методов объекта
В листинге 18.3 показан пример метода объекта Oracle. Задачей этого метода
является перебор строк заказа и подсчет стоимости каждой строки с учетом нало-
Постоянное хранение объектов в Oracle 713
гов. Функция начинается с объявления трех переменных и затем перебирает в
цикле FOR набор объектов Lineltems. Оператор
FOR i in 1..SELF.Lineltems.COUNT LOOP
означает следующее: присвоить переменной значение 1, выполнить инструкции
до конца блока, обозначенного END LOOP, и прибавить к i единицу. Эти
операторы следует повторять, пока значение i не окажется больше, чем число строк
в атрибуте Lineltems.
Листинг 18.3. Пример метода Oracle
CREATE OR REPLACE TYPE BODY obj_0RDER AS
MEMBER FUNCTION total Items RETURN NUMBER IS
ItemPtr objJTEM;
OrderTotal NUMBER :=0
i INTEGER;
BEGIN
FOR I in 1...SELF.Lineltems.COUNT LOOP
UTL_REF.SELECT_OBJECT(LineItims(i).ItemRef. itemPtr):
OrderTotal := orderTotal + SELF.Lineltems(i).Quantity *
itemPtr.Price;
END LOOP;
RETURN orderTotal;
END:
END;
Оператор
UTL_REF.SELECT_OBJECT(LineItems(i).ItemRef. itemPtr)
вызывает класс, предоставляемый в составе библиотеки классов Oracle.
Назначение этой функции состоит в том, чтобы присваивать переменной itemPtr
значение действительного указателя на объект obj_ITEM, на который ссылается ItemRef
в текущей строке.
После того как этот оператор будет выполнен, с помощью itemPtr можно
ссылаться на любые свойства obj_ITEM. Это делается следующим оператором, где
itemPtr.Price имеет значение атрибута Price в объекте obj_ITEM, на который
ссылается текущая строка.
Не беспокойтесь, если пока не все из этого вам понятно. Стремитесь к
пониманию роли и задач, а не подробностей работы операторов в листинге 18.3.
Из этого изложения вы должны уяснить общие характеристики и природу
объектов Oracle и понять, каким образом они продвигают традиционные базы данных
в сторону объектно-ориентированного программирования.
714 Глава 18. Объектно-ориентированные базы данных
Стандарты ООСУБД
Над определением стандартов объектно-ориентированных баз данных, который
мог бы использоваться в качестве основы для построения ООСУБД, работают
несколько групп. Здесь мы рассмотрим работу двух из этих групп. Первая
состоит из представителей комитетов ANSI и ISO, целью которых является
расширение стандарта SQL92 для поддержки обработки объектов. Вторая группа, Object
Management Group, представляет собой консорциум производителей объектных
баз данных и других заинтересованных сторон и занимается построением другого
важного промышленного стандарта — обобщенной модели объектов (Common
Object Model) и языка описания интерфейсов (Interface Definition Language).
Как и следует ожидать, в первом стандарте в качестве отправной точки выбрана
перспектива баз данных, а движение осуществляется в сторону объектного
мышления. Второй стандарт движется от объектов к управлению данными. Оба
стандарта являются важными.
SQL3
SQL3 — это расширение стандарта SQL92, включающее поддержку
объектно-ориентированных баз данных. В разработке обсуждаемого здесь проекта
стандарта SQL3 принимают участие комитеты по стандартизации ANSI X3H2
и ISO/IEC JTC1/SC21/WG3. Работа над этим стандартом не окончена, и в
будущих вариантах вероятны изменения по сравнению с текущим проектом. Более
того, SQL3 является стандартом на продукцию, а не собственно продуктом. На
сегодняшний момент нет ни одной коммерческой СУБД, реализующей этот
стандарт. Вам следует рассматривать этот раздел в большей степени как описание
возможного пути эволюции реляционных СУБД, а не как описание конкретных
возможностей продукта.
SQL3 уходит корнями в традиции баз данных, а не в традиции объектного
мышления. Целью комитетов, работающих над SQL3, является описание
стандарта, вертикально совместимого с SQL92. Это означает, что все возможности
и функции SQL92 будут и в SQL3. Следовательно, SQL3 выглядит и является
средством для работы с реляционными базами данных, к которому добавлены
объектные функции, а не новым средством работы с
объектно-ориентированными базами данных.
В SQL3 появляются три группы новых идей: поддержка абстрактных типов
данных, расширение синтаксиса определения таблиц и дополнительные
языковые конструкции, делающие SQL3 самодостаточным с вычислительной точки
зрения языком.
Абстрактные типы данных
В SQL3 абстрактный тип данных (abstract data type ), или АТД (ADT), — это
определяемая пользователем структура, эквивалентная объекту ООП. Абстракт-
Стандарты ООСУБД 715
ные типы данных имеют методы, элементы данных и идентификаторы. Они могут
быть и подтипами других абстрактных типов данных, так как поддерживается
наследование. Для реализации логики методов абстрактных типов данных может
использоваться как SQL (с новыми расширениями), так и внешние языки,
например Java, С# и C++.
Абстрактный тип данных может использоваться в SQL-выражении,
храниться в таблице, а также и то и другое одновременно. Если абстрактный тип данных
фигурирует в одном или более SQL-выражении, но не хранится в какой-либо
таблице, то он является временным; постоянным абстрактный тип данных
можно сделать, поместив его в таблицу.
В листинге 18.4 приведен пример определения абстрактного тина данных для
объекта СОТРУДНИК, описывающего сотрудника компании. Текущий синтаксис
SQL3 набран прописными буквами, а код, предоставляемый разработчиком. —
строчными. Конкретный синтаксис нам не важен, потому что он может
измениться. Вместо этого следует обратить внимание на то, что этот абстрактный тип
данных, подобно объекту ООП, имеет элементы данных и функции (методы).
Элементы данных включают атрибуты ИмяСотрудника, Личный Номер, ДатаНайма,
ТекущаяЗарплата и виртуальный элемент данных Зарплата (элемент данных,
существующий только как результат вычисления функции). Методов имеется
три: узнать_3арплату, изменить_3арплату и удалить__Сотрудника.
Листинг 18.4. Пример определения абстрактного типа данных в SQL3
CREATE OBJECT TYPE Сотрудник WITH OID VISIBLE
(ИмяСотрудника VARCHAR NOT NULL.
ЛичныйНомер CHAR(7)
Зарплата UPDATABLE VIRTUAL GET with узнать_3арплату SET WITH
изменить_3арплату.
PRIVATE
ДатаНайма DATE
ТекущаяЗарплата CURRENCY
PUBLIC
ACTOR FUNCTION узнать_3арплату (:Е Сотрудник) RETURNS CURRENCY
{здесь должен быть код, который проверяет полномочия пользователя.
вызывающего метод, и возвращает текущую зарплату.
если полномочия достаточны}
RETURN Зарплата
END FUNCTION.
ACTOR FUNCTION изменить_3арплату (:Е Сотрудник) RETURNS Сотрудник
{здесь должен быть код. который проверяет полномочия пользователя,
вызывающего метод, и устанавливает новое значение зарплаты.
если полномочия достаточны}
RETURN :E
END FUNCTION, .
продолжение
716 Глава 18. Объектно-ориентированные базы данных
Листинг 18.4 (продолжение)
DESTRUCTOR FUNCTION удалить_Сотрудника (:Е Сотрудник)
RETURNS NULL
{код, выполняющий необходимую подготовку и проверку
перед удалением сотрудника}
DESTROY :E
RETURN :E
END FUNCTION,
В SQL3 определены два вида абстрактных типов данных: АТД-объект (OBJECT)
и АТД-значеиие (VALUE). АТД-объект представляет собой идентифицируемую,
независимую структуру данных, которой присваивается идентификатор,
называемый OID. Этот идентификатор является уникальным значением,
существующим на протяжении всей жизни объекта. Если нужно передавать О ID другим
функциям или хранить его в других таблицах, в первую строку определения
объекта необходимо добавить фразу WITH OID VISIBLE. Это было сделано в листинге 18.4.
Значения OID — это указатели на объекты; сохранение OID в таблице
означает сохранение в ней указателя на объект. Это может быть удобно, но создает
одну проблему. При уничтожении абстрактного типа данных его OID
становится недействительным, но данное конкретное значение OID может храниться
в строках таблиц, которые даже не находятся в памяти, когда происходит
уничтожение абстрактного типа данных. Стандарт SQL3 не указывает, что должно
происходить в этом случае. Очевидно, необходимо в программе проверять OID
на допустимость, прежде чем пытаться его использовать.
Второй вид абстрактного типа данных — АТД-значение. АТД-значениям не
присваиваются О ID, и они могут существовать только в том контексте, в
котором они были созданы. Если АТД-значеиие создается как столбец таблицы, оно
будет сохранено вместе с этой таблицей. Однако сослаться на этот абстрактный
тип данных будет невозможно, кроме как через имя таблицы. Если
АТД-значение создается функцией, оно будет временным и прекратит свое существование
при освобождении данной функцией памяти.
Код в листинге 18.4 определяет АТД-объект Сотрудник как тип. Имя типа
может использоваться в определениях таблиц точно так же, как и встроенные типы
данных. В листинге 18.5 определена таблица Отдел; у нее есть атрибут Название-
Отдела типа CHAR(IO), атрибут Менеджер типа Сотрудник и атрибут Администратор,
также типа Сотрудник. Таким образом, этот абстрактный тип данных
используется в определении таблицы наряду с любыми другими типами.
Листинг 18.5. Определение таблицы с использованием абстрактного типа
данных Сотрудник
CREATE TABLE Отдел
(НазваниеОтдела char (10),
Менеджер Сотрудник,
Администратор сотрудник INSTANCE)
При определении столбца, имеющего абстрактный тип данных, для указания
того, что должно храниться в таблице — объект или указатель на объект, — ис-
Стандарты ООСУБД 717
пользуется ключевое слово INSTANCE. Если оно указано, то в столбце хранятся
данные объекта. Если нет, в столбце хранится указатель на объект. Если
абстрактный тип данных представляет собой АТД-значение, то подразумевается
INSTANCE.
В листинге 18.5 для столбца Менеджер ключевое слово INSTANCE не указано, но
оно указано для столбца Администратор. Это означает, что каждая строка
таблицы Отдел будет в столбце Менеджер содержать указатель на объект типа Сотрудник,
а в столбце Администратор — данные и методы.
Открытые элементы данных объекта могут использоваться в
SQL-операторах точно так же, как обычные столбцы таблиц. Например, для таблицы в
листинге 18.1 рассмотрим следующий SQL-запрос:
SELECT НазваниеОтдела. Менеджер.0ID, Менеджер.Имя, Администратор.0ID,
Администратор.Имя
FROM Отдел
При выполнении этого запроса из таблицы Отдел будут извлечены атрибуты
НазваниеОтдела, Менеджер.ОЮ, Администратор.ОЮ и Администратор.Имя. По
значению атрибута Менеджер.ОЮ СУБД найдет экземпляр объекта Сотрудник, на
который он указывает. Затем СУБД извлечет из этого объекта атрибут Менеджер.Имя
и возвратит его в ответе на этот запрос. Результат будет таким же, как если бы
все объекты Менеджер хранились в таблице. Очевидно, что если OID,
хранящийся в таблице, стал недействительным по причине удаления объекта, на который
он указывает, СУБД должна будет каким-то образом обработать эту ошибку.
Рассмотрим SQL-оператор
SELECT НазваниеОтдела. Менеджер.Имя. Менеджер.Зарплата
FROM Отдел
Для выполнения этого оператора СУБД нужно будет обратиться к таблице
Отдел, получить OID менеджера, получить экземпляр объекта Сотрудник, который
представляет этого менеджера, и вызвать его функцию узнать_3арплату, которая
материализует виртуальный столбец Зарплата. Функция узнать_3арплату может
при запуске выполнять аутентификацию пользователя, например, запрашивая
имя пользователя или пароль либо предлагая выполнить какие-то другие
действия, прежде чем СУБД сможет получить запрашиваемые данные. Когда
функция узнать_3арплату возвратит значение или код ошибки, указывающий, что
данные предоставлены не будут, СУБД может выполнить форматирование данных
для этого сотрудника. Аналогичные действия потребуются для обработки
каждой строки таблицы Отдел.
Закрытые элементы данных являются локальными переменными объекта.
Соответственно, следующий SQL-запрос является ошибочным:
SELECT НазваниеОтдела. Менеджер.ТекущаяЗарплата
FROM Отдел
Единственный способ извлечь значение атрибута ТекущаяЗарплата из объекта
Сотрудник — через функцию узнать_3арплату.
718 Глава 18. Объектно-ориентированные базы данных
Столбцам могут присваиваться значения, как и в обычных SQL-операторах.
Так, например, выражение
UPDATE Отдел
SET Администратор.Имя = "Фред П. Джонсон"
WHERE НазваниеОтдела = "Бухгалтерия"
изменит значение атрибута Имя объекта Администратор, существующего в отделе
под названием «Бухгалтерия».
В связи с тем, что некоторые объекты представляются указателями, а не
значениями данных, иногда можно получить неожиданные результаты. Рассмотрим
следующий запрос:
UPDATE Отдел
SET Менеджер.Имя = "Фред П. Джонсон"
WHERE НазваниеОтдела = "Бухгалтерия"
Этот оператор не назначает сотрудника по имени Фред П. Джонсон новым
менеджером бухгалтерии. Вместо этого он меняет имя сотрудника, который
является менеджером в настоящий момент. Меняется имя сотрудника, то есть
в любой другой таблице, имеющей ссылку на данный объект Сотрудник, его имя
также изменится. Если на должность менеджера в бухгалтерии еще не назначен
ни один сотрудник, этот оператор выдаст ошибку.
Чтобы заменить менеджера бухгалтерии другим сотрудником, которого зовут
Фред П. Джонсон, объект Менеджер должен указывать на правильный экземпляр
объекта Сотрудник. Это можно сделать с помощью следующего SQL-кода:
UPDATE Отдел
SET Менеджер =
SELECT Сотрудник.0ID
FROM Сотрудник
WHERE Имя = "Фред П. Джонсон"
WHERE НазваниеОтдела = "Бухгалтерия"
С концептуальной точки зрения этот оператор является правильным. Будет
ли он в реальности работать в СУБД, реализующей стандарт SQL3, — это,
разумеется, зависит от разработчиков СУБД. Как уже отмечалось, поскольку SQL3
находится в стадии разработки и поскольку ни в одном продукте этот стандарт
еще не реализован, можно считать, что данное изложение указывает
стратегическое направление развития промышленности, а не конкретный промышленно-
стандартизованный синтаксис.
Определение абстрактных типов данных дает возможность создавать, хранить
и изменять объекты в SQL. Стандартом SQL3 предложены и другие изменения
в SQL. Рассмотрим их далее.
Табличные расширения SQL3
SQL3 расширяет определение таблиц в нескольких отношениях. Прежде всего,
таблицы в SQL3 имеют идегтгификатор строки (row identifier), представляющий
Стандарты РОСУ БД 719
собой уникальный идентификатор каждой строки таблицы. Этот
идентификатор — тоже самое, что и суррогатный ключ, термин, который мы использовали
в предыдущих главах. Приложения могут использовать этот идентификатор, если
он вводится явно путем указания в определении таблицы фразы WITH IDENTITY.
В любой таблице, определенной таким образом, создается скрытый столбец под
названием IDENTITY. Значения из этого столбца могут использоваться
приложением, но он не включается в результаты выполнения оператора SELECT *.
Рассмотрим таблицу в листинге 18.6 и следующие два SQL-оператора:
SELECT ИмяПреподавателя, Идентификатор
FROM ПРЕПОДАВАТЕЛЬ
и
SELECT *
FROM ПРЕПОДАВАТЕЛЬ
Результатом первого оператора будет таблица с двумя столбцами, в первом
из которых будет имя преподавателя, а во втором — значение идентификатора
строки. Результатом второго оператора будет таблица с тремя столбцами: Имя-
Преподавателя, Телефон и Офис.
Листинг 18.6. Определение таблицы с ключевым словом WITH IDENTITY
CREATE TABLE ПРЕПОДАВАТЕЛЬ WITH IDENTITY
(ИмяПреподавателя char (10),
Телефон char (7),
Офис char (5)
)
Вторым дополнением к концепции таблицы в SQL3 является введение трех
типов таблиц: SET, MULTISET и LIST. Таблица типа SET — это таблица без
повторяющихся строк; таблица типа MULTISET может иметь повторяющиеся строки и
эквивалентна понятию таблицы в SQL92. (Это определение, конечно, игнорирует
столбец IDENTITY, поскольку с учетом этого столбца ни одна таблица не имеет
повторяющихся строк.) Наконец, таблица типа LIST — это таблица, упорядоченная
по одному или нескольким столбцам.
Третьим дополнением к концепции таблиц в SQL3 является подтаблица (sub-
table). Подтаблица является подмножеством другой таблицы, называемой пад-
таблицей (supertable). Подтаблица наследует все столбцы своей надтаблицы и
может также иметь свои собственные столбцы. Таблица, имеющая подтаблицу или
надтаблицу, имеет неявно определенный идентификатор строки. В листинге 18.7
определены два типа преподавателей: ШТАТНЫЙ_ПРЕПОДАВАТЕЛЬн ВНЕШТАТНЫЙ.
ПРЕПОДАВАТЕЛЬ. Таблица ШТАТНЫЙ_ПРЕПОДАВАТЕЛЬ имеет столбцы
ИмяПреподавателя, Телефон, Офис и ДатаЗачисленияВШтат. Таблица ВНЕШТАТНЫЙ_ПРЕПОДАВАТЕЛЬ
имеет столбцы ИмяПреподавателя, Телефон, Офис и ДатаСледующегоРассмотрения.
Хотя эти таблицы определены без ключевого слова WITH IDENTITY, они имеют
столбец IDENTITY, поскольку являются подтипами.
720 Глава 18. Объектно-ориентированные базы данных
Листинг 18.7. Определение подтаблиц
CREATE TABLE ПРЕПОДАВАТЕЛЬ WITH IDENTITY
(ИмяПреподавателя char (10).
Телефон char (7).
Офис char (5)
)
CREATE TABLE ШТАТНЫЙ^ПРЕПОДАВАТЕЛЬ UNDER ПРЕПОДАВАТЕЛЬ
(ДатаЗачисленияВШтат Date)
CREATE TABLE ВНЕШТАТНЫЙ_ПРЕПОДАВАТЕЛЬ UNDER ПРЕПОДАВАТЕЛЬ
(ДатаСледующегоРассмотрения Date)
Поразмыслите немного над последствиями добавления к понятию таблиц
абстрактных типов данных и подтипов. Как абстрактные типы данных, так и
таблицы могут иметь подтипы, но это не одно и то же. Подтипы абстрактных типов
данных определяют одну иерархию обобщения, а подтипы таблиц — другую.
Иерархии могут быть вложенными одна в другую, раздельными или частично
перекрывающимися. Это является поводом для критики SQL3 за его
чрезмерную сложность в этом отношении, и интересно будет увидеть, какая часть этой
сложной структуры будет в действительности реализована в СУБД.
Расширения языка SQL
В SQL3 методы абстрактных типов могут быть сами написаны на SQL. Чтобы
сделать эту возможность более реальной, предложены дополнительные языковые
элементы, делающие SQL полноценным в вычислительном отношении языком
программирования. Предложенные расширения перечислены в табл. 18.4.
Таблица 18.4. Предложенные расширения стандарта SQL3
Оператор Цель
DESTROY Уничтожает АТД-объект; допустим только в функциях-деструкторах
ASSIGNMENT Позволяет присвоить результат выполнения SQL-запроса локальной
переменной, столбцу или АТД-атрибуту
CALL Вызы вает SQL- п роцедуру
RETURN Возвращает значение, вычисленное процедурой или функцией
CASE Выбирает путь, по которому пойдет выполнение программы
в зависимости от значения управляющей переменной
IF THEN ELSE Условный оператор
WHILE LOOP Оператор цикла
До сих пор SQL был языком, ориентированным на множества. Операторы
SELECT выделяли множество строк и выполняли с ними некоторые действия.
Добавление языковых элементов, представленных в табл. 18.4, изменит эту
характеристику. В SQL станет возможна реализация логики «одна строка за один
прием». Это изменение сделает SQL еще более похожим на традиционные языки
программирования. Это необходимо, если предполагается использовать SQL для
написания методов абстрактных типов данных, но означает также
фундаментальную смену парадигмы SQL.
Стандарты РОСУ БД 721
ODMG-93
ODMG (Object Data Management Group, Группа управления объектными
данными) — это консорциум производителей объектных баз данных и других
заинтересованных промышленных экспертов, который применил идеи другой группы, OMG
(Object Management Group, Группа управления объектами), к проблеме объектных
баз данных. Первый отчет ODMG был представлен в 1993 г. и поэтому называется
ODMG-93. Этот стандарт вышел из объектно-ориентированного
программирования, а не из традиционных реляционных баз данных. Следовательно, в качестве
базовой конструкции в нем выступает объект, а не таблица, как в SQL3.
ODMG-93 — это определение интерфейсов для продуктов, работающих с
объектными данными. Реализация идей ODMG-93 может весьма различаться.
Продукт ODMG-93, предназначенный для хранения и манипулирования данными
объектов C++, может иметь совершенно другую организацию, чем продукт для
хранения и манипулирования объектами языка Smalltalk. Эти два продукта могут
быть весьма различными, и все же реализующими интерфейсы ODMG-93.
Поскольку ODMG-93 вырос из контекста объектно-ориентированного
программирования, его детальное описание требует существенного знания ООП.
Такое описание выходит за рамки этой книги. Мы сосредоточим наше внимание
на фундаментальных концепциях, лежащих в основе отчета ODMG-93. В
следующем списке представлены пять ключевых идей, согласно описанию Мэри
Лумис (Mary Loomis)1.
♦ Объекты являются фундаментальными единицами.
♦ Каждый объект имеет постоянный, сохраняющийся в течение всего
времени существования объекта уникальный идентификатор.
♦ Объекты могут классифицироваться по типам и подтипам.
♦ Состояние объекта определяется его данными и связями.
+ Поведение объекта определяется его методами.
Объекты — фундаментальные единицы
Согласно объектной модели ODMG, объекты являются фундаментальными
единицами хранения и манипулирования. В отличие от SQL3, где в качестве
фундаментальной единицы выступает таблица, а объекты хранятся в столбцах таблиц,
базовой сущностью в ODMG является объект. Концепция ODMG более похожа
на концепцию объектной программы в листинге 18.1. То есть прикладная
программа определяет объекты сами по себе, а сделать ли их постоянными — решает
ООСУБД. Никаких других структур типа таблиц не требуется.
В соответствии с моделью ODMG, объект может быть изменяемым (mutable)
и неизменяемым (immutable). Изменяемые объекты, как следует из их названия,
могут быть изменены; неизменяемые объекты являются постоянными, и ни одно
приложение не может изменить состояние такого объекта. Реализация
неизменяемости возлагается на ООСУБД.
Магу Е. S. Loomis, Object Databases, The Essentials. Reading, MA: Addison-Wesley, 1995, с 88-110.
722 Глава 18. Объектно-ориентированные базы данных
Каждый объект имеет пожизненный уникальный
идентификатор
Вторая фундаментальная идея объектной модели ODMG состоит в том, что
каждому объекту присваивается уникальный идентификатор, который является
действительным на протяжении времени существования объекта. Более того,
идентификатор должен быть действительным вне зависимости от того, где хранится
объект — на внешнем носителе или в оперативной памяти. Настройка по адресам
должна выполняться ООСУБД явно; прикладные программы могут
использовать указатели на объекты так, как если бы они всегда были действительны.
Этот стандарт оставляет свободу в определении конкретной формы
объектного идентификатора. Таким образом, различные производители ООСУБД
могут использовать различные способы задания идентификаторов объектов. Это
означает, что идентификаторы объектов из различных баз данных, управляемых
разными СУБД, не обязательно будут совместимыми. Для нераспределенных
баз данных это вряд ли составит проблему, так как все объекты в данной
объектной базе данных будут создаваться и храниться одной и той же СУБД.
В распределенной системе проблема идентификации объектов является более
сложной по двум причинам: во-первых, потому, что идентификаторы объектов
в различных СУБД могут иметь различные форматы, а во-вторых, потому, что
идентификаторы объектов не обязательно будут уникальными в масштабе
нескольких баз данных. Этот вопрос оставлен без внимания в стандарте ODMG-93.
Объекты могут организовываться в иерархии
типов и подтипов
Объектная модель стандарта ODMG-93 указывает, что объекты организуются
в группы по типу. Объекты создаются как принадлежащие к определенному типу.
Все объекты одного и того же типа имеют одинаковые характеристики и
поведение. Объекты могут определяться как подтипы других объектов. В этом случае
они наследуют все характеристики и поведение родительского типа. Согласно
стандарту, объект создается как экземпляр определенного типа, и этот экземпляр
не может изменить свой тип.
Термины тип и класс часто используются как синонимы. Согласно Мэри Лу-
мис, это неправильно. Объектный класс — это логическая группа объектов, как
они определены в ODMG-93; классы имеют подклассы, наследующие от своих
родителей их характеристики и поведение. Тип — это реализация класса на
конкретном языке. Так, например, класс Сотрудник представляет собой логическое
определение данных и методов; он может иметь подклассы Продавец и Бухгалтер,
являющиеся его наследниками. Реализация класса Сотрудник на C++ называется
типом, а реализации на C++ подклассов Продавец и Бухгалтер называются
подтипами1. В языке Smalltalk класс Сотрудник может реализовываться по-другому. Эта
реализация будет являть собой другой тип. Различение класса и типа помогает
отделить логические определения от конкретных реализаций логических структур.
Объектные классы (а следовательно, и типы) могут иметь свойства. Стандарт
ODMG указывает, что каждый класс имеет имя и ограничения уникальности,
Mary E. S. Loomis, Object Databases, The Essentials. Reading, MA: Addison-Wesley, 1995, с 96.
Стандарты ООСУБД 723
являющиеся его свойствами. Совокупность всех экземпляров объектного класса
называется экстентом (extent) объекта. Любой атрибут или комбинация
атрибутов может быть объявлена уникальной в масштабе экстента. Например, в классе
Сотрудник атрибут НомерСотрудника может быть объявлен уникальным, как может
быть объявлено уникальным сочетание {Имя, Фамилия} и т. д. Поскольку
требования уникальности относятся ко всему экстенту, а не к любому данному
экземпляру объекта, такие требования являются свойствами класса, a Pie экземпляра
класса. Таким образом, имя класса Сотрудник и требование, чтобы
НомерСотрудника был уникальным, являются свойствами класса. Сам по себе НомерСотрудника,
однако, является свойством экземпляра класса Сотрудник.
Поскольку ODMG представляет собой стандарт на интерфейс, а не на его
реализацию, здесь не делаются попытки описать, как должно осуществляться
хранение типов и подтипов и манипулирование ими. Интерфейс просто
показывает, что объекты должны записываться и считываться классом и что должно
быть обеспечено наследование.
Состояние определяется значениями данных и связями
В соответствии со стандартом ODMG, состояние любого объекта представляется
его свойствами. Этими свойствами могут быть либо атрибуты, либо связи.
Атрибут — это символьное значение или набор значений. Дата Найма и ТекущаяЗарпла-
та — это значения констант. ЗарплатаРанее — набор значений констант. Связь —
это свойство, указывающее на наличие отношений между экземпляром одного
объекта и одним или несколькими экземплярами других объектов. В качестве
примера связи можно привести свойство Отдел.
ODMG указывает набор операций, которые могут выполняться над связями.
Эти операции перечислены в табл. 18.5. Операции различаются по
максимальной кардинальности связи. Это делается потому, что в случае связи 1:1 свойства
являются однозначными, и наборы свойств рассматривать не требуется. В случае
связи 1:N или N:M свойство имеет много элементов, поэтому создается
множество, и программа должна уметь перебирать его элементы.
Таблица 18.5. Операции над связями в ODMG
Операция Действие
Set Создает связь 1:1
Clear Уничтожает связь 1:1
lnsert__element Добавляет элемент на множественную сторону связи 1:N или N:M
Remove_element Удаляет элемент с множественной стороны связи 1 :N или N:M
Get Возвращает ссылку на объект в связи 1:1
Traverse Возвращает ссылку на набор объектов на множественной стороне
связи 1:N или N:M
Create_iterator Создает структуру для обработки объектов из набора, ссылка
на который получена с помощью операции Traverse
Когда объекты имеют связь, эта связь должна становиться постоянной, когда
делается постоянным один из объектов. Стандарт не указывает, как должна
724 Глава 18. Объектно-ориентированные базы данных
представляться связь и какими способами должна осуществляться настройка
связей по адресам. Эти вопросы должны решаться при создании ООСУБД.
Поведение объекта определяется его операциями
Поведение объектного типа определяется его методами. Все объекты заданного
типа имеют одинаковые методы, и объекты подтипов наследуют эти методы.
Если объект подтипа переопределяет метод, он тем самым замешает метод,
унаследованный от родителя. Если, например, объект Сотрудник имеет метод узнать_3ар-
плату, и объект Продавец, подтип объекта Сотрудник, также имеет метод узнать_
Зарплату, для получения сведений о зарплате продавца будет использоваться
собственный метод этого объекта, Продавец!узнать_Зарплату.
Объекты взаимодействуют между собой, вызывая методы друг друга. Иногда
говорят, что объекты передают друг другу сообщения, где сообщением является
строка наподобие Продавец!узнать_Зарплату, включающая имя объектного типа
и имя метода этого типа. У сообщений, разумеется, могут быть параметры.
Назначение ООСУБД состоит в обеспечении постоянного хранения
объектов. Стандарт ODMG указывает, что объекты имеют методы, поэтому в число
функций ООСУБД, претендующей на соответствие этому стандарту, должно
входить хранение и управление методами. На самом деле современные ООСУБД
весьма отличаются по степени поддержки постоянного хранения методов.
Некоторые из них в действительности вообще не обеспечивают такой поддержки.
Другие поддерживают в какой-то степени, но не позволяют создавать версии объектов.
Хранение методов является важным вопросом, и, вероятно, возможности
ООСУБД в этой сфере в будущем будут улучшены. Ни одно приложение не
является статичным: требования меняются, и необходимо адаптировать поведение
объектов к этим изменениям. Более того, методы могут меняться и при
отсутствии изменений в структуре данных объекта. Без средств управления методами
у двух экземпляров объекта могут оказаться различные версии методов.
Рассмотрим пример. Допустим, экземпляр класса Продавец, который мы
обозначим Продавец А, создается и сохраняется с одной версией метода назначить^
Зарплату. Теперь предположим, что способ вычисления зарплаты продавца
изменился, и соответственно был изменен метод назначить_3арплату. После этого был
создан и сохранен объект Продавец Б. Теперь Продавец А и Продавец Б будут
казаться эквивалентными в том, что касается их данных, но в действительности
это не так. Без управления методами со стороны СУБД не существует способа
определить, что Продавец А и Продавец Б представляют собой различные версии
объекта Продавец.
Эта ситуация не отличается от того, что происходит сегодня в прикладных
программах, не имеющих отношения к ООСУБД, поэтому сторонники ООСУБД
могут утверждать, что ООСУБД не ухудшили ситуацию. Однако это
представляется лишь отговоркой. Если определено, что объекты имеют свойства,
описывающие их данные, и свойства, описывающие их поведение, то неправомочно
утверждать, что постоянное хранение объектов относится только к одной
разновидности свойств и не относится к другой. Слишком многое из того, что обещает
нам объектное мышление, останется за бортом, если наряду с управлением
данными ООСУБД не будут обеспечивать управление методами.
Резюме 725
i —
Резюме
Реляционные базы данных не слишком приспособлены для хранения объектов
ООП, поскольку объекты могут содержать сложные структуры, плохо
подходящие для хранения в таблицах. Кроме того, объекты имеют методы, которые также
нужно хранить. Для постоянного хранения объектов были разработаны
специализированные объектно-ориентированные СУБД, но они не имели
коммерческого успеха, так как требовали преобразования существующих реляционных
данных в формат ООСУБД. Выигрыш не стоил затраченных средств. Вместо этого
начали появляться СУБД, сочетающие реляционный и объектный подходы к
хранению объектов. Такие СУБД получили название объектно-реляционных.
В объектно-ориентированном программировании (ООП) программы состоят
из инкапсулированных объектов — логических структур, имеющих элементы
данных и характеризуемых определенным поведением. Интерфейс — это как бы
«внешний вид» объекта, а реализация — его инкапсулированная внутренняя
структура. Объекты могут иметь подклассы, которые наследуют атрибуты и
методы своих надклассов. Полиморфизм допускает существование нескольких
версий одного и того же метода: компилятор вызывает правильную версию
метода во время выполнения, в зависимости от класса объекта.
Класс — это логическая структура объекта; группа объектных классов
называется библиотекой объектных классов. Экземпляры объектного класса
называются экземплярами объекта, или просто объектами. Конструкторы объектов —
это методы, выделяющие память под объекты и создающие соответствующие
структуры; деструкторы уничтожают объекты и освобождают оперативную
память. Временные объекты существуют только во время выполнения программы,
а постоянные объекты записываются на физический носитель и существуют вне
рамок работы программы.
Постоянное хранение объектов может быть обеспечено с помощью
традиционных систем обработки файлов, реляционных СУБД или
объектно-ориентированных СУБД. Использование традиционных систем обработки файлов создает
существенную нагрузку на программиста и имеет смысл только в приложениях,
содержащих несколько простых объектов, структура которых меняется редко.
Постоянное хранение объектов возможно также с помощью реляционных СУБД,
но программист при этом должен преобразовывать объектные структуры в
отношения, писать SQL-запросы и разрабатывать алгоритмы настройки по адресам.
Использование ООСУБД — это наиболее простой и прямолинейный способ
постоянного хранения объектов.
СУБД Oracle поддерживает постоянное хранение объектов с
использованием объектно-реляционного подхода. Можно определять типы объектов и
применять их в таблицах как столбцовые объекты, массивы переменной длины,
вложенные таблицы или строчные объекты. Можно также определять и «чистые»
объекты; такие объекты могут включать массивы переменной длины и
вложенные таблицы. Они могут также содержать указатели на объекты, определенные
как REF-атрибуты. Наконец, такие объекты могут иметь методы, которые могут
обращаться к библиотекам классов Oracle.
726 Глава 18. Объектно-ориентированные базы данных
SQL3 — это расширение SQL-92, которое предусматривает абстрактные типы
данных (АТД), дополнения к концепции таблиц и новые возможности языка
SQL. Абстрактные типы данных, постоянное хранение которых обеспечивается
путем записи их в таблицу, могут быть двух типов: АТД-объект и АТД-значение.
АТД-объекты имеют идентификаторы, называемые OID. В SQL3 таблицы
имеют идентификаторы строк и могут иметь подтипы. Определено три типа таблиц:
SET, MULTISET и LIST. В табл. 18.4 приведен список расширений SQL,
предложенных в SQL3.
Пятью ключевыми идеями стандарта ODMG-93 являются представление об
объекте как о фундаментальной структуре данных, наличие у объектов
пожизненных уникальных идентификаторов, организация объектов в иерархии типов
и подтипов, представление состояния объекта с помощью состояния его данных
и связей, а также определение поведения объекта с помощью его действий.
Семантические объекты, как они определены в главе 4, реализуют стандарт
ODMG для атрибутов данных, но не для поведения объекта.
Вопросы I группы
1. Объясните, чем объектно-ориентированное программирование отличается
от традиционного программирования.
2. Почему реляционные базы данных более популярны, чем объектные?
3. Дайте определение объекта ООП.
4. Дайте определения терминов ипкапсупировттый, атрибут и метод.
5. Объясните разницу между интерфейсом и реализацией.
6. Что такое наследование?
7. Что такое полиморфизм?
8. Дайте определения терминов объектный класс, библиотека объектных
классов и экземпляр объекта.
9. Объясните, в чем состоят функции конструкторов и деструкторов объектов.
10. Укажите, в чем разница между временным и постоянным объектом.
11. Объясните различие в записи КЛИЕНТШайти и КЛИЕНТ.Индекс.
12. Какова функция ключевого слова NOTHING в листинге 18.1?
13. Какова функция ключевого слова ME в листинге 18.1?
14. Что такое обратный вызов и для чего он используется?
15. Что означает термин настройка по адресам?
16. Кратко охарактеризуйте задачи, стоящие перед программистом при
использовании для постоянного хранения объектов традиционной системы
обработки файлов.
17. Кратко охарактеризуйте задачи, стоящие перед программистом при
использовании для постоянного хранения объектов реляционной СУБД.
Вопросы I группы 727
18. Укажите преимущества и недостатки использования ООСУБД для
постоянного хранения объектов.
19. Напишите операторы Oracle, определяющие объектный тип Рпате (имя
человека) с тремя атрибутами: FirstName, MiddleName и LastName (имя,
отчество и фамилия). Сохраните этот тип как столбцовый объект в таблице
PERSON (человек).
20. Напишите оператор Oracle, создающий массив переменной длины, который
может содержать максимум 100 объектов типа Рпате. Напишите
операторы, создающие таблицу данных о клубе под названием CLUB1, имеющую
столбцы с суррогатным ключом, названием клуба (ClubName) и массив
переменной длины с именами людей.
21. Напишите операторы Oracle, создающие таблицу CLUB2, аналогичную CLUB1,
но хранящую список имен людей во вложенной таблице, а не в массиве
с переменной длиной. Назовите вложенную таблицу Рпате_ТаЫе.
22. Объясните, в чем разница между таблицами СШВ1 и СШВ2.
23. Напишите операторы Oracle, создающие таблицу с Рпате как строчным
объектом.
24. Объясните назначение REF-атрибутов на рис. 18.19. Чем эти атрибуты
отличаются от внешних ключей?
25. Объясните назначение следующих двух операторов:
FOR I in l..SELF.Lineitems.COUNT LOOP
и
UTI_REF.SELECT_OBJECT(LineItems(i).ItemRef, itemPtr)
Что такое SQL3?
Что такое абстрактный тип данных (АТД)?
Объясните разницу между АТД-объектом и АТД-значением.
Что такое OID? Для чего он используется?
Объясните, что должна делать СУБД при выполнении следующего SQL-
оператора над абстрактным типом данных, изображенным в листинге 18.5:
SELECT НазваниеОтдела. Менеджер.Телефон. Администратор.Телефон
FROM Отдел
Что произойдет, когда СУБД выполнит следующий SQL-оператор над
абстрактным типом данных, показанным в листинге 18.5:
UPDATE Отдел
SET Менеджер.Имя = "Джон Джекоб Астор"
Напишите SQL-оператор, который нужно выполнить над абстрактным
типом данных в листинге 18.5 для назначения на должность менеджера
другого сотрудника.
728 Глава 18. Объектно-ориентированные базы данных
33. Что такое идентификатор строки в SQL3?
34. Объясните, чем различаются SET, MULTISET и LIST в SQL3.
35. Объясните разницу между подтаблицей, надтаблицей и таблицей.
36. Что такое ODMG-93?
37. Перечислите пять ключевых идей ODMG-93.
38. В чем заключается различие между типом и классом в ODMG-93?
39. Чем отличаются свойство и атрибут в ODMG-93?
40. Что такое экстент?
41. Что такое свойства класса в ODMG-93?
42. Какие значения могут иметь свойства в стандарте ODMG?
43. Какие значения могут иметь атрибуты в стандарте ODMG?
44. Какие значения могут иметь свойства связей в стандарте ODMG?
45. В чем важность постоянного хранения методов? Какая проблема может
возникнуть, если такое хранение не обеспечивается?
46. Объясните, в чем семантические объекты соответствуют стандарту ODMG,
а в чем нет.
Вопросы II группы
47. Рассмотрите требования и реляционную структуру базы данных галереи
View Ridge в главе 10. Рассмотрите использование типов Oracle, а также
столбцовых объектов, массивов переменной длины, вложенных таблиц
и строчных объектов в контексте потребностей галереи. Какие изменения
вы бы внесли в реляционную структуру? Могли бы вы порекомендовать
заменить таблицы TRANSACTION или WORK массивами переменной длины
или вложенными таблицами? Если да, то как это сделать? Если нет, то
почему? Покажите, как бы вы использовали REF-атрибуты Oracle для
устранения необходимости в таблице пересечения. Стоит ли, по вашему
мнению, идти этим путем?
48. Рассмотрите типы Oracle, а также столбцовые объекты, массивы
переменной длины, вложенные таблицы и строчные объекты в контексте
семантической объектной модели. Какие элементы этой модели
соответствуют типам? Массивам с переменной длиной? Вложенным таблицам?
Покажите, как вы использовали бы объектно-реляционные возможности
Oracle для моделирования каждого из типов семантических объектов,
описанных в главе 7.
Приложение А
Структуры данных
Все операционные системы предоставляют услуги по управлению данными.
Но для удовлетворения специфических нужд СУБД этих услуг, вообще говоря,
недостаточно. Поэтому для повышения производительности СУБД строят и
поддерживают специальные структуры данных, о которых и пойдет речь в этом
приложении.
Вначале мы обсудим плоские файлы и некоторые проблемы, возникающие
при необходимости обрабатывать такие файлы в различном порядке. Затем мы
обратимся к трем специализированным структурам данных: последовательным
спискам, связным спискам и индексам (или инвертированным спискам). Далее
мы продемонстрируем, как с помощью различных структур данных можно
представить каждую из трех специализированных структур, описанных в главе 6
(деревья, простые сети и сложные сети). В конце мы рассмотрим представление
и обработку множественных ключей.
Хотя для работы с большинством СУБД не требуется исчерпывающего
знания структур данных, приведенные здесь основы являются необходимыми для
администраторов баз данных и системных программистов, работающих с СУБД.
Знакомство со структурами данных помогает также при оценке и сравнении
между собой различных СУБД.
Плоские файлы
Плоский файл (flat file) — это файл, не содержащий повторяющихся групп.
Принцип доступа к плоскому файлу может быть любым — последовательным,
последовательным с индексацией или прямым. Плоские файлы используются на
протяжении многих лет в коммерческих системах обработки данных. Обычно они
обрабатываются в некотором заранее определенном порядке — например, по
возрастанию значения ключевого поля.
Обработка плоских файлов в различном порядке
Иногда пользователям нужно обрабатывать плоские файлы такими способами,
которые не имеют простой реализации при данной структуре файла. Рассмотрим,
например, файл ЗАНЯТИЯ на рис. АЛ, я. Чтобы составить расписание занятий
730 Приложение А. Структуры данных
студентов, требуется упорядочить данные по полю НомерСтудента, а чтобы
составить список группы — по полю НомерГруппы. Разумеется, при физическом
хранении записи могут быть упорядочены только по одному из полей — НомерСтудента
или НомерГруппы, но не по обоим полям одновременно. Традиционное решение
проблемы обработки записей в различном порядке состоит в том, чтобы
отсортировать записи по номерам студентов, составить расписания занятий, затем
отсортировать записи по номерам групп и составить списки групп.
Файл ЗАНЯТИЯ
НомерСтудента | НомерПредмета [ Семестр
Данные для примера
Файл СЧЕТ г£
НомерСчета [ Товар(ы) г1
?
200
100
300
200
300
100
70
30
20
30
70
20
2000S
2001F
2001F
2000S
2000S
2000S
Данные для примера
1000
1010
1020
1030
10
50
10
50
20
30
20
90
30
40
а 6
Рис. А.1. Хранение записей: а — в плоском файле; б — в файле, не являющемся плоским
В некоторых приложениях, например в системах пакетной обработки, это
решение оказывается эффективным, несмотря на свою неуклюжесть. Но представьте,
что сортировку требуется выполнить одновременно обоими способами,
поскольку два параллельно работающих пользователя имеют различные представления
файла ЗАНЯТИЯ. Что делать в этом случае?
Одно из решений — создать две копии файла ЗАНЯТИЯ и отсортировать их
в нужном порядке, как показано на рис. А.2. В связи с тем, что данные в такой
структуре упорядочены в определенной логической последовательности, ее
иногда называют последовательным списком (sequential list). Последовательные
списки можно хранить в виде файлов с последовательным доступом. Однако
обычно СУБД не делают этого, так как последовательное чтение файла — процесс
долгий. Кроме того, файлы последовательного доступа невозможно обновить
в середине без перезаписи всего файла. К тому же, хранение нескольких копий
одного и того же последовательного списка неэффективно, так как это может
привести к нарушению целостности данных. К счастью, существуют структуры
данных, позволяющие обрабатывать записи в различном порядке, но не
требующие дублирования данных. Такими структурами являются, среди прочих,
индексы (indexes) и связные списки (linked lists).
Замечание по поводу адресации записей
Обычно СУБД создает в своих файлах прямого доступа физические записи
большого размера, или блоки. В этих блоках содержатся логические записи. Как
правило, одна физическая запись содержит множество логических. Здесь мы предпо-
Плоские файлы 731
ложим, что обращение к физической записи происходит по ее относительному
номеру. Например, логическая запись может принадлежать физической записи
с номером 7, 77 или 10 000. Таким образом, относительный номер записи — это
физический адрес логической записи. Если одна физическая запись содержит
несколько логических записей, адрес логической записи должен также указывать ее
положение внутри физической записи. Следовательно, полный адрес логической
записи может иметь структуру вида «относительный номер записи 77,
смещение 100». Это означает, что запись начинается с байта 100 физической записи 77.
Номер- Номер- Номер- Номер-
Студента Предмета Семестр Студента Предмета Семестр
300
100
100
200
200
300
20
20
30
30
70
70
2001F
2000S
2001F
2000S
2000S
2000S
! 100
I 100
200
| 200
300
300
30
20
70
30
20
70
2001F
2000S
2000S
2000S
2001F
2000S
а б
Рис. А.2. Файл ЗАНЯТИЯ, организованный в виде последовательного списка:
а — с упорядочением по полю НомерСтудента; б — с упорядочением по полю НомерГруппы
Для упрощения примеров в тексте мы будем предполагать, что одна физическая
запись содержит только одну логическую, чтобы нам не пришлось задумываться
о смещениях байтов внутри физических записей. Хотя это и не соответствует
действительности, зато ограничивает изложение только существенными моментами.
Упорядочение с помощью связных списков
Связные списки (linked lists) позволяют производить логическое упорядочение
записей, в общем случае не упорядоченных физически. Для создания связного
списка к каждой записи добавляется специальное поле — поле ссылки. Это поле
содержит адрес (в нашем случае — относительный номер) следующей записи в
логической последовательности. Например, на рис. А.З изображен
модифицированный файл ЗАНЯТИЯ со связным списком, в котором записи упорядочены по полю
НомерСтудента. Обратите внимание, что поле ссылки в последней по логическому
порядку записи имеет нулевое значение.
На рис. АЛ показан файл ЗАНЯТИЯ с двумя связными списками, один из
которых упорядочен по полю НомерСтудента, а другой — по полю НомерГруппы.
Каждая запись имеет два поля ссылки, по одному на каждый список.
При вставке и удалении связные списки имеют огромное преимущество над
последовательными. Например, чтобы вставить в файл ЗАНЯТИЯ запись о
студенте 200 и группе 45, пришлось бы переписать оба списка, приведенные на рис. А.2.
В случае связных списков новую запись можно добавить в конец физического
списка, а чтобы она заняла правильное место в связных списках, потребуется
изменить только значения двух полей ссылок. Эти изменения показаны на рис. А.5.
732 Приложение А. Структуры данных
Номер-
Студента
200
100
300
200
300
| 100
Номер-
Предмета
70
30
20
30
70
20
Семестр
2000S
2001F
2001F
2000S
2000S
2000S
Ссылка
4
6
5
3
0
1 '
Относительный
номер записи
1
2
3
4
5
6
Начало списка = 2
Рис. А.З. Файл ЗАНЯТИЯ, упорядоченный по полю НомерСтудента
с помощью связного списка
Относительный Номер- Номер- Ссылка Ссылка
номер записи Студента Предмета Семестр на студента на предмет
1
2
3
4
5
6 t , .
Начало списка студентов = 2
Начало списка предметов = 6
Рис. А.4. Файл ЗАНЯТИЯ, упорядоченный двумя различными способами
с помощью связных списков
200
100
300
200
300
100
70
30
20
30
70
20
2000S
2001F
2001F
2000S
2000S
2000S
4
6
5
3
0
1
5
1
4
2
0
3
200
100
300
200
300
100
200
70
30
20
30
70
20
45
2000S
2001F
2001F
2000S
2000S
2000S
2000S
4
6
5
7
0
1
3
5
7
4
2
0
3
1
Относительный Номер- Номер- Ссылка Ссылка
номер записи Студента Предмета Семестр на студента на предмет
1
2
3
4
5
6
7
Начало списка студентов = 2
Начало списка предметов = 6
Рис. А.5. Файл ЗАНЯТИЯ после вставки новой записи (упорядоченный
двумя способами с помощью связных списков)
Когда запись удаляется из последовательного списка, на ее месте возникает
пустота. Но в связанных списках запись можно удалить, просто изменив
значения полей ссылок, или указателей. На рис. А.6 запись о студенте 200 из группы
30 логически удалена из файла ЗАНЯТИЯ. Ни одна другая запись не имеет ссылки
на ее адрес, так что она оказывается эффективно удаленной из цепочки, хотя
физически по-прежнему существует.
Плоские файлы 733
Относительный Номер- Номер- Ссылка Ссылка
номер записи Студента Предмета Семестр на студента на предмет
200
100
300
200
300
I 100
200
70
30
20
30
70
20
45
2000S
2001F
2001F
2000S
2000S
2000S
2000S
7
6
5
7
0
1
3
5
7
2
2
0 -
3
1
Начало списка студентов = 2
Начало списка предметов = 6
Рис- А.6. Файл ЗАНЯТИЯ после удаления студента 200 из группы 30 (упорядоченный
двумя способами с использованием связных списков)
Есть много вариантов связных списков. Можно создать кольцевой список
(circular list), или кольцо (ring), записав в поле ссылки последней записи вместо
нуля адрес первой записи в списке. Теперь можно найти любой элемент в списке,
начав с произвольного элемента. На рис. А.7, а показан кольцевой список,
упорядоченный по полю НомерСтудента. Двусвязпый список (two-way linked list) имеет
ссылки в обоих направлениях. На рис. А.7, б изображен двусвязный список,
упорядоченный по возрастанию и по убыванию поля НомерСтудента.
Относительный Номер- Номер-
номер записи Студента Предмета Семестр Ссылка
! 200
100
300
200
300
100
70
30
20
30
70
20
2000S
2001F
2001F
2000S
2000S
2000S
4
6
5
3
2
1
Начало списка = 2
а
Ссылка Ссылка
на список, на список,
Относительный Номер- Номер- упорядоченный упорядоченный
номер записи Студента Предмета Семестр по возрастанию по убыванию
200
100
300
200
300
100
70
30
20
30
70
20
2000S
2001F
2001F
2000S
2000S
2000S
4
6
5
3
2
1
6
0
4
1
3
2
Начало списка, упорядоченного по возрастанию = 2
Начало списка, упорядоченного по убыванию = 5
б
Рис. А.7. Файл ЗАНЯТИЯ, упорядоченный по полю НомерСтудента с использованием:
а — кольцевого списка; б — двусвязного списка
734 Приложение А. Структуры данных
Записи, упорядоченные посредством связных списков, не могут храниться
в файлах с последовательным доступом, так как для работы со ссылками
необходима та или иная форма прямого доступа. Таким образом, для обработки
связных списков требуется либо последовательный доступ с индексацией, либо
прямой доступ.
Упорядочение с помощью индексов
Логическое упорядочение записей может также производиться с помощью
индексов (indexes), или, как их еще называют, инвертирован) 1ых списков (inverted lists).
Индекс представляет собой таблицу, где значениям некоторого поля
сопоставлены ссылки на записи, содержащие эти значения. Например, на рис. А.8, а показан
файл ЗАНЯТИЯ с неупорядоченными записями, а на рис. А.8, б изображен индекс
на поле НомерСтудента. В этом индексе номера студентов расположены по
порядку, и для каждого номера имеется ссылка на соответствующую запись в исходных
данных.
Относительный Номер- Номер- Номер- Относительный
номер записи Студента Предмета Семестр Студента номер записи
200
100
300
200
300
100
70
30
20
30
70
20
2000S
2001F I
2001F '
2000S I
2000S
2000S
100
100
200
200
300
300
2
6
1
4
3
5
а б
Номер- Относительный
Студента номер записи
20
20
30
30
70
70
3
6
2
4
1
5
в
Рис. А.8. Файл ЗАНЯТИЯ с соответствующими индексами: а — файл ЗАНЯТИЯ;
б — индекс по полю НомерСтудента; в — индекс по полю НомерГруппы
Как можно видеть, индекс представляет собой не что иное, как
отсортированный список номеров студентов. Для последовательной обработки файла
ЗАНЯТИЯ по полю НомерСтудента нужно просто последовательно обрабатывать
индекс, читая из файла записи, на которые указывают ссылки. На рис. А.8, в
изображен еще один индекс для файла ЗАНЯТИЯ, упорядоченный по полю Номер-
Группы.
Плоские файлы 735
Для работы с индексами упорядочиваемые данные должны содержаться в
файле с прямым или индексируемым последовательным доступом, хотя для
хранения самих индексов можно использовать любой тип файлов, В реальности почти
все СУБД хранят и данные, и индексы в файлах прямого доступа.
Если сравнить связный список с индексом, между ними обнаружится
коренное различие. В связном списке указатели хранятся вместе с данными. Каждая
запись имеет поле ссылки, содержащее указатель на следующую по порядку
запись. При использовании же индексов указатели хранятся отдельно от данных —
собственно в индексах. Таким образом, сами по себе данные не содержат
указателей. В коммерческих СУБД используются оба подхода к хранению указателей.
Бинарные деревья
Специальным приложением концепции индексов, или инвертированных
списков, являются бинарные деревья — многоуровневые индексы, предоставляющие
возможность как последовательной, так и прямой обработки записей. Благодаря
особенностям своей структуры они также обеспечивают определенное
повышение эффективности обработки.
Бинарное дерево — это индекс, состоящий из двух частей: последовательного
набора (sequence set) и индексного набора (index set). (Эти термины
используются в документации компании IBM, описывающей структуру VSAM-файла.
Вам могут встретиться другие, синонимичные термины.) Последовательный па-
бор представляет собой индекс, содержащий указатели на все записи в файле.
Этот индекс физически упорядочен, обычно по значению первичного ключа.
Такая структура позволяет обращаться к записям последовательно, считывая
один за другим адреса записей из последовательного набора и по ним считывая
сами записи.
Индексный набор — это индекс, указывающий на группу записей в
последовательном наборе. Эта структура обеспечивает быстрый доступ к записям в файле,
и именно в индексном наборе и заключается уникальность бинарных деревьев.
Пример бинарного дерева изображен на рис. А.9, а конкретный экземпляр
этой структуры показан на рис. АЛО. Обратите внимание, что нижняя строчка на
рис. А.9 — последовательный набор — представляет собой обычный индекс. Он
содержит указатель на каждую запись в файле (хотя для краткости данные и
адреса записей были опущены). Также заметьте, что элементы последовательного
набора сгруппированы по три. Записи в каждой группе физически упорядочены,
и каждая группа связана со следующей посредством связного списка, как можно
видеть на рис. АЛО.
Взгляните на индексный набор на рис. А.9. Верхняя запись содержит два
значения, 45 п 77. Следуя левой линии связи (к записи с относительным номером 2),
мы можем обратиться к записям, значения ключей которых меньше или равны
45; следуя средней линии связи, мы можем обратиться к записям, значения
ключей которых больше 45 и меньше или равны 77; наконец, следуя правой линии
связи (к записи с относительным номером 4), мы можем обратиться к записям,
значения ключей которых больше 77.
OH31
ч Индексный
набор
ОН32>|7 IJ27T
|| з|| 7\\ |10||13||27|| |30||35||45|| |4б| |47| |53| | |55||б7| |бб| | |бб||73||77Ц
ОН3101 ОН3102 ОН3103 ОН3104 ОН3105 ОН3106 ОН3107 ОН3108 ОН3109
Последовательный набор (инвертированный список, указывающий на записи с данными)
Рис. А.9. Общая структура простого бинарного дерева
Плоские файлы 737
ОНЗ Ссылка 1 Значение 1 Ссылка 2 Значение 2 Ссылка 3
1
2
3
4
2
101
104
107
45
7
53
84
3
102
105
108
77
27
65
89
4
103
106
109
Индексный набор
R1 Адрес 1
R2
Адрес 2 R3 Адрес 3 Ссылка
101
102
103
104
105
106
107
108
109
1
10
30
46
55
66
78
86
91
Ри
Указатель на 6
с. А.10
Приме
3
13
35
47
57
73
80
88
92
р бин
Указатель на 8
iapHoro
дерева
7
27
45
53
65
77
84
89
94
со с
Указатель на 12
труктурс
)Й, СООТВ
102
103
104
105
106
107
108
109
0
етств
Последовательный
набор
(адреса записей
сданными опущены)
ующей рис. А.9
Аналогичным образом, на следующем уровне имеется три значения и три
указателя на каждый элемент индекса. Всякий раз, когда мы спускаемся на
уровень ниже, мы сужаем область своего поиска. Например, если от верхней записи
мы проследуем по левой линии связи, а от следующего уровня — по правой
линии, мы сможем обратиться ко всем записям, значения ключей которых
больше 27, но меньше или равны 45. На первом уровне мы исключили все записи,
значения ключей которых больше 45.
Бинарные деревья по определению являются сбалансированными. Это
значит, что все записи находятся на одинаковом расстоянии от верхней записи
индексного набора. Это свойство бинарных деревьев обусловливает их
эффективность, хотя алгоритмы вставки и удаления записей оказываются сложнее, чем
для обычных деревьев (которые могут быть несбалансированными), поскольку
для того, чтобы при этих операциях сохранить все записи на одинаковом
расстоянии, может потребоваться модификация нескольких записей.
Резюме по структурам данных
На рис. А.11 изображены все методы упорядочения плоских файлов. Для этой
цели могут применяться три различных структуры данных. Одна из таких
структур — последовательный список; его недостаток заключается в следующем: чтобы
одновременно иметь записи, отсортированные в различном порядке, требуется
дублировать данные. В связи с тем, что последовательные списки не
используются при работе с базами данных, далее мы их рассматривать не будем. При исполь-
738 Приложение А. Структуры данных
зовании связных списков и бинарных деревьев дублирования данных не
требуется. Бинарные деревья являются особым приложением индексов.
Упорядочение:
логическая
структура
Возможная
структура
данных
Метод
доступа
Обычно
Редко
Рис. А.11. Структуры данных и принципы доступа, используемые для упорядочения плоских
файлов
Как показано на рис. А.11, последовательные списки могут храниться в файлах
с любым принципом доступа. На практике, однако, обычно они хранятся в файлах
последовательного доступа. Кроме того, хотя и связные списки, и индексы могут
храниться и в файлах последовательного доступа с индексированием, и в файлах
прямого доступа, СУБД всегда хранят их в файлах прямого доступа.
Представление бинарных связей
В этом разделе мы рассмотрим, каким образом каждый из рассмотренных нами
в данной главе шести видов связей между записями (деревья, простые сети и
сложные сети) представляется с помощью связных списков и индексов.
Обзор видов связей между записями
Записи могут быть связаны между собой тремя способами. Дерево имеет одну
или несколько связей «один ко многим», но каждая дочерняя запись имеет
максимум одного родителя. Данные сотрудника профессорско-преподавательского
Упорядоченный
плоский
файл
Последовательный
список
Связный
список
Инвертированный
список
4V- ^v
Последовательный
Индексируемый
последовательный
Прямой
Представление бинарных связей
739
состава, показанные на рис. А. 12, являют собой пример дерева. Дерево имеет
несколько связей 1:N, но каждая дочерняя запись, как можно видеть из рис. А. 13,
имеет только одного родителя.
(Зарплата д Зарплата)(Зарплата) ( Курс )( Курс )( Курс )( Курс ) ( Курс
Рис. А. 12. Пример записи о сотруднике профессорско-преподавательского состава
Рис. А. 13. Схема дерева, описывающего сотрудника ППС
Простая сеть — совокупность записей и связей вида 1:N между ними.
Отличие простой сети от дерева состоит в том, что в простой сети дочерний узел
может иметь более одного родителя, если родители принадлежат различным типам
записей. Экземпляр показанной на рис. А. 14 простой сети, состоящей из
записей о студентах, их руководителях и специальностях, схематически изображен
на рис. А.15.
Сложная сеть также является совокупностью записей и связей между
ними, но связи в ней имеют вид «многие ко многим», а не «один ко многим». Связь
между студентами и занятиями, которые они посещают, представляет собой
сложную сеть. Экземпляр такой связи можно видеть на рис. А. 16, а общую
схему — на рис. А. 17.
740 Приложение А. Структуры данных
РУКОВОДИТЕЛИ
СПЕЦИАЛЬНОСТИ
S1 | 1 S2 1 1 S3 1 1 S4 | | S5
СТУДЕНТЫ
Рис. А. 14. Пример простой сети
Рис. А. 15. Общая структура простой сети
СТУДЕНТЫ [А
ПРЕДМЕТЫ I 1 1 1 2 1
Рис. А. 16. Прим
3 I I 4 | I 5 I
ер сложной сети
| СТУДЕНТЫ |
N
| ПРЕДМЕТЫ |
I 6 I
Рис. А.17. Общая структура сложной сети
Ранее мы видели, что связные списки и индексы можно использовать для
обработки записей в порядке, отличном от того, в котором они физически
хранятся. Эти же структуры данных можно использовать для хранения и обработки
связей между записями.
Представление деревьев
Деревья могут представляться с помощью последовательных списков, связных
списков и индексов. В варианте с последовательными списками приходится дуб-
Представление бинарных связей 741
лировать большое количество данных, и кроме того, СУБД не используют
последовательные списки для представления деревьев. Поэтому речь здесь будет идти
только о связных списках и индексах.
Представление деревьев с помощью связных списков
На рис. А. 18 показана древообразная структура, в которой записи типа ПОСТАВЩИК
являются родителями, а записи типа СЧЕТ — потомками. На рис. А. 19 изображены
два экземпляра этой структуры, а на рис. А.20 показан последовательный файл,
в котором хранятся все записи ПОСТАВЩИК и СЧЕТ. Запись ПОСТАВЩИК АА имеет
относительный номер 1, а запись ПОСТАВЩИК ВВ — относительный номер 2. Как
показано на рисунке, записи типа СЧЕТ расположены одна за другой. Обратите
внимание, что эти записи никак не упорядочены, и упорядочение здесь не нужно.
ПОСТАВЩИК
ь_
СЧЕТ
Рис. А.18. Пример дерева, связывающего записи ПОСТАВЩИК и СЧЕТ
ПОСТАВЩИК АА
110 I 127.50~| I 118 I 99.50~~1 | 112 | 18.95 | | 114 ] 27.50 [ | 119 | 8.9?"
Рис. А. 19. Два экземпляра дерева ПОСТАВЩИК-СЧЕТ
Содержимое записи
Номер
записи
1
2
3
4
5
6
7
Рис. А.20. Представление деревьев на рис. А. 19 в файле
Трудность состоит в том, что из этого файла невозможно определить,
какие счета пришли от каких поставщиков. Решить эту проблему можно с
помощью связного списка. Для этого в каждую запись следует добавить поле ссылки.
В этом поле будет храниться адрес некоторой другой записи, связанной с ней.
Например, в поле ссылки записи ПОСТАВЩИК АА мы поместим адрес записи,
представляющей первый счет от данного поставщика. Это запись СЧЕТ 110, имеющая
ПОСТАВЩИК АА
' ПОСТАВЩИК ВВ
118
119
112
114
110
99.50 I
8.95
18.95 I
27.50
127.50
742 Приложение А. Структуры данных
относительный номер 7. В поле ссылки этой записи мы поместим указатель на
запись, представляющую следующий счет от поставщика АА, то есть на
запись СЧЕТ 118 с относительным номером 3. Чтобы показать, что больше потомков
в данной цепочке нет, в поле ссылки записи с относительным номером 3 мы
запишем 0.
Пример реализации этого метода показан на рис. А.21. Исследовав этот
рисунок, вы увидите, что аналогичный набор ссылок использован для представления
связей между поставщиком ВВ и счетами от него.
Содержимое записи Поле ссылки
1 ПОСТАВЩИК АА
ПОСТАВЩИК ВВ
| 118
I 119
112
114
110
99.50
8.95
18.95
27.50
127.50
7
5
0
0
6
4
3
Относительный
номер записи
1
2
3
4
5
6
7
Рис. А.21. Представление деревьев с помощью связных списков
В структуру на рис. А.21 намного легче вносить изменения, чем в
последовательный список записей. Предположим, например, что нам нужно добавить новый
счет за номером 111, пришедший от поставщика АА. Для этого нужно только
добавить в файл новую запись и вставить ее в связный список. Физически данную
запись можно поместить куда угодно. Но куда ее следует поместить логически?
Обычно у приложения на этот счет имеется некоторое требование, например такое:
потомки должны быть логически упорядочены в порядке возрастания номера
счета. В этом случае запись СЧЕТ 110 должна указывать на запись СЧЕТ 111 (с
относительным номером 8), а новая запись, СЧЕТ 111, должна указывать на запись
СЧЕТ 118 (с относительным номером 3). Эти изменения показаны на рис. А.22.
Относительный
номер записи
1
2
3
4
5
6
7
8
Содержимое записи Поле ссылки
ПОСТАВЩИК АА
ПОСТАВЩИК ВВ
118
119
112
114
110
111
99.50
8.95
18.95
27.50
127.50
19.95
7
5
0
0
6
4
8
3
Вставленная
запись
Рис. А.22. Файл, показанный на рис. А.21 после добавления счета номер 111
Удаление счета происходит так же просто. Чтобы удалить счет номер 114, мы
просто изменяем указатель записи, которая в данный момент указывает на за-
Представление бинарных связей 743
пись СЧЕТ 114. В данном случае это запись СЧЕТ 112 с относительным номером 5.
В поле ссылки этой записи мы записываем значение, которое имел указатель
записи СЧЕТ 114 до ее удаления. Таким образом, запись СЧЕТ 112 теперь указывает
на запись СЧЕТ 119 (рис. А.23). Итак, мы исключили одно звено из цепочки и
соединили между собой два других звена, которые оно ранее связывало.
Относительный
номер записи
1
2
3
4
5
6
7
8
Содержимое записи Поле ссылки
ПОСТАВЩИК АА
ПОСТАВЩИК ВВ
118
119
112
114
110
111
99.50
8.95
18.95
27.50
127.50
19.95
7
5
0
0
4
4 !
8 |
3
Вставленная
запись
Рис. А.23. Удаление счета номер 114 из файла, показанного на рис. А.22
Представление деревьев с помощью индексов
Древообразную структуру можно также представить с помощью индексов. Метод
заключается в хранении каждой связи «один ко многим» в виде индекса. По этим
спискам далее устанавливается связь между родителем и потомками.
Обратившись к записям ПОСТАВЩИК и СЧЕТ на рис. А.21, мы увидим, что
записи ПОСТАВЩИК АА (с относительным номером 1) принадлежат записи СЧЕТ 110
(относительный номер 7) и СЧЕТ 118 (относительный номер 3). Таким образом,
запись с относительным номером 1 является родителем записей с
относительными номерами 7 и 3. Данный факт можно представить в виде индекса,
изображенного на рис. А.24. Этот индекс связывает адрес родителя с адресами каждого из
его потомков.
Родительская Дочерняя
запись запись
1
1
2
2
2
7
3
5
6
4
Рис. А.24. Представление связи ПОСТАВЩИК-СЧЕТ с помощью индексов
Если дерево имеет несколько связей 1:N, потребуется несколько индексов, по
одному на каждую связь. Для структуры на рис. А. 13 потребуется пять индексов.
Представление простых сетей
Как и деревья, простые сети могут быть представлены с помощью связных
списков и индексов.
744 Приложение А. Структуры данных
Представление простых сетей с помощью связных
списков
Рассмотрим простую сеть, изображенную на рис. А.25. Прежде всего, эта
структура действительно является простой сетью, поскольку все связи в ней имеют вид
1:N, а записи типа ДОСТАВКА имеют родителей различных типов. Каждая запись
типа ДОСТАВКА имеет в качестве родителей запись типа КЛИЕНТ и запись типа
ГРУЗОВИК. Связь между записями КЛИЕНТ и ДОСТАВКА имеет вид 1:N, поскольку
одному клиенту может доставляться несколько заказов. Связь между записями
ГРУЗОВИК и ДОСТАВКА также имеет вид 1:N, поскольку различные заказы могут
доставляться одним и тем же грузовиком (если считать, что размеры
доставляемых товаров достаточно малы, чтобы поместиться на одном грузовике).
Экземпляр такой сети показан на рис. А.26.
Рис. А.25. Структура простой сети
Д100
Д200
П
\ дзоо к
V
Ч Д400 \"S
\ Д500 Ц_
Л Г2 |
У
\
\
\
—°1 гз 1
Рис. А.26. Пример простой сети со структурой, соответствующей рис. А.25
Чтобы представить простую сеть с помощью связных списков, для каждой
связи 1:N нужно создать набор указателей. В данном случае это означает, что
нужно создать один набор указателей, связывающий записи КЛИЕНТ и ДОСТАВКА,
и один набор указателей, связывающий записи ДОСТАВКА и ГРУЗОВИК. Так,
например, запись КЛИЕНТ будет содержать один указатель (на первую связанную с ней
запись ДОСТАВКА), запись ГРУЗОВИК будет содержать один указатель (на первую
связанную с ней запись ДОСТАВКА), а запись ДОСТАВКА будет иметь два указателя:
один — на следующую запись ДОСТАВКА, принадлежащую той же записи КЛИЕНТ,
и на следующую запись ДОСТАВКА, принадлежащую той же записи ГРУЗОВИК. Эта
схема изображена на рис. А.27.
Простая сеть имеет по меньшей мере две связи 1:N, каждая из которых может
быть представлена с помощью индекса, как было показано в ходе обсуждения
Представление бинарных связей 745
деревьев. Рассмотрим, например, простую сеть, изображенную на рис. А.25. Она
имеет две связи 1:N: одна между записями ГРУЗОВИК и ДОСТАВКА, а другая —
между записями ДОСТАВКА и КЛИЕНТ. Каждую из этих связей можно хранить в виде
индекса. На рис. А.28 показаны два индекса, с помощью которых можно
представить пример на рис. А.26. Будем предполагать, что записи находятся на тех же
позициях, что и на рис. А.27.
Относительный
номер записи
1
2
3
4
5
6
7
8
9
10
Содержимое записи Поля ссылок
СЮ
С20
Т1
Т2
тз
S100
S200
S300
S400
S500
6
7
9
8
10
0
0
6
9
8
7
0
10
0
0
ZTX^
Ссылки Ссылки
на клиентов на грузовики
Рис. А.27. Представление простой сети с помощью связных списков
Запись
о клиенте
Запись
о доставке
Запись
о машине
Запись
о доставке
1
1
I 2
2
2
6
9
7
8
10
3
3
' 4
5
5
6
7
9
8
10
Рис. А.28. Представление простой сети с помощью индексов
Представление сложных сетей
Сложные сети могут быть представлены множеством способов. Их можно
разбивать на деревья или простые сети, а уже эти простые структуры представлять
с помощью одной из рассмотренных только что методик. Кроме того, их можно
представлять непосредственно с помощью индексов. Связные списки не
используются СУБД для непосредственного представления сложных сетей. На
практике сложные сети почти всегда разбиваются на более простые структуры, поэтому
далее мы будем рассматривать только такие представления.
Распространенный подход к представлению сложной сети состоит в
сведении ее к простой сети и последующем представлении получившейся простой
746 Приложение А. Структуры данных
сети с помощью связных списков или индексов. Обратите, однако, внимание, что
связи в сложной сети соединяют между собой две записи, а в простой сети — три
записи. Поэтому, чтобы преобразовать сложную сеть в простую, требуется
создать третий тип записи.
Запись, создаваемая при преобразовании сложной сети в простую, называется
записью пересечения (intersection record). Рассмотрим сложную сеть, отражающую
посещение занятий студентами. Запись пересечения будет содержать уникальный
ключ записи СТУДЕНТ и уникальный ключ соответствующей ей записи ЗАНЯТИЕ.
Запись пересечения не будет содержать никаких других данных приложения, хотя
в ней могут быть поля ссылок. Общая структура этой связи показана на рис. А.29.
Экземпляр связи СТУДЕНТ-ЗАНЯТИЕ представлен на рис. А.ЗО (здесь
предполагается, что имена записей, обозначенные С1, 31 и т. д., являются уникальными).
Пересечение
СТУДЕНТ-ПРЕДМЕТ
Рис. А.29. Преобразование сложной сети в простую
Рис. А.ЗО. Экземпляр связи СТУДЕНТ-ЗАНЯТИЕ с записями пересечения
Представление бинарных связей 747
Обратите внимание, что связь записей СТУДЕНТ и ЗАНЯТИЕ с записью
пересечения имеет вид 1:N. Таким образом, мы создали простую сеть, которую можно
представить с помощью связных списков или индексов, как было показано
ранее. Файл с примером такой простой сети, для представления которой
используются связные списки, изображен на рис. А.31.
Относительный
номер записи
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Содержимое записи Поле ссылки
S1
S2
, S3
' С1
С2
СЗ
С4
С5
S1C1
S1C3
S1C5
S2C1
S2C2
S2C3
S2C4
S2C5
S3C1
S3C3
S3C4
S3C5
9
12
17
10
11
0
13
14
15
16
0
18
19
20
0
9
13
ю I
15
11
12
14
16
17
0 I
18
19
20 ,
0
0
0
0
Ссылки Ссылки
на студентов на предметы
Рис. А.31. Пример сети со структурой, соответствующей рис. А.ЗО
Резюме по представлению связей
На рис. А.32 изображены все способы представления связей между записями.
Деревья могут быть представлены с помощью последовательных списков (хотя
мы не обсуждали этот подход), связных списков или индексов.
Последовательные списки не используются в СУБД. Простую сеть можно разбить на деревья
и затем представить с помощью соответствующих структур данных, а можно
представить непосредственно с помощью связных списков или индексов.
Сложную сеть можно преобразовать в дерево или в простую сеть (с помощью записей
пересечения) либо представить непосредственно с помощью индексов.
748 Приложение А. Структуры данных
Вид связи
между
записями
Структуры
данных
Принцип
доступа
к файлу
Преобразование „
Последовательный
список
Связный
список
Индекс
(инвертированный
список)
Последовательный
Обычно
Редко
Рис. А.32- Представление связей между записями с помощью различных
структур данных и принципов доступа
Представление вторичных ключей
Во многих случаях термином ключ обозначается одно или несколько полей,
уникальным образом идентифицирующих запись. Такой ключ обычно называется
первичным ключом. Но иногда приложениям нужно обращаться к записям и
обрабатывать их по вторичному ключу, который обладает иными свойствами, чем
первичный. Вторичный ключ может быть уникальным (например, имя
преподавателя) или неуникальным (например, почтовый индекс клиента). В этом разделе
термином множество (set) мы будем обозначать все записи, имеющие
одинаковое значение неуникального вторичного ключа; например, множество записей,
в которых поле Индекс имеет значение 98040.
Для представления вторичных ключей можно использовать и связные списки,
и индексы, но связные списки пригодны только в случае неуникальных ключей.
Представление вторичных ключей 749
Индексы же могут использоваться для представления как уникальных, так и
неуникальных ключей.
Представление вторичных ключей с помощью
связных списков
Рассмотрим файл КЛИЕНТ, структура которого показана на рис. А.ЗЗ. Первичным
ключом является НомерСчета; есть также вторичный ключ, МаксимальныйКредит.
Возможные значения поля МаксимальныйКредит — 500, 700 и 1000. Таким
образом, у нас будет три набора записей: с максимальным кредитом 500, 700 и 1000.
НомерСчета
Имя
Адрес
МаксимальныйКредит ОстатокНаСчете
ПервичныйКлюч ВторичныйКлюч
Рис. А.ЗЗ. Структура файла КЛИЕНТ
Чтобы представить этот вторичный ключ с помощью связных списков,
добавим в структуру файла КЛИЕНТ поле ссылки. В этом поле ссылки мы создадим
связный список для каждого набора записей. На рис. А.34 показана база данных
с одиннадцатыо клиентами, где для краткости показаны только поля НомерСчета
и МаксимальныйКредит. К каждой записи добавлено поле ссылки. Предположим,
что одна запись в базе данных соответствует физической записи в файле
прямого доступа, использующем относительную адресацию записей.
НАЧАЛО-500 = 1
НАЧАЛО-700 = 3
НАЧАЛО-1000 = 4
Относительный
номер записи
1
2
3
4
5
6
7
8
9
10
11
Рис. А.34. Представление вторичного ключа МаксимальныйКредит
с помощью связного списка
Чтобы знать, где начинается каждый связный список, нужны три указателя.
Каждый такой указатель называется головой списка (head) и хранится отдельно от
данных. Головой связного списка покупателей с максимальным кредитом $500
является запись с относительным номером 1. Запись 1 указывает на запись 2,
Ссылка
2
7
5
6
10
8
0
9
11
0
0
Номер-
Счета
101
301
203
004
204
905
705
207
309
409
210
МаксимальныйКредит
500
500
700
1000
700
1000
500
1000
1000
700
1000
Прочие
данные
750 Приложение А. Структуры данных
которая, в свою очередь, указывает на запись 7. Запись 7 имеет нулевое значение
в поле ссылки, указывающее на то, что это конец списка. Следовательно,
множество записей клиентов с максимальным кредитом $500 состоит из записей с
относительными номерами 1, 2 и 7. Аналогичным образом множество записей
клиентов с максимальным кредитом $700 состоит из записей с относительными
номерами 3, 5 и 10, а множество записей клиентов с максимальным кредитом $1000
состоит из записей с относительными номерами 4, 6, 8, 9 и И.
Возьмем для примера запрос: сколько счетов с максимальным кредитом $1000
имеют баланс, превышающий $900?. Чтобы ответить на подобный запрос,
можно использовать связный список записей с максимальным кредитом $1000. При
этом считывать из файла и обрабатывать нужно только те записи, которые
принадлежат множеству с максимальным кредитом $1000. Хотя преимущество
этого подхода не ощущается явно в этом небольшом примере, представьте, что есть
100 000 записей КЛИЕНТ, и только 100 из них принадлежат искомому множеству.
Если бы связного списка не было, пришлось бы провести поиск по всем 100 000
записям; при наличии же связного списка требуется обработать только 100
записей, а именно записи из множества с максимальным кредитом $1000. Таким
образом, использование связного списка экономит 99 900 операций чтения.
Подход с использованием связных списков для представления вторичных
ключей не всегда эффективен. В частности, если записи в наборе
обрабатываются не по порядку, связные списки оказываются неэффективными. Например,
если часто требуется найти 10-ю, 120-ю или п-ю запись в множестве с
максимальным кредитом $500, обработка будет идти медленно. При прямом доступе
связные списки неэффективны.
Кроме того, если приложение требует, чтобы вторичные ключи создавались
и разрушались динамически, использование связных списков нежелательно.
Всякий раз, когда создается новый ключ, к каждой записи необходимо добавить
поле ссылки, для чего зачастую необходимо реорганизовать всю базу данных,
а это требует больших затрат времени и средств.
Наконец, если вторичные ключи имеют уникальные значения, длина каждого
списка будет равна 1, и для каждой записи в базе данных будет иметься
отдельный связный список. Поскольку работа в такой ситуации невозможна, связные
списки нельзя использовать для представления уникальных ключей.
Предположим, например, что файл КЛИЕНТ содержит еще одно поле с уникальным
значением — например, НомерСоциальнойСтраховки. Если мы попытаемся представить
этот уникальный вторичный ключ с помощью связного списка, каждый помер
социальной страховки будет отдельным связным списком. Более того, каждый
связный список будет иметь всего один элемент — запись, содержащую данный
номер социальной страховки.
Представление вторичных ключей
с помощью индексов
Второй способ представления вторичных ключей — это использование индексов.
Для каждого вторичного ключа создается свой индекс. Конкретная реализация
этого подхода зависит от того, являются ли значения ключей уникальными.
Представление вторичных ключей 751
Случай уникальных вторичных ключей
Предположим, что файл ЗАПИСЬ (см. рис. А.ЗЗ) помимо показанных на рисунке
полей содержит поле НомерСоциальнойСтраховки, являющееся вторичным ключом.
Чтобы обеспечить доступ к записям в файле по полю НомерСоциальнойСтраховки,
нужно просто построить индекс по этому полю. Данные для примера показаны на
рис. А.ЗЗ, а, а соответствующий индекс — на рис. А.ЗЗ, б. В этом индексе записи
адресуются по их относительным номерам. Можно было бы для этой цели
использовать поле НомерСчета; в этом случае СУБД находила бы в индексе нужный
номер социальной страховки, получала бы соответствующий номер счета, а затем
определяла бы по нему относительный адрес записи.
Номер
Относительный Номер- Максимальный- социальной
номер записи Счета Кредит страховки
101
301
203
004
500
500
700
1000
000-01-0001 |
000-01-0005 !
000-01-0009
000-01-0003
а
Номер Относительный
социальной номер
страховки записи
000-01-0001
000-01-0003
000-01-0005
000-01-0009
1
4
2
3
б
Рис. А.35. Представление уникального вторичного ключа с помощью индексов:
а — пример файла КЛИЕНТ (с номером социальной страховки);
б — индекс для вторичного ключа НомерСоциальнойСтраховки
Случай неуникальных вторичных ключей
Индексы могут также использоваться для представления неуникальных
вторичных ключей, но поскольку каждое множество связанных записей может
содержать неизвестное число элементов, записи в индексе имеют переменную длину.
Например, на рис. А.36 показан индекс множеств с различным максимальным
кредитом для файла КЛИЕНТ. Каждое из множеств с максимальным кредитом
$500 и $700 состоит из трех элементов, поэтому соответствующие записи в
индексе содержат по три номера счета. Множество с максимальным кредитом $1000
состоит из пяти элементов, поэтому запись индекса для этого множества
содержит пять номеров счетов.
В реальности представление и обработка неуникальных ключей представляют
собой сложные задачи. Коммерческие СУБД применяют для этих целей несколько
752 Приложение А. Структуры данных
различных схем. В одном популярном методе используются таблица значений
(values table) и таблица вхождений (occurrence table). Каждая запись в таблице
значений состоит из двух полей, первое из которых содержит значение ключа.
Ключ МаксимальныйКредит файла КЛИЕНТ имеет три значения: 500, 700 и 1000.
Второе поле записи в таблице значений представляет собой указатель на запись
в таблице вхождений. Таблица вхождений содержит адреса записей, и те из них,
которые имеют одно и то же значение вторичного ключа, расположены в одной
строке таблицы. На рис. А.37 изображены таблица значений и таблица
вхождений для ключа МаксимальныйКредит.
Максимальный- ^ ч та
Кредит г" " " ^
500
700
1000
101
203
004
301
204
905
705
409
207
309
210
Рис. А.36. Индекс для ключа МаксимальныйКредит из рис. А.ЗЗ
Таблица значений Таблица вхождений
НомерСчета
МаксимальныйКредит г— %
101
203
004
301
204
905
705
409
207
309
210
500
700
i 1000
Рис. А.37. Таблица значений и таблица вхождений для ключа
МаксимальныйКредит из рис. А.ЗЗ
Для нахождения записей с заданным значением вторичного ключа
производится поиск этого значения в таблице значений. Когда нужное значение
найдено, по указателю в таблице вхождений находятся адреса записей, имеющих
данное значение ключа.
Когда в файл добавляется новая запись, СУБД должна обновить индексы для
каждого поля вторичного ключа. В случае неуиикальных ключей она должна
сначала убедиться, что значение ключа новой записи присутствует в таблице
значений; если это так, СУБД добавляет адрес новой записи в соответствующую
строку таблицы вхождений. Если такого значения нет, СУБД должна добавить
новую запись в таблицу значений и таблицу вхождений.
При удалении записи ее адрес должен быть удален из таблицы вхождений.
Если в строке таблицы вхождений не остается ни одного адреса, соответствующее
значение вторичного ключа должно быть также удалено из таблицы значений.
Когда изменяется значение поля вторичного ключа записи, адрес этой записи
должен быть удален из одной строки таблицы вхождений и добавлен в другую.
Если изменение заключается в присваивании ключу нового значения, в таблицу
значений необходимо добавить соответствующую запись.
Резюме 753
Подход с использованием индексов для представления вторичных ключей
преодолевает ограничения, которыми характеризуется подход с использованием
связных списков. Прежде всего, возможна непосредственная обработка множеств.
Например, можно сразу получить третью запись из множества, не обрабатывая
первую и вторую. Кроме того, можно динамически создавать и уничтожать
вторичные ключи. Никаких изменений в самих записях не делается: вместо этого
СУБД создает дополнительные таблицы — таблицу значений и таблицу
вхождений. Наконец, возможна эффективная обработка уникальных ключей.
Недостатки этого подхода заключаются в том, что он требует большего
объема файлового пространства (на таблицы расходуется больше избыточного
пространства, чем на указатели), и в том, что программирование СУБД оказывается
более сложным. Обратите внимание: прикладное программирование не
обязательно будет в этом случае проще или сложнее; просто программное обеспечение
для СУБД, обрабатывающее индексы, написать сложнее, чем программное
обеспечение, обрабатывающее связные списки. Наконец, обработка обновлений
обычно происходит медленно из-за операций чтения и записи, требуемых для доступа
к значениям в таблице вхождений и их поддержания.
Резюме
В этом приложении мы рассмотрели структуры данных, используемые в базах
данных. Плоский файл — это файл, не содержащий повторяющихся групп.
Плоские файлы могут быть упорядочены с использованием последовательных
списков (путем физического упорядочивания записей в необходимой
последовательности), связных списков (путем добавления к каждой записи указателя на
другую логически связанную с ней запись) и индексов (путем построения
отдельной от данных таблицы, содержащей указатели на связанные записи). Бинарные
деревья представляют собой специальное приложение индексов.
Последовательные списки, связные списки и индексы (или инвертированные
списки) являются фундаментальными структурами данных. (Хотя
последовательные списки редко используются при обработке баз данных.) С помощью этих
структур можно представлять связи между записями, а также вторичные ключи.
Три основные структуры связей между записями — деревья, простые сети
и сложные сети — могут быть представлены с помощью связных списков и
индексов. Простую сеть можно разбить на деревья и затем представить с помощью
соответствующих структур данных; сложную сеть можно преобразовать в простую
сеть, содержащую записи пересечения, и затем представить теми же способами,
что и простую сеть.
Вторичные ключи используются для доступа к данным по значениям
некоторых полей, отличных от поля первичного ключа. Вторичные ключи могут быть
уникальными и неуникальиыми. Неуникальные вторичные ключи могут быть
представлены с помощью связных списков или индексов. Уникальные
вторичные ключи могут быть представлены только с помощью индексов.
754 Приложение А. Структуры данных
Вопросы I группы
1. Дайте определение плоского файла. Приведите пример (отличный от того,
который дан в тексте) плоского файла и файла, не являющегося плоским.
2. Покажите, как организовать хранение данных в файле из вопроса 1
одновременно в двух различных порядках с помощью, последовательных
списков.
3. Покажите, как организовать хранение данных в файле из вопроса 1
одновременно в двух различных порядках с помощью связных списков.
4. Покажите, как организовать хранение данных в файле из вопроса 1
одновременно в двух различных порядках с помощью инвертированных
списков.
5. Дайте определение дерева и приведите пример этой структуры.
6. Изобразите экземпляр дерева со структурой, определенной в ответе на
вопрос 5.
7. Представьте экземпляр дерева из ответа на вопрос 6 с помощью связных
списков.
8. Представьте экземпляр дерева из ответа на вопрос 6 с помощью индексов.
9. Дайте определение простой сети и приведите пример этой структуры.
10. Изобразите экземпляр простой сети со структурой, определенной в ответе
на вопрос 9.
И. Представьте экземпляр простой сети из ответа на вопрос 10 с помощью
связных списков.
12. Представьте экземпляр простой сети из ответа на вопрос 10 с помощью
индексов.
13. Дайте определение сложной сети и приведите пример этой структуры.
14. Изобразите экземпляр сложной сети со структурой, определенной в ответе
на вопрос 13.
15. Преобразуйте сложную сеть из ответа на вопрос 14 в простую сеть и
представьте экземпляр такой сети с использованием индексов.
16. Объясните разницу между первичным и вторичным ключами.
17. Объясните разницу между уникальным и неуникальным ключами.
18. Определите структуру файла с уникальным вторичным ключом.
Представьте экземпляр такого файла с помощью индекса по вторичному ключу.
19. Определите неуникальный вторичный ключ для файла из ответа на
вопрос 18. Представьте экземпляр этого файла с помощью связного списка
по вторичному ключу.
20. Выполните то же самое, что и в вопросе 19, но с использованием индекса
по вторичному ключу.
Вопросы I группы 755
Вопросы II группы
21. Разработайте алгоритм, создающий список идентификаторов всех
студентов, входящих в каждую из групп1, используя структуру со связным
списком, показанную на рис. А.4.
22. Разработайте алгоритм, добавляющий новые записи в структуру на рис. А.4.
Результирующая структура должна быть похожа на ту, которая
изображена на рис. А.5.
23. Разработайте алгоритм, создающий список идентификаторов всех
студентов, входящих в каждую из групп, используя структуру с индексом,
показанную на рис. А.8, а} б и б.
24. Разработайте алгоритм, добавляющий новые записи в структуру,
показанную на рис. А.8, я, который модифицировал бы оба соответствующих
индекса на рис. А.8, бив.
25. Разработайте алгоритм, удаляющий записи из структуры, показанной на
рис. А.34, где изображен вторичный ключ, представленный с помощью
связного списка. Если будут удалены все записи для одной из кредитных
категорий (например, с максимальным кредитом $1000), следует ли также
удалять голову соответствующего списка? Обоснуйте свой ответ.
26. Разработайте алгоритм, добавляющий новую запись в структуру,
показанную на рис. А.34. Предположим, что новая запись имеет иное значение
максимального кредита, чем остальные записи. Следует ли добавить эту
запись и создать новый связный список? Или следует отказать во вставке
этой записи? Кто должен принимать данное решение?
Под группой здесь понимается совокупность людей, посещающих занятия по некоторому предмету
по определенному расписанию. Таким образом, один и тот же студент может входить в несколько
групп. — Прим. перев.
Приложение Б
Создание семантических
объектных моделей
в программе Tabledesigner
Tabledesigner — это программа для Windows 95, 98, NT и Windows 2000,
позволяющая создавать семантические объектные модели и преобразовывать их в базы
данных Access и других СУБД. Кроме того, с помощью этой программы можно
восстановить семантическую объектную модель по существующей базе данных.
Если затем модифицировать полученную модель, Tabledesigner
соответствующим образом изменит схему базы данных и данные. Наконец, Tabledesigner
позволяет создавать ASP-страницы, выполняющие создание, чтение, обновление
и удаление представлений семантических объектов посредством любого браузера
с помощью чистого HTML. Чтобы воспользоваться последней функцией,
необходимо поместить созданные ASP-страницы на web-сервер под управлением IIS
или Personal Web Server с ASP-расширениями. Перечень функций программы
Tabledesigner представлен в следующем списке.
+ Создание семантической объектной модели:
♦ генерация базы данных Access на основе модели;
♦ генерация базы данных SQL Server на основе модели;
♦ генерация SQL-операторов, создающих или модифицирующих базу
данных.
♦ Восстановление модели существующей базы данных:
♦ создание копии базы данных и изменение ее схемы;
♦ создание копии базы данных (с данными) и изменение ее схемы и
данных с помощью средств моделирования;
♦ создание копии базы данных (без данных) и изменение ее схемы с
помощью средств моделирования;
♦ привязка к базе данных и изменение ее схемы и данных с помощью
средств моделирования.
Создание семантических объектных моделей в программе Tabledesigner 757
+ Создание web-приложений:
♦ создание представлений семантических объектов;
♦ генерация ASP-страниц для создания, чтения, обновления и удаления
представлений семантических объектов;
♦ созданные таким образом страницы могут быть загружены в Microsoft
Visual Interdev для дальнейшей обработки.
Для получения копии программы Tabledesigner зайдите на сайт www.prenhall.
com/kroenke/. Там вы найдете инструкции по загрузке. Загрузив программу,
установите ее согласно инструкциям. Пользование программой в рамках курса
теории баз данных является бесплатным. К Tabledesigner прилагается
подробная документация, содержащая много полезной информации помимо тех
сведений, которые изложены в настоящем приложении. Для доступа к
документации выберите в главном меню команду Help (Справка), после чего окно
программы примет вид, показанный на рис. Б.1. Особенно полезной может
оказаться книга «Learning to use Tabledesigner Developer», изображенная
открытой на рис. Б.1.
х=- *l
Ш Object» T7
S3 GENERIC OBJECT
Data Hen* v
О State
О Street
О Text
& Couiter
в True/False
3 Phone Numb*
О Percent
О Quantify
О *Nwe
О UdenblieiText
О Sldentifier-Nuroeric
0 CurrencyAmotint
& JCompanyName
©City
0 Description
£3 Eventfime
О EventDate
О Area Code
azp
О EM«I
a url
О Image Path
»£ !)«!« Groups xr
«eAddres*
&ЩРШ11ш»^
ЭШШ^А-^. :1 :
СЩ. Atopic* and tim efck Display,. Or cfcsk ^^ U^n^a^^tk^
ф About Tabtedesigner
Ф Setting Up
\jQ Learning to Use Tabledesignei
|?j AUomated features and processes
Ш Wndows and workspaces in Tabtedesignw
Ш Ways to team
Ш QuickStart: the fewest steps
[2) Step 8y Step: a comprehensive overview
Ш Step By Step: workhg with locked models
Ш Creating your first T ebtedesigner model
=2) Designing a model
Ш Tips for getting started
|?) Comparing Tabledesigner to other databases and theories
<& Getting More Information
ф Databases
*::%JP3:ЩУ:1К 1: ■ с105* ( МпШас |
-
z!
Cancel
Рис. Б.1. Справка Tabledesigner
758 Приложение Б. Создание семантических объектных моделей
Создание семантической
объектной модели
Чтобы создать новую семантическую объектную модель, выберите в главном
меню команду File ► New (Файл ► Новый) или нажмите кнопку «Новый документ»
на панели инструментов (первая кнопка слева). Появится окно, показанное на
рис. Б.2. В этом окне вы можете выбрать так называемый исходный набор (starter
kit), представляющий собой совокупность готовых моделей и доменов для
разных приложений. В этом примере мы воспользуемся исходным набором Generic
(Общий), но можно выбрать и другой.
Рис. Б. 2. Выбор исходного набора
В следующем окне с левой стороны будет показан список доменов, а справа —
пустая область проектирования. Для создания семантического объекта
переведите указатель мыши в область проектирования, нажмите левую клавишу мыши
Создание семантической объектной модели 759
и переместите мышь, удерживая клавишу нажатой. На экране возникнет
прямоугольник. Отпустите левую клавишу мыши, и прямоугольник превратится в
окно объекта, показанное на рис. Б.З. Чтобы дать новому объекту имя, введите его
в текстовое поле в окне объекта. Назовем созданный объект STUDENT.
rabledestoner
Re E<ft Create Options Window Нф
: РНУ1 АШМ'ШЙ
|Ц] Object* г?
©GENERIC OBJECT
Ш Obiect
S> Dala Иеяю ту
G> Stew
CD Street
Q T«*fc
Q> Counter
О Тнл/Fafee j
c5 Phone Number
C5 Peicerrt
£3 Quantity
3 *Name
8 tildertfAer-Tfcxt
(Э $}dertViJisr-Kune»o
£3 CutfencyAmount
j Э $ Company Nam©
О Сйу
C5 Description
(Э Evert Time
S* EverdOate
c5 Area Code
\ 8 Zip
& EMdH
О URL
(3 Image Pa*h J
-><? Data Gmup* ^
*§ Phonfc
I eg AdtJtess I
ш^я^ши
|ШГ:»|11р||Ш: ' Databases *: * \ffifilЩ У^ЩЩ^
Рис. Б.З. Создание и присвоение имени семантическому объекту
Чтобы добавить атрибут к объекту STUDENT, в списке доменов в левой части
экрана щелкните на домене Name (имя) и перетащите его в окно объекта. Table-
designer создаст в объекте STUDENT атрибут, который унаследует все свои
свойства от домена Name. Щелкните на атрибуте Name в объекте STUDENT и нажмите
клавишу <Enter>, В появившемся текстовом поле вместо имени атрибута по
умолчанию (Name) введите имя StudentName.
Все домены и атрибуты (обратите внимание, что в Tabledesigner атрибуты
называются элементами) имеют свойства. Чтобы увидеть их, щелкните правой
760 Приложение Б. Создание семантических объектных моделей
кнопкой мыши на домене Name в списке доменов. Tabledesigner покажет
свойства домена Name. Теперь щелкните правой кнопкой мыши на атрибуте StudentName
объекта STUDENT. На экране появится окно свойств атрибута StudentName,
показанное на рис. Б.4. Свойства будут теми же, что и у домена Name, за исключением
имени атрибута ~~ StudentName. Красный цвет, которым показано имя атрибута,
означает, что соответствующее свойство родительского домена переопределено
в данном атрибуте. Закройте окно свойств атрибута. Нажмите <Ctrl> + <Z>, чтобы
отменить изменение имени атрибута (кстати, в Tabledesigner можно отменить
до 30 шагов работы).
Рис. Б.4. Свойства атрибута StudentName
После этого перетащите в объект STUDENT домен Phone (телефон) из раздела
Data Group в списке доменов и поместите его за атрибутом Name. Щелкните на
стрелке рядом с именем Phone, в результате чего раскроется содержимое данной
Создание семантической объектной модели 761
группы — атрибуты Area Code (код региона) и Phone Number (местный номер), как
показано на рис. Б.5. Аналогичным образом добавьте группу Address (адрес).
Рис. Б.5. Пример группового атрибута
Теперь создайте в области проектирования второй объект, как описано выше,
и назовите его CLASS (группа). Перетащите в этот объект домены Name и Quantity
(количество). Атрибут Quantity переименуйте в CreditHours (учебные часы).
Взглянув на свойства домена Quantity, вы увидите, что он имеет целочисленный тип
данных (Integer). Если в вашем вузе учитываются дробные части учебных часов,
можно поменять тип данных атрибута CreditHours. Для этого следует щелкнуть
правой кнопкой мыши на имени атрибута и в открывшемся окне свойств выбрать
тип данных 7 digit Decimal Number (7-значное десятичное число).
Чтобы создать связь между двумя семантическими объектами, щелкните на
значке слева от имени объекта STUDENT в верхней части окна объекта. Перетащите
762 Приложение Б. Создание семантических объектных моделей
этот значок в объект CLASS, поместив его за атрибутом CreditHours. В результате
между объектами STUDENT и CLASS будет создана связь. После этого ваша модель
должна будет выглядеть так, как показано на рис. Б.6.
■Рйе Edit Create Options
Window Help
| Ш Object» v'
©GENERIC OBJECT
1 GDSTUDENT
j ® CUSS |
[ £3 Data items v I
0 Slate
9 Sheet j
fin Text
0 Counter
(3 Тше/Fafee
9 Phone Number
9 Percent j
9 Quanta
9 *Name
9 lietenfcText
9 $!etemifief-Nunrie>ic
0 СшегкуАтодо
9 $ Company Name j
1 6 City
9 Description ]
d EventTtme
9 Evert.Date
0 Area Code
fin Zip
9 EM*1
9 URL
9 Image Path
| »:? Data (stoup* v
»o Phoite
ee Address
^1й1.*1И
fat
О *5tudentName q-1
«S РЬзпе o-1 r?
О Area Code on
9 Phone Number cm
«£ Address $„-. v
(3 Street 0-1
О City o^
(3 State ($.1
О Zip Q-1
Щ [CLASS] ои
О *Namec^
flJ CredftHour* г
"'"""'"""'" ;:■'•'?■■'•■'■■■'••••■•- ;■;■•■•■•■•■ ••-™- — --^r £&":&Um''
Рис. Б.6. Создание связи между объектами STUDENT и CLASS
Кардинальность связи можно изменить, щелкнув на нижнем индексе 0-1
атрибутов связи объектов STUDENT или CLASS. При этом появится окно установки
максимального и минимального кардинального числа, показанное на рис. Б.7.
В раскрывающемся списке Maximum allowed (Максимально допустимое
количество) выберите N. Если хотите, можно также выбрать конкретное число,
например 7. Это не повлияет на схему, но генерируемые программой ASP-страницы
будут реализовывать это ограничение.
Далее создайте третий объект, ADVISOR (руководитель), с атрибутами,
показанными на рис. Б.8. Чтобы пронаблюдать последствия наследования доменов,
Создание семантической объектной модели 763
измените имя домена Phone в списке доменов. Для этого щелкните на имени
левой кнопкой мыши и нажмите клавишу <Enter>. В качестве нового имени введите
Campus Phone (телефон в студгородке). Обратите внимание, что имена атрибутов
Phone в объектах STUDENT и ADVISOR поменялись на Campus Phone. Эти атрибуты
наследуют все изменения в свойствах соответствующих доменов.
Рис. Б.7. Изменение кардинальности связи
Теперь все готово для создания базы данных. Поскольку Tabledesigner может
модифицировать созданную схему, для создания базы данных полной схемы не
требуется. Если хотите, вы можете наращивать ее постепенно.
Щелкните на значке с изображением диска в панели инструментов
(девятый слева значок) или выберите из меню команду Create ► Database (Создать ►
Базу данных). Сохраните вашу модель под каким-нибудь удобным именем;
здесь мы выбрали имя Examplel. После сохранения модели Tabledesigner выведет
764 Приложение Б. Создание семантических объектных моделей
окно, показанное на рис. Б.9. В раскрывающемся списке ODBC Driver (Драйвер
ODBC) вы можете выбрать СУБД, которая будет работать с созданной базой
данных.
Рис. Б.8. Объектная модель из трех элементов
Поскольку перед созданием этого примера мы установили SQL Server, имя
этой СУБД фигурирует в списке. Чтобы сгенерировать таблицы для базы
данных SQL Server, выберите из списка SQL Server и затем войдите в эту СУБД,
как описано в главе 13. Используйте локальный сервер, в качестве имени
пользователя введите sa и вместо базы данных по умолчанию выберите ту, в
которую вы хотите поместить создаваемые таблицы. В данном примере мы
использовали созданную нами ранее базу данных для SQL Server. После
этого Tabledesigner создаст необходимые таблицы и поместит их в выбранную
Создание семантической объектной модели 765
вами базу данных. На рис. Б. 10 изображены таблицы, созданные для модели
на рис. Б.8.
щшшшм
| Э Ob ecu nz I
Ш GENERIC OBJECT |
© STUDENT I
т cuss I
т advisor I
\о Da a Items ^ 1
<3 Stale 1
& Street I
j & Text s|
J & Countei I
I d? True^alse ж
1 13 Phone Number |
1 0 Percent 1
1 0 Quantity I
j 0 *Name 1
j d? SidertiiiiesTexi 1
1 13 SlderWiej-Numeric 1
j (3 CurrencyAinount .1
1 0 SCoropanyName 1
} <3 Qy : j
j (3 Description j
1 0 Es'er-dTime -1
J d? EvenlDate (
I d? Area Code 1
\ 0 2p I
0 £Mai 1
d? URL I
0 Image Path J
j eg Data Group* к? |j
j «tffbon* {L
| «£ Addre$* j
■m
& *SludertNa«ie ои
Database;.-
D ate Soufce Name
jEXAMPLEI
IsoTserver
d
шшш
p-1
IN
.,,.....^.,.^
Рис. Б.9. Выбор СУБД
Если вы не установили SQL Server, но установили Access, вы можете выбрать
в списке ODBC Drivers на рис. Б. 10 драйвер Access, и тогда Tabledesigner создаст
базу данных для Access.
Tabledesigner может также показать SQL-операторы, используемые для
создания базы данных, перед их выполнением. Для этого выберите команду Create ►
SQL Text Only (Создать ► SQL (только текст)). В результате этого в подкаталог
SQL каталога, куда была установлена программа Tabledesigner, будет помещен
текстовый файл с SQL-операторами. Эти действия необходимо выполнить до
создания базы данных, иначе в очереди не будет SQL-операторов, ожидающих
выполнения.
766 Приложение Б. Создание семантических объектных моделей
Рис. Б. 10. Таблицы SQL Server для модели из рис. Б.9
Реконструкция семантической объектной
модели по имеющейся базе данных
Кроме создания новых моделей программа Tabledesigner способна генерировать
полную или частичную модель существующей базы данных. Для этого сначала
необходимо создать источник данных ODBC для базы данных, анализ которой
вы хотите произвести. В данном примере мы будем использовать базу данных
Northwind.mdb, которая поставляется в комплекте с Microsoft Access.
Чтобы настроить источник данных ODBC для базы данных Northwind,
откройте администратор ODBC, выбрав в меню Tabledesigner команду File ► ODBC
Administrator (Файл ► Администратор ODBC). Перейдите на вкладку System DSN
(Системный источник данных), как показано на рис. БЛ1, и нажмите кнопку Add
(Добавить). Из списка драйверов выберите Microsoft Access и нажмите кнопку
Finish (Готово). Введите имя источника данных (в этом примере мы
использовали имя Northwind) и нажмите кнопку Select (Выбрать). Найдите каталог, в
котором расположен файл Northwind.mdb. Его местоположение может быть
различным, в зависимости от того, как вы установили Access. Если вы не знаете, где
искать этот каталог, используйте команду Find (Найти) в главном меню Windows
и укажите имя файла Northwind.mdb. Далее перейдите в этот каталог в
администраторе ODBC и нажмите ОК.
Откройте новую модель в Tabledesigner. Щелкните на вкладке Databases
(Базы данных), расположенной под списком доменов. Вы увидите список
файловых, пользовательских и системных источников данных, имеющихся на вашем
компьютере. Поскольку мы создали системный источник данных, щелкните на
Реконструкция семантической объектной модели 767
надписи System Data Sources (Системные источники данных) и найдите имя
вашего источника данных. Щелкните на кнопке со знаком +, находящейся слева от
этого имени, и в левом окне (рис. Б. 12) будут показаны все таблицы в базе данных.
Перетащите имя вашей базы данных (здесь Northwind) в пустую область
проектирования в правом окне. Сохраните модель (здесь мы использовали имя RE1).
15Mai х|ъ1#| ^^Ш^^^Ш^ЁТ^^Ш^^
Ш Objects \?
©GENERIC OBJECT
S STUDENT
5 CUSS
IS ADVISOR
Q Data Item* v
3 State
6 Street
& Text
О Counts*
& True/False
13 Phone Number
& Percent
& Quantity
& *Narae
S> ШепШйЯ'ТЫ
(3 lldenlifiet-Nurrrf
(3 CutiencyAttourv
О $ Company Nad
3 Dty
3 Description
О EventTime
& EventDate
S> Area Code
8 Zip
3 ЕМай
3 URL
& Image Path
-« Pat» Groups
iOOK Data 5ou*c*i ШШШШШ
Ш CLASS
jU«* DS*i. ,;^em ?** I № OSH} Drivers j Twang) Connection Footing \ At-cjt J :Щ
Add...
Ш;
Щ':::'•
ia
ШШ:
|у^ш0вЦ$ригёеЖ:,>': :.
Name* :=•:
EX2
ex3
fiWfOHf
FoodMart2000
LocelSeiYet
M0DEL1
Model2
Model3
M51
MS2
nwi
:j Drfve?.-;i:;=:: :••;■•
SQL Server
Microsoft Aecess Driver (*.rndb)
SQL Server
Microsoft Access Oliver ("mdb)
SQL Server
Microsoft Access Driver C.mdb)
Microsoft Access Driver ("mdb)
SQL Server
SQL Server
SQL Server
SOL Server
H
~~j
zi
Remove
Configure .
Ш1
*Щ:Ап ODBC System data source stores «formation aboU how tocorwe^to;>!
||)f';S:the indicated del« piovtder. A System data source is visible toJR у^й^Щ'1
:#|fOf*.this nv&chjne,«^eludingNT service* . .^-йЩ; |
Рис. Б.11. Создание источника данных ODBC с помощью ODBC Administrator
После этого появится диалоговое окно, изображенное на рис. Б.13. Чтобы
узнать, что означают предлагаемые варианты выбора, щелкните на кнопке Help
(Справка). Пока выберите последний вариант, при котором создается новая база
данных, но данные в нее не копируются, а происходит настройка файлов
импорта Tabledesigner для последующего копирования. Обычно этот вариант
используется, когда нужно скопировать только часть данных, используя фильтры, но
здесь мы не будем заниматься этим.
768 Приложение Б. Создание семантических объектных моделей
Рис. Б. 12. Реконструкция объектной модели базы данных Northwind
Когда нужный вариант выбран, Tabledesigner создает базу данных,
соответствующую модели. Выберите из предлагаемого списка какую-нибудь СУБД и
нажмите кнопку Create (Создать). Результатом будет модель, подобная
изображенной на рис. Б.14, и база данных, содержащая копии таблиц из базы Northwind.
Теперь вы можете вносить изменения в модель и менять структуру базы данных
с помощью Tabledesigner.
Для демонстрации копирования данных и изменения схем приведем другой
пример. Закройте текущую модель и выберите новую. Щелкните на вкладке
Databases и выберите System Data Sources. Щелкните на имени Northwind, чтобы
открыть список таблиц. Удерживая нажатой клавишу <Ctrl>, щелкните на таблицах
Products (Продукция) и Suppliers (Поставщики), Перетащите эти таблицы в
пустую область проектирования. Сохраните новую модель (мы использовали имя
RE2) и выберите третий вариант, Create new database and copy all data now (Создать
Реконструкция семантической объектной модели 769
новую базу данных и сразу скопировать все данные), как показано на рис. Б.15.
Нажмите О К и выберите СУБД. В этом примере мы снова воспользовались
SQL Server. Можно также использовать Access.
} Customm*
б tOustomeriD j.f
О *Comper*Nsme ц
б CentetfName 0.}
б СоЫШПЬ ол
б Address q.j
б * City 0-1
б *flegfon0,i
б *PostdCode0.1
1 б Countiy 0>1
J б Phone o_}
О Faxp-1
ffi|0fdef8lQ.M
I Ш Ptodod*
И б *ProductfD Li
ij б *Pfoduc*Name -^
If б QuanMyPwUrrt о_1
l| 6 UmtPrice o-1
If 6 UnWnStoek ой
У б UratsQnDrde» o-1
i| О Reo»de«tevel o-i
If О DlSCOntmyeC 1.1
IP*
jjs1
|J{B|Q
И
Celegwies j 0.1
SuppSeuj^
rdttO<<eUltbM
ш\
i\
%\
li
r'j
Ш
Ш
О JCategofylD *_l
О *Cai«$«yNeme 1.1
О Description o-1
15 Ptclwe см
S{P»odijcts]Q>N
ШШЗШЯШШИ-
6 ICrdelD bt
О *0rde>0ete он
б RequiredDate q.-j
О *ShsppedO*fc o-l
б FwigH ои
О ShipName ci
О SfcpAdcfress 0-1
О ShipDty 0-1
3 StopRegbn ои
Q *ShipPostalCode 0и
3 Sftpteunliy o-i
Щ 'jEmptoyeeTJnn
GO f
Ш
E553o-i
|0rd» Detail q.m
© Shippe**
3 *Sbpt>eitD ,.j
IS Pbone0-1
13 *С*«<>апуЫагое i.-j
; б Cofs»J9C«NAme o»i
13 Conractfitte ои
| JS Address o.i
jfll СйУ0_,
I б Region 0.i
IO *PostelCede o-l
: О Counby Q.1
О Phone o-t
| О Гек 0.1
б HomePage 0-1
Щ {Produce | Q-n
] Ш EmpWye**
|| О SE^ployeelD j.-.
II О *L<^J4 водами
[О Firs^art«^i
1|б TJtfe0.f
|]б TtieOfCourtesye-
11 О 6(rthDate q.i
ij 6 HireDa** Q.1
j^
$\
Ш
Ij
li
■;|!
1 jd Address 04 ^||
Рис. Б. 13. Создание схемы базы данных без данных
Iftofar Detaifa
»Un(tP»tcei.i
» Quantity 1И
1 £1 Discount i .1
ffl *|Ptoducts)i^ I
S
:>■••■;• ■ ■■?*№№&&
ffi Cuftoete**
О XCustomeflD ui
О *СогярапуЫйп>е 1.1
3 Conlectfc<*tu» qh
О ContecrtMe 0>1
б Address q-1
б *Cfcy 0-1
О * Region o-1
б "PoM^Code о-1
б COOfrfry Д.}
б Phone 0.1
О F-ах о-1
| ffi Product*
JO *P»o-±ctf0 1.1
| О *PioductNa«w>i.i
О Q»jenWyPerU>* 0,1
О УпйЙ^в <и
О UnrtjinStock 0.1
3 UnJu0n0rd« 0.1
i £3 fieo/de«leve{ 0-1
lio DiscofUjrwed 1^
t.I Ш *|Ci>tegone$ j q.1
[|Ш *(iuppfa>*.io.i
;j(aiOrdetDrtafe|n^
1:1::?Ш^^Ж«^^*?^^.
Q StC^eeor/D 1.1
! Q Descj^son 0-1
О Pciwe 0-1
I ® |P№ducto j 0-N
О tutdetlD t.-f
б *0г<Ь0й1* 0-1
б *S^edDafe 0.1
б Г«>вН o-l
б ЗНфКзгпе ои
б Sh©ftdt*esi 0.1
О ShscOly 0-1
О Sh«^e0M3n Q..1
О *ShpP*s^Ccde 0-1
О Sh^Coortij- 0-1
ffl "'ICu^offAc?'! q,i
Ш ShJww*. s
б IShppeiiD 1И
б CoffipaiiyName ^
f? Pbor*o.1
Э SSuppterlD 1.1
О *Ссщмг^ате }.{
б CurJaccName q.1
в СдгААс!ТЙе q_i
3 Address jj.f
б Сну ои
б Region 0-1
О *Ревг*£сое ovi
б Covnrry 0-1
О Phone 0.1
» Fdxo.»
б HomePeee qui
S (Products) 0^
^
|0 tEmpioyeetD 14
Щ& *l4*(Name 1.1
Щ 6 FifslName 1.1
Ща Trite q.^
Ив TsOeGfCourtesyo-'
В a BifthDate 0.1
Ц О KneOete 0.1
« (3 Address 0-1
Ш№!ШШтШ1т^у-
Л
^
1
|
1
■ЭД
.ij
.:У
Рис. Б. 14. Восстановленная семантическая объектная модель базы данных Northwind
770 Приложение Б. Создание семантических объектных моделей
Рис. Б. 15. Построение двухтабличной выдержки из базы данных Northwind
Если вы выберете SQL Server, вам придется пройти процедуру
аутентификации три раза: первый раз — для установления соединения через драйвер ODBC,
второй — непосредственно перед созданием таблиц, и третий — при записи
данных в таблицы. В качестве имени пользователя указывайте sa, как это делалось
в главе 13. При использовании Access процесс будет намного проще.
Сейчас у вас есть база данных с двумя заполненными таблицами: Products
и Suppliers. Эти таблицы имеют связь 1:N, как показывает модель на рис. Б.16.
Предположим, нам нужно изменить базу данных так, чтобы можно было указать
нескольких поставщиков для одного продукта и нескольких контактных лиц для
одного поставщика. Внесем соответствующие изменения в модель и посмотрим,
какие следствия они будут иметь для базы данных.
Реконструкция семантической объектной модели 771
Прежде всего, изменим максимальное кардинальное число связи между
объектами Products и Suppliers со стороны объекта Products, поставив N вместо 1. Для
этого нужно щелкнуть на индексе 0-1 объектного атрибута Suppliers в объекте
Products и в раскрывающемся списке Maximum cardinality (Максимальное
кардинальное число) в открывшемся диалоговом окне выбрать N. Процедура остается
той же, что и прежде.
Рис. Б. 16. Реконструированные семантические объекты Products и Suppliers
Теперь, чтобы один производитель мог иметь нескольких доверенных лиц,
создадим для них группу Contact и установим для этой группы максимальное
кардинальное число N. Для создания группы при нажатой клавише Shift
щелкните на атрибутах ContactName (имя доверенного лица) и ContactTitle (титул дове-
772 Приложение Б. Создание семантических объектных моделей
ренного лица). После этого они должны оказаться выделенными, как показано
на рис. Б. 17. Щелкните на кнопке группировки (пятая справа на панели
инструментов). В открывшемся диалоговом окне введите имя группы — Contact —
и нажмите ОК. Теперь у нас имеется группа с двумя атрибутами — ContactName
и ContactTitle. Чтобы один производитель мог иметь нескольких доверенных лиц,
следует сделать максимальное кардинальное число этой группы большим
единицы. Для этого нужно щелкнуть на индексе 0-1 группы Contact и выбрать
максимальное кардинальное число. На рис. Б. 18 ему присваивается значение N.
Нажмите 0 К для подтверждения выбора.
Рис. Б. 17. Создание группы Contact
Прежде чем двигаться дальше, рассмотрим, что нужно будет сделать
программе Tabledesigner. Поскольку связь между объектами Products и Suppliers теперь
Реконструкция семантической объектной модели 773
не 1:N, aN:M, необходимо будет создать новую таблицу пересечений. Однако
база данных уже заполнена информацией, поэтому программа Tabledesigner
должна будет переместить данные в таблицу пересечений, чтобы сохранить
существующую связь. Затем для группы Contact нужно будет создать новую таблицу
и переместить в нее все данные доверенных лиц. Все это будет сделано, когда вы
щелкнете на значке базы данных.
Рис. Б. 18. Установка максимального кардинального числа группы Contact
На рис. Б. 19 показана схема базы данных для SQL Server, созданная
программой Tabledesigner после внесения этих изменений. Из рисунка видно, что в базе
данных появились две новые таблицы: таблица пересечений и таблица Contact.
На рис. Б.20 показан фрагмент данных. Обратите также внимание, что в эти
таблицы корректным образом перенесены старые данные.
774 Приложение Б. Создание семантических объектных моделей
*<« 2: Нъщ 'outmm m '$ 81 Se*v& ЕжалЫ* &<ШШШШШ%1Ш:
ШШМШШ&ШшШШШ
т
\г.
•к*
.-.
s2 ProcJuctae:
GOHtmrf'H&tMC-.y
1а1ЯуИЯЦ|Щ
P<«3uclM«me
Catage'ytD
<34«nt3yP«'DrtK
илЛ?<ке
UndalnSlosk
OmtoOrtOr^Iei
ftaar4«r b?v«;t
Obeonbnu^d
Ш1^ШШШШЛШЩ/ШМШШШ^
ю1
v«c«ft«r
.Ы
v»cN»i
«топе*
smalhol
.<tmalh.il
snwHnl
bit
4
40
• 4
SO
a
i
2
г
,i
ю
«
:Ю
.0
19
5
S
s
0
с
Iff
0
0
0
4
0
0
0
с
Ui
Рис. Б. 19. Структура базы данных SQL Server после внесения изменений в модель
Рис. Б.20. Данные в базе после внесения изменений в модель
Публикация базы данных в Web 775
Этот пример показывает преимущества работы на уровне модели, а не на
уровне базы данных. Внесение этих изменений вручную потребовало бы по
крайней мере нескольких часов работы.
Публикация базы данных в Web
Помимо создания и модификации схем, программа Tabledesigner может
генерировать наборы web-страниц, позволяющих создавать, читать, обновлять и
удалять данные в представлениях базы данных через Интернет. (Если какие-то из
используемых здесь терминов вам не знакомы, обратитесь к главе 10.) Эти
страницы могут обрабатываться IIS под управлением Windows 98 и Personal Web
Server под управлением Windows 98 или ME. В последнем случае необходимо
установить компоненты, необходимые для обработки ASP-страниц.
Дальнейшую информацию по этому вопросу можно найти в документации на Personal
Web Server.
Процесс генерации таких страниц прост: создайте представления, которые
требуется опубликовать, и запустите мастер Web Publishing Wizard программы
Tabledesigner Созданные страницы необходимо затем поместить в каталог, где
их сможет найти IIS или Personal Web Server. Поскольку в этих страницах
используется JScript, каталог должен быть помечен как содержащий сценарные
файлы. Это можно сделать, изменив свойства каталога приложения.
Дальнейшую информацию по этому вопросу можно найти в документации Microsoft или
справочной системе программы Tabledesigner.
Процесс генерации ASP-страниц мы будем иллюстрировать на примере
модели RE2, созданной в предыдущем разделе. Разумеется, вместо нее можно
использовать любую другую модель. Чтобы создать представление семантического
объекта, откройте модель, с которой вы желаете работать (здесь это RE2.apm),
и щелкните на вкладке View (Вид), расположенной под областью
проектирования. В левом окне теперь будет отображаться список представлений и объектов.
Перетащите объект Products из раздела объектов в пустую область
проектирования. После этого в области проектирования появятся два окна, как показано
на рис. Б.21. Представление Products List (в правом окне на рисунке)
предназначено для вывода списка экземпляров объекта Products. Чаще всего оно
используется для отображения результатов запросов. Второе представление, Products Form
(в левом окне), предназначено для ввода данных. В этом представлении в
каждый момент времени показывается только один объект.
Сначала рассмотрим представление Products List. Галочка рядом с каким-
либо элементом означает, что он будет показан в web-форме. В данном случае по
умолчанию выбраны элементы ProductID (идентификатор продукта), ProductName
(название продукта) и CategorylD (идентификатор категории). Предположим,
нам не требуется иметь в представлении Products List идентификатор продукта
и идентификатор категории. Чтобы удалить их из представления, дважды щелк-
776 Приложение Б. Создание семантических объектных моделей
ните на галочках напротив элементов ProductID и CategorylD. Галочки исчезнут,
показывая, что соответствующие элементы были удалены из представления.
Теперь откройте объектный атрибут Suppliers, для чего щелкните на стрелке
рядом с ним. Эта группа представляет связь с объектом Suppliers в
представлении семантического объекта Products. Поставьте галочки напротив
элементов CompanyName (название компании) и Contact (доверенное лицо).
Раскройте группу Contact. После этого экран должен выглядеть так, как показано на
рис. Б.22.
T.ibiedeskmer
k View» у?
S* Products For ro View
V Products List View
1 Objects ^7
Ш Suppliers
S Products
j Ш Products Fo*rn View ^
I • & SProductID ^
1 ^ & ^ProductName i_-j
• & *CategorylD 0-i
I J S QuantityPerUnft 0-1
I i/ 0 IMPfice 0-1
| <f 8 UnitsJnStock 0,-j
j ^ & IMsOnGrder q.j
1 J & ReorderLevel ои
I ^ 0 Discontinued ^.-)
дцруз]
| ^ Ш *Suppfie<$ q,-j v- |i
j • 0 SSuppJierlD ^ ^
| J & *Comp<anyN<5!'ne,j,i
I Ȥ Contact 0.n {>
I & Address q.-j
0 City o-1
j 8 Region q^
| ^ 0 *Po$UlCode 0-1
j & Country Q„i
j & Phone g„i
I 0 Fax 0-1
j & HomePage q^
г^^^щ^^^^^^щ^^щщщ
IВО Products List View ^
j J & $ProductlD 1.1
j ^ 0 *P(oduc*Narj» 1e1
j • 0 *CategwyiD q^
J В QuantkyPetUnit 0-1
I 0 UnitPrice 0.1
j & UnitsinStock o-i
J 8 UnitsOnOfder 0-i
l & ReojdeiLevel 0-1
j & Discontinued ^
МВЙЯЖЙМ^гвЯР!
| • & $Suppfie»iD ^
j J 9 *CcmpanyName ^
| ol Contact qj$ {>
1 0 Address q~1
I 0 City o-i
I & Ведюп o_^
j ^ 0 *PostalCode q.1
j 0 Country 0-1
I 0 Phone o-1
] & Fax o-i
j & HomePage o-i
Щ
iiiihiiiiiiiiiiiiiiiii
;.-|num
Рис. Б.21. Исходный вид представлений Products Form и Products List
Теперь рассмотрим представление Products Form. Снимите часть галочек
так, чтобы в представлении остались только элементы ProductID, ProductName,
UnitPrice (цена), UnitsinStock (количество товара в наличии) и CompanyName (в объ-
Публикация базы данных в Web 777
екте Suppliers). Экран после этих действий должен выглядеть так, как показано
на рис. Б.23.
Выполните аналогичную процедуру с представлениями объекта Suppliers.
Добавьте или удалите элементы так, как считаете нужным. Один из возможных
наборов представлений этого объекта изображен на рис. Б.24. Теперь все готово
к публикации приложения в Web.
Ш Table designs r
|р$ ; Edit Create options Wndow Нф
• ",/f яШМ
у лш
£* Views ^r
8* Products Form View
V Products List View
Ш Object* v
Ш Suppliers
S Products
Ш Products Fo»m View ^7
•
V
•
•
4
•
4
•
V
0 XPtoductlD 1.1
fj *ProduclName ^.1 j
0 *Caleg.o*yJD 0.1 j
0 QuantityPetUnit он
& Unitpiice Q.i |
0 UnftslnStock 0.1 i
9 UnrtsGnO»def n-j
0 R eadef Level 0.1
0 Discon&ujed \ „\
1 «^ Ш *Supplier$ 0-1 ^ ||
1/ 0 SSuppfeflD 1e1 1
^ О *СотрапуКате^1 :
«# Contact o-N ^
О Address ои
S City o-i
& Region n^
• О "PosUlCode ^
0 Country Q_i j
6» Phone 0-1
0 Fax 0..J 1
О HomePage q.i i
щшшшшшяшшш
& iPtoductlD 1.1
0 *Product.Namei.i
& * Category} D 0.1
5 GuanbtyPerUnit 0-1
6 UntfPfice 0^
& UratslnSlock 0-1
О Unit$0nD»def 0-1
& Reotdedevel q.1
0 Discontinued j.j
Ш * Suppliers 0.1 nz
& *SuppiierlD ^
/ & *CompanyName ц
</ *8 Contact o.n *&
</ & ContactName 0-1
J & ContactTitte q^
& Address n_i
& City 0-1
9 Region q^
& *Po*taiCode 0.1
& Country 0.1
& Phone 0-1
& Fax Q.1
& HomePage q^
.•'.^.trOS:^?^''^:''. -
: :v::f>:V:1::^H:5ili:1|:il-W:.; ■:' ^^^
'"Tl^jSyM;:.
Рис. Б.22. Изменения в структуре представления Products List
Для запуска мастера Web Publishing Wizard выберите в меню команду File ►
Publish Web Application (Файл ► Опубликовать приложение в Web). Сохраните
модель, когда программа предложит вам это сделать, и щелкните на кнопке Next
(Далее). В следующем окне мастера появится список представлений,
предназначенных для публикации. Мы хотим опубликовать все указанные представления,
778 Приложение Б. Создание семантических объектных моделей
поэтому нужно снова нажать кнопку Next. В следующем окне мастера,
показанном на рис. Б.25, Tabledesigner спрашивает, каким набором шаблонов вы хотите
воспользоваться. Выберите то, что предлагается по умолчанию, снова нажав
кнопку Next
щТаЫейё«|длсг
лШ12У
S* Views ^
S* Pioducts Form View
V Products Lis* View
ffl Objects v
0D Suppliers
Ш Products
I / О £Prcdue*!D 1.1
-j ^ 3 '*ProductNaroe i_i ]
j 3 *CategoryiD q-1
I 3 QuantttyPerUrd 0-i
j ^ О UnitPrice 0-1
j J О UnftslnSiock он
I & UnifcOriOrdef q.1
j 3 flecrdeiLevel 0-1
j 3 Discontinued ^ ^
J «^ IS "Suppliers 0-i ^
j 3 SSuppiterlD i„i j
j ^ d? *CompanyName 1^ j
j °$ ContecC fj.N £>
I О Address q^ I
J 0 Qy o^
] О Region o-i |
J 8 "Postatode 0,1
j 3 Country q^ |
1 О Phone o>-j ]
.] & Fax fj.i
j Q HomePage q^
''<\:Pf±QbfctiP,
*>U£
3 *PioductiD 1 ж1
' 8 *ProdudN«ne1.1
3 *Category}D 0-1
В QuamityPerUnA 0-i
С UmPtice o-i
3 UnitsfnStock o_-j
& UnftsOnOrder 0.1
3 Reorder!, evel q,^
3 Discontinued ^
> Ш ^Suppliers Q-1 v
3 ISuppheriD^
^ (3 *CompanyNaroe ^ .-j
V? «S Contact Q4v{ v
^ & ContaclName q.j
V 3 ContactTftle Q-1
3 Address q„4
3 Oyo-1
3 Редюп o.i
3 *Postatode Q.1
(3 Country ой
3 Phone q..j
3 F«< on
3 HomePage q.i
' $Ш :Й'
Рис. Б.23. Изменения в структуре представления Products Form
Далее мастеру необходимо знать, в какой каталог следует поместить ASP-
страницы, поэтому следует указать каталог, который вы настроили для этой
цели. В качестве альтернативы можно воспользоваться каталогом,
предложенным по умолчанию программой Tabledesigner, а затем назначить этому каталогу
привилегии для web-публикации. В любом случае следует ввести имя
существующего каталога и нажать кнопку Next. В следующем окне мастера введите имя
приложения (например, Sample Application) и нажмите кнопку Next.
Публикация базы данных в Web 779
I 4 О *Оз№р«-^дте м
V
V
V
*
3 AxfefceSS 0-1
3 Ci?y w
CJ Rtflton q.i
3 * Postcode q.1
3 Country q.1
3 РЬелв(м
3 f-"«K (j.-,
3 HomePage ot
GD Products c-N ^
3 fPMducKOi.i
/ 3 *Pux*jctNartier
3 ^CifeCO'^D 0>i
3 QuadfrPeiUrt* Q.1
3 UraiPric* q.1
mbs—'1
j V 3 UrusfnStock. o_i |]
13 UrdsGrflKto 01
13 FteuuM.ftvel o-i
О Discontinued (.1
risaaa
иамвмязажйиаашвтаааашт-'1^
ГГ1Шйи1пптпппп11дтшшп1П11П1плгп1птпппш11П11а j
GD Supplers L>sl View -7 j
V
V
*
3 JSuppMDi.t
О *Ож&вгФ*г* 1.1
3 Adcfre» 0.1
3 С&у ол
О Regkr, <>.<
13 *PcelelCode o-t
О County q.1 |
3 P4oeo.t i
3 F34 ci
13 HwnePag* o-t
Ш PfuducU o-N V
3 *Pw&»c«0 1.1
V О *Рих*х*1згое чи j
1 3 *CaJ«go^D 0.j Jj
О Quantf^wUr* o-i j
3 UnrtPric* o-1
3 UnitslnStock. o_t
13 U«f50n0»d« c-1
О ReautoLevei 0.^ ]
3 Disecrtirusd i.f |
IBSSr"1^!
I v
V
у
V
*
О JPfOdudlD м
3 *PradurtN«ne t_t i
CJ *C*ejjo<yiL> c«i j
CJ QuenfcyPwUral q_i
3 UmtPjjce q.1 ]
3 UrAslnStoc* c-1
О UrtfsQrtOsder 0.1
3 Rec^deiLflve) a-1 I
3 &;*cor*rwed м |
GD *Suppfer» 0.1 tt
3 *5иге**К>1-1
^ 3 *Co№p«fi)>Nan* i..j
•? Ointatf o-N i> I
CJ A4ie$* 0.1 I
»С»Г0и |
О П*зюп o-1
3 *PodaCode q.1 j
3 Couwy 0.1
3 Phcrtso-t
CJ F« ол !
О tiCtt#P«JbQ.1 j
к^ШиКнАшШДшш^ШШш^А.
{GD Products List \tew ^
3 *P'*duc»iO 1.1
^ 3 *Pfwj-jetNanw 1.1
CJ *C#*wir> 0-1
3 Gu«rt%P»Un* Q_i
3 UrAPriee c-1
13 Ur*WnStock си
13 Ur*«0nQrci« 0.1
I 3 ReofderLevH ои
| CJ О'жспИглад f.1
^ Ш *Suppl»fs M *v
3 «SumMD li
,/ 3 * Company *n«i-i
j V "S Cwrfae» c.« v
| V 3 CcrAactNem* 0.1
] • 3 Otfacttitk 0.j
3 Address Qj1
ЗОуо-1
13 ftegi*> Q.i
3 *Ро*«дСск1е q.1
I 3 Cote*y q.«
j 3 Phone о.»
j 3 Fax 0.1
] 3 HonwPage,%i
UU^I
"1
Рис. Б.24. Окончательный вид представлений объектов Products и Suppliers
Аррйса*ШЩШ!И!шШ:
:; :{$&^Щ^Й^ use to gsri&&e Vfeb *&^йй(Г;
Т -^^Ш;|^ё$Ь^^Щ^|; box next So.the v^naff»;^.^;
*T table
12 Products Form View
(3 Products List View
($ Suppliers Form View
■vj] Suppliers List View
Select -
Clear A!!
ШШ:1Ш^^У'1 ^ЩЙ^'. { H^ I
Рис. Б.25. Задание представлений для публикации
В очередном окне мастера примите предложенный по умолчанию вариант,
при котором приложение не будет сразу регистрироваться. В открывшемся
после этого окне, показанном на рис. Б.26, можно ввести имя пользователя и
пароль по умолчанию, если вы хотите, чтобы создаваемое вами приложение
могли запускать посторонние. Поскольку в нашем случае это не предполагается,
780 Приложение Б. Создание семантических объектных моделей
ничего не вводите и нажмите кнопку Finish (Готово). После этого Tabledesigner
сгенерирует ASP-страницы. В заключение программа спросит, хотите ли вы
запустить хмастер Microsoft Web Publishing Wizard. В качестве ответа выберите
No (Нет).
Application £е*щМШШ!Ж1
*J
|||0|ИШ'раде 1о зе^ЩамИ u*e|jpra and;|ipword for the
HI ||Ш|М applicaHc|>:||; |i$e wH||-j|^rig о||||;|Ье database.
aulojpdc*%>,you тиЙШо 5еЦЙ$Ше checlgffit.
tabfe n
г tog c^iBiiiiiiiil
•fisck
IFinasb
He?
Рис. Б.26. Окно установки имени пользователя и пароля по умолчанию
Чтобы запустить созданное приложение, загрузите в браузер страницу с
именем default.asp из каталога, выбранного вами для размещения ASP-страниц.
Например, если вы выбрали каталог mywebs/apps/, то в поле адреса браузера
следует ввести строку mywebs/apps/default.asp и нажать <Enter>. Возможно, вам
потребуется несколько модифицировать эту строку, в зависимости от настроек
вашего web-сервера.
После этого браузер должен соединиться с web-сервером и вывести окно
аутентификации. Если вы работаете с SQL Server, введите имя пользователя sa
без пароля или какое-либо другое действительное имя пользователя и щелкните
на кнопке Login (Войти в систему). Если вы используете Access, ничего не
вводите, а просто нажмите Login.
Теперь с помощью созданных ASP-странпц вы можете работать с базой
данных. Выберите из раскрывающегося списка страницу Products и нажмите
кнопку Query (Запрос). Окно браузера примет вид, аналогичный изображенному на
рис. Б.26. Поскольку Tabledesigner поддерживает запрос из формы, в поля
запроса можно вводить символы поиска. На рис. Б.27 пользователь ввел строку
<<>0» в поле UnitsInStock и строку «New*» в поле CompanyName. Следовательно,
Публикация базы данных в Web 781
пользователь ищет продукты, количество которых на складе больше нуля, а имя
поставщика начинается с символов «New».
*1 Sample Application A«rfication::4 MicrosoftШ&Ш**
т 111? :ЩШ -=ЮШ
fffifr*NjjS jigj http://locdlhost/Dfi/Re2/home.asp
Sample Application Application [vjewrfEdit zl ЩЩ*™ 3 fo^T 3
I
ProdactlD:
ёШШШИЩЙ
Search for Products
ProdttctName:
UnitPrice: 1
UnitsinStodc: I
:.-' Search: JxjtlJtetel
Biiiiii
Search for Products
ЩЬос^ intrant.
Рис. Б.27. Запрос из формы
При нажатии кнопки Search (Поиск) на экран выводится представление
Products List, показанное на рис. Б.28. Обратите внимание, что все показанные
в нем продукты поставляются компаниями, чьи названия начинаются с «New».
Если пользователь щелкнет на названии одного из продуктов, например на
первом, сведения об этом продукте будут отображены в представлении Products Form.
Экземпляр этого представления показан на рис. Б.29. Генерируемые программой
Tabledesigner страницы весьма удобны в использовании, и по-настоящему
оценить их мощь можно, только создав такое приложение и поработав с ним
некоторое время.
Кстати, подумайте теперь над тем, что должна сделать программа Tabledesigner,
чтобы выполнить приведенный здесь запрос. Фильтр по элементу CompanyName
применяется к таблице Suppliers, но представление Products List основано на
таблице Products. Более того, связь между этими таблицами имеет вид N:M. Это
означает, что для выполнения запроса программа Tabledesigner должна создать левое
внешнее соединение и внутреннее соединение через таблицу пересечений.
782 Приложение Б. Создание семантических объектных моделей
ЗИл«>»1е AwfeMAfwj ^р^^ЩЖ^/^аШ^
k$te^:$fc '^\^^ф^^::Г(^У:И1Л^, i
ШШШ**Й*-Ш8;:$:в
j:j:*idur«s j<gj b**p.»7to<a**«,'OB/P.e2/hof<» asfr
*1Ш*
Sample Application Application |y*eWEd*-""'^j \Мй Ke№". zj |0««5ЩЩ*3
л!
щ^щрт^^^р^^щщ
Рис. Б.28. Результаты выполнения запроса, показанного на рис. Б. 27
i .^Sa«wle; ЛШсаЩ*
= ffe €<& Vfcv» Favor*** Tods H%Jp
; I ::^.8аЛ - ** - || §] t# * *Й Search ^Favorites ^HSfcry j %* ф gg • Jg|
; Address [^] http://!ocalhost/OB/Re2/home.asp
j^j ^p<3o tJnks':
Sample Application Application (vicw/ш jj \AM New j-j JQw*y 3
Products
ШШШШШШШШШЩ^ШШШШШшШШ^ШШШШШ
ProdustID: 6$
ProductName: Louisiana Fi*ry Hoi: Pepper Sauce
UmtPrfce: $210,500 00
Units InStock: 76
'<<i8iSlN«fei; tajt>> Edit Q ucry 0*l«te Exit Heb
Products
ш
111 111 fill ШЩШШШШЁЩЩЩМ
.d
Рис. Б.29. Продукты, показанные в представлении Products Form
Упражнения 783
Следующие шаги
У программы Tabledesigner, кроме того, что описано здесь, имеется еще множество
возможностей и функций. Дальнейшую информацию вы можете найти в
справочной документации к программе. Разумно начинать чтение с раздела Applications ►
Development Process Overview (Приложения ► Обзор процесса разработки). С
помощью Tabledesigner можно нормализовать данные в базах данных и
электронных таблицах, которые еще не нормализованы. Информацию о нормализации вы
найдете в разделе Normalization Overview (Обзор нормализации).
Упражнения
Создайте в программе Tabledesigner модель данных университета Highline,
описанную в главе 4 (см. рис. 4.13). На основе этой модели создайте базу данных для
Access или SQL Server. Исследуйте получившуюся схему и объясните, как
каждая из таблиц связана с моделью. Измените модель таким образом, чтобы
преподаватель мог работать более чем на одной кафедре. Заново сгенерируйте базу
данных и объясните произошедшие изменения.
1. Создайте в программе Tabledesigner модель данных с примером каждого
из следующих типов семантических объектов:
1) простой;
2) композитный;
3) составной;
4) гибридный;
5) архетип/версия;
6) ассоциативный.
Создайте базу данных на основе этой модели и исследуйте получившиеся
таблицы. Объясните, какие принципы проектирования использует Table-
designer и в каких случаях эти принципы отличаются от описанных в главе 7.
2. Откройте в Tabledesigner новую модель и выберите исходный набор
Recruiting (данные о найме персонала). Исследуйте модель и создайте на ее
основе базу данных. Предложите, как можно было бы улучшить эту модель.
Измените модель и заново сгенерируйте базу данных. Объясните
изменения, сделанные в структуре базы данных.
3. Выполните упражнение 1. Для каждого из объектов создайте
представление, выводящее список экземпляров объекта (List), и представление,
предназначенное для ввода данных (Form). С помощью Tabledesigner создайте
ASP-страницы для обработки этих представлений. Поместите созданные
ASP-страницы в каталог, видимый для IIS или Personal Web Server.
Загрузив эти страницы в браузер, создайте с их помощью экземпляры
объектов КАФЕДРА, СТУДЕНТ и ПРЕПОДАВАТЕЛЬ. Также с помощью ASP-страниц
свяжите между собой несколько объектов. Откройте базу данных и посмот-
784 Приложение Б. Создание семантических объектных моделей
рите, какие значения имеют поля внешних ключей. Дайте обоснование
этих значений с помощью связей, созданных вами между объектами.
4. Установите SQL Server, если вы еще не сделали этого. Следуя примеру,
приведенному в этом приложении, создайте системный источник данных
ODBC для базы данных pubs. Необходимо будет выбрать драйвер SQL Server
и пройти процесс идентификации, инициируемый СУБД. Выберите
локальный (local) сервер, имя пользователя sa (без пароля) и базу данных pubs.
Выполните частичное восстановление схемы базы данных по таблицам
publishers (издательства), authors (авторы), titles (названия) и titleauthor
(статус автора), создайте на основе этой схемы базу данных для Access
(используйте SQL Server, если у вас нет Access) и скопируйте в нее
имеющиеся данные. Дайте новой базе данных имя pubs2. Измените модель
pubs2 таким образом, чтобы книга с одним и тем же названием могла
издаваться несколькими издательствами. Заново сгенерируйте базу данных
и исследуйте произошедшие изменения. Откройте таблицу title в базе
данных pubs и выведите ее содержимое. Откройте таблицу title в базе данных
pubs2 и выведите ее содержимое. Откройте также таблицу пересечения
в базе данных pubs2 и выведите ее содержимое. Объясните различия
между этими таблицами.
5, Создайте базу данных pubs2, как описано в упражнении 4. Создайте
представления для таблиц publisher, author и title. Сделайте так, чтобы
представление author включало названия всех книг данного автора, а
представление title включало псех авторов, имеющих книгу с данным названием.
Создайте web-страницы для этих представлений. С помощью этих страниц
укажите для некоторых книг второго и третьего автора. Закройте
web-приложение и исследуйте значения внешних ключей в таблицах базы данных.
Дайте обоснование этих значений в свете сделанных вами изменений.
Алфавитный указатель
#, 67
#, символ UML, 101
&, в SQL, 585
%, символ SQL, 310
, в Oracle, 427
-, символ UML, 101
/, в Oracle, 427
_, символ SQL, 310
+, символ UML, 101
INF, 176
2NF, 176
3NF, 178
4NF, 183
5NF, 183
abstract data type, 714
abstraction, 570
ACID, 394
Active Data Objects, 574
active repository, 414
Active Server Processor, 522
ActiveX controls, 522
ad Char, константа, 580
ADO, 562, 574
adParamlnput, константа, 580
ADT, 714
after-images, 409
ALTER, оператор, 435
Apache, 523
Apache Tomcat, 524, 619
Append, метод, 580
applet, 607
application failure, 458
application logic, 370
application metadata, 40, 57
application program, 25, 70
archetype object, 154
archetype/version object, 154
ARCHIVELOG, режим, 458
ARPANET, 516
AS, ключевое слово, 442
Ashton-Tate, 43
ASP, 522
association object, 148
atomic, 382
attribute, 83, 166, 693
AUTOJNCREMENT, ключевое слово, 617, 635
AutoNumber, тип данных, 65
AVG, функция, 312
axe, 662
В
band, 68
banded report writer, 68
before-image, 409
Berners-Lee, Tim, 517
BETWEEN, оператор, 310
bill of materials, 232
binary relationship, 85
BK/NF, 180
Borland, 43
bottom-up database development, 73
Boyce-Codd normal form, 180
branch, 229
built-in functions, 312
bulk-logged recovery, 506
business rule constraint, 366
business rules, 60
callable statement, 611
callback, 698
candidate key, 179
card, 548
Cartesian product, 290
Cascade Style Sheets, 528
cascading delete, 344
CASE-средства, 96
CGI, 523
change, команда, 426
786 Алфавитный указатель
check box, 350
check constraint, 436
checkpoint, 412
child, 214, 229
circular list, 733
class attribute, 100
class library, 694
client, 647
client-server database architecture, 45
client-server system, 647
Codd, E. E, 42
Codd, E.E, 166
collection, 571
column, 167
column object, 705
COLUMN, ключевое слово, 436
Command, объект, 575, 579
CommandTcxt, свойство, 580
Execute, метод, 580
Parameters, коллекция, 579
Append, метод, 580
CommandText, свойство, 580
Common Gateway Interface, 523
complete backup, 504
complex network, 231
composite attribute, 83
composite identifier, 84
composite object, 138
compound object, 141
concurrent transactions, 383
concurrent update problem, 386
Connection, объект, 575
Open, метод, 577
consistent backup, 459
constraint, 184
constructor, 694
control files, 458
Count, свойство, 578
COUNT, функция, 312
CREATE TABLE, оператор, 470
CreateObject, метод, 576
CRUD, 331
CSS, 528,533
cube, 660
CurrVal, метод, 431
cursor concurrency, 501
cursor variable, 442
CursorType, свойство, 578
D
data access language, 304
data administration, 379, 679
data administrator, 679
data consumer, 571
data definition language, 277
data dictionary, 39
data directory, 39
data entry form, 63
data integrity, 36
data manipulation language, 281
data mart, 677
data modeling, 73
data owner, 682
data proponent, 682
data provider, 571
data repository, 414
data source, 563
data structure diagram, 215
data sublanguage, 304
data warehouse, 669
database, 39
database administration, 379
database management system, 44
database processing system, 37
database save, 408
database scheme, 59
datafiles, 457
dBase II, 43
DBMS, 25
DBMS engine, 58
DDL, 277
dead transactions, 459
deadlock, 389
deadly embrace, 389
deck, 548
DECLARE CURSOR, оператор, 502
default namespace, 543
deleted, псевдотаблица, 495
deletion anomaly, 172
desc, команда, 430
description, команда, 430
Description, свойство, 579
design tools subsystem, 57
destructor, 694
detail band, 68
determinant, 168
DHTML, 32, 528
DICT, таблица, 452
difference, 289
differential backup, 504
dimension, 662
dirty read, 395
distinct identity, 120
DISTINCT, ключевое слово, 308
distributed database, 46
distributed database system, 651
distributed system, 651
Distributed Transaction Service, 655
distributed update conflict, 654
DKNF, 184
Алфавитный указатель 787
DML, 281
Document Object Model, 528
Document Type Declaration, 531
DOM, 528,539
domain, 60, 125, 184
domain/key normal form, 184
drill down, 672
driver, 564
driver manager, 564
DriverManager, класс, 609
getConnection, метод, 609
DROP, оператор, 433
drop-down list box, 348
DTD, 531
DTS, 655
dynamic cursor, 398
E
encapsulated structure, 693
Enterprise Oracle, 460
entity, 82
entity class, 82
entity instance, 83
entity-relationship diagram, 86
entity-relationship model, 82
equijoin, 293
ER-diagram, 86
Error, объект
Description, свойство, 579
Errors, коллекция, 575, 578
ER-диаграмма, 86
exclusive lock, 388
Execute, метод, 580
executeQuery, метод, 610
execute Update, метод, 610
exit, команда, 427
explicit lock, 388
extensible Markup Language, 530
extensible Style Language
for Transformations, 533
extent, 723
F
Fagin, R., 175
FETCH, оператор, 490
field, 167,571
field list, 63
Field, объект, 575
Name, свойство, 578
Value, свойство, 578
Fields(O), свойство, 578
Fields, колекцня
Count, свойство, 578
Fields, коллекция, 575, 578
fifth normal form, 183
file, 167
file data source, 568
file-processing system, 35
file-sharing, 648
firewall, 517
first normal form, 176
flat file, 729
Focus, 44
footer band, 68
foreign key, 61, 211
form, 25,345
form processor, 58
FORM, тег, 588
formatting, 331
formula domain, 137
forward only cursor, 397
fourth normal form, 183
fragment, 362
FROM, оператор, 307
full recovery, 506
functional dependency, 168
G
get, метод HTML, 588
getColumnCount, метод, 610
getColumnName, метод, 610
getConnection, метод, 609
GETDATE(), функция, 498
getMetaData, метод, 610
GRANT, оператор, 457
group attribute, 120
group identifier, 124
growing phase, 389
H
HAS-A relationship, 86
HAVING, оператор, 314
head, 749
header band, 68
hierarchy, 229
horizontal fragment, 651
horizontal partition, 651
horizontal security, 368
hotkeys, 69
HTML, 526
HTTP, 32,517
HttpServlet, класс, 618
hybrid object, 144
hypercube, 660
hypertext transfer protocol, 517
788 Алфавитный указатель
I
IAccessor, интерфейс, 573
iColumnsInfo, интерфейс, 574
ID-dependent entity, 89
identifier, 84
IIS, 522, 575
immutable, 721
implementation, 572, 693
implicit lock, 388
implied object, 355
IN OUT, ключевое слово, 441
IN, ключевое слово, 441
IN, оператор, 309
inconsistent backup, 459
inconsistent read problem, 386
index, 40, 55, 730
index set, 735
INDEX, ключевое слово, 435
Indexed, свойство столбца, 61
indexes, 734
Ingress, AA
inheritance, 94, 694
inner join, 295
inserted, псевдотаблица, 495
insertion anomaly, 172
instance failure, 458
interface, 572, 693
Internet, 516
Internet Information Server, 575
Internet Server Application Program
Interface, 522
interprocess materialization, 331
inter-relation constraint, 174
intersection, 289
intersection record, 746
intersection relation, 218
intranet, 517
inverted list, 734
IRowSet, интерфейс, 573
is null, 67
IS NULL, оператор, 311
ISAPI, 522
IsObject, функция, 583
J
Jakarta, 619
Java, 606
Java bean, класс, 624
Java Server Pages, 524, 618
Java servlet, 524
Java virtual machine, 607
JDBC, 606
Jet Engine, 58
join, 292
join view, 438
JSP, 524,618
К
key, 169, 184
keyset cursor, 398
L
labeled namespace, 543
LAN, AA
left outer join, 294
level, 663
LIKE, оператор, 310
linked list, 731
Linux, 523
LIST, команда, 426
local area network, AA
localhost
в MySQL, 637
lock granularity, 388
LOCK TABLES, оператор, 638
locking hints, 502
LockType, свойство, 578
log, 409
logical key, 276
logical unit of work, 382
lost update problem, 386
Lotus Approach, 57
LUW, 382
M
mainframe, 45
maintenance plan, 280, 507
many-to-many relationship, 194
many-to-one relationship, 193
markup language, 526
materialization, 331
materialized view, 654
MAX, функция, 312
maximum cardinality, 86
measure, 662
media failure, 458
member, 663
menu, 69
metadata, 39
method, 571,693
microbrowser, 548
Microsoft, 562
Microsoft Access 2002, 57
Microsoft Transaction Server, 572
MIN, функция, 312
Алфавитный указатель 789
minimum cardinality, 87
mixed partition, 651
modification anomaly, 172
MODIFY, оператор, 436
MoveFirst, метод, 583
MoveNext, метод, 583
MTS, 572
multiplexing, 458
inulti-tier driver, 565
multi-value attribute, 137
multi-value dependency, 180
multi-valued attribute, 83
mutable, 721
MySQL, 607,632
N
Name, свойство, 578
namespace, 540
natural join, 293
nested table, 705
new, префикс, 448
Netscape Web Server, 523
network, 516
NextVal, метод, 431
NOARCH1VELOG, режим, 458
node, 229
NO LOCK, блокировочная подсказка, 502
non-object attribute, 137
nonrepeatable read, 395
nonunique, 84
normal form, 166, 175
normalization, 43, 52, 166
NOT IN, оператор, 309
not-type valid XML document, 532
NSAPI, 524
null value, 238
О
OASIS, 551
object, 694
object class, 571, 694
object diagram, 121
object identifier, 124
object instance, 694
object link, 121
Object Management Group, 96
object oriented DBMS, 47
object-oriented DBMS, 692
object-oriented programming, 693
object-relational database, 47
object-relational DBMS, 692
occurrence table, 752
ODBC, 560
ODBC conformance level, 565
offline ReDo files, 458
OID, 716
О LAP, 660
OLAPcube, 660
old, префикс, 449
OLE, 568
OLE DB, 560, 568
OMG, 96
On Error Resume Next, оператор, 583
one-to-one relationship, 191
on-line analytic processing, 660
online ReDo files, 458
OODBMS, 692
OOP, 47,693
Open Database Connectivity standard, 559
open source, 606
Open, метод, 577
optimistic locking, 390
OPTIMISTIC, поведение курсора, 501
optimizing, 413
option button, 349
Oracle, 44, 47, 422
Oracle Configuration Assistant, мастер, 423
Oracle Loader, 460
Oracle Recovery Manager, 460
ORDER BY, оператор, 311
OUT, ключевое слово, 441
outer join, 294
overhead data, 55
p
page header, 68
paired attributes, 123
Parameter, объект, 580
Parameters, коллекция, 575, 579
Append, метод, 580
parent, 214, 229
parent object, 152
parent/subtype object, 151
parsing, 539
passive repository, 414
persistent, 694
pessimistic locking, 391
Peter Chen, 82
phantom read, 395
physical description, 125
physical key, 276
polymorphism, 694
post, метод HTML, 588
prepared statement, 611
primary key, 179
private, 101,516
790 Алфавитный указатель
processing rights and responsibilities, 398
product, 290
projection, 291
property, 83, 571
protected, 101
prototype, 72
public, 101,516
Q
QBE, 66
query, 66
Query Analyzer, 471
query by example, 66
query by form, 67
query language, 284
query /update language, 284
Query-by-Exainple, 282
Query-by-Form, 282
R
radio button, 349
RDS, 529
read committed, 396
READ COMMITTED, уровень изоляции, 500
read only, 454
read uncommitted, 395
READ UNCOMMITTED, уровень
изоляции, 500
READ_ONLY, поведение курсора, 501
record, 167
recordset, 338, 570
Record Set, объект, 575, 577
CursorType, свойство, 578
LockType, свойство, 578
MoveNext, метод, 583
MoveFirst, метод, 583
Update, метод, 595
recovery model, 505
recursive relationship, 219
recursive relationships, 87
ReDo files, 458
referential integrity constraint, 174, 359
relation, 52, 166
relational algebra, 281
relational calculus, 282
relational database, 44
relational database model, 42
relational model, 166
relational schema, 275
relationship, 84
relationship cardinality constraint, 360
relationship class, 84
relationship degree, 84
relationship instance, 84
Remote Data Services, 529
REPEATABLE READ, уровень изоляции, 501
repeatable reads, 396
replication, 508
report, 25,68,352
report header, 68
request-oriented, 517
requirements data model, 76
resource locking, 387
Response, объект, 595
Write, метод, 595
ResuItSet, объект
getMetaData, метод, 610
right outer join, 295
ring, 733
RMAN, 460
rollback, 409
rollback segment, 453
roll forward, 409
root, 229
row, 167
row identifier, 718
row object, 705
row trigger, 448
rowset, 570,573
rsMeta, объект, 610
getColumnCount, метод, 610
getColumnName, метод, 610
rule, 476
run-time subsystem, 58
s
SAX, 539
scheme, 59
SCN, 453
scripting engine, 520
SCROLLLOCK, поведение курсора, 501
scrollable cursor, 397
second normal form, 176
SELECT, оператор, 307
selection, 292
self-describing, 39
semantic description, 125
semantic object, 119
semantic object attribute, 121
semantic object diagram, 121
semantic object model, 118
semantic object view, 126
SEQUEL, 304
sequence, 431
sequence set, 735
sequential list, 730
Алфавитный указатель
serializable, 389,396
SERIALIZABLE, уровень изоляции, 501
server, 647
Server, объект
CreateObject, метод, 576
service provider, 573
servlet, 607
SET, оператор, 324
shared lock, 388
shrinking phase, 389
siblings, 229
simple attribute, 120
simple network, 231
simple object, 138
Simple Object Access Protocol, 530
simple recovery, 505
single-tier driver, 564
single-value attribute, 137
slice, 663
snapshot, 654
snowflake schema, 667
SOAP, 530
SQL, 304
SQL Access Group, 563
SQL conformance level, 567
SQL Plus, 424
SQLServer, 58,467
SQL3, 304
SQL92, 304
star schema, 665
start, команда, 430
stateless, 517
statement level consistency, 394
statement of requirements, 72
Statement, объект, 610
executeQuery, метод, 610
executeUpdate, метод, 610
static cursor, 397
stored procedure, 285
stored procedures, 61
strong entity, 89
sub form, 63
subquery, 316
subtable, 719
subtype, 92
subtype object, 152
suffix.adp, 59
suffix.mdb, 59
SUM, функция, 312
Sun, 606
supertable, 719
supertype, 92
supertype object, 152
surrogate key, 66, 234
swizzling, 700
SysDate, функция, 436
System Change Number, 453
system data source, 568
system tables, 54
T
table, 167
table data provider, 572
target namespace, 543
TCP/IP, 516
teleprocessing, 646
teleprocessing system, 646
ternary relationship, 221
third normal form, 178
three-level architecture, 519
Tomcat, 524,619
top-down database development, 72
transaction, 41
transaction boundaries, 369
transaction isolation level, 395
transaction level consistency, 395
transactions, 382
TRANSACT-SQL, 487
transform-oriented language, 282
transient, 694
transitive dependence, 178
tree, 229
trigger, 285
tuning, 413
tuple, 166
twins, 229
two-phase commit, 655
two-phase locking, 389
two-way linked list, 733
type-valid XML document, 532
и
UML, 96
union, 289
union compatible, 289
union incompatible, 289
unique, 84
UNIQUE, ключевое слово, 435
Unix, 523
UNLOCK TABLES, оператор, 638
Update, метод, 595
UPDATE, оператор, 324
URI, 543
user data model, 73
user data source, 568
user group, 400
user model, 40
792 Алфавитный указатель
user view, 156
USER_SOURCE, таблица, 452
USER_TABLES, таблица, 452
USER_TR1GGERS, таблица, 452
user-defined data type, 475
v
Value, свойство, 578
variable length array, 705
version object, 154
vertical fragment, 651
vertical partition, 651
vertical security, 368
view, 126, 336
view instance, 336
w
W3C, 526
wait-for graph, 455
WAP, 518,548
weak entity, 89
web server, 520
web-сервер, 520
web-форма, 350
Wireless Application Protocol, 518, 548
Wireless Markup Language, 518, 548
WML, 518, 548
WMLScript, 548
World Wide Web Consortium, 526
Write, метод, 595
X
X/Open, 563
XML, 32,530
XML Namespaces, 542
XML Schema, 540
XML.ORG, 551
XML-документ
допустимый по типу, 532
недопустмый по типу, 532
XPath, 539
XQL, 540
XSL, 539
XSL-FO, 539
XSLT, 533
Y
Year, тип данных, 635
А
абстрактный тип данных, 714
абстракция, 570
автоматическая нумерация, 65
администратор данных, 679
администрирование базы данных, 379
администрирование данных, 379, 679
амперсанд, 585
аномалия
вставки, 172
модификации, 172
удаления, 172
апплет, 607
архитектура
клиент-сервер, 45
с совместным использованием
файлов, 45, 648
трехуровневая, 519
ассоциативный объект, 148, 257
атрибут, 83, 166, 275, 693
закрытый, 101
защищенный, 101
класса, 100
композитный, 83
многозначный, 83, 137
необъектный, 137
однозначный, 137
открытый, 101
семантического объекта
групповой, 120
объектный, 121
простои, 120
атрибуты
парные, 123
Б
база данных, 39, 52
безопасность, 398
интернет-технологии, 45
коллективная, 33
многопользовательская, 28
объектно-реляционная, 47
однопользовательская, 28
организационная, 30
персональная, 33
распределенная, 46
реляционная, АА
реляционная модель, 42
сетевая (Интернет), 33, 45
схема, 59
уровень детализации, 40
безопасность
вертикальная, 368
горизонтальная, 368
Алфавитный указатель 793
безопасность базы данных, 398
Бернерс-Ли, Тим, 517
бесстатусность, 517,524
библиотека классов, 694
бинарная связь, 85
бинарное дерево, 735
близнецы, 229
блокировка, 58
блокировочные подсказки, 502
брандмауэр, 517
братья, 229
браузер, 521
в
вертикальный раздел, 651
вертикальный фрагмент, 651
ветвь, 229
виртуальная машина Java, 607
владелец данных, 682
вложенная таблица, 705
вложенный запрос, 316
внешнее соединение, 294, 320
левое, 294
правое, 295
внешний ключ, 61,211
внутреннее соединение, 295
восстановление, 457
Всемирный Web-консорциум, 526
встроенные функции, 312
вторая нормальная форма, 176
выборка, 292
выборочная модель восстановления, 506
вызываемый оператор, 611
г
генератор отчетов
полосной, 68
гибридный объект, 144, 253
разновидности, 254
гиперкуб, 660
гиперссылка, 350
горизонтальный раздел, 651
горизонтальный фрагмент, 651
«горячие» клавиши, 69
готовый оператор, 611
график ожидания, 455
группа
вложенная, 247
группировка, 314
групповой атрибут, 120
групповой идентификатор, 124
Д
данные
администрирование, 679
вставка, 323
дублирование, 36
избыточные, 55
каталог, 39
модификация, 324
неструктурированные, 32
пользователя, 52
словарь, 39
структурированные, 32
удаление, 324
целостность, 36
двусвязный список, 733
двухфазная фиксация, 655
декартово произведение, 290
деловой регламент, 60
документирование, 95
дерево, 229
бинарное, 735
деструктор, 694
детерминант, 168
диаграмма
объектная, 121
диаграмма структуры данных, 215
диаграмма «сущность—связь», 86
динамический курсор, 398
диспетчер драйвера, 564
дифференциальная резервная копия, 504
документ
XML
допустимый но типу, 532
недопустимый по типу, 532
домен, 60, 125. 184, 275, 357
семантическое описание, 125
уникальный, 60
физическое описание, 125
формула, 137
доменно-ключевая нормальная форма, 184
драйвер, 564
JDBC, 607
многоуровневый, 565
одноуровневый, 564
дублирование данных, 36
Е
естественное соединение, 293
ж
журнал, 409
794 Алфавитный указатель
3
завершающий триггер, 448
зависимость
многозначная, 180
транзитивная, 178
заголовок
отчета, 68
страницы, 68
закрытая сеть, 516
закрытый атрибут, 101
замещающий триггер, 448
запись, 167
зависшая, 362
запрос, 66
вложенный, 316
из формы, 67, 282
по образцу, 66, 282
защищенный атрибут, 101
и
иерархия, 229
идентификатор, 84
групповой, 124
композитный, 84
неуникальный, 84
семантического объекта, 124
строки, 718
уникальный, 84
идентификационно-зависимая сущность, 89
избыточные данные, 55
изменяемый объект, 721
измерение, 662
инвертированный список, 734
индекс, 40, 55, 276. 435, 485, 734
кластеризованный, 486
некластеризоваиный, 486
индексный набор, 735
инкапсулированная структура, 693
Интернет, 516
интерфейс, 572
объекта, 693
интрасеть, 517
информационная лавка, 677
информационное хранилище, 669
исключения
обработка, 614
источник данных, 563, 567
пользовательский, 568
системный, 568
файловый, 568
к
Кант, Иммануил, 111
кардинальное число
максимальное, 86, 122
кардинальность, 122
максимальная, 86
минимальная, §7
карта, 548
каскадное удаление, 344
каскадные таблицы стилей, 528
каталог данных, 39
класс, 571
объектный, 571
связей, 84
семантического объекта, 120
сущностей, 82
клиент, 647
клиент-серверная архитектура баз данных, 45
клиент-серверная система, 647
ключ, 169, 184, 275
внешний, 61, 211
логический, 276
первичный, 179
суррогатный, 66, 234
физический, 276
ключевой курсор, 398
ключ-кандидат, 179
Кодд, Э. Ф., 42, 166
коллекция, 571
колода, 548
кольцевой список, 733
кольцо, 733
команда, 575
композитный атрибут, 83
композитный объект, 138, 246
конструктор, 694
контрольное ограничение, 436
контрольные файлы, 458
конфликт
распределенных обновлений, 654
корень, 229
кортеж, 166, 275
куб, 660
кубОЬАР, 660
курсор
динамический, 398
ключевой, 398
последовательный, 397
статический, 397
л
логика приложения, 370
логический ключ, 276
локальная сеть, 28, 44
Алфавитный указатель 795
М
максимальная кардинальность, 86
максимальное кардинальное число, 86
массив переменной длины, 705
мастер
форм, 63
материализация, 331
межпроцессовая, 331
материализованное представление, 654
межпроцессовая материализация, 331
меню, 69
мера, 662
мертвые транзакции, 459
метаданные, 39, 54
приложений, 40, 57
метка транзакции, 503
метод, 571, 693
микробраузер, 548
микрокомпьютеры, 43
минимальная кардинальность, 87
многозначная зависимость, 180
многозначный атрибут, 83, 137
мпогопозиционный переключатель, 349
многоуровневый драйвер, 565
моделирование данных, 73
модель
данных пользователя, 73
пользовательская, 40
реляционная, 166
требовании к данным, 76
модель «сущность—связь», 82
модель восстановления, 505
выборочная, 506
полная, 506
простая, 505
моментальный снимок, 654
мультиплексирование, 458
н
набор
записей, 338, 570
индексный, 735
последовательный, 735
строк, 570, 573
надтаблица, 719
надтип, 92
наследование, 94, 694
настройка по адресам, 700
независимость программ от данных, 38
неизменяемый объект, 721
необъектный атрибут, 137
непустой столбец, 436
несовместимость но объединению, 289
несогласованная резервная копия, 459
нормализация, 43, 52, 166, 207
нормальная форма, 175
вторая, 176
доменно-ключевая, 184
первая, 176
пятая, 183
третья, 178
четвертая, 183
нормальная форма Бойса-Кодда, 180
нормальные формы, 166
о
обработка исключений, 614
обратный вызов, 698
объединение, 289
объект
ассоциативный, 148, 257
вида архетип/версия, 154, 261
вида родитель/подтип, 151, 258
временный, 694
гибридный, 144, 253
изменяемый, 721
композитный, 138, 246
надтипа, 152
неизменяемый, 721
ООП, 694
подразумеваемый, 355
подтипа, 152
постоянный, 694
простои, 138, 245
родительский, 152
семантический, 119,245
составной, 141, 249
объект-архетип, 154
объект-версия, 154
объектная модель документов, 528
объектная ссылка, 121
объектно-ориентированная СУБД, 692
объектно-ориентированное
программирование, 47, 693
объектно-реляционная СУБД, 692
объектные привилегии, 402
объектный идентификатор, 124
объектный класс, 571, 694
ограничение, 184
делового регламента, 366
домена, 357
кардинальности связи, 359
ссылочной целостности, 35Э, 479
ограничения
ссылочной целостности, 174
целостности по внешнему ключу, 174
796 Алфавитный указатель
однозначный атрибут, 137
одноуровневый драйвер, 564
ООП, 47,693
ООСУБД, 692
оперативная аналитическая обработка
данных, 660
оператор
вызываемый, 611
готовый, 611
ориентированность на запрос, 517
ось, 662
отдельный феномен, 120
открытая сеть, 516
открытый атрибут, 101
отношение, 52, 166, 274
пересечения, 218, 252
плохо структурированное, 52
хорошо структурированное, 52
отчет, 25,68,331,352
п
параметр, 575
параметрическое разбиение, 672
парные атрибуты, 123
первая нормальная форма, 176
первичиыН ключ, 179
переключатель, 349
многопозицнонпый, 349
переменная-курсор, 442
пересечение, 289
перехват события, 71
план обслуживания, 280
плоский файл, 729
поведение курсора, 501
оптимистическая блокировка, 501
пессимистическая блокировка, 501
только чтение, 501
подразумеваемый объект, 355
подсистема
обработки, 58
средств проектирования, 57
иодтаблица, 719
подтип, 92
поле, 167,571,575
подъязык данных, 304
полиморфизм, 694
полная модель восстановления, 506
полная резервная копия, 504
полоса, 68
заголовков, 68
колонтитулов, 68
содержимого, 68
полосной генератор отчетов, 68
пользовательская модель, 40
пользовательский источник данных, 568
пользовательский тип данных, 475
пользовательское представление, 156
помеченное пространство имен, 543
порт
80, 619
8080, 619
последовательность, 431
последовательный курсор, 397
последовательный набор, 735
последовательны!'! список, 730
поставщик
данных, 572
услуг, 573
поставщик данных, 571
поставщик табличных данных, 572
потомок, 214,229
потребитель данных, 571
права и обязанности по обработке, 398
правило, 476
предваряющий триггер, 448
представление, 126, 336, 482
в SQL, 437
материализованное, 654
обновляемое, 484
семантического объекта, 126
представление соединения, 438
привилегии, 457
объектные, 402
системные, 402
привязка поля формы к столбцу, 63
прикладная программа, 25, 70
программа
прикладная, 25, 70
проектирование, 291, 307
проекция, 292
произведение, 290
простая модель восстановления, 505
простая сеть, 231
простой атрибут, 120
простой объект, 138, 245
пространства имен XML, 542
пространство имен, 540
по умолчанию, 543
помеченное, 543
целевое, 543
прототип, 72
процессор
форм, 58
пустое значение, 238, 350
пустой столбец, 436
пятая нормальная форма, 183
Алфавитный указатель 797
Р
раздел
вертикальный, 651
горизонтальный, 651
смешанный, 651
разность, 289
разработка базы данных
сверху вниз, 72
снизу вверх, 73
рамки транзакции, 369
раскрывающийся список, 348
распорядитель данных, 682
распределенная система, 651
реализация, 572, 693
резервная копня
дифференциальная, 504
несогласованная, 459
полная, 504
согласованная, 459
резервное копирование, 457
резервное копирование и восстановление, 58
рекурсивная связь, 87, 219
реляционная алгебра, 281
реляционная база данных, 44
реляционная модель, 166
реляционная модель базы данных, 42
реляционная схема, 275
реляционное исчисление, 282
репликация, 508
родитель, 214, 229
родительский объект, 152
роль, 401, 457
С
самодокументированность, 39
сбой
носителя, 458
приложения, 458
экземпляра, 458
свойство, 83, 571
связный список, 731
связь, 84, 479
«многие ко многим», 86, 194, 252
«многие к одному», 193, 250
«один к одному», 85, 249
«подозрительная», 213
«один ко многим», 59, 85, 250
бинарная, 85
обладания, 86
рекурсивная, 87, 219
тернарная, 221
типа «ИМЕЕТ», 86
сегмент отката, 453
семантическая объектная диаграмма, 121
семантическая объектная модель, 118, 245
семантический объект, 119,245
представление, 126
семантический объектный атрибут, 121
семантическое описание домена, 125
сервер, 647
сервлет, 607, 608
сервлет^уа, 524
сернализуемость, 389, 396
сеть, 516
закрытая, 516
локальная, 28, АА
открытая, 516
простая, 231
сложная, 231
сильная сущность, 89
синоним, 450
синтаксический анализ, 539
система
обработки
базы данных, 37
обработки файлов, 35
распределенная, 651
распределенных баз данных, 651
удаленной обработки, 646
управления базами данных, 25, 44
системные привилегии, 402
системные таблицы, 54
системный источник данных, 568
слабая сущность, 89
словарь данных, 39
словарь метаданных, 452
сложная сеть, 231
слой, 663
«смертельное объятие», 389
смешанный раздел, 651
снимок
моментальный, 654
совместимость по объединению, 289
согласованная резервная колия, 459
соединение, 292, 575
внешнее, 294, 320
левое, 294
правое, 295
внутреннее, 295
естественное, 293
эквивалентное, 293
сортировка, 311
составной объект, 141,249
список
двусвязный, 733
инвертированный, 734
кольцевой, 733
798 Алфавитный указатель
список (продолжение)
материалов, 232
полей, 63
последовательный, 730
связный, 731
ссылка
объектная, 121
ссылочная целостность
ограничения, 174
стандарты, 526
статический курсор, 397
степень связи, 84
столбец, 167
непустой, 436
пустой, 436
столбцовый объект, 705
строка, 167
строчный триггер, 448
структура данных
диаграмма, 215
СУБД, 25,52,57
объектно-ориентированная, 47, 692
субформа, 63
суррогатный ключ, 66, 234
сущность, 82
идентификационно-зависимая, 89
сильная, 89
слабая, 89
«сущность—связь»
диаграмма, 86
модель данных, 82
схема
реляционная, 275
схема базы данных, 59
схема «звезда», 665
схема «снежинка», 667
сценарный интерпретатор, 520
т
таблица, 167
таблицы
системные, 54
табличный формат, 63
тернарная связь, 221
техническое задание, 72
тип данных
абстрактный, 714
транзакции
мертвые, 459
транзакция, 41
рамки, 369
устойчивая, 394
транзитивная зависимость, 178
третья нормальная форма, 178
трехуровневая архитектура, 519
триггер, 285, 495
AFTER, 448
BEFORE, 448
INSTEAD OF, 448
завершающий, 448
замещающий, 448
предваряющий, 448
строчный, 448
у
удаленная обработка, 646
узел, 229
уникальный идентификатор ресурсов, 543
управление транзакциями, 58
уровень, 663
уровень изоляции
«завершенное чтение», 396, 455, 500
«незавершенное чтение», 395, 500
«сериализуемость», 396, 455, 501
«только чтение», 454, 456
воспроизводимое чтение, 396, 501
уровень изоляции транзакции, 500
уровень соответствия
ODBC 565
SQL, 567
Ф
Фагин, Р., 175
файл, 167
плоский, 729
файловый источник данных, 568
файлы данных, 457
файлы отката, 458
архивные, 458
онлайновые, 458
оффлайновые, 458
текущие, 458
физический ключ, 276
физическое описание домена, 125
фиксация
двухфазная, 655
флажок, 350
форма, 25,283,331,345
ввода данных
в браузере, 63
форма для ввода ланпых, 63
форматирование, 331
формула, 137
формы
нормальные, 166
Алфавитный указатель 799
фрагмент, 362
вертикальный, 651
горизонтальный, 651
функциональная зависимость, 168
X
хранимая процедура, 284
хранимые процедуры, 61
Ц
целевое пространство имен, 543
целостность данных, 36
ч
Чей, Питер, 82
четвертая нормальная форма, 183
число изменении и системе, 453
член, 663
чтение
воспроизводимое, 396
незавершенное, 395
завершенное, 396
э
ЭВМ 45
эквивалентное соединение, 293
экземпляр
объекта
ООП, 694
представления, 336
связи, 84
семантического объекта, 120
сущности, 83
экстент, 723
элементы управления ActiveX, 522
Я
ядро СУБД, 58
для Access 2002, 58
язык
доступа к данным, 304
запросов, 284
запросов и обновлений, 284
манипулирования данными, 281
ориентированный на преобразование, 282
разметки, 526
язык определения данных, 277