/

































































































































Автор: Крылов В.В. Самохвалова С.С.
Теги: компьютерные технологии кибернетика телекоммуникации
ISBN: 5-94157-569-6
Год: 2005




Текст
В. В. Крылов
С. С. Самохвалова
ТЕОРИЯ
ТЕЛЕТРАФИКА
И ЕЕ ПРИЛОЖЕНИЯ
Основы теории систем массового обслуживания
для задач телекоммуникаций
Как измерить трафик в телефонной
и компьютерной сети
Почему в современных компьютерных сетях
нужно использовать самоподобные (фрактальные)
модели трафика
Какая из систем обработки пакетов имеет
большую производительность
Как используется язык GPSS,
сети Петри и другие инструменты
и программные средства моделирования
в анализе телекоммуникационных систем и сетей
Чем определяется пропускная способность
ТСР-соединения
УЧЕБНОЕ ПОСОБИЕ
Мп/
УДК 681.3.06(075.8)
ББК 32.811я73
К85
Крылов В. В., Самохвалова С. С.
К85 Теория телетрафика и ее приложения. — СПб.: БХВ-Петербург,
2005. — 288 с.: ил.
ISBN 5-94157-569-6
В учебном пособии дается современное изложение основ теории те-
летрафика, ориентированное на практическое использование. Пред-
ставлено достаточно полное описание программных инструментов для
построения имитационных моделей телекоммуникационных систем с
помощью языка GPSS и сетей Петри. Содержится материал по анализу
систем массового обслуживания классическими методами теории веро-
ятностей и случайных процессов. Рассмотрены примеры практического
анализа характеристик качества обслуживания (QoS) в телекоммуника-
ционных системах.
Для студентов и специалистов
в области телекоммуникационных и компьютерных сетей и систем
УДК 681.3.06(075.8)
ББК 32.811я73
Группа подготовки издания:
Главный редактор
Зам. главного редактора
Зав. редакцией
Редактор
Компьютерная верстка
Корректор
Дизайн обложки
Зав. производством
Екатерина Кондукова
Людмила Еремеевская
Григорий Дабни
Анна Кузьмина
Ольги Сергиенко
Зинаида Дмитриева
Игоря Цырулышкова
Николай Тверских
Лицензия ИД N« 02429 от 24.07.00. Подписано в печать 01.03.05.
Формат 70х100’/16. Печать офсетная, Усл. печ. л. 23,22.
Тираж 2500 экз. Заказ No 3884
"БХВ-Петербург", 194354, Санкт-Петербург, ул. Есенина, 5Б.
Санитарно-эпидемиологическое заключение на продукцию
No 77.99.02.953.Д.006421.11.04 от 11.11.2004 г. выдано Федеральной службой
по надзору в сфере защиты прав потребителей и благополучия человека.
Отпечатано с готовых диапозитивов
в ГУП "Типография “Наука”
199034, Санкт-Петербург, 9 линия, 12
ISBN 5-94157-569-6
© Крылов В. В., Самохвалова С. С., 2005
© Оформление, издательство "БХВ-Петербург", 2005
Оглавление
К читателю..............................................................6
Предисловие.............................................................8
Введение................................................................9
Глава 1. Предметная область теории телетрафика.........................11
Информационные процессы и конфликты обслуживания.......................11
Конфликты в системах массового обслуживания........................12
Основные определения теории телетрафика............................14
Измерения трафика..................................................16
Измерения интенсивности трафика....................................23
Контрольные вопросы и задания..........................................34
Глава 2. Модели данных для описания телетрафика........................35
Модели потоков событий.................................................35
Пуассоновский (простейший) поток................................. 37
Примитивный поток..................................................40
Потоки событий с произвольным законом распределения................41
Равномерное распределение........................................42
Треугольное распределение........................................42
Нормальное распределение.........................................43
Бета-распределение...............................................45
Логнормальное распределение......................................46
Распределение хи-квадрат (/^-распределение)......................47
Распределение Стьюдента..........................................47
Г-распределение Фишера...........................................48
Распределение Парето.............................................49
Распределение Вейбулла...........................................50
Гамма-распределение..............................................51
Самоподобные (фрактальные) модели трафика..........................51
Программное моделирование трафика......................................59
Основные принципы моделирования потока событий.....................59
Модели потоков событий............................................'63
Контрольные вопросы и задания..........................................68
Глава 3. Модели систем массового обслуживания..........................69
Задачи анализа и проектирования телекоммуникационных сетей и систем....69
Базовая модель СМО и классификация по Кендалу......................71
Имитационные модели СМО............................................80
4
Оглавление
Основы моделирования средствами языка GPSS..........................85
Структура модели на GPSS........................................86
Основные исполняемые блоки GPSS.................................88
GENERATE......................................................89
TERMINATE.....................................................91
SEIZE.........................................................91
RELEASE.......................................................91
ADVANCE.......................................................91
QUEUE.........................................................92
DEPART........................................................92
STORAGE.......................................................92
ENTER.........................................................93
LEAVE.........................................................93
TRANSFER......................................................93
Работа c GPSS World........................................... 94
Контрольные вопросы...............................................1103
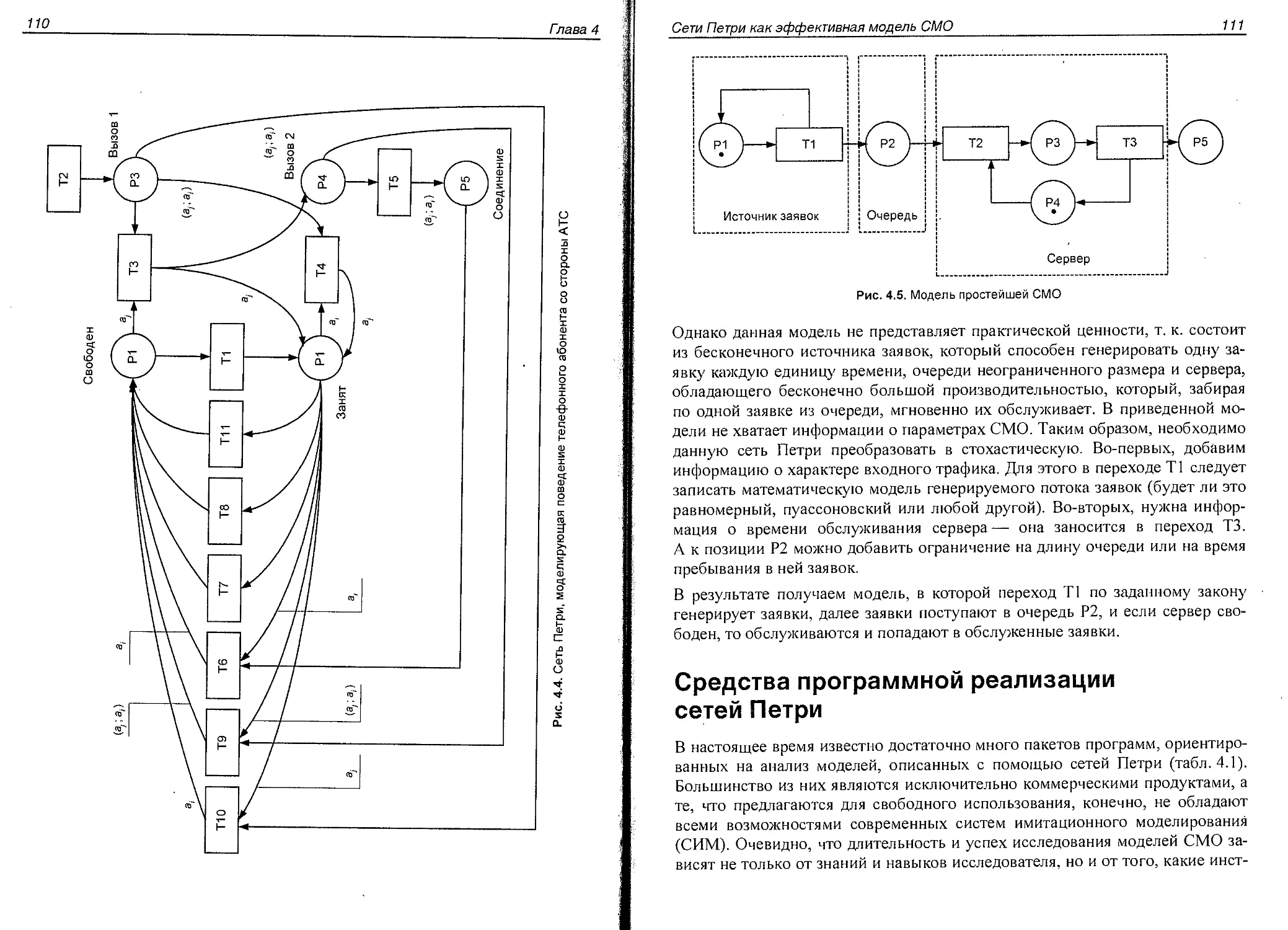
Глава 4. Сети Петри как эффективная модель СМО...................104
Сети Петри — инструмент для описания и исследования динамических систем.... 104
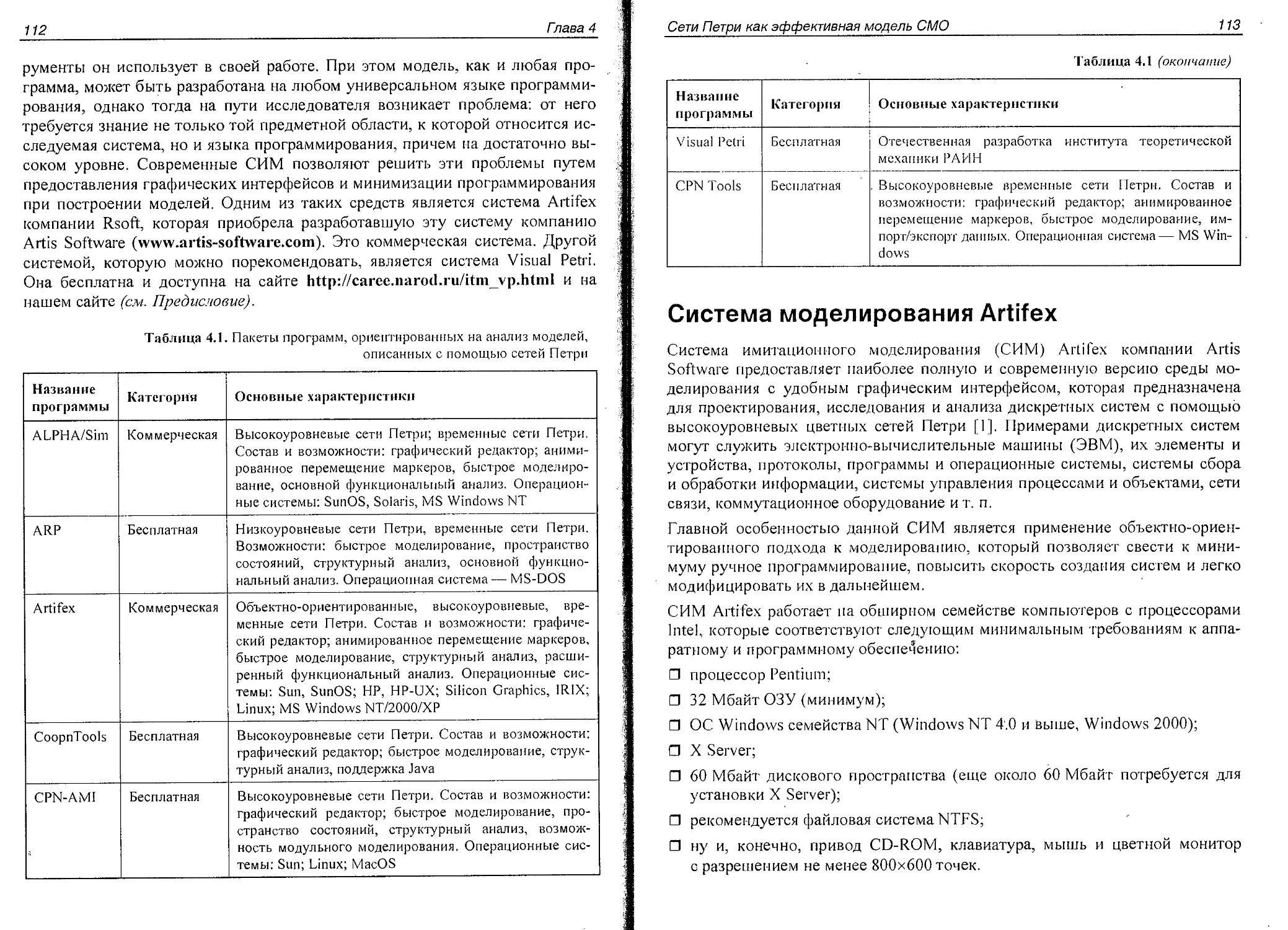
Средства программной реализации сетей Петри........................111
Система моделирования Artifex......................................113
Контрольные вопросы и задания......................................135
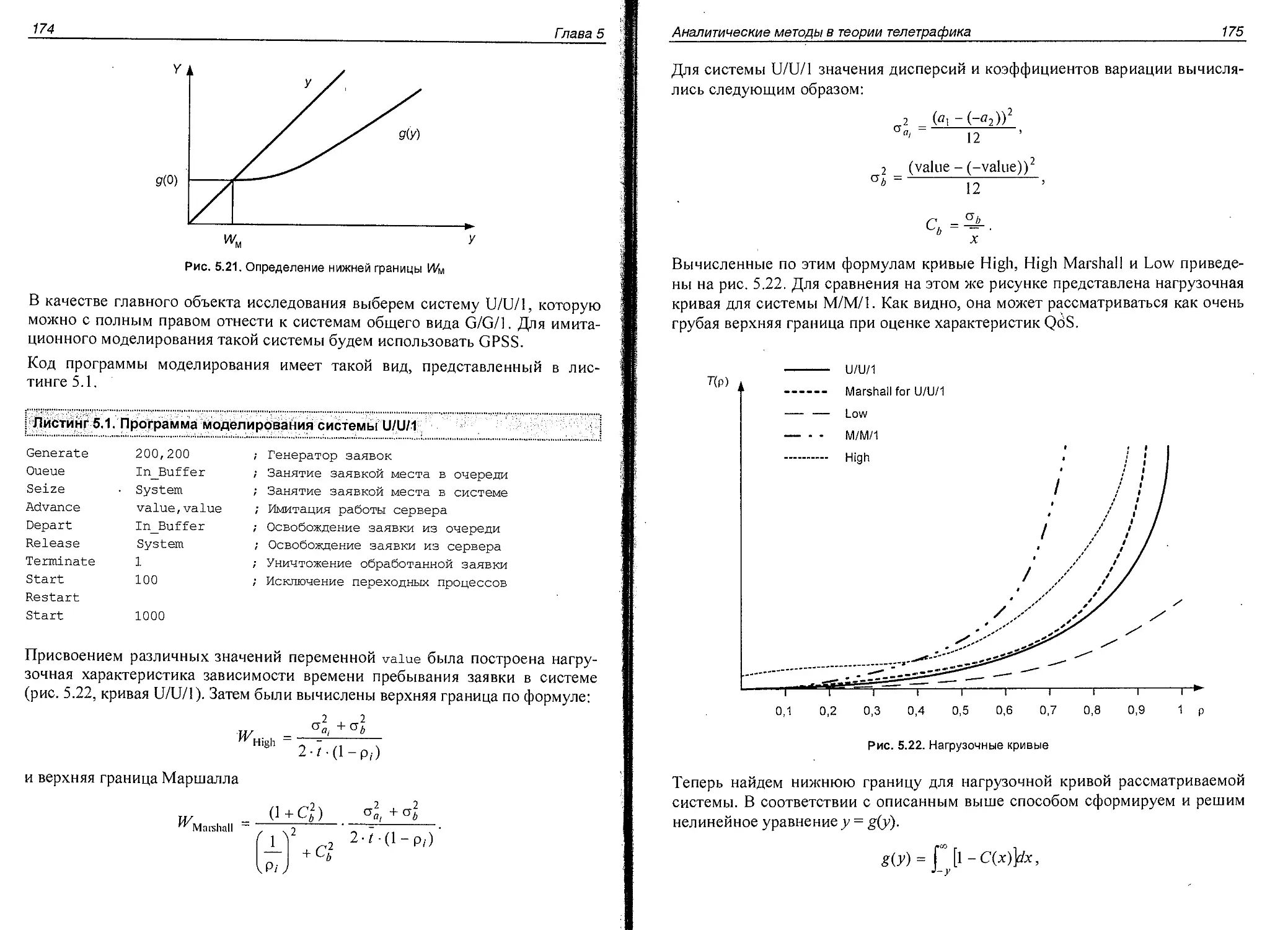
Глава 5. Аналитические методы в теории телетрафика.................136
Вероятностная модель СМО...........................................136
Непрерывные цепи Маркова.......................................140
Анализ систем массового обслуживания типа М/М/т:<®.................146
Система М/М/1..................................................146
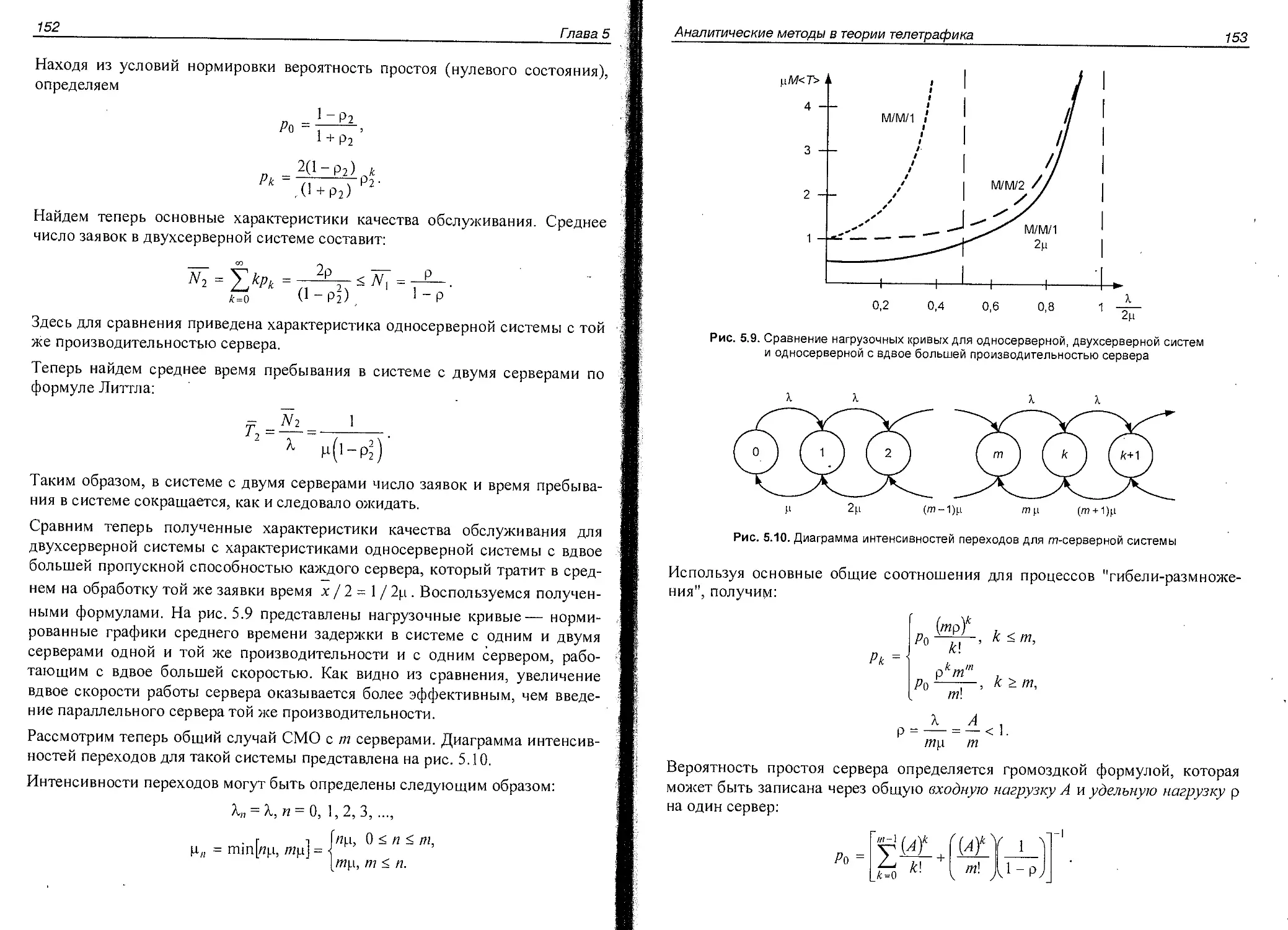
Система с несколькими серверами................................151
Анализ системы с ограниченной длиной очереди M/M/m:N...............154
Анализ системы M/M/PN..........................................155
Анализ систем с полными потерями...............................157
Модель Энгсета..................................................160.
Анализ систем с произвольным распределением времени обслуживания...163
Системы с произвольным распределением времени обслуживания
и входного потока..................................................167
Системы с самоподобным входным потоком и детерминированным временем
обслуживания.......................................................177
Контрольные вопросы................................................179
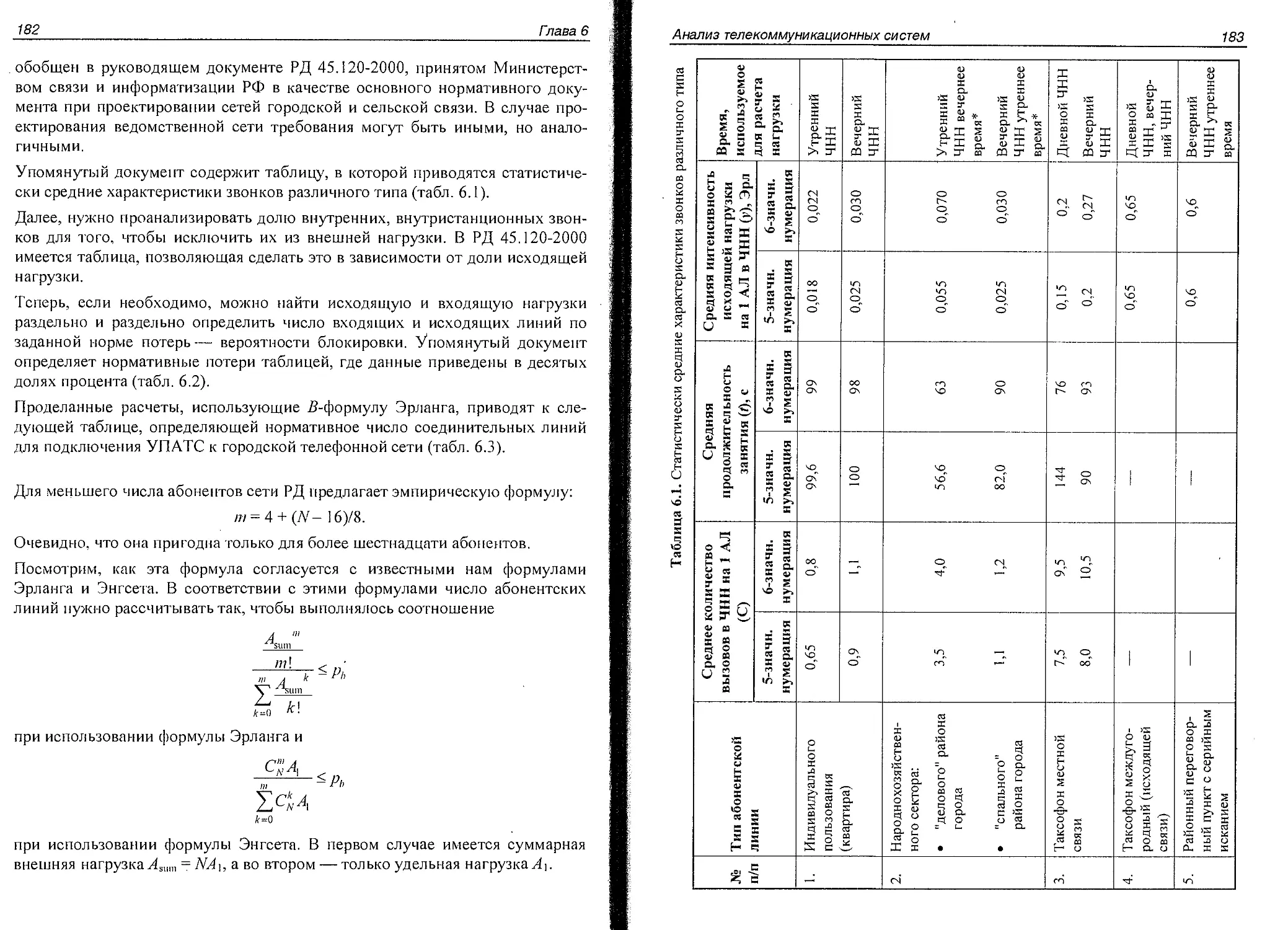
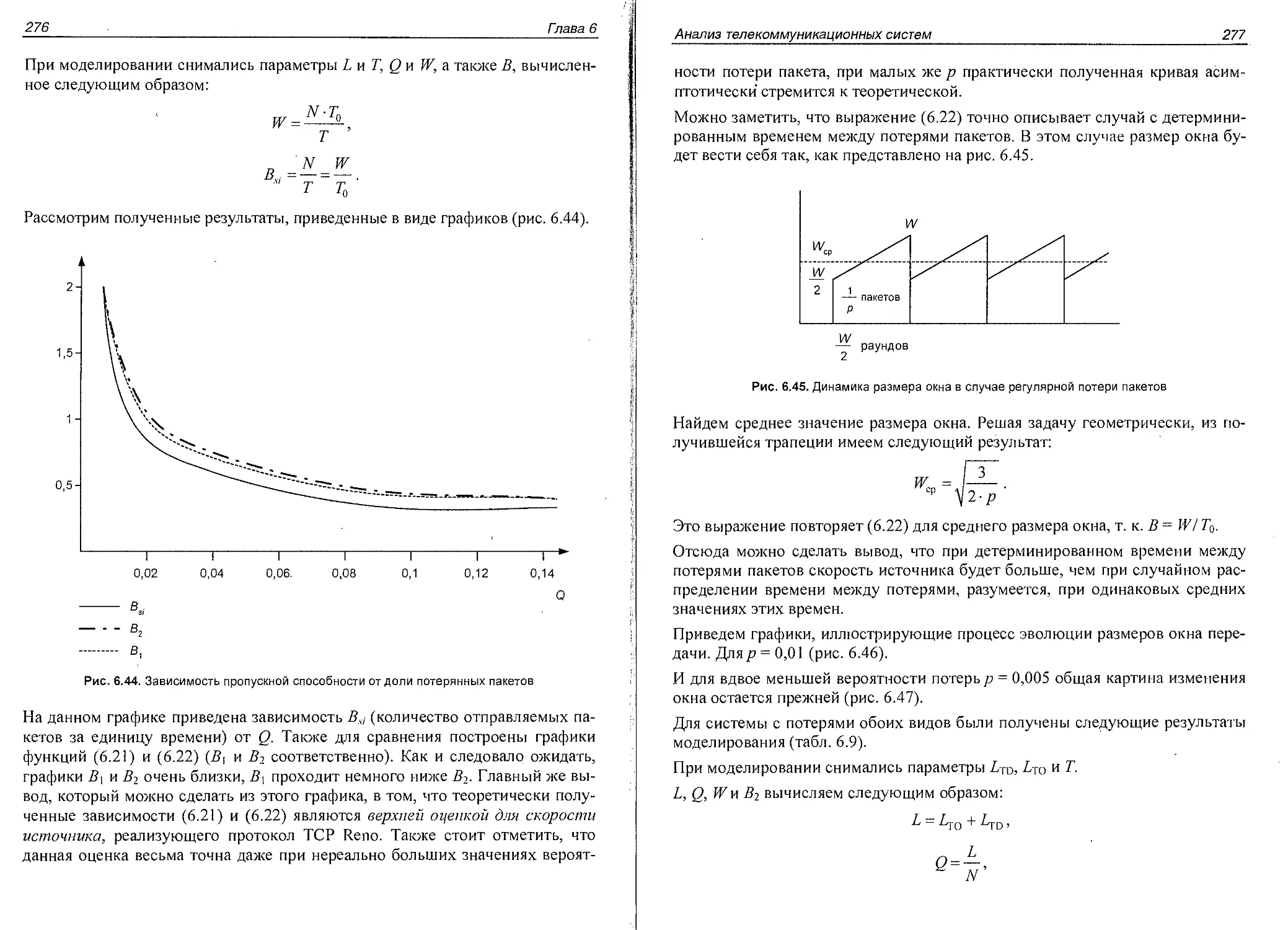
Глава 6. Анализ телекоммуникационных систем........................181
Расчет необходимого числа соединительных линий.....................181
Анализ сетей массового обслуживания................................187
Марковские сети без потерь................................... 187
Сети с блокировками (потерями).................................193
Анализ и оптимизация коммутационных систем.....................196
Сравнение характеристик QoS в коммутируемых сетях................. 204
Время доставки пакетов по сети с установлением соединения
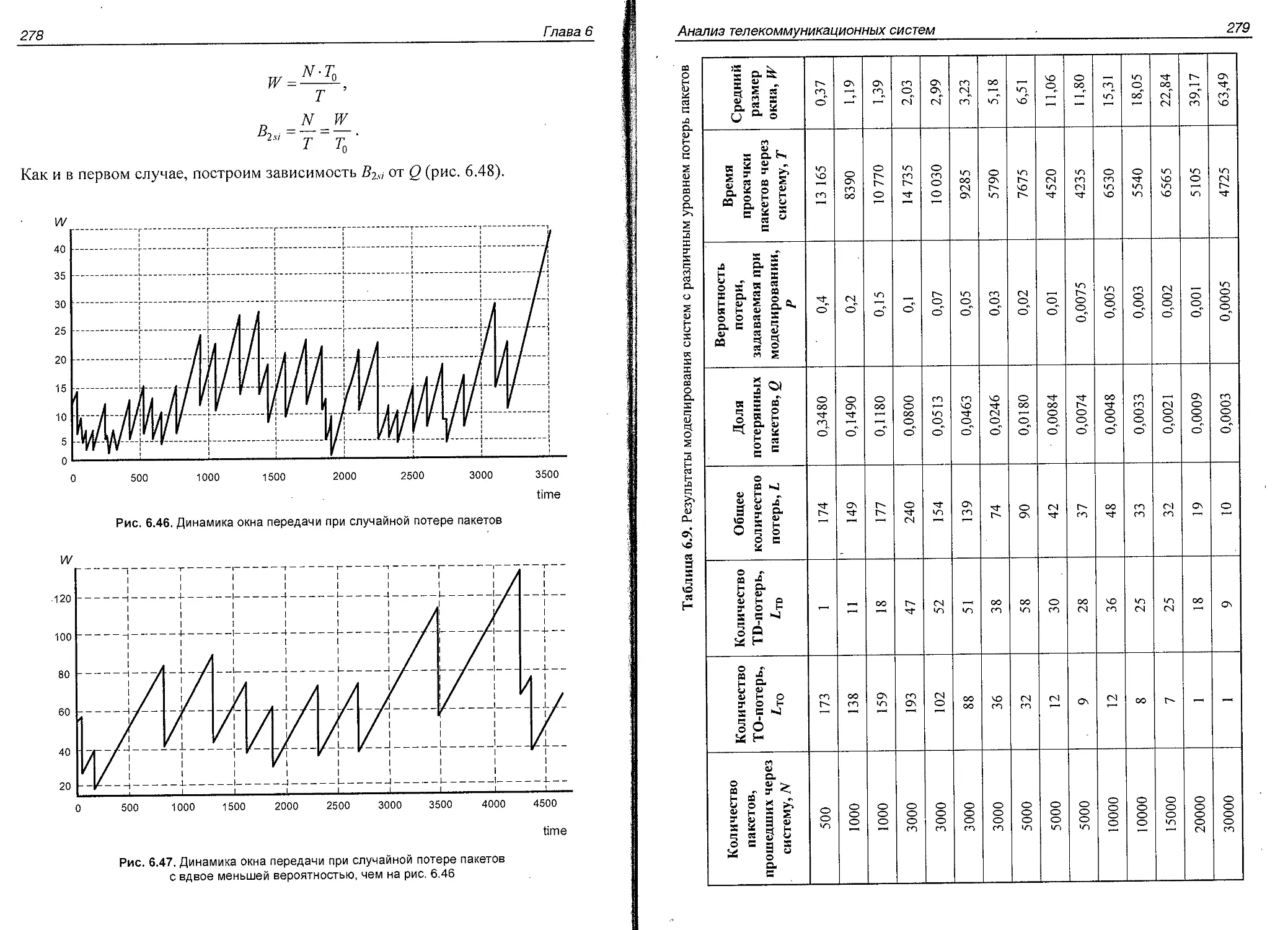
в модели коммутации каналов....................................205
Оглавление
5
Время доставки в сети без установления соединения в модели
с коммутацией пакетов.............................................212
Сравнение характеристик сетей с установлением и без установления
соединения........................................................216
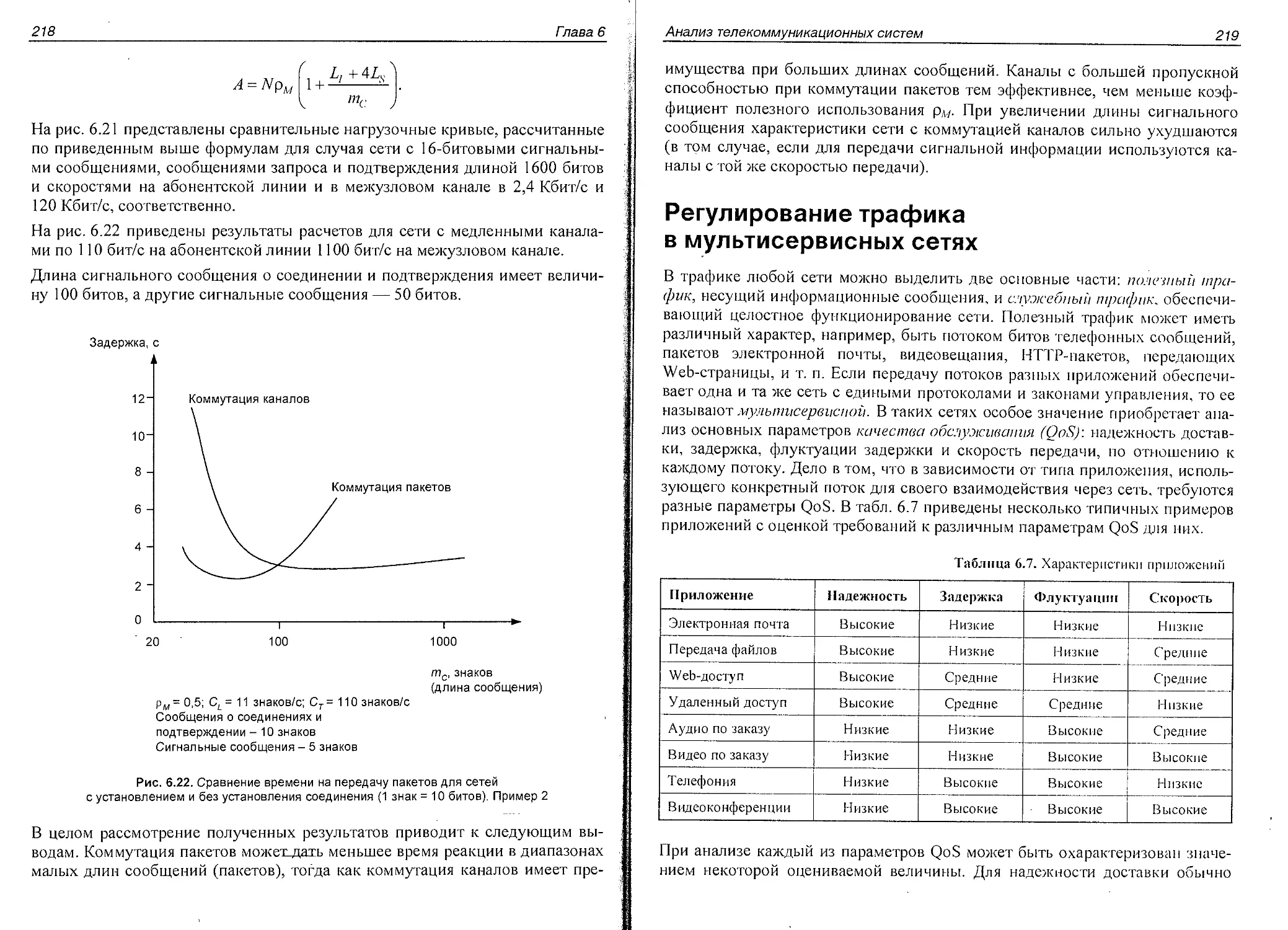
Регулирование трафика в мультисервисных сетях.........................219
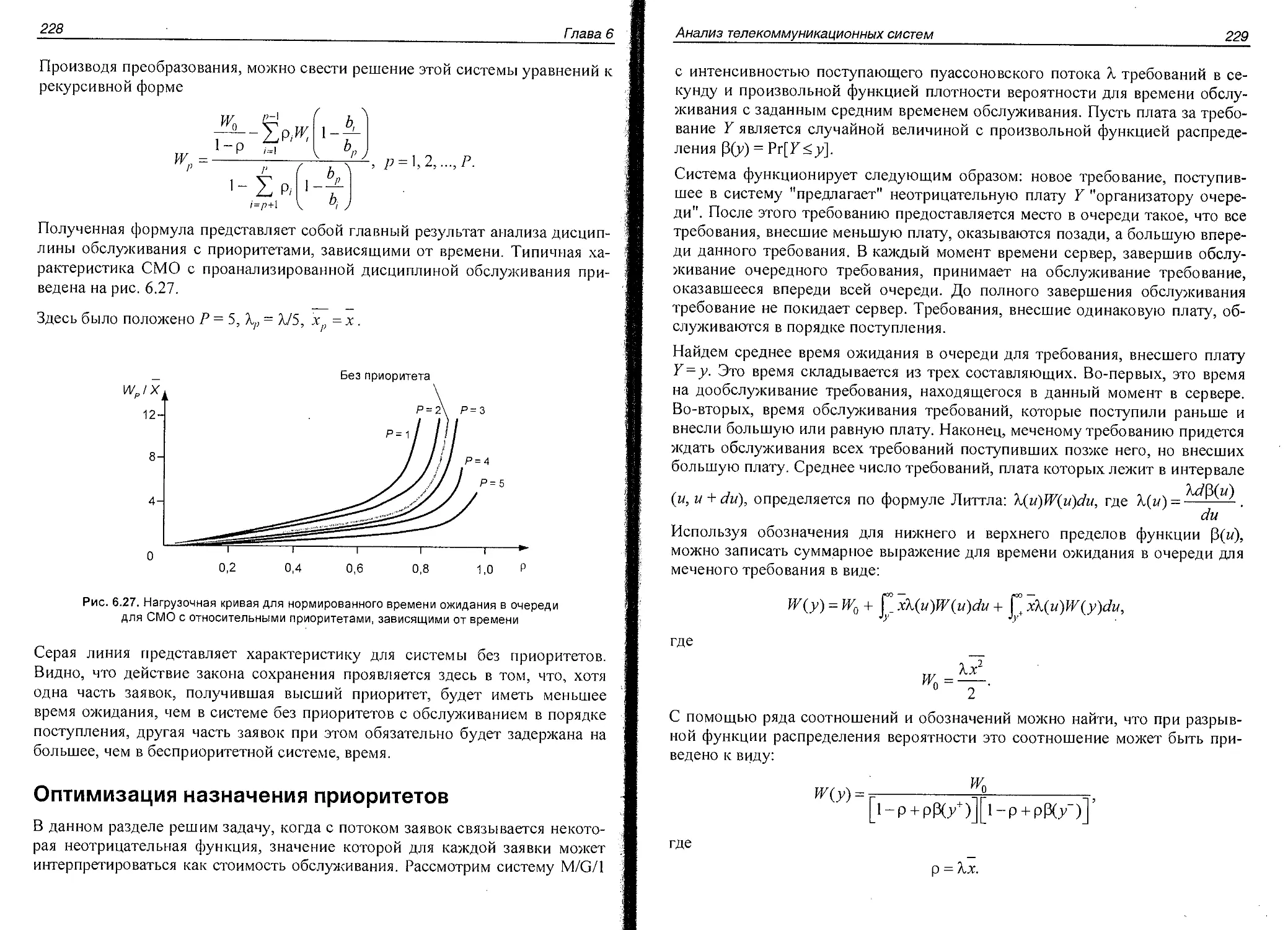
Анализ систем массового обслуживания с приоритетами...............220
Оптимизация назначения приоритетов................................228
Модели интеграции трафика с различными ведущими параметрами QoS...;232
Интеграция на основе обслуживания в порядке поступления.........233
Стратегия абсолютного приоритета................................238
Стратегия подвижной границы.....................................241
Управление доступом к среде...........................................247
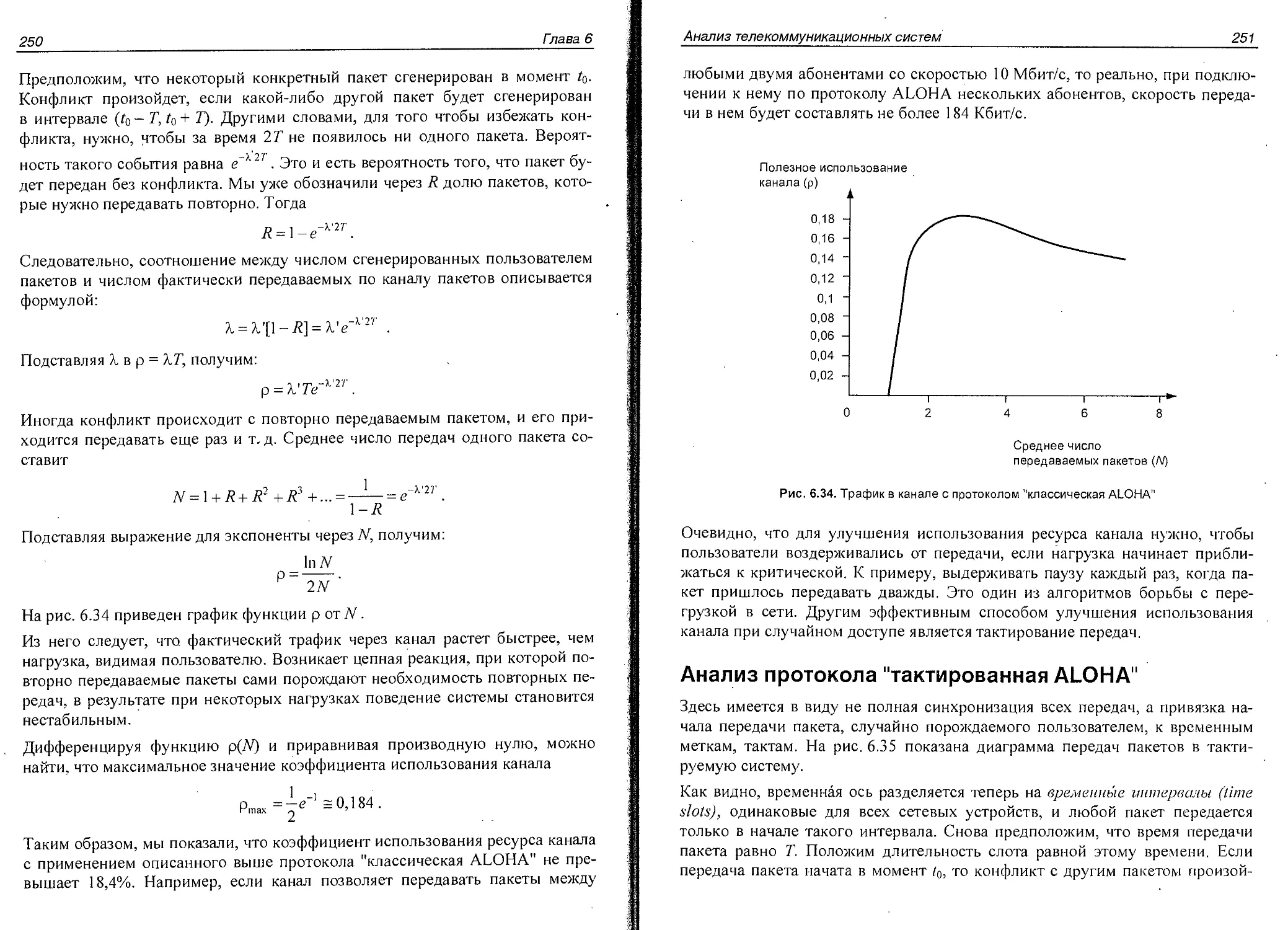
Анализ протокола "классическая ALOHA".............................248
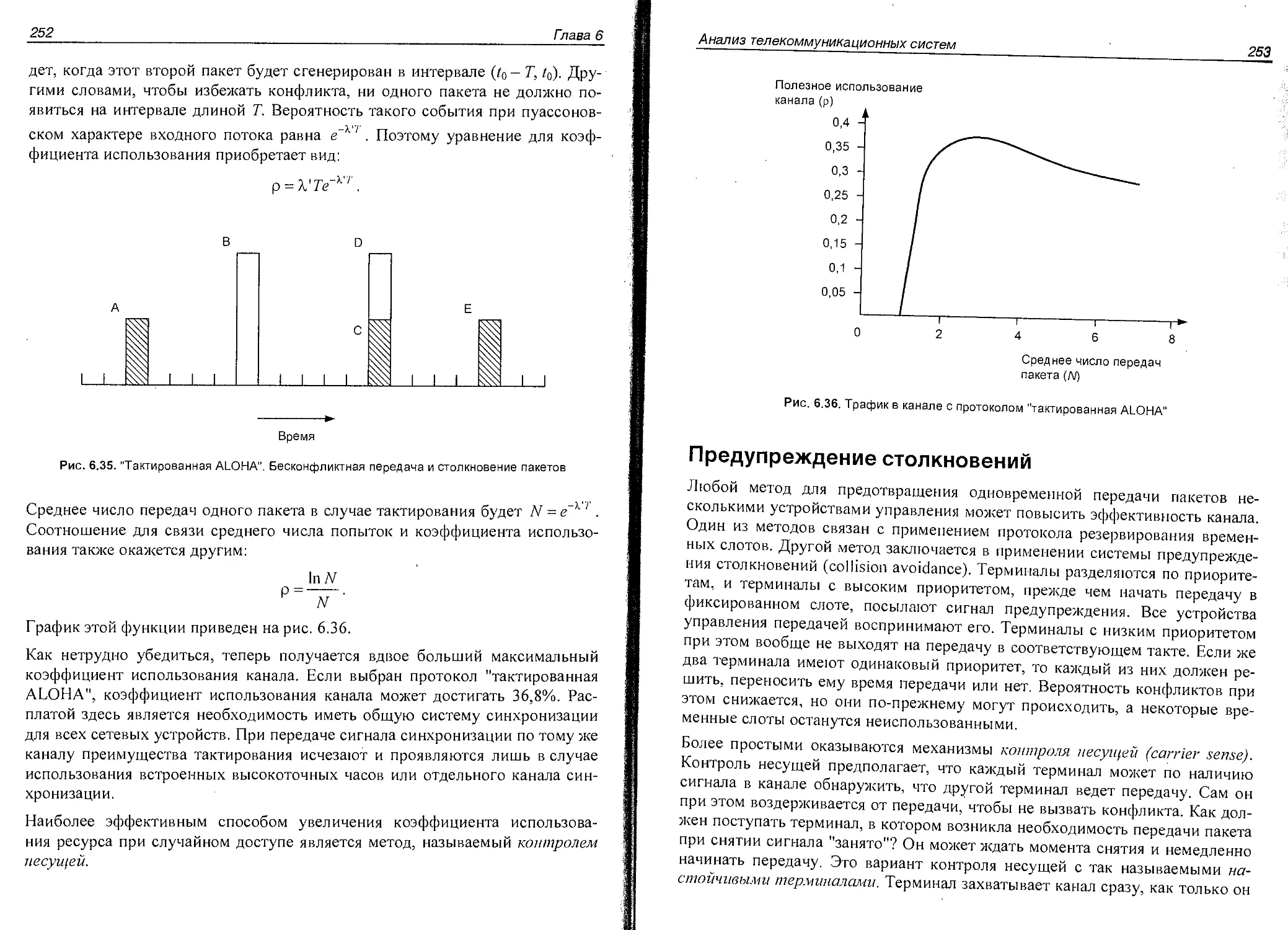
Анализ протокола "тактированная ALOHA"............................251
Предупреждение столкновений.......................................253
Анализ необходимого размера входных буферов в устройствах АТМ-сетей...255
Модель D+G/D/I и основные соотношения.............................256
Системы с конечным размером буфера................................258
Анализ и моделирование протокола TCP..................................261
Аналитические результаты..........................................261
Моделирование сетью Петри.........................................265
Контрольные вопросы...................................................282
Список литературы.....................................................283
Предметный указатель..................................................284
К читателю
Изучая материал этой книги, читатели узнают, что единицей измерения ин-
тенсивности трафика является эрланг, а математический аппарат, разра-
ботанный гениальным российским математиком А. А. Марковым, лежит в
основе почти всех известных аналитических результатов разработок систем
массового обслуживания. Поэтому авторы решили привести краткие спра-
вочные сведения об Эрланге и Маркове.
Агнер Краруп Эрланг (Agner Krarup Erlang) родил-
ся в 1878 г. в городе Лонборге в Дании. Он был
пионером в изучении трафика в телекоммуникаци-
онных системах. Им была впервые выведена фор-
мула для расчета доли вызовов, получающих об-
служивание на сельской телефонной станции, и
кому придется ожидать, пока делаются внешние
вызовы.
В 1909 г. он опубликовал свою первую работу:
"Теория вероятностей и телефония" (The Theory of
Probabilities and Telephone Conversations). Эта ра-
бота оказалась признанной во всем мире, а его
формула была принята для использования в круп-
нейшей почтовой службе мира— Главной почте
Великобритании (General Post Office in the UK).
Эрланг не был женат. Двадцать лет он проработал
в Копенгагенской телефонной компании и умер
в 1929 г. В сороковых годах прошлого столетия в
его честь была названа единица измерения трафи-
ка в телекоммуникационных системах, а его фор-
мула до сих пор используется при расчетах совре-
менных телекоммуникационных сетей.
(Перевод статьи
http://www.erlang.eom/whatis.html#tribute)
К читателю
7
Андрей Андреевич Марков родился 14 июня
1856 года. В цикле работ, опубликованном в
1906—1912 гг., заложил основы одной из общих
схем естественных процессов, которые можно
изучать методами математического анализа. Впо-
следствии эта схема была названа цепями Марко-
ва и привела к развитию нового раздела теории
вероятностей — теории случайных процессов.
В качестве примера случайных процессов можно
назвать диффузию газов, химические реакции, ла-
винные процессы и т. д. Важное место в творчест-
ве Маркова занимают вопросы математической
статистики. Он вывел принцип, эквивалентный
понятиям несмещенных и эффективных стати-
стик, которые в настоящее время получили широ-
кое применение. В математическом анализе Мар-
ков развил теорию моментов и теорию приближе-
ния функций, а также аналитическую теорию
непрерывных дробей.
Предисловие
С помощью этой книги читатели познакомятся с теорией телетрафика в не-
сколько отличном от классического изложении. Это, безусловно, имеет как
свои положительные, так и отрицательные стороны. Авторы стремились из-
ложить свой взгляд на проблематику данной научной дисциплины и методо-
логию решения задач, а также подобрали примеры практического при-
менения теории, исключительно опираясь на свое понимание важности и
методической целесообразности. Поэтому если кто-то из читателей будет
разочарован неполнотой или неудачной ориентацией представленных сведе-
ний, то авторы полностью берут на себя эту вину. Но мы будем радоваться
вместе с теми, кто, прочитав эту книгу, найдет ответы на свои вопросы.
Изложенный материал был впервые прочитан одним из авторов для студен-
тов специальности "Сети связи и системы коммутации" Нижегородского го-
сударственного технического университета в 1998/99 учебном году и был
опубликован в виде конспекта лекций [8]. К настоящему времени он пре-
терпел существенные изменения, которые нашли свое отражение в данной
книге.
Авторы благодарят сотрудников факультета информационных технологий
Нижегородского государственного технического университета за многие по-
лезные замечания, сделанные в процессе обсуждения рукописи, студентов,
в процессе работы с которыми авторы многому научились сами.
Особая благодарность Даше Кучиновой, чей труд над редактированием ру-
кописи позволил читателям избежать встречи со многими ошибками и опе-
чатками, сделал материал более наглядным и ясным, Анатолию Ивановичу
Гречихину, вложившему в улучшение текста немало труда и творческой
энергии.
Мы благодарим также компанию ARTIS Software Corporation
(www.artis-software.com) за предоставленную возможность использова-
ния продукта Artifex 4.2.
Авторы приносят свои извинения за те недостатки, которые еще не удалось
выявить, и с благодарностью отнесутся ко всем замечаниям и пожеланиям.
Многие программы, демонстрационные материалы и PowerPoint-презента-
цию по материалам этой книги можно найти на нашем сайте по адресу:
http://www.nntu.nnov.ru/tct.
Введение
Общеизвестен факт, что развитие современных телекоммуникационных сис-
тем проходит под действием двух сил, имеющих различные истоки: с одной
стороны традиционных телефонных компаний и поставщиков телефонного
оборудования, а с другой — производителей средств компьютерной техники
и провайдеров услуг Интернета. Каждая из сторон борется за потребителя и
основным оружием в этой борьбе является качество предоставляемых услуг.
Это весьма трудно определимое понятие в телекоммуникационной индустрии
имеет, к счастью, немало количественных характеристик. В книге, которая
лежит перед вами, мы попытаемся изложить теоретические основы количест-
венного описания многих понятий, связанных с качеством телекоммуникаци-
онных услуг. Научной основой измерения и прогнозирования качества рабо-
ты телекоммуникационной сети является теория телетрафика, которая вырос-
ла на почве традиционной телефонии и унаследовала из нее свое название.
Телетрафик— это понятие, которое может быть определено как движение
сообщений (информационных потоков). Теория телетрафика— научная
дисциплина о закономерностях и количественном описании процессов дви-
жения этих сообщений в сетях и системах. Начало теории телетрафика вос-
ходит к работам датского математика Агнера Крарупа Эрланга, исследовав-
шего статистические характеристики работы телефонных сетей и опублико-
вавшего в 1909 году свою основополагающую работу "Теория вероятностей и
телефония" (The Theory of Probabilities and Telephone Conversations). Цифро-
визация и интеллектуализация сетей связи и особенно их построение на
принципах компьютерных сетей потребовали использования существенно
новых методов анализа работы сетей, отсутствовавших в арсенале классиче-
ской теории телетрафика. В то же время методы анализа компьютерных сетей
развивались в направлении оценок производительности, а не привычных для
связистов понятий качества услуг связи, и не могли быть применены непо-
средственно при оценивании транспортных услуг сети связи с компьютерной
архитектурой. Потребность в таких оценках, а иначе говоря, необходимость
развития теории телетрафика применительно к компьютерным сетям связи
привела к появлению целого ряда исследований и сопровождающих их пуб-
ликаций. Однако результаты этих исследований не стали еще привычным
10
Введение
подходом для инженеров, проектирующих и эксплуатирующих системы и
сети связи. В настоящем учебном пособии авторы попытались дать совре-
менное изложение основ теории телетрафика, ориентированное на практиче-
ское использование. Расположение и подбор материала в книге предполагает
систематическое изучение и не претендует на легкость использования в каче-
стве справочника. Кроме того, авторы ориентировались на читателей, вла-
деющих курсом вузовской высшей математики, дискретной математики,
знающих основы построения телекоммуникационных систем и сетей.
Авторы надеются, что, изучив основные методы теории телетрафика, вы
сможете рассчитать характеристики качества обслуживания в телекоммуни-
кационных системах, управлять основными параметрами качества обслужи-
вания реальных сетей и систем и измерять их, а также предложить опти-
мальные с точки зрения качества обслуживания технические решения при
проектировании новых сетей и систем. Вопросы построения сетей с гаранти-
рованным качеством услуг являются предметом внимания Международного
союза электросвязи (International Telecommunication Union, ITU), особенно
в связи с развертыванием работ по созданию глобальных сетей третьего и
четвертого поколений.
ITU выделяет Traffic Engineering в явном и неявном виде как одно из важ-
нейших направлений деятельности специалистов по телекоммуникациям и
посвящает ему целый ряд рекомендаций, определения и методики из которых
будут использованы далее в настоящем пособии. В этом отношении взгляд
авторов на теорию телетрафика не всегда совпадает с классическим изложе-
нием, принятым в отечественной литературе. В классическом учебнике по
теории телетрафика [6] при необходимости вы найдете терминологию и под-
ходы к решению задач, относящихся к классической телефонии.
В конце книги приведен достаточно обширный список литературы и интере-
сующиеся проблемами анализа характеристик качества в сетях смогут найти
для себя более детальное изложение многих рассмотренных вопросов.
ГЛАВА 1
Предметная область
теории телетрафика
В этой главе рассматриваются те задачи, которые во многом послужили ис-
точником развития теории телетрафика, и приводится постановка проблемы в
достаточно общем виде.
Информационные процессы
и конфликты обслуживания
Телефонные сети с самого начала несли в себе компромисс между удовле-
творением потребностей в коммуникации всех абонентов и технико-
экономической эффективностью. В самом деле, для обеспечения связи между
двумя абонентами можно построить сеть, которая просто связывает любую
пару отдельным дуплексным каналом связи, т. е. строится по принципу
"каждый с каждым". Если сеть должна связывать N абонентов, то число ка-
налов при этом будет равно числу сочетаний из N по 2, обозначаемое обычно
. На рис. 1.1, <7 показана такая сеть для пяти абонентов. Однако стоимость
развертывания такого количества каналов при сколько-нибудь значительном
числе абонентов становится неприемлемой, и уже первые телефонные сети
стали строиться с использованием коммутаторов — технических устройств,
позволяющих соединять выходы каналов с входами других каналов по необ-
ходимости, т. е. переключать направления движения сообщений. Если по-
строить сеть с N абонентами по принципу коммутируемой сети с одним ком-
мутатором, то число каналов, которое потребуется построить, станет рав-
ным N. На рис. 1.1,6 показана структура такой сети.
Однако проблема развертывания большого количества каналов заменяется
при этом на другую — проблему построения коммутационного узла, способ-
ного осуществлять все необходимые переключения. Важнейшей частью пер-
72
Глава 1
вых коммутационных узлов были операторы — люди, которые осуществляли
собственно подсоединение проводов, идущих от одного абонента к другому.
Так появилась проблема обеспечения качества услуги соединения. Оператор
мог соединять слишком медленно, ведь он обслуживал сразу многих абонен-
тов, и кому-то приходилось ждать, пока он освободится для осуществления
следующего соединения. Кроме того, при большом числе длительных звон-
ков в руках оператора могло просто не оказаться достаточного количества
соединительных шнуров, с помощью которых производилась коммутация.
В этом случае в соединении просто приходилось отказывать. Уже самые пер-
вые телефонные сети могли сравниваться между собой по количественным
характеристикам качества предоставляемых ими услуг, описывающим за-
держку в предоставлении соединения и вероятности отказа в соединении.
Собственно, именно эти две характеристики являются ключевыми и при про-
ведении анализа любой современной телекоммуникационной сети, если вме-
сто простейшей услуги соединения понимать любую, предоставляемую
сетью или системой. Чтобы понять причину наследования проблемы обеспе-
чения качества сетевой услуги от первых телефонных сетей с "барышней" до
самых современных волоконно-оптических, следует рассмотреть более под-
робно механизм возникновения задержек и отказов.
Рис. 1.1. Некоммутируемая (а) и коммутируемая (б) сети
Конфликты в системах массового обслуживания
Между работой телефонистки на коммутационном узле и многими другими
системами, в том числе и без участия человека, нетрудно провести аналогии,
в которых проявляется задержка реагирования, зависящая от интенсивности
Предметная область теории телетрафика
13
прихода требований на предоставление услуги или даже отказ в такой услуге.
Это популярные парикмахерские и аттракционы в парке, кабинеты чиновни-
ков, скачивание информации с интересного сайта в Интернете, работа опера-
ционной системы Windows на вашем компьютере. Все эти системы объеди-
няет наличие внутреннего конфликта между несколькими поступающими на
обслуживание запросами из-за невозможности системы удовлетворить эти
запросы одновременно в силу ограниченности ресурсов исполнения. Иными
словами, все эти системы могут быть отнесены к общему классу динамиче-
ских, т.’е. функционирующих во времени систем, на вход которых поступают
запросы, обслуживание каждого из которых занимает какое-то рабочее время
некоторого ресурса системы, а число таких ресурсов недостаточно для одно-
временного обслуживания всех запросов. Наука, занимающаяся исследовани-
ем подобных систем, получила название теории систем массового обслужи-
вания, а в зарубежной литературе — теория очередей (Queuing Theory). Ком-
мутатор с телефонисткой, а значит и вся коммутируемая телефонная сеть,
конечно, также может рассматриваться как система массового обслуживания
(СМО). В этом смысле теория телетрафика является разделом теории СМО,
однако, наличие весьма специфических особенностей потока сообщений в
сетях связи и высокая интенсивность их исследований приводят к выделению
теории телетрафика в отдельную научную дисциплину.
Основу всех процессов в телекоммуникационных системах составляет пере-
дача и обработка сообщений, под которыми в этой книге понимается некото-
рое одномерное представление информации с выделенными началом и кон-
цом. Появление в системе каждого сообщения будем отождествлять с требо-
ванием (arrival) на его передачу или обработку. Обработка или передача
каждого сообщения занимает некоторое конечное время, называемое в тео-
рии телетрафика временем обслуживания (holding lime). Часть системы, уча-
ствующая в процессе передачи или обработки сообщения так, что одновре-
менно с ним никакое другое сообщение не может обрабатываться этой
частью, назовем сервером (server). Таким образом, если система содержит
ровно один сервер, то в каждый момент времени она способна обслуживать
не более чем одно требование. Если на такую систему, занятую обслужива-
нием, в течение интервала времени обслуживания поступит еще одно требо-
вание, то оно не сможет быть обслужено. Это простейший случай ресурсного
конфликта — требования, поступающие друг за другом, не могут быть об-
служены немедленно при поступлении или, как говорят, в реальном масшта-
бе времени из-за того, что сервер не успевает обслужить требования за время
между их поступлениями. Конфликт не возникнет, если система будет со-
держать не один, а несколько серверов, включенных так, чтобы поступающие
требования распределялись для обслуживания на любой свободный из них в
данный момент. Однако, очевидно, что если время обработки окажется соиз-
14
Глава 1
меримым с интервалом между поступлением требований, то и в системе с
несколькими серверами может возникнуть ресурсный конфликт— посту-
пившее требование не сможет получить немедленного обслуживания, т. к.
все серверы окажутся занятыми в данный момент. В этом случае система мо-
жет просто проигнорировать поступившее требование. Оно будет отброшено,
а система, как говорят, будет считаться заблокированной. Вероятность такого
события является важной характеристикой системы. Ее принято называть
вероятностью блокировки (blocking probability). Чтобы ни одно требование
не было потеряно в результате ресурсного конфликта, в системе может быть
предусмотрен специальный буфер памяти, содержащий требования, которые
не могут быть обслужены немедленно при поступлении из-за занятости всех
серверов. В этом случае говорят, что в системе организуется очередь (queue)
требований, или что рассматривается система с очередями (queuing system).
В очереди может оказаться не одно, а несколько требований, если количество
поступающих требований за некоторый интервал времени превысит число
освободившихся за это время серверов. Если очередь не будет бесконечно
нарастать, все требования рано или поздно будут обслужены, однако время
их пребывания в очереди окажется разным и может рассматриваться как слу-
чайная величина. Распределение этой случайной величины также является
важнейшей характеристикой системы обслуживания. Часто для оценки каче-
ства используется только ее среднее значение — среднее время ожидания
обслуживания (average waiting time). Таким образом, недостаточность ресур-
сов в телекоммуникационной системе может приводить либо к потерям по-
ступающих на обработку или передачу сообщений, либо к задержке их об-
служивания.
Основные определения теории телетрафика
В настоящем разделе будем придерживаться основных определений, приве-
денных в рекомендациях Е.600 Международного союза электросвязи (ITU).
Базовые понятия, на которые опираются многие определения, интуитивно
очевидны. Это связь, или коммуникация (communication) — процесс передачи
информации в соответствии с некоторыми правилами, и соединение (con-
nection) — некоторая ассоциация двух или более устройств внутри сети или
посредством сети для осуществления связи между ними.
В изложении часто будет встречаться также термин ресурс (resource), как
общее название физических или концептуальных сущностей внутри теле-
коммуникационных сетей, использование которых определяется однозначно,
и термин пользователь (user), как общий термин для всех внешних по отно-
шению к сети сущностей, которые используют соединения через сеть для
коммуникации.
Предметная область теории телетрафика 15
В процессе коммуникации пользователей в сети возникает поток сообще-
ний — телетрафик или просто трафик, который может быть охарактеризован
количественно. Очевидным параметром трафика является его объем (traffic
volume). Для цифровых систем эта величина естественным образом ассоции-
руется с числом битов, переданных за заданное время. Однако для аналого-
вых систем такой подход оказывается неприемлемым. Более того, при ис-
пользовании цифровых систем со сложными способами модуляции и кодиро-
вания сигналов определение объема трафика становится неоднозначным.
Сравним нашу ситуацию с трафиком автомобильного движения на дороге.
Мы говорим о большом трафике, если автомобили очень плотно заполняют
полосы движения, а количество груза в них (аналогия переносимых битов
информации) и даже число автомобилей не имеет при этом большого значе-
ния. Приведенная аналогия позволяет охарактеризовать объем трафика как
меру занятости пространства для движения. Роль такого пространства для
телетрафика играет время, в пределах которого доступен тот или иной ресурс
сети. Поэтому мы будем называть объемом трафика, пропущенного тем или
иным ресурсом, величину суммарного, интегрального интервала времени,
в течение которого данный ресурс был занят за анализируемый период вре-
мени. Иногда эту величину называют работой ресурса за заданное время.
Единицей работы можно считать секундозанятие ресурса. Иногда можно
прочитать о часозанятии, а порой даже просто об объеме трафика в секундах
или часах. Однако рекомендации ITU дают размерность объема трафика в
эрлангочасах. Чтобы понять смысл такой единицы измерения, следует рас-
смотреть еще один важнейший количественный параметр трафика— интен-
сивность трафика (traffic intensity). В отечественной литературе по телефо-
нии можно прочитать об этой величине как об интенсивности нагрузки. При
этом чаще всего говорят о средней интенсивности трафика (нагрузки) на не-
котором заданном пуле (наборе) ресурсов, обслуживающих трафик. Интервал
времени усреднения также обычно задается. Если в каждый момент времени t
из заданного интервала (Zj, /2) число занятых обслуживанием трафика ресур-
сов из данного набора равно А((), то средняя интенсивность трафика может
быть оценена как
A(t], t2) = —J— j 2 A(t')dt.
Ф — ( Z|
Величина интенсивности трафика характеризуется как среднее число ресур-
сов, занятых обслуживанием трафика на заданном интервале времени. Еди-
ницей измерения интенсивности трафика (нагрузки) является один эрланг
(1 Эрл, 1 Е). Из определения интенсивности ясно, что 1 эрланг— это такая
интенсивность трафика, которая требует полной занятости одного ресурса
или, иначе говоря, при которой ресурсом выполняется работа величиной в
16
Глава 1
одно секундозанятие за время в одну секунду. При этом объем трафика в од-
но секундозанятие занимает единицу ресурса ровно на одну секунду.
В качестве примера приведем случай пропуска трафика через телефонную
абонентскую линию. Эта линия может рассматриваться как единственный
ресурс, и тогда максимальная интенсивность трафика, которая может быть
обслужена этой линией, равна одному эрлангу. Тогда за каждый час эта ли-
ния пропустит объем трафика в один эрлангочас, а за минуту — одну шести-
десятую эрлангочаса. Интенсивность трафика в данной линии может быть и
меньше эрланга. Например, считается, что в среднем один абонент создает с
помощью своего телефона и абонентской линии нагрузку на местную АТС
порядка двухсот миллиэрлангов при усреднении за сутки. Зная эту величину,
можно говорить, что одну пятую времени в среднем в сутки абонентская ли-
ния будет находиться в состоянии занято (busy), а оставшиеся четыре пятых
в состоянии простой (idle). Когда речь идет об обслуживании трафика не
единственным ресурсом, а набором ресурсов (например, поток клиентов в
парикмахерской обслуживает не один, а несколько мастеров), расчет интен-
сивности и объема трафика становится более сложным. Для корректного оп-
ределения этих параметров необходимо провести измерения динамики со-
стояния каждого ресурса и выполнить обработку этих измерений.
Измерения трафика
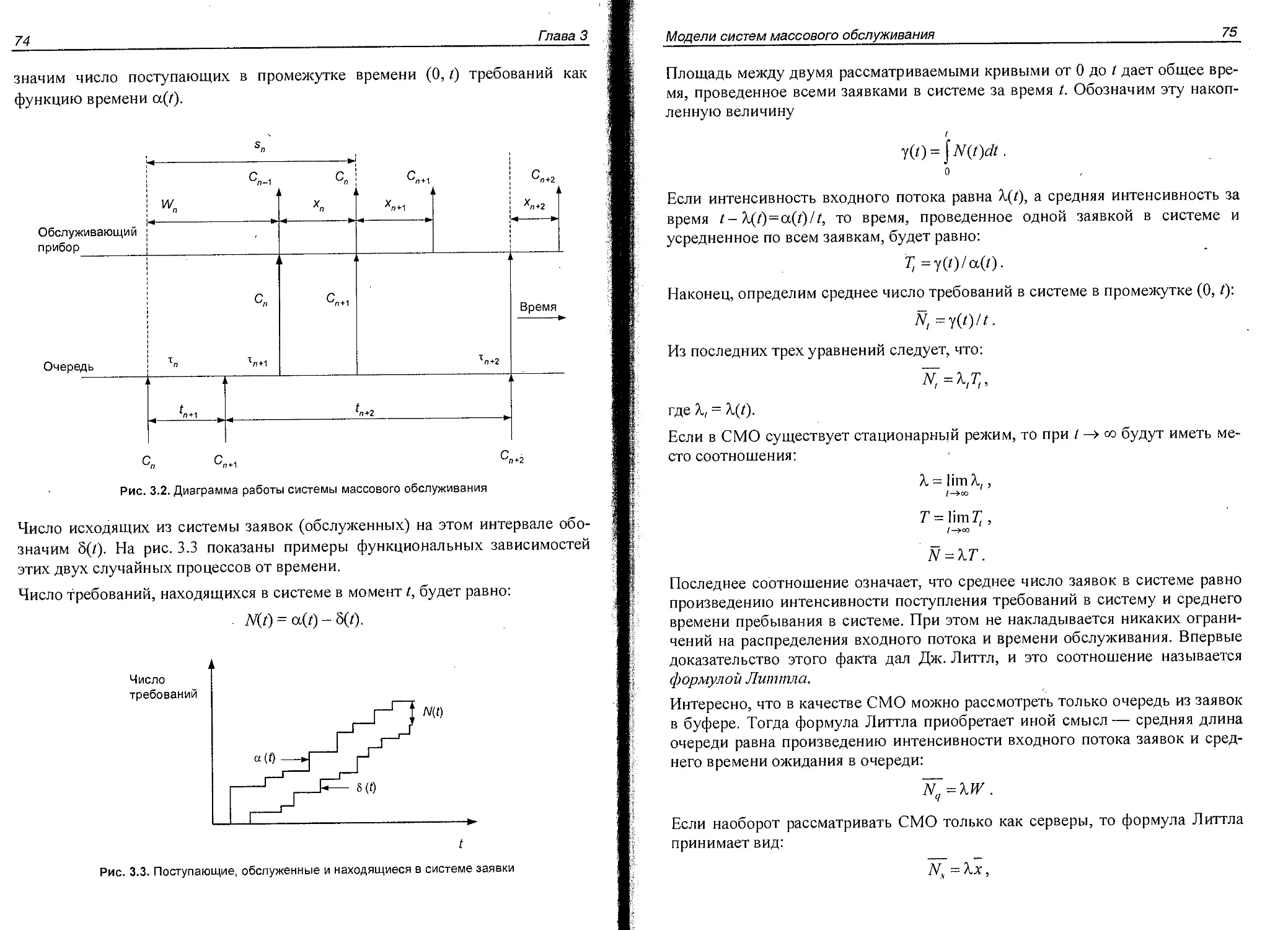
Сначала рассмотрим, как можно отображать работу СМО, имеющую не-
сколько ресурсов, которые одновременно обслуживают некоторый трафик.
Будем далее говорить о таких ресурсах, как о серверах, которые обслуживают
поток заявок или требований. Одним из наиболее наглядных и часто упот-
ребляемых способов изображения процесса обслуживания заявок пулом сер-
веров является диаграмма Ганта (Gantt). Эта диаграмма представляет собой
прямоугольную систему координат, ось абсцисс которой изображает время, а
на оси ординат помечаются дискретные точки, соответствующие серверам
пула. Далее, каждый интервал времени, когда сервер занят обслуживанием
заявки из входного потока, отмечается отрезком жирной горизонтальной
прямой. На рис. 1.2 изображена диаграмма Ганта для системы с тремя серве-
рами. В первые три интервала времени (будем считать их для определенности
секундой) заняты первый и третий серверы, следующие две секунды — толь-
ко третий, затем одну секунду работает только второй, потом, две секунды
второй и первый, и последние две секунды работает только первый.
Построенная диаграмма позволяет произвести расчеты объема трафика и его
интенсивности. Сразу заметим, что построенная диаграмма Ганта отражает
только обслуженный или пропущенный трафик (traffic carried), поскольку
ничего не говорит о том, поступали ли в систему заявки, которые не смогли
быть обслужены серверами. При построении диаграммы Ганта для посту-
Предметная область теории телетрафика
17
лающего трафика (traffic offered) нужно строить горизонтальные отрезки,
ассоциируя их начала с моментами поступления заявки, длины — с требуе-
мым временем обслуживания и располагая их по оси ординат таким образом,
чтобы такие отрезки не пересекались. В любом случае, объем трафика вы-
числяется как суммарная длина всех отрезков диаграммы Ганта. Разность
между объемами поступающего и пропущенного трафиков называется объ-
емом избыточного трафика (overflow traffic). Приведенная выше диаграмма
позволяет найти объем пропущенного трафика за время в Ю секунд:
£7(0,10) = 3 • 2 + 2 1 +1 • 1 + 2 • 2 + 2 • I = 15 [Es].
Мы привели результат в эрлангосекундах или секундозанятиях. Теперь пе-
рейдем к более сложному расчету интенсивности трафика.
Свяжем с каждым временным интервалом, отложенным по оси абсцисс, це-
лое число, равное количеству серверов, занятых на этом единичном интерва-
ле. Эта величина была нами ранее обозначена как A(f) — мгновенная интен-
сивность. Для нашего примера, где дискретность измерения составляет
1 секунду, можно представить мгновенную интенсивность следующей после-
довательностью:
А(/)= {2, 2, 2, 1, 1, 1,2, 2, 1, 1}.
Найдем теперь среднюю за период в 10 секунд интенсивность трафика.
В соответствии с приведенной выше формулой получим
16
Глава 1
одно секундозанятие за время в одну секунду. При этом объем трафика в од-
но секундозанятие занимает единицу ресурса ровно на одну секунду.
В качестве примера приведем случай пропуска трафика через телефонную
абонентскую линию. Эта линия может рассматриваться как единственный
ресурс, и тогда максимальная интенсивность трафика, которая может быть
обслужена этой линией, равна одному эрлангу. Тогда за каждый час эта ли-
ния пропустит объем трафика в один эрлангочас, а за минуту — одну шести-
десятую эрлангочаса. Интенсивность трафика в данной линии может быть и
меньше эрланга. Например, считается, что в среднем один абонент создает с
помощью своего телефона и абонентской линии нагрузку на местную АТС
порядка двухсот миллиэрлангов при усреднении за сутки. Зная эту величину,
можно говорить, что одну пятую времени в среднем в сутки абонентская ли-
ния будет находиться в состоянии занято (busy), а оставшиеся четыре пятых
в состоянии простой (idle). Когда речь идет об обслуживании трафика не
единственным ресурсом, а набором ресурсов (например, поток клиентов в
парикмахерской обслуживает не один, а несколько мастеров), расчет интен-
сивности и объема трафика становится более сложным. Для корректного оп-
ределения этих параметров необходимо провести измерения динамики со-
стояния каждого ресурса и выполнить обработку этих измерений.
Измерения трафика
Сначала рассмотрим, как можно отображать работу СМО, имеющую не-
сколько ресурсов, которые одновременно обслуживают некоторый трафик.
Будем далее говорить о таких ресурсах, как о серверах, которые обслуживают
поток заявок или требований. Одним из наиболее наглядных и часто упот-
ребляемых способов изображения процесса обслуживания заявок пулом сер-
веров является диаграмма Ганта (Gantt). Эта диаграмма представляет собой
прямоугольную систему координат, ось абсцисс которой изображает время, а
на оси ординат помечаются дискретные точки, соответствующие серверам
пула. Далее, каждый интервал времени, когда сервер занят обслуживанием
заявки из входного потока, отмечается отрезком жирной горизонтальной
прямой. На рис. 1.2 изображена диаграмма Ганта для системы с тремя серве-
рами. В первые три интервала времени (будем считать их для определенности
секундой) заняты первый и третий серверы, следующие две секунды — толь-
ко третий, затем одну секунду работает только второй, потом, две секунды
второй и первый, и последние две секунды работает только первый.
Построенная диаграмма позволяет произвести расчеты объема трафика и его
интенсивности. Сразу заметим, что построенная диаграмма Ганта отражает
только обслуженный или пропущенный трафик (traffic carried), поскольку
ничего не говорит о том, поступали ли в систему заявки, которые не смогли
быть обслужены серверами. При построении диаграммы Ганта для посту-
Предметная область теории телетрафика
17
лающего трафика (traffic offered) нужно строить горизонтальные отрезки,
ассоциируя их начала с моментами поступления заявки, длины— с требуе-
мым временем обслуживания и располагая их по оси ординат таким образом,
чтобы такие отрезки не пересекались. В любом случае, объем трафика вы-
числяется как суммарная длина всех отрезков диаграммы Ганта. Разность
между объемами поступающего и пропущенного трафиков называется объ-
емом избыточного трафика (overflow traffic). Приведенная выше диаграмма
позволяет найти объем пропущенного трафика за время в 10 секунд:
Г7(0,10) = 3- 2 + 2-1 + 1-1 + 2- 2 + 2-1 = 15 [Es].
Мы привели результат в эрлангосекундах или секундозанятиях. Теперь пе-
рейдем к более сложному расчету интенсивности трафика.
Свяжем с каждым временным интервалом, отложенным по оси абсцисс, це-
лое число, равное количеству серверов, занятых на этом единичном интерва-
ле. Эта величина была нами ранее обозначена как A(t)—мгновенная интен-
сивность. Для нашего примера, где дискретность измерения составляет
1 секунду, можно представить мгновенную интенсивность следующей после-
довательностью :
Л(/)= {2, 2, 2, 1, 1, 1, 2, 2, 1, 1}.
Найдем теперь среднюю за период в 10 секунд интенсивность трафика.
В соответствии с приведенной выше формулой получим
2 + 2 + 2 + 1 + 1 + 1 + 2 + 2 + 1 + I
10
= 1,5[Е].
18
Глава 1
Таким образом, построенная диаграмма позволила рассчитать среднюю ин-
тенсивность трафика, пропущенного (обслуженного) рассматриваемой сис-
темой из трех серверов. Она оказалась равной 1,5 Эрл.
Диаграмма Ганта позволяет найти средние интенсивности на любых интерва-
лах времени. Например, мы можем определить среднюю интенсивность за
первые 5 секунд измерений и за вторые 5 секунд. Первая половина интервала
измерений дает оценку для интенсивности трафика (2+2+2+1 +1 )/5 =
= 1,6 Эрл, а вторая половина— (1 + 2 + 2+ 1 +1 )/5 = 1,4 Эрл. Значит, в зависи-
мости от выбора интервала усреднения, оценка средней интенсивности будет
различной. Рекомендации ITU Е.500 определяют для оценки интенсивности
трафика в телефонных сетях интервал времени усреднения в 15 минут. Изме-
рение ведется непрерывно и постоянно, накапливая набор данных в виде по-
следовательности чисел подобно приведенному выше примеру. Построив
график изменения интенсивности трафика (нагрузки), можно определить ча-
совой интервал, когда интенсивность была максимальной (сумма четырех
соседних значений является наибольшей). Время, соответствующее этому
интервалу принято называть часом наибольшей нагрузки (ЧНН) или в англо-
язычной литературе — busy hour. Обычно интервал времени, соответствую-
щий ЧНН, повторяется каждые сутки, например, с 11 до 12 часов ежедневно.
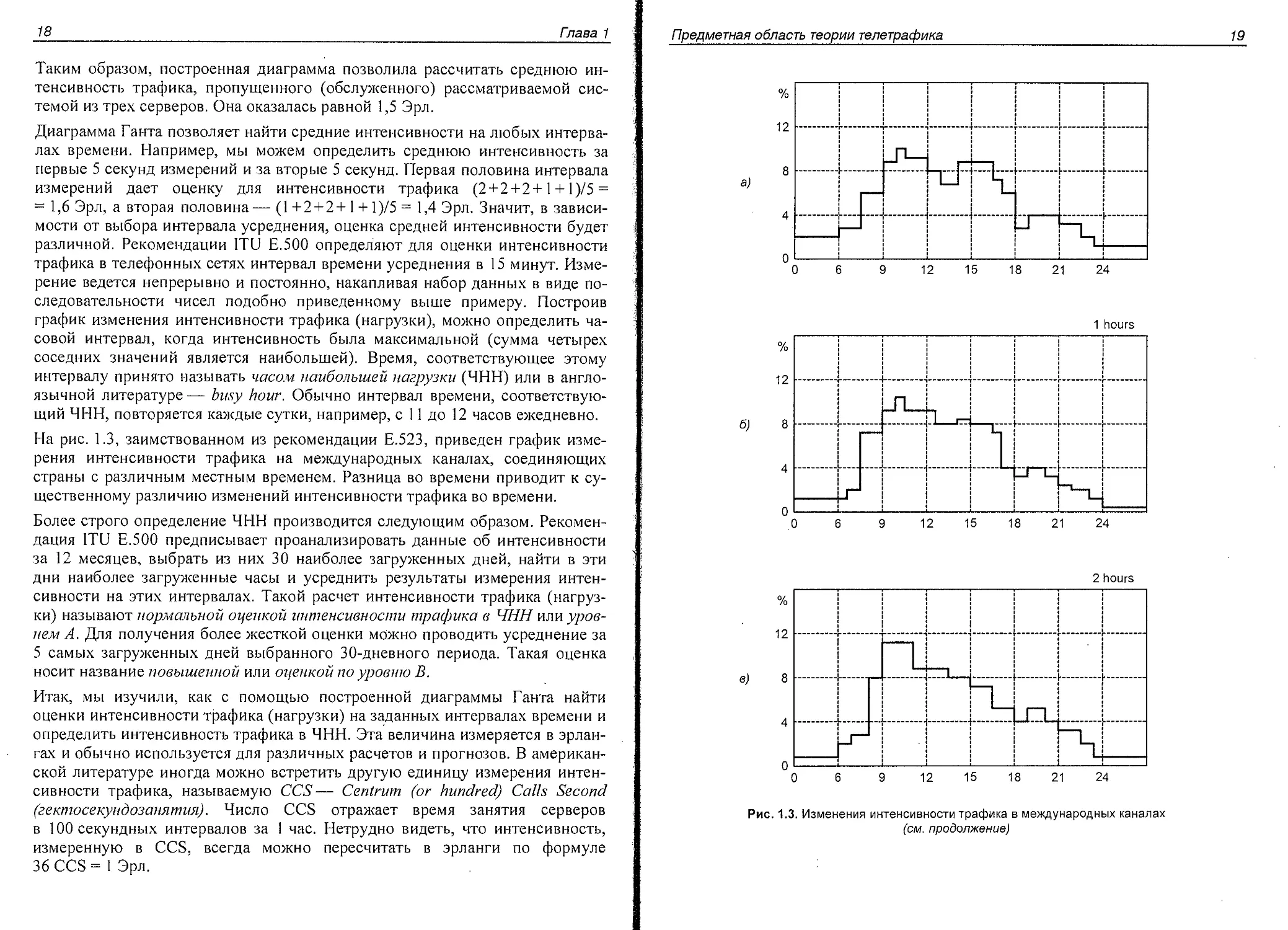
На рис. 1.3, заимствованном из рекомендации Е.523, приведен график изме-
рения интенсивности трафика на международных каналах, соединяющих
страны с различным местным временем. Разница во времени приводит к су-
щественному различию изменений интенсивности трафика во времени.
Более строго определение ЧНН производится следующим образом. Рекомен-
дация ITU Е.500 предписывает проанализировать данные об интенсивности
за 12 месяцев, выбрать из них 30 наиболее загруженных дней, найти в эти
дни наиболее загруженные часы и усреднить результаты измерения интен-
сивности на этих интервалах. Такой расчет интенсивности трафика (нагруз-
ки) называют нормальной оценкой интенсивности трафика в ЧНН или уров-
нем А. Для получения более жесткой оценки можно проводить усреднение за
5 самых загруженных дней выбранного 30-дневного периода. Такая оценка
носит название повышенной или оценкой по уровню В.
Итак, мы изучили, как с помощью построенной диаграммы Ганта найти
оценки интенсивности трафика (нагрузки) на заданных интервалах времени и
определить интенсивность трафика в ЧНН. Эта величина измеряется в эрлан-
гах и обычно используется для различных расчетов и прогнозов. В американ-
ской литературе иногда можно встретить другую единицу измерения интен-
сивности трафика, называемую CCS— Centrum (or hundred) Calls Second
(гектосекундозанятия). Число CCS отражает время занятия серверов
в 100 секундных интервалов за 1 час. Нетрудно видеть, что интенсивность,
измеренную в CCS, всегда можно пересчитать в эрланги по формуле
36 CCS = 1 Эрл.
Предметная область теории телетрафика
19
Рис. 1.3. Изменения интенсивности трафика в международных каналах
(см. продолжение)
20
Глава 1
3 hours
0)
е)
5 hours
Рис. 1.3. Продолжение
Предметная область теории телетрафика
21
Рис. 1.3. Продолжение
22
Глава 1
к)
л)
Рис. 1.3. Продолжение
Предметная область теории телетрафика
23
Рис. 1.3. Окончание
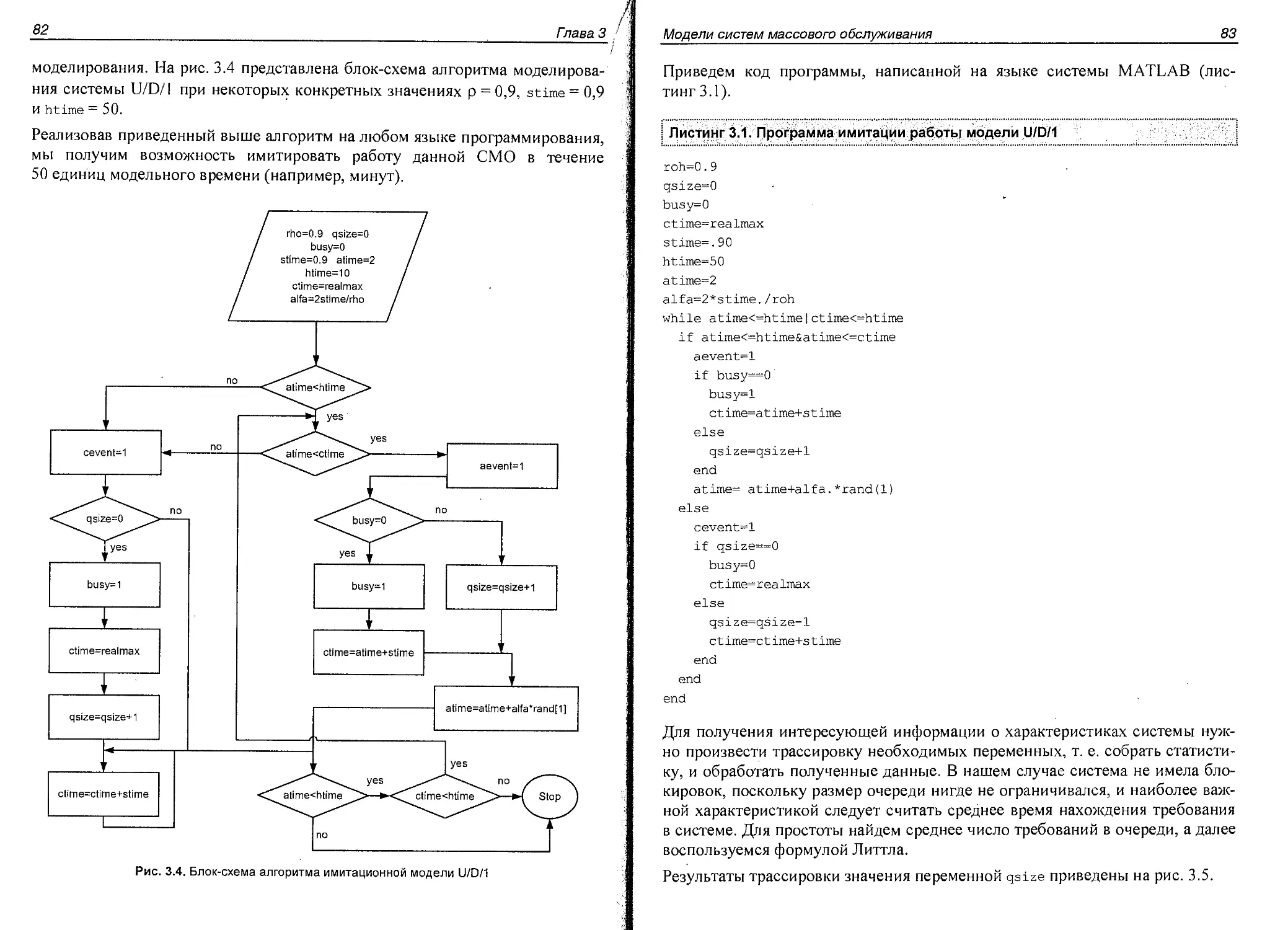
Рассмотрим теперь, как практически можно построить диаграммы Ганта и
измерять интенсивность трафика.
Измерения интенсивности трафика
В этом разделе рассмотрим простые практические способы измерения интен-
сивности трафика как в телефонных системах, так и в пакетных сетях.
Самая простая задача, которая может быть решена каждым читателем, — это
измерение интенсивности трафика абонентской линии домашнего телефона.
Для проведения измерений нужно изготовить переходник-индикатор к теле-
фонной розетке по схеме, приведенной на рис. 1.4, а также запастись часами
с секундомером, листом бумаги и карандашом.
к телефонному
аппарату
Рис. 1.4. Схема переходника-индикатора
Работа переходника-индикатора состоит в определении состояния телефон-
ной линии по току в линии. Если линия свободна, ток в ней мал из-за высоко-
го сопротивления цепи телефона при положенной трубке. Если линия занята,
трубка поднята, сопротивление цепи резко уменьшается, ток возрастает. Све-
тодиод индикатора включен так, что загорается при занятости линии, инди-
цируя состояние busy. Потухший светодиод соответствует состоянию idle.
Включите переходник в телефонную розетку и вставьте телефонный разъем
24
Глава 1
в переходник. При опущенной трубке светодиод не должен гореть. Подними-
те трубку — светодиод должен загореться. Располагайтесь поудобнее с часа-
ми-секундомером и бумагой, так, чтобы лампочка индикатора была вам хо-
рошо видна. Измерительная система готова к работе.
Запишите начальный момент времени, когда вы приступили к наблюдению за
состоянием линии. Когда кто-то из ваших домашних возьмет трубку, лампоч-
ка загорится. Зафиксируйте этот момент времени. Когда лампочка погаснет,
отразите длительность интервала занятия на бумаге так же. Поступайте так
каждый раз при вспыхивании лампочки. Этот процесс часто называют мони-
торингом состояния. Просидев у лампочки сутки-другие, вы сможете постро-
ить диаграмму Ганта для вашей телефонной линии, вычертив ось времени,
разметив ее и проведя отрезки жирной линией для всех интервалов времени,
когда горела лампочка индикатора.
Далее приведены табл. 1.1 и 1.2, заполненные одним из наших друзей, проси-
девшим у индикатора сутки, и диаграмма Ганта, которую он построил
(рис. 1.5).
Таблица 1.1. Статистика
Начало вызова Конец вызова Длительность, минут Всего, часов
08:20 08:23 3 0,05
09:00 09:10 10 0,2166
17:15 17:18 3 0,2666
17:20 17:22 2 0,3
17:25 17:29 4 0,3666
18:30 18:40 10 0,5333
19:10 19:20 10 0,7
19:30 19:56 26 1,1333
20:00 20:15 15 1,38
20:30 20:37 7 1,5
21:05 21:15 10 1,6666
22:00 22:05 5 1,75
22:30 22:43 13 1,9666
23:00 23:02 1 1,9833
23:30 23:31 1 2,0
Предметная область теории телетрафика
25
8:00 9:00 10:00 11:00 12:00 13:00 14:00 15:00 16.00 17:00 18:00 19:00 20:00 21:00 22:00 23:00 0:00
Рис. 1.5. Результаты мониторинга домашней телефонной линии
Таблица 1.2. Среднее значение интенсивности трафика
по 15-минутным интервалам
Интервал времени Интенсив- ность трафика Интервал времени Интенсив- ность трафика Интервал времени Интенсив- ность трафика
8:00—8-.15 0,0 19:00—19:15 0,333 21:45—22:00 0,0
8:15—8:30 0,2 19:15—19:30 0,333 22:00—22:15 0,33
8:30—8:45 0,0 19:30—19:45 1,0 22:15—22:30 0,0
8:45—9:00 0,0 19:45—20:00 0,733 22:30—22:45 0,866
9:00—09:15 0,666 20:00—20:15 1,о 22:45—23:00 0,0
09:15—17:15 0,0 20:15—20:30 0,0 23:00—23:15 0,066
17:15—17:30 0,666 20:30—20:45 0,466 23:15—23:30 0,0
17:30—17:45 0,0 20:45—21:00 0,0 23:30—23:45 0,066
17:45—18:00 0,0 21:00—21:15 0,666 23:45—08:00 0,0
18:00—18:15 0,0 21:15—21:30 0,0 23:30—23:45 0,066
18:30—18:45 0,666 21:30—21:45 0,0
Рассчитаем среднюю за сутки интенсивность трафика или телефонную на-
грузку на эту абонентскую линию. Для этого сложим длины всех отрезков,
соответствующих состоянию busy, и разделим на общую длительность ин-
тервала измерения— 24 часа. Получилось, что средняя интенсивность тра-
фика составляет всего 0,083 Эрл или 83 мЭрл (миллиэрланга).
Теперь разобьем ось времени на 15-минутные интервалы и найдем среднюю
интенсивность на каждом таком интервале. Получится таблица из 95 чисел.
26
Глава 1
Выберем из этой таблицы группу из соседних четырех чисел, сумма которых
является наибольшей. Получится, что этот участок приходится на интервал
времени от 19:15 до 20:15. Это и есть ЧНН— час наибольшей нагрузки.
Сумма соответствующих средних интенсивностей, деленная на 4, составляет
0,766 Эрл. Такова была интенсивность трафика в час наибольшей нагрузки
в тот день, когда проводился мониторинг.
Теперь приведем несколько математических определений. Сначала опреде-
лим, сколько раз загоралась лампа индикатора за время мониторинга. Это
число говорит о том, сколько раз наступило событие busy или, что то же са-
мое, — число поступлений требований на обслуживание. Обозначим это чис-
ло п. Если разделить это число на длительность интервала мониторинга Т, то
получим среднее число поступлений требований в единицу времени, сред-
нюю частоту поступлений или, как часто ее называют, среднюю интенсив-
ность потока требований. Эту величину принято обозначать
Если взглянуть на диаграмму Ганта, то можно заметить, что отрезки, пред-
ставляющие собой интервалы занятости (обслуживания) имеют различную,
случайную длину. Поскольку число таких отрезков равно в точности п, то
можно суммарную длину этих отрезков (обозначим ее s) записать в виде про-
изведения
S = п • X ,
где х — средняя длительность занятия (обслуживания).
Важность введения этого параметра видна из следующего. Поскольку сред-
няя интенсивность трафика (обозначим ее р) определяется как отношение
суммарного времени обслуживания к общему времени мониторинга, то в на-
ших обозначениях можно записать
Таким образом, мы показали, что средняя интенсивность трафика является
функцией только среднего числа поступлений требований в единицу времени
и средней длительности их обслуживания.
Эта величина также называется средней нагрузкой и также ассоциируется
с коэффициентом использования ресурса (сервера). Действительно, как видно
непосредственно из диаграммы Ганта, отношение s/T можно интерпретиро-
вать именно как относительную долю времени, когда сервер занят работой по
обслуживанию поступивших требований. Если он тратит на обслуживание
половину всего времени, то коэффициент использования естественно считать
Предметная область теории телетрафика 27
равным 50%, если вообще не включался за время мониторинга, то коэффици-
ент использования равен 0. Если разбить все время мониторинга на несколько
частей и сосчитать коэффициент использования для каждой из них, то можно
отложить эти значения по радиусам единичного круга, соответствующим вы-
деленным интервалам. Получившаяся диаграмма позволяет в динамике ви-
деть, как используется сервер. Такие диаграммы носят специальное назва-
ние — диаграммы Кивиата (Kiviat). Построим диаграмму Кивиата для наше-
го примера.
Как видно из рис. 1.6, телефонная линия 80% времени не использовалась, за-
то 10% времени использовалась на 100% и 10% времени— на 80%. Интер-
претация величины р как средней интенсивности трафика в диаграмме Ки-
виата позволяет сделать выводы о нестационарности трафика, определив до-
ли времени с различной интенсивностью.
(0:15-1:15)
(1:15-2:15) 23:15-0:15
(12:15-13:15)
Рис. 1.6. Диаграмма Кивиата для телефонной линии
Теперь обратимся к более сложной задаче, которая состоит в мониторинге
пучка линий. Такой пучок называют обычно трайком (trunk). Чаще всего это
28
Глава 1
30—120 линий, обслуживающих трафик на некотором направлении. Конечно,
можно представить себе 120 лампочек и людей, наблюдающих за ними с ка-
рандашами в руках, но это бессмыслица. Система, которая могла бы произ-
водить мониторинг пучка линий, строится на базе многоканального преобра-
зователя "напряжение-код" и компьютера. Преобразователь измеряет напря-
жение на каждой линии и в виде двоичного кода вводит эти данные в
компьютер. В качестве аппаратных средств (hardware) такой системы может
служить обычный ПК с вставленными платами типа L-761 производства
фирмы Л-Кард, или PCI-1713 производства Advantech. Для работы измерите-
ля параметров трафика нужно написать специальную программу, которая бу-
дет измерять напряжение на каждом канале с дискретностью около 5—10 се-
кунд, принимать решение о состоянии каждой линии (busy/idle), усреднять по
интервалам в 15 минут и записывать результаты в log-файл. Далее получен-
ные данные могут обрабатываться для расчета объема и интенсивности тра-
фика на любом заданном интервале времени.
Теперь обратимся к измерению трафика в сетях, где сообщения представлены
пакетами Символов, которые могут иметь различную длину и передаваться
друг за другом по каналам связи, соединяющим между собой узлы сети —
устройства объединения, ответвления и перенаправления пакетов. Будем го-
ворить о трафике между любыми элементами сети, т. е. физическими или ло-
гическими устройствами, имеющими собственный сетевой адрес, по соеди-
няющим их каналам связи. Можно измерять также исходящий трафик из не-
которого сетевого элемента независимо от получателя или входящий трафик
в выбранный сетевой элемент, откуда бы он ни исходил. Измерение трафика
при этом сводится к подсчету числа пакетов, проходящих по выбранному пу-
ти, и измерению длины каждого из пакетов. Обозначим число пакетов, про-
шедших за время Т (секунд), буквой п, длину z'-го пакета— /, (битов), а ско-
рость передачи информации по каналу — R (бит/с).
Тогда можно определить среднюю за время Т интенсивность трафика на дан-
ном интерфейсе как отношение времени, занятого пакетами, к общему вре-
мени измерения:
S'
j - 1 ,
Т R Т
Единицей измерения интенсивности трафика здесь также является эрланг,
однако в практике пакетных сетей часто оценивают интенсивность трафика
величиной
I--L— = AxR, .
Т
измеряемой в битах или байтах в секунду.
Предметная область теории телетрафика 29
При постоянной длине пакета интенсивность трафика характеризуют просто
количеством пакетов в секунду. Иногда, даже при переменной длине пакетов,
вычисляют сначала среднюю длину пакета, а затем пользуются описанием
интенсивности трафика как числа пакетов в секунду. Приведенные здесь
применяемые на практике величины, характеризующие интенсивность тра-
фика, всегда могут быть выражены в эрлангах, если разделить их значение на
скорость передачи, и потому не приводят к противоречиям при использова-
нии. Здесь же мы еще раз напомним, что интенсивность трафика измеряется
не тем, насколько быстро перемещаются пакеты, а насколько "плотно" они
движутся. Если сказать, что интенсивность трафика есть 300 пакетов/с сред-
ней длиной 1000 бит, то для сети Ethernet, где скорость передачи 10 Мбит/с,
это одно (А = 0,003 Эрл), а для телефонного модема, работающего на скоро-
сти 32 000 бит/с— совсем другое (Л = 0,9375 Эрл). В последнем случае мо-
дем просто перегружен и задержки, возникающие при передаче, будут недо-
пустимыми. Однако, рассуждая в рамках одной и той же скорости передачи,
в качестве меры интенсивности трафика вполне допустимо для сравнения
применять величину I.
Как можно измерять интенсивность трафика в сетях передачи пакетов? Оче-
видно, что для этого необходимо регистрировать время появления каждого
пакета и его длину. Для проведения измерений такого рода существуют спе-
циальные приборы— анализаторы пакетов, которые позволяют выполнять
гораздо более сложный анализ трафика, чем измерение интенсивности. На-
пример, анализаторы протоколов серии RC-88/-100/-88WL/-100WL позволя-
ют определять время доставки пакетов выбранного типа протокола, длину
пакета, выделять ошибочные пакеты, систематизировать полученную инфор-
мацию в виде графиков, таблиц и диаграмм. Можно применять для измере-
ний и обычный компьютер, на который должна быть установлена специаль-
ная программа — монитор сети. Существует большое количество различных
программ для мониторинга сети, особенно для работы под управлением опе-
рационной системой UNIX. Для компьютеров с ОС Windows таких монито-
ров существенно меньше. Одной из лучших можно считать программу
Network Monitor компании Microsoft (http://www.microsoft.com).
Network Monitor— это достаточно мощное средство, простая версия которо-
го поставляется( вместе с Windows NT Server и Windows 2000 Server и позво-
ляет наблюдать сетевой трафик, проходящий через данный компьютер. Рас-
ширенная версия Microsoft Network Monitor поставляется с Microsoft Systems
Management Server и помогает захватывать весь сетевой трафик любого сег-
мента сети. Кроме того, Network Monitor позволяет декодировать и отобра-
жать большое количество перехваченной таким образом информации.
Еще одним стандартным средством мониторинга сетевого трафика является
набор сетевых анализаторов Netboy австралийской компании NDG Software
30
Глава 1
(http://www.ndgsoftware.com). Пакет Netboy содержит три отдельные сете-
вые утилиты: PacketBoy, EtherBoy и WebBoy, каждая из которых представля-
ет собой специализированную программу для сбора данных— пакетов, ин-
формации о функционировании сети Ethernet и протокола HTTP, соответст-
венно.
Утилита PacketBoy является анализатором и декодером протоколов и предна-
значена для просмотра активности пользователей и анализа сетевых проблем.
Это приложение захватывает и анализирует все сетевые пакеты, позволяет
установить и настроить правила для включения захвата пакетов при опреде-
ленных условиях, разрешает настроить фильтры для уже захваченных паке-
тов, а также производит декодирование протоколов TCP/IP (включая прото-
колы уровня приложений, такие как NFS, RPC, HTTP), протоколов Novell
Netware (IPX) (включая NCP, SPX, SAP и RIP) и протоколов Appletalk.
Утилита EtherBoy обеспечивает мониторинг в реальном режиме времени се-
тевых потоков по различным протоколам. Она дает возможность просмотра
всего трафика ЛВС (локальной вычислительной сети), а также обнаруживает
все сетевые устройства в сети, включая нарушающие систему безопасности.
Приложение формирует отчеты в различных вариантах, в том числе HTML,
отображает в реальном времени статистику, трафик и проблемы с сетевыми
соединениями на конкретных хостах.
Утилита WebBoy — почти точная копия утилиты EtherBoy с той лишь разни-
цей, что она предназначена для мониторинга трафика в среде Web. В генери-
руемых утилитой WebBoy отчетах в основном содержатся сведения, касаю-
щиеся активности адресов URL в локальных или региональных сетях, но на-
ряду с этим она может представить отчеты общего характера о трафике в
Интернете, например, списки последних соединений, распределенные по
главным машинам и протоколам.
Кроме стандартных коммерческих программ для мониторинга сети сущест-
вует ряд свободно (или условно свободно) распространяющихся приложений,
доступных через Интернет. Они не обладают всеми возможностями стан-
дартных программ, но тоже весьма полезны и удобны. Одной из таких про-
грамм является CommView, TamoSoft Inc. (http://www.tamos.com), которая
предоставляет свою программу в условно свободное пользование (на 30 дней).
Программа CommView предназначена для мониторинга сетевой активности
путем сбора и анализа пакетов любой Ethernet-сети. С помощью этой про-
граммы можно видеть список сетевых соединений, 1Р-статистику и исследо-
вать отдельные пакеты (например, IP-пакеты декодируются вплоть до самого
низкого уровня с полным анализом распространенных протоколов). Перехва-
ченные пакеты могут быть сохранены в файл для последующего анализа, а
также экспортированы в другие форматы. Гибкая система фильтров делает
Предметная область теории телетрафика
31
возможным отбрасывать ненужные пакеты и перехватывать только необхо-
димые.
Это приложение разработано для сетей небольших или средних размеров и
может быть запущено на любой системе Windows 95/98/МЕ или Window
NT/2000/XP. Ему необходим сетевой адаптер Ethernet (или Wireless Ethernet)
с поддержкой стандарта NDIS 3.0. Программа может работать и со стандарт-
ным модемом в режиме сетевого подключения по dial-up.
CommView осуществляет полный анализ следующих протоколов: ARP,
BCAST, BMP, DHCP, DIAG, DNS, FTP, GRE, HTTP, ICMP, ICQ, 1GMP, IPv4,
IPv6, IPX, NCP, NDS, NetBIOS, NLSP, POP3, PPP, PPPoE, RARP, RDP, RIPX,
RSVP, RTSP, SAP, SER, SMB, SMTP, SNMP, SOCKS, SPX, TCP, TELNET,
UDP, WDOG. Разработчики обещают расширять список анализируемых про-
токолов.
Интерфейс программы состоит из четырех вкладок, позволяющих просмат-
ривать данные и выполнять различные действия с перехваченными пакетами.
Чтобы начать сбор пакетов, необходимо выбрать сетевое устройство из спи-
ска на панели управления и нажать кнопку Start Capture (Начать сбор) —
рис. 1.7. Если в сети есть трафик, проходящий через выбранное устройство,
CommView начнет отображать информацию.
— Start Capture — Выбор сетевого
(Начать сбор) устройства
Q CommView - Evaluation Version •
I |ile Search View Tools Settings .Rules Help | : . .
g. l ' NETGEAR FA310TX Fast Ethernet Adapter ( ’ '
IBU IP Statistics ijg; packetsJ ^ Logging | Rules | (<4j) Alarms |
Locai lP -- I Remote IP (in | Out | Direction | Sessions | Ports | Hostname | В
(capture: ((Pkts: 16 In 121 out 1160 pas; । Auto-saving * (Rules: Off 'Alarms: Of i6% CPU Us< i
Рис. 1.7. Внешний вид окна программы CommView
По результатам мониторинга сетевого трафика CommView создает различные
виды отчетов. Наиболее наглядным вариантом является представление в гра-
32
Глава 1
фическом виде (рис. 1.8). В данном случае можно ознакомиться с такими па-
раметрами сетевой статистики, как количество пакетов в секунду, байтов в
секунду и общее количество пакетов, захваченных за время сбора. Используя
другие вкладки окна Statistics (Статистика), можно посмотреть:
□ распределение основных IP-протоколов (TCP, UDP и ICMP) и субпрото-
колов уровня приложений (HTTP, FTP, POP3, SMTP, TELNET, NNTP,
NetBIOS, HTTPS и DNS);
П распределение размера пакетов;
□ список активных LAN-хостов по адресам МАС, со статистикой передачи
данных;
□ список активных LAN-хостов по IP-адресам, со статистикой передачи
данных.
Данные каждой вкладки можно сохранить или в формате Bitmap, или в тек-
стовом файле с разделителем "точка с запятой".
;; Statistics
General | ipprot. j IPSub-prot. ] Slzrss ] LAN Hosts(MAC) | LANHosts(IP) j Errors j Report |
Capture time elapsed since last reset (hh:mm:ss): 00:01:46
Г Applv current rules
Reset
Рис. 1.8. Отчет по результатам мониторинга сетевого трафика
Кроме этого, программа CommView способна создавать автоматические от-
четы в HTML- или текстовом формате с разделителем "точка с запятой". Се-
Предметная область теории телетрафика
33
тевая статистика может строиться на базе всех пакетов, проходящих через
адаптер, или с учетом текущих правил на захват пакетов. CommView позво-
ляет сохранять перехваченные пакеты в файле с расширением ccf (CommView
Capture Files) в собственном формате. Сохраненные в собственном формате
файлы отчетов можно посмотреть встроенной утилитой просмотра Log
Viewer. Для более поздних версий CommView существует множество других
форматов для создания отчетов (например, в бинарном (bin) или текстовом
(txt) или с расширением csv — удобным для просмотра в Microsoft Excel).
Это позволяет проводить обработку собранных данных с целью изучения за-
кономерностей в исследуемом трафике. Например, можно построить гисто-
граммы распределения интервала времени между поступлениями пакетов или
гистограмму распределения длин пакетов. В одном из экспериментов, прове-
денном на домашнем компьютере в режиме dial-up с помощью CommView,
был записан файл меток времени поступления пакетов и их длины. Затем
этот файл экспортировался в MS Excel и был обработан с целью построения
гистограмм. На рис. 1.9 показана полученная гистограмма для интервала
времени между соседними пакетами, а на рис. 1.10 — для длин пакетов.
. Число пакетов
в интервал.
Интервал времени, ’
цена деления = 20 мс .
Рис. 1.9. Гистограмма интервалов между пакетами
Даже простое визуальное рассмотрение гистограмм позволяет заключить, что
распределение длин пакетов носит монотонно убывающий характер (от дли-
ны пакета), а интервалы между пакетами распределены существенно более
2 Зак 3884
34
Глава 1
сложным немонотонным образом. Обрабатывая полученные файлы, можно
найти другие характеристики потока пакетов как случайного процесса.
Рис. 1.10. Гистограмма длин пакетов
Контрольные вопросы и задания
1. Какие понятия и определения теории СМО вы узнали?
2. Какие понятия и определения теории телетрафика вы узнали?
3. Как определить объем трафика и интенсивность трафика?
4. Программы для мониторинга сетей. Функции и возможности.
5. Задан ие.
Собрать и обработать статистику (зависимость числа пакетов от интервала
времени между пакетами n(delta) и зависимость числа пакетов от размера
пакетов n(size)) с помощью приложения CommView. Сделать выводы на
основе проведенного эксперимента.
ГЛАВА 2
Модели данных
для описания телетрафика
В данной главе вы познакомитесь с математическими моделями процессов,
описывающих трафик в телекоммуникационных системах. Для освоения это-
го материала вам потребуется вспомнить теорию вероятностей и провести
некоторое время за компьютером. Мы будем использовать для иллюстрации
функции языка MATLAB, де-факто ставшего в последнее время языком пуб-
ликаций для инженеров-исследователей и студентов технических универси-
тетов.
Модели потоков событий
Если посмотреть на распечатку работы монитора пакетной или телефонной
сети, то можно увидеть, что моменты времени поступления пакетов или заня-
тия линий представляют некоторый набор случайных чисел. Эти числа обра-
зуют неубывающую случайную последовательность, которую принято назы-
вать случайным потоком. Для описания таких потоков можно использовать
либо понятие распределения количества событий, приходящихся на выбран-
ные определенным образом интервалы времени, либо распределение интер-
вала времени между соседними событиями. В первом случае модель потока
дается распределением дискретной случайной величины, а во втором— не-
прерывной случайной величины. Как следует из смысла понятий, и в том и в
другом случае речь идет о распределении неотрицательных величин. Будем
говорить, что нам удалось найти удовлетворительную модель потока собы-
тий, если мы смогли написать программу, выдающую последовательно друг
за другом числа, которые могут быть интерпретированы как моменты време-
ни наступления событий, образующих поток, эквивалентный моделируемому.
Понятие эквивалентности реального потока и модельного потока событий
существенно зависит от задачи, для которой используется модель. Мы будем
36
Гпава 2
считать модель эквивалентной реальному потоку, если рассчитанные с по-
мощью модельного потока характеристики качества обслуживания СМО
(время ожидания, вероятность блокировки и т. п.) будут допустимо мало от-
личаться от характеристик реальной системы.
При выборе модели потока иногда могут помочь априорные знания о его ха-
рактерных свойствах. Теория случайных потоков выделяет следующие прин-
ципиальные свойства:
□ стационарность— независимость вероятностных характеристик от вре-
мени. Так вероятность поступления определенного числа событий в ин-
тервале времени длиной I для стационарных потоков не зависит от выбора
начала его измерения;
□ последействие— вероятность поступления событий в интервале (/,, /2)
зависит от событий, происшедших до момента /ц
□ ординарность — вероятность поступления двух и более событий за бес-
конечно малый интервал времени А/ есть величина бесконечно малая, бо-
лее высокого порядка малости, чем А/.
Важнейшими численными параметрами случайного потока являются интен-
сивность Потока и параметр потока. Для ординарных потоков они совпадают,
а для неординарных, т. е. для тех, в которых могут одновременно поступать
несколько событий, эти величины различаются.
Интенсивностью потока называют математическое ожидание числа событий
в единицу времени в данный момент. То есть это предел отношения среднего
числа событий на интервале А/ к длине этого интервала, стремящейся к нулю:
Л(/)= lim
Дг-^-0
N(l,t + А/)
А/
Параметром потока называют предел отношения вероятности поступления
хотя бы одного события на интервале (/, / + А/) к длине этого интервала,
стремящейся к нулю:
^(/)= iimZk^£±^2.
Д/-Ы) Д/
Как следует из последней формулы, вероятность поступления хотя бы одного
события в заданном бесконечно малом интервале с точностью до бесконечно
малых более высокого порядка, прямо пропорциональна параметру потока:
Л>1(/, i + Az) = A,(/)AZ + о(А/).
Заметим здесь, что для стационарного процесса параметр потока и интенсив-
ность — величины постоянные, не зависящие от времени. Рассмотрим теперь
несколько подробнее существующие модели потоков.
Модели данных для описания телетрафика 37
Пуассоновский (простейший) поток
Так называют стационарный ординарный поток без последействия. Он зада-
ется набором вероятностей ЛСО поступления i событий в промежутке време-
ни длиной t. Можно показать, что при этих предположениях формула для ве-
роятностей дается выражением:
Проанализируем основные характеристики пуассоновского потока. Построим
сначала семейство графиков, описывающее вероятность появления разного
числа событий в интервале заданной длины. Нетрудно заметить, что время
как таковое не определяет эту вероятность, а участвует только в произведе-
нии с интенсивностью потока. Поэтому будем строить графики вероятностей,
используя безразмерный аргумент
х = Xt.
Для построения графиков в системе MATLAB нужно написать программу,
представленную в листинге 2.1.
! Листинг 2.1. Построение графиков
х=0:0.1:15;
у1=х.*ехр(~х);
у2=(х/2).*у!;
уЗ=(х/3).*у2;
у4=(х/4).*уЗ
у5= (х/5) . *у4 ;
plot (х, yl, ' -ш', х, у2, х,уЗ, ' —', х, у4, ' -. ', х, у5, ' -г')
В результате будут получены графики, подобные показанным на рис. 2.1.
Нетрудно видеть, что зависимость вероятности поступления i событий воз-
растает с увеличением интервала х = А./ пока х < i, а с дальнейшим ростом ин-
тервала вероятность убывает и всегда стремится к нулю. Этот факт говорит,
что наиболее вероятное число поступивших заявок за интервал длиной t
близко к значению Xt.
Определим математическое ожидание (среднее) и дисперсию числа событий
в заданном интервале.
i=0 /=1 !-
D, =i2 -(/)2 =
38
Глава 2
Рис. 2.1. Распределение Пуассона для различного числа событий
Как видно, если разделить среднее значение числа событий в интервале t на
длительность этого интервала, то получится как раз интенсивность потока
Л(О = у = Х.
Среднеквадратическое отклонение числа событий от среднего равно
о, - -yfkt, т. е. пропорционально корню из длины интервала.
Зная вероятность наступления заданного числа событий в произвольном ин-
тервале времени, можно найти вероятности наступления не менее z событий в
заданном интервале или вероятность наступления не более z событий в этом
интервале:
Л=0
оо
k=i
Найдем теперь распределение интервала между соседними событиями непре-
рывной случайной величины т > 0. Очевидно, что вероятность того, что вели-
чина т < t некоторого заданного интервала есть то же самое, что и вероят-
Модели данных для описания телетрафика 39
ность наступления хотя бы одного, события в этом интервале. Следовательно,
можно записать:
P(T<t) = Pi>_1(t) = 1-Р0 (0 = 1-^'.
Для определения плотности распределения вероятности т нужно произвести
дифференцирование функции распределения
at - 4
Таким образом, мы нашли, что интервал между событиями в пуассоновском
потоке событий имеет экспоненциальное (показательное) распределение. Из
этого, разумеется, следует и обратное утверждение: если интервал между со-
седними событиями распределен по экспоненциальному закону, то поток со-
бытий является пуассоновским.
Найдем основные характеристики интервала между событиями для пуассо-
новского потока. Математическое ожидание экспоненциально распределен-
ной случайной величины будет
т = | tp(t)dt^tXe~x'dt = —,
дисперсия
ОО 1 «
Л = J I2 p(t)dt - г = —, от = -.
о Х
Пуассоновские потоки широко применяются в качестве модели реальных по-
токов благодаря тому, что обладают очень важным свойством аддитивности.
Если взять 2V источников пуассоновских потоков событий с интенсивностями
%к, и рассмотреть новый поток как суммарный поток всех событий от этих
источников, то результирующий поток окажется также пуассоновским с ин-
тенсивностью
N
=•
4=1
Можно также расщеплять пуассоновский поток с интенсивностью X на m пу-
ассоновских с интенсивностями Хк. Для этого нужно определить полную слу-
чайную систему из m событий vk с вероятностями рк, наступление каждого из
которых будем считать фактом переключения на к-е направление. При по-
ступлении каждого нового события С, в пуассоновском потоке будем нахо-
дить совместное событие (декартово произведение) [Cz х vk ] и относить его
40
Гпава 2
к Л-му потоку. Каждый из образованных таким образом т потоков будет пу-
ассоновским с интенсивностью X* = На рис. 2.2 проиллюстрировано рас-
щепление и слияние пуассоновских потоков.
Рис. 2.2. Сохранение пуассоновского характера при объединении и расщеплении потоков
Обобщением простейшего потока является нестационарный пуассоновский
поток. Для этого потока событий не выполняется свойство стационарности, и
вероятность поступления событий в интервале может зависеть от выбора на-
чала этого интервала. Определим вероятность поступления ровно z событий в
интервале (Zo, t0 + Z) с помощью функции среднего числа событий на этом ин-
тервале
A(z0, Zo + Z) = j Х(т)б/х
I»
или средней интенсивности на этом интервале
X(/q , /q + z) / z.
Такая вероятность задается как
р. (/0 , tQ + /) = К’,» +0] e-pln ,/„+/)
z!
Модель в виде нестационарного пуассоновского потока может в некоторых
случаях отразить поведение трафика более адекватно. Например, наличие
ЧНН (час наибольшей нагрузки) может быть отражено ростом средней ин-
тенсивности в определенное время суток.
Примитивный поток
Этот поток событий можно считать своеобразным нестационарным пуассо-
новским потоком с параметром потока, зависящим от состояния системы, на
Модели данных для описания телетрафика
41
которую поступает данный поток. Если обозначить состояние системы
О < k< N, то для примитивного потока полагают
к = \ = a{N-k).
Среднее значение параметра примитивного потока может быть найдено через
распределение вероятностей состояний обслуживающей системы {рк}:
ъ=Т^кРк-
Чаще всего модель примитивного потока используется при описании обслу-
живания нескольких независимых одинаковых пуассоновских источников
одной системой. Суммарный пуассоновский поток на входе системы при
этом может быть описан суммой потоков каждого из источников. Суммарная
интенсивность (равная параметру потока в силу ординарности) при этом
должна определяться суммой интенсивностей каждого из потоков. При полу-
чении обслуживания события от каждого из таких источников, данный ис-
точник исключается из числа создающих нагрузку на систему. Если отожде-
ствить состояние системы с числом источников, получивших обслуживание
в данный момент времени, то можно использовать значение
- сфУ - к)
как интенсивность потока, порожденного источниками, не получившими об-
служивания. Средняя интенсивность на один источник будет определяться
как
Модель примитивного потока удобна для представления абонентской нагруз-
ки на телефонный коммутатор. Каждый абонент является источником неза-
висимого пуассоновского потока заявок-звонков. Совокупная нагрузка на
коммутатор определяется суммой таких потоков. Однако когда абонент по-
лучает обслуживание своего звонка, его поток исчезает из совокупного вход-
ного потока, и интенсивность входного потока уменьшается скачком.
Потоки событий
с произвольным законом распределения
Мы рассмотрим ряд распределений случайной величины, которая может опи-
сывать интервал времени между поступлениями событий. Каждое такое рас-
пределение порождает собственный вид потока событий. Свое название эти
потоки событий обычно наследуют от типа распределения межсобытийного
интервала.
42
Гпава 2
Равномерное распределение
Непрерывная случайная величина х, принимающая значения на отрезке [а, Ь},
распределена равномерно на [а, Ь\, если ее плотность распределения Р(х) и
функция распределения F(x) имеют соответственно вид:
Математическое ожидание и дисперсия:
а + Ъ \Ъ с
ц =------, о" = 2----
2 12
Треугольное распределение
Треугольное распределение (рис. 2.3) — это распределение вероятностей не-
прерывной случайной величины, принимающей значения на отрезке
х е [а, Ь], функция вероятности которого задается формулой
Р(х) =
2(х-а)
(Ь-а)(с-а}
2(Ъ-х}
(b-a}(b-c}
, а<х<с,
,с<х<Ь.
Функция распределения:
(х - а)2
(й - а)(с - а)
F(x) = - j (b-rf
(b - а}(Ъ - с)
, а < х < с,
,с<х<Ь,
где с е [а, Ь] — мода (точка, где плотность вероятности непрерывной слу-
чайной величины достигает максимума).
Модели данных для описания телетрафика
43
Рис. 2.3. Функция плотности вероятности и функция распределения (треугольное)
Математическое ожидание:
3
Абсолютные моменты:
=^(а2+ь2
' 1 ( 3 А
li, = — (а +Ь
10'
Центральные моменты:
ц2 = +^2 +с2 -ab-ac-bcj,
ц3 = -^y(<7 + Z>-2c)(a + c-2Z>)(Z> + c-2a),
ц4 = (а2 + Ь2 + с2 - ab - ас - Ьс} .
2 + ab+ac + bc^,
с3 + a2b + а2 с + Ь2 а + Ь2с + с2 а + c2b + abc^.
Нормальное распределение
Случайная величина X нормально распределена с параметрами ц и о> 0, если
ее плотность распределения Р(х) и функция распределения F(x) имеют
соответственно вид (рис. 2.4):
(х-в)2
(2а2)
44
Гпава 2
F(x) = ^=l=j
dz,
где ц — математическое ожидание, а о2 — дисперсия.
Рис. 2.4. Функция плотности вероятности и функция распределения (нормальное)
Часто используемая запись Х~Х(ц, а) означает, что случайная величинах
имеет нормальное распределение с параметрами ц и а.
Говорят, что случайная величинах имеет стандартное нормальное распре-
деление, если ц = 0 и а = 1 (Х~ N(0, 1)). Плотность и функция распределения
стандартного нормального распределения имеют вид:
V2
Р(х) = -4=е 2 ,
х/2п
х ?
F(.r) = Ф(х) = -Х=- Ге 2 dz,
V27T1
где Ф(х) — функция Лапласа.
Функция распределения нормальной величины Х~ Х(ц, а) выражается через
функцию Лапласа следующим образом:
^(х) = Ф
Нормально распределенная случайная величина может принимать непрерыв-
ный ряд значений от -оо до +оо. В теории случайных потоков приходится ог-
раничивать значения неотрицательными величинами, полагая значения
функции плотности вероятности нулевыми на отрицательной полуоси. При
Модели данных для описания телетрафика
45
этом приходится вносить изменения во все значения функции для неотрица-
тельных аргументов так, чтобы выполнялось условие нормировки
| P(x')dx = 1.
Бета-распределение
Бета-распределение (рис. 2.5)— это распределение вероятностей непрерыв-
ной случайной величины, принимающей значения на отрезке [0, 1], вероят-
ность которого задается формулой:
/1 __а.-1 к* (. р\
11—Л J X 1 ICC -гр) / хВ—I
Р(х) = А-1— — = V / (] _ ХР
В(сс,р) Г(а)Г(рР 1
а функция распределения не выражается в элементарных, а только в специ-
альных функциях: В(сс, Р) — бета-функция, Г(х) = ^zx~'e~~dz — гамма-функ-
о
ция Эйлера, и сс, р > 0.
Математическое ожидание рассчитывается так:
Г(сс + р)
Г(а)Г(₽)
Jx“ 1 (1 -xf ' xdx =
о
Г(а + р) Г(а + 1)Г(р) сс
Г(сс)Г(р) Г(сс + р + 1) " сс + р’
центральные моменты берутся по формуле:
Г(сс + р)Г(сс + г)
Г(сс)Г(сс + р + т)
1
ц;'. = |р(х)(х-ц)'<* =
о
Рис. 2.5. Функция плотности вероятности и функция распределения (бета)
46
Гпава 2
Дисперсия определяется более простым выражением
<? =------og-------
(а+Р) (а + Р + 1)
Мода распределения В(сс, Р) есть
„ _ а-1
сс + Р-2
Логнормальное распределение
Случайная, величина X имеет логнормальное распределение с параметрами сс
и р, если случайная величина 1п(А) имеет нормальное распределение с пара-
метрами а> 0 и р>0. Функция распределения и функция плотности вероят-
ностей логнормального распределения (рис. 2.6) имеют соответственно вид:
1 In -V '-|па
F(x) = —= f е dt,
О<27Г о
(In х-In а)2 •
Р(х)-—т=е 2а2
хау/2п
Математическое ожидание и дисперсия:
Рис. 2.6. Функция плотности вероятности и функция распределения (логнормальное)
Модели данных для описания телетрафика 47
Распределение хи-квадрат (%2-распределение)
Пусть Х\, Х2,Х„— независимые случайные величины, каждая из которых
имеет стандартное нормальное распределение N(0, 1), Составим случайную
величину
х2 = х,2 + х2+...+х2.
Ее закон распределения называется х2-распределением с и степенями свобо-
ды. Плотность вероятности этой случайной величины вычисляется по фор-
муле:
О,
z < О,
л-2 2
2 е 2, z>0.
Здесь Г(х) = jz* 'е Zdz —гамма-функция Эйлера,
о
Математическое ожидание и дисперсия равны, соответственно:
Рх2 = п; О22 = 2и .
Распределение Стыодента
Пусть случайная величина £, имеет стандартное нормальное распределение, а
случайная величина х« имеет х2-распределение с и степенями свободы. Если
у 2 w сЕ/
и — независимы, то про случайную величину = у г—-- говорят,
/ Vb/"
что она имеет распределение Стыодента с п степенями свободы. Плотность
вероятности этой случайной величины (рис. 2.7) вычисляется по формуле:
п +1
7>т» =
п Г -
I 2
где х с R.
Математическое ожидание случайной величины т„ равно 0, а дисперсия:
48
Гпава 2
Рис. 2.7. Функция плотности вероятности и функция распределения (Стьюдента)
х
При больших п распределение Стьюдента практически не отличается
МО, 1).
от
^распределение Фишера
Пусть случайные величины и %2 независимы и имеют распределение %2
спит степенями свободы, соответственно. Тогда о случайной величине
Е,
и
т
говорят, что она имеет ^-распределение. Плотность вероятности (рис. 2.8)
этой случайной величины вычисляется по формуле:
j 77 + /77 j
Л- (-Т> = -7М2Д~Р~
v777
1 2 Ы
in+u
ИХ 2
т J
где т>0, Г(х) — гамма-функция Эйлера.
Математическое ожидание и дисперсия соответственно равны:
т
--------, 777 >
/77 - 2
2 ,2/772 (?7 + т - 2)
77 (/77 - 2)2 (/77 — 4)
Модели данных для описания телетрафика
49
Рис. 2.8. Функция плотности вероятности и функция распределения (Фишера)
Распределение Парето
Плотность вероятностей и функция распределения для случайной величины,
распределенной по Парето (рис. 2.9), имеют вид
ab“
х"+|
и определены только на интервале х > Ь.
Рис. 2.9. Функция плотности вероятности и функция распределения (Парето)
50
Гпава 2
Абсолютные моменты: , ab Pi = .> а-1 , ab2 а-2 , ab3 Рз= .• <7-3
Центральные моменты: ab2 Ц-7 ~ , («-1)2(г/-2) 2й(<7 + 1)63 ~(ц-1)3(а-2)(а-3)’
Распределение Парето имеет математическое ожидание только при a> 1, а
дисперсию ТОЛЬКО При <7? >2. ab _2 ab2
а-\ ’ ° (ц-1)2(а-2)
Распределение Вейбулла
Случайная величина £, имеет распределение Вейбулла с параметрами Ло и а,
если ее функция распределения и функция плотности вероятностей имеют
соответственно вид:
F(x) = l-e"₽v\
Р(х) = а • Р • .
Математическое ожидание имеет вид:
- - ( 1 А
Ц = р “Г 1+- .
I «у
Дисперсия:
э --( ( 21 Y1
а2=р “Г 1 + - -Г2 1+- ,
РР a. J Р aj)
где Г(х) — гамма-функция Эйлера.
Модели данных для описания телетрафика 51
Г амма-распределение
Случайная величина £, имеет Г-распределение (гамма-распределение) с пара-
метрами а и Ь, если ее функция плотности вероятностей имеет вид:
----X
Г(й)
0,
Р(х) =
х<0,
где Г(а) — гамма-функция Эйлера, а > О, b > 0.
Математическое ожидание и дисперсия равны:
а 2 а
ц = — ; о = —.
Ь2
Самоподобные (фрактальные) модели трафика
Во всех рассмотренных ранее моделях потоков событий считалось, что веро-
ятность появления следующего события зависит только от времени, прошед-
шего с момента совершения предыдущего события, и не зависит от всей пре-
дыстории появления событий ранее. Однако в некоторых случаях такие мо-
дели не могут адекватно отразить реальный поток событий. Поэтому кроме
потоков без последействия приходится рассматривать и такие, в которых ве-
роятность появления следующего события зависит от наступления событий
в предыдущих интервалах времени. Типичным примером таких потоков яв-
ляются потоки с ограниченным последействием. Для них задается конечный
набор функций распределения для соседних интервалов ik между поступле-
нием к событий. Одним из наиболее типичных потоков с ограниченным по-
следействием является стационарный поток с запаздыванием — поток Паль-,
ма. Функции распределения вероятности для интервалов между соседними
событиями потока Пальма задаются через условную вероятность ф0(7) отсут-
ствия событий в интервале длиной /, если в начале этого интервала поступало
событие, следующим образом:
Рг(\ </) = Х^фо(х)Дг, k = V,
Рг(тА <щ) = 1-ф(М к >2.
Здесь величина X выражает интенсивность потока и равна, как обычно, об-
ратной величине среднего промежутка времени между соседними события-
ми. При экспоненциальной функции ф0(/) = е“х' поток Пальма превращается
в пуассоновский. Иногда его называют потоком Эрланга первого порядка.
Производя "просеивание" потока Пальма, т. е. отбрасывая каждое второе,
52 Гпава 2
каждое третье, каждое n-е событие, получают потоки, которые называют !
потоками Эрланга второго порядка, третьего порядка и, соответственно, '
n-го порядка. Для потока Эрланга порядка п функция распределения имеет вид:
/7-1
/=0 '
Введение моделей с последействием позволяет отразить свойства потоков с
памятью, однако приведенные выше модели Пальма и Эрланга оказываются ;
малоподходящими, если в потоке событий обнаруживается так называемая
долгосрочная зависимость (long range dependent) или самоподобие (self-
similarity). На интуитивном уровне это означает, что число событий на задан-
ном временном интервале может зависеть от числа событий, поступивших в j
весьма отдаленные от него интервалы времени. При этом часто процесс но-
сит пачечный (bursty) характер. Типичным способом измерения такой зави-
симости для случайных процессов является определение функции корреляции.
Будем рассматривать в качестве значения случайного процесса число собы-
тий, поступающих в систему в единицу времени. Это, конечно, неотрица-
тельная случайная величина. Случайный процесс будем рассматривать как
дискретную последовательность таких случайных величин, т. е. аргументом
будем считать порядковый номер такой единицы времени:
Х= {X,: t = 0, 1,2, ...}.
Положим, что все рассматриваемые далее случайные процессы относятся ’
к стационарным случайным процессам с ограниченной ковариацией, т. е. ;
Cov(X, ,Xl+k) = (X. -X)(Xl+k -X) <
с дисперсией :
D(X) = (X,~X)2=g2 i
и автокорреляционной функцией
СМЛЛ.Щ
Для того чтобы охарактеризовать принадлежность процесса к классу процес-
сов, имеющих долгосрочную зависимость или самоподобие, необходимо рас-
смотреть агрегированные из него процессы, построенные с помощью усред-
нения значений исходного процесса на непересекающихся временных интер-
валах:
. , 1 '«
= 1, 2, 3,... ; Х^ = -^Х^т+, .
1 ’ т :=\
Модели данных для описания телетрафика
53
Очевидно, что агрегированные процессы также будут стационарны и имеют
ограниченную ковариацию.
Как метко определил в своей работе [11] один из патриархов отечественной
теории телетрафика В. И. Нейман, "три источника и три составные части тео-
рии самоподобных процессов" выражены в медленном убывании дисперсии,
долгосрочной зависимости и флуктуационном характере спектра мощности
таких процессов.
Убывание дисперсии асимптотически описывается соотношением
П(А<"'))«ш»-р,0<р<1,т^оо, (2.1)
т. е. вариация агрегированных процессов — средних выборок — уменьшается
медленнее, чем величина, обратная размеру выборки.
Долгосрочной зависимостью в самоподобных процессах называют наличие
расходимости автокорреляционной функции процесса:
Ег(^) = °°’ Дк)*к~*. (2.2)
к
Это означает, что спад автокорреляционной функции происходит гиперболи-
чески медленно.
Наконец, говоря о флуктуационном характере спектра мощности, понимают
под этим аналогию со спектром мощности флуктуаций электронного потока:
./(со) ® ссо‘7, со —> 0, у = 1 — Р, (2.3)
где
/(co) = ^r(Z:K"”\
к
Наличие перечисленных выше свойств у случайного процесса означает, что
его автокорреляционная функция совпадает с автокорреляционными функ-
циями агрегированных процессов точно
г(к) = гт(к)
или асимптотически
7'(&) —> г"'(£), 777 —>00.
Собственно эти соотношения и определяют название самоподобного процес-
са: корреляционные свойства такого процесса, усредненного на различных
временных интервалах, остаются неизменными.
Важнейшим параметром, характеризующим "степень" самоподобности слу-
чайного процесса, является параметр Хёрста (Hurst).
54
Гпава 2
Для выборочного случайного набора Xj (/= 1, можно определить выбо-
рочное среднее
| N
М
выборочную дисперсию
-'V A-=l
и интегральное отклонение
D}=±Xk-jM.
к=\
Определим изменчивость случайного процесса на интервале N как неубы-
вающую функцию длины интервала
Rn = max D, - min D,.
\<j<N 7 \<J<N 7
Херстом было показано, что для большинства естественных процессов отно-
шение
я
s 2 J
или иначе
R N
log(-)«/flog(—)
О 2,
при больших N.
Величина Н получила название параметра Херста и лежит в интервале
0,5 <Н< 1,0. Для процессов, не обладающих свойством самоподобия, величи-
на параметра Херста равна 0,5. Для самоподобных процессов с долгосрочной
зависимостью этот параметр изменяется в пределах 0,7—0,9. Параметр р, ко-
, торый был введен выше для задания асимптотических свойств характеристик
I самоподобных случайных процессов, может быть выражен через параметр
'^Херста: Р = (1 -Н)/2.
Можно оценить другим способом степень самоподобия процесса, определив
непосредственно величину Р из соотношения (2.1):
lim logZ)(Ar(",)) = -piog(/7?) + log(<7).
Таким образом, построив в логарифмическом масштабе зависимость отноше-
ния R/S от логарифма числа выборок или зависимость логарифма дисперсии
для агрегированных процессов от логарифма степени агрегирования, можно
Модели данных для описания телетрафика
55
оценить величину параметра Херста или соответственно Р как тангенс угла
наклона аппроксимирующей кривой (рис. 2.10).
Впервые на самоподобие процессов, описывающих трафик в пакетных сетях,
обратили внимание в начале 90-х годов прошлого века. Лиланд (W. Е. Leland)
и его коллеги (М. S. Taqqu, W. Willinger, D. V. Wilson) выступили с докладом
и опубликовали статью [2], которая многократно цитировалась целое десяти-
летие. В ней были приведены результаты экспериментального анализа тра-
фика в пакетной сети и показано, что распределение числа пакетов в единицу
времени очень хорошо описывается самоподобным случайным процессом с
параметром Херста около 0,65—0,8. В начале этой статьи приводятся очень
наглядные графики зависимости числа пакетов в единицу времени. Мы при-
ведем некоторые из этих графиков (рис. 2.11). По горизонтальной оси в них
отложено текущее время, так что в дискретном представлении его макси-
мальное значение равно одной тысяче единиц, а единица измерения времени
на каждом графике различна: от 0,01 секунды до 100 секунд. Обычно эту ве-
личину называют временной шкалой. По вертикальной оси отложено число
пакетов в сети, поступившее за выбранную единицу времени.
Уже первый взгляд на графики и их сравнение наводят на мысль о чрезвы-
чайном сходстве. Это и есть проявление самоподобия. Процессы, описываю-
щие трафик в различных временных масштабах, шкалах, имеют близкие ста-
тистические свойства.
Простейшими самоподобными процессами являются фрактальное броунов-
ское движение и фрактальный гауссовский шум.
56
Гпава 2
10 000
о
о юоо
Time = 100 Seconds
Time = 10 Seconds
Time = 1 Second
0 1000
Time = 0,01 Second
Рис. 2.11. Экспериментальные данные о трафике в сети
Понятие фрактал, появившееся в конце 70-х годов XX века, с середины 80-х
прошлого столетия прочно вошло в обиход математиков и программистов.
Слово "фрактал" образовано от латинского fractus и в переводе означает "со-
стоящий из фрагментов". Оно было предложено Бенуа Мандельбротом в
1975 году для обозначения нерегулярных, но самоподобных структур, кото-
рыми он занимался. Рождение фрактальной геометрии принято связывать с
выходом в 1977 году книги Б. Мандельброта "Фрактальная геометрия приро-
ды" ("The Fractal Geometry of Nature"). В его работах использованы научные
Модели данных для описания телетрафика
57
результаты других ученых, работавших в период 1875—1925 годов в той же
области (Пуанкаре, Фату, Жюлиа, Кантор, Хаусдорф). Но только в наше вре-
мя удалось объединить их работы в единую систему. Вы можете прочитать
работы Мандельброта в переводе [10].
Одним из основных свойств фракталов является самоподобие. В самом про-
стом случае небольшая часть фрактала содержит информацию обо всем
фрактале. Определение фрактала, данное Мандельбротом, звучит так: "Фрак-
талом называется структура, состоящая из частей, которые в каком-то
смысле подобны целому".
Простейший фрактал имеет вид, представленный на рис. 2.12.
За один шаг алгоритма каждый из отрезков, составляющих ломаную, заменя-
ется на ломаную, в соответствующем масштабе. В результате бесконечного
повторения этой процедуры получается геометрический фрактал.
Наглядно увидеть рост фракталов можно, используя апплет на сайте: Iittp://
www.shodor.org/master/fractal/software/Snowflake.html.
—-.............. —»
л = 0
п = 1
Рис. 2.12. Простейшие фракталы
58
Гпава 2
Нормированное фрактальное броуновское движение (Fractal Brownian Mo-
tion, fBM) с параметром Херста Н— это случайный процесс (Хф^, обла-
дающий следующими свойствами:
□ X, имеет стационарные нормально распределенные случайные прира-
щения;
□ Хо = 0, Xh -X =0 для любых /|, /2;
□ (Xh -Xt )2 = к 1t2 -t} |2// для любых t}, t2;
OX, — нормально распределенная случайная величина для любого t > 0.
Из последнего пункта также можно сделать следующий вывод:
D(Xti - Л,) = (^,2-Л,)2 - (Л2-Л,)2 = к I /2 - (I2".
Последовательность приращений fBM, т. е. его производная в определенном
смысле, образует фрактальный гауссовский шум (Fractal Gaussian Noise,
fGN).
Фрактальный гауссовский шум (черный шум) — это* стационарный гауссов-
ский процесс с заданными параметрами (т, ст') и автокорреляционной функ-
цией
г(£) = |(|£ + 1|2" -2|£|2" + ^мП-
Исходя из самых общих соображений, можно показать, что параметр Херста
сохраняется при суммировании любого конечного числа независимых само-
подобных процессов с фиксированным параметром самоподобия.
Действительно, для суммы независимых случайных процессов функция кор-
реляции равна сумме функций корреляции слагаемых, если каждая из функ-
ций имела асимптотическое поведение в соответствии с выражением (2.1).
Тем самым сохраняются все важнейшие характеристики самоподобия.
Одной из таких характеристик является величина выбросов процесса. Для
самоподобных процессов характер выбросов сохраняется при рассмотрении
процесса в различных масштабах времени. Это означает, что если вы будете
записывать нагрузку на каком-либо элементе сети с дискретностью, напри-
мер, 10 миллисекунд, то, рассматривая график изменения нагрузки во време-
ни на интервалах 10 секунд, 10 минут или 10 часов, вы не заметите сущест-
венных различий в поведении кривой. В этом смысле самоподобие графиков
может быть охарактеризовано соотношением
МО = any(J~).
а
Модели данных для описания телетрафика 59
Величину а можно называть коэффициентом самоподобия непрерывных про-
цессов.
Для нас далее важнейшим из рассмотренных здесь свойств самоподобных
процессов является то, что такие процессы имеют выбросы, величина кото-
рых сохраняется как для агрегированных из них процессов (т. е. при усредне-
нии по различным временным интервалам), так и при суммировании незави-
симых самоподобных процессов.
Это означает, что распределение числа событий во времени для трафика,
представимого самоподобным процессом, носит характер сложной взаимо-
связанной последовательности случайны,х пачек поступлений. Это делает
моделирование такого потока событий весьма сложной задачей.
Программное моделирование трафика
Будем считать, что нам удалось смоделировать некоторый экспериментально
измеряемый трафик с помощью программной модели, если разработанная
(или подобранная из готовых) программа в результате своего функциониро-
вания генерирует последовательность чисел, определяющих моменты време-
ни поступления событий (заявок, требований, пакетов), такой, что свойства
порожденного потока событий совпадают со свойствами моделируемого экс-
периментального потока с заданной точностью.
Основные принципы
моделирования потока событий
В основе моделирования потока событий лежит генерирование значений дей-
ствительной (реже целой) переменной, имеющей смысл текущего модельного
времени, которые определяют моменты поступления требований. Обозначим
эту переменную A TIME. Чаще всего генерируются не сами моменты, а интер-
валы времени между происшедшим событием и поступлением следующего.
Если обозначить последовательность таких межсобытийных интервалов А\,
Aj,..., А,,..., то на каждом шаге моделирования
ATIME = ATIME + А^
Величина межсобытийного интервала является случайной величиной и гене-
рируется с помощью специальных программных функций, называемых дат-
чиками случайных чисел. Простейшие датчики случайных чисел генерируют
значения случайной величины, имеющей равномерное распределение в ин-
тервале (0, 1). Основная проблема разработки таких программ состоит в не-
обходимости обеспечить случайные числа с помощью детерминированного
процесса исполнения. Реально такие программы генерируют псевдослучайные
60
Гпава 2
числа. Качество последовательностей, генерируемых датчиком случайных
чисел, оценивается близостью к действительно случайным с помощью мно-
гих тестов. Как показал многолетний опыт разработки, наиболее эффектив-
ными алгоритмами работы датчиков случайных чисел являются так называе-
мые конгруэнтные генераторы. Алгоритм их работы может быть описан сле-
дующими соотношениями:
х/+1 = (б/x, + с) mod (и?),
или
х/+1 = (хл;) mod (от).
Здесь всюду а, с, х„ х— целые числа, а в качестве выходного псевдослучай-
ного числа используется действительное U^Xj/m. Операции вычисления по
модулю (mod) обеспечиваются работой алгоритма в' компьютерах с конечной
разрядностью. Приведем сначала демонстрационный пример работы такого
алгоритма при следующих параметрах:
Xj = (3x,_j)mod(32).
Так как 32 = 25, следовательно, здесь используются пятиразрядные машинные
слова для представления целых чисел. Пока эти числа не превышают 3 1, ре-
зультаты операций очевидны. При превышении этого значения будет исполь-
зоваться остаток от деления на целое, кратное 32.
Xo = 1 00001 U= 1/32 = 0,03125
Xi = 3 00011 /7= 3/32 = 0,09375
x? = 9 01000 U = 9/32 = 0,28125
x-3 = 27 non /7=27/32 = 0,84375
X4 = 81 mod 32 = 17 10001 U= 17/32 = 0,53125
x5 = 51 mod 32 = 19 10011 U = 19/32 = 0,59375
Xf, = 57 mod 32 = 25 11001 /7=25/32 = 0,78125
xq = 75 mod 32 = 11 01011 U = 11/32 = 0,34375
Если продолжить вычисление, то на следующем шаге будет получена едини-
ца и цикл замкнется. Далее последовательность нельзя будет считать псевдо-
случайной. Ясно, что чем больше период, тем последовательность лучше от-
ражает свойства случайного потока. Нетрудно убедиться, что период будет
зависеть как от выбора т, так и от начального значения х. На практике при-
меняют несколько различных генераторов с различными параметрами. Наи-
более типичными являются генераторы с именами функций URN 13 (Unified
Random Number) и URN38.
Модели данных для описания телетрафика
Для первого из них период составляет 1 073 741 824. Алгоритм для него име-
ет вид:
xt — 663 60894 lx,_| mod232 .
Для второго:
х, =513х;_1 mod32768 .
Итак, мы увидели, как программным путем реализовать генератор значений
случайных интервалов.
В системе MATLAB вы можете генерировать массив X из п случайных чисел,
равномерно распределенных на интервале (0, 1) с помощью функции
X = rand(n)
Системы моделирования работы систем массового обслуживания обычно
включают такие датчики внутри функций, описывающих потоки событий.
Для задания потока событий с равномерным распределением интервала меж-
ду событиями от Л-до Л +73 в системе моделирования GPSS (General
Purpose Simulation System), которую мы будем рассматривать в следующей
главе, например, достаточно записать
GENERATE А,В
При этом сразу станет генерироваться последовательность событий, интервал
времени между которыми будет случайной величиной с равномерным рас-
пределением со средним значением А и отклонением от среднего равным В
в каждую сторону (рис. 2.13). Нетрудно найти, что дисперсия интервала бу-
дет составлять величину о2 = В2!}!.
Р(Х)
1/(2В)
А—В
А+В х
Рис. 2.13. Функция плотности вероятности для равномерного распределения
Если необходимо реализовать поток с интервалами между поступающими
событиями, распределенными по закону, отличному от равномерного, то, как
62
Гпава 2
правило, используют механизм нелинейного преобразования случайной ве-
личины. Суть такого преобразования состоит в следующем. Если случайная
величина Xраспределена по равномерному закону на интервале (0, 1), то зна-
чения неслучайной действительной функции f(X) также будут являться слу-
чайной величиной К, функция распределения которой будет равна F(y) =
= f}(y) = ?{¥-У}- Соответственно обращая это утверждение, получаем, что
для генерации случайной величины с функцией распределения F(y) можно
построить детерминированную функцию f(x) = F~\x) и получать искомые
случайные числа как значения этой функции от аргумента, определяемого
числом, являющимся случайной величиной с равномерным законом распре-
деления на интервале (1,0).
Приведем в качестве важного практического примера получение случайных
чисел, распределенных по экспоненциальному закону. Этот механизм ис-
пользуется в системе GPSS для формирования пуассоновского потока, в ко-
тором межсобытийный интервал имеет именно экспоненциальное распреде-
ление. Пусть необходимо генерировать случайные числа с функцией плотно-
сти вероятности
Р(х) = -е~х,\х>0
X
из случайных чисел с равномерной плотностью вероятности на интервале
(0,1).
Сначала найдем функцию распределения по плотности вероятности
А'
= f f(y)dy =
'1-е-г/\х>0
0, х- < 0.
Затем определим обратную функцию, решая такое уравнение:
,-л7Х
е~ш=]-у
-х/Л, = 1п(1 - у)
х ~ -Л, 1п(1 - у)
Далее можно записать,* что обратная функция, определенная конечно, только
на интервале (0, 1) будет иметь вид:
F-’(y) = -A.ln(l-y).
Имея последовательность равномерно распределенных случайных чисел, на-
пример, сгенерированную URN38, можно вычислять значения случайных чи-
Модели данных для описания телетрафика
63
сел с экспоненциальным распределением и средним значением X с помощью
следующего алгоритма
X, = -А.1п(1-Ц).
Поступая аналогично, можно генерировать случайные интервалы с любым
заданным законом распределения.
В системе GPSS генерирование потока событий с произвольной функцией
распределения интервала между событиями задается функцией
GENERATE A,FN$EXPON
Функция, задающая преобразование равномерно распределенной случайной
величины в экспоненциально распределенную, задается в GPSS таблично —
списком пар, разделенных косой чертой (slash) значений "аргумент—
запятая—значение функции" (листинг 2.2).
Листинг 2.2. Список пар для функции равномерно распределенной
случайной величины
EXPON FUNCTION
О,0/0.1,0.104/.2,.222/.3,.355/.4,.509/.6,.915/.7,1.2/.75,1.38/.8,1.6/
.84,1.83/.88,2.12/.9,2.3/.94,2.81/.95,2.99/.96,3.2/.97,3.5/.98,3.9/
.99, 4.6/.995,5.3/.998, 6.2/.999,7/.9998,8
Это, конечно, таблица функции— In(1 - у). Для умножения на константу ис-
пользуется возможность функции GPSS generate. При указании в качестве
второго аргумента имени функции первый аргумент (в нашем случае а) будет
умножаться на значения этой функции, и межсобытийный интервал будет
определяться как случайная величина с плотностью вероятности, определяе-
мой заданной функцией преобразования равномерного закона распределения
с учетом этого множителя.
Так могут генерироваться потоки событий с произвольными законами рас-
пределения интервалов между поступлением событий. Однако этот подход
оказывается непригодным для генерирования потоков с долгосрочной зави-
симостью — самоподобных процессов.
Модели потоков событий
В отличие от материала, изложенного выше, моделирование процессов фрак-
тального характера еще не стало хорошо изученным предметом и находится в
стадии развития. Многие алгоритмы моделирования, опубликованные в по-
следнее время, постоянно совершенствуются. Мы предлагаем здесь несколь-
ко базовых подходов, которые представляются нам подходящими для реа-
лизации.
64
Гпава 2
Рассмотрим получение последовательности чисел, представляющих случай-
ную реализацию фрактального броуновского движения или фрактального
гауссовского шума с заданными параметрами.
Существуют два относительно простых пути генерирования случайной реа-
лизации fBM. Это методы, называемые удачным случайным приращением
(Successful Random Addition, SRA) и случайным смещением промеэ/суточных
точек (Random Midpoint Displacement, RMD). Они обеспечивают весьма точ-
ное соответствие сгенерированной последовательности фрактальному бро-
уновскому движению с заданными свойствами. Для получения fGN из fBM
достаточно, согласно определению, продифференцировать последний.
Основную идею обоих алгоритмов можно представить с помощью рис. 2.14.
---------►
Равномерно
распределенная
случайная
величина
Нормально
распределенная
случайная
величина
Рис. 2.14. Генерирование реализации самоподобного случайного процесса
Интерполирование промежуточных точек по двум соседним в данном алго-
ритме использовано для создания коррелированных нормально распределен-
ных приращений процесса. Добавляя же смещения ко всем точкам реализа-
ции, получаем самоподобную нормально распределенную последователь-
ность. Итоговые значения последовательности получаются в результате
линейной комбинации нормально распределенных величин. Следовательно,
по свойству гауссового распределения результирующие значения также бу-
дут распределены нормально.
Пошаговый алгоритм RMD конструирования реализации fBM {АД на вре-
менном интервале (О, I) с заданной дисперсией ^и параметром Херста Н
выглядит следующим образом.
Модели данных для описания телетрафика
65
1. Задаем значения Хо =0 и Х} = N(0, Стд), где АДО, Стц) — значение нор-
мально распределенной случайной величины с параметрами m = 0 и
а- = Сто.
2. Значение Хт находится с помощью линейной интерполяции, т. е.
Х]/2=(Хо+Х,)/2.
3. Добавляем к интерполированной точке А”1/2 случайное смещение с дис-
персией S'2, вычисляемой исходя из определения fBM.
Согласно определению
ад2-^)=|/2-/,Г °о
для любых 0 < t\ < l2 < 1. В то же время, согласно алгоритму вычислений,
дисперсия D(Xl/7-X0) будет складываться из дисперсии интерполиро-
ванной точки и дисперсии смещения S2:
ЛД/2-Хо =[(%, + Хо)/2 +A^J-X, =(Xt -X0)/2 + Xol.,ct,
D(Xin_-X0^^D(Xi~X0) + S^.
Имеем:
=2-2"-q2
2~2-Cq+S2 =2"2W -а2
S2=(2-2W-2-2)-a2
с2 _ 1 z, -2Л-2ч 2
2~11 ’
4. Рекурсивно повторяем шаги 2 и 3 для интервалов (АЛ0; ХЧ2), (Х1/2;Х})
и т. д. до получения значений всех точек искомой последовательности.
Для вычисления дисперсии случайного приращения 8^, используемой на
n-м шаге рекурсии, применяем обобщение результатов, полученных
на шаге 3:
1 г 1 Y"
D(Xy2„-X0) = --D(XV2„.,-Xo) + S2=^-J -а2,
3 Зак. 3884
66
Гпава 2
;2=2-^« .стЗ_2-2 ,2-2ВД)
с2 т-2Нп ъ-2Нп+2Н-2\ 2
Sn=(2 -2 )-о0,
S2 = 1 Г1-22"~21о2
22Я п °'
Отличие алгоритма SRA от RMD состоит в следующем. В RMD случай-
ные приращения прибавляются к точкам только один раз, в процессе фор-
мирования точки (значение каждой точки равняется "интерполированное
значение + случайное смещение"). В отличие от него, в SRA случайное
смещение прибавляется ко всем уже сформированным точкам. Таким об-
разом, в SRA каждая точка формируется в результате суммирования не-
скольких случайных смещений, в зависимости от шага рекурсии. Соответ-
ственно дисперсия для случайного смещения /7-го шага алгоритма будет
рассчитываться несколько иначе, и от вышеописанного алгоритма RMD
алгоритм SRA будет отличаться двумя последними шагами.
5. Добавляем ко всем уже рассчитанным точкам, т. е. Хо, Х{, X1P случай-
ное смещение с дисперсией S2, вычисляемой исходя из определения fBM.
Согласно определению
D{Xti-Xti-)=\t2-t{\2H о2
для любых 0 < t\ < t2 < 1. В то же время, согласно алгоритму вычислений,
дисперсия D(XV1 -%о) будет складываться из дисперсии интерполиро-
ванной точки и удвоенной дисперсии смещения S2 [8]:
П(А1/2- = n(A,-2f0) + 2S2.
Имеем:
1-£(А,-А0) + 2£2=2-2/<<
-,-2 2 , тС2 --2W 2
2 * cTq “F 2 nj । — 2 * ?
St =1.(2-“-2*4 a,,
Модели данных для описания телетрафика
67
6. Рекурсивно повторяем шаги 2 и 3 для интервалов (Хо; %1/2),
и т. д. до получения значений всех точек искомой последовательности.
Для вычисления дисперсии случайного приращения , используемой на
п-м шаге рекурсии, применяем обобщение результатов, полученных
на шаге 3:
1 (1 У"
D(X]/2„ -2f0) = --Z)(X1/2„., -%0) + 2^ J -а2,
z у// / у/,
2~2 -1 | •п2+2£2= — -а2,
I 2»-i I и ” I 2” j и
по2 Э-2Л» _2 э-2 э-2//(»-!) 2
2Sn =2 • ст0 - 2 -2 • СГО ,
г.2 _ 1 z9-2W-» э-2//»+2Л-2ч _2
А2 2 ' ' °0 ’
е2 1 1 п2Л-2ч 2
Проверка, проводимая для генерируемых по этим алгоритмам случайных по-
следовательностей, показывает, что метод RMD дает более точное соответст-
вие определению фрактального броуновского движения, чем SRA. Однако
можно заметить, что это связано с появлением зависимости от параметра
Херста коэффициента пропорциональности к в формуле
D^-X^k^-tft".
При моделировании трафика полученные последовательности должны ис-
пользоваться как данные для генерации пачек событий. Каждый элемент по-
следовательности определяет длину пачки на элементарном временном ин-
тервале. Всего в последовательности будет иметься 2" точек после проведе-
ния и итераций. Таким образом, методы, описанные выше, позволяют
сгенерировать конечные отрезки событий, а значит, и конечные временные
отрезки моделируемого трафика. Для генерирования реализаций трафика
произвольной протяженности применяются другие, более сложные алгорит-
мы. Многие из них связаны с так называемым многомасштпабиым представ-
лением самоподобных процессов. При этом процесс моделируется как иерар-
хия процессов, протекающих в разных масштабах времени. Быстрые случай-
ные потоки имеют параметры, определяемые более медленными случайными
потоками, которые, в свою очередь, зависят от еще более медленных потоков,
и т. д.
Программное моделирование самоподобных процессов и вычисления важ-
нейших характеристик, таких как корреляционная размерность, корреляци-
68
Гпава 2
онная энтропия и параметр Херста, можно осуществить, используя програм-
му Fractan 4.4 на сайте http://impb.psn.ru/~sychyov.
Контрольные вопросы и задания
1. Назовите основные понятия модели потоков событий (стационарность,
последействие, ординарность, интенсивность потока, параметр потока).
2. Что такое пуассоновский поток? Перечислите его свойства, параметры.
Дайте определение примитивному потоку.
3. Что вы знаете о потоках событий с произвольным законом распределения?
4. Расскажите о самоподобных моделях трафика. Опишите виды зависи-
мости.
5. Задание.
Используя данные о трафике, собранные с помощью программы
CommView, построить зависимость интенсивности трафика от времени
для достаточно длительного интервала времени и рассчитать по ней па-
раметр Херста.
6. Расскажите о фрактальном броуновском движении и фрактальном гаус-
совском шуме.
7. Каковы основные принципы моделирования потока событий?
8. Какова основная идея генерирования самоподобных процессов?
9. Опишите два основных алгоритма генерирования fBM. В чем их основное
отличие?
ГЛАВА 3
Модели систем
массового обслуживания
В данной главе мы покажем, как моделируются потоки событий совместно
с процессами обработки этих событий серверами, в качестве обслуживающих
приборов. Собственно система массового обслуживания (СМО) и представ-
ляет собой такое совместное описание: "входной поток требований и способ
обработки требований". Однако прежде чем перейти к моделям СМО, приве-
дем некоторые рассуждения о том, зачем вообще строить модели и модели-
ровать такие системы.
Задачи анализа и проектирования
телекоммуникационных сетей и систем
Первая задача— задача анализа— возникает в тех случаях, когда телеком-
муникационная система уже построена и функционирует. Целями анализа
являются поиск реальных характеристик СМО, сравнение их с проектными
характеристиками, предоставление объективных оценок качества работы сис-
темы. В итоге анализ позволяет определить причины снижения качества об-
служивания по сравнению с проектными характеристиками и выдать реко-
мендации по устранению этих причин. Иногда анализ требуется произвести
после внесения изменений в систему или после подключения новых источни-
ков нагрузки.
Как важнейшую составную часть анализ включает в себя выработку понима-
ния всех основных процессов, происходящих в системе. Понять — значит
суметь мысленно воспроизвести. Количественные пределы человеческого
мышления заставляют воспроизводить познаваемую сущность не во всей ее
полноте, а в упрощенном, схематичном виде. Говорят, что мышление вос-
производит модель объекта. Модель по своей сути — это абстракция, резуль-
70
Глава 3
тат игнорирования, отбрасывания всего несущественного с точки зрения
строящего модель. В простейшем случае, когда по каким-то причинам нельзя
или неизвестно от каких сторон объекта можно абстрагироваться, использу-
ют простейшую форму модели — масштабную модель. Это физическая мо-
дель, имеющая все те же составные элементы, что и объект, но только мень-
ших размеров. Например, физическая модель телекоммуникационной сети
может представлять собой собранное в одной комнате сетеобразующее обо-
рудование, соединенное между собой имитаторами каналов реальной сети.
Если такая модель слишком громоздка или слишком дорога, то физическая
модель может быть построена на основе некоторого типового фрагмента сети
и имитатора поступающей нагрузки. Такую модель принято называть про-
тотипом. Что позволяет делать прототип? С помощью реальных анализато-
ров трафика измеряются характеристики сети, изучается влияние параметров
оборудования и нагрузки на характеристики качества и т. п. Как правило, ре-
зультаты, полученные на прототипе, требуется масштабировать для получе-
ния оценок в реальной сети. Таким образом, физическая модель содержит в
себе имитаторы трафика, упрощенное оборудование, анализаторы характери-
стик. Основным недостатком физического моделирования, прототипирова-
ния, в частности, является очень высокая стоимость работ. Иногда требова-
ния высокой идентичности модели объекта критически важны. Например, на
Земле всегда имеется точная копия космического аппарата, запущенного на
орбиту. Такая копия является физической моделью, на которой отрабатыва-
ются действия экипажа при нештатных ситуациях или выясняются возмож-
ные причины отклонения характеристик объекта от проектных. Но при ма-
лейшей возможности отказаться от физического моделирования для познания
свойств объекта более выгодно строить его абстрактные математические мо-
дели. Они могут быть любого уровня абстрагирования, от очень грубых до
весьма детальных. Но их реализация, как правило, осуществляется в виде
некоторой компьютерной программы и потому существенно дешевле, чем
физическая модель. Кроме того, такие модели чрезвычайно удобны для вне-
сения всевозможных изменений, измерений, наглядных представлений (на-
пример, визуализации внутренних процессов). Главное же достоинство мате-
матических моделей систем состоит в том, что их можно строить задолго до
построения собственно самой реальной системы. Тем самым математические
модели образуют основу для второй важнейшей задачи — проектирования
телекоммуникационных сетей и систем.
Задача проектирования включает в себя несколько различных этапов, обсуж-
дается в соответствующих научных и учебных дисциплинах и не входит в
предмет теории телетрафика. Однако теория телетрафика имеет непосредст-
венное отношение к выполнению многих из этих этапов. Вам, наверное, уже
очевидно, что рассмотренные в главе 1 методы измерения трафика должны
использоваться на этапе тестирования проектируемой системы. Математиче-
Модели систем массового обслуживания 71
ские же модели систем массового обслуживания лежат в основе важных ран-
них этапов проектирования — анализа требований, разработки функциональ-
ной организации системы, определения параметров элементов системы и
некоторых других.
Базовая модель СМО
и классификация по Кендалу
Базовыми составляющими, определяющими математическую модель СМО,
являются описания входного потока требований и обрабатывающих их сер-
веров. В общем случае, требование, поступившее в систему и заставшее все
серверы занятыми, помещается в специальный накопитель — очередь. Размер
этого накопителя, определяющий максимально возможную длину очереди,
может быть различным. В предельных случаях он может быть равным беско-
нечности, тогда все поступающие требования принимаются системой, или
равным нулю, тогда все требования, поступившие при занятых серверах, бу-
дут отброшены системой, или, как принято говорить, заблокированы. В про-
межуточном случае, при конечной максимальной длине очереди, часть тре-
бований, заставших все серверы занятыми, будут помещены в свободное
пространство накопителя, и только если накопитель окажется полным, требо-
вания окажутся заблокированными.
Схематично структуру СМО можно отобразить каскадным соединением на-
копителя и пула серверов (рис. 3.1).
На вход накопителя поступает входной поток требований, математическая
модель которого задается. Каждой модели входного потока принято ставить в
соответствие условное обозначение. Например, для пуассоновского потока
такое обозначение состоит из единственной буквы М, в честь математика
Маркова, который построил исчерпывающую теорию случайных процессов и
систем с памятью. Пуассоновский поток является простейшим случаем мар-
ковских процессов.
Рис. 3.1. Схематичное изображение системы массового обслуживания
72 Гпава 3
Серверы рассматриваемой СМО должны быть описаны с помощью задания
распределения вероятности длины интервала времени, расходуемого на об-
служивание одного требования. Таким образом, математическая модель сер-
вера — это случайная величина, определяющая время обработки требования
(события). В зависимости от функции распределения вероятности серверы
классифицируются наподобие входным процессам и получают такие же сим-
волические обозначения. Например, сервер с экспоненциальной плотностью
вероятности для времени обслуживания будет обозначаться также буквой М,
отмечая марковский характер потока освобождений сервера. Количество сер-
веров в системе играет принципиальную роль и отмечается целым числом.
Тройку основных условных обозначений (тип входного потока, время об-
служивания в сервере, число серверов) объединяют в одно условное обозна-
чение типа системы массового обслуживания через слэш (slash). Например,
М/М/1. Такое обозначение СМО говорит о том, что входной поток систе-
мы — марковский (пуассоновский), время обслуживания в сервере имеет
экспоненциальное распределение и в системе один такой сервер. Условное
обозначение, которое здесь приведено, было впервые предложено Кендалом
и может кроме указанных трех основных обозначений содержать дополни-
тельные. Эти дополнительные символы указываются после трех основных
через двоеточие и могут обозначать особенности системы:
a/b/c:d/e/f.
Например, обозначение M/M/m:Loss означает, что СМО обрабатывает пуас-
соновский поток требований с помощью т серверов, с экспоненциальным
распределением времени обслуживания и полными потерями, т. е. все требо-
вания, пришедшие в систему с занятыми серверами, будут потеряны (забло-
кированы). Значит, размер накопителя в данной СМО равен нулю, и все тре-
бования сразу поступают на серверы.
Ниже приведены наиболее часто встречающиеся условные обозначения ком-
понентов и примеры условных обозначений СМО:
□ М— марковская модель (экспоненциальное распределение интервала
времени);
□ D — детерминированная величина интервала времени;
□ Е* — эрланговское распределение /г-го порядка;
□ U — равномерное (uniform) распределение интервала времени;
□ G — произвольное (general) распределение интервала времени;
□ fBM — фрактальное броуновское движение как модель для числа событий
в единицу времени;
□ fGN — фрактальный гауссовский шум.
Модели систем массового обслуживания
73
Например:
□ a/b/c:Loss — система с нулевой длиной очереди (полными потерями);
□ а/Ь/с/:к — система с максимальным размером очереди, равным к',
□ G/G/1 — система с произвольным законом распределения интервала вре-
мени между входными требованиями (обычно задается функцией плотно-
сти вероятности с произвольным временем обслуживания требова-
ния (обычно задается функцией плотности вероятности Ь(х)) и одним сер-
вером. Размер входного накопителя предполагается неограниченным;
□ fBM/D/1 — система с входным потоком, описываемым самоподобным
процессом типа фрактального броуновского движения и единственным
сервером с постоянным временем обслуживания требований.
Рассмотрим теперь временную диаграмму работы системы массового обслу-
живания, отразив на ней последовательность поступления требований, поме-
щение требований во входную очередь и их обработку серверами. Для опре-
деленности будем рассматривать систему с одним сервером и произвольными
распределениями времени между входными событиями и времени обслужи-
вания. Введем следующие обозначения:
□ С„ — п-е входное требование (arrival);
а tn — интервал времени между приходом предыдущего требования и С„;
□ хп — время обслуживания требования С„ (holding time).
Для отрезка входного потока можно нарисовать диаграмму вида, представ-
ленного на рис. 3.2.
Наглядно в динамике работу СМО можно посмотреть, загрузив Java-апплет по
адресу http://www.dcs.ed.ac.uk/honie/jeli/Sinijava/queueing/niml_q/mnil_q.litnil
или его копию из папки mini с нашего сайта (http://www.nntu.niiov.ru/tct).
Апплет демонстрирует, как происходит процесс поступления входных требо-
ваний в случайные моменты времени, и как сервер обрабатывает их, затрачи-
вая на каждое из них случайное время. Требования, поступившие при заня-
том сервере, накапливаются в очереди. Количество требований в очереди по-
стоянно меняется, но если присмотреться внимательно, то со временем оно
может стать в среднем достаточно устойчивым. Причем, чем больше будет
интенсивность потока требований на входе системы, тем большее число тре-
бований будет находиться в очереди. Значит, и все большее время требование
будет вынуждено находиться в накопителе, прежде чем поступит в сервер на
обработку. Как мы уже говорили в главе 1, среднее время нахождения требо-
вания в системе является одним их важных показателей работы СМО. Можно
установить соотношение между средним числом требований в системе, ин-
тенсивностью входного потока среднего времени пребывания в системе. Обо-
Гпава 3
74
значим число поступающих в промежутке времени (О, Z) требований как
функцию времени a(Z).
Очередь
Обслуживающий
прибор
Время
Рис. 3.2. Диаграмма работы системы массового обслуживания
Число исходящих из системы заявок (обслуженных) на этом интервале обо-
значим 8(z). На рис. 3.3 показаны примеры функциональных зависимостей
этих двух случайных процессов от времени.
Число требований, находящихся в системе в момент Z, будет равно:
N(j) = a(z) - 8(z).
Число
требований
Рис. 3.3. Поступающие, обслуженные и находящиеся в системе заявки
Модели систем массового обслуживания
75
Площадь между двумя рассматриваемыми кривыми от 0 до Z дает общее вре-
мя, проведенное всеми заявками в системе за время Z. Обозначим эту накоп-
ленную величину
y(z) = fW)^-
о
Если интенсивность входного потока равна А.(7), а средняя интенсивность за
время z - A.(Z) = a(Z)/Z, то время, проведенное одной заявкой в системе и
усредненное по всем заявкам, будет равно:
7; =y(z)/a(Z).
Наконец, определим среднее число требований в системе в промежутке (О, Z):
N, =
Из последних трех уравнений следует, что:
где X, = X(Z).
Если в СМО существует стационарный режим, то при z —> со будут иметь ме-
сто соотношения:
X = lim X,,
Т = lim?;,
/—>со
N = XT.
Последнее соотношение означает, что среднее число заявок в системе равно
произведению интенсивности поступления требований в систему и среднего
времени пребывания в системе. При этом не накладывается никаких ограни-
чений на распределения входного потока и времени обслуживания. Впервые
доказательство этого факта дал Дж. Литтл, и это соотношение называется
формулой Литтла.
Интересно, что в качестве СМО можно рассмотреть только очередь из заявок
в буфере. Тогда формула Литтла приобретает иной смысл — средняя длина
очереди равна произведению интенсивности входного потока заявок и сред-
него времени ожидания в очереди:
Если наоборот рассматривать СМО только как серверы, то формула Литтла
принимает вид:
дГ = Хх,
76
Гпава 3
где Ns— среднее число заявок в серверах, ах — среднее время обработки
в сервере.
В любом случае;
T = x + W.
Одним из основных параметров, которые используются при описании СМО,
является коэффициент использования (utilization factor). Это фундаменталь-
ный параметр, т. к. он определяется как отношение интенсивности входного
потока к пропускной способности системы. Поскольку пропускная способ-
ность СМО, содержащей т серверов, может быть определена как щХ, то ко-
х
эффициешп использования может быть выражен:
Хх
Р = — •
т
Нетрудно видеть, что коэффициент использования равен в точности интен-
сивности нагрузки, если СМО содержит один сервер, и в т раз меньше для
систем с ш серверами. Величина коэффициента использования равна средне-
му значению долей занятости серверов и 0 < р < 1.
Если в СМО типа G/G/1 существует стационарный режим и известна вероят-
ность р0 того, что сервер окажется свободным, то коэффициент использова-
ния будет связан с этой вероятностью как р = 1 -р0.
Введем еще два важных понятия, связанных с функционированием СМО.
Остаточным временем обслуживания назовем время, которое осталось за-
тратить на обслуживание требования, находящегося в сервере к моменту
прихода следующего требования. Среднее остаточное время обслуживания
будем обозначать РС0. Незавершенной работой R назовем время, которое
должно пройти до полного ухода всех требований из системы с момента пре-
кращения поступлений требований на ее вход.
Незавершенная работа в момент прихода последнего требования равна сумме
времени ожидания требования в очереди системы и времени дообслуживания
предыдущего требования.
Чтобы рассмотреть более тонкие результаты теории телетрафика, нам пона-
добится уточнить, каким образом могут выбираться требования из входной
очереди и передаваться серверам на обработку. Всюду выше мы предполага-
ли, что, во-первых, любой из освободившихся серверов может подбирать
требование из очереди на обработку, и, во-вторых, требования образовывали
естественную очередь, и первым на обслуживание попадало то требование,
которое пришло в очередь раньше. Оба эти правила не являются обязатель-
Модели систем массового обслуживания
77
ными. Если в системе выполняется первое из приведенных правил, то такая
система называется СМО с полнодоступными серверами. В противополож-
ность можно рассматривать СМО с неполнодоступным включением серверов.
В таких системах существует некоторый механизм регулирования назначения
серверов для тех или иных требований. Для этого во входном потоке требо-
ваний выделяются классы требований, которые различаются механизмом
распределения серверов, и в зависимости от того, к какому классу принадле-
жит поступившее требование, оно направляется на определенный сервер, за-
крепленный за данным классом. Если окажется, что среди закрепленных сер-
веров свободных нет, то требование будет помещено в очередь независимо от
существования других свободных серверов в системе.
Второе правило определяет СМО без приоритетов. Иначе говоря, в таких
системах действует правило "первый пришел— первый обслужен" (First
Input First Output, FIFO). Для входных требований могут применяться и дру-
гие правила. Например, "последний пришел— первый обслужен" (Last
Input First Output, LIFO). В более общем случае во входном потоке также мо-
гут быть выделены классы требований и назначен механизм приоритетного
обслуживания. В теории СМО принято говорить о дисциплинах обслужива-
ния. Каждая дисциплина обслуживания имеет свое условное обозначение
и может использоваться в качестве дополнительного символа в типе СМО в
классификации Кендала. Простейшая из дисциплин— "первый пришел —
первый обслужен", — обозначается FCFS (First Came First Served). Она
обычно не указывается, т. е. используется по умолчанию. Другая, обратная
дисциплина LCFS (Last Came First Served), называемая также стеком, должна
быть указана. Например: M/M/3: К/LCFS. Существует также еще много раз-
личных дисциплин обслуживания:
□ SPT/SJE— первоочередное обслуживание требований с кратчайшим
временем обслуживания;
□ SRPT — первоочередное обслуживание требований с кратчайшим време-
нем дообслуживания;
□ SEPT — первоочередное обслуживание требований с кратчайшим сред-
ним временем обслуживания
и др.
Предположим, что требования принадлежат одному из Р различных приори-
тетных классов, обозначаемых индексом р= 1, 2, 3, ..., Р. Каждому требова-
нию, находящемуся в системе в момент времени /, ставится в соответствие
значение некоторой приоритетной функции qp(j). Чем больше значение этой
функции, тем выше приоритет требования. Всякий раз, когда принимается
решение для выбора требования на обслуживание, выбор делается в пользу
требования с наибольшим значением приоритетной функции. В простейшем
78
Гпава 3
случае в качестве приоритетной функции выбирается просто значение р. То-
гда приоритет требования тем выше, чем больший номер класса принадлеж-
ности оно имеет. Предположим, что требования из приоритетного класса р
образуют поток с интенсивностью требований в секунду. Время обслужи-
вания каждого требования из этого класса выбирается независимо в соответ-
ствии с распределением с плотностями вероятности Ьр(х) со средним значе-
нием
ХР = 17 xb!’^dx
Введем следующие определения:
Р=1
х^2^—хр,
р=\
Рр ^рхР’
_ и
Р = ^ = ЕРг
р=|
Здесь р интерпретируется как доля времени, в течение которого сервер занят
(р < 1), а каждый из парциальных коэффициентов р/;— как доля времени,
в течение которого сервер занят обслуживанием заявок из приоритетного
класса с номером р.
Если требование в процессе обслуживания может быть удалено с сервера и
возвращено в очередь при поступлении требования с более высоким приори-
тетом, то говорят, что система работает с абсолютным приоритетом. Если
обслуживание любого требования, находящегося на сервере, не может быть
прервано, то говорят, что СМО работает с относительным приоритетом.
Будем использовать далее следующие обозначения:
□ Wp— среднее значение времени ожидания в очереди требований из при-
оритетного класса
□ Тр — среднее время пребывания в системе требований классар.
Tp=Wp+Xp.
Основное внимание будем уделять системам с относительным приоритетом.
Рассмотрим процесс с момента поступления некоторого требования из при-
оритетного класса р. Будем далее называть это требование меченым.
Модели систем массового обслуживания 79
Первая составляющая времени ожидания для меченого требования связана с
требованием, которое оно застает на сервере. Эта составляющая равна оста-
точному времени обслуживания другого требования. Обозначим Wo среднюю
задержку меченого требования, связанную с наличием другого требования на
обслуживании, и будем использовать это обозначение далее. Зная распреде-
ление времени между соседними поступлениями входных требований для
каждого приоритетного класса, можно всегда вычислить эту величину.
Вторая составляющая времени ожидания для меченого требования определя-
ется тем, что перед меченым требованием обслуживаются другие требования,
которые меченое требование застало в очереди. Обозначим i число требова-
ний из класса, которые застало в очереди меченое требование (из класса р) и
которые обслуживаются перед ним — Nip. Среднее значение данной величи-
ны будет определять величину среднего значения этой составляющей за-
держки
/=1
Третья составляющая задержки связана с требованиями, поступившими по-
сле того, как пришло меченое требование, однако получившими обслужива-
ние раньше него. Число таких требований обозначим Mip. Среднее значение
этой составляющей задержки находится аналогично и составляет
р______
^М,Р
/=|
Складывая все три составляющие, получаем, что среднее время ожидания
в очереди для меченого требования определяется формулой
Wp=Wo + fjxi(N~ + ~M~p), р = ],2,...,Р. (3.1)
/=1
Очевидно, что независимо от дисциплины обслуживания число требований
Nip и М,р в системе не может быть произвольным, поэтому существует неко-
торый набор соотношений, связывающий между собой задержки для каждого
требования из приоритетного класса. Важность этих соотношений для СМО
позволяет называть их законами сохранения. Основой законов сохранения
для задержек является тот факт, что незаконченная работа в любой СМО
в течение любого интервала времени занятости не зависит от порядка обслу-
живания, если система является консервативной (требования не исчезают
внутри системы, и сервер не простаивает при непустой очереди).
Распределение времени ожидания существенно зависит от порядка обслужи-
вания, но если дисциплина обслуживания выбирает требования независимо
80
Гпава 3
от времени их обслуживания (или любой меры, зависящей от времени обслу-
живания), то распределение числа требований и времени ожидания в системе
инвариантно относительно порядка обслуживания.
Для СМО любого типа можно показать, что для любой дисциплины обслу-
живания должно выполняться следующее важное равенство:
£p,,wp=r-w0.
р=|
Это равенство означает, что взвешенная сумма времени ожидания никогда не
изменяется, независимо от того, насколько сложна или искусно подобрана
дисциплина обслуживания. Если удается сократить задержку для одних тре-
бований, то она немедленно возрастет для других.
В правой части стоит разность средней незавершенной работы и остаточного
времени обслуживания.
Такие общие закономерности для СМО позволяют делать некоторые выводы
о поведении конкретных телекоммуникационных сетей и систем, однако не
позволяют получить каких-либо количественных результатов. Для получения
таких важных характеристик, как среднее время пребывания требований в
системе или вероятность блокировки требования, нужно строить более кон-
кретную поведенческую модель СМО. Одним из наиболее прямых подходов к
построению поведенческих математических моделей является построение
имитационных моделей.
Имитационные модели СМО
В настоящее время имитационные модели строятся в виде программ, разра-
батываемых на обычных языках программирования, таких как С, C++, Java,
или на специализированных языках и в специализированной визуальной
среде.
Построение программы имитации поведения СМО основано на программи-
ровании цепочки событий, начиная от входных требований, поступающих в
случайные моменты времени, занятия и освобождения серверов в соответст-
вии со случайным характером длительности обработки каждого требования,
помещения и чтения событий из очереди в соответствии с дисциплиной об-
служивания и доступностью серверов. Итогом работы программы является
получение статистических отчетов о процессах в системе. Поскольку интерес
представляют некоторые усредненные характеристики типа среднего по всем
требованиям времени нахождения в системе, то для получения устойчивых
статистических оценок требуется проимитировать весьма большое количест-
во рабочих циклов моделируемой системы. Пусть, например, анализируется
Модели систем массового обслуживания 81
система с блокировкой входящих требований. Если уровень блокировок в
системе характеризуется величинами порядка I О5, то для получения стати-
стически устойчивых оценок (с точностью порядка 1%) придется имитиро-
вать прохождение через систему не менее нескольких миллионов требований.
Это накладывает условия на быстродействие алгоритмов имитации. Медлен-
ные алгоритмы будут существенно снижать ценность имитационной модели
и требовать повышенных вычислительных ресурсов.
Рассмотрим простейший алгоритм имитации системы с одним сервером, без
приоритетов, с неограниченным размером входного накопителя. В алгоритме
используются перечисленные ниже сущности и их атрибуты-переменные.
О Сущность SERVER имеет атрибут busy, который может принимать два
значения busy=0, если SERVER находится в состоянии idle (свободен), и
busy= 1, если SERVER находится в состоянии busy (занят). Другой атрибут
сущности SERVER назовем ctime. Это момент времени, в который обслу-
живание поступившего па сервер требования будет завершено. Если сер-
вер свободен, то данный атрибут может считаться бесконечно большим
и ему присваивается наибольшее машинное число.
□ Сущность QUEUE имеет атрибутом число требований, находящихся в
очереди, не считая того, которое находится на сервере на обслуживании.
Обозначим соответствующую переменную qsize.
□ Сущность AGEN — это механизм, определяющий моменты поступления
в систему требований. Атрибут atime будет представлять текущий момент
поступления очередного входного требования. Будем считать, что atime
генерируется некоторым датчиком входного потока событий с помощью
генератора случайных интервалов, описанного выше (см. paid. "Модели
потоков событии" главы 2), и считывается программой имитации.
□ . Сущность SGEN — это механизм, определяющий случайное время обслу-
живания требования, поступившего на сервер. Атрибут stime будет пред-
ставлять случайную величину, задающую время обслуживания того тре-
бования, которое находится в данный момент на сервере. Для начала бу-
дем полагать его постоянной величиной.
Если считать, что входной поток генерируется с помощью датчика равномер-
но распределенных случайных чисел, например URN 13, т. е.
<7, = URN 13,
atime — atime + Cl/,
то моделируемая система может быть описана как U/D/1.
Зададим максимальное значение модельного времени переменной htime. Дос-
тижение значения ctime этой величины будет вызывать остановку процесса
моделирования. На рис. 3.4 представлена блок-схема алгоритма моделирова-
ния системы U/D/I при некоторых конкретных значениях р = 0,9, stime = 0,9
И htime = 50.
Реализовав приведенный выше алгоритм на любом языке программирования,
мы получим возможность имитировать работу данной СМО в течение
50 единиц модельного времени (например, минут).
Рис. 3.4. Блок-схема алгоритма имитационной модели U/D/1
Модели систем массового обслуживания 83
Приведем код программы, написанной на языке системы MATLAB (лис-
тингЗ.1).
i Листинг 3.1. Программа имитации работы модели U/D/1
roh=0.9
qsize=0
busy=0
ctime=realmax
stime=.90
htime=50
atime=2
alfa=2*stime./roh
while atime<=htime|ctime<=htime
if atime<=htime&atime<=ctime
aevent=l
if busy—0'
busy=l
ctime=atime+stime
else
qsize=qsize+l
end
atime= atime+alfa.*rand(1)
else
cevent=l
if qsize==0
busy=0
ctime=realmax
else
qsize=qsize-l
ct ime=ct ime+s time
end
end
end
Для получения интересующей информации о характеристиках системы нуж-
но произвести трассировку необходимых переменных, т. е. собрать статисти-
ку, и обработать полученные данные. В нашем случае система не имела бло-
кировок, поскольку размер очереди нигде не ограничивался, и наиболее важ-
ной характеристикой следует считать среднее время нахождения требования
в системе. Для простоты найдем среднее число требований в очереди, а далее
воспользуемся формулой Литтла.
Результаты трассировки значения переменной qsize приведены на рис. 3.5.
84
Гпава 3
t
Рис. 3.5. Изменение длины очереди в системе в процессе моделирования
По полученным данным нетрудно найти такую важную характеристику
СМО, как среднее значение длины очереди за время моделирования:
avqsize = 1,73.
Величина X = naevent/htime, поскольку среднюю интенсивность поступления
требований можно оценить, разделив общее число поступивших требований
naevent. на протяженность моделирования.
В нашем случае поступило 70 требований и оценка для параметра потока бу-
дет равна X = 1,4 (сообщений/мин).
Тогда по формуле Литтла получаем
... 1 TV avqsize , .
W = — N,----------= 1,21 (мин).
X " X
Это означает, что среднее время нахождения требования в очереди было рав-
но 1,21 минуты. С учетом среднего времени обработки, а в нашем случае оно
в точности равно 0,9 минуты, можно получить оценку для среднего времени
пребывания требования в системе:
Т = W + х = 1,21 + 0,9 = 2,11 (мин).
Так с помощью имитационного моделирования СМО U/D/1 при Х=1,4,
р = Хл = 0,9 получили, что среднее время пребывания требования в системе
будет составлять около 2 минут.
Итак, мы показали, как строится программа имитационного моделирования, и
как могут быть использованы результаты ее работы для определения харак-
теристик моделируемой системы. Для более сложных систем программа бу-
дет разрастаться и лишаться наглядности. Поэтому для программирования
имитационных моделей применяют особые системы моделирования. Они
имеют специальные готовые модули для компактного описания всех основ-
ных сущностей моделируемых систем, могут гибко изменять статистические
характеристики входного потока и времени обслуживания, программировать
Модели систем массового обслуживания
85
работу многосерверных систем с различным обслуживанием. При необходи-
мости моделирования сложных пакетных сетей мы рекомендуем пользоваться
свободно распространяемыми пакетами программ J-Sim (http://www.j-sim.org)
и ns2 (http://www.cse.unsw.edu.au/~ainustafa/network_simulator_2.htm).
Первый из них написан на языке Java, а второй— на C++. Каждый из них
может легко модифицироваться под конкретные задачи. Здесь мы рассмот-
рим инструментарий, основанный на использовании специализированного
языка описания процессов в СМО. Исторически первым и наиболее простым
из таких специализированных языков является GPSS.
Основы моделирования
средствами языка GPSS
Аббревиатура GPSS означает General Purpose Simulation System. Этот язык
имеет более чем двадцатилетнюю историю, и трансляторы с него были реа-
лизованы для многих компьютеров. В данной книге будем пользоваться вер-
сией GPSS World, ориентированной для работы на IBM-совместимых компь-
ютерах под управлением MS Windows 9х или MS Windows 2000/ХР.
Язык GPSS предназначен для исследования дискретных систем. Такие систе-
мы изменяют свое состояние в определенные моменты времени, в промежут-
ках между этими моментами состояние систем постоянно. Язык GPSS осуще-
ствляет моделирование с точки зрения событий, т. е. изменений, происходя-
щих в исследуемой системе. Работа модели представляется как движение
требований, называемых в GPSS транзакциями, через различные блоки, опи-
сываемые операторами языка. Каждый блок программы, написанной на языке
GPSS, выполняет присущее ему действие только в тех случаях, когда через
него проходит транзакция. В этом смысле понятие маршрута заявки-тран-
закции близко к понятию пути исполнения программы. Поскольку в системе
в каждый момент времени могут присутствовать несколько транзакций, сле-
дующих различными маршрутами, процесс моделирования можно предста-
вить как многопоточное псевдопараллельное исполнение кода, описывающе-
го модель. Тем не менее данное обстоятельство не создает серьезных слож-
ностей при написании кода ввиду того, что язык GPSS является языком
специального назначения, учитывающим особенности построения подобных
моделей и автоматически управляющим различными аспектами параллельно-
го исполнения программы, например, совместным доступом к глобальным
ресурсам. Все вышесказанное свидетельствует о том, что язык GPSS, будучи
в принципе похожим на традиционные языки программирования, обладает
рядом концептуальных отличий, непонимание которых может оказаться кри-
тическим для успешного практического применения данного средства.
86
Гпава 3
Структура модели на GPSS
GPSS World позиционируется как объектно-ориентированная версия модели-
рующей среды программирования. Поддерживается четыре типа объектов:
Model Objects, Simulation Objects, Report Objects, Text Objects.
Объект первого типа создается в виде последовательности инструкций языка
GPSS, называемых блоками. Состав и последовательность записи этих блоков
определяют способ и порядок обработки событий-транзакций в моделируе-
мой системе. Модель всегда содержит источники и обработчики транзакций.
Для организации сложных и множественных экспериментов в GPSS World
имеются также специальные встроенные средства программирования на язы-
ке PLUS (Programming Language Under Simulation). Объект типа Model пол-
ностью описывает моделируемую систему и условия моделирования.
Запустив транслятор среды GPSS World, вы получите объект типа Simulation.
Этот объект является интерпретируемым кодом и может быть запущен на
выполнение нужное число раз с целью получения достаточного для понима-
ния объема статистической информации о моделируемой системе.
В процессе исполнения будет порожден объект третьего типа— Report. Этот
объект содержит типичную для анализа систем массового обслуживания ин-
формацию, например, коэффициенты использования серверов, средние дли-
ны очередей и т. п.
Объекты четвертого типа (Text) не являются обязательными при выполнении
моделирования и используются при описании особо сложных моделей и по-
лучения исходного кода для архивирования и переноса.
Мы рассмотрим сначала создание объекта типа Model. Дальнейшее изложе-
ние не претендует на полноту описания возможностей GPSS World. Вы мо-
жете получить полное руководство по этой системе на сайте http://
www.minutemansoftvvare.com и там же взять последнюю версию системы
моделирования. Мы будем использовать описание для реализации GPSS
World Student Version 4.3.5, которая находится также на нашем сайте
(см. Предисловие).
Модель системы состоит из последовательности управляющих и исполняе-
мых выражений. Исполняемые выражения, называемые блоками (blocks),
описывают логику потока транзакций в ходе моделирования. Однако само
наличие исполняемых выражений в GPSS-программе не вызывает каких-либо
действий. Только когда на входе в блок появляется транзакция, в модели
происходят изменения. Блок может содержать до четырех полей: label,
operator, operand, comment.
Крайнее левое поле предназначается для поля label (метка), которое ставится,
только если есть необходимость организовать ветвление. Метка может со-
Модели систем массового обслуживания
87
держать до семи алфавитно-цифровых символов, образующих идентифика-
тор (identifier).
Поле operator (оператор) располагается справа от метки. Каждый оператор
определяет вид действий, которые будут исполняться, когда транзакция по-
явится на входе данного блока.
Далее расположено поле operand (операнд). Количество операндов, тип каж-
дого из них зависят от назначения блока. Рассмотрим, например, блок
10 ADVANCE 10,4
Этот блок имеет метку ю и не имеет комментариев (comment). Оператор
advance означает, что транзакция, которая попадет в данный блок, будет
удерживаться в нем заданный операндами интервал времени. Спецификация
10,4, записанная в поле операндов, показывает, что транзакция будет удер-
живаться в этом блоке в течение случайного интервала времени с равномер-
ным распределением со средним, равным 10, и минимальным значением
10 - 4 = б, а максимальным 10 + 4 = 14 единиц модельного времени. Это озна-
чает, что выход транзакции из блока будет задержан с вероятностью 1/9 на
одно из значений 6, 7, 8, 9, 10, 11, 12, 13, 14.
В большинстве случаев в качестве операндов могут использоваться значения
по умолчанию. Поскольку каждый операнд отделяется от предыдущего запя-
той, то при использовании значений по умолчанию необходимо просто ста-
вить запятую слева от следующего за опущенным значением. Рассмотрим
пример: оператор generate может иметь до семи операндов, каждый из кото-
рых несет определенный смысл для задания параметров генерируемого пото-
ка транзакций А, В, С, D, Е, F, G. Если записать
GENERATE 5,,,17
то это будет означать, что для операнда А задано значение 5, D = 17, а опе-
ранды В, С, Е, F и G определены по умолчанию. В следующем разделе при-
веден список основных блоков языка GPSS и описаны их назначение и опе-
ранды.
Посмотрите в качестве примера код на GPSS, который моделирует процессы
в системе U/D/1 (листинг 3.2). Здесь использованы те же значения парамет-
ров входного потока и сервера, что и в алгоритме, приведенном на рис. 3.4.
Листинг 3.2. Моделирование процессов в системе U/D/1
GENERATE
QUEUE
SEIZE
DEPART
12,3
IN_BUFFER
ROUTER
IN_BUFFER
88
Гпава 3
ADVANCE 10,0
RELEASE ROUTER
TERMINATE 1
Основные исполняемые блоки GPSS
В табл. 3.1 приведены основные исполняемые блоки (операторы) и их назна-
чение.
Таблица 3.1. Основные исполняемые блоки GPSS
Оператор Назначение
GENERATE Создает транзакции в системе
TERMINATE Уничтожает транзакции
SEIZE Занимает сервер
RELEASE Освобождает сервер
ADVANCE Задержка, удержание транзакции
QUEUE Ставит транзакцию в очередь
DEPART Исключает транзакцию из очереди
STORAGE Создает массив серверов (многосерверную систему)
ENTER Занимает один либо несколько серверов в многосерверной системе
LEAVE Освобождает один либо несколько серверов в многосерверной системе
TRANSFER Осуществляет ветвление в передаче заявок
RESET Сбрасывает статистику и относительное время, не влияет на транзакции и абсолютное время
RMULT Устанавливает параметр генератора случайных чисел
CLEAR Сбрасывает статистику и удаляет все транзакции из системы, переза- пускает моделирование
ASSIGN Присваивает значение параметру транзакции
INITIAL Присваивает начальное значение глобальной переменной
SAVEVALUE Присваивает значение глобальной переменной
MARK Сохраняет абсолютное время в параметре заявки
TABLE Создает таблицу для построения гистограммы распределения перемен- ной
QTABLE Создает таблицу для построения гистограммы распределения длины очереди
Модели систем массового обслуживания
89
Таблица 3.1 (окончание)
Оператор Назначение
TABULATE Вносит значение в таблицу
PRIORITY Устанавливает приоритет транзакции
PREEMPT Вытесняет транзакцию, занимающую сервер
RETURN Возвращает вытесненную транзакцию на сервер
TEST Выполняет сравнение двух величин и осуществляет ветвление в пере- даче транзакций в зависимости от результата сравнения
LOOP Организует цикл в передаче транзакций
LOGIC Изменяет значение логической переменной
GATE Осуществляет задержку или перенаправление транзакций в зависимо- сти от указанного условия
SELECT Осуществляет поиск варианта, удовлетворяющего некоторому призна- ку, среди указанных вариантов
EQU Присваивает значение переменной
LINK' Исключает транзакцию из модели и включает ее в пользовательскую цепь транзакций
UNLINK Исключает транзакцию из пользовательской цепи заявок и возвращает ее в модель
Всего GPSS содержит 53 исполняемых блока, о которых имеется полная ин-
формация в справочной системе программы.
Приведем далее более детальное описание основных операторов языка GPSS.
GENERATE,
Любая модель должна содержать хотя бы один источник транзакций.
В подавляющем большинстве моделей с этой целью используется оператор
GENERATE А, В, С, D, Е, F
Создает транзакции в системе.
Аргументы:
□ а— среднее значение временного интервала между транзакциями; по
умолчанию равно 0, что означает поступление неограниченного числа
транзакций;
□ в— половинное отклонение значения интервала между транзакциями.
Этот интервал определяет равномерное распределение случайной вели-
90
Гпава 3
чины на отрезке [а-в, д+в]. Значение по умолчанию равно 0, при этом
интервал является детерминированной величиной. Если в качестве этого
аргумента указано имя функции, значение интервала равно произведению
аргумента а на значение этой функции;
□ с— время поступления первой транзакции. По умолчанию этот аргумент
игнорируется, и первая транзакция поступает в момент времени, опреде-
ляемый аргументами айв;
□ d—число транзакций, которые будут созданы данным блоком. После
достижения этого числа блок прекращает создание транзакций. Если дан-
ный аргумент не указан, создание транзакций будет продолжаться в тече-
ние всего процесса моделирования;
□ в— приоритет транзакций, создаваемых данным блоком (целое число от О
до 127). Значение по умолчанию равно нулю— низший приоритет;
□ в— количество числовых параметров (не более 100) у создаваемых дан-
ным блоком транзакций. Значение по умолчанию равно 12.
Такие параметры могут использоваться, например, для нахождения протя-
женности интервала модельного времени, занимаемого созданной порцией
транзакций. Для этого можно каждую транзакцию из этой порции снабдить
параметром, присваивая ему значение момента времени генерации данной
транзакции. Сравнивая значение этого параметра на выходе модели с теку-
щим временем, можно найти интересующий интервал.
Примеры записи блоков generate.
□ Блок
GENERATE 7
будет создавать транзакции каждые 7 единиц модельного времени, и та-
ким образом будет смоделирован детерминированный поток требований.
□ Блок
GENERATE 7,2
будет создавать транзакции в случайные моменты времени так, что сред-
нее значение межсобытийного интервала будет равно 7, а все значения
окажутся равномерно распределенными в интервале от 5 до 9.
□ Блок
GENERATE 20,3,,15
создаст ровно 1 5 транзакций со случайным межсобытийным интервалом,
определяемым равномерно распределенной в диапазоне от 17 до 23 слу-
чайной величиной.
Модели систем массового обслуживания
91
□ Блок
GENERATE 20.3,,15,2,25
будет создавать в точности такую же последовательность из 15 транзак-
ций, как и в предыдущем примере, но, кроме того, эти транзакции будут
иметь приоритет, равный двум, а каждая транзакция сможет иметь 25 па-
раметров.
TERMINATE
Синтаксис:
TERMINATE А
Уничтожает транзакции, поступающие в этот блок.
Аргумент:
□ а— величина, на которую уменьшается значение счетчика уничтоженных
транзакций при удалении одной транзакции. Значение по умолчанию рав-
но 0, т. е. значение счетчика не изменяется.
SEIZE
Синтаксис:
SEIZE А
Транзакция, поступающая в этот блок, либо занимает указанный в аргументе
а сервер, если он свободен, либо ставится в очередь, если сервер занят.
Аргумент:
□ а—имя занимаемого сервера.
RELEASE
Синтаксис:
RELEASE А
Освобождает сервер, указанный в аргументе а. При этом предполагается, что
транзакция, освобождающая сервер, занимает его.
Аргумент:
□ а— имя освобождаемого сервера.
ADVANCE
Синтаксис:
ADVANCE А, В
92
Гпава 3
Задерживает транзакцию, поступающую в этот блок, на временной интервал,
значение которого есть равномерно распределенная случайная величина на
отрезке [д- в, а + в].
Аргументы:
□ а — среднее время задержки, по умолчанию равно нулю;
□ в— половинное отклонение времени задержки. Значение по умолчанию
равно 0, что приводит к детерминированному времени задержки. Если
в качестве этого аргумента указано имя функции, значение времени за-
держки равно произведению аргумента д на значение этой функции.
QUEUE
Синтаксис:
QUEUE А
Ставит транзакцию в указанную очередь, имя которой указано в аргументе д.
Неявно заданные очереди автоматически создаются для всех серверов. Блок
queue создает явно заданную очередь. Такую очередь можно использовать
для управления движением транзакций и сбора статистики.
Аргумент:
□ а— имя очереди, в которую ставится транзакция.
DEPART
Синтаксис:
DEPART А
Удаляет транзакцию из очереди, имя которой указано в аргументе д. При
этом предполагается, что транзакция находится в этой очереди.
Аргумент:
□ а— имя очереди, из которой исключается транзакция.
STORAGE
Синтаксис:
A STORAGE В
Создает массив серверов (многосерверную систему).
Аргументы:
□ а— имя массива серверов;
□ в—число серверов в массиве.
Модели систем массового обслуживания 93
ENTER
Синтаксис:
ENTER А, В
Занимает в серверов из массива серверов а. Если указанное число серверов
свободно-, транзакция проходит через этот блок без задержки. В противном
случае транзакция ставится в очередь.
Аргументы:
□ а—имя массива серверов;
□ в — требуемое число серверов. Значение по умолчанию равно 1.
LEAVE
Синтаксис:
LEAVE А, В
Освобождает в серверов из массива серверов а. При этом предполагается, что
число занятых серверов не меньше указанного.
Аргументы:
□ а—имя массива серверов; .
□ в— число освобождаемых серверов. Значение по умолчанию равно 1.
TRANSFER
Синтаксис:
TRANSFER А, В, С
Реализует ветвление в пути распространения транзакций. Существуют три
режима ветвления:
□ безусловный режим— транзакция передается на указанный блок незави-
симо от состояния системы;
□ статистический режим — транзакция направляется на один из двух ука-
занных блоков случайным образом с определенной вероятностью;
□ условный режим.— транзакция направляется в предпочитаемый блок,
если он свободен, или в альтернативный блок — в противном случае.
В любом случае транзакции всегда разрешен вход в данный блок, после чего
она направляется в блок назначения. Если вход в этот блок запрещен, тран-
закция остается в блоке transfer.
94 Гпава 3
Аргументы: j
□ а— определяет режим ветвления. Может принимать следующие значения: J
• если аргумент а не указан, режим ветвления — безусловный, и тран- |
закции направляются в блок, указанный в аргументе в;
• если аргумент а является десятичной дробью от 0 до I, режим ветвле-
ния— статистический, и аргументы в и с указывают метки блоков, на
которые транзакция передается с вероятностями 1 - р и р, соответст-
венно;
• если в качестве аргумента а указано both, режим ветвления— услов-
ный, и аргументы вис означают метки предпочитаемого и альтерна-
тивного блоков, соответственно;
□ в и с— метки блоков. Аргумент в должен быть указан в режиме безуслов- j
ного перехода, в режиме статистического и условного ветвления он может
быть пропущен, что соответствует указанию блока, непосредственно сле-
дующего за блоком transfer. Аргумент с не используется в режиме безус-
ловного перехода и должен быть указан в режимах статистического и ус-
ловного ветвления.
Теперь мы можем разработать модель на GPSS.
Работа с GPSS World
После запуска системы GPSS World в меню нужно выбрать команду File |
New | Model. Откроется окно объекта типа Model. Далее можно либо наби- ;
рать текст операторов модели прямо в появившемся окне, либо, что более '
удобно, воспользоваться командой Edit | Insert GPSS Blocks и, выбирая
нужные операторы, заполнять соответствующие формы. В результате в окне J
модели будет сформировано полное описание моделируемой системы (лис- ?
тинг 3.3). Пусть это будет уже рассмотренная выше U/D/1. <
Листинг 3.3. Полное описание моделируемой системы U/D/1
GENERATE 12,3
QUEUE IN_BUFFER
SEIZE ROUTER
DEPART IN_BUFFER
ADVANCE 10,0
RELEASEROUTER
TERMINATE 1
Для создания следующего объекта типа Simulation нужно выбрать в меню
команду Command | Create Simulation. Откроется новое окно с информаци-
Модели систем массового обслуживания
95
ей о выполненной трансляции. Далее в меню Command можно задать режим
интерпретации модели. При выборе команды Start открывается окно, в кото-
ром следует указать, сколько транзакций должно быть порождено в процессе
моделирования, на каком объеме данных будет рассматриваться статистика
моделируемой системы. Слишком большое количество транзакций приводит
к неоправданному росту времени моделирования, слишком малое— к недос-
товерности полученных результатов. Это число сильно зависит от модели-
руемой системы, и никаких общих рекомендаций по его выбору дать невоз-
можно. В практике имитационного моделирования принято, что если удвое-
ние числа транзакций не приводит к существенному с точки зрения
экспериментатора изменению статистики, то такое число можно считать дос-
таточным. Запустим модель с параметром start, равным 1000.
В результате будет создан объект типа Report, и его окно откроется автома-
тически. Рассмотрим содержимое этого окна для нашего примера (лис-
тинг 3.4).
Листинг 3.4. Содержимое окна объекта типа Report
GPSS World Simulation Report — Untitled Model 1.1.1
Wednesday, December 10, 2003 12:15:46
START TIME 0.000 END TIME BLOCKS FACILITIES 1 STORAGES 0
12043 .101 7
NAME IN_BUFFER ROUTER VALUE 10000.000 10001.000
LABEL 1 2 3 4 5 6 7 LOC GENERATE QUEUE SEIZE DEPART ADVANCE RELEASE TERMINATE BLOCK TYPE 1000 1000 1000 1000 1000 1000 1000 ENTRY COUNT 0 0 0 0 0 0 0 CURRENT COUNT RETRY 0 0 0 0 0 , 0 0
FACILITY ENTRIES ROUTER 1000 UTIL. 0.830 AVE. TIME 10.000 AVAIL. OWNER 1 0 PEND INTER 0 0 RETRY DELAY 0 0
QUEUE MAX CONT IN BUFFER 1 0 . ENTRY 1000 ENTRY(0) 836 AVE.CONT. AVE 0.007 0 .TIME AVE. .089 0. .(-0) RETRY .544 0
96 Гпава 3 ;
FEC XN PRI BDT ASSЕМ CURRENT NEXT PARAMETER VALUE
1001 0 2045.266 1001 0 1
После заголовка располагается информация о модельном времени, числе бло-
ков и неиспользованных ресурсах. Далее следует запись о расположении ,
исполняемых блоков в программе и числе транзакций, прошедших через
каждый блок. По этой информации можно проследить, как происходил про-
цесс генерирования и распределения транзакций во время моделирования.
Наиболее содержательными являются строки о статистике блоков, накапли-
вающих транзакции. Это серверы, которые в GPSS называются facility, и
очереди queue. В левом столбце указывается имя сервера или очереди. Далее
для серверов указывается число вошедших транзакций, значение коэффици-
ента использования, среднее время, которое проводили транзакции в данном
сервере, и некоторая информация о процессах моделирования. Для очередей ‘
сначала записывается максимальное количество транзакций, которое было в
очереди за время моделирования, потом число транзакций в момент оконча-
ния моделирования, затем число заявок, вошедших в очередь за все время
моделирования, далее записывается число транзакций, вошедших в пустую
очередь, потом средняя длина очереди за время моделирования, среднее вре-
мя нахождения транзакции в данной очереди за это время и среднее время
отсутствия транзакций в данной очереди. Последний столбец не несет содер-
жательной информации.
Наиболее важная статистическая информация содержится в строках, описы-
вающих два важнейших блока нашей модели очереди с именем in buffer и
сервера с именем router. Для сервера приводятся такие сведения, как число
поступивших транзакций, коэффициент использования, среднее время об-
служивания. Обратите внимание, что в нашем примере были заданы средний
интервал поступления транзакций в блоке generate, равный 12, и среднее
время обслуживания в блоке advance, равное 10. Их отношение определяет
нагрузку 10/12 = 0,833, а значит, и такой же коэффициент использования сер-
вера, поскольку он один. Однако в Report мы видим, что коэффициент ис-
пользования сервера router был равен 0,830. Среднее время обслуживания в
сервере составило 10,0. Отличие результата моделирования от теоретическо-
го значения определяется числом проведенных циклов моделирования, кото-
рое в нашем примере составило 1000. Увеличив это число в несколько раз,
можно снизить погрешность. Из текста Report Object можно определить
среднее число транзакций, находящихся в очереди и в системе в целом.
В нашем примере в очереди в установившемся состоянии будет находиться
0,007 транзакции, а среднее время, которое транзакция проводит в очереди,
равно 0,089.
Модели систем массового обслуживания
97
Сравним полученные экспериментальные результаты и теоретические, сле-
дующие из формулы Литтла. Согласно этой формуле
'N'^'kW.
Подставим в качестве параметра потока 1/12 и, умножив его на время ожида-
ния, получим 0,089/12 = 0,007416. Как видно, результат вполне согласуется с
получаемым теоретически.
GPSS World позволяет легко анализировать СМО с произвольными законами
распределения интервала между входными транзакциями и времени обслу-
живания. Используя методику формирования случайной величины с задан-
ной плотностью вероятности, путем нелинейного преобразования равномер-
но распределенной случайной величины, описанной в разд. "Пуассоновский
(простейший) поток" главы 2, можно произвести моделирование произволь-
ной системы G/G/w. Приведем здесь пример модели на GPSS для системы
M/U/1 (листинг 3.5).
Листинг 3.5. Пример модели для системы M/U/1
EXPON FUNCTION RN1,C24
0,0/.1,.104/.2,.222/.3,.355/.4,.509/.5,.69/.6,.915/.7,1.2/.75,1.38
.8,1.6/.84,1.83/.88,2.12/.9,2.3/.92,2.52/.94,2.81/.95,2.99/.96,3.2
.97,3.5/. 98,3.9/. 99, 4.6/. 995, 5.3/. 998, 6.2/. 999, 7/.9998, 8
GENERATE 100,FN$EXPON
QUEUE LINE
'SEIZE GP_SERV
DEPART LINE
ADVANCE 50,50
RELEASE GP_SERV
TERMINATE 1
GPSS World позволяет в удобной графической форме отобразить изменение
различных переменных в процессе работы системы. Для отображения изме-
нения среднего времени пребывания транзакции в очереди line используем
системный числовой атрибут qt$line.
Для этого достаточно создать Model Object, написать исполняемую програм-
му, затем выполнить команду Command | Create Simulation. Далее выбрать
команду Window | Simulation Window, указать Plot Window и заполнить
форму для графика, задав имя qt$line в поле Expression.
Теперь в процессе моделирования после выбора команды Command | Start
появится окно, которое в нашем примере покажет, как изменялась длина оче-
реди в процессе работы системы. На рис. 3.6 приведен полученный график.
4 Зак. 3884
98
Гпава 3
Рис. 3.6. Изменение длины очереди в системе в процессе моделирования
Расширение возможностей моделирования на GPSS допустимо также благо-
даря включению в его состав специального процедурного языка PLUS. Он
позволяет встраивать в код программы и даже внутрь блоков GPSS выраже-
ния и функции. Например, для генерирования случайного потока с экспонен-
циальным распределением времени между событиями можно записать
GENERATE(Exponential(1,0,А))
Для того чтобы завершить знакомство с моделированием на GPSS, познако-
мимся с важным практическим примером — исследованием сети Ethernet.
Модель с именем Ethernet, может быть загружена из каталога GPSS World
Student Version\Sample Models. Она предоставляет возможности изучения
влияния многих параметров настройки сети, работающей по протоколу
Ethernet, и открывает пользователю уникальные возможности прогнозирова-
ния влияния загрузки сети на показатели качества.
Внимательно прочитайте комментарии к модели и запустите ее на моделиро-
вание.
Модели систем массового обслуживания 99
Как видите, выходной Report позволяет получить массу полезной информа-
ции о работе сети. Изучив блоки, входящие в модель, и поняв их работу, мо-
жете считать себя специалистом по GPSS. Теперь вы можете смело модерни-
зировать сеть Ethernet (листинг 3.6), внося изменения в модель, и даже напи-
сать модели для сетей других типов.
Листинг 3.6. Модель сети Ethernet
; GPSS World Sample File - ETHERNET.GPS
10 Mbps Ethernet Model
(c) Copyright 1993, Minuteman Software.
All Rights Reserved.
Messages arrive exponentially, as one of two types: short
or long. A Node is selected and held for the duration of
message transmission and any collision backoffs.
Each Node on the Ethernet is busy with a single message
until it is sent, or after some number of collisions (with
transmission attempts from other nodes) a permanent error
is declared and the node is released.
Time is in units of milliseconds. Nodes are presumed
to be 2.5 m. apart. The node ID numbers are used to
determine the separation distance when calculating
the collision window. The propagation delay to an adjacent
node is 0.01 microsecond. Each bit is transmitted in 0.1
microsecond. The interframe gap is modelled by having the
sender hold the Ethernet for an additional delay after it
has sent its message.
Messages are represented by GPSS Transactions. Nodes
and the Ethernet are represented by GPSS Facilities. An
additional Facility is used during jamming to prevent the
startup of any new messages.
A collision results from multiple transmission attempts
at two or more nodes. The signal propagation delay
prevents nodes from having simultaneous knowledge of
100
Глава 3
each other, thereby leading to this possibility. The time
interval until the signal from the other node 'can be
detected is called the node's "Collision Window".
Collisions are represented by removing the transmitting
Transaction from ownership of the Ethernet and sending it
to a backoff routine. The new owner jams the Ethernet
briefly and then goes through the backoff, itself. When a
Transaction's message is being sent, the transaction has
ownership of the Ethernet Facility at priority 0, and can
be PREEMPTed by Transactions which are at priority 1.
When a Transaction is jamming, it has ownership of the
Ethernet Facility at priority 1, and is never itself
PREEMPTed.
Arguments:
1. Node_Count
2. Min_Msg
3. Max_Msg
4. Fraction_Short_Msgs
5. Intermessage_Time
Number of Nodes 2.5 m. apart
Bits
Bits
Parts per thousand
Global Interarrivals
********************************************.* **************************
Node_Count EQU 100 ;Total Ethernet Nodes
Intermessage_Time EQU 1.0 ;Avg. Global Arrival every msec.
Min_Msg EQU 512 ;The Shortest Message in bits
Max_Msg EQU 12144 ;The Longest Message in bits
Fraction_Short_Msgs EQU 600 • ;Short Msgs in parts per thousand
Slot__Time EQU 0.0512 ;512 bit times
Jam_Time EQU 0.0032 ;32 bit times
Backof f_Limi t EQU 10 ;No more than 10 backoffs
Interframe Time EQU 0.0096 ;96 bit times
***********************************************************************
Definitions of GPSS Functions and Variables.
****************** *****************************************************
Backoff_Delay VARIABLE Slot_Time#V$Backrandom;Calc the Backoff Delay
Backrandom VARIABLE 1+(RN4@((2AV$Backmin)-1))
Backmin VARIABLE (10#(10'L'P$Retries))+(P$Retries#(10'GE'P$Retries))
Node_Select VARIABLE 1+(RN3@Node_Count)
Модели систем массового обслуживания
101
Collide VARIABLE ABS((X$Xmit_Node-P$Node_ID)/100000)
'GE'(ACl-X$Xmit_Begin)
Msgtime VARIABLE (0.0001)#V$Msgrand
Msgrand _ VARIABLE Min_Msg+(RN1'G'Fraction_Short_Msgs)#(Max_Msg-Min_Msg)
***********************************************************************
* The Message Delay Histogram
***********************************************************************
Msg_Delays QTABLE Global_Delays,1,1,20
***********************************************************************
* Main Body of Model
***********************************************************************
***********************************************************************
* Message Generation
***********************************************************************
GENERATE (Exponential(1,0,Intermessage_Time))/Single msg
/ generator
ASSIGN Node_ID,V$Node_Select /Acquire a Node ID.
ASSIGN MessageJTime,V$Msgtime /Calc and Save XMIT Time.
ASSIGN Retries,0 /No Collisions at start.
***********************************************************************
* Wait for the Node to finish any previous work.
***********************************************************************
QUEUE Global__Delays /Start timing
SEIZE P$Node_ID /Wait for, occupy, the Node
Try_To_Send PRIORITY 1 /Don't Lose Control
SEIZE Jam /Wait for any
RELEASE Jam /Jam to end.
TEST E F$Ethernet,1,Start _Xmit/If Ethernet Free, jump.
***********************************************************************
* The Ethernet is busy. We check to see if we are in the
* Sender's "Collision Window". If so, this node would
* start transmitting anyway, since the carrier would not
* yet be sensed. In that case, we must initiate a Collision.
* If Prop Delay to Sender is >= Xmit Time up till now,
* collide.
102
Гпава 3
***********************************************************************
TEST Е V$Collide,1,Start_Xmit/No Collision. Go Wait for it.
Collision PREEMPT Ethernet, PR,Backoff,,RE;Remove the old owner.
SEIZE Jam /Jam the Ethernet.
ADVANCE Jam_Time ;Wait the Jam Time.
RELEASE Jam ;End the Jam.
RELEASE Ethernet ;Give up the Ethernet.
PRIORITY 0 ;Back to Normal priority.
Backoff ASSIGN Retries+, 1 /Increment the Backoff Ct.
TEST LE P$Retries ,Backoff_Limit,Xmit_Error;Limit retries
ADVANCE V$Backoff _Delay ;Wait to initiate retry.
TRANSFER,Try_To_Send ;Go try again.
***********************************************************************
* Get the Ethernet, and start sending.
***********************************************************************
Start_Xmit SEIZE Ethernet Xmit__Node, P$Node_ Xmit_Begin,AC1 0 P$Message_Time Interframe_Time Ethernet ;Get Ethernet, wait if nec. ID;Identify the sender. /Mark the start xmit time. /Ensure we can be PREEMPTed /Wait until Msg. is sent. /Hold the Ethernet for gap. /Give up the Ethernet.
SAVEVALUE SAVEVALUE PRIORITY ADVANCE ADVANCE RELEASE
Free_Node RELEASE DEPART TERMINATE P$Node_ID Global_Delays /Give up the node / to the next msg. /Destroy the Message.
********** **********, t****************'* :******************************
Xmit—Error SAVEVALUE Error_Count+,1 /Count the Error.
TRANSFER , Free__Node / and get out of the way.
**********1 t****************^ /*****************************:
Timer Segment
***********************************************************************
GENERATE 1000
TERMINATE 1
;Each Start Unit is 1 Second.
В последнее время опубликовано несколько неплохих книг на русском языке,
которые можно использовать для детального изучения возможностей GPSS
World. Мы приведем здесь ссылки на две из них: [9, 14].
Язык GPSS, несмотря на свою универсальность, для тонкого моделирования
СМО может показаться неудобным для тех, кто не любит скриптовые языки
Модели систем массового обслуживания
103
и предпочитает им графические модели. Одной из таких моделей является
представление СМО сетями Петри.
Контрольные вопросы
1. Опишите базовую модель СМО. Приведите классификацию СМО.
2. Какие основные понятия определяют имитационную модель? Напишите
простейший алгоритм имитационного моделирования системы D/U/1.
3. Опишите основные объекты языка GPSS. Перечислите основные испол-
няемые блоки. Промоделируйте на GPSS систему М/М/2.
ГЛАВА 4
Сети Петри
как эффективная модель СМО
Сети Петри — инструмент для описания
и исследования динамических систем
Для изучения системы массового обслуживания требуется сначала логически
описать ее модель, в которой должны реально воплотиться наиболее инте-
ресные для изучения и исследования свойства системы. При этом для описа-
ния могут быть использованы различные средства. С одной стороны, СМО
можно описать словесно. Это самый простой способ, но и самый неэффек-
тивный, т. к. дает возможность максимум понять, как работает система, но не
позволяет изучить ее свойства и, тем более, проследить какие-либо измене-
ния в ее работе. Можно к словесному описанию добавить еще и схематичное
изображение. Тогда модель СМО будет гораздо более понятной, т. к. ее мож-
но будет наблюдать визуально. Однако, как правило, схематичное представ-
ление несет минимум информации, кроме того, такой моделью нельзя на-
глядно отобразить функционирование системы во времени. Поэтому работать
с подобной моделью можно только на раннем этапе исследования СМО, ис-
пользуя ее как наглядное пособие в изучении статических свойств системы.
С другой стороны, СМО можно описать в виде совокупности математических
соотношений, представив модель реальной СМО с помощью алгебраических,
дифференциальных, интегральных и других уравнений. Такой подход ис-
пользуется для установления зависимостей между входными и выходными
параметрами системы и незаменим для глубокого исследования свойств
СМО. Но и у него есть ряд недостатков. Во-первых, большая сложность раз-
работки такой модели, заключающаяся в отображении реальных свойств сис-
темы абстрактным языком математики. Во-вторых, из-за изобилия математи-
ческих соотношений страдает наглядность создаваемой системы, а это ус-
ложняет восприятие модели как физически реального объекта. Кроме того, во
Сети Петри как эффективная модель СМО
105
многих практических задачах интерес представляет не столько количествен-
ная оценка параметров системы, сколько ее работа в различных ситуациях,
при смене условий и с течением времени, а выполнить это в данном случае
довольно нелегко. Еще одним недостатком моделей в виде систем уравнений
является то, что при добавлении нового компонента в модель или нового па-
раметра, как правило, приходится менять все уравнения, заново выстраивать
цепочку математических соотношений. Особенно сильно проявляются опи-
санные выше недостатки при исследовании сложных, иерархических систем,
к которым и относятся большинство моделей СМО. А можно воспользовать-
ся менее формальным и более наглядным средством описания, которое пре-
доставляет аппарат сетей Петри. Сети Петри разрабатывались специально
для моделирования тех систем, которые содержат взаимодействующие па-
раллельные компоненты. Впервые сети Петри предложил немецкий матема-
тик Карл Адам Петри. В своей докторской диссертации "Kommunikation mit
Automaten" ("Связь автоматов") Петри сформулировал основные понятия
теории связи асинхронных компонентов вычислительной системы. В частно-
сти, он подробно рассмотрел описание причинных связей между событиями.
Его диссертация посвящена главным образом теоретической разработке ос-
новных понятий, с которых начали развитие сети Петри.
Сеть Петри — это инструмент для описания и исследования динамических
систем. Развитие теории сетей Петри проводилось по двум направлениям.
Формальная теория сетей Петри занимается разработкой основных средств,
методов и понятий, необходимых для применения сетей Петри. Прикладная
теория сетей Петри связана главным образом с применением сетей Петри к
моделированию систем и их анализу. В настоящее время она содержит боль-
шое количество моделей, методов и средств анализа, имеющих обширное ко-
личество приложений практически во всех отраслях вычислительной техники
и даже вне ее. В соответствии с требованиями прикладных областей были
разработаны различные расширения сетей Петри, направленные на учет вре-
менных, вероятностных характеристик, использование данных, построение
иерархических моделей и т. д.
Одно из основных достоинств сетей Петри заключается в том, что они могут
быть представлены как в графической форме, что обеспечивает их нагляд-
ность, так и в аналитической.
При графической интерпретации сеть Петри является графом особого вида,
состоящим из вершин двух типов — позиций (position) и переходов (tran-
sition), соединенных ориентированными дугами, причем каждая дуга может
связывать лишь разнотипные вершины (позицию с переходом или переход
с позицией). Вершины-позиции обозначаются кружками, вершины — пере-
ходы — прямоугольниками (или черточками) (см. пример на рис. 4.1).
106
Гпава 4
Рис. 4.1. Простая сеть Петри
В содержательном плане переходы соответствуют событиям, присущим ис-
следуемой системе, а позиции— условиям их возникновения. Переход (со-
бытие) характеризуется определенным числом входных и выходных позиций,
соответствующих предусловию и постусловию данного события. Совокуп-
ность переходов, позиций и дуг позволяет описать статическую систему. Для
описания динамики вводится еще один объект— так называемый маркер
(token), или метка позиции, которая соответствует выполнению того или ино-
го условия (обозначается точкой внутри позиции). Расположение маркеров в
позициях называется разметкой септ. Переход считается активным, если в
каждой его входной позиции есть хотя бы один маркер, что равносильно вы-
полнению всех необходимых условий для наступления события. Наступление
события в терминах сетей Петри представляется срабатыванием перехода
(рис. 4.2), при этом маркеры из входных позиций изымаются и добавляются в
каждую выходную позицию. Текущее состояние исследуемой системы опре-
деляется распределением маркеров по позициям сети, а динамика поведения
системы отображается перемещением маркеров по позициям сети.
Строгое аналитическое определение сетей Петри хорошо представлено в [7]
и [12], поэтому здесь излагаться не будет, ограничимся описанием наиболее
важных расширений сетей Петри. Это приоритетные сети, сети с цветными
маркерами (раскрашенные или цветные) и структурированные сети.
Приоритетные сети—это сети, учитывающие приоритетные соотношения
между переходами. В сетях данного типа при наличии двух и более активных
переходов сработать может лишь переход, имеющий высший приоритет.
Структурированные сети служат для моделирования иерархических систем,
Сети Петри как эффективная модель СМО
107
которые наряду с неделимыми компонентами содержат составные компонен-
ты, сами представляющие собой системы. В раскрашенных сетях каждому
переходу ставится в соответствие функция, определяющая маркирование вы-
ходных позиций в зависимости от цветов входных маркеров. Расширение
простых сетей в цветные заключается в добавлении перечисленной ниже ин-
формации к элементам сети.
□ Маркеры вместо простого обозначения выполнения условия преобразуют-
ся в объект, который может содержать в себе один или более параметров,
каждый из которых способен принимать дискретный набор значений.
В соответствии с этим маркеры различаются по типам параметров (пере-
менных). Чтобы отличать маркеры различных типов, их можно окраши-
вать в различные цвета (поэтому сети называют цветными).
□ К местам добавляется информация о типах маркеров, которые могут нахо-
диться в данном месте.
□ К переходам может быть добавлена информация с предикатом активиза-
ции перехода, в зависимости от переменных, содержащихся в маркерах.
□ К начальной маркировке сети добавляется информация о значениях пере-
менных, содержащихся в маркерах.
Рис. 4.2. Маркированная сеть Петри.
Пример изменения разметки сети при срабатывании переходов
Приведем пример цветной сети Петри, которая моделирует поведение от-
дельного абонента телефонной сети (рис. 4.3).
Позиции сети соответствуют состояниям процесса установления телефонной
связи, а переходы — смене соответствующих состояний. В процессе работы
108
Гпава 4
Рис. 4.3. Сеть Петри, моделирующая поведение телефонного абонента
со стороны пользователя
каждый телефонный аппарат может быть переведен из пассивного состояния
"ожидание" (Р1) в такое, при котором трубка снята и слышен "непрерывный
гудок". Далее во время набора номера "сигнала нет" до тех пор, пока не по-
явятся либо короткие гудки, свидетельствующие о том, что вызываемый або-
Сети Петри как эффективная модель СМО
109
нент (с/,) занят, либо длинные гудки, указывающие, что телефон вызываемого
абонента звонит. В последующем абонент а,- может поднять трубку, и теле-
фонная связь будет установлена до тех пор, пока вызывающий абонент не
вернется в пассивное состояние, отсоединив тем самым абонента а,.
В дополнение к сети, описывающей функционирование отдельных абонен-
тов, на рис. 4.4 представлена сеть Петри, отражающая синхронизацию между
ними. Анализ синхронизирующей сети показывает, что каждый абонент мо-
жет быть свободен или занят. Пара (ср, а^), которой помечена позиция "Вы-
зов ]", показывает, что абонент ср вызван абонентом ср. Когда абонент ср сво-
боден, вызов (<7„ at) может перейти в фазу "Вызов 2" и при снятии трубки
абонентом ср устанавливается соединение.
Работа телефонной сети, таким образом, описывается двумя сетевыми моде-
лями, наложенными друг на друга (т. е. с разных точек зрения моделирую-
щих одни и те же события — переходы, имеющие одинаковые номера). Эти
две сети Петри представляют собой наглядную формальную модель, позво-
ляющую прочувствовать многие слабоуловимые свойства интерпретируемой
телефонной системы. Например, можно проследить, что произойдет, если
абонент вызывает сам себя, или если соединение может быть прервано толь-
ко со стороны вызывающего (а не вызываемого) абонента. При вербальном
(не формальном) описании такие подробности можно легко забыть или ис-
толковать неоднозначно.
В дополнение к описанным выше существуют расширения сетей Петри, с
помощью которых некоторые количественные характеристики исследуемых
систем можно определить аналитически. Это временные и стохастические
сети. Именно стохастические сети Петри наиболее полно позволяют описать
элементы СМО. Стохастические сети — это сети Петри, в которые вводятся
некоторые вероятностные атрибуты, например вероятности или плотности
вероятностей срабатывания активных переходов.
Еще один пример сети Петри приведен на рис. 4.5.
Эта сеть Петри схематично описывает простейшую СМО, состоящую из ис-
точника заявок, сервера и очереди. Маркер в позиции PI соответствует го-
товности источника заявок к выдаче очередной заявки. Обратная связь пере-
хода Т1 с позицией Р1 необходима для генерации последующих заявок
в каждую единицу времени, таким образом формируется входной поток зая-
вок. Позиция Р2 моделирует очередь, которая в данном случае может быть
бесконечна (т. к. на нее не наложены никакие ограничения), но может быть и
всегда пустой (если сервер обладает бесконечной производительностью).
Маркер в позиции Р4 моделирует свободное состояние сервера (т. к. переход
Т2 может сработать и забрать очередную заявку из очереди только при нали-
чии этого маркера). Соответственно отсутствие маркера в позиции Р4 гово-
рит о том, что в данный момент сервер занят.
110
Гпава 4
Свободен
Рис. 4.4. Сеть Петри, моделирующая поведение телефонного абонента со стороны АТС
Сети Петри как эффективная модель СМО
111
Рис. 4.5. Модель простейшей СМО
Однако данная модель не представляет практической ценности, т. к. состоит
из бесконечного источника заявок, который способен генерировать одну за-
явку каждую единицу времени, очереди неограниченного размера и сервера,
обладающего бесконечно большой производительностью, который, забирая
по одной заявке из очереди, мгновенно их обслуживает. В приведенной мо-
дели не хватает информации о параметрах СМО. Таким образом, необходимо
данную сеть Петри преобразовать в стохастическую. Во-первых, добавим
информацию о характере входного трафика. Для этого в переходе Т1 следует
записать математическую модель генерируемого потока заявок (будет ли это
равномерный, пуассоновский или любой другой). Во-вторых, нужна инфор-
мация о времени обслуживания сервера— она заносится в переход ТЗ.
А к позиции Р2 можно добавить ограничение на длину очереди или на время
пребывания в ней заявок.
В результате получаем модель, в которой переход Т1 по заданному закону
генерирует заявки, далее заявки поступают в очередь Р2, и если сервер сво-
боден, то обслуживаются и попадают в обслуженные заявки.
Средства программной реализации
сетей Петри
В настоящее время известно достаточно много пакетов программ, ориентиро-
ванных на анализ моделей, описанных с помощью сетей Петри (табл. 4.1).
Большинство из них являются исключительно коммерческими продуктами, а
те, что предлагаются для свободного использования, конечно, не обладают
всеми возможностями современных систем имитационного моделирования
(СИМ). Очевидно, что длительность и успех исследования моделей СМО за-
висят не только от знаний и навыков исследователя, но и от того, какие инет-
112
Гпава 4
рументы он использует в своей работе. При этом модель, как и любая про-
грамма, может быть разработана на любом универсальном языке программи-
рования, однако тогда на пути исследователя возникает проблема: от него
требуется знание не только той предметной области, к которой относится ис-
следуемая система, но и языка программирования, причем на достаточно вы-
соком уровне. Современные СИМ позволяют решить эти проблемы путем
предоставления графических интерфейсов и минимизации программирования
при построении моделей. Одним из таких средств является система Artifex
компании Rsoft, которая приобрела разработавшую эту систему компанию
Artis Software (www.artis-software.com). Это коммерческая система. Другой
системой, которую можно порекомендовать, является система Visual Petri.
Она бесплатна и доступна на сайте http://caree.narotl.ru/itni_vp.htnil и на
нашем сайте (см. Предисловие).
Таблица 4.1. Пакеты программ, ориентированных на анализ моделей,
описанных с помощью сетей Петри
Название программы Категория Основные характеристики
ALPHA/Sim Коммерческая Высокоуровневые сети Петри; временные сети Петри. Состав и возможности: графический редактор; аними- рованное перемещение маркеров, быстрое моделиро- вание, основной функциональный анализ. Операцион- ные системы: SunOS, Solaris, MS Windows NT
ARP Бесплатная Низкоуровневые сети Петри, временные сети Петри. Возможности: быстрое моделирование, пространство состояний, структурный анализ, основной функцио- нальный анализ. Операционная система— MS-DOS
Artifex Коммерческая Объектно-ориентированные, высокоуровневые, вре- менные сети Петри. Состав и возможности: графиче- ский редактор; анимированное перемещение маркеров, быстрое моделирование, структурный анализ, расши- ренный функциональный анализ. Операционные сис- темы: Sun, SunOS; HP, HP-UX; Silicon Graphics, IRIX; Linux; MS Windows NT/2000/XP
CoopnTooIs Бесплатная Высокоуровневые сети Петри. Состав и возможности: графический редактор; быстрое моделирование, струк- турный анализ, поддержка Java
CPN-AMI Бесплатная Высокоуровневые сети Петри. Состав и возможности: графический редактор; быстрое моделирование, про- странство состояний, структурный анализ, возмож- ность модульного моделирования. Операционные сис- темы: Sun; Linux; MacOS
Сети Петри как эффективная модель СМО
113
Таблица 4.1 (окончание)
Название программы Категория Основные характеристики
Visual Petri Бесплатная Отечественная разработка института теоретической механики РАИН
CPN Tools Бесплатная . Высокоуровневые временные сети Петрн. Состав и возможности: графический редактор; анимированное перемещение маркеров, быстрое моделирование, им- порт/экспорт данных. Операционная система— MS Win- dows
Система моделирования Artifex
Система имитационного моделирования (СИМ) Artifex компании Artis
Software предоставляет наиболее полную и современную версию среды мо-
делирования с удобным графическим интерфейсом, которая предназначена
для проектирования, исследования и анализа дискретных систем с помощью
высокоуровневых цветных сетей Петри [1]. Примерами дискретных систем
могут служить электронно-вычислительные машины (ЭВМ), их элементы и
устройства, протоколы, программы и операционные системы, системы сбора
и обработки информации, системы управления процессами и объектами, сети
связи, коммутационное оборудование и т. п.
Главной особенностью данной СИМ является применение объектно-ориен-
тированного подхода к моделированию, который позволяет свести к мини-
муму ручное программирование, повысить скорость создания систем и легко
модифицировать их в дальнейшем.
СИМ Artifex работает па обширном семействе компьютеров с процессорами
Intel, которые соответствуют следующим минимальным требованиям к аппа-
ратному и программному обеспечению:
□ процессор Pentium;
□ 32 Мбайт ОЗУ (минимум);
□ ОС Windows семейства NT (Windows NT 4.0 и Выше, Windows 2000);
□ X Server;
□ 60 Мбайт дискового пространства (еще около 60 Мбайт потребуется для
установки X Server);
□ рекомендуется файловая система NTFS;
□ ну и, конечно, привод CD-ROM, клавиатура, мышь и цветной монитор
с разрешением не менее 800x600 точек.
114
Гпава 4
Кроме того, Artifex работает и под управлением UNIX-систем, но в данной
книге это описано не будет, и всю интересующую информацию можно найти
в справочной системе Artifex. СИМ Artifex состоит из графического редакто-
ра, с помощью которого строится модель исследуемой системы и задаются ее
основные параметры, текстового редактора для написания управляющих
функций, непосредственно среды моделирования и средств сбора и анализа
статистики. Построенные с помощью графического редактора модели, а так-
же созданные с помощью текстового редактора управляющие функции сред-
ствами автоматической кодогенерации системы преобразуются в файлы с
кодом на языке С (или C++) с контролем синтаксических и логических пра-
вил, а затем автоматически преобразуют модель объекта в исполняемый код,
понятный для среды моделирования Artifex. Весь процесс моделирования,
начиная от построения модели и заканчивая обработкой результатов, обслу-
живается менеджером моделей (Artifex.Model Manager), внешний вид которо-
го представлен на рис. 4.6.
N Artifex*Model Manager
File View Medel y.3teiate: Treplov
Insert title
- rootDir. CAArtife^Projects
objDir: obj_bach
-JgexsDir: exe_bach
4j5]toplevel: BACH
E}—^Artifex.Model units
4—|^ЁЕИЯ
S—(giArUfex.Validate units
—^JArtifex.Data units
—[«jArtjfex.GUI units
—JjjArUfex.OLE units
—^Artifex.Deploy units
— Q Sources units
— Q Include units
— 3System Include units
— Q Other units
Рис. 4.6. Менеджер моделей
Для создания модели определяется некоторое рабочее пространство — про-
ект, который состоит из набора нескольких файлов и конфигураций. Это де-
лает менеджер моделей для каждой новой исследуемой системы. При созда-
нии нового проекта в менеджере моделей необходимо указать каталоги, где
будут храниться все файлы проекта. Каждая такая конфигурация с набором
файлов однозначно определяет исполняемый файл модели, который в резуль-
Сети Петри как эффективная модель СМО
115
тате будет генерироваться. На рис. 4.6 показан только что созданный пустой
проект, о чем свидетельствуют знаки вопроса на значке модели и перечерк-
нутые значки папок, означающие незаданные каталоги для проекта:
□ rootDir— это основной каталог созданного проекта, где будут формиро-
ваться все Artifex-модули;
□ objDir — это каталог для хранения промежуточных временных файлов;
□ exeDir— это каталог для хранения конечных исполняемых файлов для
среды моделирования.
Создать или изменить перечисленные каталоги можно, воспользовавшись
контекстным меню, вызываемым щелчком правой кнопкой мыши— коман-
ды Create и Change, соответственно.
СИМ Artifex представляет собой интегрированные в единую оболочку сред-
ства, позволяющие легко создавать, моделировать и анализировать любые
системы. Данные средства вызываются с помощью менеджера моделей. Пре-
жде всего, это графический редактор моделей. Для его запуска необходимо
воспользоваться меню, появляющимся при щелчке правой кнопки мыши на
блоке со знаком вопроса. Команда Create Model вызывает запуск редактора.
Блок со знаком вопроса является первым модулем модели и автоматически
генерируется менеджером моделей при создании каждого нового проекта.
Знак вопроса на нем говорит о том, что он абсолютно пустой, как бы пригла-
шая начать его заполнение. Имя блока (в данном случае ВАСИ) автоматиче-
ски задается по имени всего проекта и может быть изменено в процессе соз-
дания модели.
Следующее средство, интегрированное в СИМ Artifex, — компилятор C/C++.
Вызывается он также из менеджера моделей нажатием соответствующей
кнопки S или через меню: Validate | Build. Так как Artifex-проект состоит
из нескольких файлов, причем не все они имеют формат программ на C/C++,
процесс компиляции был бы довольно трудоемок и занимал бы много време-
ни, поэтому для удобства и упрощения моделирования используется именно
команда Build, осуществляющая сборку. В процессе сборки автоматически
анализируются все файлы проекта, а конечным результатом этой операции
является исполняемый файл модели. Если при сборке обнаружатся ошибки,
сообщения о них будут помещены в специальное окно выходных данных.
Полученный после выполнения команды Build файл модели предназначен
для среды моделирования Artifex (Artifex.Validate), которая вызывается с по-
мощью кнопки 33: в менеджере моделей. В ней, запустив на исполнение
свою модель, можно изучить все те свойства исследуемой системы, которые
были заложены в процессе создания модели. Здесь же собирается статистика
эксперимента.
116
Глава 4
В процессе моделирования СИМ Artifex собирает статистику по некоторым ]
стандартно определенным критериям (критерии также можно определять и •
самим пользователям), а затем предоставляет графическую интерпретацию <
проведенного эксперимента. Это делается с помощью встроенного графине- ;
ского средства Artifex.Measure — кнопка н в менеджере моделей. j
Для наглядности рассмотрим моделирование в Artifex на примере. На рис. 4.5 (
была показана структурная схема простейшей СМО на языке сетей Петри.
Именно ее и возьмем в качестве иллюстрации моделирования в системе ?
Artifex.
Сначала модель необходимо представить в виде графических примитивов. '
Для этого вызывается графический редактор. Главное окно графического ре-
дактора моделей состоит из двух областей (рис. 4.7): области для создания
структуры класса модели (class-browser area) и области для графического
создания модели (drawing area).
File . Edit View : Draw Tools .Help. . ,
-_aj ф|ж|
[g BAQH (O+) -J
ф-О Interface
—Q Input
—Q Output
— Q. Portsets
-gjCMN Units
— 2^ Paranteters
I—g| Description
Q-[0] Body
— TR Include
— Q Used Units
E 3-^ Local Variables
E HQ Code Sections
ЕЪ® Token Types
— g Description
-QiMAIN^SUBNET
Ell
В
Q
<>
©
©
О
Subnet: MAIN-SUBNET Priority: 0 Page: MAIN_PAGE
Рис. 4.7. Графический редактор моделей
Графический редактор также имеет две панели инструментов. Одна— гори-
зонтальная — находится под главным меню и представляет собой набор наи-
более часто используемых команд, таких как Open, Save, Zoom, Paste и не-
которые другие. Вторая — между областью дерева класса и областью форми-
Сети Петри как эффективная модель СМО
117
рования модели — панель графических примитивов, которые служат для по-
строения модели. Ниже перечислены наиболее часто применяемые элементы,
описание остальных элементов приведены в руководстве к СИМ Artifex.
□ [[В}| (объект (object)) — это экземпляр класса. Каждый "объект" может со-
стоять из подобъектов, которые в свою очередь могут являться экземпля-
рами других классов. Простая сеть Петри может не содержать ни одного
"объекта", а структурированная сеть Петри строится как раз с помощью
этих элементов. Любой объект модели существует независимо от других
"объектов" и создает свои копии параметров и локальных переменных
(Д Parameters и Д Local Variables).
□ сз — реализация элемента сети Петри "переход" (transition). Каждый "пе-
реход" обязательно имеет:
• имя, с помощью которого и различается среди других "переходов" дан-
ного класса;
• идентификатор (XT_NAME), генерируемый автоматически графиче-
ским редактором для последующего обращения к "переходу";
□
• приоритет, который по умолчанию задается нулевым.
Элемент сети Петри "позиция" реализуется несколькими вариантами:
• Q (place)—это внутренняя или обычная позиция; используется как
базовый элемент; .
• (§> (input place) — входная позиция; применяется в структурированных
моделях сетей Петри; с ее помощью "объект" получает маркеры от дру-
гих "объектов" модели;
• @ (output place) — выходная позиция; с ее помощью "объект" посыла-
ет маркеры другим "объектам" модели.
Каждая "позиция" так же, как и переход, обязательно имеет имя и иденти-
фикатор (ХР _NAME).
Используя эти примитивы, в графической области редактора создадим иско-
мую модель. На рис. 4.8 показан один из возможных вариантов построения
СМО — источник заявок, сервер и несколько вспомогательных элементов.
Как упоминалось выше, в СИМ Artifex применяется объектно-ориенти-
рованный подход к созданию моделей. Этот подход позволяет рассматривать
исходную модель как набор объектов, каждый из которых представлен соб-
ственным классом. Информация о классах и объектах показана в области для
создания структуры класса модели.
Базовый класс всей модели представлен значком Д|. Он генерируется авто-
матически при создании нового проекта и по умолчанию имеет его имя. Каж-
118
Гпава 4
дый класс в Artifex создается с помощью языков программирования С или
C++, о чем свидетельствует надпись на значке класса— [jgi] или |^|. Дерево
класса (рис. 4.9) состоит из двух частей — Interface и Body. Interface отра-
жает графическую часть модели — количество и виды используемых прими-
тивов, их свойства и т. д. Эта часть дерева очень полезна при моделировании
Рис. 4.8. Графическая модель простейшей СМО в Artifex
[gj BACH (C++)
Ф-Д Interface
—Q Input
—Q Output
—E Description
ЕЭ-g] Body
—Q Used Units
i+H^ Local Variables
l+l-IFIl Code Sections
£ Token Types
—ЦЯ Description
-Q]MAIN_SUBNET
' Ниям
Рис. 4.9. Область для создания структуры класса модели
Сети Петри как эффективная модель СМО
119
больших структурированных сетей Петри. Body отражает программируемую
часть модели, где задаются переменные, создаются свои функции и т. д.
Здесь же создаются разные типы маркеров (Token Types) для реализации
цветных сетей Петри (тип nul присваивается автоматически маркерам неок-
рашенных сетей). При заполнении данной секции используется синтаксис
языка C++ (или С в зависимости от того, какой язык выбран для всего
класса). Однако помимо стандартных функций этих языков в СИМ Artifex
есть свой набор функций, которые обеспечивают более доступное представ-
ление свойств сетей Петри. Их описание можно найти в руководстве к СИМ
Artifex. Наиболее полезные и применяемые при моделировании СМО, пере-
числены ниже.
□ int xx_fetchtoken(int place, void *tok_db)
Изымает маркер из определенной позиции.
Аргументы:
• place (xp_placename) — имя позиции, из которой необходимо изъять
маркер;
• tok_db — указатель на массив, в котором будет храниться изъятый мар-
кер вместе с содержащимися в нем данными. Если маркер имеет тип
nul (т. е. не несет в себе никакой информации), то этот аргумент игно-
рируется. Если информация в маркерах есть, а аргумент опущен, то
маркер и его данные уничтожаются безвозвратно.
Для того чтобы отследить выполнение вызванной функции, можно по-
смотреть значения, которые она возвращает:
• 0 — выполнение прошло без ошибок;
• -1 — имя места было задано некорректно;
• ~2 — в момент выполнения функции в названном месте не оказалось
маркера. Массив при этом не меняется.
□ int xx_inserttoken(int place, void *tok_db,
xx_address *dest_address)
Добавляет маркер в определенную позицию.
Аргументы:
• place — имя позиции, в которую будет установлен маркер
(xp_placename);
• tok_db— указатель на массив, содержащий данные для маркера (опус-
кается, если тип маркера nul);
• dest_address — используется для указания специального адреса объек-
та, в случае когда маркер выпускается в выходную позицию, которая
120 Глава 4 ?
имеет несколько выходных линий к разным объектам. Если этот аргу- 1
мент равен nul, то маркер адресуется всем связанным с местом объ- i
ектам. <
Возвращает значения: i
• 0 — выполнение прошло без ошибок;
• -1 — имя места было задано некорректно.
□ int xx_tokennumber(int place) >
Возвращает число маркеров, находящихся в очереди в определенной по- ?
зиции (текущую длину очереди). ,
Аргумент: ’
• place — имя позиции, очередь в которой надо узнать (xp_placename). ?
П int xx_firenumber(int transition)
Возвращает текущее число срабатываний определенного перехода.
Аргумент:
• transition— имя перехода, для которого выполняется функция
(XTJTRANSITIONNAME). ’
О int xx_initmeasure(char *name) )
Создает новый пользовательский параметр измерения.
Аргумент:
• name — имя параметра (до 80 символов, чувствительно к регистру).
Возвращает:
• новый уникальный идентификатор, который используется в функции i
xx_writesample;
• -1 — аргумент name не задан или задан не верно;
• -2 — параметр с таким именем уже существует.
□ int xx_writesample(int id, double value)
Добавляет новую выборку параметра измерения, заданного с помощью
хх initmeasure.
Аргументы:
• id— определенный пользователем идентификатор (полученный с по-
мощью функции xx_initmeasure);
• value — имя переменной, значения которой в процессе моделирования
являются выборками параметра моделирования.
Сети Петри как эффективная модель СМО
121
Возвращает:
• 0 — выборка взята удачно;
• -4 — идентификатор id неверно задан.
П void xx_copytoken(void destination, void ‘source)
Копирует данные, содержащиеся в маркере, в маркеры того же типа. Ис-
пользуется для перемещения информации из входного маркера в выход-
ной маркер (иначе при срабатывании перехода информация теряется).
Аргументы:
• destination — имя позиции-получателя маркера;
• source — имя позиции-источника маркера.
□ int xx_fdelay (int transition__code, double delay)
int xx_rdelay(int transition_code, double delay)
Устанавливают задержку на срабатывание определенного перехода.
Обе функции вносят задержку в переход. Причем если задержка установ-
лена функцией xx_fdeiay, то переход при появлении в его входных пози-
циях маркера не срабатывает и не забирает из них маркеры, а выжидает
определенное функцией xx_fdeiay время и лишь потом срабатывает. А ес-
ли задержка определена с помощью функции xx_rdeiay, то переход сраба-
тывает, вынимая маркер из входных позиций, но в выходные позиции его
помещает только после окончания задержки.
Аргументы:
• transition_code — имя перехода (xt^transitionname)-,
• delay — значение задержки.
Возвращает:
• -I—в случае ошибки;
• 0 — при правильном выполнении.
Функции xx_fdeiay и xx_rdeiay устанавливают задержку только для пере-
хода, в котором вызываются, и только для следующего срабатывания пе-
рехода. Все ошибки, возникающие при выполнении этих функций в про-
цессе моделирования (например отрицательное значение задержки), выво-
дятся в стандартное окно ввода/вывода, сопровождающее моделирование.
□ double xx_gettime()
Возвращает текущее время моделирования.
□ int xx_readparameters(char *filename)
Читает значения параметров из файла. Сами параметры (их имена) долж-
ны быть заданы в секции Body. Файл должен быть сохранен в каталоге
122-
Гпава 4
проекта до начала компиляции и состоять из строк вида имя_объекта:
имя_парсшетра=значеиие_параметра.
Возвращает:
• -1—выполнение завершилось ошибкой;
• 0 — выполнение прошло удачно.
□ void xx_setparameter(char *object_name, char *par_name,
char *par_value)
Еще один способ установить значения параметров в объекте (чаще ис-
пользуется в секции Initial Action).
Аргументы:
• object_name — имя объекта;
• par_name — имя параметра;
• par_value — значение параметра.
а xu_Rnd!nt(void)
Вызывает генератор значений случайных чисел, равномерно распреде-
ленных на интервале от 0 до значения параметра xu_rnd_rand_max (по
умолчанию xu_rnd_rand_max = 231 - 1, т. е. 2 147 483 647). Начальное зна-
чение также может быть отличным от 0 (по умолчанию), для этого нужно
использовать функцию xu_RndSetseed(seed). Все другие генераторы
случайных чисел используют эту функцию для получения других
законов распределения. Кроме этого, можно самостоятельно опре-
делить генератор случайных чисел с помощью функции
xu_RndSetRndintFunction(xu _lNT(*Rndlnt) (void)) (ее описание приводит-
ся в руководстве по Artifex).
а xu_RndNExp(XU_D0U3LE mean)
Возвращает значение случайной величины, распределенной по экспонен-
циальному закону со средним mean .
В СИМ Artifex представлены еще несколько функций для задания законов
распределения:
О xu_RndClippedGauss()
□ xu_RndDouble()
а xu_RndErlang()
tJ xu_RndGauss()
□ xu_RndGeom()
□ xu_RndPoisson()
Их описания можно найти в руководстве к Artifex.
Сети Петри как эффективная модель СМО
123
Итак, на рис. 4.8 представлена графическая модель простейшей СМО, со-
стоящей из источника заявок, очереди и сервера. Теперь, используя описан-
ные выше функции Artifex, добавим к модели несколько количественных ха-
рактеристик и получим раскрашенную сеть Петри, моделирующую СМО ти-
па М/М/1.
Так как по умолчанию маркер в Artifex имеет тип null и не несет никакой
информации, то необходимо создать новый тип маркера. Для этого в дереве
класса ВАСН находим секцию Token Types, по щелчку правой кнопки мыши
появляется контекстное меню, в котором находится команда Create new type.
На рис. 4.10 показано окно, в котором создается новый тип маркера TOKEN и
описываются параметры, присущие данному типу.
Рис. 4.10. Свойства маркера TOKEN
Получившийся маркер может нести в себе информацию в переменной timel
(созданной для записи времени поступления на сервер), time2 (время выхода
из сервера) и time (для хранения разницы двух предыдущих значений, т. е.
времени обслуживания). Таким образом, наблюдая за значениями перемен-
ной time в каждом маркере, можно собрать статистику по времени обслужи-
вания заявки на сервере. Если же требуется статистику отобразить графиче-
ски, то для этого необходимо создать новый пользовательский параметр из-
мерения: в секции Local Variables создаем переменную типа int с именем
msl_id (это будет идентификатор параметра); в секции Initial Actions создаем
строку:
XX->msl_id = xx_initmeasure("Service time for Server")
где time— имя параметра (рис. 4.11). Теперь остается запомнить значения
переменной time в созданном параметре измерения (как это делается, будет
показано ниже).
124
Гпава 4
File Edit View Draw Tools Help
BACH (C++)
Q
A
0
-Q input
—Output
—Q Portsets
—F?|| CMN Units
-IFI Description
S Include
Used Units
Local Variables
Code Sections
—ПД Define
—j^jTypcdef
—Functions
—ГП Initial actions
I—fT] F]naj actions
[ Token types
—£T] Description
©
0
A
:r.H /ИдкФН
Subnet: MAIN-SUBNET Priority. 0 Page: MAIN J=AGE
Рис. 4Л1. Добавление пользовательского параметра измерения
Теперь построим пуассоновский источник заявок. В модели на рис. 4.8 ис-
точник заявок состоит из позиции start и перехода generate, который при
срабатывании забирает маркер из позиции start и помещает его в позицию
next и таким образом генерирует заявку. Очевидно, что для генерации сле-
дующей заявки необходимо сначала вернуть маркер в позицию start. Так
работает простой генератор заявок, но для того чтобы источник вырабатывал
не сплошной поток заявок, а именно пуассоновский, необходимо подчинить
время между генерацией двух соседних заявок экспоненциальному закону.
Для этого в модель вносится задержка на срабатывание, т. е. переход generate
забирает маркер из предыдущей позиции, задерживает на определенное вре-
мя, а лишь затем помещает его в следующую позицию. Описанные действия
задаются в свойствах перехода generate на вкладке Action (т. е. действия, ко-
торые необходимо выполнить в момент срабатывания перехода) — рис. 4.12.
Как видно из рисунка, в момент срабатывания перехода generate создаются
переменные Value и lambda. На следующем этапе переменной value присваи-
вается случайная величина, распределенная по экспоненциальному закону
С параметром lambda (value=xu_RndNExp(lambda)), и вносится задержка, равная
значению этой случайной величины (xx_fdelay(xt_generate,value)). Теперь
полученный источник будет генерировать пуассоновский поток заявок.
Сети Петри как эффективная модель СМО
125
В действиях перехода на рис. 4.12 присутствует еще одна функция Artifex —
xx_copytoken(next,start).. Она производит копирование информации из мар-
кера, вынутого из предыдущей позиции (start), в маркер, помещенный в сле-
дующую позицию (next).
Transition GENERATE 1д B»qV„
asic Attribute] Piec0cate | jActlohj Description
Basic Attributes] -Predicate.
.double value;
double lambda=10;
value = xu_RndNExp(lambda);
xx_fdelay(XT_GENERATE,value);
xx_copytoken(NEXT,START);
Line: 1
Column: 1
Д'
double value;
double tintel;
double lambda=12.5;
value = xu_RndHExp(lambda);
x x_rd e1ay(X T_s ER V ER, v a 1 u e);
xx_copytoken(IDLErNEXT);
NEXT~>t intel »xx_gett ime();
J
Line; 1 Column: 1
Ok | Print - |' Cancel |
Ok | Print... |
Cancel | Help |
Рис. 4.12. Свойства перехода GENERATE
Рис. 4.13. Свойства перехода SERVER
Позиция next в данной модели интерпретируется как очередь, в которую по-
падает заявка после генерации, и если в этой позиции не поставить никаких
условий на количество маркеров или на их время пребывания, то получится
бесконечная очередь, из которой заявки могут попасть только на обслужива-
ние в сервер.
Сервер, обслуживающий заявки по экспоненциальному закону, можно по-
строить с помощью одного-единственного перехода (server), задав в его
свойствах параметры, аналогичные переходу generate (рис. 4.13). Однако в
данном случае сервер будет забирать маркер из позиции next, как только он
туда поступил, независимо оттого, закончена или нет обработка предыдущей
заявки. Таким образом, получится, что сервер может обслуживать несколько
заявок одновременно. Чтобы этого не допустить, добавлена позиция busy,
присутствие в ней маркера свидетельствует о том, что сервер свободен. Как
только заявка поступает на обслуживание, маркер из позиции busy изымается
и возвращается туда только после окончания обслуживания, что будет озна-
чать, что сервер свободен и готов обслуживать следующую заявку.
Из рис. 4.13 можно заметить, что, в отличие от перехода generate, в сервере
используется для задержки функция xx_rdelay вместо xx_fdelay. Кроме того,
в позиции server присутствует еще одна строка:
NEXT->timel=xx_gettime();
Дословно она означает: в маркере, взятом из позиции next, найти параметр
timel и присвоить ему значение, возвращаемое функцией xx_gettime().
126
Гпава 4
А возвращает эта функция текущее время моделирования. Таким образом,
производится запись времени поступления на сервер.
После обслуживания сервером заявки уже без задержек поступают через
промежуточные вспомогательные блоки в конечную позицию end, где и ска-
пливаются. Переход from_server в данной модели введен для определения
времени окончания обслуживания, т. к. действия перехода server выполня-
ются только в момент его срабатывания (т. е. когда он изымает маркер из
входной позиции), и поэтому в момент выхода маркера из перехода записать
время уже нельзя. А поскольку между этими двумя переходами не вносится
задержки, то время выхода из одного является временем входа в другой. По-
этому в свойствах перехода from_server указываются действия по записи
времени окончания обслуживания в переменную time2. Кроме того, ищется
время обслуживания (как разница между time2 и timel) и запоминается в по-
следнем параметре маркера token— переменной time. Для сбора значений
времени обслуживания используется функция xx_writesample (рис. 4.14)
с параметрами xx->msl_id (созданный ранее идентификатор) и time (значения
этой переменной собираются).
юр I ROM SHjVER.inBACri;-,^ J
Basic Attributes | Predicate J Actionf Description'
double time;
IDLE->time2=xx_gettime();
t ime=IDLE->t inie2-IDLE->t imel;
IDLE->time^time;
xx_writesample(XX->msl_id,time);
Ok | .Print... [ cancel [ Help [
Рис. 4.14. Свойства перехода FROM_SERVER
На этом создание Петри — модели СМО М/М/1 для Artifex заканчивается.
Задачу по созданию исполняемой модели берет на себя Artifex.Model
Manager. На рис. 4.15 показана последовательность действий, необходимых
пользователю для того, чтобы получить исполняемую модель. Естественно,
сначала нужно сохранить модель в графическом редакторе и перейти к ме-
неджеру моделей, где сначала обновляем информацию о модели, а затем
командой Validate | Build (рис. 4.15) передаем менеджеру моделей работу по ~
созданию исполняемой модели.
Как уже указывалось выше, преимуществом СИМ Artifex является полная
автоматизация создания исполняемых моделей. После выполнения команды
Сети Петри как эффективная модель СМО
127
Validate | Build появляется окно с сообщениями о произведенных действиях
и обнаруженных ошибках.
— Компиляция
модели
Запуск
модели
Обновление
модели —
Рис. 4.15. Менеджер моделей
На рис. 4.16 проиллюстрирован процесс компиляции модели ВАСН, который
завершился без ошибок. Перейдем к менеджеру моделей и запустим на ис-
полнение (см. рис. 4.15) модель ВАСН. Появится окно среды моделирования
(рис. 4.17).
Для запуска моделирования следует нажать кнопку Run на верхней панели
инструментов среды. При этом появится еще одно окно — окно вво-
да/вывода — такое же, как при компиляции модели. В этом окне отражается
ход моделирования (для этого нужно активировать трассировку— кнопка
trace). Сюда же выводится информация с помощью средств языков програм-
мирования (например, функцией printfO). Эксперимент можно проводить
в двух режимах: пошаговом (выпадающие кнопки Step Fine и Step Coarse) и
до заданного времени (выпадающая кнопка On End).
Кнопка Step Fine позволяет отслеживать все действия, происходящие в моде-
ли: появление маркера, активизацию перехода, срабатывание перехода и др.
128
Глава 4
—>
Build "bdrh" (tide hj. command к
Artifex-Ualidate Version 4.2-2 Vi
Copyright <c> 1989-1999 ARTIS S.r.l.
I - Vriting file C:\Artifcx\ProjcctsSobj_bach\xv_bach\nakef ile. ,
- ’ 4\j- J -
Translating ПХС unit BACH to HA” ;* .. , ..
Translating AXC unit BACH to С" ’.'-г , = ’ '-’У
Generating Model's top-level nodule BACH" -
All sources for Validate have been produced." '•
All files for Validate have been updated." _ ’
Compiling Artifex class BACH" - •
class BACH: xxJBACH_topography:l: warning: "xx_BACH_topography’initialiscdand
declared "extern* , r t. -,.,t
”------> Compiling model's top-level <BACH>" ' ".
"-------—> Linking executable C:\Artifex\Projects\exo_bachSxO_bach" ; . <«
C:\ArtifexSProjects\exc_bachXx0_bach.exe
"---:—> Simulator of model BACH has been updated.”
3
'ress anti key to continue .
Рис. 4.16. Окно вывода информации о компиляции модели
Шаг моделирования при нажатии кнопки Step Coarse равен срабатыванию
перехода.
Моделирование также можно завершить при наступлении какого-либо усло-
вия. Для этого необходимо при создании модели использовать специальные
функции Artifex (например, xx_halt ()).
Сеги Петри как эффективная модель СМО
129
Проведение эксперимента при необходимости может включать многократ-
ный прогон модели с целью получения нужной выборки для определения
оценок характеристик системы. Количество прогонов модели в зависимости
от условий задачи может быть задано при подготовке модели либо опреде-
ляться в процессе эксперимента с помощью процедуры автоматической оста-
новки.
В процессе пошагового моделирования предоставляется возможность наблю-
дения не только за динамикой поведения модели, но и за изменением ее
количественных параметров. Доступно это через контекстное меню, вызы-
ваемое щелчком правой кнопки мыши. Так, если щелкать по определенной
позиции (например, позиции END— рис. 4.18), то появится меню, с по-
мощью которого можно посмотреть содержание очереди в данной позиции
(рис. 4.19).
File View Simulation Sample Tools Help
H | a | !4| %| 'S | С"Э | | | End | trace ] И | >| | H | ► | d Coarse Ц
Session; sessionl Current State: ACTIVE trace off Current Time; VT s 599.289705107* ;
SERVER IDLE.TOKEN FROht_5ERUER
BUSV:fOKEN(1)
END TOKEN
Examine Queue
Info...
Connected Transitions...
it' ' . Г? .
.Put Token - :
•Break On Event .
Set Breakpoint...
Рис. 4.18. Меню для просмотра параметров позиции
В данном случае в позиции находилось 5 маркеров (обслуженных заявок), их
параметры соответствуют определенным выше значениям времени.
Возможно также пошаговое выполнение моделирования и остановка по неко-
торому условию. Результаты моделирования могут быть представлены в виде
5 Зак. 3884
130
Гпава 4
таблиц и графиков. При этом существует как стандартный сбор статистики,
так и возможность задать пользовательские параметры и отслеживать их из-
менение с помощью графиков и гистограмм. Для запуска сбора статистики
необходимо, во-первых, отразить это в параметрах запуска (стандартно для
списка Sample установить значение on, т. к. по умолчанию установлено
off— рис. 4.20), а во-вторых, в меню среды моделирования Sample указать,
для каких элементов необходимо собирать статистику (в данном случае это
переходы generate, server и from_server — рис. 4.21).
Run: bach (bach) Simulator Inpul/Outpul
8ИИЯИМ
place END in \
1:
5:
(double)
(double)
(double)
(double)
(double)
(double) .,
’double) ’
^double) '•
.double) .*
(double)
(double}
(double)
(double)
(double)
(double)
axj.000
>ach
bachelor
GG1
timel
times
time •
timel
times
time
timel
time?
time
timel
time?
time
timel
times
time
0.000000
7.944548
7.944548
1.339210
9.878887
8.S39677
6.689473
42.031062
36.141589 .
= 15.459541
= 55.506600
« 40.047059
* 27.175551
« 74.133557
= 46.958006
Рис. 4.19. Очередь в позиции END
Context Files
Tine Unit.
output
Trace on:
Arguments: [
Artifex.Measure
Run Name: |runOOl • Coverage
Sample:
Cancel |
on
f-----
Ok
Help |
Рис. 4.20. Активация сбора статистики в эксперименте
2
3
4
off (
Сети Петри как Эффективная модель СМО
131
Рис. 4.21. Задание элементов для сбора статистики
После этого нужно провести эксперимент и выйти из среды моделирования.
По умолчанию результат эксперимента сохраняется под именем sessionl, но
можно сохранить и под своим именем.
Далее в менеджере моделей запускаем Artifex.Measure — средство для гра-
фической интерпретации собранной статистики так, как это показано на
рис. 4.22:
1. На панели инструментов в окне Artifex.Measure следует нажать кнопку
Start Measure .
2. В появившемся окне Artifex.Measure: Insert title в списке Selected Runs
надо выделить имя файла статистики и нажать кнопку User Measures.
3. В следующем появившемся окне в списке Selected Measures выбрать (ес-
ли еще не выбран) параметр, для которого нужно посмотреть статистику,
и нажать кнопку Plot.
При этом кнопка User Measure позволяет строить график по определенным
пользователем параметрам, а кнопка Simulation обеспечивает вывод стан-
дартной статистики по выбранным ранее элементам (см. рис. 4.21).
На рис. 4.23 приведен график параметра Service time for Server, определен-
ного выше.
132
Гпава 4
Стандартно же статистика собирается для переходов и позиций отдельно.
На рис. 4.24 приведен список возможных графиков для переходов, а на
рис. 4.25 —для позиций.
Выбрав в качестве графических представлений задержку между событиями
(Release delay) и время ожидания маркера в очереди (Token wait time), мож-
но получить наглядные графики, показывающие динамику процессов в моде-
лируемой системе.
X ‘ у'. *У ; \ '............................ yJiiLy
File View Model Validate Deploy Help ' J
| » K| ®| ш| is|a| q|
x .’y " ’ . .:........... - , ’ .J »
File
Run List ’ > Selected Runs
Рис. 4.22. Построение графиков
В заключение этой главы приведем эти графики для нашего примера
(рис. 4.26 и 4.27).
Сети Петри как эффективная модель СМО
133
Рис. 4.23. График параметра Service time for Server
Firings
Predicate evaluations
Firing rate
Predicate- evaluation rate?'.
Firing period?<л?•????
Predicate evaluation period
Firing delay
Release delay
Transition scheduling . .
. Total, firings, and evaluations; d
Рис. 4.24. Статистика для переходов
134
Гпава 4
Token mean wait time
Token arriva L rate .
Token departures rate
Token arrival period
. : Token departures period :
Рис. 4.25. Статистика для позиций
Рис. 4.26. Статистика по задержке между двумя маркерами
для перехода GENERATE
Сеги Петри как эффективная модель СМО
135
Рис. 4.27. Статистика по времени ожидания маркеров в позиции NEXT
Контрольные вопросы и задания
I. Что такое сети Петри? Приведите пример сети Петри и поясните его ра-
боту.
2. Какие вы знаете расширения сетей Петри? В чем их принципиальная осо-
бенность?
3. Какие вы знаете программные реализации сетей Петри? Попробуйте про-
моделировать простейшие СМО, используя пакет Artifex.
ГЛАВА 5
Аналитические методы
в теории телетрафика
Несмотря на имеющиеся мощные средства моделирования систем массового
обслуживания, обнаружение закономерностей в поведении систем такого ти-
па в процессе моделирования часто оказывается неразрешимой задачей. Бо-
лее того, само доверие к результатам моделирования может быть достигнуто
только при сравнении получаемых результатов с некоторыми известными,
эталонными. Для получения таких эталонных результатов и изучения зако-
номерностей в поведении систем обработки событий применяют аналитиче-
ские методы. Их суть состоит в получении моделей в виде математических
соотношений, уравнений для интересующих характеристик СМО. Решая эти
уравнения, можно получить зависимости нужных характеристик от всех па-
раметров модели. Проблемой является построение таких математических мо-
делей СМО, которые, с одной стороны, достаточно адекватно отражали бы
свойства реальных систем, а с другой стороны, позволяли бы найти решения
уравнений в замкнутой форме. Практически все известные аналитические
результаты удается получить, опираясь на математический аппарат, разрабо-
танный гениальным российским математиком А. А. Марковым.
Вероятностная модель СМО
Поскольку принципиальным аспектом работы СМО является случайный ха-
рактер входного потока событий, то все их математические модели будут ве-
роятностными или, как принято называть, стохастическими уравнениями.
Их решения будут определять некоторые распределения вероятностей для
дискретных величин или плотности вероятности для непрерывных величин.
Во многих случаях знание распределений не является необходимым, и тогда
исследуемые характеристики будут описываться некоторыми средними —
математическим ожиданием, дисперсией и т. п.
Аналитические методы в теории телетрафика 137
Одним из важнейших разделов математики, применяемых в теории телетра-
фика,является аппарат цепей Маркова. Известны дискретные и непрерывные
цепи Маркова. Будем говорить, что задана дискретная цепь Маркова, если
для последовательности случайных величин выполняется равенство
Pr[x„ = yjX, = = /л_,|]= Р[х„ = j | Х„_{ = /„J.
Это означает, что поток случайных величин определяется только вероят-
ностью перехода от предыдущего значения случайной величины к после-
дующему. Зная начальное распределение вероятностей, можно найти распре-
деление на любом шаге. Величины i„ можно интерпретировать как номера
состояний некоторой динамической системы с дискретным множеством со-
стояний (типа конечного автомата). Если вероятности переходов не зависят
от номера шага, то такая цепь Маркова называется однородной и ее опреде-
ление задается набором вероятностей
Pj = p[xn=j\xn _,=/].
Для однородной марковской цепи можно определить вероятности перехода
из состояния i в состояние j за т шагов:
= <. = ЛТ, =d-S',r%-
к
где т = 2, 3, ...
Цепь Маркова называется неприводимой, если каждое ее состояние может
быть достигнуто из любого другого состояния. Состояние i называется по-
глогцающим, если для негорп = I.
Состояние называется возвратным, если вероятность попадания в него за ко-
нечное число шагов равна 1. В другом случае состояние относится к невоз-
вратным. Возвратное состояние может быть периодическим и апериодиче-
ским в зависимости от наличия кратных шагов возврата. Введем вероятности
возврата в состояние i через п шагов после ухода из этого состояния: .
Они позволяют определить среднее число шагов или, иначе говоря, среднее
время возврата:
и, - .
Л=1
Состояние называется возвратным нулевым., если среднее время возвращения
в него равно бесконечности, и возвратным ненулевым, если это время конеч-
но. Известны две важные теоремы.
138
Гпава 5
ТЕОРЕМА 1
Состояния неприводимой цепи Маркова либо все невозвратные, либо
все возвратные нулевые, либо все возвратные ненулевые. В случае пе-
риодической цепи все состояния имеют один и тот же период.
Вторая теорема рассматривает вероятности достижения состояний в стацио-
нарном (т. е. не зависящем от начального распределения вероятностей) ре-
жиме. Соответствующее распределение вероятностей также называют ста-
ционарным. Нахождение стационарного распределения вероятностей дости- 1
жения состояний — одна из основных задач теории телетрафика.
ТЕОРЕМА 2
Для неприводимой и апериодической цепи Маркова всегда существуют
предельные вероятности, не зависящие от начального распределения
вероятностей. Более того, имеет место одна из следующих двух воз-
можностей:
все состояния цепи невозвратные или все возвратные нулевые, и то-
гда все предельные вероятности равны нулю и стационарного со-
стояния не существует;
все состояния возвратные ненулевые, и тогда существует стацио-
нарное распределение вероятностей:
тс,- =--------,
' Л/,.
Состояние называется эргодическим, если оно апериодично и возвратно не-
нулевое. Если все состояния цепи Маркова эргодичны, то вся цепь называется
эргодической. Предельные вероятности эргодической цепи Маркова называ-
ют вероятностями состояния равновесия. При этом имеется в виду, что
зависимость от начального распределения вероятностей полностью отсутст-
вует.
Цепь Маркова с конечным числом состояний (конечная цепь) удобно изо-
бражать в виде ориентированного графа, называемого диаграммой переходов
(рис. 5.1). Вершины графа ассоциируются с состояниями, а ребра— с веро-
ятностями переходов. Вычисления вероятностей достижения состояний про-
изводятся прямыми методами или с помощью ^-преобразования.
Аналитические методы в теории телетрафика
139
Рис. 5.1. Диаграмма переходов дискретной цепи Маркова
Введем матрицу вероятностей переходов и вектор-строку вероятностей на
шаге и:
Распределение вероятностей на произвольном шаге тогда будет подчиняться
матричному соотношению:
7С(") =7С("-|)Р. !
Оно позволяет рекуррентно вычислять все вероятности состояний. Для нахож-
дения предельного распределения (стационарного) нужно решить уравнение:
л = пР,
которое раскрывается в систему линейных уравнений
л0 = А)0л0 + Poiл I + /?02л2 +
л! = /?10л0 + /?ПЛ1 + /712л2 + •••
л// - /7//()л0 +
Его можно решать как систему линейных алгебраических уравнений, если
цепь конечна.
Для примера, показанного на рис. 5.1, имеем
О
1/4
1/4
3/4 1/4
О 3/4
1/4 1/2
и решение матричного уравнения сводится к решению системы трех урав-
нений:
ло = Оло + (1 /4)л1 + (1 / 4)л2;
л, = (3/4)л0 + 0л| + (1 /4)л2;
л2 = (1/4)л0+(3/4)л, +(1/2)л2
140
Гпава 5
Коэффициенты первого уравнения в этой системе дополняют до единицы
сумму коэффициентов второго и третьего уравнений; это свидетельствует
о линейной зависимости между ними. Поэтому для решения системы уравне-
ний нужно ввести дополнительное нормирующее условие. В данном примере:
1 = Лд + Л I + Л 2 •
Решая систему полученных уравнений, имеем:
л0 =1/5 = 0,20;
л, =7/25 = 0,28;
л, = 13/25 = 0,52.
Уравнение для вероятности достижения состояния в переходном режиме ре-
шить значительно труднее. Некоторого упрощения можно достигнуть, ис-
пользуя z-преобразование. Применим его к уравнению для переходных веро-
ятностей
Обозначая соответствующие преобразования, получим:
n(z) = n(0)[7-zP]',
где I— единичная матрица, Р— матрица переходов.
Все полученные здесь математические результаты относились к однородным
марковским процессам, где вероятности переходов не зависят от времени.
В более общем случае такая зависимость имеет место.
Рассмотрим вероятности перехода системы из состояния i на т-м шаге в со-
стояние j на n-м шаге для п > т.
Можно показать, что эти вероятности связаны между собой так называемым
уравнением Чепмена — Колмогорова (Chapman — Kolmogorov)-.
Рц") = ZP/кп-^Рк^п-У,n)
к
Для однородных цепей Маркова эти уравнения упрощаются, т. к.
Pij(m,n) =
и сводятся к анализируемым выше.
Непрерывные цепи Маркова
Случайный процесс/ф) с дискретным множеством значений образует непре-
рывную цепь Маркова, если
Pr[X(/) = j| Х(т) for т, <т<т2 </] = Pr[X(/) = j\ АДт2)].
Аналитические методы в теории телетрафика
141
Будущие состояния зависят от прошлого только через текущее состояние.
Для непрерывной цепи Маркова основным также является уравнение Чепме-
на — Колмогорова, для однородной цепи имеющее вид:
Р(Т + 0 = P(T)P(t).
Здесь P(f) представляет собой матрицу вероятностей переходов из состояния i
в состояние j за время / с элементами
Ру(t) = Рг{%(/ + т) = j\ Х(т) = <}.
Если обозначить вероятности того, что в момент / состояние цепи определя-
ется вектором л(/), то их эволюция во времени полностью определяется мат-
ричным уравнением
л(/) = л(0)Р(Г).
Сама по себе матрица вероятностей переходов для непрерывной марковской
цепи, как правило, неизвестна. Ее значения часто удается найти, решая сис-
тему дифференциальных уравнений, которая в матричной форме может быть
записана так:
= P(t)Q .
dt v '
Здесь матрица Q называется матрицей интенсивностей переходов. Она пола-
гается известной. Ее элементы имеют следующий смысл: если в момент вре-
мени t система находилась в состоянии то вероятность перехода в течение
промежутка времени (/, l + А/) в произвольное состояние Е, задается величи-
ной (<7,/(/) + о(А/)), а вероятность сохранить состояние Е, — величиной
О-2^(0 +об-
вернемся к основным понятиям, определяющим СМО. Это, во-первых, по-
ток входных событий, во-вторых, один или несколько (пул) серверов, работа
которых описывается случайным интервалом времени обслуживания, и, на-
конец, очередь, в которой может находиться случайное число ожидающих
обслуживания заявок (требований, транзакций). Система функционирует во
времени, т. е. преобразует входной поток заявок в поток обслуженных заявок,
и может быть классифицирована как динамическая система. Используем для
ее описания концепцию состояния. Исчерпывающим описанием состояния
такой системы в любой момент времени будет являться число требований в
очереди, в серверах, и значение времени, прошедшего с момента поступления
требований на обработку в каждый сервер.
Обозначим указанные выше значения следующим образом: т— число сер-
веров, N4 — число требований в очереди, Nx— число требований в серверах,
т„ где i = 1, 2,..., т — значения отрезков времени, проведенного требованием
142
Гпава 5
в каждом из серверов. Если ввести функцию in(Z), численно равную количе-
ству входных требований, поступивших в систему в интервал времени t + dt,
то формально уравнения эволюции системы во времени могут быть описаны
следующим образом:
Рг(^/ЛЛ.,т|,т2,...,т„,)(/ + Л) = ф[(^/,^.,т1,т2,...,т„,),’ш(/)].
Это означает, что в каждый последующий момент времени распределение
вероятностей состояния системы зависит только от предыдущего состояния и
входного потока.
Введенная здесь модель формально проста, однако не дает возможности по-
лучить какие-либо аналитические результаты. Поэтому рассмотрим сначала
ее упрощенный, но чрезвычайно полезный частный случай, сведя ее к непре-
рывной цепи Маркова. Во-первых, положим число серверов равным 1. Будем
предполагать также, что входной поток представляет собой ординарный про-
цесс, для которого вероятность одновременного появления двух и более тре-
бований в один момент времени равна 0. Точнее говоря, будем предполагать,
что вероятность появления требования на малом интервале (/, t + dt) пропор-
циональна длине этого интервала и может зависеть только от состояния сис-
темы в момент t. Обозначим эту вероятность p+(k) = Xkdt + o(dt). Коэффици-
ент перед dt определяет интенсивность входного потока, а второе слагаемое
означает бесконечно малую более высокого порядка, чем dt. Нетрудно ви-
деть, что приведенное условие определяет стационарный ординарный вход-
ной поток. Определим теперь процесс обслуживания требований в сервере.
Выясним вероятность того, что требование покинет сервер в малый интервал
времени (/, t + df), как величину, прямо пропорциональную этому интервалу
времени, с точностью до бесконечно малых более высокого порядка малости.
Предположим, что интенсивность обслуживания также может зависеть от
состояния системы в данный момент. Тогда формула для описания вероятно-
сти ухода требования из сервера будет иметь вид:
/?_(Л) = \s.kdt + o(dt).
При сделанных предположениях можно определить состояние системы в мо-
мент t как суммарное число требований в очереди и в сервере: k^N^+N,
и записать уравнение состояний в виде:
Рг(Л, t + dt) = Ф[Л, р+, р_, t].
Конкретизация вида функции в правой части может быть получена из
простых соображений. Система, которую мы рассматриваем, может интер-
претироваться в терминах биологического плана как некоторая популяция,
численностью к, в которой в каждый малый интервал времени с заданной
вероятностью способен либо появиться новый экземпляр (рождение члена
Аналитические методы в теории телетрафика 143
популяции), либо исчезнуть ровно один экземпляр с заданной вероятностью.
Альтернативой может быть сохранение численности на этом интервале неиз-
менной. В литературе такую систему называют процессом "гибели-размно-
жения". На рис. 5.2 приведена графическая иллюстрация поведения описан-
ной системы.
Рис. 5.2. Процесс переходов в непрерывной цепи Маркова
Нетрудно видеть, что, по формуле полной вероятности,
P(k,t+dt) = P(k -\,t)p+(k-1) + P(k + ],t)p_(k + I) +
+P(k,t)(]-p+(k)-p_(k)). (5J)
Так нам удалось записать функцию Ф[Л, р+, р_, в конкретном виде. Для
нахождения решения уравнения (5.I) нужно преобразовать его к известным
в математике типам уравнений. Преобразуем его, раскрыв скобки в правой
части и перегруппировав слагаемые:
P(k,t + dt)- P(k,t) = [/?+ (к) + p_(k)]P(k,t) +
+P(k-1,l)p+(k-Y) + P(k + \,t)p_(k + I).
Теперь подставим введенные ранее выражения для вероятностей прихода и
ухода требований и произведем деление на de.
Р(к, t + dt)- Р(к, t) _
dt
= -(^ + )Р(к, t) + Р(к - I, t) + цА+,Р(к + 1,0 +
144
Гпава 5
Следует сразу помнить, что здесь мы имеем систему уравнений, поскольку
соотношение должно выполняться для каждого к> 0. Для к - 0 соотношение
будет выглядеть иначе, поскольку отрицательного числа требований в систе-
ме быть не может:
/’(0, t + dt ) - P(Q, t) , n/_ x n/1 .
—-------= -XoP(O, Г) + p,P(l, t).
В пределе мы получим следующую систему дифференциальных уравнений
= ~(.^к + нл)^(^>0 + -Ь0 + +1>0; -1,
(5.2)
~^ = -^(0, о + Ц.Л1, О-
dt
В соответствие этой системе уравнений можно поставить наглядную диа-
грамму интенсивностей переходов, которая аналогична диаграмме переходов
для дискретных цепей Маркова (рис. 5.3).
Рис. 5.3. Диаграмма интенсивностей переходов непрерывной цепи Маркова
Окружностям здесь соответствуют дискретные состояния, а дуги определяют
интенсивности потоков вероятности (а не вероятности!) переходов от од-
ного состояния к другому.
Имеет место своеобразный "закон сохранения"-, разность между интенсив-
ностью, с которой система попадает в состояние к, и интенсивностью, с кото-
рой система покидает это состояние, должна равняться интенсивности изме-
нения потока в это состояние (производной по времени).
Применение закона сохранения позволяет получать уравнения для любой
подсистемы марковской цепи типа процесса "гибели-размножения". Особен-
но эффективным оказывается построение решений в стационарном, устано-
вившемся режиме, когда можно полагать, что вероятности в произвольный,
достаточно отдаленный момент времени, остаются постоянными.
Приравнивая производную по времени нулю, получаем систему разностных
уравнений:
Аналитические методы в теории телетрафика
145
-(^ + )А + Vi А-1 + HuiРы = 0; к > 1,
-коро + Н1Д =О;к = о.
Полагая интенсивности
Х-1 = А._2 ” А,„з = ... ~ 0;
Цо = Ц-1 = Ц-2 = JLU-3 = ... = 0,
второе уравнение выписывать отдельно далее не потребуется. Итак, стацио-
нарный режим в цепи Маркова будет описываться системой разностных
уравнений и условием нормировки для вероятностей
+ Рк)Рк + ^k-lPk-] + Pu1 Рк +1 = 0>
СО
Е^ = 1-
к = 0
Нетрудно видеть, что эти уравнения легко выводятся из закона сохранения
интенсивностей вероятностей. В стационарном режиме разность потоков
равна нулю, и полученные выше уравнения приобретают смысл уравнений
равновесия или баланса, как их и называют:
"кк-\Рк-\ + HA + l/’A + l = O'-к + У'-к^Рк
Интенсивность потока вероятностей в состояние к равна интенсивности по-
тока из этого состояния.
Решать уравнение баланса можно, сначала определив при к= 0 значение
Ад
Р\ =— Ро-
УЧ
Затем, построив систему уравнений для к = 1, можно получить
Pi =
^(Л1
И1Р2
Ро-
Далее получаем:
АоА|А2 ... A^-i
PiP2p3 ...ц*.
ui у
Ро = А)П~2~’
/=0 Н/+1
А л-
Pk+i =-------Рк-
Pui
Из условия нормировки:
Ро =
146
Гпава 5
Система, описываемая полученными выше выражениями, будет иметь ста-
ционарные вероятности состояний, когда она эргодическая. Это условие мо-
жет быть выражено через соотношение интенсивностей. Необходимо и дос-
таточно, чтобы существовало некоторое значение к, начиная с которого вы-
полнялось бы неравенство
-^<С <1.
Ц к +1
Для большинства реальных систем массового обслуживания это неравенство
выполняется.
Таким образом, нам удалось построить математическую модель, описываю-
щую весьма широкий класс СМО, для которой найдено решение в замкнутой
форме.
Анализ систем массового обслуживания
типа М/М/т:о)
Предметом рассмотрения в этом разделе будут системы, на входе которых
пуассоновский поток требований, распределение времени обслуживания в
серверах— экспоненциальное, число серверов— т, а длина входной очере-
ди ничем не ограничивается (см. классификацию СМО, разд. "Базовая модель
СМО и классификация по Кендалу" главы 3). Начнем с анализа простейшей
модели с одним сервером.
Система М/М/1
На рис. 5.4 приведена простейшая схема такой системы. Она содержит буфер,
способный хранить очередь бесконечной длины, состояние которой может
быть отождествлено с числом заявок, содержащихся в системе в каждый мо-
мент времени.
Поступающие
пакеты
Очередь
Сервер
Обслуженные
пакеты
Рис. 5.4. Схема системы М/М/1
Так как входной процесс ординарный, то в каждый момент времени к очере-
ди может добавиться только одна заявка; поскольку сервер один, то в каждый
Аналитические методы в теории телетрафика
147
момент времени может быть обслужена, т. е. уйти из очереди, лишь одна за-
явка. Таким образом, рассматриваемая СМО относится к процессу класса
"гибели-размножения". Для анализа необходимо конкретизировать парамет-
ры системы. Распределение вероятностей входного потока и времени обслу-
живания позволяет полагать интенсивности вероятностей в модели постоян-
ными:
= Д £=0,1,2,...,
£ = 1,2,3, ...
Здесь х — среднее время обслуживания в сервере. На рис. 5.5 приведена
диаграмма интенсивностей переходов для рассматриваемой системы.
Рис. 5.5. Диаграмма интенсивностей переходов в системе М/М/1
Полученное ранее общее решение позволяет сразу записать вероятность того,
что в стационарном состоянии в системе будет находиться £ заявок:
£ > 0.
Найдем начальное значение вероятности, учитывая сходимость соответст-
вующего ряда
1 , X ,
--------= 1 - — = 1 _ р.
А-/Ц ц
1-£/ц
Окончательно получаем формулу для вероятности длины очереди рк =
= (1 - р)р\ £=0, 1, 2, 3, ... Такое распределение случайной величины носит
название геометрического.
На рис. 5.6 приведен график вероятностей того, что в системе находится £
заявок в установившемся режиме.
Теперь найдем наиболее интересные характеристики. Важной характеристи-
кой системы является среднее число заявок в системе.
148
Гпава 5
Зная вероятности каждого из возможных значений, найдем математическое
ожидание:
СО со
N = YkPk =(1-P)^V =7^-.
iU *=о 1 - Р
График среднего числа заявок в системе в зависимости от значения коэффи-
циента использования или нагрузки показан на рис. 5.7.
Рис. 5.6. Стационарное распределение вероятностей состояний в системе М/М/1
Р
Р
а) б)
Рис. 5.7. Зависимость среднего числа заявок (а) и времени пребывания в системе (б),
или нагрузочная кривая для СМО М/М/1
Аналитические методы в теории телетрафика
149
Найдем теперь дисперсию числа заявок в системе:
4 = = 7--Р- '2
k = 0 U ~ Р/
Для нахождения среднего значения времени пребывания в системе восполь-
зуемся формулой Литтла:
л Л р YH. .
X ( 1 - р Y X ) 1-р
На рис. 5.7 также приведен график зависимости среднего времени пребыва-
ния в системе в зависимости от коэффициента использования (нагрузки). Та-
кой график называют нагрузочной кривой для СМО.
Рассматривая полученные результаты, нетрудно видеть, что при увеличении
коэффициента использования как число заявок в системе, так и время
пребывания в ней неограниченно возрастают при приближении р к единице.
Такой вид зависимости от коэффициента использования характерен почти
для всех СМО.
Найдем вероятность того, что в системе будет находиться не менее чем к зая-
вок, а также вероятность, что в системе менее к заявок.
Рг[^ = £ Р, = £ О - р)р' = Р*>
i=k !=к
Рг[</с] = 1-р*.
Рассмотрим теперь характеристики очереди. Поскольку среднее число требо-
ваний в системе складывается из среднего числа требований в очереди и
среднего числа требований в сервере, то из формулы
^=^7+^7
следует, что
___ _ 2
N(, = TV - р = -Р—.
1-р
Время ожидания в очереди в среднем по всем заявкам можно найти по фор-
муле Литтла:
W =-N(l =—2—
X (/ ц(1 - р)
150
Гпава 5
Очень часто время ожидания или пребывания в системе записывают в нор-
мированном виде, показывая, во сколько раз оно возрастает по сравнению со
средним временем обслуживания собственно на сервере по причине наличия
очереди. Например, для полного времени пребывания в системе М/М/1
Для системы М/М/1 можно сравнительно легко найти весьма важную стати-
стическую характеристику— функцию плотности вероятности для времени
ожидания в очереди и даже общего времени отклика системы (времени пре-
бывания в системе).
Поскольку вероятность отсутствия требований в системе равна pQ = 1 - р, а
для нескольких требований время ожидания складывается из суммы незави-
симых экспоненциально распределенных случайных величин с одинаковым
- 1 „
средним равным х = —, то в соответствии с известной теоремой их суммар-
Н
ная плотность вероятности описывается гамма-распределением:
ц"х"~|е~рА
Г(и)
Производя необходимые преобразования, можно показать, что функция
плотности вероятности для времени ожидания в очереди будет равна
1УДГ) = ц^'(1 - р)р£ = рр(1 _ р)с<м('-Р)' .
А для полного времени пребывания в системе функция плотности вероятно-
сти получается
И/(0 = ц(1-р)е”м(1’р)'.
Итак, в ходе анализа простейшей системы М/М/1 нам удалось в аналитиче-
ском виде найти все практически интересные характеристики QoS системы
(Quality of Service, качество обслуживания).
На нашем сайте (см. Предисловие) вы можете найти Java-апплет в папке mini,
который позволяет наглядно видеть процессы в системе М/М/1. Изменяя па-
раметры входного потока и сервера, можно наблюдать изменения в поведе-
нии системы. Эта программа позволяет увидеть как стационарное поведение
системы, так и переходный процесс, который не был отражен в нашей конеч-
ной модели.
Аналитические методы в теории телетрафика
151
Система с несколькими серверами
Рассмотрим сначала простой случай системы, содержащей два сервера, лю-
бой из которых доступен для поступающих на вход заявок (рис. 5.8). Систе-
мы с несколькими серверами такого типа называют полнодоступными. Оче-
видно, что по сравнению с односерверной системой производительность бу-
дет выше. Сразу отметим, что в конечном итоге интересно сравнение с
односерверной системой, время обслуживания в которой в среднем вдвое
меньше, т. е. мы найдем ответ на вопрос: что эффективнее— удвоение
скорости обработки или распараллеливание обработки? Пусть двухсервер-
ная система имеет сервер (процессор), затрачивающий на обработку время
Х=1/ц.
Рис. 5.8. Системы с двумя серверами (а)
и с одним сервером вдвое большей производительности (б)
Система М/М/2 может быть представлена как процесс "размножения-гибели"
с параметрами:
А* = К
Ц1 - ц, ц„ = 2ц, V/? > 2.
Наличие множителя 2 для интенсивностей вероятности ухода заявок из сер-
вера при числе заявок в системе, равном двум и более, определяется тем фак-
том, что в этих случаях вероятность освобождения сервера удваивается. По-
скольку серверов два, и оба заняты, то вероятность освобождения хотя бы
одного сервера вдвое больше, чем в том случае, когда занят только один.
Найдем сначала распределение вероятностей в стационарном режиме:
т—г А,- (XY А 1 k _ э k
Pk - Ро I I--" I t- -^°7ГТр _^o2P2,
ф=ой'+1 АйЛМ 2k
A
P2 = V~-
2ц
152
Гпава 5
Находя из условий нормировки вероятность простоя (нулевого состояния),
определяем
п - 1-Р2
Ро - I >
1 + р2
Рк =
2(1-Р2).
,(1 + Р2) 2’
Найдем теперь основные характеристики качества обслуживания. Среднее
число заявок в двухсерверной системе составит:
Ж = Укрк = —
h (1-р2Л ’-р
Здесь для сравнения приведена характеристика односерверной системы с той
же производительностью сервера.
Теперь найдем среднее время пребывания в системе с двумя серверами по
формуле Литтла:
f jV2 _ 1
х ~ц(1-р1)’
Таким образом, в системе с двумя серверами число заявок и время пребыва-
ния в системе сокращается, как и следовало ожидать.
Сравним теперь полученные характеристики качества обслуживания для
двухсерверной системы с характеристиками односерверной системы с вдвое
большей пропускной способностью каждого сервера, который тратит в сред-
нем на обработку той же заявки время х / 2 = 1 / 2ц. Воспользуемся получен-
ными формулами. На рис. 5.9 представлены нагрузочные кривые— норми-
рованные графики среднего времени задержки в системе с одним и двумя
серверами одной и той же производительности и с одним сервером, рабо-
тающим с вдвое большей скоростью. Как видно из сравнения, увеличение
вдвое скорости работы сервера оказывается более эффективным, чем введе-
ние параллельного сервера той же производительности.
Рассмотрим теперь общий случай СМО с т серверами. Диаграмма интенсив-
ностей переходов для такой системы представлена на рис. 5.10.
Интенсивности переходов могут быть определены следующим образом:
= X, п = 0, 1,2, 3, ...,
. г т (пи, 0 < п < т,
Ц„ = ГП1П[ИЦ, /иц] = (
(/иц, т < и.
Аналитические методы в теории телетрафика
153
Рис. 5.9. Сравнение нагрузочных кривых для односерверной, двухсерверной систем
и односерверной с вдвое большей производительностью сервера
Рис. 5.10. Диаграмма интенсивностей переходов для m-серверной системы
Используя основные общие соотношения для процессов "гибели-размноже-
ния", получим:
Рк =
(тр)к ,
Л! ’ к ’
Ркт'п .
до----—, к >т,
т\
Вероятность простоя сервера определяется громоздкой формулой, которая
может быть записана через общую входную нагрузку А и удельную нагрузку р
на один сервер:
Ро =
/л-1 / Лк
у И)
к'
к=0
ч т'- Д1-Р
154
Гпава 5
Полученные здесь соотношения предоставляют возможность расчета всех
характеристик QoS. Приведем наиболее известную формулу, позволяющую
найти вероятность того, что поступающая в систему заявка окажется в очере-
ди. Эту формулу широко используют в телефонии: она определяет вероят-
ность того, что поступающий на пучок из т линий вызов не застанет ни од-
ной свободной линии и будет поставлен в очередь на обслуживание. Данную
формулу часто называют С-формулой Эрланга'.
С(т, А).= уг
Ь к''
A"'
iTi 7 Po '
m\ (1 - p)
Через С-формулу Эрланга компактно выражаются многие характеристики
системы. Среднее число заявок в очереди равно
Вероятность того, что в системе находится Л заявок, записывается как
Pr(/V =£) = р"-'"(1-р)С(/щ А).
Среднее число занятых серверов может быть найдено как
В = тр.
Соответственно среднее число свободных будет разностью средних:
I = т - В = т - тр = т(\ - р).
Модель СМО, описываемая С-формулой Эрланга, называется также Lost
Calls Delayed (LCD).
Анализ системы
с ограниченной длиной очереди M/M/m:N
В реальных системах входной буфер имеет конечный размер, т. е. размер па-
мяти, отведенной для хранения заявок, ограничен: при поступлении доста-
точно большого числа заявок, превышающего размер буфера, наступает бло-
кировка. Блокировка, т. е. невозможность обслужить поступившую на вход
заявку, является случайным событием, и его вероятность определяется веро-
ятностью того, что число поступивших заявок превысит максимальное значе-
ние числа заявок в системе.
Аналитические методы в теории телетрафика
155
Анализ системы M/M/1 :N
Рассмотрим случай, когда число серверов m равно I (рис. 5.11).
Л/-1
Рис. 5.11. Система с ограниченной длиной очереди и одним сервером
Рассмотрим СМО, для которой фиксировано максимальное число ожидаю-
щих заявок. Предположим, что в системе может присутствовать N заявок,
включая находящуюся на обслуживании в сервере. Любое поступившее сверх
этого числа требование получает отказ и немедленно покидает систему.
В телефонии такие вызовы называют потерянными. Поступающие заявки
образуют пуассоновский поток, а обслуживание осуществляется одним сер-
вером с показательным законом распределения времени обработки. Приспо-
собим для описания такой системы модель процесса "гибели-размножения":
\-k,k<N,
~ [О, k > N,
Р* = Ц,
где к= I, 2, 3, ..., N.
Эта система эргодична, и диаграмма интенсивностей переходов может быть
изображена так, как показано на рис. 5.12.
Рис. 5.12. Диаграмма интенсивностей переходов для системы с конечным буфером
Найдем распределение вероятностей в стационарном режиме непосредствен-
но из общей формулы:
Рк = А)П“’ к - N’
156
Гпава 5
Pk = Ро - >
рк = 0,к > N.
к <N,
Теперь определим начальную вероятность, следуя общей формуле:
(х/иХД= 1-х/н
i-(Vh) J '
Таким образом, окончательная формула для стационарных вероятностей
будет:
О, k<Q-k>N.
Проанализируем характеристики качества обслуживания (QoS) для такой
системы. Важнейшей характеристикой будет являться вероятность блоки-
ровки, т. е. потери заявки. Очевидно, что это произойдет с вероятностью пе-
реполнения буфера, поэтому для расчета вероятности блокировки можно ис-
пользовать формулу:
Рв = рк^ = Л/) = т-£Мг-
1 - о
Например, для системы с коэффициентом использования 0,5 при размере бу-
фера N= 18 вероятность блокировки будет больше 10"6, а при размере
N= 19 — меньше этого значения. Следовательно, для получения вероятности
блокировки такой величины необходимо предусмотреть размер буфера не
менее 19.
Среднее число заявок может быть найдено как:
77 _ (1 - р)р Y п-I = Р____+ l)p/V + l
1-р"-'£о ч-р- i-р"*' '
Соответственно среднее время пребывания в системе на основе формулы
Липла
T = -N.
к
Определим пропускную способность системы как число заявок, обслуживае-
мых системой в одну секунду. Очевидно, что при вероятности блокировки рц
Аналитические методы в теории телетрафика
157
пропускная способность может быть найдена как чистая интенсивность по-
ступлений, т. е.:
у = Х(1-рй).
С точки зрения выхода системы пропускная способность может быть опреде-
лена иначе. Если система всегда была бы не пуста, то ее производительность
равнялась бы величине, обратной среднему времени обслуживания, т. е. ц.
Однако, поскольку часть времени система может простаивать, вероятность
того, что в ней нет ни одной заявки, отлична от нуля, реальная производи-
тельность может быть выражена как:
У = Ц(1 - Ро)-
Подставив выражение для вероятности простоя сервера в системе с беско-
нечным размером буфера, получим:
У = ц(1 - (I - р)) = X => рн = 0 .
Для системы с конечным буфером получаем:
1-р
В качестве реального примера рассмотрим концентратор сети с коммутацией
пакетов, который обрабатывает пакеты со средней длиной 1200 битов. При
скорости передачи в канале 2400 бит/с средняя пропускная способность его
составит ц = 2пакета/с. Если полный входной поток имеет интенсивность
X = 1 пакет/с, то р = 0,5 и можно рассчитать, что при размере буфера Л/=9
пакетов в среднем по 1200 битов вероятность блокировки составит 0,001. Для
того чтобы получить вероятность блокировки 0,000001, нужно предусмотреть
буфер длиной не менее 19 пакетов по 1200 битов, т. е. около 2850 байтов.
На нашем сайте (см. Предисловие) можно найти апплет для вычисления ха-
рактеристик многоканальной СМО с ограниченной длиной очереди типа
M/M/s:m, имеющей пуассоновский входной поток, накопитель в tn мест и
дисциплину обслуживания — FIFO с блокировкой. Эта программа позаим-
ствована с сайта: http://www.uran.donetsk.ua/~students/fvti/calc/main/smo
/second.htm.
Важным частным случаем систем с ограниченной длиной очереди являются
системы без входной очереди. Их принято обозначать M/M/m:Loss.
Анализ систем с полными потерями
Предметом рассмотрения теперь будет система без образования очереди для
заявок, поступивших в моменты, когда все m серверов были заняты. Такие
158
Гпава 5
заявки будут просто теряться. В телефонии это типичный случай коммутиро-
вания на конечном коммутационном поле. Опишем такую систему подходя-
щим процессом типа "гибели-размножения". Его параметры могут быть оп-
ределены как:
f А,, п < т,
= 1л
|0, п> т.
щ, = пр,
где n = 1, 2, 3, ..., т.
Такая система оказывается также эргодичной, и диаграмма интенсивностей
переходов, приведенная на рис. 5.13, позволяет найти распределение вероят-
ностей:
ГТ л f А-У 1
Рк - Ро I I 7: т~ - Ро — ту,
+ £ (! + ')ц W к'-
Ро =
к\
Рис. 5.13. Диаграмма интенсивностей переходов для m-серверной системы
с полными потерями
Основной характеристикой QoS для этой системы является средняя доля
времени, когда все серверы оказываются занятыми. В этом случае говорят,
что в системе наступила блокировка. Вероятность такой блокировки опреде-
ляется по формуле, носящей в телефонии название В-формулы Эрланга или
формулы потерь Эрланга-.
Рв=В(т,А) = р„, =
к=0
ПТ.
Аналитические методы в теории телетрафика
159
И '
Данная формула играет столь большую роль в телефонии, что ее значения
табулированы, и существует масса таблиц, обратного расчета, т. е. определе-
ния нагрузки, при которой обеспечивается заданная вероятность блокировки
для конкретного количества серверов. Такая таблица важна при расчетах
многих сетей и систем массового обслуживания. Модель СМО, описываемая
S-формулой Эрланга, называется также Lost Calls Cleared (LCC). Для практи-
ческих расчетов удобно использовать специальный программный калькуля-
тор, который предоставляется на сайте компании Westbay по адресу
http://www.erlang.com/calculator/erlb/. На нашем сайте (см. Предисловие)
имеется приложение, которое позволяет проводить любые расчеты, исполь-
зующие формулу Эрланга. На рис. 5.14 приведен графический интерфейс
этого Эрланг-калькулятора (Erlang В Calculator).
II Erlang В Calculator
1 ВНТ (Erl.) ' ; f Unknown ' Blocking : C Unknown ; Lines Unknown [
i.j i' 1 0 010 ' I —,
Calc, | Results I Help |
Рис. 5.14. Интерфейс программы Erlang В Calculator компании Westbay
Для того чтобы рассчитать вероятность блокировки с помощью представлен-
ного калькулятора, нужно сначала пометить как неизвестную (отметить пе-
реключатель Unknown) величину вероятности блокировки (для поля
Blocking), а затем ввести значение нагрузки в эрлангах в поле ВНТ (Erl.), а
количество серверов— в поле Lines. В поле Blocking появится значение ве-
роятности блокировки.
Данная программа позволяет рассчитывать также значение нагрузки по из-
вестному значению вероятности блокировки и количеству серверов, а также
необходимое число серверов по заданной нагрузке и вероятности блокиров-
ки. Для этого достаточно только пометить, что является неизвестным, и за-
полнить остальные окна.
5-формула Эрланга позволяет компактно записать выражение для среднего
числа занятых серверов: 1
В = /1(1 - В(т, А))
и среднего числа свободных серверов:
I = т - А(1 - В(т, А)).
160
Гпава 5
В заключение приведем полезную рекурсивную формулу для вычисления
значений ^-функции Эрланга. Она может пригодиться при ручных расчетах:
[В(т + 1, Л)]’1 = Л)]-1 + 1.
^-формула и С-формула Эрланга связаны между собой соотношением
С(т, А) =----.
1 - р[1 - В(т, Л)]
Модель Энгсета
Теперь рассмотрим несколько иную постановку задачи для системы с пол-
ными потерями.
В некоторых практических задачах важно учитывать характер изменения по-
ступающей нагрузки при постановке на обслуживание очередного входного
требования. Так, в традиционной телефонии обслуживание вызова от одного
из клиентов снижает входящую нагрузку на величину интенсивности потока,
создаваемого данным клиентом. В этих задачах принято описывать входной
поток как примитивный (см. разд. "Примитивный поток" главы 2). Будем
считать, что система также не имеет входного буфера, и это полностью соот-
ветствует модели традиционного телефонного коммутатора. Тогда она может
быть представлена как система массового обслуживания, имеющая М вход-
ных линий, которая распределяет поступающие с них заявки на т серверов.
Схема такой системы представлена на рис. 5.15.
Рис. 5.15. m-серверная система с полными потерями, соответствующая модели Энгсета
Интенсивность входного потока зависит от количества занятых обслужива-
нием серверов таким образом, что интенсивность входного потока линейно
убывает с числом занятых серверов:
= Х(М- и).
Аналитические методы в теории телетрафика
161
Максимальная нагрузка, поступающая на один вход, определяется как
А
Р '
4
Вероятность, что при показательном законе распределения времени обслу-
живания в стационарном режиме окажутся занятыми к серверов, будет опре-
деляться формулой, которая может быть получена из анализа диаграммы ин-
тенсивностей переходов, приведенной на рис. 5.16.
Рис. 5.16. Диаграмма интенсивностей переходов
для m-серверной системы с полными потерями, соответствующей модели Энгсета
Систему такого типа можно назвать М/М/т:М. Модель позволяет рассчитать
вероятность, что будут заняты все серверы. Для этого сначала выпишем вы-
ражения для интенсивностей переходов
0 < п < m - 1,
1,1 = [О,
Г/щ,
Ил - ]
[Л7Ц,
Воспользуемся общей формулой для расчета вероятностей состояний:
AqA|A.2 ...At._| т-r А,-
Рк = ро = ро I I
ШИгМз---^ 7=о ^>+1
п> m.
0 < п < т,
п>т.
Подставляя интенсивности переходов для нашего случая
л-лПт^ = с«4£) . Os*
j_Q V Х/Г4 \ Г4 J
(гп-п)\п\'
6 Зак. 3884
162
Гпава 5
после некоторых преобразований получается распределение, известное под
названием распределения Энгсета'.
ск дк
Л ----------L. * = 0,1,2,..,,».;
1=0
Полученный результат позволяет рассчитать вероятность, что будут заняты
все серверы, т, е. система окажется заблокированной.
Л. '—•
к=0
Данная формула отличается от полученной ранее В-формулы Эрланга.
На практике применима также модель Молина (Molina), которая называется
моделью потерянных вызовов Lost Calls Held (LCH). Это математическая мо-
дель блокировки телефонного трафика, в которой блокированные обращения
сохраняются в течение определенного времени задержки, хотя и не обслужи-
ваются. Данная модель подобна модели, описываемой С-формулой Эрланга.
Вероятность блокировки для N линий, создающих интенсивность А в соот-
ветствии с LCH, имеет вид:
Вд = е
00 лк
У —.
к'
к = 1\’+\ *
Модель Энгсета часто применяется для расчета потерь при небольшом числе
источников вызовов. В этих случаях уменьшение интенсивности входного
потока за счет исключения источника, который получил обслуживание, ока-
зывается существенным. При большом количестве источников доля интен-
сивности входного потока от каждого из них по сравнению с общей интен-
сивностью оказывается незначительной, В этих случаях результаты расчета
по формулам Эрланга и Энгсета будут весьма близкими. В пределе при
Мсо, Х->0, так что Ло = ML = const, формула Энгсета непосредственно
переходит в формулу Эрланга.
Компания Westbay также включает в состав своего продукта для расчета по-
терь программный Энгсет-калькулятор (Engset Calculator)— рис. 5.17. Его
также можно найти на нашем сайте (см. Предисловие).
Для того чтобы воспользоваться данным калькулятором, нужно сначала
пометить, какую величину надо рассчитать (установить переключатель
Аналитические методы в теории телетрафика
163
Unknown для соответствующего поля), например, число серверов (для поля
Lines), затем ввести три другие известные величины (число источников тра-
фика (Number of traffic sources), нагрузку (BHT (Erl.)), вероятность блоки-
ровки (Blocking), число серверов (Lines)).
I^.Engset Calculator
I Number of traffic sources: | ' 500 ; s
! BHT (Erl.) Blocking Lines
> C Unknown I Г Unknown 1 C* Unknown
LIZZZZZJiI...........°°1° i LZ Z
Calc. | Results | t Help [
Рис, 5.17. Интерфейс программы Engset Calculator компании Westbay
Анализ систем с произвольным
распределением времени обслуживания
В рассмотренных выше случаях аналитического исследования систем массо-
вого обслуживания время между поступлением входных заявок и время об-
служивания заявок в серверах описывается случайными величинами с экспо-
ненциальным законом распределения. В данном разделе попытаемся проана-
лизировать системы, для которых входной поток заявок остается пуассо-
новским, тогда как время обслуживания в сервере может описываться
случайной величиной с произвольным заданным распределением. К сожале-
нию, для таких систем удается провести вывод формул до конца, только если
они содержат ровно один сервер, В классификации Кендала такие системы
обозначаются M/G/1. Буква G определяет общий (general) вид распределения
случайной величины времени обслуживания.
Пусть на входе системы действует пуассоновский процесс со средней интен-
сивностью X, т. е. плотность вероятности для интервала времени между по-
ступлениями заявок на входе описывается формулой
a(f) = /.е~1'.
Распределение времени обслуживания в сервере обозначим некоторой произ-
вольной функцией плотности вероятности Ь(х). По своему физическому
смыслу она должна быть определена на правой полуоси и удовлетворять
условию нормировки.
J b(x)dx = 1.
о
164
Гпава 5
Зададим среднее значение времени обслуживания
со
х = J xb(x')dx .
о
Будем определять интенсивность поступающего трафика (интенсивность по-
ступающей нагрузки) и, в данном случае, коэффициент использования серве-
ра, т. е. долю времени, затрачиваемого им на обработку заявок, как
р = кх .
В основе анализа вновь будет лежать распределение вероятностей для со-
стояния системы. Однако нетрудно видеть, что теперь знание вероятности
числа заявок, находящихся в системе в каждый момент времени jV(/), оказы-
вается недостаточным для предсказания вероятности этого числа в следую-
щий момент. Полученная система не описывается больше в целом цепью
Маркова. Несмотря на это, можно найти формулы для среднего значения
времени ожидания заявки в очереди и среднего времени пребывания заявки в
системе.
В среднем каждая заявка, поступившая в систему, будет ожидать обслужива-
ния в течение времени обслуживания всех находящихся в очереди и при-
шедших ранее заявок, а также времени освобождения сервером последней из
заявок. Таким образом, среднее время ожидания в очереди может быть опи-
сано соотношением
W=Nx + R.
Второе слагаемое здесь является средней незавершенной работой, опреде-
ленной в разд. "Базовая модель СМО и классификация по Кендалу" главы 3.
В соответствии с формулой Литтла:
N = kW,
W = Wkx + R,
1-p
Теперь представим, как изменяется незавершенная работа в нашей системе.
Очевидно, что с течением времени незавершенная работа линейно убывает,
пока сервер обрабатывает заявку, и скачком увеличивается с каждым новым
поступлением заявки на сервер. На рис. 5.18 приведен график этого процесса
в виде ломаной зубчатого вида.
Для определения среднего значения незавершенной работы достаточно про-
интегрировать эту функцию и разделить полученную величину на длину ин-
Аналитические методы в теории телетрафика
165
тервала интегрирования. Поскольку все участки кривой имеют вид прямо-
угольных равнобедренных треугольников, получаем
'о <=! <=1
Отсюда следует важная формула для определения среднего значения времени
ожидания обслуживания в системе М/G/l, известная как формула Поляче-
ка — Хинчина (Pollaczek — Khinchin) или сокращенно РК-формула:
2(1-р)
Рис. 5.18. Изменение незавершенной работы в СМО
Найденная формула для среднего времени ожидания в очереди позволяет не-
медленно найти среднее время пребывания заявки в системе:
T=x+W.
Таким образом, для системы М/G/l среднее время пребывания заявок зависит
не только от величины средней интенсивности поступающего трафика, но и
от второго момента распределения времени обслуживания. Часто для харак-
теристики второго момента используют коэффициент вариации (формы):
С2=(о/х)2.
Тогда формулы для среднего времени ожидания и пребывания в системе мо-
гут быть представлены в виде
2(1-р) 2 1-р ’
166
Глава 5
Применение формулы Литтла позволяет получить и формулы для среднего
числа заявок в очереди и среднего числа заявок, находящихся в системе:
Vx7 ’ 1
N=kW = ..
2(1-р)
Р2
1-р ’
2
/,х2
/У = Х7, = Хх + -^— = р + 12_^._Р__.
2(1-р) 2 1-р
Поскольку система М/М/1 является частным случаем, интересно проверить,
даст ли формула Полячека — Хинчина уже известный нам результат. По-
ложим 4
b(x) = ц е
Найдем второй момент:
х2 = | х2/>(х)<Ух = ц |;
о о
• Подставляя его в РК-формулу, получаем:
1-р
2 • Xdx = .
И
Р
1 -р ’
1
Т = 1 + -&-
I 1-Р
I ~Р
где С; =1, т. е. о = х .
Как и следовало ожидать, результаты полностью совпали.
Другим важным случаем систем с произвольным распределением времени
обслуживания являются системы с постоянным, детерминированным време-
нем обслуживания. В таких системах на вход поступает случайный пуассо-
новский поток заявок, а сервер затрачивает на обработку любой из них одно
и то же время. В обозначениях Кендала это системы M/D/1. Для таких систем
второй момент распределения времени обслуживания совпадает с квадратом
среднего времени обслуживания. Коэффициент вариации здесь равен нулю.
Для систем с детерминированным временем обслуживания РК-формула дает:
тт 1 Р2
N = р + —-—,
Р 21 —р
li 1 Р I ~
7 = 1 + V I Н’
к 2 1 - р j
Аналитические методы в теории телетрафика 167
Мы неоднократно будем использовать формулу Полячека — Хинчина при
анализе реальных систем, поскольку весьма часто экспоненциальное при-
ближение для распределения времени обслуживания в сервере оказывается
непригодным. Например, при анализе коммутаторов пакетов следует учиты-
вать наличие у каждого пакета заголовка фиксированной длины, что требует
учета во времени обслуживания некоторой постоянной добавки, даже если
предположить, что распределение длин пакетов удовлетворительно описыва-
ется экспоненциальным распределением.
Системы с произвольным распределением
времени обслуживания и входного потока
Следующее серьезное обобщение связано с отказом от пуассоновского харак-
тера входного потока.
Как следует из определения, этот класс систем предполагает, что распределе-
ние интервалов времени между поступлением входных заявок-требований и
распределение времени обслуживания в сервере описываются произвольны-
ми функциями плотности вероятности (система G/G/1). Обозначим функцию
плотности вероятности входного потока заявок ц(х), а функцию плотности
вероятности времени обслуживания Ь(х). Рассмотрим последовательность
поступающих заявок на обслуживание — требований, пронумерованных ин-
дексами, и вспомним обозначения, введенные ранее:
□ С„ — п-е требование, поступающее в систему;
□ t„ — промежуток времени между поступлениями w-го и (и - 1)-го требова-
ний, плотность вероятности <?(/) не зависит от и;
□ хп — время обслуживания и-го требования, плотность вероятности Ь(х)
также не зависит от гт,
□ Wn — время ожидания и-го требования в очереди.
Напомним определение незавершенной работы для системы массового об-
служивания. Незавершенная работа в каждый момент времени— это оста-
точное время, необходимое для освобождения системы от всех требований,
находящихся в ней к этому моменту. Очевидно, что для системы G/G/1 зна-
чение незавершенной работы непосредственно перед поступлением и-го тре-
бования в точности равно времени w„. Таким образом, последовательность
этих значений будет образовывать дискретную марковскую цепь, вероятно-
сти переходов которой могут быть определены по характеристикам входного
потока и времени обслуживания. Зная эти переходные вероятности, можно
найти все характеристики изучаемой СМО.
168
Гпава 5
Рассмотрим два случая поступления требования С„ в систему — поступление
в занятую систему (рис. 5.19) и в свободную систему (рис. 5.20).
И4
Обслуживающий
прибор
Очередь
Время
Очередь
Рис. 5.19. Случай, когда требование С,,., поступает в занятую систему
Обслуживающий
прибор
Время
Рис. 5.20. Случай, когда требование C,wl поступает в свободную систему
Аналитические методы в теории телетрафика 169
Нетрудно видеть, что для первого случая
+ хп ~ 61+1 — 0 ^Si + I — + хп ~ C + I •
Для второго случая
=> ^,+1=0.
Определим случайную величину, равную разности между временем обслу-
живания требования с номером п и промежутком времени между поступле-
ниями (п + 1 )-го и и-го требований:
un = хп ~ 61+1 •
Фундаментальное свойство этой случайной величины состоит в том, что для
стабильных СМО, т. е. имеющих стационарное распределение вероятностей
состояний, ее математическое ожидание должно быть отрицательным. Смысл
данного утверждения понятен из определения. Очевидно, что в среднем вре-
мя обслуживания должно быть меньше времени между поступлениями со-
седних требований. Используя эту величину, можно записать выражение для
рекуррентного определения величин Wn в компактном виде:
ГО, + w„ < 0 ,
"+* >„+«„, ^,+«„>0.
И;+1 = max [0, Wn +«„].
Решая это уравнение последовательно, начиная с нулевого требования, мож-
но получить
Wn = max[0, u„_{, un_{ + un_2,..., u„_\ + ... + ut, +... + », + u0 +f^0].
Условие стабильности un < 0 может быть записано в более привычной
форме:
«я = хп - 61+1 = xn-tn=x-~t 1),
При выполнении этого условия будет существовать стационарное распреде-
ление вероятностей
lim Рг[И^, <у] = Рг[ГГ <y] = F(y).
Эта функция распределения может быть записана через искомую плотность
вероятности для времени ожидания в очереди:
у
F(y) = j
-со
170
Гпава 5
Для ее нахождения Линдли получил интегральное уравнение, носящее его
имя:
и<у) = <
j w(y - u)c(u)du, у > 0 ,
О, у<0.
Функция с(л) определяется, в свою очередь, корреляционным интегралом,
похожим на свертку плотностей вероятности входного потока заявок и вре-
мени обслуживания,
00
с(и) = J a(t + u)b(t)dt.
о
Решить уравнение Линдли в общем случае не удается. Если ввести преобра-
зования Лапласа от функций плотности вероятности
A(s) = J a(f)e s'dt,
о
B(s) = j b(x)e~sxdx,
о
то удается записать для преобразования Лапласа корреляционного интеграла:
C(s) = Л(-5)Л(5) ,
И/(5)[Л(-s)B(s) - 1] = 0 .
Определение функции комплексной переменной W(s) из последнего уравне-
ния согласно методам теории функций комплексной переменной сводится к
представлению разности в квадратных скобках в виде отношения функций
комплексной переменной, имеющих специальное расположение нулей в пра-
вой и левой полуплоскостях комплексной переменной s:
/l(-s)£(s)-l =
Т_(5)
При R.e(s)>0 функция в числителе должна быть аналитической и не иметь
нулей в этой полуплоскости. Функция в знаменателе должна быть аналитиче-
ской в левой полуплоскости и не иметь там нулей. Решение для преобразова-
ния Лапласа функции плотности вероятности времени ожидания в очереди
может быть записано в виде:
Аналитические методы в теории телетрафика 171
л->0 5
Константа К есть вероятность того, что требование не будет стоять в очереди.
Вычисления показывают, что, несмотря на возможность выразить функцию
плотности вероятности времени ожидания в любом конкретном случае без
заданных плотностей <?(/) и Ь(х), записать в общем случае аналитическое ре-
шение для характеристик качества обслуживания системы G/G/1 не удается.
Так для среднего времени ожидания требования в очереди можно получить
формулу только в виде, содержащем некоторые неизвестные параметры:
W : +gA+fl2(1 -Р)2 l2_
2/(1 - р) 21
Здесь известные параметры ст„, О/, — среднеквадратичные отклонения для
входного потока требований и времени обслуживания, t — среднее значение
интервала времени между входными требованиями. Вторая дробь есть отно-
шение второго момента к среднему значению случайной величины 1— про-
должительности свободного состояния в системе G/G/1. Это вычитаемое не
определяется в явном виде, и формула для W не позволяет непосредственно
вычислить среднюю задержку в системе.
Найдем приближенное значение данной величины при больших значениях
нагрузки. Используем разложение функций комплексной переменной И(л) и
B(s') в ряд Маклорена:
Л(-5) = 1+?5 + -^~ + о(52),
2 2
D/ ч 1 “ Х S / 2\
B(s) = l-xs + -^- + o(s ),
A(-S)B(s) -1=5 t - X + 5 — +------Xt + o(52) .
Поскольку нас интересует значение функции плотности вероятности при
большой нагрузке, можно ограничиться рассмотрением функции IV(s) при
малых значениях s. Нетрудно видеть, что последнее выражение, как функция
комплексной переменной, имеет два нуля. Первый из них очевиден: 5, = 0.
Для нахождения второго корня будем пренебрегать квадратом разности меж-
ду средним временем обслуживания и средним интервалом между поступле-
ниями. Приближенное значение корня будет равно
2/(1 - р)
2 , „1 ’
172 Гпава 5
Таким образом, в качестве приближения в окрестности нуля можно считать
2 2
Д-5)5(5)-1«5(5-52)^у^-,
T+(j) « 5(5 -52)С
2 2
с =
К = lim(5-52)C = -s2C,
л*-»0
и/(5)* ~52 = 1—L_;
s(s-s2) s s - s2
2/(1—p)
, . 2/(1 - p) ст2+ст2 'У
w(y)«—У----y-e ° ” ,
<J„ + <5b
2 2
py ~ ga + gZ>
2(1 - p)/
Как видно, приближение при большой нагрузке позволяет считать распреде-
ление времени ожидания в очереди экспоненциальным, а среднее время рас-
считывать по полученной выше формуле.
Кроме приведенной здесь формулы для больших значений р во многих слу-
чаях более точные результаты могут быть найдены с использованием верхней
и нижней границ для времени ожидания без предположения о величине на-
грузки. Строгое значение для верхней границы можно найти, используя по-
лученную выше формулу для W. Путем простых преобразований нетрудно
показать, что для любых значений нагрузки будет выполняться неравенство
W < pJ +.<4 = ру
2/(1-р) H'gh
Можно видеть, что верхняя граничная оценка оказывается тем более точной,
чем больше величина нагрузки. Другими исследователями (Marshall) была
получена другая формула для верхней границы. При ее выводе автор исходил
из требования превращения оценки в точное выражение для задержки в сис-
теме М/G/l при подстановке в формулу соотношений, справедливых для пу-
ассоновского входного потока.
1 . _.2 _.2
ру +аь
(l/p)2+C2L2/(l-p)J’
Аналитические методы в теории телетрафика
173
с _ С/>
Здесь использован введенный ранее параметр С/,— коэффициент вариации
времени обслуживания.
Нахождение нижней границы проще всего выполняется в предположении,
что входной поток может быть отнесен к классу случайных потоков событий
с монотонным возрастанием интенсивности. Для таких классов случайных
потоков функция распределения удовлетворяет соотношению:
>0, v, >, 0.
В этом случае нижняя граница для среднего времени ожидания требования
в очереди может быть определена формулой:
Р G + Р(Р ~ 2) _ jy < jy
2Ц1 - р) Low
В более общем случае нахождение нижней границы дается через решение
нелинейного уравнения:
У = g(y),
£(Г)=[
J-y
С(х) = £с(/)(/г,
с
(•СО
(/) = + t)b(x)dx .
Графически решение нелинейного уравнения y = g(y) дается точкой пересе-
чения (рис. 5.21) прямой Y-y и K=g(y). Это решение и определяет собой
величину точной нижней границы для среднего значения времени ожидания
требования в очереди WLow: JVlow < W.
Итак, анализ СМО G/G/1, в которой учитывается вид функции плотности ве-
роятности как входного потока заявок, так и времени обслуживания, позволя-
ет в ряде случаев получить некоторые оценки, которые могут быть использо-
ваны как более точные по сравнению с максимально высокими, получаемыми
при использовании марковских моделей.
Рассмотрим теперь пример нахождения верхних и нижних границ для оценки
характеристик качества обслуживания в системах общего вида.
174
Гпава 5
Рис. 5.21. Определение нижней границы И/м
В качестве главного объекта исследования выберем систему U/U/1, которую
можно с полным правом отнести к системам общего вида G/G/1. Для имита-
ционного моделирования такой системы будем использовать GPSS.
Код программы моделирования имеет такой вид, представленный в лис-
тинге 5.1.
Листинг 5.1. Программа моделирования системы U/U/1
Generate
Queue
Seize
Advance
Depart
Release
Terminate
Start
Restart
Start
200,200
In_Buffer
System
value,value
In_Buffer
System
1
100
1000
; Генератор заявок
; Занятие заявкой места в очереди
; Занятие заявкой места в системе
; Имитация работы сервера
; Освобождение заявки из очереди
; Освобождение заявки из сервера
; Уничтожение обработанной заявки
; Исключение переходных процессов
Присвоением различных значений переменной value была построена нагру-
зочная характеристика зависимости времени пребывания заявки в системе
(рис. 5.22, кривая U/U/1). Затем были вычислены верхняя граница по формуле:
^High
2 2
2-7(1 -pf)
и верхняя граница Маршалла
^Marshall
(1+Ф
ста, + al
2 -7 -(1 - р,-)
Аналитические методы в теории телетрафика
175
Для системы U/U/1 значения дисперсий и коэффициентов вариации вычисля'
лись следующим образом:
2 (Д| -(-Д2))2
~ п ’
СТ
(value - (-value))2
12
2
b
ь
х
Вычисленные по этим формулам кривые High, High Marshall и Low приведе-
ны на рис. 5.22. Для сравнения на этом же рисунке представлена нагрузочная
кривая для системы М/М/1. Как видно, она может рассматриваться как очень
грубая верхняя граница при оценке характеристик Q6S.
Рис. 5.22. Нагрузочные кривые
Теперь найдем нижнюю границу для нагрузочной кривой рассматриваемой
системы. В соответствии с описанным выше способом сформируем и решим
нелинейное уравнение у = g(y).
g(y)=f [1-C(x)]cfx,
J-у
176
Гпава 5
где функция С(х) равна
C(x) = J*c(/)tfr.
Сначала найдем корреляционный интеграл
с(Г) = + t)b(x)dx .
На рис. 5.23 иллюстрируется определение функции с(7).
Рис. 5.23. Вычисление корреляционного интеграла
Затем (рис. 5.24) показано нахождение интегральной функции распределения
С(/) и графическая иллюстрация решения нелинейного уравнения.
t
C(t. 1)
У
д(у D
1-СЦ, 1) ------у
а) б)
Рис. 5.24. Вычисление интегральной функции (а) и решение нелинейного уравнения (б)
На рис. 5.22 был приведен график нижней границы для рассматриваемой сис-
темы. Как видно, кривая нижней границы действительно отсекает область,
ниже которой нет значений характеристики QoS.
Аналитические методы в теории телетрафика
177
Для желающих изучить аналитические методы исследования СМО более де-
тально рекомендуем замечательную книгу [3].
Системы с самоподобным входным потоком
и детерминированным временем
обслуживания
Как было показано в разд. "Самоподобные (фрактальные) модели трафика"
главы 2, сети с пакетной коммутацией характеризуются наличием долгосроч-
ных зависимостей в интенсивности трафика, сильным отличием статистиче-
ских свойств потоков пакетов от пуассоновского потока и даже любых дру-
гих потоков, определяемых одномерной функцией плотности вероятности
интервала между событиями. Более адекватной моделью потоков в таких се-
тях являются самоподобные процессы. Рассмотрим простейший случай СМО
с одним сервером с детерминированным временем обслуживания
1
х = —,
М
входной поток которой представляет собой фрактальное броуновское движе-
ние. Будем называть такую систему далее fBM/D/1. Исследование характери-
стик данной системы представляет собой сложную математическую задачу.
Мы не будем давать ее детальное решение. Впервые оно было получено в
работах Нороса (Ilkka Norros) [4]. Им было показано, что число требований
в рассматриваемой системе в любой момент времени может быть представ-
лено случайной величиной
N(г) = sup( А(г) - A(t) - ц(/ - 5)),
s<t
где
Л(г) = kt + y[akZ(t).
Случайный процесс Z(/) является здесь нормализованным фрактальным бро-
уновским движением с параметром Херста, равным Н, а положительный ко-
эффициент а является некоторым масштабирующим множителем.
Рассматривается случай, когда
Норосом было показано, что вероятность того, что количество требований
в системе N превысит заданную величину х, может быть представлена как
некоторая функция
178
Глава 5
( -1 А (7
Pr(/V > х) = Рг sup[Z(r) - ^==- И >
(/>о ylak J \-Jak J
\
ц - к
Jak
Если зафиксировать эту вероятность и положить равной наперед заданной
величине Pr(2V> х) = 8, то из вышеприведенного выражения следует
ц(// 2)//Z%(l-//)/// =fll/(2//)/-l(g) = const.
Полагая Н= 1/2, мы получаем случай СМО, близкой к М/М/1. Из вышепри-
веденного выражения следует, что
р
х = const " .
1 -Р
Это будет в точности совпадать с полученной нами ранее формулой для сис-
темы М/М/1, если полагать константу равной единице. Для нашего общего
случая самоподобного процесса получаем соотношение
х = constp’/^’-^l -р)-///<1-").
Если считать константу также равной единице, то результаты Нориса могут
быть интерпретированы как нахождение аналитического решения для систе-
мы fBM/D/1. Полагая по формуле Литтла N = кТ , можно найти оценку для
среднего времени пребывания требования в такой системе. В нормированном
виде она дается формулой
(//-1/2)/(1-//)
ЦГ= (1-р)/'/<'-") '
Для сравнения приведем следующие из полученных нами ранее выражений
аналогичные формулы для системы М/М/1:
и для системы M/D/1:
Если изобразить на одном графике нагрузочные кривые среднего времени
пребывания требований в системе для всех этих систем, то получится семей-
ство кривых (рис. 5.25), из которого следует, что при любой нагрузке система
с входным потоком заявок, имеющим характер самоподобного процесса, бу-
дет тратить на обработку больше времени, чем при отсутствии самоподобия,
т. е. в системе M/D/1.
Аналитические методы в теории телетрафика
179
..... М/М/1
-----fBM/D/1
-----M/D/1
Рис. 5.25. Определение среднего времени пребывания в системе
Особенно неожиданным для исследователей оказался тот факт, что время об-
работки превысило даже оценку, полученную в предположении экспоненци-
ального распределения времени обслуживания, т. е. для системы М/М/1. Ра-
нее считалось, и мы это видели при анализе верхней границы для СМО обще-
го вида G/G/1, что система типа М/М/1 дает самую завышенную оценку для
времени пребывания, по сравнению со всеми другими способами оценивания.
Приведенный на рис. 5.25 график был рассчитан для параметра самоподобия
Херста, равного 0,65. Можно видеть, что с ростом степени самоподобия зна-
чение времени пребывания становится еще больше. Таким образом, мы ана-
литическим путем показали, что наличие самоподобия в трафике пакетной
сети приводит к существенному ухудшению характеристик качества обслу-
живания по сравнению с любыми другими распределениями входного по-
тока.
Контрольные вопросы
1. Опишите вероятностную модель СМО. Приведите основные определения
и теоремы.
180
Гпава 5
2. В чем особенности вероятностной модели на основе непрерывных цепей
Маркова? В чем заключается "закон сохранения" для СМО?
3. Проанализируйте функционирование системы М/М/1 на основе процесса
"гибели-размножения".
4. Проанализируйте функционирование системы М/М/m. Проведите срав-
нительный анализ системы М/М/1 и М/М/п.
5. Опишите СМО с ограниченной длиной очереди. Какие новые вероятно-
стные характеристики вы узнали? В чем состоит принципиальное отли-
чие данной СМО от систем с бесконечной длиной очереди?
6. Объясните основную характеристику QoS-системы с полными потерями.
Как можно качественно определить эту характеристику?
7. Опишите модели Энгсета и Молина. Приведите их вероятностные харак-
теристики.
8. Почему СМО типа М/G/l не подходит под определение процесса "гибе-
ли-размножения"? Приведите основные формулы. Как эти результаты со-
гласуются с результатами, полученными для СМО типа M/G/l, M/D/1?
9. Опишите СМО типа G/G/1. Приведите основные характеристики данной
системы.
10. Найдите верхнюю и нижнюю границы для системы U/D/1.
ГЛАВА 6
Анализ
телекоммуникационных систем
Содержание этой главы, с одной стороны, можно рассматривать как набор
примеров, на которых иллюстрируется применение методов и результатов
теории телетрафика к решению важных практических задач в области теле-
коммуникаций. С другой стороны, весь представленный ниже материал со-
держит целый ряд результатов, которые сами по себе представляют ценность
для разработчиков сетей и систем и инженеров, эксплуатирующих такие сис-
темы.
Начнем наше изложение с простого примера выбора телефонного комму-
татора.
Расчет необходимого числа
соединительных линий
Предметом нашего рассмотрения будет телефонный коммутатор, который
предназначен для концентрации абонентской нагрузки и передачи ее в сеть.
Примером таких коммутаторов являются учрежденческие производственные
АТС, называемые УПАТС, а в зарубежной литературе — РВХ (Private Branch
exchange). Аналогичную методику расчетов можно применять и для расчета
оконечных АТС городской телефонной сети. Поскольку задачей рассматри-
ваемой системы является сбор нагрузки от подключенных к коммутатору
внутренних абонентов, осуществление собственно коммутации внутренних
звонков и передача от внешних абонентов к внутренним абонентам и обрат-
но, то она может быть представлена как СМО, обслуживающая потоки заявок
трех типов: внутренние, входящие и исходящие звонки. Нагрузка, создавае-
мая всеми тремя типами звонков, обычно определяется на основе прошлого
опыта построения подобных систем. В отечественной практике этот опыт
182
Глава 6
обобщен в руководящем документе РД 45.120-2000, принятом Министерст-
вом связи и информатизации РФ в качестве основного нормативного доку-
мента при проектировании сетей городской и сельской связи. В случае про-
ектирования ведомственной сети требования могут быть иными, но анало-
гичными.
Упомянутый документ содержит таблицу, в которой приводятся статистиче-
ски средние характеристики звонков различного типа (табл. 6.1).
Далее, нужно проанализировать долю внутренних, внутристанционных звон-
ков для того, чтобы исключить их из внешней нагрузки. В РД 45.120-2000
имеется таблица, позволяющая сделать это в зависимости от доли исходящей
нагрузки.
Теперь, если необходимо, можно найти исходящую и входящую нагрузки
раздельно и раздельно определить число входящих и исходящих линий по
заданной норме потерь— вероятности блокировки. Упомянутый документ
определяет нормативные потери таблицей, где данные приведены в десятых
долях процента (табл. 6.2).
Проделанные расчеты, использующие 5-формулу Эрланга, приводят к сле-
дующей таблице, определяющей нормативное число соединительных линий
для подключения УПАТС к городской телефонной сети (табл. 6.3).
Для меньшего числа абонентов сети РД предлагает эмпирическую формулу:
т = 4 + (N- 16)/8.
Очевидно, что она пригодна только для более шестнадцати абонентов.
Посмотрим, как эта формула согласуется с известными нам формулами
Эрланга и Энгсета. В соответствии с этими формулами число абонентских
линий нужно рассчитывать так, чтобы выполнялось соотношение
л
sum
..._____< ,/
т л к ~Ph
EAmm
L-\
к-Л)
при использовании формулы Эрланга и
при использовании формулы Энгсета. В первом случае имеется суммарная
внешняя нагрузкаХ1||Л = NA\, а во втором — только удельная нагрузка^,.
Анализ телекоммуникационных систем
183
Таблица 6.1. Статистически средние характеристики звонков различного типа
Время, используемое для расчета нагрузки I Утренний ЧНН Вечерний ЧНН Утренний ЧНН вечернее время* Вечерний ЧНН утреннее время* Дневной ЧНН Вечерний ЧНН Дневной ЧНН, вечер- ний ЧНН Вечерний ЧНН утреннее время
Средняя интенсивность исходящей нагрузки на 1 АЛ в ЧНН (у), Эрл 6-значн. нумерация 0,022 0,030 О о о о о o' 0,2 0,27 0,65 0,6
5-значн. ! нумерация 00 o' 0,025 2 S o' о" 0,15 0,2 0,65 0,6
Средняя продолжительность занятия (/), с 1 6-значн. нумерация 66 86 S о 76 93
5-значн. ( нумерация 99,6 100 чо о чэ сч ЧП 00 2 ° 1 1
Среднее количество вызовов в ЧНН на 1 АЛ (С) 6-значн. нумерация 0,8 — о сч "Г г— 2
5-значн. нумерация 0,65 0,9 3,5 1,1 7,5 8,0 1 1
Тип абонентской линии Индивидуального пользования (квартира) Народнохозяйствен- ного сектора: • "делового" района города • "спального" района города Таксофон местной ! СВЯЗИ Таксофон междуго- родный (исходящей связи) Районный переговор- ный пункт с серийным исканием
н/п сч СП "Г МП
184
Гпава 6
Время, используемое для расчета нагрузки Утренний ЧНН вечернее время Утренний ЧНН вечернее время Утренний ЧНН вечернее время
Средняя интенсивность исходящей нагрузки на 1 АЛ в ЧНН (у), Эрл 6-значн. нумерация 0,075 0,075 0,15 О ”
5-значн. нумерация 0,075 0,075 0,15 £ 2
Средняя продолжительность занятия (/), с 6-значн. нумерация 1
5-значн. нумерация 1 1
Среднее количество вызовов в ЧНН на 1 АЛ (С) 6-значн. нумерация 1
5-значн. нумерация
Тип абонентской линии Линии от малых У АТ С, подключаемых к станции на правах абонента Устройство передачи данных (соединение по телефонному алгоритму) Факс группы 2, 3 (соединение по теле- фонному алгоритму) Абонент ЦСИС, УПАТС ЦСИС-ОПТС • нагрузка на доступ (2B+D) • нагрузка на доступ (30B+D)
№ п/п 40 об
2 X § 3 § X X Си о Е
о 5 х те
X о
Ес s о X те
гг d) О- (jj1 э Си X
X те Си , о Q
05 X о те | + СО
те X 03 м 1 и н < S § 3 5 X и О 05 о £
О CL О 8 CL. X X m
X Z 1 d) X § g
5 О 1 1 &
ezi о 1 те
X * те гг t С О § X X i те
о О о£ СО о г
те g X Он -е- те X
о а Я и
Q. Е Z X те 1—< 05 X 5 8 ю о
05 X э g. '5Ь Q X X о X X те § S те те и S О
1 о X те 8 д
те 1
и d) и |
05 X X X те 05 8 ио "3 те Й) 05 те X § си Ё X X те и о О н ,и 05 X о ио Е &
03 d) о 05 X О
S/* с те X те
О $ X те )Х
X (ф * Й &
и X И d) S 1 те о
о ю 03 те S 1 те X те 8 ю
1 >х 5
1 и 3 |=; Cl.
я X X X и го X Q
те См и +
О- те s и X СО
05 X X и X о те Н < 1 гч тег
о X те 05 о X
1 о | те X сс э
CU О и те й § и н £ X и CQ & те £ те м X 5 X
X те < о X <<*
S О CQ и ° 5
о э те о О- -6- X а 05 X X X те те те X о Си Е О Е те d> м
Ё и S X те 8 те Q А 2 те
X О и X X г
X Cl. XT Ё и те и i §
X г. X £ О- м
X X и г> X о
и X X м Е( и о. си те X X о ю 1 °
X ю 03 Е? те 1 те те О Z У Q
X 1 г ) м С GO
со Q )Х и а 5 н < § Е °C те >»
X X те т те те о ю X О н < с 05 О О в § £ « о п ч s S
S S о. те X 05 те 8 X X S ю о те 5 5 X "Е
Е X ь О м X X о те
Анализ телекоммуникационных систем
185
Таблица 6.2. Нормативные потери
№ п/п Виды связи Суммарные потери вызовов от абонента до абонента, %о
На ГТС
1. При местной связи 20
2. При местной связи с УПАТС, с пригородной зоной 25
3. При внутризоновой связи 40/80*
4. Для абонентов (в том числе и абонентов СПС):
• от абонента ОПС до УСС; • от УСС до экстренной службы; • от УСС до справочно-информационных и заказных служб (муниципальных и других операторов); • от абонента до службы АМТС по ЗСЛ; • от УСС до служб доступа к федеральным сетям персо- нального радиовызова общего пользования (ПРВОП) 1 1 Должны быть не более 30 20 По согласованию с оператором
На СТС
5. При местной связи 30/70*
6. При внутризоновой связи 40/80*
7. Для абонентов (в том числе и абонентов СПС): • от абонента ОС до ЦС (УСС); • от ЦС (УСС) до экстренных спецслужб • от ЦС (УСС) до справочно-информационных и заказ- ных служб (муниципальных и других операторов); • от ЦС до службы АМТС по ЗСЛ; • от ЦС (УСС) до служб доступа к федеральным сетям персонального радиовызова общего пользования (ПРВОП) 10 1 Должны быть не более 30 10 По согласованию с оператором
Примечание. * — при взаимодействии проектируемой и существующей сетей.
Для расчета CJT, использующих ОКС № 7, пользоваться данной таблицей.
186
Глава 6
Таблица 6.3. Нормативное число соединительных линий для подключения
УПАТС к городской телефонной сети
Количество абонентов с правом выхода на сеть общего пользования Количество соединительных линий для УПАТС (УПАТС Э)
Промышленных предприятий и учреждений Административно-хозяйственных, проектных и научных организаций, гостиниц
Исходящие Входящие Исходящие Входящие
при наличии автоматической междугородной связи мест- ной связи между- город- ной связи при наличии автоматической междугородной связи мест- ной связи между- городной связи
100 6 5 3 7 7 3
200 9 9 4 И 10 4
300 12 11 4 15 14 5
400 14 13 5 17 16 6
500 17 15 6 21 19 7
600 19 17 6 24 22 7
700 22 20 6 27 25 8
800 24 22 7 30 28 8
900 27 24 7 33 30 9
1000 30 26 8 34 30 9
1500 42 36 10 50 44 12
2000 50 44 12 60 54 15
Примечание. При использовании интерфейса PRA количество универсальных двусторонних
линий (каналов В) определяется суммированием количества CJT (исходящих и входящих), ука-
занных в таблице.
Воспользуемся программными калькуляторами для этих формул. (Они име-
ются на нашем сайте или могут быть запущены с сайта www.erlang.com.) Мы
подобрали значение удельной нагрузки на абонента и вероятность блокиров-
ки так, чтобы результаты расчетов максимально приближались к расчетам по
эмпирической формуле. Получилось, что эмпирическая формула соответст-
вует удельной нагрузке на абонента в 0,03 Эрл, а норма потерь -задана веро-
ятностью блокировки в 0,002. Мы свели в таблицу полученные нами итого-
вые результаты. В ней также даны расчеты и для микроАТС с числом або-
нентов, меньше 16 (табл. 6.4).
Анализ телекоммуникационных систем
187
Таблица 6.4. Сравнение результатов расчетов соединительных линий
Количество абонентов Количество линий по эмпирической формуле Количество линий по формулам Эрланга/Энгсета
4 — 3/2
8 — 3/3
16 4 4/4
24 5 5/5
36 7 6/6
48 8 7/7
100 9 10/10
150 21 12/12
200 27 15/14
Тем самым мы подтвердили, что при использовании эмпирической формулы,
приведенной в РД 45.120-2000, будет обеспечено качество обслуживания не
хуже, чем при проведении расчетов по точным формулам. Однако нетрудно
видеть, что для числа абонентов от 100 до 200 количество линий может быть
сокращено по сравнению с предлагаемым по эмпирической формуле.
Анализ сетей массового обслуживания
Марковские сети без потерь
До сих пор рассматривались марковские системы, в которых каждая заявка
проходила только одну операцию обслуживания. Такие системы можно на-
звать однофазными. Если заявка получает обслуживание более чем в одном
сервере, то говорят о многофазных системах или о сетях массового обслужи-
вания (Queuing Networks). В общем случае каждый узел такой сети может со-
держать СМО определенного типа, а заявки способны поступать в сеть в раз-
личных точках и, получив обслуживание в одном узле, переходить на обслу-
живание в другой для дальнейшей обработки. При исследовании сети
необходимо задавать ее топологическую структуру, т. к. она определяет воз-
можные переходы заявок между узлами. Требуется также описать маршруты
отдельных заявок и вероятностные модели потоков заявок между узлами
сети.
Рассмотрим простейшую последовательную систему с двумя узлами
(рис. 6.1).
188
Гпава 6
Сразу обратим внимание, что это топологическая структура сети, а не диа-
грамма состояний. Предположим, что входной пуассоновский поток с интен-
сивностью Л, поступает на первый узел, в котором находится СМО типа
М/М/1 с сервером, имеющим показательное распределение времени обслу- '
живания со средним значением 1/ц. Будем считать, что второй узел состоит
из единственного обслуживающего прибора с показательным распределени-
ем времени обслуживания и с интенсивностью, также равной ц. Основная '
задача заключается в вычислении распределения промежутков времени меж- '
ду последовательными заявками, поступающими в узел 2, т. е. уходящими из /
узла 1.
Пусть d(f) — плотность распределения вероятностей промежутков между по-
следовательными заявками на выходе узла 1. Выразим эту функцию распре-
деления для двух случаев: когда при уходе заявки СМО не пуста и когда при
уходе заявки из СМО-1 в буфере не было другой заявки, т. е. СМО-1 пуста. ;
В первом случае следующая заявка появится на выходе сразу через интервал
времени обслуживания. Это событие будет происходить с вероятностью, рав-
ной 1 - ро (вероятность, что СМО не пуста). Следовательно, плотность веро-
ятности между выходами заявки из узла 1 будет совпадать с плотностью ве-
роятности времени обслуживания в сервере Ь(х). Для второго случая еле- ;
дующая заявка покинет сервер через интервал, равный сумме интервала j
между входными событиями и времени обслуживания. Это событие будет i
происходить с вероятностью, равной вероятности простоя системы, т. е. i
ро = (1 - р). Поскольку эти два интервала распределены независимо, то плот-
ность распределения вероятностей их суммы, как известно, равна свертке
плотностей распределения суммируемых случайных величин. Для ее вычис-
ления удобно воспользоваться преобразованием Лапласа. Обозначим преоб-
разование Лапласа для плотности вероятности суммы двух промежутков
времени — время до поступления следующего требования и время обслужи-
вания этого требования — как Do(s). Соответственно преобразование Лапласа
плотности распределения суммы равно произведению преобразований ис-
ходных плотностей распределения. Если обозначить преобразования Лапласа
для плотностей вероятности интервалов между событиями входного потока ;
A(s), а для времени обслуживания в сервере — B(.s'), то преобразование Лап-
Анализ телекоммуникационных систем
189
ласа плотности вероятности промежутка времени между выходными заявка-
ми для случая пустого узла 1 будет
A(s) = A(s)B(s).
Поскольку в системе М/М/1 распределения интервалов экспоненциальные
как для входных событий, так и для времени обслуживания, имеем:
Л(5) - [ ‘ke~iJe~xldt - ——;
о * + 7-
B(s) = \yLe^le-x,dt = -^-.
о S + V
Общее распределение интервала между выходными заявками можно записать
как
ад = (1 - р0 )B(s)+PoDo (5) = p-L+(1 - р)-\ .
Л' + Ц .S+AiS' + Ц Л' + А.
Следовательно, плотность вероятности распределения промежутков времени
между заявками, покидающими узел 1, является также случайной величиной
с показательным законом распределения с тем же самым параметром. Это
значит, что СМО типа М/М/1 превращает пуассоновский поток на входе в
пуассоновский поток на выходе с тем же самым параметром. Данный резуль-
тат называют теоремой Бёрке. Им было показано, что указанный факт имеет
место для всех СМО типа М/М/т. На основании этой теоремы можно иссле-
довать многофазные последовательностные схемы.
Для произвольной сети массового обслуживания результат получается более
сложным и выражается теоремой Джексона.
Рассмотрим сеть (рис. 6.2), содержащую Nузлов, причем каждый /-й узел со-
стоит из 777, серверов с показательным распределением времени обслуживания
с параметром р.,. В каждый узел извне поступает пуассоновский поток заявок
с интенсивностью у,. Покидая z'-узел, заявка с вероятностью Гу поступает ву-й
узел.
Обозначив Д полную интенсивность потока, поступающего в /-й узел, можно
показать, что должно выполняться условие баланса
/= 1,2, ...,2V.
/=|
Вероятность того, что заявка после обслуживания в i-м узле вообще покинет
N
сеть, будет равна 1 - .
190
Глава 6
M/M/mj
Рис. 6.2. Сеть из многих СМО
Выполнение условия эргодичности марковской модели каждого узла будет
обеспечено, если Л, < /77,ц,.
Джексоном было доказано далеко не тривиальное утверждение, что каждый
узел в сети ведет себя так, как если бы он был независимой СМО типа М/М/т
с входящим пуассоновским потоком Л,. В общем случае полный входящий
поток не является пуассоновским. Состояние сети с N узлами описывается
вектором, компонентами которого являются количества заявок в каждом из
узлов сети (ki, к2, ..., кД
Джексону удалось доказать, что стационарная вероятность этого состояния
раскладывается в произведение безусловных распределений
р(к\, к2, ..., kN) =P\(k})p2(jc2)...p^kN),
которые представляют собой стационарные вероятности для классической
системы М/М/т. Этот удивительный результат называется теоремой Джек-
сона.
Исследование сети с помощью изложенной здесь методики приводит к гро-
моздким системам уравнений для определения интенсивностей входных по-
токов. Опытным путем было показано, что для получения многих результа-
тов вместо условий глобального равновесия для сети в целом можно приме-
нять условия локального равновесия для отдельных подсистем, что позволит
сильно упростить задачу.
Определим систему уравнений локального равновесия как систему уравне-
ний, в которых интенсивность потока из данного состояния сети за счет ухо-
да заявок из узла i приравнивается к интенсивности потока в данное состоя-
ние сети за счет поступления требований в узел /. Покажем это на примере
(рис. 6.3).
Анализ телекоммуникационных систем
191
Рис. 6.3. Замкнутая сеть стремя узлами
Пусть в замкнутой сети с тремя (N = 3) узлами циркулируют два требования
(К = 2). При этом
Г)2 = = Г31 = 1, Гц - О
для остальных индексов. Состояние сети описывается тройками: (к\, кг, кз),
причем к{ + кг + кз = 2. Всего в сети возможно J;-i = С42 = 6 различных со-
стояний. На рис. 6.4 изображена диаграмма интенсивностей переходов между
этими состояниями.
Рис. 6.4. Диаграмма интенсивностей переходов для сети, приведенной на рис. 6.3-
Если записать систему уравнений глобального равновесия, то она будет со-
стоять из шести уравнений, одно из которых обычно избыточно из-за суще-
ствования условия нормировки1:
ц3/>(2, 0, 0) = щрО, 1, 0);
PiXO, 2,0)==ц2Ж U);
1 Поэтому приводятся только пять уравнений.
192
Глава 6
giXh 1, o) +Ц3р(1, 1,0) = ЦзАЬО, 1) + Ц1р(0, 2, 0);
|Д.2/?(О, 1,1) + Ц1/?(0, 1,1) = (-12^(0, о, 2) + ЦзХ1, 1, 0);
цзХ 1,0, 1) + Ц2/Х 1,0, 1) = Ц|р(О, 1,1) + Цз^(2, О, 0).
В каждом из этих уравнений левая часть соответствует потоку, исходящему
из данного состояния, а правая — потоку, входящему в это состояние.
С точки зрения локального равновесия первые три уравнения именно такими
и являются. В остальных уравнениях видно, что первое слагаемое правой
части уравновешивается первым слагаемым левой части. И также для вторых
слагаемых.
Следовательно, уравнения локального равновесия могут быть выписаны так:
Ц1Р(1, 1, 0) = р-з/Х 1,0, 1);
ЦзХ1, 1,0) = Ц1/Х0, 2, 0).
Первое из этих уравнений описывает локальный баланс для узла 1, а вто-
рое — для узла 2. Всего образуется девять уравнений локального равновесия,
из которых четыре избыточны. Решение дается следующими формулами:
р(1,0,1) = — р(2,0,0);
Ц2
XI, 1,0) = —Ж 0,0);
Pi
/Х0,1,1) = ^-Х2,0, 0);
Р1Х
j9(2, 0,0) =
/ V / у
! Из , Рз , (и2) , Рз
ц2 Ц| Ц,Ц2 1^2,
Как видно, решение уравнений локального равновесия отыскать значительно
проще. В любом случае поиск стационарных вероятностей сводится к реше-
нию больших систем линейных уравнений.
Анализ телекоммуникационных систем 193
Заметим еще раз, что рассмотренные сети массового обслуживания удовле-
творяли свойствам эргодической марковской цепи.
Сети с блокировками (потерями)
Рассмотренный выше марковский подход к анализу сетей массового обслу-
живания позволяет рассчитать вероятности состояний для сетей с узлами,
которые являются СМО типа М/М/т. При этом предполагается, что каждый
узел содержит бесконечный накопитель, и все заявки будут обслужены через
некоторое время. Другой постановкой задачи является анализ сети с узлами,
в которых может быть СМО с блокировкой заявок. Часто такими СМО вы-
ступают коммутационные схемы, имеющие конечные пучки соединительных
линий. Другой моделью являются сети с множественным доступом к фикси-
рованному числу каналов.
Рассмотрим в качестве примера (рис. 6.5) подключение сельского абонента С
через абонентскую линию с блокиратором в пункте В к сельской АТС, кото-
рая, в свою очередь, имеет два канала связи с АТС в пункте А. Требуется оп-
ределить вероятность блокировки звонка абоненту С из пункта А. Поставим
в соответствие рассматриваемой сети так называемый вероятностный граф
(граф Ли), с вершинами А, В и С и ребрами а, Ъ, с, соответствующими пото-
кам заявок. Будем называть их далее звеньями и параметризовать значениями
некоторых вероятностей их занятия.
Рис. 6.5. Соединение абонента С с абонентом А через АТС В
Метод Ли состоит в том, что вероятность блокировки пути между любыми
вершинами графа может быть рассчитана как вероятность совместного заня-
тия всех соединяющих эти вершины звеньев в предположении, что вероятно-
сти занятия каждого из звеньев независимы.
Вероятность совместного занятия может быть рассчитана с помощью извест-
ных теорем теории вероятностей для сложных событий.
Обозначим вероятности занятия звеньев а, Ь, с соответственно w£„ wh, wc.
7 Зак. 3884
194
Гпава 6
Вероятности того, что звено свободно, можно найти как
qa = 1 -
Ць = 1 - w/,;
qc = 1 - Не-
вероятность блокировки пути АВ будет определяться как совместная вероят-
ность занятости а и b: wclW/>.
Вероятность свободное™ этого пути: 1 — waw/>.
Общая вероятность свободное™ пути АС будет
(1 - wawh) • qc = (1 - • (1 - иу).
Тогда вероятность блокировки пути АС будет
Рв= 1 -(1
Граф, рассмотренный здесь, относится к классу параллельно-последова-
тельных. Для расчета вероятностей таких графов в общем случае применя-
ются простые правила, сведенные в табл. 6.5.
Таблица 6.5. Правила для расчета вероятностей
параллельно-последовательных графов
Характеристика Правило
Вероятность занятости (блокировки) и; = 1-7,
Вероятность свободности(неблокированности) Q, = । - Л’;
Параллельное включение звеньев ip = 1Р] • ip2 • и;. 1Р„
Последовательное включение звеньев q = Ql-Q2-ql -ч„
Бывают случаи, когда граф сети не сводится к параллельно-последова-
тельным схемам. Например, мостиковый граф (рис. 6.6).
vu2
vu2
Рис. 6.6. Мостиковый граф
Анализ телекоммуникационных систем
195
Для такого графа можно получить вероятность блокировки пути АВ в виде
Рн(АГ) = 0 - W2 )2 [Wl + W2 0 - Vt'l )] + 2м'з С - И?3 ) [WI + М>2 (1 - W, )]2 +
Графы типа приведенных выше часто встречаются при анализе многозвенных
коммутационных схем. Там они имеют более сложный вид, например, как на
рис. 6.7 и 6.8.
Рис. 6.8. Пример не параллельно-последовательного графа
Для этих графов можно получить явные выражения для вероятности блоки-
ровки пути АВ\
□ для рис. 6.7 =>р^А1Г) = 1 -{1 -[1 -(1 - W| )(1 -w,)]'"'}(1 -М'з);
п,2
□ для рис. 6.8 => рВ(АВ) = £С*2 w^--k (1 - И'зУ [w, + W2 (1 - И', .
к=0
В том случае, если граф получается слишком сложным, можно пользоваться
методом оценочных графов. Строятся граф оценки сверху путем разделения
вершин и отбрасывания ребер для упрощения расчета и граф оценки снизу
путем объединения части вершин. Рассчитываются вероятности блокировки
для оценочных графов, которые станут служить соответственно верхней и
нижней границами, между которыми и будет находиться значение вероятно-
сти блокировки для исходного графа.
196
Гпава 6
Анализ и оптимизация коммутационных систем
Простейшая коммутационная система— это однофазная (однозвенная) схе-
ма, называемая коммутатором. Коммутатор имеет п входов и т выходов,
каждый из которых может быть соединен с любым входом (рис. 6.9).
Входы
1 2 п
1
2
3
т
Выходы
Рис. 6.9. Простейший коммутатор
Выходы иногда объединяются в группы, которые определяют так называе-
мые направления.
Коммутатор может быть неблокирующим, если выполнено соотношение
п < т, и блокирующим в противном случае. Блокируемость коммутатора оп-
ределяется невозможностью части входов получить доступ ни к одному из
выходов. Блокируемость может быть общей, когда все выходы рассматрива-
ются равнозначными, и в определенном направлении, когда недоступными
оказываются все выходы данного направления.
Важнейшей характеристикой коммутационной системы является число точек
поля коммутации— управляемых точек соединения. Для коммутатора оно
равно
С = пят.
Например, для коммутатора 8x8 число точек коммутации равно 64. Это озна-
чает, что реализующая данный коммутатор электрическая цепь должна со-
держать 64 независимых контакта— электронных ключа. Для АТС на
10 000 абонентов реализация в виде простого коммутатора привела бы к не-
обходимости построения цепи с 100 000 000 ключей.
В современной технике коммутационных систем применяются две основные
технологии коммутации — пространственная и временная. Первая из них
основана на реальных матрицах электронных ключей, а вторая использует
временное мультиплексирование входных потоков и последующее перекре-
Анализ телекоммуникационных систем 197
стное демультиплексирование. В любом случае число точек коммутации,
пространственных или временных, ограничивается полупроводниковой тех-
нологией, возможностями теплоотвода и стоимостными факторами и требует
снижения. В связи с этим для построения систем коммутации со многими
входами и выходами применяют многозвенные схемы, которые позволяют
обеспечить управляемое соединение входов и выходов, используя меньшее,
чем в простом коммутаторе число точек коммутации.
Многозвенные системы кроме коммутаторов содержат фйксированные со-
единения между ними, называемые промежуточными линиями (ПЛ).
Таким образом, анализ многозвенных коммутационных схем относится к
анализу сетей массового обслуживания и может проводиться описанными
выше методами.
Здесь мы рассмотрим один специфический метод анализа, который применим
при малом числе звеньев, но дает весьма точные результаты. Это комбина-
торный метод Якобеуса. Покажем применение данного метода на примере
двухзвенной коммутационной системы с полнодоступным включением ПЛ
(рис. 6. Ю).
Количество выходов из каждого коммутатора звена в этой схеме для направ-
ления с номером j равно 1. Будем считать, что к рассматриваемому моменту
вызов поступил на один из входов схемы. Например, на второй вход первого
коммутатора. Установление соединения через схему заключается в использо-
вании одной из свободных ПЛ и одного из свободных выходов требуемого
направления, взаимно доступных друг другу. Для обслуживания поступивше-
го вызова могут быть использованы т ПЛ и т выходов требуемого направле-
ния. Блокировка наступит в трех случаях:
□ заняты все ПЛ, которые могут быть использованы для обслуживания;
□ заняты все выходы в требуемом направлении;
□ комбинация свободных ПЛ и свободных выходов требуемого направления
не является взаимно доступной.
Если вероятность занятия любых i из т промежуточных линий, принадлежа-
щих коммутатору первого звена, обозначить W„ а вероятность занятия опре-
деленных т - i выходов (соответствующих свободным ПЛ) обозначить через
то, в соответствии со сказанным, вероятность блокировки схемы может
быть записана как
т
P8=ZW^-
г-0
Метод Якобеуса предполагает, что события, определяемые этими вероятно-
стями, независимы и могут быть заданы распределениями Эрланга или Бер-
нулли.
198
Гпава 6
Рис. 6.10. Пример двухзвенной коммутационной системы
При распределении Эрланга вероятность занятия i серверов в пучке из ш сер-
веров при интенсивности нагрузки на пучок, равной А, принимается равной
значению 5-функции Эрланга
Анализ телекоммуникационных систем
199
Вероятность занятия m- i фиксированных серверов из пг серверов в пучке
может быть рассчитана из следующих соображений. Зафиксируем опреде-
ленные z серверы из т доступных и предположим, что их занятие происходит
равновероятно. Тогда, если в системе с вероятностью pi+/ занято i+j серве-
ров, то вероятность занятия одной определенной комбинации будет в число
сочетаний раз меньше:
P,+J
Ci+J
^tll
Поскольку зафиксированные серверы могут быть заняты с любыми другими j
серверами в соответствующем числу сочетаний комбинациях, то можно по-
лучить формулу для вероятности занятия фиксированных i серверов из пг.
/7. = У
./ = 0 '
Подставляя выражение для вероятности занятия / + / серверов по 73-формуле
Эрланга, получаем:
А р'*' Д(и,р)
Так как нам необходимо знать вероятность занятия in- I серверов, полу-
чаем:
, = = В(т,А) =
В(гп -(jn -1). A) '
Если использовать распределение Энгсета для вероятностей занятия серве-
ров, то при равенстве числа серверов и количества источников трафика для
вероятностей занятия фиксированного числа серверов получается так назы-
ваемое распределение Бернулли.
Подставим в формулу Энгсета М= т. При этом
Pk =
С*,А*
III
i=Q
сУ
(1+р)*
x"i/< к /1 . \in-k
= Ста(\-а)
р X
а =----: =-----.
1 + р X + ц
Параметр распределения Бернулли а имеет смысл вероятности занятости сер-
вера, а величина 1 - а — вероятности его простоя.
200
Гпава 6
При использовании распределения Бернулли для задания вероятности любых
i серверов из т устройств соответствующие вероятности могут быть опреде-
лены как
Ч=С'р(1-рГ',
Здесь в качестве р выступает средняя нагрузка на одну линию в пучке.
Использование в формуле для вероятности блокировки различных распреде-
лений требует дополнительных предположений.
Если коммутаторы первого уровня имеют равное число входов и выходов
(схема без сжатия и расширения), то для ПЛ можно принять распределение
Бернулли. Если для выходов двухзвенной схемы также принять распределе-
ние Бернулли, считая, что количество коммутаторов первого звена неболь-
шое, то можно подсчитать вероятность блокировки по формуле:
т
Рв = 0 - тТ~' ~(b + c-Ьс)'".
i=0
Здесь приняты обозначения: Ъ — средняя интенсивность нагрузки, обслужи-
ваемой одной ПЛ, Эрл; с — средняя интенсивность нагрузки, обслуживаемой
одним выходом рассматриваемого направления, Эрл.
Если число коммутаторов первого звена достаточно велико, то целесообразно
для выходов данного направления принять распределение Эрланга, и тогда
подстановка в формулу вероятности блокировки дает:
/ М
„ V»-'. b'" В(т.А')
Рв ,11 j./° / L-i ц с л у
,=оу£_ уР_,=о I- в\т,-\
,^7! I Ъ)
Если для образования каждого направления в каждом коммутаторе второго
звена отводится не один, a q выходов, то в модели Бернулли для выходов
можно получить формулу:
b + c-bc4 \ .
А в модели Эрланга для выходов:
B(mq, А)
а
B\mq,— I
Анализ телекоммуникационных систем
201
При наличии сжатия в звене первого уровня можно считать пригодной мо-
дель Бернулли для первого звена и модель Эрланга для второго. Тогда веро-
ятность блокировки может быть определена по формуле
В схемах с расширением, т. е. когда количество выходов в коммутаторах пер-
вого звена превышает число входов, можно рассчитать вероятность блоки-
ровки по формуле
B(mq, А)
Р“=1Г^\
В nq,~~
I a J
Здесь символом а обозначена средняя интенсивность нагрузки, обслуженной
одним входом коммутатора первого звена.
Таким образом, мы получили ряд формул для расчета вероятности блокиров-
ки двухзвенной системы коммутации.
Теперь перейдем к анализу более сложных коммутационных схем. На прак-
тике в электронных системах часто используется трехзвенная схема комму-
тации (рис. 6.11).
Ступень 1 Ступень 2 Ступень 3
Рис. 6.11. Трехзвенная коммутационная система
Схема содержит N/n входных и N/n выходных коммутаторов, образующих
соответственно первую и третью ступени коммутации. Вторая ступень ком-
мутации состоит из к квадратных коммутаторов с N/n входами и выходами.
С помощью ПЛ каждый выход коммутатора первой ступени соединяется с
разными коммутаторами второй ступени, так что подключаемый вход соот-
ветствует месту коммутатора первой ступени. Иначе говоря, выходы первого
202
Гпава 6
коммутатора первой ступени подключаются к первым входам коммутаторов
второй ступени, выходы второго коммутатора— ко вторым входам всех
коммутаторов второй ступени и т. д. Аналогично соединяются через ПЛ вы-
ходы коммутаторов второй ступени со входами коммутаторов третьей.
Если подсчитать число точек коммутации для этой схемы, то его можно вы-
разить формулой:
С = 2 — \пк + к — =2Nk + k\ — \ .
\ n J \ J \ n)
При надлежащем выборе параметров n wk сложность коммутационной схемы
может быть существенно ниже, чем при однозвенном построении, когда ко-
личество точек коммутации в точности равно NxN.
Обеспечивая выигрыш в количестве точек коммутации, многозвенная схема
может, как было показано на примере двухзвенной структуры, привести к
возникновению блокировок. Для трехзвенной схемы условие неблокируемо-
сти было получено Ч. Клосом:
к = 2п - 1.
Вывод этого соотношения проводится из простых рассуждений в предполо-
жении занятости п - 1 входов коммутаторов первой и третьей ступеней. По-
скольку при этом будут заняты и - 1 коммутаторов второй ступени, то для
установления и-го соединения необходим еще один коммутатор второй сту-
пени. Отсюда
к = (и -1) + (ф - 1) + 1 = 2п -1 .
Число точек коммутации для неблокирующей трехзвенной схемы будет
равно
/ \2
Cnoblock=2M2«-l) + (2"-l) - •
\п )
Количество коммутаторов в первой и третьей ступенях также можно выбрать.
Попытаемся минимизировать число точек коммутации, варьируя количество
входов п. Дифференцируя по п и решая уравнение, получим:
3
Copt «4^.
Очевидно, что это существенно меньше, чем NxN для однозвенной схемы.
Например, при N= 100 000 для однозвенной схемы число точек коммутации
составило бы фантастическое значение 1О10. Для трехзвенной неблокирую-
Анализ телекоммуникационных систем
203
щей схемы оно составит около 1,7-108. Еще большей экономии в сложности
схемы можно достигнуть, применяя многозвенные схемы с блокировкой, но
на очень низком уровне.
Для анализа таких схем применяют метод Якобеуса и более простой метод
вероятностных графов Ли. Рассмотрим пример такого анализа для приведен-
ной выше трехзвенной схемы.
На рис. 6.12 представлен вероятностный граф, отражающий две группы кана-
лов, которые должны соединяться друг с другом. Блокировка может возник-
нуть, если k < 2п - 1. Кроме того, будем считать, что в системе не использу-
ется концентрация, т. е. к> п, и блокировка входных или выходных коммута-
торов исключена.
Рис. 6.12. Граф Ли для трехзвенной схемы коммутации
Если положить вероятность занятия входного канала равной значению пара-
метра биноминального распределения, который, как было показано ранее,
определяется через параметр входного потока и среднее время обслуживания
и» — 7
А. -г ц
и предполагаемая нагрузка будет распределена равномерно между всеми
коммутаторами промежуточного звена, то вероятность занятия ПЛ будет
равна
ап
w = —.
к
В соответствии с полученной выше формулой для графа Ли с параллельно-
последовательной структурой можно сразу записать
=[i-(i-^)2]
I't
204
Гпава 6
Нужно заметить, что эта вероятность не равна нулю даже при выполнении
условия неблокируемости Клоса. Это говорит о погрешности формул, полу-
чаемых с помощью графов Ли.
Приведем таблицу для сравнения результатов расчета вероятности блокиров-
ки трехзвенной схемы методом графов Ли и метода Якобеуса (табл. 6.6).
Таблица 6.6. Результаты расчета вероятности блокировки трехзвенной схемы
методом графов Ли и метода Якобеуса
п к Рв по Ли Рв по Якобеусу
64 64 0,002 0,002
64 68 0,0002 0,00016
64 72 1,5хЮ“5 6,2x10'6
64 76 8х10“7 1,5x10'7
120 128 10~7 3,5x10'8
240 256 10“'4 1,3х 10'15
Из анализа полученных результатов видно, что метод Ли дает несколько за-
вышенную оценку, особенно заметную для больших размеров коммутацион-
ной схемы.
Сравнение характеристик QoS
в коммутируемых сетях
Коммутируемые сети можно разделить на сети с установлением соединения и
с коммутацией дейтаграмм. К сетям с установлением соединения прежде
всего относятся традиционные телефонные сети. Чтобы поговорить с кем-
либо, нужно поднять трубку, набрать номер, а по окончании разговора поло-
жить ее. Первые два действия относятся к фазе установления соединения, а
последнее— к фазе разъединения. По этому принципу построены сети пере-
дачи данных, использующие протокол Х.25. Чтобы подключиться к Х.25,
компьютер устанавливает соединение с удаленным компьютером, т. е. со-
вершает телефонный звонок. Этому соединению присваивается уникальный
номер, по которому и определяется место назначения передаваемых затем
пакетов. В данной сети может существовать одновременно много таких со-
единений. Развитием протокола Х.25 явились сети с технологией ретрансля-
ции кадров (Frame Relay). В последнее время развитие технологий с установ-
лением соединения привело к появлению сетей с несколько странным назва-
Анализ телекоммуникационных систем
205
нием: асинхронный режим передачи (Asynchronous Transfer Mode, ATM).
Причиной этого наименования был отказ от принятого в цифровых телефон-
ных сетях синхронного, жестко привязанного ко времени, принципа передачи
всех байтов, относящихся к каждому каналу. В сетях ATM осуществляется
передача пакетов по так называемым виртуальным каналам. представляю-
щим собой соединения с уникальными идентификаторами.
Мы рассмотрим сравнение сетей с установлением соединения с сетями, где
соединение не устанавливается. Сети, использующие такие технологии, часто
называют дейтаграммными. В них каждый пакет имеет адрес назначения,
который используется маршрутизаторами сети для перенаправления посылки
каждого пакета в отдельности по наилучшему пути с точки зрения данного
узла сети в данный момент времени. Поэтому пакеты, относящиеся к одному
и тому же сообщению, могут передаваться каждый по своему маршруту,
приходить не в том порядке, в каком были переданы, и, возможно, теряться в
дороге. Шуточная формулировка принципа работы таких сетей такова: "По-
слал пакет, и молча стой, авось дойдет".
Время доставки пакетов по сети
с установлением соединения
в модели коммутации каналов
Передача данных по сетям с коммутацией каналов осуществляется в три фа-
зы: установление соединения, передача данных, разъединение. Для реализа-
ции этих процессов применяется система сигнализации. На рис. 6.13 упро-
щенно показаны сигнальные сообщения, которыми обмениваются абоненты и
коммутационные узлы в процессе передачи.
Передача сигнала может осуществляться как по специальному общему для
всех коммутируемых каналов, каналу сигнализации (ОКС), так и в полосе ба-
зового канала, по которому передаются информационные сообщения. Рас-
смотрим сначала последний случай. Найдем время установления соединения,
которое будет являться функцией нагрузки в сети, длины управляющих и
информационных сообщений, интенсивности передачи сигнальных сообще-
ний и данных (скорости передачи), а также числа каналов, предоставленных
для связи. Рассмотрим модель сети с коммутацией каналов в виде системы
обслуживания, в которой вызовы ожидают освобождения каналов, а не бло-
кируются. Отбросим на этом этапе проблему маршрутизации, предположив
сеть полносвязной. На рис. 6.14 показана модель СМО, соответствующая
сделанным предположениям. Два узла коммутации А и В связаны между со-
бой N каналами (СЛ) с пропускной способностью С/,, бит/с. Пусть это также и
скорость передачи по абонентскому шлейфу. С этой скоростью данные будут
206
Гпава 6
передаваться по каналу после установления соединения. Вызовы от абонент-
ских устройств поступают на узел А и находятся в очереди, пока не станет
свободным хотя бы одна СЛ до узла В.
Процессор узла или
искатель, начинающий
установление
соединения
Рис. 6.13. Установление соединения в сети с коммутацией каналов
Абонентские
устройства
N канальных соединительных
Рис. 6.14. Модель системы обслуживания для сети с коммутацией каналов
Анализ телекоммуникационных систем
207
На рис. 6.15 показаны все составляющие времени Тс— времени установления
соединения от момента передачи сообщения запроса до момента приема со-
общения о начале передачи. Временем на соединение узла В и получателя
пренебрегаем. Показанные отрезки времени нужны для передачи каждого из
сигнальных сообщений, обработка в узлах А и В требует в каждом случае
среднее время Т . Среднее время ожидания в очереди в узле А до освобож-
дения одного из N каналов обозначено W .
Время установления соединения, Тс
Посылка
вызова
Обработка
в узле А
Время
ожидания
Сообщение
о
соединении
Обработка
в узле В
Ответное
сообщение
Обработка
в
узле А
Начало
передачи
TSR Т0 ™ Tl Т0 TR С TS
ЬК р I р г( р о
Рис. 6.15. Составляющие времени установления соединения
Теперь примем для простоты, что каждое сигнальное сообщение имеет одну
и ту же длину и требует времени передачи Т$. Время передачи сообщения
о соединении примем равным 7}. При таком упрощении время соединения
равно:
тс =зт; + т; +зт; + w.
Для расчета среднего времени ожидания М<W> воспользуемся моделью
системы обслуживания типа M/M/N с бесконечной длиной буфера и N серве-
рами. Предположение о пуассоновском распределении потока вызовов явля-
ется, как правило, адекватным в задачах со многими абонентами, допущение
о показательном распределении времени обслуживания существенно более
грубое, однако описание времени обслуживания статистикой общего вида
сильно усложнит задачу.
Пусть интенсивность потока вызовов в узел А равна X, а среднее значение
времени обслуживания— I/ц. Тогда можно использовать модель M/M/N со
следующими характеристиками интенсивностей переходов
л,, — л,
ц„ = др; и < N,
р„ = Лфц и > N.
208
Гпава 6
Здесь п— состояние СМО, т. е. количество установленных соединений,
включая обслуживаемый вызов. Решение уравнений равновесия для данной
системы было приведено ранее. Введя параметр
X
Р = — ,
цУ
стационарные вероятности состояний определяем как
Р„
(W .
, Pq>
n<N,
Po =
Wp)" , 1 , (W)"
n! 1-p N\
Теперь можно определить все необходимые характеристики качества обслу-
живания. Найдем сначала вероятность того, что сообщение будет задержано
в системе, т. е. заявка не найдет свободного сервера. Очевидно, что эта веро-
ятность равна
СО
^1/ — Рп ~
n=N
W" А
(1-р)?/!
Мы ранее получали эту формулу. Она известна как С-формула Эрланга:
P№=C(N, pN).
Обратите внимание, что вторым аргументом в С-формуле Эрланга является
полная нагрузка на пучок каналов, а не удельная нагрузка р< 1. Будем для
определенности обозначать далее полную нагрузку А = pN. Эта нагрузка, ко-
нечно, также измеряется в эрлангах.
Рассмотрим пример. Пусть нагрузка на узел Х/ц = 0,8 и в одном случае узел
имеет один исходящий канал (N= 1), а в другом— пять (N= 5). Вычислим
С(1,0,8) = 0,8 и С(5, 0,8) = 0,0018. Таким образом, применение пяти каналов
вместо одного сокращает вероятность задержки более чем в 400 раз.
Найдем теперь среднее число сообщений, ожидающих обслуживание. Оно
равно разности между средним числом сообщений в системе и средним чис-
лом сообщений, находящихся на обслуживании:
т= Ё nPn~N Y Pn=-^~C(N,A).
n=N+l * P
Анализ телекоммуникационных систем 209
В качестве подтверждения правильности сделанного вывода можно найти
значение среднего числа ожидающих сообщений для N= 1. Оно получится в
точности таким, как было выведено ранее для СМО типа М/М/1:
Теперь найдем среднее число и сообщений, находящихся в системе и число
s сообщений, находящихся в обслуживании. Вычисление показывает, что
п - in + s,
s = Np = А.
Пользуясь формулой Литтла теперь можно найти задержку Т (время пребы-
вания) в узле и среднее время W ожидания для сообщения
I C(N,A)
Для иллюстрации вернемся к рассмотренному ранее примеру. Пусть А = 0,8.
При N = I получим, что среднее время ожидания составит
W = \/р^- = 4/р,
0,2
а средняя задержка
Т = 5/ц.
При среднем времени занятия канала 1/ц=106с получим W = 0,4х Ю“бс,
Т = 0,5x10-6с. Если теперь увеличить число исходящих каналов до пяти, то
при тех же предположениях будем иметь W = 0,004/ц = 4х 10~9с . Таким об-
разом, применение многоканальной системы резко снижает время ожидания
обслуживания.
С другой стороны, интересен вопрос о целесообразности разделения одного
канала фиксированной пропускной способности на несколько менее произво-
дительных каналов.
Пусть имеется канал с пропускной способностью 2,048 Мбит/с, и нужно ре-
шить, стоит ли разделить его на 32 канала по 64 Кбит/с. Предположим, что
210
Гпава 6
1/ц= 10 мс, т. е. сообщения имеют среднюю длину 640 битов. Средняя за-
держка при нагрузке А = 0,8 при пяти каналах будет равна
-=101£(5Л8) =
5-0,8
Если же использовать один двухмегабитный канал, значение среднего време-
ни ожидания будет равно W = 24 мс , что существенно меньше. Таким обра-
зом, один канал с большей пропускной способностью предпочтительнее, чем
составленный из каналов с меньшей пропускной способностью для передачи
некоторого заданного объема пакетов данных.
В случае передачи сообщений по сети с коммутацией каналов собственно
время передачи пакета данных Ты представляет собой только одну из состав-
ляющих и для определения величины среднего времени обслуживания 1/ц
необходимо учитывать все составляющие времени занятия канала. Опреде-
лим среднее значение этого полного времени занятия канала:
д, =1/ц = 4д+?;+4?;+д7.
Данная формула соответствует временной диаграмме занятия канала, изо-
браженной на рис. 6.16 в предположении, что все сигнальные сообщения
имеют одну и ту же длительность Ts.
Продолжительность занятия, Тн
Сооб- щение о соеди- нении Обра- ботка в узле В Отмена сооб- щения Обра- ботка в узле А Начало передачи Информ, сооб- щение Отбой Обра- ботка в узле А Сооб- щение о разъ- единении Обра- ботка в узле В
т, д тв т р тм ^со т р ~тР
Сигнализация и обработка Время разъединения
Дэнныв
Рис. 6.16. Составляющие времени занятия канала
С уже сделанной оговоркой о предположении экспоненциальности распреде-
ления этого времени (из формулы видно, что это сумма случайных величин)
будем использовать полученное ранее соотношение для расчета среднего
времени ожидания обслуживания:
N-А 11
Анализ телекоммуникационных систем
211
где
А = \ТН.
Введем величину, определяющую параметр удельного полезного использо-
вания канала pw = ХТщ/N. Этот параметр отличается от обычного коэффици-
ента использования p = ,kTH/N, который не различает время на передачу ин-
формационного сообщения и время на передачу сигнальных сообщений.
Рис. 6.17. Нормированное время установления соединения для N = 10 каналов
Рассмотрим зависимость нормированного времени установления соединения
в сети с коммутацией каналов Тс/Тм от параметра удельного полезного ис-
пользования канала при различных длительностях передачи сигнальной ин-
формации. Примем для определенности время передачи сообщения о соеди-
нении 7} = 0,1 Тм. Обозначим rsig время для передачи всех других сигнальных
сообщений (4Тф. Пусть узел имеет N= 10 исходящих каналов. На рис. 6.17
приведены две нагрузочные кривые, позволяющие проанализировать некото-
рые характерные черты сети с установлением соединения. Графики построе-
ны для двух случаев — когда значение времени для передачи сигнальных со-
общений rsig различаются в десять раз. Значение длительности сообщения
о соединении полагалось в десять раз меньшим, чем время передачи пакетов:
7} = 0,17м- Как видно из графиков, такое различие приводит к разным пре-
дельным значениям параметра полезного использования канала от 0,67
212
Глава 6
до 0,88 при меньших в десять раз длительностях сигнальных пакетов. Также
видно, что увеличение нагрузки на узел сначала медленно, а затем резко уве-
личивает время установления соединения, причем сокращение сигнальных
сообщений в любом случае уменьшает это время.
Время доставки в сети
без установления соединения
в модели с коммутацией пакетов
Теперь перейдем к рассмотрению сети с передачей данных, не ориентирован-
ной на соединение. В такой сети каждый пакет доставляется индивидуальным
маршрутом, и передача пакета считается завершенной только после получе-
ния подтверждения о его приеме. На рис. 6.18 приведен фрагмент сети, со-
стоящий из двух узлов и соединяющих их дуплексных каналов. Для сопоста-
вимости результатов с сетью с коммутацией каналов будем считать полную
интенсивность потока во входящем узле равной X, пропускную способность
дуплексного канала между узлами положим равной Ст = NC/. в каждом на-
правлении, где величина Clt определяет максимальную скорость доступа к
узлу от конечного пользователя (пропускная способность абонентской ли-
нии). В этой сети принципиально отсутствуют расходы времени на установ-
ление соединения, однако в качестве накладных расходов выступает время на
Абонентские шлейфы,
пропускная способность, К другому
CL бит/с узлу
Очереди пакетов 3. 3
Рис. 6.18. Фрагмент сети без установления соединений
Анализ телекоммуникационных систем
213
получение подтверждений о приеме пакета. Рассмотрим два способа переда-
чи подтверждений. Первый состоит в передаче от узла отдельных пакетов с
информацией о подтверждении, а второй предполагает, что в информацион-
ные пакеты обратного направления встраиваются специальные поля битов
подтверждения о приеме пакетов встречного направления.
Рассмотрим сначала первый способ. Пусть каждый принятый пакет генери-
рует отдельное подтверждение фиксированной длины L/ битов. Тем самым в
каждом узле образуется поток пакетов переменной длины, состоящих из не-
которого фиксированного поля длины L, и поля случайной длины со средним
значением тс. Такие пакеты поступают в очередь на входном узле и обслу-
живаются в порядке поступления.
Очевидно, что здесь мы должны использовать модель СМО с произвольным
распределением времени обслуживания в силу специфики структуры паке-
тов. В каждом пакете должны содержаться заголовок и другая служебная ин-
формация, размер которой не может быть нулевым. Это приводит к нулевой
вероятности малых времен обслуживания. Поставим задачу найти среднее
время отклика Т» от узла до узла, используя модель M/G/l. На рис. 6.19 пока-
зано, как можно рассматривать входную очередь и какой вид функции рас-
пределения времени обслуживания можно принять.
Найдем среднее значение времени обслуживания пакета х. Поскольку весь
выходной поток узла считывается в канал со скоростью С/, можно записать,
что время на передачу будет равно
(Z; +mc)/C7. =/;,
Первая составляющая представляет собой время на передачу "заголовков", а
вторая составляющая — время на передачу собственно данных. Средняя дли-
на подтверждений также равна /Л. Таким образом, среднее "эквивалентное"
время обслуживания в системе М/G/l следует принять равным
х ~ 2^/’ + + 2th '
Поскольку поступления двух типов входящих сообщений равновероятны, и
обслуживание происходит в порядке поступления, можно считать, что коэф-
фициент использования для данной системы будет определяться как
Р = 2U = + 2th) = pw (1 + 2t„ I tm ).
Здесь был введен параметр рд./ = — эффективный коэффициент использо-
вания передаваемых через канал битов. Его смысл полностью совпадает с
введенным выше с тем же обозначением коэффициента для сети с коммута-
цией каналов. Действительно, его можно ввести исходя из соотношений:
214
Гпава 6
pM = kTM/N,
Тм = mJ С,.,
t„, = mJ Cr,
Cr = NCi. => t„,= TMIN.
Таким образом, мы ввели для сети с коммутацией пакетов параметр сравне-
ния, совпадающий с параметром сети, ориентированной на соединение.
Распределение
длин пакетов
(биты)
X подтверждений/ед. времени
Выходной
накопитель
бит/подтверждение
Рис. 6.19. Модель передачи подтверждающих пакетов
Вспомним теперь, что для СМО типа M/G/l среднее время ожидания зависит
от второго момента распределения времени обслуживания. Найдем
.г2 = 0,5(/; + (с, + lh)" + t;n).
Используя формулу Полячека — Хинчина, получаем выражение для среднего
значения времени ожидания пакета в системе
w = ~\jh + (С« + /л)~ +C,j/('-P)’
= Рл/ +th +'л Ю/О-Р).
Анализ телекоммуникационных систем
215
В конечном счете, общее время задержки передачи пакета от узла до узла
складывается из только что полученного времени задержки в очереди в уз-
ле Л и задержки в очереди подтверждений в узле В, а также среднего времени
передачи пакета и времени передачи подтверждения. Его часто называют RTT
(Round Trip Time). Искомое время равно
T^+'lt.+ZW.
Для сравнения полученной величины задержки передачи со временем соеди-
нения в сети с коммутацией каналов нормируем указанную величину на вре-
мя передачи данных по абонентской линии, как это делалось ранее. Вводя
обозначение отношения длины управляющего пакета к длине информацион-
ного пакета
k = ±L.= ldl_,
mc
получим
\ + 2к +
2рдД1+£ + £2)
1 -рл/(1 +2^) .
На рис. 6.20 приведены нагрузочные кривые для этой величины от pw при тех
же параметрах сети, что и сети с коммутацией каналов к = 0,1, N = 10.
Рассмотрение и сравнение нагрузочных кривых показывает: если сигнальные
сообщения имеют ту же длину, что и сообщения об установлении соедине-
ний, то максимальное использование канала в сети с коммутацией канала со-
ставляет величину в 0,67. При длине сигнальных сообщений в десять раз
меньшей эта величина возрастала до 0,88. В сети с коммутацией пакетов по-
лезное использование не превышает 0,83. На рис. 6.20 приведены также на-
грузочные кривые для второго способа передачи подтверждающих прием
пакета сообщений в теле обратных пакетов (вложенные подтверждения).
Можно показать, что в данном случае нормированное время отклика может
рассчитываться по формуле
Т» !Thl.
! , , Рд./(1+^'+(^')2)/2
2
N
где
k' = t'hltm >к.
Как видно из графика, вложенные подтверждения несколько эффективнее
при малых нагрузках и сильно ухудшают характеристики сети при больших
нагрузках. На этом же рисунке приведены результаты расчетов, сделанные
216
Гпава 6
в приближении экспоненциального распределения времени обслуживания.
Как видно, учет второго момента распределения незначительно влияет на ре-
зультаты даже при больших нагрузках, если только правильно выбрать сред-
ние значения.
Рис. 6.20. Нормированное время отклика в сети без установления соединения
Сравнение характеристик сетей
с установлением и без установления соединения
В заключение приведем сравнение двух видов коммутации в зависимости от
длины пакета передаваемых данных. Будем определять величину задержки
передачи пакета в системе как функцию длины информационной части паке-
та тс.
Для сети с коммутацией каналов величина задержки передачи определяется
временем соединения Тс = W + Tt + ЗД., где среднее время ожидания в очере-
ди и время на передачу сигнализационных сообщений необходимо выразить
через длины пакетов, пропускные способности и сопоставимую величину
Анализ телекоммуникационных систем
217
тс, бит/с
CL - 2,4 Кбит/с; Ст= 120 Кбит/с (Л/= 50)
Сообщения запроса и
подтверждения - 1600 битов
Сигнальные сообщения - 16 битов
Рис. 6.21. Сравнение времени на передачу пакетов для сетей
с установлением и без установления соединения. Пример 1
коэффициента эффективного использования рд/. Для сети с коммутацией па-
кетов и потоком подтверждений будем находить время ответа ТГ), выражен-
ное через те же самые величины.
. эт + ^/wC)
///«•' “г X ч
. f, 2LA
1-Рм 1------L
k mc )
TC=M{W) + {L, +3LS)/Ch,
— ^C{N,A)TH
N-A ’
Th + L< +4A’)>
218
Гпава 6
На рис. 6.21 представлены сравнительные нагрузочные кривые, рассчитанные
по приведенным выше формулам для случая сети с 16-битовыми сигнальны-
ми сообщениями, сообщениями запроса и подтверждения длиной 1600 битов
и скоростями на абонентской линии и в межузловом канале в 2,4 Кбит/с и
120 Кбит/с, соответственно.
На рис. 6.22 приведены результаты расчетов для сети с медленными канала-
ми по 110 бит/с на абонентской линии 1100 бит/с на межузловом канале.
Длина сигнального сообщения о соединении и подтверждения имеет величи-
ну 100 битов, а другие сигнальные сообщения — 50 битов.
Задержка, с
тс, знаков
(длина сообщения)
рм = 0,5; CL = 11 знаков/с; СТ = 110 знаков/с
Сообщения о соединениях и
подтверждении - 10 знаков
Сигнальные сообщения - 5 знаков
Рис. 6.22. Сравнение времени на передачу пакетов для сетей
с установлением и без установления соединения (1 знак = 10 битов). Пример 2
В целом рассмотрение полученных результатов приводит к следующим вы-
водам. Коммутация пакетов можеттдать меньшее время реакции в диапазонах
малых длин сообщений (пакетов), тогда как коммутация каналов имеет пре-
Анализ телекоммуникационных систем
219
имущества при больших длинах сообщений. Каналы с большей пропускной
способностью при коммутации пакетов тем эффективнее, чем меньше коэф-
фициент полезного использования p,w. При увеличении длины сигнального
сообщения характеристики сети с коммутацией каналов сильно ухудшаются
(в том случае, если для передачи сигнальной информации используются ка-
налы с той же скоростью передачи).
Регулирование трафика
в мультисервисных сетях
В трафике любой сети можно выделить две основные части: полезный тра-
фик, несущий информационные сообщения, и служебным трафик, обеспечи-
вающий целостное функционирование сети. Полезный трафик может иметь
различный характер, например, быть потоком битов телефонных сообщений,
пакетов электронной почты, видеовещания, HTTP-пакетов, передающих
Web-страницы, и т. п. Если передачу потоков разных приложений обеспечи-
вает одна и та же сеть с едиными протоколами и законами управления, то ее
называют му.ныписервисной. В таких сетях особое значение приобретает ана-
лиз основных параметров качества обслуживания (QoS): надежность достав-
ки, задержка, флуктуации задержки и скорость передачи, по отношению к
каждому потоку. Дело в том, что в зависимости от типа приложения, исполь-
зующего конкретный поток для своего взаимодействия через сеть, требуются
разные параметры QoS. В табл. 6.7 приведены несколько типичных примеров
приложений с оценкой требований к различным параметрам QoS для них.
Таблица 6.7. .Характеристики приложений
Приложение Надежность Задержка Флуктуации Скорость
Электронная почта Высокие Низкие Низкие Низкие
Передача файлов Высокие Низкие Низкие Средние
Web-доступ Высокие Средние Низкие Средние
Удаленный доступ Высокие Средние Средние Низкие
Аудио по заказу Низкие Низкие Высокие Средние
Видео по заказу Низкие Низкие Высокие Высокие
Телефония Низкие Высокие Высокие Низкие
Видеоконференции Низкие Высокие Высокие Высокие
При анализе каждый из параметров QoS может быть охарактеризован значе-
нием некоторой оцениваемой величины. Для надежности доставки обычно
220
Гпава 6
используется вероятность потерь или блокировки пакетов, для задержки —
среднее время пребывания пакета в системе, анализ флуктуаций чаще всего
сводят к оцениванию дисперсии времени ожидания пакетов в буфере. Анализ
пропускной способности ведется обычно как определение максимального
значения параметра входного потока, при котором обеспечивается допусти-
мое значение других параметров QoS. Мы рассмотрим задачу расчета пара-
метров QoS и выбора алгоритмов управления трафиком в сетях для достиже-
ния наилучших значений этих параметров. Как правило, в основе таких алго-
ритмов лежат борьба с перегрузкой и обслуживание на основе приоритетов.
Анализ систем массового обслуживания
с приоритетами
В разд. "Базовая модель СМО и классификация по Кендалу" главы 3 были
рассмотрены основные дисциплины обслуживания, введены понятия абсо-
лютного и относительного приоритетов обслуживания и представлен важный
закон сохранения для времени пребывания в СМО с приоритетами. Теперь
получим основные аналитические отношения для времени пребывания в
СМО. Как было введено в разд. "Базовая модель СМО и классификация по
Кендалу" главы 3, фиксируя некоторое поступающее в систему требование
как меченое, ему ставится в соответствие приоритетная функция qp(J), значе-
ние которой будет определять приоритет меченого требования относительно
других, уже поступивших требований. Для среднего времени ожидания в
очереди для меченого требования мы получили формулу
Wp=W0 + ^Xl(Nip + Mlp), р = \,2,...,Р. (6.1)
/=1
Напомним введенные обозначения:
П средняя задержка меченого требования, связанная с наличием другого
требования в сервере на обслуживании
/=] /=1
х, —среднее время обслуживания в сервере;
К— интенсивность поступлений для требования Z-го приоритетного
класса;
р„ xj — удельная нагрузка и второй момент времени обслуживания для
этого класса требований;
Анализ телекоммуникационных систем
221
□ Л(/; — число требований из класса z, которое застало в очереди меченое
требование (из классар), и которые обслуживаются перед ним;
□ М1р— число требований, поступивших после того, как пришло меченое
требование, однако получивших обслуживание раньше него.
Рассмотрим расчет среднего времени ожидания для СМО с обслуживанием
в порядке приоритета, задаваемого приоритетной функцией
=Р-
На рис. 6.23 приведена схема функционирования СМО с такой дисциплиной
обслуживания: поступающее требование ставится в очередь слева от требо-
вания с равным или большим приоритетом.
Очередь
Обслуживающий прибор
Рис. 6.23. СМО с обслуживанием в порядке простого приоритета
Воспользуемся формулой для Wp. Исходя из механизма функционирования,
можно сразу выписать:
лГ = 0, z = 1,2,...,/2-1,
Mip = 0, / = 1, 2,...,/2.
Все требования более высокого, чем у меченого, приоритета будут обслуже-
ны раньше. Из формулы Литтла число требований класса z, находящихся
в очереди, будет равно
= i = p,p+],p + 2,...,P.
Требования более высокоприоритетных классов, поступившие в систему по-
сле меченого требования, пока оно находится в очереди, также будут обслу-/
жены перед ним. Так как меченое требование будет находиться в очереди
в среднем Wp секунд, то число таких требований будет равно
222
Гпава 6
Непосредственно из формулы (6.1) получаем:
i=P /=/)+!
Wo + S РЖ
и/ =___________
р р
1-Ер,
Эта система уравнений может быть решена рекуррентно, начиная с W\, Wt_
ит. д.:
W =
” (1-V1)(1-CT/,)’
(6.2)
Полученная формула позволяет рассчитывать характеристики качества об-
служивания для всех приоритетных классов. На рис. 6.24 показано, как из-
меняется нормированная величина времени ожидания в очереди для СМО
с пятью приоритетными классами с одинаковыми интенсивностями потока
требований каждого приоритетного класса и равным средним временем об-
служивания требований каждого класса.
Особую задачу представляет определение законов распределения времени
ожидания, которое мы здесь не рассматриваем.
Теперь изучим систему с абсолютными приоритетами и обслуживанием в
порядке приоритета с дообслуживанием. Применим подход, полностью ана-
логичный рассмотренному ранее. Средняя задержка в системе меченого тре-
бования также состоит из трех составляющих: первая составляющая — сред-
нее время обслуживания, вторая — задержка из-за обслуживания тех требо-
ваний равного или более высокого приоритета, которые меченое требование
застало в системе. Третья составляющая средней задержки меченого требо-
вания представляет собой задержку за счет любых требований, поступающих
в систему до ухода
оритет. Расписывая
в системе, получим:
меченого требования и имеющих строго больший при-
все эти три
составляющие общего времени нахождения
р
у т /2
,=Р+1Р' /? (1-у,)(1-у+1)
Анализ телекоммуникационных систем
223
а)
Рис. 6.24. Нагрузочные кривые СМО с обслуживанием в порядке относительных приоритетов
(Р = 6, Лр = л/5, хР = х ): а — р < 1; б — р > 1
Весьма интересной задачей является выбор приоритетов для заявок различ-
ных классов. Поскольку справедлив закон сохранения, оптимизация имеет
смысл только при рассмотрении некоторых дополнительных атрибутов каж-
дого класса требований. Предположим, что можно оценить каждую секунду
задержки заявки приоритетного класса р некоторой стоимостью Ср. Тогда
средняя стоимость секунды задержки для системы может быть выражена че-
рез среднее число требований каждого класса, находящихся в системе:
c=fc„y;=fp,,c„+fc,M-,.
/>=1 л=1 р=\
Решим задачу нахождения дисциплины обслуживания с относительными
приоритетами для системы М/G/l, которая минимизирует среднюю стой-
224
Гпава 6
мость задержки С. Пусть имеется Р приоритетных классов заявок с заданной
интенсивностью поступления и средним временем обслуживания. Перенесем
в левую часть постоянную сумму и выразим правую часть через известные
параметры:
p=i p=i л'/>
Задача состоит в минимизации суммы в правой части этого равенства путем
выбора соответствующей дисциплины обслуживания, т. е. выбора последова-
тельности индексов р.
Обозначим
С
f = =, g =Р Ж .
Jp ’ Ьр Vp' р-
лр
В этих обозначениях задача выглядит так: нужно минимизировать сумму
произведений при условии
р р
^fpgp^m\\v, £g/;= const.
р=\ р=А
Условие независимости суммы функций g/; от выбора дисциплины обслужи-
вания определяется законом сохранения. Иначе говоря, задача состоит в ми-
нимизации площади под кривой произведения двух функций, при условии,
что площадь под кривой одной из них постоянна.
Сначала упорядочим последовательность значений fp: f <fj< ... </„ а затем
выберем для каждого fp свое значение gp так, чтобы минимизировать сумму
их произведений. Интуитивно ясно, что оптимальная стратегия выбора со-
стоит в подборе наименьшего значения gp для наибольшего fp. Далее для ос-
тавшихся значений следует поступать тем же образом. Поскольку gp = Wppp,
то минимизация сводится к минимизации значений средней задержки. Таким
образом, решение рассматриваемой задачи оптимизации состоит в том, что из
всех возможных дисциплин обслуживания с относительным приоритетом
минимум средней стоимости обеспечивает дисциплина с упорядоченными
приоритетами в соответствии с неравенствами:
G < Q < < ^1’
^1 -X ‘у .X j)
Теперь рассмотрим случай назначения приоритетов, изменяющихся со вре-
менем. Такой порядок может избавить систему от чрезмерно долгого нахож-
дения в очереди низкоприоритетных требований.
Анализ телекоммуникационных систем
225
На практике часто встречается задача назначения приоритетов в зависимости
от времени поступления заявки. Например, для того чтобы никакие требова-
ния не задерживались в системе очень долго, несмотря на общую нагрузку,
организуют дисциплину обслуживания, при которой чем дольше заявка на-
ходится в системе, тем ее приоритет становится выше.
Рассмотрим приоритетные функции, линейно зависящие от времени, с кру-
тизной нарастания, зависящей от номера класса, к которому принадлежит
требование.
Предположим, что некоторое меченое требование поступает в момент т
и получает в момент / приоритет, определяемый значением приоритетной
функции
7/0 = 0-^,,,
О<<b2 <Ь3 <...<Ьр.
Всякий раз, когда сервер готов к обслуживанию нового требования, он выби-
рает из очереди требование с наивысшим мгновенным приоритетом — наи-
большим значением приоритетной функции. Требования из класса с большим
значением р наращивают приоритет с большей скоростью, чем требования из
низшего приоритетного класса. На рис. 6.25 показан пример, как поступив-
шее позже требование, но из высшего приоритетного класса, может получить
обслуживание быстрее, чем поступившее ранее требование из менее приори-
тетного класса. Это произойдет, если сервер освободится позже момента /о-
При освобождении сервера до этого момента обслуживание получит первое
из поступивших требований.
Исследуем эту систему при экспоненциальном распределении времени об-
служивания.
Рис. 6.25. Изменение значений приоритетных функций в СМО
с относительными приоритетами
8 Зак. 3884
226
Гпава 6
Найдем среднее число требований, поступивших позже меченого, из классов
с р > i, которые будут обслужены раньше меченого. Очевидно, что для таких
требований скорость нарастания приоритетной функции меньше скорости
нарастания приоритетной функции меченого требования и, следовательно,
число указанных требований равно нулю. Теперь определим число таких тре-
бований для классов с большей, чем у меченого, скоростью нарастания при-
оритетной функции р < i. Из рассмотрения рис. 6.25 можно видеть, что за-
держка меченого требования в системе для этого случая Wp = /0 - т связана
с интервалом времени, на котором поступают заявки, опережающие меченое
требование Г, = т, - т, соотношением
bpWp = b^Wp-^.
Отсюда получаем, что этот интервал равен
Следовательно, при интенсивности %, входящего потока для требований /'-го
класса находим среднее число "обгоняющих" требований:
= i>p-
ь,
Рассмотрим теперь меченое требование из класса р, поступающее в момент
т = 0 и находящееся в очереди в течение времени tp.
На рис. 6.26 показано, что значение функции приоритета этого требования к
моменту поступления на сервер будет равно bptp. При поступлении меченого
требования оно застает в очереди п, требований из класса i. Одно из таких
требований, показанное на рис. 6.26, поступило в момент t = -t\. Определим
теперь среднее число требований из класса i, которые поступают до нулевого
значения момента времени, находятся в нулевой момент еще в очереди и по-
лучают обслуживание раньше меченого требования. Из рис. 6.26 можно ви-
деть, что этому условию удовлетворяет требование из класса i, которое по-
ступает в момент-/! и ожидает в очереди в течение времени
IV, =W, (/|),/! <W, (/,)</, +t2.
Из рассмотрения соотношений на рисунке видно, что
Анализ телекоммуникационных систем
227
Рис. 6.26. Изменение приоритетной функции меченого требования
Тогда среднее число требований
= XJ”[1-Pr(w(</)X/-X,
[1 - Рг(м' < у)]<7у =
При i > р
Подставив вычисленные средние значения для "обгоняющих" требований,
получим систему линейных уравнений для величин задержки меченого тре-
бования:
/=„ /=1
/2 = 1,2,3,...,Р.
228
Гпава 6
Производя преобразования, можно свести решение этой системы уравнений к
рекурсивной форме
Полученная формула представляет собой главный результат анализа дисцип-
лины обслуживания с приоритетами, зависящими от времени. Типичная ха-
рактеристика СМО с проанализированной дисциплиной обслуживания при-
ведена на рис. 6.27.
Здесь было положено Р = 5, = Х/5, х = х.
Рис. 6.27. Нагрузочная кривая для нормированного времени ожидания в очереди
для СМО с относительными приоритетами, зависящими от времени
Серая линия представляет характеристику для системы без приоритетов.
Видно, что действие закона сохранения проявляется здесь в том, что, хотя
одна часть заявок, получившая высший приоритет, будет иметь меньшее
время ожидания, чем в системе без приоритетов с обслуживанием в порядке
поступления, другая часть заявок при этом обязательно будет задержана на
большее, чем в бесприоритетной системе, время.
Оптимизация назначения приоритетов
В данном разделе решим задачу, когда с потоком заявок связывается некото-
рая неотрицательная функция, значение которой для каждой заявки может
интерпретироваться как стоимость обслуживания. Рассмотрим систему M/G/1
Анализ телекоммуникационных систем
229
с интенсивностью поступающего пуассоновского потока X требований в се-
кунду и произвольной функцией плотности вероятности для времени обслу-
живания с заданным средним временем обслуживания. Пусть плата за требо-
вание Y является случайной величиной с произвольной функцией распреде-
ления Р(у) = Рг[К <у].
Система функционирует следующим образом: новое требование, поступив-
шее в систему "предлагает" неотрицательную плату Y "организатору очере-
ди". После этого требованию предоставляется место в очереди такое, что все
требования, внесшие меньшую плату, оказываются позади, а большую впере-
ди данного требования. В каждый момент времени сервер, завершив обслу-
живание очередного требования, принимает на обслуживание требование,
оказавшееся впереди всей очереди. До полного завершения обслуживания
требование не покидает сервер. Требования, внесшие одинаковую плату, об-
служиваются в порядке поступления.
Найдем среднее время ожидания в очереди для требования, внесшего плату
Y=y. Это время складывается из трех составляющих. Во-первых, это время
на дообслуживание требования, находящегося в данный момент в сервере.
Во-вторых, время обслуживания требований, которые поступили раньше и
внесли большую или равную плату. Наконец, меченому требованию придется
ждать обслуживания всех требований поступивших позже него, но внесших
большую плату. Среднее число требований, плата которых лежит в интервале
(м, u + du), определяется по формуле Литтла: Y(u)W(u)du, где Х(м) = .
du
Используя обозначения для нижнего и верхнего пределов функции (3(м),
можно записать суммарное выражение для времени ожидания в очереди для
меченого требования в виде:
W\y) = JY0 + £ xX(u)JY(u)du + £ rt(u)JY(y)du,
где
С помощью ряда соотношений и обозначений можно найти, что при разрыв-
ной функции распределения вероятности это соотношение может быть при-
ведено к виду:
УУТу) ---------------;
[1 - р + рРС/)] [1 - Р + Р₽(.У~)] ’
где
р = А,х.
230
Гпава 6
При абсолютно непрерывной функции плотности вероятности получим
W
№(У) = ------5-----у.
[1-р + рР(у)]
Таким образом, мы получили конечное среднее время ожидания для всех
требований, которые вносят плату выше, чем некоторое критическое зна-
чение:
О, р < 1,
р-|(м)=>Р(у) = г/.
В пределе, когда размер платы стремится к бесконечности, среднее время
ожидания стремится к РУ0. Нетрудно убедиться, что когда размеры платы для
всех требований одинаковы,
[ЪУ>У0-
Это известный результат для СМО типа М/G/l при обслуживании в порядке
поступления, как и следовало ожидать, поскольку равная плата равносильна
ее отсутствию с точки зрения распределения приоритетов.
При распределении приоритетов можно рассмотреть и другие стоимостные
задачи. Определим оптимальное распределение платы за приоритеты в сле-
дующих предположениях. Пусть имеется зависимость стоимости от времени
задержки в очереди для каждого требования, т. е. существует возможность
определить, сколько стоит каждая секунда ожидания в очереди. Опишем эту
зависимость с помощью случайного коэффициента нетерпения а.
Очевидно, что общие затраты клиента при обслуживании будут состоять из
платы за место в очереди и потерь от времени ожидания. Для требования
с фиксированным коэффициентом нетерпения эти затраты равны
с(а) = Л + ар)/(л)-
Пусть для всей совокупности клиентов можно определить функцию распре-
деления вероятностей коэффициентов нетерпения Р(а) = Рг[а <а].
Анализ телекоммуникационных систем
231
Сформулируем следующую задачу оптимизации: найти функцию уа, которая
минимизирует среднюю стоимость С при условии ограничения всей средней
платы некоторой заданной величиной В:
min С - min
C(a)p(a')da,
dP(a)
da
В = f yap(a)da.
Определим р(а) = р/?(а)-
Преобразуя минимизируемый интеграл, получим:
С = f [Л + aW(ya)]p(o)da,
С-В= £aW(ya)/?(а)<7а = ap(a)FT(уа)da.
Из закона сохранения в непрерывной форме:
£ p(a)FT (уа )da = FT0
следует, что решение задачи минимизации стоимости сводится к нахожде-
нию такой функции, при которой минимальна площадь под кривой произве-
дения p(a)FT(a)xa, в то время как площадь под кривой, определяемой пер-
вым сомножителем, должна оставаться постоянной.
Путем рассуждений о согласованности возрастания и убывания функций,
входящих в произведение, можно сделать вывод, что решением задачи явля-
ются все функции, удовлетворяющие условию:
> 0, a S .
da
Множество S такое, что
j./2(a)rfa = 0.
Выберем самую простую строго возрастающую функцию — линейную. Та-
ким образом, будем считать, что плата пропорциональна коэффициенту не-
терпения, т. е.
Уа = Ка.
232
Глава б'
Применяя ограничение средней платы
В - К а/?(а)<7а ,
получим, что, если считать средний коэффициент нетерпения равным А,
В
у? = —а
с А
Это и есть функция оптимальной платы.
В качестве примера рассмотрим систему с показательным распределением
платы:
Р(у) = 1 - , ст > 0, у > 0 .
Время ожидания можно непосредственно вычислить:
(1-ре~о>)2
Используя рассмотренное правило оптимальной платы, можно найти распре-
деление коэффициента нетерпения:
л
—ста
Р(а) = 1-е А .
Следовательно, средняя стоимость получается:
c=±AnJ„.
ст р 1-р
Описанная оптимизация является глобальной и позволяет найти функции
платы, которые минимизируют общую среднюю стоимость.
Познакомившись с общими теоретическими аспектами работы МО с приори-
тетами, перейдем к рассмотрению практической задачи распределения ресур-
са для различных видов трафика.
Модели интеграции трафика
с различными ведущими параметрами QoS
Рассмотрим объединение двух видов нагрузки — критичной к задержкам и ее
дрожанию—джиттеру, например, речь или видеоконференции, и нагрузки,
некритичной к задержке и джиттеру, но требующей надежной доставки паке-
тов— данных. Впервые необходимость интеграции таких видов нагрузки
встретилась при разработке сетей ISDN (Integrated Service Digital Network)
[15]. Эти сети объединяют передачу речи с установлением соединения по
Анализ телекоммуникационных систем
233
коммутируемым цифровым каналам и передачу данных от подключенных к
сети компьютеров. Каждый абонент сети ISDN имеет возможность одновре-
менно пользоваться телефоном и получать и передавать данные с помощью
своего компьютера. Эта проблема стоит и в других мультисервисных сетях,
например в сети GSM/GPRS, и ее решение сводится к разработке алгоритма
управления канальным ресурсом (полосой пропускания) для предоставления
каждому из видов трафика.
Будем называть нагрузку, создаваемую трафиком, требующим гарантирован-
ной полосы пропускания, нагрузкой первого класса. Будем считать, что ин-
тенсивность поступления ВЫЗОВОВ (требований на соединение) равна А,|, а
среднее время занятия — 1 /Ц|. Нагрузка этого типа требует одного временно-
го канала и при отсутствии свободных каналов — блокируется.
Второй из видов нагрузки, создаваемой трафиком данных, назовем нагрузкой
второго класса. Интенсивность поступлений ПАКЕТОВ положим равной А-г,
а средняя длина пакета определяет время обслуживания 1/ц2- Заявки данной
группы ставятся в очередь при отсутствии свободных каналов. В этом и со-
стоит основное различие двух классов нагрузки с точки зрения теории теле-
трафика. Обычно Xi /хт. = ц2 /ц, » 1 . Далее это отношение будет обозначать-
ся символом а.
Для обслуживания нагрузки в зависимости от класса может быть выделено
фиксированное или переменное число каналов. В зависимости от способа
предоставления каналов для заявок разного класса будет получаться различ-
ное качество обслуживания нагрузки. Наша задача— проанализировать раз-
личные методы обслуживания.
Интеграция
на основе обслуживания в порядке поступления
При этой стратегии обслуживания любому пользователю при его появлении
независимо от класса нагрузки назначается виртуальный канал (временной
слот в системах с временным разделением). При отсутствии свободного ка-
нала запросы на соединение блокируются, а пакеты помещаются в буфер.
Найдем точное решение задачи определения характеристик качества обслу-
живания интегральной сети с такой стратегией интеграции. Приемлемая
сложность задачи получается для простейшего случая разделения ресурса в
виде одного (N= 1) канала. Однако, несмотря на простоту случая, он позво-
ляет проследить все важнейшие особенности рассматриваемого способа объ-
единения. Для более общего случая с большим числом каналов N будут при-
ведены приближенные формулы.
Построим диаграмму переходов состояний системы массового обслуживания,
соответствующей рассматриваемой задаче. СМО имеет двумерную структуру
234
Гпава 6
пространства состояний (рис. 6.28). Обозначим стационарные вероятности
нахождения системы в каждом из состояний рц. Верхний ярус состояний i = 1
соответствует случаю занятости канала заявкой первого класса, а нижний
ярус i = 0 описывает состояния при отсутствии заявки первого класса. Значе-
ние j определяет число заявок второго класса, находящихся в системе. Пере-
ходы между состояниями в точности соответствуют возможным процессам в
системе. Так, при занятости канала заявкой первого класса, его освобождение
происходит с интенсивностью p.t в состояние, определяемое числом заявок
второго класса, находящихся на обслуживании. Поступление новой заявки
второго класса производит переход в состояние с j + 1 с интенсивностью А,2, а
ее обслуживание выполняет переход в состояние су - 1 с интенсивностью ц2,
но только в случае отсутствия заявки первого класса (z = 0).
/ пакетов в системе
Рис. 6.28. Диаграмма интенсивностей переходов при стратегии обслуживания
в порядке поступления
Выпишем уравнения баланса для всех состояний.
(X,+Х2)р00 +ц2р()| (6.3)
(X, + ц2)/;0; = X2jp0j + рхрч + Ц2р0/+1,у > I (6.4)
(pi + А,2 )р|0 = Л,|/?оо (6-5)
(ц,+Х2)/?|/=Х2/?17_|,у>1 (6.6)
% %
Обозначая, как обычно, pj = —, р2 =— и используя уравнения (6.3) и (6.4),
Bi ’ Ц2
можно получить выражения для вероятностей состояний:
Анализ телекоммуникационных систем
235
Poi =Рг [1+РЛ1 + Р2)]Аю
P\j — , А10 ~ о , , Роо
' ^ap2+lj ЛР2 + U к1 + аРз)
Мы использовали здесь безразмерную величину, определяющую соотноше-
ние между временем обслуживания заявок первого и второго класса
a = ц2 / ц,.
Для определения вероятностей при i - 0 воспользуемся методом производя-
щих функций [5]. Это просто z-преобразование последовательности из веро-
ятностей. Определим производящую функцию:
Go(z) = E/M7 •
,/=о
Умножим правую и левую часть уравнения (6.4) на z’ и, суммируя по всем j,
начиная с единицы, можно получить следующее алгебраическое уравнение
для функции комплексной переменной — производящей функции:
I + ар2
J(z) = -ЛРзгЦ] _ ар? (z ~ 1)].
1 + ар2
При выводе этих уравнений использовались следующие вспомогательные
соотношения:
03
Е A i2'1 ~ Л (z)_ Роо ’
7 = 1
Ъ^2'-2 (<Л)(г) Роо 2РоО,
7=1
Еа./7
а-Р,Хр2 =
(l + ap2)[l-ap2(z-l)] °0'
В уравнении для G0(z) в правой и левой частях может быть выделен сомно-
житель г. После сокращения на него можно записать выражение для произво-
дящей функции:
^o(z) ~ Poo
] ! ^P1P2
1 -ap,(z-l)
О-РгО"’-
236
Глава 6
Единственной неизвестной остается вероятность в нулевой точке. Воспользу-
емся условием нормировки и свойством производящей функции:
7=0 7=1
Ел/ =Go(l) = AoO + P^Xl-Po)"'
7=0
X/’i/^Pi/’oo
7=0
Теперь можно найти характеристики качества обслуживания. Вероятность
блокировки заявок первого класса равна вероятности 1 -р00.
Pi
В качестве подтверждения правдоподобности полученного соотношения
найдем значение вероятности блокировки при отсутствии заявок второго
класса, т. е. при
р - ] _ и - Р1 +Pz
1 в ~ 1 Роо . ,
1 +Р|
Это в точности значение вероятности блокировки системы с одним сервером,
получаемое при расчете по 5-формуле Эрланга.
Теперь найдем среднее значение задержки нагрузки второго класса. Сначала
найдем среднее число пакетов в системе, а затем воспользуемся формулой
Литтла.
- v- . . А . dG0(z) А .
j=LJPu = ZjPoi+ZjP4=-Gr~ +LJPh’
i,.i 7=0 7=1 aZ r=I 7 = 1
dG^z) p2 ! gp,p2
dz _=i 1 - p2 1 + P|
V1 f 1— P2
=a-pip2-—
' U+pJ
Анализ телекоммуникационных систем
237
Р2 ! аР1Р2
1 - р2 1 + Р(
Заметим, что первое слагаемое описывает задержку в системе М/М/1, а вто-
рое слагаемое определяет увеличение количества пакетов в очереди за счет
состязаний за доступ к каналу с заявками первого класса. Условие равновесия
для нагрузки второго класса не зависит от нагрузки первого класса и состоит
в выполнении неравенства р2 < 1.
Воспользовавшись формулой Литтла, найдем нормированную задержку зая-
вок второго класса:
р2 1-р, 1+р,
Обычно при интеграции заявки первого класса, например телефонные разго-
воры, имеют существенно большую длительность, чем заявки второго класса,
а именно пакеты, причем а» 1. Как видно из полученной формулы, задерж-
ка пакетов сильно возрастает по сравнению с чистой пакетной сетью. Инте-
ресно, как изменится ситуация при достаточно большом числе каналов. Слу-
чай с N> I был проанализирован и позволил предложить приближенную
формулу расчета вероятности блокировки для нагрузки первого класса
в виде:
р AB(N-],A)
” N - А2 + pB(N-],АУ
где
А — Л| + А-,,
причем формула
An
B(N,A) = ~^-
4 ’ ' .V АК
является известной формулой Эрланга. Последнее соотношение точно при
а = 1 и может быть применено для других значений а в силу слабой зависи-
мости вероятности блокировки от ее величины.
Рассмотрим пример. Пусть 1 /ц( = 100 с, 1/ц2 = Ю мс. Тогда сс= 10 000. Пусть
нагрузки таковы, что р, = 0,1, р2 = 0,4. Тогдар8 = 0,45, т. е. весьма значитель-
на. В то же время задержка для пакетов ц2Т = 1,7 + 990 = 991,7, что сущест-
венно превышает задержку без учета влияния "разговорной" нагрузки. Фак-
238
Гпава 6
тическое время задержки составит 9,9 с вместо 1,7 мс для соответствующей
системы М/М/1, когда пакеты поступали бы в отдельный канал.
Как показывает анализ, стратегия интеграции нагрузки в порядке поступле-
ния запросов не обеспечивает приемлемого регулирования характеристик
качества обслуживания.
Стратегия абсолютного приоритета
Другим способом интеграции является стратегия абсолютного приоритета
заявок первого класса.
В этом случае заявки первого класса при поступлении, безусловно, снимают
с обслуживания заявки второго класса. Очевидно, что при этом вероятность
блокировки для заявок первого класса никак не зависит от нагрузки второго
класса и определяется только числом каналов и нагрузкой первого класса.
Вероятность блокировки рассчитывается по 5-формуле Эрланга:
А"
у А
Определить среднее значение времени задержки для нагрузки второго класса
удается аналитически только для случая N= 1. Вероятность блокировки при
этом равна
Нетрудно видеть, что данное значение меньше, чем для вероятности блоки-
ровки в сети с интеграцией обслуживания в порядке поступления, в силу то-
го, что отсутствует влияние заявок второго класса. Найдем теперь задержку
обслуживания для таких заявок. Снова построим диаграмму переходов со-
стояний для модели системы с указанной дисциплиной обслуживания клас-
сов заявок. Пространство состояний системы так же, как и в предыдущем
случае, будет двумерным, а структура переходов еще более сложной. На
рис. 6.29 приведена диаграмма состояний для интегральной сети с абсолют-
ным приоритетом заявок первого класса. Основным отличием диаграммы
является наличие переходов из состояний нижнего яруса с i = 0 для всех j
в состояния верхнего яруса (г = 1) при тех же j с интенсивностью А,]. Эти пе-
реходы отражают процесс снятия заявки второго класса с обслуживания не-
медленно при поступлении заявки первого класса с вероятностью, равной
А.1А/, в течение промежутка времени (t, t + Д/).
Анализ телекоммуникационных систем
239
I пакетов в системе
Рис. 6.29. Диаграмма интенсивностей переходов при стратегии обслуживания
с абсолютным приоритетом
Составим уравнения равновесия для построенной модели системы. Они ока-
зываются более сложными, чем для предыдущего случая. Выпишем сначала
уравнения для нулевого состояния.
(Л.|+Л.2)роо=ц1р1О+ц2Ро1 (6.7)
(ц,+Х,)/2|0 =Z.,/200 (6.8)
Их сразу можно разрешить относительно вероятностей состояний, сосед-
них начальному, а затем выписать уравнения для остального множества со-
стояний:
_ 7-] _ р, Дю
Р\о ~ - Роо ~ .
ц, + Л2 1 + ар2
(6-9)
(6.10)
Ро\ “ РтРоО
14-
14- ар2
(А.|4-А.24-ц2)^о/_|=А.2я74-Ц1Р1/4-Ц2Ро,/+1; (6.11)
(А.2+Ц1)А/=А-1Ау+А-2А./-|; 7^ (6.12)
Для решения этой системы уравнений воспользуемся методом производящих
функций. Введем
Go (*) = Е A izJ > Gi (г) = Ё Р\ iz' ’
7=0 7=0
с0(1)4-с,(1) = Ед/=1-
240
Гпава 6
Умножим (6.11) и (6.12) на z', и, суммируя по всем значениям j = 1, 2, 3, ...,
найдем после некоторых выкладок:
(X, +Z-2 + H2)[G0(z)“Ao] = VGo(*) + Ц| [ед-р,0] +—[Go^-Ac-zA,]’
Z
(Х-2 + Ц])[G0(z) - £>|0] = \ [Go(z) - р00] + P2zGt (z).
Решая систему алгебраических уравнений и подставляя выражения (6.9) и
(6.10), получим выражения для производящих функций. Далее, используя
условия нормировки, выразим вероятность нулевого состояния
О,(г) = P|G»(Z) .
1 +(l-z)ap2
Go (z) = ——--------~----------------------,
az'p2 - z(p2 + Pj p2 + ap; + ap2) +1 + ap2
1
Poo ~ , P2-
1 + Pi
Последнее соотношение позволяет установить нетривиальное условие ста-
бильности в системе (существования стационарного распределения вероятно-
стей) для максимального значения коэффициента нагрузки со стороны заявок
второго класса, т. е. на коммутацию пакетов
^2 < Ц20 ^)-
Смысл полученного неравенства состоит в необходимости обеспечения сред-
ней поступающей нагрузки второго класса меньшей, чем остаток пропускной
способности канала после обслуживания нагрузки первого класса. В против-
ном случае очередь из заявок второго класса просто переполнится, и они ни-
когда не будут обслужены (не получат доступ к каналу).
При выполнении же этого условия среднее число заявок в очереди будет ко-
нечным и может быть определено непосредственно через производящие
функции по формуле:
Воспользуемся формулой Литтла и вычислим в явном виде значение норми-
рованного среднего времени задержки в системе для заявок второго класса:
Анализ телекоммуникационных систем
241
иГ-Ц27-7 - (l+pj'+api
2 Л,2 р2 [1 -р2(1 + р,)](1 + р,)
В качестве подтверждения правдоподобности полученного результата поло-
жим равной нулю интенсивность нагрузки первого класса. Получающееся
при этом выражение будет в точности соответствовать известному выраже-
нию для задержки заявок в системе М/М/1.
Рассмотрим в качестве примера исходные данные для предыдущего раздела.
При I/щ = 100 с, 1/р.2= 10 мс, а= 10 000, pi = 0,1, р2 = 0,4 вероятность бло-
кировки для нагрузки первого рода будет равна 0,09, что в 5 раз меньше, чем
для интеграции в порядке поступления заявок. Однако при этом нормирован-
ная средняя задержка для пакетов возрастет с Цл_Т- 992 до 1600, т. е. более
чем на 60%.
Можно показать, что в общем случае при достаточно больших а выигрыш в
вероятности блокировки при переходе на интеграцию с абсолютным приори-
тетом по сравнению с обслуживанием в порядке поступления будет опреде-
ляться отношением
Ci.abs ~ Pi
^,Г1ГО Рг
В то же самое время задержка пакетов возрастет в отношении
Т 1
^НГО 1 ~ Р2
Таким образом, стратегия интеграции с абсолютным приоритетом, гаранти-
руя заданное качество обслуживания для соединений, приемлема только для
очень низких нагрузок со стороны передачи пакетов.
Стратегия подвижной границы
Сочетания гарантированной вероятности блокировки для соединений и ми-
нимально возможной задержки при заданной пропускной способности канала
удается достигнуть, применяя адаптивное распределение ресурса — страте-
гию подвижной границы.
При этом методе интеграции общий ресурс из N каналов делится на две час-
ти. Одна часть, содержащая N\ каналов, предназначается для обслуживания
нагрузки первого класса (запросов на соединение). Другая часть, содержащая
N2 = N-N] каналов, резервируется для пакетов— обслуживания нагрузки
второго класса. Пакеты могут занимать также любой из /У) каналов, отведен-
ных для обслуживания нагрузки первого класса, если он не используется
242
Гпава 6
в данный момент времени. Однако при поступлении заявки первого класса
она имеет абсолютный приоритет перед нагрузкой второго класса и сбрасы-
вает при необходимости пакет, занимающий один из N] каналов. В этом и
состоит смысл подвижной границы между группами каналов, отведенных для
двух различных классов нагрузки. На рис. 6.30 приведена иллюстрация этого
метода.
Подвижная граница
л/2
N каналов
Рис. 6.30. Иллюстрация метода подвижной границы
Очевидно, что вероятность блокировки для нагрузки первого класса при та-
кой стратегии предоставления ресурса определяется по 5-формуле Эрланга
для ЛА| серверов. Задержка для пакетов при этом будет не хуже, чем рассчи-
танная для системы с N2 серверами, а лучше, поскольку вся оставшаяся от
обслуживания нагрузки первого класса пропускная способность системы бу-
дет также использоваться для обслуживания пакетов. В системе такого типа
может возникнуть перегрузка для нагрузки второго класса. Максимально до-
пустимая величина этой нагрузки не должна превышать
Д < N -1 = N - 4 (1 - Рв) = N2 + pv, - 4 (1 - ) ].
Здесь вероятность блокировки для нагрузки первого класса определяется по
5-формуле Эрланга. Записанное соотношение может быть интерпретировано
как интуитивно очевидное, поскольку выражает собой условие не превышать
единицу для среднего на один сервер коэффициента использования по отно-
шению к нагрузке второго класса
N-i
В знаменателе при этом находится выражение, описывающее среднее число
каналов, доступных для очереди пакетов. С другой стороны, оно может быть
Анализ телекоммуникационных систем 243
переписано в виде условия ограничения величиной N полной средней нагруз-
ки на систему:
А = А2 + A^\-Pb)<N .
Общий анализ системы с подвижной границей оказывается слишком слож-
ным с алгебраической точки зрения. Поэтому при аналитическом исследова-
нии применяются приближенные методы. Раздельно изучаются два возмож-
ных режима— не перегруженный (А2 < Nt) и режим перегрузки при наруше-
нии этого неравенства. Мы далее построим точное решение задачи с
подвижной границей, но только для случая, когда N = 2. При этом для реали-
зации стратегии существует единственная возможность выделения под на-
грузку первого класса TV) = 1 одного канала. Тогда пакеты станут получать
один канал в любом случае, и два, если заявка на соединение будет отсутст-
вовать. Поступление такой заявки немедленно будет снимать с обслуживания
один из пакетов и ставить в общую очередь из заявок второго класса. Рас-
смотрим диаграмму состояний для описанной системы (рис. 6.3 I).
/ состояние 2 класса
Рис. 6.31. Диаграмма интенсивностей переходов для метода подвижной границы
Пространство состояний для нее также двумерное, и состояния могут быть
разделены на два яруса, соответствующих случаям i = 0 — соединение не ус-
тановлено и i— I —соединение установлено. В последнем случае диаграмма
состояний полностью соответствует системе М/М/1, поскольку один каналь-
ный интервал из двух занят под нагрузку первого класса, а второй использу-
ется как обычная система с ожиданием. При i = 0 имеем диаграмму, соответ-
ствующую модели М/М/2, поскольку в случае, когда отсутствует нагрузка
первого класса, все канальные интервалы (а их у нас два) обслуживают па-
кетную нагрузку. Переходы между ярусами происходят при поступлении за-
явки на соединение с интенсивностью А,ц которое переключает систему об-
244
Гпава 6
служивания пакетов с двухсерверной на односерверную, или при завершении
соединения с интенсивностью которое производит обратное переключе-
ние. Выпишем пять уравнений равновесия для рассматриваемой системы.
(Ц[ + + ^-2 )P\J ~\P0j+ Р-2Р1(./+1) + 7 — 1 (6.13)
(А,, + А., + 2ц.2)р0/= 2P2A)(j+i) + р.|/2|j + ^2Po(j-\)> 7 — 2 (6.14)
(Z-2 +В1)Рю = ^oo + B2P11 (6-15)
(Z-!+\>Ио =ВгА)1+B1P10 (6.16)
(X, +7.2 + P2)Poi = 2Р2Ро2 +Н|Рц +^27Л)о (6.17)
Для нахождения решения построенной системы уравнений требуются еще
два уравнения. Одно из них — это условие нормировки всех вероятностей, а
в качестве второго будет использовано свойство корней многочлена знамена-
теля одной из производящих функций.
Определим две производящие функции
./=0
Умножая почленно уравнение (6.13) на? и суммируя по всем значениям J > 0,
преобразуем это уравнение в алгебраическое относительно производящих
функций. Повторяя ту же процедуру с уравнением (6.14) и исключая неиз-
вестные составляющие с помощью (6.15), (6.16), получим в итоге:
6, (z)[zp, + (z - 1)(ц2 - ^2г)] = \zG0(z) + p2(z- 1)/2,о>
G0(z)[zA,, +(z-l)(2p2 +^)] = Ц12б1(2) + ц2(^-1)(2/’()о + W)-
Эти уравнения позволяют сразу выписать несколько важных соотношений,
приводящих к определению вероятности блокировки нагрузки первого класса.
Pi
60(1) + 6,(1) = ^Д/=1,
ij
Goo)=ipOJ=^-,
./=0 *+Pi
ч<|)=Ёр1,=-|ф-=л..
,/=0 1 + Pl
Анализ телекоммуникационных систем
245
Последнее соотношение в точности соответствует 5-формуле Эрланга для
односерверной системы.
Теперь перейдем к определению среднего времени задержки пакетов. Скла-
дывая уравнения для производящих функций, сокращая общий множитель
(z- 1) в правой и левой частях и учитывая, что Л,2/ ц2 = р2, найдем следующее
соотношение:
Go(z)(2 - P2Z) + <50)0 - P2Z) = 2Poo + (.Po\z + РюЪ
z = 1,
о , 1
2Poo + Poi + Pio =l-p2 +:--
1 + Pl
Введем несколько обозначений:
Цэ 1
а = —, a = 2-р-(1 -р2) +-------.
Bi I + Pi
Тогда можно найти в явном виде выражения для вероятностей
Д2 + р, +ар2)/?00 -а
аг/-(р! +2а)д)0
Р\о ~ .
а-1
Выпишем теперь выражения для производящих функций:
Q = Z(2P00 + PoiZ + Рю) + ~ DC1 ~ P2ZX2Poo + P01Z)
° а(2 - p2z)(z -1)(1 - p2z) + z(2 - p2z) + p[Z(l - p2z) ’
G (Z) = PizGo(z) + a(z~J)Pio
1 a(z-l)(l-p2z) + z
Найдем соотношение для среднего числа пакетов в системе, исходя из фор-
мулы для производящих функций:
- dG0(z) dG,
j =—+-—L
dz z=l dz z=l
—:---г «Pio +(I + Pi)(p2 +Poi)-“L(I -p2)
o(l + Pi)L 1 + Pi
В качестве подтверждающих правдоподобность полученного выражения со-
отношений найдем предел правой части при стремлении к нулю нагрузки
первого класса и предел при стремлении этой нагрузки к бесконечности.
(2-р2)(2 + р2)’
246
Гпава 6
Р2
О-Р2)’
Pl ->С0.
В первом случае результат в точности соответствует модели М/М/2, а во вто-
ром — модели М/М/1, что и согласуется с нашими представлениями.
Воспользовавшись формулой Литтла, выпишем выражение для нормирован-
ной задержки в системе:
).цГ-
j' _ 11 а
р, а-[р2(1 + р,)
Р\о , 1 О Рг)
U+Pi)
+ ^ + 1
Р2
Это выражение еще не является окончательным, поскольку содержит три ве-
роятности, связанные только двумя уравнениями. Воспользуемся некоторы-
ми свойствами корней знаменателя выражения для производящей функции
Со(г). Обратимся к выписанному выше выражению для этой функции.
D0(z) = а(2- p2z)(z-1)(1 - p2z) + z(2 - p2z) + p,z(l - p2z).
Пусть zq — корень многочлена Do. Из определения производящей функции
необходимо выполнение требования:
/?o(zo) = O=>|zo|<l.
При этом значении z выражение для числителя также должно обратиться
в ноль. Полученное при этом выражение
W = 0
и определяет третье необходимое уравнение для нахождения всех вероятно-
стей, входящих в выражение для задержки. Решение алгебраического урав-
нения третьей степени в общем случае не дается в виде конечной формулы.
Мы используем приближенное решение этого уравнения для нахождения
двух различных формул определения задержки пакетов в системе с подвиж-
ной границей (6.18)— для малых нагрузок второго класса, и (6.19)— для
больших нагрузок:
а»1, р2 <1,
ц2Т=------4----- +
а(1 + Pi )(2 + р2) а(1 + р,)
(6.18)
а = 2-р = (1-р,) + -----,
1 + Pi
Анализ телекоммуникационных систем
247
а »1, р2 > 1,
(6.19)
^т-,1 l+_JL_+£<azl)a
a[_ 2+р2 р2а+р1)
a = 2-p = 2-p2 J—.
1 + Р|
На рис. 6.32 приведены нагрузочные кривые для нормированной задерж-
ки при различных значениях нагрузки первого класса.
Рис. 6.32. Нагрузочные кривые для систем с подвижной и фиксированной границей
Для сравнения приведен график задержки для системы с фиксированным
разделением каналов для двух классов нагрузки (по одному каналу на каж-
дый). Как видно из сравнения, стратегия подвижной нагрузки дает сущест-
венный выигрыш в характеристиках качества обслуживания по сравнению
с другими способами интеграции каналов. Анализ показывает, что такое пре-
имущество только усиливается при увеличении числа канальных ресурсов.
Управление доступом к среде
В этом разделе мы познакомимся с основами анализа методов управления
доступом к среде, называемого в англоязычной компьютерной литературе
Media Access Control (МАС). Предметом анализа выберем исторически пер-
вую схему доступа, которая, однако, является основой для большинства алго-
248
Гпава 6
ритмов управления случайным доступом. Впервые ее разработали профессор
Н. Абрамсон со своими студентами в Гавайском университете в 1970 году.
Они назвали ее ALOHA. В числе стажеров в это время был и Боб Меткалф —
сегодня всемирно известный изобретатель сети Ethernet, который положил
в основу своего изобретения именно алгоритмы ALOHA.
Рассмотрим способ объединения нескольких абонентов в сеть путем простого
соединения их между собой общей средой передачи. Например, это может
быть эфир, куда производят излучение радиопередатчики абонентов, а их
приемники принимают из эфира все излучаемые сигналы, как это было в пер-
вой радиосети Абрамсона. Это может быть общий коаксиальный кабель, со-
единяющий компьютеры, как, например, в первой сети Ethernet у Меткалфа.
Сегодня такой общей средой служат хабы (hubs), объединяющие между со-
бой сетевые карты ПК. В любом случае используется принцип эфира: все
слышат всех. Иногда это называют общим каналом. Пусть передача сообще-
ний в такой сети производится пакетами, включающими в себя адрес получа-
теля, передаваемый абонентами некоторым случайным образом по мере не-
обходимости. Если бы для каждого радиообмена можно было выделять от-
дельную полосу частот и/или интервал времени, то все пакеты передавались
бы независимо. Такой механизм используется, например, в сетях сотовой свя-
зи стандарта GSM. Разделения можно достигнуть и другим способом, произ-
водя расширение спектра специальными кодовыми последовательностями,
как это сделано в системах с CDMA. В любом случае в силу случайности
возникновения пакетов любой метод разделения требует избыточного ресур-
са. В протоколе ALOHA никакого резервирования ресурсов не производится.
Здесь каждый абонент может полностью использовать полосу пропускания
общего канала. Расплатой за такой агрессивный характер использования яв-
ляется возможность конфликта, столкновения пакетов от различных абонен-
тов. Анализ последствий такого конфликта и является предметом теории те-
летрафика.
Анализ протокола "классическая ALOHA"
Ясно, что протокол ALOHA будет работать хорошо, если время передач мало
по сравнению с общим временем доступности канала. На рис. 6.33 показаны
случаи бесконфликтного обмена пакетами и случай столкновения.
Предположим, что все пользователи канала в среднем генерируют X пакетов
в секунду. Будем считать, что пакеты имеют фиксированную длину с про-
должительностью передачи Тсекунд. Предположим, что все пользователи
генерируют пакеты независимо и так, что вероятность передачи пакета в те-
чение любого интервала времени описывается законом Пуассона. Следова-
тельно, модель протокола ALOHA может быть представлена СМО типа
Анализ телекоммуникационных систем 249
M/D/1. Коэффициент использования канала будет определяться в наших обо-
значениях как р = XT. А его смысл в данном контексте будет связан с отно-
шением полезного времени для передачи пакетов к общему времени. Общее
время расходуется на передачу не только пакетов, сгенерированных источни-
ками сообщений, но и повторно передаваемых пакетов, возникающих вслед-
ствие конфликтов. Таким образом, фактическая интенсивность потока паке-
тов в общем канале будет больше, чем интенсивность их генерирования ис-
точниками. Обозначим эту фактическую интенсивность как
X' = А,(1 + R).
Терминал 1 Терминал 2 Терминалы 1 и 2 Терминал 1 Терминал 2
посылает посылает посылают не получил не получил
пакет пакет пакеты подтверждения подтверждения
с наложением и поэтому и поэтому
во времени повторяет посылку повторяет посылку
Время ожидания перед
повторной передачей -
случайная величина
Рис. 6.33. "Классическая ALOHA". Бесконфликтная передача и столкновение пакетов
Величина R определяет долю пакетов, передаваемых повторно из-за столкно-
вения. Найдем вероятность столкновения и бесконфликтной передачи. Веро-
ятность того, что за время / будет сгенерировано и пакетов, равна:
/>.<0=^.
77!
а вероятность, что за это время не будет сгенерировано ни одного пакета:
250
Гпава 6
Предположим, что некоторый конкретный пакет сгенерирован в момент /0.
Конфликт произойдет, если какой-либо другой пакет будет сгенерирован
в интервале (t0 -T,to + Т). Другими словами, для того чтобы избежать кон-
фликта, нужно, чтобы за время 2Т не появилось ни одного пакета. Вероят-
ность такого события равна 27 . Это и есть вероятность того, что пакет бу-
дет передан без конфликта. Мы уже обозначили через R долю пакетов, кото-
рые нужно передавать повторно. Тогда
R = \-e~V2T.
Следовательно, соотношение между числом сгенерированных пользователем
пакетов и числом фактически передаваемых по каналу пакетов описывается
формулой:
А. = А.'[1-7?] = Ке~к'2Г .
Подставляя А, в р = АТ, получим:
р = А.Те’Г27'.
Иногда конфликт происходит с повторно передаваемым пакетом, и его при-
ходится передавать еще раз и т, д. Среднее число передач одного пакета со-
ставит
N = 1 + 7? + R2 + 7?3+... = —— = е~х'2Г.
1-7?
Подставляя выражение для экспоненты через N, получим:
In N
Р~ 2N '
На рис. 6.34 приведен график функции р от N.
Из него следует, что фактический трафик через канал растет быстрее, чем
нагрузка, видимая пользователю. Возникает цепная реакция, при которой по-
вторно передаваемые пакеты сами порождают необходимость повторных пе-
редач, в результате при некоторых нагрузках поведение системы становится
нестабильным.
Дифференцируя функцию p(N) и приравнивая производную нулю, можно
найти, что максимальное значение коэффициента использования канала
р,пах =-<?-’ = 0,184.
III од z
Таким образом, мы показали, что коэффициент использования ресурса канала
с применением описанного выше протокола "классическая ALOHA" не пре-
вышает 18,4%. Например, если канал позволяет передавать пакеты между
Анализ телекоммуникационных систем
251
любыми двумя абонентами со скоростью 10 Мбит/с, то реально, при подклю-
чении к нему по протоколу ALOHA нескольких абонентов, скорость переда-
чи в нем будет составлять не более 184 Кбит/с.
Полезное использование
канала (р)
Среднее число
передаваемых пакетов (Л/)
Рис. 6.34. Трафик в канале с протоколом "классическая ALOHA"
Очевидно, что для улучшения использования ресурса канала нужно, чтобы
пользователи воздерживались от передачи, если нагрузка начинает прибли-
жаться к критической. К примеру, выдерживать паузу каждый раз, когда па-
кет пришлось передавать дважды. Это один из алгоритмов борьбы с пере-
грузкой в сети. Другим эффективным способом улучшения использования
канала при случайном доступе является тактирование передач.
Анализ протокола "тактированная ALOHA"
Здесь имеется в виду не полная синхронизация всех передач, а привязка на-
чала передачи пакета, случайно порождаемого пользователем, к временным
меткам, тактам. На рис. 6.35 показана диаграмма передач пакетов в такти-
руемую систему.
Как видно, временная ось разделяется теперь на временные интервалы (lime
slots), одинаковые для всех сетевых устройств, и любой пакет передается
только в начале такого интервала. Снова предположим, что время передачи
пакета равно Т. Положим длительность слота равной этому времени. Если
передача пакета начата в момент /0, то конфликт с другим пакетом произой-
252
Глава 6
дет, когда этот второй пакет будет сгенерирован в интервале (70 - Т, 10). Дру-
гими словами, чтобы избежать конфликта, ни одного пакета не должно по-
явиться на интервале длиной Т. Вероятность такого события при пуассонов-
ском характере входного потока равна е“х 1 . Поэтому уравнение для коэф-
фициента использования приобретает вид:
Время
Рис. 6.35. ’’Тактированная ALOHA”. Бесконфликтная передача и столкновение пакетов
Среднее число передач одного пакета в случае тактирования будет N = е~к .
Соотношение для связи среднего числа попыток и коэффициента использо-
вания также окажется другим:
InW
Р” N
График этой функции приведен на рис. 6.36.
Как нетрудно убедиться, теперь получается вдвое больший максимальный
коэффициент использования канала. Если выбран протокол "тактированная
ALOHA", коэффициент использования канала может достигать 36,8%. Рас-
платой здесь является необходимость иметь общую систему синхронизации
для всех сетевых устройств. При передаче сигнала синхронизации по тому же
каналу преимущества тактирования исчезают и проявляются лишь в случае
использования встроенных высокоточных часов или отдельного канала син-
хронизации.
Наиболее эффективным способом увеличения коэффициента использова-
ния ресурса при случайном доступе является метод, называемый контролем
несущей.
Анализ телекоммуникационных систем
253
Среднее число передач
пакета (Л/)
Рис. 6.36. Трафик в канале с протоколом "тактированная ALOHA"
Предупреждение столкновений
Любой метод для предотвращения одновременной передачи пакетов не-
сколькими устройствами управления может повысить эффективность канала.
Один из методов связан с применением протокола резервирования времен-
ных слотов. Другой метод заключается в применении системы предупрежде-
ния столкновений (collision avoidance). Терминалы разделяются по приорите-
там, и терминалы с высоким приоритетом, прежде чем начать передачу в
фиксированном слоте, посылают сигнал предупреждения. Все устройства
управления передачей воспринимают его. Терминалы с низким приоритетом
при этом вообще не выходят на передачу в соответствующем такте. Если же
два терминала имеют одинаковый приоритет, то каждый из них должен ре-
шить, переносить ему время передачи или нет. Вероятность конфликтов при
этом снижается, но они по-прежнему могут происходить, а некоторые вре-
менные слоты останутся неиспользованными.
Более простыми оказываются механизмы контроля несущей (carrier sense).
Контроль несущей предполагает, что каждый терминал может по наличию
сигнала в канале обнаружить, что другой терминал ведет передачу. Сам он
при этом воздерживается от передачи, чтобы не вызвать конфликта. Как дол-
жен поступать терминал, в котором возникла необходимость передачи пакета
при снятии сигнала "занято"? Он может ждать момента снятия и немедленно
начинать передачу. Это вариант контроля несущей с так называемыми на-
стойчивыми терминалами. Терминал захватывает канал сразу, как только он
254
Гпава 6
освободится. К несчастью, может оказаться, что другой настойчивый терми-
нал поступит так же, и конфликт произойдет сразу после освобождения кана-
ла. Альтернативой является протокол с ненастойчивыми терминалами.
В этом случае, если канал оказывается занятым, терминал с помощью датчи-
ка случайных чисел откладывает попытку передачи на более поздний мо-
мент. Повысить эффективность использования канала могут оба варианта
контроля несущей— как с настойчивыми, так и с ненастойчивыми термина-
лами. Задержки при этом увеличиваются, но незначительно, по сравнению с
задержками из-за повторных запросов в перегруженном канале. Третий вари-
ант контроля несущей позволяет получить такую же эффективность исполь-
зования канала, как в варианте с ненастойчивыми терминалами, но при суще-
ственно меньших задержках. Его называют методом с p-настойчивыми тер-
миналами. В нем при освобождении терминал с вероятностью р передает
пакет немедленно, а с вероятностью 1 - р откладывает передачу на случай-
ный интервал времени. Можно подобрать вероятность немедленной передачи
для получения максимальной производительности в зависимости от трафика
в сети.
На рис. 6.37 представлены графики, показывающие эффективность вариантов
контроля несущей.
Среднее число попыток
Рис. 6.37. Влияние контроля несущей на эффективность использования канала
Анализ телекоммуникационных систем
255
Варианты с ненастойчивыми и /^-настойчивыми терминалами позволяют по-
лучить коэффициент использования до 80% ресурса канала. (Результаты по-
лучены имитационным моделированием на GPSS.)
Эффективность контроля несущей зависит от того, насколько задержки рас-
пространения в канале малы по сравнению со временем передачи пакета. Это
условие выполняется в низкоскоростных сетях или сетях с малой протяжен-
ностью трасс. В гигабитных сетях или сетях со спутниковыми геостационар-
ными ретрансляторами добиться его выполнения не удается. Здесь приходит-
ся применять более сложные методы, например, передачу отдельного сигнала
занятости перед передачей пакета.
Анализ необходимого размера
входных буферов в устройствах АТМ-сетей
Сети с асинхронным режимом передачи (ATM), уже упомянутые в разд. "Ре-
гулирование трафика в мулыписервисных сетях"ранее в этой главе, основа-
ны на передаче пакетов фиксированной длины, называемых ячейками. В этих
сетях существует сервис передачи трафика с постоянной битовой скоростью
(Constant Bit Rate, CBR). Передача ячеек осуществляется в строго фиксиро-
ванные моменты времени. Тем самым, принцип функционирования таких
сетей должен обеспечивать высокую равномерность трафика и, как следст-
вие, высокий уровень использования каналов при гарантированном QoS, на-
пример, задержке обслуживания, поскольку системы D/D/n имеют характери-
стики обслуживания, не зависящие от нагрузки р до значений, сколь угодно
близких к единице. В системах D/D/n нет необходимости иметь входной на-
копитель, поскольку очередь не должна образовываться при любых меньших
единицы значениях нагрузки на сервер. Однако реально это оказывается не
так, и практически любое устройство в сети ATM должно иметь входной бу-
фер. Причиной этого является наличие случайных задержек на пути распро-
странения. Из-за задержек возникает входная очередь, размер которой будет
ограничиваться объемом накопителя. Не поместившиеся в накопитель ячейки
будут потеряны. Важным вопросом проектирования АТМ-сетей является
обеспечение малого уровня потерь ячеек для трафика с постоянной битовой
скоростью.
В данном разделе мы рассмотрим определения размера такого буфера, обес-
печивающего заданный уровень потерь ячеек, как функции параметров сети.
Будем предполагать, что источник порождает непрерывный поток ячеек оди-
наковой длины с постоянной скоростью, определяемой некоторой детерми-
нированной переменной. Обработка каждой ячейки также производится за
постоянное время, поэтому узел получателя имеет ту же производительность,
256
Гпава 6
что и источник. Будем также полагать, что время обработки в этом узле из-
меряется одной условной единицей времени. Для анализа поведения очереди
во входном буфере используем новую модель потока событий: детерминиро-
ванно-сгенерированный и стохастически-запаздывающий поток. При этом
функцию распределения величины времени, на которую оказывается запо-
здавшим появление каждого события, будем считать произвольной (general
distribution). Если обозначить событие (ячейку), сгенерированную в детерми-
нированный момент времени t, как Ch то момент появления ячейки будет оп-
ределяться величиной l + ^i. Величина — случайная, распределенная по
закону, заданному некоторой функцией распределения общего вида. По-
скольку время обработки в узле для каждой ячейки постоянно, то модель, ко-
торую мы будем рассматривать далее, можно обозначить как D+G/D/1.
Необходимо заметить, что такая модель имеет две существенные разновид-
ности. Первая из них может использоваться для описания сетей с использо-
ванием технологии передачи дейтаграмм, т. е. независимой передачи каждого
пакета (ячейки) по сети и, как следствие, при этом нужно считать незави-
симыми случайными величинами. В другой разновидности модели величины
запаздывания являются связанными. Этот случай корректно описывает сети
с установлением виртуального соединения, а значит, и АТМ-сети.
Модель D+G/D/1 и основные соотношения
Разобьем ось времени на интервалы (слоты) одинаковой единичной длины.
Слот, начинающийся в момент t и оканчивающийся в момент / + 1, будем на-
зывать слотом с номером /. В начале каждого слота генерируется ровно одна
ячейка, обозначенная С„ которая не поступает в очередь сразу, а запаздывает
на случайный интервал времени, т. е. получает задержку и поступает в оче-
редь в момент t+ где случайная величина е {0, 1, 2, ...} и имеет конеч-
ное математическое ожидание. Мы будем считать, что любая ячейка поступа-
ет в очередь в момент предшествующий границе начала слота, а покидает
очередь в момент t+, сразу после границы начала соответствующего слота.
Рассмотрим поведение системы D+G/D/1. Будем говорить, что ячейка С,
опаздывает к моменту времени т, если / <т < t + Другими словами, эта
ячейка была сгенерирована не позже т, а поступила в очередь позже т. Мно-
жество ячеек, которые опаздывают к моменту /, будем называть опаздываю-
щей популяцией ячеек и обозначать количество ячеек в этой популяции P(t).
На рис.6.38 показано поведение процессов генерирования и поступления
ячеек во входную очередь для системы D+G/D/1.
Пусть Л(/-) обозначает число ячеек, которые поступили в очередь к моменту
Г-, a Q(t)— число ячеек, которые находятся в буфере в момент t (включая,
Анализ телекоммуникационных систем
257
конечно, A(t-)'). Общая незаконченная работа в момент t описывается суммой
ячеек, которые находятся в очереди и опаздывают к этому моменту:
[/(О-ЛО + лсн.
Число отложенных ячеек Р(9) = 4
I
| Ячейки, поступающие в очередь
I
Сгенерированные ячейки
Рис. 6.38. Расположение временных слотов и поступление ячеек
Введем понятие "голода" в системе как события, при котором ячейки не об-
рабатываются из-за того, что в очереди нет готовых к обработке ячеек. Мо-
мент /, в который оказывается Q(f) = 0, назовем точкой начала голодания, а
момент Z+ 1 —точкой окончания голодания; в этом случае слот t можно на-
зывать голодным слотом. Будем также обозначать через S(t) общее число то-
чек начала голодания, которые расположены левее точки t.
Одно из главных утверждений, которое будет далее использоваться, опреде-
ляет связь числа опаздывающих ячеек и числа опаздывающих к этому момен-
ту ячеек:
P(t) + A{t-)^P(t-\) + \.
Доказательство этого утверждения следует непосредственно из определений
и анализа описанного поведения системы. Можно показать также, что мате-
матическое ожидание
P(Z)<^.
Рассмотрим сначала систему с бесконечным размером буфера. Анализ пока-
зывает, что для любого t > 1 незавершенная работа связана с числом точек
голодания соотношением U(t) = S(f) + 1.
Само это соотношение не столь интересно, как следующее из него неравенст-
во C/(Z)<C/(Z') для всех 1 <t <Р. Данное неравенство говорите неустойчиво-
9 Зак. 3881
258
Гпава 6
сти системы D+G/D/1, поскольку с течением времени незавершенная работа
монотонно не убывает. Однако характер неустойчивости здесь непохож каче-
ственно на процессы неустойчивости в других типах систем массового об-
служивания. Дело в том, что обычно рост незавершенной работы происходит
постепенно, а в нашем случае рост незавершенной работы определяется пач-
кой поступлений. Точнее говоря, рост незавершенной работы до некоторой
заданной величины к может осуществиться, только если пачка из к требова-
ний будет запаздывать совместно.
Можно доказать следующее утверждение: если U(fy) = к> 0, то существует
такой момент 1 <t'<tQ, что A(t'-) + P(t') = k. Это и означает, что моменту
достижения незавершенной работой некоторого значения предшествует мо-
мент, когда в точности данное значение принимает число поступающих
в очередь и запаздывающих к этому моменту требований.
Интересно заметить, что если величина запаздывания ограничена некоторым
числом //?, то U(t) < т +1 .
Системы с конечным размером буфера
Будем считать, что максимальная длина очереди в системе ограничивается
числом В> 1. Требование, поступающее в полностью заполненную очередь,
теряется. Потеря происходит в момент 1-. Количество потерянных требова-
ний к этому моменту будем обозначать /(/-). Нетрудно показать, что
/(Н = {{20-
Действительное число требований, которое поступило в очередь к моменту t,
определяется разностью А(р~) - 1(1-). Общее число потерянных требований
к моменту / может быть определено как
Л(О = £/(Г).
1=1
Между потерями и числом точек голодания существует жесткая связь:
Z(/) + t7(/) = 5(0 + 1.
В пределе при больших / эта связь выглядит еще более определенной и, что
очень важно, определяет границу неравенства для вероятности превышения
числа запаздывающих требований размера буфера:
lim = lim < lim Рг{Р(/) > В}.
/~>СО / ,-»СО t
Анализ телекоммуникационных систем
259
Наиболее практически важными являются соотношения, позволяющие оце-
нить вероятность потерь требований в зависимости от характеристик запаз-
дывания и размера буфера.
Сначала рассмотрим случай, когда все величины запаздываний — независи-
мые случайные числа, имеющие одинаковые законы распределения. Этот
случай описывает практическую ситуацию в сети с дейтаграммным механиз-
мом передачи пакетов.
Пусть
А=Рг{^}
и
Pk=Pr£>k}.
Тогда вероятность достижения числом принимаемых ячеек заданной величи-
ны к в стационарном режиме может быть найдена как
Пт Рг{Д/-) = &}< Ёа, Ё Р,2- Ё Д-
'1=0 '2='|+1 '(Ч-| + 1
Аналогично можно показать, что для незаконченной работы выполняется не-
равенство
limPr{P(/) + W-W} <^Р,2 Ё р„- Ё Л -
6=1 'l='2+1 't='*-l+l
Несколько громоздкие формулы становятся совершенно понятными для кон-
кретных распределений вероятностей запаздывания. Одним из простейших,
но важных, случаев является геометрическое распределение, для которого
Рк =РРк ’
Рк=Рк-
Здесь р — некоторое положительное число, не превышающее единицу.
Для такого распределения из приведенных выше формул следует, что в пре-
деле при больших I выполняются неравенства:
рГ{р(о+дн^п-А-.
/=11 ~ р
Практический смысл этих соотношений состоит в том, что из них можно по-
лучить оценку вероятности превышения размера буфера в виде:
260
Глава 6
ЦП
к п-
*+1т~г Р
Теперь рассмотрим случай сетей с установлением виртуального соединения.
Для них принципиальным является тот факт, что ячейки не могут обгонять
друг друга, поскольку следуют по одному и тому же пути. Распределение за-
паздываний здесь должно подчиняться правилу: если = Л, то । > к- 1.
Основной результат, который может быть получен при этих предположениях,
может быть сформулирован так: в пределе при достижении системой стацио-
нарного режима вероятность, что число запаздывающих ячеек равно задан-
ному числу к, равна вероятности 'того, что запаздывание в сети будет состав-
лять ровно к временных единиц. Это утверждение также может быть исполь-
зовано для определения вероятности потерь для буфера конечной длины.
Отношение скоростей
Теоретические
Практические
------loss (теоретические)
------ > в
— — Pink
------ loss (практические)
а) 6)
Рис. 6.39. Расчеты вероятности потерь и сравнение с результатами моделирования
Основными результатами описанного исследования является расчет необхо-
димого размера буфера для устройств сети ATM. Если выполнить расчеты по
выведенным выше формулам для вероятностей потерь, то определение необ-
ходимого размера буфера может быть сделано графическим путем. На
рис. 6.39 приведено несколько графиков для границ вероятностей потерь и
Анализ телекоммуникационных систем
261
проиллюстрировано сравнение теоретически полученных соотношений и ре-
зультатов имитационного моделирования системы D+G/D/1.
Были вычислены по полученным формулам и построены по результатам
имитационного моделирования границы вероятности потерь, а также
Pink = Рг{Л7) > P(t -1), P(Z) > В},
Рт{Р(Г)>В}
(рис. 6.39, а), в зависимости от характеристик распределения запаздываний.
В качестве параметра при построении графиков использовалось отношение
скоростей передачи пакетов в сети и скорости источника или получателя. Эта
величина всегда превышает единицу в несколько раз.
На рис. 6.39, б приведена вероятность превышения размера очереди длины
буфера Рг{£, > В] в зависимости от размера буфера.
Главный результат, который мы здесь проиллюстрировали, состоит в том, что
эффекты случайного характера, проявляющиеся в сети, могут играть сущест-
венную роль даже в тех случаях, когда системы проектируются со строго
фиксированными временем обслуживания и временем генерации пакетов.
Анализ и моделирование протокола TCP
Протокол TCP (Transmission Control Protocol) является широко используемым
протоколом транспортного уровня в сетях с дейтаграммной передачей паке-
тов [13]. Такие сети и называют часто TCP/IP в силу того, что ТСР-протокол
является их неотъемлемой частью, несмотря на то, что другой транспортный
протокол UDP также используется в данных сетях. Главным сервисом, пре-
доставляемым этим протоколом вышележащему уровню, является обеспече-
ние надежной передачи пакетов по ненадежной дейтаграммной сети. Из-за
сильных изменений, постоянно происходящих в интерсетях, протокол содер-
жит механизмы глубокой адаптации к условиям передачи пакетов, обеспече-
ние повторной передачи пакетов в случае их потери, упорядочение в нужной
последовательности и, наконец, регулирование скорости передачи пакетов
в зависимости от условий распространения к адресату.
Аналитические результаты
В этом разделе проанализируем производительность протокола TCP с меха-
низмом регулировки скорости, называемым алгоритмом Рено (Reno). Основ-
ным показателем производительности будем считать величину средней ско-
рости передачи пакетов:
262 Гпава 6
В = lim—
t
где t— время, N,— количество пакетов, переданных за временной интер-
вал [0, /].
Протокол TCP Reno использует для передачи пакетов метод скользящего ок-
на, причем размер окна динамически меняется. При приеме пакета прини-
мающая сторона посылает подтверждение (АСК). Для упрощения модели
вероятность потери подтверждения принимается за 0, т. е. подтверждения не
теряются. Подтверждения могут посылаться как на один, так и на несколько
(обычно два) пакетов. В данной работе примем количество пакетов Ь, под-
тверждаемых в одном АСК, равным 1, что позволит значительно упростить
модель протокола, не отразившись существенно на результатах. При получе-
нии АСК-передатчик увеличивает размер окна W на величину MW. Передача
ведется так называемыми раундами. Поясним это понятие. В начале передачи
посылается первый раунд (W пакетов, пусть начальное значение W равня-
ется 1). После подтверждения этого пакета W увеличивается на 1/И7, т. е. W
станет равным 2, начинает посылаться второй раунд, в котором уже 2 пакета.
И так далее. Таким образом, W увеличивается на 1 при приеме W АСК, т. е.
каждый раунд. После получения подтверждения первого пакета из текущего
раунда сразу же посылается первый пакет следующего раунда. Среднее время
длительности раунда обозначим как RTT (round trip time). Фактически это
время, прошедшее с момента передачи пакета до получения подтверждения
на него, т. к. длительность самой передачи считаем пренебрежимо малой.
Пусть длительность каждого раунда будет фиксированной величиной, равной
математическому ожиданию RTT, опять же для упрощения модели. Соответ-
ственно, размер окна станет расти линейно во времени.
Рассмотрим процесс индикации потери пакета. Здесь возможны два случая:
или придут четыре одинаковых подтверждения (triple-duplicate (TD) loss),
или вывод о потере пакета будет сделан по прошествии некоторого тайм-аута
То, на протяжении которого не будет принято ни одно подтверждение (time-
out (ТО) loss).
В случае потери пакета все последующие пакеты этого раунда также счита-
ются потерянными, подтверждения на них не посылаются. Стоит отметить,
что подтверждение содержит в себе номер следующего ожидаемого пакета.
В случае, если приемник решает, что произошла потеря, он не подтверждает
следующие принятые пакеты текущего раунда, но т. к. несколько пакетов
этого раунда были удачно приняты и подтверждены, передатчик начнет от-
сылку пакетов следующего раунда. На них приемник будет высылать под-
тверждения, содержащие номер потерянного (ожидаемого) пакета. Одно та-
кое подтверждение уже было принято, после прихода еще трех передатчиком
Анализ телекоммуникационных систем
263
будет сделан вывод, что произошла потеря пакета. Это TD-потеря. Если же
при передаче потеряется первый, второй или третий пакет раунда, то три
одинаковых подтверждения прийти не смогут, т. к. из следующего раунда
окажутся отосланными менее трех пакетов. В результате будет вынесено ре-
шение о ТО-потере (ТО-потеря первого рода). Также потеря по тайм-ауту
будет получена в случае неполучения пакета с номером в раунде больше трех
и последующей потери первого, второго или третьего пакета из следующего
раунда (ТО-потеря второго рода).
Была получена зависимость между размером окна W, вероятностью р и веро-
ятностью Vтого, что тип потери пакета будет ТО:
w, - minR .
L 1-0-rt" J
Данная зависимость в пределе дает более простую:
Е(^)= limg0(jy) = min 1,— .
В этом можно убедиться, построив графики рис. 6.40 (здесь р = 0,01).
----- V(W)
----- V0(W)
Рис. 6.40. Зависимость вероятности потери пакета по тайм-ауту от размера окна
Из анализа можно сделать вывод, что с уменьшением р ТО-потери второго
рода встречаются значительно реже, чем первого рода. Действительно, поте-
ря первого рода имеет вероятность порядка р (не дошел один пакет), а второ-
го рода— порядка р2 (не получены два пакета). Таким образом, при даль-
нейшем моделировании не будем учитывать потери второго рода, что также
упрощает модель.
Вернемся непосредственно к зависимости В(р), которую мы хотели исследо-
вать. Разделим моделирование на две части: в первой допустим, что будем
иметь только TD-потери пакетов, во второй :—TD- и ТО-потери.
264
Гпава 6
Для первого случая была получена точная формула:
ад-
\-р 2 + Ь 8(1-р) [2 + г>т
р ЗЬ у ЗЪр _ зь
2 + b l2b(l-p) (2 + bY
Т- ---+ , —-——+ ------ +1
6 у Зр V 6 )
(6.20)
Для потерь обоих типов имеем более сложную аппроксимацию:
д2 (jp) «---------------J---- ----------.
RTT • + То min ^1,3^J• р(1 + 32/г) (6'21)
Очевидно, что при малых р система с TD- и ТО-потерями дает такие же
результаты, как и система только с TD-потерями (рис. 6.41):
1—J4- (6.22)
1 RTT\2Z>p
В(Р)
В2(Р)
Рис. 6.41. Зависимость средней скорости передачи от вероятности потери пакета
Напомним еще раз, что при моделировании будем брать b = I (подтвержде-
ние для каждого пакета), и приступим непосредственно к построению имита-
ционных моделей для оценки точности полученных приближенных формул.
Анализ телекоммуникационных систем 265
Моделирование сетью Петри
Построение модели и моделирование производилось с помощью пакета
Artifex. При создании моделей целью не ставилось полное моделирование
протокола TCP Reno, а лишь получение интересующей нас зависимости ско-
рости передатчика от вероятности потери пакета. Таким образом, модели
представляют собой упрощенные реализации части TCP Reno, максимально
простые с учетом допущений, оговоренных в теоретической части и не
влияющих на конечный результат моделирования.
Моделирование производилось следующим образом: измерялось время, не-
обходимое для прокачки некоторого количества пакетов через систему, реа-
лизующую TCP Reno, при заданных вероятностях потери пакета и длитель-
ности раунда передачи. Для исключения из рассмотрения начального (неста-
ционарного) участка размер окна в начале передачи будем брать равным не
единице, а среднему значению размера окна, подсчитанному по теоретиче-
ским формулам.
Для описания потерь типа TD была построена модель в виде сети Петри, изо-
браженная на рис. 6.42.
На данной схеме кружками обозначены позиции (place), прямоугольника-
ми — переходы (transition).
Параметры модели представлены в листинге 6.1.
Листинг 6.1. Параметры модели
Double р; //Вероятность потери пакета
Double RTT; //Время длительности раунда
Маркеры класса packet имеют следующие переменные (листинг 6.2).
Листинг 6.2. Переменные маркеров класса packet
int is_ack;
unsigned int round;
unsigned 'int number;
Используемые переменные даны в листинге 6.3.
Листинг 6.3. Используемые переменные
int w;
double wd;
266
Глава 6
int for_del;
unsigned int round;
unsigned int number;
int is_error;
unsigned int error_round;
unsigned int err_num;
int ready_to_sliv;
TX(3000)
Рис. 6.42. Сеть Петри для системы с многократными подтверждениями
Секция инициализации модели — листинг 6.4.
Листинг 6.4. Секция инициализации модели
XX->w = 3;
XX->wd = (double)3.OOOQOl;
XX->for_del = 0;
Анализ телекоммуникационных систем
267
XX->number = 0;
XX->round = 1;
XX->is_error = 0;
XX->ready_to_sliv = 0;
XX->err_round = 0;
XX->err_num = 0;
xu_RndSetSeed(899);
Переход transmittion (приоритет 0) представлен в виде:
□ Predicate (ЛИСТИНГ 6.5);
□ Action (ЛИСТИНГ 6.6).
Листинг 6.5. Predicate для перехода transmittion
(CONTROL_W->number < XX->err_num) || (!XX->is_error)
Листинг 6.6. Action для перехода transmittion
xx_rdelay(XT_TRANSMITTION,XX->RTT);
RX->is_ack = (xu_RndDouble() > XX~>p);
if (XX->is_error) RX->is_ack = 1;
if (XX->err_round == XX->round) RX->is_ack = 1;
if (RX->is_ack == 0) XX->err_round = XX->round;
XX->numbe r++;
RX->round = XX->round;
RX->number = XX->number;
if (XX->number==XX->w)
{
XX->number = 0;
XX->round++;
};
Переход ack (приоритет 1) представлен в виде:
□ Predicate (ЛИСТИНГ 6.7);
□ Action (листинг 6.8).
( Листинг 6.7. Predicate для перехода аск
RX->is ack
268
Гпава 6
] Листинг 6.8. Action для перехода аск
if (XX->is_error == 0) XX->wd = XX->wd + (double)1/(XX->w);
printf("WD = %f intWD = %d w = %d r %d n %d\n",XX->wd,(int)XX->wd,XX->w,
RX->round,RX->number);
if ((XX->is_error == 1) && (RX->round == XX->err_round +1) &&
(RX->number == XX->err_num - 1))
XX->ready_to_sliv = 1;
Переход err (приоритет 0) представлен в виде:
□ Action (листинг 6.9).
I Листинг 6.9. Action для перехода ehr
printf("Error occured! r = %d n = %d\n",RX->round,RX->number);
if (xx_tokennumber(XP_W) > 1)
{
XX->for_del = (int)(XX->w/2 + 0.000001);
XX->is_error = 1;
XX->err_num = RX->nuniber;
XX->err_round = RX->round;
if (XX->err_num,= 1) XX->ready_to_sliv = 1;
};
Переход inc (приоритет 0) представлен в виде:
□ Predicate (ЛИСТИНГ 6.10);
□ Action (листинг 6.11).
L Листинг 6.10. Predicate для перехода INC
XX->w < (int)XX->wd
(Листинг 6.11. Action для перехода inc
XX->w = (int)XX->wd;
printf("Wdinc = %f\n",XX->wd);
Переход sliv (приоритет 1) представлен в виде:
□ Predicate (листинг 6.12);
□ Action (листинг 6.13).
Анализ телекоммуникационных систем
269
Листинг 6.12. Predicate для перехода sliv
(XX->for_del > 0) ii (XX->ready_tc_sliv)
| Листинг 6.13. Action для перехода sliv
XX->for_del = XX->for_del - 1;
if (XX->for_del == 0)
{
XX->is_error = 0;
XX->ready_to_sliv = 0;
XX->w = XX->w - (int)(XX->w/2 + 0.000001);
XX->wd = (double)XX->w + (double)0.000001;
XX->number = 0;
XX->round++;
};
Принцип работы заключается в следующем. В тх лежит 3000 пакетов, время
передачи которых и будет измеряться. В control_w и w находится количество
маркеров, равное размеру окна для первого раунда передачи. Позиция w под-
ключена параллельно с control_w для удобства снятия графика эволюции
размеров окна. В w всегда содержится количество маркеров, равное текущему
размеру окна, тогда как в control_w это имеет место лишь в некоторые
моменты времени. Из тх и control_w маркеры поступают в переход
transmittion, где происходит задержка пакетов на RTT, а также заполняются
поля маркеров (номер раунда, порядковый номер в раунде, признак потери
пакета), далее пакеты поступают в rx, откуда посылаются подтверждения
(содержащие ту же информацию). Если признак потери отрицательный — это
подтверждение идет в переход аск, где увеличивается размер окна на 1/W и
далее, опять в control_w, на следующий цикл. Также в этом случае маркеры
посылаются в succsefully_recieved (для подсчета удачно принятых пакетов)
и в storage для проверки предиката на переходе inc, который каждый раунд
пропускает один маркер из storage в control_w (а также в w), что реализует
рост размера окна. Если же признак потери положительный, маркер идет в
переход err, в котором высчитывается, на сколько нужно уменьшить размеры
окна, а также выставляются флаги о детектировании потери. После этого по
маркеру идет в lost_packets (количество потерянных пакетов) и в control_w
для корректной организации уменьшения размеров окна. Далее, при обнару-
жении потери из control_w в transmittion уходит столько пакетов, сколько
подтверждений было принято в предыдущем раунде (пакеты после потерян-
270
Гпава 6
ного также считаются потерянными). Данные пакеты уже не влияют на рост
окна, а также они не теряются, чтобы не происходило двойного уменьшения
размеров окна. После их прибытия обратно в control_w выставляется флаг
готовности к процессу сброса лишних маркеров из цикла для уменьшения
размеров окна: переход sliv открывается и пропускает половину маркеров из
control_w и ив garbage, после чего он закрывается, устанавливая флаг о нали-
чии потери в исходное положение. Далее начинается новый цикл передачи,
но уже с новым размером окна.
Теперь усложним модель так, чтобы она отражала оба вида потерь. На
рис. 6.43 изображена такая сеть Петри.
Параметры модели — листинг 6.14.
ТХ(ЗООО)
Рис. 6.43. Сеть Петри для системы с потерями по тайм-ауту
и многократными подтверждениями
Анализ телекоммуникационных систем
271
Листинг 6.14. Параметры модели
Double р;
Double RTT;
Double ТО;
//Вероятность потери пакета
//Время длительности раунда
//Тайм-аут при ТО-потере
Маркеры класса раскет2 несколько отличаются от packet и имеют перемен-
ные, перечисленные в листинге 6.15.
: Листинг 6.15. Переменные маркёра класса ₽аскет2
int err_type;
unsigned int round;
unsigned int number;
Используемые переменные— те же, что и в первой модели плюс коэффици-
ент умножения переменной тайм-аута (листинг 6.16).
Листинг 6.16. Используемые переменные
int w;
double wd;
int for_del;
unsigned int round;
unsigned int number;
int is_error;
unsigned int error_round;
unsigned int err_num;
int ready_to_sliv;
int mult_tO;
Секция инициализации модели та же по смыслу (листинг 6.17).
Листинг 6.17. Секция инициализации модели
XX->w = 12;
XX->wd = (double)12.000001;
XX->for__del = 0;
XX->number = 0;
XX->round = 1;
XX->is_error = 0;
XX->ready__to_sliv = 0;
272
Гпава 6
XX->err_round = 0;
XX->err_num = 0;
XX->mult_tO = 1;
xu_RndSetSeed(1986);
Переход transmittion (приоритет 0) представлен в виде:
а Predicate (листинг 6.1 8);
а Action (листинг 6.19).
( Листинг 6.18. Predicate для перехода transmittion
(CONTROL_W->number < XX->err_num) || (XX->is_error -- 0)
Листинг 6.19. Action для перехода transmittion
xx_rdelay(XT_TRANSMITTION,XX->RTT);
RX->err_type = 1;
if (xu_RndDouble() > XX->p) RX->err_type = 0;
if (XX->is_error) RX->err_type = 0;
if (XX->err_round == XX->round) RX->err_type = 0;
if (RX->err_type == 1) XX->err_round = XX->round;
XX->number++;
RX->round = XX->round;
RX->number = XX->number;
if ((RX->err_type == 1) && (RX->number <= 3)) RX->err_type = 2;
if (XX->number==XX->w)
{
XX->number = 0;
XX->round++;
};
Переход ack (приоритет 0) представлен в виде:
а Predicate (листинг 6.20);
а Action (листинг 6.21).
| Листинг 6.20. Predicate для перехода АСК
RX->err_type == 0
Анализ телекоммуникационных систем
273
Листинг 6.21. Action для перехода аск
if (XX->is_error == 0) XX->wd = XX~>wd + (double)1/(XX->w);
print!("WD = %f intWD = %d w = %d r %d n %d\n",XX->wd,(int)XX->wd,
XX->w,RX->round,RX->number);
if ((XX->is_error == 1) && (RX->round == XX->err_round +1) &&
(RX->number == XX->err_num - 1))
XX->ready_to_sliv = 1;
XX->mult_tO = 1;
Переход inc (приоритет 0) представлен в виде:
□ Predicate (листинг 6.22);
□ Action (листинг 6.23).
Листинг 6.22. Predicate для перехода inc
XX->w < (int)XX->wd
; Листинг 6.23. Action для перехода inc
XX->w = (int)XX->wd;
printf("Wdinc = %f\n",XX->wd);
Переход timeout (приоритет 0) представлен в виде:
□ Action (листинг 6.24).
I Листинг 6.24. Action для перехода timeout
xx_rdelay(XT_TIMEOUT,XX->T0 * XX->mult_tO);
if (XX->mult < 64) XX->mult_tO = XX->mult_tO * 2;
Переход td_err (приоритет 0) представлен в виде:
□ Predicate (листинг 6.25);
□ Action (листинг 6.26).
I Листинг 6.25. Predicate для перехода TD_ERR
RX->err_type == 1
г Листинг 6.26. Action для перехода td_err
XX~>for_del = (int)(XX->w/2 + 0.000001);
printf("TD Error occured! r = %d n = %d\n",RX->round,RX->number);
274
Гпава 6
XX->is_error = 1;
XX->err_num = RX->number;
XX->err_round = RX->round;
if (XX->err_num == 1) XX->ready_to_sliv = 1;
Переход to_err (приоритет 0) представлен в виде:
□ Predicate (листинг 6.27);
а Action (листинг 6.28).
Листинг 6.27. Predicate для перехода to_err
RX->err_type == 2
Листинг 6.28. Action для перехода to_err
XX->for_del = XX->w;
printff'TO Error occured! r = %d n = %d\n",RX->round,RX->number);
XX->is_error = 2;
XX->err_num = RX->number;
XX->err_round = RX->round;
XX->ready_to_sliv = 1;
Переход sliv (приоритет 1) представлен в виде:
а Predicate (листинг 6.29);
□ Action (листинг 6.30).
Листинг 6.29. Predicate для перехода SLIV
(XX->for_del > 0) && (XX->ready_to_sliv)
Листинг 6.30. Action для перехода sliv
XX->for_del = XX->for_del - 1;
if (XX->for_del == 0)
(
if (XX->is_error == 1) XX->w = XX->w - (int)(XX->w/2 + 0.000001);
if (XX->is_error == 2) XX->w = 1;
XX->wd = (double)XX->w + (double)0.000001;
XX->is_error = 0;
XX->ready__to_sliv = 0;
XX->number = 0;
XX->round++;
};
Анализ телекоммуникационных систем
275
Данная модель представляет собой несколько расширенную версию преды-
дущей. Часть, реализующая TD-потери, осталась без изменений, поменялся
только тип маркеров, и то лишь по смыслу: теперь потери могут быть двух
видов. Добавился переход tojerr, через который пойдут маркеры, сигнализи-
рующие о ТО-потере. Напомним, что ТО-потеря происходит, если потерян-
ный пакет имеет первый, второй или третий порядковый номер в раунде. При
прохождении маркера через to_err сразу открывается переход sliv, через ко-
торый из системы выводятся все маркеры, имитируя падение размера окна
передачи до нуля. Из to_err маркеры поступают в to_loss_packets (для под-
счета количества ТО-потерь) и в to_init_place, откуда через переход timeout,
задерживаясь в нем на тайм-аут То, один маркер попадает в control_w, запус-
кая следующий цикл передачи. Если и в нем происходит потеря, то время
тайм-аута удваивается, и т. д. Это значение может расти до 64То. При удач-
ном приеме хотя бы одного пакета размер тайм-аута сокращается опять до Го.
Выполненное моделирование позволило получить ряд интересных результа-
тов (табл. 6.8).
Таблица 6.8. Результаты моделирования
Количество пакетов, прошедших через систему, 7V Количество потерь, L Доля потерянных пакетов, Q Вероятность потери, задаваемая при моделировании, Р Время прокачки пакетов через систему, Т Средний размер окна, W
3000 439 0,1463 0,2 12 280 2,44
3000 400 0,1333 0,15 11 670 2,57
3000 239 0,0796 0,1 8650 3,46
3000 159 0,0530 0,07 6840 4,38
3000 115 0,0383 0,05 5630 5,32
3000 68 0,0226 0,03 4170 7,19
5000 79 0,0158 0,02 5620 8,89
5000 36 0,0072 0,01 3560 14,04
5000 34 0,0068 0,0075 3490 14,32
10000 43 0,0043 0,005 5510 18,14
10000 30 0,0030 0,003 4630 21,59
15000 32 0,0021 0,002 5470 27,42
20000 15 0,0007 0,001 4400 45,45
30000 11 0,0004 0,0005 4670 64,23
276
Гпава 6
При моделировании снимались параметры L и Т, Q и W, а также В, вычислен-
ное следующим образом:
т
Рассмотрим полученные результаты, приведенные в виде графиков (рис. 6.44).
-------в2
------- S)
Рис. 6.44. Зависимость пропускной способности от доли потерянных пакетов
На данном графике приведена зависимость Bsi (количество отправляемых па-
кетов за единицу времени) от Q. Также для сравнения построены графики
функций (6.21) и (6.22) (В\ и Bi соответственно). Как и следовало ожидать,
графики В\ и В-> очень близки, В\ проходит немного ниже 52. Главный же вы-
вод, который можно сделать из этого графика, в том, что теоретически полу-
ченные зависимости (6.21) и (6.22) являются верхней оценкой для скорости
источника, реализующего протокол TCP Reno. Также стоит отметить, что
данная оценка весьма точна даже при нереально больших значениях вероят-
Анализ телекоммуникационных систем
277
ности потери пакета, при малых же р практически полученная кривая асим-
птотически стремится к теоретической.
Можно заметить, что выражение (6.22) точно описывает случай с детермини-
рованным временем между потерями пакетов. В этом случае размер окна бу-
дет вести себя так, как представлено на рис. 6.45.
— раундов
Рис. 6.45. Динамика размера окна в случае регулярной потери пакетов
Найдем среднее значение размера окна. Решая задачу геометрически, из по-
лучившейся трапеции имеем следующий результат:
Это выражение повторяет (6.22) для среднего размера окна, т. к. В = WI То.
Отсюда можно сделать вывод, что при детерминированном времени между
потерями пакетов скорость источника будет больше, чем при случайном рас-
пределении времени между потерями, разумеется, при одинаковых средних
значениях этих времен.
Приведем графики, иллюстрирующие процесс эволюции размеров окна пере-
дачи. Для р = 0,01 (рис. 6.46).
И для вдвое меньшей вероятности потерь р = 0,005 общая картина изменения
окна остается прежней (рис. 6.47).
Для системы с потерями обоих видов были получены следующие результаты
моделирования (табл. 6.9).
При моделировании снимались параметры ZTD, Лто и Т.
L, Q, Wи В2 вычисляем следующим образом:
Л = L,i0 + Д-р,
Таблица 6.9. Результаты моделирования систем с различным уровнем потерь пакетов
Количество пакетов, прошедших через систему, N Количество ТО-потерь, Lto Количество TD-потерь, Ltd Общее количество потерь, L Доля потерянных пакетов, Q Вероятность потери, задаваемая при моделировании, Р Время прокачки пакетов через систему, Т Средний размер окна, W
500 173 1 174 0,3480 0,4 13 165 0,37
1000 138 11 149 0,1490 0,2 8390 1,19
1000 159 18 177 0,1180 0,15 10 770 1,39
3000 193 47 240 0,0800 0,1 14 735 2,03
3000 102 52 154 0,0513 0,07 10 030 2,99
3000 88 51 139 0,0463 0,05 9285 3,23
3000 36 38 74 0,0246 0,03 5790 5,18
5000 32 58 90 0,0180 0,02 7675 6,51
5000 12 зо 42 0,0084 0,01 4520 11,06
5000 9 28 37 0,0074 0,0075 4235 11,80
10000 12 36 48 0,0048 0,005 6530 15,31
10000 8 25 33 0,0033 0,003 5540 18,05
15000 7 25 32 0,0021 0,002 6565 22,84
20000 1 18 19 0,0009 0,001 5105 39,17
30000 1 9 10 0,0003 0,0005 4725 63,49
278 Гпава 6 j Анализ телекоммуникационных систем-279
280
Гпава 6
- В2
Рис. 6.48. Зависимость пропускной способности отдели потерь Q
График В2 представляет собой полученную ранее теоретически зависи-
мость (6.21). Аналогично, она оказывается верхней оценкой для скорости пе-
редатчика.
Также приведем графики процесса эволюции размеров окна передачи для
большей вероятности потерь.
Для р = 0,2 динамика окна изображена на рис. 6.49.
Здесь хорошо видны последовательности ТО-потерь, в результате которых
происходит экспоненциальный рост длительности тайм-аута.
Для очень малых потерь при ул = 0,001 имеет место иная (рис. 6.50) зависи-
мость.
Здесь ТО-потери практически не возникают: на данном графике видна лишь
одна такая потеря пакета, вызвавшая падение размеров окна до единицы.
В результате проведенного моделирования системы пакетной передачи с
плавающим окном, использующей протокол TCP Reno, удалось практически
подтвердить верность аналитических выражений, а также сделать вывод
о том, что приближенные выражения с высокой степенью точности аппрок-
симируют практические зависимости, являясь их верхней границей.
Анализ телекоммуникационных систем
281
time
Рис. 6.49. Процесса эволюции размеров окна передачи р = 0,2
И/
1000 2000 3000 4000 5000
time
Рис. 6.50. Динамика окна передачи при маЬом уровне потерь
282 Гпава 6
Контрольные вопросы
1. Как выбирается число исходящих каналов для УПАТС?
2. При каких условиях технология коммутации пакетов уступает коммута-
ции каналов?
3. В чем состоит основная идея стратегии подвижной границы при распреде-
лении ресурса между голосовым и файловым трафиком?
4. Почему полезное использование канала при множественном случайном
доступе не может быть сколь угодно приближено к единице?
5. С какой целью производится изменение передающего окна в протоколе
TCP?
Список литературы
1. Artifex 4.2 Modeling Guide. — ARTIS Software corporation1.
2. Leland W. E., Taqqu M. S., Wil I inger W., Wilson D. V. On the self-similar na-
ture of Ethernet traffic // IEEE Transaction on networking. - - Vol. 12.—
1994, —№ 1, —P. 2—15.
3. Medhi J. Stochastic models in queueing theory. — Academic Press, 2003.
4. Norros Ilkka. A storage model with self-similar input. — Queueing Systems,
1994.
5. Грэхем P., Кнут Д., Паташник О. Конкретная математика. Основание ин-
форматики.— М.: Мир, 1998.
6. Корнышев Ю. Н., Пшеничников А. П., Харкевич А. Д. Теория телетрафи-
ка: Учебник для вузов. — М.: Радио и связь, 1996.
7. Котов В. Е. Сети Петри. — М.: Наука, ГРФМЛ, 1984.
8. Крылов В. В. Теория телетрафика (Основы теории систем массового об-
служивания для задач телекоммуникаций) — Н. Новгород: НГТУ, 2000.
9. Кудрявцев Е. М. GPSS World. Основы имитационного моделирования
различных систем. — М.: ДМК, 2003.
10. Мандельброт Б. Фрактальная геометрия природы//Компьютинг в мате-
матике, физике, биологии. Пер. с англ. — М.: Изд-во Института компью-
терных исследований, 2002.
11. Нейман В. И. Самоподобные процессы и их применение в теории теле-
трафика // Труды МАС. — 1999. — № 1 (9). — С. 11—15.
12. Спиридонов А. М. Сети Петри в моделировании и управлении.— Л.:
Наука, Ленинградское отделение, 1989.
13. Таненбаум Э. Компьютерные сети. 4-е изд. — СПб.: Питер, 2003.
14. Учебное пособие по GPSS World. — Казань: Мастер Лайн, 2002.
15. Шварц М. Сети связи: протоколы, моделирование и анализ. В 2-х ч. Пер.
с англ. — М.: Наука, 1992.
Это фирменное руководство, которое можно заказать на сайте http://artis-sortwarc.coin.
Предметный указатель
А F
ALOHA 248 0 классическая 248 0 тактированная 251 ALPHA/Sitn 112 ARP 112 Arrival 13 Artifex 112, 265 Asynchronous Transfer Mode (ATM) 205 Average waiting time 14 First Came First Served (FCFS) 77 Fractal Brownian Motion (IBM) 58 Fractal Gaussian Noise (fGN) 58 Fractan 4.4 68 Frame Relay 204 G Gantt 16 General Purpose Simulation System (GPSS)
В 61, 85, 174 6 Mode! Objects 86
Block 86 Blocking probability 14 Bursty 52 Busy hour 18 5-формула Эрланга 158 6 Report Objects 86 6 Simulation Objects 86 0 Text Objects 86 6 основные блоки 88 н
С Holding time 13 Hub 248
Carrier sense 253 Hurst 53
Chapman — Kolmogorov 140
Communication 14 ConimVicw 30 Connection 14 Constant Bit Rate (CBR) 255 CoopnTools 112 CPN Tools 113 1 Identifier 87 Integrated Service Digital Network (ISDN) 232 International Telecommunication Union (ITU) 10
CPN-AM1 112 С-формула Эрланга 154 J
E J-Sim 85
Engset Calculator 162 Erlang В Calculator 159 EtherBoy 30 К Kiviat 27
Предметный указатель
285
L R
Last Came First Served (LCFS) 77 Long range dependent 52 Lost Calls Cleared (LCC) 159 Lost Calls Delayed (LCD) 154 Random Midpoint Displacement (RMD) 64 Reno 261 Resource 14 Round trip time (RTT) 215, 262
M s
Media Access Control (MAC) 247 Molina 162 Self-similarity 52 Server 13 Successful Random Addition (SRA) 64
N T
Netboy 29 Network Monitor 29 Time slots 251 Time-out loss 262 Token 106
0 Traffic carried 16 Traffic intensity 15
Overflow traffic 17 Traffic offered 17 Traffic volume 15
P Transition 105 Triple-duplicate loss 262 Trunk 27
PackctBoy 30 РК-формула 165 Pollaczek — Khinchin 165 Position 105 Private Branch exchange (PBX) 181 u Utilization factor 76
Q V Visual Petri 112, 113
Quality of Service (QoS) 150 Queue 14 Queuing system 14 Queuing Theory 13 w Web Boy 30
286
Предметный указатель
А
Алгоритм Рено 261
Асинхронный режим передачи 205
Б
Блок 86
Блокировка 154
В
Вероятностный граф 193
Вероятность:
0 блокировки 14, 156
0 состояния равновесия 138
Возвратное состояние:
0 апериодическое 137
0 периодическое 137
Временная шкала 55
Временной интервал 251
Время обслуживания 13
Г
Гамма-распредслснис 150
Граф:
0 Ли 193
0 мостиковый 194
0 параллельно-последовательный 194
д
Датчик случайных чисел 59
Двухзвенная коммутационная система 197
Детерминированный процесс исполнения
59
Джиттер 232
Диаграмма:
0 Ганта 16
о Кивиата Т1
0 переходов 138
Длительность раунда 262
Долгосрочная зависимость 52, 53
3
Законы сохранения СМО 79
Звено 193
И
Идентификатор 87
Интенсивность потока 36
0 вероятности 144
К
Качество обслуживания (QoS) 150, 219
Классификация по Кендалу 72
Коммуникация 14
Коммутатор 11, 196
0 блокирующий 196
0 неблокирующий 196
Коммутация:
0 временная 196
0 пространственная 196
Конгруэнтные генераторы 60
Коэффициент:
О использования ресурса 26
О использования СМО 76
0 самоподобия непрерывных процессов
59
м
Маркер 106
Масштабная модель 70
Мгновенная интенсивность 17
Метод:
0 контроля несущей 252, 253
0 Ли 193
0 оценочных графов 195
0 с р-настойчивыми терминалами 254
0 Я кобеуса 197
Механизм приоритетного обслуживания
77
Многозвенная схема 197
Модель:
0 Молина 162
0 Энгсета 162
н
Нагрузка:
0 второго класса 233
0 первого класса 233
Нагрузочная кривая 149
Направление 196
Незавершенная работа 76
Предметный указатель
287
О
Общий канал сигнализации (ОКС) 205
Одинаковые подтверждения 262
Остаточное время обслуживания 76
Очередь 14, 141
п
Параметр:
0 потока 36
0 Хёрста 53
Передача трафика с постоянной битовой
скоростью 255
Переход 105
0 активный 106
Позиция 105
Потеря заявки 156
Потерянный вызов 155
Поток:
0 /^-распределение 47
0 ^-распределение Фишера 48
0 бета-распределение 45
0 входной 142
0 гамма-распрсдслсннс 51
0 логнормальное распределение 46
0 нормальное распределение 43
0 Пальма 51
0 пуассоновский 37
0 равномерное распределение 42
0 распределение Всйбулла 50
О распределение Парето 49
О распределение Стыодента 47
0 с ограниченным последействием 51
О стандартное нормальное распределение
44
0 треугольное распределение 42
0 Эрланга w-го порядка 52
0 Эрланга первого порядка 51
Поток входных событий 141
Приоритет:
0 абсолютный 78
0 относительный 78
Промежуточная линия (ПЛ) 197
Прототип 70
Процесс:
0 гибели-размножения 143
0 марковский 71
0 ординарный 142
0 пачечный 52
О самоподобный 53, 177
Пул серверов 141
Р
Разметка сети 106
Распределение:
'0 Бернулли 199
0 геометрическое 147
0 Энгсета 162
Ресурс 14
С
Самоподобие 52
Сервер 13
Сеть:
0 дейтаграммная 205
0 коммутируемая 11
0 мультисервисная 219
о некоммутнрусмая 11
0 Петри 105, 265
О приоритетная 106
0 раскрашенная 107
0 с коммутацией дейтаграмм 204
0 с технологией ретрансляции кадров 204
0 с установлением соединения 204
0 стахостическая 109
0 структурированная 106
Система:
0 заблокированная 14
О марковская:
° многофазная 187
° однофазная 187
0 полнодоступиая 151
Система массового обслуживания (СМО)
13,69
0 без приоритетов 77
0 вероятностная модель 136
0 имитационная модель 80
0 консервативная 79
0 поведенческая модель 80
О с неполнодостунным включением
серверов 77
О с полнодоступнымп серверами 77
Система с очередями 14
Случайное смещение промежуточных
точек 64
Случайный поток 35
О ординарность 36
О последействие 36
О стационарность 36
Соединение 14
288
Предметный указатель
Среднее время ожидания обслуживания
14
Средняя интенсивность потока
требований 26
Средняя нагрузка 26
Стек 77
Стохастическое уравнение 136
Схема без сжатия и расширения 200
т
Телетрафик 9
Теорема Джексона 189
Теория:
0 очередей 13
0 систем массового обслуживания 13
0 телетрафика 9
Терминал:
0 настойчивый 253
0 ненастойчивый 254
Транзакция 85 '
Транк 27
Трафик:
0 избыточный 17
0 интенсивность 15
0 обслуженный 16
0 объем 15
0 полезный 219
0 поступающий 17
0 пропущенный 16
0 служебный 219
Требование 13 .
0 меченое 78
У ?
Удачное случайное приращение 64:
Уравнение Чепмена — Колмогорова 140
Учрежденческая производственная АТС
(УПАТС) 181
Ф
Формула:
0 Литтла 75
0 Полячека — Хинчина 165, 214
0 потерь Эрланга 158
Фрактальное броуновское движение 55,
58
Фрактальный гауссовский шум 55, 58
Функция корреляции 52
X
Хаб 248
ц
Цепь Маркова:
0 возвратное ненулевое состояние 137
0 возвратное нулевое состояние 137
0 возвратное состояние 137 ,
0 дискретная 137 >
0 невозвратное состояние 137
0 непрерывная 140 .
0 непроводимая 137
0 однородная 137
0 поглощающее состояние 137
0 эргодическое состояние 138
ч
Час наибольшей нагрузки (ЧНН) 18
Число:
0 псевдослучайное 60
0 случайное 59
0 точек поля коммутации 196
. э А
Эрланг 15 .
Крылов Владимир Владимирович, доктор техни-
ческих наук, профессор кафедры теории цепей и
телекоммуникаций Нижегородского государствен-
ного технического университета, управляющий
отдела исследований и разработок Intel Corporation
в России. Действительный член Российской акаде-
мии инженерных наук, постоянный член IEEE. Автор
учебных изданий (учебника, учебных пособий и монографий) и бо-
лее 200 научных статей по разнообразной тематике в области
информационных технологий.
Самохвалова Светлане Свргвввна, последова-
тель В. В. Крылова в науке, в настоящее время
W_ работает в компании ТЭЛМА по разработке про-
Т J граммного обеспечения телекоммуникационного
4и>- • оборудования. Первой в России освоила програм-
jA. —- А мные продукты Artis Software и Compuware, по-
- •> строила и исследовала модели сетей связи подраз-
делений Газпрома, Нижегородского Связьинформа и др.
ТЕОРИЯ
ТЕАЕТРАФИКА
И ЕЕ ПРИЛОЖЕНИЯ
Учитывая современность и актуальность темы, учебное пособие будет
полезно не только студентам, но и специалистам в области анализа
телефонных и компьютерных сетей и систем. Подробно рассказывает-
ся, какой смысл скрывает в себе слово “телетрафик”, в каких единицах
он измеряется и почему в пакетных компьютерных сетях его часто из-
меряют в килобайтах, а в системах сотовой связи говорят о минутах
и часах. Для описания моделей используется специфический матема-
тический аппарат марковских цепей. Представлено достаточно полное
описание программных инструментов для построения имитационных
моделей телекоммуникационных систем с помощью языка GPSS и се-
тей Петри. Содержится обширный материал по анализу систем массо-
вого обслуживания классическими методами теории вероятностей
и случайных процессов.
БХВ-Петербург
194354, Санет ктервуж
ул. Есенина, 5Б
E-mail: maiiebhv.ru
Internet* www bh ru
Телефакс: (812) 591-6243
hhv