/
































































































































































































































































































































































































































































































































Теги: компьютерные технологии специализированные и управляющие электронные вычислительные машины дискретного действия программирование комп
ISBN: 5-318-00559-4
Год: 2001




Текст
анатомия^
ПК ♦
Процессоры
Pentium 4
Athlon и Duron
СЕРИЯ
анатомия
пк<
^ППТЕР’
анатомия ч
пке
Пр©це«©ры
РегоШот 4
ЖЫ©и ю ®йрэй
Михаил Гук
Виктор Юров
Санкт-Петербург • Москва • Харьков • Минск
ПИТЕР*
2001
Михаил Гук, Виктор Юров
Процессоры Pentium 4, Athlon и Duron
Главный редактор
Заведующий редакцией
Литературный редактор
Художник
Иллюстрации
Корректор
Верстка
Е. Строганова
И. Корнеев
А. Жданов
Н. Биржаков
М. Жданова
В. Листова
Р. Гришанов
ББК 32.973.23
УДК 681.325.5
Гук М., Юров В.
Г93 Процессоры Pentium 4, Athlon и Duron. — СПб.: Питер, 2001. — 512 с.: ил.
ISBN 5-318-00559-4
Книга посвящена архитектуре, системе команд, интерфейсам и функционированию современных
процессоров семейства х86 как фирмы Intel, так и совместимых с ними изделий конкурирующих фирм.
Подробно рассмотрена архитектура 32-разрядных процессоров, со всеми ее расширениями. В книге име-
ется объяснение многих системных функций реального и защищенного режимов, которые не рассмат-
риваются в большинстве распространенных литературных источников. Приводится описание всех команд
микропроцессоров Pentium 4 и Athlon (и всех младших моделей). Уделено внимание применению процес-
соров в персональных компьютерах, совместимости с программным обеспечением, особенностям много-
процессорных систем. Материал иллюстрирован временными диаграммами, блок-схемами и справочными
таблицами, необходимыми разработчикам как программных, так и аппаратных средств. Книга предназ-
начена для широкого круга читателей, ее можно рассматривать и как учебное пособие для студентов,
углубленно изучающих вычислительную технику, и как справочник прикладного и системного програм-
миста.
© М. Гук, В. Юров, 2001
© Издательский дом «Питер», 2001
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было
форме без письменного разрешения владельцев авторских прав.
Информация, содержащаяся в данной книге, получена из источников, рассматриваемых издательством как
надежные. Тем не менее, имея в виду возможные человеческие или технические ошибки, издательство не
может гарантировать абсолютную точность и полноту приводимых сведений и не несет ответственность за
возможные ошибки, связанные с использованием книги.
ISBN 5-318-00559-4
ЗАО «Питер Бук», 196105, Санкт-Петербург, Благодатная ул., д. 67.
Лицензия ИД № 01940 от 05.06.00.
Налоговая льгота — общероссийский классификатор продукции ОК 005-93, том 2; 95 3000 — книги и брошюры.
Подписано к печати 26.09.01. Формат 70x100/16. Усл. п. л. 41,28. Тираж 5000. Заказ
Отпечатано с готовых диапозитивов в ФГУП ордена Трудового Красного Знамени «Техническая книга»
Министерства РФ по делам печати, телерадиовещания и средств массовых коммуникаций
198005, Санкт-Петербург, Измайловский пр., 29
Краткое содержание
Предисловие...........................................18
1. Введение..........................................21
2. Программная модель 32-разрядных процессоров.......47
3. Математический сопроцессор, блоки ММХ и ХММ.......76
4. Система команд....................................94
5. Защищенный режим...............•.................119
6. Кэширование памяти...............................154
7. Особые режимы работы процессоров.................174
8. Совместимость, различия и идентификация процессоров.196
9. Процессоры фирмы Intel...........................216
10. Процессоры AMD и других фирм.....................236
11. Применение процессоров в PC......................250
Приложение 1. Команды процессоров х86................280
Приложение 2. Список сокращений, включая имена регистров,
структур данных и флагов.............................491
Алфавитный указатель.................................500
Содержание
Предисловие.....................................................18
Интернет................................................................19
От издательства.................................................20
1. Введение....................................................21
1.1. Что делает процессор в компьютере?.........................21
1.2. Краткий исторический экскурс...............................32
1.3. Архитектура, микроархитектура и поколения процессоров......35
1.4. NetBurst — микроархитектура процессора Pentium 4...........42
2. Программная модель 32-разрядных процессоров .... 47
2.1. Типы данных................................................48
2.2. Регистры процессора........................................52
2.3. Организация памяти.........................................61
2.3.1. Модель памяти в реальном режиме......................63
2.3.2. Режимы адресации.....................................65
2.3.3. Стек.................................................67
2.3.4. Плоская и многосегментная модели памяти и «нереальный» режим.69
2.4. Ввод-вывод.................................................70
2.5. Прерывания и исключения....................................71
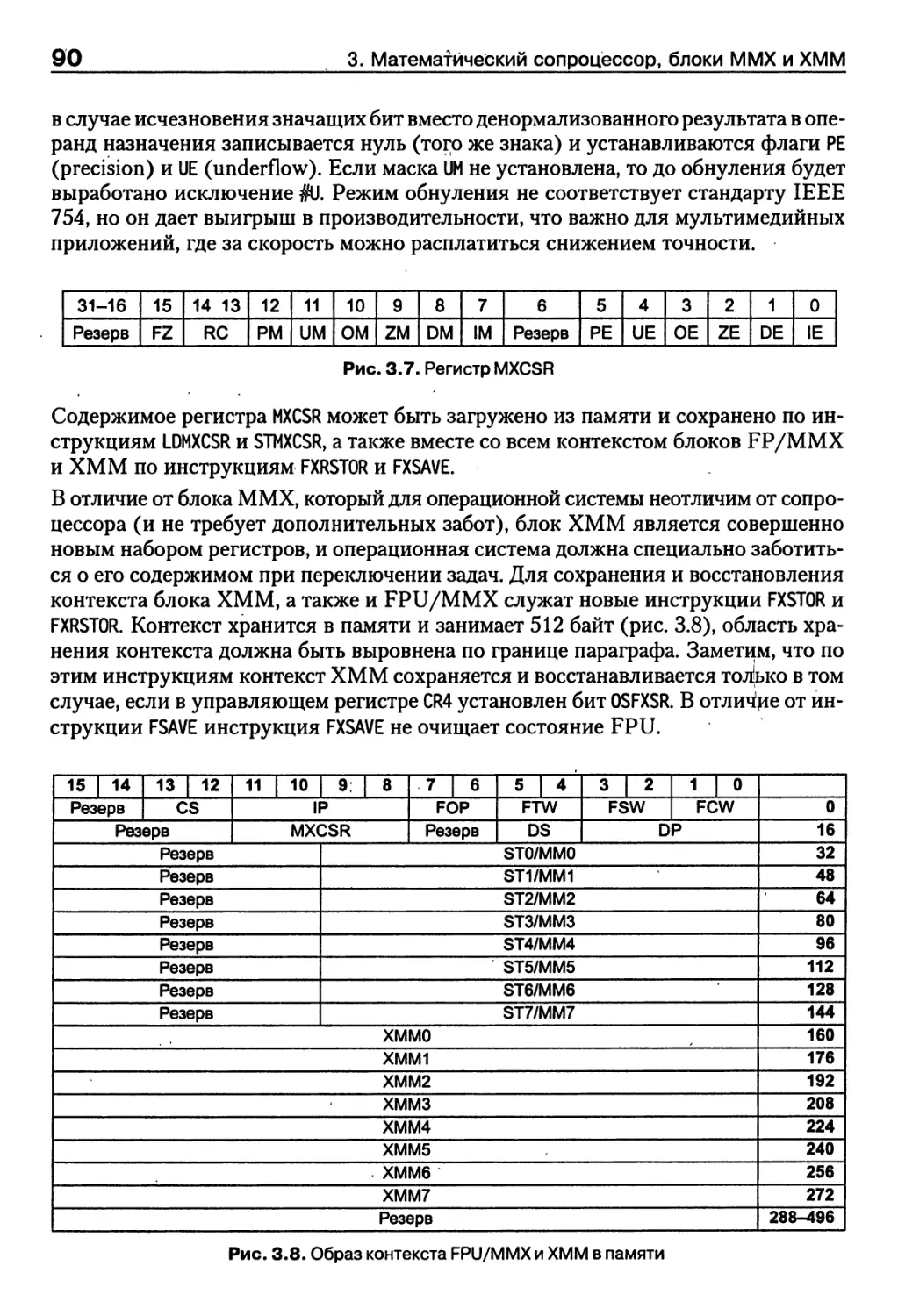
3. Математический сопроцессор, блоки ММХ и ХММ ... 76
3.1. Математический сопроцессор х87.............................77
3.1.1. Форматы данных FPU...................................77
3.1.2. Программная модель FPU...............................79
3.1.3. Исключения сопроцессора..............................84
3.1.4. Интерфейс сопроцессора...............................85
3.2. Технология ММХ.............................................86
3.3. Расширение SSE и SSE2 — блок ХММ...........................89
3.4. Расширение 3DNow!..........................................92
4. Система команд..............................................94
5. Защищенный режим ......................................... 119
5.1. Основные понятия защищенного режима.......................119
5.2. Дескрипторы и таблицы.....................................123
Содержание
7
5.3. Привилегии................................................128
5.4. Защита....................................................130
5.5. Переключение задач........................................132
5.6. Страничное управление памятью.............................136
5.7. Виртуализация прерываний..................................145
5.8. Режим виртуального процессора 8086 (V86 и EV86)...........147
5.9. Переключение между реальным и защищенным режимами.........151
6. Кэширование памяти........................................ 154
6.1. Принципы кэширования......................................154
6.1.1. Кэш прямого отображения.............................157
6.1.2. Наборно-ассоциативный кэш...........................160
6.1.3. Ассоциативный кэш...................................161
6.1.4. Пакетный режим передачи данных......................161
6.2. Кэширование в современных процессорах.....................162
6.3. Управление кэшированием...................................167
7. Особые режимы работы процессоров.......................... 174
7.1. Начальный сброс и тестирование............................174
7.2. Обновление микрокода......................................178
7.3. Программные средства отладки..............................180
7.4. Режим зондовой отладки....................................184
7.5. Режим системного управления SMM...........................185
7.6. Метки реального времени и мониторинг производительности...191
7.7. Синхронизация и управление энергопотреблением.............193
8. Совместимость, различия и идентификация
процессоров................................................... 196
8.1. Совместимость процессоров.................................196
8.2. Идентификация процессоров.................................200
8.2.1. Инструкция CPUID....................................205
8.3. Основные характеристики процессоров.......................212
9. Процессоры фирмы Intel.................................... 216
9.1. Процессоры Р6.............................................216
9.1.1. Конструктивы процессоров шестого поколения..........224
9.2. Процессор Pentium 4.......................................226
10. Процессоры AMD и других фирм............................ 236
10.1. Процессоры фирмы AMD для сокетов 5 и 7...................236
10.2. Процессоры Athlon и Duron фирмы AMD......................239
10.3. Процессоры фирм Cyrix, VIA, IBM и другие.................247
11. Применение процессоров в PC............................. 250
11.1. Установка и замена процессоров — сокеты и слоты..........250
11.1.1. Выбор частоты и напряжения питания.................261
8
Содержание
11.2. Синхронизация и разгон......................................269
11.3. Охлаждение процессоров......................................273
11.4. Мультипроцессорные и избыточные системы.....................276
11.4.1. Симметричные мультипроцессорные системы...............276
11.4.2. Системы с избыточным контролем функциональности.......279
Приложение 1. Команды процессоров х86 ............... 280
П1.1. Целочисленные команды.......................................281
ААА...........................................................281
AAD...........................................................282
ААМ...........................................................282
AAS...........................................................282
ADC приемник, источник........................................282
ADD приемник, источник........................................283
AND приемник, источник........................................283
ARPL приемник, источник.......................................284
BOUND индекс, границы массива.................................284
BSF результат, источник.......................................285
BSR результат, источник.......................................285
BSWAP источник................................................286
ВТ источник, индекс...........................................286
ВТС источник, индекс..........................................286
BTR источник, индекс..........................................287
BTS источник, индекс..........................................287
CALL цель.....................................................287
CBW...........................................................289
CDQ...........................................................289
CLC......................................................... 289
CLD...........................................................289
CLI...........................................................289
CLTS..........................................................289
СМС...........................................................290
CMOVcc приемник, источник.....................................290
СМР операнд!, операнд2........................................291
CMPS приемник, источник.......................................292
CMPXCHG приемник, источник....................................292
CMPXCHG8B приемник............................................293
CPUID.........................................................293
CWD...........................................................300
CWDE..........................................................300
DAA...........................................................300
DAS...........................................................300
DEC операнд...................................................300
DIV делитель..................................................301
ENTER размер_кадра, лексический_уровень.......................301
HLT...........................................................302
IDIV делитель.................................................302
Содержание
9
IMUL множитель-1............................................302
IN аккумулятор, ном_порта...................................303
INC операнд.................................................304
INS приемник, порт..........................................304
INT номер_прерывания, INTO..................................305
INVD........................................................306
INVLPG адрес................................................306
IRET........................................................306
Jcc метка...................................................307
JCXZ........................................................309
}МРцель.....................................................309
LAHF........................................................310
LAR приемник, источник......................................310
LDS приемник, источник, LES приемник, источник, LFS приемник,
источник, LGS приемник, источник, LSS приемник, источник....311
LEA приемник, источник......................................312
LEAVE.......................................................312
LGDT источник...............................................312
LIDT источник...............................................313
LLDT источник...............................................313
LMSW источник...............................................313
LOCK........................................................313
LODS источник...............................................314
LOOP метка..................................................314
LOOPE..................................................... 315
LSL приемник, источник......................................315
LTR источник................................................316
MOV приемник, источник......................................316
MOVS приемник, источник.....................................317
MOVSX приемник, источник....................................318
MOVZX приемник, источник....................................318
MUL множитель_1.............................................319
NEG приемник................................................319
NOP.........................................................319
NOT приемник................................................320
OR приемник, маска..........................................320
OUT ном_порта, аккумулятор..................................320
OUTS порт, источник.........................................321
POP приемник................................................321
POPA/POPAD..................................................322
POPF........................................................322
PREFETCHT0 источник.........................................323
PUSH источник...............................................323
PUSH А......................................................324
10
Содержание
PUSHF.........................................................324
RCL операнд, количсство_сдвигов...............................324
RCR операнд, количество_сдвигов...............................325
RDMSR.........................................................325
RDPMC.........................................................326
RDTSC.........................................................326
REP...........................................................326
RET...........................................................327
ROL операнд, количество_сдвигов...............................328
ROR операнд, количество_сдвигов...............................329
RSM...........................................................329
SAHF..........................................................330
SAL операнд, кол ичество_сд вигов.............................330
SAR операнд, количество_сдвигов...............................330
SBB операнд_1, операпд_2......................................331
SCAS приемник.................................................331
SETcc операнд.................................................332
SFENCE........................................................333
SGDT источник.................................................333
SIDT источник.................................................333
SHL операнд, количество_сдвигов...............................334
SHLD приемник, источник, количество_сдвигов...................334
SHR операнд, кол-во_сдвигов...................................335
SHRD приемник, источник, количество сдвигов...................335
SLDT приемник.................................................336
SMSW приемник.................................................336
STC...........................................................336
STD...........................................................336
STI...........................................................336
STOS приемник.................................................337
STR приемник..................................................337
SUB операнд_1, операнд_2......................................337
SYSENTER......................................................338
SYSEXIT приемник, источник....................................339
TEST приемник, источник.......................................340
UD2..........................:................................340
VERR селектор.................................................340
VERW селектор.................................................341
WAIT..........................................................341
WBINVD........................................................341
WRMSR.........................................................341
XADD приемник, источник.......................................342
XCHG операнд_1, операнд_2.....................................342
XLAT адрес_таблицы_байт.......................................343
XOR приемник, источник...................................... 343
П1.2. Команды сопроцессора.........................................344
F2XM1.........................................................344
Содержание 11
FABS......................................................344
FADD......................................................344
FADDP.....................................................345
FBLD источник.............................................345
FBSTP приемник............................................346
FCHS......................................................346
FCLEX.....................................................346
FCMOVcc приемник, источник................................346
FCOM......................................................347
FCOMI операнд_1, операнд_2................................348
FCOMIP операнд_1, операпд_2...............................349
FCOMP.....................................................349
FCOMPP....................................................349
FCOS......................................................349
FDECSTP...................................................350
FDIV......................................................350
FDIVP.....................................................351
FDIVR.....................................................351
FDIVRP....................................................352
FFREE регистр_сопроцессора................................352
FIADD слагаемое_1.........................................352
FICOM операнд_2...........................................353
FICOMP операнд............................................353
FIDIV источник............................................353
FIDIVR делимое............................................354
FILD источник.............................................354
FINCSTP...................................................354
FIMUL сомпожитель_2.......................................354
FINIT.....................................................355
FIST приемник.............................................355
FISTP приемник............................................356
FISUB вычитаемое..........................................356
FISUBR уменьшаемое........................................356
FLD источник..............................................357
FLDCW источник............................................357
FLDENV источник...........................................357
FLD1......................................................358
FLDL2T....................................................359
FLDL2E....................................................359
FLDLG2....................................................359
FLDLN2....................................................359
FLDPI.....................................................360
FLDZ......................................................360
FMUL......................................................360
FMULP.....................................................361
FNCLEX....................................................361
FNINIT....................................................361
12
Содержание
FNOP...................................................361
FNSAVE приемник........................................362
FNSTCW приемник........................................363
FNSTENV источник.......................................363
FNSTSW приемник........................................364
FPATAN.................................................364
FPREM..................................................365
FPREM1.................................................365
FPTAN..................................................366
FRNDINT................................................366
FRSTOR источник........................................367
FSAVE приемник.........................................367
FSCALE.................................................368
FSIN...................................................368
FSINCOS................................................368
FSQRT..................................................368
FST приемник...........................................368
FSTCW приемник.........................................369
FSTENV приемник........................................369
FSTP приемник..........................................370
FSTSW приемник.........................................370
FSUB...................................................370
FSUBP..................................................371
FSUBR..................................................371
FSUBRP.................................................372
FTST...................................................372
FUCOM..................................................373
FUCOMI значение_1, значепие_2..........................373
FUCOMIP значение!, зпачепие_2..........................374
FUCOMP.................................................374
FUCOMPP................................................375
FWAIT..................................................375
FXAM...................................................375
FXCH...................................................375
FXTRACT................................................376
FYL2X..................................................376
FYL2XP1................................................376
П1.3. Команды блока MMX............’.......................377
EMMS...................................................377
MASKMOVQ источник, маска...............................377
MOVD приемник, источник................................377
MOVNTQ. приемник, источник.............................378
MOVQ приемник, источник................................378
PACKSSWB приемник, источник............................379
PACKUSWB приемник, источник............................379
PADDB приемник, источник...............................380
Содержание
13
PADDSB приемник, источник.......................................380
PADDUSB приемник, источник......................................381
PAND приемник, источник.........................................382
PANDN приемник, источник........................................382
PAVGB приемник, источник........................................382
PCMPEQB приемник, источник......................................382
PCMPGTB приемник, источник......................................383
PEXTRW приемник, источник, маска................................384
PINSRW приемник, источник, маска................................384
PMADDWD приемник, источник......................................384
PMAXSW приемник, источник.......................................385
PMAXUB приемник, источник.......................................385
PMINSW приемник, источник.......................................386
PMINUB приемник, источник.......................................386
PMOVMSKB приемник, источник.....................................386
PMULHUW приемник, источник......................................387
PMULHW приемник, источник.........................:.............387
PMULLW приемник, источник.......................................388
POR приемник, источник..........................................389
PSADBW приемник, источник.......................................389
PSHUFW приемник, источник, маска................................389
PSLLW приемник, источник........................................390
PSRAW приемник, источник........................................391
PSRLW приемник, источник........................................392
PSUBB приемник, источник........................................392
PSUBSB приемник, источник.......................................393
PSUBUSB приемник, источник......................................393
PUNPCKHBW приемник, источник....................................394
PUNPCKLBW приемник, источник....................................395
PXOR приемник, источник.........................................396
П1.4. Команды блока ХММ............................................396
ADDPS приемник, источник........................................396
ADDSS приемник, источник........................................396
ANDNPS приемник, источник.......................................397
ANDPS приемник, источник........................................397
CMPPS приемник, источник, условие...............................397
CMPSS приемник, источник, условие...............................399
COMISS приемник, источник.......................................399
CVTPI2PS приемник, источник.....................................400
CVTPS2PI приемник, источник.....................................400
CVTSI2SS приемник, источник.....................................401
CVTSS2SI приемник, источник.....................................401
CVTTPS2PI приемник, источник....................................402
CVTTSS2SI приемник, источник....................................403
DIVPS приемник, источник........................................403
DIVSS приемник, источник........................................404
FXRSTOR источник................................................404
14
Содержание
FXSAVE приемник...................................................405
LDMXCSR источник..................................................405
MAXPS приемник, источник..........................................405
MAXSS приемник, источник..........................................406
MINPS приемник, источник..........................................406
MINSS приемник, источник..........................................406
MOVAPS приемник, источник.........................................407
MOVHLPS приемник, источник........................................407
MOVHPS приемник, источник.........................................407
MOVLHPS приемник, источник........................................408
MOVLPS приемник, источник.........................................408
MOVMSKPS приемник, источник.......................................409
MOVNTPS приемник, источник........................................409
MOVSS приемник, источник..........................................409
MOVUPS приемник, источник.........................................410
MULPS приемник, источник..........................................410
MULSS приемник, источник..........................................411
ORPS приемник, источник...........................................411
RCPPS приемник, источник..........................................412
RCPSS приемник, источник..........................................412
RSQRTPS приемник, источник........................................412
RSQRTSS приемник, источник........................................413
SHUFPS приемник, источник, маска..................................413
SQRTPS приемник, источник.........................................414
SQRTSS приемник, источник.........................................415
STMXCSR приемник..................................................415
SUBPS приемник, источник..........................................415
SUBSS приемник, источник..........................................415
UCOMISS приемник, источник........................................416
UNPCKHPS приемник, источник.......................................416
UNPCKLPS приемник, источник.......................................417
XORPS приемник, источник..........................................417
П1.5. Команды блока ХММ (SSE2)........................................417
ADDPD приемник, источник..........................................417
ADDSD приемник, источник..........................................418
ANDPD приемник, источник..........................................418
ANDNPD приемник, источник.........................................418
CLFLUSH адрес_байта...............................................419
CMPPD приемник, источник, условие.................................419
CMPSD приемник, источник, условие.................................420
COMISD приемник, источник, условие................................420
CVTDQ2PD приемник, источник.......................................421
CVTDQ2PS приемник, источник.......................................421
CVTPD2DQ приемник, источник.......................................422
CVTPD2PI приемник, источник.......................................423
CVTPD2PS приемник, источник.......................................423
CVTPI2PD приемник, источник.......................................424
Содержание 15
CVTPS2DQ приемник, источник................................425
CVTPS2PD приемник, источник................................425
CVTSD2SI приемник, источник................................426
CVTSD2SS приемник, источник................................427
CVTSI2SD приемник, источник................................427
CVTSS2SD приемник, источник...j............................428
CVTTPD2PI приемник, источник............................. 429
CVTTPD2DQ приемник, источник...............................429
CVTTPS2DQ приемник, источник...............................430
CVTTSD2SI приемник, источник...............................431
DIVPD приемник, источник...................................431
DIVSD приемник, источник...................................432
LFENCE адрес_байта.........................................432
MASKMOVDQU источник, маска.................................432
MAXPD приемник, источник...................................433
MAXSD приемник, источник...................................433
MFENCE.....................................................434
MINPD приемник, источник...................................434
MINSD приемник, источник...................................434
MOVAPD приемник, источник..................................435
MOVD приемник, источник....................................435
MOVDQA приемник, источник..................................436
MOVDQU приемник, источник..................................436
MOVDQ2Q приемник, источник.................................436
MOVHPD приемник, источник..................................436
MOVLPD приемник, источник..................................437
MOVMSKPD приемник, источник................................437
MOVNTDQ приемник, источник.................................438
MOVNTI приемник, источник..................................438
MOVNTPD приемник, источник.................................438
MOVQ приемник, источник....................................438
MOVQ2DQ приемник, источник.................................439
MOVSD приемник, источник...................................439
MOVUPD приемник, источник..................................439
MULPD приемник, источник...................................440
MULSD приемник, источник...................................440
ORPD приемник, источник....................................440
PACKSSWB/PACKSSDW приемник, источник.......................441
PACKUSWB приемник, источник................................442
PADDB/PADDW/PADDD приемник, источник.......................443
PADDQ приемник, источник...................................443
PADDSB/PADDSW приемник, источник...........................444
PADDUSB/PADDUSW приемник, источник.........................444
PAND приемник, источник....................................445
PANDN приемник, источник...................................445
PAUSE......................................................445
PAVGB/PAVGW приемник, источник.............................446
16
Содержание
PCMPEQB/PCMPEQW/PCMPEQD приемник, источник................446
PCMPGTB/PCMPGTW/PCMPGTD приемник, источник................447
PEXTRW приемник, источник, маска..........................447
PINSRW приемник, источник, маска..........................448
PMADDWD приемник, источник................................448
PMAXSW приемник, источник.................................448
PMAXUB приемник, источник.................................449
PMINSW приемник, источник.................................449
PMINUB приемник, источник.................................449
PMOVMSKB приемник, источник...............................450
PMULHUW приемник, источник................................450
PMULHW приемник, источник.................................451
PMULLW приемник, источник.................................451
PMULUDQ приемник, источник................................452
POR приемник, источник....................................452
PSADBW приемник, источник.................................453
PSHUFD приемник, источник, маска..........................454
PSHUFHW приемник, источник, маска.........................455
PSHUFLW приемник, источник, маска.........................456
PSLLDQ приемник, количество_сдвигов.......................458
PSLLW/PSLLD/PSLLQ приемник, количество_сдвигов............458
PSRAW/PSRAD приемник, количество_сдвигов..................459
PSRLDQ приемник, количество сдвигов.......................459
PSRLW/PSRLD/PSRLQ приемник, количество_сдвигов............460
PSUBB/PSUBW/PSUBD приемник, источник......................460
PSUBQ приемник, источник..................................461
PSUBSB/PSUBSW приемник, источник..........................461
PSUBUSB/PSUBUSW приемник, источник........................462
PUNPCKHBW/PUNPCKHWD/PUNPCKHDQ/PUNPCKHQDQ
приемник, источник........................................462
PUNPCKLBW/PUNPCKLWD/PUNPCKLDQ/PUNPCKLQDQ
приемник, источник........................................463
PXOR приемник, источник...................................464
SHUFPD приемник, источник, маска..........................465
SQRTPD приемник, источник.................................465
SQRTSD приемник, источник.................................465
SUBPD приемник, источник..................................466
SUBSD приемник, источник..................................466
UCOMISD приемник, источник, условие.......................466
UNPCKHPD приемник, источник...............................467
UNPCKLPD приемник, источник...............................467
XORPD приемник, источник..................................467
П1.6. Команды 3DNow!™........................................468
FEMMS.....................................................469
PAVGUSB приемник, источник................................469
PF2ID приемник, источник..................................470
PFACC приемник, источник..................................470
Содержание
17
PFADD приемник, источник...........................................470
PFCMPEQ приемник, источник.........................................470
PFCMPGE приемник, источник.........................................471
PFCMPGT приемник, источник.........................................471
PFMAX приемник, источник...........................................471
PFMIN приемник, источник...........................................471
PFMUL приемник, источник...........................................472
PFRCP приемник, источник...........................................472
PFRCPIT1 приемник, источник........................................472
PFRCPIT2 приемник, источник........................................473
PFRSQIT1 приемник, источник........................................473
PFRSQRT приемник, источник.........................................473
PFSUB приемник, источник...........................................474
PFSUBR приемник, источник..........................................474
PI2FD приемник, источник...........................................474
PMULHRW приемник, источник.........................................475
PREFETCH источник..................................................475
П1.7. Расширение набора команд 3DNow!™ и ММХ™
для микропроцессора AMD Athlon™...................................475
PF2IW приемник, источник...........................................476
PFNACC приемник, источник..........................................477
PFPNACC приемник, источник.........................................477
PI2FW приемник, источник...........................................477
PSWAPD приемник, источник..........................................478
П1.8. Исключения.......................................................478
П1.8.1. Общие исключения (для всех режимов) — вектор прерывания 13.478
П1.8.2. Исключения защищенного режима (РМ).........................479
П 1.8.3. Исключения реального режима (RM)..........................485
П1.8.4. Исключения режима виртуального 8086 (VM)...................487
П1.8.5. Исключения с плавающей точкой (NE) — вектор прерывания 16..490
Приложение 2. Список сокращений, включая имена
регистров, структур данных и флагов................................... 491
Алфавитный указатель.................................................. 500
Предисловие
Эта книга стала очередной в серии книг о процессорах: «Процессоры Intel: от 8086
до Pentium II» (1997 г.), «Процессоры Pentium II, Pentium Pro и просто Pentium»
(1999 г.), «Процессоры Pentium III, Athlon и другие» (2000 г.). За «отчетный» год
для персональных компьютеров получили массовое распространение процессоры
Pentium III, Athlon и Duron и вышел очередной процессор Pentium 4. Принципи-
альных архитектурных расширений он не внес — появились только новые инст-
рукции, в основном для блоков регистров ХММ и ММХ. Однако в микроархитекту-
ре фирма Intel оторвалась от своей «рабочей лошадки» Р6, прослужившей с 1995 г.,
выдержавшей почти 10-кратное повышение тактовой частоты и обросшей всячес-
кими расширениями. Все эти новшества нашли отражение в новой книге. Книга
начинается с вводной «экскурсии» по компьютеру с объяснением задач и возмож-
ностей процессора, а завершается полным описанием всех команд, написанным
Виктором Юровым (см. приложение 1). Процессоры пятого поколения и ниже из
книги исключены (остались лишь упоминания о том, чем они не располагали),
описание шестого поколения сокращено в пользу «бенефициантов». При необхо-
димости сведения о них можно почерпнуть в [10,11]. Информация о процессорах
дана по состоянию на лето 2001 года — сюда попали процессоры Pentium 4, Athlon,
Duron, Pentium III для сокета 370 и описывается отличие этого сокета от сокета
для Celeron. Новшества архитектурных расширений — SSE2, ХММ, «приключе-
ния» серийного номера, управление кэшируемостью через РАТ и кое-что еще —
также можно найти в этой книге. Дополнено описание идентификации процессо-
ров, особенно для процессоров AMD. Как всегда, исправлены некоторые неточно-
сти, обнаруженные при пересмотре ранее написанного текста. Некоторые ошиб-
ки были обнаружены читателями предыдущих книг, за что им большое спасибо.
Процессоры в книге рассматриваются больше с точки зрения программиста,
и прикладного, и системного. Книга ориентирована на подготовленных читателей,
которые прекрасно знают, что такое биты и байты, низкие и высокие логические
уровни и не путают вольты, ватты и амперы. Книга поможет разобраться в режи-
мах работы современных процессоров — реальном, защищенном, виртуальном и
режиме системного управления. Эти знания полезны не только разработчикам
аппаратуры и программного обеспечения, но и любознательным пользователям
PC. Вы узнаете, что делается «за кулисами» операционной системы, откуда берет-
ся сообщение «Нарушение общей защиты» и какие «недопустимые операции»
пыталось выполнить приложение, снятое операционной системой защищенного
режима. Конечно, все технические подробности и нюансы в одной книге изложить
Интернет
19
невозможно — это займет много места (книга станет толстой и дорогой), времени
(книга устареет до своего появления) и утомит тех многочисленных читателей,
которым эти сведения вряд ли понадобятся. Для читателей, более углубленно
интересующихся работой компьютера, можно посоветовать книгу М. Гука «Аппа-
ратные средства IBM PC. Энциклопедия», 2-е издание. В энциклопедии, конеч-
но же, информации по процессорам меньше, чем в данной книге, зато там есть
масса сведений о смежных предметах — системных платах, подсистеме памяти,
шинах и т. д.
Предыдущими книгами для изучения микропроцессоров пользуются студен-
ты ряда вузов, в том числе и «Политеха» (СПбГТУ), часть из которых проходят
подготовку в «базовом лагере» Михаила Гука — ЦНИИ робототехники и техни-
ческой кибернетики (http://www.rtc.neva.ru). Надеюсь, эта книга будет не менее
полезной.
Для удобства восприятия материала в книге принята система текстовых выделе-
ний. Курсивом выделены ключевые слова (например, первый раз встречающиеся
определения), а также названия состояний, в которых могут пребывать некоторые
объекты. В названиях электрических сигналов, например НИМ#, символ «#» ука-
зывает на инверсность (низкий уровень сигнала отвечает активному состоянию).
Названия инструкций (команд), регистров и бит имеют иной вид — например HALT
(инструкция), CRO.PE (бит РЕ регистра CR0). Исключения (особые случаи) обозна-
чаются, например, как #GP (общая защита). Список сокращенных названий регис-
тров, флагов и т. п. специфических категорий приведен в приложении 2.
Книга не могла бы появиться без мощной информационной поддержки, обеспе-
ченной коллективом создателей сети RUSNet (http://www.neva.ru) в ЦНИИ РТК.
Благодаря возможности работы по высокоскоростному каналу связи с Интерне-
том авторы не испытывали затруднений с получением PDF-документов мегабайт-
ных размеров.
Оперативную web-поддержку книги (дополнения, исправления и статьи по смеж-
ным темам) можно найти на сайте Михаила Гука по адресу http://www.neva.ru/
mgook. Свои замечания и пожелания присылайте по электронной почте на адрес
Mgook@stu.neva.ru.
Интернет
♦ Фирма Intel: http://www.intel.com, http://www.intel.ru (на русском языке).
♦ Фирма AMD: http://www.amd.com.
♦ Аппаратные средства компьютеров iXBT Hardware: http://ixbt.stack.net (на рус-
ском языке).
♦ Недокументированные свойства и ошибки процессоров х86: http://www.x86.org.
♦ Разгон процессоров: http://www.overclock.com.
♦ Применение процессоров, аппаратные средства PC: http://www.sysdoc.pair.com.
♦ Поддержка книг Михаила Гука, статьи: http://www.neva.ru/mgook.
20
Предисловие
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу электронной по-
чты comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
Подробную информацию о наших книгах вы найдете на web-сайте издательства
http://www.piter.com.
1. Введение
1.1. Что делает процессор в компьютере?
Как известно, процессор является основным вычислительным блоком компьюте-
ра, в наибольшей степени определяющим его мощь (или немощь, нужное подчерк-
нуть). Процессор является устройством, исполняющим программу — последова-
тельность команд (инструкций), задуманную программистом и оформленную в
виде модуля программного кода: Чтобы понять, что делает процессор, рассмотрим
его в окружении системных компонентов IBM PC-совместимого компьютера.
Этой компьютерной архитектурой, естественно, не ограничивается сфера приме-
нения процессоров семейства х86, которым посвящена данная книга.
Всем известный IBM PC-совместимый компьютер представляет собой реализа-
цию так называемой фон-неймановской архитектуры вычислительных машин.
Эта архитектура была предложена Джорджем фон Нейманом еще в 1945 году и
имеет следующие основные признаки. Машина состоит из блокауправления, ариф-
метико-логического устройства (АЛУ), памяти и устройств ввода-вывода. В ней
реализуется концепция хранимой программы', программы и данные хранятся в од-
ной и той же памяти. Выполняемые действия определяются блоком управления
и АЛУ, которые вместе являются основой центрального процессора. Центральный
процессор выбирает и исполняет команды из памяти последовательно, адрес оче-
редной команды задается «счетчиком адреса» в блоке управления. Этот принцип
исполнения называется последовательной передачей управления. Данные, с ко-
торыми работает программа, могут включать переменные — именованные облас-
ти памяти, в которых сохраняются значения с целью дальнейшего использования
в программе. Фон-неймановская архитектура — не единственный вариант по-
строения ЭВМ, есть и другие, которые не соответствуют указанным принципам
(например, потоковые машины). Однако подавляющее большинство современных
компьютеров основано именно на этих принципах, включая и сложные многопро-
цессорные комплексы, которые можно рассматривать как объединение фон-ней-
мановских машин. Конечно же, за более чем полувековую историю ЭВМ класси-
ческая архитектура прошла длинный путь развития. Тем не менее ПК можно
разложить «по полочкам» следующим образом.
Центральный процессор (АЛУ с блоком управления) реализуется микропроцес-
сором семейства х86 — от 8086/88 до Pentium 4 и Athlon (и это не конец исто-
рии). При всей своей внутренней суперскалярности, суперконвейеризированнос-
ти и спекулятивности (см. п. 1.3), внешне процессор соблюдает вышеупомянутый
принцип последовательной передачи управления. Набор арифметических, логи-
22
1. Введение
ческих и прочих инструкций (см. главу 4) насчитывает несколько сотен, а для
потоковой обработки придуман принцип SIMD — множество комплектов данных,
обрабатываемых одной инструкцией (расширения MMX, 3DNow!, SSE). Процес-
сор имеет набор регистров (см. п. 2.2), часть которых доступна для хранения опе-
рандов, выполнения действий над ними и формирования адреса инструкций и
операндов в памяти. Другая часть регистров используется процессором для слу-
жебных (системных) целей, доступ к ним может быть ограничен (есть даже про-
граммно-невидимые регистры).
Память «расползлась» по многим компонентам. Оперативная память (ОЗУ) —
самый большой массив ячеек памяти со смежными адресами — реализуется, как
правило, на модулях (микросхемах) динамической памяти. Для повышения про-
изводительности обмена данными (включая и считывание команд) оперативная
память кэшируется сверхоперативной памятью (см. п. 6.1). Первый, а зачастую и
второй уровень кэширования территориально располагается в микропроцессоре.
Оперативная память вместе с кэшем всех уровней (теперь даже до трех) представ-
ляет собой единый массив памяти, непосредственно доступный процессору для
записи и чтения данных, а также считывания программного кода. Кроме опера-
тивной память включает также и постоянную (ПЗУ), из которой можно только
считывать команды и данные, и некоторые виды специальной памяти (например,
видеопамять графического адаптера). Вся эта память вместе с оперативной рас-
полагается в едином пространстве с линейной адресацией. В любом компьютере
обязательно есть постоянная память, в которой хранится программа начального
запуска компьютера и минимально необходимый набор сервисов (ROM BIOS).
Память дополняется устройствами хранения данных, например дисковыми. Эти
устройства предназначены для записи данных с целью последующего считывания
(возможно, и на другом компьютере). От рассмотренной выше памяти, называе-
мой также внутренней, устройства хранения отличаются тем, что процессор не
имеет непосредственного доступа к данным по линейному адресу. Доступ к дан-
ным на устройствах хранения выполняется с помощью специальных программ,
обращающихся к контроллерам этих устройств.
Устройства ввода-вывода (УВВ) служат для преобразования информации из
внутреннего представления в компьютере (биты и байты) в форму, доступную
окружающим, и обратно. Под окружающими понимаем как людей, так и другие
машины (например, технологическое оборудование, которым управляет компью-
тер). К устройствам ввода относятся клавиатура, мышь, джойстик, микрофон, ска-
нер, видеокамера, различные датчики; к устройствам вывода — дисплей, принтер,
плоттер, акустические системы (наушники), исполнительные механизмы. Список
устройств ввода-вывода безграничен — благодаря фантазии и техническому про-
грессу в него входят все новые и новые устройства; так, например, шлем виртуаль-
ной реальности из области фантастики вышел в производственно-коммерческую.
Устройства хранения к УВВ относить некорректно, поскольку здесь преобразования
информации ради доступности внешнему миру не происходит — что сохранил
(неважно, на каком носителе), то и прочитал (если удалось). Устройства хране-
ния вместе с УВВ можно объединить общим понятием периферийные устройства.
1.1. Что делает процессор в компьютере?
23
Существует еще большой класс коммуникационных устройств, предназначенных
для передачи информации между компьютерами и(или) их частями. Эти устрой-
ства обеспечивают, например, соединение компьютеров в локальные сети или под-
ключение терминала (это УВВ) к компьютеру через пару модемов.
Периферийные и коммуникационные устройства (и даже память) снабжаются
контроллерами или адаптерами, которые доступны процессору. Все компоненты
компьютера представляются для процессора в виде наборов ячеек памяти или(и)
портов ввода-вывода. Процессор может адресоваться к ним с точностью до одного
байта — набора смежных восьми бит. Каждый байт (ячейка памяти, порт) имеет
собственный уникальный физический адрес. Этот адрес устанавливается на сис-
темной шине процессором, когда он инициирует обращение к данной ячейке или
порту. В семействе х86 и PC-совместимых компьютерах пространства адресов
ячеек памяти и портов ввода-вывода разделены. Это предусмотрено с обеих
сторон: процессоры позволяют, а компьютеры используют данное разделение.
В принципе это разделение не обязательно, существуют процессоры, для которых
все внешние ячейки рассматриваются только как память. Контроллеры и адапте-
ры периферийных устройств могут и не использовать порты в пространстве вво-
да-вывода, если их регистры отображены на пространство памяти. Отображение
на память неудобно тем, что для регистров ,периферийных контроллеров трудно
выбрать постоянное место приписки. Оперативную память всегда стремятся пред-
ставлять в виде единого непрерывного массива ячеек со смежными физическими
адресами, следовательно, для регистров можно выделить зону адресов либо до
начального адреса ОЗУ, либо после конечного. То и другое плохо: либо из адресов
ОЗУ уйдет область, начинающаяся с нулевого адреса (процессоры х86 использу-
ют ее для векторов прерываний), либо начало зоны регистров придется отодви-
нуть очень далеко в область старших адресов, чтобы ее не «достала» оперативная
память. Напомним, что за историю PC типовой объем ОЗУ вырос уже на три по-
рядка и подбирается к гигабайту. Семейство х86 стартовало с разрядности шины
адреса памяти 20 бит (8086/88), что позволяло адресовать 210 e 1 048 576 ячеек
(1 Мбайт). Нынешние процессоры имеют разрядность физического адреса памя-
ти 32 и даже 36 бит, что позволяет адресовать до 4 и 64 Гбайт соответственно.
Пространство ввода-вывода использует только младшие 16 бит адреса, что позво-
ляет адресовать до 65 384 однобайтных регистров. Адреса «исторических» систем-
ных устройств PC не изменились с самого рождения — это дань совместимости,
которая без разделения пространств вряд ли бы просуществовала столько лет.
Пространства памяти и ввода-вывода неравнозначны не только по объему, но и по
способам обращения. Способов адресации к ячейке памяти в х86 великое множе-
ство (см. п. 2.3), в то время как для адресации ввода-вывода их существует только
два. К памяти возможна (и широко используется) виртуальная адресация, при
которой для программиста, программы и даже пользователя создается иллюзия
оперативной памяти гигантского размера. В этом случае реальный физический
адрес процессор формирует из логического адреса (указанного программистом) под
управлением операционной системы, поддерживающей виртуальную память.
Иллюзия большого объема создается операционной системой с помощью уст-
ройств хранения и специальных аппаратных средств процессора (см. п. 5.6). Воз-
24
1. Введение
можна и реальная адресация к памяти — в этом случае физический адрес совпада-
ет с логическим. К портам ввода-вывода обращаются только по реальным адресам,
правда, и здесь возможна виртуализация, но уже чисто программными средства-
ми операционной системы. И, наконец, самое существенное различие пространств
памяти и ввода-вывода: процессор может считывать инструкции для исполнения
только из пространства памяти. Конечно, через порт ввода можно считать фраг-
мент программного кода (что и происходит, например, при считывании данных с
диска), но для того, чтобы этот код исполнить, его необходимо записать в память.
Процессор исполняет программный код, находящийся к моменту исполнения в
пространстве памяти. Программный код — это последовательность команд, или
инструкций, каждая из которых определенным образом закодирована и располо-
жена в целом числе смежных байт памяти. Каждая инструкция обязательно имеет
операционную часть, несущую процессору информацию о требуемых действиях.
Операндная часть, указывающая процессору, где находится его «предмет труда» —
операнды, может присутствовать в явном или неявном виде и даже отсутствовать.
Операндная часть может описывать от нуля до двух операндов, участвующих в
данной инструкции (есть инструкции, в которые кроме двух операндов задается
еще и параметр инструкции). Здесь могут быть сами значения операндов (непо-
средственные операнды); явные или неявные указания на регистры процессора,
в которых находятся операнды; адрес ячейки памяти (или его составная часть);
регистры процессора, участвующие в формировании адреса, и разные комбина-
ции этих компонентов. Длина инструкции в семействе х86 может быть от одного
до 12 байт и определяется типом инструкции. Исторически сложившийся формат
инструкций х86 довольно сложен, и «понять», сколько байт занимает конкретная
инструкция, процессор может, лишь декодировав ее первые 1-3 байт. Инструк-
ции могут предшествовать префиксы (к счастью, всегда однобайтные), указываю-
щие на изменение способа адресации, размера операнда или(и) необходимость
многократного (по счетчику и условию) повторения данной инструкции (см. гла-
ву 4). Адрес (логический) текущей исполняемой инструкции хранится в специ-
альном регистре — указателе инструкций (Instruction Pointer, IP), который соот-
ветствует счетчику команд фон-неймановской машины. После исполнения так
называемой линейной инструкции этот указатель увеличивает свое значение на ее
длину, то есть указывает на начало следующей инструкции. Линейная инструк-
ция не нарушает порядок выполнения, определяемый последовательностью рас-
положения инструкций в памяти (по нарастанию адреса). Кроме линейных инст-
рукций существуют инструкции передачи управления, среди которых различают
инструкции переходов и вызовов процедур. Эти инструкции в явном или неявном
виде содержат информацию об адресе следующей выполняемой инструкции, ко-
торый может указывать на относительно произвольную ячейку памяти. Инструк-
ции переходов и вызовов могут быть безусловными (ни от чего не зависящими) и
условными. Произойдет условный переход (вызов) или нет, зависит от состояния
флагов (признаков) на момент исполнения данной инструкции. Если переход (вы-
зов) не состоится, то исполняется инструкция, расположенная в памяти следом за
текущей. Вызов процедуры характерен тем, что перед ним процессор сохраняет в
стеке (стек — это область ОЗУ) адрес следующей инструкции, и на этот адрес пе-
1.1. Что делает процессор в компьютере?
25
редается управление после завершения исполнения процедуры (этот адрес извле-
кается из стека при выполнении инструкции возврата). При переходе в стеке ни-
чего не сохраняется, то есть переход выполняется безвозвратно.
Последовательность исполнения инструкций, предписанная программным кодом,
может быть нарушена под воздействием внутренних или внешних (относительно
процессора) причин. К внутренним причинам относятся исключения (exceptions) —
особые ситуации, возникающие при выполнении инструкций (см. п. 2.5). Нагляд-
ным примером исключения является попытка деления на ноль. При возникнове-
нии условия исключения процессор автоматически выполняет вызов процедуры
обработки исключения, после которой он может вернуться к повторному испол-
нению инструкции, породившей исключение, или следующей за ней. Вариант
поведения зависит от типа произошедшего исключения. Исключения широко
используются современными операционными системами, на основе обработки
исключений строится система виртуальной памяти и реализуются многие функ-
ции многозадачных операционных систем. Внешними причинами изменения нор-
мальной последовательности инструкций являются аппаратные прерывания —
вызовы процедур под воздействием электрических сигналов, поступающих на
специальные выводы процессора (см. п. 2.5). Эти сигналы могут подаваться со-
вершенно неожиданно для исполняемой программы, правда, у программиста есть
возможность заставить процессор (компьютер) игнорировать все прерывания или
их часть. Злоупотреблять этой возможностью нельзя (да и не всегда она есть),
поскольку на аппаратных прерываниях строится, например, отсчет времени и дру-
гие системные и прикладные функции компьютера. Источниками аппаратных
прерываний являются контроллеры и адаптеры периферийных устройств, гене-
раторы меток времени, системы управления питанием и другие подсистемы. Есть
еще так называемые программные прерывания, но они отнюдь не нарушают после-
довательность инструкций, предписанную программистом. Поэтому прерывани-
ями они, по сути, не являются — это всего лишь особый способ вызова процедур,
широко используемый для вызова системных сервисов BIOS и операционной
системы. И наконец, последовательность инструкций может изменяться по сиг-
налу аппаратного сброса или инициализации процессора. С этого, собственно,
и начинается функционирование компьютера: процессор переводится в исходное
состояние и запускается. При этом указатель инструкций совместно с другими
регистрами, участвующими в формировании адреса инструкции, генерирует адрес,
на 15 байт меньший максимального физического адреса (у процессоров Р6 возмо-
жен выбор между значением FFFFFFFFOh и FFFFOh). По этому адресу должна
располагаться инструкция, с которой начинается инициализация компьютера.
Итак, начнем с аппаратного сброса. Во время действия этого сигнала процессор
пассивен — он не управляет системной шиной. Процессор подготавливается к ра-
боте, воспринимая со своих выводов сигналы, задающие его конфигурацию (ко-
эффициент умножения, роль в многопроцессорных системах и некоторые другие
параметры). Внутренний кэш очищается, регистры (не все) приводятся в опреде-
ленное состояние. После окончания сигнала процессор по определенному адресу
(см. выше) выбирает из памяти и исполняет первую инструкцию — управление
передается на точку входа в программу инициализации компьютера. Программа
26
1. Введение
инициализации, называемая POST (PowerOn Self Test — самотестирование по вклю-
чению), хранится в постоянной памяти ROM BIOS (ПЗУ базовой системы вво-
да-вывода). Первым делом необходимо выполнить инициализацию процессора —
установить желаемый режим и значения некоторых регистров. Далее выполняет-
ся проверка работоспособности и инициализация подсистем компьютера. Эта
«раскрутка» выполняется в несколько этапов, постепенно вовлекая в работу про-
тестированные подсистемы. Поначалу программа может смело пользоваться толь-
ко регистрами процессора и постоянной памятью, предварительно ее проверив
(например, путем подсчета контрольной суммы). Если ПЗУ исправно, можно дви-
гаться дальше, в противном случае лучше остановиться. Пока неизвестна работо-
способность ОЗУ, оперативной памятью пользоваться нельзя и, следовательно,
недоступны вызовы процедур и обработка прерываний (вызвать-то процедуру
можно, а вот возврат не гарантируется, поскольку адрес возврата берется из стека,
то есть из ОЗУ). Далее инициализируется ОЗУ (программируются регистры чип-
сета, управляющие параметрами контроллера памяти и регенерацией) и выпол-
няется тестирование небольшого блока в его начале. Если тест прошел успешно,
то для дальнейшей работы можно уже пользоваться вызовами и прерываниями
(не забыв проинициализировать таблицу прерываний), а также памятью для хра-
нения переменных — в таком окружении работать гораздо удобнее. Теперь можно
проинициализировать и протестировать дисплейный адаптер, — дальнейшая рас-
крутка пойдет уже с «ожившим» экраном. Далее тестируется ОЗУ в полном объе-
ме, определяется наличие контроллеров и адаптеров, они инициализируются и
тестируются. Теперь система BIOS «знает» реальную конфигурацию компьюте-
ра и готова к загрузке операционной системы. Векторы прерываний, за которые
отвечает BIOS, проинициализированы — ими можно пользоваться. В этот момент
можно войти в меню встроенной утилиты конфигурирования — BIOS Setup, ко-
торая позволяет изменять настройки различных подсистем компьютера. После
окончания работы этой утилиты программу инициализации (POST) приходится
выполнять снова — конфигурация может стать уже иной. Программа POST завер-
шается вызовом процедуры начальной загрузки.
Для процессоров, начиная с шестого поколения, у POST есть дополнительная забо-
та — загрузить «заплатки» микропрограмм самого процессора (update microcode,
см. п. 7.2). Эти заплатки позволяют исправить некоторые ошибки, выявленные в
процессорах определенных моделей и партий выпуска. Без них основные функ-
ции процессор, конечно, выполнять будет, но в современных сложных операцион-
ных системах и приложениях, как говорится, возможны варианты. Информация
о том, какие заплатки требуются конкретному процессору, и сами заплатки хранят-
ся в ROM BIOS. Если BIOS про установленный процессор (какой именно про-
цессор установлен, POST может определить программно, см. п. 8.2) ничего не «зна-
ет», то и заплатки не загрузит. По этой причине может потребоваться обновление
версии BIOS, которое на современных системных платах выполняется довольно
просто (если производитель своевременно «выкладывает» образ BIOS на своем
web-сайте).
Процедура начальной загрузки (bootstrap loader) вызывается как программное пре-
рывание (BIOS Int 19h). Эта процедура определяет первое готовое устройство из
1.1. Что делает процессор в компьютере?
27
списка разрешенных и доступных (гибкий или жесткий диск, компакт-диск, сетевой
адаптер) и пытается загрузить с него в ОЗУ короткую программу загрузки. Эта
программа может выполняться в два этапа: сначала с жесткого диска загружается
главный загрузчик MBR (Master Boot Record) и ему передается управление. Глав-
ный загрузчик определяет на диске активный раздел, загружает загрузчик этого
раздела и передает управление ему. В свою очередь загрузчик активного раздела
загружает необходимые файлы операционной системы и передает ей управление.
Напомним, что «передать управление» означает выполнить инструкцию перехо-
да на адрес точки входа в программу, загруженную в оперативную память. Опера-
ционная система выполняет инициализацию подведомственных ей программных
и аппаратных средств. Она добавляет новые сервисы, вызываемые, как правило,
тоже через программные прерывания, и расширяет некоторые сервисы BIOS. Под
управлением операционной системы загружаются и исполняются пользователь-
ские приложения и разные вспомогательные процессы и утилиты. Операционная
система ведает распределением всех ресурсов компьютера — памяти (как опера-
тивной, так и пространства на устройствах хранения данных), процессорного
времени (в многозадачных системах), периферийных и коммуникационных уст-
ройств. Она же предоставляет интерфейс пользователя, с помощью которого за-
пускаются приложения, настраиваются параметры ОС и выполняются иные дей-
ствия пользователя. По окончании работы современные ОС требуют корректного
закрытия (shutdown) — завершения работы приложений и сохранения информа-
ции, необходимой пользователю и операционной системе, на энергонезависимых
носителях (на диске). Только после этого компьютер можно выключать или вы-
полнять аппаратный сброс кнопкой Reset. Если выключить или сбросить компью-
тер (в смысле нажать кнопку Reset) до выполнения операций завершения, могут
появиться проблемы при последующей загрузке: потеря несохраненных данных
(пользовательских или системных настроек), потеря фрагментов дисковой памя-
ти (кластеров) и даже разрушение ОС, требующее ее переустановки. Компьюте-
ры в конструктиве АТХ «умеют» сами выключать питание по завершении рабо-
ты ОС, что упрощает правила поведения пользователя.
После этого беглого описания цикла работы компьютера (от включения до вы-
ключения) чуть подробнее остановимся на таких моментах, как прерывания, за-
щищенный режим, многозадачность, виртуальная память.
Процессор фон-неймановской машины фактически может выполнять только один
процесс, передавая управление от инструкции к инструкции согласно исполняе-
мой программе. При этом могут исполняться переходы, ветвления и вызовы про-
цедур, но вся эта цепочка запрограммирована разработчиком программы. Теперь
рассмотрим случай, когда во время этого процесса случается асинхронное по от-
ношению к процессу событие, требующее реакции компьютера. Для примера рас-
смотрим нажатие клавиши на клавиатуре. Клавиатура (это устройство ввода) по
нажатию (как и отпусканию) любой клавиши по своему интерфейсу генерирует
специальное сообщение, содержащее код этого события (скан-код клавиши). Кон-
троллер клавиатуры, находящийся на системной плате, принимает этот код в свой
внутренний регистр и сигнализирует об этом двумя способами: устанавливает
флаг готовности (бит в регистре состояния, который может быть прочитан про-
28
1. Введение
цессором по адресу известного порта ввода) и генерирует сигнал запроса прерыва-
ния (сигнал IRQ1). Этот сигнал поступает на вход контроллера прерывания — сис-
темного устройства, обслуживающего запросы от множества линий (о дисципли-
не обслуживания здесь говорить не будем). Контроллер прерываний формирует
сигнал запроса, поступающий на вход маскируемого прерывания процессора (сиг-
нал INTR). Если у процессора маскируемые прерывания разрешены, то он запро-
сит у контроллера номер вектора прерывания, соответствующего данному источ-
нику прерывания. В нашем случае (сигнал от клавиатуры) это будет вектор 9.
Получив значение вектора, процессор сохранит в стеке адрес следующей инструк-
ции исполняемого процесса и выполнит вызов процедуры обработки прерывания,
адрес которой задан в 9-м элементе таблицы прерываний. В нашем компьютере эта
процедура считает скан-код из контроллера клавиатуры (в ответ он сбросит бит
готовности в своем регистре состояния), выполнит минимально необходимые дей-
ствия, связанные с получением этого кода, и некоторые манипуляции с контрол-
лером прерываний, позволяющие ему правильно реагировать на последующие
запросы прерываний. Процедура обработки прерывания завершается специаль-
ной инструкцией возврата (IRET), по которой управление вернется прерванному
процессу. Кроме маскируемых прерываний есть и немаскируемое прерывание с
фиксированным вектором 2, для которого у процессора имеется отдельный вход
NMI, а также системное прерывание SMI. Нюансы обработки прерываний процес-
сором рассмотрены в п. 2.5. Альтернативой прерываниям для реакции на асинх-
ронное событие может быть программный опрос готовности УВВ — полинг. Чтобы
обеспечить реакцию на асинхронное событие, исполняемый процесс в нашем слу-
чае должен периодически опрашивать (читать из порта ввода) регистр состояния
контроллера клавиатуры и, если будет замечен установленный флаг готовности,
исполнять процедуру обработки данного события. Непригодность такого подхо-
да в данном случае вполне очевидна — любой процесс, во время которого требует-
ся реакция на асинхронное событие (а самому процессу это событие может быть и
безразлично), должен быть загроможден периодическими вставками программно-
го кода опроса готовности. Кроме «лохматого» вида самой программы, на опрос
тратится процессорное время, и в основном бесполезно (клавиши нажимают не
так уж часто). Если опрос производить редко, то время реакции на событие может
недопустимо возрасти. Прерывания могут использоваться и в сочетании с Полин-
гом: процесс опроса готовности (возможно, нескольких устройств) периодически
запускается по прерываниям от системного таймера.
Прерывания используют и для переключения задач в многозадачных системах (см.
п. 5.5). Пусть, например, имеются два процесса (грубо говоря, две прикладные
программы), которые должны выполняться как бы одновременно (по-настоящему
одновременно один фон-неймановский процессор их выполнить не может). Можно
запустить один процесс, а через некоторое время его работы по аппаратному преры-
ванию (от таймера) сохранить в памяти контекст задачи — образ ее текущего состо-
яния (все регистры, программно-доступные этому процессу) и запустить другой
процесс. Через некоторое время по следующему прерыванию выполнить обратное
переключение контекста: сохранить состояние второго процесса (в другом месте
памяти), загрузить в регистры процессора образ состояния первого процесса и про-
1.1. Что делает процессор в компьютере?
29
должить его выполнение. Эти переключения задач следует выполнять с частотой,
создающей у пользователя иллюзию непрерывности и одновременности исполне-
ния обеих программ. Понятно, что ресурсы процессора (производительность) в
этом случае делятся между задачами пропорционально выделяемым им квантам
времени. Чтобы пользователя такая производительность процессов удовлетворя-
ла (а еще учтем накладные расходы на сохранение и восстановление образов при
переключениях), у процессора должна быть достаточная мощность. Процессоры
семейства х86, начиная со второго и, особенно, с третьего (386) поколения, имеют
встроенные средства многозадачности (число задач почти не ограничено), работа-
ющие в защищенном режиме. Переключение задач производится по сигналу преры-
вания от таймера совершенно «прозрачно» для процессов, работающих псевдопарал-
лельно. Благодаря этой прозрачности программисту, разрабатывающему прикладную
программу, в большинстве случаев не надо заботиться о реализации многозадачной
работы. В распоряжение его программы предоставляется виртуальная машина
(тоже фон-неймановская), в которой управление передается последовательно этой
программой, как будто она — единственный процесс. Конечно, поддержка виртуаль-
ных машин требует определенных усилий со стороны многозадачной операцион-
ной системы, которой приходится распределять не только процессорное время, но
и память, устройства хранения, ввода-вывода и коммуникационные устройства —
то есть все ресурсы реального компьютера. В этом ей помогают специальные сред-
ства, введенные в процессоры х86 2-3-го поколений и постоянно развиваемые в
следующих поколениях.
Чтобы процессы не мешали друг другу (по недосмотру или умышленно), требу-
ются меры принудительной защиты критически важных ресурсов. Современные
операционные системы используют защищенный режим процессора, в котором эти
меры реализуются на аппаратном уровне. Поскольку программа может взаимо-
действовать с подсистемами компьютера только через пространства памяти и пор-
тов ввода-вывода, а также аппаратные прерывания, то защищать нужно эти три
типа ресурсов. Самую сложную защиту имеет память. Операционная система
выделяет каждому процессу области памяти — сегменты — различного назначе-
ния и с разными правами доступа. Из одних сегментов можно только читать дан-
ные, в другие возможна и запись. Для программного кода выделяются специаль-
ные сегменты, инструкции могут выбираться и исполняться только из них. По
отношению’к принципу хранимое™ программы это является искусственным ог-
раничением для фон-неймановской машины, но его целесообразность очевидна.
Процессору «безразлично» содержимое ячейки памяти, на которую передано уп-
равление, — он всегда пытается трактовать ее как код инструкции (или префикс).
Если ошибочно управление передано на область данных, то дальнейшее поведе-
ние процессора непредсказуемо — это так называемый «вылет». Защита не позво-
ляет передать управление на сегмент данных — сработает исключение защиты,
которое обрабатывается операционной системой, и ошибочный процесс будет
принудительно завершен. Таким образом, вероятность вылета уменьшается. Что-
бы выдержать принцип хранимое™ программы, на время ее загрузки в память или
на время программной модификации ту же область объявляют и сегментом данных,
в который разрешена запись. Система защиты может полностью контролировать
30
1. Введение
распределение памяти, генерируя исключения в случаях различных нарушений.
Конечно же, эффективность защиты (устойчивость компьютера к ошибкам) в зна-
чительной мере определяется предусмотрительностью разработчиков операцион-
ной системы. Средства распределяемое™ и защиты памяти, ввода-вывода и пре-
рываний подробно описаны в главе 5.
Чем сложнее программа и больше объем обрабатываемых ею данных, тем больше
ее потребности в памяти. В первых процессорах семейства память предоставля-
лась в виде сегментов размером по 64 Кбайт, а суммарный объем программно ад-
ресуемой памяти ограничивался размером 1 Мбайт. Архитектура PC ограничи-
вала размер оперативной памяти объемом в 640 Кбайт, начиная с нулевых адресов.
Эта область называется стандартной памятью (conventional memory), и для приклад-
ных программ из нее остается доступной область порядка 400-550 Кбайт (осталь-
ное «съедает» операционная система вместе с разными драйверами). Потребнос-
ти решаемых задач довольно быстро переросли эти ограничения, и в процессоры
ввели средства организации виртуальной памяти. Впервые они появились в мо-
дели 80286, но удобный для употребления вид приняли только в 32-разрядных
процессорах (80386 и выше). Во-первых, было снято ограничение на размер сегмен-
та в 64 Кбайт — теперь любой сегмент может иметь почти произвольный размер
до 4 Гбайт. Во-вторых, был введен механизм страничной переадресации памяти
(paging, см. п. 5.6). Теперь любая страница (область фиксированного размера)
виртуальной логической памяти (адресуемой программой в пределах выделенных
ей сегментов) может отображаться на любую область физической памяти (реаль-
но установленной оперативной). Отображение поддерживается с помощью спе-
циальных таблиц страничной переадресации, в которых кроме связи адресов есть
указание на присутствие страницы в физической памяти на данный момент вре-
мени. Теперь страница памяти, не нужная процессору в данный момент времени,
может быть выгружена на устройство хранения (диск), а на ее место, при необхо-
димости, загружена нужная страница. Заявку на загрузку нужной страницы дела-
ет сам процессор, без каких-либо усилий выполняемой программы: если програм-
ме потребовалась ячейка виртуальной памяти из страницы, образа которой сейчас
нет в физической памяти, вырабатывается специальное исключение. Обработчик
этого исключения (это часть ОС) найдет свободную физическую страницу (вы-
грузив на диск ту, которая, по его мнению, пока не нужна), «подкачает» на нее с
диска требуемую информацию и вернет управление процессу, прерванному исклю-
чением. Сам процесс ничего «не заметит» (кроме некоторой задержки в выполне-
нии инструкций). Таким образом, в распоряжение всех процессов, исполняемых
на компьютере псевдопараллельно, предоставляется виртуальная оперативная
память, размер которой ограничен суммой объема физической оперативной па-
мяти и областью дисковой памяти, выделенной для подкачки страниц. Процесс
подкачки (замещения) страниц называется свопингом (swaping), а области диско-
вой памяти, выделяемые для этих целей, — файлами подкачки, или своп-файлами
(swap file). Прикладной вывод из этих рассуждений: если на компьютере переста-
ют запускаться приложения, что сопровождается сообщениями о недостаточном
объеме оперативной памяти, — проверьте наличие свободного места на жестких
дисках, используемых для подкачки. Этот вывод, естественно, относится только к
операционным системам защищенного режима (Windows, UNIX, OS/2 и т. д.).
1.1. Что делает процессор в компьютере?
31
Теперь вернемся к исполнению инструкций обработки данных — инструкций
выполнения арифметических или логических функций. Во многих случаях инст-
рукция работает с парой операндов — операндом назначения dest (destination) и
операндом-источником src (source). Традиционная схема действия инструкции:
dest = F(dest, src), где F — некоторая функция от двух переменных. Это означает,
что при выполнении инструкции процессор извлекает из указанных в инструк-
ции мест (регистр, память, константа в самой инструкции) пару двоичных чисел
и результат действия над ними записывает на место одного из них (dest). Для
выполнения той же функции над следующей парой чисел требуется повторное
исполнение инструкции, но уже с другой парой операндов. Такой принцип ис-
полнения естественен для базовой архитектуры процессоров х86. В процессоры
Pentium, «под занавес» их развития, было введено расширение ММХ, направлен-
ное на ускорение обработки потоков и массивов данных (см. п. 3.2). Ключевым в
этом расширении стал принцип SIMD (Simple Instruction — Multiple Data, одна
инструкция на множество данных). Здесь вводятся новые упакованные форматы
данных: в один регистр ММХ можно помещать не только один операнд (64-бит-
ное число), но и пару 32-битных, четверку 16-битных или восьмерку 8-битных
чисел. Одна инструкция ММХ выполняет однотипные действия сразу над всеми
числами, упакованными в регистры ММХ, заданные операндной частью данной
инструкции. Поначалу набор инструкций ММХ ограничивался целочисленной
арифметикой и логикой, и он стал стандартом для всех современных процессоров
х86. Позже появились расширения 3DNow! (от AMD) и SSE (от Intel) для чисел
в формате с плавающей точкой, сильно различающиеся по набору инструкций.
Несколько слов о числах с плавающей точкой. Архитектура процессора 8086 по-
зволяет выполнять арифметические функции (сложение, вычитание, умножение
и деление) над целочисленными данными (знаковыми и беззнаковыми, двоичны-
ми и двоично-десятичными) разрядностью 8 или 16 бит. В процессорах 386+ можно
обрабатывать и 32-разрядные числа. Для работы с числами в формате с плавающей
точкой (представленными в виде мантиссы и порядка) предусмотрен математи-
ческий сопроцессор. Сопроцессор представляет собой набор 80-битных регистров
и специализированное арифметическое устройство, которое кроме четырех ариф-
метических действий способно вычислять значение квадратного корня, тригоно-
метрических функций, логарифмов и степеней чисел. Сопроцессор может только
перехватывать адресованные ему инструкции из потока команд, выполняемых
центральным процессором, а все манипуляции с памятью выполняет центральный
процессор. Сложные функции сопроцессора требуют довольно больших затрат
времени, но во время их выполнения центральный процессор может продолжать
выполнение инструкций, вплоть до момента появления следующей инструкции,
адресованной сопроцессору. Однако эта эпизодическая параллельность вычислений
не противоречит принципу последовательной передачи управления (самостоятель-
но сопроцессор передать управление не способен). При отсутствии сопроцессора его
функции можно выполнять программно целочисленными средствами центрального
процессора, но сопроцессор их выполняет в сотни и тысячи раз быстрее. Программ-
ная эмуляция сопроцессора может включаться прозрачно для прикладных программ,
обращающихся к сопроцессору. Для этого используется механизм исключений.
На этом завершим «обзорную экскурсию» по компьютеру.
32
1. Введение
1.2. Краткий исторический экскурс
Первый 16-разрядный процессор i8086 фирма Intel выпустила в 1978 году. Частота —
5 МГц, производительность — 0,33 MIPS для инструкций с 16-битными операн-
дами (позже появились процессоры 8 и 10 МГц). Технология 3 мкм, 29 000 тран-
зисторов. Адресуемая память — 1 Мбайт (казалось, так много!). Через год появил-
ся i8088 — тот же процессор, но с 8-разрядной шиной данных. С него началась
история IBM PC, неразрывно связанная со всем дальнейшим развитием процес-
соров Intel. Массовое распространение и открытость архитектуры IBM PC при-
вели к лавинообразным темпам появления нового программного обеспечения,
разрабатываемого крупными, средними и мелкими фирмами, а также энтузиастами-
одиночками. Технический прогресс тогда и сейчас был бы немыслим без развития
процессоров, но, с учетом огромного объема уже существующего программного
обеспечения для PC, уже тогда возник принцип обратной программной совмести-
мости — старые программы должны работать на новых процессорах. Таким образом,
все нововведения в архитектуре последующих процессоров приходилось пристраи-
вать к существующему ядру. На процессорах отражались и особенности архитек-
туры PC. Взять, например, векторы прерываний. Фирма Intel зарезервировала
первые 32 вектора «для служебного пользования», однако на них «наехали» пре-
рывания BIOS PC. В результате появился дополнительный способ обработки
исключений сопроцессора, применяемый в более поздних моделях процессоров.
Процессор i80286, знаменующий следующий этап архитектуры, появился только
в 1982 году. Он уже имел 134 000 транзисторов (технология 1,5 мкм) и адресовал
до 16 Мбайт физической памяти. Его принципиальные новшества — защищенный
режим и виртуальная память размером до 1 Гбайт — не нашли массового приме-
нения; большей частью он использовался как очень быстрый процессор 8088.
Рождение 32-разрядных процессоров (архитектура IA-32) ознаменовалось в
1985 году моделью i80386 (275 000 транзисторов, 1,5 мкм). Разрядность шины дан-
ных (как и внутренних регистров) достигла 32 бит, адресуемая физическая па-
мять — 4 Гбайт. Появились новые регистры, новые 32-битные операции, суще-
ственно доработан защищенный режим, были введены режим V86 и страничное
управление памятью. Процессор нашел широкое применение в PC; на его благо-
датной почве стал разрастаться «самый большой вирус» — Microsoft Windows с
приложениями. С этого времени стала заметна тенденция «положительной обрат-
ной связи»: на появление нового процессора производители ПО реагируют выпу-
ском новых привлекательных продуктов, последующим версиям которых становит-
ся тесно на новом процессоре. Появляется более производительный процессор, но
после непродолжительного восторга и его ресурсы быстро признаются недоста-
точными, затем история повторяется. Этот «замкнутый круг», конечно, естестве-
нен, ио есть обоснованное подозрение, что большие ресурсы развращают (или, по
крайней мере, расслабляют) разработчика ПО, не принуждая его напрягаться в
поисках более эффективных способов решения задачи. Примером эффективного
программирования можно считать игрушки на Sinclair ZX-Specrtum, которые ра-
ботают на «игрушечных» (простите за каламбур) ресурсах — 8-разрядном процес-
1.2. Краткий исторический экскурс
33
соре и 64 (128) Кбайт ОЗУ. С противоположными примерами большинство пользо-
вателей PC сталкиваются регулярно, но, имея процессор Celeron 600 и 64 Мбайт
ОЗУ, на них не всегда обращают внимание.
История процессора 80386 повторила судьбу 8086/8088: первую модель с 32-раз-
рядной шиной данных (впоследствии названной 386DX) сменила модель 386SX с
16-разрядной шиной. Процессор довольно легко вписывался в архитектуру PC АТ,
ранее базировавшуюся на процессоре 80286.
Процессор Intel486DX появился в 1989 году. Транзисторов — 1,2 млн, технология
1 мкм. От процессора 80386 существенно отличается размещением на кристалле
первичного кэша и встроенного математического сопроцессора — FPU (предыду-
щие процессоры использовали внешние сопроцессоры х87). Кроме того, для по-
вышения производительности в этом CISC-процессоре (как и в последующих)
применено RISC-ядро. Далее появились его разновидности, отличающиеся нали-
чием или отсутствием сопроцессора, применением внутреннего умножения час-
тоты, политикой кэширования и другим. Тогда же Intel занялась энергосбереже-
нием, что отразилось и в линии 386 — появился процессор Intel386SL.
В 1993 году появились первые процессоры Pentium с частотой 60 и 66 МГц — 32-
разрядные процессоры с 64-разрядной шиной данных. Транзисторов — 3,1 млн,
технология 0,8 мкм, питание 5 В. От 486 процессор Pentium принципиально от-
личается суперскалярной архитектурой — способностью за один такт выпускать
с конвейеров до двух инструкций (что, конечно, не означает возможности прохожде-
ния инструкции через процессор за полтакта). Интерес к процессору со стороны
производителей и покупателей PC сдерживался его очень высокой ценой. Кроме
того, возник скандал с ошибкой в сопроцессоре. Хотя фирма Intel математически
обосновала невысокую вероятность ее проявления (раз в несколько лет), она (фир-
ма, а не ошибка) все-таки пошла на бесплатную замену уже проданных процессо-
ров на новые, исправленные.
Процессоры Pentium с частотой 75,90 и 100 МГц, появившиеся в 1994 году, пред-
ставляли второе поколение процессоров Pentium. При почти том же числе тран-
зисторов они выполнялись по технологии 0,6 мкм, что позволило снизить потреб-
ляемую мощность. От первого поколения отличались внутренним умножением
частоты, поддержкой мультипроцессорных конфигураций и другим типом корпуса.
Появились версии (75 МГц в миниатюрном корпусе) для мобильных применений
(блокнотных PC). Процессоры Pentium второго поколения стали весьма популяр-
ными в PC. В 1995 году были выпущены процессоры на 120 и 133 МГц, выполнен-
ные уже по технологии 0,35 мкм (первые процессоры на 120 МГц делались по тех-
нологии 0,6 мкм). Год 1996-й называют годом Pentium — появились процессоры
на 150, 166 и 200 МГц, и Pentium стал рядовым процессором в массовых PC.
Параллельно с Pentium развивался и процессор Pentium Pro, который отличался
«динамическим исполнением», направленным на увеличение числа параллельно
исполняемых инструкций. Кроме того, в его корпусе разместили вторичный кэш,
работающий на частоте ядра, — для начала объемом 256 Кбайт. Однако на 16-разряд-
ных приложениях, а также в среде Windows 95 он был ничуть не быстрее Pentium.
Процессор содержит 5,5 млн транзисторов ядра и 15,5 млн транзисторов для вто-
34
1. Введение
ричного кэша объемом 256 Кбайт. Первый процессор с частотой 150 МГц появил-
ся в начале 1995 года (технология 0,6 мкм), а уже в конце года были достигнуты
частоты 166, 180 и 200 МГц (технология 0,35 мкм), а кэш увеличен до 512 Кбайт.
После долгих обещаний в начале 1997 года фирма Intel выпустила процессоры
Pentium ММХ. Технология ММХ (MultiMedia extensions, мультимедийные расши-
рения) предполагает параллельную обработку группы операндов одной инструкци-
ей. Технология ММХ призвана ускорить выполнение мультимедийных приложений,
в частности операций с изображениями и обработки сигналов. Ее эффективность
вызывала споры в среде разработчиков, поскольку выигрыш в самих операциях
обработки «съедается» проигрышем на дополнительных операциях упаковки-рас-
паковки. Кроме того, ограниченная разрядность ставит под сомнение применение
ММХ в декодерах MPEG-2, в которых требуется обработка 80-битных операндов.
Кроме ММХ эти процессоры по сравнению с обычным Pentium имеют удвоенный
объем первичного кэша и некоторые элементы архитектуры, позаимствованные у
Pentium Pro, что повышает производительность Pentium ММХ на обычных при-
ложениях. Процессоры Pentium ММХ имеют 4,5 млн транзисторов и выполнены
по технологии 0,35 мкм. Развитие линейки моделей Pentium ММХ остановилось.
Последние достигнутые тактовые частоты — 166, 200 и 233 МГц. Для мобильных
применений (блокнотных ПК) процессоры под кодовым названием Tillamook
выпускались по технологии 0,25 мкм, тактовая частота достигла 266 МГц при
уменьшенной потребляемой мощности.
В мае 1997 года появился процессор Pentium II. Он представляет собой слегка
урезанный вариант ядра Pentium Pro с более высокой внутренней тактовой часто-
той, в которое ввели поддержку ММХ. Трудности размещения вторичного кэша и
процессорного ядра в корпусе одной микросхемы преодолели нехитрым спосо-
бом — кристалл с ядром (processor core) и набор кристаллов статической памяти
и дополнительных схем, реализующих вторичный кэш, разместили на небольшой
печатной плате-картридже. Первые процессоры имели частоту ядра 233, 266 и
300 МГц (технология 0,35 мкм), летом 1998 года была достигнута частота 450 МГц
(технология 0,25 мкм), причем внешняя тактовая частота с 66 МГц повысилась до
100 МГц. Вторичный кэш этих процессоров работает на половине частоты ядра.
В 1999 году появились процессоры Pentium III — в них ввели новый блок 128-
битных регистров ХММ и новые инструкции, названные SSE. Частота ядра под-
бирается к 1 ГГц, частота системной шины — 100 и 133 МГц. С конструктивами
начались «колебания генеральной линии» (см. п. 12.1), и теперь снова предпочтение
отдается процессорам со штырьковыми выводами (необходимость картриджей
отпадает). На базе Pentium II появилось семейство «облегченных» процессоров
Celeron, сначала без вторичного кэша, а потом и с интегрированным вторичным
кэшем размером 128 Кбайт. Позже процессоры Celeron приобрели и расширение
SSE. Для мощных компьютеров имеется семейство процессоров Хеоп, которое
охватывает и Pentium II, и Pentium III. Для этих процессоров характерен больший
объем вторичного кэша, поддержка более чем двухпроцессорных конфигураций и
более крупный картридж. Есть процессоры Pentium П/Ш и для мобильных при-
менений. Подробнее о процессорах шестого поколения см. в п. 10.2.
1.3. Архитектура, микроархитектура и поколения процессоров
35
В конце 2000 года вышел процессор Pentium 4 (кодовое название Willamette) —
тоже 32-разрядный представитель семейства х86, по микроархитектуре принад-
лежащий к новому, седьмому (по классификации Intel) поколению. С программ-
ной точки зрения его можно рассматривать как Pentium III с очередным расшире-
нием системы команд — SSE2. С внешней аппаратной точки зрения это процессор
с системной шиной нового типа, в которой кроме повышения тактовой частоты
применили ставшие уже привычными принципы двукратной (2х) и четырехкрат-
ной (4х) синхронизации, а также предпринят ряд мер по обеспечению работоспо-
собности на ранее немыслимых высоких частотах. Микроархитектура процессо-
ра, получившая название NetBurst, разработана с учетом высоких частот как ядра
(1,4 и 1,5 ГГц для начала), так и системной шины (100 МГц с четырьмя передача-
ми за каждый такт). Название микроархитектуры указывает на сетевую направ-
ленность процессора — его мощь потребуется для ресурсоемких мультимедийных
Интернет-приложений.
В объявленных планах Intel (которые меняются) было утверждение, что это будет
завершением линии процессоров IA-32. В 2001 году ожидается его мобильный
вариант — Northwood, а также серверный вариант — Foster.
Конечно же, перечисленными моделями не исчерпывается весь мировой ассорти-
мент микропроцессоров. Это только представители семейства процессоров Intel,
имеющих обобщенное название х86. Ряд фирм (например, AMD, Cyrix, IBM, VIA)
выпускали и выпускают процессоры, совместимые с перечисленными процессора-
ми Intel и имеющие свои характерные особенности. Обычно они слегка отставали
от изделий Intel, выпускаемых в то же время. Однако процессор К7 — Athlon и
Duron от AMD — изменил ситуацию. Ряд фирм (DEC, Motorola, Texas Instruments,
IBM) имеют разработки процессоров, существенно отличающиеся от семейства
х86; есть другие классы процессоров и у Intel. Среди них присутствуют и гораздо
более мощные процессоры, относящиеся как к RISC-, так и к CISC-архитектуре.
1.3. Архитектура, микроархитектура
и поколения процессоров
Здесь сделаем небольшое отступление в область архитектуры и микроархитекту-
ры процессоров, дадим некоторые определения и поясним деление на поколения.
Под архитектурой процессора понимается его программная модель, то есть
программно-видимые свойства. Эта книга посвящена процессорам с архитекту-
рой IA-32 (Intel Architecture 32 bit) — 32-разрядным процессорам семейства х86.
Под микроархитектурой понимается внутренняя реализация этой программной
модели. Для одной и той же архитектуры IA-32 разными фирмами и в разных по-
колениях применяются существенно различные микроархитектурные реализа-
ции, при этом, естественно, стремятся к максимальному повышению производи-
тельности (скорости исполнения программ).
В микроархитектуре процессоров пятого и шестого поколений — Pentium, Pentium
Pro, Pentium MMX и, наконец, Pentium II — существенное значение имеет реали-
36
1. Введение
зация различных способов конвейеризации и распараллеливания вычислитель-
ных процессов, а также других технологий, не свойственных процессорам прежних
поколений.
Конвейеризация (pipelining) предполагает разбивку выполнения каждой инструк-
ции на несколько этапов, причем каждый этап выполняется на своей ступени кон-
вейера процессора. При выполнении инструкция продвигается по конвейеру по
мере освобождения последующих ступеней. Таким образом, на конвейере одновре-
менно может обрабатываться несколько последовательных инструкций, и произво-
дительность процессора можно оценивать темпом выхода выполненных инструк-
ций со всех его конвейеров. Для достижения максимальной производительности
процессора — обеспечения полной загрузки конвейеров с минимальным числом
лишних штрафных циклов (penalty cycles) — программа должна составляться с
учетом архитектурных особенностей процессора. Конечно, и код, сгенерированный
обычным способом, будет исполняться на процессорах классов Pentium и Р6 дос-
таточно быстро. Конвейер «классического» процессора Pentium имеет пять сту-
пеней. Конвейеры процессоров с суперконвейерной архитектурой (superpipelined)
имеют большее число ступеней, что позволяет упростить каждую из них и, следо-
вательно, сократить время пребывания в них инструкций.
Скалярным называют процессор с единственным конвейером, к этому типу отно-
сятся все процессоры Intel до 486 включительно. Суперскалярный (superscalar)
процессор имеет более одного (Pentium — два) конвейера, способных обрабаты-
вать инструкции параллельно. Pentium является двухпотоковым процессором
(имеет два конвейера), Pentium Pro — трехпотоковым.
Переименование регистров (register renaming) позволяет обойти архитектурное
ограничение на возможность параллельного исполнения инструкций (доступно
всего восемь общих регистров). Процессоры с переименованием регистров фак-
тически имеют более восьми общих регистров, и при записи промежуточных ре-
зультатов устанавливается соответствие логических имен и физических регист-
ров. Таким образом, одновременно может исполняться несколько инструкций,
ссылающихся на одно и то же логическое имя регистра, если, конечно, между ними
нет фактических зависимостей по данным.
Продвижение данных (data forwarding) подразумевает начало исполнения инструк-
ции до готовности всех операндов. При этом выполняются все возможные дей-
ствия, и декодированная инструкция с одним операндом помещается в исполни-
тельное устройство, где дожидается готовности второго операнда, выходящего с
другого конвейера.
Предсказание переходов (branch prediction) позволяет продолжать выборку и де-
кодирование потока инструкций после выборки инструкции ветвления (условно-
го перехода), не дожидаясь проверки самого условия. В процессорах прежних по-
колений инструкция перехода приостанавливала конвейер (выборку инструкций)
до исполнения собственно перехода, па чем, естественно, терялась производитель-
ность. Предсказание переходов направляет поток выборки и декодирования по
одной из ветвей. Статический метод предсказания работает по схеме, заложенной
1.3. Архитектура, микроархитектура и поколения процессоров
37
в процессор, считая, что переходы по одним условиям, вероятнее всего, произой-
дут, а по другим — нет. Динамическое предсказание опирается на предысторию
вычислительного процесса — для каждого конкретного случая перехода накаплива-
ется статистика поведения, и переход предсказывается, основываясь именно на ней.
Исполнение по предположению, называемое также спекулятивным (speculative
execution), идет дальше — предсказанные после перехода инструкции не только
декодируются, но и по возможности исполняются до проверки условия перехода.
Если предсказание сбывается, то труд оказывается ненапрасным, если не сбыва-
ется — конвейер оказывается недогруженным и простаивает несколько тактов.
Исполнение с изменением последовательности инструкций (out-of-order execution),
свойственное RISC-архитектуре, теперь реализуется и для процессоров х86. При
этом изменяется порядок внутренних манипуляций данными, а внешние (шин-
ные) операции ввода-вывода и записи в память выполняются, конечно же, в по-
рядке, предписанном программным кодом. Однако эта способность процессора в
наибольшей степени может блокироваться несовершенством программного кода
(особенно 16-битных приложений), если он генерируется без учета возможности
изменения порядка.
Сейчас существует множество архитектур процессоров, которые делятся на две
глобальные категории — RISC и CISC.
♦ RISC — Reduced (Restricted) Instruction Set Computer — процессоры (компью-
теры) с сокращенной системой команд. Эти процессоры обычно имеют набор
однородных регистров универсального назначения, причем их число может
быть большим. Система команд отличается относительной простотой, коды
инструкций имеют четкую структуру, как правило, с фиксированной длиной.
В результате аппаратная реализация такой архитектуры позволяет с неболь-
шими затратами декодировать и выполнять эти инструкции за минимальное
(в пределе 1) число тактов синхронизации. Определенные преимущества дает
и унификация регистров.
♦ CISC — Complete Instruction Set Computer — процессоры (компьютеры) с пол-
ным набором инструкций, к которым относится и семейство х86. Состав и на-
значение их регистров существенно неоднородны, широкий набор команд ус-
ложняет декодирование инструкций, на что расходуются аппаратные ресурсы.
Возрастает число тактов, необходимое для выполнения инструкций.
Процессоры х86 имеют самую сложную в мире систему команд. Хорошо ли это,
вопрос спорный, но груз совместимости с программным обеспечением для IBM
PC, имеющим уже 20-летнюю историю, не позволяет расставаться с этим «насле-
дием тяжелого прошлого». В процессорах семейства х86, начиная с 486, применя-
ется комбинированная архитектура — CISC-процессор имеет RISC-ядро.
В настоящее время семейство х86 насчитывает 7 поколений процессоров.
Первое поколение (процессоры 8086 и 8088 и математический сопроцессор 8087)
задало архитектурную основу — набор неравноправных 16-разрядных регистров,
сегментную систему адресации памяти в пределах 1 Мбайт с большим разнообра-
38
1. Введение
зием режимов, систему команд, систему прерываний и некоторые другие черты.
В процессорах применялась «малая» конвейеризация — пока одни узлы выпол-
няли текущую инструкцию, блок предварительной выборки выбирал из памяти
следующую. На выполнение каждой инструкции уходило в среднем по 12 тактов
процессорного ядра.
Второе поколение (80286 с сопроцессором 80287) привнесло в семейство защи-
щенный режим, позволяющий задействовать виртуальную память размером до
1 Гбайт для каждой задачи, пользуясь адресуемой физической памятью в преде-
лах 16 Мбайт. Защищенный режим является основой для построения многозадач-
ных операционных систем (ОС), в которых система привилегий жестко регла-
ментирует взаимоотношения задач с памятью, ОС и друг с другом. Защищенный
режим 80286 не нашел массового применения — эти процессоры в основном ис-
пользовались как «очень» быстрые 8086. Их производительность повысилась не
только за счет роста тактовой частоты, но и за счет значительного усовершенство-
вания конвейера. Здесь на выполнение инструкции уходило в среднем по 4,5 так-
та. Во втором поколении появились новые инструкции: системные (для обслужи-
вания механизмов защищенного режима) и несколько прикладных (в том числе
для блочного ввода-вывода — основы программного обмена с портами РЮ). На-
личие защищенного режима не отменяет возможности работы в реальном режиме
8086, и эта возможность сохраняется во всех последующих поколениях (дань со-
вместимости с программным обеспечением, включая и MS-DOS).
Третье поколение (386/387 с суффиксами DX и SX, определяющими разрядность
внешней шины) ознаменовалось переходом к 32-разрядной архитектуре IA-32.
Кроме расширения диапазона непосредственно представляемых величин (16 бит
отображают целые числа в диапазоне 0-65 535 или от -32 767 до +32 767, 32
бита — более чем 4 миллиарда) увеличился и объем адресуемой памяти (до 4 Гбайт
реальной, 64 Тбайт виртуальной). Для этого почти все программно-доступные
регистры были расширены и получили в названии приставку «Е» (EAX, ЕВХ...).
В систему команд ввели возможность переключения разрядности адресации ц<
данных. Защищенный режим был несколько усовершенствован, но оставлена и об-
ратная совместимость с 286. На таком процессоре стала «расцветать» система MS
Windows — сначала оболочка, а потом и операционная система. В плане организа-
ции исполнения инструкций существенных изменений, повлекших за собой со-
кращение числа тактов на инструкцию, не произошло — те же средние 4,5 такта,
но частота уже достигла 40 МГц.
Четвертое поколение (486, опять-таки DX и SX) в видимую архитектурную мо-
дель больших изменений не внесло, но зато был принят ряд мер для повышения
производительности. В этих процессорах значительно усложнен исполнительный
конвейер — основные операции выполняет RISC-ядро, «задания» для которого
готовят из входных CISC-инструкций х86. Этот конвейер стал способным выда-
вать «на-гора» очередные инструкции в среднем за каждые два такта. Конечно,
каждая инструкция проходит через весь конвейер процессора за гораздо большее
количество тактов, но темп выполнения в потоке именно таков. Производитель-
ность конвейера процессора оторвалась от возможностей доставки инструкций и
1.3. Архитектура, микроархитектура и поколения процессоров
39
данных из оперативной памяти, и прямо в процессор ввели быстродействующий
первичный кэш объемом 8-16 Кбайт. В этом же поколении отказались от внеш-
него сопроцессора: теперь он размещается либо на одном кристалле с централь-
ным (называется FPU), либо его нет вообще. По сравнению с предыдущим поко-
лением и сопроцессор стал работать значительно эффективнее, а тактовая частота
в этом поколении достигла 133 МГц (у AMD, а у Intel — только 100).
Пятое поколение — процессор Pentium у Intel и К5 у AMD — привнесло суперска-
лярную архитектуру. Суперскалярность означает наличие более одного конвейе-
ра. У процессоров пятого поколения после блоков предварительной выборки и
первой стадии декодирования инструкций имеются два конвейера, U-конвейер и
V-конвейер. Каждый из этих конвейеров имеет ступени окончательного декоди-
рования, исполнения инструкций и буфер записи результатов. U-конвейер «уме-
ет» все, у V-конвейера возможности немного скромнее. Конвейеризирован и блок
FPU. Процессор с такой архитектурой может одновременно «выпускать» до двух
выполненных инструкций, но в среднем получается 1 такт на инструкцию. Не все
инструкции могут выполняться парно, эффективность использования конвейеров
(коэффициент их загрузки или простоя) зависит от программного кода — есть
широкие возможности оптимизации. В процессорах применяется блок предска-
зания ветвлений (инструкций программы, выполняемых после очередного услов-
ного перехода или вызова), в обязанности которого входит не оставлять конвейе-
ры без работы «на поворотах» алгоритмов. Для быстрого снабжения конвейеров
инструкциями и данными из памяти шина данных процессоров имеет разрядность
64 бит, из-за чего поначалу их даже ошибочно называли 64-разрядными процес-
сорами. На закате этого поколения появилось расширение ММХ, новизна кото-
рого заключается в принципе SIMD: одна инструкция выполняет действия сразу
над несколькими (2,4 или 8) комплектами операндов. В ММХ появился и новый
тип арифметики — с насыщением (saturated): если результат операции не умеща-
ется в разрядной сетке, то вместо переполнения (антипереполнения) устанавли-
вается максимально (минимально) возможное значение числа.
Шестое поколение процессоров Intel (микроархитектура Р6) началось с Pentium
Pro и продолжается по сей день в процессорах Pentium II, Pentium III, Celeron и
Xeon. Его лейтмотивом является динамическое исполнение, под которым понима-
ется исполнение инструкций не в том порядке (out of order), как это предполага-
ется программным кодом, а в том, как «удобно» процессору. Инструкции, посту-
пающие на конвейер, разбиваются на простейшие микрооперации p-ops (из-за
ограниченного набора символов в HTML и документах других форматов часто
встречается обозначение «uops»), которые далее выполняются суперскалярным
процессорным ядром в порядке, удобном процессору. Ядро процессора содержит
несколько конвейеров, к которым подключаются исполнительные устройства це-
лочисленных вычислений, обращений к памяти, предсказания переходов и вычис-
лений с плавающей точкой. Несколько различных исполнительных устройств
могут объединяться на одном конвейере. Результаты «беспорядочно» выполняе-
мых микроопераций собираются в переупорядочивающем буфере и в корректном
порядке записываются в память (и порты ввода-вывода). Чтобы можно было од-
40
1. Введение
повременно выполнять разные инструкции с одними и теми же программно-адре-
суемыми регистрами, внутри процессора выполняется аппаратное переименова-
ние регистров (их у процессора больше, чем доступных по программной модели).
Конечно, при этом учитывается и связь по данным, которая сковывает «беспоря-
дочные» параллельные исполнения, даже пользуясь дополнительными регистра-
ми. В процессорах 6-го поколения реализовано исполнение по предположению:
процессор пытается исполнить инструкцию, последующую (по его мнению) за
переходом еще до самого перехода. В итоге всех этих ухищрений среднее число
тактов на инструкцию у Pentium Pro сократилось до 0,5 такта. В систему команд
были введены новые инструкции, позволяющие писать более эффективные коды
(с точки зрения минимизации ветвлений).
Полтакта на инструкцию — звучит, конечно, странно. Но если вспомнить о 8-байт-
ной шине данных, позволяющей за один такт загрузить «кусок» кода, содержаще-
го несколько команд, и о нескольких исполнительных устройствах, одновременно
приступающих к их выполнению, то вопросы рассеиваются. Правда, вопрос дос-
тавки инструкций и данных из памяти к ядру процессора становится острым, и
один первичный кэш здесь не спасает. В то время как частоты ядра процессора (и
первичного кэша) неуклонно растут по мере усовершенствования технологий из-
готовления микросхем (чем тоньше, тем быстрее), частота системной шины, по
которой процессор обменивается данными с памятью, так быстро расти не может.
Здесь уже сильно сказываются паразитные параметры проводников и разъемов,
которые остаются относительно большими по размерам. Кроме того, и сама опе-
ративная память не такая уж быстрая. Проблему доставки «сырья» для работы
процессоров 6-го поколения фирма Intel стала решать, используя так называемую
двойную независимую шину (DIB). Одна из шин процессора, «фасадная» (FSB —
Front Side Bus), связывает его с системной платой, на которой находится и опера-
тивная память. Другая шина связывает процессор с вторичным кэшем, который
находится в одной упаковке с процессором (для пользователя вторичный кэш
неотделим от процессора). Частота FSB долгое время оставалась в пределах 66 МГц,
что обеспечивало пиковую пропускную способность 528 Мбайт/с. Лишь совсем
недавно эта частота поднялась до 100 и даже 133 МГц. А вот тактовая частота вто-
рой шины пропорциональна частоте ядра — либо полная частота, либо ее полови-
на. Пиковую пропускную способность этой шины можно оценить, умножив ее
тактовую частоту на 8 — число байт данных на шине (у новых процессоров
Pentium III разрядность этой шины уже 32 байта). Первое время в рекламных це-
лях даже предлагалось складывать пропускные способности этих шин — получа-
ются внушительные цифры (позже эти арифметические упражнения исчезли из
статей). Не надо забывать, что вторичный кэш все-таки только отображает некото-
рые области основной памяти, а связаться с ней он может только через системную
шину процессора (FSB). Наличие двойной независимой шины у Intel является
одним из атрибутов шестого поколения. Системная шина при этом имеет прото-
кол, принципиально отличающийся от протокола шины процессоров Pentium.
Фирма AMD в своих процессорах шестого поколения (Кб) реализовала «беспо-
рядочное исполнение», но двойную независимую шину применять не стала. Вме-
1.3. Архитектура, микроархитектура и поколения процессоров
41
сто этого была увеличена тактовая частота той же шины, которая использовалась
в Pentium — весьма эффективной в однопроцессорных конфигурациях. Двойная
шина (но без торжественного объявления) появилась лишь в процессорах K6-IIL
Благодаря такому решению сокет-7 (Super?) пережил целых два поколения про-
цессоров. По микроархитектуре (способу реализации «беспорядочного исполне-
ния») процессоры Кб заметно отличаются от своих «1п1еГовских собратьев».
Как пятое поколение по ходу развития было «сдобрено» расширением ММХ (це-
лочисленное), так шестое поколение получило расширение 3DNow! (AMD) и SSE
(Intel). Однако в отличие от единого ММХ эти два расширения не эквивалентны.
У них общая идея «потоковой» направленности и реализации SIMD для чисел с
плавающей точкой (см. п. 3.3). Поток в данном контексте подразумевает, что с его
данными должны выполняться однотипные операции. Кроме того, данные, уже
прошедшие обработку, в дальнейшем этим вычислительным процессом исполь-
зоваться не будут и ими не следует засорять кэш. Теперь появились инструкции
загрузки данных в кэш, а также записи в память, минуя кэш. Прежде такого явно-
го управления кэшированием не было.
Микроархитектура Р6 честно отработала на ряде моделей процессоров, начиная с
Pentium Pro (1995 г., 0,6 мкм, 150 МГц) и до Pentium III (2000 г., 0,18 мкм, 1 ГГц).
На частоте выше 1 ГГц она «сломалась», и Pentium III-1,13 ГГц был отозван из
продажи из-за нестабильности работы. У предыдущего поколения «живучести»
было меньше — первый Pentium имел частоту 60 МГц (1993 г.), последний — толь-
ко 233 (1997 г.), хотя, возможно, здесь кроме технических аспектов сильно влияют
и маркетинговые соображения.
Седьмое поколение (по AMD) началось с процессора Athlon (см. п. 11.2). Причис-
ление его к новому поколению мотивировано развитием суперскалярности и су-
перконвейерности, которая теперь охватила и блок FPU (в прежних поколениях
FPU если и конвейеризировали, то не распараллеливали). Седьмое поколение
процессоров Intel началось годом позже с процессора Pentium 4, микроархитек-
туре которого посвящен следующий раздел. Pentium 4 стартовал с 1,4 ГГц (техно-
логия 0,18 мкм), каких частот он достигнет — покажет время.
Фирма Intel сейчас занимается 64-разрядпой архитектурой — такая разрядность
позволит считать целые числа с числом разрядов почти до 2 х 1019 (словарного
запаса, чтобы назвать такое число, авторам не хватило). Скоро должен выйти 64-
разрядный процессор Itanium, разрабатываемый под кодовым названием Merced.
Его архитектура — IА-64 — должна будет обеспечивать совместимость с существу-
ющим ПО для используемой ныне архитектуры IA-32.
В начале 2000 года фирма Transmeta заявила процессор Crusoe, который является
аппаратно-программным комплексом. Этот комплекс работает нетрадиционным
способом: инструкции х86 транслируются в длинные слова VLIW (Very Long
Instruction Word) регулярной структуры длиной 64 или 128 бит, которые исполня-
ются процессорным ядром. При этом оттранслированные инструкции хранятся в
кэш-памяти и при многократном исполнении транслируются лишь единожды.
Ядро процессора исполняет элементы кода в строгом порядке. С этим процессо-
ром уже могут работать ОС Windows 9x/NT/2000, Linux. Плавающее энергопот-
42
1. Введение
ребление составляет от 10-20 мВт до 1-3 Вт, в зависимости от выполняемой ра-
боты. Процессор имеет наилучшее отношение производительности к потреблению
и предназначается для мобильных систем.
Семейство х86 фирмы Intel началось с 16-разрядного процессора 8086. Все следу-
ющие модели процессоров, в том числе 32-разрядные (386,486, Pentium, Pentium
Pro, Pentium II, Celeron, Pentium III и Pentium 4) и с 64-разрядным расширением
MMX, включают в себя систему команд и программную модель предыдущих, обес-
печивая совместимость с ранее написанным ПО. Далее в тексте знак + означает,
что описание верно как для указанного процессора, так и для следующих за ним
процессоров. При этом 286 означает процессор 80286,386 — 80386,..., Р5 — Pentium,
Р6 — семейство процессоров 6-го поколения, включая Pentium Pro, Pentium II и
Celeron. Например, Р5+ означает применимость к процессорам Pentium, Pentium
ММХ, Pentium Pro, Pentium II, Celeron, Pentium III, Pentium 4.
1.4. NetBurst — микроархитектура
процессора Pentium 4
Рассмотрим микроархитектуру процессора Pentium 4, носящую торжественное
название NetBurst. Это название вызывает две ассоциации: Network (сеть) — рабо-
та с сетевыми приложениями и Burst (взрыв, вспышкА) — в компьютерной техни-
ке это быстрая обработка каких-либо пакетов. Расширение системы команд и из-
менения микроархитектуры, пришедшие с новым процессором, ориентированы на
задачи, которые становятся посильными для обычных настольных компьютеров:
♦ потоковые приложения, включая обработку видеоинформации в реальном вре-
мени — как декодирование сжатой информации, так и более сложные задачи
кодирования;
♦ редактирование видеоизображений;
♦ трехмерная визуализация;
♦ обработка видеосигнала в качестве источника данных;
♦ связь с телевидением высокой четкости (HDTV);
♦ распознавание речи;
♦ Интернет-телефония.
Процессор Pentium 4 имеет конвейер, состоящий, как и у Р6, из трех частей:
♦ устройство предварительной обработки инструкций в порядке их следования
в программном коде (in order front end), результатом его работы является по-
следовательность микроопераций;
♦ исполнительное ядро, исполняющее микрооперации в удобном для него поряд-
ке (out of order execution core);
♦ блок упорядоченного завершения (in-order retirement unit), отражающий ре-
зультаты выполнения микроопераций в изменениях состояния архитектурных
регистров и внешней памяти и портов.
1,4. NetBurst — микроархитектура процессора Pentium 4
43
В процессоре Pentium 4 применена так называемая гиперконвейерная архитекту-
ра: конвейер, по которому проходят инструкции от момента считывания кода
инструкции из памяти до ее завершения, состоит из очень большого числа ступе-
ней. Гиперконвейер Pentium 4 состоит из 20 ступеней; для сравнения — суперкон-
вейер процессоров Р6 имеет 10 ступеней (или 12, смотря как считать), а конвейер
Pentium — всего 5. Здесь «супер» и «гипер» — определения, применяемые фирмой
Intel. Общая задача для конвейера любого процессора х86 одна и та же, правда,
новые инструкции требуют более сложных действий по их выполнению. Удлине-
ние конвейера позволяет упростить задачи, выполняемые каждой его ступенью
ради упрощения аппаратной логики ступеней. Упрощенная логика может рабо-
тать быстрее — более короткая цепочка логических вентилей вносит меньшие
задержки распространения сигнала. Это позволяет уменьшить период тактовых
импульсов, то есть повысить частоту ядра.
Поскольку продвижение инструкций по ступеням конвейера синхронизируется
внутренним тактовым сигналом процессора, сокращение задержки на каждой сту-
пени позволяет повысить тактовую частоту. Тактовая частота определяет темп
схода инструкций с конвейера, то есть максимальную производительность про-
цессора, выражаемую в миллионах выполненных инструкций в секунду. Макси-
мальной производительности процессор достигает, когда его конвейер полностью
загружен. При этом единичная инструкция выполняется не так уж и быстро — ей
нужно «прошагать» по всем ступеням конвейера, и чем он будет длиннее, тем доль-
ше (в числе тактов) будет это путешествие. Однако если удлинение конвейера
позволяет увеличить тактовую частоту, то время прохождения конвейера может
и не увеличиться.
Для того чтобы конвейер не простаивал, еще с процессоров Р6 начали применять
спекулятивное исполнение и изменение порядка выполнения инструкций. Блок
выборки и декодирования инструкций «вбрасывает» на конвейер как можно боль-
ше инструкций, устремляясь вперед, по программе. Микрооперации, на которые
были разобраны инструкции х86, складываются на станции резервирования, от-
куда их по мере возможностей выхватывает «беспорядочное» исполнительное
ядро. На линейных участках программного кода (там, где нет ветвлений) такой
способ работы с хорошей загруженностью конвейера дает высокую производи-
тельность. Когда в программе встречаются ветвления (условные переходы), начи-
нается спекулятивное исполнение инструкций (оно же исполнение по предполо-
жению). Блок предсказания ветвлений выбирает (по своим критериям) ветвь,
инструкции которой посылаются на декодирование, и продолжается интенсивная
работа конвейера до фактического исполнения самого перехода. Если ветвь была
предсказана правильно, то работа конвейера продолжается. Ошибочно предска-
занный переход обходится дорого: все, что было декодировано и исполнено пос-
ле инструкции ветвления, идет насмарку, и в конвейер запускается инструкция,
с которой начинается действительно требуемая ветвь. То есть спекуляция не уда-
лась, «припасенный товар» приходится выбрасывать и снова тратить время на
прохождение инструкции по всему конвейеру (а он длинный!). Из этих рассужде-
ний следует два вывода: надо точнее предсказывать ветвления (к сожалению, пой-
44
1. Введение
тти по двум ветвям сразу процессоры пока не могут) и сокращать потери времени,
связанные с неизбежными ошибками предсказаний. Именно эти меры и приняты
в процессоре Pentium 4.
Блок-схема микроархитектуры NetBurst приведена на рис. 1.1. На ней толстыми
линиями выделены наиболее интенсивно используемые пути.
Рис. 1.1. Блок-схема процессора Pentium 4
Первое, что бросается в глаза, — отсутствие первичного кэша инструкций, в кото-
ром у прежних процессоров хранились копии фрагментов ОЗУ и вторичного кэша,
содержащие ранее исполненные инструкции и следующие за ними строки. Вмес-
то него теперь имеется кэш трасс исполнения ТС (Execution Trace Cache), в кото-
ром хранятся трассы. Трассами называют последовательности микроопераций,
в которые были декодированы инструкции х86. Кэш трасс совместно с блоком вы-
борки и декодирования образует устройство предварительной обработки, выпол-
няющее следующие функции:
♦ предварительную выборку инструкций, которые предполагается исполнить;
♦ декодирование инструкции в микрооперации;
♦ генерацию микрокодов для сложных инструкций;
♦ доставку декодированных инструкций из кэша трассы;
♦ предсказание переходов, используя «продвинутый» алгоритм.
В этом устройстве микроархитектура NetBurst позволяет сократить задержки,
вызванные декодированием инструкций с Целевого адреса, указанного в перехо-
де, а также потери производительности декодеров в случаях, когда точка перехода
или целевой адрес находятся в середине строки кэша. Последовательность мик-
роопераций хранится в кэше трассы в порядке потока исполнения, в результате
чего микрооперации, соответствующие инструкции целевого адреса, будут рас-
полагаться за микрооперациями инструкции ветвления даже в одной строке
1.4. NetBurst — микроархитектура процессора Pentium 4
45
кэша. В прежних процессорах они оказывались в разных строках кэша, что очень
невыгодно с точки зрения скорости обмена с кэш-памятыо, оптимизированной для
передач целыми строками. Кроме того, память кэша трассы используется эффек-
тивнее, чем в обычном первичном кэше инструкций — в ТС не попадают инструк-
ции, которые никогда не будут исполняться. Кэш трассы способен хранить до 12 К
микроопераций и за каждый такт доставлять ядру до трех микроопераций.
Кэш трасс и транслирующий механизм кооперируются с аппаратурой предсказа-
ния ветвлений. Целевые адреса ветвлений предсказываются по своим линейным
адресам. Если целевая инструкция уже имеется в кэше трасс, то ее готовая после-
довательность микроопераций берется из ТС. Если ее в кэше нет, то приходится
инструкцию выбирать из иерархии памяти — вторичного кэша (на кристалле про-
цессора) или ОЗУ — и декодировать.
Для предсказания ветвлений используется комбинация статических и динамичес-
ких методов, а также прямые указания программного рода. Статическое предска-
зание исходит из того, что условные переходы назад, ^скорее всего, сбудутся (это
типовой цикл), а условные переходы вперед не сбудутся (это свойство следует
учитывать при написании циклических участков программ). Статическое пред-
сказание требуется для тех инструкций перехода, линейный адрес которых отсут-
ствует в буфере ВТВ, используемом для динамического предсказания. В буфере
ВТВ накапливается статистика прохождения данных инструкций, по которой и
принимается решение о том, какую ветвь прорабатывать конвейеру. Эта стати-
стика обновляется, когда инструкция перехода выходит из блока завершения.
По сравнению с Р6 размер буфера ВТВ увеличен в 8 раз (теперь он хранит до 4 К
адресов инструкций ветвлений). И наконец, в Pentium 4 процессору можно про-
граммно «намекнуть», будет переход или нет. Для этого введена пара новых пре-
фиксов (branch hints), которые можно ставить перед командами условных перехо-
дов (3Eh, если переход, скорее всего, будет, и 2Eh, если нет). Правда в руководстве
по оптимизации туманно говорится о том, что не всякий процессор поймет этот
намек на всех инструкциях ветвлений, но хуже не будет (предыдущие процессоры
эти коды игнорируют). «Намеки» используются только на этапе построения трасс,
и если в ВТВ данной инструкции еще нет, они перекрывают статическое предска-
зание.
Исполнительное ядро имеет пиковую пропускную способность, превышающую
возможности блока предварительной обработки и блока завершения. Диспетчер
способен за один такт запустить в разные исполнительные блоки до 6 микроопе-
раций. Большинство исполнительных блоков способно начинать исполнение но-
вой инструкции каждый такт. Ряд блоков АЛУ могут начинать и по две инструк-
ции за такт (они их исполняют за полтакта). Многие инструкции FPU могут
стартовать через каждые два такта. Микрооперации могут стартовать, как только
для них появляются входные данные и находятся доступные ресурсы.
По сравнению с Р6 исполнительное ядро стало более производительным по
количеству тактов, требуемых для исполнения микроинструкций. С учетом ро-
ста и самой тактовой частоты повышение производительности получается су-
щественным.
46
1. Введение
Блок завершения работает практически так же, как и в Р6. Он позволяет за каждый
такт завершать до трех микроопераций.
О системе кэширования и интерфейсе системной шины Pentium подробнее гово-
рится в п. 9.2. В руководстве по оптимизации упоминается и кэш 3-го уровня, ко-
торый, возможно, появится у серверных вариантов процессора.
Как видно, микроархитектура NetBurst будет иметь максимальную производи-
тельность исполнения предсказуемых (линейных и циклических) участков про-
грамм, характерных для приложений, на которые и ориентирован новый процес-
сор (см. выше). На непредсказуемо ветвящихся программах, к которым относятся,
например, офисные приложения, длинный гиперконвейер оказывается менее эф-
фективным, чем конвейер Р6, если бы его удалось разогнать до частот 1,4 ГГц и
выше. Но утешают две вещи — изначально высокая частота Pentium 4 и отсутствие
потребности в «сумасшедшей» производительности для офисных приложений,
в работе которых «участвует» пользователь, гораздо более медлительный по своей
человеческой природе. Но, возможно, разработчики офисных приложений най-
дут способ загрузить и гигагерцовые процессоры (автор пробовал для профессио-
нальной работы запускать Word 2000 на простом Pentium — темперамент заста-
вил вернуться к более «легкому» Word 7).
Кэширование трасс, а не инструкций х86 напоминает о процессоре Crusoe фирмы
Transmeta, о котором было объявлено в начале 2000 года (см. выше) — идеи похожие.
2. Программная модель
32-разрядных процессоров
История 32-разрядных процессоров Intel началась с процессора Intel386. Он воб-
рал в себя все черты своих 16-разрядных предшественников 8086/88 и 80286 для
обеспечения совместимости с громадным объемом ПО, существовавшего на мо-
мент его появления. Однако в процессорах 80386 преодолено жесткое ограниче-
ние на длину непрерывного сегмента памяти — 64 Кбайт. В защищенном режиме
32-разрядных процессоров оно отодвинулось до 4 Гбайт — предела физически
адресуемой памяти, что тогда можно было считать почти «бесконечностью». Эти
процессоры имеют поддержку виртуальной памяти объемом до 64 Тбайт, встро-
енный блок управления памятью поддерживает механизмы сегментации и стра-
ничной трансляции адресов (paging). Процессоры обеспечивают четырехуровне-
вую систему защиты пространств памяти и ввода-вывода, а также переключение
задач. Система команд расширена при сохранении всех команд 8086,80286. Про-
цессор может работать в одном из двух режимов и переключаться между ними
достаточно быстро как в ту, так и в другую сторону:
Real Address Mode — режим реальной адресации (или просто реальный режим —
Real Mode), полностью совместим с 8086. В этом режиме возможна адресация
до 1 Мбайт физической памяти (на самом деле, как и у 80286, почти на 64 Кбайт
больше).
Protected Virtual Address Mode — защищенный режим виртуальной адресации (или
просто защищенный режим — Protected Mode). В этом режиме процессор позво-
ляет адресовать до 4 Гбайт физической памяти, через которые при использовании
механизма страничной адресации могут отображаться до 64 Тбайт виртуальной
памяти каждой задачи.
Существенным дополнением является Virtual 8086 Mode — режим виртуального
процессора 8086. Этот режим является особым состоянием задачи защищенного
режима, в котором процессор функционирует как 8086. На одном процессоре в
таком режиме может параллельно исполняться несколько задач с изолированны-
ми друг от друга ресурсами. При этом использование физического адресного про-
странства памяти управляется механизмами сегментации и трансляции страниц.
Попытки выполнения недопустимых команд, выхода за рамки отведенного про-
странства памяти и разрешенной области ввода-вывода контролируются системой
защиты.
«Неофициальный» режим Big Real Mode, он же Unreal Mode, который поддерживают
все 32-разрядные процессоры, позволяет адресоваться ко всему 4-гигабайтному
48
2. Программная модель 32-разрядных процессоров
пространству памяти. В этом режиме инструкции исполняются так же, как и в ре-
альном режиме, но с помощью дополнительных сегментных регистров FS и GS про-
граммы получают непосредственный доступ к данным во всей физической памяти.
Процессоры, начиная с Pentium и некоторых моделей 486, поддерживают также
особый режим системного управления System Management Mode (SMM), при кото-
ром процессор выходит в иное, изолированное от остальных режимов простран-
ство памяти. Этот режим используется в служебных и отладочных целях.
Переходы процессора между режимами иллюстрирует рис. 2.1.
Рис. 2.1. Граф переходов между режимами процессора
Процессоры могут оперировать с 8-, 16- и 32-битными операндами, строками байт,
слов и двойных слов, а также с битами, битовыми полями и строками бит.
В архитектуру процессоров введены средства отладки и тестирования.
В этой главе мы рассмотрим базовую программную модель, общую для всех су-
ществующих на данный момент 32-разрядных процессоров х86. Эта модель
охватывает набор регистров процессора, организацию памяти и ввода-вывода,
типы данных, систему команд, прерывания и исключения. Работе процессора в
защищенном режиме (сегментации, защите, страничной переадресации) посвяще-
на глава 5.
2.1. Типы данных
Рассматриваемые процессоры непосредственно поддерживают (используют в ка-
честве операндов) знаковые и беззнаковые целые числа, строки байт, цифр и сим-
волов, битовые строки, указатели и числа с плавающей точкой. В семействе х86
принято, что слова записываются в двух смежных байтах памяти, начиная с млад-
шего. Адресом слова является адрес его младшего байта. Двойные слова записыва-
ются в четырех смежных байтах, опять-таки начиная с младшего байта, адрес ко-
торого и является адресом двойного слова. Этот порядок называется Little-Endian
2.1. Типы данных
49
Memory Format. В других семействах процессоров применяют и обратный поря-
док — Big-Endian Memory Format, в котором адресом слова (двойного слова) яв-
ляется адрес его старшего байта, а младшие байты располагаются в последующих
адресах. Для взаимного преобразования форматов слова имеется инструкция XCHG,
двойного слова — BSWAP (486+).
На рис. 2.2 приведены форматы данных, обрабатываемых целочисленным блоком
АЛУ всех 32-разрядных процессоров.
♦ Бит (Bit) — единица информации. Бит в памяти задается базой (адресом сло-
ва) и смещением (номером бита в слове).
♦ Битовое поле (Bit Field) — группа до 32 смежных бит, располагающихся не
более чем в 4 байтах.
♦ Битовая строка (Bit String) — набор смежных бит длиной до 4 Гбит.
♦ Байт (Byte) — 8 бит.
♦ Числа без знака', байт/слово/двойное/учетверенное слово (Unsigned Byte/
Word/Double Word/Quade Word), 8/16/32/64 бит.
♦ Целые числа со знаком: байт/слово/двойное/учетверенное слово (Integer Byte/
Word/Double Word/Quade Word). Единичное значение самого старшего бита
(знак) является признаком отрицательного числа, которое хранится в допол-
нительном коде.
♦ Двоично-десятичные числа (BCD — Binary Coded Decimal):
• 8-разрядные упакованные (Packed BCD), содержащие два десятичных раз-
ряда в одном байте;
• 8-разрядные неупакованные (Unpacked BCD), содержащие один десятич-
ный разряд в байте (значение бит 7:4 при сложении и вычитании несуще-
ственно, при умножении и делении они должны быть нулевыми).
♦ Строки байт, слов и двойных слов (Bit String, Byte String, Word String, Double
Word String) длиной до 4 Гбайт.
♦ Указатели:
• длинный указатель (48 бит) — 16-битный селектор (или сегмент) и 32-бит-
ное смещение;
• короткий указатель — 32-битное смещение;
• просто указатель (32 бит, единственный тип указателя для 8086 и 80286) —
16-битный селектор (или сегмент) и 16-битное смещение.
16-разрядные процессоры из приведенных типов данных не поддерживают учет-
веренные слова всех типов, битовые поля и строки, строки двойных слов, корот-
кие и длинные указатели.
Числа в формате с плавающей точкой и упакованные 80-битные BCD-числа об-
рабатываются блоками FPU процессоров класса 486 и выше, а также сопроцессо-
рами 8087/287/387. Упакованные 64-битные и 128-битные данные обрабатыва-
ются процессорами с ММХ и SSE. Форматы данных, обрабатываемых блоками
FPU/ММХ и ХММ, представлены на рис. 2.3.
50
2. Программная модель 32-разрядных процессоров
1 0 7 0 +N 7 0 1 +1 0 7 07 0
Байт со знаком II |ll 1 Байт iiipii Строка без знака байт 1111111 • • • 1111111 1111111
Знак - 15 Слово со знаком +1 0 14 8 7 0 +2*N 15 0 1 +2 0 15 015 0
111111 1111111 Строка слов 1111111 • • • lllllll lllllll
Знак “ J MSB LSB I5 +1 8 7 ° 0 +4*N 31 0 +4 0 31 0 31 0
Слово без знака 1111111 1111111 Строка двойных слов lllllll • • • lllllll lllllll
Двойное с MSB и +3 LSB +21615 ° 0 Двойное 31 +3 +216 15 +1 ° 0
слово со знаком 111111 111111 1 111111 1111111 слово без знака 11||||| llljlll 1 1111111 11Г| in
Знак-1 MSB LSB MSB LSB
Учетверенное^ +6 +5 +д +3 +2 0
со знаком 63 4847 3231 1615--°
Знак-1 L
MSB
LSB
Указатель
Длинный
48-битный
указатель
Упакованное
BCD-число
7 4 3 О
"1—FT" 1 Г 1
Старшая Младшая
цифра цифра
+3 +2 +1 О
31_______________________________О
1 Г1[111 111111111111111 111 [If 1
I_____________________________________________________________L
SELECTOR OFFSET
Учетверенное
слово +7 +6 +5 +4 +3 +2 +1 О
знака 63 4847 3231 1615 °
MSB LSB
7 4 3 О
Неупакованное
BCD-число
+3
31
1 1 1 xxxx 1 1 1
Цифра
+2 +1 О
„ - 0
Короткий 11111111ГГ Г111 11 Г | ГГ11111'11
32-битный Illi
указатель ...—
OFFSET
+5 +4 +3 +2 +1 О
47 О
ттгртт 1111111 1111111 1111111 1111111 111| 111
I_____________I___________________________I
SELECTOR OFFSET
А+268435455
А-268435456
Битовая строка
BIT О
Битовое поле
1111111 II11111 1111111 1111111 1111111 irqrrr
!◄—Поле длиной от 1 до 32 бит—► |
Рис. 2.2. Типы данных, обрабатываемых целочисленным АЛУ
2.1. Типы данных
51
Число подразумевается «1»
с плавающей точкой
повышенной точности
79 78 64 63 62 О
Порядок Мантисса (дробная часть)
L Знак L Целая часть
Упакованное двоично-десятичное целое число
79 78 72 71 68 67 64 63
43 О
XXX BCD17 BCD16 BCD0
*-Знак
Упакованные байты (для ММХ)
63 56 55 48 47 40 39 32 31 24 23 16 15 8 7 0
Число 7 Число 6 Число 5 Число 4 Число 3 Число 2 Число 1 Число 0
Упакованные слова (для ММХ)
63____________________48 47______________32 31_____________16 15_______________0
Число 3 Число 2 Число 1 Число 0
Упакованные двойные слова (для ММХ)
63_______________________________________32 31________________________________0
Число 2 Число 0
Учетверенное слово (для ММХ)
63 0
Число
Упакованные числа с плавающей точкой одинарной точности (для ХММ)
127___________________96 95______________64 63_____________32 31 23 22 0
Порядок Мантисса Порядок Мантисса Порядок Мантисса Порядок Мантисса
^Знак lJ-6ht=1 *-ЗнакlJ-6ht=1 l3h3klJ-6ht=1 *-Знак lJ-6ht=1
Число 3 Число 2 Число 1 Число 0
Рис. 2.3. Типы данных, обрабатываемых блоками FPU/ММХ и ХММ
52
2. Программная модель 32-разрядных процессоров
♦ Действительные числа в формате с плавающей точкой'.
• одинарной точности (Single Precision), 32 бит — 23 бит мантисса, 8 бит по-
рядок;
• двойной точности (Double Precision), 64 бит — 52 бит мантисса, И бит по-
рядок;
• повышенной точности (Extended Precision), 80 бит — 64 бит мантисса, 15 бит
порядок.
♦ Двоично-десятичные 80-битные упакованные числа (18 десятичных разрядов
и знак).
♦ Упакованные действительные числа одинарной точности в формате с плаваю-
щей точкой, обрабатываются блоком ХММ.
♦ Упакованные целые числа, знаковые и беззнаковые, обрабатываются блоком
ММХ:
• упакованные байты (Packed byte) — восемь байт;
• упакованные слова (Packed word) — четыре слова;
• упакованные двойные слова (Packed doubleword) — два двойных слова;
• учетверенное слово (Quadword) -- одно слово.
Для 16-разрядных процессоров, естественно, все форматы чисел для блоков ММХ
и ХММ недоступны.
2.2. Регистры процессора
Процессоры х86 имеют регистры, подразделяющиеся на следующие категории:
♦ регистры общего назначения;
♦ указатель инструкций;
♦ регистр флагов;
♦ регистры сегментов;
♦ системные адресные регистры;
♦ управляющие регистры;
♦ регистры отладки;
♦ регистры тестирования;
♦ модельно-специфические (зависящие от конкретной модели процессора) ре-
гистры.
Основные регистры процессора архитектуры IA-32, с которыми работают при-
кладные программы, показаны на рис. 2.4. Эти регистры относятся к видимой для
прикладных программ части архитектуры х86 и представляют собой расширение
набора регистров 16-разрядных процессоров 8086/8088 и 80286. Расширения
выделены серым цветом.
2.2. Регистры процессора
53
Общие регистры данных и адресов
31 16 15 О
АН АХ AL
- 'V/sA ВН ВХ BL
СН СХ CL
„ ' г ч DH DX DL
А SI
DI
ВР
SP
ЕАХ
ЕВХ
ЕСХ
EDX
ESI
EDI
EBP
ESP
Регистры сегментов
Указатель инструкций и регистр флагов
31 1615 О
IP
FLAGS
EIP
EFLAGS
Рис. 2.4. Основные регистры 32-разрядных процессоров
У 16-разрядных процессоров регистры общего назначения АХ, ВХ, СХ, DX состоят из
двух 8-битных половинок, к которым можно независимо обращаться по символи-
ческим именам АН, ВН, CH, DH (старшие байты — High) и AL, BL, CL, DL (младшие бай-
ты — Low). Регистры-указатели SP (Stack Pointer — указатель стека), BP (Base
Pointer — базовый регистр) и индексные регистры SI (Source Index — индекс ис-
точника), DI (Destination Index — индекс назначения) допускают только 16-бит-
ное обращение. Адрес текущей инструкции хранится в 16-битиом указателе ко-
манд IP (Instruction Pointer). Регистры в командах могут адресоваться явно. В ряде
команд подразумевается неявное использование регистров:
♦ АХ — умножение, деление, ввод и вывод слова;
♦ AL — умножение, деление, ввод и вывод байта; десятичная арифметика, транс-
ляция (XLAT);
♦ АН — умножение и деление байта;
♦ ВХ — трансляция;
♦ СХ — счетчик циклов и указатель длины строковых операций;
♦ CL — сдвиги с указанием переменной;
♦ DX — умножение и деление слова, ввод и вывод с косвенной адресацией;
♦ SP — операции со стеком;
♦ SI, DI — строковые операции.
В процессорах IА-32 все эти регистры расширены до 32 бит и к прежнему обозна-
чению их имен добавилась приставка Е (Extended — расширенный). Отсутствие
приставки в имени означает ссылку на младшие 16 бит расширенных регистров.
Существуют понятия разрядности адреса и данных. Разрядность адреса определя-
ет, сколько бит (16 или 32) используется в регистрах, формирующих адрес дан-
ных или инструкций, расположенных в памяти. Разрядность данных определяет,
сколько бит (16 или 32) используется в инструкциях, оперирующих словами (ин-
54
2. Программная модель 32-разрядных процессоров
струкции с байтами всегда оперируют с 8 битами). В реальном режиме по умолча-
нию разрядность адреса и данных — 16 бит. В защищенном режиме разрядность
адреса и данных по умолчанию определяется дескриптором кодового сегмента.
Инструкции, которые прежде адресовались к 16-разрядным регистрам, теперь могут
адресоваться и к 32-разрядным расширенным при том же коде операции. Что имен-
но подразумевается в данный момент, определяется текущим значением разряд-
ности слова операнда по умолчанию (16 или 32 бит) и может быть изменено на
противоположное значение с помощью префикса SIZ. Как и в 8086, возможно не-
зависимое обращение к младшему и старшему байтам регистров АХ, ВХ, СХ и DX.
Указатель инструкций EIP содержит смещение следующей исполняемой инструк-
ции относительно базы сегмента кода. При 16-битной адресации используются
только младшие 16 бит (IP).
Регистр флагов EFLAGS является расширением регистра FLAGS до 32 бит (рис. 2.5).
Биты 0—15, определенные для 8086 и 80286, имеют прежнее назначение. Флаги
состояния OF, SF, ZF, AF, PF и CF хранят признаки результатов выполнения арифме-
тических и логических операций над операндами, расположенными в регистрах
общего назначения и в памяти (исполнение инструкций блоками FPU, ММХ и
ХММ держится особняком). Операции пересылки данных на флаги состояния вли-
яния не оказывают. Значение этих флагов анализируется при исполнении услов-
ных инструкций. Кроме флагов состояния в регистре имеются управляющие и си-
стемные флаги, влияющие на поведение процессора, в том числе на обработку
маскируемых аппаратных прерываний (IF) и на направление движения в строко-
вых операциях (DF). По сравнению с 80286, появились биты VM и RF, ряд флагов
добавился с появлением процессоров 4-го и 5-го поколений. Содержимое регист-
ра флагов (FLAGS или EFLAGS) может быть сохранено в стеке и восстановлено из него,
но ряд системных флагов в защищенном режиме управляем и наблюдаем не на всех
уровнях привилегий (см. главу 5). Флаги состояния могут быть скопированы в
регистр АН и, наоборот, загружены из него. Кроме того, флаги состояния могут быть
загружены из блока FPU, и тогда результаты выполнения инструкций в FPU мбж-
но использовать в условных инструкциях.
31 15 8 0
0 0 0 0 0 0 0 0 0 0 I D X V I Р X V I F X А С X V М X R F X 0 N Т X I IOPL X | X О F S D F с I F X Т F X S F S Z F S 0 А F S 0 Р F S 1 С F S
Рис. 2.5. Регистр флагов EFLAGS (X — системный флаг,
S — флаг состояния, С — управляющий флаг)
Назначение бит регистра EFLAGS описано ниже.
♦ ID (Id Flag) — флаг доступности команды идентификации CPUID (Р5+ и некото-
рые 486).
♦ VIP (Virtual Interrupt Pending) — виртуальный запрос прерывания (Р5+). '
♦ VIF (Virtual Interrupt Flag) — виртуальная версия флага IF (разрешения пре-
рывания) для многозадачных систем (Р5+).
2.2. Регистры процессора
55
♦ AC (Alignment Check) — флаг контроля выравнивания. При исполнении про-
грамм с уровнем привилегий 3 в случае обращения к операнду, который не
выровнен по соответствующей границе (2, 4, 8 байт), и при установленном
флаге АС произойдет исключение #АС с нулевым кодом ошибки (о мнемониках
исключений см. и. 2.5). На уровнях привилегий 0,1,2 контроль выравнивания
не производится (486+).
♦ VM (Virtual 8086 Mode) — в защищенном режиме включает режим виртуально-
го процессора 8086. Попытка использования привилегированных инструкций
в этом режиме вызовет исключение #GP. Бит может устанавливаться только в
защищенном режиме: инструкцией IRET на нулевом уровне привилегий или
переключением задач на любом уровне привилегий. На бит не действует инст-
рукция POPF, а инструкция PUSHF в этот бит всегда заносит 0. Его единичное зна-
чение может сохраниться только в образе EFLAGS, сохраняемом при прерыва-
нии, переключении задач или переходе в режим SMM.
♦ RF (Resume Flag) — флаг возобновления, используется совместно с регистрами
точек останова.
♦ IOPL (Input/Output Privilege Level) — уровень привилегий ввода-вывода.
♦ NT (\ <ed Task Flag) — флаг вложенной задачи.
♦ OF (Overflow Flag) — флаг переполнения. Устанавливается, если результат
арифметической операции не умещается в операнде назначения.
♦ DF (Direction Flag) — флаг управления направлением в строковых операциях.
При единичном значении индексные регистры, участвующие в строковых опе-
рациях, автоматически декрементируются на количество байт операнда, при
нулевом — инкрементируются. Флаг управляется программно, инструкциями
CLD и STD.
♦ IF (Interrrupt-enable Flag) — флаг управления прерываниями. При единичном
значении разрешается выполнение маскируемых аппаратных прерываний. На
этот флаг можно воздействовать программно, явными инструкциями (CLI и STI)
и неявными инструкциями восстановления регистра флагов; процессор ма-
нипулирует флагом и автоматически, при обработке прерываний (см. п. 2.5).
В защищенном режиме появляются дополнительные тонкости (см. п. 5.7).
♦ TF (Trap Flag) — флаг трассировки (пошагового режима). При его установке
после выполнения каждой команды вызывается внутреннее прерывание типа 1
(INT 1).
♦ SF (Sign Flag) — флаг знака. Указывает на единичное значение старшего бита
результата — признак отрицательного числа.
♦ ZF (Zero Flag) — флаг нулевого результата.
♦ AF (Auxiliary Flag) — флаг дополнительного переноса (заема) в тетраде для де-
сятичной арифметики.
♦ PF (Parity Flag) — флаг паритета, устанавливается при четном числе единиц
результата.
56
2. Программная модель 32-разрядных процессоров
♦ CF (Carry Flag) — флаг переноса (заема) старшего бита в арифметических опера-
циях. Этот флаг может быть программно установлен или сброшен специальны-
ми инструкциями (STC, CLC, СМС), благодаря этому свойству его широко использу-
ют для сигнализации условия завершения процедур (например, сигнализации
об ошибках).
Регистры сегментов содержат 16-битные указатели (в реальном режиме) или се-
лекторы дескрипторов (в защищенном режиме) сегментов CS (Code Segment — сег-
мент кодов команд), SS (Stack Segment — сегмент стека), DS (Data Segment —
сегмент данных), ES, FS и GS — дополнительные сегменты данных. Сегментных реги-
стров FS и GS в 16-разрядных процессорах не было. Содержимое сегментных регист-
ров не может быть модифицировано (увеличено или уменьшено), они допускают
лишь загрузку и сохранение содержимого. Использование сегментных регистров
определяется типом обращения к памяти. Для многих типов обращений возможно
применение альтернативных сегментных регистров, которое вводится префиксами
команд CS:, SS:, DS:, ES: FS: или GS: (см. п. 2.3.2). С каждым из шести сегментных регист-
ров связаны программно-недоступные скрытые регистры дескрипторов (их еще на-
зывают Segment Descriptor Cache — кэш сегментных регистров), автоматически заг-
ружаемые при загрузке соответствующих сегментных регистров. В защищенном
режиме в регистры дескрипторов из таблицы дескрипторов загружается 32-битный
базовый адрес, 32-битный лимит (размер сегмента) и атрибуты сегментов. По со-
держимому этих скрытых регистров при каждом обращении к памяти выполняется
вычисление линейного адреса и проверка защиты, причем именно эти регистры
задают свойства сегментов как в защищенном, так и в реальном режимах. Образ
этих 96-битных регистров доступен в режиме SMM (см. п. 7.5) и внутрисхемной
эмуляции (ICE, см. п. 7.4), форматы специфичны для каждой модели (поколения)
процессоров. В реальном режиме, в который процессор входит по аппаратному
сбросу, лимит (размер сегмента) фиксирован — 64 Кбайт, атрибуты не использу-
ются, а в качестве базового адреса заносится значение сегментного регистра, сдви-
нутое на 4 бита влево. В защищенном режиме лимит может задаваться в пределах
1 байт-4 Гбайт. Нештатным переключением из защищенного в реальный режим
можно добиться и нестандартного размера сегментов (см. п. 5.9).
Кроме регистров общего назначения, предназначенных для использования при-
кладными программами, процессоры имеют ряд регистров системного назначения.
Этих регистров в процессорах 8086/88 не было, а в процессоре 80286 присутство-
вала лишь часть из них и не в полном объеме.
Управляющие регистры (Control Registers) CRO, CR1, CR2, CR3 хранят признаки состо-
яния процессора, общие для всех задач (рис. 2.6).
Регистр CRO обеспечивает общее управление режимами работы процессора. Назна-
чение бит регистра CRO представлено ниже.
♦ РЕ (Protection Enable) — разрешение защиты. Установка этого флага инструк-
цией LMSW или LOAD CRO переводит процессор в защищенный режим, возвраще-
ние в реальный режим (сброс флага) возможен только по инструкции LOAD CRO.
Сброс бита РЕ является частью довольно длинной последовательности инструк-
ций, подготавливающих корректное переключение в реальный режим.
2.2. Регистры процессора
57
Рис. 2.6. Управляющие регистры CR0-CR4
♦ MP (Monitor Processor Extension) — мониторинг сопроцессора. Установка MP = 1
позволяет вызывать исключение ММ по первой же ожидающей инструкции FPU
после переключения задач (при TS = 1) для сохранения и восстановления кон-
текста сопроцессора.
♦ ЕМ (Processor Extension Emulated) — эмуляция сопроцессора. Установка этого
флага вызывает появление исключениями (или прерывания от сопроцессора)
при каждой команде, относящейся к сопроцессору, что позволяет прозрачно
осуществлять его программную эмуляцию.
♦ TS (Task Switch) — флаг переключения задач, устанавливается автоматически
при переключении задач. При TS = 1 и MP = 1 следующая команда, относящая-
ся к сопроцессору, вызовет исключение ММ, что позволяет программно опреде-
лить, относится ли контекст сопроцессора к текущей задаче. Бит сбрасывается
инструкцией CLTS. Сочетание МР = О, ЕМ = О, TS = 0, устанавливаемое по аппа-
ратному сбросу, обеспечивает полную совместимость с 8086/88 (исключе-
ние ММ не вырабатывается). Сочетание MP = 1, ЕМ » 0 используется при нали-
чии сопроцессора, а МР = 0, ЕМ = 1 — при его программной эмуляции.
♦ ЕТ (Extension Туре) — индикатор поддержки инструкций математического со-
процессора. Используется в процессорах 486+, для 486SX ЕТ = 0, для осталь-
ных процессоров ЕТ = 1.
58
2. Программная модель 32-разрядных процессоров
♦ NE (Numeric Error) — разрешение стандартного (для Intel, но не для PC) меха-
низма сообщения об ошибке FPU через генерацию исключения (486+).
♦ WP (Write Protect) — разрешение защиты страниц памяти.
♦ AM (Alignment Mask) — разрешение контроля выравнивания (контроль вырав-
нивания выполняется только на уровне привилегий 3 при AM = 1 и АС = 1).
♦ NW (Not Writethrough) — запрет сквозной записи кэша и циклов аннулирования.
♦ CD (Cache Disable) — запрет заполнения кэша (попадания в ранее заполненные
строки при этом обслуживаются кэшем).
♦ PG (Paging Enanable) — включение механизма страничной переадресации памяти.
Регистр CR0 является расширением регистра MSW процессора 80286, в котором были
определены лишь биты РЕ, МР, ЕМ и TS. Для обеспечения программной совместимо-
сти команды LMSW и SMSW, предназначавшиеся для процессоров 80286, затрагивают
только эти младшие 4 бита.
Регистр CR1 не используется.
Регистр CR2 (Page Fault Linear Address) хранит 32-битный линейный адрес, по
которому был получен последний отказ страницы памяти.
Регистр CR3 (Page Directory Base Register) в старших 20 битах хранит физический
базовый адрес таблицы каталога страниц. Из младших 12 бит в процессорах 486+
используются следующие:
♦ PCD (Page-Level Cache Disable) — запрет кэширования страницы (один из ис-
точников аппаратного сигнала PCD для управления внешним кэшем);
♦ РЫТ (Page-Level Writes Trough) — кэширование страницы со сквозной записью
(один из источников аппаратного сигнала РИТ для управления внешним кэшем).
Регистр CR4 (присутствует в процессорах Pentium и выше) содержит биты разреше-
ния архитектурных расширений. Назначение бит регистра CR4 представлено ниже.
♦ VME (Virtual-8086 Mode Extensions) — разрешение использования виртуально-
го флага прерываний в режиме V86, что позволяет повысить производитель-
ность за счет сокращения лишних вызовов монитора виртуальных машин.
♦ PVI (Protected-Mode Virtual Interrupts) — разрешение использования виртуаль-
ного флага прерываний в защищенном режиме.
♦ TSD (Time Stamp Disable) — превращение инструкции RDTSC (чтение счетчика
меток реального времени) в привилегированную.
♦ DE (Debugging Extensions) — расширение возможностей отладки (разрешение
точек останова на инструкциях обращения к заданным портам ввода-вывода).
♦ PSE (Page Size Extension) — расширение размера страницы (4 Кбайт и 4 Мбайт).
♦ РАЕ (Physical Addres Extension) — расширение физического адреса (страницы
4 Кбайт и 2 Мбайт, 36-битная адресация).
♦ MCE (Machine-Check Enable) — разрешение машинного контроля (выработки
исключения #МС по машинной ошибке) (Р5+).
2.2. Регистры процессора
59
♦ PGE (Paging Global Extensions) — разрешение глобальности в страничной пере-
адресации. При PGE = 1 по команде MOV CR3 в TLB очищаются только вхожде-
ния с неустановленным битом глобальности G (Р6+).
♦ РСЕ (Performance-monitoring Counter Enable) — разрешение обращения к счет-
чикам событий (инструкция RDPMC) на любом уровне привилегий.
♦ OSFXSR — флаг использования инструкций FXSAVE/FXRSTOR для быстрого сохра-
нения и восстановления состояния FPU/ММХ при переключении контекста.
При инициализации процессора флаг обнуляется; он может быть установлен
операционной системой, если она эти инструкции использует, а процессор их
поддерживает. Признак поддержки инструкций — бит FXSR (EDX.24) после вы-
зова CPUID(l) (Р6+).
♦ OSXMMEXCPT — флаг поддержки операционной системой исключений от блока
ХММ (SIMD-инструкций с плавающей точкой) (Р6+).
Системные адресные регистры предназначены для ссылок на сегменты и таблицы
в защищенном режиме (рис. 2.7).
Register) программно загружаются 6-байтными операндами, включающими 32-
битный линейный базовый адрес и 16-битный лимит глобальной таблицы деск-
рипторов и таблицы дескрипторов прерываний. В регистр задачи TR (Task Register)
и регистр селектора локальной таблицы дескрипторов LDTR (Local Descriptor Table
register) загружаются 16-битные селекторы дескрипторов сегмента состояния за-
дачи TSS и локальной таблицы дескрипторов LDT. Эта загрузка вызывает автома-
тическую загрузку самих дескрипторов, содержащих 32-битные поля линейного
базового адреса и лимита, а также полей атрибутов в связанные с ними невиди-
мые регистры дескрипторов.
Регистры отладки (Debug Register) предназначены для задания и управления от-
ладочными точками останова.
Регистры DR0.. .DR3 (Linear Breakpoint Address 0...3) хранят 32-битные линейные
адреса точек останова.
Регистры DR4, DR5 в процессорах 80386 и 486 не используются, обращение к ним
эквивалентно обращению к регистрам DR6, DR7. В процессоре Pentium при вклю-
60
2. Программная модель 32-разрядных процессоров
ченном расширении отладки обращение к этим регистрам вызывает исключение
недопустимого кода операции (#UD).
Регистр DR6 (Breakpoint Status) отражает состояние контрольной точки.
Регистр DR7 (Breakpoint Control) управляет установкой контрольных точек.
Состав регистров тестирования (Test Register) варьируется в зависимости от типа
процессора. Процессоры 80386 имели только два регистра, предназначенных для
тестирования кэша страничной переадресации — TR6 и TR7, для процессора 486
состав регистров расширен: TR3 — регистр данных внутреннего кэша, TR4 — тесто-
вый регистр состояния кэша, TR5 — управляющий регистр тестирования кэша, TR6
(Test Control) — управляющий регистр для теста кэширования страниц, TR7 (Test
Status) — регистр данных для теста кэширования страниц.
В процессорах Pentium и выше тестовые регистры входят в группу модельно-спе-
цифических регистров MSR. Для этих процессоров обращение к регистрам TRx вы-
зывает исключение #UD недопустимого кода операции.
Мо дельно-специфические регистры MSR (Model-Specific Registers) предназначены
для управления расширениями отладки, мониторингом производительности, ма-
шинным контролем, кэшированием областей физической памяти и другими функ-
циями. Их назначение привязывается к микроархитектуре конкретного процес-
сора, состав меняется от модели к модели, доступ привилегирован. Инструкции
обмена с этими 64-битными регистрами подразумевают, что данные находятся в
паре EDX:EAX, а номер указывается в регистре ЕСХ, что позволяет неограниченно (до
4 миллиардов) увеличивать число этих регистров.
Доступность регистров различных групп зависит от режима работы процессора и
уровня привилегий задачи. В табл. 2.1 показана возможность загрузки (занесения
значения в регистр) различных регистров и сохранения их в памяти в трех режи-
мах работы процессора.
Таблица 2.1. Доступность регистров 32-разрядных процессоров
Режим Регистры Реальный Загрузка 1 Сохранение Защищенный Виртуального 8086 Загрузка Сохранение
Загрузка Сохранение
Общего назначения Да Да Да Да Да Да
Сегментов Да Да Да Да Да Да
Флагов Да Да Да Да IOPL1 IOPL1
Управляющие Да Да PL=O PL=O Нет Да
GDTR, IDTR Да Да PL=O Да Нет Да
LDTR.TR Нет Нет PL=O Да Нет Нет
Отладки Да Да PL=O PL=O Нет Нет
Тестирования Да Да PL=O PL=O Нет Нет
MSR PL=O Р1=0 PL=O PL=O Нет Нет
1 PUSHF и POPF чувствительны к уровню привилегий.
2.3. Организация памяти
61
2.3. Организация памяти
В процессорах х86 предусматривается разделение пространств памяти и ввода-вы-
вода. Пространство памяти (Memory Space) предназначено для хранения кодов
инструкций и данных, для доступа к которым имеется богатый выбор способов
адресации (24 режима). Память для процессоров представляется в виде линейной
последовательности байт.
Память для 32-разрядных процессоров 80x86 подразделяется на байты (8 бит),
слова (16 бит), двойные слова (32 бит) и учетверенные слова (64 бит). Слово
(word) записывается в двух смежных байтах, начиная с младшего. Адресом слова
является адрес его младшего байта (Low byte). Следующий байт (адрес на едини-
цу больше) содержит старший (High) байт слова. Слово может размещаться в
памяти как по четному (Even), так и по нечетному (Odd) адресу. Выравнивание
по границе слова означает, что адрес четный (младший бит адреса у адресуемого
элемента — нулевой). Двойное слово (double word) записывается в четырех смеж-
ных байтах, опять-таки начиная с младшего байта, адрес которого и является ад-
ресом двойного слова. Выравнивание по границе двойного слова означает нуле-
вое значение двух младших бит адреса. Все пространство памяти разбивается на
параграфы — области из 16 смежных байт, начиная с нулевого адреса. Выравни-
вание по границе параграфа означает, что четыре младших бита адреса — нуле-
вые. В принципе любой адресуемый элемент памяти может начинаться с любого
байта памяти, однако в ряде случаев выдвигается требование выравнивания опе-
рандов по границе своего класса. Выровненные элементы передаются по внешней
шине за минимальное число тактов. Обращение к невыровненным элементам в
ряде случаев вызывает исключение.
Более крупными единицами организации памяти являются страницы и сегмен-
ты. Память может логически организовываться в виде одного или множества сег-
ментов переменной длины (в реальном режиме — фиксированной). Кроме сегмен-
тации, в защищенном режиме возможно разбиение (Paging) логической памяти
на страницы размером 4 Кбайт, каждая из которых может отображаться на любую
область физической памяти. Начиная с 5-го поколения, появилась возможность
увеличения размера страницы до 4 Мбайт (см. п. 5.6). Сегментация и разбиение
на страницы могут применяться в любых сочетаниях. Сегментация является сред-
ством организации логической памяти на прикладном уровне. Разбиение на стра-
ницы применяется на системном уровне для управления физической памятью.
Сегменты и страницы могут выгружаться из физической оперативной памяти на
диск и по мере необходимости подкачиваться с него обратно в физическую память.
Таким образом реализуется виртуальная память.
Применительно к памяти различают три адресных пространства: логическое, ли-
нейное и физическое. Основным режимом работы 32-разрядных процессоров счи-
тается защищенный режим, в котором работают все механизмы преобразования
адресных пространств (рис. 2.8).
62
2. Программная модель 32-разрядных процессоров
Сегментный
регистр
Рис. 2.8. Формирование адреса памяти 32-разрядных процессоров в защищенном режиме
Логический адрес, также называемый виртуальным, состоит из селектора сегмента
(в реальном режиме — просто адреса сегмента) и эффективного адреса, называе-
мого также смещением (offset). Селектор сегмента хранится в старших 14 битах
сегментного регистра (CS, DS, ES, SS, FS или GS), участвующего в адресации конкрет-
ного элемента памяти. По значению селектора из специальных таблиц, хранящих-
ся в памяти, извлекается начальный адрес сегмента. Эффективный адрес форми-
руется суммированием компонентов base, index, displacement с учетом масштаба
scale (см. п. 2.3.2). Поскольку каждая задача может иметь до 16 Кбайт селекторов
(214), а смещение, ограниченное размером сегмента, может достигать 4 Гбайт, ло-
гическое адресное пространство для каждой задачи может достигать 64 Тбайт. Все
это пространство виртуальной памяти в принципе доступно программисту (при
условии поддержки со стороны операционной системы).
Блок сегментации транслирует логическое адресное пространство в 32-битное
пространство линейных адресов. Линейный адрес образуется сложением базового
адреса сегмента с эффективным адресом. Базовый адрес сегмента в реальном ре-
жиме образуется умножением содержимого используемого сегментного регистра
на 16 (как и в 8086). В защищенном режиме базовый адрес загружается из деск-
риптора, хранящегося в таблице, по селектору, загруженному в используемый сег-
ментный регистр.
32-битный физический адрес памяти образуется после преобразования линейного
адреса блоком страничной переадресации. Он выводится на внешнюю шину ад-
реса процессора. В простейшем случае (при отключенном блоке страничной пе-
2.3. Организация памяти
63
реадресации) физический адрес совпадает с линейным. Включенный блок стра-
ничной переадресации осуществляет трансляцию линейного адреса в физический
страницами размером 4 Кбайт (для последних поколений процессоров также воз-
можны страницы размером 2 или 4 Мбайт). Блок обеспечивает расширение раз-
рядности физического адреса процессоров шестого поколения до 36 бит. Блок
переадресации может включаться только в защищенном режиме, подробнее его
назначение и работа будут рассмотрены в п. 5.6.
Для обращения к памяти процессор (совместно с внешней схемой) формирует
шинные сигналы, для шины ISA — MEMWR# (Memory Write) и MEMRD# (Memory
Read) для операций записи и чтения соответственно. Шина адреса разряднос-
тью 32/36 бит позволяет адресовать 4/64 Гбайт физической памяти, но в реаль-
ном режиме доступен только 1 Мбайт, начинающийся с младших адресов.
Для монополизации шины на время выполнения команды предусмотрена инст-
рукция-префикс LOCK, которая запрещает процессору отдавать управление шиной
до окончания выполнения данной команды. Таким образом можно обеспечить
целостность данных в тех случаях, когда к области данных, участвующих в коман-
де, возможен доступ и со стороны другого процессора (контроллера) — например,
при работе с программными семафорами в цикле чтение-модификация-запись.
2.3.1. Модель памяти в реальном режиме
В реальном режиме адресации памяти обеспечивается совместимость с процессо-
ром 8086/8088, который своей 20-разрядной адресной шиной охватывает простран-
ство физической памяти в 1 Мбайт. Формирование 20-разрядного физического
адреса с использованием 16-разрядных регистров иллюстрирует рис. 2.9. Логически
память разбивается на сегменты размером по 64 Кбайт. Физический адрес памяти
(поступающий на шину адреса разрядностью 20 бит) состоит из двух 16-битных
частей — адреса сегмента (Seg) и исполнительного адреса ЕА (executive address),
суммируемых со смещением на 4 бита. Сдвиг адреса сегмента на 4 бита влево эквива^
лентен его умножению на 16, следовательно, физический адрес РА - 16 х Seg + ЕА.
Адрес сегмента Seg хранится в одном из регистров CS, DS, SS или ES.
Исполнительный адрес, также называемый эффективным адресом, может быть
константой, содержимым регистра, содержимым ячейки памяти или суммой не-
скольких величин (например, двух регистров и константы), но эта сумма являет-
ся 16-разрядной (перенос игнорируется). Таким образом, физический адрес никог-
да не перейдет границу 64-килобайтного сегмента, на начало которого указывает
текущий сегментный указатель. Сегмент получается как бы свернутым в кольцо
(wrapped): по мере увеличения суммируемых компонентов исполнительный ад-
рес растет, но после достижения значения FFFFh снова обнуляется и начинает
расти с начала. С одной стороны, это свойство обеспечивает некоторую защиту
сегментов друг от друга (хотя некорректно написанная программа может легко
перезагрузить указатель сегмента и повредить данные другого сегмента), но, с дру-
гой стороны, сегментация памяти является существенным неудобством для на-
64
2. Программная модель 32-разрядных процессоров
писания больших программных модулей. В 1976 году ограничение в 64 Кбайт
памяти для одного модуля при общем объеме памяти 1 Мбайт, конечно же, не
казалось пугающим, но в дальнейшем, по мере усложнения программного обеспе-
чения, это ограничение стало очень неудобным. Свернутым в кольцо оказывается
и все пространство физической памяти: по мере увеличения исполнительного ад-
реса и адреса сегмента физический адрес растет, но только до значения FFFFFh,
после чего обнуляется и начинает расти с начала. Сворачивание сегментов и всего
адресного пространства в процессорах 8086/88 никак не контролируется.
15 о
Рис. 2.9. Формирование физического адреса памяти процессором 8086/8088
С сегментацией связаны понятия ближнего и дальнего адреса (вызова, перехода).
При ближнем (Near) или внутрисегментном обращении доступ к требуемой ячей-
ке памяти осуществляется только указанием смещения, а адрес сегмента опреде-
ляется текущим содержимым соответствующего регистра сегмента. При дальнем
(Far) или межсегментном обращении указывается полный адрес, содержащий 16-
битное значение сегмента (загружаемое в соответствующий сегментный регистр)
и 16-битное смещение. Естественно, что дальние обращения выполняются медлен-
нее (хотя бы из-за пересылки большего количества байт адреса).
Процессор может обращаться как к одному байту памяти, так и к слову, состояще-
му из двух байт, или к двойному слову (4 байта). Двойное слово обычно использу-
ется для хранения полного адреса, и в нем располагается сначала слово смещения
(в порядке L—Н), а затем сегмента (в том же порядке). Сегментация памяти и по-
рядок L—Н являются характерной чертой процессоров х86. Вполне очевидно, что
2.3. Организация памяти
65
любой сегмент может начинаться только на границе параграфа (четыре младших
бита адреса — нулевые).
Для совместимости с процессором 80286 32-разрядные процессоры повторяют
ошибку этой модели, связанную с переносом, возникающим при сложении адреса
сегмента с эффективным адресом. Эту ошибку, с радостью используемую разра-
ботчиками программного обеспечения (она позволяет чуть расширить размер
доступной памяти в реальном режиме), «узаконили» и в следующих поколениях
процессоров. При вычислении физического адреса (см. рис. 2.9) возможно возник-
новение переполнения, которое с 20-разрядной шиной адреса приводило к свора-
чиванию пространства в кольцо. Если, например, Seg = FFFFh и ЕА = FFFFh, физи-
ческий адрес, вычисленный по формуле РА = 16 х Seg + ЕА, получается равным
10FFEF. Процессором 8086 он трактуется как 0FFEF — адрес, принадлежащий
первому мегабайту. Однако на выходе А20 процессора 80286 в этом случае устано-
вится единичное значение, что соответствует адресу ячейки из второго мегабайта
физической памяти. Для обеспечения полной программной совместимости с 8086
в схему IBM PC/AT был введен специальный вентиль GateA20, принудительно
обнуляющий бит А20 системной шины адреса. 32-разрядные процессоры имеют
специальный вход А20М, по которому в реальном режиме принудительно обнуля-
ется внешний бит адреса А20. Вентиль в PC управляется через программно-управ-
ляемый бит контроллера клавиатуры 8042 или более быстрым способом (Gate А20
Fast Control), определяемым чипсетом системной платы.
В реальном режиме у процессоров IA-32 размер сегмента фиксирован — как и у
8086, он составляет 64 Кбайт (FFFFh). Попытка использования эффективного
адреса, выходящего за границу сегмента, при 32-битной адресации вызывает ис-
ключение #GP. При 16-битной адресации при вычислении эффективного адреса
возможный перенос в разряд А16 игнорируется и сегмент «сворачивается в коль-
цо» (как и в 8086). Средства контроля следят и за переходом через границу сег-
мента во время обращения по «приграничному» адресу. При попытке адресации к
слову, имеющему смещение FFFFh, или двойному слову со смещением FFFDh-
FFFFh (их старшие байты выходят за границу сегмента), или выполнения инст-
рукции, хотя бы один байт которой не умещается в данном сегменте, процессор
вырабатывает исключение #GP. При попытке выполнения инструкции сопроцес-
сора (ESCAPE) с операндом памяти, не умещающимся в сегменте, вырабатывается
исключение 9 — Processor Extension Segment Overrun Interrupt (только для 80386).
2.3.2. Режимы адресации
Система команд 32-разрядпых процессоров предусматривает 11 режимов адреса-
ции. При этом только в двух случаях операнды не связаны с памятью. Это опе-
ранд-содержимое регистра, которое берется из любого 8-, 16- или 32-битного
регистра процессора, и непосредственный операнд (8,16 или 32 бит), который со-
держится в самой команде. Остальные девять режимов (табл. 2.2) так или иначе
обращаются к памяти.
66
2. Программная модель 32-разрядных процессоров
При обращении к памяти эффективный адрес вычисляется с использованием сле-
дующих компонентов.
♦ Смещение (Displacement или Disp) — 8-, 16- или 32-битное число, включенное
в команду.
♦ База (Base) — содержимое базового регистра. Обычно используется для указа-
ния на начало некоторого массива.
♦ Индекс (Index) — содержимое индексного регистра. Обычно используется для
выбора элемента массива.
♦ Масштаб (Scale) — множитель (1, 2, 4 или 8), указанный в коде инструкции.
Этот элемент используется для указания размера элемента массива, доступен
только при 32-битной адресации.
Эффективный адрес вычисляется по формуле
ЕА = Base + Index х Scale + Disp
Отдельные слагаемые в этой формуле могут отсутствовать. Возможные режимы
адресации приведены в табл. 2.2.
Таблица 2.2. Режимы адресации памяти 32-разрядных процессоров
Режим Адрес
Прямая адресация (Direct Mode) EA=Disp
Косвенная регистровая адресация (Register Indirect Mode) EA=Base
Базовая адресация (Based Mode) EA=Base+Disp
Индексная адресация (Index Mode) EA=lndex+Disp
Масштабированная индексная адресация (Scaled Index Mode) EA=Scalexlndex+Disp1
Базово-индексная адресация (Based Index Mode) EA=Base+lndex
Масштабированная базово-индексная адресация (Based Scaled Index Mode) EA=Base+Scalexlndex1
Базово-индексная адресация co смещением (Based Index Mode with Displacement) EA=Base+lndex+Disp
Масштабированная базово-индексная адресация co смещением (Based Scaled Index Mode with Displacement) EA=Base+Scalexlndex+Disp1
1 Масштабирование индекса возможно только при 32-битной адресации.
Процессор может работать с 32-битной или 16-битной адресацией. 16-битная ад-
ресация функционирует так же, как и в процессорах 8086 и 80286, при этом в каче-
стве компонентов адреса используются младшие 16 бит соответствующих регист-
ров. При 32-битной адресации применяются расширенные 32-разрядные регистры
и дополнительные режимы с масштабированием индекса. Различия 16- и 32-бит-
ных режимов адресации иллюстрирует табл. 2.3.
2.3. Организация памяти
67
Таблица 2.3. Различия режимов адресации
Компонент 16-битная адресация 32-битная адресация
Базовый регистр ВХ или ВР Любой 32-битный регистр общего назначения
Индексный регистр SI или DI Любой 32-битный регистр общего назначения, кроме ESP
Масштаб Нет (всегда 1) 1,2,4 или 8
Смещение 0, 8 или 16 бит 0, 8 или 32 бит
В реальном режиме по умолчанию используется 16-битная адресация, но с помо-
щью префикса изменения разрядности адреса (Address Length Prefix) для текущей
инструкции можно переключиться на 32-битную. При этом появляются дополни-
тельные возможности адресации (масштабирование), но вычисляемое значение
эффективного адреса все равно не может преодолеть 64-килобайтный барьер —
при попытке обратиться по такому эффективному адресу генерируется исключе-
ние #GP — General Protection Fault.
В защищенном режиме адресация по умолчанию определяется битом D дескрип-
тора используемого кодового сегмента: при D = 0 — 16 бит, при D = 1 — 32 бита.
Префикс разрядности адреса переключает разрядность для текущей инструкции
на противоположную.
При обращениях к памяти использование сегментных регистров по умолчанию
определяется типом обращения (табл. 2.4). Для большинства типов обращения на
время исполнения текущей инструкции возможно при необходимости указание
альтернативного сегментного регистра, что обеспечивает префикс замены сегмен-
та (CS:, DS:, ES:, SS:, FS: или GS:) перед кодом инструкции. Однако сами инструкции
всегда выбираются только из кодового сегмента.
Таблица 2.4. Использование сегментных регистров при обращении к памяти
Тип обращения к памяти Сегментный регистр
по умолчанию альтернативный
Выборка команд CS Нет
Стековые операции SS Нет
Строка-приемник ES Нет
Любые другие ссылки на память, кроме тех, которые используют в качестве базового регистр ВР, ЕВР или ESP DS CS, ES, SS, FS, GS
Ссылки на память, использующие в качестве базового регистр ВР, ЕВР или ESP SS CS, DS, ES, FS, GS
2.3.3. Стек
Стек представляет собой непрерывную область памяти, адресуемую регистрами
ESP (указатель стека) и SS (селектор сегмента стека). Особенность стека заключа-
ется в том, что данные в него помещаются и извлекаются по принципу «первым
вошел — последним вышел». Данные помещаются в стек с помощью инструкции
68
2. Программная модель 32-разрядных процессоров
PUSH (заталкивание), а извлекаются по инструкции POP (вытаскивание). За одну
операцию можно поместить или извлечь только слово (2 байта) или двойное
слово (4 байта). Указатель стека ESP (или SP) показывает на верхушку стека — дан-
ные, которые будут извлечены по инструкции POP. При помещении данных первым
делом указатель стека декрементируется на 2 или 4, в зависимости от разрядности
данных; после этого данные помещаются в сегмент, определенный регистром SS,
со смещением, определяемым новым значением ESP. При извлечении данные считы-
ваются из памяти по адресу SS:ESP, после чего указатель стека инкрементируется на 2
или 4. Таким образом, при помещении данных в стек область, занимаемая стеком в
стековом сегменте, как бы растет вниз. При извлечении данных стек сжимается вверх.
Кроме явного доступа к стеку посредством инструкций PUSH и POP стек автоматически
используется процессором при выполнении инструкций вызова (CALL), возвратов (RET
и IRET), входа и выхода из процедур (ENTER и LEAVE), а также при обработке прерыва-
ний. По инструкции CALL в стек помещается адрес возврата — значение регистров
CS и EIP, указывающие на инструкцию, следующую после инструкции вызова (при
ближних вызовах сегментный регистр в стеке не сохраняется). По прерыванию в
стек помещается значение регистра EFLAGS, а затем адрес инструкции, следующей за
той, на которой произошло прерывание. По инструкциям возврата эти значения из-
влекаются из стека в соответствующие регистры, и процессор продолжает выполнять
прерванную последовательность инструкций. Исключение работает аналогично
прерыванию, по следом за содержимым EIP в ряде случаев в стек помещается также
слово кода ошибки, которое должно быть извлечено обработчиком исключения.
Стек используют для разных целей:
♦ организации прерываний, вызовов и возвратов;
♦ временного хранения данных, когда под них нет смысла выделять фиксиро-
ванные места в памяти;
♦ передачи и возврата параметров при вызовах процедур.
Для передачи параметров процедур служит регистр ЕВР (ВР), который тоже использует
сегментный регистр SS. Чтобы передать параметры процедуре, вызывающая програм-
ма помещает их в стек в определенном порядке и выполняет вызов. Вызванная про-
цедура может использовать стек и для своих локальных целей (в том числе и вы-
зова вложенных процедур). Чтобы иметь доступ к переданным ей данным в стеке,
вызываемая процедура первым делом может скопировать содержимое ESP в ЕВР,
после чего к переданным ей параметрам (и возвращаемым в вызывающую програм-
му) может адресоваться относительно регистра ЕВР. Перед возвратом процедура
может обратно скопировать ЕВР в ESP, в результате в верхушке стека гарантированно
окажется адрес точки возврата вызывающей программы. Для выделения и освобож-
дения в стеке областей под переменные служат инструкции ENTER и LEAVE, исполь-
зуемые языками высокого уровня при вызовах процедур с передачей параметров.
Разрядность элементов, с которыми по умолчанию работают инструкции PUSH и
POP, определяется битом D в дескрипторе кодового сегмента текущей задачи (см.
п. 5.2): 0 — 16 бит (инкремент/декремент ESP на 2), 1—32 бита (инкремент/декре-
мент ESP на 4). Разрядность может быть изменена на противоположную для конк-
ретной инструкции префиксом SIZ. Когда в 32-битном стеке сохраняют или из-
влекают содержимое сегментных регистров (они всегда 16-битные), процессор
2.3. Организация памяти
69
автоматически их расширяет до 32 бит пулями. Для остальных 16-битных операн-
дов такая автоматическая коррекция не выполняется:
Разрядность указателя стека определяется битом В в текущем дескрипторе сегмента
стека: 0 — используется SP, максимальный размер стека 64 Кбайт; 1 — ESP, макси-
мальный размер стека 4 Гбайт. Для реального режима, а также для режима V86
используется 16-битный указатель SP и разрядность стековых операций — 16 бит.
До использования стека он должен быть инициализирован — значения селектора
SS и указателя ESP устанавливаются так, чтобы они указывали на область реально
существующей оперативной памяти (стек в ПЗУ, естественно, работать не может).
При работе с 16-битными элементами указатель стека должен быть выровнен по
границе слова, с 32-битными — по границе двойного слова. В противном случае
гарантировано заметное снижение производительности процессора, а возможна и
неработоспособность программ. Прикладные программы, как правило, от опера-
ционной системы получают готовый к употреблению стек. При выполнении опе-
раций, использующих стек, возможно появление исключения #SS (нарушение гра-
ницы или отсутствие сегмента стека). В защищенном режиме сегмент состояния
задачи содержит четыре селектора сегментов стека (для разных уровней привиле-
гий), но в каждый момент используется, естественно, только один стек (регистры
SS и ESP в процессоре представлены только в одном экземпляре, они определяют
стек на текущем уровне привилегий). Если при вызове процедуры (прерывании,
исключении) происходит переключение стекового сегмента, значения регистров
EFLAGS, CS, EIP и код ошибки (если используется) сначала временно сохраняются
внутри процессора, а после загрузки нового сегмента стека сохраняются уже в нем.
2.3.4. Плоская и многосегментная модели
памяти и «нереальный» режим
Процессоры IА-32 позволяют реализовать различные модели памяти. Простейшей
организацией является плоская модель памяти: вся память представляется единой
линейной последовательностью байт. Это классическая реализация фон-нейма-
новской архитектуры — здесь хранятся и данные, и коды. Ответственность за кор-
ректное использование памяти ложится целиком на прикладного программиста —
он должен заботиться о том, чтобы данные не затерли коды или на них не «наехал»
растущий стек. Чтобы получить плоскую модель, достаточно все сегментные ре-
гистры загрузить селектором дескриптора, описывающим одну и ту же область
памяти, но с разными свойствами для кода, стека и данных. Плоская модель не
может быть использована в реальном режиме — в ней не вся адресуемая память
будет доступной. Противоположностью плоской модели является сегментированная
защищенная модель: память состоит из независимых сегментов. Каждой программе
в любой момент предоставляется сегмент кода, сегмент стека и до четырех сегментов
данных. Сегменты выбираются селекторами из таблиц, подготовленных операцион-
ной системой. Распределением памяти ведает операционная система. Некорректные
обращения приложений к памяти блокируются системой защиты, которая управ-
ляется операционной системой. Принцип хранимости программ соблюдается, но
для записи или чтения кодов в качестве данных требуются некоторые искусственные
приемы (переопределение сегментов). Промежуточное положение занимает модель
70
2. Программная модель 32-разрядных процессоров
памяти реального режима. Здесь память организуется в виде сегментов, но неза-
висимости и защищенности сегментов нет. Эта модель была вынужденной, она
требовалась, чтобы обеспечить возможность адресации к объему памяти 1 Мбайт
при помощи 16-разрядных регистров. Такую модель до сих пор используют при-
ложения, написанные для операционных систем реального режима типа MS-DOS.
Неофициальный, но существующий «нереальный» режим работы процессора (Unreal),
он же «большой реальный» (Big real), основан на управлении свойствами сегментов
со стороны скрытых регистров их дескрипторов (а не самих программно-видимых
регистров CS, DS, ES, SS, FS и GS). Эти скрытые дескрипторы инициализируются при
аппаратном сбросе в «неинтересное» состояние, а также автоматически загружаются
из дескрипторов сегментов в защищенном режиме, позволяя адресоваться уже ко
всему объему памяти. При переходе в реальный режим, если не следовать указаниям
фирмы Intel, содержимое скрытых регистров можно и сохранить, если не трогать
соответствующих сегментных регистров. Однако первая же загрузка в сегментный
регистр сбросит «приятную» установку соответствующего регистра дескриптора
в стандартные реальные значения (лимит 64 Кбайт, база — сдвинутое на 4 бита
влево значение сегментного регистра), и через этот сегментный регистр будет до-
ступен лишь первый мегабайт памяти (с небольшим довеском при открытом вен-
тиле А20). Поскольку все сегментные регистры 16-разрядных процессоров (CS, DS,
ES и SS) приложениями и операционной системой очень часто перезагружаются, для
этих сегментов «нереальные» настройки «долго не проживут». Кодовый сегмент
«не переживет» ни одного дальнего вызова процедуры (при этом переопределяется
CS). Остаются лишь сегментные регистры FS и GS, которые 16-разрядными приложе-
ниями и ОС не затрагиваются. Именно через их сегменты программы и могут полу-
чить доступ ко всему пространству памяти, но только для доступа к данным, с помо-
щью префиксов замены сегментов в инструкциях обращения к памяти. Программный
код из этих сегментов непосредственно исполнить невозможно, но можно по мере
необходимости «подкачивать» блоки кода в первый мегабайт адресуемой памяти.
2.4. Ввод-вывод
32-разрядные процессоры позволяют адресовать до 64 Кбайт однобайтных регист-
ров (портов ввода-вывода) в отдельном от памяти пространстве. Процессоры могут
обращаться к портам разрядностью в байт или слово, причем разрядность слова
(16 или 32 байт) определяется текущим режимом адресации и может изменяться
с помощью префикса инструкций. При операциях ввода-вывода линии А[ 16:31]
не используются. Адрес устройства задается либо в команде (только младший
байт, старший — нулевой), либо берется из регистра DX (полный 16-битный адрес).
Команды ввода-вывода вызывают шинные циклы, на шине ISA в них активные
сигналы IORD#, I0WR#.
Во избежание недоразумений и для экономии шинных циклов рекомендуется
выравнивать адреса 16-битных портов по границе слова, а 32-битных — по грани-
це двойного слова. Обращения по выровненным адресам выполняются за один
цикл системной шины. Обращения по невыровненным адресам выполняются за
несколько циклов, причем однозначная последовательность адресов обращений
(которая зависит от модели процессора) не гарантируется. Так, например, одна
2.5. Прерывания и исключения
71
инструкция вывода слова по нечетному адресу приведет к генерации двух смеж-
ных шинных циклов записи. При программировании обращений следует учитыг
вать специфику устройств ввода-вывода. Если, например, устройство допускает
только 16-разрядные обращения, то старший байт его регистров будет доступен
лишь при вводе-выводе слова по четному адресу.
Строковые команды обеспечивают блочный ввод-вывод со скоростью, превыша-
ющей аналогичные операции со стандартным контроллером DMA.
В адресном пространстве ввода-вывода область 0F8-0FF зарезервирована для
использования сопроцессором (при обращении к сопроцессору процессор 80386
выставляет единицу на самой старшей линии шины адреса, что позволяет упрос-
тить процедуру дешифрации адресов).
В защищенном режиме инструкции ввода-вывода являются привилегированными.
Это означает, что они могут исполняться задачами только с определенным уровнем
привилегий, определяемым полем IOPL регистра флагов или битовой картой разре-
шения ввода-вывода (I/O Permission Bitmap), хранящейся в сегменте состояния зада-
чи. Несанкционированная попытка выполнения этих инструкций вызовет исключе-
ние 13 (#GP) — нарушение защиты (знаменитое сообщение «General Protection Error»).
Все операции с портами ввода-вывода выполняются без какого-либо кэширова-
ния и строго в порядке, предписанном программным кодом. Это естественно, по-
скольку порты ввода-вывода задействуют для управления различными аппарат-
ными средствами, и последовательность управляющих воздействий и считываний
состояния не должна нарушаться. В принципе для этих целей можно использо-
вать и область пространства памяти — так называемое отображение ввода-вывода
на память. Тогда для этой области памяти должно быть запрещено кэширование
и установлен строгий порядок записей. Процессоры Р6 позволяют этого добиться
путем формирования атрибутов страниц памяти в регистрах MTRR (см. п. 6.3). Про-
цессоры 4-5 поколения позволяют аппаратно запрещать кэширование с помощью
входного сигнала KEN, который можно связать с дешифратором зоны адресов па-
мяти, предназначенной для ввода-вывода. Порядок операций у этих процессоров
всегда строгий. Процессоры первых поколений кэширование не поддерживают,
так что отображение ввода-вывода на память у них проблем не вызывает.
2.5. Прерывания и исключения
Прерывания и исключения нарушают нормальный ход выполнения программы
для обработки внешних событий или сигнализации о возникновении особых ус-
ловий или ошибок.
Прерывания подразделяются на аппаратные (маскируемые и немаскируемые),
вызываемые электрическими сигналами на входах процессора, и программные,
выполняемые по команде INT хх. Программные прерывания, строго говоря, преры-
ваниями не являются — это лишь своеобразный способ вызова процедур, но про-
цессором они обрабатываются как разновидность прерываний.
По прерыванию или исключению процессор сохраняет в стеке регистр (E)FLAGS и
указатель CS:(E)IP на ту инструкцию, которую он должен будет выполнить после
обработки прерывания. Этой инструкцией будет следующая за той, во время ис-
72
2. Программная модель 32-разрядных процессоров
полнения которой произошло прерывание, или та же самая (при исключениях-
отказах, см. далее). В защищенном режиме при возникновении ряда исключений
в стеке сохраняется еще и код ошибки. После сохранения этих значений процес-
сор переходит к исполнению кода обработчика данного прерывания (исключе-
ния), определяя точку входа в него через номер (0-255) по таблице прерываний.
Обработчик прерывания (исключения) должен заканчиваться специальной инст-
рукцией возврата IRET, по которой из стека восстанавливается указатель CS:(E)IP и
прежнее значение флагов. Для исключений, в которых сохраняется и код ошибки,
обработчик до выполнения инструкции IRET должен извлечь из стека код ошибки.
Аппаратные прерывания подразделяются на маскируемые и немаскируемые. Про-
цессор может воспринимать прерывания после выполнения каждой команды,
длинные строковые команды имеют для восприятия прерываний специальные
окна. Аппаратные прерывания вызываются сигналами на входах INTR и NMI, а ддя
процессоров последних поколений они могут приходить по шине APIC. 1
Маскируемые прерывания вызываются переходом в высокий уровень сигнала на входе
INTR (Interrupt Request) при установленном флаге разрешения (IF = 1). В этом слу-
чае процессор сохраняет в стеке регистр флагов, сбрасывает флаг IF и вырабатывает
два следующих друг за другом (back to back) цикла подтверждения прерывания, в
которых генерируются управляющие сигналы INTA# (Internipt Acknowledge). Высо-
кий уровень сигнала INTR должен сохраняться, по крайней мере, до подтверждения
прерывания. Первый цикл подтверждения холостой, по второму импульсу внешний
контроллер прерываний передает по шине номер вектора, обслуживающего аппарат-
ное прерывание данного типа. Прерывание с полученным номером вектора выпол-
няется процессором так же, как и программное. Обработка текущего прерывания
может быть, в свою очередь, прервана немаскируемым прерыванием, а если обра-
ботчик установит флаг IF, то и другим маскируемым аппаратным прерыванием.
Немаскируемые прерывания выполняются независимо от состояния флага IF по
сигналу NMI (Non Mascablc Interrupt). Высокий уровень на этом входе вызовет
прерывание с типом (вектором) 2, которое выполняется так же, как и маскируе-
мое. Его обработка не может прерываться под действием сигнала на входе NMI до
выполнения команды IRET.
Исключения (exceptions), или особые случаи, подразделяются на отказы, ловушки
и аварийные завершения. Различия заключаются в сохраняемых значениях CS:(E)IР.
Отказ (fault) — это исключение, которое обнаруживается и обслуживается до
выполнения инструкции, вызывающей ошибку. После обслуживания этого ис-
ключения управление возвращается снова на ту же инструкцию (включая все пре-
фиксы), которая вызвала отказ. Отказы, использующиеся в системе виртуальной
памяти, позволяют, например, подкачать с диска в оперативную память затребо-
ванную страницу или сегмент.
Ловушка (trap) — это исключение, которое обнаруживается и обслуживается пос-
ле выполнения инструкции, его вызывающей. После обслуживания этого исклю-
чения управление возвращается на инструкцию, следующую за вызвавшей ловуш-
ку. К классу ловушек относятся и программные прерывания.
Аварийное завершение (abort) — это исключение, которое не позволяет точно ус-
тановить инструкцию, его вызвавшую. Оно используется для сообщения о серьез-
ной ошибке, такой как аппаратная ошибка или повреждение системных таблиц.
2.5. Прерывания и исключения
73
Набор и обработка исключений реального и защищенного режимов различны. Под
исключения в процессорах Intel резервируются векторы 0-31 в таблице прерываний,
однако в PC часть из них перекрывается системными прерываниями BIOS и DOS.
Процедура, обслуживающая прерывание или исключение, определяется по таб-
лице прерываний с помощью номера — восьмибитного указателя (вектора) пре-
рывания. Указатель для программных прерываний задается командой, для мас-
кируемых аппаратных прерываний вводится от внешнего контроллера во втором
цикле INTA# (или по шине APIC), немаскируемое прерывание имеет фиксирован-
ный вектор, а исключения генерируют и передают вектор внутри процессора.
Каждому номеру (0-255) прерывания или исключения соответствует элемент в
таблице дескрипторов прерываний IDT (Interrupt Descriptor Table). В реальном
режиме таблица прерываний содержит дальние адреса (двойные слова) обслу-
живающих процедур и после сброса располагается, начиная с нулевых адресов.
Командой LIDT можно изменять положение таблицы в пределах первого мегабайта,
а размер (03FFh) может быть уменьшен до 007Fh. Однако перемещение и умень-
шение размера таблицы в IBM PC не используют, поскольку ПО может обращать-
ся к элементам таблицы просто по адресам памяти, предполагая ее стандартное
местоположение. При попытке обслуживания прерывания с номером, выходящим
за размер таблицы, генерируется исключение #DF. В защищенном режиме таблица
IDT содержит 8-байтные дескрипторы прерываний, может иметь размер от 32 до
256 дескрипторов и располагаться в любом месте физической памяти.
Анализ условий обслуживания прерываний н исключений выполняется в следу-
ющем порядке (по убыванию приоритета).
1. Проверка на исключение-ловушку отладки (#0В) по выполненной инструкции
(пошаговый режим через флаг TF или точка останова по данным через регист-
ры отладки).
2. Проверка на исключение-отказ отладки (#0В) по последующей инструкции (точ-
ка останова по инструкции через регистр отладки).
3. Немаскируемое прерывание (аппаратное по входу NMI).
4. Маскируемое прерывание (аппаратное по входу INTR при IF = 1).
5. Проверка на исключение-отказ сегментации (#NP или #GP) при выборке следу-
ющей инструкции.
6. Проверка на исключение-отказ страницы (#PF) при выборке следующей инст-
рукции.
7. Проверка на отказ декодирования следующей инструкции (#UD или #GP).
8. Для операции WAIT проверка флагов TS и МР (исключение#NM, если TS = 1иМР = 1).
9. Для операции ESCAPE (инструкция математического сопроцессора) проверка
флагов ЕМ и TS (исключение #NM, если ЕМ = 1 или TS = 1).
10. Для операции WAIT или ESCAPE проверка на исключение #MF от сопроцессора.
И. Проверка на отказ сегментации (#NP, #SS, #GP) или отказ страницы (#PF) для
операндов, используемых в инструкции.
Двойной отказ (Double Fault) — исключение #DF — возникает, когда при обработ-
ке исключения, связанного с сегментацией (#TS, #NP, #SS пли #GP), процессор обна-
74
2. Программная модель 32-разрядных процессоров
руживает исключение, отличное от отказа страницы (#PF). Также двойной отказ
возникает, если при обработке исключения отказа страницы #PF обнаруживается
исключение другого типа. В этом случае тоже исполняется исключение #DF.
Если во время обслуживания исключения отказа страницы случается еще один отказ
страницы, то происходит аварийный останов (Shutdown) процессора. Во время
аварийного останова никакие новые инструкции не выполняются. Из этого состоя-
ния процессор можно вывести только аппаратно — сигналом NMI, оставляя его в за-
щищенном режиме, или сигналом RESET, переводящим процессор в реальный режим.
Прерывания и исключения процессора, работающего в защищенном режиме, при-
ведены в табл. 2.5. В примечаниях отмечены случаи, когда исключение реального
режима отличается от защищенного.
Таблица 2.5. Прерывания и исключения защищенного режима
Номер Функция Мнемоника Тип
0 Переполнение при делении на 0 #DE Fault
1 Исключение отладки #DB Fault/Trap
2 Немаскируемое прерывание (NMI) - Interrupt
3 Исключение отладки (INT 3) #ВР Trap
4 Исключение по переполнению (INTO) #OF Trap
5 Прерывание по контролю диапазона (BOUND) #BR Fault
6 Недопустимый код операции #UD Fault
7 Сопроцессор недоступен или переключалась задача #NM Fault
81 Двойной отказ #DF Abort, EC=0
9 Нарушение границы сегмента сопроцессором (только 386/387) - Fault, EC
102 Недопустимый сегмент состояния задачи #TS Fault, EC
112 Сегмент отсутствует #NP Fault, EC
123 Нарушение границы сегмента стека или сегмент стека отсутствует #SS Fault, EC
134 Общее нарушение защиты #GP Fault, EC
142 Отказ страницы #PF Fault, EC
15 Зарезервировано — —
16 Исключение сопроцессора #MF Fault
172 Контроль выравнивания (486+) #AC Fault, EC=0
182 Машинный контроль (Р5+) #MC Abort, EC
19 Исключение блока ХММ (Р6+) #XF Fault
19-31 Зарезервировано - -
0-255 Аппаратные (маскируемые) и программные прерывания INT п - Trap
1 В реальном режиме — вектор прерывания не попадает в таблицу.
2 В реальном режиме не возникают, но возможны в режиме V86.
3 В реальном режиме — нарушение границы сегмента стека.
4 В реальном режиме — нарушение границы сегмента данных или кода.
2.5. Прерывания и исключения
75
При отработке исключений 8-14,17 и 18 в защищенном режиме процессор сохра-
няет в стеке слово кода ошибки ЕС (Error Code). Если оно отлично от нуля, то в его
битах [15:3] содержится селектор дескриптора, с которым связана ошибка, или
описание причины отказа (для исключения 14 #PF). Код ошибки сохраняется пос-
ле содержимого EFLAGS, CS и EIP. Формат кода ошибки приведен на рис. 2.10 (код
ошибки для исключения #PF имеет иной формат, см. п. 5.6).
♦ Бит EXT — признак внешнего события. EXT = 1 означает, что событие, вызвав-
шее ошибку, является внешним по отношению к программе, вызвавшей ис-
ключение (например, аппаратное прерывание).
♦ Бит IDT — признак того, что поле индекса относится к дескриптору в IDT (при
IDT = 0 индекс относится к GDT или LDT).
♦ Бит TI — признак глобальной (TI = 0) или локальной (TI = 1) таблицы деск-
рипторов (используется только при IDT = 0).
♦ Поле Index определяет дескриптор, с которым связано исключение, в таблице,
заданной битами IDT и TI.
31_________1615 3 2 1 О
| Резерв (OOOOh) | Index | TI | Ют|еХт]
Рис. 2.10. Формат кода ошибки
В процессорах 8086/88 аппаратные и программные прерывания обрабатываются
так же, как и в реальном режиме 32-разрядных процессоров, но таблица прерыва-
ний имеет фиксированный размер (256 векторов) и положение (с нулевых адре-
сов). Понятие исключений в них еще не вводилось, но были внутренние прерыва-
ния с номерами 0,1 и 4. Исключения 5—13 вместе с двойным отказом и аварийным
остановом были введены в процессорах 80286.
3. Математический
сопроцессор,
блоки ММХ и ХММ
Блоки, упомянутые в заголовке главы, в архитектуре процессоров IA-32 х86 дер-
жатся особняком. Они присутствуют не во всех процессорах и даже по схемотех-
нической реализации являются пристройками к центральному процессору с его
набором обычных целочисленных регистров. Данные блоки предназначены для
ускорения вычислений. Математический сопроцессор позволяет использовать
несколько форматов чисел с плавающей точкой — FP-форматов. Операции с та-
кими числами можно выполнять и программно средствами целочисленного про-
цессора, но сопроцессор выполняет эти операции аппаратно во много раз быстрее.
Блок ММХ дает ускорение целочисленных вычислений за счет одновременной
обработки одной инструкцией целого пакета чисел (пар чисел). Блок ХММ ком-
бинирует эти два приема — обрабатывает одной инструкцией пакет из четырех
чисел в FP-формате. То же, но в меньших масштабах (пакет из двух чисел пли их
пар) делает расширение 3DNow!, которое появилось на год раньше ХММ. Исто-
рически первым появился сопроцессор. Блок ММХ ради совместимости с опера-
ционными системами «спрятали» в то же оборудование, что и сопроцессор. Так
появился комбинированный блок, называемый блоком FP/MMX, или FPU/
ММХ. Расширение 3DNow! «спрятали» в блок ММХ. И только блок ХММ, ис-
пользуемый расширением SSE процессоров Pentium III, стал полностью новым
самостоятельным набором регистров.
При отсутствии математического сопроцессора прикладная программа все-таки
может использовать инструкции FPU, но для этого операционная система долж-
на поддерживать эмуляцию сопроцессора. Эмулятор сопроцессора — это програм-
ма-обработчик прерывания от сопроцессора или исключения #NM, которая должна
«выловить» код операции сопроцессора, определить местонахождение данных и
выполнить требуемые вычисления, используя целочисленную арифметику цен-
трального процессора. Понятно, что эмуляция будет выполняться во много раз
медленнее, чем те же действия, выполняемые настоящим сопроцессором. Тем не
менее эмуляция позволяет все-таки пользоваться прикладными программами,
требующими вычислений с плавающей точкой. Для этого в регистре CR0 должно
быть установлено сочетание флагов ЕМ = 1, МР = 0. Для эмуляции в IBM PC обыч-
но устанавливают значение NE = 0. Тогда каждая инструкция FPU автоматически
3.1. Математический сопроцессор х87
77
будет вызывать эмулятор генерацией запроса прерывания (а не исключения #NM,
как было бы при NE = 1).
Эмуляция для блоков ММХ и ХММ не предусматривается — эти блоки предназна-
чены для ускорения вычислений в приложениях реального времени, и выполнять
их с крайне низкой скоростью эмуляции было бы просто бессмысленно. Если уста-
новлен флаг эмуляции ЕМ = 1, то любая инструкция ММХ вызовет исключение#UD.
3.1. Математический сопроцессор х87
Математический сопроцессор предназначен для расширения вычислительных
возможностей центрального процессора — выполнения арифметических опера-
ций, вычисления основных математических функций (тригонометрических, экс-
поненты, логарифма) и т. д. В разных поколениях процессоров он назывался по-
разному — FPU (Floating Point Unit — блок чисел с плавающей точкой) пли NPX
(Numeric Processor extension — числовое расширение процессора).
Сопроцессор поддерживает семь типов данных: 16-, 32-, 64-битные целые числа;
32-, 64-, 80-битные числа с плавающей точкой и 18-разрядпые числа в двоично-
десятичном формате. Формат чисел с плавающей точкой соответствует стандар-
там IEEE 754 и 854. Применение сопроцессора повышает производительность
вычислений в сотни раз. С программной точки зрения сопроцессор и процессор
выглядят как единое целое. В современных (486+) процессорах FPU располагает-
ся на одном кристалле с центральным процессором. Для процессоров 386 и ниже
сопроцессор был отдельной микросхемой, подключаемой к локальной шине ос-
новного процессора. В любом случае сопроцессор исполняет только свои специ-
фические команды, а всю работу по декодированию инструкций и доставке дан-
ных осуществляет CPU. Сопроцессор может выполнять вычисления параллельно
с центральным процессором, независимо от переключения задач в защищенном
режиме. Как и основной процессор, сопроцессор может работать в реальном или
защищенном режиме и переключать разрядность — 16 или 32. Переключение
режимов влияет на формат отображения регистров сопроцессора в оперативной
памяти, при этом формат используемых внутренних регистров не изменяется.
3.1.1. Форматы данных FPU
Сопроцессор оперирует данными в формате с плавающей точкой, который позво-
ляет представлять существенно больше действительных чисел, чем целочислен-
ное АЛУ центрального процессора. Арифметические операции (здесь под ариф-
метическими понимаются операции, изменяющие значения операндов, а также
операции сравнения) в FPU выполняются над 80-битными числами, представлен-
ными во внутреннем формате расширенной точности (рис. 3.1). Формат позволя-
ет представлять следующие категории чисел:
♦ нули (положительный и отрицательный) — оба значения эквивалентны;
♦ денормализованные конечные числа (положительные и отрицательные);
78
3. Математический сопроцессор, блоки ММХ и ХММ
♦ нормализованные конечные числа (положительные и отрицательные);
♦ бесконечность (положительная и отрицательная).
Числа представляются в аффинном пространстве. Это означает, что меньше
любого конечного числа, а +°° больше любого конечного числа.
79 78 64 63 О
Sign Exponent Significand
(знак) (порядок) (мантисса) •
Рис. 3.1. Формат внутреннего представления чисел
Бит Sign определяет знак числа: 0 — положительное, 1 — отрицательное число.
Поле Exponent хранит смещенное значение двоичного порядка числа (biased
exponent). Смещение позволяет все значения порядков допустимого диапазона
чисел представлять положительным числом, при этом значению 000...000 соответству-
ют минимальные (по модулю) числа, значению 111...110 — максимальные допус-
тимые числа, а значению 111...111 — бесконечно большие числа. Нуль может быть
положительным или отрицательным, в зависимости от бита знака, при этом и ман-
тисса, и порядок у него нулевые. Мантисса (Significand) нормализованного числа,
отличного от нуля, всегда имеет вид «1,ххх....ххх», то есть представляет величину,
не меньшую единицы. У бесконечностей (тоже положительной и отрицательной)
мантисса нулевая. Денормализованные числа имеют нулевой порядок (смещенное
значение) и мантиссу вида «0,ххх...ххх» (отличную от нуля). Денормализованные
числа — это слишком малые величины, которые представляются и обрабатывают-
ся с точностью меньшей, чем позволяет разрядность регистров сопроцессора.
Кроме вещественных чисел (конечных нормализованных и денормализованных,
нулей и бесконечностей) регистры сопроцессора могут содержать не-числа NaN
(Not a Number) четырех видов.
♦ -SNaN и +SNaN — порядок 111... 111, мантисса 1,0ххх...ххх (ненулевая). Эти
сигнализирующие не-числа (signaling NaN) вызывают исключения сопроцес-
сора, если с ними пытаются выполнять арифметические действия.
♦ -QNaN и +QNaN — порядок 111...111, мантисса 1,1ххх...ххх (ненулевая). Эти
«тихие» не-числа (quiet NaN) не вызывают исключений при арифметических
операциях.
Внешние операнды могут быть представлены в одном из форматов, приведенных
на рис. 2.3 (см. главу 2). Характеристики форматов чисел, поддерживаемых сопро-
цессором, приведены в табл. 3.1. При их загрузке в FPU и сохранении результатов
преобразования форматов во внутренний и обратно выполняются автоматичес-
ки. Во внешних представлениях вещественных чисел целая часть мантиссы все-
гда подразумевается равной единице. В расширенном формате целая часть зада-
ется явно (бит 63), она имеет нулевое значение только при представлении нулей и
денормализованных чисел. Смещение порядка составляет 127 для одиночного,
1023 для двойного и 16 383 для расширенного вещественного форматов.
Форматы вещественных чисел представляют только множество дискретных зна-
чений множества чисел, расположенных на непрерывной бесконечной числовой
3.1. Математический сопроцессор х87
79
оси. Диапазон и плотность значений зависят от выбранного формата представле-
ния. Заметим, что не все десятичные дроби могут быть представлены точно в дво-
ичном коде. Так, например, дробь 1/10 не имеет точного двоичного представле-
ния (аналогично тому, что 1/3 = 0,33333(3)).
Тип
Диапазон нормализованных значений
Таблица 3.1. Форматы чисел, поддерживаемых сопроцессором
Длина, Точность
бит двоичная десятичная двоичный десятичный
вещественные числа Одиночные 32 24 7 2-126<|х|<2127 1,18хЮ-38<|х|<3,40x10м
(single) Двойные 64 53 15-16 2-Ю22<|х|<2Ю23 2,23x10-308< | х | < 1,79х 10308
(double) Расширенные 80 64 19 2-16382<|х|<216383 3,37x10-4932<|х | <1,18x104932
(extended) Двоичные целые Слова 16 15 4 -215<х<215-1 -32768<х<32767
(word) Короткие 32 31 9 -231<х<231-1 -2,14х109<х<2,14х109
(short) Длинные 64 63 18 -263<х<263-1 -9,22x10,e<x<9.22x10,e
(long) Упакованное двоично-десятичное BCD 80 18 — -10,3+1<х<10,в-1
Сопроцессор контролирует числа, участвующие в арифметических операциях.
При загрузке денормализованного операнда в регистр FPU и попытке выполне-
ния арифметических инструкций хотя бы с одним денормализованным операн-
дом сопроцессор фиксирует условие исключения #0 (об исключениях см. ниже).
Денормализованные числа могут появляться при выполнении вычислений, в этом
случае сопроцессор фиксирует факт исчезновения значащих разрядов и генери-
рует исключение #U. При попытке выполнения арифметических операций с не-
числами, а также с недопустимыми значениями операндов (например, извлечение
квадратного корня из отрицательного числа) вырабатывается исключение#!. При
переполнении вырабатывается исключение #0, при попытке деления на нуль не-
нулевого операнда вырабатывается исключение #Z.
Если результат вычисления невозможно представить точно в выбранном форма-
те, сопроцессор выполняет округление результата в сторону соседнего допусти-
мого значения. Правила округления программируются. Вместо автоматического
выполнения округления сопроцессор может вырабатывать исключение #Р.
3.1.2. Программная модель FPU
С программной точки зрения сопроцессор содержит блок регистров данных, ре-
гистр управления и группу регистров состояния и указателей (рис. 3.2).
80
3. Математический сопроцессор, блоки ММХ и ХММ
Регистры данных FPU (арифметический стек)
Поля Физические 79 78 64 63 0 Относительные
регистра тегов номера Знак Порядок Мантисса номера (ТОР=3)
TAG(0) R(0) ST(5)
TAG(1) R(1) ST(6)
TAG(2) R(2) ST(7)
TAG(3) r-R(3) ST(0)
TAG(4) R(4) ST(1)
TAG(5) R(5) ST(2)
TAG(6) R(6) ST(3)
TAG(7) R(7) ST(4)
Указатели, регистры состояния и управления
Рис. 3.2. Регистры математического сопроцессора
Регистры данных R0-R7 разрядностью 80 бит организованы в стек. Номер регистра,
являющегося текущей вершиной стека, хранится в поле ТОР регистра состояния.
Операция push уменьшает значение в поле ТОР на 1 и помещает данные в регистр,
являющийся новой вершиной стека. Операция pop записывает данные с вершины
стека в память или регистр и инкрементирует указатель. Инструкции адресуют
регистры либо явно, либо неявно. Неявная адресация подразумевает операнд, на-
ходящийся в вершине стека. Явная адресация подразумевает указание смещения
регистра относительно вершины стека (на рис. 3.2 — номера ST( 1)). Внутренняя
шина имеет 84 разряда для ускорения выполнения операций, но в программной
модели важна внешняя логическая структура. С каждым регистром связано двух-
битное поле тегов (tag field), предназначенное для быстрого анализа состояния
регистра. Комбинация бит 00 (Valid) указывает просто на наличие операнда в
регистре, 01 (Zero) — на его нулевое значение, 10 (Special) — специальное назна-
чение, 11 (Empty) — регистр пустой. Поля тегов объединены в одно слово тегов ТМ
(Tag Word). Теги модифицируются только сопроцессором — при восстановлении
их из образа регистров, сохраненного в памяти, используется только информация
«пустой» (И) или «непустой» (00, 01, 10). Значение тега для непустого регистра
сопроцессором определяется по фактическим данным.
Слово состояния SW (Status Word) отражает общее состояние сопроцессора (рис. 3.3).
Единичное значение бита В (Busy) указывает на занятость выполнением операции
3.1. Математический сопроцессор х87
81
или наличие необслуженного запроса на прерывание исключения (в FPU 486+
этот бит сохранен исключительно для обеспечения совместимости с 8087). Поле
ТОР указывает на вершину стека. Биты С[0:3] определяют код условия (Condition
Code), интерпретируемый в зависимости от выполненной инструкции. Если пос-
ле выполнения инструкции FSTSWAX, пересылающей слово состояния NPX в регистр
АХ, выполнить инструкцию SAHF, биты кода условия переносятся в регистры фла-
гов процессора, что позволяет использовать их в инструкциях условных перехо-
дов. Новые инструкции FPU Р6 (FCOMI, FCOMIP, FUCOMI и FUCOMIP) изменяют флаги
регистра EFLAGS непосредственно, а инструкции FCMOVEcc позволяют выполнять
условные пересылки по состоянию этих флагов. Таким образом, из программного
кода исключаются лишние инструкции и ветвления.
♦ Бит ES (Error Summary Status) устанавливается при возникновении немаски-
рованного исключения, при этом вырабатывается и сигнал на выходе FERR#
(ERROR# в 80287/387).
♦ Бит SF (Stack Flag) устанавливается при некорректной операции со стеком
(переполнение сверху или снизу).
♦ Биты 0-5 устанавливаются при возникновении соответствующих исключений.
Рис. 3.3. Слово состояния сопроцессора
Слово состояния 8087 имело некоторые отличия: бит 7 с тем же назначением на-
зывался IR (Interrupt Request), а флаг SF отсутствовал (бит 6 не использовался).
Управляющее слово CW (Control Word) служит для выбора параметров выполняе-
мых операций (рис. 3.4).
15 8 7 0
1 1 XXX X 1 rc —Г" PC 1 -Г" X X 1 р м и м О м Z м D М 1 м
Рис. 3.4. Управляющее слово сопроцессора
Единичные значения бит 0-5 маскируют отдельные исключения. Поле PC (Precision
Control) задает точность: 00 — 24 бит (одинарная), 10 — 53 бита (двойная), И —
64 бит (расширенная), 01 — зарезервировано. Поле RC (Rounding Control) опреде-
ляет способ округления: 00 — к ближайшему значению (четному), 01 — по направле-
нию к -оо, Ю — по направлению к +«>, И — по направлению к 0. Сопроцессор 8087
имел бит общей маски прерывания (бит 7), а бит 12 — IC (Infinity Control) — управ-
82
3. Математический сопроцессор, блоки ММХ и ХММ
лял представлением бесконечности: 0 — аффинное, 1 — проекционное представ-
ление. В сопроцессорах 80287+ представление бесконечности всегда аффинное.
Указатели инструкций и данных служат для сохранения адреса выполняемой ин-
струкции и адреса операнда в памяти. В реальном и защищенном режимах рабо-
ты сопроцессора указатели имеют различное назначение. В реальном режиме хра-
нится линейный адрес указателя инструкции FPU (FPU IP) и операнда (FPU 0Р),
в защищенном режиме хранятся их селекторы (FPU CS Selector и FPU OP Selector)
и смещения (FPU IP Offset и FPU OP Offset). Форматы также зависят и от разрядно-
сти операндов. Заметим, что сопроцессоры 80287+ сохраняют в указателе инст-
рукций адрес, указывающий на все префиксы инструкции, в то время как в 8087
адрес указывал на саму инструкцию.
31 16 15 о
1 РЕЗЕРВ 1 cw
РЕЗЕРВ sw
। РЕЗЕРВ 1 TW
FPU IP । OFFSET
00000 OPCODE[10:0] FPU CS SELECTOR i
FPU IP । I 1 OFFSET
I РЕЗЕРВ FPU OP SELECTOR
31 16 15 । 0
РЕЗЕРВ CW |
РЕЗЕРВ SW I
РЕЗЕРВ | I TW 1
РЕЗЕРВ 1 FPU IP[15:0]
0000 FPU IP[15:0] 0 OPCODE[10:0]
РЕЗЕРВ FPU OP[15:0]
0000 FPU IP[15:0] , , I 1 000 000000000 1 !
Рис. 3.5. Образы контекста FPU в 32-битном формате: а — защищенный; б — реальный режим
3.1. Математический сопроцессор х87
83
В регистре OpCode хранится код последней исполнявшейся неуправляющей инст-
рукции, причем из двухбайтного кода операции сохраняются только И младших
бит (5 старших всегда равны ПОИ, этот код называют «Escape»).
Состояние сопроцессора (контекст FPU) может сохраняться в памяти. Форматы
образов контекста в 32-битном защищенном и реальном режимах приведены на
рис. 3.5, 16-битные форматы — на рис. 3.6. Сами регистры данных блока ММХ
сохраняются в 80-байтной области, следующей за образами, представленными на
рисунках. Сохранение и восстановление контекста происходит только по специ-
альным инструкциям. Автоматически сохранение контекста ни по прерываниям,
ни по переключению задач, ни по входу в режим SMM не производится. При пе-
реключении задач процессор устанавливает флаг TS в регистре CR0. Если в CR0 ус-
тановлен флаг MP = 1, то при TS e 1 первая же инструкция FPU (ожидающая) вы-
зовет исключение сопроцессора.. Обработчик этого исключения должен принять
меры по переключению контекста, после чего сбросить флаг TS.
Инструкции FSTENV/FNSTENV сохраняют только регистр состояния, регистр управ-
ления, регистр тегов и указатели (сам стек регистров не сохраняется). Обратно
состояние загружается по инструкции FLDENV. Инструкции FSAVE/FNSAVE сохраня-
ют полный контекст FPU, включая и стек регистров; после выполнения этих ин-
струкций сопроцессор оказывается в исходном состоянии (как после FINIT/FNINIT).
Восстановить полный контекст можно по инструкций FRSTOR. В процессорах с бло-
ком ХММ (Pentium III) появились новые инструкции сохранения/восстановле-
ния полного контекста всех блоков FPU/ММХ и ХММ — FXSAVE и FXRSTOR соот-
ветственно. Сохраняемые образы имеют иной формат (см. п. 3.3). Инструкция
FXSAVE не проверяет ожидающие исключения и не инициализирует FPU (состоя-
ние FPU после нее не изменяется).
Рис. 3.6. Образы контекста FPU в 16-битном формате: а — реальный режим и V86;
б — защищенный режим
84
3. Математический сопроцессор, блоки ММХ и ХММ
3.1.3. Исключения сопроцессора
В процессе выполнения инструкций сопроцессора могут возникать особые слу-
чаи — исключения. Каждому типу исключений соответствует флаг регистра состо-
яния и бит маски в управляющем регистре (табл. 3.2). С помощью масок можно
подавлять генерацию исключений по различным классам условий (единичное
значение бита маскирует исключение). При возникновении условия исключения
устанавливается флаг данного исключения в регистре состояния. Флаги накап-
ливаются в регистре до явного сброса по инструкции FCLEX или FNCLEX. Незамаски-
рованное исключение вызывает также установку общего флага ES и аппаратный
сигнал ошибки на выходе сопроцессора.
Таблица 3.2. Исключения сопроцессора
Флаг Маска Исключение
IE IM #l (Invalid Operation) — недействительная операция: извлечение данных из пустого регистра, неопределенный результат (0/0 или «>-«>), извлечение квадратного корня из отрицательного числа, операция с нечисловыми переменными и т. п. Если установлен флаг SF, то исключение связано с переполнением стека сверху или снизу
DE DM #D (Denormalized Operand) — денормализован хотя бы один из операндов
ZE ZM #Z (Zero Divide) — деление на нуль ненулевого операнда
ОЕ ОМ #0 (Overflow) — переполнение
UE UM #U (Underflow) — потеря точности (исчезновение значащих разрядов)
РЕ PM #Р (Precision) — результат не может быть точно представлен в заданном формате, при этом выполняется округление
Возникновение замаскированного исключения только фиксируется в регистре
состояния, не вызывая прерывания, а сопроцессор выполняет соответствующую
данному типу внутреннюю процедуру обработки исключения для продолжения
работы. Внутренние процедуры обработки пригодны для большинства вычисле-
ний. Незамаскированное исключение обрабатывается внешней процедурой. Внеш-
няя процедура обработки исключений, выполняемая центральным процессором
по сигналу от сопроцессора, может считать в память содержимое регистров указа-
телей вместе со словами управления, состояния, тегов, а также кодом операции,
вызвавшей исключение. Процессор анализирует состояние флага ES при исполне-
нии последующей инструкции WAIT/FWAIT или иной ожидающей (waiting) инструк-
ции FPU. Ожидающими являются инструкции, у которых мнемоника имеет пре-
фикс «F»; для ряда инструкций FPU имеются неожидающие версии с префиксом
«FN», при их исполнении флаг ES не анализируется.
При обработке немаскированных исключений могут возникать проблемы синх-
ронизации, обусловленные параллельностью работы FPU и остальных блоков
процессора. Обработка исключений обычно подразумевает какие-либо действия
по корректировке операндов, которые могут находиться в регистрах CPU или
памяти. Процедура исключения вызывается лишь по следующей инструкции FPU
(ожидающей). Если после порождения исключения и до его фактической обра-
3.1. Математический сопроцессор х87
85
ботки CPU «испортит» значения операндов, то, естественно, процедура обработ-
ки исключения не сможет выполнить полезные действия. Чтобы разрешить эту
проблему, следом за инструкцией FPU, потенциально угрожающей выработкой
немаскированного исключения, и перед инструкцией CPU, влияющей на операн-
ды «опасной» инструкции FPU, следует ввести ожидающую инструкцию FPU
(хотя бы FWAIT, если нет полезной работы).
Обработка исключений внешними процедурами для процессоров 486+ возможна
в двух режимах. Естественный для процессора режим включается установкой
флага NE регистра CR0. При этом незамаскированное исключение сопроцессора
вызовет исключение процессора #MF — сразу по возникновении, перед следующей
инструкцией FPU (ожидающей) или перед инструкцией ММХ. Исключение вы-
зовет соответствующую процедуру обработки #MF по вектору 16 (10h).
Способ, естественный для IBM PC, выбирается сбросом флага NE. В этом случае
исключение #MF процессором внутренне не вырабатывается, а внешний обработ-
чик может быть вызван по аппаратному прерыванию от сигнала FERR#. После
этого режим работы процессора в случае обнаружения сопроцессором условия
немаскированного исключения будет определяться входным сигналом IGNNE#.
Если он пассивен, то процессор приостановится (сразу или перед следующей ин-
струкцией FPU) для реакции на аппаратное прерывание по сигналу FERR#. Если
сигнал IGNNE# активен, то приостановки не будет (но сигнал FERR# вырабатыва-
ется). Этот способ уходит корнями еще в PC АТ-286, где аппаратный сигнал ошиб-
ки сопроцессора заводился на вход вторичного контроллера прерываний IRQ13,
вызывая в случае исключения сопроцессора прерывание 117 (75h). Такое реше-
ние, очевидно, было принято во избежание конфликта с впдеосервисом (BIOS INT
10h), который вместе с остальными сервисами BIOS незадачливые разработчики
PC определили на зарезервированную (но почти не используемую в 8086) область
векторов прерываний. С точки зрения программирования вычислений этот спо-
соб хуже, поскольку маскируемое прерывание может вырабатываться асинхронно
по отношению к процессу, выполняемому FPU. Исключение же вырабатывается
синхронно со следующей инструкцией сопроцессора, что явно облегчает опреде-
ление связанного с ним контекста. Однако с точки зрения программирования бо-
лее частых, чем вычисления, операций с экраном (видеосервис BIOS INT 10h как
раз перекрывает исключение #MF, имеющее номер 16 - 1 Oh) использовать штатные
исключения #MF невыгодно, поскольку обработчик, разбираясь с источником пре-
рывания или исключения, будет тратить слишком много времени.
С инструкциями, относящимися к сопроцессору, также могут быть связаны исклю-
чения 7 (#NM, эмуляция сопроцессора или переключение задачи), 9 (нарушение
границы сегмента) и 13 (#GP, нарушение защиты), которые обсуждались выше.
3.1.4. Интерфейс сопроцессора
Интерфейс взаимодействия сопроцессора с основным процессором существенно
менялся дважды.
Сопроцессор 8087 для 8086/8088 и 80186/80188 подключается параллельно прак-
тически ко всем интерфейсным сигналам центрального процессора. Отслеживая
86
3. Математический сопроцессор, блоки ММХ и ХММ
сигналы состояния CPU, сопроцессор вместе с ним просматривает и декодирует
инструкции, «вылавливая» из них свои (по коду «Escape»). Если команда подра-
зумевает обмен данными с памятью, CPU «помогает» сопроцессору в вычислении
адреса, освобождая его от всех хитростей формирования физического адреса, при-
нятых в 8086. После отработки всех циклов передачи процессор переходит к вы-
полнению следующей инструкции, а сопроцессор начинает вычисления. После
вычислительной инструкции, исполняемой сопроцессором, должна следовать
команда WAIT (или FWAIT, что одно и то же), по которой процессор дожидается низ-
кого уровня сигнала на входе TEST#, связанного с выходом BUSY 8087. Сигнал за-
нятости BUSY вырабатывается сопроцессором на время выполнения вычисления,
чем и обеспечивается его синхронизация. Команду WAIT целесообразно вводить не
сразу после команды вычисления, а непосредственно перед тем, как потребуются
результаты вычислений — тогда процессор и сопроцессор могут некоторое время
работать параллельно. Для сигнализации об исключениях используется сигнал I NT
прерывания от сопроцессора. В IBM PC сигнал прерывания от сопроцессора че-
рез логическую схему поступает на вход NMI CPU и вызывает немаскируемое пре-
рывание (вектор 2).
Сопроцессоры 80287 и 80387 с процессорами 80286 и 80386 обмениваются данны-
ми через шинные циклы ввода-вывода, автоматически генерируемые CPU. При
этом в пространстве ввода-вывода занимается область адресов 00F8-00F0h (386
при этом выставляет единицу на старшей линии адреса). Синхронизация, как и
раньше, организуется с помощью сигнала BUSY#. Теперь операция WAIT встроена
во все инструкции, относящиеся к сопроцессору, поэтому необходимость в при-
менении отдельной инструкции WAIT перед каждой командой отпала. Незамаски-
рованное исключение вызывает активный сигнал на выходе ERROR#. Этот выход,
по замыслу разработчиков, должен соединяться с одноименным входом про-
цессора, и тогда при следующей инструкции сопроцессора будет генерироваться
исключение #MF (10h). Однако в IBM PC АТ этот выход заводится не на процес-
сор, а на вход вторичного контроллера прерываний IRQ13, вызывающий прерыва-
ние 117 (75h).
Процессоры 486 и выше могут иметь лишь встроенный сопроцессор, интерфейс с
внешним сопроцессором у них не предусмотрен. Теперь выработка исключений
не требует внешнего аппаратного интерфейса. Однако для совместимости с архи-
тектурой IBM PC процессоры 486+ имеют в регистре CRO флаг NE и пару сигналов
FERR# и IGNNE#. Сигнал ошибки сопроцессора FERR# аналогичен сигналу ERROR#
сопроцессора 287/387 — он вырабатывается в случае возникновения немаскиро-
ванного исключения. Входной сигнал IGNNE# заставляет процессор игнорировать
исключения сопроцессора (не приостанавливаться по ним).
3.2. Технология ММХ
Технология ММХ ориентирована на приложения мультимедиа, 2В/ЗВ-графику
и коммуникации. Это расширение базовой архитектуры появилось только после
выхода второго поколения процессоров Pentium. Основная идея ММХ заключа-
3.2. Технология ММХ
87
ется в одновременной обработке нескольких элементов данных за одну инструк-
цию — так называемая технология SIMD (Single Instruction — Multiple Data).
Расширение MMX использует новые типы упакованных 64-битных целочислен-
ных данных:
♦ упакованные байты (Packed byte) — восемь байт;
♦ упакованные слова (Packed word) — четыре слова;
♦ упакованные двойные слова (Packed doubleword) — два двойных слова;
♦ учетверенное слово (Quadword) — одно слово.
Эти типы данных могут специальным образом обрабатываться в 64-битных реги-
страх ММХО—ММХ7, представляющих собой младшие биты стека 80-битных
регистров FPU. Каждая инструкция ММХ выполняет действие сразу над всем
комплектом операндов (8,4, 2 или 1), размещенных в адресуемых регистрах. Как
и регистры FPU, эти регистры ММХ не могут использоваться для адресации памя-
ти. Совпадение регистров ММХ и FPU накладывает ограничения на чередование
кодов FPU и ММХ — забота об этом лежит на программисте приложений с ММХ.
Еще одна особенность технологии ММХ — поддержка арифметики с насыщением
(saturating arithmetic). Ее отличие от обычной арифметики с циклическим пере-
полнением (wraparound mode) заключается в том, что при возникновении пере-
полнения в результате фиксируется максимально возможное значение для данно-
го типа данных, а перенос игнорируется. В случае переполнения снизу в результате
фиксируется минимально возможное значение. Граничные значения определяют-
ся типом (знаковый или беззнаковый) и разрядностью переменных. Такой режим
вычислений удобен, например, для определения цветов.
В систему команд введено 57 дополнительных инструкций для одновременной
обработки нескольких единиц данных. Одновременно обрабатываемое 64-битное
слово может содержать как одну единицу обработки, так и 8 однобайтных, 4 двух-
байтных или 2 четырехбайтных операнда. Новые инструкции включают следую-
щие группы:
♦ арифметические (Arithmetic Instructions), куда входят сложение и вычитание
в разных режимах, умножение и комбинация умножения и сложения;
♦ сравнение (Comparison Instructions) элементов данных на равенство или по
величине;
♦ преобразование форматов (Conversion Instructions);
♦ логические инструкции (Logical Instructions) — И, И-НЕ, ИЛИ и исключаю-
щее ИЛИ, выполняемые над 64-битными операндами;
♦ сдвиги (Shift Instructions) — логические и арифметические;
♦ пересылки данных (Data Transfer Instructions) между регистрами ММХ и це-
лочисленными регистрами или памятью;
♦ очистка ММХ (Empty ММХ State) — установка признаков пустых регистров
в слове тегов.
Инструкции ММХ не влияют на флаги условий в слове состояния FPU.
88
3. Математический сопроцессор, блоки ММХ и ХММ
Регистры ММХ в отличие от регистров FPU адресуются физически, а не относитель-
но значения указателя стека ТОР. Более того, любая инструкция ММХ обнуляет
поле ТОР регистра состояния FPU. В слове тегов свободному регистру соответствует
комбинация 11, остальные комбинации указывают только на занятость регистра.
После каждой операции ММХ биты тегов регистра назначения обнуляются. Неис-
пользуемые в ММХ биты [79:64] регистров FPU заполняются единицами, так что
ошибочная обработка данных ММХ инструкцией FPU приведет к исключению.
Инструкции ММХ не порождают новых исключений. Исключения при выполне-
нии инструкций ММХ могут возникать только в случае нарушения границ в об-
ращениях к памяти (как при обмене данными, так и при выборке инструкции).
Однако если предшествующая инструкция FPU породила условие исключения,
то оно произойдет при выполнении инструкции ММХ. После его обработки ин-
струкция ММХ может быть благополучно исполнена.
С инструкциями ММХ могут применяться префиксы замены сегмента и измене-
ния разрядности адреса (влияют на инструкции, обращающиеся к памяти). Ис-
пользование префиксов изменения разрядности операнда и повторов зарезерви-
ровано (может привести к непредсказуемым результатам). Префикс Lock вызывает
исключение #UD.
Инструкции ММХ доступны из любого режима процессора. При переключении
задач необходимо следить за корректностью сохранения контекста, как и при ра-
боте с FPU.
Любая инструкция ММХ вызывает обнуление полей тегов всех регистров FPU/
ММХ, что для FPU означает наличие действительных данных во всех регистрах.
Последующая инструкция для FPU над «неправильными» данными может при-
вести к непредсказуемому результату, поскольку «входной контроль» данных осу-
ществляется по состоянию тегов. Чтобы застраховаться от подобных неприятно-
стей, после инструкций ММХ и перед инструкциями FPU в программный код
вводят инструкцию EMMS, которая устанавливает в слове тегов значение FFFFh (все
регистры пустые).
Различие в способе адресации регистров (относительная для FPU и явная прямая
в ММХ), обнуление тегов инструкциями ММХ и некоторые другие нюансы не
позволяют чередовать инструкции FPU и ММХ. Блок FPU/ММХ может рабо-
тать либо в одном, либо в другом режиме. Если, к примеру, в цепочку инструкций
FPU нужно вклинить инструкции ММХ, после чего продолжить вычисления FPU,
то перед первой инструкцией ММХ приходится сохранять контекст (состояние
регистров) FPU в памяти, а после этих инструкций снова загружать контекст. На
эти сохранения и загрузки расходуется процессорное время, в результате возмож-
на полная потеря выигрыша от реализации технологии SIMD. Совпадение регис-
тров ММХ и FPU оправдывают тем, что для сохранения контекста ММХ при пе-
реключении задач не требуется доработок в операционной системе — контекст
ММХ сохраняется тем же способом, что и FPU, с которым умели работать издав-
на. Таким образом, операционным системам было все равно, какой процессор ус-
тановлен — с ММХ или без. Но для того чтобы реализовать преимущества SIMD,
приложения должны «уметь» ими пользоваться (и не проиграть на переключениях).
3.3. Расширение SSE и SSE2 — блок ХММ
89
Частое чередование кодов FPU и ММХ может снизить производительность за счет
необходимости сохранения и восстановления весьма объемного контекста FPU.
Наличие поддержки ММХ определяется по биту 23 регистра EDX после вызова
инструкции CPUID(l).
3.3. Расширение SSE и SSE2 — блок ХММ
Процессоры Pentium III имеют так называемое потоковое расширение SSE (Streaming
SIMD Extensions). В те времена, когда будущий Pentium III называли еще Kathmai,
фирма Intel объявила о новых инструкциях KNI (Kathmai New Instruction), так
что SSE — это синоним «староинтеловского» KNI. Новые процессоры имеют до-
полнительный независимый блок из восьми 128-битных регистров, названных
ХММ0...ХММ7 (очевидно, extended MultiMedia), и регистр состояния/управления
MXCSR. В каждый из регистров ХММ помещаются четыре 32-битных числа в формате
с плавающей точкой одинарной точности. Блок позволяет выполнять векторные
(они же пакетные) и скалярные инструкции. Векторные инструкции реализуют
операции сразу над четырьмя комплектами операндов. Скалярные инструкции
работают с одним комплектом операндов — младшим 32-битным словом. При
выполнении инструкций с ХММ традиционное оборудование FPU/ММХ не ис-
пользуется, что позволяет эффективно смешивать инструкции ММХ с инструк-
циями над операндами с плавающей точкой. Здесь блоки процессора меняются
ролями — регистры ММХ, наложенные на регистры традиционного сопроцессо-
ра, используются для целочисленных потоковых вычислений, а вычисления с пла-
вающей точкой (правда, только с одинарной точностью, но для мультимедийных
приложений ее хватает) возлагаются на новый блок ХММ. Кроме инструкций с
новым блоком ХММ в расширение SSE входят и дополнительные целочисленные
инструкции с регистрами ММХ, а также инструкции управления кэшированием.
Новые инструкции с регистрами ММХ, как и их предшественники из «классичес-
кого» ММХ, не допускают чередования с инструкциями FPU без переключения
контекста FPU/MMX.
Регистр MXCSR используется для управления обработкой числовых исключений,
установки режима округления и режима очистки, а также чтения флагов состоя-
ния ХММ. Формат регистра приведен на рис. 3.7. Поле RC (управление округле-
нием), флаги исключений MXCSRQ5:0] и маски исключений MXCSR[7:12] по назначе-
нию аналогичны одноименным битам управляющего слова FPU, но относятся к
операциям в регистрах ХММ. При возникновении условия незамаскированного
исключения ХММ процессор вырабатывает исключение #XF (вектор 19). Каждый
флаг исключения относится ко всему пакету операндов, участвующих в операции
ХММ. Если флаг устанавливается, это означает, что при исполнении хотя бы в
одном комплекте операндов возникли условия данного исключения. Единичное
значение маски запрещает генерацию исключения и включает внутреннюю про-
цедуру обработки данного условия. После сброса все исключения замаскирова-
ны. Исключения генерируются только в процессе исполнения инструкций ХММ
(загрузка регистра MXCSR значением с установленными флагами исключений не
вызовет). Бит FZ включает режим обнуления (flush to zero): когда он установлен,
90
3. Математический сопроцессор, блоки ММХ и ХММ
в случае исчезновения значащих бит вместо денормализованного результата в опе-
ранд назначения записывается нуль (того же знака) и устанавливаются флаги РЕ
(precision) и UE (underflow). Если маска UM не установлена, то до обнуления будет
выработано исключение #U. Режим обнуления не соответствует стандарту IEEE
754, но он дает выигрыш в производительности, что важно для мультимедийных
приложений, где за скорость можно расплатиться снижением точности.
31-16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
Резерв FZ RC РМ им ОМ ZM DM IM Резерв РЕ UE ОЕ ZE DE IE
Рис. 3.7. Регистр MXCSR
Содержимое регистра MXCSR может быть загружено из памяти и сохранено по ин-
струкциям LDMXCSR и STMXCSR, а также вместе со всем контекстом блоков FP/MMX
и ХММ по инструкциям FXRSTOR и FXSAVE.
В отличие от блока ММХ, который для операционной системы неотличим от сопро-
цессора (и не требует дополнительных забот), блок ХММ является совершенно
новым набором регистров, и операционная система должна специально заботить-
ся о его содержимом при переключении задач. Для сохранения и восстановления
контекста блока ХММ, а также и FPU/ММХ служат новые инструкции FXSTOR и
FXRSTOR. Контекст хранится в памяти и занимает 512 байт (рис. 3.8), область хра-
нения контекста должна быть выровнена по границе параграфа. Заметим, что по
этим инструкциям контекст ХММ сохраняется и восстанавливается только в том
случае, если в управляющем регистре CR4 установлен бит OSFXSR. В отлич!це от ин-
струкции FSAVE инструкция FXSAVE не очищает состояние FPU.
15 | 14 13 I 12 11 I 10 |9j LL 7 | 6 5 | 4 3 I 2 1 I 0
Резерв CS IP FOP FTW FSW FCW 0
Резерв MXCSR Резерв DS DP 16
Резерв STO/MMO 32
Резерв ST1/MM1 48
Резерв ST2/MM2 64
Резерв ST3/MM3 80
Резерв ST4/MM4 96
Резерв ST5/MM5 112
Резерв ST6/MM6 128
Резерв ST7/MM7 144
ХММО 160
ХММ1 176
ХММ2 192
ХММЗ 208
ХММ4 224
ХММ5 240
ХММ6 256
ХММ7 272
Резерв 288-496
Рис. 3.8. Образ контекста FPU/ММХ и ХММ в памяти
3.3. Расширение SSE и SSE2 — блок ХММ
91
В образе контекста присутствуют следующие поля:
♦ CS, IP и FOP — селектор кодового сегмента, указатель инструкции и код опера-
ции (аналогичны соответствующим полям FPU/MMX);
♦ DS и DP — селектор и указатель адреса операнда (аналогичны соответствующим
полям указателя данных FPU/MMX);
♦ FTW, FSW и FCW — слово тегов, слово состояния и управляющее слово FPU;
♦ ST0/MM0...ST7/MM7 — образы регистров стека FPU/блока ММХ;
♦ ХММО...ХММ7 и MXCSR — образы регистров блока ХММ.
С инструкциями SSE могут использоваться префиксы замены сегмента и измене-
ния разрядности адреса (влияют на инструкции, обращающиеся к памяти). Исполь-
зование префиксов изменения разрядности операнда зарезервировано (может при-
вести к непредсказуемым результатам). Префикс Lock вызывает исключение #UD.
Из префиксов повтора можно использовать только безусловный (REP) и только
для «потоковых» инструкций (с ХММ). Остальные применения префиксов по-
втора могут привести к непредсказуемым результатам.
Приложение для работы с расширением SSE должно убедиться в его присутствии.
Для использования SIMD-инструкций с плавающей точкой требуются следующие
условия (если они не выполняются, то инструкции SSE будут вызывать исключе-
ния #UD):
♦ CR0.EM (бит 2) = 0 (эмуляция запрещена);
♦ CR4.0SFXSR (бит 9) = 1 (поддержка сохранения состояния ХММ при переклю-
чении контекста);
♦ CPUID.XMM (бит 25 EDX) = 1 (процессор поддерживает SSE).
Для возможности использования целочисленных SIMD-инструкций значение бита
CR4.0SFXR неважно, для использования новых инструкций кэширования достаточ-
но убедиться в наличии ХММ по инструкции CPUID.
В процессоре Pentium 4 набор инструкций получил очередное расширение — SSE2,
в основном касающееся добавления новых типов 128-битных операндов для бло-
ка ХММ:
♦ упакованная пара вещественных чисел двойной точности;
♦ упакованные целые числа: 16 байт, 8 слов, 4 двойных слова или пара учетве-
ренных (по 64 бита) слов.
В процессор введены новые функции целочисленной арифметики SIMD, 128-раз-
рядные для регистров ХММ и такие же 64-разрядные для регистров ММХ; ряд
старых инструкций ММХ распространили и на ХММ (в 128-битном варианте);
добавлены инструкции преобразований для новых форматов данных, а также рас-
ширены возможности «перемешивания» данных в блоке ХММ. Кроме того, рас-
ширена поддержка управления кэшированием и порядком исполнения операций
с памятью. Инструкции SSE2 предназначены для ЗО-графики, кодирования/деко-
дирования видео, а также шифрования данных. Признаком наличия SSE2 явля-
ется бит 26 EDX при вызове CPUID(l).
92
3. Математический сопроцессор, блоки ММХ и ХММ
3.4. Расширение 3DNow!
Расширение 3DNowl, введенное фирмой AMD в процессорах К6-2, расширяет
возможности ММХ. Оно позволяет оперировать с новым типом данных — парой
упакованных чисел в формате с плавающей точкой. Эти числа занимают по двой-
ному слову в 64-битных регистрах ММХ. Процессор К6-2 имеет два исполнитель-
ных блока, которые способны одновременно выполнять операции с плавающей
точкой над своими регистрами. Каждая такая операция занимает всего два такта,
операции полностью конвейеризируются. Таким образом, с конвейеров процес-
сора за каждый такт могут сходить четыре результата операций с плавающей точ-
кой. В систему команд добавлена 21 новая инструкция ММХ, большая часть ко-
торых предназначена для обработки упакованных чисел с плавающей точкой.
Имеется и новая целочисленная MMX-инструкция усреднения восьми пар 8-бит-
пых чисел, предназначенная для декодеров MPEG-2. Кроме того, имеется коман-
да быстрого переключения FPU-ММХ и предварительной выборки в первичный
кэш данных. Технология 3DNow! дает заметный результат при обработке графики,
хотя не претендует на вытеснение графических ускорителей, а призвана служить
их мощным дополнением. При этом сохраняется программная совместимость с
прежними процессорами и операционными системами (поскольку регистры ММХ
отображаются на регистры FPU, для них работают традиционные механизмы со-
хранения контекста в многозадачных ОС).
Расширение 3DNow! работает с упакованными данными в FP-формате одинар-
ной точности, а также упакованными (8 байт, 4 слова, 2 двойных слова) и 64-бит-
ными целыми числами, размещая их в младших 64 битах регистров FPU/MMX.
Каждое из двух упакованных FP-чисел представляется в том же формате, что и
числа одинарной точности FPU (в соответствии с IEEE 754). Однако операции с
ними не вызывают числовых исключений и не устанавливают никаких флагов
исключений. В случае выхода результата за границы представимых величин воз-
вращаемый результат соответствует граничным представимым числам (не беско-
нечностям), то есть FP-арифметика выполняется с насыщением. В случае исчез-
новения значащих разрядов (underflow) результат обнуляется. Арифметические
операции с некорректными операндами исполняются без генерации исключений,
однако результат при этом непредсказуем. Округление результатов операции
выполняется всегда только в сторону ближайшего числа, в инструкциях преобра-
зований целочисленных форматов в FP и обратно округление выполняется в сто-
рону нуля (усечение).
Исполнение инструкции 3DNow! (как и ММХ) может вызвать исключение сопро-
цессора, если на момент ее исполнения имеется ожидающее исключение FPU.
Переключение задач для сохранения и восстановления контекста 3DNow! отсле-
живается так же, как и для FPU/ММХ, — по флагу TS в регистре CR0. Традицион-
ные средства ОС для сохранения контекста FPU действуют для оборудования
всего комплексного блока FP/MMX/3DNow!.
3.4. Расширение 3DNow!
93
С инструкциями 3DNow! могут использоваться префиксы замены сегмента и из-
менения разрядности адреса (влияют на инструкции, обращающиеся к памяти).
Префиксы изменения разрядности операнда и повторов игнорируются. Префикс
Lock вызывает исключение #UD;
В процессорах Athlon и Duron набор инструкций 3DNow! был дополнен. Появи-
лись 5 новых инструкций для сигнальных процессоров (DSP), работающих с упа-
кованными FP-числами; еще 19 инструкций расширяют набор инструкций ММХ,
а также служат для управления кэшированием. Эти 19 инструкций совпадают с
одноименными инструкциями SSE.
Поддержка 3DNow! определяется по биту 31 (должен быть единичным) регистра
EDX после вызова CPUID(8000_0001h). Наличие расширения для сигнальных процес-
соров определяется по биту 30, наличие расширенного набора ММХ — по биту 22.
Использование инструкций 3DNow! (основных и расширенных) на процессоре без
поддержки этого расширения вызовет исключение #UD.
4. Система команд
Система команд 32-разрядных процессоров является существенно расширенной
системой команд процессоров 8086/80286. Расширения касаются увеличения раз-
рядности адресов и операндов, более гибкой системы адресации, появления прин-
ципиально новых типов данных (битовые строки и поля) и команд.
Команды (инструкции) содержат одно- или двухбайтный код инструкции, за ко-
торым может следовать несколько байт, определяющих режим исполнения коман-
ды, и операнды. Команды могут использовать до трех операндов (или ни одного).
Операнды могут находиться в памяти, регистрах процессора или непосредствен-
но в команде. Для 32-разрядных процессоров разрядность слова (word) по умол-
чанию может составлять 32, а не 16 бит. Это распространяется на многие инструк-
ции, включая и строковые. В реальном режиме и режиме виртуального процессора
8086 по умолчанию используется 16-битная адресация и 16-битные операнды-
слова. В защищенном режиме режим адресации и разрядность слов по умолчанию
определяются дескриптором кодового сегмента. Перед любой инструкцией может
быть указан префикс переключения разрядности адреса или слова. При адресации
памяти использование сегментного регистра, предусмотренного командой, в ряде
инструкций может подавляться префиксом изменения сегмента (Segment Override).
Назначение префиксов показано в табл. 4.1. Префиксы могут указываться в лю-
бом сочетании (всего до четырех на одну инструкцию и не более одного из каждой
группы), их действие распространяется только на одну инструкцию.
Таблица 4.1. Назначение префиксов инструкций
Префикс Назначение
SIZ Изменение разрядности слова данных (386+)
ADDRSIZ Изменение разрядности адреса (386+)
CS: SS: DS: ES: FS: GS: Изменение используемого сегментного регистра (FS: и GS: только для 386+)
LOCK Захват локальной шины на время выполнения инструкции
REP Префиксы повтора строковых операций до обнуления регистра СХ
REPE/REPZ (СХ декрементируется на каждом повторе) — безусловного
REPNE/REPNZ и условного (при ZF=1 и ZF=0 соответственно)
В системе команд насчитывается несколько сотен инструкций, которые можно
группировать по разным признакам. Для удобства «навигации» здесь все инструкции
сгруппированы по функциональной общности, к каждой группе даются краткие
комментарии. Детальные описания каждой инструкции, включая коды инструк-
4. Система команд
95
ций и возможные исключения, собраны в приложении 1, в котором инструкции,
относящиеся к целочисленному АЛУ, математическому сопроцессору, блокам
ММХ и ХММ, а также расширению 3DNow! приводятся в алфавитном порядке.
Там же перечислены все возможные причины исключений.
Для некоторых инструкций в представленных ниже таблицах через косую черту
указаны мнемоники-синонимы, расшифровка дается применительно к первой из
них или наиболее лаконичной.
Инструкции пересылки данных (см. табл. 4.2, а также п. 1.1 в приложении 1) по-
зволяют передавать константы или переменные между регистрами и памятью,
а также портами ввода-вывода в различных комбинациях, но в памяти может нахо-
диться не более одного операнда. В эту группу отнесены и инструкции преобразова-
ния форматов — расширений и перестановки байт. Операции со стеком выполня-
ются словами с разрядностью, определяемой текущим режимом. При помещении
в стек слова указатель стека SP уменьшается на число байт слова (2 или 4), при
извлечении — увеличивается. «Классические» (8086) инструкции, пересылки не
влияют на содержимое регистра флагов. Инструкции пересылки по результатам
сравнения (CMPXCHG) модифицируют флаг ZF. Новые инструкции условной пере-
сылки (CMOVxx) позволяют сократить число ветвлений в программе.
Таблица 4.2. Инструкции пересылки данных
Инструкция Описание
BSWAP Перестановка байт из порядка младший-старший (L—Н) в порядок старший-младший (H-L) (486+)
CBW/CWDE Преобразование байта AL в слово АХ (расширение знака AL в АН: АН заполняется битом AL.7) или слова АХ в двойное слово ЕАХ
CMOVA/CMOVNBE Пересылка, если выше ((CF ИЛИ ZF)=0) (Р6+)
CMOVAE/CMOVNB Пересылка, если не ниже (CF=0) (Р6+)
CMOVB/CMOVNAE Пересылка, если ниже (CF=1) (Р6+)
CMOVBE/CMOVNA Пересылка, если не выше ((CF ИЛИ ZF)=1) (Р6+)
CMOVC Пересылка, если перенос (CF=1) (Р6+)
CMOVE/CMOVZ Пересылка, если равно (ZF=1) (Р6+j
CMOVG/CMOVNLE Пересылка, если больше (SF=(OF И ZF)) (Р6+)
CMOVGE/CMOVNL Пересылка, если больше или равно (SF=OF) (Р6+)
CMOVL/CMOVNGE Пересылка, если меньше (ZF#OF) (Р6+)
CMOVLE/CMOVNG Пересылка, если меньше или равно (SF#OF или ZF=0) (Р6+)
CMOVNC Пересылка, если нет переноса (CF=0) (Р6+)
CMOVNE/CMOVNZ Пересылка, если не равно (ZF=0) (Р6+)
CMOVNO Пересылка, если нет переполнения (OF=0) (Р6+)
CMOVNP/CMOVPO Пересылка, если нет паритета (нечетность) (Р6+)
CMOVNS Пересылка, если неотрицательно (SF=0) (Р6+)
CMOVO Пересылка, если переполнение (OF=1) (Р6+)
продолжение^
96
4. Система команд
Таблица 4.2 (продолжение)
Инструкция Описание
CMOVP/CMOVPE CMOVS Пересылка, если паритет (четность) (Р6+) Пересылка, если отрицательно (SF=1) (Р6+)
CMPXCHGr/m,r CMPXCHG8Bm64 Обмен по результату сравнения байта, слова или двойного слова (486+) Обмен по результату сравнения учетверенного слова (5+)
CWD/CDQ Преобразование слова АХ в двойное слово DX:AX (расширение знака, DX заполняется битом АХ. 15) или двойного слова ЕАХ в учетверенное EDX:EAX
IN Ввод из порта ввода-вывода в AL/(E)AX
MOV Пересылка (копирование) данных
MOVSX Копирование байта/слова со знаковым расширением до слова/ двойного слова(386+)
MOVZX Копирование байта/слова с нулевым расширением до слова/ двойного слова(386+)
OUT Вывод в порт из AL/(E)AX
POP Извлечение слова данных из стека в регистр или память, (E)SP инкрементируется
POPA(POPAII) POPAD Извлечение данных из стека в регистры DI, SI, BP, ВХ, DX, СХ, АХ (286+) Извлечение данных из стека в регистры EDI, ESI, EBP, ЕВХ, EDX, ЕСХ, ЕАХ(386+)
PUSH Помещение слова из регистра или памяти в стек после декремента (E)SP
PUSHA (PUSH All) Помещение в стек регистров АХ, СХ, DX, ВХ, SP (исходное значение), BP.SI.DI (286+)
PUSHAD Помещение в стек регистров ЕАХ, ЕСХ, EDX, ЕВХ, ESP (исходное значение), EBP, ESI, EDI (386+)
XCHG Обмен данными (взаимный) между регистрами или регистром и памятью
Инструкции ввода-вывода (см. п. 1.1 в приложении 1) позволяют пересылать как
одиночный байт или слово между портом и регистром процессора (инструкции IN и
OUT, см. табл. 4.2), так и блок байт (слов) между портом и группой смежных ячеек
памяти (инструкции INSB/INSW и OUTSB/OUTSW с префиксом повтора, см. ниже). Непо-
средственная адресация порта в команде обеспечивает доступ только к первым 256 ад-
ресам портов, косвенная (через регистр DX) — ко всему пространству ввода-вывода
(64 Кбайт). Разрядность операнда и адрес должны согласовываться с физическими
возможностями и особенностями поведения адресуемого устройства (см. п. 2.4). При
работе с памятью такие нюансы во внимание принимать обычно не приходится.
Инструкции двоичной арифметики (см. табл. 4.3, а также п. 1.1 в приложении 1)
выполняют все арифметические действия с байтами, словами и двойными слова-
ми, кодирующими знаковые или беззнаковые целые числа. Умножение и деление
для 8086 возможны только с аккумулятором, результат для 16-битных операндов
расширяется в регистре DX. Для 286+ возможно двух- и трехадресное умножение с
расширением только в старший байт (два байта для 386+).
4. Система команд
97
Таблица 4.3. Инструкции двоичной арифметики
Инструкция Описание
ADC ADD CMP DEC DIV IDIV IMUL INC MUL NEG SBB SUB XADD Сложение двух операндов с учетом переноса от предыдущей операции Сложение двух операндов Сравнение (вычитание без сохранения результата — установка флагов) Декремент (вычитание 1, но не действует на флаг CF) Деление беззнаковое Деление знаковое Умножение знаковое Инкремент (сложение с 1, но не действует на флаг CF) Беззнаковое умножение Изменение знака операнда Вычитание с заемом Вычитание Обмен содержимым и сложение (486+)
Инструкции десятичной арифметики (табл. 4.4) являются дополнением к преды-
дущим. Они позволяют оперировать с неупакованными (биты [7:4] = 0, биты [3:0]
содержат десятичную цифру 0-9) или упакованными (биты [7:4] содержат стар-
шую, биты [3:0] — младшую десятичную цифру 0-9) двоично-десятичными чис-
лами. Арифметические операции над этими числами требуют применения инст-
рукций коррекции форматов.
Таблица 4.4. Инструкции десятичной арифметики
Инструкция Описание
ААА AAD1 ААМ1 AAS DAA DAS Десятичная коррекция после сложения двух неупакованных чисел Десятичная коррекция перед делением неупакованного двузначного числа Десятичная коррекция после умножения двух неупакованных чисел Десятичная коррекция после вычитания двух неупакованных чисел Десятичная коррекция AL после сложения двух упакованных чисел Десятичная коррекция AL после вычитания двух упакованных чисел
1 Инструкции AAD и ААМ допускают обобщенный формат вызова, при котором коррекция выполняет-
ся по любому модулю (а не только по модулю 10).
Инструкции логических операций (см. табл. 4.5, а также п. 1.1 в приложении 1) выпол-
няют все функции булевой алгебры над байтами, словами или двойными словами.
Таблица 4.5. Инструкции логических операций
Инструкция Описание
AND NOT OR XOR Логическое И Инверсия (переключение всех бит) Логическое ИЛИ Исключающее ИЛИ
98
4. Система команд
Сдвиги и вращения (циклические сдвиги) выполняются над регистром или опе-
рандом в памяти (см. табл. 4.6, а также п. 1.1 в приложении 1). Число позиций, на
которое производится сдвиг, берется непосредственно из операнда или регистра
CL по модулю 8 для однобайтного операнда и по модулю 16 или 32 для операнда-
слова, в зависимости от разрядности данных (32 только для 386+). Биты, вытал-
киваемые при сдвигах, попадают во флаг CF. При сдвигах влево и простом сдвиге
вправо освобождающиеся биты заполняются нулями (инструкции SAL и SHL — си-
нонимы). При арифметическом сдвиге вправо старший бит (знак) сохраняет свое
значение. При циклических сдвигах выталкиваемые биты попадают и во флаг CF,
и в освобождающиеся позиции. В сдвигах могут участвовать и два операнда (ин-
струкции SHLD и SHRD).
Таблица 4.6. Инструкции сдвигов
Инструкция Описание
RCL Циклический сдвиг влево через бит переноса
RCR Циклический сдвиг вправо через бит переноса
ROL Циклический сдвиг влево
ROR Циклический сдвиг вправо
SAL Сдвиг арифметический влево
SAR Сдвиг арифметический (с сохранением старшего бита) вправо
SHL Сдвиг влево
SHR Сдвиг вправо
SHLD Сдвиг влево и вставка данных в освободившиеся позиции (386+)
SHRD Сдвиг вправо и вставка данных в освободившиеся позиции (386+)
Инструкции обработки бит и байт (см. табл. 4.7, а также п. 1.1 в приложении 1)
позволяют проверять (копировать в CF) и устанавливать значение указанного опе-
ранда, а также искать установленный бит. Битовые операции выполняются над 16-
или 32-битным словом памяти или регистром. Инструкции BSF, BSR и ВТ не изме-
няют значения слова; BTC, BTR и BTS воздействуют на указанный бит слова. Номер
интересующего бита берется из операнда по модулю 16 или 32, в зависимости от
разрядности.
Операции с байтами обеспечивают условную установку значений 00h или Olh.
Инструкция тестирования может выполняться над байтом, словом или двойным
словом.
Таблица 4.7. Инструкции обработки бит и байт
Инструкция Описание
BSF Сканирование бит (поиск единичного) вперед
BSR Сканирование бит назад
ВТ Тестирование бита (загрузка в CF)
ВТС Тестирование и изменения значения бита
4. Система команд
99
Инструкция Описание
BTR Тестирование и сброс бита
BTS Тестирование и установка бита
SALC Условная (по CF) установка AI в FFh или 00h (не документировано, код D6h)
SETA/ SETNBE Установка байта в 01 h, если выше ((CF ИЛИ ZF)=0), иначе в 00h
SETAE/ SETNB/ SETNC Установка байта в 01 h, если не ниже (CF=0), иначе в 00h
SETB/ SETNAE/ SETC Установка байта в 01 h, если ниже (CF=1), иначе в 00h
SETBE/ SETNA Установка байта в 01 h, если не выше (CF ИЛИ ZF)=1, иначе в 00h
SETE/ SETZ Установка байта в 01 h, если равно (ZF= 1), иначе в 00h
SETG/ SETNLE Установка байта в 01 h, если больше (SF=(OF И ZF)), иначе в 00h
SETGE/ SETNL Установка байта в 01 h, если больше или равно (SF=OF), иначе в 00h
SETL/ SETNGE Установка байта в 01 h, если меньше (ZF*OF), иначе в 00h
SETLE/ SETNG Установка байта в 01 h, если меньше или равно (SF*OF или ZF=0), иначе в 00h
SETNE/ SETNZ Установка байта в 01 h, если не равно (ZF=0), иначе в 00h
SETNO Установка байта в 01 h, если нет переполнения (OF=0), иначе в 00h
SETNS Установка байта в 01 h, если неотрицательно (SF=0), иначе в 00h
SETO Установка байта в 01 h, если переполнение (OF=1), иначе в 00h
SETPE/ SETP Установка байта в 01 h, если паритет (четность), иначе в 00h
SETPO/ SETNP Установка байта в 01 h, если нет паритета (нечетность), иначе в 00h
SETS Установка байта в 01 h, если отрицательно (SF=1), иначе в 00h
SETC Установка байта в 01 h, если перенос (CF=1), иначе в 00h
SETNC Установка байта в 01 h, если нет переноса (CF=0), иначе в 00h
TEST Проверка бит (логическое И без записи результата — установка флагов)
Передача управления (см. табл. 4.8, а также п. 1.1 в приложении 1) осуществляет-
ся с помощью инструкций безусловных и условных переходов, вызовов процедур
и прерываний (исключений). Безусловный переход (JMP) может быть как внутри-
сегментным (ближним или коротким), так и межсегментным (дальним). Адрес
перехода может непосредственно указываться в команде, а при косвенной адреса-
ции адрес перехода находится в регистре или памяти и может иметь дополнитель-
100
4. Система команд
ные слагаемые. Короткий переход (short) может передавать управление только на
адрес назначения, удаленный от текущего в пределах -128...+127 байт, ближний
(near) — в пределах сегмента. При дальнем (far) переходе адрес назначения (не-
посредственный или косвенный) включает новое значение указателя инструкций
и значение (или селектор) сегмента кода, обеспечивая доступ к любой точке памя-
ти (в пределах, разрешенных защитой).
Таблица 4.8. Инструкции передачи управления
Инструкция Описание
JMP Безусловный переход
Вызовы процедур и прерываний
BOUND Проверка индекса на нарушение границ массива с генерацией INT 5 (286+)
CALL Вызов процедуры
INT3 Выполнение программного прерывания 3 — ловушки отладки (однобайтный код команды)
INT Выполнение программного прерывания с любым номером
INTO Выполнение программного прерывания 4, если OF=1
IRET/ IRETD Возврат из прерывания (разные мнемоники для одного кода)
RET Возврат из процедуры
Циклы (счетчик циклов: СХ при 16-битной адресации, ЕСХ — при 32-битной)
LOOP (Е)СХ=(Е)СХ-1 и переход, если (Е)СХ*О
LOOPE/ LOOPZ (Е)СХ=(Е)СХ-1 и переход, если (Е)СХ*О и ZF=1
LOOPNE/ LOOPNZ (Е)СХ=(Е)СХ-1 и переход, если (Е)СХ*О и ZF=O
Условные переходы
JC Переход, если перенос (CF=1)
JE/JZ Переход, если равно (ZF=1)
JNC Переход, если нет переноса (CF=O)
JNE/JNZ Переход, если не равно (ZF=O)
JNP/JPO Переход, если нечетный паритет (PF=O: число единичных бит нечетное)
JP/JPE Переход, если четный паритет (PF=1: число единичных бит четное)
JCXZ Переход, если СХ=0
JECXZ Переход, если ЕСХ=О (386+)
Условные переходы беззнаковые
JA/JNBE Переход, если выше ((CF ИЛИ ZF)=O)
JAE/JNB Переход, если не ниже (CF=O)
JB/JNAE Переход, если ниже (CF=1)
JBE/JNA Переход, если не выше (CF ИЛИ ZF)=1
Условные переходы знаковые
JG/JNGE Переход, если больше (SF=(OF И ZF))
JGE/JNL Переход, если больше или равно (SF=OF)
4. Система команд
101
Инструкция Описание
JL/JNGE JLE/JNG JNO Переход, если меньше (ZF*OF) Переход, если меньше или равно (SF*OF или ZF=O) Переход, если нет переполнения (OF=0)
JNS Переход, если неотрицательно (SF=O)
JO Переход, если переполнение (OF=1)
JS Переход, если отрицательно (SF=1)
Условные переходы в 8086 и 80286 возможны только короткие (8-байтное смеще-
ние), процессоры 386+ допускают переход в пределах 16- или 32-байтного смеще-
ния, в зависимости от режима адресации. Условные переходы выполняются по
состоянию флагов и (или) содержимому регистра СХ (ЕСХ). Инструкции циклов
комбинируют условный переход с декрементом регистра СХ (ЕСХ).
Инструкция вызова процедуры (CALL) сохраняет адрес следующей за ней инструк-
ции в стеке и передает управление в заданную точку. По инструкции возврата (RET)
сохраненный адрес восстановится в указателе инструкций (и в CS при дальнем
вызове). Как и безусловный переход, вызов и возврат могут быть как внутрисегмент-
ными (ближними), так и межсегментными, допуская те же режимы адресации.
В защищенном режиме межсегментные переходы, вызовы и возвраты осуществ-
ляются через шлюзы вызовов. Здесь первая часть (16 бит) указателя используется
как селектор сегмента, дескриптор которого находится в GDT или LDT. Тип дескрип-
тора (сегмент кода, шлюз вызова или задачи, сегмент состояния задачи TSS) оп-
ределяет действия, выполняемые при вызове.
♦ Если дескриптор относится к сегменту кода, с тем же уровнем привилегий (или
подчиненного), то дальний переход или вызов выполняется так же, как и в ре-
альном режиме. Если уровни привилегий не совпадают и сегмент неподчинен-
ный, генерируется исключение
♦ Дескриптор шлюза вызова используется для вызова процедуры как с иным
уровнем привилегий (при этом переключается стек), так и без смены уровня
(стек не переключается). При этом вторая часть указателя (смещение) игнори-
руется. Данный тип вызова рекомендуется для вызовов между 16- и 32-разряд-
ными сегментами кода.
♦ Для переключения задач используется дескриптор шлюза задач (косвенно опи-
сывающий новый сегмент TSS) или непосредственно TSS. При этом управле-
ние передается повой задаче в ту точку, на которой она была приостановлена.
Строковые операции (см. табл. 4.9, а также п. 1.1 в приложении 1) выполняются с
операндами в памяти, адресуемыми регистрами DS:SI (DS:ESI) для источника и
ES:DI (ES: EDI) для приемника. Операции могут использоваться с префиксами
условного или безусловного повтора. После каждой пересылки или сравнения
индексные регистры (SI, DI или оба) участвующих операндов автоматически инк-
рементируются или декрементируются на количество байт, участвующих в опе-
рации (1,2 или 4). Направление модификации определяется флагом DF: DF = 0 —
102
4. Система команд
инкремент, DF = 1 — декремент. Строковые инструкции ввода-вывода с префик-
сами повтора позволяют достигать высоких скоростей обмена с портами при ус-
ловии полной загрузки процессора.
Таблица 4.9. Инструкции строковых операций
Инструкция Описание
CMPSB, CMPSD, CMPSW Сравнение строк байт, слов или двойных слов с записью результата сравнения в регистр флагов
INSB, INSD, INSW Запись байта, слова или двойного слова, введенного из порта, в память (286+)
LODSB, LODSD, LODSW MOVSB, MOVSD, MOVSW Копирование байта, слова или двойного слова из строки в AL/(E)AX Копирование байта, слова или двойного слова из одной строки в другую
OUTSB, OUTSD, OUTSW SCASB, SCASD, SCASW Вывод байта, считанного из памяти, в порт (286+) Сканирование строки байт, слов или двойных слов — сравнение с AL/(E)AX и запись результата сравнения в регистр флагов
STOSB, STOSD, STOSW REP Запись байта, слова или двойного слова в строку из АЦ/(Е)АХ Префикс повтора строковых операций до обнуления (Е)СХ, (Е)СХ декрементируется на каждом повторе
REPE/REPZ Префикс условного повтора строковых операций — выполнения REPnpnZF=1
REPNE/ REPNZ Префикс условного повтора строковых операций — выполнения REP при ZF=O
Операции с флагами (см. табл. 4.10, а также п. 1.1 в приложении 1.1) позволяют из-
менять значения отдельных флагов, а также сохранять их значение в стеке (или
регистре АН) и восстанавливать сохраненные значения.
Таблица 4.10. Инструкции работы с флагами
Инструкция Описание
CLC CLD Сброс флага переноса (CF=O) Сброс флага направления (DF=0 — инкремент (E)SI, (Е)DI)
CLI СМС LAHF Запрет маскируемых аппаратных прерываний (IF=0) Инверсия флага переноса (CF=1 -CF) Загрузка флагов (SRZE0:AE0:PE1 :CF) в регистр АН
POPF(POP Flags) POPFD PUSHF(PUSH Flags) PUSHFD SAHF Извлечение данных из стека в регистр флагов (EFLAGSf 15:0]) Извлечение данных из стека в расширенный регистр флагов EFLAGS Помещение в стек регистра флагов (EFLAGS[ 15:0]) Помещение в стек расширенного регистра флагов EFLAGS Загрузка флагов SF, ZF, AF, PF, CF из бит 7,6,4, 2, 0 регистра АН
STC Установка флага переноса (CF=1)
STD Установка флага направления (DF=1 — декремент (Е)SI, (Е)DI)
STI Разрешение маскируемых аппаратных прерываний (IF= 1)
4. Система команд
103
Инструкции загрузки указателей (см. табл. 4.11, а также п. 1.1 в приложении 1)
позволяют загружать дальние указатели из памяти в регистр общего назначения
и соответствующий сегментный регистр. Кроме того, с сегментными регистрами
возможны стековые операции PUSH и POP, а также обмен через регистры общего
назначения (MOV).
Таблица 4.11. Инструкции загрузки указателей
Инструкция Описание
LDS Загрузка дальнего указателя из памяти в DS и регистр общего назначения
LES Загрузка дальнего указателя из памяти в ES и регистр общего назначения
LFS Загрузка дальнего указателя из памяти в FS и регистр общего назначения
LGS Загрузка дальнего указателя из памяти в GS и регистр общего назначения
LSS Загрузка дальнего указателя из памяти в SS и регистр общего назначения
В табл. 4.12 приведены разные инструкции, не входящие в вышеперечисленные
классы (см. также п. 1.1 в приложении 1).
Таблица 4.12. Разные инструкции
Инструкция Описание
CPUID Получение информации о процессоре (Р5+)
LEA Загрузка эффективного адреса
XLAT/ XLATB Трансляция(перекодирование)
NOP Нетоперации
UD2 Неопределенные 2-байтные инструкции (вызывают исключение #UD)
ENTER Выделение блока параметров в стеке
LEAVE Освобождение блока параметров в стеке
Инструкция ENTER служит для подготовки вызовов процедур (с поддержкой вло-
женности) в языках высокого уровня. Она выделяет область переменных в стеке.
Обратная инструкция LEAVE восстанавливает исходное значение указателя стека.
Инструкции математического сопроцессора (FPU) имеют свою специфику зада-
ния операндов (см. табл. 4.13, а также п. 1.2 в приложении 1). Переменная st(0)
находится на вершине стека сопроцессора, st(i) смещена от вершины на 1. За-
грузка данных начинается с декремента указателя стека сопроцессора (поле ТОР) —
перемещения вершины. Если новая вершина не пустая (по полю TAG) или стек
исчерпан, вызывается исключение с указанием причины. После загрузки поле TAG
устанавливается в соответствии с загруженным числом. При извлечении из стека
производится инкремент ТОР, а в поле TAG старой вершины устанавливается при-
знак пустой ячейки. Попытка использования пустого регистра в операциях или
для сохранения результатов в памяти вызывает исключение. Инструкции с пре-
фиксом F предварительно проверяют флаг исключения ES (они называются ожи-
дающими инструкциями), инструкции с префиксом FN флаг исключения не про-
104
4- Система команд
веряют (неожидающие инструкции). Ряд инструкций не вызывает исключения в
случае, если обнаруживаются операнды не-числа (NaN).
Таблица 4.13. Инструкции FPU
Инструкция Описание
Пересылки данных
FBLD Преобразование и помещение (push) числа в упакованном BCD-формате из памяти в стек
FBSTP Извлечение из стека и запись в память в упакованном BCD-формате (10 байт, 18 цифр)
FCMOVB Пересылка, если ниже (CF=1) (Р6+)
FCMOVBE Пересылка, если не выше (CF ИЛИ ZF)=1 (Р6+)
FCMOVE Пересылка, если равно (ZF= 1) (Р6+)
FCMOVNB Пересылка, если не ниже (CF=O) (Р6+)
FCMOVNBE Пересылка, если выше ((CF ИЛИ ZF)=O) (Р6+)
FCMOVNE Пересылка, если не равно (ZF=O) (Р6+)
FCMOVNU Пересылка, если не NaN (PF=O) (Р6+)
FCMOVU Пересылка, если NaN (unordered) (PF=O) (Р6+)
FILD Загрузка (push) целого числа из памяти
FIST Запись в память в формате целого числа
FISTP Запись в память в формате целого числа с извлечением
FLD Загрузка (push) вещественного числа
FST Сохранение (копирование) числа в памяти (в вещественном формате) или в регистре стека
FSTP Запись числа в память (в вещественном формате) или в регистр стека с извлечением
FXCH Обмен значениями вершины стека и регистра
Загрузка констант
FLD1 Загрузка (push) + 1,0
FLDL2E Загрузка (push) Iog2(e)
FLDL2T Загрузка (push) Iog2( 10)
FLDLG2 Загрузка (push) lg(2)
FLDLN2 Загрузка (push) ln(2)
FLDPI Загрузка(push)p
FLDZ Загрузка (push) + 0,0
Базовая арифметика
FABS Нахождение абсолютного значения
FADD Сложение вещественных чисел
FADDP Сложение вещественных чисел с извлечением
FCHS Изменение знака
4. Система команд
105
Инструкция Описание
FDIV Деление вещественных чисел
FDIVP Деление вещественных чисел с извлечением
FDIVR Обратное деление вещественных чисел
FDIVRP Обратное деление вещественных чисел с извлечением
FIADD Сложение с целым числом
FIDIV Деление на целое число
FIDIVR Обратное деление целых чисел
FIMUL Умножение на целое число
FISUB Вычитание целого числа
FISUBR Вычитание из целого числа
FMUL Умножение вещественных чисел
FMULP Умножение вещественных чисел с извлечением
FPREM Нахождение частичного остатка
FPREM1 Нахождение частичного остатка в стандарте IEEE (387+)
FRNDINT Округление до ближайшего целого
FSCALE Масштабирование — умножение на округленную в сторону нуля степень числа 2
FSQRT Извлечение квадратного корня
FSUB Вычитание вещественного числа
FSUBP Вычитание вещественных чисел с извлечением
FSUBR Обратное вычитание числа
FSUBRP Обратное вычитание с извлечением
FXTRACT Выделение мантиссы и порядка числа
Сравнение данных
FCOM Сравнение вещественных чисел (установка флагов сопроцессора)
FCOMI Сравнение и соответствующая установка флагов в EFLAGS (ZF, PF, CF) (Р6+)
FCOMIP Сравнение и соответствующая установка флагов в EFLAGS (ZF, PF, CF), с извлечением (Р6+)
FCOMP Сравнение вещественных чисел с извлечением
FCOMPP Сравнение вещественных чисел с двойным извлечением
ЯСОМ Сравнение с целочисленным операндом из памяти
FICOMP Сравнение с целочисленным операндом из памяти с извлечением
FTST Проверка на нуль
FUCOM Сравнение без генерации исключения в случае NaN (387+)
FUCOMI Сравнение без генерации исключения в случае NaN и соответствующая установка флагов в EFLAGS (ZF, PF, CF) (P6+)
FUCOMIP Сравнение без генерации исключения в случае NaN и соответствующая установка флагов в EFLAGS (ZF, PF, CF) с извлечением (Р6+)
продолжение^
106
4. Система команд
Таблица 4.13 (продолжение)
Инструкция Описание
FUCOMP Сравнение без генерации исключения в случае NaN с извлечением (387+)
FUCOMPP Сравнение без генерации исключения в случае NaN с двойным извлечением (387+)
FXAM Анализ числа — установка кода условия в СО, С2, СЗ
Трансцендентные функции
F2XM1 Вычисление 2х-1
FCOS Косинус(387+)
FPATAN Арктангенс частного с извлечением
FPTAN Вычисление тангенса и загрузка (push) в стек +1,0
FSIN Вычисление синуса (387+)
FSINCOS Вычисление синуса и косинуса с помещением (push) в стек (387+)
FYL2X Вычисление Y х log2(X)
FYL2XP1 Вычисление Y х 1од2(Х+1)
Управление сопроцессором
FCLEX Сброс флагов исключений с предварительной проверкой ожидающих немаскированных исключений
FDECSTP Декремент указателя стека FPU
FFREE Освобождение регистра — пометка как свободного
FINCSTP Инкремент указателя стека FPU
FINIT Инициализация FPU с предварительной проверкой ожидающих исключений
FLDCW Загрузка управляющего слова (FPU CW) из памяти
FLDENV Загрузка состояния сопроцессора из памяти, сохраненного инструкциями FSTENV/FNSTENV
FNCLEX Сброс флагов исключений без проверки ожидающих
FN1NIT Инициализация FPU без проверки ожидающих исключений
FNOP Пустая операция FPU
FNSAVE Сохранение состояния сопроцессора и стека регистров в памяти без проверки ожидающих исключений
FNSTCW Сохранение управляющего слова без проверки ожидающих исключений
FNSTENV Сохранение состояния сопроцессора (SR, CR, TAGW, FIP и FDP) в памяти без проверки ожидающих исключений
FNSTSW Запись слова состояния без проверки ожидающих исключений
FRSTOR Загрузка состояния сопроцессора и регистров из памяти
FSAVE Сохранение состояния сопроцессора и стека регистров в памяти с предварительной проверкой ожидающих исключений
FSTCW Сохранение управляющего слова с предварительной проверкой ожидающих исключений
FSTENV Сохранение состояния сопроцессора (SR, CR, TAGW, FIP и FDP) в памяти с предварительной проверкой ожидающих исключений
4. Система команд
107
Инструкция Описание
FSTSW Запись слова состояния для последующего переноса кода завершения в регистр флагов с предварительной проверкой ожидающих исключений ч
WAIT/FWAIT Синхронизация — останов CPU до завершения текущей операции FPU, проверка ожидающих исключений FPU
Инструкции ММХ (см. табл. '4.14, а также п. 1.3 в приложении 1) появились в про-
цессорах Pentium ММХ и с тех пор поддерживаются всеми более современными
процессорами (Pentium Pro, появившийся раньше, эти инструкции не поддержи-
вает). Они имеют сложную мнемонику, которая включает следующие элементы:
♦ префикс Р (Packed), указывающий на обработку упакованных форматов;
♦ мнемонику операции (например, ADD, CMP или XOR);
♦ суффикс, идентифицирующий тип насыщения: US (Unsigned Saturation) — на-
сыщение беззнаковое, S (Signed saturation) — насыщение знаковое;
♦ суффикс, идентифицирующий тип данных: В — упакованные байты, W — упа-
кованные слова, D — упакованные двойные слова, Q —учетверенное слово.
Инструкции, у которых типы входных и выходных данных различаются (напри-
мер, преобразования), имеют два суффикса.
Для инструкций пересылки данных операнды источника и назначения могут на-
ходиться в памяти (т32 или т64\ целочисленных регистрах (гг32) или регистрах
ММХ (тт). Для остальных инструкций, кроме вышеперечисленных, операнд-
источник может быть и непосредственным, а операнд назначения всегда является
регистром ММХ. Для операндов, находящихся в памяти, применимы все суще-
ствующие режимы адресации.
Таблица 4.14. Инструкции ММХ
Инструкция Описание
EMMS Очистка стека регистров — установка всех единиц в слове тегов
Пересылка данных
MOVD Пересылка данных в младшие 32 бита регистра ММХ (с заполнением старших бит нулями) или из младших 32 бит регистра ММХ
MOVQ Пересылка данных (64 бит) из/в регистр ММХ
Преобразование форматов
PACKSSDW Упаковка со знаковым насыщением четырех двойных слов в четыре слова
PACKSSWB Упаковка со знаковым насыщением восьми слов в восемь байт
PACKUSWB Упаковка с насыщением восьми знаковых слов в восемь беззнаковых байт
PUNPCKHBW Чередование в регистре назначения байт старшей половины операнда- источника с байтами старшей половины операнда назначения
PUNPCKHWD Чередование в регистре назначения слов старшей половины операнда- источника со словами старшей половины операнда назначения
продолжение#
108
4. Система команд
Таблица 4.14 (продолжение)
Инструкция Описание
PUNPCKHDQ Чередование в регистре назначения двойного слова старшей половины операнда-источника с двойным словом старшей половины операнда назначения
PUNPCKLBW Чередование в регистре назначения байт младшей половины операнда- источника с байтами младшей половины операнда назначения
PUNPCKLWD Чередование в регистре назначения слов младшей половины операнда- источника со словами младшей половины операнда назначения
PUNPCKLDQ Чередование в регистре назначения двойного слова младшей половины операнда-источника с двойным словом младшей половины операнда назначения
Упакованная арифметика
PADDB PADDW PADDD PADDSB PADDSW PADDUSB PADDUSW PMADDWD Сложение упакованных байт (слов или двойных слов) без насыщения (с циклическим переполнением) Сложение знаковых упакованных байт (слов) с насыщением Сложение упакованных беззнаковых байт (слов) с насыщением Умножение четырех знаковых слов операнда-источника на четыре знаковых слова операнда назначения. Два двойных слова результатов умножения младших слов суммируются и записываются в младшее двойное слово операнда назначения. Два двойных слова результатов умножения старших слов суммируются и записываются в старшее двойное слово операнда назначения
PMULHW Умножение упакованных знаковых слов с сохранением только старших 16 бит элементов результата
PMULLW Умножение упакованных знаковых или беззнаковых слов с сохранением только младших 16 бит элементов результата
PSUBB PSUBW PSUBD Вычитание упакованных байт (слов или двойных слов) без насыщения (с циклическим антипереполнением)
PSUBSB PSUBSW Вычитание упакованных знаковых байт (слов) с насыщением
PSUBUSB PSUBUSW Вычитание упакованных беззнаковых байт (слов) с насыщением
Логика
PAND Логическое И
PANDN Логическое И mm/m64 и инверсного значения mm
POR Логическое ИЛИ
PXOR Сравнение PCMPEQB PCMPEQD PCMPEQW Исключающее ИЛИ Сравнение (на равенство) упакованных байт (слов, двойных слов). Все биты элемента результата будут единичными (True) при совпадении соответствующих элементов (байт, слов или двойных слов) операндов и нулевыми (False) при несовпадении
4. Система команд
109
Инструкция Описание
PCMPGTB PCMPGTD PCMPGTW Сравнение (по величине) упакованных знаковых байт (слов, двойных слов). Все биты элемента результата будут единичными (True), если соответствующий элемент операнда назначения больше элемента операнда-источника, и нулевыми (False) в противном случае
Сдвиги и вращения
PSLLD PSLLQ PSLLW Логический сдвиг влево упакованных слов (двойных, учетверенных) операнда назначения на количество бит, указанных в операнде-источнике, с заполнением младших бит нулями
PSRAD PSRAW Арифметический сдвиг вправо упакованных двойных (учетверенных) знаковых слов операнда назначения на количество бит, указанных в операнде- источнике, с заполнением младших бит битами знаковых разрядов
PSRLD PSRLQ PSRLW Логический сдвиг вправо упакованных слов (двойных, учетверенных) операнда назначения на количество бит, указанных в операнде-источнике, с заполнением старших бит нулями
Инструкции SSE (см. табл. 4.15, а также пп. 1.3 и 1.4 в приложении 1) появились в
процессорах Pentium III. Они делятся на три основные группы: инструкции над
числами в блоке ХММ, дополнительные целочисленные SIMD-ииструкции (в бло-
ке ММХ) и новые инструкции кэширования. Основное число новых инструкций
предназначено для работы с блоком ХММ. Векторные инструкции выполняются
сразу над четырьмя парами чисел. Скалярные инструкции выполняются только
над числами, расположенными в младших 32 битах операндов. Операнд-источник
для инструкций ХММ может быть как регистром ХММ, так и 128-битной ячей-
кой памяти. Для многих инструкций требуется, чтобы операнд в памяти был вы-
ровнен по границе параграфа. При обработке скалярными инструкциями операн-
да в памяти пересылка между памятью и регистрами ХММ производится для всего
128-битного слова, хотя используется только 32 бита.
Таблица 4.15. Инструкции расширения SSE
Инструкция Описание
Пересылка данных с участием регистров ХММ
MOVAPS Пересылка 128-битных данных между памятью и регистрами ХММ или между регистрами ХММ. Данные в памяти должны быть выровнены по границе 16-байтного параграфа
MOVUPS Пересылка 128-битных данных между памятью и регистрами ХММ или между регистрами ХММ (без требования выравнивания)
MOVHPS Пересылка 64-битных данных между памятью и старшей половиной регистров ХММ или между регистрами ХММ (младшая половина ХММ не изменяется)
MOVHLPS Пересылка старшей половины источника в младшую половину назначения (старшая половина регистра назначения не меняется)
MOVLHPS Пересылка младшей половины источника в старшую половину назначения (младшая половина регистра назначения не меняется)
MOVLPS Пересылка 64-битных данных между памятью и младшей половиной регистров ХММ или между регистрами ХММ (старшая половина ХММ не изменяется)
продолжение^
110
4. Система команд
Таблица 4.15 (продолжение)
Инструкция Описание
MOVMSKPS . Сборка старших бит упакованных операндов из регистра ХММ в регистр общего назначения (биты 31,63,95 и 127 регистра ХММ попадают в биты 0, 1,2 и 3 регистра-приемника, остальные биты приемника будут нулевыми)
MOVSS Пересылка скалярного операнда (младшие 32 бита) между памятью и регистрами ХММ или между регистрами ХММ
(Арифметические инструкции над числами в FP-формате в регистрах ХММ
ADDPS Векторное сложение
SUBPS Векторное вычитание
ADDSS Скалярное сложение
SUBSS Скалярное вычитание
MULPS MULSS Векторное умножение Скалярное умножение
DIVPS Векторное деление
DIVSS Скалярное деление
SQRTPS SQRTSS MAXPS Векторное извлечение квадратного корня Скалярное извлечение квуадратного корня Векторное нахождение максимума
MAXSS Скалярное нахождение максимума
MINPS MINSS Сравнение CMPPS Векторное нахождение минимума Скалярное нахождение минимума Векторное сравнение (задается полный набор 12 условий, как в инструкциях условных переходов). В том элементе операнда назначения, для которого условие сравнения выполняется, устанавливаются все единицы (32 бита), где не выполняется — все нули
CMPSS Скалярное сравнение (12 условий), аналогично предыдущему, но только для младших 32 бит
COMISS Скалярное сравнение с установкой бит ZF, PF и CF регистра EFLAGS (биты OF, SF и AF обнуляются)
UCOMISS Скалярное сравнение, но без генерации исключения в случае NaN (при этом ZF=PF=CF=1)
Инструкции преобразований
CVTPI2PS Преобразование двух знаковых целых из регистра ММХ или 64-битной ячейки памяти в два младших FP-числа в регистре ХММ (старшая пара не изменяется). При необходимости выполняется округление
CVTSI2SS Преобразование знакового целого из 32-битного регистра или 64-битной ячейки памяти в младшее упакованное FP-число в регистре ХММ (старшие три числа не изменяются). При необходимости выполняется округление
CVTPS2PI Преобразование двух младших FP-чисел из регистра ХММ или памяти в пару целых знаковых в регистре ММХ или 64-битной ячейки памяти. При необходимости выполняется округление; если результат не умещается, возвращается значение бесконечности (80000000h)
4. Система команд
111
Инструкция Описание
CVTTPS2PI Преобразование, аналогичное CVTPS2PI, но при невозможности точного преобразования выполняется усечение
CVTSS2SI Преобразование младшего FP-числа из регистра ХММ в целое знаковое в 32-битном регистре. При необходимости выполняется округление; если результат не умещается, возвращается значение бесконечности (80000000h)
CVTTSS2SI Преобразование, аналогичное CVTSS2SI, но при невозможности точного преобразования выполняется усечение
Логические инструкции в блоке ХММ
ANDPS Логическое И двух пакетов операндов
ANDNPS Логическое И-НЕ двух пакетов операндов
ORPS Логическое ИЛИ двух пакетов операндов
XORPS Исключающее ИЛИ двух пакетов операндов
Перестановки операндов в ХММ
SHUFPS Перестановка слов в регистре ХММ под управлением 8-битного непосредственного операнда
UNPCKHPS Переупаковка старших половин с чередованием слов в результате
UNPCKLPS Переупаковка старших половин с чередованием слов в результате
Управление состоянием
LDMXCSR Загрузка регистра MXCSR
STMXCSR Сохранение регистра MXCSR
FXSAVE Сохранение состояния блоков FP/MMX и ХММ
FXRSTOR Восстановление состояния блоков FP/MMX и ХММ
Дополнительные целочисленные SIMD-инструкции (выполняются с операндами в регистрах
ММХ, входят и в расширенный набор 3DNow!)
PAVGB/PAVGW PEXTRW Нахождение среднего упакованных беззнаковых байт или слов Извлечение 16-битного слова из регистра ММХ в младшую половину 32-битного регистра (старшая половина обнуляется). Номер слова определяется младшими битами непосредственного операнда
PINSRW Помещение младшей половины 32-битного регистра в выбранное слово регистра ММХ. Номер слова определяется младшими битами непосредственного операнда
PMAXUB/ PMAXSW Нахождение максимума упакованных беззнаковых байт/знаковых слов
PMINUB/ PMINSW Нахождение минимума упакованных беззнаковых байт/знаковых слов
PMOVMSKB Сборка старших бит упакованных байт в 8-битную маску, помещаемую в целочисленный регистр
PMULHUW Умножение беззнаковых слов с сохранением старших половин произведений
PSADBW Нахождение суммы модулей разности пар слов (результат — 16-битное число)
PSHUFW Перемешивание слов под управлением 8-битного непосредственного операнда
продолжение#
112
4. Система команд
Таблица 4Z. 15 (продолжение)
Инструкция Описание
Управление кэшированием (входят и в расширенный набор 3DNow!)
MASKMOVQ Выборочная запись байт из регистра ММХ в память, минуя кэш
MOVNTQ Запись из регистра ММХ в память, минуя кэш
MOVNTPS Запись из регистра ХММ в память, минуя кэш (адрес должен быть выровнен по границе параграфа)
PREFETCHTO PREFETCHT1 PREFETCHT2 PREFETCHNT Загрузка 32 или более байт в кэш-память
SFENCE Выгрузка результатов всех предыдущих инструкций в кэш-память
Новые инструкции управления кэшированием обеспечивают запись содержимо-
го регистров ММХ и ХММ в память, минуя кэш, что позволяет избегать «загряз-
нения» кэш-памяти промежуточными данными. Появилась и возможность «зака-
чивать» требуемые данные в кэш прежде использующих их инструкций.
По сравнению с расширением 3DNow! набор инструкций SSE шире, часть инст-
рукций пересекается, но и в 3DNow! имеются уникальные инструкции, не реали-
зованные в SSE.
Инструкции SSE2 (см. табл. 4.16, а также пп. 1.3 и 1.4 в приложении 1) появились
в процессорах Pentium 4. Большая их часть предназначена для работы с числами
с плавающей точкой двойной точности (64-битные операнды), расположенными
в регистрах ХММ, векторными (упакованная пара 64-битных чисел) и скалярны-
ми (старшим или младшим числом). Они обеспечивают векторные и скалярные
пересылки этих чисел, арифметические инструкции (сложение, вычитание, умно-
жение, деление, извлечение корня, нахождение максимума и минимума), сравне-
ние чисел, преобразования форматов, перестановки операндов, а также побитные
логические функции. Появились и SIMD-ииструкции обработки 32- и 64-битных
целых чисел, расположенных в регистрах ХММ. Новые инструкции управления
кэшированием позволяют миновать кэш при записи в память из регистров ХММ
и общих регистров, упорядочивать последовательности загрузки данных из памя-
ти и записи в память и выполнять некоторые другие действия.
Таблица 4.16. Инструкции SSE2
Инструкция Описание
Инструкции пересылки данных (чисел с плавающей точкой двойной точности между
регистрами ХММ, а также регистрами ХММ и памятью)
MOVAPD Пересылка пары упакованных выровненных чисел
MOVUPD Пересылка пары упакованных невыровненных чисел
MOVHPD Пересылка старшего упакованного числа
MOVLPD Пересылка младшего упакованного числа
4. Система команд
113
Инструкция Описание
MOVMSKPD Извлечение знаковой маски из пары чисел
MOVSD Пересылка скалярного числа
Арифметические инструкции над операндами с плавающей точкой двойной точности
в регистрах ХММ
ADDPD Векторное сложение
ADDSD Скалярное сложение
SUBPD Векторное вычитание
SUBSD Скалярное вычитание
MULPD Векторное умножение
MULSD Скалярное умножение
DIVPD Векторное деление
DIVSD ' Скалярное деление
SQRTPD Векторное извлечение квадратного корня
SQRTSD Скалярное извлечение квадратного корня
MAXPD Векторное нахождение максимума
MAXSD Скалярное нахождение максимума
MINPD Векторное нахождение минимума
MINSD Скалярное нахождение минимума
Логические инструкции над упакованными 64-битными операндами в регистрах ХММ
(побитные функции)
ANDPD Логическое И
ANDNPD Логическое И-НЕ
ORPD Логическое ИЛИ
XORPD Исключающее ИЛИ
Инструкции сравнения упакованных (векторных) и скалярных операндов с плавающей
точкой двойной точности в регистрах ХММ с помещением результата в операнд-приемник
или регистр EFLAGS
CMPPD Сравнение векторное
CMPSD Сравнение скалярное
COMISD Упорядоченное сравнение скалярных чисел с помещением результата в биты регистра EFLAGS (если хоть один из операндов QNaN или SNaN, генерируется исключение #1 и EFLAGS не модифицируется)
UCOMISD Неупорядоченное сравнение (тоже, но исключение #1 генерируется только в случае SNaN)
Инструкции перестановок и распаковки операндов с плавающей точкой двойной точности
в регистрах ХММ
SHUFPD Перестановка элементов в упакованных операндах
UNPCKHPD Распаковка и чередование старших элементов (в приемнике собираются старшие части операндов)
продолжение &
114
4. Система команд
Таблица 4.16 (продолжение)
Инструкция Описание
UNPCKLPD Распаковка и чередование младших элементов (в приемнике собираются младшие части операндов)
Инструкции преобразований в формат и из формата упакованных и скалярных чисел с плавающей точкой двойной точности
CVTPD2PI Преобразование упакованных чисел с плавающей точкой в упакованные целые (двойные слова)
CVTTPD2PI Преобразование с усечением упакованных чисел с плавающей точкой двойной точности в упакованные целые (двойные слова)
CVTPI2PD Преобразование упакованных целых (двойных слов) в упакованные числа с плавающей точкой двойной точности
CVTPD2DQ Преобразование упакованных чисел с плавающей точкой в упакованные целые (двойные слова)
CVTTPD2DQ Преобразование с усечением упакованных чисел с плавающей точкой' двойной точности в упакованные целые (двойные слова)
CVTDQ2PD Преобразование упакованных 32-битных целых в упакованные числа с плавающей точкой двойной точности
CVTPS2PD Преобразование упакованных чисел с плавающей точкой одинарной точности в числа двойной точности
CVTPD2PS Преобразование упакованных чисел с плавающей точкой двойной точности в числа одинарной точности
CVTSS2SD Преобразование скалярного числа с плавающей точкой одинарной точности в число двойной точности
CVTSD2SS Преобразование скалярного числа с плавающей точкой двойной точности в число одинарной точности
CVTSD2SI Преобразование скалярного числа одинарной точности в 32-битное целое
CVTTSD2SI Преобразование с усечением скалярного числа двойной точности в 32-битное целое
CVTSI2SD Преобразование 32-битного целого в число двойной точности
Инструкции преобразований с числами одинарной точности
CVTDQ2PS Преобразование упакованных 32-битных целых в упакованные числа с плавающей точкой одинарной точности
CVTPS2DQ Преобразование упакованных чисел одинарной точности в числа двойной точности
CVTTPS2DQ Преобразование с усечением упакованных чисел одинарной точности в числа двойной точности
Целочисленные 128-битные SIMD-инструкции
MOVDQA Пересылка выровненного 128-битного операнда
MOVDQU Пересылка невыровненного 128-битного операнда
MOVQ2DQ Пересылка 64-битного целого из ММХ в ХММ
MOVDQ2Q Пересылка 64-битного целого из ХММ в ММХ
PMULUPQ Умножение упакованных беззнаковых 32-битных целых
PADDQ Сложение упакованных 64-битных целых
4. Система команд
115
Инструкция Описание
PSUBQ PSHUFLW PSHUFHW PSHUFD PSLLDQ PSRLDQ PUNPCKHQDQ PUNPCKLQDQ Вычитание упакованных 64-битных целых Перестановка упакованных младших слов Перестановка упакованных старших слов Перестановка упакованных двойных слов Логический сдвиг 64-битных чисел влево Логический сдвиг 64-битных чисел вправо Распаковка старших 64-битных чисел Распаковка младших 64-битных чисел
Управление кэшированием
CLFLUSH Очистка и инвалидация строки кэша (всех уровней), связанной с указанным операндом в памяти
LFENCE MFENCE PAUSE MASKMOVDQU MOVNTPD MOVNTDQ MOVNTI Упорядочивание операций загрузки из памяти Упорядочивание операций загрузки и записи Улучшение выполнения цикла ожидания Выборочная запись байтов из ХММ в память, минуя кэш Запись пары упакованных чисел из ХММ в память, минуя кэш Запись 128-битного числа из ХММ в память, минуя кэш Запись двойного слова из регистра общего назначения в память, минуя кэш
Инструкции 3DNow! (см. табл. 4.17, а также п. 1.5 в приложении 1), появившиеся
с процессорами AMD К6-2, поддерживаются всеми последующими процессора-
ми AMD и некоторыми другими процессорами. Процессоры Intel этот набор не
поддерживают, хотя в SSE имеются инструкции, совпадающие с частью инструкций
3DNow!. В процессорах Athlon расширение 3DNow! получило дополнительные
инструкции для сигнальных процессоров (табл. 4.18). Целочисленные инструк-
ции ММХ и управления кэшированием совпадают с одноименными инструкция-
ми SSE (см. последние две группы в табл. 4.15).
Таблица 4.17. Инструкции расширения 3DNow!
Инструкция Описание
FEMMS PREFETCH PAVGUSB PI2FD Быстрый вход-выход в ММХ или FPU Предвыборка строки с данными в первичный кэш Нахождение среднего для упакованных 8-битных беззнаковых целых Преобразование упакованных 32-битных целых в формат с плавающей точкой
PF2ID Преобразование упакованных чисел в формате с плавающей точкой в 32-битные целые
PMULHRW Умножение 16-битных упакованных целых с округлением
Операции с упакованными числами в формате с плавающей точкой
PFADD Сложение
PFSUB Вычитание
продолжение#
116
4. Система команд
Таблица 4.17 (продолжение)
Инструкция Описание
PFSUBR Обратное вычитание
PFACC Накопление
PFMUL Умножение
PFCMPGE Сравнение (больше или равно)
PFCMPGT Сравнение (больше)
PFCMPEQ Сравнение(равно)
PFMIN Нахождение минимума
PFMAX Нахождение максимума
PFRCP Приближенное вычисление обратных величин (Reciprocal Approximation)
PFRCPIT1 Первая итерация вычисления обратных величин (Reciprocal First Iteration Step)
PFRCPIT2 Вторая итерация вычисления обратных величин квадратных корней (Reciprocal/Reciprocal Square Root Second Iteration Step)
PFRSQRT Приближенное вычисление обратных величин квадратных корней (Reciprocal Square Root Approximation)
PFRSQIT1 Первая итерация вычисления обратных величин квадратных корней (Reciprocal Square Root Frst Iteration Step)
Таблица 4.18. Инструкции расширения 3DNow! для сигнальных процессоров
Инструкция . Описание
PF2IW Преобразование FP-чисел в целые слова с расширением знаком
PFNACC Накопление разности (вычисление разностей пар FP-чисел в каждом из операндов)
PFPNACC Накопление суммы и разности FP-чисел
PI2FW Преобразование целых слов в FP-числа
PSWAPD Перестановка двойных слов
К системным инструкциям (см. табл. 4.19, а также п. 1.1 в приложении 1) отно-
сятся инструкции управления защитой — загрузки и сохранения регистров дес-
крипторов и регистра задачи; проверки и выравнивания привилегий; обмена с
управляющими, отладочными и модельно-специфическими (включая тестовые)
регистрами; управления кэшированием, захвата шины и остановки процессора.
Для прикладных программ использование этих инструкций нехарактерно, их при-
менимость и защищенность иллюстрирует табл. 4.20.
Таблица 4.19. Системные инструкции
Инструкция Описание
ARPL Выравнивание RPL: если в первом операнде поле RPL (биты 1,0) меньше, чем во втором, оно устанавливается из второго и ZF=1; иначе ZF=0
CTS/CLTS HLT Сброс флага переключения задач в регистре CRO (TF=O) (286+) Останов процессора (непрерывное выполнение NOP до аппаратного прерывания)
4. Система команд
117
Инструкция Описание
INVD Аннулирование данных во внутреннем кэше и инициация аннулирования во внешнем без обратной записи (486+)
INVLPG Аннулирование элемента таблицы трансляции TLB. В ряде случаев аннулируется вся таблица (486+)
LAR LGDT LIDT Загрузка байта прав доступа из дескриптора Загрузка GDTR из памяти (6 байт) Загрузка IDTR из памяти (6 байт)
LLDT Загрузка LDTR (16-битного селектора) из регистра или памяти
LMSW LOCK Загрузка MSW (часть регистра CR0) Префикс блокировки (захвата) шины на время выполнения последующей инструкции
LSL Загрузка регистра лимитом сегмента
LTR MOVCRn Загрузка регистра задачи Загрузка/чтение управляющего регистра п (п=0,2,3,4)
MOVDRn MOVTRn Загрузка/чтение регистра отладки п Загрузка/чтение регистра тестирования п (для 386 и 486)
RDMSR Чтение модельно-специфического регистра MSRn, адресуемого ЕСХ, в EDX:EAX(P5+)
RDPMC Чтение счетчика монитора производительности, адресуемого ЕСХ, в EDX:EAX(P5+)
RDTSC RSM Чтение счетчика тактов в EDX:EAX (Р5+) Возврат из режима SMM
SGDT SIDT SLDT Сохранение GDTR в памяти (6 байт) Сохранение IDTR в памяти (6 байт) Сохранение LDTR (16-битного селектора) в регистре или памяти
SMSW STR Сохранение MSW в регистре или памяти (16 бит) Сохранение селектора из TR
VERR Проверка возможности чтения в сегменте: установка ZF=1, если задаче позволено чтение в сегменте
VERW Проверка возможности записи в сегменте: установка ZF=1, если задаче позволена запись в сегмент
WBINVD Обратная запись модифицированных строк, аннулирование внутренней кэш-памяти, инициация аннулирования во внешнем кэше (486+)
WRMSR Запись в модельно специфический регистр MSRn, заданный в ЕСХ, из EDX:EAX(P5+)
Таблица 4.20. Применимость и защищенность системных инструкций для прикладных программ
Инструкция Применимость Защищенность
LLDT SLDT Нет Да Нет Нет
LGDT Нет Да
продолжение &
118
4. Система команд
Таблица 4.20 (продолжение)
Инструкция Применимость Защищенность
SGDT Нет Нет
LTR Нет Да
STR Нет Нет
LIDT Нет Да
SIDT Нет Нет
MOVCRn Да Да (только загрузка)
SMSW Да Нет
LMSW Нет Да
CLTS Нет Да
ARPL Да’ Нет
LAR Да Нет
LSL Да Нет
VERR Да Нет
VERW Да Нет
MOVDBn Нет Да
INVD Нет Да
WBINVD Нет Да
INVLPG Нет Да
HLT Нет Да
LOCK Да Нет
RSM Нет Да
RDMSR(P5+) Нет Да
WRMSR(P5+) Нет Да
RDPMC(P5+) Да Да2
RDTSC(P5+) Да Да2
LDMXCSR (PIII+) Да Нет
STMXCSR (PIII+) Да Нет
1 Используется прикладными программами, выполняющимися на CPL1 или 2.
2 Доступом к инструкциям на CPL=3 управляют флаги TSD и РСЕ регистра CR4.
5. Защищенный режим
Защищенный режим Protected Mode, точнее Protected Virtual Address Mode (защи-
щенный режим виртуальной адресации), является основным (наиболее естествен-
ным) режимом работы 32-разрядных процессоров. В этом режиме процессор по-
зволяет адресовать до 4 Гбайт (до 64 Гбайт в Р6) физической памяти, посредством
которой при использовании механизма страничной адресации могут отображаться
до 64 Тбайт виртуальной памяти каждой задачи. Режим виртуального процессо-
ра 8086 — Virtual 8086 Mode, или V86, — является особым состоянием задачи защи-
щенного режима, в котором процессор функционирует как 8086 с возможностью
использования 32-разрядных адресов и операндов.
Защищенный режим появился еще в процессоре 80286, но имел не все возможности,
доступные в 32-разрядных процессорах. Приведенное ниже описание защищенно-
го режима применимо и к процессору 80286, но с учетом следующих ограничений:
♦ регистры CRn, DRn и TRn отсутствуют;
♦ вход в защищенный режим осуществляется только по загрузке MSW с РЕ = 1,
выход в реальный — только по аппаратному сбросу;
♦ режима виртуального процессора 8086 нет;
♦ форматы дескрипторов имеют 16-битные поля лимита и 24-битные поля базо-
вого адреса, что ограничивает размер сегмента до 64 Кбайт, объем физической
памяти не превосходит 16 Мбайт, виртуальной — 1 Гбайт;
♦ обращение к памяти за границей 16 Мбайт приводит к кольцевому «сворачи-
ванию» адреса — обращение к 17-му мегабайту физически адресует первый (что
справедливо и для 386SX);
♦ режимы 32-битных адресов и данных отсутствуют;
♦ блок страничной переадресации отсутствует (физический адрес памяти экви-
валентен логическому);
♦ ограничения на операции ввода-вывода накладываются только через IOPL, би-
товой карты разрешения ввода-вывода нет.
5.1. Основные понятия защищенного режима
Защищенный режим предназначен для обеспечения независимости выполнения
нескольких задач, что подразумевает защиту ресурсов одной задачи от возможно-
го воздействия другой (под задачами подразумеваются как приложения, так и за-
дачи операционной системы).
120
5. Защищенный режим
Основным защищаемым ресурсом является память, в которой хранятся коды, дан-
ные и различные системные таблицы (например, таблица прерываний). Защищать
требуется и совместно используемую аппаратуру, обращение к которой обычно
происходит через операции ввода-вывода и прерывания. В защищенном режиме
процессор аппаратно реализует многие функции защиты, необходимые для построе-
ния супервизора многозадачной ОС, в том числе механизм виртуальной памяти.
Защита памяти основана на сегментации. Сегмент — это блок пространства памяти
определенного назначения. К элементам сегмента возможно обращение с помо-
щью различных инструкций процессора, использующих разные режимы адреса-
ции для формирования адреса в пределах сегмента. Максимальный размер сегмен-
та — 4 Гбайт (для процессоров 8086 и 80286 предел был всего 64 Кбайт). Сегменты
памяти выделяются задачам операционной системой, но в реальном режиме лю-
бая задача может переопределить значение сегментных регистров, задающих по-
ложение сегмента в пространстве памяти, и «залезть» в чужую область данных или
кода. В защищенном режиме сегменты тоже распределяются операционной сис-
темой, но прикладная программа может использовать только разрешенные для нее
сегменты памяти, выбирая их с помощью селекторов из предварительно сформи-
рованных таблиц дескрипторов сегментов.
Процессор может обращаться только к тем сегментам памяти, для которых имеются
дескрипторы в таблицах. Механизм сегментации формирует линейный адрес по
схеме, приведенной на рис. 5.1. Дескрипторы выбираются с помощью 16-битных
селекторов, программно загружаемых в сегментные регистры; формат селекторов
приведен на рис. 5.2. Индекс совместно с индикатором таблицы TI позволяет вы-
брать дескриптор из локальной (TI = 1) или глобальной (TI = 0) таблицы дескрип-
торов. Для неиспользуемых сегментных регистров предназначен нулевой селек-
тор сегмента, формально адресующийся к самому первому элементу глобальной
таблицы. Попытка обращения к памяти по такому сегментному регистру вызовет
исключение. Исключение возникнет и при попытке загрузки нулевого селектора
в регистр CS или SS. Поле RPL указывает требуемый уровень привилегий (см. ниже).
Дескрипторы представляют собой 8-байтные структуры данных, используемые
для определения свойств программных элементов (сегментов, шлюзов и таблиц).
Дескриптор определяет положение элемента в памяти, размер занимаемой им об-
ласти (лимит), его назначение и характеристики защиты. Все дескрипторы хра-
нятся в таблицах, обращение к которым поддерживается процессором аппаратно.
Защита памяти путем сегментации не позволяет:
♦ использовать сегменты не по назначению (например, пытаться трактовать об-
ласть данных как коды инструкций);
♦ нарушать права доступа (пытаться модифицировать сегмент, предназначен-
ный только для чтения, обращаться к сегменту, не имея достаточных привиле-
гий и т. п.);
♦ адресоваться к элементам, выходящим за лимит сегмента;
♦ изменять содержимое таблиц дескрипторов (то есть параметров сегментов), не
имея достаточных привилегий.
5.1. Основные понятия защищенного режима
121
Логический адрес
15 0 31 О
Рис. 5.1. Формирование линейного адреса в защищенном режиме
15 3 2 1 0
Index ’Т I RPL
Рис. 5.2. Формат селектора
Защищенный режим предоставляет средства переключения задач. Состояние каж-
дой задачи (значение всех связанных с ней регистров процессора) может быть
сохранено в специальном сегменте состояния задачи TSS, на который указывает
селектор в регистре задачи TR. При переключении задач достаточно загрузить но-
вый селектор в регистр задачи, и состояние текущей задачи автоматически сохра-
нится в ее TSS, а в процессор загрузится состояние новой (возможно, ранее пре-
рванной) задачи и начнется (продолжится) ее выполнение.
Четырехуровневая иерархическая система привилегий предназначена для управ-
ления использованием привилегированных инструкций и доступом к дескрипто-
рам. Уровни привилегий нумеруются от’0 до 3, нулевой уровень соответствует
максимальным (неограниченным) возможностям доступа и отводится для ядра
операционной системы. Уровень 3 имеет самые ограниченные права и обычно
предоставляется прикладным задачам. Систему защиты часто изображают в виде
концентрических колец, соответствующих уровням привилегий (рис. 5.3), а сами
уровни привилегий иногда называют кольцами защиты. Сервисы, предоставляе-
мые задачам, могут находиться в разных кольцах защиты. Передача управления
между задачами контролируется шлюзами (Gate), называемыми также вентилями,
122
5. Защищенный режим
проверяющими правила использования уровней привилегий. Через шлюзы зада-
чи могут получить доступ только к разрешенным им сервисам других сегментов.
Интерфейсы
операционной
системы
Приложения
Расширения ОС
PL=3
PL=2
Минимальные
привилегии
Системные
сервисы
PL=1
Ядро ОС
PL=0
Максимальные
привилегии
Рис. 5.3. Уровни привилегий
Уровни привилегий относятся к дескрипторам, селекторам и задачам. Кроме того,
в регистре флагов имеется поле привилегий ввода-вывода, с помощью которого обеспе-
чивается доступ к инструкциям ввода-вывода и управлению флагом прерываний.
Дескрипторы и привилегии являются основой системы защиты: дескрипторы
определяют структуры программных элементов (без которых эти элементы невоз-
можно использовать), а привилегии определяют возможность доступа к дескрип-
торам и выполнения привилегированных инструкций. Любое нарушение защиты
приводит к возникновению специальных исключений, обрабатываемых ядром
операционной системы.
Механизм виртуальной памяти позволяет любой задаче использовать логическое
адресное пространство размером до 64 Тбайт (16 К сегментов по 4 Гбайт). Для
этого каждый сегмент в своем дескрипторе имеет специальный бит, который ука-
зывает на присутствие данного сегмента в оперативной памяти в текущий момент
времени. Неиспользуемый сегмент может быть выгружен из оперативной памяти
во внешнюю (например, дисковую), о чем делается пометка в его дескрипторе. На
освободившееся место из внешней памяти может восстанавливаться содержимое
другого сегмента (этот процесс называется свопингом, или подкачкой), и в его
дескрипторе делается пометка о присутствии в памяти. При обращении задачи к
отсутствующему сегменту процессор вырабатывает соответствующее исключение,
обработчик которого и заведует виртуальной памятью в операционной системе.
5.2. Дескрипторы и таблицы
123
Механизм страничной переадресации обеспечивает виртуализацию памяти, адре-
суемой логическим адресом, на уровне страниц фиксированного размера. После
подкачки сегмента (страницы) выполнение задачи продолжается, так что виртуа-
лизация памяти для прикладных задач прозрачна (если не принимать во внима-
ние задержку, вызванную подкачкой).
Процессор предоставляет только необходимые аппаратные средства поддержки
защиты и виртуальной памяти, а их реальное использование и устойчивость работы
программ и самой операционной системы защищенного режима, конечно же, зависят
от корректности построения ОС и предусмотрительности ее разработчиков. Хоро-
шо спроектированная операционная система защищенного режима может обес-
печить устойчивость ОС даже при некорректном поведении прикладных задач.
5.2. Дескрипторы и таблицы
Существуют три типа таблиц дескрипторов — локальная таблица дескрипторов
LDT (Local Descriptor Table), глобальная таблйца дескрипторов GDT (Global Descriptor
Table) и таблица дескрипторов прерываний IDT (Interrupt Descriptor Table). Разме-
ры таблиц могут находиться в пределах 8 байт-64 Кбайт, что соответствует чис-
лу элементов в таблице от 1 до 8 К.
С каждой из этих таблиц связан соответствующий регистр процессора (рис. 5.4).
Регистры GDTR и IDTR имеют программно-доступное 16-битное поле лимита, зада-
ющее размер таблицы, и 32-битное (у 80286 — 24-битное) поле базового адреса,
определяющее положение таблицы в пространстве линейных (у 80286 — физичес-
ких) адресов памяти. У регистра LDTR программно доступно только 16-битное поле
селектора, по которому из GDT автоматически загружаются программно-недоступ-
ные и невидимые поля базового адреса и лимита.
Рис. 5.4. Регистры дескрипторов таблиц
124
5. Защищенный режим
Команды загрузки регистров таблиц (LGDT, LIDT и LLDT) являются привилеги-
рованными (выполняются только на уровне привилегий 0). Команды LGDT и LIDT
загружают из памяти 6-байтное поле, содержащее базовый адрес и лимит соот-
ветствующей таблицы. Команда LLDT загружает только селектор, ссылающийся
на дескриптор, содержащий базовый адрес и лимит локальной таблицы деск-
рипторов.
Глобальная таблица (GDT) содержит дескрипторы, доступные всем задачам. Она
может содержать дескрипторы любых типов, кроме дескрипторов прерываний и
ловушек. Нулевой элемент этой таблицы процессором не используется. Локаль-
ная таблица (LDT) может быть собственной для каждой задачи и содержит только
дескрипторы сегментов, шлюзы задач и вызовов. Сегмент недоступен задаче, если
его дескриптора пет в текущий момент ни в GDT, ни в LDT.
Выбор таблицы (локальная или глобальная) определяется по значению бита TI
селектора, а положение (номер) дескриптора задается 13-битным полем INDEX се-
лектора. При ссылке на дескриптор, выходящий за лимит таблицы, возникает ис-
ключение #GP.
Таблица дескрипторов прерываний, используемая в защищенном режиме, может
содержать описания до 256 прерываний. В таблице могут присутствовать только
шлюзы задач, прерываний и ловушек. Базовый адрес и лимит таблицы загружает-
ся привилегированной командой LIDT (аналогично LGDT). Размер IDT должен быть
не менее 256 байт, чтобы в нее поместились все зарезервированные прерывания
процессора. Ссылка на элементы IDT происходит по командам INT, аппаратным
прерываниям и исключениям процессора. При возникновении прерывания или
исключения, дескриптор которого выходит за лимит таблицы, вырабатывается
исключение #DF.
Дескрипторы имеют 8-байтный формат как для 16-разрядных (80286), так и для
32-разрядных процессоров. Назначение дескриптора определяется полями байта
управления доступом (Access Rights Byte) — байта со смещением 5. Дескрипторы
16- и 32-разрядных процессоров отличаются разрядностью поля базового адреса
(24 и 32 бит) и трактовкой поля лимита, которое должно обеспечивать размер сег-
мента до 64 Кбайт или 4 Гбайт соответственно. Два старших байта у дескрипто-
ров 80286 всегда нулевые (из-за требований совместимости с последующими
процессорами, объявленными при выпуске 80286), что позволяет их отличать и
корректно использовать, выполняя 16-битные приложения защищенного режима
на 32-разрядных процессорах.
Два старших байта дескрипторов 32-разрядных процессоров содержат расшире-
ния полей BASE и LIMIT, бит дробности G (Granularity), определяющий, в каких еди-
ницах задан лимит: G s 0 — в байтах, G = 1 — в страницах по 4 Кбайт (что и обес-
печивает максимальную длину в 4 Гбайт).
В дескрипторах сегментов, отсутствующих в физической памяти (Р = 0), процес-
сор контролирует только байт управления доступом. Назначение остальных байт
определяется ОС.
5.2. Дескрипторы и таблицы
125
Дескрипторы сегментов кода и данных определяют базовый адрес, размер сегмен-
та, права доступа (чтение, чтение/запись, только исполнение кода или исполне-
ние/чтение), а для систем с виртуальной памятью еще и присутствие сегмента в
физической памяти (рис. 5.5 и 5.6).
Зарезервировано
7 0 7 0
+7
+5
+3
+1
15 8 7 0
PDPL1 0EWA
BASE 23...16
SEGMENT BASE 15...0
SEGMENT LIMIT 15...0
+6
+4
+2
0
б
Рис. 5.5. Дескриптор сегмента данных: а — 32-битный формат;
б — 16-битный формат в стиле 80286
Рис. 5.6. Дескриптор сегмента кода: а — 32-битный формат;
6—16-битный формат в стиле 80286
В байте управления доступом поля имеют следующее назначение.
♦ Бит 7 — Р (Present) — присутствие в памяти. При Р = 1 сегмент отображен в
физической памяти, при Р = 0 отображения нет, и поля базового адреса и ли-
мита не используются.
♦ Биты 6, 5 — DPL (Descriptor Privilege Level) — атрибуты привилегий сегмента.
♦ Бит 4 — A (Accessed), — обращение. А = 0 — к сегменту не было обращения, А = 1 —
селектор данного сегмента загружался в регистр сегмента или для него выпол-
нялась команда тестирования.
126
5. Защищенный режим
Поля дескриптора сегмента данных (включая и стек) перечислены ниже.
♦ Бит 2 — Е (Expand Down) — контролируемое направление расширения: Е = 0 —
расширение вверх (смещение не должно превышать значения лимита), Е = 1 —
расширение вниз (стек, у которого смещение должно превышать значение лимита).
♦ Бит 1 — W (Writeable) — разрешение (W = 1) или запрет (W = 0) записи данных
в сегмент.
Для сегментов данных (включая и стек), расширяемых вниз (Е = 1), бит В (Big)
в предпоследнем байте дескриптора определяет верхнюю границу сегмента:
при В = 0 - FFFFh (максимальный размер сегмента — 64 Кбайт), при В = 1 —
FFFFFFFFh (максимальный размер сегмента — 4 Гбайт). Этот же бит в дескрип-
торе сегмента стека определяет разрядность указателя стека: при В = 0 задейству-
ется 16-битный SP, разрядность данных при операциях с подразумеваемым ис-
пользованием стека (PUSH, POP, CALL, RET и т. п.) — 16 бит; при В = 1 задействуется
32-битный ESP, разрядность данных при тех же операциях — 32 бит.
В сегмент кода запись невозможна, лимит указывает на его последний байт, а биты
типа имеют следующее назначение.
♦ Бит 2 — С (Conforming, подчиненность, или конформность): при С = 1 код мо-
жет исполняться, если текущий уровень привилегий (CPL) не ниже уровня при-
вилегий дескриптора (DPL); при С = 0 (неподчиненный сегмент) управление к
данному сегменту может передаваться, только если CPL - DPL.
♦ Бит 1 — R (Readable) — разрешение (R = 1) или запрет (R = 0) чтения сегмента
инструкциями обращения к памяти. При R = 0 из сегмента возможна только вы-
борка инструкций (исполнение кода). Запись в сегмент кода возможна только
через псевдоним (Alias) — сегмент данных с разрешенной записью, имеющий
те же значения базы и лимита.
♦ Бит D (Default Operation Size) в предпоследнем байте определяет разрядность
адресов и операндов по умолчанию: D в 0 — 16 бит, D = 1 — 32, бит.
Системные сегменты предназначены для хранения локальных таблиц дескрипто-
ров LDT (Local Descriptor Table) и состояния задач TSS (Task State Segment). Их
дескрипторы определяют базовый адрес, лимит сегмента (1-64 Кбайт), права до-
ступа (чтение, чтение/запись, только исполнение кода или исполнение/чтение) и
присутствие сегмента в физической памяти (рис. 5.7).
В байте управления доступом у этих дескрипторов бит Р определяет действитель-
ность (Р = 1) или недействительность (Р » 0) содержимого сегмента. Поле уровня
привилегий DPL используется исключительно в дескрипторах сегментов состояния
задач. Поскольку обращение к локальным дескрипторам возможно только по при-
вилегированным командам, поле DPL для дескрипторов таблиц не используется.
Поле Туре (1—3, 9-В) определяет тип сегмента:
♦ 0,8 — недопустимые значения;
♦ 1 — доступный сегмент состояния задачи 80286 (Available TSS-286);
♦ 2 — таблица локальных дескрипторов (LDT);
♦ 3 — занятый сегмент состояния задачи 80286 (Busy TSS-286);
♦ 9 — доступный сегмент состояния задачи 386+ (Available TSS-386);
5.2. Дескрипторы и таблицы
127
♦ А — не определено (зарезервировано);
♦ В — занятый сегмент состояния задачи 386+ (Busy TSS-386).
31_________________ 16 15__________________________ О
SEGMENT BASE 15...0 SEGMENT LIMIT 15...0
BASE 31...24 G 0 0 0 LIMIT 19...16 P DPL _L 0 TYPE I । । BASE 23...16
Зарезерв i ировано
P DPL 0 TYPE । । i i BASE 23...16
SEGMENT BASE 15...0 ।
SEGMENT LIMIT 15...0 i
Рис. 5.7. Дескриптор системных сегментов: а — 32-битный формат;
б — 16-битный формат 80286
Межсегментная передача управления непосредственно (командами JMP, CALL, INT,
RET и IRET) возможна только к сегментам кода с тем же уровнем привилегий либо
к подчиненным сегментам, уровень привилегий которых выше, чем CPL (при этом
CPL не изменяется). Для переходов с изменением уровня привилегий используются
шлюзы. Для каждого способа косвенной межсегментной передачи управления име-
ются соответствующие шлюзы, которые позволяют процессору автоматически
выполнять контроль защиты. Шлюзы вызова (Call Gates) используются для вызовов
процедур со сменой уровня привилегий, шлюзы задач (Task Gates) — для переключе-
ния задач, а шлюзы прерываний (Interrupt Gates) и ловушек (Trap Gates) определяют
процедуры обслуживания прерываний. Шлюзы вызова позволяют автоматичес-
ки копировать заданное число слов из старого стека в новый. Шлюзы прерываний
отличаются от шлюзов ловушек только тем, что они запрещают прерывания (сбра-
сывают IF), а шлюзы ловушек — нет. Для каждого типа шлюзов используются со-
ответствующие дескрипторы шлюзов (Gate Descriptors). Формат дескрипторов
шлюзов приведен на рис. 5.8. В байте управления доступом у этих дескрипторов
бит Р определяет действительность (Р = 1) или недействительность (Р = 0),содер-
жимого сегмента, поле DPL — уровень привилегий, поле Туре -г тип шлюза:
♦ 4 — шлюз вызова 80286 (Call Gate);
♦ 5 — шлюз задачи (любой: 16; и 32-разрядной);
♦ 6 — шлюз прерывания 80286 (Interrupt Gate);
♦ 7 — шлюз ловушки 80286 (Trap Gate);
♦ С — шлюз вызова 386+ (Call Gate);
♦ D — зарезервирован;
♦ Е — шлюз прерывания 386+ (Interrupt Gate);
♦ F — шлюз ловушки 386+ (Trap Gate).
128
5. Защищенный режим
Л 1 ЗарезерЕ i зировано
Р DPL 0 TYPE 1 । । y y y WORD . , COUNT 4...0
DESTINATION SELECTOR 15...2 XX
DESTINATION OFFSET 15...0
15 8 7 О
Рис. 5.8. Дескрипторы шлюзов: а — 32-битный формат; 6—16-битный формат в стиле 80286
Поле Word Count (0-31, C-F) используется только в шлюзах вызовов и определяет
число слов из стека вызывающего процесса, автоматически копируемых в стек вызы-
ваемой процедуры. Для сегментов 80286 слова 16-битные, для 386+ — 32-битные.
Слово Destination Selector для шлюзов вызова, прерываний и ловушек задает се-
лектор целевого сегмента кода, а для шлюза задачи — селектор целевого TSS.
Слово Destination Offset задает смещение (адрес) точки входа в целевом сегменте.
При использовании шлюзов может возникнуть исключение #GP, которое означает,
что селектор указывает на некорректный тип дескриптора. При попытке задей-
ствовать недействительный шлюз (Р = 0) возникает исключение #NP.
5.3. Привилегии
В защищеннохМ режиме процессор имеет четырехуровневую систему привилегий,
которая управляет использованием привилегированных инструкций и доступом
к дескрипторам (и связанным с ними сегментам). Уровни привилегий нумеруют-
ся от 0 до 3, высшие привилегии соответствуют нулевому уровню. Уровни приви-
легий обеспечивают защиту задач, изолируемых друг от друга локальными таб-
лицами дескрипторов. Сервисы операционной системы, обработчики прерываний
и другое системное обеспечение могут включаться в виртуальное адресное про-
странство каждой задачи и защищаться системой привилегий. Каждая часть сис-
темы работает на своем уровне привилегий. Задачи, дескрипторы и селекторы
имеют собственные атрибуты привилегий.
Привилегии задач (Task Privilege) оказывают влияние да выполнение инструкций
и использование дескрипторов. Текущий уровень привилегии задачи CPL (Current
Privilege Level) определяется двумя младшими битами регистра CS. Уровень CPL
задачи может изменяться только при передаче управления к новому сегменту че-
рез дескриптор шлюза. Задача начинает выполняться с уровня CPL, указанного
селектором кодового сегмента внутри TSS, когда задача инициируется посредством
5.3. Привилегии
129
операции переключения задач. Задача, выполняемая на нулевом уровне привиле-
гий, имеет доступ ко всем сегментам, описанным в GDT, и является самой привиле-
гированной. Задача, выполняемая на уровне 3, имеет самые ограниченные права
доступа. Текущий уровень привилегий может изменяться только при передаче
управления через шлюзы.
Привилегии дескриптора (Descriptor Privilege) задаются полем DPL байта управле-
ния доступом. DPL определяет наибольший номер уровня привилегий (фактичес-
ки, наименьшие привилегии), с которым возможен доступ к данному дескрипто-
ру. Самый защищенный дескриптор имеет DPL = 0, к нему имеют доступ только
задачи с CPL = 0. Самый незащищенный дескриптор имеет DPL = 3, его могут ис-
пользовать задачи с CPL = 0,1,2,3. Это правило применимо ко всем дескрипторам,
за исключением дескриптора LDT.
Привилегии селектора (Selector Privilege) задаются полем RPL (Requested Privilege
Level) — двумя младшими битами селектора. С помощью RPL можно урезать эф-
фективный уровень привилегий EPL (Effective Privilege Level), который определя-
ется как максимальное из значений CPL и RPL. Селектор с RPL = 0 не вводит допол-
нительных ограничений.
Контроль доступа к сегментам данных производится при исполнении команд,
загружающих селекторы в SS, DS, ES, FS и GS. Команды загрузки DS, ES, FS и GS должны
ссылаться на дескрипторы сегментов данных или сегментов кодов, допускающих
чтение. Для получения доступа эффективный уровень привилегий EPL должен
быть равным или меньшим (арифметически) уровня привилегий DPL дескрипто-
ра. Исключением из этого правила является читаемый подчиненный сегмент кода,
который может быть прочитан задачей с любым CPL. Если эффективный уровень
привилегий не разрешает доступ или ссылка производится на некорректный тип
дескриптора (на дескриптор шлюза или на дескриптор только исполняемого ко-
дового сегмента), вырабатывается исключение #GP. При ссылке на несуществую-
щий дескриптор вырабатывается исключение #NP.
Команды загрузки SS должны ссылаться на дескриптор сегмента данных, допуска-
ющий запись. При этом DPL и RPL должны быть равны CPL. Нарушение этого усло-
вия и ссылка на дескриптор другого типа порождают исключение #GP, при ссылке
на несуществующий дескриптор вырабатывается исключение #SS.
Контроль типов и привилегий при передаче управления производится при загрузке
селектора в регистр CS. Тип дескриптора, на который ссылается данный селектор,
должен соответствовать выполняемой инструкции. Нарушение типа (например,
ссылка инструкции JMP на шлюз вызова) порождает исключение #GP. При переда-
че управления действуют следующие правила привилегий, нарушение которых
также приводит к исключению #GP:
♦ команды JMP или CALL могут ссылаться либо на подчиненный сегмент кода с
уровнем DPL, большим или равным CPL, либо на неподчиненный сегмент с DPL,
равным CPL;
130
5. Защищенный режим
♦ прерывания внутри задачи или вызовы, которые могут изменить уровень при-
вилегий, могут передавать управление кодовому сегменту с уровнем привиле-
гий, равным или большим уровня привилегий CPL, только через шлюзы с тем
же или меньшим уровнем привилегий, чем CPL;
♦ инструкции возврата, которые не переключают задачи, могут передать управле-
ние только кодовому сегменту с таким же или меньшим уровнем привилегий;
♦ переключение задач может выполняться с помощью вызова, перехода или пре-
рывания, которые ссылаются на шлюз задачи или сегмент состояния задачи
(TSS) с тем же или меньшим уровнем привилегий.
Смена уровня привилегий, происходящая при передаче управления, автоматичес-
ки вызывает переопределение стека. Начальное значение указателя стека SS: SP для
уровня привилегий 0, 1, 2 содержится в TSS. При передаче управления по коман-
дам JMP или CALL в CS: SP загружается новое значение указателя стека, а старые зна-
чения помещаются в новый стек. При возврате на прежний уровень привилегий
его стек восстанавливается (как часть инструкции RET или IRET). Для вызовов под-
программ с передачей параметров через стек и сменой уровня привилегий из пре-
дыдущего стека в новый копируется фиксированное число слов, заданное в шлю-
зе. Команда межсегментного возврата RET с выравниванием указателя стека при
возврате корректно восстановит значение предыдущего указателя.
Привилегии и битовая карта разрешения ввода-вывода контролируют возможность
выполнения операций ввода-вывода и управления флагом прерываний IF. Уро-
вень привилегий ввода-вывода определяется полем IOPL (Input/Output Privelege
Level) регистра флагов. Значение IOPL можно изменить только при CPL = 0.
При CPL < IOPL на операции ввода-вывода и управление флагом IF никаких огра-
ничений не накладывается. При CPL > IOPL попытка ввода-вывода, выполненная
задачей с TSS класса 80286, вызывает исключение #GP (отказ). Если CPL > IOPL, а с
задачей связан сегмент TSS 386+, инструкции ввода-вывода могут выполняться
только по адресам портов, для которых установлены нулевые биты в карте разре-
шения ввода-вывода, имеющейся в TSS. Попытки обращения к портам, которым
соответствуют единичные биты карты или которые не попали в карту (ее размер
может усекаться), вызывают исключение #GP.
При CPL > IOPL попытка выполнения инструкций CLI и STI вызывает исключение
#GP. Попытка неявного управления флагом прерываний со стороны инструкций
загрузки или восстановления регистра флагов блокируется без генерации исклю-
чений. Вопросы виртуализации прерываний будут рассмотрены в пп. 5.7 и 5.8.
5.4. Защита
Для надежной работы многозадачных систем необходима защита задач друг от
друга. Защита предназначена для предотвращения несанкционированного досту-
па к памяти и выполнения критических инструкций — команды HLT, которая оста-
навливает процессор, команд ввода-вывода, управления флагом разрешения пре-
5.4. Защита
131
рываний и команд, влияющих на сегменты кода и данных. Механизмы защиты
вводят следующие ограничения:
♦ ограничение использования сегментов (например, запрет записи в только чита-
емые сегменты данных или попытки исполнения данных как кода). Возможно
использование только тех сегментов, дескрипторы которых описаны в GDT и LDT;
♦ ограничение доступа к сегментам через правила привилегий;
♦ ограничение набора инструкций — выделение привилегированных инструкций
или операций, которые можно выполнять только при определенных уровнях
CPL и IOPL;
♦ ограничение возможности межсегментных вызовов и передачи управления.
В защищенном режиме при исполнении инструкций процессор выполняет про-
верки условий, порождающих исключения.
Проверка при загрузке сегментных регистров,
♦ Превышение лимита таблицы дескрипторов — #GP.
♦ Несуществующий дескриптор сегмента — #NP или #SS.
♦ Нарушение привилегий — #GP.
♦ Загрузка неверного дескриптора или типа сегмента — #GP:
• загрузка в SS сегмента кода или сегмента данных только для чтения;
• загрузка управляющих дескрипторов в DS, ES или SS;
• загрузка только исполняемых сегментов в DS, ES или SS;
• загрузка сегмента данных в CS.
Проверка ссылок операндов.
♦ Запись в сегмент кода или сегмент данных только для чтения — #GP.
♦ Чтение из только исполняемого сегмента кодов — #GP.
♦ Превышение лимита сегмента — #SS или #GP.
Проверка привилегий инструкций.
♦ CPL * 0 при выполнении инструкций LIDT, LLDT, LGDT, LTR, LMSW, CTS, HLT, INVD, INVLPG,
WBINVD и операций с регистрами DRn, TRn, CRn — #GP.
♦ CPL > IOPL при выполнении инструкций STI, CLI, а для 80286 еще и инструкции
с префиксом LOCK — #GP.
♦ CPL > IOPL при выполнении инструкций IN, INS, OUT, OUTS с портами, не разрешен-
ными битовой картой ввода-вывода — #GP.
При выполнении команд IRET и POPF с недостаточным уровнем привилегий биты
IF и IOPL в регистре флагов не изменяются, исключения не порождаются:
♦ IF не меняется при CPL > IOPL;
♦ IOPL не меняется, если CPL > 0.
132
5. Защищенный режим
Проверки при передаче управления по инструкциям JMP, CALL, RET, INT и IRET включа-
ют как проверку ссылок по лимиту (в «ближних» формах JMP, CALL и RET выполня-
ются только эти проверки), так и проверку правил привилегий при межсегмент-
ных передачах через шлюзы.
Для того чтобы задачи не «нарывались» на срабатывание защиты, в систему ко-
манд введены специальные инструкции тестирования указателей. Они позволя-
ют быстро удостовериться в возможности использования селектора или сегмента
без риска порождения исключения.
♦ ARPL — выравнивание RPL. При исполнении этой команды RPL селектора при-
равнивается к максимальному значению из текущего RPL селектора и поля RPL
в указанном регистре. Если при этом RPL изменился, устанавливается ZF = 1.
♦ VERR — проверка возможности чтения: если сегмент, на который указывает се-
лектор, допускает чтение, устанавливается ZF « 1.
♦ VERW — проверка возможности записи: если сегмент, на который указывает се-
лектор, допускает запись, устанавливается ZF = 1.
♦ LSL — чтение лимита сегмента в регистр, если позволяют привилегии. При ус-
пехе устанавливается ZF = 1.
♦ LAR — чтение байта доступа дескриптора в регистр, если позволяют привиле-
гии. При успехе устанавливается ZF = 1.
Некоторые функции защиты выполняются механизмом страничной переадреса-
ции, однако в отличие от «непробиваемой» сегментной защиты существуют спо-
собы обхода страничной защиты на уровне пользователя (CPL = 3).
5.5. Переключение задач
Для многозадачных и многопользовательских операционных систем важна спо-
собность процессора к быстрому переключению выполняемых задач. Опера-
ция переключения задач процессора (Task Switch Operation) сохраняет состоя-
ние процессора и связь с предыдущей задачей, загружает состояние новой задачи
и начинает ее выполнение. Переключение задач выполняется по инструкции меж-
сегментного перехода (JMP) или вызова (CALL), ссылающейся на сегмент состоя-
ния задачи TSS (Task State Segment) или дескриптор шлюза задачи в GDT или LDT.
Переключение задач может происходить также по аппаратным и программным
прерываниям и исключениям, если соответствующий элемент в IDT является дес-
криптором шлюза задачи. Дескриптор TSS указывает на сегмент, содержащий пол-
ное состояние процессора, а дескриптор шлюза задачи содержит селектор, указы-
вающий на дескриптор TSS.
Каждая задача должна иметь связанный с ней TSS. 32-разрядные процессоры до-
пускают и 16-битный (в стиле 80286) формат TSS (рис. 5.9 и 5.10).
5.5. Переключение задач
133
0)
3
CO
0>
X
6
s
3
CL
&
E
0)
TSS LIMIT I BASE |
ACCESS RIGHTS
or
e
a
—I
Ш
co
Ю
or
16 15
31
0000000000000000 | BACK LINK SELECTOR
ESP0
0000000000000000 I | SSO
ESP1
0000000000000000 I SS1
ESP2
0000000000000000 I SS2
CR3
EIP
EFLAGS
ЕАХ
ЕСХ
EDX
ЕВХ
ESP
ЕВР
ESI
EDI
0000000000000000 ES
0000000000000000 CS
0000000000000000 SS
0000000000000000 DS
0000000000000000 FS
0000000000000000 GS
0000000000000000 LDT
BIT_MAP-OFFSET(15:0) 0000000000000000 I T„
Доступно
о
I TSSBASE
4 8 С Стек для CPL 0,1,2
10
14
18_ 1С 20 24 28 2С 30 34 38
ЗС 40 Состояние
44 текущей
48 4С 50 54 58 5С 60 задачи
О
DEBUG
TRAP BIT
24123
1б|15
31
255 248 247 240 239 232 231 224
31 24 23 16 15 8 7 0
63 56 55 48 47 40 39 32
95 88 87 80 79 72 71 64
96
Карта разрешения ввода-вывода
65471 (I/O Permission Bitmap)
65503 65472
65535 65504
BIT_MAP_ OFFSET
OFFSET + 000С
HFFH'
OFFSET+ 1FF4
OFFSET + 1FF8
OFFSET + 1FFC
OFFSET + 2000
J TSS LIMIT=OFFSET+2000H
0
31
SEGMENT BASE15...0 SEGMENT LIMIT 15...0
BASE31...24G1 0 0 P DPL 0 TYPE BASE
Рис. 5.9. Сегмент состояния задачи TSS 386+
134
5. Защищенный режим
Оба типа сегментов содержат образы регистров процессора, раздельные указате-
ли стеков для уровней привилегий 0, 1 и 2, а также обратную ссылку на селек-
тор TSS вызвавшей задачи. Свободное поле TSS может использоваться по усмотре-
нию ОС. TSS для процессоров 386+ содержит элементы, отсутствующие в 80286:
битовые карты разрешения ввода-вывода и перенаправления прерываний, а также
бит отладочной ловушки Т (при Т = 1 переключение в данную задачу вызывает
5.5. Переключение задач
135
исключение отладки). Последним элементом TSS 386+ должен быть байт OFFh.
Карту перенаправления прерываний поддерживают только процессоры с расши-
рением VME (см. п. 5.8). Значение поля лимита дескриптора для TSS 286 должно
превышать 002Bh, а для TSS 386+ — 0064h.
Карта разрешения ввода-вывода (I/O Permission Bit Мар), расположенная в кон-
це TSS 386+, имеет по одному биту на каждый адрес портов ввода-вывода. Разре-
шению обращения соответствует нулевое значение бита. Максимальный размер
таблицы (2000h), соответствующий всем 64 Кбайт адресов, может быть урезан
лимитом TSS, но байт-терминатор OFFh должен обязательно вписываться в лимит TSS.
Порты с адресами, не попавшими в усеченную таблицу, считаются недоступными.
Текущий сегмент TSS идентифицируется специальным регистром задачи TR (Task
Register). Этот регистр содержит селектор, ссылающийся на дескриптор теку-
щего TSS. Процраммно-невидимые регистры базового адреса и лимита, связанные
с TR, загружаются при загрузке в TR нового селектора.
Для возврата управления задаче, вызвавшей текущую задачу или ею прерванной,
используется инструкция IRET. В регистре флагов имеется флаг вложенной зада-
чи NT (Nested Task), который управляет функцией инструкции IRET. При NT = О IRET
работает обычным образом, оставаясь в текущей задаче. При NT = 1 (текущая за-
дача — вложенная) IRET выполняет переключение в предыдущую задачу.
Когда инструкции CALL, JMP или INT выполняют переключение задач, старый (кро-
ме случая JMP) и новый сегмент TSS помечаются как занятые (меняется значение
TYPE в их дескрипторах), и в поле обратной ссылки в новом TSS устанавливается
значение селектора старого TSS. Инструкции CALL и INT, переключающие задачи,
устанавливают в новой задаче бит NT. Прерывание, не вызывающее переключения
задач, сбросит бит NT. Этот бит может устанавливаться и сбрасываться инструк-
циями POPF и IRET.
Смена контекста блоков FP/MMX и ХММ (или просто сопроцессора) при пере-
ключении задач автоматически не производится, поскольку новой задаче эти бло-
ки могут и не понадобиться. Всякий раз при переключении задач процессор уста-
навливает бит TS (Task Switched) в CRO (MSW) — указание на то, что контекст блоков
FP/MMX и ХММ может относиться к другой задаче. Процессор обнаруживает
первое использование данных блоков (по первой инструкции FPU, ММХ или
ХММ) после переключения задач и вырабатывает исключение #NM. Обработчик
этого исключения сам определит, необходима ли смена контекста, и выполнит ее,
после чего сбросит флагТ5. Таким образом, удается избегать потерь времени, связан-
ных с сохранением и восстановлением довольно громоздкого контекста, ненужных,
если задаче не требуется оборудование FPU/MMX и ХММ. Обработчик исключе-
ния #NM является частью операционной системы с вытесняющей многозадачностью,
которая сама заботится о сохранении и восстановлении контекста во время пере-
ключения задач. Приложения в такой ОС ведут себя «беззаботно» (собственно,
иначе они и не могут, поскольку переключения задач для них происходят в произволь-
ных точках программного кода). Приложения для кооперативных многозадачных
ОС, использующие данные блоки, сами должны принимать меры по сохранению
контекста этих блоков при каждой передаче управления операционной системе.
136
5. Защищенный режим
5.6. Страничное управление памятью
Страничное управление (Paging) является средством организации виртуальной
памяти с подкачкой страниц по запросу (Demand-Paged Virtual Memory). В отли-
чие от сегментации, которая организует программы и данные в модули различно-
го размера, страничная организация оперирует с памятью как с набором страниц
одинакового размера. В момент обращения страница может присутствовать в
физической оперативной памяти, а может быть выгруженной на внешнюю (дис-
ковую) память. При обращении к выгруженной странице памяти процессор вы-
рабатывает исключение^ — отказ страницы, а программный обработчик исклю-
чения (часть ОС) получит необходимую информацию для свопинга — подкачки
отсутствующей страницы с диска. Страницы не й^еют прямой связи с логичес-
кой структурой данных или программ. В то вреМ^ак селекторы можно рассмат-
ривать как логические имена модулей кодов и данных, страницы представляют
части этих модулей. Учитывая обычное свойство локальности (близкого рас-
положения требуемых ячеек памяти) кода и ссылок на данные, в оперативной
памяти в каждый момент времени следует хранить только небольшие области
сегментов, необходимые активным задачам. Эту возможность (а следовательно,
и увеличение допустимого числа одновременно выполняемых задач при ограни-
ченном объеме оперативной памяти) как раз и обеспечивает страничное управле-
ние памятью. Страничная переадресация может использоваться с сегментацией
без каких-либо требований по согласованию границ сегментов и страниц. Однако
от разумности распределения сегментов по страницам будет зависеть произво-
дительность компьютера, поскольку подкачка страниц занимает значительное
время.
Многие процессоры Р6 имеют разрядность шины адреса 36 бит, что позволяет
адресовать до 64 Гбайт физической памяти. Поскольку архитектура IA-32 пред-
полагает разрядность линейного адреса 32 бит, старшие 4 бита могут появиться
только в результате работы блока страничной переадресации. Без использования
дополнительных возможностей переадресации (РАЕ или PSE-36) биты внешней
шины адреса А[35:32] принудительно обнуляются.
В первых 32-разрядных процессорах (начиная с 80386) размер страницы состав-
лял 4 Кбайт. Начиная с Pentium, появилась возможность увеличения размера стра-
ницы до 4 Мбайт, одновременно с использованием страниц размером 4 Кбайт (ре-
жим PSE). В процессорах Р6 был введен режим расширения физического адреса
до 36 бит, при котором допустимы страницы размером 4 Кбайт и 2 Мбайт (режим
РАЕ). В Pentium III появилась возможность использования страниц размером
4 Мбайт с 36-битной физической адресацией (режим PSE-36). Режимом странич-
ной переадресации управляют биты PG в регистре CRO, флаги РАЕ и PSE в CR4 и бит
размера страницы PS в РОЕ — элементе каталога страницы (табл. 5.1). Естественно,
управление режимом возможно только в пределах возможностей конкретного
процессора. 1
5.6. Страничное управление памятью
137
Таблица 5.1. Режимы страничной переадресации
CRO.PG CR4.PAE CR4.PSE PDE.PS Размер страницы Разрядность физического адреса, бит
0 X X X Трансляция запрещена 32
1 0 0 X 4 Кбайт 32
1 0 1 0 4 Кбайт 32
1 0 1 1 4 Мбайт 32(PSE) 36(PSE-36)
1 1 X 0 4 Кбайт 36 (РАЕ)
1 1 X 1 2 Мбайт 36 (РАЕ)
Базовый механизм страничного управления использует двухуровневую табличную
трансляцию линейного адреса в физический (рис. 5.11).
Линейный адрес
31 22 21 12 11 О
Рис. 5.11. Базовый механизм страничной переадресации
Механизм имеет три части: каталог страниц (Page Directory), таблицы страниц
(Page Table) и собственно страницы (Page Frame). Механизм включается установкой
бита PG = 1 в регистре CR0. Регистр CR2 хранит линейный адрес отказа (Page Fault
Linear Address) — адрес памяти, по которому был обнаружен последний отказ стра-
ницы. Регистр СИЗ хранит физический адрес каталога страниц (Page Directory
Physical Base Address). Его младшие 12 бит всегда нулевые (каталог выравнивает-
ся по границе страницы).
138
5. Защищенный режим
Каталог страниц размером 4 Кбайт содержит 1024 32-битных строки PDE (Page
Directory Entry). Каждая строка (рис. 5.12, о) содержит 20 старших бит адреса
таблицы следующего уровня (младшие биты этого адреса всегда нулевые) и при-
знаки (атрибуты) этой таблицы. Индексом поиска в каталоге страниц являются
10 старших бит линейного адреса (А22-А31).
31 12 11 9876543210
Базовый адрес таблицы страниц 1 1 Доступны G Р S 0 А Р С D Р W Т и / S R / W р
31 12 11 9876543210
Базовый адрес страницы 1 1 Доступны G i D А Р С D Р W т и / S R / W р
Рис. 5.12. Структура 32-битных элементов страничного преобразования:
а — строка каталога (PDE); б — строка таблицы (РТЕ)
Каждая таблица страниц также имеет 1024 строки РТЕ (Page Table Entry) анало-
гичного формата (рис. 5.12, б), но эти строки содержат базовый физический адрес
(Page Frame Address) и атрибуты самих страниц. Индексом поиска в таблице яв-
ляются биты А12-А21 линейного адреса. Физический адрес получается из адреса
страницы, взятого из таблицы, и младших 12 бит линейного адреса.
Строки каталога и таблиц имеют следующие биты атрибутов.
♦ Р (Present) — бит присутствия. Р = 1 означает возможность использования дан-
ной строки для трансляции адреса. Бит присутствия вхождений в таблицы,
используемые текущим исполняемым кодом, должен быть установлен. Про-
граммный код не должен его изменять «на ходу». Если Р = 0, то все остальные
биты доступны операционной системе и могут использоваться для получения
информации о местонахождении данной страницы (на диске).
♦ A (Accessed) — признак доступа, который устанавливается перед любым чте-
нием или записью по адресу, в преобразовании которого участвует данная
строка.
♦ D (Dirty) — признак, который устанавливается перед операцией записи по ад-
ресу, в преобразовании которого участвует данная строка. Таким образом по-
мечается использованная — «грязная» страница, которую в случае замещения
необходимо выгрузить на диск.
Биты Р, A, D модифицируются процессором аппаратно в заблокированных шин-
ных циклах. При их программной модификации в многопроцессорных системах
должен использоваться префикс LOCK, гарантирующий сохранение целостности
данных.
5.6. Страничное управление памятью
139
Поле OS Reserved программно использует ОС. Оно может хранить, например, ин-
формацию о «возрасте» страницы, необходимую для реализации замещения по
алгоритму LRU (Least Recently Used — наиболее давно не использовавшаяся стра-
ница замещается первой).
Бит PWT (Page Write Through) определяет политику записи при кэшировании,
а бит PCD (Page Cache Disable) запрещает кэширование памяти для обслуживае-
мых страниц или таблиц (используются на процессорах 486+).
Бит PS (Page Size) задает размер страницы (только в РОЕ). При PS = 0 страница
имеет размер 4 Кбайт, PS = 1 используется в расширениях РАЕ и PSE (см. ниже).
Механизм защиты страниц различает два уровня привилегий: пользователь (User)
и супервизор (Supervisor). Пользователю соответствует уровень привилегий 3,
супервизору — уровни 0,1 и 2. Строки таблиц имеют атрибуты защиты страниц —
биты U (User) и W (Writable — возможна запись); в некоторых описаниях те же
биты называются U/S (User/Supervisor) и R/W (Read/Write). Эти атрибуты в стро-
ке каталога страниц относятся ко всем страницам, на которые ссылается данная
строка через таблицу второго уровня. Атрибуты защиты в строке таблицы стра-
ниц относятся к конкретной странице памяти, которую она обслуживает. Права
доступа к странице приведены в табл. 5.2. Если атрибуты защиты в PDE и РТЕ раз-
личаются, то результирующие атрибуты определяются согласно табл. 5.3. Защи-
та на уровне страниц включается установкой бита WP (Write Protect) в регистре
CR0, по аппаратному сбросу он обнуляется.
Таблица 5.2. Защита на уровне страниц
U(U/S) W(R/W) Разрешено при PL=3 Разрешено при PL=O, 1,2
0 0 Нет Чтение/запись
0 1 Нет Чтение/запись
1 0 Только чтение Чтение/запись
1 1 Чтение/запись Чтение/запись
Таблица 5.3. Комбинация атрибутов защиты
PDE РТЕ и W Результат PDE и W РТЕ и W Результат
и W и W и W
1 0 1 0 1 0 0 0 1 0 0 1
1 0 1 1 1 0 0 0 1 1 0 1
1 1 1 0 1 0 0 1 1 0 0 1
1 1 1 1 1 1 0 1 1 1 0 1
1 0 0 0 0 1 0 0 0 0 0 1
1 0 0 1 0 1 0 0 0 1 0 1
1 1 0 0 0 1 0 1 0 0 0 1
1 1 0 1 0 1 0 1 0 1 0 1
140
5. Защищенный режим
Бит G (Global), появившийся в Р6, определяет глобальность страницы. Он анали-
зируется только в строке, указывающей на страницу физической памяти (в РТЕ для
страниц в 4 Кбайт, в PDE — для страниц 2 Мбайт или 4 Мбайт). Этот бит, управля-
емый только программно, позволяет пометить страницы глобального использова-
ния (например, ядра ОС). При установленном бите PGE в регистре CR4 строки с
указателями на глобальные таблицы не будут аннулироваться в TLB (см. ниже)
при загрузке CR3 или переключении задач, что снижает издержки на обслужива-
ние виртуальной памяти.
Механизм страничного управления при обращении к памяти может порождать
исключение #PF. Оно возникает при обращении к отсутствующей странице и при
нарушении прав доступа, определяемых уровнем привилегий и битами U и W. Для
идентификации причины отказа в стек помещается 16-битный код ошибки, фор-
мат которого приведен на рис. 5.13. Хотя названия битов совпадают с атрибутами
строк, их назначение отличается. Бит U/S указывает на уровень привилегий, при
котором произошел отказ (1 — пользователь, 0 — супервизор). Бит W/R указывает
на операцию, при которой произошел отказ (0 — чтение, 1 — запись). Бит Р указы-
вает на причину отказа (1 — отсутствие страницы в памяти, 0 — нарушение защи-
ты). Биты U не используются. Проверка защиты на уровне страниц выполняется
после проверок защиты сегментов. Если при попытке доступа к памяти сработала
защита сегментов, то проверка на уровне страниц уже не выполняется.
15 3 2 1 0
и и и и и и и и и и и и и и / S W / R р
Рис. 5.13. Формат кода ошибки при отказе страницы
Обращение при каждой операции доступа к памяти к двум таблицам, расположен-
ным в памяти, существенно снижает производительность. Для предотвращения
этого замедления в процессор введен буфер ассоциативной трансляции TLB
(Translation Look aside Buffer) для хранения интенсивно используемых строк таб-
лиц. В процессорах 80386 и 486 буфер представляет собой четырехканальный
наборно-ассоциативный кэш на 32 строки таблиц трансляции. Такой размер по-
зволяет хранить информацию о трансляции 128 Кбайт памяти, что в большинстве
случаев многозадачного использования дает коэффициент кэш-попаданий 98 %,
то есть только 2 % обращений к памяти требуют дополнительных обращений к
таблицам. В процессоре Pentium имеются раздельные TLB для инструкций и дан-
ных, а в Р6 буферы разделены еще и по размеру обслуживаемых страниц (4 Кбайт
и 2 Мбайт/4 Мбайт).
Когда страничное управление разрешено (бит PG = 1 в CRO), блок страничной пе-
реадресации получает 32-битный линейный адрес от блока сегментации. Его стар-
шие 20 бит сравниваются со значениями из TLB, и в случае попадания физичес-
кий адрес вычисляется по начальному адресу страницы, полученному из TLB,
5.6. Страничное управление памятью
141
азатем выводится на шину адреса. Если соответствующей строки в TLB нет, произ-
водится чтение строки из страничного каталога. Если строка имеет бит Р = 1 (таб-
лица присутствует в памяти), в ней устанавливается бит доступа А и производит-
ся чтение указанной ею строки из таблицы второго уровня. Если и в этой строке
Р = 1, процессор обновляет в ней биты А и D, вычисляет физический адрес и, нако-
нец, производит обращение по этому адресу. Если на этих этапах встречается Р = О,
вырабатывается исключение #PF, обработчик которого должен принять меры по
загрузке затребованной страницы в оперативную память. Поскольку это исклю-
чение классифицируется как отказ, после его обработки (успешной) повторяется
доступ к затребованной ячейке памяти. Во время его обработки может еще раз
возникнуть исключение #PF, но это не приведет к двойному отказу.
Обработчик исключения #PF, поддерживающий подкачку страниц по запросу,
должен скопировать страницу с внешней (дисковой) памяти в оперативную, за-
грузить адрес страницы в строку таблицы и установить бит присутствия Р. Посколь-
ку в TLB могла оставаться старая некорректная копия строки, необходимо объ-
явить содержимое TLB недействительным (произвести очистку). После этого
процесс, породивший исключение, может быть продолжен.
Буферы TLB для прикладных задач (CPL >0) программно невидимы, с ними ра-
ботает только ОС с CPL = 0. ОС должна корректно сгенерировать начальные таб-
лицы трансляции и обрабатывать исключения отказов. В случае изменения таб-
лиц (и при изменении значений бита Р в любых таблицах) она должна очищать
буферы TLB (целиком или конкретные вхождения). Очистка всех буферов (кро-
ме глобальных вхождений при установленном бите PGE) происходит при загрузке
регистра CR3, выполняемой явно или по переключению задач. При изменении ото-
бражения одиночной страницы очистка может выполняться по инструкции INVLPG,
которая по возможности очистит только конкретное вхождение в TLB, но в ряде
случаев может обновить и весь буфер.
Процессоры Pentium и выше кроме стандартных страниц 4 Кбайт могут опериро-
вать и страницами размером 4 Мбайт, что позволяет уменьшить накладные рас-
ходы на обслуживание страничного режима при возросших потребностях про-
грамм в памяти. Расширение размера страницы (Page Size Extension) разрешается
установкой бита PSE в регистре CR4. При CR4.PSE = 0 страничное преобразование
работает по базовой схеме (см. рис. 5.11). При CR4.PSE = 1 процессор анализирует
бит 7, определенный теперь как PS (Page Size — размер страницы) строки каталога
страниц (PDE). Если PDE.PS = 0, эта строка ссылается на таблицу страниц размером
4 Кбайт и обработка идет по схеме, представленной на рис. 5.11. Если PDE.PS = 1,
то биты 31:12 этой строки являются базовым физическим адресом страницы
размером 4 Мбайт — здесь ступень таблицы страниц исключена (рис. 5.14). Фор-
мат строки каталога (PDE) для страницы с расширенным размером приведен на
рис. 5.15, а.
В процессорах Pentium III появилась возможность использования 36-битной физи-
ческой адресации для страниц размером 4 Мбайт — режим PSE-36. Формат PDE
142
5. Защищенный режим
для таких страниц приведен на рис. 5.15, б. Здесь ранее неиспользуемые биты 16-13
хранят старшие 4 бита (РА-2) физического адреса А[36:32] (прежде они должны
были быть нулевыми). Новый бит РАТ1 используется для задания атрибута стра-
ниц (см. ниже), прежде он был зарезервирован (должен был быть нулевым).
31
О
Линейный адрес
22 21
Рис. 5.14. Страничная переадресация в режиме PSE
31 22 21 13 12 11 9 8 7 6 5 4 3 2 1 0
Базовый адрес страницы 1 1 Доступно G PS 1 D А Р С D Р W Т и / S R / W р
31 22 21 17 16 13 12 11 9 8 7 6 5 4 3 2 1 0
Базовый адрес страницы (РА-1) Баз. адр. (РА-2) 1 1 1 Доступно G PS 1 D А Р С D Р W Т и / S R / W р
Рис. 5.15. Строка каталога (PDE) для страницы 4 Мбайт: а — для 32-битного физического
адреса; б — для 36-битного физического адреса (PSE-36)
Все процессоры Р6 поддерживают расширение физического адреса (Physical Ad-
dress Extensions) до 64 Гбайт. Это расширение включается установкой бита РАЕ
в регистре CR4, при этом расширение PSE становится недоступным (бит PSE игно-
рируется). Здесь блок страничной переадресации оперирует уже 64-битными
элементами (рис. 5.16).
5.6. Страничное управление памятью
143
PDPTE
63 36 35 32
.г/ . X <• Л > • 'А гг *-*5» , % > г ' 4 N»’ гг? <•;•*••• ? *!• ' л# v > >• %-/• <<; •’ > Базовый адрес...
31 12 11 9 8 5 4 3 2 1 0
Базовый адрес каталогов страниц Доступны ;=dPe^j^;g С р W т . "л?'А Дй 1
й?* t г-f Базовый адрес...
б
31 12 11 9876543210
Базовый адрес таблицы страниц I 1 Доступны 0 PS 0 А Р С Р W и / R / р
0 D т S W
РТЕ4К оо 36 35 32
ч <• Д >с ' * < ,'•<•*; Д' Ч ' Т"’#*Лл<<{*♦*'*>#• Базовый адрес...
чу
в 31 12 11 9876543210
Базовый адрес страницы 1 1 Доступны G (0) D А Р С D Р W Т и / S R / W р
PDE2M
63 36 35 32
s.:<z J ? • •• £ • . ’ v < »!<' ' КХ ••*•' £л*' v< ••"р > "• •? -г - • г -;v s-X-X а; . >•«•г А- -г •%<,-.. < Л • Базовый адрес...
указателей на каталоги; б — строка каталога для страницы 4 Кбайт; в — строка таблицы
для страниц 4 Кбайт; г — строка каталога для страниц 2 Мбайт
144
5. Защищенный режим
32-битный регистр CR3 хранит указатель (Page Directory Base Pointer) на малень-
кую таблицу 64-битных указателей, находящуюся в первых 4 Гбайт памяти. Два
старших бита [31:30] линейного адреса выбирают из этой таблицы указатель на
одну из 4 таблиц каталогов. Следующие 9 бит [29:21] линейного адреса выбирают
элемент из этой таблицы, который, в зависимости от бита PS, может быть как ссыл-
кой на таблицу страниц (PS = 0), так и базовым адресом страницы памяти (PS = 1).
При PS = 0 биты [20:12] линейного адреса выбирают страницу размером 4 Кбайт
из таблицы, а биты [11:0] являются смещением в этой странице. При PS = 1 биты
[20:0] линейного адреса являются смещением внутри страницы размером 2 Мбайт.
Схемы страничного преобразования для режима РАЕ приведены на рис. 5.17 и
5.18, а структура элементов — на рис. 5.16. Для задания атрибута страниц (см. ниже)
в элементы, описывающие страницы, ввели новый бит РАТ1, прежде он был заре-
зервирован (должен был быть нулевым).
Линейный адрес
31 30 29 21 20 12 11 0
Рис. 5.17. Страничная переадресация в режиме РАЕ для страниц 4 Кбайт
5.7. Виртуализация прерываний
145
Линейный адрес
31 30 29 21 20 0
Рис. 5.18. Страничная переадресация в режиме РАЕ для страниц 2 Мбайт
Как видно из схемы, расширение размера адресуемой памяти в режиме РАЕ требу-
ет полного изменения структуры программной системы страничного преобразования.
Для процессоров с PSE-36 расширение размера адресуемой памяти вполне мирно
уживается с традиционной схемой страничного преобразования и расширением
PSE. При этом не появляется дополнительной ступени (таблицы указателей). Нали-
чие у процессора расширений размеров страниц и физического адреса можно обна-
ружить с помощью инструкции CPUID. Если процессор эту инструкцию не поддер-
живает, то у него нет и этих средств. Возможность режима PSE определяется по
биту 3 регистра EDX после вызова CPUID(l), РАЕ — по биту 6, PSE-36 — по биту 17.
5.7. Виртуализация прерываний
Согласно базовой архитектуре 32-разрядных процессоров, в защищенном режи-
ме инструкции CLI и STI, управляющие флагом прерывания IF, являются чувстви-
тельными к уровню привилегий. Если уровень привилегий задачи позволяет
(CPL < IOPL), они будут воздействовать на флаг прерываний, как и инструкции,
воздействующие на этот флаг неявно. Попытка их использования при CPL > IOPL
вызовет исключение-отказ #GP. Инструкции, управляющие флагом прерывания
неявно, исключения не вызывают, но и не изменяют состояния флага.
Прикладные программы должны иметь возможность защитить себя от воздей-
ствия внешних прерываний. Для защиты критичных участков кода обычно при-
146
5. Защищенный режим
меняют инструкции CLI и STI, которые могут встречаться в прикладных задачах
довольно часто. Отработка исключений каждый раз по их появлению значитель-
но снижает производительность вычислительного процесса. В то же время позво-
лять прикладным программам напрямую управлять флагом прерывания про-
цессора далеко не всегда допустимо, поскольку это может приводить к потере
управления операционной системой. В многозадачной системе с разделяемыми
устройствами внешние прерывания первоначально обрабатываются операцион-
ной системой, которая определяет, к какой задаче (задачам) относится каждое
конкретное прерывание. ОС должна иметь возможность сообщить соответствую-
щей задаче (или всем) о его возникновении, но только в тот момент, когда задача
имеет состояние с разрешенными прерываниями.
Задача, которая должна обрабатывать аппаратные прерывания, может получать
их как в реальном виде (как «настоящие» внешние прерывания), так и в виртуальном.
Когда приложению передаются реальные прерывания, для него становится проблема-
тичным использование виртуальной памяти с подкачкой страниц по запросу. Если
страница с обработчиком окажется выгруженной, то по возникновению аппарат-
ного прерывания потребуется подкачка страницы, занимающая значительное вре-
мя. Для обработчиков прерываний такое время реакции окажется неприемлемым.
Чтобы избежать подкачки страниц по аппаратным прерываниям, обработчики
прерываний должны располагаться в ядре ОС, постоянно присутствующем в па-
мяти. Если задача-приемник прерывания находится в прерываемом состоянии,
ОС сигнализирует ей о возникновении прерывания сразу. Если задача находится
в непрерываемом состоянии, ОС сигнализирует ей о прерывании только после
перехода в прерываемое состояние. Таким образом, задаче передаются виртуаль-
ные прерывания. В этом случае возможно использование виртуальной памяти,
поскольку обработчики, выполняющие критические по времени действия, всегда
находятся в памяти.
Виртуализация прерываний на основе вышеупомянутых базовых свойств процес-
сора выполняется ОС чисто программно, однако обработка потока частых исклю-
чений весьма неэффективна.
В процессорах Pentium и последних моделях 486 появились новые аппаратные
средства виртуализации прерываний. В регистре EFLAGS появились флаги вирту-
ального разрешения прерывания VIF и ожидающего прерывания VIP. В регистре
CR4 бит PVI (Protected-Mode Virtual Interrupt) разрешает виртуализацию флага
прерываний в защищенном режиме для задач с CPL = 3. При VIP = 0, а также при
VIP = 1 и CPL < 3 инструкции CLI и STI будут вести себя вышеописанным спосо-
бом — либо управлять флагом IF, либо вызывать исключение #GP. При VIP = 1 и
CPL = 3 их поведение меняется:
♦ если IOPL а 3, то CLI и STI переключают флаг IF;
♦ если IOPL < 3 и VIP а 0 (нет ожидающего прерывания), то CLI и STI просто уп-
равляют флагом VIF;
♦ если IOPL < 3 и VIP e 1 (присутствует ожидающее прерывание), то попытка
разрешения прерывания (установки VIF), используя STI, вызовет исключение
#GP, обработчик которого и «донесет» задаче весть об имевшем место внешнем
прерывании.
5.8. Режим виртуального процессора 8086 (V86 и EV86)
147
Итак, флаг виртуального разрешения прерывания VIF указывает на прерываемое
или не прерываемое состояние задачи, выполняемой на CPL = 3; этот флаг не за-
трагивает всего процессора. Флаг ожидающего прерывания VIР устанавливается в
образе регистров задачи операционной системой, если внешнее прерывание при-
шло в момент, когда задача находилась в непрерываемом состоянии. Мониторинг
перехода задачи в состояние с разрешенными прерываниями осуществляется про-
цессором автоматически без лишних затрат времени.
Флаги, участвующие в виртуализации прерываний:
♦ VIР — модифицируется инструкцией IRETD, если CPL = 0;
♦ VIF — модифицируется инструкцией IRETD, если CPL = 0, и инструкциями CLI и
STI, как было показано вышё;
♦ IOPL — модифицируется инструкцией IRET(D) и POPF(D), если CPL в 0;
♦ IF — модифицируется инструкцией IRET(D) и POPF(D), если CPL < IOPL, и инст-
рукциями CLI и STI, как было показано выше.
Наличие у процессора средств виртуализации прерываний можно обнаружить с
помощью инструкции CPUID. Если процессор эту инструкцию не поддерживает, то
у него нет и этих средств.
5.8. Режим виртуального процессора 8086
(V86 и EV86)
Прикладные программы для 8086 могут исполняться на 32-разрядных процессо-
рах как в реальном режиме, так и в режиме виртуального процессора 8086 (V86),
который является особым состоянием задачи защищенного режима. Назначение
этого режима — формирование виртуальной машины, эмулирующей процессор
8086. Виртуальная машина формируется программными средствами операцион-
ной системы — монитором V86, который поддерживается специальными аппарат-
ными средствами процессора. Режим V86 позволяет пользоваться аппаратными
средствами поддержки многозадачности. В этом режиме работают защита и меха-
низм страничной переадресаций, позволяющий адресоваться к любой области
пространства физической памяти размером 4 Гбайт. Выполнение приложений
8086 в среде V86 возможно параллельно с приложениями защищенного режима.
Страничная переадресация позволяет параллельно выполняться нескольким за-
дачам V86 с возможностью совместного использования общих областей кода опе-
рационной системы и разделения реальных аппаратных ресурсов компьютера.
Режим V86 появился с процессором 80386, в процессорах Pentium и последних
моделях 486 появилось его расширение — EV86 (Enhanced Virtual 8086). Цель
этого расширения заключалась в переносе ряда функций формирования вирту-
альной машины с программного обеспечения на аппаратные средства процессора,
что существенно повышает производительность.
Монитор V86 представляет собой модуль 32-битного программного кода, испол-
няющийся с CPL = 0. Он содержит обработчики прерываний и исключений, сред-
148
5. Защищенный режим
ства инициализации задач V86 и эмуляции операций ввода-вывода. Монитор тес-
но связан с обработчиком исключения #GP, через который в основном и происхо-
дит общение с приложениями 8086.
Приложение 8086 «привыкло» работать в среде своей ОС (например, MS-DOS) и
пользоваться ее сервисами. В V86 ОС реального режима может работать на той
же виртуальной машине, что и приложение, а может и эмулироваться средствами
ОС защищенного режима. Первый способ проще — здесь в V86 может быть запу-
щена традиционная ОС (например, MS-DOS). Второй способ требует затрат на
разработку средств эмуляции, но только в этом случае можно получить все преи-
мущества реальной многозадачности.
В режиме V86 программе доступны все регистры 8086, а с помощью префикса
изменения разрядности операндов — и их 32-битные расширения. В качестве сег-
ментных регистров через префиксы замены сегментов возможно также использо-
вание регистров GS и FS, которых в реальном режиме процессора 8086 нет. По умол-
чанию адресация 16-битная, но с помощью префикса изменения разрядности
адреса возможна 32-битная адресация. Набор команд включает все команды 8086
и последующие расширения, реализованные в 80286,80386,486 и Pentium. Попыт-
ка выполнения системных инструкций, допустимых только для защищенного ре-
жима — LTR, STR, LLDT, SLDT, LAR, LSL, ARPL, VERR и VERW, — вызовет исключение #UD.
Модель памяти в режиме V86 имеет некоторые особенности. Одним из основ-
ных различий реального и защищенного режимов является трактовка содер-
жимого сегментных регистров. В режиме V86, как и в реальном режиме, для полу-
чения линейного адреса содержимое сегментных регистров сдвигается на четыре
разряда влево и суммируется с эффективным адресом. 1 Мбайт (точнее, область
0-10FFEFh) адресуемого таким образом пространства с помощью страничной
трансляции может отображаться в любую область 4 Гбайт физической памяти.
С помощью страничной трансляции можно добиться «сворачивания в кольцо»
памяти размером 1 Мбайт, свойственного 8086 (отобразив адреса выше FFFFFh
на ту же физическую память, что и начинающиеся с нуля). Поскольку таблица
трансляции задается управляющим регистром CR3, в многозадачном окружении
при переключении задач автоматически загрузится и требуемая таблица трансля-
ции. Превышение исполнительным адресом границы 64 Кбайт (в том числе при
32-битной адресации) вызывает исключение #SS или #GP. Настоящий процессор
8086 в таком случае переходит к нулевым адресам того же сегмента, как бы свер-
нувшегося в кольцо.
Все программы, запущенные в режиме V86, выполняются со всеми проверками
защиты. Они автоматически получают уровень привилегий 3, то есть минималь-
ные привилегии (реальный режим подразумевает уровень привилегий 0). Попыт-
ка выполнения привилегированных инструкций вызывает исключение #GP. К этим
инструкциям относятся LIDT, LGDT, LMSW, CTS, HLT, а также операции с регистрами DRn,
TRn, CRn, MSR.
В режиме V86 понятие чувствительности к уровню привилегий при вводе-выводе
(IOPL-sensitive) имеет особую трактовку. Инструкции ввода-вывода IN, OUT, (REP)
5.8. Режим виртуального процессора 8086 (V86 и EV86)
149
INS, (REP) OUTS в режиме V86 не чувствительны к IOPL, а управление доступом к
портам осуществляется только через битовую карту ввода-вывода в сегменте со-
стояния задачи. Попытка обращения к запрещенным портам вызовет исключе-
ние #6Р. Битовая карта может быть усеченной (это достигается сочетанием лимита
TSS и смещения карты разрешения), тогда «отрезанные» адреса будут соответство-
вать запрещенным портам.
Особую проблему в режиме V86 составляет обработка прерываний — как про-
граммных, так и аппаратных. Здесь чувствительными являются инструкции INT п,
PUSHF, POPF, STI, CLI и IRET, которые могут воздействовать на флаг прерываний IF.
Однако инструкции INT3, INTO и BOUND не чувствительны к IOPL.
Если установить IOPL в 3, то задача, исполняемая в режиме V86, будет выпол-
няться с максимальной производительностью, имея возможность непосредствен-
но управлять флагом прерываний IF. Однако для многозадачных систем защищен-
ного режима такие «вольности» недопустимы, поскольку ОС может быть легко
лишена возможности управления системой. Чтобы этого не происходило, ОС долж-
на сделать виртуальным флаг IF для задач V86, для чего устанавливают IOPL < 3.
Это приводит к тому, что все чувствительные инструкции задачи V86, приводя-
щие к изменениям флага IF, будут вызывать исключения-отказы, по которым бу-
дет производиться переключение в монитор виртуальных машин (часть многоза-
дачной ОС защищенного режима). Однако частая обработка этих исключений
значительно снизит производительность виртуальной машины V86.
Инструкции INT п, которые широко используются, например, в сервисах DOS и
BIOS, приводят к выходу из режима V86. Все прерывания и исключения влекут
за собой смену уровня привилегий на уровень операционной системы защи-
щенного режима. Если IOPL < 3, то все прерывания через исключения-отказы при-
водят к выходу в монитор виртуальной машины. При IOPL < 3 прерывания вы-
зывают исполнение соответствующих процедур защищенного режима, которые
задаются ОС (приложения 8086 «не понимают» таких обработчиков). Обработ-
чик, заданный ОС, может распознать, что прерывание пришло из V86, по образу
регистра EFLAGS в стеке. Далее ОС может либо обработать это прерывание само-
стоятельно, эмулируя выполнение требуемых функций, либо переслать его к ОС
реального режима, работающей в режиме V86 (reflecting interrupt — отражение
прерывания). Частые переключения режимов (задач), которые происходят при
выполнении прерываний, снижают производительность.
Приложение 8086, которое должно обрабатывать аппаратные прерывания, мо-
жет получать их как в реальном виде (как внешние прерывания), так и в вир-
туальном. В режиме V86 виртуализация прерываний выполняется программно
монитором ОС.
В конечном итоге ОС защищенного режима может прозрачно для приложения
8086, работающего в режиме V86, эмулировать окружение обычной машины 8086,
включая прерывания и перехват обращения к портам. Однако при уровне IOPL < 3,
обеспечивающем устойчивость системы с полной виртуализацией, производи-
тельность виртуальной машины будет низкой.
150
5. Защищенный режим
Проблему виртуализации прерываний позволяет разрешить расширенный режим —
EV86. При IOPL в 3 приложение 8086 по-прежнему имеет возможность управлять
флагом IF (инструкциями CLI, STI). Изменения касаются работы при IOPL < 3. Те-
перь чувствительные инструкции не вызывают безусловного исключения-отказа,
а воздействуют на виртуальную версию флага прерываний VIF в регистре EFLAGS.
Этот флаг не влияет на восприятие процессором внешних (маскируемых) преры-
ваний, а лишь указывает на состояние задачи EV86 — разрешила или запретила
она обработку прерываний. При этом, во-первых, повышается производитель-
ность — инструкции CLI и STI теперь не приводят к отказам, а во-вторых, упроща-
ется монитор, обеспечивающий программную виртуализацию флага прерываний
(в V86 монитор должен был отслеживать все инструкции, влияющие на IF, — CLI,
STI, PUSHF, POPF, INT и IRET). Аппаратная виртуализация флага приводит к значи-
тельному повышению производительности.
Режим EV86 включается установкой бита VME в регистре CR4. В этом режиме сег-
мент состояния задачи TSS-386 приобретает новую 32-байтную структуру — кар-
ту перенаправления прерываний (interrupt redirection bitmap). По структуре она
напоминает карту разрешения портов ввода-вывода и располагается в TSS прямо
перед ней — слово IO_BITMAP_OFFSET является указателем на ее конец (см. рис. 5.9).
Каждый бит карты перенаправления соответствует одному из 256 (32 х 8) про-
граммных прерываний, вызываемых инструкцией INT п. На программные преры-
вания, вызываемые иным образом, исключения и аппаратные прерывания карта
перенаправления действия не оказывает. Если бит установлен, то соответствую-
щее прерывание вызовет исключение-отказ с выходом из EV86 в монитор. Если
бит сброшен, прерывание обрабатывается процедурой реального режима без вы-
хода из EV86.
Для работы с IOPL < 3 предназначены новые флаги — VIF и VIP. Эти флаги может
анализировать и модифицировать только монитор, работающий на уровне CPL « 0.
Теперь инструкции задачи EV86, связанные с флагом IF, не приводят к выходу в
монитор по исключению-отказу, а воздействуют только на флаг VIF, не затрагивая
реального флага управления прерываниями IF. Однако этот факт от приложения
EV86 скрывается — везде вместо IF подставляется VIF. Флаг VIF является указате-
лем для монитора на состояние задачи EV86 — запрещены или разрешены преры-
вания. Если монитор должен сообщить задаче EV86 о внешнем прерывании, то в
случае, если прерывания задачей разрешены, он это может сделать сразу. Если
прерывания запрещены (VIF = 0), монитор установит флаг ожидающего преры-
вания VIP. Теперь как только задача EV86 попытается разрешить прерывания,
исполнив инструкцию STI или иным способом, до фактической установки флага
VIF выработается исключение-отказ #GP, по которому монитор получит управле-
ние и вызовет процедуру обслуживания ожидающего прерывания. Флаги VIF и VIP
позволяют существенно упростить виртуализацию прерываний монитором и по-
высить производительность.
Новые возможности виртуализации прерываний работают при IOPL <*3, однако
инструкция PUSHF в режиме EV86 симулирует IOPL = 3, поэтому задача EV86 не
сможет определить свой реальный уровень IOPL по образу регистра EFLAGS в стеке.
5.9. Переключение между реальным и защищенным режимами 151
Поведение процессора в режиме EV86 при IOPL = 3 иначе как удивительным не
назовешь, но для такого «беззащитного» варианта этот режим, пожалуй, и не нужен.
Вход в режим V86 — установка бита VM в регистре EFLAGS — возможен одним из двух
способов:
♦ выполнением инструкции IRET в 32-битном режиме, когда образ EFLAGS сохра-
нен в стеке с установленным битом VM (при CPL = 0, иначе бит VM не установится);
♦ переключением на задачу с TSS-386+, у которой в TSS образ EFLAGS имеет уста-
новленный бит VM.
При использовании режима EV86 необходимо также установить бит VME в регис-
тре CR4.
Выход из режима V86 (EV86) возможен только при обработке прерывания. Если
вызываемая процедура имеет CPL « 0, то бит VM будет сброшен и процедура будет
выполняться в защищенном режиме. Если ее CPL > 0, произойдет исключение #GP —
нарушение защиты. Если прерывание вызывает переключение задач, состояние
регистров с установленным флагом VM сохранится в TSS старой задачи, к которой
можно будет вернуться. Новый режим (защищенный или V86) установится в со-
ответствии с TSS новой задачи.
Значение бита VM не может быть изменено никакими другими способами; кроме
того, его значение не может быть прочитано — при любом программном сохране-
нии регистра флагов значение VM всегда показывается нулевым. Так что приложение,
выполняемое в среде V86, никак не может ни переключить режим процессора, ни
распознать, в каком режиме — реальном или виртуальном — оно исполняется. Это,
конечно же, справедливо при корректно построенном мониторе виртуальной ма-
шины V86, являющемся частью ОС защищенного режима. Процессор для этого
предоставляет все необходимые аппаратные средства, позволяющие выполнить
полную эмуляцию 8086.
5.9. Переключение между реальным
и защищенным режимами
Переключение процессора в защищенный режим из реального осуществляется за-
грузкой в CRO слова с единичным значением бита РЕ (Protect Enable). Для совмести-
мости с ПО для 80286 бит РЕ может быть установлен также инструкцией LMSW. До
переключения в памяти должны быть проинициализированы необходимые таблицы
дескрипторов IDT и GDT. Сразу после включения защищенного режима процессор
имеет CPL = 0. Для всех 32-разрядных процессоров рекомендуется выполнять сле-
дующую последовательность действий для переключения в защищенный режим.
1. Запретить маскируемые прерывания сбросом флага IF, а возникновение не-
маскируемых прерываний блокировать внешней логикой. Программный код
на время «переходного периода» должен гарантировать отсутствие исключе-
ний и не использовать программных прерываний. Это требование вызвано
сменой механизма вызова обработчиков прерываний.
152
5. Защищенный режим
2. Загрузить в GDTR базовый адрес GDT (инструкцией LGDT).
3. Инструкцией MOV CR0 установить флаг РЕ, а если требуется страничное управ-
ление памятью, то и флаг PG.
4. Сразу после этого должна выполняться команда межсегментного перехода (JMP
Far) или вызова (CALL Far) для очистки очереди инструкций, декодированных в
реальном режиме, и выполнения сериализации процессора. Если включается
страничное преобразование, то коды инструкций MOV CR0 и JMP или CALL должны
находиться в странице, для которой физический адрес совпадает с логическим
(для кода, которому передается управление, это требование не предъявляется).
5. Если планируется использование локальной таблицы дескрипторов, инструк-
цией LLDT загрузить селектор сегмента для LDT в регистр LDTR.
6. Инструкцией LTR загрузить в регистр задач селектор TSS для начальной задачи
защищенного режима.
7. Перезагрузить сегментные регистры (кроме CS), содержимое которых еще от-
носится к реальному режиму, или выполнить переход или вызов другой зада-
чи (при этом перезагрузка регистров произойдет автоматически). В неисполь-
зуемые сегментные регистры загружается нулевое значение селектора.
8. Инструкцией LIDT загрузить в регистр IDTR адрес и лимит IDT — таблицы деск-
рипторов прерываний защищенного режима.
9. Разрешить маскируемые и немаскируемые аппаратные прерывания.
Переключение процессора из защищенного режима в реальный возможно не только
через аппаратный сброс, как это было у 80286, по и сбросом бита РЕ в CRO. При этом
для корректного перехода, согласно документации на процессоры, должны выпол-
няться следующие действия.
1. Запретить маскируемые прерывания флагом IF, немаскируемые — внешней схемой.
2. Если включена страничная трансляция, то необходимо обеспечить равенство
линейных и физических адресов для текущего исполняемого кода (перейти на
такую страницу), а также для таблиц GDT и IDT. Обнулить бит PG в регистре CRO
и загрузить нули в CR3 для очистки кэш-буфера TLB.
ПРИМЕЧАНИЕ--------------------------------------------------------------
Необходимость обнуления бита PG вызывает у авторов некоторые сомнения, однако в офици-
альных информационных материалах фирмы Intel по процессорам 80386,486 и Pentium ука-
зывается, что страничная трансляция работает только в защищенном режиме. Есть непро-
веренные (личным опытом) предположения, что включать и управлять ею можно только в
защищенном режиме, а использовать — еще и в реальном.
3. Передать управление читаемому сегменту с лимитом 64 Кбайт.
4. Загрузить в сегментные регистры SS, DS, ES, FS и GS селектор дескриптора (нену-
левой), в котором установлен лимит 64 Кбайт, байтовая дробность (G - 0), рас-
ширяемость вверх (Е = 0), доступность записи (W = 1) и присутствие (Р = 1).
Если сегментные регистры не перезагружать, исполнение будет продолжаться
с атрибутами, унаследованными от защищенного режима.
5.9. Переключение между реальным и защищенным режимами
153
5. Инициализировать таблицу векторов прерываний реального режима (в пре-
делах первого мегабайта) и указать на нее инструкцией LIDT.
6. Сбросить бит РЕ для перехода в реальный режим.
7. Выполнить дальний переход на программу реального режима, что сбросит оче-
редь инструкций, декодированных в защищенном режиме, и загрузит соответ-
ствующие права доступа к сегменту кода.
8. Загрузить корректные значения в сегментные регистры и указатель стека.
9. Разрешить прерывания.
После этого загружаются остальные регистры. Процессор теперь работает в реаль-
ном режиме, по умолчанию с 16-разрядными адресами и данными.
Шаги 3 и 4 предназначены для загрузки программно-недоступных регистров дес-
крипторов сегментов параметрами стандартного реального режима. Однако вме-
сто них можно создать и «нереальный» (Unreal, по Р. Коллинзу) режим, отличаю-
щийся от реального возможностью доступа к сегментам большого (до 4 Гбайт)
размера (см. главу 2). Правда, у процессоров 80286 и 80386 лимит кодового сег-
мента принудительно ограничивается размером 64 Кбайт, но у более новых про-
цессоров большой размер допустим для всех сегментов. «Нереальный режим»
часто используется менеджерами памяти для DOS и игровыми программами, тре-
бующими большого объема памяти.
6. Кэширование памяти
Архитектура современных 32-разрядных процессоров включает ряд средств кэши-
рования памяти: два уровня кэша инструкций и данных (LI Cache и L2 Cache),
буферы ассоциативной трансляции (TLB) блока страничной переадресации и буфе-
ры записи. Эти средства в разных вариациях (на кристалле, картридже процессора
или на системной плате) представлены в системах на процессорах, начиная с четвер-
того поколения. В процессоре 80386 (Intel) имелся только буфер TLB, а кэш-память,
устанавливаемая на системной плате, процессором никак не поддерживалась.
6.1. Принципы кэширования
Основная память компьютеров реализуется на относительно медленной динами-
ческой памяти (DRAM), обращение к ней приводит к простою процессора — по-
являются такты ожидания (wait states). Статическая память (SRAM), построен-
ная, как и процессор, на триггерных ячейках, по своей природе способна догнать
современные процессоры по быстродействию и сделать ненужными такты ожи-
дания (или хотя бы сократить их количество). Разумным компромиссом для по-
строения экономичных и производительных систем стал иерархический способ
организации оперативной памяти. Идея заключается в сочетании основной памя-
ти большого объема на DRAM с относительно небольшой кэш-памятью на быст-
родействующих микросхемах SRAM.
В переводе слово кэш (cache) означает «тайный склад», «тайник» («заначка»).
Тайна этого склада заключается в его «прозрачности» — адресуемой области па-
мяти для программы он не добавляет. Кэш является дополнительным быстродей-
ствующим хранилищем копий блоков информации из основной памяти, вероят-
ность обращения к которым, в ближайшее время велика. Кэш не может хранить
копию всей основной памяти, поскольку его объем во много раз меньше основной
памяти. Он хранит лишь ограниченное количество блоков данных и каталог (cache
directory) — список их текущего соответствия областям основной памяти. Кроме
того, кэшироваться может не вся память, доступная процессору.
При каждом обращении к памяти контроллер кэш-памяти по каталогу проверяет,
есть ли действительная копия затребованных данных в кэше. Если она там есть,
то это случай кэш-попадания (cache hit) и данные берутся из кэш-памяти. Если
действительной копии там нет, это случай кэш-промаха (cache miss) и данные
берутся из основной памяти. В соответствии с алгоритмом кэширования блок дан-
ных, считанный из основной памяти, при определенных условиях заместит один
6.1. Принципы кэширования
155
из блоков кэша. От интеллектуальности алгоритма замещения зависит процент
попаданий и, следовательно, эффективность кэширования. Поиск блока в списке
должен производиться достаточно быстро, иначе «задумчивость» в принятии ре-
шения сведет на нет выигрыш от применения быстродействующей памяти. Обра-
щение к основной памяти может начинаться одновременно с поиском в каталоге,
а в случае попадания — прерываться (архитектура Look Aside). Это экономит вре-
мя, но лишние обращения к основной памяти ведут к увеличению энергопотреб-
ления. Другой вариант: обращение к внешней памяти начинается только после
фиксации промаха (архитектура Look Through), при этом теряется, по крайней
мере, один такт процессора, зато экономится энергия.
В современных компьютерах кэш обычно строится по двухуровневой схеме. Пер-
вичный кэш (LI Cache) встроен во все процессоры класса 486 и выше, то есть явля-
ется внутренним. Объем этого кэша невелик (8-32 Кбайт). Чтобы повысить про-
изводительность, для данных и команд часто используется раздельный кэш (так
называемая Гарвардская архитектура — противоположность Принстонской с об-
щей памятью для команд и данных). Вторичный кэш (L2 Cache) для процессоров
486 и Pentium является внешним (устанавливается на системной плате), а у Р6
располагается в одной упаковке с ядром и подключается к специальной внутрен-
ней шине процессора.
Кэш-контроллер должен обеспечивать когерентность (coherency) — согласован-
ность данных кэш-памяти обоих уровней с данными в основной памяти, при том
условии, что обращение к этим данным может производиться не только процессо-
ром, но и другими активными (bus-master) адаптерами, подключенными к шинам
(PCI, VLB, ISA и т. д.). Следует также учесть, что процессоров может быть не-
сколько и у каждого может быть свой внутренний кэш.
Контроллер кэша оперирует строками (cache line) фиксированной длины. Стро-
ка может хранить копию блока основной памяти, размер которого, естественно,
совпадает с длиной строки. С каждой строкой кэша связана информация об адре-
се скопированного в нее блока основной памяти и ее состоянии. Строка может
быть действительной (valid) — это означает, что в текущий момент времени она
достоверно отражает соответствующий блок основной памяти, или недействи-
тельной. Информация о том, какой именно блок занимает данную строку (то есть
старшая часть адреса или номер страницы), и о ее состоянии называется тегом
(tag) и хранится в связанной с данной строкой ячейке специальной памяти тегов
(tag RAM). В операциях обмена с основной памятью обычно строка участвует
целиком (несекторированный кэш), для процессоров 486 и выше длина строки
совпадает с объемом данных, передаваемых за один пакетный цикл (для 486 — это
4x4 = 16 байт, для Pentium — 4 х 8 = 32 байт). Возможен и вариант секторирован-
ного (sectored) кэша, при котором одна строка содержит несколько смежных яче-
ек — секторов, размер которых соответствует минимальной порции обмена дан-
ных кэша с основной памятью. При этом в записи каталога, соответствующей
каждой строке, должны храниться биты действительности для каждого сектора
данной строки. Секторирование позволяет экономить память, необходимую для
хранения каталога при увеличении объема кэша, поскольку большее количество бит
156
6. Кэширование памяти
каталога отводится под тег, и выгоднее использовать дополнительные биты действи-
тельности, чем увеличивать глубину индекса (количество элементов) каталога.
Строки кэша под отображение блока памяти выделяются при промахах операций
чтения, в Р6 строки заполняются и при записи. Запись блока, не имеющего копии
в кэше, производится в основную память (для повышения быстродействия запись
может производиться через буфер отложенной записи). Поведение кэш-контрол-
лера при операции записи в память, когда копия затребованной области находит-
ся в некоторой строке кэша, определяется его алгоритмом, или политикой записи
(Write Policy). Существуют две основные политики записи данных из кэша в основ-
ную память: сквозная запись WT(Write Through) и обратная запись WB (Write Back).
Политика WT предусматривает одновременное выполнение каждой операции за-
писи (даже однобайтной), попадающей в кэшированный блок, в строку кэша и в
основную память. При этом процессору при каждой операции записи придется
выполнять относительно длительную запись в основную память. Алгоритм дос-
таточно прост в реализации и легко обеспечивает целостность данных за счет по-
стоянного совпадения копий данных в кэше и основной памяти. Для него не нуж-
но хранить признаки присутствия и модифицированности — вполне достаточно
только информации тега (при этом считается, что любая строка всегда отражает
какой-либо блок, а какой именно — указывает тег). Но эта простота оборачивает-
ся низкой эффективностью записи. Существуют варианты этого алгоритма с при-
менением отложенной буферизованной записи, при которой данные в основную
память переписываются через FIFO-буфер во время свободных тактов шины.
Политика WB позволяет уменьшить количество операций записи на шине основ-
ной памяти. Если блок памяти, в который должна производиться запись, отобра-
жен в кэше, то физическая запись сначала будет произведена в эту действитель-
ную строку кэша, которая отмечается как грязная (dirty), или модифицированная,
то есть требующая выгрузки в основную память. Только после этой выгрузки (запи-
си в основную память) строка станет чистой (clean), и ее можно будет использо-
вать для кэширования других блоков без потери целостности данных. В основную
память данные переписываются только целой строкой. Эта выгрузка контролле-
ром может откладываться до наступления крайней необходимости (обращение к
кэшированной памяти другим абонентом, замещение в кэше новыми данными)
или выполняться в свободное время после модификации всей строки. Данный
алгоритм сложнее в реализации, но существенно эффективнее, чем WT. Поддерж-
ка системной платой кэширования с обратной записью требует обработки до-
полнительных интерфейсных сигналов для выгрузки модифицированных строк
в основную память, если к этой области производится обращение со стороны та-
ких контроллеров шины, как другие процессоры, графические адаптеры, контрол-
леры дисков, сетевые адаптеры и т. п.
В зависимости от способа определения взаимного соответствия строки кэша и обла-
сти основной памяти различают три архитектуры кэш-памяти: кэш прямого отобра-
жения (direct-mapped cache), полностью ассоциативный кэш (fully associative cache)
и их комбинация — частично- или наборно-ассоциативный кэш (set-associative
cache).
6.1. Принципы кэширования
157
6.1.1. Кэш прямого отображения
В кэш-памяти прямого отображения адрес памяти, по которому происходит обра-
щение, однозначно определяет строку кэша, в которой может находиться требуе-
мый блок. Принцип работы такого кэша поясним на примере несекторированно-
го кэша объемом 256 Кбайт с размером строки 32 байта и объемом кэшируемой
основной памяти 64 Мбайт — типичный кэш системной платы для Pentium. Струк-
туру памяти в такой системе иллюстрирует рис. 6.1.
________Тад
125_____18
Номер страницы
основной памяти
Index
17_____________5
Номер строки
в странице
4 р| Адрес кэшируемой памяти
Смещение
в строке
Рйс. 6.1. Кэш прямого отображения
Кэшируемая основная память условно разбивается на страницы (в данном случае по
256 Кбайт), размер которых совпадает с размером кэш-памяти (256 Кбайт). Кэш-
память (и, условно, страницы основной памяти) делится на строки (256 Кбайт/
32 байт - 8 К строк). Архитектура прямого отображения подразумевает, что каж-
дая строка кэша может отображать из любой страницы кэшируемой памяти толь-
ко соответствующую ей строку (на рис. 6.1 они находятся на одном горизонталь-
158
6. Кэширование памяти
ном уровне). Поскольку объем основной памяти много больше объема кэша, на
каждую строку кэша может претендовать множество блоков памяти с одинаковой
младшей частью адреса (смещением внутри страницы). Одна строка в определен-
ный момент может, естественно, содержать копию только одного из этих блоков.
Номер (адрес) строки в кэш-памяти называется индексом (index). Тег несет ин-
формацию о том, какой именно блок занимает данную строку (то есть старшая
часть адреса или номер страницы). Память тегов должна иметь количество ячеек,
равное количеству строк кэша, а ее разрядность должна быть достаточной, чтобы
вместить старшие биты адреса кэшируемой памяти, не попавшие на шину адреса
кэш-памяти. Кроме адресной части тега, с каждой строкой кэша связаны биты
признаков действительности и модифицированное™ данных.
В начале каждого обращения к кэшируемой памяти контроллер первым делом счи-
тывает ячейку каталога с соответствующим индексом, сравнивает биты адреса тега
со старшими битами адреса памяти и анализирует признак действительности. Этот
анализ выполняется в специальном цикле слежения (snoop cycle), который иногда
называют циклом запроса (inquire). Если в результате анализа выясняется, что
требуемого блока нет в кэше, генерируется (или продолжается) цикл обращения
к основной памяти (кэш-промах). В случае попадания запрос обслуживается кэш-
памятью. В случае промаха после считывания основной памяти приемником ин-
формации новые данные помещаются в строку кэша (если она чистая), а в ее тег
помещаются старшие биты адреса и устанавливается признак действительности
данных. Независимо от объема затребованных данных в кэш из основной памя-
ти строка переписывается вся целиком (поскольку признак действительности
относится ко всем ее байтам). Если контроллер кэша реализует упреждающее
считывание (read ahead), то в последующие свободные циклы шины обновляется
также следующая строка (если она была1 чистой). Чтение «про запас» позволяет
при необходимости осуществлять пакетный цикл чтения из кэша через границу
строки.
Такой кэш имеет самую простую аппаратную реализацию и применяется во вторич-
ном кэше большйнства системных плат. Однако ему присущ серьезный недоста-
ток, вполне очевидный при рассмотрении рис. 6.1. Если в процессе выполнения
программы процессору поочередно будут требоваться блоки памяти, смещенные
относительно друг друга на величину, кратную размеру страницы (на рисунке эти
блоки расположёны на одной горизонтали в разных страницах), то кэш будет «буксо-
вать» — работать интенсивно, но вхолостую (cache trashing). Очередное обращение
будет замещать данные, считанные в предыдущем и необходимые в следующем
обращении, то есть будет иметь место сплошная череда кэш-промахов. Переклю-
чение страниц в многозадачных ОС также снижает количество кэш-попаданий,
что отражается на производительности системы. Увеличение размера кэша при
сохранении архитектуры прямого отображения даст не очень существенный эф-
фект, поскольку разные задачи будут претендовать на одни и те же строки кэша.
Не увеличивая объема кэша, можно повысить эффективность кэширования изме-
нением его структуры, о чем пойдет речь ниже.
6.1. Принципы кэширования
159
Объем кэшируемой памяти (MCACHEd) пРи архитектуре прямого отображения оп-
ределяется объемом кэш-памяти (VCACHE) и разрядностью памяти тегов (N):
М = V х 2N
1V1CACHED V CACHE
В нашем случае:
Мгагнрп e 256 Кбайт х 28 = 64 Мбайт
Иногда в описании кэша прямого отображения фигурирует понятие набор (set),
что может сбить с толку. Оно применяется вместо термина строка (line) в секто-
рированном кэше прямого отображения^ а сектор тогда называют строкой. С набо-
ром (как и строкой несекторированного кэша) связана информация о теге, отно-
сящаяся ко всем элементам набора (строкам или секторам). Кроме того, каждый
элемент набора (строка или сектор) имеет собственный бит действительности в
кэш-каталоге (рис. 6.2).
Кэш-каталог Кэш-память
(Tag SRAM) (Cache SRAM)
Tag
127 ~20
Номер страницы
основной памяти
Index
19 7
Номер
строки
Sect.
6 | 5
Номер
сектора
4 0|
Смещение
в секторе
Адрес кэшируемой памяти
Рис. 6.2. Секторированный кэш прямого отображения
160
6. Кэширование памяти
6.1.2. Наборно-ассоциативный кэш
Наборно-ассоциативная архитектура кэша позволяет каждому блоку кэшируемой
памяти претендовать на одну из нескольких строк кэша, объединенных в набор (set).
Можно считать, что в этой архитектуре есть несколько параллельно и согласованно
работающих каналов прямого отображения, где контроллеру кэша приходится при-
нимать решение о том, в какую из строк набора помещать очередной блок данных.
В простейшем случае каждый блок памяти может помещаться в одну из двух строк
(Two Way Set-Associative Cache — двухканальный наборно-ассоциативный кэш).
Такой кэш должен содержать два банка памяти тегов (рис. 6.3).
Кэш-каталог (Tag SRAM + LRU)
Рис. 6.3. Двухканальный наборно-ассоциативный кэш
Номер набора (индекс), в котором может отображаться затребованный блок дан-
ных, однозначно определяется средней частью адреса (как номер строки в кэше
прямого отображения). Строка набора, отображающая требуемый блок, опреде-
ляется сравнением тегов (как и в ассоциативном кэше), параллельно выполняе-
мым для всех каналов кэша. Кроме того, с каждым набором должен быть связан
признак, определяющий строку набора, подлежащую замещению новым блоком
данных в случае кэш-промаха (на рисунке в ее сторону указывает стрелка). Канди-
датом на замещение обычно выбирается строка, к которой дольше всего не обраща-
лись (алгоритм LRU — Least Recently Used). При относительно большом количе-
стве каналов (строк в наборе) прибегают к некоторому упрощению — алгоритм
Pseudo -LRU для четырех строк (Four Way Set Associative Cache) позволяет при-
нимать решения, используя всего 3 бита. Возможно также применение алгоритма
замещения FIFO (первым вошел — первым вышел) или даже случайного (random)
замещения, что проще, но менее эффективно.
Наборно-ассоциативная архитектура широко применяется для первичного кэша
современных процессоров. Объем кэшируемой памяти определяется так же, как и
6.1. Принципы кэширования
161
й предыдущем варианте, но здесь фигурируют объем одного банка (а не всего каша)
и разрядность относящихся к нему ячеек тега.
6.1.3. Ассоциативный кэш
В отличие от предыдущих у полностью ассоциативного кэша любая его строка
может отображать любой блок памяти, что существенно повышает эффективность
использования ограниченного объема кэша. При этом все биты адреса кэширован*
ного блока, за вычетом битов, определяющих положение (смещение) данных в
строке, хранятся в памяти тегов. В такой архитектуре для определения наличия
затребованных данных в кэш-памяти требуется сравнение со старшей частью ад-
реса тегов всех строк, а не одной или нескольких, как при прямом отображении
или наборно-ассоциативной архитектуре. Естественно, последовательный пере-
бор ячеек памяти тегов отпадает “ на это может уйти слишком много времени.
Остается параллельный анализ всех ячеек, что является сложной аппаратной за-
дачей, которая пока решена только для небольших объемов первичного кэша в
некоторых процессорах. Применение полностью ассоциативной архитектуры во
вторичном кэше пока не предвидится.
6.1.4. Пакетный режим передачи данных
Режим пакетной передачи (Buret Mode) предназначен для ускорения операций
пересылки строк кэша в процессорах 486+. Строка кэша процессора 486 имеет
длину 16 байт, следовательно, для ее пересылки требуются четыре 32-разрядных
шинных цикла. Для пересылки 32-байтиой строки кэша Pentium* требуются тоже
четыре такта, поскольку разрядность передач составляет 64 бита. Использование кэша
предполагает, что строка должна в нем присутствовать целиком. Пакетный цикл
(Burst Cycle) оптимизирован именно для операций обмена внутреннего кэша с опе-
ративной памятью. В этом цикле адрес и сигналы идентификации типа шинного
цикла выдаются только в первом такте пакета, а в каждом из последующих тактов
могут передаваться данные, адрес которых уже не пересылается по шине, а вычисля-
ется из первого адреса по правилам, известным процессору и контроллеру памяти.
В процессорах Pentium пакетные циклы выполняются только при обращениях к
памяти (в 486 пакетным мог быть и цикл ввода-вывода). Как при чтении, так и
при записи они позволяют целиком передавать строку кэша. Пакетные циклы свя-
заны только с кэшируемой памятью, при этом кэшируемость памяти подразуме-
вает и поддержку пакетного режима. Один пакетный цикл не может пересекать
границу строки кэша. Кроме того, имеется специфический порядок следования
адресов в пакетном цикле, который определяется начальным адресом пакета. Во
время пакетного цикла сигналы разрешения байт ВЕ[7:0] и биты адреса (включая
и А[4:3]) не меняются - память вычисляет последующие адреса самостоятельно.
Порядок чередования адресов приведен в табл. 6.1. Пакетная запись применяется
только для выгрузки строк кэша, при этом пакеты всегда выровнены по границам
строк. Признаком пакетного цикла (и его окончания) является сигнал CACHE#.
Внешняя система не может прервать пакетный цикл, начатый процессором.
162
6. Кэширование памяти
Таблица 6.1. Последовательность адресов в пакетном цикле Pentium
Первый адрес Второй адрес Третий адрес Четвертый адрес
0 8 10h 18h
8 0 18h 10h
10h 18h 0 8
18h 10h 8 0
Для системной шины Р6 идея пакетных циклов сохраняется, но ее интерфейс спе-
цифичен (см. п. 10.3). Вышеприведенный порядок чередования (interleaving) ад-
ресов в пакетном цикле характерен для всех процессоров Intel и совместимых с
ними, начиная с 486. Он оптимизирован для двухбанковой организации памяти,
подразумевающей чередование банков, используемых в соседних передачах па-
кетного цикла. С точки зрения памяти у каждой микросхемы во время пакетно-
го цикла могут изменяться только два младших бита адреса (независимо от раз-
рядности шины данных процессора). Данный порядок чередования поддерживает
любая память с пакетным режимом: динамическая BEDO DRAM, SDRAM и ста-
тическая Sync Burst SRAM, РВ SRAM, DR DRAM. Процессоры других семейств
(например, Power PC) используют линейный (linear) порядок адресов в пакете.
Микросхемы пакетной памяти обычно имеют входной сигнал, задающий порядок
адресов для конкретного применения.
Во время пакетного цикла, как и в обычном цикле, темп обмена (число тактов ожида-
ния) задается устройством: оно вводит сигнал BRDY# по готовности данных. Времен-
ная диаграмма пакетных циклов обращения к памяти (главным образом, чтения)
является основной характеристикой производительности памяти компьютера. Ее
описывают числом тактов системной шины, требуемых для каждой передачи пакета.
При этом, естественно, оговаривают и саму частоту. Так, например, для динамичес-
кой памяти BEDO-50 нс достижимый идеал — цикл 5-1-1-1 на частоте 66 МГц.
6.2. Кэширование в современных
процессорах
Структура средств кэширования 32-разрядных процессоров Intel приведена на
рис. 6.4. Первичный кэш инструкций тесно связан с блоком предварительной выбор-
ки, первичный кэш данных — с исполнительным блоком процессора. В процессоре
Pentium 4 вместо первичного кэша инструкций имеется кэш трассы (см. п. 1.4).
В процессоре 486 применяется единый первичный кэш. Вторичный кэш — общий,
в Р6 он подключен к выделенной внутренней шине кэш-памяти. В процессорах 486
и Pentium вторичный кэш является внешним и подключается к системной шине
процессора. В процессорах Celeron 266 и 300 вторичный кэш отсутствует. Длина
строки кэша: 64 байт — в Pentium 4,32 байт — в Р5+, 16 байт — в 486. Строки про-
цессор заполняет всегда целиком пакетными циклами чтения (4 передачи на стро-
ку) из основной памяти, выровненными по 32-байтным границам (16-байтным в
486). В Pentium 4 выравнивание производится по 64-байтным границам, а загруз-
ка строки требует 8 передач. Любой внутренний запрос (кроме специальных
6.2. Кэширование в современных процессорах
163
инструкций передач, введенных в расширения 3DNow! и SSE) процессора на
обращение к памяти направляется во внутренний кэш, если на кэширование тре-
буемого адреса не наложены ограничения (см. ниже). Если затребованная область
памяти присутствует в строке внутреннего кэша, то он обслужит этот запрос.
В случае промаха запрос удовлетворяется сразу, как только затребованные дан-
ные считываются из ОЗУ, — заполнение строки до конца может происходить
параллельно с обработкой полученных данных. Выделение и замещение строк у
процессоров до Р6 выполняется только для кэш-промахов при чтении, при про-
махах записи заполнение строк производится только в Р6 и выше. Кэширование
доступно в любом режиме процессора (в SMM должны применяться меры предо-
сторожности, учитывающие переход в иное адресное пространство памяти).
Рис. 6.4. Кэширование в процессорах Intel
Буфер ассоциативной трансляции TLB хранит вхождения в каталог и таблицы
страниц, к которым обращались в последнее время. В процессоре 486 для данных
и инструкций применяется единый буфер TLB, в процессорах более поздних мо-
делей этот буфер разделен. В Р6 большие страницы (2 Мбайт в режиме РАЕ и
4 Мбайт в режиме PSE) обслуживаются раздельными буферами TLB. Буферы
TLB активны в защищенном режиме при разрешенной страничной трансляции.
При запрещенной трансляции или в реальном режиме TLB сохраняет свое содер-
жимое до явной или неявной его очистки.
Буферы записи связаны с исполнительным блоком процессора. Они позволяют на
некоторое время откладывать фактическую запись во внешний кэш и основную
память, уступая шину для других обменов, необходимых для исполнения следую-
щих инструкций. Буферы процессоров последних поколений позволяют также
комбинировать записи в память WC (см. ниже). При этом записи в соседние ячей-
ки памяти, порождаемые несколькими исполненными инструкциями, физически
164
б. Кэширование памяти
выполняются за один цикл обращения к памяти. Запись буферизуется во всех
режимах процессора. Буферизация записи в порты ввода-вывода не производится.
Все механизмы кэширования в основном прозрачны для прикладных программ и
после разрешения кэширования пропускают через себя потоки инструкций и дан-
ных без требования явного программного управления. Однако знание особеннос-
тей механизмов кэширования помогает в оптимизации кода. Так, например, мож-
но определить оптимальные размеры одновременно обрабатываемых структур
данных, при котором кэш не «буксует» (cache thrashing, см. выше). Процессоры
разных моделей имеют различные характеристики отдельных элементов кэша, что
иллюстрирует табл. 6.2. Определить характеристики элементов кэша процессоров
Р6 позволяет вызов инструкции CPU1D(2) (см. п. 8.2.1).
Таблице 0.2. Характеристики элементов кэша
Элемент Характеристика1
Кэш трасе Pentium 4:12 К микроопераций, 0WSA Р6 и ниже: нет
Каш инструкций L1 Pentium 4: “-нет Р6 и Pentium: 0/16 Кбайт, 4W8A (2W8A в первых процессорах Pentium).
486:8/10 Кбайт, 4W8A, комбинирован о кэшем данных
Кэш данных L1 Pentium 4: в Кбайт, 4W8A, отрока 64 байт Р6:8/16 Кбайт, 2W8A Pentium: 8/1 в Кбайт, 4W8A (2W8A в первых процессорах Pentium). 486: ом. выше
Общий кэш L2 Pentium 4:266 Кбайт, BW8A, оскторированный, строка 64 байт Р6:0/128/266/612/1024/2048 Кбайт, 4W6A Pentium: на системной плате, типично 266/512 Кбайт, 4WSA 486: на системной плате, типично 128/256 Кбайт
TLB инструкций Pentium 4:128 вхождений, 4WSA
для страниц 4 Кбайт Р6, Pentium: 32 вхождении, 4WSA Pentium ММХ: 32 вхождения, ассоциативный 486:32 вхождения, 4WSA, объединен о TLB данных
TLB данных Pentium 4:64 вхождении, полностью наборно-ассоциативный,
для страниц 4 Кбайт разделяемый с TLB данных для больших страниц Р6, Pentium: 64 вхождения, 4W8A Pentium ММХ: 64 вхождения, ассоциативный 488: ом. выше
TL0 инструкций Pentium 4: большие страницы фрагментируются
для больших страниц Р6:2 вхождения, 2W8A Pentium: тот же, что и для страниц 4 Кбайт 486: большие страницы не поддерживаются
TLB данных Pentium 4: разделяемый о TLB данных страниц 4К
для больших страниц Р6:8 вхождений, 4W8A Pentium: 8 вхождений, 4W8A, тот же, что и для страниц 4 Кбайт 486: большие страницы не поддерживаются
Буферы записи Pentium 4:24 вхождения
(WC-буферы) Р6:12 вхождений Pentium ММХ: 4 буфера по 1 вхождению Pentium: 2 буфера по 1 вхождению 486:4 вхождения
'8WSA - nwbMUKhitiL'ibiiwH ifti6optio-iiecoaiiHTHiiitwn кэш, 4WSA “ четырехканальный наборио-аесо*
цнагиниыП кэш, 2WSA днухканальный наборно'йееоциатшшый кэш.
6.2, Кэширование в современных процессорах
165
Кэш-память процессоров строится с учетом возможности обращений к памяти со
стороны внешних абонентов — других процессоров или иных контроллеров шины.
Процессоры имеют механизмы внешнего слежения за состоянием собственного
кэша с соответствующими аппаратными интерфейсами. Для поддержания со-
гласованности данных кэша и основной памяти процессор отрабатывает циклы
слежения (Snoop Cycle, или Inquire Cycle), инициированные внешней (для него)
системой. В этих циклах, происходящих при обращении к памяти со стороны
внешнего абонента, процессор определяет присутствие затребованной области в
своем собственном кэше. Если область отображается в кэше, то действия процес-
сора зависят от состояния соответствующей строки кэша и типа внешнего обра-
щения. Обращение по записи вызовет аннулирование данной строки. Обращение
по чтению к области, соответствующей модифицированной («грязной») строке,
вызовет выгрузку ее содержимого в основную память, прежде чем внешний або-
нент выполнит реальное считывание. В процессорах Р6 обращение к «грязной»
строке со стороны другого процессора может вызывать выгрузку ее содержимого
непосредственно в обращающийся процессор, что экономит время. Выгрузка этой
строки в основную память будет произведена позже, согласно алгоритму обрат-
ной записи.
Кэш процессоров, начиная с Pentium, поддерживает протокол MESI, названный
по определяемым им состояниям М(Modified), E(Exclusive), S (Shared) и 7 (Invalid).
Первичный кэш инструкций реализует протокол лишь в части «57», поскольку он
не допускает записи. Состояния строк для каждого процессора определяются сле-
дующим образом:
♦ M-состояние — строка присутствует в кэше только этого процессора и моди-
фицирована, то есть отличается от содержимого основной памяти; запись в эту
строку не приведет к генерации внешнего (по отношению к локальной шине)
цикла обращения;
♦ Е-состояние — строка присутствует в кэше только этого процессора, но не мо-
дифицирована (ее копия в основной памяти действительна); запись переведет
ее в М-состояние, не вызывая внешнего цикла обращения;
♦ 5-состояние — строка присутствует в кэше этого процессора и потенциально
может присутствовать в кэшах других процессоров, копия в памяти действи-
тельна; запись в нее должна сопровождаться сквозной записью в основную па-
мять, что повлечет аннулирование соответствующих строк в других кэшах;
♦ 7-состояние — строка отсутствует в кэше, ее чтение может привести к генера-
ции цикла заполнения строки; запись в нее будет сквозной и выйдет на внеш-
нюю шину.
Процессор контролирует операции записи в память на попадание в область, пред-
ставленную в кэше инструкций. Контроль выполняется на уровне физических
адресов, в случае попадания строка аннулируется. На случай самомодифицирую-
щегося кода в Р5 и Р6 дополнительно выполняется контроль на попадание записи
в предварительно выбранные инструкции. Этот контроль выполняется на уровне
166
6. Кэширование памяти
линейных адресов, в случае попадания очередь предварительно выбранных инст-
рукций аннулируется. Если программа модифицирует область кода, обращаясь к
нему через иной линейный адрес, чем тот, что используется в потоке инструкций,
перед выполнением модифицированной инструкции должна выполняться сериа-
лизация (инструкцией CPUID).
Реализации систем на процессорах 486 опирались на механизм, работающий ана-
логично протоколу MESL Контроль модификации предварительно выбранных
инструкций не производился. Для корректного исполнения после модификации
кода должна была выполняться инструкция перехода, аннулирующая очередь
предварительно выбранных инструкций.
В пространстве памяти компьютера имеются области, для которых кэширование
принципиально недопустимо (например, разделяемая память адаптеров) или для
которых непригодна политика обратной записи. Кроме того, кэширование иногда
полезно отключать при выполнении однократно исполняемых участков програм-
мы (например, инициализации) с тем, чтобы из кэша не вытеснялись более полез-
ные фрагменты.
В процессорах шестого поколения в связи с их «беспорядочностью» и «спекуля-
тивностью» обращения к памяти могут производиться с различными методами
повышения эффективности. По возможностям кэширования память можно клас-
сифицировать следующим образом.
♦ Строго некэшируемая память UC (Uncacheable). Все обращения процессора
по чтению и записи выполняются строго в порядке, предписанном программ-
ным кодом, и выходят на системную шину. Никакие спекулятивные чтения и
предварительные выборки не используются. Такой тип требуется для ввода-
вывода, отображенного на память. Работа процессора в таком режиме с обыч-
ным ОЗУ приведет к значительному снижению производительности.
♦ Некэшируемая память UC- имеет те же свойства, но в процессорах Pentium III
и Pentium 4 память с этим типом программированием регистров MTRR может
быть переопределена в WC.
♦ Память с комбинируемой записью WC (Write Combining). Некэшируемая па-
мять, когерентность памяти не поддерживается протоколом шины. Спекуля-
тивное чтение допустимо, записи могут комбинироваться и откладываться до
любого события, вызывающего сериализацию (инструкция CPUID, обращение к
некэшируемой памяти, прерывание...). Такой тип применим, например, для
видеопамяти графического адаптера (порядок записей не важен).
♦ Память со сквозной записью WT (Write-through). Кэшируемая память, все
операции записи отражаются в кэше и выходят на системную шину. Чтения по
возможности выполняются из кэша, кэш-промахи вызывают заполнение строк
кэша. Спекулятивное чтение и комбинирование записей разрешено. Данный
тип применим, например, для буферов кадров, а также для памяти, к которой
могут обращаться устройства, подключенные к шине и не поддерживающие
протоколов обеспечения когерентности.
♦ Память с обратной записью WB (Write-back). Кэшируемая память, все опера-
ции чтения и записи по возможности выполняются только с кэш-памятью.
6.3. Управление кэшированием
167
Запись на системную шину выходит только при необходимости освобождения
строк или по требованию от; других абонентов шины, что уменьшает необяза-
тельный трафик шины. Спекулятивное чтение и комбинирование записи раз-
решено. Этот тип самый производительный, но требует поддержки протокола
обеспечения когерентности от всех абонентов шины, обращающихся к данной
области памяти.
♦ Память с защищенной записью WP (Write protected). Кэшируемая память,
чтения по возможности выполняются из кэша, промахи вызывают заполнение
строк. Записи выходят на системную шину и вызывают аннулирование строк
в кэшах всех остальных абонентов шины (процессоров).
Доступные методы кэширования зависят от возможностей процессора (табл. 6.3).
Базовые методы (сквозная и обратная запись или отмена кэширования) управля-
ются атрибутами PCD (Page Cache Disable — запрет кэширования страницы) и PWT
(Page Write Through — сквозная запись для страницы) системы управления стра-
ничной переадресации, более совершенные методы программируются только че-
рез регистры MTRR или РАТ (см. ниже), если таковые имеются в процессоре.
Таблица 6.3. Методы кэширования в процессорах 4-6-го поколений
Метод кэширования Pentium 4 Р6 Pentium i486
ис + + + + •
WC + 4-1.2 - -
WT 4- 4- 4-3 4-3
WB 4- 4- 4-3
WP 4- 4-1 — —
’ Программируется через MTRR или РАТ.
Присутствует только в Pentium III и выше.
3 Спекулятивное чтение отсутствует.
6.3. Управление кэшированием
Механизм управления кэшированием включает в себя как программные флаги, так
и аппаратные средства, позволяющие разрешать и ограничивать возможности
кэширования. Программные средства управления включают флаги управляющих
регистров и биты элементов каталога и таблиц страниц, а также специальные инст-
рукции. Аппаратные средства включают входные сигналы разрешения кэширова-
ния и управления политикой записи и очистки кэша, а также выходные сигналы
управления вторичным кэшем. В Р6 имеются также регистры MTRR, определяющие
возможности кэширования на уровне областей физической памяти. Эти механиз-
мы имеют различные области воздействия. Если разные механизмы определяют
возможности кэширования конкретной области памяти по-разному, будет реали-
зовано самое жесткое из ограничений: запрет кэширования имеет приоритет над
разрешением, а политика WT отменяет политику WB.
168
6. Кэширование памяти
Кэшированием управляют на этапе заполнения строк, последующие кэш-попада-
ния чтений памяти будут обслуживаться только из кэша. Кроме того, существует
возможность аннулирования строк — объявление их недостоверными и очистка
всей кэш-памяти.
Для программного управления кэшированием имеются инструкции аннулирования
(инвалидации) INVD и WBINVD. Инструкция INVD аннулирует строки внутреннего
кэша без выгрузки модифицированных строк, поэтому ее неосторожное исполь-
зование при включенной политике обратной записи может привести к нарушению
целостности данных в иерархической памяти. Инструкция WBINVD предваритель-
но выгружает модифицированные строки в основную память (при сквозной запи-
си ее действие совпадает с INVD).
В процессорах с расширениями SSE и 3DNowl появились новые инструкции, свя-
занные с кэшированием. Теперь можно выгружать данные из регистров ММХ и
ХММ в оперативную память, минуя кэш, а также записывать группу байт памяти
в строку кэша заданного уровня, не помещая их в какие бы то ни было регистры
процессора. В последующих расширениях (SSE2) появились и дополнительные
возможности управления: можно выгружать и очищать строку кэша, связанную с
требуемым операндом, выгружать данные, минуя кэш, и из регистров общего на-
значения. Таким образом можно освобождать место в кэше, когда программе уже
не потребуются определенные данные, и не захламлять его однократно использу-
емыми данными. Появились и инструкции, позволяющие упорядочивать (вызы-
вать сериализацию) операции загрузки данных из памяти и записи в память (вы-
гружать буферы записи).
Аппаратная очистка внутренней кэш-памяти при сквозной записи (обнуление бит
достоверности всех строк) осуществляется внешним сигналом FLUSH# за один
такт системной шины (и, конечно же, по сигналу RESET). При обратной записи
очистка кэша подразумевает также выгрузку всех модифицированных строк в
основную память. Для этого, естественно, может потребоваться значительное чис-
ло тактов системной шины.
Аннулирование строк выполняется при записи в отображаемую ими область па-
мяти со стороны внешних контроллеров (например, других процессоров). Если
внешний (по отношению к рассматриваемому процессору) контроллер выпол-
няет запись в память, процессору должен быть подан сигнал. Для процессоров
Pentium этим сигналом является AHOLD. По этому сигналу процессор немедленно
отдает управление только шиной адреса, на которую внешним контроллером ус-
танавливается адрес памяти, сопровождаемый стробом EADS#. Если адресуемая
память присутствует в первичном кэше, процессор сбрасывает бит достоверности
этой строки (она освобождается).
Общее программное управление кэшированием осуществляется посредством бит
управляющего регистра CRO: CD (Cache Disable) и NW (No Write Through). Возмож-
ны следующие сочетания бит регистра.
♦ CD—О, NW—0 — разрешен нормальный режим работы с максимально возможной
эффективностью (политика WB, если поддерживается). Для отдельных обла-
стей или страниц памяти кэширование может ограничиваться (запрещаться
или устанавливаться политика WT).
6.3. Управление кэшированием
169
♦ CD—О, NW-1 — запрещенная комбинация (вызывает отказ #GP).
♦ CD-I, NW-0 — заполнение кэша запрещено, когерентность памяти поддерживает-
ся. Попадания чтения обслуживаются из кэша. Попадания записи модифици-
руют строки, при этом операции записи выходят в основную память (в 486 для
любых строк, а в Р5 и Р6 только для строк в S-состоянии). Аннулирование строк
разрешено, внешнее слежение (сообщение состояния) выполняется. Эффект
от такой установки бит аналогичен временному переводу сигнала KEN# в вы-
сокое (пассивное) состояние. Этот режим может использоваться для времен-
ного отключения кэша, после которого возможно его включение без очистки.
♦ CD-I, NW—1 — заполнение кэша запрещено, когерентность памяти не поддержи-
вается. Попадания чтения обслуживаются из кэша, попадания записи моди-
фицируют кэш, но не основную память. Аннулирование строк заблокировано,
очистку вызывают только инструкции INVD и WBINVD, внешнее слежение выпол-
няется. Если после установки такого значения выполнить очистку кэша (см.
выше), кэш будет полностью отключен. Если же перед установкой этого соче-
тания бит кэш был заполнен, а очистка не производилась, кэш превращается в
«замороженную» область статической памяти.
При использовании страничной переадресации в управлении кэшированием при-
нимают участие биты PCD и PWT регистра CR3 и элементов каталога и таблиц стра-
ниц. В регистре CR3 эти биты управляют кэшированием таблицы каталогов. В эле-
ментах каталога таблиц (РОЕ) эти биты управляют кэшированием таблиц страниц,
на которые они ссылаются. В элементах таблиц страниц (РТЕ) эти биты управля-
ют кэшированием обслуживаемых страниц. В Р6 бит PGE регистра CR4 разрешает
использование бита глобальности страницы G для управления аннулированием
вхождений в TLB (см. п. 5.4).
Для управления кэшированием на аппаратном уровне процессоры 486 и Р5 име-
ют входы KEN# и WB/WT#. Внешние схемы (чипсет системной платы) могут зап-
рещать процессору кэшировать определенные области памяти установкой высо-
кого уровня сигнала KEN# во время циклов доступа процессора к этим областям
памяти. Этот сигнал управляет только возможностью заполнения строк кэша из
адресованной области памяти (с дискретностью, равной размеру строки). Для
процессоров с WB-кэшем имеется входной сигнал WB/WT#, который может упро-
стить политику записи для данного адреса до WT. Выходные сигналы PCD н PWT
управляют работой вторичного (внешнего) кэша (они же управляют и внутрен-
ним кэшем). В циклах обращения к памяти, когда страничные преобразования не
используются (например, при обращении к таблице каталогов страниц), источни-
ком сигналов являются биты PCD и PWT регистра CR3, при обращении к таблице стра-
ниц — биты PCD и PWT из дескриптора соответствующего элемента каталога, при
обращении к самим данным страницы — биты PCD и PWT из дескриптора страницы.
Кроме того, оба этих сигнала могут принудительно устанавливаться общими би-
тами управления кэшированием СО и WT регистра CR0.
В архитектуру Р6 введены регистры MTRR (Memory Type Range Registers), которые
реализуют вышеописанные функции аппаратного управления кэшированием,
а также изменение порядка записи для определенных областей памяти. С помощью
170
6. Кэширование памяти
этих регистров в физической памяти может быть определено до 96 областей адресов
с одинаковым типом кэширования. Такое распределение позволяет оптимизи-
ровать операции с ОЗУ, ПЗУ, видеобуферами и адаптерами ввода-вывода, ото-
браженными на пространство памяти. По аппаратному сбросу регистры MTRR
устанавливаются в такое состояние, которое ведет к объявлению некэшируе-
мой всей физической памяти. Дальнейшая инициализация, выполняемая обычно
во время процедуры POST BIOS, программирует регистры в соответствии с
реальным распределением памяти. Типы памяти и их характеристики приведены
в табл. 6.4.
Таблица 6.4. Типы памяти, определяемые регистрами MTRR
Мнемоника Код в MTRR1 Кэширование Политика WB Спекулятивное2 чтение Порядок операций
UC (UnCacheable) 0 Нет Нет Да Строгий
WC (Write Combining) 1 Нет Нет Да Слабо- упорядоченный (Weak Ordering)
WT (Write- Through) 4 Да Нет Да Спекулятивный (Speculative Processor Ordering)
WP (Write- Protected) 5 Чтение — да Запись —нет Нет Да Спекулятивный
WB (Write- Back) 6 Да Да Да Спекулятивный
UC- (UnCacheable) 7 Нет Нет Да Строгий
1 Коды 2,3,8-255 зарезервированы, их применение в Р6 вызывает исключение защиты. Код 7 применим
только для задания свойств через РАТ.
2 Чтение, результат которого может не требоваться программе.
Регистры MTRR входят в число модельно-специфических регистров (MSR). Они
определяют наборы фиксированных зон для первого мегабайта физической па-
мяти и зоны (в Р6 — 8 зон) произвольного размера для памяти в любом диапазоне
адресов. Наличие MTRR определяется инструкцией CPUID по флагу MTRR (бит 13 в
EDX). 64-битный регистр MTRRcap определяет возможности MTRR. Количество про-
извольных зон определяется полем VCNT (биты 7:0, для Р6 — 8 зон), флаг FIX (бит 8)
определяет наличие фиксированных зон; а флаг WC (бит 10) указывает на поддерж-
ку памяти типа WC.
Общее управление MTRR осуществляется записью в 64-битный регистр MTRRdefType.
Флаг Е (бит И) разрешает использование MTRR; если он сброшен, вся память
определяется как UC. Флаг FE (бит 10) разрешает использование фиксирован-
ных зон. Поле Туре (биты 7:0) задают тип памяти по умолчанию (памяти, не
попавшей ни в одну из зон). Для физически отсутствующей памяти рекоменду-
ется тип UC.
6.3. Управление кэшированием
171
Для управления фиксированными зонами используются следующие регистры:
♦ MTRRf i х64К_00000 — для отображения восьми зон по 64 Кбайт в диапазоне адре-
сов 0-7FFFFh;
♦ MTRRf 1х16К_80000 и MTRRfixl6K_A0000 — для отображения 16 зон по 16 Кбайт в
диапазоне адресов 80000h-BFFFFh;
♦ MTRRfix4K_C0000, MTRRf 1х4К_С8000 ... MTRRf 1x4K_F8000 (8 регистров) - для отобра-
жения 64 зон по 4 Кбайт в диапазоне адресов COOOOh-FFFFFh.
Каждый байт этих 64-битных регистров несет информацию о типе памяти (см.
табл. 6.4) для отображаемой им зоны (младшему байту соответствует область с
меньшими адресами).
Для управления каждой из зон произвольного размера используются пары регис-
тров (суффикс п определяет номер регистра).
♦ MTRRphysBasen — регистр базового физического адреса зоны. Поле Туре (биты
7:0) определяет тип памяти для зоны, поле PhysBase (биты 35:12) — ее базовый
адрес (старшие 24 бита, младшие 12 — нулевые). Зоны определяются по гра-
ницам страниц размером 4 Кбайт.
♦ MTRRphysMaskn — регистр маски физического адреса. Поле PhysMask (биты 35:12)
задает маску зоны, флаг V (бит И) определяет действительность данных дан-
ной регистровой пары. Маска определяется так, чтобы результат операции И
над ней и адресом, принадлежащим зоне, совпадал с результатом той же опера-
ции над ней и базовым адресом.
Перекрытие произвольных зон допускается лишь для типов UC или UC и WB
(в области перекрытия тип будет UC), для перекрытий зон иных типов поведение
процессора непредсказуемо.
При определенных значениях масок задаваемые ими зоны перестают быть непре-
рывными. На области разрывов будет распространяться тип памяти по умолча-
нию. Использование таких масок не приветствуется, поскольку оно может по-
требовать присутствия реальной памяти во всем диапазоне физических адресов
(4 или 64 Гбайт).
Если произвольная зона перекрывает фиксированную, то на перекрытую об-
ласть распространяется определение фиксированной зоны (при установленном
флаге FE).
Если используются большие страницы (размером 2 или 4 Мбайт), каждая стра-
ница может накрывать несколько зон, определенных в MTRR. Если эти зоны име-
ют разные свойства, поведение процессора будет непредсказуемо (тип страниц
памяти кэшируется в TLB). Чтобы избежать этой неопределенности, используя
большие страницы следует заботиться об однотипности зон памяти, на которые
отображается данная область (корректно программировать MTRR).
Запись в регистр MTRRcap, как и в неопределенные поля других регистров MTRR,
или попытка использования типов памяти, отличных от приведенных в табл. 6.4,
вызывает исключение #GP.
172
6. Кэширование памяти
Регистры MTRR позволяют управлять статически определенными зонами физи-
ческой памяти. Эта задача ложится, как правило, на BIOS компьютера. В процес-
сорах Pentium III введен новый способ управления свойствами памяти на уровне
страниц, который позволяет операционной системе и приложениям динамически
выбирать оптимальные свойства каждой страницы памяти с точки зрения повы-
шения производительности. Этот способ основан на таблице атрибутов страниц
РА Т(Page Attribute Table). Прежде на уровне страниц свойства памяти задавались
битами PCD и PWT. Теперь в элементах, описывающих страницы, определен бит РАТ1
(PAT index), ранее зарезервированный (бит 12 в PDE 2/4 Мбайт и бит 7 в РТЕ
4 Кбайт, см. п 5.6). В процессор введен новый регистр MSR с именем РАТ (адрес
277h), представляющий собой таблицу атрибутов страниц. В этой таблице име-
ются восемь элементов (трехбитных полей РА0...РА7, рис. 6.5). Путем комбинации
трех бит РАТ1, PCD, PWT для конкретной страницы выбирается соответствующий
элемент таблицы. В этом элементе хранится код типа памяти (0-7), назначенный
этой комбинации данных бит. Код типа соответствует определениям для MTRR
(см. табл. 6.4), но дополнительно для РАТ определили еще тип для кода 7. Для тех
страниц, с которыми не связаны биты РАН, возможно использование только пер-
вых четырех элементов РАТ. После аппаратного сброса в РАТ устанавливаются
определения типов памяти, как показано в последней графе табл. 6.5. Операци-
онная система (только при CPL 0) может изменить эти определения по своему
усмотрению, выбирая наиболее приемлемый метод кэширования для каждой ком-
бинации бит PATi, PCD, PWT.
6Э 58 56 50 48 42 40 34 32
Резерв РА7 Резерв РА6 Резерв РА5 Резерв РА4
31 26 24 18 16 10 8 2 0
Резерв РАЗ Резерв РА2 Резерв РА1 Резерв РАО
Рио. 6.5. Формат регистра РАТ
Таблица 6.5. Индексирование в РАТ и тип памяти, определяемый по аппаратному сбросу
РАН PCD PWT Элемент РАТ Тип после RESET
0 0 0 0 6(WB)
0 0 1 1 4(WT)
0 1 0 2 7(UC~)
0 1 1 3 0(UC)
1 0 0 4 6(WB)
1 0 1 5 4(WT)
1 1 0 6 7(UC-)
1 1 1 7 0(UC)
6.3. Управление кэшированием
173
Тип памяти, заданный через MTRR, может отличаться от типа, заданного в РАТ.
Результат взаимодействия определений типов памяти через MTRR, биты PWT, PCD
и РАТ1 можно выяснить по специальным таблицам. Если в процессорах Р6 имеется
MTRR и он запрещен битом 11 (Е) регистра MTRRDefType, то вся память становится
некэшируемой (UC). Определение UC в РАТ всегда обеспечивает пекэшируемость
области памяти (перекрывает назначение WC в MTRR), UC перекрывается на’
значением WC в MTRR на ту же область. Таким образом, надежно запретить к»’
ширование для страницы можно только при PCD - 1 и PWT • 1.
Буферы трансляции адресов (TLB) обновляются процессором прозрачно для про-
грамм, Для аннулирования отдельных вхождений служит инструкция INVLPG. Ан-
нулирование всех вхождений TLB, за исключением отмеченных как глобальные
флагом 0, происходит при записи в регистр CR3 или изменении его состояния при
переключении задач. Аннулирование всех вхождений с игнорированием флага
глобальности происходит при изменении состояния (в обе стороны) входа FLUSH#,
записи в регистр MTRR (в Р6), модификации флагов Р6 или РЕ в регистре CRO или
флагов PSE, PGE или РАЕ в регистре CR4.
Буферы записи прозрачны для программ даже в мультипроцессорных системах,
Порядок внешних операций записи всегда соответствует программному коду, Вы-
грузка буферов в память может откладываться процессором с целью оптимизации,
но ряд условий вызывает немедленную выгрузку буферов:
♦ возникновение исключения или прерывания;
♦ выполнение инструкций ввода-вывода;
♦ выполнение инструкций сериализации (в Р6);
♦ выполнение операции LOCK;
♦ выполнение инициализации шины по сигналу BINIT# (в Р6).
7. Особые режимы
работы процессоров
В этой главе рассматриваются режимы «нерегулярной» работы процессоров, остаю-
щиеся «за кадром» для рядового пользователя. Здесь описана начальная инициа-
лизация процессора, его самотестирование и загрузка «заплаток» микрокода. Далее
рассматриваются средства отладки, как чисто программной, так и зондовой (с помо-
щью внешних средств). Описание режима SMM в одном ряду с запуском и отлад-
кой может показаться странным, но на самом деле вполне оправдано. Этот режим
с обособленным пространством памяти стоит несколько особняком от реального
и защищенного режимов, а также режима V86 и может использоваться в целях отлад-
ки. Далее описаны средства мониторинга производительности, а завершается глава
вопросами синхронизации и связанными с ними возможностями энергосбережения.
7.1. Начальный сброс и тестирование
Аппаратный сброс (Hardware Reset) выполняется процессором при включении
питания и по сигналу RESET. По высокому уровню сигнала на входе RESET (по
низкому уровню сигнала RESET# в Р6) процессор прекращает выполнение инст-
рукций и перестает управлять локальной шиной. По окончании сигнала RESET
процессор считывает конфигурационную информацию с некоторых входных линий
интерфейса (в зависимости от типа процессора) и начинает функционирование.
Таким образом, устанавливаются коэффициент умножения тактовой частоты,
режим (WB/WT) работы кэша, роль процессора в многопроцессорных системах
и способ подачи сигналов прерываний (для процессоров, имеющих APIC). Уров-
ни конфигурирующих сигналов задаются чипсетом системной платы, в соответ-
ствии с ролью процессора и установками CMOS Setup.
Если во время окончания сигнала RESET на определенном входе процессора удер-
живать низкий уровень сигнала, процессор начнет выполнять внутренний тест
BIST (Built-In Self-Test). Тестированию подвергается большая часть оборудова-
ния процессора, что для процессоров 80386 и 486 требует примерно миллиона
тактов, а для Р6 — около 5,5 млн, занимая десятки миллисекунд. По окончании
самотестирования процессор начинает работу как после обычного сброса, а ре-
гистр ЕАХ содержит сигнатуру результата тестирования. Об успешном выполне-
нии теста свидетельствует нулевое значение сигнатуры.
7.1. Начальный сброс и тестирование
175
Сброс переводит процессор в реальный режим и устанавливает ряд регистров в опре-
деленное состояние. В частности, устанавливаются следующие значения регистров:
♦ FLAGS = 0002h и биты VM и RF его расширения обнуляются;
♦ в регистре CR0 обнуляются биты PG, TS, ЕМ, МР и РЕ;
♦ CS - FOOOh;
♦ EIP = OOOOFFFOh;
♦ DS = ES = SS = FS = GS = OOOOh;
♦ регистр DX содержит информацию о типе процессора (см. п. 8.3).
Аппаратный сброс аннулирует строки кэш-памяти, буферов трансляции (TLB) и
таблиц переходов (ВТВ), а также устанавливает регистры FPU и ММХ в опреде-
ленное состояние (но не такое, как по инструкции FINIT). При вышеуказанном
сочетании регистров CS:IP, находясь в реальном режиме, процессор начинает вы-
полнение инструкции, считанной по физическому адресу FFFFFFFOh. Это про-
исходит потому, что в скрытых регистрах кодового сегмента устанавливается база
FFFFOOOOh и лимит OFFFFh, а именно они и определяют реальное положение
сегмента. Такое определение действует до первой перезагрузки CS при команде
межсегментного перехода или вызова либо при обслуживании прерывания или
исключения. Исполняемый программный код должен обеспечить инициализацию
системы (регистров процессора, структур данных в памяти).
Итак, после сброса и до первой команды межсегментного перехода или вызова на
шине адреса в реальном режиме биты А[20:31] в циклах выборки команд имеют
единичное значение. Из этого следует, что, по крайней мере, на начальный период
времени после сигнала RESET компьютер должен иметь образ BIOS в адресах
FFFFFFFO-FFFFFFFFh, в то время как в PC на 8086/88 ROM BIOS располага-
лась под границей первого мегабайта (FFFFFh), а АТ-286 имели ее образ и под
границей 16-го мегабайта (FFFFFFh). Удаление BIOS из первого мегабайта
памяти в режиме нормальной работы невозможно, поскольку векторы прерыва-
ний, ссылающиеся на сервисы BIOS, в реальном режиме могут адресоваться толь-
ко к памяти в диапазоне адресов O-OFFFFFh (0-10FFEF при открытом вентиле
Gate А20).
Процессоры Р6 допускают выбор положения вектора начального запуска: если во
время действия сигнала RESET# линия A6# перейдет из активного состояния в
неактивное, то адрес первой инструкции будет OFFFFOh (1М-16), в противном
случае — OFFFFFFFOH (4 G-16). Правда, этой возможностью похоже и не пользу-
ются, а уже в Pentium 4 она отсутствует.
Процессоры Pentium и выше имеют дополнительный вход IN IT. Действия по это-
му сигналу отличаются от аппаратного сброса следующими моментами:
♦ тест BIST не запускается;
♦ внутренняя кэш-память не очищается (но TLB и ВТВ сбрасываются);
♦ значения регистров MSR (включая MTRR) не изменяются;
♦ состояние FPU не изменяется.
176
7. Особые режимы работы процессоров
Этот сигнал может использоваться для перевода процессора в реальный режим
(в стиле 80286) с сохранением данных в кэше, Такой же «мягкий* сброс возможен
и по сообщению, получаемому процессором по шине APIC,
Процессоры Р6 и Pentium ориентированы на мультипроцессорные системы. Для
них начальный сброс имеет дополнительные нюансы,
♦ Pentium: роль процессора (первичный/вторичный) определяется аппаратны-
ми сигналами в момент спада сигнала RESET. Программный код инициализа-
ции выполняет только первичный процессор, вторичный процессор останов-
лен. Запуск вторичного процессора выполнится по сообщению, принятому им
от первичного процессора по шипе APIC. Это сообщение выдается под управ-
лением исполняемой программы инициализации,
♦ Р6: все процессоры на шине (один в случае однопроцессорной системы) одно-
временно выполняют протокол мультипроцессорной инициализации на шине
APIC, определяя загрузочный процессор (BSP - Bootstrap Processor), Далее
программный код инициализации выполняет только процессор BSP, осталь-
ные процессоры остановлены, Их запуск произойдет по сообщениям, переда-
ваемым по шине APIC от BSP под управлением исполняемой им программы.
Для процессоров Р6 и Pentium 4 текущую аппаратную конфигурацию можно оп-
ределить программно, по содержимому MSR с адресом 2Ah, который в Р6 называ-
ется EBL_CR_POWERON, а в Pentium 4 - EBC~HARD_POWERON. В табл. 7,1 приведены биты
регистра и сигналы, задающие различные свойства в момент окончания аппарат-
ного сброса. Некоторые биты доступны и для записи (RW). Как видно из табли-
цы, в Pentium 4 сигналами можно устанавливать меньше параметров. Судьба воз-
можности перемещения вектора начального запуска неясна - с одной стороны, бит
12 MSR сохранил назначение, с другой стороны, в информационном листке не
приводится имя сигнала, с помощью которого этим свойством можно управлять.
Правда, судя по документации на чипсеты Intel, этой возможностью, похоже, не
пользуются и для Р6. Что касается коэффициента умножения частоты, то у боль-
шинства современных процессоров он зафиксирован, хотя существуют и специ-
альные экземпляры с управляемым коэффициентом умножения.
Таблица 7.1. Конфигурирование процессоров Рб и Pentium 4
Сигнал Рв Pentium 4 Вит M8R Назначение
— — 1 Разрешение контроля шины (RW)
- 2 Разрешение реакции на контроль шины (на FRCERR# в Рв) (RW)
— 3 Разрешение генерации AERR# (RW)
« 4 Разрешение формирования BERR# инициатору транзакции (RW)
6 Разрешение формирования BERR# по внутренней ошибке инициатора (RW)
A9# - Разрешение реакции на BERR#
A9# Запрет реакции на MCERR#
- - 7 Разрешение генерации BINIT# (RW)
7.1, Начальный сброс и тестирование
177
Сигнал ГО Pentium 4 Вит MSR Назначение
FLUSH# SMI# 8 Перевод всех сигналов в третье состояние Output Trletate
INIT# INIT# 8 Запуок BIST
A8# 10 Разрешение реакции на AERR#
A10# A10# 12 Разрешение реакции на BINIT#. В Pentium 4 низкий уровень А10# запрещает реакцию, в Р6 — разрешает
A7# A7# 13 Уменьшение глубины очереди упорядоченных запросов (In-order Queue depth) о 8 до 1
A6# 14 Перемещение вектора отерта после аппаратного сброса в адрес OFFFFOh
A5# 16 Включение режима FRC. При низком уровне BR0# — процессор ведущий, при высоком — проверочный
А[12:11]# A[12:11]# [17:16] Задание идентификатора кластера APIC (0-3), работа APIC разрешается программно
BR1#,BR0# BR1#,BRO# [21:20] Задание идентификатора агента симметричной системы
UNT[1:0], А20М#, IGNNE# [26:22] Коэффициент умножения частоты (задание, если он не заблокирован)
» 26 Разрешение снижения потребления в режиме Standby (RW)
AIS# - Запрет «парковки» шины
Тестирование аппаратных средств процессора возможно не только по аппаратно-
му сбросу (тест BIST), Начиная с процессоров 80386, стали применяться тесто*
вые регистры TRn, с помощью которых выполняется тестирование буферов TLB,
а в 486 - и внутреннего кэша. Начиная с Pentium, тестовые регистры, значительно
измененные по составу, были включены в состав регистров MSR,
Начиная с некоторых моделей 486, в процессоры стали включать поддержку тес-
тового интерфейса JTAG. Для его использования необходимо внешнее (по отно-
шению к тестируемой системе) оборудование (компьютер), подключаемое к
процессору всего четырьмя сигнальными линиями. Для подключения по JTAG
возможна установка переходных колодок между сокетом и процессором. Сигна-
лы интерфейса JTAG не связаны с основным интерфейсом процессора. По интер-
фейсу JTAG возможен запуск теста BIST, а также воздействие па входы и конт-
роль выходных сигналов процессора согласно сценарию программы тестирования,
Интерфейс JTAG может применяться также для отладочных целей, о чем речь
пойдет дальше.
Процессоры, начиная с Pentium, имеют встроенные средства проверки функцио-
нирования аппаратуры во время работы. В случае обнаружения аппаратной ошиб-
ки эти процессоры вырабатывают исключение #МС (Machine Check Exception —
исключение машинного контроля). Сведения об обнаруженной ошибке хранятся
в специальных регистрах из состава MSR. По их содержимому обработчик исклю-
чения #МС может дать сообщение операционной системе и определить возможность
178
7. Особые режимы работы процессоров
повторного исполнения инструкции, во время которой была обнаружена ошибка.
Возможности машинного контроля Pentium ограничены проверкой паритета
шины данных при операциях считывания и успешности завершения шинных цик-
лов обмена. Для обслуживания исключения #МС предназначены два регистра:
P5_MC_TYPE (тип ошибки) и P5_MC_ADDR (адрес). В Р6 применяется архитектура MCA
(Machine Check Architecture) с расширенными возможностями: контролируются
паритет на шине адреса, а также ошибки ЕСС-контроля, кэш-памяти и буфе-
ров TLB. Состав регистров расширен. Имеются глобальные регистры описания
возможностей контроля (MCG CAP), состояния (MCG_STATUS) и управления (MCG_CTL,
в Pentium Pro отсутствует), а также банк регистров сообщений об ошибках. Каждо-
му тестируемому аппаратному блоку в банке соответствует набор из регистров
управления (МС i_CTL), состояния (МС i_STATUS), адреса (МС i_ADDR) и смешанного
назначения (МС i_MISC). Наличие средств машинного контроля определяется по
флагу MCE, а на расширенную архитектуру указывает флаг MCA в списке свойств,
сообщаемом по инструкции CPUID(l).
Варианты тестирования внутренних узлов в значительной степени зависят от
модели процессора, и их рассмотрение в рамках данной книги не представляется
возможным. После описания процедуры обновления микрокода (для Р6) мы пе-
рейдем к прикладным вопросам отладки программно-аппаратных средств, пола-
гая, что их основа — микропроцессор — функционирует исправно.
7.2. Обновление микрокода
Фирма Intel постоянно модернизирует свои процессоры, и даже в пределах одной
модели процессоры разного времени выпуска различаются степпингом (см. п. 8.2).
Для процессоров каждого степпинга известны свои ошибки (errata) и методы их
исправления. Микроархитектура Р6 позволяет исправлять эти ошибки путем за-
грузки в процессор блока «заплаток», являющегося, очевидно, набором фрагмен-
тов микропрограмм. Обновление микрокода (Microcode Update) должно выпол-
няться во время инициализации процессора после аппаратного сброса (по сигналу
RESET#), загруженный микрокод действует только до следующего аппаратного
сброса (инициализация сигналом INIT# на загруженное обновление не влияет).
Фирма Intel отвечает за корректность работы своих процессоров только при загру-
женных «заплатках» и для каждого степпинга выпускает специальный блок дан-
ных (в виде файла). Таким образом, процессор определенного степпинга рассмат-
ривается как комплект из собственно процессора и «заплаток». Заплатки фирма
помещает на своем сайте, правда, доступ к ним закрыт паролями. Пароли сообща-
ются официальным дилерам, так что за свежими «заплатками» следует обращать-
ся именно к ним. Если дилер не способен предоставить «заплатки» (или сообщить
пароль), то можно усомниться в его легальности. Загрузка актуальных заплаток
организуется в процессор в два этапа: требуемый образ «зашивается» в BIOS из-
готовителем компьютера или пользователем; на этапе инициализации компьюте-
ра BIOS организует загрузку микрокода в процессор. Если BIOS не поддержива-
ет процессор требуемого степпинга, следует обновить либо всю BIOS, либо только
7.2. Обновление микрокода
179
область с микрокодами. Вопросы обновления BIOS выходят за рамки данной книги
(см. [8,9] ), здесь рассматривается только процессорная сторона данного вопроса.
«Заплатки» поставляются в виде блоков данных размером 2048 байт и никакого
исполняемого кода не содержат. Формат блока приведен на рис. 7.1.
31 0
Update Data (данные обновления, 2000 байт) 48
Резерв (20 байт) 28
Processor Flags (флаги процессора) 24
Резерв (24) | Р7 | Р6 I Р5 I Р4 | РЗ | Р2 I Р1 | Р0
Loader Revision (версия загрузчика) 20
Checksum (контрольная сумма) 16
Processor (идентификатор процессора) 12
Резерв (18) Тип (2) Семейство (4) Модель (4) Степпинг (4)
Date (дата выпуска) 8
Месяц (8) | День (8) | Год (16)
Update Revision (версия обновления) 4
Header Revision (версия заголовка) 0
Рис. 7.1. Формат блока обновления микрокода
Блок состоит из 48-байтного заголовка (номер версии заголовка указывается в
самом его начале) и собственно данных обновления (2000 байт). Целостность все-
го блока проверяется контрольной суммой — сумма всех 512 двойных слов блока
должна быть нулевой. Поле версии обновления позволяет определить, загружено
ли данное обновление в процессор (см. ниже). Блок обновления приемлем только
для процессора, имеющего тот же идентификатор (тип, семейство, модель, степ-
пинг), сообщаемый по инструкции CPUID(l), который указан в заголовке блока.
Младшие биты в слове Processor Flags определяют, к каким «платформам» при-
менимо данное обновление. Идентификатор платформы процессора считывается
из MSR BBL_CR_OVRD (адрес 17h), где его значение (0—7) задается битами [52:50].
Блок применим, если флаг (Р0...Р7), соответствующий его идентификатору плат-
формы, будет единичным (блок может подходить к процессорам с разными иден-
тификаторами платформы). Обновление должно загружаться загрузчиком, вер-
сия которого соответствует указанной в заголовке. Загрузчик версии 1 (другие
пока не описаны) записывает линейный адрес данных в MSR 79h. Для этого в ре-
гистр ЕАХ заносится линейный адрес начала данных обновления (адрес блока +48),
EDX = 0, ЕСХ = 79h и выполняется инструкция WRMSR. Микрокод должен обновлять-
ся до инициализации контроллера вторичного кэша. Данные обновления не долж-
ны пересекать границу сегмента (требований к выравниванию нет); если включе-
на страничная переадресация, данные, естественно, должны быть доступны.
180
7, Особь1о Режимы работы процессоров
Обновление может выполняться многократно без каких-либо побочных эффек-
тов. Успешность и версию произведенного обновления можно проверить программ-
но, не изменяя состояния обновления. Процессор с загруженным обновлением по
инструкции CPUIO(l) кроме возврата результата, описанного в п. 8.2, записывает
сигнатуру (значение версии обновления) в MSR 08Bh (если обновление не про-
изводилось, содержимое MSR не меняется). Для проверки загруженной версии
обновления предварительно обнуляют MSR ()8Bh (инструкцией WRMSR), затем вы-
полняют CPUID(l) и читают MSR 08ВЬ (инструкцией RDMSR). Полученное в ЕОХ зна-
чение сравнивают с номером версии обновления из заголовка. Если полученное
значение меньше, чем в заголовке, значит, блок содержит более свежую версию и
имеет смысл выполнить обновление данным блоком (и проконтролировать его
успешность). Попытка загрузить обновление с идентификатором, не соответству-
ющим данному процессору, не удастся (процессор проигнорирует эту попытку).
В мультипроцессорных системах обновляемые данные для каждого процессора
должны соответствовать его типу, модели, стегшингу и идентификатору платформы.
Фирма Intel рекомендует включить поддержку обновления микрокода в систем-
ную BIOS. Для этого в BIOS Int 15Ьназпачаютсяфункции,вызываемыесАХ я D042h,
код подфункции задается в BL:
♦ BL s 0 — проверка наличия сервиса обновления, чтение номера версии загруз-
чика и числа блоков обновления, хранящихся в энергонезависимой памяти;
♦ BL e 1 — запись нового блока данных в энергонезависимое хранилище (флэш-
память);
♦ BL « 2 — управление обновлением: разрешение обновления при инициализации
процессора и чтение состояния разрешения обновления (без изменения само-
го состояния); по соображениям безопасности возможность запретить обнов-
ления отсутствует;
♦ BL и 3 — чтение определенного блока данных обновления из энергонезависи-
мой памяти в буфер ОЗУ.
Эти сервисы позволяют вводить в систему новые блоки обновления на свободное
место или вместо неиспользуемых блоков без полной замены BIOS. Ответствен-
ность за выбор места, на которое записываются новые данные обновления, лежит
на BIOS. С помощью этих сервисов можно выполнить и полный переучет имею-
щихся «заплаток».
7.3. Программные средства отладки
Процессоры имеют внутренние средства, предназначенные для облегчения про-
цесса отладки программного обеспечения. Эти средства позволяют передать уп-
равление программе-отладчику по наступлению какого-либо заранее указанного
события = исполнению инструкции по заданному адресу, обращению к ячейке
памяти или порту ввода-вывода, выполнению очередной инструкции. Програм-
7.3. Программные средства отладки
181
ма-отладчик (debuger — извлекатель «блох») позволяет проанализировать, а если
надо и модифицировать состояние процессора, памяти и портов в точке останова,
и продолжить исполнение отлаживаемой программы, возможно, задав новые ус-
ловия останова. Отладчик получает управление через обработчики следующих
исключений:
♦ исключение 1 — #DB (Debug exception) — событие отладки;
♦ исключение 3 — #ВР (Breakpoint exception) — передача управления отладчику
по инструкции INT 3.
Для задания событий отладки используется ряд средств:
♦ флаг TF (trap) в регистре EFLAGS — генерация исключения #DB после исполнения
любой инструкции;
♦ флаг Т (trap) в TSS — генерация исключения #0В при переключении на задачу с
установленным флагом (286+);
♦ регистры отладки DR0-DR3, DR6, DR7 — генерация исключения #DB по заданным
адресам памяти (386+) и ввода-вывода (Pentium*).
Однобайтная инструкция INT 3, используемая программными отладчиками, вызыва-
ет исключение #ВР. От двухбайтных инструкций I NT п эта инструкция, кроме компакт-
ности, отличается нечувствительностью к IOPL как в защищенном режиме, так и в
режиме V86. Отладчик (или программист во время отладки) расставляет эти инст-
рукции (код CCh) вместо кодов операций в интересующих точках. Такие точки
останова могут быть расставлены только в ОЗУ, что нс позволяет останавливать-
ся этим методом в точках программного кода, записанного в ПЗУ. Преимуществом
данного способа является неограниченность числа возможных точек останова.
Исключение #0В вызывается по событиям отладки или после исполнения каждой
инструкции при установленном флаге пошагового режима TF. Когда в образе ре-
гистра флагов отладчиком устанавливается TF - 1, при возврате из обработчика
точки останова инструкция IRET установит флаг TF, и после исполнения следую-
щей инструкции отлаживаемой программы сработает ловушка.
Регистры отладки, пришедшие в архитектуру х86 с процессором 80386, предостав-
ляют более прогрессивные средства, позволяющие расставлять точки останова
даже в ПЗУ и перехватывать обращения к данным. Расширения отладки, введен-
ные в архитектуру Pentium, дают возможность останавливаться и по обращениям
к портам. Структура регистров приведена на рис. 7.2.
Процессоры имеют четыре регистра для хранения 32-битных линейных адресов
контрольных точек DR0...DR3.
Регистр DR7 (Debug Control Register) используется для управления отладкой.
Поля LEN1 определяют размер области, адресуемой регистрами DR0...DR3, попадание
в которую вызывает срабатывание ловушки:
♦ 00 — байт;
♦ 01 — слово (2 байта);
182
7. Особые режимы работы процессоров
♦ 10 — не определено;
♦ 11 — двойное слово.
Поля RW1 задают тип перехватываемого обращения:
♦ 00 — выборка инструкции;
♦ 01 — только запись данных в память;
♦ 10 — в 80386 и 486 не используется; в процессорах Р5+ при включении расши-
рения отладки (бит DE e 1 в регистре CR4) — обращение к портам ввода-вывода;
♦ 11 — чтение или запись данных в память.
0— для 386,486
- для Р5+
Рис. 7.2. Регистры отладки
По типу исключения перехват выборки инструкции классифицируется как отказ
(fault, обрабатывается до выполнения инструкции), а обращение к данным — как
ловушка (trap, обрабатывается после передачи данных).
Бит GD (Global Debug Register Access Detect), доступный только в реальном режи-
ме или в защищенном режиме на уровне CPL = 0, позволяет отслеживать любые
попытки доступа к отладочным регистрам. При GD = 1 любая попытка обращения
вызовет исключение #0В (отказ).
Биты GE и LE (Global и Local Exact data breakpoint match) определяют, будет ли
исключение генерироваться сразу после завершения операции обмена при вклю-
ченной ловушке на область данных или оно произойдет несколько позже (или
никогда). Бит LE автоматически сбрасывается при переключении задач, на бит GE
переключение не действует. Ловушка на инструкции всегда срабатывает сразу.
Биты Gi и Li (Global и Local breakpoint enable) разрешают срабатывание ловушек
по контрольным точкам. Биты Li автоматически сбрасываются при переключении
задач, на биты Gi переключение не действует. Автоматический сброс бита Li пре-
дотвращает лишние срабатывания при переключении задач.
7.3. Программные средства отладки
183
Регистр состояния отладки DR6 (Debug Status Register) позволяет обработчику #DB
легко определить его причину. Причин может быть несколько, их идентифициру-
ют биты DR6:
♦ Вт — срабатывание контрольной точки по регистру DR1;
♦ BS — ловушка пошагового режима;
♦ ВТ — ловушка переключения задач (по биту Т в TSS);
♦ BD — отказ в попытке доступа к регистрам отладки при GD = 1.
Флаги Вт имеют достоверное значение только для контрольных точек с установ-
ленными битами L1 и(или) Gi.
Флаг RF (Resume Flag) в регистре EFLAGS позволяет подавить генерацию повтор-
ных исключений (после выхода из обработчика) по одной контрольной точке.
Процессоры Р6 имеют средства регистрации последнего произошедшего перехо-
да, прерывания или исключения. Для этого в состав MSR введены пять 32-битных
регистров.
Ниже перечислены биты регистра DebugCtl MSR.
♦ Бит 0 — LBR (Last Branch/Intemipt/Exception) — разрешение регистрации исход-
ного и целевого адреса перехода/прерывания/исключения. По исключению
отладки флаг автоматически сбрасывается.
♦ Бит 1 — BTF (Single-step on Branches) — установка пошагового режима по об-
наружении перехода. Флаг (как и TF) автоматически сбрасывается по входу в
обработчик исключения отладки.
♦ Биты [2:5] — PBi (Performance monitoring/Breakpoint pins) — разрешение ин-
дикации (импульсами) прохождения точек останова, определенных регистра-
ми DR0...DR3 на выводы ВР0#...ВРЗ#. При РЫ = 0 выводятся события монитора
производительности.
♦ Бит 6 — TR (Trace message enable) — разрешение вывода исходного и целевого
адреса переходов/прерывания/исключения на системную шину в виде сооб-
щений трассировки переходов (при этом в регистрах трассировки информа-
ция будет неопределенной).
В регистр LastBranchFromlP процессор заносит содержимое IP, соответствующее
инструкции ветвления, а в LastBranchToIP — целевой адрес перехода. При возникно-
вении прерывания или исключения (кроме исключений отладки) в эти регистры
помещаются адрес инструкции, во время которой произошло исключение (пре-
рывание), и адрес обработчика. Предварительно содержимое этих регистров ко-
пируется в LastExceptionFromlP и LastExceptionToIP.
Вышеописанные средства подразумевают наличие программы-отладчика, под уп-
равлением и (или) при резидентном наблюдении которой выполняется отлажива-
емая программа. Отладчик обычно функционирует под управлением операционной
системы. Из этого следует, что операционная система должна быть работоспособной.
Кроме того, отлаживаемая программа может случайно или умышленно (напри-
184
7. Особые режимы работы процессоров
мер, с целью защиты от взлома) «испортить» отладчик или блокировать его дей-
ствия. Для таких случаев, а также для отладки системных средств (ОС или BIOS)
требуются «независимые» отладочные средства. Такими средствами являются
внутрисхемные эмуляторы (ICE — In-Circuit Emulator), представляющие собой
весьма дорогие специализированные программно-аппаратные комплексы. Сред-
ства поддержки внутрисхемного эмулятора встраивались в процессоры, начиная
с 80386, однако не освещались в общедоступной документации. В этих процессо-
рах имеются вышеописанные регистры отладки, а попадание в точки останова,
вместо исключения #ВР, может приводить к переходу в режим ICE. Для такого
перенаправления предназначена инструкция ICEBP. В режиме ICE процессор об-
ращается к шине по альтернативным сигналам, и вместо оперативной памяти от-
лаживаемого компьютера процессору подставляется внутренняя память ICE. Для
шины отлаживаемого компьютера процессор кажется отключенным (управляю-
щие сигналы шинных циклов не формируются). В режиме ICE возможен доступ
и к обычной памяти — для этого существуют инструкции UMOV (аналогичные обыч-
ным инструкциям MOV). Для выхода в нормальный режим служит инструкция LOADALL,
которая предварительно загружает все (включая невидимые) регистры процессора
из образа, хранящегося в памяти эмулятора (эта инструкция существует только в
80286 и в 80386, причем коды и форматы образа для этих двух процессоров не совпа-
дают). Вход в режим ICE возможен также по аппаратному сигналу от эмулятора.
Для целей отладки можно использовать режим SMM (если отлаживать не его об-
работчик): по аппаратному прерыванию SMI процессор выходит в «параллель-
ное» пространство памяти, предварительно выгрузив в нее содержимое всех ви-
димых и невидимых регистров процессора. Зная структуру их образа (зависящую
от модели), можно проанализировать состояние процессора и даже обойти защи-
ту (сменив в образе значение CPL на нулевое и получив неограниченные привиле-
гии). Режим SMM сильно напоминает ICE — как по идее, так и по структурам
данных в сохраняемом образе. Однако в SMM нельзя войти по событиям отладки,
и процессор в этом режиме не имеет встроенных средств доступа к обычной памяти.
Более дешевый и мощный вариант внешнего отладчика использует зондовый режим
(probe mode), обеспечиваемый средствами JTAG в процессорах, начиная с Pentium.
7.4. Режим зондовой отладки
Возможность зондовой отладки появилась в процессорах Pentium. Зондовый ре-
жим предоставляет возможности отладки, превосходящие внутрисхемную эмуля-
цию (ICE), доступную на предыдущих процессорах. Ранее процессор выводился
из нормального режима работы в изолированное адресное пространство, что по-
зволяло полностью отделить ПО эмуляции от отлаживаемой среды. Эта среда
теряла управление процессором — он ей представлялся неактивным. Аналогичный
«уход» осуществляется и в режиме SMM, который также может использоваться в
отладочных целях. Однако процессор в режиме ICE или SMM поддерживал ак-
тивность на шине, что обеспечивало ему выборку, декодирование и исполнение
программного кода эмулятора.
7.5. Режим системного управления SMM
185
Зондовый режим — Probe Mode — обеспечивает возможность отладочных дей-
ствий при внешне действительно статическом состоянии процессора. Отладочные
инструкции и результаты их выполнения передаются между процессором отла-
живаемой системы и тестирующим компьютером по интерфейсу JTAG, изолиро-
ванному от системной шины. Циклы обращения к памяти или портам появятся
на системной шине только в том случае, когда их затребует отладчик для анализа
и(или) модификации содержимого.
Зондовый режим организован как расширение набора инструкций JTAG, исполь-
зующих несколько новых регистров boundary scan и пару дополнительных сигна-
лов R/S# и PRDY. Новые инструкции обеспечивают вход в режим и выход из него,
построение зондовой инструкции в регистре PIR (Probe Instruction Register) и ее
исполнение, доступ к регистру данных зонда PDR (Probe Data Register) и некото-
рые другие функции. В зондовом режиме процессор неактивен: выборка инструк-
ций не производится, прерывания (включая NMI и SMI) и исключения остаются
не обслуженными до выхода из режима. Циклы слежения и заполнения строк кэша
в зондовом режиме могут производиться, поскольку операции с памятью выпол-
няются и при разрешенном кэшировании.
В зондовый режим можно войти тремя способами.
♦ По инструкции Begin Probe Mode. Ее прием по JTAG останавливает процессор
на ближайшей границе инструкций. Установкой сигнала PRDY процессор сиг-
нализирует о готовности к приему зондовой инструкции по JTAG. Выход из
зондового режима возможен по инструкции End Probe Mode или сигналу R/S#
(его нужно перевести из высокого уровня в низкий и обратно).
♦ По переходу в низкий уровень сигнала R/S#; О готовности процессор также
сообщает сигналом PRDY. Выйти из режима в этом случае можно только по
переводу R/S# в высокий уровень.
♦ По исключению отладки #ВР. Для этого в регистре PMCR (Probe Mode Control
Register) должен быть установлен бит IBP (бит 0), что штатно осуществляется
инструкцией ICEBP, передаваемой по JTAG. В этом случае по любому событию
отладки (см. п. 7.3) вместо генерации исключения процессор переходит в зон-
довый режим, о чем сигнализирует высоким уровнем PRDY. Выход из режима
возможен как по инструкции End Probe Mode, так и по сигналу R/S#.
Зондовые инструкции собираются в регистре PIR. Этот регистр имеет полное уп-
равление всеми исполнительными блоками процессора (для Pentium это оба кон-
вейера и ядро FPU), поэтому зондовые инструкции в значительной степени при-
вязаны к модели процессора. Инструкции обеспечивают доступ (чтение и запись)
ко всем внутренним регистрам процессора, включая MSR и скрытые регистры.
На действия этих инструкций нет никаких ограничений защиты.
7.5. Режим системного управления SMM
Современные модели 32-разрядных процессоров (начиная с некоторых модифи-
каций 486 и 386SL) кроме обычных режимов — реального, защищенного и V86 —
имеют дополнительный режим системного управления SMM (System Management
186
7. Особые режимы работы процессоров
Mode). Этот режим предназначен для выполнения ряда действий с полной изоля-
цией их от прикладного программного обеспечения и даже операционной систе-
мы. Главным образом, этот режим предназначен для реализации системы управ-
ления энергопотреблением, хотя может использоваться и в иных целях.
В режим SMM процессор может войти только по сигналу на входе SMI# (System
Management Interrupt), процессоры Р5+ могут войти в SMM и при приеме соот-
ветствующего сообщения по шине APIC. Сигнал SMI# для процессора является
немаскируемым прерыванием с наивысшим приоритетом. Обнаружив активный
сигнал SMI# (низкий уровень), процессор по завершении текущей инструкции и
выгрузки буферов записи переключается в режим SMM. Для процессоров 386SL,
486 и Pentium о переходе в режим SMM свидетельствует выходной сигнал SMIACT#,
процессоры Р6 в режиме SMM каждый цикл системной шины отмечают иденти-
фикатором EXF4. Сразу при входе в SMM процессор сохраняет свой контекст —
почти все регистры — в специальной памяти SMRAM, которая представляет со-
бой выделенную область физической памяти, доступ к которой разрешается внеш-
ними (по отношению к процессору) схемами в шинных циклах обращения к
памяти только при наличии сигнала SMIACT# (EXF4 в Р6). После сохранения кон-
текста процессор переходит к выполнению обработчика SMI, который располо-
жен в той же памяти SMRAM. Обработчик представляет собой последователь-
ность обычных инструкций, исполняемых процессором в режиме, напоминающем
реальный. При входе в режим SMM автоматически запрещаются аппаратные
прерывания (включая и немаскируемые) и не генерируются исключения, так что
действия процессора однозначно определяются программой обработчика SMI.
Процедура обработчика завершается инструкцией RSM, по которой процессор вос-
станавливает свой контекст из образа, хранившегося в SMRAM, и возвращается в
обычный режим работы.
При возврате из SMM возможны некоторые варианты в зависимости от действий
обработчика (в пределах возможностей SMM данного процессора). Во-первых,
обработчик может программно внести изменения в образ контекста процессора,
и при его восстановлении процессор вернется не в то состояние, в котором произош-
ло прерывание SMI. Во-вторых, возможен выбор варианта для случая, когда пре-
рывание SMI возникло во время останова процессора по инструкции HALT: можно
вернуться снова на инструкцию останова или перейти к выполнению следующей
за ней инструкции. В-третьих, процессоры, начиная с Pentium второго поколения
(и Enhanced 486 фирмы AMD), поддерживают возможность рестарта (повторного
выполнения) инструкции ввода-вывода, предшествующей появлению сигнала SMI#.
Возможность рестарта инструкции ввода-вывода является расширением режима
SMM. Ее используют, например, когда прикладная программа (или системный
драйвер) пытается обратиться операцией ввода-вывода к периферийному устрой-
ству, находящемуся в «спящем» режиме. Системная логика в этом случае должна
выработать сигнал SMI# раньше сигнала RDY#, завершающего шинный цикл ре-
стартуемой инструкции ввода-вывода. Обработчик SMI «разбудит» устройство,
после чего операция ввода-вывода рестартует, и прикладное ПО (или драйвер) «не
заметит», что устройство пребывало в спячке. Таким образом, управление энер-
7.5. Режим системного управления SMM
187
гопотреблением может быть организовано на уровне BIOS способом, совершенно
прозрачным для программного обеспечения (в том числе и ОС). Прозрачность
SMM обеспечивается следующими свойствами этого режима:
♦ возможностью только аппаратного входа в SMM;
♦ исполнением кода SMM в отдельном адресном пространстве;
♦ полным сохранением состояния прерванной программы в области SMRAM;
♦ запретом обычных прерываний;
♦ восстановлением состояния прерванной задачи по выходу из режима SMM.
Память SMRAM должна быть физически или логически выделенной областью
размером от 32 Кбайт (минимальные потребности SMM) до 4 Гбайт. SMRAM рас-
полагается, начиная с адреса SMIBASE (по умолчанию ЗООООЬ), и распределяется
относительно этого адреса следующим образом:
♦ FEOOh-FFFFh (по умолчанию 3FE00h-3FFFFh) — область сохранения контек-
ста (распределяется, начиная со старших адресов по направлению к младшим);
♦ 8000h (38000h) — точка входа в обработчик (SMI Handler);
♦ 0-7FFFh (30000h-37FFFh) — свободная область.
Официальная часть карты сохранения контекста представлена в табл. 7.2. Не-
осторожная модификация полей, запрещенных для записи, может привести к не-
предсказуемым (для непосвященных) результатам. В зарезервированных полях
скрывается автоматически сохраняемый управляющий регистр CR4 и программно
невидимые скрытые регистры дескрипторов для CS, DS, ES, FS, GS и SS, но местополо-
жение и формат их образа зависят от модели процессора. Фирма Intel их объяви-
ла «не читаемыми», доступ к ним позволяет обойти сегментную защиту. Зная их
местоположение, можно, например, написать такой обработчик SMI, который
выведет задачу V86 на CPL = 0.
Таблица 7.2. Карта контекста процессора в SMRAM
Смещение относительно SMBASE Регистр (поле) Разрешение записи
FFFCh CRO Нет
FFF8h CR3 Нет
FFF4h EFLAGS Да
FFFOh EIP Да
FFECh EDI Да
FFE8h ESI Да
FFE4h EBP Да
FFEOh ESP Да
FFDCh EBX Да
FFD8h EDX Да
FFD4h ECX Да
продолжение,?
188
7. Особые режимы работы процессоров
Таблица 7.2 (продолжение)
Смещение относительно SMBASE Регистр (поле) Разрешение записи
FFDOh EAX Да
FFCCh DR6 Нет
FFC8h DR7 Нет
FFC4h TR1 Нет
FFCOh LDT Base1 Нет
FFBCh GS1 Нет
FFB8h FS1 Нет
FFB4h DS1 Нет
FFBOh SS1 Нет
FFACh CS1 Нет
FFA8h ES1 Нет
FFA7h.,.FF98h Зарезервировано Нет
FF94h IDT Base Нет
FF93h...FF8Ch Зарезервировано Нет
FF88h GDT Base Нет
FF87h.„FF04h Зарезервировано Нет
FF02h Auto HALT Restart (слово) Да
FFOOh I/O Instruction Restart (слово) Да
FEFCh SMM Revision Identifier (двойное слово) Нет
FEF8h. SMBASE (двойное слово) Да
FEF7h,..FE00h Зарезервировано Нет
1 Старшие 2 байта зарезервированы.
При входе в SMM автоматически не сохраняются:
♦ регистры FPU;
♦ CR2;
♦ DR0...DR5;
♦ MSR, включая MTRR (для 486 — TR3.. .TR7);
♦ состояние контроллера JTAG;
♦ регистры машинного контроля;
♦ регистры APIC.
Если режим SMM используется для отключения питания процессора с возможно-
стью быстрого «пробуждения», память SMRAM, хранящая контекст процессора,
должна быть энергонезависимой. Память SMRAM должна быть схемотехничес-
ки защищена от доступа прикладных программ. Процессор генерирует специаль-
ный выходной сигнал SMIACT# (EXF4) во время обработки SMI, который и должен
7.5. Режим оистемнбго управления SMM
189
являться ключом доступа к этой памяти. Если SMRAM не является энергонеза-
висимой, то системная логика должна обеспечить возможность ос инициализации
(записи программного кода обработчика) процессором из обычного режима ра-
боты до появления сигнала SM1#.
Если память SMRAM «затеняет» какую-либо используемую область ОЗУ, то возни-
кает вопрос о корректности кэширования этой области (по SM1 автоматическое
аннулирование и выгрузка модифицированных строк не производится). Исклю-
чить ложные кэш-нопадания в режиме SMM позволяет подача сигнала FLUSH#
одновременно е 8MI# - тогда до входа в SMM произойдет обратная запись и ан-
нулирование строк (эта операция имеет более высокий приоритет). Пассивное
состояние входа KEN# во время режима SMM предохранит кэш от заполнения
строк. В Р6 аналога сигнала KSN# нет - запрет кэширования должен выполнять-
ся программированием MTRR.
Операционный режим SMM имеет следующие свойства:
♦ вычисление адресов аналогично реальному режиму;
♦ лимит ограничен значением 4 Гбайт;
♦ флаг прерываний IF сброшен;
♦ немаскируемые прерывания (NMI) запрещены;
♦ флаг TF в регистре EFLAGS сброшен, пошаговый режим запрещен;
♦ регистр DR7 сброшен, отладочные ловушки запрещены:
♦ инструкция RSM разрешена (в других режимах она вызывает исключение невер-
ного кода операции);
♦ по умолчанию используется 16-битный режим регистров, стека и кодов операций.
Состояние регистров процессора при входе в SMM иллюстрирует табл. 7.3.
ОДлица 7,8. Состояние региотров при входе a SMM
Регистр Состояние
Общие регистры Но определено
EFLAGS ОООООООЙИ
et₽ 0000600011
База CS 8ММ Base (по умолчанию 30000К)
Селектор CS Значение 8ММ Вале, сдвинутое на 4 разряда вправо (3000И)
Селекторы 08, Е8, F3, G8, §8 оооок
БааыОБ, gS.PS, @8,88 OOOOOOOOOh
Лимиты 08,88, F8, @8,88 OFFFFFFFFh
СЙО Биты 0,2,3 и 31 сброшены (₽Н, ИМ, TS и PG); остальные не модифицированы
BR6 Не определено
BR7 00000400h _
190
7. Особые режимы работы процессоров
В режиме SMM можно разрешить использование прерываний, однако предва-
рительно необходимо позаботиться о корректной инициализации таблицы пре-
рываний (инструкцией LDTR), по крайней мере, для используемых векторов.
Маскируемые аппаратные прерывания могут быть разрешены просто установкой
флага IF, немаскируемое прерывание разрешается программным вызовом его об-
работчика.
Контекст математического сопроцессора (и регистры ММХ) при прерывании SMI
автоматически не сохраняется, поскольку операции FPU в режиме SMM вряд ли
кому-либо потребуются. Однако если SMI используется для выключения процес-
сора, контекст FPU может быть программно сохранен обработчиком. Очевидно,
то же касается и блока регистров ХММ, но в фирменном руководстве этот момент
умалчивается.
Обработчик SMI может определить возможности SMM, предоставляемые данным
процессором, по двойному слову идентификатора SMM (Revision Identifier),
сохраненному в области контекста по адресу SMBASE + FEFCh:
♦ биты [15:0] задают номер версии архитектуры SMM;
♦ бит 16 указывает на возможность рестарта инструкции ввода-вывода;
♦ бит 17 указывает на возможность изменения базового адреса SMRAM и векто-
ра обработчика SMI.
Для управления рестартом инструкции ввода-вывода используется слово (I/O
instruction restart slot) по адресу SMBASE + FFOOh. Если обработчик запишет в это
слово значение OFFh, то по выходу из SMM инструкция, во время которой прои-
зошло прерывание SMI, будет выполнена заново (однако, если это не инструкция
ввода-вывода, поведение процессора непредсказуемо). Если обработчик не изме-
нит нулевое значение этого слова, после выхода из SMM процессор перейдет к
следующей инструкции. Рестарт инструкции ввода-вывода возможен только при
входе в SMM по сигналу SMI#. Вход по сообщению SMI, пришедшему по шине
APIC, не дает возможности рестарта, поскольку это сообщение приходит асинх-
ронно по отношению к выполнению инструкций процессора.
Значение ЗОООЬ базового адреса SMRAM, устанавливаемое по аппаратному сбро-
су (сигналу RESET) процессора, во время исполнения обработчика SMI может быть
программно изменено на значение, выровненное по границе 32 Кбайт. Для этого
достаточно изменить значение базового адреса в области сохраненного контекста
по адресу SMBASE + FEF8h (SMM Base slot), и после исполнения инструкции RSM при
обработке следующего сигнала SMI# будет использоваться новая область. Есте-
ственно, необходимо позаботиться о том, чтобы в новой области присутствовал
код обработчика. Сигнал INIT процессора Pentium не изменяет значения базового
адреса SMRAM.
Возможностью рестарта инструкции HALT управляет бит 0 слова по адресу SMBASE +
FF02h. Если прерывание SMI произошло во время выполнения инструкции HALT
(останова процессора), бит устанавливается в единичное значение. Если обработ-
чик SMI сохранит это значение, по выходу из SMM процессор повторно выпол-
7.6. Метки реального времени и мониторинг производительности
191
нит ту же инструкцию HALT. Если бит сбросить, то по выходу из SMM процессор
перейдет к следующей инструкции.
Для обеспечения возможности рестарта инструкции ввода-вывода необходимо
установить бит 9 в регистре TR12 (для процессоров Pentium второго поколения и
выше).
Если при восстановлении контекста по инструкции RSM процессор обнаружит, что
обработчик установил некорректные значения бит регистров CR0 или CR4 или невы-
ровненный базовый адрес SMRAM, по выходу из режима SMM процессор перей-
дет в состояние Shutdown (аварийный останов).
7.6. Метки реального времени
и мониторинг производительности
Процессоры Pentium и следующие за ними модели имеют 64-битный счетчик ме-
ток реального времени TSC (Time Stamp Counter), входящий в состав MSR. Этот
счетчик инкрементируется с каждым тактом процессорного ядра; отсчет начина-
ется с нуля по аппаратному сбросу сигналом RESET. Разрядность регистра обеспе-
чивает счет без переполнения в течение нескольких тысячелетий. Счетчик про-
должает счет как при исполнении инструкции HLT, так и при остановке процессора
по сигналу STPCLK# (для энергосбережения). Чтение счетчика обеспечивает ин-
струкция RDTSC, установкой бита TSD в CR4 ее можно сделать привилегированной
(доступной лишь при CPL = 0). Защищенная ОС через обработчик исключения для
пользовательских задач может эмулировать действие инструкции, подставляя
«угодное» ОС значение «реального» времени. Чтение и запись TSC возможны так-
же по инструкциям обращения к MSR (при CPL = 0), причем запись может выпол-
няться только в младшие 32 бита, а старшие биты при операции записи обнуля-
ются. Присутствие счетчика TSC определяется по инструкции CPUID(l).
Средства мониторинга производительности (Р5+) включают два 40-битных счет-
чика, которые независимо программируются на подсчет определенных событий
или измерение длительности состояний. Учитываться могут различные события,
связанные с шинными операциями, исполнением инструкций, событиями во внут-
ренних узлах, с работой конвейеров, кэша, контролем точек останова и т. п. Счет-
чики программно управляемы — имеется возможность указания подсчитываемых
событий, чтения, записи, запуска и останова счетчиков, а также действий, выпол-
няемых при их переполнении. Кроме того, имеются внешние сигналы РМО и РМ1,
которые программируются на указание факта срабатывания или переполнения
соответствующих счетчиков. Поскольку эти сигналы могут менять свое значение
с частотой, не превышающей частоту системной шины, из-за внутреннего умно-
жения частоты каждое появление сигналов может отражать несколько (но не боль-
ше, чем коэффициент умножения) срабатываний счетчиков. Взаимодействие со
счетчиками зависит от модели (счетчики входят в состав MSR), списки учитыва-
емых событий различны для Pentium и Р6.
192
7. Особые режимы работы процессоров
В процессорах Pentium имеются три регистра, доступных в качестве MSR (при CPL « 0).
Это собственно счетчики СТРО и CTR1, а также управляющий регистр CESR (Control
And Event Select Register). Поля управляющего регистра перечислены ниже.
♦ ES0 (биты 5:0) и ESI (биты 21:16) - выбор событий (event select) для монито-
ринга (64 варианта).
♦ ССО (биты 8:6) и СИ (биты 24:22) — управление счетчиками (counter control):
• ООО — запрет счета;
• 001 — счет событий при CPL < 3:
• 010 — счет событий при CPL * 3;
• 011 - счет событий при любом CPL;
• 100 — запрет счета;
• 101 - счет длительности при CPL <3;
• 110 - счет длительности при CPL » 3;
• 111- счет длительности при любом CPL.
♦ РСО (бит 9) и РС1 (бит 25) - флаги управления внешними выводами (Pin Control).
При Pci ° 0 выводы сигнализируют об инкременте счетчика, при Рс1 -1 -
о переполнении.
В процессорах Р6 с каждым счетчиком (PerfCtrO и PerfCtrl) связан собственный
управляющий регистр: PerfEvtSel 0 и PerfEvtSel 1 соответственно. Все опи доступны в
качестве MSR, но, кроме того, для доступа к счетчикам имеется специальная инст-
рукция ВОРМС. Установкой в CR4 бита РСЕ ее можно сделать привилегированной.
В регистрах PerfEvtSel! определены следующие поля:
♦ Event select (биты 7:0) — выбор событий;
♦ Unit mask (биты 15:8) - маска блока, уточняющая тип событий;
♦ USR (бит 16) -- флаг счета при CPL > 0 (user mode);
♦ OS (бит 17) — флаг счета при CPL - 0 (operating system mode);
♦ Е (бит 18) - обнаружение границы событий (edge detect); позволяет опреде-
лять среднее время нахождения в определенном состоянии;
♦ PC (бит 19) — флаг управления внешним выводом (Pin Control); при PC « 1
вывод сигнализирует об инкременте счетчика, при Pci 0 - о переполнении;
♦ INT (бит 20) “ разрешение генерации исключения через локальный контрол-
лер АР1С по переполнению счетчика (APIC interrupt enable);
♦ EN (бит 22, только для PerfEvtSelO) - флаг разрешения счета (действует на оба
счетчика);
♦ INV (бит 23) -- флаг инверсии результата сравнения с маской;
♦ Counter mask (биты 31:24) - маска счетчика: если за один цикл число событий,
подлежащих учету, больше (при INV а 1 - меньше) или равно значению мас-
ки, то счетчик инкрементируется; иначе “ сохраняет значение. Используется
для таких событий, как завершение исполнения инструкций (их может быть
несколько за один такт).
7.7. Синхронизация и управление энергопотреблением
193
7.7. Синхронизация и управление
энергопотреблением
Синхронизация процессоров осуществляется внешним сигналом, определяющим
частоту системной шины (FSB Clock). Ядро процессора синхронизируется с по-
мощью умножителя частоты, выполненного по схеме генератора с фазовой авто-
подстройкой частоты. Схема фазовой автоподстройки поддерживает заданное
соотношение частоты внутреннего генератора и внешнего сигнала BCLK. Умноже-
ние частоты в процессоре выполняется с помощью внутреннего управляемого гене-
ратора, включенного в контур системы фазовой автоподстройки частоты (ФАПЧ).
Структурная схема умножителя приведена на рис. 7.3. Контур фазовой автоподстрой-
ки PLL (Phase Lock Loop) в установившемся режиме обеспечивает пулевой фазовый
сдвиг (а следовательно, и совпадение частот) на входах фазового детектора. Эти
сигналы образуются путем деления частот FBUS (частота шины) и FC0RE (частота ядра)
на соответствующие целочисленные коэффициенты, следовательно, в стационар-
ном режиме выполняется условие: FC0RF/kl = FBlJS/k2 или Fcorf = FBUS х klД2.
Рис. 7.3. Схема умножения частоты (ГУН — генератор, управляемый
напряжением; ФД — фазовый детектор)
Целочисленное деление частоты обеспечивается триггерами или управляемыми
счетчиками. Нулевой сдвиг фаз, необходимый для точной привязки внутренних
тактов к синхронизации внешней шины, обеспечивается системой автоматическо-
го регулирования с астатизмом. Это подразумевает некоторую инерционность —
при изменении частоты FBUS на время переходного процесса условия синхрониза-
ции выполняться не будут. Точно так же переходный процесс возникает при сме-
не коэффициентов. Поскольку поведение процессора, у которого внутреннее так-
тирование не привязано к синхронизации внешней шины, непредсказуемо, смена
внешней частоты и коэффициентов деления допустима только во время действия
аппаратного сброса. После установки параметров синхронизации аппаратный
сброс должен удерживаться еще некоторое время, за которое переходный процесс
завершится, и установится нулевой сдвиг фаз.
Коэффициент умножения частоты либо фиксирован (на конечном этапе изготов-
ления процессора), либо задается уровнями сигналов на определенных входах
процессора во время действия сигнала RESET#. Диапазон частот системной шины,
при котором обеспечивается захват в системе ФАПЧ, ограничен и задается в спе-
цификациях на процессоры.
194
7. Особые режимы работы процессоров
Современные процессоры потребляют значительную мощность (десятки ватт),
которая, естественно, выделяется в виде тепла. Мощность (и тепловыделение)
растут с повышением тактовой частоты. Если от процессора не требуется макси-
мально возможная производительность, его можно «притормозить» для снижения
потребления. Минимальную мощность процессор потребляет при остановленном
тактовом генераторе, при этом он не выполняет никаких функций, а последующая
подача синхронизации должна сопровождаться сигналом аппаратного сброса
RESET. Схемы внутреннего умножения требуют стабильности внешней частоты
во время работы процессора, так что для временного снижения потребления при-
ходится использовать специальные механизмы. На рис. 7.4 приведены состояния
(с точки зрения потребления), в которых могут находиться современные процес-
соры. В нормальном состоянии (NormalState) процессор выполняет все свои функ-
ции, здесь потребление максимальное.
6. Deep Sleep
Останов синхронизации (BCLK)
SLP#
SLP#
снят
5. Sleep
Восстановление синхронизации (BCLK)
Рис. 7.4. Диаграмма переходов режимов пониженного энергопотребления
По сигналу STPCLK# процессор выгружает буферы записи и входит в режим Stop
Grant, в котором прекращается тактирование большинства узлов процессора, что
вызывает снижение энергопотребления примерно в 10 раз. В этом состоянии он
прекращает исполнение инструкций и не обслуживает прерывания, однако продол-
жает слежение за шиной, отслеживая кэш-попадания. Из этого состояния процессор
выходит по снятию сигнала STPCLK#. Управление сигналом STPCLK# совместно с
использованием режима SMM реализует механизм расширенного управления
питанием АРМ (Advanced Power Management). При отсутствии активности внеш-
няя схема (чипсет) по команде, исполненной в режиме SMM, устанавливает дан-
ный сигнал. По пробуждающему событию внешняя схема (без участия процессо-
ра, который «спит») снимает сигнал, и процессор продолжает работу. Кроме того,
с помощью сигнала STPCLK# возможно замедление процессора (с пропорциональным
снижением потребляемой мощности), если па этот вход подавать периодический
импульсный сигнал, который фактически будет модулировать внутреннюю так-
товую частоту процессора. Скважность импульсов определит коэффициент про-
7.7. Синхронизация и управление энергопотреблением
195
стоя процессора и, следовательно, его производительность (это как бы эквивалент-
но снижению условной тактовой частоты). В новых процессорах (Pentium 4)
появились встроенные средства управления потреблением через снижение про-
изводительности (см. п. 9.2). Напомним, что во время приостановки внутреннего
тактирования процессор не обслуживает прерывания (им приходится ожидать),
так что модуляция тактовой частоты приводит к увеличению времени гарантиро-
ванного отклика на прерывания.
В состояние пониженного энергопотребления Auto HALT PowerDown процессор
переходит при исполнении инструкции HALT. В этом состоянии процессор реаги-
рует на все прерывания и также продолжает слежение за шиной.
В состоянии Sleep (спящий режим), которое вызывается сигналом SLP#, процес-
сор не тактирует свои внутренние узлы (кроме схемы умножителя частоты). Пре-
рывания и циклы слежения не воспринимаются. Процессор может реагировать
только на сигналы SLP#, STPCLK# и RESET#. По снятию сигнала SLP# процессор
возвращается в состояние Stop Grant и возобновляет тактирование своего блока
управления шиной и APIC. Потребляемый ток составляет менее 1 А.
В состояние «глубокого сна» Deep Sleep процессор переходит при остановке так-
тового сигнала на входе BCLK. В этом режиме процессор не выполняет никаких
функций и его ток потребления снижается до долей ампера.
Средства управления потреблением появились с процессорами Pentium второго
поколения, где реализованы состояния 1-4. Процессоры Pentium П/Ш и Celeron
имеют дополнительные состояния 5 и 6 (процессоры Хеоп состояния 6 не имеют).
8. Совместимость,
различия и идентификация
процессоров
В этой главе речь пойдет о различиях процессоров: что стоит за принципом со-
вместимости, как узнать тип процессора, как архитектура влияет на производи-
тельность.
8.1. Совместимость процессоров
В архитектурной линии Intel Architecture (IA-32) процессоры следующих моделей
вбирают в себя все свойства и инструкции предыдущих. Правда, некоторые инст-
рукции объявлены не архитектурными, а зависящими от модели, и их наличие и
функционирование в следующих моделях не гарантируется. В табл. 8.1 перечис-
лены расширения набора инструкций относительно базовой модели 32-разрядных
процессоров (80386).
Таблица 8.1. Расширения набора инструкций 32-разрядных процессоров
Инструкции Условия реализации и примечания
Инструкции, введенные в Pentium 4
Расширение SSE2 CPUID(1):EDX.26=1
Инструкции, введенные в Р6 Расширение SSE CPUID(1): EDX.25=1
CMOV CPUID(1): EDX.15=1
FCMOV, FCOMI CPUlD( 1): (EDX.O И EDX. 15)=1
RDPMC Зависит от модели. Имеется и в последних моделях Pentium
UD2 Инструкции, введенные в процессоры AMD Кб, К7
Расширение 3DNow! CPUID(8000_0001h): EDX.31=1
Расширение 3DNow! CPUID(8000_0001h): EDX.30=1
для сигнальных процессоров Расширенный набор ММХ CPUID(8000_0001h): EDX.22=1
8.1. Совместимость процессоров
197
Инструкции Условия реализации и примечания
Инструкции, введенные в Pentium
CMPXCHG8B CPUID(1):EDX.8=1
CPUID Имеется и в последних моделях 486, определяется по возможности модификации бита EFLAG.21
RDTSC CPUID(1):EDX.4=1
RDMSR.WRMSR Инструкции ММХ Инструкции, введенные в 486 BSWAP, XADD, CMPXCHG, INVD, WBINVD, INVLPG, RSM1 CPUID(1): EDX.5=1 CPUID(1): EDX. 23=1
1 Инструкция RSM есть и в 386SL.
16-разрядные процессоры 8086/88 и 80286 «умеют» выполнять большинство ин-
струкций 32-разрядных процессоров, но с 16-битным ограничением на разряд-
ность адресов и операндов. Кроме того, в них отсутствует ряд инструкций, пере-
численных ниже.
В процессорах 80286/287 отсутствуют следующие инструкции:
♦ загрузка сегментных регистров SS, FS и GS (LSS, LFS и LGS);
♦ условные переходы с большим смещением;
♦ битовые инструкции (ВТ, BTC, BTR, BTS);
♦ сканирование бит (BSF, BSR);
♦ ‘ двойные сдвиги (SHLD, SHRD);
♦ условная установка байт (SET сс);
♦ пересылка с расширением (MOVSXB, MOVSXW, MOVZXB, MOVZXW);
♦ обобщенные операнды в умножении;
♦ обмен с управляющими регистрами CR;
♦ обмен с регистрами отладки DR;
♦ обмен с регистрами тестирования TR (отсутствует, начиная с Pentium);
♦ инструкции сопроцессора FPREM1, FUCOM, FUCOMP и FUCOMPP.
Помимо перечисленных в предыдущем списке, в процессорах 8086 отсутствуют
следующие инструкции:
♦ ввод-вывод строк (INSB, INSW, OUTSB, OUTSW);
♦ умножение на константу (IMUL);
♦ сохранение константы в стеке (PUSH), сохранение и восстановление группы ре-
гистров (PUSHA, РОРА);
♦ сдвиги с непосредственным указанием числа позиций (в инструкциях RCL, RCR,
ROL, ROR, SAL, SAR, CHL, SHR число позиций определяется только через CL);
198
8. Совместимость, различия и идентификация Процессоров
♦ вход в процедуры (ENTER) и выход из процедур (LEAVE);
♦ проверка границ (BOUND);
♦ системные инструкции, связанные с защищенным режимом.
Состав регистров и флагов по мере «взросления» процессоров постоянно расширя-
ется. Принцип совместимости программного обеспечения, написанного для ран-
них моделей процессоров, со следующими моделями предписывает осторожно
обращаться с неиспользуемыми (зарезервированными) битами и регистрами:
♦ не изменять значения бит, не используемых в данном процессоре;
♦ гарантировать нечувствительность программ к значению этих бит;
♦ при загрузке регистров в зарезервированные биты записывать нули;
♦ не пытаться использовать эти биты для хранения каких-либо признаков.
Как уже указывалось выше, в семействе процессоров х86 декларируется обратная
совместимость новых моделей с предыдущими. Это означает, что программный
код, написанный для процессора 8088, должен таким же образом исполняться и
на 80386, и на Pentium II, и на любых других совместимых процессорах. В боль-
шинстве случаев так и происходит, но программы на более новых процессорах
исполняются, естественно, быстрее. Здесь кроется один из подводных камней со-
вместимости. Дело в том, что большинство программ для PC выполняет не только
вычисления, но и управляет различным внутренним и внешним оборудованием.
При этом оборудование требует определенной последовательности действий и
соблюдения временных характеристик. Устройства с невысоким быстродействи-
ем не могут, например, воспринимать последовательные обращения к ним, иду-
щие в соседних тактах системной шины ввода-вывода. Программные способы
организации задержек должны опираться на сведения о модели (и, если есть воз-
можность, о тактовой частоте) процессора, на котором исполняется код. Иначе
возможны перекосы в обе стороны, которые могут приводить к разнообразным
неприятным эффектам. С программными задержками связаны, в частности, про-
блемы применения процессоров Cyrix, которые идентифицируются неправильно
(как 486). Их архитектурные преимущества оборачиваются неработоспособнос-
тью некоторых программ.
Для введения программных задержек при обращении к портам ввода-вывода в
BIOS компьютеров на процессорах 8088, 80286 и 80386 использовалась команда
короткого безусловного перехода (JMP SHORT) на следующий адрес. Эта команда
сбрасывала конвейер (очередь декодированных инструкций), и процессор был
вынужден снова делать выборку кода операции из памяти, а в это время порт «пе-
реводил дух» перед следующим обращением. Такой способ задержки применялся
не только в BIOS, но и в загружаемых программах.
Однако этот способ введения программной задержки для процессоров, имеющих
внутренний, кэш (то есть 486 и выше, а также некоторые модели 80386), не при-
годен. Здесь команда JMP, ранее безусловно приводящая к генерации внешнего
8.1. Совместимость процессоров
199
цикла обращения к памяти, скорее всего, будет обслужена из внутреннего кэша,
и желаемой задержки не произойдет. Одним из способов введения внешнего цик-
ла шины между циклами вывода является явная операция чтения некэшируемой
области памяти. Эта операция в процессорах с упорядоченным выполнением ин-
струкций будет выполнена только после завершения предыдущего цикла вывода,
а последующая операция вывода начнется только по завершении этого чтения.
Благодаря конвейерной архитектуре в процессорах последних поколений на раз-
ных стадиях выполнения обычно находится несколько инструкций. В процессо-
рах шестого поколения применяется изменение порядка выполнения операций,
и чтение памяти может обогнать другие операции на внешней шине. Если порядок
операций, включая чтение памяти, имеет существенное значение, может потребовать-
ся сериализация выполнения операций. Сериализация означает, что все модифи-
кации флагов, регистров и памяти, выполняемые предыдущими инструкциями,
должны завершиться до выборки из памяти и исполнения последующей инструк-
ции. При этом очищается очередь предварительно выбранных инструкций. Сериа-
лизация происходит после выполнения инструкций INVD, INVLPG, IRET, IRETD, LGDT,
LLDT, LIDT, LTR, WBINVD, CPUID, RSM, WRMSR, а также инструкций загрузки управляющих и
отладочных регистров. Однако большинство этих инструкций в защищенном ре-
жиме зависят от уровня привилегий. Инструкция CPUID, введенная с процессором
Pentium, позволяет выполнять сериализацию на любом уровне привилегий.
Хотя кэширование, буферизация записи и параллельное исполнение инструкций
происходит прозрачно для программы, иногда приходится учитывать их действие
(например, в случае самомодифицирующегося программного кода) и знать меха-
низм их работы. Это позволяет, например, оптимизировать размеры структур дан-
ных с тем, чтобы их обработка не вызывала «пробуксовывания» или «захламле-
ния» кэша (cahe Trashing), когда каждое последующее чтение данных вызывает
замещение целой строки, особенно досадное в том случае, если замещающие дан-
ные повторно не потребуются, в отличие от нужных данных из замещенных ими
строк. В принципе возможны ситуации, когда кэширование будет замедлять ис-
полнение программы постоянным чтением из основной памяти не полностью ис-
пользуемых строк.
Кроме скорости исполнения процессоры отличаются и некоторыми нюансами
выполнения инструкций, которые обычно не влияют на выполнение программ, но
могут использоваться для идентификации процессоров. Так, например, инструк-
ция PUSH SP на процессоре 8086/88 исполняется иначе, чем на 80286 и более позд-
них, — различие касается порядка выполнения декремента указателя стека и его
сохранения в стеке.
Процессоры последних поколений имеют архитектурные расширения, полагаться
на которые без предварительной идентификации типа процессора весьма рискован-
но. Определив возможности процессора, программа может эффективно исполь-
зовать поддерживаемые им расширения архитектуры. Посредством программи-
рования регистров MSR можно управлять расширениями архитектуры, естественно,
только в сторону отключения имеющихся возможностей.
200
8. Совместимость, различия и идентификация процессоров
8.2. Идентификация процессоров
Возможность программного определения типа процессора была заложена в архи-
тектуру процессоров х86 с самого начала. В любом процессоре IA-32 сразу после
аппаратного сброса в регистре (E)DX можно прочитать номер семейства (3 — 386,
4 — 486, 5 — Pentium, 6 — Р6...), модели, типа и степпипга. Расшифровка основ-
ных полей приводится в табл. 8.2. Кроме полей, перечисленных в таблице, имеет-
ся поле степпипга (биты 3:0) — номера версии процессора в пределах одной моде-
ли. Поле «тип» (биты 13:12) различает процессоры ОЕМ-версий (00), OverDrive
(01) и Dual (10); значение 11 зарезервировано. Наиболее интересная информация
содержится в полях «семейство» (биты 11:8) и «модель» (биты 7:3). Старшие биты
(14-31) регистра EDX пока не используются (они нулевые). Процессоры 80386
имели несколько иное назначение бит: поле «семейство» совпадает, поле «модель»
занимает биты 15:11, биты 7:0 отводятся под степпинг. Для процессоров ранних
поколений регистр DH содержит идентификатор процессора (01 — 8086/88, 02 —
80286), DL — номер модели. Поле «модель» позволяет отличать, например, Pentium
ММХ от «просто» Pentium 75-233 МГц или Pentium 60-66 МГц, Celeron от
Pentium II или Pentium Pro. Поле «степпинг» без таблиц не расшифровать, оно
несет информацию О нюансах, например, исправлены ли те или иные ошибки,
возможный диапазон частот (определяется косвенно и не точно).
Таблица 8.2. Коды идентификации процессоров
Тип EDX[13:12] Семейство EDX[11:8] Модель EDX[7;4] Процессор
00 0100 0000 lntel486DX
00 0100 0001 lnte!486DX
00 0100 0010 lntel486SX
00 0100 0011 Intel487, lntelDX2, lntelDX2 OverDrive, AMD DX2 в режиме WT
00 0100 0100 IntelSXL
00 0100 0101 lntelSX2 OverDrive
00 0100 0111 lntelDX2 Enhanced в режиме WB, AMD DX2 в режиме WB
00 0100 1000 lntelDX4 OverDrive, AMD DX4 в режиме WT
00 отоо 1001 AMD DX4 в режиме WB
00 0100 1110 Am5x86 в режиме WT
00 0100 1111 Am5x86 в режиме WB
01 0100 1000 Intel DX4 OverDrive
00 0101 0000 AMD K5-PR75,90,100
00 0101 0001 Pentium 60, 66 Pentium OverDrive для Pentium 60, 66AMDK5-PR120,133
00 0101 0010 Pentium 75,90,100,120,133, 150,166, 200 AMD K5-PR166
8.2. Идентификация процессоров
201
Тип EDX[13:12] Семейство EDX[11:8] Модель EDX[7:4] Процессор
01 0101 0010 Pentium OverDrive 75, 90,100,120, 133
01 0101 0011 Pentium OverDrive для 486
00 0101 0100 Pentium MMX (166, 200, 233)
01 0101 0100 Зарезервировано (OverDrive для Pentium 75, 90, 100,120,133)
00 0110 0001 Pentium Pro
00 0110 0011 Pentium II первого поколения (233-300 МГц)
01 0110 0011 Pentium II OverDrive
00 0110 0101 Pentium II Deschutes (333-450 МГц), Celeron (266, 300 МГц), Xeon
00 0110 0110 Celeron 300A, 333- 533
00 0110 0111 Pentium III и Pentium III Xeon
00 0110 1000 Pentium III Coppermine, Pentium III Xeon, Celeron 533A, 566,600
Информация из (E)DX доступна только для BIOS в самом начале запуска машины
(ее может считать тест POST). Поскольку система BIOS ориентирована на процес-
соры одного поколения (семейства), проблем с различием использования регист-
ра (E)DX не возникает. Потребность в идентификации процессора операционной
системой и приложениями созревала по мере расширения диапазона функцио-
нальных возможностей и уровня производительности процессоров. Начиная с
процессоров Pentium, появилась новая инструкция CPUID, по которой любая про-
грамма на любом уровне привилегий в любой момент времени могла получить ту
же информацию, что и BIOS после сброса, и вдобавок 32-битный набор флагов
расширений базовой архитектуры, реализованных в данном процессоре. Получен-
ную информацию программа может использовать, например, для выбора испол-
няемого кода, оптимального для данного процессора (или отказа исполнения на
«недостойном» ее процессоре), а также для настройки констант программных реа-
лизаций задержек. Инструкция CPUID поддерживалась и в ряде последних моде-
лей процессоров класса 486. Формат инструкции практически безгранично рас-
ширяем, с ее помощью процессор может выдать хоть весь свой словесный портрет
(если эту возможность заложат его разработчики). Однако информация для CPUID
«зашивается» в процессор на этапе изготовления кристалла, что нс позволяет,
например, «выпытать» у процессора его официальную тактовую частоту (она оп-
ределяется позже — на этапе тестирования уже готового процессора). Эта инфор-
мация была бы полезна при борьбе, например, с пиратским разгоном (перемарки-
ровкой) процессоров, что, в общем-то, волнует изготовителя.
Следующий шаг, уже явно нацеленный на учет и контроль, был сделан в процес-
соре Pentium II Хеоп. Здесь имеется специальная постоянная (только для чтения)
память процессорной информации PIROM (Processor Information ROM), которая
хранит такие данные, как электрические спецификации ядра процессора и кэш-
202
8. Совместимость, различия и идентификация процессоров
памяти (диапазоны частот и питающих напряжений), S-спецификацию (степ-
пинг) и 64-битный серийный номер процессора. Кроме того, имеется энергонеза-
висимая память Scratch EEPR0M, которая предназначена для занесения систем-
ной информации поставщиком процессора (или компьютера с этим процессором)
и может быть защищена от последующей записи. Для взаимодействия с PIROM и
Scratch EEPROM (а также устройством термоконтроля) процессор имеет допол-
нительную последовательную шину SMBus (System Management Bus) — отдель-
ный электрический интерфейс, с которым работает чипсет системной платы. Об-
ращение к указанным учетным данным получается довольно сложным — это целая
процедура, привязанная к реализации чипсета, а не одна инструкция.
И наконец, в Intel решили соединить всеобщий учет (и контроль) с простотой
доступа: в процессор Pentium III ввели расширение инструкции CPUID, по которо-
му легко можно получить 64-битный уникальный идентификатор данного процес-
сора. Идентификатор процессора, по замыслу Intel, должен стать дополнительным
средством аутентификации в Интернете (и других сетях) наряду с именем пользо-
вателя и паролем, вводимыми вручную. Однако если имя и пароль можно сменить
в любое время, идентификатор присваивается навечно и принудительно, хотя
имеется возможность запретить процессору сообщать свой идентификатор. Вот
эта всеобщая инвентаризация и вызвала бурю обсуждений прав на частную жизнь
пользователей нового процессора. После жарких споров фирма Intel, «идя навстре-
чу пожеланиям трудящихся», постановила, что по умолчанию выдача идентифи-
катора запрещена, а разрешается только с ведома пользователя. Как подчеркивает
Intel, идентификатор сообщается пассивно, то есть компьютер с новым процессо-
ром, ОС и браузером не кричит на весь мир «я — номер такой-то!». Это естествен-
но, поскольку для идентификации процессор должен исполнить фрагмент про-
граммного кода, в котором вызывается инструкция CPUID и интерпретируются ее
результаты.
Для управления выдачей идентификатора в модельно-специфическом регистре
BBL_CR_CTL (MSR 119h) выделяется запрещающий бит (бит 21). Он может быть
установлен в 1 программно, с помощью инструкции обращения к MSR, и тогда по
инструкции CPUID будет доступна только традиционная информация. Заметим, что
инструкции обращения к MSR обычно привилегированы, то есть могут выпол-
няться только на уровне привилегий ядра ОС. По аппаратному сбросу процессо-
ра (и только так!) бит обнуляется, и полная идентификация разрешается. Дек-
ларированное «отключение по умолчанию» возлагается на ОС, и для Windows
предлагается специальная утилита, опрашивающая значение бита MSR и управ-
ляющая его установкой, а также сообщающая прочитанный (по возможности)
идентификатор. Для использования ОС, отличных от Windows, Intel рекоменду-
ет разработчикам BIOS включать фрагмент кода аналогичного назначения в BIOS
Setup (здесь любое переключение будет требовать перезагрузки).
Основная информация о процессоре предоставляется по инструкции CPUID, дос-
тупность которой определяется через бит 21 (ID) регистра EFLAGS: в процессорах,
поддерживающих эту инструкцию, можно программно установить его в единицу
8.2. Идентификация процессоров
203
(в иных процессорах он всегда будет читаться нулевым). По инструкции CPUID(0)
можно определить производителя процессора и возможности данной инструкции.
Вызов CPUID(l) сообщает сигнатуру процессора — тип, семейство, модель и степ-
пинг (см. табл. 8.2), а также список расширений архитектуры (см. п. 8.2.1). Как
видно из табл. 8.2, одному и тому же сочетанию типа, семейства и модели может
соответствовать несколько типов процессоров, например, Pentium II и Pentium II
Xeon по ним неразличимы. Эти процессоры различаются элементами системы
кэширования, и их можно распознать по дескрипторам (см. п. 8.2.1), сообщаемым
по инструкции CPUIDC2). И, наконец, серийный номер процессора, если это позво-
лено (см. ниже), можно узнать по CPUID(3). Серийный номер появился с процессо-
рами Pentium III (он был введен еще в кристалл Celeron модели 6, но на конечном
этапе производства эту возможность отключали).
Заметим, что здесь нигде в явном виде не фигурирует тактовая частота процессо-
ра — для каждой модели и степпинга выпускаются процессоры с некоторым диа-
пазоном тактовых частот, а конкретное значение обозначается на корпусе после
испытаний и отбраковки. В процессорах Xeon «официальная» тактовая частота
заносится в энергонезависимую память конфигурации, откуда может быть счита-
на по интерфейсу SMBus. Доступ к этой памяти осуществляется по процедурам,
определяемым чипсетом системной платы, но не по одной определенной инструк-
ции процессора. Возможно, тактовую частоту можно определить и по серийному
номеру процессора, но пока па этот счет нет официальных указаний.
Идентификация процессора требуется на разных уровнях ПО. Первым делом
идентификацию выполняет BIOS — для того, чтобы сообщить о найденных про-
цессорах пользователю и выполнить необходимые настройки под конкретную
модель и степпинг процессора. Для процессоров 6-го поколения эта информация
позволяет определить, какими ошибками (erratum, см. п. 7.2) «страдает» данный
процессор и какими «заплатками» эти ошибки нейтрализуются. Нейтрализация
ошибок может выполняться как модификацией микрокода процессора (update
microcode, см. п. 7.2), так и созданием специфических фрагментов программного
кода для обработчиков прерываний и исключений. Эти «заплатки» могут входить
как в операционные системы, так и в BIOS. Если конкретный процессор «не зна-
ком» для BIOS или ОС, «заплатки» для него не будут загружены и возможны раз-
личные неожиданности при работе. В этом случае стоит позаботиться об обнов-
лении BIOS (для флэш-BIOS это технически несложно) или о приобретении
загружаемых «заплат» для ОС.
В зависимости от обнаруженного процессора ОС может использовать те или иные
варианты реализации своих функций. ОС защищенного режима (а теперь иными
практически и не пользуются) разрешает или запрещает те или иные архитектур-
ные расширения (в основном записью в регистр CR4). Прикладным программам
остается только согласиться с предлагаемым набором свойств процессора или
отказаться от работы. Прикладные программы могут получать информацию о
процессоре по инструкции CPUID при любом уровне привилегий, а привилегиро-
ванные программы (PL = 0) могут пользоваться и данными CR4.
204
8. Совместимость, различия и идентификация процессоров
Рассмотрим возможности идентификации процессоров разных поколений. Про-
граммам, загружаемым операционной системой, да и самой ОС информация о
процессоре из регистра EDX недоступна (аппаратный сброс был слишком давно).
Задача идентификации осложняется тем, что поколение процессора заранее не-
известно. Когда появился процессор 80286, его (и все последующие) отличали от
8086/88 по значениям, сохраняемым в стеке инструкцией PUSH SP: первые процес-
соры сначала декрементировали указатель стека, а потом его сохраняли. Для иден-
тификации процессоров, начиная еще с 16-разрядпых, рекомендуется анализ зна-
чения регистра флагов, сохраненного по инструкции PUSHF после попытки его
изменения. Приведем параметры регистра флагов в том порядке, в каком их ана-
лизируют при идентификации типа:
♦ у процессоров 8086/88 биты 12-15 всегда установлены — попытка их сброса
не удается;
♦ у 80286 в реальном режиме биты 12-15 всегда сброшены;
♦ у 32-разрядных процессоров в реальном режиме бит 15 всегда сброшен, а биты
12-14 хранят последнее загруженное в них значение; в защищенном режиме
бит 15 всегда сброшен, а бит 14 хранит последнее загруженное в него значение
(биты 12, 13 можно изменить только при IOPL = 0).
Для 32-разрядных процессоров анализируется EFLAG:
♦ бит 18 доступен, начиная с процессоров 486, а у 80386 его невозможно изме-
нить;
♦ биты 19 (VIF) и 20 (VIP) у процессоров, не поддерживающих расширения вир-
туального режима (VME), всегда пулевые;
♦ бит 21 (ID) определяет возможность использования инструкции CPUID (призна-
ком доступности инструкции является возможность программного изменения
значения этого бита).
Для определения присутствия сопроцессора выполняют инструкцию FNINIT, за-
тем — инструкцию FNSTENV, после чего проверяют корректность образа сопроцес-
сора, сохраненного в памяти. Тип сопроцессора обычно определяется типом CPU,
кроме процессора 80386, который может работать как с 80287, так и с 80387. Их
можно, различить по способу представления +°° и -«>: у 287 они одинаковы, у 387 -
различны.
BIOS компьютера определяет тип установленного процессора (начиная с 5-го
поколения Intel и 4-го AMD) в начале теста POST по инструкции CPUID, по кото-
рой процессор сообщает идентификатор производителя (разработчика), семей-
ство, модель и степпинг. По этим данным BIOS формирует имя процессора (на-
пример, «Intel Pentium III»), которое POST выводит на экран (и сообщает в
CMOS Setup). Текстовые названия известных процессоров прописаны в теле
BIOS, так что неверное название в сообщении свидетельствует о слишком старой
(для данного процессора) версии BIOS. Процессоры AMD имя процессора сооб-
щают по инструкции CPUID, так что тесту POST не требуется искать имена по таб-
лицам. В процессорах Intel эта возможность появилась, только начиная с Pentium 4.
8.2. Идентификация процессоров
205
Текущую тактовую частоту ядра POST определяет с помощью системного тайме-
ра, либо выполняя определенный цикл инструкций и подсчитывая число; прохо-
дов за известный интервал, либо снимая показания счетчика меток реального вре-
мени (TSC) в начале и конце интервала измерения. Последний способ точнее, по он
работает только на процессорах, имеющих этот счетчик (Pentium и выше). Чте-
нием определенных модельно-специфических регистров процессора POST может
определить установленный коэффициент умножения частоты.
8.2.1. Инструкция CPUID
Инструкция CPUID, доступная, начиная с Pentium и некоторых моделей 486, вы-
зывается с параметром, заданным в регистре ЕАХ. Значение ЕАХ при вызове CPUID,
указанное в скобках, определяет функцию вызова.
ВНИМАНИЕ--------------------------------------------------------
CPUID(x) — это не мнемоника какого-либо языка программирования, а сокращенная форма
записи, принятая в данной книге.
♦ CPUID(O) — в регистре ЕАХ возвращается максимально допустимое значение
параметра вызова; в регистрах ЕВХ, EDX и ЕСХ процессор возвращает символьную
строку, идентифицирующую производителя. Символы строки размещаются
в регистрах в указанном порядке, начиная с младших байт. Процессоры AMD7
возвращают строку «AuthenticAMD» (ЕВХ = 6874754 th, ЕСХ = 444D4163h, EDX =
69746Е65И). Процессоры Intel возвращают строку «Genuinelntel»:
• ЕВХ = 756E6547h — «Genu», символ «G» в регистре BL; '
• EDX = 49656E69h — «inel», символ «i» в регистре DL;
• ЕСХ = 6C65746Eh — «ntel», символ «п» в регистре CL.
♦ CPUID(l) — в младшем слове регистра ЕАХ процессор возвращает код идентифика-
ции (см. табл. 8.2) — он же сигнатура процессора и старший элемент 96-битного
серийного номера (в Pentium 4 положение полей изменено, см. ниже). Это же
значение содержится в регистре DX после аппаратного сброса. В других регистрах:
• ЕАХ[3:0] — степппнг;
• ЕАХ[7:4] — модель;
• ЕАХ[11:8] — семейство;
• ЕАХ[13:12] — тип;
• ЕАХ[31:14] — зарезервировано (0);
• ЕВХ[7:0] — брэнд-индекс (пли 0);
• ЕВХ[31:8] = 0 (резерв), для процессоров Pentium 4 см. ниже;
• ЕСХ = 0 (резерв);
• EDX содержит список имеющихся расширений базовой архитектуры — ото-
бражает регистр свойств (Feature Flags register). Назначение бит регистра
приведено в табл. 8.3.
206
8. Совместимость, различия и идентификация процессоров
♦ CPUID(2) — в регистрах ЕАХ, ЕВХ, ЕСХ, EDX возвращаются параметры конфигурации
процессора. Младшие 8 бит ЕАХ сообщают, сколько раз нужно подряд вызвать
инструкцию (с ЕАХ = 2) для получения полной информации о процессоре. Ос-
тальные байты регистра ЕАХ и других регистров содержат дескрипторы отдель-
ных узлов, которые расшифровываются по специальным таблицам. Призна-
ком использования каждого из регистров ЕАХ, ЕВХ, ЕСХ, EDX является нуль в его
бите 31.
Вызов инструкции CPUID(2) стал возможен с появлением процессоров Intel
6-го поколения (в процессорах AMD он недоступен, см. ниже). Пока что по
нему сообщаются только дескрипторы элементов кэширования (табл. 8.4).
Например, для Pentium Pro по CPUID(2) возвращается ЕАХ = 03020101h, ЕВХ = О,
ЕСХ = О, EDX e 06040A42h. Это означает, что вызов нужно делать однократно
(AL = 1); TLB инструкций для страниц размером 4 Кбайт имеет 32 вхождения
(Olh), для страниц 4 Мбайт — 2 вхождения; TLB данных для страниц 4 Кбайт —
на 64 вхождения (03h), для страниц 4 Мбайт — на 8 вхождений (04h); первич-
ный кэш инструкций — 8 Кбайт (06h), данных — 8 Кбайт (0Ah); вторичный
кэш - 256 Кбайт (42h).
♦ CPUID(3) — получение младших 64 бит серийного номера процессора (Intel
Processor Serial Number), доступно только в Pentium III (семейство 6, модель 7
и выше):
• EDX — средние 32 бита идентификатора;
• ЕСХ — младшие 32 бита идентификатора.
Полный идентификатор имеет длину 96 бит. Старшие 32 бита — код иденти-
фикации процессора, возвращаемый в ЕАХ по CPUID(l). Доступность вызова оп-
ределяется по биту PN регистра свойств (после CPUID(l) бит EDX.18 » 1). После
аппаратного сброса у процессоров, поддерживающих сообщение идентифика-
тора, этот вызов разрешен. Запретить сообщение идентификатора до следую-
щего аппаратного сброса можно установкой в единицу бита 21 регистра. Фраг-
мент программы на ассемблере для запрета сообщения номера приведен ниже.
После запрета бит PN обнуляется. Снова разрешить сообщение номера про-
граммно невозможно, повторное разрешение возможно только через аппарат-
ный сброс (по сигналу RESET, но не INIT#).
MOV ЕСХ, 119h
RDMSR ;загрузка значения MSR в EDX-.EAX
OR ЕАХ, 0020 OOOOh модификация бита 21
WRMSR ;запись в MSR
♦ Вызовы инструкций CPUID с ЕАХ > 3 (в пределах разрешенного значения, со-
общенного процессором при вызове CPUID(O)) зарезервированы для будущих
применений.
8.2. Идентификация процессоров
207
Таблица 8.3. Назначение флагов расширения архитектуры
Бит Название Назначение
0 FPU Floating Poin Unit — наличие математического сопроцессора
1 VME Virtual-8086 Mode Enhancements — расширение режима V86 (виртуализация флага прерываний)
2 DE Debugging Extensions — расширение отладки (возможность остановки по обращению к портам)
3 PSE Page Size Extension — возможность применения размера страницы в 4 Мбайт
4 TSC Time Stamp Counter — наличие счетчика меток реального времени
5 MSR Model Specific Register — поддержка модельно-специфических регистров в стиле Pentium (инструкции RDMSR, WRMSR)
6 РАЕ Physical Address Extension — возможность расширения физического адреса до 36 бит
7 MCE Machine Check Exception — поддержка исключения машинного контроля #МС
8 СХ8 Поддержка инструкции CMPXCHG8B
9 APIC Наличие встроенного программно-доступного контроллера прерываний APIC
10 - Зарезервировано
11 SEP Sysenter Present — поддержка инструкций быстрых системных вызовов SYSENTER и SYSEXIT
12 MTRR Memory Type Range Registers — наличие регистра управления кэшированием MTRRcap
13 PGE Page Global Enable — поддержка бит глобальности в элементах каталога и таблиц страниц, а также бита PGE в регистре CR4
14 MCA Machine Check Architecture — поддержка архитектуры машинного контроля
15 CMOV Conditional Move — поддержка инструкций условной пересылки CMOVcc, а если есть FPU, то и инструкций FCMOVCC и FCOMI
16 PAT Page Attribute Table — поддержка таблиц атрибутов страниц (РАТ)
17 PSE-36 36-bit Page Size Extension — возможность использования 36-битной физической адресации для страниц в 4 Мбайт
181 PSN Processor Serial Number — поддержка сообщения 96-битного серийного номера по инструкции CPUID(3)
191 CLFSH Поддержка инструкции CLFLUSH
201 — Зарезервировано
211 DTS Debug Trace Store — поддержка отладочной записи истории переходов или архитектурных состояний
221 ACPI Наличие регистров MSR, позволяющих программировать модуляцию частоты синхронизации
23 MMX Поддержка ММХ
24 FXSR Fast floating point save and restore — поддержка инструкций быстрого сохранения и восстановления контекста FPU (инструкций FXSAVE и FXRSTOR). Указывает и на доступность индикатора использования этих инструкций операционной системой (CR4.OSFXSR)
продолжением
208
8. Совместимость, различия и идентификация процессоров
Таблица 8.3 (продолжение)
Бит Название Назначение
251 SSE Поддержка инструкций расширения SSE (наличие блока ХММ)
26’ SSE2 Поддержка инструкций расширения SSE2
271 SS Self Snoop —самослежение. Поддержка управления конфликтующих типов памяти путем выполнения опроса собственного кэша для шинных транзакций
28 Зарезервировано
291 ТМ Thermal Monitor — автоматическое понижение производительности при перегреве
30,31 - Зарезервировано
1 Биты используются только в процессорах Intel.
Таблица 8.4. Дескрипторы элементов кэширования процессоров Intel
Дескриптор Значение1
00h Нулевой дескриптор (в неиспользуемых байтах)
01h TLB инструкций: страницы 4 Кбайт, 4WSA, 32 вхождения
02h TLB инструкций: страницы 4 Мбайт, FA, 2 вхождения
03h TLB данных: страницы 4 Кбайт, 4WSA, 64 вхождения
04h TLB данных: страницы 4 Мбайт, 4WSA, 8 вхождений
06h Кэш инструкций (L1): 8 Кбайт, 4WSA, длина строки 32 байта
08h Кэш инструкций (L1): 16 Кбайт, 4WSA, длина строки 32 байта
OAh Кэш данных (L1): 8 Кбайт, 2WSA, длина строки 32 байта
OCh Кэш данных (L1): 16 Кбайт, 2WSA, длина строки 32 байта
40h Нет вторичного кэша
41h Вторичный кэш 128 Кбайт, 4WSA, длина строки 32 байта
42h Вторичный кэш 256 Кбайт, 4WSA, длина строки 32 байта
43h Вторичный кэш 512 Кбайт, 4WSA, длина строки 32 байта
44h Вторичный кэш 1 Мбайт, 4WSA, длина строки 32 байта
45h Вторичный кэш 2 Мбайт, 4WSA, длина строки 32 байта
50h TLB команд: страницы 4 Кбайт и 2 Мбайт либо только 4 Мбайт, 64 входа
51h TLB команд: страницы 4 Кбайт и 2 Мбайт либо только 4 Мбайт, 128 входов
52h TLB команд: страницы 4 Кбайт и 2 Мбайт либо только 4 Мбайт, 256 входов
5Bh TLB данных: страницы 4 Кбайт и 4 Мбайт, 64 входа
5Ch TLB данных: страницы 4 Кбайт и 4 Мбайт, 128 входов
5Dh TLB данных: страницы 4 Кбайт и 4 Мбайт, 256 входов
66h Кэш данных (L1): размер 8 Кбайт, 4WSA, длина строки 64 байта
67h Кэш данных (L1): размер 16 Кбайт, 4WSA, длина строки 64 байта
68h Кэш данных (L1): размер 32 Кбайт, 4WSA, длина строки 64 байта
8.2. Идентификация процессоров
209
Дескриптор Значение1
70h Кэш трасс: размер 12 Кбайт, 8WSA
71h Кэш трасс: размер 16 Кбайт, 8WSA
72h Кэш трасс: размер 32 Кбайт, 8WSA
79h Кэш L2: размер 128 Кбайт, 8WSA, секторированный, длина строки 64 байта
7Ah Кэш L2: размер 256 Кбайт, 8WSA, секторированный, длина строки 64 байта
7Bh Кэш L2: размер 512 Кбайт, 8WSA, секторированный, длина строки 64 байта
7Ch Кэш L2: размер 1 Мбайт, 8WSA, секторированный, длина строки 64 байта
82h Кэш L2: размер 256 Кбайт, 8WSA, длина строки 32 байта
84h Кэш L2: размер 1 Мбайт, 8WSA, длина строки 32 байта
82h Кэш L2: размер 2 Мбайт, 8WSA, длина строки 32 байта
’2WSA — двухканальиый наборно-ассоциативный кэш, 4WSA — 4-капальный, 8WSA — 8-канальпый,
FA — полностью ассоциативный кэш.
В процессоре Pentium 4 значения, выдаваемые по CPUID(l), изменились:
♦ ЕАХ[3:0] — степпинг;
♦ ЕАХ[7:4] — модель;
♦ ЕАХ[11:8]=1111 — признак использования расширенного поля семейства;
♦ ЕАХ[13:12]-тип;
♦ ЕАХ[ 15:14] — зарезервировано (0);
♦ ЕАХ[ 19:16] — расширенная модель;
♦ ЕАХ[23:20] — расширенное семейство;
♦ ЕАХ[31:24] — зарезервировано (0);
♦ ЕВХ[7:0] — брэнд-индекс (пли 0);
♦ ЕВХ[ 15:8] — длина строки, очищаемой инструкцией CLFLUSH (для получения дли-
ны возвращенное значение следует умножить па 8);
♦ ЕВХ[31:24] — физический идентификатор APIC процессора;
♦ ЕСХ = 0 (резерв);
♦ EDX содержит список имеющихся расширений базовой архитектуры (см. табл. 8.3).
Брэнд-индекс служит для нахождения официального названия процессора в таб-
лице, которая должна храниться в BIOS (0 — индекс не поддерживается, 1 —
Celeron, 2 — Pentium III, 3 — Pentium III Xeon, 8 — Pentium 4).
Кроме того, появились расширенные функции CPUID, вызываемые со значениями
ЕАХ = 8000000011 и выше:
♦ CPUID(80000000h) — в регистре ЕАХ возвращается максимально допустимое
значение параметра вызова расширенных функций;
210
8. Совместимость, различия и идентификация процессоров
♦ CPUID(80000001h) — резерв для расширения сигнатуры и особенностей процес-
сора (по следам фирмы AMD);
♦ CPUID(80000002h, 80000003b и 80000004h) — выдача строки имени процессора
(brand string) в регистрах EAX, ЕВХ, ЕСХ и EDX.
48-символьная ASCIIZ-строка названия собирается путем последовательных
вызовов указанных функций, в каждом регистре хранятся 4 соседних символа,
из которых самый левый находится в младшем байте. Эти четверки символов
собираются в том же порядке, в котором они перечислены выше. Строка завер-
шается символом NUL (00Ь), выравнивается по правому краю, а слева свобод-
ные места заполняются пробелами (20h). В строке кроме собственно названия
указывается официальная допустимая частота (но текущее значение может
отличаться). Первые процессоры имеют строку «Intel(R) Pentium (R) 4 CPU
1500 MHz».
Фирма AMD ввела расширенные функции CPUID гораздо раньше Intel, еще с про-
цессора К5 модели 1, но из стандартных в ее процессорах используются только
функции 0 и 1. В сигнатуре процессора, возвращаемой функцией CPUID(l) в реги-
стре ЕАХ, используются только поля семейства, модели и степпинга, а биты 31:12
не используются. Примечательно, что к одному и тому же семейству (0101b = 5)
относятся разные процессоры, но их можно различить по полю модели: К5 — мо-
дели 0, 1, 2 и 3; Кб — модели 6 и 7, К6-2 — модель 8, К6-Ш — модель 9. К семейст-
ву 6 (но седьмому поколению!) относятся процессоры Athlon — модели 1 (он же К7),
2 и 4; Duron — модель 3. В списке расширений (регистр EDX) назначение бит
совпадает с приведенным в табл. 8.3, за исключением неиспользуемых (у AMD)
бит (см. примечание к таблице). Расширенные функции 80000000-80000004h
совпадают с вышеописанными, функция 80000001b в регистре EDX возвращает
расширенные флаги свойств (extended features flags). Эти флаги в большинстве
своем совпадают с возвращаемыми по функции CPUID(l), но с некоторыми исклю-
чениями:
♦ бит И — наличие инструкций SYSCALL и SYSRET;
♦ бит 22 — фирменное (AMD) расширение инструкций ММХ;
♦ бит 30 — наличие расширенных инструкций AMD 3DNow!;
♦ бит 31 — наличие инструкций AMD 3DNow!.
Процессоры AMD имеют дополнительные расширенные функции, позволяющие
прочитать описания системы кэширования:
♦ CPUID(80000005h) — сообщение информации о первичном кэше (для всех про-
цессоров, начиная с К5) и первичных буферах TLB (для Athlon и Duron);
♦ CPUID(80000006h) — сообщение информации о вторичном кэше (для процессо-
ров, начиная с К6-Ш) и вторичных буферах TLB (для Athlon и Duron).
Форматы описаний для разных процессоров различаются.
8.2. Идентификация процессоров
211
Для процессоров Athlon и Duron функция 80000005b сообщает:
♦ в регистрах ЕАХ и ЕВХ параметры первичных буферов TLB для больших (2М/
4М) и нормальных (4К) страниц соответственно:
• биты 31:24 — ассоциативность для TLB данных (число каналов, FF — пол-
ная ассоциативность);
• биты 23:16 — число вхождений для TLB данных для страниц 2М (для стра-
ниц 4М — вдвое меньше);
• биты 15:8 — ассоциативность для TLB инструкций (аналогично);
• биты 7:0 — число вхождений для TLB инструкций;
♦ в регистрах ЕСХ и EDX параметры первичного кэша данных и инструкций соот-
ветственно: ,
• биты 31:24 — размер, Кбайт;
• биты 23:16 — ассоциативность (аналогично);
• биты 15:8 — число строк, обслуживаемых одним тегом;
• биты 7:0 — длина строки, байт.
Для процессоров Athlon, Duron и К6-НГ функция 80000006b сообщает:
♦ в регистрах ЕАХ и ЕВХ параметры вторичных буферов TLB для больших (2 Мбайт/
4 Мбайт) и нормальных (4 Кбайт) страниц соответственно:
• биты 31:28 — ассоциативность для TLB данных (0 — L2 отсутствует; 1 — пря-
мого отображения; 2,4 или 8 — число каналов; F — полная ассоциативность);
• биты 27:16 — число вхождений для TLB данных для страниц 2 Мбайт (для
страниц 4 Мбайт — вдвое меньше);
• биты 15:12 — ассоциативность для TLB инструкций (аналогично);
• биты 11:0 — число вхождений для TLB инструкций;
♦ в регистре ЕСХ параметры вторичного кэша:
• биты 31:16 — размер, Кбайт;
• биты 15:12 — ассоциативность (аналогично);
• биты 11:8 — число строк, обслуживаемых одним тегом;
• биты 7:0 — длина строки, байт.
Для процессоров К5 и Кб функция 80000005b сообщает:
♦ в регистре ЕАХ параметры буферов TLB:
• биты 31:24 — ассоциативность для TLB данных (число каналов, FF — пол-
ная ассоциативность);
1 Для процессора K6-III, не имеющего вторичных TLB, регистры ЕАХ и ЕВХ не используются.
212
8. Совместимость, различия и идентификация процессоров
• биты 23:16 — число вхождений для TLB данных;
• биты 15:8 — ассоциативность для TLB инструкций (аналогично);
• биты 7:0 — число вхождений для TLB инструкций;
♦ в регистре ЕСХ и EDX параметры первичного кэша данных и инструкций соот-
ветственно:
• биты 31:24 — размер, Кбайт;
• биты 23:16 — ассоциативность (аналогично);
• биты 15:8 — число строк, обслуживаемых одним тегом;
• биты 7:0 — длина строки, байт.
8.3. Основные характеристики
процессоров
На сегодняшний день наибольший интерес представляют процессоры пятого,
шестого и седьмого поколений, границы между которыми стараниями фирм-кон-
курентов размыты. Эти процессоры сравниваются в табл. 8.5, в которой представ-
лены архитектурные особенности современных процессоров фирм Intel, AMD,
Cyrix, VIA и Centaur (некоторые процессоры Cyrix выпускаются под торговой
маркой IBM и VIA).
Самые массовые на сегодняшний день — процессоры Intel 6-го поколения со всем
их многообразием сокетов и слотов. Как видно из таблицы, в слот 1 (SC242)
можно установить любой из «настольных» процессоров — Pentium II, Celeron
(до 433 МГц) и Pentium III. В сокет-370 можно установить Celeron 300А и выше,
Pentium III с улучшенным кэшем 256 Кбайт и VIA Cyrix III, но с оглядкой на про-
блемы совместимости первой и второй редакций сокета (см. п. 11.1). При нали-
чии подходящего переходника процессоры для сокета-370 могут быть установле-
ны и в слот 1. Слот 2 предназначен для мощных процессоров Xeon — как с SSE,
так и без него. Для сокета S, кроме старых Pentium Pro, можно установить Pentium II
Overdrive («Xeon-ЗЗЗ»). При наличии специального переходника в сокет 8 можно
установить и Celeron (понижение напряжения обеспечивается регулятором на
переходнике).
Конечно же, интерес представляют и процессоры класса 486, которые с успе-
хом применяются как встраиваемые управляющие процессоры, отличающие-
ся от своих более поздних собратьев меньшей ценой, низким энергопотребле-
нием и более легким согласованием с 8- и 16-разрядной периферией. Среди них
самый привлекательный процессор — это Ат5х86, имеющий многие черты ар-
хитектуры пятого поколения и интерфейс, совместимый с 486. И, конечно же,
большой парк эксплуатируемых нынче PC с процессорами класса 486 про-
существует еще несколько лет, удовлетворяя потребности многочисленных
пользователей.
Таблица 8.5. Сравнительные характеристики процессоров 5-7-го поколений
Процессор Частота системной шинм, МГц Частота ядра, МГц (PR) Кэш L1, Кбайт (инструкции/ данные) Кэш L2 Поддержка ММХ Сокет (слот) Питание, В
Процессоры фирмы Intel
Pentium (1-е поколение) 60,66 60,66 16(8/8) - - Сокет 4 5
Pentium (2-е поколение) 50,60,66 75,90,100,120,133, 150,166,180,200 16(8/8) - - Сокет 5,7 3,3 2,9/3,3
Pentium ММХ 66 166,200,233 32(16/16) - + Сокет 7 2,8/3,3
Pentium Pro 50,60,66 150,166,180,200 16(8/8) 256 Кбайт, 512 Кбайт - Сокет 8 3,3
Pentium II OverDrive 66 333 32(16/16) 512 Кбайт + Сокет 8 2,5
Pentium II 66,100 233,266,300,350, 400,450 32(16/16) 512 Кбайт + Слот 1 2,8 2,0
Pentium II Xeon 100 400,450 32(16/16) 512 Кбайт, 1 Мбайт, 2 Мбайт + Слот 2 2,0
Celeron 66 266,300 32(16/16) - + Слот 1, сокет-370 2,0
Celeron 66 300А, 333,366,400, 433,466,500,533 32(16/16) 128 Кбайт + Слот 1 (до433 МГц), сокет-370 2,0
Celeron (Coppermine) 66,100 533А, 566-766,800, 850,900 32(16/16) 128 Кбайт +, SSE Сокет-370 1,5
Pentium III 100,133 450,500,533,550, 600 32(16/16) 512 Кбайт +, SSE Слот 1 2,0-2,05
Pentium III (Coppermine) 100,133 500,533,550,600, 650,667,700,733, 750,800,850,866, 900,9331000,1130 32(16/16) 256 Кбайт +, SSE Слот 1, сокет-370 (до 1 ГГц) 1,65-1,80
продолжением
Таблица 8.5 (продолжение)
Процессор Частота системной шины, МГц Частота ядра, МГц (PR) Кэш L1, Кбайт (инструкции/ данные)
Pentium III Xeon (настольный) 100,133 600-866 32(16/16)
Pentium III Xeon (серверный) 100 500,550 32(16/16)
Pentium 4 4x100 Процессоры фирмы AMD 1400,1500,1700 -78
AMDK5 50,60,66 PR75,90,100,120, 133,166 24(16/8)
AMD Кб MMX 66 PR166.200,233, 266,300,333 64(32/32)
AMDK6-2 66,100 300,333,350,380, 400,450,475,500, 533,550 64(32/32)
AMD K6-III 100 400,450 64(32/32)
AMD Athlon модели 1 и 2 2x100 550,600,650,700, 750,850,900,950, 1000 128 (64/64)
AMD Athlon, модель 4 2x100,2x133 800,900,950,1000, 1100,1200,1300, 1000,1130,1200, 1330 128(64/64)
AMD Duron 200 600,650,700,800, 850,900 128 (64/64)
Кэш L2 Поддержка ММХ Сокет (слот) Питание, В
256 Кбайт +.SSE Слот 2 2,0
512 Кбайт, 1 Мбайт, 2 Мбайт +, SSE Слот 2 2,0
256 Кбайт +, SSE2 Сокет 423 1.6
- - Сокет 5,7 3,3 2,5-2,9/3,3
- + Сокет 7 2,9/3,3 3,2/3,3 2,2/3,3
- +; 3DNow! Сокет 7 2,2/3,3
256 Кбайт +;3DNow! Сокет 7
512 Кбайт-
8 Мбайт
+; 3DNow!
с расшире-
нием
СлотА
256 Кбайт +; 3DNow! с расшире- нием Сокет А
1,6-1,7/2,5-3,3
1,7-1,75
64 Кбайт
+; 3DNow!
с расшире-
нием
Сокет А
Процессор Частота системной шины, МГц Частота ядра, МГц (PR) Кэш L1, Кбайт (инструкции/ данные) Кэш L2 Поддержка ММХ Сокет (слот) Питание, В
Процессоры фирмы Cyrix Cyrix 6x86 50,55,60, PR120,133,150, 16 — - Сокет 5,7 3,3-3,52
(M1):6x86L 66,75 166,200 Сокет 7 2,8/3,3
Cyrix 6х86МХ 60,66,75,83 PR166,200,233,266 16 - + Сокет 7 2,9/3,3
Cyrix 6x86MII- 66,75,100 xxxGP PR300,333,350 16 - + Сокет 7
Процессоры фирмы VIA VIA Cyrix MII+ 133 16 256 Кбайт +; 3DNow! с расшире- нием Сокет-370
VIA Cyrix III 133 (Joshua) 433,466,500, 64 533—700 256 Кбайт +; 3DNow! с расшире- нием Сокет-370
Процессоры фирмы Centaur Winchip C6 60,66,75 180-240 64(32/32) — + Сокет5 3,3-3,5
Winchip 2 60,66,75,100 200-300 64(32/32) - + Сокет7 3,3-3,5
1 Вместо первичного кэша инструкций имеется кэш трасс на 12 К микроопераций.
9. Процессоры фирмы Intel
Фирма Intel на протяжении долгих лет являлась бесспорным лидером в разработке
и выпуске процессоров порожденного ею семейства х86. В IBM PC применялись
процессоры всех поколений, первые четыре поколения в этой книге уже практи-
чески не рассматриваются (интересующиеся могут обратиться к дополнительной
литературе [7, 8, 10]).
С процессоров Pentium фирмы Intel началось пятое поколение процессоров семей-
ства х86. По базовой регистровой архитектуре и системе команд они являются 32-
разрядными процессорами, но имеют 64-битную шину данных, благодаря чему их
иногда ошибочно называли 64-разрядными. Шина адреса позволяет адресовать
4 Гбайт физической памяти. Процессоры Pentium ММХ (Р55С) — последнее по-
коление процессоров Pentium. Кроме MMX-расширения в архитектуре Pentium
ММХ имеется ряд усовершенствований, повышающих его производительность и
на обычных операциях. Последняя модель Pentium имела частоту ядра 233 МГц,
Pentium ММХ — 266 МГц.
По интерфейсу шина процессора Pentium стала развитием шипы процессора 486.
Если шина 486 ориентирована на максимальную гибкость и простоту подключе-
ния устройств с различной разрядностью, то шина Pentium — на достижение мак-
симальной производительности. Интерфейс рассчитан на применение внешнего
вторичного кэша и внутреннего первичного с возможностью работы как со сквоз-
ной (WT), так и с обратной записью. Интерфейс позволяет объединять до двух
процессоров на одной шине для реализации SMP или FRC. Интерфейс Pentium
используется в сокетах 4, 5, и 7 процессорами разных производителей.
9.1. Процессоры Р6
К шестому поколению процессоров Intel относится Pentium Pro, все разновиднос-
ти процессоров Pentium II/III, а также Celeron. Процессоры этого поколения
имеют обобщенное название Р6. С точки зрения принципа организации вычисле-
ний, главное отличие этого поколения заключается в динамическом исполнении,
при котором внутри процессора инструкции могут исполняться не в том порядке
(out of order), который предполагает программный код. Это решение призвано
повысить производительность процессора за счет улучшения архитектуры; а не
повышения тактовой частоты. Некоторые идеи такого рода реализованы и в про-
цессорах, описанных в п. 10.1. Динамическое исполнение резко повышает частоту
запросов процессорного ядра к шине за данными и инструкциями, поскольку ядро
9.1. Процессоры Р6
217
одновременно обрабатывает несколько инструкций. Для обхода узкого места —
внешней шины — в Р6 применена архитектура двойной независимой шины DIB
(Dual Independent Bus), реализующая, по сути, две отдельные шины. Одна из этих
шин используется только для связи с кристаллом вторичного кэша, расположен-
ным в том же корпусе микросхемы или картридже, что и процессор. Эта шина
является локальной и в геометрическом смысле — проводники имеют длину по-
рядка единиц сантиметров, что позволяет использовать ее на высокой частоте так-
тирования, вплоть до частоты ядра. Значительный объем вторичного кэша обес-
печивает удовлетворение большинства запросов к памяти сугубо локально, при
этом коэффициент загрузки внутренней шины достигает 90 %. Вторая шина про-
цессорного кристалла выходит на внешние выводы микросхемы (картриджа), она
и является системной, или «фасадной» шиной FSB (Front-Side Bus) процессо-
ра Р6. Эта шина работает на внешней частоте независимо от внутренней шины.
По статистике работы с приложениями середины 90-х годов загрузка процессором
внешней шины для обычных «настольных» применений составляет порядка 10 %
от ее пропускной способности, а для серверных применений может достигать 60 %
при четырехпроцессорной конфигурации. Таким образом, ограниченная пропуск-
ная способность внешней шины (533 Мбайт/с при 66,67 МГц и 1064 Мбайт/с при
133 МГц в пике пакетной передачи) перестает служить фактором, обесцениваю-
щим производительность процессора. Однако для современных процессоров и
приложений и этой пропускной способности уже не хватает. Снижение нагрузки
на внешнюю шину позволяет эффективно использовать многопроцессорную ар-
хитектуру. Системная шина Р6 более эффективна для объединения процессоров
по симметричной архитектуре, чем шипы предыдущих процессоров, оптимизиро-
ванные для обмена с памятью. Она позволяет без дополнительных схем объеди-
нять до четырех процессоров, хотя в обычных процессорах Pentium П/Ш возмож-
ности объединения урезаны до двух.
В ходе эволюции шестого поколения к системе команд Pentium Pro, расширенной
относительно Pentium с целью сокращения условных переходов, было добавлено
расширение ММХ — так появился Pentium II. Затем идею ММХ — одновремен-
ное исполнение одной инструкции над группой операндов — распространили и на
инструкции с плавающей точкой: SSE (Streaming SIMD Extensions) — основной
козырь Pentium III. Правда, несколько раньше то же самое (но в меньшем объеме)
было сделано фирмой AMD — расширение 3DNow! было реализовано уже в про-
цессорах К6-2 для сокета 7.
Микроархитектура Р6 честно отработала на ряде моделей процессоров, начиная с
Pentium Pro (1995 г., 0,6 мкм, 150 МГц) и до Pentium III (2000 г., 0,18 мкм, 1 ГГц).
На частоте выше 1 ГГц она «сломалась», и первая партия Pentium Ш-1,13 ГГцбыла
отозвана из продажи из-за нестабильности работы. У предыдущего поколения
«живучести» было меньше — первый Pentium имел частоту 60 МГц (1993 г.), по-
следний — только 233 (1997 г.), хотя, возможно, здесь кроме технических аспектов
сильно влияют и маркетинговые соображения.
Процессоры Pentium Pro (1995 г., технология 0,5 мкм, впоследствии 0,35 мкм)
выпускались с частотами ядра 150,166,180 и 200 МГц и объемом вторичного кэша
218
9. Процессоры фирмы Intel
256 и 512 Кбайт (1024 Кбайт в специальных моделях). Раздельный первичный кэш
инструкций и данных имеет объем 8+8 Кбайт. Вторичный кэш работает на часто-
те ядра. Частота системной шины — 60 или 66 МГц. Достоверность данных вто-
ричного кэша в некоторых модификациях контролируется с помощью ЕСС. Про-
цессоры могут работать в симметричных мультипроцессорных системах (SMP) —
до четырех процессоров на общей шине. Объединяемые процессоры должны иметь
одинаковые коэффициенты умножения частоты (единая тактовая частота шины
подразумевается). Для этих процессоров был введен сокет 8. В 1998 году для заме-
ны этих процессоров был выпущен Pentium II OverDrive (август 1998 г.) на базе
ядра процессора Xeon (см. ниже) с частотой 333 МГц (шина — 66,6 МГц), вторич-
ным кэшем 512 Кбайт (кэшируемый объем памяти — 64 Гбайт), работающим на
частоте ядра, и фиксированным коэффициентом умножения (KF - 5, при частоте
шины 60 МГц частота ядра будет 300 МГц). Модернизации поддаются не все сис-
темные платы. Внешний регулятор напряжения не требуется — процессор «заказы-
вает» напряжение питания ядра 2,5 В, а встроенный регулятор VRM, установленный
на его радиаторе, понижает Vccp до 2,0 В. Этот процессор допускает построение
двухпроцессорных систем, 3- и 4-процессорные конфигурации не поддерживаются.
При этом использование Pentium Pro в паре с новым процессором недопустимо.
Цена, определенная фирмой (599 долларов), как всегда заставляет задуматься о
целесообразности модернизации имеющейся системы. Дальнейшее развитие про-
цессоров для сокета 8 (более высокие тактовые частоты) не предусматривается,
поскольку, начиная уже с частоты ядра 350 МГц, внешняя частота процессоров
Pentium II — 100 МГц — недоступна для сокета 8.
Процессоры Pentium II сочетают архитектуру Pentium Pro с технологией ММХ.
По сравнению с Pentium Pro удвоен размер первичного кэша (16+16 Кбайт), раз-
мер вторичного кэша варьируется от 0 до 2 Мбайт. В процессоре используется
новая технология корпусов — картридж с печатным краевым разъемом, на кото-
рый выведена системная шина (Single Edge Contact Cartridge — SECC). На карт-
ридже размером 14 x 6,2 x 1,6 см установлена микросхема ядра процессора (CPU
Core), несколько микросхем, реализующих вторичный кэш, и вспомогательные
дискретные элементы (резисторы и конденсаторы). Снятие вторичного кэша с
микросхемы процессора позволяет использовать для кэш-памяти и памяти тегов
микросхемы сторонних производителей, специализирующихся на выпуске сверх-
быстродействующей памяти. Объем вторичного кэша определяется емкостью и
числом установленных микросхем памяти. В то же время сохраняется независи-
мость шины вторичной кэш-памяти, которая тесно связана с ядром процессора
собственной локальной шиной.
Первые процессоры Pentium II (до выпуска они имели кодовое название Klamath),
появившиеся весной 1997 года, насчитывали около 7,5 млн транзисторов только
в процессорном ядре и выполнялись по технологии 0,35 мкм, питание 2,8 В. Они
имели тактовые частоты ядра 233, 266 и 300 МГц при частоте системной шины
66,6 МГц. При этом вторичный кэш работал на половинной частоте ядра и кэширо-
вал только первые 512 Мбайт пространства памяти. Для этих процессоров был раз-
работан слот 1, по составу сигналов сильно напоминающий сокет 8 для Pentium Pro.
9.1. Процессоры Р6
219
Однако слот 1 позволяет объединять лишь пару процессоров для реализации сим-
метричной мультипроцессорной системы либо системы с избыточным контролем
функциональности (FRC). Таким образом, этот процессор представляет собой
более быстрый Pentium Pro с поддержкой ММХ, но урезанным мультипроцесси-
рованием. Первые модели по инструкции CPUID сообщают идентификатор 063xh.
Следующее поколение Pentium II, имевшее кодовое название Deshutes, появилось
в 1998 году и выполнялось уже по технологии 0,25 мкм, питание 2,0 В. Это позво-
лило поднять тактовую частоту (чем мельче элементы, тем меньше они рассеива-
ют мощность, что особенно критично на высоких частотах). Процессор на 333 МГц
имеет частоту шины 66,6 МГц, а процессоры на 350,400 и 450 МГц — уже 100 МГц.
Для работы на такой частоте эффективна оперативная память на микросхемах
SDRAM (синхронная динамическая память), у которой в середине пакетного цик-
ла данные передаются в каждом такте. Эти процессоры также устанавливаются
в слот 1 (опять-таки не более двух в системе). Начиная с процессоров 350 МГц,
объем памяти, кэшируемой на L2, увеличили до 4 Гбайт. По инструкции CPUID со-
общается идентификатор 065xh.
Процессоры Pentium III (1999 г.) являются дальнейшим развитием Pentium II.
Кодовое название до выхода — Katmai. Их главным отличием является расшире-
ние набора SIMD-ииструкций — SSE (Streaming SIMD Extensions), предваритель-
но называвшееся KNI (Katmai New Instructions), основанное на новом блоке 128-
разрядных регистров ХММ. Этот блок позволяет одной инструкцией выполнять
операции сразу над четырьмя комплектами 32-разрядных операндов в формате с
плавающей точкой (одинарная точность). При выполнении новых инструкций
оборудование традиционного устройства FPU/ММХ не используется, что позво-
ляет эффективно смешивать инструкции ММХ с инструкциями над операндами
с плавающей точкой. Инструкции с регистрами ХММ могут работать и в скаляр-
ном режиме (с одним комплектом операндов). Кроме арифметических есть и ло-
гические инструкции. Появились и новые возможности управления кэшировани-
ем. Расширена инструкция CPUID, по которой теперь можно получить уникальный
64-битный идентификатор процессора (тот, что у Xeon можно было прочесть по
SMBus). «Простые» Pentium III в упаковке,SECC или SECC2 устанавливаются в
слот 1, в FC-PGA — в сокет-370, Pentium III Xeon — в слот 2. По возможностям
мультипроцессорных конфигураций эти процессоры аналогичны своим предше-
ственникам Pentium II и Pentium II Xeon. Возможность избыточных конфигура-
ций (FRC) есть только у Pentium III Xeon. Частота ядра начинается с 500 МГц,
частота системной шины — 100 и 133 МГц. Вторичный кэш в первых моделях
Pentium III — 512 Кбайт с ЕСС-контролем — работает на половине частоты ядра,
расположен на картридже в виде отдельных микросхем (собственно память и па-
мять тегов). Первые модели по инструкции CPUID сообщают идентификатор 067xh.
Процессоры с ядром Coppermine (иногда сокращенно называют CuMine) тоже
называются Pentium III. Несмотря на слово copper (Си — медь) в названии, мед-
ных проводников в них нет. Технология 0,18 мкм, 28 млн транзисторов, площадь
кристалла — 106 мм2. Выпускаются в картридже SECC-2 для слота 1 (SC-242) и в
корпусе FC-PGA (Flip-Chip PGA) для сокета-370. Первичный кэш 32 Кбайт (16+16),
220
9. Процессоры фирмы Intel
па кристалле ядра расположен улучшенный вторичный кэш (Advanced Transfer
Cache) размером 256 Кбайт с ЕСС-контролем, который работает па частоте ядра.
Вторичный кэш связан с ядром шиной разрядностью 256 бит (у предыдущих Р6 с
отдельно расположенным кэшем и процессоров Celeron с интегрированным кэшем
разрядность шины данных кэша составляла 64 бпт). По сравнению с Celeron и
первыми моделями Pentium III, вторичный кэш CuMine имеет меньшую латент-
ность (задержку от запроса до начала пересылки данных), а пропускная способ-
ность его шины выросла в 4 раза. Например, для процессоров Pentium III 533В и
533ЕВ пропускная способность шипы вторичного кэша составляет 533 х 8 = 4,2 и
533 х 32 = 17 Мбайт/с соответственно. Набор инструкций включает SSE и выда-
чу серийного номера процессора. Напряжение питания для сокета-370 — 1,6 В, для
слота 1 — 1,65 В. Частота системной шины 100 и 133 МГц. Коэффициенты ум-
ножения фиксированы изготовителем. Анонсированы модели с частотами 500
(100 х 5), 533 (133 х 4), 550 (100 х 5,5), 600 (100 х 6 или 133 х 4,5), 650 (100 х 6,5),
667 (133 х 5), 700 (100 х 7), 733 (133 х 5,5), 750 (100 х 7,5), 800, 850, 866, 933,
1000 МГц. В обозначении процессора, например Pentium Ш-533ЕВ, буква Е озна-
чает улучшенный кэш, буква В — частоту шины 133 МГц (без буквы В — 100 МГц).
Маркировка процессоров Pentium III довольно сложно расшифровывается, нос
марта 2000 года для процессоров в корпусе FC-PGA она упрощается. Так, вместо
маркировки вида RB805526PY600256 будет более понятная надпись вида 600/256/
100/1.6V — частота ядра/размер кэша Ь2/частота шины/напряжение питания.
В марте 2000 года вышли модели на 850 и 866 МГц. Предыдущие модели (500 и
550 МГц) в корпусах FC-PGA не поддерживают SMP, но, начиная с 600 МГц, под-
держку SMP обещают. Процессоры в SECC2 имеют то же назначение выводов, что
и их предшественники для слота 1. Однако модернизация старых плат может упе-
реться в старую версию BIOS и в невозможность обеспечения низкого (1,65 В) на-
пряжения питания. Процессоры в FC-PGA отличаются от семейства Celeron, для
которых был введен сокет-370, назначением пяти выводов, и по этой причине со-
вместимости со старыми платами (возможно, на чипсетах i440BX/ZX) не будет.
По инструкции CPUID процессор сообщает идентификатор 068xh.
Для «самых простых» компьютеров весной 1998 года выпустили облегченный
вариант процессора Pentium II, названный Celeron. Процессоры Celeron с ядром
Covington (технология 0,25 мкм, питание 2 В) имеют частоты 266 и 300 МГц
(частота шины — 66 МГц) и тоже устанавливаются в слот 1, но их картриджи не-
сколько проще и называются иначе — SEPP (Single Edge Processor Package). Они
не имеют микросхем вторичного кэша и задней крышки защитного кожуха.
Исключение вторичного кэша заметно отразилось на производительности (систем-
ные платы для слота 1 вторичного кэша, естественно, не имеют). По инструкции
CPUID сообщается идентификатор 065xh.
При падении цен на системные платы и дешевизне самого процессора Celeron
машины начального уровня оказались действительно недорогими.
Летом 1998 года вышла следующая модель Celeron, известная также под названи-
ем Mendocino. Сюда относятся процессоры Celeron 300А (с частотой 300 МГц) и
9.1. Процессоры Р6
221
Celeron 333-533 МГц. Процессоры имеют небольшой (128 Кбайт) вторичный кэш,
установленный на кристалле ядра и работающий на полной частоте ядра (как у
Pentium Pro, но с несколько большей латентностью). Процессоры с частотами 300-
433 МГц выпускались и под слот 1 (технология 0,25 мкм, питание 2,0 В), и для
сокета-370 (технология 0,22 мкм, питание 2,0 В) в корпусе PPGA. В корпусе PPGA
выпускаются процессоры с частотой до 533 МГц, при этом частота системной
шины — только 66 МГц. По инструкции CPUID сообщается идентификатор 066xh.
Весной 2000 года появились процессоры Celeron на ядре Coppermine (0,18 мкм,
питание 1,5 В), их еще называют Celeron II. Как и у всех последних процессоров
семейства Celeron, вторичный кэш имеет размер 128 Кбайт, а частота шины равна
66 МГц. Главное отличие — поддержка инструкций SSE. Начальная частота
ядра — 533 МГц (Celeron 533А). Начиная с частоты 800 МГц, наконец-то поднята
частота шины до 100 МГц. По инструкции CPUID сообщается идентификатор 068xh.
Упаковка FC-PGA (для сокета-370). По назначению выводов процессор «услов-
но» совместим с платами для Celeron (сигнал RESET# там же, но требуется изоля-
ция вывода АМ2 от шины GND).
Ниже перечислены некоторые особенности, которые — помимо широко известных
особенностей вторичного кэша (либо его нет, либо есть размером 128 Кбайт) —
отличают процессор Celeron от процессора Pentium II.
♦ Разрядность шины адреса сокращена с 36 до 32 бит (адресуемая память —
4 Гбайт).
♦ Контроль паритета шины адреса и шины запроса, ЕСС-контроль шины дан-
ных и контроль неисправимых ошибок шины отсутствует, как и сигнал инициа-
лизации шины.
♦ Процессоры предназначены только для одиночных конфигураций: из сигна-
лов запроса шины официально остался только BR0#, что не позволяет реали-
зовать симметричные двухпроцессорные конфигурации. Реально сигнал BR1#
в некоторых моделях присутствует, что позволяет использовать Celeron и в
двухпроцессорных SMP-системах.
♦ Коэффициенты умножения частоты фиксированы. Внешняя частота — 66 МГц
(задается заземленными линиями BSEL[1:0]#).
Для мощных компьютеров (серверов) предназначено семейство Хеоп — «утяже-
ленные» варианты процессоров Pentium II и Pentium III. Для них ввели новый
слот 2, который (вместе с интерфейсом нового процессора) позволяет строить как
избыточные системы с FRC, так и симметричные 1-, 2-, 4- и даже 8-процессорные
системы. Вторичный кэш, как и в Pentium Pro, работает на частоте ядра (а не на ее
половине). Объем вторичного кэша — 512 Кбайт, 1 или 2 Мбайт при кэширова-
нии до 64 Гбайт (все адресное пространство при 36-битной адресации). Процес-
соры Хеоп отличаются не только большей мощностью, но и большими размера-
ми— 15,2 х 12,7 х 1,9 см.
Процессоры Хеоп имеют новые средства хранения системной информации. Посто-
янная (только для чтения) память процессорной информации PIROM (Processor
Information ROM) хранит такие данные, как электрические спецификации ядра
222
9. Процессоры фирмы Intel
процессора и кэш-памяти (диапазоны частот и питающих напряжений), S-специ-
фикацию и серийный 64-битный номер процессора. По инструкции CPUID такая
информация недоступна, что открывало возможность перемаркировки. Энерго-
независимая память Scratch EEPROM предназначена для занесения системной
информации поставщиком процессора (или компьютера с этим процессором) и
может быть защищена от последующей записи. Процессор оборудован термодат-
чиком (термодиод на кристалле ядра) с программируемым устройством контро-
ля температуры. Это устройство имеет аналого-цифровой преобразователь, калиб-
руемый по термодиоду конкретного процессора на этапе тестирования картриджа.
Константа настройки термометра заносится в PIROM. Устройство термоконтро-
ля программируется — задается частота преобразований и пороги температуры,
по достижении которых вырабатывается сигнал прерывания. Для взаимодействия
с PIROM, Scratch EEPROM и устройством термоконтроля процессор имеет до-
полнительную последовательную шину SMBus (System Management Bus).
Процессоры Pentium II Xeon на ядре Deshutes (0,25 мкм) имеют частоту шины
100 МГц, частота ядра — 400-500 МГц. Набор инструкций — Р6+ММХ.
Процессоры Pentium III Xeon под кодовым названием Tanner (0,25 мкм) имеют
частоту шины 100 МГц, частота ядра — от 500 МГц. Вторичный кэш — 512 Кбайт,
1 Мбайт или 2 Мбайт (для 550 МГц пока только 512 Кбайт), кэш работает на час-
тоте ядра. Набор инструкций — P6+MMX+SSE. Этот процессор позиционирует-
ся как серверный (поддерживает 4/8 процессорные конфигурации SMP).
Процессоры Pentium III Xeon под кодовым названием Cascades (0,18 мкм) имеют
частоту шины 133 МГц, частота ядра — от 600 МГц. Вторичный кэш — 256 Кбайт,
расположен на кристалле ядра, работает на частоте ядра. Первые модели в SMP
работают только в двухпроцессорных конфигурациях. Планируется увеличение
вторичного кэша до 2 Мбайт и повышение частоты до 866 МГц. Эти процессо-
ры позиционируются для мощных рабочих станций (чем они отличаются от
Coppermine, кроме дополнительных устройств, доступных по шине SM Bus, не
совсем понятно).
Мобильные процессоры семейства Р6 предназначены для установки в блокнот-
ные ПК и другие малогабаритные системы с автономным питанием. Эти про-
цессоры выпускаются в нескольких конструктивных исполнениях: миниатюрный
корпус BGA1, BGA2 с выводами для припаивания, Micro-PGA2 со штырьковыми
выводами, мини-картридж с 240-штырьковым разъемом и модули с коннекто-
рами ММС-1 и ММС-2. В этих исполнениях могут быть процессоры четырех
типов: мобильный Pentium III, мобильный Pentium II с внешним вторичным
кэшем, мобильный Celeron с кэшем 128 Кбайт и мобильный Pentium II со встро-
енным кэшем 256 Кбайт. Мобильные процессоры имеют ряд отличий от обычных
Pentium П/Ш:
♦ не поддерживается функционально-избыточный контроль (FRC) и двухпро-
цессорные конфигурации;
♦ понижено напряжение питания, на некоторых процессорах напряжение пита-
ния ядра уже ниже 1 В;
♦ понижена нагрузочная способность интерфейсных схем;
9.1. Процессоры Р6
223
♦ введено новое состояние пониженного потребления Quick Start, которое от-
личается от состояния Stop Grant тем, что в нем не отслеживаются транзак-
ции симметричных агентов (другого процессора), слежение ведется только за
приоритетными агентами шины, поэтому потребление в состоянии Quick Start
существенно меньше, чем в Stop Grant.
Представление о конструктивах дает фотография, опубликованная на сайте iXBT
Hardware (http://ixbt.stack.net) и представленная на рис. 9.1.
Рис. 9.1. Варианты мобильных процессоров
Слева изображен процессор в корпусе BGA1 (он же PBGA-B615) размером 35 х
32 х 2,8 мм. Он имеет матрицу шариковых выводов BGA (Ball Grid Array) 24 х 26
с шагом 1,27 мм для припаивания к печатной плате.
Мини-картриджи (на рисунке — в центре) имеют размер 56 х 60 мм при толщине
5,5 мм. Коннектор — миниатюрный 240-штырысовый с матрицей 8 х 30. У мини-
картриджей термоконтроль реализуется так же, как и в процессоре Хеоп, — тер-
модиод подключен к контроллеру, с которым обеспечивается связь по шине SMBUS
(интерфейс 12С).
Справа на фотографии изображен модуль ММС-1 (Mobile Module Connector 1).
Он представляет собой печатную плату размером 102 х 64 мм, снабженную двумя
140-контактными разъемами. Эта пара разъемов имеет фиксированное назначе-
ние выводов и называется Connector 1. Толщина модуля — 8 мм (не считая слегка
выступающей части коннекторов). На плате установлен кристалл ядра процессо-
ра, микросхемы вторичного кэша (если он не на кристалле процессора), ядро чип-
сета i440BX и ряд вспомогательных схем. Для подключения модуля электроника
компьютера должна включать микросхему PIIX4E, в таком сочетании становятся
доступными функции энергосбережения для памяти, кэша и процессора. Мост
i440BX обеспечивает на внешнем коннекторе интерфейсы шин PCI 2.1 (3,3 В) и
шины динамической памяти (до 3 модулей SO DIMM EDO или SDRAM). Встроен-
ный преобразователь напряжения питает модуль при подаче на вход напряжения
постоянного тока 5-21 В. Для питания внешней электроники от преобразователя
на коннектор выводятся напряжения +3,3 В и +5 В, подача которых управляется
в соответствии с текущим режимом потребления. Модуль снабжен теплоотводя-
щей пластиной и средствами термоконтроля, с которыми взаимодействует по
шине SMBUS. Управление питанием и термоконтроль соответствуют ACPI 1.0.
224
9. Процессоры фирмы Intel
Модули ММС-2 отличаются от ММС-1 поддержкой AGP версии 1.0 с частотой
шины 66 МГц (режим х2 со скоростью передачи около 500 Мбайт/с). Порт AGP
требует большого количества контактов, поэтому коннектор модуля ММС-2 имеет
уже 400 контактов. Модули выпускаются с теми же процессорами, что и ММС-1.
9.1.1. Конструктивы процессоров
шестого поколения
Шестое поколение процессоров отличается большим разнообразием конструкти-
вов — одних только коннекторов имеется 4 типа: сокет 8, слот 1, слот 2 и сокет-370.
Эти сокеты и слоты предназначены только для процессоров Intel — былой совме-
стимости с AMD, Cyrix и другими уже нет (теперь сокет-370 использует и фирма
VIA). Корпусов (упаковок) тоже много — SPGA, SECC1, SECC 2, SEPP, PPGA (это
не считая мобильных процессоров).
Процессоры Pentium Pro выпускались в корпусе со штырьковыми выводами (SPGA),
в одном корпусе (микросхеме) размещался и кристалл процессора, и кристаллы
кэш-памяти. Проблемы с изготовлением и размещением вторичного кэша Pentium
Pro в одной микросхеме с ядром были решены с переходом на новый конструктив -
картридж с краевым печатным разъемом SECC (Single Ended Edge Connector).
Этот конструктив стали применять начиная с Pentium II. Картридж представляет
собой печатную плату (субстрат), на которую с двух сторон устанавливаются ком-
поненты поверхностного монтажа — кристалл ядра и стандартные микросхемы
вторичного кэша (собственно кэш-памяти и тегов). Вариации с быстродействием
процессора и размером кэша выливаются лишь в изменение комплектации карт-
риджа (количества и номенклатуры установленных микросхем). В процессорах
Celeron идея упаковки в картридж себя изжила — одну микросхему ядра легко
упаковать в обычный корпус со штырьковыми выводами. Это получается пример-
но на 10 долларов дешевле, чем в полупустой SEPP. Так появился Celeron в кор-
пусе PPG A (Plastic Pin Grid Array), напоминающий по виду добрый старый
Pentium. Теперь в этой упаковке выпускают и новые процессоры Pentium III с
интегрированным кэшем. Процессоры Pentium II Хеоп и Pentium III Хеоп тоже
выпускаются в картриджах SECC, по гораздо большего размера.
Процессоры, предназначенные для слота 1 (SC242), имеют разные названия «упа-
ковки» (рис. 9.2, а),
♦ SECC — картридж процессоров Pentium II и Pentium III. Представляет собой
печатную плату с установленными компонентами. К микросхемам ядра и кэша
прилегает распределяющая тепло термопластина (thermal plate), к которой
снаружи крепится вентилятор (или иное охлаждающее устройство). Спереди
картридж закрыт крышкой. Допустимая температура пластины — +70...75°С
(в зависимости от частоты процессора).
1 Здесь и далее позволим себе нс ставить точки после каждой прописной буквы аббревиатуры (S.E.C.C.,
S.E.P.P., как пишет Intel).
9.1. Процессоры Р6
225
♦ SECC 2 — картридж, которым снабжаются те же процессоры, начиная с часто-
ты 350 МГц (хотя для тех же частот выпускаются и модели в SECC). От пре-
дыдущего отличается тем, что не имеет термопластипы — внешние «холодиль-
ники» прижимаются прямо к корпусам микросхем ядра и кэша, что снижает
тепловое сопротивление и повышает эффективность охлаждения. Сами процес-
соры, устанавливаемые на SECC 2, могут быть как в корпусах PLGA (Plastic
Land Grid Array), так и в OLGA (Organic Land Grid Array). Последние применя-
ются для процессоров с частотой 400 МГц и выше и отличаются более высокой
допустимой температурой — 90 °C против 80 °C, допустимых для PLGA. Заме-
тим, что допустимая температура микросхем кэша — 105 °C.
♦ SEPP (Single Edge Processor Package) — картридж процессоров Celeron, не име-
ющий пи термопластины, ни крышки. Внешний радиатор прижимается прямо
к корпусу ядра, а микросхем вторичного кэша у процессоров Celeron нет.
Рис. 9.2. Процессоры Р6: а — для слота 1; б — для сокета-370; в — для слота 2
Процессоры для сокета-370 исполняются в корпусе PPGA или FC-PGA (рис. 9.2, б)
со штырьковыми выводами. Эти корпуса различаются способом размещения кри-
сталла (FC — Flip Chip, перевернутый кристалл). У PPGA штырьковые выводы
выходят контактами и па внешнюю поверхность корпуса процессора, у FC-PGA —
нет; кроме того, у них различается назначение нескольких выводов. Эти же про-
цессоры могут устанавливаться и в платы со слотом 1 и даже сокетом 8 через спе-
циальные переходные адаптеры-конверторы. Обратных адаптеров не бывает.
Для охлаждения процессоров используется радиатор с вентилятором. Венти-
лятор подключается через отдельный разъем (рис. 9.3) и снабжается датчиком
вращения, вырабатывающим по паре импульсов (сигнал SENSE) на каждый обо-
226
9. Процессоры фирмы Intel
рот ротора. Датчик вращения имеют не все модели процессоров (в Celeron PPGA
не используется). По линии+12V подается питание (7-13,8 В), потребляемый
ток — до 100 мА.
SENSE
+12V
GND
Рис. 9.3. Разъем вентилятора картриджа Pentium II
Процессоры Pentium Pro выполнены в корпусе SPGA с 387 выводами, у которого
некоторые зоны выводов расположены в шахматном порядке (модифицирован-
ный SPGA-корпус).
Процессоры Pentium //выпускаются в виде картриджей SECC, а начиная с частоты
350 МГц — в SECC 2. Все элементы картриджа SECC закрыты общим кожухом.
Процессоры Pentium ///выпускаются в виде картриджей SECC 2, модели с ядром
Coppermine выпускаются также в корпусах FC-PGA.
Процессоры Celeron выпускались как в упаковке SEPP для установки в слот 1, так
и в корпусах PPGA или FC-PGA для установки в сокет-370. В упаковке SEPP (кар-
тридж без задней крышки кожуха) выпускались процессоры, начиная с частоты
266 МГц (без вторичного кэша). Начиная с частоты 466 МГц, эта упаковка не ис-
пользуется. В корпусе PPGA стали выпускать процессоры, начиная с Celeron ЗООА
(с кэшем 128 Кбайт). Процессоры в PPGA несколько отличаются в интерфейсе
питания и потребляют чуть меньшую мощность. Процессоры Celeron 533А, 566,
600... выпускаются в корпусах FC-PGA. Нюансы интерфейса питания учтены в
распространенных переходниках сокет-370 — слот 1. Эти переходники позволя-
ют использовать дешевые процессоры в PPGA в платах со слотом 1, а при простой
доработке переходника — даже в двухпроцессорных конфигурациях.
Процессоры Pentium IIХеоп и Pentium IIIХеоп (рис. 9.2, в) выпускаются в картрид-
жах SECC большого размера и устанавливаются в слот 2.
9.2. Процессор Pentium 4
Процессор Pentium 4 является по-настоящему однокристальным. На одном
кристалле размещено около 42 млн транзисторов, выполненных по технологии с
разрешением 0,18 мкм (в Pentium III Coppermine «всего» 28 млн транзисторов).
Частота ядра первых моделей составляет 1,4 или 1,5 ГГц. Процессор, кроме
собственно вычислительного ядра, имеет кэш-память двух уровней. Вторич-
ный кэш — общий для инструкций и данных, имеет размер 256 Кбайт и разряд-
ность шины 256 бит (32 байта), как и в последних Pentium III. Шина вторичного
кэша работает на частоте ядра, что обеспечивает ее пропускную способность
32 х 1,4 = 44,8 Гбайт/с (48 Гбайт/с для 1,5 ГГц). Как утверждает Intel, это в 2,8 раза
больше, чем у Pentium Ш-1 ГГц. Однако здесь что-то не так: в документации на
9.2. Процессор Pentium 4
227
Pentium III указывается, что у процессоров с улучшенным кэшем объемом 256 Кбайт
(Advanced Transfer Cache) 256-битная шина кэша работает на частоте ядра, что для
1 ГГц дает пропускную способность 32 Гбайт/с. В «агитационных» материалах по
Pentium 4 при сравнении для Pentium Ш-1 ГГц указана пропускная способность
16 Гбайт/с (на обычный кэш это тоже не похоже, поскольку его пропускная спо-
собность всего 8 Гбайт/с). Так что либо кэш Pentium III-1000 не так быстр, как
обещали, либо Pentium 4 в этом плане не настолько отрывается от предшествен-
ника. Вторичный кэш имеет ЕСС-контроль, позволяющий обнаруживать и ис-
правлять ошибки. Первичный кэш данных имеет такую же высокую пропускную
способность (>44,8 Гбайт/с), но его объем сократился вдвое (8 Кбайт против 16 в
Pentium III). Первичный кэш инструкций в привычном понимании отсутствует, его
заменил кэш трассы (trace cache). В нем хранятся последовательности микроопе-
раций, в которые декодированы инструкции. В этом кэше могут помещаться до
12 К микроинструкций. Об этом нововведении и других подробностях внутрен-
ней микроархитектуры см. в п. 1.4.
Внешний вид самого процессора вполне обычный (рис. 9.4), но он требует радиа-
тора «выдающегося» размера и веса. Такой радиатор уже не повесить на корпус
процессора — нужны специальные крепежные стойки, проходящие через систем-
ную плату и крепящиеся к металлическому шасси (плата их тоже не выдержит).
Кристалл процессора в упаковке OLGA смонтирован на промежуточной плате
(interposer) со штырьковыми выводами, устанавливаемой в новый 423-контакт-
ный сокет. Сверху кристалл накрыт металлической крышкой, к которой должен
прилегать радиатор. Процессор требует мощного охлаждения — при напряжении
питания 1,6 В он потребляет ток до 40,6 А (1,4 ГГц) или 43 А (1,5 ГГц), что соот-
ветствует рассеиваемой мощности 65-70 Вт! В режиме пониженного потребления
(состояние stop grant) процессор потребляет 8,5 А, а в состоянии «глубокого сна»
(deep sleep) — 6,6 А (вот уж не замерзнет во сне!). Однако помимо того, что эту
мощность нужно отводить от процессора и из корпуса компьютера, ее еще нужно
получить от блока питания, который для нового процессора должен иметь мощ-
ность большую, чем привычные 250 Вт. Pentium III-1000 по потреблению скром-
нее в 2 раза. Pentium 4 имеет встроенные средства термоконтроля. Предельно до-
пустимая температура корпуса — 70 °C.
Рис. 9.4. Процессор Pentium 4
228
9. Процессоры фирмы Intel
Интерфейс системной шины процессора рассчитан только на однопроцессорные
конфигурации, что, по утверждению фирмы, и позволило использовать такой
простой конструктив1» Отсутствует также и возможность избыточного функцио-
нального контроля (FRC). Интерфейс во многом напоминает шину Р6 — прото-
кол также ориентирован на одновременное выполнение нескольких транзакций,
в основных цепях используются физические сигналы AGTL+. Однако здесь при-
нят ряд мер по обеспечению высокой пропускной способности. В материалах по
процессору (даже в сугубо техническом информационном листке) говорится о
частоте шины 400 МГц с «четырехкратной накачкой» (quad pumped). Поясним, что
это означает, чтобы не подвергаться соблазну излишних умножений. Тактовая
частота системной шины составляет 100 МГц, но частота передачи адресов и дан-
ных выше. Общая синхронизация осуществляется двумя парафазными сигналами
BCLK0 и BCLK1 (для повышения точности используются дифференциальные при-
емники). Источник информации с общей синхронизацией должен выдавать свои
данные по фронту BCLK0 (и они появятся с некоторой задержкой), а приемник
должен их фиксировать по следующему фронту BCLK0. Новая информация по
линиям с общей синхронизацией может передаваться на каждом такте с частотой
100 МГц. Для 2- и 4-кратпой передачи используется синхронизация от источника
данных. строб синхронизации, по которому приемник фиксирует данные, форми-
руется в том же месте, что и передаваемая информация. По шине адреса информа-
ция передается в режиме 2х и стробами являются сигналы ADSTB0# (для линий
А[16:3]#, REQ[4:0]#) и ADSTB1# (для А[35:17]#). По спаду этих стробов передает-
ся (и фиксируется приемником) адрес, а по фронту — информация о типе тран-
закции. Разделение шины по синхронизирующим стробам на две части позволяет
повысить точность синхронизации (уменьшается перекос, вызванный неодина-
ковостью трасс проводников). Таким образом, в каждом такте шины (за 10 нс)
передается и адрес, и тип транзакции (у Р6 это занимало 2 такта, что требовало
15-30 нс). По шине данных информация передается с четырехкратной частотой,
для чего используются пары стробирующих сигналов DSTBp[0:3]# и DSTBn[0:3]#
с периодом 5 пс (частота 200 МГц). Стробы сдвинуты относительно друг другана
2,5 нс (половину своего маленького такта), синхронизация по их спадам (четные
передачи по DSTBp[0:3]# и нечетные — по DSTBn[0:3]#) и дает учетверенную час-
тоту передачи. Для уменьшения перекосов каждые 16 бит данных пользуются от-
дельными линиями стробов.
Разрядность шины данных, как и в предыдущих двух поколениях процессоров,
составляет 64 бита (8 байт), что в режиме 4х дает максимальную пропускную спо-
собность 100 х 4 х 8 = 3,2 Гбайт/с. У процессоров Pentium III шина обеспечивала
133 х 8 = 1,06 Гбайт/с, так что по этому параметру у Pentium 4 улучшение трое-
кратное. Шина адреса имеет разрядность 36 бит, что позволяет адресовать те же
64 Гбайт памяти, из которых кэшируются только первые 4 Гбайт.
Интересное решение принято для уменьшения помех при переключениях сигна-
лов. Каждая пара байтов шины данных может передаваться в прямом или инверс-
1 Можно подумать, что картриджи процессоров Pentium II, III п первых Celeron(!) были задуманы ради
удобства построения многопроцессорных плат, а не из-за технологических проблем со вторичным кэшем.
9.2. Процессор Pentium 4
229
ном виде, независимо от других байтов. Естественно, источник данных сигнали-
зирует приемнику о текущем способе представления соответствующим сигналом
DBI[3:0]#. Решение о том или ином способе передачи принимается источником
перед передачей каждой порции данных с таким расчетом, чтобы количество ли-
ний данных, изменяющих свое состояние, было минимальным. Это позволяет
уменьшить броски тока и электромагнитные помехи. По сравнению с Р6 несколь-
ко изменилось назначение сигналов контроля паритета шин, изъята возможность
ЕСС-контроля системной шины данных. В цепях питания предпринят ряд мер по
снижению помех, питание аналоговых схем автоподстройки фазы изолировано
от питания цифрового ядра. Назначение сигналов системной шины приведено в
табл. 9.1, их разводка по выводам процессора — в табл. 9.2 и 9.3.
Таблица 9.1. Сигналы системной шины процессора Pentium 4
Сигнал Тип Назначение
Основные сигналы системной шины
А[35:3]# I/O Address — сигналы шины адреса. По спаду ADSTB[1:0]# передается адрес, по фронту — информация о типе транзакции. По окончании действия сигнала RESET# процессор с шины адреса получает конфигурационную информацию
A20M# I А20 Mask — маскирование бита А20 физического адреса для эмуляции адресного пространства 8086 в реальном режиме
ADS# I/O Address Strobe — строб адреса, вводимый инициатором обмена как индикатор действительности адреса. По этому сигналу все агенты шины начинают проверку паритета и протокола, декодирование адреса, внутреннее слежение и другие операции, связанные с новой транзакцией
ADSTB[1:O]# I/O Стробы информации на линиях А[ 16:3]#, REQ[4:0]#(ADSTB0#) nA[35:17]#(ADSTB1#)
AERR# I/O Address Parity Error — ошибка паритета на шине адреса. При соответствующем конфигурировании сигнал может приводить к аварийному прекращению транзакции
АР[1:О]# I/O Address Parity — биты паритета шины адреса. Паритет для А[35:24]# в 1 -й подфазе передается по АРО#, во 2-й — по АР1 #. Паритет для А[23:3]# и REQ[4:0]# в 1 -й подфазе передается по АР1 #, во 2-й — по АРО#. Сигнал корректного паритета должен иметь низкий уровень, если низкий уровень имеет нечетное число контролируемых сигналом линий
BCLK[1:O] I Bus Clock — синхронизация шины (дифференциальный сигнал). Значения всех синхронных сигналов действительны по положительному перепаду BCLK0
BINIT# I/O Bus Initialization — инициализация шины. Если конфигурированием использование сигнала разрешено, то он вызывает прерывание текущей транзакции с потерей данных и сброс в исходное состояние управляющих автоматов всех агентов шины и их циклических идентификаторов арбитража
BNR# I/O Block Next Request — запрос блокировки следующей транзакции. Вводится любым агентом шины как запрос на приостановку, когда он не может воспринять следующую транзакцию
продолжением
230
9. Процессоры фирмы Intel
Таблица 9.1 (продолжение)
Сигнал Тип Назначение
ВРМ[5:0]# I/O Breakpoint Monitor — сигналы от процессора, указывающие на попадание в точку останова или срабатывание счетчиков мониторинга производительности процессора. При использовании зонда BPM4# работает как PRDY#, BPM5# — как PREQ#
BPRI# I Bus Priority Request — сигнал, используемый для арбитража запросов на владение шиной
BRO# I/O Bus Request — запрос шины
D[63:0]# I/O Data — сигналы 64-разрядной шины данных. Источник данных при передаче указывает на их действительность сигналом DRDY#
DBI[3:0]# I/O Признаки инверсии данных: DBI3# — для D[63:48]#, DBI2# — для D[47:32]#, DBI1# — для D[31:16]#, DBI0# — для D[ 15:0]#
DBSY# I/O Data Bus Busy — шина данных занята. Используется агентом, передающим данные, для указания на занятость шины данных
DEFER# I Сигнал, указывающий на то, что исходный порядок выполнения транзакций не гарантируется
DP[3:0]# I/O Data Parity — паритет шины данных: DP3# — для D[63:48]#, DP2# — для D[47:32]#, DP1# — для D[31:16]#, DP0# — для D[ 15:0]#
DSTBN[3:0]#, DSTBP[3:0]# I/O Стробы шины данных: DSTBX3# — для D[63:48]#, DSTBX2# — для 0(47:32]#, DSTBX1# — для D[31:16]#, DSTBX0# — для D[15:0]#
DRDY# I/O Data Ready — готовность данных. Устанавливается источником данных для указания на присутствие достоверных данных на шине
FERR# 0 Floating-point Error — ошибка (немаскированное исключение) FPU (аналогичен сигналу ERROR# сопроцессора Intel387)
FLUSH# I Асинхронный сигнал на очистку внутреннего кэша. По этому сигналу выполняются все обратные записи и аннулируются строки кэша обоих уровней. Новые строки не выделяются до окончания действия сигнала. Значение сигнала во время окончания действия сигнала RESET# используется для конфигурирования процессора
HIT#, HITM# I/O Сигналы результатов операции слежения за транзакцией. HIT# (Snoop Hit) указывают на кэш-попадание. HITM# (Hit Modified) указывает на попадание в модифицированную строку, запрещая другим контроллерам шины обращаться к этим данным до выполнения обратной записи
IERR# 0 Internal Error — сигнал обнаружения внутренней ошибки. Обычно появляется вместе с транзакцией Shutdown. Сигнал ошибки сохраняется до его программного сброса обработчиком NMI или аппаратного сброса сигналами RESET#, BINIT# или IN IT#
IGNNE# I Ignore Numeric Error — игнорировать ошибки сопроцессора — запрет вырабатывания исключения. Используется для совместимости с АТ, где вместо исключения вырабатывается аппаратное прерывание. Во время действия сигнала RESET# используется для конфигурирования множителя частоты
INIT# I Initialization — «мягкая» инициализация процессора. Сигнал приводит к сбросу общих регистров и переходу по вектору, заданному при конфигурировании по включению. Содержимое кэш-памяти, буферов записи и регистров FPU не затрагивается. Если сигнал активен во время окончания действия сигнала RESET#, процессор выполняет BIST
9.2. Процессор Pentium 4
231
Сигнал Тип Назначение
UNT[1:0] (NMI, INTR) I Local APIC Interrupt — входы прерываний локальных контроллеров APIC. Если работа APIC запрещена, UNTO становится сигналом INTR, LINT1 — сигналом NMI. По сигналу RESET# работа APIC разрешается, и входы функционируют в режиме APIC, который может быть отменен программно
LOCK# I/O Блокировка шины на время транзакции
MCERR# I/O Machine Check Error — неисправимая (фатальная) ошибка
PROCHOT# 0 Перегрев процессора (если термоконтроль разрешен, то сигнал указывает на активность работы цепей термоконтроля)
REQ[4:0]# I/O Request Command — запрос команды. Вводится текущим владельцем шины для определения типа активной транзакции
RESET# I Сброс процессора — конфигурирование процессора, инициализация регистров, очистка кэша обоих уровней (без выполнения обратной записи) и переход к вектору сброса (OFFFFFFFOh). Если по окончании действия сигнала активен сигнал INIT#, процессор выполняет BIST
RS[2:O]# I Response Status — состояние ответчика. Сигналы управляются агентом, отвечающим за завершение текущей транзакции
RSP# I Response Parity — бит паритета для сигналов RS[2:0]#
SMI# I System Management Interrupt — сигнал прерывания для входа в режим SMM
TRDY# I Target Ready — сигнал, которым целевое устройство указывает на готовность приема данных к записи или неявной обратной записи
Определение наличия процессора, конфигурирования питания,
синхронизации и параметров сигналов
SKTOCC# О Socket Occupied — сокет занят (признак присутствия процессора)
PWRGOOD I Power Good — сигнал исправности питания, указывающий на стабильность питающих напряжений и сигнала синхронизации
VID[4:0] О Voltage ID — выводы идентификации для автоматической установки уровня питающего напряжения. Эти выводы могут быть либо свободными, либо подключаться к шине GND. Блок питания должен установить соответствующее напряжение (см. п. 11.1) или отключиться
TESTHI[1O:O] I Сигнал, подключаемый к источнику Vcc В через резистор 1-10 кОм
Питание
VSS I Общий провод питания (схемная земля)
VCC I Питание ядра
VCCA I Изолированное питание цепей PLL процессорного ядра
VSSA I Изолированный общий провод питания цепей PLL
VCCIOPLL I Изолированное питание цепей PLL шинного интерфейса
VCCSENSE, VSSSENSE О Выводы для измерения напряжения питания ядра (соединяются с VCC и VSS внутри процессора)
GTLREF I Опорное напряжение для линий GTL+, типично GTLREF = 2/3 Vcc. Напряжение должно подаваться на каждый из выводов GTLREF
продолжение^
232
9. Процессоры фирмы Intel
Таблица 9.1 (продолжение)
Сигнал Тип Назначение
Управление энергопотреблением
SLP# I Sleep — сигнал, переводящий процессор из состояния Stop Grant
в состояние Sleep (спящий режим)
STPCLK# I Stop Clock — асинхронный сигнал, переводящий процессор
в состояние Stop Grant с малым энергопотреблением
Сигналы тестового адаптера JTAG
ТСК I Test Clock — вход синхронизации шины тестирования Test Bus, называемой также ТАР (Test Access Port)
TDI I Test Data In — последовательный вход данных интерфейса JTAG
TDO О Test Data Out — последовательный выход данных интерфейса JTAG
TMS I Test Mode State — выбор режима тестирования no JTAG
TRST# I Test Reset — сигнал сброса логики ТАР (самосброс происходит автоматически по включению)
DBR О Дополнительный сигнал сброса для отладочного порта (не является процессорным сигналом)
ITP_CLK[1:0] I Копия сигналов BCLK для отладочного порта (не является сигналом процессора)
Сигналы термодатчика
THERMDA THERMDC - Анод и катод термодиода, использующегося для измерения температуры ядра
THERMTRIP# О Thermal Trip — сигнал останова процессора по перегреву. Если внутренняя температура поднимается примерно до135 ’С, процессор останавливается и формирует данный сигнал, который может быть сброшен только сигналом RESET# после снижения температуры ниже этого порога
Таблица 9.2. Назначение контактов процессора Pentium 4
Контакт Сигнал Контакт Сигнал Контакт Сигнал
A3# F30 A15# А27 A27# А13
A4# С29 A16# D24 A28# F20
A5# D30 A17# А29 A29# С21
A6# С31 A18# С27 A30# А19
A7# F28 A19# D26 A31# С11
A8# D28 A20# А17 A32# А9
A9# F26 A21# С17 A33# А11
A10# С23 A22# А21 A34# С15
A11# А31 A23# С19 A35# D12
A12# С25 A24# F22 A20M# Т38
A13# А25 A25# D22 ADS# F36
A14# А23 A26# А15 ADSTB0# G25
9.2. Процессор Pentium 4
233
Контакт Сигнал Контакт Сигнал Контакт Сигнал
ADSTB1# G21 D20# AM38 D57# AT14
APO# F16 D21# AU39 D58# AW13
AP1# D14 D22# AP36 D59# AU13
BCLKO AR7 D23# AN39 D60# AT12
BCLK1 AP8 D24# AK36 D61# AP14
BINIT# F18 D25# AR37 D62# AW17
BNR# E35 D26# AT38 D63# AP12
BPMO# F8 D27# AN35 DBI0# AL39
BPM1# F12 D28# AU35 DBI1# AU37
BPM2# F10 D29# AW39 DBI2# AT22
BPM3# E7 D30# AT34 DBI3# AW15
BPM4# C13 D31# AL37 DBR# AV2
BPM5# D6 D32# AW31 DBSY# B34
BPRI# L37 D33# AT32 DEFER# J35
BRO# B36 D34# AU29 DPO# AW33
COMPO AU27 D35# AP26 DP1# AW35
COMP1 F24 D36# AU33 DP2# AW27
DO# Y38 D37# AW29 DP3# AT26
D1# AD36 D38# AU31 DRDY# G37
D2# W37 D39# AT30 DSTBNO# AG35
D3# AE37 D40# АТ28 DSTBN1# AP32
D4# AG39 D41# АР24 DSTBN2# AP22
D5# AA35 D42# AU25 DSTBN3# AP18
D6# V36 D43# АР28 DSTBPO# AJ35
D7# AF38 D44# AW25 DSTBP1# AP30
D8# W39 D45# АТ24 DSTBP2# AP20
D9# AE39 D46# AW23 DSTBP3# AP16
D10# AB36 D47# AU23 FERR# P38
D11# AD38 D48# AU19 HIT# K36
D12# AH36 D49# АТ20 HITM# D36
D13# AJ37 D50# AU21 IERR# C7
D14# AC37 D51# AW21 IGNNE# M38
D15# AA39 D52# AW19 INIT# D8
D16# AT36 D53# АТ18 ITP_CLKO AU1
D17# AK38 D54# AU17 ITP_CLK1 AW1
D18# AP34 D55# АТ16 LINTO H36
D19# AW37 D56# AU15 LINT1 W35
продолжение &
234
9. Процессоры фирмы Intel
Табл и ца 9.2 (продолжение)
Контакт Сигнал Контакт Сигнал Контакт Сигнал
LOCK# АЗЗ REQ4# F32 TDI J39
MCERR# D10 RESERVED AT4 TDO P36
PROCHOT# F38 RESET# AW11 THERMDA H38
PWRGOOD AW9 RSO# M36 THERMDC E39
REQO# СЗЗ RS1# N35 THERMTRIP# U37
REQ1# D32 . SMI# K38 TMS D38
REQ2# F34 STPCLK# C5 TRDY# A35
REQ3# D34 TCK R37 I TRST# R35
Таблица 9.3. Контакты питания процессора Pentium 4
Контакт Сигнал
VCC.SENSE VCCA N39 AU5
VCCIOPLL AW3
VIDO C1
VID1 B2
VID2 B4
VID3 A3
VID4 A1
VSS_SENSE VSSA R39 AV4
GTLREF AC35, AP10, F14, T36
TESTHI[0:10] VSS A7, AT10, AT6, AT8, AU7, AU9, AU11, AW5, D16, D18, D20 ААЗ, AA37, AA7, AB2, AB6, AC1, AC39, AC5, AD4, AD8, АЕЗ, AE7, AF2, AF36, AF6, AG1, AG5, AH38, AH4, AH8, AJ3, AJ7, AK2, AK6, AL1, AL35, AL5, AM4, AM8, AN3, AN37, AN7, AP2, AP6, AR1, AR11, AR15, AR19, AR23, AR27, AR31, AR35, AR39, AR5, AU3, AV12, AV16, AV20, AV24, AV28, AV32, AV36, AV8, B12, B16, B20, B24, B28, B32, B38, B8, C35, C39, D4, E11, E15, E19, E23, E27, ЕЗ, E31, E37, F2, F6, G1, G11, G15, G17, G23, G27, G31, G35, G5, H4, H8, J3, J7, K2, K6, L1, L39, L5, M4, M8, N3, N37, N7, P2, P6, R1, R5, T4, T8, U3, U7, V2, V38, V6, W1, W5, Y4, Y8
VCC A37, A39, AA1, AA5, AB38, AB4, AB8, АСЗ, AC7, AD2, AD6, AE1, AE35, AE5, AF4, AF8, AG3, AG37, AG7, AH2, AH6, AJ1, AJ39, AJ5, AK4, AK8, AL3, AL7, AM2, AM36, AM6, AN1, AN5, AP38, AP4, AR13, AR17, AR21, AR25, AR29, AR3, AR33, AR9, AT2, AV10, AV14, AV18, AV22, AV26, AV30, AV34, AV38, AV6, B10, B14, B18, B22, B26, B30, B6, C3, C37, D2, E1, E13, E17, E21, E25, E29, E33, E5, E9, F4, G13, G19, G29, G3, G33, G39, G7, G9, H2, H6, J1, J37, J5, K4, K8, L3, L35, L7, М2, M6, N1, N5, P4, P8, R3, R7, T2, T6, U1, U39, U5, V4, V8, W3, W7, Y2, Y36, Y6
Интерфейс системной шины несовместим с предыдущими процессорами, поэто-
му специально для Pentium 4 фирма Intel выпустила новый чипсет i860. Он обла-
дает всеми современными возможностями и ориентирован на память RDRAM
9.2. Процессор Pentium 4
235
(Rambus). Для обеспечения требуемой производительности памяти канал RDRAM
должен быть 32-разрядный, так что модули RIMM приходится устанавливать
парами.
Процессор имеет новинку — встроенные цепи термоконтроля ТСС (Thermal
Control Circuit), которые модулируют внутреннюю частоту синхронизации для
снижения рассеиваемой мощности (и производительности). Предусмотрены два
режима — автоматический, при котором ТСС включается, когда температура про-
цессора подходит к критической, и программируемый (по запросу). Схема термо-
контроля управляется через модельно-специфические регистры. От BIOS требу-
ется, чтобы по умолчанию был разрешен автоматический термоконтроль.
В автоматическом режиме как только температура процессора превысит задан-
ный порог, внутренняя синхронизация становится прерывистой: около 3 мкс син-
хронизация подается, на следующие 3 мкс синхронизация останавливается. В этом
режиме процессор работает с половинной производительностью. Признаком состоя-
ния автоматического понижения потребления является бит О MSR IA32_THERM_STATUS
MSR (19Ch), единичное значение бита 1 того же регистра означает, что с момента
последнего аппаратного сброса (или программного сброса этого бита) термоконт-
роль срабатывал. Автоматический термоконтроль разрешается битом 3 MSR
IA32_MISC_ENABLE MSR (адрес lAOh, по умолчанию бит сброшен — термоконт-
роль запрещен). Признаком наличия автоматического термоконтроля является
флаг ТМ - бит EDX.29 CPUID(l).
В режиме по запросу, предназначенному для реализации функций ACPI, можно
программно включить понижение потребление и запрограммировать соотноше-
ние рабочего и нерабочего полупериодов в диапазоне от 1:8 до 8:1. Для этого вве-
ден MSR IA32_TERM_C0NTR0L (адрес 19Ah), в котором битами 3:1 задается относи-
тельная длительность работающей синхронизации (ООО — резерв, 001 — 12,5 %,
010 — 25 %..., 111 — 87,5 %, по умолчанию — 12,5 %), а бит 4 включает схему моду-
ляции. По умолчанию (после аппаратного сброса) модуляция отключена. Если
при включенной модуляции включится автоматическое управление, то оно при-
нудительно установит режим 1:1 (50 %, что будет не очень здорово, если процес-
сор почему-то перегревался, скажем, на 1/8 своей мощности). С помощью MSR
IA32_THERM_INTERRUPT (19Bh) процессор можно запрограммировать на генерацию
прерываний по достижении температуры верхнего порога (бит 0) и по ее сниже-
нию до нижнего порога (бит 1). Векторы и способы доставки прерываний задают-
ся программированием APIC процессора. Признаком возможности программиру-
емой модуляции, поддержки прерываний термоконтроля в APIC и наличия MSR
IA32_THERM_STATUS, IA32_THERM_INTERRUPT и IA32_THERM_C0NTR0L является флаг ACPI -
бит EDX.22 CPUID(l).
10. Процессоры AMD
и других фирм
Вскоре после выхода процессора Pentium 75 МГц ряд фирм (AMD, Cyrix, IBM)
стали выпускать Pentium-совместимые процессоры. Сокеты 5 и 7 были разрабо-
таны фирмой Intel для своих процессоров пятого поколения. Однако другие фир-
мы в использовании инфраструктуры этого сокета (чипсеты, системные платы)
пошли дальше, внеся в свои изделия черты процессоров шестого поколения. Про-
цессоров, совместимых с Р6, совсем немного. В отличие от Intel, «похоронившей»
сокет 7 на частоте 266 МГц (последний Pentium ММХ имел частоту 266 МГц),
фирмы AMD, Cyrix и IBM продолжают наращивать мощности процессоров этого
класса. На начало 2000 года доступны процессоры с тактовой частотой до 533 МГц,
догоняющие по возможностям процессоры Pentium П/Ш при меньших ценах.
Однако в отличие от процессоров Intel ни один из них не обеспечивает работу
в симметричных мультипроцессорных системах. Среди системных плат с соке-
том 7 появилась категория «Super 7», подразумевающая возможность установки
быстрых процессоров при частоте системной шины до 100 МГц с поддержкой
порта AGP и некоторых других новомодных усовершенствований. При этом про-
пускная способность внешней шины не уступает шине Pentium II. Более эконо-
мичный (за счет простоты) протокол обмена частично компенсирует преимуще-
ства двойной независимой шины Р6, где вторичный кэш может работать па частоте
ядра (или ее половине). Когда процессорам фирмы AMD сокет Super 7 стал тес-
новат, фирма ввела свои собственные слоты и сокеты.
10.1. Процессоры фирмы
AMD для сокетов 5 и 7
Фирма AMD выпускает несколько семейств процессоров, предназначенных для
установки в сокет 7 (некоторые версии К5 могут работать в сокете 5). Процессо-
ры программно совместимы с семейством х86 и имеют логотип, указывающий на
совместимость с Windows. Однако их можно смело устанавливать только в те си-
стемные платы, в описании которых есть явное указание на их поддержку. В про-
тивном случае возможны сбои в работе кэш-памяти, которые не выявляются мно-
гими тестовыми программами. Системные платы, поддерживающие процессоры
AMD, учитывают специфику режимов работы буферных интерфейсных схем.
10. L Процессоры фирмы АМР для сокетов 5 и 7
237
Процессоры AMD, как всегда, отличаются наличием развитых средств SMM и
управления энергопотреблением. Цена этих процессоров ниже аналогичных из-
делий Intel.
AMD К5 PR75/90/100/120/133/166 и выше — Pentium-совместимые процессоры,
предназначенные для установки в сокет 7. По сравнению с процессорами Intel эти
процессоры имеют некоторые черты шестого поколения: более сложный конвей-
ер, исполнение по предположению, изменение порядка выполнения инструкций,
переименование регистров и некоторые другие. В обозначении производительно-
сти применяются символы PR (P-Rating), причем тактовая частота ядра может
быть ниже значения PR. Иногда те же процессоры обозначаются как AMD 5К86
75 MHz (90, 100...).
Процессоры имеют внешние частоты 50, 60 и 66,66 МГц, но используют иные ко-
эффициенты умножения (см. п. 11.1).
AMD Кб, он же AMD Кб ММХ (частота ядра 300,266,233,200 и 166 МГц), — про-
цессор, выпущенный на месяц раньше Pentium II, по архитектуре ядра и свойствам
напоминающий Pentium II, но без встроенного вторичного кэша. Производитель-
ность AMD Кб 200 для приложений Windows сопоставима с Intel Celeron 300.
Вопрос применимости этого процессора в широко распространенных системных
платах упирается в основном в поддержку конкретной версией BIOS, замена ко-
торой при использовании флэш-памяти не представляет собой большой техничес-
кой проблемы. Процессор имеет первичный кэш объемом 64 Кбайт (32 Кбайт для
данных и столько же для инструкций). Кэш данных — двухпортовый, поддержи-
вает обратную запись. Кэш инструкций имеет дополнительную область для пред-
варительно декодированных инструкций. Предсказание переходов выполняется
по двухступенчатой схеме, обеспечивая достоверность предсказаний на уровне
95 %. Не вдаваясь в подробности архитектурных решений, можно сказать, что в
этом процессоре отражены практически все достижения, имеющиеся в процессо-
ре Pentium II, включая режимы управления энергопотреблением и тактировани-
ем. В отличие от процессоров Intel Р54 и Р55, процессор AMD Кб не имеет встро-
енных средств поддержки многопроцессорных систем, включая APIC. У него
отсутствует сигнал проверки шинных операций (BUSCHK), нет зондового режи-
ма, а также не выводятся сигналы точек останова (ВР) и монитора производитель-
ности (РМ).
Питание ядра (VCC2) и интерфейсных цепей (VCC3 = 3,3 В) разделено, что сни-
жает рассеиваемую мощность. В режиме Stop Grant потребление снижается до
сотен милливатт. В версии для мобильных применений AMD Кб 300 потребляет
всего 6,6 Вт.
Входная частота — 66,66 МГц; коэффициент умножения задается тремя сигнала-
ми BF[2:0] в соответствии с данными табл. 10.1. Процессор Кб имеет дополнитель-
ный вход управления множителем частоты BF2, отсутствующий у Pentium. По
назначению выводов BF[1:O] при BF2= 1 процессор совпадает с Intel Pentium
ММХ, для получения коэффициентов 4,5-5,5 системная плата должна иметь тре-
тий джампер.
238
10. Процессоры АМР и других фирм
Таблица 10.1. Коэффициенты умножения процессоров AMD Кб
BF[2:0] KF BF[2:0] KF
100 2,5 000 4,5
101 3,0 001 5.0
110 2,0 010 4,0
111 3,5 011 5,5
Процессоры AMD Кб-2 представляют собой дальнейшее развитие Кб. Здесь (и в
Кб модели 9) применена технология 3DNow! — расширение технологии ММХ (см.
п. 3.4), которая позволяет значительно повысить производительность вычислений
с плавающей точкой, необходимых для трехмерной графики и обработки аудио-
сигналов. Частота внешней шины поднята до 100 МГц, частота ядра: 266,300,333,
350 (первая модель); 380, 400, 450, 475, 500, 533 и 550 МГц (вторая модель). Во
второй модели улучшена работа с кэшем. Процессоры с частотой 350 МГц и выше
при работе с ОС Windows 95 требуют установки специальных «заплаток», кото-
рые доступны на сайте AMD.
Весной 2000 года выпущен К6-2+ — процессор для сокета 7 с интегрированным
вторичным кэшем 128 Кбайт, работающем на частоте ядра (500 МГц). Технология
0,18 мкм. Расширение 3DNow! включает расширение для DSP. Процессор предна-
значен для мобильных применений. Ранее был выпущен мобильный К6-2р (400,433,
450 и 475 МГц) с частотой шины 100 МГц, технология 0,25 мкм. Процессор имеет
только первичный кэш 64 Кбайт. Набор инструкций включает инструкции 3DNow!.
Процессор AMD K6-III (Sharptooth) является самым мощным процессором для со-
кета 7 (точнее, Super 7), и написание его названия намекает на вызов процессору
Pentium III (предшественники обозначались скромнее — Кб, К6-2). Вызов на состя-
зание вполне обоснованный — по результату ряда тестов производительности К6-
Ш-450 МГц находится где-то между Pentium Ш-450 и 500 МГц. Это наводит на
размышления о том, действительно ли так уж нужен сложный интерфейс Р6. Глав-
ный козырь процессора К6-Ш — трехуровневая (!) система кэширования памяти.
Как и у предыдущих процессоров (Кб, Кб-2), здесь имеется первичный кэш разме-
ром 64 Кбайт (по 32 Кбайт для данных и инструкций) — это в два раза больше,
чем у Pentium II, III. Но теперь к нему добавлен вторичный кэш размером 256 Кбайт,
расположенный на одном кристалле с процессором и работающий на полной часто-
те ядра. Не будем сравнивать эту конфигурацию с процессорами Хеоп, где вторич-
ный кэш с той же скоростью может иметь объем до 2 Мбайт, — это уже процессо-
ры другого (серверного) класса. У Pentium III вторичный кэш либо такой же, либо
в два раза больше, но медленнее; у Celeron — та же скорость, но размер 128 Кбайт.
Процессор К6-Ш устанавливается в плату с Super 7, на которой тоже может быть
до 2 Мбайт кэш-памяти, и теперь она станет кэшем 3-го уровня. Конечно, скорость
обмена с этим кэшем уже не такая высокая (до 800 Мбайт/с), поскольку ограни-
чена частотой системной шины. Тем не менее этот кэш тоже вносит свою лепту в
ускорение обмена данными с памятью за счет меньшего, чем у SDRAM, времени
задержки (latency). В итоге процессор К6-Ш может располагать кэшем с суммар-
10.2. Процессоры Athlon и Duron фирмы AMD
239
ным объемом до 2368 Кбайт, из которых 320 Кбайт доступны на полной частоте
ядра. По архитектуре процессор K6-III относится к шестому поколению.
Для блокнотных ПК выпускаются процессоры AMD-K6-III+ с частотой 500 МГц;
технология 0,18 мкм. Команды 3DNow! имеют расширения для DSP.
10.2. Процессоры Athlon
и Duron фирмы AMD
Процессор Athlon (К7) до появления Pentium 4 был самым высокопроизводитель-
ным (из реально выпускаемых) членом семейства х86. Этот процессор по многим
номинациям был признан лучшим процессором 1999 года. Производительность
достигается не только высокой тактовой частотой, но и особой суперконвейерной
суперскалярной микроархитектурой. Эта архитектура при тех же прилагательных
в названии существенно отличается от других процессоров AMD и Intel, и мы ее
бегло рассмотрим.
Трехканальный декодер инструкций х86 выбирает их из памяти, пользуясь кэшем
инструкций и мощным блоком предсказания ветвлений. Характерные для х86
«разнокалиберные» инструкции (они могут иметь длину от 1 до 15 байт) преоб-
разуются в унифицированные макрооперации (MacroOPs). Управляющий блок
инструкций (ICU) занимается диспетчеризацией декодированных инструкций,
которые он может получать от декодера в количестве до трех инструкций за каждый
такт. Блок ICU является переупорядочивающим буфером инструкций, способным
одновременно обслуживать до 72 макроопераций. Блок распределяет макроопе-
рации по исполнительным устройствам процессора, выполняет переименование
регистров и снимает «готовую продукцию» с исполнительных конвейеров. Процес-
сор имеет три независимых конвейера целочисленных вычислений, три конвейера
для вычисления адресов операндов и трехканальное устройство для вычислений
с плавающей точкой, причем для последних впервые в истории х86 применяется
полностью конвейеризированная суперскалярная «машина» с изменением порядка
исполнения инструкций. Она выполняет все инструкции традиционного устрой-
ства FPU (х87), а также инструкции ММХ и 3DNow!. Этим достигается произво-
дительность до 4 Гфлопс (на 1000 МГц, 4 вычисления за такт) при вычислениях с
одинарной точностью и более 1,5 Гфлопс с двойной точностью.
Система команд кроме обычного набора инструкций 6-го поколения включает
ММХ и расширенную технологию 3DNow!. Расширение 3DNow! к 21 новой инст-
рукции, введенной в К6-2, добавляет еще 24. Двенадцать новых целочисленных
SIMD-инструкций предназначены для повышения эффективности вычислений,
связанных с распознаванием речи и видеокодированием, и еще 7 инструкций —
для ускорения передачи данных. Пять новых инструкций относятся к функциям
сигнальных процессоров (DSP), они позволяют повысить производительность та-
ких приложений, как программные модемы (включая ADSL), MP3 и процессоры
объемного звучания (Dolby Digital surround sound).
240
г 10. Процессоры АМР и других фирм
Преимущества процессора Athlon проявляются на приложениях, использующих
интенсивные вычисления (особенно с плавающей точкой) и, естественно, опти-
мизированных под расширенную систему команд.
Процессор Athlon моделей 1 (технология 0,25 мкм) и 2 (0,18 мкм, начиная с 550 МГц)
выполнен в виде картриджа с 242-контактным краевым разъемом и предназначен
для установки в слот А. Механическая совместимость со слотом 1 была принята в
угоду производителям системных плат, которые уже обзавелись всей инфраструк-
турой для картриджей процессоров Intel. Электрически Athlon и Pentium П/Ш
несовместимы. Процессор имеет первичный кэш рекордного размера — 128 Кбайт
(64 для данных .и 64 для инструкций) и вторичный кэш, размещенный на картрид-
же процессора. Скорость обмена со вторичным кэшем программируется в зависи-
мости от применяемых микросхем кэш-памяти. Отношение частоты ядра к часто-
те обмена с кэшем для процессоров 550-700 МГц составляет 2:1, для процессоров
750 и 800 МГц — 2,5:1,900 МГц и выше — 3:1. Максимальную скорость шины вто-
ричного кэша имеет процессор на 700 МГц, дальше с ростом частоты ядра скорость
обмена со вторичным кэшем падает(!). Объем вторичного кэша может быть от
512 Кбайт до 8 Мбайт, на кристалле процессора имеется память тегов для 512-
килобайтного кэша. Вторичный кэш может использовать микросхемы с напряже-
нием 2,5 или 3,3 В.
Первая модель процессора Athlon (начиная с 500 МГц) выполнялась по техноло-
гии 0,25 мкм, около 22 млн транзисторов размещались на площади 184 мм2. Вто-
рая модель (начиная с 550 МГц) производится по технологии 0,18 мкм, и пло-
щадь кристалла уменьшилась до 102 мм2. Процессоры 550-750 МГц (модель 2,
кэш 512 Кбайт) имеют напряжение питания ядра 1,6 В и потребляют мощность
28-35 Вт (первая модель потребляет несколько больше). Процессор на 800 МГц
питается от 1,7 В и потребляет 43 Вт, на 1000 МГц потребляет 60 Вт.
В процессорах Athlon модели 4 вторичный кэш размером 256 Кбайт размещен на
одном кристалле с ядром, обмен с ним выполняется па полной частоте ядра. Од-
нако в отличие от Pentium III с интегрированным кэшем в Athlon разрядность
шины данных вторичного кэша осталась той же 8-байтной (а не 32-байтной), так
что по скорости вторичного кэша Athlon проигрывает. Это позволяет упаковать
процессор в корпус со штырьковыми выводами для нового сокета A (Socket-462),
напоминающего сокет-370, но с дополнительными рядами контактов и механичес-
кими ключами (отсутствующие гнезда в некоторых позициях).
Процессор Duron — облегченный вариант К7 (кодовое название — Spitfire). У него
вторичный кэш, уменьшенный до 64 Кбайт, но работающий на частоте ядра, рас-
полагается на кристалле ядра. Процессор выпускается в корпусе PGA для уста-
новки в сокет А. Процессор имеет номер модели 3 — у процессоров Athlon и Duron,
как и других, нумерация модели идет сквозная.
В маркировке процессоров Athlon и Duron как всегда трудно выявить общую систе-
му. Процессоры Athlon моделей 1 и 2 имеют маркировку bh№AMD-K7550MTR51B.
Здесь первая часть (AMD-K7550) обозначает тип (К7) и тактовую частоту про-
цессора (550 МГц). Следующая буква описывает тип упаковки (М — модуль, Р —
корпус PGA). Следующие буквы (в данном случае Т и R) кодируют напряжение
10.2. Процессоры Athlon и Duron фирмы AMD
241
питания (Т — 1,6 В, Р — 1,7 В, М — 1,75 В, N — 1,8 В) и допустимую температуру
корпуса (R — 70 °C, S — 95 °C, Т — 90 °C). Затем следует цифра, задающая объем
вторичного кэша (5 — 512 Кбайт, 1 — 1 Мбайт, 2 — 2 Мбайт...), и цифра, определя’
ющая коэффициент деления тактовой частоты для вторичного кэша (1 — 2:1, 2 —
2,5:1). Последняя буква задает предельную частоту системной шины (В — 200 МГц,
С - 266 МГц).
Процессоры Athlon модели 4 в модульном исполнении маркируются несколько
иначе, например, AMD-A0850MPR24B. Здесь буква «А» означает Athlon и частота
задается 4-значным числом, в размере вторичного кэша 2 означает 256 Кбайт, а в
коэффициенте деления 4 — 1:1. Для тех же процессоров в корпусе PGA в обозна-
чении AMD-A1200AMS3C размеру кэша 256 Кбайт соответствует цифра 3, а ко-
эффициент деления уже не указывается.
В маркировке процессора Duron — AMD-D800AUT1B — буква D означает Duron,
А — корпус PGA, U — питание 1,6 В, Т — допустимую температуру 90 °C, В — частоту
FSB 200 МГц, цифра 1 — кэш 64 Кбайт.
В качестве системной шины для Athlon и Duron взята шина EV6 от процессоров
Alpha, имеющая тактовую частоту 200 МГц и пропускную способность 1,6 Гбайт/с.
Работать на такой высокой частоте обмена позволяет технология синхронизации
от источника данных, в перспективе частота шины может быть увеличена до 400 М Гц.
В шине используется пакетный протокол передачи данных. Системная шина со-
стоит из трех высокоскоростных каналов:
♦ однонаправленный канал процессорных запросов;
♦ однонаправленный зондовый (probe) канал;
♦ двунаправленный 72-битный канал данных, включающий 8-битную коррекцию
ошибок (ЕСС).
Кроме того, процессор имеет ряд дополнительных управляющих и синхронизи-
рующих сигналов, а также набор традиционных (но устаревших) сигналов, свой-
ственных всем процессорам х86.
В качестве электрического интерфейса используется низковольтная логика с диф-
ференциальными приемниками и малой амплитудой сигнала, наподобие HSTL.
Дифференциальные приемники требуют подачи опорного напряжения VREF. Состав
и назначение сигналов процессора раскрывает табл. 10.2. В табл. 10.3 приведено
расположение сигнальных выводов для процессоров, выполненных в виде моду-
лей (для слота А), и процессоров в корпусах PGA (для сокета А). Линии питания
для слота А показаны в табл. 10.4. Состав сигналов в сокете А несколько шире, чем
в слоте; специфические линии сокета А и линии питания приведены в табл. 10.5.
Как видно из таблицы, в сокете имеется множество вспомогательных сигналов,
которые на системных платах обычно не используются. Сигналы K7CLKOUT и
K7CLKOUT# предназначены для терминации линии тактовой частоты. Заметим,
что по назначению и расположению выводов сокет А для процессоров Athlon (мо-
дели 4) и Duron различий не имеет (не то, что Pentium III и Celeron).
242
10. Процессоры АМР и других фирм
Таблица 10.2. Сигналы процессоров Athlon и Duron
Сигнал Тип Назначение
A20M# I A20 Mask — маскирование бита A20 физического адреса для эмуляции адресного пространства 8086 в реальном режиме
CLKFWDRST I Сброс цепей передачи синхронизации (для системы и процессора)
CONNECT I Вход, используемый для управления потреблением и инициализации цепей передачи синхронизации (по сбросу)
COREFB+(COREFB) COREFB- (COREFB#) 0 Выходы обратной связи по питанию процессорного ядра
FERR# 0 Floating-point Error — ошибка (немаскированное исключение) FPU (аналогичен сигналу ERROR# сопроцессора Intel387)
FID[3:0] 0 Выходы, по которым процессор сообщает системе, какой коэффициент умножения частоты использует ядро
IGNNE# I Ignore Numeric Error — игнорировать ошибки сопроцессора — запрет вырабатывания исключения. Используется для совместимости с АТ, где вместо исключения вырабатывается аппаратное прерывание. Во время действия сигнала RESET# используется для конфигурирования множителя частоты
INIT# I Initialization — «мягкая» инициализация процессора. Сигнал приводит к сбросу общих регистров и переходу по вектору, заданному при конфигурировании по включению. Содержимое кэш-памяти, буферов записи и регистров FPU не затрагивается. Если сигнал активен во время окончания действия сигнала RESET#, процессор выполняет BIST
INTR I Вход запроса маскируемого аппаратного прерывания
NMI I Вход запроса немаскируемого аппаратного прерывания
PICCLK I Вход синхронизации шины APIC
PICD[1:0]# I/O Двунаправленная шина APIC
PROCRDY 0 Выход, используемый для управления потреблением и инициализации цепей синхронизации от источника данных
PWROK I Питание ядра в норме (сигнал процессору)
RESET# I Сброс процессора — конфигурирование процессора, инициализация регистров, очистка кэша обоих уровней (без выполнения обратной записи) и переход к вектору сброса (OFFFFFFFOh). Если по окончании действиясигнала активен сигнал INIT#, процессор выполняет BIST
SADDIN[14:2]# I Однонаправленный канал зонда и передачи команд от системы к процессору
SADDINCLK# I Синхронизация вышеуказанных линий
SADDOUT[14:2]# 0 Однонаправленный канал запросов процессора к системе и ответов зонда
SADDOUTCLK# 0 Синхронизация вышеуказанных линий
SCHECK[7:0]# I/O Биты ЕСС для линий SDATA[63:0]#
SDATA[63:0]# I/O Двунаправленная шина данных
10.2. Процессоры Athlon и Duron фирмы AMD
243
Сигнал Тип Назначение
SDATAINCLK[3:0]# I Линии синхронизации данных к процессору (отдельные для каждого 16-битного слова, формируются системой)
SDATAINVAL# I Линия сигнализации подачи данных к процессору
SDATAOUTCLK[3:0]# 0 Линии синхронизации данных от процессора (отдельные для каждого 16-битного слова, формируются процессором)
SDATAOUTVAL# I Линия сигнализации приема данных к процессору
SFILLVAL# I Сигнал подтверждения действительности передачи данных к процессору
SMI# I System Management Interrupt — сигнал прерывания для входа в режим SMM
STPCLK# I Stop Clock —* асинхронный сигнал, переводящий процессор в состояние Stop Grant с малым энергопотреблением
SYSCLK, SYSCLK# I Дифференциальный сигнал общей синхронизации
VCC2SEL 0 Сигнализация питания микросхем SRAM вторичного кэша: высокий уровень —* 2,5 В, низкий — 3,3 В
VID[3:0] 0 Сигналы идентификации требуемого напряжения питания
Таблица 10.3. Расположение сигналов процессоров Athlon и Duron
Сигнал Контакт Сигнал Контакт
СлотА СокетA СлотА СокетA
A20M# A21 АЕ1 RESET# A17 AG3
CLKFWDRST A105 AJ21 SADDIN[0]# - AJ29
CONNECT A103 AL23 SADDIN[1]# — AL29
COREFB- A121 AG13 SADDIN[10]# B109 AL37
COREFB+ A120 AG11 SADDIN[11]# B102 AG35
FERR A11 AG1 SADDIN[12]# B120 AN29
FID[0] A119 W1 SADDIN[13]# B112 AN35
FID[1] A118 W3 SADDIN[14]# B116 AN31
FID[2] A117 Y1 SADDIN[2]# B104 AG33
FID[3] A116 Y3 SADDIN[3]# B106 AJ37
IGNNE# A19 AJ1 SADDIN[4]# B107 AL35
INIT# A12 AJ3 SADDIN[5]# B100 АЕЗЗ
INTR A15 AL1 SADDIN[6]# A95 AJ35
NMI A13 AN3 SADDIN[7]# A93 AG37
PICCLK1 АЗ N1 SADDIN[8]# A97 AL33
PICD[0]1 A5 N3 SADDIN[9]# B110 AN37
PICD[1]1 A7 N5 SADDINCLK# B114 AJ33
PROCRDY A106 AN23 SADDOUT[0]# - Л
PWROK A111 AE3 SADDOUT[1]# - J3
продолжение^
244
10. Процессоры АМР и других фирм
Таблица 10.3( продолжение)
Сигнал Контакт Сигнал Контакт
СлотА СокетА СлотА СокетA
SADDOUT[10]# A23 G1 SDATA[22]# B62 Е37
SADDOUT[11]# A25 Е1 SDATA[23]# B64 G35
SADDOUT[12]# B8 АЗ SDATA[24]# A77 Q33
SADDOUT[13]# ВЗ G5 SDATA[25]# A75 N33
SADDOUT[14]# В1 G3 SDATA[26]# A72 L33
SADDOUT[2]# В16 С7 SDATA[27]# A73 N35
SADDOUT[3]# В18 А7 SDATA[28]# A70 L37
SADDOUT[4]# А27 Е5 SDATA[29]# A69 J37
SADDOUT[5]# В13 А5 SDATA[3]# B90 Y35
SADDOUT[6]# В14 Е7 SDATA[30]# A61 А37
SADDOUT[7]# В4 С1 SDATA[31]# A63 Е35
SADDOUT[8]# В11 С5 SDATA[32]# A57 Е31
SADDOUT[9]# В10 сз SDATA[33]# A55 Е29
SADDOUTCLK# В6 ЕЗ SDATA[34]# A53 А27
SCHECK[0]# В83 U37 SDATA[35]# A49 А25
SCHECK[1]# А85 Y33 SDATA[36]# A43 Е21
SCHECK[2]# В71 L35 SDATA[37]# A47 С23
SCHECK[3]# А65 ЕЗЗ SDATA[38]# B45 С27
SCHECK[4]# А51 Е25 SDATA[39]# B40 А23
SCHECK[5]# В52 А31 SDATA[4]# B84 U35
SCHECK[6]# В22 С13 SDATA[40]# B58 А35
SCHECK[7]# В34 А19 SDATA[41]# B57 С35
SDATA[0]# В92 АА35 SDATA[42]# B55 СЗЗ
SDATA[1]# А81 W37 SDATA[43]# B54 С31
SDATA[10]# А89 АСЗЗ SDATA[44]# B48 А29
SDATA[11]# В97 АС37 SDATA[45]# B47 С29
SDATA[12]# А83 Y37 SDATA[46]# A45 Е23
SDATA[13]# В94 АА37 SDATA[47]# B44 С25
SDATA[14]# В95 АС35 SDATA[48]# A41 Е17
SDATA[15]# А79 S35 SDATA[49]# B25 Е13
SDATA[16]# В78 Q37 SDATA[5]# B81 U33
SDATA[17]# В76 Q35 SDATA[50]# A37 Е11
SDATA[18]# В73 N37 SDATA[51]# A39 С15
SDATA[19]# В70 J33 SDATA[52]# АЗЗ Е9
SDATA[2]# В86 W35 SDATA[53]# B23 А13
SDATA[20]# В68 G33 SDATA[54]# A31 С9
SDATA[21]# В66 G37 SDATA[55]# A29 А9
10.2. Процессоры Athlon и Duron фирмы AMD
245
Сигнал Контакт Сигнал Контакт
СлотА СокетA СлотА СокетA
SDATA[56]# B42 С21 SDATAINCLK[2]# B50 E27
SDATA[57]# B38 А21 SDATAINCLK[3]# B28 E15
SDATA[58]# B37 Е19 SDATAINVAL# A101 AN33
SDATA[59]# B35 С19 SDATAOUTCLK[0]# A91 AE35
SDATA[6]# B80 S37 SDATAOUTCLK[1]# B60 C37
SDATA[60]# B32 С17 SDATAOUTCLK[2]# A59 АЗЗ
SDATA[61]# A35 А11 SDATAOUTCLK[3]# B20 C11
SDATA[62]# B30 А17 SDATAOUTVAL# A99 AL31
SDATA[63]# B26 А15 SFILLVAL# B118 AJ31
SDATA[7]# B74 S33 SMI# A9 AN5
SDATA[8]# A87 ААЗЗ STPCLK# A18 AC1
SDATA[9]# B98 АЕ37 SYSCLK A109 AN17
SDATAINCLKfO]# B88 W33 SYSCLK# A108 AL17
SDATAINCLK[1]# A67 J35
1 У процессоров без APIC сигнал отсутствует.
Таблица 10.4. Питание в слоте А
Сигнал Контакт
GND B31, B2, B115, B117, ВЗЗ, B69, B77, B39, B99, B101, B19, B36, B12, B9, B56, B75, B121, B87, B89, B79, B82, B85, B29, B15, B61, B27, B53, B51, B63, B65, B49, B43, B41, B96, B21, B46, B113, B111, B17, B103, B108, B119, B105, B67, B93, B59, B5, B91, B7, B24, B72
VCCCORE A24, АЗО, A32, A104, A76, A64, A62, A44, A110, A60, A26, A82, A48, A92, A90, A84, A80, A36, A40, A78, A100, A56, A52, A50, A54, A68, A66, A42, A34, A102, A96, A46, A88, A38, A94, A22, A74, A107, A28, A86, A98, A58, A71
VCC_SRAM VCC2SEL A16, A14, A10, A8, A6, A4, A2, A20 A1
VID[0] VID[1] VID[2] VID[3] A112 A113 A114 A115
Таблица 10.5. Питание и специальные сигналы в сокете А
Сигнал Контакт
ANALOG AJ13
K7CLKOUT AL21
K7CLKOUT# AN21
продолжение^
246
10. Процессоры АМР и других фирм
Таблица 10.5 (продолжение)
Сигнал Контакт
Сигналы для отладочных и тестовых целей
DBRDY AA1
DBREQ# FLUSH# PLLBYPASS# PLLBYPASSCLK PLLBYPASSCLK# PLLMON1 PLLMON2 PLLTEST# RSTCLK RSTCLK# SCANCLK1 SCANCLK2 SCANINTEVAL SCANSHIFTEN SYSVREFMODE тек TDI TDO TMS TRST# Питание VCCCORE AA3 AL3 AJ25 AN15 AL15 AN13 AL13 AC3 AN19 AL19 S1 S5 S3 Q5 AA5 Q1 U1 U5 Q3 U3 H12, X30, B4, AJ5, Z8, AB30, AF14, AF18, AF22, AF26, AM34, AK36, AK34, H16, АКЗО, AK26, AK22, AK18, AK14, AK10, AL5, AH26, AM30, AH22, H20, AH 18, AH 14, AH 10, AH4, AH2, AF36, AF34, AD6, AM26, AD4, H24, AD2, AB36, AB34, AB32, Z6, Z4, Z2, X36, X34, AM22, M8, X32, V6, V4, V2, T36, T34, T32, R6, R4, R2, P30, AM18, P36, P34, P32, M4, M6, М2, K36, K34, K32, R8, H4, H2, AM14, F36, F34, F32, F28, F24, F20, F16.T30, F12, D32, D28, AM10, D24, D20, D16, D12, D8, D4, V8, D2, B36, B32, AM2, B28, B24, B20, B16, B12, B8
VCC_Z VCCA VID[0] VID[1] VID[2] VID[3] VID[4] VREF_SYS VSS_Z AC7 AJ23 L1 L3 L5 L7 J7 W5 AE7
10.3. Процессоры фирм Cyrix, VIA, IBM и другие
247
Сигнал Контакт
VSS1 Н14, Х8, В6, В2, АМ4, АК6, АМ6, Z30, АВ8, AF12, AF16, AF20, AF24, АМ36, АК32, АК28, Н18, АК24, АК20, АК16, АК12, АК4, АК2, АН36, АМ32, АН34, Н22, АН32, АН28, АН24, АН20, АН16, АН 12, AF4, AF2, AD36, Н26, AD34, AD32, АВ6, АВ4, АВ2, Z36, Z34, Z32, Х6, АМ28, МЗО, Х4, Х2, V36, V34, V32, Тб, Т4, Т2, R36, R34, Р8, АМ24, R32, Р6, Р4, Р2, М36, М34, М32, Кб, К4, R30, К2, АМ20, Н36, Н34, F26, F22, F18, F14, F10, F6.T8, F4, F2, АМ16, D36, D34, D30, D26, D22, D18, D14, V30, D10, D6, В34, АМ12, ВЗО, В26, В22, В18, В14, В10
ZN АС5
ZP АЕ5
Ключи и неиспользуемые контакты
AMD Pin AH6
KEY N7, Y7, AG7, AG15, AG29, G25, G17, G9
NC AG19, G21, AG21, G19, AL25, AL27, AN25, AN27, AA31, AC31, AH30, AH8, AJ7, AJ9, AK8, AL7, AL9, AM8, AN7, F30, F8, НЮ, H28, H30, H32, H6, H8, K30, K8, AE31, AG23, AG25, AG31, AG5, AJ11, AJ15, AJ17, AJ19, AJ27, AL11, AN11, AN9, G11, G13, G27, G29, G31, J31, J5, L31, N31, Q31, S31, S7, U31, U7, W31, W7, Y31, Y5, AD30, AD8, AF10, AF28, AF30, AF32, AF6, AF8
Протокол шины EV6 поддерживает многопроцессорность, что является новинкой
для AMD — предыдущие процессоры этой фирмы мультипроцессирование не
поддерживали. Для поддержки процессоров Athlon и Duron фирма выпустила
чипсет AMD-750, состоящий из двух микросхем: системного контроллера и пери-
ферийного контроллера. Системный контроллер AMD-751 обеспечивает связь
процессора, динамической памяти SDRAM PC 100, порта AGP (66 МГц, режим 2х)
и шины PCI. Чипсет допускает установку до трех модулей DIMM SDRAM специ-
фикации PC 100 с суммарным объемом до 768 Мбайт, возможен ЕСС-контроль
достоверности. Шина PCI (версии 2.2) может обслуживать до 6 контроллеров.
Системный контроллер имеет буферы, обеспечивающие возможность одновре-
менного выполнения обмена данными между парами его «клиентов» (процессор,
память, порт AGP и шина PCI). Периферийный контроллер AMD-756 имеет мост
PCI-ISA, включающий все системные устройства PC-совместимого компьютера
(контроллеры прерываний, прямого доступа к памяти, клавиатуры и мыши, тай-
мер, интерфейс флэш-BIOS). Двухканальный контроллер IDE обеспечивает все
современные режимы обмена (до UltraDMA-33/66). Контроллер USB выполняет
функции центрального хаба и имеет 4 порта для подключения устройств.
10.3. Процессоры фирм
Cyrix, VIA, IBM и другие
Процессоры фирмы Cyrix по архитектуре выбиваются из пятого поколения, причем
в обе стороны. В них применяется «принстонская» архитектура первичного кэша
(общий кэш для инструкций и данных) с некоторыми дополнительными архитек-
248
10. Процессоры АМР и других фирм
турными особенностями. Специальный механизм (Data Dependency Removal)
снижает число остановок конвейеров процессора («больное место» Pentium Pro
на 16-разрядных приложениях).
Cyrix6x86 (МУ), сокращенно Сх86, — процессоры, по выводам совместимые с Pentium,
но имеющие архитектурные черты шестого поколения процессоров. К ним отно-
сятся переименование регистров, исполнение по предположению, изменение по-
рядка выполнения инструкций ит. д. Унифицированный первичный кэш разме-
ром 16 Кбайт используется как для инструкций, так и для данных; дополнительно
имеется 256-байтный кэш инструкций. Процессор устанавливается в сокет 7. Несмот-
ря на то что архитектура по некоторым параметрам превосходит даже Pentium,
Windows 95 и некоторые диагностические программы могут ошибочно идентифи-
цировать процессор 6x86 как 486. Однако если BIOS поддерживает процессор
Cyrix, в заставке теста POST тип процессора определяется верно. Если бы Win-
dows 95 определяла его как Pentium, программы, использующие специфические
инструкции Pentium, могли бы работать некорректно, поскольку не все эти инст-
рукции реализованы в процессоре Сх86. Как и в процессорах Cyrix 5x86, имеется
та же «болезнь роста» — на этом процессоре могут «зависать» некоторые програм-
мы, в частности написанные с помощью системы Clipper. Дело опять-таки в задерж-
ках, реализованных на программных циклах. Для их удлинения фирма предла-
гает специальные программы-замедлители, которые можно получить по адресу
ftp://ftp.cyrix.com/tech/pipeloop.exe. Для использования пакета 3D-Studio с данным
процессором предлагаются «заплатки», доступные по адресу ftp://ftp.ktx.com/
d о wnload/patches/3dsr4/fast_cpu/fstep ufx.exe.
В обозначении вида Cyrix 6x86-Pl20+ символы 120+ означают производитель-
ность, превышающую производительность процессора Pentium 120 МГц (P-Rating).
Выпускались процессоры Р120+, Р133+, Р150+, Р166+ и Р200+. Их отличитель-
ной особенностью является фиксированный коэффициент умножения, равный
двум, и тактовые частоты ядра, меньшие, чем у соответствующих процессоров
Pentium. Внешние частоты процессоров составляют 50,55,60,66,66 и 75 МГц, что
создавало некоторые проблемы: частота 55 МГц (для Р133+) имелась не на всех
системных платах, а 75 МГц для многих компонентов системных плат времен
Pentium являлась слишком высокой. Потребляемая мощность достигает 25 Вт (на
уровне Pentium Pro), что предъявляет более жесткие требования к охлаждению
процессора и рассеиваемой мощности внешнего регулятора напряжения. Процес-
соры с раздельным питанием 6x86L по энергопотреблению и охлаждению особых
проблем не создают.
Cyrix 6х86МХ — усовершенствованный вариант процессора Ml, включающий
поддержку ММХ, реализацию специфических инструкций Pentium (мониторинг
производительности, счетчик меток реального времени) и расширенный до 64 Кбайт
унифицированный первичный кэш. В процессоре имеются архитектурные черты,
характерные для шестого поколения процессоров Intel, — переименование регис-
тров, исполнение по предположению, изменение порядка выполнения инструкций
ит. д. Дальнейшим развитием семейства являются процессоры Cyrix MIL Пита-
ние ядра и интерфейсных схем разделено, изменяемые коэффициенты умноже-
ния 2, 2,5, 3 и 3,5 облегчают выбор внешней частоты.
10.3. Процессоры фирм Cyrix, VIA, IBM и другие
249
Фирма IBM продавала под своей торговой маркой процессоры разработки Cyrix,
выпускаемые на своих заводах. Их обозначения совпадают с принятыми для Cyrix
(с заменой названия фирмы).
Процессор тР6 фирмы Rise — экономичный (по потреблению) процессор для со-
кета 7 с поддержкой ММХ. Первичный кэш — 16 Кбайт (8+8). Р-рейтинг — от 166
до 366 МГц.
Фирма IDT (Integrated Device Technology) выпускала процессор IDT-C6, он же
Winchip, разработанный ее дочерней фирмой Centaur — дешевый (и не быстрый)
процессор для сокета 5. Процессор по архитектуре ближе к 486 (не суперскаляр-
ный), но имеет очень малое энергопотребление. Позже появился Winchip-2 — про-
цессор для сокета Super 7. В процессорах применена конвейеризация FPU, улуч-
шен блок ММХ и появилась поддержка 3DNow! (для процессоров с маркировкой
«3D»), частоты 200-300 МГц. Winchip-2A — то же, но с исправленной ошибкой в
3DNow!. Теперь фирму Centaur купила фирма VIA.
Процессор VIA Cyrix III, выпущенный фирмой VIA (купившей Cyrix) под именем
Joshua, предназначен уже для сокета-370. Поддерживает наборы инструкций ММХ
и 3DNow!. Первичный кэш — 64 Кбайт (единый), на кристалле интегрирован кэш
L2 размером 256 Кбайт, работающий на полной частоте процессора.
11. Применение
процессоров в PC
Поскольку наибольшее распространение процессоры семейства х86 нашли в IBM
PC-совместимых компьютерах, применение процессоров мы рассмотрим именно
с точки зрения их установки на системную плату PC.
11.1. Установка и замена
процессоров — сокеты и слоты
С установкой процессоров приходится сталкиваться, например, при модерниза-
ции компьютеров. Начиная с процессоров 486, процедура модернизации (upgrade —
повышение уровня) компьютеров посредством замены процессора на более мощ-
ный стала традиционной. Системные платы стали выпускать с расчетом на различ-
ные модификации и тактовые частоты процессоров — получился своеобразный
конструктор «собери сам». Процессоры стали устанавливать в стандартизованные
ZIF-сокеты (Zerp Insertion Force, колодка с нулевым усилием вставки), а затем и в
слоты — щелевые двухрядные разъемы. Назначение выводов разъемов обычно
определяется процессорами-первопроходцами от фирмы Intel, а другие фирмы в
своих процессорах выдерживают совместимость с этими сокетами. Начиная с
процессоров К7, фирма AMD повела свою линию сокетов и слотов. Унификация
расположения выводов процессоров одного класса и наличие конфигурационных
переключателей на системных платах позволяют пользователю заменять старые
процессоры на более мощные. Легкость установки процессора при его замене позво-
ляет выполнять эту операцию даже не слишком подготовленным пользователям.
В зависимости от сложности процессора (числа выводов), его рассеиваемой мощ-
ности и назначения применяются различные типы корпусов:
♦ DIP (Dual In-line Package) — корпус с двухрядным расположением штырько-
вых выводов;
♦ PGA (Pin Grid Array) — керамический корпус с матрицей штырьковых выво-
дов;
♦ SPGA (Staggered PGA) — керамический корпус с шахматным расположением
штырьковых выводов;
♦ модифицированный SPGA — корпус со штырьковыми выводами, часть из ко-
торых расположена в шахматном порядке;
11.1. Установка и замена процессоров — сокеты и слоты
251
♦ PPGA (Plastic Pin Grid Array) — пластиковый корпус с шахматным располо-
жением штырьковых выводов;
♦ FC-PGA (Flip Chip Pin Grid Array) — новый вариант SPGA с «перевернутым»
положением кристаллов;
♦ PQFP (Plastic Quad Flat Pack) — пластиковый корпус с выводами по сторонам
квадрата;
♦ SQFP (Small Quad Flat Pack) — миниатюрный корпус с выводами по сторонам
квадрата;
♦ TCP (Таре Carrier Package) — миниатюрный корпус с ленточными выводами,
расположенными по периметру корпуса (выводы закреплены на защитной
полимерной пленке);
♦ BGA (Ball Grid Array) — корпус с матрицей шариковых выводов для поверх-
ностного монтажа;
♦ SECC (Single Edge Connector Cartridge) — картридж: печатная плата с крае-
вым разъемом, заключенная в кожух;
♦ SEPP (Single Edge Processor Package) — картридж без задней крышки;
♦ ММС-1, ММС-2 (Mobile Module Connector) — модули для процессоров мо-
бильного применения;
♦ Mini-cartridge — миниатюрный картридж (для процессоров мобильного при-
менения).
Процессоры в корпусах DIP занимали слишком много места на плате, им на смену
пришли компактные корпуса PGA, PPGA, SPGA (обычный и модифицированный)
и FC-PGA, которые, как правило, устанавливаются в ZIF-сокет, Корпуса PQFP и
SQFP предназначены для установки в специальные колодки или припаивания к
плате. Самые компактные (из наиболее «многоножечных») корпуса TCP и BGA
предназначены для припаивания к системной плате портативных систем или кар-
триджам. Картриджи SECC и SEPP устанавливаются в щелевые разъемы-слоты.
Мини-картриджи и модули ММС присоединяются штырьковыми разъемами.
В «добрые старые времена» процессоров четвертого — пятого поколений их раз-
работчики стремились к взаимной совместимости, причем не только программ-
ной, но и аппаратной. В любую системную плату можно было установить процес-
сор из широкого спектра возможных — от Intel, AMD, Cyrix и прочих фирм.
Для установки процессоров 486 предназначены сокеты типов 1,2,3 и 6 (рис. 11.1).
Сокет 1 имеет 169 контактов матрицы 17 х 17, сокеты 2, 3 и 6 имеют матрицу
19 х 19, внешние ряды которой не используются процессорами в корпусах PGA-
168 и 169. При этом три внутренних ряда контактов по назначению совпадают с
разводкой выводов процессора 486, но имеют смещенную нумерацию: ножка А1
корпуса PGA-168 и 169 попадает в гнездо В2 матрицы 19 х 19. Внешние ряды мат-
рицы используются как дополнительные контакты питания процессоров Pentium
OverDrive. Сокет 3 отличается от сокета 2 возможностью питания 3 В. Малорасп-
ространенный сокет 6 имеет питание только 3,3 В. В первых процессорах 486 при-
менялся кэш только со сквозной записью (WT); сигналы, специфичные для WB-
кэша, теоретически могут присутствовать (или отсутствовать) во всех этих типах
252
11. Применение процессоров в PC
сокетов. Поскольку выводы некоторых управляющих сигналов процессоров в кор-
пусах PGA-168, PGA-169 и PGA-237 не совпадают, системные платы, поддержи-
вающие разные модели, должны иметь джамперы для их перекоммутации.
Самый мощный процессор для этих сокетов — Агп5Х86-Р75, он же AMD-X5-133:
при частоте ядра 133 МГц имеет производительность на уровне Pentium-75, пита-
ние 3,3 В (или 3,45 В), но, к сожалению, работает на полную мощность не на всех
системных платах.
A BCDE FGHJ К LMN PQRS
A BCDE FGHJ К LMN PQRST U
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
ОООООООО
оооооооо
ОООООООО
ооооооооо
ооооооооо
ооооооооо
ООО
ООО
ООО
ООО
ООО
ООО
ООО
ООО
ООО
ООО
ООО
Ключ
ООО
ООО
ООО
ООО
ООО
ООО
ООО
ООО
ООО
ООО
ООО
ооооооооооооооооо
ооооооооооооооооо
ооооооооооооооооо
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
A BCDE FGHJ К LMN PQRS
19
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
OOOOOOOOOOOOOOOOOOO
ooooooooooooooooooo
OOOOOOOOOOOOOOOOOOO
OOOOOOOOOOOOOOOOOOO
oooo
oooo
oooo
oooo
oooo
oooo
oooo
oooo
oooo
oooo
oooo
oooo
oooo
oooo
oooo
oooo
oooo
oooo
oooo
oooo
ooooooooooooooooooo
oooooooooooooooooo
oooooooooooooooooo
oooooooooooooooo
19
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
A BCDE FGHJ К LMN PQRST U
a 6
Рис. 11.1. Сокеты для 486: a — сокет 1; б — сокеты 2,3 и 6
Для установки процессоров с интерфейсом Pentium существуют три типа соке-
тов — 4,5 и 7. Интерфейс имеет 64-битную шину данных и 32-битную шину адреса,
а также довольно простой протокол обмена, допускающий как одиночные, так и
пакетные передачи данных. Пакетные передачи ориентированы на обмен данными
между процессором и кэшированной оперативной памятью, причем вторичный
кэш располагается на системной плате. Интерфейс допускает простое объедине-
ние до двух процессоров на одной шине, но в плане организации симметричных
мультипроцессорных систем он уступает по эффективности интерфейсу процес-
соров Р6, изначально ориентированному на транзакции от многих контроллеров
шины (процессоров). Однако в настольных компьютерах мультипроцессирование
до сих пор массово не используется (это слишком дорого). Что же касается скоро-
сти обмена данными (пиковой), то она определяется произведением разрядности
шины данных (в обоих интерфейсах — по 64 бит) и тактовой частоты. Оба интер-
фейса стартовали с тактовой частоты 66 МГц, но фирма AMD первой официаль-
но подняла ее до 100 МГц. Правда, в процессорах Р6 обмен процессора с вторич-
ным кэшем системную шину не загружает, но лишь после того, как требуемая
информация загружена в кэш через ту же шину. Атрибутом системной платы с со-
кетом Super 7 стал и порт AGP, так что теоретически на них с успехом могут ус-
11.1. Установка и замена процессоров — сокеты и слоты
253
танавливаться все современные графические карты. Современные контроллеры
IDE с режимом UltraDM А-33/66, контроллеры памяти, шины USB и порты (СОМ
и LPT) на платах Super 7 практически не отличаются от своих собратьев на пла-
тах под слот 1, 2 и сокет-370. Так что решающее слово — за процессором.
Сокет 4 предназначен для процессоров Pentium первого поколения (60 и 66 МГц).
Он имеет матрицу выводов 21 х 21 и напряжение питания 5 В. В нашей стране этот
тип сокета широкого распространения не получил из-за дороговизны тогда еще
новых процессоров; процессоры для этого сокета выпускала только фирма Intel.
Сокет 5 (рис. 11.2) предназначен для процессоров Pentium второго поколения с
частотой до 100 МГц, у которых коэффициент умножения фиксирован (1,5) и в
которых применяется одно напряжение питания — около 3,3 В. Выводы его мат-
рицы размером 37 х 37 расположены в шахматном порядке. Из-за отсутствия раз-
деления питания ядра и интерфейсных схем этот сокет приемлем не для всех про-
цессоров с интерфейсом Pentium.
37
36
35
34
зз
32
31
30
29
28
27
26
25
24
23
22
21
20
19
18
17
.16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
ооооооооооооооооооо
оооооооооооооооооо
ооооооооооооооооооо
оооооооооооооооооо
о о о о о о о
о
о
о
о
о
о
о
о
о
о
о
о
о
о
о
о
о
о
о
о
о
о
о
о о
о о
о о
о о
о о
оооооооооооо
Выводы на процессорах
отсутствуют
О
О О
О
О О
О
О О
О
О О
О
О О
О
О О
о
о о
о
о о
о
о о
о
о о
о
о о
о
о о
о
о о
о
оооооооооооо
оооооооооооооооооо
ооооооооооооооооооо
оооооооооооооооооо
оооооооооооооооооо
37
36
35
34
33
32
31
30
29
28
27
26
25
24
23
22
21
20
19
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
о о о о о
Рис. 11.2. Сокеты 5 и 7
254
11. Применение процессоров в PC
Сокет 7 с такой же матрицей (37 х 37) предназначен для процессоров Pentium
второго поколения с более высокими частотами. Он позволяет задавать коэффи-
циент умножения частоты сигналами BF[ 1:0], а если системная плата с этим соке-
том рассчитана на применение процессоров AMD, то имеется и сигнал BF2. Для
установки процессоров с раздельным питанием ядра и интерфейсных схем (тех-
нология VRT, применяемая во всех MMX-процессорах Р55С и последних «обыч-
ных» процессорах Pentium) сокет 7 предусматривает две шины питания VCC2 и VCC3.
На системной плате при этом должны находиться два регулятора напряжения: для
ядра (VCC2) и интерфейсных схем (VCC3). Их номинальные напряжения определя-
ются типом процессора. Сокет 7, появившийся задолго до выхода Pentium ММХ,
для которого он был предназначен, оказался самым «долгоиграющим» — хотя фир-
ма Intel «похоронила» его с процессорами Pentium ММХ-266, конкурентами до
сих пор для него выпускаются процессоры. В сокете Super 7 «официальная» час-
тота системной шины поднята до 100 МГц.
Фирма AMD для сокета 7 выпускала процессоры, начиная с К5, а сейчас уже Кб,
К6-2 и K6-III. Для этих процессоров (кроме K6-III) вторичный кэш располагает-
ся на системной плате, что и уберегло конструктив от серьезных потрясений. Для
сокета 7 процессоры выпускали и другие фирмы, но они постепенно ушли со
сцены (включая и Cyrix). Архитектура процессоров Кб относится к шестому
поколению (предсказание ветвлений, изменение порядка исполнения инструк-
ций и т. п.).
Для своих процессоров шестого поколения фирма Intel стала «радовать» пользо-
вателей калейдоскопом сокетов и слотов. Интерфейс системной шины процессо-
ров Р6 имеет большое число сигналов и сложный протокол, ориентированный на
многопроцессорные системы. Лицензиями на использование шины Р6 фирма не
разбрасывалась, так что альтернативы процессорам Intel для новых сокетов и сло-
тов долгое время не было (лишь недавно вышел VIA Cyrix III для сокета-370).
Сокет 8 (рис. 11.3) был разработан для процессора Pentium Pro. Для сокета 8 было
выпущено всего несколько моделей процессоров Pentium Pro 150-200 МГц, прав-
да, с разными вариантами вторичного кэша (от 0,5 до 2 Мбайт). После выхода
модели процессора Pentium Pro 200 МГц (конец 1995 г.), на котором солидно выг-
лядели серверы (особенно в 2-4-процессорной конфигурации), следующий про-
цессор для сокета 8 появился в 1998 году — Pentium II OverDrive: 333 МГц, рас-
ширение ММХ и урезание мультипроцессирования лишь до двухпроцессорного.
Недавно появился и переходник для установки Celeron (PPGA) в сокет 8 на платы
для Pentium Pro (фирма PowerLeap). На этом переходнике установлен и регулятор
напряжения, поскольку платы для Pentium Pro «не умеют» выдавать требуемого
низкого напряжения питания.
В широкие массы потребителей процессоры шестого поколения начали внедрять-
ся в виде Pentium II, и под новый процессор фирма ввела новый слот 1 (рис. 11.4).
Отказ от сокета (точнее, от традиционного корпуса процессора со штырьковыми
выводами) был вызван технологическими сложностями размещения вторичного
кэша рядом с процессорным ядром. При этом всех уверяли, что слот 1 (потом его
назвали SC242) — это прогрессивно, всерьез и надолго. Однако для процессора
11.1. Установка и замена процессоров — сокеты и слоты
255
МПС0^-О)МПСП^О)МП(*)^О)МПСПт- О) Ь- Ю СО
ВС ВА AY AW AU AS AQ AN AL AJ AG AF OOOOOOOOOOOOOOOOOOO OOOOOOOOOOOOOOOOOOO О О О О О О О О О О О О О О О о о о о о о о о о о о о о о о о о о о о о о о о о °о°оЖ о о о о о о о о о о О О О О О О О О О О О О О О О О О О О О О О О О О О О О О О О О О О О о о о о о О^О^ОХХ О О ОиОЛО» ВС ВА AY AW AU AS AQ AN AL AJ AF AG
AE AC AB о о о о о о о о о о О О ООО ООООО jO^ClOi Ол AE AB AC
AA Y X о о о о о о о о о о ОС1 01 OJO jOjDjD <ОЛ AA X Y
W U T о о о о о °о°оЖ о о о о о W T u
s Q p ООО о о Жй о о о о о s P Q
N L К о о о о о о о о о о о о о о о о о о о о N К L
J G F о о о о о О О ООО ЛОЛОЛОI ОЛ О О О О О J F G
E с В о о о о о °о°о°о°о° °О° °О° °о° °о° °о° о о о о о °oWo° E в c
A о о о о о о о о о о о о о о о о о о о ООООО У A
СО^СЧОСОСО’ФСМОСОСО’ФСЧОСОСО’ФСМО ’Ф’Ф’Ф’ФСОСОСОСОСОСЧСЧСЧСЧСЧт-^-^-^-^-СОСО’ФСЧ
NinC05-0)N.incnr-0)Nin(ni-0)NlO(*)i-a)NlOC0r-
•’Ф’ФтГ<’ФСОСОСОСОСОСЧСЧСЧС\|С\|<<-т-т-ч-т-
Рис. 11.3. Сокет 8
Celeron, который поначалу выпустили вообще без вторичного кэша, появился
сокет-370, но, якобы, только для дешевых процессоров Celeron в корпусе PGA.
А процессор Celeron тем временем «обзавелся» вторичным кэшем — маленьким
(128 Кбайт), но быстрым и совмещенным с кристаллом ядра. То есть необходимость
в слоте вроде отпала, но перспективы сокета все равно не казались радужными.
Фирма утверждала, что для сокета будет выпускаться только Celeron и частота
системной шины выше 66 МГц ему не полагается. Для «серьезных» процессоров
Pentium II, а позже и Pentium III с полноразмерным кэшем (512 Кбайт) продол-
жал позиционироваться слот 1 с частотой шины 66,100 МГц, а затем и 133 МГц.
А для «самых серьезных» есть еще и слот 2 — у него и контактов больше (330 про-
тив 242), и картриджи для него крупнее (длина около 6” против 5"). В этих больших
картриджах выпускают процессоры Xeon — Pentium II и Pentium III, у которых
кэш больше и быстрее (как, кстати, и у Pentium Pro). Тем временем частота ядра
Celeron растет неуклонно, но частоту шины выше 66 МГц ему официально долгое
время не поднимали. С появлением Pentium III Coppermine с быстрым встроен-
ным кэшем средних размеров для сокета-370 определили частоты шины 100 и
133 МГц, и теперь перспектив у слота 1 стало меньше, чем у сокета-370. И, нако-
нец, только после появления Pentium 4 (для совсем другого сокета) процессоры
Celeron получили частоту шины 100 МГц (начиная с частоты ядра 800 МГц).
256
11. Применение процессоров в PC
Рис. 11.4. Слот 1 (SC242)
Сокет-370 (рис. 11.5) пережил уже две редакции. Первоначально он был введен
для процессоров Celeron, позже с некоторыми изменениями сокет-370 приспосо-
били и к Pentium III с ядром Coppermine. Казалась бы логичной полная совмести-
мость процессоров Celeron и Pentium III с сокетом (игнорируя неиспользуемые
сигналы), но все не так просто. Есть пять выводов с изменившимся назначением,
из-за которых процессор, вставленный в сокет, может отказаться работать.
♦ Сигнал аппаратного сброса RESET# у процессоров Celeron (включая и послед-
ние, с SSE) выведен на контакт Х4, у Pentium III — на АН4. У универсальных
системных плат сигнал сброса подается на оба вывода (при необходимости
такую перемычку легко напаять на плату-переходник, на системной плате па-
ять страшнее). Без аппаратного сброса процессор запускаться не будет.
♦ Контакт АМ2 на системных платах под Celeron соединяли с шиной GND. Для
процессоров Pentium III и Celeron с SSE этот вывод значится зарезервирован-
ным; причем требуется, чтобы он оставался свободным. Освободить на печат-
ной плате контакт, связанный с шиной, дело почти невозможное. Однако если
не жалко процессор и не волнует вопрос с гарантией, то этот (и только этот!)
вывод можно «откусить» прямо на процессоре. Другой вариант — снять крыш-
ку сокета и выпаять (выкусить) контактный лепесток.
♦ У процессоров Pentium III и Celeron с SSE введены новые сигналы RTTCTRL и
SLEWCTRL. Их контакты (S35 и Е27) рекомендуется соединять с шиной GND
через резисторы 300 Ом, но, похоже, их можно оставлять и неподключенными.
Есть и еще некоторые различия определения выводов, ио они не так существенны.
Эти «колебания генеральной линии» сильно осложняют покупателям выбор сис-
темной платы, для которой хотелось бы иметь перспективы установки новых про-
цессоров — прогрессивных и доступных по цене. Для процессоров Р6 ряд фирм
выпускает переходники-конверторы различного назначения, разрешающие неко-
торые проблемы модернизации. Наиболее распространены переходники «сокет-
слот» (сокет па картридже), которые позволяют устанавливать процессоры в кор-
пусах PPGA или FC-PGA (Celeron и Pentium III) в слот 1. Поскольку назначение
выводов этих процессоров несколько различается (см. выше), старые переходни-
ки для Celeron могут не подходить для Pentium III. Возможно, потребуется соеди-
нение перемычкой выводов сокета АН4 и Х4 (для сигнала RESET#)„ а также от-
ключение вывода АМ2 от шины GND (если не жалко процессор, то этот вывод можно
«откусить» прямо на процессоре). Следует помнить, что процессоры Pentium III
имеют напряжение питания 1,6-1,65 В, Celeron II — 1,5 В, в то время как старые
11.1. Установка и замена процессоров — сокеты и слоты
257
процессоры Celeron питаются от 2 В. Если регулятор напряжения на системной
плате не позволяет установить требуемое низкое напряжение, процессор может
сгореть. На универсальных переходных платах имеются джамперы, обеспечиваю-
щие выбор конфигурации. С их помощью можно использовать процессоры и в
нештатном режиме: изменять напряжение питания (коммутацией линий VID[3:0]),
частоту системной шины (линии BSEL[1:0]), а также устанавливать Celeron в двух-
процессорных системах. Обратных переходников (для установки картриджа в
слот) не бывает. Для использования Pentium III в платах с сокетом под Celeron
выпускают переходник Socket-370 — FC-PGA (сокет с ножками).
<С0 о Q ш ш 0 Z <соооши.01-}^_|5г *_jSzclOq:c/)i-:d>£x>n<<<<<<<<<<<<<
37 О О О О О о о о ооооооооооо 37
36 О О О О ООО о оооооооооо 36
35 О О О О О о о о ооооооооооо 35
34 О О О О ООО о оооооооооо 34
33 о о о о о о о о ооооооооооо 33
32 о о о о ООО о оооооооооо 32
31 ООО ООО 31
30 ООО ООО 30
29 ООО ООО 29
28 ООО ООО 28
27 ООО ООО 27
26 ООО ООО 26
25 ООО ООО 25
24 ООО ООО 24
23 ООО ООО 23
22 ООО ООО 22
21 ООО ООО 21
20 ООО ООО 20
19 ООО ООО 19
18 ООО ООО 18
17 ООО ООО 17
.16 ООО ООО 16
15 ООО ООО 15
14 ООО ООО 14
13 ООО ООО 13
12 ООО ООО 12
11 ООО ООО 11
10 ООО ООО 10
9 ООО ООО 9
8 ООО ООО 8
7 ООО ООО 7
6 о о о о ООО о оооооооооо 6
5 о о о о о о о о ооооооооооо 5
4 о о о о ООО о оооооооооо 4
3 о о о о о о о о ооооооооооо 3
2 о о о о ООО о оооооооооо 2
1 о о о о о о о оооооооооо 1
Рис. 11.5. Сокет-370
Седьмое поколение процессоров ознаменовано появлением новых сокетов и слотов.
Для процессора Athlon фирма AMD ввела слот А, механически (и только!) совме-
стимый со слотом 1 (SC242). Более дешевые процессоры Duron, а также Athlon
258
* 11. Применение процессоров в PC
модели 4 (кэш 256 Кбайт) используют сокет А, он же сокет 462 (рис. 11.6). И в сло-
те, и в сокете используется шина EV-6, которая не применяется в процессорах х86
иных фирм.
<ЩООШи.0
<mODLUU_0Z-9^_jZZQ.OQrcOI-D>$X>N<<<<<<<<<<<<<
37
36
35
34
33
32
31
30
29
28
27
26
25
24
23
22
21
20
19
18
17
.16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
ооооооооооооо
ооооооооооооо
оооооооооооооо
оооооооооооооо
оооооооооооооо
оооооооооооооо
ооооооооооооооо
ооооооооооооооо
о о о о
о о о о
о о о о
о о о о
о о о о
о о о о
о о о •
о о о о
о о о о
о о о о
о о о о
о о о о
о о о о
о о о о
о о о •
о о о о
о о о о
о о о о
о о о о
о о о о
о о о о
оооооооооооооооо
OOO<OOO<OOOO<OOO
ооооооооооооооо*
оооооооооооооооо
оооооооооооооооо
оооооооооооооооо
оооооооооооооооо
ооооооооооооооо
37
36
35
34
33
32
31
30
29
28
27
26
25
24
23
22
21
20
19
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
о о о о о о
о о о о о
о о о о о
о о о о
о о о о о
о о о о
о о о о
ООО
о о о о
о о о о
• о о о
о о о о
о о о о
о о о о
о о о о
о о о о
о о о о
о о о о
о о о о
о о о о
ООО
о о
ООО
о о
ООО
о о
ООО
о о
ООО
о о
ООО
о о
ООО
о о
ООО
о о
о о
О О
О
О о
о
о о
о
о о
Рис. 11.6. Сокет 462 (сокет А)
Для процессора Pentium 4 был введен новый сокет 423 (рис. 11.7), не совместимый
ни с какими прежними. О переходниках не может быть и речи, поскольку шина
Pentium 4 сильно отличается от шины Р6. Для этого процессора требуется мощ-
ный блок питания — процессор на 1,5 ГГц потребляет 70 Вт.
Основные данные по ныне существующим сокетам и слотам приведены в табл. 11.1.
Новые процессоры сейчас выпускаются «только» для сокета 7 (Super 7), слота 1,
слота 2, слота А, сокета-370, сокета 423 и сокета А, так что выбирая системную
плату, приходится сначала определиться с типом желаемого процессора.
11.1. Установка и замена процессоров — сокеты и слоты
259
39 О О О О о о о о о о о о о о о о о о о о 39
38 о о о о о о о о о о о о о о о о ООО 38
37 о о о о о о о о о о о о о о о о о о о о 37
36 о о о о о о о о о о о о о о о о ООО 36
35 о о о о о о о о о о о о о о о о о о о о 35
34 ООО ООО 34
33 о о о о ООО 33
32 ООО ООО 32
31 о о о о ООО 31
30 ООО ООО 30
29 о о о о ООО 29
28 ООО ООО 28
27 о о о о ООО 27
26 ООО ООО 26
25 о о о о о о о 25
24 ООО ООО 24
23 о о о о ООО 23
22 ООО ООО 22
21 о о о о ООО 21
20 ООО ООО 20
19 о о о о ООО 19
18 ООО ООО 18
17 о о о о ООО 17
.16 ООО ООО .16
15 о о о о ООО 15
14 ООО ООО 14
13 о о о о ООО 13
12 ООО ООО 12
11 о о о о ООО 11
10 ООО ООО 10
9 о о о о ООО 9
8 о о о о о о о о о о о о о о о о ООО 8
7 О О О о о о о о ОЛ о о о о о о о о о о о 7
6 о о о о о о о о о о о о о о о о ООО 6
5 о о о о о о о о о о о о о о о о о о о о 5
4 о о о о о О О о о о о о о о о о ООО 4
3 о о о о о о о о о о о о о о о о о о о о 3
2 о о о о о о о о о о о о о о о о ООО 2
1 о о о о о о о о о о о о о о о о о о о о 1
Рис. 11.7. Сокет 423
Таблица 11.1. Сокеты и слоты
Сокет (слот) Число выводов Матрица (слот) Питание, В Поддерживаемые процессоры
Сокет 1 168/169 17x17 PGA 5 486SX/SX2, DX/DX21
Сокет 2 238 19x19 PGA 5 486SX/SX2, DX/DX2, Pentium ODP2
Сокет 3 237 19x19 PGA 5 или 3,3 486 SX/SX2, DX/DX2, DX4, Pentium ODP, DX4ODP, Am486, Am5x86-P75 (AMD-X5- 133),Cx486,Cx5x86
Сокет 4 273 21x21 PGA 5 Pentium P5 60/66, Pentium 60/66ODP
Сокет 5 320 37x37 SPGA 3,3 Pentium P54 75/100, Pentium 75/1OOODP
продолжение^
260
.11, Применение процессоров в PC
Таблица 11.1 (продолжение)
Сокет (слот) Число выводов Матрица (слот) Питание, В Поддерживаемые процессоры
Сокет 6 235 19x19 PGA 3,3 486DX4, DX4 Pentium ODP
Сокет 7 (Super 7) 321 37x37 SPGA 2,0-3,3/ 3,3 Pentium Р54, Р55 (ММХ), Р55С, Р55СТ, AMD К5, Кб, K6-II, K6-III Сх6х86,6х86МХ, 6х86МП, VIA Cyrix МП
Сокет 8 387 Модифицирован- ная матрица 34x47 SPGA 2,1-3,5/ 3,3 Р6 Pentium Pro, Pentium II OverDrive
Сокет-3703 370 37x37 SPGA 1,3-2,05 Celeron, Pentium III, VIA Cyrix III
Сокет423 423 39x39 SPGA 1,6 Pentium 4
Слот1 242 Двухрядный 1,3-2,8/ Pentium ll/lll, Celeron
(SC242) слот 2x121 3,3
Слот 2 330 Двухрядный слот2x165 (1,3-2,8)/ (1,3-3,3) Xeon (Pentium ll/lll)
СлотА 242 Двухрядный слот 2x121 (1,3-2,05)/ (2,5 или 3,3) Athlon
Сокет А 462 37x37 SPGA 1,3-2,05 Athlon, Duron
1 Возможна установка DX4 с дополнительным стабилизатором напряжения 3,3 В.
2 ODP — OverDrive Processor.
3Назначение выводов АМ2, АН4, Х4, Е27 и S35 может быть различным (см. выше).
К сожалению, полной совместимости между всеми процессорами, устанавливае-
мыми в сокет (слот) одного типа, нет. Возможный тип устанавливаемого процес-
сора определяется следующими свойствами системной платы:
♦ типом сокета (слота);
♦ наличием двух раздельных источников питания, если того требует процессор;
♦ возможностью установки необходимых напряжений питания процессора и
допустимой мощности регуляторов напряжения;
♦ возможностью установки требуемой частоты синхронизации и коэффициента
ее умножения;
♦ поддержкой процессора конкретной версией BIOS;
♦ указанием на применимость данного процессора, сделанным разработчиком
системной платы в ее описании (или указанием конкретного типа системной
платы в списке совместимости, публикуемом разработчиком процессора).
Если первые четыре пункта определяются однозначно, то для последних, как го-
ворится, возможны варианты. Версию BIOS (особенно если применяется флэш-
память) можно обновить и обеспечить тем самым поддержку устанавливаемого
процессора. Что касается списков совместимости, то они условны. Разработчик
платы может заранее заявить о совместимости с будущим процессором, но будут
11.1. Установка и замена процессоров — сокеты и слоты
261
ли они «жить дружно» — вопрос. Напротив, разработчик процессоров может не
включить конкретную системную плату в свой список совместимости, но они смоп-
гут нормально работать в паре. Типов системных плат гораздо больше, чем типов
процессоров, и, если производитель платы не позаботился о доставке образцов
своих изделий для тестирования с конкретным процессором, такая плата может
не попасть в список изготовителя процессоров. Существуют и «черные списки» —
списки несовместимости, заполняемые сборщиками компьютеров.
BIOS определяет тип установленного процессора (начиная с 5-го поколения Intel
и 4-го AMD) в начале теста POST по инструкции CPUID (см. п. 8.2.1), по которой
процессор сообщает идентификатор производителя (разработчика), семейство,
модель и степпинг. По этим данным BIOS формирует имя процессора (например,
«Intel Pentium III»), которое POST выводит на экран (и сообщает в CMOS Setup).
Текстовые названия известных процессоров прописаны в теле BIOS, так что не-
верное название в сообщении свидетельствует о слишком старой (для данного
процессора) версии BIOS. Процессоры AMD имя процессора сообщают по инст-
рукции CPUID, так что тесту POST не требуется искать имена по таблицам. В про-
цессорах Intel эта возможность появилась, только начиная с Pentium 4. Текущую
тактовую частоту ядра POST определяет с помощью системного таймера, либо
выполняя определенный цикл инструкций и подсчитывая число проходов за из-
вестный интервал, либо снимая показания счетчика меток реального времени (TSC)
в начале и конце интервала измерения. Последний способ точнее, но работает толь-
ко на процессорах, имеющих этот счетчик (Pentium и выше). Чтением определен-
ных модельно-специфических регистров процессора POST может определить ус-
тановленный коэффициент умножения частоты.
Идентифицировав процессор, POST может выполнить загрузку «заплаток» мик-
рокода процессора (download microcode), если в BIOS имеются блоки, подходя-
щие для установленного процессора, и загрузка не запрещена. Отсутствие блока
для устанавливаемого процессора является поводом для перепрошивки BIOS,
хотя «заплатки» можно загружать и из файла в начале загрузки ОС.
11.1.1. Выбор частоты и напряжения питания
Для установленного процессора требуется задать напряжение питания и частоту
ядра, которая определяется частотой системной шины (FSB Frequency) и коэф-
фициентом умножения. Эти параметры задаются вручную или с различной сте-
пенью автоматизации, для чего используются джамперы или настройки CMOS
Setup (Soft Menu). В сокетах 1-7 пользователь может устанавливать все эти парамет-
ры сравнительно произвольно, руководствуясь своими знаниями об устанавлива-
емом процессоре и, возможно, идеями разгона. В сокетах и слотах для процессо-
ров 6-7-го поколений предусмотрен интерфейс, с помощью которого процессор
сообщает требуемое напряжение питания, автоматически управляя регулятором
напряжения. В сокетах и слотах для Pentium П/Ш предусмотрен и автоматичес-
кий выбор частоты FSB (66,100 или 133 МГц). Интерфейс прост: выделяется не-
сколько сигнальных линий, часть из которых заземляется внутри корпуса (карт-
262
л 11. Применение процессоров в PC
риджа) процессора. В нижеприведенных таблицах значения 0 соответствуют за-
земленным линиям, 1 — свободным. Генератор синхронизации и регулятор напря-
жения работают под управлением вышеуказанных сигналов, отрабатывая задания
в соответствии со своими возможностями. Если регулятор не может выдать тре-
буемый номинал, он вообще не должен подавать напряжение.
Коэффициент умножения у большинства современных процессоров теперь фик-
сирован, что совместно с автоматизацией выбора частоты и напряжения связыва-
ет руки оверклокерам («разгонщикам»). Но на их радость не все производители
системных плат придерживаются строгих правил, предписываемых изготовите-
лями процессоров, и предлагают выбор между автоматическим и ручным (произ-
вольным) выбором параметров. Но и на «строгих» платах в слоте можно «обма-
нуть» процессор, заклеивая или заземляя требуемые контакты на краевом разъеме
картриджа. Для сокета этот «обман» осложняется. В переходниках «сокет-слот»
перекоммутация линий технически проще (да и потери от возможного поврежде-
ния переходника меньше, чем для системной платы); во многих переходниках
имеются специальные джамперы, позволяющие вручную устанавливать парамет-
ры даже для самых «строгих» автоматических плат. Однако ручное задание пара-
метров небезопасно.
ВНИМАНИЕ-----------------------------------------------------------
Установка завышенной частоты ядра и завышенного напряжения питания опасно для процес-
соров, особенно без принятия должных мер по охлаждению.
Рассмотрим интерфейсы конфигурирования процессоров в различных сокетах и
слотах.
В «старинных» сокетах 1,2,3 и 6 для 486-х процессоров заземление линии CLKMUL
приводит к снижению коэффициента умножения: в DX4 с 3 до 2, в DX2 — с 2 до 1.
В процессорах Intel CLKMUL выведен на контакт R17 сокета 1 (S18 сокетов 2,3
и 6); в процессорах AMD 486DX2 и 486DX4-100 — на В13 (С14). В процессорах
Аш5х86 заземление R17 приводит к повышению коэффициента умножения с 3
до 4. У процессоров с WB-кэшем на контакт В13 (С14) выведен сигнал WB/WT#,
который управляет алгоритмом кэширования (заземлен — WT). У процессоров с
низковольтным питанием сигнал VOLDET#, выведенный на контакт S4 (Т5), за-
казывает низкое (3,3 В) напряжение питания (если заземлен в процессоре). На-
пряжение питания в сокете 1 можно проконтролировать на выводах В7, В9, ВИ...,
в сокетах 2,3 и 6 — на выводах С8, CIO, С12... (и А9, А10, All, А16...).
В сокетах 5, 7 и Super 7 коэффициент умножения задается джамперами, заземля-
ющими специально выделенные линии интерфейсных сигналов BFO (Y33), BF1
(Х34) и BF2 (W35), причем у разных семейств и моделей процессоров одной и
той же комбинации этих сигналов соответствуют разные коэффициенты умноже-
ния частоты (табл. 11.2). Эти линии «подтягиваются» к высокому уровню рези-
сторами, расположенными внутри процессора. Процессор считывает заданный
коэффициент в момент окончания сигнала аппаратного сброса. Напряжение пи-
тания ядра в сокетах 7 задается вручную, как правило, четырьмя джамперами в
11.1. Установка и замена процессоров — сокеты и слоты
263
двоичном коде. Снятым джамперам соответствует минимальное напряжение 2,0
или 2,1 В, установка джампера на контакты 1-2 дает прибавку 0,1 В, 3-4 — 0,2 В,
5-6 — 0,4 В, 7-8 — 0,8 В. Возможна и иная нумерация контактов, но наглядность
двоичного кода сохраняется. У более старых (и менее универсальных) плат вмес-
то двоичного кода может использоваться несколько фиксированных значений
напряжения, выбираемых меньшим числом джамперов. Напряжение ядра (VCC2)
можно проверить на контактах А07, А09, АН... Напряжение питания интерфейса
(VCC3) фиксировано (3,3 В), его можно проверить на контактах А19, А21, А23...
В сокете 5 на все питающие контакты (А07, А09, А11—А19, А21, А23...) подается
единое напряжение 3,3 В.
Таблица 11.2. Коэффициенты умножения для сокетов 5 и 7
BF[2:0] Pentium 75-133 МГц Pentium (и ММХ) 166-233 МГц AMDK5 модель 0 AMDK5 модель 1 и 2 AMD Кб, К6-2, K6-III
111 1,5 3,5 1,5 1,5 3,5
110 2,0 2,0 2,0 1,5 2,0 или 6,0
101 3,0 3,0 — Резерв 3.0
100 2,5 2,5 — 1,75 2,5
011 — — — — 5,5
010 — — - - 4,0
001 — — - — 5,0
000 - - - - 4,5
Процессоры Р6 принимают (если могут) коэффициент по линиям А20М#, IGNNE#,
LINT1/NMI и LINT0/INTR, причем для всех процессоров принята единая кодировка
коэффициентов (табл. 11.3). Этими сигналами задается коэффициент умножения
у процессоров Pentium Pro (официально к - 2-4), Pentium II с частотами 233-
300 МГц (официально 2-4,5), Pentium II/III Хеоп. Конкретные процессоры поддер-
живают лишь часть этих коэффициентов (фактически часто большее количество,
чем по официальным данным). У процессоров Pentium II с частотами 350-450 МГц,
всех процессоров Celeron и Pentium III коэффициенты фиксированы в зависимос-
ти от спецификации. Информацию о текущей настройке умножителя можно
получить по значению бит 25:22 MSR-регистра с адресом 2Ак (см. соответствую-
щий столбец таблицы).
Таблица 11.3. Коэффициенты умножения частоты для процессоров Р6
Коэффициент умножения LINT[1] LINT[O] A20M# IGNNE# MSR2Ak [25:22]
1,5 Н Н Н L 1110
2 L L L L 0011
2 Н Н Н Н 1100
2,5 L Н L L 0111
продолжение^
264
11. Применение процессоров в PC
Таблица 11.3( продолжение)
Коэффициент умножения LINT[1] LINT[O] A20M# IGNNE# MSR2Ak [25:22]
3 L L L Н 0001
3,5 L Н L Н 0101
4 L L Н L 0010
4,5 L Н Н L 0110
5 L L н Н 0000
5,5 L Н н Н 0100
6 Н L L L 1011
6.5 Н Н L L 1111
7 Н L L Н 1001
7,5 Н Н L Н 1101
8 Н L Н L 1010
Резерв Н L Н Н 1000
Номера контактов
Сокет 8 AG41 AG43 А11 А9
Сокет-370 L37 М36 АЕЗЗ AG37
Слот1 В16 А17 А5 А8
Слот 2 В28 А27 А14 А17
Для процессоров фирмы Intel используются частоты системной шины (FSB Clock)
66, 100 и 133 МГц (в первых процессорах Pentium Pro использовали и 60 МГц).
Частота 66 МГц применяется в Pentium Pro, первых моделях Pentium II и во всех
моделях Celeron (вплоть до моделей с частотой ядра 766 МГц). Частота шины
100 МГц появилась в процессорах Pentium II, начиная с частоты ядра 350 МГц,
и Celeron-800. Частота 133 МГц появилась в Pentium Ш-533. Процессоры Pentium III
для некоторых значений частоты ядра выпускаются в двух модификациях. Про-
цессоры с буквой «В», стоящей после значения частоты, рассчитаны на частоту
системной шины 133 МГц. У них коэффициент умножения ниже, чем у процессо-
ров с той же частотой ядра и частотой шины 100 МГц (без буквы «В»). Например,
Pentium Ш-600В имеет коэффициент 4,5 (133 х 4,5 = 600), a Pentium Ш-600 — 6
(100x6 = 600).
Естественно, что конкретная вычислительная система может работать только на
частоте, поддерживаемой всеми ее компонентами — процессором (всеми процес-
сорами), чипсетом и генератором синхронизации. Для выбора частоты исполь-
зуются сигналы BSEL[1:0]#. Сигнал BSEL0# сначала назывался 100/66#, BSEL1#
определили с тех пор, как ввели частоту 133 МГц. В процессорах Хеоп сигналам
BSEL[1:0]# соответствуют сигналы SELFSB[1:0]# (пока что эти процессоры рабо-
тают только на частоте шины 100 МГц).
По сигналам BSEL[1:0]# все компоненты согласуют свои возможности (реализу-
ется монтажное И, а затем выбирается минимальное значение частоты, как показа-
но на рис. 11.8). У процессоров на 66 МГц оба вывода заземлены внутри картрид-
11.1. Установка и замена процессоров —- сокеты и слоты
265
жа (корпуса), на 100 МГц заземлен только BSEL1#, на 133 МГц — оба свободны.
На системных платах, не поддерживающих частоту 66 МГц, сигнал BSEL0# (100/66#)
должен соединяться с сигналом RESET#. Тогда процессор, работающий только'на
66 МГц, не будет запускаться (он сам себе удержит низкий уровень на RESET#) и
не выйдет из строя от перегрева. Аналогично, на плате, поддерживающей только
133 МГц, с цепями сброса должен соединяться сигнал BSEL1#. Генератор синхро-
низации устанавливает частоту в зависимости от этих сигналов так, как показано
в табл. 11.3 (L — низкий уровень, Н — высокий).
в
Рис. 11.8. Управление частотой синхронизации: а — схема с процессором FSB = 100 МГц;
б — процессор с FSB = 66 МГц; в — процессор с FSB = 133 МГц
Частота шины вторичного кэша зависит от модели процессора. У процессоров
Pentium Pro, Celeron и Xeon (Pentium.II/III) она равна частоте ядра. У процессоров
Pentium II шина кэша работает на половине частоты ядра. У процессоров Pen-
tium III возможны два варианта: «обычный» кэш размером 512 Кбайт, расположен-
ный на картридже процессора, работает на половине частоты ядра; «улучшенный»
кэш (АТС) размером 256 Кбайт, расположенный на кристалле ядра (Coppermine),
работает на полной частоте ядра. Процессоры с улучшенным кэшем имеют в окон-
чании наименования букву «Е» (например, Pentium Ш-600ЕВ).
В сокете 8 кроме вышеописанного коэффициента задается напряжение питания,
которое процессор заказывает по линиям VID[3:0] (контакты AS7, AS5, AS3 и AS1)
в соответствии с табл. 11.4. Правда, этим интерфейсом для задания напряжения
практически не пользуются. Напряжение питания ядра можно проверить на кон-
тактах В4, В8, В16...
266
11. Применение процессоров в PC
Таблица 11.4. Идентификация питания в сокете 8
VID[3:0] Напряжение, В VID[3:0] Напряжение, В
0000 3,5 1000 2,7
0001 3,4 1001 2,6
0010 3,3 1010 2,5
0011 3,2 1011 2,4
0100 3,1 1100 2,3
0101 3,0 1101 2,2
0110 2,9 1110 2.1
0111 2.8 1111 Нет CPU
В слоте 1 линий идентификации больше — VID[4:0] на контактах А121, ВИЭ, А119,
А120 и В120 (табл. 11.5). Напряжение питания ядра можно проверить на контак-
тах В13, В17, В25..., напряжение питания вторичного кэша (3,3 В) — на контактах
ВИЗ, В117, В121 (в Celeron и Pentium III с интегрированным кэшем это питание
не используется). Кроме того, появились сигналы выбора частоты FSB — сигналы
BSEL0 (он же 100/66#) и BSEL1 на контактах В21 и А14, по которым процессор
заказывает частоту в соответствии с табл. 11.6. Поначалу был задействован лишь
сигнал 100/66#.
Таблица 11.5. Идентификация питания в слотах 1,2 и сокете-370
VID[4:0] Напряжение, В VID[4:0] Напряжение, В
01111 1,30 11111 Нетпроцессора
01110 1,35 11110 2,1
01101 1,40 11101 2,2
01100 1,45 11100 2,3
01011 1,50 .11011 2,4
01010 1,55 11010 2,5
01001 1,60 11001 2,6
01000 1,65 11000 2,7
00111 1,70 10111 2,8
00110 1,75 10110 2,9
00101 1,80 10101 3,0
00100 1,85 10100 3,1
00011 1,90 10011 3.2
00010 1,95 10010 3,3
00001 2,00 10001 3,4
00000 2,05 10000 3,5
11.1. Установка и замена процессоров — сокеты и слоты
267
ПРИМЕЧАНИЕ---------------------------------------------------
Процессоры Pentium II могут иметь питание ядра 1,8-2,8 В, Pentium III — 1,8-2,05 В, вторичный
кэш питается от 3,3 В. Процессоры Xeon (Pentium II и Pentium III) могут иметь питание ядра
1,8-2,1 В, питание вторичного кэша — 1,8-2,8 В.
Таблица 11.6. Выбор частоты синхронизации системной шины Р6
BSEL1 (SELFSB1) BSELO (SELFSBO) Частота, МГЦ
0 0 66
0 1 100
1 0 Резерв
1 1 133
В сокете-370линии идентификации VI D[3:0] расположены на контактах AJ37, AL37,
АМ36 и AL35, напряжения соответствуют табл. 11.5, считая, что VID4 = 0. Напряже-
ние питания ядра можно проверить на контактах BIO, В14, В18... Сигналы выбора
частоты BSEL0 и BSEL1 расположены на контактах AJ33 и AJ31 соответственно.
В слоте 2 имеются раздельные идентификаторы питания ядра VID_CORE[4:0] на
контактах А150, В149, А147, А148 и В151 и вторичного кэша VID_L2[4:0] на кон-
тактах В154, В155, А153, А154, В152 (см. табл. 11.5). Напряжение питания ядра
можно проверить на контактах В2, В5, ВИ..., напряжение питания вторичного
кэша — на контактах В106, В109, В112... Сигналы выбора частоты SELFSB0 и
SELFSB1 расположены на контактах А9 и А7.
В сокете 423 линии идентификации VID[4:0] расположены на контактах А1, АЗ,
В4, В2 и С1, здесь регулировка напряжения более тонкая (табл. 11.7). Выбор час-
тоты шины пока не предусмотрен. Напряжение питания ядра можно проверить
на контактах А37, А39, В10...
Таблица 11.7. Идентификация питания в сокете 423
VID[4:0] VCC-MAX VID[4:0] VCC-MAX
11111 Отключено 01111 1,475
11110 1,100 01110 1,500
11101 1,125 01101 1,525
11100 1,150 01100 1,550
11011 1,175 01011 1,575
11010 1,200 01010 1,600
11001 1,225 01001 1,625
11000 1,250 01000 1,650
10111 1,275 00111 1,675
10110 1,300 00110 1,700
10101 1,325 00101 1,725
10100 1,350 00100 1,750
продолжение#
268
11. Применение процессоров в PC
Таблица 11.7 (продолжение)
VID[4:0] VCC-МАХ VID[4:0] VCC-МАХ
10011 1,375 00011 1,775
10010 1,400 00010 1,800
10001 1,425 00001 1,825
10000 1,450 00000 1,850
Процессоры Athlon и Duron сообщают чипсету коэффициент умножения частоты
по линиям FID[3:0]. С помощью этих выходов (типа «открытый сток»), «подтяги-
ваемых» к высокому уровню резисторами, расположенными на системной плате,
процессор сообщает чипсету коэффициент умножения. В зависимости от коэффи-
циента чипсет формирует пакет инициализации SIP, который передается про-
цессору по специальному последовательному интерфейсу. Процессор сообщает
и напряжение питания по линиям VID[3:0]. Коэффициент умножения, напряже-
ние питания и быстродействие кэша задаются перемычками на корпусе процессо-
ра, которые можно нарисовать обычным карандашом.
В слоте А для VID[3:0] используются контакты А115, А114, А113 и А112 (табл. 11.8),
для FID[3:0] — Al 16, Al 17, Al 18 и Al 19 (табл. 11.9). Напряжение питания ядра
можно проверить на контактах А24, А26, А28..., вторичного кэша — на А2, А4, А6...
Таблица 11.8. Идентификация питания в слоте А
V1D[3:O] VCC.CORE, В VID[3:0] VCC_CORE, В
oooo' 2,05 1000 1,65
0001 2,00 1001 1,60
0010 1,95 1010 1,55
0011 1,90 1011 1,50
0100 1,85 1100 1,45
0101 1,80 1101 1,40
0110 1,75 1110 1,35
0111 1,70 1111 1,30
Таблица 11.9. Кодирование коэффициента умножения процессоров Athlon и Duron
FID[3:0] Коэффициент
oooo 11
0001 11,5
0010 12
0011 12,51
0100 5
0101 5.5
0110 6
0111 6.5
FID[3:0] Коэффициент
1000 7
1001 7,5
1010 8
1011 8,5
1100 9
1101 9,5
1110 10
1111 10,5
1 Процессорам с любыми коэффициентами, превышающими 12,5, требуются одинаковые данные SIP.
11.2. Синхронизация и разгон 269
В сокете А (сокете-462) для VID[4:0] используются контакты J7, L7, L5, L3 и L1,
здесь кодировка напряжения иная (табл. 11.10); для FID[3:0J используются контак-
ты Y3, Yl, W3 и W1 (см. табл. 11.9). Напряжение питания ядра можно проверить
на контактах В4, В8, В12.
Таблица 11.10. Идентификация питания в сокете А
VID[4:0] VCCCORE VID[4:0] VCC-CORE
00000 1,850 10000 1,450
00001 1,825 10001 1,425
00010 1,800 10010 1,400
00011 1,775 10011 1,375
00100 1,750 10100 1,350
00101 1,725 10101 1,325
00110 1,700 10110 1,300
00111 1,675 10111 . 1,275
01000 1,650 11000 1,250
01001 1,625 11001 1,225
01010 1,600 11010 1,200
01011 1,575 11011 1,175
01100 1,550 11100 1,150
01101 . 1,525 11101 1,125
01110 1,500 11110 1,100
01111 1,475 11111 NoCPU
11.2. Синхронизация и разгон
Основной тактовый генератор системной платы вырабатывает высокостабильные
импульсы опорной частоты, используемой для синхронизации процессора; памя-
ти и шин ввода-вывода. Поскольку быстродействие этих подсистем существенно
различается, каждая из них может синхронизироваться со своей частотой. Кроме
этих тактовых частот на системной плате присутствуют и другие — для синхро-
низации COM-портов, системного и CMOS-таймеров, НГМД и других перифе-
рийных адаптеров, но они не привлекают к себе внимания (нет поводов для их
изменения). Когда появились компьютеры с тактовой частотой, обеспечивающей
производительность выше стандартной модели XT (4,77 МГц) или АТ (8 МГц),
для обеспечения совместимости с программами, у которых какие-либо задержки
формировались путем подсчета циклов процессора, ввели режим и переключатель
Turbo. В режиме Turbo процессор работает на максимальной скорости, а в «нор-
мальном» — на пониженной, обеспечивающей «эталонную» производительность.
Со временем производительность компьютера даже на пониженной скорости
ушла далеко вперед от начального «эталона», и большого смысла переключение
270
11. Применение процессоров в PC
режима уже не имеет. Когда говорят о производительности компьютера, обычно
подразумевают, что он работает в режиме Turbo, так что этот режим и следовало
бы называть нормальным. При наличии переключателя Turbo в машинах с процессо-
ром 8088/286/386 обычно переключали частоту синхронизации. В компьютерах
на процессорах 486 и выше частоту оперативно переключать нельзя по разным
причинам (например, собьется умножитель частоты процессора). В них переклю-
чатель Turbo, если он имеется, может, например, отключать вторичное кэширова-
ние или включать режим прерывистой синхронизации (см. режим управления
синхронизацией процессоров в п. 7.7).
Ниже перечислены присутствующие на системной плате частоты.
♦ Host Bus Clock, она же FSB Clock, — частота системной шины (внешняя часто-
та шины процессора). Эта частота является опорной для всех других и уста-
навливается перемычками (джамперами). Современные процессоры исполь-
зуют частоты 50, 55, 60, 66, 75, 83, 100, 112, 125, 133, 200 и 266 МГц. Частоты
75 МГц и выше выдвигают весьма высокие требования к технологии изготов-
ления системных плат, чипсетов, памяти и микросхем обрамления. Процессо-
ры класса 486 использовали частоты 16, 25, 33 и 40 МГц.
♦ CPU Clock, или Core Speed, — внутренняя частота процессора, на которой ра-
ботает его вычислительное ядро. На системной плате эта частота не присут-
ствует, но могут присутствовать средства задания коэффициента умножения.
Коэффициент умножения большинства современных процессоров фиксиро-
ван изготовителем; раньше его задавали перемычками на системной плате, за-
земляющими определенные выводы процессора. Способы задания коэффици-
ентов для разных моделей процессоров приведены выше. Заметим, что не все
модели процессоров воспринимают все сигналы управления коэффициентом
умножения. Кроме того, одному и тому же положению джамперов могут соот-
ветствовать разные значения коэффициентов — трактовка управляющих сиг-
налов зависит от марки и модели процессора.
♦ Memory Bus Clock — частота синхронизации памяти SDRAM, DDR SDRAM
или RDRAM, должна соответствовать спецификации применяемых модулей.
Повышение этой частоты позволяет повысить производительность памяти,
что особенно важно для систем с портом AGP.
♦ AGP Clock — частота порта AGP, номинал — 66,6 МГц.
♦ PCI Bus Clock — частота шины PCI. Слишком низкая частота шины PCI тор-
мозит обмен данными, что особенно заметно на графических адаптерах, SCSI-
контроллерах и адаптерах скоростных локальных сетей, установленных в слоты
PCI. Слишком высокая частота может привести к неустойчивости работы адап-
теров. Согласно спецификации PCI 2.0 частота должна быть 25-33,3 МГц.
Спецификация PCI 2.1 допускает применение частоты шины 66,6 МГц по со-
гласию всех абонентов шины. Исходя из этого, в синхронных чипсетах опти-
мальные частоты внешней шины процессора составляют 33,3 МГц для 486 и
66,6, 100 или 133 МГц для процессоров пятого и шестого поколений. Частота
41,5 или 37,5 МГц для ряда адаптеров PCI может оказаться слишком высокой,
поэтому применять внешнюю частоту 75 или 83 МГц следует с осторожностью.
11.2. Синхронизация и разгон
271
♦ ISA Bus Clock — частота шины ISA, которая должна быть близка к 8 МГц. Она
обычно задается в BIOS Setup через коэффициент деления системной часто-
ты. Гнаться за ее оптимизацией в современных компьютерах, у которых все
адаптеры, критичные к скорости обмена, либо расположены на локальных
шинах системной платы, либо установлены в слоты PCI, AGP или VLB, смыс-
ла не имеет.
♦ VLB Bus Clock — частота шины VLB, определяемая аналогично PCI Bus Clock.
Платы с шиной VLB обычно имеют джампер, переключаемый в зависимости
от того, превышает ли системная частота значение 33,3 МГц.
Вышеперечисленные частоты синхронизации в той или иной степени взаимосвя-
заны между собой. В синхронных чипсетах частоты соседних подсистем связаны
жестко, как правило, простыми отношениями вроде 1:2, 1:3, 2:3. В асинхронных
чипсетах частоты относительно независимы, что открывает больше перспектив
для оптимизации производительности и «разгона» (overclocking) компьютера.
Разгоняют все, что можно: процессор, память, PCI, AGP и графический контрол-
лер. Мечта оверклокера — плата с асинхронным чипсетом и большим количеством
значений частоты для каждой подсистемы, что позволяет близко подходить к
физическому пределу быстродействия. «Породистые» платы (например, от Intel),
таких возможностей не предоставляют. Если штатные средства (джамперы или
настройки CMOS Setup) не позволяют выставить желаемые частоты, для разгона
иногда заменяют кварцевый резонатор на другой, обеспечивающий их при штат-
ных коэффициентах деления (умножения). Однако перепайка резонатора (как и
других компонентов) наверняка приведет к потере гарантии на системную плату.
Наиболее частый объект разгона — центральный процессор, теории и практике его
разгона посвящено много статей и сайтов Сети (например, iXBT.com). Изложен-
ные ниже взаимосвязи быстродействия компонентов, частоты, напряжения пита-
ния и рассеиваемой мощности применимы и к остальным подсистемам — памяти,
шинам расширения, порту AGP и самому графическому акселератору. Правда,
в этих подсистемах нет возможности «играть» напряжением питания (кроме неко-
торых моделей акселераторов). Для памяти и шин расширения повышение часто-
ты может приводить к уменьшению возможного числа устанавливаемых модулей
и карт расширения. Это вполне понятно, поскольку каждый модуль (карта рас-
ширения) вносит свою нагрузку на шину (активную и реактивную), что приводит
к затягиванию процессов переключения.
Вполне очевидно, что производительность конкретного процессора зависит от
тактовой частоты ядра и частоты системной шины. Первая составляющая опреде-
ляет темп обработки, а вторая — скорость доставки инструкций и данных. Макси-
мально допустимая тактовая частота определяется как задержками между раз-
личными сигналами, так и предельной рассеиваемой мощностью. К примеру, для
ячейки памяти после подачи адреса невозможно достоверно считать данные ра-
нее, чем через характерное для нее время доступа. Мощность, рассеиваемая циф-
ровыми схемами, возрастает с ростом частоты их переключений. Когда мощность,
выделяемая процессором, начинает превышать энергию, отводимую радиатором,
272
11. Применение процессоров в PC
процессор перегревается и начинает сбоить, а позже необратимо выходит из строя
(сгорает). Заметим, что чем меньше размеры элементов, тем меньше энергии не-
обходимо затратить на их переключение. Этим объясняется, что процессоры, вы-
полненные по более тонкой технологии (современный уровень — 0,18 мкм), ра-
ботают на более высоких частотах и потребляют меньшую мощность, чем их
предшественники (например, 0,25 мкм). Мощность, рассеиваемая процессором,
снижается и при понижении напряжения питания. Но при этом замедляются пе-
реходные процессы и, следовательно, снижается допустимая частота синхрониза-
ции (а снижение частоты, в свою очередь, уменьшает потребляемый ток). Повы-
шение тактовой частоты само по себе увеличивает потребляемую мощность, а для
стабильности работы (повышения быстродействия внутренней логики) может
потребоваться некоторое повышение напряжения питания, что даст дополнитель-
ное увеличение потребляемой мощности. Таковы, в общих чертах, причины вза-
имного влияния частоты, напряжения питания и выделяемой мощности. В со-
временных процессорах частота ядра определяется частотой внешней шины и
коэффициентом умножения. Возможность независимого выбора внешней часто-
ты синхронизации и внутреннего коэффициента умножения как раз и обеспечи-
вает условия «разгона» процессоров, а наличие управляемого регулятора напря-
жения позволяет подобрать подходящее питание.
Если вы хотите поэкспериментировать с «разгоном», соблюдайте осторожность.
Не пытайтесь удвоить скорость, есть «разумные» пределы. Не повышайте сразу
напряжение питания, проверьте степень нагрева процессора и радиатора стаби-
лизатора напряжения после повышения частоты. Кстати, перегреть можно не толь-
ко сам процессор — может расплавиться пластмассовый сокет. Если работа неста-
бильна, проверьте установки временных характеристик для ОЗУ и кэша в CMOS
Setup. Повышать напряжение имеет смысл, только если температура приемлема,
а работа неустойчива. При этом следует помнить, что повышение напряжения
может и не привести к устойчивой работе.
Разогнанный процессор может нормально тестироваться программами типа
Checklt, PCCheck, но устойчивая работа компьютера возможна далеко не всегда.
Проверкой работоспособности системы может стать длительная активная работа
с каким-либо «тяжелым» приложением, например, в среде Windows 95 или NT,
лучше в многозадачном режиме. Поскольку разгоном чаще всего пользуются для
ускорения игр, признаком работоспособности может быть и длительное устойчи-
вое функционирование игры в демонстрационном режиме. Причиной неустойчи-
вой работы может являться недостаточное быстродействие динамической памя-
ти и вторичного кэша (в Pentium II его, возможно, придется отключить). Эффект
от «разгона» процессора может нивелироваться относительно медленной памя-
тью, поскольку при переходе на более высокую частоту системной шины BIOS
совместно с чипсетом увеличит число тактов ожидания в циклах памяти. Измене-
ние частоты системной шины может приводить и к снижению частоты шины PCI,
что также понизит производительность компьютера в целом.
При тщательном подборе всех компонентов возможна ситуация, когда разогнан-
ный компьютер будет устойчиво работать в реальных приложениях. Если это не
11.3. Охлаждение процессоров
273Ь
так, то при сбоях, «зависаниях» и «вылетах» не ругайте команду Билла Гейтса (для
этого есть масса других поводов), а восстановите «статус кво». Стоит ли риско-
вать из-за 10 % прироста производительности в ответственных применениях, ре-
шайте сами. Следует иметь в виду, что фирма-производитель ставит маркировку
частоты, исходя из обоснованных критериев качества и надежности.
11.3. Охлаждение процессоров
Вопрос охлаждения процессора стал актуальным, начиная с процессоров 486. Про-
цессор 486SX-33 еще не требовал установки специального радиатора. Однако с
повышением тактовой частоты мощность, рассеиваемая процессором, возрастает.
Кроме того, потребляемая мощность зависит от интенсивности работы процессора:
разные инструкции задействуют различные части процессора, и при увеличении
доли «энергоемких» инструкций мощность, рассеиваемая процессором, повыша-
ется. Существуют даже специальные тестовые программы для проверки теплово-
го режима, способные перегреть процессор с недостаточным охлаждением и дове-
сти его до сбоев и даже разрушения.
Для охлаждения процессоров применяют радиаторы {Heat Sink — теплоотводы).
Радиатор эффективно работает, только если обеспечивается его плотное прилега-
ние к верхней поверхности корпуса процессора (даже тонкий воздушный зазор
значительно снижает теплопроводность). Весьма эффективно использование теп-
лопроводной мастики, которую наносят тонким слоем на корпус процессора, после
чего радиатор «притирают» к процессору. Хорошие результаты дает и приклеи-
вание радиатора к процессору двусторонней «самоклейкой», но только специ-
ально предназначенной для этих целей, поскольку обычные «липучки» не термо-
стойки и имеют большое тепловое сопротивление. Когда пассивного теплоотвода,
обеспечиваемого радиатором, рассчитанным на естественную циркуляцию возду-
ха внутри корпуса компьютера, оказывается недостаточно, применяют активные
теплоотводы (Cooler, Fan). Они имеют вентиляторы, устанавливаемые на радиа-
тор процессора или на сам процессор. Вентиляторы обычно являются съемными
устройствами, питающимися от источника +12 В через специальный переход-
ной разъем. Размеры (габаритные и установочные) вентиляторов и радиаторов
для процессоров 486, Pentium (они разные для процессоров 60-66, 75-180 и
200-233 МГц), Pentium Pro, Pentium II/III, Celeron различаются — чем новее про-
цессор, тем больше радиатор и вентилятор. Процессор Pentium 4 только подтвер-
ждает это правило.
Для особо горячих процессоров (в основном для их разгона) применяют и полу-
проводниковые холодильники на модулях, использующих эффект Пельтье. Хо-
лодильник Пельтье работает тепловым насосом: он отбирает тепло с одной сторо-
ны модуля и выделяет его на другой стороне, обеспечивая разность температур до
нескольких десятков градусов. При этом он и сам потребляет значительную мощ-
ность, соизмеримую с потребляемой мощностью охлаждаемого элемента (то есть
десятки ватт), и выделяет ее в виде тепла. Таким образом, вентилятор, обдувающий
274
11. Применение процессоров в PC
радиатор холодильника Пельтье, должен выносить из корпуса компьютера зна-
чительно больше тепла, чем выделяет сам процессор. Это является расплатой за
возможность охлаждения отдельных элементов до температуры, меньшей, чем
температура окружающего воздуха. Здесь имеются и побочные эффекты — на
холодной части может конденсироваться влага, что чревато утечками тока (замы-
канием проводников). Холодильник питается либо от общего блока питания ком-
пьютера (по линии +5 В), либо от отдельного источника питания. Холодильник
может быть управляемым и неуправляемым; в управляемом холодильнике имеет-
ся термодатчик, который включает холодильник лишь при определенном пороге
температуры охлаждающей стороны. Неуправляемый холодильник может замо-
розить процессор (до зависания) при переходе процессора в энергосберегающий
режим. Отключенный (вышедший из строя) холодильник представляет собой
теплоизолятор, под которым процессор, работающий на полной мощности, может
сгореть. Цена холодильника зависит от его мощности и на 2000 год составляет
несколько десятков долларов.
Стандарт конструктива АТХ предусматривает установку процессора прямо под
блоком питания, при этом для обдува радиатора могут использоваться: внутрен-
ний вентилятор блока питания, дополнительный внешний вентилятор, устанав-
ливаемый снаружи блока питания, вентилятор процессора. Теоретически все они
должны работать согласованно — на обдув воздухом радиатора процессора. В про-
тивном случае их суммарная эффективность падает. При наличии большого ра-
диатора в корпусе АТХ можно обойтись и без отдельного вентилятора на процес-
соре.
Процессоры Р6 имеют внутренний датчик температуры, аварийно останавливаю-
щий процессор в случае перегрева. Для измерения температуры процессоры Р6
имеют термодиод, его анод и катод выведены на контакты процессора. В процес-
соре Хеоп к термодиоду подключен встроенный электронный термометр, который
при перегреве вырабатывает сигнал, используемый для генерации прерывания.
Вентиляторы современных процессоров могут иметь датчик вращения, выраба-
тывающий пару импульсов за один оборот. Сигнал датчика выведен на разъем
питания вентилятора, обработка сигнала возлагается на компоненты системной
платы. Системная плата со встроенными средствами мониторинга позволяет про-
граммно измерять температуру процессора (по термодиоду), частоту вращения
вентиляторов, а в критической ситуации вырабатывать прерывание для оповеще-
ния ОС и пользователя.
Большинство современных процессоров допускают температуру до +85 °C (Pentium
допускали до +70 °C). Температура измеряется в центре верхней поверхности кор-
пуса процессора (не радиатора!) в установившемся рабочем режиме. Процессоры
для мобильных применений обычно имеют меньшую потребляемую мощность и
более высокую допустимую температуру корпуса. Существуют специальные ис-
полнения процессоров, допускающих расширенный температурный диапазон.
Они, естественно, дороже обычных и в PC применяются довольно редко.
11.3. Охлаждение процессоров
275
Остальные компоненты, требующие отвода тепла, охлаждаются аналогично про-
цессорам — радиаторами, вентиляторами, а то и холодильниками Пельтье. Общие
соображения по тепловому режиму системного блока довольно просты.
♦ Просторный системный блок позволяет легче обеспечить нормальный режим
охлаждения всех компонентов.
♦ На пути воздушных потоков не должно быть препятствий в виде непроходи-
мых «джунглей» проводов и шлейфов. Вентиляционные отверстия в корпусе
не должны быть перекрыты.
♦ Два и более вентилятора, гоняющих воздух по одному пути, должны работать
согласованно (не гнать воздух навстречу друг другу).
♦ Сильно нагревающиеся компоненты следует по возможности отдалять от дру-
гих, особенно чувствительных к нагреву.
♦ Периодически следует чистить компьютер — пыль, оседающая на компонен-
тах (в том числе и радиаторах), препятствует их охлаждению. Нельзя допус-
кать попадания посторонних предметов (обрывков бумаги, а также проводов и
шлейфов) в лопасти вентиляторов.
Системная плата может иметь входы для подключения датчиков температуры.
Датчик на гибком кабеле должен входить в комплект поставки платы. Установив
датчик на критичном устройстве (винчестере, графической карте), можно наблю-
дать за его температурой с помощью утилиты CMOS Setup или специальной за-
гружаемой утилиты. Если позволяет ПО, то можно настроить и порог предупреж-
дения о критической температуре.
Вентилятор как электромеханическое устройство принципиально имеет мень-
шую надежность (срок жизни), чем процессор и другие электронные компоненты.
С вентиляторами могут быть связаны неприятности разной степени тяжести — от
повышенного шума при работе до отказа (остановки). От повышенного шума по-
могает периодическая смазка оси вентилятора. Для смазки вентилятор приходит-
ся снимать с радиатора (или корпуса блока питания); место смазки подшипника
закрыто наклейкой-шильдиком. Смазывать подшипник можно обычным машин-
ным маслом (жидким). Для чистки вала и подшипников приходится еще и сни-
мать ротор, для чего необходимо снять фиксирующую шайбу, находящуюся под
той же наклейкой. Снизить шум от вибрации вентилятора можно смягчением его
крепления — установке демпфирующих шайб и другими «домашними» метода-
ми. Вентилятор на пониженных оборотах шумит меньше (но и дует слабее) — на
этом основано «интеллектуальное» управление (fan processing), реализуемое до-
вольно простыми средствами. Частой причиной остановки вентилятора является
касание лопастями вентилятора внутренних соединительных проводов (интер-
фейсных шлейфов дисков и кабелей для подключения кнопок и индикаторов ли-
цевой панели). Поэтому рекомендуется после сборки компьютера подвязывать
провода к шасси корпуса — целее будут и вентилятор, и провода. Существуют вен-
тиляторы с сигнализацией неисправности: они имеют датчик вращения и про-
стенькую вмонтированную плату электроники. Эта плата включается между
разъемом стандартного динамика PC и самим динамиком. При остановке венти-
276
11. Применение процессоров в PC
лятора динамик начинает пищать. Признаком наличия такого устройства являет-
ся характерная «мелодия», звучащая при включении питания (ее невозможно спу-
тать с однотональными «писками» диагностики POST).
11.4. Мультипроцессорные
и избыточные системы
В современных ПК встречаются варианты установки нескольких (двух или более)
процессоров на одной системной шине. При этом возможна мультипроцессорная
(SMP — Symmetric Multi-Processing) конфигурация и системы с избыточным кон-
тролем функциональности (FRC — Functional Redundancy Checking). Платы для
симметричных мультипроцессорных систем (пятого и шестого поколений) име-
ют пару сокетов (слотов). В них устанавливают процессоры, пригодные для ис-
пользования в таких конфигурациях. До недавних пор в мультипроцессорных
системах применялись только процессоры фирмы Intel — конкурирующие фир-
мы (AMD, Cyrix и IBM) мультипроцессированием не занимались. Эту «тради-
цию» нарушила фирма AMD своим новым процессором Athlon. Шина процессо-
ров Р6 поддерживает непосредственное объединение до четырех процессоров
(Pentium Pro и Хеоп), но на системных платах больше двух слотов обычно не раз-
мещают (не хватает места). В четырехпроцессорных системах чаще применяют
двухпроцессорные модули, устанавливаемые в общую системную плату или кросс-
плату. Следует помнить, что в симметричных мультипроцессорных системах внут-
ренние частоты всех процессоров должны совпадать (внешняя частота у них одна,
поскольку исходит от общего генератора синхронизации). Для этих целей лучше
брать все процессоры с одним степпингом и одинаково устанавливать для них
конфигурационные джамперы.
11.4.1. Симметричные мультипроцессорные
системы
Процессоры Pentium (начиная со второго поколения) имеют специальные интер-
фейсные средства для построения мультипроцессорных систем (с двумя и более
процессорами). Целью объединения процессоров является достижение симмет-
ричной мультипроцессорной обработки SMP (Symmetric Multi-Processing). В сим-
метричной системе SMP каждый процессор выполняет свою задачу, порученную
ему операционной системой. Поддержку SMP имеют такие ОС, как Novell NetWare,
Microsoft Windows NT и различные диалекты UNIX. Процессоры, объединенные
общей локальной шиной, разделяют общие ресурсы компьютера, включая память
и внешние устройства. В каждый момент времени шиной может управлять толь-
ко один процессор, по определенным правилам они меняются ролями.
Поскольку каждый из процессоров имеет свой внутренний первичный кэш, ин-
терфейс обязан поддерживать согласованность данных во всех иерархических сту-
пенях оперативной памяти — в первичном и вторичном кэшах и основной памяти
11.4. Мультипроцессорные и избыточные системы
277
(в Pentium вторичный кэш у процессоров общий). Эта задача решается с помо-
щью локальных циклов слежения, воспринимаемых процессором, даже не управ-
ляющим шиной в данный момент.
Для обработки аппаратных прерываний в многопроцессорных системах традици-
онные аппаратные средства становятся непригодными, поскольку прежняя схема
подачи запроса INTR и передачи вектора в цикле INTA# явно ориентирована на
единственность процессора. Для решения этой задачи в процессоры, начиная со
второго поколения Pentium, введен расширенный программируемый контроллер
прерываний APIC (Advanced Programmable Interruption Controller). Этот контрол-
лер имеет внешние сигналы локальных прерываний LINT[1:0] и трехпроводную
интерфейсную шину (PICD[1:0] и PICCLK), по которым процессоры связываются с
контроллером APIC системной платы. Для локальных запросов прерываний про-
цессоры имеют линии UNTO, LINT1. Локальные прерывания обслуживаются толь-
ко тем процессором, на выводы которого поступают сигналы их запросов. Общие
(разделяемые) прерывания (в том числе и SMI) приходят к процессорам в виде
сообщений по интерфейсу APIC. При этом контроллеры предварительно програм-
мируются — тем самым определяются функции каждого из процессоров в случае
возникновения того или иного аппаратного прерывания. Контроллеры APIC каждо-
го из процессоров и контроллер системной платы, связанные интерфейсом APIC,
выполняют маршрутизацию прерываний (Interrupt Routing), причем как статичес-
кую, так и динамическую. Внешне программный интерфейс обработки прерываний
остается совместимым с управлением контроллером 8259А, что обеспечивает про-
зрачность присутствия APIC для прикладного программного обеспечения.
Симметричные системы имеют специальные механизмы арбитража доступа к
локальной шине. Процессор — текущий владелец шины — отдаст управление
шиной другому процессору по его запросу только по завершении операции. Сбло-
кированные циклы не могут прерываться другим процессором, кроме случая, ког-
да обращение к памяти попадает в область, модифицированный образ которой
находится в кэше другого процессора. В таком случае этому процессору отдается
управление для выполнения обратной записи из кэша.
Мультипроцессорные системы в принципе могут использовать процессоры раз-
личного степпинга, но частоты ядра у них должны совпадать (шина, естественно,
синхронизируется общим сигналом).
Возможности и способы реализации SMP зависят от модели процессора. Заметим,
что средства поддержки SMP в семействе х86 имеются только у процессоров Intel.
Интерфейс Pentium (начиная со второго поколения) позволяет на одной локаль-
ной системной шине устанавливать два процессора, при этом почти все их одно-
именные выводы просто непосредственно объединяются. Роль конкретного про-
цессора в системе фиксирована — она определяется внешними сигналами во время
спада сигнала RESET. Один из процессоров назначается первичным (Primary)
или загрузочным (BSP — Bootstrap Processor), другой — вторичным (DP — Dual
Processor). После сигнала RESET сразу начинает функционировать только первич-
ный процессор (BSP), выполняя программный код инициализации. Второй про-
цессор начнет функционирование только после приема соответствующего сооб-
щения по шине APIC, посланного под управлением программы инициализации.
278
11. Применение процессоров в PC
Циклы слежения выполняются по сигналу ADS#, генерируемому другим процессо-
ром. Ответами на локальные циклы слежения являются сигналы PHIT# и PHITM#,
а роль сигналов HIT# и HITM# остается прежней — они используются во внешних
(по отношению к обоим процессорам) циклах слежения, инициируемых сигнала-
ми EADS#.
Арбитраж доступа выполняется с помощью «приватных» сигналов запроса (PBREQ#)
и подтверждения передачи (PBGNT#) управления локальной шиной. Сигналы
обычного системного арбитража (HOLD, HLDA, BOFF#) в двухпроцессорной систе-
ме действуют обычным образом, но воспринимаются и управляются поочередно
текущим владельцем локальной шины.
Режим обработки прерываний посредством APIC разрешается сигналом APICEN
по аппаратному сбросу, впоследствии он может быть запрещен программно.
В процессорах Р6 заложены более развитые возможности SMP. Системная шина
Р6, в отличие от локальной шины Pentium, изначально ориентирована на разде-
ляемое управление множеством симметричных (до четырех на шине) и несиммет-
ричных (до восьми) агентов. Сокет 8 (Pentium Pro) и слот 2 (Pentium II Хеоп)
позволяют объединять до четырех процессоров, слот 1 (Pentium II) допускает
объединение не более двух процессоров. Процессоры Pentium II OverDrive для
сокета 8 тоже допускают объединение не более двух процессоров. Фирма Intel
объясняет это ограничение большой паразитной индуктивностью контактов со-
кета (на первый взгляд это неубедительно, поскольку внешняя шина работает на
тех же частотах, что и у Pentium Pro). Какой из процессоров станет первичным
(BSP), определяется по загрузочному протоколу, — здесь нет жесткой аппаратной
привязки роли процессора к его «географическому» адресу. Это позволяет повы-
сить надежность SMP-системы, поскольку любой процессор может без механичес-
кого вмешательства во время инициализации взять на себя роль BSP. Протокол
мультипроцессорной инициализации работает на шине APIC, он позволяет управ-
лять инициализацией до 15 процессоров. Арбитраж процессоров выполняется с
помощью сигналов BREQ#[0:3] согласно общему протоколу. Процессоры могут
пользоваться содержимым «чужого» кэша без его предварительной выгрузки в
основную память.
Из процессоров Р6 для симметричных систем предназначены Pentium Pro (до 4
процессоров), Pentium П/Ш (двухпроцессорные системы) и Pentium П/Ш Хеоп
(до 4 на шине и до 8 в системе). Процессоры Celeron официально предназначены
лишь для однопроцессорных конфигураций. Однако реально сигнал BR1# у про-
цессоров имеется, правда, не там, где хотелось бы. У процессоров в корпусе PGA
он выведен на контакт AN15 (в сокете-370 для Pentium III вывод AN15 предназна-
чен для питания терминаторов VTT). Если использовать такой процессор с пере-
ходником в слот 1 (для двухпроцессорной системной платы), то на переходнике
достаточно организовать связь контакта В75 краевого разъема с контактом AN 15
процессорного сокета. Это сделать совсем несложно, если на месте В75 имеется
контактная ламель и печатная дорожка, заканчивающаяся переходным контактом
(отверстие с металлизацией). Если ламель есть, но без проводника, то подпаять к
ней провод так, чтобы переходник нормально вставлялся в слот, несколько слож-
11.4. Мультипроцессорные и избыточные системы
279
нее. Есть и переходники, подготовленные к дуальному использованию Celeron
самим изготовителем — на них имеется специальный джампер для штатного и
нештатного назначения контакта В75. На процессорах в картриджах SEPP контакт
В75 соединен с шиной VCC_CORE (на субстрате), а сигнал BR1# имеется только на
кристалле ядра. Умельцы ухитряются освобождать контакт В75 и соединять его с
выводом сигнала BR1 # кристалла ядра. Таким образом, удается использовать Celeron
и в двухпроцессорных системах, что привлекательно, учитывая его дешевизну.
В симметричных мультипроцессорных системах фирма Intel не рекомендует ис-
пользовать различающиеся внутренние частоты для процессоров, подключенных
к одной шине (внешняя частота у них, естественно, должна быть единой). Возмож-
ность работы процессоров с разными частотами может не поддерживаться и опе-
рационной системой с SMP.
Из «не-интеловских» процессоров х86 возможность работы в SMP имеют пока
только процессоры Athlon фирмы AMD (кроме первой модели).
11.4.2. Системы с избыточным
контролем функциональности
В конфигурации с избыточным контролем функциональности FRC (Functional
Redundancy Checking) два процессора (пара Master/Checker) выступают как один
логический. Основной процессор (Master) работает в обычном однопроцессорном
режиме. Проверочный процессор (Checker) выполняет все те же операции «про
себя», не управляя шиной, и сравнивает выходные сигналы основного (проверяемо-
го) процессора с теми сигналами, которые он генерирует сам, выполняя те же опе-
рации без выхода на шину. В случае расхождения вырабатывается сигнал ошибки
(IERR# в Pentium, FRCERR в Р6), который может обрабатываться как прерывание.
Поддержка FRC появилась, начиная с процессоров Pentium (но в Pentium ММХ
ее нет); она имеется и у процессоров фирмы AMD.
Приложение 1. Команды
процессоров х86
Порядок описания команд в этом приложении следующий:
♦ в заголовок вынесена схема команды, поясняющая общий набор и назначение
операндов;
♦ в следующей строке дается название команды, расшифровка ее мнемоники и
назначение;
♦ далее следует синтаксис команды (сложный синтаксис приводится в виде ди-
аграмм), при описании которого используются следующие обозначения:
• г8, г 16, г32 — операнд в одном из регистров размером байт, слово или двой-
ное слово;
• rxmm0..rxmm7 — операнд в одном из регистров расширения ММХ с плаваю-
щей точкой;
• rmmx0..rmmx7 — операнд в одном из регистров целочисленного расширения
ММХ;
• т8, m16, m32, т48, т64 — операнд в памяти размером байт, слово, двойное
слово или 48 бит;
• i8, i16, i32 — непосредственный операнд размером байт, слово или двойное
слово;
• а8, а16, а32 — относительный адрес (смещение) в сегменте кода;
♦ машинный код для всех сочетаний операндов описываемой команды (при
сложном синтаксисе машинный код включается в синтаксис);
♦ состояние флагов после выполнения команды;
♦ описание действия команды;
♦ описание флагов после выполнения команды, при этом приводятся сведе-
ния только о флагах, изменяемых командой, и используются следующие
обозначения:
• 1 — флаг устанавливается (равен 1);
• 0 — флаг сбрасывается (равен 0);
• г — значение флага зависит от результата выполнения команды;
• ? — после выполнения команды флаг не определен;
♦ список исключений.
П1.1. Целочисленные команды
281
На многих диаграммах в целях компактности возможные сочетания операндов
показаны в виде следующей конструкции:
—|т8,16,32[-0Ч г8,16,32 |—
Конструируя команду на основе подобной синтаксической диаграммы, вы долж-
ны помнить о соответствии типов. Допустимы только следующие сочетания: «г8,
т8», «г 16, т16», «г32, т32», а сочетание, например, «г8, т16» недопустимо. Одна-
ко есть единичные случаи, когда подобные сочетания возможны; тогда они огова-
риваются специальным образом.
Описание машинного кода приводится в двух вариантах.
♦ В двоичном виде. Это описание применяется для демонстрации особенностей
внутренней структуры машинной команды. Байты машинного представления
машинной команды отделяются двоеточием.
♦ В шеснадцатеричном виде. Каждый байт машинного представления команды
представлен двумя шестнадцатеричными цифрами. Часто за одним (двумя и
более) первым байтом следует обозначение: /цифра. Это означает, что поле reg
в байте modr/m используется как часть кода операции и цифра представляет
содержимое этого поля.
Вместо цифры может стоять символ «г» - /г. Как уже не раз отмечалось, большин-
ство команд процессора - двухоперандные. Один операнд располагается в регис-
тре, местоположение другого операнда определяет байт ModR/M - это может быть
либо регистр, либо ячейка памяти. Более того, если операнд - ячейка памяти, то
содержимое байта ModR/M определяет номенклатуру компонентов машинного кода
команды, которые должны использоваться для вычисления эффективного адреса.
При описании команд могут быть опущены некоторые из перечисленных пунк-
тов. Например, отсутствие пункта «синтаксис» говорит о том, что он совпадает со
схемой команды. Отсутствие пункта «исключения» означает, что при выполнении
данной команды исключения не возникают. То же касается описания флагов.
Некоторые регистры программной модели процессора имеют внутреннюю струк-
туру. Указание того, о каком поле такого регистра идет речь, показано следующим
образом: имя_регистра.имя_поля.
П1.1. Целочисленные команды
ААА
AAA (Ascii Adjust after Addition) — корректировка результата сложения однораз-
рядных неупакованных BCD-чисел командой ADD.
Машинный код: 37
Действие: если младший полубайт регистра al>9 или af=1, то (al)=(al)+6; (ah)=ah+1;
af=1, cf=1. В противном случае af=cf=O. В обоих случаях (al)=(al) AND Ofh.
Флаги: OF=? SF=? ZF=? AF=r PF=? CF=r
282
Приложение 1. Команды процессоров х86
AAD
AAD (Ascii Adjust АХ before Division) — подготовка двузначного неупакованного
BCD-числа в регистре АХ для операции деления.
Машинный код: D5 ОА
Действие: (AL)=(AHx10)+AL; (AH)=00h.
Замечание: микропроцессор воспринимает другой машинный код этой команды,
не имеющий мнемоники, — D5 i8. Ее действие: (AL)=(AHxi8)+AL; (AH)=00h.
Флаги: OF=? SF=r ZF=r AF=? PF=r CF=?
AAM
AAM (Ascii Adjust AX AFter Multiply) — коррекция результата умножения двух
неупакованных BCD-чисел.
Действие: разделить содержимое регистра AL на 10; частное записать в регистр АН,
остаток в регистр AL.
Машинный код: D4 ОА
Замечание: микропроцессор воспринимает другой машинный код этой команды -
D4 i8 (без мнемоники). Ее действие: разделить содержимое регистра AL на i8; част-
ное записать в регистр АН, остаток — в регистр AL. Если i8=0, то микропроцессор
генерирует исключение #DE — ошибка деления.
Флаги: OF=? SF=r ZF=r AF=? PF=r CF=?
AAS
AAS (Ascii Adjust AL AFter Substraction) — коррекция результата вычитания ко-
мандой SUB двух неупакованных одноразрядных BCD-чисел.
Действие: если младший полубайт регистра AL>9 или флаг AF=1, то выполняются
действия: значение младшего полубайта AL уменьшается на 6; АН=АН-1; флаги AF
и CF устанавливаются в 1. Если ни одно из этих условий не присутствует, то AAS
устанавливает флаги AF=CF=0. В обоих случаях значение старшего полубайта ре-
гистра AL обнуляется.
Машинный код: 3F
Флаги: OF=? SF=? ZF=? AF=r PF=? CF=r
ADC приемник, источник
ADC (Addition with Carry) — сложение с учетом значения флага переноса CF.
Действие: приемник=приемник+источник+СР.
Флаги: OF=r SF=r ZF=r AF=r PF=r CF=r
Исключения: PM: #GP(0): 1, 2,3; #SS(0): 1; #PF(fault-code); #AC(0) RM; #GP: 1;
#SS: 1 VM; #GP(0): 1; #SS(0): 1; #PF(fault-code), #AC(0).
П1.1. Целочисленные команды
283
—| adc [
~~i8~~|------JJ/j
~йб~|--------
i32 I--------
ts. 16,32 t~fj
r8,16,32 — [OOO1 OOdw j _1l"req1_recj2J
m8,16,32 — roOOWOiw : mod req r/m[
----|m8,16,32[~O~rl >3.16.32 P [j^OOOOswTmo^^^
4 r8,16,32 |—fooOIOOQw: mod req r7m[
ADD приемник, источник
ADD (ADDition) — сложение двух целочисленных двоичных операндов.
— add
Гроооо!^
r8,16,32 |О-г| i8,16,32 |—
-| г8,16,32 |— fpOOOOOdwj Jj reglrecjij
-| m8,16,32]— •0000001w : mod req r7m[
----|m8,16,32 |~Ot~I >8,16,32 |— [ 1 OOOOOswj mod_^(^r/m_:J87{6/32^
L| r8,16,32"|— jodobbbbw : mod req r7m[
Действие: приемник=приемник+источник. При переполнении приемника флаг CF
устанавливается в 1.
Флаги: OF=r SF=r ZF=r AF=r PF=r CF=r
Исключения: PM: #GP(0): 1, 2,3; #SS(O): 2; #PF(fault-code); #AC(0) RM: #GP: 1;
#SS: 1 VM: #GP(0): 1, #SS(O): 1, #PF(fault-code), #AC(0).
AND приемник, источник
AND (logical AND) — логическое И.
Действие: приемник=приемник AND источник.
Флаги: OF=0 SF=r ZF=r AF=? PF=r CF=O
Исключения: PM: #GP(0): 2,4,5; #SS(O): 1; #PF(fault-code); #AC(0) RM: #GP: 1;
#SS: 1 VM: #GP(0): 1, #SS(O): 1, #PF(fault-code), #AC(0).
284
Приложение 1. Команды процессоров х86
and
al
И 6
□2
ax
eax
г8,16,32 К>т 18,16,32
г8,16,32
т8,16,32
Г0011001_00_:_ _ _ _ i8_;
[j OQOOOsw : Jj_i_OO rec[ £ ij
[001 OOOdwj Jj reqljecj2 J
[OOlOOOiwj mod req r/_m|
_8/16/3_2__[
----|m8,16,32pQrl i8'16>32 |— !j OOOOOswjmod Jj^r/m_:j8/i6/32]
4 r8,16,32~|— [OO10OOOwj mod req r/m]
10000011 : mod 100 r/m :
i8
ARPL приемник, источник
ARPL (Adjust RPL field of segment selector) — настройка поля RPL селектора.
-| arpl (-j-|~r16 |<>{7пП-foil'
4 m16 |O-| r16 j- LQLtoAOfi jjpod _reg _r/m _l
Действие: операнд приемник содержит селектор вызываемой программы, операнд
источник — селектор вызывающей программы. Команда ARPL сравнивает биты
RPL селектора приемника с битами RPL селектора источника и в зависимости от
результатов этого сравнения выполняет действия:
♦ если RPL-приемника < RPL-источника, то: ZF=1; (RPL-npneMHHKa)=(RPL-ncTO4HHKa).
♦ если RPL-приемника > RPL-источника, то: ZF=O.
Флаги: ZF=r
Исключения: PM: #GP(0): 1, 2, 5; #SS(O): 1; #PF(fault-code); #AC(0) RM: #UD:
1 VM: #UD: 1.
BOUND индекс, границы массива
BOUND (check array index against BOUNDs) — контроль нахождения индекса
массива в границах.
bound
LQLLQpp_ip_?^
Действие: сравнить значение в 16/32-разрядном регистре индекс с двумя значе-
ниями нижний_индекс и верхний_индекс-^размер_операнда_в_байтах. Значения
нижний_индекс и верхний_индекс расположены последовательно в двух ячейках
П1.1. Целочисленные команды
285
памяти размером слово/двойное слово, адресуемых операндом границы массива.
Если в результате проверки значение из регистра вышло за пределы указанного
диапазона значений, то возбуждается прерывание с номером 5, если нет — програм-
ма продолжает выполнение.
Исключения: PM: #GP(0): 2, 5; #BR #SS(0): 1; #PF(fault-code); #AC(0) #UD: 1
RM: #BR #UD: 2; #GP: 1; #SS: 1 VM: #BR #UD: 1 #GP(0): 1; #SS(0): 1; #PF(fault-
code); #AC(0).
BSF результат, источник
BSF (Bit Scan Forward) — определение номера позиции в операнде источник край-
него справа единичного бита.
П6,т16 к--ГббббГЩ: Wffi 1 991П?Й jeg г/m •
r32,m32 P iQQQQ W j ItQtW 9Q’J_1_refli?_rPgj]
Действие: просмотр битов операнда источник, начиная с младшего. Номер пози-
ции первого единичного бита слева записывается в регистр результат, флаг ZF
устанавливается в 0. Если единичных битов нет, то флаг ZF=1, регистр результат
не определен.
Флаги: OF=? SF=? ZF=r AF=? PF=? CF=?
Исключения: PM: #GP(0): 2, 5; #SS(0): 1; #PF(fault-code); #AC(0) RM: #GP: 1;
#SS: 1 VM: #GP(0): 1; #SS(0): 1; #PF(fault-code); #AC(0).
BSR результат, источник
BSR (Bit Scan Reverse) — определение номера позиции крайнего слева единично-
го бита в операнде источник.
bsr
г16
"г32
r16,m16 к— lQQQQWJ11QV31 91 :mod _г§9 -г/г0 ]
г32,т32Р iQQQQ W 3110ffil 91 LtVesi?~грЬЗ J
Действие: команда просматривает биты операнда источник, начиная со старшего
бита 15/31, и если встретился единичный бит, то флаг ZF устанавливается в 0, а в
регистр результат записывается номер позиции (отсчет осуществляется относи-
тельно нулевой позиции), в которой встретился единичный бит. Если единичных
битов нет, то флаг ZF устанавливается в 1. Диапазон значений результата зави-
сит от разрядности второго операнда: для 16/32-разрядных операндов это, соот-
ветственно, 0...15/0...31.
Флаги: OF=? SF=? ZF=r AF=? PF=? CF=?
Исключения: PM: #GP(0): 2, 5; #SS(0): 1; #PF(fault-code); #AC(0) RM: #GP: 1;
#SS: 1 VM: #GP(0): 1; #SS(0): 1; #PF(fault-code); #AC(0).
286
Приложение 1. Команды процессоров х86
BSWAP источник
BSWAP (Byte SWAP) — изменение порядка следования байт операнда источник.
Исходное состояние г32
О_______8_________16_______24_______Ц
И , а I 2 , с I 3 ,4 I 5 f I
_______________\L w__________________
I 5 f I з , 4 I 2 , с I 1 , a I
Состояние r32 после выполнения команды
Синтаксис: bswap г32
Машинный код: 0000111 Г. 11001 г32
ВТ источник, индекс
ВТ (Bit Test) — определение значения конкретного бита в операнде источник.
_______t f iQQOOII11 ;1_01_000_1_1_:mod regj7m]
r16j32 I *iOoo^TiiKoioOTjjiiiёйСreat
I Г [pOOOtlli’WlfLQj.OjffJPPjegJ.'ie'j
Действие: номер проверяемого бита операнда источник задается содержимым
операнда индекс. После выполнения команды флаг CF устанавливается значени-
ем проверяемого бита.
Флаги: OF=? SF=? ZF=? AF=? PF=? CF=r
Исключения: PM: #GP(0): 2, 5; #SS(O): 1; #PF(fault-code); #AC(0) RM: #GP: 1;
#SS: 1 VM: #GP(0): 1; #SS(O): 1; #PF(fault-code); #AC(0).
BTC источник, индекс
BTC (Bit Test and Complement) — определение и инвертирование значения задан-
ного бита в операнде источник.
—I btc
_____| (- ГбббО1_1_1 j ;1_01_1j 0j i :_mod reg r/_m ]
d.62?-J L r0000lTllK0lTipiirij ZregYregl •
.J.?-1 Г rpppoiTijJiFeg fje"’
L L POOQlfUJlQ
Действие: номер проверяемого бита операнда источник задается вторым операн-
дом индекс (значение из диапазона 0...31). После выполнения команды значение
П1.1. Целочисленные команды
287
выбранного бита инвертируется, а флаг CF устанавливается исходным значением
этого бита.
Флаги: OF=? SF=? ZF=? AF=? PF=? CF=r
Исключения: PM: #GP(0): 2,4,5; #SS(0): 1; #PF(fault-code); #AC(0) RM: #GP: 1;
# SS: 1 VM: #GP(0): 1; #SS(O): 1; #PF(fault-code); #AC(0).
BTR источник, индекс
BTR (Bit Test and Reset) — определение значения заданного бита в операнде
источник и сброс его в 0.
r16,32j
i8 -I г
‘ ljOr/m: jejj
Действие: номер проверяемого бита операнда источник задается операндом ин-
декс (значение из диапазона 0...31). После выполнения команды флаг CF устанав-
ливается исходным значением этого бита, а сам бит в 0.
Флаги: OF=? SF=? ZF=? AF=? PF=? CF=r
Исключения: PM: #GP(0): 2,4,5; #SS(0): 1; #PF(fault-code); #AC(0) RM: #GP: 1;
# SS: 1 VM: #GP(0): 1; #SS(0): 1; #PF(fault-code); #AC(0).
BTS источник, индекс
BTS (Bit Test and Set) — определение значения заданного бита в операнде источ-
ник и установка его в 1.
0000flii jpjpj0j j Fff reg2 regj]
Действие: номер проверяемого бита задается операндом индекс (значение из
диапазона 0...31). После выполнения команды флаг CF устанавливается исход-
ным значением этого бита, а сам бит в 1.
Флаги: OF=? SF=? ZF=? AF=? PF=? CF=r
Исключения: PM: #GP(0): 2,4,5; #SS(O): 1; #PF(fault-code); #AC(0) RM: #GP: 1;
# SS: 1 VM: #GP(0): 1; #SS(0): 1; #PF(fault-code); #AC(0).
CALL цель
CALL (CALL) — вызов процедуры или переключение задачи.
288
Приложение 1. Команды процессоров х86
Машинный код:
CALL ге116(32) - 11101000:смещ^16/32
CALL r16(32)/т 16(32) — 11111111:mod 010 г/т
CALL ptr16:16(32) — 10011010: смещение : сегмент
CALL т 16:16(32)- 11111111: mod 011 г/т
Действие: возможны следующие варианты задания операнда цель:
♦ rel 16/32 — близкий относительный переход. Значение rel 16/32 трактуется как
знаковое и является смещением перехода относительно следующей за CALL
команды в сегменте кода, то есть адрес_цели=(Е1Р/1Р)+(ге116/32). В стек зано-
сится содержимое EIP/IP;
♦ г 16/32 или m 16/32 — близкий абсолютный косвенный переход. Цель — г 16/32
или m 16/32, содержимое которых является смещением команды в текущем
сегменте кода, которой передается управление. В EIP/IP загружается содержи-
мое из г16/32 или т16/32. В стек заносится содержимое EIP/IP;
♦ m 16:16(32) — дальний абсолютный косвенный переход. Цель — адрес ячейки
памяти размером 32/48 бит со структурой m 16:16(32), содержащей компонен-
ты адреса перехода;
♦ ptr16:16(32) — дальний абсолютный переход. Цель — компоненты полного адре-
са в виде 4- или 6-байтного указателя, по которому необходимо произвести
переход.
Особенности выполнения команды CALL в двух последних вариантах определя-
ются режимом работы процессора:
♦ в реальном режиме или режиме виртуального 8086 (РЕ=О или (РЕ=1 и VM=1)) в
EIP/IP и CS загружаются значения смещения и адреса сегмента из указателя в
памяти или команде CALL. В стек заносится содержимое EIP/IP и CS;
♦ в защищенном режиме (РЕ = 1 и VM = 0) анализируется байт прав доступа AR в
дескрипторе целевого сегмента. В зависимости от его значения производится
пять типов перехода к цели:
• передача управления подчиненному сегменту кода;
• передача управления неподчиненному сегменту кода;
• передача управления через шлюз вызова;
• переключение задачи (селектор соответствует дескриптору — шлюзу задачи);
• переключение задачи (селектор соответствует дескриптору — сегменту TSS).
Флаги (кроме переключения задачи): не изменяются.
При переключении задачи значения флагов изменяются содержимым регистра
EFLAGS в сегменте состояния TSS задачи, на которую производится переключение.
Исключения: PM: # АС(0); #GP(0): 2,3,6,7,8; #GP(selector): 2,3,4,5,6,7,8,9,10,11;
#NP(seIector): 1; #PF(fault-code); #SS(O): 1,2; #SS(selector): 1,2,3; #TS(selector): 1,2,
3,4, 5, 6; RM: #GP: 1,2; VM: #AC(0); #GP(0): 1.
П1.1. Целочисленные команды
289
CBW
CBW (Convert Byte to Word) — преобразование байта в слово.
Действие: команда копирует знаковый бит регистра AL на все биты регистра АН.
Машинный код: 98
CDQ
CDQ (Convert Double word to Quad word) — преобразование двойного слова в
учетверенное слово.
Действие: команда копирует знаковый бит регистра ЕАХ на все биты регистра EDX.
Машинный код: 99
CLC
CLC (CLear Carry flag) — сброс флага переноса CF.
Машинный код: f8
Флаги: CF=0
CLD
CLD (CLear Direction flag) — сброс флага направления DF.
Машинный код: fc
Флаги: DF=0
CLI
CLI (CLear Interrupt flag) — сброс флага прерывания IF.
Машинный код: fa
Флаги: IF=0 (если CPL<=IOPL)
Замечания: флаг IF не сбрасывается, если (CR0.PE=1, CPL>IOPL и VM=0) или
(CR0.PE=1, ЮРКЗ и VM=1). Флаг IF и команды CLI и STI не влияют на генерацию
исключений и прерывания NMI.
Исключения: PM: #GP(0): 1; VM: #GP(0): 2.
CLTS
CLTS (CLear Task Switched flag in crO) — сброс флага переключения задач TS в
регистре CRO (бит 3) в 0.
Машинный код: Of 06
Исключения: PM: #GP(0): 10; VM: #GP(0): 3.
290
Приложение 1. Команды процессоров х86
СМС
CMC (CoMplement Carry flag) — инвертирование флага переноса CF.
Машинный код: f5
Флаги: CF=r
CMOVcc приемник, источник
CMOVcc (Conditional MOVe) — передача данных при выполнении условий, оп-
ределяемых состоянием соответствующих флагов.
| m16 I
ТЕЗГ}
l| IT132 I
LQf.42cw/cdi F
LQf 46 cw/cdi F
LQf 44 cw/cdi F
LQf 4tcw7cdJ F
iQ£4d cw/cdi F
LQf 4q cw/cdi F
LQf 4e cw/cdi F
7 - - -i-n 1 cmova/
S)147 cw/cdj F cmovnbe
cmovae/
LQf 43 cw/cdi F cmovnb/
cmovnc
cmovb/
cmovc/
cmovnae
cmovbe/
cmovna
cmove/
cmovz
cmovg/
cmovnle
cmovge/
cmovnl
cmovl/
cmovnge
cmovle/
cmovng
cmovne/
cmovnz
cmovno
cmovnp/
cmovpo
cmovns
LQf.45 cw/cdi F
LQf 41 cw/cdi F
LQf 4b cw/cdi F
LQf 49 cw/cdi F
LQf 40 cw/cdi Fl cmovo
LQf 4a cw/cdj F
rQf 48 cw/cdj F
cmovp/
cmovpe
cmovs
Действие: если состояние флагов (см. таблицу) соответствует условиям выпол-
нения команды, то произвести пересылку значения источника в приемник. В про-
тивном случае закончить выполнение команды без пересылки.
Мнемокод Значения флагов
CMOVA/CMOVNBE CF=O и ZF=O
CMOVAE/CMOVNB/CMOVNC CF=O
CMOVB/CMOC/CMOVNAE/ CF=1
П1.1. Целочисленные команды
291
Мнемокод Значения флагов
CMOVBE/CMOVNA CMOVE/CMOVZ CMOVG/CMOVNLE CMOVGE/CMOVNL CMOVL/CMOVNGE CMOVLE/CMOVNG CMOVNE/CMOVNZ CMOVNO CF=1 nnnZF=1 ZF=1 ZF=O и SF=OF SF=OF SFO0F ZF=1 или SFOOF ZF=0 OF=0
CMOVNP/CMOVPO CMOVNS PF=0 SF=0
CMOVO OF=1
CMOVP/CMOVPE CMOVS PF=1 SF=1
Исключения: PM: #АС(0): 1; #GP(0): 2,3; #PF(fault-code); #SS(0): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0): 1; #GP(0): 1; #PF(fault-code); #SS(0): 1.
CMP операнд1, операнд2
CMP (CoMPare two operands) — сравнение двух операндов.
10011101w £ mod reg_ r/m [
;_10000011 £ mod 111_ r/m : _ _ i8
•00111100_:_i8_____I
•ooiriioi^jj^^
rfow^
[00 llLOOdw I 1
•001 yjOOw £ mpd_reg_r/nj
Действие: операнды операнд1 и операнд2 сравниваются методом вычитания, при
этом сами операнды не изменяются. По результатам сравнения устанавливаются
флаги (см. SBB).
Флаги: OF=r SF=r ZF=r AF=r PF=r CF=r
Исключения: PM: #AC(0); #GP(0): 2, 3; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
292
Приложение 1. Команды процессоров х86
CMPS приемник, источник
CMPSB
CMPSW
CMPSD
CMPS/CMPSB/CMPSW/CMPSD (CoMPare String Byte/Word/Double word
operands) — сравнение цепочек байт/слов/двойных слов. Адреса сравниваемых
элементов цепочек предварительно загружаются: источника — в пару регистров
DS:ESI/SI; приемника — в пару регистров ES:EDI/DI.
—lcmPsbl—
ffoTo^
•wTooijJj
—|cmPsw|— [Tofoo111*
—lcmPsdl— fib’fooiijj
Действия:
1. Вычесть элементы {источник - приемник).
2. В зависимости от состояния флага DF изменить значение регистров ESI/SI и
EDI/DI: если DF=0 — содержимое этих регистров увеличивается на длину эле-
мента цепочки; если DF=1 — содержимое этих регистров уменьшается на дли-
ну элемента цепочки.
3. В зависимости от результата вычитания устанавливаются флаги: если элемен-
ты цепочек не равны, то CF=1, ZF=0; если элементы цепочек или цепочки в
целом равны, то CF=0, ZF=1.
4. При наличии префикса повторения выполнить определяемые им действия (см.
команды REPE/REPNE).
Флаги: OF=r SF=r ZF=r AF=r PF=r CF=r
Исключения: PM: #AC(0); #GP(0): 2, 3; #PF(fault-code); #SS(0): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(0): 1.
CMPXCHG приемник, источник
CMPXCIIG (CoMPare and eXCHanGe) — сравнение с аккумулятором и обмен.
Действие: если аккумулятор (AL/AX/EAX) и приемник не равны, то установить ZF=0;
переслать содержимое приемник в аккумулятор (AL/AX/EAX). Если аккумулятор и
приемник равны, то установить ZF=1; переслать источник в приемник.
Флаги: OF=r SF=r ZF=r AF=r PF=r CF=r
П1.1. Целочисленные команды
293
CQQQQX4JJllJ^lJZy^w:mpd_reg_r/rn]
ГООООfljl Г-TojjpOOwj if reg2 regi
Исключения: PM: #AC(0); #GP(0): 1,2,3; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #SS(O): 1.
CMPXCHG8B приемник
CMPXCHG8B (CoMPare and eXCHanGe 8 Bytes) — сравнение и обмен восьми байт.
Синтаксис: cmpxchg8b m64
Машинный код: 00001111 11000111 mod 001 г/т
Действия: сравнить содержимое регистров EDX:EAX и ячейки памяти приемник
(т64). Если (EDX:EAX)=(m64), то ZF=1, (m64)=(ECX:EBX). В противном случае ZF=O,
(EDX:EAX)=(m64).
Флаги: ZF=r
Исключения: PM: #AC(0); #GP(0): 1, 2, 3; #PF(fault-code); #SS(O): 1; #UD: 2;
RM: #GP: 1; #SS: 1; #UD: 3; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1;
#UD: 2.
CPUID
CPUID (CPU IDentification) — получение информации о текущем процессоре.
Машинный код: Of а2
Действие: возвратить в регистрах ЕАХ, ЕВХ, ЕСХ и EDX информацию, идентифи-
цирующую процессор и описывающую его архитектурные особенности. Номенк-
латура запрашиваемой информации задается значением в регистре ЕАХ, которое
необходимо поместить туда при вызове команды CPUID.
Определить факт поддержки данным микропроцессором команды CPUID можно
попыткой манипуляции флагом ID (бит 21) в регистре EFLAGS. Если программа
может изменять его значение, то это означает, что данный процессор поддержива-
ет команду CPUID.
В отличие от предыдущих моделей процессоров, информация, возвращаемая
командой CPUID в Pentium 4, разделена на две группы: основная и расширенная.
Основная информация возвращается при задании входных значений в регистре
ЕАХ от 0 до 3. Расширенная информация возвращается при входных значениях
в регистре ЕАХ от 80000000 до 80000004. Предшествующие модели процессоров
возвращают только основную информацию.
В разделах ниже приведены сведения о номенклатуре информации, формируе-
мой Pentium 4, в зависимости от исходного содержимого регистра ЕАХ.
294
Приложение 1. Команды процессоров х86
ЕАХ = О
Если ЕАХ = 0, то в регистрах процессора формируется следующая информация:
♦ ЕАХ=п, где п — максимально допустимое значение параметра, которое может
быть помещено в регистр ЕАХ для задания режима сбора информации. Разные
модели процессоров поддерживают разные максимальные входные значения в
регистре ЕАХ при вызове CPUID;
Семейство процессоров Основная информация Расшиоенная информация
До i486 включительно CPUID не реализована CPUID не реализована
Некоторые i486 и Pentium 1h He реализована
Pentium Pro/ll/Celeron 2h He реализована
Pentium III 3h He реализована
Pentium 4 2h 80000004
♦ (EBX)+(EDX)+(ECX) — в этих регистрах содержится строка-идентификатор про-
цессора «Genuinelntel».
ЕАХ = 1
Если ЕАХ=1, то в регистрах процессора сформируется следующая информация:
♦ ЕАХ=п — информация о микропроцессоре (табл. П1.1 и П 1.2);
♦ EDX=n — информация о возможностях процессора (табл. П1.3);
♦ ЕВХ= п — возвращаются три несвязанные между собой порции информации
(табл. П.4).
Таблица П1.1. Поля регистра ЕАХ после выполнения команды CPUID (при ЕАХ=1)
Биты ЕАХ Назначение
0...3 Версия изменений модели
4...7 Модель в семействе (см. следующую таблицу)
8...11 Семейство микропроцессоров (см. следующую таблицу)
12... 13 Тип процессора (00 — обычный процессор; 01 — Overdrive-процессор;
10 — процессор для использования в двухпроцессорных системах; 11 — резерв)
16... 19 Расширенное семейство
20...27 Расширенная модель
Таблица П1.2. Значения бит4...7 и 8...11 регистра ЕАХ
Биты ЕАХ (8...11) Биты ЕАХ (4...7) Тип процессора
0100 0000 ил и 0001 I486DX
0100 0010 I486SX
0101 0010 Pentium 75-200
П1.1. Целочисленные команды
295
Биты ЕАХ (8.. .11) Биты ЕАХ (4...7) Тип процессора
0101 0100 Pentium ММХ 166-200
0110 0001 Pentium Pro
0110 0011 Pentium II, модель 3
0110 0101 Pentium II, модель 5, Pentium II Xeon
0110 0110 Celeron, модель 6
0110 0111 Pentium III и Pentium III Xeon
0110 0011 Pentium II OverDrive
1111 0000 Pentium IV
Если значения в полях семейства и(или) модели (см. табл. П1.1) больше или равны
0FH, то это означает, что команда CPUID генерирует два дополнительных поля в
регистре ЕАХ - расширенного семейства и модели (см. табл. П1.1). Численные зна-
чения семейства и модели, большие 0FH, находятся в диапазоне 0FH...FFH (млад-
шая шестнадцатеричная цифра всегда равна 0FH).
Таблица П1.3. Поля регистра EDX после выполнения команды CPUID (при ЕАХ=1)
Биты EDX Мнемоника Назначение (если биты установлены)
0 FPU Присутствует сопроцессор с набором команд i387
1 VME Поддержка расширенных возможностей режима виртуального 18086: битов CR4.VME и CR4.PVI; программного перенаправления прерываний с помощью карты перенаправления прерываний в TSS; флагов EFLAGS.VIF и EFLAGS.VIP
2 DE Расширения отладки. Поддержка точек прерывания ввода- вывода (точки останова по обращению к портам) для предоставления расширенных возможностей отладки; доступ к регистрам DR4 и DR5. Флаг CR4.DE= 1
3 PSE Поддержка 4-мегабайтных страниц
4 TSC Поддержка счетчика меток реального времени
5 MSR Поддержка команд RDMSR и WRMSR для работы с модельно- зависимыми регистрами
6 PAE Процессор поддерживает физические адреса, большие чем 32 бита, расширенный формат элемента таблицы страниц, дополнительный уровень трансляции страничного адреса и 2 мегабайтные страницы
7 MCE Поддержка исключения 18 — машинного контроля
8 CX8 Поддержка команды CMPXCHG8B
9 APIC Микропроцессор содержит программно доступный контроллер прерываний APIC
10 Резерв
11 SEP Поддержка команд быстрых системных вызовов SYSENTER и SYSEXIT
продолжение^
296
Приложение 1. Команды процессоров х86
Таблица П1.3 (продолжение)
Биты EDX Мнемоника Назначение (если биты установлены)
12 MTRR Поддержка регистра управления кэшированием MTRR_CAP (относится к MSR-регистрам)
13 PGE Поддержка работы с битом G, определяющим глобальность страницы в PTDE и РТЕ. Бит CR4.PGE=1
14 MCA Поддержка архитектуры машинного контроля (MSR-регистр MCG.CAP)
15 CMOV Поддержка команд условной пересылки CMOV и, если установлен бит EDX.0, поддержка команд FCOMI и FCMOV
16 PAT Поддержка таблицы атрибутов страниц
17 PSE-36 Поддержка 36-разрядной физической адресации с 4Мбайт страницами
18 PSN Поддержка процессором собственной идентификации по уникальному 96-битному номеру, и эта подержка активна
19 CLFSH Поддержка команды CLFSH
20 Резерв
21 DS Поддержка процессором записи отладочной информации в резидентный буфер памяти. Этот буфер используется средствами трассировки переходов (BTS — branch trace store) и точной событийно-основанной выборки (PEBS - precise event-based sampling)
22 ACPI Поддержка средств контроля температуры процессора и программного управления часами
23 MMX Поддержка целочисленного ММХ-расширения
24 FXCR Процессор поддерживает команды FXSAVE и FXRSTOR
25 SSE Поддержка ММХ-расширения с плавающей точкой (SSE)
26 SSE2 Поддержка ММХ-расширения с плавающей точкой (SSE2)
27 SS Поддержка процессором управления противоречивыми типами памяти (conflicting memory types) путем слежения за структурами кэш-памяти для активных транзакций на шине
28 — Резерв
29 TM Тепловой монитор. Процессор содержит электрическую схему автоматического теплового контроля (ТСС—thermal control circuitry)
30,31 — Резерв
Таблица П1.4. Поля регистра ЕВХ после выполнения команды CPUID (при ЕАХ=1)
Биты 0.. .7 Индекс марки — это число обеспечивает вход в таблицу строки марки, которая
содержит строки марок для IA-32 процессоров
Биты 8... 15 Размер строки кэша, сбрасываемой на диск командой CLFLUSH
Биты 16... 23 Резерв
Биты 24...31 Физический номер локального APIC процессора
П1.1. Целочисленные команды 297
ЕАХ=2
Если ЕАХ=2, то в регистрах ЕАХ, ЕВХ, ЕСХ и EDX формируется информация о кэш-
памяти первого уровня и TLB-буферах. Первый байт регистра ЕАХ содержит чис-
ло, означающее, сколько раз необходимо последовательно выполнить команду
CPUID (при ЕАХ=2) для получения полной информации о кэш-памяти первого
уровня и TLB-буферах (Pentium 4 возвращет 1). Другие байты регистра ЕАХ и все
байты регистров ЕВХ, ЕСХ и EDX содержат однобайтовые дескрипторы, характери-
зующие кэш-память и TLB-буферы (см. таблицу). Старший бит каждого регист-
ра характеризует достоверность информации в регистре. Если он равен нулю, то
информация достоверна, иначе — регистр не используется. Порядок следования
однобайтовых дескрипторов в ЕАХ, ЕВХ, ЕСХ и EDX не определен, они могут появ-
ляться в любом порядке.
Значения дескрипторов, описывающих кэш-память и дескрипторы TLB
Содержание дескриптора Значение
00h Нулевой дескриптор
01h TLB команд: размер страницы — 4 Кбайт, наборно- ассоциативный 4-канальный, 32 входа
02h TLB команд: размер страницы — 4 Мбайт, наборно- ассоциативный, 2 входа
03h TLB данных: размер страницы — 4 Кбайт, наборно- ассоциативный 4-канальный, 64 входа
04h TLB данных: размер страницы — 4 Мбайт, наборно- ассоциативный 4-направленный, 8 входов
06h Кэш команд первого уровня: размер 8 Кбайт, наборно- ассоциативный 4-канальный, длина строки 32 байта
08h Кэш команд первого уровня: размер 16 Кбайт, наборно- ассоциативный 4-канальный, длина строки 32 байта
Oah Кэш данных первого уровня: размер 8 Кбайт, наборно- ассоциативный 2-канальный, длина строки 32 байта
Och Кэш данных первого уровня: размер 16 Кбайт, наборно- ассоциативный 4-канальный, длина строки 32 байта
40h Кэш-память второго уровня (L2) отсутствует. Если процессор содержит полноценный кэш второго уровня (L2), то отсутствует кэш-память третьего уровня (L3)
41 h Кэш-память второго уровня: размер 128 Кбайт, наборно- ассоциативный 4-канальный, длина строки 32 байта
42h Кэш-память второго уровня: размер 256 Кбайт, наборно- ассоциативный 4-канальный, длина строки 32 байта
43h Кэш-память второго уровня: размер 512 Кбайт, наборно- ассоциативный 4-канальный, длина строки 32 байта
44h Кэш-память второго уровня: размер 1 Мбайт, наборно- ассоциативный 4-канальный, длина строки 32 байта
продолжение^
298
Приложение 1. Команды процессоров х86
(продолжение)
Содержание дескриптора Значение
45h Кэш-память второго уровня: размер 2 Мбайт, наборно- ассоциативный 4-канальный, длина строки 32 байта
50h TLB команд: страницы 4 Кбайт и 2 Мбайт либо только 4 Мбайт, 64 входа
51h TLB команд: страницы 4 Кбайт и 2 Мбайт либо только 4 Мбайт, 128 входов
52h TLB команд: страницы 4 Кбайт и 2 Мбайт либо только 4 Мбайт, 256 входов
5Bh 5Ch 5Dh 66h TLB данных: страницы 4 Кбайт и 4 Мбайт, 64 входа TLB данных: страницы 4 Кбайт и 4 Мбайт, 128 входов TLB данных: страницы 4 Кбайт и 4 Мбайт, 256 входов Кэш данных первого уровня: размер 8 Кбайт, наборно- ассоциативный 4-канальный, длина строки 64 байта
67h Кэш данных первого уровня: размер 16 Кбайт, наборно- ассоциативный 4-канальный, длина строки 64 байта
68h Кэш данных первого уровня: размер 32 Кбайт, наборно- ассоциативный 4-канальный, длина строки 64 байта
70h Кэш трассировки: размер 12 Кбайт, наборно-ассоциативный 8-канальный
71h Кэш трассировки: размер 16 Кбайт, наборно-ассоциативный 8-канальный
72h Кэш трассировки: размер 32 Кбайт, наборно-ассоциативный 8-канальный
79h Кэш-память второго уровня: размер 128 Кбайт, наборно- ассоциативный 8-канальный, секторированный, длина строки 64 байта
7 Ah Кэш-память второго уровня: размер 256 Кбайт, наборно- ассоциативный 8-канальный, секторированный, длина строки 64 байта
7Bh Кэш-память второго уровня: размер 512 Кбайт, наборно- ассоциативный 8-канальный, секторированный, длина строки 64 байта
7Ch Кэш-память второго уровня: размер 1 Мбайт, наборно- ассоциативный 8-канальный, секторированный, длина строки 64 байта
82h Кэш-память второго уровня: размер 256 Кбайт, наборно- ассоциативный 8-канальный, длина строки 32 байта
84h Кэш-память второго уровня: размер 1 Мбайт, наборно- ассоциативный 8-канальный, длина строки 32 байта
82h Кэш-память второго уровня: размер 2 Мбайт, наборно- ассоциативный 8-канальный, длина строки 32 байта
Процессоры семейства Pentium 4 при вызове команды CPUID (ЕАХ=2) возвратят
в регистрах следующую информацию: ЕАХ = 66 5В 50 01 h; ЕВХ=0; ЕСХ=0; EDX=00
7А 70 00h.
П1.1. Целочисленные команды
299
ЕАХ = 3
Задание ЕАХ=3 возможно только в процессоре Pentium III, который формирует
следующее содержимое регистров ЕАХ, ЕВХ, ЕСХ и EDX:
ЕАХ Резерв
ЕВХ Резерв
ЕСХ Биты 00—31 96-битного серийного номера процессора
EDX Биты 31 —63 96-битного серийного номера процессора
Дополнительные возможности
идентификации процессора
Команда CPUID процессора Pentium 4 расширяет возможности по идентификации
процессора {brand identification — идентификацию марки). Теперь это можно
сделать в двух видах — численном {brand index) и строковом {brand string).
Индекс марки был добавлен к команде CPUID процессора Pentium III Хеоп. Ин-
декс марки обеспечивает точку входа в таблицу идентификации марки, которая
поддерживается в памяти системным программным обеспечением и доступна в
системе на уровне кода пользователя. В этой таблице каждый индекс марки ассо-
циирован со ASCII-строкой идентификации марки, которая содержит официаль-
ное название семейства процессора Intel и номер модели процессора (например,
строка «Intel Pentium III processor»).
При выполнении команды CPUID (ЕАХ=1) индекс марки возвращается в младшем
байте регистра ЕВХ. Программное обеспечение использует этот индекс, чтобы оп-
ределить местоположение строки идентификации марки процессора в таблице
идентификации марки. Первый элемент (индекс марки 0) в этой таблице зарезер-
вирован для совместимости с предыдущими процессорами, которые не поддер-
живают подобную идентификацию. Ниже приведены определенные к настояще-
му времени индексы марок.
0 1 2 3 4-7 и 5-255 8 Этот процессор не поддерживает возможность идентификации марки Celeron Pentium III Intel Pentium III Xeon Резерв Intel Pentium 4 processor
Архитектурно строка марки определена как ASCIIZ-строка длиной 48 байт. Для
того чтобы использовать строку марки в программе, команду CPUID необходи-
мо вызывать 3 раза, последовательно задавая в регистре ЕАХ значения 80000002,
80000003, 80000004. Результат каждого вызова - 16 ASCII-символов в регистрах
ЕАХ, ЕВХ, ЕСХ и EDX, составляющих очередной фрагмент строки марки. В общем
случае рекомендован следующий алгоритм получения строки марки:
300
Приложение 1. Команды процессоров х86
Выполнить CPUID (EAX=80000000h). Если после выполнения команды значение в
регистре ЕАХ=80000004, то это говорит о том, что текущий процессор поддерживает
работу со строкой марки.
CWD
CWD (Convert Word to Double word) — преобразование слова в двойное слово.
Действие: команда копирует значение старшего бита регистра АХ на все биты ре-
гистра DX.
Машинный код: 99
CWDE
CWDE (Convert Word to Double Word Extended) — преобразование слова в двой-
ное слово с учетом знака.
Действие: расширение знакового бита АХ на все разряды ЕАХ.
Машинный код: 98
DAA
DAA (Decimal Adjust AL for Addition) — десятичная коррекция результата сложе-
ния двух упакованных BCD-чисел с целью получения правильного двузначного
десятичного числа.
Действие:
1. Если AF=1 или значение младшей тетрады AL>9, то (AL)=(AL)+6; AF=1; при воз-
никновении переноса при сложении — установить CF. Иначе AF=O.
2. Если CF=1 или значение старшей тетрады AL>9, то (AL)=(AL)+60; CF=1. Иначе CF=O.
Машинный код: 27
Флаги: OF=? SF=r ZF=r AF=r PF=r CF=r
DAS
DAS (Decimal Adjust for Subtraction) — десятичная коррекция после вычитания
двух BCD-чисел в упакованном формате.
Действие:
1. Если AF=1 или значение младшей тетрады AL>9, то (AL)=(AL)-6; AF=1; при воз-
никновении заема при вычитании — установить CF. Иначе AF=O.
2. Если CF= 1 или значение старшей тетрады AL>9, то (AL)=(AL)-60; CF= 1. Иначе CF=O.
Машинный код: 2f
Флаги: OF=? SF=r ZF=r AF=r PF=r CF=r
DEC операнд
DEC (DECrement operand by 1) — уменьшение значения операнда на единицу.
П1.1. Целочисленные команды
301
— dec [-^[78,16,32 hl L6jj56ire£j
I—{m8,16,32|— LW1 lltw:mod 001 j7m;
Флаги: OF=r SF=r ZF=r AF=r PF=r, флаг cf нс изменяется.
Исключения: PM: #AC(0); #GP(0): 1,2,3; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
DIV делитель
DIV (DIVide unsigned) — беззнаковое деление операндов — делимое и делитель.
— div М*. 16,321-- •’{fl10ST156 тГJ
Чпп8,16,32|~-]_fl 11Qllwjpod _Q1 Pj/Tl
Действие: делимое задается неявно и его размер зависит от размера делителя, кото-
рый явно указывается в команде. Местоположения делимого, делителя, частного и
остатка в зависимости от их размера показаны в следующей таблице.
Размер операнда Делимое Делитель Частное Остаток Максимальное частное
Слово/байт АХ r/m8 AL AH 255
Дв. слово/слово DX:AX r/m16 AX DX 65,535
Учете, слово/дв. слово EDX:EAX r/m32 EAX EDX 232-1
Флаги: OF=? SF=? ZF=? AF=? PF=? CF=?
Исключения: PM: #DE; #GP(0): 2, 3; #PF(fault-code); #SS(O): 1; RM: #DE; #GP:
1; #SS: 1; VM: #AC(0); #DE; #GP(0): 1; #PF(fault-code); #SS(O): 1.
ENTER размер_кадра, лексический_уровень
ENTER (make stack frame for procedure parameters) — установить кадр стека для
локальных переменных процедуры.
Синтаксис: ENTER mem 16,0/1/18
Машинный код: 11001000:mem_16:0/1 /i8
Действие: первый операнд размер_кадра определяет размер кадра стека, второй
операнд лексический_уровенъ задает лексическую вложенность кадра стека. Зна-
чение лексический_уровень определяет количество указателей кадра стека, копи-
руемых в область дисплея нового кадра стека из предыдущего кадра. Оба операн-
да непосредственные.
Исключения: PM: #PF(fault-code); #SS(O): 4; RM: #SS: 2; VM: #PF(fauIt-code);
#SS(O): 2.
302
Приложение 1. Команды процессоров х86
HLT
HLT (HaLT) — останов процессора.
Действие: команда переводит процессор в состояние останова. Выполнение
будет продолжено по приходу разрешенного прерывания, NMI или аппаратного
сброса. Команда HLT является привилегированной.
Машинный код: f4
Исключения: PM: #GP(0): И; VM: #GP(0): 4.
IDIV делитель
IDIV (Integer signed DIVide) — целочисленное деление со знаком.
idiv —т~~| г8,16,32~|— [j 1 llQiJw: 11 Jjj_reg_ I
-|m8,16,32|— 10’llwimod 7l 1 j7mj
Действие: делимое задается неявно и его размер зависит от размера делителя, ко-
торый явно указывается в команде. Местоположения делимого, делителя, частно-
го и остатка в зависимости от их размера показаны в следующей таблице.
Размер операнда Делимое Делитель Частное Остаток Максимальное частное
Слово/байт АХ r/m8 AL АН -128... +127
Дв. слово/слово DX:AX r/m 16 AX DX -32,768...+32,767
Учете, слово/дв. слово EDX: ЕАХ r/m32 EAX EDX -231 232-1
Остаток всегда имеет знак делимого. Знак частного зависит от состояния знако-
вых битов (старших разрядов) делимого и делителя.
Флаги: OF=? SF=? ZF=? AF=? PF=? CF=?
Исключения: PM: #AC(0); #DE; #GP(0): 2,3; #PF(fault-code); #SS(O): 1; RM: #DE;
#GP: 1; #SS: 1; VM: #AC(0); #DE; #GP(0): 1; #PF(fault-code); #SS(O): 1.
IMUL множитель_1
IMUL множитель_1, множитель_2
IMUL произведение, множитель_1, множитель_2
IMUL (Integer Signed MULtiply) — умножение целочисленное co знаком.
Действие: команда имеет три формы, отличающиеся количеством операндов.
♦ С одним операндом требует явного указания местоположения только одного
сомножителя, который может быть расположен в ячейке памяти или регистре.
Местоположение произведения в зависимости от размеров множителя_1 и
множителя_2 показано в следующей таблице.
П1.1. Целочисленные команды
303
Размер множителей Множитель_1 Множитель_2 Произведение
Байт AL R/m8 АХ
Слово АХ R/m 16 DX:AX
Дв. слово DX:AX R/m32 EDX:EAX
♦ С двумя операндами — первый операнд определяет местоположение первого
сомножителя. На его место впоследствии будет записан результат. Второй
операнд определяет местоположение второго сомножителя.
♦ С тремя операндами — первый операнд определяет местоположение результа-
та, второй операнд — местоположение первого сомножителя, третий операнд
может быть непосредственно заданным значением размером в байт, слово или
двойное слово.
rTl_1_ip_11w:mpd_1_6l r/m!
191 IQlQWjpod reg_r/_mj _ j8 _]
[7Hl 01001: mod reg r/m : i16 j
Грj10101_1_:_mod reg _r/_m j _ |8 _]
rpjlQlQQlLTPdjesj/TJ- _____!
Г pfl QlQOIjmodreg j7m j32______j
Г 91191Q11J JPQd jeg _r/_m j _ |8 _]
Г91lOlQllLTPd reg_r/m J _ i8 J
Гр j 10IQOIjmodreg j7m _: _ j32_j
Флаги (для однооперандной команды): OF=1 CF=1 — значимые биты переносят-
ся в верхнюю половину результата; OF=0 CF=0 — результат помещается точно в
младшей половине результата. Состояние остальных флагов: SF=? ZF=? AF=? PF=?
Флаги (для двух- и трехоперандной команды): OF=1 CF=1 — результат слишком
большой и усекается; OF=1 CF=1 — размер результата точно соответствует операн-
ду назначения. Состояние остальных флагов: SF=? ZF=? AF=? PF=?
Исключения: PM: #AC(0); #GP(0): 2, 3; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
IN аккумулятор, ном.порта
IN (INput from port) — ввод операнда размером байт, слово, двойное слово из
порта ввода-вывода в один из регистров AL/AX/EAX. Номер порта задается вто-
рым операндом в виде непосредственного значения (0...255) или значения в реги-
стре DX.
304
Приложение 1. Команды процессоров х86
[1110010WJ
18
Исключения: PM: #GP(0): 12; VM: #GP(0): 5.
INC операнд
INC (INCrement by 1) — увеличение операнда размером байт, слово, двойное сло-
во на 1. Команда не воздействует на флаг CF.
г8,16,32 I-!- ГоЙЮО’гёя J
т8,16,321—
Флаги: OF=r SF=r ZF=r AF=r PF=r
Исключения: PM: AC(0); #GP(0): 1, 2,3; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS(O): 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
INS приемник, порт
INSB
INSW
INSD
INS/INSB/INSW/INSD (Input String Byte/Word/Double word operands) — ввод
строк байт/слов/двойных слов из порта ввода-вывода в память.
Действие: номер порта ввода-вывода — в регистре DX, адрес ячейки памяти —
в ES:EDI/DI. Замена сегментного регистра недопустима. Команда передает эле-
мент из порта ввода-вывода в память и в зависимости от состояния флага DF
изменяет значение в регистре EDI/DI: если DF=O, то увеличить содержимое этих
регистров на длину структурного элемента последовательности; если DF=1, то
уменьшить содержимое этих регистров на длину структурного элемента последо-
вательности.
При наличии префикса выполняются определяемые им действия (см. команду REP).
П1.1. Целочисленные команды
305
Исключения: PM: #АС(0); #GP(O): 1,12,13; #PF(fault-code); RM: #GP: 1; #SS: 1;
VM: #AC(0); #GP(O): 5; #PF(fault-code).
INT номер_прерывания
INTO
INT (INTerrupt) — вызов подпрограммы обслуживания прерывания.
Ltippjlbbj
ujppjiqLjIj
INTO (INTerrupt if Overflow) — прерывание, если переполнение.
Машинный код: се
Действие: команда INT генерирует вызов подпрограммы обслуживания прерыва-
ния с номером (0...255), заданным операндом команды.
В реальном режиме INT п записывает в стек регистр флагов EFLAGS/FLAGS и адрес
возврата — содержимое регистров CS и EIP/IP. Далее сбрасываются в ноль флаги
IF, TF и АС, после чего управление передается на программу обработки прерыва-
ния с номером п.
В защищенном режиме проверяются условия: VM=1 и IOPL<3. Если они выпол-
няются, то возбуждается #GP(O). Иначе — проверяется тип дескриптора — он
должен быть шлюзом ловушки, задачи, прерывания.
♦ Шлюз задачи — селектор в дескрипторе шлюза указывает на дескриптор TSS в
GDT. Производится переключение задач (с вложением) и отслеживаются ус-
ловия возникновения исключений.
♦ Шлюз ловушки или прерывания — при этом возможны два типа передачи уп-
равления обработчику прерывания: прерывание в режиме виртуального 8086,
передача управления между уровнями привилегий.
Существуют две более специализированные команды вызова обработчиков пре-
рываний: INTO и INT 3. Команда INTO инициирует прерывание с номером 4, если
установлен флаг OF. Команда INT 3 генерирует специальный однобайтовый код
операции (Occh), который предназначается для вызова обработчика исключения
отладки.
Флаги: в зависимости от режима работы процессора флаги IF, TF, NT, AC, RF и VM
могут быть очищены. Если прерывание использует шлюз задачи, то любые флаги
могут быть установлены или очищены в соответствии с образом EFLAGS в TSS
новой задачи.
Исключения: PM: #GP(0): 14; #GP(seIector): 12—19; #NP(selector): 2; #PF(fault-
code); #SS(O): 5; #SS(selector): 1, 2; #TS(selector): 7-11; RM: #GP: 1, 3; #SS: 3, 4;
VM: #BP; #GP(0): 6,7; #GP(seIector): 1—7; #NP(selector); #OF; #PF(fault-code);
#SS(seIector): 1, 2; #TS(selector): 1—5.
306
Приложение 1. Команды процессоров х86
INVD
INVD (INValiDate cache) — недостоверность кэш-памяти всех уровней.
Машинный код: Of 08
Действие: очистка кэш-памяти первого уровня (внутренней) и генерация сигна-
ла на очистку кэш-памяти второго уровня (внешней).
Исключения: PM: #GP(0): 10; VM: #GP(0): 8.
INVLPG адрес
INVLPG (INValiDate PaGe) — недостоверность элемента буфера TLB.
Синтаксис: INVLPG mem
Машинный код: 00001111:00000001 :mod 111 r/m
Действие: просмотреть элементы буфера TLB на предмет того, что адрес, ука-
занный в команде, соответствует одному из элементов этого буфера. Если со-
ответствие выявлено, то пометить данный элемент буфера TLB как недостовер-
ный и закончить работу. Если соответствия не выявлено, то закончить работу
команды.
Исключения: PM: #GP(0): 10; #UD: 3; RM: #UD: 4; VM: #GP(0): 9.
IRET
I RETD
IRET/IRETD (Interrupt RETurn) — возврат из прерывания.
Машинный код: cf
Действия: зависят от режима работы микропроцесссора.
♦ В реальном режиме — последовательное извлечение из стека содержимого ре-
гистров: EIP/IP, CS и EFLAGS/FLAGS. Возобновление работы прерванной про-
граммы.
♦ В защищенном режиме — действия команды IRET определяются флагами NT
и VM в регистре EFLAGS, а также значением флага VM в образе EFLAGS, со-
храненного в текущем стеке. В зависимости от их состояния процессор вы-
полняет следующие виды возврата: возврат из режима V86; возврат в режим
V86; возврат коду на другом уровне привилегий; возврат из вложенной за-
дачи. Если NT=0, то производятся действия по возврату управления пре-
рванной программе, при этом характер этих действий зависит от соотношения
уровней привилегированности прерванной программы и программы обра-
ботки прерывания. Если NT=1, то производятся действия по переключению
задач.
Флаги: все флаги в регистре EFLAGS могут быть модифицированы.
П1.1. Целочисленные команды
307
Исключения: PM: #АС(0); #GP(0): 15,16; #GP(selector): 9,10,20—27; #NP(selector):
3; #PF(fault-code); #SS(O): 6; RM: #GP: 4; #SS: 5; VM: #AC(0); #GP(0): 10, 11;
#PF(fault-code); #SS(O): 3.
Jcc метка
Jcc (Jump if Condition Code is met) — переход, если выполнено условие сс.
I—ГРJ Ифп5_смёц^8_1
I—
I—rPQQQlllU^^
Действие: команды условного перехода в зависимости от своей мнемоники ана-
лизируют флаги, и если проверяемое условие истинно, то производится переход к
ячейке, обозначенной операндом. Если проверяемое условие ложно, то произво-
дится переход к следующей команде.
Кодирование поля условия сс в формате машинной команды приведено в ниже-
следующей таблице. Здесь тетрада ttt обозначает проверяемое условие, ап — на-
личие отрицания.
tttn Мнемоника Условие
0000 О Overflow — переполнение
0001 NA No Overflow — нет переполнения
0010 В, NAE Below, Not Above or Equal — ниже; не больше или равно
0011 NB.AE Not Below, Above or Equal — не ниже; выше или равно
0100 E,Z Equal, Zero — равно; нуль
0101 NE, NZ Not Equal, Not Zero — не равно; не нуль
0110 BE, NA Below or Equal, Not Above — ниже или равно; не выше
0111 NBE.A Not Below or Equal, Above — не ниже или равно; выше
1000 S Sign — знак
1001 NS Not Sign — нет знака
1010 P, PE Parity, Parity or Equal — паритет; паритет или равно
1011 NP,PO Not Parity, Parity and Overflow — нет паритета; нечетность
1100 L, NGE Less than, Not greater than or equal to — меньше, чем; не больше, чем или равно
1101 NL,GE Not less than, Greater than or equal to — не меньше, чем; больше, чем или равно
1110 LE, NG Less than or equal to, Not greater than — меньше, чем или равно; не больше, чем
1111 NLE,G Not less than or equal to, Greater than — не меньше, чем или равно; больше, чем
308
Приложение 1. Команды процессоров х86
В следующей таблице приведен перечень команд условного перехода Jcc, анали-
зируемых ими флагов и соответствующих им логических условий перехода.
Команда Состояние проверяемых флагов Условие перехода
JA CF=OmZF=O Если выше
JAE CF = O Если выше или равно
JB CF=1 Если ниже
JBE CF = 1 или ZF = 1 Если ниже или равно
JC CF=1 Если перенос
JE ZF=1 Если равно
JZ ZF=1 ЕслиО
JG ZF = OnSF = OF Если больше
JGE SF = OF Если больше или равно
JL SFOOF Если меньше
JLE ZF=1 или SFOOF Если меньше или равно
J NA CF=1nZF=1 Если не выше
JNAE CF=1 Если не выше или равно
JNB CF = O Если не ниже
JNBE CF=OnZF=O Если не ниже или равно
JNC CF = O Если нет переноса
JNE ZF = O Если не равно
JNG ZF= 1 или SFOOF Если не больше
JNGE SFOOF Если не больше или равно
JNL SF = OF Если не меньше
JNLE ZF=O и SF=OF Если не меньше или равно
JNO OF=0 Если нет переполнения
JNP PF = O Если количество единичных бит результата нечетно (нечетный паритет)
JNS SF = O Если знак плюс (знаковый (старший) бит результата равен 0)
JNZ ZF = O Если нет нуля
JO OF=1 Если переполнение
JP PF=1 Если количество единичных бит результата четно (четный паритет)
JPE PF=1 То же, что и JP, то есть четный паритет
JPO PF = O То же, что и JNP
JS SF=1 Если знак минус (знаковый (старший) бит результата равен 1)
JZ ZF=1 Если ноль
Логические условия «больше» и «меньше» относятся к сравнениям целочислен-
ных значений со знаком, а «выше и «ниже» — к сравнениям целочисленных значе-
ний без знака.
Исключения: PM: #GP(0): 17; RM: #GP: 5; VM: #GP(0): 12.
П1.1. Целочисленные команды
309
JCXZ
JECXZ метка
JCXZ/JECXZ (Jump if CX=Zero/Jump if ECX=Zero) — переход, если CX/ECX ра-
вен нулю.
Машинный код: 11100011: сменив
Действие: если содержимое СХ/ЕСХ равно 0, то выполняется переход к ячейке,
обозначенной операндом метка, в противном случае управление передается сле-
дующей за JCXZ/JECXZ команде программы.
Команда JCXZ/JECXZ может выполнять только близкие переходы в пределах
-128...+127 байт, считая от следующей за ней команды.
Исключения: см. команду JCC.
JMP цель
JMP (JuMP) — безусловный переход к цели.
Машинный код:
JMP ге18 — 11101011:смещ_8
JMP rel 16(32) - 11101001 .смени6/32
JMP r16(32)/m 16(32) - 11111111:mod 100 r/m
JMP ptr16:16(32) — 11101010: смещение : сегмент(селектор)
JMP m16:16(32) — 11111111: mod 101 r/m
Действие: возможны следующие варианты задания операнда цель:
♦ ге!8/16/32 — короткий относительный переход. Значение ге18/16/32 трактует-
ся как знаковое и является смещением перехода относительно следующей за
JMP команды в сегменте кода, то есть адрес_цели=(Е1Р/1Р)+(ге18/16/32);
♦ r16(32)/m16(32) — близкий абсолютный косвенный переход. Цель — регистр
г16(32) или ячейка памяти т16(32), содержащие адрес перехода в текущем сег-
менте кода;
♦ ptr16:16(32) — дальний абсолютный переход. Цель — компоненты полного
адреса в виде 4- или 6-байтного указателя, по которому необходимо произвести
переход;
♦ ml6:16(32) — дальний абсолютный косвенный переход. Цель — адрес ячейки
памяти размером 32/48 бит со структурой m 16:16(32), содержащей компонен-
ты адреса перехода.
Выполнение команды при дальнем переходе зависит от режима работы про-
цессора:
♦ в реальном режиме или режиме виртуального 8086 команда JMP передает уп-
равление по адресу, определяемому операндом цель, который может задавать-
ся прямо (ptr16:16(32)) или косвенно (т16:16(32));
310
Приложение 1. Команды процессоров х86
♦ в защищенном режиме выполняются три типа переходов: дальний переход
в подчиненый или неподчиненный сегмент кода; дальний переход через шлюз
вызова; переключение задачи.
Команду JMP нельзя использовать для передачи управления между уровнями
привилегий.
Флаги: изменяются только при переключении задачи.
Исключения: PM: #АС(0); #GP(0): 3, 18, 19, 2; #NP(selector): 4, 5; #PF(fault-
code); #SS(O): 1; RM: #GP: 1; #SS: 1; VM: #AC(0); #GP(0): 1,13; #SS(O): 1.
LAHF
LAHF (Load AH register from register Flags) — загрузка регистра АН содержимым
младшего байта регистра EFLAGS/FLAGS флагов (CF, PF, AF, ZF и SF).
Машинный код: 9f
LAR приемник, источник
LAR (Load Access Rights byte) — загрузка байта прав доступа AR в регистр общего
назначения.
-| 1аг Foobbj
l| m16 Р
Ч г32 к>ПзГЪГоЬЬ^
j m32 р
Действие: выясняется доступность дескриптора, селектор которого находится в
операнде источник. Если дескриптор недоступен на текущем уровне привилегий
или по какой-то другой причине, то флаг ZF устанавливается в 0 и работа коман-
ды заканчивается. Если дескриптор доступен, то действия команды зависят от
установленного размера операнда.
♦ 16-битный — из дескриптора извлекаются биты 32...47, которые помещаются в
16-битный регистр приемник. Далее выполняется операция приемник=приемник
ANDOffOOh.
♦ 32-битный — из дескриптора извлекаются биты 32...61, которые помещаются в
32-битный регистр приемник. Далее выполняется операция приемник=приемник
AND 00f?ff00h. Тетрада «?» не определена.
Ниже в таблице определены допустимые для команды LAR типы дескрипторов
сегментов. Тип определяет значение младшей тетрады байта AR в дескрипторе
при установленном в единицу бите S.
Тип Название Допустимость
О Резерв Нет
1 Доступный 16-битный TSS Да
П1.1. Целочисленные команды
311
Тип Название Допустимость
2 LDT Да
3 Занятый 16-битный TSS Да
4 16-битный шлюз вызова Да
5 16/32-битный шлюз задачи Да
6 16-битный шлюз прерывания Нет
7 16-битный шлюз ловушки Нет
8 Резерв Нет
9 Доступный 32-битный TSS Да
A Резерв Нет
В Занятый 32-битный TSS Да
C 32-битный шлюз вызова Да
D Резерв Нет
E 32-битный шлюз прерывания Нет
F 32-битный шлюз ловушки - Нет
Флаги: ZF=r
Исключения: PM: #АС(0); #GP(0): 2,3; #PF(fault-code); #SS(O): 1; RM: #UD: 5;
VM: #UD: 5.
LDS приемник, источник
LES приемник, источник
LFS приемник, источник
LGS приемник, источник
LSS приемник, источник
LDS/LES/LFS/LGS/LSS (Load far pointer) — загрузка из памяти полного указателя.
les I
ir6600TM1lfl0jj0100 jmodreg 7/m!
C00001Jj11:jpj100103nod£egr/rn!
И
1SS-F
Действие: в зависимости от действующего режима адресации (use16 или use32)
загружаются первые два/четыре байта из ячейки памяти источник в 16/32-разрядный
регистр, указанный операндом приемник. Следующие два байта в области источник
должны содержать сегментную составляющую некоторого адреса или селектор, —
они, в зависимости от используемой команды, загружаются в регистр DS/ES/FS/GS/SS.
Исключения: PM: #АС(0); #GP(0): 3,2,21; #GP(selector): 33,34; #NP(selector): 6;
#PF(fault-code); #SS(0): 1; #SS(selector): 1; #UD: 4; RM: #GP: 1; #SS: 1; #UD: 6;
VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1; #UD: 4.
312
Приложение 1. Команды процессоров х86
LEA приемник, источник
LEA (Load Effective Address) — загрузка эффективного адреса (смещения) операн-
да источник в приемник.
—| lea hTr16 K>Rnem~]-r—pjQQOlLOLm^
Ч г32 |Q|mem(-
Действие: показано в таблице ниже и зависит от действующего режима адреса-
ции и размера операнда — use 16 или use32.
Размер операнда Размер адреса Действие
16 16 Вычисляется 16-битный эффективный адрес операнда источник и сохраняется в 16-битном регистре приемник
16 32 Вычисляется 32-битный эффективный адрес операнда источник. Младшие 16 бит этого адреса сохраняются в 16-битном регистре приемник
32 16 Вычисляется 16-битный эффективный адрес операнда источник. Этот адрес расширяется нулем и сохраняется в 32-битном регистре приемник
32 32 Вычисляется 32-битный эффективный адрес операнда источник и сохраняется в 32-битном регистре приемник
Исключения: PM: #UD: 4; RM: #UD: 6; #UD: 4.
LEAVE
LEAVE (High Level Procedure Exit) — выход из процедуры высокого уровня.
Машинный код: с9
Действие: команда копирует ЕВР/ВР в ESP/SP, тем самым восстанавливая содер-
жимое ESP/SP значением, которое было до вызова процедуры. Далее в регистр
ЕВР/ВР из новой вершины стека извлекается значение, тем самым восстанавлива-
ется кадр вызывающей программы.
Исключения: PM: #АС(0); #PF(fault-code); #SS(O): 7; RM: #GP: 6; VM: #AC(0);
#GP(0): 14; #PF(fault-code).
LGDT источник
LGDT (Load Global Descriptor Table) — загрузка регистра глобальной таблицы
дескрипторов.
Синтаксис: LGDT m48
Машинный код: 00001111:00000001: mod 010 r/m
П1.1. Целочисленные команды
313
Действие: команда загружает 16 бит размера и 32 бита значения базового адреса
начала таблицы GDT в памяти в системный регистр GDTR.
Исключения: PM: #GP(0): 3,10,2; #PF(fault-code); #SS(O): 1; #UD: 4; RM: #GP: 1;
#SS: 1; #UD: 6; VM: #GP(0): 1.
LIDT источник
LIDT (Load Interrupt Descriptor Table) — загрузка регистра глобальной таблицы
дескрипторов.
Синтаксис: LIDT m48
Машинный код: 00001111:00000001: mod 011 r/m
Действие: команда аналогична LGDT, но для дескрипторной таблицы прерыва-
ний IDT.
Флаги и исключения: см. команду LGDT.
LLDT источник
LLDT (Load Local Descriptor Table register) — загрузка регистра локальной деск-
рипторной таблицы.
Синтаксис: LLDT m16/r16
Машинный код: 00001111:00000000:mod 010 r/m
Действие: команда выполняет загрузку 16-битного регистра LDTR значением из
памяти (размером в слово) или 16-битного регистра.
Исключения: PM: #GP(selector): 35; #NP(selector): 7; #PF(fault-code); #SS(O): 1;
RM: #UD: 7; VM: #UD: 5.
LMSW источник
LMSW (Load Machine Status Word) — загрузка слова состояния машины (млад-
ших 16 бит регистра CR0) значением из слова памяти или 16-битного регистра
общего назначения.
Синтаксис: LMSW m16/r16
Машинный код: 00001111:00000001 :mod 110 r/m
Исключения: PM: #GP(0): 3, 10, 2; #PF(fault-code); #SS(O): 1; RM: #GP: 1; VM:
#GP(0): 1,3; #PF(fault-code).
LOCK
LOCK (LOCK signal prefix) — префикс выдачи сигнала LOCK.
Машинный код: f0
Действие: команда LOCK формирует префикс, инициирующий выдачу микропро-
цессором сигнала блокировки системной шины LOCK. Используется в многопро-
314
Приложение 1. Команды процессоров х86
цессорных конфигурациях для обеспечения монопольного владения системной
шиной. Сигнал LOCK может формироваться лишь с определенной номенклатурой
команд процессора, работающих в цикле чтение — модификация-запись. К их
числу относятся: BTS, BTR, BTC, XCHG, ADD, OR, ADC, SBB, AND, SUB, XOR, NOT, NEG,
INC, DEC. Команда BTS всегда формируется с префиксом LOCK.
Исключения: PM: #UD: 5; RM: #UD: 8; VM: #UD: 6.
LODS источник
LODSB
LODSW
LODSD
LODS/LODSB/LODSW/LODSD (LOad String Byte/Word/Double word operands) —
загрузка строки байт/слов/двойных слов.
—I lods
esqi 1—'
gs-]-|m16F
lodsb -DJyPJjPPj
lodsw -?PjPjjPjj
lodsd -?W®?JpJj
Действие: команда загружает элемент из последовательности (цепочки) в регистр-
аккумулятор AL/AX/EAX. Адрес элемента содержится в паре DS: ESI/SI. Кроме опе-
рации извлечения элемента команда изменяет значение SI на величину, равную
длине элемента цепочки. Знак этой величины зависит от состояния флага DF: DF=0 —
значение положительное, DF=1 — значение отрицательное.
Исключения: PM: #АС(0); #GP(0): 3, 2; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
LOOP метка
LOOP (LOOP according to cx\ecx counter) — управление циклом co счетчиком в CX\ECX.
Машинный код: 11100010: смещ_8
Действие: выполнить декремент содержимого регистра СХ\ЕСХ; проанализировать
регистр СХ\ЕСХ: если СХ\ЕСХ=0, передать управление следующей за LOOP коман-
де, в обратном случае (если СХ\ЕСХ>0) передать управление команде, метка кото-
рой указана в качестве операнда. Смещение метки относительно текущего значе-
ния регистра IP\EIP должно быть в диапазоне -128...+127 байт.
Исключения: PM: #GP(0): 20.
П1.1. Целочисленные команды
315
LOOPE
LOOPZ метка
LOOPNE
LOOPNZ метка
LOOPE/LOOPZ (LOOP control by register сх/есх not equal 0 and ZF=1) и LOOPNE/
LOOPNZ (LOOP control by register cx/ecx not equal 0 and ZF=0) — управление
циклом по CX/ECX с учетом значения флага ZF.
Машинный код:
LOOPZ/LOOPE- 11100001: смещ_8
LOOPNZ/LOOPNE —11100000: смеисв
Действие: выполнить декремент содержимого регистра СХ\ЕСХ; проанализиро-
вать регистр СХ\ЕСХ и флаг ZF. Если СХ\ЕСХ=0, передать управление следующей
за LOOPxx команде, в противном случае (если СХ\ЕСХ>0) передать управление ко-
манде, метка которой указана в качестве операнда LOOPxx. Если ZF=0, то для ко-
манд LOOPE/LOOPZ это означает выход из цикла, а для команд LOOPNE/LOOPNZ —
переход к началу цикла. Если ZF=1, то для команд LOOPE/LOOPZ это означает пе-
реход к началу цикла, а для команд LOOPNE/LOOPNZ — выход из цикла.
Исключения: см. команду LOOP.
LSL приемник, источник
LSL (Load Segment Limit) — загрузка предела сегмента.
—| isi Ы не Ю[Г не h~[ooopjjj
Ч m161
Ч г32 ЮгГг32~|
ЦЪзгр
Действие: извлечь из дескриптора, селектор которого содержит источник, значе-
ние размера сегмента и загрузить его в 16/32-битный регистр приемник. При этом
проверяются условия: селектор не нулевой; селектор видим на текущем уровне
привилегий; значение селектора актуально для текущих пределов дескрипторной
таблицы GDT или LDT; тип дескриптора допустим в команде LSL (см. таблицу
ниже). Если эти условия выполняются, то флаг ZF устанавливается в 1; в прием-
ник загружается значение размера сегмента (в байтах). Если эти условия не вы-
полняются, то флаг ZF устанавливается в 0; приемник не изменяется.
Типы дескрипторов, допустимых в команде LSL
Тип Назначение дескриптора
1 h Доступный TSS i286
2h LDT
продолжение^
316
Приложение 1. Команды процессоров х86
(продолжение)
Тип Назначение дескриптора
3h Занятый TSS i286
8h Недействительный
9h Доступный TSS i486
Obh Занятый TSS i486
Tun определяет значение младшей тетрады байта AR в дескрипторе при установ-
ленном в единицу бите S.
Флаги: ZF=r
Исключения: PM: #АС(0); #GP(0): 3, 2; #PF(fault-code); #SS(O): 1; RM: #UD: 9;
VM: #UD: 7.
LTR источник
LTR (Load Task Register) — загрузка регистра задачи.
Синтаксис: LTR r16/m16
Машинный код: 00001111:00000000:mod 011 r/m
Действие: помещение в регистр TR содержимого источника, который представля-
ет собой селектор сегмента TSS. После этого сегмент TSS отмечается занятым, для
чего устанавливается бит А в байте AR.
Исключения: PM: #GP(0): 3,10,2; #GP(selector): 36,37; #NP(selector): 8; #PF(fault-
code); #SS(O): 1; RM: #UD: 10; VM: #UD: 8.
MOV приемник, источник
MOV (MOVe operand) — копирование содержимого операнда источник в опе-
ранд приемник.
|m8,16,32|
| r8.16.32
m8,16,32
al,ax,eax
i8,16,32
r8.16.32
m8,16,32
Т;1 91 QQQdwj- смеи^Тб/зЗ
И1ППП11ш • 11 ППП ген • ifl
Г"|- ! 112Q0T1: 11 000 reg_:J8/1_6/32_ J
—!.
— 11999194^1
— UPPPJPI^.ltpPjpsijZtj
I__ !J1999ilwTmodPPPj7m‘Й8Л6/321
I 11999199.^1 Л}®41®9 J/Pl!
------------i^llOOirnod sreg386.r/rn:
r16,m16|---LlQ99VJP_:_T9^_s_r®9??9 iC™ J
-| (8,16,32 |
sreg
Исключения: PM: #AC(0); #GP(0): 1,3,2,21; #GP(selector): 35—39; #NP(selector): 6;
#PF(fault-code); #SS(O): 1; #SS(selector): 1; #UD: 6; RM: #GP: 1; #SS: 1; #UD: 11;
VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1; #UD: 9,
П1.1. Целочисленные команды
317
MOV приемник, источник
MOV (MOVe to/from system registers) — пересылка операнда в системные регис-
тры (или из системных регистров).
Действие: содержимое операнда источник копируется в операнд приемник. Один
из операндов — системный регистр.
Флаги: OF=? SF=? ZF=? AF=? PF=? CF=?
Исключения: PM: #DB; #GP(0): 11, 39-41; #UD: 14; RM: #DB; #GP: 14; #UD: 21;
VM: #GP: 27, 28.
— mov
cr0,2,3,4 f
—| drO,1,2,3,67
—G>—| r32 |-------
~|—O—Tr32~|-------
cr0,2,3,4|-------
drO,1,2,3,6,7 ]--
MOVS приемник, источник
MOVSB
MOVSW
MOVSD
MOVS/MOVSB/MOVSW/MOVSD (MOVe data from String to string) — пересыл-
ка строк байтов/слов/двойных слов.
movsb
L| es,gs,fshC?
L| es,gs,fs[^
L| es,gs,fs|<>F
1 оюоюо;
— movsd
movsw — Hpiippj Ojj
— Fjoiooloi;
Действие: команда копирует байт, слово или двойное слово из операнда источник
в операнд приемник, при этом адреса элементов предварительно должны быть за-
гружены: адрес источника — в пару регистров DS:ESI/SI (DS по умолчанию, допус-
кается замена сегмента); адрес приемника — в пару регистров ES:EDI/DI (замена
сегмента не допускается).
В зависимости от состояния флага DF команда изменяет значение регистров ESI/
SI и EDI/DI: если DF=0, то содержимое этих регистров увеличивается на длину
318
Приложение 1. Команды процессоров х86
структурного элемента последовательности; если DF=1, то содержимое этих реги-
стров уменьшается на длину структурного элемента последовательности.
Для пересылки нескольких следующих друг за другом элементов необходимо
использовать префикс REP.
Исключения: PM: #АС(0); #GP(0): 1,2,5; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
MOVSX приемник, источник
MOVSX (MOVe with Sign extension) — пересылка co знаковым расширением.
Действие: команда преобразует операнд со знаком в эквивалентный ему операнд
со знаком большей размерности. Для этого содержимое операнда источник, начи-
ная с младших разрядов, записывается в операнд приемник. Старшие биты опе-
ранда приемник заполняются значением знакового разряда операнда источник.
movsx
Нб}-0-г-Г^
Hm8
-{m8}
r16
Исключения: PM: #AC(0); #GP(0): 3, 2; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #GP(0): 1; #PF(fault-code); #SS(O): 1.
MOVZX приемник, источник
MOVZX (MOVe with Zero-eXtend) — пересылка с нулевым расширением.
— movzx
r8
m8
"ИГ
Действие: команда преобразует операнд без знака в эквивалентный ему операнд
без знака большей размерности. Для этого содержимое операнда источник, начи-
ная с его младших разрядов, записывается в операнд приемник. Старшие разряды
операнда приемник заполняются двоичным нулем.
Исключения: PM: #АС(0); #GP(0): 3, 2; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
П1.1. Целочисленные команды
319
MUL множитель_1
MUL (unsigned MULtiply) — умножение целочисленное без учета знака.
— mu* ~г]г8,16,32]—
Hm8,16,32|— [lijjpjlwTrnodjjoo“r7mj
Действие: команда выполняет умножение двух операндов без учета знаков. Явно
задается один из операндов — множителъ_1. Множитель_2 задается неявно и его
расположение фиксированно — в регистре AL\AX\EAX. Расположение результата
умножения определяется кодом операции и размером сомножителей, как показа-
но в следующей таблице.
Размер операндов Множитель_1 Множитель_2 Назначение
Байт AL r/m8 АХ
Слово АХ г/т 16 DX:AX
Двойное слово ЕАХ г/т32 EDX: ЕАХ
Флаги: если старшая половина результата нулевая: OF=CF=0 SF=? ZF=? AF=? PF=?,
если старшая половина результата ненулевая: OF=CF=1 SF=? ZF=? AF=? PF=?.
Исключения: PM: #AC(0); #GP(0): 3, 2; #PF(fault-code); #SS(O):1; RM: #GP: 1;
# SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
NEG приемник
NEG (two’s complement NEGation) — изменить знак.
— ne9 -г|г8,16,32]—
-|m8,16,32|— [iljj j
Действие: команда вычисляет двоичное дополнение (0 - приемник) операнда
приемник.
Флаги:
♦ если приемник равен нулю: CF=0 OF=r SF=r ZF=r AF=r PF=r;
♦ если приемник не равен нулю: CF=1 OF=r SF=r ZF=r AF=r PF=r.
Исключения: PM: #AC(0); #GP(0): 1,2,5; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
# SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
NOP
NOP (No OPeration) — нет операции.
320
Приложение 1. Команды процессоров х86
Машинный код: 90
Действие: отсутствует. Единственный эффект от использования NOP — инкре-
мент регистра EIP.
NOT приемник
NOT (NOT operand) — инвертирование всех битов операнда приемник.
— по* ~г| г8,16,32~1— 11jJAJw £ 11 _01_0 req J
-]m8,16,32|— [ijjjpjjwjjpodjOW г/m J
Исключения: PM: #AC(0); #GP(0): 1,2,5; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
OR приемник, маска
OR (logical inclusive OR) — логическое включающее ИЛИ.
! 10000011 £ mod 001 j/m_:_ _ J8
i 00001100 : i8
tQ0001J_0_1: _____
[j OOOOOswj _ij_001_ rec[ £
[QQQQlQdwj Jj reqi_reg2_
[00001_01_w_: mod req r/m
8_/16/32_j
!ipppppswj_modpOJ_r/mjj8/1_6/32[
[r00001_00wJ mod J/™'
Действие: команда выполняет операцию логического ИЛИ над соответствующи-
ми парами бит операндов приемник и маска: приемник= приемник OR маска.
Флаги: CF=OF=0 SF=r ZF=r AF=? PF=r
Исключения: PM: #AC(0); #GP(0): 3,4,2; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
OUT ном.порта, аккумулятор
OUT (OUTput to port) — вывод значения из регистра AL/AX/EAX {аккумулятор) в
порт ввода-вывода, номер которого определяется операндом ном_порта.
П1.1. Целочисленные команды
321
Fl1j 00 j Тб j _№ порта ]
Fill 00Tif: _№ порта ]
Fiiioiiio!
Исключения: PM: #GP(0): 12; VM: #GP(0): 5.
OUTS порт, источник
OUTSB
OUTSW
OUTSD
OUTS/OUTSB/OUTSW/OUTSD (OUTput Byte/Word/Double word String to
port) — вывод строки байт/слов/двойных слов в порт.
г8,16,32
т8,16,32
outsb —iQtLWPj
— outsw —rpTlQiJJL'
— outsd —fQ’lLQjjflj
Действие: команда копирует элементы размером байт/слово/двойное слово из
источника в порт ввода-вывода. Номер порта ввода-вывода загружается в регистр
DX. Адрес ячейки памяти, из которой копируются данные, содержится по адресу
DS:ESI/SI (допускается замена сегмента). По результатам команды значение реги-
стров ESI/SI изменяется на длину элемента. Направление изменения зависит от
состояния флага DF: если DF=0, то содержимое регистров ESI/SI увеличивается на
длину элемента последовательности; если DF=1, то содержимое регистров ESI/SI
уменьшается на длину элемента последовательности.
Для пересылки последовательности элементов необходимо использовать пре-
фикс REP.
Исключения: PM: #AC(0); #GP(0): 2,12,24; RM: #GP: 1; #SS: 1; VM: #AC(0); #GP(0):
5; #PF(fault-code).
POP приемник
POP (POP a value from the stack) — извлечение значения из стека.
11 Зак. 424
322
Приложение 1. Команды процессоров х86
! J 0001j 11 11 000 reg _ _ _ <
pl 0001111 : mod 000 r7m !
m16t32 [•
. - dstestss~}
- ds,es,ss,fs,gs |— fdOOOl111:10 sreg386 001J
Действие: команда восстанавливает содержимое вершины стека в регистр, ячей-
ку памяти или сегментный регистр, после чего содержимое ESP/SP увеличивается
на 4 байта для use32 и на 2 байта для use 16. Недопустимо восстановление значе-
ния в сегментный регистр CS.
Исключения: PM: #AC(0); #GP(0): 1—3, 21, 38—41; #NP(selector): 6; #PF(fault-
code); #SS(O): 1, 6; #SS(selector): 1; RM: #GP: 1; VM: #AC(0); #GP(0): 1; #PF(fault-
code).
POPA/POPAD
POPA/POPAD (POP All general-purpose registers) — выталкивание всех регист-
ров общего назначения из стека.
Машинный код: 61
Действие: команда POPA/POPAD восстанавливает содержимое всех регистров об-
щего назначения (DI/EDI, SI/ESI, ВР/ЕВР, SP/ESP, ВХ/ЕВХ, DX/EDX, CX/ECX, АХ/ЕАХ)
из стека, после чего значение указателя стека SP/ESP увеличивается на 16/32.
Содержимое DI/EDI восстанавливается первым. Содержимое SP/ESP при этом не
восстанавливается. Какие именно регистры — 16- или 32-разрядные — извлекаются
из стека, зависит от установленного размера операнда. При необходимости измене-
ния размера операнда для инструкции POPA/POPAD можно использовать префикс 66h.
Исключения: PM: #AC(0); #PF(fault-code); #SS(O): 1; RM: #SS: 6; VM: #AC(0);
#PF(fault-code); #SS(O): 4.
POPF
POPFD
POPF/POPFD (Pop stack into eFlags register) — извлечение регистра флагов из
стека.
Машинный код: 9d
Действие: команда POPF/POPFD восстанавливает из стека содержимое регистра
флагов FLAGS/EFLAGS, после чего увеличивает значение регистра-указателя стека
SP/ESP на 2/4. Размерность выталкиваемого регистра зависит от установленного
размера операнда. Действие команды POPF/POPFD зависит от режима работы
микропроцессора.
♦ В защищенном режиме на уровне привилегий 0 (или в реальном режиме) в
регистре FLAGS/EFLAGS могут быть изменены любые незарезервированные
П1.1. Целочисленные команды
323
флаги (за исключением флагов VIP, VIF и VM). Флаги VIP и VIF очищаются,
а флаг VM не изменяется.
♦ В защищенном режиме на уровне привилегий, большем чем 0, но меньшем или
равным значению в поле IOPL, все флаги могут быть изменены за исключени-
ем поля IOPL и флагов VIР, VIF и VM. При этом поле IOPL и флаг VM не изменя-
ются, а флаги VIP и VIF очищаются. Флаг IF изменяется, если выполнение
производится на уровне, равном или меньшем значению поля IOPL, в против-
ном случае исключения не происходит, но и привилегированные биты не
изменяются.
♦ В режиме виртуального 8086 для использования команды POPF/POPFD уровень
привилегий I/O (IOPL) должен быть равен 3 (при этом флаги VM, RF, IOPL, VIP,
и VIF не изменяются). Если уровень привилегий меньше 3, то команда POPF/
POPFD вызывает исключение общей защиты (#GP).
Флаги: изменяются все флаги, кроме зарезервированных и флага VM.
Исключения: PM: #АС(0); #PF(fault-code); #SS(O): 6; RM: #SS: 5; VM: #AC(0);
#GP(0): 15, 16; #PF(fault-code); #SS(O): 3.
PREFETCHTO источник
PREFETCHT1 источник
PREFETCHT2 источник
PREFETCHNTA источник
PREFETCH — предварительная запись в кэш-память данных из оперативной памяти.
Синтаксис и машинный код:
PREFETCHTO mem - 00001111:00011000:mod 01 r/m
PREFETCHT1 mem - 00001111:00011000:mod 10 r/m
PREFETCHT2 mem - 00001111:00011000:mod 11 r/m
PREFETCHNTA mem - 00001111:00011000:mod 00 r/m
Действие: проверить, есть ли строка байт в кэш-памяти — если есть, то никаких
перемещений не производится. Если данных в кэш-памяти нет, то производится
помещение их в кэш-память того уровня, который определяется конкретной ко-
мандой: prefetchtO — загрузка строки в кэш-память всех уровней; prefetchtl — за-
грузка строки в кэш-память всех уровней, за исключением уровня 0; prefetcht2 —
загрузка строки в кэш-память всех уровней, за исключением уровней 0 и 1;
prefetchnta — загрузка строки в кэш уровня 1.
Количество записываемых байт зависит от конкретного процессора, но минималь-
ное количество составляет 32 байта.
PUSH источник
PUSH (PUSH operand onto the stack) — размещение операнда в стеке.
324
Приложение 1. Команды процессоров х86
— push Ы~И6.32 1
-| т16,32
| i8,16,32 |
-| ds.es,ss~|-
rpTiHbsQ'ili'iK32/_7_’."j
I opo_sreg86 J.13.!
_|ds,es.ss.fs,gs|— IPPPP.1 j"li:jPAr?9"3§6.Q9P2
1 j
Действие: уменьшить значение регистра-указателя стека SP/ESP на 2/4 и затем
записать значение источника в вершину стека.
Исключения: РМ: #АС(0); #GP(0): 2,3; #PF(fault-code); #SS(0): 1; RM: #GP: 1;
#SS: 1, 2; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
PUSHA
PUSHAD
PUSHA/PUSHAD (PUSH All general-purpose registers) — запись всех регистров
общего назначения в стек.
Машинный код: 60
Действие: уменьшить значение указателя стека ESP/SP на 16/32 (в зависимости от
значения атрибута размера адреса — use 16 или use32), после чего разместить в стеке
регистры общего назначения в следующей последовательности: АХ/ЕАХ, СХ/ЕСХ, DX/
EDX, ВХ/ЕВХ, SP/ESP, ВР/ЕВР, SI/ESI, DI/EDI (содержимое DI/EDI будет на вершине сте-
ка). В стек помещается содержимое SP/ESP, которое было до выполнения команды.
Исключения: PM: #AC(0); #PF(fault-code); #SS(O): 1; RM: #GP: 7; VM: #AC(0);
#GP(0): 17; #PF(fault-code).
PUSHF
PUSHFD
PUSHF/PUSHFD (PUSH Flags/eFlags register onto stack) — размещение регист-
ра флагов в стеке.
Машинный код: 9с
Действие: уменьшить значение указателя стека SP/ESP на 2/4, после чего помес-
тить в вершину стека содержимое регистра FLAGS/EFLAGS. При этом флаги VM и
RF (биты 16 и 17) не копируются, вместо этого значения для этих флагов в образе
EFLAGS, сохраненном на стеке, устанавливаются равными нулю.
Исключения: PM: #АС(0); #PF(fault-code); #SS(O): 4; VM: #АС(0); #GP(0): 15;
#PF(fault-code).
RCL операнд, количество_сдвигов
RCL (Rotate operand through Carry flag Left) — циклический сдвиг операнда влево
через флаг переноса.
П1.1. Целочисленные команды
325
U19 IQQQwj mod p_W_ r/m J
jilOW0|wj mod 0J (Г r/m _|
Fl‘l obbobwmod 010 r/m : i8
Действие: каждый раз при циклическом сдвиге разрядов операнда влево старший
его бит становится значением флага переноса CF. Старое содержимое CF вдвига-
ется в операнд справа и становится значением его младшего бита.
Флаги: CF=r OF=?r
Флаг OF представляет интерес, если сдвиг осуществляется на один разряд, и не-
определен для многобитового сдвига (поэтому обозначен ?г). По значению фла-
га OF можно судить о факте изменения знакового (старшего) разряда операнда:
OF=1, если после операции сдвига влево значения флага CF и старшего бита
операнда различны; OF=0, если после операции сдвига влево значения флага CF и
старшего бита операнда совпадают.
Исключения: PM: #AC(0); #PF(fault-code); #GP(0): 2, 5, 25; #SS(O): 1; RM:
#GP: 1; #SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
RCR операнд, количество_сдвигов
RCR (Rotate operand through Carry flag Right) — циклический сдвиг операнда
вправо через флаг переноса.
гсг
г8,16,32 кчЭ-гГП-
т8,16,32р
i8
[j 101bbbvjT:_mod 6i_1_ r/m J
[J 101001 w: _mo"d_6_1_1_ r/m _!
Г11 OObbbw: mod 011 r/m : i8
Действие: каждый раз при циклическом сдвиге разряда операнда вправо млад-
ший его бит становится значением флага переноса CF. Старое содержимое CF
вдвигается в операнд слева и становится значением его старшего бита.
Флаги: CF=r OF=?r
Флаг OF представляет интерес, если сдвиг осуществляется на один разряд, и не-
определен для многобитового сдвига (поэтому обозначен ?г). По значению флага
OF можно судить о факте изменения знакового (старшего) разряда операнда:
0F=1, если значения флага CF и старшего бита операнда до операции сдвига раз-
личны; OF=0, если значения флага CF и старшего бита операнда до операции сдвига
совпадают.
Исключения: PM: #AC(0); #GP(0): 2, 5, 25; #PF(fault-code); #SS(O): 1; RM:
#GP: 1; #SS: 1; VM: #AC(0): 1; #GP(0): 1; #PF(fault-code); #SS(O): 1.
RDMSR
RDMSR (ReaD from Model Specific Register) — чтение из регистра MSR.
Машинный код: Of 32
326
Приложение 1. Команды процессоров х86
Действие: проверить условия: уровень привилегий нулевой; в регистре ЕСХ нахо-
дится значение, адресующее один из регистров MSR. Если хотя бы одно из этих
условий не выполняется, то закончить выполнение команды. Если выполняются
оба условия, то поместить значение регистра, адресуемого содержимым регистра
ЕСХ, в пару 32-битных регистров EDX:EAX.
Исключения: PM: #GP(0): 10, 26; RM: #GP: 8; VM: #GP(0): 18.
RDPMC
RDPMC (ReaD Performance-Monitoring Counters) — чтение счетчиков произво-
дительности процессора.
Машинный код: Of 33
Действие: проверить выполнение одного из условий: регистр ЕСХ содержит О
или 1 и бит CR4.PCE=1; бит CR4.PCE=0 и СР1=0. Если одно из этих условий вы-
полнено, то переслать содержимое счетчика, идентифицированного содержимым
регистра ЕСХ (0 или 1), в пару регистров EDX:EAX и закончить выполнение коман-
ды. Если ни одно из этих условий не выполнено, то закончить выполнение коман-
ды с возбуждением исключения общей защиты.
Исключения: PM: #GP(0): 27, 28; RM: #GP: 9,10; VM: #GP(0): 19, 20.
RDTSC
RDTSC (ReaD from Time Stamp Counter) — чтение 64-разрядного счетчика меток
реального времени — TSC (Time Stamp Counter).
Машинный код: Of 31
Действие: проверить состояние второго бита регистра CR4.TSD (Time Stamp
Disable — отключить счетчик меток реального времени): если CR4.TSD=0, то
выполнение команды RDTSC разрешается на любом уровне привилегий; если
CR4.TSD=1, то выполнение команды RDTSC разрешается только на нулевом уров-
не привилегий. Если выполнение команды разрешено на текущем уровне привиле-
гий, то выполнить сохранение значения 64-битного MSR-счетчика TSC в паре 32-
битных регистров EDX:EAX. Если выполнение команды запрещено, то закончить
работу.
Исключения: PM: #GP(0): 29; RM: #GP: И; VM: #GP(0): 21.
REP
REPE
REPZ
REPNE
REPNZ
REP/REPE/REPZ/REPNE/REPNZ (REPeat string operation prefix) — повторить
цепочечную операцию.
П1.1. Целочисленные команды
327
Машинный код:
REP/REPE/REPZ - f3
REPNE/REPNZ - f2
Действие: команды REP/REPE/REPZ/REPNE/REPNZ заставляют повторять цепо-
чечную команду количество раз, указанное в регистре ЕСХ, или до тех пор, пока не
выполнится обозначенное флагом ZF условие. Префикс REP может быть добавлен
к командам INS, OUTS, MOVS, LODS и STOS. Префиксы REPE, REPNE, REPZ и REPNZ
могут быть добавлены к командам CMPS и SCAS. Префиксы REPZ и REPNZ —
синонимы префиксов REPE и REPNE. Поведение префикса REP неопределено при
использовании его с командами, отличными от цепочечных.
В следующей таблице приведены условия завершения повторения цепочечных
команд при использовании с ними определенных префиксов.
Префикс повторения Условие завершения 1 Условие завершения 2
REP ЕСХ=0 Нет
REPE/REPZ ЕСХ=0 ZF=0
REPNE/REPNZ ЕСХ=0 ZF=1
Выяснить, какое именно условие привело к завершению выполнения цепочечной
команды, можно, анализируя значение в регистре ЕСХ (командой JECXZ) или про-
веряя флаг ZF (командами JZ, JNZ и JNE).
Флаги: не изменяются (за исключением использования префиксов с командами
CMPS и SCAS, которые устанавливают флаги в регистре EFLAGS).
Исключения: отсутствуют, однако исключения могут быть сгенерированы коман-
дой, с которой связан префикс повторения.
RET
RETF число
RET/RETF (RETurn/RETurn Far from procedure) — возврат ближний (дальний)
из процедуры.
Машинный код:
СЗ (ret — близкий возврат в вызывающую процедуру);
СВ (ret — дальний возврат в вызывающую процедуру);
С2116 (ret 116 — близкий возврат с выталкиванием 116 байт из стека);
СА116 (ret 116 — дальний возврат с выталкиванием 116 байт из стека).
Действие: передача управления по адресу, расположенному на вершине стека.
Этот адрес обычно помещается в стек командой CALL, его значение соответствует
команде, следующей за командой CALL. Необязательный операнд число определя-
ет количество байт стека, которые будут вытолкнуты после выталкивания адреса
328
Приложение 1. Команды процессоров х86
возврата. Команда RET используется для выполнения трех различных вариантов
возврата управления.
♦ Близкий возврат — возврат управления вызывающей процедуре в пределах
текущего сегмента кода (внутрисегментный возврат). При этом из вершины сте-
ка выталкивается значение в регистр EIP. Регистр CS не изменяется. Процессор
продолжает выполнение кода в том же сегменте, но по другому смещению.
♦ Дальний возврат — возврат управления вызывающей процедуре, расположен-
ной в отличном от текущего сегменте кода (межсегментый возврат). При этом
из вершины стека последовательно выталкиваются значения в регистры EIP
и CS. Процессор продолжает выполнение кода в другом сегменте.
♦ Дальний возврат между уровнями привилегий — дальний возврат управления
коду на уровне привилегий, отличном от текущего. Этот вид возврата может
быть выполнен только в защищенном режиме. Его механизм подобен механиз-
му дальнего возврата, за исключением того, что процессор следит за уровнями
привилегий и правами доступа к сегментам кода и стека, которым возвращает-
ся управление для определения возможности подобной передачи управления.
Команда RET очищает регистры DS, ES, FS и GS, если они ссылаются на соот-
ветствующие сегменты, недоступные на новом уровне привилегий. Так как
при межуровневом возврате управления производится переключение стека, то
команда RET также производит загрузку этих регистров из стека. Если в вызы-
ваемую процедуру передавались параметры, то при возврате в команде RET
необходимо указать параметр число для их удаления.
Исключения: PM: #АС(0); #GP(0): 15,30; #GP(selector): 25,43—50; #NP(selector): 3;
#PF(fault-code); #SS(0): 6, 12; RM: #GP: 4; #SS: 5; VM: #AC(0); #GP(0): 10;
#PF(fault-code); #SS(0): 3.
ROL операнд, количество_сдвигов
ROL (Rotate operand Left) — циклический сдвиг операнда влево.
f iiOWOOw: mod 000 r/m!
L11® lOOiw 1 99? У m J
Г iiOOObbw: mod ООО r/m : i8~
Действие: каждый раз при циклическом сдвиге разрядов операнда влево его старший
выдвигаемый бит вдвигается в операнд справа и становится одновременно значением
младшего бита операнда и флага переноса Cf.
Флаги: CF=r OF=?r SF=r ZF=r PF=r AF=?
Флаг OF представляет интерес, если сдвиг осуществляется на один разряд, и не
определен для многобитового сдвига (поэтому обозначен ?г). По значению флага
OF можно судить о факте изменения знакового (старшего) разряда операнда: OF=1,
если после операции сдвига влево значения флага CF и старшего бита операнда
П1.1. Целочисленные команды
329
различны; OF=0, если после операции сдвига влево значения флага CF и старшего
бита операнда совпадают.
Исключения: PM: #АС(0); #GP(0): 2, 5,25; #PF(fault-code); RM: #GP: 1; #SS: 1;
VM: #AC(0); #GP(0): 1; #SS(0): 1.
ROR операнд, количество_сдвигов
ROR (Rotate operand Right) — циклический сдвиг операнда вправо.
[" iiOWOfw: mod 001 r7m !
niooodow: mod Obi r7m : i8 [
Действие: каждый раз при циклическом сдвиге разрядов операнда вправо млад-
ший его бит вдвигается в операнд слева и становится одновременно значением его
старшего бита и флага CF.
Флаги: CF=r OF=?r SF=r ZF=r PF=r AF=?
Флаг OF представляет интерес, если сдвиг осуществляется на один разряд, и не-
определен для многобитового сдвига (поэтому обозначен ?г). По изменению флага
OF можно судить о факте изменения знакового (старшего) разряда операнда:
0F=1, если после операции сдвига влево значения флага cf и старшего бита опе-
ранда различны; OF=0, если после операции сдвига влево значения флага CF и
старшего бита операнда совпадают.
Исключения: PM: #АС(0); #GP(0): 2,5,25; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(0): 1.
RSM
RSM (Resume from System Management mode) — возврат процессора из S-режима
с восстановлением контекста.
Машинный код: Of аа
Действие: проверить контекст прерванной программы на предмет выполне-
ния условий: в регистре CR0 недопустимая комбинация значений бит; установ-
лен любой из зарезервированных битов в регистре CR4; начало области памяти,
с которой работает процессор в S-режиме, не выровнено на границу, кратную 32 Кбайт.
Если хотя бы одно из условий имеет место, то процессор переходит в состояние
ожидания. Если ни одно из условий не имеет места, то выполняется возврат из
S-режима и восстановление контекста из определенной области памяти. Данная
операция напоминает восстановление контекста при переключении из вложен-
ной задачи.
Флаги: изменяются в соответствии с содержимым регистра EFLAGS восстанавли-
ваемого контекста.
Исключения: PM: #UD: 7; RM: #UD: 12; VM: #UD: 10.
330
Приложение 1. Команды процессоров х86
SAHF
SAHF (Store АН register into register Flags) — загрузка регистра флагов EFLAGS/
FLAGS из регистра ah.
Машинный код: 9е
Действие: команда загружает значение из младшего байта регистра АН в регистр
EFLAGS/FLAGS. При этом флаги SF, ZF, AF, PF и CF инициализируются битами 7,6,
4, 2 и 0 регистра АН. Биты 1,3 и 5 регистра EFLAGS/FLAGS не изменяются, то есть
остаются равными значениям 1, 0 и 0 соответственно.
Флаги: SF=r ZF=r AF=r PF=r CF=r
SAL операнд, количество_сдвигов
SAL (Shift Arithmetic operand Left) — арифметический сдвиг операнда влево.
L1191999^. i !™?SL 199 j/p? J
01001 w £ mod100 r/m j
Г IIOOOOOw: mod W0 r/m : i8 ]
Действие: сдвиг всех битов операнда влево на количество разрядов количество-
сдвигов, при этом выдвигаемый слева бит становится значением флага перено-
са CF. Одновременно справа в операнд вдвигается нулевой бит.
Флаги: CF=r OF=?r SF=r ZF=r PF=r AF=?
Флаг OF представляет интерес, если сдвиг осуществляется на один разряд, и не-
определен для многобитового сдвига (поэтому обозначен ?г). По значению флага
OF можно судить о факте изменения знакового (старшего) разряда операнда: если
OFsl, то текущее значение флага CF и значения выдвигаемого слева бита операнда
различны; если OFs0, то текущее значение флага CF и значения выдвигаемого слева
бита операнда совпадают.
Исключения: PM: #AC(0); #GP(0): 1,2,5; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
SAR операнд, количество_сдвигов
SAR (Shift Arithmetic operand Right) — арифметический сдвиг операнда вправо.
LlLQ.W9^ £ mod TH _r7m j
f 110iOOIw: mod lil r/m!
Г1 WOOOOw: mod 111 r/m : i8 1
Действие: сдвиг всех битов операнда вправо на количество разрядов количе-
ство_сдвигов, при этом выдвигаемый справа бит становится значением флага пе-
П1.1. Целочисленные команды
331
реноса CF. Одновременно слева в операнд вдвигается не нулевой бит, а значение
старшего бита операнда, то есть по мере сдвига вправо освобождающиеся места
заполняются значением знакового разряда.
Флаги: CF=r OF=? SF=r ZF=r PF=r AF=?
В отличие от других команд сдвига, команда SAR всегда сбрасывает в ноль флаг
OF в операциях сдвига на один разряд.
Исключения: PM: #АС(0); #GP(0): 1,2,5; #PF(fault-code); #SS(0): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
SBB операнд_1, операнд_2
SBB (integer SuBtraction with Borrow) — вычитание с заемом.
lippOOOswjjnod 0J1_r/m_:J8/^^^
[pool lOOw 2 mod re^ r7m [
•000111??_:_Ю______!
rfppp^iwT^
[pOOIIOdw j 11 reqj reg2 J
•000 llblw 2 mod re£ r7m}
r16,32
m16,32
U PPPPP112011 r/m 2 _ _ J8
Действие: операнд_1=операнд_1 -{операнд_2+CF). Состояние флага CF представ-
ляет собой заем от предыдущего вычитания. Команда SBB не различает знаков
операндов. Вместо этого процессор устанавливает флаги OF и CF, для того чтобы
показать заем для знакового и беззнакового операндов. Флаг SF отражает знак ре-
зультата (состояние его старшего бита).
Флаги: CF=r OF=r SF=r ZF=r PF=r AF=r
Исключения: PM: #AC(0); #GP(0): 1,2,5; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
SCAS приемник
SCASB
SCASW
SCASD
SCAS/SCASB/SCASW/SCASD (SCAn String Byte/Word/Double word) - ска-
нирование строки байтов/слов/двойных слов.
Машинный код: SCASB —• ае, SCASW/SCASD — at
332
Приложение 1. Команды процессоров х86
Действие: команда сканирования SCAS сравнивает путем вычитания значение в
регистре EAX/AX/AL и значение в ячейке памяти, локализуемой парой регистров
ES:EDI/DI. По результату вычитания устанавливаются флаги (в том числе ZF).
Размер сравниваемых элементов зависит от применяемой команды. Чтобы эту
команду можно было использовать для поиска значения в последовательности
элементов, имеющих размерность байт, слово или двойное слово, необходимо ис-
пользовать один из префиксов REPE или REPNE. Эти префиксы не только застав-
ляют циклически выполняться команду поиска пока ЕСХ/СХОО, но и отслежива-
ют состояние флага ZF (см. команды REP/REPE/REPNE). Направление просмотра
задается флагом DF: если DF=0 — просмотр от начала цепочки к ее концу; DF=1 —
просмотр от конца цепочки к ее началу.
Флаги: CF=r OF=r SF=r ZF=r PF=r AF=r
Исключения: PM: #AC(0); #GP(0): 31—33; #PF(fault-code); RM: #GP: 1; #SS: 1;
VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
SETcc операнд
SETcc (SET byte on condition) — установка байта по условию.
•oooo 1 TH C1QQ1Ж l tpAPQQ Ж!
Действие: команда проверяет условие, заданное модификатором в коде операции
сс (фактически состояние определенных флагов, как показано ниже), и устанав-
ливает операнд логическим значением 01 h или 00h в зависимости от истинности
этого условия.
Команда Проверяемые флаги Логическое условие
SETA/SETNBE CF=0nZF=0 (выше)/(не ниже или равно)
SETAE/SETNB CF = 0 (выше или равно)/(не ниже)
SETB/SETNAE CF=1 (ниже)/(не выше или равно)
SETBE/SETNA CF=1 hbhZF=1 (ниже или равно)/(не выше)
SETC CF=1 Перенос
SETE/SETZ ZF=1 Ноль
SETG/SETNLE ZF = 0hbh SF = OF (больше)/(не меньше или равно)
SETGE/SETNL SF = OF (больше или равно)/(не меньше)
SETL/SETNGE SFOOF Если SF О OF
SETLE/SETNG ZF=1 или SFOOF (меньше или равно)/(не больше)
SETNC CF = 0 Нетпереноса
SETNE/SETNZ ZF = 0 Не равно нулю
SETNO OF=0 Нетпереполнения
П1.1. Целочисленные команды
333
Команда Проверяемые флаги Логическое условие
SETNP/SETPO PF = 0 (неравенство)/(нет контроля четности)
SETNS SF = 0 Нет знака, число положительное
SETO OF=1 Переполнение
SETP/SETPE PF=1 Контроль четности/равенство
SETS SF=1 Если знак минус, число отрицательное
Исключения: PM: #GP(0): 1-3; #PF(fault-code); #SS(O): 1; RM: #GP: 1; #SS: 1;
VM: #GP(0): 1; #PF(fault-code); #SS(O): 1.
SFENCE
SFENCE (Store FENCE) — гарантированная запись информации из кэш-памяти
всех уровней.
Машинный код: 00001111:10101110:11111000
Действие: сохранить данные из кэш-памяти по соответствующим адресам опера-
тивной памяти.
SGDT источник
SGDT (Store Global Descriptor Table) — сохранение регистра глобальной дескрип-
торной таблицы.
Машинный код: 00001111:00000001 :mod 000 r/m
Действие: сохраняет содержимое системного регистра GDTR в область памяти
размером 48 бит. Структурно эти 48 бит представляют 16 бит размера и 32 бита
значения базового адреса начала таблицы GDT в памяти. Если установлен атри-
бут размера операнда 32 бита, то 16 бит поля предела помещаются в младшее сло-
во области памяти, а 32 бита базового адреса — в старшее двойное слово 48-битовой
области памяти. Если установлен атрибут размера операнда 16 бит, то 16 бит предела
помещаются в младшее слово области и 24 бита базового адреса — в 3,4 и 5 байты
(6 байт равен нулю).
Исключения: PM: #АС(0); #GP(0): 1-3; #PF(fault-code); #SS(O): 1; #UD:8; RM:
#GP: 1; VM: #AC(0); #GP(0): 1; #PF(fauIt-code); #SS(O): 1; #UD: 11.
SIDT источник
SIDT (Store Interrupt Descriptor Table) — сохранение регистра глобальной деск-
рипторной таблицы прерываний.
Машинный код: 00001111:00000001 :mod 001 r/m
Действие: сохраняет содержимое системного регистра GDTR в область памяти
размером 48 бит. Структурно эти 48 бит представляют 16 бит размера и 32 бита
значения базового адреса начала таблицы GDT в памяти. Если установлен атри-
334
Приложение 1. Команды процессоров х86
бут размера операнда 32 бита, то 16 бит поля предела помещаются в младшее сло-
во области памяти, а 32 бита базового адреса — в старшее двойное слово 48-битовой
области памяти. Если установлен атрибут размера операнда 16 бит, то 16 бит предела
помещаются в младшее слово области и 24 бита базового адреса — в 3, 4, 5 байты
(6 байт равен нулю).
Исключения: PM: #АС(0); #GP(0): 1-3; #PF(fault-code); #SS(O): 1; #UD: 8;
RM: #GP: 1; #SS: 1; #UD: 13; VM: #AC(0); #PF(fault-code); #SS(O): 1.
SHL операнд, количество.сдвигов
SHL (SHift logical Left) — логический сдвиг операнда влево.
51119.199^1199 Цй} J
Г i 10OOOOw": mod 100’ г/m ? ' 18 ‘1
Действие: сдвиг всех битов операнда влево на количество разрядов количество_сдви-
гов, при этом выдвигаемый слева бит становится значением флага переноса CF.
Флаги: CF=r OF=?r SF=r ZF=r PF=r AF=?
Флаг OF представляет интерес, если сдвиг осуществляется на один разряд, и не-
определен для многобитового сдвига (поэтому обозначен ?г). По его значению
можно судить о изменении знакового разряда операнда: если OF=1, то текущее
значение флага CF и выдвигаемого слева бита операнда различны; если OF=0, то
текущее значение флага CF и выдвигаемого слева бита операнда совпадают.
Исключения: PM: #АС(0); #GP(0): 1-3; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
SHLD приемник, источник, количество.сдвигов
SHLD (SHift Left Double word) — сдвиг двойного слова влево.
— shld
И 6
Г16
m16
J®"-
AcLh
r32
m32
8
“ LQ9PPJJ j 1J JPJPPj Pj J _n?od jeg . !
Действие: команда сдвигает операнд приемник влево на число битов количе-
ство_сдвигов. Операнд источник обеспечивает биты, которые вдвигаются в при-
емник справа (начиная с бита 0 операнда приемник). Операнд количество_сдвигов -
целое число без знака, которое может быть непосредственным 8-битовым значе-
нием или содержимым регистра CL
П1.1. Целочисленные команды
335
Флаги: CF=r OF=?r SF=r ZF=r PF=r AF=?
Флаг CF заполняется последним битом, сдвинутым из операнда приемник. Флаг
OF устанавливается в 1 для одноразрядного сдвига, если изменился знаковый раз-
ряд приемника, иначе — он равен нулю. Если операнд количество_сдвигов равен
нулю, то флаги не изменяются.
Исключения: PM: #АС(0); #GP(0): 1—3; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(0): 1.
SHR операнд, кол-во_сдвигов
SHR (SHift logical Right) — логический сдвиг операнда вправо.
shr
L1LQ.LQ99^. i191У™J
£ mod101 r/m j
rilOOOOOw: modi 01 r/m: i8 [
Действие: сдвиг всех битов операнда вправо на число битов количество_сдвигов,
при этом выдвигаемый справа бит становится значением флага переноса CF. Одно-
временно слева в операнд вдвигается нулевой бит.
Флаги: CF=r OF=? SF=r ZF=r PF=r AF=?
Флаг CF содержит значение последнего вдвинутого в него бита. Флаг OF устанав-
ливается равным старшему значащему биту первоначального операнда.
Исключения: PM: #AC(0); #GP(0): 1—3; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
SHRD приемник, источник, количество.сдвигов
SHRD (SHift Right Double word) — сдвиг двойного слова вправо.
8
00001111 :10101100 : mod reg r/m_:
i8
r32
m32
- L9.Q.°-°JJ j 1J 1°1°J j 91J199 j/Т-:
Действие: сдвиг операнда приемник вправо на число битов количество_сдвигов.
Операнд источник обеспечивает биты, которые вдвигаются в приемник слева (начи-
ная со старшего бита операнда приемник). Операнд количество_сдвигов — целое
число без знака, которое может быть непосредственным 8-битовым значением
или содержимым регистра CL.
Флаги: CF=r OF=?r SF=r ZF=r PF=r AF=?
336
Приложение 1. Команды процессоров х86
Флаг CF заполняется последним битом, сдвинутым из операнда приемник. Флаг
OF устанавливается в 1 для одноразрядного сдвига, если изменился знаковый раз-
ряд приемника, иначе — он равен нулю.
Исключения: PM: #АС(0); #GP(0): 1—3; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS(O): 1; VM: #AC(0); #GP(0): 1.
SLDT приемник
SLDT (Store Local Descriptor Table register) — сохранение регистра локальной
дескрипторной таблицы LDTR в ячейке памяти или регистре.
Синтаксис: SLDT m16/r16
Машинный код: 00001111: 00000000 : mod 000 r/m
Исключения: PM: #АС(0); #GP(0): 1—3; #PF(fault-code); #SS(O): 1; RM: #UD:
14; VM: #UD: 12.
SMSW приемник
SMSW (Store Machine Status Word) — сохранение слова состояния машины.
Синтаксис: SMSW m16/r16
Машинный код: 00001111:00000001 : mod 100 r/m
Действие: сохранить значение младших 16 бит регистра CR0 в слове памяти
или 16-битном регистре общего назначения.
Исключения: PM: #AC(0); #GP(0): 1—3; #PF(fauIt-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
STC
STC (Set Carry Flag) — установка флага переноса CF в единицу.
Машинный код: f9
Флаги: CF=1
STD
STD (SeT Direction Flag) — установка флага направления DF в единицу.
Машинный код: fd
Флаги: DF=1
STI
STI (SeT Interrupt flag) — установка флага прерывания IF в единицу.
Машинный код: fb
Флаги: IF=1
Исключения: PM: #GP(0): 9; VM: #GP(0): 2.
П1.1. Целочисленные команды
337
STOS приемник
STOSB
STOSW
STOSD
STOS/STOSB/STOSW/STOSD (Store String Byte/Word/Double word operands) —
сохранение строки байтов/слов/двойных слов.
- stosb -[ipjpIpjSj
- stosw
- stosd -twjpjojjj
Действие: команда записывает элемент из регистра AL/AX/EAX в ячейку памяти,
адресуемую парой ES:DI/EDI. После этого значение регистра DI/EDI изменяется
на величину, равную длине элемента цепочки. Знак этого изменения зависит
от состояния флага DF: если DF=0, то DI/EDI увеличивается; если DF=1, то DI/EDI
уменьшается.
Исключения: PM: #АС(0); #GP(0): 1, 31,32; #PF(fault-code); RM: #GP: 12; VM:
#AC(0); #GP(0): 22; #PF(fault-code).
STR приемник
STR (Store Task Register) — сохранение регистра задачи TR в слове памяти или 16-
битном регистре приемник.
Синтаксис: STR r16/m16
Машинный код: 00001111: 00000000 : mod 001 r/m
Исключения: PM: #АС(0); #GP(0): 1—3; #PF(fault-code); #SS(O): 1; RM: #UD:
15; VM: #UD: 13.
SUB операнд_1, операнд_2
SUB (SUBtract) — вычитание.
Действие: команда выполняет целочисленное вычитание: операнд_1 ^операнд_2-
операнд_1. Команда SUB не различает знаков операндов. Вместо этого она соот-
ветствующим образом устанавливает флаги.
Флаги: OF=r SF=r ZF=r AF=r PF=r CF=r
Исключения: PM: #AC(0); #GP(0): 1—3; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
338
Приложение 1. Команды процессоров х86
sub
al
ax
eax
— lQ.0J_0JJPPj....L8_____!
— ~JJjp?J
- rfppppp^
r8,16,32 — foOIOIOcIwj Jjreg1jeg2J
m8,16,32|—
i16 |---
□T|-----
i8,16,32
___|m8,16,32 hQrl 18,16,32"]— ijppOOOswTrnodJAt^Li87i6/32]
L| r8,16,32]— fooiOIOOwj mod reg r/m[
r16,32
m 16,32
; 10000011 : mod 101 j/m_: _ J8
8
8
SYSENTER
SYSENTER (fast transition to SYStem call ENTry point) — быстрый переход к точ-
ке входа в коде на уровне 0.
Машинный код: 0F 34
Действие: команда SYSENTER предназначена для обеспечения максимально
эффективного перехода к коду на нулевом кольце защиты (СР1=0). Команда
устанавливает регистры CS, EIP, SS, ESP значениями, указанными операцион-
ной системой в определенных модельно специфических регистрах: CS — в зна-
чение SYSENTER_CS_ MSR; EIP - в значение SYSENTER_EIP_MSR; SS - в значе-
ние, равное сумме (8+SYSENTER_CS_MSR); ESP - SYSENTER_ESP_MSR. Команда
SYSENTER всегда передает управление коду защищенного режима на CPL=0. Команда
SYSENTER может быть вызвана из всех режимов, за исключением реального режи-
ма. Команда требует выполнения следующих условий со стороны операционной
системы:
♦ целевой селектор CS соответствует 32-битному сегменту кода на нулевом коль-
це, отображенному на плоское пространство адресов 0-4 Гбайт с доступом по
чтению и выполнению;
♦ целевой селектор ss соответствует 32-битному сегменту стека кольца 0, отобра-
женному на плоское адресное пространство 0-4 Гбайт с доступом по чтению,
записи. Величина этого селектора (селектора SS кольца 0) равна сумме (CS+8).
Операционная система посредством указанных выше модельно-специфических
регистров внутри процессора должна обеспечить необходимые значения для ре-
гистров CS, EIP, SS и ESP с тем, чтобы корректно передать управление точке входа
кода в кольце защиты 0. Эти регистры доступны по чтению и записи посредством
команд RDMSR и WRMSR. Адреса модельно-специфических регистров представле-
ны ниже.
П1.1. Целочисленные команды
339
Имя Описание Адрес
SYSENTER_CS_MSR Целевой селектор CS на кольце 0 174h
SYSENTER_ESP_MSR Целевой ESP на кольце 0 175h
SYSENTER_EIP_MSR Целевой EIP точки входа на кольце 0 176h
Исключения: PM: #GP(0): 34; RM: #GP: 15.
SYSEXIT приемник, источник
SYSEXIT (fast transition from system call entry point) — быстрый возврат из кода
на уровне 0.
Машинный код: 0F 35
Действие: команда SYSEXIT обеспечивает максимально эффективный переход к коду
на кольце защиты 3 (CPL=3) из кода на кольце защиты 0 (CPL=0). Команда SYSEXIT
устанавливает регистры CS, EIP, SS, ESP значениями, указанными операционной си-
стемой в определенных модельно специфических регистрах или регистрах общего
назначения: CS — в значение, равное сумме (16+SYSENTER_CS_MSR); EIP — в значе-
ние из регистра EDX; SS — в значение, равное сумме (24+SYSENTER_CS_MSR); ESP —
в значение из регистра ЕСХ. Команда SYSEXIT всегда передает управление коду на
уровне 3 (СР1=3) защищенного режима в рамках плоской модели памяти. Коман-
да SYSEXIT может быть вызвана только в защищенном режиме при CPL=0. Коман-
да требует выполнения следующих условий со стороны операционной системы:
♦ целевой селектор CS соответствует 32-битному неподчиненному сегменту
кода на кольце защиты 3, отображенному на адресное пространство 0-4 Гбайт,
с атрибутами: доступ по выполнению и чтению;
♦ целевой селектор SS соответствует 32-битному сегменту стека на кольце 3,
отображенном на адресное пространство 0-4 Гбайт с атрибутами: расширяе-
мый вверх, доступен по чтению и записи.
Операционная система посредством указанных модельно-специфических регис-
тров внутри процессора должна обеспечить необходимые значения для регистров
CS, EIP, SS и ESP с тем, чтобы корректно передать управление точке входа кода
в кольце защиты 3. Эти регистры доступны по чтению и записи посредством ко-
манд RDMSR и WRMSR.
Имя Описание
Селектор CS Селектор целевого сегмента кода на кольце 3. Его значение равно сумме (16+(SYSENTER_CS_MSR))
Селектор SS Селектор целевого сегмента стека SS на уровне 3. Его значение равно сумме (24+(SYSENTER_CS_MSR))
EIP Адрес возврата в коде на кольце 3. Это целевая точка входа, и она назначается значением, содержащимся в регистре EDX
ESP ESP возврата на кольце защиты 3. Назначается значением, содержащимся в регистре ЕСХ
340
Приложение 1. Команды процессоров х86
Исключения: PM: #GP(0): 34,35; RM: #GP: 15.
TEST приемник, источник
TEST (TEST operand) — логическое И.
i10101000: i8
•10WW01J_____i16____•
[l 00001 Ow j Jjreq1jeg2J
ElQOOOIOwj mod reg r/m [
Действие: выполняет операции логического умножения над операндами приемник
и источник. Результат операции формируется во временной памяти, сами операнды
не изменяются: бит результата равен 1, если соответствующие биты операндов рав-
ны 1, в остальных случаях бит результата равен 0. Для анализа результата использу-
ется флаг ZF, который равен 1, если результат логического умножения равен нулю.
Флаги: OF=0 CF=0 SF=r ZF=r PF=r AF=?
Исключения: PM: #AC(0); #GP(0): 2, 3; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
UD2
UD2 (UnDefined instruction) — генерация исключения недействительного кода
операции.
Машинный код: Of 0b
Исключения: PM: #UD: 9; RM: #UD: 8; VM: #UD: 8.
VERR селектор
VERR (VERify the segment for Reading) — определение возможности чтения из
сегмента, заданного операндом селектор.
Синтаксис: VERR r16/m16
Машинный код: 00001111: 00000000 : mod 100 r/m
Действие: проверить выполнение условий: определен ли селектор в таблицах
GDT или LDT; указывает ли дескриптор, адресуемый селектором, на сегмент
кода или данных (и никакой другой); является ли сегмент считываемым; прове-
рить уровень привилегий:
♦ если сегмент кода является подчиненным, то поле DPL его дескриптора может
иметь любое значение;
П1.1. Целочисленные команды
341
♦ в противном случае должно выполняться условие: DPL_дескриптора>=СР1_ and
RPL_ce лектора.
Если проверка по приведенным выше условиям положительна, то установить
флаг ZF в 1, иначе — установить флаг ZF в 0.
Флаги: ZF= г
Исключения: PM: #AC(0); #GP(0): 2,3; #PF(fauIt-code); #SS(O): 1; RM: #UD: 16;
VM: #UD: 14.
VERW селектор
VERW (VERify the segment for Writing) — определение возможности записи в
сегмент данных, заданный операндом селектор.
Синтаксис: VERW r16/m16
Машинный код: 00001111: 00000000 : mod 101 r/m
Действие: проверить выполнение условий: определен ли селектор в таблицах
GDT или LDT; указывает ли дескриптор, адресуемый селектором, на сегмент дан-
ных (и никакой другой); является ли сегмент записываемым. Если условия вы-
полняются, то установить флаг ZF в ,1; в противном случае установить флаг ZF в 0.
Флаги: ZF= г
Исключения: PM: #AC(0); #GP(0): 2,3; #PF(fault-code); #SS(O): 1; RM: #UD: 16;
VM: #UD: 14.
WAIT
WAIT (WAIT) — приостановить работу процессора до поступления сигнала от
сопроцессора об окончании обработки последней команды.
Машинный код: 9Ь
Флаги: С0=С1=С2=СЗ=?
Исключения: PM: #NM: 1; RM: #NM: 1; VM: #NM: 1.
WBINVD
WBINVD (Write Back and INValiDate cache) — очистка кэш-памяти.
Машинный код: Of 09
Действие: очистить содержимое кэш-памяти первого уровня; записать содержи-
мое кэш-памяти второго уровня в основную память; очистить содержимое кэш-
памяти второго уровня.
Исключения: PM: #GP(0): 10; VM: #GP(0): 24.
WRMSR
WRMSR (WRite to Model Specific Register) — запись значения в один из 64-раз-
рядных MSR-регистров. Номер регистра задается в регистре ЕСХ.
Машинный код: Of 30
342
Приложение 1. Команды процессоров х86
Действие: проверить следующие условия: уровень привилегий нулевой; в регист-
ре ЕСХ значение, идентифицирующее один из MSR-регистров. Если хотя бы
одно из этих условий не выполняется, то закончить работу команды. Если выпол-
няются оба условия, то переслать значение пары 32-битных регистров EDX:EAX
в 64-битный MSR-регистр, номер которого задан в регистре ЕСХ.
Исключения: PM: #GP(0): 10,26; RM: #GP: 8; VM: #GP(0): 26.
XADD приемник, источник
XADD (eXchange and ADD) — обмен и сложение операндов приемник и источник.
Действие: команда XADD обменивает содержимое операнда приемник с операн-
дом источник, затем формирует сумму их значений в операнде приемник. Эта ко-
манда может использоваться с префиксом LOCK.
ГР'РРР'^
•0000fiji_: jj OOOOOwrnodre^r/mj
Флаги: CF=r PF=r AF=r SF=r ZF=r OF=r
Исключения: PM: #AC(0); #GP(0): 1—3; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
XCHG операнд_1, операнд_2
XCHG (eXCHanGe Register/Memory with Register) — обмен значениями между
операндами операнд_1 и операнд_2.
—| xchg
al Н г8 |
ax |-Q- -| г1б]
еахЮ“ —| г32
r8 K> -| al |
-|т8 |
m8 КУ Ч Г8
г-| ах
—| т16
т1бКУ Ч г16
-| еах
~|т32
|т32кУ Ч г32
|"Г1ррЗ‘огёд]
•<10000ii wTH гё£ ООО" [
["ЯррТо^ХГ'
UPPPPTlP 2 JLQ9P-j
‘ UPPPPllQiri®^!®^^
•-ЯррЗрТГЙ
UPPPPj"11 i j1РРО riГб "J
UPPPPiiIiiji^L^g-^Tj
•-.ТооТсГйб
i йрр'р'м^^
” UP?PPlliiri9.4.L®Q.L/[Pj
П1.1. Целочисленные команды
343
Исключения: PM: #АС(0); #GP(0): 1,2,3; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(O): 1.
XLAT адрес_таблицы_байт
XLATB
XLAT/XLATB (Table Look-up Translation) — преобразование байта.
Машинный код: d7
Действие: команда вычисляет адрес в памяти: DS:BX+(AL). Далее команда извле-
кает байт по этому адресу и помещает его в регистр AL. Несмотря на наличие опе-
ранда адрес_таблицы_байтов в команде XLAT, адрес последовательности байт, из
которой будет осуществляться выборка байта для подмены в регистре AL, должен
быть предварительно загружен в пару DS.BX(EBX). Команда XLAT допускает заме-
ну сегмента.
Исключения: PM: #GP(0): 2, 3; #PF(fault-code); #SS(O): 1; RM: #GP: 1; #SS: 1;
VM: #GP(0): 1; #PF(fault-code); #SS(0): 1.
XOR приемник, источник
XOR (logical exclusive OR) — логическое исключающее ИЛИ.
[OJ)JJO1pOj____[8______;
ГЛ QQQQbsw’ГJi
[001 IjOOdw 2 j 1 reglreg2J
[001IjOOIw£ rnqd req r7m [
i8,16,32 -
!JpppppswjjnodJ1pj/mjJ8/16/32[
r8,16,32 |— rpP1100bw2 mod £eg.£7nf[
Действие: выполнение операции логического исключающего ИЛИ над парами
бит двух операндов: бит результата равен 1, если значения соответствующих би-
тов операндов различны, в остальных случаях бит результата равен 0. Результат
помещается в операнд приемник.
Флаги: OF=r CF=r SF=r ZF=r PF=r AF=?
Исключения: PM: #AC(0); #GP(0): 1,2,3; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#SS: 1; VM: #AC(0); #GP(0): 1; #SS(O): 1.
344
Приложение 1. Команды процессоров х86
П1.2. Команды сопроцессора
F2XM1
F2XMl(2x-l) — вычисление 2х-1.
Действие: исходный операнд (значение степени х в диапазоне -1<х<1) хранится в
регистре ST0. Команда вычисляет значение 2х-1, а результат помещает в вершину
стека сопроцессора.
Машинный код: d9 fO
Флаги (SWR): С1 устанавливается в 1 при переполнении стека или в 0 при антипе-
реполнении (установлены биты SWR.IE и SWR.SF). При возникновении исключения
сопроцессора #Р (неточный результат) состояние флага показывает направле-
ние выравнивания (1 — в большую сторону); СО, С2, СЗ не определены.
Исключения: NE: #IS, #IA, #D, #U, #Р; PM: #NM: 1; RM: #NM: 1; VM: #NM: 1.
FABS
FABS (ABSolute value) — получение абсолютного значения (модуля) числа в ST0.
Действие: знаковый бит ST0 установить в 0.
Машинный код: d9 е1
Флаги (SWR): С1 устанавливается в 1 при переполнении стека или в 0 при анти-
переполнении (установлены биты SWR.IE и SWR.SF); СО, С2, СЗ не определены.
Исключения: NE: #IS; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FADD
FADD слагаемое_1
FADD слагаемое_1, слагаемое_2
FADD (ADDition) — сложение двух вещественных значений
—I fadd |------------1 Fdecii
-| fadd|-r-|m32real|-|Lci8/6J
4m64real|------1ГаёйП
НмЫЖНЯЖЬ ED
4st(i) |-O—|st(O)H Sgjsfttil
Действие: команда имеет три варианта расположения операндов.
♦ Без операндов — исходные значения: &Ц0)=слагаемое_1, ST( 1 }=слагаемое_2.
Команда выполняет сложение: ST(1)-ST(O)+ST(1). Последнее действие — вы-
талкивание значения из регистра ST(0). Результат сложения — в ST(0).
П1.2. Команды сопроцессора
345
♦ С одним операндом — исходные значения: т32/т64=слагаемое_1, ST(0)=
слагаемое_2. Команда выполняет сложение: ST(0)=ST(0)+m32/m64.
♦ С двумя операндами — слагаемое_1 содержится в ST(0)/ST(i), слагаемое_2 —
в ST(i)/ST(0). Результат сложения помещается в регистр ST(0) для команды
FADD ST(O),ST(i) или регистр ST(i) для команды FADD st(i),ST(O).
Флаги (SWR): см. команду F2XM1.
Исключения: NE: #IS, #IA, #D, #U, #О, #Р; PM: #АС(0); #GP(0): 2, 5; #NM: 1;
#PF(fault-code); #SS(O): 1; RM: #GP: 1; #SS: 1; VM: #AC(0); #GP(0): 1; #NM: 2;
#PF(fault-code); #SS(O): 1.
FADDP
FADDP слагаемое_1
FADDP слагаемое_1, слагаемое_2
FADDP (ADDition and Pop) — сложение с выталкиванием двух вещественных
значений.
faddi
-ГабП-о-Га(0)1
ЧЗЭ---------
Действие: Команда имеет три варианта расположения операндов.
♦ Без операндов — аналогична команде FADD без операндов.
♦ С операндом ST(i) — исходные значения: ST (\)=слагаемое_1, ST (Прелагаемое_2.
Команда выполняет сложение ST(i)=ST(O)+ST(i). Последним действием —
выталкивание значения из регистра ST(0), после чего результат сложения
оказывается в регистре ST(i-1).
♦ С двумя операндами ST(0) и ST(i) — исходные значения: ST прелагаемое_1,
ST(Прелагаемое_2. Команда выполняет сложение ST(i)=ST(O)+ST(i). Последним
действием — выталкивание значения из регистра ST(0), после чего результат
сложения оказывается в регистре ST(i-1).
Флаги (SWR) и исключения: см. описание команды FADD.
FBLD источник
FBLD (Load Binary coded Decimal) — загрузка десятичного числа в стек сопро-
цессора.
Синтаксис: FBLD m80dec
Машинный код: df/4
Действие: команда преобразует операнд источник, который содержится в памяти
в формате двоично-десятичного числа, в расширенный формат и помещает его
регистр ST(0).
346
Приложение 1. Команды процессоров х86
Флаги (SWR): см. команду FABS.
Исключения: NE: #IS; PM: #АС(0); #GP(0): 2, 5; #NM: 1; #PF(fault-code); RM:
#GP: 1; #NM: 1; #SS: 1; VM: #AC(0); #GP(0): 1; #NM: 2; #PF(fault-code); #SS(O): 1.
FBSTP приемник
FBSTP (STore Bed integer and Pop) — сохранение десятичного значения в памяти
с выталкиванием.
Синтаксис: FBSTP m80
Машинный код: df/6
Действие: исходный операнд — в регистре ST(0). Команда преобразует исходный
операнд в двоично-десятичный формат и записывает его в область памяти приемник
размером 10 байт (18 двоично-десятичных цифр). Последнее действие команды —
выталкивание исходного операнда из вершины стека.
Замечание: если в стеке было не целое число, то оно подвергается округлению в
соответствии с полем CWR.RC.
Флаги (SWR): см. команду F2XM1.
Исключения: NE: #IS, #IA #Р; PM: #AC(0); #GP(0): 2, 5, 36; #NM: 1; #PF(fault-
code); #SS(O): 1; RM: #GP: 1; #NM: 1; #SS: 1; VM: #AC(0); #GP(0): 1; #NM: 2;
#PF(fault-code); #SS(O): 1.
FCHS
FCHS (Change Sign) — инвертирование знака значения в ST(0).
Машинный код: d9 е0
Флаги (SWR): см. команду FABS.
Исключения: NE: #IS; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FCLEX
FCLEX (CLear Exceptions) — сброс флагов исключений в регистре SWR.
Машинный код: 9b db е2
Действие: сбрасывает флаги в регистре SWR: все флаги исключений — РЕ, UE, ОЕ,
ZE, DE, IE (биты 0...5); флаг суммарной ошибки работы сопроцессора ES (бит 6);
флаг ошибки работы стека сопроцессора SF (бит 7); флаг занятости В (бит 15).
Перед обнулением флагов команда FCLEX выполняет проверку условий ошибки с
плавающей точкой.
Флаги (SWR): С1, СО, С2, СЗ не определены.
Исключения: PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FCMOVcc приемник, источник
FCMOVcc (Floating-point Conditional MOVe) — условная пересылка данных
между регистрами сопроцессора.
П1.2. Команды сопроцессора
347
I da сЬ-Ы IF Fdacg+nh mtQi- fcmovb fcmove fcmovbe fcmovu fcmovnb fcmovne - {st(O)J<>LstQj-
IdLdp+LlF rdbd8+i~IH fcmovnbe fcmovnu
Действие: проверить состояние флагов в регистре EFLAGS (см. таблицу). Если
состояние флагов соответствует условиям выполнения команды, то переслать
значение из источника (ST(i)) в приемник (ST(0)). В противном случае закончить
выполнение команды без пересылки.
Мнемокоды Значения флагов в регистре EFLAGS
FCMOVB CF=1
FCMOVE ZF=1
FCMOVBE CF=1 MnnZF=1
FCMOVU PF=1
FCMOVNB CF=0
FCMOVNE ZF=0
FCMOVNBE SF=0 и ZF=0
FCMOVNU PF=0
Флаги (SWR): см. команду FABS.
Исключения: NE: #IS; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FCOM
FCOM операнд_2
FCOM (COMpare) — сравнение вещественных чисел.
—|fcom[— I — — IF d8 d11
-|mozreai| 1 ao/z i |Г~Нг/2 1
4st(i) 1—
Действие: сравнение значения в регистре ST(0) и операнда операнд_2, указанного
в команде (mem32/64/ST(i)) или принимаемого по умолчанию (регистр ST(1)).
Результат сравнения определяется состоянием битов СЗ, С2 и СО регистра SWR.
операнды не сравнимы С3=1, С2= 1, С0=1
операнд_2 > операнд^ 1 СЗ=0, С2=0, С0=1
продолжение#
348
Приложение 1. Команды процессоров х86
(продолжение)
операнд_2 < операнд_1 СЗ=0, С2=0, С0=0
операнд_2=операнд_ 1 С3= 1, С2=0, С0=0
Флаги (SWR): С1 устанавливается в 1 при переполнении стека или в 0 при анти-
переполнении (установлены биты SWR.IE и SWR.SF); С2 устанавливается в 1, если
операнды не сравнимы; СО, СЗ — результат сравнения.
Исключения: NE: #IS, #1А (в стеке непредставимые значения (СЗС2С0-111),
#D; PM: #АС(0); #GP(0): 2, 5; #NM: 1; #PF(fault-code); #SS(O): 1; RM: #GP: 1;
#NM: 1; #SS: 1; VM: #AC(0); #GP(0): 1; #NM: 2; #PF(fault-code); #SS(O): 1.
FCOMI операнд_1, операнд_2
FCOMI (COMpare real and set EFLAGS) — сравнение вещественных значений и
установка EFLAGS.
Синтаксис: FCOMI ST(0),ST(i)
Машинный код: db fO+i
Действие:
1. Проверить, поддерживаются ли форматы чисел в операнду и операнд_2.
2. Если один или оба операнда — не числа или числа в неподдерживаемом сопро-
цессором формате, то проверить, замаскировано ли исключение недействитель-
ной операции сопроцессора в управляющем регистре сопроцессора CWR:
• если бит CWR.IM=1 (то есть исключение замаскировано), то установить
флаги ZF=PF=CF=1. После этого закончить работу команды;
• если бит CWR.IM=0 (то есть исключение не замаскировано), то возбудить
исключение недействительной операции сопроцессора, в результате чего
управление будет передано соответствующему обработчику;
• если оба операнда — корректные вещественные числа, то продолжить рабо-
ту команды.
3. Выполнить вычитание (операнд_1-операнд_2).
4. По результатам вычитания установить флаги ZF, PF, CF в регистре EFLAGS, как
показано ниже.
Результат сравнения ZF PF CF
St(0)>ST(i) 0 0 0
St(O)<ST(i) 0 0 1
St(O)=ST(i) 1 0 . 0
Неподдерживаемые форматы 1 1 1
Флаги (EFLAGS): ZF=r PF=r CF=r
Флаги (SWR): см. команду FABS.
Исключения: NE: #IS, #IA; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
П1.2. Команды сопроцессора
349
FCOMIP операнд_1, операнд_2
FCOMIP (Floating-point COMpare, set EFLAGS and Pop) — сравнение веще-
ственных чисел, установка регистра EFLAGS и выталкивание операнда из верши-
ны стека.
Синтаксис: FCOMIP ST(0),ST(i)
Машинный код: df fO+i
Действия: аналогичны FCOMI. Последняя операция — выталкивание значения
из ST(0).
Флаги (EFLAGS), флаги (SWR) и исключения: см. описание команды FCOMI.
FCOMP
FCOMP операнд
FCOMP (COMpare and Pop) — сравнение вещественных чисел и выталкивание
из стека.
-|т64геа!|----------1 ГЬс/3~~!
WI------------1 й&ЗйЗ
Действия: аналогичны FCOM. Последняя операция — выталкивание значения
из ST(O).
Флаги (SWR) и исключения: см. описание команды FCOM.
FCOMPP
FCOMPP (COMpare and Pop and Pop) — сравнение вещественных чисел и двой-
ное выталкивание из стека.
Машинный код: de d9
Действия: аналогичны FCOM. Последняя операция — выталкивание значений из
ST(0) и ST(1).
Флаги (SWR) и исключения: см. описание команды FCOM.
FCOS
FCOS (COSine) — вычисление косинуса.
Машинный код: d9 ft
Действия: значение угла в радианах х (-263<=х<=+263) хранится в регистре ST(0).
Команда преобразует число из ST(0) в значение косинуса и записывает его обрат-
но в регистр ST(O).
350
Приложение 1. Команды процессоров х86
Флаги (SWR): С1 устанавливается в 1 при переполнении стека или в 0 при антипе-
реполнении (биты SWR.IE и SWR.SF в регистре установлены). При возникновении
исключения #Р состояние флага С1 показывает направление выравнивания (1 —
в большую сторону). Если С2=1, то С1 неопределен. С2 устанавливается в 1, если
значение исходного операнда выходит за границу |х|<=263, иначе — С2=0. СО, СЗ не
определены.
Исключения: NE: #IS, #1 A; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FDECSTP
FDECSTP (DECrement Stack Top Pointer) — уменьшение указателя вершины
стека на единицу.
Машинный код: d9 f6
Действия: если поле SWR.ST=O, то выполнить присваивание ST=7, в противном
случае выполнить декремент ST=ST-1.
Флаги (SWR): С1 устанавливается в 0; СО, С2, СЗ не определены.
Исключения: PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FDIV
FDIV делитель
FDIV делимое, делитель
FDIV (Divide) — деление двух вещественных чисел.
—{fdiv |------------1 Fdef9~l
-------------1ЕЖ0
L|m64real|---1 Г3с7~6~|
ЧЙ!7}-гЧЖ1-0-ГЖ1-1 Ш+i]
Действия: команда FDIV имеет три варианта расположения операндов.
♦ Без операндов — исходные значения: ЗЦ^делимое, ST(О)=делитпель. Команда
выполняет деление: ST(1 )=ST( 1 )/ST(O). Последнее действие — выталкивание
значения из ST(O). Окончательный результат — в регистре ST(O).
♦ С одним операндом — исходные значения: ST(Отделимое, т32(64)геа1=делитель.
Команда выполняет деление ST(0)=ST(0)/(m32(64)real.
♦ С двумя операндами — делимое и делитель хранятся в двух регистрах стека,
один из которых ST(O). Выполняется деление делимое=(делимое/делитель).
Флаги (SWR): см. команду F2XM1.
Исключения: NE: #IS, #IA, #D, #Z, #U, #0, #Р; PM: #АС(0); #GP(O): 2,5; #NM: 1;
#PF(fault-code); RM: #GP: 1; #NM: 1; #SS: 1; VM: #AC(O); #GP(O): 1; #PF(fault-
code); #NM: 2; #SS(O): 1.
П1.2. Команды сопроцессора
351
FDIVP
FDIVP делимое, делитель
FDIVP (DIVide and Pop) — деление двух вещественных чисел с последующим
выталкиванием из стека.
-|fdivP|-----------1 r_de~f9~j
HfdivpH---------------d Se.f8+i]
Действия: команда имеет два варианта расположения операндов.
♦ Без операндов — аналогична команде FDIV без операндов.
♦ С двумя операндами — исходные значения: ST делимое (ST(O) использовать
нельзя), ЗТ(0)=делитель. Команда выполняет деление делимое=(делимое/дели-
тель). Последнее действие команды — выталкивание значения из вершины стека
сопроцессора. Результат выполнения операции сохраняется в регистре ST(i-1).
Флаги (SWR) и исключения: см. описание команды FDIV.
FDIVR
FDIVR делимое
FDIVR делитель, делимое
FDIVR (Reverse order DIVide) — деление двух вещественных чисел в обратном
порядке.
—| fdivr |------------1 Г de f 1~1
—| fdivr r-|m32real |-1 [_d8/7_J
Цт64геа1|-----1 ГЗс/7~!
Scroti!
Действия: команда имеет три варианта расположения операндов.
♦ Без операндов — исходные значения: ST(Ъ)=делимое, ЗТ (А)-делитель. Команда
выполняет деление: ST(1)=ST(0)/ST(1) {делимое/делитель). Последнее дей-
ствие — выталкивание значения из регистра ST(O). Результат операции — в реги-
стре ST(0).
♦ С одним операндом — исходные значения: т32(64)геа1=делшюе, ST (0)=делитель.
Команда выполняет деление: ST(0)=(m32(64)real)/ST(0).
♦ С двумя операндами — источник и приемник хранятся в двух регистрах стека,
один из которых ST(0). Команда выполняет деление делитель=(делимое/делитель).
Флаги (SWR) и исключения: см. описание команды FDIV.
352
Приложение 1. Команды процессоров х86
FDIVRP
FDIVRP делитель, делимое
FDIVRP (Reverse order DIVide and Pop) — деление двух вещественных чисел в
обратном порядке с последующим выталкиванием из стека.
4fdivrP|-------------1 LdeJl j
—|fdivrp[—1---------г| [de Ю+ij
Действия: команда имеет два варианта расположения операндов.
♦ Без операндов — аналогично команде FDIVR.
♦ С двумя операндами — исходные значения: ST (Отделимое, ST делитель.
Команда выполняет деление: ST(i)=ST(O)/ST(i). Последнее действие команды -
выталкивание значения из вершины стека сопроцессора. Результат опера-
ции — в регистре ST(i-1).
Флаги (SWR) и исключения: см. описание команды FDIV.
FFREE регистр_сопроцессора
FFREE (FREE floating-point regiSTer) — освобождение регистра стека сопро-
цессора.
Синтаксис: FFREE ST(i)
Машинный код: dd cO+i
Действия: выбрать в регистре тегов TWR двухбитовое поле tt, соответствующее
регистру ST(i), и установить в нем значение 11b.
Флаги (SWR): С1, СО, С2, СЗ не определены.
Исключения: PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FIADD слагаемое_1
FIADD (Integer ADDition with real value) — сложение значения в целочисленном
формате с вещественным значением.
-jfiaddHpl nn16int |-1 [de/0_. j
Ч m32int |----1 [d£/Oj
Действия: исходные операнды — хх\ХЬ(32)\г\Х=слагаемое_1, ST(^-слагаемое 2. Коман-
да выполняет сложение: ST (О)=(источник^приемник).
Флаги (SWR) и исключения: см. описание команды FADD.
П1.2. Команды сопроцессора
353
FICOM операнд_2
FICOM (Integer COMpare) — сравнение целого и вещественного значений.
—]ficom|—Ч m16int |-1 Г_ЦЙ2_ j
Ч m32int |---1 ГJa72_j
Действия: сравнение значения в регистре ST(0) и целочисленного операнда в
ячейке памяти m16/32int, местоположение которого явно указано в команде как
операнд_2. Результат сравнения определяется состоянием битов СЗ, С2 и СО реги-
стра SWR сопроцессора.
операнды не сравнимы
операнд_2 > операнд_ 1
операнд_2 < операнд_1
операнд_2 = операнд_ 1
С3=1, С2=1, С0=1
СЗ=0, С2=0, С0=1
СЗ=0, С2=0, С0=0
С3=1, С2=0, С0=0
Флаги (SWR) и исключения: см. описание команды FCOM.
Исключения: NE: #IS, #IA, #D; PM: #АС(0); #GP(0): 2, 5; #NM: 1; #PF(fault-
code); #SS(O): 1; RM: #GP: 1; #NM: 1; #SS: 1; VM: #AC(0): 1; #GP(0): 1; #NM: 1;
#PF(fault-code); #SS(O): 1.
FICOMP операнд
FICOMP (Integer COMpare and Pop) — сравнение целого и вещественного значе-
ний с выталкиванием из стека.
4ficomp|—Ч m16int |---1 Lde/3_J
I—| m32int |--1 [j3a~/3_ j
Действия: аналогичны команде FICOM. Последнее действие — выталкивание зна-
чения из вершины стека.
Флаги (SWR) и исключения: см. описание команды FICOM.
FIDIV источник
FIDIV (DIVide on Integer value) — деление вещественного числа на целочисленное.
Ч fidiv [—4 m16»nt |--1 j
I—I m32int |--1 L.0a/6_J
Действия: исходные значения: ЗТ(0)=делимое, тХ6(32)\пХ=делителъ (источник).
Команда выполняет деление: 8Т(0)=делимое/делителъ.
Флаги (SWR) и исключения: см. описание команды FDIV.
354
Приложение 1. Команды процессоров х86
FIDIVR делимое
FIDIVR (Reverse order DIVide on Integer value) — обратное деление целочислен-
ного значения на вещественное.
1 r_de7/_72
1 ir-da/7_’j
Действия: исходные значения: m16(32)int ^делимое, $Т(О)=делителъ. Команда вы-
полняет деление: 8Т(0)=делимое/делшпель.
Флаги (SWR) и исключения: см. описание команды FDIV.
FILD источник
FILD (LoaD Integer) — загрузка целочисленная.
-|m32int |-
—| m64int
1 Ldf/P_“'
1 Ldb/0 “j
Действия: преобразование целого значения из операнда источник в веществен-
ное расширенное представление, после чего указатель вершины стека сопроцессо-
ра (поле SWR.TOP) уменьшается на 1. Результат преобразования помещается в
регистр ST(0).
Флаги (SWR): С1 устанавливается в 1 при переполнении стека; СО, С2, СЗ не оп-
ределены.
Исключения: NE: #IS; PM: #АС(0); #GP(0): 2,5; #NM: 1; #PF(fault-code); #SS(0): 1;
RM: #GP: 1; #NM: 1; #SS: 1; VM: #AC(0); #GP(0): 1; #NM: 2; #PF(fault-code); #SS;
#SS(0): 1.
FINCSTP
FINCSTP (INCrement Stack Top Pointer) — увеличение величины указателя вер-
шины стека на единицу.
Машинный код: d9 f7
Действия: если поле SWR.TOP=7, то выполнить присваивание SWR.TOP=0, в про-
тивном случае выполнить инкремент SWR.TOP=SWR.TOP+1.
Флаги (SWR): С1 устанавливается в 0; СО, С2, СЗ не определены.
Исключения: PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FIMUL сомножитель_2
FIMUL (Integer Multiply) — умножение целого значения на вещественное.
П1.2. Команды сопроцессора
355
—| fimul|—т~Ч ml6int |--1 L.de/1_J
I—{m32int |----1
Действия: исходные значения: ЗТ(0)=сомножителъ_1, т^6(32)1п{=сомножителъ_2.
Команда выполняет умножение: (31(3)=сомножителъ_1*сомножитель_2). Если
значение операнда сомножителъ_2 не целое, то результат операции будет неопре-
деленным.
Флаги (SWR): см. команду F2XM1.
Исключения: NE: #IS, #IA, #D, #U, #О, #Р; PM: #АС(0); #GP(0): 2, 5; #NM: 1;
#PF(fault-code); #SS(0): 1; RM: #GP: 1; #NM: 1; #SS: 1; VM: #GP(0): 1; #NM: 2;
#PF(fault-code); #SS(0): 1.
FINIT
FINIT (INITializing a device FPU) — инициализация сопроцессора.
Машинный код: 9b db еЗ
Действия: проверить наличие установленных битов исключений в регистре SWR.
Если какие-то из них установлены, то вызвать обработчики соответствующих
исключений; установить регистры сопроцессора: CWR=037f; SWR=0000; TWR=ffff;
регистры указателей данных DPR и команд IPR установить в 0.
Флаги (SWR): С1=С0=С2=СЗ=0
Исключения: PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FIST приемник
FIST (Integer STore) — сохранение целочисленное.
—| fist |—r~| m16int~~|-1 r_d_f/2-_ J
4 m32int |-----1 udb/2J
Действия: исходя из значения в поле RC (управление округлением) регистра
CWR, округлить число в вершине стека до соответствующего целого значения:
если RC=00b, то округление до ближайшего целого; если RC=01 b, то округление до
ближайшего меньшего целого; если RC=10b, то округление до ближайшего боль-
шего целого; если RC=11b, то дробная часть числа отбрасывается. Результат пре-
образования поместить в ячейку памяти, адрес которой указан операндом приемник.
Если величина преобразованного значения превышает по модулю максимально
представимое число в операнде приемник, то в нем формируется наибольшее от-
рицательное число — 80 00 или 80 00 00 00.
Флаги (SWR): см. команду F2XM1.
Исключения: NE: #IS, #IA, #Р; PM: #AC(0); #GP(0): 1, 2, 5; #NM: 1; #PF(fault-
code); #SS(0): 1; RM: #GP: 1; VM: #AC(0); #GP(0): 1; #NM: 2; #PF(fault-code);
#SS(0): 1.
356
Приложение 1. Команды процессоров х86
FISTP приемник
FISTP (Integer STore and Pop) — сохранение целочисленное с выталкиванием.
-1 m32int f
—| m64int |-
1 i®Lj
1 ЕЖ J
№
Действие: то же, что п FIST, за исключением дополнительного действия — выталкива-
ния значения из вершины стека. В отличие от команды FIST в команде FISTP резуль-
тат целочисленного преобразования может быть не только 16 и 32 бита, но и 64 бита.
Флаги (SWR) и исключения: см. описание команды FIST.
FISUB вычитаемое
FISUB (SUBtraction of Integer) — вычитание целочисленного значения из веще-
ственного.
—{fisub |—иг—| m16int |-1 Lde/4 J
I—| m32int |----1 Г da/4 I
Действия: исходные значения: ST(3)=уменьшаемое, гоАЬ(32)\п\=вычитаемое. Коман-
да преобразует вычитаемое в вещественное число в расширенном формате, после
чего выполняет действие: 31(3)=(уменъшаемое-вычитаемое).
Флаги (SWR): см. команду F2XM1.
Исключения: NE: #IS, #1А, #D, #U, #0, #Р; PM: #АС(О); #GP(O): 2, 5; #NM: 1;
#PF(fault-code); #SS(O): 1; RM: #GP: 1; #NM: 1; #SS: 1; VM: #AC(O); #GP(O): 1;
#NM: 2; #PF(fault-code); #SS(O):1.
FISUBR уменьшаемое
FISUBR (Reverse SUBtract from Integer) — обратное вычитание вещественного
значения из целочисленного значения.
—|fisubr|—|—Tm16int |---1 L.de/5 J
L-| m32int ]----1 r.da/5 j
Действия: исходные значения: гоАЪ(32)=уменьшаемое, ST (0)=вычитаемое. Коман-
да преобразует уменьшаемое в вещественное число в расширенном формате, пос-
ле чего выполняет действие: ST(O)=(уменьшаемое-вычитаемое).
Флаги (SWR): см. команду F2XM1.
Исключения: NE: #IS, #IA, #D, #U, #0, #Р; PM: #АС(О); #GP(O): 2, 5; #NM: 1;
#PF(fault-code); #SS(O): 1; RM: #GP: 1; #NM: 1; #SS: 1; VM: #AC(O); #GP(O): 1;
#NM: 2; #PF(fault-code); #SS(O): 1.
П1.2. Команды сопроцессора
357
FLD источник
FLD (LoaD real) — загрузка в стек вещественного значения.
1Г d9/0"]
1L db/5_“J
1У 9 cp+i]
Действия: источник — значение в вещественном формате т32/т64/т80 или в ре-
гистре ST(i). Команда уменьшает значение поля SWR.TOP на единицу; проверяет
тег для регистра стека, физический помер которого в данный момент времени на-
ходится в поле SWR.TOP. Если содержимое тега не равно 11b (регистр не пустой),
то устанавливаются биты SWR.SF и SWR.IE и выполнение команды заканчивает-
ся. Если содержимое тега равно 11b, то анализируется тип операнда и выполня-
ются следующие действия:
♦ если операнд источник является вещественным значением в памяти т32/т64
бита, то оно преобразуется в вещественное число в расширенном формате, пос-
ле чего записывается в вершину стека;
♦ если операнд источник является вещественным значением в памяти разме-
ром 80 бит или регистром стека, то он копируется в вершину стека.
Флаги (SWR): С1 устанавливается в 1 при переполнении стека или в 0; СО, С2, СЗ
не определены.
Исключения: NE: #IS, #IA, #D; PM: #AC(0); #GP(0): 1, 2, 5; #NM: 1; #PF(fault-
code); #SS(0): 1; RM: #GP: 1; #NM: 1; #SS: 1; VM: #GP(0): 1; #NM: 2; #PF(fault-
code); #SS(0): 1.
FLDCW источник
FLDCW (LoaD Control Word) — загрузка регистра управления CWR содержимым
ячейки памяти источник.
Синтаксис: FLDCW ml6
Машинный код: d9 /5
Флаги (SWR): С1 устанавливается в 1 при переполнении стека или в 0; СО, С2, СЗ
не определены.
Исключения: PM: #AC(0); #GP(0): 2, 5; #NM: 1; #PF(fauIt-code); #SS(0): 1; RM:
#GP: 1; #NM: 1; #SS: 1; VM: #AC(0); #GP(0): 1; #NM: 2; #PF(fault-code); #SS(0): 1.
FLDENV источник
FLDENV (LoaD ENVironment) — загрузка рабочей среды сопроцессора.
Синтаксис: FLDCW m 14/28
Машинный код: d9 /4
358
Приложение 1. Команды процессоров х86
Действия: определить режим работы процессора (R, V или Р) и размер операнда
для текущего сегмента кода (задается значением атрибута use: use16 или use32):
если use 16, то размер буфера, из которого будет производиться восстановление
среды сопроцессора, равен 14 байт; если use32, то размер буфера, из которого бу-
дет производиться восстановление среды сопроцессора, равен 28 байт. Далее из
области памяти источник, начальный адрес которой указан операндом формата
m 14/28, произвести запись информации в следующие регистры сопроцессора:
CWR; SWR; TR; IPR; DPR. Структура области памяти, содержащей образ рабочей
среды сопроцессора, показана ниже.
use 16 и R-режим use 16 и P-режим
Регистр cwr 0 Регистр cwr 0
Регистр swr 2 Регистр swr 2
Регистр twr 4 Регистр twr 4
Регистр ipr (0-15) 6 Регистр ipr (0-15) 6
ipr(16-19) |o| Кодоперации(О-Ю) 8 Селектор cs 8
Регистр dpr (0-15) 10 Регистр dpr (0-15) 10
dpr(16—19) | 000000000000 12 Селектор операнда 12
15 11 0 15 0
use32 и R-режим
оооооооооооооооо Регистр cwr 0
оооооооооооооооо Регистр swr 4
оооооооооооооооо Регистр twr 8
оооооооооооооооо Регистр ipr (0-15) 12
0000 | ipr( 16-31) |о|Код операции(О-Ю) 16
оооооооооооооооо | Регистр dpr (0-15) 20
0000 I dpr(16-31) | 000000000000 24
31 15 11 0
use32 и Р-режим
оооооооооооооооо Регистр cwr 0
оооооооооооооооо Регистр swr 4
оооооооооооооооо Регистр twr 8
Регистр ipr (0-31) 12
оооооооооооооооо | Регистр ipr (31-47) 16
Регистр DPR (0-31) 20
0000 000000000000 | Регистр dpr (31-47) 24
31 15 11 0
Флаги (SWR): С1 устанавливается в 1 при переполнении стека или в 0; СО, С2, СЗ
не определены.
Исключения: PM: #AC(0); #GP(0): 2, 5; #NM: 1; #PF(fault-code); #SS(0): 1; RM:
#GP: 1; #NM: 1; #SS: 1; VM: #AC(0); #GP(0): 1; #NM: 2; #PF(fanlt-code); #SS(0): 1.
FLD1
FLD1 (LoaD conSTant +1.0) — загрузка вещественной единицы.
Машинный код: d9 f8
П1.2. Команды сопроцессора
359
Действия: SWR.TOP=SWR.TOP-1; ST(0)=+1.0.
Флаги (SWR): С1 устанавливается в 1 при переполнении стека; СО, С2, СЗ не оп-
ределены.
Исключения: NE: #IS; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FLDL2T
FLDL2T (LoaDing log210) — загрузка двоичного логарифма десяти.
Машинный код: d9 е9
Действия: SWR.TOP=SWR.TOP-1; ST(0)=log210.
Флаги (SWR): С1 устанавливается в 1 при переполнении стека; СО, С2, СЗ не оп-
ределены.
Исключения: NE: #IS; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FLDL2E
FLDL2E (LoaDing log2e) — загрузка двоичного логарифма числа е.
Машинный код: d9 еа
Действия: SWR.TOP=SWR.TOP-1; ST(0)=log2e.
Флаги (SWR): С1 устанавливается в 1 при переполнении стека; СО, С2, СЗ не оп-
ределены.
Исключения: NE: #IS; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FLDLG2
FLDLG2 (LoaDing log102) — загрузка десятичного логарифма числа 2.
Машинный код: d9 ес
Действия: SWR.TOP=SWR.TOP-1; ST(0)=log102.
Флаги (SWR): С1 устанавливается в 1 при переполнении стека; СО, С2, СЗ не оп-
ределены.
Исключения: NE: #IS; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FLDLN2
FLDLN2 (LoaDing logc2) — загрузка натурального логарифма числа 2.
Машинный код: d9 ed
Действие: SWR.TOP=SWR.TOP-1; ST(0)=ln(2).
Флаги (SWR): С1 устанавливается в 1 при переполнении стека; СО, С2, СЗ не оп-
ределены.
Исключения: NE: #IS; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
360
Приложение 1. Команды процессоров х86
FLDPI
FLDPI (LoaDing л) — загрузка числа п.
Машинный код: d9 eb
Действия: SWR.TOP=SWR.TOP-1; ST(0)=n.
Флаги (SWR): С1 устанавливается в 1 при переполнении стека; СО, С2, СЗ не
определены.
Исключения: NE: #1S; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FLDZ
FLDZ (LoaDing 0) — загрузка нуля.
Машинный код: d9 ее
Действия: SWR.TOP=SWR.TOP-1; st(O)=+O.O.
Флаги (SWR): С1 устанавливается в 1 при переполнении стека; СО, С2, СЗ не оп-
ределены.
Исключения: NE: #IS; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FMUL
FMUL множитель"!
FMUL множитель_1, множите л ь_2
FMUL (Multiply) — умножение.
4 fouil |-------------1 [de c9 J
—| fmul |—r-|m32reai]-1 Г Jd8/1_ ]
I—|m64real |--1 Г jdc7T]
4 fault НЧ Ho—I s*(i) H
I—| st(i) j—O—|st(O) H Idcjce+iJ
Действия: команда имеет три варианта расположения операндов.
♦ без операндов — исходные значения: ЗУ (У)-множит ель, ST(Ъ)=множитель_2.
Команда выполняет умножение: ЗУ(})=(множителъ_1*множителъ_2). Послед-
нее действие — выталкивание значения из регистра ST(0). Результат умноже-
ния — в ST(0);
♦ с одним операндом — исходные значения: т32(64)=множитель_1, 8Т(0)=мио-
житель_2. Команда выполняет умножение ЗУ(3)^(множитель_1*множитель_2)\
♦ с двумя операндами — множитель_1 хранится в ST(0)/ST(i), множитель_2 —
в ST(i)/ST(0). Команда выполняет умножение (множитель _1* множитель_2).
Результат умножения помещается либо в регистр ST(0) для команды fmul
ST(0),ST(i), либо в регистр ST(i) для команды fmul ST(i),ST(0).
П1.2. Команды сопроцессора
361
Флаги (SWR): см. команду F2XM1.
Исключения: NE: #IS, #IA, #D, #U, #0, #Р; PM: #АС(О): 1; #GP(O): 2,5; #NM: 1;
#PF(fault-code); #SS(O): 1; RM: #GP: 1; #NM: 1; #SS: 1; VM: #AC(O): 1; #GP(O): 1;
#NM: 2; #PF(fault-code); #SS; #SS(O): 1.
FMULP
FMULP множитель_1, множитель_2
FMULP (Multiply and Pop) — умножение с выталкиванием.
—|fmulp|—[----------1 r.de‘_c?"j
Sic8+j;
Действия: по действиям аналогична команде FMUL, за исключением дополнитель-
ного действия — выталкивания значения из ST(O).
Флаги (SWR) и исключения: см. описание команды FMUL.
FNCLEX
FNCLEX (No errorteST CLear Exceptions) — сброс исключений без проверки ошибок.
Синтаксис: FNCLEX
Машинный код: db е2
Действия: аналогичны FCLEX, за исключением того, что команда FNCLEX перед об-
нулением флагов не выполняет проверки условий ошибки с плавающей точкой.
Флаги (SWR): С1, СО, С2, СЗ не определены.
Исключения: PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FNINIT
FNINIT (No error teST INITializing a device FPU) — инициализация устройства
FPU без проверки ошибок.
Машинный код: db еЗ
Действия: проверить наличие установленных бит исключений в регистре SWR;
установить регистры сопроцессора: CWR= 03 7fh; SWR = 00 00; TWR= ff ff; регистры
указателей данных DPR и команд IPR установить в 0.
Флаги (SWR): С1=С0=С2=СЗ=0
Исключения: PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FNOP
FNOP (No OPeration) — команда не выполняет никаких действий. Эффект ее при-
менения заключается в том, что она занимает место (два байта) в потоке команд.
362
Приложение 1. Команды процессоров х86
Машинный код: d9 dO
Флаги (SWR): С1=С0=С2=СЗ=0
Исключения: PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FNSAVE приемник
FNSAVE (No error teST SAVE fpu STate) — сохранение полной среды сопроцессо-
ра без проверки исключений.
Синтаксис: FNSAVE m94/108
Машинный код: dd /6
Действия: определить режим работы процессора (R, V или Р) и размер опе-
ранда для текущего сегмента кода (определяется значением атрибута use: use 16
или use32). Это необходимо для определения размера буфера (94 или 108 байт),
в котором будет сохраняться полная среда сопроцессора. Далее производится
запись информации из следующих регистров сопроцессора в область памяти,
начальный адрес которой указан операндом т94/108: регистра управления CWR;
регистра состояния SWR; регистра тегов TR; регистра указателя команд IPR;
регистра указателя данных DPR; регистров стека сопроцессора ST(0)...ST(7).
Последним действием команды является приведение сопроцессора в началь-
ное состояние путем установки регистров в следующее состояние: CWR = 03 7fh;
SWR = 00 00; TWR = ff ff; регистры указателей данных DPR и команд IPR устанав-
ливаются в 0.
Ниже показана структура области памяти, формируемая командой FNSAVE.
use16 и R-режим
Регистр cwr 0
Регистр swr 2
Регистр twr 4
Регистр ipr (0-15) 6
ipr(16-19) 101 Код операции(0-10) 8
Регистр dpr (0-15) 10
dpr(16—19) | 000000000000 12
st(O) 14
st(1) 24
st(7) 84
15 11 0
use 16 и Р-режим
Регистр cwr 0
Регистр swr 2
Регистр twr 4
Регистр ipr (0-15) 6
Селектор cs 8
Регистр dpr (0-15) 10
Селектор операнда 12
st(O) 14
st(1) 24
st(7) 84
15 0
Флаги (SWR): С1=С0=С2=СЗ=0
Исключения: PM: #AC(0); #GP(0): 2,5; #NM: 1; #PF(fault-code); #SS(0): 1; RM:
#GP: 1; #NM: 1; #SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(0): 1.
П1.2. Команды сопроцессора
363
use32 и R-режим
0000000000000000 Регистр cwr 0
0000000000000000 Регистр swr 4
0000000000000000 Регистр twr 8
0000000000000000 Регистр ipr (0-15) 12
0000 I IPR(16-31) |о| Код операции(О-Ю) 16
0000000000000000 | | Регистр dpr (0-15) 20
0000 I DPR(16-31) I 000000000000 24
st(O) 28
st(1) 38
st(7) 98
31 15 11 0
use32 и P-режим
0000000000000000 Регистр cwr 0
0000000000000000 Регистр swr 4
0000000000000000 Регистр twr 8
Регистр IPR (0-31) 12
0000000000000000 | Регистр ipr (31-47) 16
Регистр DPR (0-31) 20
0000 000000000000 Регистр dpr (31-47) 24
st(O) 28
st(1) 38
st(7) 98
31 15 0
FNSTCW приемник
FNSTCW (STore Control Word (No error teST)) — сохранение значения регистра
управления CWR сопроцессора в слове памяти без проверки исключений.
Синтаксис: FNSTSWm16
Машинный код: d9 /7
Флаги (SWR): С1=С0=С2=СЗ=0
Исключения: PM: #АС(0); #GP(0): 1, 2, 5; #NM: 1; #PF(fault-code); #SS(0): 1;
RM: #GP: 1; #NM: 1; #SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(0): 1.
FNSTENV источник
FNSTENV (No error teST STore ENVironment) — сохранение среды сопроцессора
в памяти.
Синтаксис: FNSTENV m 14/28
Машинный код: d9 /6
364
Приложение 1. Команды процессоров х86
Действия: определить режим работы процессора (R, V или Р) и размер операнда
для текущего сегмента кода (определяется значением атрибута use: use16 или
use32). Это необходимо для определения размера буфера (14 или 28 байт), в кото-
рый будет производиться запись среды сопроцессора. В область памяти, началь-
ный адрес которой указан операндом т14/28, произвести запись информации из
следующих регистров сопроцессора: регистра управления CWR; регистра состоя-
ния SWR; регистра тегов TR; регистра указателя команд IPR; регистра указателя
данных DPR. Установить маски всех исключений в единицы (замаскировать
исключения).
Структура области памяти, сформированная командой, показана на рисунке в
описании команды FLDENV.
Флаги (SWR): С1 СО, С2, СЗ не определены.
Исключения: PM: #АС(0); #GP(0): 1, 2, 5; #NM: 1; #PF(fault-code); #SS(0): 1;
RM: #GP: 1; #NM: 1; #SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(0): 1.
FNSTSW приемник
FNSTSW (No error teST STore Status Word) — сохранение значения регистра со-
стояния SWR в слове памяти или регистре АХ без проверки исключений.
-]fnstswL-| m16 |-1 [dd/7j
-| ax |----1 [df eO'
Флаги (SWR): C1 CO, C2, СЗ не определены.
Исключения: PM: #AC(0); #GP(0): 1, 2, 5; #NM: 1; #PF(fault-codc); #SS(0): 1;
RM: #GP: 1; #NM: 1; #SS: 1; VM: #AC(0); #GP(0): 1; #PF(fault-code); #SS(0): 1.
FPATAN
FPATAN (Partial ArcTANgent) — вычисление частичного арктангенса.
Машинный код: d9 f3
Действие: исходные операнды: значение х в регистре ST(0); значение у в регистре
ST( 1). Команда вычисляет значение арктангенса частного х/у; выталкивает значе-
ния х и у из стека сопроцессора; записывает результат вычисления арктангенса в
вершину стека — регистр ST(0).
Исходные операнды х и у должны отвечать условию: 0<у<х<+оо Если это не так,
необходимо использовать следующие формулы приведения:
arctg(x)=-arctg(-x); arctg(x)=7i/2-arctg(l/x)
Флаги (SWR): см. команду F2XM1.
Исключения: NE: #IS, #IA, #D, #U, #Р; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
П1.2. Команды сопроцессора
365
FPREM
FPREM (Partial REMainder) — вычисление частичного остатка от деления ST(0)
HaST(1).
Машинный код: d9 f8
Действия: делимое хранится в ST(0); делитель — в ST( 1). Команда вычитает значе-
ния полей порядков в ST(0) и ST(1).
♦ Если полученная разность меньше 64, то выполнить деление l=ST(0)/ST(1), ре-
зультат которого округлить путем усечения к ближайшему меньшему целому;
записать в ST(0) новое значение, равное ST(0)= ST(0)-(ST(1)*l); установить бит
SWR.C2=0 — это означает, что в ST(0) получен истинный остаток, удовлетворя-
ющий требованию остаток<делителя\ установить биты С0С1СЗ в SWR равны-
ми значениям трех младших битов значения частного I — I2ItIQ.
♦ Если полученная разность больше 64, то установить бит SWR.C2=1 — это озна-
чает, что в ST(0) будет получен пока только частичный остаток, не удовлетво-
ряющий требованию остаток<делителя, и нужно будет повторить обращение
к команде FPREM для получения истинного остатка, удовлетворяющего ука-
занному требованию; присвоить п значение из диапазона 32...63; выполнить
деление l=(ST(0)/ ST( 1 ))/2(d-n); выполнить округление I путем усечения к бли-
жайшему меньшему целому; записать в ST(0) значение, равное ST(0)=ST(0)-
-(ST(1 )*l*2(d-n)).
Флаги (SWR): СО устанавливается равным биту 2 частного; С1 устанавливается
в 0 при переполнении стека или устанавливается равным биту 0 частного; С2 ус-
танавливается в 0, если получен конечный остаток, или в 1, если остаток все еще
частичный; СЗ устанавливается равным биту 1 частного.
Исключения: NE: #IS, #IA, #D, #U; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FPREM 1
FPREM1 (Partial REMainder IEEE-754) — вычисление частичного остатка от де-
ления ST(0) на ST(1) (стандарт IEEE-754).
Машинный код: d9 f5
Действие: делимое хранится в регистре ST(0), делитель — в регистре ST( 1). Коман-
да вычитает значения полей порядков в ST(0) и ST( 1).
♦ Если полученная разность d меньше 64, то выполнить деление l=ST(0)/ST(1),
результат которого округляется к ближайшему меньшему целому; записать в
ST(0) новое значение, равное ST(0)=ST(0)-(ST(1)*l); установить бит SWR.C2=0 —
это означает, что в ST(0) получен истинный остаток, удовлетворяющий требо-
ванию остаток<делителя\ установить биты С0С1СЗ в SWR равными значени-
ям трех младших битов частного I — IJJ^
366
Приложение 1. Команды процессоров х86
♦ Если полученная разность d больше 64, то установить бит SWR.C2=1 — это оз-
начает, что в ST(0) будет получен пока только частичный остаток, не удовлет-
воряющий требованию остаток<делителя, и нужно будет повторить обраще-
ние к команде FPREM для получения истинного остатка, удовлетворяющего
указанному требованию; присвоить п значение из диапазона 32...63; выпол-
нить деление l=(ST(0)/ST(1))/2(d-n); выполнить округление I путем усечения к
ближайшему меньшему целому; записать в ST(0) значение, равное ST(0)=ST(0)-
-(ST(1)*l*2(d-n)).
Команда FPREM 1 используется для точного деления чисел, в соответствии с тре-
бованиями стандарта на вычисления с плавающей точкой IEEE-754, согласно ко-
торому величина остатка должна быть меньше половины модуля (делителя).
Флаги (SWR): СО устанавливается равным биту 2 частного; С1 устанавливается
в 0 при переполнении стека пли устанавливается равным биту 0 частного; С2 ус-
танавливается в 0, если получен конечный остаток, или в 1, если остаток все еще
частичный; СЗ устанавливается равным биту 1 частного.
Исключения: NE: #IS, #IA, #D, #U; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FPTAN
FPTAN (Partial TANgent) — вычисление частичного тангенса угла в радианах из
регистра ST(0).
Машинный код: d9 f2
Действия: если значение в ST(0) находится в диапазоне -263...263, установить бит
с2 в 0, вычислить тангенс значения в ST(0), записать результат в ST(0), записать в
стек вещественную единицу. Окончательное содержимое регистров: ST(0)= 1.0,
ST( 1) — тангенс угла. Если значение в ST(0) не находится в диапазоне -263...263,
установить бит С2 в 1.
Флаги (SWR): см. команду FCOS.
Исключения: NE: #IS, #IA, #D, #U, #Р; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FRNDINT
FRNDINT (RouNd INTeger) — округление значения в регистре ST(0) до целого.
Машинный код: d9 fc
Действия: выполнить округление значения в ST(0) в соответствии со значени-
ем поля CWR.RC: если CWR.RC=00b, то округлить до ближайшего целого; если
CWR.RC=01b, то округлить до ближайшего меньшего целого; если CWR.RC=10b, то
округлить до ближайшего большего целого; если CWR.RC=11b, то округлить от-
брасыванием дробной части числа. Записать результат округления в ST(0).
Флаги (SWR): см. команду F2XM1.
Исключения: NE: #IS, #IA, #D, #Р; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
П1.2. Команды сопроцессора
367
FRSTOR источник
FRSTOR (ReSTore fpu STate) — восстановление полной среды сопроцессора.
Синтаксис: FRSTOR m94/108
Машинный код: dd /4
Действия: определить режим работы процессора (R, V или Р) и размер операнда
для текущего сегмента кода. Эти значения определяют размер буфера (94 или
108 байт), из которого будет производиться восстановление полной среды сопроцес-
сора. После этого произвести запись информации в следующие регистры сопро-
цессора из области памяти, начальный адрес которой указан операндом источ-
ник т94/108: регистр управления CWR; регистр состояния SWR; регистр тегов TR;
регистр указателя команд IPR; регистр указателя данных DPR; регистры стека со-
процессора ST(0)...ST(7).
Структура области памяти, формируемая командой FRSTOR, показана на рисунке
в описании команды FNSAVE.
Флаги (SWR): C1, СО, С2, СЗ формируются в соответствии с новым содержимым
регистра CWR.
Исключения: PM: #AC(0); #GP(0): 2, 5; #NM: 1; #PF(fauIt-code); #SS(0): 1; RM:
#GP: 1; #NM: 1; #SS: 1; VM: #AC(0); #GP(0): 1; #NM: 2; #PF(fault-code); #SS(0): 1.
FSAVE приемник
FSAVE (SAVE fpu STate) — сохранение полной среды сопроцессора.
Синтаксис: FNSAVE m94/108
Машинный код: 9b dd /6
Действия: проверить наличие незамаскированных особых случаев в регистре SWR.
Определить режим работы процессора (R, V или Р) и размер операнда для теку-
щего сегмента кода. Эти значения определяют размер буфера (94 или 108 байт),
в который будет производиться сохранение полной среды сопроцессора. Произвес-
ти запись информации из следующих регистров сопроцессора в область памяти,
начальный адрес которой указан операндом приемник т94/108: регистра управле-
ния CWR; регистра состояния SWR; регистра тегов TR; регистра указателя команд
IPR; регистра указателя данных DPR; регистров стека сопроцессора ST(0)...ST(7).
Привести сопроцессор в начальное состояние, установив регистры сопроцессора
в следующее состояние: CWR= 03 7fh; SWR= 00 00; TWR= ff ff; регистры указателей
данных DPR и IPR команд устанавливаются в 0.
Структура области памяти, формируемая командой FSAVE, показана на рисунке в
описании команды FNSAVE.
Флаги (SWR): C1, СО, С2, СЗ сохраняются и очищаются.
Исключения: PM: #AC(0); #GP(0): 2, 5; #NM: 1; #PF(fault-code); #SS(0): 1; RM:
#GP: 1; #NM: 1; #SS: 1; VM: #AC(0); #GP(0): 1; #NM: 2; #PF(fault-code); #SS(0): 1.
368
Приложение 1. Команды процессоров х86
FSCALE
FSCALE (SCALE) — масштабирование значения в ST(0).
Машинный код: d9 fd
Действия: исходные значения: ST(0)=x, ST(1)=y. Вычислить выражение ST(0)=x*2y.
Команда не очищает регистр ST( 1).
Флаги (SWR): см. команду F2XM1.
Исключения: NE: #IS, #IA, #D, #U, #0, #Р; PM: #NM: 1; RM: #NM: 1; VM: #NM: 1.
FSIN
FSIN (calculation of SINe) — вычисление синуса значения угла в радианах из реги-
стра ST(O).
Машинный код: d9 fe
Действия: если значение х в регистре ST(O) находится в диапазоне -263<=х<=+263,
то CWR.C2=0; ST(O)=sin(x). В обратном случае оставить значение в вершине стека
без изменений и установить бит CWR.C2=1.
Флаги (SWR): см. команду FCOS.
Исключения: NE: #IS, #IA, #D, #Р; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FSINCOS
FSINCOS (SINe and COSine) — вычисление синуса и косинуса значения угла в
радианах из регистра ST(O).
Машинный код: d9 fb
Действия: если значение х находится в диапазоне -263<=х<=+263, то: CWR.C2=0;
ST(O)=sin(x); CWR.T0P=CWR.T0P-1; ST(0)=cos(x). Если x не в диапазоне, то оста-
вить значение в вершине стека без изменений и установить бит CWR.C2=1. Конеч-
ный результат в регистрах: ST(0)=cos(x), ST(1)=sin(x).
Флаги (SWR): см. команду FCOS.
Исключения: NE: #IS, #1 A, #D, #U, #Р; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FSQRT
FSQRT (SQuare RooT) — вычисление ST(O)=VST(O).
Машинный код: d9 fa
Флаги (SWR): см. команду F2XM1.
Исключения: NE: #IS, #IA, #D, #P; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FST приемник
FST (STore real value) — сохранение вещественного значения из регистра ST(O).
П1.2. Команды сопроцессора
369
1L39/2J)
1 Ldd/2j]
1 &d jdO+j]
Действия: если приемник является ячейкой памяти, то перед сохранением произво-
дится округление числа в вершине стека до значения, соответствующего размеру
мантиссы приемника. Порядок числа также приводится при необходимости к разме-
ру порядка приемника. Режим округления выбирается исходя из значения в поле
CWR.RC. После этого округленное значение из регистра ST(0) копируется в ячейку
памяти или в регистр, указанные операндом приемник.
Флаги (SWR): см. команду F2XM1.
Исключения: NE: #IS, #IA, #U, #0, #Р; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FSTCW приемник
FSTCW (STore Control Word) — сохранение управляющего слова сопроцессора.
Синтаксис: FSTCW m16
Машинный код: 9b d9 /7
Действия: сохранить управляющее слово сопроцессора CWR в слове памяти при-
емник с проверкой наличия незамаскированных особых случаев в регистре SWR.
Флаги (SWR): С1, СО, С2, СЗ не определены.
Исключения: PM: #АС(О); #GP(O): 1, 2,5; #NM: 1; #PF(fault-code); #SS(O): 1; RM:
#GP: 1; #NM: 1; #SS: 1; VM: #AC(O); #GP(O): 1; #NM: 2; #PF(fault-code); #SS(O): 1.
FSTENV приемник
FSTENV (STore fpu ENVironment) — сохранение среды сопроцессора в памяти.
Синтаксис: FSTENV m 14/28
Машинный код: 9b d9 /6
Действия: проверить наличие незамаскированных особых случаев в регистре SWR.
Определить режим работы процессора (R, V или Р) и размер операнда для текущего
сегмента кода. Эти значения определяют размер буфера (14 или 28 байт), в который
будет производиться запись среды сопроцессора. В область памяти, начальный адрес
которой указан операндом приемник т14/28, произвести запись информации из
следующих регистров сопроцессора: регистра управления CWR; регистра состояния
SWR; регистра тегов TR; регистра указателя команд IPR; регистра указателя данных
DPR. Установить маски всех исключений в единицу (замаскировать исключения).
Структура области памяти, сформированная командой, показана на рисунке в
описании команды FLDENV.
Флаги (SWR): С1, СО, С2, СЗ не определены.
Исключения: PM: #АС(О); #GP(O): 1, 2, 5; #NM: 1; #PF(fault-code); #SS(O): 1; RM:
#GP: 1; #NM: 1; #SS: 1; VM: #AC(O); #GP(O): 1; #NM: 2; #PF(fault-code); #SS(O): 1.
370
Приложение 1. Команды процессоров х86
FSTP приемник
FSTP (STore real value and Pop) — сохранение с выталкиванием вещественного
значения из вершины стека.
—| fstp |—4m32real}
1 Dig"!
Ч st(') I
|[Ж!
IfaddB+il
Действия: действия команды аналогичны действиям команды FST. Последнее дей-
ствие — увеличение указателя вершины стека SWR.TOP=SWR.TOP+1.
Флаги (SWR) и исключения: см. команду FST.
FSTSW приемник
FSTSW (STore Status Word) — сохранение слова состояния сопроцессора.
Ч fstsw к-[ггйб~]----------1 L?b_’dd77J
-| ах |----------1 ГэБ аГёб]
Действия: сохранение слова состояния сопроцессора (регистра SWR) в слове па-
мяти или регистре АХ с проверкой наличия незамаскированных особых случаев в
регистре SWR.
Флаги (SWR): С1, СО, С2, СЗ не определены.
Исключения: PM: #АС(0); #GP(0): 1, 2, 5; #NM: 1; #PF(fault-code); #SS(O): 1;
RM: #GP: 1; #NM: 1; #SS: 1; VM: #AC(0); #GP(0): 1; #NM: 2; #PF(fault-code);
#SS(O): 1.
FSUB
FSUB вычитаемое
FSUB уменьшаемое, вычитаемое
FSUB (SUBtraction) — вычитание вещественных значений.
4fsub|-------------------1 Fdee9j
4feub~|—4m32real|--------1 Г"08lTj
Цт64геа1|-1 Г dc/4~l
4fsubld8~e0+i]
st(i) |-0—|st(O) H FdceS+i]
П1.2. Команды сопроцессора
371
Действия: команда имеет три варианта расположения операндов.
♦ Без операндов — исходные операнды: ST (0)=вычитаемое, ST(^уменьшаемое.
Команда выполняет вычитание ST(1)=ST(1 )-ST(0). Последнее действие — вы-
талкивание значения из регистра ST(0). Результат вычитания — в ST(0).
♦ С одним операндом — исходные операнды: ST (^-уменьшаемое', т32(64)=вычи-
таемое. Команда выполняет вычитание ST(0)=ST(0)-m32/m64.
♦ С двумя операндами — исходные операнды: уменьшаемое — в ST(0)/ST(i), вычи-
таемое — в ST(i)/ST(0). Команда выполняет вычитание {уменьшаемое-вычи-
таемое) и помещает результат в регистр ST(0) для команды fsub ST(0),ST(i) или
в ST(i) для команды fsubST(i),ST(O).
Флаги (SWR): см. команду F2XM1.
Исключения: NE: #IS, #IA, #D, #U, #0, #Р; PM: #АС(О); #GP(O): 2, 5; #NM: 1;
#PF(fault-code); #SS(O): 1; RM: #GP: 1; #NM: 1; #SS: 1; VM: #AC(O); #GP(O): 1;
#NM: 2; #PF(fauit-code); #SS(O):1.
FSUBP
FSUBP уменьшаемое, вычитаемое
FSUBP (SUBtraction of real value from real value and Pop) — вычитание веществен-
ных значений с выталкиванием.
—|fsubp|—I----------1 ГЭее9]
S'ё-е8+i]
Действия: команда имеет два варианта расположения операндов.
♦ Без операндов — аналогична команде FSUB без операндов.
♦ С двумя операндами — исходные операнды: ST (3}~ вычитав мое, ЗТ('\)=умень-
шаемое. Команда выполняет вычитание ST(i)=ST(i)-ST(O), после чего выталки-
вает значение из ST(O). Результат вычитания — в ST(i-1).
Флаги (SWR) и исключения: см. описание команды FSUB.
FSUBR
FSUBR уменьшаемое
FSUBR вычитаемое, уменьшаемое
FSUBR (Reverse SUBtraction) — обратное вычитание вещественных значений.
Действия: команда имеет три варианта расположения операндов.
♦ Без операндов — исходные значения: ST( 1 )=вычитаемое, ST (3)-уменьшаемое.
Команда выполняет вычитание ST(1)=ST(0)-ST(1). Последнее действие — вы-
талкивание значения из ST(O). Результат вычитания — в ST(O).
372
Приложение 1. Команды процессоров х86
-|fsubr|--------------1 F'de el l
4feubrHrlm32reall-----1 L d8/~5~J
L|ni64real|----1 Г dc/5"l
—jfsubrHH st(O) |—O—] st(i) H jd8 e8+j|
l—| st(i) HO—|st(O) H Йс’еО+j]
♦ С одним операндом — исходные значения: т32/т64=г/л<енъшаелюе, 8Т(0)=вычи-
таемое. Команда выполняет вычитание ST(0)=m32/m64-ST(0).
♦ С двумя операндами — уменьшаемое помещается в регистр ST(i)/ST(0), вычитае-
мое — в регистр ST(0)/ST(i). Команда выполняет вычитание (уменьшаемое-
вычитаемое) и помещает результат в регистр ST(0) для команды fsubr ST(O),ST(i)
или в ST(i) для команды fsubr ST(i),ST(0).
Флаги (SWR) и исключения: см. описание команды FSUB.
FSUBRP
FSUBRP вычитаемое, уменьшаемое
FSUBRP (Reverse Subtraction and Pop) — обратное вычитание вещественных
значений с выталкиванием.
—IfsubrpHi------------1 LdeeTj
4st(i) HD-] st(0) Н фе eQ+ij
Действия: команда имеет два варианта расположения операндов.
♦ Без операндов — аналогична команде FSUBR без операндов.
♦ С двумя операндами — исходные значения: ST (\)=вычитаемое, ST ((^уменьша-
емое. Команда выполняет вычитание ST(i)=ST(O)-ST(i). Последнее действие-
выталкивание значения из регистра ST(0). Результат обратного вычитания на-
ходится в ST(i-1).
Флаги (SWR) и исключения: см. описание команды FSUB.
FTST
FTST (TeST) — сравнение значения в ST(0) с нулем.
Машинный код: d9 е4
Действия: сравнить значение в вершине стека с нулем. По результатам работы
установить биты СЗС2С0 в регистре CWR (см. ниже).
Флаги (SWR): С1 устанавливается в 1 при переполнении стека, иначе — сбрасывает-
ся в 0; СО, С2, СЗ устанавливаются в соответствии с результатами работы команды.
Исключения: NE: #IS, #IA, #D; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
П1.2. Команды сопроцессора
373
ST(0) не определено СЗС2С0=111
ST(0)=0 СЗС2С0=100
ST(0)<0 СЗС2С0=001
ST(0)>0 СЗС2С0=000
FUCOM
FUCOM источник
FUCOM (Unordered COMpare real) — неупорядоченное сравнение вещественных
значений.
-----1 LddJTL>
]----IFddeO+Jj
Действия: команда имеет два варианта расположения операндов. В команде
FUCOM без операндов сравниваемые значения находятся в регистрах стека ST(0) и
ST( 1). В команде FUCOM с одним операндом сравниваемые значения находятся в
регистрах стека ST(0) и ST(i). Команда выполняет сравнение значений, по резуль-
татам которого устанавливаются флаги СЗС2С0 в регистре CWR (см. ниже).
ST(0) и ST( 1 (i)) несравнимы СЗС2СО111
ST(0)= ST( 1 (i)) C3C2C0=100
ST(0)< ST( 1 (i)) C3C2C0=001
ST(0)> ST(1(i)) C3C2COOOO
Флаги (SWR): С1 устанавливается в 1 при переполнении стека; СО, С2, СЗ уста-
навливаются в соответствии с результатами работы команды.
Исключения: NE: #IS, #IA, #D; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FUCOMI значение_1, значение_2
FUCOMI (Floating-point COMpare and set EFLAGS) — сравнение вещественных
чисел в регистрах стека ST(0) и ST(i) с установкой флагов в EFLAGS.
Синтаксис: FUCOMI ST(0),ST(i)
Машинный код: db e8+i
Действия:
1. Проверить, поддерживаются ли форматы чисел в обоих операндах. Если один
или оба операнда не-числа (кроме «тихих» не-чисел) или числа в неподдер-
живаемом сопроцессором формате, то проверить, замаскировано ли исключе-
ние недействительной операции сопроцессора в управляющем регистре сопро-
цессора CWR:
374
Приложение 1. Команды процессоров х86
• если бит CWR.IM=1 (то есть исключение замаскировано), то установить
флаги ZF=PF=CF=1. После этого закончить работу команды;
• если бит CWR.IM=0 (то есть исключение не замаскировано), то возбудить
исключение недействительной операции сопроцессора, в результате чего
управление будет передано соответствующему обработчику;
• если оба операнда корректные вещественные числа или «тихие» не-числа,
то продолжить работу команды.
2. Выполнить вычитание (значение _1-значение _2).
3. По результатам вычитания установить флаги ZF, PF, CF в регистре EFLAGS, как
показано ниже.
Результат сравнения ZF PF CF
St(O)>ST(i) 0 0 0
St(O)<ST(i) 0 0 1
St(O)=ST(i) 1 0 0
Неподдерживаемые форматы (кроме «тихих» не-чисел) 1 1 1
Флаги (SWR): С1 устанавливается в 1 при переполнении стека; СО, С2, СЗ уста-
навливаются в соответствии с результатами работы команды.
Исключения: PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FUCOMIP значение_1, значение_2
FUCOMIP (Floating-point COMpare, set EFLAGS and Pop) — сравнение веще-
ственных чисел с выталкиванием значения из ST(0) и установка EFLAGS.
Синтаксис: FUCOMI ST(0),ST(i)
Машинный код: df e8+i
Действия: аналогично FUCOMI. Последнее действие — выталкивание значения из
вершины стека сопроцессора.
Флаги (SWR) и исключения: см. описание команды FUCOML
FUCOMP
FUCOMP источник
FUCOMP (Unordered COMpare real and Pop) — неупорядоченное сравнение с
выталкиванием.
-jfucomph-------------1 L.dd e9.J
*—I st(i) |-1 jddГеЗ+il
Действия: аналогично FUCOM. Последнее действие — выталкивание значения из
вершины стека сопроцессора.
П1.2. Команды сопроцессора
375
Флаги (SWR) и исключения: см. описание команды FUCOM.
FUCOMPP
FUCOMPP (Unordered COMpare and double Pop) — неупорядоченное сравнение
с выталкиванием.
Машинный код: da е9
Действия: аналогично FUCOM. Два последних действия — выталкивание значений
из регистров ST(0) и ST(1).
Флаги (SWR) и исключения: см. описание команды FUCOM.
FWAIT
FWAIT (WAIT) — останов процессора.
Машинный код: 9Ь
Действия: команда приостанавливает работу основного процессора до поступле-
ния сигнала от сопроцессора об окончании обработки последней команды.
Флаги (SWR): СО, С1, С2, СЗ не определены.
Исключения: PM: #NM: 2; RM: #NM: 2; VM: #NM: 1.
FXAM
FXAM (eXAMine) — определение типа операнда в регистре ST(0).
Машинный код: d9 е5
Действия: команда определяет тип операнда в ST(0) и, исходя из него, устанавли-
вает биты СЗС2С1С0 (см. ниже). В бит С1 помещается знак операнда в ST(0). Со-
держимое битов СЗС2С0 характеризует тип операнда (см. таблицу ниже).
СЗС2СОООО Неизвестный формат
СЗС2С0=001 Не-число
СЗС2С0=010 Корректное вещественное число
СЗС2С0=011 Бесконечность
СЗС2С0=100 Нуль
СЗС2С0=101 Пусто
СЗС2С0=110 Денормализованное число
Исключения: PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FXCH
FXCH источник
FXCH (eXCHange regiSTer contents) — обменять содержимое регистров стека.
376
Приложение 1. Команды процессоров х86
—| fxch Ч------1Г39. с9']
Ч st(i) |-1 @9jS+i]
Действия: команда имеет два варианта расположения операндов. В команде FXCH
без операндов исходные значения находятся в регистрах стека ST(0) и ST( 1). В коман-
де FXCH с одним операндом исходные значения находятся в регистрах стека ST(0)
и ST(i). Команда FXCH выполняет обмен значений между регистрами ST(0) и ST(i).
Флаги (SWR): С1 устанавливается в 1 при переполнении стека, иначе — сбрасы-
вается в 0; СО, С2, СЗ не определены.
Исключения: NE: #IS; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FXTRACT
FXTRACT (eXTRACT exponent and sifnificand) — выделить порядок и мантиссу
значения в ST(0).
Машинный код: d9 f4
Действия: выделить значение порядка и поместить его в регистр ST( 1); выделить
значение мантиссы и поместить ее в вершину стека сопроцессора — регистр ST(0).
Флаги (SWR): см. команду FABS.
Исключения: NE: #IS, #IA, #Z, #D; PM: #NM: 1; RM: #NM: 1; VM: #NM: 2.
FYL2X
FYL2X (compute YxLog2(X)) — вычислить ylog2(x).
Машинный код: d9 f 1
Действия: исходные значения: ST(1)=y, ST(0)=x. Команда помещает результат вы-
числения выражения у*1од2(х) в регистр ST(0).
Флаги (SWR): см. команду F2XM1.
Исключения: NE: #IS, #IA, #Z, #D, #U, #0, #Р; PM: #NM: 1; RM: #NM: 1; VM:
#NM: 2.
FYL2XP1
FYL2XP1 (compute YxLog2(X Plus 1)) — вычислить ylog2(x+l).
Машинный код: d9 f9
Действия: у хранится в ST( 1), х — в ST(O). Значение в ST( 1) должно находиться в
диапазоне а в ST(O) — в диапазоне -(1 -V(2)/2)...(1 -л/(2)/2). Если значение в
ST(O) лежит вне диапазона, то результат операции неопределен. Команда запи-
сывает результат вычисления выражения ylog2(x+1) в регистр ST(O).
Флаги (SWR): см. команду F2XM1.
Исключения: NE: #IS, #IA, #Z, #D, #U, #0, #Р; PM: #NM: 1; RM: #NM: 1; VM:
#NM: 2.
П1.3. Команды блока ММХ
377
П1.3. Команды блока ММХ
EMMS
EMMS (Empty ММХ State) — подготовка сопроцессора к исполнению команд.
Машинный код: Of 77
Действие: команда переводит все поля регистра тегов сопроцессора TWR в единич-
ное состояние.
Исключения: PM: #MF; #NM: 3; #UD: 10; RM: #MF; #NM: 3; #UD: 17; VM: #MF;
#NM: 3; #UD: 15.
MASKMOVQ источник, маска
MASKMOVQ (byte MASK write) — запись байт в память из регистра ММХ по
маске (выборочная).
Синтаксис: MASKMOVQ rmmxl, rmmx2
Машинный код: 00001111:11110111:11 rmmxl rmmx2
Действие: последовательно проверяются знаковые биты всех байт маски, и если
какой-то из этих бит равен 1, то соответствующий байт источника копируется
в область памяти, начальный адрес которой содержится в регистрах DS:DI/EDI.
Если знаковый бит равен нулю, то соответствующий байт в приемнике будет ну-
левым.
maskmovq источник, маска
Пример: maskmovq rmmxO,rmmxl
Источник (ХММ-регистр)
rmmxO I и7 I иб I иб I и4
Маска (ХММ-регистр) Ф Ф Ф Ф
rmmxl в 11 Pi. , IQi ,
V Ф V V
Приемник(m64) I I . 00 I иб .1 . PQ I 0.0 I иЗ.,.,1 И2..1.-0.0. I иО I. J
<-------------------- Старшие адреса оперативной памяти ф
ds:di/edi
Особенность работы команды в том, что при копировании не используется кэш-
память.
Исключения: PM: #AC(0); #GP(0): 37; #MF; #NM: 3; #PF(fault-code); #SS(O): 13;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF; #NM:
3; #PF(fault-code); #UD: 15.
MOVD приемник, источник
MOVD (Move Double word) — перемещение двойного слова.
378
Приложение 1. Команды процессоров х86
—I movd kH^mxl~Oylrri32l~rl Гб? 6ё7г1
Действие:
♦ если приемник является регистром ММХ, поместить в биты 0-31 приемника
значение источника; поместить в биты 32-63 приемника нулевое значение;
♦ если приемник является 32-разрядной ячейкой памяти или регистром общего
назначения, то поместить в приемник значение бит 0-31 источника (регистра
ММХ).
Исключения: PM: #AC(0); #GP(0): 1,2; #MF; #PF(fault-code); #SS(0): 1; #UD: 10;
RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF; #NM: 3;
#PF(fault-code); #UD: 15.
MOVNTQ приемник, источник
MOVNTQ (MOVe 64 bits Non Temporal) — запись 64 бит в память из регистра
ММХ (без использования кэш-памяти).
Синтаксис: MOVNTQ m64,rmmx
Машинный код: 00001111:11100111 :mod rmmx r/m
Исключения: PM: #AC(0); #GP(0): 37; #MF; #NM: 3; #PF(fault-code); #SS(O): 13;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
MOVQ приемник, источник
MOVQ (Move Quadword) — переместить учетверенное слово.
—I movci Ну^гттх|чЭ-т-|т64Н4 [Of 6f/rj
rmmx
| rmmx |
Действие:
♦ если приемник является регистром ММХ, поместить туда значение источни-
ка — регистра ММХ или 64-разрядной ячейки памяти;
♦ если приемник — 64-разрядная ячейка памяти, поместить в приемник значение
регистра ММХ.
Исключения: PM: #AC(0); #GP(0): 1,2; #MF; #NM: 3; #PF(fault-code); #SS(O): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
П1.3. Команды блока ММХ
379
PACKSSWB приемник, источник
PACKSSDW приемник, источник
PACKSSWB (Pack with Signed Saturation Words to Bytes) — упаковка co знако-
вым насыщением слов в байты. PACKSSDW (Pack with Signed Saturation Double
Words to Words) — упаковка co знаковым насыщением двойных слов в слова.
Э~]гттх|-| [Qfj6ib/r
]rmmx(
в
Действие: команды преобразуют восемь/четыре элемента размером в слово/
двойное слово в восемь/четыре элемента размером в байт/слово (см. рисунок
ниже). Если значение элемента источника превышает допустимое значение эле-
мента приемника, то в элементе приемника формируется предельный результат в
соответствии с принципом знакового насыщения:
♦ PACKSSWB — 07fh для положительных чисел и 080h для отрицательных;
♦ PACKSSDW — 07fffh для положительных чисел и 08000h для отрицательных.
packsswb приемник,источник
Источник Приемник (ММХ-регистр)
Приемник (ММХ-регистр)
packssdw приемник,источник
Источник Приемник (ММХ-регистр)
Приемник (ММХ-регистр)
Исключения: PM: #АС(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(0): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 5.
PACKUSWB приемник, источник
PACKUSWB (Pack with Unsigned Saturation Words to Bytes) — упаковка с без-
знаковым насыщением слов в байты.
Синтаксис: PACKUSWB rmmxl,rmmx2/m64
Машинный код: Of 67 /rmmxl
380
Приложение 1. Команды процессоров х86
Действие: команда преобразует восемь элементов размером в слово в восемь
элементов размером в байт (см. рисунок ниже). Если пересылаемое значение
больше допустимого для поля приемника, то в нем формируется предельный
результат в соответствии с принципом беззнакового насыщения, что соответству-
ет значениям Offh для положительных чисел и 00h для отрицательных.
packuswb приемник,источник
Источник Приемник (ММХ-регистр)
Приемник (ММХ-регистр)
Исключения: PM: #АС(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(O): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
# NM: 3; #PF(fault-code); #UD: 15.
PADDB приемник, источник
PADDW приемник, источник
PADDD приемник, источник
PADDB (Packed ADDition Bytes) — сложение упакованных байт. PADDW (Packed
ADDition Words) — сложение упакованных слов. PADDD (Packed ADDition Double
words) — сложение упакованных двойных слов.
Синтаксис: PADDB/PADDW/PADDD rmmx1,rmmx2/m64
Машинный код:
PADDB - Of fc /г
PADDW - Of fd /rmmxl
PADDD — Of fe /rmmxl
Действие: команда в зависимости от кода операции складывает соответствую-
щие элементы операндов источника и приемника размером байт/слово/двойное
слово. При возникновении переполнения результат формируется в соответствии
с принципом циклического переполнения и помещается в операнд приемник.
Исключения: PM: #АС(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(O): 1;
#UD: 10; RM: #GP: 13; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF; #NM: 3;
#PF(fault-code); #UD: 15.
PADDSB приемник, источник
PADDSW приемник, источник
PADDSB (Packed ADDition signed Bytes with Saturation) — сложение упакован-
ных байт co знаковым насыщением. PADDSW (Packed ADDition signed Words with
Saturation) — сложение упакованных слов co знаковым насыщением.
П1.3. Команды блока ММХ
381
Синтаксис: PADDSB/PADDSW rmmx1,rmmx2/m64
Машинный код:
PADDSB — Of ес /rmmxl
PADDSW - Of ed /rmmxl
Действие: команда в зависимости от кода операции складывает соответствую-
щие элементы операндов источника и приемника размером байт/слово с учетом
знака. При возникновении переполнения результат формируется в соответствии
с принципом знакового насыщения:
♦ PADDSB — 07fh для положительных чисел и 080h для отрицательных;
♦ PADDSW — 07fffh для положительных чисел и 08000h для отрицательных.
Результат помещается в операнд приемник.
Исключения: PM: #АС(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(0): 1;
#UD: 10; RM: #GP: 13; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #NM: 3; #UD:15.
PADDUSB приемник, источник
PADDUSW приемник, источник
PADDUSB (Packed ADDition Unsigned Bytes with Saturation) — сложение упако-
ванных байт с беззнаковым насыщением. PADDUSW (Packed ADDition Unsigned
Words with Saturation) — сложение упакованных слов с беззнаковым насыщением.
Синтаксис: PADDUSB/PADDUSW rmmxl,rmmx2/m64
Машинный код:
PADDUSB - Of de /rmmxl
PADDUSW - Of dd /rmmxl
Действие: команда в зависимости от кода операции складывает без учета знака
соответствующие элементы операндов источника и приемника размером байт/
слово. При возникновении переполнения результат формируется в приемнике в
соответствии с принципом беззнакового насыщения:
♦ PADDUSB — Offh и 00h для результатов сложения, соответственно, больших
или меньших максимально/минимально представимых значений в беззнако-
вом байте;
♦ PADDUSW — Offffh и OOOOh для результатов сложения, соответственно, больших
или меньших максимально/минимально представимых значений в беззнако-
вом слове.
Результат помещается в операнд приемник.
Исключения: PM: #AC(0); #GP(0): 2; #MF; #NM: 3; #SS(0): 1; #UD: 10; RM:
#GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF; #NM: 3; #PF(fault-
code); #UD: 15.
382
Приложение 1. Команды процессоров х86
PAND приемник, источник
PAND (Packed logical AND) — упакованное логическое И.
Синтаксис: PAND rmmxl,rmmx2/m64
Машинный код: Of db /rmmxl
Действие: команда выполняет побитовую операцию логическое И над всеми бита-
ми операндов источника и приемника. Результат помещается в операнд приемник.
Исключения: PM: #АС(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(0): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PANDN приемник, источник
PANDN (Packed logical AND Not) — упакованное логическое И-НЕ.
Синтаксис: PANDN rmmxl,rmmx2/m64
Машинный код: Of df /rmmxl
Действие: команда выполняет побитовую операцию логическое И-НЕ над всеми
битами операндов источника и приемника. Результат помещается в операнд приемник.
Исключения: PM: #AC(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(0): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PAVGB приемник, источник
PAVGW приемник, источник
PAVGB/PAVGW (Packed Average) — упакованное среднее.
Синтаксис: PAVGB/PAVGW rmmxl,rmmx2/m64
Машинный код:
PAVGB - 00001111:11100000:mod rmmxl r/m
PAVGW - 00001111:11100011:mod rmmxl r/m
Действие: выполнить параллельное сложение байт/слов источника и приемника
и сдвинуть результат сложения на один разряд вправо (деление на 2).
Исключения: PM: #AC(0); #GP(0): 37; #MF; #NM: 3; #PF(fault-code); #SS(0): 13;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PCMPEQB приемник, источник
PCMPEQW приемник, источник
PCMPEQD приемник, источник
PCMPEQB (Packed CoMPare for Equal Byte) — сравнение на равенство упакован-
ных байт. PCMPEQW (Packed CoMPare for Equal Word) — сравнение на равен-
П1.3. Команды блока ММХ
383
ство упакованных слов. PCMPEQD (Packed CoMPare for Equal Double word) —
сравнение на равенство упакованных двойных слов.
Синтаксис: PCMPEQB/PCMPEQW/PCMPEQD rmmxl,rmmx2/m64
Машинный код:
PCMPEQB - Of 74 /rmmxl
PCMPEQW - Of 75 /rmmxl
PCMPEQD - Of 76 /rmmxl
Действие: команды сравнивают на равенство элементы источника и приемника и
формируют элементы результата по следующему принципу:
♦ если элемент источника равен соответствующему элементу приемника, то эле-
мент результата устанавливается, в зависимости от применяемой команды, рав-
ным одному из следующих значений: Offh, Offffh, Offffffffh;
♦ если элемент источника не равен соответствующему элементу приемника, то
элемент результата устанавливается, в зависимости от применяемой команды,
равным одному из следующих значений: 00h, OOOOh, OOOOOOOOh.
Результат помещается в операнд приемник.
Исключения: PM: #АС(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(0): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
# NM: 3; #PF(fault-code); #UD:15.
PCMPGTB приемник, источник
PCMPGTW приемник, источник
PCMPGTD приемник, источник
PCMPGTB (Packed CoMPare for Greater Than Byte) — сравнение по условию
«больше чем» упакованных байт. PCMPGTW (Packed CoMPare for Greater Than
Word) — сравнение по условию «больше чем» упакованных слов. PCMPGTD
(Packed CoMPare for Greater Than Double word) — сравнение по условию «боль-
ше чем» упакованных двойных слов.
Синтаксис: PCMPGTB/PCMPGTW/PCMPGTD rmmxl,rmmx2/m64
Машинный код:
PCMPGTB-Of 64 /rmmxl
PCMPGTW - Of 65 /rmmxl
PCMPGTD - Of 66 /rmmxl
Действие: команда производит сравнение по условию «больше чем» элементов
операндов источника и приемника и формирует элементы результата по следую-
щему принципу:
♦ если элемент приемника больше соответствующего элемента источника, то
элемент результата устанавливается, в зависимости от применяемой команды,
равным одному из следующих значений: Offh, Offffh, Offffffffh;
384
Приложение 1. Команды процессоров х86
♦ если элемент приемника не больше соответствующего элемента источника, то
элемент результата устанавливается, в зависимости от применяемой команды,
равным одному из следующих значений: 00h, OOOOh, OOOOOOOOh.
Результат помещается в операнд приемник.
Исключения: PM: #АС(0); #GP(0): 2; #MF; #PF(fault-code); #SS(O): 1; #UD: 10;
RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF; #NM: 3;
#PF(fault-code); #UD: 15.
PEXTRW приемник, источник, маска
PEXTRW (Extract Word) — извлечение 16-битного слова из регистра ММХ по
маске.
Синтаксис: PEXTRW r32, rmmx, i8
Машинный код: 00001111:11000101:11 rmmx r32:i8
Действие: команда выделяет два младших бита непосредственного операнда маска.
Их значение определяет номер слова в операнде источник (регистр ММХ). Дан-
ное слово перемещается в младшие 16 бит операнда приемник, представляющего
собой 32-разрядный регистр общего назначения. Старшие 16 бит этого регистра
обнуляются.
Исключения: PM: #GP(0): 37; #MF; #NM: 3; #PF(fault-code); #SS(O): 13; #UD:
10; RM: #GP: 13; #MF; #NM: 3; #UD: 15; VM: #GP(0): 25; #MF; #NM: 3; #PF(fault-
code); #UD: 15.
PINSRW приемник, источник, маска
PINSRW (Insert Word) — вставка 16-битного слова в регистр ММХ.
Синтаксис: PINSRW mm,r32/m16,i8
Машинный код: 00001111:11000100:mod reg r/m:i8
Действие: команда выделяет два младших бита непосредственного операнда маска.
Их значение определяет номер слова в операнде приемник, который представляет
собой регистр ММХ. В это слово будут перемещены младшие 16 бит операнда
источник, который представляет собой 32-разрядный регистр общего назначения
или 16-битную ячейку памяти.
Исключения: PM: #AC(0); #GP(0): 37; #MF; #NM: 3; #PF(fault-code); #SS(0): 13;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 15; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PMADDWD приемник, источник
PMADDWD (Packed Multiply and ADD Word to Double word) — упакованное
знаковое умножение знаковых слов операндов источник и приемник с последую-
щим сложением промежуточных результатов в формате двойного слова.
П1.3. Команды блока ММХ
385
Синтаксис: PMADDWD rmmxl ,rmmx2/m64
Машинный код: Of f5 /rmmxl
Действие: команда производит умножение с учетом знака четырех знаковых слов
операнда источника на четыре знаковых слова приемника и формирует элементы
результата в соответствии со следующей схемой:
pmaddwd приемник,источник
I d.1 I с.1 I b.1 I а1 I Источник
Приемник (ММХ-регистр)
I Т 02 I
Приемник (ММХ-регистр)
Промежуточные
результаты
(32 бита)
При переполнении результат устанавливается равным 8000 0000 8000 0000h. Ситуа-
ция переполнения возникает, если все элементы обоих операндов равны 8000h.
Исключения: PM: #AC(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(O): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PMAXSW приемник, источник
PMAXSW (return Packed MAXimum Signed integer Word) — возврат максималь-
ных упакованных знаковых слов.
Синтаксис: PMAXSW rmmxl,rmmx2/m64
Машинный код: 00001111:11101110:mod rmmxl r/m
Действие: команда определяет наибольшее слово для каждой пары упакованных
слов источника и приемника с учетом знака и заменяет им соответствующие слова
приемника.
Исключения: PM: #AC(0); #GP(0): 37; #NM: 3; #PF(fault-code); #SS(0): 1; #UD: 10;
RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF; #NM: 3;
#PF(fault-code); #UD:15.
PMAXUB приемник, источник
PMAXUB (return Packed MAXimum Unsigned integer Byte) — возврат максималь-
ных упакованных беззнаковых байт.
Синтаксис: PMAXUB rmmxl,rmmx2/m64
Машинный код: 00001111:11011110:mod rmmxl r/m
Действие: для каждой пары байтовых элементов источника и приемника определить
наибольший без учета знака и заменить им соответствующий элемент приемника.
386
Приложение 1. Команды процессоров х86
Исключения: PM: #АС(0); #GP(0): 37; #MF; #NM: 3; #PF(fault-code); #SS(0): 13;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PMINSW приемник, источник
PMINSW (return Packed MINimum Signed integer Word) — возврат минимальных
упакованных знаковых слов.
Синтаксис: PMINSW rmmxl ,rmmx2/m64
Машинный код: 00001111:11101010:mod rmmxl r/m
Действие: для каждой пары элементов (размером 16 бит) источника и приемника
команда определяет наименьший с учетом знака и заменяет им соответствующий
элемент приемника.
Исключения: PM: #AC(0); #GP(0): 37; #MF; #NM: 3; #PF(fault-code); #SS(O): 13;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PMINUB приемник, источник
PMINUB (return Packed MINimum Unsigned integer Byte) — возврат минималь-
ных упакованных беззнаковых байт.
Синтаксис: PMINUB rmmxl ,rmmx2/m64
Машинный код: 00001111:11011010:mod rmmxl r/m
Действие: для каждой пары байтовых элементов источника и приемника команда
определяет наименьший без учета знака и заменяет им соответствующий элемент
приемника.
Исключения: PM: #AC(0); #GP(0): 37; #MF; #NM: 3; #PF(fault-code); #SS(O): 13;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD:17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PMOVMSKB приемник, источник
PMOVMSKB (Packed MOVe Byte MaSK to integer) — перемещение байтовой
маски в целочисленный регистр.
Синтаксис: PMOVMSKB r32,rxmm
Машинный код: 00001111:11010111:11 r32 rmmx
Действие: команда извлекает и копирует значения старшего бита каждого из упа-
кованных байт в младшую тетраду 32-битного целочисленного регистра общего
назначения. Остальные разряды целочисленного регистра обнуляются.
Исключения: PM: #AC(0); #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10;
RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF; #NM: 3;
#PF(fault-code); #UD: 15.
П1.3. Команды блока ММХ
387
pmovmskb приемник, источник
Источник (ММХ-регистр)
Приемник г32
PMULHUW приемник, источник
PMULHUW (Packed MULtiply and return High Unsigned Words) — умножение
упакованных беззнаковых слов с возвратом старших слов результата.
Синтаксис: PMULHUW rmmxl,rmmx2/m64
Машинный код: 00001111:11100100:mod rmmxl r/m
Действие: команда производит умножение четырех слов источника и приемника
без учета знака и формирует элементы результата в соответствии с приведенной
ниже схемой. Как видно из нее, в результате умножения слов операндов источник
и приемник получаются промежуточные результаты размером 32 бита. Далее
старшее слово (16 бит) из каждого промежуточного результата умножения исход-
ных элементов помещается в 16-битный элемент окончательного результата. Ре-
зультат помещается в операнд приемник.
pmulhuw приемник, источник
I d.1 I с.1 I b.1 I а1 I Источник
Приемник (ММХ-регистр)
Промежуточные
результаты
(32 бита)
Исключения: PM: #AC(0); #GP(0): 37; #MF; #NM: 3; #PF(fault-code); #SS(O): 13;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PMULHW приемник, источник
PMULHW (Packed MULtiply and return High Words) — упакованное знаковое
умножение слов с возвратом старшего слова результата.
Синтаксис: PMULHW rmmxl,rmmx2/m64
Машинный код: Of е5 /rmmxl
388
Приложение 1. Команды процессоров х86
Действие: команда производит умножение четырех слов источника и приемника
с учетом знака и формирует элементы результата в соответствии со следующей
схемой.
pmulhw приемник, источник
I d.1 I с.1 I b.1 I а1 I Источник
Приемник (ММХ-регистр)
Промежуточные
результаты
(32 бита)
Результат помещается в операнд приемник. Как видно из схемы, в результате
умножения слов операндов источник и приемник получаются промежуточные
результаты размером 32 бита. Далее старшее слово (16 бит) из каждого промежу-
точного результата умножения исходных элементов помещается в 16-битный
элемент окончательного результата.
Исключения: PM: #АС(0); #GP(0): 37; #MF; #NM: 3; #PF(fault-code); #SS(0): 13;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PMULLW приемник, источник
PMULLW (Packed MULtiply and return Low Words) — упакованное знаковое
умножение слов с возвратом младшего слова результата.
Синтаксис: PMULLW rmmx1,rmmx2/m64
Машинный код: Of d5 /г
Действие: команда производит умножение с учетом знака четырех слов операнда
источника на четыре слова приемника и формирует результат в соответствии со
следующей схемой.
pmullw приемник, источник
I d.1 I с.1 I b.1 I а1 I Источник
Промежуточные
результаты
(32 бита)
Приемник (ММХ-регистр)
Как видно из этой схемы, в результате умножения слов источника и приемника полу-
чаются промежуточные результаты размером 32 бита. Далее младшее слово (16 бит)
П1.3. Команды блока ММХ
389
из каждого 32-битного элемента промежуточного результата умножения исход-
ных элементов помещается в 16-битный элемент результата (операнд приемник).
Исключения: PM: #АС(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(O): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
POR приемник, источник
POR (Packed logical OR) — упакованное логическое ИЛИ.
Синтаксис: POR rmmxl, rmmx2/m64
Машинный код: Of eb /rmmxl
Действие: команда производит побитовую операцию логическое ИЛИ над всеми
битами операндов источника и приемника. Результат помещается в операнд приемник.
Исключения: PM: #AC(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(0): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PSADBW приемник, источник
PSADBW (Packed Sum of Absolute Differences) — суммарная разница значений пар
беззнаковых упакованных байт.
Синтаксис: PSADBW rmmxl,rmmx2/m64
Машинный код: 00001111:11110110:mod rmmxl r/m
Действие: для каждой пары байт операндов источник и приемник вычислить модуль
разности, после чего сложить полученные модули. Результат записать в младшее
слово приемник, старшие три слова операнда приемник обнулить.
Исключения: PM: #AC(0); #GP(0): 37; #NM: 3; #PF(fault-code); #SS(0): 13;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PSHUFW приемник, источник, маска
PSHUFW (Packed Shuffle Word) — перераспределение упакованных слов.
Синтаксис: PSHUFW rmmxl ,rmmx2/m64,i8
Машинный код: 00001111:01110000:mod rxmml r/m: i8
Действие: каждая пара бит маски определяет номер слова источника, которое
будет перемещено в приемник следующим образом.
♦ маска[1:0]
• 00 приемник[00...16] источник[00...15]
• 01 приемник[00...16] <— источник! 16...31]
• 10 приемник[00...16] <— источник[32...47]
• И приемник[00...16] <— источник[48...63]
390
Приложение 1. Команды процессоров х86
♦ маска[3:2]
• 00 приемник[16...31] источник[00...15]
• 01 приемник[16...31] <— источник[16...31]
• 10 приемник[16...31] источник[32..,47]
• И приемник[16..,31] <— источник[48...63]
♦ маска[5:4]
• 00 приемник[32-47] <- источник[00...15]
• 01 приемник[32-47] источник[16..,31]
• 10 приемник[32-47] источник[32...47]
• И приемник[32-47] источник[48...63]
♦ маска[7:6]
• 00 приемник[47-63] источник[00...15]
• 01 приемник[47-63] источник[16...31]
• 10 приемник[47-63] <- источник[32...47]
• И приемник[47-63] <— источник[48...63]
Работа команды PSHUFW показана на следующей схеме.
pshufw приемник, источник, маска
Источник rmmx/m64 Приемник rmmx
1 ч3 1 $ 1 1 V 1 1 ч 1 П3 ' nJ 1 1° 1
Маска i8 .
rW
I иа1и0.1.,иЗмИ01 иЗ'.иО I иЗ.'иО I
Приемник rmmx
Исключения: PM: #AC(0); #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM; #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PSLLW приемник, источник
PSLLD приемник, источник
PSLLQ приемник, источник
PSLLW (Packed Shift Left Logical Words) — логический сдвиг влево упакованных
слов. PSLLD (Packed Shift Left Logical Double words) — логический сдвиг влево
упакованных двойных слов. PSLLQ (Packed Shift Left Logical Quarter word) —
логический сдвиг влево упакованных учетверенных слов.
П1.3. Команды блока ММХ
391
- | psllw |—|rmmx|—0д-|т64[—т-| ГбПЧ/Я
Цгттхр
- I Psllw |—|rmmx|—Q—| Гб? 7Т/б!
- | pslld |—|гттх|-0-|-|т64Р-г| Г Of f2/r|
1-|гттхр
- ] pslld |—|гттх[—0—|~18~|—| [0f72/6l
— I Psllcl |-Чгптт4Юу^п64]-^ ГбНЗ/г !
Чгттхр
- I psllq |—[mnmx|—Q—T~i8~]—11(Й 73/б1
Действие: команда сдвигает влево биты в элементах размером слово/двойное
слово/учетверенное слово приемника на количество разрядов, определяемое опе-
рандом источник. Одновременно справа в каждый элемент вдвигаются нулевые
значения. Результат помещается в операнд приемник.
Исключения: PM: #АС(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(0): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PSRAW приемник, источник
PSRAD приемник, источник
PSRAW (Packed Shift Right Arithmetic Words) — арифметический сдвиг вправо
упакованных слов. PSRAD (Packed Shift Right Arithmetic Double words) — ариф-
метический сдвиг вправо упакованных двойных слов.
—-|psrad |—|гттхРОу^гп64|--|-| ГбТ е2/г]
Цплтхр
—| psrad|—|гттх|-0—| i8 |—| Гб7 72/4]
Действие: команда сдвигает вправо биты в элементах приемник размером слово/
двойное слово на количество разрядов, определяемое операндом источник. Одно-
временно слева в разряды каждого элемента вдвигаются биты, количество кото-
рых определяется операндом источник. Значение вдвигаемых слева бит равно
знаковому биту соответствующего элемента. Результат помещается в операнд
приемник.
Исключения: PM: #AC(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(O): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
392
Приложение 1. Команды процессоров х86
PSRLW приемник, источник
PSRLD приемник, источник
PSRLQ приемник, источник
PSRLW (Packed Shift Right Logical Words) — логический сдвиг вправо упакован-
ных слов. PSRLD (Packed Shift Right Logical Double words) — логический сдвиг
вправо упакованных двойных слов. PSRLQ (Packed Shift Right Logical Quarter
word) — логический сдвиг вправо упакованных учетверенных слов.
-I psriw[—roFdjTFj
Цплтхр
—| psriw[—[rmmx|—©—| i8 |—I r6f 71/2!
—| psrld |—|rmmx|—(>r-|m64|—r-| [W d2/r]
Цгттхр
-| psrld |—|rmmx|-0—| i8 |—| Гб? 72/21
-j psrlq |—|гттх|-О-г-|т64Н-| pdf d3/rl
ЦгттхР
-j psrlq |—|rmmx|-Q—| 18 |—| ,r6f73/2|
Действие: команда производит сдвиг вправо бит элементов размером слово/
двойное слово/учетверенное слово приемника на количество разрядов, определяе-
мое операндом источник. Одновременно слева в каждый элемент вдвигаются ну-
левые биты. Результат помещается в операнд приемник.
Исключения: PM: #АС(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(0): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PSUBB приемник, источник
PSUBW приемник, источник
PSUBD приемник, источник
PSUBB (Packed Subtraction Bytes) — вычитание упакованных байт. PSUBW
(Packed Subtraction Words) — вычитание упакованных слов. PSUBD (Packed
Subtraction Double words) — вычитание упакованных двойных слов.
Синтаксис: PSUBB/PSUBW/PSUBD rmmxl,rmmx2/m64
Машинный код:
PSUBB- Off8/rmmxl
PSUBW-Of f9/rmmxl
PSUBD-Of fa/rmmxl
Действие: команда вычитает из элементов источника элементы приемника разме-
ром байт/слова/двойное слово в зависимости от кода операции. При переполне-
П1.3. Команды блока ММХ
393
нии результат формируется в соответствии с принципом циклического перепол-
нения. Результат помещается в операнд приемник.
Исключения: PM: #АС(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(0): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PSUBSB приемник, источник
PSUBSW приемник, источник
PSUBSB (Packed Subtraction with signed Saturation Bytes) — вычитание упако-
ванных байт co знаковым насыщением. PSUBSW (Packed Subtraction with signed
Saturation Words) — вычитание упакованных слов co знаковым насыщением.
Синтаксис: PSUBSB/PSUBSW rmmxl,rmmx2/m64
Машинный код:
PSUBSB - Of е8 /rmmxl
PSUBSW - Of e9 /rmmxl
Действие: источник хранится в регистре ММХ или 64-битной ячейке памяти;
приемник — в регистре ММХ. Команда производит вычитание элементов источ-
ника и приемника размером байт/слово в зависимости от кода операции. Вычита-
ние элементов производится с учетом их знака. При возникновении переполне-
ния результат формируется в соответствии с принципом знакового насыщения:
♦ PSUBSB — 07fh для положительных чисел и 080h для отрицательных;
♦ PSUBSW — 07fffh для положительных чисел и 08000h для отрицательных.
Результат помещается в операнд приемник.
Исключения: PM: #AC(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(0): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PSUBUSB приемник, источник
PSUBUSW приемник, источник
PSUBUSB (Packed Subtraction with Unsigned Saturation Bytes) — вычитание упа-
кованных байт с беззнаковым насыщением. PSUBUSW (Packed Subtraction with
Unsigned Saturation Words) — вычитание упакованных слов с беззнаковым насы-
щением.
Синтаксис: PSUBUSB/PSUBUSW rmmxl,rmmx2/m64
Машинный код:
PSUBUSB - Of d8 /rmmxl
PSUBUSW - Of d9 /rmmxl
Действие: источник хранится в регистре ММХ или 64-битной ячейке памяти;
приемник — в регистре ММХ. Команда производит вычитание без учета знака эле-
ментов операндов источника и приемника размером байт/слово в зависимости от
394
Приложение 1. Команды процессоров х86
кода операции. При возникновении переполнения результат формируется в соот-
ветствии с принципом беззнакового насыщения:
♦ PSUBUSB — 00h для результатов вычитания, меньше нуля;
♦ PSUBUSW — OOOOh для результатов вычитания, меньше нуля.
Результат помещается в операнд приемник.
Исключения: PM: #АС(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(0): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PUNPCKHBW приемник, источник
PUNPCKHWD приемник, источник
PUNPCKHDQ приемник, источник
PUNPCKHBW (Unpack High Packed Bytes to Words) — распаковка старших упа-
кованных байт в слова. PUNPCKHWD/PUNPCKHDQ (Unpack High Packed Bytes
to Words to Double words) — распаковка старших упакованных слов в двойные
слова. PUNPCKHDQ (Unpack High Packed Bytes to Double words to Quarter
word) — распаковка старших упакованных двойных слов в учетверенные слова.
Синтаксис: PUNPCKHBW/PUNPCKHWD/PUNPCKHDQ rmmxl,rmmx2/m64
Машинный код:
PUNPCKHBW - Of 68 /rmmxl
PUNPCKHWD - Of 69 /rmmxl
PUNPCKHDQ - Of 6a /rmmxl
Действие: команды производят размещение элементов из операндов источник и
приемник согласно следующей схеме.
punpckhbw приемник, источник
Источник Приемник (ММХ-регистр)
Т1 шш1 гл
Л, Л, Л,
Приемник (ММХ-регистр)! I 1 I I I I П
punpckhwd приемник, источник
Источник
Приемник (ММХ-регистр)
Приемник (ММХ-регистр) [
punpckhdq приемник, источник
Источник
Приемник (ММХ-регистр)
Приемник (ММХ-регистр)| I I I I II
П1.3. Команды блока ММХ
395
Результат помещается в операнд приемник.
Исключения: PM: #АС(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(O): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
PUNPCKLBW приемник, источник
PUNPCKLWD приемник, источник
PUNPCKLDQ приемник, источник
PUNPCKLBW (Unpack Low Packed Bytes to Words) — распаковка младших упа-
кованных байт в слова. PUNPCKLWD (Unpack Low Packed Words to Double
words) — распаковка младших упакованных слов в двойные слова. PUNPCKLDQ
(Unpack Low Packed Double words to Quarter word) — распаковка младших упако-
ванных двойных слов в учетверенные слова.
Синтаксис: PUNPCKLBW/PUNPCKLWD/PUNPCKLDQ rmmxl,rmmx2/m64
Машинный код:
PUNPCKLBW - Of 60 /rmmxl
PUNPCKLWD - Of 61 /rmmxl
PUNPCKLDQ - Of 62 /rmmxl
Действие: команды производят размещение элементов из операндов источник и
приемник согласно следующей схеме.
punpcklbw приемник, источник
Источник Приемник (ММХ-регистр)
Приемник (ММХ-регистр)
punpcklwd приемник, источник
Источник
LI. । Ч1Щ
Приемник (ММХ-регистр) | |
punpckldq приемник, источник
Источник
Приемник ^ММХ-регистр)
Приемник (ММХ-регистр) [
Исключения: PM: #AC(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(O): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
396
Приложение 1. Команды процессоров х86
PXOR приемник, источник
PXOR (Packed logical Exclusive OR) — упакованное логическое исключающее
ИЛИ.
Синтаксис: PXOR rmmxl ,rmmx2/m64
Машинный код: Of ef /rmmxl
Действие: команда производит побитовую операцию логическое исключающее
ИЛИ над всеми битами операндов источник и приемник. Результат помещается в
операнд приемник.
Исключения: PM: #АС(0); #GP(0): 2; #MF; #NM: 3; #PF(fault-code); #SS(0): 1;
#UD: 10; RM: #GP: 13; #MF; #NM: 3; #UD: 17; VM: #AC(0); #GP(0): 25; #MF;
#NM: 3; #PF(fault-code); #UD: 15.
П1.4. Команды блока ХММ
ADDPS приемник, источник
ADDPS (ADDition Packed Single-precision float-point) — сложение упакованных
значений в формате ХММ.
Синтаксис: ADDPS rxmml, rxmm2/m128
Машинный код: 00001111:01011000:mod rxmml r/m
Действие: алгоритм работы команды показан на рисунке ниже.
addps приемник, источник
Источник _________________________________________
rxmm/m128 I иЗ I и2 I и1 I иО I
© ® © ©
Приемник__________________________________________
rxmm I пЗ I п2 I ni I пО I
Приемник__________ ____________________
rxmml иЗ+пЗ I П2+И2 I п1+и1 I пО+и0 ZJ
Исключения: NE: #О, #U, #1, #Р, #D; PM: #GP(0): 37; #NM: 3; #PF(fault-code);
#SS(O): 13; #UD: 10,11,12,13; #XM; RM; #GP: 13; #NM: 3; #UD: 17,18; #XM; VM:
исключения реального режима; #PF(fault-code).
ADDSS приемник, источник
ADDSS (ADD Scalar Single-precision float-point) — скалярное сложение значений
в формате ХММ.
Синтаксис: ADDSS rxmml, rxmm2/m128
Машинный код: 11110011:00001111:01011000:mod rxmml r/m
П1.4. Команды блока ХММ
397
Действие: алгоритм работы команды показан на рисунке ниже.
addss приемник, источник
Источник _____________________________________________
rxmm/m32 I иЗ _ и2.___________I____и! —.1______HQ____J
Приемник_________________________________ ®__________
rxmm [____пЗ . .1..п2... i П1 . 1 пО_______I
Приемник __________________________________ =
rxmm I...пЗ. . 1.. .л2...I . П.1 I пр+иО .... |
Исключения: NE: #0, #U,. #1, #Р, #D; РМ: #АС: 4; #GP(O): 37; #NM: 3; #PF(fault-
code); #SS(O): 13; #UD: 10-13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM:
исключения реального режима; #AC(0); #PF(fault-code).
ANDNPS приемник, источник
ANDNPS (bit-wise logical AND Not for Packed Single-precision float-point) — пораз-
рядное логическое И-НЕ над упакованными значениями в формате ХММ.
Синтаксис: ANDNPS rxmml, rxmm2/m128
Машинный код: 00001111:01010101 :mod rxmml r/m
Действие: инвертировать биты операнда приемник; над каждой парой битов операндов
приемник (после инвертирования) и источник выполнить операцию логического И.
Исключения: PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10,12,13;
RM: #GP: 13; #NM: 3; #UD: 7; VM: исключения реального режима; #PF(fault-code);
#UD: 16, 17.
ANDPS приемник, источник
ANDPS (bit-wise logical AND for Packed Single-precision float-point) — поразряд-
ное логическое И над каждой парой бит операндов источник и приемник.
Синтаксис: ANDPS rxmml, rxmm2/m128
Машинный код: 00001111:01010100:mod rxmml r/m
Исключения: 1; PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10,12,
13; RM: #GP: 13; #NM: 3; #UD: 17, 19, 20; VM: исключения реального режима;
#PF(fault-code)
CMPPS приемник, источник, условие
CMPPS (CoMPare Packed Single-precision float-point) — сравнение упакованных
значений в формате ХММ
Синтаксис: CMPPS rxmml, rxmm2/m128, i8
Машинный код: 00001111:11000010:mod rxmml r/m: i8
Действие: условие, в соответствии с которым производится сравнение каждой пары
элементов операндов приемник и источник, задается явно в виде непосредственного
398
Приложение 1. Команды процессоров х86
операнда (см. ниже). В результате сравнения в приемнике формируются единич-
ные (если условие выполнено) или нулевые элементы (если условие не выполнено).
Условие Описание условия Отношение Эмуляция Код маски 18 Результат, если опе- ранд NaN Исключение#!, если операнд qNAN/sNAN
Eq Equal (равно) xmm1== xmm2 000b False Нет
Lt less-than (меньше чем) xmm1« xmm2 001b False Да
Le less-than- or-equal (меньше чем или равно) xmm1«= xmm2 010b False Да
greater than (больше чем) xmm1>> xmm2 Пере- становка с сохране- нием, It False Да
greater- than-or- equal (больше чем или равно) xmm1»= xmm2 Пере- становка с сохране- нием, le False Да
Unord Unordered (одно из чисел QNAN) xmml ? xmm2 011b True Нет
Neq not-equal (не равно) !(xmm1== xmm2) 100b True Нет
Nit not-less- than (не меньше чем) I(xmm1 « xmm2) 101b True Да
Nle not-less- than-or- equal (не меньше чем или равно) !(xmm1«= xmm2) 110b True Да
not-greater- than (не больше чем) !(xmm1>> xmm2) Пере- становка с сохране- нием, nit True Да
not-greater- than-or- equal (не больше чем или равно) !(xmm1»= xmm2) Пере- становка с сохране- нием, nle True Да
Ord Ordered (числа hoQNAN) !(xmm1 ?xmm2) 111b False Нет
П1.4. Команды блока ХММ
399
Исключения: 1; NE: #1, #D; PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(0): 13;
#UD: 10-13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM: исключения
реального режима; #PF(fault-code).
CMPSS приемник, источник, условие
CMPSS (CoMPare Scalar Single-precision float-point) — скалярное сравнение зна-
чений в формате ХММ.
Синтаксис: CMPSS rxmml, rxmm2/m32, i8
Машинный код: 11110011:00001111:11000010:mod rxmml r/m: i8
Действие: для пары значений операндов приемник и источник выполняется срав-
нение, в результате которого формируются единичные (если условие выполнено)
или нулевые элементы (если условие не выполнено). Значение источника может
быть расположено в 32-битной ячейке памяти или в младшем двойном слове реги-
стра ХММ. Значение приемника расположено в младшем двойном слове другого ре-
гистра ХММ. Возможные значения условий приведены в описании команды CMPPS.
Исключения: NE: #1, #D; PM: #AC(0); #GP(0): 37; #NM: 3; #PF(fault-code);
#SS(O): 13; #UD: 10-13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM: ис-
ключения реального режима; #AC(0); #PF(fault-code).
COMISS приемник, источник
COMISS (COMpare ordered Scalar Single-precision float-point COMpare and Set
EFLAGS) — скалярное упорядоченное сравнение значений в формате ХММ с ус-
тановкой EFLAGS.
Синтаксис: COMISS rxmml, rxmm2/m32
Машинный код: 00001111:00101111 .mod rxmml r/m
Действие: команда сравнивает пару значений операндов приемник и источник,
в результате чего устанавливаются флаги в регистре EFLAGS, как показано ниже.
Значение источника может быть расположено в 32-битной ячейке памяти или
младшем двойном слове регистра ХММ. Значение приемника расположено в
младшем двойном слове другого регистра ХММ.
Соотношение операндов Значение флагов
Приемник>источник OF=SF=AF=ZF=PF=CF=0
Приемник<источник OF=SF=AF=ZF=PF=0; CF=1
Приемник=источник OF=SF=AF=PF=CF=0; ZF=1
Приемник или источник=д№М или sNaN OF=SF=AF=0; ZF=PF=CF=1
При возникновении незамаскированных исключений значение EFLAGS не изме-
няется.
Исключения: NE: #1, #D; PM: #AC(0); #GP(0): 37; #NM: 3; #PF(fault-code);
#SS(O): 13; #UD: 10-13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM: исклю-
чения реального режима; #AC(0); #PF(fault-code).
400
Приложение 1. Команды процессоров х86
CVTPI2PS приемник, источник
CVTPI2PS (Conversion Two Packed signed Int32 to Packed Single-precision float-
point) — преобразование двух упакованных 32-битных целых в два упакованных
вещественных значения.
Синтаксис: CVTPI2PS rxmml, rmmx2/m64
Машинный код: 00001111:00101010:mod rxmml r/m
Действие: алгоритм работы команды показан на рисунке ниже.
Источник
rmmx/m64
Приемник
rxmm
cvtpi2ps приемник, источник
Приемник
rxmm
Целые
иТ 1 И0 1
I пЗ I I п2 I п.1 1 по 1
Преобразование irtt->float
I пЗ I L_u2_ 1 и1 I иО I
Вещественные
В случае когда не удается выполнить точное преобразование, результат округля-
ется в соответствии с полем MXCSR. RC.
Исключения: NE: #Р; PM: #АС(0); #GP(0): 37; #MF; #NM: 3; #PF(fault-code);
#SS(O): 13; #UD: 10-13; #XM; RM: #AC; #GP: 13; #MF; #NM: 3; #UD: 17-20;
#XM; VM: исключения реального режима; #AC(0); #PF(fault-code).
CVTPS2PI приемник, источник
CVTPS2PI (Conversion Two Packed Single-precision float-point to Packed signed
Int32) — преобразование двух вещественных целых в два упакованных 32-битных
целых.
Синтаксис: CVTPS2PI rmmxl, rmmx2/m128
Машинный код: 00001111:00101101 :mod rmmxl r/m
Действие: алгоритм работы команды показан на рисунке ниже.
Вещественные
I ИЗ I и2 |.. I
Г. nji I . jg I
Преобразование
Источник
rxmm/m128
Приемник
rmmx
cvtps2pi приемник, источник
Приемник
rmmx
Целые
П1.4. Команды блока ХММ
401
Если преобразованный результат больше, чем максимально возможное целочис-
ленное 32-битное значение, то возвращается значение 80000000b. В случае когда
не удается выполнить точное преобразование, значение округляется в соответствии с
полем MXCSR.RC.
Исключения: NE: #1, #Р; PM: #AC(0); #GP(0): 37; #MF; #NM: 3; #PF(fault-code);
#SS(O): 13; #UD: 10—13; #XM; RM: #GP: 13; #MF; #NM: 3; #UD: 17-20; #XM; VM:
исключения реального режима; #AC(0); #PF(fault-code).
CVTSI2SS приемник, источник
CVTSI2SS (ConVerT Scalar signed Int32 to Scalar Single-precision float-point) —
скалярное преобразование знакового 32-битного целого в вещественное значение.
Синтаксис: CVTSI2SS rxmm, r32/m32
Машинный код: 11110011:00001111:00101010:mod rxmm r/m
Действие: алгоритм работы команды показан на рисунке ниже.
Источник
r32/m32
Целое
г-4-i
Приемник
гхтт
cvtsi2ss приемник, источник
Приемник
гхтт
I ПЗ I........П1.. .1 J1.0.. J
Преобразование
j ini>float...
I ~пЗ I п2 I п1 I иО I
Вещественное
В случае когда не удается выполнить точное преобразование, значение округляется
в соответствии с полем MXCSR.RC.
Исключения: NE: #Р; PM: #AC(0); #GP(0): 37; #NM: 3; #PF(fault-code); #SS(0): 13;
#UD: 10-13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM: исключения
реального режима; #AC(0); #PF(fault-code).
CVTSS2SI приемник, источник
CVTSS2SI (ConVerT Scalar Single-precision float-point to Scalar signed Int32) —
скалярное преобразование вещественного целого в 32-битное знаковое целое.
Синтаксис: CVTSS2SI r32,rxmm/m128
Машинный код: 11110011:00001111:00101101 :mod r32 r/m
Действие: значение источника хранится в младшем двойном слове регистра
ХММ или в 128-битной ячейке памяти. Приемник — один из 32-битных регистров.
Алгоритм работы команды показан на рисунке ниже.
402
Приложение 1. Команды процессоров х86
Вещественное
Источник X
rxmm/m128 1. .лЗ..I ...л2 . I п1 I ПО . I
Приемник ----[—.
г32 .. I—4°_1
cvtss2si приемник, источник >jn^HMe
Приемник , ж.—.
г32 Мр
Целое
Если преобразованный результат больше, чем максимально возможное целочис-
ленное 32-битное значение, то возвращается значение 80000000b. В случае когда
не удается выполнить точное преобразование, значение округляется в соответ-
ствии с полем MXCSR. RC.
Исключения: NE: #1, #Р; PM: #AC(0); #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13;
#UD: 10-13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM: исключения
реального режима; #AC(0); #PF(fault-code).
CVTTPS2PI приемник, источник
CVTTPS2PI (ConVerT Truncate two Packed Single-precision float-point to Packed
signed Int32) — преобразование (путем отбрасывания дробной части) двух веще-
ственных целых в два упакованных 32-битных целых значения.
Синтаксис: CVTTPS2PI rmmx,rxmm/m128
Машинный код: 00001111:00101100:mod rmmx r/m
Действие: алгоритм работы команды показан на рисунке ниже.
Вещественные
Источник ^ч1
rxmm/m1281 ИЗ I I И j । И,Р
Приемник
rmmx
cvttps2pi приемник, источник
i nh j do i
Отбросить дробную,
часть значения :
Целые
Приемник
rmmx
Если преобразованный результат больше, чем максимально возможное целочис-
ленное 32-битное значение, то будет возвращено значение 80000000b.
Исключения: NE: #I,#P; PM: #AC(0); #GP(0): 37; #MF; #NM: 3; #PF(fault-code);
#SS(O): 13; #UD: 10-13; #XM; RM: #GP: 13; #MF; #NM: 3; #UD: 17-20; #XM; VM:
исключения реального режима; #AC(0); #PF(fault-code).
П1.4. Команды блока ХММ
403
CVTTSS2SI приемник, источник
CVTTSS2SI (ConVerT Truncate Scalar Single-precision float-point to Scalar signed
Int32) — скалярное преобразование (путем отбрасывания дробной части) веще-
ственного целого в знаковое целое.
Синтаксис: CVTTSS2SI r32,rxmm/m128
Машинный код: 11110011:00001111:00101100:mod r32 r/m
Действие: значение источника хранится в младшем двойном слове регистра ХММ
или в 128-битной ячейке памяти. Приемник — один из 32-битных регистров.
Алгоритм работы команды показан на рисунке ниже.
Вещественное
Источник
rxmm/m128
; Отбросить дробную
часть значения
I 'пО!
Целое
Приемник
г32
cvttss2si приемник, источник
Приемник
г32
Если преобразованный результат больше, чем максимально возможное целочис-
ленное 32-битное значение, то будет возвращено значение 80000000b.
Исключения: NE: #I,#P; PM: #AC(0); #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13;
#UD: 10-13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM: исключения
реального режима; #AC(0); #PF(fault-code).
DIVPS приемник, источник
DIVPS (DIVide Packed Single-precision float-point) — деление упакованных зна-
чений в формате ХММ согласно следующей схеме.
divps приемник, источник I пО J
Приемник rxmm 1— пЗ I о2 1 01
Источник © © © ©
rxmm/m128 I— и2 1 и2 | И1 J ИЙ I
Приемник rxmm I— пЗ/иЗ 1 п2/и2 1 п1/и1 I пО/иО I
Синтаксис: DIVPS rxmm 1,rxmm2/m 128
Машинный код: 00001111:01011110:mod rxmm r/m
Исключения: 1; NE: #О, #U, #1, #Z, #P, #D; PM: #GP(0): 2,37; #NM: 3; #PF(fault-
code); #SS(O): 13; #UD: 10-13; #XM; RM: #GP: 13; #UD: 17-20; #XM; VM: исклю-
чения реального режима; #PF(fault-code).
404
Приложение 1. Команды процессоров х86
DIVSS приемник, источник
DIVSS (Divide Scalar Single-precision float-point) — скалярное деление значений
в формате ХММ согласно следующей схеме.
divss приемник, источник
Приемник
rxmm I пЗ I п2 I п1 I пО I
Источник _______________________________ (7)_______
rxmm/m321 иЗ I и2 I и1 I иО
Приемник _____________________________________=
rxmm I пЗ I п2 I п1 I пО/иО ~1
Синтаксис: DIVSS rxmml,rxmm2/m32
Машинный код: 11110011:00001111:01011110:mod rxmml r/m
Исключения: 1; NE: #0, #U, #1, #Z, #P, #D; PM: #GP(0): 37; #NM: 3; #PF(fault-
code); #SS(O): 13; #UD: 10-13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM:
исключения реального режима; #AC(0); #PF(fault-code).
FXRSTOR источник
FXRSTOR (ReSTORe Fp and mmX state and streaming simd extension state) — вос-
становление без проверки наличия незамаскированных исключений с плавающей
точкой состояния сопроцессора, целочисленного и потокового ММХ-расширений
из 512-байтной области памяти (см. рисунок ниже).
Синтаксис: FXRSTOR m512
Машинный код: 00001111:10101110:mod 001 m512
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
Резерв CS ip FOP FTW FSW FCW 0
Резерв mxcsr Резерв ds dp 16
Резерв stO/rmmxO 32
Резерв st1/rmmx1 48
Резерв st2/rmmx2 64
Резерв st3/rmmx3 80
Резерв st4/rmmx4 96
Резерв st5/rmmx5 112
Резерв st6/rmmx6 128
Резерв st7/rmmx7 144
rxmmO 160
rxmml 176
rxmm2 192
rxmm3 208
rxmm4 224
гхтт5 240
гхттб 256
гхтт7 272
Резерв 288
Резерв
Резерв 496
П1.4. Команды блока ХММ
405
Исключения: 2; РМ: #АС: 4; #GP(0): 38; #NM: 3; #SS(O): 13; #UD: 10; RM: #GP:
13; #NM: 3; #UD: 17; VM: исключения реального режима; #AC: 5; #PF(fault-code).
FXSAVE приемник
FXSAVE (SAVE Fp and mmX state and streaming simd extension state) — сохране-
ние состояния сопроцессора, целочисленного и потокового ММХ-расширений
в 512-байтной области памяти (см. рисунок в описании команды FXRSTOR).
Синтаксис: FXSAVE m512
Машинный код: 00001111:10101110:mod ООО т512
Исключения: 2; NE: #1, #Р; PM: #AC(0); #GP(0): 37; #NM: 3; #SS(O): 13; #UD: 10;
RM: #GP: 13; #NM: 3; #UD: 17; VM: исключения реального режима; #AC(0);
#PF(fault-code).
LDMXCSR источник
LDMXCSR (LoaD streaming simd extension control/status register MXCSR) — за-
грузка регистра состояния/управления mxcsr из 32-битной ячейки памяти.
Регистр состояния/управления mxcsr
| резерв | fz | гс| rc|pm|um|om|zm|dm|im| -|ре|ue| ое| ze|de | ie |
31 15 10 5 0
Синтаксис: LDMXCSR m32
Машинный код: 00001111:10101110:mod 010 т32
Замечание: по умолчанию регистр MXCSR загружается значением 1180.
Исключения: 1; PM: #AC(0); #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13;
#UD: 10,12,13; RM: #GP: 13; #NM: 3; #UD: 17,19,20; VM: исключения реального
режима; #AC(0); #PF(fault-code).
MAXPS приемник, источник
MAXPS (return MAXimum Packed Single-precision float-point) — возврат макси-
мального из упакованных значений в формате ХММ.
Синтаксис: MAXPS rxmm 1,rxmm2/m 128
Машинный код: 00001111:01011111 :mod rxmml r/m
Действие: команда извлекает максимальные значения в каждой из четырех пар
вещественных чисел в коротком формате. При этом происходит сравнение значений
соответствующих элементов источника и приемника, по результатам которого
выполняются действия:
♦ если элемент приемника или элемент источника является сигнализирующим
не-числом — sNAN, то в элемент приемника помещается значение источника;
♦ иначе, если элемент источника больше элемента приемника, то в элемент при-
емника помещается элемент источника.
406
Приложение 1. Команды процессоров х86
В остальных случаях значения источника и приемника не изменяются.
Исключения: 1,3; NE: #1, #D; PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13;
#UD: 10-13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM: исключения
реального режима; #PF(fault-code),
MAXSS приемник, источник
MAXSS (return MAXimum Scalar Single-precision float-point) — скалярный возврат
максимального значения в формате ХММ.
Синтаксис: MAXSS rxmml ,rxmm2/m32
Машинный код: 11110011:00001111:01011111 :mod rxmml r/m
Действие: команда извлекает максимальное из двух вещественных чисел в коротком
формате. При этом происходит сравнение значений младшей пары элементов
источника и приемника, по результатам которого выполняются действия, анало-
гичные рассмотренным в описании команды MAXPS. Старшие три элемента источ-
ника и приемника не изменяются.
Исключения: 1, 3; NE: #1, #D; PM: #AC(0); #GP(0): 37; #NM: 3; #PF(fault-code);
#SS(0): 13; #UD: 10—13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM: ис-
ключения реального режима; #AC(0); #PF(fault-code).
MINPS приемник, источник
MINPS (return MINimum Packed Single-precision float-point) — возврат минималь-
ного упакованного значения в формате ХММ.
Синтаксис: MINPS rxmm 1,rxmm2/m 128
Машинный код: 00001111:01011101 :mod rxmml r/m
Действие: команда извлекает минимальные значения в каждой из четырех пар
вещественных чисел в коротком формате. При этом происходит сравнение значений
соответствующих элементов источника и приемника, по результатам которого
выполняются действия, аналогичные рассмотренным в описании команды MAXPS.
Исключения: 1; NE: #1, #D; PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(0): 13;
#UD: 10-13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM: исключения
реального режима; #PF(fault-code).
MINSS приемник, источник
MINSS (return MINimum Scalar Single-precision float-point) — скалярный возврат
минимального значения в формате ХММ.
Синтаксис: MINSS rxmm1,rxmm2/m32
Машинный код: 11110011:00001111:01011101 :mod rxmml r/m
Действие: команда извлекает минимальное из двух вещественных чисел в коротком
формате. При этом происходит сравнение значений младшей пары элементов
источника и приемника, по результатам которого выполняются действия, анало-
гичные рассмотренным в описании команды MAXPS.
П1.4. Команды блока ХММ
407
Старшие три элемента источника и приемника не изменяются.
Исключения: NE: #1, #D; PM: #АС(0); #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13;
#UD: 10-13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM: исключения
реального режима; #AC(0); #PF(fault-code).
MOVAPS приемник, источник
MOV APS (MOVe Aligned four Packed Single-precision float-point) — перемещение
выровненных 128 бит источника в соответствующие биты приемника.
movaps|-|—|rxmm|-Q-j-lm128H ГобОбТИ!:06T6T6o5irnoclremrnr/mi
ЧгёгптН
Исключения: 1; PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10-13;
RM: #GP: 13; #NM: 3; #UD: 17, 19, 20; VM: исключения реального режима;
#PF(fault-code).
MOVHLPS приемник, источник
MOVHLPS (MOVe High to Low Packed Single-precision float-point) — копирова-
ние содержимого старшей половины регистра ХММ (источника) в младшую по-
ловину другого регистра ХММ (приемника).
movhlps приемник, источник
Приемник_____________________________________________
rxmm I пЗ I п2 I п1 I п0--------------------------1
Источник ____________________________________________
remm I иЗ I | и1 I ИО I
Приемник ____ _______________________________________
rxmm I пЗ I п2 I иЗ I и2 _ J
Синтаксис: MOVHLPS rxmml, rxmm2
Машинный код: 00001111:00010010:11 rxmml ,rxmm2
Исключения: PM: #NM: 3; #UD: 10,12,13; RM: #NM: 3; #UD: 17,19, 20; VM: ис-
ключения реального режима.
MOVHPS приемник, источник
MOVHPS (MOVe High Packed Single-precision float-point) — перемещение верх-
них упакованных значений в формате ХММ из источника в приемник.
—|movhps|—r-|rxmm|—GH m64H
Ч т641—O~|rxmm[—1 Г00бб1Т11"01М
408
Приложение 1. Команды процессоров х86
Действие:
♦ если источник — 64-битный операнд в памяти, то команда MOVHPS перемещает
его содержимое в старшую половину приемника, представляющего собой
регистр ХММ;
♦ если источник — регистр ХММ, то команда MOVHPS перемещает содержимое
его старшей половины в приемник, который представляет собой 64-битный
операнд в памяти.
Исключения: PM: #АС(0); #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD:
10,12,13; RM: #GP: 13; #NM: 3; #UD: 17,19,20; VM: исключения реального режи-
ма; #AC(0); #PF(fault-code).
MOVLHPS приемник, источник
MOVLHPS (MOVe Low to High Packed Single-precision float-point) — перемеще-
ние нижних упакованных значений в формате ХММ в верхние.
Синтаксис: MOVLHPS rxmml, rxmm2
Машинный код: 00001111.00010110:11 rxmml,rxmm2
Действие: команда копирует содержимое младшей половины регистра ХММ
{источника) в старшую половину другого регистра ХММ {приемника). После
операции изменяется только содержимое старшей половины приемника.
Исключения: PM: #NM: 3; #UD: 10,12,13; RM: #NM: 3; #UD: 17,19, 20; VM: ис-
ключения реального режима.
MOVLPS приемник, источник
MOVLPS (MOVe Unaligned Low Packed Single-precision float-point) — перемеще-
ние невыровненных нижних упакованных значений в формате ХММ.
—|movlps |—r-|rxmm|—Q—| m64 Н F0060lil~Fb7)0T6bi0:rn^
L-1 т64 |—О4гхтт|—| ГООО01111"бб01001 1:mod rxrnm r/rril
Действие: команда копирует содержимое младшей половины регистра ХММ в 64-
битную ячейку памяти или из нее:
♦ если источник — 64-битный операнд в памяти, то его содержимое перемещает-
ся в младшую половину приемника, представляющего собой регистр ХММ;
♦ если источник — регистр ХММ, то содержимое его младшей половины пе-
ремещается в приемник, который представляет собой 64-битный операнд в
памяти.
Исключения: PM: #AC(0); #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD:
10,12,13; RM: #GP: 13; #NM: 3; #UD: 17,19,20; VM: исключения реального режи-
ма; #AC(0); #PF(fault-code).
П1.4. Команды блока ХММ
409
MOVMSKPS приемник, источник
MOVMSKPS (MOVe sign MaSK Packed Single-precision float-point to integer) —
перемещение знаковой маски в целочисленный регистр.
Синтаксис: MOVMSKPS r32, rxmm
Машинный код: 00001111:01010000:11 r32 rxmm
Действие: команда формирует маску из знаковых разрядов четырех чисел с пла-
вающей точкой в коротком формате, упакованных в регистр ХММ (источник).
После операции содержимое всего 32-битного регистра (приемника) изменяется
следующим образом: в его младшую тетраду заносится знаковая маска, остальные
разряды регистра обнуляются.
movmskps приемник, источник
Приемник г32 ?,?.!?,?]
Источник (ХММ-регистр) Q Ю> I' и
rxmm _______ L
0010
Приемник г32
Исключения: PM: #MF; #NM: 3; #UD: 10,12,13; RM: #NM: 3; #UD: 17,19,20; VM:
исключения реального режима.
MOVNTPS приемник, источник
MOVNTPS (MOVe Non Temporal aligned four Packed Single float-point) — запись
в память 128 бит из регистра ХММ, минуя кэш.
Синтаксис: MOVNTPS ml28,rxmm
Машинный код: 00001111:00101011 :mod rxmm r/m
Исключения: 1; PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10,12,
13; RM: #GP: 13; #NM: 3; #UD: 17, 19, 20; VM: исключения реального режима;
#PF(fault-code).
MOVSS приемник, источник
MOVSS (MOVe Scalar Single-precision float-point) — перемещение скалярных зна-
чений в формате ХММ.
—I movss |----|гхтт(~О-г| т32 Н 01 Нбб iTOOOOI11 i~:00~0i 007)0~mod~rxmm ~r/rrii
ДН 010 ooTIWoHT^^
—| т32Р<>—|гхтт|—| 0110бб10~бббб1~1Г17ббо1l666lTmddl^
Действие: команда копирует младшие 32 бита источника в младшие 32 бита прием-
ника. Если используется операнд в памяти, то в команде указывается адрес, соот-
410
Приложение 1. Команды процессоров х86
ветствующий адресу младшего байта данных в памяти. Если в качестве источника
используется операнд в памяти, то эти 32 бита копируются в младшее двойное
слово 128-битного приемника — регистра ХММ, остальные 96 бит этого регистра
устанавливаются в 0.
Источник Источник _
rxmm I из I и2 I и1 I иР~! m32 I иО I
Приемник : Приемник :
rxmm 1пЗ 1 п2 I п1 I rflFl rxmmI ПЭ I П2 I. П1 I ГЙД
movss приемник, источник
Приемник ___________ V Приемник V
rxmm 1пЗ ! п2 I п1 I иО I rxmm I О . I Q I О L . иф I
Источник_________________________
rxmm 1иЗ I и2 I и1 I иО I
Приемник •
т32 I . ПО I
movss приемник, источник
Приемник J V t
т32 l-..ИЯ I
Исключения: PM: #АС(0); #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD:
10,12,13; RM: #GP: 13; #NM: 3; #UD: 17,19,20; VM: исключения реального режи-
ма; #AC(0); #PF(fault-code).
MOVUPS приемник, источник
MOVUPS (MOVe Unaligned four Packed Single-precision float-point) — перемеще-
ние невыровненных упакованных значений в формате ХММ.
ips}—;—|rxmm[-O-|-|m128H fQO^lfFOOOrdOOOimocIrxmrnr/ml
ЧБсглтЦ
Действие: переместить 128 бит источника в соответствующие биты приемника.
Исключения: PM: #AC(0); #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10;
RM: #GP: 13; #NM: 3; #UD: 17; VM: исключения реального режима; #AC(0);
#PF(fault-code).
MULPS приемник, источник
MULPS (MULtiply Packed Single-precision float-point) — умножение упакованных
значений в формате ХММ.
Синтаксис: MULPS rxmm 1,rxmm2/m 128
Машинный код: 00001111:01011001 :mod rxmml r/m
П1.4. Команды блока ХММ
411
Действие: команда умножает четыре пары вещественных чисел в коротком фор-
мате. Схема работы команды MULPS показана на следующем рисунке.
mulps приемник, источник
Приемник
rxmm L o3 I I 02 I I nJ J Qfl I
Источник О О О О
rxmm/m128 I— иЗ I И2 : I И1—_ J ий I
Приемник = - -
rxmm L п32и2 I о£и2 1 п1*и1 J ПОЙ I
Исключения: 1; NE: #0, #U, #1, #Р, #D; PM: #GP(O): 37; #NM: 3; #PF(fault-code);
#SS(O): 13; #UD: 10, 11; #XM; RM: #GP: 13; #NM: 3; #UD: 17, 18; #XM; VM: ис-
ключения реального режима; #PF(fault-code).
MULSS приемник, источник
MULSS (MULtiply Scalar Single-precision float-point) — умножение скалярных
значений в формате ХММ.
Синтаксис: MULSS rxmm1,rxmm2/m32
Машинный код: 11110011:00001111:01011001 :mod rxmml r/m
Действие: команда умножает вещественные значения в младших парах операн-
дов в формате ХММ. Операнды источник и приемник находятся в регистре ХММ,
кроме того, операнд источник может находиться в 32-битной ячейке памяти. Схе-
ма работы команды MULSS показана на следующем рисунке.
mulss приемник, источник
Приемник___________________________________________________
rxmm I пЗ I п2 I п1 I пО I
Источник ______________________________________ Q__________
rxmm/m32 |.... м3,....1......И2...1, , И1 ....J____ЛЙ_____]
Приемник _______ ____________ __________________ °
rxmm I пЗ I п2 I п1 I п0жи0 |
\
Исключения: 1; NE: #О, #U, #1, #Р, #D; PM: #GP(0): 37; #NM: 3; #PF(fault-code);
#SS(O): 13; #UD: 10,11; #XM; RM: #GP: 13; #NM: 3; #UD: 17,18; #XM; VM: ис-
ключения реального режима; #AC(0); #PF(fault-code).
ORPS приемник, источник
ORPS (bit-wise logical OR for Packed Single-precision float-point) — поразрядное
логическое ИЛИ над каждой парой бит упакованных операндов источник и при-
емник в формате ХММ.
Синтаксис: ORPS rxmml, rxmm2/m128
Машинный код: 00001111:01010110:mod rxmml r/m
412
Приложение 1. Команды процессоров х86
Исключения: 1; PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(0): 13; #UD; 10; RM:
#GP: 13; #NM: 3; #UD: 17; VM: исключения реального режима; #PF(fault-code).
RCPPS приемник, источник
RCPPS (ReCiProcal Packed Single-precision float-point) — вычисление обратных
упакованных значений в формате ХММ.
Синтаксис: RCPPS rxmml, rxmm2/m128
Машинный код: 00001111:01010011 :mod rxmml r/m
Действие: команда вычисляет обратные значения элементов источника по фор-
муле 1/(элемент_источника). Максимальная ошибка вычисления: еггог«=1.5*2"12.
Схема работы команды RCPPS показана на следующем рисунке.
repps приемник, источник
Источник rxmm/m1281 k|3 I и2 I и1 I иО I
Приемник rxmm I 1/иЗ I 1/и2 I 1/и1 I lXi5~l
Исключения: 1; PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10; RM:
#GP: 13; #NM: 3; #UD: 17; VM: исключения реального режима; #PF(fault-code).
RCPSS приемник, источник
RCPSS (ReCiProcal Scalar Single-precision float-point) — скалярное вычисление
обратного упакованного значения в формате ХММ.
Синтаксис: RCPSS rxmml, rxmm2/m32
Машинный код: 11110011:00001111:01010011 :mod rxmml r/m
Действие: команда вычисляет обратное значение младшего элемента операнда
источник по формуле 1/(элемент_источника). Максимальная ошибка вычисления:
еггог«=1.5‘2'’2.
Исключения: РМ: #АС: 5; #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10;
RM: #GP: 13; #NM: 3; #UD: 17; VM: #AC: 5; исключения реального режима;
#PF(fault-code).
RSQRTPS приемник, источник
RSQRTPS (Reciprocal SQuare RooT Packed Single-precision float-point) — вычисле-
ние обратных значений квадратного корня упакованных значений в формате ХММ.
Синтаксис: RSQRTPS rxmml, rxmm2/m128
Машинный код: 00001111:01010010:mod rxmml r/m
Действие: команда для каждого элемента элемент_источника операнда источник
выполняет следующие два действия: вычислить квадратный корень элемент_ис-
точника; вычислить обратную величину полученного значения корня по формуле:
1/<(элемент_источника). Максимальная ошибка вычисления: еггог«=1.5*2-12.
П1.4. Команды блока ХММ
413
Исключения: 1; PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(0): 13; #UD: 10,12,13;
RM: #GP: 13; #NM: 3; #UD: 17, 19, 20; VM; исключения реального режима;
#PF(fault-code).
RSQRTSS приемник, источник
RSQRTSS (Reciprocal SQuare RooT Scalar Single-precision float-point) — скаляр-
ная аппроксимация обратных значений квадратного корня упакованных значений
в формате ХММ.
Синтаксис: RSQRTSS rxmml, rxmm2/m32
Машинный код: 11110011.00001111:01010010:mod rxmm r/m
Действие: команда для младшего элемента элемент_источника операнда источник
выполняет следующие два действия: вычисляет корень квадратный элемент_ис-
точника; вычисляет обратную величину полученного значения корня по формуле:
1/^(элемент_источника). Максимальная ошибка вычисления: еггог«=1.5*2"12. Стар-
шие элементы операнда приемник не изменяются.
Исключения: PM: #AC(0); #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10;
RM: #GP: 13; #NM: 3; #UD: 17; VM: исключения реального режима; #AC: 5;
#PF(fault-code).
SHUFPS приемник, источник, маска
SHUFPS (Shuffle Packed Single-precision float-point) — перераспределение упако-
ванных значений в формате ХММ.
Синтаксис: SHUFPS rxmml, rxmm2/m128,i8
Машинный код: 00001111:11000110:mod rxmml r/m: i8
Действие: команда перераспределяет любые два из четырех двойных слов приемника
в два младших двойных слова того же приемника и любые два из четырех двойных
слов источника в два старших двойных слова приемника. Если использовать один
и тот же регистр ХММ в качестве источника и приемника, то можно выполнять
любые перестановки в пределах одного регистра. Каждая пара бит маски опреде-
ляет номер двойного слова источника или приемника, которое будет перемещено
в приемник следующим образом:
♦ маска[1:0]
• 00 приемник[00...31] <— источник[00...31]
• 01 приемник[00...31] <— источник[32...63]
• 10 приемник[00...31] <— источник[64...95]
• И приемник[00...31] <— источник[96...127]
♦ маска[3:2]
• 00 приемник[32...63] <— источник[00...31]
• 01 приемник[32...63] источник[32...63]
414
Приложение 1. Команды процессоров х86
• 10 приемник[32...63] источник[64...95]
• 11 приемник[32...63] <— источник[96...127]
♦ маска[5:4]
• 00 приемник[64...95] <— источник[00...31]
• 01 приемник[64...95] источник[32...63]
• 10 приемник[64...95] источник[64...95]
• И приемник[64...95] источник[96...127]
♦ маска[7:6]
• 00 приемник[96...127] <— источник[00...31]
• 01 приемник[96...127] <— источник[32...63]
• 10 приемник[96...127] <— источник[64...95]
• И приемник[96...127] источник[96...127]
Схематически работа команды SHUFPS показана на следующем рисунке.
shufps приемник, источник, маска
Источник rxmm/m128.______ Приемник rxmm____________
I ^3 I и2..1-д1...1..j^L.I I. . .пЗ., ,1 ng I Ijl. I
Приемник rxmm
Исключения: 1; PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(0): 13; #UD: 10,12,13;
RM: #GP: 13; #NM: 3; #UD: 17, 19, 20; VM: исключения реального режима; #PF
(fault-code).
SQRTPS приемник, источник
SQRTPS (SQuare RooT Packed Single-precision float-point) — корень квадратный
упакованных значений в формате ХММ.
Синтаксис: SQRTPS rxmml, rxmm2/m128
Машинный код: 00001111:01010001 :mod rxmml r/m
Действие: команда извлекает квадратный корень из четырех упакованных веще-
ственных чисел в коротком формате.
Исключения: 1; NE: #1, #Р, #D; PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13;
#UD: 10-13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM: исключения
реального режима; #PF(fault-code).
П1.4. Команды блока ХММ
415
SQRTSS приемник, источник
SQRTSS (SQuare RooT Scalar Single-precision float-point) — скалярное извлече-
ние квадратного корня.
Синтаксис: SQRTSS rxmml, rxmm2/m32
Машинный код: 11110011.00001111:01010001 .mod rxmml r/m
Действие: команда извлекает квадратный корень из младшего двойного слова
операнда источник, который должен представлять собой упакованное веществен-
ное число в формате ХММ.
Исключения: NE: #1, #Р, #D; PM: #AC(0); #GP(0): 37; #NM: 3; #PF(fault-code);
#SS(O): 13; #UD: 10-13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM:
исключения реального режима; #AC(0); #PF(fault-code).
STMXCSR приемник
STMXCSR (STore Streaming SIMD Extension Control/Status register MXCSR) —
сохранение регистра управления/состояния MXCSR в 32-битной ячейке памяти.
Синтаксис: STMXCSR m32
Машинный код: 00001111:10101110:mod 011 т32
Исключения: PM: #АС(0); #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD:
10,12,13; RM: #GP: 13; #NM: 3; #UD: 17,19,20; VM: исключения реального режи-
ма; #AC(0); #PF(fault-code).
SUBPS приемник, источник
SUBPS (SUBtract Packed Single-precision float-point) — вычитание упакованных
значений в формате ХММ.
Синтаксис: SUBPS rxmml, rxmm2/m128
Машинный код: 00001111:01011100:mod rxmml r/m
Исключения: 1; NE: #О, #U, #1, #Р, #D; PM: #GP(0): 37; #NM: 3; #PF(fault-code);
#SS(O): 13; #UD:10-13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM:
исключения реального режима; #PF(fault-code).
SUBSS приемник, источник
SUBSS (SUBtract Scalar Single-precision float-point) — вычитание скалярных зна-
чений в формате ХММ.
Синтаксис: SUBSS rxmml, rxmm2/m32
Машинный код: 11110011:00001111:01011100:mod rxmm r/m
Действие: команда вычитает значения младшей пары вещественных чисел в фор-
мате ХММ.
416
Приложение 1. Команды процессоров х86
Исключения: NE: #О, #U, #1, #Р, #D; PM: #АС(0); #GP(0): 37; #NM: 3; #PF(fault-
code); #SS(0): 13; #UD; 10-13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM:
исключения реального режима; #AC(0); #PF(fault-code).
UCOMISS приемник, источник
UCOMISS (Unordered Scalar Single-fp COMpare and set eflags) — неупорядоченное
скалярное сравнение значений в формате ХММ с установкой флагов в EFLAGS.
Синтаксис: UCOMISS rxmml, rxmm2/m32
Машинный код: 00001111:00101110:mod rxmml r/m
Действие: сравнение пары вещественных элементов в коротком формате, распо-
ложенных в младшем двойном слове операндов в формате ХММ. В результате
выполнения команды формируются значения флагов ZF, PF и CF, а флаги OF, SF и
AF устанавливаются в 0 (см. ниже). В процессе работы команда распознает специ-
альные значения qNaN и sNaN. При возникновении незамаскированных исключе-
ний расширения ХММ регистр EFLAGS не изменяется.
Соотношение операндов Значение флагов
Приемник>источник
Приемник<источник
Приемник=источник
Приемник или источник=8ЫаЫ
OF=SF=AF=0; ZF=0; PF=0; CF=0
OF=SF=AF=0; ZF=0; PF=O; cf=1
OF=SF=AF=0; ZF=1; PF=0; CF=0
OF=SF=AF=0; ZF=1; PF=1; CF=1
Исключения: NE: #1, #D; PM: #AC(0); #GP(0): 37; #NM: 3; #PF(fault-code);
#SS(O): 13; #UD: 10-13; #XM; RM: #GP: 13; #NM: 3; #UD: 17-20; #XM; VM:
исключения реального режима; #AC(0); #PF(fault-code).
UNPCKHPS приемник, источник
UNPCKHPS (Unpack High Packed Single-precision float-point data) — чередова-
ние верхних упакованных значений в формате ХММ.
Синтаксис: UNPCKHPS rxmml, rxmm2/m128
Машинный код: 00001111:00010101 :mod rxmml r/m
Действие: перемещение путем чередования двух старших двойных слова прием-
ника и источника. Младшие двойные слова приемника и источника игнорируют-
ся. Схема выполнения команды UNPCKHPS показана на следующем рисунке.
unpckhps приемник, источник
Источник rxmm/m 128 Приемник rxmm
I иЗ I и2 | и1 I иТП j пЗ I п2 I . П.1—J ДД
_________________________W у
I Ji3 I пЗ I и2 I п2 I Приемник rxmm
П1.5. Команды блока ХММ (SSE2)
417
Исключения: 1; PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10,12,13;
RM: #GP: 13; #NM: 3; #UD: 17, 19, 20; VM: исключения реального режима;
#PF(fault-code).
UNPCKLPS приемник, источник
UNPCKLPS (Unpack Low Packed Single-precision float-point data) — чередование
нижних упакованных значений в формате ХММ.
Синтаксис: UNPCKLPS rxmml, rxmm2/m128
Машинный код: 00001111:00010100:mod rxmml r/m
Действие: перемещение путем чередования двух младших двойных слова прием-
ника и источника. Старшие двойные слова приемника и источника игнорируются.
Схема работы команды UNPCKLPS показана на следующем рисунке.
unpcklps приемник, источник
Источник rxmm/m128 Приемник rxmm
I пЗ I п2 I пТТ"пВ"1
у Ф
Приемник rxmm I и1 I п1 I иО I пО »
Т____________________
Исключения: 1; PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10,12,
13; RM: #GP: 13; #NM: 3; #UD: 17, 19, 20; VM: исключения реального режима;
#PF(fault-code).
XORPS приемник, источник
XORPS (bit-wise logical XOR for Packed Single-precision float-point) — поразряд-
ное логическое ИСКЛЮЧАЮЩЕЕ ИЛИ над упакованными значениями в фор-
мате ХММ.
Синтаксис: XORPS rxmml, rxmm2/m128
Машинный код: 00001111:01010111:mod rxmml r/m
Исключения: PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10,12,13;
RM: #GP: 13; #NM: 3; #UD: 17, 19, 20; VM: исключения реального режима;
#PF(fault-code).
П1.5. Команды блока ХММ (SSE2)
ADDPD приемник, источник
ADDPD (ADD Packed Double-precision floating-point values) — сложение упако-
ванных значений с плавающей точкой двойной точности.
Синтаксис: ADDPD rxmml, rxmm2/m128
Машинный код: 66 OF 58 /г
418
Приложение 1. Команды процессоров х86
Действие: сложить пары упакованных значений с плавающей точкой двойной
точности источника и приемника (аналогично команде ADDPS) и сохранить резуль-
тат сложения в соответствующих упакованных значениях с плавающей точкой
двойной точности приемника.
Исключения: SIMD (NE): #0, #U, #1, #Р, #D; PM: #GP(O): 37,42; #NM: 3; #ХМ;
#PF(fault-code); #SS(O): 13; #UD: 10-12,15; RM: #GP: 13,16; #NM: 3; #UD: 17-19,
22; #XM; VM: исключения реального режима; #PF(fault-code).
ADDSD приемник, источник
ADDSD (ADD Scalar Double-precision floating-point values) — сложение скаляр-
ных упакованных значений с плавающей точкой двойной точности.
Синтаксис: ADDSD rxmml, rxmm2/m64
Машинный код: F2 OF 58 /г
Действие: сложить младшие упакованные значения с плавающей точкой двойной
точности источника и приемника (аналогично команде ADDSS) и сохранить резуль-
тат сложения в младшем упакованном значении с плавающей точкой двойной точ-
ности приемника.
Исключения: SIMD (NE): #0, #U, #1, #Р, #D; PM: #GP(O): 37; #PF(fault-code);
#SS(O): 13; #NM: 3; #XM; #UD: 10,11,12,15; #AC(0)_cpl3; RM: #GP: 13; #NM: 3;
#UD: 17, 18, 19, 22; #XM; VM: исключения реального режима; #PF(fault-code);
#AC(0)_u.
ANDPD приемник, источник
ANDPD (bitwise logical AND of Packed Double-precision floating-point values) —
поразрядное логическое И над упакованными значениями с плавающей точкой
двойной точности.
Синтаксис: ANDPD xmm1, xmm2/m128
Машинный код: 66 OF 54 /г
Действие: выполнить поразрядное логические И над двумя упакованными значе-
ниями с плавающей точкой двойной точности по схеме: приемник[Г27прием-
нику 127-0] побитное_АМО источнику 127-0].
Исключения: PM: #GP(0): 37, 42; #SS(O): 13; #NM: 3; #ХМ; #PF(fault-code);
#UD: 10-12,15; RM: #GP: 13,16; #NM: 3; #UD: 17-19, 22; #XM; VM: исключения
реального режима; #PF(fault-code).
ANDNPD приемник, источник
ANDNPD (bitwise logical AND NOT of Packed Double-precision floating-point
values) — поразрядное логическое И-НЕ над упакованными значениями с плава-
ющей точкой двойной точности.
Синтаксис: ANDNPD xmm1, xmm2/m128
П1.5. Команды блока ХММ (SSE2)
419
Машинный код: 66 OF 55 /г
Действие: выполнить операцию поразрядного логического И-НЕ над парами упа-
кованных значений с плавающей точкой двойной точности в приемнике и источ-
нике по схеме: приемник[121((НОТпрмемиык[127-0]) побитное АЫП источ-
ник^!-0]).
Исключения: PM: #GP(0): 37, 42; #SS(0): 13; #NM: 3; #PF( fault-code); #UD: 10,
11,12,15; #XM; RM: #GP: 13,16; #NM: 3; #UD: 17,18,19,22; #XM; VM: исключе-
ния реального режима; #PF(fault-code).
CLFLUSH адрес_байта
CLFLUSH (FLUSH Cache Line) — сброс на диск строки кэша, содержащей ад-
рес_байта.
Синтаксис: CLFLUSH m8
Машинный код: OF АЕ /7
Действие: объявить недействительной строку кэша, которая содержит линейный
адрес адрес_байта на всех уровнях иерархии кэшей данных и команд процессора.
Если на одном из уровней иерархии кэшей строка «грязная» (противоречит со-
держимому памяти), то перед объявлением ее недействительной она записывает-
ся в память.
Возможность использования команды CLFLUSH на данном процессоре необходи-
мо выяснить с помощью CPUID. Выровненный размер строки кэша, на который
воздействует CLFLUSH, также определяется командой CPUID.
Исключения: PM: #GP(0): 37; #PF(fault-code); #SS(0): 13; #UD: 16; RM: #GP: 13;
#UD: 23; VM: исключения реального режима; #PF(fault-code).
CMPPD приемник, источник, условие
CMPPD (CoMPare Packed Double-precision floating-point values description) —
сравнение упакованных значений с плавающей точкой двойной точности.
Синтаксис: CMPPD xmm1, xmm2/m128, imm8
Машинный код: 66 OF С2 /г i8
Действие: сравнить упакованные значения с плавающей точкой двойной точнос-
ти в приемнике и источнике. Результат сравнения для каждой пары упакованных
чисел представляется в виде маски: единичная маска ffffffffffffffffh — значения чисел
равны, нулевая маска OOOOOOOOOOOOOOOOh — значения не равны. Условие сравнения
задается непосредственным операндом условие, первые 3 бита которого определяют
тип сравнения. Остальные биты зарезервированы. Соответствие значений операн-
да условие условию сравнения следующее: 0 (приемник = источник), 1 (прием-
ник < источник), 2 (приемник< источник), 3 (приемник и (или) источник — NAN или
в неопределенном формате), 4 (приемник* источник), 5 (-^(приемник <источник)),
6 (-^(приемник < источник)), 7 (упакованные значения приемника и источника —
правильные значения с плавающей точкой двойной точности). Для проверки
420
Приложение 1. Команды процессоров х86
остальных условий необходимо вначале поменять содержимое приемника и ис-
точника, а затем использовать команду CMPPD со следующими значениями опе-
ранда условие', 1 (приемник > источник), 2 (приемник> источник), 5 (-^(приемник>
источник)), 6 (-^(приемник > источник)).
Исключения: SIMD (NE): #1 (если операнд SNaN или QNaN), #D; PM: #GP(O):
37, 42; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10-12, 15; #XM; RM: #GP: 13,
16; #NM: 3; #UD: 17,19, 22; #XM; VM: исключения реального режима; #PF(fault-
code).
CMPSD приемник, источник, условие
CMPSD (CoMPare Scalar Double-precision floating-point values description) — срав-
нение скалярных значений с плавающей точкой двойной точности.
Синтаксис: CMPSD xmm1, xmm2/m64, imm8
Машинный код: F2 OF С2 /г i8
Действие: сравнить упакованные значения с плавающей точкой двойной точнос-
ти в разрядах [63-0] приемника и источника. Формирование проверяемого усло-
вия и результата выполнения команды аналогичны соответствующим атрибутам
команды CMPPD.
Исключения: SIMD (NE): #1 (если операнд SNaN или QNaN), #D; PM: #GP(0):
37; #SS(O): 13; #PF(fault-code); #NM: 3; #XM; #UD: 10-12, 15; #AC(0)_cpl3;
RM: #GP: 13, 16; #NM: 3; #XM; #UD: 17—19, 22; VM: исключения реального
режима; #PF(fault-code); #AC(0)_u.
COMISD приемник, источник, условие
COMISD (COMpare Scalar ordered Double-precision floating-point values and set
EFLAGS) — сравнение упорядоченных скалярных значений с плавающей точкой
двойной точности и установка регистра EFLAGS.
Синтаксис: COMISD xmm1, xmm2/m64
Машинный код: 66 OF 2F /г
Действие: сравнить упорядоченные скалярные значения с плавающей точкой
двойной точности в разрядах [63-0] приемника и источника. По результату срав-
нения установить флаги ZF, PF и CF в регистре EFLAGS: приемник > источник
(ZF = 0, PF = 0, CF = 0), приемник > источник (ZF = 0, PF = 0, CF = 1), приемник = ис-
точник (ZF = 1, PF = 0, CF = 0), приемник и(или) источник NAN или в неопределен-
ном формате (ZF = 1, PF = 1, CF = 1). Флаги OF, SF и AF устанавливаются в 0. В случае
генерации немаскированного исключения с плавающей точкой регистр EFLAGS
не модифицируется.
Исключения: SIMD (NE): #1 (если операнд SNaN или QNaN), #D; PM: #GP(0): 37;
#SS(O): 13; #PF(fault-code); #NM: 3; #XM; #UD: 10-12, 15; #AC(0)_cpl3; RM:
П1.5. Команды блока ХММ (SSE2)
421
#GP: 13; #NM: 3; #ХМ; #UD: 17—19, 22; VM: исключения реального режима;
#PF(fault-code); #AC(0)_u.
CVTDQ2PD приемник, источник
CVTDQ2PD (ConVerT packed Doubleword Integers to Packed Double-precision
floating-point values) — преобразование двух упакованных 32-битных целых в два
упакованных значения с плавающей точкой двойной точности.
Синтаксис: CVTDQ2PD rxmml, rxmm2/m64
Машинный код: F3 OF Е6
Действие: алгоритм работы команды показан на рисунке ниже.
Источник
rxmm/m64
Приемник
rxmm
cvtdq2pd приемник, источник
Приемник
rxmm
Исключения: PM: #GP(0): 37; #SS(0): 13; #PF(fault-code); #NM: 3; #XM; #UD:
10, И, 12, 15; #AC(0)_cpl3; RM: #GP: 13; #NM: 3; #UD: 17-19, 22; #XM; VM:
исключения реального режима; #AC: 5; #PF(fault-code); #AC(0)_u.
CVTDQ2PS приемник, источник
CVTDQ2PS (ConVerT Packed Doubleword integers to Packed Single-precision floating-
point values) — преобразование четырех упакованных 32-битных целых со знаком
в четыре упакованных значения с плавающей точкой одинарной точности.
Синтаксис: CVTDQ2PS rxmml, rxmm2/m128
Машинный код: OF 5В /г
Действие: алгоритм работы команды показан на рисунке ниже.
В случае когда не удается выполнить точное преобразование, значение округляется
в соответствии с полем MXCSR.RC.
Исключения: SIMD (NE): #Р; PM: #GP(0): 37, 42; #SS(0): 13; #PF(fault-code);
#NM: 3; #XM; #UD: 10-12, 15; RM: #GP: 13, 16; #NM: 3; #XM; #UD: 17-19, 22;
VM: исключения реального режима; #AC: 5; #PF(fault-code).
422
Приложение 1. Команды процессоров х86
Источник
rxmm/m128
Приемник
rxmm
cvtdq2ps приемник, источник
Приемник
rxmm
Целые со знаком
| иЗ | и2 | и1 | иО |
127 ” 95 . 63 " - . 31 • О
I-------------------Г1!-' — !--!----1--1
I п1 I | | п0! ‘ I
127 63 j i I О
;г| Преобразование ;
! j _ _ 10 t?2->fl_qat3_2_ _ _ J
I иЗ I и2 I и1 I иО I
127 \J95 V 63 / 3L^ 0
Вещественные
(32 бита)
CVTPD2DQ приемник, источник
CVTPD2DQ (ConVerT Packed Double-Precision Floating-Point Values to Packed
Doubleword integers) — преобразование двух упакованных значений с плавающей
точкой двойной точности в два упакованных 32-битных целых.
Синтаксис: CVTPD2DQ rxmml, rxmm2/m128
Машинный код: F2 OF Е6
Действие: алгоритм работы команды показан на рисунке ниже.
Источник
rxmm/m128
Приемник
rxmm
cvtpd2dq приемник, источник
Приемник
rxmm
; Преобразование floatk>intj
i------------------i--1
!
___________________ у у
1000000001000000001 и1 I иО I
127 64 63г\3231/1 О
Целые
В случае когда не удается выполнить точное преобразование, значение округля-
ется в соответствии с полем MXCSR.RC. Если преобразованный результат больше
чем максимально возможное целочисленное 32-битное значение, то возвращает-
ся значение 80000000b.
П1.5. Команды блока ХММ (SSE2)
423
Исключения: SIMD (NE): #1, #Р; PM: #GP(0): 37, 42; #NM: 3; #PF(fault-code);
#SS(0): 13; #UD: 10-12, 15; #XM; RM: #GP: 13, 16; #NM: 3; #UD: 17, 18, 19, 22;
#XM; VM: исключения реального режима; #PF(fault-code).
CVTPD2PI приемник, источник
CVTPD2PI (ConVerT Packed Double-precision floating-point values to Packed
doubleword Integers) — преобразование двух упакованных значений с плавающей
точкой двойной точности в два упакованных 32-битных целых.
Синтаксис: CVTPD2PI rmmx, rxmm/m128
Машинный код: 66 OF 2D /г
Действие: алгоритм работы команды показан на рисунке ниже.
Источник
rxmm/m128
Приемник
rmmx
cvtpd2pi приемник, источник
Приемник
rmmx
Вещественные
и1 | иО
Целые
В случае когда не удается выполнить точное преобразование, значение округля-
ется в соответствии с полем MXCSR.RC. Если преобразованный результат больше
чем максимально возможное целочисленное 32-битное значение, то возвращает-
ся значение 80000000b.
Исключения: SIMD (NE): #1, #Р; PM: #GP(0): 37,42; #SS(0): 13; #PF(fault-code);
#MF; #NM: 3; #XM; #UD: 10, 11, 12, 15; RM: #GP: 13, 16; #NM: 3; #MF; #XM;
#UD: 17—19, 22; VM: исключения реального режима; #PF(fault-code).
CVTPD2PS приемник, источник
CVTPD2PS (CoVerT Packed Double-precision floating-point values to Packed Single-
precision floating-point values) — преобразование двух упакованных значений с пла-
вающей точкой двойной точности в два упакованных значения с плавающей точ-
кой одинарной точности.
Синтаксис: CVTPD2PS rxmml, rxmm2/m128
Машинный код: 66 OF 5А /г
424
Приложение 1. Команды процессоров х86
Действие: алгоритм работы команды показан на рисунке ниже.
В случае когда не удается выполнить точное преобразование, значение округляет-
ся в соответствии с полем MXCSR.RC.
Исключения: SIMD (NE): #О, #U, #1, #Р, #D; PM: #GP(0): 37, 42; #SS(0): 13;
#PF(fault-code); #NM: 3; #XM; #UD: 10-12, 15; RM: #GP: 13, 16; #NM: 3; #XM;
#UD: 17—19, 22; VM: исключения реального режима; #PF(fault-code).
CVTPI2PD приемник, источник
CVTPI2PD (ConVerT Packed doubleword Integers to Packed Double-precision
floating-point values) — преобразование двух упакованных 32-битных целых в два
упакованных значения с плавающей точкой двойной точности.
Синтаксис: CVTPI2PD rxmm, rmmx/m64
Машинный код: 66 OF 2А /г
Действие: алгоритм работы команды показан на рисунке ниже.
Вещественные
П1.5. Команды блока ХММ (SSE2)
425
Исключения: PM: #GP(0): 37; #SS(O): 13; #PF(fault-code); #NM: 3; #MF; #XM;
#UD: 10-12,15; #AC(0)_cpl3; RM: #GP: 13; #NM: 3; #MF; #XM; #UD: 17-19,22;
VM: исключения реального режима; #AC; #PF(fault-code); #AC(0)_u.
CVTPS2DQ приемник, источник
CVTPS2DQ (ConVerT Packed Single-precision floating-point values to packed Doub-
leword integers) — преобразование четырех упакованных значений с плавающей
точкой одинарной точности в четыре упакованных 32-битных целых со знаком.
Синтаксис: CVTPS2DQ rxmml, rxmm2/m128
Машинный код: 66 OF 5В /г
Действие: алгоритм работы команды показан на рисунке ниже.
В случае когда не удается выполнить точное преобразование, значение округля-
ется в соответствии с полем MXCSR.RC. Если преобразованный результат больше
чем максимально возможное целочисленное 32-битное значение, то возвращает-
ся значение 80000000b.
Исключения: SIMD (NE): #1, #Р; PM: #GP(0): 37,42; #SS(0): 13; #PF(fault-code);
#MF; #NM: 3; #XM; #UD: 10, 11, 12, 15; RM: #GP: 13, 16; #NM: 3; #MF; #XM;
#UD: 17—19, 22; VM: исключения реального режима; #PF(fault-code).
CVTPS2PD приемник, источник
CVTPS2PD (CoVerT Packed Single-precision floating-point values to Packed Double-
precision floating-point values) — преобразование двух упакованных значений с
плавающей точкой одинарной точности в два упакованных значения с плаваю-
щей точкой двойной точности.
Синтаксис: CVTPS2PD rxmml, rxmm2/m64
Машинный код: OF 5А /г
426
Приложение 1. Команды процессоров х86
Действие: алгоритм работы команды показан на рисунке ниже.
Источник
rxmm/m64
Приемник
rxmm
cvtps2pd приемник, источник
Приемник
rxmm
Вещественные (32 бита)
• | И1 | ИО |
~127’ 64 63 j 32 31 | О
п2 | п1 i ~|
"127 64 63 5 ’ О
И-** •
• Преобразование float32->float64;
Вещественные (64 бита)
Исключения: PM: #GP(0): 37; #SS(O): 13; #PF(fault-code); #NM: 3; #XM; #UD:
10-12,15; #AC(0)_cpl3; RM: #GP: 13; #NM: 3; #XM; #UD: 17-19,22; VM: исклю-
чения реального режима; #PF(fault-code); #AC(0)_u.
CVTSD2SI приемник, источник
CVTSD2SI (ConVerT Scalar Double-precision floating-point value to Doubleword
Integer) — преобразование скалярного значения с плавающей точкой двойной точ-
ности в 32-битное целое.
Синтаксис: CVTSD2SI r32, rxmm/m64
Машинный код: F2 OF 2D /г
Действие: алгоритм работы команды показан на рисунке ниже.
Источник
rxmm/m64
Приемник
г32
cvtsd2si приемник, источник
Приемник
г32
Вещественные (64 бита)
f и1 | иО |
’1’2'7’ 63 I О
I . .? 0........1
31 ! О
! Преобразование!
I float64->irit32 •
I----*---1
|____иО__I
31 | о
Вещественное
(32 бита)
В случае когда не удается выполнить точное преобразование, значение округля-
ется в соответствии с полем MXCSR.RC. Если преобразованный результат больше
П1.5. Команды блока ХММ (SSE2)
427
чем максимально возможное целочисленное 32-битное значение, то возвращает-
ся значение 80000000b.
Исключения: SIMD (NE): #1, #Р; PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O):
13; #UD: 10-12, 15; #XM; #AC(0)_cpl3; RM: #GP: 13; #NM: 3; #UD: 17-19, 22;
#XM; VM: исключения реального режима; #PF(fault-code); #AC(0)_u.
CVTSD2SS приемник, источник
CVTSD2SS (ConVerT Scalar Double-precision floating-point value to Scalar Single-
precision floating-point value) — преобразование скалярного значения с плаваю-
щей точкой двойной точности в скалярное значение с плавающей точкой одинар-
ной точности.
Синтаксис: CVTSD2SS rxmml, rxmm2/m64
Машинный код: F2 OF 5А /г
Действие: алгоритм работы команды показан на рисунке ниже.
Вещественные (64 бита)
Источник
rxmm/m64
Приемник
rxmm
cvtsd2ss приемник, источник
Приемник
rxmm
f и1 | иО |
Т27’ 63 . о
I n1 I по j I
127 63 | О
! Преобразование!
I _ ?Р?1?4->(1оа132_!
I..
J27 у /31~у °
Не изменяются Вещественное
(32 бита)
В случае когда не удается выполнить точное преобразование, значение округляется
в соответствии с полем MXCSR.RC.
Исключения: SIMD (NE): #О, #U, #1, #Р, #D; PM: #GP(0): 37; #NM: 3; #PF(fault-
code); #SS(0): 13; #UD: 10-12, 15; #XM; #AC(0)_cpl3; RM: #GP: 13; #NM: 3;
#XM; #UD: 17—19, 22; VM: исключения реального режима; #PF(fault-code);
#AC(0)_u.
CVTSI2SD приемник, источник
CVTSI2SD (ConVerT Signed doubleword Integer to Scalar Double-precision floating-
point value) — преобразование 32-битного целого значения со знаком в упакован-
ное значение с плавающей точкой двойной точности.
Синтаксис: CVTSI2SD rxmm, r/m32
428
Приложение 1. Команды процессоров х86
Машинный код: F2 OF 2А /г
Действие: алгоритм работы команды показан на рисунке ниже.
Источник
г32/т32
Приемник
rxmm
cvtsi2sd приемник, источник
Приемник
rxmm
Целое со знаком
I и1 —I
31 | о
[ I п0 | |
127 L_ Q
! Преобразование!
| п1 | и1 У |
127 J 63 О
Не изменяется Вещественное
(64 бита)
Исключения: PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10-12,
15; #XM; #AC(0)_cpl3; RM: #GP: 13; #NM: 3; #UD: 17-19, 22; #XM; VM: исклю-
чения реального режима; #AC(0)_u; #PF(fault-code).
CVTSS2SD приемник, источник
CVTSS2SD (ConVerT Scalar Single-Precision floating-point value to Scalar Double-
precision floating-point value) — преобразование скалярного значения с плавающей
точкой одинарной точности в скалярное значение с плавающей точкой двойной
точности.
Синтаксис: CVTSS2SD rxmml, rxmm2/m32
Машинный код: F3 OF 5А /г
Действие: алгоритм работы команды показан на рисунке ниже.
Источник
rxmm/m32
Приемник
rxmm
cvtss2sd приемник, источник
Вещественные (32 бита)
Приемник
rxmm
Не изменяется Вещественное
(64 бита)
П1.5. Команды блока ХММ (SSE2)
429
Исключения: PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(0): 13; #UD: 10—12,
15; #XM; #AC(0)_cpl3; RM; #GP: 13; #NM: 3; #UD: 17-19,22; #XM; VM: исклю-
чения реального режима; #AC(0)_u; #PF(fault-code).
CVTTPD2PI приемник, источник
CVTTPD2PI (ConVerT with Truncation Packed Double-precision floating-point
values to Packed doubleword Integers) — преобразование (путем отбрасывания
дробной части) двух упакованных значений с плавающей точкой двойной точно-
сти в два упакованных 32-битных целых значения.
Синтаксис: CVTTPD2PI rmmx, rxmm/m128
Машинный код: 66 OF 2С /г
Действие: алгоритм работы команды показан на рисунке ниже.
Если преобразованный результат больше чем максимально возможное целочис-
ленное 32-битное значение, то будет возвращено значение 80000000b.
Исключения: SIMD (NE): #I,#P; PM: #GP(0): 37, 42; #MF; #NM: 3; #PF(fault-
code); #SS(0): 13; #UD: 10-12, 15; #XM; RM: #GP: 13, 16; #MF; #NM: 3; #UD:
17—19, 22; #XM; VM: исключения реального режима; #PF(fault-code).
CVTTPD2DQ приемник, источник
CVTTPD2DQ (ConVerT with Truncation Packed Double-precision floating-point
values to packed Doubleword integers) — преобразование усечением двух упако-
ванных значений с плавающей точкой двойной точности в два упакованных 32-
битных целых.
Синтаксис: CVTTPD2DQ rxmml, rxmm2/m128
Машинный код: 66 OF Е6
Действие: алгоритм работы команды показан на рисунке ниже.
430
Приложение 1. Команды процессоров х86
Источник
rxmm/m128
Приемник
rxmm
cvttpd2dq приемник, источник J Отбросить дробную часть значения •
___
Приемник Г booooobbboooooob’ f ” nl” Т ”иЬ'''!
rxmm ----------------------
127 63 \32 31/7 О
Целые
В случае когда не удается выполнить точное преобразование, значение округляется в
сторону нуля. Если преобразованный результат больше чем максимально возмож-
ное целочисленное 32-битное значение, то возвращается значение 80000000b.
Исключения: SIMD (NE): #1, #Р; PM: #GP(0): 37, 42; #NM: 3; #PF(fault-code);
#SS(O): 13; #UD: 10-12,15; #XM; RM: #GP: 13,16; #NM: 3; #UD: 17-19, 22; #XM;
VM: исключения реального режима; #PF(fault-code).
CVTTPS2DQ приемник, источник
CVTTPS2DQ (ConVerT with Truncation Packed Single-precision floating-point values
to packed Doubleword integers) — преобразование (путем отбрасывания дробной
части) четырех упакованных значений с плавающей точкой одинарной точности
в четыре упакованных 32-битных целых со знаком.
Синтаксис: CVTTPS2DQ rxmml, rxmm2/m128
Машинный код: F3 OF 5В /г
Действие: алгоритм работы команды показан на рисунке ниже.
Целые со знаком
П1.5. Команды блока ХММ (SSE2)
431
В случае когда не удается выполнить точное преобразование, значение округляется в
сторону нуля. Если преобразованный результат больше чем максимально возмож-
ное целочисленное 32-битное значение, то будет возвращено значение 80000000b.
Исключения: SIMD (NE): #1, #Р; PM: #GP(0): 37, 42; #NM: 3; #PF(fault-code);
#SS(0): 13; #UD: 10-12,15; #XM; RM: #GP: 13,16; #NM: 3; #UD: 17-19,22; #XM;
VM: исключения реального режима; #PF(fault-code).
CVTTSD2SI приемник, источник
CVTTSD2SI (ConVerT with Truncation Scalar Double-precision floating-point
value to Signed doubleword Integer) — преобразование (путем отбрасывания дроб-
ной части) скалярного значения с плавающей точкой двойной точности в 32-бит-
ное целое.
Синтаксис: CVTTSD2SI r32, rxmm/m64
Машинный код: F2 OF 2С /г
Действие: алгоритм работы команды показан на рисунке ниже.
cvttsd2si приемник, источник
Источник
rxmm/m64
Приемник
г32
Вещественные (64 бита)
Приемник
г32
I *1 I
Целое
В случае когда не удается выполнить точное преобразование, значение округляется в
сторону нуля. Если преобразованный результат больше чем максимально возмож-
ное целочисленное 32-битное значение, то будет возвращено значение 8000000011.
Исключения: SIMD (NE): #I,#P; PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(0):
13; #UD: 10-12, 15; #XM; #ДС(0)_ср13; RM: #GP: 13; #NM: 3; #UD: 17-19, 22;
#XM; VM: исключения реального режима; #AC(0)_u; #PF(fault-code).
DIVPD приемник, источник
DIVPD (DIVide Packed Double-precision floating-point values) — деление упако-
ванных значений с плавающей точкой двойной точности.
Синтаксис: DIVPD xmm1, xmm2/m128
Машинный код: 66 OF 5Е /г
432
Приложение 1. Команды процессоров х86
Действие: разделить пары упакованных значений с плавающей точкой двойной
точности источника и приемника по схеме: приемник[ЪЗ-$\<г-приемник\&3-0] / ис-
точник[63-0]; приемник[127-64]<г-приемник[\27-64] / источник[\27-№\.
Исключения: SIMD (NE): #0, #U, #1, #Z, #P, #D; PM: #GP(O): 37,42; #SS(O): 13;
#PF(fault-code); #NM: 3; #UD: 10-12, 15; #XM; RM: #GP: 13, 16; #NM: 3; #UD:
17—19, 22; #XM; VM: исключения реального режима; #PF(fault-code).
DIVSD приемник, источник
DIVSD (DIVide Scalar Double-Precision Floating-Point Values) — деление скаляр-
ных упакованных значений с плавающей точкой двойной точности.
Синтаксис: DIVSD rxmml, rxmm2/m64
Машинный код: F2 OF 5Е /г
Действие: разделить младшие упакованные значения с плавающей точкой двой-
ной точности источника и приемника по схеме: приемник[&3-^]<г-приемник\&3-Щ /
источник[ЪЗ-$у, приемник[127-64] — не изменяется.
Исключения: SIMD (NE): #0, #U, #Z, #1, #P, #D; PM: #GP(O): 37; #NM: 3;
#PF(fault-code); #SS(O): 13; #UD: 10-12, 15; #XM; #AC(0)_cpl3; RM: #GP: 13;
#NM: 3; #UD: 17—19, 22; #XM; VM: исключения реального режима; #PF(fault-
code), #AC(0)_u.
LFENCE адрес.байта
LFENCE (Load FENCE) — упорядочить операции загрузки.
Синтаксис: LFENCE
Машинный код: OF AE /5
Действие: выполнить упорядочивание исполнения команд загрузки из памяти,
которые были инициированы перед этой командой LFENCE. Эта операция гаранти-
рует, что каждая команда загрузки, за которой следует в программе команда LFENCE,
глобально видима перед любой другой командой загрузки, за которой следует
команда LFENCE. Команда LFENCE упорядочивается относительно команд загруз-
ки, других команд LFENCE, MFENCE и любых команд упорядочивания {сериализа-
ции, типа команды CPUID). Она не упорядочивается относительно команд сохра-
нения в памяти или команды SFENCE.
Исключения: отсутствуют.
MASKMOVDQU источник, маска
MASKMOVDQU (Store Selected Bytes of Double Quadword) — выборочная запись
байт из источника в память с использованием байтовой маски в приемнике.
Синтаксис: 66 OF F7 /г
Машинный код: MASKMOVDQU rxmml, rxmm2
Действие: сохранить выбранные байты операнда источник в 128-разрядную ячей-
ку памяти. Операнд маска определяет байты источника, которые сохраняются в
П1.5. Команды блока ХММ (SSE2)
433
памяти. Местоположение первого байта ячейки памяти приемника, в которую со-
храняются байты, определяются парой DS:DI/EDI. Старший значащий бит каждо-
го байта операнда маска определяет, будет ли сохранен в приемнике соответству-
ющий байт источника: 0 — байт не сохраняется; 1 — байт сохраняется. Команда
MASKMOVEDQU генерирует указание процессору не использовать кэш. Это указание
реализуется посредством метода кэширования WC (Write Combining — память с
комбинированной записью). При этом операции упорядочивания, осуществляе-
мые командами SFENCE или MFENCE, необходимо использовать совместно с ко-
мандами MASKMOVEDQU. Для многопроцессорной конфигурации это особенно
важно, так как различным процессорам могут требоваться различные типы памя-
ти для чтения/записи ячейки приемника.
Исключения: PM: #GP(0): 37 (в том числе при нулевой маске); #NM: 3; #PF(fault-
code); #SS(0): 13 (в том числе при нулевой маске); #UD: 10, 12, 15; RM: #GP: 13
(в том числе при нулевой маске); #NM: 3; #UD: 17,19,22; VM: исключения реаль-
ного режима; #PF(fault-code).
MAXPD приемник, источник
MAXPD (return MAXimum Packed Double-precision floating-point values) — воз-
врат максимальных упакованных значений с плавающей точкой двойной точности.
Синтаксис: MAXPD rxmml, rxmm2/m128
Машинный код: 66 OF 5F /г
Действие: сравнить упакованные значения с плавающей точкой двойной точности
в источнике и приемнике и заместить максимальными из них соответствующие
упакованные значения в приемнике. Если значение в источнике — SNAN (не QNAN),
то оно помещается в приемник. Если только одно значение в приемнике или ис-
точнике — не число NaN (SNaN или QNAN), то в приемник помещается содержи-
мое источника, которое может быть либо NAN, либо правильным значением чис-
ла с плавающей точкой.
Исключения: SIMD (NE): #1 (в том числе, если источник = QNaN), #D; PM:
#GP(0): 37, 42; #SS(0): 1;#NM: 3; #PF(fault-code); #UD: 10-12, 15; #XM; RM:
#GP: 13, 16; #NM: 3; #UD: 17—19, 22; #XM; VM: исключения реального режима;
#PF(fault-code).
MAXSD приемник, источник
MAXSD (return MAXimum Scalar Double-precision floating-point value) — возврат
максимального скалярного значения с плавающей точкой двойной точности.
Синтаксис: MAXSD rxmml, rxmm2/m64
Машинный код: F2 OF 5F /г
Действие: сравнить значения с плавающей точкой двойной точности в разрядах
[63-0] источника и приемника и заместить максимальным из них значение в раз-
рядах [63-0] приемника. Если значение в источнике — SNAN (не QNAN), то оно
помещается в приемник. Если только одно значение в приемнике или источнике —
434
Приложение 1. Команды процессоров х86
не число NaN (SNaN или QNAN), то в приемник помещается содержимое источ-
ника, которое может быть либо NAN, либо правильным значением числа с плава-
ющей точкой. Значение в разрядах [127-64] приемника не изменяется.
Исключения: SIMD (NE): #1 (в том числе, если источник = QNaN), #D; PM:
#GP(0): 37; #SS(O): 1; #NM: 3; #PF(fault-code); #UD: 10-12, 15; #XM; #AC(0)_
cp!3; RM: #GP: 13; #NM: 3; #UD: 17—19, 22; #XM; VM: исключения реального
режима; #PF(fault-code); #AC(0)_u.
MFENCE
MFENCE (Memory FENCE) — упорядочить операции загрузки и сохранения.
Синтаксис: MFENCE
Машинный код: OF АЕ /6
Действие: выполнить упорядочивание команд загрузки из памяти и сохранения в
памяти, которые были инициированы перед этой командой MFENCE. Эта операция
гарантирует, что каждая команда загрузки и сохранения, за которой следует в про-
грамме команда MFENCE, глобально видима перед любой другой командой загрузки
и сохранения, за которой следует команда MFENCE. Команда MFENCE упорядочива-
ется относительно команд загрузки и сохранения, других команд LFENCE, MFENCE,
SFENCE и любых команд упорядочивания (сериализации, типа команды CPLIID).
Исключения: отсутствуют.
MINPD приемник, источник
MINPD (return MINimum Packed Double-precision floating-point values) — возврат
минимальных упакованных значений с плавающей точкой двойной точности.
Синтаксис: MINPD xmm1, xmm2/m128
Машинный код: 66 OF 5D /г
Действие: сравнить упакованные значения с плавающей точкой двойной точнос-
ти в источнике и приемнике и заместить минимальными из них соответствующие
упакованные значения в приемнике. Если значение в источнике — SNAN (не QNAN),
то оно помещается в приемник. Если только одно значение в приемнике или ис-
точнике — не число NaN (SNaN или QNAN), то в приемник помещается содержи-
мое источника, которое может быть либо NAN, либо правильным значением чис-
ла с плавающей точкой.
Исключения: SIMD (NE): #1 (в том числе, если источник = QNaN), #D; PM:
#GP(0): 37, 42; #SS(O): 1; #NM: 3; #PF(fault-code); #UD: 10-12, 15; #XM; RM:
#GP: 13, 16; #NM: 3; #UD: 17—19, 22; #XM; VM: исключения реального режима;
#PF(fault-code).
MINSD приемник, источник
MINSD (return MINimum Scalar Double-precision floating-point value) — возврат
минимального скалярного значения с плавающей точкой двойной точности.
П1.5. Команды блока ХММ (SSE2)
435
Синтаксис: MINSD xmm1, xmm2/m64
Машинный код: F2 OF 5D /г
Действие: сравнить значения с плавающей точкой двойной точности в разрядах
[63-0] источника и приемника и заместить минимальным из них значение в разря-
дах [63-0] приемника. Если значение в источнике — SNAN (не QNAN), то оно по-
мещается в приемник. Если только одно значение в приемнике или источнике — не
число NaN (SNaN или QNAN), то в приемник помещается содержимое источника,
которое может быть либо NAN, либо правильным значением числа с плавающей
точкой. Значение в разрядах [127-64] приемника не изменяется.
Исключения: SIMD (NE): #1 (в том числе, если источник = QNaN), #D; PM:
#GP(0): 37; #SS(O): 1; #NM: 3; #PF(fault-code); #UD: 10-12, 15; #XM; #AC(0)_
cpl3; RM: #GP: 13; #NM: 3; #UD: 17—19, 22; #XM; VM: исключения реального
режима; #PF(fault-code); #AC(0)_u.
MOVAPD приемник, источник
MOVAPD (MOVe Aligned Packed Double-precision floating-point values) — пере-
мещение упакованных выровненных значений с плавающей точкой двойной точ-
ности.
Синтаксис и машинный код:
OF 28 /г MOVAPS xmm1, xmm2/m128
OF 29 /г MOVAPS xmm2/m128, xmml
Действие: переместить два двойных учетверенных слова (содержащих два упако-
ванных значения с плавающей точкой двойной точности) из источника в прием-
ник. Операнд в памяти должен быть выровнен на 16-байтовой границе.
Исключения: PM: #GP(0): 37,42; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10-12,
15; #XM; RM: #GP: 13,16; #NM: 3; #UD: 17—19,22; #XM; VM: исключения реаль-
ного режима; #PF(fault-code).
MOVD приемник, источник
MOVD (Move Double word) — перемещение двойного слова между ХММ-регист-
ром и 32-разрядным регистром (ячейкой памяти).
Синтаксис и машинный код:
66 OF 6Е /г MOVD rxmm, r/m32
66 OF 7E /г MOVD r/m32, rxmm
Действие:
♦ Если приемник является ХММ-регистром, поместить в биты 0-31 приемника
значение источника; поместить в биты 32-127 приемника нулевое значение.
♦ Если приемник является 32-разрядной ячейкой памяти или регистром общего
назначения, то поместить в приемник значение бит 0-31 источника (ХММ-ре-
гистра).
436
Приложение 1. Команды процессоров х86
Флаги: не изменяются.
Исключения: PM: #GP(0): 1,2; #MF; #PF(fault-code); #SS(O): 1; #UD: 10,12,15;
#NM 3; #AC(0)_cpl3; RM: #GP: 13; #MF; #NM: 3; #UD: 17,19,22; VM: #PF(fault-
code); #AC(0)_u.
MOVDQA приемник, источник
MOVDQA (MOVe Aligned Double Quadword) — перемещение выровненных 128
бит из источника в приемник.
Синтаксис и машинный код:
66 OF 6F/г MOVDQA rxmml, rxmm2/m128
66 OF 7F /г MOVDQA rxmm2/m128, rxmml
Действие: переместить содержимое источника в приемник. Операнд в памяти дол-
жен быть выровнен на 16-байтовой границе.
Исключения: PM: #GP(0): 2,42; #NM: 3; #SS(O): 1; RM: #GP: 13,16; #NM: 3; #UD:
17, 19, 22; #PF(fault-code); VM: исключения реального режима; #PF(fault-code).
MOVDQU приемник, источник
MOVDQU (MOVe Unaligned Double Quadword description) — перемещение не-
выровненных 128 бит из источника в приемник.
Синтаксис и машинный код:
F3 OF 6F /г MOVDQU xmm1, xmm2/m128
F3 OF 7F/r MOVDQU xmm2/m128, xmm1
Действие: переместить содержимое источника в приемник.
Исключения: PM: #GP(0): 2; #NM: 3; #PF(fault-code); #SS(O): 1; #UD: 10,12,15; RM:
#GP: 13; #NM: 3; #UD: 17,19,22; VM: исключения реального режима; #PF(fault-code).
MOVDQ2Q приемник, источник
MOVDQ2Q (MOVe Quadword from ХММ to MMX register description) — переме-
щение младшего учетверенного слова ХММ-регистра в ММХ-регистр.
Синтаксис: MOVDQ2Q mm, xmm
Машинный код: F2 OF D6
Действие: переместить содержимое источника в приемник по схеме: приемник <-
источник\&5-§].
Исключения: PM: #NM: 3; #UD: 10, 12,15; #MF; RM: исключения защищенного
режима; VM: исключения защищенного режима.
MOVHPD приемник, источник
MOVHPD (MOVe High Packed Double-precision floating-point value) — переме-
щение старшего упакованного значения с плавающей точкой двойной точности.
П1.5. Команды блока ХММ (SSE2)
437
Синтаксис и машинный код:
66 OF 16 /г MOVHPD rxmm, m64
66 OF 17 /г MOVHPD т64, rxmm
Действие: переместить учетверенное слово (содержащее упакованное значение с
плавающей точкой двойной точности) из источника в приемник. Источник и при-
емник могут быть либо ХММ-регистром, либо 64-разрядной ячейкой памяти (но
не одновременно). Для регистрового операнда перемещению подвергается стар-
шее учетверенное слово (разряды [64-127]). Младшее учетверенное слово ХММ-
регистра (разряды [0-63]) не изменяется.
Исключения: PM: #GP(0): 37; #NM: 3; #: F(fault-codc); #SS(0): 13; #UD: 10, 13,
19; #AC(0)_cpl3; RM: #GP: 13; #NM: 3; #UD: 12,13,17; VM: исключения реально-
го режима; #PF(fault-code); #AC(0)_u.
MOVLPD приемник, источник
MOVLPD (MOVe Low Packed Double-precision floating-point value) — перемеще-
ние младшего упакованного значения с плавающей точкой двойной точности.
Синтаксис и машинный код:
66 OF 12 /г MOVLPD rxmm, m64
66 OF 13 /г MOVLPD т64, rxmm
Действие: переместить учетверенное слово (содержащее упакованное значение с
плавающей точкой двойной точности) из источника в приемник. Источник и при-
емник могут быть либо ХММ-регпстром, либо 64-разрядной ячейкой памяти (но
не одновременно). Для регистрового операнда перемещению подвергается млад-
шее учетверенное слово (разряды [0-63]). Старшее учетверенное слово ХММ-ре-
гистра (разряды [64-127]) не изменяется.
Исключения: PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(0): 13; #UD: 10, 12,
13; #AC(0)_cpl3; RM: #GP: 13; #NM:'3;#UD: 17,19,20; VM: исключения реально-
го режима; #PF(fault-code); #AC(0)_u.
MOVMSKPD приемник, источник
MOVMSKPD (extract Packed Double-precision floating-point sign MaSK) — из-
влечение 2-битной знаковой маски упакованных значений с плавающей точкой
двойной точности.
Синтаксис: MOVMSKPD r32, rxmm
Машинный код: 66 OF 50 /г
Действие: извлечь знаковые разряды из упакованных значений с плавающей точ-
кой двойной точности операнда источник (ХММ-регистр) и сохранить получен-
ную знаковую маску в двух младших битах операнда приемник (32-битный общий
регистр).
Исключения: PM: #NM: 3; #ХМ; #UD: 10—12,15; RM: исключения защищенного
режима; VM: исключения защищенного режима.
438
Приложение 1. Команды процессоров х86
MOVNTDQ приемник, источник
MOVNTDQ (store Double Quadword using Non-Temporal hint description) — сохра-
нение двойного учетверенного слова из ХММ-регистра в память без использова-
ния кэша.
Синтаксис: 66 OF Е7 /г
Машинный код: MOVNTDQ m128, rxmm
Исключения: PM: #GP(0): 37, 42; #NM: 3; #PF(fault-code); #SS(0): 13; #UD: 10,
12,15; RM: #GP: 13,16; #NM: 3; #UD: 17,19,22; VM: исключения реального режи-
ма; #PF(fault-code).
MOVNTI приемник, источник
MOVNTI (store doubleword using Non-Temporal hint description) — сохранение
двойного слова из 32-разрядного регистра общего назначения в память без исполь-
зования кэша.
Синтаксис: OF СЗ /г
Машинный код: MOVNTI m32, г32
Исключения: PM: #GP(0): 37; #PF(fault-code); #SS(0): 13; #UD: 15; RM: #GP: 13,
16; #NM: 3; #UD: 22; VM: исключения реального режима; #PF(fault-code).
MOVNTPD приемник, источник
MOVNTPD (store Packed Double-Precision floating-point values using Non-Temporal
hint) — сохранение упакованных значений с плавающей точкой двойной точнос-
ти из ХММ-регистра в память без использования кэша.
Синтаксис: 66 OF 2В /г
Машинный код: MOVNTPD m128, rxmm
Исключения: PM: #GP(0): 37, 42; #NM: 3; #PF(fault-code); #SS(0): 13; #UD: 10,
12,15; RM: #GP: 13,16; #NM: 3; #UD: 17,19,22; VM: исключения реального режи-
ма; #PF(fault-code).
MOVQ приемник, источник
MOVQ (Move Quadword) — переместить учетверенное слово.
Синтаксис и машинный код:
F3 OF 7Е MOVQ rxmml, rxmm2/m64
66 OF D6 MOVQ rxmm2/m64, rxmml
Действие:
♦ Если приемник и источник являются ХММ-регистрами, то изменить содержи-
мое приемника следующим образом: приемник[&5-Ъ]<г-источник[&3-0]*, разряды
приемник[ 127-64] не изменяются.
П1.5. Команды блока ХММ (SSE2)
439
♦ Если приемник — 64-разрядная ячейка памяти, то изменить содержимое при-
емника следующим образом: приемник[63-0]<г-источник[63-0].
♦ Если источник — 64-разрядная ячейка памяти, то изменить содержимое при-
емника следующим образом: приемник[63-0]<г-источник[63-0]; приемник[63-
0]^-0000000000000000Н.
Флаги: не изменяются.
Исключения: PM: #GP(0): 1,2; #SS(O): 1; #UD: 10,12,15; #NM: 3; #MF; #PF(fault-
code); #AC(0)_cpl3; RM: #GP: 13; #MF; #NM: 3; #UD: 17,19,22; VM: исключения
реального режима; #PF(fault-code); #AC(0)_u.
MOVQ2DQ приемник, источник
MOVQ2DQ (MOVe Quadword from MMX to XMM register description) — пере-
мещение учетверенного слова из MMX-регистра в младшее учетверенное слово
ХММ-регистра.
Синтаксис: MOVQ2DQ rxmm, rmmx
Машинный код: F3 OF D6
Действие: переместить содержимое источника в приемник по схеме: приемник[&3-
0] <— источник; приемник[\Т1 -64] <— 00000000000000000b.
Исключения: PM: #NM: 3; #UD: 10, 12, 15; #MF; RM: исключения защищенного
режима; VM: исключения защищенного режима.
MOVSD приемник, источник
MOVSD (MOVe Scalar Double-precision floating-point value) — перемещение ска-
лярного значения с плавающей точкой двойной точности.
Синтаксис и машинный код:
F2 OF 10 /г MOVSD rxmml, rxmm2/m64
F2 OF 11 /г MOVSD rxmm2/m64, rxmml
Действие: переместить скалярное значение с плавающей точкой двойной точнос-
ти из разрядов [0-63] источника в разряды [0-63] приемника. Если операнды —
XMM-регистры, то разряды [64-127] приемника не изменяются. Если источник —
ячейка памяти, то разряды [64-127] приемника обнуляются.
Исключения: PM: #GP(0): 37; #SS(O): 13; #PF(fault-code); #NM: 3; #XM; #UD:
10-12,15; #AC(0)_cpl3; RM: #GP: 13; #NM: 3; #UD: 17-19,22; #XM; VM: исклю-
чения реального режима; #PF(fault-code); #AC(0)_u.
MOVUPD приемник, источник
MOVUPD (MOVe Unaligned Packed Double-precision floating-point values) — пе-
ремещение невыровненных упакованных значений с плавающей точкой двойной
точности.
440
Приложение 1. Команды процессоров х86
Синтаксис и машинный код:
66 OF 10 /г MOVUPD xmm 1, xmm2/m 128
66 OF 11 /г MOVUPD xmm2/m128, xmm1
Действие: переместить два двойных учетверенных слова (содержащих два упако-
ванных значения с плавающей точкой двойной точности) из источника в прием-
ник, Не требуется выравнивания операнда в памяти на 16-байтовой границе.
Исключения: PM: #GP(0): 37; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10—12,
15; #XM; RM: #GP: 13; #NM: 3; #UD: 17—19,22; #XM; VM: исключения реального
режима; #PF(fault-code).
MULPD приемник, источник
MULPD (MULtiply Packed Double-precision floating-point values) — умножение
упакованных значений с плавающей точкой двойной точности.
Синтаксис: MULPD rxmml, rxmm2/m128
Машинный код: 66 OF 59 /г
Действие: умножить пары упакованных значений с плавающей точкой двойной
точности источника и приемника по схеме: приемник[6)5-Ъ]<г-приемник\63-$\ х ис-
точник[&3-Щ\ приемник[\21 -64]<—ирмел/нмк[127-64] х источнику 127-64].
Исключения: SIMD (NE): #0, #U, #1, #Р, #D; PM: #GP(0): 37, 42; #SS(O): 13;
#NM: 3; #PF(fault-code); #UD: 10-12, 15; #XM; RM: #GP: 13, 16; #NM: 3; #UD:
17—19, 22; #XM; VM: исключения реального режима; #PF(fault-code).
MULSD приемник, источник
MULSD (MULtiply Scalar Double-precision floating-point values) — умножение
скалярных упакованных значений с плавающей точкой двойной точности.
Синтаксис: MULSD rxmml, rxmm2/m64
Машинный код: F2 OF 59 /г
Действие: умножить младшие упакованные значения с плавающей точкой двой-
ной точности источника и приемника по схеме: приемник[$5-$\<г-приемник\&5-§\ х
источник[$5-Ъ]\ приемник[121 -64] — не изменяется.
Исключения: SIMD (NE): #0, #U, #1, #Р, #D; PM: #GP(0): 37; #SS(O): 13; #NM: 3;
#PF(fault-code); #UD: 10-12, 15; #XM; #AC(0)_cpl3; RM: #GP: 13; #NM: 3;
#UD: 17—19, 22; #XM; VM: исключения реального режима; #PF(fault-code);
#AC(0)_u.
ORPD приемник, источник
ORPD (bitwise logical OR of Double-precision floating-point values) — поразрядное
логическое ИЛИ над упакованными значениями с плавающей точкой двойной
точности.
Синтаксис: ORPD xmm1, xmm2/m128
П1.5. Команды блока ХММ (SSE2)
441
Машинный код: 66 OF 56 /г
Действие: выполнить операцию поразрядного логического ИЛИ над парами
упакованных значений с плавающей точкой двойной точности в приемнике и
источнике по схеме: приемник[\21приемник[\21-Q]) побитное_ОИ мстиоч-
ник[ 127-0].
Исключения: PM: #GP(0): 37,42; #NM: 3; #PF(fault-code); #SS(O): 13; #UD: 10-12,
15; #XM; RM: #GP: 13,16; #NM: 3; #UD: 17-19,22; #XM; VM: исключения реаль-
ного режима; #PF(fault-code).
PACKSSWB/PACKSSDW приемник, источник
PACKSSWB (Pack with Signed Saturation Words to Bytes) — упаковка co знако-
вым насыщением слов в байты. PACKSSDW (Pack with Signed Saturation Double
Words to Words) — упаковка co знаковым насыщением двойных слов в слова.
Синтаксис и машинный код:
66 OF 63 /г PACKSSWB rxmml, rxmm2/m128
66 OF 6B /г PACKSSDW rxmml, rxmm2/m128
Pack sswb приемники, источники
Источники Приемники (ХММ-регистр)
Источники Приемники (ХММ-регистр)
442
Приложение 1. Команды процессоров х86
Действие: команды преобразуют шестнадцать/восемь элементов размером в сло-
во/двойное слово из источника и приемника в шестнадцать/восемь элементов в
операнде приемник размером в байт/слово (см. рисунок ниже). Если значение эле-
мента источника превышает допустимое значения элемента приемника, то в элемен-
те приемника формируется предельный результат в соответствии с принципом
знакового насыщения:
♦ PACKSSWB — 07fh для положительных чисел и 080h для отрицательных;
♦ PACKSSDW — 07fffh для положительных чисел и 08000h для отрицательных.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fauIt-code).
PACKUSWB приемник, источник
PACKUSWB (PACK with Unsigned Saturation Description) — упаковка с беззна-
ковым насыщением слов в байты.
Синтаксис: PACKUSWB rxmml, rxmm2/m128
Машинный код: 66 OF 67 /г
Действие: команда преобразует шестнадцать элементов из источника и приемни-
ка размером в слово в шестнадцать элементов в приемнике размером в байт (см.
рисунок ниже). Если пересылаемое значение больше допустимого для поля при-
емника, то в нем формируется предельный результат в соответствии с принципом
беззнакового насыщения, что соответствует значениям Offh для положительных
чисел и 00h для отрицательных.
Pack sswb приемники, источники
Источники Приемники (ХММ-регистр)
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
П1.5. Команды блока ХММ (SSE2)
443
PADDB/PADDW/PADDD приемник, источник
PADDB (Packed ADDition Bytes) — сложение упакованных байт. PADDW (Packed
ADDition Words) — сложение упакованных слов. PADDD (Packed ADDition
Double words) — сложение упакованных двойных слов.
Синтаксис и машинный код:
66 OF FC /г PADDB rxmm 1,rxmm2/m 128
66 OF FD /r PADDW rxmml, rxmm2/m128
66 OF FE /r PADDD rxmml, rxmm2/m128
Действие: команда в зависимости от кода операции складывает соответствую-
щие элементы операндов источника и приемника размером байт/слово/двойное
слово. При возникновении переполнения результат формируется в соответствии
с принципом циклического переполнения и помещается в операнд приемник.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(O): 1; #UD: 10,12,15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
PADDQ приемник, источник
PADDQ (ADD Packed Quadword integers description) — сложение учетверенных
слов.
Синтаксис и машинный код:
OF D4 /г PADDQ rmmxl ,rmmx2/m64
66 OF D4 /г PADDQ rxmml ,rxmm2/m 128
Действие: сложить 64-битные целые значения в источнике и приемнике. Исходя
из типа источника, возможны две схемы умножения:
< источник — ММХ-регистр или ячейка памяти т64: приемник[ЪЗ-$\<г-прием-
нмк[63-0] + источник[&3-Щ\ приемник — ММХ-регистр;
♦ источник — XMM-регистр или ячейка памяти: приемник[^3^]<г-приемник[о3-^]
+ источник[&5-$\\ приемник[127-64]<г-приемник[Д27-64] + источнику 127-64].
В результате выполнения команды PADDQ регистр EFLAGS не отражает факта воз-
никновения ситуации переполнения или переноса. Когда результат умножения
слишком большой, чтобы быть представленным в 64-битном элементе приемника,
то он «заворачивается» (перенос игнорируется). Для обнаружения подобных си-
туаций программное обеспечение должно использовать другие методы.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2,42; #SS(O): 1; #UD: 10,12,15; #NM: 3; #PF(fault-code);
RM: #GP: 13, 16; #UD: 17, 19, 22; #NM: 3; VM: исключения реального режима;
#PF(fault-code).
444
Приложение 1. Команды процессоров х86
PADDSB/PADDSW приемник, источник
PADDSB (Packed ADDition signed Bytes with Saturation) — сложение упакован-
ных байт co знаковым насыщением. PADDSW (Packed ADDition signed Words with
Saturation) — сложение упакованных слов co знаковым насыщением.
Синтаксис и машинный код:
66 OF ЕС /г PADDSB rxmml, rxmm2/m128
66 OF ED /г PADDSW rxmml, rxmm2/m128
Действие: команда в зависимости от кода операции складывает соответствую-
щие элементы операндов источника и приемника размером байт/слово с учетом
знака. При возникновении переполнения результат формируется в соответствии
с принципом знакового насыщения:
♦ PADDSB — 07fh для положительных чисел и 080h для отрицательных;
♦ PADDSW — 07fffh для положительных чисел и 08000h для отрицательных.
Результат помещается в операнд приемник.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
PADDUSB/PADDUSW приемник, источник
PADDUSB (Packed ADDition unsigned Bytes with Unsigned Saturation) — сложе-
ние упакованных байт с беззнаковым насыщением. PADDUSW (Packed ADDition
unsigned Words with Unsigned Saturation) — сложение упакованных слов с беззна-
ковым насыщением.
Синтаксис и машинный код:
66 OF DC /г PADDUSB rxmml, rxmm2/m128
66 OF DD /r PADDUSW rxmml, rxmm2/m128
Действие: команда в зависимости от кода операции складывает без учета знака
соответствующие элементы операндов источника и приемника размером байт/
слово. При возникновении переполнения результат формируется в приемнике в
соответствии с принципом беззнакового насыщения:
♦ PADDUSB — Offh и 00h для результатов сложения соответственно больших
или меньших максимально/минимально представимых значений в беззнако-
вом байте;
♦ PADDUSW — Offffh и OOOOh для результатов сложения соответственно больших
или меньших максимально/минимально представимых значений в беззнако-
вом слове.
Результат помещается в операнд приемник.
П1.5. Команды блока ХММ (SSE2)
445
Флаги: не изменяются.
Исключения: PM: #GP(0): 2,42; #SS(0): 1; #UD: 10,12,15; #NM: 3; #PF(fault-code);
RM: #GP: 13, 16; #UD: 17, 19, 22; #NM: 3; VM: исключения реального режима;
#PF(fault-code).
PAND приемник, источник
PAND (Packed logical AND) — упакованное логическое И.
Синтаксис: PAND rxmml, rxmm2/m128
Машинный код: 66 OF DB /г
Действие: команда выполняет побитовую операцию логическое И над всеми бита-
ми операндов источника и приемника. Результат помещается в операнд приемник.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
PANDN приемник, источник
PANDN (Packed logical AND Not) — упакованное логическое И-НЕ.
Синтаксис: PANDN rxmml, rxmm2/m128
Машинный код: 66 OF DF /г
Действие: команда выполняет побитовую операцию логическое И-НЕ над всеми
битами операндов источника и приемника. Результат помещается в операнд при-
емник.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
PAUSE
PAUSE (Spin Loop Hint) — улучшить выполнение цикла ожидания-занятости.
Синтаксис: PAUSE
Машинный код: F3 90
Действие: улучшить выполнение цикла ожидания-занятости (spin-wait loops). При
выполнении подобных циклов процессор Pentium 4 испытывает проблему при за-
вершении цикла, обнаруживая возможное нарушение доступа к памяти. Команда
PAUSE подсказывает процессору, что данная кодовая последовательность — цикл
ожидания-занятости. Процессор использует эту подсказку, чтобы игнорировать
возможную ситуацию нарушения доступа к памяти в большинстве случаев. Это
улучшает работу процессора вплоть до значительного снижения его энергопотреб-
446
Приложение 1. Команды процессоров х86
ления. По этой причине рекомендуется включать команду PAUSE во все циклы
ожидания-занятости.
Исключения: отсутствуют.
PAVGB/PAVGW приемник, источник
PAVGB/PAVGW (Packed Average) — упакованное среднее.
Синтаксис и машинный код:
66 OF ЕО, /г PAVGB rxmml, rxmm2/m128
66 OF ЕЗ /г PAVGW rxmml, rxmm2/m128
Действие: выполнить параллельное сложение байт/слов источника и приемника
и сдвинуть результат сложения на один разряд вправо (деление на 2).
Флаги: не изменяются.
Исключения: PM: #GP(0): 2,42; #SS(O): 1; #UD: 10,12,15; #NM: 3; #PF(fault-code);
RM: #GP: 13, 16; #UD: 17, 19, 22; #NM: 3; VM: исключения реального режима;
#PF(fauIt-code).
PCMPEQB/PCMPEQW/PCMPEQD
приемник, источник
PCMPEQB (Packed CoMPare for Equal Byte) — сравнение на равенство упакован-
ных байт. PCMPEQW (Packed CoMPare for Equal Word) — сравнение на равен-
ство упакованных слов. PCMPEQD (Packed CoMPare for Equal Double word) —
сравнение на равенство упакованных двойных слов.
Синтаксис и машинный код:
66 OF 74 /г PCMPEQB rxmml, rxmm2/m128
66 OF 75 /г PCMPEQW rxmml, rxmm2/m128
66 OF 76 /r PCMPEQD rxmml, rxmm2/m128
Действие: команды сравнивают на равенство элементы источника и приемника и
формируют элементы результата по следующему принципу:
♦ если элемент источника равен соответствующему элементу приемника, то эле-
мент результата в зависимости от применяемой команды устанавливается
равным одному из следующих значений: Offh, Offffh, Offffffffh;
♦ если элемент источника не равен соответствующему элементу приемника, то
элемент результата в зависимости от применяемой команды устанавливается
равным одному из следующих значений: 00h, OOOOh, OOOOOOOOh.
Результат помещается в операнд приемник.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF( fault-code).
П1.5. Команды блока ХММ (SSE2)
447
PCMPGTB/PCMPGTW/PCMPGTD
приемник, источник
PCMPGTB (Packed CoMPare for Greater Than Byte) — сравнение по условию
«больше чем» упакованных байт. PCMPGTW (Packed CoMPare for Greater Than
Word) — сравнение по условию «больше чем» упакованных слов. PCMPGTD
(Packed CoMPare for Greater Than Double word) — сравнение по условию «боль-
ше чем» упакованных двойных слов.
Синтаксис и машинный код:
66 OF 64 /г PCMPGTB rxmml, rxmm2/m128
66 OF 65 /г PCMPGTW rxmml, rxmm2/m128
66 OF 66 /r PCMPGTD rxmml, rxmm2/m128
Действие: команда производит сравнение по условию «больше чем» элементов
операндов источника и приемника и формирует элементы результата по следую-
щему принципу:
♦ если элемент приемника больше соответствующего элемента источника, то
элемент результата в зависимости от применяемой команды устанавливается
равным одному из следующих значений: Offh, Offffh, Offffffffh;
♦ если элемент приемника не больше соответствующего элемента источника, то
элемент результата в зависимости от применяемой команды устанавливается
равным одному из следующих значений: 00h, OOOOh, OOOOOOOOh.
Результат помещается в операнд приемник.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10,12,15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
PEXTRW приемник, источник, маска
PEXTRW (Extract Word) — извлечение 16-битного слова из XMM-регистра по
маске.
Синтаксис: PEXTRW r32, rxmm, imm8
Машинный код: 66 OF С5 /г i8
Действие: команда выделяет четыре младших бита непосредственного операнда
маска. Их значение определяет номер слова в операнде источник (ХММ-регистр).
Данное слово перемещается в младшие 16 бит операнда приемник, представляю-
щего собой 32-разрядный регистр общего назначения. Старшие 16 бит этого ре-
гистра обнуляются.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
448
Приложение 1. Команды процессоров х86
PINSRW приемник, источник, маска
PINSRW (Insert Word) — вставка 16-битного слова в регистр ММХ.
Синтаксис: PINSRW rxmm, r32/m16, imm8
Машинный код: 66 OF С4 /г i8
Действие: команда выделяет четыре младших бита непосредственного операнда
маска. Их значение определяет номер слова в операнде приемник, который пред-
ставляет собой ХММ-регистр. В это слово будут перемещены младшие 16 бит
операнда источник, который представляет собой 32-разрядный регистр общего
назначения или 16-битную ячейку памяти.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
PMADDWD приемник, источник
PMADDWD (Packed Multiply and ADD Word to Double word) — упакованное зна-
ковое умножение знаковых слов опер ,лдов источник и приемник с последующим
сложением промежуточных результатов в формате двойного слова.
Синтаксис: PMADDWD rxmml, rxmm2/m128
Машинный код: 66 OF F5 /г
Действие: работа команды аналогична команде PMADDWD, описанной в разделе
«Команды блока ММХ», за исключением того, что вместо MMX-регистров исполь-
зуются ХММ-регистры и разрядность операндов в памяти повышается до 128 бит.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
PMAXSW приемник, источник
PMAXSW (MAXimum of Packed Signed Word integers) — возврат максимальных
упакованных знаковых слов.
Синтаксис: PMAXSW rxmml, rxmm2/m128
Машинный код: 66 OF ЕЕ /г
Действие: команда определяет наибольшее слово для каждой пары упакованных
слов источника и приемника с учетом знака и заменяет им соответствующие слова
приемника.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
П1.5. Команды блока ХММ (SSE2)
449
PMAXUB приемник, источник
PMAXUB (MAXimum of Packed Unsigned Byte integers) — возврат максимальных
упакованных беззнаковых байт.
Синтаксис: PMAXUB rxmml, rxmm2/m128
Машинный код: 66 OF DE /г
Действие: для каждой пары байтовых элементов источника и приемника опреде-
лить наибольший без учета знака и заменить им соответствующий элемент при-
емника.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
PMINSW приемник, источник
PMINSW (MINimum of Packed Signed Word integers) — возврат минимальных
упакованных злаковых слов.
Синтаксис: PMINSW rxmml, rxmm2/m128
Машинный код: 66 OF ЕА /г
Действие: для каждой пары элементов (размером 16 бит) источника и приемника
команда определяет наименьший с учетом знака и заменяет им соответствующий
элемент приемника.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-codc).
PMINUB приемник, источник
PMINUB (MINimum of Packed Unsigned Byte integers) — возврат минимальных
упакованных беззнаковых байт.
Синтаксис: PMINUB rxmml, rxmm2/m128
Машинный код: 66 OF DA /г
Действие: для каждой пары байтовых элементов источника и приемника команда
определяет наименьший без учета знака и заменяет им соответствующий элемент
приемника.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fauIt-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
450
Приложение 1. Команды процессоров х86
PMOVMSKB приемник, источник
PMOVMSKB (MOVe Byte MaSK) — перемещение байтовой маски в целочислен-
ный регистр.
Синтаксис: PMOVMSKB r32, rxmm
Машинный код: 66 OF D7 /г
Действие: команда извлекает и копирует значения старшего бита каждого из упа-
кованных байт XMM-регистра в младшие 16 бит 32-битного целочисленного реги-
стра общего назначения. Остальные разряды целочисленного регистра обнуляются.
Флаги: не изменяются.
Исключения: PM: #UD: 10,12,15; #NM: 3; RM: исключения защищенного режи-
ма; VM: исключения защищенного режима.
PMULHUW приемник, источник
PMULHUW (MULtiply Packed Unsigned integers and store High result) — умно-
жение упакованных беззнаковых слов с возвратом старших слов результата.
Синтаксис: PMULHUW rxmml, rxmm2/m128
Машинный код: 66 OF Е4 /г
pmulhuw приемник, источник
127 111 95 79 63 47 31 15 0
и7 иб и5 и4 иЗ и2 и1 иО
Источник
@ @@ @@@@@
127 111 95 79 63 47 31 15 0
127 111 95 79 63 47 31 15 0
Приемник (ХММ-регистр)
Приемник (ХММ-регистр)
Действие: команда производит умножение упакованных слов источника и при-
емника без учета знака и формирует элементы результата в соответствии с приве-
денной ниже схемой. Как видно из нее, в результате умножения слов операндов
источник и приемник получаются промежуточные результаты размером 32 бита.
П1.5. Команды блока ХММ (SSE2)
451
Далее старшее слово (16 бит) из каждого промежуточного результата умножения
исходных элементов помещается в 16-битный элемент окончательного результа-
та. Результат помещается в операнд приемник.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(O): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fauIt-code).
PMULHW приемник, источник
PMULHW (MULtiply Packed signed integers and store High result) — упакованное
знаковое умножение слов с возвратом старшего слова результата.
Синтаксис: PMULHW rxmml, rxmm2/m128
Машинный код: 66 OF Е5 /г
Действие: команда производит умножение упакованных слов источника и при-
емника с учетом знака и формирует элементы результата в соответствии со схе-
мой, приведенной при описании команды PMULHUW.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(O): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
PMULLW приемник, источник
PMULLW (MULtiply Packed signed integers and store Low result) — упакованное
знаковое умножение слов с возвратом младшего слова результата.
Синтаксис: PMULLW xmm1, xmm2/m128
Машинный код: 66 OF D5 /г
Действие: команда производит умножение с учетом знака упакованных слов ис-
точника и приемника и формирует элементы результата в соответствии с приве-
денной ниже схемой.
Как видно из этой схемы, в результате умножения слов источника и приемника
получаются промежуточные результаты размером 32 бита. Далее младшее слово
(16 бит) из каждого 32-битного элемента промежуточного результата умножения
исходных элементов помещается в 16-битный элемент результата (операнд при-
емник).
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
452
Приложение 1. Команды процессоров х86
pmullw приемник, источник
127 111 95 79 63 47 31 15 О
и7 иб и5 и4 иЗ и2 и1 иО
@ @ @ (*)@@@@
127 111 95 79 63 47 31 15 О
127 111 95 79 63 47 31 15 О
Приемник (ХММ-регистр)
Приемник (ХММ-регистр)
PMULUDQ приемник, источник
PMULUDQ (MULtiply Packed Unsigned Doubleword integers description) — ум-
ножение 32-битных целых значений без учета знака и сохранение результата в
ХММ-регистре.
Синтаксис и машинный код:
OF F4 /г PMULUDQ rmmxl, rmmx2/m64
66 OF F4/г PMULUDQ rxmml, rxmm2/m128
Действие: умножить 32-битные целые значения со знаком в источнике и прием-
нике. Исходя из типа источника, возможны две схемы умножения:
♦ источник — ММХ-регистр или ячейка памяти т64: приемник[&3-9]<г-прием-
ник[31 -0] х источш1к[3\-9\}
♦ источник — ХММ-регистр или ячейка памяти: приемник[&3-О\<г-приемник[31-О\ х
источпик\3\-9}\ приемник[127-64]<-приемник[95-64] х источник[95-64].
Когда результат умножения слишком большой, чтобы быть представленным в
приемник, то он «заворачивается» (перенос игнорируется).
Флаги: не изменяются.
Исключения: PM: #GP(0): 2,42; #SS(O): 1; #UD: 10,12,15; #NM: 3; #PF(fault-code);
RM: #GP: 13, 16; #UD: 17, 19, 22; #NM: 3; VM: исключения реального режима;
#PF(fault-codc).
POR приемник, источник
POR (bitwise logical OR) — упакованное логическое ИЛИ.
Синтаксис: POR rxmml, rxmm2/m128
П1.5. Команды блока ХММ (SSE2)
453
Машинный код: 66 OF ЕВ /г
Действие: команда производит побитовую операцию логическое ИЛИ над всеми би-
тами операндов источника и приемника. Результат помешается в операнд приемник.
Флаги: нс изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fauIt-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
PSADBW приемник, источник
PSADBW (Compute Sum of Absolute Differences) — суммарная разница значений
пар беззнаковых упакованных байт.
Синтаксис: PSADBW rxmml, rxmm2/m128
Машинный код: 66 OF F6 /г
Действие: для каждой пары байт двух упакованных учетверенных слов операндов
источник и приемник вычислить модуль разности, после чего сложить полученные
модули. Результат записать в младшее слово каждого из двух упакованных учет-
веренных слов приемника, старшие три слова в упакованных учетверенных сло-
вах приемника обнулить. Принцип работы программы поясняет схема ниже.
psadbw приемник, источник
Источник
127 119 111 103 95 87 79 71 63 55 47 39 31 34 15 7 0
127 111 95 79 63 47 31 15 0
Приемник (ХММ-регистр)
454
Приложение 1. Команды процессоров х86
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
PSHUFD приемник, источник, маска
PSHUFD (SHUFfle Packed Doublewords) — копирование двойных слов из ХММ-
операнда источник в ХММ-операнд приемник.
Синтаксис: PSHUFD xmm1, xmm2/m128, imm8
Машинный код: 66 OF 70 /г i8
Действие: на основе значения пар бит маски копировать двойные слова из источ-
ника в приемник. Каждая пара бит маски определяет номер слова источника для
перемещения в приемник следующим образом:
♦ маска[1:0]:
• 00 приемник\9...3\] источник^...3\]\
• 01 приемник[9...3\} источник[32...63];
• 10 приемник[0...31] источник[64...95];
• И приемник[0...31] источник[96...127];
♦ маска[3:2]:
• 00 приемник[32...63] источник[0...31];
• 01 приемник[32...63] источник[32...63];
• 10 приемник[32...63] источник[64...95];
• И приемник[32...63] источник[96...127];
♦ маска[5:4]:
• 00 приемник[64...95] источник[0...31];
• 01 приемник[64...95] источник[32..,63];
• 10 приемник[64...95] источник[64...95];
• И приемник[64...95] источник[96...127];
♦ маска[7:6]:
• 00 ирн&мш/к[96...127] <— источник[0...31];
• 01 ирн&мник[96...127] источник[32...63];
• 10 прн&мник[96...127] <— источник[64...95];
• 11 прн&мнмк[96...127] источник[96...127].
Если использовать один и тот же ХММ-регистр в качестве источника и приемни-
ка, то можно выполнять любые перестановки двойных слов в пределах одного
ХММ-регистра, в том числе и инициализацию значением одного двойного слова
других двойных слов. Работу команды PSHUFD поясняет следующая схема:
П1.5. Команды блока ХММ (SSE2)
455
Источник rxmn/m128
127 96 95 64 63 32 31 О
127 96 95 64 63 32 31 О
Приемник rxmm
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(O): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #NM: 3; #UD: 17,19,22; VM: исключения реального режи-
ма; #PF(fault-code).
PSHUFHW приемник, источник, маска
PSHUFHW (SHUFfle Packed High Words) — копирование слов из старшего учет-
веренного упакованного слова XMM-операнда источник в старшее учетверенное
упакованное слово XMM-операнда приемник.
Синтаксис: PSHUFHW xmm 1, xmm2/m128, imm8
Машинный код: F3 OF 70 /г i8
Действие: на основе значения пар бит маски копировать слова из старшего упако-
ванного учетверенного слова источника в старшее учетверенное упакованное сло-
во приемника. Каждая пара бит маски определяет номер слова источника для пе-
ремещения в приемник следующим образом:
♦ маска[1:0]:
• 00 приемник\в4...79] источник\в4...79];
• 01 приемник[в4..Л9] <г- источников...95];
• 10 приемник[в4..Л9] <г- источник[96...И1];
• И приемник[64...79] источник^ 12...127];
♦ маска[3:2]:
• 00 приемник[89...95] источник\в4...79];
• 01 приемник\8в...95] источник\8в...95];
• 10 приемник\8в...95] источников...! 11];
• И приемник[80...95] источник^ 12... 127];
456
Приложение 1. Команды процессоров х86
♦ маска[5:4]:
• 00 приелник[9в...]ЛЛ} источник[64...79];
• 01 приемник[96... 111] источников...95];
• 10 приемник[96... 111 ] источников...111];
• 11 приемник[96...111] источник[112...127];
♦ маска[7:б]:
• 00 приемник[112..Л27] источник[64...79];
• 01 приемник[112...127] источников...95];
• 10 приемник^ 112...127] источник[96...И1];
• И приемпик[112...127] источник^ 12...127].
Если использовать один и тот же ХММ-регистр в качестве источника и прием-
ника, то можно выполнять любые перестановки слов в пределах старшего учетве-
ренного слова одного ХММ-регистра, в том числе и инициализацию значени-
ем одного слова других слов. Работу команды PSHUFHW поясняет следующая
схема.
Источник rxmn/m128
127 112 111 96 95 80 79 64 63 О
127 112 111 96 95 80 79 64 63
Приемник rxmm
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(O): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
PSHUFLW приемник, источник, маска
PSHUFLW (SHUFfle Packed Low Words) — копирование слов из младшего учет-
веренного упакованного слова ХММ-операнда источник в младшее учетверенное
упакованное слово ХММ-операнда приемник.
П1.5. Команды блока ХММ (SSE2)
457
Синтаксис: PSHUFLW rxmml, rxmm2/m128, imm8
Машинный код: F2 OF 70 /г i8
Действие: на основе значения пар битл/ясхт/ копировать слова из младшего учет-
веренного слова источника в младшее учетверенное слово приемника. Каждая
пара бит маски определяет номер слова источника для перемещения в приемник
следующим образом:
♦ маска[1:0]:
• 00 приемник[00...15] источник[00...15];
• 01 приемник[00...15] источник[16...31];
• 10 приемник[00...15] источник[32...47];
• И приемник[00...15] источник[48...63];
♦ маска[3:2]:
• 00 приемник[16...31] <- источник[00...15];
• 01 приемник[16...31] <— источник[16...31];
• 10 приемник[16...31] <— источник[32...47];
• И приемник[16...31] источник[48...63];
♦ маска[5:4]:
• 00 приемник[32...47] источник[00...15];
• 01 приемник[32...47] <- источник[16...31];
• 10 приемник[32...47] <- источник[32...47]\
• И приемник[32...47] <— источник[48...63]\
♦ маска[7:б]:
• 00 приемник\47...63] источник^... 15];
• 01 приемник[47...63] источник[16...31];
• 10 приемник[47...63] <— источник[32...47];
• И приемник[47...63] <- источник[48...63].
Если использовать один и тот же ХММ-регистр в качестве источника и прием-
ника, то можно выполнять любые перестановки слов в пределах младшего учетве-
ренного слова одного ХММ-регистра, в том числе и инициализацию значением
одного слова других слов. Работу команды PSHUFLW поясняет схема, показанная
далее.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(O): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #UD: 17,19,22; #NM: 3; VM: исключения реального режи-
ма; #PF(fault-code).
458
Приложение 1. Команды процессоров х86
Источник rxmm/n128
127 63 4847 32 31 16 15 О
Кодирование
бит маски:
00 — иО
01 — и1
10 — и2
11 — иЗ
Приемник rxmn
PSLLDQ приемник, количество_сдвигов
PSLLDQ (Shift Double Quadword Left Logical) — логический сдвиг влево прием-
ника на число байт количество_сдвигов.
Синтаксис: PSLLDQ xmm1, imm8
Машинный код: 66 OF 73 /7 i8
Действие: сдвиг влево приемника на число байт, указанных непосредственным
операндом количество_сд вигов. Освобождаемые слева младшие байты обнуляют-
ся. Если значение, указанное операндом количество _сдвигов, больше чем 15, опе-
ранд приемник обнуляется.
Флаги: не изменяются.
Исключения: #UD: 10,12,15; #NM: 3; RM: исключения защищенного режима; VM:
исключения защищенного режима.
PSLLW/PSLLD/PSLLQ приемник,
количество_сдвигов
PSLLW/PSLLD/PSLLQ (SHIFt packed data Left Logical) — сдвиг влево логичес-
кий приемника на число бит количество_сдвигов.
Синтаксис и машинный код:
66 OF F1 /г PSLLW rxmml, rxmm2/m128
66 OF 71 /6 ib PSLLW rxmml, imm8
66 OF F2 /r PSLLD rxmml, rxmm2/m128
66 OF 72 /6 ib PSLLD rxmml, imm8
66 OF F3 /r PSLLQ rxmml, rxmm2/m128
66 OF 73 /6 ib PSLLQ rxmml, imm8
П1.5. Команды блока ХММ (SSE2)
459
Действие: сдвиг упакованных элементов приемника (слов, двойных слов, учетве-
ренных слов) влево на число бит, указанных операндом количество_сд вигов. Ос-
вобождаемые слева биты замещаются нулевыми. Если значение, указанное опе-
рандом количество _сдвигов, больше чем 15 (для слов), 31 (для двойных слов) или
63 (для учетверенных слов), то значение операнда приемник устанавливается рав-
ным 0. Операнд количество__сдвигов может быть либо XMM-регистром (128-раз-
рядной ячейкой памяти), либо непосредственным 8-разрядным операндом.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #NM: 3; #UD: 17,19,22; VM: исключения реального режи-
ма; #PF(fault-code).
PSRAW/PSRAD приемник, количество_сдвигов
PSRAW/PSRAD (SHIFt Packed data Right Arithmetic) — сдвиг вправо арифме-
тический приемника на число бит количество_сдвигов.
Синтаксис и машинный код:
66 OF Е1 /г PSRAWxmml, xmm2/m128
66 OF 71 /4 i8 PSRAW xmml, imm8
66 OF E2 /r PSRAD xmml, xmm2/m128
66 OF 72 /4 i8 PSRAD xmml, imm8
Действие: сдвиг упакованных элементов приемника (слов, двойных слов) вправо
на число бит, указанных операндом количество-Сдвигов, Освобождаемые справа
биты заполняются значением знакового разряда элемента данных. Если значение,
указанное операндом количество _сдвигов, больше чем 15 (для слов) или 31 (для
двойных слов), то каждый элемент данных приемника заполняется начальным
значением знакового разряда элемента. Операнд количество^сдвигов может быть
либо XMM-регистром (128-разрядной ячейкой памяти), либо непосредственным
8-разрядным операндом.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(O): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #NM: 3; #UD: 17,19,22; VM: исключения реального режи-
ма; #PF(fault-code).
PSRLDQ приемник, количество_сдвигов
PSRLDQ (Shift Double Quadword Right Logical) — сдвиг вправо приемника на
число байт количество_сдвигов.
Синтаксис: PSRLDQ xmml, imm8
Машинный код: 66 OF 73 /3 i8
Действие: сдвиг вправо приемника на число байт, указанных непосредственным
операндом количествО-Сдвигов, Освобождаемые справа младшие байты обнуляются.
460
Приложение 1. Команды процессоров х86
Если значение, указанное операндом количество_сдвигов, больше чем 15, операнд
приемник обнуляется.
Флаги: не изменяются.
Исключения: #UD: 10, 12, 15; #NM: 3; RM: исключения защищенного режима;
VM: исключения защищенного режима.
PSRLW/PSRLD/PSRLQ приемник,
количество-сдвигов
PSRLW/PSRLD/PSRLQ (Shift Packed Data Right Logical) — сдвиг вправо логи-
ческий приемника на число бит количество_сдвигов.
Синтаксис и машинный код:
66 OF D1 /г PSRLW rxmml, rxmm2/m128
66 OF 71 /2 i8 PSRLW rxmml, imm8
66 OF D2 /r PSRLD rxmml, rxmm2/m128
66 OF 72 /2 i8 PSRLD rxmml, imm8
66 OF D3 /r PSRLQ rxmml, rxmm2/m128
66 OF 73 /2 i8 PSRLQ rxmml, imm8
Действие: сдвиг упакованных элементов приемника (слов, двойных слов, учетве-
ренных слов) вправо на число бит, указанных операндом количество _сдвигов. Ос-
вобождаемые справа биты замещаются нулевыми. Если значение, указанное опе-
рандом количество_сдвигов, больше чем 15 (для слов), 31 (для двойных слов) или
63 (для учетверенных слов), то значение операнда приемник устанавливается рав-
ным 0. Операнд количество ^сдвигов может быть либо ХММ-регистром (128-раз-
рядной ячейкой памяти), либо непосредственным 8-разрядным операндом.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(O): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #NM: 3; #UD: 17,19,22; VM: исключения реального режи-
ма; #PF(fault-code).
PSUBB/PSUBW/PSUBD приемник, источник
PSUBB (Packed Subtraction Bytes) — вычитание упакованных бант. PSUBW (Packed
Subtraction Words) — вычитание упакованных слов. PSUBD (Packed Subtraction
Double words) — вычитание упакованных двойных слов.
Синтаксис и машинный код:
66 OF F8 /г PSUBB rxmml, rxmm2/m128
66 OF F9 /г PSUBW rxmml, rxmm2/m128
66 OF FA/r PSUBD rxmml, rxmm2/m128
Действие: команда вычитает из элементов источника элементы приемника разме-
ром байт/слова/двойпое слово в зависимости от кода операции. При псреполне-
П1.5. Команды блока ХММ (SSE2)
461
нии результат формируется в соответствии с принципом циклического перепол-
нения. Результат помещается в операнд приемник.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #NM: 3; #UD: 17,19,22; VM: исключения реального режи-
ма; #PF(fault-code).
PSUBQ приемник, источник
PSUBQ (SUBtract Packed Quadword integers description) — вычитание учетверен-
ных слов.
Синтаксис и машинный код:
OF FB /г PSUBQ rmmxl, rmmx2/m64
66 OF FB /г PSUBQ rxmml, rxmm2/m128
Действие: вычесть 64-битные целые значения в источнике и приемнике. Исходя
из типа источника, возможны две схемы умножения:
♦ источник — ММХ-регистр или ячейка памяти т64: приемник[&3^\<г-прием-
ник[63-0] - источник[&3-О\\ приемник — ММХ-регистр;
♦ источник — ХММ-регистр или ячейка памяти: приемник[ЪЗ-$\<г-приемник[63-
0] - источник[63-0]; приемник[127-64]<—приемник[127-64] - источнику 127-64].
В результате выполнения команды PSUBQ регистр EFLAGS не отражает факта воз-
никновения ситуации переполнения или переноса. Когда результат умножения
слишком большой, чтобы быть представленным в 64-битно.м элементе приемника,
то он «заворачивается» (перенос игнорируется). Для обнаружения подобных си-
туаций программное обеспечение должно использовать другие методы.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(O): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #NM: 3; #UD: 17,19,22; VM: исключения реального режи-
ма; #PF(fault-code).
PSUBSB/PSUBSW приемник, источник
PSUBSB (Packed Subtraction with signed Saturation Bytes) — вычитание упако-
ванных байт co знаковым насыщением. PSUBSW (Packed Subtraction with signed
Saturation Words) — вычитание упакованных слов co знаковым насыщением.
Синтаксис и машинный код:
66 OF Е8 /г PSUBSB rxmml, rxmm2/m128
66 OF E9 /г PSUBSW rxmml, rxmm2/m128
Действие: вычесть элементы источника и приемника размером байт/слово в зави-
симости от кода операции. Вычитание элементов производится с учетом их знака.
462
Приложение 1. Команды процессоров х86
При возникновении переполнения результат формируется в соответствии с прин-
ципом знакового насыщения:
♦ PSUBSB — 07fh для положительных чисел и 080h для отрицательных;
♦ PSUBSW — 07fffh для положительных чисел и 08000h для отрицательных.
Результат помещается в операнд приемник.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #NM: 3; #UD: 17,19,22; VM: исключения реального режи-
ма; #PF(fault-code).
PSUBUSB/PSUBUSW приемник, источник
PSUBUSB (Packed Subtraction with Unsigned Saturation Bytes) — вычитание упа-
кованных байт с беззнаковым насыщением. PSUBUSW (Packed Subtraction with
Unsigned Saturation Words) — вычитание упакованных слов с беззнаковым насы-
щением.
Синтаксис и машинный код:
66 OF D8 /г PSUBUSB xmml, xmm2/m128
66 OF D9 /г PSUBUSW xmml, xmm2/m128
Действие: вычесть без учета знака элементы операндов источника и приемника
размером байт/слово в зависимости от кода операции. При возникновении пере-
полнения результат формируется в соответствии с принципом беззнакового на-
сыщения:
♦ PSUBUSB — 00h для результатов вычитания меньших нуля;
♦ PSUBUSW — OOOOh для результатов вычитания меньших нуля.
Результат помещается в операнд приемник.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
code); RM: #GP: 13,16; #NM: 3; #UD: 17,19,22; VM: исключения реального режи-
ма; #PF(fault-code).
PUNPCKHBW/PUNPCKHWD/PUNPCKHDQ/
PUNPCKHQDQ приемник, источник
PUNPCKHBW/PUNPCKHWD/PUNPCKHDQ/PUNPCKHQDQ (UNPaCK High
Data) — распаковка старших упакованных байт (слов, двойных слов, учетверен-
ных слов) в слова (двойные слова, учетверенные слова, двойное учетверенное слово).
Синтаксис и машинный код:
66 0F 68 /г PUNPCKHBW rxmml, rxmm2/m128
66 OF 69 /г PUNPCKHWD rxmml, rxmm2/m128
П1.5. Команды блока ХММ (SSE2)
463
66 OF6A/r PUNPCKHDQ rxmml, rxmm2/m128
66 OF 6D /г PUNPCKHQDQ rxmml, rxmm2/m128
Действие: команды PUNPCKHBW, PUNPCKHWD, PUNPCKHDQ и PUNPCKHQDQ про-
изводят размещение с чередованием элементов из операндов источник и прием-
ник согласно следующей схеме:
PUNPCKHBW:
приемник]!-0} приемник]! 1-84};
приемник]15-8} источник]! 1-64];
приемник]23-18} приемник]!9-!2};
приемник]31-24} <— источник]! 9-! 2};
приемник]39-32} приемник]8!-80};
приемник]4!-40] <- источник]8!-80};
приемник]55-48} приемник]95-88};
приемник]83-56] источник]95-88};
PUNPCKHWD:
приемник] 15-0] приемник]!9-84};
приемник]31-16] <- источник]!9-64};
приемник]4!-32] приемник]95-80};
приемник]83-48} источник]95-80};
PUNPCKHDQ:
приемник]31-0] <- приемник]95-84};
приемник\83-32} источник]95-84};
PUNPCKHQDQ:
прмел/нмк[71-64] приемник] 103-96];
приемник]!9-!2} <— источник] 103-96];
приемник]8!-80} приемник]! 11-104};
приемник]95-88] <- источник]111-104};
приемник] 103-96] <— приемник]! 19-112];
приемник]! 11-104} <- источник] 119-112];
приемник]! 19-112] приемник]12!-120};
приемник]12!-120] источник]12!-120};
приемник]!9-64] <— приемник]! 11-96];
приемник]95-80} <— источник]! 11-96];
приемник]! 11-96] <— приемник] 127-112];
приемник]12!-112} <— источник]12!-112};
приемник]95-64} <- приемник] 127-96];
приемник] 127-96] <- источник] 127-96];
приемник] 127-64] источник] 127-64];
приемник]83-0} приемник] 127-64];
Флаги: не изменяются.
Исключения: PM: #GP(0): 2,42; #MF; #NM: 3; #PF(fault-code); #SS(0): 1; #UD: 10;
#AC(0)_cpl3; RM: #GP: 13,16; #MF; #NM: 3; #UD: 17; VM: исключения реально-
го режима; #PF(fault-code).
PUNPCKLBW/PUNPCKLWD/PUNPCKLDQ/
PUNPCKLQDQ приемник, источник
PUNPCKLBW/PUNPCKLWD/PUNPCKLDQ/PUNPCKLQDQ (UNPaCK Low
Data) — распаковка младших упакованных байт (слов, двойных слов, учетверенных
слов) в слова (двойные слова, учетверенные слова, двойное учетверенное слово).
Синтаксис и машинный код:
66 OF 60 /г PUNPCKLBW rxmml, rxmm2/m128
66 OF 61 /г PUNPCKLWD rxmml, rxmm2/m128
66 OF 62 /r PUNPCKLDQ rxmml, rxmm2/m128
66 OF 6C /r PUNPCKLQDQ rxmml, rxmm2/m128
464 Приложение 1. Команды процессоров х86
Действие: команды PUNPCKLBW, PUNPCKLWD, PUNPCKLDQ и PUNPCKLQDQ про-
изводят размещение с чередованием элементов из операндов источник и прием-
ник согласно следующей схеме:
PUNPCKLBW:
приемнику!-0] <— приемнику!-0];
приемник[у5-8] <— источнику!-0];
приемник\23-!6] <— приемник[15-8];
приемник[31-24] <— источнику 15-8];
приемник[39-32] <— приемнику23-!6];
приемник[47-40] <— источник[23-16];
приемникУ55-48] <— приемникуЗ!-24\;
приемник[63-56] <— источникуЗ!-24];
PUNPCKLWD:
приемнику! 5-0] <— приемник[15-0];
приемник[31-16\ <— источнику!5-0];
приемнику47-32] <— приемник[31-16];
приемник[63-48] <— источник[31-16];
PUNPCKLDQ:
приемник[71-64] <— приемник[39-32];
приемник[79-72] <— wctt7o</hwk[39-32];
при емник[87-80] <— приемник[47-40];
приемник[95-88] <- источник[47-40];
приемник[ 103-96] <— приемник[55-48];
приемпик[111-104] <- источник[55-48];
приемник[119-112] <— приемник[63-56];
приемнику127-120] <- источникубЗ-56];
приемник[79-64] <- приемнику47-32];
приемнику95-80] <— источнику47-32];
приемнику! 11-96] <— приемнику63-48];
приемнику!27-!!2] <- источникубЗ-48];
приемник[3!-0] <— приемникуЗ!-0];
приемиикуб3-32] <— источнику3!-0];
приемнику95-64] <— приемник[63-32];
приемнику 127-96] источникуб3-32];
PUNPCKLQDQ:
приемникубЗ-0] <— приемникубЗ-0];
приемнику!27-64] <— источникубЗ-0];
Флаги: не изменяются.
Исключения: PM: #GP(0): 2,42; #MF; #NM: 3; #PF(fault-codc); #SS(0): 1; #UD: 10;
#ЛС(0)_ср13; RM: #GP: 13, 16; #MF; #NM: 3; #UD: 17; VM: исключения реально-
го режима; #PF(fault-code); #ЛС(0)_и.
PXOR приемник, источник
PXOR (Packed logical Exclusive OR) — упакованное логическое исключающее ИЛИ.
Синтаксис: PXOR xmml, xmm2/m128
Машинный код: 66 OF EF /г
Действие: команда производит побитовую операцию логическое исключающее
ИЛИ над всеми битами операндов источник и приемник. Результат помещается в
операнд приемник.
Флаги: не изменяются.
Исключения: PM: #GP(0): 2, 42; #SS(0): 1; #UD: 10, 12, 15; #NM: 3; #PF(fault-
codc); RM: #GP: 13,16; #NM: 3; #UD: 17,19,22; VM: исключения реального режи-
ма; #PF(fault-code).
П1.5. Команды блока ХММ (SSE2)
465
SHUFPD приемник, источник, маска
SHUFPD (Shuffle Packed Double-Precision Floating-Point Values Description) —
перестановка упакованных значений с плавающей точкой двойной точности.
Синтаксис: SHUFPD xmm1, xmm2/m128, imm8
Машинный код: 66 OF С6 /г i8
Действие: переместить упакованные значения с плавающей точкой двойной точ-
ности из приемника и источника в приемник в соответствии со значением непо-
средственного операнда маска. Биты маски определяют номера упакованных
значений с плавающей точкой двойной точности в источнике или приемнике, кото-
рые будут перемещены в приемник следующим образом:
♦ маскаЛ » 0: приемник[63-0] <— приемнпк[63-0];
♦ маскаЛ - 1: приемник[63-0] <— приемпик[127-64];
♦ маскаЛ = 0: приемник[ 127-64] <— источник[63-0];
♦ маскаЛ = 1: приемник[ 127-64] <- источннк[127-64].
Для перестановки в пределах одного регистра можно использовать один и тот же
регистр ХММ в качестве источника и приемника.
Исключения: PM: #GP(0): 37,42; #NM: 3; #PF(fault-code); #SS(0): 13; #UD: 10-12,
15; #XM; RM: #GP: 13,16; #NM: 3; #UD: 17-19,22; #XM; VM: исключения реаль-
ного режима; #PF(fault-code).
SQRTPD приемник, источник
SQRTPD (compute SQuare RooTs of Packed Double-precision floating-point values) —
вычисление квадратного корпя упакованных значений с плавающей точкой двой-
ной точности.
Синтаксис: SQRTPD rxmml, rxmm2/m128
Машинный код: 66 OF 51 /г
Действие: вычислить значения квадратных корней упакованных значений с пла-
вающей точкой двойной точности источника по следующей схеме: приемник[&3-
0]<— SQRT(wc7?2O4Wwk[63-0]); приемник[Г11SQWV{ucmo4iiuK\ 127-64]).
Исключения: SIMD (NE): #О, #U, #1, #Р, #D; PM: #GP(0): 37, 42; #SS(0): 13;
#PF(fault-code); #NM: 3; #XM; #UD: 10-12, 15; RM: #GP: 13, 16; #NM: 3; #XM;
#UD: 17—19, 22; VM: исключения реального режима; #PF(fault-code).
SQRTSD приемник, источник
SQRTSD (compute SQuare RooT of Scalar Double-precision floating-point value) —
вычисление квадратного корня скалярного упакованного значения с плавающей
точкой двойной точности.
Синтаксис: SQRTSD rxmml, rxmm2/m64
Машинный код: F2 OF 51 /г
466
Приложение 1. Команды процессоров х86
Действие: вычислить значение квадратного корня младшего упакованного значе-
ния с плавающей точкой двойной точности источника по схеме: приемник[63-0]<—
SQRT(ucmo«HUK[63-0]); приемник 127-64] — не изменяется.
Исключения: SIMD (NE): #1, #Р, #D; PM: #GP(0): 37; #NM: 3; #PF(fault-code);
#SS(O): 13; #UD: 10-12,15; #XM; #AC(0)_cpl3; RM: #GP: 13; #NM: 3; #UD: 17-19,
22; #XM; VM: исключения реального режима; #PF(fault-code); #AC(0)_u.
SUBPD приемник, источник
SUBPD (SUBtract Packed Double-precision floating-point values) — вычитание упа-
кованных значений с плавающей точкой двойной точности.
Синтаксис: SUBPD rxmml, rxmm2/m128
Машинный код: 66 OF 5С /г
Действие: вычесть пары упакованных значений с плавающей точкой двойной
точности источника и приемника по схеме: приемник\&3-$\<г-приемник\§3-0\ - ис-
/почнмк[63-0]; приемник[127-64]*-приемник[127-64] - источник[ 127-64].
Исключения: SIMD (NE): #0, #U, #1, #Р, #D; PM: #GP(0): 37,42; #NM: 3; #PF(fault-
code); #SS(O): 13; #UD: 10,11,12,15; #XM; RM: #GP: 13,16; #NM: 3; #UD: 17,18,
19, 22; #XM; VM: исключения реального режима; #PF(fault-code).
SUBSD приемник, источник
SUBSD (SUBtract Scalar Double-precision floating-point values) — вычитание ска-
лярных упакованных значений с плавающей точкой двойной точности.
Синтаксис: SUBSD rxmml, rxmm2/m64
Машинный код: F2 OF 5С /г
Действие: вычесть младшие упакованные значения с плавающей точкой двойной
точности источника и приемника по схеме: приемник[ЪЗ-Ъ]^приемник[ЪЗ~Ъ] - ис-
точник\63-О\\ приемник[121 -63] — не изменяется.
Исключения: SIMD (NE): #0, #U,. #1, #Р, #D; PM: #GP(0): 37; #NM: 3; #PF(fault-
code); #SS(O): 13; #UD: 10-12, 15; #XM; #AC(0)_cpl3; RM: #GP: 13; #NM: 3;
#UD: 17—19, 22; #XM; VM: исключения реального режима; #PF(fault-code);
#AC(0)_u.
UCOMISD приемник, источник, условие
UCOMISD (Unordered COMpare Scalar Double-precision floating-point values and
set EFLAGS) — сравнение неупорядоченных скалярных значений с плавающей точ-
кой двойной точности и установка регистра EFLAGS.
Синтаксис: UCOMISD xmm1, xmm2/m64
Машинный код: 66 OF 2Е /г
Действие: сравнить неупорядоченные скалярные значения с плавающей точкой
двойной точности в разрядах [63-0] приемника и источника. По результату срав-
нения установить флаги ZF, PF и CF в регистре EFLAGS (см. описание команды
П1.5. Команды блока ХММ (SSE2)
467
COMISD). Отличие команды COMISD от команды UCOMISD состоит в генерации
исключения недействительной операции с плавающей точкой (#l): COMISD генериру-
ет его, когда приемник и(или) источник — QNAN или SNAN; команда UCOMISD ге-
нерирует #1 только в случае, если один из исходных операндов — SNAN. В случае
генерации немаскированного исключения с плавающей точкой регистр EFLAGS не
модифицируется.
Исключения: SIMD (NE): #1 (если операнд — SNaN), #D; PM: #GP(0): 37; #NM:
3; #PF(fault-code); #SS(0): 13; #UD: 10,11,12,15; #XM; #AC(0)_cpl3; RM: #GP: 13;
#NM: 3; #UD: 17—19, 22; #XM; VM: исключения реального режима; #PF(fault-
code); #AC(0)_u.
UNPCKHPD приемник, источник
UNPCKHPD (UNPaCK and interleave High Packed Double-precision floating-point
values) — разделение и чередование старших упакованных значений с плавающей
точкой двойной точности.
Синтаксис: UNPCKHPD xmm1, xmm2/m 128
Машинный код: 66 OF 15 /г
Действие: разделить старшие упакованные значения с плавающей точкой двойной
точности в источнике и приемнике и поместить их с чередованием в приемник по
схеме: приемник\&3-$\ приемник[ 127-64]; приемник[ 127-64] <- источник[127-64].
Исключения: PM: #GP(0): 37, 42; #NM: 3; #PF(fault-code); #SS(0): 13; #UD: 10,
12,15; RM: #GP: 13,16; #NM: 3; #UD: 17—19,22; #XM; VM: исключения реального
режима; #PF(fault-code).
UNPCKLPD приемник, источник
UNPCKLPD (UNPaCK and interleave Low Packed Double-precision floating-point
values) — разделение и чередование младших упакованных значений с плавающей
точкой двойной точности.
Синтаксис: UNPCKLPD xmm1, xmm2/m128
Машинный код: 66 OF 14 /г
Действие: разделить младшие упакованные значения с плавающей точкой двой-
ной точности в источнике и приемнике и поместить их с чередованием в приемник
по схеме: приемник[&3-§\ приемник\<оЗ-О\\ приемник[127-64] <- источник[63-0].
Исключения: PM: #GP(0): 37,42; #NM: 3; #PF(fault-code); #SS(0): 13; #UD: 10-12,
15; #XM; RM: #GP: 13,16; #NM: 3; #UD: 17-19,22; #XM; VM: исключения реаль-
ного режима; #PF(fault-code).
XORPD приемник, источник
XORPD (bitwise logical XOR for Double-precision floating-point values) — пораз-
рядное логическое исключающее ИЛИ над упакованными значениями с плаваю-
щей точкой двойной точности.
468
Приложение 1. Команды процессоров х86
Синтаксис: XORPD xmml, xmm2/m128
Машинный код: 66 OF 57 /г
Действие: выполнить операцию поразрядного логического исключающего ИЛИ
над парами упакованных значений с плавающей точкой двойной точности в прием-
нике и источнике по схеме: приемник[127-0]<г-приемник[ 127-0]) побитное__ХОИ
источник[ 127-0].
Исключения: PM: #GP(0): 37,42; #NM: 3; #PF(fault-code); #SS(0): 13; #UD: 10-12,
15; #XM; RM: #GP: 13,16; #NM: 3; #UD: 17-19,22; #XM; VM: исключения реаль-
ного режима; #PF(fault-code).
П1.6. Команды 3DNow!™
Формат команд 3DNow! основан на обычном для платформы х86 формате modR/M.
Синтаксис ассемблера для этих команд следующий:
мнемоника_команды_3с1поы! mmregl, mmreg2/mem64
Приемник (mmregl) должен быть регистром ММХ (mm0...mm7), а источник (mmreg2/
mem64) может быть либо регистром ММХ, либо 64-битной ячейкой памяти.
Машинное представление команды 3DNow! начинается всегда одинаково — с двух
следующих подряд байт OFh, первый из которых является префиксом команды,
а второй — кодом операции. Чтобы различать команды 3DNow!, используется тре-
тий байт кода операции — суффикс (3DNow!__suffix). Суффикс располагается на
месте байта непосредственного операнда. Таким образом, команда 3DNow! имеет
следующий формат:
OFh OFh modR/M [sib] [displacement] 3DNow!_suffix
Сочетание операндов (mmregl и mmreg2/mem64) определяет те значения, кото-
рые используются в полях: modR/M, [sib] и [displacement]. Они соответствуют
соглашениям по кодированию машинной команды, принятым для платформы
х86. Значение суффикса (3DNow!_suffix) определяется конкретной командой. Ниже,
при описании команд, суффикс указан в пункте «Машинный код» и отделен наклон-
ной чертой. Например, команда PFMUL, в зависимости от сочетания операндов,
может быть представлена в виде следующих машинных команд.
Машинный код Команда
0F0FCA/B4 OFOFOB /В4 0F0F4B0A/B4 26 0F0F0B/B4 0F0F4C 83 0А/В4 PFMUL mmregl, mmreg2 PFMULmmregl, [ebx] PFMULmmregl, [ebx+10] PFMUL mmreg 1, es: [ebx] PFMUL mmreg 1, [ebx+eax*4+10]
Полный перечень суффиксов для команд 3DNow! приведен в представленной
ниже таблице. Для кодирования команд FEMMS и PREFETCH используется одиноч-
ный префикс кода операции Of.
П1.6. Команды 3DNow!™
469
Имя команды Суффикс команды Имя команды Суффикс команды
PAVGUSB BF PFSUB 9A
PFADD 9E PFSUBR Aa
PFACC AE PFRCP 96
PFCMPGE 90 PFRSQRT 97
PFCMPGT AO PFMUL B4
PFCMPEQ BO PFRCPIT1 A6
PFMIN 94 PFRSQIT1 A7
PFMAX A4 PFRCPIT2 B6
PI2FD 0D PMULHRW B7
PF2ID 1D
Ниже в описании команд отсутствует пункт «Синтаксис», так как для всех команд,
за исключением FEMMS и PREFETCH, он одинаков и выглядит следующим образом:
мнемокод mmregl, mmreg2/mem64
Кроме того, список исключении всех команд, кроме команд FEMMS и PREFETCH,
также одинаков, поэтому пункт «Исключения» имеется только в описании команд
FEMMS, PREFETCH, а также первой из «стандартных» команд — PAVGUSB.
В схеме команды используются термины приемник (mmregl) и источник (mmreg2/
mem64).
FEMMS
FEMMS (Faster Enter/Exit of the MMX or floating-point State) -- подготовка со-
процессора к исполнению его команд.
Действие: см. описание команды EMMS из системы команд целочисленного рас-
ширения ММХ.
Машинный код: Of Ое
Исключения: PM: #UD: 10, #NM: 1; #MF; RM: #UD: 17; #NM: 3; #MF; VM: #UD:
15; #NM: 3; #MF.
PAVGUSB приемник, источник
PAVGUSB (AVeraGe of Unsigned Packed 8-bit(Byte) values) — вычисление округ-
ленного среднего значения восьми пар упакованных беззнаковых бант операндов
источник и приемник.
Действие: для каждой пары элементов (размером в байт) вычислить выражение:
ЭлементПриемника=(ЭлементПриемника+ЭлементИсточника)/2
Машинный код: Of Of/bf
Исключения: PM: #UD: 10, #NM: 1; #MF; #SS(0): 1; #GP(0): 2; #AC(0); RM: #UD: 17;
#NM: 3; #MF; #GP: 13; #AC; VM: #UD: 15; #NM: 3; #MF; #GP(0): 25.
470
Приложение 1. Команды процессоров х86
PF2ID приемник, источник
PF2ID (Converts packed floating-point operand to packed 32-bit integer) — преобра-
зование упакованного вещественного в упакованное целое.
Действие: преобразование с усечением к нулю упакованных вещественных значе-
ний размером в двойное слово из операнда источник в два упакованных целочис-
ленных значения (также размером в двойное слово) в операнде приемник. Если в
процессе преобразования получается значение, превышающее максимально допус-
тимое, то соответствующий элемент результата дополняется до 7FFF_FFFFh или
8000_0000h.
Машинный код: Ofh Of/1 d
PFACC приемник, источник
PFACC (Floating-point Accumulate) — накопление с плавающей точкой.
Машинный код: Ofh Of/ae
Действие: сложение старшего и младшего элементов операндов источник и при-
емник и сохранение результата соответственно в младшем и старшем словах при-
емника, как показано ниже:
ЭлементПриеиника[31:0]-ЭленентПриемника[31:0]+ЭлементПриемника[63:32]
ЭлементПриемника[63:32]-ЭлементИсточника[31:0]+ЭлементИсточника[63:32]
Элементы обоих операндов — вещественные значения одинарной точности с 24-
битной мантиссой.
PFADD приемник, источник
PFADD (Packed, floating-point addition) — упакованное сложение с плавающей
точкой.
Машинный код: Of 0f/9e
Действие: команда PFADD производит упакованное сложение элементов разме-
ром в двойное слово операндов источник и приемник по следующей формуле:
ЭленентПриенника-ЭлементПриенника+ЭлементИсточника
Элементы обоих операндов — вещественные числа одинарной точности (с 24-раз-
рядной мантиссой).
PFCMPEQ приемник, источник
PFCMPEQ (Packed Floating-point CoMParison, EQual to) — упакованное сравне-
ние на равенство упакованных операндов с плавающей точкой одинарной точно-
сти приемник и источник.
Машинный код: Of Of/bO
П1.6. Команды 3DNow!™
471
Действие: по результатам сравнения в приемнике формируются элементы двух типов:
♦ из единичных бит (FFFF_FFFFh), если соответствующие элементы операнда
приемник и источник равны;
♦ из нулевых бит (0000_0000h), если соответствующие элементы операнда при-
емник и источник не равны.
PFCMPGE приемник, источник
PFCMPGE (Packed Floating-point CoMParison, Greater than or Equal to) — срав-
нение на БОЛЬШЕ ИЛИ РАВНО упакованных элементов в формате веществен-
ного числа одинарной точности операндов приемник и источник.
Машинный код: Of 0f/90
Действие: по результатам сравнения в приемнике формируются элементы двух типов:
♦ из единичных бит (FFFF_FFFFh), если соответствующий элемент операнда
приемник больше или равен элементу операнда источник;
♦ из нулевых бит (0000_0000h) в противном случае.
PFCMPGT приемник, источник
PFCMPGT (Packed floating-point comparison, greater than) — упакованное сравне-
ние на БОЛЬШЕ элементов операндов с плавающей точкой источник и приемник.
Машинный код: Of Of/aO
Действие: по результатам сравнения формируются элементы результата двух типов:
♦ из единичных бит (FFFF_FFFFh), если выполняется условие сравнения;
♦ из нулевых бит (0000_0000h) в противном случае.
PFMAX приемник, источник
PFMAX (Packed Floating-point MAXimum) — упакованный максимум с плаваю-
щей запятой.
Машинный код: Of 0f/a4
Действие: команда формирует элементы результата (приемника) из максималь-
ных значений соответствующих двух пар элементов операндов приемник и источ-
ник, представляющих собой вещественные значения одинарной точности:
ЭлементПриемника=тах(ЭлементПриемника, ЭлементИсточника)
PFMIN приемник, источник
PFMIN (Packed floating-point minimum) — упакованный минимум с плавающей
точкой.
Машинный код: Of Of/94
472
Приложение 1. Команды процессоров х86
Действие: команда формирует элементы результата (приемника) из минимальных
значений соответствующих двух пар элементов операндов приемник и источник,
представляющих собой вещественные значения одинарной точности:
ЭлементПриемника=т1п(ЭлементПриемника, ЭлементИсточника)
PFMUL приемник, источник
PFMUL (Packed Floating-point MULtiplication) — упакованное умножение с пла-
вающей точкой двух пар вещественных элементов одинарной точности (с 24-бит-
ной мантиссой) операндов источник и приемник:
ЭлементПриемника=ЭлементПриемникахЭлементИсточника
Машинный код: Of Of/b4
PFRCP приемник, источник
PFRCP (Floating-point ReCiProcal approximation) — округленное значение обрат-
ной величины с плавающей точкой.
Машинный код: Of Of/96
Действие: PFRCP — скалярная команда, возвращающая округленное обратное
значение величины, находящейся в младшей половине операнда источник. Полу-
ченный результат дублируется в обе половины 64-битного операнда приемник:
ЭлементПриемника[31:0]=reci procal(ЭлементИсточника[31:0])
ЭлементПриемника[63:32]=reci procal(ЭлементИсточника[31:0])
Операнд источник имеет 24-битную мантиссу, точность результата распространяет-
ся до 14 бит. Для увеличения точности, вплоть до 24 бит мантиссы вещественно-
го значения одинарной точности, требуется использование двух дополнительных
команд — PFRCPIT1 и PFRCPIT2. Первый шаг этого приближения или улучшения
точности (PFRCPIT1) требует предварительного выполнения команды PFRCP.
Ниже показана последовательность команд (с их операндами), необходимая для
вычисления отношения q=a/b с точностью до 24 бит. В этой последовательности
показано место команды PFRCP:
Х° = PFRCP(b)
X1 = PFRCPITKb. Х°)
X2 = PFRCPIT2CX1, Х°)
q = PFMULCa. X2)
PFRCPIT1 приемник, источник
PFRCPIT1 (Packed Floating-point ReCiProcal, first ITeration step) — первый ите-
ративный шаг упакованного приближения с плавающей точкой.
Машинный код: Of 0f/a6
Действие: PFRCPIT 1 — векторная команда, выполняющая первый промежуточный
шаг в итерации Ньютона—Рафсона (Newton—Raphson) для улучшения точности при-
П1.6. Команды 3DNowl™
473
ближения при вычислении обратной величины Ь, производимого командой PFRCP
(второй и последний шаг вычисления этой итерации дает точность 24 бита).
PFRCPIT2 приемник, источник
PFRCPIT2 (Packed Floating-point ReCiProcal/reciprocal square root, second ITeration
step) — второй итеративный шаг упакованного приближения обратной величины
с плавающей точкой (приближения квадратного корня).
Машинный код: Of 0f/b6
Действие: PFRCPIT2 — векторная команда, выполняющая второй и последний
промежуточный шаг в итерации Ньютона—Рафсона для улучшения точности вы-
числения обратной величины или обратной величины квадратного корня, произ-
водимых командами PFRCP и PFSQRT соответственно.
Поведение этой команды зависит только от комбинации исходных операндов,
один из которых (приемник) является результатом выполнения команды PFRCPIT1
или PFRSQIT1 и второй операнд (источник) — результатом выполнения команды
PFRCP или PFRSQRT.
PFRSQIT1 приемник, источник
PFRSQIT1 (Packed Floating-point Reciprocal SQuare root, first ITeration step) —
первое приближение обратного значения квадратного корня упакованного значе-
ния с плавающей точкой.
Машинный код: Of 0f/a7
Действие: PFRSQIT1 — векторная команда, выполняющая первый промежуточ-
ный шаг в итерации Ньютона—Рафсона для улучшения приближения обратного
значения квадратного корня, производимого командой PFSQRT (второй и послед-
ний шаг завершает вычисление с точностью 24 бита).
Следующий пример показывает место команд PFMUL и PFRSQIT 1 в последовательности
команд, используемых для вычисления выражения a=l/sqrt(b) с точностью 24 бита:
Х° = PFRSQRT(b)
X1 = PFMULCX0. Х°)
X2 = PFRSQITKb, XI)
а = PFRCPIT2(X2. Х°)
Поведение этой команды определяется комбинацией операндов, один из которых
является также операндом команды PFRSQRT, а другой получают в результате
выполнения команды PFMUL.
PFRSQRT приемник, источник
PFRSQRT (Floating-point Reciprocal SQuare RooT approximation) — приближе-
ние обратной величины квадратного корня значения с плавающей точкой.
Машинный код: Of Of/97
474
Приложение 1. Команды процессоров х86
Действие: PFRSQRT — скалярная команда, возвращающая обратное значение квад-
ратного корня невысокой точности. Результат выполнения команды копируется
в младшую и старшую половину 64-битного результата:
ЭлементПриемника[31:0] = reciprocal square гоо1(ЭлементИсточника[31:0])
ЭлементПриемника[63:32] = reciprocal square гоо1(ЭлементИсточника[31:0])
Исходный операнд имеет 24-битную мантиссу, а результат — точность 15 бит.
Отрицательные операнды обрабатываются аналогично положительным. Знак ре-
зультата совпадает со знаком исходного операнда. Увеличение точности (до 24 бит)
мантиссы требует двух дополнительных команд — PFRSQIT1 и PFRCPIT2. Следую-
щий пример показывает место команды PFRSQRT в последовательности команд,
используемых для вычисления выражения a=l/sqrt(b) с точностью 24 бита:
Х° = PFRSQRT(b);
X1 = PFMUL(X°, Х°):
X2 - PFRSQITKb, X1);
а - PFRCPIT2CX2, Х°).
PFSUB приемник, источник
PFSUB (Packed Floating-point SUBtraction) — упакованное вычитание двух пар
элементов с плавающей точкой.
Действие: упакованное вычитание двух пар элементов с плавающей точкой опе-
рандов источник и приемник:
ЭлементПриемника=ЭлементПриемника-ЭлементИсточника
Машинный код: Of 0f/9a
PFSUBR приемник, источник
PFSUBR (Packed Floating-point Reverse SUBtraction) — упакованное обратное
вычитание двух пар элементов с плавающей точкой.
Действие: упакованное обратное вычитание двух пар элементов с плавающей
точкой одинарной точности операндов источник и приемник:
ЭлементПриемника= ЭлементИсточника-ЭлементПриемника
Машинный код: Of Of/aa
PI2FD приемник, источник
PI2FD (Packed 32-bit Integer to Floating-point conversion) — преобразование упа-
кованных 32-битных целочисленных значений.
Действие: преобразование упакованных 32-битных целочисленных значений
операнда источник в эквивалентные значения с плавающей точкой операнда
приемник:
ЭлементПриемника= f1 oat(ЭлементИсточника)
П1.7. Расширение набора команд 3DNow!™ и ММХ™ для AMD Athlon™
475
Если в результате преобразования получается вещественное значение, мантисса
которого превышает по величине максимально допустимую, она усекается.
Машинный код: Of Of/Od
PMULHRW приемник, источник
PMULHRW (MULtiply signed packed 16-bit values with Rounding and store the
High 16 bits) — умножение с округлением упакованных знаковых 16-битных зна-
чений и сохранением старших 16 бит результата.
Машинный код: Of 0f/b7
Действие: команда умножает четыре знаковых целочисленных слова операнда
источник на четыре знаковых целочисленных слова операнда приемник. После
умножения команда PMULHRW складывает младшие 16 бит 32-битного результата,
округленного в большую сторону, со значением 8000h. Старшие 16 бит резуль-
тата сохраняются в операнде приемник,
PREFETCH источник
PREFETCHW источник
PREFETCH/PREFETCHW Prefetch processor cache line into LI data cache (Dcache) —
выборка строки данных с упреждением из кэша процессора в кэш данных.
Синтаксис: PREFETCH(w) mem8
Машинный код: OF 0D
Действие: команда загружает строку кэша процессора в кэш данных. Адрес этой
строки определяется операндом источник. Для процессора AMD размер строки —
32 байта. Команда PREFETCH загружает строку кэша, даже если адрес mem8 не
совпадает с началом строки (хотя некоторые модели микропроцессора, включая
семейство процессоров AMD-Кб, могут выполнять заполнение кэша, начиная от
промаха обращения в кэш или адреса mem8). Если происходит удачное обраще-
ние в кэш (строка уже находится в кэше данных) или обнаружена ошибка памяти,
цикл шины не инициируется и команда обрабатывается как NOP.
П1.7. Расширение набора команд 3DNow!™
и ММХ™ для микропроцессора AMD Athlon™
С появлением микропроцессора AMD Athlon™ технология 3DNowI™ поднялась
на следующий уровень эффективности и функциональных возможностей. В про-
цессоре AMD Athlon добавлено 24 новых команды к существующему набору ко-
манд 3DNow! и ММХ, из которых 19 новых команд, расширяющих возможности
существующей технологии ММХ, приведены в показанной ниже таблице. Они
являются аналогами соответствующих команд расширения ММХ микропроцес-
сора Pentium (см. раздел «Команды блока ММХ»).
476
Приложение 1. Команды процессоров х86
Расширение технологии ММХ™
Имя команды Машинный код Имя команды Машинный код
MASKMOVQ 0FF7 PMOVMSKB 0FD7
MOVNTQ 0FE7 PMULHUW 0FE4
PAVGB OFEO PREFETCHNTA OF 18 О1
PAVGW OF E3 PREFETCHTO OF 18 11
PEXTRW 0FC5 PREFETCHT1 OFh 18h21
PINSRW 0FC4 PREFETCHT2 0F18 31
PMAXSW OF Ее PSADBW 0FF6
PMAXUB OF De PSHUFW OF 70
PMINSW OFEa SFENCE OFAE/7
PMINUB OF Da
1 Цифра после машинного кода обозначает различные режимы выбора с упреждением в байте ModR/M.
Пять новых команд, расширяющих возможности 3DNow! технологии DSP, при-
ведены ниже и полностью описаны в этом разделе.
Расширение набора команд 3DNow!™
Имя команды Машинный код Имя команды Машинный код
PF2IW 0F0F/1C PI2FW 0F0F/0C
PFNACC 0F0F/8A PSWAPD 0F0F/BB
PFPNACC 0F0F/8E
ПРИМЕЧАНИЕ ----------------------------------------------------
По пункту «Синтаксис» соглашения аналогичны описанию команд 3DNow! (см. раздел «Ко-
манды 3DNow!™»). Список исключений у всех команд одинаков, поэтому пункт «Исключения»
имеется только у команды pf2iw.
PF2IW приемник, источник
PF2IW (Packed Floating-point to Integer Word conversion with sign extend) — пре-
образование с усечением и расширением знака вещественных значений одинар-
ной точности упакованных элементов операнда источник в 16-битные упакован-
ные целочисленные элементы операнда приемник.
Машинный код: Of Of/ 1с
Действие: преобразование осуществляется в соответствии с таблицей.
Элемент источника
Элемент приемника
О
Допустимое значение, | источник | < 1
О
О
П1.7. Расширение набора команд 3DNow!™ и ММХ™ для AMD Athlon™
477
Элемент источника Элемент приемника
Допустимое значение, -32768<источник=-1 Допустимое значение, 1 <=источник<32768 Допустимое значение, источник>=32768 Допустимое значение, источник<=-32768 Неподдерживаемый формат Округленный к нулю источник Округленный к нулю источник 0x0000_7FFF 0xFFFF_8000 Не определен
Исключения: РЕ: #UD: 10, #NM: 1; #MF; #SS(0): 1; #GP(0): 2; #AC: 4; RM: #UD: 17;
#NM: 3; #MF; #GP: 13; #AC; VM: #UD: 15; #NM: 3; #MF; #GP(0): 25.
PFNACC приемник, источник
PFNACC (Packed Floating-point Negative ACCumulate) — упакованное отрица-
тельное накопление с плавающей точкой.
Машинный код: Of 0f/8a
Действие: команда производит отрицательное накопление из двух двойных слов
операндов приемник и источник'.
ЭлементПриемника[31 0]=ЭлементПриемника[31 0]-ЭлементПриемника[63 32]
ЭлементПриемника[63 32]=ЭлементИсточника[31 0]-ЭлементИсточника[63 32]
PFPNACC приемник, источник
PFPNACC (Packed Floating-point mixed Positive-Negative ACCumulate) — смешан-
ное отрицательное и положительное накопление.
Машинный код: Of 0f/8e
Действие: команда выполняет смешанное отрицательное и положительное накоп-
ление двух двойных слов операндов приемник и источник'.
ЭлементПриемника[31 0]=ЭлементПриемника[31 0]-ЭлементПриемника[63 32]
ЭлементПриемника[63 32]=ЭлементИсточника[31 0]+ЭлементИсточника[63 32]
PI2FW приемник, источник
PI2FW (Packed 16-bit Integer to Floating-point conversion) — преобразование
16-битных значений упакованных элементов.
Машинный код: Of Of/Oc
Действие: преобразование 16-битных значений упакованных элементов опе-
ранда источник в вещественные значения одинарной точности операнда при-
емник:
ЭлементПриемника[31 0]=Т1оа1(ЭлементИсточника[15 0])
ЭлементПриемника[63 32]=Т1оа1(ЭлементИсточника[47 32])
478
Приложение 1. Команды процессоров х86
PSWAPD приемник, источник
PSWAPD (Packed swap doubleword) — перестановка младшего и старшего двойно-
го слова.
Машинный код: Of Of/bb
Действие: перестановка младшего и старшего двойного слова операнда источник'.
ЭлементПриемника[63 32]=ЭлементИсточника[31 0]
ЭлементПриемника[31 0]=ЭлементИсточника[63 32]
П1.8. Исключения
В данном разделе содержатся сведения об исключениях, возникающих при работе
команд микропроцессора Intel Pentium III. В предыдущих разделах этого прило-
жения для большинства команд приводился список исключений, которые могли
возникнуть при их работе в разных режимах функционирования микропроцессо-
ра. Чтобы связать информацию об исключениях в этом разделе с их описанием
для конкретной команды, в книге использована простая система кодировки. Суть
ее состоит в следующем. Ниже все исключения группируются в соответствии с
тем режимом работы микропроцессора, в котором они возникают. Внутри этих
групп исключения группируются в соответствии с номером вектора прерывания,
с помощью которого микропроцессор сигнализирует о возникновении исключения.
Далее для этого вектора все возможные причины возникновения исключений
пронумерованы (некоторые номера в последовательности могут отсутствовать,
что не является ошибкой или упрощением). Эти номера и приводятся в описани-
ях исключений в командах.
П1.8.1. Общие исключения (для всех
режимов) — вектор прерывания 13
Причина Описание причины
1 Исключение общей защиты при отсутствии выравнивания по 16-байтовой
границе (независимо от сегмента)
2 Если обнаружение исключений запрещено, исключение общей защиты сообщает,
что адрес не выровнен по 16-байтовой границе. Если исключение #АС разрешено
(и CPL равно 3), возникновение #АС не гарантировано, так как это зависит от
реализации процессора. Во всех подобных случаях для обнаружения нарушений
выравнивания необходимо использовать исключение общей защиты. Кроме того,
значение границы выравнивания, при несоблюдении которой возникает #АС,
зависит от реализации процессора (для Pentium III это 16 байт), в то время как
#GP возникает при нарушении границы выравнивания 4/8/16 байт
3 Исключение общей защиты при отсутствии выравнивания по 16-байтовой
границе, включая невыровненную ссылку в пределах сегмента стека
П1.8. Исключения
479
П1.8.2. Исключения защищенного режима (РМ)
#GP(0) — вектор прерывания 13. Исключение общей защиты
Причина Описание причины
1 Адресат расположен в сегменте, недоступном для записи
2 Исполнительный адрес операнда памяти расположен вне пределов сегментов CS, DS, ES, FS или GS
3 Регистры CS, DS, ES, FS или GS используются для обращения к памяти и при этом содержат нулевой селектор сегмента
4 Операнд приемник указывает на сегмент, недоступный для записи
5 Регистры DS, ES, FS или GS содержат нулевой селектор сегмента
6 Целевое смещение в операнде приемник расположено вне нового предела сегмента кода
7 Селектор сегмента в операнде приемник нулевой
8 Селектор сегмента кода в шлюзе нулевой
9 CPL больше (имеет меньшие привилегии), чем IOPLтекущей программы или процедуры
10 CPL больше 0
12 CPL больше (имеет меньшие привилегии), чем уровень привилегий ввода/вывода (IOPL), и любой из соответствующих битов разрешения ввода/вывода в TSS для порта ввода/ вывода, к которому производится обращение, установлен в единицу
13 Некорректный исполнительный адрес операнда памяти в сегменте ES
14 Адрес команды в таблице IDT или в шлюзе прерывания, ловушки или задачи - указывает за пределы сегмента кода
15 Код возврата или селектор сегмента стека нулевые
16 Команда возврата расположена вне пределов вызывающего сегмента кода
17 Смещение, по которому осуществляется переход, расположено вне пределов сегмента кода
18 Смещение целевого операнда в шлюзе вызова или TSS расположено вне пределов сегмента кода
19 Селектор сегмента в операнде приемник, шлюзе вызова, шлюзе задачи или TSS нулевой
21 В регистр SS загружается нулевой селектор
24 Регистр сегмента содержит нулевой селектор сегмента
25 Операнд источник расположен в сегменте, недоступном для записи
26 Значение в ЕСХ определяет зарезервированный или неопределенный MSR-адрес
27 Текущий уровень привилегий ненулевой, 6htCR4.PCE=0
28 Значение в регистре ЕСХ не равно 0 или 1
29 Установлен 6htCR4.TSD, CPL больше нуля
30 Команда возврата расположена вне пределов сегмента кода возврата
продолжение^
480
Приложение 1. Команды процессоров х86
(продолжение)
Причина Описание причины
31 Исполнительный адрес операнда в памяти расположен вне пределов сегмента ES
32 Регистр ES содержит нулевой селектор
33 Сформирован некорректный исполнительный адрес операнда памяти в сегменте ES
34 SYSENTER_CS_MSR содержит нуль
35 CPL ненулевой
36 Регистр сегмента загружается селектором сегмента, который указывает на сегмент данных, недоступный для записи
37 Некорректный исполнительный адрес операнда памяти в сегменте CS, DS, ES, FS или GS
38 Некорректный исполнительный адрес операнда памяти в сегменте CS, DS, ES, FS или GS, или сделана попытка загрузки ненулевых значений в зарезервированные биты регистра MXCSR
39 Сделана попытка записи недопустимых разрядных комбинаций в CR0 (к примеру, установка флага PG в 1, когда флаг РЕ установлен в 0, или установка флага CD в 0, когда флаг NE установлен в 1)
40 Сделана попытка записи 1 в любой зарезервированный бит CR4
41 Сделана попытка записи зарезервированных бит в таблицу указателей каталога страницы, когда флаги CR4.PAE и CR0.PG установлены в 1
42 Операнд в памяти (независимо от сегмента) не выровнен на границу 16 байт
#GP(selector) — вектор прерывания 13. Исключение общей защиты
Причина Описание причины
1 Индекс селектора сегмента расположен вне пределов таблицы дескрипторов
2 Дескриптор сегмента, указанный селектором сегмента в операнде приемник, не является дескриптором подчиненного или неподчиненного сегмента кода, шлюза вызова, задачи или сегмента TSS
3 Для неподчиненного сегмента кода DPL не равен CPL, или RPL больше, чем CPL
4 DPL для подчиненного сегмента кода больше, чем CPL
5 DPL из шлюза вызова, задачи или сегмента TSS меньше, чем CPL или RPL селектора шлюза вызова, задачи или сегмента TSS
6 Дескриптор сегмента для селектора сегмента из шлюза вызова не указывает на то, что это сегмент кода
7 Селектор сегмента из шлюза вызова — вне пределов дескрипторной таблицы
8 DPL для сегмента кода, полученного из шлюза вызова, больше, чем CPL
9 Селектор сегмента для TSS имеет бит локальный/глобальный, установленный как локальный
10 Дескриптор сегмента TSS определяет, что TSS занят или недоступен
11 Индекс селектора шлюза прерывания, ловушки, задачи, сегмента кода или сегмента TSS — вне пределов дескрипторной таблицы
12 Селектор сегмента в шлюзе прерывания, ловушки или задачи — нулевой
П1.8. Исключения
481
Причина Описание причины
14 Номер вектора прерывания — вне пределов таблицы IDT
15 Дескриптор таблицы IDT — не дескриптор прерывания, ловушки или задачи
16 Прерывание сгенерировано командой int n, int 3 или into, и DPL дескриптора прерывания, ловушки или задачи — меньше, чем CPL
17 Селектор сегмента в шлюзе прерывания или ловушки не указывает на дескриптор сегмента для сегмента кода
20 Индекс селектора сегмента — вне пределов дескрипторной таблицы
21 RPL селектора сегмента кода, куда будет возвращено управление, больше, чем CPL
22 DPL подчиненного сегмента кода больше, чем RPL селектора сегмента кода, в который возвращается управление
23 DPL для неподчиненного сегмента кода не равен RPL селектора сегмента кода
24 DPL дескриптора сегмента стека не равен RPL селектора сегмента кода, куда осуществляется возврат
25 Сегмент стека — сегмент данных, не доступный по записи
26 RPL селектора сегмента стека не равен RPL селектора сегмента кода, куда осуществляется возврат
27 Дескриптор сегмента для сегмента кода не указывает, что это кодовый сегмент
30 Дескриптор сегмента для селектора сегмента в шлюзе задачи не указывает на доступный TSS
33 Загружается регистр SS, и выполняется любое из следующих условий: индекс селектора сегмента не в пределах дескрипторной таблицы, RPL селектора сегмента не равен CPL, сегмент — не доступный по записи сегмент данных, DPL не равен CPL
34 Если регистры DS, ES, FS или GS загружаются ненулевым селектором сегмента и выполняется любое из следующих условий: индекс селектора сегмента выходит за пределы дескрипторной таблицы; сегмент не является ни сегментом данных, ни читаемым сегментом кода; сегмент — сегмент данных или неподчиненный сегмент кода и RPL и CPL больше, чем DPL
35 Селекторный операнд не указывает на таблицу GDT, или если вход в GDT — не соответствует LDT. Селектор сегмента — вне пределов GDT
36 Селектор источник указывает на сегмент, который не является сегментом TSS, или это сегмент TSS задачи, который помечен как занятый
37 Селектор указывает на таблицу LDT или за пределы GDT
38 Индекс селектора сегмента указывает за пределы дескрипторной таблицы
39 Загружается регистр SS, a RPL селектора сегмента и DPL дескриптора сегмента не равны CPL
40 Регистр SS загружается селектором недоступного по записи сегмента данных
41 Регистры DS, ES, FS и GS загружаются селектором сегмента, не являющегося сегментом данных или читаемым сегментом кода
42 Загружаются регистры DS, ES, FS или GS селектором сегмента данных или неподчиненного сегмента кода, но RPL и CPL больше, чем DPL
43 RPL селектора сегмента кода, в который возвращается управление, меньше CPL
продолжение#
482
Приложение 1. Команды процессоров х86
(продолжение)
Причина Описание причины
44 Индекс селектора сегмента кода или стека, которым возвращается управление, не в пределах дескрипторной таблицы
45 Дескриптор сегмента кода, которому возвращается управление, не указывает на сегмент кода
46 Сегмент кода, которому возвращается управление, является неподчиненным сегментом кода, и DPL его дескриптора не равен RPL селектора
47 Сегмент кода, которому возвращается управление, является подчиненным, и DPL его дескриптора больше, чем RPL селектора
49 RPL селектора сегмента стека не равен RPL селектора сегмента кода, которому возвращается управление
50 DPL дескриптора сегмента стека не равен RPL селектора сегмента кода, которому возвращается управление
#SS(0) — вектор прерывания 12. Ошибка стека
Причина Описание причины
1 2 Исполнительный адрес операнда памяти указывает за пределы сегмента SS При записи адреса возврата, флагов или кода ошибки в стек производится выход за границы сегмента стека, и не происходит его переключения
4 5 Новое значение SP или регистра ESP указывает за пределы сегмента стека При записи адреса возврата, параметров или указателя сегмента стека в стек превышается граница сегмента стека, и не происходит его переключения
6 7 9 12 13 Вершина стека вне его пределов Регистр ЕВР указывает на адрес вне пределов текущего сегмента стека Начальный или конечный адрес стека расположен вне его пределов Сегмент стека, которому возвращается управление, отсутствует в памяти Некорректный адрес в сегменте SS
#SS(selector) — вектор прерывания 12. Ошибка стека
Причина Описание причины
1 Загружается регистр SS, и соответствующий сегмент отмечен как отсутствующий в памяти
2 При переключении стека превышается граница нового сегмента стека при записи адреса возврата, флагов, кода ошибки или указателя сегмента стека
3 При переключении стека недостаточно памяти для адреса возврата, параметров или указателя сегмента стека
# NM — вектор прерывания 7. Отсутствие устройства (сопроцессора)
Причина Описание причины
1 2 3 CR0.EM=1 nnnCR0.TS=1 CR0.MP=1 nCR0.TS=1 CR0.TS=1
П1.8. Исключения
483
# NP — вектор прерывания 11. Отсутствие сегмента
Причина Описание причины
1 Регистр DS, ES, FS или GS загружается селектором сегмента, который отмечен как отсутствующий
2 Сегмент кода или TSS, сегмент для селектора в шлюзе прерывания, ловушки, задачи отсутствует
3 Сегмент кода или стека, куда возвращается управление, отсутствует
4 Сегмент кода, к которому производится обращение, отсутствует
5 Шлюз вызова, задачи или TSS отсутствует
6 Регистры DS, ES, FS или GS загружаются ненулевым селектором сегмента, и сегмент отмечен отстствующим
7 Дескриптор LDT отсутствует
8 TSS отмечен как отсутствующий
#TS(selector) — вектор прерывания 10. Неправильный TSS
Причина Описание причины
1 Адрес в соответствии со значениями селектора нового сегмента стека и ESP из сегмента TSS указывает за пределы сегмента стека
2 Новый селектор сегмента стека нулевой
3 RPL селектора нового сегмента стека в TSS не равен DPL дескриптора сегмента кода
4 DPL дескриптора сегмента стека для нового сегмента стека не равен DPL дескриптора сегмента кода
5 Новый сегмент стека представляет собой недоступный по записи сегмент данных
6 Индекс селектора сегмента для сегмента стека расположен за пределами таблицы дескрипторов
7 RPL селектора сегмента стека в TSS не равен DPL сегмента кода, к которому производится обращение посредством шлюза ловушки или прерывания
8 DPL дескриптора сегмента стека, указанного селектором сегмента стека в TSS, не равен DPL дескриптора сегмента кода для шлюза прерывания или ловушки
9 Селектор сегмента стека в TSS нулевой
10 Сегмент стека из TSS представляет собой недоступный по записи сегмент данных
11 Индекс селектора сегмента для сегмента стека расположен вне пределов таблицы дескрипторов
#UD — вектор прерывания 6. Неправильный (неопределенный) код операции
Причина Описание причины
1 Второй операнд не расположен в памяти
2 Операнд приемник не расположен в памяти
продолжение &
484
Приложение 1. Команды процессоров х86
(продолжение)
Причина Описание причины
3 Операнд является регистром
4 Исходный операнд не расположен в памяти
5 Префикс LOCK используется с командой, не перечисленной в разделе (см. описание префикса LOCK). Другие исключения могут быть сгенерированы командой, которой предшествует префикс LOCK
6 Предпринята попытка загрузки регистра CS
7 Предпринята попытка выполнить команду, когда процессор работает не в режиме SMM
8 Операнд приемник представляет собой регистр
9 Команда гарантированно вызывает исключение недопустимого кода операции во всех режимах функционирования микропроцессора
10 CR0.EM=1
11 Ошибка при немаскированном численном SIMD-исключении (CR4.OSXMMEXCPT=0)
12 CR4.OSFXSR(6ht9) = 0
13 CPUID.XMM(6ht 25 EDX)=0
14 Бит CR4.DE=1, и выполнена команда mov с использованием DR4 или DR5
15 В результате работы команды CPUID(EAX=1) флаг SSE2 (бит 26 EDX) равен 0
16 В результате работы команды CPUID(EAX=1) флаг CLFSH (бит 19 EDX) равен 0
Другие исключения защищенного режима
Исключение Номер вектора Описание причины
#AC(0) Alignment Check 17 Невыровненная ссылка на память. Чтобы произошло исключение #АС, должны быть истинны три условия: установлен CR0.AM; установлен EFLAGS.AC; CPL=3
#AC(0)_cpl3 17 Сделана невыровненная ссылка на память при активном режиме проверки выравнивания и текущем уровне привилегий равном 3
#ХМ SIMD Floating- Point Numeric Error 19 Ошибка при немаскированном численном SIMD- исключении (CR4.OSXMMEXCPT=1)
#DB Debug 1 Производится обращение к любому из регистров отладки, в то время как флаг DR7.GD=1
#DE Divide Error 0 Исходный операнд (делитель) равен нулю. Результат (частное) слишком большой для адресата
#MF Floating-Point Error (Math Fault) 16 Имеется задержанное исключение сопроцессора
#BR BOUND Range Exceeded 5 Обнаружено нарушение границы
П1.8. Исключения
485
П1.8.3. Исключения реального режима (RM) #GP — вектор прерывания 13. Исключение общей защиты
Причина Описание причины
1 Исполнительный адрес операнда в памяти выходит за пределы сегмента CS, DS, ES, FS или GS
2 Смещение адресата расположено вне пределов сегмента кода
3 Номер вектора прерываний расположен вне пределов таблицы IDT
4 Указатель команды, на которую производится возврат, расположен вне пределов вызывающего сегмента кода
5 Смещение перехода расположено вне пределов сегмента CS или вне диапазона адресов от Одо FFFFH. Это может происходить при использовании префикса 32-битного размера адреса
6 Регистр ЕВР указывает на адрес вне диапазона от 0 до Offffh
7 Регистры ESP или SP содержат 7,9,11,13,15
8 Значение в ЕСХ определяет зарезервированный или несуществующий MSR-адрес
9 ФлагСА4.РСЕ=0
10 Значение в регистре ЕСХ не равно 0 или 1
11 ФлагСР4.Т8О=1
12 Исполнительный адрес операнда в памяти расположен вне пределов сегмента ES
13 Любая часть операнда находится вне диапазона адресов от 0 до FFFFH
14 Предпринята попытка записи 1 в любой зарезервированный бит в CR4
15 Текущий режим работы процессора — незащищенный
16 Операнд в памяти (независимо от сегмента) не выровнен на границу 16 байт
# NM — вектор прерывания 7. Отсутствие устройства (сопроцессора)
Причина Описание причины
1 CR0.EM=1 илиСР0.Т8=1
2 CR0.MP=1 и CR0.TS=1
3 CR0.TS=1
#SS — вектор прерывания 12. Ошибка стека
Причина Описание причины
1 Исполнительный адрес операнда в памяти расположен вне пределов сегмента SS
2 Новое значение регистров SP или ESP расположено вне пределов сегмента стека
3 При записи в стек возникает нарушение его границ
4 При записи в стек адреса возврата, флагов или кода ошибки превышаются его границы (переключение стека не производится)
5 Вершина стека расположена вне его пределов
6 Адрес начала или конца стека расположен вне его пределов
486
Приложение 1. Команды процессоров х86
#UD — вектор прерывания 6. Неправильный (неопределенный) код операции
Причина Описание причины
1 Команда ARPL не распознается в реальном режиме
2 3 4 5 Второй операнд не расположен в памяти Операнд приемник не расположен в памяти Операнд является регистром Команда LAR не распознается в реальном режиме
6 Операнд источник не расположен в памяти
7 Команда LLDT не распознается в реальном режиме
8 Префикс LOCK используется с командой, не перечисленной в разделе (см. описание префикса LOCK). Другие исключения могут быть сгенерированы командой, которой предшествует префикс LOCK
9 Команда LSL не распознается в реальном режиме
10 Команда LTR не распознается в реальном режиме
11 Предпринята попытка загрузки регистра CS
12 Предпринята попытка выполнить команду, когда процессор не работает в режиме SMM
13 Операнд приемник является регистром
14 Команда SLDT не распознается в реальном режиме
15 16 17 Команда STR не распознается в реальном режиме Команды VERR И VERW не распознаются в реальном режиме CR0.EM=1
18 19 20 Ошибка при немаскированном численном SIMD-исключении (CR4.OSXMMEXCPT=0) CR4.OSFXSR (бит9)=0 CPUID.XMM (бит 25 EDX)=0
21 Бит CR4.DE=1, и выполнена команда mov с использованием DR4 или DR5
22 В результате работы команды CPUID (ЕАХ=1) флаг SSE2 (бит 26 EDX) равен 0
23 В результате работы команды CPUID (ЕАХ=1) флаг CLFSH (бит 19 EDX) равен 0
Другие исключения реального режима
Исключение Номер вектора Описание причины
#АС Alignment Check 17 Невыровненная ссылка к памяти
#BR BOUND Range Exceeded 5 Нарушение границы
#DB Debug 1 Производится обращение к любому из регистров отладки, в то время как флаг DR7.GD=1
#DE Divide Error 0 Исходный операнд (делитель) равен нулю. Результат (частное) слишком большой для адресата
#MF Floating-Point Error (Math Fault) 16 Имеется задержанное исключение сопроцессора
#XM SIMD Floating- Point Numeric Error 19 Ошибка при немаскированном численном SIMD-исключении (CR4.OSXMMEXCPT=1)
П1.8. Исключения
487
П1.8.4. Исключения режима виртуального 8086 (VM)
#GP(0) — вектор прерывания 13. Исключение общей защиты
Причина Описание причины
1 Исполнительный адрес операнда памяти выходит за пределы сегмента CS, DS, ES, FS или GS
2 CPL больший (имеет меньшие привилегии), чем IOPL текущей программы или процедуры
3 CPL больше 0
5 Любой из битов разрешения ввода-вывода в TSS для порта ввода-вывода, к которому производится обращение, равен единице
6 (Для команд int n, into, bound.) IOPL меньше 3, или DPL дескриптора шлюза прерывания, ловушки или задачи не равен 3
7 Указатель команды в IDT или в шлюзе прерывании, ловушки или задачи расположен вне пределов сегмента кода
8 Команда INVD не может быть выполнена в режиме виртуального 8086
9 Команда INVLPG не может быть выполнена в режиме виртуального 8086
10 Указатель команды возврата расположен за пределами сегмента кода, которому возвращается управление
11 IOPL не равен 3
12 Смещение перехода расположено вне пределов сегмента CS или вне диапазона адресов от 0 до FFFFH. Эта ситуация может возникнуть, если используется префикс 32-битного размера адреса
13 Целевой операнд расположен вне пределов сегмента кода
14 Регистр ЕВР указывает на адрес вне диапазона исполнительных адресов от Одо Offffh
15 Уровень привилегий ввода-вывода меньше 3
16 Предпринята попытка выполнения команды POPF/POPFD с префиксом изменения размера операнда
17 Регистры ESP или SP содержат 7,9,11,13,15
18 Команда RDMSR не распознается в режиме виртуального 8086
19 ФлагСВ4.РСЕ=0
20 Значение в регистре ЕСХ не равно 0 или 1
21 <t>narCR4.TSD=0
22 Исполнительный адрес операнда в памяти расположен вне предела сегмента ES
23 Текущий режим работы процессора — незащищенный
24 Команда WBINVD не может быть выполнена в режиме виртуального 8086
25 Любая часть операнда находится вне диапазона адресов от 0 до ffffh
26 Команда WRMSR не распознается в режиме виртуального 8086
27 Регистры отладки не могут быть загружены или считаны в режиме виртуального 8086
28 Эти команды не могут быть выполнены в режиме виртуального 8086
488
Приложение 1. Команды процессоров х86
#GP(selector) — вектор прерывания 13. Исключение общей защиты
Причина Описание причины
1 Селектор сегмента в шлюзе прерывания, ловушки, задачи нулевой
2 Индекс селектора сегмента кода, TSS, шлюза прерывания, ловушки или задачи расположен вне пределов таблицы дескрипторов
3 Номер вектора прерываний вне пределов IDT
4 Дескриптор таблицы IDT не является дескриптором прерывания, ловушки или задачи
5 Прерывание сгенерировано командой int п, и DPL дескриптора шлюза прерывания, ловушки или задачи меньше, чем CPL
6 Селектор сегмента в шлюзе прерывания или ловушки не указывает на дескриптор сегмента кода
7 Селектор сегмента для TSS имеет установленный бит локальный/глобальный как локальный
# NM — вектор прерывания 7. Отсутствие устройства (сопроцессора)
Причина Описание причины
1 CR0.MP=1 и CR0.TS=1
2 CR0.EM=1 илиСП0.Т8=1
3 CR0.TS=1
#SS(0) — вектор прерывания 12. Ошибка стека
Причина Описание причины
1 Исполнительный адрес операнда памяти расположен вне пределов сегмента SS
2 Новое значение в регистре SP или ESP указывает за пределы сегмента стека
3 Вершина стека расположена вне пределов сегмента стека
4 Адрес начала или конца стека расположен вне пределов сегмента стека
#SS(selector) — вектор прерывания 12. Ошибка стека
Причина Описание причины
1 Регистр SS загружается селектором отсутствующего сегмента
2 При записи в стек адреса возврата, флагов, кода ошибки, указателя сегмента стека или данных превышаются границы сегмента стека
#TS(selector) — вектор прерывания 10. Неправильный TSS
Причина Описание причины
1 RPL селектора сегмента стека в TSS не равен DPL сегмента кода, к которому производится обращение посредством шлюза ловушки или прерывания
2 DPL дескриптора сегмента стека для сегмента стека TSS не равен DPL дескриптора сегмента кода для шлюза прерывания или ловушки
П1.8. Исключения
489
Причина Описание причины
3 Селектор сегмента стека в TSS нулевой
4 Сегмент стека в TSS представляет собой недоступный по записи сегмент данных
5 Индекс селектора сегмента для сегмента стека расположен вне пределов таблицы дескрипторов
#UD — вектор прерывания 6. Неправильный (неопределенный) код операции
Причина Описание причины
1 Команда ARPL не распознается в режиме виртуального 8086
2 Операнд приемник не расположен в памяти
3 Команда LAR не может быть выполнена в режиме виртуального 8086
4 Исходный операнд не расположен в памяти
5 Команда LLDT распознана в режиме виртуального 8086
6 Префикс LOCK используется с командой, не перечисленной в разделе (см. описание префикса LOCK). Другие исключения могут быть сгенерированы командой, которой предшествует префикс LOCK
7 Команда LSL не распознается в режиме виртуального 8086
8 9 Команда LTR не распознается в режиме виртуального 8086 Предпринята попытка загрузки регистра CS
10 Предпринята попытка выполнения команды, когда процессор не работает в режиме SMM
11 Операнд приемник является регистром
12 Команда SLDT не распознается в режиме виртуального 8086
13 14 Команда STR не распознается в режиме виртуального 8086 Команды VERR и VERW не распознаются в режиме виртуального 8086
15 16 CR0.EM=1 CR4.OSFXSR (бит9) = 0
17 CPUID.ХММ (бит 25 EDX) = 0
Другие исключения режима виртуального 8086
Исключение Номер вектора Описание причины
#NP(selector) Segment Not Present 11 Сегмент кода или TSS, шлюз прерывания, ловушки, задачи отсутствует в памяти
#OF Overflow 4 Выполнена команда into и установлен флаг OF
#PF(fault-code) Page Fault 14 Отсутствие страницы
#AC(0)_u 17 Сделана невыровненная ссылка на память при активном режиме проверки выравнивания
#AC(0) Alignment Check 17 Разрешена проверка выравнивания и предпринята невыровненная ссылка к памяти (если текущий уровень привилегий равен 3)
продолжение#
490
Приложение 1. Команды процессоров х86
(продолжение)
Исключение Номер вектора Описание причины
#BR BOUND Range Exceeded 5 Нарушение границы
#BP Breakpoint 3 Выполнена команда int 3
#DE Divide Error для адресата 0 Делитель равен 0. Частное слишком велико
#MF Floating-Point Error (Math Fault) 16 Имеется задержанное исключение сопроцессора
П1.8.5. Исключения с плавающей
точкой (NE) — вектор прерывания 16
Мнемоника Название
#IS или #1А Некорректная операция с плавающей точкой: переполнение или антипереполнение стека (#IS); недопустимая арифметическая операция (#1А)
#Z Деление на вещественный ноль
#D Денормализованная операция с плавающей точкой
#0 Численное переполнение с плавающей точкой
#U Численное антипереполнение с плавающей точкой
#Р Неточный результат с плавающей точкой
Приложение 2. Список
сокращений, включая
имена регистров,
структур данных и флагов
БИС Большая (по степени интеграции) ИС, содержащая 100-5000 компонентов
ИС Интегральная схема (чип)
ОЗУ Оперативное запоминающее устройство (RAM)
ОС Операционная система (OS)
ПЗУ Постоянное запоминающее устройство (ROM)
ПК Персональный компьютер (PC)
по Программное обеспечение (Software)
СБИС Сверхбольшая (по степени интеграции) ИС, содержащая более 100 000 компонентов (ULSI)
ТТЛ Транзисторно-транзисторная логика (TTL)
ттлш Транзисторно-транзисторная логика с диодами Шоттки (TTLS)
#АС Alignment Check, исключение контроля выравнивания (вектор 17)
#ВР Breakpoint, прерывание отладки INT 3 (вектор 3)
#BR BOUND Range Exceeded, прерывание по контролю диапазона BOUND (вектор 5)
#D Denormalized Operand, денормализованный операнд FPU или ХММ
#DB Debug, исключение отладки (вектор 1)
#DE Divide Error, исключение деления на 0 (вектор 0)
#DF Double Fault, исключение «двойной отказ» (вектор 8)
#GP General Protection, общее исключение защиты (вектор 13)
#1 Invalid Operation, недействительная операция FPU или ХММ
#MC Machine Check, исключение машинного контроля (вектор 18)
#MF Math Fault, исключение сопроцессора (вектор 16)
#NM No Math Coprocessor, исключение недоступности сопроцессора (вектор 7)
#NP Segment Not Present, исключение отсутствия сегмента (вектор 11)
#0 Overflow, переполнение FPU или ХММ
492
Приложение 2. Список сокращений
#OF Overflow, прерывание по переполнению INTO (вектор 4)
#Р Precision, округление FPU или XMM
#PF Page Fault, исключение по отказу страницы (вектор 14)
#SS Stack-Segment Fault, исключение по сегменту стека (вектор 12)
#TS Invalid TSS, исключение по недопустимому TSS (вектор 10)
#U Underflow, потеря точности FPU или ХММ
#UD Undefined Opcode, исключение по недопустимому коду операции (вектор 6)
#XF ХММ Fault, числовое исключение в блоке ХММ (вектор 19)
#z Zero Divide, деление на нуль ненулевого операнда FPU или ХММ
3DNow! Расширение технологии ММХ, предложенное AMD
A 1. Accessed, флаг обращения к сегменту (в дескрипторе). 2. Accessed, флаг обращения к странице (PDE.5 или РТЕ.5)
AC Alignment Check, флаг контроля выравнивания (EFLAGS. 18)
AF Auxiliary Flag, флаг дополнительного переноса (заема) (EFLAGS.4)
AH Регистр, старшие 8 бит АХ
AL Регистр, младшие 8 бит АХ
AM Alignment Mask, флаг разрешения контроля выравнивания (CR0.18)
APIC Advanced Peripheral Interrupt Controller, усовершенствованный контроллер прерываний
ASCII American Standard Code for Information Interchange, американский стандартный код обмена информацией
AT Advanced Technology, передовая технология; PC с процессорами 80286 и выше
AX Регистр общего назначения (младшие 16 бит ЕАХ)
В Big, флаг разрядности сегмента стека (в дескрипторе)
BASE Поле базового адреса сегмента, 32 бит (в дескрипторе)
BCD Binary Coded Decimal, двоично-десятичный код
BEDODRAM Burst EDO, динамическая память с фиксацией данных в выходном регистре и внутренним счетчиком адреса для пакетного цикла
BH Регистр, старшие 8 бит ВХ
BIOS Basic Input/Output System, базовая система ввода-вывода
BIOS INT BIOS Interrupt, прерывание, обслуживаемое BIOS
BIST Built In Self Test, встроенный тест самопроверки
BL Регистр, младшие 8 бит ВХ
BP Регистр указателя базы (младшие 16 бит ЕВР)
BSP Bootstrap Processor, загрузочный (первичный) процессор в SMP
BTB Branch Target Buffer, буфер таблицы переходов
BX Регистр общего назначения (младшие 16 бит ЕВХ)
C Conforming, флаг конформности (подчиненности) сегмента (в дескрипторе)
CD Cache Disable, флаг запрета кэширования (CR0.30)
Приложение 2. Список сокращений
493
CF Carry Flag, флаг переноса (заема) (EFLAGS.0)
СН Регистр, старшие 8 бит СХ
CISC Complex Instruction Set Computer, компьютер co сложным набором команд (например, на CPU 80x86)
CL Регистр, младшие 8 бит СХ
CMOS Complimentary Metal Oxide Semiconductor, комплиментарная структура металл-оксид-полупроводник (КМОП)
CPL Current Privilege Level, поле текущего уровня привилегий (CS[ 1:0])
CPU Central Processor Unit (центральный процессор)
CRO Управляющий регистр, 32 бит
CR1 Управляющий регистр, не используется
CR2 Регистр линейного адреса отказа страницы, 32 бит
CR3 Регистр базового адреса каталога страниц, 32 бит
CR4 Управляющий регистр, 32 бит
CS Регистр селектора сегмента кода, 16 бит
CW Control Word, регистр управляющего слова FPU, 16 бит
CX Регистр общего назначения (младшие 16 бит ЕСХ)
D 1. Default Operation Size, флаг разрядности операндов (в дескрипторе). 2. Dirty, флаг «грязной» страницы (РТЕ.6)
DE 1. Denormalized Operand Exception, флаг денормализованного операнда FPU(SW.1). 2. Debugging Extensions, флаг расширения отладки (CR4.3)
DF Direction Flag, флаг направления в строковых операциях (EFLAGS. 10)
DH Регистр, старшие 8 бит DX
DI Регистр индекса строки-назначения (младшие 16 бит EDI)
DIB Dual Independent Bus, двойная независимая шина (в Р6)
DIP Dual In-line Package, корпус (микросхемы) с двухрядным расположением штырьковых выводов
DL Регистр, младшие 8 бит DX
DM Denormalized Operand Mask, маска исключения денормализованного операнда FPU (CW. 1)
DMA Direct Memory Access, прямой доступ к памяти
DOS Disk Operating System, дисковая операционная система (ДОС)
DPL Descriptor Privilege Level, поле уровня привилегий сегмента (в дескрипторе)
DR0...3 Регистры линейного адреса точек останова
DR4,5 DR6 Регистры отладки, не используются Регистр состояния контрольных точек
DR7 Регистр управления отладкой
DRAM Dynamic Random-Access Memory, динамическая память
DS Регистр селектора сегмента данных, 16 бит
494
Приложение 2. Список сокращений
DX Регистр общего назначения (младшие 16 бит EDX)
ЕАХ Регистр общего назначения, 32 бит
ЕВР Регистр указателя базы, 32 бит
ЕВХ Регистр общего назначения, 32 бит
ЕСС Error Checking and Correcting Memory, обнаружение и исправление ошибок (в памяти)
ЕСХ Регистр общего назначения, 32 бит
EDI Регистр индекса строки-назначения, 32 бит
EDO DRAM Extended (Enhanced) Data Out DRAM, динамическая память с фиксацией данных в выходном регистре
EDX Регистр общего назначения, 32 бит
EEPROM Electrical Erasable Programmable Read-Only Memory, электрически перезаписываемая постоянная память
EFLAGS Регистр флагов расширенный, 32 бит
EIP Регистр указателя инструкций, 32 бит
EM Processor Extension Emulated, флаг эмуляции сопроцессора (CR0.2)
EPL Effective Privilege Level, эффективный уровень привилегий
EPROM Erasable Programmable Read-Only Memory, стираемая (ультрафиолетовым облучением) перезаписываемая память
ES 1. Регистр селектора сегмента данных, 16 бит. 2. Error Summary Status, общий флаг исключения FPU (SW.7)
ESI Регистр индекса строки-источника, 32 бит
ESP Регистр указателя стека, 32 бит
ET Extension Туре, флаг поддержки инструкций математического сопроцессора (CR0.4)
EV86 Enhanced V86, расширенный режим V86
FIFO First-In, First-Out, «первым пришел — первым обслужен» (дисциплина обслуживания на основе последовательной очереди)
FLAGS Регистр флагов (младшие 16 бит EFLAGS)
FLOPS Floating Point Operations Per Second, количество операций с плавающей точкой, выполняемых за 1 секунду
FP Floating Point, плавающая точка (формат представления чисел)
FPM DRAM Fast Page Mode DRAM, динамическая память с быстрым последовательным доступом в пределах страницы («стандартная» DRAM)
FPU Floating-Point Unit, сопроцессор для обработки чисел с плавающей точкой, то же, что NPU
FRAM Ferroelectric RAM, ферроэлектрическая память (не путать с памятью на магнитных сердечниках)
FRC Functional Redundancy Checking, избыточный контроль функциональности
FS Регистр селектора сегмента данных, 16 бит
G 1. Granularity, бит дробности (в дескрипторе). 2. Global, флаг глобальности страницы (РТЕ.8)
Приложение 2. Список сокращений
495
GDT Global Descriptor Table, глобальная таблица дескрипторов
GDTR Регистр глобальной таблицы дескрипторов, 48 бит
GND GrouND, земля, общий провод питания
GS Регистр селектора сегмента данных, 16 бит
Н High — старший (байт), высокий (уровень сигнала)
IC Integrated Circuit, интегральная схема, чип (ИС)
IC Infinity Control, флаг управления представлением бесконечности в 8087 (CW. 12)
ID Id Flag, флаг доступности инструкции CPUID (EFLAGS.21)
IDT Interrupt Descriptor Table, таблица дескрипторов прерываний
IDTR Interrupt Descriptor Table Register, регистр таблицы дескрипторов прерываний, 48 бит
IE Invalid Operation Exception, флаг недействительной операции FPU (SW.O)
IEEE 1149.1 Интерфейс тестирования JTAG
IF Interrrupt-enable Flag, флаг разрешения прерываний (EFLAGS.9)
IM Invalid Operation Mask, маска исключения недействительной операции FPU (CW.O)
INDEX Поле выбора селектора (Seg[ 15:3])
INT Interrupt, прерывание (вектор прерывания)
IO Input/Output, ввод-вывод
IOPL Input/Output Privilege Level, поле уровня привилегий ввода-вывода, 2 бита (EFLAGS.[13:12])
IP Регистр указателя инструкций (младшие 16 бит EIP)
ISA Industry Standard Architecture, промышленная стандартная архитектура, тип системной шины IBM PC
JTAG Последовательный интерфейс тестирования цифровых устройств (IEEE 1149.1)
L Low — младший (байт), низкий (уровень сигнала)
LDT Local Descriptor Table, локальная таблица дескрипторов
LDTR Регистр селектора локальной таблицы дескрипторов, 16 бит
LIMIT Поле лимита сегмента, 20 бит (в дескрипторе)
LRU Least Recently Used, дольше всех неиспользовавшийся (блок данных в кэше)
LSB Least Significant Bit, младший бит
LSI Large Scale Integration, высокая степень интеграции микросхем (БИС, содержащая 100-5000 компонентов)
MCE Machine-Check Enable, флаг разрешения машинного контроля (CR4.6)
MESI Modified-Exclusive-Shared-lnvalid, протокол поддержания когерентности памяти при наличии кэша, названный по определяемым им состояниям строк: Модифицирована-Исключительна-Разделяема-Недействительна
MFLOPS Million Floating Point Operations Per Second, миллион операций с плавающей точкой за секунду, мера скорости FPU (мегафлопс)
MIPS Mega Instructions Per Second, миллион инструкций (команд процессора) в секунду, мера скорости CPU (мипс)
MMU Memory Management Unit, блок управления памятью
496
Приложение 2. Список сокращений
ММХ MultiMedia Extensions, расширение системы команд CPU для мультимедийных приложений
ММХх Регистры ММХ, 64 бит
МР Monitor Processor Extension, флаг мониторинга сопроцессора (CR0.1)
MSI Medium Scale Integration, малая степень интеграции (ИС из 10-100 компонентов)
MSR Модельно-специфические регистры
MSW Machine Status Word, регистр состояния машины (младшие 16 6htCR0)
MTRR Memory Type Range Registers, регистры определения типов памяти (в составе MSR Р6)
MXCSR Регистр управления и состояния блока ХММ
NE Numeric Error, флаг разрешения генерации исключений от FPU (CR0.5)
NMI Non-Maskable Interrupt, немаскируемое прерывание
NPU Numeric Processor Unit, математический сопроцессор
NPX Numeric Processor Extension, математическое расширение процессора (аналогично NPU)
NT Nested Task Flag, флаг вложенной задачи (EFLAGS. 14)
NVRAM Non-Volatile RAM, энергонезависимая память
NW Not Writethrough, флаг запрета сквозной записи кэша и циклов аннулирования (CR0.29)
OE Overflow Exception, флаг переполнения FPU (SW.3)
OEM Original Equipment Manufacturer, производитель (например, компьютеров); противопоставляется конечному пользователю
OF Overflow Flag, флаг переполнения (EFLAGS. 11)
OM Overflow Mask, маска исключения переполнения FPU (CW.3)
OSFXSR Флаг использования инструкций FXSAVE/FXRSTOR (CR4.9)
OSXMMEXCPT Флаг поддержки операционной системой исключений от блока ХММ (CR4.10)
P 1. Present, флаг присутствия сегмента (в дескрипторе). 2. Present, флаг присутствия страницы (PDE.0 или РТЕ.О)
PAE Physical Address Extension, режим расширения физического адреса до 36 бит; флаг включения режима (CR4.5)
PAT Регистр-таблица атрибутов страниц (MSR)
PB SRAM Pipelined BurstSRAM, пакетно-конвейерная синхронная статическая память
PC 1. Personal Computer, персональный компьютер (ПК), подразумевается совместимость с IBM PC 2. Precision Control, поле управления точностью FPU (CW.[9:8])
PCD 1. Page Cache Disable, флаг запрета кэширования для страницы (PDE.4 или РТЕ.4) 2. Page-Level Cache Disable, флаг запрета кэширования страницы (CR2.4)
PCE Performance-monitoring Counter Enable, флаг разрешения мониторинга производительности (CR4.8)
PCI Peripherial Component Interconnect bus, шина взаимодействия периферийных компонентов
Приложение 2. Список сокращений
497
PDE Page Directory Entry, строка каталога страниц
РЕ 1. Precision Exception, флаг потери точности FPU (SW.5). 2. Protection Enable, флаг разрешения защиты (CRO.O)
PF Parity Flag, флаг паритета (EFLAGS.2)
PG Paging Enanable, флаг включения механизма страничной переадресации (CR0.31)
PGA Pin Grid Array, керамический корпус ИС с матрицей штырьковых выводов
PGE Paging Global Extensions, флаг разрешения глобальности в страничной переадресации (CR4.7)
PIC Programmable Interruption Controller, программируемый контроллер прерываний
РЮ Programming Input/Output, программируемый ввод-вывод
PLL Phase Lock Loop, петля фазовой автоподстройки
РМ Precision Mask, маска исключения потери точности FPU (CW.5)
POST Power On Self Test, тест начального включения
PPGA Plastic Pin Grid Array, термоустойчивый пластмассовый корпус ИС
PQFP Plastic Quad Flat Pack, пластиковый корпус ИС с выводами по сторонам квадрата
PROM Programmable Read-Only Memory, однократно программируемая постоянная память
PS Page Size, флаг размера страницы (PDE.7)
PSE Page Size Extension, флаг расширения размера страницы (CR4.4)
PTE Page Table Entry, строка таблицы страниц
PVI Protected-Mode Virtual Interrupts, флаг разрешения виртуализации флага прерываний (CR4.1)
PWT 1. Page Write Through, флаг сквозной записи для страницы (РОЕ.Зили РТЕ.З). 2. Page-Level Writes Trough, флаг кэширования страницы со сквозной записью (CR0.3)
R Readable, флаг разрешения чтения сегмента (в дескрипторе)
RAM Random Access Memory, память с произвольным доступом (ОЗУ)
RC Rounding Control, поле управления округлением FPU (CW. [11:10])
RF Resume Flag, флаг возобновления выполнения (EFLAGS. 16)
RISC Reduced Instruction Set Computer, компьютер на процессоре с сокращенным набором команд
ROM Read Only Memory, постоянное запоминающее устройство (ПЗУ)
RPL Requested Privilege Level, поле запрашиваемого уровня привилегий (Seg[ 1:0], кроме CS)
SDRAM Synchronous DRAM, синхронная динамическая память (сверхбыстродействующая)
SECC Single Edge Connector Cartridge, картридж с краевым разъемом — конструктив процессора Pentium II
Seg Регистр селектора сегмента (CS, DS, ES, SS, FS или GS)
498
Приложение 2. Список сокращений
SEPP Single Edge Processor Package, конструктив процессора с краевым разъемом (Celeron)
SF 1. Sign Flag, флаг знака (EFLAGS.7). 2. Stack Flag, флаг некорректной операции со стеком FPU (SW.6)
SI Регистр индекса строки-источника (младшие 16 бит ESI)
SIMD Single Instruction Multiple Data, одновременная обработка нескольких единиц данных одной инструкцией (в ММХ-технологии)
SMM System Management Mode, режим системного управления
SMP Symmetrical Multiprocessing, симметричная мультипроцессорная обработка
SMRAM System Management RAM, память, доступная в режиме SMM
SP Регистр указателя стека (младшие 16 бит ESP)
SPGA Staggered PGA, корпус ИС с шахматным расположением выводов
SQFP Small Quad Flat Pack, миниатюрный корпус ИС с выводами по сторонам квадрата
SRAM Static Random Access Memory, статическая память
SS Регистр селектора сегмента стека, 16 бит
SSE Streaming SIMD Extension, потоковое расширение
STx Регистры стека FPU, 80 бит
SW Status Word, регистр слова состояния FPU, 16 бит
Sync Burst SRAM Синхронная пакетная статическая память
TAGx Поле тегов регистра STx FPU
ТАР Test Acess Port, средства доступа диагностического оборудования
TCP Таре Carrier Package, миниатюрный корпус ИС с ленточными выводами
TF Trap Flag, флаг пошагового режима (EFLAGS.8)
TI Table Indicator, флаг выбора таблицы дескрипторов (Seg.2)
TLB Translation Lookaside Buffer, буфер ассоциативной трансляции адресов страниц
TOP Поле указателя вершины стека FPU (SW[ 13:11])
TR Регистр задачи, 16 бит
TRx Регистры тестирования
TS Task Switch, флаг переключения задач (CR0.3)
TSC Time Stamp Counter, счетчик меток реального времени
TSD Time Stamp Disable, флаг ограничения использования инструкции RDTSC (CR4.2)
TSS Task Status Segment, сегмент состояния задачи
TTL Transistor-Transistor Logic, транзисторно-транзисторная логика (ТТЛ)
Type U Поле типа сегмента (в дескрипторе) User, флаг привилегии защиты страницы (PDE.2 или РТЕ.2)
UE Underflow Exception, флаг переполнения снизу FPU (SW.4)
ULSI Ultra Large Scale Integration, сверхбольшая степень интеграции, более 100 000 компонентов (СБИС)
Приложение 2. Список сокращений
499
им Underflow Mask, маска исключения переполнения снизу FPU (CW.4)
UMA 1. Upper Memory Area, область верхней памяти PC. 2. Unified Memory Architecture, архитектура с унифицированной (однородной) памятью
UMB Upper Memory Block, блок верхней памяти
V86 Virtual 8086 Mode, режим виртуального 8086
VIF Virtual Interrupt Flag, виртуальный флаг разрешения прерывания (EFLAGS. 19)
VIP Virtual Interrupt Pending, флаг виртуального запроса прерывания (EFLAGS.20)
VM Virtual 8086 Mode, флаг режима виртуального 8086 (EFLAGS. 17)
VME Virtual-8086 Mode Extensions, флаг разрешения режима EV86 (CR4.0)
VRT Voltage Reduction Technology, технология изготовления логических ИС с пониженным напряжением питания
W 1. Writeable, флаг разрешения записи в сегмент (в дескрипторе) 2. Writeable, флаг разрешения записи в странице (PDE. 1 или РТЕ. 1)
WB Write Back, обратная запись (алгоритм кэширования)
WP Write Protect, флаг разрешения защиты страниц памяти (CR0.16)
WT Write Through, сквозная запись (алгоритм кэширования)
х86 Семейство процессоров, совместимых по системе команд с 8086/8088:8088, 8086,80286,80386,486, Pentium, Pentium Pro Pentium II и т. д.
ХММ Блок регистров SIMD с плавающей точкой
XT Extended Technology, расширенная технология, компьютеры на процессоре 8086
ZE Zero Divide Exception, флаг исключения деления на нуль FPU (SW.2)
ZF Zero Flag, флаг нулевого результата (EFLAGS.6)
ZIF-socket Zero Insertion Force-socket, колодка (сокет) для ИС с нулевым усилием вставки
ZM MXCSR. Zero Divide Mask, маска исключения деления на нуль FPU (CW.2)
Алфавитный указатель
#%&
#АС (исключение), 74
#ВР (исключение), 74,181,184,185
#BR (исключение), 74
#DB (исключение), 73,74,181—183,491
#DE (исключение), 74
#DF (исключение), 73,74,124,491
#GP (исключение), 55,65,67,71,73,74,85,124,
128-131,145,146,148-151,169,171,491
#МС (исключение), 58,74,177,207,491
#MF (исключение), 74
#NM (исключение), 57,73,74,85,135,491
#NP (исключение), 73,74,128,129,131,491
#OF (исключение), 74
#PF (исключение), 73.74,136,140,141,492
#SS (исключение), 73,74,129,131,148,492
#TS (исключение), 74
#UD (исключение), 74
+ (обозначение), 42
286, 32
инструкции, 197
интерфейс сопроцессора, 86
386
интерфейс сопроцессора, 86
характеристики, 32
386SL, 33
3DNow!, 92,238
486, 33
новые инструкции, 197
сопроцессор, 86
80287, 86
80387, 86
8086, 32
инструкции, 197
организация памяти, 61
регистры, 53
8087, 85
8088, 32
А
А
битРОЕиРТЕ, 138
бит дескриптора, 125
признак доступа, 138
ААА, 281
AAD, 282
ААМ, 282
AAS, 282
АС (флаг), 55
ACPI (флаг наличия), 207
ADC, 282
ADD, 283
ADDPD, 417
ADDPS, 396
ADDSD, 418
ADDSS, 396
AF (флаг), 55
AGP Clock, 270
AM (флаг CRO), 58
AMD, 236
AMD5K86, 237
AMD K5, 237
AMDK6
новые инструкции, 196
характеристики, 237
AMDK6-2, 238
AMDK6-III, 238
AMDK7, 196
AND, 283
ANDNPD, 418
ANDNPS, 397
ANDPD, 418
ANDPS, 397
APIC, 188,192,231,277
APIC (флаг наличия), 207
ARPL, 284
Athlon, 239,268
в
BASE (поле дескриптора), 124
BCD, 49
BD(6htDR6), 183
BEDODRAM, 162
Bi(6HTDR6), 183
Big-Endian, 49
Big Real Mode, 70
BIOS, 32,175
INT lOh, 85
положение для 386+, 175
BIOS Setup, 271
BIST, 174
BOUND, 284
BS(6htDR6), 183
BSF, 285
BSP, 176,277
BSR, 285
BSWAP, 286
ВТ, 286
BT(6htDR6), 183
BTB, 175
BTC, 286
BTF (бит DebugCtlMSR), 183
Алфавитный указатель
501
BTR, 287
BTS, 287
С
С (бит дескриптора), 126
CALL, 287
CBW, 289
CCi (поле CESR), 192
CDGtmarCRO), 58
CDQ, 289
Celeron, 220
CESR (регистр), 192
СР(флаг), 56
CFLSH (флаг наличия), 207
CISC, 37
CLC, 289
CLD, 289
CLFLUSH, 419
CLI, 289
CLTS, 289
CMC, 290
CMOV (флаг наличия), 207
CMOVcc, 290
CMP, 291
CMPPD, 419
CMPPS, 397
CMPS, 292
CMPSB, 292
CM PSD, 292,420
CMPSS, 399
CMPSW, 292
CMPXCHG, 292
CMPXCIIG8B, 293
COMISD, 420
COMISS, 399
Cooler, 273
Core Speed, 270
Counter mask (ноле PerfEvtSel), 192
CPL, 126,128
CPU Clock, 270
CPUID, 293
дескрипторы кэширования, 208
инструкция, 205
флаг наличия, 204
флаг расширения, 207
CR1 (регистр), 58
CR2 (регистр), 58
CR3 (регистр), 58
CTRi (регистр), 192
CVTDQ2PD, 421
CVTDQ2PS, 421
CVTPD2DQ, 422
CVTPD2PI, 423
CVTPD2PS, 423
CVTPI2PD, 424
CVTPI2PS, 400
CVTPS2DQ, 425
CVTPS2PD, 425
CVTPS2P1, 400
CVTSD2SI, 426
CVTSD2SS, 427
CVTSI2SD, 427
CVTSI2SS, 401
CVTSS2SD, 428
CVTSS2SI, 401
CVTTPD2DQ, 429
CVTTPD2P1, 429
CVTTPS2DQ, 430
CVTTPS2PI, 402
CVTTSD2S1, 431
CVTTSS2S1, 403
CWD, 300
CWDE, 300
СХ8 (флаг наличия), 207
Cyrix, 247
Cyrix 6x86, 248
Cyrix 6х86МХ, 248
D
D
6htPDEhPTE, 138
бит дескриптора, 126
признак грязной страницы, 138
DAA, 300
DAS, 300
DE
флагСР4, 58
флаг наличия, 207
DebugCtlMSR(MSR), 183
DEC, 300
Deep Sleep, 195
Destination Offset (слово дескриптора), 128
Destination Selector (слово дескриптора), 128
ОЕ(флаг), 55
DIB, 217
DIP, 250
DIV, 301
DIVPD, 431
DIVPS, 403
DIVSD, 432
D1VSS, 404
DPL (поле дескриптора), 125—127
DR0...DR3 (регистры), 181
DR6 (регистр), 183
DR7 (регистр), 181
DRAM, 154
DRx (регистры), 59
DTS (флаг наличия), 207
Duron, 240,268
Е
Е
бит дескриптора, 126
флаг PerfEvtSel, 192
ЕСС, 178
EFLAGS, 54
ЕМ(флагСРО), 57
EMMS, 377
EN (флаг PerfEvtSel), 192
ENTER, 301
EPL, 129
ES (флаг SW FPU), 81
ESi (иоле CESR), 192
ЕТ (флаг CR0), 57
EV86
описание, 147
502
Алфавитный указатель
EV86 (продолжение) отличия от V86, 150 прерывания, 150 Event select (поле PerfEvtSel), 192 FPTAN, 366 FPU, 77 исключения, 84 слово состояния, 80
F F2XM1, 344 FABS, 344 FADD, 344 FADDP, 345 Fan, 273 FBLD, 345 FBSTP, 346 FCIIS, 346 FCLEX, 346 FCMOVcc, 346 FCOM, 347 FCOM1, 348 FCOM1P, 349 FCOMP, 349 FCOMPP, 349 FCOS, 349 FDECSTP, 350 FDIV, 350 FDIVP, 351 FDIVR, 351 FDIVRP, 352 FEMMS, 469 FFREE, 352 FIADD, 352 FICOM, 353 FICOMP, 353 FI DIV, 353 FIDIVR, 354 FIFO (замещение), 160 FILD, 354 FIMUL, 354 FINCSTP, 354 FINIT, 355 FIST, 355 fiSTp, 356 стек регистров, 80 теги, 80 указатели инструкций и данных, 82 управляющее слово, 81 флаг наличия, 207 FRC, 276,279 FRNINT, 366 Front-Side Bus, 217 FRSTOR, 367 FSAVE, 367 FSB Clock, 270 FSCALE, 368 FSIN, 368 FSINCOS, 368 FSQRT, 368 FST, 368 FSTCW, 369,370 FSTENV, 369 FSTP, 370 FSUB, 370 FSUBP, 371 FSUBR, 371 FSUBRP, 372 FTST, 372 FUCOM, 373 FUCOMI, 373 FUCOM1P, 374 FUCOMP, 374 FUCOMPP, 375 FWAIT, 375 FXAM, 375 FXCH, 375 FXRSTOR, 404 FXSAVE, 405 FXSR (флаг наличия), 207 FXTRACT, 376 FYL2X, 376 FYL2XP1, 376
FISUB, 356 FISUBR, 356 FLD, 357 FLD1, 358 FLDCW, 357 FLDENV, 357 FLDL2E, 359 FLDL2T, 359 FLDLG2, 359 FLDLN2, 359 FLDPI, 360 FLDZ, 360 FMUL, 360 FMULP, 361 FNCLEX, 361 FN1NIT, 361 FNOP, 361 FNSAVE, 362 FNSTCW, 363,364 FNSTENV, 363 FPATAN, 364 FPREM, 365 FPREM 1, 365 G G бит PDE и PTE, 140 бит дескриптора, 124 признак глобальности страницы, 140 GD(6htDR7), 182 GDTR (регистр), 59 GE(6htDR7), 182 Gi(6irrDR7), 182 н HLT, 302 1 IBM, PC 247 IC (бит CS 8087), 81 ICE, 184 ID (флаг), 54 I DIV, 302 IDT (таблица дескрипторов прерываний), 73 IDT-C6, 249
Алфавитный указатель
503
IDTR (регистр), 59 IF (флаг), 55 IMUL, 302 IN, 303 INC, 304 INIT, 175 INS, 304 INSB, 304 1NSD, 304 INSW, 304 INT, 305 INT (флаг PerfEvtScl), 192 INTO, 305 INV (флаг PerfEvtScl), 192 INVD, 306 INVLPG, 306 IOPL(поле EFLAGS), 55,130 IR (флаг SW 8087), 81 IRET, 306 I RETD, 306 ISA, 271 LODSW, 314 LOOP, 314 LOOPE, 315 LOOPNE, 315 LOOPNZ, 315 LOOPZ, 315 LRU, 139,160 LSL, 315 LSS, 311 LTR, 316 M Ml, 248 MASKMOVDQU, 432 MASKMOVQ, 377 MAXPS, 405 MAXSD, 433 MAXSS, 406 MCA (флаг наличия), 207 MCE разрешение машинного контроля, 58
J JCC, 307 JCXZ, 309 JECXZ, 309 JMP, 309 флагСК4, 58 флаг наличия, 207 Merced, 41 MESI, 165 MFENCE, 434 MINPD, 434
К K7(AMD), 35 Klamath, 218 MINPS, 406 MINSD, 434 M1NSS, 406 ММХ, 86 инструкции, 107
L LAIIF, 310 LAR, 310 LastBranchFromlP(MSR), 183 LastBranchToIP(MSR), 183 LastExceptionFromlP(MSR), 183 LastExceptionToIP(MSR), 183 LBR(6ht DebugCtlMSR), 183 LDMXCSR, 405 LDS, 311 LDT, 126 LDTR (регистр), 59 LE(6htDR7), 182 LEA, 312 LEAVE, 312 LENi (поле DR7), 181 LES, 311 LFENCE, 432 LFS, 311 LGDT, 312 LGS, 311 Li(6htDR7), 182 LIDT, 313 LI M IT (поле дескриптора), 124 Little-Endian, 48 LLDT, 313 LMSW, 313 LOCK, 313 LODS, 314 LODSB, 314 LODSD, 314 флаг наличия, 207 MOV, 316,317 MOVAPD, 435 MOVAPS, 407 MOVD, 377,435 MOVDQ2Q 436 MOVDQA, 436 MOVDQU, 436 MOVHLPS, 407 MOVHPD, 436 MOVHPS, 407 MOVLHPS, 408 MOVLPD, 437 MOVLPS, 408 MOVMSKPD, 437 MOVMSKPS, 409 MOVNTDQ, 438 MOVNTI, 438 MOVNTPD, 438 MOVNTPS, 409 MOVNTQ, 378 MOVQ, 378,438 MOVQ2DQ, 439 MOVS, 317 MOVSB, 317 MOVSD, 317,439 MOVSS, 409 MOVSW, 317 MOVSX, 318 MOVUPD, 439 MOVUPS, 410
504
Алфавитный указатель
MOVZX, 318
МР(флагСЯО), 57
mP6, 249
MSR, 175,177,188,191,199
Р6, 170,183,192
Pentium, 192
регистры, 60
флаг наличия, 207
MTRR
регистры, 169
флаг наличия, 207
MUL, 319
MULPD, 440
MULPS, 410
MULSD, 440
MULSS, 411
N
NE^arCRO), 58
NEG, 319
NOP, 319
NOT, 320
NT (флаг), 55
NW^arCRO), 58
о
OF (флаг), 55
OR, 320
ORPD, 440
ORPS, 411
OS (флаг PerfEvtSel), 192
OSFXSR (флаг CR4), 59
О5ХММЕХСРТ(флагСР4), 59
OUT, 320
OUTS, 321
OUTSB, 321
OUTSD, 321
OUTSW, 321
overclocking, 271
OverDrive Pentium II, 218
P
P
битРОЕиРТЕ, 138
бит дескриптора, 125
P5 (обозначение), 42
P55C, 216
P6, 216
картридж, 226
коэффициент умножения, 263
мультипроцессорные системы, 278
новые инструкции, 196
обзор, 217
обозначение, 42
управление энергопотреблением, 195
частота шины, 264
PACKSSDW, 379,441
PACKSSWB, 379,441
PACKUSWB, 379,442
PADDB, 380,443
PADDD, 380,443
PADDQ, 443
PADDSB, 380,444
PADDSW, 380,444
PADDUSB, 381,444
PADDUSW, 381,444
PADDW, 380,443
PAE
флагСР4, 58
флаг наличия, 207
PAND, 382,445
PANDN, 382,445
PAT (флаг наличия), 207
PAUSE, 445
PAVGB, 382,446
PAVGUSB, 469
PAVGW, 382,446
PBSRAM, 162
PBi(6HTDebugCtlMSR), 183
PC
поле CS FPU, 81
флаг PerfEvtSel, 192
PCD
битРОЕиРТЕ, 139
флaгCRЗ, 58
PCE (флаг CR4), 59
PCI, 270
PCi (бит CESR), 192
PCMPEQB, 382,446
PCMPEQD, 383,446
PCMPEQW, 383,446
PCMPGTB, 383,447
PCMPGTD, 383,447
PCMPGTW, 383,447
PE
сброс, 153
установка, 152
флагСВО, 56
Pentium, 33,216
MMX, 216
двухпроцессорные системы, 277
интерфейс шины, 216
новые инструкции, 197
энергопотребление, 195
Pentium 4
новые инструкции, 196
характеристики, 164
Pentium II, 34,218
Deshutes, 219
Klamath, 218
OverDrive, 218
Хеоп, 221
Pentium III, 219
Pentium MMX, 34
Pentium Pro, 33,217
PerfCtr(MSR), 192
PerfEvtSel (MSR), 192
PEXTRW, 447
PF (флаг), 55
PF2ID, 470
PF2IW, 476
PFACC, 470
PFADD, 470
PFCMPEQ 470
PFCMPGE, 471
PFCMPGT, 471
PFMAX, 471
Алфавитный указатель
505
PFMIN, 471
PFMUL, 472
PFNACC, 477
PFPNACC, 477
PFRCP, 472
PFRCPIT1, 472
PFRCPIT2, 473
PFRSQIT1, 473
PFRSQRT, 473
PFSUB, 474
PFSUBR, 474
PG (флаг CRO), 58
PGA, 250
PGE
флaгCR4, 59
флаг наличия, 207
PI2FD, 474
PI2FW, 477
PINSRW, 384,448
PIROM, 221
PLL, 193
PMADDWD, 384,448
PMAXSW, 385,448
PMAXUB, 385,449
PMINSW, 386,449
PMINUB, 386,449
PMOVMSKB, 386,450
PMULHRW, 475
PMULHUW, 387,450
PMULHW, 387,451
PMULLW, 388,451
PMULUDQ 452
POP, 321
POPA, 322
POPAD, 322
POPF, 322
POPFD, 322
POR, 389,452
POST, 170
PPGA, 251
PQFP, 251
PREFETCH(W), 475
PREFETCHNTA, 323
PS (бит PDE и PTE), 139
PSADBW, 389,453
PSE
флагСР4, 58
флаг наличия, 207
PSE-36 (флаг наличия), 207
PSHUFD, 454
PSHUFHW, 455
PSHUFLW, 456
PSHUFW, 389
PSLLD, 390,458
PSLLDQ, 458
PSLLQ 390,458
PSLLW, 390,458
PSN (флаг наличия), 207
PSRAD, 391,459
PSRAW, 391,459
PSRLD, 392,460
PSRLDQ 459
PSRLQ, 392,460
PSRLW, 392,460
PSUBB, 392,460
PSUBD, 392,460
PSUBQ 461
PSUBSB, 393,461
PSUBSW, 393,461
PSUBUSB, 393,462
PSUBUSW, 393,462
PSUBW, 392,460
PSWAPD, 478
PUNPCKHBW, 394,462
PUNPCKHDQ 394,462
PUNPCKHQDQ 462
PUNPCKHWD, 394,462
PUNPCKLBW, 395,463
PUNPCKLDQ 395,463
PUNPCKLQDQ 463
PUNPCKLWD, 395,463
PUSH, 323
PUSHA, 324
PUSHAD, 324
PUSHF, 324
PUSHFD, 324
PVI (флагСК4), 58
PWT
бит PDE и PTE, 139
флагСКЗ, 58
PXOR, 396,464
R
R (бит дескриптора), 126
RCOKUieCS FPU), 81
RCL, 324
RCPPS, 412
RCPSS, 412
RCR, 325
RDMSR, 325
RDPMC, 326
RDTSC, 326
REP, 326
REPE, 326
REPNE, 326
REPNZ, 326
REPZ, 326
RESET, 174
RET, 327
RF (флаг), 55,183
RISC, 37
ROL, 328
ROR, 329
RPL, 129
RSM, 329
RSQRTPS, 412
RSQRTSS, 413
RWi (mvieDR7), 182
s
SAHF, 330
SAL, 330
SAR, 330
SBB, 331
SCAS, 331
SCASB, 331
SCASD, 331
506
Алфавитный указатель
SCASW, 331 Scratch EEPROM, 222 SDRAM, 162 SECC, 218,224,226,251 SECC 2, 225 SEP (флаг наличия), 207 SEPP, 220,225 SETcc, 332 SF флаг, 55 флаг SW FPU, 81 SFENCE, 333 SGDT, 333 SHL, 334 SHLD, 334 SHR, 335 SHRD, 335 SHUFPD, 465 SHUFPS, 413 Shutdown, 74,191,230 SIDT, 333 SIMD, 87 SLDT, 336 SMBus, 222 SMI, 186 SMM, 48,184,185 идентификатор, 190 контекст процессора, 187 регистры, 189 режим, 189 SMP, 276 SMRAM, 186,187 SMSW, 336 SPGA, 250 SQFP, 251 SQRTPD, 465 SQRTPS, 414 SQRTSD, 465 SQRTSS, 415 SRAM, 154,162 SS (флаг наличия), 208 SSE (флаг наличия), 208 SSE2 (флаг наличия), 208 STC, 336 STD, 336 STI, 336 STMXCSR, 415 STOS, 337 STOSB, 337 STOSD, 337 STOSW, 337 STR, 337 SUB, 337 SUBPD, 466 SUBPS, 415 SUBSD, 466 SUBSS, 415 SYS ENTER, 338 SYSEXIT, 339 TEST, 340 ТЕ(флаг), 55,181 TLB, 140,163,173,175 TOP, 80 TR бит DebugCtlMSR, 183 регистр, 59 TRx (регистры), 60 TS (флаг CRO), 57 TSC, 191 TSC (флаг наличия), 207 Т5О(флагСР4), 58 TSS, 126,132 Type (поле дескриптора), 126, 127 и U (бит PDE и РТЕ), 139 UCOMISD, 466 UCOMISS, 416 UD2, 340 Unit mask (поле PerfEvtSel), 192 UNPCKHPD, 467 UNPCKHPS, 416 UNPCKLPD, 467 UNPCKLPS, 417 Unreal Mode, 70 upgrade, 250 USR (флаг PerfEvtSel), 192 V V86 вход-вы ход, 151 защита, 148 монитор, 147 прерывания, 149 расширение EV86, 150 режим, 147 VERR, 340 VERW, 341 VIA Cyrix III, 249 VIF(флаг), 54,146 VIP (флаг), 54,146 VM (флаг), 55 VME флагСЯ4, 58 флаг наличия, 207 VRT, 254 w w бит PDE и PTE, 139 бит дескриптора, 126 WAIT, 341 WB(k31u), 156 WBINVD, 341 Winchip, 249 Word Count (иоле дескриптора), 128 WP (флаг CRO), 58 WRMSR, 341
T T (бит TSS), 181 TAG (поле), 103 TCP, 251 WT(K3iii), 156 X XADD, 342 XCHG, 342
Алфавитный указатель
507
Хеоп, 221
XLAT, 343
XLATB, 343
XOR, 343
XORPD, 467
XORPS, 417
Z
гГ(флаг), 55
ZI F-сокет, 251
А
аварийное завершение, 72
адрес
база, 66
ближний, 64
виртуальный, 62
внутрисегментный, 64
дальний, 64
индекс, 66
исполнительный, 63
линейный, 62
логический, 62
масштаб, 66
межсегментный, 64
сегмента, 63
смещение, 66
физический, 62,63
эффективный, 63
адресация
памяти, 61
режимы, 65
аппаратные прерывания
в мультипроцессорных системах, 277
виды, 71
описание, 71
арифметические инструкции, 96
архитектура процессоров, 35
ассоциативный кэш, 161
Б
база, 66
байт, 49
бит, 49
буфер записи, 163,173
В
ввод-вывод
адресация, 70
битовая карта разрешения, 71
вектор прерывания, 72
вентили, 121
вентиляторы, 273
виртуализация прерываний, 145
виртуальная машина, 58
виртуальная память, 122
виртуальный 8086, 147
вторичный кэш, 155
вторичный процессор, 176
вызов
процедуры, 101
шлюзы, 127
г
глобальная страница, 59, 140
глобальная таблица дескрипторов, 124
д
данные
биты (поля, строки), 49
пересылка, 95
продвижение, 36
типы, 48,49
упакованные ММХ, 87
числа, 49
двойная независимая шина, 216
двойной отказ, 73
дескрипторы, 120
байт управления доступом, 124
регистры, 59
таблица, глобальная, 124
таблица, локальная, 124
таблица, прерываний, 124
таблицы, 120,123
формат, 124
шлюзов, 127
3
задачи
переключение, 121,132
шлюзы, 127
запись
обратная, 156
сквозная, 156
защита
в многозадачных системах, 130
на уровне страниц, 139
защищенный режим, 119
286, 119
основы, 119
защищеипый-реальпый, переключение, 151
зондовая отладка, 184
зондовый режим, 185
и
избыточный контроль функциональности, 279
изменение последовательности инструкций, 37
индекс, 66
источника, 53
назначения, 53
строки кэша, 158
инструкции
3DNow!, 115
CPUID, 205
ММХ, 87,107
арифметические, 96
вызова процедуры, 101
двоичной арифметики, 97
десятичной арифметики, 97
загрузки указателей, 103
изменение последовательности исполнения, 37
логические, 97
обработки бит и байт, 98
передачи управления, 100
пересылки данных, 95
508
Алфавитный указатель
инструкции (продолжение)
перехода, 99
префиксы, 94
разные, 103
сдвига, 98
системные, 116
сопроцессора, 103, 104
строковые, 101,102
указатель, 54
флаговые, 102
формат, 94
интерфейс Pentium, 252
исключения
#ВР, 181
#DB, 181
аварийное завершение, 72
анализ условий, 73
двойной отказ, 73,74
контроль выравнивания, 74
контроль диапазона, 74
ловушка, 72
машинный контроль, 74
нарушение границы, 74
нарушение защиты, 74
недопустимый код, 74
недопустимый сегмент, 74
отказ, 72
отказ страницы, 74
отладки, 74,181
ошибка сопроцессора, 74
переполнение, 74
процессора, 72
сегмент отсутствует, 74
сопроцессора, 74
исключения сопроцессора, 84
DE, 84
IE, 84
ОЕ, 84
РЕ, 84
UE, 84
ZE, 84
исполнение
по предположению, 37
с изменением последовательности
инструкций, 37
спекулятивное, 37
к
карта
перенаправления прерываний, 135
разрешения ввода-вывода, 135
каталог
кэш, 154
страниц, 138
когерентность кэша, 155
команды, 94
конвейеризация, 36
конформность сегмента, 126
коэффициент умножения
AMDK5, 237
AMD Кб, 238
Р6, 263
кэш, 154,162
Look Aside, 155
Look Through, 155
MESI, 165
MTRR, 169
WB, 156
WT, 156
аннулирование строк, 168
ассоциативный, 161
вторичный, 155
грязная строка, 156
замещение, 160
индекс строки, 158
каталог, 154
когерентность, 155
модифицированная строка, 156
набор, 159,160
11аборно-ассощ >ати в н ый, 160
несекторированный, 155
очистка, 168
первичный, 155
политика записи, 156
попадание, 154
промах, 154
прямого отображения, 157
сектор, 155,159
секторированный, 155,159
сквозная запись (WT), 156
строка, 155,159
тег, 155
управление, 167
управление аппаратное, 169
управление программное, 168
у преждающее чтение, 158
функционирование, 154
характеристики, 164
цикл запроса, 158
цикл слежения, 158
чистая строка, 156
кэширование, 154
линейный адрес, 62
ловушки
описание, 72
В1ЛЮЗЫ, 127
логические инструкции, 97
логический адрес, 62
локальная таблица дескрипторов, 124
локальная шина Р6, 217
м
маска
DM, 84
IE, 84
ОМ, 84
РМ, 84
UM, 84
ZM, 84
маскируемые прерывания, 72
масштаб, 66
математический сопроцессор, 77
метки реального времени, 191
Алфавитный указатель
509
многопроцессорные системы, 276
модельно-специфические регистры, 60
мониторинг производительности
Р5+, 191
Р6, 192
средства, 191
н
набор (кэш), 160
наборно-ассоциативный кэш, 160
немаскируемые прерывания, 72
о
организация памяти, 61
отказ, 72
двойной, 73
отладки, 73
сегментации, 73
страницы, 73
отладка
зондовая, 184
исключения, 181
программная, 180
регистры, 59,181
события, 181
охлаждение, 273
вентиляторы, 273
радиаторы, 273
холодильник Пельтье, 273
п
пакетный цикл, 161
память
V86, 148
адресация, 61
байт, 64
ближний (внутрисегментный) адрес, 64
виртуальная, 122
дальний (межсегментный) адрес, 64
двойное слово, 64
кэширование, 154
организация, 61,63
параграф, 61
слово, 64
страницы, 136
параграф, 61
первичный кэш, 155
первичный процессор, 176
передача
пакетная, 161
управления, 99,127
переименование регистров, 36
переключение
задач, 121,132
реальный-защищенный, 151
перенаправление прерываний, 150
переходник «сокет-слот», 256
питание Pentium, 237
подкачка, 136
подчиненность сегмента, 126
поле бит, 49
политика записи кэша, 156
предсказание переходов, 36
прерывания, 74
анализ условий, 73
аппаратные, 71
в многопроцессорных системах, 277
вектор, 72
виртуализация, 145
маскируемые, 72
немаскируемые, 72,74
перенаправление (EV86), 150
программные, 71
таблица дескрипторов, 73,124
шлюзы, 127
префикс
изменения сегмента, 94
переключения разрядности, 94
привилегии, 121,128
ввода-вывода, 130
дескриптора, 129
задач, 128
селектора, 129
смена уровня, 130
эффективный уровень, 129
применение процессоров, 250
программная модель процессоров, 47
программная отладка, 180
программные прерывания, 71
продвижение данных, 36
процедуры вызов, 101
процессор
386, 32
486, 33
6x86, 248
6х86МХ, 248
AMD, 236
Athlon, 239
Celeron, 220
Cyrix, 247
Duron, 240
IBM, 247
IDT-C6, 249
K5, 237
K6-2, 238
K6-III, 238
mP6, 249
Pentium II, 218
Pentium III, 219
Pentium 4, 226—235
Pentium MMX, 216
Pentium Pro, 217
VIA Cyrix III, 249
Winchip, 249
Xeon, 221
возможность установки, 260
для сокетов 5 и 7, 236,247
замена, 251
идентификация, 204,261
коды идентификации, 200
конфигурирование, 261
напряжение питания, 261
основные характеристики, 212
применение, 250
применимость, 260
программная модель, 47
расширение набора инструкций, 196
сброс, 174
510
Алфавитный указатель
процессор (продолжение)
симметричные системы, 276
скалярный, 36
совместимость, 196,198
сравнение архитектур, 35
сравнение поколений, 212
суперскалярный, 36
температурный режим, 274
тестирование, 177
умножение частоты, 193
частота ядра, 261
шестого поколения, 216
процессоры 32-разрядные, 47
защищенный режим, 47
реальный режим, 47
регистры, 52
режим виртуального 8086, 47
режим системного управления, 48
р
радиаторы, 273
разгон, 271
расширение
размера страницы, 141
физического адреса, 142
реальный режим, 47
реальный-защищспный, переключение, 151
регистры
32-разрядных процессоров, 52
8086, 53
CR1, 58
CR2, 58
CR3, 58
GDTR, 59
IDTR, 59
LDTR, 59
TR, 59
дескрипторов, 59
доступность, 60
модельно специфические, 60
отладки, 59,181
переименование, 36
сегментов, 56,67
тестирования, 60
указатель инструкций, 54
управляющие, 56
флагов, 54
режим
V86, 147
адресации, 65
большой реальный, 70
виртуального 8086, 147
защищенный, 119
нереальный, 70
реальный, 47
системного управления, 185
рестарт
инструкции HALT, 190
инструкции ввода-вывода, 190
с
сброс, 174
свопинг, 136
сегмент, 120
конформность, 126
сегмент (продолжение)
регистры, 56
состояния задачи, 132
сектор (кэш), 159
секторированный кэш, 159
селектор, 120
сериализация, 152,166,199
симметричная мультипроцессорная обработка, 276
синхронизация
общая, 228
от источника данных, 228
процессора, 193
системной платы, 269
сопроцессора, 86
шины, 229
система команд, 94
системная плата, 269
системы
многопроцессорные, 276
с избыточным контролем функциональности, 279
скалярные процессоры, 36
слежение (цикл), 158
слово
двойное, 64
кода ошибки, 75
учетверенное, 52
слот, 250
1, 218,254,266
2, 221,226,255,267
А, 268
типы,259
смещение, 66
совместимость процессоров, 196
сокет, 250
1, 251,262
2, 251,262
3, 251,262
370, 255,256,267
4, 252,253
423, 258,267
462, 258
5, 252,253,262
6, 251,262
7, 252,254,262
8, 254,265
Super 7, 262
Super 7, 252
А, 258
для 486, 251
типы, 259
сокет-слот, переходник, 256
сопроцессор
287 и 387, 86
8087, 85
FPU486+, 86
инструкции, 103
математический, 77
обработка исключений, 84
регистр состояния, 80
стек, 80
Алфавитный указатель
511
сопроцессор (продолжение)
указатели инструкций и данных, 82
управляющее слово, 81
спекулятивное исполнение, 37
сравнение процессоров, 212
страница памяти, 136
страничная переадресация
базовый механизм, 137
расширение физического адреса, 142
расширенные страницы, 141
строка
бит, 49
каталога страниц, 138
кэша, индекс, 158
кэша, описание, 155
кэша, термин, 159
таблицы страниц, 138
строковые инструкции, 101
суперскалярные процессоры, 36
т
таблица
дескрипторов, 120
дескрипторов, глобальная, 124
дескрипторов, локальная, 124
дескрипто!юв, прерываний, 124
страниц, 138
тег (кэш), 155
тестирование
JTAG, 177
TLB, 177
процессора, 177
типы данных, 48
У
указатель
длинный, 49
инструкций, 24,54
короткий, 49
простой, 49
стека, 69
умножение частоты
AMDK5, 237
AMD Кб, 238
Р6, 263
управляющие регистры, 56
упреждающее чтение, 158
Ф
физический адрес, 62
флаги
инструкции, 102
расширения архитектуры, 207
регистр, 54
ц
циклы слежения (запроса), 158
ч
частота
порта AGP, 270
синхронизации памяти, 270
системной шины, 270
шины
ISA, 271
PCI, 270
VLB, 271
ядра процессора, 270
чипсет
асинхронный, 271
синхронный, 271
число
без знака, 49
двоично-десятичное, 49,52
действительное, 52
с плавающей точкой, 52
со знаком, 49
чтение упреждающее, 158
ш
шина
Pentium, 216
внутренняя, 217
двойная независимая, 216
системная, 217
шлюзы, 121,127
вызова, 127
задач, 127
ловушек, 127
прерываний, 127
э
энергопотребление
Р6, 195
Pentium, 195
ИЗДАТЕЛЬСКИЙ ДОМ
nPtTFf-D ® ВНИМАНИЕ СПЕЦИАЛИСТАМ
Я Я ЯЯ Я ЯшЯ^ КНИЖНОГО БИЗНЕСА!
WWW.PITER.COM
УВАЖАЕМЫЕ ГОСПОДА!
ИЗДАТЕЛЬСКИЙ ДОМ «ПИТЕР» ПРИГЛАШАЕТ ВАС К ВЗАИМОВЫГОДНОМУ СОТРУДНИЧЕСТВУ.
ЗА ДОПОЛНИТЕЛЬНОЙ ИНФОРМАЦИЕЙ ОБРАЩАЙТЕСЬ В НАШИ ПРЕДСТАВИТЕЛЬСТВА,
КОТОРЫЕ НАХОДЯТСЯ ПО СЛЕДУЮЩИМ АДРЕСАМ:
Россия, г. Москва
Представительство издательства «Питер», м. «Калужская»,
ул. Бутлерова, д. 176, оф. 207 и 240, тел./факс (095)
777-54-67. E-mail: sales@piter.msk.ru
Россия, г. Санкт-Петербург
Представительство издательства «Питер», м. «Электро-
сила», ул. Благодатная, д. 67, тел.: (812) 327-93-37,
294-54-65. E-mail: sales@piter.com
Украина, г. Харьков
Представительство издательства «Питер»,
тел. (0572) 14-96-09, факс: (0572) 28-20-04, 28-20-05.
Почтовый адрес: 61093, г. Харьков, а/я 9130.
E-mail: piter@tender.kharkov.ua
Украина, г. Киев
Филиал Харьковского представительства издательства
«Питер», тел./факс: (044) 490-35-68, 490-35-69. Адрес для
писем: 04116, г. Киев-116, а/я 2. Фактический адрес: 04073,
г. Киев, пр. Красных Казаков, д. 6, корп. 1.
Е- mail: off ice ©> pi ter- press, kiev. ua
Беларусь, г. Минск
Представительство издательства «Питер», тел./факс
(375172) 16-00-06. Почтовый адрес: 220023, г. Минск,
ул. Кедышко, д. 19. E-mail: piterbel@tut.by
КАЖДОЕ ИЗ ЭТИХ ПРЕДСТАВИТЕЛЬСТВ
РАБОТАЕТ ПО ЕДИНОМУ СТАНДАРТУ
ИЗДАТЕЛЬСКОГО ДОМА «ПИТЕР».
КНИГИ ИЗДАТЕЛЬСКОГО ДОМА «ПИТЕР» ВЫ МОЖЕТЕ ПРИОБРЕСТИ ОПТОМ И В РОЗНИЦУ
У НАШИХ РЕГИОНАЛЬНЫХ ПАРТНЕРОВ.
Башкортостан
Уфа, «Азия», ул. Зенцова, д. 70 (оптовая продажа), маг.
«Оазис», ул. Чернышевского, д. 88, тел./факс (3472)
50-39-00. E-mail: asiaufa@ufanet.ru
Дальний Восток
Владивосток, «Приморский Торговый Дом Книги»,
тел./факс (4232) 23-82-12. Почтовый адрес: 690091,
ул. Светланская, д. 43.
E-mail: bookbase@mail.primorye.ru
Хабаровск, «Мирс», тел. (4212) 22-74-58, факс
22-73-30. Почтовый адрес: 680000, г. Хабаровск,
ул. Ким-Ю-Чена, д. 21.
E-mail: postmaster@bookmirs.khv.ru
Хабаровск, «Книжный мир», тел. (4212) 32-85-51, факс
32-82-50. Почтовый адрес: 680000, ул. Карла Маркса,
Д. 37.
Европейские регионы России
Архангельск, «Дом Книги», тел. (8182) 65-41-34, факс
65-41-34. Почтовый адрес: 163061, пл. Ленина, д. 3.
E-mail: book@pressa.gazinter.net
Калининград, «Пресса», тел. (0112) 53-66-97, факс
53-63-87. Почтовый адрес: 236040, ул. Подполковника
Иванникова, д. За.
E-mail: book@pressa.gazinter.net
Северный Кавказ
Ессентуки, «Россы», ул. Октябрьская, 424, тел./факс
(87934) 6-93-09. E-mail: rossy@kmv.ru
Сибирь
Братск, «Прометей», тел./факс (3953) 43-18-76.
Почтовый адрес: 665708, ул. Кирова, д. 35.
Иркутск, «Антей-книга», тел./факс (3952) 33-42-47.
Почтовый адрес: 664003, ул. Карла Маркса, д. 20.
E-mail: antey@irk.ru
Иркутск, «ПродаЛитъ», тел. (3952) 59-13-70, факс
51-23-31. Почтовый адрес: 664031, г. Иркутск,
ул. Байкальская, д. 172, а/я 1397.
E-mail: prodalit@irk.ru; http://www.prodalit.irk.ru
Нижневартовск, «Дом книги», тел. (3466) 23-27-14, факс
23-59-50. Почтовый адрес: 628606, пр. Победы, д.12.
Новосибирск, «Топ-книга», тел. (3832) 36-10-26, факс
36-10-27. Почтовый адрес: 630117, а/я 560.
E-mail: office@top-kniga.ru; http://www.top-kniga.ru
Тюмень, «Друг», ул. Республики, д. 211, тел./факс (3452)
21-02-20. E-mail: drug@tyumen.ru
Тюмень, «Фолиант», тел. (3452) 27-36-06, факс
27-36-1 1. Почтовый адрес: 625039, ул. Харьковская,
д. 83а. E-mail: foliant@tyumen.ru
Красноярск, «Книжный мир», тел./факс (3912) 27-39-71.
Почтовый адрес: 660049, пр. Мира, д. 86.
E-mail: book-world@public.krasnet.ru
Татарстан
Казань, «Таис», тел. (8432) 72-34-55, факс 72-27-82.
Почтовый адрес: 420073, ул. Гвардейская, д. 9а.
E-mail: tais@bancorp.ru
Урал
Екатеринбург, магазин № 14, ул. Челюскинцев, д. 23,
тел./факс (3432) 53-24-90. E-mail: gvardia@mail.ur.ru
Екатеринбург, «Валео-книга», тел./факс (3432) 42-07-75,
тел. 42-56-00. E-mail: valeo@emts.ru
Михаил Гук
Виктор Юров
анатомия
пк<
Процессоры Pentium 4
Athlon и Duron
В этой книге вы найдете все об используемых в настоящее время
в компьютерах процессорах, вплоть до суперсовременного Pentium 4
и Athlon. Из нее вы узнаете о роли процессора в компьютере, посмотрите,
какие изменения происходили в процессорах при переходе от поколения
к поколению, и познакомитесь с их архитектурой и микроархитектурой.
В книге описаны все команды процессоров!
В книге представлены следующие разделы:
♦ программная модель 32-разрядных процессоров
♦ математический сопроцессор и блоки ММХ и ХММ
♦ система команд
♦ работа в защищенном режиме
♦ кэширование памяти
♦ работа в нерегулярном режиме
♦ процессоры шестого и седьмого поколений от Intel
♦ процессоры AMD, IBM, Cyrix и VIA
♦ применение микропроцессоров в PC1
Вас интересует «анатомия» персонального
компьютера? Рекомендуем книги: