/





















































































































































































































































































































































































Автор: Григорьев В.Л.
Теги: компьютерные технологии математика программирование электроника электротехника микропроцессоры
ISBN: 5-900676-02-1
Год: 1993




Текст
В.Л. Григорьев
Микропроцессор i486
Архитектура
и программирование
(в 4-х книгах)
КНИГА 2
КНИГА 3
КНИГА 4
Москва 1993
Совместное издание
В.Л. Григорьев
Микропроцессор i486. Архитектура и npoiраммирование. (в 4-х
книгах). Кинга 2. Аппаратная архиickiура. Книга 3. Устройство с
плавающей гонкой Книга 4. Справочник ио cncicxtc команд.— М.,
ГРАНАЛ, 1993.- с. 382, ил. 54
ISBN 5-900676-02-1
В новых кишах извссиною авюра описаны впущенная архи iскiура
процессора i4<So. внешняя намян». шипа процессора, циклы шины,
с 1111 i.l 11>н ыс Шинн процессора, opiaim зацня памяш н ввода-вы вода на шине,
передача данных, управление шиной, управление клн-памянио. управление
ошибками с нлаваюшеп ючкои. приведены синииы и временные дшп раммы
ею paooibi. подрооно рассмощена впущенная ор|апизапня. про1раммпая
модель (ины oopauai ывасмых данных н снсчема команд ycipoiiciBa с
нлаваюшеп ючкои. ocooeiniocin спсчемы команд п справочные сведения по
командам процессора t4<Sn
Kiihih рассчн ।апы па снсцналнсчов
В.Л. Григорьев
Микропроцессор i486. Архитектура и программирование
(в 4-х книгах). Книга 2. Аппаратная архитектура. Книга 3.
Устройство с плавающей точкой. Книга 4. Справочник по
системе команд.
Главный редактор Андрей Артамошкин
Издание подготовлено совместно с ТОО «БИНОМ»
ISBN 5-900676-02-1
© IOO «I РЛНАЛ» 1993 I
Оглавление
млЗйллй. Si Al —... JJX .rj_. a.»- . а» j-S^. Х/л ij
* f, ~ t *.• - • t i -X •» •** I > ** — • * * * * £ -J " »«’•«“ *> *\ * *• <|
Глава!. Внутренняя архитектура........................... 9
1.1. Обзор новых средств и применений
процессора i486.................................. 9
1.2. Внутренняя архитектура.................... 17
1.3. Производительность........................ 33
1.3.1. Влияние внутренней кэш-памяти....... 35
1.3.2. Внутренние буферы записи............ 37
1.4. Внешняя память............................ 38
1.4.1. Особенности проектирования
динамических ЗУПВ........................... 41
1.5. Производительность операций с плавающей
точкой........................................ 42
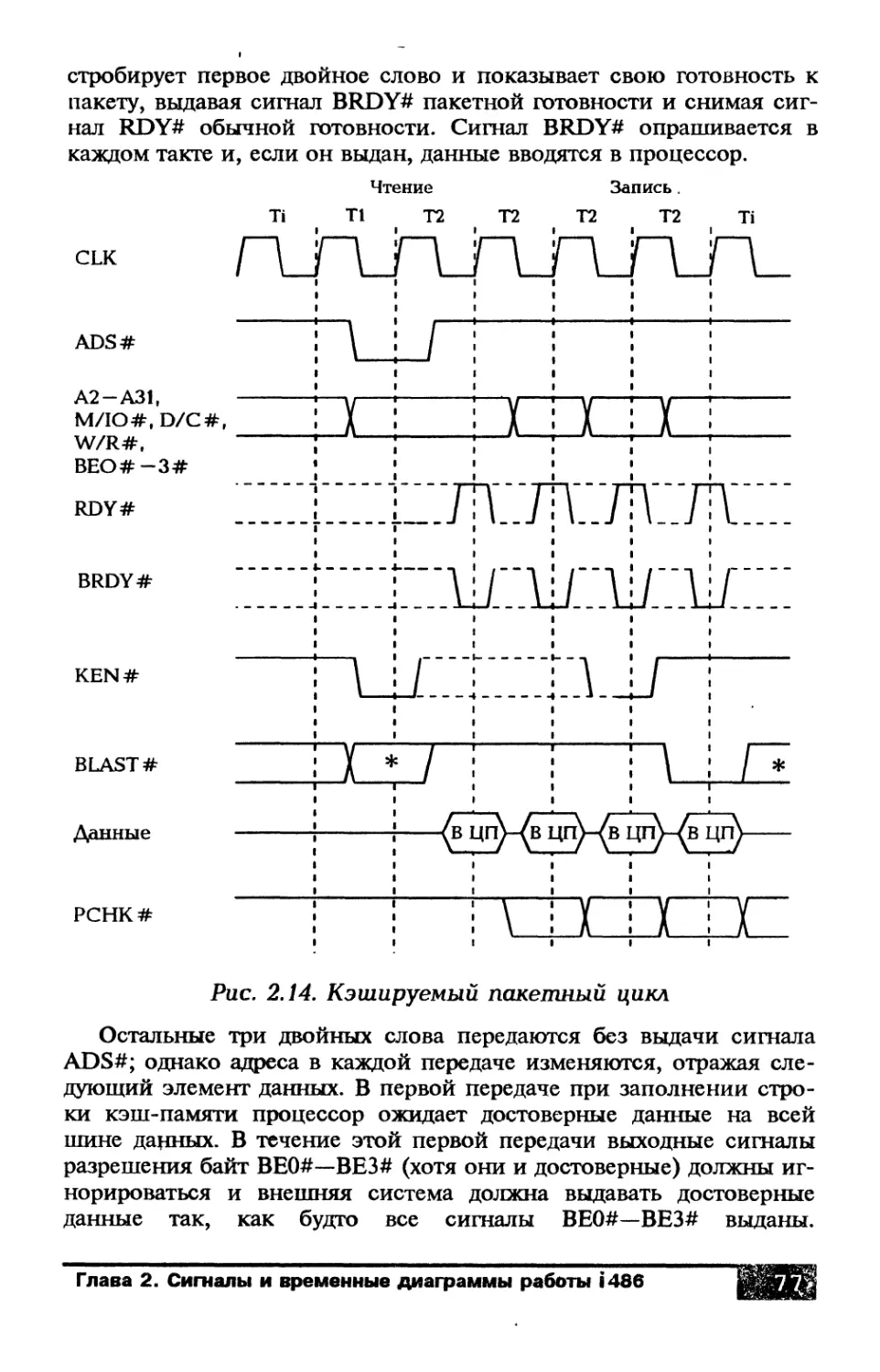
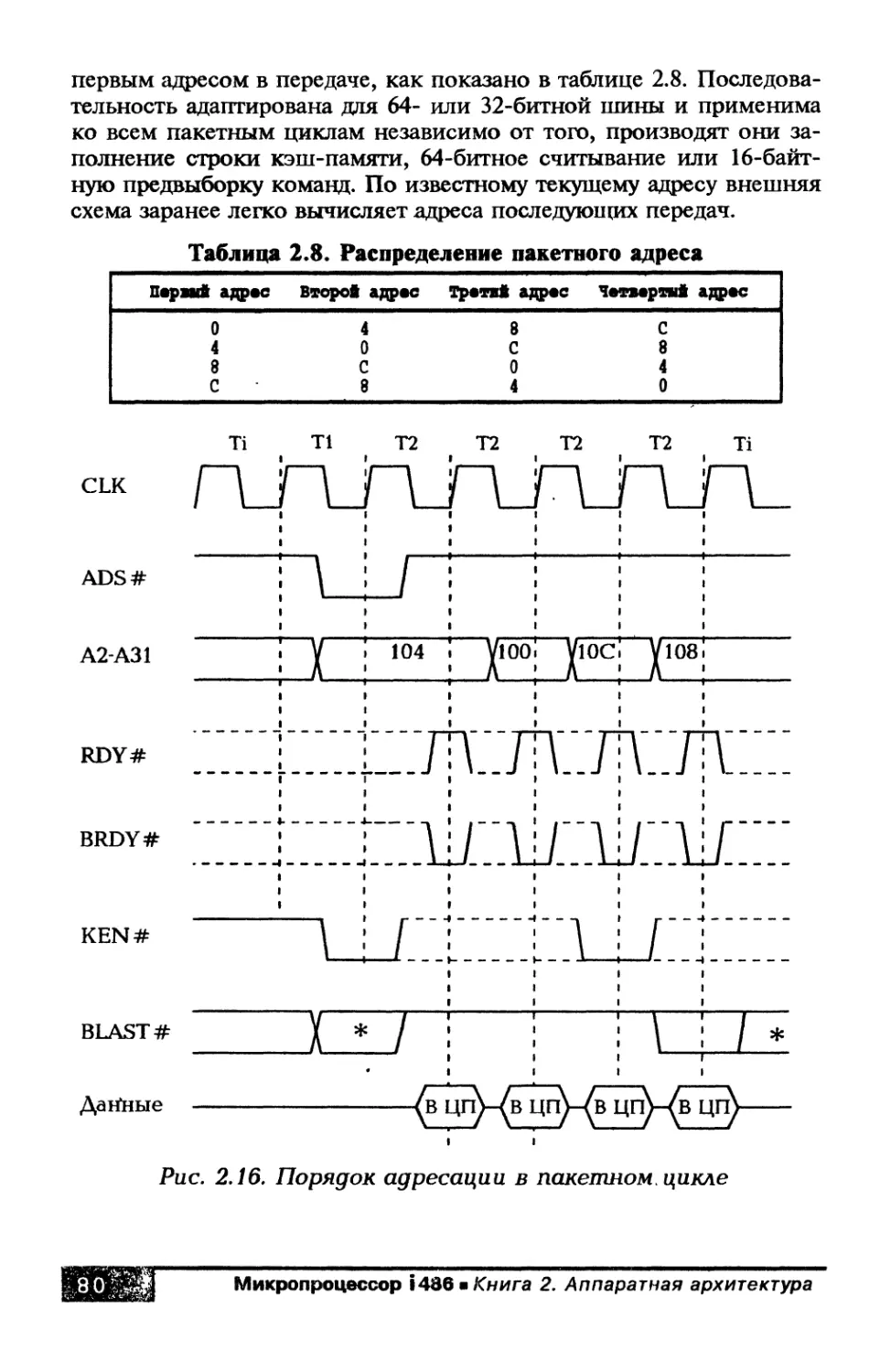
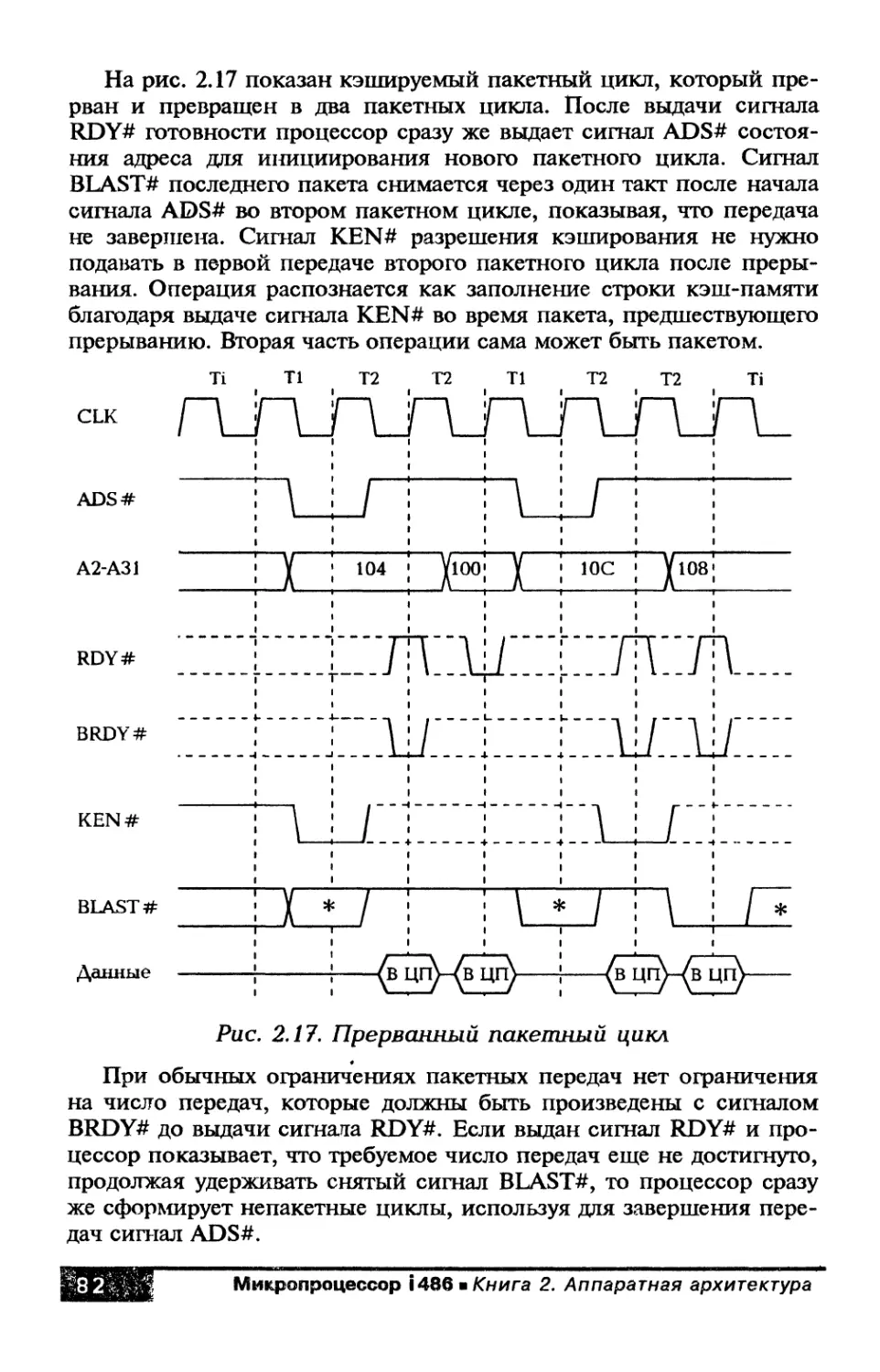
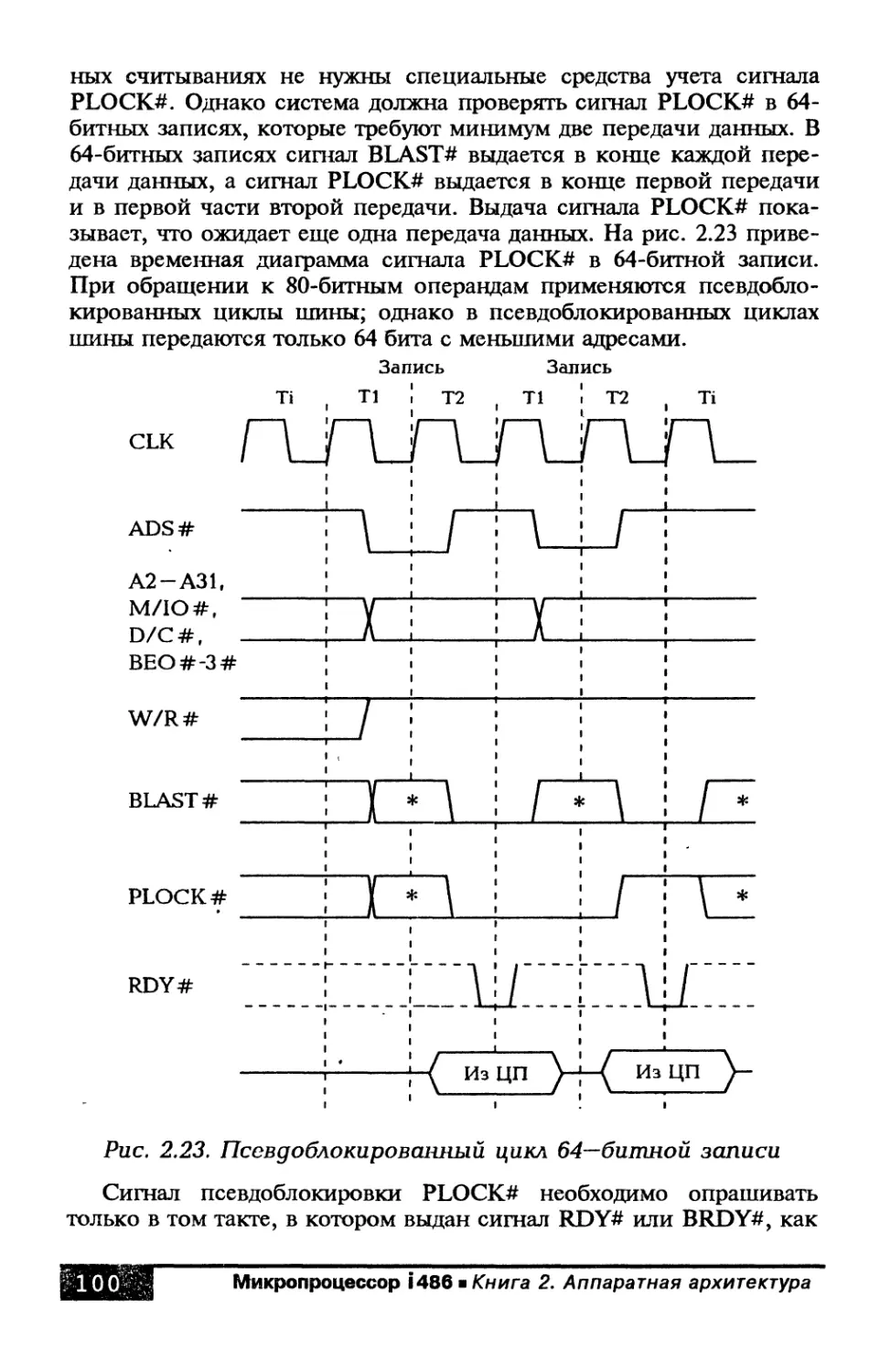
Глава 2. Сигналы и временные диаграммы
работы процессора i486................................ 43
2.1. Шина процессора........................... 43
2.2. Циклы шины................................ 44
2.3. Сигнальные линии процессора............... 46
2.4. Временная диаграмма и формирование
синхронизации................................... 56
2.5. Организация памяти и ввода-вывода на шине.. 59
2.6. Передачи данных......................... 65
2.6.1. Непакетные циклы.................... 67
2.6.2. Пакетные циклы...................... 73
2.6.3. Размер шины......................... 83
Оглавлений
2.7. Управление шиной........................ 88
2.7.1. Сброс............................. 88
2.7.2. Прерывания.......................... 89
2.7.3. Специальные циклы шины.............. 93
2.7.4. Захват шины......................... 94
2.7.5. Блокировка шины..................... 96
2.7.6. Псевдоблокировка шины............... 99
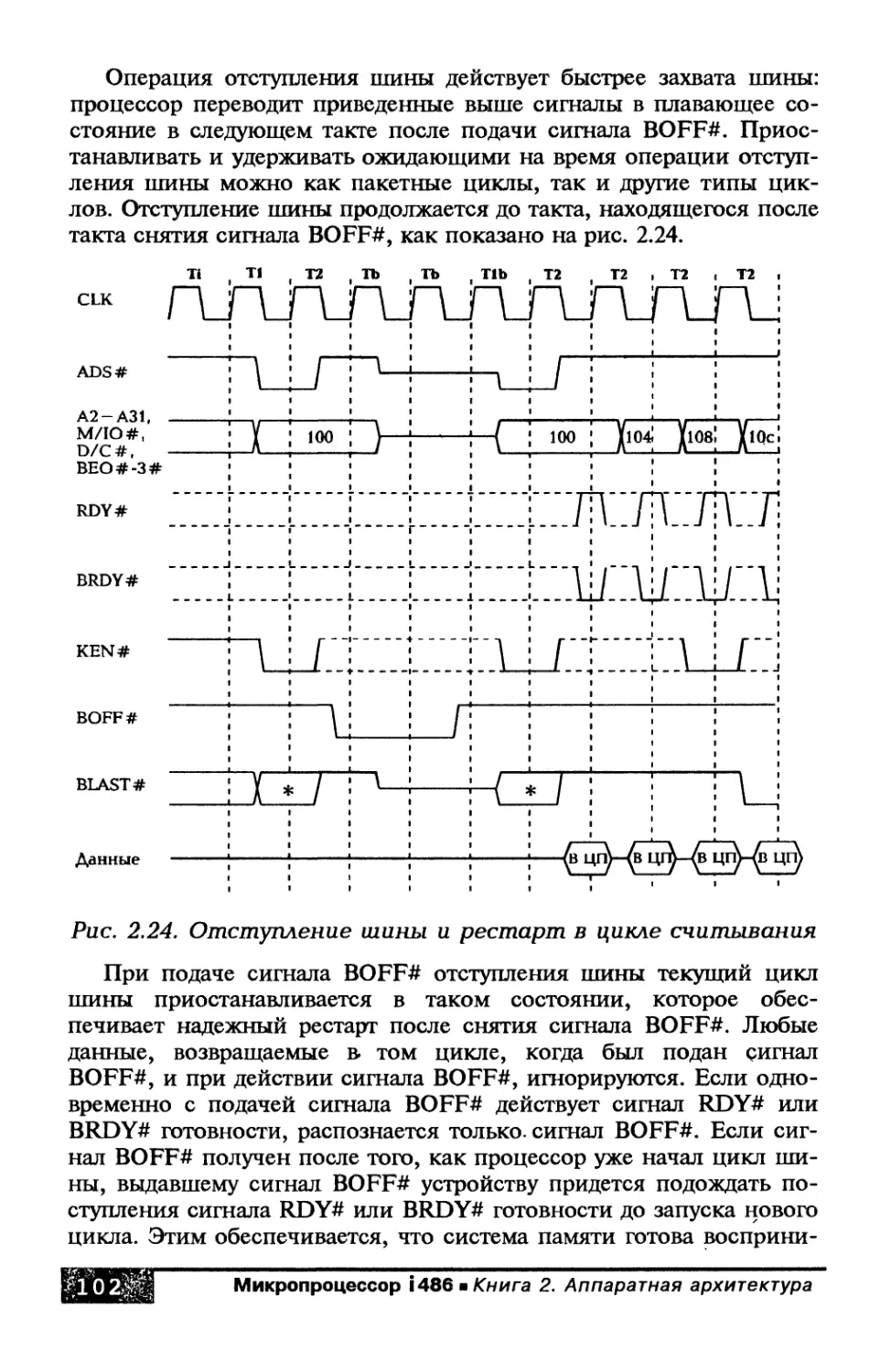
2.7.7. Отступление шины....................101
2.8. Управление кэш-памятью.....................103
2.8.1. Управление кэш-памятью на уровне
страниц......................................104
2.8.2. Недостоверность внутренней кэш-
памяти......................................105
2.8.3. Очистка внутренней кэш-памяти.......107
2.8.4. Цикл очистки кэш-памяти.............107
2.8.5. Цикл обратной записи и очистки кэш-
памяти ....................................107
2.9. Управление ошибками с плавающей точкой....108
Литература ..............................................110
Предисловие..............................................113
Глава 1. Архитектура устройства с плавающей точкой.......121
1.1. Сопроцессорные конфигурации..............121
1.2. Внутренняя организация устройства FPU....123
1.3. Программная модель устройства FPU........125
1.4. Форматы численных данных.................132
1.5. Режимы работы и состояние................141
1.6. Система команд...........................148
1.6.1. Особенности задания команд.........149
1.6.2. Машинные форматы команд............150
1.6.3. Особенности программирования на
языке ассемблера..........................151
1.6.4. Команды передач данных.............153
1.6.5. Арифметические команды.............157
1.6.6. Команды сравнения..................163
1.6.7. Команды трансцендентных функций.....167
1.6.8. Команды управления.................170
1.7. Внешний интерфейс устройства FPU.........176
Микропроцессор i486. Архитектура и программирование
Глава 2. Специальные вычислительные ситуации...........179
2.1. Специальные численные значения............180
2.1.1. Денормализованные
вещественные числа.........................180
2.1.2. Нули................................184
2.1.3. Бесконечность..................... 186
2.1.4. Нечисла........................... 188
2.1.5. Неопределенность....................190
2.1.6. Кодирование типов данных............191
2.1.7. Неподдерживаемые форматы............193
2.2. Численные особые случаи...................195
2.2.1. Обработка численных особых случаев...195
2.2.2. Недействительная операция...........197
2.2.3. Деление на нуль.....................199
2.2.4. Денормализованный операнд...........199
2.2.5. Численные переполнение
и антипереполнение.........................200
2.2.6. Неточный результат (точность).......203
2.2.7. Приоритет особых случаев............204
Глава 3. Вопросы системной организации и совместимости..205
3.1. Особенности архитектуры...................205
3.2. Инициализация.............................206
3.3. Эмуляция..................................208
3.4. Обработка численных особых случаев........208
3.5. Совместимость
с сопроцессорами 8087, 80287 и 80387...........210
3.5.1. Отличия от систем 80386/80387.......211
3.5.2. Отличия от систем 80286/80287...... 213
3.5.3. Отличия от систем 8086/8087.........219
Глава 4. Особенности программирования устройства FPU...221
4.1. Инструментальные
средства программирования......................221
4.1.1. Языки высокого уровня...............221
4.1.2. Ассемблер ASM386/486................224
4.1.3. Сравнительный
пример программирования....................227
4.2. Параллельная работа..................:....231
4.2.1. Управление параллельностью..........231
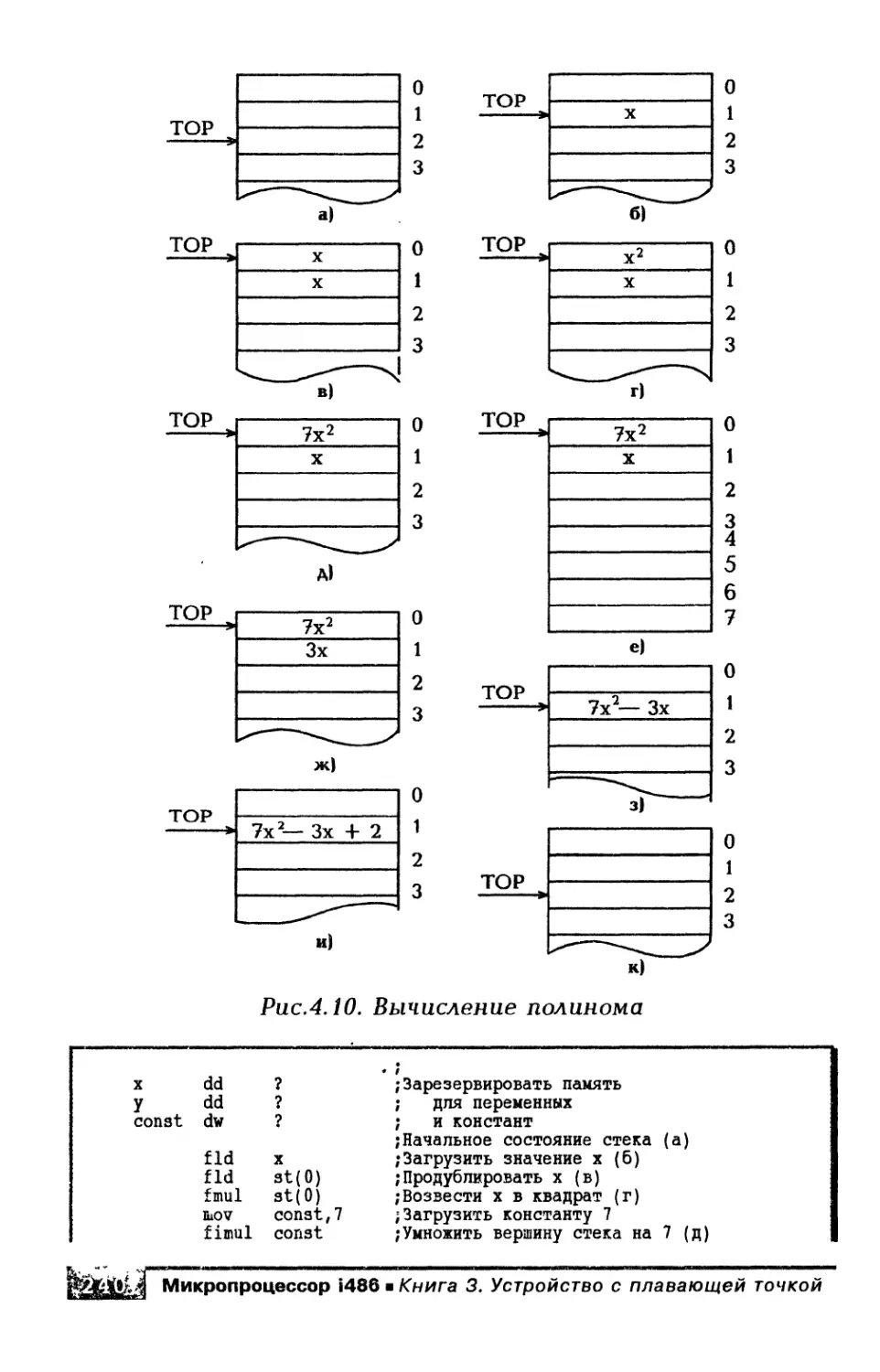
4.3. Примеры численного программирования........234
4.3.1. Пример условного перехода...........234
4.3.2. Примеры обработки особых случаев.....237
4.3.3. Примеры численных программ..........239
Литература........................................244
Оглавление
Глава 1. Особенности описания системы команд.............247
1.1. Атрибуты размера операнда и размера адреса..247
1.2. Формат команды..............................248
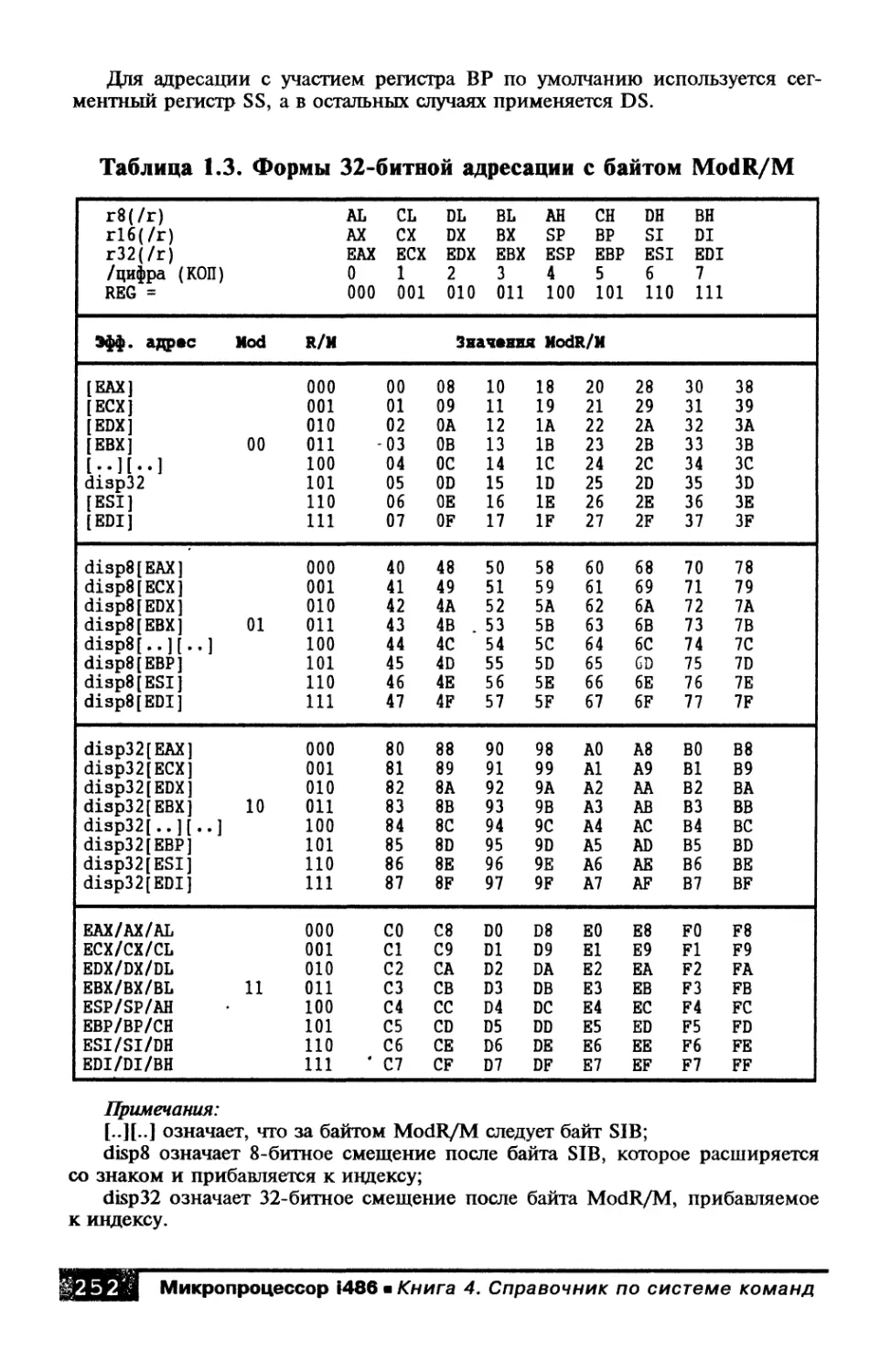
1.3. Байты ModR/M и SIB..........................250
1.4. Как знакомиться с системой команд...........254
Глава 2. Справочные сведения по командам процессора i486.264
Литература...............................................382
Zt _
I43G. Архитектура
АППАРАТНАЯ
АРХИТЕКТУРА
Микропроцессор
Внутренняя архитектура
1.1. Обзор новых средств и применений
процессора i486
Процессор i486 фирмы Intel представляет собой наиболее произ-
водительный процессор семейства 80x86. Он совместим вверх по
двоичному коду с предыдущими процессорами 8086/8088, 80186,
80286, 80386 (модели 386DX и 386SX) и привносит в персональные
компьютеры средства процессоров больших машин.
Среди наиболее важных внутренних устройств процессора i486
отметим наличие целочисленного операционного устройства, уст-
ройства с плавающей точкой, заменяющего собой отдельную мик-
росхему математического сопроцессора, устройства управления па-
мятью и кэш-памяти. Благодаря размещению устройств на одном
кристалле многие связывающие их сигналы стали внутренними, что
обеспечивает большую производительность процессора. Повыше-
ние уровня интеграции позволяет сократить размеры печатной пла-
ты, а это снижает стоимость и упрощает проектирование систем.
В зависимости от частоты синхронизации и особенностей конк-
ретного применения производительность процессора i486 в
2—4 раза выше производительности процессора 80386. В
процессоре i486 (как и в процессоре 80386) реализована сегментная
и страничная защита памяти.
Внутренняя конвейеризация команд сокращает время их выпол-
нения. Реализуя внутренние управление памятью и кэширование,
процессор i486 снижает требования к быстродействию памяти.
Шина процессора i486 значительно быстрее шины процессора
80386.
В ней применяется одночастотная синхронизация (1х) и под-
держиваются контроль по паритету (четности), пакетные циклы,
Глава 1. Внутренняя архитектура
кэшируемые циклы, циклы недостоверности кэш-памяти и 8/16-
битные шины данных. Применение синхронизации 1х упрощает
проектирование системы, сокращая в два раза частоту синхрониза-
ции для внешних устройств, уменьшает высокочастотное излучение
и упрощает генерирование сигналов синхронизации.
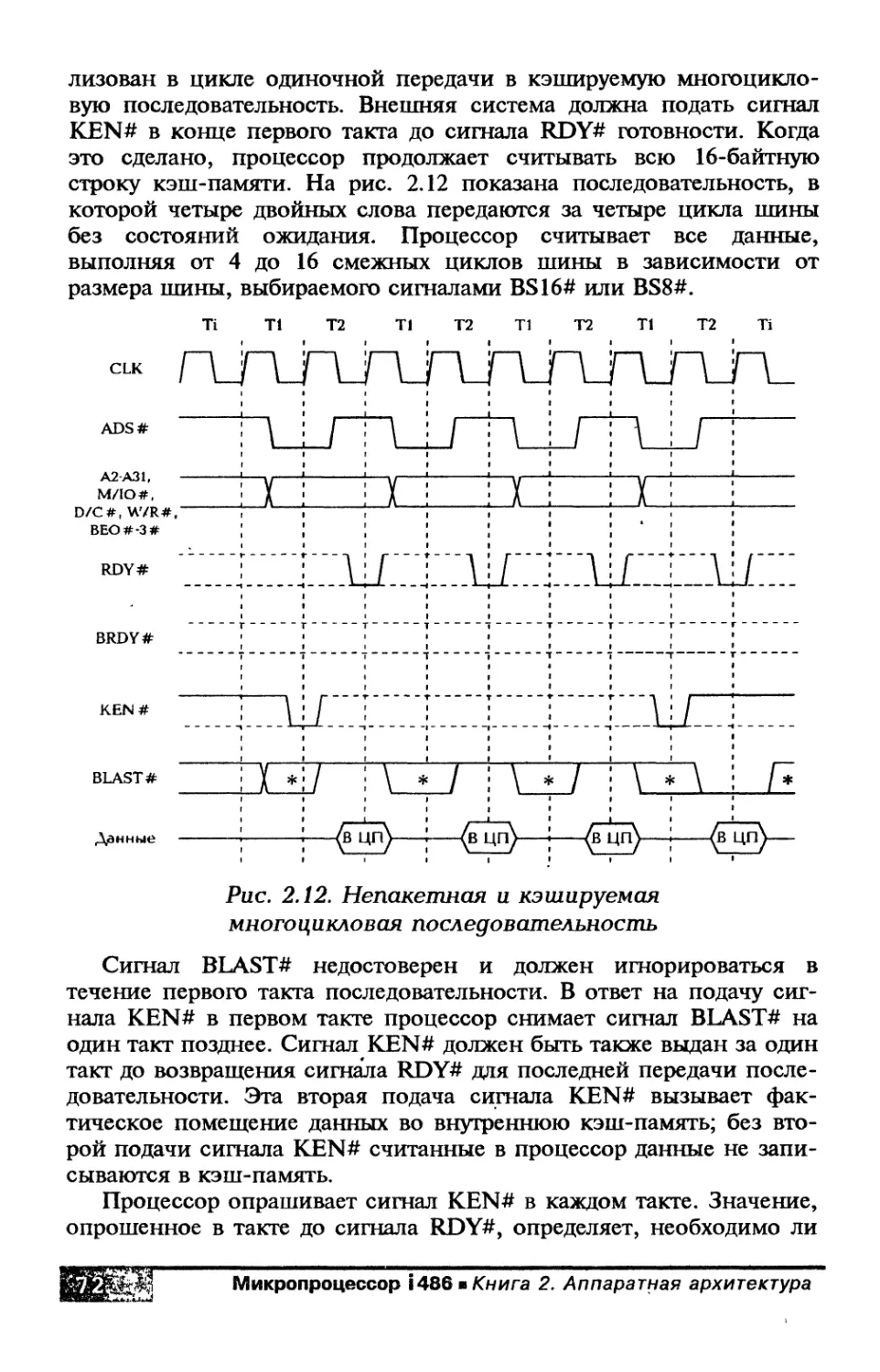
В процессоре i486 предусмотрены быстрые пакетные циклы для
таких операций считывания, которые требуют несколько циклов
шины. В пакетных циклах процессор передает 32-битное двойное
слово за один такт синхронизации (в процессоре 80386 на одну пе-
редачу требуются минимум два такта). Чтобы в пакете память рабо-
тала без состояний ожидания, можно использовать внешнюю кэш-
память, банки памяти с расслоением или микросхемы дина-
мических ЗУПВ с адресацией статического столбца.
По сравнению с процессором 80386 команды выполняются за
меньшее число тактов, а многие команды выполняются всего за
один такт. Внутренняя кэш-память обеспечивает непрерывную ско-
рость в один запрос процессора на каждый такт. Для эффективного
переключения задач в многопользовательских и мультизадачных
системах реального времени процессор i486 (как и процессор 80386)
одной командой или прерыванием осуществляет полное пере-
ключение задачи.
Тестирование процессора поддерживается встроенным самокон-
тролем, причем результаты встроенного самоконтроля доступны во
внутреннем регистре. Предусмотрена проверка кэш-памяти и ассо-
циативного буфера преобразования на уровне языка ассемблера.
ВОЗМОЖНОСТИ ПРОЦЕССОРА. Среди наиболее важных от-
метим следующие возможности процессора i486:
Совместимость по двоичному коду с процессорами 8086/8088,
80186, 80286, 80386.
Выполнение полного набора арифметических и логических
операций над 8/16/32-битными данными с использованием полно-
разрядного арифметико-логического устройства и восьми регистров
общего назначения.
Прямая адресация физической памяти 4 Гбайт при наличии
внешних 32-битных шин адреса и данных.
Поддержка внутренним устройством с плавающей точкой
32/64/80-битных форматов чисел, удовлетворяющих стандарту
IEEE-754 на операции с*плавающей точкой. Это устройство совме-
стимо по двоичному коду с сопроцессорами 8087, 80287, 80387.
Целостность памяти поддерживают механизмы сегментного и
страничного управления адресами и защиты в составе внутреннего
устройства управления памятью. Это требуется в мультизадачной
среде и при организации виртуальной памяти.
Микропроцессор i486 и Книга 2. Аппаратная архитектура
Внутренняя кэш-память со сквозной записью может хранить
8 Кбайт данных и команд. При попадании кэш-память действует с
такой же скоростью, как и регистры процессора.
В процессоре предусмотрено управление обратной записью и
очисткой внешней кэш-памяти, поэтому он может обеспечить со-
гласованность содержимого кэш-памяти в мультипроцессорной
среде.
Совмещение выборки, декодирования, выполнения команды и
преобразование адреса, т.е. конвейеризация команд, обеспечивает
выполнение многих команд за один такт.
Пакетные циклы позволяют считывать из памяти двойное слово
на каждый такт. Благодаря этому можно очень быстро заполнять
внутреннюю кэш-память и буфер опережающей выборки
(предвыборки) команд.
С помощью внутренних буферов записи процессор после записи
продолжает внутренние операции, не ожидая окончания операции
записи на шине.
Средство отступления (bus backoff) шины позволяет процессору
i486 передать управление шиной другому ведущему шины, а когда
шина становится доступной, осуществить рестарт своего цикла
шины.
Возможность рестарта команды допускает продолжение Про-
граммы после особого случая, вызванного безуспешной попыткой
обращения к памяти. Такая возможность имеет важное значение
для организации виртуальной памяти с заменой страниц по требо-
ванию.
Внешние контроллеры могут динамически изменять эффек-
тивную ширину шины данных (8, 16 или 32 бита).
РЕЖИМЫ РАБОТЫ И СОВМЕСТИМОСТЬ. Процессор i486
может выполнять программы в нескольких режимах, которые обес-
печивают совместимость по объектному коду с программами, разра-
ботанными для процессоров 8086, 80286 и 80386. Программно уста-
навливаются такие режимы работы:
Реальный режим (R-режим). После сброса или включения
питания процессор работает в R-режиме. Этот режим опирается на
базовую архитектуру процессора 8086, но допускает обращение к
32-битным регистрам. Механизм образования адреса, максималь-
ный размер памяти 1 Мбайт и обработка прерываний идентичны
И~режиму4 процессора 80286. Доступны почти все команды
процессора i486, но принимаемый по умолчанию размер операндов
составляет 16 бит; чтобы использовать 32-битные регистры и
режимы адресации, перед командами требуются префиксы замены.
Гжша 1. Внутренняя архитектура
Основное назначение R-режима состоит в том, чтобы подготовить
процессор к работе в защищенном режиме.
Защищенный режим (P-режим). Когда программы выполняются
в P-режиме, становятся доступными все возможности процессора
i486. В дополнение к сегментной защите допускается страничная
организация памяти. Линейное адресное пространство составляет
4 Гбайт и можно выполнять программы, рассчитанные на
виртуальную память 64 Тбайт. Программы для процессоров 8086,
80286 и 80386 можно выполнять с привлечением средств аппарат-
ной защиты процессора i486. В P-режиме применяется более слож-
ный механизм адресации, чем в R-режиме.
Режим виртуального 8086 (VM86- или V-режим). Этот режим,
являющийся подрежимом P-режима, допускает выполнение
программ процессора 8086 с привлечением механизмов сегментной
и страничной защиты Р-режима. V-режим предоставляет большую
гибкость для выполнения программ процессора 8086 по сравнению
с R-режимом. Работая в V-режиме, процессор i486 может выпол-
нять операционные системы и прикладные программы процессора
8086 одновременно с операционной системой и прикладными про-
граммами процессоров 80286 и 80386.
УПРАВЛЕНИЕ ПАМЯТЬЮ. Устройство управления памятью
поддерживает сегментную и страничную организацию памяти. Сег-
ментация обеспечивает несколько независимых защищенных ад-
ресных пространств. Такое средство защиты ограничивает те по-
вреждения, которые может вызвать ошибка в программе. Устрой-
ство сегментации отображает видимые программистам отдельные
адресные пространства на единое ^сегментированное адресное
пространство.
Страничная организация обеспечивает доступ к структурам дан-
ных, которые больше пространства физической памяти, путем хра-
нения данных частично в памяти и частично на диске. При этом
линейное адресное пространство разбивается на блоки по 4 Кбайт,
называемые страницами. Обычно программы одновременно ис-
пользуют небольшое число страниц, поэтому процессор со стра-
ничной памятью может моделировать большое адресное простран-
ство, используя относительно небольшое ЗУПВ и дисковую память.
ВНУТРЕННЯЯ КЭШ-ПАМЯТЬ. Прозрачная для программ
кэш-память 8 Кбайт хранит внутри процессора те команды и дан-
ные, к которым производились последние обращения. Если про-
цессору требуется считать данные, имеющиеся в кэш-памяти, она
предоставляет их и сравнительно медленного обращения к внешней
памяти производить не нужно. При этом повышается скорость пе-
редач и сокращается загрузка шины процессора. Кэш-память реа-
Микропроцессор i486 * Книга 2. Аппаратная архитектура
лизована по принципу сквозной записи: все записи в кэш-память
немедленно передаются и в основную память, которую представ-
ляет кэш-память (в кэш-памяти с обратной записью обновление
основной памяти производится отдельной операцией). Запись во
внутреннюю кэш-память производится только при попадании. Для
уменьшения влияния операций записи на производительность про-
цессор буферирует циклы записи; операция, которая записывает
данные в память, может закончиться до фактического производства
цикла записи на шине.
Для помещения новой информации во внутреннюю кэш-память
процессор осуществляет заполнение строки кэш-памяти. В этой
операции в строку кэш-памяти считываются четыре двойных слова,
т.е. 16 байт; это наименьшая единица хранения, которую можно
распределить в кэш-памяти. Большинство циклов считывания на
шине процессора возникают из-за промахов в кэш-памяти, которые
вызывают заполнения строк кэш-памяти.
Для систем с несколькими ведущими шины предусмотрены ме-
ханизмы обеспечения согласованности содержимого памяти и кэ-
шированных данных. Они защищают процессор i486 от считывания
неверных данных из внутренней или внешней кэш-памяти. Когда,
например, процессор i486 пытается считать из памяти операнд, ко-
торый хранится в кэш-памяти другого ведущего шины, этот другой
ведущий шины должен форсировать запись своих кэшированных
данных в память прежде, чем процессор может завершить свое
считывание из памяти. Такая операция требуется потому, что кэ-
шированные данные могут быть обновлены и, следовательно, от-
личаются от данных, хранимых в памяти.
Большинство систем памяти оптимизируют скорость обращения
для цикла считывания, так как в типичной системе большинство
обращений к памяти являются считываниями. Внутренняя кэш-па-
мять процессора i486 изменяет эту пропорцию. Большинство зап-
росов считывания возникает из-за промахов в кэш-памяти, поэтому
на внешней шине преобладают циклы записи.
УСТРОЙСТВО С ПЛАВАЮЩЕЙ ТОЧКОЙ. Внутреннее уст-
ройство с плавающей точкой осуществляет операции с плавающей
точкой над 32/64/80-битными числами, форматы которых опреде-
лены в стандарте IEEE-754. Архитектура этого устройства совмес-
тима по двоичному коду с сопроцессорами 808? и 80287 и полнос-
тью совместима с сопроцессором 80387.
Команды с плавающей точкой выполняются наиболее быстро,
когда они целиком находятся в процессоре, т.е. все операнды ока-
зываются во внутренних регистрах или кэш-памяти. Если же дан-
ные приходится считывать из внешних ячеек или записывать в них,
требуемое для этого время минимизируют пакетные передачи, а ме-
--'.v
н!3‘
Глава 1. Внутренняя архитектура
ханизм блокировки шины обеспечивает монополизацию шины на
все время передачи. Предусмотрены сигналы шины для контроля
ошибок в операциях с плавающей точкой и управления реакцией
процессора на такие ошибки.
КОхМПОНЕНТЫ СИСТЕМЫ. Фирма Intel предлагает не-
сколько микросхем, которые полностью совместимы с процессором
i486 и используются для проектирования высокопроизводительных
систем с минимальными усилиями и расходами. Для компонент,
которые не допускают прямого подключения к шине процессора
i486, применяются стандартные промышленные интерфейсы, на-
пример системная шина MULTIBUS II.
Среди компонент, которые обеспечивают прямой интерфейс С
шиной процессора i486, следует отметить однокристальный 32-бит-
ный сетевой сопроцессор 82596, предназначенный для управления
сетевыми данными и функциями физического слоя сети. Систем-
ные 32-битные периферийные микросхемы семейства 82320 обес-
печивают эффективный и дешевый интерфейс с шинами расшире-
ния Микроканала для систем PS/2, а микросхемы семейства 82350
предназначены для интерфейса с шинами расширения EISA. Для
построения внешней кэш-памяти емкостью 64К или 128К (с нара-
щиванием до 512 Кбайт), полностью совместимой с процессором
i486, выпускается модуль 485Turbocache Module. Наконец, в систе-
мах с процессором i486 можно применять разнообразные програм-
мируемые логические устройства.
СФЕРЫ ПРИМЕНЕНИЯ. Процессор i486 рассчитан на широ-
кий спектр однопроцессорных и мультипроцессорных систем.
Примером однопроцессорной системы может служить персональ-
ный компьютер, который обеспечивает высокую производитель-
ность благодаря встроенным операциям с плавающей точкой, уп-
равлению памятью и кэшированию. В более сложных системах
можно ввести несколько процессоров, которые обеспечивают на
уровне микросхем эквивалентные функции уровня плат. Такие раз-
работки обычно применяются в многопользовательских машинах,
научных и инженерных рабочих станциях. Типичная система, пред-
ставляющая собой нечто среднее между однопроцессорной систе-
мой и более сложной мультипроцессорной системой, представлена
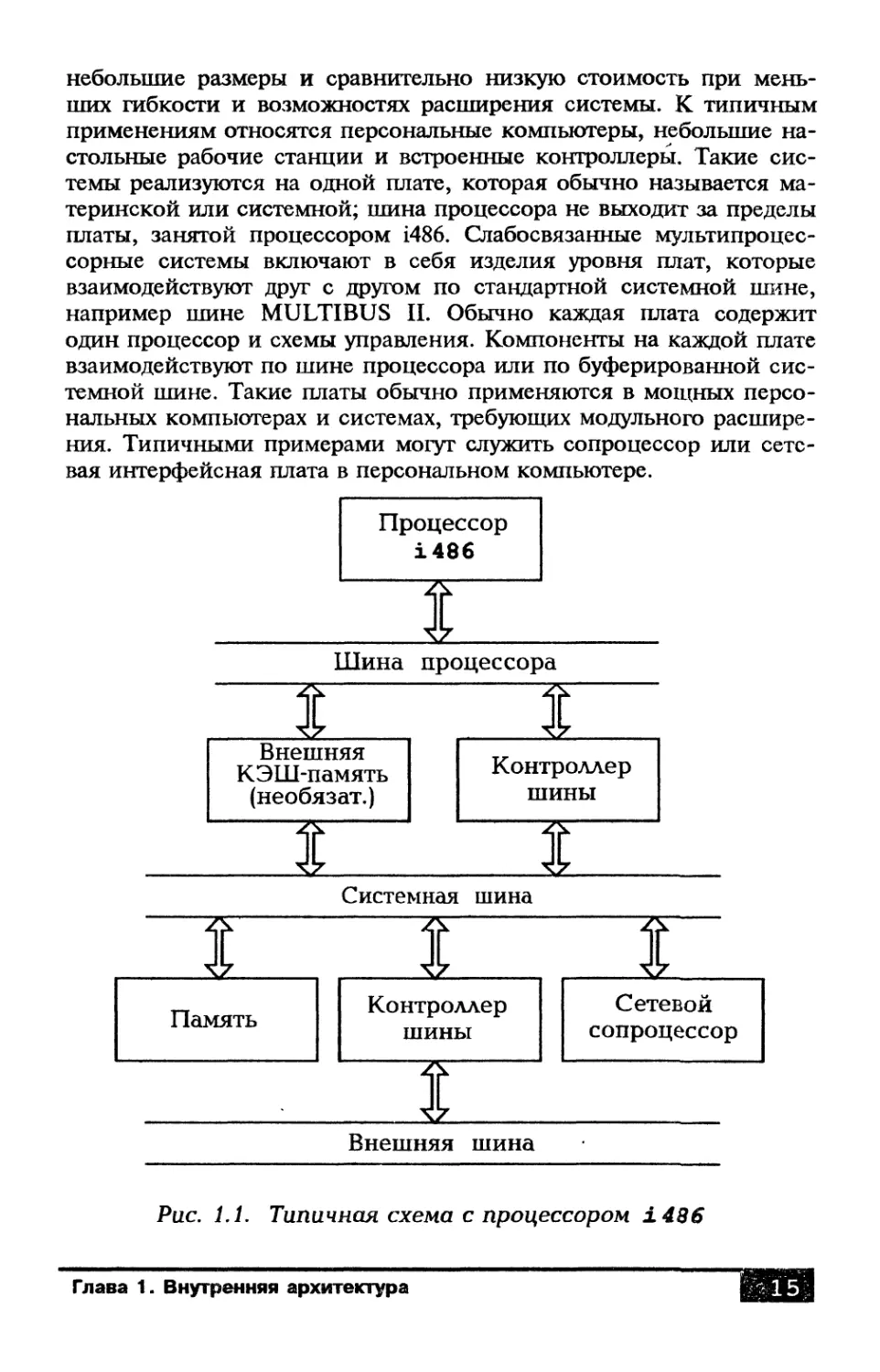
на рис. 1.1. В этой системе применяется один процессор i486 с
внешней кэш-памятью и сетевым сопроцессором 82596.
В однопроцессорных системах процессор управляет всеми пе-
риферийными ресурсами и интеллектуальными устройствами, а
также выполняет все программы. Процессор i486 реализует эти
функции более эффективно и для более широкого круга задач, чем
прежние процессоры. Однопроцессорные системы обеспечивают
Микропроцессор i486 и Книга 2. Аппаратная архитектура
i-'.e tC
небольшие размеры и сравнительно низкую стоимость при мень-
ших гибкости и возможностях расширения системы. К типичным
применениям относятся персональные компьютеры, небольшие на-
стольные рабочие станции и встроенные контроллеры. Такие сис-
темы реализуются на одной плате, которая обычно называется ма-
теринской или системной; шина процессора не выходит за пределы
платы, занятой процессором i486. Слабосвязанные мультипроцес-
сорные системы включают в себя изделия уровня плат, которые
взаимодействуют друг с другом по стандартной системной шине,
например шине MULTIBUS IL Обычно каждая плата содержит
один процессор и схемы управления. Компоненты на каждой плате
взаимодействуют по шине процессора или по буферированной сис-
темной шине. Такие платы обычно применяются в мощных персо-
нальных компьютерах и системах, требующих модульного расшире-
ния. Типичными примерами могут служить сопроцессор или сете-
вая интерфейсная плата в персональном компьютере.
Внешняя шина
Рис. 1.1. Типичная схема с процессором i486
Глава 1. Внутренняя архитектура
115
Внешняя кэш-память позволяет достичь максимально высокой
производительности системы. Особенно важную роль внешняя
кэш-память играет в сильносвязанных мультипроцессорных систе-
мах. В состав внешней кэш-памяти входят собственно микросхемы
памяти (обычно микросхемы быстрых статических ЗУПВ) и кон-
троллер. Подавляющее большинство систем с процессором i486 от-
носятся к следующим типам: персональные компьютеры, мини-
компьютеры и рабочие станции, а также встроенные контроллеры.
В обычной архитектуре персонального компьютера большинство
периферийных устройств размещается на отдельных съемных пла-
тах. Расширение обычно ограничено платами памяти и платами
ввода-вывода. Применяется стандартная архитектура ввода-вывода,
например архитектура Микроканала или EISA. Очень важную роль
играют стоимость и размеры системы. В такой среде применять
внешнюю кэш-память не обязательно, особенно если производи-
тельность системы не является критическим параметром.
Миникомпьютеры и рабочие станции можно реализовать по
слабосвязанной архитектуре. Обычно здесь допускается расширение
числа центральных процессоров, модулей памяти и устройств
ввода-вывода. Применяются стандартные системные шины, напри-
мер MULTIBUS II. По сравнению с персональными компьютерами
миникомпьютеры и рабочие станции больше ориентируются на
производительность и меньше на стоимость. Для высокопроизводи-
тельных систем может потребоваться сильносвязанная архитектура.
Высокая производительность процессора i486 размывает совре-
менные различия между персональными компьютерами, миником-
пьютерами и рабочими станциями. Персональные компьютеры
можно рассматривать как дешевые миникомпьютеры, разделяющие
программы и данные с настольными рабочими станциями. В
отличие от персональных компьютеров в миникомпьютерах приме-
няется память с исправлением ошибок и внешняя кэш-память. К
шине процессора подключаются быстрые коммуникационные кон-
троллеры, например сетевой сопроцессор 82596.
Большинство встроенных контроллеров выполняют задачи ре-
ального времени. Производительность процессора i486 и его совме-
стимость с огромной базой программного обеспечения для процес-
сора 80386 оказываются при выборе процессора важнейшими фак-
торами. Обычно встроенные контроллеры реализуются как авто-
номные системы с меньшими возможностями, чем другие приклад-
ные системы, так как они специально приспосабливаются к одной
среде.
Если код (программа) должен храниться в энергонезависимом
ПЗУ или стираемом ППЗУ, но критическим параметром оказывает-
ся и производительность, то код можно скопировать в специально
предусмотренное для этого ЗУПВ («теневое» ЗУПВ). Часто исполь-
Микропроцессор i486 Книга 2. Аппаратная архитектура
зуемые процедуры и переменные, например обработчики прерыва-
ний и стеки прерываний, можно заблокировать во внутренней кэш-
памяти процессора и к ним всегда обеспечивается быстрый доступ.
Обычно во встроенных контроллерах требуется меньше памяти,
чем в других прикладных системах, а управляющие программы
представляют собой тщательно отработанные процедуры машин-
ного уровня, которые обеспечивают оптимальную производитель-
ность дая ограниченного круга задач. Процессор непосредственно
взаимодействует с устройствами ввода-вывода и динамическим
ЗУПВ, а другие периферийные устройства подключаются к систем-
ной шине.
1.2. Внутренняя архитектура
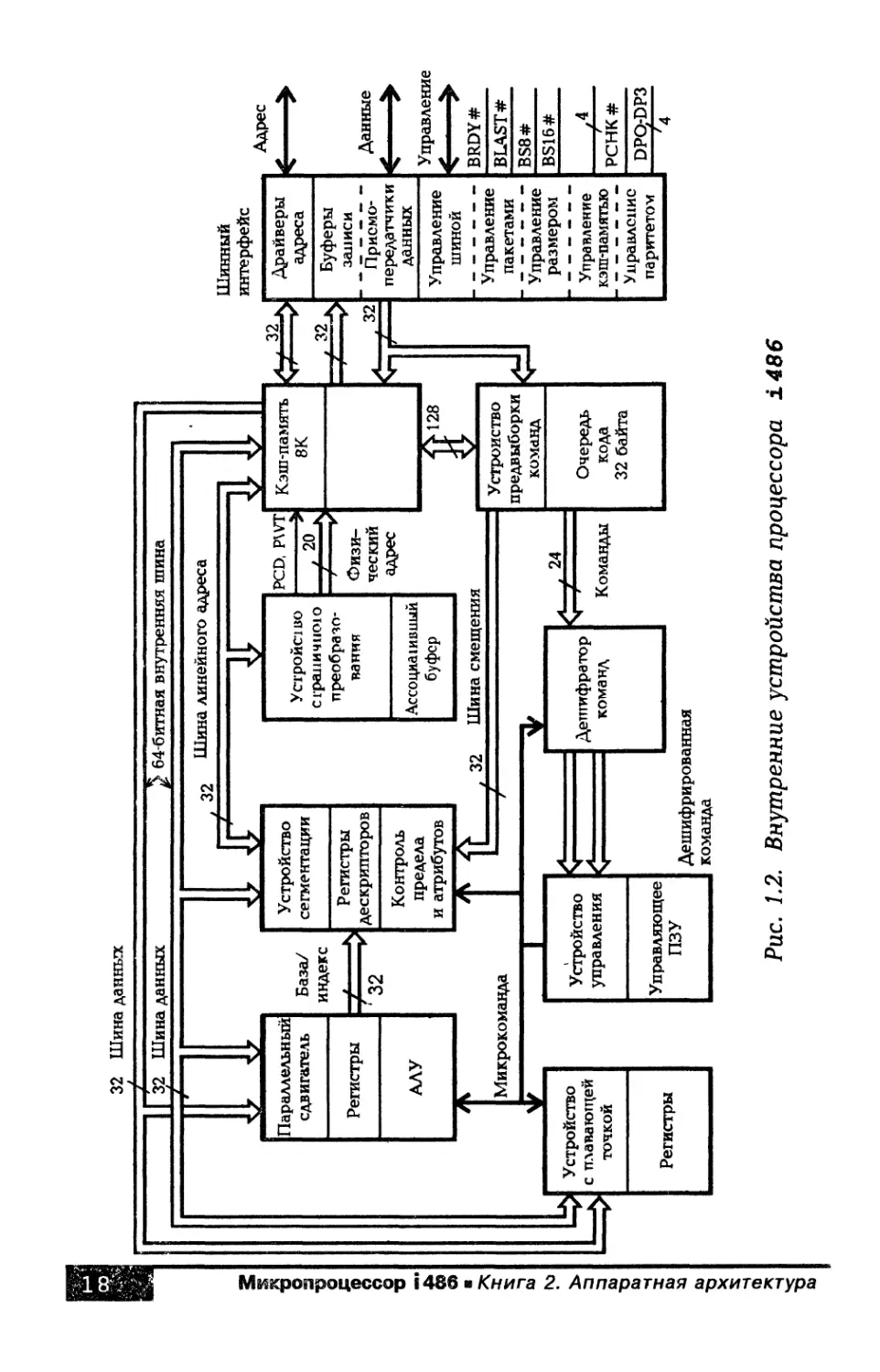
В состав процессора i486 входят девять внутренних функцио-
нальных устройств, которые работают параллельно. Подробная
внутренняя архитектура процессора приведена на рис. 1.2, а менее
подробная, но достаточная для ознакомления, на рис. 1.3. Сравни-
тельно автономными внутренними устройствами процессора i486
являются:
— устройство шинного интерфейса или просто шинный
интерфейс;
— внутренняя кэш-память;
— устройство опережающей выборки (предай борки) команд;
— двухступенчатый дешифратор команд;
— устройство управления;
— целочисленное устройство;
— устройство с плавающей точкой;
— устройство сегментации;
— устройство страничного преобразования адреса.
Отметим, что внутренняя архитектура процессора i486 очень по-
хожа на архитектуру процессора 80386, разумеется, с добавлением
внутренней кэш-памяти и устройства с плавающей точкой.
Сигналы внешней 32-битной шины процессора подаются во
внутренние устройства через шинный интерфейс. На внутренней
стороне шинный интерфейс и кэш-память передают адреса по 32-
битной двунаправленной шине. Данные передаются из кэш-памяти
в шинный интерфейс по 32-битной шине данных. Тесно связанные
кэш-память и устройство предвыборки одновременно восприни-
мают выбранные с опережением команды из шинного интерфейса
по разделенной 32-битной шине данных, которую кэш-память ис-
пользует также дая получения операндов. Находящиеся в кэш-па-
мяти команды доступны устройству предвыборки, которое имеет
32-байтную очередь команд, ожидающих выполнения.
Глава 1. Внутренняя архитектура
Макропроцессор i486 и Книга 2. Аппаратная архитектура
32 Шина данных
32
Рис. 1.2. Внутренние устройства процессора i486
Шинный
интерфейс
Драйверы
адреса
Буферы
записи
Приемо-
передатчики
данных
Управление
шиной
Управление
пакетами
Управление
размером
Управление
кэш-памятью
Управление
паритетом
Адрес
Данные
«—>
Управление
<----->
BRDY#
BLAST#
BS8#
BS16#
,4
PCHK#
DPO/DP3
*4
Шина процессора
Рис. 1.3. Упрощенная внутренняя архитектура
процессора i486
Когда внутренние запросы данных или команд можно удовлет-
ворить из кэш-памяти, сравнительно медленные циклы внешней
ншны процессора не выполняются. Шинный интерфейс привлека-
» юн, если операция требует обращения к шине процессора. Таким
образом, многие внутренние операции оказываются «прозрачными»
/|дя внешней системы.
Гл.?<;а 1. Внутренняя архмтозпура
Дешифратор команд преобразует команды в управляющие сиг-
налы низкого уровня и точки входа в микрокод (микропрограммы).
Устройство управления выполняет микрокод и управляет це-
лочисленным устройством, устройством с плавающей точкой и уст-
ройством сегментации. Результаты вычислений помещаются во
внутренние регистры целочисленного устройства и устройства с
плавающей точкой или в кэш-память. Кэш-память разделяет две
32-битные шины данных с устройством сегментации, целочислен-
ным устройством и устройством с плавающей точкой. Эти две
шины можно использовать совместно как 64-битную шину для
передач между устройствами. Когда 64-битные дескрипторы
сегментов передаются из кэш-памяти в устройство сегментации, 32
бита прямо передаются по одной шине данных, а другие 32 бита
передаются через целочисленное устройство, поэтому все 64 бита
достигают устройства сегментации одновременно.
Формирование адреса производят устройства сегментациии
страничного преобразования. Логические адреса преобразуются ус-
тройством сегментации в линейные адреса, которые передаются в
устройство страничного преобразования и кэш-память по 32-бит-
ной шине линейного адреса. Устройство страничного преобразова-
ния превращает линейные адреса в физические, которые направля-
ются в кэш-память по 20-битной шине.
КОНВЕЙЕРИЗАЦИЯ КОМАНД. Не все команды требуют при
своем выполнении участия всех внутренних устройств. Когда же
команда требует участия нескольких устройств, каждое устройство
обрабатывает параллельно другие команды на различных этапах
выполнения. Несмотря на то, что каждая команда обрабатывается
последовательно, в процессоре в различной стадии выполнения
всегда находятся несколько команд. Такой прием называется кон-
вейеризацией команд (см. рис. 1.4). Одновременно выполняются
операции, связанные с предвыборкой команд, дешифрированием
команд, выполнением микрокода, а также целочисленные опера-
ции, операции с плавающей точкой, сегментации, страничного
преобразования, управления кэш-памятью и шинного интерфейса.
На рис. 1.4 показан эффект параллелизма для одной команды:
предвыборка команды, двухступенчатое дешифрирование, выпол-
нение и запись в регистр результата выполнения команды. Каждый
элемент в этом конвейере реализует свою функцию за один такт
синхронизации. Внутренняя конвейеризация в процессоре i486
обеспечивает выигрыш в производительности по сравнению со
многими однотактными RISC-процессорами: в процессоре i486
данные можно загрузить из кэш-памяти одной командой и исполь-
зовать следующей командой уже в очередном такте синхронизации.
Такой выигрыш объясняется наличием первой ступени дешифри-
е20
Микропроцессор i486 Книга 2. Аппаратная архитектура
рования, которая инициирует обращение к памяти до собственно
выполнения. Так как в большинстве компиляторов и прикладных
программ после команды загрузки находятся команды, оперирую-
щие загруженными данными, подобный прием оптимизирует вы-
полнение имеющихся программ.
CLK
Синхро-
низация
Выборка
команды
Первая сту-
пень деши-
фрирования
Вторая сту-
пень деши-
фрирования
Выполнение
Запись
в регистр
Рис. 1.4. Конвейеризация команд
Однако в этом методе пришлось пойти на компромисс: последо-
вательность команд, которая изменяет содержимое регистра, а за-
гс м использует этот регистр для обращения к памяти, длится три
такта вместо двух. Но этот компромисс оказывается не-
значительным недостатком, так как большинство команд с обраще-
нием к памяти используют «устойчивое» содержимое указателя сте-
ка или указателя кадра, поэтому дополнительный такт требуется
редко. Компиляторы часто вводят «буферную» команду между ко-
мандой, которая изменяет регистр адреса, и командой, которая ис-
пользует этот регистр. Такой код совместим с процессором 80386, а
в процессоре i486 введены специальная схема инкремен-
ia/декремента стека и дополнительный регистровый порт для вы-
полнения соседних команд включения в стек и извлечения из стека
за один такт каждая.
ШИННЫЙ ИНТЕРФЕЙС. Это устройство учитывает приорите-
ты обращений к шине и координирует передачи данных, осуществ-
ляет предвыборку команд и выполняет функции согласования дей-
ствий между внутренними устройствами процессора и внешней си-
стемой. На внутренней стороне это устройство взаимодействует с
кэш-памятью и устройством предвыборки по трем 32-битным ши-
Глава 1. Внутренняя архитектура №
нам, как показано на рис. 1.2. На внешней стороне шинный интер-
фейс формирует сигналы шины процессора. За исключением сиг-
налов определения цикла все циклы внешней шины (считывание
из памяти, предвыборки команд, заполнения строк кэш-памяти и
др.) выглядят для внешних схем обычными циклами процессора,
причем все циклы имеют одинаковую временную диаграмму. В со-
ставе шинного интерфейса имеются следующие компоненты:
Драйверы адреса для формирования сигналов адреса А2—А31 и
сигналов разрешения байт ВЕ#0—ВЕЗ#. Старшие 28 сигналов ад-
реса являются двунаправленными, позволяя внешней схеме пере-
дать в процессор адрес строки кэш-памяти, содержимое которой
объявляется недостоверным.
Приемопередатчики шины данных, предназначенные для
управления двунаправленными сигналами данных DO—D31 шины
процессора.
Схемы для управления (по тактам синхронизации) размером
шины данных с помощью двух входных сигналов BS8# и BS16#.
Можно задать три размера внешней шины данных — 32, 16 и 8 бит.
Буферы записи, обеспечивающие буферирование до четырех
запросов записи, что позволяет продолжать многие внутренние
операции, не ожидая окончания циклов записи на шине процессо-
ра.
Схемы формирования циклов шины и управления шиной, которые
реализуют большой набор циклов шины и управляющих функций,
включая пакетные передачи, непакетные передачи (одно- и
многотактные), арбитраж шины (запрос шины, захват шины, под-
тверждение захвата шины, блокировка шины, псевдоблокировка
шины и отступление шины). Два программно-управляемых выхода
обеспечивают кэширование страниц по тактам. Предусмотрены
один вход и один выход для управления пакетными считываниями.
Схемы формирования и контроля паритета (четности), с по-
мощью которых четный паритет формируется при записи и контро-
лируется при считывании. Сигнал ошибки PCHK# фиксирует
ошибку паритета при считывании.
Схемы управления кэш-памятью поддерживают операции
управления и согласования кэш-памяти. Три входа позволяют
внешней системе управлять согласованностью данных, хранимых во
внутренней кэш-памяти. Два специальных цикла шины предостав-
ляют процессору возможность управлять согласованностью внеш-
ней кэш-памяти.
Для поддержки кэш-памяти шинный интерфейс считывает 16-
байтные кэшируемые операнды, команды и другие данные на шине
процессора и передает их во внутреннюю кэш-память. Когда со-
держимое кэш-памяти обновляется от внутреннего источника, на-
пример из регистра, шинный интерфейс записывает обновленную
1436 а Книга 2. Аппаратная архитектура
информацию во внешнюю память. Некэшируемые передачи
считывания передаются в целочисленное устройство или устрой-
ство с плавающей точкой без помещения в кэш-память.
В ходе предвыборки команд шинный интерфейс считывает ко-
манды с шины процессора и передает их в устройство предвыборки
команд и кэш-память. Устройство предвыборки команд после этого
может получать команды непосредственно из кэш-памяти.
Шинный интерфейс имеет временные регистры для буфериро-
вания до четырех 32-битных передач записи в память. Можно бу-
ферировать адреса, данные или управляющую информацию. Нельзя
буферировать одиночные записи с отображением на ввод-вывод, но
многократные записи ввода-вывода допускается буферировать. Бу-
феры могут воспринимать записи в память со скоростью одной
операции за такт синхронизации. После буферирования запроса за-
писи внутреннее устройство, сформировавшее запрос, освобожда-
ется для продолжения обработки. Если не ожидается запрос с более
высоким приоритетом и шина свободна, на шине процессора сразу
же инициируется цикл записи. Когда заполнены все четыре буфера
записи, все последующие передачи записи ожидают в процессоре
освобождения буфера записи.
Шинный интерфейс может пропускать ожидающие запросы
считывания вперед буферированных записей. Объясняется это тем,
что ожидающие считывания могут задержать работу внутреннего ус-
тройства, а ожидающие записи не оказывают заметного воздей-
ствия на скорость обработки. Записи передаются на шину процес-
сора в том же порядке, в котором они были получены от внутрен-
них устройств («первый пришел — первый ушел»). Однако сформи-
рованный впоследствии запрос считывания (данных или команды)
может быть пропущен раньше буферированных записей. Для защи-
। ы от считывания неверных данных такое пропускание считываний
раньше буферированных записей разрешается, если только все бу-
ферированные записи привели к попаданию в кэш-памяти. Так как
внешнее считывание формируется только при промахе в кэш-памя-
П1 и пропускается вперед буферированных записей, если все эти
шписи вызвали попадание в кэш-памяти, любое считывание на
внешней шине с рассмотренным средством защиты никогда не
приведет к считыванию из той ячейки, в которую будет произво-
питься буферированная запись. Для конкретного набора буфериро-
ванных записей такое «пропускание вне очереди» можно произвес-
ти только один раз, так как возвращаемые при считывании данные
могут заменить данные, готовые к записи из буферов записи. Чтобы
идя конкретного набора буферированных записей «пропускание вне
очереди» происходило не более одного раза» все буферированные
шписи при пропускании вперед запроса считывания отмечаются
как промахи в кэш-памяти. Отмеченные таким образом буфериро-
Глава 1. Внутренняя архитектура
<’23:
ванные записи передаются на шину процессора ранее следующего
запроса считывания. При объявлении данных во внутренней кэш-
памяти недостоверными все ожидающие запросы также отмечаются
как промахи в кэш-памяти. Запрещение кэш-памяти запрещает и
буферы записи, что устраняет возможность изменения порядка
циклов шины.
Процессор может сформировать сигналы дая блокирования пос-
ледовательной серии циклов шины. После этого такие циклы мож-
но выполнить без вмешательства других ведущих шины, если вне-
шняя схема учитывает сигналы блокирования. Одним из примеров
блокированной операции является считывание-модификация-за-
пись семафора, когда обновляется ячейка управления ресурсом.
Никакие другие операции на шине не разрешаются до завершения
заблокированного обновления семафора.
Когда формируется блокированный цикл считывания, попытка
считывания из внутренней кэш-памяти не производится. Первыми
заканчиваются все ожидающие записи из буферов. Только после
этого выполняется часть считывания блокированной операции,
данные обновляются, результат помещается в буфер записи и на
шине процессора производится цикл записи. Такая последователь-
ность действий гарантирует, что все записи выполняются в том по-
рядке, в каком они были запрошены.
Для поддержания целостности данных накладываются некото-
рые ограничения на передачи в ячейки ввода-вывода и из них:
Считывания ввода-вывода никогда не кэшируются;
Считывания ввода-вывода никогда не производятся раньше
буферированных записей в память. Благодаря этому процессор за-
кончит модификацию всех ячеек памяти до считывания состояния
из устройства;
Одиночные записи ввода-вывода никогда не буферируются.
Следовательно, при выполнении команды OUT внутренние
операции прекращаются до завершения на шине процессора всех
буферированных записей и записи ввода-вывода. При этом
внешней схеме отводится время сформировать цикл
недостоверности кэш-памяти или замаскировать прерывания до
выполнения процессором следующей команды. Процессор
закончит модификацию всех ячеек памяти перед записью в ячейку
ввода-вывода. Однако повторяющиеся команды OUT можно
буферировать.
ВНУТРЕННЯЯ КЭШ-ПАМЯТЬ. Кэш-память хранит копии
последних считанных команд, операндов и других данных. Когда
процессор запрашивает информацию, уже находящуюся в кэш-па-
мяти (попадание), цикл шины не нужен. Когда же процессор зап-
рашивает информацию, отсутствующую в кэш-памяти (промах),
Микропроцессор i486 • Книга 2. Аппаратная архитектура
информация считывается в кэш-память за одну или несколько
16-байтных кэшируемых передач данных, называемых заполнением
строки кэш-памяти. Если формируется запрос записи в область,
находящуюся в кэш-памяти, выполняются два действия: обновляет-
ся кэш-память и записываемые данные передаются в основную па-
мять. Эти действия называются сквозной записью. Кэш-память пе-
редает данные в другие устройства по двум 32-битным шинам. Она
воспринимает линейные адреса по 32-битной шине и соответству-
ющие физические адреса по 20-битной шине. Кэш-память и уст-
ройство предвыборки команд тесно связаны. 16-байтные блоки ко-
манд из кэш-памяти можно быстро передать в устройство предвы-
борки. Оба устройства считывают информацию 16-байтными бло-
ками. К кэш-памяти можно обращаться в каждом такте синхрони-
зации. Она работает с физическими адресами, что минимизирует
число раз очистки кэш-памяти. Когда запрещена сама кэш-память
и функции сквозной записи, кэш-память можно использовать как
быстродействующее ЗУПВ. Кэш-память имеет четырехнаправ-
ленную (или четырехканальную) ассоциативную по множеству
организацию. Для хранения данных из конкретной области памяти
в кэш-памяти есть четыре места.
Блок
Направление
Физический адрес
Рис. 1.5. Организация внутренней кэш-памяти
Четырехнаправленная ассоциативность является компромиссом
между быстродействием кэш-памяти с прямым отображением при
попаданиях и большим коэффициентом попаданий полностью ас-
Глава 1. Внутренняя архитектура
социативной кэш-памяти. Как показано на рис. 1.5, блок данных
8 Кбайт разделен по четырем направлениям, каждое из которых
имеет 128 16-байтных множеств или строк кэш-памяти. Строка
кэш-памяти содержит данные из 16 соседних байтных адресов в
памяти, начиная с адреса, кратного 16. Адресация кэш-памяти осу-
ществляется путем разделения старших 28 бит физического адреса
на три части (см. рис. 1.5). Семь бит поля индекса определяют но-
мер множества из 128 множеств, имеющихся в кэш-памяти. Стар-
шие 21 бит являются полем тэга (признака); эти биты сравниваются
с тэгами каждой строки в индексированном множестве и показы-
вают, хранится ли 16-байтная строка кэш-памяти по данному фи-
зическому адресу. Младшие четыре бита физического адреса выби-
рают байт внутри строки кэш-памяти.
Находящееся в блоке достоверности/LRU 4-битное поле досто-
верности показывает, являются ли в данный момент кэшированные
данные по имеющемуся физическому адресу достоверными. Когда
при считывании возникает промах, в кэш-память записывается
16-байтный блок, содержащий запрошенную информацию.
Соседние с запрошенными данные также считываются в кэш-
память, но точная позиция данных в строке кэш-памяти зависит от
ее расположения в памяти, относительно адресов, кратных 16.
Допускается кэширование произвольной области памяти, но
любую страницу в памяти можно объявить некэшируемой, устанав-
ливая бит в ее элементе таблицы страниц. Когда на шине иниции-
руется считывание из памяти, внешняя схема может сообщить,
можно ли поместить данные в кэш-память. Если считывание кэши-
руется, процессор пытается считать всю 16-байтную строку кэш-
памяти.
В кэш-памяти реализован принцип сквозной записи. Заполне-
ние строки выполняется только при промахе в операции
считывания и никогда при промахе в операции записи. Когда в
процессоре разрешены обычное кэширование и сквозная запись,
каждая внутренняя запись в кэш-память (попадание) не только об-
новляет кэш-память, но передается в устройство шинного интер-
фейса и по шине процессора записывается в память. Единственная
ситуация, в которой данные в кэш-памяти отличаются от соответ-
ствующих данных в памяти, возникает, когда цикл записи процес-
сора в память задерживается из-за буферирования в устройстве
шинного интерфейса или когда внешний ведущий шины изменяет
область памяти, отображенную на внутреннюю кэш-память.
Замещение в кэш-памяти реализуется по алгоритму псевдо-LRU
(наиболее давно используемый). Здесь для каждого множества в
блоке достоверности/LRU отведено три бита (см. рис. 1.5). Биты
LRU обновляются при каждом попадании в кэш-памяти или за-
полнении строки. Каждая строка кэш-памяти имеет свой бит
ж®
Микропроцессор i486 Книга 2. Аппаратная архитектура
достоверности, показывающий, содержит ли строка достоверные
данные.
При очистке кэш-памяти или сбросе процессора все биты дос-
товерности сбрасываются в 0. Когда производится заполнение
строки кэш-памяти, место дня заполнения выбирается просто на-
хождением любой недостоверной строки. Если недостоверных
строк нет, то заменяемую («перезаписываемую») строку кэш-памя-
ти выбирают биты LRU. Биты достоверности не устанавливаются
для строк, являющихся частично достоверными.
Алгоритм псевдо-LRU действует следующим образом. Когда в
цикле считывания происходит промах и в кэш-память необходимо
передать из памяти новую строку, приходится выбирать для запол-
нения одну из четырех строк множества. Если в множестве есть не-
достоверная строка (ее бит достоверности содержит 0), то для за-
полнения выбирается именно эта строка. Когда же все строки в
множестве достоверны (все 4 бита достоверности содержат 1), за-
меняемая строка выбирается с привлечением бит из блока LRU.
Обозначим строки в множестве через L0, LI, L2 и L3. Каждому
множеству в блоке LRU соответствуют три бита ВО, В1 и ВЗ, кото-
рые модифицируются при каждом попадании и заполнении следу-
ющим образом:
—- если последнее обращение в множестве было к строке L0 или
LI, то бит ВО устанавливается в состояние 1, а при обращении к
строке L2 или L3 бит ВО сбрасывается в 0;
— если последнее обращение в парс L0—L1 было к строке L0, то
бит В1 устанавливается в состояние 1, а при обращении к строке L1
бит В1 сбрасывается в 0;
— если последнее обращение в паре L2—L3 было к строке L2, то
бит В2 устанавливается в состояние 1, а при обращении к строке L3
бит В2 сбрасывается в 0.
Выбор заменяемой строки (когда все строки в множестве досто-
верны) определяет содержимое бит ВО, В1 и В2:
ВО Bl В2
0 0 х заменяется строка L0;
0 1 х заменяется строка L1;
1x0 заменяется строка L2;
1.x 1 заменяется строка L3.
Строки кэш-памяти можно по отдельности объявить недосто-
верными, задавая операцию недостоверности кэш-памяти на шине
процессора. При инициировании такой операции кэш-память
сравнивает объявляемый недостоверным адрес с тэгами строк, на-
ходящихся в кэш-памяти, и сбрасывает бит достоверности при об-
наружении соответствия (равенства). Предусмогрена также опера-
- 1
Глава 1. Внутренние архитэхтур^
ция очистки кэш-памяти, которая превращает в недостоверное все
содержимое кэш-памяти.
Конфигурацией кэш-памяти управляют два бита в регистре со-
стояния машины (CR0). Один из этих бит разрешает кэширование
(заполнение строк кэш-памяти), а второй — сквозную запись в па-
мять. Четыре возможные конфигурации приведены в таблице 1.1.
Таблица 1.1. Виды конфигурации кэш-памяти
Разревевве кэв-памятв Разревевве сквозной записв Режвм работы
нет нет Заполнения строк, сквозная запись и объявление кэш-памяти недостоверной запрещены. Такая конфигурация позволяет использовать внутреннюю кэш- память как быстродействующее ЗУПВ.
нет да Заполнения строк запрещены, а сквозная запись и объявлеиие кэш-памяти недостоверной разрешены. Эта конфигурация позволяет программе запрещать кэш-память на короткое время, а затем разрешать без очистки содержимого.
да нет Недопустимая конфигурация.
да Да Заполнения строк, сквозная запись и объявление кэш-памяти недостоверной разрешены. Это обычная рабочая конфигурация кэш-памяти.
Когда кэширование разрешено, кэшируются считывания из па-
мяти и предвыборки команд. Такие передачи кэшируются, если
внешняя схема подает входной сигнал разрешения кэш-памяти в
данном цикле шины и если текущий элемент таблицы страниц раз-
решает кэширование. В тех циклах, где кэширование запрещено
при промахе, заполнение строки кэш-памяти не производится. Од-
нако кэш-память продолжает действовать, несмотря на то, что она
запрещена для заполнения. Уже находящиеся в кэш-памяти данные
используются, если, конечно, они являются достоверными. Только
когда все данные в кэш-памяти отмечены как недостоверные, что
происходит при очистке кэш-памяти, все внутренние запросы
считывания приводят к формированию внешних циклов шины.
Микропроцессор i486 • Книга 2. Аппаратная архитектура
Когда разрешена сквозная запись, все записи, включая и вызвав-
шие попадания, инициируют запись в память. Операции недосто-
верности удаляют строку из кэш-памяти, если адрес недостоверных
данных отображается на строку кэш-памяти. Когда сквозная запись
запрещена, внутренний запрос записи, вызвавший попадание в
кэш-памяти, не приводит к производству записи в память, а опера-
ции недостоверности запрещены. Когда запрещены кэширование и
сквозная запись, кэш-память можно использовать как быстродей-
ствующее статическое ЗУПВ. В такой конфигурации на шину про-
цессора передаются только записи, вызвавшие промах, а операции
недостоверности игнорируются.
УСТРОЙСТВО ПРЕДВЫБОРКИ КОМАНД. Когда шинный
интерфейс не выполняет циклов шины выполнения команды, уст-
ройство предвыборки команд привлекает его для опережающей вы-
борки (предвыборки) команд. Считывая команды заранее, процес-
сор редко должен ожидать в цикле предвыборки команды на шине
процессора.
Циклы предвыборки команд считывают 16-байтные блоки ко-
манд, начиная по адресам, численно больших адреса последней
выбранной команды. Начальный адрес формирует устройство пред-
выборки, которое напрямую соединено с устройством страничного
преобразования (это соединение на рис. 1.3 не показано). 16-байт-
ные блоки предварительной выборки одновременно подаются в ус-
тройство предвыборки и кэш-память. В устройстве предвыборки
имеется очередь предвыборки, которая хранит 32 байта команд.
Когда каждая команда считывается из очереди, ее код операции
подается в устройство дешифрирования команд, а смещение, т.е.
константа в команде, подается в устройство сегментации, где
участвует в вычислении адреса. Если в выполняемой протрамме
встречаются циклы, устройство предвыборки получает копии ранее
выполненных команд из кэш-памяти, т.е. считываний из основной
памяти не производится.
Запрос шины от устройства предвыборки имеет низший приори-
тет. Если предположить обращение к памяти без состояний ожида-
ния, то действия предвыборки никогда не задерживают выполне-
ние. Однако при отсутствии ожидающей передачи опережающая
выборка использует те циклы шины, которые иначе оказывались
бы холостыми. Устройство предвыборки очищается, когда наруша-
ется естественный порядок выполнения команд, например при пе-
реходах, переключениях задач, особых случаях и прерываниях.
Устройство предвыборки никогда не обращается за конец сег-
мента кода и к странице, которая не присутствует в памяти. Однако
в некоторых аппаратных механизмах предвыборка может вызвать
проблемы. Например, предвыборка может вызвать прерывание,
Глава 1. Внутренняя архитектура
когда выполнение программы приближается к концу памяти.
Чтобы предотвратить опережающее считывание за конкретный ад-
рес, команды не должны быть ближе к этому адресу на один байт
плюс один выравненный 16-байтный блок.
УСТРОЙСТВО ДЕШИФРИРОВАНИЯ КОМАНД. Устройство
дешифрирования команд получает команды от устройства предвы-
борки и в двухступенчатом процессе преобразует их в управляющие
сигналы низкого уровня и точки входа микрокода, т.е. микропрог-
рамм (см. рис. 1.3). Первая ступень дешифрирования, показанная
на рис. 1.4, инициирует обращение к памяти. Эго позволяет вы-
полнить двухкомандную последовательность, которая загружает и
обрабатывает данные, всего за два такта.
Устройство дешифрирования команд одновременно обрабаты-
вает байты префиксов команд, коды операций, байты адресации
modR/M и смещения. На его выходах формируются аппаратные
микрокоманды для устройства сегментации, целочисленного уст-
ройства и устройства с плавающей точкой. Рассматриваемое уст-
ройство очищается при каждой очистке устройства предвыборки
команд.
УСТРОЙСТВО УПРАВЛЕНИЯ. Устройство управления интер-
претирует слово команды и точки входа микрокода, полученные от
устройства дешифрирования команд. Оно имеет выходы дня управ-
ления целочисленным устройством и устройством с плавающей
точкой, а также управляет сегментацией, так как команды могут
определять выбор конкретного сегмента.
Устройство управления содержит микрокод (управляющие мик-
ропрограммы) процессора. Многие команды имеют всего одну
строку микрокода, поэтому в среднем они выполняются за один
такт синхронизации. На рис. 1.4 показано, как механизм конвейе-
ризации расчленяет выполнение команд.
ЦЕЛОЧИСЛЕННОЕ УСТРОЙСТВО. Целочисленное опсраци-
онное устройство (называемое также трактом данных — datapath)
идентифицирует, где хранятся данные, и выполняет все арифме-
тические и логические команды из системы команд процессора
80386 и несколько новых команд. Оно имеет восемь программно-
доступных 32-битных регистров общего назначения, несколько спе-
циализированных регистров, арифметико-логическое устройство
АЛУ и параллельный сдвигатель, обеспечивающий сдвиг в любом
направлении и на любое число разрядов. Команды загрузки, сохра-
нения, сложения, вычитания, логических операций и сдвигов вы-
полняются за один такт.
^z J Микропроцессор i486 а Книга 2. Аппаратная архитектура
Целочисленное устройство и устройство с плавающей точкой
соединены двумя 32-битными двунаправленными шинами, которые
применяются совместно для передач 64-битных операндов. Эти же
шины связывают операционные устройства с кэш-памятью. Содер-
жимое регистров общего назначения подается по отдельной
32-битной шине в устройство сегментации для формирования
эффективных адресов.
УСТРОЙСТВО С ПЛАВАЮЩЕЙ ТОЧКОЙ. Устройство с пла-
вающей точкой имеет такие же систему команд и набор регистров,
как и математический сопроцессор 80387. Оно содержит регистро-
вый стек из восьми 80-битных регистров и специализированные
схемы для интерпретации 32/64/80-битных форматов чисел, опре-
деленных в Стандарте IEEE 754. Выходной сигнал на шине процес-
сора сообщает внешней подсистеме об ошибках с плавающей
точкой, а она может подать в процессор входной сигнал, показы-
вающий, что процессор должен игнорировать ошибки и продолжать
обычные операции.
УСТРОЙСТВО СЕГМЕНТАЦИИ. Под сегментом понимается
защищенное независимое адресное пространство. Сегментация
применяется для изолирования прикладных программ, вызова про-
цедур восстановления и локализации влияния ошибок программи-
рования.
47 32 31 0
Селектор сегмента Смещение в сегменте
После сегментации Логический адрес 31 22 21 12 11 0
Смещение в каталоге Смещение в таблице Смещение в странице
После Линейный адрес 31 12 11 0
страничного преобразования Базовый адрес страницы Смещение в странице
Физический адрес
Рис. 1.6. Форматы адресов в процессоре i486
Устройство сегментации преобразует сформированный програм-
мой сегментированный адресу называемый логическим или вирту-
альным адресом, в несегментированный линейный адрес. Местона-
хождения и атрибуты сегментов в линейном адресном пространстве
Глава 1. Внутренняя архитектура
хранятся в структурах данных, называемых дескрипторами сегмен-
тов. Устройство сегментации производит вычисление адреса, при-
влекая дескрипторы сегментов и смещения, выделенные из команд.
После этого линейные адреса посылаются в устройство стра-
ничного преобразования и кэш-память. Параллельно с вычисле-
нием линейного адреса производится контроль атрибутов сегмента.
При обращении к сегменту первый раз его дескриптор копиру-
ется во внутренний регистр процессора и в дальнейшем при необ-
ходимости берется из этого регистра. Программа может иметь до
16383 сегментов. В любой момент времени во внутренних регистрах
процессора могут находиться до шести дескрипторов сегментов. На
рис. 1.6 показаны взаимосвязи между логическим, линейным и фи-
зическим адресами памяти.
УСТРОЙСТВО СТРАНИЧНОГО ПРЕОБРАЗОВАНИЯ. Устрой-
ство страничного преобразования обеспечивает доступ к структурам
данных, которые больше имеющегося пространства памяти, храня
их частично в памяти и частично на диске. При страничном преоб-
разовании линейное адресное пространство разделяется на блоки
по 4 Кбайт, называемые страницами, а дня отображения линейного
адреса в физический применяются структуры данных в памяти, на-
зываемые таблицами страниц. Элементами таблиц страниц являют-
ся своеобразные дескрипторы страниц, которые проще дескрипто-
ров сегментов. Физические адреса используются кэш-памятью
и/или выдаются на шину процессора. Устройство страничного пре-
образования фиксирует такие ситуации, как обращение к странице,
отсутствующей в памяти, и формирует особые случаи, называемые
страничными нарушениями. При страничном нарушении операци-
онная система должна передать нужную страницу с диска в память.
При необходимости она может освободить пространство в памяти,
отсылая некоторую другую страницу на диск (такая замена одной
страницы на другую называется свопингом). Если страничное пре-
образование программно запрещено, физический адрес совпадает с
линейным адресом. В устройство страничного преобразования вхо-
дит ассоциативный буфер преобразования {Translation Lookaside
Buffer или TLB), который хранит 32 наименее давно используемых
элемента таблицы страниц. Структуры данных буфера TLB показа-
ны на рис. 1.7. Устройство страничного преобразования просматри-
вает линейные адреса в TLB. Если оно не находит линейного адре-
са в TLB, устройство формирует запрос на загрузку в TLB правиль-
ного физического адреса из таблицы страниц в памяти. Только ког-
да правильный элемент таблицы страниц находится в TLB, иници-
ируется цикл шины. Когда устройство страничного преобразования
отображает страницу из линейного адресного пространства на стра-
ницу в физической памяти, оно изменяет только 20 старших бит
Микропроцессор i486*Книга 2. Аппаратная архитектура
линейного адреса. Младшие 12 бит физического адреса берутся не-
изменными из линейного адреса.
Рис. 1.7. Организация буфера TLB
В течение достаточно короткого временного интервала боль-
шинство программ обращаются только к небольшому числу стра-
ниц. В такой ситуации страницы обычно находятся в памяти, а ин-
формация о преобразовании адреса содержится в буфере TLB. В
типичных системах TLB удовлетворяет до 99% запросов на доступ к
шблицам страниц. В качестве стратегии замещения в буфере TLB
применяется такой же алгоритм псевдо-LRU, как и во внутренней
кэш-памяти. Буфер TLB очищается при загрузке базового регистра
каталога страниц (регистр CR3). При считывании из каталога стра-
ниц или таблицы страниц могут возникать страничные нарушения.
Для передач новых данных в буфер TLB можно использовать кэш-
память, но это нежелательно, когда обновлением буфера TLB уп-
равляет внешняя схема. В отличие от сегментации страничное пре-
образование невидимо для прикладных программ и не защищает от
изменения программами данных вне ограниченной части памяти.
Страничное преобразование видимо операционной системе, кото-
рая использует его для удовлетворения требований памяти при-
кладных программ.
1.3. Производительность
Производительность является важнейшим параметром любой
вычислительной системы. Общепринятым показателем производи-
н льности является скорость выполнения программы, которая зави-
Глава 1. Внутренняя архитектура
: Заказ 4317
сит от множества факторов: быстродействия процессора, частоты1
синхронизации, запаздывания памяти, скорости передачи данных,
памяти, размера памяти, времени обращения к диску, скорости
дисковых передач, времени обращения к дисплею, эффективности
компилятора, эффективности операционной системы, особеннос-
тей реализованных в программе алгоритмов и т.д. В этом разделе
показано влияние на производительность параметров памяти.
Проектирование системы памяти имеет важное значение. Про-
цессор i486 быстрее любой практической системы памяти. Однако
его внутренние устройства (например, кэш-память, буферы записи,
устройство предвыборки команд) позволяют работать даже с мед-
ленной внешней памятью.
Идеальная подсистема памяти должна работать без состояний
ожидания. Все циклы шины в процессоре i486 завершаются всего за
два такта при одиночном обращении и за пять тактов при заполне-
нии строки кэш-памяти. Следовательно, для работы на частоту
33 МГц потребуется много микросхем памяти с временем
обращения 15 нс. В реальных системах применяются микросхемы
динамических ЗУПВ с временем обращения 60—100 нс.
Максимальную производительность определяет частота синхро-
низации процессора. Чем выше частота, тем быстрее работает про-
цессор, но для повышения производительности всей системы тре-
буется все более быстрая память. Процессор i486 спроектирован та-
ким образом, что рост общей производительности обеспечивается
при повышении частоты и постоянстве быстродействия памяти.
Главной характеристикой памяти является число состояний
ожидания при считывании элемента данных. На частоте 33 МГц
операция считывания требует память с временем обращения 15 нс
Для медленной памяти с состояниями ожидания к времени обра-
щения на частоте 33 МГц добавляются 30 нс. Состояния ожидания
вводятся во всех практических разработках системы памяти.
В процессоре i486 появился новый показатель системы
памяти — скорость передач при считывании, который играет
важную роль при заполнении внутренней кэш-памяти. В
большинстве считываний процессор может передавать данные из
памяти каждый такт, что вдвое скорее отдельных циклов памяти
Системы памяти, поддерживающие столь высокую скорость
передач, повышают производительность на 10—20%.
Еще одним важйым показателем является время цикла записи
Внутренняя кэш-память со сквозной записью формирует записей
примерно вдвое больше, чем считываний. Скорость записи особен-
но важна для 16-битных программ, которые формируют больше за-
писей, чем 32-битные программы. Время цикла записи огра-
ничивает производительность системы, когда загрузка шины при-
ближается к допустимому максимуму. Общий метод повышения
Микропроцессор i486 Книга 2. Аппаратная архитектура
производительности системы памяти заключается в применении
к > ш-памяти. Процессор i486 имеет внутреннюю кэш-память, кото-
рая удовлетворяет большинство запросов считывания. Выигрыш
производительности при введении внешней кэш-памяти у процес-
< ора i486 меньше, чем у процессора 80386 и он сильно зависит от
особенностей применения. В некоторых применениях внешняя
к нп-память обеспечивает рост производительности менее 5%, в
большинстве применений он составляет 10—15%, а в небольшом
числе применений даже до 40%. Для многих применений процес-
i ора i486 внешняя кэш-память не нужна.
Процессор i486 выполняет команды за меньшее число тактов,
чем предыдущие процессоры фирмы Intel. В нем реализовано не-
»колько приемов, обеспечивающих выполнение многих часто
встречающихся команд за один такт. Процессор имеет внутреннюю
к и и-память для кода и данных, а также конвейерное операционное
устройство; он дешифрирует многие простые команды непосред-
। гвенно в аппаратные действия и использует буферы записи для со-
। пасования скорости выполнения с быстродействием шины памяти.
Один из приемов анализа влияния этих способов на производи-
нльность заключается в сравнении среднего времени выполнения
идной команды. Для этого фирма Intel измерила по множеству про-
|рамм частоты использования команд. После умножения частот на
число тактов и суммирования произведений получается среднее
число тактов на команду. Результаты расчетов показали, что в про-
цессоре i486 среднее время выполнения команды составляет
I 95 тактов, а в процессоре 80386 — 4.919 тактов, т. е. для це-
иочисленных программ производительность повышена в 2.5 раза.
Для команд с плавающей точкой повышение производительности
। щс больше.
Важно отметить, что процессор i486 не может обеспечить высо-
кую скорость при запрещенной кэш-памяти. Его внутренняя кэш-
память удовлетворяет большинство (90—95%) запросов считывания,
л нее записи требуют производства циклов внешней шины.
1.3.1. Влияние внутренней кэш-памяти
Процессор i486 имеет очень высокую скорость выполнения опе-
раций, составляющую для наиболее распространенных команд
нее in один такт. Так как внешняя память не может обеспечивать
на иные в каждом такте, для повышения общей производительности
фсбуется внутренняя кэш-память, допускающая очень быстрое об-
ращение и скрывающая различия в скорости внешней шины и про-
цессора. Размер, организация, принцип записи, замещение при
промахе и шинная организация внутренней кэш-памяти процессора
i486 были выбраны для поддержки широкого круга применений.
I лава 1. Внутренняя архитектура
Размер внутренней кэш-памяти составляет 8 Кбайт. Она содер-
жит код и данные и организована как четырехнаправленная ассо-
циативная по множеству кэш-память с дайной строки 16 байт.
Строки могут быть достоверными или недостоверными, а частично
достоверных строк нет. Запросы считывания формирует либо про-
грамма (запрос данных), либо устройство предвыборки команд
(запрос кода). Обычно эти запросы удовлетворяет внутренняя кэш-
память, но в случае промаха формируется запрос внешней шины.
Считывание из некэшируемых областей памяти представляет собой
обычное считывание. Если же запрос считывания обращается к
кэшируемой области памяти, процессор инициирует заполнение
строки, которое требует производства дополнительных циклов
шины.
На производительность системы влияет размер строки кэш-па-
мяти. Если он слишком велик, то сокращается число блоков, кото-
рые могут разместиться в кэш-памяти. Кроме того, при увеличении
дайны строки растет запаздывание внешней памяти при заполне-
нии строки. Сокращение размера строки приводит к уменьшению
коэффициента попаданий. Шина процессора i486 оптимизирована
на размер строки 16 байт. Так как процессор может обращаться к
четырем байтам памяти в каждом цикле шины и дайна строки со-
ставляет 16 байт, дая заполнения строки требуются четыре цикла
шины. Для уменьшения запаздывания при считывании строк кэш-
памяти процессор допускает пакетные циклы, в которых четыре
байта данных можно считывать в процессор каждый такт. Благо-
даря пакетным циклам 16-байтная строка считывается в процессор
за пять тактов.
Для обновления содержимого основной памяти применяется
принцип сквозной записи, т.е. все операции записи от процессора
инициируют цикл внешней шины. Кроме того, при попадании об-
новляется и внутренняя кэш-память. Принцип сквозной записи
обеспечивает автоматическую согласованность между внутренней
кэш-памятью и внешней памятью. Если все операции программы
используют внутренние ресурсы, достигается ее самое быстрое вы-
полнение, так как все запросы удовлетворяют внутренние регистры
и кэш-память. Однако при промахах в операциях считывания и во
всех операциях записи приходится обращаться к внешней шине,
что снижает производительность системы. В зависимости от при-
менения коэффициент попаданий внутренней кэш-памяти достига-
ет примерно 95%. Такой высокий коэффициент попаданий имеет
три основных следствия:
1. Повышается производительность. Процессор i486 может
считывать данные из внутренней кэш-памяти каждый такт, что по-
зволяет операционному устройству выполнять многие команды за
один такт.
Микропроцессор i486 л Книга 2. Аппаратная архитектура
2. Сокращается использование шины. Так как подавляющее
большинство считываний удовлетворяет внутренняя кэш-память,
процессор i486 значительную часть времени не обращается к шине.
В систему можно вводить дополнительные ведущие шины, не на-
сыщая шину и, как следствие, не ухудшая производительность.
3. На внешней шине увеличивается отношение числа записей к
числу считываний. Число считываний сокращается, но число запи-
сей остается неизменным. Следовательно, основная память должна
иметь малое запаздывание в операциях записи.
Внутри процессора к кэш-памяти подключены два отдельных
128-битных буфера предвыборки. Их можно заполнить данными из
внутренней кэш-памяти или внешней памяти всего за один такт.
Поскольку широкие буферы удовлетворяют несколько операций
предвыборки, удается избежать ухудшения производительности,
связанного с объединением кэш-памяти данных и кэш-памяти ко-
манд. Для оптимизации производительности при заполнении стро-
ки применяется так называемый обход. Считанные в первом цикле
данные посылаются прямо запрашивающему устройству. Благодаря
этому до использования запрошенных данных не нужно ожидать
заполнения всей строки.
В процессорах без внутренней кэш-памяти значительная часть
времени выполнения приходится на обращения к внешней шине.
Предвыборки кода и считывания данных должны производиться из
внешней памяти; следовательно, большинством обращений к шине
являются считывания и обычно системы памяти оптимизируются
на считывание (см. табл. 1.2).
Таблица 1.2. Операции на, шине процессора
Операция Вез кэв-памяти С кзш-памятыо
Считывание 42% 8%
Опережающая выборка 22% 15%
Запись 36% 77%
Высокий коэффициент попаданий во внутренней кэш-памяти
сокращает число внешних считываний. Из-за применения в кэш-
памяти принципа сквозной записи число записей на шине не
уменьшается, но теперь циклы считывания составляют не-
значительную часть всех циклов шины (см. табл. 1.2). Для повыше-
ния производительности систем с процессором i486 внешнюю па-
мять следует оптимизировать по циклам записи.
1.3.2. Внутренние буферы записи
Выше показано, что в системах с процессором i486 малое запаз-
дывание записи важнее, чем в предыдущих процессорах. Процессор
i486 имеет четыре буфера записи, позволяющие ему работать без
Глава 1. Внутренняя архитектура
запаздывания в операциях записи. Буферы можно заполнять каж-
дый такт. Когда все четыре буфера пустые и шина холостая, запрос
записи проходит на внешнюю шину, обходя буферы. Если же при
формировании внутреннего запроса записи шина недоступна, то
запись буферируется и передается на шину, как только она осво-
бождается. Когда при записи возникает попадание в кэш-памяти,
она сразу же обновляется.
Обычно записи выполняются на внешней шине в том порядке, в
каком они поступили в буферы записи. Однако иногда считывание
из памяти можно пропустить раньше всех записей. Если все записи
в буферы вызвали попадание в кэш-памяти, а считывание вызвало
промах, то считывание наверняка не будет конфликтовать с ожи-
дающими записями.
Следовательно, циклы шины можно переупорядочить, чтобы
операция считывания была произведена раньше освобождения бу-
феров записи. Буферы записи как бы изолируют внутреннее опера-
ционное устройство от шины. Выполнение программы продолжа-
ется без задержек на запаздывание записи. Кроме того, переупоря-
дочивание иногда позволяет продолжить выполнение программы,
даже если некоторые буферы записи заполнены.
1.4. Внешняя память
Достижение высокой производительности систем с процессором
i486 требует тщательно спроектированной внешней памяти. Для
повышения экономичности память реализуется на микросхемах
статических и динамических ЗУПВ. Микросхемы статических
ЗУПВ имеют меньшее время обращения и не требуют циклов реге-
нерации. Микросхемы динамических ЗУПВ характеризуются боль-
шей плотностью и меньшей стоимостью, но требуют Схем регенера-
ции и введения состояний ожидания из-за большего времени об-
ращения.
Общая производительность системы прямо связана с быстродей-
ствием памяти. Подавляющее большинство циклов шины использу-
ется для обращения к памяти за командами и данными. По мере
повышения быстродействия процессора требуется все более быст-
рая память.
Применение в системке только быстрой статической памяти ока-
зывается слишком дорогим. При введении менее дорогих медлен-
ных микросхем увеличивается число состояний ожидания и снижа-
ется производительность. На частотах выше 25 МГц оптимальной
производительности памяти можно достичь, применяя очень быст-
рые микросхемы памяти, но применять только такие микросхемы
неэкономично. Реализация памяти на медленных микросхемах
I3
Микропроцессор i486 Книга 2. Аппаратная архитектура
снижает стоимость, но при этом снижается производительность си-
стемы.
Компромисса между стоимостью и производительностью можно
достичь, разделяя функции и применяя комбинацию медленной и
быстрой памяти. Наиболее часто используемые функции возлага-
ются на быструю память. Чаще всего на быстродействующих мик-
росхемах статических ЗУГТВ реализуется внешняя кэш-память.
Обычно система внешней памяти состоит из комбинации мик-
росхем СППЗУ и динамических ЗУПВ. Микросхемы СППЗУ име-
ют довольно большое время обращения. Эти энергонезависимые
устройства, в основном, применяются для хранения процедур ини-
циализации и после инициализации обращения к ним произво-
дятся редко. Следовательно, производительность систему прак-
тически не зависит от запаздывания микросхем СППЗУ. Однако
ддя достижения наивысшей производительности содержимое
СППЗУ можно скопировать в динамическое ЗУПВ («теневая» па-
мять).
На производительность системы влияет организация массива
микросхем динамических ЗУПВ. Для сокращения среднего запаз-
дывания при обращении к динамическому ЗУПВ применяются та-
кие способы, как адресация со статическим столбцом и расслоение.
Процессор i486 может выполнять минимальные непакетные
циклы за два такта. Такие циклы называются циклами 2—2 так как
циклы считывания и записи занимают по два такта. Первая цифра
2 показывает время цикла считывания, а вторая — время цикла за-
писи. Обращения к устройствам, которые не могут отреагировать к
концу второго такта, требуют введения состояний ожидания. Когда
состояние ожидания необходимо добавлять к циклу записи, по-
лучается система 2—3. Внешняя система формирует сигнал готов-
ности RDY# и он опрашивается в конце второго такта. Если в мо-
мент опроса сигнал RDY# подан, он показывает, что внешняя сис-
тема поместила достоверные данные при считывании или что сис-
тема восприняла данные при записи. Состояния ожидания вводятся
при пассивном сигнале RDY# в конце второго такта.
Для повышения производительности при считывании процессор
i486 поддерживает пакетные циклы. Его шина допускает пакетиро-
вание последовательных слов из памяти в кэш-память каждый такт.
Благодаря наличию внутренней кэш-памяти введение дополнитель-
ных состояний ожидания влияет на производительность процессора
i486 меньше, чем в предыдущих процессорах. Одно состояние ожи-
дания в системе с процессором 386DX ухудшает производитель-
ность примерно на 20%, а с процессором i486 — всего на 6%.
Процессор i486 может выполнять цикл внешней шины за два
такта. Для достижения оптимальной производительности обраще-
ния к памяти также должны выполняться за два такта, чтобы уст-
Глава 1. Внутренняя архитектура
ранить состояния ожидания. Однако при высокой частоте синхро-
низации непрактично и слишком дорого реализовать всю память
без состояний ожидания. На частоте 25 МГц состояние ожидания
добавляет к времени обращения 40 нс. Несмотря на то, что работа с
одним состоянием ожидания увеличивает время цикла шины на
50%, пропорционального снижения производительности не наблю-
дается. Фактическое снижение зависит от применения и варьирует-
ся от смеси команд, размера внешней кэш-памяти и числа обраще-
ний к памяти.
Некоторые способы организации динамических ЗУПВ позво-
ляют уменьшить число состояний ожидания и поддержать высокую
производительность системы даже при использовании сравнитель-
но медленных микросхем.
Отметим очевидное влияние на производительность наличия
четырех внутренних буферов записи. Так как более 75% внешних
циклов являются записями, запаздывание записи из-за медленной
внешней памяти должно влиять на производительность сильнее,
чем запаздывание считывания. Однако внутренние буферы записи
снижают зависимость от запаздывания записи.
Как показано ранее, около 90—95% внутренних запросов
считывания процессора i486 удовлетворяет внутренняя кэш-память.
Однако остальные 5—10%, которые вызывают промахи в кэш-памя-
ти, приводят к выполнению циклов считывания на внешней шине.
Внешняя кэш-память сокращает состояния ожидания для этих
циклов считывания, повышая производительность системы. Для
систем с процессором i486 фирма Intel предлагает модуль внешней
кэш-памяти 485Turbocache емкостью 64К или 128 Кбайт. Допуска-
ется каскадировать несколько модулей с увеличением емкости кэш-
памяти до 256К или 512 Кбайт. Применение модуля повышает про-
изводительность различных приложений и операционных сред по-
разному. Коэффициент попаданий во вторичной кэш-памяти зави-
сит от выполняемой программы и произвольности адресации памя-
ти. В системах с интенсивным применением мультизадачности дос-
тигается значительное повышение производительности.
Как и процессор, модуль 485Turbocache имеет размер строки в
четыре двойных слова. В операции считывания из кэш-памяти в
модуль подается адрес и производится сравнение тэгов. В случае
соответствия фиксируется попадание и данные пакетируются в
процессор i486. Данные можно передавать за два такта для первого
двойного слова и за один такт для последующих трех двойных слов.
Это соответствует наиболее быстрому циклу считывания при попа-
дании в кэш-цамять. В случае промаха данные выбираются из ос-
новной памяти и посылаются в процессор i486 и модуль
485Turbocache Module. В операциях записи модуль работает как
кэш-память процессора i486, обновляя данные при попадании и не
Микропроцессор i486 • Книга 2. Аппаратная архитектура
обновляя при промахе. По принципу сквозной записи основная
память обновляется во всех операциях записи.
1.4.1. Особенности проектирования динамических ЗУПВ
Для высокопроизводительной системы с процессором i486 тре-
буется эффективное динамическое ЗУПВ. Обычно обращение к ди-
намическому ЗУПВ начинается с выдачи сигнала RAS# (строб ад-
реса строки), который фиксирует в микросхеме представленный ад-
рес строки. Так как микросхемы динамических ЗУПВ имеют муль-
типлексные линии адреса, внешний адрес после этого нужно пере-
ключить для представления адреса столбца. В конце подается сиг-
нал CAS# (строб адреса столбца), который фиксирует адрес столбца
и разрешает выходные буферы микросхемы. В простейшем дина-
мическом ЗУПВ для каждого обращения вводится фиксированное
число состояний ожидания. Например, можно спроектировать сис-
тему так, что все обращения производятся за шесть тактов. Однако
во многих микросхемах динамических ЗУПВ есть специальные ре-
жимы работы, основанные на способе обновления адреса строки,
которые позволяют повысить производительность.
В способе со статическим столбцом матрица микросхем дина-
мических ЗУПВ разделяется на физические страницы памяти. Каж-
дая страница соответствует набору адресов столбцов с использова-
нием одного и того же адреса строки. Размер страницы памяти за-
висит от используемых микросхем и адресов строки. Первое обра-
щение к странице производится как обычное обращение с выдачей
вначале сигнала RAS#, а затем сигнала CAS#. Если следующее об-
ращение к памяти приходится на ту же самую страницу, то не нуж-
но модифицировать адрес строки. Предыдущий адрес строки оста-
ется зафиксированным («защелкнутым») в микросхеме. Когда про-
цессор выдает новый адрес для следующего обращения, изменяется
адрес столбца и на выходах микросхемы появляются нужные дан-
ные. Для микросхем динамических ЗУПВ, которые поддерживают
способ со статическим столбцом, не нужно снимать и повторно
выдавать сигнал CAS#.
Рассмотренный способ особенно полезен для быстрых пакетных
циклов. Так как в пакетных циклах обращения производятся к од-
ной и той же странице памяти, с микросхемами динамических
ЗУПВ, поддерживающими способ статического столбца, можно ре-
ализовать однотактный пакетный цикл.
Более сложный способ повышения производительности дина-
мических ЗУПВ заключается в организации расслоения, которое
возможно при использовании нескольких банков памяти. При рас-
слоении управление каждым банком осуществляется отдельно. По-
ка длится обращение к одному банку, другие банки готовятся к сле-
дующему обращению.
Глава 1. Внутренняя архитектура
В системе с процессором i486 внутренняя кэш-память умень-
шает число циклов считывания, поэтому до 77% внешних циклов
шины являются циклами записи. При выполнении программы за-
писи возникают цепочками по две в 60—70% времени, а цепочками
по три в 40—50% времени. Подсистему динамического ЗУПВ мож-
но оптимизировать на цепочки записей; один из способов зак-
лючается в применении отложенной записи с помощью буфера за-
писи. Отложенная запись означает, что сигнал RDY# возвращается
в процессор до завершения операции записи. Это позволяет избе-
жать зависимости процессора от запаздывания записи.
1.5. Производительность операций *
с плавающей точкой
Устройство с плавающей точкой (Floating-Point Unit или FPU)
процессора i486 содержит схемы для выполнения системы команд с
плавающей точкой. Оно работает параллельно с целочисленным
АЛУ и реализует арифметические и трансцендентные функции.
FPU усовершенствовано, что повысило его производительность в
3—4 раза по сравнению с сопроцессором 80387. Это устройство
имеет умножитель, который оперирует с восемью битами в такте
синхронизации в отличие от двух бит в сопроцессоре 80387. Внут-
ренняя кэш-память процессора i486 намного ускоряет операции
загрузки и сохранения с плавающей точкой. Для повышения
производительности схемы с плавающей точкой процессора i486
были усовершенствованы так, чтобы сократить число тактов на
выполнение часто встречающихся команд. Улучшен татрке
интерфейс с регистрами и шинами процессора, так как все
взаимодействующие устройства находятся на одном кристалле. В
таблице 1.3 приведено сравнение числа тактов на команду для
сопроцессора 80387 и FPU процессора i486.
Таблица 1.3. Сравнение выполнения команд
с плавающей точкой
Комавда Чвсло тактов в 80387 Чвсло тактов в i486
FLD - загрузка 14 3
FST - сохранение И 3
FADD/FSUB - сложение, 23-31 8-20
вычитание
FMUL - умножение 29-57 16
FDIV - деление 88 73
Микропроцессор i486 Книга 2. Аппаратная архитектура
Сигналы и
временные диаграммы
работы процессора i486
2.1. Шина процессора
Шину процессора образуют сигналы микросхемы процессора
i486, через которые он взаимодействует с другими устройствами си-
стемы. Сигналы шины классифицируются по их функциям в груп-
пы сигналов адреса и данных, управления шиной и арбитража, оп-
ределения цикла шины, управления кэш-памятью и управления
ошибками с плавающей точкой.
Среди особенностей шины процессора i486 следует отметить:
демультиплексированные 32-битные шины адреса и данных,
одночастотную (1х) синхронизацию, операции захвата шины, опе-
рации блокирования и псевдоблокирования шины, пакетные пере-
дачи (до 16 байт), кэшируемые передачи, поддержку согласованнос-
ти внутренней и внешней кэш-памяти, обработку ошибок с плава-
ющей точкой, маскируемые и немаскируемые прерывания, поддер-
жку 8/16-битных периферийных устройств, поддержку «за-
ворачивания» адреса на 1 Мбайт процессора 8086, формирование и
контроль паритета (четности).
Способ использования шины процессора оказывает сильное
влияние на производительность системы. Обычно к шине под-
ключается только небольшое число устройств, которым требуется
быстрое взаимодействие с процессором и разделение совместимых
сигналов с соблюдением основного ограничения на ширину полосы
шины: минимум 50% ширины полосы необходимо зарезервировать
Глава 2. Сигналы и временные диаграммы работы i486
м
для процессора i486. Обычно к шине подключаются такие устрой-
ства, как сетевой сопроцессор, контроллер внешней (второго уров-
ня) кэш-памяти или другие подобные быстродействующие устрой-
ства. В большинстве систем шина процессора сопряжена с одной
или несколькими системными шинами. При этом расширяется эф-
фективная ширина полосы и обеспечивается большая гибкость
расширения системы. Организация внешних шин не обязательно
должна совпадать с набором сигналов шины процессора.
В действиях шины процессора i486 преобладают циклы записи.
Такая ситуация не характерна для большинства других систем, где
доминируют циклы считывания, которые могут приводить к ожи-
данию процессора. Благодаря таким средствам процессора i486, как
внутренняя кэш-память, устройство предвыборки команд и под-
держка пакетных передач, любая подсистема памяти, которая спо-
собна обеспечить скорость в одну передачу за такт синхронизации,
может послужить основой высокопроизводительной системы.
Большинство запросов команд и данных быстро удовлетворяются
из внутренней кэш-памяти и устройства предвыборки команд без
производства циклов на шине процессора.
Шина процессора может поддерживать несколько внешних кэш-
памятей. Предусмотрено достижение согласованности внутренней
кэш-памяти процессора, внешней кэш-памяти и основной памяти.
Можно сообщить внешней кэш-памяти о записи («выгрузке») ее
содержимого в память или очистке; допускается селективное
объявление недостоверными отдельных строк внутренней кэш-па-
мяти, а также очистка всей внутренней кэш-памяти.
Для минимизации времени ожидания в процессоре 80386 при-
меняется конвейеризация адреса. В процессоре i486 для достижения
высокой производительности вместо конвейеризации адреса
применяются пакетные считывания во внутреннюю кэш-память.
Этот прием совместно с более простой синхронизацией шины 1х и
более тщательным планированием цикла шины привел к более
простым внешним схемам.
Два входа динамически управляют размером шины для под-
ключения к шине данных процессора 8/16-битных устройств. На
выравнивание байт и слов внутри границ двойного слова не накла-
дывается никаких ограничений, однако для передачи данных, не
выравненных по границам двойных слов, требуется больше циклов
шины, чем минимальное чйсло. Шина поддерживает «заворачи-
вание» адреса на 1 Мбайт процессора 8086.
2.2. Ц*4!«лы шины
Взаимодействие процессора с внешними компонентами системы
реализуется с помощью циклов шины. Процессор формирует
Микропроцессор i486 Книга 2. Аппаратная архитектура
циклы шины, образующие две основные группы. В группу циклов
передач данных входят следующие циклы: предвыборка
(считывание) команд из памяти, считывание данных из памяти,
считывание данных из подсистемы ввода-вывода, запись данных в
память, запись данных в подсистему ввода-вывода. Во вторую груп-
пу входят цикл подтверждения прерывания и четыре специальных
цикла шины: останов, отключение (shutdown), очистка кэш-памяти,
обратная запись («выгрузка») кэш-памяти и очистка.
Некоторые формируемые процессором циклы шины могут или
должны быть блокированными или псевдоблокированпыми. Вне-
шние схемы могут осуществить операцию захвата шины и осуще-
ствить на шине процессора свои циклы, включая циклы недосто-
верности внутренней кэш-памяти.
С точки зрения внешних схем данные можно передавать как
двойные слова, слова или байты в зависимости от указанного раз-
мера шины. С точки зрения процессора все передачи используют
32-битную шину данных, но в некоторых передачах разрешены
только определенные байты.
Имеются два основных типа циклов шины, которые передают
данные. В непакетных циклах передаются до четырех байт с макси-
мальной скоростью два такта синхронизации на элемент данных
(двойное слово, слово или байт). Когда передается один элемент
данных, цикл называется циклом одиночной передачи. Когда
одиночные циклы повторяются последовательно, они образуют
многоцикловую последовательность.
Пакетный цикл обеспечивает максимальную скорость передачи
более одного элемента данных. В таком цикле передаются до
16 байт со скоростью один элемент данных за такт синхронизации.
Пакетные циклы введены для кэшируемых считываний (строка
внутренней кэш-памяти состоит из 16 байт), но их можно приме-
нять для считываний чисел с плавающей точкой, считываний из
дескрипторных таблиц и других типов передач.
Внутренние передачи в процессоре, например считывания из
внутренней кэш-памяти, не появляются на шине процессора. Од-
нако записи в кэш-память всегда появляются на шине, так как в
кэш-памяти применяется принцип сквозной записи: все записи пе-
редаются в память и попадают во внутреннюю кэш-память, если
только адресованные данные уже хранятся в кэш-памяти.
Помимо рассмотренных циклов передач данных имеются цикл
подтверждения прерывания и четыре специальных цикла шины.
Подробнее об этих циклах см. раздел 2.7.3.
Глава 2. Сигналы и временные диаграммы работы i486
2.3. Сигнальные линии процессора
На рис. 2.1 показана разводка контактов корпуса процессора
i486 и принцип нумерации контактов, а в
таблице 2.1 — соответствие сигналов номерам контактов. Отметим,
что все неиспользуемые входы должны иметь внешние резисторы,
подключенные к земле или источнику питания. Отметим также, что
асинхронными (относительно сигнала CLK) являются только
сигналы немаскируемого прерывания NMI и игнорирования
ошибки с плавающей точкой IGNNE#.
17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1
S о о о о 0 о о О о о о о о о о о о S
R о о о о О о о о о о о о о о о о о R
Q о о о о О о о о о о о о о о о о о Q
Р о о о о о о р
N о о о Q о о N
М о о о б о о М
L о о о О о о L
К о о о о а о К
J о о о Вид сверху о о о J
Н о о о о о Q н
G о 0 о о о О G
F о о о о © ® F
Е о о о о о О Е
D о о о о о о D
С о о о о О о О о о о о о о о о о о С
В о о о о о о О о о о 0 о о о о о о В
А о о о © о о о о о о О о о о о о о А
17 16 15 14 13 12 11 •10 9 8 7 6 5 4 3 2 1
Рис. 2.1. Разводка контактов корпуса процессора i486
Микропроцессор i486 и Книга 2. Аппаратная архитектура
Таблица 2.1. Разводка контактов корпуса процессора i486
Адрес Данные Упр&вленне Ее подключены Пнт&ние Земли
А2 Q14 DO Pl A20MI D15 A3 B7 A7
АЗ R15 D1 N2 ADSI S17 A10 B9 A9
А4 S16 D2 N1 AHOLD Al 7 Al 2 Bll AH
А5 Q12 D3 H2 BEO! K15 A13 C4 B3
А6 S15 D4 М3 BE14 J16 Al 4 C5 B4
А7 Q13 D5 J2 BE2! J15 BIO E2 B5
А8 R13 D6 L2 ВЕЗ 1 F17 B12 El 6 El
А9 QH D7 L3 BLAST! R16 B13 G2 E17
А10 S13 D8 F2 BOFFI D17 B14 G16 G1
АН R12 D9 DI BRDII H15 B16 H16 G17
А12 S7 D10 E3 BREQ Q15 CIO JI Hl
А13 Q10 Dll Cl BS8! D16 CH K2 H17
А14 S5 D12 G3 BS16! Cl 7 C12 K16 KI
А15 R7 D13 D2 CLK C3 C13 L16 KI 7
А16 Q9 D14 КЗ D/Ci M15 G15 М2 LI
А17 Q3 D15 F3 DPO N3 R17 Ml 6 L17
А18 R5 D16 J3 DPI Fl S4 P16 Ml
А19 Q4 D17 D3 DP2 H3 R3 Ml 7
А20 Q8 D18 C2 DP3 A5 R6 Q2
А21 Q5 D19 Bl EADS! B17 R8 R4
А22 Q7 D20 Al FERRI C14 R9 S6
А23 S3 D21 B2 FLUSH! C15 RIO S8
А24 Q6 D22 A2 HLDA P15 RU S9
А25 R2 D23 A4 HOLD E15 R14 S10
А26 S2 D24 A6 IGNNE! Al 5 Sil
А27 S1 D25 B6 INTR Al 6 S12
А28 R1 D26 C7 KEN! F15 S14
А29 Р2 D27 C6 LOCK! Hl 5
АЗО РЗ D28 C8 M/IOl N16
А31 Q1 D29 A8 NMI B15
D30 C9 PCD J17
D31 B8 PCHKI QI 7
PWT L15
PLOCKI Q16
RDY1 F16
RESET С16
W/R# N17
Некоторые входные сигналы имеют внутренние резисторы, под-
ключенные к земле или источнику питания.
В таблице 2.2 приведена дополнительная информация о
выходных и двунаправленных сигналах процессора i486 (здесь ВВ
означает вход-выход).
Сигнальные линии процессора i486 объединяются в следующие
функциональные группы: сигналы шины адреса и данных, сигналы
определения цикла и управления, сигналы управления шиной, сиг-
налы управления кэш-памятью и сигналы управления ошибками с
плавающей точкой. Некоторые сигналы шины процессора имеют
двойное назначение: одно для обычных операций, а второе для тес-
тирования микросхемы; далее рассматриваются только обычные
функции сигналов.
Глава 2. Сигналы и временные диаграммы работы i486
Таблица 2.2. Выходные и двунаправленные сигналы
Сигнал Тип Когда находится в плаваюцем состоянии
А4-А31 BB Захват шины и захват адреса
А2-АЗ Выход Захват шины и захват адреса
D0-D31 BB Захват шины
BE0I-BB3# Выход Захват шины
DP0-DP3 BB Захват шины %
ADSI Выход Захват шины
M/I0I Выход Захват шины
D/CI Выход Захват шины
W/RI Выход Захват шины
BLAST! Выход Захват шины
LOCK! Выход Захват шины
PLOCKI Выход Захват шины
PCD Выход Захват шины
PWT Выход Захват шины
PCHKI Выход (никогда)
BREQ Выход (никогда)
HLDA Выход (никогда)
FERRI Выход (никогда)
ШИНЫ АДРЕСА И ДАННЫХ. Шины адреса и данных образу-
ют тракты, по которым в циклах шины реализуются передачи дан-
ных.
Внутренние
Вход/выход Выход
31 20 4 3 2 1 0
1 I.I t I I 1, 1 ..11L .1.1.1 I I I I I I
Маска 1 Мбайт
Адрес двойного слова
Кодирование
ВЕп #
Рис. 2.2. Сигналы адреса
Шина адреса состоит из сигналов адреса А2—А31 (Address),
которые приведены на рис. 2.2 и представляют собой смесь
двунаправленных и выходных сигналов (сигналы А4—А31 являются
двунаправленными, а сигналы А2—АЗ только выходными). Как
выходы, сигналы А2—А31 передают в пространство памяти или
ввода-вывода 30-битный физический адрес двойного слова. Как
входы, сигналы А4—А31 определяют адреса во внутренней кэш-
памяти, которые объявляются недостоверными в цикле
недостоверьюсти кэш-памяти, управляемом внешней схемой. Биты
Микропроцессор i486*Книга 2. Аппаратная архитектура
АО—Al действуют только внутри процессора; из них формируются
четыре рассматриваемых далее сигнала разрешения байт
ВЕО#—ВЕЗ#.
Процессор действует с адресацией с младшего конца: младший
байт двойного слова находится по меньшему адресу, а старший байт
по большему адресу.
Вход A20M# маски (Mask) бита адреса 20 обеспечивает эмуля-
цию заворачивания адреса на 1 Мбайте, которое действует в про-
цессоре 8086. Этот вход заставляет процессор i486 маскировать
(сбрасывать в 0) бит 20 физического адреса при поиске во внутрен-
ней кэш-памяти и при записи в память по шине процессора. При
обычной работе сигнал A20M# требуется только в R-режиме, кото-
рый эмулирует процессор 8086.
Образующие шину данных двунаправленные сигналы DO—D31
(Data) могут передавать двойное слово данных (рис. 2.3). По
линиям DO—D7 передается младший байт, а по линиям D24—D31
старший. Достоверные байты на 32-битной шине определяются
сигналами разрешения байт ВЕ0#-ВЕЗ#. Контрольный бит паритета
для каждого байта определяют сигналы DP0—DP3 (Data Parity).
Вход/выход
... 1. 1.1 1 1 1 1 1 ...1.. 1 1-1.11. 1 1 . J 1 I 11 1..I
31 24 29 16 15 8 7 0
Старший ВЕЗ# Разрешения байт 1 BE2# 1 BE1# 1 Младший 1 ВЕО*
DP3 Паритет данных 1 DP2 1 DPI 1 DP0
Рис. 2.3 Сигналы данных
Выходные сигналы разрешения байт ВЕО#—ВЕЗ# (Byte Enable)
показывают, какие байты на шине данных являются достоверными
(рис. 2.3). Сигналы разрешения байт необходимо игнорировать для
первой передачи кэшируемых циклов. Помимо функций разреше-
ния байт на шине данных эти сигналы выполняют две дополни-
тельные функции: их можно декодировать для формирования сиг-
налов АО, А1 и ВНЕ# {Byte High Enable — разрешение старшего
байта), которые применяются для адресации 8/16-битных систем, и
кодирования специальных циклов шины.
Входные сигналы размера шины BS8# и BS16# (Bus Size) совме-
стно с адресом данных управляют последовательностью, в которой
Глава 2. Сигналы и временные диаграммы работы i486
формируются сигналы разрешения байт. Сигналы BS8# и BS16# за-
ставляют процессор выполнить несколько циклов шины для удов-
летворения передач данных для 8/16-битных устройств. Передачи
двойных слов преобразуются в соответствующее число передач слов
или байт. Сигналы BS8# и BS16# необходимо формировать для
каждой передачи данных.
Двунаправленные сигналы паритета данных DPO—DP3 несут
контрольные биты паритета (четности) каждого байта на линиях
ЕЮ—D31 (рис. 2.3). Для использования контроля по паритету
внешняя схема должна зафиксировать эти сигналы при записи и
сформировать входы паритета при считывании. На паритет
контролируются только разрешенные байты.
Выходной сигнал контроля паритета PCHK# (Parity СНесК) по-
казывает ошибку паритета в одном или нескольких из четырех
байт, опрошенных в последнем такте передачи считывания. На па-
ритет контролируются только разрешенные байты. После таких
ошибок процессор продолжает свою обычную работу. Любое требу-
емое действие должна предпринимать внешняя схема.
ОПРЕДЕЛЕНИЕ ЦИКЛА И УПРАВЛЕНИЯ. Сигналы опреде-
ления цикла и управления определяют тип и направление цикла
(см. в таблице 2.3), моменты времени, когда данные становятся
достоверными или недостоверными, и кэшируемость цикла.
Таблица 2.3. Определение цикла шины
И/10* D/CI W/RI Тип передачи
с 0 0 Подтверждение прерывания
0 0 1 Специальные циклы шины (см. также BE0I-BE3#)
с 1 0 Считывание данных из ввода-вывода
0 1 1 Запись данных во ввод-вывод
1 0 0 Предвыборка (считывание) команд из памяти
1 0 1 (зарезервирован)
1 1 0 Считывание данных из памяти
2 1 1 Запись данных в память
Группу сигналов определения цикла шины и управления обра-
зуют следующие сигналы.
Выходной сигнал состояния адреса ADS# (ADdress State) пока-
зывает, что на шине процессора действуют достоверные сигналы
адреса и определения цикла. Выдача этого сигнала отмечает начало
цикла шины. В иг пакетных циклах шины каждый адрес отмечается
выдачей отдельного сигнала ADS# и одиночной передачей данных.
В пакетных циклах шины выдача сигнала ADS# отмечает начало
последовательности адресов и соответствующих передач данных.
Выходной сигнал памяти/ввода-вывода M/IO# (Memory/Input-
Output) предназначен дня того, чтобы отличить пространство памя-
М и препроцессор j 486 Книга 2. Аппаратная архитектура
ти от пространства ввода-вывода. Он применяется для определения
цикла шины. Для циклов останова и отключения кодирование это-
го сигнала противоположно принятому в процессоре 80386.
Выходной сигнал данных/управления D/C# (Data/Control) от-
личает циклы данных от всех остальных циклов и применяется для
определения цикла шины.
Выходной сигнал затаси/считываяня W/R# (Write/Read) пока-
зывает, является цикл записью или считыванием* и применяется
для определения цикла шины.
Входной сигнал яепакетной готовности RDY# (ReaDY) показы-
вает, что внешнее устройство представило достоверные данные на
шине данных или что внешнее устройство восприняло данные про-
цессора. Медленные устройства могут сформировать сигнал RDY#,
вводя состояния ожидания до стабилизации данных. Сигнал RDY#
всегда заканчивает текущий цикл шины, даже если он выдан в се-
редине пакетного цикла.
Входной сигнал пакетной готовности BRDY# (Batch ReaDY)
применяется вместо сигнала RDY# в пакетных передачах. Он ана-
логичен сигналу RDY#, хотя и не прекращает текущий пакетный
цикл. Процессор реагирует на сигнал BRDY#, полагая, что в сле-
дующем такте будет новая передача данных. В пакете можно пере-
дать максимум 16 байт со скоростью одно двойное слово, одно сло-
во или один байт за такт синхронизации. Выдача сигнала BLAST#
прекращает пакет.
Выходной сигнал последнего пакета BLAST# (Batch LAST) по-
казывает последнюю передачу любого цикла передачи данных
(пакетного или непакетного) с точки зрения процессора. Когда вы-
дается сигнал BLAST#, возвращаемый в процессор сигнал BRDY#
действует так же, как сигнал RDY#. Если сигнал BLAST# не выдан,
для завершения цикла требуются дополнительные передачи. Они
могут быть произведены в пакетном цикле, если внешняя память
допускает пакеты или в виде многоцикловой последовательности.
Входной сигнал разрешения кэш-памяти KEN# (cache ENable)
разрешает внутреннюю кэш-память. Можно кэшировать почти лю-
бой цикл считывания, являющийся пакетным или непакетным.
Когда активный сигнал KEN# подан правильно, текущий цикл
считывания преобразуется в заполнение строки кэш-памяти и будут
считываться 16 байт. Процессор выполнит столько последователь-
ных циклов, сколько требуется для заполнения 16-байтной строки
кэш-памяти. Сигнал KEN# в циклах записи игнорируется; записы-
ваемые процессором данные помещаются в кэш-память только при
попадании, т.е. только в том случае, когда их адрес находится в
кэш-памяти.
УПРАВЛЕНИЕ ШИНОЙ. Сигналы управления шиной, цикл
подтверждения прерывания и специальные циклы шины влияют на
Глава 2. Сигналы и временные диаграммы работы i486
5t
временную диаграмму обращения и защитные действия на шине
процессора. В приведенном далее списке сигналы и циклы сгруп-
пированы под двумя заголовками: действующие во всех системах и
действующие только в системах с несколькими ведущими шины.
1. Сигналы и циклы, используемые во всех системах:
Одиночный входной сигнал синхронизации CLK (CLocK) уп-
равляет временной диаграммой процессора и шины. Все временные
параметры определяются относительно нарастающего фронта сиг-
нала синхронизации, в котором применяются ТТЛ-уровни напря-
жения.
Входной сигнал сброса RESET вызывает инициализацию про-
цессора в известное начальное состояние. В зависимости от
значений других сигналов при действии сигнала сброса произво-
дится инициализация всех регистров или только регистров,-не от-
носящихся к плавающей точке; кроме того, процессор может вы-
полнить разнообразные тесты.
Входной сигнал маскируемого прерывания INTR (INTerrupt
Request), если он не замаскирован программно, прерывает процес-
сор и заставляет его подтвердить прерывание, считывая вектор или
номер прерывания из внешнего контроллера прерываний. Процес-
сор не имеет отдельного выхода для подтверждения прерывания;
вместо этого он выполняет особый цикл шины подтверждения пре-
рывания, в котором из внешней схемы считывается вектор преры-
вания.
Входной сигнал немаскируемого прерывания NMI (Non-Maskcd
Interrupt) прерывает процессор и заставляет его выполнить конк-
ретную процедуру обслуживания прерывания без считывания из
внешней схемы вектора прерывания. Немаскируемые прерывания
сигнализируют о ситуациях, требующих немедленного внимания
процессора, например отключение питания.
Специальный цикл останова показывает, что процессор приос-
тановил свои операции. Он формируется при выполнении команды
останова HLT.
Специальный цикл отключения показывает, что процессор пре-
кратил все свои операции. Он формируется при возникновении не-
скольких особых случаев защиты.
2. Сигналы, используемые в системах с несколькими ведущими
шины:
Выходной сигнал запроса шины BREQ (Bus REQuest) показывает,
что процессор требует доступа к шине или что он в данное время
использует шину. Этот сигнал подается во внешнюю схему ар-
битража, которая управляет доступом к шине нескольких ведущих
шины. Сигнал BREQ формируется всегда, когда процессор имеет
ожидающий цикл, независимо от того, управляет процессор шиной
или нет. Этот сигнал никогда не переводится в плавающее состоя-
Микропроцессор i486 Книга 2. Аппаратная архитектура
ние. Следовательно, сигнал BREQ можно выдавать во время захвата
шины (HOLD), отступления шины (BOFF#) или захвата адреса
(AHOLD).
Входной сигнал захвата шины HOLD заставляет процессор ос-
вободить шину. Он используется другими ведущими шины для по-
лучения доступа к шине. В ответ процессор после завершения те-
кущего цикла шины (или последовательности блокированных цик-
лов шины) переводит большинство сигнальных линий в плавающее
состояние и выдает подтверждающий сигнал HLDA. Захват шины
отличается от запроса шины, который рассмотрен выше. Захват
шины распознается во время сброса.
Выходной сигнал подтверждения захвата шины HLDA (HoLD
Acknowlegment) показывает, что процессор в ответ на вход HOLD
перевел большинство своих сигнальных линий в плавающее
(высокоимпедансное) состояние. Во время захвата шины процессор
продолжает внутренние операции, так как большинство запросов
шины удовлетворяют кэш-память и устройство предвыборки ко-
манд. Если процессору потребуется шина, он выдает сигнал BREQ.
Выходной сигнал блокировки шины LOCK# позволяет процес-
сору произвести несколько циклов шины без прерываний по входу
HOLD. Сигнал LOCK# формируется в операциях считывания-мо-
дификации-записи (Read-Modify-Write — RMWf в циклах подтвер-
ждения прерывания и загрузок дескрипторов сегментов. Помимо
этих операций он выдается при модификации семафоров, управля-
ющих доступом к разделенным ресурсам. В системах с внешней
кэш-памятью блокированные циклы должны всегда вызывать цикл
системной шины. В заблокированных циклах процессор не распоз-
нает запрос HOLD, но распознает запрос BOFF# или AHOLD (см.
далее).
Выходной сигнал псевдоблокировки шины PLOCK# (Pseudo-
LOCK), как и сигнал LOCK#, позволяет процессору выполнить не-
сколько циклов шины без прерываний по входу HOLD. Сигнал
PLOCK# выдается во всех многоцикловых последовательностях, в
которых передаваемые данные выравнены по границам
счетверенных слов. Это возникает при передаче 64-битных
операндов с плавающей точкой и заполнении строки кэш-памяти.
Сигналы BLAST# и PLOCK# имеют дополняющую взаимосвязь.
Когда сигнал BLAST# снимается и достоверен, выдается сигнал
PLOCK# — за исключением первой передачи 64-битной записи. В
циклах с псевдоблокировкой процессор не распознает сигнал
HOLD, но распознает запрос BOFF# или AHOLD.
Входной сигнал отступления шины BOFF# (Bus backOFF) пока-
зывает, что другому ведущему шины требуется закончить цикл ши-
ны раньше окончания текущего цикла процессора. Он применяется
для исключения «смертельного объятия» (или «клинча»), когда ни
Глава 2. Сигналы и временные диаграммы работы i486
процессор, ни другой ведущий шины не могут закончить свои опе-
рации, так как каждый ожидает некоторого действия другого. Сиг-
нал BOFF# распознается в любой момент времени. Реакция про-
цессора на сигнал BOFF# аналогична реакции на сигнал HOLD, но
оказывается более быстрой; когда подается сигнал BOFF #, шина
всегда освобождается в следующем такте и подтверждения не выда-
ется. Когда сигнал BOFF# снимается, процессор надежно осуще-
ствляет рестарт того цикла шины, который был прекращен. Если
одновременно с сигналом BOFF# подается сигнал RDY# или
BRDY#, распознается только сигнал BOFF#.
УПРАВЛЕНИЕ КЭШ-ПАМЯТЬЮ. Данные кэшируемых
считываний сохраняются во внутренней кэш-памяти процессора
емкостью 8 Кбайт, когда действует входной сигнал KEN# и удов-
летворяются рассмотренные далее другие условия. Управление кэш-
памятью обеспечивает согласованность внутренней кэш-памяти,
основной памяти и внешней кэш-памяти в тех циклах, которые
модифицируют любую из них.
Каждая страница 4 Кбайт в основной памяти может
подчиняться принципу кэшируемости и сквозной записи (или об-
ратной записи) с управлением по тактам. Управление на уровне
страниц обеспечивают два выходных сигнала.
Выходной сигнал запрещения кэширования страницы PCD (Page
Cache Disable) показывает, является ли текущая страница кэ-
шируемой. Информация берется из элементов таблицы страниц,
используемых внутренней кэш-памятью, и может применяться для
управления внешним кэшированием.
Активный выходной сигнал сквозной/обратной записи PWT (Page
Write-Through) определяет для текущей страницы принцип
сквозного кэширования (в котором модификации во внешней кэш-
памяти немедленно записываются в память). Снятый сигнал PWT
допускает принцип кэширования с обратной записью, в котором
модификации в кэш-памяти записываются в память только по спе-
циальному запросу. Этот сигнал, который также берется из элемен-
тов таблицы страниц, полезен только для внешней кэш-памяти;
внутренняя кэш-память всегда действует со сквозной записью.
Три входных сигнала вызывают объявление недостоверной части
или всей внутренней кэш-памяти.
Входной сигнал захвата адреса AHOLD (Address HOLD) застав-
ляет процессор перевести шину адреса в плавающее состояние в
следующем такте синхронизации. Это позволяет вешнему устрой-
ству передать адрес в процессор для объявления недостоверной
строки внутренней кэш-памяти. Адрес стробируется входным сиг-
налом EADS#. В плавающее состояние переводится только шина
адреса; остальные сигналы шины остаются активными. Подгверж-
4544W
Микропроцессор i486 Книга 2. Аппаратная архитектура
дсние захвата адреса не выдается. При сбросе сигнал AHOLD при-
меняется дая тестирования.
Входной сигнал недостоверности строки внутренней кэш-памяти
EADS # (External ADdress State) показывает, что в процессор по-
дается и является достоверным адрес 16-байтной строки кэш-памя-
ти. Это приводит к немедленному объявлению недостоверной стро-
ки кэш-памяти по этому адресу, если адрес соответствует кэширо-
ванной области. Сигнал EADS# применяется совместно с сигналом
AHOLD. В большинстве случаев процессор может воспринимать
адрес недостоверной строки в каждом такте синхронизации. За
одну операцию захвата адреса можно объявить недостоверными не-
сколько строк.
Входной сигнал очистки внутренней кэш-памяти FLUSH# зас-
тавляет процессор очистить все содержимое его внутренней кэш-
памяти. Так как эта кэш-память действует по принципу сквозной
записи, ее содержимое уже записано в память. При сбросе сигнал
FLUSH# участвует в тестировании процессора.
Два специальных цикла шины управляют недостоверностью и
обратной записью дая внутренней и внешней кэш-памяти.
Цикл очистки кэш-памяти выполняет два действия: превращает в
недостоверное все содержимое внутренней кэш-памяти и запра-
шивает внешнюю кэш-память объявить недостоверным все ее со-
держимое. Внешняя кэш-память не должна записывать ее содержи-
мое в память перед очисткой. Этот цикл инициирует команда INVD
(INValiDate cache).
Цикл обратной записи и очистки кэш-памяти выполняет три
действия: превращает в недостоверное все содержимое внутренней
кэш-памяти, запрашивает внешнюю кэш-память записать все дос-
товерное содержимое в память (т.е. осуществить обратную запись
или «выгрузку») и запрашивает внешнюю кэш-память объявить не-
достоверным все ее содержимое после обратной записи. Функция
обратной записи не применяется к внутренней кэш-памяти, кото-
рая действует по принципу сквозной записи. Данный цикл иници-
ирует команда WBINVD (Write-Back and INValiDate cache).
УПРАВЛЕНИЕ ОШИБКАМИ С ПЛАВАЮЩЕЙ ТОЧКОЙ. Длг
поддержания совместимости с сообщениями операционной систе-
мы DOS об ошибках с плавающей точкой предназначены два сиг-
нала. Один из них извещает систему об ошибках в устройстве с
плавающей точкой процессора, а второй сообщает процессору о
действиях при возникновении ошибки. Реализованный механизм
совместим с управлением ошибками в других процессорах семей-
ства 8086 и со средой DOS.
Выходной сигнал ошибки с плавающей точкой FERR# (Floating
ERRor) показывает, что возникла незамаскированная ошибка с
Глава 2. Сигналы и временные диаграммы работы i486
плавающей точкой. Он аналогичен сигналу ERROR# сопроцессо-
ров 80287 и 80387. Ради совместимости с сообщением об ошибке
DOS сигнал FERR# подается на вход INTR немаскируемых преры-
ваний процессора.
Входной сигнал игнорирования ошибки с плавающей точкой
IGNNE# (IGNore Numerical Error) сообщает процессору о том, чтобы
игнорировать ошибку с плавающей точкой и продолжить
выполнение программы. Если сигнал IGNNE# снят при обнаруже-
нии ошибки с плавающей точкой, процессор либо останавливается
и ожидает прерывания, либо переходит к прерыванию по ошибке с
плавающей точкой (вектор 16) в зависимости от состояния одного
из бит в регистре управления.
2.4. Временная диаграмма
и формирование синхронизации
В процессоре i486 применяется одночастотная (1х) синхрониза-
ция. Все операции на шине (за исключением двух асинхронных
входов NMI и IGGNE#) привязаны к нарастающему фронту сигна-
ла CLK.
Применение синхронизации 1х имеет два преимущества по
сравнению с двухчастотной синхронизацией 2х, которая применя-
ется в процессоре 386. Во-первых, синхронизация 1х упрощает про-
ектирование системы, так как частота для внешних устройств по-
нижается в два раза. Во-вторых, сокращается до минимума высо-
кочастотное излучение и упрощается генератор синхронизации. Для
достижения высокой производительности применяется частота
синхронизации 25 МГц и выше.
ДИАГРАММА СОСТОЯНИЙ ШИНЫ. При выполнении рас-
смотренных ранее операций шина может проходить через пять со-
стояний. Переход из одного состояния в другое осуществляется в
каждом такте синхронизации, даже в том случае, когда когда пере-
ход связан с возвратом в предшествующее состояние. Сами состоя-
ния приведены в таблице 2.4, а диаграмма состояний показана на
рис. 2.4. Звездочка на рис. 2.4 означает следующий события: после-
дняя передача цикла; подан сигнал RDY# или BRDY#; сняты сиг-
налы HOLD, AHOLD и BOFF#; ожидает новый цикл шины. Двой-
ная звездочка на этом же рисунке означает такие события: после-
дняя передача цикла; подан сигнал RDY# или BRDY#; сняты сиг-
налы HOLD и AHOLD; нет ожидающего нового цикла при снятом
сигнале BOFF#.
МВ
Микропроцессор i486 Книга 2. Аппаратная архитектура
Сняты
Таблица 2.4. Состояния шины
Состоял* Опвсааве .
Ti Холостая шина. Сигналы адреса и состояния либо имеют неопределенные значения, либо шина находится в высокоимпедансном (плавающем) состоянии.
Т1 Первый такт цикла шины. Выданы достоверные адрес и состояние, формируется сигнал ADSI.
Т2 Второй и последующие такты цикла шины. В цикле записи выдаются данные, а в цикле считывания ожидаются данные. Опрашиваются сигналы RDYI и BRDYi.
Tib Первый такт рестартируемого цикла шины. Выдаются достоверные адрес и состояние и формируется сигнал ADSI. Внешне это состояние невозможно отличить от состояния Т1.
Tb Второй и последующие такты отмененного цикла шины.
Глава 2. Сигналы и временные диаграммы работы i486
Когда не выполняется цикла шины или когда поданы сигналы
HOLD или BOFF#, шина зацикливается в холостом состоянии Ti.
Шина переходит в состояние Т1, когда запускается новый цикл
шины и нет сигналов захвата или отступления шины. Шина пере-
ходит в состояние Т2, если в течение одного такта Т1 не получен
сигнал BOFF#. Шина зацикливается в состоянии Т2 до восприятия
сигнала RDY# или последнего сигнала BRDY# в пакетном цикле
или подачи сигнала BOFF#.
Шина возвращается в состояние Т1, если приняты сигналы
BRDY# или RDY# для непакетной передачи или приняты после-
дние сигналы BRDY# или RDY# для последней передачи пакетного
цикла, при условии, что ожидается новый цикл шины, а все
сигналы HOLD, AHOLD и BOFF# сняты. Если подается сигнал
HOLD или AHOLD или если не ожидает новый цикл шины, при
отсутствии сигнала BOFF# шина возвращается в холостое
состояние Ti.
Если при нахождении шины в состоянии Т1 или Т2 подан сиг-
нал BOFF #, шина переходит в состояние отступления ТЬ. Она ос-
тается в этом состоянии при действии сигналов HOLD, AHOLD
или BOFF#. Когда все эти сигналы снимаются, шина переходит в
состояние Tib, готовая к рестарту отмененного цикла. Шина пере-
ходит в состояние Т2 в следующем такте, если сигнал BOFF# оста-
ется снятым. В противном случае шина переходит в состояние ТЬ.
В таблице 2.5 приведены шесть условий, когда процессор пере-
водит сигналы шины, включая шину адреса, в плавающее состоя-
ние, т.е. эффективно отключается от шины и не управляет ею.
Таблица 2.5. Процессор эффективно отключается от шины...
Когда ... Процессор ...
В холостом состоянии Ti подается сигнал HOLD, ... Переводит шину в плавающее состояние и в следующем такте выдает сигнал HLDA.
В состоянии отступления (ТЬ) выдается сигнал HOLD, ... Остается в состоянии ТЬ. Шина не переводится в плавающее состояние.
Подан сигнал HOLD, подан сигнал RDY# и сигнал BOFF# снят в состоянии Т2, ... Переводит шину в плавающее состояние и в следующем такте выдает сигнал HLDA.
Подан сигнал HOLD, подан сигнал BRDY# и сигнал BOFF# снят в состоянии Т2 для последней передачи пакетной или непакетной передачи, ... Переводит шину в плавающее состояние и в следующем такте выдает сигнал HLDA.
Подан сигнал BOFF#, ... Переводит шину в плавающее состояние без выдачи сигнала HLDA.
Подан сигнал AHOLD, ... В следующем такте переводит в плавающее состояние линии А2-А31.
Микропроцессор i486 и Книга 2. Аппаратная архитектура
ФОРМИРОВАНИЕ СИНХРОНИЗАЦИИ. Для синхронизации
всех внутренних действий процессор использует только один ТТЛ-
вход CLK. Сигнал CLK применяется без деления его частоты (1х).
Процессор допускает работу в широком диапазоне частот, но при
пассивом сигнале RESET быстро изменять частоту сигнала CLK
нельзя.
БАЗОВАЯ ОПЕРАЦИЯ СЧИТЫВАНИЯ. Непакетные передачи
данных занимают минимум два такта синхронизации. В течение
первого такта адрес источника или получателя данных помещается
на линии адреса и выдается сигнал ADS#. В этот же момент време-
ни сигналы М/Ю#, D/C# и W/R# определяют тип и направление
передачи. Например, при считывании данных из памяти сигналы
M/IO# и D/C# имеют высокий уровень, а сигнал W/R# низкий
уровень. Во втором такте синхронизации данные передаются в про-
цессор в конце такта, если сформирован входной сигнал RDY#. В
противном случае процессор ожидает поступления сигнала RDY#.
2.5. Организация памяти и ввода-вывода на шине
Как и в других процессорах семейства 8086, система команд
процессора i486 поддерживает адресное пространство памяти, кото-
рое отделено от адресного пространства портов ввода-вывода (ВВ).
Допускается адресация памяти до 4 Гбайт (32-битные адреса) и
портов ввода-вывода до 64 Кбайт (16-битные адреса). Пространства
памяти и ввода-вывода имеют аппаратную поддержку защиты и
мультизадачное™.
СТРУКТУРА ШИНЫ ДАННЫХ. Для программиста ячейки па-
мяти и порты ВВ доступны как 8/16/32-битные элементы и как дру-
гие структуры данных. Слово образуют два любых байта с последо-
вательными адресами, а двойное слово — четыре любых байта с
последовательными адресами. Однако аппаратно память и ВВ на
шине данных считаются последовательностью двойных слов
(максимум 230 32-битных ячеек памяти и 214 32-битных портов
ВВ). С точки зрения процессора каждая ячейка с двойным словом
имеет четыре отдельно адресуемых байта с соседними адресами.
Каждая 32-битная ячейка памяти начинается по физическому адре-
су, который кратен четырем.
Младший байт двойного слова передается по линиям DO—D7
шины данных, а старший байт — по линиям D24—D31. Кроме того,
младший байт двойного слова является байтом с наименьшим адре-
сом, а старший байт — байтом с наибольшим адресом, как показа-
но на рис. 2.5.
Глава 2. Сигналы и временные диаграммы работы i486
9f
N + F N + E N + D N + C
N + B N+A N + 9 N + 8
N + 7 N+6 N + 5 N + 4
N + 3 N + 2 N+1 N *
31 24 23 16 15 8 7 О
। 1 । » » I 1 I. 11-1--L- —L-J 1.1.1 1 1 ..... 1 1 1 1 1 1 1
Старший Младший
--ВЕЗ#—х—BE2#----х—ВЕ1 # х—BEO#------
Рис. 2.5. Структура шины данных
Аппаратно пространства памяти и ВВ необходимо реализовать
как четыре секции. Каждая секция подключается к байту на шине
данных (D0-D7, D8-D15, D16—D23 и D24-D31). Когда
процессор считывает двойное слово, он обращается к одному байту
из каждой секции.
31
О
0
2 0
3 1 0
ВЕЗ#
BE2#
BE1#
BEO#
Адреса
байт
Адреса
слов
Адреса
двойных
слов
Рис. 2.6. Адресация байт, слов и двойных слов
Старшие биты физического адреса А2—А31 адресуют двойные
слова памяти. Два младших бита физического адреса используются
только внутри процессора для формирования выходных сигналов
разрешения байт (ВЕО#—ВЕЗ#).
Способ адресации байт, слов и двойных слов показан на
рис. 2.6. При реализации четырех секций памяти сигналы
Микропроцессор i486 • Книга 2. Аппаратная архитектура
ВЕО#—ВЕЗ# используются как сигналы выбора секций и каждая
секция передает данные по одному байту шины процессора.
Выравненное
двойное слово
Невыравненное
двойное слово
Выравненное
слово
Выравненное
слово
Выравненное
слово
Невыравненное
слово
Рис. 2.7. Выравнивание данных на 32—битной
тине данных
ВЫРАВНИВАНИЕ ДАННЫХ. Обычно программы считают дан-
ные выравненными, если адрес данных кратен их ширине. Однако
схемы процессора i486 учитывают выравнивание менее строго. Пе-
редачи по полной 32-битной шине данных процессора считаются
выравненными, если данные не перекрывают ipaunn двойных слов.
Слово выравнено, если его можно считать в любой из трех возмож-
ных позиций в пространстве двойного слова (см. в таблице 2.6 и
рис. 2.7).
Таблица 2.6. Выравнивание данных
Передаваемы» байты Разрешенные байт»
4 байта 3-2-1-0
3 байта 3-2-1 2-1-0
2 байта 3-2
2-1
1-0
1 байт 3
2
1
О
Глава 2. Сигналы и временные диаграммы работы i486
Выравнивание данных влияет на производительность процессо-
ра: передачи выравненных слов и двойных слов занимают один
цикл шины, а передачи невыравненных слов и двойных слов тре-
буют двух циклов шины.
Выравненное двойное слово имеет адрес, в котором два млад-
ших бита содержат нули. Выравненное слово может иметь любой
адрес, за исключением адреса, в котором два младших бита уста-
новлены в 1. Если адресуемое слово находится в середине границы
двойного слова (байты 1 и 2 разрешены, но не байты 0 и 3), с аппа-
ратной точки зрения слово выравнено — оно будет передаваться в
одном цикле по полной 32-битной шине — даже если при этом
сформируется нарушение контроля выравнивания.
Первый цикл шины: А31-А2 = п + 4
32-битная память
------—*--------------------------
Данные Данные
ВЕЗ# BE2# BE1# BEO#
110 0
Второй цикл шины: А31-А2 = п
32-битная память
Данные Данные
0 0 11
Рис. 2.8. Передача невыравненного двойного слова
На рис. 2.8 показано считывание невыравненного двойного
слова из ячейки памяти п+2. Операция занимает два цикла шины
[У 6 2
Микропроцессор i486 • Книга 2. Аппаратная архитектура
вместо одного. В первом цикле обращение производится к
верхнему слову двойного слова по адресам п+4 и п+5 с выдачей
сигналов BE1# и ВЕО#. Во втором цикле считывается нижнее слово
по адресам п+2 и п+3 с выдачей сигналов ВЕЗ# и ВЕ2#.
Для максимальной совместимости программ с аппаратной сре-
дой программисты должны хранить слова данных выравненными по
двухбайтным границам, двойные слова выравненными по
четырехбайтным границам и счетверенные слова (например, опе-
ранды с плавающей точкой и дескрипторы сегментов) выравнен-
ными по 8-байтным границам. Выравнивание счетверенных слов
полезно потому, что процессор может считать выравненное
счетверенное слово из своей внутренней кэш-памяти за один такт
синхронизации. Такое выравнивание удобно и в ожидании будущих
процессоров с 64-битными шинами данных.
Для отметки невыравненных данных предусмотрен программный
механизм. Он контролирует слова данных для операндов-слов,
двухсловные данные для операндов-двойных слов и
четырехсловные данные для операндов-счетверенных слов. Генери-
руется прерывание 17, если
— бит контроля выравнивания АС в регистре слова состояния
машины (регистр управления CR0) установлен в 1;
— бит контроля выравнивания ЛС не замаскирован;
— контролируются данные на уровне пользователя 3.
Как показано выше, выравненные слова, в которых разрешены
байты 1 и 2 (но не байты 0 и 3), сформируют нарушение контроля
выравнивания, но, тем не менее, передаются в одном цикле шины.
НЕВЕРНАЯ ПРЕДВЫБОРКА КОМАНДЫ. Процессор может
осуществить предвыборку команд по адресам памяти, которых про-
граммисты не ожидают. Например, в процессе предвыборки воз-
можно обращение за концом программы в памяти. Устройство
предвыборки никогда не считывает за концом сегмента команд и не
обращается к неприсутствующей странице. При попытке выпол-
нить команду, которая нарушает предел сегмента или обращается к
неприсутствующей странице, формируется особый случай.
Проблема возникает только в той ситуации, когда при предвы-
борке производится обращение за конец физической памяти без
особого случая превышения предела сегмента или страничного на-
рушения. Такая ситуация может появиться в системах R-режима,
имеющих память менее 1 Мбайт. Внешние схемы могут отреагиро-
вать на такое обращение неверными данными, неготовностью или
неисправностью. Если, например, память кончается по адресу
0FFFFH, то при обращении по большему адресу возникнут ошибка
паритета или таймаут. Чтобы предотвратить предвыборку команд
выше адреса 0FFFFH, последний байт последней команды должен
Глава 2. Сигналы и временные диаграммы работы i486
находиться по адресу 0FFEEH. При этом между выполняемыми
командами и концом памяти вводится один свободный байт и вы-
равненный 16-байтный блок. Если программа никогда не выполня-
ется за концом памяти, но предвыборка оттуда может происходить,
следует обеспечить, чтобы предвыборка оканчивалась готовностью
и чтобы имел место правильный паритет.
СТРУКТУРА ПОРТОВ ВВОДА-ВЫВОДА. Процессор поддер-
живает два способа адресации 8/16/32-битных устройств ВВ. Уст-
ройства с отображением на ВВ адресуются через отдельное про-
странство ВВ с помощью команд ВВ и поддерживаются специаль-
ным аппаратным механизмом защиты. Устройства с отображением
на память адресуются через пространство памяти, причем порты ВВ
считаются адресами памяти; для доступа к портам применяется си-
стема команд общего назначения, а защита обеспечивается меха-
низмом сегментации и страничной организации памяти.
Системы с отображением на ВВ отображены на пространство ВВ
64 Кбайт (диапазон от 0 до 65535). Для выбора портов необходимы
схемы декодирования выходных сигналов M/IO# и D/C#. Порты
адресуются косвенно с привлечением регистра DX или прямо с по-
мощью байта, закодированного в команде. Прямая адресация допу-
стима только для адресов в диапазоне от 0 до 255. Если число пор-
тов невелико, то ради простоты и быстродействия все порты следу-
ет разместить в этом нижнем диапазоне. В системах с отображе-
нием на ВВ наиболее просто реализуется дешифрирование адреса.
При отображении ВВ на память из-за намного большего адрес-
ного пространства (4 Гбайт физической памяти) требуется более
сложный способ дешифрирования адреса. Этот метод допустимо
применять, если устройства ВВ реагируют, как ячейки памяти. При
отображении ВВ на память нельзя применять команды и структуры
данных ВВ, но зато здесь применимы все остальные команды ши-
рокого назначения. Поддержку защиты и мультизадачное™ для
портов ВВ с отображением на память обеспечивает сегментация и
страничная организация памяти.
Как и слова в памяти, 16-битные порты ВВ должны быть вырав-
нены по четным адресам, чтобы все слова можно было передавать
за один цикл пгины. Как и двойные слова в памяти, 32-битные
порты следует выравнивать по адресам, кратным четырем. Процес-
сор допускает передачи дайных из невыравненных портов, но при
этом требуется лишний цикл шины. При обращении к порту, кото-
рый пересекает границу двойного слова, независимо от того, ото-
бражен он на ВВ или память, первое обращение производится к
старшему двойному слову.
Схемы ВВ не должны опираться на тот порядок байт, который
процессор использует при обращении к памяти, за исключением
Микропроцессор i486 Книга 2. Аппаратная архитектура
порядка, определенного для пакетных передач. Фирма Intel остави-
ла за собой право изменения порядка байт в непакетных циклах
шины.
Сигнал PCHK# контроля паритета формируется в циклах памя-
ти и ВВ. Если порты не возвращают биты паритета при
считывании, выход PCHK# при обращении к ВВ следует маскиро-
вать, чтобы избежать соответствующих прерываний. Это относится
к вводу-выводу с отображением на память и ВВ. Внутри процессора
сигнал PCHK# маскируется, чтобы предотвратить сообщения об
ошибках паритета в цикле подтверждения прерывания и в специ-
альных циклах шины. Процессор i486 выполняет циклы ВВ с
учетом буферов записи.
16- И 8-БИТНЫЕ ПЕРИФЕРИЙНЫЕ УСТРОЙСТВА. Входные
сигналы BS16# и BS8# размера шины позволяют внешней системе
по тактам определять, будет ли адресуемое периферийное устрой-
ство передавать по шине процессора только 8 или 16 бит данных.
Если устройство не может возвратить все запрошенные байты, про-
цессор выполнит достаточно циклов шины для завершения пере-
дачи. Данные должны быть представлены по всей ширине 32-бит-
ной шины процессора, даже если этого нельзя произвести одно-
временно.
Если 8- или 16-битные запоминающие устройства поддерживают
кэшируемые передачи в процессор, внешняя схема должна обнару-
жить первую передачу кэшируемого цикла и правильно разместить
байты на шине данных процессора во время этой первой передачи.
2.6. Передачи данных
При передачах данных, называемых также циклами данных, по
шине процессора пересылаются команды, операнды и другие дан-
ные. Каждый элемент данных (двойное слово, слово или байт)
идентифицируется адресом и сигналами разрешения байт.
Циклы шины управляют передачами данных с помощью после-
довательности смены сигналов на шине. Начало циклов шины пе-
редачи данных отмечается выдачей выходного сигнала состояния
адреса ADS#. На временных диаграммах начало и конец цикла
шины обычно показываются вертикальными пунктирными линия-
ми.
Один цикл шины может включать в себя более одной передачи
данных; например, пакетные циклы передают несколько элементов
данных в одном цикле. Обратное утверждение справедливо для
8/16-битных размеров шины: одна 32-битная передача данных за-
нимает несколько циклов шины.
Глава 2, Сигналы и временные диаграммы работы i486
3 Заказ 4317
Передачи данных осуществляются двумя основными способами.
С помощью непакетных циклов производятся некэшируемые опе-
рации считывания или записи памяти или ВВ, а также кэшируемые
операции считывания из памяти (включая предвыборку команд). С
привлечением пакетных циклов реализуются некэшируемые опера-
ции считывания памяти или ВВ и (для небольших размеров шины)
записи, а также кэшируемые операции считывания из памяти
(включая предвыборку команд).
Непакетные циклы, которые передают один элемент данных, на-
зываются циклами одиночной передачи. Непрерывная серия непа-
кетных циклов одиночной передачи называется многоцикловой
последовательностью. С помощью кэшируемых циклов в процес-
соре образуются внутренние копии последних считанных команд,
операндов и других данных. Когда процессор формирует запрос
считывания, он вначале проверяет наличие адресуемых данных в
кэш-памяти. Если данные по нужному адресу ранее считаны в кэш-
память и достоверны (попадание), цикл шины не требуется. Если
же нужные данные отсутствуют или недостоверны (промах), про-
цессор осуществляет считывание из памяти. При считывании из
памяти, которое было вызвано промахом, процессор передает в
кэш-память 16 байт (заполнение строки кэш-памяти), если кэши-
рование разрешено. В заполнения строки кэш-памяти преобразу-
ются только считывания из памяти; записываемые данные поме-
щаются в кэш-память, если только их адрес уже кэширован.
Пакетные циклы являются самым быстрым способом передачи
более одного элемента данных и могут заметно повысить произво-
дительность системы. В таких циклах передаются до 16 байт смеж-
ных выравненных данных с максимальной скоростью в один эле-
мент данных за такт синхронизации. Пакетные циклы введены, в
основном, для заполнений строки кэш-памяти, но их можно при-
менять и для некэшируемых передач с участием меньшего числа
байт. В таблице 2.7 приведены ограничения на пакетные и
кэшируемые циклы.
Тип цикла Ограничения
Пакетные циклы Можно пакетировать только считывания из памяти или ВВ, которые требуют более одной передачи данных, например операции предвыборки команд. Пакетные записи можно выполнять только по 16- или 8-битным шинам данных максимум для четырех байт.
Кэшируемые циклы Допускается кэшировать только считывания из памяти (включая предвыборку команд). Считывания с отображением на ВВ и подтверждения прерывания кэшировать нельзя.
Микропроцессор i486 Книга 2. Аппаратная архитектура
2.6.1. Непакетные циклы
Непакетная передача одного элемента данных называется цик-
лом одиночной передачи. Минимальный цикл одиночной передачи
считывания или записи длится два такта. Он называется циклом
шины «2—2», так как циклы считывания и циклы записи занимают
по два такта. Если внешняя схема не может отреагировать в
течение второго такта, цикл шины 2—2 можно превратить в цикл
«3—3», в котором циклы считывания и циклы записи занимают по
три такта. Непрерывная серия непакетных циклов одиночных
передач называется многоцикловой последовательностью. Из
непакетных циклов можно кэшировать только многоцикловые
последовательности.
Ti CLK /\ ADS# А2-А31, Чте Tl L ние T2 J 3ai Tl L 1ИСЬ T2 J Чте Tl c ние T2 Зап T1 ись T2 Ti
M/IO#, X' JL X X
D/C#, BEO#-3# W/R# \ \_ J /./1 ‘ \ J////.
l/: i * 1/1 / * ://l > \
RDY# /./i
BLAST# X * \
Данные —(bl in)— —45Г ur) /bi цп) (B Цп)
PC H к # \ u J
Рис. 2.9. Непакетный и некэшируемый цикл 2—2
НЕКЭШИРУЕМЫЕ ЦИКЛЫ 2-2. На рис. 2.9 приведена вре-
менная диаграмма некэшируемых циклов одиночных передач, т.е.
самого быстрого непакетного цикла шины, который поддерживает
процессор. (На этом и последующих рисунках звездочка означает
недостоверный сигнал, а пунктирные линии показывают, что
значение сигнала безразлично.) Цикл начинается с появления ста-
бильного адреса и выдачи процессором сигнала ADS# состояния
Глава 2. Сигналы и временные диаграммы работы i486
адреса, показывающего, что сигналы адреса и определения цикла
шины выданы. Первый такт используется только для передачи ад-
реса и определения цикла шины. В случае цикла считывания вне-
шние устройства в это время производят дешифрирование и подго-
товку данных.
В течение второго такта сигнал ADS# снимается, но шина адре-
са и другие сигналы определения цикла шины остаются стабиль-
ными. Для завершения передачи внешняя схема должна выдать
сигнал RDY# готовности перед самым концом второго такта. Про-
цессор опрашивает сигнал RDY# по нарастающему фронту сигнала
CLK в третьем такте. Сигнал RDY# показывает, что внешнее уст-
ройство может воспринимать данные при записи или возвратить
данные при считывании.
Сигнал RDY# игнорируется в конце первого такта цикла шины.
Во втором такте поступление этого сигнала не просто показывает
восприятие или достоверность данных, но и разрешает выдачу сле-
дующего сигнала ADS#, если требуется больше передач данных.
При правильной подаче сигнала RDY# сигнал BRDY# пакетной го-
товности (он применяется для вызова пакетной передачи) в течение
цикла шины может находиться в любом состоянии. Сигнал RDY#
всегда имеет старшинство над сигналом BRDY# при опросе их по
нарастающему фронту сигнала CLK во втором такте. Если внешняя
система не может отреагировать вовремя, она не должна выдавать
сигнал RDY# (и сигнал BRDY#) до получения правильной реакции
(о введении состояний ожидания см. далее).
Процессор выдает сигнал BLAST# последнего пакета в после-
днем (втором) такте цикла шины (см. рис. 2.9). Он показывает, что
передача завершена после одного цикла. Несмотря на то, что сиг-
нал BLAST# предназначен, в основном, для использования с па-
кетными циклами, процессор выдает его во всех циклах шины, по-
казывая, когда он ожидает окончания последней передачи цикла.
На рис. 2.9 показаны четыре чередующихся цикла считывания и
записи. В циклах записи данные не появляются на шине до второго
такта. Благодаря этому отводится время на прохождение записыва-
емых данных через внутренние устройства процессора, а также вре-
мя приемопередатчикам внешней шины на стабилизацию после
предыдущего цикла считывания. Время сохранения записываемых
данных значительно больше времени сохранения считываемых дан-
ных, чтобы обеспечить работу с медленной памятью. Памяти может
потребоваться фиксировать адрес записываемых данных, если ее
время сохранения больше времени сохранения процессора. Так как
большинство запросов считывания процессора приводят к попада-
ниям в кэш-памяти (цикла шины нет), необходимо оптимизировать
системы по циклам записи.
Микропроцессор i486 и Книга 2. Аппаратная архитектура
В циклах считывания производится контроль по паритету. Вы-
ходной сигнал PCHK# контроля паритета показывает ошибку пари-
тета от предыдущего такта. Он оказывается достоверным через один
такт после сигнала RDY# готовности. На паритет контролируются
только разрешенные байты. После ошибок паритета процессор
продолжает обычные операции. Внешняя схема должна зафиксиро-
вать ошибки паритета и при необходимости предпринять соответ-
ствующее действие.
CLK
ADS#
А2-А31,
М/Ю#,
D/C#,
ВЕО#-3#
W/R#
RDY#
BLAST#
Данные
Рис. 2.10. Непакетный, и некотируемый цикл 3—3
НЕКЭШИРУЕМЫЕ ЦИКЛЫ 3-3. Если внешняя система не
может отреагировать на цикл считывания или записи в интервале,
определяемом временем установления и сохранения, сигнал RDY#
должен быть снят в конце второго такта. При этом в цикл шины
вводятся состояния ожидания (дополнительные такты). Цикл шины
с одним состоянием ожидания для циклов считывания и записи на-
зывается циклом «3—3» одиночной передачи. В таком цикле
считывания и записи длятся по три такта синхронизации, как пока-
зано на рис. 2.10. На каждый такт со снятым сигналом RDY#
добавляется одно состояние ожидания, поэтому появляются циклы
«4—4» и т.д. Допускается добавить любое число состояний
Глава 2. Сигналы и временные диаграммы работы i486
ожидания, а внешняя схема может вводить различное число
состояний ожидания для циклов считывания и записи.
Во время состояний ожидания выходные сигналы шины адреса,
определения цикла и шины данных остаются стабильными. Однако
сигнал BRDY# должен быть снят на всех фронтах синхронизации,
где снят сигнал RDY#. Если этого не обеспечить, процессор может
инициировать пакетный цикл. Сигнал BLAST# выдается в после-
днем (здесь третьем) такте.
Контроль паритета осуществляется так же, как в циклах 2—2. В
высокопроизводительных системах нужно избегать состояний ожи-
дания и применять циклы 2—2, а также рассматриваемые далее па-
кетные циклы.
Ti Т1 Т2 Т1 Т2 Ti
ADS#
А2-А31,
M/IO#,
D/C#, W/R#,
BEO#-3#
RDY#
KEN#
BLAST#
Данные
Первые Вторые
данные данные
Рис. 2.11. Непакетная и некэишруемая
многоцикловая последовательность
НЕКЭШИРУЕМЫЕ МНОГОЦИКЛОВЫЕ ПОСЛЕДОВА-
ТЕЛЬНОСТИ, Этот вид передачи представляет собой серию циклов
одиночных передач. Последовательности могут быть вызваны внут-
ренними запросами процессора или внешними запросами системы
памяти. Они применяются в тех ситуациях, когда нужно передать
Микропроцессор i486 Книга 2. Аппаратная архитектура
более двойного слова данных. Например, процессор может иници-
ировать непакетные некэшируемые последовательности, считывая
128-битные команды, 64-битные операнды с плавающей точкой или
невыравненное двойное слово. Система внешней памяти может
вызвать последовательности, когда она считывает или записывает
32-битные данные по 8/16-битной шине данных.
Многоцикловая последовательность представлена на рис. 2.11;
она считывает два элемента данных в последовательности из двух
циклов шины. Последовательность начинается точно так же, как
цикл 2—2, с выдачи сигнала ADS# состояния адреса. После этого
процессор показывает, что это многоцикловая последовательность,
снимая сигнал BLAST# в конце второго такта первого цикла шины.
Внешняя система подает сигнал RDY# готовности, завершая пер-
вый цикл шины. Каждый следующий цикл в последовательности
начинается с выдачи сигнала ADS# и заканчивается возвращением
сигнала RDY#. Последовательность заканчивается, когда подан
сигнал RDY# при выданном сигнале BLAST#.
Если данные, считываемые или записываемые в многоцикловой
последовательности, выравнены на ширину передаваемых данных
(32, 64 или 128 бит), выдается сигнал псевдоблокировки шины
PLOCK#. Контроль паритета осуществляется так же, как в циклах
2-2.
КЭШИРУЕМЫЕ МНОГОЦИКЛОВЫЕ ПОСЛЕДОВАТЕЛЬ-
НОСТИ. Этот вид передач применяется для заполнения строки
внутренней кэш-памяти процессора. Кэшируются только последо-
вательности считывания. Кэш-память не поддерживает распределе-
ния строки при записи и во время циклов записи входной сигнал
KEN# разрешения кэширования не опрашивается. Когда формиру-
ется внутренний запрос записи, процессор помещает данные в
свою кэш-память, если только они записываются по уже кэширо-
ванному адресу.
Кэшируемые последовательности считывания похожи на рас-
смотренные выше некэшируемые многоцикловые последовательно-
сти за исключением следующих условий:
— В начале и конце заполнения строки кэш-памяти должен
быть подан входной сигнал KEN#.
— Кэшируются только считывания из памяти и предвыборки
команд. Блокированные считывания, циклы подтверждения преры-
вания и считывания с отображением на ввод-вывод не кэшируются.
— Бит запрещения кэширования страницы PCD в базовом ре-
гистре каталога страниц CR3 должен быть сброшен в 0.
— Бит разрешения кэш-памяти СЕ в регистре состояния маши-
ны CR0 должен быть установлен в 1.
Если удовлетворяются приведенные выше условия, процессор
изменяет запрос считывания из памяти, который мог бы быть реа-
Глава 2. Сигналы и временные диаграммы работы i486
лизован в цикле одиночной передачи в кэшируемую многоцикло-
вую последовательность. Внешняя система должна подать сигнал
KEN# в конце первого такта до сигнала RDY# готовности. Когда
это сделано, процессор продолжает считывать всю 16-байтную
строку кэш-памяти. На рис. 2.12 показана последовательность, в
которой четыре двойных слова передаются за четыре цикла шины
без состояний ожидания. Процессор считывает все данные,
выполняя от 4 до 16 смежных циклов шины в зависимости от
размера шины, выбираемого сигналами BS16# или BS8#.
Рис. 2.12. Непакетная и кэшируемая
многоцикловая последовательность
Сигнал BLAST# недостоверен и должен игнорироваться в
течение первого такта последовательности. В ответ на подачу сиг-
нала KEN# в первом такте процессор снимает сигнал BLAST# на
один такт позднее. Сигнал KEN# должен быть также выдан за один
такт до возвращения сигнала RDY# для последней передачи после-
довательности. Эта вторая подача сигнала KEN# вызывает фак-
тическое помещение данных во внутреннюю кэш-память; без вто-
рой подачи сигнала KEN# считанные в процессор данные не запи-
сываются в кэш-память.
Процессор опрашивает сигнал KEN# в каждом такте. Значение,
опрошенное в такте до сигнала RDY#, определяет, необходимо ли
Микропроцессор i486 я Книга 2. Аппаратная архитектура
преобразовать цикл шины в заполнение строки кэш-памяти и нуж-
но ли данные преобразованного цикла шины загружать в кэш-па-
мять после окончательного считывания. Между первой и второй
подачами сигнал KEN# не определен за исключением каждого
фронта сигнала CLK, когда он должен удовлетворять временам ус-
тановления и сохранения. Сигналы KEN#, BS8# и BS16# являются
синхронными входами. Сигналы BS8# и BS16# размера шины так-
же опрашиваются в каждом такте для определения того, требуются
ли дополнительные циклы шины для завершения передачи.
Когда цикл шины впервые преобразуется в заполнение строки
кэш-памяти, процессор ожидает достоверные данные на всей шине
данных. Следовательно, выходные сигналы ВЕО#—ВЕЗ#
разрешения байт (хотя и достоверные) должны игнорироваться во
время первой передачи заполнения строки кэш-памяти, а система
памяти должна выдать достоверные данные так, как если бы
выданы все сигналы ВЕО#—ВЕЗ#. Ожидаются те данные, которые
адресуются сигналами А2—А31. После первой передачи заполнения
строки кэш-памяти сигналы разрешения байт должны
использоваться для всех последующих передач заполнения строки
кэш-памяти. Это относится к непакетным и пакетным
заполнениям строки кэш-памяти.
Сигнал KEN# может изменить состояние несколько раз до пре-
вращения цикла одиночной передачи в кэшируемую многоцикло-
вую последовательность. Контроль паритета производится так же,
как для циклов 2—2.
2.6.2. Пакетные циклы
Пакетные циклы являются самым быстрым способом передачи
данных. В одном пакете можно передать до 16 байт. Самый быст-
рый пакетный цикл требует два такта для первой передачи и по од-
ному такту для всех последующих передач; для сравнения напом-
ним, что непакетные циклы требуют минимум два такта на каждую
передачу. Пакеты имеют ограничение: они могут передавать только
выравненные блоки данных по смежным адресам. Однако благодаря
этому они обеспечивают очень быстрый доступ к микросхемам па-
мяти с дешифрацией статического столбца.
Пакетные циклы, как и непакетные циклы, могут быть кэширу-
емыми или некэшируемыми. Кэшируемые пакеты загружают смеж-
ный 16-байтный выравненный блок команд или данных в строку
внутренней кэш-памяти. Некэшируемые пакетные циклы также
оказывают значительное влияние на производительность. Любое
многоцикловое считывание процессор может преобразовать в па-
кет. Он будет пакетировать только то число байт, которое требуется
для завершения передачи. Например, будут пакетироваться только
Глава 2. Сигналы и временные диаграммы работы i486
восемь байт с плавающей точкой в 64-битном некэпгируемом па-
кетном считывании. Кэшируемые и некэшируемые пакеты могут
прерываться или вводить состояния ожидания. Пакетные записи
производятся только при ограничении размера шины (подан сигнал
BS8# или BS16#). Ради совместимости вверх в будущем процессор
i486 в операции записи всегда выдает сигнал BLAST# последнего
пакета, если сняты сигналы BS8# или BS16#.
Контроль паритета производится так же, как в непакетных цик-
лах. Выходной сигнал PCHK# контроля паритета показывает
ошибку паритета в считанных данных во время предыдущего цикла.
Он достоверен в следующем такте после сигнала BRDY# пакетной
готовности. Контролируются только фактические данные. Далее
рассматриваются сначала некэшируемые пакеты, а затем кэшируе-
мые пакеты.
НЕКЭШИРУЕМЫЕ ПАКЕТЫ. Условиями некэшируемого па-
кетного цикла являются:
— Вместо сигнала RDY# готовности необходимо выдавать
входной сигнал пакетной готовности BRDY# с той же временной
диаграммой, как и RDY#.
— Пакетируются считывания памяти и ввода-вывода, требую-
щие больше одиночной передачи данных. Предвыборки команд яв-
ляются пакетируемыми. Циклы подтверждения прерывания и цик-
лы записи (исключая записи до четырех байт при размере шины 16
или 8 бит) не являются пакетируемыми.
— Адреса всех данных должны приходиться на смежную вырав-
ненную область. Число передаваемых байт зависит от конкретной
операции.
Некэшируемый пакетный цикл приведен на рис. 2.13. В этом
примере два двойных слова передаются за три такта. Пакет
начинается с того, что процессор выдает адрес и сигнал ADS# со-
стояния адреса, как и в непакетных циклах. Однако при этом про-
цессор показывает, что требуется или может быть воспринято более
одного элемента данных, удерживая сигнал BLAST# снятым в
конце второго такта. Одновременно внешняя система показывает
свою готовность к пакету, подавая сигнал BRDY# пакетной
готовности и снимая сигнал RDY# обычной готовности. Входной
сигнал BRDY# пакетной готовности действует так же, как сигнал
RDY# готовности; он показывает, что внешняя система выдала дос-
товерные считываемые данные или восприняла записываемые дан-
ные и что можно начать следующую передачу в цикле.
Несмотря на то, что сигнал BLAST# в некэшируемых пакетах
снят в конце второго такта, состояние этого сигнала не должно ис-
пользоваться внешней схемой для определения того, кэшируется ли
Микропроцессор i486 • Книга 2. Аппаратная архитектура
текущий пакет. Снятием сигнала BLAST# управляют состояния
других сигналов, например сигнала KEN# разрешения кэш-памяти.
Ti.Tl.T2.T2 . Ti Ti
CLK /\ ... 1 1 1 » 1 1
ADS# / ‘ ' ’
А2-А31, ' 1 1 1 1 1 1 1 1 1
N4/IO#, D/C# W/R# X : V : : । Л . । _ ।
ВЕО#—3# 1 1 1 1 1 1 1 Г I . 1 1 1 ,
RDY# . /Л.л . ..
1 1 1 1 1 1 1 1 , 1
BRDY# \./ W .
[Z П КТ 1 1 1 1 1 1 1 1 1
KJtilN 7F 1 1 1 > 1 1 1 1 i
BLAST# X ’ _J : \ : / *
1 1 1 1 1 1 /Р Г f П \_/ R Т [П \ 1 ,
ДаННЫс ( D Ц11/“Л D ЦП J J । 1 ।
Рис. 2.13. Некэишруемый пакетный цикл
После этого сигнал ADS# больше не выдается. Адрес сменяется
для каждой передачи после возвращения сигнала BRDY# от преды-
дущей передачи. Сигналы А4—А31 изменяются только в начале па-
кетного цикла, но сигналы А2—АЗ и сигналы разрешения байт из-
меняются в начале каждой передачи данных в пакетном цикле.
В некэшируемых пакетах после возвращения каждого элемента
данных производится инкремент адреса. (Это не всегда справедливо
для кэшируемых пакетов — см. далее). Например, на рис. 2.13 пос-
ледовательно адресуются два двойных слова. Сигнал BLAST# пос-
леднего пакета действует так же, как в непакетных циклах. Он сни-
мается в конце второго такта в первой пакетной передаче, показы-
вая, что для завершения передач данных в цикле шины требуются
дополнительные передачи. В последней передаче сигнал BLAST#
выдается, показывая, что конец цикла совпадает со следующим
сигналом BRDY# пакетной готовности.
Глава 2. Сигналы и временные диаграммы работы i486
Для передач, которые процессор не может пакетировать
(подтверждение прерывания и все циклы записи 32-битных дан-
ных), подача сигнала BRDY# действует так же, как подача сигнала
RDY#. Сигнал BRDY# игнорируется, если в том же такте возвра-
щается сигнал RDY#. Если в любом временном интервале пакет-
ного цикла возвращается сигнал RDY# готовности, пакетирование
останавливается и, если не подан сигнал BRDY# (показывая, что
для завершения цикла больше передач не нужно), процессор про-
должает непакетные передачи до окончания передачи всех данных.
КЭШИРУЕМЫЕ ПАКЕТЫ. Кэшируемые пакетные циклы ока-
зываются наиболее важным способом передач данных для высоко-
производительных систем. Они обеспечивают наиболее быстрое за-
полнение строк внутренней кэш-памяти, т.е. самого быстродей-
ствующего источника считываемых данных, а считывание является
для процессора одной из длительных операций.
Для использования кэшируемых пакетных циклов должны удов-
летворяться следующие условия пакетируемости и кэшируемости:
— Входной сигнал разрешения кэш-памяти KEN# должен быть
подан в начале и конце заполнения строки кэш-памяти.
— Вместо сигнала RDY# готовности должен подаваться входной
сигнал пакетной готовности BRDY# с аналогичной временной ди-
аграммой.
— Пакетируются считывания памяти и ввода-вывода, которые
требуют более одной передачи данных.
— 16-байтная выравненная область памяти всегда считывается
как строка кэш-памяти, безотносительно начального адреса в
16-байтной области.
— Кэшируются только считывания из памяти и предвыборки
команд. Блокированные считывания, циклы подтверждения преры-
вания и считывания с отображением на ввод-вывод не кэшируются.
— Бит запрещения кэширования страницы PCD в базовом ре-
гистре каталога страниц CR3 должен быть сброшен в 0.
— Бит разрешения кэш-памяти СЕ в регистре состояния.маши-
ны CR0 должен быть установлен в 1.
Кэшируемый пакетный цикл показан на рис. 2.14. Он заполняет
строку кэш-памяти по полной 32-битной шине данных и передает
четыре двойных слова. Пакет начинается с того, что процессор вы-
дает адрес и сигнал ADS#, как и в непакетных циклах. Внешняя
система выдает сигнал KEN# в конце первого такта и снимает его
вскоре после начала второго такта. Когда сигнал KEN# выдан и
снят таким образом, процессор снимает сигнал BLAST# последнего
пакета, показывая, что для завершения цикла требуются дополни-
тельные передачи. После этого процессор пытается считать все
четыре двойных слова. В конце второго такта внешняя система
Микропроцессор i486 «Книга 2. Аппаратная архитектура
стробирует первое двойное слово и показывает свою готовность к
пакету, выдавая сигнал BRDY# пакетной готовности и снимая сиг-
нал RDY# обычной готовности. Сигнал BRDY# опрашивается в
каждом такте и, если он выдан, данные вводятся в процессор.
Чтение Запись.
Рис. 2.14. Кэшируемый пакетный цикл
Остальные три двойных слова передаются без выдачи сигнала
ADS#; однако адреса в каждой передаче изменяются, отражая сле-
дующий элемент данных. В первой передаче при заполнении стро-
ки кэш-памяти процессор ожидает достоверные данные на всей
шине данных. В течение этой первой передачи выходные сигналы
разрешения байт ВЕО#—ВЕЗ# (хотя они и достоверные) должны иг-
норироваться и внешняя система должна выдавать достоверные
данные так, как будто все сигналы ВЕО#—ВЕЗ# выданы.
Глава 2. Сигналы и временные диаграммы работы i486
Ожидаются данные, которые адресуются сигналами А2—А31. Во
всех последующих циклах заполнения строки кэш-памяти сигналы
разрешения байт могут использования обычным образом. Адреса
всегда оказываются внутри той выравненной 16-байтной области,
которая соответствует строке внутренней кэш-памяти. Такая
область начинается в ячейке хххххххОН и кончается в ячейке
xxxxxxxFH. По первому адресу в пакете внешняя схема может легко
заранее определить адреса последующих передач.
Последовательность адресов зависит от первого выданного адреса.
После возвращения первого сигнала BRDY# пакетной готовнос-
ти в последней передаче цикла выдается сигнал BLAST# последне-
го пакета, показывая, когда процессор ожидает конца пакета. В
конце пакетного цикла должен быть вновь выдан сигнал KEN#
разрешения кэширования на один такт раньше последнего сигнала
BRDY#. Если такой сигнал KEN# не подается, считанные в про-
цессор четыре двойных слова не записываются в кэш-память.
Если сигнал BLAST# выдан в том такте, где возвращается сиг-
нал BRDY#, то сигнал BRDY# учитывается так же, как сигнал
RDY#; пакетная передача подходит к концу и либо процессор ини-
циирует новый цикл шины, либо шина переводится в холостое со-
стояние. Если выданы оба сигнала BRDY# и RDY#, то сигнал
BRDY# игнорируется; в этом случае пакетный цикл отменяется
преждевременно и начинается новый цикл шины, если для
окончания заполнения строки кэш-памяти требуются дополнитель-
ные циклы. В последней передаче пакетного цикла сигнал BRDY#
действует аналогично сигналу RDY#.
Выходной сигнал BLAST# последнего пакета зависит от сигна-
лов KEN #, BS8# и BS16#, опрошенных в предыдущем такте. По
этой причине сигнал BLAST# недостоверен в первом такте любого
цикла шины или когда шина находится в холостом состоянии.
Сигнал BLAST# необходимо опрашивать только во втором и после-
дующем тактах, когда возвращен первый сигнал BRDY# цикла.
Так как в течение цикла сигналы BS8# и BS16# размера шины
могут изменяться динамически, они также могут вызвать снятие
сигнала BLAST#, а затем выдачу его вновь. Такая ситуация возни-
кает, например, если сигнал BS8# выдан тогда, когда процессор
ожидает передачи последнего двойного слова. Процессор выполнит
четыре байтных передачи и сигнал BLAST# выдается в последней
передаче.
В циклах записи и ввода-вывода сигнал KEN# игнорируется.
Записи в память сохраняются в кэш-памяти только при попадании.
ВВЕДЕНИЕ СОСТОЯНИЙ ОЖИДАНИЯ. Пакетные циклы не
обязательно должны возвращать данные в каждом такте. Процессор
стробирует пакетные данные только при подаче сигнала BRDY#
Микропроцессор i486 я Книга 2. Аппаратная архитектура
пакетной готовности. Следовательно, удерживание сигнала BRDY#
снятым задержит передачу за счет введения состояний ожидания.
Рис. 2.15. Изменение сигнала KEN# в кэшируемом цикле
ИЗМЕНЕНИЕ СИГНАЛА KEN# В КЭШИРУЕМОМ ЦИКЛЕ.
Сигнал KEN# в начале пакетного цикла может измениться не-
сколько раз, пока он стабилизируется за такт до выдачи сигнала
BRDY# или RDY#. Эта ситуация показана на рис. 2.15, где введены
состояния ожидания. Диаграмма сигнала BLAST# повторяет сигнал
KEN# через один такт. В первом такте приведенного примера вне-
шняя система выдает сигнал KEN# и процессор реагирует снятием
сигнала BLAST# в следующем такте. Во втором такте сигнал KEN#
снимается и, так как не выдаются ни сигнал BRDY# (для кэшируе-
мых пакетных циклов), ни сигнал RDY# (для кэшируемых непакет-
ных циклов), цикл превращается в цикл одиночной передачи. Про-
цессор реагирует выдачей сигнала BLAST# в следующем такте. На-
конец, в третьем такте вновь выдается сигнал KEN#, превращая
цикл в заполнение строки кэш-памяти, и сигнал BLAST# снима-
ется в следующем такте. Сигнал BRDY# или RDY# выдается в
четвертом такте, запуская заполнение строки кэш-памяти.
ВЫРАВНИВАНИЕ И РАСПРЕДЕЛЕНИЕ ДАННЫХ. Процес-
сор представляет каждый запрос данных в порядке, определяемом
Глава 2. Сигналы и временные диаграммы работы i486
первым адресом в передаче, как показано в таблице 2.8. Последова-
тельность адаптирована для 64- или 32-битной шины и применима
ко всем пакетным циклам независимо от того, производят они за-
полнение строки кэш-памяти, 64-битное считывание или 16-байт-
ную предвыборку команд. По известному текущему адресу внешняя
схема заранее легко вычисляет адреса последующих передач.
Таблица 2.8. Распределение пакетного адреса
Первый адрес Второй адрес Третий адрес Четвертый адрес
0 4 8 С
4 0 С 8
8 С 0 4
С 8 4 0
Ti Tl Т2 Т2 Т2 Т2 Ti
CLK /\ _______ 1 f i if i i i । ______ *- 1 1
ADS# । i i 1 1 1 1 1
А2-А31 X 104 : ^100 X'oc X108:
RDY# BRDY# KEN# 1 Г.Ж.Т 1 1 1 1 1 ./ : 1 I 1 T.T IM /.U. . 1 1 1 1
BLAST# J_2 J i • I \ [1 *
ДаЦные
Рис. 2.16. Порядок адресации в пакетном, цикле
Микропроцессор i486« Книга 2. Аппаратная архитектура
Передаваемые в пакетных циклах данные ожидаются по тем же
сигналам данных, что и в непакетных циклах. Передачи данных мо-
гут производиться с применением 8/16-битного размера шины. При
использовании любого меньшего 32 бит размера шины для завер-
шения операций требуется больше передач, чем для полной 32-бит-
ной шины. Если подан сигнал BS8# или BS16#, процессор за-
канчивает передачу текущего двойного слова перед обработкой сле-
дующего. В каждом двойном слове первым передается старшее сло-
во. В каждом слове первым передается старший байт. Например,
кэшируемый цикл, начатый по адресу 104 при подаче сигнала
BS16#, формирует пакетную последовательность адресов 104, 104,
100, 102? ЮС, 10, 108, 10А (см. рис. 2.16).
Если во время кэшируемого пакетного цикла подается сигнал
BS8# или BS16#, пакет может растянуться до 16 передач данных
(16 байт по 8-битной шине). Распределение адресов и
местонахождение данных на шине данных в этом случае
оказывается другим. В первой передаче при заполнении строки
кэш-памяти процессор ожидает достоверных данных на всей шине
данных. Выходные сигналы разрешения байт ВЕО#—ВЕЗ#
необходимо игнорировать и внешняя система должна выдать
достоверные данные так, как будто сигналы ВЕО#—ВЕЗ# выданы.
Оба сигнала BS8# и BS16# опрашиваются за такт раньше
возвращения сигнала BRDY#. Таким образом, входные сигналы
размера шины необходимо сохранять в течение всего пакета, если
адресованное устройство не может динамически изменить размер
шины в течение цикла.
ПРЕДВЫБОРКА КОМАНД. Предвыборки команд являются па-
кетируемыми передачами данных, которые считывают до заверше-
ния выравненный блок из 16 байт команд во внутренние кэш-па-
мять и устройство предвыборки процессора. Такое считывание
осуществляется пакетной передачей из последовательно больших
адресов. Адреса формирует устройство предвыборки команд. Циклы
предвыборки команд имеют особое кодирование сигналов M/IO#,
D/C# и W/R# определения цикла шины.
ПРЕРЫВАЕМЫЕ ПАКЕТЫ. Некоторые системы памяти не мо-
гут реагировать на пакетные циклы с приведенной выше адресной
последовательностью. Для работы с такими системами пакетный
цикл можно прервать, выдавая сигнал RDY# обычной готовности
вместо BRDY# пакетной готовности. После прерывания процессор
автоматически формирует другой обычный пакетный цикл для за-
вершения необходимых передач. Внешняя система может отреаги-
ровать на прерванный пакетный цикл другим пакетным циклом.
Глава 2. Сигналы и временные диаграммы работы i486
На рис. 2.17 показан кэшируемый пакетный цикл, который пре-
рван и превращен в два пакетных цикла. После выдачи сигнала
RDY# готовности процессор сразу же выдает сигнал ADS# состоя-
ния адреса для инициирования нового пакетного цикла. Сигнал
BLAST# последнего пакета снимается через один такт после начала
сигнала ADS# во втором пакетном цикле, показывая, что передача
не завершена. Сигнал KEN# разрешения кэширования не нужно
подавать в первой передаче второго пакетного цикла после преры-
вания. Операция распознается как заполнение строки кэш-памяти
благодаря выдаче сигнала KEN# во время пакета, предшествующего
прерыванию. Вторая часть операции сама может быть пакетом.
Рис. 2.17. Прерванный пакетный цикл
При обычных ограничениях пакетных передач нет ограничения
на число передач, которые должны быть произведены с сигналом
BRDY# до выдачи сигнала RDY#. Если выдан сигнал RDY# и про-
цессор показывает, что требуемое число передач еще не достигнуто,
продолжая удерживать снятый сигнал BLAST#, то процессор сразу
же сформирует непакетные циклы, используя для завершения пере-
дач сигнал ADS#.
Микропроцессор i486 Книга 2. Аппаратная архитектура
Порядок, в котором процессор адресует данные в прерванном
пакетом цикле, представлен в таблице 2.8. Этот порядок не
изменяет смешивание сигналов RDY# обычной и BRDY# пакетной
готовности.
ИДЕНТИФИКАЦИЯ ПЕРВОЙ ПЕРЕДАЧИ КЭШИРУЕМОГО
ЦИКЛА. Сигналы разрешения байт ВЕО#—ВЕЗ# достоверны в лю-
бых цикле или передаче за исключением первой передачи кэширу-
емого цикла. Во время такой передачи сигналы ВЕО#—ВЕЗ#
должны игнорироваться и внешняя система должна формировать
достоверные данные так, как будто все сигналы ВЕО#—ВЕЗ#
выданы.
Для определения первой передачи кэшируемого цикла прихо-
дится опрашивать сигналы BLAST#, RDY# и BRDY#. Если сигнал
BLAST# выдан с непосредственно предшествующим сигналом
RDY# или BRDY#, то следующая кэшируемая передача будет пер-
вой передачей кэшируемого цикла.
2.6.3. Размер шины
Для управления циклами на 8- и 16-битной шине применяются
входные сигналы размера шины BS8# и BS16#, а также выходные
сигналы разрешения байт ВЕ0#-ВЕЗ#.
Входные сигналы BS8# и BS16# размера шины удобны для ин-
терфейса с устройствами ввода-вывода или 8-битным ПЗУ. Эти
сигналы позволяют внешней системе по тактам определять, может
ли адресованное внешнее устройство выдавать 8/16 бит данных.
Рассматриваемые сигналы совместно с адресом нужных данных уп-
равляют той последовательностью, в которой формируются сигналы
ВЕО#—ВЕЗ#. Сигналы разрешения байт ВЕО#—ВЕЗ# сообщают
внешнему устройству, какие байты на полной 32-битной шине дан-
ных достоверны в любых цикле или передаче. Единственным ис-
ключением из этого является первая передача кэшируемого цикла
считывания (заполнение строки кэш-памяти), когда сигналы
ВЕО#—ВЕЗ# должны игнорироваться, а внешняя система должна
формировать данные так, как будто выданы все сигналы
ВЕО#—ВЕЗ#.
Без подачи сигналов BS8# или BS16# размер шины данных со-
ставляет 32 бита. Сигналы BS8# и BS16# допускается применять в
непакетных и пакетных циклах. Если поданы оба этих сигнала,
распознается только сигнал BS8#. Подача сигналов BS8# или BS16#
может заставить процессор выполнить дополнительные циклы ши-
ны для завершения передачи.
Интерфейс с меньшими размерами шины совершенно от-
личается от интерфейса, используемого в процессоре 80386. В от-
личие от процессора 80386 процессор i486 ожидает найти данные на
Глава 2. Сигналы и временные диаграммы работы i486
всех четырех адресованных байтах шины данных. Внешняя схема
должна осуществить интерфейс всех четырех байт, используя вы-
ходные сигналы ВЕО#—ВЕЗ# и обнаружение первой передачи за-
полнения строки кэш-памяти для управления внешним своппером
{swapper — «обмениватель») байт.
ВРЕМЕННАЯ ДИАГРАММА. Пример использования сигнала
BS8# приведен на рис. 2.18. Процессор запрашивает 24 бита инфор-
мации. Внешняя система выдает сигнал BS8#, показывая, что в
цикле может быть представлено только 8 бит. После этого для за-
вершения передачи процессор выполняет два дополнительных цик-
ла. Он опрашивает сигналы BS8# и BS16# в такте перед возвраще-
нием сигнала RDY# готовности. Временные параметры для сигна-
лов BS8# и BS16# аналогичны параметрам для сигнала KEN#; по-
дача сигнала BS8# или BS16# за один такт раньше сигналов RDY#
или BRDY# показывает ширину шины.
Данные
Рис. 2.18. Цикл с размером шины 8 бит
Дополнительные циклы, вызванные сигналами BS8# или BS16#,
являются независимыми циклами шины. Входы должны выдаваться
для каждого дополнительного цикла. Адресуемое устройство может
Микропроцессор i486 и Книга 2. Аппаратная архитектура
изменять число возвращаемых им байт по тактам. Процессор удер-
живает сигнал BLAST# последнего пакета снятым до последнего
цикла передачи.
ВЫРАВНИВАНИЕ ДАННЫХ. Так как процессор работает
только с байтами, словами и двойными словами, некоторые комби-
нации сигналов разрешения байт ВЕО#—ВЕЗ# никогда не формиру-
ются. Например, никогда не выполняется цикл шины с активными
сигналами BE0# и ВЕ2#; такая передача соответствует операции с
двумя несмежными байтами. Одиночная трехбайтная передача ни-
когда не возникает, но трехбайтная передача адреса или данных с
предшествующей или последующей однобайтной передачей может
возникать для невыравненных двойных слов.
Процессор не производит автоматического выравнивания дан-
ных на шине процессора с 8/16-битной шины. Системы с 8/16-бит-
ными устройствами дая выравнивания их байт на шине процессора
должны использовать внешнюю схему. Обычно такие устройства
относятся к ВВ, где лишняя задержка не оказывает значительного
влияния на производительность.
Несмотря на то, что сигналы BS8# и BS16# опрашиваются в
каждом такте, используется только состояние, полученное в такте
перед подачей сигналов RDY# или BRDY# готовности. Если па-
мять работает без состояний ожидания, входами размера шины
можно управлять статическими логическими уровнями только в
том случае, если пространства всей физической памяти и ВВ ис-
пользуют один и тот же размер шины.
МНОГОЦИКЛОВЫЕ ПОСЛЕДОВАТЕЛЬНОСТИ. Подачей
входных сигналов BS8# или BS16# размера шины одиночный цикл
шины можно превратить в несколько циклов. Например, подача
сигнала BS8# превращает непакетную передачу двойного слова в
четыре байтные передачи. В каждой из четырех байтных передач на
линиях А2—А31 шины адреса сохраняется одно и то же значение.
Процессор попытается считать максимально возможное число байт.
После считывания первого байта двойного слова процессор разре-
шит три оставшихся байта во втором цикле. Если вновь подается
сигнал BS8#, процессор разрешает два оставшихся байта в третьем
цикле. Если вместо сигнала BS8# подается сигнал BS16#, два ос-
тавшихся байта будут считываться в третьем цикле и передача
двойного слова заканчивается.
В таблице 2.9 показаны состояния сигналов разрешения байт
дая первого и второго циклов шины многоцикловой
последовательности, в которой подается сигнал BS8# или BS16#.
Глава 2. Сигналы и временные диаграммы работы i486
Таблица 2,9
Первый цикл Второй цикл, B88I ВЕЗ| BE 21 ВВП ВБ0| Второй цикл, BS16I ВЕЗ! BE2I ВВП ВЕО!
BB3# BE2I ВВП ВВ01
1 1 1 0 нет нет нет нет нет нет нет нет
1 1 0 0 1 1 0 1 нет нет нет нет
1 0 0 0 1 0 0 1 1 0 1 1
0 0 * 0 0 0 , 0 0 1 0 0 1 1
1 1 0 1 нет нет нет нет нет нет нет нет
1 0 0 1 1 0 1 1 1 0 1 1
0 0 0 1 0 0 1 1 0 0 1 1
1 0 1 1 нет нет нет нет нет нет нет нет
0 0 1 1 0 1 1 1 нет нет нет нет
0 1 1 1 нет нет нет нет нет нет нет нет
КЭШИРУЕМЫЕ СЧИТЫВАНИЯ ИЗ ПАМЯТИ. При малых
размерах шины можно кэшировать только считывания из памяти. В
любом кэшируемом считывании из памяти сигналы ВЕО#-ВЕЗ#
разрешения байт необходимо игнорировать (хотя они и достовер-
ные) в первой передаче кэшируемого цикла. Когда обычный цикл
считывания превращается в кэшируемый цикл подачей сигнала
KEN#, процессор считывает целые двойное слова, адресованное по
линиям А2—А31, хотя могут быть разрешены меньше байт. Если
выбран 8-битный размер шины, процессор считывает младший байт
двойного слова в первом цикле заполнения строки кэш-памяти,
даже если первоначальный цикл шины не выбирал этот байт для
считывания. При выборе 16-битного размера шины процессор
считывает младшее слово. Во второй и последующих передачах за-
полнения строки кэш-памяти выходные сигналы ВЕО#—ВЕЗ# пра-
вильно идентифицируют те байты, которые ожидает процессор.
Процессор может не использовать все разрешенные байты, когда
поданы входные сигналы BS8# или BS16#. В таблице 2.10 показано,
какие позиции бит использует процессор для всех допустимых ком-
бинаций сигналов разрешения байт и для всех размеров шины.
Наиболее простое правило гласит: когда разрешены несколько
байт, возвращаются только младшие байт или байты, которые уст-
ройство может выдать на шину данных.
Таблица 2.10
BS3# ВБ2! ВЕИ ВЕО! Нет выбора (32-битная инна) BS16* (1б-6итвая вина) В88! (8-битная шина)
I 1 1 0 D0-D7 D0-D7 D0-D7
1 1 0 0 D0-D15 D0-D15 D0-D7
1 0 0 0 D0-D23 D0-D15 D0-D7
0 0 0 0 D0-D31 D0-D15 D0-D7
1 1 0 1 D8-D15 D8-D15 D8-D15
1 0 0 1 D8-D23 D8-D15 D8-D15
0 0 0 1 D8-D31 D8-D15 D8-D15
1 0 1 1 D16-D23 D16-D23 D16-D23
0 0 1 1 D16-D31 D16-D31 D16-D23
0 1 1 1 D24-D31 D24-D31 D24-D31
Микропроцессор i486 Книга 2. Аппаратная архитектура
ПАКЕТНЫЕ ЦИКЛЫ. Пакетные циклы считывания допускает-
ся возвращать по 8/16-битной шине данных. В этом случае пакет-
ный цикл можно растянуть до 16 передач (16 байт при заполнении
строки кэш-памяти). Распределение адресов и данных такое же, как
и в непакетных циклах. Одиночные 32-битные некэшируемые
считывание или запись процессора можно осуществить за четыре 8-
битных пакетных цикла. Пример пакетной записи приведен на рис.
2.19. Пакетные записи могут производиться только при выдаче
сигнала BS8# или BS16#.
Ti CLK / \ TI T2 T2 T2 T2 Ti । • । । / \ J \ •/ I 7 i । « । । • •I» » ; »
ADS# / । » । । 1 ; ; ; ; । • • ।
Адрес X 1 I ! ! a
(iii I»»» I»'»
BE0#-3# X J X i X ; X ; X
RDY# I 1 • 1
BRDY# - — / □hfafakz I'll 1 ' 1 1
BS8# ; \l ;
1 1 1 ' 1 I'll I'll
BLAST# X ’ L7 i : \J_£*
1 1 1 1 1 ' 1 1
Данные — / Из ЦП \ ' । ' i ’ i ' • । । ।
Рис. 2.19. Пакетная запись на 8—битной шине
При выполнении пакетного цикла процессор опрашивает сигна-
лы BS8# и BS16# размера шины в такте перед возвратом каждого
Глава 2. Сигналы и временные диаграммы работы i486
сигнала BRDY# пакетной готовности. Следовательно, входные сиг-
налы размера шины нужно поддерживать активными в течение все-
го пакета^ если адресуемое устройство не может изменять число
байт, возвращаемых в каждом цикле.
2.7. Управление шиной
Сигналы управления шиной и специальные циклы связаны с
доступом к шине и обработки необычных ситуаций, например пре-
рываний и сброса. К сигналам и специальным циклам шины, ис-
пользуемым во всех системах, относятся сброс RESET, прерывания
INTR и NMI, останов и отключение (специальные циклы шины). В
системах с несколькими ведущими шины требуются также сигналы
захвата шины HOLD, блокировки шины LOCK#, псевдоблокиров-
ки шины PLOCK# и отступления шины BOFF#.
2.7.1. Сброс
Входной сигнал сброса RESET осуществляет запуск или рестарт
процессора, причем во время сброса можно вызвать разнообразные
тесты. Далее дается обзор того, как сброс использует или влияет на
различные сигналы шины процессора.
Когда процессор обнаруживает на входе RESET переход от низ-
кого уровня к высокому, он прекращает все свои действия. Когда
сишал RESET возвращается на низкий уровень, регистры процес-
сора инициализируются на известные внутренние состояния и про-
цессор начинает считывать команды по адресу сброса. Обычно сиг-
нал RESET формирует внешний генератор синхронизации, обес-
печивая стабильный сигнал сброса во всей системе.
Если подан один сигнал RESET, инициализируются только ре-
гистры, не относящиеся к плавающей точке. После действия сигна-
ла RESET внутренние регистры с плавающей точкой не определены
за одним исключением: если питание и сигнал CLK остаются в
пределах спецификаций в течение всего времени действия сигнала
RESET, регистры остаются в том же состоянии, в каком они нахо-
дились по нарастающему фронту сигнала RESET.
При подаче сыпала RESET вид тестирования определяется дей-
ствием одного или нескольких сигналов. Если при сбросе подан
сигнал AHOLD захвата адреса, вызывается встроенный самоконт-
роль и инициализируются все регистры процессора. Без подачи
сигнала AHOLD инициализируются только регистры, не относящи-
еся к плавающей точке. До окончания самоконтроля никакие цик-
лы шины не выполняются. Сигнал A20M# маскирования линии 20
адреса при подаче сигнала RESET должен опрашиваться как по-
данный. Если при действии RESET подан сигнал FLUSH #, вызы-
Микропроцессор i486« Книга 2. Аппаратная архитектура
вается тест высокого импеданса (плавающего состояния). Все вы-
ходные и двунаправленные сигналы переводятся в плавающее со-
стояние, включая и сигналы HLDA, BREQ, FERR# и РСНК#. Пос-
ле снятия сигнала RESET шина процессора остается в холостом со-
стоянии Ti. Состояния выходных сигналов после сброса приведены
в таблице 2.11.
При включении питания сигнал RESET необходимо подать в
течение определенного интервала после стабилизации напряжения
питания и сигнала CLK внешней синхронизации, чтобы внутрен-
ний генератор процессора синхронизировался с сигналом CLK.
Таблица 2.11
Состояние
Сигналы
Высокий уровень
Низкий уровень
Высокий импеданс
Не определены
LOCK#, ADSl, PCHK#
HLDA, BREQ
D0-D31, DP0-DP3
A2-A31, BE0I-BE3I, W/Rl, M/IOl, D/CI,
PLOCKl, BLAST#, PCD, PWT, FERRI
До выборки первой команды процессор не запрашивает шину и
освобождает управление шиной при восприятии запроса HOLD. До
выборки первой команды сигналы INTR и NMI не распознаются.
Несмотря на то, что маскируемые прерывания запрещены, запре-
тить NMI невозможно. Внешние схемы должны препятствовать по-
явлению сигнала NMI до построения дескрипторной таблицы пре-
рываний IDT и инициализации стека.
2.7.2. Прерывания
Имеются три типа запросов прерываний: маскируемые аппарат-
ные прерывания INTR, немаскируемые аппаратные прерывания
NMI и программные прерывания (команда INT или программные
особые случаи). Подача сигналов INTR и NMI представляет собой
асинхронное событие. Процессор не распознает прерывания в опе-
рации сброса, а в операции захвата шины распознает только одно
прерывание NMI.
Для обслуживания прерывания процессор завершает выполне-
ние текущей команды и сохраняет свое текущее состояние в стеке
вместе с информацией о задаче, если требуется переключение за-
дачи. Затем процессор обслуживает прерывание, передавая управ-
ление одной из 256 программно определенных процедур обслужи-
вания прерываний. Дескрипторы точек входа процедур обслужива-
ния находятся в дескрипторной таблице прерываний (Interrupt
Descriptor Table — IDT), которая размещается в памяти. Для общего
использования доступны не все 256 дескрипторов точек входа; пер-
вые 32 из них зарезервированы фирмой Intel. Для обращения к
Глава 2. Сигналы и временные диаграммы работы i486
конкретной процедуре обслуживания процессору требуется вектор
прерывания или индекс элемента таблицы IDT, в котором нахо-
дится соответствующий дескриптор точки входа. Источник вектора
прерывания зависит от типа прерывания. Только прерывания по
входу INTR заставляют процессор получать вектор прерывания от
внешней схемы; прерывания NMI всегда используют один и тот же
вектор, а программные прерывания определяют вектор как операнд
команды или особого случая.
Подача входного сигнала NMI немаскируемого прерывания
обычно показывает катастрофическое событие, требующее немед-
ленного внимания, например отключение питания, ошибка парите-
та при передаче по шине или ошибка паритета в памяти. Для обес-
печения стабильности работы на входе NMI предусмотрен двухтак-
тный синхронизатор. Прерывание NMI запускается фронтом; нара-
стающий фронт сигнала после внутренней синхронизации исполь-
зуется для генерирования запроса прерывания. Сигнал NMI должен
быть вначале снят минимум на два такта, а затем подан. Запрос не
должен оставаться активным до завершения обслуживания преры-
вания; требуется, чтобы сигнал NMI был активным один такт синх-
ронизации при удовлетворении требований установления и сохра-
нения. Сигнал NMI действует правильно, если он удерживается ак-
тивным произвольное число тактов синхронизации. Чтобы зафик-
сировать второе немаскируемое прерывание при обслуживании
предыдущего, сигнал NMI должен быть снят минимум на два такта
до его новой подачи. Зафиксировать и оставить ожидающим можно
только один сигнал NMI; все остальные сигналы теряются.
Для получения вектора прерывания циклы подтверждения пре-
рывания не выполняются. Вместо этого распознанное прерывание
NMI всегда заставляет процессор выполнить процедуру обслужива-
ния, дескриптор точки входа которой находится во втором элемен-
те дескрипторной таблицы прерываний. Для предотвращения ре-
курсивных вызовов NMI его восприятие внутренне маскируется
при вызове процедуры NMI до выполнения команды IRET возврата
из прерывания. На время обслуживания прерывания NMI в R-pe-
жиме процессор запрещает запросы INTR, хотя они могут быть
разрешены в процедуре обслуживания. В P-режиме запрещение
запросов INTR определяется шлюзом во втором элементе таблицы
IDT.
В отличие от входа NMI вход INTR является чувствительным к
уровню; активный сигнал INTR должен сохраняться до начала об-
служивания прерывания. Вход INTR так же, как вход NMI, имеет
двухтактный синхронизатор. Достоверный входной сигнал INTR
распознается внутренним устройством выполнения команд через
два такта синхронизации после его появления. Сигнал INTR опра-
шивается в начале каждой команды.
СТЯаЕЙЯ Микропроцессор i486 Книга 2. Аппаратная архитектура
Сигнал INTR должен быть вначале снят, а затем удерживаться
до его подтверждения. Прерывание будет обслуживаться, если вос-
приятие сигнала INTR не замаскировано флажком разрешения
прерываний IF (бит 9) в регистре EFLAGS. Этот флажок автома-
тически сбрасывается в 0 (т.е. прерывания запрещаются), когда
инициируется операция прерывания, что препятствует появлению
близких последовательных прерываний. Сигнал INTR при сбро-
шенном в 0 флажке IF игнорируется. Флажок IF необходимо уста-
новить в 1 (т.е. разрешить прерывания) программно в подходящем
месте процедуры обслуживания прерывания.
Рис. 2.20. Временная диаграмма подтверждения прерывания
Процессор подтверждает прерывание по входу INTR, выполняя
два блокированных цикла считывания, которые запрашивают вне-
шнюю схему предоставить вектор прерывания. Операция подтверж-
дения прерывания показана на рис. 2.20. Передачи подтверждения
прерывания аналогичны обычным передачам данных за ис-
ключением сигнала А2. В подтверждении прерывания участвуют
следующие сигналы:
ADS# — переводится на низкий уровень, показывая начало
каждой передачи;
М/Ю#, D/C#, W/R# — переводятся на низкий уровень, по-
казывая подтверждение прерывания;
LOCK# — переводится на низкий уровень для блокирования
всех операций захвата в течение обеих передач;
А31—АЗ и BE0# — переводятся на низкий уровень в течение
обеих передач;
Глава 2. Сигналы и временные диаграммы работы i486
А2 — переводится на высокий уровень в первой передаче и на
низкий уровень во второй передаче;
ВЕЗ#, BE2# и BE1# — переводятся на высокий уровень в
течение обеих передач.
Во время первого цикла считывания, показанного на рис. 2.20,
все данные на шине игнорируются. Как и в обычных передачах, для
окончания цикла в процессор должен быть возвращен сигнал
RDY# готовности. Можно также возвратить сигнал BRDY# пакет-
ной готовности, хотя циклы подтверждения прерывания не являют-
ся пакетируемыми. После этого перед началом второго цикла про-
цессор вводит четыре холостых такта. В течение второго
считывания данные на линиях DO—D7 считаются вектором преры-
вания. С помощью сигнала RDY# готовности можно обычным об-
разом ввести состояния ожидания.
Допускается вложение маскируемых прерываний, если не про-
исходит переполнения стека. Вложение возникает, если распозна-
ется прерывание и флажок прерывания установлен, хотя обслужи-
вание предыдущего прерывания еще не закончено. Последнее рас-
познанное прерывание будет первым обслуженным. Если одновре-
менно распознаются прерывания по входам NMI и INTR, старшин-
ство имеет немаскируемое прерывание NMI.
Внутреннее устройство управления учитывает прерывания NMI
или INTR только на границах команд или (в случае команд пере-
сылки цепочек) на границах повторений. Наибольшее запаздыва-
ние реакции на прерывание возникает, когда запрос воспринят при
выполнении длинной команды, например умножения.
Чтобы прерывание было подтверждено в конце конкретной ко-
манды, запрос должен быть выдан минимум за три такта до
окончания выполнения команды. Это позволяет прерыванию прой-
ти через двухтактный синхронизатор и оставляет третий такт на за-
вершение текущей команды (т.е. препятствует инициированию сле-
дующей команды). Если внутреннее устройство не восприняло пре-
рывание во время с предотвращением выполнения следующей ко-
манды, прерывание не действует до окончания этой команды (при
условии, чго сигнал INTR все еще действует). Микрокод обслужи-
вания прерывания вызывается через два холостых такта.
Таким образом, наибольшее время запаздывания прерывания
определяется суммой следующими величин:
два такта для синхронизации прерывания;
самая продолжительная команда (например, умножение, де-
ление или переключение задачи в Р-режиме);
два холостых такта;
один такт для входа в микрокод обслуживания прерывания.
КИМ
Микропроцессор i486 Книга 2. Аппаратная архитектура
2.7.3. Специальные циклы шины
Процессор инициирует специальные циклы шины аналогично
передачам данных, но сигналы определения цикла имеют значения,
приведенные в таблице 2.12. Одна из четырех операций
определяется выходными сигналами ВЕО#—ВЕЗ#, которые обычно
применяются для разрешения байт на шине данных. Специальные
операции шины используют тот же протокол, что и передачи
данных, включая выдачу сигналов RDY# или BRDY# для
подтверждения завершения операции.
Таблица 2.12
M/IO# D/Cl W/Ri BE3I BE2f BE1I ВЕ0| Операцвя
0 0 11110 Отключение
0 0 1110 1 Очистка кэш-памяти
0 0 110 11 Останов
0 0 10 111 Обратная запись кэш-памяти и очистка
ОСТАНОВ. Останов возникает при выполнении команды HLT.
Эту команду можно использовать как реакцию на невосстановимую
ошибку, например ошибку паритета, или на ошибку в программе.
Останов можно применить также для указания о неисправности
процессора в ходе встроенного самоконтроля, инициируемого при
сбросе.
Внешне останов отличается от отключения только выходами
шины адреса и способностью процессора подтверждать захват ши-
ны в состоянии останова. Процессор остается в состоянии останова
до восприятия сигнала по одному из входов INTR, NMI или
RESET.
ОТКЛЮЧЕНИЕ. Отключение (shutdown) возникает, когда про-
цессор обрабатывает двойное нарушение и встречает нарушение
защиты. Это свидетельствует об ошибке в структурах данных опе-
рационной системы, например в дескрипторах сегментов состояния
задач (если для обработки особых случаев применяет переключение
задач), дескрипторах сегментов или элементах таблиц страниц. Для
регистрации диагностической информации желательно вызвать об-
работчик немаскируемого прерывания NMI.
В состоянии отключения процессор не выполняет никаких опе-
раций на шине. Процессор остается в состоянии отключения до
восприятия одного из двух входных сигналов NMI или RESET.
Глава 2. Сигналы и временные диаграммы работы i486
2,7.4. Захват шины
Имеющиеся в системе ведущие шины запрашивают управление
шиной подачей входного сигнала HOLD захвата шины. При вос-
приятии этого сигнала процессор завершает текущую операцию
шины или последовательность блокированных или псевдоблокиро-
ванных циклов, переводит большинство своих выходных сигналов в
высокоимпедансное состояние и выдает сигнал подтверждение
HLDA. Шина остается в состоянии захвата до • снятия сигнала
HOLD. Во время захвата шины процессор продолжает операции с
информацией из внутренних кэш-памяти и устройства предвыбор-
ки команд до появления необходимости обращения к шине; при
этом он выдает сигнал BREQ запроса шины.
При захвате шины применяется такой же протокол подтвержде-
ния захвата, что и в прежних процессорах семейства 8086. Выход-
ные сигналы HLDA, BREQ, PCHK# и FERR# не переводятся в
плавающее состояние и могут быть выданы при захвате шины.
Процессор распознает и реагирует на сигнал HOLD при сбросе. Во
время захвата шины распознаются входные сигналы AHOLD,
EADS# и BOFF#. Вход AHOLD (захват адреса) не связан с опера-
цией захвата шины; он применяется для объявления
недостоверности кэш-памяти.
До подтверждения захвата шины завершаются следующие опе-
рации:
Текущий цикл шины (пакетный или непакетный) или текущая
последовательность циклов шины, в которых сигнал BLAST#
снят во всех передачах данных, кроме последней;
Псевдоблокированные циклы, т.е. многоцикловые последо-
вательности, в течение которых выдается сигнал PLOCK#;
Блокированные циклы.
В состоянии захвата шины могут находиться несколько процес-
соров и внешняя схема арбитража может использовать их сигналы
запроса шины BREQ, определяя, какие процессоры готовы к вы-
полнению циклов шины.
ВРЕМЕННАЯ ДИАГРАММА. При подаче сигнала HOLD про-
цессор прекращает управление следующими выходными сигналами:
А2-А31, D0-D31, DP0-DP3, ВЕОЗ-ВЕЗ#, PWT, PCD, М/Ю#,
D/C#, W/R#, LOCK#, PLOCK#, ADS# и BLAST#.
Подтверждение процессора заключается в переводе в плавающее
состояние сигналов адреса и данных и выдаче сигнала HLDA под-
тверждения захвата, как показано на рис. 2.21. Сигналы LOCK#,
М/Ю#, D/C#, W/R#, ADS#, А2-А31, ВЕ0#-ВЕЗ# и D0-D31
удерживаются в высокоимпедансном состоянии. Некоторые
сигналы, например ADS# и LOCK#, требуют внешних резисторов,
Микропроцессор i486 * Книга 2. Аппаратная архитектура
подключенных к питанию, которые гарантируют их пассивность
при переходах между ведущими шины.
Ti Ti Tl T2 Ti TI
TI
Рис. 2.21. Временная диаграмма захвата шины
Так как линии BREQ, HLDA и FERR# не переводятся в плава-
ющее состояние, ими не должен управлять никакой другой веду-
щий шины. Процессор остается в состоянии захвата до снятия сиг-
нала HOLD. Запрашивающий ведущий шины должен сохранять
сигнал HOLD до своей готовности вернуть управление шиной про-
цессору.
В состоянии захвата процессор продолжает выполнять команды
из внутренних кэш-памяти и устройства предвыборки до тех пор,
пока ему не потребуется обращение к шине. Процессор может
сформировать и сохранить до четырех циклов записи без обраще-
ния к шине. Если в цикле считывания выборка команды вызывает
промах во внутренней кэш-памяти или требуется более четырех за-
писей, операции прекращаются до освобождения шины.
В состоянии захвата процессор контролирует только сигналы
HOLD, RESET, NMI и INTR. Распознается и запоминается один
запрос прерывания NMI для подтверждения после окончания опе-
рации захвата. Несмотря на то, что в состоянии захвата входной
Глава 2. Сигналы и временные диаграммы работы i486
сигнал прерывания INTR контролируется, он должен сохраняться
поданным до выполнения цикла подтверждения прерывания после
окончания операции захвата шины.
После снятия сигнала HOLD процессор начинает управлять
шиной и снимает сигнал HLDA в следующем такте. Если в процес-
соре ожидает цикл шины, он начинается в этом же такте.
ЗАПАЗДЫВАНИЕ ЗАХВАТА ШИНЫ. Максимальное запазды-
вание HOLD определяется максимальной продолжительностью
блокированных циклов (см. далее). Подача сигнала AHOLD захвата
адреса может предотвратить распознавание процессором сигнала
HOLD. Например, подача сигнала AHOLD в третьем из четырех
циклов BS8# препятствует распознаванию сигнала HOLD.
2.7.5. Блокировка шины
При активном выходном сигнале LOCK# процессор не под-
тверждает запрос захвата шины. Блокировка шины предотвращает
прерывание непрерывных циклов процессора, которые нужно вы-
полнить целиком. На рис. 2.22 показан типичный пример
использования сигнала LOCK#, который формируется в следующих
операциях процессора:
Операции считывания-модификации-записи при:
— выполнении команд TEST или SET (модификации семафо-
ра),
— выполнении команды XCHG с операндом в памяти,
— наличии префикса LOCK перед некоторыми командами
(например, XADD и CMPXCHG),
— модификации бита обращения в дескрипторах сегментов,
— модификации бит обращения и «грязный» в элементах таб-
лицы страниц,
— установке бита занятости в дескрипторе сегмента состояния
задачи TSS,
— установке бита обращения в дескрипторе сегмента.
Циклы подтверждения прерывания.
Блокированные циклы считывания не кэшируются. В системах с
внешней кэш-памятью между шиной процессора и системной ши-
ной блокированные циклы всегда должны вызывать цикл систем-
ной шины. Этим обеспечивается согласованная синхронизация
между несколькими абонентами на системной шине. Во время бло-
кированных циклов процессор не распознает запрос HOLD, но
распознает запросы BOFF# и AHOLD.
ВРЕМЕННАЯ ДИАГРАММА. Последовательность блокирован-
ных циклов показана на рис. 2.22. Выходной сигнал LOCK# блоки-
Микропроцессор i486 яКнига 2. Аппаратная архитектура
ровки шины выдается по нарастающему фронту сигнала CLK пер-
вого блокированного цикла шины одновременно с сигналом ADS#
и снимается после восприятия сигнала RDY # готовности в конце
последнего блокированного цикла шины. Продолжительность сиг-
нала LOCK# влияет на максимальное запаздывание захвата шины
HOLD, так как сигнал HOLD не распознается до снятия сигнала
LOCK#. Длительность сигнала LOCK# зависит от выполняемой
команды и числа состояний ожидания в цикле.
Запись
Чтение
ADS#
W/R#
RDY#
Данные
LOCK#
А2-А31,
М/Ю#,
D/C#,
ВЕО#-3#
CLK
Рис. 2.22. Блокированные циклы шины
В R-режиме максимальная длительность сигнала LOCK# состав-
ляет два цикла шины плюс примерно два такта (в команде XCHG и
блокированных операциях считывания-модификации-записи). В
P-режиме максимальная длительность сигнала LOCK# составляет
пять циклов шины плюс примерно 15 тактов (при восприятии ап-
паратного или программного прерывания, когда процессор выпол-
няет блокированное считывание пшюза из дескрипторной таблицы
прерываний, считывание целевого дескриптора и запись бита об-
4 Заказ 4317
Глава 2. .Сигналы и временные диаграммы работы i486
ращения в целевом дескрипторе). Наличие состояний ожидания
влияет на длительность циклов шины.
ЗАПАЗДЫВАНИЕ БЛОКИРОВКИ ШИНЫ. Выполнение ко-
манды (точнее, префикса блокировки) LOCK вызывает выдачу сиг-
нала LOCK# на два цикла шины (каждый из которых может быть
расщеплен на несколько циклов в случае невыравненных данных
или размера шины 8/16 бит) плюс два такта на операцию арифме-
тико-логического устройства.
Обращения к глобальной дескрипторной таблице (Global
Descriptor Table — GDT) или локальной дескрипторной таблице
(Local Descriptor Table — LDT) блокируют шину для установки в 1
бита обращения A (Accessed) в находящихся в памяти дескрипторах
(если он уже не установлен). Дескрипторы считываются без выдачи
сигнала LOCK# блокировки. Если бит А не установлен в 1, деск-
риптор считывается повторно с выданным сигналом LOCK# (два
4-байтных цикла считывания), бит А устанавливается в 1, а затем
четыре байта записываются в память для модификации половины
дескриптора. При этом сигнал LOCK# выдается в течение трех
циклов шины (два считывания, а затем одна запись) плюс восемь
тактов. Когда бит обращения А установлен, для последующих
считываний того же дескриптора применяются неблокированные
циклы. Операционная система может минимизировать длитель-
ность сигнала LOCK#, выравнивая дескрипторные таблицы по 8-
байтным границам и храня их в 32-битной памяти, чтобы избежать
использования сигналов BS8# или BS16 # размера шины.
Обращения к таблицам страниц выдают сигнал LOCK# для ус-
тановки бита грязный D (Dirty) и/или бита обращения А в элемен-
тах каталога страниц или таблицы страниц. Вначале элемент
считывается без активного сигнала LOCK#. Если любой из указан-
ных бит сброшен в 0, элемент считывается повторно с выданным
сигналом LOCK#, нужный бит устанавливается в 1, а затем элемент
записывается в память. Сигнал LOCK# выдается на два цикла ши-
ны плюс четыре такта. Элементы таблиц страниц всегда выравнены
и хранение из в 32-битной памяти позволяет предотвратить запаз-
дывание блокировки из-за сигналов BS8# или BS16# размера ши-
ны.
Наихудшее запаздывание блокировки возникает при считывании
элемента дескрипторной таблицы: оно занимает восемь тактов
плюс два цикла считывания плюс один цикл записи. Префикс
LOCK вызывает самое продолжительное запаздывание при выпол-
нении блокированных команд BTS, ВТС или BTR (проверка и ус-
тановка/инвертирование/сброс бита): они длятся четыре такта плюс
один цикл считывания плюс один цикл записи (каждый из циклов
9
Микропроцессор i486 Книга 2. Аппаратная архитектура
может быть расщеплен на несколько циклов из-за невыравненных
данных или размера шины в 8 или 16 бит).
2.7.6. Псевдоблокировка шины
С помощью выходного сигнала PLOCK# псевдоблокировки реа-
лизуется новое средство защиты, которого нет в процессоре 80386.
Этот сигнал выполняет функцию, аналогичную функции сигнала
блокировки шины LOCK# — процессор не подтверждает запрос
захвата шины при выданном сигнале PLOCK#, предотвращая пре-
рывание последовательных циклов. Однако сигнал PLOCK# выда-
ется при обстоятельствах, которые отличаются от условий выдачи
сигнала блокировки LOCK#. Псевдоблокирование защищает пере-
дачи выравненных данных, которые длиннее 32 бит. Сигнал
PLOCK# выдается только для циклов в одном направлении (циклы
считывания или циклы записи, но не циклы считывания-модифи-
кации-записи). Типичный пример использования сигнала PLOCK#
показан на рис. 2.23. Во время псевдоблокированных циклов про-
цессор не распознает сигнал HOLD захвата шины, хотя он будет
распознавать запрос BOFF# отступления шины или AHOLD захва-
та адреса. Сигнал PLOCK# формируется в следующих операциях:
Любая передача данных длиннее 32 бит, в которой данные
выравнены по храницам, равным размеру структуры данных,
т.е. любая многоцикловая последовательность с выравнен-
ными данными;
Когда снят сигнал BLAST# последнего пакета (этот случай
перекрывается с первым);
Во время первого цикла 64-битной записи с плавающей
точкой.
Псевдоблокированные циклы включают в себя 16-байтные за-
полнения строки кэш-памяти, считывания или записи 64-битных
операндов с плавающей точкой и передачи двойных слов по 8/16-
битной шине. Сигнал псевдоблокировки PLOCK# выдается, если
только передаваемые данные выравнены по границам, равным раз-
меру структуры данных: 32-битные данные должны быть выравнены
по 4-байтным границам, 64-битные данные должны быть вырав-
нены по 8-байтным границам, а 16-байтные заполнения строки
кэш-памяти должны быть выравнены по 16-байтным границам. В
противном случае потребуются дополнительные передачи и псевдо-
блокирование их не производится.
Процессор по возможности пакетирует циклы считывания
длиннее 32 бит. В пакетных циклах все данные передаются в одном
цикле шины. Сигнал PLOCK# полезен для внешней схемы только в
передачах, которые требуют более одного цикла шины. В системах,
которые не прерывают пакетные циклы сигналом BOFF#, в пакет-
Глава 2. Сигналы и временные диаграммы работы i486
ных считываниях не нужны специальные средства учета сигнала
PLOCK#. Однако система должна проверять сигнал PLOCK# в 64-
битных записях, которые требуют минимум две передачи данных. В
64-битных записях сигнал BLAST# выдается в конце каждой пере-
дачи данных, а сигнал PLOCK# выдается в конце первой передачи
и в первой части второй передачи. Выдача сигнала PLOCK# пока-
зывает, что ожидает еще одна передача данных. На рис. 2.23 приве-
дена временная диаграмма сигнала PLOCK# в 64-битной записи.
При обращении к 80-битным операндам применяются псевдобло-
кированных циклы шины; однако в псевдоблокированных циклах
шины передаются только 64 бита с меньшими адресами.
Запись Запись
CLK
ADS#
А2-А31,
М/Ю#,
D/C#,
ВЕО#-3#
W/R#
Из ЦП
BLAST#
PLOCK#
RDY#
Из ЦП
Рис. 2.23. Пссвдоблокировапный цикл 64—битной записи
Сигнал псевдоблокировки PLOCK# необходимо опрашивать
только в том такте, в котором выдан сигнал RDY# или BRDY#, как
'1004,
Микропроцессор i486 • Книга 2. Аппаратная архитектура
показано на рис. 2.23. Выдача сигнала PLOCK# показывает, что
следующий цикл псевдоблокирован в текущем цикле. Сигналы
PLOCK# и BLAST# всегда противоположны, за исключением пер-
вой передачи 64-битной записи с плавающей точкой. Выдача сиг-
нала PLOCK# зависит от входных сигналов KEN#, BS8# и BS16#.
Сигнал PLOCK# может изменять состояние в течение цикла, но
стабилен в том такте, где выдается сигнал RDY# или BRDY#.
Имеются ситуации, в которых сигналы PLOCK# и LOCK# вы-
даются одновременно, например при загрузке 64-битного деск-
риптора сегмента, в которых операнды длиннее 32 бит (и, следова-
тельно, защищаются сигналом PLOCK#) и специально защищаются
сигналом LOCK#.
2.7.7. Отступление шины
В некоторых циклах шины, инициируемых процессором, для их
завершения может потребоваться, чтобы внешний ведущий шины
закончил свои циклы шины. Например, обращение к данным, ко-
торые находятся во внешней кэш-памяти другого процессора, мо-
жет потребовать, чтобы другой процессор осуществил обратную за-
пись кэшированных данных в памятЬ. Отступление шины приме-
няется для того, чтобы избежать такого «смертельного об’ятия»,
когда ни процессор, ни другой ведущий шины не могут завершить
свою операцию, так как каждый из них ожидает чего-то от другого.
Входной сигнал BOFF# показывает, что другому ведущему шины
требуется закончить цикл шины, чтобы мог быть закончен текущий
цикл процессора. Реакция процессора на отступление шины ана-
логична операции захвата шины, но более быстрая; процессор ос-
вобождает шину в следующем такте и подтверждение не выдается.
Когда сигнал BOFF# снимается, процессор надежно осуществляет
рестарт отмененного цикла шины.
Отступление -шины называется также рестартом цикла шины,
так как любой текущий цикл при подаче сигнала BOFF# будет во-
зобновлен при снятии этого сигнала. Рестартируемый цикл
начинается с новой выдачи сигнала ADS#, но передача продолжа-
ется из состояния в том такте, в котором появился сигнал BOFF#.
Любая передача, законченная до поступления сигнала BOFF#,
считается правильной и не повторяется.
ВРЕМЕННАЯ ДИАГРАММА. Входной сигнал BOFF# отступле-
ния шины опрашивается в каждом такте. При подаче этого сигнала
процессор прекращает управление выходными сигналами А2—А31,
D0-D31, DP0-DP3, ВЕО#—ВЕЗ#, PWT, PCD, M/IO#, D/C#,
W/R#, LOCK#, PLOCK#, ADS# и BLAST#.
Глава 2. Сигналы и временные диаграммы работы i486
Операция отступления шины действует быстрее захвата шины:
процессор переводит приведенные выше сигналы в плавающее со-
стояние в следующем такте после подачи сигнала BOFF#. Приос-
танавливать и удерживать ожидающими на время операции отступ-
ления шины можно как пакетные циклы, так и другие типы цик-
лов. Отступление шины продолжается до такта, находящегося после
такта снятия сигнала BOFF#, как показано на рис. 2.24.
Рис. 2.24. Отступление шины и рестарт в цикле считывания
При подаче сигнала BOFF# отступления шины текущий цикл
шины приостанавливается в таком состоянии, которое обес-
печивает надежный рестарт после снятия сигнала BOFF#. Любые
данные, возвращаемые в том цикле, когда был подан сигнал
BOFF#, и при действии сигнала BOFF#, игнорируются. Если одно-
временно с подачей сигнала BOFF# действует сигнал RDY# или
BRDY# готовности, распознается только, сигнал BOFF#. Если сиг-
нал BOFF# получен после того, как процессор уже начал цикл ши-
ны, выдавшему сигнал BOFF# устройству придется подождать по-
ступления сигнала RDY# или BRDY# готовности до запуска нового
цикла. Этим обеспечивается, что система памяти готова восприни-
Микропроцессор i486 «Книга 2. Аппаратная архитектура
мать следующий цикл шины. Если сигнал BOFF# подан при холос-
том состоянии шины, процессор переходит в состояние захвата
шины в следующем такте. Таким образом сигнал BOFF# может
предотвратить запуск следующего цикла шины.
При отступлении шины процессор переводит в плавающее со-
стояние те же сигналы, что и при захвате шины, но сигнал HLDA
подтверждения не выдается. Шина данных переводится в плаваю-
щее состояние, если сигнал BOFF# подан в цикле записи. Каждая
передача шины между ведущими шины длится два такта, чтобы не
было перекрытия в управлении шиной.
2.8. Управление кэш-памятью
Ранее было показано, как циклы шины превращаются в кэши-
руемые циклы. Когда в системах с несколькими ведущими шины
разрешено кэширование, управление кэш-памятью обеспечивает
согласованность между внутренней кэш-памятью процессора, ос-
новной памятью и внешними (второго уровня) кэш-памятями, ког-
да обновляется содержимое любой памяти. На рис. 2.25 показана
система с внешней кэш-памятью.
Рис. 2.25. Организация кэш-памяти второго уровня
Управление кэш-памятью на уровне страниц реализовано двумя
выходными сигналами: PCD — запрещение кэширования страницы
Глава 2. Сигналы и временные диаграммы работы i486
(внутренняя и внешняя кэш-память) и PWT — сквозная запись или
обратная запись страницы (внешняя кэш-память).
Для превращения строки внутренней кэш-памяти в недостовер-
ную предусмотрены два действующих совместно входных сигнала:
EADS# — недостоверность строки кэш -памяти (внутренняя кэш-
память) и AHOLD — захват адреса (внутренняя кэш-память).
Для очистки внутренней кэш-памяти предусмотрен входной
сигнал FLUSH#. Операции очистки, а также очистки и обратной
записи реализуются для внутренней и внешней кэш-памяти двумя
специальными циклами шины:
— Цикл очистки кэш-памяти. Инициируется командой INVD
(внутренняя и внешняя кэш-память).
— Цикл обратной записи и очистки кэш-памяти. Инициируется
командой WBINVD (внешняя обратная запись, внутренняя и
внешняя кэш-память).
2.8.1. Управление кэш-памятью на уровне страниц
Кэширование и обновление памяти опираются на страницы:
каждая страница 4 Кбайт может иметь свои управление кэшируе-
мостью и принцип сквозной или обратной записи, которыми мож-
но управлять по тактам. Для управления кэш-памятью на уровне
страниц по тактам предусмотрены два программно-управляемых
выходных сигнала PCD и PWT.
Выходной сигнал запрещения кэширования страницы PCD уп-
равляет кэшируемостью текущей страницы в предположении, что
все остальные условия для кэширования удовлетворяются. Когда
соответствующий бит сброшен программой, выходной сигнал сни-
мается и кэширование для внутренней кэш-памяти разрешено. Вы-
ход PCD можно использовать для разрешения внешней кэш-памя-
ти. При выдаче сигнала PCD внутреннее кэширование запрещается,
даже если подан входной сигнал KEN#; внутри процессор управ-
ляющий бит PCD объединяется по И с сигналом KEN#.
Выходной сигнал сквозной записи страницы PWT полезен толь-
ко для внешней кэш-памяти; внутренняя кэш-память всегда дей-
ствует по принципу сквозной записи. Выданный сигнал PWT опре-
деляет для текущей страницы принцип сквозного кэширования:
изменения в кэш-памяти записываются в память. Снятый сигнал
PWT разрешает внешней кэш-памяти для текущей страницы рабо-
тать по принципу обратной записи.
Когда страничное преобразование разрешено (в регистре CR0
бит PG =1), выходные сигналы PCD и PWT соответствуют элемен-
ту таблицы страниц текущей страницы, который находится в ассо-
циативном буфере преобразования адреса (Translation Lookaside
Buffer — TLB). Выходы активны, когда производится обращение к
Микропроцессор i486 Книга 2. Аппаратная архитектура
странице, отображаемой буфером TLB. Для обычных циклов памя-
ти с разрешенным страничным преобразованием выходы PCD и
PWT берутся из элемента таблицы страниц второго уровня. В цик-
лах обновления буфера TLB выходы PCD и PWT берутся из регист-
ра управления CR3.
Когда страничное преобразование запрещено (бит PG = 0) или
когда циклы обходят страничное преобразование (например, обра-
щения к вводувыводу с отображением на память, прерывания и ос-
тановы), процессор выдает на выходы PCD и PWT состояния соот-
ветствующих бит из регистра управления CR3. Они находятся в со-
стоянии 0 при сбросе, но программа уровня 0 может сформировать
любое значение.
2.8.2. Недостоверность внутренней кэш-памяти
Шина адреса процессора i486 является двунаправленной. В про-
цессор можно передать адреса для объявления недостоверной
любой строки кэш-памяти. В системе необходимо предусмотреть
регистры-защелки адреса; они предотвращают потерю адресной
информации, когда шина адреса направлена в процессор.
Превратить содержимое кэш-памяти в недостоверное можно в
любой момент время. Так как шина адреса в пакетной передаче не
используется, превращать кэш-память в недостоверную можно
одновременно с пакетными передачами. Во время непакетных
циклов одиночных передач с состояниями ожидания сделать кэш-
память недостоверной можно в течение состояний ожидания, если
имеется внешняя защелка адреса для превращаемой в
недостоверную строки.
Превращение строки кэш-памяти в недостоверную начинается с
выдачи внешней схемой сигнала захвата адреса AHOLD. В следую-
щем такте процессор переводит линии А2—А31 в плавающее
состояние, разрешая внешнему ведущему шины передать в
процессор адрес 16-байтной строки кэш-памяти. Подтверждения
захвата адреса не выдается. Управлять сигналами АЗ, А2 и
ВЕО#—ВЕЗ# не нужно, так как наименьшей единицей хранения в
кэш-памяти являются четыре двойных слова. После этого внешняя
схема подает сигнал EADS#. Можно превратить в недостоверные
несколько адресов, подавая сигнал EADS# несколько раз при
действии сигнала AHOLD. Обычная работа шины возобновляется
со снятием сигнала AHOLD.
Сигнал AHOLD распознается всегда, даже при сбросе, хотя
сброс превращает в недостоверную всю кэш-память. При захвате
адреса данные можно возвратить для одного ранее начатого цикла;
процессор отключается только от шины адреса. При захвате адреса
процессор не инициирует следующий цикл шины. Допускается
Глава 2. Сигналы и временные диаграммы работы i486
прерывать блокированные и псевдоблокированные последователь-
ности.
На время превращения строки кэш-памяти в недостоверную
другие операции в кэш-памяти, например запрос ее содержимого,
задерживаются. Ненужные циклы объявления кэш-памяти недосто-
верной снижают производительность системы. Нельзя пытаться
сделать кэш-память недостоверной в конце заполнения строки
кэш-памяти. В том такте, когда строка фактически записывается в
кэш-память (последний такт заполнения или первый следующий за
ним), сигнал EADS# игнорируется. Сигнал EADS# не распознается
только в этой ситуации.
Рис. 2.26. Цикл недостоверности внутренней кэш-памяти
Цикл превращения внутренней кэш-памяти в недостоверную
показан на рис. 2.26.
СКОРОСТЬ ОПЕРАЦИИ НЕДОСТОВЕРНОСТИ. Процессор
опрашивает сигнал EADS# в каждом такте и может производить
Микропроцессор i486*Книга 2. Аппаратная архитектура
операции недостоверности кэш -памяти по одной в такте, за ис-
ключением последнего такта заполнения строки кэш-памяти. Та-
кую скорость можно обеспечить, если сигнал EADS# снимается в
следующих одном или обоих моментах времени:
Такт, в котором сигнал RDY# или BRDY# готовности выдан
последний раз в передаче;
Такт, находящийся сразу за тактом, в котором сигнал RDY#
или BRDY# выдан последний раз в передаче.
Эти условия допускают реализацию двух типов систем. Простая
система с кэш-памятью может ограничить выполнение операций
недостоверности через такт и может не следить за действиями ши-
ны. Системы, в которых требуются операции недостоверности в
каждом такте, должны следить за шиной процессора, фиксируя
приведенные выше условия для сигнала RDY# или BRDY#.
2.8.3. Очистка внутренней кэш-памяти
Данный цикл превращает в недостоверную всю внутреннюю
кэш-память. Когда адрес модифицированных данных не известен,
операцию частичной недостоверности производить нельзя и един-
ственной альтернативой остается очистка кэш-памяти. Изменения
информации, относящейся к отображению адреса, также требуют
очистки кэш-памяти. Очистку кэш-памяти производит подача на
один такт сигнала FLUSH#.
Помимо очистки, которая сбрасывает всю кэш-память, но раз-
решает ей начать сохранение новых данных со следующего такта,
можно также запретить кэш-память. Запрещение кэш-памяти со-
стоит из двух действий: установки в 1 бит PCD и PWT в регистре
CR3 и очистки кэш-памяти.
2.8.4. Цикл очистки кэш-памяти
При выполнении команды INVD выполняется специальный
цикл шины, который вызывает выдачу активного сигнала BE1# и
снятие сигналов ВЕО#, BE2# и ВЕЗ#. Команда INVD заставляет
внутреннюю кэш-память сделать все ее содержимое недостоверным.
Внешняя схема должна дешифрировать этот цикл, чтобы заставить
внешнюю кэш-память сделать недостоверным все ее содержимое
(перед очисткой внешняя кэш-память не должна записывать свое
содержимое в память).
2.8.5. Цикл обратной записи и очистки кэш-памяти
Этот специальный цикл шины похож на цикл очистки кэш-па-
мяти, но он добавляет для внешней кэш-памяти функцию обратной
записи. Цикл формируется при выполнении команды WBINVD,
Глава 2. Сигналы и временные диаграммы работы i486
которая вызывает выдачу активного сигнала ВЕЗ# и снятие сигна-
лов ВЕ0#-ВЕ2#.
Команда WBINVD заставляет внутреннюю кэш-память сделать
недостоверным все ее содержимое. Внешняя схема должна дешиф-
рировать этот цикл, чтобы заставить внешнюю кэш-память запи-
сать все ее содержимое в память, а затем заставить внешнюю кэш-
память сделать недостоверным все ее содержимое.
В отличие от внутренней кэш-памяти процессора со сквозной
записью кэш-память с обратной записью не производит немедлен-
ной модификации памяти при получении данных в цикле записи.
Вместо этого в поле тэга каждого блока кэш-памяти устанавливает-
ся бит, если кэш-память содержит более свежие данные, чем соот-
ветствующая область памяти. Только при перезаписи такого блока
содержащиеся в нем данные записываются в память. При этом
уменьшается нагрузка на шину.
2.9. Управление ошибками с плавающей точкой
Для поддержания совместимых с операционой системой DOS
сообщений об ошибках с плавающей точкой применяются два сиг-
нала. Выходной сигнал FERR# ошибки с плавающей точкой пока-
зывает, что возникла незамаскированная ошибка с плавающей
точкой. Входной сигнал IGNNE# игнорирования численной ошиб-
ки сообщает процессору игнорировать ошибки с плавающей точкой
и продолжать выполнение.
В каждой команде с плавающей точкой (за исключением команд
управления без ожидания) процессор контролирует, не сформиро-
вала ли предыдущая команда с плавающей точкой незамаскирован-
ный численный особый случай (переполнение, антипереполнение,
деление на нуль и т.д.). При наличии ошибки процессор сообщает
об этом, выдавая активный сигнал FERR#. В этом отношении сиг-
нал FERR# аналогичен выходному сигналу ERROR# матема-
тических сопроцессоров 80287 и 80387.
Если сигнал IGNNE# снят при обнаружении ошибки с плаваю-
щей точкой, процессор либо останавливается и ожидает прерыва-
ния, либо переходит по ячейке прерывания с плавающей точкой
(вектор 16) в зависимости от состояния бита NE численной ошиб-
ки в регистре состояния мащины (младшая половина регистра уп-
равления CR0). Эти два способа вызова обработчиков особого
случая одинаковы в системах с процессорами 80286/80287 и
80386/80387.
Если бит NE в регистре CR0 установлен в 1, процессор форми-
рует прерывание 16, т.е. прерывание ошибки с плавающей точкой.
Если бит NE сброшен в 0, процессор останавливается и ожидает
Микропроцессор i486 Книга 2. Аппаратная архитектура
внешнего прерывания. Бит NE сбрасывается в 0 при действии сиг-
нала сброса RESET; такое состояние принимается по умолчанию.
Принимаемый по умолчанию механизм (NE = 0) эмулирует со-
общения об ошибках в системах с процессорами 8086/8087 и под-
держивается ради совместимости с DOS. Он требует наличия внеш-
него контроллера прерываний для контроля выхода FERR# и гене-
рирования необходимых прерываний (обычно по входу INTR не-
маскируемых прерываний). Контроллер прерываний может разре-
шить выполнение команд с плавающей точкой до сброса условия
ошибки (т.е. внутри обработчика прерывания), подавая в процессор
сигнал IGNNE#. Когда подан сигнал IGNNE# (и бит NE = 0),
процессор выполняет команды с плавающей точкой, несмотря на
предшествующие ошибки.
Глава 2. Сигналы и временные диаграммы работы i486
Литература
1. Брамм IL, Брамм Д. Микропроцессор 80386 и его
программирование. М.: — Мир, 1990.
2. i486 Processor hardware reference manual. — Intel, 1990,
3. Microprocessors. Volume II. Intel, 1991.
4. Strauss E. Inside the 80386. — Brady, 1986.
5. Strauss E. 80386 technical reference. — Brady, 1987.
Микропроцессор i486 • Книга 2. Аппаратная архитектура
Микропроцессор
i486
^новные-харшт
Формат
ДнапаЕОЕ
•Целое-слово* * * *цс.
• Короткое * целое•К
• Длинное•целое• • Д
•Упакованное• деся
• Короткое•веществ
• Длинное•веществе
• Временное • ьещест:
ДВОИЧНЫЕ
целых- двозгшых
104
q
УСТРОЙСТВО
с
ПЛАВАЮЩЕЙ ТОЧКОЙ
Предисловие
Расширение сферы применения микропроцессоров постоянно
предъявляет все более высокие требования к их быстродействию,
допустимым форматам данных и точности вычислений. Однокрис-
тальные микропроцессоры с длиной слова 8 и 16 бит оперируют
фактически с двумя простыми форматами численных данных: зна-
ковыми и беззнаковыми (порядковыми) целыми двоичными
числами, хотя с определенными ограничениями допускают деся-
тичные целые числа. Вычислительные возможности их ограничены
только арифметическими операциями. Программная реализация
сложных команд связана со значительным снижением производи-
тельности. Более того, появившиеся стандарты на численные дан-
ные и особенности их обработки, во-первых, усложнили форматы
чисел (достаточно сказать, что числа с плавающей точкой могут
иметь 15 бит порядка и 64 бита мантиссы) и, во-вторых, потребова-
ли учета многочисленных особых случаев и единообразных реакций
на их возникновение. Программная реализация операций над
числами в стандартных форматах становится очень громоздкой.
Как возможный подход представляется применение секционных
микропроцессоров. Разработав соответствующие микропрограммы,
можно реализовать практически любые операции с приемлемым
быстродействием. Однако такое решение имеет свои недостатки,
один из которых заключается в увеличении числа микросхем
(например, для параллельного процессора с длиной слова 80 бит
потребуется десять 8-битных процессорных секций). Кроме того,
объем микропрограмм^, рассчитанных на стандартные форматы
чисел, специальные численные значения и разнообразные особые
случаи, окажется чрезмерно большим.
В сложившейся к концу 70-х годов ситуации плодотворным ока-
зался принцип специализации, который давно применялся в про-
цессорах средних и больших компьютеров. Суть его заключается в
разработке специализированных процессорных модулей со своими
системами команд, ориентированными на конкретные приложения,
— процессор арифметики с плавающей точкой, процессор базы
данных, графический процессор, процессор ввода-вывода и др. Та-
кие вспомогательные процессоры работают под общим управлени-
ем центрального (главного) процессора и обычно разделяют с ним
основную память. Специализация позволяет достичь очень высоко-
Предисловие
го быстродействия и повысить эффективную производительность
системы благодаря параллельной работе нескольких процессоров.
Имеются две основные конфигурации сильно связанных муль-
типроцессорных систем, т. е. систем, в которых процессоры взаи-
модействуют через основную память. Конфигурация с независи-
мыми процессорами предполагает наличие у каждого вспомога- s
тельного процессора своей программы, содержащей команды имен-
но этого процессора. При необходимости центральный процессор
формирует блок параметров для вспомогательного процессора и
инициирует его действия специальным сигналом. После этого цен-
тральный и вспомогательный процессоры работают параллельно,
выполняя свои программы. В такой конфигурации у вспомогатель-
ного процессора могут быть локальные память и периферийные ус-
тройства. Типичным примером рассмотренной конфигурации слу-
жат системы, в которых применяется, процессор ввода-вывода.
В сопроцессорной конфигурации вспомогательный процессор
(именно его называют сопроцессором) подключается к системной
шине параллельно центральному процессору. Сопроцессор не име-
ет своей отдельной программы и не может считывать команды из
памяти, но может обращаться к памяти для записи и считывания
данных, запрашивая для этого шину у центрального процессора.
Кроме того, сопроцессор контролирует системную шину и может
перехватывать адреса и данные при обращениях к памяти цент-
рального процессора. Часть кодов операций центрального процес-
сора резервируется для команд сопроцессора и действия централь-
ного процессора при их «выполнении» сводятся максимум к фор-
мированию адреса памяти и обращению к ней. Сопроцессор не
может выполнять команды центрального процессора, но свои ко-
манды выполняет очень быстро (по сравнению и их программной
эмуляцией командами центрального процессора). Таким образом,
программа оказывается смесью команд центрального процессора и
сопроцессора, причем выборку команд из памяти осуществляет
только центральный процессор, а затем команды подаются парал-
лельно в оба процессора. Каждый из них выбирает из общего ко-
мандного потока и выполняет свои команды. Такое своеобразное
«разделение труда» позволяет достичь очень высокой производи-
тельности в тех задачах, на которые ориентирован сопроцессор.
Отчетливо сознавая .необходимость мощной «численной» под-
держки своих универсальных процессоров, фирма Intel, начиная с
процессора 8086, предлагает микросхемы численных процессоров.
Они называются численными процессорами расширения NPX
(Numeric Processor extension), процессорами численных данных NDP
(Numeric Data Processor) или численными (арифметическими или
математическими) сопроцессорами. За 80-е годы были выпущены
сопроцессоры 8987 (для процессора 8086), 80287 (для 80286) и 80387
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
(дая 80386), а в процессоре i486 сопроцессор реализован в виде уст-
ройства с плавающей точкой (Floating Point Unit — FPU) как состав-
ная часть универсального процессора на одном с ним кристалле.
Каждый новый сопроцессор имеет более высокое быстродействие,
чем его предшественники, и расширенную систему команд. Вместе
с тем программные модели сопроцессоров почти не изменяются,
что объясняется необходимостью удовлетворения стандарта на
числа с плавающей точкой IEEE-754 и требованиями совместимо-
сти. Отечественными аналогами процессоров 8086/8087 являются
процессор К1810ВМ86 и сопроцессор К1810ВМ87.
Первый сопроцессор 8087 и все последующие сопроцессоры
рассчитаны на применение в системах с интенсивной численной
обработкой, в которых:
— численные данные изменяются в очень широком диапазоне
или включают в себя нецелые значения;
— при реализации алгоритмов возникают очень большие или
очень малые промежуточные результаты;
— требуется высокая точность вычислений с сохранением
большого числа значащих разрядов;
— необходима производительность, превышающая возможности
центрального процессора;
— необходимо получить совместимые ц точные результаты про-
граммистами — не специалистами в численной математике.
Математический сопроцессор помогает сократить расходы на
программирование и повысить производительность систем, работа-
ющих не только с вещественными числами, но и с двоичными
числами многократной точности, а также с десятичными числами.
Приведем несколько типичных примеров применений сопроцес-
соров, дая которых раньше приходилось привлекать миникомпью-
теры и большие компьютеры.
Обработка экономической информации. Сопроцессор вос-
принимает десятичные операнды и дает десятичные результаты с
точностью до 18 разрядов, что упрощает программирование бухгал-
терских задач. Для финансовых расчетов удобно применять коман-
ды возведения в степень и логарифмирования.
Моделирование. Высокое быстродействие сопроцессора по-
зволяет применять его дая решения сложных задач моделирования,
дая которых раньше требовались миникомпьютеры и большие ком-
пьютеры.
Графические преобразования. Сопроцессор пригоден дая
графических приложений, где он может реализовать много функ-
ций параллельно с центральным процессором; примерами таких
функций служат повороты, масштабирование и интерполяция.
Промышленное управление. Сопроцессор автоматически решает
проблемы динамического изменения диапазона, а его повышенная
Предисловие
точность позволяет настроить функции управления на более
точную и эффективную работу. Применение сопроцессора в си-
стемах управления повышает их надежность и безопасность, а его
высокое быстродействие процессора обеспечивает работу в реаль-
ном времени.
Системы числового управления. Сопроцессор позволяет пе-
ремещать и точно позиционировать исполнительные органы стан-
ков с программным управлением в реальном времени. Наличие в
сопроцессоре тригонометрических операций упрощает преобразо-
вание координат.
Роботы. Объединение небольших размеров и малого потреб-
ления энергии с мощными вычислительными возможностями де-
лают сопроцессор незаменимым для позиционирования манипуля-
торов с шестью степенями свободы.
Навигация. На базе сопроцессора реализуются малогабаритные и ,
точные системы инерциальной навигации. Встроенные три- '
тонометрические функции значительно упрощают вычисление мес-
тонахождения по собранным данным.
Сбор данных. Сопроцессор можно использовать для анализа,
масштабирования и сжатия больших объемов данных в процессе их
сбора, что снижает требования к емкости памяти для хранения
данных и сокращает время на их анализ.
Необходимо отчетливо представлять себе, что сопроцессоры не ।
могут работать изолированно от центрального процессора. Вдвоем |
они образуют мощный тандем, производительность которого в
задачах численной обработки в 10—50 раз и более выше производи-
тельности одного центрального процессора. В этом тандеме объе-
динены системы команд, внутренние регистры и форматы данных
обоих процессоров.
Конечно, при совместной работе двух процессоров возникают (
специфические проблемы их взаимодействия — разделение общей
системной шины, доступ к памяти, синхронизация по командам и
данным. Оказалось, что решение этих проблем не требует сложных'
технических приемов и специальных усилий программистов.
С появлением сопроцессора 80287 бысгрые численные,
вычисления были расширены на мультизадачные и многопользова-
тельские системы с процессором 80286. Несколько задач, исполы!1
зующие сопроцессор, могли опираться на управление памятью И
средства защиты процессора 80286.
К третьему поколению численных процессоров фирмы Intel от-
носятся математические сопроцессоры 80387 модели (387DX И
387SX). Они реализуют окончательный стандарт IEEE-754 на ариф-
метику с плавающей точкой, имеют новые три-го неметрические
команды и производятся по новой технологии CHMOS-III, которая
позволяет повысить частоту синхронизации. В этих сопроцессорах
ииимишг—..-".. ............ ....—... ........ ..—q
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
команды выполняются за меньшее число тактов. Сопроцессор
80387 с дополнительными командами привносит большие удобства
и надежность в численное программирование и делает его доступ-
ным для тех приложений, где требуется большее быстродействие и
большая память 32-битного микропроцессора 80386.
Сопроцессоры совершенствовались по быстродействию и систе-
ме команд. В процессоре i486 достижения микроэлектроники по-
зволили разместить математический сопроцессор на одном крис-
талле с центральным процессором. Устройство FPU процессора
i486 представляет собой внутренний эквивалент сопроцессора
387DX, удовлетворяющий стандарту IEEE-754 и новому более об-
щему стандарту IEEE-854. Размещение устройства FPU на крис-
талле процессора значительно повышает производительность
численных вычислений.
В приведенной ниже таблице приведены результаты сравнения
времени выполнения нескольких численных команд процессора
i486 (33 МГц) и эквивалентных операций в сопроцессоре 387DX
(16 МГц). Как видно из таблицы, внутреннее FPU обеспечивает
повышение производительности примерно в 5 раз. Процессор i486
(33 МГц) умножает 32- и 64-битные числа с плавающей точкой
примерно за 0.33 и 0.42 мкс, соответственно. Конечно, фактическая
производительность процессора в конкретной системе зависит от
особенностей применения.
Сравнение быстродействия в численной обработке
Команда с плавающей точкой Отношение производительности (33 МГц) к 386DX/387DX (16 МГц)
i486
FADD ST,ST(i) Сложение 4.2
FDIV dword var Деление 2.0
FYL2X Логарифм 2.5
FPATAN Арктангенс 2.2
F2XM1 Возведение в степень 2.2
FLD ST(O),ST(i) Передача данных 5.5
Целочисленное устройство (Integer Unit — IU), выступающее в
роли центрального процессора, и FPU процессора i486 координи-
руют свои действия прозрачно для программ. Более того, встроен-
ные средства координации позволяют IU выполнять другие коман-
ды одновременно с работой FPU. В программах можно использо-
вать такую параллельность для дальнейшего повышения производи-
тельности системы. Производительность процессора i486 в
численных приложениях сравнима с производительностью больших
миникомпьютеров и в то же время он совместим по объектному
коду с математическими сопроцессорами 8087, 80287, 80387.
Устройство FPU процессора i486 обеспечивает не только про-
стое повышение скорости вычислительных задач; оно делает дос-
Предисловие
тупными большинству пользователей функциональность и мощь
точных численных расчетов. Такие средства, имеющиеся в боль-
шинстве языков программирования высокого уровня, доступны и
дая процессора i486.
Как и предыдущие сопроцессоры, устройство FPU спроектиро-
вано на получение точных устойчивых результатов, характерных дая
алгоритмов, реализуемых по методу «карандаша и бумаги». В стан-
дарте IEEE-754 этому было уделено особое внимание с пониманием
важности превращения численных расчетов в простые и безопас-
ные. Например, в большинстве компьютеров может возникнуть пе-
реполнение, когда два числа с плавающей точкой одинарной
точности умножаются друг на друга, а затем произведение делится
на третье число, даже хотя окончательный результат является допу-
стимым 32-битным числом. В такой ситуации FPU формирует пра-
вильный округленный результат.
В большинстве компьютеров прямые алгоритмы не дают совмес-
тимых корректных результатов (и не показывают, когда они некор-
ректные). Для получения на традиционных компьютерах коррект-
ных результатов с учетом всех условий обычно требуются сложные
численные приемы, с которыми большинство программистов не
знакомо. Для процессора i486 прикладные программисты среднего
уровня с помощью прямых алгоритмов могут разработать более на-
дежные программы. Этот простой факт значительно сокращает рас-
ходы на получение безопасных и точных программных продуктов,
ориентированных на численные вычисления.
Помимо поддержки традиционных научных расчетов процессор
i486 имеет встроенные средства дая экономических вычислений. Он
может обрабатывать десятичные числа длиной до 18 разрядов без
ошибок округления, выполняя точную арифметику над целыми
числами со значениями до 264 или 1018. Точная арифметика требу-
ется в финансовых расчетах, где ошибки округления могут привес-
ти к невосполнимым денежным потерям.
Процессор i486 имеет несколько численных средств, доступных
опытным пользователям. К ним относятся направленное округле-
ние, постепенное антипереполнение и запрограм-мированные сред-
ства обработки особых случаев.
Средства автоматической обработки особых случаев обес-
печивают гибкость в разработке численных программ без серьезных
усилий программиста. В численных расчетах процессор i486 автома-
тически обнаруживает особые ситуации, которые могут потенци-
ально нарушить расчеты (например, деление на 0 или извлечение
корня квадратного из отрицательного числа). По умолчанию внут-
ренние схемы обрабатывают эти ситуации так, чтобы получить при-
емлемый результат и продолжить вычисления без прерывания про-
граммы. Но при обнаружении особого случая процессор может
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
вызвать программный обработчик особого случая для получения
специальных результатов.
Процессор i486 имеет класс команд, называемых ESCAPE, кото-
рые имеют общий формат. Такие ESC-команды представляют со-
бой численные команды для устройства FPU и являются частью
объединенной системы команд.
Численная обработка в процессоре i486 опирается на регистро-
вый стек. Программисты могут считать восемь 80-битных регистров
либо фиксированным набором регистров (команды оперируют явно
указанными регистрами), либо классическим стеком (команды ра-
ботают с одним или двумя верхними элементами стека).
В устройстве FPU все числа хранятся в едином 80-битном рас-
ширенном формате. Операнды в памяти могут быть представлены
16-, 32- или 64-битными целыми числами, 32-, 64- или 80-битными
числами с плавающей точкой или 18-разрядными десятичными
числами, которые автоматически преобразуются в расширенный
формат при загрузке в регистры устройства FPU. Результаты
вычислений при записи в память преобразуются в формат
получателя.
В следующей таблице приведены семь численных типов данных,
поддерживаемых устройством FPU, а также их диапазоны. В каж-
дом из вещественных форматов в соответствии со стандартом
IEEE-854 допускаются денормализованные значения. Отметим, что
расширенный вещественный формат эквивалентен двойному рас-
ширенному формату стандарта IEEE-854.
Численные типы данных
Тип данных Число Значащие Нормализованный
бит разряды (дес.) диапазон (дес.)
Целое слово 16 4 -32768 £ х < +32767
Короткое целое 32 9 -2x10’ £ х +2x10’
Длинное целое 64 18 -9x1018 £ х 5 +9x1018
Упакованное десятичное 80 18 -99...99 <. х < +99...99 < 3.4x1038
Одинарное вещественное 32 7 1.18хЮ-3« < |х
Двойное вещественное 64 15-16 2.23x10-308 < х < 1.79x10308
Расширенное веществ. 80 19 3.37хЮ-<’32 < х < 1.18 х Ю«3-
Все операнды хранятся в памяти так, что младшая цифра нахе
дится по меньшему (начальному) адресу. Численные команды об-
ращаются к операндам и сохраняют результаты, используя только
этот начальный адрес. Для достижения максимальной производи-
тельности каждый операнд должен начинаться в памяти по адресу,
кратному числу байт в длине операнда.
В следующей таблице приведены классы численных команд. Для
использования численных возможностей процессора i486 не требу-
ется никаких программных приемов, так как все численные коман-
ды и типы данных прямо поддерживают ассемблер ASM486 и языки
Предисловие
высокого уровня как фирмы Intel, так и других фирм. Численные
процедуры можно разрабатывать на ассемблере ASM486 и языках
PL/M-386/486, Си-386/486, Фортран-386/486 и Ада-386/486.
Основные численные команды
Класс Типы команд
Передачи данных Загрузка (все типы данных), сохранение (все типы данных), обмен.
Арифметические Сложение, вычитание, умножение, деление, обратное вычитание, обратное деление, извлечение корня квадратного, масштабирование, выделение, нахождение остатка, выделение целой части, смена знака, нахождение абсолютного значения.
Сравнения Сравнение, анализ, проверка.
Трансцендентные Тангенс, арктангенс, синус, косинус, синус и косинус, степень 2, двоичный логарифм.
Управление процессором Загрузка/сохранение слова управления, сохранение слова состояния, загрузка/сохранение среды, сохранение/восстановление полного состояния, сброс особых случаев, инициализация.
Кроме того, для разработки численных программ применимы
все инструментальные средства, рассчитанные на процессоры
8086/8087, 80286/80287, 80386/80387.
Все языки высокого уровня дают программистам доступ к
вычислительной мощности и скорости процессора i486, не требуя
понимания его архитектуры. Вопросы параллельности и синхрони-
зации решаются автоматически. Детали архитектуры, рассматрива-
емые далее, предназначены для программистов, работающих на ас-
семблере ASM386/486.
При разработке процессора i486 было введено несколько архи-
тектурных улучшений. В частности, более простым стал интерфейс
устройства FPU (наличие его представлено всего двумя внешними
сигналами), реализованы автоматическая синхронизация парал-
лельной работы двух процессоров, автоматическая настройка уст-
ройства FPU на режим работы целочисленного устройства,
улучшены операции некоторых команд и др.
Относительная простота программирования и поразительные
возможности устройства FPU делают его доступным большой груп-
пе пользователей, не знакомых с тонкостями программирования
сложных вычислительных задач. По существу, это устройство эф-
фективно расширяет набор регистров и систему команд це-
лочисленного устройства без специальных усилий со стороны про-
граммиста. Только необходимость синхронизации по данным тре-
бует учета совместной работы двух процессоров.
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
Архитектура устройства
с плавающей точкой
В этой главе достаточно подробно рассмотрено устройство с
плавающей точкой FPU процессора i486: его внутренняя организа-
ция, программная модель, типы обрабатываемых данных и система
команд. При необходимости изложение сопровождается небольши-
ми программными фрагментами.
1.1. Сопроцессорные конфигурации
Как отмечалось в предисловии, необходимо отчетливо представ-
лять себе механизм взаимодействия процессоров в сопроцессорных
конфигурациях. Ниже рассмотрены некоторые общие вопросы это-
го механизма применительно к реализации сопроцессора в виде от-
дельной микросхемы. Для устройства FPU процессора i486 меха-
низм взаимодействия значительно упрощен. По отношению к уст-
ройству FPU в качестве центрального процессора выступает це-
лочисленное устройство процессора i486.
Сопроцессоры проектируются с учетом их потенциальных обла-
стей применения. На эти области ориентируются форматы обраба-
тываемых ими данных и система команд. Сопроцессор под-
ключается к системной шине параллельно с центральным процес-
сором и может работать только с ним. Объясняется это тем, что со-
процессор не имеет своей индивидуальной программы и не может
самостоятельно инициировать выборку команд из программной па-
мяти. Его команды замешаны в командном потоке центрального
процессора. Выборку команд осуществляет только центральный
процессор, все команды попадают в оба процессора, а выполняет
каждый из них только qboh команды.
Глава 1. Архитектура устройства с плавающей точкой
tl21j
Часть кодов операций центрального процессора резервируется
для сопроцессора и «выполнение» соответствующих команд цент-
ральным процессором сводится максимум к обращению к памяти
за операндом. Если выбранная команда оказывается командой цен-
трального процессора, он выполняет ее обычным образом, а сопро-
цессор не привлекается — он просто игнорирует такие команды.
Когда выбирается команда сопроцессора, действия центрального
процессора зависят от специфики конкретной команды. Если ко-
манда не связана с обращением к памяти, центральный процессор
ее игнорирует и переходит к следующей команде. Но если команда
требует обращения к памяти, центральный процессор вычисляет
физический адрес операнда и обращается к памяти. При этом со-
процессор перехватывает с общей шины физический адрес операн-
да, а в операции со считыванием из памяти — еще и данные. После
этого сопроцессор реализует конкретные действия по выполнению
команды. Они могут производиться параллельно с дальнейшими
действиями центрального процессора, что повышает эффективную
производительность системы.
Приведенное выше простое объяснение взаимодействия цент-
рального процессора и сопроцессора требует уточнения для тех си-
туаций, когда их совместная работа требует синхронизации. Дей-
ствительно, центральный процессор как бы «проскакивает» коман-
ды сопроцессора и продолжительность их выполнения равна не-
значительному времени обращения к памяти. Реальное выполнение
этих команд в самом сопроцессоре обычно требует гораздо больше
времени, особенно таких сложных команд, как возведение в сте-
пень или вычисление тригонометрической функции. Далее показа-
но, что элементарные и быстро выполняемые в обычных процессо-
рах операции загрузки и сохранения могут оказаться для сопроцес-
сора сложными и продолжительными. Объясняется этот парадокс
преобразованием чисел из одного формата в другой.
СИНХРОНИЗАЦИЯ ПО КОМАНДАМ. Когда центральный
процессор выбирает дая выполнения команду сопроцессора, после-
дний может быть занят операциями своей предыдущей команды и,
естественно, не может начать выполнять выбранную команду. Дру-
гими словами, центральный процессор не должен пропускать в со-
процессор его команды быстрее, чем сопроцессор может их выпол-
нять. Следовательно, перёд каждой командой сопроцессора должна
находиться специальная команда центрального процессора, которая
только проверяет текущее состояние сопроцессора и, если он занят,
переводит центральный процессор в состояние ожидания. Разуме-
ется, такое ожидание оказывается дая центрального процессора
бесполезной потерей времени. Таким образом, системе команд
центрального процессора потребуется команда проверки состояния
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
сопроцессора, а введение этих команд в объектную программу пе-
ред каждой командой сопроцессора могут осуществить ассемблер
или компилятор автоматически без специальных указаний про-
граммиста.
Принципиально команду проверки состояния и ожидания мож-
но помещать и после каждой команды сопроцессора. Но в этом
случае центральный процессор не будет выполнять никаких команд
до тех пор, пока сопроцессор не освободится, и степень паралле-
лизма работы обоих процессоров ухудшается.
СИНХРОНИЗАЦИЯ ПО ДАННЫМ. Если выполняемая сопро-
цессором команда записывает операнд в ячейку памяти перед пос-
ледующей командой центрального процессора, которая обращается
к этой же ячейке, также необходима аналогичная команда проверки
состояния сопроцессора. В том случае, когда сопроцессор не успел
записать результат в память до того, как он потребовался централь-
ному процессору, последний должен ожидать завершения действий
сопроцессора. Автоматически учесть такие ситуации довольно
сложно, поэтому вводить команды, которые проверяют состояние
сопроцессора и при необходимости заставляют центральный про-
цессор ожидать, должен программист.
Когда команда сопроцессора требует дополнительных обраще-
ний к памяти, сопроцессор должен запрашивать шину у централь-
ного процессора. При получении разрешения (или подтверждении
запроса) сопроцессор самостоятельно инициирует обращение к па-
мяти. Следовательно, в механизме взаимодействия центрального
процессора и сопроцессора необходимы сигналы запро-
са/разрешения шины. Конечно, для внутреннего устройства FPU
такие внешние сигналы не нужны.
1.2. Внутренняя организация устройства FPU
Устройство FPU состоит из двух сравнительно автономных уст-
ройств: устройства управления и численного операционного
(исполнительного) устройства.
Устройство управления предназначено для восприятия команд,
считывания и записи данных, выполнения команд управления, а
также согласования действий FPU с целочисленным устройством.
Первые 5 бит кода операции устройства FPU одинаковы
(код 11011) — они определяют команду ESCAPE с плавающей
точкой. По существу, мнемоника ESC в системе команд предыду-
щих процессоров как бы заменяет собой мнемоники всех команд
устройства FPU и в ассемблерных программах не употребляется —
вместо нее указывается одна из команд устройства FPU. Свою ко-
манду устройство управления либо выполняет само, либо передает
Глава 1. Архитектура устройства с плавающей точкой
в численное операционное устройство, а команды целочисленного
устройства оно игнорирует.
Целочисленное устройство различает несколько типов команды
ESC. Если в команде требуется обращение к памяти, оно вычисляет
физический адрес, а затем инициирует цикл обращения к памяти.
При считывании из памяти целочисленное устройство игнорирует
возвращаемые данные, т. е. для него это действие оказывается фик-
тивным считыванием. Когда команда ESC не связана с обращением
к памяти, целочисленное устройство просто переходит к следую-
щей команде.
Воспринятая устройством FPU команда ESC может потребовать
загрузки операнда из памяти или записи результата в память, но
может быть и не связана с обращением к памяти. В первых двух
случаях устройство управления FPU использует цикл фиктивного
считывания, инициируемый целочисленным устройством. Оно вос-
принимает и сохраняет тот адрес операнда, по которому це-
лочисленное устройство обращается к памяти. (Отметим, что фор-
мат адреса или указателя операнда, сохраняемый устройством FPU,
зависит от режима работы процессора i486. Подробнее об этом
см. разд. 1.3). Если команда определяет загрузку (т. е. передачу дан-
ных в устройство FPU), устройство управления воспринимает пер-
вое и, возможно, единственное слово или двойное слово операнда в
момент его появления на пгине данных.
Когда длина операнда превышает двойное слово, устройство уп-
равления сразу запрашивает шину у целочисленного устройства и
считывает остальную часть операнда. Команда с записью в память
заставляет устройство управления зафиксировать адрес операнда
(по-прежнему формат указателя операнда зависит от режима рабо-
ты процессора i486). Если FPU готово к операции записи, устрой-
ство управления запрашивает шину у целочисленного устройства и
записывает результат по ранее перехваченному адресу. В зависимо-
сти от длины результат инициируется необходимое число последо-
вательных циклов шины.
В устройстве управления есть два программно доступных
16-битных регистра, в которых хранятся слово управления CW и
слово состояния SW (их назначение и форматы см. в разд. 1.5). Ре-
гистры указателей содержат адреса команды и операнда, а также 11
бит кода операции. Эти указатели явно в командах не адресуются,
но их содержимое может быть передано в память и в них можно
загружать слова из памяти как элементы среды и полного состоя-
ния устройства FPU. В основном ими оперируют процедуры обра-
ботки особых случаев.
Численное операционное устройство выполняет численные ко-
манды, так или иначе связанные с внутренним регистровым стеком.
В его составе есть несколько быстродействующих специализиро-
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
ванных модулей, реализующих операции над мантиссами и поряд-
ками, а также параллельные сдвиги. Параллельные передачи по
внутренней шине данных осуществляются с очень высокой скорос-
тью.
С точки зрения программиста устройство FPU можно считать
просто расширением целочисленного устройства в части регистров,
допустимых форматов чисел и системы команд. Взаимодействие
между ними на аппаратном уровне невидимо (или прозрачно) для
программ.
1.3. Программная модель устройства FPU
Напомним, что в программную или регистровую модель любого
процессора включаются только те регистры, которые доступны про-
граммисту на уровне машинных команд. С такой точки зрения уст-
ройство FPU имеет удивительно простую программную модель.
Оно, как и большинство других математических сопроцессоров,
опирается на общую стековую организацию. Ее применение обус-
ловлено несколькими обстоятельствами. Одно из них заключается в
том, что в математических расчетах результат текущей операции
часто может заместить один или оба исходных операнда и. является
операндом следующей команды. Стековая организация позволяет в
этих случаях применять так называемые безадресные
(нуль-адресные) команды небольшой длины, сокращая число обра-
щений к памяти и, следовательно, повышая быстродействие про-
цессора. Представление математических выражений в обратной
польской записи естественно приводит к стековой организации
процессора, который вычисляет эти выражения.
Основу программной модели устройства FPU, показанной на
рис. 1.1, образует регистровый стек из восьми 80-битных регистров
данных RO — R7, называемых также численными или арифме-
тическими регистрами. В этих хранятся числа, представленные в
форме с плавающей точкой в расширенном вещественном формате
(ранее этот формат назывался временным вещественным форма-
том). Такой формат является единственным внутренним форматом
чисел в устройстве FPU. В любой момент времени трехбитное поле
TOP (TOP of stack) в слове состояния SW определяет регистр, явля-
ющийся текущей вершиной стека и обозначаемый ST(0) или просто
ST (Stack Тор). Если, например, в поле ТОР содержится 011В
(см. рис. 1.2), то вершиной стека будет регистр R3 и именно он ука-
зывается в командах как ST(0) или ST. Регистр R4 находится сразу
«ниже» регистра ST и обозначается ST(1). Регистр R2 оказывается в
самом «низу» стека и обозначается ST(7). Другими словами, регистр
ST(0) содержит последнее включенное в стек значение, регистр
ST(1)—предпоследнее и т. д. Отметим, что все команды устройства
Глава 1. Архитектура устройства с плавающей точкой
<2 5:'
FPU рассчитаны на такую относительную адресацию и даже на
языке ассемблера нельзя работать с физическими регистрами
RO - R7.
Регистровый стек Тэги
CW Регистр управления
15 0
SW Регистр состояния
15 0
TW Слово тэгов
47 О
IP Указатель команды
47
DP
Указатель данных
Рис. 1.1. Программная модель устройства FPU
Операция загрузки или включения в стек (push) осуществляет
декремент поля ТОР и загружает адресуемые данные в новую вер-
шину стека, что приводит к автоматической перенумерации регист-
ров. В операции сохранения и извлечения из стека (pop) в по-
лучатель, например в память, передается содержимое текущей вер-
шины стека, а затем производится инкремент поля ТОР. Таким об-
разом, в стандартных стековых операциях поле ТОР выполняет
функции традиционного указателя стека SP (Stack Pointer).
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
1 3 TOP 11
SW 0 , 1 _,_L_j S
ti 1 V
J
R0 ST(5)
R1 ST(6) i
R2 ST(7) i i i
R3 Вершина стека ST(O) <—H 1
R4 ST(1) 1 1 1
R5 ST(2) 1 1 1
R6 ST(3) / /
R7 - ST(4) ✓
Рис. 1.2. Организация стека устройства FPU
Многие численные команды имеют несколько режимов адреса-
ции, позволяющих программисту неявно оперировать вершиной
стека или явно определять конкретные регистры относительно
ТОР. Ассемблер ASM386/486 поддерживает эти режимы адресации
регистров, используя обозначения ST(0) или просто ST для текущей
вершины стека и ST(i) для i-ro регистра в стеке (0 < i £ 7). Если,
например, ТОР содержит 011В (вершиной стека является регистр
3), то следующая команда суммирует содержимое двух регистров
стека (регистров 3 и 5):
FADD ST,ST(2)
В организации регистрового стека устройства FPU имеется не-
сколько отличий от классического стека, который в большинстве
современных процессоров аппаратно реализуется в памяти.
Во-первых, стек имеет круговую (кольцевую) организацию. Это
означает, что если поле ТОР содержит 000В и производится его
декремент, новым содержимым ТОР будет 111В, а если поле ТОР
содержит 111В и осуществляется его инкремент, новым содержи-
мым будет 000В. Контроль за использованием стека должен осуще-
ствлять программист. В частности, необходимо помнить, что мак-
Глава 1. Архитектура устройства с плавающей точкой
Й12 7:
симальное число включений в стек без промежуточных извлечений
равно 8, а девятое включение «перезапишет» значение, включенное
в стек первым. (На самом деле сопроцессор зафиксирует здесь осо-
бые случаи нарушения стека и недействительной операции и
«перезаписывание» произойдет, если только прерывание от этих
особых случаев замаскировано или запрещено.)
Во-вторых, в численных командах допускается явное или неяв-
ное обращение к регистрам стека с модификацией или без моди-
фикации поля ТОР. Так, в унарных операциях операндом служит
содержимое вершины стека, а результат замещает операнд. Напри-
мер, команда FSQRT замещает число из вершины стека значением
корня квадратного из этого числа. В некоторых бинарных опера-
циях операндами служат числа в двух верхних регистрах стека, а ре-
зультат помещается на место одного из них. Более того, команда
сравнения FCOMPP сравнивает содержимое двух верхних регистров
стека и удаляет его, производя инкремент ТОР на 2. Наконец, в
бинарных операциях допускается явное указание регистров, содер-
жащих операнды.
Программист работает относительно текущей вершины стека и
не употребляет абсолютных имен регистров RO, R1 и т. д. Принятые
в устройстве FPU организация стека и Адресация регистров упро-
щают программирование с использованием подпрограмм. Через
стек удобно передавать подпрограмме параметры и осуществлять
доступ к ним в процессе ее выполнения, а также обращаться к ре-
зультатам после завершения подпрограммы. Применяя для пере-
дачи параметров стек, а не специализированные регистры, вызыва-
ющие программы получают большую гибкость в использовании
стека. До тех пор, пока стек не заполнен, каждая программа перед
вызовом численной подпрограммы просто загружает параметры в
стек. После этого подпрограмма адресует свои параметры как ST,
ST(1) и т. д., несмотря на то, что в одном вызове ТОР относится,
например, к физическому регистру R3, а в другом — к физическому
регистру R5.
В третьих, устройство FPU имеет команды, в которых не выдер-
живаются обычные соглашения о стеке. Например, команда FST
(сохранение в памяти) передает содержимое вершины стека в па-
мять, но не производит инкремента поля ТОР. Другая команда
FXCH (обмен) позволяет обменять содержимое вершины стека и
любого другого регистра.
С каждым регистром стека ассоциируется двухбитный тэг
(признак), совокупность которых образует слово тэгов TW (Tag
Word). Тэг регистра R0 находится в младших битах этого слова, а
тэг регистра R7 в старших битах (см. рис. 1.3). Тэг в общем виде
показывает, что содержится в соответствующем регистре и помогает
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
устройству FPU в выполнении команд. Содержимое тэга интерпре-
тируется следующим образом:
00 - допустимое ненулевое число,
01 - нуль,
10 - специальное значение (нечисло, не поддерживаемый формат,
бесконечность или денормализованное число),
11 - пустой регистр.
15 О
Тэг R7 1 Тэг R6 1 Тэг R5 1 Тэг R4 1 Тэг R3 Тэг R2 i Тэг R1 1 Тэг R0 i
Рис. 1.3. Формат слова тэгов TW
Тэг с кодом 11В показывает отсутствие данных; в этом случае
регистр называется пустым и одно из действий устройства FPU при
инициализации заключается в загрузке в биты тэгов всех регистров
кода 11В. Попытка команды извлечь число из пустого регистра
фиксируется как особые случаи нарушения стека и недействитель-
ной операции. Кроме того, попытка загрузить число в непустой ре-
гистр также вызывает регистрацию аналогичных особых случаев.
Программист может использовать слово тэгов для упрощения ин-
терпретации содержимого регистров без сложного декодирования
фактических данных (разумеется, после передачи этого слова в па-
мять). Так как размещение тэгов соответствует физическим регист-
рам RO — R7, для ассоциирования тэгов с относительными регист-
рами ST(O) — ST(7) потребуется привлекать поле ТОР из слова со-
стояния.
Точные значения тэгов образуются при выполнении команд со-
хранения среды FSTENV и сохранения полного состояния FSAVE в
соответствии с фактическим содержимым непустых регистров сте-
ка. При выполнении других команд устройство FPU модифицирует
слово тэгов, только показывая пустой или непустой регистр стека.
Остальными регистрами в программной модели устройства FPU
являются 16-битные регистры управления и состояния, а также два
48-битных регистра указателей команды и операнда. Форматы и
функции регистров управления и состояния рассматриваются в
разделе 1.5.
Информация, содержащаяся в регистрах указателях команды и
операнда (совместно их иногда называют указателями особого
случая), предназначена только для процедур обработки особых
случаев. Когда устройство FPU выполняет численную команду, оно
автоматически сохраняет в этих регистрах адреса численной коман-
ды и ее операнда (если он есть), а также первые 11 бит кода опера-
ции. Регистры указатели доступны только в командах сохранения
среды FSTENV, сохранения полного состояния FSAVE, загрузки
Глава 1. Архитектура устройства с плавающей точкой
5 Заказ 4317
среды FLDENV и восстановления, т. е. загрузки, полного состоя-
ния FRSTOR.
Под средой устройства FPU понимается содержимое регистров
управления, состояния, тэгов и обоих указателей. Команда
FSTENV передает его в область памяти с начальным адресом, ука-
занным в команде. Полное состояние устройства FPU представляет
собой содержимое всех регистров программной модели — среды и
восьми регистров стека. Команда FSAVE передает полное состоя-
ние в область памяти с начальным адресом, указанным в команде.
Для возвращения среды и полного состояния в регистры устройства
FPU предусмотрены команды FLDENV и FRSTOR соответственно.
При сохранении в памяти указатели команды и данных пред-
ставляются в одном из четырех форматов в зависимости от режима
работы процессора i486 (R- или P-режим) и действия атрибута раз-
мера операнда (32- или 16-битный операнд). В V-режиме применя-
ются форматы R-режима. На рис. 1.4 — 1.7 показаны форматы ука-
зателей, сохраняемых в памяти командой сохранения среды
FSTENV (такое представление иногда называют «образом в памя-
ти»). Отметим, что в P-режиме указатели команды и данных не со-
держат кода операции, поэтому при необходимости обработчик
особого случая считывает код операции из памяти.
31 23 15 7 О
1 * 1 1 Селектор операнда
Смещение операнда
* Селектор CS
Смещение IP
* Слово тэгов
* Слово состояния
* Слово управления
* Зарезервированы
Pug. 1.4. Хранение в памяти указателей команды и данных
в 32-битном формате Р-режима
Команда сохранения полного состояния FSAVE в дополнение к
среде сохраняет в памяти содержимое всех регистров стека в 16-
или 32-битном формате. Таким образом, для сохранения полного
состояния в 32-битном формате требуется область памяти из
108 байт, а в 16-битном — из 94 байт. Благодаря информации,
Микропроцессор i486 г Книга 3. Устройство с плавающей точкой
сохраняемой в памяти командами FSTENV или FSAVE, процедура
обработки особого случая может точно определить команду и
операнд, вызвавшие особый случай, установить причину его
возникновения и предпринять соответствующие корректирующие
действия.
31 23 15 7 О
0 0 0 0 1 1 1 Указатель операнда 31-16 । 000000000000
* Указатель операнда 15-0
0 0 0 0 Указатель команды 31-16 0 Код операции 10-0
* Указатель команды 15-0
* Слово тэгов
* СЛОВО состояния
* Слово управления
* Зарезервированы
Рис. 1.5. Хранение в памяти указателей команды и данных
в 32-битном формате R-режима
Сохраняемый в памяти адрес команды учитывает все предше-
ствующие команде префиксы, как это реализовано в сопроцессорах
80387 и 80287. Однако в сопроцессоре 8087 сохраняемый адрес ко-
манды показывает на код операции численной команды без учета
префиксов.
15 7 0
---------------г_________________
I Селектор операнда СН
Смещение операнда АН
Селектор CS 8Н
Смещение IP 6Н
Слово тэгов 4Н
Слово состояния 2Н .
Слово управления 0
Рис. 1.6. Хранение в памяти указателей команды и данных
в 16-битном формате Р-режима
Отметим, что команды управления FINIT, FLDCW, FSTCW,
FSTSW, FCLEX, FSTENV, FLDENV, FSAVE и FRSTOR не дей-
Глава 1. Архитектура устройства с плавающей точкой
DP 19 - 16 । । । । 000000000000 1 1 1 1 1 1 1 1 1 1 1
Указатель операнда 15-0
IP 19 - 16 0 Код операции 10-0
Указатель команды 15-0
Слово тэгов
Слово состояния
Слово управления
ствуют на указатель данных. Отметим также, что за исключением
указанных команд, значение указателя данных не определено, если
предыдущая численная команда не имела операнда в памяти.
15 7 о
СН
АН
8Н
6Н
4Н
2Н
О
Рис. 1.7. Хранение в памяти указателей команды и данных
в 16-битном формате R-режима
Большинство прикладных программистов не касается регистров
указателей и регистра тэгов, а также команд, манипулирующих сре-
дой и полным состоянием устройства FPU. Эти средства пред-
назначены только для разработчиков процедур обработки особых
случаев; такие процедуры обычно входят в состав системного про-
граммного обеспечения.
1.4. Форматы численных данных
Система вещественных чисел, применяемая в ручных
вычислениях, предполагается бесконечной и непрерывной. Это оз-
начает, что не существует никаких ограничений на диапазон ис-
пользуемых чисел и на точность (количество значащих цифр) их
представления. Для любого вещественного числа имеется беско-
нечно много чисел, которые больше и меньше его, а между любыми
двумя вещественными числами также находится бесконечно много
чисел; например, между числами 2.5 и 2.6 находятся числа 2.51,
2.5897, 2.500001 и т. д. ‘
Реализовать такую систему чисел в технических устройствах
нельзя. Во всех компьютерах размеры регистров и ячеек памяти
фиксированы, что ограничивает систему представимых чисел. Ог-
раничения касаются как диапазона, так и точности представления
чисел, т. е. система машинных чисел оказывается конечной и диск-
ретной, образуя подмножество системы вещественных чисел.
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
На рис. 1.8 система чисел с плавающей точкой двойной
точности устройства FPU показана на числовой оси (для простоты
взяты десятичные числа, хотя процессор оперирует двоичными
числами). Точки соответствуют тому подмножеству вещественных
чисел, которые устройство FPU может представить как данные и
результаты вычислений. Диапазон нормализованных чисел двойной
точности составляет примерно от ±2.23 х 10“308 до ±1.79 х 10308,
В программах редко требуются числа вне этого диапазона. Для
сравнения скажем, что диапазон чисел в IBM/370 составляет от
±0.54 х 10“78 до ±0.72 х 1076.
Отрицательные числа
Положительные числа
12 3 4
t 308 -308 t
*—1.79x10 -2.23X 10 -I
-308
2.23 х 10
1.79 х 10
Рис. 1.8. Нормализованные вещественные числа
двойной точности
Конечные промежутки на рис. 1.8 означают, что устройство FPU
может представить многие, но не все вещественные числа из своего
диапазона представимых чисел. Между двумя соседними числами с
плавающей точкой всегда есть промежуток и возможно, что
истинный результат вычисления попадет именно в него. В этом
случае устройство FPU округляет истинный результат до такого
числа, которое оно может представить. Следовательно, веществен-
ное число, которое требует больше разрядов, чем может предста-
вить'устройство FPU (например, 20-разрядное число), представля-
ется с потерей точности. Отметим, что представимые числа распре-
делены по числовой оси неравномерно. Фактически между любыми
соседними степенями двух находится одинаковое количество пред-
ставимых чисел (например, между 2 и 4 есть столько же представи-
мых чисел, сколько между 65536 и 131072). По мере увеличения
чисел промежутки между представимыми числами становятся все
больше и больше. Однако все целые числа из диапазона от —264 до
+264 представляются точно.
Во внутренних операциях устройство FPU фактически исполь-
зует систему чисел, которая является надмножеством показанной
на рис. 1.8. Нормализованный диапазон внутреннего формата
(называемого расширенным вещественным) составляет от ±3.37 х
(109—4932) до ±1.18 x 104092, а точность до 19 десятичных
разрядов. Такой формат предназначен для обеспечения
дополнительных диапазона и точности представления констант и
промежуточных результатов, а не для данных и окончательных
результатов.
Глава 1. Архитектура устройства с плавающей точкой
133-
С практической точки зрения множество вещественных чисел
устройства FPU оказывается достаточно большим и плотным,
чтобы не накладывать никаких ограничений в подавляющем боль-
шинстве приложений. По сравнению с большинством компьюте-
ров, включая большие компьютеры, процессор i486 обеспечивает
очень хорошее приближение системы вещественных чисел. Однако
важно помнить, что это не абсолютно точное представление и что
машинная арифметика вещественных чисел принципиально оказы-
вается приближенной.
Устройство FPU оперирует численными данными в семи вне-
шних форматах, образующих три класса: двоичные целые, упако-
ванные десятичные целые и двоичные вещественные числа, т. е.
числа с плавающей точкой. Может показаться неожиданным, что
устройство FPU работает с целыми числами, так как их может об-
рабатывать целочисленное устройство. Но если исключить поддер-
жку данных этого типа, устройство FPU не смогло бы само
вычислять выражения, в которых фигурируют целые и веществен-
ные числа.
Рис. 1.9. Форматы чисел устройства FPU
Т".... ... ——........................................
MWgHg Микропроцессор i486 Книга 3. Устройство с плавающей точкой
Поддерживаемые устройством FPU форматы чисел показаны на
рис. 1.9, а их основные характеристики (диапазон и точность) при-
ведены в таблице 1.1. Отметим, что во всех форматах старший
(левый) бит отведен для знака числа со стандартным кодированием
знака: 0 означает плюс, а 1 — минус. Старшие разряды всех чисел
(и полей внутри чисел) находятся слева. На рис. 1.9 и в дальнейшем
приняты следующие сокращения: ЦС — целое слово, КЦ — корот-
кое целое, дц — длинное целое, УПК — упакованное десятичное,
ОТ — вещественное число одинарной точности (ранее такие числа
назывались короткими вещественными), ДТ — вещественное число
двойной точности (прежнее название — длинное вещественное) и
РТ — вещественное число расширенной точности (прежнее
название — временное вещественное).
Таблица 1.1. Основные характеристики форматов чисел
Формат Диапазок Точность Особенность
Целое слово ЦС 104 16 бит Дополнительный код
Короткое целое КЦ 109 32 бита Дополнительный код
Длинное целое ДЦ 1019 64 бита Дополнительный код
Упакованное десятичное УПК 1018 18 цифр Прямой код
Короткое вещественное ОТ 10±38 24 бита Неявный бит F0
Длинное вещественное ДТ 1О±308 53 бита Неявный бит F0
Временное вещественное РТ Ю±4932 64 бита Явный бит F0
ДВОИЧНЫЕ ЦЕЛЫЕ ЧИСЛА. Три формата целых двоичных
чисел (ЦС, КЦ и ДЦ) отличаются только длиной и, следовательно,
диапазоном допустимых чисел. Только в этих форматах для пред-
ставления чисел применяется стандартный дополнительный код; он
используется только в этом формате. Число нуль имеет единствен-
ное кодирование (положительный нуль), в котором все биты со-
держат нули. Форматы целого слова и короткого целого соответ-
ствуют аналогичным форматам целочисленного устройства. Наи-
большее положительное число кодируется как 011... 11, а наиболь-
шее (по модулю) отрицательное число имеет вид 100...00.
Двоичные целые форматы существуют только в памяти. При
загрузке они автоматически преобразуются в 80-битный формат РТ.
Все двоичные целые числа точно представимы в формате РТ.
УПАКОВАННЫЕ ДЕСЯТИЧНЫЕ ЦЕЛЫЕ ЧИСЛА. Десятич-
ные целые числа (УПК) представляются в прямом коде и упако-
ванном формате, т. е. каждый байт содержит две десятичных цифры
в коде 8421. Старший бит левого байта отведен дня знака числа, а
остальные биты этого байта игнорируются, но при записи в память
в них помещаются нули.
Глава 1. Архитектура устройства с плавающей точкой
В отличие от предыдущих форматов для десятичных чисел при-
нят прямой код. Напомним, что основная причина использования
дополнительного кода заключается в том, чтобы складывать и
вычитать знаковые и беззнаковые целые числа одними и теми же
командами. Однако в устройстве FPU нет операций над деся-
тичными числами (вся десятичная арифметика представлена только
двумя командами загрузки и сохранения), а прямой код проще пре-
образовывать в последовательность символов для печати по сравне-
нию с дополнительным кодом. Как всегда, в прямом коде появля-
ются два представления нуля — положи-тельный и отрицательный
нули; устройство FPU не различает их. Младшая тетрада в старшем
байте не используется, что объясняется совместимостью со стан-
дартами некоторых языков програм-мирования.
Следует иметь в виду, что при наличии в тетраде запрещенных
комбинаций 1010В — 1111В результат загрузки десятичного операн-
да не определен. Другими словами, устройство FPU не контроли-
рует правильность десятичных цифр.
Десятичный целый формат существуют только в памяти. При
загрузке такие числа автоматически преобразуются в 80-битный
расширенный вещественный формат. Все десятичные целые числа
точно представимы в расширенном вещественном формате.
ВЕЩЕСТВЕННЫЕ ЧИСЛА. Для вещественных чисел применя-
ется формат с плавающей точкой (ОТ, ДТ и РТ). Значащие цифры
числа находятся в поле мантиссы (или дроби — Fraction) , поле по-
рядка (или экспоненты — Exponent) показывает факти-ческое по-
ложение двоичной точки в разрядах мантиссы, а бит знака S опре-
деляет знак числа. Мантисса представлена в прямом коде. Парамет-
ры для трех форматов вещественных чисел приведены в табл. 1.2.
Таблица 1.2. Параметры форматов вещественных чисел
Параметр Одинарный ОТ Формат Двойной ДТ Расширенный РТ
Длина формата в битах 32 64 80
Длина мантиссы (точность) 24 53 64
Длина порядка в битах 8 И 15
Emax +127 +1023 +16383
Emin -126 -1022 -16382
Смещение порядка < +127 +1023 +16383
Порядок Е задается в смещенной форме; он равен истинному
порядку, увеличенному на значение смещения (bias):
Е = истинный порядок 4- смещение
Смещенный порядок называется также характеристикой; ее
можно считать целым положительным или беззнаковым числом.
"""" ..... .. ...................«—Т— 1.1.111
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
Значение смещения для соответствующих форматов равно 127, 1023
и 16383. Задание порядка в форме со смещением упрощает опера-
цию сравнения чисел с плавающей точкой, превращая ее в опера-
цию сравнения целых чисел, а выполнение остальных операций
практически не усложняется. Так как операции с целыми числами
выполняются значительно быстрее операций над числами с плава-
ющей точкой, сравнение чисел с плавающей точкой производится
быстрее, что важно в алгоритмах с большим числом сравнений, на-
пример в алгоритмах сортировки. Отметим, что смещенные поряд-
ки 00...0 и 11... 1 зарезервированы для специальных значений
(см. далее).
Числа с плавающей точкой длиной 32 и 64 бита применяются во
многих компьютерах и обычно называются числами с одинарной и
двойной точностью. Как правило, порядок имеет фиксированную
длину, определяя один и тот же диапазон представимых чисел, а
для повышения точности вводятся дополнительные биты мантиссы.
При этом схемы арифметико-логического устройства в процессоре
усложняются незначительно. Однако при удвоении длины числа
предпочтительнее часть бит отвести для расширения порядка. По-
этому порядок чисел в формате ДТ устройства FPU состоит из 11
бит. Такой порядок обеспечивает, в частности, получение точного
произведения без переполнения и антипереполнения, когда сомно-
жители представлены в формате ОТ.
Значение числа с плавающей точкой равно
(-l)S х 2(Е-смещение) х (F0).(Fl)(F2)...(Fn),
где п для различных форматов равно 23, 52 или 63. Отметим на-
личие в мантиссе бита F0 единиц. В форматах чисел с плавающей
точкой большинства компьютеров бит F0 отсутствует, и мантисса
оказывается правильной дробью.
Устройство FPU обычно поддерживает представление мантиссы
в нормализованной форме, т. е. старший бит равен 1. Следова-
тельно, за исключением числа нуль мантисса состоит из целой
части и дроби в следующем виде:
1.(Fl)(F2)...(Fn),
где Fi равно 0 или 1. Благодаря нормализации достигается одно-
значное представление чисел и устраняются старшие нули в числах,
меньших единицы, что максимизирует количество значащих цифр
мантиссы при ее фиксированной длине.
В форматах ОТ и ДТ бит F0 при передачах чисел и хранении их
в памяти не фигурирует. Это так называемый скрытый или неяв-
ный бит, который в нормализованных числах содержит 1. Следова-
тельно, в этих форматах невозможно представить числа, которые не
нормализованы (за исключением нулевого порядка — см. далее).
Кроме того, скрытый бит не позволяет представить в этих форматах
Глава 1. Архитектура устройства с плавающей точкой
нуль и он должен кодироваться как специальное значение. Отме-
тим также, что скрытый бит можно реализовать только при основа-
нии, на степень которого умножается мантисса, равным 2.
Числа в формате РТ (т. е. числа с расширенной точностью)
имеют явный бит F0. Такой формат позволяет несколько повысить
скорость выполнения операций и обеспечить некоторые преимуще-
ства, благодаря простоте представления чисел, не являющихся нор-
мализованными.
Покажем представление десятичного числа —247.375 в веще-
ственных форматах устройства FPU. Двоичный код его равен
-11110111.011В и истинный порядок равен +7. Смещенный порядок
в трех вещественных форматах равен 134, 1030 и 16390. С учетом
бита F0 имеем такие представления:
•ормат Знак Порядок Мантисса
Одинарная точность 1 10000110 11101110110...0
Двойная точность 1 10000000110 11101110110...0
Расширенная точность 1 100000000000110 Ц1101110110...0
Числа в форматах ОТ и ДТ существуют только в памяти. При
загрузке числа в одном из этих форматов в регистр устройства FPU
оно автоматически преобразуется в 80-битный формат РТ, исполь-
зуемый для внутренних операций. Аналогично данные из регистров
можно преобразовать в формат ОТ или ДТ для сохранения их в па-
мяти. Формат РТ также допускает сохранение в памяти и обычно
применяется для промежуточных результатов, которые нельзя хра-
нить в регистрах. (Вот почему элементарные и быстрые для других
процессоров команды загрузки и запоминания двоичных и особен-
но десятичных чисел выполняются устройством FPU довольно дол-
го.) Таким образом, формат РТ является единственным внутренним
форматом представления чисел, причем в нем абсолютно точно ко-
дируются любые загружаемые из памяти числа. Числа в формате РТ
можно передавать в память; это приходится делать для хранения
промежуточных результатов из-за нехватки внутренних регистров.
Благодаря аппаратному преобразованию всех внешних форматов
данных в формат РТ программист Может не заботиться о явных
преобразованиях форматов. Например, умножение числа с плаваю-
щей точкой на упакованное десятичное число осуществляется столь
же просто, как умножение двух целых чисел. Конечно, при возвра-
щении результата в память* программист должен обеспечить, чтобы
формат получателя был достаточен для восприятия результата.
Устройство FPU может представить огромное количество, но,
разумеется, не все вещественные числа из диапазонов своих форма-
тов. Между любыми двумя соседними числами всегда существует
промежуток и результат операции может попасть именно в этот
промежуток. В такой ситуации устройство FPU округляет истин-
|13э|
Микропроцессор I486 Книга 3. Устройство с плавающей точкой
ный результат до числа, которое оно может представить. Следова-
тельно, вещественное число с большим количеством значащих
цифр, чем допускает устройство FPU, будет представлено неточно.
Тем не менее, целые числа из диапазона от —2^4 до +264
представляются в формате РТ абсолютно точно.
СПЕЦИАЛЬНЫЕ ЧИСЛЕННЫЕ ЗНАЧЕНИЯ. Помимо пред-
ставления положительных и отрицательных чисел форматы
численных данных устройства FPU допускают описание других
объектов или специальных значений. Такие специальные значения
обеспечивают дополнительную гибкость, но большинству пользова-
телей не нужно разбираться в них, чтобы успешно применять
численные возможности процессора i486. Ниже кратко описаны
специальные значения, а подробное изложение специальных значе-
ний и связанных с ними особых случаев дается в главе 2.
К специальным значениям относятся де нормализованные веще-
ственные числа, нули, отрицательные и положительные беско-
нечности, нечисла (Not-a-Number — NaN), неопределенность и не-
поддерживаемые форматы. Для представления специальных
значений зарезервированы минимальный 00...00 и максимальный
11... 11 смещенные порядки.
Денормализованные вещественные числа. Под денормализован-
ным вещественным числом понимается число, которое меньше ми-
нимального нормализованного числа для каждого вещественного
формата, поддерживаемого устройством FPU. Такие числа имеют
минимальный смещенный порядок и ненулевую мантиссу.
Истинный нуль. Значение нуль в вещественных и десятичном
форматах является знаковым, а двоичный целый нуль всегда поло-
жителен. В вычислениях знак нуля не учитывается, и обычно про-
граммист может не заботиться о наличии знакового нуля. Нуль в
вещественных форматах кодируется с нулевыми смещенным поряд-
ком и мантиссой.
Бесконечность. Вещественные форматы поддерживают знаковые
представления бесконечностей. Эти значения кодируются со сме-
щенным порядком из всех единиц 11... 11 и мантиссой 1.00...00.
Знаки бесконечностей учитываются и сравнения возможны. Беско-
нечности всегда интерпретируются в аффинном смысле, т. е.
-оо < (любое конечное число) < +оо
Нечисла. Нечисло NaN (Not-a-Number) является представителем
класса специальных значений, существующих только в веществен-
ных форматах. Оно имеет смещенный порядок из всех единиц, лю-
бой знак и любую мантиссу за исключением 1.00...00 (такая мантис-
са отведена для бесконечностей).
Глава 1. Архитектура устройства с плавающей точкой
Устройство FPU формирует специальное нечисло, называемое
вещественной неопределенностью, реагируя на замаскированный
особый случай недействительной операции. Оно имеет отрицатель-
ный знак, смещенный порядок 11... 11, а мантисса равна 1.100...00.
Неопределенность предусмотрена для вычислительных ситуаций, в
которых человек говорит «не знаю». Типичным примером такой си-
туации является деление 0 на нуль.
Все остальные нечисла создаются либо программистом, либо
получаются из значений, определенных программистом, и обычно
применяются для ускорения отладки программ.
Неподдерживаемые форматы. Формат РТ имеет много двоичных
наборов, которые не попадают ни в один из ранее рассмотренных
классов. К неподдерживаемым форматам относятся так называемые
псевдонечисла, псевдобесконечности, ненормализованные числа и
псевдоденормализованные числа (см. табл. 2.10), которые были вве-
дены в сопроцессоре 8087, а в дальнейшем были исключены.
ХРАНЕНИЕ ЧИСЕЛ В ПАМЯТИ. Напомним, что в процессоре
i486, как и в других процессорах фирмы Intel, принято хранение
многобайтных элементов данных по принципу «младшее — по
меньшему адресу». Этот же принцип распространяется и на хране-
ние в памяти чисел устройства FPU.
Логически во всех форматах левый бит является старшим, а пра-
вый младшим. В физической памяти первым, т. е. по меньшему ад-
ресу, хранится младший байт (этот адрес считается и адресом всего
числа), а последним, т. е. по большему адресу, — старший байт. Та-
кой своеобразный «обратный» порядок размещения данных в памя-
ти принят в большинстве современных компьютеров. Передача
данных всегда начинается с младшего адреса.
РЕКОМЕНДАЦИИ ПО ПРИМЕНЕНИЮ. В подавляющем
большинстве применений для исходных данных и результатов
рекомендуется использовать формат ДТ. Он обеспечивает дос-
таточные для получения правильных результатов диапазон и
точность, требуя от программиста минимальных усилий. Формат
ОТ целесообразен в системах с ограничениями на память, но, ко-
нечно, он имеет меньшие диапазон и точность. Его удобно приме-
нять для отладки программ, так как ошибки округления проявля-
ются в этом формате наиболее быстро. Формат РТ не предназначен
для представления входных и выходных данных, его следует приме-
нять для хранения промежуточных результатов, в циклических
фрагментах и для представления констант. Его огромный диапазон
и высокая точность (значительно большие, чем у базовых форма-
тов) гарантируют защиту окончательных результатов от ошибок ок-
ругления, а также уменьшают вероятность возникновения перепол-
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
нений и анггипереполнений. Как правило, такие ситуации свиде-
тельствуют об ошибках в данных или программе. Формат РТ обес-
печивает получение результатов с 19-ю десятичными значащими
цифрами. Даже когда длинная последовательность вычислений
приводит к значительным накопленным ошибкам округления, по-
теря трех или четырех цифр точности сохраняет достаточно точный
результат при представлении его в формате ДТ.
1.5. Режимы работы и состояние
Устройство FPU имеет два программно-доступных 16-битных
регистра, содержимое которых определяет его режим работы и те-
кущее состояние. Форматы этих регистров, в которых находятся
слово управления CW (Control Word) и слово состояния SW (Status
Word), приведены на рис. 1.10.
15 7 0
X X X X 1 —_| 1 RC PC X X РМ им ом ZM DM IM
15 7 0
в сз ТОР 1 1 С2 С1 СО ES SF РЕ UE ОЕ ZE DE IE
Рис. 1.10. Формат регистров управления CW и состояния SW
СЛОВО УПРАВЛЕНИЯ. Слово управления определяет дая уст-
ройства FPU один из нескольких вариантов обработки численных
данных. Для каждого варианта программист задает маскирование
особых случаев, точность вычислений и способ округления. Следо-
вательно, программа может сформировать в памяти «образ» необхо-
димого слова управления, а затем заставить устройство FPU загру-
зить его в регистр CW. Кроме того, содержимое полей слова управ-
ления устанавливается при инициализации процессора и может
быть оставлено по умолчанию. Рассмотрим назначение отдельных
полей слова управления.
Маски особых случаев. Шесть младших бит слова управления
представляют собой индивидуальные маски особых случаев, т. е.
необычных и ошибочных ситуаций, обнаруживаемых устройством
FPU при выполнении программы. К битам масок относятся:
PM (Precision Mask) - маска точности,
UM (Underflow Mask) - маска антипереполнения,
ОМ (Overrflow Mask) - маска переполнения,
ZM (divide-by-zero Mask) - маска деления на нуль,
DM (Denormalized Mask) - маска денормализованного операнда,
IM (Invalid operation Mask) - маска недействительной операции.
Глава 1. Архитектура устройства с плавающей точкой
Если любой из этих бит установлен в состояние 1, то возникно-
вение соответствующего особого случая не будет вызывать преры-
вания процессора (особый случай запрещен или замаскирован), а
если бит содержит 0 — устройство FPU активно сигнализирует об
особом случае.
Особый случай дснормализованного операнда фиксируется, ког-
да в операции встречается денормализованный операнд. При по-
пытке деления ненулевого конечного числа на нуль устройство
FPU регистрирует особый случай деления на нуль. Этот же особый
случай может возникать и в других операциях, например
вычисления остатка. Особый случай переполнения возникает, когда
порядок истинного результата выходит за диапазон (т. е. больше)
максимального допустимого порядка получателя. Переполнение
может возникнуть, например, при преобразовании числа из форма-
та РТ в другие форматы. Если же значение истинного порядка ре-
зультата слишком мало, фиксируется особый случай антиперепол-
нения. Примерами могут служить возведение в квадрат числа 10“3000
или преобразование очень малого числа из формата РТ в форматы
ОТ или ДТ. В типичных вычислительных алгоритмах появление
очень больших или очень малых чисел характерно, в основном, для
промежуточных, а не окончательных результатов. Если хранить
промежуточные результаты в формате РТ, переполнение и
антипереполнение в устройстве FPU возникают очень редко
(действительно, трудно представить себе числа большие 104932 иди
меньшие 1О~4932, имеющие какой-то практический смысл). Нако-
нец, когда результат операции не может быть точно представлен в
формате получателя, устройство FPU производит округление его и
фиксирует особый случай (потери) точности. Примером может
служить деление 2 на 9; представить абсолютно точно дробь 0.222...
устройство FPU не может. Другим примером может служить преоб-
разование числа из формата РТ в формат с меньшей точностью.
Особый случай точности возникает довольно часто и указывает
лишь на то, что происходит некоторая, обычно приемлемая, потеря
точности; он предназначен для применений, в которых требуется
только точное выполнение операций.
Анализ рассмотренных особых случаев показывает, что для каж-
дого из них нетрудно предусмотреть возвращение математически
приемлемого результата операции, вызвавшей особый случай:
Деяормализованный операнд (минимум один из операндов
денормализован, т. е. имеет наименьший порядок и ненулевую
мантиссу) — продолжить операцию обычным образом.
Деление на нуль (делитель равен нулю, а делимое является
ненулевым числом и не бесконечностью) — возвратить как резуль-
тат операции бесконечность с правильным знаком.
Микропроцессор i486 • Книга 3. Устройство с плавающей точкой
Переполнение (результат операции слишком велик для пред-
ставления в формате получателя) — возвратить как результат опе-
рации наибольшее конечное число или бесконечность.
Антипереполнение (истинный результат операции не равен нулю,
но слишком мал для представления в формате получателя, или,
если антипереполнение замаскировано, денормализация вызывает
потерю значимости) — возвратить как результат операции
денормализованное число или нуль.
Точность (истинный результат операции точно не представим в
формате получателя; или результат округляется в соответствии с
режимом округления) — продолжить операцию обычным образом.
Наиболее тяжелым является особый случай недействительной
операции, который вбирает в себя все ошибочные ситуации, не вы-
явленные рассмотренными выше особыми случаями и который, как
правило, свидетельствует об ошибке в программе. Он включает в
себя несколько ситуаций, которые не имеют очевидных решений
как предыдущие особые случаи. Например, без анализа
вычислительных шагов, которые привели к делению нуля на нуль,
невозможно образовать приемлемый результат. Это же относится к
умножению и делению бесконечностей, умножению бесконечности
на нуль, сложению бесконечностей с разными знаками, извлечению
корня квадратного из отрицательного числа, любой операции с
нечислом, загрузке в непустой регистр, считыванию из пустого ре-
гистра и т. д. Лучшее, что можно предпринять при возникновении
особого случая недействительной операции — это возвратить как
результат так называемое «тихое» нечисло (см. главу 2), или це-
лочисленную или десятичную неопределенность. Таким образом,
после возникновения нечисла оно не исчезает, а распространяется
в последующих вычислениях.
Обнаружение особых случаев недействительной операции, деле-
ния на нуль и денормализованного операнда происходит до выпол-
нения операции, а остальные особые случаи регистрируются только
после вычисления истинного результата. Если возник «ранний»
особый случай, стек и память еще не были модифицированы и со-
держат такие данные, как будто виноватая команда не выполнялась.
При обнаружении «позднего» особого случая содержимое стека и
памяти изменено.
Возникновение особого случая отмечается установкой в 1 соот-
ветствующего флажка в слове состояния, а также бита суммарной
ошибки ES. Кроме того, выдается также активный сигнал FERR#
ошибки с плавающей точкой. Далее устройство FPU проверяет
маску в слове управления CW и определяет, следует ли только заре-
гистрировать особый случай (маска содержит 1) или сообщить об
этом процессору как о нарушении устройства FPU (прерывание 16)
с последующим вызовом процедуры обработки особого случая
Глава 1. Архитектура устройства с плавающей точкой
(маска содержит 0). В первом варианте устройство FPU реализует
встроенную реакцию без прерывания программы, а во
втором — прерывает процессор.
Маскированные реакции устройства FPU были тщательно раз-
работаны так, чтобы образовать наиболее правильный результат для
каждого условия. Выше были приведены наиболее естественные ре-
акции для всех особых случаев. Как видно в большинстве особых
случаев, устройство FPU образует наиболее естественный
численный результат, который может участвовать в дальнейших
вычислениях и только в особом случае недействительной операции
возвращает нечисло. Поэтому в большинстве прикладных программ
рекомендуется маскировать все особые случаи кроме недействи-
тельной операции.
В устройстве FPU принято следующее старшинство особых
случаев (в порядке убывания): недействительная операция, денор-
мализованный операнд, деление на нуль, переполнение, антипере-
полнение и точность.
Управление точностью. Двухбитное поле управления точностью
PC (Precision Control) определяет точность вычислений в 24 бита
(PC = 00), 53 бита (PC = 10) или 64 бита (PC = 11). По умолчанию
вводится наиболее подходящий режим с максимальной точностью
64 бита, обеспечиваемой расширенным вещественным форматом.
Остальные режимы предусмотрены в стандарте IEEE-754 только
для совместимости с некоторыми языками программирования. За-
дание пониженной точности (сокращение длины мантиссы) ликви-
дирует достоинство формата РТ по достижению максимальной
точности, а производительность устройства FPU не повышается.
При выборе меньшей точности округление дробного значения сбра-
сывает неиспользуемые правые биты. Управление точностью влияет
только на команды сложения FADD, вычитания FSUB, умножения
FMUL, деления FDFV и извлечения корня квадратного FSQRT.
Управление округлением. В устройстве FPU есть три недоступ-
ные программисту дополнительных бита (защиты, округления и за-
висания), которые позволяют округлять числа в соответствии с бес-
конечно точным истинным результатом. Когда получатель может
воспринять бесконечно точный истинный результат, устройство
FPU выдает его. Округление появляется в арифметических опера-
циях и при сохранении, когда формат получателя не позволяет
точно представить бесконечно точный истинный результат. Напри-
мер, вещественное число округляется, если оно сохраняется в более
коротком вещественном формате или в целочисленном формате.
Округление вносит ошибку (погрешность), величина которой в лю-
бом режиме округления не превосходит единицы младшего разряда,
сохраняемого в результате.
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
Устройство FPU имеет четыре режима округления, выбираемых
полем RC (Rounding Control) слова управления. Если истинный ре-
зультат b не может быть точно представлен в получателе, устрой-
ство FPU определяет два представимых числа а и с, которые наибо-
лее близки к b (а < Ъ < с). После этого процессор округляет
(изменяет) b на а или с в соответствии с режимом, выбранным по-
лем RC, как показано в таблице 13. Округление вносит в результат
ошибку, которая меньше 1 того младшего разряда, до которого ок-
ругляется результат.
Таблица 13. Режимы округления
Поле RC Режим округления Действие округления
00 Округление к ближайшему а или с, ближайшее к Ь;
01 Округление вниз при равенстве выбрать четное число (младший бит равен 0) а
10 (К -<ю) Округление вверх с
11' (К +оо) Усечение (к 0) Меньшее из а и с
Округление к ближайшему принимается по умолчанию и при-
годно для большинства приложений; оно обеспечивает наиболее
точную (ошибка не более половины младшего разряда) и статис-
тически несмещенную оценку результата, т. е. ошибка оказывается
знакопеременной.
Округление к ближайшему имеет специальный случай, когда
полученный результат находится точно посередине между двумя
представимыми числами. Обычно в этой ситуации производится
округление вверх, что приводит к появлению ненужного смещения.
Чтобы исключить его, в устройстве FPU при b — а = с ~ b осуще-
ствляется округление к четному из чисел а и с, т. е. к числу, млад-
ший бит которого содержит нуль. Следовательно, «средние» резуль-
таты округляются и вверх, и вниз; такой способ округления называ-
ется иногда «несмещенным округлением к ближайшему четному».
Усечение или округление к 0 используется для целочисленной
арифметики.
Округление вниз и округление вверх называются направленным
округлением и применяются в интервальной арифметике. Она по-
зволяет определить верхнюю и нижнюю границы многоэтапного
вычисления, когда промежуточные результаты надо округлять.
Управление округлением влияет только на арифметические ко-
манды.
Бит 12 слова управления устройство FPU игнорирует, а в сопро-
цессорах 8087 и 80287 он управляет режимом интерпретации беско-
нечности IC (Infinity Control), определяя одну из двух моделей: про-
ективную (IC = 0) или аффинную (IC = 1). В проективном режиме
Глава 1. Архитектура устройства с плавающей точкой
два специальных значения «плюс бесконечность» и «минус беско-
нечность» считаются одним и тем же значением «бесконечность»,
не имеющим знака. В аффинном режиме допускаются значения
бесконечности со знаками плюс и минус. Устройство FPU поддер-
живает только аффинный режим.
СЛОВО СОСТОЯНИЯ. 16-битное слово состояния отражает
общее состояние устройства FPU. Его можно сохранить в памяти с
помощью команд сохранения слова состояния FSTSW/FNSTSW,
сохранения среды FSTENV/FNSTENV и сохранения полного со-
стояния FSAVE/FNSAVE или передать в регистр АХ командами
FSTSW AX/FNSTSW АХ для последующего анализа целочисленным
устройством.
В слове состояния SW младшие 6 бит отведены для регистрации
особых случаев, смысл которых рассмотрен выше. Флажки особых
случаев обозначаются так:
РЕ {Precision Error)
UE (Underflow Error)
OE (Overflow Error)
ZE (divide-by-Zero Error)
DE (Denormalized operand Error)
IE (Invalids operation Error)
- ошибка точности,
- ошибка антипереполнения,
- ошибка переполнения,
- ошибка деления на нуль,
- ошибка ненормализованного операнда,
- ошибка недействительной операции.
При обнаружении любого из незамаскированных особых случаев
устройство FPU устанавливает в состояние 1 соответствующий
флажок и формирует активный выходной сигнал FERR#, сообщая
об особом случае (прерывание 16). Процедура обработки особого
случая считывает слово состояния для определения конкретной
причины особого случая. Отметим, что устройство FPU самостоя-
тельно никогда не сбрасывает биты особых случаев; их можно сбро-
сить только программно командами инициализации FINIT, сброса
особых случаев FCLEX, загрузки среды FLDENV, сохранения пол-
ного состояния FSAVE и восстановления полного состояния
FRSTOR. Это позволяет программе производить проверку наличия
особых случаев после группы команд, а не после каждой команды.
Бит 7 нарушения стека SF (Stack Fault) предназначен для того,
чтобы фиксировать ошибки в работе регистрового стека. Устрой-
ство FPU устанавливает его в состояние 1, если команда вызывает
переполнение стека (включение в уже заполненный стек) или ан-
типереполнение стека (извлечение из пустого стека). Когда SF — 1,
бит кода условия С1 показывает переполнение (Cl = 1) или анти-
переполнение (С1 =0) стека. Отметим, что нарушение стека фик-
сируется также, как особый случай недействительной операции.
Бит 8 суммарной ошибки ES (Error Summary) устанавливается в
состояние 1 при возникновении любого особого случая и участвует
в формировании выходного сигнала FERR#.
Микропроцессор i486 • Книга 3. Устройство с плавающей точкой
Биты кода условия СЗ — СО похожи на арифметические флажки
процессора i486 в регистре EFLAGS. Они фиксируют особенности
результатов команд сравнения, проверки и анализа. Воздействие
таких команд на биты кода условия показано в таблице 1.4. Биты
СЗ — СО, в основном, применяются для условных переходов. Ко-
манда FSTSW АХ передает слово состояния в регистр АХ, позволяя
программе процессора i486 проверить их. Команда SAHF копирует
биты СЗ — СО из регистра АН в биты флажков процессора i486, уп-
рощая условные переходы. Отображение кода условия на биты
флажков показано в таблице 1.5.
Таблица 1.4. Интерпретация кода условия
Команда CO C3 С2 С1
FCOM, FCOMP, FCOMPP, FTST, FUCOM, FUCOMP, FUCOMPP, FICOM, FICOMP Результат сравнения Операнды не сравнимы Нуль или O/U#
FXAM Класс операнда |3нак или O/U#
FPREM, FPREM1 Q2 QO 0= 1= 'приведение зав. 'приведение не зав. Q1 или O/U#
FIST, FBSTP, FRNDINT, FST, FSTP, FADD, FMUL, FDIV, FDIVR, FSUB FSUBR, FSCALE, FSQRT, FPATAN, F2XM1, FYL2X, FYL2XP1 НЕ ОПРЕДЕЛЕНЫ Округление вверх или 0/U#
FPTAN, FSIN, FCOS, FSINCOS 0= HE ОПРЕДЕЛЕНЫ 1= 'приведение зав. 'приведение не зав. Округление вверх или 0/U# (не опр. при С2=1)
FCHS, FABS< FXCH, FINCSTP, FDECSTP, FLD, FXTRACT, FILD, FBLD, FSTPfpacm.), загрузки констант HE ОПРЕДЕЛЕНЫ Нуль или 0/U#
FLDEHV, FRSTOR | | Каждый бит загружается из памяти
FLDCW, FSTENV, FSTCW, FSTSW, FCLEX НЕ ОПРЕДЕЛЕНЫ
FINIT, FSAVE | Нуль Нуль Нуль Нуль
Примечания:
O/U#. Когда оба бита IE и SF слова состояния установлены, показывая
особый случай стека, этот бит различает переполнение (Cl = 1) и антипере-
полнение (С1 = 0).
Глава 1. Архитектура устройства с плавающей точкой
Приведение. Если команды FPREM и FPREM1 дают остаток меньше
модуля, приведение завершено. Когда приведение не завершено, значение в
вершине стека является частичным остатком, который можно использовать
как вход для дальнейшего приведения. В командах FPTAN, FSIN, FCOS и
FSINCOS бит приведения установлен, если операнд в вершине стека слиш-
ком большой. В этой ситуации в вершине стека сохраняется исходный опе-
ранд.
Округление вверх. Кохда бит РЕ слова состояния установлен, этот бит
показывает, было ли последнее округление в команде вверх.
НЕ ОПРЕДЕЛЕНЫ. Конкретные значения бит отсутствуют.
Таблица 1.5. Соответствие
между кодом условия и флажками
Флажок FPU Флажок EFLAGS
СО CF
С1 (нет)
С2 PF
СЗ ZF
Трехбитное поле вершины стека ТОР показывает, какой из
внутренних регистров данных является текущей вершиной стека.
Бит 15 занятости В (Busy) предусмотрен только для совместимо-
сти с процессором 8087. Он устанавливается в состояние 1, когда
зафиксирован незамаскированный особый случай в битах 5 — 0,
т. е. установлен в 1 бит ES.
1.6. Система команд
Команды устройства FPU удобно разделить на 5 групп: команды
передач данных, арифметические команды, команды сравнения,
команды трансцендентных операций и команды управления. Ти-
пичная команда воспринимает один или два операнда, выполняет
указанную операцию и возвращает результат. Содержимое
регистров наиболее часто служит операндами, но может
привлекаться и содержимое ячеек памяти. Операнды некоторых
команд определяются неявно, например, безоперандная команда
FSQRT извлекает корень квадратный из числа, находящегося в
вершине стека ST(0), и помещает результат в ST(0). Другие
команды допускают или требуют явного задания операндов.
Например, имеются команды с одним явным и одним неявным
операндом, которым обычно является содержимое вершины стека.
При рассмотрении команд привлекаются стандартные обо-
значения, принятые в описаниях процессоров фирмы Intel. Напом-
ним, что src обозначает источник, т. е. операнд, значение которого
команда не изменяет, a dst обозначает получатель, т. е. операнд,
значение которого замещается результатом операции.
Микропроцессор I486 Книга 3. Устройство с плавающей точкой
1.6.1. Особенности задания команд
Команды бинарных операций, например сложения, вычитания и
др., допускают несколько форм. В случае пустого поля операнда
(нуль-адресная команда) операция выполняется с двумя верхними
элементами стека ST(O) и ST(1). После производства операции
осуществляется инкремент указателя стека и результат помещается
в новую вершину стека, заменяя исходное содержимое ST(1). Здесь
два операнда заменяются в стеке одним результатом — такое дей-
ствие считается классической операцией стековых машин.
Когда в бинарной операции определен один операнд, она вы-
полняется с привлечением указанного в команде регистра (или
ячейки памяти) и содержимого вершины стека. Результат загружа-
ется в старую вершину стека и указатель стека не изменяется. От-
метим, что команды с плавающей точкой либо считывают из памя-
ти, либо записывают в нее; ни одна из таких команд не производит
обеих операций.
Если же в бинарной команде указаны два операнда, ими являет-
ся содержимое двух регистров стека, причем одним из них будет
ST(0), а вторым — ST(i). Принимая указанный выше смысл
источника и получателя, имеем три возможных случая:
— источником является ST(0), а получателем — ST(i);
— источником выступает ST(i), а получателем — ST(0);
— источником служит ST(0), получателем — ST(i), и
производится инкремент указателя стека, т. е. извлечение из стека
(операнд-источник «пропадает»).
При программировании удобна такая возможность, как обратная
(Reverse) форма несимметричных операций вычитания и деления.
Например, в обычной форме команды деления получатель делится
на источник, а в обратной форме источник делится на получатель.
В обеих формах результат помещается в получатель. Наличие об-
ратной формы команд позволяет в некоторых ситуациях избежать
операций обмена содержимого двух регистров стека.
Как было показано выше, многие команды допускают несколько
способов задания операндов. Например, команда FADD сложения
вещественных чисел разрешает запись без операндов, только с ис-
точником или с источником и получателем. Альтернативные фор-
мы указания операндов условно показываются с помощью наклон-
ной черты (slash), причем черта без последующей специ-фикации
означает отсутствие явно задаваемых операндов. Например, коман-
да FADD имеет такой общий вид:
FADD //src/dstfSrc
Эта запись подразумевает три возможных формы команды: без
операндов, с одним источником, с получателем и источником.
Глава 1. Архитектура устройства с плавающей точкой
1^14 9В
В мнемониках команд устройства FPU приняты соглашения:
— первая буква всегда F (Floating) и обозначает плавающую
точку (отметим, что ни одна из команд целочисленного устройства
не начинается с буквы F, поэтому в программе сразу заметны ко-
манды устройства FPU);
— вторая буква I (Integer) обозначает операцию с целым
двоичным числом из памяти, буква В (Binary-coded decimal) — опе-
рацию с десятичным операндом из памяти, а «пустая» вторая буква
определяет операцию с вещественными числами;
— предпоследняя или последняя буква R указывает обратную
операцию (для вычитания и деления);
— последняя буква Р (Pop) идентифицирует команду, заключи-
тельным действием которой является извлечение из стека.
1.6.2. Машинные форматы команд
Устройство FPU имеет пять форматов команд, представленных
на рис. 1.11. Во всех форматах минимальная длина команды состав-
ляет два байта и все команды начинаются с двоичного набора
11011В, который выделяет класс команд устройства FPU (ESC).
Отметим, что операнд в памяти в ассемблерных программах разре-
шается указывать с привлечением любого режима адресации про-
цессора i486.
Рис, 1.11. Форматы команд устройства FPU
Команды с форматам^, показанными на рис. 1.11(а,б),
осуществляют обращение к памяти, поэтому поля mod (режим) и
г/m (регистр/память) во втором байте, а также байт sib (масштаб,
индекс, база) имеют тот же смысл, что и в командах
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
целочисленного устройства. Напомним, что эти поля определяют,
как формируется эффективный адрес ЕА (Effective Address) памяти.
Данные команды в зависимости от кодирования* поля mod могут не
иметь или иметь байты смещения disp, участвующего в
формировании ЕА.
Команда с форматом, приведенном на рис. 1.11(a), передает
данные в память и считывает их из памяти, включая соответствую-
щие передачи в командах управления устройства FPU. Команды с
форматом, показанном на рис. 1.11(6), выполняют арифметические
операции и сравнения. Поле формата памяти MF (Memory Format)
определяет тип операнда, находящегося в памяти. Оно имеет сле-
дующее кодирование:
00 - вещественное число одинарной точности (32 бита),
01 - короткое целое двоичное число (32 бита),
10 - вещественное число двойной точности (64 бита),
11 - целое слово (16 бит) или упакованное десятичное число
(80 бит).
Во всех остальных форматах поле mod содержит комбинацию
11В. В командах целочисленного устройства эта комбинация задает
режим регистровой адресации, который не относится к устройству
FPU. Именно такие команды целочисленное устройство
«проскакивает», не производя никаких действий. Команды с фор-
матом, приведенном на рис. 1.11(b), выполняют арифме-тическис
операции и операции сравнения с привлечением регистровой
стека устройства FPU. В этом формате поле reg (регистр) регистр
стека ST(i). Бит R (Reverse) показывает, возвращается результат в
вершину стека (R = 0) или в другой регистр стека, т. е. оь
показывает операции обратного вычитания и деления. Бит Р (?oj)
идентифицирует, производится ли после операции извлечение из
стека (Р = I) или нет (Р = 0).
Формат на рис. 1.11 (г) относится к командам, оперирующим
константами, а также к трансцендентным и дополнительным ариф-
метическим командам. Для этих команд характерно отсутствие яв-
ных спецификаций операндов, т. е. операнды определяются неявно
кодом операции.
Наконец, формат на рис. 1.11(д) зарезервирован для команд уп-
равления устройством FPU, которые не обращаются к памяти. В
этом формате, как и в предыдущем, нет явной спецификации опе-
рандов.
1.6.3. Особенности программирования на языке ассемблера
При рассмотрении команд устройства FPU будут приводиться
примеры записи команд на языке ассемблера. Поэтому целесооб-
разно привести минимальные сведения по этому языку, которые
необходимы для понимания смысла команд.
«та
Глава 1. Архитектура устройства с плавающей точкой
Ассемблер ASM386/486 позволяет программисту пользоваться
всеми ресурсами процессора i486, включая, конечно, команды уст-
ройства FPU, его регистры и данные всех форматов.
Расширенные форматы данных устройства FPU требуют введе-
ния в ассемблер специальных директив определения данных. Для
задания переменных и констант целочисленного устройства приме-
няются следующие директивы резервирования памяти:
DB - определить байт,
DW - определить слово (16 бит),
DD - определить двойное слово (32 бита).
Резервирование памяти для переменных и констант устройства
FPU осуществляют следующие директивы:
DW - определить слово (16 бит),
DD - определить двойное слово (32 бита),
DQ - определить счетверенное слово (64 бита),
DT - определить 10 байт (80 бит).
С каждой переменной и константой, определяемой этими ди-
рективами, ассоциируется тип, значение которого равно дайне ре-
зервируемой памяти в байтах. В процессе ассемблирования произ-
водится контроль совместимости типа переменной или константы
и формата операнда в команде. Например, в команде загрузки
десятичного числа
FBLD GAMMA,
будет зафиксирована ошибка, если тип переменной GAMMA не
равен 1G. Кроме того, тип операнда сообщает ассемблеру, какую
машинную команду он должен генерировать (напомним о поле MF
в командах с обращением к памяти).
Иногда программисту необходимо воспользоваться командой,
тип операнда которой не объявлен директивой — это так называе-
мые анонимные обращения к памяти. Но поскольку ассемблер все-
таки должен знать тип операнда, его можно задать в команде с по-
мощью указателя PTR (PoinTeR). Например, в команде
FLD [ВХ],
неясно, что загружается в вершину стека — вещественное число
одинарной или двойной точности. В команде с указателем типа
FLD QWORD PTR [ВХ]
определена загрузка вещественного числа двойной точности
(64 бита).
Ассемблер не контролирует тип операнда в команде управления
устройства FPU, так как в них структура операнда подразумевается
смыслом команды. Например, команда восстановления полного со-
стояния
FRSTOR [ВР]
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
предполагает, что в зависимости от режима и размера операнда
регистр ВР адресует 94- или 108-байтную область в стеке (адресация
с регистром ВР определяет обращение к текущему сегменту стека),
в которой ранее было сохранено полное состояние устройства FPU.
Ассемблер обычно допускает несколько способов записи кон-
стант. Двоичные целые константы можно задавать как двоичные
наборы (с заключительным дескриптором В), десятичные целые (с
дескриптором D или без дескриптора), восьмеричные целые (с дес-
криптором О или Q) и как шестнадцатеричные числа (с дескрипто-
ром Н). Упакованные десятичные числа обычно представляются
как десятичные целые, но ассемблер допускает и другие формы.
Вещественные числа требуется записывать в формате с десятичной
точкой, но для специальных значений (бесконечность, нечисло и
ненормализованное число) целесообразно применять шестнадца-
теричную форму. Ниже приведены примеры определения одной и
той же константы: —87:
EVEN
W_INT DW ШШШ0101001В ;Двоичное целое
S_INT DD 0FFFFFFA9H ;Короткое целое
L_INT DQ -87 ;Длинное целое
S_REAL DD -87.0 ;Одинарная точность
L_REAL DQ -8.7E1 ;Двойная точность
P_DEC DT -87 ;Упакованное десятичное
Отметим, что в строке L REAL фигурирует запись веществен-
ного числа в форме с показателем (Е — Exponent) степени десяти.
Специальная директива EVEN (четный) заставляет ассемблер
назначить константе W INT четный адрес. Такое выравнивание по
границам слов повышает производительность процессора, так как
слово с четным адресом всегда передается за один цикл шины, а
передача слова с нечетным адресом может потребовать двух циклов
шины. Так как длина всех форматов устройства FPU кратна длине
слова, можно указать единственную директиву EVEN перед не-
сколькими константами и переменными.
1.6.4. Команды передач данных
Команды этой группы производят передачи данных между реги-
страми стека, а также между вершиной стека и памятью. Одной ко-
мандой число из памяти, представленное в любом внешнем форма-
те, преобразуется в формат РТ и загружается (включается) в стек.
Аналогичным образом, но в обратном порядке, осуществляется пе-
редача числа в память с извлечением или без извлечения из стека.
Команды передач данных автоматически модифицируют регистр тэ-
гов устройства FPU.
Глава 1. Архитектура устройства с плавающей точкой
КОМАНДЫ ЗАГРУЗКИ. В трех командах загрузки (LoaD) веще-
ственных чисел FLD sic, целых двоичных чисел FILD sic и целых
десятичных чисел FBLD src устройство FPU выполняет два дей-
ствия:
— производит декремент указателя стека (поля ТОР), т. е. обра-
зует новую вершину стека;
— передает адресуемый операнд в новую вершину стека ST(0).
Таким образом, команды загрузки эквивалентны операции
включения в стек PUSH. Для предотвращения переполнения стека
перед загрузкой проверяется тэг регистра ST(0), т. е. новой верши-
ны стека. Если регистр не отмечен как пустой, устанавливаются
флажки SF и IE.
В команде FLD источником src может быть регистр стека ST(i)
или вещественное число в памяти, представленное в любом из трех
форматов. Если источником является регистр, номер регистра соот-
ветствует ситуации до декремента указателя вершины стека. На-
пример, команда FLD ST(0) дублирует вершину стека.
Если операнд-источник представлен в форматах ОТ или ДТ, он
автоматически преобразуется в расширенный вещественный фор-
мат и может быть зарегистрирован особый случай денормализован-
ного операнда DE. Загрузка вещественного расширенного операнда
не требует преобразования, поэтому особый случай DE не возни-
кает.
В команде FILD src операнд может быть в любом из це-
лочисленных форматов — ЦС, КЦ или ДЦ. Операнд-источник заг-
ружается без ошибки округления. Чтобы избежать особого случая
недействительной операции, ST(7) должен быть пустым.
Операнд команды FBLD src считается 80-битным целым деся-
тичным числом; устройство FPU не контролирует наличие в нем
запрещенных тетрад 1010В — 1111В, и при наличии их в операнде
результат загрузки не определен. Команда FBLD преобразует деся-
тичный операнд-источник в расширенный вещественный формат и
включает его в стек устройства FPU. Отметим, что команды FILD и
FBLD являются точными, т. е. в них отсутствует ошибка
округления.
Приведем несколько примеров ассемблерного кодирования ко-
манд загрузки.
FLD ST(O) t ;Копирует вершину стека
FLD QWORD PTR [ВХ] * ;Загружает длинное вещественное
FILD WORD PTR ARR [DI] ;Загружает целое слово
FBLD VOLUME ;Загружает целое десятичное
Примечание.
Во всех приводимых здесь и далее примерах при отсутствии явной
спецификации типа операнда предполагается, что он определен
соответствующей директивой.
Микропроцессор 1486в Книга 3. Устройство с плавающей точкой
КОМАНДЫ СОХРАНЕНИЯ. Две команды сохранения (STore)
FST dst и FIST dst производят передачу содержимого ST(0) в память
без модификации указателя стека и, разумеется, самого ST(0).
В команде FST dst получателем может быть регистр стека ST(i)
или вещественная переменная в памяти (только в форматах ОТ или
ДТ). Мантисса ST(0) округляется в соответствии с полем RC и дай-
ной мантиссы получателя, а порядок корректируется с учетом дай-
ны и значения смещения формата получателя. Когда ST(0) отмечен
специальным значением, мантисса не округляется, а усекается
справа; порядок также усекается справа. Такие действия сохраняют
вид специального значения, поэтому в дальнейшем оно может быть
правильно загружено и отмечено.
В команде FIST dst получателем является переменная в памяти,
имеющая форматы ЦС или КЦ. Команда округляет содержимое
ST(0) до целого в соответствии с полем RC и передает результат в
получатель. При наличии в ST(0) отрицательного нуля он сохраня-
ется как положительный нуль, т. е. знак отрицательного нуля с
плавающей точкой теряется. Команда FIST устанавливает флажок
IE, если в ST(0) находится «тихое» нечисло.
Отметим, что в рассматриваемых командах не допускается по-
лучатель в формате ДЦ (FIST) и РТ (FST). Объясняется такая не-
симметричность недостатком двоичных наборов для кодов опера-
ций устройства FPU.
Примеры ассемблерных команд сохранения:
FST ST(5) ;Передает ST(0) в регистр стека
FST [BP][SI] ;Передает вещественное в память
FIST WORD PTR MEAN ;Передает в память целое слово
КОМАНДЫ СОХРАНЕНИЯ С ИЗВЛЕЧЕНИЕМ ИЗ СТЕКА.
Команды FSTP dst, FISTP dst и FBSTP dst помимо передачи содер-
жимого ST(0) в получатель осуществляют извлечение из стека: ре-
гистр, бывший вершиной стека, отмечается как пустой и произво-
дится инкремент указателя стека. Перед сохранением проверяется
тэг регистра ST(0) и, если он показывает пустой регистр, устанав-
ливаются флажки SF и IE.
Действие команды FSTP очень похоже на действие команды
FST с добавлением извлечения из стека. Однако она позволяет пе-
редать в память число в формате РТ, чего не может команда FST.
Команда FISTP, похожая на команду FIST, обеспечивает пере-
дачу в память числа в любом формате целых двоичных чисел —
ЦС, КЦ и ДЦ. Последний формат отсутствует в команде FST.
Округление до целого производится в соответствии с полем RC.
Наконец, команда FBSTP dst преобразует содержимое ST(0) в
упакованное целое десятичное число (производя округление в со-
ответствии с полем RC), передает его в память и производит из-
Глава 1. Архитектура устройства с плавающей точкой
влечение из стека. Эта команда устанавливает флажок IE, когда
ST(0) содержит «тихое» нечисло.
Примеры записи рассмотренных команд на языке ассемблера:
FSTP ST(0) ;Извлечение из стека без передачи
FISTP DWORD PTR [ВХ] ;Передача в память в формате КЦ
FISTP QWORD PTR [SI] ;Передача в память в формате ДЦ
FBSTP PAYROLL ;Передача десятичного целого
В командах сохранения обоих видов при преобразовании форма-
та числа может возникнуть несколько особых случаев. Если в про-
цессе округления число изменяется, генерируется особый случай
(потери) точности. Когда округленное число слишком велико для
формата получателя, фиксируется особый случай переполнения.
Наконец, при преобразовании в форматы ОТ или ДТ возникает
особый случай антипереполнения, когда округленное число не яв-
ляется нулем, но меньше порога антипереполнения формата по-
лучателя.
КОМАНДА ОБМЕНА. Команда обмена содержимого регистров
FXCH //dst ST(0) о (dst),
где получателем dst выступает ST(i), обменивает содержимое по-
лучателя dst и вершины стека ST(0). В случае пустого поля операн-
да обменивается содержимое регистров ST(1) и ST(0). Наличие ко-
манды FXCH объясняется тем, что многие команды устройства
FPU оперируют содержимым вершины стека ST(0), а с помощью
команды FXCH их действия можно распространить на все регистры
стека. Например, следующие три команды формируют в ST(5)
значение корня квадратного из находящегося в нем числа:
FXCH ST(5) ;Содержимое ST(5) в вершине стека
FSQRT ;Извлечь корень квадратный из ST(0)
FXCH ST(5) ;Возвратить на прежнее место
Отметим, что команда FXCH ST(0) эквивалентна холостой ко-
манде.
КОМАНДЫ ЗАГРУЗКИ КОНСТАНТ. В устройстве FPU пре-
дусмотрены простые команды загрузки наиболее часто
встречающихся в вычислениях констант:
FLDZ Загрузка нуля +0.0
FLD1 Загрузка единицы +1.0
FLDPI Загрузка П - 3.14159...
FLDL2T Загрузка двоичного логарифма десяти
FLDL2E Загрузка двоичного логарифма числа е = 2.71...
FLDLG2 Загрузка десятичного логарифма двух
FLDLN2 Загрузка натурального логарифма двух
Загрузка осуществляется путем включения (push) константы в
стек, т. е. декремента указателя стека и передачи в новую вершину
15 б'5'
Микропроцессор 1486 а Книга 3. Устройство с плавающей точкой
стека значения константы, представленного в формате РТ. Так как
в этом формате каждая из констант занимала бы 10 байт памяти,
приведенные выше двухбайтные команды загрузки обеспечивают
экономию памяти и повышение производительности, а также уп-
рощают программирование.
Внутри устройства FPU константы приведенных выше команд
хранятся более точно, чем обеспечивает формат РТ. При загрузке
константы устройство FPU округляет более точную внутреннюю
константу в соответствии с полем RC (управления округлением)
слова управления. Однако, несмотря на это округление особый
случай точности не формируется (для обеспечения совместимости).
Когда управление округлением задает округление к ближайшему,
устройство FPU образует такие же константы, какие имеются в со-
процессорах 8087/80287.
1,6,5. Арифметические команды
Набор арифметических команд устройства FPU включает в себя
разнообразные варианты основных арифметических операций, а
также удобные команды извлечения корня квадратного, масштаби-
рования и др. В таблице 1.6 приведены допустимые комбинации
операций и операндов для основных арифметических операций. В
дополнение к четырем обычным операциям команды двух обратных
операций делают вычитание и деление симметричными, анало-
гичными сложению и умножению. Отметим, что эти команды
рассчитаны на разработку эффективных алгоритмов; в частности,
они позволяют программисту обращаться к памяти столь же легко,
как к регистровому стеку устройства FPU.
Таблица 1.6 Формы арифметических команд
Форма команды ] Анамоннка Операции) Пример записи
Стековая Fop [ST(1),ST] FSUB
Регистровая Fop ST(i),ST ST,ST(i) FADD FDIV ST,ST(2) ST(5),ST
Регистровая с извлечением FopP ST(i),ST FMULP ST(3),ST
Операнд в памяти (вещественный) Fop [ST,JOT/ДТ FADD BETA
Операнд в памяти (целочисленный) Fop [5Т,]ЦС/КЦ FIDIV GAMMA
В таблице 1.6 квадратные скобки обозначают неявные операнды,
которые в ассемблерных командах могут не указываться.
Аббревиатура op (operation) означает мнемонику одной из следу-
ющих операций:
op = ADD dst <- (dst) + (src)
SUB dst <- (dst) - (src)
Глава 1. Архитектура устройства с плавающей точкой
-4L57
SUBR dat <- (src) - (dst)
MUL dst <- (dst) * (src)
DIV dst <- (dst) / (src)
DIVR dst <- (src) I (dst)
Стековая форма превращает устройство FPU в классическую
стековую машину. В этой форме поле операнда является пустым: в
качестве источника подразумевается вершина стека ST(0), а по-
лучателя — следующий регистр стека ST(1). Выполнив операцию,
устройство FPU производит инкремент указателя стека и помещает
результат в новую вершину стека.
Регистровая форма представляет собой обобщение стековой
формы: одним из операндов является содержимое вершины стека, а
вторым — произвольный регистр стека; результат можно загрузить
на место любого из операндов. Указание получателем вершины
стека обеспечивает удобный доступ к операндам из других
регистров. Когда же вершина стека служит источником, регистр-
получатель превращается в аккумулятор.
Часто операнд, находящийся в вершине стека ST(0), необходим
только для одной операции, а в дальнейшем не требуется. Регист-
ровая форма с извлечением из стека обеспечивает выбор вершины
стека в качестве источника и последующее уничтожение этого опе-
ранда посредством инкремента указателя стека. Указание операндов
в виде ST(1),ST(O) с мнемоникой извлечения из стека эквивалентно
классической стековой операции.
Две формы команд с обращением к памяти позволяют исполь-
зовать как источник вещественное или целое число, находящееся в
памяти. Это удобно в тех ситуациях, когда операнды привлекаются
редко и их хранение в регистрах нецелесообразно. Для указания та-
ких операндов применяются все режимы адресации памяти цент-
рального процессора. Отметим, что вещественные числа в памяти
не могут быть в формате РТ, а целые числа — в формате ДЦ.
Таким образом, все 6 операций имеют следующие формы:
- вещественные числа Fop //src/dst, src
FopP dst, src
- целые числа Flop src
Приведем возможные формы арифметических команд, опериру-
ющих вещественными числами и имеющих мнемоники FADD,
FADDP, FSUB, FSUBP, FSUBR, FSUBRP, FMUL, FMULP, FDIV,
FDIVP, FDIVR и FDIVRP на примере команды сложения (здесь
mem32 и тет64 обозначают переменные в памяти, имеющие фор-
мат ОТ и ДТ):
FADD ;ST(1) <- ST(1) + ST и извлечение
FADD mem32 ;ST <- S’t + mem32
FADD mem64 ;ST <- ST + mem64
FADD ST(i) ;ST <- ST + ST(i)
FADD ST,ST(i) ;ST <- ST + ST(i)
FADD ST(i),ST ;ST(i) <- ST(i) + ST
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
FADDP ST,ST(i) ;ST <- ST + ST(i) и извлечение
FADDP ST(i),ST ;ST(i) <- ST(i) + ST и извлечение
Приведем также возможные формы команд, один из це-
лочисленных операндов которых находится в памяти, с мнемони-
ками FIADD, FISUB, FISUBR, FIMUL, FIDIV и FIDIVR (здесь
me ml 6 и тет32 обозначают переменные в памяти, имеющие фор-
мат ЦС и КЦ):
FIADD meml6 ;ST <- ST + mem!6
FIADD mem32 ;ST <- ST + mem32
При программировании следует учитывать следующее обстоя-
тельство. Хотя устройство FPU имеет полный набор команд це-
лочисленной арифметики, применять их в массовом порядке не
рекомендуется, так как в них быстродействие системы ухудшается.
Так, целочисленное устройство выполняет 16-битное сложение ре-
гистр — память за 1 или 3 такта, а аналогичная команда устройства
FPU занимает 20 — 35 тактов. Объясняется такая несколько пара-
доксальная ситуация тем, что в устройстве FPU для обработки це-
лых чисел применяется формат РТ. Преимущества устройства FPU
при обработке таких «малых» для него чисел проявляются в специ-
альных вычислениях с привлечением вещественных и целых чисел.
Благодаря тому, что оно представляет любые числа в одном и том
же формате, в вычислениях могут участвовать числа различных
форматов.
В заключение сделаем замечание о явном и неявном указании
стековых операндов. В стековой форме регистр ST(0) всегда подра-
зумевается источником, а регистр ST(1) — получателем, и они в ко-
мандах явно не фигурируют. Отсутствующие операнды могут
вызвать некоторую путаницу. Дело в том, что команда с двумя
неявными операндами имеет другой смысл, чем та же самая
команда с явными операндами. По соглашению два неявных
операнда сообщают ассемблеру о том, что после выполнения
операции следует произвести извлечение из стека. Например,
команда FADD подразумевает источником ST(0) и получателем
ST(1). Ассемблер транслирует эту команду как FADDP ST(1), ST(0),
которая отличается от команды FADD ST(1),ST. Поэтому
целесообразно, хотя бы на первых порах, явно указывать в
командах оба операнда.
Во всех арифметических операциях может возникать множество
особых случаев. Уникальна в этом отношении операция деления, в
которой могут возникнуть все 6 особых случаев, которые регистри-
рует устройство FPU.
Приведем несколько примеров арифметических команд:
FADD ST,ST(5)
FIADD WORD PTR [SI}
FSUBP ST(2),ST
;Сложение содержимого регистров
;Прибавить целое слово
;Вычитание содержимого регистров
Глава 1. Архитектура устройства с плавающей точкой
FMUL QWORD PTR [ВР]
FDIVR DWORD PTR [DI]
FIDIVR DWORD PTR [BX+5]
;Умножение ча вещественное ДТ
;Деление на вещественное ДТ
;Деление на короткое целое
ДОПОЛНИТЕЛЬНЫЕ КОМАНДЫ. К арифметическим отно-
сятся также 8 дополнительных команд, имеющих безоперандную
форму.
Команда FSQRT извлечения корня квадратного заменяет число,
находящееся в вершине стека, значением его корня квадратного. В
этой команде по определению полагается, что значение корня из —О
равно — 0. Относительно команды FSQRT отметим следующее. Во-
первых, она выполняется практически столь же быстро, как и
команда деления. Во-вторых, точность ее соответствует точности
обычных арифметических операций (погрешность результата равна
половине младшего бита мантиссы). Наконец, в команде FSQRT
доступны режимы округления. По существу, программисты могут
считать извлечение корня обычной арифметической операцией
вместо того, чтобы интуитивно избегать ее.
Когда ST(0) содержит отрицательное число, фиксируется особый
случай недействительной операции. Значение корня квадратного из
бесконечности считается бесконечностью.
Команда FSCALE масштабирования интерпретирует содержимое
регистра ST(1) как целое двоичное число и прибавляет его к сме-
щенному порядку числа в ST(0):
FSCALE ST(0) <- ST(0) x 2ST(1)
Таким образом, эта команда производит быстрое умножение
(когда ST(1) > 1) или деление (когда ST(1) < 1) содержимого вер-
шины стека на целую степень 2.
Команду FSCALE можно использовать как команду, обратную
команде FXTRACT (см. далее). Однако, так как команда FSCALE
не извлекает порядок, после нее нужно выполнить команду FSTP
ST(1), чтобы полностью уничтожить действие предшествующей ко-
манды FXTRACT.
Ограничений на диапазон масштабного множителя в ST(1) нет.
Если значение не является целым числом, команда FSCALE ис-
пользует ближайшее целое, меньшее по величине; т. е. она усекает
значение масштаба к 0. Если полученное целое равно 0, значение в
ST не изменяется.
Нахождение масштаба не в вершине стека ST(0), а в регистре
ST(1), обеспечивает удобное масштабирование последовательности
чисел, например элементов массива. На каждый элемент требуются
три операции — загрузка, масштабирование и сохранение.
Команда FPREM вычисляет частичный остаток (см. далее) от
деления числа, находящегося в вершине стека ST(0), на содержимое
ST(1) и загружает результат в ST(0):
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
FPREM ST(O) <- ST(O) - q x ST(1) f
где q — целое число. Другими словами, здесь содержимое ST(1)
выступает модулем в операции нахождения остатка. Знак остатка
совпадает со знаком исходного делимого.
Команда FPREM не соответствует команде вычисления остатка
стандарта IEEE-754. Для получения такого остатка следует пользо-
ваться командой FPREM 1. Команда FPREM введена ради совмес-
тимости с сопроцессорами 8087 и 80287.
Описание операции команды FPREM на псевдоязыке имеет
следующий вид:
EXPDIF <— порядок (ST) - порядок (ST (1));
IF EXPDIF < 64
THEN
Q <— целое, полученное при усечении ST/ST(1) к нулю;
ST <— ST - (ST(1) * Q);
C2 <— 0;
CO,C1,C3 <— три младших бита Q; (* Q2,Q1,QO *)
ELSE
C2 <— 1;
N <-- число между 32 и 63;
QQ <— целое, полученное при усечении ST/ST(1)/2(KXPDIF~~и)
к нулю;
ST <— ST - (ST( 1) * QQ *
FI;
Эта команда предназначена, в основном, дая приведения аргу-
мента (операнда) периодических функций в диапазон, допустимый
в командах устройства FPU. Для повышения точности вычисления
функций необходимо, чтобы команда FPREM давала точный ре-
зультат (т. е. без регистрации особого случая точности и действия
округления); Этого можно достичь только путем последовательных
масштабированных вычитаний модуля из делимого до достижения
момента, когда вычитание без получения отрицательной разности
невозможно, т. е. когда очередная разность меньше модуля. Такой
способ требует значительного времени в тех ситуациях, когда ис-
ходное делимое намного больше модуля с соответствующей задерж-
кой целочисленного устройства. Чтобы предотвратить «зависание»
без реакции на запросы прерываний, команда FPREM рассчитана
на итеративное выполнение в программном цикле. Она производит
максимум 64 вычитания и возвращает полученный при этом резуль-
тат, даже если необходимы дальнейшие вычитания. За одну итера-
цию при выполнении команды FPREM значение в ST(0) может
уменьшиться в 264 раз.
Когда команда FPREM дает остаток меньше модуля, ее функция
считается законченной и бит С2 кода условия в слове состояния
SW будет содержать 0. Если же приведение не закончено, бит
С2 — 1 и результат в вершине стека ST(0) называется частичным
остатком. Программа должна проверить состояние С2 после коман-
6 Заказ 4317
Глава 1. Архитектура устройства с плавающей точкой
6 ife
ды FPREM и при необходимости инициировать ее повторное вы-
полнение с использованием как делимого частичного остатка из
ST(0). Потребуется цикл примерно такого вида:
REPEAT: FPREM
if С2 = 1 goto REPEAT
Проверка бита С2 производится с привлечением целочисленного
устройства: слово состояния SW передается в регистр АХ, затем
команда SAHF пересылает код условия в регистр флажков EFLAGS
и состояние бита С2 показывает флажок PF. Другой способ опреде-
ления завершения команды FPREM заключается в сравнении ST(0)
и ST(1): остаток получен, если ST (0) меньше ST(1).
Прерывающая процедура с более высоким приоритетом, кото-
рой требуется устройство FPU, может вызывать переключение кон-
текста между циклами вычисления остатка.
Кроме остатка в ST(0) команда FPREM образует в битах СЗ, С1,
СО слова состояния три младших бита частного (фактически по
своим весам они упорядочены как СО, СЗ, С1). Это важно в при-
ведении аргумента для функции тангенса (используя модуль л/4),
так как позволяет локализовать исходный угол в правильном октан-
те единичной окружности.
В сопроцессоре 80387 и устройстве FPU появилась новая коман-
да FPREM 1 вычисления частичного остатка в стандарте 1ЁЕЕ-754.
Действует она так же, как и команда FPREM, но производит
вычисление остатка, равного ST(0) — q х ST (1), где q —- ближайшее
к ST(O)/ST(1) целое число. Величина остатка меньше половины мо-
дуля.
Описание операции команды FPREM 1 на псевдоязыке имеет
такой вид:
EXPDIF <— порядок(ST) - порядок(ST(1));
IF EXPDIF < 64
THEN
Q <— целое, полученное при усечении ST/ST(1) к нулю;
ST <— ST - (ST( 1) * Q);
C2 <— 0;
CO,C1,C3 <— три младших бита Q; (* Q2,Q1,QO *)
ELSE
C2 <— 1;
N <— число между 32 и 63;
QQ <— целое, ближайшее к ST/ST(l)/2(nFDir"M);
ST <— ST - (ST( 1) * QQ x 2(nFDIr-»);
FI;
Команда FRNDINT округления до целого осуществляет округ-
ление числа в ST(0) до целого. Режим округления задает поле RC в
слове управления CW. Например, число 486.875 в вершине стека
будет заменено на число 486 (округление вниз или отбрасывание)
или на число 487 (округление вверх или к ближайшему).
Микропроцессор i486 и Книга 3. Устройство с плавающей точкой
Команда FXTRACT выделения компонент числа с плавающей
точкой преобразует число из ST(O) в два числа, представляющие
собой фактические значения его порядка и мантиссы. Другими
словами, эта команда расщепляет значение в ST на порядок и ман-
тиссу. Порядок заменяет исходный операнд в стеке, а мантисса
включается в стек. После выполнения команды FXTRACT новая
вершина стека ST содержит мантиссу в формате вещественного
числа: знак совпадает со знаком операнда, истинный порядок равен
нулю (смещенный порядок равен 16383 или 3FFFH), а мантисса
идентична мантиссе исходного операнда. В ST(1) находится
значение истинного (несмещенного) порядка исходного операнда,
представленное как вещественное число.
Для иллюстрации действия команды FXTRACT предположим,
что ST содержит порядок +4 (т. е. поле порядка содержит 4003Н).
После выполнения команды FXTRACT регистр ST(1) будет содер-
жать вещественное число +4.0; его знак положительный, поле по-
рядка содержит 4001Н (истинный порядок +2) и мантисса равна
1.00..00В. Другими словами, значение в ST(1) равно 1.0 х 22 = 4.
Если в ST находится операнд, истинный порядок которого равен —7
(т. е. поле порядка содержит 3FF8H), то команда FXTRACT
возвратит «порядок» —7; после ее выполнения в ST(1) поля знака и
порядка содержат С001Н (отрицательный знак, истинный
порядок 2) и мантисса равна 1.1100..00В. Другими словами,
значение в ST(1) будет равно —1.75 х 22 = —7.0. В обоих случаях
после команды FXTRACT поля знака и мантиссы ST совпадают с
исходным операндом, поле порядка содержит 3FFFH (истинный 0).
Когда операнд равен 0, команда FXTRACT образует 0 в ST(0) и
минус бесконечность в ST(1).
Эта команда применяется вместе с командой FBSTP для преоб-
разования чисел из формата РТ в десятичный формат при выводе
чисел на дисплей или принтер. Отметим, что с помощью команды
FSCALE «разложенное» число можно превратить в исходное.
Две последние команды выполняют элементарные операции на-
хождения абсолютного значения и изменения знака числа, которое
содержится в вершине стека:
FABS ST(O) <- |ST(O)|
FCHS ST(0) -ST(O)
1.6.6. Команды сравнения
Команды данной группы предназначены для анализа числа в
вершине стека (иногда по отношению>к другому числу) и формиро-
ванию кода условия в слове состояния SW. К ним относятся срав-
нение, проверка (или сравнение с нулем) и анализ (получение под-
робной информации о числе). Имеются специальные формы ко-
Глава 1. Архитектура устройства с плавающей точкой
•163.
манд, допускающие сравнение с целым или вещественным числом,
находящимся в памяти, и извлечения из стека после сравнения.
Проверить образованный код условия может только целочисленное
устройство.
Команды вещественного сравнения сравнивают вершину стека с
источником, которым может быть регистр или операнд в памяти
(одинарной или двойной точности). Если операнд не указан, про-
изводится сравнение ST с ST(1). Отметим, что во всех командах
сравнения знак нуля игнорируется, т. е. —0.0 считается равным +0.0.
Команда сравнения вещественных чисел FCOM //src производит
сравнение ST(0) и источника src. Источником может быть регистр
стека или вещественное число в памяти (в формате ОТ или ДТ).
Если поле операнда пустое, сравниваются ST(0) и ST(1). Код усло-
вия отражает отношение между числами-операндами в соответ-
ствии с таблицей 1.7. Операнды считаются несравнимыми или не-
упорядоченными, когда хотя бы один из них является нечислом.
Таблица 1.7. Установка кода условия после сравнения
Условна СЗ C2 Cl co
ST(.O) > (src) 0 0 X 0
ST(O) < (src) 0 0 X 1
ST(O) = (src) 1 0 X 0
He сравнимы 1 1 X 1
После выполнения команд FSTSW АХ и SAHF биты СЗ, С2 и
СО оказываются во флажках ZF, PF и CF регистра EFLAGS про-
цессора 80386. Для перехода по результату сравнения можно ис-
пользовать команды JE, JNE, JA, JAE, JB и JBE, а для проверки
операндов-нечисел применить команду JP.
Отметим, что команда FCOM сигнализирует об особом случае
недействительной операции, если хотя бы один из операндов явля-
ется «тихим» нечислом.
Команда FCOMP //src сравнения и извлечения из стека дей-
ствует аналогично команде FCOM, но дополнительно осуществляет
извлечение из стека.
Следующая команда FCOMPP сравнения ST(0) с ST(1) и двой-
ного извлечения из стека похожа на команду FCOMP ST(1), но до-
полнительно она производит еще одно извлечение из стека, так что
оба операнда оказываются уничтоженными.
Описание рассмотренных команд сравнения на псевдоязыке
имеет следующий вид:
CASE (отношение операндов) 0F
Не сравнимы: СЗ, С2, СО <— 111;
ST > SRC: СЗ, С2, СО <— ООО;
ST < SRC: СЗ, С2, СО <— 001;
ST = SRC: СЗ, С2, СО <— 100;
^16 4"
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
IF команда = FCOMP THEN Pop(ST); FI;
IF команда = FCOMPP THEN Pop(ST); Pop(ST); FI;
Если любой операнд является нечислом или представлен в не-
поддерживаемом формате или если возникает нарушение стека,
формируется особый случай недействительной операции и коды
условия показывают «не упорядочены».
При выполнении команды FICOM src содержимое источника,
интерпретируемое как целое число в формате ЦС или КД, преобра-
зуется в формат РТ и сравнивается с содержимым регистра ST(0).
Результат сравнения представлен битами кода условия в соответ-
ствии с таблицей 1.7. Команда FICOMP src производит такие же
действия и дополнительно извлекает из стека. В обеих этих коман-
дах в качестве источника может выступать только память.
Если любой операнд является нечислом или представлен в не-
поддерживаемом формате или если возникает нарушение стека,
формируется особый случай недействительной операции и коды
условия показывают «не упорядочены».
В сопроцессоре 80387 и устройстве FPU появились три новые
команды неупорядоченного вещественного сравнения FU-
COM/FUCOMP/FUCOMPP. Описание операций этих команд на
псевдоязыке имеет такой вид:
CASE (отношение операндов) 0F
Не сравнимы: СЗ, С2, СО <— 111;
ST > SRC: СЗ, С2, СО <— ООО;
ST < SRC: СЗ, С2, СО <— 001;
ST = SRC: СЗ, С2, СО <— 100;
IF команда = FUCOMP THEN Pop(ST); FI;
IF команда = FUCOMPP THEN Pop(ST); Pop(ST); FI;
Таким образом, команды неупорядоченного вещественного
сравнения сравнивают вершину стека с источником, которым дол-
жен быть регистр. Если операнд не указан, производится сравнение
ST с ST(1). После команды коды условия показывают отношение
между ST и операндом-источником в соответствии с таблицей 1.7.
Если любой операнд является сигнализирующим нечислом или
представлен в неподдерживаемом формате или если возникает на-
рушение стека, формируется особый случай недействительной опе-
рации и коды условия показывают «не упорядочены».
Если любой операнд является тихим нечислом, биты условия
показывают «не упорядочены». В отличие от обычных команд срав-
нения (FCOM и др.) команды неупорядоченного сравнения не
формируют особый случай недействительной операции при встрече
тихого нечисла как операнда .
Команда FTST производит проверку числа в ST(O) посредством
сравнения его с нулем. Результат проверки фиксируется в коде ус-
ловия так же, как в команде FCOM, но с заменой источника (src)
на нуль.
Глава 1. Архитектура устройства с плавающей точкой
КГ65Й
Последняя в этой группе команда FXAM анализа содержимого
вершины стека формирует в битах СЗ — СО подробное сообщение
об особенностях операнда. Описание операции этой команды на
псевдоязыке имеет следующий вид:
С1 <— знаковый бит ST;
CASE (тип объекта в ST) OF
Неподдерживаемый формат: СЗ, С2, СО <— ООО;
Нечисло: СЗ, С2, СО <— 001;
Нормализованное число: СЗ, С2, СО <— 010;
Бесконечность: СЗ, С2, СО <— 011;
Нуль: СЗ, С2, СО <— 100;
Пустой: СЗ, С2, СО <— 101;
Денормализованное число: СЗ, С2, СО <— ПО;
Неподдерживаемый формат включают в себя специальные
двоичные наборы, например псевдонули и ненормализованные
числа, которые допускаются в сопроцессорах 8087 и 80287, но в со-
процессоре 80387 и устройстве FPU отсутствуют.
После сравнения код условия можно передать в регистр АХ с
помощью команды FSTSW АХ для его анализа. Для управления ус-
ловным переходом удобно применять команду TEST (проверяя
флажки устройства FPU в регистре АХ). Прежде всего нужно про-
верить, не показывает ли результат неупорядоченные операнды. Та-
кая ситуация возникает, если, например, один из операндов явля-
ется нечислом. Содержимое регистра АХ проверяется командой
TEST с маской 0400Н; при этом флажок ZF = 0, если перво-
начальное сравнение показало, что операнды не упорядочены. Ко-
мандой JNZ управление при необходимости передается коду, обра-
батывающему ситуацию с неупорядоченными операндами. После
выявления неупорядоченного сравнения содержимое регистра АХ
проверяется командой TEST с соответствующей константой из таб-
лицы 1.8, а затем производится требуемый условный переход.
Таблица 1.8. Константы в команде TEST
для условного перехода
Порядок Константа Переход
ST > операнд 4500Н JZ
ST < операнд 0100Н JNZ
ST = операнд 4000Н JNZ
Не упорядочены 0400Н JNZ
В этом алгоритме условных переходов не всегда нужно отсеивать
ситуацию с неупорядоченными операндами. Если программа тща-
тельно тестирована и содержит периодические проверки появления
тихих нечисел, необязательно проверять неупорядоченность при
каждом сравнении.
Код условия могут модифицировать и команды, не входящие в
класс команд сравнения. Чтобы гарантировать невозможность
ЩпбЯ
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
случайного изменения кода условия, его сразу же после операции
сравнения следует сохранить в памяти.
1.6.7. Команды трансцендентных функций
Команды настоящей группы выполняют базовые вычисления,
относящиеся к тригонометрическим, обратным тригономет-
рическим, логарифмическим и показательным функциям. При про-
граммной реализации этих функций производительность це-
лочисленного устройства оказывается очень низкой (достаточно
напомнить о формате РТ, с которым работает устройство FPU).
Операнды команд находятся в одном или двух верхних регистрах
стека, и результат также возвращается в стек. Предполагается, что
операнды нормализованы и находятся в допустимом для каждой из
команд диапазоне. При нарушении этих требований результат опе-
рации не определен; более того, устройство FPU не оповещает об
этом никаким особым случаем. В тригонометрических операциях
предполагается, что аргументы представлены в радианах.
Логарифмические и показательные операции выполняются с
основанием 2.
Результаты трансцендентных команд имеют очень высокую
точность. Абсолютное значение относительной ошибки ' в них
меньше 2-62.
Тригонометрические функции допускают практически неогра-
ниченный диапазон операндов, а другие трансцендентные команды
требуют нахождения аргументов в более ограниченном диапазоне.
Команды FPREM и FPREM 1 позволяют привести допустимый опе-
ранд периодической функции в требуемый диапазон. Для приведе-
ния аргументов в ожидаемый диапазон и необходимой коррекции
результата с учетом исходных аргументов требуются подготовитель-
ные и заключительные программы.
Когда аргумент тригонометрической функции находится в допу-
стимом диапазоне, он автоматически приводится к соответствую-
щему множителю 2 х л (с точностью 66 бит) с помощью того же
механизма, который применяется в командах FPREM и FPREM 1.
Значение п для автоматического приведения выбрано таким, чтобы
гарантировать отсутствие потери значимости операнда при нахож-
дении его в определенном диапазоне.
Внутреннее значение п равно
4 х 0.C90FDAA2 2168С234 С Н
Программа может использовать явное значение тс в
вычислениях, результаты которых позднее появляются как аргу-
менты тригонометрических функций. В этом случае (например, при
явном приведении тригонометрического операнда, находящегося
Глава 1. Архитектура устройства с плавающей точкой
вне диапазона) значение п должно совпадать с его внутренним
66-битным представлением. Этим обеспечивается согласованность
результатов с автоматическим приведением аргумента, выполняе-
мым тригонометрическими функциями. 66-битное значение числа п
нельзя представить числом в формате РТ, поэтому его нужно коди-
ровать как два или более чисел. Обычно оно представляется суммой
старшей части, содержащей 33 старших бита, и младшей части, со-
держащей 33 младших бита. При использовании двухэлементного
числа п все вычисления необходимо выполнять для каждой части
отдельно и суммировать результаты в конце.
Трудностей поддержания согласованного значения п для приве-
дения аргумента можно избежать, если применять тригономет-
рическую функцию только к аргументам, находящимся в диапазоне
механизма автоматического приведения, или производить все при-
ведения аргументов (до величины, меньшей л/4) программно.
Команда FPTAN вычисления частичного тангенса воспринимает
в ST(0) число в диапазоне от —263 до +264, которое считается ис-
ходным углом в радианах. Она возвращает результат в двух верхних
регистрах стека: значение тангенса исходного угла tg(ST) замещает
аргумент и в стек включается 1.0. Такое необычное представление
результата объясняется совместимостью с предыдущими сопроцес-
сорами 8087 и 80287, в которых команда FPTAN дает тангенс, рав-
ный ST(1)/ST(O) и значение в ST(0), не равно 1.0. Следовательно, в
этих сопроцессорах для получения тангенса требуется еще операция
деления (этим и объясняется происхождение термина «частичный
тангенс»). Кроме того, включение в стек 1.0 упрощает вычисление
остальных тригонометрических функций. Например, котангенс
(являющийся обратной величиной тангенса) можно вычислить, вы-
полняя после команды FPTAN команду FDIVR.
Если операнд находится вне диапазона допустимых значений,
бит кода условия С2 устанавливается в 1 и содержимое ST остается
неизменным. Программист приводит операнд к абсолютному значе-
нию, меньшему 253, вычитая соответствующее кратное 2 х л.
Чтобы избежать особого случая недействительной операции, ре-
гистр ST(7) должен быть пустым.
При выполнении команды FPTAN процессор i486 периодически
контролирует прерывания и может отменить ее дая обслуживания
прерывания.
Команда FPATAN вычисления частичного арктангенса
вычисляет arctg ((ST(1)/(ST(O)). После нахождения значения функ-
ции производится извлечение из стека, и угол замещает два операн-
да в вершине стека. Результат имеет тот же знак, что и операнд из
ST(1), и величину меньше л. Термин «частичный арктангенс» унас-
ледован от предыдущих сопроцессоров, в которых накладывались
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
ограничения на значения в ST(1) и ST(0). В сопроцессоре 80387 и
устройстве FPU ограничений на диапазон допустимых аргументов
команды FPATAN не существует.
Тот факт, что команда FPATAN воспринимает два аргумента и
вычисляет арктангенс их отношения, упрощает вычисление осталь-
ных тригонометрических функций. Например, arcsin(x) (который
равен arctg(x/((l — x2)V2) можно вычислить такой последовательно-
стью операций:
— включить х в стек устройства FPU;
— вычислить и включить в стек (1 — х2)1/2;
— выполнить команду FPATAN.
При выполнении команды FPATAN процессор i486 контролиру-
ет прерывания и может отменить ее для обслуживания прерывания.
Обе команды FPTAN и FPATAN являются очень точными
(погрешность результата составляет несколько единиц младшего
разряда) и выполняются довольно быстро — всего примерно в 3 ра-
за медленнее операции деления.
В сопроцессоре 80387 и устройстве FPU появились новые ко-
манды вычисления синуса FSIN, косинуса FCOS, а также синуса и
косинуса FSINCOS. Все они воспринимают в ST(0) исходный угол,
измеряемый в радианах и находящийся в диапазоне от —263 до +263.
Если угол находится вне диапазона, команды не выполняются, бит
кода условия С2 устанавливается в состояние 1 и содержимое ST(0)
не изменяется. Обеспечить нахождение операнда в диапазоне,
вычитая соответствующее кратное 2 х л, должен программист.
Команды FSIN и FCOS возвращают результат на месте аргу-
мента, а команда FSINCOS возвращает значение синуса на месте
аргумента и включает значение косинуса в стек.
При выполнении всех этих команд процессор i486 периодически
контролирует прерывания и они могут быть отменены для
обслуживания прерывания.
Команда с несколько необычной мнемоникой F2XM1 вычисляет
значение функции Y = 2х — 1 (в мнемонике отражена функция ко-
манды — два в степени X минус 1). Значение X берется из
вершины стека ST(0) и должно находиться в диапазоне от -1.0 до
+ 1.0. Если значение X находится вне этого диапазона, результат
операции не определен.
На первый, взгляд более естественной кажется команда, которая
вычисляет 2х вместо 2х — 1. Однако команда F2XM1 позволяет по-
лучить очень точный результат, когда аргумент X близок к 0. На-
пример, значение 2° 000001 приблизительно равно 1.000000693. Не-
трудно убедиться в том, что вычитание 1 сохраняет в результате
больше значащих цифр.
Можно осуществить возведение в степень X любых чисел,
пользуясь тождеством Vх = 2х х log2(Y). Необходимые для
Глава 1. Архитектура устройства с плавающей точкой ИЯЖаМ
десятичных и натуральных степеней константы встроены в
сопроцессор (см. команды загрузки констант из разд. 1.6.4), а
команда FYL2X вычисляет двоичный логарифм числа.
Команда FYL2X предназначена для вычисления значения функ-
ции Z = Y х log2(X). Аргумент X находится в вершине стека ST(0), а
аргумент Y — в регистре ST(1). Аргумент X может быть любым
положительным числом, а аргумент Y — любым числом. Команда
производит извлечение из стека аргументов и включает Z в новую
вершину стека, т. е. замещает Y. С помощью этой команды удобно
вычисляются логарифмы чисел по любому основанию с примене-
нием тождества logn(X) = logn(2) х log2(X). Для загрузки двоичных
логарифмов 10 и числа е имеются команды FLDL2T и FLDL2E
(см. разделе 1.6.4).
Если операнд в ST(0) отрицательный, возникает особый случай
недействительной операции.
При выполнении этой команды процессор i486 периодически
контролирует прерывания, и она может быть отменена для
обслуживания прерывания.
Последняя. из команд этой группы — команда FYL2XP1
вычисляет значение функции Z = Y х log2(X+l). Аргумент X
берется из вершины стека ST(0) и должен находиться в диапазоне
от —(1 — 2V2/2) до +(1 — 2V2/2), а аргумент Y находится в ST(1) и
может быть любым. Команда производит извлечение аргументов из
стека и включает Z в стек, т. е. на место Y.
Команда FYL2XP1 обеспечивает большую точность по сравне-
нию с командой FYL2X при вычислении логарифмов чисел, очень
близких к 1. Задание как аргумента функции числа eps « 1 вместо
1 + eps позволяет сохранить в аргументе больше значащих цифр.
Если операнд в ST находится вне допустимого диапазона, ре-
зультат команды FYL2XP1 не определен.
При выполнении этой команды процессор i4861 периодически
контролирует прерывания, и она может быть отменена для
обслуживания прерывания.
1.6,8. Команды управления
Команды этой группы, приведенные в таблице 1.9, ориентиро-
ваны, в основном, на операции системного уровня. Для приклад-
ных программистов наиболыций интерес представляют команды,
оперирующие словами управления и состояния. С их помощью
можно задать режим работы сопроцессора, а также проанализиро-
вать результаты команд сравнения и проверки.
Отметим, что команда FSTSW обычно применяется для услов-
ного перехода. Остальные команды в вычислениях почти не ис-
пользуются; они предназначены для управления устройством FPU
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
на системном уровне. К таким действиям относятся инициализация
устройства FPU, обработка численных особых случаев и пере-
ключение задач.
Таблица 1.9. Команды управления
Мнбмошпса Операция
F[N]INIT Инициализация сопроцессора
FLDCW src Загрузка слова управления
F[N]STCW dst Сохранение слова управления
F[N]STSW dst Сохранение слова состояния
F[N]STSW AX Сохранение слова состояния в АХ
F[N]CLEX Сброс флажков особых случаев
FLDENV src Загрузка среды
F[N]STENV dst Сохранение среды
F[N]SAVE dst Сохранение полного состояния
FRSTOR src Восстановление полного состояния
FINCSTP Инкремент указателя стека
FDECSTP Декремент указателя стека
FFREE ST(i) Освобождение регистра
FNOP Холостая команда
FWAIT Ожидание
Как видно из таблицы 1.9, для многих команд имеются альтер-
нативные мнемоники, второй буквой которых является N. Общий
смысл наличия буквы N (No wait — не ожидать) состоит в том, что
соответствующая команда не проверяет незамаскированные особые
случаи и выполняется немедленно. Когда команда управления за-
кодирована мнемоникой в форме «без ожидания», ассемблер не
вставляет перед ней команду WAIT, поэтому перед выполнением
команды управления устройство FPU не проверяет наличие особых
случаев с плавающей точкой.
Единственными командами «без ожидания» являются те, кото-
рые приведены в таблице 1.9. Все остальные команды с плавающей
точкой процессор синхронизирует автоматически; все операнды пе-
редаются до инициирования следующей команды. Благодаря авто-
матической синхронизации для правильного выполнения команд,
не связанных с управлением, не требуется предшествующая коман-
да WAIT.
Синхронизация особых случаев опирается на команду WAIT.
Так как целочисленное устройство и устройство FPU работают па-
раллельно, возможно, что особый случай с плавающей точкой раз-
рушит важную информацию до вызова обработчика особого случая.
Указание команды WAIT или FWAIT в правильном месте позволяет
избежать такой ситуации.
Отметим, что команды разрешения/запрещения прерываний
FENI/FDISI сопроцессора 8087 и команда FSETPM сопроцессора
80287 в процессоре i486 не выполняют никаких функций. Если их
коды операций обнаруживаются в командном потоке, процессор
Глава 1. Архитектура устройства с плавающей точкой
-17U
i486 не выполняет никакой конкретной операции и его внутреннее
состояние не изменяется. Более подробное описание различий опе-
раций с плавающей точкой в процессоре i486 и сопроцессорах
8087/80287/387DX приведено в главе 3.
Команда F[N]INIT инициализации сопроцессора выполняет
операции, описываемые на псевдоязыке следующим образом:
CW <— 037FH; (* Слово управления *)
SW <— 0; (* Слово состояния *)
TW <-- FFFFH; (* Слово тэгов *)
FEA <— 0; FDS <— 0; (* Указатель данных *)
FIP <-- 0; FOP <— 0; FCS <— 0; (* Указатель команды *)
Команды инициализации переводят устройство FPU в известное
состояние независимо от его предыдущих действий.
Слово управления устанавливается на 037FH (округление к бли-
жайшему, все особые случаи замаскированы, определена макси-
мальная 64-битная точность). Слово состояния SW сбрасывается
(нет Установленных флажков особых случаев, регистр R0 является
вершиной стека). Все регистры стека отмечены как пустые. Указа-
тели ошибки (команды и данных) сброшены. Отметим, что первой
командой устройства FPU после включения питания должна быть
команда FNINIT.
Команда FINIT перед выполнением инициализации контроли-
рует ошибки с плавающей точкой, a FNINIT — не контролирует.
Команды FINIT и FNINIT переводят устройство FPU в такое
же состояние, что и аппаратный сигнал сброса RESET со встроен-
ным самоконтролем. В процессоре i486 эти команды, в отличие от
сопроцессора 80387, сбрасывают указатели ошибки.
Основное назначение команды FLDCW src состоит в том, чтобы
загрузить в регистр управления CW устройства FPU новое содер-
жимое из источника (им должно быть целое слово в памяти) с це-
лью установки или изменения режима работы, например режима
округления. Отметим, что , если в слове состояния установлен лю-
бой флажок особого случая, загрузка нового слова управления мо-
жет привести к формированию особого случая перед выполнением
следующей команды. Поэтому перед загрузкой нового слова управ-
ления рекомендуется сбрасывать флажки особых случаев.
Команды F[N]STCW dst и F[N]STSW dst осуществляют сохране-
ние текущего слова состояния и управления, соответственно, в
ячейке памяти, определяемой получателем dst или в регистре АХ
целочисленного устройства. Получатель в памяти должен иметь
формат целого слова.
Команды FSTCW и FSTSW перед сохранением слова управления
состояния контролируют наличие особых случаев, а команды FN-
STCW и FSTSW не контролируют.
Й172
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
Команда F[N]STSW применяется, в основном, для условного
перехода (после команд сравнения, FPREM, FPREM1 или FXAM).
Ее также можно использовать для вызова обработчиков особых
случаев (при опросе бит особых случаев) в среде, где прерывания
отсутствуют.
В команде FNSTSW АХ регистр АХ модифицируется до выпол-
нения процессором i486 дальнейших команд. Сохраняется состоя-
ние, полученное после предыдущей команде ESC.
Функция команды F[N]CLEX сброса особых случаев зак-
лючается в том, чтобы сбросить в нуль в слове состояния SW уст-
ройства FPU флажки особых случаев, флажок состояния особого
случая и флажок занятости (биты 0 — 7 и бит 15). Данную команду
процедура обработки особых случаев должна выполнить перед воз-
вратом в прерванную программу, иначе сразу же будет сформирова-
но новое прерывание, в результате чего может возникнуть беско-
нечный цикл.
Команда FCLEX перед сбросом флажков особых случаев конт-
ролирует ошибки с плавающей точкой, а команда FNCLEX не кон-
тролирует.
Команда F[N]SAVE dst предназначена для сохранения текущего
полного состояния устройства FPU (среды и регистрового стека) в
определенный получатель dst, а затем реинициализирует FPU как
после выполнения команды F[N]INIT. Среда устройства FPU со-
стоит из слова управления, слова состояния, слова тэгов и указате-
лей ошибок (данных и команды).
Формат состояния в памяти зависит от размера операнда и те-
кущего рабочего режима процессора i486. Атрибут USE текущего
сегмента кода определяет размер операнда: 94-байтный операнд от-
носится к сегменту USE 16, а 108-байтный операнд относится к сег-
менту USE32. Форматы среды для обоих размеров операндов в R- и
P-режимах приведены на рис. 1.4 — 1.7. (В V-режиме применяется
формат R-режима.) Регистры стека, начиная с ST и кончая ST(7),
сохраняются в 80 байтах, расположенных сразу после образа среды.
Команды FSAVE и FNSAVE не сохраняют состояние устройства
FPU до прекращения всех его действий. Следовательно, сохранен-
ный образ состояния отражает состояние FPU после выполнения
ранее декодированной команды.
Если программа должна считывать образ состояния после ко-
манды сохранения, она должна выдать команду FWAIT, что обес-
печивает окончание сохранения.
Команды сохранения полного состояния обычно применяются в
тех ситуациях, когда операционная система должна выполнить пе-
реключение контекста, когда обработчику особого случая требуется
состояние FPU или когда программа хочет передать подпрограмме
«чистое» устройство FPU.
Глава 1. Архитектура устройства с плавающей точкой
Восстановление полного состояния реализуется командой
FRSTOR src, которая перезагружает состояние устройства FPU
(среда и регистровый стек) из области памяти, определенной опе-
рандом-источником src. Эти данные должны быть записаны преды-
дущей командой FSAVE или FNSAVE. Среда устройства FPU со-
стоит из слова управления, слова состояния, слова тэгов и указате-
лей ошибок (данных и команды). Формат среды в памяти зависит
от размера операнда и текущего рабочего режима процессора. Ат-
рибут USE текущего сегмента кода определяет размер среды: 14-
байтный операнд относится к сегменту USE16, а 28-байтный опе-
ранд относится к сегменту USE32. Форматы среды для обоих раз-
меров операндов в R- и P-режиме приведены на рис. 1.4 — 1.7. (В
V-режиме применяется формат R-режима.) Регистры стека, начиная
с ST и кончая ST(7), находятся в 80 байтах, расположенных сразу
после образа среды. Команду FRSTOR необходимо выполнять в
том же рабочем режиме, который был в соответствующей команде
FSAVE или FNSAVE. Необходимо, чтобы информация о состоянии
была ранее запомнена командой F[N]SAVE и не модифицировалась
другими командами. Сопроцессор реагирует на свое новое состоя-
ние сразу же по завершении команды FRSTOR.
Если образ состояния содержит незамаскированный особый
случай, то его загрузка приводит к формированию особого случая.
Команды сохранения среды FSTENV dst и FNSTENV dst запи-
сывают текущую среду устройства FPU в указанный получатель dst,
а затем маскируют все особые случаи с плавающей точкой. Среда
устройства FPU состоит из слова управления, слова состояния,
слова тэгов и указателей ошибок (данных и команды). Обычно ин-
формация о среде сохраняется в стеке целочисленного устройства.
Формат среды в памяти зависит от размера операнда и текущего
рабочего режима процессора i486. Атрибут USE текущего сегмента
кода определяет размер операнда: 14-байтный операнд относится к
сегменту USE16, а 28-байтный — к сегменту USE32. Форматы
среды для обоих размеров операндов в R- и P-режимах приведены
на рис. 1.4 — 1.7. (В V-режиме применяется формат R-режима.)
Команды FSTENV и FNSTENV не сохраняют среду до прекра-
щения всех действий устройства FPU. Следовательно, сохраненный
образ среды отражает состояние FPU после выполнения ранее де-
кодированной команды.
Команды сохранения среды часто применяются в обработчиках
особых случаев, так как они обеспечивают доступ к указателям
ошибок устройства FPU. Обычно среда сохраняется в стеке, орга-
низуемом в памяти. После сохранения среды команды FSTENV и
FNSTENV устанавливают в 1 маски всех особых случаев в слове
управления. Этим предотвращается прерывание обработчика особо-
го случая ошибками с плавающей точкой. Отметим, что команда
Микропроцессор i486 и Книга 3. Устройство с плавающей точкой
F[N]STENV выполняется примерно в три раза быстрее команды
F[N]SAVE.
Команда FSTENV перед сохранением среды контролирует осо-
бые случаи с плавающей точкой, a FNSTENV — не контролирует.
Парная предыдущей команде команда FLDENV src осуществляет
загрузку среды сопроцессора из области памяти, определяемой ис-
точником src.
Среда устройства FPU состоит из слова управления, слова со-
стояния, слова тэгов и указателей ошибок (данных и команды).
Формат среды в памяти зависит от размера операнда и текущего
рабочего режима процессора. Атрибут USE текущего сегмента кода
определяет размер операнда: 14-байтный операнд относится к сег-
менту USE16, а 28-байтный — к сегменту USE32. Форматы среды
для обоих размеров операндов в R- и P-режимах приведены на
рис. 1.4 — 1.7. (В V-режиме применяется формат R-режима.)
Команду FLDENV необходимо выполнять в том же рабочем
режиме, который был в соответствующей команде FSTENV или
FNSTENV.
Если образ среды содержит незамаскированный особый случай,
то его загрузка приводит к формированию особого случая.
Команды FINCSTP и FDECSTP производят только инкремент и
декремент указателя стека и не передают никаких данных. Регистр
предыдущей вершины стека при выполнении команды FINCSTP не
изменяется и не отмечается как пустой, т. е. действие этой коман-
ды не эквивалентно извлечению из стека. Команда FDECSTP как
бы осуществляет включение в стек, но включаемое значение отсут-
ствует; регистры тэгов не изменяются.
Команда FFREE ST(i) записывает в тэг указанного регистра 11В,
т. е. отмечает регистр как пустой, но содержимое регистра ST(i) и
указатель стека ТОР не изменяются.
Команда ожидания FWAIT заставляет процессор i486 перед про-
должением проверить ожидающие незамаскированные особые
случаи.
Как показывает код операции, команда FWAIT фактически яв-
ляется альтернативной мнемоникой команды WAIT, а не командой
ESC. Указание команды FWAIT после команды ESC гарантирует,
что любые незамаскированные особые случаи, которые может выз-
вать команда, обрабатываются до того, как процессор может изме-
нить результат команды.
Холостая (или пустая) команда FNOP не производит никаких
операций. Она не влияет ни на что, кроме указателей команды.
Глава 1. Архитектура устройства с плавающей точкой
1.7. Внешний интерфейс устройства FPU
В предыдущих микропроцессорных семействах' 8086/80286
фирмы Intel, в которых математический сопроцессор выполнен в
виде отдельной микросхемы, взаимодействие сопроцессора с цент-
ральным процессором осуществляется с помощью пяти внешних
сигнальных линий. Напомним, что сопроцессор не может самосто-
ятельно обращаться к памяти для выборки команд и считыва-
ния/записи операндов. При необходимости производства этих опе-
раций он должен запрашивать о них центральный процессор.
Два сигнала QS0-QS1 состояния внутренней очереди (команд),
которые являются выходными у центрального процессора и вход-
ными у сопроцессора, обеспечивают синхронную работу очередей
команд центрального процессора и сопроцессора.
При помощи двунаправленной линии RQ/E запроса/разрешения
шины сопроцессор запрашивает системную шину у центрального
процессора при необходимости считывания из памяти или записи в
память дополнительных слов операндов.
Выходной сигнал INT прерывания сопроцессора через програм-
мируемый контроллер прерываний подается на вход INTR цент-
рального процессора. Этим сигналом сопроцессор сообщает цент-
ральному процессору о возникновении любого незамаскированного
особого случая.
Наконец, выходной сигнал BUSY занятости сопроцессора пода-
ется на вход TEST# центрального процессора. Это соединение
обеспечивает необходимую синхронизацию по командам и данным.
Командой ожидания WAIT центральный процессор проверяет со-
стояние сопроцессора и при необходимости (т. е. когда сопроцес-
сор занят) переводится в состояние ожидания.
В семействе 80386 интерфейс сопроцессора и центрального про-
цессора претерпел существенные изменения. Центральный процес-
сор взаимодействует с сопроцессором через два порта ввода-выво-
да, один из которых является портом команды/состояния, а второй
портом данных. Когда процессор 80386 встречает команду
сопроцессора, он копирует ее в порт команды по адресу 800000F8H.
После этого он может продолжить выборку очередной команды и
свои обычные операции. Если сопроцессору требуется больше
информации, например при необходимости считать операнд из
памяти, он формирует активный сигнал на линии PEREQ (Processor
Extension RE Questподключенной к процессору 80386. На
следующей границе между командами процессор 80386 производит
считывание из порта команды/состояния для определения
характера запроса. Если запрос связан с передачей операнда,
процессор считывает или записывает данные между памятью и
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
портом данных с адресом 800000FCH. Когда сопроцессору
требуется дальнейшее обслуживание, он сохраняет активный сигнал
PEREQ. Сопроцессор 80387 не имеет внешних линий адреса и схем
для выполнения циклов шины.
На время выполнения сопроцессором своей команды он форми-
рует активный сигнал на линии BUSY# (занят), информируя про-
цессор 80386 о том, что не может воспринимать следующую свою
команду. Процессор 80386 не выбирает следующую команду сопро-
цессора до тех пор, пока сигнал на линии BUSY# не станет пассив-
ным. Хотя оба процессора и могут работать параллельно, каждый
из них в любой момент времени выполняет одну команду. Для
достижения максимальной производительности не следует
группировать команды сопроцессора, оперирующие числами с
плавающей точкой. В идеальной ситуации новую команду
сопроцессору нужно передавать, как только он закончит
предыдущую. На практике такая ситуация почти невозможна и эф-
фективное программирование заключается в достижении макси-
мального параллелизма в работе процессоров.
При возникновении незамаскированного особого случая сопро-
цессор формирует активный сигнал на выходной линии ERROR#.
Процессор 80386 не воспринимает его до выборки следующей ко-
манды сопроцессора. В это время он распознает ошибку сопроцес-
сора как особый случай 16. Для определения причины возникшей
ошибки обработчик особого случая должен проанализировать слово
состояния сопроцессора.
В процессоре 80386 предусмотрена также работа с сопроцессо-
ром 80287. Основное различие в характере взаимодействия между
ними связано с 16-битной шиной сопроцессора 80287. Выбором 16-
или 32-битного протокола взаимодействия управляет бит ЕТ типа
расширения (Extension Туре): при ЕТ = 1 действует 32-битный про-
токол (80387), а при ЕТ = 0 — 16-битный протокол (80287).
Интересно отметить, что схемы взаимодействия устроены таким
образом, что процессор 80386 автоматически устанавливает бит ЕТ
в правильное состояние при включении питания.
На действия процессора 80386 при встрече им команды сопро-
цессора влияют еще два бита в регистре управления CR0. Для про-
граммной эмуляции функций сопроцессора необходимо установить
в 1 бит эмуляции ЕМ (EMulate). Когда процессор 80386 встречает
команду сопроцессора и бит ЕМ =1, он генерирует особый
случай 7 недоступности сопроцессора. Процедура обработки этого
особого случая должна распознать команду сопроцессора и
смоделировать ее выполнение. Бит присутствия сопроцессора МР
(Math Present) своим состоянием показывает наличие (MP = 1) или
отсутствие (МР = 0) в системе сопроцессора. Очевидно, ситуация, в
Глава 1. Архитектура устройства с плавающей точкой
которой ЕМ = 1 и MP = 1, является запрещенной. Правильные
состояния бит ЕМ и МР необходимо задавать программно.
Так как устройство FPU в процессоре i486 является внутренним,
его интерфейс значительно упрощен. В частности, к устройству
FPU относятся всего два внешних сигнала: выходной сигнал
FERR# показывает, что возникла незамаскированная ошибка с
плавающей точкой, а входной сигнал IGNNE# сообщает процессо-
ру о том, что нужно игнорировать .ошибки с плавающей точкой и
продолжать выполнение программы.
В каждой команде с плавающей точкой (за исключением команд
управления без ожидания) процессор контролирует, не сформиро-
вала ли предыдущая команда с плавающей точкой незамаскирован-
ный численный особый случай (переполнение, антипереполнение,
деление на нуль и т. д.). При наличии ошибки процессор сообщает
об этом, выдавая сигнал FERR#. В этом отношении сигнал FERR#
аналогичен выходному сигналу ERROR# математических сопроцес-
соров 80287 и 80387.
Если сигнал IGNNE# при обнаружении ошибки с плавающей
точкой пассивен, процессор либо останавливается и ожидает пре-
рывания, либо переходит по ячейке прерывания с плавающей
точкой (вектор 16) в зависимости от состояния бита численной
ошибки NE в регистре состояния машины (CR0). Эти два способа
вызова обработчиков особого случая одинаковы в системах, ис-
пользующих процессор 80286 и сопроцессор 80287, и в системах,
использующих процессор 80386 и сопроцессор 80387:
Если бит NE в регистре управления CR0 установлен в 1, процес-
сор формирует прерывание 16, т. е. прерывание ошибки с плаваю-
щей точкой. Когда же бит NE сброшен в 0, процессор останавлива-
ется и ожидает внешнего прерывания. Бит NE сбрасывается при
действии сигнала сброса RESET; такое состояние принимается по
умолчанию.
Принимаемый по умолчанию механизм (NE = 0) эмулирует со-
общения об ошибках в системах 8086/8087 и поддерживается ради
совместимости с операционной системой DOS. Он требует наличия
внешнего контроллера прерываний для контроля выхода FERR# и
генерирования необходимых прерываний (обычно по входу INTR).
Контроллер прерываний может разрешить выполнение команд с
плавающей точкой до сброса условия ошибки (т. е. внутри обра-
ботчика прерывания), подавая в процессор активный сигнал
IGNNE#. Когда подан активный сигнал IGNNE# (и бит NE = 0),
процессор выполняет команды с плавающей точкой, несмотря на
предшествующие ошибки. Входной сигнал IGNNE# может быть
асинхронным относительно синхронизации процессора.
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
Специальные
вычислительные ситуации
^Г^З£^ЭД№БМНБЯШ18£3&ОЗЯМ№£ЁЙ!^
Помимо представления положительных и отрицательных чисел
форматы численных данных устройства FPU допускают описание
других объектов или специальных значений. Такие специальные
значения обеспечивают дополнительную гибкость, но большинству
пользователей не нужно разбираться в них, чтобы успешно приме-
нять численные возможности процессора i486. В этой главе описа-
ны специальные значения, которые возникают в некоторых ситуа-
циях и смысл каждого из них. Рассмотрены также численные осо-
бые случаи ддя программистов обработчиков особых случаев.
При обсуждении специальных вычислительных ситуаций удобно
различать арифметические и неарифметические команды. К не-
арифметическим относятся те команды, которые не имеют операн-
дов или передают свои операнды без существенного изменения;
арифметические же команды производят существенные изменения
своих операндов. Два класса команд определены в таблице 2.1.
Таблица 2.1. Арифметические и неарифметические команды
Неарифметические команды Арифметические команды
FABS FCHS FCLEX FDECSTP FFREE FINCSTP FINIT FLD (регистр-регистр) FLD (формат РТ из памяти) FLD константа FLDCW FLDENV FNOP FRSTOR FSAVE FST(P) (регистр-регистр) FSTP (формат РТ в память) FSTCW FSTENV FSTSW FWAIT FXAM FXCH F2XM1 FADD(P) FBLDFBSTP FCOM(P)(P) FCOS FDIV(R)(P) FIADD FICOM(P) FIDIV(R) FILD FIMUL FIST(P) FISUB(R) FLD (преобразование формата) FMUL(P) FPATAN FPREM FPREM1 FPTAN FRNDINT FSCALE FSIN FSINCOS FSQRT FST(P) (преобразование формата) FSUB(R)(P) FTST • FUCOM(P)(P) EXTRACT FYL2X FYL2XP1
Глава 2. Специальные вычислительные ситуации
2.1. Специальные численные значения
В дополнение к обычным целочисленным и вещественным
значениям данных форматы чисел процессора i486 допускают коди-
рование множества специальных значений. Эти специальные
значения имеют смысл и могут дать важную информацию о резуль-
татах вычислений или операциях, которые сформировали их. К
специальным значениям относятся денормализованные веществен-
ные числа, нули, отрицательные и положительные бесконечности,
нечисла (Not-a-Number — NaN), неопределенность и неподдержива-
емые форматы.
Далее поясняются происхождение и смысл специальных
значений, а в таблице 2.6 — 2.9 в конце раздела приведено их коди-
рование для каждого численного типа данных.
2.1.1. Денормализованные вещественные числа
Обычно устройство FPU хранит ненулевые вещественные числа
в нормализованной форме с плавающей точкой; бит целой части
мантиссы всегда содержит 1. Бит целой части явно хранится в РТ и
неявно подразумевается единицей в форматах ОТ и ДТ. При удале-
нии старших нулей нормализованное представление обеспечивает
максимальное число значащих цифр в мантиссе заданной длины.
Когда численное значение приближается к 0, нормализованное
представление не позволяет точно выразить значение. Для точного
определения того, какие значения требуют специальной обработки,
далее применяется термин tiny («крошечный»). Число R называется
числом tiny, когда —2Emin < R < 0 или 0 < R < +2Emin. (В гл. 1 бы-
ло показано, что Emin равно —126 для ОТ, —1022 для формата ДТ и
—16382 для формата РТ.) Другими словами, ненулевое число назы-
вается числом tiny, когда его порядок слишком отрицателен для со-
хранения в формате получателя.
Для обработки таких ситуаций устройство FPU может хранить и
обрабатывать вещественные числа, которые не являются нормали-
зованными, т. е. числа с нулевыми старшими битами мантиссы.
Денормализованные числа обычно возникают, когда результат
вычисления дает число tiny.
Денормализованные значения обладают двумя свойствами:
— смещенный порядок хранится с наименьшим значением
(нуль);
— бит целой части мантиссы (явный или неявный) равен 0.
Старшие нули денормализованных чисел допускают представле-
ние меньших чисел за счет некоторой потери точности (число бит
мантиссы сокращается из-за старших нулей). В типичных алгорит-
мах очень малые значения обычно возникают как промежуточные,
Микропроцессор i486 Книга 3 Устройство с плавающей точкой
а не окончательные, результаты. Хранение промежуточных резуль-
татов в формате РТ допускает представление малых величин до
±3.37x10-4932; следовательно, в численных приложениях денорма-
лизованные числа возникают очень редко. Тем не менее, устрой-
ство FPU может загружать, сохранять и обрабатывать денормализо-
ванные вещественные числа при их появлении.
Наличие денормализованных чисел учитывается в трех аспектах.
— по мере возможности устройство FPU избегает их появления,
т.е. оно всегда нормализует вещественные числа за исключением
появления очень малых чисел;
— устройство FPU формирует незамаскированный особый
случай антипереполнения, позволяющий программисту обнаружить
ситуации, в которых появляются денормализованные числа;
— устройство FPU формирует особый случай денормализован-
ного операнда DE, позволяющий программисту обнаружить ситуа-
ции, когда денормализованные числа участвуют в вычислениях.
Денормализация на один бит означает инкремент порядка ис-
тинного результата и вставку старшего нуля в мантиссу со сдвигом
остальной части мантиссы на один бит вправо. Денормализованные
значения могут появляться в любом вещественном формате
(одинарном, двойном или расширенном). Диапазоны денормализо-
ванных значений в каждом формате показаны в таблице 2.2.
Таблица 2.2. Денормализованные значения
Формат Наименьшая величина Наибольшая величина
Точная Приближенная Точная Приближенная
ОТ 2-150 Ю-46 2-126-2-150 Ю-38
ДТ 2-1075 10-324 2-Ю22-2М075 Ю-308
РТ 2-16384 Ю-4956 2-16382-2-16461 Ю-4932
В процессе денормализации образуется денормализованное
значение или 0. Денормализованные значения легко идентифици-
руются по их порядкам, которые всегда равны минимуму их форма-
тов; в смещенной форме это всегда цепочка 00...00. Такое значение
порядка назначено и нулю, но у денормализованного значения не-
нулевая мантисса. Денормализованное значение в регистре от-
мечается как специальное. Далее в таблицах 2.8 и 2.9 будет приве-
дено кодирование денормализованных значений в каждом из веще-
ственных форматов.
Процесс денормализации приводит к потере значимости, если
справа от, мантиссы выдвигаются ненулевые биты. В предельном
случае выдвигаются и заменяются старшими нулями все биты ман-
тиссы истинного результата. В такой ситуации результатом денор-
мализации становится истинный нуль, и при нахождении его в ре-
гистре он отмечается как нуль специальным тэгом.
Глава 2. Специальные вычислительные ситуации
В большинстве приложений денормализованные значения
встречаются очень редко. Типичные отлаженные алгоритмы фор-
мируют очень малые результаты только при вычислении проме-
жуточных подвыражений; обычно окончательный результат прием-
лем для представления в форматах ОТ или ДТ. Если проме-
жуточные результаты представляются в формате РТ (как это и
рекомендуется), огромный диапазон этого формата делает антипе-
реполнение маловероятным. Денормализованные значения могут
появиться, когда программа образует так много промежуточных ре-
зультатов, что их невозможно хранить в регистровом стеке или в
памяти в формате РТ. Если ограничения памяти заставляют приме-
нять для промежуточных результатов формат ОТ или ДТ и по-
лучаются малые значения, могут возникать антипереполнение и
особые случаи денормализованного операнда DE.
Когда денормализованное число в формате ОТ или ДТ служит
операндом-источником и особый случай денормализованного опе-
ранда замаскирован, устройство FPU автоматически нормализует
число при преобразовании его в формат РТ.
В арифметике с плавающей точкой невозможно абсолютно
точно выполнить все операции с любыми операндами; неизбежна
аппроксимация или приближение, когда точный результат не'пред-
ставим как переменная с плавающей точкой. Чтобы обеспечить ма-
тематическую приемлемость приближений, требуются такие схемы,
удовлетворяющие стандартам точности, которые можно моделиро-
вать некоторыми неравенствами вместо равенств.
Рассмотрим типичный оператор присваивания
X <-- Y0Z (где € некоторая операция)
В режиме округления по умолчанию (округление к ближайшему)
каждая операция выполняется с абсолютной ошибкой, не превы-
шающей половины расстояния между двумя числами с плавающей
точкой, ближайшими к истинному результату. Пусть х есть
значение переменной с именем X, у — значение переменной К, a z
— переменной Z. Обычно у и z из-за накопленных ошибок от-
личаются от желаемых значений и того, что было бы получено при
отсутствии ошибки. При вычислении X мы полагаем, что у и z яв-
ляются наилучшими приближениями и пытаемся вычислить х мак-
симально точно. Если результат y@z представим точно, то мы ожи-
даем, что х = y@z и это есть то, что мы получаем для каждой алгеб-
раической операции в устройстве (например, когда y@z есть у + z,
У ~ Z, у х z, y/z, sqrt г). Но если значение y@z должно быть аппрок-
симировано, как это обычно бывает, то х должен отличаться от y@z
не более, чем половина расстояния между двумя представимыми
числами, которые окружают y@z. Расстояние зависит от двух фак-
торов:
.822
Микропроцессор i486 Книга 3 Устройство с плавающей точкой
1. Точности, с которой производится вычисление; она определя-
ется либо битами PC управления точностью в регистре управления
CW, либо используемым в памяти форматом. Напомнцм, что уст-
ройство FPU поддерживает одинарную (24 значащих бита), двой-
ную (53 значащих бита) и расширенную (64 значащих бита)
точность.
2. Насколько близок результат операции y@z к нулю. В этом от-
ношении наличие в устройстве FPU денормализованных чисел ока-
зывается существенным достоинством по сравнению с процессора-
ми, где их нет.
В любой системе чисел с плавающей точкой плотность предста-
вимых чисел больше вблизи нуля, чем вблизи наибольших предста-
вимых величин. Однако в компьютерах, где нет денормализованных
чисел, существует огромный (конечно, в масштабах минимальных
чисел) промежуток между нулем и ближайшими к нему соседями
(см. рис. 2 1).
0 + + + + + + + | +++++++|-+-+-+-+-+-+-+-|-------------------+-+-+
\К---------- Нормализованные числа --->
Денормализованные числа
О | + + + + + + + | - + - + - + - + - + - + - + - |-+-+-+
б) Н------ Нормализованные числа --->
Рис.2.1. Система вещественных чисел
а - с денормализованными числами,
б - без денормализованных чисел
Рис. 2.1(a) относится к системе чисел с плавающей точкой, в ко-
торой допускаются денормализованные числа. Для простоты пока-
заны ’ только положительные числа, имеющие всего четыре
значащих бита вместо 24, 53 или 64 значащих бит, имеющихся в ус-
тройстве FPU. Каждая вертикальная черточка означает число, пред-
ставимое в четырех значащих битах, а более длинные черточки по-
казывают степени 2. Горизонтальные черточки распределены рав-
номерно; те из них, которые не пересекают вертикальные черточки,
соответствуют числам, которые не представимы с принятой
точностью. Денормализованные числа находятся между нулем и
ближайшей степенью 2. Их плотность не меньше, чем остающихся
ненулевых чисел.
На рис. 2.1(6) показана система чисел с плавающей точкой, в
которой нет денормализованных чисел. Здесь имеются два больших
промежутка с положительной (он показан на рисунке) и отрица-
тельной (не показан) стороны от нуля. Промежуток между нулем и
Глава 2. Специальные вычислительные ситуации
ближайшим к нему соседом отличается от промежутка между сосе-
дом и ближайшим большим числом в 8 х 106 (формат ОТ),
4.5 х 1015 (формат ДТ) и 9.2 х 1018 (формат РТ) раз. Наличие таких
промежутков затрудняет анализ ошибок.
Преимущество наличия денормализованных чисел становится
очевидным, если рассмотреть, что происходит при замаскирован-
ном особом случае антипереполнения и попаданием результата
операции y@z в промежуток между нулем и наименьшим нормали-
зованным числом. Устройство FPU возвращает ближайшее денор-
мал изованное число, что можно назвать «постепенным или плав-
ным антипереполнением». Здесь ситуация не отличается от округ-
ления, производимого при попадании результата y@z в диапазон
нормализованных чисел.
С другой стороны, в системе без денормализованных чисел как
результат возвращается нуль, и это действие оказывается более не-
точным, чем округление. Устройство FPU процессора i486 и сопро-
цессор 80387 обрабатывают денормализованные значения не так,
как сопроцессоры 8087 и 80287 (подробнее см. разд. 2.2.4).
2.1.2. Нули
Значение нуль в вещественных и десятичном форматах является
знаковым, а двоичный целый нуль всегда положителен. В
вычислениях знак нуля не учитывается, и обычно программист мо-
жет не заботиться о существовании знакового нуля. При необходи-
мости о знаке нуля можно узнать с помощью команды FXAM ана-
лиза содержимого вершины стека.
Программист может кодировать нуль и он может быть образован
устройством FPU как маскированная реакция на особый случай ан-
типереполнения. Если нуль загружается в регистр или образуется в
регистре, регистр отмечается специальным тэгом нуля. В табли-
це 2.3 показаны результаты команд с нулевыми операндами и воз-
можности получения нуля при ненулевых операндах (здесь через X
и Yобозначены ненулевые положительные операнды).
Таблица 2.3. Нулевые операнды и результаты
Операцкя Операнды Результат
FLD,FBLD ±0 о (5)
FILD + 0 + 0
FST,FSTP,FRNDINT ±0 о (5)
+x + 0 (1)
-x -о (1)
FBSTP ±0 0 (5)
FIST,FISTP ±0 0 (5)
+x + 0 (3)
-x -0 (4)
184?
Микропроцессор i486 Книга 3 Устройство с плавающей точкой
Таблица 2.3. (Продолжение)
Операция Операнды Результат
FCHS + 0 -0
-0 + 0
FABS ±0 + 0
Сложение + 0 плюс +0 + 0
-0 плюс -0 -0
+ 0 плюс -0, -0 плюс +0 ±0 (2)
-x плюс +Х, +Х плюс -X ±0 (2)
+ 0 плюс ±Х, ±Х плюс ±0 X (6)
Вычитание + 0 минус -0 + 0
-0 минус +0 -0
+ 0 минус + 0, -0 минус -0 ±0 (2)
+x минус +Х, -X минус -X X (7)
±0 минус ±Х, ±Х минус ±0 X (6)
Умножение ±0 х ±0 0 (8)
±0 х ±Х, ±Х х ±0 0 (8)
+x х +Y, -X х -у + 0 (1)
+x х -У, -X х +у -о (1)
Деление ±0 / +0 Недействительная операция
±x / ±0 « (8)
±x / ±0 0 (8)
/ + 0 / +Х, -0 / НС + 0
+ 0 / нс, -о / +х -0
-x / -¥, +Х / + Y + 0 (1)
-X / +Y, +Х / -Y -0 (1)
FPREM,FPREM1 ±0 ост ±0 Недействительная операция
±x ост ±0 Недействительная операция
+ 0 ост ±Х + 0
-0 ост ±Х “0
+x ост ±У +0 (Y точно делит X)
-X ост ±У -0 (Y точно делит X)
FSQRT ±0 о (5)
Сравнение ±0 : +Х ±0 < +х
±0 : ±0 ±0 = ±0
±0 : -X ±0 > -X
FTST ±0 ±0 = 0
FXAM + 0 С3=1, С2=С1=С0=0
-0 СЗ=С1=1, С2=С0=0
FSCALE ' ±0 масшт. на -оо о (5)
±0 масшт. на +оо Недействительная операция
±0 масшт. на X 0 (5)
FXTRACT + 0 ST=+0, ST(l)=-oo
Деление на нуль
-0 ST=-0, ST(l)=-ro
Деление на нуль
FPTAN ±00 (5)
FSIN (или результат ±00 (5)
SIN в FSINCOS)
FCOS (или результат ±0 + 1
COS в FSINCOS)
FPATAN ±0 / +х 0 (5)
±0 / -х я (5)
±x / ±0 я/2 (6)
±0 / +0 0 (5)
±0 / -о я (5)
Г лава 2. Специальные вычислительные ситуации
Ц1“85?
Таблица 2.3. (Продолжение)
Операция Операнды Результат
+ оо / ±0 +л/2
-00 / ±0 -л/2
±0 / +оо 0 (5)
±0 / -оо л (5)
F2XM1 + 0 + 0
-0 -0
FYL2X ±Y х log(±0) Деление на нуль
±0 х log(±0) ч Недействительная операция
FYL2XP1 +Y х log(±0 + 1) 0 (5)
-Y x log(±0 + 1) Ч) (5)
Примечания:
1 — предельное антипереполнение денормализует операнд к нулю.
2 — знак определяется режимом округления (плюс для округления к бли-
жайшему, минус при округлении вниз).
3 — 0 < X < 1 и режим округления не вверх.
4-1 < X < 0 и режим округления не вниз.
5 — знак исходного нулевого операнда.
6 — знак исходного операнда X.
7 — дополнение знака исходного операнда X.
8 — исключающее ИЛИ знаков операндов.
2.13. Бесконечность
Вещественные форматы поддерживают знаковые представления
бесконечностей. Эти значения кодируются со смещенным поряд-
ком из всех единиц и мантиссой 1.00...00; если бесконечность нахо-
дится в регистре, он отмечается тэгом специального значения.
Программист может кодировать бесконечность или ее создает
устройство FPU в результате маскированной реакции на особые
случаи переполнения или деления на нуль. Отметим, что в зависи-
мости от режима округления маскированная реакция вместо беско-
нечности может вернуть наибольшее допустимое значение, пред-
ставимое в получателе.
Знаки бесконечностей учитываются и сравнения возможны.
Бесконечности всегда интерпретируются в аффинном смысле, т. е.
-оо < (любое конечное число) < +оо
Арифметика с бесконечностями не сигнализирует об особых
случаях, исключая операции, приведенные в таблице 2.4 {X
означает нулевой или ненулевой положительный операнд, a Y —
ненулевой положительный операнд).
Таблица 2.4. Бесконечные операнды и результаты
Операция Операнды Результат
FLD,FBLD ±ОО » (1)
FST,FSTP,FRNDINT ±ОО 00 (1)
18&;.:
Микропроцессор i486 Книга 3 Устройство с плавающей точкой
Таблица 2.4. (Продолжение)
Операция Операнды Результат
FCHS +оО —оо
—оо +оо
FABS ±оо +оо
Сложение +оо + +оо +оо
—оо + —оо —оо
+оо + —оо Недействительная операция
—оо + +оо Недействительная операция
±00 + ±х 00 (1)
±Х + ±оо 00 (1)
Вычитание +оо оо +оО
—оо — +оо —оо
+оо — +оо Недействительная операция
—оо — —оо Недействительная операция
±00 - ±Х 00 (1)
±Х — ±оо оо (2)
Умножение ±оо X ±оо оо (4)
±ОО х ±Y, ±Y X ±00 оо (4)
±0 х оо, ±оо х ±0 Недействительная операция
Деление ±оо / ±оо Недействительная операция
±00 / +Х оо (4)
±Х / ±» 0 (4)
±оо / ±0 00 (4)
FPREM,FPREM1 ±оо ОСТ. ±оо Недействительная операция
±оо ОСТ. ±Х Недействительная операция
±Х ОСТ. ±оо X (3), Q=0
FSQRT —оо Недействительная операция
+оо Недействительная операция
Сравнение +оо : +оо +оо = +оо
—оо : —оо —оо = —оо
+оо : —оо +оо > —оо
—оо : +оо —оо < +оо
+оо : ±Х +оо > X
-оо : ±Х -оо < X
±Х : +оо X < +оо
±Х : -оо X > -оо
FTST +оо +оо > 0
—оо -оо < 0
FXAM +оо С0=С2=1, С1=СЗ=0
—оо С0=С1=С2=1, СЗ=0
FSCALE ±оо масшт. на —оо Недействительная операция
±оо масшт. на +оо со (1)
±оо масшт. на ±Х 00 (1)
±0 масшт. на +оо ±0 (6)
±0 масшт. на -оо Недействительная операция
±Y масшт. на +оо 00 (5)
±Y масшт. на —оо 0 (5)
FXTRACT ±0О ST=oo (1),
ST(l)=+oo
FPATAN ±оо / ±х я/2 (1)
±Y / +оо 0 (5)
±Y / -оо я (5)
±оо / +оо я/4 (5)
±оо / —оо З‘я/4 (5)
Глава 2. Специальные вычислительные ситуации
Таблица 2.4. (Продолжение)
Операция Операнды Результат
±оо / ±0 л/2 (5)
+0 / +<х> +0
+0 / —оо +л
—0 / +оо -0
• —0 / —оо —л
F2XM1 +оо +оо
—ОО -1
FYL2X ±оо х 1од(1) Недействительная операция
±оо X 1од(Х>1) 00 (1)
±оо х 1од(0<Х<1) оо (2)
±Y х 1од(+оо) ОО (1)
±0 х 1од(+оо) Недействительная операция
±Y х 1од(—оо) Недействительная операция
FYL2XP1 ±оо х 1од(1) Недействительная операция
±оо х 1од(Х>0) оо (1)
±оо х 1од(— 1<Х<0) ОО (2)
±Y х 1од(+оо) «, (5)
±0 х 1од(+оо) Недействительная операция
±Y х 1од{— оо) Недействительная операция
Примечания:
1 — знак исходного бесконечного операнда.
2 — дополнение знака исходного бесконечного операнда.
3 — знак исходного операнда.
4 — исключающее ИЛИ знаков операндов.
5 — знак исходного операнда Y.
6 — знак исходного нулевого операнда.
2.1.4. Нечисла
Нечисла NaN являются представителем класса специальных
значений, существующих только в вещественных форматах. Они
имеют смещенный порядок из всех единиц, любой знак и любую
мантиссу за исключением 1.00...00 (такая мантисса отведена для
бесконечностей). Нечисло в регистре отмечается тэгом специально-
го значения.
Имеются два класса нечисел — сигнализирующие нечисла SNaN
(Signalling NaN) и «тихие» нечисла QNaN (Quiet NaN). Из тихих
нечисел особо интересна вещественная неопределенность.
СИГНАЛИЗИРУЮЩИЕ НЕЧИСЛА. Сигнализирующее
нечисло имеет нуль в старшем бите мантиссы, а остальные биты
мантиссы имеют любое значение. Устройство FPU никогда не
формирует сигнализирующее нечисло как результат, но распознает
сигнализирующие нечисла, когда они служат операндами. Арифме-
тические операции (определенные в начале этой главы) с сигнали-
зирующими нечислами вызывают особый случай недействительной
операции (за исключением операций загрузок из стека, а также ко-
манд FXCH, FCHS и FABS).
Микропроцессор i486 Книга 3 Устройство с плавающей точкой
Разрешая особый случай недействительной операции, програм-
мист может использовать сигнализирующие нечисла для вызова об-
работчика особого случая. Общность такого подхода и большое
число имеющихся значений нечисел предоставляют опытному про-
граммисту средство, помогающее в множестве специальных ситуа-
ций.
Например, компилятор может использовать сигнализирующие
нечисла как неинициализированные (вещественные) элементы мас-
сива. Компилятор может поместить в каждый элемент массива сиг-
нализирующее нечисло, мантисса которого содержит индекс
(относительную позицию) элемента. Если прикладная программа
пытается обратиться к элементу, который не был инициализирован,
она получит нечисло, помещенное туда компилятором. Если осо-
бый случай недействительной операции разрешен, возникает пре-
рывание и вызывается обработчик особого случая. Он может опре-
делить, к какому элементу производилось обращение, так как поле
адреса операнда указателей обработчика особого случая показывает
на нечисло, а нечисло содержит индекс элемента массива.
ТИХИЕ НЕЧИСЛА. Тихое нечисло имеет единицу в старшем
бите мантиссы. Устройство FPU формирует тихое нечисло, называ-
емое вещественной неопределенностью (см. далее), как реакцию по
умолчанию на некоторые особые условия. Устройство FPU может
образовать другие тихие нечисла, преобразуя сигнализирующие
нечисла. Для этого в старший бит мантиссы помещается 1, а ос-
тальные биты мантиссы не изменяются; следовательно, ди-
агностическая информация в мантиссе тихого нечисла сохраняется
и в сигнализирующем нечисле.
Устройство FPU формирует специальное тихое нечисло, называ-
емое вещественной неопределенностью, реагируя на замаскирован-
ный особый случай недействительной операции. Оно имеет отри-
цательный знак, а мантисса равна 1.100...00. Все остальные нечисла
создаются либо программистом, либо получаются из значений, оп-
ределенных программистом.
Тихие и сигнализирующие нечисла поддерживаются во всех
операциях. Тихое нечисло формируется как маскированная реакция
на особые случаи недействительной операции и как результат опе-
рации, в которой минимум один из операндов является тихим
нечислом. При формировании тихих нечисел действуют правила,
приведенные в таблице 2.5 (QNaN — тихое нечисло, SNaN — сиг-
нализирующее нечисло).
Отметим, что обработка операнда, являющего* я тихим
нечислом, имеет больший приоритет, чем все остальные особые
случаи, исключая некоторые особые случаи недействительной опе-
рации (см. далее раздел по приоритетам особых случаев).
Глава 2. Специальные вычислительные ситуации
Г 189'
Таблица 2.5. Правила формирования тихих нечисел
Операция Действа»
Вещественная операция над SNaN и QNaN Возвращается операнд QNaN
Вещественная операция над двумя SNaN Возвращается QNaN, полученное из из SNaN с большей мантиссой
Вещественная операция над двумя QNaN Возвращается QNaN с большей мантиссой
Вещественная операция над SNaN и другим числом Возвращается QNaN, полученное при преобразовании SNaN
Вещественная операция над QNaN и другим числом Возвращается QNaN
Недействительная операция без участия нечисел Возвращается QNaN — вещественная неопределенность
Тихие нечисла можно применять, например, для ускорения от-
ладки. На ранних этапах отладки в программе часто есть несколько
ошибок. Обработчик особого случая может при своем вызове со-
хранять в памяти диагностическую информацию. После этого он
подставляет тихое нечисло как результат ошибочной команды, ко-
торое показывает на соответствующую область памяти. Затем про-
грамма продолжается, создавая различные нечисла для каждой
ошибки. После окончания программы нечисла привлекаются для
обращения к диагностическим данным, сохраненным в памяти в
моменты возникновения ошибок. За один прогон можно обнару-
жить и исправить много ошибок.
Во встроенных системах, когда вычисленные результаты
участвуют в дальнейших расчетах, необнаруженные тихие нечисла
могут привести к недостоверности всех последующих результатов.
Следует периодически контролировать тихие нечисла предусматри-
вая механизм исправления ошибок, если эти нечисла появляются.
2.1.5. Неопределенность
В каждом численном типе данных одно уникальное кодирование
зарезервировано для представления специального значения неопре-
деленности. Устройство FPU формирует такое значение как реак-
цию на замаскированный особый случай недействительной опера-
ции. В вещественных форматах значение неопределенности есть
тихое нечисло (см. выше).
Команда FBSTP сохраняет уцакованную десятичную неопреде-
ленность; однако попытка указать ее в команде FBLD приведет к
неопределенному результату. Следовательно, такую неопределен-
ность нельзя загрузить из упакованного десятичного целого числа.
В двоичных целых числах одно и то же кодирование представля-
ет собой либо неопределенность, либо наибольшее отрицательное
число (~215, —231 или —263); Устройство FPU сохраняет такое
значение как реакцию на недействительную операцию или когда
[Ят Микропроцессор i486 Книга 3 Устройство с плавающей точкой
значение в регистре-источнике представляет или округляется к
наибольшему отрицательному целому числу, которое можно пред-
ставить в получателе. Когда появление неопределенности нео-
днозначно, для выяснения причины ее появления нужно проверить
флажок особого случая недействительной операции. Если такой
код загружается или участвует в арифметической операции или
сравнении, он всегда считается отрицательным числом.
2.1.6. Кодирование типов данных
В таблицах 2.6 — 2.9 дано кодирование специальных значений в
каждом из численных типов данных. Младшие биты показаны
справа и хранятся по меньшим адресам. Знаковый бит всегда
является левым битом байта с наибольшим адресом.
Таблица 2.6. Кодирование двоичных целых чисел
Класс Звак Велвчвва
4- (Наибольшее) 0 11. ...И
(Наименьшее) ’о’ оо: :::oi
Нуль 0 00. ...00
(Наименьшее) 1 11. ...11
(Наибольшее/неопределенность (* ) ’1" и. .*.’.’11
Слово: 15 бит
Короткое: 31 бит
Длинное: 63 бита
Примечание:
* Если это кодирование применяется как операнд-источник (например, в
целочисленной затрузке или арифметической операции), устройство FPU ин-
терпретирует его как наибольшее отрицательное число, представимое в фор-
мате (-215, -231, -263). Устройство FPU в двух ситуациях передает такое ко-
дирование в целочисленный получатель:
1. Если результат является наибольшим отрицательным числом.
2. Как реакцию на замаскированный особый случай недействительной
операции, и тогда оно представляет специальное значение целочисленной
неопределенности.
Таблица 2.7. Кодирование упакованных десятичных чисел
Класс Звак Велвчвва
Цифра Цифра Цифра Цифра .. Цифра
+ (Наибольшее) 0 . 0000000 1001 1001 1001 1001 .. . 1001
(Наименьшее) 6 0000000 0000 0000 0000 0000 .. . 0001
Нуль 0 0000000 0000 0000 0000 0000 .. . 0000
- Нуль 1 0000000 0000 0000 0000 0000 .. . 0000
(Наименьшее) 1 0000000 0000 0000 0000 0000 .. . 0001
(Наибольшее) i 0000000 1001 1001 1661 1001 .. . 1001
Неопределенность* 1 1111111 1111 ни ииии ииии ииии**
| - 1 байт -| --9 байт — |
Глава 2. Специальные вычислительные ситуации
Примечание:
* Команда FBSTP сохраняет упакованную десятичную неопределенность
в реакции на незамаскированный особый случай недействительной операции.
Попытка затрузки ее командой FBLD ведет к неопределенному результату.
* * UUUU означает, что биты могут содержать любое значение.
Таблица 2.8. Кодирование вещественных чисел в форматах ОТ и ДТ
Класс Звак СмещежввЛ порядок Мавтвсса ff-ff *
ПОЛОЖИТЕЛЬНЫЕ
Нечнсла
Тихие 0 и., ..11 11., ..11
11? ?11 10? ?оо
Сигнализирующие 0 и.. ..11 01., ..11
0 11? ?11 00? ?01
Бесконечность 0 11., ..11 00.. ..00
Веществеввые
Нормализованные 0 11.. ..10 и.. ..11
0 00? ?01 00? ?оо
Денормализованные 0 00.. ..00 11.. ..11
0 00? ?00 00? ?01
Нуль 0 00.. ..00 00.. ..00
ОТРИЦАТЕЛЬНЫЕ
Нуль 1 00.. ..00 00.. ..00
Вецествеввме
Денормализованные 1 00.. ,.00 00.. ..01
*1 00? ?00 11? ?и
Нормализованные 1 00.. ,.01 00.. .00
1 11? ?10 11? ?11
Бесконечность 1 11.. ,.11 00.. .00
Кечвсла
Сигнализирующие 1 11.. ,.11 00.. .01
1 . 11? ?11 01? .*11
Неопределенность 1 и.. ,.11 10.. .00
Тихие 1 и? ?11 11? .’11
Формат ОТ: I 8 бит I 123 бита!
Формат ДТ: [11 бит | |52 бита|
Примечание:
* Бит целой части подразумевается и не сохраняется.
Ц11ИИЦ1||||Ц
ЯНЬей Микропроцессор i486 Книга 3 Устройство с плавающей точкой
Таблица 2.9. Кодирование вещественных чисел в формате РТ
Класс Знак Смещенный порядок Мантисса l.ff-ff
ПОЛОЖИТЕЛЬНЫЕ
Нечисла
Тихие 0 11.. .и 1 11. ..11
11Й Л1 1 10.* :.оо
Сигнализирующие 0 11.. .11 1 01. ..и
0 11Й Л1 1 об: :.oi
Бесконечность 0 И.. .11 1 00. ..00
Вещественные
Нормализованные 0 11.. .10 1 11. ..п
0 оой :oi 1 об: :.оо
Денормализованные 0 00.. .00 0 и. ..п
0 ООЙ :оо 1 об: :.oi
Нуль 0 00.. .00 0 00. ..00
ОТРИЦАТЕЛЬНЫЕ
Нуль 1 00.. .00 0 00. ..00
Вещественные
Денормализованные 1 00.. .00 0 00. ..01
1 оо:: :оо 0 й: :.и
Нормализованные 1 00.. .01 1 00. ..00
1 и*.: до 1 й: *..11
Бесконечность 1 и.. .11 1 00. ..00
Нечисла
Сигнализирующие 1 и.. .11 1 00. ..01
1 и" Л1 1 ой .*.11
Неопределенность 1 и.. .11 1 10. ..00
Тихие 1 и" Л1 1 й: :.и
|15 бит | |64 бита]
2.L7. Неподдерживаемые форматы
Формат РТ имеет много двоичных наборов, которые не попада-
ют ни в один из ранее рассмотренных классов. Такие неподдержи-
ваемые форматы приведены в таблице 2.10. Некоторые из них под-
держивает математический сопроцессор 80287, но большинство из
них сопроцессор 80387 и устройство FPU процессора 1487 не под-
держивают. Эти изменения потребовались из-за корректировки
Глава 2. Специальные вычислительные ситуации L
7 Заказ 4317
окончательного варианта стандарта IEEE-854, в котором эти типы
данных отсутствуют.
Существовавшие ранее псевдонечисла, псевдобесконечности и
ненормализованные числа теперь не поддерживаются. Когда они
встречаются как операнды, устройство FPU генерирует особый
случай недействительной операции. Устройство FPU не образует
значений, которые ранее назывались псевдоденормализованными
числами; однако как операнды они обрабатываются правильно.
Порядок считается равным 00...01, а мантисса не изменяется.
Формируется особый случай денормализованного операнда.
Таблица 2.10. Неподдерживаемые форматы
Класс Знак Смещенный порядок Мантисса f.ff-ff
ПОЛОЖИТЕЛЬНЫЕ
ПсевдоЫаЫ
Тихие 0 11.. .11 0 11.. .11
11/ ’11 0 16/ .00
Сигнализирующие 0 11.. .11 0 01.. .11
0 и/ Л1 0 об/ .01
Псевдобесконечность 0 п.. .11 0 00.. .00
Вещественные
Ненормализованные 0 и.. .10 0 11.. .11
0 оо/* ^(Н 0 об/ .00
Псевдоденормализованные 0 00.. .00 1 11.. .11
0 оо/ .00 1 об.*.* .00
ОТРИЦАТЕЛЬНЫЕ
Вещественные
Псевдоденормализованные 1 00.. .00 1 11.. .11
1 оо/. *00 1 об/ .00
Ненормализованные 1 11.. .10 0 11.. .11
1 оо/ *.01 0 об/ .00
Псевдобесконечность 1 11.. .11 0 00.. .00
ПсевдоВаМ
Сигнализирующие 1 11.. .11 0 01.. .11
1 11/ ’.11 0 об/. .01
Тихие 1 11.. .11 0 11.. .11
1 11/ Л1 0 16/. .00
|15 бит | |64 бита|
>194*
Микропроцессор i486 Книга 3 Устройство с плавающей точкой
2.2. Численные особые случаи
При выполнении численных команд устройство FPU распознает
шесть классов численных особых случаев:
I — недействительная операция (нарушение стека;
недействительная команда стандарта IEEE-854);
Z — деление на нуль;
D — денормализованный операнд;
О — численное переполнение;
U — численное антипереполнение;
Р — неточный результат (точность).
2.2.1. Обработка численных особых случаев
Когда возникает численный особый случай, устройство FPU
предпринимает одно из двух возможных действий:
— устройство FPU само формирует наиболее приемлемый ре-
зультат операции и выполнение программы продолжается;
— для обработки особого случая вызывается программа-обра-
ботчик.
Каждому из шести особых случаев соответствует бит флажка в
слове состояния SW и бит маски в слове управления CW. Если осо-
бый случай замаскирован (соответствующий бит маски в слове уп-
равления содержит 1), устройство FPU предпринимает действие по
умолчанию и продолжает вычисления. Если же особый случай не
замаскирован (маска содержит 0), перед выполнением следующей
команды WAIT или команды с плавающей точкой, не относящейся
к управлению, вызывается программный обработчик особого
случая. В зависимости от состояния бита NE в регистре управления
CR0 целочисленного устройства обработчик вызывается либо через
вектор прерывания 16 (NE = 1), либо через внешнее прерывание
(NE = 0).
Отметим, что при маскировании особых случаев устройство FPU
может обнаружить несколько особых случаев в одной команде, так
как оно продолжает выполнение команды после своей маскирован-
ной реакции. Например, устройство FPU может обнаружить денор-
мализованный операнд, выполнить маскированную реакцию на
этот особый случай, а затем обнаружить антипереполнение.
АВТОМАТИЧЕСКАЯ ОБРАБОТКА ОСОБЫХ СЛУЧАЕВ. Для
каждого встреченного особого случая устройство FPU предприни-
мает корректирующие действия. Такие маскированные реакции бе-
зопасны и приемлемы для большинства численных приложений.
Как пример автоматической обработки особый случаев рассмот-
рим вычисление сопротивления трех параллельно включенных ре-
зисторов по стандартной формуле
Глава 2. Специальные вычислительные ситуации
195
1
R =----------------
1/R1 + 1/R2 + 1/R3
Если R1 становится равным 0, сопротивление цепи будет равно
0. При маскировании особых случаев деления на нуль и точности
устройство FPU сформирует правильный результат.
Управляя масками особых случаев в слове управления CW, про-
граммист может возложить ответственность за большинство особых
случаев на устройство FPU, резервируя для программной обработки
наиболее серьезные ситуации. Разрабатывать обработчики особых
случаев довольно сложно, а маскированные реакции рассчитаны на
получение приемлемого результата для каждой встречающейся на
практике ситуации. Для большинства приложений маскирование
всех особых случаев обеспечивает удовлетворительные результаты с
минимумом усилий со стороны программиста. Некоторые особые
случаи при отладке программы следует оставить незамаскирован-
ными, а при выполнении отлаженной программы замаскировать.
Например, особый случай недействительной операции обычно сви-
детельствует об ошибке в программе, которую необходимо исправ-
лять.
Флажки особых случаев в слове состояния SW «накапливают»
особые случаи, возникшие после их последнего сброса. Установ-
ленный флажок можно сбросить только командой FCLEX, инициа-
лизацией устройства FPU или перезаписью флажков с помощью
команд FRSTOR возвращения полного состояния и FLDENV заг-
рузки среды. Это позволяет программисту замаскировать все осо-
бые случаи, выполнить программу, а затем по слову состояния про-
верить возникшие особые случаи.
ПРОГРАММНАЯ ОБРАБОТКА ОСОБЫХ СЛУЧАЕВ. Если ус-
тройство FPU встречает незамаскированный особый случай, перед
выполнением следующей команды WAIT или команды с плаваю-
щей точкой, не связанной с управлением, вызывается обработчик
особого случая. Вызов производится через вектор прерывания 16
или внешнее прерывание в зависимости от состояния бита NE в
регистре управления CR0 целочисленного устройства.
Если бит NE = 1, незамаскированный особый случай с плаваю-
щей точкой генерирует прерывание 16 перед выполнением следую-
щей команды WAIT или команды с плавающей точкой, не связан-
ной с управлением. Прерывание 16 предназначено для вызова опе-
рационной системы, которая переходит к обработчику особого
случая.
Если NE = 0 (и входной сигнал IGNNE# пассивен), незамаски-
рованный особый случай вызывает «замораживание» процессора
перед выполнением следующей команды WAIT или команды с пла-
ЮЖ Микропроцессор i486 Книга 3 Устройство с плавающей точкой
вающей точкой, не связанной с управлением. Процессор ожидает
внешнего прерывания, которое должна сформировать внешняя схе-
ма в ответ на выходной сигнал FERR# ошибки с плавающей
точкой. (На выходе FERR# появляется активный сигнал независи-
мо от состояния бита NE.) Внешнее прерывание вызывает проце-
дуру обработки особого случая. Если бит NE = 0 и вход IGNNE#
активен, процессор игнорирует особый случай и продолжает опера-
ции. Сообщение об ошибке через внешнее прерывание предусмот-
рено ради совместимости с операционной системой DOS.
Процедура обработки особого случая обычно является частью
системного программного обеспечения. Типичная реакция на осо-
бый случай может состоять из следующих действий:
— инкремент счетчика особых случаев для последующей инди-
кации или печати;
— печать или вывод на экран диагностической информации
(например, среды устройства FPU и регистров);
— прекращение дальнейшего выполнения программы или ис-
пользование указателей особого случая дая построения команды,
которая не будет вызывать особого случая, и ее выполнение.
Прикладные программисты должны познакомиться с реакциями
операционной системы на численные особые случаи по
руководствам на операционную систему.
2.2.2. Недействительная операция
Этот особый случай возникает в стековых операциях, а также в
арифметических операциях. Флажок стека SF в слове состояния
SW показывает, операция какого класса вызвала особый случай.
Когда SF = 1, в стековой операции возникло переполнение или ан-
типереполнение стека, а при SF = 0 в арифметической операции
встретился неверный операнд.
ОСОБЫЙ СЛУЧАИ СТЕКА. Когда SF = 1, показывая стековую
операцию, бит O/U# в коде условия (бит С1) позволяет различить
переполнение и антипереполнение стека:
O/U# = 1 — переполнение стека, т. е. команда пытается произ-
вести включение в непустую ячейку стека;
O/U# = 0 — антипереполнение стека, т. е. команда пытается из-
влечь из пустой ячейки стека.
Когда особый случай недействительной операции замаскирован,
устройство FPU возвращает неопределенность (тихое нечисло). Это
значение перезаписывает регистр-получатель, разрушая его перво-
начальное содержимое. Если же особый случай недействительной
операции не замаскирован, вызывается обработчик особого случая.
Глава 2. Специальные вычислительные ситуации
Вершина стека ТОР не изменяется и исходные операнды сохраня-
ются.
НЕВЕРНАЯ АРИФМЕТИЧЕСКАЯ ОПЕРАЦИЯ. В этот класс
включены неверные операции, определенные в стандарте IEEE-854.
Устройство FPU сообщает о неверной операции в ситуациях, пока-
занных в таблице 2.11. Здесь же показаны реакции устройства FPU,
когда особый случай замаскирован. При незамаскированном осо-
бом случае вызывается обработчик и операнды остаются неизмен-
ными. В общем, регистрация недействительной операции свиде-
тельствует об ошибке в программе.
Таблица 2.11. Маскированные реакции на неверные операции
Условие Маскированная реакция *
Любая арифметическая операция с неподдерживаемым форматом Возвращает неопределенность
Любая арифметическая операция с сигнализирующим нечислом Возвращает тихое нечисло
Операции сравнения и проверки: один или оба операнда нечисла Устанавливает условие "несравнимы"
Сложение бесконечностей с разными знаками или вычитание бесконечностей с одинаковыми знаками Возвращает неопределенность
Умножение бесконечности на 0 или 0 на бесконечность Возвращает неопределенность
Деление бесконечности на бесконечность или 0 на 0 Возвращает неопределенность
Команды FPREM или FPREM1, когда делитель 0 или делимое бесконечность Возвращает неопределенность, устанавливает в 1 бит С2
Команды FCOS, FPTAN, FSIN, FSINCOS, когда аргументом является бесконечность Возвращает неопределенность, устанавливает в 1 бит С2
FSQRT с отр. операндом (кроме FSQRT (-0) = -0), FYL2X с отр. операндом (кроме FYL2X (-0) равно бесконечности), FYL2XP1 с операндом более отрицательным, чем -1 Возвращает неопределенность
Команды FIST(P), когда регистр- источник пустой, содержит нечисло, бесконечность или превышает диапазон получателя Сохраняет целочисленную неопределенность
Команда FBSTP, когда регистр- источник пустой, содержит нечисло, бесконечность или превышает 18 десятичных разрядов Сохраняет упакованную десятичную неопределенность
Команда FXCH, когда один или оба регистра отмечены пустыми Превращает пустые регистры в неопределенность и затем выполняет обмен
Д98^
Микропроцессор i486 Книга 3 Устройство с плавающей точкой
2.2.3. Деление на нуль
Если команда пытается делить конечный ненулевой операнд на
нуль, устройство FPU сообщает об особом случае деления на нуль.
Он возникает в командах F(I)DIV(R)(P), а также в командах FYL2X
и FXTRACT, производящих деление. Маскированная реакция для
команд FDIV и FYL2X возвращает знаковую бесконечность, знак
которой равен исключающему ИЛИ знаков операндов. В команде
FXTRACT регистр ST(1) устанавливается на минус бесконечность, а
ST(0) на нуль со знаком исходного операнда. Если особый случай
деления на нуль замаскирован, вызывается обработчик особого
случая и операнды остаются неизменными.
2.2.4. Денормализованный операнд
Если арифметическая команда пытается оперировать денорма-
лизованным операндом, устройство FPU сообщает об особом
случае денормализованного операнда. Денормализованные операн-
ды могут ухудшить значимость из-за потери младших бит, поэтому
в некоторых приложениях следует избегать операций с такими опе-
рандами. Это можно обеспечить с помощью обработчика особого
случая, который реагирует на незамаскированные особые случаи
денормализованного операнда. Большинство пользователей маски-
руют этот особый случай, поэтому вычисления продолжаются; ана-
лиз потери точности производится при получении окончательного
результата.
Когда этот особый случай замаскирован, устройство FPU уста-
навливает бит DE в слове состояния SW и продолжает операцию.
При обработке постепенного атипереполнения и денормализован-
ных чисел устройство FPU дает результаты не хуже, а часто лучше,
чем компьютеры, возвращающие при атипереполнении нуль. Фак-
тически денормализованный операнд в форматах ОТ или ДТ при
загрузке нормализуется в формате РТ. Дополнительная точность
внутреннего формата РТ благоприятно сказывается на последую-
щих операциях.
Если же особый случай денормализованного операнда не замас-
кирован, устанавливается бит DE в слове состояния SW и вызыва-
ется обработчик особого случая. Команда не изменяет операнды и
они доступны обработчику для анализа.
Устройство FPU процессора i486 и сопроцессор 80387 обрабаты-
вают денормализованные значения не так, как сопроцессоры 8087 и
80287. Это отличие вызвано пересмотром стандарта IEEE-754 после
их появления. Различие проявляется, когда особый случай денор-
мализованного операнда замаскирован. Устройство FPU и сопро-
цессор 80387 автоматически нормализуют денормализованные
Глава 2. Специальные вычислительные ситуации
;199
числа, а сопроцессоры 8087 и 80287 формируют денормализован-
ный результат.
Различие в обработке денормализованных чисел серьезных труд-
ностей не вызывают. Обычно в процессоре i486 и сопроцессоре
80387 особый случай денормализованного операнда маскируется. В
программах, которые предназначены также дая сопроцессора 80287,
этот особый случай часто не маскируется и предусматривается об-
работчик, который нормализует все денормализованные значения.
Такой обработчик для устройства FPU и сопроцессора 80387 не ну-
жен.
Программа может определить, выполняется она в устройстве
FPU и сопроцессоре 80387 или на старых сопроцессорах
8087/80287. Для распознавания сопроцессоров 8087/80287 рекоме-
ндуется приведенный ниже ассемблерный фрагмент. Его можно
применить дая селективного маскирования особого случая денор-
мализованного операнда дая устройства FPU и сопроцессора 80387.
Для поддержки сопроцессоров 8087/ 80287 потребуется обработчик
особого случая. Показанный фрагмент можно использовать также
дая установки флажка, разрешающего применять новые команды
устройства FPU и сопроцессора 80387.
finit ;Режим бесконечности по умолчанию: ; проективный для 8087/80287, ; аффинный для 80387 и i486
fldl fldz fdiv fid fchs fcompp fstsw mov sahf jz ;Образовать бесконечность st ;Образовать отрицательную бесконечность ;Сравнить -бесконечность и +беоконечность temp Сопроцессоры 8087/80287 покажут равенство ах,temp Using_8087
2.2.5. Численные переполнение и антипереполнение
Если порядок численного результата слишком велик дая веще-
ственного формата получателя, устройство FPU сигнализирует о
численном переполнении, а если порядок результата слишком мал
дая представления в формате получателя, сообщается о численном
антипереполнении. В любом из этих особых случаев результат опе-
рации находится вне диапазона вещественного формата получателя.
Типичные алгоритмы формируют очень большие и очень малые
числа при вычислении промежуточных, а не окончательных резуль-
татов. Из-за огромного диапазона внутреннего формата РТ в про-
граммах дая процессора i486 переполнения и атипереполнения воз-
никают очень редко.
?20б
Микропроцессор I486 Книга 3 Устройство с плавающей точкой
ПЕРЕПОЛНЕНИЕ. Особый случай переполнения может возни-
кать, когда округленный истинный результат превышает наиболь-
шее конечное число в формате получателя. Этот особый случай
может возникнуть в большинстве арифметических команд и ко-
манд, связанных с преобразованием формата: FST(P), F(I)ADD(P),
F(I)SUB (R)(P), F(I)MUL(P), FDIV(R)(P), FSCALE, FYL2X и
FYL2XP1.
Реакция на возникновение переполнения зависит от того, за-
маскирован особый случай переполнения или нет. Если особый
случай переполнения замаскирован, возвращаемое значение зави-
сит от режима округления (см. табл. 2.12). Когда же особый случай
переполнения не замаскирован, реакция зависит от того, сохраняет
команда результат в стеке или в памяти.
— Если получателем является стек, то истинный результат де-
лится на 224576 и округляется. (Смещение 24576 равно Зх213.) Ман-
тисса округляется до соответствующей точности (определяемой по-
лем PC слова управления, если оно управляет командой, или до
расширенной точности). Бит округления вверх (С1) в слове состоя-
ния устанавливается, если мантисса округляется вверх.
Смещение порядка на 24576 обычно приводит число в середину
диапазона порядка, поэтому его можно использовать в последую-
щих операциях масштабирования с меньшим риском вызова даль-
нейших особых случаев. Однако с командой FSCALE может
случиться так, что результат оказывается слишком большим и вы-
зывает переполнение даже после смещения. Здесь немаскированная
реакция совпадает с маскированной реакцией для округления к
ближайшему, т. е. ±оо. Рассмотренный прием введен для того,
чтобы обработчик ловушки обнаружил, что уменьшение порядка на
—24576 не действует.
— Если получателем является память (только в командах сохра-
нения), то результат в памяти не сохраняется. Вместо этого операнд
остается в стеке неизменным. Так как данные в стеке имеют фор-
мат РТ, обработчик особого случая может либо повторно выпол-
нить команду после коррекции операнда, либо округлить мантиссу
в стеке до точности получателя, как требует стандарт. Если про-
грамма должна продолжаться, обработчик должен сразу же сохра-
нить значение в ячейке памяти получателя.
АНТИПЕРЕПОЛНЕНИЕ. Антипереполнение может возникнуть
при выполнении команд FST(P), FADD(P), FSUB(R)(P), FMUL(P),
F(I)DIV(R)(P), FSCALE, FPREM(l), FPTAN, FSIN, FCOS,
FSINCOS, FPATAN, F2XM1, FYL2X и FYL2XP1.
Глава 2. Специальные вычислительные ситуации BBBJ
Таблица 2.12. Результаты маскированного переполнения
Режим округления Знак истинного результата Результат
К ближайшему + +оо —ОО
К —оо + Наибольшее конечное положит, число —00
К +оо + +оО Наибольшее конечное отрицат. число
К нулю + Наибольшее конечное положит, число Наибольшее конечное отрицат. число
К антипереполнению приводят два взаимосвязанных события:
— получение столь малого результата, который позднее может
вызвать некоторый другой особый случай (например, переполнение
при делении);
— получение неточного результата, т.е. полученный результат
отличается от того, который получается при неограниченных диа-
пазонах порядка и точности.
Какое из этих событий регистрирует особый случай антипере-
полнения, зависит от маскирования этого особого случая:
— особый случай антипереполнения замаскирован; об особом
случае антипереполнения сообщается, когда результат оказывается
tiny («крошечным») и неточным;
— особый случай антипереполнения не замаскирован; об осо-
бом случае антипереполнения сообщается при получении результа-
та tiny независимо от его неточности.
Реакция на антипереполнение также зависит от маскирования.
1. Маскированная реакция» Результат превращается в денорма-
лизованное число или нуль. Регистрируется также особый случай
точности.
2. Немаскированная реакция. В такой ситуации реакция зависит
от того, сохраняет команда результат в стеке или в памяти.
— Если получателем является стек, то истинный результат ум-
ножается на 224576 и округляется. (Смещение 24576 равно Зх213.)
Мантисса округляется до соответствующей точности (определяемой
полем PC управления точностью в слове управления CW, если это
поле действует на команду или до расширенной точности). Бит ок-
ругления вверх (С1) в слове состояния устанавливается, если ман-
тисса округляется вверх.
:202
Микропроцессор I486 Книга 3 Устройство с плавающей точкой
Смещение порядка на 24576 обычно приводит число в середину
диапазона порядка, поэтому его можно использовать в последую-
щих операциях масштабирования с меньшим риском вызова даль-
нейших особых случаев. Однако с командой FSCALE может
случиться так, что результат оказывается слишком большим и вы-
зывает переполнение даже после смещения. Здесь немаскированная
реакция совпадает с маскированной реакцией для округления к
ближайшему, т.е. ±оо. Рассмотренный прием введен для того, чтобы
обработчик ловушки обнаружил, что уменьшение порядка на —24576
не действует.
— Если получателем является память (только в командах сохра-
нения), то результат в памяти не сохраняется. Вместо этого операнд
остается в стеке неизменным. Так как данные в стеке имеют фор-
мат РТ, обработчик особого случая может либо повторно выпол-
нить команду после коррекции операнда, либо округлить мантиссу
в стеке до точности получателя, как требует стандарт. Если про-
грамма должна продолжаться, обработчик должен сразу же сохра-
нить значение в ячейке памяти получателя.
2.2.6. Неточный результат (точность)
Особый случай точности возникает, когда результат операции
неточно представим в формате получателя. Например, дробь 1/3
невозможно точно представить в двоичной форме. Рассматривае-
мый особый случай возникает довольно часто и показывает, что
произошла некоторая (обычно приемлемая) потеря точности.
Обычно он возникает в трансцендентных командах, что объясняет-
ся их природой.
Бит С1 (округление вверх) показывает, округлялся ли неточный
результат вверх (Cl = 1) или усекался (С1 = 0).
Особый случай точности сопровождает особый случай атипере-
полнения, когда происходит также потеря значимости. Если анти-
переполнение замаскировано, об особом случае антипереполнения
сообщается только при наличии потери точности; поэтому флажок
точности всегда установлен. Когда антипереполнение не замаски-
ровано, потери точности может быть или не быть; о конкретной
ситуации сообщает бит точности.
Этот особый случай предусмотрен дня приложений,
рассчитанных только на точную арифметику. В большинстве про-
грамм он маскируется. Устройство FPU помещает в получатель ок-
ругленный результат или результат с переполнением или антипере-
полнением независимо от возникновения ловушки.
Глава 2. Специальные вычислительные ситуации
-203 >
2.2.7. Приоритет особых случаев
Процессор i486 обрабатывает особые случаи в соответствии с ус-
тановленным старшинством. Старшинство означает, что отмечается
особый случай с высоким приоритетом и результат формируется в
соответствии с требованиями этого особого случая. Особые случаи
с низким приоритетом не отмечаются даже при их появлении. На-
пример, деление сигнализирующего нечисла на нуль вызывает осо-
бый случай недействительной операции (из-за нечисла), а не деле-
ния на нуль; маскированным результатом будет вещественная нео-
пределенность, а не бесконечность. Однако особые случаи денор-
мализованного операнда и точности могут сопровождать особые
случаи численного переполнения или антипереполнения.
Принято следующее старшинство численных особых случаев:
1. Особый случай недействительной операции, подразделяемый
на:
— антипереполнение стека;
— переполнение стека;
— операнд в неподдерживаемом формате;
— операнд является сигнализирующим нечислом.
2. Операнд является тихим нечислом. Несмотря на то, что один
операнд, являющийся тихим нечислом, не считается особым
случаем, обработка его имеет старшинство над особыми случаями с
меньшими приоритетами. Например, деление тихого нечисла на
нуль вызывает особый случай тихого нечисла, а не деления на нуль.
3. Любой другой, не упомянутый выше, особый случай недей-
ствительной операции или деление на нуль.
4. Денормализованный операнд. Если этот особый случай замас-
кирован, выполнение команды продолжается и может возникнуть
особый случай с меньшим приоритетом.
5. Численные переполнение и антипереполнение. Может от-
мечаться также неточный результат.
6. Неточный результат (точность).
Когда особые случаи переполнения или антипереполнения за-
маскированы, никаких дополнительных программ не требуется для
того, чтобы результаты процессора i486 удовлетворяли требованиям
стандарта IEEE-854. Когда же эти особые случаи не замаскированы,
они предоставляют обработчику возможность предпринять другие
действия в командах сохранения. Результат в память не передается,
а остается в стеке неизменным. Обработчик может округлить ман-
тиссу операнда в стеке до точности получателя, как этого требует
стандарт, или скорректировать операнд и повторно выполнить ко-
манду.
Микропроцессор i486 Книга 3 Устройство с плавающей точкой
Вопросы
системной организации
и совместимости
В системном программировании требуется более детальное по-
нимание устройства FPU, чем в прикладном программировании. На
системного программиста возлагается решение таких вопросов, как
инициализация, обработка особых случаев, синхронизация по дан-
ным и командам. Именно эти вопросы рассматриваются в настоя-
щей главе. В нее же включен материал по совместимости устрой-
ства FPU с предыдущими математическими сопроцессорами фирмы
Intel.
ЗЛ. Особенности архитектуры
На программном уровне устройство FPU служит расширением
целочисленного устройства процессора i486 в части регистров и си-
стемы команд. Однако на аппаратном уровне имеются более слож-
ные механизмы взаимодействия этих устройств. Далее рассматрива-
ется это взаимодействие и показаны особенности, представляющие
интерес для системных программистов.
В отличие от сопроцессора 80287 (но как и сопроцессор 80387)
устройство FPU процессора i486 действует одинаково, независимо
от работы процессора в R-, Р- или V-режиме.
Численные команды могут обращаться к любой ячейке памяти,
доступной текущей задаче. При работе в P-режиме все обращения к
операндам в памяти автоматически контролируются механизмами
управления памятью и защиты, как и все другие обращения к памя-
ти текущей задачи. Нарушения защиты, ассоциированные с
Глава 3. Вопросы системной организации и совместимости
численными командами, заставляют процессор автоматически пе-
рейти к соответствующему обработчику особого случая.
Для программиста рабочий режим влияет только на способ
представления в памяти указателей команды и данных устройства
FPU при выполнении команд FSAVE и FSTENV. Каждая из этих
команд формирует один из четырех форматов в зависимости от ра-
бочего режима и атрибута размера операнда (см. гл. 1).
3.2. Инициализация
Одной из главных задач системного программного обеспечения
является инициализация, контроль и управление аппаратными и
программными ресурсами системы, включая и устройство FPU. В
этом разделе обсуждаются вопросы инициализации и управления,
включая обработку особых случаев, возникающих при выполнении
численных команд.
При инициализации системы с процессором i486 системные
программы должны инициализировать устройство FPU и устано-
вить флажки в регистре CR0, показывающие состояние численной
среды. Эти действия легко и просто осуществляются как часть об-
щей инициализации системы.
Системные программы должны загрузить соответствующие
значения в биты МР, ЕМ и NE регистра управления CR0.
Бит МР (контроль сопроцессора) определяет, будут ли перехва-
тываться команды WAIT, когда контекст устройства FPU от-
личается от контекста текущей задачи. Если МР = 1 и TS = 1, то
команда WAIT вызывает нарушение недоступности устройства
(вектор 7). Бит МР применялся в микропроцессорах 80286 и 80386,
чтобы поддержать использование команды WAIT для ожидания ус-
тройства, отличающегося от численного сопроцессора. Устройство
должно сообщать о своем состоянии сигналом BUSY#. Так
процессор i486 не имеет такого входа, бит МР стал ненужным и д ля
правильной работы должен находиться с состоянии 1.
Бит ЕМ (эмуляция сопроцессора) определяет, выполняются ли
команды ESC устройством FPU или вызывают прерывание с векто-
ром 7 для программной обработки (ЕМ =1). Бит ЕМ применяется
в процессоре 80386 для того, чтобы численные программы для сис-
тем с процессорами 80386/80387 можно было выполнять при отсут-
ствии сопроцессора 80387 с помощью программы-эмулятора. При
обычной работе процессора i486 бит ЕМ должен находиться в со-
стоянии 0.
Бит NE (численный особый случай) определяет, обрабатываются
ли незамаскированные особые случаи с плавающей точкой через
вектор прерывания 16 (NE = 1) или через внешнее прерывание
(NE = 0). С системах, использующих для вызова обработчика
mr Микропроцессор i486 Книга 3. Устройство с плавающей точкой
численного особого случая внешний контроллер прерываний, бит
NE должен находиться в состоянии 0. В других системах с автома-
тическим вызовом обработчика через прерывание 16 бит NE следу-
ет установить в 1.
Инициализация устройства FPU означает перевод его в извест-
ное состояние, не зависящее от любых предшествующих действий.
Всю инициализацию производит одна команда FINIT. Маски всех
ошибок устанавливаются в 1, все регистры отмечаются пустыми, в
поле ТОР загружается 000В и задаются режимы управления округ-
лением и точностью. Состояние устройства FPU после команды
FINIT/FNINIT приведено в таблице 3.1.
Таблица 3.1. Состояние устройства FPU после инициализации
Поле Зжаченяе Интерпретация
Слово управления 037FH
(Управление 0 Аффинная
бесконечностью) ♦
Управление округлением 00 Округление к ближайшему
Управление точностью 11 64 бита
Маски особых случаев 111111 Все замаскированы
Слово состояния ООООН
(Занятость) 0
Код условия 0000
Вершина стека 000 Вершиной стека является регистр 0
Суммарный особый случай 0 Нет особых случаев
Флажок стека 0
Флажки особых случаев 00000 Нет особых случаев
Слово тэгов FFFFH
Тэги 11 Пустой
Регистры Не изменяются
Указатели особого случая
Код команды Сброшен
Адрес команды Сброшен
Адрес операнда Сброшен
Примечание:
* Процессор i486 не имеет управления бесконечностью. Программы для
сопроцессора 80287 могут вести себя в процессоре i486 по-другому, если они
зависят от этого бита.
Команда FNINIT переводит устройство FPU в такое же состоя-
ние, что и аппаратный сигнал RESET с запросом встроенного са-
моконтроля. Когда же встроенный самоконтроль не запрошен, ап-
паратный сигнал RESET сохраняет состояние устройства FPU не-
изменным. После сброса необходимо выполнить команду FNINIT.
Глава 3. Вопросы системной организации и совместимости
1^207
3.3. Эмуляция
Установка бита ЕМ в 1 заставляет процессор при встрече коман-
ды ESC вызывать программный обработчик особого случая через
вектор 7 (устройство недоступно). Бит ЕМ применялся для выпол-
нения численных программ на процессоре 80386 с программным
эмулятором сопроцессора 80387. Численные программы,
рассчитанные на нестандартный эмулятор 80387, могут не выпол-
няться в процессоре i486 без эмулятора. Установка бита ЕМ в 1 по-
зволяет выполнять на процессоре такие программы или программы,
в которых применяется нестандартная арифметика с плавающей
точкой.
3.4. Обработка численных особых случаев
После инициализации устройства FPU и начала выполнения
программы оно может иногда сообщать о численных особых
случаях. В данном разделе речь идет об особенностях обработчиков
особых случаев (сами численные особенные случаи подробно рас-
смотрены в гл. 2 ).
Если устройство FPU обнаруживает условие незамаскированно-
го особого случая, то перед следующей командой WAIT или коман-
ды с плавающей точкой, не связанной с управлением, вызывается
обработчик особого случая. Вызов производится через вектор пре-
рывания 16 или внешнее прерывание в зависимости от состояния
бита NE.
Если NE = 1, незамаскированный особый случай с плавающей
точкой формирует прерывание 16 перед командой WAIT или другой
командой с плавающей точкой, не связанной с управлением. Пре-
рывание 16 служит вызовом операционной системы, которая пере-
дает управление обработчику особого случая.
Если NE = 0 (и вход IGNNE# пассивный), незамаскированный
особый случай вызывает «замораживание» процессора перед вы-
полнением следующей команды WATT или команды с плавающей
точкой, не связанной с управлением. Процессор ожидает внешнего
прерывания, которое должна сформировать внешняя схема в ответ
на выходной сигнал FERR#. (Независимо от состояния бита NE
при возникновении незамаскированного численного особого случая
на выходе FERR# появляется активный сигнал.) Внешнее прерыва-
ние вызывает процедуру обработки особого случая. Если бит
NE = 0 и вход IGNNE# активен, процессор игнорирует особый
случай и продолжает операции. Сообщение об ошибке через внеш-
v20
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
нее прерывание предусмотрено ради совхместимости с операцион-
ной системой DOS.
Конечно, при обработке численных ошибок процессор не дол-
жен искажать численный контекст, а в ходе дальнейших действий
он должен сбросить ошибку и попытаться исправить ее. Способ ре-
ализации этих действий программистами зависит от конкретной
реализации; однако в большинстве обработчиков особых случаев
предусматриваются такие основные действия:
— сохранить среду устройства FPU (слова управления, состоя-
ния и тэгов, указатели команды и операнда);
— сбросить биты особых случаев в слове состояния SW;
— разрешить прерывания;
— идентифицировать особый случай, анализируя слова управ-
ления и состояния в сохраненной среде;
— предпринять системно-зависимое действие по исправлению
обнаруженного особого случая;
— осуществить возврат в прерванную программу и возобновить
обычные операции.
В тех ситуациях, когда возникает несколько особых случаев, ус-
тройство FPU сообщает об одном из них в соответствии со стар-
шинством, указанном в гл. 1. Например, при делении тихого
нечисла на нуль сигнализируется об особом случае недействитель-
ной операции, а не о делении на нуль.
Принципиально имеется много разновидностей процедур обра-
ботки численных особых случаев. Эти процедуры могут изменить
арифметические и программные правила устройства FPU. Такие
изменения могут переопределить предпринимаемое по умолчанию
исправление ошибки, модифицировать представление устройства
FPU для программиста или заменить определение арифметических
операций.
Например, изменение в реакции на особый случай может
заключаться в выполнении денормализованной арифметики над
денормализованными числами, загружаемыми из памяти. Измене-
ние в представлении может обеспечить расширение регистрового
стека в память дня получения «бесконечного» количества
численных регистров. Арифметику устройства FPU можно изме-
нить на автоматическое расширение диапазона и точности при их
недостатке. Все эти функции можно реализовать в процессоре i486
с помощью особых случаев и процедур восстановления прозрачно
дня прикладного программиста.
Некоторые другие, зависящие от приложения действия, могут
включать в себя следующее:
— инкремент счетчика особых случаев для последующей инди-
кации или печати;
Глава 3. Вопросы системной организации и совместимости
— печать или вывод на экран диагностической информации
(например, среды устройства FPU и регистров);
— прекращение дальнейшего выполнения программы;
— сохранение в результате диагностического значения (нечисла)
и продолжение вычислений.
Отметим, что в зависимости от приложения, особый случай мо-
жет быть или не быть ошибкой. После того, как обработчик испра-
вит условие, вызвавшее особый случай, можно осуществить рестарт
виноватой команды с плавающей точкой. Однако этого нельзя
осуществить с помощью команды IRET, так как после виноватой
команды на следующей команде WAIT или ESC возникнет ловуш-
ка. Обработчик особого случая должен получить (с помощью ко-
манды FSAVE или FSTENV) адрес виноватой команды в иниции-
ровавшей ее задаче, образовать ее копию, выполнить копию в кон-
тексте виноватой задачи, а затем командой IRET произвести воз-
врат к текущему командному потоку.
Чтобы исправить ситуацию, вызвавшую особый случай, обра-
ботчики должны распознать точное состояние устройства FPU в
момент вызова обработчика и уметь восстановить его состояние
при появлении особого случая. Для восстановления состояния уст-
ройства FPU программисты должны понимать, когда фактически
распознаются особые случаи при выполнении численной команды.
Особые случаи недействительной операции, деления на нуль и
денормализованного операнда обнаруживаются до начала выполне-
ния операции, а об особых случаях переполнения, антипереполне-
ния и точности не сообщается до получения истинного результата.
Когда обнаружен ранний особый случай, регистровый стек устрой-
ства FPU и память еще не модифицированы и выглядят так, как
будто виноватая команда не выполнялась.
При обнаружении позднего особого случая регистровый стек и
память выглядят так, как будто команда завершена, т.е. они могут
быть модифицированы. (Однако в операции сохранения и сохране-
ния с извлечением незамаскированные антипереполнение и пере-
полнение обрабатываются как ранний особый случай: память не
модифицирована и извлечения из стека не было.) Примеры про-
грамм в гл. 4 содержат основные части нескольких обработчиков
численных особых случаев.
3.5. Совместимость с сопроцессорами 8087,
80287 и 80387
В этом разделе рассматриваются вопросы, возникающие при пе-
реносе на процессор i486 численных программ, разработанных для
предшествующих математических сопроцессоров. Для программ
i 210'1
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
процессор i486 выглядит очень похоже на систему с процессорами
80386/80387. Программы, которые работали в системе 80386/80387
независимо от того, разработаны они для этой системы или перене-
сены с системы 8086/8087, с небольшими модификациями будут ра-
ботать и на процессоре i486. Для прямого переноса программ с сис-
темы 80286/80287 или 8086/8087 на процессор i486 необходимо рас-
смотреть некоторые дополнительные вопросы.
3.5.1. Отличия от систем 80386/80387
Приведем отличия процессора i486 от системы с процессорами
80386/ 80387, которые могут повлиять на выполнение численных
программ.
1. Биты регистра управления
В процессоре 80386 бит ЕТ (тип расширения) в регистре CR0
применяется для указания того, имеется в системе математический
сопроцессор 80287 (ЕТ = 0) или 80387 (ЕТ = 1). В схемах процес-
сора i486 этот бит не используется. При сбросе бит ЕТ инициали-
зируется на 0.
В процессоре i486 бит NE (численный особый случай) в регист-
ре CR0 определяет, сообщается ли об особых случаях с плавающей
точкой внутри через вектор прерывания 16 (NE =1) или через
внешнее прерывание (NE = 0). При сбросе бит NE инициализиру-
ется на 0, поэтому программа, в которой применяется внутренний
механизм сообщения об ошибке, должна установить этот бит в 1.
В процессорах 80286 и 80386 бит МР (контроль сопроцессора) в
регистре CR0 определяет, вызывают ли команды WAIT ловушку,
когда контекст устройства FPU отличается от контекста текущей
задачи. Если MP = 1 и TS = 1, то команда WAIT вызывает наруше-
ние недоступности устройства (вектор прерывания 7). В процессо-
рах 80286 и 38086 бит МР предназначен для поддержки применения
команды WAIT с целью ожидания другого устройства, а не матема-
тического сопроцессора. Устройство сообщает о своем состоянии
сигналом BUSY#. Так как процессор i486 не имеет этого сигнала,
бит МР больше не нужен и для правильной работы должен нахо-
диться в состоянии 1.
2. Инициализация и сброс RESET
При аппаратном сбросе регистры с плавающей точкой не изме-
няются, если не запрошен встроенный самоконтроль. Когда же са-
моконтроль не запрошен, аппаратный сброс действует почти так
же, как команда FINIT; единственное различие состоит в том, что
команда FINIT сохраняет регистры стека неизменными, а аппарат-
ный сброс и самоконтроль сбрасывают их в 0.
Глава 3. Вопросы системной организации и совместимости
При аппаратном сбросе или по команде FINIT сопроцессор
80387 сигнализирует об ошибке. Процессор i486, как и сопроцессор
80287, не делает этого.
В процессоре i486 команда FINIT очищает указатели ошибки
(данных и команды). -
3. Особые случаи
В процессоре i486 команда ESC с неопределенным кодом опера-
ции вызывает особый случай недействительной операции (вектор
прерывания 6). Неопределенные коды операций ESC, как и допус-
тимые коды операций ESC, вызывают особый случай недоступно-
сти устройства (вектор прерывания 7), когда в регистре CR0 уста-
новлен бит TS или ЕМ. Процессор i486 не контролирует условия
ошибки с плавающей точкой при встрече неопределенного кода
операции ESC.
Невыравненный операнд данных в программе уровня привиле-
гий 3 вызывает особый случай выравнивания (вектор прерывания
17) за исключением стековой части команд FSAVE/FRESTOR.
В процессоре i486 команда WAIT иногда выполняется как ко-
манда NOP. Это происходит, когда WAIT предшествует команде,
которая сама чего-то ожидает в ходе своего выполнения. В такой
ситуации сообщение о численном особом случае в процессоре i486
может появиться на одну команду позднее, чем в системе с процес-
сорами 80386/80387.
В процессоре i486, когда первая половина записываемого опе-
ранда находится внутри сегмента или страницы, а вторая вне их,
нарушение памяти может вызвать сохранение первой половины без
второй. В подобной ситуации в системе с процессорами
80386/80387 не сохраняется ничего.
Когда в процессоре i486 возникает нарушение сегмента в сере-
дине операции FLDENV, может случиться, что часть среды загру-
жена, а часть нет. В таких ситуациях в слове управления CW уст-
ройства FPU остается значение 007FH.
В процессоре i486 не возникает прерывание 9. В тех ситуациях,
где сопроцессор 80387 формирует прерывание 9, процессор i486
просто отменяет команду. Однако здесь требуется некоторая осто-
рожность. Нарушения памяти (особенно страничные нарушения)
при появлении в командах FLDENV или FRESTOR, когда опера-
ционная система производит переключение задачи, могут вызвать
потерю среды с плавающей Точкой. Фирма Intel настоятельно
рекомендует, чтобы область сохранения среды с плавающей точкой
была в той же странице, где находится сегмент TSS.
4. Трансцендентные команды
В процессоре i486 при наличии ожидающего запроса INTR
трансцендентные команды могут быть прекращены в конкретных
контрольных точках. Поэтому трансцендентные команды следует
sgfg
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
применять в такой среде, где сигнал INTR не ожидается в пределах
200 тактов синхронизации.
3.5.2. Отличия от систем 80286/80287
В данном разделе приведены отличия процессора i486 и систем с
процессорами 80386/80387 от систем с процессорами 80286/80287 и
8086/ 8087; проанализировано также влияние этих отличий на про-
граммы, которые должны переноситься с системы 80286/80287 на
процессор i486.
Отличия, касающиеся типов данных и обработки особых случаев
сведены в таблице 3.2. В таблице 3.3 приведены отличия, относя-
щиеся к словам тэгов, управления и состояния. В таблице 3.4 со-
держатся отличия, связанные с системами команд. В этих таблицах
приняты обычные обозначения особых случаев:
IE - особый случай недействительной операции,
DE - особый случай денормализованного операнда
ZE - особый случай деления на нуль,
РЕ - особый случай точности,
0Е - особый случай переполнения,
UE - особый случай антипереполнения.
Кроме того, аббревиатура QNaN означает тихое нечисло, а
SNaN — сигнализирующее нечисло.
Таблица 3.2. Типы данных и обработка особых случаев
Объект Описание различий Влияние на программы
Система i486 и 80386/80387 Система 80286/80286
Нечисло Различают тихие QNaN и сигнализирующие SNaN нечисла. Процессоры образуют только QNaN. Особый случай IE возникает только при встрече SNaN (но в командах FCOM, FIST и FBSTP особый случай IE возникает и для QNaN). Образует только один вид нечисел (эквивалент QNaN), но формирует особый случай IE при встрече любого вида NaN. Неинициализи- рованные ячейки памяти с QNaN нужно заменить на SNaN, чтобы 1496 и 80386/ 80387 вызвали особый случай при обращении к таким ячейкам.
Псевдонуль, псевдо-NaN, псевдобеск. и ненорм. числа Не образуют и не поддерживают эти форматы. При встрече в арифметической операции возникает особый случай IE. Эти форматы определены и обрабатываются специальным образом. Нет. Процессоры i486 и 80386/80387 не образуют эти форматы.
Биты слова тэгов для неподдерж. Неподдерживаемые форматы отмечаются тэгом специального Псевдонуль и ненормализованные отмечаются как Возможно изменение обработчика
Глава 3. Вопросы системной организации и совместимости
Таблица 3.2. (Продолжение)
Объект Описание различий Система i486 Система и 80384/80387 80286/80286 Влияние на программы
форматов значения (код 10В). достоверные (00В), а остальные как специальные (10В). особых случаев.
Особый случай IE Не возникает особый случай IE при встрече денормализованного числа в командах FSQRT, FDIV, FPREM и при преобразовании в десятичное или целое. Число нормализуется и операция продолжается. При встрече денормализованного числа в этих командах возникает особый случай IE. Нет. Программы в i486 и 80386/80387 продолжаются, а в 80286/ 80287 формируется особый случай.
Особый случай DE В трансцендентных командах и FXTRACT возникает особый случай DE. В этих командах особый случай DE не возникает. Возможно изменение обработчика особых случаев.
Особый случай ОЕ ОЕ замаскирован Если задано округление к нулю, результатом является наибольшее положительное или отрицательное (по модулю) число. ОЕ замаскирован Не сообщает об особом случае ОЕ, если маскированная реакция не есть бесконечность. При округлении к нулю результат ±беоконечность. Нет для округления к ближайшему. При округлении к нулю результат отличается младшим битом мантиссы.
ОЕ не замаскирован Фиксируется особый случай РЕ. При сохранении результата в стеке мантисса округляется по битам PC или коду операции. ОЕ не замаскирован Особый случай РЕ не фиксируется и мантисса не изменяется. При сохранении результата в стеке он отличается, но отличие заметно только обработчику.
Особый случай UE (см. примечание) При маскировании UE о нем сообщается, когда результатом является число tiny и денормализация приводит к потере точности. Реакция на UE Когда UE не маскирован, при сохранении результата в стеке мантисса округляется При маскировании UE и округлении к нулю об особом случае сообщается независимо от потери точности. Реакция на UE Когда UE не маскирован, при сохранении результата в Нет при маскировании UE. Когда UE не маскирован, при сохранении результата в стеке он отличается, но отличие заметно только
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
Таблица 3.2. (Продолжение)
Объект Описание различий Система i486 Система и. 80386/80387 80286/80286 Влияние на программы
по битам PC или до расширенной точности. стеке мантисса не округляется. обработчику.
Старшинство особых случаев Нет различий в старшинстве особого случая DE, независимо от того, замаскирован он или нет. Когда особый случай DE не маскирован, он старше всех других особых случаев. Нет. В i486 и 80386/80387 предотвращена ненужная нормализация.
Примечание:
Причиной антипереполнения могут быть два взаимосвязанных события:
— получение как результата числа tiny; это число, будучи очень малым,
может вызвать в последующем другой особый случай, например переполне-
ние при делении;
— потеря точности при денормализации числа tiny.
Какое из этих событий вызывает особый случай антипереполне-
ния, зависит от того, замаскирован особый случай антипереполне-
ния или нет.
Таблица 3.3. Слова состояния SW, управления CW и тэгов TW
Объект Описание различий Влияние на программы
Система i486 и 80386/80387 Система 80286/80286
Биты СЗ-СО слова SW После команды FINIT, незаконченной FPREM и аппаратного сброса эти биты содержат нули. В указанных ситуациях биты СЗ-СО не изменяются. Нет
Бит С2 слова SW Показывает незавершенность команды FPTAN. Для команды FPTAN этот бит не определен. Нет. Программы не проверяют С2 после FPTAN.
Управление бесконеч- ностью Поддерживается только аффинное замыкание. Бит IC (бит 12) программируется, но не влияет на работу. Поддерживаются аффинное и проективное замыкания. После сброса действует проективное замыкание. Программы, рассчитанные на проективное замыкание, дадут другие результаты.
Глава 3. Вопросы системной организации и совместимости
^'215?.
Таблица 3.3. (Продолжение)
Объект Описаине различий Система i486 Система я 80386/80387 80286/80286 Влияние иа программы
Бит ошибки стека SF (бит 6) При фиксации особого При фиксации случая IE из-за стека особого1случая IE устанавливаются бит IE устанавливается и бит SF. Бит С1 только бит 0 (IE), позволяет различить Бит 6 переполнение и зарезервирован, антипереполнение стека. Бит SF позволяет отличить особые случаи IE, вызванные переполнением или антипереполнением стека, от особых случаев численных операций. Нет. Существующие обработчики особых случаев изменять не нужно. Новые обработчики могут использовать дополнительную информацию.
Слово тэгов TW При загрузке слова тэгов командами FLDENV и FRSTOR учитываются только коды пустой (ИВ) и непустой (00В, 01В, 10В). Последующие операции с непустым регистром анализируют его содержимое, а не тэг. Команды FSTENV и FSAVE проверяют непустые регистры и помещают в тэги правильные значения. Тэг проверяется перед каждым к регистру и отражает последнее содержимое регистра. Программист может загрузить в тэг значение, которое расходится с содержимым регистра; сопроцессор верит тэгу. Программа может работать неправильно, если она использует команду FLDENV или FRSTOR для изменения тэгов на значения, отличные от истинного содержимого.
Таблица 3.4. Система команд
Объект Описание различий Система i486 Система и 80386/80387 80286/80286 Влияние на программы
FBSTP,FDIV, FIST(P), FPREM, FSQRT Поддерживается операция с денормализованным операндом. Может возникать особый случай UE. Денормализован- ный операнд вызывает особый случай IE. Антипереполнение невозможно. Может потребоваться изменение обработчика особого случая UE.
FSCALE Диапазон масштабирующего операнда не ограничен. Если 0 < 1ST(1)| < 1, то масштаб равен 0 и ST(0) не изменяется. При потере точности Диапазон Другой масштабирующего результат при операнда ограничен. 0 <|ST(1)| <1 Если 0 < |ST(1) < 1, результат не определен и особого
"216x1
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
Таблица 3.4.(Продолжение)
Объект Описание различий Система i486 Система на и 80386/80387 80286/80286 Влияние программы
(UE замаскирован) возникает особый случай РЕ. случая не регистрируется.
FPREM1 Вычисляет частичный остаток в соответствии со стандартом IEEE-754. Отсутствует Нет
FPREM Биты СО, СЗ, С1 слова состояния SW содержат точные три младших бита частного. Биты частного не являются точными при выполнении приведения для 64й + М, где N £ 1 и М = 1 или М = 2. Нет
FUCOM, FUCOMP, FUCOMPP Выполняют неупорядоченное сравнение в соответствии со стандартом IEEE-754. Отсутствуют Нет
FPTAN Диапазон операнда |ST(0)| < 26^ менее < ограничен; во внутреннем приведении операнда применяется более точное значение я/4. При переполнении стека и маскированном особом случае IE регистры ST(0) и ST(1) содержат тихие нечисла. Диапазон операнда ограничен |ST(0)| < л/4, поэтому требуется приведение командой FPREM. При переполнении стека и маскировании IE исходный операнд не изменяется, но включается в ST(1) Нет
FSIN,FCOS, FSINCOS Выполняют часто встречающиеся тригонометрические функции. Отсутствуют Нет
FPATAN Диапазоны операндов не ограничены. Значение |ST(0)| должно быть меньше значения |ST(1)T|. Нет
F2XM1 Более широкий диапазон операнда -1 < ST(0) < +1 0 Допустимый диапазон операнда < ST(0) < 0.5 Нет
FLD в формате РТ Не сообщает об особом случае DE, так как эта команда не относится к арифметическим. Сообщает об особом случае DE. Нет
Глава 3. Вопросы системной организации и совместимости
Таблица 3.4. (Продолжение)
Объект Описание различий Влияние иа программы
Система i486 а 80386/80387 Система 80286/80286
FXTRACT При нулевом операнде фиксируется особый случай ZE и ST(1) содержит —оо. Если операнд равен +оог то об особом случае не сообщается. При нулевом операнде ST(1)=O и особый случай не фиксируется. Если операнд равен +оо, фиксируется особый случай IE. Нет. Обычно в программах обходят нулевой и бесконечный, операнды
Загрузка константы Действует управление округлением. Управление округлением не действует. См. примечание 1
FLD в форматах ОТ и ДТ Денормализованное число при загрузке преобразуется в формат РТ (для стека). Денормализованное число преобразуется в ненормализованное. Если следующая команда FXAM или FXTRACT, результаты различаются.
FLD в форматах ОТ или ДТ При загрузке SNaN возникает особый случай IE. При загрузке SNaN особого случая IE не возникает. Потребуется изменить обработчик особого случая.
FSETPM Считается холостой командой (FNOP). Сообщает 80287 о работе в Р-режиме. Нет
FXAM При обнаружении пустого регистра не помещает в биты СЗ-СО комбинаций 1101В или 1111В. Может образовать указанные комбинации. Нет
Трансцен- дентные команды Могут формировать различные результаты в бите округления вверх слова состояния SW. Бит округления вверх не определен. Нет
Примечания’.
1. Результаты совпадают с результатами процессоров 80286/80287 при ок-
руглении к нулю и к минус бесконечности (а для команды FLDL2T и при
округлении к ближайшему). Результаты различаются на 1 в младшем бите
мантиссы при округлении к плюс бесконечности и к ближайшему (исключая
команду FLDL2T). Команды FLD1 и FLDZ всегда дают одинаковые результа-
ты.
Основной причиной рассмотренных отличий является совмес-
тимость со стандартом IEEE-754 на арифметику с плавающей
•218^
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
точкой. Среди других причин отметим стремление несколько повы-
сить производительность процессора i486 (см., например, отличия в
обработке слова тэгов, приведенные в таблице 3.3), а также усовер-
шенствование внутренних схем процессора (например, теперь после
выполнения команды FPREM биты СО, СЗ, С1 всегда содержат
точные значения трех младших бит частного).
3.5.3. Отличия от систем 8086/8087
Процессор i486 при работе в R-режиме будет выполнять про-
граммы сопроцессора 8087 без серьезной модификации. Однако
из-за отличий в обработке особых случаев может потребоваться из-
менить процедуры их обработки. Далее подробно показано, как
программы сопроцессора 8087 перенести на процессор i486.
1. Сопроцессор 8087 требует наличия контроллера прерываний
(обычно им служит микросхема 8259А фирмы Intel) для прерывания
центрального процессора при возникновении незамаскированного
особого случая. Поэтому в обработчике прерывания для сопроцес-
сора 8087 необходимо удалить все команды, относящиеся к кон-
троллеру прерываний.
2. Команды разрешения F[N]ENI и запрещения F[N]DISI пре-
рываний сопроцессора 8087 в процессоре i486 не выполняют полез-
ной функции. Если процессор i486 встречает их в своем командном
потоке, команды игнорируются, т.е. не изменяется ни одно из
внутренних состояний процессора. Несмотря на то, что код с таким
командами можно выполнить на процессоре i486, маловероятно,
что содержащие эти команды процедуры обработки особых случаев
окажутся полностью переносимыми.
3. В R- и P-режимах (но не в V-режиме) вектор прерывания 16
должен адресовать процедуру обработки численного особого случая.
В Урежиме монитор V-режима можно запрограммировать на другое
местонахождение вектора прерывания для численных особых
случаев.
4. Адрес команды ESC, сохраняемый процессором i486,
учитывает все префиксы перед кодом операции ESC. Соответству-
ющий адрес, сохраняемый в системе 8086/8087, не учитывает пре-
фиксы.
5. В P-режиме (не включая V-режим) формат сохраняемых про-
цессором i486 указателей команды и данных отличается от формата
этих объектов сопроцессора 8087. В P-режиме не сохраняется код
операции команды; при необходимости обработчик прерывания
считывает код операции из памяти.
6. Прерывание 7 в процессоре i486 возникает при установленных
битах TS или ЕМ в слове MSW (TS = 1 или ЕМ = 1). Если TS = 1,
Глава 3. Вопросы системной организации и совместимости
^219%'
команда WAIT также вызывает прерывание 7. Обработчик особого
случая для процессора i486 должен учитывать такие ситуации.
7. Если начальный адрес численного операнда находится вне
размера сегмента, формируется прерывание 13. Необходим обра-
ботчик прерывания, сообщающий о таких ошибках программиро-
вания. v
8. За исключением команд управления устройством FPU все
численные команды процессора i486 синхронизируются автома-
тически — процессор автоматически ожидает окончания передачи
всех операндов до перехода к следующей команде ESC. Для дости-
жения синхронизации явные команды WAIT не нужны. Для сопро-
цессора 8087, работающего совместно с процессором 8086 или 8088,
для синхронизации необходимы явные команды WAIT перед каж-
дой численной командой. Несмотря на то, что программы сопро-
цессора 8087 с явными командами WAIT выполняются на процес-
соре i486 без повторного ассемблирования, такие команды WAIT не
нужны.
9. Так как процессор i486 не требует команды WAIT перед каж-
дой численной командой, ассемблер ASM386/486 не вставляет их.
Однако ассемблер ASM86 автоматически вставляет команду WAIT
перед каждой командой ESC. Несмотря на то, что образованные ас-
семблером ASM86 численные программы будут выполняться пра-
вильно в процессоре i486, повторное ассемблирование кода с при-
влечением ассемблера ASM386/486 обеспечиг более компактный и
быстрый код.
Команды управления для устройства FPU можно кодировать,
применяя формы мнемоник «с ожиданием» и «без ожидания».
10. Адрес операнда в памяти, сохраняемый командами FSAVE
или FSTENV, не определен, если предыдущая команда ESC не об-
ращалась к памяти.
11. Так как процессор i486 при возможности автоматически
нормализует денормализованные числа, программу сопроцессора
8087, использующую особый случай денормализованного операнда
просто для нормализации денормализованных операндов, можно
выполнять на процессоре i486, маскируя особый случай денормали-
зованного операнда. В такой ситуации процессор i486 не привлека-
ет обработчик особого случая денормализованного операнда сопро-
цессора 8087. Численные программы выполняются быстрее, когда
процессор i486 производит нормализацию денормализованных опе-
рандов.
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
Особенности
программирования
устройства FPU
В этой главе показано, как программисты на ассемблере
ASM386/486 и некоторых языках высокого уровня могут использо-
вать численные возможности процессора i486, и приведено не-
сколько примеров численного программирования. Принятый уро-
вень изложения дает программистам базовое понимание программ-
ных средств, привлекаемых для численного программирования, но
все их возможности не рассматриваются.
4.1. Инструментальные средства программирования
4.1.1. Языки высокого уровня
Фирма Intel предлагает несколько языков высокого уровня
С-386/486 и PL/M-386/486, которые автоматически используют
численную систему команд там, где это возможно. Другие про-
граммные фирмы разработали компиляторы многих языков высоко-
го уровня.
Каждый из языков высокого уровня имеет специальные
численные библиотеки, позволяющие программам использовать
численные возможности устройства FPU. При программировании
численных приложений на любом из языков не требуются никаких
специальных программных соглашений.
Программистам на языках ассемблера ASM386/486 и
PL/M-386/486 библиотечные процедуры доступны в поддерживаю-
щей библиотеке. Такие библиотеки реализуют многие функции
Глава 3.Особенности программирования устройства FPU
языков высокого уровня, включая обработчики особых случаев,
преобразования ASCII-чисел в форму с плавающей точкой и более
полный набор трансцендентных функций, чем имеющийся в
численной системе команд процессора i486.
ПРОГРАММЫ НА ЯЗЫКЕ Си. Программисты на языке Си за-
ставляют компилятор Си автоматически генерировать численные
команды процессора i486 при указаний типов данных double и float.
Тип float соответствует формату ОТ, а тип double — формату ДТ.
Оператор #include <math.h> заставляет математические функции,
например sin и sqrt, возвращать значения типа double. Следующий
фрагмент иллюстрирует ту легкость, с которой в Си-программах
используются численные возможности процессора i486.
/**********************************************
* *
* ПРИМЕР Си-ПРОГРАММЫ *
* *
**********************************************/
/** При необходимости подключить /usr/include/stdio.h
/** Подключить математические об'явления **/
^include </usr/include/mat.h>
Idefine PI 3.1415926535897943
main()
{
double sin_resultz cos_result;
double angle_deg = 0.0, angle_rad;
int i, no_of_trial = 4;
for( i = 1; i <= no_of_trial; i++){
angle_rad = angle_deg * PI / 180.0;
sin_result = sin (angle_rad);
cos_result = cos (angle_rad);
printff"синус %f градусов равен %f\n", angle.deg, sin_result);
printff"косинус %f градусов равен %f\n\n", angle_deg,
cos_result);
angle_deg = angle_deg + 30.0;
/** и т.д. **/
}
ПРОГРАММЫ НА ЯЗЫКЕ PL/M-386/486. Программисты на
языке PL/M-386/ 486 могут обращаться к очень удобному подмно-
жеству численных возможностей процессора i486. В нем тип дан-
ных REAL соответствует формату ОТ. Этот тип данных обес-
печивает диапазон около 8.43 х 1О”37 < |Х| < 3.38 х Ю38 с семью де-
сятичными значащими разрядами. Такое представление подходит
для данных в большинстве применений микрокомпьютеров.
Полезность типа данных REAL обеспечивается также практикой
компилятора PL/M-386/486 хранить промежуточные результаты в
222
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
формате РТ. Другими словами, для промежуточных результатов
применяются полные диапазон и точность процессора i486. Появ-
ление особых случаев переполнения, антипереполнения и точности
наиболее вероятно в промежуточных вычислениях, а не в по-
лучении окончательного результата выражения. Хранение проме-
жуточных результатов в формате РТ уменьшает вероятность пере-
полнения и антипереполнения и устраняет округление как серьез-
ную причину ошибок до выполнения присваивания результата.
Компилятор образует команды с плавающей точкой для
вычисления выражений, содержащих типы данных REAL
(константы или переменные). Это означает, что операции сложе-
ния, вычитания, умножения, деления, сравнения и присваивания с
типами REAL будет производить устройство FPU. С другой сторо-
ны, выражения типа INTEGER вычисляет целочисленное устрой-
ство.
Пять встроенных процедур, приведенные в таблице 4.1, позво-
ляют программисту работать с командами управления устройства
FPU. Типичная программа на языке PL/M-386/486 до выполнения
любой арифметической операции подготавливает устройство FPU с
помощью процедуры INITSREALS MATHSUNIT, а затем конфигу-
рирует устройство с помощью процедуры SETSREALSMODE. Вто-
рая процедура загружает слово управления и ее 16-битный параметр
имеет формат слова управления. Рекомендуется значение этого па-
раметра ОЗЗН (округление к ближайшему, 64-битная точность, за-
маскированы все особые случаи, кроме недействительной опера-
ции). Однако программист может задать и другие значения.
Таблица 4.1. Встроенные процедуры языка PL/M-386/486
Процедура Команда управления Описание
IHIT$REAL$MATH$UNIT FINIT Инициализация устройства FPU
SET$REAL$MODE FLDCW Задает маски особых случаев, округление, точность
GET$REALERROR FNSTSW и FNCLEX Сохраняет, а затем сбрасывает флажки особых случаев
SAVE$REAL$STATUS FNSAVE Сохраняет полное состояние
RESTORE$REAL$STATUS FRSTOR Восстанавливает полное состояние
Если какой-нибудь особый случай не замаскирован, необходимо
предусмотреть обработчик особого случая в форме процедуры пре-
рывания, вызываемой через вектор прерывания 16. Обработчик мо-
жет использовать процедуру GETSREALSERROR для получения
младшего байта слова состояния устройства FPU и последующего
Глава 3.Особенности программирования устройства FPU
сброса флажков особых случаев. Возвращаемый процедурой
GETSREALSERROR байт содержит флажки особых случаев, кото-
рые можно проверить для определения причины особого случая.
. Процедуры SAVESREALSSTATUS и RESTORES REALS STATUS
предназначены для мультизадачной среды, где текущая задача
может быть прервана другой , использующей устройство FPU.
Операционная система должна вызывать процедуру SAVESREALS
STATUS перед выполнением любого оператора, который влияет на
устройство FPU; к ним относятся процедуры INITSREALSUNIT и
SETS REALS MODE, а также арифметические выражения.
Процедура SAVESREALSSTATUS сохраняет полное состояние
устройства FPU в стеке, находящемся в памяти, процедура
RESTORESREALSSTATUS возвращает эту информацию. Задача,
прервавшая текущую должна вызвать эту процедуру перед своим
окончанием, чтобы восстановить прежнее состояние устройства
FPU. Это позволяет прерванной задаче возобновить свое выполне-
ние с точки прерывания.
4.1.2. Ассемблер ASM386/486
Язык ассемблера ASM386/486 предоставляет программистам дос-
туп ко всем средствам процессора i486.
ОПРЕДЕЛЕНИЕ ДАННЫХ. Директивы ассемблера DW
(определить слово — 16 бит), DD (определить двойное слово — 32
бита), DQ (определить счетверенное слово — 64 бита) и DT
(определить 10 байт) распределяют память для численных перемен-
ных и констант. Как и в других директивах распределения памяти,
ассемблер ассоциирует тип с каждой определенной в этих директи-
вах переменной. Значение типа равно длине единицы памяти в
байтах (10 для DT, 8 для DQ и т. д.). Ассемблер контролирует тип
любой переменной, закодированной в команде, проверяя ее совме-
стимость с командой. Например, кодирование FIADD ALPHA будет
отмечено как ошибочное, если тип ALPHA не равен 2 или 4, так
как целочисленное сложение применимо только к слову и двойно-
му слову. Тип операнда также сообщает ассемблеру, какую машин-
ную команду формировать; несмотря на то, что для программиста
есть только команда FIADD, для каждого типа операнда требуется
различная машинная команда.
Иногда желательно использовать команду с операндом, который
не имеет объявленного типа. Если, например, регистр ВХ адресует
целочисленную переменную в формате двойного слова, программи-
сту удобно закодировать FIADD [ВХ]. Это можно осуществить, ин-
формируя ассемблер о типе операнда в команде FIADD DWORD
Микропроцессор i486 а Книга 3. Устройство с плавающей точкой
PTR [ВХ]. Соответствующими заменами для других единиц памяти
являются WORD PTR, QWORD PTR и TBYTE PTR.
Однако ассемблер не контролирует типы операндов в командах
управления. Запись команды FRSTOR [ВР] предполагает, что про-
граммист подготовил регистр ВР для адресации области (вероятно,
в стеке), в которой ранее было сохранено 94-байтное полное состо-
яние устройства FPU.
Начальные значения для численных констант можно кодировать
несколькими способами. Двоичные целые константы допускается
определять как битовые цепочки, десятичные целые, восьмеричные
целые или 16-ричные цепочки. Упакованные десятичные значения
обычно записываются как десятичные целые числа, хотя ассемблер
воспринимает и преобразует другие представления целых чисел.
Вещественные значения допускается записывать как обычные деся-
тичные вещественные числа (требуется десятичная точка), деся-
тичные числа в научной нотации и как 16-ричные цепочки. После-
дние предназначены, в основном, для определения специальных
значений, например бесконечностей, нечисел и денормализованных
чисел. Проще всего инициализировать численные константы с по-
мощью обычных десятичных чисел и научной нотации. Приведем
несколько способов установки различных типов данных на одно и
то же значение.
EVEN
; Все директивы определяют константу -126
; Отметим дополнительный код для целых двоичных чисел
WORD-INTEGER DW 111111111000010B
SHORT-INTEGER DD 0FFFFFF02H
LONG-INTEGER DQ -126
SINGLE-REAL DD -126.0
DOUBLE-REAL DQ -1.26E2
PACKED-DECIMAL DT -126 /
DT 0C0057E00000000000000R
EXTENDED-REAL
Далее знак и
'R' означает
; Выравнивание на слово
; Битовая цепочка
; Начинается с цифры
; Обычное десятичное
; Имеется точка
; Научная нотация
; Обычное десятичное
порядок равны 'С005', мантисса равна '7Е00...00',
вещественный тип данных
Отметим, что указание перед численными переменными и кон-
стантами директивы EVEN вызывает выравнивание операндов по
границам слов. При этом достигается более высокая скорость пере-
дач данных.
ЗАПИСИ И СТРУКТУРЫ. в численном программировании
удобно пользоваться записями RECORD и структурами STRUC.
Запись позволяет определить двоичные поля слов управления, со-
стояния и тэгов. Ниже показано одно из определений слова состо-
яния и применение его в процедуре, которая опрашивает устрой-
ство FPU, когда оно закончит команду.
Глава 3.Особенности программирования устройства FPU
8 Заказ 4317
; Резервирует пространство для слова состояния
STATUS-WORD
; Формат полей слова состояния
STATUS RECORD
& BUSY: 1,
& COND_CODE3: 1,
& STACK-TOP: 3,
& COND-CODE2: 1,
& COND-CODEl 1,
& COND_CODEO: 1,
& INT-REQ: 1,
& SJFLAG: 1,
& P_FLAG: 1,
& U-FLAG: 1,
& O-FLAG: 1,
& Z.FLAG: 1,
& D_FLAG: 1,
& I-FLAG: 1
; Приводить до завершения:
REDUCE: FPREM1
FNSTSW STATUS-WORD
TEST STATUS-WORD, MASK_COND_CODE2
JNZ REDUCE
Так как структуры позволяют группировать различные, но взаи-
мосвязанные типы данных, они часто служат естественным спосо-
бом представления организации данных «реального мира». Повы-
шает гибкость программирования и тот факт, что шаблон структуры
можно «передвигать» по памяти. Далее показана простая структура
для представления данных, содержащих серию выборок оценок.
При необходимости эту простую структуру можно реорганизовать
для более эффективного выполнения программы. Если два двойных
вещественных поля показать до целочисленных полей, то (при ус-
ловии, что структура помещается только по адресам, кратным 8) все
поля оптимально выравниваются для эффективного обращения к
памяти и кэширования. Структуру можно также применить для оп-
ределения информации, которую сохраняют и загружают команды
FSTENV и FLDENV.
SAMPLE STRUC
N_OBS DD ? ; Короткое целое
MEAN DQ ? ; Двойное вещественное
MODE DW ? ; Целое слово
STD_DEV DQ ? ; Двойное вещественное
; Массив наблюдений — целые слова
TEST-SCORES DW 1000 DUP (?)
SAMPLE ENDS
РЕЖИМЫ АДРЕСАЦИИ. К численным данным в памяти мож-
но обращаться с любым режимом адресации, который обес-
печивают байт ModR/M и (необязательно) байт SIB. Это означает,
что численные типы данных можно включать в агрегаты данных от
простых до сложных в соответствии с требованиями приложения.
Режимы адресации и нотация ассемблера ASM386/486 для опреде-
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
ления их в командах обеспечивают простой и понятный способ об-
ращения к структурам, массивам, массивам структур и другим орга-
низациям данных. В таблице 4.2 приведено несколько примеров
численных команд с операндами, показывающими различные ре-
жимы адресации памяти.
Таблица 4.2. Примеры режимов адресации
Кодирование Интерпретация
FIADD ALPHA ALPHA - простой скаляр (прямой режим)
FDIVR ALPHA.BETA BETA — поле в структуре, которая "наложена" на ALPHA (прямой режим)
FMUL QWORD PTR [BX] ВХ содержит адрес длинной вещественной переменной (косвенный регистровый режим)
FSUB ALPHA[SI] ALPHA - массив, a SI содержит смещение элемента в массиве (индексный режим)
FLD [BP].BETA ВР содержит адрес структуры с стеке процессора, а ВЕТА - поле в структуре (базовый режим)
FBLD TBYTE PTR [BX][DI] ВХ содержит адрес десятичного массива, a DI — смещение элемента в массиве (базовый индексный режим)
4.L3. Сравнительный пример программирования
На рис. 4.1 и 4.2 приведена простая численная программа на
языках PL/M-386/486 и ASM386/486. Программа обращается к мас-
сиву Х$ARRAY, который содержит 0—100 вещественных значений
в формате ОТ; целочисленная переменная N$OF$X показывает
число элементов массива, которые должна анализировать про-
грамма. Программа проходит по массиву, накапливая три суммы:
SUM$X - сумма значений массива,
SUM$INDEXES - сумма значений элементов, умноженных на их индексы,
причем индекс первого элемента равен 1, второго 2 и т.д.,
SUM$SQUARES - сумма квадратов элементов массива.
Конечно, в реальной программе нужно еще сохранить и исполь-
зовать полученные суммы. Слово управления устанавливается на
рекомендуемые значения: округление к ближайшему, 64-битная
точность, прерывания разрешены и все особые случаи, кроме не-
действительной операции, замаскированы. Предполагается, что
имеется обработчик особого случая недействительной операции,
который вызывается прерыванием 16.
Программа на языке PL/M-386/486 (см. рис. 4.1) довольно про-
ста и показывает, как легко в этом языке использовать численные
возможности процессора i486. После объявления переменных про-
грамма вызывает встроенные процедуры для инициализации уст-
ройства FPU и загрузки слова управления. Программа очищает пе-
ременные для сумм, а затем проходит по массиву XSARRAY в цик-
Глава 3.Особенности программирования устройства FPU
227;
ле DO. Цикл учитывает соглашение языка PL/M386/486 считать
индекс первого элемента массива равным 0. При вычислении
SUMSINDEXES встроенная процедура FLOAT преобразует I + 1 из
целого числа в вещественное, так как язык не поддерживает
«смешанную» арифметику. Одно из достоинств устройства FPU со-
стоит в том, что оно поддерживает арифметику со смешанными ти-
пами данных (так как все значения преобразуются во внутренний
80-битный формат РТ).
/*************о*****************о*******************
* *
* МОДУЛЬ ARRAYSUM *
* *
*****************************************************/
array$sum: do;
declare (sum$x, sum$indexes, sum$squares) real;
declare x$array(100) real;
declare (n$of$x, i) integer;
declare control$FPU literally '03-3eh';
/* Предполагается, что x$array и n$of$x инициализированы */
call init$real$math$unit;
call set$real$mode{control$FPU);
/* Очистить суммы */
sum$x, sum$indexes, sum$squares = 0.0;
/* Цикл по массиву с накоплением сумм */
do i = 0 to n$of$x - 1;
sum$x = sum$x + x$array(i);
sum$indexes = sum$indexes + (x$array(i)*float(i+l));
sum$squares = sum$squares + (x$arrayji)*x$array(i));
end;
/* и далее */
end array$sum;
Puc. 4.1 . Пример программы на языке PL/M-386/486
В программе на ассемблере (см. рис. 4.2) определяется внешняя
процедура INITFPU, которая делает различные требования по
инициализации процессора и его эмулятора прозрачными для
исходного кода. После определения данных и подготовки сег-
ментных регистров и указателя стека программа вызывает проце-
дуру INITFPU и загружает слово управления. Вычисления
начинаются со следующих трех команд, которые очищают три реги-
стра посредством включения в стек нуля. Как показано на рис. 4.3,
эти три регистра остаются внизу стека, а временные переменные
включаются в стек и извлекаются из него над ними.
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
name arraysum
extrn initFPU:far ;Определить процедуру инициализации
распределить пространство для данных
data segment rw public
controlJFPU dw 033eh
n_of_x dd ?
x_array dd 100 dup (?) -
sum_squares dd ?
sum_indexes dd ?
sum_x dd ?
data ends
распределить стековое пространство процессора
stack stackseg 400
;Начало кода
code segment er public
assume ds:data, ss:stack
start:
mov ax,data
mov ds,ax
mov ax,stack
mov eax,Oh
mov ss,ax
mov esp,stackstart stack
;Полагаем, что x_array и n_of_x инициализированы
; Подготовить FPU или его эмулятор
call initFPU
fldcw control_FPU
/Очистить три регистра для сумм
fldz
fldz
fldz
;Подготовить счетчик в ЕСХ и индекс в ESI
mov ecx,n_of_x
imul ecx
mov esi,eax
регистр ESI содержит индекс последнего элемента + 1
;Проход по массиву х_аггау и накопление сумм
sum_next:
;Зарезервировать один элемент и включить в стек
sub esi,type x_array
fid x_array[esi]
/Прибавить к сумме и продублировать в стеке
fadd st{3),st
fid st
/Возвести в квадрат, прибавить к сумме (index+1)
; и уничтожить
fmul st, st
faddp st(2), st
/Уменьшить индекс для следующей итерации
dec n_of_x
loop sum_next
/Извлечь из стека в память
pop_results:
fstp sum_squares
fstp sum_indexes
fstp sum__x
fwait
/Дальнейшие операции ... code ends
end start, ds:data, ss:stack
Рас. 4.2. Пример программы на языке ASM386/486
Глава 3.Особенности программирования устройства FPU
22°$
Для управления итерациями при обработке массива применяет-
ся команда LOOP. В регистр ЕСХ, который команда LOOP автома-
тически уменьшает на 1, загружается число элементов массива
N$OF$X. Регистр ESI применяется для выбора (индексирования)
элементов массива. Программа проходит по массиву от конца к
началу, поэтому регистр ESI инициализируется на элемент перед
первым обрабатываемым элементом. Для определения числа байт в
каждом элементе массива используется оператор ТУРЕ. Это позво-
ляет применить программу для массива XSARRAY вещественных
чисел двойной точности, изменив определение DD на DQ и вы-
полнив повторное ассемблирование.
Рис.4.3. Действия команд и регистрового стека
На рис. 4.3 показано действие команд в цикле на регистровый
стек. Предполагается, что программа выполняет первую итерацию,
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
что N$OF$X содержит 20 и что элемент X$ARRAY(19) содержит
значение 2.5. При окончании цикла три суммы остаются в трех вер-
хних элементах стека, поэтому программа просто извлекает их в
ячейки памяти.
4.2. Параллельная работа
Так как целочисленное устройство Ш и устройство FPU явля-
ются отдельными операционными устройствами, допускается вы-
полнение численных команд FPU одновременно с выполнением
команд в IU. Такое одновременное выполнение различных команд
называется параллельностью или параллелизмом (concurrency).
Для достижения параллельности не требуется специальных при-
емов программирования; численные команды для устройства FPU
просто помещаются вместе с командами для устройства Ш. Це-
лочисленные и численные команды инициируются в том порядке, в
каком они появляются в командном потоке. Но так так численные
команды обычно выполняются дольше целочисленных операций,
устройство Ш часто может выполнить несколько своих команд,
прежде чем устройство FPU закончит ранее инициированную ко-
манду.
Конечно, параллельность повышает производительность систе-
мы, но вместе с тем она предъявляет несколько правил, которые
необходимо соблюдать для правильной синхронизации двух уст-
ройств.
Все языки высокого уровня фирмы Intel автоматически поддер-
живают и управляют параллельной работой устройств процессора
i486. Однако программирующие на ассемблере должны разбираться
в параллельное! j и управлять ею в обмен на гибкость и
эффективность программирования на языке ассемблера. Этот раз-
дел предназначен для программистов на ассемблере и опытных про-
граммистов на языке высокого уровня.
4.2.1. Управление параллельностью
Действия численных программ можно разделить на две области:
управление программой и арифметика. Первая часть осуществляет
такие действия, как выбор выполняемых функций, вычисление ад-
ресов численных операвдов и упра^кление циклом. Арифметическая
часть просто суммирует, вычитает, умножает и реализует другие
операции над численными операндами. Процессор i486 рассчитан
на отдельное и эффективное выполнение' этих двух частей.
Управление параллельностью необходимо для контроля особого
случая перед разрешением программе изменить значение, только
что использованное устройством FPU. Почти каждая численная
команда в ошибочных обстоятельствах может сформировать особый
Глава 3.Особенности программирования устройства FPU
случай. Для программистов на языках высокого уровня всю требуе-
мую синхронизацию автоматически обеспечивает компилятор. В
языке ассемблера ответственность за синхронизацию особых
случаев возлагается на программиста.
Трудность заключается в том, что программист может не ожи-
дать, что его численная программа вызовет численные особые
случаи, но в некоторых системах они возникают регулярно. Для
лучшего понимания вопроса, рассмотрим, что происходит, когда
устройство FPU обнаруживает особый случай.
При возникновении особого случая в зависимости от выбора
программиста процессор i486 реагирует двумя способами.
1 .) Для выбранных особых случаев устройство FPU может пред-
принять корректирующие действия, принимаемые по умолчанию.
Программы могут замаскировать отдельные типы особых случаев,
показывая, что при их появлении устройство FPU должно сформи-
ровать безопасный и приемлемый результат. Корректирующие дей-
ствия, по умолчанию устройство FPU считает частью команды, выз-
вавшей особый случай; внешний сигнал об особом случае не выда-
ется. Когда обнаруживается особый случай, в регистре состояния
SW устанавливается флажок, но нет информации о том, где и когда
возник особый случай. Если устройство FPU реализует корректи-
рующие действия по умолчанию для всех особых случаев, необхо-
димости синхронизации особых случаев нет. Однако выше показа-
но, что этого недостаточно для игнорирования синхронизации осо-
бых случаев при разработке программ, использующих устройство
FPU.
2 .) Альтернатива корректирующих действий по умолчанию со-
стоит в извещении целочисленного устройства Ш о возникшем
особом случае. Когда появляется незамаскированный особый
случай, устройство FPU прекращает дальнейшее выполнение
численной команды и извещает об этом событии. На следующей
команде ESC или WAIT процессор переходит к программному об-
работчику особого случая. После этого обработчик может реализо-
вать любые восстановительные процедуры, требующиеся для обна-
руженного устройством FPU численного особого случая. Некото-
рые команды ESC не контролируют особые случаи; к ним отно-
сятся формы «без ожидания» команд FNINIT, FNSTENV, FNSAVE,
FNSTSW, FNSTCW и FNCLEX.
Когда устройство FPU сигнализирует о незамаскированном осо-
бом случае, ему требуется помощь. Тот факт, что особый случай не
был замаскирован, показывает, что дальнейшее выполнение
численной программы с соблюдением арифметических и про-
граммных правил устройства FPU не имеет смысла.
Если разрешена параллельная работа, состояние процессора,
когда он распознает особый случай, не определено. Возможно, что
aFwgS Микропроцессор i486 Книга 3. Устройство с плавающей точкой
в момент появления особого случая он изменил много своих внут-
ренних регистров и выполняет совершенно другую программу. Для
таких ситуаций в устройстве; FPU предусмотрены специальные ре-
гистры, которые модифицируются в начале каждой численной ко-
манды дая описания состояния численной программы при попытке
выполнить виноватую команду.
Синхронизация особых случаев обеспечивает, что устройство
FPU при появлении незамаскированного численного особого
случая находится в четко определенном состоянии. Без него проце-
дуры восстановления не смогут определить, почему возник особый
случай и каким образом его обработать.
Далее показана настоятельная необходимость учета синхрониза-
ции особых случаев при разработке численных программ, даже если
они рассчитаны на первое выполнение с замаскированными осо-
быми случаями. Если программа в дальнейшем попадает в среду,
где особые случаи не замаскированы, она может работать непра-
вильно. Пример того, как некоторые команды, написанные без
учета синхронизации особых случаев, вначале действуют пра-
вильно, а при переходе в новую среду неверно, показан программ-
ным фрагментом на рис. 4.4.
fild count inc count fsqrt ;Команда устройства FPU ;Целочисленная команда изменяет операнд '♦Следующая команда устройства FPU - ; здесь обнаруживается ошибка ; от предыдущей команды устройства FPU
fild count fsqrt ;Команда устройства FPU '•Следующая команда устройства FPU - ; здесь обнаруживается ошибка
inc count ; от предыдущей команды устройства FPU '•Целочисленная команда изменяет операнд
Рис. 4.4. Примеры синхронизации особых случаев
Неправильная синхронизация особых случаев. На рис. 4.4 пока-
заны три команды, которые загружают целое число, извлекают ко-
рень квадратный и производят инкремент целого числа. Синхрон-
ная работа устройства FPU допускает правильное выполнение этой
программы, когда в команде FILD не возникают особые случаи.
Ситуация изменяется, если численный регистровый стек расши-
ряется в память. Для расширения стека устройства FPU в память,
особый случай недействительной операции не маскируется.
Включение в заполненный регистр или извлечение из пустого реги-
стра устанавливают флажок SF и формируют особый случай недей-
ствительной операции.
Глава 3.Особенности программирования устройства FPU
Процедура восстановления должна распознать такую ситуацию,
скорректировать стек, а затем выполнить первоначальную опера-
цию. Но в показанном примере процедура будет работать неверно.
Дело в том, что инкремент значения COUNT произведен до вызова
обработчика особого случая, поэтому процедура восстановления
загрузит неверное значение COUNT, что приведет к ненадежной
работе программы или ее отказу.
ПРАВИЛЬНАЯ СИНХРОНИЗАЦИЯ ОСОБЫХ СЛУЧАЕВ.
Синхронизация особых случаев опирается на команду WAIT. Когда
возникает незамаскированный особый случай, устройство FPU по-
сылает в процессор внутренний сигнал об ошибке. Когда
встречается следующая команда WAIT (или команда ESC, не свя-
занная с управлением), сигнал ошибки подтверждается и вызывает-
ся программный обработчик особого случая. Если команда ESC или
WAIT находятся в правильном месте, процессор еще не разрушил
важной для восстановления особого случая информации.
4.3. Примеры численного программирования
В этом разделе приведены примеры численных программ для
процессора i486 на языке ассемблера ASM386/486. Они ил-
люстрируют некоторые способы, полезные для программирования
систем с процессором i486 в численных приложениях.
4,3.1. Пример условного перехода
Как было показано в главе 1, некоторые численные команды
помещают информацию об особенностях результата в биты кода
условия слова состояния устройства FPU. Есть много способов
реализации условного перехода после сравнения, но все они
подчиняются следующей общей схеме:
— выполнить сравнение;
— сохранить слово состояния (его можно передать сразу в ре-
гистр АХ);
— проверить биты кода условия;
— осуществить переход по результату проверки.
Следующий фрагмент показывает сравнение двух вещественных
чисел А и В в формате, находящихся в памяти (аналогичный код
можно использовать с командой FTST), А сравнивается с В.
Само сравнение требует загрузки значения А в вершину стека
устройства FPU и сравнения его со значением В (с извлечением из
стека в одной команде). После этого слово состояния SW передает-
ся в регистр АХ целочисленного устройства.
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
A DQ ?
В DQ ?
fid** А /Загрузить А в вершину стека FPU
fcomp В /Сравнить А:В, извлечь А
fstsw ах /Сохранить результат в регистре АХ
/В регистре АХ находится результат сравнения (коды условия)
;Передать коды условия во флажки
sahf
;Использовать условные переходы
/
jp A_B_unordered Проверить бит С2 (PF)
jb Adless ;Проверить бит СО (CF)
je A^equal Проверить бит СЗ (ZF)
A^greater: ;C0 (CF) = 0, C3 (ZF) =0
A^equal: ;C0 (CF) = 0, C3 (ZF) = 1
Adless: ;C0 (CF) = 1, C3 (ZF) =0
A_B_unordered: ; C2 (PF) = 1
Рис. 4.5. Условные переходы после сравнения
Между числами А и В существуют четыре отношения порядка, и
биты СЗ, С2 и СО кода условия показывают, какое из них имеет ме-
сто. Эти биты в младшем байте слова состояния SW расположены
так, что соответствуют флажкам нуля, паритета и переноса (ZF, PF
и CF) при передаче этого байта во флажки. В приведенном фраг-
менте флажки ZF, PF и CF регистра EFLAGS устанавливаются на
значения СЗ, С2 и СО слова состояния, а затем флажки проверяют-
ся командами условного перехода. Полученный код оказывается
очень компактным и требует всего семь команд.
Команда FXAM воздействует на все четыре бита кода условия.
На рис. 4.6 показано применение таблицы переходов для определе-
ния характеристик проверяемого значения. Таблица переходов
FXAM_TBL инициализируется на 32-битные значения 16 меток по
числу комбинаций кода условия. Отметим, что четыре элемента
таблицы содержат одно и то же значение EMPTY (пустой). Первые
две комбинации кода условия соответствуют EMPTY, а еще два
элемента таблицы процессор i486 и сопроцессор 80387 никогда не
используют, но они требуются для выполнения этого программного
фрагмента на сопроцессоре 80287.
Программа выполняет команду FXAM и сохраняет слово состо-
яния в регистре АХ. Затем производится позиционирование бит
кода условия так, чтобы в регистре АХ получилось число, равное
умноженному на 2 коду условия. Для этого сбрасываются ненужные
Глава 3.Особенности программирования устройства FPU
биты в слове состояния, бит СЗ сдвигается вправо, чтобы оказаться
рядом с битом С2, и сдвигом влево код умножается на 2.
&
&
&
; Таблица переходов для процедуры анализа
FXAM.TBL DD POS_UNNORM, POS_NAN, NEGJJNNORM, NEG.NAN,
POS_NORM, POS-INFINITY, NEG-NORM, .
NEG_INFINITY, POS.ZERO, EMPTY, NEG-ZERO,
EMPTY, POS-DENORM, EMPTY, NEG-DENORM, EMPTY
; Анализ ST и сохранение результата (кодов условий)
fxam
xor eax,eax ;Очистить EAX
fstsw ax
;Вычислить смещение в таблице переходов
and ах,0100011100000000В ,‘Сбросить все биты кроме СЗ - СО
shr еах,6 ;Сдвинуть С2-С0 на место (000XXX00)
sal ah,5 ;На место СЗ (00X00000)
or al,ah ;СЗ рядом с С2 (00XXXX00)
xor ah,ah ;Убрать старую копию СЗ
;Перейти к процедуре, "адресуемой" кодом условия
jmp FXAM_TBL[eax]
;Здесь назначения переходов по одному
; для каждого результата команды FXAM
POS-UNNORM:
POS.NAN:
NEgIuNNORM:
NEWNAN:
POS-NORM:
POS-INFINITY:
NEG-NORM:
NEG_INFINITY:
POslzERO:
EMPTY:
NEG_ZERO:
POS_DENORM:
NEGJDENORM:
Puc. 4.6. Условный переход после команды FXAM
Полученное значение используется как индекс, выбирающий
одно из смещений в таблице FXAM_TBL (умножение на 2
требуется потому, что каждый элемент в FXAM TBL содержит два
байта). Команда безусловного перехода JMP осуществляет передачу
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
управления отмеченной процедуре для обработки каждого
возможного результата команды FXAM.
4.3.2. Примеры обработки особых случаев
Имеется много подходов к созданию обработчиков особых
случаев. Удобный прием заключается в том, чтобы представить об-
работчик из секций «пролога», «тела» и «эпилога». Такая процедура
вызывается через прерывание 16.
При передаче управления обработчику особого случая прерыва-
ния запрещаются аппаратно. Пролог выполняет все функции, кото-
рые должны быть защищены от возможного прерывания ис-
точником с более высоким приоритетом. Обычно они состоят в со-
хранении регистров и передаче диагностической информации из
устройства FPU в память. Когда критическая обработка закончена,
пролог разрешает прерывания для восприятия их от источников с
более высоким приоритетом.
Тело обработчика прерывания анализирует диагностическую
информацию и предпринимает реакцию, обязательно зависящую от
применения, например останов процессора, вывод сообщения или
попытка исправить ситуацию и продолжить выполнение.
Действия эпилога противоположны действиям пролога; эпилог
восстанавливает процессор до такого состояния, которое позволяет
ему возобновить выполнение программы. Эпилог не должен загру-
жать в устройство FPU флажок незамаскированного особого
случая, иначе сразу же возникнет еще один особый случай.
На рис. 4.7 — 4.9 приведены наброски трех обработчиков особых
случаев. Они показывают вид прологов и эпилогов для различных
ситуаций, а также комментарии о включении тела обработчика, за-
висящего от применения.
Фрагменты на рис. 4.7 и 4.8 довольно похожи; единственное су-
щественное различие состоит в выборе команд для сохранения и
восстановления состояния устройства FPU. Здесь приходится идти
на компромисс между командой FSAVE сохранения полного состо-
яния, предоставляющей больше диагностической информации, и
более быстрой командой FSTENV сохранения среды. В приложени-
ях, которые чувствительны к запаздыванию прерывания и не тре-
буют анализа регистров, команда FSTENV помогает сократить про-
должительность той «критической области», где процессор не рас-
познает запрос другого прерывания.
После тела обработчика эпилог готовит процессор к возобнов-
лению выполнения с точки прерывания (т.е. с той команды, кото-
рая находится после команды, вызвавшей незамаскированный осо-
бый случай). Отметим, что флажки особых случаев в памяти до заг-
рузки их в устройство FPU сбрасываются в 0 (фактически в приве-
денных примерах сбрасывается все слово состояния в памяти).
Глава 3.Особенности программирования устройства FPU
В примерах на рис. 4.7 и 4.8 предполагается, что сам обработчик
не формирует незамаскированный особый случай. Когда же это
возможно, следует применять общий подход, показанный на
рис. 4.9. Здесь в прологе сохраняется полное состояние устройства
FPU, а затем загружается новое слово управления.
save_all proc
;Сохранить регистры, выделить стек для образа состояния FPU
push ebp
mov ebp,e’sp
sub esp,108
/Сохранить полное состояние FPU, разрешить прерывания
fnsave [ebp-108]
sti
i
/Здесь зависящие от применения команды обработки
7
;Сбросить флажки особых случаев в памяти
восстановить модифицированное состояние
mov byte ptг [ebp-104],Oh
frstor [ebp-108]
/Освободить стек, восстановить регистры
mov esp,ebp
pop ebp
/Возврат в прерванную программу
iret
save_all endp
Рис. 4.7. Обработчик особого случая
с сохранением полного состояния
save_environment proc
‘ /Сохранить регистры, выделить стек для образа среды FPU
push ebp
mov ebp,esp
sub esp,28
/Сохранить среду FPU, разрешить прерывания
fnstenv [ebp-28]
sti
/Здесь зависящие от применения команды обработки
I
/Сбросить флажки особых случаев в памяти
/Восстановить модифицированную среду
mov byte ptr [ebp-24],Oh
fldenv [ebp-28]
/Освободить стек, восстановить регистры
mov esp,ebp
pop ebp
/Возврат в прерванную программу
iret
save_environment endp
Рис. 4.8. Обработчик особого случая
с уменьшенным запаздыванием
?238 .
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
Отметим, что при создании подобного обработчика нужно
проявить особое внимание, чтобы не получить бесконечных
вызовов обработчика.
local_control dw ? ;Предполагается инициализированным
reentrant proc
/Сохранить регистры, выделить стек для образа состояния FPU
push ebp
mov ebp,esp
sub esp,108
/Сохранить состояние, загрузить новое слово управления,
/ разрешить прерывания
fnsave [ebp-108]
fldcw local_control
sti
/Здесь зависящие от применения команды обработки
/Возникающие незамаскированные особые случаи будут повторно
/ вызывать обработчик особого случая.
;₽сли требуется локальная память, ее необходимо
; распределять в стеке
/Сбросить флажки особых случаев в памяти
/Восстановить модифицированное состояние
mov byte ptr [ebp-104],Oh
frstor [ebp-108]
/Освободить стек, восстановить регистры
mov esp,ebp
pop ebp
/Возврат в прерванную программу
iret
reentrant endp
Рис. 4.9. Реентрантпый обработчик особых случаев
4.3.3. Примеры численных программ
Приведем несколько простых примеров особенностей програм-
мирования устройства FPU и работу его регистрового стека.
ПРОГРАММА 1. Вычисление полинома
Следующий фрагмент производит вычисление полинома
у = Зх2 — 7х + 2 в предположении, что переменные х и у представ-
лены в коротком вещественном формате (32 бита). Константы 3, 7
и 2 представлены в формате целого слова (16 бит). Начальной вер-
шиной стека является регистр R2, т. е. поле ТОР в слове состояния
SW содержит 010В. Содержимое стека в ходе выполнения про-
граммы показано на рис. 4.10.
Глава 3.Особенности программирования устройства FPU
0 Т'ГЛР 0
1 V/JF
1 X 1
1 ОР
2 2
3 3
тор т а) 6)
0 1 (Jr y2 0
X
X 1 X 1
2 2
з 3
ТОР г в) ТОР । r)
0 7v2 0
/Xх /Xх
X 1 X 1
2 2
3 3
4
д) 5
TOP 1 6
7х2 0 7
Зх 1 e)
2 Т/'МЭ 0
1 Ur
3 7x2— 3x 1
2
ТОР ж) 0 3) 3
2 о__ 1 о |
/х — Зх + 2 2 — 0 1
з TOP y —
— z 3
к)
Рис.4.10. Вычисление полинома
X dd ? /Зарезервировать память
У dd ? ; для переменных
const dw ? / и констант /Начальное состояние стека (а)
fid X ;Загрузить значение х (б)
fid st(0) ;Продублировать х (в)
fmul st(0) /Возвести х в квадрат (г)
1L0V const,7 /Загрузить константу 7
fimul const /Умножить вершину стека на 7 (д)
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
mov const,3
fild const
fmulp st(2),st
fsubrp st(l),st
mov const,2
fiadd const
fstp у
Загрузить константу 3
;Передать ее в сопроцессор (е)
;Образовать Зх, извлечь из стека (ж)
;Образовать 7х* - Зх, извлечь (з)
;Загрузить константу 2
;Образовать значение полинома (и)
Сохранить результат, извлечь (к)
ПРОГРАММА 2. Обобщенное суммирование численного массива.
Следующая подпрограмма показывает одну интересную возмож-
ность устройства FPU. Автоматическое преобразование входных
данных во внутренний формат, а выходных данных в формат
получателя позволяет разрабатывать в некотором смысле универ-
сальные подпрограммы. В них тип обрабатываемых данных переда-
ется как параметр, а обработка в устройстве FPU оказывается оди-
наковой для всех внешних типов данных.
Подпрограмма SUMMA типа NEAR вычисляет сумму элементов
массива, которыми могут быть целые 16-битные числа, а также ве-
щественные числа в форматах ОТ и ДТ. Подпрограмме передаются
в стеке адреса массива ARRAY, переменной TYPE, определяющей
длину элементов массива (2, 4 или 8), переменной N, задающей
число элементов массива, и переменной SUM, в которой возвраща-
ется вычисленная сумма. Подпрограмма, вызывается оператором
вида
CALL SUMMA (ARRAY, TYPE, N, SUM)
Стек после выполнения команды CALL показан на рис. 4.11.
Стек
Адрес массива
Адрес типа
Адрес числа N
Адрес суммы
Адрес возврата EIP <---ESP
Старое (EBP) <---ESP
4-20
4-16
4-12
4-8
4-4
0
Рис.4.11. Формат стека для подпрограммы
push ebp
mov ebp,esp
mov ebx,[ebp]+20
Подготовить стековый
; кадр
;Адрес массива в ЕВХ
Глава 3.Особенности программирования устройства FPU
mov esi,[ebp]+16 ,-Адрес TYPE в ESI
mov eax,[esi] ;Тип элементов в регистре ЕАХ
mov esi,[ebp]+12 ;Адрес N в ESI
mov ecx,[esi] ;Число элементов в ЕСХ
;Подготовка завершена
fldz ;Регистр для суммы
cmp ecx,0 ;Проверить число элементов
jle done ;Массива нет
ladd: cmp eax, 2 ;Формат целого слова ?
jne noint ;Нет, перейти
fiadd word ptrJebx] ;Да, прибавить элемент
jmp next
noint: cmp eax, 4 ;Формат ОТ ?
jne nosng ;Нет, перейти
fadd dword ptr [ebx] ;Да, прибавить элемент
jmp next
nosng: fadd qword ptr [ebx] ;Формат ДТ
next: add ebx,eax ;Продвинуть указатель
loop ladd ;Повторить при необходимости
done: mov edi,[ebp]+8 ;Адрес суммы в EDI
fstp qword ptr [edi] ;Сохранить сумму
pop ebp
fwait ;Ожидать окончания FSTP
ret 16 ;Возврат
ПРОГРАММА 3. Преобразование вещественного числа из фор-
мата ОТ в формат ДТ
В процедуре осуществляется преобразование вещественного
числа, представленного в формате ОТ устройства FPU, в формат
ДТ. Такое преобразование не может вызвать переполнения и
антипереполнепия. Необходимо проверять и правильно представ-
лять нуль и бесконечность.
Предполагается, что исходное число находится в регистре ЕАХ и
является нормализованным. При преобразования корректируется
смещенный порядок и производится дополнение младших бит
мантиссы нулями. Полученное 64-битное вещественное число в
формате ДТ возвращается в EDX:EAX. Когда исходное число
является бесконечностью, флажок CF устанавливается в 1.
convsd public
convsd proc
push ebx ;Сохранить регистр EBX
sub edx,edx ;Учесть младшие биты
xchg eax,edx ;Число в регистре EDX
mov ebx,edx ;Скопировать число
shr ebx,23 ;Выделить смещенный
and bx,0ffh ’ ; порядок
jz done ;Если нуль - конец
cmp bx,0ffh Проверить бесконечность
jz infin ;Есть бесконечность
add bx,1023-127 ;Новое смещение
shrd eax,edx,3 ;Сдвинуть мантиссу в ЕАХ
sar edx, 3 ;Место для порядка
shl ebx,20 ;Сдвинуть порядок
and edx,800fffffh ;Сохранить знак
Ж
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
or edx,ebx ;Вставить порядок
done: POP ret ebx ;Восстановить EBX ;Возврат
infin: and or stc edx,80000000b edx,7ff00000b ;Образовать бесконечность установить флажок CF
convsd jmp endp done ; и выйти
ПРОГРАММА 4. Преобразование вещественного числа из фор-
мата ДТ в формат ОТ
В следующей процедуре осуществляется преобразование веще-
ственного числа, находящегося в памяти и представленного в фор-
мате ДТ устройства FPU, в формат ОТ. Такое преобразование мо-
жет вызвать появление переполнения или антипереполнения.
Предполагается, что исходное нормализованное число адресуют
регистры DS.SI. Если в процессе преобразования возникает пере-
полнение или антипереполнение, возвращается бесконечность или
нуль и флажок CF установлен в 1. Преобразованное число возвра-
щается в регистр ЕАХ.
convds public
convds proc
push edx ;Сохранить рабочие
push ebx ; регистры
sub eax,eax Подготовить регистр ЕАХ
mov bx,[si+6] ;Взять смещенный порядок
mov dx,bx ;Сохранить знак
shr bx,4 ;Выделить порядок
and bx,7ffh ;Убрать знак
jz done ;Если нуль - конец
sub bx,1023 ;Убрать старое смещение
add bx,127 ;Учесть новое смещение
cmp bx,l Проверить антипереполнение
jl setcf ;Есть антипереполнение
mov ah,dh ;Возвратить знак
or ax,7f80h Подготовить бесконечность
shl eax,16 Порядок и знак на месте
cmp bx,254 Проверить макс, порядок
jg done ;Если равен макс. - конец
shl bx,7 ;Порядок на место
and dx,8000h ;Выделить знак
or bx,dx ;Объединить с порядком
shl ebx,16 ;Meсто для мантиссы
mov eax,[si+4] ;Старшие
mov edx,[si] ; и младшие биты мантиссы
shld eax,edx,3 ;Образовать мантиссу
and eax,7fffffh Подготовить для порядка
or eax,ebx ;Объединить с порядком
done: POP ebx ;Восстановить
Pop ret edx ; регистры ;Возврат
setcf: or stc al,al Установить флажки ; нуля и переноса
convds jmp endp done ;К возврату
Глава 3.Особенности программирования устройства FPU
fe-243fc
Литература
1. Брамм П., Брамм Д. Микропроцессор 80386 и его
программирование. М.: — Мир, 1990.
2. Григорьев ВЛ. Программирование однокристальных
микропроцессоров. М.: — Энергоатомиздат, 1987.
3. Григорьев ВЛ. Архитектура и программирование арифме-
тического сопроцессора. М.: — Энергоатомиздат, 1991.
4. Морс С.П., Д.Алберт. Архитектура микропроцессора 80286.
М.: — Радио и связь, 1990.
5. Б.Э. Смит, М.Т. Джонсон. Архитектура и программирование
микропроцессора Intel 80386. М.: — ТОО "Конкорд", 1992.
6. Brumm Р., Brumm D. 80386 assembly language: a complete
tutorial and subroutine library. — 7X5 Books, 1988.
7. i486 Processor programmer’s reference manual. — Intel, 1990.
8. Nelson R.P. The 80386 book. — Microsoft Press, 1988.
9. Strauss E. 80386 technical reference. — Brady, 1987.
10. Turley J.L. Advanced 80386 programming techniques.
McGraw-Hill, 1988.
Микропроцессор i486 Книга 3. Устройство с плавающей точкой
Микропроцессор
i486
HffiW™ СПРАВОЧНИК
по
СИСТЕМЕ КОМАНД
Особенности описания
системы команд
В данной главе рассмотрены особенности и условные обо-
значения, принятые для описания системы команд процессора i486
в главе 2.
1.1. Атрибуты размера операнда и размера адреса
При выполнении команды процессор i486 может адресовать па-
мять, используя 16- или 32-битные адреса. Следовательно, с каждой
командой, в которой фигурирует адрес памяти, ассоциируется ат-
рибут размера адреса 16 или 32 бита. 16-битные адреса подразуме-
вают применение 16-битных смещений в командах и формирование
16-битных смещений в сегменте (т.е. относительных адресов в сег-
менте), как результат вычисления эффективного адреса (Effective
Address — ЕА). 32-битные адреса подразумевают применение 32-
битных смещений в командах и формирование 32-битных смеще-
ний в сегменте. Аналогично, команда, обращающаяся к словам (16
бит) или двойным словам (32 бита), имеет атрибут размера операн-
да 16 или 32 бита.
Атрибуты определяются принимаемыми по умолчанию
значениями, префиксами команды и (для программ, в ыполняю-
щихся в P-режиме) битами спецификации размера в дескрипторах
сегментов.
Для программ, выполняющихся в P-режиме, бит D (Default — по
умолчанию) в дескрипторах исполняемых сегментов определяет
принимаемые по умолчанию атрибуты для размера адреса и размера
операнда. Эти атрибуты по умолчанию применимы к выполнению
всех команд в сегменте. Бит D, сброшенный в 0, задает принимав -
Глава 1. Особенности описания системы команд
мыс по умолчанию размер адреса и размер операнда 16 бит, а уста-
новленный в 1 — 32 бита.
Программы, которые выполняются в R- или V-режиме, имеют
по умолчанию 16-битные адреса и операнды.
Машинное кодирование команды может включать в себя два
однобайтных префикса: префикс AddressSize размера адреса с кодом
67Н и префикс OperandSize размера операнда с кодом 66Н. Эти
префиксы заменяют («перевешивают») принимаемые по умолчанию
атрибуты сегмента для последующей команды. В таблице 1.1
показаны действия всех комбинаций размеров по умолчанию и
замен.
Таблица 1.1. Атрибуты эффективного размера
Бит D сегмента = ... 0 0 0 0 1 1 1 1
Префикс размера операнда 66Н N N Y Y N N Y Y
Префикс размера адреса 67Н N Y N Y N Y N Y
Эффективный размер операнда 16 16 32 32 32 32 16 16
Эффективный размер адреса 16 32 16 32 32 16 32 16
Примечание:
Y — да, этот префикс присутствует.
N — нет, этот префикс не присутствует.
Неявно обращающиеся к стеку команды (например, POP ЕАХ)
также имеют атрибут размера адреса стека 16 или 32 бита. Команды
с атрибутом размера адреса 16 бит используют 16-битный указатель
стека SP, а команды с атрибутом размера адреса 32 бита используют
указатель стека ESP для образования адреса вершины стека.
Атрибутом размера адреса стека управляет бит В (Big — боль-
шой) дескриптора сегмента данных в регистре SS. Значение В = О
выбирает атрибут размера адреса стека 16 бит, а значение В = 1 оп-
ределяет атрибут размера адреса стека 32 бита.
1.2. Формат команды
Общий формат команд процессора i486 приведен на рис. 1.1.
Команды состоят из необязательных префиксов, одного или двух
байт главного кода операции, возможного спецификатора адреса,
содержащего байты ModR/M и SIB, смещения в команде (если оно
требуется) и поля непосредственных данных (если оно требуется в
команде).
В главном коде операции (т.е. в первом байте команды) можно
определить меньшие поля, которые задают направление операции
(запись результата в регистр или память), размер смещения в ко-
Микропроцессор i486 Книга 4. Справочник по системе команд
манде (displacement), а также определяют регистр или знаковое
расширение. Кодирование этих полей зависит от класса операции.
Префикс команды Префикс размера адреса Префикс размера операнда Префикс замены сегмента
0 или 1 0 или 1 0 или 1 0 или 1
Число байт
КОП ModR/M SIB Смещение в команде Непосредственный операнд
1 или 2 0 или 1 0 или 1 0,1,2 или 4 0,1,2 или 4
Число байт
Рис. 1.1. Общий формат команд процессора i486
Большинство команд с обращением к памяти после главного
кода операции имеют байт режима адресации. Этот байт, называе-
мый байтом ModR/M, определяет используемую форму адреса. Не-
которые коды байта ModR/M показывают наличие второго байта
режима адресации, называемого байтом SIB (Scale — масштаб, In-
dex — индекс, Base — база), который находится после байта
ModR/M и определяет полный режим адресации.
Режимы адресации могут включать смещение в команде, кото-
рое находится сразу после байта ModR/M или байта SIB. Размер
имеющегося смещения составляет 8, 16 или 32 бита.
Если команда определяет непосредственный операнд, он всегда
находится после байт смещения. Имеющийся непосредственный
операнд всегда является последним полем команды.
Префиксы команды имеют такие коды:
F3H — префикс повторения REP (применяется только в
цепочечных командах);
F3H — префикс повторения REPE/REPZ (применяется только в
цепочечных командах);
F2H — префикс повторения REPNE/REPNZ (применяется
только в цепочечных командах);
F0H — префикс блокировки шины LOCK.
Префиксы замены сегмента, замены размера операнда и замены
размера адреса кодируются следующим образом:
2ЕН -
36Н-
ЗЕН —
26Н -
64Н—
префикс замены сегмента CS;
префикс замены сегмента SS’
префикс замены сегмента DS;
префикс замены сегмента ES;
префикс замены сегмента FS;
Глава 1. Особенности описания системы команд
65Н — префикс замены сегмента GS;
66Н — префикс замены размера операнда;
67Н — префикс замены размера адреса.
1.3. Байты ModR/M и SIB
Во многих командах процессора i486 байты ModR/M и SIB на-
ходятся после кода операции. Они содержат следующую информа-
цию (см. их формат на рис. 1.2):
— тип индексирования или номер регистра, используемого в
команде;
— используемый регистр или дополнительные сведения для вы-
бора команды;
— информацию о базе, индексе и масштабе.
7 6 5 4 3 2 1 0
MOD REG/КОП । । R/M
7 6 5 4 3 2 1 0
SS । Index BASE । ।
Рис. 1.2. Форматы байт ModR/M и SIB
Байт ModR/M состоит из трех полей:
Поле mod, которое занимает два старших бита байта,
объединяется с полем r/m, образуя 32 возможных значения: восемь
регистров и 24 режима индексирования.
Поле reg, занимающее следующие за полем mod три бита,
определяет либо номер регистра, либо дополнительные три бита
кода операции. Смысл поля r/m определяет первый байт (код опе-
рации) команды.
Поле г/m, находящееся в трех младших битах, может определять
регистр как местонахождение операнда, или служит частью кодиро-
вания режима адресации совместно с полем mod.
Базовая индексная и масштабированная индексная формы 32-
битной адресации требуют наличия байта SIB. Присутствие байта
SIB определяет специальное кодирование байта ModR/M. Байт SIB
содержит' следующие поля:
Поле ss в двух старших бита задает масштабный коэффициент.
Поле index, занимающее три следующих бита, определяет номер
регистра, служащего индексным регистром.
Поле base в трех младших битах содержит номер регистра,
который является базовым регистром.
Значения и соответствующие формы адресации для байт
ModR/M и SIB показаны в таблицах 1.2, 1.3 и 1.4. Таблица 1.2
Микропроцессор i486 и Книга 4. Справочник по системе команд
содержит 16-битные формы, определяемые байтом ModR/M. В
таблице 1.3 приведены 32-битные формы адресации, определяемые
байтом ModR/M. Наконец, в таблице 1.4 показаны 32-битные
формы адресации, определяемые байтом SIB. Во всех этих таблицах
приведены шестнадцатеричные значения байта ModR/M.
Таблица 1.2. Формы 16-битной адресации с байтом ModR/M
г8(/г) г16(/г) г32(/г) /цифра (КОП) REG = AL AX EAX 0 000 CL ex ECX 1 001 DL DX EDX 2 010 BL BX EBX 3 on AH SP ESP 4 100 CH BP EBP 5 101 DH SI ESI 6 no BH DI EDI 7 111
Эфф. адрес Mod R/M Звачеввя ModR/M
[BX+SI] 000 00 08 10 18 20 28 30 38
[BX+DI] 001 01 09 11 19 21 29 31 39
[BP+SI] 010 02 0A 12 1A 22 2A 32 ЗА
[BP+DI] 00 on 03 0B 13 IB 23 2B 33 ЗВ
[SI] 100 04 ОС 14 1C 24 2C 34 ЗС
[DI] 101 05 0D 15 ID 25 2D 35 3D
displ6 110 06 0E 16 IE 26 2E 36 ЗЕ
[BX] 111 07 OF 17 IF 27 2F 37 3F
[BX+SI]+disp8 000 40 48 50 58 60 68 70 78
[BX+DI]+disp8 001 41 49 51 59 61 69 71 79
[BP+SI]+disp8 010 42 4A 52 5A 62 6A 72 7А
[BP+DI]+disp8 01 Oil 43 4B 53 5B 63 6B 73 7В
[SI]+disp8 100 44 4C 54 5C 64 6C 74 7С
[DI]+disp8 101 45 4D 55 5D 65 6D 75 7D
[BP]+disp8 no 46 4E 56 5E 66 6E 76 7Е
[BX]+disp8 111 47 4F 57 5F 67 6F 77 7F
[BX+SI]+displ6 000 80 88 90 98 A0 A8 ВО В8
[BX+DI]+displ6 001 81 89 91 99 Al A9 Bl В9
[BP+SI]+displ6 010 82 8A 92 9A A2 AA В2 .ВА
[BP+DI]+displ6 10 on 83 8B 93 9B A3 AB ВЗ ВВ
[SI]+displ6 100 84 8C 94 9C A4 AC В4 ВС
[DI]+displ6 101 85 8D 95 9D A5 AD В5 BD
[BP]+displ6 no 86 8E 96 9E A6 AE В6 BE
[BX]+displ6 111 87 8F 97 9F A7 AF В7 BF
EAX/AX/AL 000 CO C8 DO D8 E0 E8 F0 F8
ECX/CX/CL 001 Cl C9 DI D9 El E9 Fl F9
EDX/DX/DL 010 C2 CA D2 DA E2 EA F2 FA
EBX/BX/BL 11 on C3 CB D3 DB E3 EB F3 FB
ESP/SP/AH 100 C4 cc D4 DC E4 EC F4 FC
EBP/BP/CH 101 C5 CD D5 DD E5 ED F5 FD
ESI/SI/DH no C6 CE D6 DE E6 EE F6 FE
EDI/DI/BH 111 C7 CF D7 DF E7 EF F7 FF
Примечания:
disp8 означает 8-битное смещение после байта ModR/M, которое расши-
ряется со знаком и прибавляется к индексу;
displ6 означает 16-битное смещение после байта ModR/M, прибавляемое
к индексу.
Глава 1. Особенности описания системы команд
Для адресации с участием регистра ВР по умолчанию используется сег-
ментный регистр SS, а в остальных случаях применяется DS.
Таблица 1.3. Формы 32-битной адресации с байтом ModR/M
г8(/г) AL CL DL BL AH CH DH BH
Е16(/г) AX ex DX BX SP BP SI DI
г32(/г) EAX ECX EDX EBX ESP EBP ESI EDI
/цифра (КОП) 0 1 2 3 4 5 6 7
REG = 000 001 010 on 100 101 110 111
Эфф. адрес Mod R/M Значения ModR/M
[ЕАХ] 000 00 08 10 18 20 28 30 38
[ЕСХ] 001 01 09 11 19 21 29 31 39
[EDX] 010 02 0A 12 1A 22 2A 32 ЗА
[ЕВХ] 00 on 03 0B 13 IB 23 2B 33 ЗВ
100 04 ОС 14 IC 24 2C 34 ЗС
disp32 101 05 0D 15 ID 25 2D 35 3D
[ESI] 110 06 0E 16 IE 26 2E 36 ЗЕ
[EDI] 111 07 OF 17 IF 27 2F 37 3F
disp8[EAX] 000 40 48 50 58 60 68 70 78
disp8[ECX] 001 41 49 51 59 61 69 71 79
disp8[EDX] 010 42 4A 52 5A 62 6A 72 7А
disp8[EBX] 01 Oil 43 4B . 53 5B 63 6B 73 7В
disp8[..][..] 100 44 4C 54 5C 64 6C 74 7С
disp8[EBP] 101 45 4D 55 5D 65 GD 75 7D
disp8[ESI] 110 46 4E 56 5E 66 6E 76 7Е
disp8[EDIj 111 47 4F 57 5F 67 6F 77 7F
disp32[EAX] 000 80 88 90 98 A0 A8 BO В8
disp32[ECX] 001 81 89 91 99 Al A9 Bl В9
disp32[EDX] 010 82 8A 92 9A A2 AA B2 ВА
disp32[EBX] 10 on 83 8B 93 9B A3 AB B3 ВВ
disp32[..][.. ] 100 84 8C 94 9C A4 AC B4 ВС
disp32[EBP] 101 85 8D 95 9D A5 AD B5 BD
disp32[ESI] 110 86 8E 96 9E A6 AE B6 BE
disp32[EDI] 111 87 8F 97 9F A7 AF B7 BF
EAX / AX/AL 000 CO C8 DO D8 E0 E8 F0 F8
ECX/CX/CL 001 Cl C9 DI D9 El E9 Fl F9
EDX/DX/DL 010 C2 CA D2 DA E2 EA F2 FA
EBX/BX/BL 11 on C3 CB D3 DB E3 EB F3 FB
ESP/SP/AH 100 C4 CC D4 DC E4 EC F4 FC
EBP/BP/CH 101 C5 CD D5 DD E5 ED F5 FD
ESI/SI/DH 110 C6 CE D6 DE E6 EE F6 FE
EDI/DI/BH 111 C7 CF D7 DF E7 EF F7 FF
Примечания:
[..][..] означает, что за байтом ModR/M следует байт SIB;
disp8 означает 8-битное смещение после байта SIB, которое расширяется
со знаком и прибавляется к индексу;
disp32 означает 32-битное смещение после байта ModR/M, прибавляемое
к индексу.
Й52
Микропроцессор i486 Книга 4. Справочник по системе команд
Таблица 1.4. Формы 32-битвой адресации с байтом SIB
г32 ЕАХ ECX EDX EBX ESP [.] ESI EDI
База 0 1 2 3 4 5 6 7
База 000 001 010 on 100 101 110 110
Маса, индекс SS Индекс Значения ModR/M
[ЕАХ] 000 00 01 02 03 04 05 06 07
[ЕСХ] 001 08 09 0A 0B ОС 0D 0E OF
[EDX] 010 10 11 12 13 14 15 16 17
[ЕВХ] 00 011 18 19 1A IB 1C ID IE IF
Нет 100 20 21 22 23 24 25 26 27
[ЕВР] 101 28 29 2A 2B 2C 2D 2E 2F
[ESI] по 30 31 32 33 34 35 36 37
[EDI] 111 38 39 ЗА 3B 3C 3D 3E 3F
[ЕАХ‘2] 000 40 41 42 43 44 45 46 47
[ЕСХ*2] 001 48 49 4A 4B 4C 4D 4E 4F
[ЕСХ*2] 010 50 51 52 53 54 55 56 57
[ЕВХ*2] 01 Oil 58 59 5A 5B 5C 5D 5E 5F
Нет 100 60 61 62 63 64 65 66 67
[ЕВР*2] 101 68 69 6A 6B 6C 6D 6E 6F
[ESI*2] по 70 71 72 73 74 75 76 77
[EDI*2] 111 78 79 7A 7B 7C 7D 7E 7F
[ЕАХ*4] 000 80 81 82 83 84 85 86 87
[ЕСХ*4] 001 88 89 8A 8B 8C 8D 8E 8F
[EDX*4] 010 90 91 92 93 94 95 96 97
[ЕВХ*4] 10 on 98 99 9A 9B 9C 9D 9E 9F
Нет 100 A0 Al A2 A3 A4 A5 A6 A7
[ЕВР*4] 101 A8 A9 AA AB AC AD AE AF
[ESI*4] по B0 Bl B2 B3 B4 B5 B6 B7
[EDI*4] 111 B8 B9 BA BB BC BD BE BF
[ЕАХ*8] 000 CO Cl C2 C3 C4 C5 C6 C7
[ЕСХ*8] 001 C8 C9 CA CB CC CD CE CF
[EDX*8] 010 DO DI D2 D3 D4 D5 D6 D7
[ЕВХ*8] 11 Oil D8 D9 DA DB DC DD DE DF
Нет 100 E0 El E2 E3 E4 E5 E6 E7
[ЕВР*8] 101 E8 E9 EA EB EC ED EE EF
[ESI*8] no F0 Fl F2 F3 F4 F5 F6 F7
[EDI*8] 111 F8 F9 FA FB FC FD FE FF
Примечания:
[*] означает disp32 без базы, если поле mod содержит 00В, в противном
случае [ESP]. Этим обеспечиваются режимы адресации:
disp32[index] (mod = 00В)
disp8 [EBP] [index] (mod - 01B)
disp32 [EBP] [index] (mod = 10B)
Глава 1. Особенности описания системы команд
2БЗ
1.4. Как знакомиться с системой команд
Команды процессора i486 описываются следующим форматом:
СМС - дополнение флажка переноса
КОП Команда Такты Описание
F5 СМС 2 Дополнение флажка переноса
После такой таблицы находятся параграфы, озаглавленные
«Операция», «Описание», «Воздействие на флажки», «Особые
случаи P-режима», «Особые случаи R-режима», «Особые случаи
V-режима» и (необязательно) «Примечания». Далее подробно
описаны соглашения об обозначениях и сокращения, принятые в
описаниях команд.
СТОЛБЕЦ КОДА ОПЕРАЦИИ. В этом столбце приведен пол-
ный объектный код, формируемый дая каждой формы команды. По
возможности коды приводятся как шестнадцатеричные байты в том
порядке, в каком они хранятся в памяти. Применяются следующие
элементы, отличающиеся от шестнадцатеричных байт:
/цифра — (в диапазоне 0—7) показывает, что байт ModR/M
использует только операнд г/m (регистр или память). Поле reg со-
держит цифру, являющуюся расширением кода операции.
/г — показывает, что байт ModR/M содержит операнд-регистр и
операнд r/m.
cb, cw, cd, ср — одно - (cb), двух - (cw), четырех - (cd) или
шестибайтное (ср) значение после кода операции, которое исполь-
зуется дая определения смещения кода и, возможно, нового значе-
ния для сегментного регистра кода.
ib, iw, id — одно - (ib), двух - (iw) или четырехбайтный (id)
непосредственный операнд, находящийся после кода операции и
байт ModR/M и SIB. Код операции определяет, является ли
операнд знаковым значением. В словах и двойных словах первым
указывается младший байт.
+rb, +rw, +rd — код регистра в диапазоне 0—7, который при-
бавляется к шестнадцатеричному байту слева от знака плюс с обра-
зованием одного байта кода операции. Принято следующее кодиро-
вание:
rb
AL = О
CL = 1
DL = 2
BL = 3
АН = 4
СН = 5
DH = 6
ВН = 7
rw
АХ = О
СХ = 1
DX = 2
ВХ = 3
SP = 4
ВР = 5
SI = 6
DI = 7
rd
ЕАХ = О
ЕСХ = 1
EDX = 2
ЕВХ = 3
ESP = 4
ЕВР = 5
ESI = 6
EDI = 7
+i — применяется в командах с плавающей точкой, когда одним
из операндов является ST(i) из регистрового стека устройства с
Микропроцессор i486 Книга 4. Справочник по системе команд
плавающей точкой (Floating Point Unit — FPU). Число i (диапазон
0—7) прибавляется шестнадцатеричному байту слева от знака плюс
с образованием одного байта кода операции.
СТОЛБЕЦ КОМАНДЫ. Этот столбец содержит синтаксис ко-
манды применительно к ассемблеру ASM386. Для представления
операндов применяются следующие обозначения:
ге!8 — относительный адрес в диапазоне 128 байт перед концом
команды и 127 байт после конца команды.
ге116, ге!32 — относительный адрес в том же сегменте кода, что
и ассемблируемая команда; ге116 относится к командам с атрибутом
размера операнда 16 бит; ге132 относится к командам с атрибутом
размера операнда 32 бита.
ptr!6:16, ptr 16:32 — далекий (FAR) указатель, обычно в сегменте
кода, отличающемся от сегмента команды. Обозначение 16:16 пока-
зывает, что значение указателя имеет две части. Значение слева от
двоеточия есть 16-битный селектор или значение, предназначенное
для сегментного регистра кода. Значение справа соответствует сме-
щению в сегменте назначения. Обозначение ptrl6:16 применяется,
когда атрибут размера операнда в команде 16 бит, a ptrl6:32 приме-
няется с 32-битным атрибутом.
г8 — один из регистров длиной байт AL, CL, DL, BL, АН, СН,
DH или ВН.
г!6 — один из регистров длиной слово АХ, СХ, DX, ВХ, SP, ВР,
SI или DI.
г32 — один из регистров длиной двойное слово ЕАХ, ЕСХ,
EDX, ЕВХ, ESP, EBP, ESI или EDI.
imm8 — непосредственное знаковое значение длиной байт с ди-
апазоном значений от -128 до +127. В командах, где imm8 участвует
с операндом длиной в слово или двойное слово, непосредственное
значение расширяется со знаком для образования слова или двой-
ного слова. Старший байт слова заполняется старшим битом не-
посредственного значения.
imml6 — непосредственное значение длиной в слово, применя-
емое для команд с атрибутом размера операнда 16 бит. Диапазон
значений от -32768 до +32767.
imm32 — непосредственное значение длиной в двойное слово,
применяемое для команд с атрибутом размера операнда 32 бита.
Диапазон значений от -2147483648 до +2147483647.
г/ш8 — однобайтный операнд, содержащийся в байтном реги-
стре (AL, BL, CL, DL, АН, ВН, CH, DH) или байта из памяти.
г/ml6 — операнд длиной слово из регистра (АХ, ВХ, СХ, DX,
SP, BP, SI, DI) или памяти, используемый в командах с атрибутом
размера операнда 16 бит. Содержимое памяти берется по адресу,
полученному при вычислении эффективного адреса.
Глава 1. Особенности описания системы команд
r/m32 — операнд длиной двойное слово из регистра (ЕАХ, ЕВХ,
ЕСХ, EDX, ESP, EBP, ESI, EDI) или памяти, используемый в ко-
мандах с атрибутом размера операнда 32 бита. Содержимое памяти
берется по адресу, полученному при вычислении эффективного ад-
реса.
ш8 — байт в памяти, адресуемый DS:SI или ES:DI (применяется
только в цепочечных командах).
т!6 — слово в памяти, адресуемое DS.SI или ES.DI
(применяется только в цепочечных командах).
т32 — двойное слово в памяти, адресуемое DS:SI или ES:DI
(применяется только в цепочечных командах).
ml6:16, ml6:32 — операнд в памяти, содержащий далекий указа-
тель из двух чисел. Число слева от двоеточия соответствует селек-
тору сегмента указателя, а число справа — смещению.
Ш16&32, ml6&169 т32&32 — операнд в памяти, состоящий из
пары элементов данных, размеры которых указаны слева и справа
от символа амперсанда. Все режимы адресации памяти, допускае-
мые операндами т16&16 и т32&32, используются в команде
BOUND для задания операнда, содержащего верхнюю й нижнюю
границы индекса массива. Элемент ml6:32 используется в командах
LIDT и LGDT для задания слова, которое загружается в поле пре-
дела, и двойного слова, которое загружается в поле базы регистров
GDTR глобальной дескрипторной таблицы и IDTR дескрипторной
таблицы прерываний.
moffs8, moffsl6, mo№32 (смещение памяти) — простая перемен-
ная в памяти типа BYTE, WORD или DWORD, которая применяет-
ся в некоторых формах команды MOV. Фактический адрес задается
простым смещением относительно базы сегмента. Число, приводи-
мое вместе с moffs, показывает его размер, который определяется
атрибутом размера адреса команды.
Sreg — сегментный регистр (ES = О, CS = 1, SS — 2, DS “ 3,
FS = 4, GS = 5).
m32real, m64real, m80real — операнды с плавающей точкой в па-
мяти, имеющие соответствующую длину.
ml6int, m32int, m64int — целочисленные операнды для устрой-
ства FPU в памяти, имеющие соответствующую длину.
mNbyte — N-байтный операнд с плавающей точкой в памяти.
ST или ST(0) — верхний элемент регистрового стека устройства
FPU.
ST(i) — i-й элемент от вершины регистрового стека устройства
FPU (i = 0, 1, 7).
СТОЛБЕЦ ТАКТОВ. Этот столбец показывает примерное число
тактов на выполнение команды. В расчетах числа тактов приняты
следующие предположения:
Микропроцессор i486 Книга 4. Справочник по системе команд
— При обращении к данным или команде происходит попада-
ние в кэш-памяти.
— Назначение команды перехода находится в кэш-памяти.
— При выполнении команды не требуются циклы объявления
кэш-памяти недостоверной.
Страничное преобразование сопровождается попаданием в
буфере преобразования (Translation Lookaside Buffer — TLB).
— Операнды в памяти выравнены.
— В вычислениях эффективного адреса участвует один базовый
регистр, а индексный регистр отсутствует; базовый регистр не явля-
ется регистром-получателем предыдущей команды.
— Не используются совместно смещение в команде и непосред-
ственный операнд.
— При выполнении команды не возникают особые случаи.
— Нет задержек в буферах записи.
Если эти условия не соблюдаются, время выполнения команды
несколько увеличивается.
В спецификациях числа тактов применяются следующие обо-
значения:
п — число повторений.
ш — число компонент следующей выполняемой команды, где
одной компонентой считаются все смещение в команде, весь не-
посредственный операнд; все остальные байты команды и каждый
префикс считаются отдельной компонентой.
рш= — число тактов на выполнение команды в P-режиме (не
указывается, когда время выполнения одинаково в R- и Р-режи-
мах).
Когда при выполнении команды возникает особый случай и его
обработчик является другой задачей, время выполнения команды
увеличивается на число тактов, необходимых для переключения за-
дачи. Этот параметр зависит от нескольких факторов:
— Типа сегмента TSS, представляющего новую задачу (сегмент
TSS процессора i486 или сегмент TSS процессора 80286).
— Выполнения текущей задачи в V-режиме.
— Работы новой задачи в V-режиме.
— Наличия попаданий в кэш-памяти.
— Применения шлюза задачи или шлюза прерывания.
В таблице 1.5 приведены времена переключения задачи в случае
попаданий в кэш-памяти и применения шлюзов задачи.
Таблица 1.5. Время переключения задачи для особых случаев
Мгодяцая задача На T6S i486 Входящая >адача На IBS 80296 На TS8 7-рвжяма
TSS VM/i486/80286 199 180 177
Глава 1. Особенности описания системы команд
9 Заказ 4317
СТОЛБЕЦ ОПИСАНИЯ. Здесь кратко поясняются различные
формы команды. Более подробно каждая команда рассматривается
в следующих параграфах.
ОПЕРАЦИЯ. Здесь содержится алгоритмическое описание ко-
манды, в котором применяется нотация языка типа Алгола или
Паскаля. Алгоритмы состоят из следующих элементов:
Комментарии заключаются в пары (* и *).
Составные операторы включаются между ключевыми словами
оператора if (IF, THEN, ELSE, FI) и do (DO, OD), а также опера-
тора case (CASE ...OF ESAC).
Имя регистра подразумевает содержимое регистра. Имя регистра
в квадратных скобках означает содержимое ячейки, адрес которой
находится в регистре. Например, ES:[DI] показывает содержимое
ячейки, относительный адрес которой находится в регистре DI
(сегмент определяется регистром ES). Запись [SI] означает содер-
жимое адреса, находящегося в регистре SI, относительно сегмента
по умолчанию DS.
Квадратные скобки применяются также для операндов в памяти,
причем они означают, что содержимым ячейки памяти является
относительное смещение. Например, запись [SRC] показывает, что
операнд-источник содержит относительное смещение.
Запись А <— В; означает, что А присваивается значение В.
Для сравнения величин применяются операторы отношений =
(равно), О (не равно), => (больше или равно), <=* (меньше или
равно). Реляционное выражение А = В истинно (TRUE), если А
равно В, в противном случае оно ложно (FALSE).
В алгоритмических описаниях применяются следующие иденти-
фикаторы:
OperandSize — атрибут размера операнда команды, равный 16
или 32 битам.
AddressSize — атрибут размера адреса, равный 16 или 32 битам.
StackAddrSize — ассоциируемый с командой атрибут размера
адреса стека, который имеет значение 16 или 32 бита.
SRC — операнд-источник; при наличии двух операндов ис-
точник находится справа.
DEST — операнд-получатель; при наличии двух операндов
получатель находится слева.
LeftSRC, RightSRC — различают два операнда (левый и пра-
вый), которые оба являются операндами-источниками.
eSP — означает регистр SP или ESP в зависимости от состояния
бита В текущего сегмента стека.
В алгоритмических описаниях применяют следующие функции:
Truncate to 16 bits(value) — уменьшает размер значения value до
16 бит, отбрасывая при необходимости старшие биты.
Микропроцессор i486 Книга 4. Справочник по системе команд
Addr(operand) — возвращает эффективный адрес операнда (ре-
зультат вычисления эффективного адреса до суммирования с базой
сегмента).
ZeroExtend(value) возвращает значение, расширенное с нулем
до атрибута размера Операнда команды. Если, например, Oper-
andSize = 32, то функция Zero Extend байта -10 превращает байт
F6H в двойное слово^ 000000F6H. Если переданное функции
Zero Extend значение и атрибут размера операнда одинаковы, функ-
ция возвращает значение неизменным.
SignExtend(value) — возвращает значение, расширенное со
знаком до атрибута размера операнда команды. Если, например,
OperandSize = 32, то функция SignExtend байта -10 превращает байт
F6H в двойное слово FFFFFFF6H. Если переданное функции Sign-
Extend значение и атрибут размера операнда одинаковы, функция
возвращает значение неизменным.
Push(value) — включает значение в стек. Число включаемых
байт определяется атрибутом размера операнда команды.
Включение в стек состоит из следующих действий:
IF StackAdrSise =16
TftEN
IF OperandSize =16
THEN
SP <— SP - 2;
SS:[SP] <-- value; (♦ два байта*)
ELSE (* OperandSize = 32 *)
SP <— SP - 4; ’ '
SS:[SP] <— value; (* четыре байта*)
FI;
ELSE (* StackAdrSize = 32 *)
IF OperandSize =16
THEN
ESP <-- ESP - 2*
SS: [ESP] <— value; (* два байта *)
ELSE (* OperandSize = 32 *)
ESP <-- ESP - 4;
SS:[ESP] <-- value; (* четыре байта *)
FI;
FI;
Pop(value) — удаляет (извлекает) значение из вершины стека и
возвращает его. Оператор ЕАХ <-- Рор(); присваивает ЕАХ 32-бит -
ное значение из вершины стека. В зависимости от атрибута размера
операнда извлекается слово или двойное слово. Извлечение из сте-
ка состоит из следующих действий:
IF StackAdrSise =16
THEN
IF OperandSize =16
THEN
ret val <— SS:[SP]; (* двухбайтное значение *)
SP <— SP + 2;
ELSE (* OperandSize = 32 *)
ret val <— SS:[SP]; (* четырехбайтное значение *)
SP <— SP + 4?
Глава 1. Особенности описания системы команд
FI;
ELSE (* StackAdrSize = 32 *)
IF Operandsize =16
THEN
ret val <-- SS:[ESP]; (* двухбайтное значение *)
ESP <— ESP + 2;
ELSE (* OperandSize = 32 *)
ret val <— SS:[ESP]; (* четырехбайтное значение *)
ESP <— ESP + 4;
FI;
FI;
RETURN(ret val); {* возвращает слово или двойное слово *)
В командах с плавающей точкой Pop(ST) означает извлечение из
регистрового стека устройства FPU.
Bit [Bit Base, BitOffset] — возвращает адрес бита внутри битовой
цепочки, представляющей собой последовательность бит в памяти
или регистре. Биты в байтах нумеруются от младшего к старшему. В
памяти два байта слова хранятся с младшим байтом по меньшему
адресу.
31 21 О
—1—1—1 1 1 1 1—1 1 1 1 1 1 1 1—1—1 1 1 1 1 1 1 i 1 1—1 1—1—
1---------BitOffset=21----------
Рис. 1.3. Смещение бита для функции В1Т[ЕАХ,21]
Если операндом базы служит регистр, смещение находится в ди-
апазоне 0...31. Смещение адресует бит в указанном регистре. При-
мер функции В1Т[ЕАХ,21] показан на рис. 1.3.
Рис. 1.4. Индексирование бит в памяти
Если BitBase есть адрес памяти, то BitOffset может находиться в
диапазоне от -2 Гбит до +2 Гбит. Адресуемый бит имеет номер
(Offset MOD 8) внутри байта с адресом (BitBase + (BitOffset DIV 8)),
где DIV означает знаковое деление с округлением к отрицательной
КОШ Микропроцессор i486 Книга 4. Справочник по системе команд
бесконечности и MOD возвращает положительное число. Рассмот-
ренные операции иллюстрируются на рис. 1.4.
I-O-Pennission(/-O-^<fJress, width) — возвращает истину TRUE
или ложь FALSE в зависимости от двоичной карты разрешения
ввода-вывода и других факторов. Эта функция определяется
следующим образом:
IF тип TSS есть 80286 THEN RETURN FALSE.; FI;
Ptr <— [TSS + 66]; (* получить указатель карты *)
BitStringAddr <— SHR (I-O-Address,3) + Ptr;
MaskShift <— I-O-Address AND 7;
CASE width OF;
BYTE: nBitMask <— 1;
WORD: nBitMask <— 3;
DWORD: nBitMask <— 15;
mAsk <— SHL (nBitMask, MaskShift);
Checkstring <— [BitStringAddr] AND mask;
IF Checkstring = 0
THEN RETURN (TRUE);
ELSE RETURN (FALSE);
FI;
Switch-Tasks — функция переключения задачи.
Примечание
В книге опущены громоздкие описания операций некоторых команд пе-
редачи управления, которые вряд ли потребуются на практике.
ОПИСАНИЕ. В этом параграфе содержится подробное описа-
ние операции, выполняемой командой.
ВОЗДЕЙСТВИЕ НА ФЛАЖКИ. Здесь показано, как команда
воздействует на флажки. Приняты следующие соглашения:
— Если команда всегда сбрасывает или всегда устанавливает
флажок, то после названия флажка указывается значение (0 или 1).
Обычно арифметические и логические команды воздействуют на
флажки единообразно. Необычные установки флажков приводятся
в параграфе «ОПИСАНИЕ».
— Указание «не определен» означает, что команда воздействует
на флажок непредсказуемым образом.
— Не показанные в описании флажки команда не изменяет.
Для команд с плавающей точкой имеется параграф «Воздействие
на флажки FPU», показывающий воздействие команды на биты ко-
ды условия слова состояния устройства FPU. Здесь же имеется па-
раграф «Численные особые случаи», где приведены флажки слова
состояния устройства FPU, которые может установить команда.
ОСОБЫЕ СЛУЧАИ P-режима, Приведены особые случаи, кото-
рые могут возникнуть при выполнении команды в защищенном
режиме (P-режиме). Обозначения особых случаев состоят из знака
номера (#), двухбуквенного сокращения и необязательного кода
Глава 1. Особенности описания системы команд
ошибки в круглых скобках. Например, #GP(0) означает особый
случай общей защиты с кодом ошибки 0. В таблице 1.6 показана
связь двухбуквенного обозначения с соответствующим номером
прерывания.
Таблица 1.6. Особые случаи
Мвемовика Прервшапе Охшсаие
IUD 6 Неверный код операции
им 7 Устройство недоступно
IDF 8 Двойное нарушение
ITS 10 Неверный сегмент TSS
*NP 11 Сегмент или шлюз не присутствуют
ISS 12 Нарушение стека
IGP 13 Нарушение общей защиты
IFF 14 Страничное нарушение
IMF 16 Ошибка с плавающей точкой
IAC 17 Контроль выравнивания
Прикладные программисты должны познакомиться по докумен-
тации операционной системы с действиями, предпринимаемыми
при возникновении особых случаев.
ОСОБЫЕ СЛУЧАИ R-режима. Приведены особые случаи, кото-
рые могут возникнуть при выполнении команды в реальном режи-
ме (R-режиме). Так как в режиме реального адреса (R-режиме)
процессор i486 контролирует меньше ошибок, особых случаев здесь
возникает меньше.
ОСОБЫЕ СЛУЧАИ V-режима. Приведены особые случаи, кото-
рые могут возникнуть при выполнении команды в режиме вирту-
ального процессора 8086 (V-режиме). Задачи виртуального процес-
сора 8086 позволяют моделировать виртуальные машины с процес-
сором 8086. Особые случаи V-режима аналогичны особым случаям
процессора 8086, но имеются и некоторые отличия.
В командах устройства с плавающей точкой FPU для численных
особых случаев применяются следующие обозначения:
IS - недействительная операция, вызванная переполнением или
антипереполнением стека;
I - недействительная операция, вызванная другими причинами
кроме переполнения или антипереполнения стека;
D - денормализованный операнд;
Р - потеря точности;
U - антипереполнение;
О - переполнение;
Z - деление на нуль.
В этих же командах применяется интерпретация кода условия,
приведенная в табдице 1.7.
Микропроцессор i486 «Книга 4 Справочник по системе команд
Таблица 1.7. Интерпретация кода условия
Команда CO C3 С2 С1
FCOM, FCOMP, FCOMPP, FTST, FUCOM, FUCOMP, FUCOMPP, FICOM, FICOMP1 Результат сравнения Операнды не сравнимы Нуль или O/U#
FXAM Класс операнда Знак или O/U#
FPREM, FPREM1 Q2 QO 0= 1= ^приведение ^приведение зав. не зав. Q1 ипи O/Ui
FIST, FBSTP, FRNDINT, FST, FSTP, FADD, FMUL, FDIV, FDIVR, FSUB FSUBR, FSCALE, FSQRT, FPATAN, F2XM1, FYL2X, FYL2XP1 НЕ ОПРЕДЕЛЕНЫ Округление вверх или O/U#
FPTAN, FSIN, FCOS, FSINCOS НЕ ОПРЕДЕЛЕНЫ 0= 1= приведение приведение зав. не зав. Округление вверх или O/U1 (не опр. при С2=1)
FCHS, FABS< FXCH, FINCSTP, FDECSTP, FLD, 4 FXTRACT, FILD, FBLD, FSTP (расш.] загрузки констант НЕ ОПРЕДЕЛЕНЫ h Нуль или O/U#
FLDENV, FRSTOR Каждый бит загружается из памяти
FLDCW, FSTENV, FSTCW, FSTSW, FCLEX НЕ ОПРЕДЕЛЕНЫ
FINIT, FSAVE Нуль Нуль Нуль Нуль
Примечания:
O/U#. Когда оба бита IE и SF слова состояния установлены, показывая
особый случай стека, этот бит различает переполнение (С1=1) и антипере-
полнение (С1=0).
Приведение. Если команды FPREM и FPREM 1 дают остаток меньше мо-
дуля, приведение завершено. Когда приведение не завершено, значение в
вершине стека является частичным остатком, который можно использовать
как вход для дальнейшего приведения. В командах FPTAN, FSIN, FCOS и
FSINCOS бит приведения установлен, если операнд в вершине стека слиш-
ком большой. В этом случае в вершине стека сохранится исходный операнд.
Округление вверх. Когда бит РЕ слова состояния установлен, этот бит
показывает, было ли последнее округление в команде вверх.
НЕ ОПРЕДЕЛЕНЫ — конкретные значения бит отсутствуют.
Г лава 1. Особенности описания системы команд
Справочные сведения
по командам
процессора i486
В этой главе приведены подробные описания всех команд про-
цессора i486 (в порядке английского алфавита).
Ради экономии объема книги использован следующий прием.
Большинство команд манипуляций данными с обращением к памя-
ти формируют особые случаи практически при одних и тех же ус-
ловиях. Поэтому в дальнейшем сноска «Далее см. ПРИМЕЧАНИЕ»
означает такие ситуации:
Особые случаиР-режима
# GP(O) при недопустимом эффективном адресе операнда в па-
мяти в сегментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) дая страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий
уровень привилегий равен 3.
Особые случацЯ-режима
Прерывание 13, если любая часть операнда находится вне про-
странства эффективного адреса от О до OFFFFH.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РР(код-нарушение) дая страничного нарушения.
#АС при невыравненном обращении к памяти, если текущий
уровень привилегий равен 3.
Микропроцессор i486 « Книга 4. Справочник по системе команд
AAA - ASCII Adjust after Addition
ASCII-коррекция после сложения
КОП Команда. Такт Описание
37 АЛА 3 Коррекция AL после сложения
Операция
IF ((AL AND OFH) > 9) (Ж (AF = 1)
THEN
AL <— (AL + 6) AND OFH;
AH <— AH f 1;
AF <— 1; CF <— 1;
ELSE
CF <— 0; AF <— 0;
FI;
Описание
Команду AAA нужно выполнять только после команды ADD, которая ос-
тавляет байтный результат в регистре AL. Младшие тетрады операндов коман-
ды ADD должны находиться в диапазоне 0—9. В этом случае команда ААА
корректирует регистр AL так, чтобы он содержал правильную десятичную
цифру результата. Если при сложении формируется десятичный перенос,
производится инкремент регистра АН и флажки AF и CF устанавливаются в
1. Если десятичного переноса нет, флажки AF и CF сбрасываются в О, а со-
держимое регистра АН не изменяется. В любом случае старшая тетрада регис-
тра AL содержит 0. Для преобразования регистра AL в ASCII-результат после
команды ААА следует выполнить команду OR AL,ЗОН.
Воздействие на флажки
Флажки AF и CF установлены в 1 при наличии десятичного переноса, а
при его отсутствии сброшены в 0; флажки OF, SF, ZF и PF не определены.
Особые случаи P-режима Нет
Особые случаи R-режима Нет
Особые случаи V-режима Нет
AAD - ASCII Adjust АХ before Division
ASCII-коррекция регистра АХ перед делением
КОП Комаида Тажга Ошкяипе
D5 ОА AAD 14 Коррекция АХ веред делением
Операция
AL <— АНХ10 + AL;
АН <— Of
Описание
Команда AAD применяется для подготовки двух неупакованных деся-
тичных цифр (младшая цифра в регистре AL, старшая в регистре АН) к опе-
рации деления, которая должна дать неупакованный результат. Для этого в
регистре AL образуется число AL + (10хАН), а затем регистр АН сбрасыва-
ется в 0. После этого в регистре АХ находится двоичный эквивалент исход-
ного неупакованного двухразрядного числа.
Воздействие на флажки
Флажки SF, ZF и PF устанавливаются по результату; флажки OF, AF и
CF не определены.
Особые случаи P-режима Нет
Особые случаи R-режима Нет
Особые случаи V-режима Нет
Глава 2. Справочные сведения по командам i486
ААМ - ASCII Adjust AX after Multiply
ASCII-коррекция регистра AX после умножения
КОП Команда Такты Описание
D4 ОА ААМ 15 Коррекция АХ после умножения
Операция
АН <— AL / 10;
AL <— AL MOD 10;
Описание
Команду ААМ нужно выполнять только после команды MUL умножения
двух неупакованных десятичных цифр, которая оставляет результат в регистре
АХ. Так как результат меньше 100, он полностью содержится в регистре AL.
Команда ААМ распаковывает результат в AL путем деления AL на 10 и по-
мещения частного (старшего разряда) в регистр АН и остатка (младшей
цифры) в регистр AL.
Воздействие на флажки
Флажки SF, ZF и PF устанавливаются по результату; флажки OF, AF и
CF не определены.
Особые случаи Р-режима Нет
Особые случаи R-режима Нет
Особые случаи V-режима Нет
AAS - ASCII Adjust after Subtraction
ASCII-коррекция после вычитания
КОП Команда Такты Описание
ЗА AAS 3 Коррекция AL после вычитания
Операция
IF ((AL AND OFH) > 9) OR (AF = 1)
THEN
AL <— AL - 6;
AL <— AL AND OFH;
AH <-- AH - 1;
AF <-- 1; CF <— 1;
ELSE
CF <-- 0; AF <-- 0;
FI;
Описание
Команду AAS нужно выполнять только после команды SUB, которая ос-
тавляет байтный результат в регистре AL. Младшие тетрады операндов коман-
ды SUB должны находиться в диапазоне 0 — 9. В этом случае команда AAS
корректирует регистр AL так, чтобы он содержал правильную десятичную
Цифру результата. Если при вычитании формируется десятичный заем, про-
изводится декремент регистра АН и флажки AF и CF устанавливаются в 1.
Если десятичного переноса нет, флажки AF и CF сбрасываются в 0, а регистр
АН не изменяется. В любом случае старшая тетрада регистра AL содержит 0.
Для преобразования регистра AL в AS СП-результат после команды AAS сле-
дует выполнить команду OR AL,ЗОН.
Воздействие на флажки
Флажки AF и CF установлены в 1 при наличии десятичного переноса, а
при его отсутствии сброшены в 0; флажки OF, SF, ZF и PF не определены.
Особые случаи Р-режима Нет
Особые случаи R-режима Нет
Особые случаи V-режима Нет
266^
Микропроцессор i486 Книга 4. Справочник по системе команд
ADC - ADd with Carry
Сложение с переносом
КОП Команда Ганты Описание
14 ib ADC AL,imm8 1 Сложение c CF непоср. байта с AL
15 iw ADC AX,innl6 1 Сложение с CF непоср. слова с АХ
15 id ADC EAX,imm32 1 Сложение с CF непоср. двойного слова с ЕАХ
80 /2 ib ADC r/m8,imm8 1/3 Сложение с CF непоср. байта с байтом г/ш
81 /2 iw ADC r/ml6,imml6 1/3 Сложение с CF непоср. слова со словом г/ш
81 /2 id ADC r/m32,imm32 1/3 Сложение с CF непоср. двойного слова с двойным словом г/ш
83 /2 ib ADC r/ml6,imm8 1/3 Сложение с CF непоср. байта со знаковым расширением со словом г/ш
83 /2 ib ADC r/m32,imm8 1/3 Сложение с CF непоср. байта со знаковым расширением с двойным словом г/ш
10 /r ADC r/m8,r8 1/3 Сложение с CF байтного per. с байтом г/ш
11 /r ADC r/ml6,rl6 1/3 Сложение с CF словного per. со словом г/ш
11 Zr ADC r/m32,r32 1/3 Сложение с CF двухсловного регистра с двойным словом г/ш
12 /r ADC r8,r/m8 1/3 Сложение с CF байта г/ш с байтным регистром
13 /r ADC rl6,r/ml6 1/3 Сложение с CF слова г/m со словным регистром
13 /r ADC r32,r/m32 Операция 1/3 Сложение с CF двойного слова г/ш с двухсловным регистром
DEST <— DEST + SRC + CF;
Описание
Команда ADC производит целочисленное сложение двух операндов DEST
и SRC и флажка переноса CF. Результат сложения присваивается первому
операнду (DEST) и соответственно устанавливаются флажки. Обычно команда
ADC применяется как часть операции многобайтного или многословного
сложения. Когда непосредственное байтное значение прибавляется к слову
или двойному слову, оно вначале расширяется со знаком до размера операн-
да.
Воздействие на флажки
Флажки OF, SF, ZF, AF, CF и PF устанавливаются в соответствии с ре-
зультатом.
Особые случаи Р-режима
# GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ
ADD
Сложение
КОП Команда ! Сайты Описании
04 ib ADD AL,imm8 1 Сложение непоср. байта с AL
05 iw ADD AX,imml6 1 Сложение непоср. слова с АХ
05 id ADD EAX,imm32 1 Сложение непоср. двойного слова с ЕАХ
80 /0 ib ADD r/m8finm8 1/3 Сложение непоср. байта с байтом г/ш
81 /0 iw ADD r/ml6rimml6 1/3 Сложение непоср. слова со словом г/ш
81 /0 id ADD r/m32,iiun32 1/3 Сложение непоср. двойного слова с двойным словом г/ш
83 /0 ib ADD r/ml6rimm8 1/3 Сложение непоср. байта со знаковым расширением со словом г/ш
83 /0 ib ADD r/m32rimm8 1/3 Сложение непоср. байта со знаковым расширением с двойным словом г/п
00 /r ADD r/m8,r8 1/3 Сложение байтного per. с байтом г/ш
01 /r ADD r/ml6,rl6 1/3 Сложение словного per. со словом г/ш
Глава 2. Справочные сведения по командам i486
01 /г ADD г/ш32,г32 1/3 Сложение двухсловного регистра
с двойным словом г/ш
02 /г ADD r8,r/m8 1/3 Сложение байта r/ш с байтным регистром
03 /г ADD rl6,r/ml6 1/3 Сложение слова r/ш со словным регистром
03 /г ADD г32,г/ш32 1/3 Сложение двойного слова г/ш
с двухсловным регистром
Операция
DEST <— DEST + SRC;
Описание
Команда ADD производит целочисленное сложение двух операндов DEST
и SRC. Результат сложения присваивается первому операнду DEST и соответ-
ственно устанавливаются флажки. Когда непосредственное байтное значение
прибавляется к слову или двойному слову, оно вначале расширяется со зна-
ком до размера операнда.
Воздействие на флажки
Флажки OF, SF, ZF, AF, CF и PF устанавливаются в соответствии с ре-
зультатом.
Особые случаи Р-режима
# GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
AND - logical AND
Логическое И
КОП Команда ! Гакты Описание
24 ib AND AL,imm8 1 Логическое И непоср. байта с AL
25 iw AND AXrimml6 1 Логическое И непоср. слова с АХ
25 id AND EAXrimm32 1 Логическое И непоср. двойного слова с ЕАХ
80 /4 ib AND r/m8,imm8 1/3 Логическое И непоср. байта с байтом г/ш
81 /4 iw AND r/ml6fimml6 1/3 Логическое И непоср. слова со словом г/ш
81 /4 id AND r/m32fimm32 1/3 Логическое И непоср. двойного слова с двойным словом г/ш
83 /4 ib AND r/ml6fimm8 1/3 Логическое И непоср. байта со знаковым расширением со словом г/ш
83 /4 ib AND r/m32fimm8 1/3 Логическое И непоср. байта со знаковым расширением с двойным словом г/ш
20 /r AND r/m8,r8 1/3 Логическое И байтного per. с байтом г/ш
21 /r AND r/ml6,rl6 1/3 Логическое И словного per. со словом г/ш
21 /r AND r/m32,r32 1/3 Логическое И двухсловного регистра с двойным словом г/ш
22 /r AND r8,r/m8 1/3 Логическое И байта г/ш с байтным регистром
23 /r AND rl6fi7ml6 1/3 Логическое И слова г/ш со словным регистром
23 /r AND r32,r/m32 1/3 Логическое И двойного слова г/ш с двухсловным регистром
Операция
DEST <— DEST AND SRC;
CF <-- 0; OF <— 0;
Описание
Каждый бит результата команды AND равен 1, если соответствующие би-
ты обоих операндов равны 1; иначе результат равен 0.
Воздействие на флажки
Флажки CF и OF сбрасываются в 0, а флажки ZF, SF и PF устанавлива-
ются в соответствии с результатом.
Особые случаи Р-режима
#GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
$2^1
Микропроцессор i486 Книга 4. Справочник по системе команд
ARPL - Adjust RPL field of selector
Коррекция поля RPL селектора
КОП Команда Тают Опксаняе
63 /г ARPL r/m 16,rl 9/9 Коррекция поля RPL в г/ш16 так, чтобы
оно было не меньше, чем RPL в г16
Операция
IF RPL биты(0,1) DEST < RPL биты(0,1) SRC
THEN
ZF <— 1;
RPL биты(0,1) DEST <— RPL биты{0,1) SRC;
ELSE
ZF <— 0;
FI;
Описание
Команда ARPL имеет два операнда. Первым операндом является 16-бит-
ная переменная в памяти или словный регистр, содержащие значение селек-
тора. Вторым операндом служит словный регистр. Если поле RPL
(запрашиваемый уровень привилегий — два младших бита) первого операнда
меньше поля RPL второго операнда, флажок ZF устанавливается в 1 и поле
RPL первого операнда увеличивается до равенства с полем RPL второго опе-
ранда. В противном случае флажок ZF сбрасывается в 0 и первый операнд не
изменяется.
Команда ARPL применяется в программах операционной системы. Она
обеспечивает, что параметр-селектор подпрограммы не более привилегирован,
чем разрешено вызывающей программе. Обычно вторым операндом команды
ARPL является регистр, содержащий значение селектора CS вызывающей
программы.
Воздействие на флажки
Флажок ZF устанавливается в 1, если поле RPL первого операнда меньше
поля RPL второго операнда.
Особые случаи Р-режима
# GP(0), если результат в незаписываемом сегменте.
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
#АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 6, так как команда ARPL не распознается в R-режиме.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
#РР(код-нарушение) для страничного нарушения.
#АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
BOUND - check array index against BOUNDS
Контроль нахождения индекса массива в границах
КОП Команда Тактк ОпвсаЕне
62 /г BOUND rl6,ml6&16 7 Проверка нахождения г16 в границах
62 /г BOUND r32,m32&32 7 Проверка нахождения г32 в границах
Операция
Глава 2. Справочные сведения по командам i486
IF (LeftSRC < [RightSRC OR LeftSRC > [RightSRC + OperandSize/Й]
(* Под нижней границей или над верхней границей ♦)
THEN Прерывание 5;
FI;
Описание
Команда BOUND обеспечивает, нахождение знакового индекса массива в
пределах, определяемых блоком памяти, который содержит верхнюю и ниж-
нюю границы. Каждая граница представлена одним словом, если атрибут
размера операнда равен 16 битам, и двойным словом, когда атрибут размера
операнда равен 32 битам. Первый операнд (регистр) должен быть больше или
равен первой границе в памяти (нижняя граница) и меньше или равен второй
границе в памяти (верхняя граница) плюс число байт размера операнда. Если
регистр не находится в границах, возникает прерывание 5; регистр EIP воз-
врата адресует команду BOUND.
Обычно структура данных границ помещается перед самим массивом, что
позволяет адресовать границы с помощью постоянного смещения от начала
массива.
Воздействие на флажки Нет
Особые случаи Р-режима
Прерывание 5, если проверка границ не проходит.
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
#АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Второй операнд должен находиться в памяти, а не в регистре. Если вы-
полняется команда BOUND, в которой байт ModR/M представляет регистр
как второй операнд, возникает особый случай #UD.
Особые случаи R-режима
Прерывание 5, если проверка границ не проходит.
Прерывание 13, если любая часть операнда вне пространства эффектив-
ного адреса от 0 до 0FFFFH.
Прерывание 6, если второй операнд является регистром.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
#РЕ(код-нарушение) для страничного нарушения.
#АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
BSF - Bit Scan Forward
Сканирование бита вперед
КОП Команда Такты Опжсажже
OF ВС BSF rl6,r/ml6 6-42/7-43 Сканирование бита вперед в слове r/m
OF ВС BSF r32,r/m32 6-42/7-43 Сканирование бита вперед
в двойном слове r/m
Операция
IF r/m = О
THEN
ZF <— 1;
регистр <— НЕ ОПРЕДЕЛЕН;
ELSE
temp <— 0; ZF <— 0;
WHILE BIT[r/m,temp=0]
ВИ Микропроцессор i486 а Книга 4. Справочник по системе команд
DO
temp <— temp + 1;
регистр <-- temp;
OD
FI;
Описание
Команда BSF сканирует биты во втором операнде (слове или двойном
слове), начиная с бита 0. Флажок ZF устанавливается в 1, если все биты нуле-
вые; в противном случае флажок ZF сбрасывается в 0 и в регистр-получатель
загружается индекс первого единичного бита.
Воздействие на флажки
Флажок ZF установлен в 1, если все биты нулевые; в противном случае
флажок ZF сброшен в 0.
Особые случаи Р-режима
Далее см. ПРИМЕЧАНИЕ.
BSR - Bit Scan Reverse
Сканирование бита назад
КОП Команда Такты Описание
OF BD BSR rl6,r/ml6 6-103/7-104 Сканирование бита назад в слове r/m
OF BD BSR r32,r/m32 6-103/7-104 Сканирование бита назад
в двойном слове r/m
Операция
IF r/m = 0
THEN
ZF <— 1;
регистр <— НЕ ОПРЕДЕЛЕН;
ELSE
temp <— Operandsize - 1; ZF <— 0;
WHILE BIT[r/m,temp=0]
DO
temp <— temp - 1; 7
регистр <— temp;
OD J
FI;
Описание
Команда BSF сканирует биты во втором операнде (слове или двойном
слове) от старшего бита к младшему. Флажок ZF устанавливается в 1, если
все биты нулевые; в противном случае флажок ZF сбрасывается в 0 и в ре-
гистр-получатель загружается индекс первого единичного бита, обнаружен-
ного при сканировании в обратном направлении.
Воздействие на флажки
Флажок ZF установлен в 1, если все биты нулевые; в противном случае
флажок ZF сброшен в 0.
Особые случаи Р-режима
Далее см. ПРИМЕЧАНИЕ.
BSWAP - Byte SWAP : " ~~
Обмен байт
КОП Команда Такты Опнсаиве
OF C8/r BSWAP r32 1 Обмен байт в 32-битном регистре для
перехода от одной формы адресации к другой
Операция
TEMP <— г32
г32(7..О) <— ТЕМР{31. .24)
Глава 2. Справочные сведения по командам i486
3*271
r32(I5..8) <— TEMP{23.. 16}
r32(23. .16) <— ТЕМР(15..8)
г32(31..24) <— TENP(7..0j
Описание
Команда В SWAP изменяет порядок байт в 32-битном регистре, преобра-
зуя значение от формы адресации со старшего/младшего конца в форму адре-
сации с младшего/старшего конца. Когда она используется с 16-битным опе-
рандом, результат в регистре-получателе не определен.
Воздействие на флажки Нет
Особые случаи P-режима Нет
Особые случаи R-режима Нет
Особые случаи К-режнма Нет
Примечание:
Команды BSWAP в процессоре 80386 нет.
ВТ - Bit Test
Проверка бита
КОП Комаяда Такте Описаиие
OF АЗ ВТ г/в16,г16 3/8 Сохранение бита во флажке переноса
OF АЗ ВТ г/ш32гг32 3/8 Сохранение бита во ©лайке переноса
OF НА / ВТ r/nl6,iimn8 3/8 Сохранение бита во ©лайке переноса
OF ВА /4 ib ВТ r/©32rimm8 3/8 Сохранение бита во флажке переноса
Операция
CF <— BITfLeftSRC, RightSRC);
Описание
Команда ВТ сохраняет во флажке переноса CF значение бита, определяе-
мого базой (первый операнд) и битовым смещением (второй операнд).
Воздействие на флажки
Флажок CF содержит значение выбранного бита.
Особые случая Р-режима
Далее см. ПРИМЕЧАНИЕ.
Примечания:
Индекс выбираемого бита можно задавать непосредственной константой в
команде или значением в регистре общего назначения. В команде использу-
ется только 8-бигное непосредственное значение. Этот операнд берется по
модулю 32, поэтому диапазон непосредственных битовых смещений равен
0...31, что позволяет выбрать любой бит в регистре. Для битовых цепочек в
памяти непосредственное поле определяет только битовое смещение внутри
слова или двойного слова. Непосредственные битовые смещения, большие 31,
поддерживаются при использовании непосредственного битового смещения в
комбинации с полем смещения (в команде) операнда в памяти. Младшие 3 —
5 бит непосредственного битового смещения сохраняются в поле непосред-
ственного битового смещения, а старшие 27 — 29 бит сдвигаются и объеди-
няются с байтным смещением (в команде) режима адресации.
При обращении к биту в памяти процессор может обратиться к четырем
байтам, начиная с адреса памяти:
эффективный адрес 4- (4 х BitOffset DIV 32) для 32-битного размера опе-
ранда или к двум байтам, начиная с адреса памяти;
эффективный адрес 4- (2 х BitOffset DIV 16) для 16-битного размера опе-
ранда. Такое действие он выполняет, даже если для достижения нужного бита
требуется обратиться только к одному байту. Поэтому следует избегать обра-
щений к областям памяти вблизи «дыр» в адресном пространстве. В
Микропроцессор i486»Книга 4. Справочник по системе команд
частности, нужно избегать обращений к регистрам ввода-вывода, отображен-
ного на память. Вместо этого применяются команды MOV для загрузки из
ггих адресов или сохранения по ним, а для манипуляций данными применя-
ется регистровая форма команды ВТ.
BTC - Bit Test and Complement '
Проверка бита и дополнение (инвертирование)
КОП Команда Такты Опнсапе
OF ВВ BTC г/ю16,г16 6/13 Сохранение бита в СЕи дополнение
OF ВВ ВТС г/в32,г32 6/13 Сохранение бита в CF и дополнение
OF ВЛ /7 ib BTC r/ml6,imm8 6/8 Сохранение бита в СР и дополнение
OP ВА /7 ib BTC r/u32,inun8 6/8 Сохранение бита в СР и дополнение
Операция
СР <— BITJLeftSRCS, RightSRCJ;
BITJLeftSRC, RightSRCJ <— NOT BIT[LeftSRC, RightSRC);
Описание
Команда ВТ сохраняет во флажке переноса CF значение бита, определяе-
мого базой (первый операнд) и битовым смещением (второй операнд), а за-
тем дополняет (инвертирует) бит.
Воздействие на флажки
Флажок CF содержит значение выбранного бита.
Далее см. команду ВТ.
BTR - Bit Test and Reset
Проверка бита и сброс в О
КОП Команда Такт» Описание
OF ВЗ BTR г/ю16,г16 6/13 Сохранение бита в CF и сброс
0F ВЗ BTR г/ю32,г32 6/13 Сохранение бита в CF и сброс
0F ВА /6 ib BTR r/ul6,imm8 6/8 Сохранение бита в CF и сброс
0F ВА /6 ib BTR r/m32,imm8 6/8 Сохранение бита в CF и сброс
Операция
CF <— BITJLeftSRCS, RightSRC);
BITJLeftSRC, RightSRCJ <— 0;
Описание
Команда BTR сохраняет во флажке переноса CF значение бита, определя-
емого базой (первый операнд) и битовым смещением (второй операнд), а за-
тем сбрасывает бит.
Воздействие на флажки
Флажок CF содержит значение выбранного бита.
Далее см. команду ВТ.
BTS - Bit Test and Set
Проверка бита и установка в 1
КОП Команда Такты Опнсанве
OF АВ BTS г/ш16,г16 6/13 Сохранение бита в CF и установка
OF АВ BTS г/т32,г32 6/13 Сохранение бита в CF и установка
OF ВА /5 ib BTS r/rol6,imm8 6/8 Сохранение бита в CF и установка
0F ВА /5 ib BTS r/m32,imro8 6/8 Сохранение бита в CF и установка
Операция
CF <— BITJLeftSRCS, RightSRC);
BITJLeftSRC, RightSRCJ <— 1;
Описание
Глава 2. Справочные сведения по командам i486
Команда BTR сохраняет во флажке переноса CF значение бита, определя-
емого базой (первый операнд) и битовым смещением (второй операнд), а за-
тем сохраняет в бите 1.
Воздействие на флажки
Флажок CF содержит значение выбранного бита.
Далее см. команду ВТ.
CALL - вызов процедуры
коп Команда Такты Описание
ЕВ CW CALL rell6 3 Вызов близкий, смещение относительно следующей команды
FF /2 CALL r/ml6 5/5 Вызов близкий косвенный через r/m
9А cd CALL ptrl6:16 18,pm=20 Вызов межсегментный прямой
9А cd CALL ptrl6:16 pm=35 Вызов шлюза, те же привилегии
9А cd CALL ptrl6:16 pm=69 Вызов шлюза, большие привилегии, без параметров
9А cd CALL ptrl6:16 pm=77+4x Вызов шлюза, большие привилегии, х параметров
9А cd CALL ptrl6:16 pm=37+ts Вызов задачи
FF /3 CALL ml6:16 17,pm=20 Вызов межсегментный через память
FF /3 CALL ml6:16 pm=35 Вызов шлюза, те же привилегии
FF /3 CALL ml6:16 pm=69 Вызов шлюза, большие привилегии, без параметров
FF /3 CALL ml6:16 pm=77+4x Вызов шлюза, большие привилегии, х параметров
FF /3 CALL ml6:16 ^m=37+ts Вызов задачи
ЕВ cd CALL rel32 Вызов близкий, смещение относительно следующей команды
FF /2 CALL r/m32 5/5 Вызов близкий косвенный через r/m
9А cp CALL ptrl6:32 18,pm=20 Вызов межсегментный прямой
9А cp CALL ptrl6:32 pm=35 Вызов шлюза, те же привилегии
9А cp CALL ptrl6:32 pm=69 Вызов шлюза, большие привилегии, без параметров
9А cp CALL ptrl6:32 pm=77+4x Вызов шлюза, большие привилегии, х параметров
9А cp CALL ptrl6:32 pm=37+ts Вызов задачи
FF /3 CALL ml6:32 17,pm=20 Вызов межсегментный через память
FF /3 CALL ml6:32 pm=35 Вызов шлюза, те же привилегии
FF /3 CALL ml6:32 pm=69 Вызов шлюза, большие привилегии, без параметров
FF /3 CALL ml6:32 pm=77+4x Вызов шлюза, большие привилегии, х параметров
FF /3 CALL Примечание ml6:32 pm=37+ts Вызов задачи
Значение ts см. в табл. 1.5.
Операция
Громоздкое алгоритмическое описание операций команды CALL опуще-
но.
Описание
Команда CALL вызывает* выполнение процедуры, указанной в операнде.
Когда процедура завершается (в процедуре выполняется команда возврата),
выполнение продолжается с команды, находящейся после команды CALL.
Далее описаны действия различных форм команды.
В близких вызовах с типами назначения г/т 16, г/т32, ге116 и ге132 изме-
нять или сохранять значение сегментного регистра не нужно. Формы CALL
ге116 и CALL ге132 для определения назначения прибавляют знаковое смеще-
ние к адресу команды после CALL. Форма с ге! 16 применяется, когда атрибут
Микропроцессор i486 Книга 4. Справочник по системе команд
размера операнда команды равен 16 битам, а форма ге132 — когда атрибут ра-
вен 32 битам. Результат сохраняется в регистре EIP. При задании ге116 стар-
шие 16 бит регистра EIP сбрасываются, что приводит к смещениям, значения
которых не превышают 16 бит. Формы CALL г/ш 16 и CALL г/ш32 определя-
ют регистр или ячейку памяти, из которых берется абсолютное смещение в
сегменте. Смещение состоит из 32 бит для атрибута размера операнда 32 бита
(г/т32) или 16 бит для атрибута 16 бит (г/ш 16). Смещение команды, находя-
щейся после команды CALL, включается в стек. Его извлекает оттуда близкая
команда RET в процедуре. Данные формы команды CALL не изменяют ре-
гистр CS.
В далеких вызовах CALL ptrl6:16 и CALL ptrl6:32 используется 4- или 6-
байтный операнд как длинный указатель вызываемой процедуры. Формы
CALL ml6:16 и ml6:32 считывают указатель из определенной ячейки памяти
(косвенно). В R- или P-режимах длинный указатель содержит 16 бит для ре-
iMCTpa CS и 16 или 32 бита для регистра EIP (в зависимости от атрибута раз-
мера операнда). Эти формы команды включают в стек как адрес возврата ре-
гистры CS и IP или EIP.
В P-режиме обе формы с длинным указателем проверяют байт AR прав
доступа, индексируемого селекторной частью длинного указателя. В зависи-
мости от значения в байте AR вызов производит один из следующих типов
передач управления:
— далекий вызов на том же уровне привилегий;
— межуровневый далекий вызов;
— переключение задачи.
Воздействие на флажки
При переключении задачи изменяются все флажки; если переключения
задачи нет, никакие флажки не изменяются.
Особые случаи Р-режима
В далеких вызовах могут возникать особые случаи #GP, #NP, #SS и #TS.
В близких прямых вызовах:
# GP(0), если процедура находится вне предела сегмента кода.
# SS(O), если включение адреса возврата превышает предел сегмента стека.
#РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
В близких косвенных вызовах:
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# GP(0), если полученное косвенное смещение находится вне предела сег-
мента кода.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Особые случаи V-режима
Те же особые случаи, что и в R-режиме.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Глава 2. Справочные сведения по командам i486
Примечание:
Любой далекий вызов 16-битного сегмента кода из 32-битного сегмента
кода должен производиться из первых 64 Кбайт 32-битного сегмента кода,
так как атрибут размера операнда команды установлен на 16, позволяя сохра-
нять только 16-битное смещение адреса возврата.
CBW/CWDE - Convert Byte to Word/Convert Word to Doubleword Extended
Преобразование байта в слово/преобразование слова
КОП
98
99
Команда
CBW
CWDE
в двойное слово (с расширением)
Такта Описание
3 АХ <— знаковое расшире
3 ЕАХ <— знаковое расти:
Описание
АХ <— знаковое расширение AL
ЕАХ <— знаковое расширение АХ
Операция
IF Operandsize = 16 (* команда CBW *)
THEN АХ <— SignExtend(AL);
ELSE (* OperandSize =32, команда CWDE *)
EAX <— SignExtend(AX);
FI;
Описание
Команда CBW преобразует знаковый байт из регистра AL в знаковое
слово в регистре АХ, распространяя старший бит регистра AL (знаковый бит)
во все биты регистра АН. Команда CWDE преобразует знаковое слово из ре-
гистра АХ в знаковое двойное слово в регистре ЕАХ, распространяя старший
бит регистра АХ в два старших байта регистра ЕАХ. Отметим, что команда
CWDE отличается от команды CWD, в которой получателем служит регист-
ровая пара DX:AX, а не регистр ЕАХ.
Воздействие на флажки Нет
Особые случаи P-режима Нет
Особые случаи R-режима Нет
Особые случаи У-режима Нет
CLC - CLear Carry flag
Сброс флажка переноса
КОП Команда Такты Описание
F8 CLC 2 Сброс флажка переноса CF
Операция
CF <— 0;
Описание
Команда CLC сбрасывает в 0 флажок CF и не влияет на остальные флаж-
ки или регистры.
Воздействие на флажки
Флажок CF сбрасывается в 0.
Особые случаи Р-режнма Нет
Особые случаи R-режима Нет
Особые случаи У-режима Нет
CLD - CLear Direction flag
Сброс флажка направления
КОП Команда Такты Описание
FC CLD 2 ч Сброс флажка направления DF
Операция
Микропроцессор i486 Книга 4. Справочник по системе команд
DF <— 0;
Описание
Команда CLC сбрасывает в 0 флажок направления DF и не влияет на ос-
юльные флажки или регистры. После ее выполнения в цепочечных операциях
будет производиться инкремент регистров SI и DI.
Воздействие на флажки
Флажок DF сбрасывается в 0.
Особые случаи Р-режима Нет
Особые случаи R-режима Нет
Особые случаи V-режима Нет
CLI - CLear Interrupt flag
Сброс флажка прерывания
КОП Команда Такты Описание
FA CLI 5 Сброс флажка прерывания IF
Операция
IF <— 0;
Описание
Команда CLI сбрасывает флажок IF, если текущий уровень привилегий
по крайней мере столь же привилегирован, как уровень привилегий ввода-
вывода IOPL. Никакие другие флажки не изменяются. Внешние прерывания
не распознаются с конца команды СИ до установки в 1 флажка IF.
Воздействие на флажки
Флажок IF сбрасывается в 0.
Особые случаи Р-режима
# GP(0), если текущий уровень привилегий больше (имеет меньшие при-
вилегии), чем уровень привилегий ввода-вывода в регистре флажков. Уровень
привилегий ввода-вывода определяет наименее привилегированный уровень,
на котором разрешается выполнять ввод-вывод.
Особые случаи R-режима Нет
Особые случаи У-режима
# GP(0) как в Р-режиме.
CLTS - CLear Task-Switched flag in CRO
Сброс флажка переключения задачи «з регистре CRO
КОП Команда Такты Описание
OF 06 CLTS 7 Сброс флажка TS переключения задачи
Операция
Флажок TS в CR0 <— 0;
Описание
Команда CLTS сбрасывает в 0 флажок переключения задачи TS в регистре
CR0. Этот флажок процессор устанавливает при Каждом переключении
сдачи. Флажок TS применяется для управления расширениями процессора
(сопроцессорами) следующим образом:
- - Если флажок TS установлен в 1, при выполнении каждой команды
LSC формируется ловушка.
— Перехватывается выполнение команды WAIT, если установлены в 1
<|шажки МР и TS.
Таким образом, если после начала выполнения команды ESC произведено
переключение задачи, может потребоваться сохранить контекст устройства
Глава 2. Справочные сведения по командам i486
FPU до выдачи новой команды ESC. Обработчик особого случая сохраняет
контекст и сбрасывает в 0 флажок TS.
Команда CLTS предназначена для системных, а не прикладных программ.
Она является привилегированной и может выполняться только на уровне
привилегий 0.
Воздействие на флажки
Флажок TS в регистре управления CR0 сбрасывается в 0.
Особые случаи Р-режима
#GP(0), если команда CLTS выполняется на уровне привилегий,
отличающемся от 0.
Особые случаи R-режима Нет (команда CLTS допускается в R-
режиме для инициализации перед переходом в Р-режим).
Особые случаи V-ре жим а Нет
СМС - CoMplement Carry flag
Дополнение (инвертирование) флажка переноса
КОП Команда Такта Описание
F5 СМС 2 Дополнение флажка переноса CF
Операция
CF <— NOT CF;
Описание
Команда СМС изменяет состояние флажка CF на противоположное и не
влияет на остальные флажки или регистры.
Воздействие на флажки
Флажок CF содержит инверсию первоначального значения.
Особые случаи Р-режима Нет
Особые случаи R-режима Нет
Особые случаи V-режима Нет
CMP - СоМPare two operands
Сравнение двух операндов
КОП Команда * Гакты Описание
зс ib CMP AL,imm8 1 Сравнение непоср. байта с AL
3D iw CMP AX,imml6 1 Сравнение непоср. слова с АХ
3D id CMP EAX,imm32 1 Сравнение непоср. двойного слова с ЕАХ
80 /7 ib CMP r/m8,imm8 1/2 Сравнение непоср. байта с байтом r/m
81 /7 iw CMP r/ml6,imml6 1/2 Сравнение непоср. слова со словом г/ш
81 /7 id CMP r/m32,imm32 1/2 Сравнение непоср. двойного слова с двойным словом r/m
83 /7 ib CMP r/ml6,imm8 CMP r/m32,imm8 1/2 Сравнение непоср. байта со знаковым расширением со словом r/m
83 /7 ib 1/2 Сравнение непоср. байта со знаковым
38 /г CMP r/m8,r8 1/2 расширением с двойным словом r/m Сравнение байтного per. с байтом r/m
39 /г CMP r/ml6,rl6 1/2 Сравнение словного per. со словом r/m
39 /г CMP r/m32,r32 1/2 Сравнение двухсловного регистра С двойным словом r/m
ЗА /г CMP r8,r/m8 1/2 Сравнение байта r/m с байтным регистром
ЗВ /г CMP rl6,r/ml6 1/2 Сравнение слова r/m со словным регистром
ЗВ /г CMP r32,r/m32 1/2 Сравнение двойного слова r/m с двухсловным регистром
Операция
Микропроцессор i486 Книга 4. Справочник по системе команд
LeftSRC - SignExtend(RightSRC);
(* команда CMP не сохраняет результат *)
Описание
Команда СМР вычитает второй операнд из первого, но в отличие от ко-
манды SUB не сохраняет результат; изменяются только флажки. Обычно она
применяется с условными переходами и командой SETcc установки байта по
условию. Если операнд более байта сравнивается с непосредственным байтом,
вначале байтное значение расширяется со знаком.
Воздействие на флажки
Флажки OF, SF, ZF, AF, CF и PF устанавливаются в соответствии с ре-
зультатом.
Особые случаи Р-режима
Далее см. ПРИМЕЧАНИЕ.
CMPS/CMSB/CMPSW/CMPSD - CoMPare String operands
коп Команда Такты Сравнение цепочечных операндов Описание
А6 CMPS m8,m8 8 Сравнение байта ES:[(E)DI] (второй операнд) с байтом [(E)SI] (первый операнд)
А7 CMPS ml6,ml6 8 Сравнение слова ES:[(E)DI1 (второй операнд) со словом [(E)SI] (первый операнд)
А7 CMPS m32,m32 8 Сравнение двойного слова ES:[(Е)DI] (второй операнд)с двойным словом [(E)SI] (первый операнд)
А6 CMPSB 8 Сравнение байт ES:[(E)DI] и DS:[SI]
А7 CMPSW 8 Сравнение слов ES:[(E)DI] и DS:1SI]
А7 CMPSD Операция 8 Сравнение двойных слов ES:[(E)DI] и DS[SI]
IF (команда = CMPSD)
(команда имеет операнды типа DWORD)
THEN Operandsize <— 32;
ELSE OperandSize <-- 16;
FI;
IF AddressSize =16
THEN
SI индекс-источника и DI индекс-получателя
ELSE (* AddressSize = 32 *)
ESI индекс-источника и EDI индекс-получателя
FI;
IF команда с байтами
THEN
[индекс-источника] - [индекс-получателя]; (* байты *)
IF DF = 0 THEN IncDec <— 1 ELSE IncDec <— -1; FI;
ELSE
IF OperandSize =16
THEN
[индекс-источника] - [индекс-получателя]; (* слова *)
IF DF = 0 THEN IncDec <— 2 ELSE IncDec <— -2; FI;
ELSE (* OperandSize = 32 *)
[индекс-источника] - [индекс-получателя]; (* двойные слова *)
IF DF = О THEN IncDec <— 4 ELSE IncDec <— -4; FI;
FI;
FI;
индекс-источника <— индекс-источника + IncDec;
индекс-получателя <-- индекс-получателя + IncDec;
Описание
Глава 2. Справочные сведения по командам i486
Команда CMPS сравнивает байт, слово или двойное слово, адресуемое ре-
гистром индекса-источника, с байтом, словом или двойным словом, адресуе-
мым регистром индекса-получателя.
Если атрибут размера адреса команды равен 16 битам, индексными регис-
трами служат SI и DI; в противном случае используются регистры ESI и EDI.
Перед выполнением команды CMPS необходимо загрузить правильные
значения индексов в регистры SI и DI (или ESI и EDI).
Сравнение производится вычитанием операнда, индексируемого регист-
ром индекса-получателя, из операнда, индексируемого регистром индекса-ис-
точника.
Отметим, что направление вычитания в команде CMPS имеет вид [SI] —
[DI] или [ESI] — [EDI]. Левый операнд (SI или ESI) является источником, а
правый операнд (DI или EDI) — по-лучателем. Такое направление противо-
положно обычному согла-шению фирмы Intel, где левый операнд служит по-
лучателем, а правый операнд — источником.
Результат вычитания не сохраняется; его отражают только флажки. Типы
операндов определяют сравнение байт, слов или двойных слов. Для первого
операнда (SI или ESI) применяется регистр DS, если отсутствует байт замены
сегмента. Второй операнд (DI или EDI) адресуется через регистр ES и замена
сегмента не допускается.
После сравнения производится автоматическое продвижение обоих ин-
дексных регистров. Если флажок DF = 0 (была выполнена команда CLD),
происходит инкремент регистров; если же флажок DF = 1 (была выполнена
команда STD), происходит декремент регистров. Величина инкремеи-
та/декремента равна 1 при сравнении байт, 2 — при сравнении слов и 4 —
при сравнении двойных слов.
Команды CMPSB, CMPSW и CMPSD являются синонимами команды
CMPS при сравнении байт, слов и двойных слов, соответственно.
Перед командой CMPS можно указать префикс повторения REPE или
REPNE для блокового сравнения СХ или ЕСХ байт, слов или двойных слов.
Подробнее о действии префиксов повторения см. описание команды REP.
Воздействие на флажки
Флажки OF, SF, ZF, AF, CF и PF устанавливаются в соответствии с ре-
зультатом.
Особые случаи Р-режима
Далее см. ПРИМЕЧАНИЕ.
CMPXCHG - CoMPare and eXCHanGe
Сравнение и обмен
коп Комаяда Яаяян Описание
OF А6/г CMPXCHG г/а8,г8 6/7 - успеяное; 6 / Ю-безуспеяное Сравнить AL с байтом r/m. При равенстве, установить ZF и загрузить байтный регистр в r/m. Иначе сбросить ZF и загрузить в AL байт r/m.
OF А7/г CMPXCHG г/ш1б,г1б 6/7 - успеяное; 6/19-безуспешное Сравнить АХ со словом r/m. При равенстве, установить ZF и загрузить словный регистр в r/m. Иначе сбросить ZF и загрузить в АХ слово r/m.
OF Аб/г CMPXCHG r/n32,r32 6/7 - успеяное; 6/1О-безуспешное Сравнить ЕАХ с с двойным словом r/m. При равенстве, установить ZF и загрузить двухсловный регистр в r/m. Иначе сбросить ZF и загрузить в ЕАХ двойное слово r/m.
М-'
$8.0
Микропроцессор i486 • Книга 4. Справочник по системе команд
Операция
IF аккумулятор = DEST
ZF <— 1; DEST <— SRC;
ELSE
ZF <— 0; аккумулятор <-- DEST;
Описание
Команда CMPXCHG сравнивает аккумулятор (регистр AL, АХ, ЕАХ) с
операндом DEST. Если они равны, значение SRC загружается в получатель
DEST. В противном случае DEST загружается в аккумулятор.
Воздействие на флажки
Флажки OF, SF, AF, CF и PF устанавливаются так же, как в команде
СМР с операндами DEST и аккумулятором. Флажок ZF устанавливается в 1,
если операнд-получатель и аккумулятор равны; в противном случае он сбра-
сывается в 0.
Особые случаи Р-режима
#GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
Примечание:
Эту команду можно использовать с префиксом LOCK. Чтобы упростить
интерфейс шины процессора, операнду-получателю цикл записи выделяется
безотносительно результата сравнения. Получатель DEST записывается обрат-
но, если сравнение безуспешное, а в противном случае в получатель записы-
вается SRC. (Процессор никогда не производит блокированного считывания
без выполнения блокированной записи). В процессоре 80386 такой команды
нет.
CWD/CDQ - Convert Word to Doubleword/Convert Doubleword to Quadword
Преобразование слова в двойное слово/преобразование
двойного слова в счетверенное слово
КОП Комаяда Такт Опвсажже
99 CWD 3 DX:AX <-- знаковое расширение АХ
99 CDQ 3 EDX:EAX <— знаковое расширение ЕАХ
Операция
IF OperandSize = 16 (* команда CWD *)
THEN
IF АХ < О THEN DX <— OFFFFH; ELSE DX <— 0; FI
ELSE (* OperandSize = 32, команда CDQ *)
IF EAX < 0 THEN EDX <— OFFFFFFFFH; ELSE EDX <— 0; FI
FI;
Описание
Команда CWD преобразует знаковое слово из регистра АХ в знаковое
двойное слово в регистровой паре DX:AX, распространяя старший бит регис-
тра АХ во все биты регистра DX. Команда CDQ преобразует знаковое двой-
ное слово из регистра ЕАХ в знаковое 64-битное целое число в регистровой
паре EDXzEAX, распространяя старший бит регистра ЕАХ (знаковый бит) во
все биты регистра EDX. Отметим, чТо команда CWD отличается от команды
CWDE, в которой получателем служит регистр ЕАХ, а не регистровая пара
DX:AX.
Воздействие на Флажки Нет
Особые случаи Р-режима Нет
Особые случаи R-режима Нет
Особые случаи V-режима Нет
Глава 2. Справочные сведения по командам i486
Й281~
DAA - Decimal Adjust AL after Addition
Десятичная коррекция AL после сложения
КОП Команда Тахты Описание
27 DAA 2 Коррекция регистра AL после сложения
Операция
IF ((AL AND OFH) > 9) OR (AF = 1)
THEN
AL <— (AL + 6); AF <— 1;
ELSE
AF <— 0;
FI;
IF (AL > 9FH) OR (CF = 1)
THEN
AL <— AL + 60H; CF <— 1;
ELSE CF <— 0;
FI;
Описание
Команду DAA нужно выполнять только после команды сложения, которая
оставляет двухразрядный байтный результат в регистре AL. Операнды ко-
манды сложения должны состоять из двух упакованных десятичных цифр. В
этом случае команда DAA корректирует регистр AL так, чтобы он содержал
правильный двухразрядный упакованный десятичный результат.
Воздействие на флажки
Флажки AF и CF установлены в 1 при наличии десятичного переноса, а
при его отсутствии сброшены в 0; флажки OF, SF, ZF и PF устанавливаются
в соответствии с результатом.
Особые случаи Р-режима Нет
Особые случаи R-режима Нет
Особые случаи V-режима Нет
DAS - Decimal Adjust AL after Subtraction
Десятичная коррекция AL после вычитания
КОП Команда Такты Ошгсажжв
?F DAS 2 Коррекция регистра AL после вычитания
Операиия
IF ((AL AND OFH) > 9) OR (AF = 1)
THEN
AL <— (AL - 6); AF <— 1;
ELSE
AF <— 0;
FI;
IF (AL > 9FH) OR (CF = 1)
THEN
AL <— AL - 60H; CF <— 1;
ELSE CF <— 0;
FI;
Описание
Команду DAS нужно выполнять только после команды вычитания, кото-
рая оставляет двухразрядный байтный результат в регистре AL. Операнды ко-
манды вычитания должны состоять из двух упакованных десятичных цифр. В
этом случае команда DAS корректирует регистр AL так, чтобы он содержал
правильный двухразрядный упакованный десятичный результат.
Воздействие на флажки
?282’‘
Микропроцессор i486 Книга 4. Справочник по системе команд
Флажки AF и CF установлены в 1 при наличии десятичного заема, а при
его отсутствии сброшены в 0; флажки OF, SF, ZF и PF устанавливаются в со-
ответствии с результатом.
Особые случаи P-режима Нет
Особые случаи R-режима Нет
Особые случаи V-режима Нет
DEC - DEC re me nt by 1
Декремент на 1
КОП Комажда Такты описание
FE /1 DEC г/ш8 1/3 Декремент байта r/m на 1
FF /1 DEC г/ш16 1/3 Декремент слова r/m на 1
DEC r/m32 1/3 Декремент двойного слова r/m на 1
48+rw DEC rl6 1 Декремент словного регистра на 1
48+rw DEC r32 1 Декремент двухсловного регистра на 1
Операция
DEST <— DEST - 1;
Описание
Команда DEC вычитает 1 из операнда. Она не изменяет флажка переноса
CF. Для воздействия на флажок CF следует воспользоваться командой SUB с
непосредственным операндом 1.
Воздействие на флажки
Флажки OF, SF, ZF, AF и PF устанавливаются в соответствии с результа-
том.
Особые случаи Р-режима
#GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ
DIV - unsigned Divide
Беззнаковое деление
КОП Команда Такты Описание
F6 /6 DIV AL,r/m8 16/16 Беззнаковое деление АХ на байт r/m (AL <-- частное, АН <— остаток)
F7 /6 DIV AX,r/ml6 24/24 Беззнаковое деление DX:AX на слово r/m (АХ <— частное, DX <— остаток)
F7 /6 DIV ЕАХ,г/m32 40/40 Беззнаковое деление EDXtEAX на двойное слово r/m (ЕАХ <— частное, EDX <— остаток) Операция
temp <— делимое/делитель
IF temp не помещается в частное
THEN Прерывание 0;
ELSE
частное <— temp;
остаток <-- делимое MOD (r/m);
FI;
Примечание:
Деления беззнаковые. Делитель определяется операндом г/m. Делимое,
частное и остаток помещаются в неявные регистры.
Описание
Команда DIV производит беззнаковое деление. Делимое задается неявно;
как операнд определяется только делитель. Остаток всегда меньше делителя.
Тип делителя определяют используемые регистры:
Глава 2. Справочные сведения по командам i486
Размер Делимое Делитель Частное Остаток
Байт АХ r/m8 AL АН
Слово DX:AX г/ml 6 АХ DX
Двойное слово EDX: ЕАХ r/m32 ЕАХ EDX
Воздействие на флажки
Флажки OF, SF, ZF, AF, CF и PF не определены.
Особые случаи Р-режима
Прерывание 0, если частное слишком велико для регистра-получателя
(AL, АХ, ЕАХ) или если делитель равен 0.
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 0, если частное слишком велико для регистра-получателя
(AL, АХ, ЕАХ) или если делитель равен 0.
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РЕ(код-нарушение) для страничного нарушения.
#АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
ENTER - make stack frame for procedure parameters
Образование стекового кадра для параметров процедуры
КОП Команда Такты Описание
С8 iw 00 ENTER imml6,0 14 Образование стекового кадра процедуры
С8 iw 01 ENTER imml6,l 17 Образование стекового кадра для параметров процедуры
С8 iw ib ENTER imml6,imm8 17+3n Образование стекового кадра
для параметров процедуры
Операиия
уровень <— уровень MOD 32
IF OperandSize = 16 THEN Push(BP) ELSE Push(EBP) FI;
(♦ Сохранить указатель стека *)
frame-ptr <— eSP
IF уровень > 0
THEN (* уровень - это правый параметр *)
FOR i <— 1 TO уровень - 1
DO
IF OperandSize =16
THEN
BP <-- BP - 2;
Push[BP]
ELSE (* OperandSize = 32 *)
EBP <— EBP - 4;
Push[EBP]
FI;
OD;
Push(frariie-ptr)
FI:
284 i
Микропроцессор i486 Книга 4. Справочник по системе команд
IF OperandSize =16 THEN BP <— frame-ptr ELSE EBP <— frame-ptr;FI;
IF StackAddrSize =16
THEN SP <-- SP - первый операнд;
ELSE ESP <— ESP - ZeroExtend{первый операнд);
FI;
Описание
Команда ENTER создает стековый кадр, требуемый большинством языков
программирования. Первый операнд определяет число байт динамической
памяти, распределяемой в стеке для вызываемой процедуры. Второй операнд
задает уровень лексического вложения (от 0 до 31) процедуры в исходном
коде языка высокого уровня. Он определяет число указателей стековых кад-
ров, копируемых в новый стековый кадр из предьщущего кадра. Регистр ВР
(или ЕВР, если атрибут размера операнда равен 32 битам) является указателем
текущего стекового кадра.
Если атрибут' размера операнда равен 16 битам, процессор использует ре-
гистр ВР как указатель стекового кадра и регистр SP как указатель стека. Если
атрибут размера операнда равен 32 битам, процессор использует регистр ЕВР
как указатель стекового кадра и регистр ESP как указатель стека.
Если второй операнд равен 0, команда ENTER включает в стек указатель
кадра (ВР или ЕВР); после этого производится вычитание из указателя стека
первого операнда и установка указателя кадра на текущее значение указателя
стека.
Например, процедура, в которой есть 12 байт локальных переменных,
должна иметь команду ENTER 12,0 в точке входа и команду LEAVE перед
каждой командой RET. Двенадцать локальных байт адресуются с отрицатель-
ными смещениями от указателя кадра.
Воздействие на флажки Нет
Особые случаи Р-режима
#SS(O), если значение SP или ESP превышает предел стека в любой точке
выполнения команды.
#РР(код-нарушение) для страничного нарушения.
Особые случаи R-режима Нет
Особые случаи V-режима Нет
F2XM1 - compute 2х - 1
Вычисление 2х — 1
КОП Команда Такты Параллельное Описание
выполнение
D9 FO F2XK1 242(140-17) 2 Замена ST на 2ST - 1
Операция
ST <— (2ST - 1);
Описание
Команда F2XM1 заменяет содержимое ST на (2ST — 1). Значение ST
должно находиться в диапазоне -1 < ST < 1.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи Р, U, D, I, IS
Особые случаи Р-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Глава 2. Справочные сведения по командам i486
Примечания:
Если операнд находится вне допустимого диапазона, результат команды
F2XM1 не определен.
Команда F2XM1 формирует очень точный результат, даже когда операнд
близок к нулю. Большие ошибки получаются, когда величина операнда близ-
ка к 1.
Для возведения в степень с произвольным основанием следует воспользо-
ваться формулой
XY = 2(Y х log2(X))
Для загрузки констант log2( 10) и log2(e) применяются команды FLDL2T и
FLDL2E. Вычисление Y х log2(X) при произвольном положительном X осу-
ществляет команда FYL2X.
FABS - ABSolute value
Нахождение абсолютного значения
КОП Комавда Такты Описание
D9 El FABS 3 Замена ST на его абсолютное значение
Операция
знаковый бит ST <-- О
Описание
Команда FABS сбрасывает в 0 знаковый бит регистра ST. При этом поло-
жительное значение остается неизменным, а отрицательное заменяется рав-
ным по величине положительным значением.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи IS.
Особые случаи Р-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты ЕМ .или TS.
Примечание:
Особый случай недействительной операции возникает только при антипе-
реполнении стека, даже если операнд является сигнализирующим нечислом
SNaN или представлен в неподдерживаемом формате
FADD/FADDP/FIADD -ADD ~
Сложение
коп Комавда Такты Параллельное Опвсавве ввшолвевве
D8 /0 FADD m32real 10(8-20) 7(5-17) Прибавление m32real к ST
DC /0 FADD m64real 10(8-20) 7(5-17) Прибавление m64reai к ST
D8 CO+i FADD ST,ST(i) 10(8-20) 7(5-17) Прибавление ST(i) к ST
DC CO+i FADD ST(i),ST 10(8-20) 7(5-17) Прибавление ST к ST(i)
DE CO+i FADDP ST(i),ST 10(8-20) 7(5-17) Прибавление ST к ST(i)
и извлечение ST
DE Cl FADD 10(8-20) 7(5-17) Прибавление ST к ST(1)
и извлечение ST
DA /0 FIADD m32int 22(19-32) 7(5-17) Прибавление m32int к ST
DE /0 FIADD ml6int 24(20-35) 7(5-17) Прибавление ml6int к ST
Микропроцессор i486 Книга 4, Справочник по системе команд
Операция
DEST <— DEST + SRC;
IF команда = FADDP THEN Pop(ST); FI?
Описание
Команды сложения суммируют операнды источника и получателя и воз-
вращают сумму в получатель. Операнд в вершине стека можно удвоить ко-
мандой
FADD ST,ST(0)
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи Р, U, О, D, I, IS.
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
#РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Если операнд-источник находится в памяти, он автоматически преобразу-
ется в формат расширенной точности.
FBLD - LoaD Binary coded decimal
Загрузка десятичного числа
КОП Комавда Такта Параллельное Описание
выполнение
D8 /4 FBLD m80dec 75(70-103) 7.7(2-8) Включение m80dec в стек FPU
Операция
Декремент указателя вершины стека устройства FPU;
ST(0) <— SRC;
Описание
Команда FBLD преобразует десятичный операнд-источник в формат рас-
ширенной точности и включает его в стек устройства FPU.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи IS.
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
Глава 2. Справочные сведения по командам i486
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-оежима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CRO установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# PF( код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Операнд-источник загружается без ошибки округления. Его знак сохраня-
ется, включая случай отрицательного нуля.
Предполагается, что упакованные десятичные цифры находятся в диапа-
зоне 0 — 9. Команда не контролирует недопустимые цифры АН — FH, и ре-
зультат загрузки числа с такими цифрами не определен.
Чтобы избежать особого случая недействительной операции, регистр ST(7)
должен быть пустым.
FBSTP - STore Binary coded decimal and Pop
Сохранение десятичного числа и извлечение из стека
КОП Команда Такт» Описание '
DF /6 FBSTP m80dec 175(172-176) Сохранение ST в m80dec
и извлечение ST
Операция
DEST <-- ST(0);
Pop(ST);
Описание
Команда FBSTP преобразует значение из регистра ST в упакованное деся-
тичное целое число, сохраняет результат в получателе в памяти и извлекает
ST из стека. Нецелочисленные значения вначале округляются в соответствии с
полем RC управления округлением слова управления.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи Р, I, IS.
Особые случаи Р-вежима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# PF( код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима.
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РГ(код-нарушение) для страничного нарушения.
Микропроцессор i486 • Книга 4, Справочник по системе команд
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
FCHS - Change Sign
Изменение знака
КОП Команда Такт Описание
D9 ВО FCHS 6 Замена ST на значение
с противоположным знаком
Операция
знаковый бит ST <-- NOT (знаковый бит ST)
Описание
Команда FCHS инвертирует знаковый бит регистра ST. При этом поло-
жительное значение заменяется на отрицательное с той же величиной и на-
оборот.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи IS.
Особые случаи Р-режима
# NM если в регистре CRO установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CRO установлены биты ЕМ или TS.
Особые случаи У-режима
# NM если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Особый случай недействительной операции возникает только при антипе-
реполнении стека, даже если операнд является сигнализирующим нечислом
SNaN или представлен в неподдерживаемом формате.
FCLEX/FNCLEX -CLear Exceptions
Сброс (флажков) особых случаев
КОП Комажда Такт Опжсажве
9В DB Е2 FCLEX 7 + минимум 3 для FWAIT Сброс Ллажков особых случаев после контроля ошибок
DB Е2 FNCLEX 7 Сброс флажков особых случаев без контроля ошибок
Операция
SW[0..7] <— 0;
SW[15] <— 0;
Описание
Команда FCLEX сбрасывает в слове состояния устройства FPU флажки
особых случаев, флажок состояния особого случая и флажок занятости.
Воздействие на Флажки устройства FPU
Биты СО, Cl, С2 и СЗ не определены.
Численные особые случаи Нет
Особые случаи Р-режима
# NM если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM если в регистре CR0 установлены биты ЕМ или TS.
Глава 2. Справочные сведения по командам i486
10 Заказ 4317
Примечание:
Команда FC LEX перед сбросом флажков особых случаев контролирует
ошибки с плавающей точкой, а команда FNCLEX не контролирует.
FCOM/FCOMP/FCOMPP - COMpare real
Сравнение вещественное
КОП Комавда Такты Опвсавве
D8 /2 FCOM m32real 4 Сравнение ST c m32real
DC /2 FCOM n»64real 4 Сравнение ST c m64real
D8 D0+i FCOM ST(i) 4 Сравнение ST c ST(i)
D8 DI FCOM 4 Сравнение ST c ST(1)
D8 /3 FCOMP m32real 4 Сравнение ST c m32real и извлечение ST
DC /3 FCOMP m64real 4 Сравнение ST с m64real и извлечение ST
D8 D8+i FCOMP ST(i) 4 Сравнение ST с ST(i) и извлечение ST
D8 D9 FCOMP 4 Сравнение ST с ST(1) и извлечение ST
DE D9 FCOMPP 4 Сравнение ST с ST(1)
и извлечение ST дважды
Операция
CASE (отношение операндов) OF
Не сравнимы: СЗ, С2, СО <— 111;
ST > SRC: СЗ, С2, СО <— ООО;
ST < SRC: СЗ, С2, СО <— 001;
ST = SRC: СЗ, С2, СО <— 100?
IF команда = FCOMP THEN Pop(ST); FI;
IF команда = FCOMPP THEN Pop(ST); Pop(ST); FI;
Соответствие флажков кода
Код условия
СО
С1
С2
СЗ
условия FPV и регистра EFLAGS:
Регистр EFLAGS
CF
Нет
PF
ZF
Описание
Команды вещественного сравнения сравнивают вершину стека ST с ис-
точником, которым может быть регистр или операнд в памяти (одинарной
или двойной точности). Если операнд не указан, производится сравнение ST
с ST(1). После команды коды условия показывают отношение между верши-
ной стека и операндом-источником.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, C2I, СЗ, как показано выше.
Численные особые случаи D, I, IS
Особые случаи Р-нежима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
290
Микропроцессор i486 Книга 4. Справочник по системе команд
#РР(код-нарушение) для страничного нарушения. >
#АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Если любой операнд является нечислом NaN или представлен в непод-
держиваемом формате или если возникает нарушение стека, формируется
особый случай недействительной операции и коды условия показывают «не
упорядочены».
Знак нуля игнорируется, т.е. -0.0 = +0.0.
FCOS - COSine
Вычисление косинуса
КОП Команда Такты Параллельное Описание
зяполнеине
D9 FF FCOS 241(193-279) 2 Замена ST на его косинус
Операция
IF операнд в диапазоне
THEN
С2 <— 0;
ST <— cos (ST);
ELSE C2 <— 1;
FI;
Описание
Команда FCOS заменяет содержимое ST на cos(ST). Диапазон угла в ST,
выраженный в радианах, составляет от -2^3 до +2^3.
Воздействие на флажки устройства FPU
Состояние бит Cl, С2 см. табл. 1.7; биты СО, СЗ не определены.
Численные особые случаи Р, U, D, I, 1S.
Особые случаи Р-режима
#NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
#NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Если операнд находится вне допустимого диапазона, устанавливается
(флажок С2 и содержимое ST остается неизменным. Обеспечить нахождение
операнда в диапазоне, вычитая соответствующее кратное 2 х PI, должен про-
граммист.
При выполнении этой команды процессор i486 контролирует прерывания
и она может быть отменена для обслуживания прерывания.
FDECSTP - DECrement Stack-Top Pointer
Декремент указателя вершины стека
КОП Команда Такты Описание
D9 F6 FDECSTP 3 Декремент указателя вернины стека
регистрового стека устройства FPU
Операция
IF ТОР = О THEN ТОР <— 7;
ELSE ТОР <— ТОР - 1;
FI;
Описание
Глава 2. Справочные сведения по командам i486
Команда FDECSTP вычитает 1 (без переноса) из трехбитного поля ТОР
слова состояния устройства FPU.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи Нет
Особые случаи Р-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Действие команды FDECSTP заключается в «повороте» стека. Она не из-
меняет содержимого регистров и тэгов и не передает никаких данных.
FDSV/FDIVP/FIDIV - Divide
Деление
коп Команда Такте Параллельно® жмдолиенн® Опнсанн®
D8 /6 FDIV m32real 73 70 Деление ST на и32геа1
DC /6 FDIV m64real 73 70 Деление ST на m64real
D8 FO+i FDIV STfST(i) 73 70 Деление ST на ST(i)
DC F8+i FDIV ST(i),ST 73 70 Замана ST(i) на ST/ST(i)
DE F8+i FDIVP ST(i),ST 73 70 Замена ST(i) на ST/ST(i) и извлечение ST
DE F9 FDIV 73 70 Замена ST(1) на ST/ST(i) и извлечение ST
DA /6 FIDIV m32int 73 70 Деление ST на m32int
DE /6 FIDIV ml6int 73 70 Операция DEST <-- DEST / другой операнд; Деление ST на ml6int
IF команда = FDIVP THEN Pop(ST); FI;
Описание
Команды деления производят деление вершины стека ST на другой опе-
ранд и возвращают частное в получатель.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи Р, U, О, Z, D, I, IS.
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РЕ(код-нарушение) для страничного нарушения.
Микропроцессор i486 в Книга 4. Справочник по системе команд
#АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Если операнд-источник находится в памяти, он автоматически преобразу-
ется в формат расширенной точности.
Время выполнения команд деления зависит от содержимого поля управ-
ления точностью PC в регистре управления устройства FPU. Если PC опреде-
ляет точность 53 бита, деление производится за 62 такта, а при задании
точности 24 бита оно длится всего 35 тактов.
FDIVR/FDIVRP/FIDIVR - Reverse Divide
Обратное деление
коп Комавда ' Гакты Параллельное выполнение Опвсавве
D8 /7 FDIVR m32real 73 70 Замена ST на m32real/ST
DC /7 FDIVR m64real 73 70 Замена ST на m64real/ST
D8 F8+i FDIVR ST,ST(i) 73 70 Замена ST на ST(i)/ST
DC FO+i FDIVR ST(i),ST 73 70 Деление ST(i) на ST
DE FO+i FDIVRP ST(i),ST 73 70 Деление ST(i) на ST и извлечение ST
DE Fl FDIVR 73 70 Деление ST(1) на ST и извлечение ST
DA /7 FIDIVR m32int 73 70 Замена ST на m32int/ST
DE /7 FIDIVR ml6int Операция 73 70 Замена ST на ml6int/ST
DEST <-- другой операнд / DEST;
IF команда = FDIVRP THEN Pop(ST); FI;
Описание
Команды обратного деления производят деление другого операнда на
вершину стека ST и возвращают частное в получатель.
Далее см. команды FDIV/FDIVP/FIDIV.
FFREE - FREE floating-point register
Освобождение регистра с плавающей точкой
КОП Комавда Такты Опвсавве
DD CO+i FFREE ST(i) 3 Отметка регистра ST(i) как пустого
Операция
ТэгЦ) <— ИВ;
Команда FFREE отмечает регистр-получатель как пустой.
Воздействие на флажки устройства FPU
Биты СО, Cl, С2, СЗ не определены.
Численные особые случаи Нет
Особые случаи Р-о ежим а
#NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
#NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Команда FFREE не изменяет содержимое регистра-получателя. Указатель
стека ТОР также не изменяется.
Глава 2. Справочные сведения по командам i486
FICOM/FICOMP - COMpare Integer
Сравнение целочисленное
КОП Команда Тактк Параллельное Описание
выполнена®
DE /2 FICOM ml6int 18(16-20) 1 Сравнение ST с ml6int
DA /2 FICOM m32int 16(15-17) ' 1 Сравнение ST c m32int
DE /3 FICOMP ml6int 18(16-20) 1 Сравнение ST c ml6int
и извлечение ST
DA /3 FICOMP m32int 16(15-17) 1 Сравнение ST c m32int
и извлечение ST
Операция
CASE (отношение операндов) OF
He сравнимы: СЗ, C2, CO <— 111;
ST > SRC: СЗ, C2, CO <— 000;
ST < SRC: СЗ, C2, CO <— 001;
ST = SRC: СЗ, C2, CO <— 100;
IF команда = FICOMP THEN Pop(ST); FI;
Соответствие флажков кода условия FPU и регистра EFLAGS:
Код условия Регистр EFLAGS
СО CF
С1 Нет
С2 PF
СЗ ZF
Описание
Команды целочисленного сравнения сравнивают вершину стека ST с
источником. После команды коды условия показывают отношение между ST
и операндом-источником.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ, как показано выше.
Численные особые случаи D, I, IS.
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Перед производством сравнения операнд из памяти преобразуется в фор-
мат расширенной точности.
Если любой операнд является нечислом NaN или представлен в непод-
держиваемом формате или если возникает нарушение стека, формируется
<2^4
Микропроцессор i486 Книга 4. Справочник по системе команд
особый случай недействительной операции, и коды условия показывают «не
упорядочены».
FILD - LoaD Integer Загрузка целочисленная
коп Команда Такты Параллельно® Описана® выполнена®
DF /0 FILD ml6int 14(13-16) 4 Включение ml6int в стек FPU
DB /0 FILD m32int И 9-12) 4(2-4) Включение m32int в стек FPU
DF /5 FILD m64int 16(10-18) 7(2-8) Включение m64int в стек FPU Операция
Декремент указателя вершины стека FPU
ST(0) <— SRC;
Описание
Команда FILD преобразует знаковый целочисленный операнд-источник в
формат расширенной точности и включает его в стек устройства FPU.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ, как показано выше.
Численные особые случаи IS.
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Операнд-источник загружается без ошибки округления. Чтобы избежать
особого случая недействительной операции, регистр ST(7) должен быть пус-
тым.
FINCSTP - INCrement Stack-Top Pointer
Инкремент указателя вершины стека
КОП Команда Такты Описание
D9 F7 FINCSTP 3 Инкремент указателя вершины стека
Операция IF ТОР = 7 THEN ELSE TOP <— TOP TOP <— 0; + 1; регистрового стека устройства FPU
FI;
Описание
Глава 2. Справочные сведения по командам i486
!95|
Команда FDECSTP прибавляет 1 (без переноса) к трехбитному полю ТОР
слова состояния устройства FPU.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи Нет
Особые случаи Р-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Действие команды FINCSTP заключается в «повороте» стека. Она не из-
меняет содержимого регистров и тэгов и не передает никаких данных. Она не
эквивалентна извлечению из стека, так как не устанавливает тэг старой вер-
шины на «пустой».
FINIT/FNINIT - инициализация устройства с плавающей точкой
КОП Команда Такт Описание
DB ЕЗ FINIT 17 + минимум Инициализация устройство FPU
3 для FWAIT после контроля онибок
DB ЕЗ FNINIT 17 Инициализация устройство FPU
без контроля онибок
Операция
CW <— 037FH; (* Слово управления *)
SW <— 0; (* Слово состояния *)
TW <— FFFFH; (* Слово тэгов *)
FEA <-- 0; FDS <— 0; (* Указатель данных *)
FIP <— 0; FOP <— 0; FCS <— 0; (* Указатель команды *)
Описание
Команды инициализации переводят устройство FPU в известное состоя-
ние независимо от его предыдущих действий.
Слово управления устанавливается на 037FH (округление к ближайшему,
все особые случаи замаскированы, 64-битная точность). Слово состояния
очищается (нет установленных флажков особых случаев, регистр R0 является
вершиной стека). Все регистры стека отмечены как пустые. Указатели ошибки
(команды и данных) сброшены.
Воздействие на Флажки устройства FPU
Биты СО, Cl, С2 и СЗ сбрасываются.
Численные особые случаи Нет
Особые случаи Р-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Осо<?ые с4у<ди У-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Команда FINIT перед выполнением инициализации контролирует ошиб-
ки с плавающей точкой, а команда FNINIT не контролирует.
Команды FINIT и FNINIT переводят устройство FPU в такое же состоя-
ние, что и аппаратный сигнал сброса RESET со встроенным самоконтролем.
В процессоре i486 эти команды, в отличие от сопроцессора 80387,
очищают указатели ошибки.
'-296'"|
Микропроцессор i486 Книга 4. Справочник по системе команд
FIST/FISTP - STore Integer
Сохранение целочисленное
коп Ктишрр Яакш Описание
DF /2 FIST nl6i&t 33(29-34) Сохранение ST в ml6int
DB /2 FIST m32int 32(29-34) Сохранение ST в ia32int
DF /3 FISTP sl6int 33(29-34) Сохранение ST в nl6int и извлечение ST
DB /3 FISTP n32int 33(29-34) Сохранение ST в ®32int и извлечение ST
DF /7 FISTP n64int Опеваиия 33(29-34) Сохранение ST в m€4int и извлечение ST
DEST <— ST(0);
IF команда = FISTP THEN Pop(ST); FI;
Описание
Команда FIST преобразует значение из регистра ST в знаковое целое
число в соответствии с полем RC управления округлением слова управления
и передает результат в получатель. Содержимое ST остается неизменным. В
команде FIST получателем может быть слово и короткое целое, а в команде
FISTP еще и длинное целое.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, C2I, СЗ, как показано выше.
Численные особые случаи Р, I, IS,
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Отрицательный нуль сохраняется с тем же кодированием, что и положи-
тельный нуль (00..00).
Если значение в регистре ST слишком велико для представления целым
числом, формируется особый случай I. Маскированная реакция заключается в
записи в память наибольшего (по модулю) отрицательного целого числа.
FLD - LoaD real
Загрузка вещественная
КОП Команда Тахты Описание
D9 /0 FLD m32real 3 Включение m32real в стек FPU
D9 /0 FLD m32real 3 Включение m32real в стек FPU
Глава 2. Справочные сведения по командам i486
^2 9 Ъ
DB /5 FLD m80real 6 Включение m80real в стек FPU
D9 CO+i FLD ST(i) 4 Включение ST(i) в стек FPU
Операция
Пекремент указателя вершины стека FPU;
ST(O) <— SRC;
Описание
Команда FLD включает операнд-источник в стек устройства FPU. Если
источником является регистр, номер регистра соответствует ситуации до дек-
ремента указателя вершины стека. Например, команда FLD ST(0) дублирует
вершину стека.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 17.; биты СО, C2I, СЗ, не определены.
Численные особые случаи D, I, IS.
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РЕ(код-иарушение) длст страничного нарушения.
#АС при невыравненног обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Если операнд-источник представлен в формате одинарной или двойной
точности, он автоматически преобразуется в формат расширенной точности.
Загрузка вещественного операнда в формате расширенной точности не требу-
ет преобразования, поэтому особые случаи I и D не возникают.
Чтобы избежать особого случая недействительной операции, регистр ST(7)
должен быть пустым.
FLD1/FLDL21/FLDL2E/FLDP1/FLDLG2/FLDLN2/FLDZ - LoaD constant"
Загрузка константы
КОП Команда L Такты Параллельное выполнение Описание
D9 F8 FLD1 4 - Включение в стек +1.0
D9 Е9 FLDL2T 8 2 Включение в стек 1од2(10)
D9 ЕА FLDL2E 8 2 Включение в стек 1од2(е)
D9 ЕВ FLDPI 8 ' 2 Включение в стек PI
D9 ЕС FLDLG2 8 2 Включение в стек 1од10(2)
D9 ED FLDLN2 8 2 Включение в стек 1оде(2)
D9 ЕЕ FLDZ 4 - Включение в стек +0.0
Операция
Декремент указателя вершины стека;
SI( :о) <- КОНСТАНТА
Описание
Микропроцессор i486 Книга 4. Справочник по системе команд
Каждая из команд загрузки констант включает наиболее распространен-
ные константы в стек устройства FPU (в формате расширенной точности).
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи IS.
Особые случаи Р-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечания:
Чтобы избежать особого случая недействительной операции, регистр ST(7)
должен быть пустым.
Используется внутренняя 66-битная константа, которая округляется до
формата расширенной точности (как определено полем RC управления ок-
руглением регистра управления). Особый случай точности не возникает.
FLDCW - LoaD Control Word
Загрузка слова управления
КОП Команда Такты Описание
D9 /5 FNLDCW m2byte 4 Загрузка слова управления из m2byte
Операиия
CW <— SRC;
Описание
Команда FLDCW заменяет текущее значение слова управления на
значение, содержащееся в указанном слове памяти.
Воздействие на флажки устройства FPU
Биты СО, Cl, С2, СЗ не определены.
Численные особые случаи Нет,
исключая имеющийся незамаскированный особый случай.
Особые случаи Р-нежима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Обычно команда FLDCW применяется для задания или изменения режи-
ма работы устройства FPU.
Глава 2. Справочные сведения по командам i486
Если бит особого случая в слове состояния установлен, загрузка нового
слова состояния, которое «размаскирует» этот особый случай, приведет к ре-
гистрации ошибки с плавающей точкой. При смене режима перед загрузкой
нового слова управления рекомендуется сбросить все ожидающие особые
случаи.
FLDENV - Load FPU ENVironment
Загрузка среды устройства FPU
КОП Команда Такты Описание
D9 /4 FLDENV ml4/ 44 R- или V-режим/ Загрузка среды FPU из
28byte 34 P-режим ml4byte или m28byte
Операция
Среда устройства FPU <-- SRC;
Описание
Среда устройства FPU состоит из слова управления, слова состояния,
слова тэгов и указателей ошибок (данных и команды). Формат среды в памя-
ти зависит от размера операнда и текущего рабочего режима процессора. Ат-
рибут USE в ассемблерной программе для текущего сегмента кода определяет
размер операнда: 14-байтный операнд относится к сегменту USE 16, а 28-бай-
тный — к сегменту USE32. (В V-режиме применяется формат R-режима.)
Команду FLDENV необходимо выполнять в том же рабочем режиме, который
был в соответствующей команде FSTENV или FNSTENV.
Воздействие на флажки устройства FPU
Биты СО, Cl, С2/СЗ загружаются из памяти.
Численные особые случаи Нет,
исключая загрузку незамаскированного особого случая.
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РЕ(код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и т R-режиме.
# РЕ(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Если образ среды содержит, незамаскированный особый случай, то ее заг-
рузка приводит к формированию особого случая.
FMUL/FMULP/FIMUL - MULtiply
Умножение
КОП Команда Такты
D8 /1 FMUL m32real 11
DC /1 FMUL m64real 14
Параллельное Описание
выполнение
8 Умножение ST на m32real
И Умножение ST на m64real
ЯГ SVk хропроцессор i486 Книга 4. Справочник по системе команд
D8 C8+i FMUL ST,ST(i) 16 13 Умножение ST на ST(i)
DC C8+i FMUL ST(i),ST 16 13 Умножение ST(i) на ST
DE C8+i FMULP ST(i),ST 16 13 Умножение ST(i) и извлечение ST на ST
DE C9 FMULP 16 13 Умножение ST(1) и извлечение ST на ST
DA /1 FIMUL m32int 23(22-24) 8 Умножение ST на m32int
DE /1 FIMUL Операция DEST <— ml6int 25(23-27) DEST * SRC; 8 Умножение ST на ml6int
IF команда = FMULP THEN Pop(ST); FI;
Описание
Команды умножения умножают операнды источник и получатель и воз-
вращают произведение в получатель.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи Р, U, О, D, I, IS.
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РЕ(код-нарушсние) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# PF(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Если операнд-источник находится в памяти, он автоматически преобразу-
ется в формат расширенной точности.
FNOP - No Operation
Холостая команда
КОП Команда Такты Описание
D9 DO FNOP 3 Никакой операции не выполняется
Описание
Команда FNOP не производит никаких операций. Она не влияет ни на
что, кроме указателя команды.
Воздействие на флажки устройства FPU
Биты СО, Cl, С2, СЗ нс определены.
Численные особые случаи Нет
Особые случаи Р-режима
# NM если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Глава 2. Справочные сведения по командам i486
301:
# NM если в регистре CRO установлены биты ЕМ или TS.
FPATAN - Partial ArcTANgent
Частичный арктангенс
КОП Комавда Такт» Параллельно* Опвсавве
змполжевва
D9 F3 FPATAN 289(218-303) 5(2-17) Замена ST(1) на arctan(STI)/ST)
н извлечение ST
Операция
ST(1) <— arctg(ST(l)/ST);
Pop(ST);
Описание
Команда частичного арктангенса вычисляет арктангенс ST(1)/ST и воз-
вращает в ST(1) вычисленное значение, представленное в радианах. После
этого производится извлечение ST. Результат имеет тот же знак, что и опе-
ранд из ST(1), и величину меньше PI.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи Р, U, D, I, IS.
Особые случаи Р-режима
# NM если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
#NM если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Ограничений на диапазон допустимых аргументов команды FPATAN не
существует.
Тот факт, что команда FPATAN воспринимает два аргумента и вычисляет
арктангенс их отношения, упрощает вычисление остальных тригономет-
рических функций.
При выполнении этой команды процессор i486 контролирует прерывания
и может отменить ее для обслуживания прерывания.
FPREM - Partial REMainder
Частичный остаток
КОП Комавда Такты Параллельное Опвсавве
вдполвевве
D9 F8 FPREM 84(10-138) 2(2-8) Замена ST(1) на остаток,
полученный при делении ST на ST(1)
Операция
EXPDIF <-- порядок(ST) - порядок(5Т(1));
IF EXPDIF <64
THEN
Q <— целое, полученное при усечении ST/ST(1) к нулю;
ST <— ST - (ST(1) х Q);
C2 <— 0;
CO,C1,C3 <— три младших бита Q; (* Q2,Q1,QO *)
ELSE
C2 <— 1;
N <— число между 32 и 63;
QQ <— целое, полученное при усечении ST/ST(1)/2А(EXPDIF-N)
к нулю;
|>3 0'2^1
Микропроцессор i486 в Книга 4. Справочник по системе команд
ST <— ST - (ST(1) x QQ x 2A (EXPDIF-N);
FI;
Описание
Команда FPREM вычисляет остаток, полученный при делении ST и a. ST
(1), и сохраняет результат в ST. Знак остатка совпадает со знаком исходного
делимого в ST. Величина остатка меньше модуля.
Воздействие на флажки устройства FPU
Состояния бит СО, Cl, С2, СЗ см. табл. 1.7.
Численные особые случаи U, D, I, IS.
Особые случаи Р-режима
#NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
#NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Команда FPREM формирует точный результат; особый случай точности
(неточность) не возникает и управление округлением не действует.
Команда FPREM не соответствует команде вычисления остатка стандарта
IEEE-754 на арифметику с плавающей точкой. Для получения остатка в стан-
дарте IEEE-754 следует пользоваться командой FPREM1. Команда FPREM
введена ради совместимости с сопроцессорами 8087 и 80287.
Команда FPREM действует итеративным вычитанием и за одно выл ; мне-
ние не может уменьшить порядок ST более, чем на 63. Если получается сста-
ток меньше модуля, функция команды считается законченной и флажок С2
сбрасывается в 0. В противном случае флажок С2 устанавливается в 1 г ре-
зультат в ST называется частичным остатком. Порядок частичного остатка
меньше порядка исходного делимого минимум на 32. Программа может по-
вторять команду (используя частичный остаток в ST как делимое) до тех пор,
пока флажок С2 не будет сброшен. Прерывающая процедура с более высоким
приоритетом, которой требуется устройство FPU, может вызывать пере-
ключение контекста между циклами вычисления остатка.
Важное применение команды FPREM связано с приведением аргументов
периодических функций. Когда приведение закончено, три младших бита
частного сохраняются во флажках СЗ, С1 и СО. Это важно в приведении ар-
гумента для функции тангенса (используя модуль PI/4), так как позволяет ло-
кализовать исходный угол в правильном октанте единичной окружности.
FPREM 1 - Partial REMaider ~
Частичный остаток
КОП Комажда Такты Параллельно* Опжсажже
ВЫЕОЛЖеЖЖ*
D9 F8 FPREM1 94(72-167) 5(2-18) Замена ST(1) на остаток,
полученный при делении ST на ST(1)
Операция
EXPDIF <— порядок(ЗТ) - порядок(ЭТ(1));
IF EXPDIF <64
THEN
Q <— целое, полученное при усечении ST/ST(1) к нулю;
ST <— ST - (ST(1) х Q);
C2 <— 0;
CO,C1,C3 <— три младших бита Q; (* Q2,Q1,QO *)
ELSE
C2 <— 1;
Глава 2. Справочные сведения по командам i486
^зоз 4
N <-- число между 32 и 63;
QQ <— целое, ближайшее i ST/ST(1)/2*(EXPDIF-N);
ST <— ST - (ST{ 1) x QQ x 2*{EXPDIF-N);
FI;
Описание
Команда FPREM1 вычисляет остаток, полученный при делении ST на
ST( 1), и сохраняет результат в ST. Величина остатка меньше половины моду-
ля.
Далее см. описание команды FPREM.
FPTAN - Partial TANgerrt
Частичный тангенс
КОП Комаида Такта Параллельное Опвсавяе
вшголжеште
39 F2 FPTAN 244(203-273) 70 Замена ST на его тангенс
и включение 1 в стек
Операция
IF операнд в диапазоне
THEN
С2 <— 0;
ST <— tan(ST);
Декремент указателя вершин» стека;
ST <— 1.0;
ELSE'
С2 <— 1;
FI;
Описание
Команда FPTAN заменяет содержимое ST на tg(ST) и затем включает 1.0 в
стек устройства FPU. Содержимое ST, выраженное в радианах, должно нахо-
диться в диапазоне от -263 до 4-263,
Воздействие на флажки устройства FPU
Состояние бит Cl, С2 см. табл. 1.7; биты СО, СЗ не определены.
Численные особые случаи Р, U, D, 1, IS.
Особые случаи Р-режима
# NM, если в регистре CRO установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Если операнд находится вне диапазона допустимых значений, флажок С2
устанавливается в 1 и содержимое регистра ST остается неизменным. Про-
граммист должен привести операнд к абсолютному значению, меньшему 2^3,
вычитая соответствующее кратное 2 х PI.
Тот факт, что команда FPTAN включает 1.0 в стек после вычисления
tan(ST), обеспечивает совместимость с сопроцессорами 8087 и 80287 и упро-
щает вычисление остальных тригонометрических функций. Например, котан-
генс (являющийся обратной величиной тангенса) можно вычислить, выпол-
няя после команды FPTAN команду FDIVR.
Чтобы избежать особого случая недействительной операции, регистр ST(7)
должен быть пустым.
При выполнении этой команды процессор i486 периодически контроли-
рует прерывания и может отменить ее для обслуживания прерывания.
зо 4?
Микропроцессор i486 • Книга 4. Справочник по системе команд
FRNDINT - RouND INTeger
Округление до целого
KOS Команда Тахтн Параллельное Описание
яндолнежне
D9 FC FRNDINT 28(21-30) 7(2-8) Округление ST до целого
Операция
ST <— округленное значение ST;
Описание
Комавда FRNDINT округляет значение в регистре ST до целого числа в
соответствии с полем RC управления округлением слова управления устрой-
ства FPU.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи Р, D, I, IS.
Особые случаи Р-ре жим а
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
КОП
DB /4
FRSTOR - ReSTORe FPU state
Восстановление полного состояния устройства FPU
Комавда
FRSTOR ш94/
108byte
Операция
Такта Опвсаизш
131 R- или V-режим/ Загрузка состояния FPU
120 P-режим из m94byte или ml08byte
Состояние устройства FPU <— SRC;
Описание
Комавда FRSTOR перезагружает состояние устройства FPU (среда и реги-
стровый стек) из области памяти, определенной операндом-источником. Эти
данные должны быть сохранены предыдущей командой FSAVE или FNSAVE.
Среда устройства FPU состоит из слова управления, слова состояния,
слова тэгов и указателей ошибок (данных и команды). Формат среды в памя-
ти зависит от размера операнда и текущего рабочего режима процессора. Ат-
рибут USE ассемблерной программы для текущего сегмента кода определяет
размер операнда: 14-байтный операнд относится к сегменту USE16, а 28-бай-
тный — к сегменту USE32. (В V-режиме применяется формат R-режима.)
Регистры стека, начиная с ST и кончая ST(7), находятся в 80 байтах,
расположенных сразу после образа среды. Команду FRSTOR необходимо
выполнять в том же рабочем режиме, который был в соответствующей коман-
де FSAVE или FNSAVE.
Воздействие на флажки устройства FPU
Биты СО, Cl, С2, СЗ загружаются из памяти.
Численные особые случаи Нет,
исключая загрузку незамаскированного особого случая.
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
Глава 2. Справочные сведения по командам i486
# NM, если в регистре CRO установлен бит ЕМ или TS.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Если образ состояния содержит незамаскированный особый случай, то его
загрузка приводит к формированию особого случая.
FSAVE/FNSAVE - store FPU state
Сохранение полного состояния устройства FPU
коп Команда Такты Описание
9В DD /6 FSAVE ш94/ 108byte 154 R- или V-режим/ 143 Р-режим + минимум 3 на WAIT Сохранение состояния FPU в m94byte или ml08byte после контроля незамаскированного особого случая. Инициализация FPU.
DD /6 FNSAVE т94/ 108byte Операция 154 R- или V-режим/ 143 Р-режим Сохранение состояния FPU в m94byte или ml08byte без контроля незамаскированного особого случая. Инициализация FPU.
DEST <— состояние устройства FPU;
Инициализировать FPU; (* эквивалент FNINIT *)
Описание
Команды сохранения записывают текущее состояние устройства FPU
(среда и регистровый стек) в определенный получатель, а затем реинициали-
зируют FPU. Среда устройства FPU состоит из слова управления, слова со-
стояния, слова тэгов и указателей ошибок (данных и команды).
Формат состояния в памяти зависит от размера операнда и текущего ра-
бочего режима процессора. Атрибут USE ассемблерной программы для теку-
щего сегмента кода определяет размер операнда: 94-байтный операнд
относится к сегменту USE16, а 108-байтный — к сегменту USE32. (В V-
режиме применяется формат R-режима.) Регистры стека, начиная с ST и
кончая ST(7), сохраняются в 80 байтах, расположенных сразу после образа
среды.
Воздействие на флажки устройства FPU
Биты СО, Cl, С2, СЗ сбра£ываются в 0.
Численные особые случаи Нет
Особые случаи Р-режима
# GI’(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# PF( код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
fe306
Микропроцессор i486 Книга 4. Справочник по системе команд
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Команды FSAVE и FNSAVE не сохраняют состояние устройства FPU до
прекращения всех его действий. Значит, сохраненный образ состояния от-
ражает состояние FPU после выполнения ранее декодированной команды.
Если программа должна считывать образ состояния после команды сохра-
нения, она должна выдать команду7 FWAIT, что обеспечивает окончание со-
хранения.
Команды сохранения обычно применяются в тех ситуациях, когда опера-
ционная система должна выполнить переключение контекста, когда обра-
ботчику особого случая требуется состояние FPU или когда программа хочет
передать подпрограмме «чистое» устройство FPU.
FSCALE - SCALE
Масштабирование
КОП Комавда Такта Параллельное Описание
наполнение
D9 FD FSCALE 31(30-32) 2 Масштабирование ST на ST(1)
Операция
ST <— ST X 2(ST(1));
Описание
Команда FSCALE интерпретирует значение в ST(1) как целое число и
прибавляет его к порядку числа в регистре ST. Таким образом, эта команда
обеспечивает быстрое умножение или деление на целую степень 2.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи Р, U, О, D, I, IS.
Особые случаи Р-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Команду FSCALE можно использовать как команду, обратную команде
FXTRACT. Однако, так как команда FSCALE не извлекает порядок, после
нее нужно выполнить команду FSTP ST(1), чтобы полностью уничтожить
действие предшествующей команды FXTRACT.
Ограничений на диапазон масштабного множителя в ST(1) нет. Если
значение не является целым числом, команда FSCALE использует ближайшее
целое, меньшее по величине; т.е. она усекает значение к 0. Если полученное
целое равно 0, значение в регистре ST не изменяется.
Глава 2. Справочные сведения по командам i486
FSIN - SINe
Вычисление синуса
КОП Команда Такты Параллельное Описание
выполнение
D9 FE FSIN 241(193-279) 2 Замена ST на его синус
Операция
IF операнд в диапазоне
THEN
С2 <— 0; ST <-- sin(ST);
ELSE С2 <— 1;
FI;
Описание
Команда FSIN заменяет содержимое ST на sin(ST). Диапазон угла в регис-
тре ST, выраженный в радианах, составляег от -2<” до +2^3.
Воздействие на флажки устройства FPU
Состояние бита Cl, С2 см. табл. 1.7; биты СО, СЗ не определены.
Численные особые случаи Р, U, D, I, IS.
Особые случаи Р-режима
&NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Если операнд находится вне допустимого диапазона, флажок С2 устанав-
ливается в 1 и содержимое ST остается неизменным. Обеспечить нахождение
операнда в диапазоне, вычитая соответствующее кратное 2 х PI, должен про-
граммист.
При выполнении этой команды процессор i486 периодически контроли-
рует прерывания и она может быть отменена для обслуживания прерывания.
FSINCOS - SINe and COSine
Вычисление синуса и косинуса
КОП Команда Такты Параллельно© Опясаняе
выполнение
D9 FB FSINCOS 291(243-329) 2 Вычисление синуса и косинуса
ST; замена ST на синус и затем
включение косинуса в стек
Операция
IF операнд в диапазоне
THEN
С2 <— 0; TEMP < - cos(ST);
ST <— sin(ST);
Декремент указателя вершины стека;
ST <— TEMP;
ELSE
С2 <— 1;
FI;
Описание
Команда FSINCOS вычисляет значения sin(ST) и cos(ST), заменяет ST на
синус и затем включает косинус в стек устройства FPU. Диапазон угла в реги-
стре ST, выраженный в радианах, составляет от -2^3 до +2^3.
Воздействие на флажки устройства FPU
Состояние бит Ci С2 см. табл. 1.7; биты СО, СЗ не определены.
Микропроцессор I486 Книга 4. Справочник по системе команд
Численные особые случаи Р, U, D, I, IS.
Особые случаи Р-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Если операнд находится вне допустимого диапазона, устанавливается
флажок С2 и ST остается неизменным. Обеспечить нахождение операнда в
диапазоне, вычитая соответствующее кратное 2 х PI, должен программист.
Быстрее выполнить команду FSINCOS, чем отдельные команды FSIN и
I COS.
При выполнении этой команды процессор i486 периодически контроли-
рует прерывания и она может быть отменена для обслуживания прерывания.
FSQRT - SOuare RooT
Вычисление корня квадратного
КОП Комаяда Такт Параллельное Описание
ввшолноние
D9 FA FSQRT 85(83-87) 70 Замена ST на корень квадратный
Операция
ST <— корёнь квадратный из ST;
Описание
Команда FSQRT заменяет значение в регистре ST на значение корня
квадратного.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи Р, D, I, IS.
Особые случаи Р-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Корень квадратный из -0.0 равен -0.0.
FST/FSTP - сохранение вещественное
коп Команда Такты Опясаяяе
D9 /2 FST m32real 7 Копирование ST в m32real
DD /2 FST m64real 8 Копирование ST в m64real
DD DO+i FST ST(i) 3 Копирование ST в ST(i)
D9 /3 FSTP m32real 7 Копирование ST в m32real и извлечение ST
DD /3 FSTP m64real 8 Копирование ST в m64real и извлечение ST
DB /3 FSTP m80real 6 Копирование ST в m80real и извлечение ST
DD D8+i FSTP ST(i) 3 Копирование ST в ST(i) и извлечение ST
Операция
DEST <— ST(O);
IF команда = FSTP THEN Pop(ST);
Глава 2. Справочные сведения по командам i486
Описание
Команда FST копирует значение в регистре ST в получатель, которым
может быть другой регистр или операнд в памяти с форматом одинарной или
двойной точности. Команда FSTP вначале копирует, а затем производит из-
влечение ST из стека; она допускает операнды в памяти в формате расширен-
ной точности, а также все типы, разрешенные в команде FST.
Если получателем является регистр, номер используемого регистра берется
до извлечения из стека.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи:
получатель — регистр или вещественное расширенной точности: IS.
получатель — одинарное/двойное вещественное: P,U,O,D,I,IS.
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РЕ(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Если получатель представлен в формате одинарной или двойной
точности, мантисса округляется до размера получателя в соответствии с полем
RC управления округлением слова управления и порядок преобразуется к
формату получателя. Контролируются возможности переполнения и анти-
переполнения.
Если регистр ST содержит нуль, +-бесконечность или нечисло NaN, то
мантисса не округляется, а усекается (справа) до размера получателя. Порядок
не преобразуется; он также усекается справа. Эти действия сохраняют
значение как бесконечность или нечисло (порядок из одних единиц).
Когда получателем оказывается непустой регистр стека, особый случай не-
действительной операции не регистрируется.
FSTCW/FNSTCW - STore Control WorcT ~ ””
Сохранение слова управления
КОП Комавда Такты Опвсавве
9В D9 /7 FSTCW m2byte 3 + минимум Сохранение слова управления в m2byte
3 на FWAIT после контроля незамаскированного
особого случая
D9 /7 FNSTCW m2byte 3 Сохранение слова управления в m2byte
без контроля незамаскированного
особого случая
Микропроцессор i486 Книга 4. Справочник по системе команд
Операция
DEST <— CW;
Описание
Команды FSTCW и FNSTCW записывают текущее значение слова управ-
ления CW в указанный получатель.
Воздействие на флажки устройства FPV
Биты СО, Cl, С2, СЗ не определены.
Численные особые случаи Нет
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Команда FSTCW перед сохранением слова управления контролирует на-
личие особых случаев, а команда FNSTCW не контролирует.
FSTENV - сохранение среды устройства FPU
КОП Команда Такты
9В D9 /6 FSTENV ш14/ 67 R- или V-режим/
28byte 56 Р-режим;
+ минимум 3 на WAIT
D9 /6 FNSTENV ш14/ 67 R- или V-режим/
28byte 56 Р-режим
Описание
Сохранение среды FPU в ml4byte
или m28byte после контроля
незамаскированного особого
случая. Затем маскирование
всех особых случаев.
Сохранение среды FPU в ml4byte
или m28byte без контроля
незамаскированного особого
случая. Затем маскирование
всех особых случаев.
Операция
DEST <— среда устройства FPU;
CW[0. .5] <— 11111В;
Описание
Команды сохранения среды записывают текущую среду устройства FPU в
указанный получатель, а затем маскируют все особые случаи с плавающей
точкой. Среда устройства FPU состоит из слова управления, слова состояния,
слова тэгов и указателей ошибок (данных и команды).
Формат среды в памяти зависит от размера операнда и текущего рабочего
режима процессора. Атрибут USE ассемблерной программы для текущего
сегмента кода определяет размер операнда: 14-байтный операнд относится к
сегменту USE16, а 28-байтный операнд относится к сегменту USE32. (В V-
режиме применяется формат R-режима.)
Глава 2. Справочные сведения по командам i486
^311?
Воздействие на флажки устройства FPU
Биты СО, Cl, С2, СЗ не определены.
Численные особые случаи Нет
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи Я-оежима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РЕ(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Команды FSTENV и FNSTENV не сохраняют среду до прекращения всех
действий устройства FPU. Следовательно, сохраненный образ среды отражает
состояние FPU после выполнения ранее декодированной команды.
Команды сохранения среды часто применяются в обработчиках особых
случаев, так как они обеспечивают доступ к указателям ошибок устройства
FPU. Обычно среда сохраняется в стеке, организуемом в памяти. После со-
хранения среды команды FSTENV и FNSTENV устанавливают маски всех
особых случаев в слове управления. Этим предотвращается прерывание обра-
ботчика особого случая ошибками с плавающей точкой.
Команда FS1ENV перед сохранением среды контролирует особые случаи
с плавающей точкой, а команда FNSTENV не контролирует.
FSTSW/FNSTSW - STore Status Word
Сохранение слова состояния
КОП Комаада Такты Охшсаява
9В DF /7 FSTSW m2byte 3 + минимум Сохранение слова состояния в ro2byte
9В DF EO FSTSW AX 3 на WAIT 3 + минимум после контроля незамаскированных особых случаев Сохранение слова состояния в АХ
DF /7 FNSTSW m2byte DF ВО FNSTSW АХ Cnepaiu ' DEST <— SW; 3 на WAIT 3 3 после контроля незамаскированных особых случаев Сохранение слова состояния в m2byte без контроля незамаскированных особых случаев Сохранение слова состояния в АХ без контроля незамаскированных особых случаев
Описание
Команды FSTSW и FNSTSW записывают текущее значение слова состоя-
ния устройства FPU в указанном получателе, которым может быть двухбайт-
ная ячейка памяти или регистр АХ.
жж
Микропроцессор i486 Книга 4. Справочник по системе команд
Воздействие на (Ьлажки устройства FPU
Биты СО, Cl, С2, СЗ не определены.
Численные особые случаи Нет
Особые случаи Р-оежима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Команда FSTSW перед сохранением состояния контролирует особые
случаи с плавающей точкой, а команда FNSTSW не контролирует.
Эти команды применяются, в основном, для условного перехода (после
команд сравнения, FPREM, FPREM 1 или FXAM). Их также можно исполь-
зовать для вызова обработчиков особых случаев (при опросе бит особых
случаев) в среде, где прерывания отсутствуют.
В команде FNSTSW АХ регистр АХ модифицируется до выполнения про-
цессором i486 дальнейших команд. Сохраняется состояние, полученное после
предыдущей команде ESC.
FSUB/FSUBP/FISUB - SUBtract
Вычитание
КОП Команда Танга Параллельное выполнение Описание
D8 /4 FSUB m32real 10(8-20) 7(5-17) Вычитание m32real из ST
DC /4 FSUB ro64real 10(8-20) 7(5-17) Вычитание m64real из ST
D8 EO+i FSUB ST,ST(i) 10(8-20) 7(5-17) Вычитание ST(i) из ST
DC E8+i FSUB ST(i),ST 10(8-20) 7(5-17) Замена ST(i) на ST - ST(i)
DE E8+i FSUBP ST(i),ST 10(8-20) 7(5-17) Замена ST(i) на ST - ST(i) и извлечение ST
DE E9 FSUB 10(8-20) 7(5-17) Замена ST(i) на ST - ST(1) и извлечение ST
DA /4 FISUB m32int 22(19-32) 7(5-17) Вычитание ro32int из ST
DE /4 FISUB Операиия ml6int 24(20-35) 7(5-17) Вычитание ml6int из ST
DEST <— ST - другой операнд;
IF команда = FSUBP THEN Pop(ST); FI;
Описание
Команды вычитания вычитают другой операнд из вершины стека и воз-
вращают разность в получатель.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи Р, U, О, D, 1, IS.
Глава 2. Справочные сведения по командам i486
Особые случаи Р-режима
# GP(O) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# NM, если в регистре CR0 установлен бит ЕМ или TS.
# АС при невыравпенном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
Те же особце случаи, что и в R-режиме.
# PF(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Если операнд-источник находится в памяти, он автоматически преобразу-
ется в формат расширенной точности.
FSUBR/FSUBRP/FISUBR - Reverse SUBtract
Обратное вычитание
коп Команда Такты Параллельное выполнение Описание
D8 /5 FSUBR m32real 10(8-20) 7(5-17) Замена ST на m32real - ST
DC /5 FSUBR m64real 10(8-20) 7(5-17) Замена ST на m64real - ST
D8 E8+i FSUBR ST,ST(i) 10(8-20) 7(5-17) Замена ST на ST(i) - ST
DC R0+i FSUBR ST(i),ST 10(8-20) 7(5-17) Вычитание ST из ST(i)
DE EO+i FSUBRP ST(i),ST 10(8-20) 7(5-17) Вычитание ST из ST(i)
и извлечение ST
DE El FSUBR 10(8-20) 7(5-17) Вычитание ST из ST(i)
и извлечение ST
DA /5 FISUBR m32int 22(19-32) 7(5-17) Замена ST на m32int - ST
DE /5 FISUBR ml6int 24(20-35) 7(5-17) Замена ST на ml6int - ST
Операция
DEST <— другой операнд - ST J
IF команда = FSUBRP THEN Pop(ST); FI;
Описание
Команды обратного вычитания вычитают вершину стека из другого one-
ранда и возвращают разность в получатель.
Далее см. описание команд FSUB/FSUBP/FISUB.
FTST - TeST
Проверка
КОП Команда Такты. Параллельное Описание
выполнение
D9 Е4 FTST 4 1 Сравнение ST с 0.0
Операция
CASE (отношение операндов) OF
Не сравнимы: СЗ, С2, СО <— 111;
ST > SRC: СЗ, С2, СО <— ООО;
ST < SRC: СЗ, С2, СО <— 001;
ST = SRC: СЗ, С2, СО <— 100;
зйдмкыя! 1 1 1 ...... .................................
Микропроцессор i486 Книга 4. Справочник по системе команд
Соответствие флажков кода условия FPU и регистра EFLAGS:
Код условия Регистр EFLAGS
СО CF
С1 Нет
С2 PF
СЗ ZF
Описание
Команда FTST сравнивает вершину стека с 0.0. После ее выполнения ко-
ды условия отражают результат сравнения.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, C2I, СЗ, как показано выше.
Численные особые случаи D, I, IS.
Особые случаи Р-режима
#NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
#NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Если регистр ST сдержит нечисло NaN или представлен в неподдерживае-
мом формате или если возникает нарушение стека, формируется особый
случай недействительной операции и коды условия показывают «не упоря-
дочены».
Знак нуля итерируется, т.е. -0.0 = +0.0.
FUCOM/FUCOMP/FUCOMPP - Unordered COMpare real
Неупорядоченное сравнение
вещественное
КОП Команда Такты Параллельное выполиеине Описание
DD EO+i FUCOM ST(i) 4 1 Сравнение ST с ST(i)
DD El FUCOM 4 1 Сравнение ST с ST(1)
DD E8+i FUCOMP ST(i) 4 1 Сравнение ST с ST(i) и извлечение ST
DD E9 FUCOMP 4 1 Сравнение ST с ST(1) и извлечение ST дважды
DA E9 FUCOMPP 4 1 Сравнение ST с ST(1) и извлечение ST дважды
Операция
CASE (отношение операндов) OF
Не сравнимы: СЗ, С2, СО <-- 111
ST > SRC: СЗ, С2, СО <— ООО;
ST < SRC: СЗ, С2, СО <— 001;
ST = SRC: СЗ, С2, СО <— 100;
IF команда = FUCOMP THEN Pop(ST); FI;
IF команда = FUCOMPP THEN Pop(ST); Pop(ST); FI;
Соответствие флажков кода условия FPU и регистра EFLAGS:
Код условия Регистр EFLAGS
СО CF
С1 Нет
С2 PF
СЗ ZF
Описание
Команды неупорядоченного вещественного сравнения сравнивают верши-
ну стека ST с источником, которым должен быть регистр. Если операнд не
Глава 2. Справочные сведения по командам i486
указан, производится сравнение ST с ST(1). После команды коды условия по-
казывают отношение между ST и операнд ом-источником.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, C2I, СЗ, как показано выше.
Численные особые случаи D, I, IS.
Особые случаи Р-режима
#NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
#NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Если любой операнд является сигнализирующим нечислом SNaN или
представлен в неподдерживаемом формате или если возникает нарушение
стека, формируется особый случай недействительной операции и коды усло-
вия показывают «не упорядочены».
Если любой операнд является тихим нечислом QNaN, биты условия пока-
зывают «не упорядочены». В отличие обычных команд сравнения (FCOM
и др.) команды неупорядоченного сравнения не формируют особый случай
недействительной операции при встрече как операнда тихого нечисла.
Знак нуля игнорируется, т.е. -0.0 = +0.0.
FWAIT - WAIT
Ожидание
КОП Комавда Такты Опвсавве
9В FWAIT (1-3) Аналогична команде WAIT
Описание
Команда FWAIT заставляет процессор перед продолжением проверить
ожидающие незамаскированные особые случаи.
Воздействие на флажки устройства FPU
Биты СО, Cl, С2, СЗ не определены.
Численные особые случаи Нет
Особые случаи Р-режима
# NM, если в регистре CR0 установлены биты МР и TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты МР и TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты МР и TS.
Примечание:
Как показывает код операции, команда FWAIT фактически является аль-
тернативной мнемоникой команды WAIT, а не командой ESC.
Указание команды FWAIT после команды ESC гарантирует, что любые
незамаскированные особые случаи, которые может вызвать команда, обраба-
тываются до того, как процессор может изменить результат команды.
FXAM - eXAMine
Анализ
КОП Комавда Такты Опвсавве
D9 Е5 FXAM 8 Сообщает тип объекта в регистре ST
Операция
С1 <— знаковый бит ST; (* 0 - положительное, 1 - отрицательное *)
CASE (тип объекта в ST) OF
>316'.'
Микропроцессор i486 Книга 4. Справочник по системе команд
Неподдерживаемый формат: СЗ, С2, СО <— ООО;
Нечисло: СЗ, С2, СО <— 001;
Нормализованное число: СЗ, С2, СО <— 010;
Бесконечность: СЗ, С2, СО <— 011;
Нуль: СЗ, С2, СО <— 100;
Пустой: СЗ, С2, СО <— 101;
Денормализованное число: СЗ, С2, СО <— 110;
Соответствие флажков кода условия FPU и регистра EFLAGS:
Код условия Регистр EFLAGS
СО CF
С1 Нет
С2 PF
СЗ ZF
Описание
Команда анализа сообщает тип объекта, содержащеюся в регистре ST, ус-
танавливая коды условия устройства FPU.
Воздействие на флажки устройства FPU
Состояния бит СО, Cl, С2, СЗ, как показано выше.
Численные особые случаи Нет
Особые случаи Р-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
FXCH - eXCHange register contents
Обмен содержимого регистров
КОП Команда Такты
D9 C8+i FXCH ST(i) 4
D9 С9 FXCH 4
Операиия
TEMP <— ST; ST <— DEST;
Описание
Обмен содержимого ST и ST(i)
Обмен содержимого ST и ST(1)
DEST <— TEMP;
Описание '
Команда FXCH обменивает содержимое регистров получателя и вершины
стека. Если получатель явно не указан, используется ST(1).
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи IS.
Особые случаи Р-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Многие численные^ команды оперируют только вершиной стека, и
команда FXCH предоставляет удобный способ применения этих команд и для
других регистров стека. Например, следующие три команды извлекают корень
квадратный из третьего регистра от вершины (в предположении, что регистр
ST не пустой):
FXCH ST(3)
FSQRT
FXCH ST(3)
Глава 2. Справочные сведения по командам i486
FXTRACT - eXTRACT exponent and srfnificand
Выделение порядка и мантиссы
КОП Комавда Такты Параллельное Опвсавва
ввшолкекве
D9 F4 FXTRACT 19(16-20) 4(2-4) Разделение ST на мантиссу
и порядок; замена ST на порядок
и включение мантиссы в стек
Операция
TEMP <— мантисса ST; ST <— порядок ST;
Декремент указателя вершины стека FPU;
ST <— TEMP;
Описание
Команда FXTRACT расщепляет значение в ST на порядок и мантиссу.
Порядок заменяет исходный операнд в стеке, а мантисса включается в стек.
После выполнения команды FXTRACT новая вершина стека ST содержит
мантиссу в формате вещественного числа: знак совпадает со знаком операнда,
истинный порядок равен нулю (смещенный порядок равен 16383 или
3FFFH), а мантисса идентична мантиссе исходного операнда. В регистре
ST(1) находится значение истинного (несмещенного) порядка исходного опе-
ранда, представленное как вещественное число.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи Z, D, I, IS.
Особые случаи Р-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Команда FXTRACT реализует надмножество функции logb(x), рекоме-
ндуемой стандартом IEEE-754.
Если исходный операнд равен 0, команда FXTRACT помещает в регистр
ST(1) минус бесконечность (порядок), а в регистр ST — значение нуль со зна-
ком исходного операнда. В такой ситуации генерируется также особый случай
деления на нуль.
Чтобы избежать особого случая недействительной операции, регистр ST(7)
должен быть пустым.
Команда FXTRACT удобна для операций возведения в степень и масшта-
бирования. Для реализации общей степенной функции приходится привле-
кать команды FXTRACT и F2XM1. Преобразование чисел из формата расши-
ренной точности в десятичное представление (например, для печати или вы-
вода на экран) требует не только команду FBSTP, но и команду FXTRACT
для масштабирования, которое не вызывает переполнения в формате расши-
ренной точности. Команда FXTRACT полезна также при отладке, так как по-
зволяет отдельно просмотреть порядок и мантиссу вещественного числа.
FYL2X - compute Yx 1од2(Х) ""
Вычисление Y х 1од2(Х)
КОП Комавда Такты Параллальвоа Опвсавва
выполвавва
D9 Fl FYL2X 311(196-329) 13 Замена ST на ST(1) х log2(ST)
и извлечение ST
318-
Микропроцессор i486 Книга 4. Справочник по системе команд
Операция
ST(1) <— ST(1) x log2(ST);
Pop(ST);
Описание
Команда FYL2X вычисляет двоичный логарифм числа из регистра ST, ум-
ножает его на содержимое регистра ST(1) и возвращает результат в регистре
ST(1). После этого производится извлечение ST. Операнд в регистре ST не
может быть отрицательным.
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи Р, U, О, Z, D, I, IS.
Особые случаи Р-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Примечание:
Если операнд в регистре ST отрицательный, возникает особый случай не-
действительной операции.
В команде FYL2X предусмотрено встроенное умножение, чтобы оптими-
зировать вычисление логарифмов по любому положительному основанию:
logb(X) = Iog2(b)<-1> х log2(X)
Для загрузки констант log2(10) и log2(e) имеются команды FLDL2T и
FLDL2E.
При выполнении этой команды процессор i486 периодически контроли-
рует прерывания и она может быть отменена для обслуживания прерывания.
FYL2XP1 - compute Y х 1од2(Х+1)
Вычисление Y х 1од2(Х+1)
КОП Комавда Такты Параллельное Описание
выполнение
D9 F9 FTL2XP1 313(171-326) 13 Замена ST на ST(1) х 1од2(5Т+1.0)
и извлечение ST
Операция
ST(1) <— ST(1) х log2(ST-H.O);
Pop(ST);
Описание
Команда FYL2X вычисляет двоичный логарифм числа (ST + 1.0), умножа-
ет его на содержимое ST(1) и возвращает результат в ST(1). После этого про-
изводится извлечение ST. Операнд в регистре ST должен находиться в диапа-
зоне:
-(1 - 2<1/2>/2) <= ST <= 2(1/2) _ 1
Воздействие на флажки устройства FPU
Состояние бита С1 см. табл. 1.7; биты СО, С2, СЗ не определены.
Численные особые случаи Р, U, D, I, IS.
Особые случаи Р-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены биты ЕМ или TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены биты ЕМ или TS.
Глава 2. Справочные сведения по командам i486
Примечание:
Если операнд в регистре ST находится вне допустимого диапазона* ре-
зультат команды FYL2XP1 не определен.
Команда FYL2XP1 обеспечивает более высокую точность по сравнению с
командой FYL2X при вычислении логарифмов чисел, очень близких к 1.
Когда число Эпсилон мало, можно получить больше значащих цифр, указы-
вая Эпсилон аргументом команды FYL2XP1, чем при определении аргумента
1 + Эпсилон для команды FYL2X.
При выполнении этой команды процессор i486 периодически контроли-
рует прерывания и она может быть отменена для обслуживания прерывания.
HUT - HaLT
Останов
КОП Команда Такты Описанж»
F4 HLT 4 Останов процессора
Операция
Переводит процессор в состояние останова.
Описание
Команда HLT прекращает выполнение команд и переводит процессор в
состояние останова (HALT). Возобновление выполнения осуществляют раз-
решенное прерывание, немаскируемое прерывание NMI или сброс. Если
после команды HLT для возобновления выполнения применяется прерывание
(включая NMI), сохраненное значение CS:IP (или CS:EIP) показывает на ко-
манду, находящуюся после команды HLT.
Воздействие па флажки Нет
Особые случаи Р-режима
Команда HLT является привилегированной; если текущий уровень приви-
легий не равен 0, возникает особый случай #GP(O).
Особые случаи R-режима Нет
Особые случаи У-режима
# GP(O), так как команда HLT является привилегированной.
IDIV - signed Divide
Знаковое деление
коп Комакда Такты Ооисавгае
F6 /7 IDIV АЬ,г/и8 19/20 Знаковое деление АХ на байт г/га (AL <— частное, АН <— остаток)
Р7 /7 IDIV АХ,г/ш16 27/28 Знаковое деление DX:AX на слово г/га (АХ <— частное, DX <— остаток)
F7 /7 IDIV ЕАХ,г/ш32 Операция 43/44 Знаковое деление EDX:EAX на двойное слово г/га (ЕАХ <— частное, EDX <— остаток)
terap <— делимое / делитель;
IF temp не помещается в частное
THEN Прерывание 0;
ELSE
частное <— teiip;
остаток <— делимое MOD (г/га);
FI;
Примечание:
Делитель определяется операндом r/т. Делимое, частное и остаток нахо-
дятся или помещаются в неявные регистры.
Описание
F320<
Микропроцессор I48S в Книга 4. Справочник по системе команд
Команда IDIV производит знаковое деление. Делимое, частное и остаток
задаются неявно в фиксированных регистрах; как операнд г/m определяется
только делитель. Остаток всегда меньше делителя. Тип делителя определяют
используемые регистры:
Размер Делимо» Делитель Частное Остаток
Байт АХ г/л8 AL АН
Слово DX:AX г/ш16 АХ DX
Двойное слово EDX:ЕАХ r/m32 ЕАХ EDX
Если получающееся частное слишком велико для получателя или делитель
равен 0, генерируется прерывание 0. Нецелые частные усекаются к нулю. Ос-
таток всегда имеет тот же знак, что и делимое, а абсолютная величина остатка
всегда меньше абсолютной величины делителя.
Воздействие на флажки
Флажки OF, SF, ZF, AF, CF и PF не определены.
Особые случаи Р-режима
Прерывание 0, если частное слишком велико для регистра-получателя
(AL, АХ, ЕАХ) или если делитель равен 0.
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РЕ(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 0, если частное слишком велико для регистра-получателя
(AL, АХ, ЕАХ) или если делитель равен 0.
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РЕ(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
IMUL - signed MULtiply
Знаковое умножение
КОП Команда Такт Описание
F6 /5 IMUL r/m8 13-18/13-18 AX <— AL x байт r/m
F7 /5 IMUL г/ml 6 13-26/13-26 DX:AX <— AX x слово r/m
F7 /5 IMUL r/m32 12-42/13-42 EDX:EAX <-- ЕАХ x двойное слово r/m
OF AF /г IMUL rl6,r/ml6 13-26/13-26 Словный регистр <— словный per. х слово r/m 4
OF AF /г IMUL r32,r/m32 13-42/13-42 Двухсловный регистр <— двухсловный
6В /г ib IMUL rl6,r/ml6, imm8 13-26/13-26 регистр х двойное слово г/ш Словный регистр <— г/шХ6 х непосредственный байт
6В /г ib IMUL гЗг^/тХб, imm8 13-26/13-26 Двухсловный регистр <-- г/m3 2 х непосредственный байт
6В /г ib IMUL rl6,imm8 13-26 Словный регистр <— словный per. х непосредственный байт
6В /г ib IMUL r32,imm8 13-42 Двухсловный регистр <— двухсловный регистр х непосредственный байт
69 /г iw IMUL rl6,r/mX6, imm!6 13-26/13-26 Словный регистр <— г/ml6 х непосредственное слово
Глава 2. Справочные сведения по командам 1480
11 Заказ 4317
69 /г id IMUL'r32,t/m32, 13Л2П^2
imm32
69 /г iw IMUL rl6,imml6 13-26/13-26
69 /г id IMUL r32,imm32 13-42/13-42
imm32
Двухсловный регистр <--’r/m32 х
непосредственное двойное слово
Словный регистр <— г/ml6 х
непосредственное слово
Двухсловный регистр <— r/m32 х
непосредственное двойное слово
Примечание:
В процессоре i486 применяется алгоритм умножения с ранним выходом.
Фактическое число тактов зависит от позиции старшего бита в оптимизиро-
ванном множителе. Оптимизация реализуется для положительных и отрица-
тельных значений. Для времени выполнения команд приводится диапазон от
минимума до максимума. Фактическое число тактов синхронизации
рассчитывается по следующей формуле:
max(log2|(ш)|, 3) + 6 тактов
фактическое число тактов = if m = 0 then 9 тактов
(где m - множитель)
Прибавить 3 такта, если множитель есть операнд в памяти.
Операция
результат <— множимое х множитель;
Описание
Команда IMUL производит знаковое умножение. В некоторых формах
команды применяются неявные регистровые операнды. Комбинации операн-
дов для йсех форм команды приведены выше.
Команда IMUL сбрасывает флажки OF и CF в 0 при следующих условиях:
#орма команды Условие для сброса флажков OF и СР
г/ю8 АХ = знаковое расширение AL до 16 бит
г/ю16 DX - знаковое расширение АХ до 32 бит
г/ю32 EDX = знаковое расширение ЕАХ до 64 бит
rl6,f/ml6 Результат точно помещается в г16
r32,r/m32 Результат точно помещается в г32
rl6,r/ml6,i]nml6 Результат точно помещается в г16
r32,r/m32,i]nm32 Результат точно помещается в г32
Воздействие на флажки
Флажки OF и CF сбрасывается в 0 при указанных выше условиях; флажки
SF, ZF, AF и PF не определены.
Особые случаи Р-режима
Далее см. ПРИМЕЧАНИЕ.
Примечание:
При использовании аккумуляторных форм (IMUL r/m8, IMUL r/m 16 и
IMUL r/m32) результат умножения доступен, даже если установлен флажок
переполнения OF, так как результат имеет вдвое больший размер, чем мно-
жимое и множитель, и его достаточно для восприятия любого произведения.
IN - коп INput from port . Ввод из порта
Команда Такты Описание
Е4 ib IN AL,imm8 14, pm=8,(*) 28 (**), vm=27 Ввод байта из непосредственного порта в AL
Е5 ib IN AX,imm8 14, pm=8,(*) 28 (**), vm=27 Ввод слова из непосредственного порта в АХ
Е5 ib IN EAX,imm8 14, pm=8,(*) 28 (**), vm=27 Ввод двойного слова из непосредственного порта в АХ
Микропроцессор i486 Книга 4. Справочник по системе команд
EC IN AL,DX 14, pm=8,(*) Ввод байта из порта DX в AL
28 (**), vm=27
ED IN AX,DX 14, pm=8,(*) Ввод слова из порта DX в AL
28 (**), vm=27
ED IN EAX,DX 14, pm=8,(*) Ввод двойного слова из
28 (**), vm=27 порта DX в ЕАХ
Примечание:
* Если CPL <= IOPL
** Если CPL > IOPL
Операция
IF (РЕ = 1) AND ((VM = 1) OR (CPL > IOPL))
THEN (* V-режим или Р-режим c CPL > IOPL *)
IF NOT Разрешение ввода-вывода (SRC, ширина(SRC))
THEN 4GP(0);
FI;
FI;
DEST <— [SRC]; (♦ Считывание из пространства ввода-вывода *)
Описание
Команда IN передает байт или слово данных из порта, номер которого
определяется вторым операндом, в регистр (AL, АХ, ЕАХ), определяемый
первым операндом. Для обращения к любому порту от 0 до 65535 его номер
помещается в регистр DX и применяется команда IN со вторым операндом
DX. Номер порта не больше 8 бит можно указать непосредственно в команде.
Воздействие на флажки Нет
Особые случаи Р-режима
# GP(0) если текущий уровень привилегий больше (менее привилегиро-
ван), чем уровень привилегий ввода-вывода, и любой из соответствующих бит
в двоичной карте разрешения ввода-вывода сегмента TSS содержит 1.
Особые случаи R-режима Нет
Особые случаи У-режима
# GP(0) если любой из соответствующих бит в двоичной карте разрешения
ввода-вывода сегмента TSS содержит 1.
Tnc - INCrement by 1 Инкремент на 1
коп Команда Такты Описание
FE /0 INC r/m8 1/3 Инкремент байта г/ш на 1
FF /0 INC г/ml6 1/3 Инкремент слова r/m на 1
FF /6 INC r/m32 1/3 Инкремент двойного слова r/m на 1
40+rw INC г16 1 Инкремент словного регистра на 1
40+rd INC г32 1 Инкремент двухсловного регистра на 1 Операция
DEST <— DEST + 1;
Описание
Команда INC прибавляет 1 к операнду. Она не изменяет состояния флаж-
ка переноса CF. Для воздействия на флажок CF следует воспользоваться ко-
мандой ADD с непосредственным операндом 1.
Воздействие на флажки
Флажки OF, SF, ZF, AF и PF устанавливаются в соответствии с результа-
том.
Особые случаи Р-режима
# GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
Глава 2. Справочные сведения по командам i486
INS/INSB/INSW/INSD - IN put from port to String
Ввод из порта в цепочку
КОП Комавда Такты Описание
6С INS r/m8,DX 17, pm=10,(*) Ввод байта из порта DX
32 (*♦), vm=30 в ES:(E)DI
6D INS r/ml6,DX 17, pm=10,(*) Ввод слова из порта DX
32 (**), vm=30 в ES:(E)DI
6D INS r/m32,DX 17, рш=10,(*) Ввод двойного слова из порта DX
32 (*♦), vm=30 в ES:(E)DI
6С INSB 17, pm=10,(*) Ввод байта из порта DX
32 (**), vm=30 в ES:(EJDI
6D INSW 17, pm=10,(*) Ввод слова из порта DX
32 (**), vm=30 в ES:(E)DI
6D INSD 17, pm=10,(*) Ввод двойного слова из порта DX
32 (**), vm=30 в ES:(E)DI
Примечание:
* Если CPL <= IOPL
* * Если CPL > IOPL
Операция
IF AddrSize =16
THEN использовать DI как индекс получателя;
ELSE (* AddrSize = 32 *)
использовать EDI как индекс получателя;
to;
IF (РЕ = 1) AND ((VM = 1) OR (CPL > IOPL))
THEN {* V-режим или Р-режим c CPL > IOPL *)
IF NOT Разрешение ввода-вывода (SRC, ширина(SRC))
THEN #GP(0);
FI;
FI;
IF команда с байтами
THEN
ES:[индекс получателя] <— [DX]; (* Считать байт *)
IF DF = 0 THEN IncDec <-- 1 ELSE IncDec <----1; FI;
FI;
IF OperandSize =16
THEN
ES:[индекс получателя] <— [DX]; (* Считать слово *)
IF DF = 0 THEN IncDec <— 2 ELSE IncDec <-----2; FI;
FI;
IF OperandSize = 32
THEN
ES:[индекс получателя] <-- [DX]; (* Считать двойное слово *)
IF DF = О THEN IncDec <— 4 ELSE IncDec <-----4; FI;
FI;
индекс получателя <— индекс получателя + IncDec;
Описание
Команда INS передает данные из входного порта, номер которого нахо-
дится в регистре DX, в байт или слово памяти по адресу Е8:индекс по-
лучателя. Операнд в памяти должен адресоваться через регистр ES; замена
сегмента не допускается. Получатель определяет регистр DI, если атрибут
размера адреса команды равен 16 битам, или регистр EDI, если атрибут раз-
мера адреса равен 32 битам.
В команде INS не допускается определение порта как непосредственного
значения; порт должен адресоваться только через регистр DX. Следовательно,
до выполнения команды INS в регистр DX необходимо загрузить правильное
значение.
*3 2<
Микропроцессор i486 Книга 4. Справочник по системе команд
Адрес получателя определяется содержимым индексного регистра по-
лучателя. Перед выполнением команды INS в него нужно загрузить правиль-
ный индекс.
После производства передачи осуществляется автоматическое продвиже-
ние регистра DI или EDI. Если флажок направления DF = 0 (была выпол-
нена команда CLD), производится инкремент DI или EDI, а при DF = 1
(выполнена команда STD) — декремент. Величина инкремента или декремен-
та равна 1 при вводе байта, 2 — при вводе слова и 4 — при вводе двойного
слова.
Команды INSB, INSW и INSD являются синонимами команды INS при
вводе байт, слов и двойных слов, соответственно. Перед командой INSB
можно указать префикс повторения REP для блокового ввода СХ байт или
слов.
Воздействие на флажки Нет
Особые случаи Р-режима
#GP(0), если текущий уровень привилегий численно больше уровня при-
вилегий ввода-вывода IOPL, и любой из соответствующих бит в двоичной
карте разрешения ввода-вывода сегмента TSS содержит 1;
#GP(0), если получатель в незаписываемом сегменте.
INT/INTO - Call to INTerrupt procedure
коп Вызов процедуры прерывания
Команда Такш Описание
cc INT 3 26 Прерывание 3 - ловушка отладчика
cc INT 3 44 Прерывание 3 - Р-режим, тот же уровень привилегий
cc INT 3 71 Прерывание 3 - Р-режим, более привилегирован
cc INT 3 82 Прерывание 3 - из V-режима на PL0
cc INT 3 37+TS Прерывание 3 - Р-режим, через шлюз задачи
CD ib INT imm8 30 Номер прерывания в байте imm8
CD ib INT imm8 44 Прерывание - Р-режим, тот же уровень привилегий
CD ib INT imm8 71 Прерывание - Р-режим, более привилегирован
CD ib INT imm8 66 Прерывание - из V-режима на PL0
CD ib INT imm8 37+TS Прерывание - Р-режим, через шлюз задачи
CE INTO Да: 28 Нет: 3 Прерывание 4 - если установлен флажок переполнения
CE INTO 46 Прерывание 4 - Р-режим, тот же уровень привилегий
CE INTO 73 Прерывание 4 - Р-режим, более привилегирован
CE INTO 84 Прерывание 4 - из V-режима на PL0
CE INTO 39+TS Прерывание 4 - Р-режим, через шлюз задачи
Примечание:
Значения ts см. в табл. 1.5.
Операция
Громоздкое алгоритмическое описание команд INT/INTO не приводится.
Описание
Команда INT п программно осуществляет вызов обработчика прерывания.
Непосредственный операнд из диапазона 0 — 255 служит индексом вызывае-
мой процедуры в дескрипторной таблице прерываний IDT. В P-режиме таб-
Глава 2. Справочные сведения по командам i486
лица IDT содержит массив 8-байтных дескрипторов; дескриптор вызываемого
прерывания должен показывать на шлюз прерывания, ловушки или задачи. В
R-режиме таблица IDT представляет собой массив 4-байтных длинных указа-
телей. В обоих режимах линейный адрес таблицы IDT определяется содержи-
мым регистра IDTR.
Команда INTO условного программного прерывания аналогична команде
INT п, но неявный номер ее прерывания равен 4 и прерывание генерируется,
если только установлен флажок переполнения OF.
Первые 32 прерывания зарезервированы фирмой Intel для системных це-
лей. Некоторые из них применяются для внутренних особых случаев.
В общем, команда INT п действует как далекий вызов, но перед адресом
возврата в стек включается регистр флажков. Возврат из процедур прерывания
осуществляет команда IRET, которая извлекает из стека флажки и адрес воз-
врата.
В R-режиме команда INT п включает в стек флажки, регистр CS и регистр
IP, а затем переходит по длинному указателю, индексируемому номером пре-
рывания.
Воздействие на флажки Нет
Особые случаи Р-режима
#GP, #NP, #SS и #TS.
Особые случаи R-режима
Нет, но если регистр SP или ESP перед выполнением команды INT или
INTO содержит 1, 3 или 5, процессор i486 переходит в состояние отключения
из-за недостаточного стекового пространства.
Особые случаи У-режима
Нарушение #GP(0), если поле IOPL меньше 3 (только для команды INT,
чтобы разрешить эмуляцию); прерывание 3 (ОССН) формирует особый случай
контрольной точки; команда INTO генерирует особый случай переполнения,
если установлен флажок переполнения OF.
Ti^TlNValfDate cache ~
Недостоверность кэш-памяти
КОП Команда Такты Описание
OF 08 INVD 4 Недостоверность всей кэш-памяти
Операция
Очистить внутреннюю кэш-память;
Сигнализировать об очистке внешней кэш-памяти;
Описание
Очищается внутренняя кэш-память и выдается специальный цикл шины,
который показывает необходимость очистки и внешней кэш-памяти. Данные
во внешней кэш-памяти с отложенной записью уничтожаются.
Воздействие на флажки Нет
Особые случаи Р-режима Нет
Особые случаи R-режима Нет
Особые случаи У-режима Нет
Примечание:
Эта команда зависит от реализации, и ее функции в будущих процессорах
фирмы Intel могут быть изменены.
На сигнал очистки внешней кэш-памяти должна отреагировать внешняя
схема.
?3 2 6^|
Микропроцессор i486 Книга 4. Справочник по системе команд
В процессоре 80386 этой команды нет. О записи грязных данных в память
см. команду WBINVD.
1NVLPG - INVaLidate TLB aritry
Недостоверность элемента буфера TLB
КОП Комавда Такты Опвсавве
OF 01/7 INVLPG ш 12 при попадании Недостоверность элемента TLB
Операция
Недостоверность элемента TLB;
Описание
Команда INVLPG применяется для задания недостоверности одного эле-
мента буфера TLB, т.е. кэш-памяти, которая применяется для элементов таб-
лиц страниц. Если буфер TLB содержит достоверный элемент, который ото-
бражает адрес операнда в памяти, этот элемент TLB отмечается как недосто-
верный.
Воздействие на флажки Нет
Особые случаи Р-режима
Формируется особый случай недействительной операции, когда в команде
указан регистровый операнд.
Особые случаи R-режима Нет
Особые случаи У-режима
Формируется особый случай недействительной операции, когда в команде
указан регистровый операнд.
Примечание: ,
Эта команда зависит от реализации, и ее функции в будущих процессорах
фирмы Intel могут быть изменены.
В процессоре 80386 этой команды нет.
IRET/IRETD - Interrupt RETurn
коп Возврат из прерывания
Команда Такты Описание
CF IRET 15 Возврат из прерывания (далекий)
CF IRET 36 Возврат из прерывания в менее привилегированную программу
CF IRET TS+32 Возврат из прерывания в другую задачу (NT=1)
CF IRETD 15 Возврат из прерывания (далекий)
CF IRETD 36 Возврат из прерывания в менее привилегированную программу
CF IRETD 15 Возврат из прерывания в V-режим
CF IRETD TS+32 Возврат из прерывания в другую задачу (NT=1)
Примечание:
Значения ts см. в табл. 1.5.
Операция
Громоздкое алгоритмическое описание команд IRET/IRETD не приводит-
ся.
Описание
В R-режиме команда IRET извлекает из стека указатель команды, регистр
CS и регистр флажков и возобновляет прерванную программу.
В P-режиме действие команды IRET зависит от состояния бита NT вло-
женной задачи в регистре флажков. Когда новый образ флажков извлекается
из стека, поле IOPL изменяется только, когда значение CPL равно 0.
Глава 2. Справочные сведения по командам i486
Если флажок NT сброшен в 0, команда IRET производит возврат из про-
цедуры прерывания без переключения задачи. Уровень привилегий кода, в
который, производится возврат, должен быть равен или менее привилегиро-
ван, чем процедура прерывания (он определяется битами RPL селектора CS,
извлекаемого из стека). Если код назначения менее привилегирован, команда
IRET также извлекает из стека указатель стека и регистр SS.
Если флажок NT установлен в 1, команда IRET производит действия, об-
ратные действиям команд CALL или INT, которые произвели переключение
задачи. Модифицированное состояние задачи, выполняющей команду IRET,
сохраняется в ее сегменте состояния задачи TSS. Если в последующем задача
вызывается вновь, выполняется код, находящийся после команды IRET.
Воздействие на флажки
Изменяются все флажки, так как регистр флажков извлекается из стека.
Особые случаи Р-режима
#GP, #NP или #SS.
Особые случаи R-режима
Прерывание 13, если любая часть извлекаемого операнда находится выше
адреса 0FFFFH.
Особые случаи У-режима
Нарушение #GP(0), если уровень привилегий меньше 3, чтобы разрешить
эмуляцию.
JMP - Jump if condition is met
Переход, если условие удовлетворяется
КОП Команда Такты Описанне
77 cb JA ге18 Короткие переходы 3,1 Если выше (CF=0 и ZF=0)
73 cb JAE ге18 3,1 Если выше или равно (CF=0)
72 cb JB ге18 3,1 Если нике (CF=1)
76 cb JBE ге18 3,1 Если нике или равно (CF=1 или ZF=1)
72 cb JC ге18 3,1 Если перенос (CF=1)
ЕЗ cb JCXZ ге18 8,5 Если регистр СХ равен 0
ЕЗ cb JECXZ ге18 8,5 Если регистр ЕСХ равен 0
74 cb JE ге18 3,1 Если равно (ZF=1)
72 cb JZ ге18 3,1 Если нуль (ZF=1)
7F cb JG ге18 3,1 Если больше (ZF=0 и SF=OF)
7D cb JGE ге18 3,1 Если больше или равно (SF=OF)
7С cb JL ге18 3,1 Если меньше (SFOOF)
7Е cb JLE ге18 3,1 Если меньше или равно (ZF=1
76 cb JNA ге18 3,1 или SFOOF) Если не выше (CF=1 или ZF=1)
72 cb JNAE ге18 3,1 Если не выше или равно (CF=1)
73 cb JNB ге18 3,1 Если не нике (CF=0)
77 cb JNBE ге18 3,1 Если не нике или равно (CF=0 и ZF=0)
73 cb JNC ге18 3,1 Если не перенос (CF=0)
75 cb JNE ге18 3,1 Если не равно (ZF=0)
7Е cb JNG ге18 3,1 Если не больше (ZF=1 или SFOOF)
7С cb JNGE ге18 3,1 Если не больше или равно (SFOOF)
7D cb JNL ге18 3,1 Если не меньше (SF=OF)
7F cb JNLE ге!8 3,1 Если не меньше или равно (ZF=0 и
71 cb JNO ге18 3,1 SF=OF) Если не переполнение (OF=0)
7В cb JNP ге18 3,1 Если не паритет (PF=0)
79 cb JNS ге18 3,1 Если не знак (SF=0)
75 cb JNZ ге18 3,1 Если не нуль (ZF=0)
70 cb J0 ге18 3,1 Если переполнение (OF=1)
7А cb JP ге18 3,1 Если паритет (PF=1)
Микропроцессор i486 • Книга 4. Справочник по системе команд
7А cb JPE re18 3,1 Если паритет четный (PF=1)
7В cb JPO re18 3,1 Если паритет нечетный (PF=0)
78 cb JS rel8 3,1 Если знак (SF=1)
74 cb JZ rel8 3,1 Если нуль (ZF=1)
Влжзхже
переходы
OF 87 cw/cd JA rell6/re!32 3,1 Если выше (CF=0 и ZF=0)
OF 83 cw/cd JAE rell6/rel32 3,1 Если выше или равно (CF=0)
OF 82 JB rell6/rel32 3,1 Если ниже (CF=1)
OF 8S cw/cd JBE rell6/rel32 3,1 Если ниже или равно (CF=1 или ZF=1)
OF 82 cw/cd JC rell6/rel32 3,1 Если перенос (CF=1)
OF 84 cw/cd JE rell6/rel32 3,1 Если равно (ZF=1)
OF 84 cw/cd JZ re!16/rel32 3,1 Если нуль (ZF=1)
OF 8F cw/cd JG rell6/rel32 3,1 Если больше (ZF=0 и SF=OF)
OF 8D cw/cd JGE rell6/rel32 3,1 Если больше или равно (SF=OF)
OF 8C cw/cd JL rell6/re!32 3,1 Если меньше (SFOOF)
OF 8E cw/cd JLE rell6/rel32 3,1 Если меньше или равно (ZF=1
или SFOOF)
OF 86 cw/cd JNA rell6/rel32 3,1 Если не выше (CF=1 или ZF=1)
OF 82 cw/cd JNAE rell6/re!32 3,1 Если не выше или равно (CF=1)
OF 83 cw/cd JNB rell6/rel32 3,1 Если не ниже (CF=u)
OF 87 cw/cd JNBE rell6/rel32 3,1 Если не ниже или равно (CF=0 и ZF=0)
OF 83 cw/cd JNC rell6/rel32 3,1 Если не перенос (CF=0)
OF 85 cw/cd JNE rell6/rel32 3,1 Если не равно (ZF=0)
OF 8E cw/cd JNG rell6/rel32 3,1 Если не больше (ZF=1 или SFO0F)
OF 8C cw/cd JNGE rell6/rel32 3,1 Если не больше или равно (SFOOF)
OF 8D cw/cd JNL rell6/rel32 3,1 Если не меньше (SF=OF)
OF 8F cw/cd JNLE rell6/rel32 3,1 Если не меньше или равно (ZF=0 и
SF=OF)
OF 81 cw/cd JNO rell6/rel32 3,1 Если не переполнение (OF=0)
OF 8B cw/cd JNP rell6/rel32 3,1 Если не паритет (PF=0)
OF 89 cw/cd JNS re!16/rel32 3,1 Если не знак (SF=0)
OF 85 cw/cd JNZ re!16/rel32 3,1 Если не нуль (ZF=0)
OF 80 cw/cd JO rell6/rel32 3,1 Если переполнение (OF=1)
OF 8A cw/cd JP rell6/rel32 3,1 Если паритет (PF=lj
OF 8A cw/cd JPE rell6/rel32 3,1 Если паритет четный (PF=1)
OF 8B cw/cd JPO rell6/rel32 3,1 Если паритет нечетный (PF=0)
OF 88 cw/cd JS rell6/rel32 3,1 Если знак (SF=1)
OF 84 cw/cd JZ rell6/rel32 3,1 Если нуль (ZF=1)
Примечание:
Первое число тактов для истинного условия (переход предпринимается), а
второе для ложного условия (переход не предпринимается). Обозначение
ге116/ге132 показывает, что данная команда отображается на две — одна с 16-
битным относительным смещением, а вторая с 32-битным относительным
смещением в зависимости от атрибута размера операнда команды.
Операция
IF условие
THEN
EIP <— SignExtend(rel8/16/32);
IF OperandSize =16
THEN EIP <— EIP AND 0000FFFFH;
FI;
FI;
Описание
Условные переходы (за исключением команды JCXZ) проверяют флажки,
которые были установлены предыдущей командой. Условия показаны в скоб-
ках в приведенной выше таблице. Термины «меньше» и «больше» относятся к
сравнениям знаковых целых чисел, а термины «выше» и «ниже» — к срав-
нениям беззнаковых целых чисел.
Глава 2. Справочные сведения по командам i486
329
Если проверяемое условие истинно, производится переход к ячейке, зада-
ваемой операндом. Кодирование команды наиболее эффективно, когда на-
значение перехода находится в текущем сегменте кода и в пределах от -128 до
+127 байт от первого байта следующей команды.
Назначение перехода может также находиться в пределах от -32768 до
+32767 (атрибут размера сегмента 16) или от -231 до + 231 — 1 (атрибут
размера сегмента 32) относительно первого байта следующей команды. Когда
назначение условного перехода находится в другом сегменте, воспользуйтесь
противоположным условием команды перехода (например, команды JE или
JNE), а затем передайте управление назначению командой безусловного пере-
хода. Например, нельзя закодировать JZ FARLABEL, а придется применить
команды JNZ BEYOND; JMP FARLABEL; BEYOND:
Так как имеется несколько способов интерпретации конкретных состоя-
ний флажков, ассемблер ASM386 для большинства кодов операций допускает
несколько мнемоник. Например, при сравнении двух символов в регистре АХ
и переходе по равенству можно применить команду JE; при объединении по
И регистра АХ с маской и переходе по нулевому результату следует приме-
нить команду JZ, являющуюся синонимом команды JE.
Команда JCXZ отличается от других условных переходов тем, что она
проверяет не флажки, а нулевое содержимое регистра СХ или ЕСХ. Ее удоб-
но применять в начале условного цикла, который заканчивается командой ус-
ловного зацикливания (например, LOOPNE TARGET LABEL). Команда
JCXZ предотвращает вход в цикл с нулевым содержимым регистра СХ или
ЕСХ, что вызывает повторение цикла 64К или 32Г раз вместо нуля.
Воздействие на флажки Нет
Особые случаи Р-режима
#GP(0), если смещение назначения вне предела сегмента кода.
Особые случаи R-режима Нет
Особые случаи V-режима Нет
Примечание:
Команда JCXZ выполняется дольше, чем две команды, которые сравни-
вают регистр-счетчик с нулем и производят переход при достижении им нуля.
Все переходы преобразуются в 16-битные выборки кода независимо от ад-
реса перехода и кэшируемссги.
jmp - jump
коп Переход Команда Такты Описание
ЕВ cb JMP ге18 3 Переход короткий
Е9 cw JMP ге116 3 Переход близкий, смещение относительно
следующей команды
FF /4 JMP г/ml6 5/5 Переход короткий косвенный
ЕА cd JMP ptrl6:16 17,pm=19 Переход межсегментный, 4-байтный
непосредственный адрес
ЕА cd JMP ptrl6:16 32 Переход к шлюзу вызова, те же привилегии
ЕА cd JMP ptrl6:16 у 42+TS . Переход через сегмент состояния задачи
ЕА cd JMP ptrl6:16z 43+TS Переход через шлюз задачи
FF /5 JMP ml6:16 13,pm=18 Переход межсегментный, косвенный
FF /5 JMP ml6:16 32 Переход к шлюзу вызова, те же привилегии
FF /5 JMP ml6:16 42+TS Переход через сегмент состояния задачи
FF /5 JMP ml6:16 42+TS Переход через шлюз задачи
FF /4 JMP r/m32 5/5 Переход короткий косвенный
ЕА ср JMP ptrl6:32 13,pm=18 Переход межсегментный, 6-байтный
непосредственный адрес
ЕА ср JMP ptrl6:32 31 Переход к шлюзу вызова, те же привилегии
,330
Микропроцессор i486 Книга 4. Справочник по системе команд
ЕА ср JMP ptrl6s32 42+TS
ЕА ср JMP ptrl6:32 43+TS
FF /5 JMP nl6s32 13,pm=18
FF /5 JMP и16:32 31
FF /5 JMP nl6:32 41+TS
FF /5 JMP B16:32 42+TS
Переход через сегмент состояния задачи
Переход через шлюз задачи
Переход межсегментный, косвенный
Переход к шлюзу вызова, те же привилегии
Переход через сегмент состояния задачи
Переход через шлюз задачи
Примечание:
Значения ts см. в табл. 1.5.
Операция
Громоздкое алгоритмическое описание команды JMP не приводится.
Описание
Команда JMP передает управление другой точке в командном потоке без
сохранения информации для возврата.
Далее приведено описание различных форм команды.
Переходы с назначением типа г/т 16, г/т32, ге116 и ге132 являются близ-
кими переходами и не изменяют содержимого сегментного регистра.
Команды JMP ге116 и JMP ге132 для образования назначения прибавляют
смещение к адресу команды, находящейся после команды JMP. Форма с ге116
применяется, когда атрибут размера операнда команды равен 16 битам
(атрибут размера сегмента 16 бит), а форма ге132 — когда атрибут размера
операнда равен 32 битам (атрибут размера сегмента 32 бита). Результат пере-
дается в регистр EIP. В форме с ге!16 старшие 16 бит регистра EIP сбрасыва-
ются, поэтому размеры смещения не превышают 16 бит.
Формы команд JMP г/т 16 и JMP г/т32 определяют регистр или ячейку
памяти, из которых берется абсолютное смещение процедуры. Считываемое
из г/m смещение составляет 32 бита для атрибута размера операнда 32 бита
(г/т32) или 16 бит, если атрибут размера операнда составляет 16 бит (r/ml6).
Формы команд JMP ptrl6:16 и JMP ptrl6:32 используют как длинный ука-
затель назначения 4- или 6-байтный операнд. В этих формах длинный указа-
тель считывается из памяти (косвенно). В R- и V-режимах длинный указатель
содержит 16 бит для регистра CS и 16 или 32 бита — для регистра EIP (в
зависимости от атрибута размера операнда). В P-режиме обе формы с
длинным указателем обращаются к байту AR прав доступа в дескрипторе,
индексируемом селекторной частью длинного указателя. В зависимости от
значения байта AR переход выполняет следующие типы передачи управления:
переход к сегменту кода на том же уровне привилегий;
— переключение задачи.
Воздействие на флажки
При переключении задачи модифицируются все флажки, а при его отсут-
ствии не изменяется ни один флажок.
Особые случаи Р-режима
В далеких переходах #GP, #NP и #TS.
Близкие прямые переходы: #GP(0), если процедура вне пределов сегмента
кода; #АС при невыравненном обращении к памяти, если текущий уровень
привилегий 3.
Близкие косвенные переходы:
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# GP, если косвенное смещение находится за пределом сегмента кода.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Глава 2. Справочные сведения по командам i486
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
#РЕ(код-нарушение) для страничного нарушения.
#АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Все переходы преобразуются в 16-битные выборки кода независимо от ад-
реса перехода и кэшируемости.
LAHF - Load Flags into АН register
Загрузка флажков в регистр АН
КОП Команда Такты Описание
9F LAHF 3 Загрузка в АН флажков SF ZF х AF х PF х CF
Операция
АН <— SF:ZF:x:AF:x:PF:x:CF;
Описание
Команда LAHF передает младший байт регистра флажков в регистр АН.
Биты, от старшего к младшему, содержат знак, нуль, неопределенное
значение, дополнительный перенос, неопределенное значение, паритет, нео-
пределенное значение и перенос.
Воздействие на флажки Нет
Особые случаи P-режима Нет
Особые случаи R-режима Нет
Особые случаи У-режима Нет
LAR - Load Access Rights byte
Загрузка байта прав доступа
КОП Команда Такты Описание
OF 02 /г LAR rl6,r/ml6 11/11 г/16 <— r/ml6, маскированный FF00
0F 02 /г LAR г32,г/ш32 11/11 г/32 <-- r/m32, маскированный OOFxFFOO
Описание
Команда LAR сохраняет отмеченную форму второго двойного слова деск-
риптора для селектора-источника, если селектор видим на текущем уровне
привилегий (с учетом поля RPL селектора) и является допустимым типом
дескриптора в пределах дескриптора. В регистр-получатель загружается стар-
шее двойное слово дескриптора, маскированное значением OOFxFFOO, и фла-
жок ZF устанавливается в 1. Буква х означает, что четыре бита, соответству-
ющие старшим четырем битам предела, в значении, которое загружает коман-
да LAR, не определены. Если селектор невидим или имеет неверный тип,
флажок ZF сбрасывается в 0.
Когда указан 32-битный размер операнда, в 32-битный регистр-
получатель загружается все 32-битное значение. При определении 16-битного
размера операнда в 16-битном регистре-получателе сохраняются младшие 16
бит этого значения.
Для команды LAR допустимы все дескрипторы сегментов кода и данных.
• Допустимые в команде LAR типы дескрипторов специальных сегментов и
шлюзов приведены в следующей таблице:
Микропроцессор i486 Книга 4. Справочник по системе команд
Тип Название Допустнмый/иодопустимый
0 Недействительный Недопустимый
1 Доступный TSS 80286 Допустимый
2 LDT Допустимый
3 . Занятый TSS 80286 Допустимый
4 Шлюз вызова 80286 Допустимый
5 Шлюз задачи 80286/i486 Допустимый
6 Шлюз ловушки 80286 Допустимый
7 Шлюз прерывания 80286 Допустимый
8 Недействительный Недопустимый
9 Доступный TSS i486 Допустимый
А Недействительный Недопустимый
В Занятый TSS i486 Допустимый
С Шлюз вызова i486 Допустимый
D Недействительный Недопустимый
Е Шлюз ловушки i486 Допустимый
F Шлюз прерывания i486 Допустимый
Воздействие на флажки
Флажок ZF сбрасывается в 0, если селектор невидим или неверного типа;
в противном случае он устанавливается в 1.
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание б, так как команда LAR в R-режиме не распознается.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
LEA - Load Effective Address
Загрузка эффективного адреса
КОП Комавда Такты Описание
8D /г LEA rl6,m 1 Сохранение в г16 эффективного адреса ш
8D /г LEA г32,ш 1 Сохранение в г32 эффективного адреса ш
Операция
IF OperandSize =16 AND AddressSize =16
THEN rl6 <— Addr(m);
ELSE
IF OperandSize =16 AND AddressSize =32
THEN
rl6 <-- Усеченный до 16 6HT(Addr(m)); (* 32-битный адрес *)
ELSE
IF OperandSize =32 AND AddressSize =16
THEN
r32 <— Усеченный до 16 6HT(Addr(m));
ELSE
IF OperandSize = 32 AND AddressSize = 32
THEN r32 <— Addr(m);
FI;
FI;
FI;
Fl;
Глава 2. Справочные сведения по командам i486
Описание
Команда LEA вычисляет эффективный адрес (смещение) и сохраняет его в
указанном регистре. Атрибут размера операнда OperandSize определяется выб-
ранным регистром. Атрибут размера адреса AddressSize определяется атрибу-
том USE сегмента, содержащего второй операнд. Атрибуты размера адреса и
размера операнда влияют на действия команды LEA следующим образом:
Размер операнда Размер адреса Выполняемое действие
16 16 Вычисляется 16-битный эффективный адрес и сохраняется в 16-битном регистре.
16 32 Вычисляется 32-битный эффективный адрес. Младшие 16 бит адреса сохраняются в 16-битном регистре.
32 16 Вычисляется 16-битный эффективный адрес. Он расширяется с нулем до 32 бит и сохраняется в 32-битном регистре.
32 32 Вычисляется 32-битный эффективный адрес и сохраняется в 32-битном регистре.
Воздействие на флажки Нет
Особые случаи Р-режима
#UD, если второй операнд является регистром.
Особые случаи R-режима
Прерывание 6, если второй операнд является регистром.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
LEAVE - high level procedure exit
Выход из процедуры
КОП Команда Такты Описание
С9 LEAVE 5 Установка SP на ВР, затем извлечение ВР
С9 LEAVE 5 Установка ESP на ЕВР, затем извлечение ЕВР
Операция
IF StackAddrSize =16
THEN
SP <— BP;
ELSE (* StackAddrSize = 32 *)
ESP <— EBP;
FI;
IF OperandSize =16
THEN
BP <— Pop();
ELSE (* OperandSize = 32 *)
EBP <— Pop();
FI;
Описание
Команда LEAVE отменяет действия команды ENTER. Копируя указатель
кадра в указатель стека, команда LEAVE освобождает стековое пространство,
используемое процедурой для локальных переменных. Старый указатель кад-
ра извлекается в регистр ВР или ЕВР, восстанавливая кадр вызывающей про-
•334 •-
Микропроцессор i486 • Книга 4. Справочник по системе команд
граммы. Последующая команда RET rm удаляет все аргументы, включенные в
стек процедуры, из которой производится выход.
Воздействие на флажки Нет
Особые случаи Р-ре жим а ч
#SS(O), если регистр ВР не показывает на ячейку в пределах текущего
сегмента стека.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
LGDT/LIDT - Load Global/lnterrupt Descriptor Table Register
Загрузка регистра глобальной дескрипторной
таблицы/дескрипторной таблицы прерываний
коп Команда Тахты Описание
OF 01 /2 LGDT Ш16&32 11 Загрузка m в GDTR
OF 01 /3 LIDT шШ32 11 Загрузка m в IDTR
Операиия
IF команда = LIDT
THEN
IF Operandsize =16
THEN IDTR.Предел.База <— ml6:24; (* Загружаются 24 бита базы *)
ELSE IDTR.Предел.База <— ml6:32;
FI;
THEN
IF Operandsize =16
THEN GDTR.Предел.База <— ml6:24; (* Загружаются 24 бита базы *)
ELSE GDTR.Предел.База <— ml6:32;
FI;
FI;
Описание
Команды LGDT и LIDT загружают значения линейного базового адреса и
предела из 6-байтного адреса операнда из памяти в регистр GDTR или IDTR.
Если в них используется 16-битный операнд, в регистр загружаются 16-
битный предел и 24-битный базовый адрес, старшие восемь бит 6-байтного
операнда игнорируются. Если используется 32-битный операнд, в регистр
загружаются 16-битный предел и 32-битный базовый адрес; старшие восемь
бит 6-байтного операнда служат старшими битами базового адреса.
Команды SGDT и SIDT всегда сохраняют все 48 бит 6-байтного операнда.
В процессоре 80286 после выполнения этих команд старшие восемь бит не
определены. В процессорах 80386 и i486 в старшие восемь бит записываются
старшие восемь бит адреса для 16- и 32-битного операнда. Если команда
LGDT или LIDT применяется с 16-битным операндом для загрузки регистра,
сохраненного командой SGDT или SIDT, то в старшие восемь бит помеща-
ются нули.
Команды LGDT и LIDT предназначены для системных программ и в
прикладных программах не встречаются. Это единственные команды, которые
в P-режиме прямо загружают линейный адрес (а не относительный адрес в
сегменте).
Воздействие на флажки Нет
Особые случаи Р-режима
Глава 2. Справочные сведения по командам i486
# GP(O), если текущий уровень привилегий не равен 0.
# UD(0), если операндом-источником является регистр.
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
#SS(O) для недопустимого адреса в сегменте SS.
#РР(код-нарушение) для страничного нарушения.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса эт 0 до 0FFFFH.
Прерывание 6, если операндом-источником является регистр.
Примечание:
Эти команды разрешены в R-режиме для инициализации Р-режима после
включения питания.
Особые случаи У-режима
Те же особые случаи, что и в к-режиме.
#РЕ(код-нарушение) для страничного нарушения.
LGS/LSS/LDS/LES/LFS - Load full pointer
Загрузка полного указателя
коп К опак да Такты Ойжсанже
С5 /г LDS г16,ш16:16 6/12 Загрузка в DS:rl6 указателя из памяти
С5 /г LDS г32,ш16:32 6/12 Загрузка в DS:r32 указателя из памяти
ЭР 32 /г LSS г16,ш16:16 6/12 Загрузка в SS:rl6 указателя из памяти
!)F В2 /г LSS r32,ml6:32 6/12 Загрузка в SS:r32 указателя из памяти
С4 /г LES rl6,ml6:16 6/12 Загрузка в ES:rl6 указателя из памяти
С4 /г LES r32,ml6:32 6/12 Загрузка в ES:r32 указателя из памяти
OF 34 /г LFS rl6,ml6sl6 6/12 Загрузка в FS:rl6 указателя из памяти
OF В4 /r LFS r32,inl6:32 6/12 Загрузка в FS:r32 указателя из памяти
OF В5 /r LGS rl6,ml6:16 6/12 Загрузка в GS:rl6 указателя из памяти
OF В5 /г LGS г32,ш16:32 Onepauuu 6/12 Загрузка в GS:r32 указателя из памяти
CASE команда 0F
LSS: Sreg есть SS; (* Загрузка регистра SS *)
LDS: Sreg есть DS; (* Загрузка регистра DS *)
LES: Sreg есть ES; (* Загрузка регистра ES ♦)
LFS: Sreg есть FS; (* Загрузка регистра FS *)
LGS: Sreg есть GS; (♦ ЗагрузКа регистра GS *}
ESAC;
IP Operandsize =16
THEN
rl6 <-- [Эффективный адрес); (* 16-битная передача *)
Sreg <— [Эффективный адрес + 2); (* 16-битная передача *)
(* В P-режиме загрузка дескриптора в сегментный регистр *)
ELSE
г32 <— [Эффективный адрес); (* 32-битная передача *)
Sreg <— [Эффективный адрес + 2); (* 32-битная передача *)
(* В P-режиме загрузка дескриптора в сегментный регистр *)
FI;
Описание
Эти команды считывают из памяти полный указатель и загружают его в
пару сегментный регистр:регистр. Полный указатель загружает 16 бит в сег-
ментный регистр SS, DS, ES, FS или GS. В другой регистр загружаются 32
бита, если атрибут размера операнда равен 32 битам, или 16 бит, если атрибут
размера операнда равен 16 битам. Другой регистр определяется операндом г16
или г32.
Микропроцессор i486 Книга 4. Справочник по системе команд
Когда производится загрузка в любой сегментный регистр, в его теневой
регистр также загружается дескриптор. Данные берутся из элемента дескрип-
торной таблицы, соответствующего селектору.
В регистры DS, ES, FS или GS можно загрузить пустой селектор (0000Н
— 0003Н), не вызывая особого случая. (Последующее обращение к сегменту,
в сегментный регистр которого загружен пустой селектор, для адресации па-
мяти вызывает особый случай #GP (0). Обращения к сегменту в памяти не
производится.)
Далее приведен список проверок в Р-режиме и предпринимаемых дей-
ствий при загрузке сегментного регистра:
IF загружается SS
IF селектор пустой THEN #GP(O); FI;
Индекс селектора должен быть в пределах его дескрипторной
таблицы ELSE #GP(селектор);
RPL селектора должен быть равен CPL ELSE |GP(селектор);
Байт AR должен•показывать записываемый сегмент ELSE #GP(селектор);
DPL в байте AR должен быть равен CPL ELSE |GP(селектор);
Сегмент должен быть отмечен как присутствующий ELSE ISS(селектор);
Загрузить в SS селектор;
Загрузить в SS дескриптор;
IF в регистр DS, ES, FS или GS загружается непустой селектор:
Индекс селектора должен быть в пределах его дескрипторной таблицы
ELSE #GP(селектор);
Байт ARcдолжен показывать сегмент данных или считываемый
сегмент кода ELSE #GP(селектор);
IF данные или неподчиненный код
THEN оба RPL и CPL должны быть меньше или равны
DPL в байте AR;
ELSE |GP(селектор);
Сегмент должен быть отмечен как присутствующий ELSE #NP(селектор);
Загрузить в сегментный регистр селектор и биты RPL;
Загрузить в сегментный регистр дескриптор;
IF в регистр DS, ES, FS или GS загружается пустой селектор:
Загрузить в сегментный регистр селектор;
Сбросить бит достоверности дескриптора;
Воздействие на флажки Нет
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
Второй операнд должен быть операндом в памяти, а не регистром.
' #GP(0), если в регистр SS загружается пустой селектор.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Второй операнд должен быть операндом в памяти, а не регистром.
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РЕ(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
1
Глава 2. Справочные сведения по командам i486
LLDT - Load Local Descriptor Table
Загрузка регистра локальной дескрипторной таблицы
КОП Команда Такты Описание
OF 00 /2 LLDT r/ml6 11/11 Загрузка селектора r/ml6 в LDTR
Операция
LDTR <— SRC;
Описание
Команда LLDT Загружает регистр локальной дескрипторной таблицы
LDTR. Операнд-слово (регистр или память) команды LLDT должен содер-
жать селектор глобальной дескрипторной таблицы GDT, а элемент таблицы
GDT должен быть дескриптором локальной дескрипторной таблицы. При
этих условиях элемент загружается в регистр LDTR. Сегментные регистры
DS, ES, FS и GS не изменяются. Поле LDT в сегменте состояния задачи не
изменяется.
Операнд-селектор может быть равен 0; в этом случае регистр LDTR от-
мечается как недостоверный. Все обращения к дескриптору (за исключением
команд LAR, VERR, VERW и LSL) вызывают нарушение #GP.
Команда LLDT предназначена для системных программ и в прикладных
программах не применяется.
Воздействие на флажки Нет
Особые случаи Р-режима
# GP(0), если текущий уровень привилегий не 0.
#СР(селекгор), если операнд-селектор не показывает на таблицу GDT или
если элемент в таблице GDT не является дескриптором локальной дескрип-
торной- таблицы.
# НР(селектор), если дескриптор таблицы LDT не присутствует.
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РЕ(код-нарушение) для страничного нарушения.
Особые случаи R-режима
Прерывание б, так как команда LLDT не распознается в R-режиме.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме (так как команда не распознается,
она не выполняется и не производит обращения к памяти).
Примечание:
Атрибут размера операнда в этой команде не действует.
LMSW - Load Machine Status Word
Загрузка слова состояния машины
КОП Команда Такты Описание
OF 01 /6 LMSW r/ml6 13/13 Загрузка r/ml6 в слово состояния машины
Операция
MSW <— г/ml6; (* в слове состояния машины сохраняются 16 бит *)
Описание
Команда LMSW загружает слово состояния машины (часть регистра CR0)
из операнда-источника. Ее можно использовать для переключения в Р-ре-
жим; в этом случае после нее должен находиться межсегментный переход для
очистки очереди команд. С помощью команды LMSW переключиться в R-
режим нельзя.
1^-ззвХ
Микропроцессор i486 я Книга 4. Справочник по системе команд
Команда LMSW предназначена для системных программ и в прикладных
программах не применяется.
Воздействие на флажки Нет
Особые случаи Р-режима
# GP(0), если текущий уровень привилегий не равен 0.
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РР(код-нарушение) для страничного нарушения.
Примечание:
Атрибут размера операнда в этой команде не действует. Она пред-
назначена для совместимости с процессором 80286; в программах для процес-
сора i486 следует пользоваться командой MOV CR0,... Команда LMSW не
влияет на биты PG и ЕТ и ее нельзя применить для сброса бита РЕ.
LOCK - Assert LOCK# signal prefix
Префикс выдачи сигнала LOCK#
КОП Команда Такты Описание
FO LOCK 1 Выдача сигнала LOCKI для следующей команды
Описание
Префикс LOCK заставляет процессор i486 вьщать сигнал LOCK# при вы-
полнении находящейся за префиксом команды. В мультипроцессорной среде
этот сигнал обеспечивает процессору i486 монопольное использование любой
разделенной памяти во время действия сигнала. Обычно для реализации
цикла считывания-модификации-записи применяется команда BTS.
Префикс LOCK действует только со следующими командами:
BTS, BTR, BTC mem, reg/imm
XCHG reg, mem
XCHG mem, reg
ADD, OR, ADC, SBB, AND, SUB, XOR mem, reg/imm
NOT, NEG, INC, DEC mem
Если префикс LOCK указан перед другой командой, генерируется ловуш-
ка неопределенного кода операции.
Команда XCHG всегда выдает сигнал LOCK# независимо от наличия или
отсутствия префикса LOCK.
На целостность префикса LOCK не влияет выравнивание поля памяти.
Блокирование памяти производится для произвольно невыравненных полей.
Воздействие на флажки Нет
Особые случаи Р-режима
# UD, если префикс LOCK указан перед командой, отсутствующей в при-
веденном выше списке; в последующей (заблокированной) команде могут
возникать другие особые случаи.
Особые случаи R-режима
Прерывание 6, если префикс LOCK указан перед командой, отсутствую-
щей в приведенном выше списке; в последующей (заблокированной) команде
могут возникать другие особые случаи.
Глава 2. Справочные сведения по командам i486
Особые случаи У-режима
#UD, если префикс LOCK указан перед командой, отсутствующей в при-
веденном выше списке; в последующей (заблокированной) команде могут
возникать другие особые случаи.
LOtTs/LO^
Загрузка цепочечного операнда
коп Команда Такты Описание
АС LODS ш8 5 Загрузка в AL байта [(E)SI]
AD LODS ml6 5 Загрузка в АХ слова [(E)Slj
AD LODS m32 5 Загрузка в ЕАХ двойного слова [(E)SI]
АС LODSB 5 Загрузка в AL байта DS;[(E)SI]
AD LODSW 5 Загрузка в АХ слова DS:[(E)SI]
AD LODSD 5 Загрузка в ЕАХ двойного слова DS:[(E)SI]
Операция
IF AddrSize = 16
THEN использовать SI как индекс источника;
ELSE (* AddrSize = 32 *)
использовать ESI как индекс источника;
FI;
IF команда с байтами
THEN
AL <— [индекс источника]; (* Загрузка байта *)
IF DF = О THEN IncDec <— 1 ELSE IncDec <-----1; FI;
ELSE
IF OperandSize = 16
THEN
AX <— [индекс источника]; (* Загрузка слова *)
IF DF = О THEN IncDec <— 2 ELSE IncDec <-----2; FI;
ELSE (* OperandSize = 32 *)
EAX <— [индекс источника]; (* загрузка двойного слова *)
IF DF = О THEN IncDec <— 4 ELSE IncDec <-----4; FI;
FI;
FI;
индекс источника <-- индекс источника + IncDec;
Описание
Команда LODS загружает в регистр AL, АХ или ЕАХ байт, слово или
двойное слово из ячейки памяти, адресуемой регистром индекса источника.
После производства передачи осуществляется автоматическое продвижение
регистра индекса источника. Если флажок направления DF = 0 (была выпол-
нена команда CLD), производится инкремент индекса, а при DF = 1
(выполнена команда STD) — декремент. Величина инкремента или декремен-
та равна 1 при загрузке байта, 2 — при загрузке слова и 4 — при загрузке
двойного слова.
Если атрибут размера адреса для команды равен 16 битам, индексом ис-
точника служит регистр SI; в противном случае атрибут размера адреса равен
32 битам и применяется регистр ESI. Адрес данных источника определятся
просто содержимым регистра SI или ESI. Перед выполнением команды
LODS в регистр SI нужно загрузить правильный индекс. Команды LODSB,
LODSW и LODSD являются синонимами команды LODS при загрузке байт,
слов и двойных слов, соответственно.
Перед командой LODS можно указать префикс повторения REP; однако
команда LODS обычно применяется в конструкции LOOP, так как дальней-
1ЯЯ Микропроцессор i486 Книга 4. Справочник по системе команд
шей обработки данных, переданных в регистры AL, АХ или ЕАХ обычно не
гребуется.
Воздействие на флажки Нет
Особые случаи Р-режима
Далее см. ПРИМЕЧАНИЕ.
LOOP/LOOPcond - LOOP control with Cx counter регистре СХ
Управление циклом co счетчиком в (
КОП Команда Такты Описаете
E2 cb LOOP ге!8 2,6 Декремент счетчика; короткий если счетчик не равен 0 переход,
El cb LOOPE ге!8 9,6 Декремент счетчика; короткий если счетчик не равен 0 и ZF переход,
El cb LOOPZ ге18 9,6 Декремент счетчика; короткий если счетчик не равен 0 и ZF переход,
E0 cb LOOPNE ге18 9,6 Декремент счетчика; короткий если счетчик не равен 0 и ZF переход,
E0 cb LOOPNZ rel8 9,6 Декремент счетчика; короткий если счетчик не равен 0 и ZF Операция переход, = 0
IF AddrSize =16 THEN CountReg есть CX ELSE CountReg CountReg <— CountReg - 1; есть ЕСХ; FI;
IF команда <> LOOP
THEN
IF (команда = LOOPE) OR (команда = LOOPZ)
THEN BranchCond <— (ZF = 1) AND (CountReg <> 0);
FI;
IF (команда = LOOPNE) OR (команда = LOOPNZ)
THEN BranchCond <— (ZF = 0) AND (CountReg <> 0);
FI;
FI;
IF BranchCond
THEN
IF OperandSize = 16
THEN
IP <— IP + SignExtend(rel8);
ELSE (* OperandSize = 32 *)
EIP <— EIP + SignExtend(rel8);
FI;
FI;
Описание
Команда LOOP производит декремент регистра-счетчика без воздействия
флажки. После этого в соответствии с формой команды проверяются усло-
вия. Если условия удовлетворяются, осуществляется короткий переход к
метке, являющейся операндом команды LOOP. Если атрибут размера адреса
равен 16 битам, регистром-счетчиком служит СХ; в противном случае приме-
няется регистр ЕСХ. Операнд команды LOOP должен находиться в диапазоне
128 байт перед командой или 127 байт после команды.
Команды LOOP обеспечивают управление повторением и объединяют уп-
равление индексом с условным переходом. В регистр-счетчик следует загру-
зить беззнаковое число повторений, а затем в конце повторяемых команд
указать команду LOOP. Назначением команды LOOP является метка, показы-
вающая начало повторений.
Воздействие на флажки Нет
Особые случаи Р-режима
#GP(0), если смещение перехода вне предела текущего сегмента кода.
Глава 2. Справочные сведения по командам i486
Особые случаи R-режима Нет
Особые случаи У-режима Нет
Примечание:
Безусловная команда LOOP выполняется дольше, чем две команды, кото-
рые производят де!фемент регистра-счетчика и переход, если в нем не дос-
тигнут 0.
Все переходы преобразуются в 16-битные выборки кода независимо от ад-
реса перехода или кэшируемости.
LSL - Load Segment Limit
Загрузка предела сегмента
коп Комавда Такты
OF 03 /г LSL rl6,r/ml6 10/10
OF 03 /г LSL r32,r/m32 10/10
OF 03 /г LSL rl6,r/ml6 10/10
OF 03 /г LSL r32,r/m32 10/10
Опвсавва
г/16 <— предел сегмента, селектор г/ml6
(байтная гранулярность)
г/32 <— r/m32 предел сегмента, селектор
r/m32 (байтная гранулярность)
г/16 <— предел сегмента, селектор г/ml6
(страничная гранулярность)
г/32 <— r/m32 предел сегмента, селектор
r/m32 (страничная гранулярность)
Описание
Команда LSL загружает в регистр собранный предел сегмента и устанав-
ливает в 1 флажок ZF при условии, что исходный селектор видим на текущем
уровне привилегий и поля RPL, что он находится внутри дескрипторной таб-
лицы и что дескриптор имеет тип, допустимый в команде LSL. В противном
случае флажок ZF сбрасывается в 0 и регистр -получатель не изменяется.
Предел сегмента загружается как значение с байтной гранулярностью. Если
дескриптор имеет предел сегмента со страничной гранулярностью, команда
LSL до загрузки его в регистр преобразует в байтный предел (сдвиг влево на
12 бит «сырого» предела из дескриптора и объединение по ИЛИ с
00000FFFH).
32-битные формы команды LSL сохраняют 32-битный предел с байтной
гранулярностью в 16-битном регистре.
Для команды LSL допустимы все дескрипторы сегментов кода и данных.
Допустимые в команде LSL типы дескрипторов специальных сегментов и
шлюзов приведены в следующей таблице:
Tbs Назвавве Допустимый/надопустимый
0 Недействительный Недопустимый
1 Доступный TSS 80286 Допустимый
2 LDT Допустимый
3 Занятый TSS 80286 Допустимый
4 Шлюз вызова 80286 Недопустимый
5 Шлюз задачи 80286/1486 Недопустимый
6 Шлюз ловушки 80286 Недопустимый
7 Шлюз прерывания 80286 Недопустимый
8 Недействительный Допустимый
9 Доступный TSS i486 Допустимый
А Недействительный Недопустимый
В Занятый TSS i486 Допустимый
С Шлюз вызова i486 Недопустимый
D Недействительный Недопустимый
Е Шлюз ловушки i486 Недопустимый
F Шлюз прерывания i486 Недопустимый
Микропроцессор i486 Книга 4. Справочник по системе команд
Воздействие на флажки
Флажок ZF сбрасывается в 0, если селектор невидим или неверного типа;
в противном случае он устанавливается в 1.
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS,
# РР(код- нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 6, так как команда LSL в R-режиме не распознается.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
LTR - Load Task Register
Загрузка регистра задачи
КОП Команда Такты Описание
OF 00 /3 LTR г/ml 6 20/20 Загрузка слова по ЕА в регистр задачи
Описание
Команда LTR загружает регистр задачи TR из регистра или ячейки памя-
ти, определенных в операнде. Закруженный сегмент TSS отмечается занятым.
Переключение задачи не происходит.
Команда LTR предназначена для системных программ и в прикладных
программах не применяется.
Воздействие на флажки Нет
Особые случаи Р-режима
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# GP(0), если текущий уровень привилегий не равен 0.
# ОР(селекгор), если указанный селектором-источником объекг не
является сегментом TSS или уже занят.
# НР(селекгор), если сегмент TSS отмечен неприсутствующим.
# РР(код-нарушение) для страничного нарушения.
Особые случаи R-режима
Прерывание 6, так как команда LTR в R-режиме не распознается.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
Примечание:
Атрибут размера операнда в этой команде не действует.
MOV - MOVe data
Передача данных
коп Комавда Такты Опвсавве
88 /г MOV r/m8,r8 1 Передача байта из регистра в байт r/m
89 /г MOV r/ml6,rl6 1 Передача слова из регистра в слово r/m
89 /г MOV r/m32,r32 . 1 Передача двойного слова из регистра в двойное слово r/m
8А /г MOV r8,r/m8 1 Передача байта r/m в регистр
8В /г MOV rl6,r/ml6 1 Передача слова r/m в регистр
Глава 2. Справочные сведения по командам i486
8В /г MOV r32,r/m32 1
8С /г MOV r/ml6,Sreg 3/3
8Е /г MOV Sreg,r/ml6 3/9
АО MOV AL,moffs8 1
Al MOV AX,moffsl6 1
Al MOV EAX,moffs32 1
A2 MOV moffs8,AL 1
A3 MOV moffsl6,AX 1
A3 MOV moffs32,EAX 1
BO + rb MOV reg8,imm8 1
B8 + rv MOV regl6,imml6 1
B8 + rd MOV reg32,imm32 1
C6 MOV r/m8finun8 1
C7 MOV r/ml6,imml6 1
C7 MOV r/m32,imm32 1
Передача двойного слова r/m в регистр
Передача сегментного регистра в слово r/m
Передача слова r/m в сегментный регистр
Передача байта (seg:offset) в AL
Передача слова (seg:offset) в АХ
Передача двойного слова (seg:offset) в ЕАХ
Передача AL в (-seg: off set)
Передача АХ в (seg:offset)
Передача ЕАХ в (seg:offset)
Передача непосредственного байта в регистр
Передача непосредственного слова в регистр
Передача непоср. двойного слова в регистр
Передача непоср. байта в байт r/m
Передача непоср. слова в слово r/m
Передача непоср. двойного слова '
в двойное слово r/m
Примечание:
Все операнды moff$8, moflfsl6 и moffs32 состоят из простого смещения от-
носительно базы сегмента. Числа 8, 16 и 32 относятся к размеру данных. Ат-
рибут размера адреса команды определяет размер смещения 16 или 32 бита.
Операция
DEST <— SRC;
Описание
Команда MOV копирует второй операнд в первый операнд.
Если операндом-получателем служит сегментный регистр (DS, ES, SS и
т.д.), в регистр также загружаются данные из дескриптора. Данные для регис-
тра берутся из элемента дескрипторной таблицы по заданному селектору. В
регистры DS и ES допускается загрузка пустого селектора (0000Н — 0003Н)
без возникновения особого случая; однако использование регистра DS или ES
вызывает особый случай #GP(0), и обращение к памяти не производится.
Передача в регистр SS запрещает все прерывания до окончания выполне-
ния следующей команды (которой обычно бывает команда MOV передачи в
регистр ESP).
Загрузка в сегментный регистр в P-режиме вызывает приведенные далее
специальные проверки и действия:
IF загружается SS
THEN
IF селектор пустой THEN iGP(O)*
FI;
Индекс селектора должен быть в пределах его дескрипторной
таблицы ELSE #GP(селектор);
RPL селектора должен быть равен CPL ELSE |GP(селектор);
Байт AR должен показывать записываемый сегмент
ELSE IGP(селектор);
DPL в байте AR должен быть равен CPL ELSE 4GP(селектор);
Сегмент должен быть отмечен как присутствующий
ELSE ISS(селектор);
Загрузить в SS селектор;
Загрузить в SS дескриптор;
FI;
IF в регистр DS, ES, FS или GS загружается непустой селектор:
THEN
Индекс селектора должен быть в пределах его дескрипторной
таблицы ELSE |GP(селектор);
Байт AR должен показывать сегмент данных или считываемый
сегмент кода ELSE #GP(селектор);
IF данные или неподчиненный код
THEN оба RPL и CPL должны быть меньше или равны
Микропроцессор i486 а Книга 4. Справочник по системе команд
DPL в байте AR;
ELSE |GP(селектор);
FI;
Сегмент должен быть отмечен как присутствующий ELSE #NP(селектор);
Загрузить в сегментный регистр селектор;
Загрузить в сегментный регистр дескриптор;
FI;
IF в регистр DS, ES, FS или GS загружается пустой селектор:
THEN
Загрузить в сегментный регистр селектор;
Сбросить бит достоверности дескриптора;
FI;
Воздействие на флажки Нет
Особые случаи Р-режима
#GP, #SS и #NP, если загружается сегментный регистр.
В противном случае:
Далее см. ПРИМЕЧАНИЕ.
MOV - MOVe to/from special registers
Передача в специальные регистры и из них
коп Команда Такты Охшсажне
OF 22 /г MOV CR0,r32 16 Передача регистра в регистр управления
OF 20 /г MOV r32,CR0/CR2/CR3 4 Передача регистра управления в регистр
OF 22 /r MOV CR2/CR3,r32 4 Передача регистра в регистр управления
OF 21 /r MOV t32,DR0 - DR3 10 Передача регистра отладки в регистр
OF 21 /r MOV r32,DR6/DR7 10 Передача регистра отладки в регистр
OF 23 /r MOV DRO - DR3,r32 11 Передача регистра в регистр отладки
OF 23 /r MOV DR6/DR7,r32 11 Передача регистра в регистр отладки
OF 24 /r MOV r32,TR4 - TR7 4 Передача регистра проверки в регистр
OF 26 /r MOV TR4 - TR7,r32 4 Передача регистра в регистр проверки
OF 24 /r MOV r32,TR3 3 Передача регистра проверки 3 в регистр регистра в регистр проверки 3
OF 26 /r MOV TR3,r32 Операция DEST <— SRC; Описание 6 Передача
Приведенные выше формы команды MOV производят сохранение или
загрузку следующих специальных регистров (в команде участвует также
регистр общего назначения):
— Регистры управления CRO, CR2 и CR3.
— Регистры отладки DRO, DR1, DR2, DR3, DR6 и DR7.
— Регистры проверки TR3, TR4, TR5, TR6 и TR&.
В этих командах всегда участвуют 32-битные операнды независимо от ат-
рибута размера операнда.
Воздействие на флажки
Флажки OF, SF, ZF, AF, PF и CF не определены.
Особые случаи Р-режима
# GP(0), если текущий уровень привилегий не равен 0.
Особые случаи R-режима Нет
Особые случаи У-режима
# GP(0) при попытке выполнить команду.
Примечание:
Эти команды должны выполняться на уровне привилегий 0 или в R-ре-
жиме; в противном случае генерируется особый случай защиты.
Поле reg в байте ModR/M определяет специальный регистр. Два бита поля
mod всегда содержат 11В. Поле r/m определяет участвующий в команде
Глава 2. Справочные сведения по командам i486
Сз45:
регистр общего назначения. Необходимо всегда устанавливать
неопределенные или зарезервированные биты на ранее считанное значение.
^VS/mOVSB/MOVSW/MOVSD- MOVedataTrom String tcTstrlng"
Передача данных из цепочки а цепочку
коп Комавда Такт Опвсавве
А4 MOVS m8,m8 7 Передача байта [(E)SI] в ES:[(E)DI]
А5 MOVS ml6,ml6 7 Передача слова [(E)SI] в ES:[(E)DI]
А5 MOVS m32,m32 7 Передача двойного слова [(E)SI] в ES:[(E)DI]
А4 MOVSB 7 Передача байта DS:[(E)SI] в ES:[(E)DI]
А5 MOVSW 7 Передача слова DS:[(E)SI] в ES:[(E)DI]
А5 ’ MOVSD 7 Передача двойного слова DS:[(E)SI] в ES:[(E)DI]
Операция
IF (команда = MOVSD) OR (команда имеет двухсловные операнды)
THEN (OperandSize <— 32;
ELSE (OperandSize <— 16;
IF AddressSize =16
THEN использовать SI как индекс источника и DI как индекс получателя;
ELSE (* AddressSize = 32 *)
использовать ESI как индекс источника и EDI как индекс получателя;
FI;
IF команда с байтами
THEN
[индекс получателя] <— [индекс источника]; (* Передача байта *)
IF DF = О THEN IncDec <— 1 ELSE IncDec <----1; FI;
ELSE
IF OperandSize =16
THEN
[индекс получателя] <— [индекс источника]; (* Передача слова *)
IF DF = О THEN IncDec <— 2 ELSE IncDec <-----2; FI;
ELSE (* OperandSize = 32 *)
[индекс получателя] <-- [индекс источника]; (* Передача
двойного слова *)
IF DF = О THEN IncDec <— 4 ELSE IncDec <-----4; FI;
FI;
FI;
индекс источника <— индекс источника + IncDec;
индекс получателя <— индекс получателя + IncDec;
Описание
Команда MOVS копирует байт, слово или из [(E)SI] в байт или слово по
адресу ES:[(E)DI]. Операнд-получатель должен адресоваться в сегменте ES,
так как замена сегмента не допускается. Замену сегмента можно использовать
для операнда-источника; по умолчанию принимается регистр DS.
Адреса источника и получателя определяются просто содержимым регист-
ров (E)SI и (E)DI, поэтому в них до выполнения команды MOVS нужно заг-
рузить правильные значения. Команды MOVSB, MOVSW и MOVSD являются
синонимами команды MOVS при передаче байт, слов или двойных слов.
После производства передачи осуществляется автоматическое продвиже-
ние регистров (E)SI и (E)DL. Если флажок направления DF = 0 (была выпол-
нена команда CLD), производится инкремент регистров, а при DF = 1
(выполнена команда STD) — декремент. Величина инкремента или декремен-
та равна 1 при передаче байта, 2 — при передаче слова и 4 — при передаче
двойного слова.
Перед командой MOVS можно указать префикс повторения REP для бло-
ковой передачи СХ байт или слов (подробнее см. описание команды REP).
Воздействие на флажки Нет
Особые случаи Р-нежима
Микропроцессор i486 Книга 4. Справочник по системе команд
#GP(O), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
MOVSX - MOVe with Sign-eXtend
Передача со знаковым расширением
КОП Команда Такт Описание
OF BE /г MOVSX rl6,r/m8 3/3 Передача байта в слово со знаковым УЧА nm'jnouuaif
OF BE /r MOVSX r32,r/m8 3/3 расширением Передача байта в двойное слово со знаковым расширением
OF BF /г MOVSX r32,r/ml6 3/3 Передача слова в двойное слово
со знаковым расширением
Операция
DEST <— SignExtend(SRC);
Описание
Команда MOVSX считывает содержимое эффективного адреса или регист-
ра как байт или слово, расширяет его со знаком до атрибута размера операн-
ды команды (16 или 32 бита) и сохраняет результат в регистре-получателе.
Воздействие на флажки Нет
Особые случаи Р-режима
Далее см. ПРИМЕЧАНИЕ.
MOVZX - MOVe with Zero-eXtend
Передача с нулевым расширением
КОП Команда Так» Описание
OF В6 /г MOVZX rl6,r/m8 3/3 Передача байта в слово с нулевым расширением
OF В6 /г MOVZX г32,г/ш8 3/3 Передача байта в двойное слово с нулевым расширением
OF В7 /г MOVZX r32,r/ml6 3/3 Передача слова в двойное слово с нулевым расширением Операция
DEST <— Zer©Extend(SRC);
Описание
Команда MOVZX считывает содержимое эффективного адреса или регис-
тра как байт или слово, расширяет его с нулем до атрибута размера операнда
команды (16 или 32 бита) и сохраняет результат в регистре-получателе.
Воздействие на флажки Нет
Особые случаи Р-режима
Далее см. ПРИМЕЧАНИЕ.
MUL - unsigned МULtiplication of AL or AX
Беззнаковое умножение AL или AX
КОП Команда Так» Описание
F6 /4 MUL AL,r/m8 13/18,13/18 Беззнаковое умножение
(АХ <-- AL * байт г/ш)
F7 /4 MUL АХ,г/ш16 13/26,13/26 Беззнаковое умножение
(DX:AX <-- АХ * слово г/ш)
F7 /4 MUL ЕАХ,г/ш32 13/42,13/42 Беззнаковое умножение
(EDX:EAX <— ЕАХ * двойное слово г/ш)
Примечание:
В процессоре i486 применяется алгоритм умножения с ранним выходом.
Фактическое число тактов зависит от позиции старшего бита в оптимизиро-
Глава 2. Справочные сведения по командам i486
|^г347^
ванном множителе. Оптимизация реализуется дня положительных и отрица-
тельных значений. Для времени выполнения команд приводится диапазон от
минимума до максимума. Фактическое число тактов синхронизации
рассчитывается по* следующей формуле:
фактическое число тактов = if и о 0 then
max(log2|(ш)|, 3) + 6 тактов
фактическое число тактов = if m = О then 9 тактов
где ш - множитель
Операция
IF операция с байтом
THEN АХ <-- AL * r/m8;
ELSE (* операция со словом или двойным словом *)
IF OperandSize =16
THEN DX:AX <— АХ * r/ml 6;
ELSE (* OperandSize = 32 *)
EDX:EAX <— EAX * r/32;
FI;
FI;
Описание
Команда MUL производит беззнаковое умножение. Ее действия зависят
от размера операнда:
— Операнд-байт умножается на значение в регистре AL и результат по-
мещается в регистр АХ. Флажки OF и CF сбрасываются в 0, если АН = 0; в
противном случае они устанавливаются в 1. — Операнд-слово умножается на
значение в регистре АХ и результат помещается в регистры DX.AX. В регист-
ре DX находятся старшие 16 бит произведения. Флажки OF и CF сбрасыва-
ются в 0, если DX = 0; в противном случае они устанавливаются в 1.
— Операнд-двойное слово умножается на значение в регистре ЕАХ и ре-
зультат помещается в регистры EDX:EAX. В регистре EDX находятся старшие
32 бита произведения. Флажки OF и CF сбрасываются в 0, если EDX = 0; в
противном случае они устанавливаются в 1.
Воздействие на флажки
Флажки OF и CF сброшены в 0, если старшая половина результата нуле-
вая; в противном случае они установлены в 1. Состояния флажков SF, ZF,
AF и PF не определены.
Особые случаи Р-режима
Далее см. ПРИМЕЧАНИЕ.
NEG - two's complement NEGation
Получение дополнительного кода (изменение знака)
КОО Команда Так» Описавие
/3 NEG r/m8 1/3 Изменение знака байта r/m
F7 /3 NEG г/ml6 1/3 Изменение знака слова r/m
F7 /3 NEG г/m32 1/3 Изменение знака двойного слова r/m
Операция
IF r/m = О THEN CF <— О ELSE CF <— 1; FI;
r/m <-- -r/m;
Описание
Команда NEG заменяет значение в регистре или в памяти на дополни-
тельный код. Операнд вычитается из нуля и результат помещается в операнд.
Если операнд ненулевой, флажок CF устанавливается в 1, а в противном
случае он сбрасывается в 0.
Воздействие на флажки
Микропроцессор i486 Книга 4. Справочник по системе команд
Флажок CF установлен в 1, если операнд ненулевой, а при нулевом опе-
ранде он сброшен в 0. Флажки OF, SF, ZF и PF устанавливаются в соответ-
ствии с результатом.
Особые случаи Р-режима
#GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
NOP - No Operation
Холостая (пустая) операция
КОП Комавда Такты Опвсавве
90 NOP 1 Не производит никаких действий
Описание
Команда NOP не выполняет никаких операций. Она занимает один байт,
но не влияет на контекст процессора, за исключением регистра (Е)1Р.
Команда NOP является альтернативной мнемоникой команды XCHG
(Е)АХ,(Е)АХ.
Воздействие на флажки Нет
Особые случаи Р-ре жима Нет
Особые случаи R-режима Нет
Особые случаи У-режима Нет
NOT - one's complement negation
Инвертирование
КОП Комавда Такты Описание
F6 /2 NOT r/m8 1/3 Инвертирование бит байта r/m
F7 /2 NOT г/ml6 1/3 Инвертирование бит слова r/m
F7 /2 NOT г/m32 1/3 Инвертирование бит двойного слова r/m
Операция
r/m <— NOT r/m;
Описание
Команда NOT инвертирует операнд; каждая 1 становится 0 и наоборот.
Воздействие на флажки Нет
Особые случаи Р-режима
#GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
OR - logical inclusive OR
Логическое включающее ИЛИ
коп
Комавда Такты Опвсавве
ОС ib OR AL,imm8 1 Логическое ИЛИ непоср. байта с AL
0D iw OR AX,imial6 1 Логическое ИЛИ непоср. слова с АХ
0D id OR EAX,imm32 1 Логическое ИЛИ непоср. двойного слова с ЕАХ
80 /1 ib OR r/m8,imm8 1/3 Логическое ИЛИ непоср. байта с байтом r/m
81 /1 iw OR r/ml6,imml6 1/3 Логическое ИЛИ непоср. слова со словом r/m
81 /1 id OR r/m32,imm32 1/3 Логическое ИЛИ непоср. двойного слова
с двойным словом r/m
83 /1 ib OR г/т16Дтш8 1/3 Логическое ИЛИ непоср. байта со знаковым
расширением со словом г/т
83 /1 ib OR r/m32/imm8 1/3 Логическое ИЛИ непоср. байта со знаковым
расширением с двойным словом г/т
08 /г OR r/m8,r8 1/3 Логическое ИЛИ байтного per. с байтом r/m
09 /г OR r/ml6,rl6 1/3 Логическое ИЛИ словного per. со словом r/m
09 /г OR r/m32,r32 1/3 Логическое ИЛИ двухсловного регистра
с двойным словом r/m
Глава 2. Справочные сведения по командам i486
ОА /г OR r8,r/m8 1/2 Логическое ИЛИ байта r/m с байтным регистром
ОВ /г OR г16,г/ml6 1/2 Логическое ИЛИ слова r/m со словным регистром
ОВ /г OR r32,r/m32 1/2 Логическое ИЛИ двойного слова г/т
с двухсловным регистром
Операция
DEST <— DEST OR SRC;
CF <— 0; OF <— 0;
Описание
Команда OR вычисляет включающее ИЛИ двух операндов и помещает ре-
зультат в первый операнд. Каждый бит результата равен 0, если соответству-
ющие биты обоих операндов равны 0; в противном случае бит результата ра-
вен 1.
Воздействие на флажки
Флажки CF и OF сбрасываются в 0, а флажки ZF, SF и PF устанавлива-
ются в соответствии с результатом; состояние флажка AF не определено.
Особые случаи Р-режима
#GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
OUT - OUTput to port
Вывод в порт
коп Комавда Такты Описание
Е6 ib OUT imm8,AL 16, pm=ll,(*) Вывод байта AL
31 (**), vm=29 в непосредственный порт
Е7 ib OUT imm8,AX 16, pm=U,(*) Вывод слова АХ
31 (**), vm=29 в непосредственный порт
Е7 ib OUT imm8,EAX 16, pm=ll,(*) Вывод двойного слова ЕАХ
31 (**), vm=29 в непосредственный порт
ЕЕ OUT DX,AL 16, pm=10,(*) Вывод байта AL
30 (**), vm=29 в порт с номером в DX
EF OUT DX,AX 16, pm=10,(*) Вывод слова АХ
30 (**)/ vm=29 в порт с номером в DX
ЕЕ OUT DX,EAX 16, pm=10,(*) Вывод двойного слова ЕАХ
30 (**), vm=29 в порт с номером в DX
Примечание
★ Если CPL <= IOPL
** Если CPL > IOPL
Операция
IF (РЕ = 1) AND ((VM = 1) OR (CPL > IOPL))
THEN (* V-режим или Р-режим c CPL > IOPL *)
IF NOT Разрешение ввода-вывода (SRC, ширина(SRC))
THEN iGP(O);
FI;
FI;
[DEST] <— SRC; (* Используется пространство ввода-вывода *)
Описание
Команда OUT передает байт, слово или двойное слово данных из регистра
(AL, АХ или ЕАХ), определенного вторым операндом, в порт, номер которо-
го определяется первым операндом. Для обращения к любому порту от 0 до
65535 его номер помещается в регистр DX и применяется команда OUT с
первым операндом DX. Если команда содержит 8-битный номер порта, про-
изводится нулевое расширение этого значения до 16 бит.
Воздействие на флажки Нет
Особые случаи Р-режима
Й5Й
Микропроцессор i486 Книга 4. Справочник по системе команд
#GP(O), если текущий уровень привилегий CPL больше (менее
привилегирован), чем уровень привилегий ввода-вывода IOPL, и любой из
соответствующих бит в карте разрешения ввода-вывода сегмента TSS
содержит 1.
Особые случаи R-режима Нет
Особые случаи У-режима
#GP(0), если любой из соответствующих бит в карте разрешения ввода-
вывода сегмента TSS содержит 1.
OUTS/OUTSB/OUTSW/OUTSD - OUTput String to port
Вывод цепочки в порт
коп Команда Тахты Описание
6Е OUTS DX,r/m8 17, pm=10,(*) 32 (**), vm=30 Вывод байта [(E)SI] в порт DX
6F OUTS DX,r/ml6 17, pm=10,(*) 32 (**), vm=30 Вывод слова [(E)SI] в порт DX
6F OUTS DX,r/n32 17, pm=10,(*) 32 (**), vm=30 Вывод двойного слова [(E)SI] в порт DX
6Е OUTSB 17, pm=10,(*) 32 (**), vm=30 Вывод байта DS:[(E)SI] в порт DX
6F OUTSW 17, pm=10,(*) 32 (**), vm=30 Вывод слова DS:[(E)SI] в порт DX
6F OUTSD 17, pm=10,(*) 32 (**), vm=30 Вывод двойного слова DS:[(E)SI] в порт DX
Примечание:
* Если CPL <= IOPL
* * Если CPL > IOPL
Операция
IF AddrSize =16
THEN использовать SI как индекс источника;
ELSE (* AddrSize = 32 *)
использовать ESI как индекс источника;
FI;
IF (PE = 1) AND ((VM = 1) OR (CPL > IOPL))
THEN (* V-режим или Р-режим c CPL > IOPL *)
IF NOT Разрешение ввода-вывода (DEST, ширина(DEST))
THEN |GP(0);
FI;
FI;
IF команда с байтами
THEN
[DX] <—[индекс источника]; (* Записать байт по адресу DX *)
IF DF = О THEN IncDec <— 1 ELSE IncDec <-----1; FI;
FI;
IF OperandSize =16
THEN
[DX] <— [индекс источника]; (* Записать слово по адресу DX *)
IF DF = О THEN IncDec <— 2 ELSE IncDec <-----2; FI;
FI;
IF OperandSize =32
THEN
[DX] <— [индекс источника!; (* Записать двойное слово *)
IF DF = О THEN IncDec <— 4 ELSE IncDec <-----4; FI;
FI;
индекс источника <— индекс источника + IncDec;
Описание
Команда OUTS передает байт, слово или двойное слово из памяти, опре-
деляемые регистром индекса источника в выходной порт, адресуемый регист-
Глава 2. Справочные сведения по командам I486
ром DX. Если атрибут размера адреса команды равен 16 битам, регистром
индекса источника служит регистр SI; в противном случае атрибут размера
адреса равен 32 битам и индекс источника берется из регистра ESI.
В команде OUTS не допускается определение порта как непосредствен-
ного значения; порт должен адресоваться только через регистр DX. Следова-
тельно, до выполнения команды OUTS в регистр DX необходимо загрузить
правильное значение.
Адрес источника определяется содержимым индексного регистра ис-
точника. Перед выполнением команды OUTS в регистр SI или ESI нужно
загрузить правильный индекс.
После производства передачи осуществляется автоматическое продвиже-
ние регистра SI или ESI. Если флажок направления DF = 0 (была выполнена
команда CLD), производится инкремент SI или ESI, а при DF = 1
(выполнена команда STD) — декремент. Величина инкремента или декремен-
та равна 1 при выводе байта, 2 — при выводе слова и 4 — при выводе
двойного слова.
Команды OUTSB, OUTSW и OUTSD являются синонимами команды
OUTS при выводе байт, слов и двойных слов, соответственно. Перед коман-
дой OUTS можно указать префикс повторения REP для блокового вывода СХ
байт или слов. Подробнее о действии префиксов повторения см. описание
команды REP.
Воздействие на флажки Нет
Особые случаи Р-режима
# GP(0), если текущий уровень привилегий численно больше уровня при-
вилегий ввода-вывода, и любой из соответствующих бит в карте разрешения
ввода-вывода сегмента TSS содержит 1.
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Особые случаи У-режима
# GP(O), если любой из соответствующих бит в карте разрешения ввода-
вывода сегмента TSS содержит 1.
# РР(код-нарушение) для страничного нарушения.
#АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
POP - POP a word from the stack
Извлечение слова из стека (TOS - вершина стека)
коп Команда Такт Описание
8F /0 POP ml6 6 «Извлечение TOS в слово памяти
8F /0 POP m32 6 Извлечение TOS в двойное слово памяти
58 + rw POP rl6 4 Извлечение TOS в словный регистр
58 + rd POP r32 4 Извлечение TOS в двухсловный регистр
IF POP DS 3 Извлечение TOS в DS
07 POP ES 3 Извлечение TOS в ЕЯ
17 POP SS 3 Извлечение TOS в SS
OF Al POP FS 3 Извлечение TOS в FS
OF A9 POP GS 3 Извлечение TOS в GS
Микропроцессор i486 Книга 4. Справочник по системе команд
Операция
IF StackAddrSize =16
THEN
IF OperandSize =16
THEN
DEST <— (SSsSP); (* копирование слова *)
gp <__ SP + 2•
ELSE (* OperandSize = 32 *)
DEST <— (SSsSP); (* копирование двойного слова *)
SP <— SP + 4;
FI;
ELSE (* StackAddrSize = 32 *)
IF OperandSize =16
THEN
DEST <— (SSsESP); (* копирование слова *)
SP <— ESP + 2;
ELSE (* OperandSize = 32 *)
DEST <— (SSsESP); (* копирование двойного слова *)
SP <— ESP + 4;
FI;
FI;
Описание
Команда POP заменяет прежнее содержимое памяти, регистра, сегментно-
го регистра на слово из вершины стека TOS процессора i486, адресуемого ре-
гистрами SS:SP (атрибут размера адреса равен 16 битам) или регистрами
SS:ESP (атрибут размера адреса равен 32 битам). Производится инкремент
указателя стека SP на 2, если атрибут размера операнда равен 16 битам, или
на 4 — при атрибуте размера операнда 32 бита. После этого регистр SP
адресует новую вершину стека.
Команда POP CS отсутствует; извлечение из стека в регистр CS произво-
дит команда RET.
Если операндом-получателем служит сегментный регистр (DS, ES, FS, GS
или SS), извлекаемое значение должно быть селектором. В P-режиме загрузка
селектора автоматически инициирует загрузку дескриптора, ассоциируемого с
этим селектором, в невидимую часть сегментного регистра; загрузка сопро-
вождается контролем информации, содержащейся в селекторе и дескрипторе.
В регистры DS, ES, FS и GS допускается извлекать пустой селектор
(0000Н — 0003Н) без генерирования особого случая защиты. Попытка обра-
щения к памяти через сегментный регистр, в который загружен пустой селек-
тор, вызывает особый случай #GP(0). Обращения к памяти не производится,
а в сегментном регистре остается пустое значение.
Команда POP SS запрещает все прерывания, включая NMI, до окончания
выполнения следующей команды. Это позволяет последовательно выполнить
команды POP SS и POP eSP без опасности иметь недействительный стек при
прерывании. Однако для загрузки регистров SS и eSP предпочтительнее
пользоваться командой LSS.
Извлечение в сегментный регистр в P-режиме вызывает приведенные да-
лее специальные проверки и действия:
IF загружается SS
THEN
IF селектор пустой THEN #GP(0);
FI;
Индекс селектора должен быть в пределах его дескрипторной
таблицы ELSE IGP(селектор);
RPL селектора должен быть равен CPL ELSE #GP(селектор);
Байт AR должен показывать записываемый сегмент
ELSE #GP(селектор);
Глава 2. Справочные сведения по командам i486
12 Заказ 4317
DPL в байте AR должен быть равен CPL ELSE #GP(селектор)}
Сегмент должен быть отмечен как присутствующий
ELSE ISS(селектор);
Загрузить в SS селектор;
Загрузить в SS дескриптор;
FI;
IF в регистр DS, ES, FS или GS загружается непустой селектор:
THEN
Индекс селектора должен быть в пределах его дескрипторной
таблицы ELSE |GP(селектор);
Байт AR должен показывать сегмент данных или считываемый
сегмент кода ELSE #GP(селектор);
IF данные или неподчиненный код
THEN оба RPL и CPL должны быть меньше или равны
DPL в байте AR;
ELSE |GP(селектор);
FI;
Сегмент должен быть отмечен как присутствующий ELSE #NP(селектор);
Загрузить в сегментный регистр селектор;
Загрузить в сегментный регистр дескриптор;
FI;
IF в регистр DS, ES, FS или GS загружается пустой селектор:
THEN
Загрузить в сегментный регистр селектор;
Сбросить бит достоверности в невидимой части регистра;
FI;
Воздействие на флажки Нет
Особые случаи Р-режима '
# GP, #SS и #NP, если загружается сегментный регистр.
, #SS(O), если текущая вершина стека вне предела сегмента стека.
# GP(0), если получатель в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
Примечание:
Соседние команды PUSH/POP не требуют дополнительных тактов.
POPA/POPAD - POP All general registers
Извлечение всех регистров общего назначения
KOTL Команда Таким Опжсажже
61 РОРА 9 Извлечение DI;SI,BP;BX,DX,CX и АХ
61 POPAD 9 Извлечение EDI,ESI,EBP,ЕВХ,EDX,ЕСХ и ЕАХ
Операция
IF OperandSize « 16 (* команда РОРА *)
THEN
DI <— Рор();
SI <— Рор();
ВР <— Рор();
выбросить <— Рор(); (♦ пропустить SP *)
ВХ <— Рор();
DX <— Рор();
СХ <— Рор();
АХ <— Рор();
ELSE (* OperandSize = 32, команда = POPAD *)
EDI <— Рор();
ESI <— Рор();
ЕВР <— Рор();
выбросить <— Рор(); (* пропустить ESP *)
ЕВХ <— Рор();
EDX <— Рор();
У35<|
Микропроцессор i486 Книга 4. Справочник по системе команд
ЕСХ <— Рор();
ЕАХ <— Рор();
FI;
Описание
Команда РОРА производит извлечение из стека восьми 16-битных
регистров общего назначения. Однако значение для SP уничтожается, а не
загружается в регистр SP. Эта команда является двойственной для команды
PUSH А и восстанавливает то содержимое регистров общего назначения,
которое в них было до выполнения команды PUSHA. Первым извлекается
регистр DI.
Команда POPAD производит извлечение из стека восьми 32-битных
регистров общего назначения. Однако значение для ESP уничтожается, а не
загружается в регистр ESP. Эта команда является двойственной для команды
PUSHAD и восстанавливает то содержимое общих регистров, которое в них
было до выполнения команды PUSHAD. Первым извлекается регистр EDI.
Воздействие на флажки Нет
Особые случаи Р-режима
# SS(O), если начальный или конечный адрес стека вне сегмента стека.
# РР(код-нарушение) для страничного нарушения.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РЕ(код-нарушение) для страничного нарушения.
POPF/POPFD - POP stack into FLAGS or EFLAGS register
Извлечение из стека в регистр FLAGS или
EFLAGS
коп Команда Такты Описание
9D POPF 9,рт=6 Извлечение вершины стека в регистр FLAGS
9D POPFD 9fpm=6 Извлечение вершины стека в регистр EFLAGS
Операция
Флажки <-- Рор();
Описание
Команды POPF и POPFD извлекают слово или двойное слово из верши-
ны стека и сохраняют значение в регистре флажков. Если атрибут размера
операнда команды равен 16 битам, извлекается слово и помещается в регистр
FLAGS. Если атрибут размера операнда равен 32 битам, извлекается двойное
слово и помещается в решстр EFLAGS. Отметим, что команды POPF и
POPFD не влияют на биты 16 и 17 регистра EFLAGS (флажки VM и RF).
Уровень привилегий ввода-вывода IOPL изменяется только при работе на
уровне привилегий 0. Флажок прерываний IF изменяется только при выпол-
нении команд на уровне, как минимум, столь же привилегированном, как
уровень привилегий ввода-вывода IOPL. (R-режим эквивалентен уровню
привилегий 0.) Если команда POPF выполняется с недостаточной привилеги-
ей, особый случай не возникает, но привилегированные биты не изменяются.
Воздействие на флажки
Модифицируются все флажки, кроме флажков VM и RF.
Особые случаи Р-режима
#SS(O), если вершина стека вне предела сегмента стека.
Особые случаи R-режима
Глава 2. Справочные сведения по командам i486
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Особые случаи У-режима
Нарушение #GP(0), если уровень привилегий ввода-вывод меньше 3,
чтобы обеспечить эмуляцию.
PUSH - PUSH operand onto stack
Включение операнда в стек
коп Команда Такты Описание
FF /6 PUSH ml6 4 Включение слова памяти
FF /6 PUSH m32 4 Включение двойного слова памяти
50 + /r PUSH Г16 1 Включение словного регистра
50 + /r PUSH r32 1 Включение двухсловного регистра
6A PUSH imm8 1 Включение непосредственного байта
68 PUSH imml6 1 Включение непосредственного слова
68 PUSH imm32 1 Включение непосредственного двойного слова
0E PUSH CS 3 Включение регистра CS
16 PUSH SS 3 Включение регистра SS
IE PUSH DS 3 Включение регистра DS
06 PUSH ES 3 Включение регистра ES
OF AO PUSH FS 3 Включение регистра FS
OF A8 PUSH Операция GS 3 Включение регистра GS
IF StackAddrSize =16
THEN
IF OperandSize =16
THEN
SP <— SP - 2;
(SS:SP) <-- (SRC) (* включение слова *)
ELSE (* OperandSize = 32 *)
SS <— SS - 4;
(SS:SP) <— (SRC) (* включение двойного слова *)
FI;
ELSE (* StackAddrSize = 32 *)
IF OperandSize =16
THEN
ESP <— ESP - 4;
(SS:ESP) <-- (SRC) (* включение слова *)
ELSE (* OperandSize = 32 *)
ESS <— ESS - 4;
(SS:ESP) <-- (SRC) (* включение двойного слова *)
FI;
FI;
Описание
Команда PUSH производит декремент указателя стека на 2, если атрибут
размера операнда команды равен 16 битам; в противном случае производится
декремент на 4. После этого операнд помещается в новую вершину стека, ад-
ресуемую указателем стека.
Команда PUSH ESP включает то значение регистра ESP, которое было до
выполнения команды. В процессоре 8086 команда PUSH SP включает новое
значение (уменьшенное на 2).
Воздействие на флажки Нет
Особые случаи Р-режима
# SS(O), если новое значение регистра SP или ESP вне предела сегмента
стека.
Далее см. ПРИМЕЧАНИЕ.
Микропроцессор i486 Книга 4. Справочник по системе команд
Примечание:
При указании операнда в памяти команда PUSH выполняется дольше,
чем две команды, которые пересылают операнд через регистр.
Соседние команды PUSH/POP не требуют дополнительных тактов.
PUSHA/PUSHAD - PUSH All general registers
Включение в стек всех общих регистров
КОП Команда Такты Описание
60 PUSHA И Включает ВР, SI и в стек DI АХ,СХ,DX,ВХ,исходный SP,
60 PUSHAD Операция 11 Включает EBP, ESI в стек и EDI ЕАХ,ЕСХ,EDX,ЕВХ,исходный ESP
IF OperandSize = 16 (* команда l PUSHA *)
THEN
Temp <-- (SP);
Push(AX);
Push(CX);
Push(DX);
Push(BX);
Push(Temp);
Push(BP);
Push(SI);
Push(DI);
ELSE (* OperandSize = 32, команда PUSHAD *)
Temp <— (ESP);
Push(EAX);
Push(ECX);
Push(EDX);
Push(EBX);
Push(Temp);
Push(EBP);
Push(ESI);
Push(EDI);
FI;
Описание
Команды PUSHA и PUSHAD сохраняют 16- или 32-битные регистры
общего назначения в стеке. Команда PUSHA производит декремент указателя
стека SP на 16 для сохранения восьми слов. Команда PUSHAD производит
декремент указателя стека ESP на 32 для сохранения восьми двойных слов.
Так как регистры включаются в стек в показанном порядке, они оказываются
в 16 или 32 новых байтах стека в обратном порядке. Последним включается
регистр DI или EDI.
Воздействие на флажки Нет
Особые случаи Р-режима
# SS(O), если начальный или конечный адрес стека вне предела сегмента
стека.
# РР(код-нарушение) при страничном нарушении.
Особые случаи R-режима
Перед выполнением команды PUSHA или PUSHAD процессор 80386 от-
ключается, если в регистре SP или ESP содержится 1, 3 или 5; если в этих ре-
гистрах содержится 7, 9, 11, 13 или 15, формируется особый случай 13.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РР(код-нарушение) при страничном нарушении.
Глава 2. Справочные сведения по командам i486
35ТЙ
PUSHF/PUSHFD - PUSH Flags register onto stack
Включение в стек регистра флажков
КОП Комавда Такты Описание
9С PUSHF 4,рт=3 Включает в стек регистр FLAGS
9С PUSHFD 4,рт=3 Включает в стек регистр EFLAGS
Операция
IF OperandSize =16
THEN Push(EFLAGS);
ELSE Push(FLAGS);
FI;
Описание
Команда PUSHF производит декремент указателя стека на 2 и копирует
регистр FLAGS в новую вершину стека; команда PUSHFD производит дек-
ремент указателя стека на 4 и копирует регистр EFLAGS в новую вершину
стека, которую адресуют регистры SS:ESP.
Воздействие на флажки Нет
Особые случаи Р-режима
#SS(O), если новое значение регистра ESP вне предела сегмента стека.
Особые случаи R-режима
Нет; при нехватке стекового пространства процессор i486 отключается.
Особые случаи У-режима
Нарушение #GP(0), если уровень привилегий ввода-вывода меньше 3,
чтобы разрешить эмуляцию.
RCIVRcIr/rOL/ROR - Rotate
Циклический сдвиг
коп Комавда Такты Опвсавие
DO /2 RCL r/m8,l 3/4 Циклический сдвиг влево один раз 9 бит (CF, байт r/m)
D2 /2 RCL r/m8,CL 8-30/9-31 Циклический сдвиг влево CL раз 9 бит (CF, байт r/m)
СО /2 ib RCL r/m8,imm8 8-30/9-31 Циклический сдвиг влево imm8 раз 9 бит (CF, байт r/m)
D1 /2 RCL r/ml 6,1 3/4 Циклический сдвиг влево один раз 17 бит (CF, слово r/m)
D3 /2 RCL r/ml6,CL 8-30/9-31 Циклический сдвиг влево CL раз 17 бит (CF, слово r/m)
С1 /2 ib RCL r/ml6,imm8 8-30/9-31 Циклический сдвиг влево imm8 раз 17 бит (CF, слово r/m)
D1 /2 RCL r/m32,l 3/4 Циклический сдвиг влево один раз 33 бит (CF, двойное слово r/m)
D3 /2 RCL r/m32,CL 8-30/9-31 Циклический сдвиг влево CL раз 33 бит (CF, двойное слово r/m)
С1 /2 ib RCL r/m32,imm8 8-30/9-31 Циклический сдвиг влево imm8 раз 33 бит (CF, двойное слово r/m)
DO /3 RCR r/m8,l 3/4 Циклический сдвиг вправо один раз 9 бит (CF, байт r/m)
D2 /3 RCR r/m8,CL 8-30/9-31 Циклический сдвиг вправо CL раз 9 бит (CF, байт r/m)
СО /3 ib RCR r/m8,imm8 8-30/9-31 Циклический сдвиг вправо imm8 раз 9 бит (CF, байт r/m)
D1 /3 RCR r/ml6,1 3/4 Циклический сдвиг вправо один раз 17 бит (CF, слово r/m)
D3 /3 RCR r/ml6,CL 8-30/9-31 Циклический сдвиг вправо CL раз 17 бит (CF, слово r/m)
Микропроцессор i486 • Книга 4. Справочник по системе команд
С1 /3 ib RCR r/ml6,imm8 8-30/9-31 Циклический сдвиг вправо imm8 раз 17 бит (CF, слово r/m)
D1 /3 RCR r/m32,l 3/4 Циклический сдвиг вправо один раз 33 бит (CF, двойное слово r/m)
D3 /3 RCR r/m32,CL 8-30/9-31 Циклический сдвиг вправо CL раз 33 бит (CF, двойное слово r/m)
С1 /3 ib RCR r/m32,imm3 8-30/9-31 Циклический сдвиг вправо imm8 раз 33 бит (CF, двойное слово r/m)
D0 /0 ROL r/m8,l 3/4 Циклический сдвиг влево один раз байта r/m
D2 /0 ROL r/m8,CL 8-30/9-31 Циклический сдвиг влево CL раз байта r/m
СО /0 ib ROL r/m8,imm8 8-30/9-31 Циклический сдвиг влево imm8 раз байта r/m
D1 /0 ROL r/ml6,l 3/4 Циклический сдвиг влево один раз слова r/m
D3 /0 ROL r/ml6,CL 8-30/9-31 Циклический сдвиг влево CL раз слова r/m
С1 /0 ib ROL r/ml6,imm8 8-30/9-31 Циклический сдвиг влево imm8 раз слова r/m
D1 /0 ROL r/m32,l 3/4 Циклический сдвиг влево один раз двойного слова r/m
D3 /0 ROL r/m32,CL 8-30/9-31 Циклический сдвиг влево CL раз двойного слова r/m
С1 /0 ib ROL r/m32,imm8 8-30/9-31 Циклический сдвиг влево imm8 раз двойного слова r/m
D0 /1 ROR r/m8,l 3/4 Циклический сдвиг вправо один раз байта r/m
D2 /1 ROR r/m8,CL 8-30/9-31 Циклический сдвиг вправо CL раз байта r/m
СО /1 ib ROR r/m8,imm8 8-30/9-31 Циклический сдвиг вправо imm8 раз байта r/m
D1 /1 ROR r/ml6,l 3/4 Циклический сдвиг вправо один раз слова r/m
D3 /1 ROR r/ml 6,CL 8-30/9-31 Циклический сдвиг вправо CL раз слова r/m
С1 /1 ib ROR r/ml6,imm8 8-30/9-31 Циклический сдвиг вправо imm8 раз слова r/m
D1 /1 ROR r/m32,l 3/4 Циклический сдвиг вправо один раз двойного слова r/m
D3 /1 ROR r/m32,CL 8-30/9-31 Циклический сдвиг вправо CL раз двойного слова r/m
С1 /1 ib ROR r/m32,imm8 8-30/9-31 Циклический сдвиг вправо imm8 раз двойного слова r/m
Операция
(* ROL - циклический сдвиг влево *)
temp <— COUNT;
WHILE (temp О 0)
DO
tmpcf <— старший бит (r/m);
r/m <-- r/m * 2 + (tmpcf);
temp <— temp - 1;
OD;
IF COUNT = 1
THEN
IF старший бит r/m <> CF
THEN OF <— 1;
ELSE OF <— 0;
FI;
ELSE OF <— не определен;
I •♦'•’.л.* ;
Й359А
Глава 2. Справочные сведения по командам i486
FI;
(* ROR - циклический сдвиг вправо *)
temp <— COUNT;
WHILE (temp <> 0)
DO
tmpcf <— младший бит (r/m);
r/m <-- r/m / 2 + (tmpcf * 2A(ширина r/m));
temp <-- temp - 1;
OD;
IF COUNT = 1
THEN
IF (старший бит r/m <> (следующий старший бит r/m)
THEN OF <— 1;
ELSE OF <— 0;
FI;
ELSE OF <— не определен;
FI;
Описание
Каждая команда циклического сдвига сдвигает биты заданного операнда в
регистре или памяти. Команды левого циклического сдвига сдвигают все биты
влево, а старший бит передается в младший. Команды правого циклического
сдвига действуют в противоположном направлении.
В командах RCL и RCR флажок переноса CF является частью сдвигаемой
величины. Команда RCL передает флажок CF в младший бит, а в него сдви-
гает старший бит; команда RCR передает флажок CF в старший бит, а в него
сдвигает младший бит. В командах ROL и ROR первоначальное состояние
флажка CF не является частью результата, а в него помещена копия выдвину-
того бита.
Число сдвигов определяется вторым операндом, которым является непос-
редственное значение или содержимое регистра CL. Для сокращения времени
выполнения команд процессор i486 не допускает счетчики сдвигов большие
31. При попытке задать счетчик больше 31 используются только его младшие
5 бит. Процессор 8086 не маскирует счетчики сдвигов, поэтому в V-режиме
процессор i486 также не маскирует счетчики сдвигов.
Флажок переполнения OF определен только в однобитных сдвигах
(второй операнд равен 1), а в остальных случаях он не определен. В левых
сдвигах бит CF после сдвига объединяется по исключающему ИЛИ со стар-
шим битом результата. В правых сдвигах для получения состояния флажка
OF по исключающему ИЛИ объединяются два старших бита результата.
Воздействие на флажки
Флажок переполнения OF определен только в однобитных сдвигах, а в
многобитных сдвигах он не определен. Флажок переноса CF содержит
значение выдвинутого в него бита. Флажки SF, ZF, AF и PF не изменяются.
Особые случаи Р-оежима
#GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
REP/REPE/REPZ/REPNE/REPNZ - REPeat following string operation
Повторение следующей цепочечной
операции
КОП Команда Такты Описание
F3 6С REP INS r/m8,DX 16+8(Е)СХ, Ввод (Е)СХ байт
рт=10+8(Е)СХ (*1)/ из порта DX
30+8(Е)СХ (*2) в ES:[(E)DIJ
vm=29+8(E)CX
Микропроцессор i486 Книга 4. Справочник по системе команд
F3 6D REP INS r/ml6,DX 16+8(E)CX, pm=10+8(E)CX (*1)/ 30+8(E)CX (*2) vm=29+8(E)CX Ввод (E)CX слов из порта DX в ES:{{E)DI]
F3 6D REP INS r/m32,DX 16+8(E)CX, Ввод (E)CX двойных слов
pm=10+8(E)CX (*1)/ из порта DX
30+8(E)CX (*2} в ES:[(E)DI]
vm=29+8(E)CX
F3 А4 REP MOVS m8,m8 5 (*3},13 (*4), Передача (Е)СХ байт
12+3(E)CX (*5) из [(E)SI] в ES:[(E)DIJ
F3 А5 REP MOVS ml6,ml6 5 (‘3),13 (*4), Передача (Е)СХ слов
12+3(E)CX (*5) из ((E)SI] в ES:[(E)DI]
F3 А5 REP MOVS n32,n32 5 (*3),13 (*4), Передача (Е)СХ двойных слов
12+3(E)CX (*5) из [(E)SI] в ES:[(E)DIj
F3 6Е REP OUTS DX,t/n8 17+5(E)CX, Вывод (Е)СХ байт
pm=ll+5(E)CX (‘1)/ из [(E)SIJ
31+5(E)CX (*2) в порт DX
vm=30+5(E)CX
F3 6F REP OUTS DX,r/ml6 17+5(E)CX, Вывод (Е)СХ слов
pm=ll+5(E)CX (*1)/ из [(E)SI]
31+5(E)CX <*2) в порт DX
vm=30+5(E)CX
F3 6F REP OUTS DX,r/m32 17+5(E)CX, Вывод (Е)СХ двойных слов
pm=ll+5(E)CX (*1)/ из [(E)SI]
31+5(E)CX (‘2) в порт DX
vm=30+5(E)CX
F2 АС REP LODS m8 5 (*3), Загрузка (Е)СХ байт
7+4(E)CX (*6) из [(E)Slj в AL
F2 AD REP LODS ml 6 5 (‘3), Загрузка (Е)СХ слов
7+4(E)CX (*6) из ((E)SI] в АХ
F2 AD REP LODS m32 5 (*3), Загрузка (Е)СХ двойных
7+4(E)CX (*«) слов из {(E)SIJ в ЕАХ
F3 АА REP STOS m8 5 (‘3), Передача (Е)СХ байт
7+49EJCX (*6) из AL в ES:[(E)DI]
F3 АВ REP STOS ml6 5 (*3), Передача (Е)СХ слов
7+49E)CX (♦€) из АХ в ES:[(E)DI]
F3 АВ REP STOS m32 5 (‘3), Передача (Е)СХ двойных слов
7+49EJCX (*6) из ЕАХ в ES:[<E)DI]
F3 А6 REPE CMPS m8,m8 5 (*3, Поиск неравных байт
7+7(E)CX в ES:[(E)DI] и [(E)SIJ
F3 А7 REPE CMPS ml6,ml6 5 (*3, Поиск неравных слов
7+7(E)CX в ES:[<E)DI] и [(E)SIJ
F3 А7 REPE CMPS m32,32 5 (‘3, Поиск неравных двойных слов
7+7(E)CX в ES:[<E)DI] и |<E)SIJ
F3 АЕ REPE SCAS m8 5 (*3), Поиск байта не-AL,
7+5(E)CX <‘6) начиная с ES:[(E)DIJ
F3 AF REPE SCAS ml6 5 (*3), Поиск слова яе-АХ,
7+5(E)CX (♦£) начиная с ES:((E)DIj
F3 AF REPE SCAS m32 5 (*3), Поиск двойного слова не-ЕАХ,
7+5(E)CX (*6) начиная с ES:[{E|DIJ
F2 А6 REPNE CMPS m8,m8 5 (‘3, Псиск равных байт
7+7(E)CX в ES:[{E)DI] и ((E)SI|
F2 А7 REPNE CMPS ml6,ml6 5 (*3, Поиск равных слов
7+7(E)CX В ES:[(E)DI] и ((E)SIJ
F2 А7 REPNE CMPS m32,32 5 (‘3, Поиск равных двойных слов
7+7(E)CX в ES:[(E)DI] и I(E)SI]
F2 АЕ REPNE SCAS m8 5 (‘3), Поиск байта AL,
7+5(E)CX (*6) начиная с ES:[^E)DIj
F2 AF REPNE SCAS ml6 5 (*3), Поиск слова АХ,
7+5(E)CX (*6) начиная с ES:[(E)DI]
F2 AF REPNE SCAS m32 5 (*3), Поиск двойного слова ЕАХ,
7+5(E)CX (*6) начиная с ES:[(E)DIJ
Глава 2. Справочные сведения по командам i486
Примечания
* 1 Если CPL <= IOPL
* 2 Если CPL > IOPL
* 3 (E)CX = 0
* 4 (E)CX = 1
* 5 (E)CX > 1
*6 (E)CX > 0
Операция
IF AddressSize = 16
THEN использовать СХ как CountReg;
ELSE (* AddressSize = 32 *) использовать ЕСХ как CountReg;
FI;
WHILE CountReg <> 0
DO
обслужить ожидающие прерывания (если они есть);
выполнить примитивную цепочечную операцию;
CountReg <— CountReg - 1;
IF примитивная операция CMPS, CMPSW, SCASB или SCASW
THEN
IF (команда REP/REPE/REPZ) AND (ZF = 1)
THEN выйти из цикла WHILE;
ELSE
IF (команда REPNZ /REPNE) AND (ZF = 0)
THEN выйти из цикла WHILE;
' FI;
FI; z'
FI;
OD; /
Описание
Префиксы REP, REPE (повторять, пока равны) и REPNE (повторять, по-
ка не равны) применимы к цепочечным операциям. Каждый префикс вызы-
вает повторение следующей за ним цепочечной команды число раз, определя-
емое регистром-счетчиком (префиксы REPE и REPNE) или до тех пор, пока
показываемое флажком ZF условие не удовлетворяется.
Префиксы REPZ и REPNZ являются синонимами префиксов REPE и
REPNE, соответственно.
Префикс REP действует только для одной цепочечной команды. Для по-
вторения блока команд применяется команда LOOP или другая конструкция
зацикливания.
Точное действие каждой итерации имеет вид:
1. Если атрибут размера адреса равен 16 битам, использовать в качестве
регистра-счетчика регистр СХ; если атрибут размера адреса равен 32 битам,
использовать в качестве регистра-счетчика регистр СХ.
2. Проверить регистр СХ. Если он содержит 0, выйти из итерации и пе-
рейти к следующей команде.
3. Подтвердить имеющиеся ожидающие прерывания.
4. Один раз выполнить цепочечную операцию.
5. Произвести декремент регистра СХ или ЕСХ на 1; флажки не модифи-
цируются.
6. В цепочечной команде SCAS или CMPS проверить флажок нуля ZF.
Если условие не удовлетворяется, выйти из итерации и перейти к следующей
команде. Выйти из итерации, если префиксом повторения является REPE и
флажок ZF = 0 (последнее сравнение показало неравенство) или префиксом
является REPNE и флажок ZF = 1 (последнее сравнение показало равенство).
7. Возвратиться к шагу 1 для производства следующей итерации.
3 6'2^.
Микропроцессор i486 Книга 4. Справочник по системе команд
Из повторяющихся команд CMPS или SCAS можно выйти, если исчерпан
счетчик или флажок нуля ZF не показывает условия повторения. Эти два
случая можно различить, привлекая либо команду JCXZ, либо команду ус-
ловного перехода с проверкой флажка ZF (команды JZ, JNZ, JNE).
Воздействие на флажки
На флажок нуля ZF влияют команды REP CMPS и REP SCAS.
Особые случаи Р-режима Нет
Особые случаи R-режима Нет
Особые случаи V-режима Нет
Примечание:
Не все порты ввода-вывода могут работать с быстродействием, которое
обеспечивают команды REP INS и REP OUTS.
Префикс повторения перед нецепочечной командой игнорируется.
RET - RETurn from procedure
Возврат из процедуры
КОП Комавда Такты Опвсавве
СЗ RET 5 Возврат из процедура (близкий)
СВ RET 13,pm=18 Возврат из процедуры (далекий),
те же привилегии
СВ RET 13,pm=33 Возврат из процедуры (далекий), меньшие
привилегии, переключение стеков
С2 iw RET imml6 5 Возврат из процедуры (близкий), извлечение imml6 байт параметров
СА iw RET imml6 13,рш=18 Возврат из процедуры (далекий),
те же привилегии,
извлечение imml6 байт параметров
СА iw RET imml6 13,рш=33 Возврат из процедуры (далекий), меньшие
привилегии, переключение стеков,
извлечение immi6 байт параметров
Операция
Громоздкое алгоритмическое описание действий команды RET не приво-
дится.
Описание
Команда RET передает управление по адресу возврата, находящемуся в
стеке. Обычно адрес помещает в стек команда вызова CALL и возврат проис-
ходит к команде, находящейся после команды CALL.
Необязательный численный параметр в команде RET определяет в стеке
число байт (OperandSize =16) или слов (OperandSize = 32), которые освобож-
даются после извлечения адреса возврата. Обычно эти элементы используются
как входные параметры вызываемой процедуры.
Для внутрисегментного (близкого) возврата адрес в стеке является смеще-
нием в сегменте, которое извлекается в указатель команды. Регистр CS не из-
меняется. В случае межсегментного (далекого) возврата адрес в стеке является
длинным указателем. Первым извлекается смещение, а затем селектор.
В R-режиме регистры CS и IP загружаются прямо. В P-режиме межсег-
ментный возврат заставляет процессор контролировать дескриптор, адресуе-
мый селектором. Байт AR прав доступа дескриптора должен показывать сег-
мент кода с равной или меньшей привилегией (численное значение равно
или больше), чем текущий уровень привилегий. Возврат к менее привилеги-
рованному уровню вызывает перезагрузку стека из значения, сохраненного
над блоком параметров.
В межуровневой передаче управления команда RET может очистить сег-
ментные регистры DS, ES, FS и GS. Если эти регистры адресовали сегменты,
Глава 2. Справочные сведения по командам i486
которые нельзя использовать на новом уровне привилегий, они очищаются
для предотвращения несанкционированного доступа с нового уровня приви-
легий.
Воздействие на Флажки Нет
Особые случаи Р-режима
#/ЭР, #NP или #SS.
#РР(код-нарушение) при страничном нарушении.
Особые случаи R-режима
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
#РР(код-нарушение) для страничного нарушения.
SAHF - Store АН into Flags
Сохранение регистра АН во флажках
КОП Комавда Такты / Описание
9Е SAHF 2 ’ Сохранение АН во флажках SF ZF х AF х PF х CF
Операция /
SF:ZFjx:AF:x:PF:x:CF АН;
Описание
Команда SAHF загружает во флажки SF, ZF, AF, PF и CF значения из
бит 7, 6, 4, 2 и 0 регистра АН, соответственно.
Воздействие на флажки
Во флажки SF, ZF, AF, PF и CF загружаются значения из регистра АН.
Особые случаи Р-режима Нет
Особые случаи R-режима Нет
Особые случаи У-режима Нет
SAL/SAR/SHL/SHR - Shift instructions
Команды сдвига
КОП Комавда Такты Описание
DO /4 SAL r/m8,l 3/4 Умножение байта r/m на 2 один раз
D2 /4 SAL r/m8,CL 3/4 Умножение байта r/m на 2 CL раз
СО /4 ib SAL r/m8,imm8 3/4 Умножение байта r/m на 2 imm8 раз
DI /4 SAL г/ml6,1 3/4 Умножение слова r/m на 2 один раз
D3 /4 SAL r/ml6,CL 3/4 Умножение слова r/m на 2 CL раз
Cl /4 ib SAL r/ml6,imm8 3/4 Умножение слова r/m на 2 imm8 раз
DI /4 SAL г/m32,1 3/4 Умножение двойного слова r/m на 2 один раз
D3 /4 SAL r/m32,CL 3/4 Умножение двойного слова r/m на 2 CL раз
Cl /4 ib SAL r/m32,imm8 3/4 Умножение двойного слова r/m на 2 imm8 раз
DO /7 SAR r/m8,l 3/4 Знаковое деление байта r/m на 2 один раз
D2 /7 SAR r/m8,CL 3/4 Знаковое деление байта r/m на 2 CL раз
СП /7 ib SAR r/m8,imm8 3/4 Знаковое деление байта r/m на 2 imm8 раз
b. /7 SAR r/ml6,l 3/4 Знаковое деление слова r/m на 2 один раз
D3 /7 SAR r/ml6,CL 3/4 «Знаковое деление слова r/m на 2 CL раз
Cl /7 ib SAR r/ml6,imm8 3/4 Знаковое деление слова r/m на 2 imm8 раз
DI /7 SAR r/m32,l 3/4 Знаковое деление двойного слова г/т
на 2 один раз
D3 /7 SAR г/m32,1 3/4 Знаковое деление двойного слова г/т
на 2 CL раз
Cl /7 ib SAR г/т32,1 3/4 Знаковое деление двойного слова г/т
на 2 imm8 раз
DO /4 SHL г/т8,1 3/4 Умножение байта r/т на 2 один раз
Микропроцессор i486 Книга 4. Справочник по системе команд
D2 СО D1 D3 С1 D1 D3 С1 /4 /4 /4 /4 /4 /4 /4 /4 ib ib ib SHL SHL SHL SHL SHL SHL SHL SHL r/m8,CL r/m8,imm8 r/ml6,l r/ml6,CL r/ml6,imm8 r/m32,l r/m32,CL r/m32,imm8 3/4 3/4 3/4 3/4 3/4 3/4 3/4 3/4 Умножение байта r/m на 2 CL раз
Умножение байта r/m на 2 imm8 раз
Умножение слова r/m на 2 один раз
Умножение слова r/m на 2 CL раз
Умножение слова r/m на 2 imm8 раз
Умножение двойного слова r/m на 2 один раз
Умножение двойного слова r/m на 2 CL раз
Умножение двойного слова r/m на 2 imm8 раз
D0 /5 SHR r/m8,l 3/4 Беззнаковое деление байта r/m на 2 один раз
D2 /5 SHR r/m8,CL 3/4 Беззнаковое деление байта r/m на 2 CL раз
СО /5 ib SHR r/m8,imm8 3/4 Беззнаковое деление байта r/m на 2 imm8 раз
D1 /5 SHR r/ml6,l 3/4 Беззнаковое деление слова r/m на 2 один раз
D3 /5 SHR r/ml6,CL 3/4 Беззнаковое деление слова r/m на 2 CL раз Беззнаковое деление слова r/m на 2 imm8 раз
С1 /5 ib SHR r/ml6,imm8 3/4
D1 /5 SHR r/m32,l 3/4 Беззнаковое деление двойного слова r/m на 2 один раз
D3 /5 SHR r/m32,l 3/4 Беззнаковое деление двойного слова r/m на 2 CL раз
С1 /5 ib SHR r/m32,l 3/4 Беззнаковое деление двойного слова r/m
на 2 imm8 раз
Примечание:
Команда SAR в отличие от команды IDIV производит округление к отри-
цательной бесконечности.
(* COUNT есть второй параметр *)
(temp) <— COUNT;
WHILE (temp <> 0)
DO
IF команда SAL или SHL
THEN CF <— старший бит r/m;
FI;
IF команда SAR или SHR
THEN CF <— младший бит r/m;
FI;
IF команда SAL или SHL
THEN r/m <-- r/m * 2;
FI;
IF команда SAR
THEN r/m <— r/m / 2 (* Знаковое деление, округление к минус
бесконечности *)
FI;
IF команда SHR
THEN r/m <-- r/m / 2 (* Беззнаковое деление *)
FI;
temp <— temp - 1;
OD;
(* Определить переполнение для различных команд *)
IF COUNT = 1
THEN
IF команда SAL или SHL
THEN OF <— старший бит r/m <> (CF);
FI;
IF команда SAR
THEN OF <— 0;
FI;
IF команда SHR
THEN OF <— старший бит операнда;
FI;
ELSE OF <— не определен;
FI;
Описание
Глава 2. Справочные сведения по командам i486
Команда SAL (и синонимичная команда SHL) сдвигает биты операнда
влево. Старший бит помещается во флажок CF, а младший бит сбрасывается
в 0.
Команды SAR и SHR сдвигают биты операнда вправо. Младший бит пе-
редается во флажок переноса CF. Это действие эквивалентно делению на 2.
Команда SAR производит знаковое деление с округлением результата к минус
бесконечности (команда IDIV действует по-другому); старший бит не изменя-
ется. Команда SHR осуществляет беззнаковое деление и старший бит сбрасы-
вается в 0.
Число сдвигов определяется вторым операндом, которым является непос-
редственное значение или содержимое регистра CL. Для сокращения времени
выполнения команд процессор i486 не допускает счетчики сдвигов большие
31. При попытке задать счетчик больше 31 используются только его младшие
пять бит. (В процессоре 8086 счетчиком сдвига служат все восемь бит.)
Флажок переполнения OF определен только в однобитных сдвигах. В ле-
вых сдвигах флажок OF сбрасывается в 0, если старший бит результата совпа-
дает с состоянием флажка CF> результата (т.е. два старших бита исходного
операнда были одинаковыми); флажок OF устанавливается в 1, если они
различаются. В команде SAR флажок OF сбрасывается после всех однобитных
сдвигов. В команде SHL флажок OF устанавливается на старший бит исход-
ного операнда.
Воздействие на флажки
Флажок OF определен только в однобитных сдвигах, а в многобитных
сдвигах он не определен. Флажки SF, ZF, CF и PF устанавливаются в соот-
ветствии с результатом.
Особые случаи Р-режима
#GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
SBB - integer SuBtraction with Borrow
Целочисленное вычитание с заемом
коп Комавда Гахты Описание
IC ib SBB AL,imm8 1 Вычитание с заемом непосредственного байта из AL
ID iw SBB AX,imml6 1 Вычитание с заемом непосредственного слова из АХ
ID id SBB EAX,imml6 1 Вычитание с заемом непосредственного двойного слова из АХ
80 /3 ib SBB r/m8,imm8 1/3 Вычитание с заемом непосредственного байта из байта r/m
81 /3 iw SBB r/ml6,imml6 1/3 Вычитание с заемом непосредственного слова из слова r/m
81 /3 id SBB r/m32,imm32 1/3 Вычитание с заемом непосредственного двойного слова из двойного слова r/m
83 /3 ib SBB r/ml6,imm8 1/3 Вычитание с заемом непоср. байта со знаковым расширением из слова r/m
83 /3 ib SBB r/m32,imm8 1/3 Вычитание с заемом непоср. байта со знаковым расш. из двойного слова r/m
18 /r SBB r/m8,r8 1/3 Вычитание с заемом байтного регистра из байта r/m
19 /r SBB r/ml6,rl6 1/3 Вычитание с заемом словного регистра из слова r/m
19 /r SBB r/m32,r32 1/3 Вычитание с заемом двухсловного регистра из двойного слова r/m
1A /r SBB r8,r/m8 1/3 Вычитание с заемом байта r/m из байтного регистра
IB /r SBB rl6,r/ml6 1/3 Вычитание с заемом слова r/m
Микропроцессор I486 Книга 4. Справочник по системе команд
из сдобного регистра
1В /г SBB r32,r/m32 1/3 Вычитание с заемом двойного слова r/m
из двухсловного регистра
Операция
IF SRC есть байт и DEST есть слово или двойное слово
THEN DEST <— DEST - (SignExtend(SRC) + CF);
ELSE DEST <— DEST - (SRC + CF);
Описание
Команда SBB суммирует второй операнд SRC с флажком CF и вычитает
результат из первого операнда DEST. Результат вычитания присваивается
первому операнду DEST и соответственно устанавливаются флажки.
Когда непосредственное байтное значение вычитается из слова или двой-
ного слова, оно вначале расширяется со знаком до размера операнда.
Воздействие на флажки
Флажки OF, SF, ZF, AF, CF и PF устанавливаются в соответствии с ре-
зультатом.
Особые случаи Р-режима
#GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
SCAS/SCASB/SCASW/SCASD - compare (SCAn) String data
коп Комавда Такты Сравнение (сканирование) цепочечных данных Опвсавве
AE SCAS m8 6 Сравнение байт AL-ES:[(E)DI], модификация (E)DI
AF SCAS ml6 6 Сравнение слов AX-ES:[(E)DI], модификация (E)DI
AF SCAS m32 6 Сравнение двойных слов EAX-ESs[(E)DI], модификация (E)DI
AE SCASB 6 Сравнение байт AL-ES:[(E)DI], модификация (E)DI
AF SCASW 6 Сравнение слов AX-ES:[(E)DI], модификация (E)DI
AF SCASD 6 Сравнение двойных слов EAX-ESs[(E)DI], модификация (E)DI Операция IF AddressSize =16 THEN использовать DI как индекс получателя; ELSE {* AddressSize = 32 ♦) использовать EDI -как индекс получателя *) FI; IF команда с байтами THEN AL - [индекс-получателя]; (* сравнение байт ♦) IF DF = 0 THEN IncDec <— 1 ELSE IncDec < 1; FI; ELSE IF OperandSize =16 THEN
АХ - (индекс-получателя]; {* сравнение слов *)
IF DF = О THEN IncDec <— 2 ELSE IncDec <------2; FI;
ELSE (* OperandSize = 32 *)
ЕАХ - [индекс-получателя]; (*~сравнение двойных слов *)
IF DF = 0 THEN IncDec <— 4 ELSE IncDec <-----4; FI;
FI;
FI;
индекс-получателя <— индекс-получателя + IncDec;
Описание
Глава 2. Справочные сведения по командам i486
Сз'б7<
Команда SCAS вычитает байт, слово или двойное слово, адресуемое реги-
стром индекса-получателя, из регистра AL, АХ или ЕАХ. Операнд должен ад-
ресоваться через регистр ES; замена сегмента не допускается.
Если атрибут размера адреса команды равен 16 битам, индексным регист-
ром служит DI; в противном случае применяется регистр EDI.
Адрес сравниваемых данных в памяти определяется просто содержимым
регистра-получателя, а не операндом команды SCAS. Операнд задает адреса-
цию через регистр ES и определяет тип данных. Перед выполнением команды
SCAS необходимо загрузить правильное значение индекса в регистр DI или
EDI.
После сравнения производится автоматическое * продвижение индексного
регистра. Если флажок направления DF = 0 (была выполнена команда CLD),
происходит инкремент регистра; если же DF e 1 (была выполнена команда
STD), происходит декремент регистра. Величина инкремента /декремента
равна 1 при сравнении байт, 2 — при сравнении слов и 4 - при сравнении
двойных слов.
Команды SCASB, SCASW и SCASD являются синонимами команды SCAS
при сравнении байт, слов и двойных слов, соответственно, которые не требу-
ют операндов. Их проще кодировать, но они не обеспечивают контроль типа
и сегмента.
Перед командой SCAS нужно указать префикс повторения REPE или
REPNE для блокового сравнения СХ или ЕСХ байт, слов или двойных слов.
Подробнее о действии префиксов повторения см. описание команды REP.
Воздействие на флажки
Флажки OF, SF, ZF, AF, CF и PF устанавливаются в соответствии с ре-
зультатом.
Особые случаи Р-режима
Далее см. ПРИМЕЧАНИЕ.
SETcc - byte SET on congition
Установка байта по условию
код Команда Такты Описание
0? 97 SETA r/in8 Установить байт 4/3 Если выше (CF=0 и ZF=0)
OF 93 SETAE r/m8 4/3 Если выше или равно (CF=0)
OF 92 SETB r/m8 4/3 Если ниже (CF=1)
OF 96 SETBE r/m8 4/3 Если ниже или равно (CF=1 или ZF=1)
OF 92 SEC r/m8 4/3 Если перенос (CF=1)
OF 94 SETS r/m8 4/3 Если равно (ZF=1)
OF 9F SETG r/a8 4/3 Если больше (ZF=O и SF=OF)
OG 9D SETGE r/m8 4/3 Если больше или равно (SF=OF)
OP 9C SETL г/в8 4/3 Если меньше (SFOOF)
OF 9E SETLE r/m8 4/3 Если меньше или равно (ZF=1
OF 96 SETEA r/m8 4/3 или SFOOF) Если не ниже или равно (CF=0 и ZF=0)
OF 93 SETNC r/m8 4/3 Если не перенос (CF=0)
OF 95 SETNE r/m8 4/3 Если не равно (ZF=0)
OF 9E SETNG r/m8 4/3 Если не больше (ZF=1 или SFOOF)
OF 9C SETNGE r/m8 4/3 Если не больше или равно (SFOOF)
OF 9D SETNL r/m8 4/3 Если не меньше (SF=OF)
OF 9F SETNLE r/m8 4/3 Если не меньше или равно (ZF=0 и SF=OF)
OF 91 SETNO r/n8 4/3 Если не переполнение (OF=0)
GF 9B SETNP r/m8 4/3 Если не паритет (PF=0)
OF 99 SETHS r/m8 4/3 Если не знак (SF=0)
OF 95 SETNZ r/a8 4/3 Если не нуль (ZF=0)
OF 90 SETO г/в8 4/3 Если переполнение (OF=1)
Микропроцессор i486 • Книга 4. Справочник по системе команд
OF 9A SETP r/n8 4/3
Of 9A SETPE r/m8 4/3
OF 9B SETPO r/m8 4/3
OF 98 SETS r/m8 4/3
OF 94 SETZ r/m8 4/3
Операция
IF условие THEN r/m8 <-- 1
Если паритет (PF=1|
Если паритет четный (PF=1)
Если паритет нечетный (PF=0)
Если знак (SF=1)
Если нуль (ZF=1)
ELSE r/m8 <— 0; FI
Описание
Комавда SETcc сохраняет в байте, определяемом операндом, единицу,
если условие удовлетворяется, или нуль, если условие не удовлетворяется.
Воздействие на флажки Нет
Особые случаи Р-режима
# GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
SGDT/SiDT - Store Global/lnterrupt Table
Сохранение регистра глобальной дескрипторной
таблицы/ регистра дескрипторной таблицы
прерываний
КОП Команда Такт
0F 01 /0 SGDT т 10
0F 01 /1 SIDT т 10
Опнсанн»
Сохранение регистра GDTR в m
Сохранение регистра IDTR в m
Операция
DEST <— 48-битное содержимое регистра БАЗА/ПРЕДЕЛ
Описание
Команды SGDT и SIDT копируют содержимое регистра дескрипторной
таблицы в шесть байт памяти, определяемые операндом. Поле ПРЕДЕЛА ре-
гистра присваивается первому слову по эффективному адресу. Если атрибут
размера операнда равен 16 битам, то следующие три байта отводятся полю
БАЗЫ регистра и в четвертый байт записывается 0. Последний байт не опре-
делен. Когда атрибут размера операнда равен 32 битам, следующие четыре
байта отводятся для поля БАЗЫ регистра.
Команды SGDT и SIDT предназначены для системных программ и в при-
кладных программах не применяются.
Воздействие на флажки Нет
Особые случаи Р-режима
Прерывание 6, если операндом-получателем является регистр.
# GP(0), если получатель в незаписываемом сегменте.
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 6, если операндом-получателем является регистр.
Прерывание 13, если любая часть операнда находится вне пространства
эффективного адреса от 0 до 0FFFFH.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РЕ(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Глава 2. Справочные сведения по командам I486
^Збй'
Совместимость
16-битные формы команд SGDT и SIDT совместимы с процессором
80286, если значение в старших восьми битах не используется. Процессор
80286 сохраняет в этих битах единицы, а процессоры 80386 и i486 сохраняют
нули, если атрибут размера операнда равен 16 битам.
SHLD - Double precisio SHift Left.
Двойной сдвиг влево
коп Комавда Taxw Описание
OF А4 SHLD r/B16,rl6,im8 2/3 В r/ml6 помещается результат SHL г/ml6, объединенный с rl6
OF А4 SHLD г/в32,г32Двв8 2/3 В г/m32 помещается результат SHL r/m32, объединенный с г32
OF А5 SHLD r/B16,r!6,CL 3/4 В г/ml6 помещается результат SHL г/ml6, объединенный с' г16
OF A5 SHLD r/B32,r32,CL Операция 3/4 В г/m32 помещается результат SHL г/m32, объединенный с г32
{♦ Счетчиком count служит беззнаковое целое, соответствующее
последнему операнду команды, - непосредственный байт
или байт в регистре CL *)
ShiftAmt <— count MOD 32;
inBits <— регистр (♦ Допускаются перекрывающиеся операнды ♦)
IF ShiftAmt = О
THEN нет операции
ELSE
IF ShiftAmt => OperandSize
THEN (* Плохие параметры *)
r/m <— HE ОПРЕДЕЛЕНО;
CF, OF, SF, ZF, AF, PF <— HE ОПРЕДЕЛЕНЫ;
ELSE (* Выполнить сдвиг *)
CF <— BITJBase, OperandSize - ShiftAmt];
(* Последний бит, выдвигаемый при выходе *)
FOR i <— OperandSize - 1 DOWNTO ShiftAmt
DO
BIT[Base,i] <— BIT[Base,i - ShiftAmt];
OD;
FOR i <— ShiftAmt - 1 DOWNTO 0
DO
BIT[BASE,i] <— BIT[inBits,i - ShiftAmt + OperandSize];
OD;
Set SF,ZF,PF (r/m);
{* SF,ZF,PF устанавливаются по результату ♦)
AF <— HE ОПРЕДЕЛЕН;
FI;
Fl;
Описание
Команда SHLD сдвигает первый операнд, определяемый полем г/m, влево
на число бит, заданное операндом-счетчиком. Второй операнд (г16 или г32)
обеспечивает биты, вдвигаемые справа (начиная с бита 0). Результат возвра-
щается в операнд г/m. Регистр остается неизменным.
Операнд-счетчик определяется либо непосредственным байтом, либо со-
держимым регистра CL. Эти операнды берутся по модулю 32, чтобы получить
число сдвигов от 0 до 31. Так как сдвигаемые биты находятся в регистрах,
команда SHLD полезна в сдвигах многократной точности (64 бита и более).
Флажки SF, ZF и PF устанавливаются в соответствии со значением результа-
та. Флажок переноса CF устанавливается на значение последнего выдвинутого
бита. Флажки OF и AF не определены.
Микропроцессор i486 Книга 4. Справочник по системе команд
Воздействие на флажки
Флажки SF, ZF и PF устанавливаются по результату; флажок CF устанав-
ливается на значение последнего выдвинутого бита; после сдвига на один бит
флажок OF установлен в 1, если произошло изменение знака, в противном
случае он сброшен в 0; после сдвига на несколько бит состояние флажка OF
не определено; флажок AF не определен (исключая сдвиг на 0 разрядов, ко-
торый не воздействует на флажки).
Особые случаи Р-режима
#GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
SHRD - Double Precision SH'rft Right
Двойной сдвиг вправо
КОП Команда Тажты Описание
OF АС SHRD r/ml6,rl6,imm8 2/3 В r/ml6 помещается результат SHR г/ml 6 объединенный с г16
OF АС SHRD r/m32,r32,imm8 2/3 В r/m32 помещается результат SHR r/m32 объединенный с г32
OF AD SHRD r/ml6,r16,CL 3/4 В г/ml6 помещается результат SHR г/ml 6 объединенный с г16
OF AD SHRD r/m32,r32,CL Операция 3/4 В г/m32 помещается результат SHR г/m32 объединенный с г32
{* Счетчиком count служит беззнаковое целое, соответствующее
последнему операнду команды, - непосредственный байт
или байт в регистре CL *)
ShiftAmt <— count MOD 32;
inBits <— регистр (* Допускаются перекрывающиеся операнды *)
IF ShiftAmt = О
THEN нет операции
ELSE
IF ShiftAmt => OperandSize
THEN (* Плохие параметры ♦)
r/m <— HE ОПРЕДЕЛЕНО;
CF, OF, SF, ZF, AF, PF <— HE ОПРЕДЕЛЕНЫ;
ELSE (♦ Выполнить сдвиг *)
CF <— BIT[r/m, ShiftAmt - 1);
(* Последний бит, выдвигаемый при выходе *)
FOR i <— О ТО OperandSize - 1 - ShiftAmt
DO
BIT[r/m,i] <— BIT[r/m,i - ShiftAmt];
0D;
FOR i <— OperandSize - ShiftAmt TO OperandSize - 1
DO
BIT[r/m,i] <— BIT[inBits,i + ShiftAmt - OperandSize];
0D;
Set SF,ZF,PF (r/m);
(* SF,ZF,PF устанавливаются по результату *)
AF <— HE ОПРЕДЕЛЕН;
FI;
FI;
Описание
Команда SHRD сдвигает первый операнд, определяемый полем г/т,
вправо на число бит, заданное операндом-счетчиком. Второй операнд (г16
или г32) обеспечивает биты, вдвигаемые слева (начиная с бита 32). Результат
возвращается в операнд г/m. Регистр остается неизменным.
Операнд-счетчик определяется либо непосредственным байтом, либо со-
держимым регистра CL. Эти операнды берутся по модулю 32, чтобы получить
Глава 2. Справочные сведения по командам i486
•0^3 7
число сдвигов от 0 до 31. Так как сдвигаемые биты находятся в регистрах,
команда SHRD полезна в сдвигах многократной точности (64 бита и более).
Флажки SF, ZF и PF устанавливаются в соответствии со значением результа-
та. Флажок CF устанавливается на значение последнего выдвинутого бита.
Флажки OF и AF не определены.
Далее см. описание команды SHLD.
SLDT - Store Local Descriptor Table register
Сохранение регистра локальной дескрипторной таблицы
КОП Команда Такты Описание
OF 00 /0 SLDT r/ml6 2/3 Сохранение регистра LDTR в слове ЕА
Операция
г/ml 6 <— LDTR;
Описание
Команда SLDT сохраняет содержимое регистра LDTR локальной дескрип-
торной таб;пщы в двухбайтных регистре или ячейке памяти, определяемыми
эффективным адресом.
Команда SLDT предназначена для системных программ и в прикладных
программах не применяется.
Воздействие на флажки Нет
Особые случаи Р-режима
# GP(0), если результат в незаписываемом сегменте.
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 6, так как команда SLDT не распознается в R-режиме.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Примечание:
Атрибут размера операнда в этой команде не действует.
SMSW - Store Machine Status Word
Сохранение слова состояния машины
КОП Команда Такта Описание
0F 01 /4 SMSW г/ml 6 2/3 Сохранение слова MSW в слове ЕА
Операция
r/ml6 <— MSW;
Описание
Команда SMSW сохраняет слово состояния машины (младшая половина
регистра CR0) в двухбайтных регистре или ячейке памяти, определяемыми
эффективным адресом ЕА.
Воздействие на флажки Нет
Особые случаи Р-режима
# GP(0), если результат в незаписываемом сегменте.
Микропроцессор i486 Книга 4. Справочник по системе команд
Далее см. ПРИМЕЧАНИЕ.
Примечание:
Эта команда предусмотрена для совместимости с процессором 80286; в
программах для процессора i486 применяется команда MOV ..., CRO.
STC - SeT Carry flag
Установка флажка переноса
КОП Комавда Такты Опвсавва
F9 STC 2 Установка флажка переноса
Операция
CF <— 1;
Описание
Команда STC устанавливает в 1 флажок переноса CF.
Воздействие на (Ьлажки
Флажок CF устанавливается в 1.
Особые случаи Р-режима Нет
Особые случаи R-режима Нет
Особые случаи У-режима Нет
STD - SeT Direction flag
Установка флажка направления
КОП Комавда Такты Описание
FD STD 2 Установка в 1 флажка направления
Операция
DF <— 1;
Описание
Команда STD устанавливает в 1 флажок направления DF, заставляя все
последующие цепочечные операции производить декремент используемых
ими регистров (E)SI и/или (E)DI.
Воздействие на флажки
Флажок DF устанавливается в 1.
Особые случаи Р-режима Нет
Особые случаи R-режима Нет
Особые случаи У-режима Нет
STI - SeT Interrupt flag
Установка флажка прерывания
КОП Комавда Такты Опвсавва
Fl STi 5 Установка в 1 флажка прерывания IF
Операция
IF <— 1;
Описание
Команда STI устанавливает в 1 флажок IF. Затем процессор реагирует на
внешние прерывания после выполнения следующей команды, если она не
запрещает прерывания. Если внешние прерывания запрещены и команда STI
указана перед командой RET (например, в конце подпрограммы), то команда
RET выполняется до распознавания внешних прерываний. По-прежнему, ес-
ли внешние прерывания запрещены и после команды STI находится команда
CLI, то внешние прерывания не распознаются, так как команда CLI при сво-
ем выполнении сбрасывает флажок IF в 0.
Глава 2. Справочные сведения по командам i486
Воздействие на флажки
Флажок IF устанавливается в 1.
Особые случаи Р-режима
@GP(0), если текущий уровень привилегий CPL больше (менее привиле-
гирован) уровня привилегий ввода-вывода IOPL.
Особые случаи R-режима Нет
Особые случаи У-режима Нет
STOS/STOSB/STOSW/STOSD - STOre String data
Сохранение цепочечных данных
коп Комаада Такты Описавва
АА STOS m8 5 Сохранение модификация Сохранение модификация AL в байте ES:[(B)DI], (B)DI ИХ в слове ES:[(E)DI], (Е)М
АВ STOS ml6 5
АВ STOS m32 5 Сохранение модификация ЕАХ в двойном слове ES:[(E)DI]( (E)DI
АА STOSB 5 Сохранение модификация AL в байте ES:[(E)DI], (В) DI
АВ STOSW 5 Сохранение модификация АХ В слове ES:[(E)DI], (В) DI
АВ STOSD 5 Сохранение модификация ЕАХ в двойном слове ES:[(B)DI], (В) DI
Операиия
IF AddrSize =16
THEN использовать ES:DI как DestReg;
ELSE {* AddrSize = 32 *) использовать ESsEDI как DestReg;
FI;
IF команда с байтами
THEN
(ES:Dest:Reg) <— AL;
IF DF = 0
THEN DestReg <— DestReg + 1;
ELSE DestReg <— DestReg - 1;
FI;
ELSE IF OperandSize =16
THEN
(ES:DestReg) <— AX;
IF DF = 0
THEN DestReg <— DestReg + 2;
ELSE DestReg <— DestReg - 2;
FI;
ELSE (* OperandSize = 32 ♦)
(ESsDestReg) <— EAX;
IF DF = 0
THEN DestReg <— DestReg + 4;
ELSE DestReg <— DestReg - 4;
FI;
FI;
FI;
Описание
Команда STOS передает содержимое регистра AL, АХ или ЕАХ в байт,
слово или двойное слово, адресуемые регистром-получателем относительно
сегмента ES. Регистром-получателем служит регистр DI для атрибута размера
адреса 16 бит или регистр EDI для атрибута размера адреса 32 бита. Операнд-
получатель адресуется лишь через регистр ES; замена сегмента не допускается.
Адрес получателя определяется содержимым регистра-получателя, а не яв-
ным операндом команды STOS. Операнд применяется только для контроля
’3 74?'
Микропроцессор i486 Книга 4. Справочник по системе команд
адресуемости через регистр ES и определения типа данных. Перед выполне-
нием команды STOS необходимо загрузить правильное значение в регистр-
получатель.
После производства передачи осуществляется автоматическая модифика-
ция регистра DI. Если флажок направления DF = 0 (была выполнена команда
CLD), производится инкремент DI, а при DF = 1 (выполнена команда STD)
— декремент. Величина инкремента или декремента равна 1 при передаче
байта, 2 — при передаче слова и 4 — при передаче двойного слова.
Команды STOSB, STOSW и STOSD являются синонимами команды STOS
при передаче байт, слов и двойных слов, соответственно. Их проще использо-
вать, но они не обеспечивают контроль типа и сегмента.
Перед командой STOS можно указать префикс повторения REP для бло-
кового заполнения байтами, словами или двойными словами, число которых
определяется регистром СХ или ЕСХ.
Воздействие на флажки Нет
Особые случаи Р-режима
#GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
STR - Store Task Register
Сохранение регистра задачи
КОП Комавда Такты Описаете
OF 00 /1 STR г/ml6 2/3 Сохранение регистра задачи в слове ЕА
Операция
г/ml 6 <— регистр задачи;
Описание
Содержимое регистра задачи TR копируется в двухбайтные регистр или
ячейку памяти, определяемые эффективным адресом ЕА операнда.
Команда STR предназначена только для системных программ и в при-
кладных программах не применяется.
Воздействие на флажки Нет
Особые случаи Р-режима
# GP(0), если результат в незаписываемом сегменте.
# GP(0) при недопустимом эффективном адресе операнда ь памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) для недопустимого адреса в сегменте SS.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 6, так как команда LTR не распознается в R-режиме.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
Примечание:
Атрибут размера операнда в этой команде не действует.
SUB - integer SUBtraction
Целочисленное вычитание
КОП Комавда Такты Опвсавве
2С ib SUB AL,imm8 1 Вычитание непосредственного байта из AL
2D iw SUB AX,imml6 1 Вычитание непосредственного
Глава 2. Справочные сведения по командам i486
|Жз75;-
слова из АХ
ID id SUB ЕАХДттИ 1 Вычитание непосредственного двойного слова из АХ
80 /5 ib SUB r/m8,imm8 1/3 Вычитание непосредственного байта из байта r/m
81 /5 iw SUB г/тЗбДттИ 1/3 Вычитание непосредственного слова из слова r/m
81 /5 id SUB r/m32,imm32 1/3 Вычитание непосредственного двойного слова из двойного слова r/m
83 /5 ib SUB r/ml6,imm8 1/3 Вычитание непоср. байта со знаковым расширением из слова r/m
83 /5 ib SUB r/m32,imm8 1/3 Вычитание с заемом непоср. байта со знаковым расш. из двойного слова r/m
28 /г SUB r/m8,r8 1/3 Вычитание байтного \ регистра из байта r/m
29 /г SUB r/ml6/rl6 1/3 Вычитание словного регистра из слова r/m
29 /г SUB r/m32,r32 1/3 Вычитание двухсловного регистра из двойного слова r/m
2А /г SUB r8,r/m8 1/2 Вычитание байта r/m из байтного регистра
2В /г SUB rl6,r/ml6 1/2 Вычитание слова r/m из словного регистра
2В /г SUB r32,r/m32 1/2 Вычитание двойного слова r/m из двухсловного регистра Операиия
IF SRC есть байт и DEST есть слово или двойное слово
THEN DFST <— DEST - (SignExtend(SRC);
ELSE DEST <— DEST - SRC;
FI;
Описание
Команда SUB вычитает второй операнд SRC из первого операнда DEST.
Результат вычитание присваивается первому операнду DEST и соответственно
устанавливаются флажки.
Когда непосредственное байтное значение вычитается из слова или двой-
ного слова, оно вначале расширяется со знаком до размера операнда.
Воздействие на Флажки
Флажки OF, SF, ZF, AF, CF и PF устанавливаются в соответствии с ре-
зультатом.
Особые случаи Р-режима
#GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
TEST - logical compare
Логическое сравнение
коп Команда Такты Описание
А8 ib TEST AL,imm8 1 Логическое И непоср. байта с AL
А9 iw TEST АХДти1б 1 Логическое И непоср. слова с АХ
А9 id TEST EAX,imm32 1 Логическое И непоср. двойного слова с ЕАХ
F6 /0 ib TEST r/m8,imm8 1/2 Логическое И непоср. байта с байтом r/m
F7 /0 iw TEST r/ml6,imml6 1/2 Логическое И непоср. слова со словом r/m
F7 /0 id TEST r/m32,imm32 1/3 Логическое И непоср. двойного слова
с двойным словом r/m
84 /г TEST r/m8,r8 1/2 Логическое И байтного per. с байтом r/m
85 /г TEST r/ml6,rl6 1/2 Логическое И словного per. со словом r/m
85 /г TEST r/m32,r32 1/2 Логическое И двухсловного регистра
с двойным словом r/m
Микропроцессор I486 Книга 4. Справочник по системе команд
Qngggugg
DEST : = LeftSRC AND RightSRC;
CF <— 0; OF <— 0;
Описание
Команда TEST образует поразрядное объединение по И своих двух опе-
рандов. Каждый бит результата равен 1, если соответствующие биты обоих
операндов равны 1; в противном случае бит результата равен 0.
Воздействие на флажки
Флажки CF и OF сбрасываются в 0, а флажки ZF, SF и PF устанавлива-
ются в соответствии с результатом.
Особые случаи Р-режима
Далее см. ПРИМЕЧАНИЕ.
VERR, VERW - VERify a segment for Reading or Writing
Проверка сегмента на считывание или запись
КОП Комавда Тавот Опвсавве
OF 00 /4 VERR r/ml6 11/11 Установка ZF=1, если из сегмента можно
считывать; селектор в г/ml6
OF 00 /5 VERW r/ml6 11/11 Установка ZF=1, если в сегмент можно
записывать; селектор в г/ml б
Операция
IF сегмент с селектором в г/ml6 доступен
с текущего уровня привилегий
AND (сегмент допускает считывание для VERR)
OR (сегмент допускает запись для VERW)
THEN ZF <— 1;
ELSE ZF <— 0;
FI;
Описание
В командах VERR и VERW двухбайтные регистр или ячейка памяти со-
держат значение селектора. Команды VERR и VERW определяют, достижим
ли сегмент, задаваемый селектором, с текущего уровня привилегий и допус-
кает ли сегмент считывание (VERR) или запись (VERW). Если сегмент досту-
пен, флажок ZF устанавливается в 1; если же сегмент не доступен, флажок ZF
сбрасывается в 0. Чтобы флажок ZF был установлен в 1, должны удовлетво-
ряться следующие условия:
— Селектор должен обозначать дескриптор в пределах таблицы (GDT
или LDT); селектор должен быть «определен».
— Селектор должен обозначать дескриптор сегмента кода или данных (а
не сегмент состояния задачи, таблицы LDT или шлюз).
— Для команды VERR сегмент должен быть считываемым, а для ко-
манды VERW — записываемым сегментом данных.
— Если сегмент кода является считываемым и подчиненным, для ко-
манды VERR уровень привилегий дескриптора DPL может иметь любое
значение; в противном случае значение DPL должно быть больше или равно
(иметь такие же или меньшие привилегии) и текущему уровню привилегий, и
полю RPL селектора.
Проверка производится так, как будто селектор сегмента загружен в ре-
гистр DS, ES, FS или GS и выполняется указанная операция (считывание или
запись). Значение селектора не может вызвать особого случая защиты, поэто-
му в программе могут возникнуть проблемы с доступом.
Глава 2. Справочные сведения по командам I486
|Щ377^
Воздействие на флажки
Флажок ZF устанавливается в 1, если сегмент доступен, и сбрасывается в
О в противном случае.
Особые случаи Р-режима
Нарушения, вызванные недопустимой адресацией операнда в памяти, ко-
торый содержит селектор; селектор не загружается ни в какой сегментный ре-
гистр, поэтому нарушений, связанных с загрузкой селектора, не возникает.
# GP(0) при недопустимом эффективном адресе операнда в памяти в сег-
ментах CS, DS, ES, FS или GS.
# SS(O) дня недопустимого адреса в сегменте SS. \
# РР(код-нарушение) для страничного нарушения. \
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
Особые случаи R-режима
Прерывание 6, так как команды VERR и VERW в R-режиме не распозна-
ются.
Особые случаи У-режима
Те же особые случаи, что и в R-режиме.
# РР(код-нарушение) для страничного нарушения.
# АС при невыравненном обращении к памяти, если текущий уровень
привилегий равен 3.
WAIT - WAIT~~~“ "
Ожидание
КОП Комавда Такты Охшсавва
9В WAIT 1-3 Заставляет процессор проконтролировать
численные особые случаи
Описание
Команда WAIT заставляет процессор перед продолжением проконтроли-
ровать ожидающие незамаскированные численные особые случаи.
Воздействие на флажки Нет
Особые случаи Р-режима
# NM, если в регистре CR0 установлены оба бита МР и TS.
Особые случаи R-режима
Прерывание 7, если в регистре CR0 установлены оба бита МР и TS.
Особые случаи У-режима
# NM, если в регистре CR0 установлены оба бита МР и TS.
Примечание:
Указание команды WAIT после команды ESC гарантирует обработку всех
незамаскированных особых случаев, которые могут возникнуть при выполне-
нии команды, до того, как процессор модифицирует результаты команды.
Альтернативной мнемоникой команды WAIT является FWAIT.
WBINVD - Write-Back and IN Vais Date cache “ “
Обратная завись и недостоверность кэш-памяти
КОП Комавда Такты Описание
OF 09 WBINVD 5 Производит обратную запись
и делает недостоверной всю кэш-память
Операция
ОЧИСТКА ВНУТРЕННЕЙ КЭШ-ПАМЯТИ
СИГНАЛ ОБРАТНОЙ ЗАПИСИ ДЛЯ ВНЕШНЕЙ КЭШ-ПАМЯТИ
СИГНАЛ ОЧИСТКИ ВНЕШНЕЙ КЭШ-ПАМЯТИ
Микропроцессор i486 Книга 4. Справочник по системе команд
Описание
Производится очистка внутренней кэш-памяти и формируется специаль-
ный цикл шины, показывающий внешней кэш-памяти выполнить обратную
запись ее содержимого в основную память. После этого формируется еще
один специальный цикл шины, вызывающий очистку внешней кэш-памяти.
Воздействие на флажки Нет
Особые случаи Р-режима Нет
Осо*, ле случаи R-режима Нет
Примечание:
Эта команда зависит от реализации, и ее функции в будущих процессорах
фирмы Intel могут быть изменены.
На сигнал очистки внешней кэш-памяти должна отреагировать внешняя
схема.
В процессоре 80386 этой команды нет.
XADD - Exchange and ADD
Обмен и сложение
коп Комавда Такты Описание
OF СО /г XADD r/m8,r8 3/4 Обмен байтного регистра и байта r/m загрузка суммы в байт r/m
OF Cl /г XADD r/ml6,rl6 3/4 Обмен словного регистра и слова r/m загрузка суммы в слово r/m
OF Cl /г XADD r/m32,r32 3/4 Обмен двухсловного регистра и двойного слова r/m; загрузка суммы в двойное слово r/m
Операция
TEMP <— DEST;
DEST <— TEMP + SRC;
SRC <— TEMP;
Описание
Команда XADD загружает DEST в SRC, а затем загружает сумму DEST и
исходного значения SRC в DEST.
Воздействие на флажки
Флажки CF, PF, AF, SF ZF и OF модифицируются так, как будто была
выполнена команда ADD.
Особые случаи Р-режима
# GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
Примечание:
Эту команду можно использовать с префиксом LOCK. В процессоре
80386 такой команды нет.
XCHG - eXCHanGe register/memory with register
Обмен регистра/памяти с регистром
коп Команда Такты Описание
90 + Г XCHG АХ,г16 3 Обмен словного регистра с АХ
90 + г XCHG г16,АХ 3 Обмен словного регистра с АХ
90 + г XCHG ЕАХ,г32 3 Обмен двухсловного регистра с ЕАХ
90 + г XCHG г32,ЕАХ 3 Обмен двухсловного регистра с ЕАХ
86 /г XCHG г/ш8,г8 3/5 Обмен байтного регистра с байтом ЕА
86 /г XCHG г8,г/т8 3/5 Обмен байтного регистра с байтом ЕА
87 /г XCHG r/ml6,rl6 3/5 Обмен словного регистра со словом ЕА
87 /г XCHG rl6,r/ml6 3/5 Обмен словного регистра со словом ЕА
87 /г XCHG r/m32,r32 3/5 Обмен двухсловного регистра
Глава 2. Справочные сведения по командам i486
с двойным словом ЕА
87 /г XCHG r32,r/m32 3/5 Обмен двухсловного регистра
с двойным словом ЕА
Операция
temp <— DEST;
DEST <— SRC;
SRC <— temp;
Описание
Команда XCHG обменивает два операнда, которые можно указывать в
любом порядке. При задании операнда в памяти выдается сигнал LOCK# не-
зависимо от наличия или отсутствия перед командой префикса LOCK и от
значения в поле IOPL.
Воздействие на флажки Нет
Особые случаи Р-режима
# GP(0), если любой операнд в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
XLAT/XLATB - table look-up transLATion
Табличное преобразование
коп Комавда Такты Описание
D7 XLAT п8 4 Установка AL на байт памяти DS:[(E)BX + беззнаковый AL]
D7 XLATB 4 Установка AL на байт памяти DS:[(Е)ВХ + беззнаковый AL]
Операция
IF AddressSize =16
THEN
AL <— (BX + ZeroExtend(AL));
ELSE (* AddressSize = 32 *)
AL <— (EBX + ZeroExtend(AL));
FI;
Описание
Команда XLAT заменяет содержимое регистра AL на байт из . элемента
таблицы. Регистр AL служит беззнаковым индексом таблицы, адресуемой ре-
гистрами DS:BX (атрибут размера адреса равен 16 битам) или регистрами
DS:EBX (атрибут размера адреса равен 32 битам).
Операнд команды XLAT допускает возможность замены сегмента. В ко-
манде XLAT всегда привлекается регистр (Е)ВХ, и в него необходимо заранее
загрузить правильное значение.
Можно использовать безоперандную форму команды XLATB, если адре-
суемая (Е)ВХ таблица уже находится в сегменте DS.
Воздействие на флажки Нет
Особые случаи Р-режима
Далее см. ПРИМЕЧАНИЕ.
XOR - logical exclusive .OR
Логическое исключающее ИЛИ
КОП Команда Такты Описание
34 ib XOR AL,imm8 1 Исключающее ИЛИ непоср. байта с AL
35 iw XOR AX,imml6 1 Исключающее ИЛИ непоср. слова с АХ
35 id XOR EAX,imm32 1 Исключающее ИЛИ непоср. двойного слова с ЕАХ
80 /6 ib XOR r/m8,imm8 1/3 Исключающее ИЛИ непоср. байта с байтом r/m
81 /6 iw XOR r/ml6,imml6 1/3 Исключающее ИЛИ непоср. слова со словом r/m
81 /6 id XOR r/m32,imm32 1/3 Исключающее ИЛИ непоср. двойного слова
|38ОЙ
Микропроцессор i486 Книга 4. Справочник по системе команд
с двойным словом r/m
83 /6 ib XOR r/ml6,imm8 1/3 Исключающее ИЛИ непоср. байта со знаковым
расширением со словом r/m
83 /6 ib XOR r/m32,imm8 1/3 Исключающее ИЛИ непоср. байта со знаковым
расширением с двойным словом r/m
30 Vr XOR r/m8,r8 1/3 Исключающее ИЛИ байтного per. с байтом r/m
31 /г XOR r/ml6,rl6 1/3 Исключающее ИЛИ словного per. со словом r/m
31 /r XOR r/m32,r32 1/3 Исключающее ИЛИ двухсловного регистра
с двойным словом r/m
32 /r XOR r8,r/m8 1/2 Исключающее ИЛИ байта r/m с байтным регистром
33 /г XOR rl6,r/ml6 1/2 Исключающее ИЛИ слова r/m со словным регистром
33 /r XOR r32,r/m32 1/2 Исключающее ИЛИ двойного слова r/m
с двухсловным регистром
Операция
DEST <— LeftSRC XOR RightSRC;
CF <— 0; OF <— 0;
Описание
Команда XOR вычисляет исключающее ИЛИ двух операндов. Каждый бит
результата равен 1, если соответствующие биты обоих операндов различны; в
противном случае бит результата равен 0.
Воздействие на флажки
Флажки CF и OF сбрасываются в 0, а флажки ZF, SF и PF устанавлива-
ются в соответствии с результатом; состояние флажка AF не определено.
Особые случаи Р-режима
#GP(0), если результат в незаписываемом сегменте.
Далее см. ПРИМЕЧАНИЕ.
Глава 2. Справочные сведения по командам i486
*лЗ 8 1 ,
Литература
1. Б.Э. Смит, М.Т. Джонсон. Архитектура и программирование
микропроцессора Intel 80386» М.: ~ ТОО "Конкорд", 1992.
2. i486 Processor programmer’s reference manual. Intel, 1990.
3. Microprocessors. Volume IL Intel, 1991.
4. Strauss E. 80386 technical reference. — Brady, 1987.
Ж"-'-’
$3821
Микропроцессор i486 Книга 4. Справочник по системе команд
Фирма БИНОМ
шом
В 1993-94 г.г. предлагает следующие издания:
Современные логические КМОП ИС
Справочник
Современные логические ТТЛ ИС
Справочник
Микропроцессоры и периферийные ИС
Справочник
Однокристальные микроЭВМ
Справочник
Микропроцессоры ф. Intel
Справочник
Совместно с Торгово-издательским бюро BHV
Word для Windows 2.0
Второе издание, дополненное
Excel 5.0
CorelDraw! 3.0
MS DOS 6.2
FoxPro 2.5 для Windows
Paradox 1.1 для Windows
MS Access 1.1 для Windows
CorelDraw! 4.0
103473, Москва-473, а/я 133, БИНОМ
Тел. (095) 973-25-65
Факс (095) 973-21-88
УДК 681.3.06
ББК 22.18
Г 83
В. Л. Григорьев
80486. Архитектура и программирование
Книги 2, 3, 4
Издательство «МИКАП», 1993 г.
103055, Москва, Тихвинский тупик, 8/7
Лицензия на издательскую деятельность № 061794 от 12.11.1992
Сдано в набор 12.11.93. Подписано в печать 24.12.93.
Формат 60^90 1/16- Усл. печ. л. 24. Бумага типографская.
Гарнитура Таймс. Тираж 30000 экз.
Заказ 4317
Отпечатано с готовых диапозитивов в гЮлиграфической фирме
«Красный пролетарий* РГИИЦ «Республика».
103473, Москва, Краснопролетарская, 16