
























































































































Автор: Рейуорд-Смит В.Дж.
Теги: математическая кибернетика вычислительная техника микропроцессоры математика математическая логика программное обеспечение эвм математическая лингвистика
ISBN: 5-256-00159-0
Год: 1988




ТЕОРИЯ
ФОРМАЛЬНЫХ
ЯЗЫКОВ
ВВОДНЫЙ КУРС
COMPUTER SCIENCE TEXTS
A First Course
in Formal
Language Theory
V. J. RAYWARD-SMITH
MA, PhD
Senior Lecturer in Computing
University of East Anglia
Norwich NR4 7TJ, UK
BLACKWELL SCIENTIFIC PUBLICATIONS
OXFORD • LONDON • EDINBURGH
BOSTON • PALO ALTO * MELBOURNE
В. Дж. Рейуорд -Смит
ТЕОРИЯ
ФОРМАЛЬНЫХ
ЯЗЫКОВ
ВВСДНЫЙ КУРС
Перевод с английского
Б. А. Кузьмина
под редакцией
И. Г. Шестакова
@ Москва «Радио и связь» 1988
ББК 32.97
Р96
УДК 519.768.2
Рейуорд-Смит В. Дж.
Р 96 Теория формальных языков. Вводный курс*. Пер. с англ. -
М.: Радио и связь, 1988. - 128 с.: ил.
ISBN 5-256-00159-0.
В книге автора из Великобритании изложены основы теории формаль-
ных языков. Использован математический аппарат теории множеств,
теории графов и математической логики. Все сведения, необходимые для
понимания рассмотренных в книге вопросов, приведены в соответствую-
щих главах. Удачно подобранные упражнения в конце каждой главы не
только поясняют, но и дополняют основной материал книги.
Для разработчиков программного обеспечения ЭВМ.
Л 2405000000-027 _
р----------------148-88
046 (01)-88
ББК 32.97
Редакция переводной литературы
Производственное издание
В. ДЖ. РЕЙУОРД-СМИТ
ТЕОРИЯ ФОРМАЛЬНЫХ ЯЗЫКОВ ВВОДНЫЙ КУРС
Заведующая редакцией О. В. Толкачева
Редактор М. Г. Коробочкина
Обложка художника А. Б. Николаевского
Художественный редактор Т. В. Бусарова
Технический редактор И. Л. Ткаченко
Корректор Т. Л. Кускова
ИБ № 1618
Подписано в печать 8.12.87 Формат 60x88/16 Бумага офс. № 2 Гарнитура
’’Пресс-роман’* Печать офсетная Усл. печ. л. 7,84 Усл. кр.-отт. 8,21 Уч.-изд. л. 8,23
Тираж 30 000 экз. Изд. №22110 Зак. № 507 Цена 55 к.
Издательство ’’Радио и связь”. 101000 Москва, Почтамт, а/я 693
Московская типография № 4 Союзполиграфпрома при Государственном комитете СССР
по делам издательств, полиграфии и книжной торговли. 129041 Москва, Б. Переяслав-
ская ул., д. 46
ISBN 5-256-00159-0 (рус.)
ISBN 0-632-01176-9 (англ.)
© 1983 by Blackwell Scientific Publications
© Перевод на русский язык, предисловие редактора пере-
вода, примечания переводчика и редактора. Издатель-
ство ’’Радио и связь”, 1988
ПРЕДИСЛОВИЕ РЕДАКТОРА ПЕРЕВОДА
Давно уже прошли те времена, когда прежде чем написать программу надо
было понять и запомнить не один десяток машинных инструкций. Современ-
ный программист формулирует свои задачи на языках программирования вы-
сокого уровня и использует язык ассемблера лишь в исключительных случа-
ях. Причин для этого много и некоторые из них очевидны: резко повышается
эффективность программирования и, в основном, становится безразличным,
на какой конкретно ЭВМ будет выполняться данная программа. В 80-е годы
резко усилилась роль мини-, микро- и персональных компьютеров.
В настоящее время рядом с суперЭВМ в самых различных областях чело-
веческой деятельности успешно используются персональные компьютеры,
при необходимости легко связываемые средствами вычислительных сетей.
Контингент и подготовка специалистов, пользующихся программными
средствами, поставляемыми с персональными компьютерами, становятся
все разнообразнее. Разнообразнее становятся и решаемые с помощью этих
средств задачи, что приводит к появлению различных специализированных,
как правило диалоговых, программных средств и, следовательно, новых язы-
ков программирования высокого и сверхвысокого уровней, таких, как Форт,
Пролог и Шелл. Наряду с этим не следует забывать и о таких языках про-
граммирования, как Си, Ада и Паскаль, популярность которых продолжает
год от года расти. Таким образом, основополагающее значение алгоритми-
ческих языков в программировании сохраняется.
Как известно, алгоритмические языки становятся доступными програм-
мисту лишь после создания трансляторов с этих языков, и с решением этой
проблемы самым тесным образом связана данная книга.
Дело в том, что теоретические основы методов проектирования алгорит-
мических языков, а также конструирования трансляторов, особенно в час-
ти грамматического и семантического анализа текста программы, уклады-
ваются в рамки теории формальных языков.
Основными достоинствами книги Рейуорда-Смита являются строгость из-
ложения и использование математического аппарата теории множеств, теории
графов и математической логики. Изложенный в книге материал представля-
ет собой учебный курс, и это оправдывает принятую автором методологию
изложения, общую для математических дисциплин. Это обстоятельство не-
маловажно для студентов, а также профессиональных программистов, ре-
шивших посвятить себя проектированию языков программирования и транс-
ляторов с них. Успешному восприятию материала способствует также изо-
билие примеров, иллюстрирующих каждую теорему и сопровождающих каж-
дое сколько-нибудь сложное логическое построение. Упражнения, приведен-
ные после каждой главы книги, дают читателю возможность не просто про-
следить практическое использование изложенных в главе положений, но и
развить их наиболее наглядным и естественным способом.
Перевод книги Рейуорда-Смита на русский язык является очень своевре-
менным и актуальным, так как появление персональных компьютеров,
оснащенных графическими средствами, безусловно приведет к появлению
большого числа разработок в области автоматизации проектирования, ин-
формационно-справочных систем и локальных вычислительных сетей. Одна-
ко грамотное и эффективное решение этих проблем невозможно без пони-
мания основ теории формальных языков.
5
Посвящается моей семье
Книга, которая не рождает мыслей,
по моему убеждению - просто за-
бавная безделушка.
Т. Л. Пикок ’’Замок чудес”
ПРЕДИСЛОВИЕ
Для большинства новичков теория формальных языков является весьма
трудным препятствием в основном из-за ее громоздких и тяжеловесных фор-
мулировок. Обойти это препятствие невозможно - каждый уважающий се-
бя программист обязан хорошо понимать процесс компиляции программ,
что, в свою очередь, приводит к необходимости знакомства с теорией фор-
мальных языков. Предлагаемая книга адресована студентам первых двух
курсов, и поэтому помимо основных материалов по теории формальных
языков содержит достаточно много дополнительных сведений из высшей
математики и теории множеств, чтобы обеспечить необходимую подготовку
к любому курсу по компиляции программ. По этой же причине основное
внимание сконцентрировано на регулярных и контекстно-независимых
грамматиках.
Большинство учебников по этой теме, в отличие от данной книги, адре-
совано студентам третьего курса и аспирантам. Они содержат более полное
и подробное изложение принципов теории формальных языков, однако
весьма трудны для понимания. Я же постарался изложить материал как
можно проще, не нарушая, тем не менее, строгости формулировок. Так, все
приведенные в первых главах теоремы доказаны очень подробно и аккурат-
но, чтобы дать возможность читателю поскорее привыкнуть к стилю изло-
жения и понять схему большинства доказательств. С каждой новой главой,
по мере того как читатель приобретает навыки в построении доказательств,
последние становятся все более лаконичными и формальными. Заключитель-
ные главы книги содержат, как правило, лишь наброски доказательств, а
главное внимание уделяется практическому использованию результатов.
Взаимная зависимость содержания глав проиллюстрирована на рис. П.1.
Материал, изложенный в гл. 1—3 и 5, соответствует, в основном, перво-
му году трехгодичного курса по теории вычислений, а вся книга — двум
годам указанного курса. Хотя, если речь идет об университете, то план та-
кого курса может быть несколько изменен или же весь материал книги мо-
жет быть положен в основу 21-часового спецкурса по теории формальных
языков.
Основным мотивом, побудившим меня взяться за написание этой книги,
6
стали многочисленные просьбы группы студентов младших курсов Калифор-
нийского университета в Санта-Барбаре, где я читал курс по теории формаль-
ных языков группе студентов, состоявшей, в основном, из новичков. Я бла-
годарен им за их энтузиазм, а кроме того, хочу выразить признательность
сотрудникам университета за помощь и поддержку при подготовке книги.
Особо хочу поблагодарить доктора Дж. П. Макьюина за полезные советы и
Т. Поттер за великолепную перепечатку рукописи книги.
В. Дж. Рейуорд-Смит
ВВЕДЕНИЕ
Приступая к изучению какого-либо языка, мы обнаруживаем, что непло-
хо подготовлены к этому. Действительно, все мы знаем хотя бы один язык —
язык, на котором мы общаемся друг с другом. Каким бы языком мы ни
пользовались в жизни (английским, французским или испанским), мы про-
должаем совершенствоваться в нем до конца своих дней. Кроме того, боль-
шинство из нас, владея одним или несколькими естественными языками,
знакомятся и даже становятся знатоками, одного или нескольких языков
программирования, например таких, как Алгол 68, Паскаль, Фортран или
Бейсик. Перечисленные языки используются для написания программ, т. е.
являются средством общения с ЭВМ. Никто, по-видимому, не станет спо-
рить с тем, что ЭВМ ”не догадывается” о смысле и назначении написанных
человеком программ, следовательно, роль языка при ’’общении” с ЭВМ
особенно высока. Если при разговоре друг с другом мы способны одно-
значно понять сказанное, когда в нем содержатся неполные или неправиль-
но построенные фразы, то при ’’общении” с ЭВМ подобные вольности не-
допустимы. Текст программ должен отвечать набору жестких правил, а ма-
лейшее отклонение от этих правил делает программы непонятными с точки
зрения ЭВМ.
В идеальном случае любое предложение на любом языке должно быть
корректно одновременно семантически (т.е. иметь разумный смысл) и син-
таксически (т. е. иметь верную грамматическую структуру). В разговорном
языке фразы иногда могут быть неверны грамматически, но всегда осмыс-
ленны. В программировании каждое предложение должно быть, в первую
очередь, корректно синтаксически, так как только в этом случае оно может
стать осмысленным.
Для того чтобы понять семантику предложения, необходимо понять его
смысл. Например, следующие предложения семантически эквивалентны:
The man hits the dog.
The dog is hit by the man.
L’homme frappe le chien.
Для того чтобы понять синтаксис предложения, необходимо рассмотреть
его грамматическую структуру. Проделаем синтаксический разбор, напри-
мер, предложения The man hits the dog (человек бьет собаку) :
8
Thejnan hits thejiog,
(ИМЯ СУЩЕСТВИТЕЛЬНОЕ) (ГЛАГОЛ) (ИМЯ СУЩЕСТВИТЕЛЬНОЕ)
Можно утверждать, что любое предложение с такой грамматической струк-
турой будет в английском языке синтаксически корректным1.
Можно описать семейство подобных простых предложений с помощью
форм Бэкуса—Наура:
(ПРОСТОЕ ПРЕДЛОЖЕНИЕ) : := (ПОДФРАЗА СУЩЕСТВИТЕЛЬНОГО)
(ГЛАГОЛ) (ПОДФРАЗА
СУЩЕСТВИТЕЛЬНОГО)
(ПОДФРАЗА СУЩЕСТВИТЕЛЬНОГО) : .= (АРТИКЛЬ) (ИМЯ СУЩЕСТВИТЕЛЬНОЕ)
(ИМЯ СУЩЕСТВИТЕЛЬНОЕ) : := CAR
(ИМЯ СУЩЕСТВИТЕЛЬНОЕ) : := MAN
(ИМЯ СУЩЕСТВИТЕЛЬНОЕ) : := DOG
(АРТИКЛЬ) : := THE
(АРТИКЛЬ) : := А
(ГЛАГОЛ): := HITS
(ГЛАГОЛ) : := EATS
Правила, определяющие грамматическую структуру простого предложения,
записаны здесь с помощью форм Бэкуса—Наура (БНФ); подобная нотация
широко используется для описания синтаксиса языков программирования.
Подробно формы Бэкуса—Наура будут обсуждены в гл.2.
В рассмотренном примере (ПРОСТОЕ ПРЕДЛОЖЕНИЕ) было определе-
но как упорядоченная последовательность:
(ПОДФРАЗА СУЩЕСТВИТЕЛЬНОГО) (ГЛАГОЛ) (ПОДФРАЗА
СУЩЕСТВИТЕЛЬНОГО).
В свою очередь, (ПОДФРАЗА СУЩЕСТВИТЕЛЬНОГО) была определена как
упорядоченная последовательность:
(АРТИКЛЬ) (ИМЯ СУЩЕСТВИТЕЛЬНОЕ).
Выбирая в качестве
первого (АРТИКЛЯ) ”ТНЕ”,
первого (ИМЕНИ СУЩЕСТВИТЕЛЬНОГО) ’’MAN”,
(ГЛАГОЛА) ’’HITS”,
второго (АРТИКЛЯ) ”ТНЕ”,
второго (ИМЕНИ СУЩЕСТВИТЕЛЬНОГО) ”DOG”,
получим, согласно определению, простое предложение вида
THE MAN HITS THE DOG.
Подобная взаимосвязь упомянутых конструкций может быть описана с по-
мощью так называемого дерева вывода (рис. В.1).
1 До конца этой главы читателю будет предложено слегка углубиться в граммати-
ку английского языка. - Прим. ред.
9
Простое предложение
Подфраза
существительного
Лодфраза.
глагола
Подфраза
существительного
' Имя
нртинль существительное
Имя
нртинль сищестВитель-
I ное
Вис. В.1
Используя определение простого предложения, можно построить множест-
во различных простых предложении и, хотя все они будут синтаксически
корректны, осмысленными могут оказаться далеко не все. Для иллюстрации
сказанного рассмотрим простое предложение вида
THE CAR EATS THE MAN1
Оно вполне корректно синтаксически, но абсолютно лишено смысла.
Рассмотрим теперь предложение, не являющееся производным от просто-
го предложения:
THEY ARE FLYING PLANES.
Первый вариант грамматического разбора этого предложения выглядит сле-
дующим образом:
THEY k ARE у < FLYING ^PLANES,
МЕСТОИМЕНИЕ ГЛАГОЛ ИМЯ ПРИЛАГАТЕЛЬНОЕ ИМЯ СУЩЕСТВИТЕЛЬНОЕ
К______________________________________ -v_ ________________7
ПОДФРАЗА СУЩЕСТВИТЕЛЬНОГО
При таком грамматическом разборе предложения смысл его заключается
в следующем: ’’они” - это самолеты, летающие в небе в данный момент.
Во втором варианте грамматического разбора этого предложения:
THEY ARE FLYING PLANES
'----------' 4-----V------' '--v---'
МЕСТОИМЕНИЕ ГЛАГОЛ ИМЯ СУЩЕСТВИТЕЛЬНОЕ
смысл его заключается в том, что ’’они” — это люди, управляющие в данный
момент полетами самолетов.
Как вы, наверное, убедились, докопаться до смысла рассмотренного пред-
ложения можно только с помощью подробного грамматического разбора.
И хотя рассмотренная в примере ситуация весьма надуманна и не претен-
дует на какие-либо обобщения в отношении естественного языка, пример
этот иллюстрирует весьма важное в отношении формальных языков обстоя-
тельство: грамматический разбор исходного текста программы, написанной
”Автомобиль ест человека”. - Прим, перев.
10
на одном из языков программирования как основной шаг на пути ее семан-
тической интерпретации, является решающим этапом компиляции програм-
мы. По этой причине программирование без знания синтаксиса используемо-
го языка программирования невозможно.
Значительное место в книге занимает исследование свойств различных
грамматик, а также их использование при создании языков программиро-
вания. Хорошее понимание теории грамматик необходимо всякому систем-
ному программисту, так как природа исследуемых им объектов непремен-
но потребует от него математических усилий. Формально данная книга адре-
сована начинающим системным программистам, однако теория формаль-
ных языков часто рассматривается как ветвь математики, а исследования в
этой области невозможны без привлечения мощного математического аппа-
рата. Желающим более подробно познакомиться с исследованиями на эту
тему, я настоятельно рекомендую обратиться к книге Hopcroft J. Е., Ul-
lman J. D. Introduction to Automata Theory, Languages and Computation.—
Addison-Wesley, Reading, Mass.
ГЛАВА 1
МАТЕМАТИЧЕСКОЕ ПРЕДИСЛОВИЕ
”Математика - это не только стро-
гая истина, — это еще и высшая кра-
сота, красота строгая и холодная как
статуя”.
Лорд Бернард Рассел
”Урок математики”
Первая глава книги представляет собой краткий обзор основных поня-
тий и положений высшей математики, без знания которых невозможно
понять остальной материал. Если читатель не знаком с этими положениями,
то рекомендуем тщательно изучить эту главу и убедиться в том, что все по-
нятно. Наоборот, если изложенный здесь материал уже известен и понятен
читателю, можно пролистать эту главу с целью познакомиться с используе-
мой в этой книге нотацией.
МНОЖЕСТВА
Множество — это набор нескольких несовпадающих объектов. Каждый из
этих объектов называется элементом множества. Если множество содержит
конечное число элементов, то оно может быть определено перечислением эле-
ментов. Например, если D — множество дней недели, то
D = {Понедельник, Вторник, Среда, Четверг, Пятница, Суббота,
Воскресенье }
— его определение.
В данном случае элементы множества D разделены запятыми, а весь на-
бор элементов заключен в фигурные скобки. Вообще говоря, порядок пе-
речисления элементов множества D не важен, т. е. запись
D = { Среда, Четверг, Понедельник, Воскресенье, Суббота, Вторник,
Пятница}
эквивалентна предыдущему определению множества D.
Если х — элемент множества Л, то это записывают следующим образом
х G А; при этом говорят, что элемент х принадлежит множеству А, или
просто, что х принадлежит А. Если х не является элементом множества
А, то это записывают следующим образом: х £ Л; при этом говорят, что
12
элемент х не принадлежит множеству А, или просто, что х не принадлежит А
Например,
Понедельник G D,
Рыба^Ё D.
Если множество А содержит бесконечное число элементов, то говорят,
что множество А бесконечно. Определить это множество простым пере-
числением его элементов невозможно. Для определения бесконечного мно-
жества используется характеристическое свойство, которым должен обла-
дать объект, чтобы стать элементом множества. В случае рассмотренного
выше множества D определить его элементы удобно с помощью следующе-
го свойства:
{х — день недели}.
Тогда определение множества Dможно записать следующим образом:
D= {х|х — день недели},
и в этом случае говорят, что ”D — множество элементов х, таких, что х —
день недели”.
Другой пример:
Р = {х |х — простое число } ,
гдеР— бесконечное множество, содержащее целые числа.
Если множество определено подобным образом, то исследуя, является
ли некоторый объект элементом этого множества, необходимо быть чрез-
вычайно внимательным. Например, если множество X определено как
Х={х|х>2},
то природа множества может быть описана лишь после рассмотрения всех
возможных значений х, так как если рассмотреть только случай ”х — целое
положительное число”, то очевидно, что число 2.1 I, в случае же, когда
”х — любое число”, число 2.1 G X. В книге будут рассматриваться множест-
ва, все элементы которых будут принадлежать одному из аналогичных
классов чисел, например: целые числа, действительные числа, целые поло-
жительные числа или действительные положительные числа.
Особую роль в теории множеств играет пустое множество. Пустое мно-
жество — это множество, которое не содержит ни одного элемента, оно
обозначается Q или { }.
Говорят, что множество А называется подмножеством множества В,
если каждый элемент множества А является элементом множества В, и это
записывается следующим образом: А <^В. Если хотя бы один элемент мно-
жества А не является элементом множества В, то множество А не явяет-
ся подмножеством множества В и это записывается следующим образом:
A <t В. Например,
{1,2,4} с {1,2,3,4,5},
но
{2,4,6} ф {1,2,3,4,5}.
13
Заметим, что Q С А для любого множества А.
Говорят, что множество А совпадает с множеством В, если каждый эле-
мент множества А является элементом множества В и, наоборот, каждый
элемент множества В является элементом множества А, и это записывается
следующим образом: А=В, что эквивалентно одновременному выполне-
нию двух условий Л С В и В С А. Например,
{1,2,3,4} ={2,1,4,3},
но
{1,2,3,4}/{2,1,3,5}.
Таким образом, множества А и В совпадают тогда и только тогда1, когда
они содержат одни и те же элементы.
Основными операциями над множествами являются унарная операция2 —
дополнение (*), бинарные операции3 - объединение (U), пересечение (А) и
вычитание (\). Предположим, что А и В — множества элементов из неко-
торого класса объектов U\ тогда эти операции определяются следующим
образом:
А9 = {х|х £А } содержит все те элементы U, которые не являются элемен-
тами множества А;
A U В = {х|х G Л или хЕВ} содержит все те элементы U, каждый из
которых является либо элементом множества Л, либо элементом мно-
жества В;
Л П В = {х[х G А их Е В} содержит все те элементы С/, каждый из кото-
рых является одновременно элементом множества Л и элементом мно-
жества В;
Л \ В = {х\х Е А, но х ф В } содержит все те элементы U, каждый из ко-
торых является элементом множества Л, но не является элементом
множества В.
Например, пусть U = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }, Л = {0, 1,3, 5 } иВ =
= {2,3,5 }; тогда
А' = {2,4,6,7,8,9},
Л оВ = {0,1,2,3,5},
ЛпВ = {3,5},
А\В = {0,1},
В\Л = {2}.
Отметим, что операции объединения и пересечения множеств ассоциативны,
например,
(ЛиВ)иС-Ли(ВиС);
(Ас\В)с\С = Ас\(Вс\С).
Операция вычитания множеств неассоциативна.
1 В качестве стандартного обозначения формулировки ’’тогда и только тогда, когда”
используется знак <=>.
2 Унарная операция - операция, совершаемая над одним операндом.
3 Бинарная операция - операция, совершаемая над двумя операндами.
14
Аналогично операции объединения и пересечения множеств коммутативны, а
операция вычитания множеств некоммутативна:
A UB=BUA;
АС\В=ВС\А.
ТЕОРЕМА 1.1. СВОЙСТВА МНОЖЕСТВ
Для любых множеств А, В и С, рассматриваемых над классом объектов U,
выполняются следующие законы:
1. Ассоциативный закон (А ив)иС=А U(BUC), (А АВ) А С=Л А (В А С).
2. Коммутативный закон A UB=BUA, А А В=В А А.
3. Закон о дополнении A UA' =U, Ап А' =<&.
4. Закон идемпотенции A <JA=A, А А А=А.
5. Закон эквивалентности ли<р=л, A A U=A.
6. Закон существования пустого множества A *JU=Ut
a п<р=$).
7. Закон инволюции 8. Закон Моргана (Л')' =А. (А ив)'=А' П В' (А П В)' = A' UB'
9. Дистрибутивный закон АО(ВПС) = (А UB)n(A UC), Л А (ВОС) = (Л А В)и(Л А с).
Поскольку операция объединения множеств ассоциативна, а объединение
двух любых множеств над классом объектов U есть множество над клас-
сом объектов U, для любого п и для любой конечной последовательности
множеств Ль А2,...,ЛЯ над классом объектов U можно записать
41 ил2и.. .ил„,или |J А,-.
i = 1
Аналогично для операции пересечения множеств можно записать
А Л2 А ... АЛ„или
i = 1
Два множества не пересекаются, если они не имеют общих элементов,
т. е. А П В = Q.
МОЩНОСТЬ И СЧЕТНОСТЬ МНОЖЕСТВА
Если число элементов множества А конечно, такое множество называют
конечным множеством, в противном случае его называют бесконечным
множеством.
Мощностью конечного множества А называют число элементов этого
множества и обозначают #(А). Например, если D — множество дней неде-
15
ли, то #(Р) = 7. Множество, имеющее мощность равную 1, называют синг-
летоном.
Рассмотрим теперь бесконечные множества и остановимся на способе
перечисления элементов такого множества. Пусть N — множество положи-
тельных целых чисел; тогда способ перечисления его элементов очевиден:
1, 2, 3, 4,..., и можно с уверенностью говорить об ’7-м положительном це-
лом числе”. Однако не очевидно (и к тому же неверно), что аналогично
можно перечислить элементы любого бесконечного множества.
Пусть Z — множество целых чисел. Можно ли перечислить элементы мно-
жества Z так, как это было сделано для элементов множества положитель-
ных целых чисел? Да, можно — достаточно перечислить пары целых чисел,
имеющих противоположные знаки, но одинаковые модули, таким образом:
О,+1,-1,+2, —2, +3,-3,...
Любой элемент z G Z обязательно попадет в эту последовательность.
Пары положительных целых чисел (fy, П2), где щ G N и п2 G N, могут
быть перечислены с помощью алгоритма, приведенного в табл. 1.1.
Таблица 1.1
Множество, элементы которого могут быть перечислены, т.е. упорядо-
чены с помощью некоторого алгоритма таким образом, что любому элемен-
ту может быть поставлен в соответствие его номер, называют счетным мно-
жеством1 . Очевидно, что всякое конечное множество счетно. В качестве
несчетного множества рассмотрим множество действительных чисел из полу-
интервала [0,1), т.е. множество действительных чисел, не меньших нуля,
но меньших единицы. Доказательство несчетности этого множества основа-
но на методе диагонализации или методе Кантора. Предположим, что рас-
сматриваемое множество счетно; тогда очевидно, что его элементы могут
быть перечислены. Запишем элементы полученной упорядоченной после-
довательности в десятичной форме:
1 -е действительное число О.апа12а13...
2-е действительное число О.а21 а22а23...
3-е действительное число О.а31 а32а33...
1 Или более строго: счетное множество — это множество, для которого существу-
ет взаимно однозначное соответствие его элементов элементам натурального ряда. -
Прим. ред.
16
где каждое — цифра. Поскольку рассматриваемое множество счетно,
любой его элемент должен в конце концов встретиться в этой последова-
тельности. Рассмотрим действительные числа вида О.аца22азз. * * и вида
0. £ и £>22^33 • • •, где
ь = Ui. + 1,если а„<9,
" [0 , если яп = 9-
Действительное число вида 0. 1^22^33 •• • лежит в полуинтервале [0,1),
но не может встретиться в приведенной последовательности действитель-
ных чисел, так как для любого целого положительного i f-м знаком числа
О.^ц^22^зз... будет цифра Ьи, по определению не совпадающая с со-
ответствующей цифрой ац соответствующего действительного числа
^•aziaz2az3» являющегося элементом построенной нами упорядоченной
последовательности. Таким образом, исходное предположение о счетнос-
ти множества действительных чисел из полуинтервала [0,1) неверно.
ПРОИЗВЕДЕНИЯ МНОЖЕСТВ
Пусть Л1 и А 2 — два множества, произведением двух множеств A i и Л2
называют такое множество, каждый элемент которого представляет собой
совокупность двух объектов (пару), при этом один из объектов пары явля-
ется элементом множества Ai, а второй — элементом множества А 2; запи-
сывается это следующим образом:
Л1 х А2 = {(а1,а2)\а1ЕА1,а2ЕА2}.
Рассмотрим простой пример: Ах = {0,1}, А2 = {x,y,z}, тогда Ах х А2 =
= {(0,х), (0,у), (0,z), (1,х), (1,у),
Произведение трех или более множеств можно определить аналогично
как множество, элементами которого являются соответственно тройки или
совокупности из п объектов:
Л1 х Л2 х Л3 = {(^i,аз)1 ^1бЛра2еЛ2, а3ЕА3>,
Л1 X Л2 X ... X Л„ = {(^1,^2,- • - ,яя)1 aiE Л1Э а2Е Л2, .. ., апЕ Л„].
Для конечных множеств легко доказать следующие утверждения:
1) #(А1УА2) = #(Л!)Х#(Л2); 2) произведение двух счетных множеств
есть множество счетное. Методом индукции по п легко показать, что для
любого п > 1 справедливо утверждение: #(А 1 ХА2 X.. . ХАп) = #А 1X #Л 2 X...
. . .Х#Ап и множество АгХА2Х. . .ХАп — счетно <=> каждое из множеств
Л1, Л2,..., Ап - счетно.
Любое подмножество множества А^ХА2 есть отношение (обозначим его
R), при этом множество Л1 называют областью определения, а множество
А 2 - областью значений1. Чаще всего мы будем рассматривать отношения, у
1 Подобно тому, как словом ’’произведение” принято обозначать одновременно и
операцию умножения, и ее результат, справедливо ожидать, что словом ’’отношение”
будет обозначено как само отношение (например <»>,=» .. .), так и множество
удовлетворяющих ему пар. - Прим. ред.
17
которых эти области представляют собой одно и то же множество, скажем,
множество А. В таком случае говорят, что отношение R С АХА определено
на множестве А. Например, если А = { 0,1,2,3 }, тогда множество упорядо-
ченных пар
L= {(0,1),(0,2),(0,3),(1,2),(1,3),(2,3)}
представляет собой отношение, отвечающее общепринятому понятию ’’стро-
го больше чем”, а множество
Е = {(0,0),(1,1),(2,2),(3,3)}
представляет собой отношение, отвечающее понятию ’’равно”. Воспользуем-
ся обычной нотацией отношений; тогда
aRb для (д, b) Е R,
aRb для (а, b) £ R.
Отношение R, определенное на множестве Л, называют рефлексивным,
если aRa для всех a Е А. Таким образом, отношение £, определенное
на множестве А, не является рефлексивным, поскольку (0, 0) £ L , а отно-
шение Е, определенное на множестве Л, является рефлексивным.
Отношение R, определенное на множестве Л, называют симметричным,
если
из aRb следует, что bRa.
Таким образом, отношение L не является симметричным, поскольку
(0,1) Е L, но (1,0) L, а отношение Е является симметричным.
Отношение R, определенное на множестве Л, называют транзитивным,
если
из aRb и bRc следует, чтооЯс.
Например, отношения L и Е, определенные на множестве Л, являются тран-
зитивными.
Если отношение R, определенное на множестве Л, является рефлексив-
ным, симметричным и транзитивным, то его называют отношением экви-
валентности.
Так, отношение Е, определенное на множестве Л, является отношением
эквивалентности.
Если R — отношение эквивалентности, определенное на множестве Л, и
элемент a Е Л, то ассоциированное с элементом а множество д содержит
все те элементы множества Л, для которых справедливо отношение экви-
валентности R, т. е.
a = {beA\aRb}.
Такое множество а называют классом эквивалентности.
Таким образом, для отношения эквивалентности Е существуют четыре
класса эквивалентности: 0 = {0}, 1 = {1}, 2 = {2}, 3 = {3}, а для отношения
эквивалентности V, определенного на множестве Л, следующим образом:
V = {(0,0), (0,2), (1,1), (1,3), (2,2), (2,0), (3,1), (3J)},_
существует всего два класса эквивалентности: 0 = 2 = {0,2} и 1 = 3 = {1,3}.
18
ТЕОРЕМА 1J
Классы эквивалентности, соответствующие отношению эквивалентности
R, определенному на множестве А, разбивают множество А на конечное
число непустых непересекающихся множеств.
Доказательство
Каждое множество а — не пустое. Действительно, a G а, поскольку отно-
шение эквивалентности R — рефлексивно, и следовательно, утверждение
aRa_справедливо. Пусть ~а и Ъ — два класса эквивалентности; тогда либо
а = b, либо а А b =Ф. Предположим обратное — существует элемент с G ~а А b ;
тогда с£дисЕ6,т.е. утверждения aRc и bRc справедливы. Поскольку
R — отношение эквивалентности, оно симметрично, и из справедливости
утверждения bRc следует справедливость утверждения cRb. Так как от-
ношение R — транзитивно, то из справедливости утверждения aRc и cRb
следует справедливость утверждения aRb^ Следовательно, элемент b G а.
Очевидно, что для любого элемента х G b справедливо bRx, и поскольку
справедливость aRb только что доказана, то из транзитивности R следует
справедливость aRx, значит ~а. Последнее означает, что b а. Анало-
гично можно показать, что а С b , следовательно а = b .
Продолжим рассмотрение классов эквивалентности. Определим отноше-
ние R на множестве натуральных чисел Nследующим образом: aRb справед-
ливо <=> | a—b | делится на 5 без остатка. В таком случае множество N раз-
бивается на 5 бесконечных классов эквивалентности:
Т = 5 = ТТ = • -,
2 = 7 = Т2 =
3=5=13 = -,
4 = 9 = 14 = -,
5 = 10= 15 = —.
Если R - произвольное отношение, определенное на множестве А, то его
рефлексивным замыканием называется наименьшее рефлексивное отноше-
ние, определенное на множестве А, для которого отношение R является
подмножеством. Например, если
Я = {(0,1),(1,1),(1,2)}
— отношение, определенное на множестве А = {0,1,2}, то его рефлексивным
замыканием является множество
{(0,0),(0,1),(1,1),(1,2),(2,2)},
симметричным замыканием является множество
{(0,1),(1,0),(1,1), (1,2), (2,2)}
а транзитивным замыканием является множество
{(0,1),(0,2),(1,1),(1,2)}.
Заметим, что рефлексивным замыканием отношения <, определенного на
множестве целых чисел, является отношение <, его симметричным замыка-
19
А В
Неполная функция
А-^В
Отображение,
не являющееся функцией
Полная, ноне взаимно
однозначная функция,
отображающая мно-
жество А на мн о-
жество В
А В
Полная взаимно однозначная
функция, отображающая
множестОо А на множество S
Рис. 1.1
нием является отношение £ , а транзитивным замыканием является само от-
ношение <.
Функция f : А -+В есть множество пар элементов (а, Ь), где a G А, b G В и
b -f (а). Таким образом, функция / : А -+В может быть определена как отно-
шение, определенное на множестве АХВ, обладающее следующим свойст-
вом: если (a, b) G / и (а, с) G /, то b = с. Такие функции / называют одноз-
начными. Если функция / определена не на всех элементах множества Л, то
ее называют неполной функцией (в противном случае ее называют полной
функцией). Полная функция/ называется функцией ”на”, если для любого
элемента b G В существует элемент a G А такой, что f (а) - Ь\ полная функ-
ция / называется взаимно однозначной, если из того, что /(^i) = /(<*2), где
ах G А, а2 Е А следует, что ai = а2. Рисунок 1.1 иллюстрирует свойства раз-
личных функций (направленные отрезки прямых на этом рисунке иллю-
стрируют соответствие аргумента функции и ее значения).
Если полная функция /: А -+В взаимно однозначно отображает множество
А на множество В, то говорят, что между множествами А нВ может быть
установлено взаимно однозначное соответствие.
Счетность множества можно определить теперь следующим образом:
множество А является счетным, если оно конечно или существует взаимно
однозначное соответствие между множествами А и jV, где N — натураль-
ный ряд.
ГРАФЫ И ДЕРЕВЬЯ
Направленным графом G = (Vt Е) называется совокупность конечного
множества узлов и определенного на этом множестве отношения. Направ-
ленный граф можно представить графически следующим образом: нари-
суем на листе бумаги столько узлов (обозначим их и), сколько элементов
20
Рис. 1.2
Рис. 1.3
имеет множество К, затем соединим два изображения узлов и и w отрез-
ком прямой, направленным от узла и к узлу w, для любой пары элементов
и, w, для которой (и, w) G Е. На рис. 1.2 изображен направленный граф
Gi = (^i > Е\), где Fi = {и, w,x},a£ ={(и, w), (и, х), (w,x), (х,и), (х,х)}.
Если для некоторой пары узлов направленного графа G = (K,F)(u,w)G Е,
то говорят, что существует дуга на графе G от узла и до узла w. Если имеет-
ся некоторая последовательность узлов и = и0, Ui, • • •, vn = w, где 0, на-
правленного графа G такая, что (uz-, uz+1) € Е для i =0, 1,..., п — 1, то го-
ворят, что существует направленный путь по графу G от узла и до узла w
длиной п. Это означает, что либо и = w, либо упомянутый путь по графу есть
последовательность направленных дуг.
Пусть G = (К, Е) — некоторый направленный граф; тогда G9 = (И*, Е9) -
направленный подграф графа (7, если V9 С К, Е9 ^Е. На рис. 1.3 представле-
ны четыре подграфа направленного графа Gi, изображенного на рис. 1.2.
Два подграфа, не имеющие общих узлов, называют раздельными подграфа-
ми. На рис. 1.3 пары подграфов аи^ивиг - примеры раздельных под-
графов.
Важной разновидностью направленного графа является дерево, определяе-
мое рекурсивно следующим образом: деревом Т = (К, Е) называют направ-
ленный граф такой, что он либо имеет один-единственный узел, называемый
корнем Т = ({г},0), либо представляет собой совокупность корня несколь-
ких раздельных подграфов 7\, Т2, • • •, Tk(k > 1) (каждый из которых яв-
ляется, в свою очередь, деревом) и дуг от корня дерева Т до узлов, являю-
щихся корнями деревьев 7\, Т2,..., Тк. На рис. 1.4 представлена графичес-
кая интерпретация дерева; убедитесь в том, что она соответствует приведен-
ному выше определению дерева.
Обычно графическое изображение дерева
имеет вид расположенного вверху корня и
направленных сверху вниз дуг. Если мы ус-
ловимся впредь пользоваться только таким
графическим представлением дерева, то на-
правленность дуг можно не указывать.
Узел дерева, из которого не исходит ни
одной дуги, называют либо внешним узлом,
либо граничным узлом, либо просто листом
21
дерева. На рисунке узлы дерева, помеченные буквами d, е, g,h и i, - внешние
узлы дерева. Если узел дерева не является внешним узлом, его называют
внутренним узлом дерева. Вообще говоря, терминология, принятая для опи-
сания деревьев, напоминает генеалогическую, например, если два узла и и w
соединены дугой, направленной от узла и к узлу w, то узел и принято называть
родительским узлом узла w. Все узлы дерева, за исключением корневого уз-
ла, имеют родительские узлы. Если узел v — родительский узел узла w, то узел
w называют дочерним узлом узла и. Любой внутренний узел дерева имеет до-
черний узел. Если направленный путь по дереву от узла и к узлу w состоит из
нескольких направленных дуг, тогда узел и называют узлом-предком узла w,
а узел w называют узлом-потомком узла и.
СТРОКИ
Используя термин строка, мы всегда подразумеваем конечную последо-
вательность символов , а2,... ,ап, каждый из которых принадлежит не-
которому конечному алфавиту X; при этом символы в строке могут пов-
торяться. Например, строка символов из алфавита Z = {0,1} выглядит сле-
дующим образом: 0001110. Если строка содержит ш символов (подсчиты-
ваются все символы строки независимо от их повторений) , то о такой строке
говорят, что она имеет длину т. Например, строка 001110 имеет длину 6.
Пустой строкой называют строку длины 0, т.е. строку, не содержащую ни
одного символа; пустую строку принято обозначать буквой е. Длина строки
обозначается |х |. В приведенном выше примере 10011101 = 6, а |е I =0.
Математическое описание строки чрезвычайно просто. Действительно,
строка — это конечное множество символов, каждый из которых является
элементом некоторого заранее определенного произвольного непустого
конечного множества символов, называемого алфавитом. Например, если
строка включает символ ’’пробел”, то это означает, что этот символ являет-
ся элементом определенного алфавита. Необходимо отметить, что во избе-
жание недоразумений в тексте символ ’’пробел” часто заменяют символом
А; таким образом, строка вида 00А11А01 является фактически условной
записью строки вида 00 11 01.
Пусть X — некоторый алфавит; обозначим через 2* множество опреде-
ленных над этим алфавитом строк. Пусть Z = {0,1}, тогда
Z* = {с,0,1,00,01,10,11,000,001,010,..
Множество Z* представляет собой, очевидно, бесконечное счетное множест-
во элементов. Используя обычную нотацию, можно записать, что х G S*,
если х — элемент множества £*, и х 2* в противном случае. Заметим, что
по определению, для любого алфавита X пустая строкам G Z*.
Если х G 2* - строка длины т, то х = где az- Е Z, 1 <т.
В таком случае, если х G 2* - строка длины m, ay G 2* - строка длины п,
то их объединение, обозначаемое ху, может быть определено как строка
длины т + п, причем первые т символов составляют строку, совпадающую
со строкой х, а последние п символов составляют строку, совпадающую со
22
строкой у. Например, если х = аха2 .. -ат9 а у - b\b2 .. .Ьп, тогда ху =
= 0102 • • . Ьп. Отметим, что объединение является ассоциативной
операцией, т.е. (xy)z = x(yz), но не является коммутативной операцией,
поскольку, вообще говоря, ху £ ух. Для пустой строки, очевидно, спра-
ведливо следующее утверждение:
£Х = Х£ = Х ДЛЯ любого ХЕЕ*
Если строка z G Z* имеет вид ху9 где х, у G Z*, то строку х называют
префиксом строки z, а строку у - суффиксом строки z. Например, если z -
= 00110, то по определению префиксом строки z является строка е, или
строка 0, или строка 00, или строка 001, или строка ООП,или, наконец,
сама строка z. Аналогично суффиксом строки может быть любая из следую-
щих строк:
г, 0, 10,110,0110,2.
Если строки х, z G Z* таковы, что для некоторых w, v Е Z* справедливо
соотношение z = wxy, то строка х называется подстрокой строки z. Напри-
мер, подстроками строки z - 00110 являются строки е, 0, 1, 00, 01, 10, 11,
001,011,110,0011,0110 и, наконец, сама строка z.
Формальным языком L над алфавитом X называется произвольное под-
множество множества S*. Если L i, L2 — два формальных языка, то их объ-
единение LxL2 = {ху\х Е Li9 у Е Ь2} также является формальным языком.
Например, если £ i = {01, 0}и£2 = {е,0,10}, то L ХЬ2 ={01,0,010,00,0110}.
Как и в случае объединения строк, операция объединения формальных язы-
ков ассоциативна, но не коммутативна. Для произвольного формального
языка £ справедливо следующее утверждение:
£{fi} = {е}£= £ •
Заметим, однако, что синглетон, содержащий пустую строку, сильно отли-
чается от пустого множества. Действительно, если £ — произвольный фор-
мальный язык, то £0 = 0 £= 0.
Объединение формального языка £ с самим собой записывается как £ 2
или в общем случае как £° = {fi}, L1 =L9L* для / > 2. За-
мыкание Клини формального языка £, обозначаемое £ , может быть опреде-
лено как L'. Если определить £ как (J £1‘ , то определение замыка-
ния Клини формального языка £ можно записать как £* =£ + U {£}. Обыч-
но совокупность строк, принадлежащих множеству Z* и имеющих длину 2,
обозначают S2, а имеющих длину 3 — соответственно X3, и т.д. Совокуп-
ность строк, принадлежащих множеству Z* и имеющих длину, большую или
равную 1, обозначают Z+. Воспользуемся принятыми обозначениями и за-
пишем следующее очевидное утверждение:
Z+ = Jr и S* = I+o{£}= Jr.
i=l i = 0
23
УПРАЖНЕНИЯ
1.1. Если A ={ab, с} и В = {с, са} - два формальных языка над алфавитом {а, Ъ, с}*,
вычислите:
А иВ; А\В; А* \В' ; АВ; ВА; А2 иВ2.
1.2. Докажите, что множество всех рациональных чисел - бесконечно и счетно.
1.3. Докажите, что множество S - бесконечно и счетно, если S* произвольный конеч-
ный алфавит.
1.4. Уровень узла на дереве Т = (К, Е) определяется следующим образом: если
узел v - корень дерева, то его уровень на дереве равен 0; в противном случае узел
v Е Tj является также узлом одного из поддеревьев дерева Т, корень которого соеди-
нен с корнем дерева Т одной дугой, и тогда уровень этого узла на дереве Т на единицу
больше его уровня на указанном поддереве.
а) Выпишите все уровни всех узлов дерева, показанного на рис. 1.4. Уровнем дерева
называется максимальный из всех уровней всех его узлов.
б) Пусть Т - дерево уровня к, и каждый его внутренний узел имеет по два дочерних
узла. Докажите, что число узлов этого дерева п удовлетворяет соотношению 2£+1 <
<и<2*+1-1.
1.5. Пусть Т - дерево. Покажите, что путь по дереву от корня до любого узла единст-
венен (воспользуйтесь методом индукции).
1.6. Пусть х Е S* тогда элемент, обратный х, может быть рекурсивно определен сле-
дующим образом: если х = €, то хг = £; в противном случае х -ay, шеаЕ ъ,ьуЕ S*
тогда хг = у7а. Запишите рекурсивное определение 1х| - длины строки, и, используя
метод индукции, докажите, что |х| = |хг | для любого х Е S* (возможно, понадобится
доказать, что I xyl =| х| +1 у| для любых х, у Е S*).
1.7. Докажите, что если R2, R2 - два определенных на множестве А отношения, то
а) если Rx - рефлексивное отношение, то Rx иЯ2 - также рефлексивное отношение;
б) если Rt и R2 - рефлексивные отношения, то Rx п R2 - также рефлексивное отно-
шение;
в) докажите то же самое для свойств симметричности и транзитивности.
1.8. Пусть R - отношение, определенное на множестве А ХВ, aS- отношение, опре-
деленное на множестве ВХС. Тогда на множестве АхС может быть определено отноше-
ние RS такое, что RS {(а, с)1 существует b е В\ (at b)E R и (b,c)E S }.Это отношение
называют композицией отношений Ли S.
а) Докажите ассоциативность операции композиции.
б) Докажите, что если R и S - полные функции ”на”, то функция RS - полная и ”на”.
1.9. Пусть RcAXB - отношение, определенное на множестве АХВ, тогда обратное
ему отношениеR'1 определено на множестве ВХА следующим образом:
Л"1 ={(M)I (a, b)E R}.
а) Докажите, что (Л"1)"1 =R-
б) Каким условиям должна удовлетворять функция R, чтобы функция Ли1 была пол-
ной функцией?
Пусть Л —В, т. е. отношение R определено на множестве Л. Покажите, что
в) R - рефлексивное отношение *=> Л*1 - рефлексивное отношение;
г) R - симметричное отношение *=> R"1 - симметричное отношение;
д) R - транзитивное отношение *=> R’1 - транзитивное отношение.
1.10. Множество всех подмножеств множества Л обозначают 2^ и называют сте-
пенью множества А.
а) Пусть Л = {а, Ь, с}. Выпишите 8 элементов множества 2^.
24
б) Покажите, что если # (А) = и, то # (2^) = 2п.
1.11. Функция f : 2^X2^ ->2^ монотонно возрастает, если из условия с Вх и
А2 с В2 следует, что f(Ax, А2) с f (Вп В2). Докажите, что операция конкатенации
множеств - монотонно возрастающая функция.
1.12. Пусть G = (К, F) - направленный граф и пусть Е* - рефлексивное замыка-
ние транзитивного замыкания множества Е. Докажите, что направленный путь по гра-
фу от узла v до узла w(v, we V) существует <=► (v, w) е Е*.
ГЛАВА 2
ВВЕДЕНИЕ В ГРАММАТИКИ
’’Бесконечность состоит из конеч-
ного”.
Теодор Ротке ’’Дальнее поле”
Большинство современных работ, посвященных языкам программирова-
ния высокого уровня, обязательно содержит раздел, где формально опре-
деляется синтаксис языка программирования. Например, синтаксис языка
программирования Паскаль обычно описывается набором синтаксических
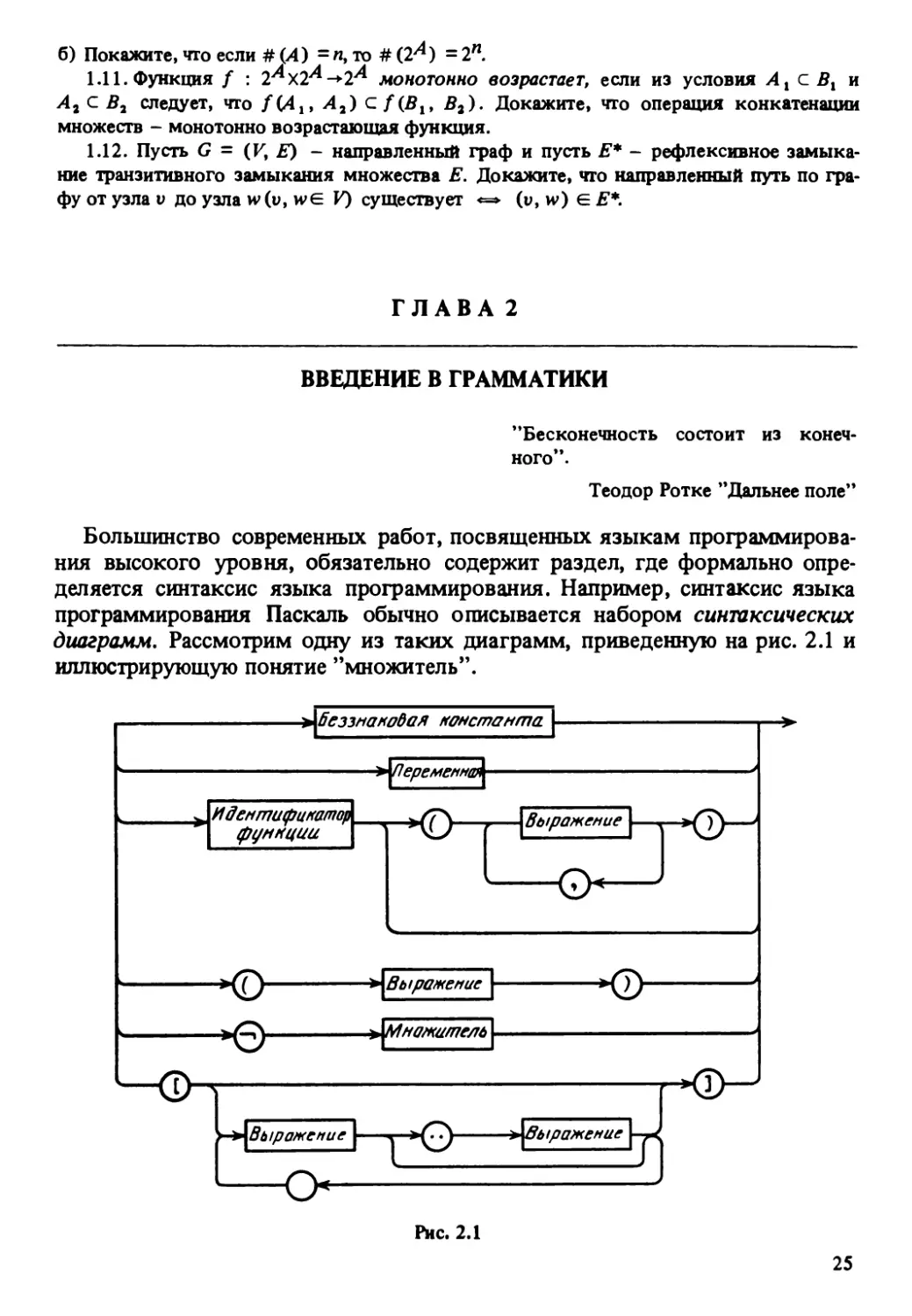
диаграмм. Рассмотрим одну из таких диаграмм, приведенную на рис. 2.1 и
иллюстрирующую понятие ’’множитель”.
Рис. 2.1
25
Любой путь по синтаксической диаграмме обязательно пройдет через не-
сколько ее узлов. Например, самый простой путь
> беззнаковая константа
проходит всего через один узел. Более сложный путь
Идентификатор
функции
Выражение
проходит через четыре узла диаграммы. Путь
еще более сложен, и т. д.
На самом деле, несложно показать, что число различных путей по рас-
сматриваемой синтаксической диаграмме бесконечно и каждый из этих пу-
тей соответствует одному из возможных определений понятия ’’множитель”.
Синтаксические диаграммы — один из простых и эффективных способов
описания синтаксических определений. Если читатель не пожалеет сил и выпи-
шет словесное определение множителя, то убедится в его чрезвычайной
громоздкости.
Каждому узлу приведенной синтаксической диаграммы, изображенному в
виде прямоугольника, например, |переменная|, соответствует, в свою оче-
редь, синтаксическая диаграмма, определяющая понятие внутри прямо-
угольника. Подобный узел называют нетерминальным узлом, а понятие, ему
соответствующее, — нетерминальным символом языка. Если же узел синтак-
сической диаграммы изображен в виде круга, например ©, то его называют
терминальным узлом, а понятие внутри круга — терминальным символом
языка.
Существует другой путь определения синтаксиса языка, альтернативный
синтаксическим диаграммам, — это формы Бэкуса—Наура (БНФ). При ис-
пользовании форм Бэкуса—Наура нетерминальные символы языка заклю-
чаются в угловые скобки вида (...) ; запись вида : := означает ’’определя-
ется как”, а символ | означает ’’или”. Перепишем определение множителя,
используя формы Бэкуса—Наура:
< множитель) : : = ( беззнаковая постоянная)
I < переменная)
I < идентификатор функции)
I (идентификатор функции) ((список выражений))
I ((выражение))
| П( множитель)
|[ ]
| [(список пар выражений) ]
Здесь (список выражений) и (список пар выражений) — новые нетерми-
нальные символы, которые определяются следующим образом:
26
(список выражений) : : = < выражение)
I < выражение), < список выражений)
и
(список пар выражений) : : = (пара выражений)
I (пара выражений), (список пар выражений),
где
(паравыражений) : :=<выражение)
I(выражение) ... (выражение).
Нотация БНФ эквивалентна синтаксическим диаграммам. Любая синтак-
сически корректная программа, написанная на некотором языке програм-
мирования, может быть определена в нотации БНФ как нетерминальный
символ некоторого языка. Однако необходимо заметить, что указанные
синтаксические определения не составляют полного описания языка про-
граммирования. Так, в языке программирования Паскаль существует ряд
дополнительных требований к исходному тексту программы, не упомина-
емых среди синтаксических определений языка программирования, на-
пример, требование описания типа всех используемых в программе пере-
менных. Сформулировать это требование с помощью нотации БНФ или
эквивалентной ей нотации невозможно. При изучении теории формальных
языков важно понимать все возможности и ограничения БНФ и эквива-
лентных ей нотаций.
КОНТЕКСТНАЯ ГРАММАТИКА
Приведенное ниже определение формальной модели грамматики очень
напоминает нотацию БНФ. Будем придерживаться следующих соглашений:
прописными буквами обозначаются нетерминальные символы языка;
строчными буквами обозначаются терминальные символы языка;
символ -> используется для обозначения отношения ’’определяется
как”.
Таким образом, простой пример грамматики может иметь следующий на-
бор правил вывода:
S^A\B
А->аА)а
B-^bBIb
Из первого правила следует, что S либо совпадает с А, либо совпадает с В.
Из второго правила следует, что А представляет собой либо строку вида а,
либо строку вида аа9 либо строку вида а а... а. Аналогичные рассуждения
справедливы для В.
Если строка Р может быть получена из строки а с помощью одного или
нескольких правил вывода, то будем записывать это следующим образом:
&=>Р. Если ai =>а2, =>а3,..., =>ап(п^ 1), то эту последователь-
ность выводов будем кратко записывать так: =>а2 ^^з =>.. .=>ап, или,
27
еще более кратко, ai=>a„. Воспользуемся теперь оп-
ределенной выше грамматикой
S =>Л =*аЛ =*ааА =>аааА =*ааа
у7\ или5=>а3.
(а) kcJ
Проиллюстрировать эту последовательность выво-
\Qj (Л/ дов можно и с помощью дерева, изображенного на
1 рис. 2.2.
09 Теперь необходимо формализовать введенные поня-
Рис. 2.2 тия. До сих пор слева от символа в правилах выво-
да был лишь один нетерминальный символ языка. Приведенное ниже опреде-
ление обобщает правила вывода, которые соответствуют формальным поня-
тиям, на строки терминальных и нетерминальных символов языка.
Контекстная грамматика может быть представлена совокупностью четы-
рех объектов (N, Г, Р, S), где
N — конечное множество нетерминальных символов языка. Согласно
принятому ранее соглашению элементы множества N обозначаются пропис-
ными буквами (иногда с нижними индексами);
Т — конечное множество терминальных символов (поэтому jVnT = <p).
Согласно ранее принятому соглашению элементы множества Т обозначают-
ся строчными буквами (иногда с нижними индексами);
Р — конечное множество продукций вида 0, где а — строка в левой
части продукции, такая, что аЕ (NU7)+, а (3 — строка в правой части про-
дукции, такая, что (ЗЕ (NUT)*; множество SEN - начальный символ
грамматики.
Например, пусть Gx = ({S, Л, В}, {a, b}, Р, S), где Р представляет собой
совокупность продукций вида
S-Л, S-B,
Л — аА, А->а,
В^ЬВУ В^Ь.
Перепишем эти продукции, используя обычную нотацию:
S —Л|В,
Л — аЛ|а,
В^ЬВ\Ь.
Заметим, что при соблюдении соглашений об обозначениях терминальных и
нетерминальных символов языка, необходимым остается лишь задание на-
бора продукций и начального символа грамматики. Если в дальнейшем на-
чальный символ грамматики будет обозначаться S, то можно опустить и это
требование.
Рассмотрим теперь контекстную грамматику (72, продукции которой
имеют вид
S->aSBC\aBC,
СВ^ВС,
28
aB—>ab,
bB^bb,
bC^bc,
cC^cc.
Это — первый пример, где в левой части продукции указана строка. Мож-
но показать, что из S можно вывести любую строку вида апЬп(^» п> 1.
Например,
S=>aSBC,
=>ааВСВС (так как 5 -► а ВС),
=>ааЬСВС (так как аВ -► ab),
=>ааЬВСС (так как СВ -► ВС\
=>ааЬЬСС (так как ЬВ->ЬЬ),
=>aabbcC (так как ЬС -► Ьс),
=>aabbcc (так как сС -> сс\
т. е. из S выводится а2Ь2с2.
До сих пор мы опирались на интуитивное понимание понятия ’’вывод”.
Воспользуемся теперь формальным определением грамматики для строгого
определения выводимой строки. Пусть G = (jV, Т,Р, S) — контекстная грам-
матика и пусть 71 а £ CVU Г) + — строка терминальных и нетерминальных
символов длиной > 1. Если а~>(3 — продукция из Р, то строка а в строке
71 а 72 может быть заменена строкой Р, и в результате получим 710 72 •
Это записывают следующим образом:
71^72 710 72»
и
при этом говорят, что строка 71^72 генерирует строку 71072, или что стро-
ка 710 72 ВЫВОДИТСЯ ИЗ строки 71 3 72 .
Если и =>а2, а2 =>а3,...,а„_ j =>а„(и> 1), то обыч-
(j и и
но пишут сокращенно «1 =^а2 ^>ап_1 » или еще короче, а! =^ап ,
и при этом говорят, что строка ап выводится из строки Qi за один или более
шагов. Далее, обозначает транзитивное замыкание отношения =>,а =>
обозначает рефлексивное замыкание отношения =>. В таком случае
G
♦ +
ai «1 = аи или а, =>ая.
1 g п 1 1 g п
Если строка аЕ (7VU Г)* такая, что 5 =>а , то строку а называют сентен-
G
циальной формой контекстной грамматики G. Сентенцией грамматики G на-
зывают произвольную сентенциальную форму из А ♦, т.е. произвольную стро-
ку терминальных символов, которая может быть выведена из начального
символа S. Тогда множество всех сентенций грамматики G называют языком»
порождаемым грамматикой G, и обозначают L (G).
29
Таким образом,
L(G)={xeT*|sXx}.
В большинстве примеров рассматривается грамматика (7, поэтому сим-
вол G можно опустить в формулировках вида =>, =>,Хи просто написать
+ 4с G G G
Предполагаем читателю вернуться к примерам, в которых рассматрива-
лись грамматики Gx и G2, чтобы убедиться в том, что
L(G1)={a"|n>l}u{bn|n>l},
L(G2}= {anbncn\n >1}.
Иногда оказывается возможным, чтобы две различные грамматики G и
G, порождали один и тот же язык, т. е. L (G) = L (G'). В этом случае гово-
рят, что грамматики G к G9 эквивалентны.
Например, грамматикой, эквивалентной грамматике G i, является грам-
матика G3, продукции которой имеют вид
S->aA\bB\a\bt
А->аА)а,
В^ЬВ\Ь.
КОНТЕКСТНО СВОБОДНЫЕ ГРАММАТИКИ
Формальное определение основных синтаксических понятий большинст-
ва языков программирования может быть дано с помощью нотации БНФ,
при этом вид левой части каждой продукции может быть ограничен лишь
единственным нетерминальным символом. Контекстные грамматики, про-
дукции которых удовлетворяют такому ограничению, в теории формаль-
ных языков носят название контекстно свободных грамматик. Строгое
определение контекстно свободной грамматики может быть таким:
контекстно свободной грамматикой называют такую контекстную
грамматику G = (N, Г, Р9 S), каждая продукция которой имеет вид
А ->0,гдеЛ G (NUT)*.
Любой язык, порожденный контекстно свободной грамматикой, назы-
вают контекстно свободным языком. Поводом к возникновению термина
’’контекстно свободный” послужил тот факт, что любой символ A G N в
сентенциальной форме грамматики G может быть раскрыт согласно продук-
ции А -► р независимо от того, какими строками он окружен внутри самой
сентенциальной формы.
Если G\ и G3 — две совпадающие контекстно свободные грамматики, то
очевидно, что L = L (Gj) =L (<73) - контекстно свободный язык. Однако
мы не можем утверждать, что L2 = L (G2) — контекстно свободный язык,
так как грамматика G2 не является контекстно свободной, но, быть может,
существует контекстно свободная грамматика, которая порождает тот же
язык L 2. Можно даже попытаться определить такую контекстно свободную
грамматику (позже будет ясно, что это — пустая трата времени). Однако
30
породить язык {anbn\n> 1} с помощью контекстно свободной грамматики
возможно, например, с помощью грамматики, имеющей продукцию
S->aSb\ab.
Напомним, что если G = (jV, Г, Р, S) — контекстно свободная граммати-
ка, то любой нетерминальный символ х G L (G) может быть выведен из
начального символа S. Общепринятым методом представления вывода не-
которой непустой строки считается дерево вывода (иногда его называют
деревом грамматического разбора). Корнем этого дерева будет начальный
символ S, остальные его узлы пометим слева направо следующим образом:
а\, а2, • • • где а^ G Г, 1 < i < и и х = аха^ .. .ап\ при этом внутренние
узлы дерева будут соответствовать нетерминальным символам языка. Пусть
А — нетерминальный символ, который может быть расширен с помощью про-
дукции вида A -^XiX2 .. .xm (Xf G T, i = 1,,.. ,m). В таком случае узел
дерева, соответствующий нетерминальному символу А, является родитель-
ским узлом для тп узлов дерева, соответствующих m нетерминальным сим-
волам xi,x2, ... ,хт (рис. 2.3).
Рассмотрим в качестве примера дерево вывода (рис. 2.4), иллюстрирую-
щее вывод сентенции а3Ь3 контекстно свободной грамматики <74, имеющей
продукции вида
А-^аА\а,
в-+ьв\ь.
Это дерево вывода в точности соответствует следующей последовательности
выводов:
=>аАВ,
=>ааАВ,
=>аааАВ,
=>аааЬВ,
=>aaabb.
31
5
5
(У) 09 хх хх
(a) (s) 0 0 0 ©
ип QD GD GD
а) б)
Рис. 2.5
Если х G L (G), то, как правило, можно найти несколько возможных ва-
риантов вывода. Например, сентенцию а3Ь2 можно вывести в G4 следующим
образом:
5 => АВ => ЛЬ В =>аАЬВ =>ааАЬВ =>aaAbb =>aaabb,
S => АВ =>аАВ =>аАЬВ =>aAbb =>aaAbb =>aaabb,
S => АВ =>аАВ =>ааАВ =>ааАЬВ =>aaabB =>aaabb.
Понятно, что все эти схемы вывода соответствуют одному и тому же
дереву вывода.
Если для любого элемента xG L (G) все возможные схемы его вывода
соответствуют одному и тому же дереву вывода, то такую контекстно сво-
бодную грамматику называют однозначной грамматикой. Если же некото-
рому элементу х Е L (G) соответствует несколько несовпадающих деревь-
ев вывода, то контекстно свободная грамматика G называется неоднознач-
ной. Например, грамматика G4 является однозначной контекстно свобод-
ной грамматикой.
Схема вывода сентенции xG L ((7) называется левосторонней, если рас-
крывается всегда самый левый нетерминальный символ сентенциальной
формы. Поскольку теперь каждому дереву вывода соответствует единствен-
ная левосторонняя схема вывода, то можно переопределить неоднознач-
ную грамматику следующим образом: контекстно свободная грамматика
G называется неоднозначной, если существует такая сентенция х G L (G),
которой можно поставить в соответствие две различные левосторонние схе-
мы вывода. Рассмотрим неоднозначную грамматику <75, имеющую про-
дукцию
Пусть сентенции abaca EL (<75) соответствуют две различные левосторон-
ние схемы вывода
5 => SbS => abS => abScS => abacS => abaca,
S => ScS => SbScS => abScS => abacS => abaca.
Соответствующие этим схемам вывода деревья вывода представлены
на рис. 2.5.
32
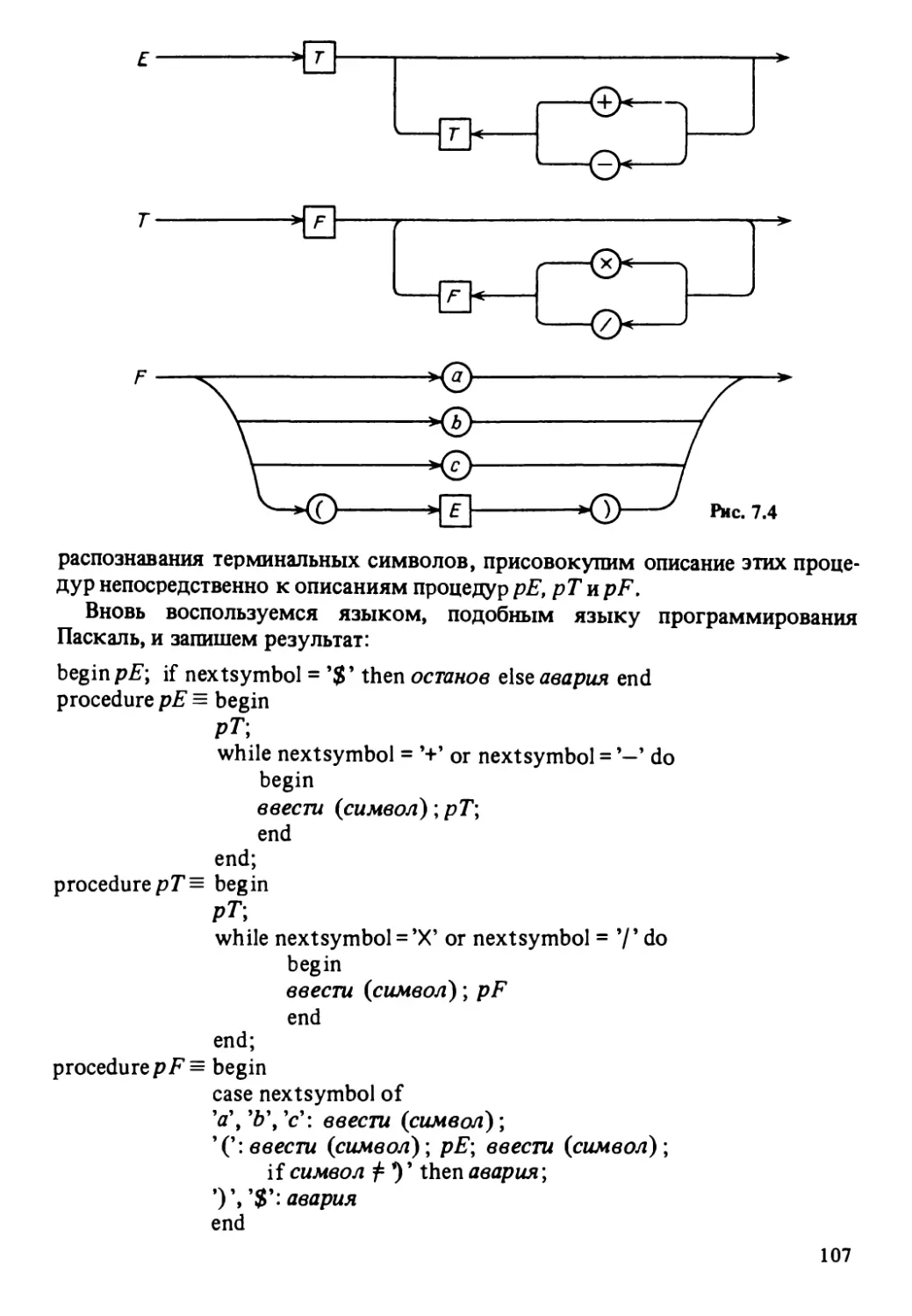
ГРАММАТИЧЕСКИЙ РАЗБОР АРИФМЕТИЧЕСКИХ ВЫРАЖЕНИЙ
Рассмотрим грамматику, предназначенную для описания арифметичес-
ких выражений, содержащих переменные a, Ь, с9 и имеющую следующие
продукции:
<выражение): :=< терм) |< выражение) + < терм) | < выражение) —< терм),
(терм) : : = (множитель) |(терм) Х<множитель) |<терм)/(множитель),
(множитель) : : = a|Z>ld ((выражение)).
Используя формальную нотацию контекстно свободных грамматик и
обозначая начальный элемент грамматики Е, запишем эти продукции по-
другому:
Е-Т|Е + Т|Е-Т,
T^F\Tx F\T / F,
F->a\b\c\(E).
Рассмотренная грамматика является однозначной грамматикой, посколь-
ку каждой сентенции, порождаемой этой грамматикой, соответствует единст-
венное дерево вывода. Одно из таких деревьев вывода представлено на рис:
2.6, а. После грамматического разбора такого дерева компилятор построит
другое дерево, называемое семантическим деревом. Семантическое дерево,
соответствующее строке aXb + с, представлено на рис. 2.6,d, и читатель лег-
ко поймет, каким образом оно было получено из дерева вывода. После со-
ответствующей обработки полученного семантического дерева компилятор
сгенерирует последовательность машинных инструкций, которые составят
программу для вычисления указанного арифметического выражения. Обыч-
но инструкции имеют следующий вид:
LOAD а
MULT b
ADD с
Грамматика, рассмотренная выше в качестве примера, представляет
упрощенный вариант грамматики, которая используется для синтаксичес-
Д ере в о вывода
(0 (?) (+) (г) 0 (?) ® © (а) @ а) Рис. 2.6 Семантическое дерево (?) (xY (?) 6)
33
Арифметическое выражение
Дерево вывода
Семантическое дерево
а + b х с
(а 4- 6) х с
Рис. 2.7
а - b - с
кого определения арифметического выражения в языке программирования
Паскаль. Вообще, если мы хотим, чтобы арифметическое выражение имело
привычную для нас семантическую интерпретацию (например, приоритет
арифметических операций, /, +, —), мы должны позаботиться не только об
однозначности используемой грамматики, но и о подходящем выборе набо-
ра ее продукций. На рис. 2.7 проиллюстрированы приведенные выше сообра-
жения.
Было бы идеально определять синтаксис любого языка программирования
с помощью контекстно свободных грамматик. Человечество накопило боль-
34
шой опыт использования таких грамматик, а техника построения деревьев
вывода хорошо изучена. Если контекстно свободная грамматика обладает
некоторыми дополнительными свойствами (мы обсудим их в следующих
главах), то в ряде случаев оказывается возможным и достаточным постро-
ить эффективный алгоритм грамматического разбора. К сожалению, хотя
большая часть синтаксических правил языка и может быть описана таким
способом, обязательно найдутся правила, которые не могут быть выраже-
ны в терминах контекстно свободных грамматик. Поэтому, несмотря на
то, что значительная часть кода компилятора и реализует различные алго-
ритмы грамматического разбора, ведущего к построению семантических
деревьев, тем не менее компилятор содержит и различные дополнительные
проверки и таблицы параметров и т. д.
ПУСТАЯ СТРОКА В ОПРЕДЕЛЕНИИ КОНТЕКСТНО СВОБОДНОЙ
ГРАММАТИКИ
В приведенном ранее определении контекстно свободной грамматики
ее продукции обязательно должны были иметь вид А -> (39 где А - нетерми-
нальный символ языка, а (3 — некоторая строка из терминальных и нетерми-
нальных символов. Это означает, что, строго говоря, корректна следующая
запись: А ~>е. Будем называть такую продукцию е-продукцией. Наличие у
контекстно свободной грамматики £-продукции осложняет как процеду-
ру грамматического разбора, так и использование грамматики для описа-
ния формального языка. Если вы были внимательны, то теперь непременно
удивитесь тому, что до сих пор е-продукции не появлялись в рассматривае-
мых нами деревьях вывода. Грамматика, не имеющая £-продукции, назы-
вается Е-своб одной грамматикой. Конечно, было бы идеально иметь дело
лишь с £-свободными грамматиками, однако если е G L (G) для некоторой
контекстно свободной грамматики, то избавиться от этой пустой строки и
не изменить порождаемого формального языка невозможно. Самое боль-
шее, на что можно рассчитывать, это преобразовать грамматику G таким об-
разом, чтобы полученная контекстно свободная грамматика G' была £-сво-
бодной грамматикой и выполнялось бы условие L(Gf) = К
счастью, найти и проделать такие преобразования несложно.
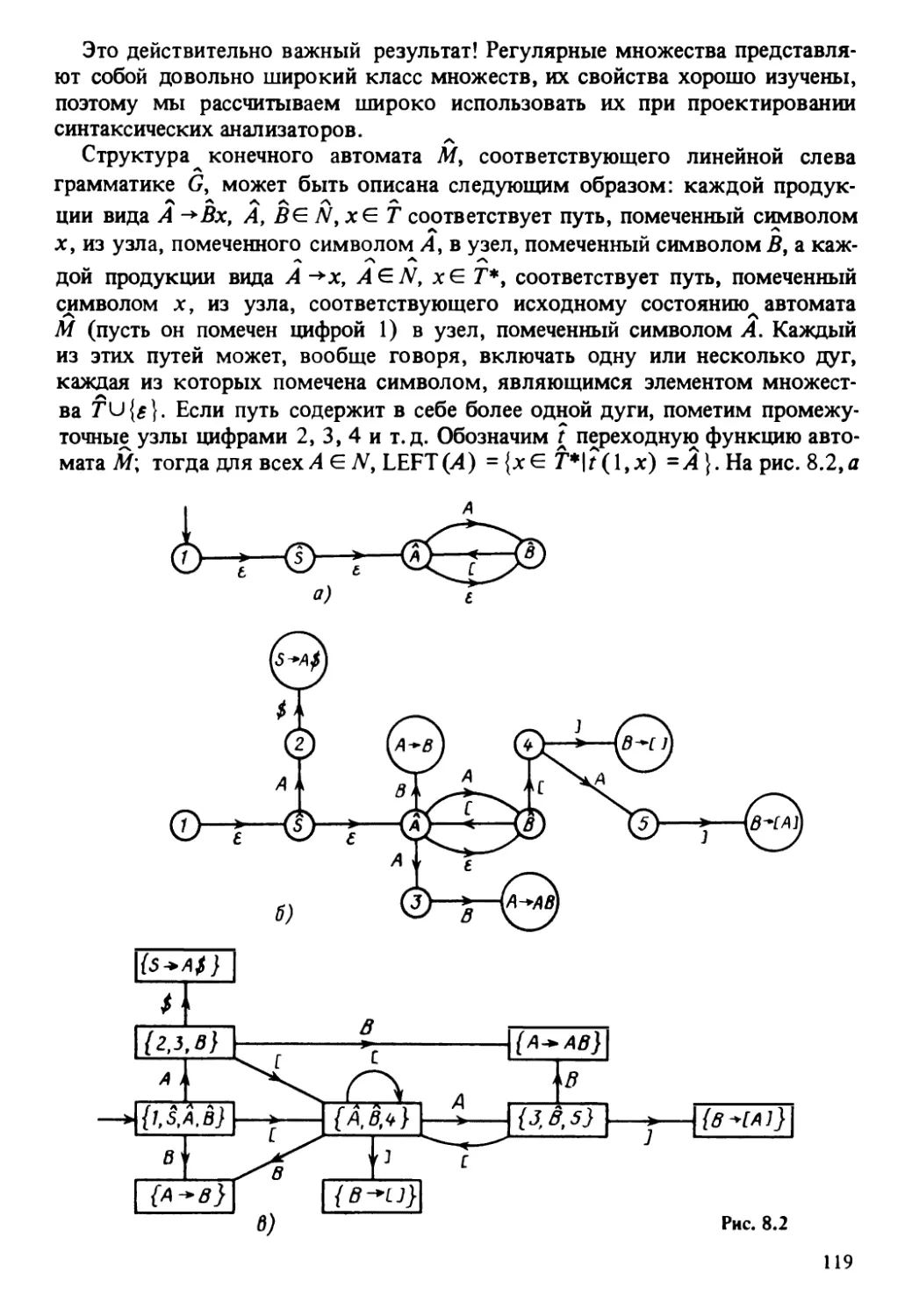
Пусть G = (jV, Г, Р, S) — контекстно свободная грамматика, имеющая
£-продукцию. Тогда построить контекстно свободную грамматику G' = (7V,
Т, Р, S), обладающую описанными выше свойствами, можно следующим
образом:
1. Объединим все имеющиеся в Р £-продукции в множество Р1
*
2. Рассмотрим все нетерминальные символы A G Nt такие, что А =>£, назо-
вем такие нетерминальные символы Е-порождающими нетерминальными
символами. Затем каждой продукции р Е Р\ содержащей в правой части
^порождающий нетерминальный символ, поставим в соответствие такую
продукцию, что в ее правой части опущены (по сравнению с продукцией р)
один или более нетерминальных символов, являющихся для грамматики
G ^-порождающими символами, и присоединим ее к множеству Р1
35
Докажем теперь, что L (Gr) = £(<7)\{£}. Пусть контекстно свободная
грамматика G имеет продукции вида
5-[£]|£,
£-Т|£ + Т|£- Т,
T-F|TxF|T/F,
F->a|b|c|e,
тогда sXe, £ Хе, Т Хе и F Хе.
Таким образом, построенная контекстно свободная грамматика имеет сле-
дующие продукции:
S-[£]|[ ]|£,
£-Т\Е + Т\Е - Т|£ + |£-| + Т\ - Т\ + | - ,
T-F|T х F\T / F\T х \Т/\ х F|/F| х |/,
F->a\b\c.
Для доказательства теоремы необходимо сначала доказать следующую
лемму.
Лемма. Для любых A G N и х G Т* справедливо следующее утверждение:
А=>х <=> А=>х.
G G'
Доказательство.
Прежде всего покажем, что еслиАХх, тоАХх. Это непосредственно
следует из справедливости следующего утверждения: если Х->0 - продук-
ция G\ то X Хд. Итак, любая схема вывода, корректная в грамматике G9
G *
корректна и в грамматике G. Для доказательства утверждения, что изЛ=>х
следует, что А Хх, для любых А G N и х G Т+, воспользуемся индукцией по
G
п - числу шагов вывода.
При п = 0 — тривиальный случай. Если п = 1, то очевидно, Р содержит одну
продукцию (пусть она имеет вид А ->х) и поскольку х эта продукция
также принадлежит и множеству продукций Р9 грамматики G9, т. е. Л=>х.
Предположим, что утверждение справедливо для всех п<к шагов вывода
непустой строки терминальных символов из нетерминального символа.
Пусть непустая строка терминальных символов х выводится из нетерми-
нального символа А на (к + 1)-м шаге. Тогда, очевидно, Р содержит про-
дукцию вида А -+Х1Х2. . .Xmi Xj G 7VU Г, где A ^Х1Х2...ХшХх. Разо-
бьем строку х на подстроки х = Х1Х2... xm таким образом, что если Xz- G N,
тоА^Хх,, а если Xz- G Г, то Xz- =xz- (и, следовательно, по определению
Xi Хх(). Некоторые подстроки х:- могут оказаться пустыми, так как грам-
матика G имеет е-продукции. Пусть индексы 1 < И < i2 <.. < ir < иц такие,
36
что Xf 1, xi2 ,..., xir — непустые подстроки из последовательности подстрок
Xi... хт, полученной из непустой строки терминальных символов. Тогда,
очевидно, х = . х1Г и Xtj где j = 1,,. .,r. Но каждый из таких
выводов состоит из числа шагов вывода, не превышающих к, и для него спра-
ведливо предположение, что Х^ для/ = 1, 2,...,г
Таким образом, из утверждения, что А Xi2 • • • Xir — продукция грам-
матики G\ следует, что А Хх для к + 1 шагов вывода. Из этого по индукции
получаем,что утверждение верно для любого к — числа шагов вывода, что и
требовалось доказать.
Из только что доказанной леммы можно сделать вывод, что 5 =>х <=> 5 =>х
для любого х Е Т+ и, следовательно, xeL(G)\{c) <=► xgL(G'). Сформулируем
теперь теорему, доказательство которой мы только что получили.
ТЕОРЕМА 2.1
Для любого контекстно свободного языка L существует е-свободная
контекстно свободная грамматика G, такая, что L(G) = L\{с}.
Позже мы покажем, что если е G L, где L — некоторый контекстно сво-
бодный язык, то контекстно свободная грамматика G, порождающая язык
£, обязательно имеет только одну продукцию вида S -►£, при этом не су-
ществует более ни одной продукции грамматики G, в правой части которой
содержался бы нетерминальный символ S. Объяснить этот факт можно
следующим образом: пусть G = (N, Т,Р, S) — е-свободная контекстно сво-
бодная грамматика, порождающая язык L\{e) ; Sf — нетерминальный сим-
вол и G' = (Nw{S'}, Г, Р и {5' ->е| 5}, S'), тогда контекстно свободная грам-
матика G9 порождает язык£ (G') = L .
УПРАЖНЕНИЯ
2.1. Определите контекстно свободные грамматики, которые порождали бы следую-
щие языки:
а) все строки - элементы множества {0,1} *, такие, что в каждой из них непосредствен-
но справа от каждого символа 0 стоит символ 1;
б) все строки - элементы множества {0,1} *, такие, что результаты чтения этих строк
символов слева направо и справа налево совпадают;
в) все строки - элементы множества {о, 1) *, которые содержат символов 0 вдвое
больше, чем символов 1.
2.2. Пусть некоторая контекстно свободная грамматика имеет продукции вида
5-ЛЯ,
A-+SA\BB\bB,
В-+Ъ\аА\е.
Определите новую контекстно свободную грамматику, которая была бы эквивалентна
данной, но имела бы единственную г -продукцию вида 5 -► г.
37
2.3. Покажите, что грамматика, имеющая продукции вида
S-+bA\aB,
A -+a\aS\bAA,
B-+b\bS\aBB,
порождает язык L с {л, Ь}*, составленный из строк, содержащих равное число симво-
лов а и символов Ь. (Воспользуйтесь методом индукции и докажите, что для любой
сентенциальной формы общее число элементов а и А равно общему числу элементов
b и В.)
2.4. Докажите, что язык L (G2) = {апЪРсп]п> 1} , ще G2 - контекстная граммати-
ка, рассмотренная в этой главе.
2.5. Покажите, что грамматика, определенная в упражнении 2.3, неоднозначна.
Покажите, что грамматика, имеющая продукции вида
S -аВ\аВ\ bAS]bA,
А->ЬАА\а,
В~*аВВ\Ь,
есть однозначная грамматика, порождающая тот же язык.
2.6. Если каждая продукция грамматики G, не являющаяся ^-продукцией, имеет
форму А -+аВ или А -+а, где Л, В Е Nt а е Т, то грамматику G называют регулярной
грамматикой.
Покажите, что если G - регулярная грамматика, то е-свободная грамматика G*,
полученная из грамматики G при доказательстве теоремы 2.1, также является регу-
лярной.
2.7. Проверьте, являются ли следующие исходные тексты синтаксически корректны-
ми программами на языке программирования Паскаль:
a) program ex (output);
begin
//1+1=2 then write (’hooray’)
end
6) program ex 2;
begin
write (1 + 1)
end.
в) program copy (fl, f2);
var fl, f2; file of char;
begin reset(fl); rewrite(f2);
while not eof(fl) do
begin f2t:=fl; put(f2); get(fl);
end
end
2.8. Напишите на языке программирования Паскаль программу, корректную с точ-
ки зрения синтаксических определений, но некорректную с точки зрения компилятора
этого языка.
38
ГЛАВА 3
РЕГУЛЯРНЫЕ ЯЗЫКИ, 1
’’Вся трудность - в выборе”.
Джордж Моор ’’Ветви гнутся”
Приведем пример использования нотации БНФ для определения целого
беззнакового числа:
(последовательность цифр) : : = 0|1|2|3|4|5|6|7|8|9
|0 (последовательность цифр) | 1 (последовательность цифр)
^(последовательность цифр) | 3 (последовательность цифр)
^(последовательность цифр) | 5 (последовательность цифр)
^(последовательность цифр) I 7 < последовательность цифр)
18 < последовательность цифр) | 9 < последовательность цифр);
(беззнаковое целое число) : : = 0 112|3|4|5|6|7|8|9
11 (последовательность цифр) | 2 (последовательность цифр)
13 < последовательность цифр) | 4 (последовательность цифр)
15 (последовательность цифр) | 6 (последовательность цифр)
17(последовательность цифр) | 8 (последовательность цифр)
19 < последовательность цифр).
Правая часть каждой формы представляет собой либо один терминаль-
ный символ, либо последовательность терминальных и нетерминальных
символов. Все символы любого языка программирования (целые числа,
идентификаторы переменных, операторы, зарезервированные слова, знаки
пунктуации) могут быть определены таким образом. Поскольку значитель-
ную часть времени компиляции программирования составляет распозна-
вание символов языка программирования в исходном тексте программы,
то есть смысл изучить грамматики, имеющие продукции такого же вида.
Подобные грамматики называют регулярными грамматиками, а порожден-
ные ими языки программирования — регулярными языками. В этой главе
будет показано, что тексты, написанные на регулярном языке, поддаются
эффективному распознаванию, а сами регулярные грамматики могут обла-
дать широким спектром необходимых нам свойств. К сожалению, возмож-
ности регулярных языков сильно ограничены, и даже самые простые про-
граммные конструкции не могут быть описаны с использованием одних
лишь регулярных грамматик. Таким образом, роль регулярных грамматик
в процессе компиляции программы ограничивается лишь распознаванием
символов языка, использованных в программе — этот этап компиляции
носит название лексического анализа. После того, как лексический анализ
закончен, требуется более изощренная техника для осуществления полного
грамматического разбора текста программы. В следующих главах мы обсу-
дим этот вопрос.
39
РЕГУЛЯРНЫЕ ГРАММАТИКИ
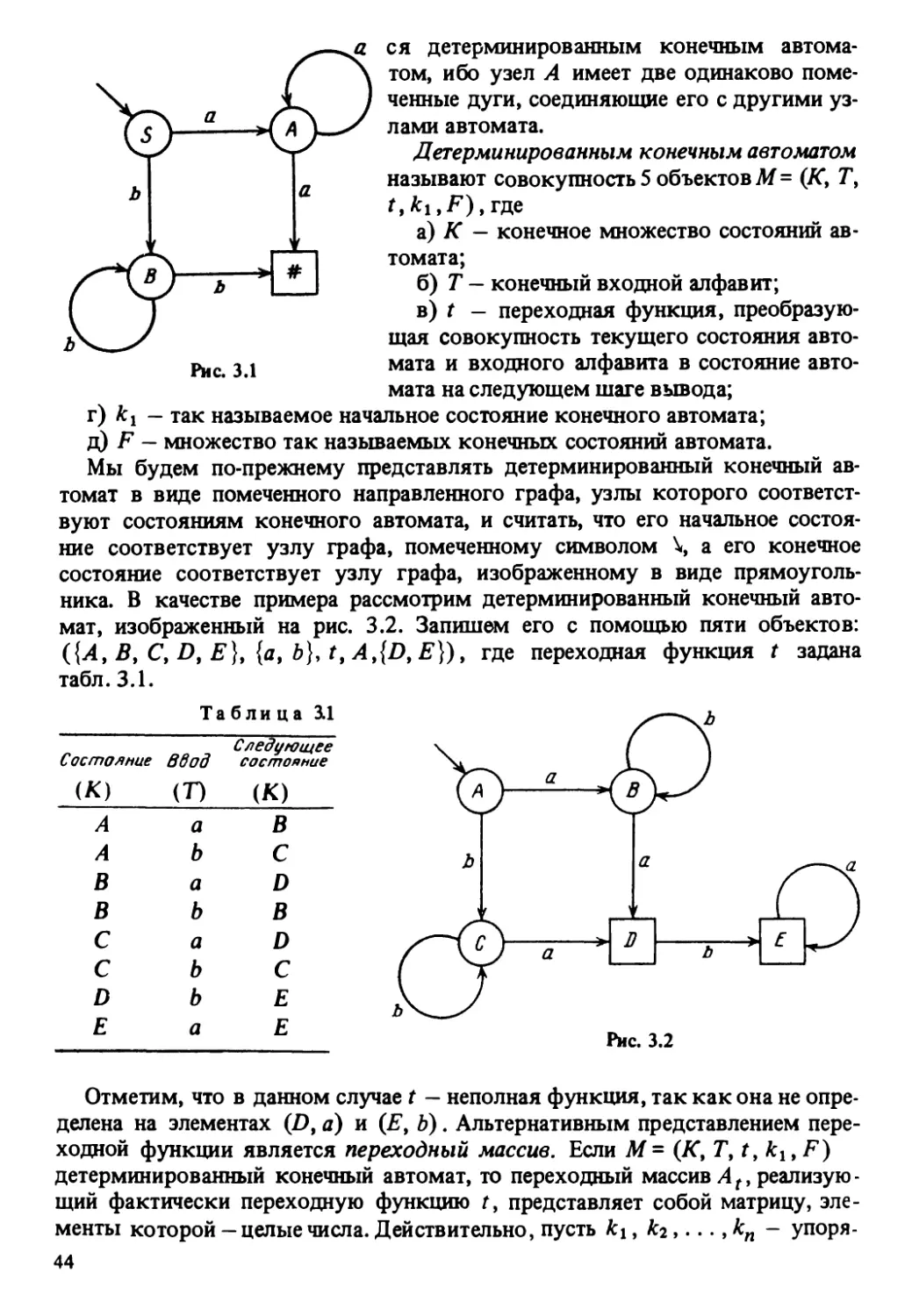
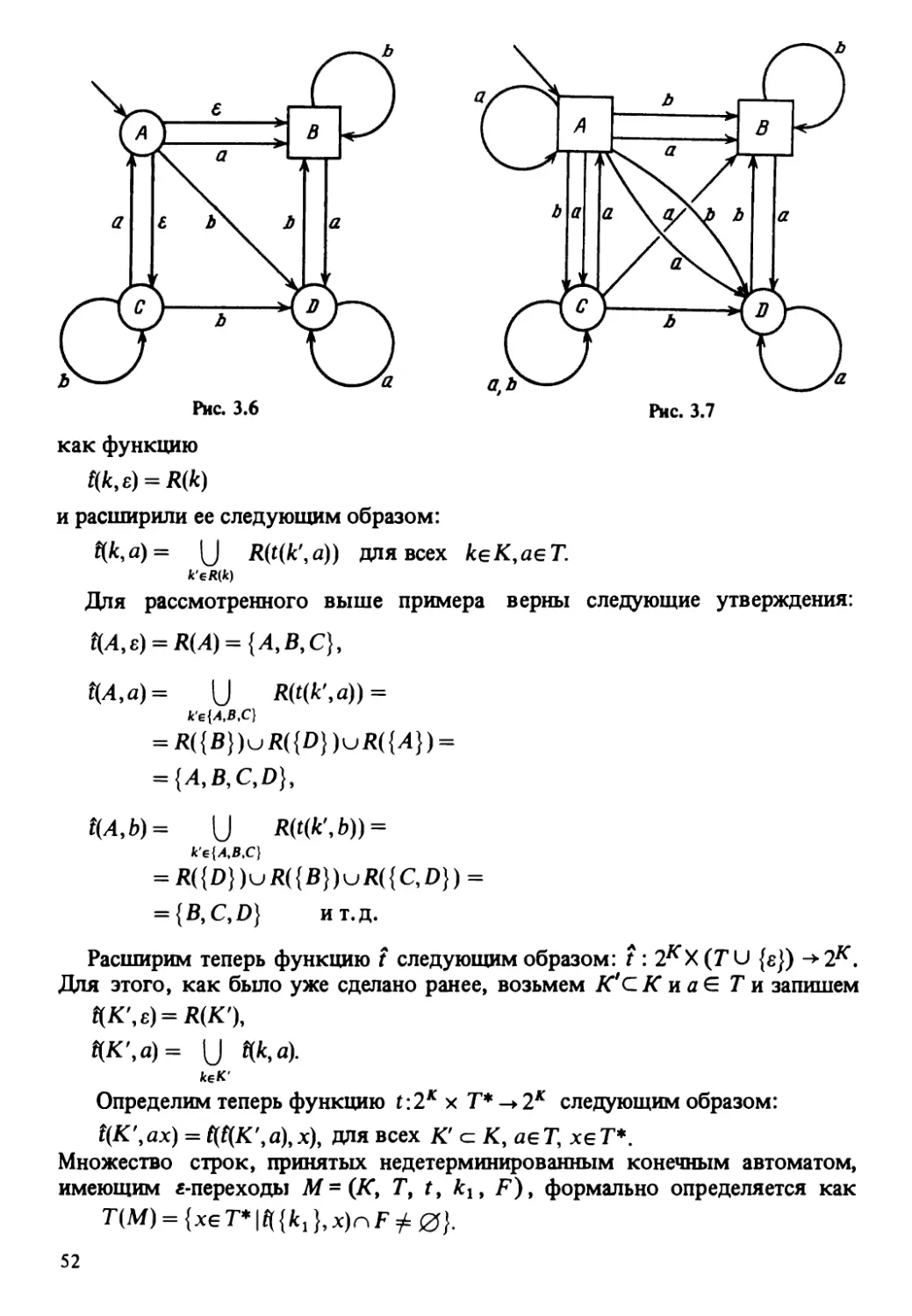
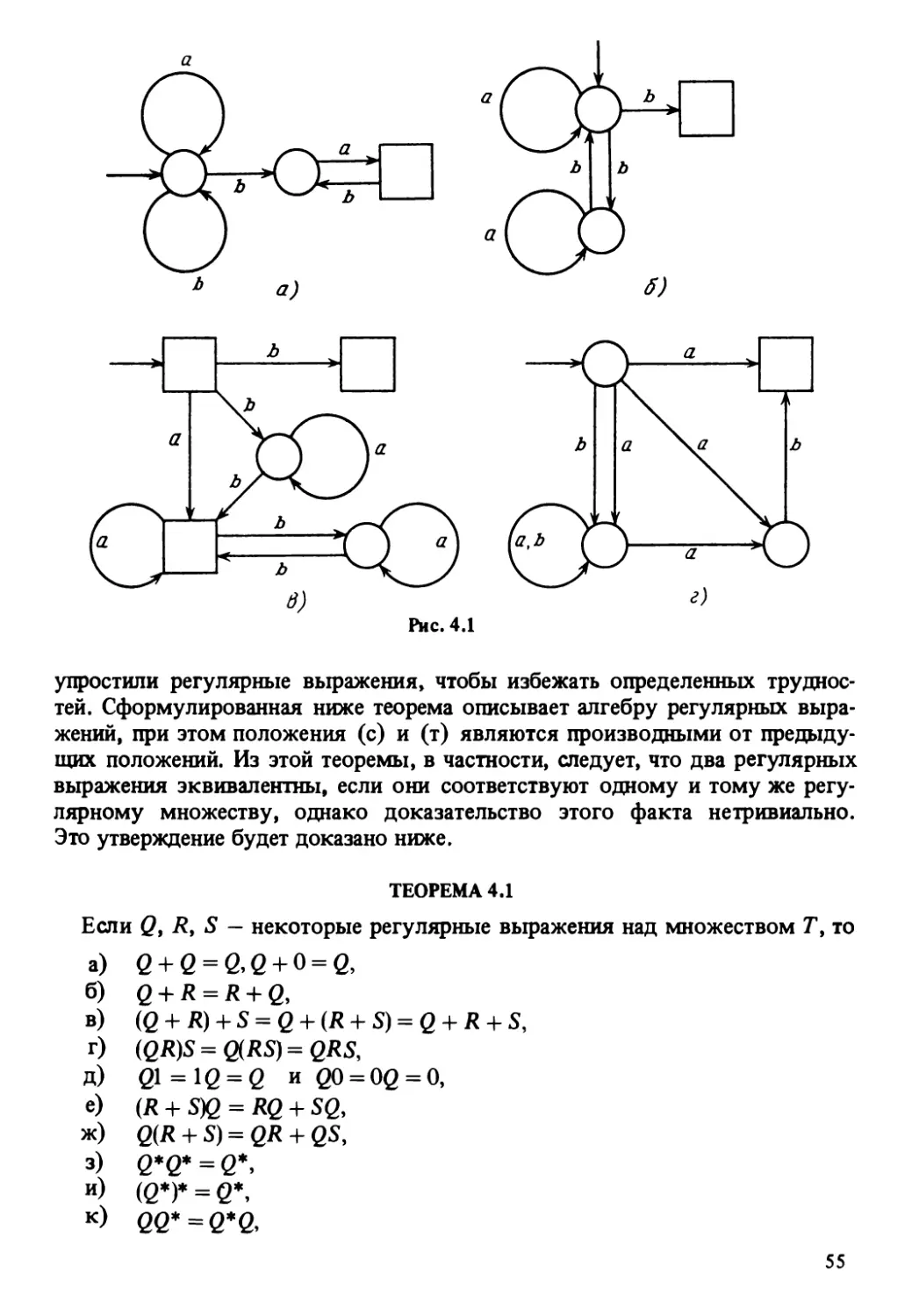
Контекстная грамматика G = (N9 T9P9S) называется регулярной грамма-
тикой, если:
1) она имеет е-продукцию вида 5 ->е, и ни одна из оставшихся продук-
ций G не содержит своей правой части нетерминального символа 5;
2) все остальные продукции грамматики G имеют вид А -+а9 где A G N9
аЕТили видЛ гдеA,BG NtaG Т.
Язык называется регулярным языком, если он порожден регулярной
грамматикой. Из этого определения и рассуждений в теореме 2.1, можно
сделать вывод, что язык L является регулярным <=>£\ {е} порожден е-сво-
бодной грамматикой.
Регулярная грамматика G\, имеющая продукции вида
S^>aS\aB9
В^ЬВ\Ь
порождает регулярный язык L(G j) = {ambn| tn, п > 1}.
Регулярный язык L-L (Gj) U{e} порожден регулярной грамматикой,
имеющей продукции вида
5-► е|aSx \аВ,
SY -*aS{\aB9
B^bB\b.
Поскольку каждая продукция регулярной грамматики специфицирует за-
мену нетерминального символа строкой, содержащей не более одного не-
терминального символа, то каждая сентенциальная форма такой грамма-
тики либо является элементом множества Г* либо содержит ровно один
элемент множества N, который, кроме того, обязательно будет самым
правым ее символом.
Если G = (N, Г, Р9 S) — £-свободная регулярная грамматика, порождаю-
щая язык L, можно легко построить £-свободную грамматику (7+ = (N, Т9
Р+, 5), порождающую язык L +, поставив в соответствие каждому элемен-
ту множества Р9 имеющему вид А -+а9 продукцию вида A -+aS9 которую
присоединим к множеству Р. Полученное в результате множество продук-
ций и есть множество Р+. Например, грамматика G| имеет продукции вида
S->aS\aB9
B^bB\b\bS.
Вернемся к общему случаю и докажем, что L (<7+) =£+. Для этого доста-
точно показать, что£ (<7+) С£ + и£ + С£ (G +). Докажем, что еслих G L (<7+),
то х G £+, воспользовавшись методом индукции по п, где п — число ’’новых”
продукций (тех продукций, которые принадлежат множеству Р*\Р)9 ис-
пользуемых для вывода строки х. Пусть п = 0, тогда схема вывода строки х
содержит только те продукции, которые принадлежат Р9 поэтому х G L и,
следовательно, х G L +.
Предположим теперь, что для всех п< к строка xG £+. Рассмотрим схе-
40
му вывода xEL (G+), которая включает к ’’новых” продукций, а продук-
ция A -+aS - последняя из них. Тогда S^>уА^Уаг = х’ где У* z ^+,
аЕТ. Очевидно, что вывод yaS=>yaz не включает новых продукций и, сле-
довательно, yaS =>yaz , значит, S=>z, т. е. zG£. Поскольку A -+aS — ’’но-
вая” продукция, то в множестве Р должна существовать продукция вида
А -+а. Тогда 5 =>уА =>уа — вывод элемента уаЕ L (<7+) включает меньше
к ’’новых” продукций, поэтому ya G L+ согласно предположению. Но из
того, что ya G L +, a z G L следует, что х = yaz Е L +, и утверждение доказано.
Если хЕ L*, то хЕ Ln для некоторого 1. Докажем методом индук-
ции по и, что если хЕ Ьп9 то х Е L (G+) для любого п. Пусть п = 1, тогда
х Е L, их может быть выведено из 5 с помощью одних лишь продукций
грамматики G. Поскольку все эти продукции являются также элементами
множества Р+, этот вывод справедлив и для грамматики (7+ и, следова-
тельно, хЕ£((7+). Предположим, что это утверждение справедливо для
всех п< к и рассмотримxELk. Тогда, очевидно, строках может быть пред-
ставлена в виде х =yz9 где у Е L , z Е . Пусть 5=>у — вывод строки J в
G
грамматике G. Последняя входящая в состав этого вывода продукция, оче-
видно, будет иметь вид А -+а9 гце у -у а, у Е Г* Таким образом, Л ~+aS —
продукция из множества Р+ и, следовательно, yS — сентенциальная форма
контекстной грамматики (7+. Согласно индуктивному предположению, су-
ществует схема вывода строки z из 5 в грамматике (7+ и, следовательно,
jzE£(G+), т.е. хЕ£(6+) для любого к9 что и требовалось доказать.
Пусть теперь L — некоторый регулярный язык, тогда L = (L \ {е}+) U {с}.
Как мы только что показали, (£ \ {е})+ — регулярный язык, и, следователь-
но, Z* — тоже регулярный язык. Сформулируем теперь теорему, первую
часть которой мы только что доказали.
ТЕОРЕМА 3.1
а) Если L — регулярный язык, то его так называемое замыкание Клини
£ * — тоже регулярный язык.
б) Если L 1 и L 2 — регулярные языки, то L i U£ 2 и L XL 2 — регулярные
языки.
Доказательство второй части теоремы также основывается на построении
новой грамматики. Основная схема доказательства будет изложена, а детали
доказательства оставлены читателю. Прежде всего, предположим, что L х и
Ь2 не содержат элемента s (если е Е L! или € Е L 2, тогда г Е L j U£ 2 и грам-
матика, порождающая язык Lx U£2 может быть построена из грамматики,
порождающей язык (L t \ {е} ) U(£2 \ {е} )). Прежде, чем приступить к по-
строению грамматики, рассмотрим один пример. Пусть = {ambn\m9 п>
> 1} —язык, порожденный грамматикой G\, описанной выше, и пусть Ь2 —
язык, порожденный грамматикой G2t имеющей продукцию S ^>cS\c9 тогда
£2 ={c"|h> 1}.
Пусть набор продукций грамматики, которую мы собираемся построить
41
и которая порождает язык Lx UP2, представляет собой просто переписан-
ные вместе продукции грамматик Gi и G2. Считать такую грамматику ис-
комой нельзя, поскольку в результате ’’спутывания” продукций двух грам-
матик могут возникнуть такие схемы вывода, что порожденные ими строки
не будут входить в язык L j UP 2.
Если это рассуждение использовать в рассмотренном выше примере, то
одна из таких схем вывода может выглядеть следующим образом: 5 =>aS =>
Мы должны быть уверены, что любая схема вывода состоит из продук-
ций грамматики Gi или продукций грамматики G2. Чтобы добиться этого,
необходимо различать нетерминальные символы грамматики Gx и нетерми-
нальные символы грамматики G2. Пусть Gj = ({S, ,Bj}, {a,b}, P^SJ име-
ет продукции
->aSi\aBi>
B^bB^b
и G2 = ({S2), {c}, P2,S2) имеет продукции
S2 ->cS2\c9
где Si,Вг и S2 — несовпадающие нетерминальные символы.
Объединим теперь эти продукции и введем новый начальный символ S.
Однако пополнить объединенный набор продукций еще одной продукцией
вида S -► S1 j S2 нельзя, так как регулярная грамматика, по определению,
не может иметь продукции такого вида. Поэтому запишем продукции ви-
да S -> а для всех таких а, что Si ->а — продукция грамматики Gi или52
-+а — продукция грамматики G2, Применим это рассуждение к вышеприве-
денному примеру
S-^aSJaBj |cS2|c,
Si-^aSi\aBi9
S2 ->cS2 |c.
Нетрудно видеть, что данная грамматика порождает язык {ambn | m, п > 1} и
о{с"|и > 1}.
В результате всех этих рассуждений, можно формально записать искомую
грамматику. Пусть Gi = (А\, Ti,Pi, Si) и G2 = (N2, T2tP2,S2) — две6-сво-
бодные регулярные грамматики, порождающие языки L i и L 2 соответст-
венно. Без потери общности можно предположить, что A N2 = . Пусть
S jVi UTV2 — новый начальный символ, и рассмотрим грамматику G = (М U
UTV2 U {S}, Ti UT2, Pi UP2 UP3, S), где Р3 - множество всех продукций ви-
да S а, где либо Si ->а Е Pi, либо S2 -►аЕ Р2. Предлагаем читателю само-
стоятельно доказать, что L (G) -L (G^ UP (G2). f
С помощью грамматик Gi и G2 построим еще одну грамматику Gr, та-
кую, что L (Gr) =L (Gi)L (G2). При этомM G\N2 = (J)fG9 = (jVi VN2, Ti UT2,
P , SO, где P9 - множество всех продукций грамматик Gi и G2, в котором
42
продукции грамматики Gi видаЛ заменены на продукции видаЛ
и снова предложим читателю самостоятельно доказать, что L — регуляр-
ный язык. В вышеприведенном примере продукции вновь построенной грам-
матики имеют вид
-+aSx \аВ1у
Bi-^bBi\bS2,
S2 —► cS21 с.
КОНЕЧНЫЙ АВТОМАТ
Любая регулярная грамматика G = (7V, Г, Р, S ) может быть представле-
на направленным графом с помеченными узлами и дугами. Каждый узел та-
кого графа может быть помечен символом, являющимся элементом мно-
жества 7V, кроме одного специального — ’’конечного” узла, помеченного сим-
волом #. Согласно принятым соглашениям, узел, соответствующий началь-
ному символу S, выделяется среди всех прочих узлов графа с помощью
символа \, а конечный узел, соответствующий символу #, изображается в
виде прямоугольника. Если грамматика G имеет продукцию А -+аВ9 то
узел графа, помеченный символом А, должен быть соединен непосредственно
с узлом, помеченным символом В, с помощью дуги, которую принято в та-
ких случаях помечать символом а. Если грамматика G имеет продукцию ви-
да А -> а, то соответствующий узел графа, помеченный символом А, соеди-
нен с узлом, помеченным символом #, дугой, помеченной символом а. Та-
ким образом, каждая дуга графа соответствует одной и только одной про-
дукции грамматики G.
Пусть регулярная грамматика G3 имеет следующие продукции:
S^aA\bB,
А-^аА\а,
В^ЬВ[Ь9
тогда она, очевидно, может быть представлена с помощью направленного
графа, изображенного на рис. 3.1.
Рассмотрим теперь некоторый путь по графу, соединяющий узел, поме-
ченный символом S, с узлом, помеченным символом #. Метки, ассоцииро-
ванные с дугами, составляющими этот путь, составят некоторую строку.
Множество таких строк совпадает с языком L (<73), а каждый такой путь
будет соответствовать одному из реальных выводов. Таким образом, путь,
составленный из дуг вида: ”от ® к ®”, ”от ® к ®”, ”от ® к ®”, от ® к
в точности соответствует схеме вывода вида S => а А =>ааА =>аааА =>аааа.
Говорят, что конечный направленный граф, имеющий один начальный
узел и один или более конечных узлов, есть конечный автомат. Мы огра-
ничимся рассмотрением лишь детерминированных конечных автоматов, т. е.
таких конечных автоматов, ни один узел которых не имеет одинаково по-
меченных дуг, соединяющих его с другими узлами автомата. В вышеприве-
денном примере конечный автомат, представленный на рис. 3.1, не являет-
43
S—ся детерминированным конечным автома-
та д том, ибо узел А имеет две одинаково поме-
Jf у ченные дуги, соединяющие его с другими уз-
а___лами автомата.
Детерминированным конечным автоматом
называют совокупность 5 объектов М = (К9 Т,
t9k19F)9rp£
а) К — конечное множество состояний ав-
томата;
б) Г — конечный входной алфавит;
в) t — переходная функция, преобразую-
щая совокупность текущего состояния авто-
мата и входного алфавита в состояние авто-
мата на следующем шаге вывода;
г) &i — так называемое начальное состояние конечного автомата;
д) F — множество так называемых конечных состояний автомата.
Мы будем по-прежнему представлять детерминированный конечный ав-
томат в виде помеченного направленного графа, узлы которого соответст-
вуют состояниям конечного автомата, и считать, что его начальное состоя-
ние соответствует узлу графа, помеченному символом \, а его конечное
состояние соответствует узлу графа, изображенному в виде прямоуголь-
ника. В качестве примера рассмотрим детерминированный конечный авто-
мат, изображенный на рис. 3.2. Запишем его с помощью пяти объектов:
({Л, В9 С9 Df Е}9 {a, b}, t9 A9{D9 £*}), где переходная функция t задана
табл. 3.1.
Таблица 31
Следующее
Состояние ввод состояние
(Ю (Т) (К)
А а в
А Ь с
В а D
В Ь В
с а D
с b С
D Ь Е
Е а Е
Рис. 3.2
Отметим, что в данном случае t — неполная функция, так как она не опре-
делена на элементах (D, а) и (£, Ь). Альтернативным представлением пере-
ходной функции является переходный массив. Если М = (К9 Tt t9 kltF)
детерминированный конечный автомат, то переходный массив At9 реализую-
щий фактически переходную функцию г, представляет собой матрицу, эле-
менты которой —целые числа. Действительно, пусть к\9 кг.кп - упоря-
44
доченная последовательность состояний автомата, a , аг,..., ат — упоря-
доченный входной алфавит; тогда элементы матрицы At удовлетворяют
условию
Если, например, и множество меток состояний конечного автомата, и вход-
ной алфавит упорядочены по алфавиту, то соответствующий переходной
массив в рассмотренном выше примере имеет вид
/2 3\
/4 2 |
I 4 3
I. 5/
\5 ./
Если (как в нашем примере) t - неполная функция, то не все элементы
матрицы A t определены.
Нас будут интересовать строки, составленные из символов, которыми
помечены дуги, соединяющие исходный узел конечного автомата с некото-
рым его конечным узлом. Множество всех таких строк для данного детер-
минированного конечного автомата М обычно обозначают Т(М) и называют
множеством строк, принимаемых М. Чтобы дать строгое определение Т (М),
расширим определение переходной функции, определив ее как функцию
t :КХ Т* Если кЕ К и хЕ Т*9 то t(k9 х) - такое состояние автомата,
которое будет достигнуто, если начиная из узла, помеченного символом к9
проследить путь, отвечающий строке х как совокупности символов, поме-
чающих отдельные дуги автомата. Понятно, что если х = е, то t(k9e)=k. Ес-
ли существуют аЕ Т9 у^Т* такие, что х =ау9 то переходную функцию t
можно определить рекурсивно с помощью соотношения t(/c,x) = t(t(k,a\y).
Вернемся к примеру и запишем
t(A, aba) = t(t(A, a), ba) =
= t(B,ba) =
= t(t(B,b),a) =
= t(B,a) = D.
Теперь множество строк T(M)ET* принимаемых автоматом М = (К9 Т9 t9
ki9F) может быть описано следующим образом:
T(M) = {xeT*\t(kl9x)eF}.
Если вас беспокоит, что переходная функция t детерминированного конеч-
ного автомата — неполная, представьте себе, что рассматриваемый нами ав-
томат имеет еще одно фиктивное состояние, которому соответствует узел
графа, помеченный символом Д, и это состояние является значением пере-
ходной функции на всех тех элементах множества (7ГХ Г), на которых она
считается неопределенной. Таким образом, для всех пар (ТСХа), на которых
функция t не определена, она принимает значение Д, т. е. t (к9 а) = Д, кроме
45
Рис. 3.3
того, очевидно, t (Д, а) = Д для всех a G Т. Воспользуемся этим рассуждени-
ем в приведенном выше примере (см. рис. 3.3). (Дуга от узла Д до узла Д,
помеченная двумя символами а и b — это стандартное сокращенное обозна-
чение двух совпадающих дуг, одна из которых была помечена символом а, а
другая символом Ь.) Если что-нибудь и может действительно внушить бес-
покойство, так это ограничение, определяющее конечный автомат как детер-
минированный конечный автомат. Избавимся от этого ограничения и позво-
лим узлам графа иметь по нескольку исходящих из них дуг, помеченных од-
ним символом. Тогда переходная функция t на таком элементе множества
КУЛ* будет иметь множество значений вместо одного. Если же для некото-
рого из них в множестве КУЛ не существует соответствующей пары (к, а),
то t (к, a) G ф, а так как (pG 2К, то t: КХТ -+2К — всегда полная функция.
Недетерминированный конечный автомат — это совокупность пяти объ-
ектов: М = (К, Г, t, кх, F), где
а) К — конечное множество состояний;
б) Г — конечный входной алфавит;
в) t — полная функция, отображающая А"Х Г2^,
называемая также переходной функцией;
г) кх Е К - начальное состояние;
д) FdK — множество конечных состояний.
Конечный автомат, приведенный на рис. 3.1, являет-
ся недетерминированным, переходная функция кото-
рого задана табл. 3.2.
Перед тем как определить множество строк, прини-
маемых данным автоматом, необходимо вновь расши-
рить определение переходной функции. Определим пе-
реходную функцию на множестве 2КХТ следующим
образом:
t(K',a) = J t(k,a) для/С'с/С, aG Т.
кеК'
Т аб ли ца 3.2
К т 2К
S а И)
S b {В}
А а {Л, #}
А b 0
В а 0
В b {В, #}
# а 0
# b 0
46
Таким образом, множество узлов конечного автомата, соединенных с
некоторым узлом из множества К9 дугами, помеченными символом а9 в
точности совпадает с множеством t (К\ а). Рассмотрим теперь определе-
ние функции t на области 2^ХТ*, определив ее область значений как 2К,
Воспользуемся для этого тем же приемом, что и в случае детерминирован-
ного конечного автомата. Если К9 СК9 то t (К99 £) = К9, и еслих = ау9аС Г*,
7€Т*,тоГ(/С',х) = r(r(tf',a),y).
Используем для иллюстрации недетерминированный конечный автомат,
приведенный На рис. 3.1, получим
t({S,A},ab) = t(t({S,A},a),b) =
= t(t(S,a)ut(A,a),b) =
= t({A9*}9b) =
= t(A,b)ut( *,b) = 0.
Определим теперь множество строк Т(М)9 принимаемых недетермини-
рованным конечным автоматом М = (К9 Т9 t9 k19 F) как множество таких
строк, каждый элемент которых совпадает с одним из символов, помечаю-
щих дуги автоматов, а строка в целом соответствует пути по графу от началь-
ного его узла до конечного, т. е.
T(M) = {xeT*|t({/c1},x)nF^0}.
ТЕОРЕМА 3.2
Множество строк L может быть принято детерминированным конечным
автоматом тогда и только тогда, когда множество строк L может быть
принято недетерминированным конечным автоматом.
Доказательство
а) Для любого детерминированного конечного автомата существует
эквивалентный ему детерминированный конечный автомат, переходная
функция которого является полной (было показано, что для этого доста-
точно фиктивно доопределить переходную функцию t). Пусть L СТ* такое,
что L=T(M) для некоторого детерминированного конечного автомата
М = (К9 Г, t9 k19 F), где t — полная функция. Рассмотрим такой недетер-
минированный конечный автомат М9 = (К9 Tt t9 klt F)t что t9 (к9 а) = {г (к9
а)} (это следует из того, что Г(М) = Г(М9) ).
б) Пусть М = (/С, Г, t9 klt F) — некоторый недетерминированный конеч-
ный автомат, тогда определим такой детерминированный конечный автомат,
что множество принимаемых им строк совпадает с множеством Т(М).
Пусть множество состояний такого детерминированного автомата совпадает
с множеством 2К9 входной алфавит совпадает с множеством Г, начальное
состояние совпадает с множеством {fci) , а переходная функция определена
как расширение функции t с областью определения 2КХТ и с областью зна-
чений 2К. По определению х Е Т(М) ({fci}, х) A F £ ф9 и если в качест-
ве множества конечных состояний детерминированного конечного автома-
47
та выбрать такое множество К9 что К1 A F то детерминированный
конечный автомат будет определен и исходное утверждение доказано.
На практике задача построения детерминированного конечного автома-
та, эквивалентного некоторому недетерминированному конечному авто-
мату, встречается довольно часто. Ограничимся рассмотрением множества
тех состояний, которые могут быть получены из начального состояния
{кг}, Таким образом, вместо того, чтобы рассматривать все 2*<А) возмож-
ных состояний автомата, ограничимся рассмотрением всех состояний t },
а) для всех a Е Т, Далее рассмотрим множество состояний t (К9, а) для всех
аЕ Г, К9 С К. Этот процесс будем продолжать до тех пор, пока полученные
таким образом состояния автомата не начнут совпадать с уже существую-
щими. Поскольку общее число различных состояний автомата не может
превышать 2*(К), то множество получаемых состояний ограничено. На рис.
3.4 представлен детерминированный конечный автомат, построенный опи-
санным выше способом из недетерминированного конечного автомата,
показанного на рис. 3.1. Отметим в заключение, что пустое множество игра-
ет в этом случае роль фиктивного состояния, и в действительности все про-
веденные к соответствующему узлу дуги могут быть опущены.
Перейдем теперь к основной теореме данной главы.
ТЕОРЕМА 3.3
Следующие три утверждения равносильны:
1) L — может быть принято некоторым недетерминированным конеч-
ным автоматом;
2) L - может быть принято некоторым детерминированным конечным
автоматом;
3) L — порождено некоторой регулярной грамматикой.
48
Доказательство
Равносильность двух первых утверждений была доказана в теореме 3.2.
Теперь аналогично докажем, что из справедливости утв. 2 следует справед-
ливость утв. 3, а из справедливости утв. 3 следует справедливость утв. 1.
Приведем здесь лишь схему доказательства, а все детали и формулировки
предоставим читателю.
Итак, пусть L — принято детерминированным конечным автоматом
М = (К9 Г, г, ^i, F). Без потери общности можно считать, что /СП Т ^0.
Определим теперь регулярную грамматику G так, чтобы L(G) =Т(М)\{е}.
Если eG Т(М)9 то кг G F и можно определить регулярную грамматику
(7* так, чтобы L (<7r) = L (G) U {е) = Т(М). Грамматика, которую надо
определить, как обычно, имеет вид G- (W, Г, Р, 5), где N-K9 S = кХ9 и
множество Р содержит все продукции вида kj -+akj , где t (kj 9 а) = kj9 а так-
же все продукции вида ->а, где t (ki9 а} = kj и kj G F, Например, пере-
обозначим узлы детерминированного конечного автомата, показанного
на рис. 3.4, не изображая фиктивное состояние детерминированного конеч-
ного автомата, как это показано на рис. 3.5; грамматика, ассоциированная
с таким автоматом, может выглядеть следующим образом:
jV={&i , ,&з, ^4, }, S=k19
а продукции ее имеют вид
->а/с2|Ыс4,
/с2~>^з1а,
-► а/с3| а9
к^>Ьк5\Ь9
k5->bk5\b.
Предоставляем читателю самостоятельно доказать, что х G L (G) <=*
Т(М)\ {е}.
Продолжим доказательство равносильности: из справедливости утв. 3
следует справедливость утв. 1.
Если L -L(G) — язык, порожденный грамматикой G = (N, Т9Р9 S)9
тогда L — множество строк, принятых недетерминированным конечным
автоматом вида (NU{#}9 Т9 t9 S {#}), где # - некоторый новый символ и
#£ Nt а переходная функция t определена следующим образом: если про-
дукция А -+а — элемент множества Р9 то множество t(At а) содержит эле-
мент #, если продукция А -+аВ — элемент множества Р9 то множество t (А 9
а) содержит элемент В. Понятно, что при таком определении переходной
функции t любой продукции из Р соответствует некоторое подмножество
множества t (А, а).
Утверждение, что для любого регулярного языка L существует детерми-
нированный конечный автомат М9 такой, что Т(М) -Ь9 можно использовать
как эффективный способ определения, является ли произвольная строка
х элементом множества L или нет. Для этого достаточно построить диаграм-
му автомата М и определить по ней, существует ли такой путь от его началь-
ного узла до конечного, что упорядоченная последовательность меток узлов
и дуг, полученная при построении такого пути, совпадает со строкой х. По-
скольку М — детерминированный конечный автомат, то существует не бо-
лее одного такого пути. Если же воспользоваться определенным выше фик-
тивным состоянием автомата, то для любого xG Г* всегда существует
в точности один путь по графу от начального узла и остается лишь выяснить,
проходит ли этот путь через конечный узел графа.
Итак, показав, что регулярные языки совпадают с множеством строк,
принимаемых детерминированными и недетерминированными конечными
автоматами, мы получили инструмент для доказательства ряда интересных
теорем.
ТЕОРЕМА 3.4
Если L — регулярный язык, порожденный грамматикой (N9 Т9 Р9 5),
то дополнение множества L в множестве T*-Z = T*\L — тоже регуляр-
ный язык.
Доказательство
Пусть М- (К9 Т9 t9 k19 F) — детерминированный конечный автомат, а
L — множество принятых им строк. Определим фиктивное состояние авто-
мата так, как выше для того, чтобы функция t стала полной. Если х G L,
то существует путь по направленному графу, такой, что упорядоченная по-
следовательность меток входящих в него узлов и дуг совпадает со строкой х
и соединяет начальный узел графа с его конечным узлом. В то же время если
х $ L, то путь, построенный в соответствии со строкой х9 начнется в узле
, а кончится не в конечном узле. Таким образом, L — множество строк,
принятых автоматом М = (К9 Т919 klt K\F) 9 и следовательно, должно быть
регулярным языком.
50
ТЕОРЕМА 3.5
Если L! и £ 2 — регулярные языки, то множество L i А £ 2 — регулярный
язык.
Доказательство
£ 1 и £ 2 — регулярные языки по теореме 3.4. Таким образом, по теореме
3.1, б множество £ ! U£ 2 — регулярный язык, но £ i Г) £2 =£ j U£2 — ре-
гулярный язык из теоремы 3.4, и утверждение доказано.
КОНЕЧНЫЙ АВТОМАТ С ^-ПЕРЕХОДАМИ
Говорят, что недетерминированный конечный автомат М = (/С, Г, Г, к19
F) имеет е-переходы, если функция t определена на множестве/СХ(Г U {с}),
т.е. r:£fX(TU {е}) -► 2К. Пример такого автомата приведен на рис. 3.6.
Если М = (К9 Т, t, к19 F) — недетерминированный конечный автомат,
имеющий Е-переходы и к9 к' G К9 такое, что к9 Е t (к9 е), то говорят, что
к9 — е-достижимо из узла к и записывают это
/с—к'.
В таком случае недетерминированный конечный автомат М может перей-
ти из состояния к в состояние к' без обработки какой-либо дополнительной
информации. Пусть у — рефлексивное и транзитивное замыкание множест-
ва £. Тогда к<==>£ = кг, т.е. существует путь по графу от узла к до к9,
состоящий из дуг, помеченных символом е и длиной > 1. Если к Е К9 то мно-
жество узлов, достижимых из узла к без обработки дополнительной инфор-
мации, обозначается R (к), что формально записывается как
R(k)={k'\k-^k'}.
Расширим это определение следующим образом: пусть К9 С К9 тогда
Я(К')= U *(*)•
кеК'
В рассмотренном выше примере R(А) = {А9В9 С}, R(B) = {B},R(C) ={С},
R(D) = {D}. R({A9B}) = R(A)vR(B)={A9B9C}.
Тогда, по определению, R ({А, В}) = R(A) UR (В) = {А, В9 С}9... Переоп-
ределим теперь переходную функцию г, определив ее на б-переходах как
Г: К х (Tu{c})-*2A таким образом, что если к€ R9 то f(fc,а) — множество
состояний (узлов), которые могут быть достигнуты из узла (состояния) к
после получения и обработки дополнительной информации в виде симво-
ла а. Например, если автомат находится в состоянии А9 то t(A9 а) = {В}.
Однако, используя лишь один раз введенный символ а9 можно перевес-
ти автомат из состояния А в состояние £>, из состояния А в состояние А и
из состояния А в состояние С. Чтобы перевести автомат в состояние £>, на-
пример, необходимо сначала достичь состояния В9 используя ^-переход,
а затем, введя символ а9 достичь состояния £>; чтобы достичь состояния А,
необходимо сначала достичь состояния С, используя ^-переход, а затем,
введя символ а9 достичь состояния А.
Итак, мы определили переходную функцию
Г: К х(Ти{е})->2*
51
как функцию
f(k,e) = R(k)
и расширили ее следующим образом:
t(k,d)= U R(t(k\a)) для всех кеК,аеТ.
k'eR(k)
Для рассмотренного выше примера верны следующие утверждения:
М,е) = К(4) = {4,В,С},
М,а)= U W',a)) =
И’е{АВ.С}
= Я({В})оЯ({Р})иК({А}) =
= {A,B,C,D},
t(A,b)= U R(t(k',b)) =
к'е{Л,В.С}
= R({D})uR({B})uR({C,D}) =
= {B,C,D} ит.д.
Расширим теперь функцию t следующим образом: t: 2КХ (ТО {е}) -+2К.
Для этого, как было уже сделано ранее, возьмем К'<^К и а € Т и запишем
f(K',c) = R(K'),
f(K',a)= J ККа).
кеК'
Определим теперь функцию t:2K х Т*-»2Х следующим образом:
t(K',ax) = для всех К' <= К, аеТ, хеТ*.
Множество строк, принятых недетерминированным конечным автоматом,
имеющим е-переходы М=(К, Т, t, kit F), формально определяется как
Т(М) = {хе Т* |Ц {fc,}, x)n F 0}.
52
Если М — такой конечный автомат, то можно определить недетермини-
рованный конечный автомат Afz = (К, Tt t', к\, F'), где К' (к, а) = t(k, а) и
F9 =F при R(ki) A F ф и F9 = FU{fc}, в противном случае недетерми-
нированный конечный автомат М не имеет е-переходов и нетрудно показать,
что Т(М} = Т(М').
ТЕОРЕМА 3.6
Если L — множество строк, принятых некоторым имеющим е-переходы
недетерминированным конечным автоматом, тогда L — регулярный язык.
На рис. 3.7 приведен недетерминированный конечный автомат, эквива-
лентный автомату, приведенному на рис. 3.6.
УПРАЖНЕНИЯ
3.1. Пусть множество строк L - подмножество множества {0,1} * таких, что справа
от символа 0 всегда находится символ 1.
а) Определите детерминированный конечный автомат, которым могут быть приняты
все строки из L.
б) Определите регулярную грамматику, порождающую язык L.
3.2. Пусть L - регулярное множество. Пусть Pref (L) = {х|х - префикс строки из
L}. Докажите, что Pref(L) - также регулярное множество. (Воспользуйтесь тем, что
L = T(Af) для некоторого детерминированного автомата М).
3.3. Докажите теорему 3.1, б.
3.4. Пусть М-{{кХ9 кг, £3},{д, &}» - недетерминированный конечный
автомат, где t (к19а) - {к2, к3}, t (к2, a) = {kit к2}, t (к3,а) - {ktк3}, 1{к19 Ь) = {А^},
f{fc2, Ь}= 0, t(k3, Ъ) - {klt fc2} . Определите недетерминированный конечный автомат
так, чтобы все строки из множества Т (М) были бы им приняты.
3.5. Постройте детерминированный конечный автомат, эквивалентный недетерми-
нированному конечному автомату, изображенному на рис. 3.6.
3.6. Гомоморфизм 6: Tj*->T2* есть полная функция, такая, что 0(g) = а и 0 (х, у) =
= 0 (х)0 (у) для любого х, у е Г*. Пусть Т,= {д, b), Т2 = {Ь, с) и 0 (д) =Ьс, 0 (Ь) =ЬЬ;
определите значения 0 (д, Ь) и 0 (Ь,д). Покажите, что если L - регулярный язык и 0 -
произвольный гомоморфизм, то 0(£ ) - регулярный язык.
3.7. Докажите теорему 3.6.
3.8. Повторите доказательство теоремы 3.1, д, используя теорему 3.6.
3.9. Опишите конечный автомат, который будет принимать любое английское слово,
начинающееся с ”un” и кончающееся на ”d”. Напишите на языке программирования
Паскаль программу подсчета числа таких слов в произвольном текстовом файле.
3.10. Пусть каждая продукция грамматики G = (А, Г, Р, S) имеет вид либо А -+Ва,
либо А ->а, Л, В е А, а е Т. Покажите, что существует недетерминированный конечный
автомат, который способен принять все строки из множества L (G). (Продукция Л -►Рд
соответствует дуге, помеченной символом д и идущей от узла В к узлу Л.)
3.11. Если каждая продукция грамматики G = (А, Г, Р, S) имеет вид Л -+хВ или
Л -►х, Л, В е N, х Е Г*, то такая грамматика называется правосторонней грамматикой.
Аналогично, если каждая продукция грамматики G имеет вид А-+Вх или вид Л -►х
Л, Be N, хе Г* то такая грамматика называется левосторонней грамматикой. Пока-
жите, что L Е Г* порожден правосторонней грамматикой *=*£ - регулярный язык *=>£
порожден левосторонней грамматикой.
53
ГЛАВА 4
РЕГУЛЯРНЫЕ ЯЗЫКИ, II
”На рисунке не должно быть ненуж-
ных линий - у машины не должно
быть ненужных частей”.
Вильям Струнк ’’Элементы стиля”
РЕГУЛЯРНЫЕ ВЫРАЖЕНИЯ
Регулярные выражения - самый точный способ описания регулярных
языков. Набор правил, определяющих регулярное выражение над множест-
вом Г, выглядит следующим образам:
I. О - соответствует пустому множеству;
1 — соответствует множеству {с}.
II. Если L = {*1, х2,... ,хп} - конечное множество строк, где xz- G Г*,
i = 1, 2,..., и, то множеству L ставится в соответствие выражение
(Х1 +х2 + ... +Х„).
III. Если ri — регулярное выражение, соответствующее регулярному языку
£1} и г 2 — регулярное выражение, соответствующее регулярному язы-
ку L 2, то выражение (г j + г 2 ) соответствует множеству £ i U £ 2 ;
выражение (ri + r2) соответствует множеству £i U£2;
выражение (rj «г2) соответствует множеству £i£2 ;
выражение (rf ) соответствует множеству 0) ;
выражение (г*) соответствуетмножеству£*.
IV. Любое выражение, не удовлетворяющее условиям I—III, не является
регулярным выражением.
Скобки в регулярном выражении можно опустить, при этом сохраняет-
ся общепринятое соглашение о старшинстве операций — самыми старшими
считаются унарные операции, затем бинарная операция % и наконец, бинар-
ная операция +.
Поскольку каждое конечное множество строк — регулярный язык, а вся-
кий регулярный язык есть множество, замкнутое относительно операций
конкатенации и замыкания Клини, то каждое регулярное выражение над
множеством Т соответствует некоторому регулярному языку из множест-
ва Г*. Например, регулярное выражение (а + b)*ba(ba)* соответствует ре-
гулярному языку {a, b}*{ba} {Ьа}* = {а,Ь}* {Ьа}+ и, следовательно, регуляр-
ное выражение (а 4- ba*b)* + b соответствует регулярному языку ({а} и
о {Ь}{а}*{Ь})*и {Ь}. Обычно определить недетерминированный конечный
автомат, который принял бы регулярный язык, соответствующий заданно-
му регулярному выражению, очень просто. Однако столь же просто при этом
допустить ошибку. Некоторые из методов построения такого определения
показаны на рис. 4.1, а — 4.1, г. В данных примерах и далее 7? обозначает
регулярный язык, которому соответствует регулярное выражение г
Вы, должно быть, заметили, что в двух из приведенных примеров, мы
54
упростили регулярные выражения, чтобы избежать определенных труднос-
тей. Сформулированная ниже теорема описывает алгебру регулярных выра-
жений, при этом положения (с) и (т) являются производными от предыду-
щих положений. Из этой теоремы, в частности, следует, что два регулярных
выражения эквивалентны, если они соответствуют одному и тому же регу-
лярному множеству, однако доказательство этого факта нетривиально.
Это утверждение будет доказано ниже.
ТЕОРЕМА 4.1
Если Q, Rt S — некоторые регулярные выражения над множеством Г, то
а) 2+2 = 2,2+0=2,
б) Q + R = R + Q,
в) (Q + R)+S = e + (R + S) = e + R + S,
г) (QR)S = &RS)=QRS,
д) Q1 = 1Q = Q и QQ = OQ = O,
е) (R + ЭД = RQ + SQ,
ж) Q(R + S) = QR + QS,
з) Q*Q* = Q*,
и) (Q*)* = Q*
к) QQ* = 2*2,
55
л) 2* = 1 + б + 22+ -- + 2к + 12*> для fc>0,
м) 1* = 1 и 0* = 1,
н) (2* + я*)* = (2*Д*)* = (Q + Я)*,
о) (RQ)*R = R(QR)\
п) (2*Я)*е* = (2 + К)*,
р) (е*я)*=(2 + к)*к + 1 и (2Я*)* = 2(е + Я)* + 1,
с) если Q = Я*5, то Q = RQ + 5;
т) если 1 R и Q = RQ + 5, то Q = К*5.
Доказательство
Большинство из этих положений очевидны, для доказательства достаточ-
но воспользоваться соответствием операций, операция + соответствует опе-
рации объединения множеств и, а операция • соответствует операции кон-
катенации множеств. Поэтому перейдем сразу к доказательству двух по-
следних положений. Сначала перепишем их следующим образом:
с) 2 = K*S = (KK* + 1)S = (изб) ил))
= RR*S + 5 = (из д) и е))
т) е = яе + s => е = я(Я2+$)+$ =
= Я22 + Я5 + 5 =
= R2(RQ +S)+ RS+ S =
= я32 + к2$+к$ + $ =
= Rk + !2 + (Rk + • • • + R + 1)5 для любого А > 0.
Теперь найдется такое к > 0, что |х | < к для любого х G Q, Поскольку
1 ^Я, тох^Я*+12 и, следовательно, х G (Я^+ .. . + Я + 1)5 т.е.хЕ Я*5*.
Таким образом, если х G Q9 то х G Я*5. Сравнив эти результаты, получим
Q=R*S. Итак, мы выяснили, что любое регулярное выражение соответству-
ет некоторому регулярному языку. Обратное утверждение также верно и
будет доказано в следующей теореме.
ТЕОРЕМА 4.2 (ТЕОРЕМА КЛИНИ)
Каждому регулярному языку из Т* соответствует регулярное выражение
над множеством Г.
Доказател ъство
Пусть L — регулярное выражение, тогда существует такой детерминиро-
ванный конечный автомат М = (К, Г, t, кх, F), что L = Т(М). Предположим,
что К = {fcb к2,... ,кп}. Если F = {£Х1, кК2,... тогда L =L i U£2 U...
... VLm, где — язык, принимаемый автоматом^ = (К, Г, t9 кх, {к^ } ).
Поскольку операции объединения по определению соответствует операция
сложения, то достаточно показать, что каждому языку £, соответствует
регулярное выражение. Таким образом, достаточно показать, что множест-
ву строк, принимаемых детерминированным конечным автоматом, имею-
56
щим одно начальное и одно конечное состояния, может быть поставлено в
соответствие некоторое регулярное выражение.
Рассмотрим автомат М = (К9 Т9 t9 k19 F) 9 состояния которого помечены
следующим образом: К = , к2,..., kn}; F = {кп}.
Обозначим Tj. (К i, / < и, ОС I См) язык, все элементы которого пред-
ставляют собой такие строки, что t (kj, х) = kj и для всех собственных пре-
фиксов у строки х верно t (kj, у) Е {km \m < I} (собственным префиксом
строки х€ Т* называют такую строку у Е Т+, что х = yv9 где и Е Т+ — неко-
торая строка, у — непустая строка, не совпадающая со строкой х). Восполь-
зуемся методом индукции и покажем, что языку Ту всегда соответствует
некоторое регулярное выражение.
Если i , то языку Ту соответствует регулярное выражение +а2 +.. •
...+аг, где Ль a2t...9ar — символы, которыми помечены дуги, соединяю-
щие узлы kj и kj автомата между собой; если же таких дуг нет, то языку
Ту соответствует 0. Если i = / , то языку Ту соответствует регулярное вы-
ражение 1 + Я1 + а2 +... + аг, где ах, а2,..., аг - символы, которыми поме-
чены дуги, соединяющие узел автомата kj с самим собой; если же таких
дуг нет, то языку Ту соответствует 1. Таким образом, мы показали, что
любому языку Т!у соответствует некоторое регулярное выражение, если I =
= 0. Далее, воспользовавшись соотношением Т1и = TltJ~1 + Т1и~1 (Т1и~ т)* Т\[ 1,
1 <7 Си, можно показать, что каждому языку ГЛ соответствует некоторое
регулярное выражение, поэтому Т (М) = Т”п и теорема доказана.
Если это соотношение вам неочевидно, рассмотрите направленный граф
недетерминированного конечного автомата М и любой путь х по этому гра-
фу. Пусть это будет путь от узла, помеченного символом kj, до узла, поме-
ченного символом kj , и проходит через все узлы, помеченные символами из
множества {&i, k2,..., kj}. Кроме того, этот путь должен либо вовсе не про-
ходить через узел, помеченный символом kj9 и тогда, очевидно, хе ли-
бо проходить через него m раз (m> 1). Разобьем путь от узла, помеченного
символом kj9 до узла, помеченного символом kj9 на следующие участки:
”0” - от узла, помеченного символом ki9 до узла, помеченного символом kj,
при первом прохождении через узел kj; ”1” — от узла kj до узла kj при вто-
ром прохождении через узел kj,..., ”ти— 1” — от узла kj до узла kj при т-м
прохождении через узел fy; — от узла kj до узла, помеченного симво-
лом kj. Теперь можно записать,чтох =x0Xi .. .х^,гдех,-символ, помечаю-
щий i-й участок пути. Так как х0е Tjf1,хj,..., хт_ j е Т1и~ \ хте Г}/ \ следова-
TenbHOjxeTjf^Tjf1)*^-1. Легко видеть, что любая строка из этого мно-
жества строк также является элементом множества Г/. , что и доказывает
эквивалентность этих строк.
МИНИМИЗАЦИЯ
При определении детерминированного конечного автомата, который дол-
жен принимать язык L , вообще говоря, выгодно, чтобы этот автомат имел
как можно меньше состояний. Такой детерминированный конечный автомат
называют минимальным детерминированным конечным автоматом. В этом
57
разделе будет показано, как строится минимальный автомат и, более того,
будет доказана его единственность.
В гл. 1 было введено понятие отношения эквивалентности на множестве
А9 которое разбивало последнее на несколько непересекающихся классов
эквивалентности и при этом класс эквивалентности, содержащий элемент
a G А обозначают а. Индексом отношения эквивалентности называют чис-
ло таких классов.
Рассмотрим теперь более подробно отношение эквивалентности, опре-
деленное на множестве Г*. Отношение эквивалентности R называют правым
инвариантом, если
из xRy для любых z G Г* следует xzRyz.
Пусть L — некоторый язык, L С Т*, определим RL - отношение, ассоци-
ированное с L , следующим образом:
xRLy <=>для любого z G T*9xz G L9ecmyz G L.
Поскольку Rl — рефлексивно, симметрично и транзитивно, оно является
отношением эквивалентности.
Если М = (7Г, Г, г, Л1, F) — детерминированный конечный автомат, то
можно таким же образом определить и отношение RM, ассоциированное с
автоматомМ9 т.е.
x^My^t(ki,x)
Иначе говоря, две строки х и у удовлетворяют отношению RM тогда и толь-
ко тогда, когда соответствующие им пути по графу соединяют начальный
его узел с одним и тем же узлом. Как и в предыдущем случае, отношение
RM является отношением эквивалентности и, более того, оно является пра-
вым инвариантом.
Предположим для простоты, что рассматриваемый детерминированный
конечный автомат имеет полную переходную функцию, и ограничимся рас-
смотрением только такого случая. Тогда отношение RM разбивает множест-
во Г* на несколько непересекающихся классов эквивалентности. Любой
класс эквивалентности содержит строки, каждая из которых соответствует
пути по графу от начального его узла к некоторому заранее заданному уз-
лу. Таким образом, каждый класс эквивалентности естественно ассоцииро-
ван с некоторым состоянием конечного автомата - элементом множества К.
Поскольку рассматриваемый конечный автомат имеет # (/б) состояний, то
существует не более # (X) классов эквивалентности и, следовательно, RM
имеет конечный индекс.
Поскольку Rm — правый инвариант, то из xRMy следует, что для всех
zG Г* справедливо xzRMyz. Пусть L - язык, принимаемый автоматом М9
т.е. £ = Т(М). Тогда xzRMyz =>t (kl9xz) = t (kl9 yz) =>t (ki ,xz) G F<=> t(k t9
yz) G F =*xz G L ^>yz G L. Итак, мы показали, что изх/?^ следуетxRLy и,
следовательно, любой класс эквивалентности, определяемый отношением
RMi является подмножеством класса эквивалентности, определяемого со-
ответствующим отношением RL Поскольку отношение RM разбивает мно-
жество Г* на конечное число классов эквивалентности, то индекс отношения
58
эквивалентности RL конечен. Каждый класс эквивалентности, определяе-
мый отношением RL , включает один или несколько классов эквивалентнос-
ти, определяемых отношением RM, и следовательно, каждому классу экви-
валентности, определяемому отношением RL, можно поставить в соответ-
ствие некоторое подмножество множества состояний конечного автомата
М. Два любых подмножества множества состояний автомата М9 ассоцииро-
ванные с двумя несовпадающими классами эквивалентности, определяемы-
ми отношением RL, не пересекаются. Если кик1 — два различных состояния
из множества состояний К9 которые являются элементами одного подмно-
жества, ассоциированного с некоторым классом эквивалентности, определя-
емым отношением RL , то для всех z G Г*, t (к9 z) G F <=> t (к*, z) G F. В та-
ком случае состояния к и к* конечного автомата называют неразличимыми.
Поскольку высказанное утверждение справедливо для любого детерми-
нированного конечного автомата, имеющего полную переходную функцию
и принимающего язык L, кажется очевидным, что любой автомат, удовлет-
воряющий этим требованиям, должен иметь не меньше, чем п состояний,
где п — индекс отношения эквивалентности RL. Более того, если М - (К,
Г, г, ki, F) иМ' = (К* 9Т'9 t', к\, F1) - два детерминированных конечных
автомата, каждый из которых имеет по п состояний и принимает язык L,
то одно и только одно из состояний каждого автомата может быть ассоци-
ировано с одним и тем же классом эквивалентности, определяемым отноше-
нием Rl . Таким образом, можно говорить о взаимно однозначном отобра-
жении множества К на множество К* 0 :К-*К\ для которого, как легко по-
казать, выполняется соотношение 0 (k)=0(k*) =>0(t(k, а}} - 0(t'(k'9a))
для любого аЕ Т. Это соотношение и доказывает единственность детермини-
рованного конечного автомата, имеющего п состояний и принимающего язык
L. Теперь мы попытаемся доказать, что такой автомат всегда существует.
Допустим, что отношение эквивалентности RL задает в множестве Г*
классы эквивалентности х i, х 2,.. . 9хп. Определим тогда детерминирован-
ный конечный автомат ML , имеющий входной алфавит Г, множество состоя-
ний к ={х 1, х 2 ,. .. 9хп}, начальное состояние к^ = 7, множество конечных
состояний F9 где х eF*=>xGL . Переходную функцию t автомата определим
следующим образом: г(х, а) -ха . Поскольку RL — правый инвариант, то
из xRLy следует, что xaRLya и, следовательно, приведенное определение де-
терминированного конечного автомата корректно. Итак,
xG Т(М} *=>t (Т,х) = х G F <=>хЕ L
и, следовательно, Т(М} -L. В результате всех этих рассуждений доказана сле-
дующая теорема.
ТЕОРЕМА 4.3 (ТЕОРЕМА МАЙХИЛЛА-НЕРОДА)
Для любого регулярного языка L существует детерминированный конеч-
ный автомат, который принимает язык L , имеет полную переходную функ-
цию и конечное число состояний, равное индексу отношения эквивалентнос-
ти R L, ассоциированного с языком L.
Любой узел автомата, определенный в соответствии с требованиями
59
Рис. 4.2
теоремы Майхилла—Нерода и не лежащий на пути от начального узла к ко-
нечному, может быть исключен из множества состояний автомата вместе с
дугами, которые соединяют его с другими узлами. Детерминированный
конечный автомат, полученный в результате выполнения подобных опера-
ций, называют минимальным детерминированным конечным автоматом,
принимающим язык L и обозначают ML .
Пусть М = (7Г, Г, t, к19 F) — некоторый детерминированный конечный
автомат, принимающий язык L и имеющий полную переходную функцию.
Опишем алгоритм построения минимального детерминированного конеч-
ного автомата ML исходя только из языка L. Наша задача — разбить мно-
жество состояний автомата М на непересекающиеся подмножества неразли-
чимых состояний. Определим отношения Do, ,... на множестве К следую-
щим образом: состояния к и к9 различимы по строке длины 0, т. е. kD^k9 <=*
<=►££ F и к9 или k$F и к9 Е F,
Пусть i > 0, состояния кик9 различимы по строке длиной </, т. е.
kDtk9 ~kDiAk'9
т.е. существует а Е Г, такое, что t (к9 a)Dj^t{k99 а). Говорят, что состояние
к различимо от состояния к9, если существует такое i > 0, что kD^k9, т.е.
kDk9 <=* существует f >0|Wz^.
Очень просто можно показать, что kD^k9 <=> существует такая строках длины
<1, что либо t (к9 х) Е F и t (к9 ,х) ф F, либо t (fc, х) ф F, a t (к9, х) Е F, Итак,
чтобы вычислить отношение D, необходимо, очевидно, последовательно вы-
числить отношения Dq , Dr,..., и если в процессе этих вычислений, на неко-
тором шаге г , окажется, что Dr +1 = Dr , то это будет означать, что итерацион-
ный процесс окончен и D = Dr . Если т = #(/0, то существует только (т2—т)
пар (kit kj ), где i . В худшем случае всякое Dz+1 отличается otDz- двумя
такими парами, и учитывая, что DQ £ 0, получим
D = Dr ,гдег < (т2 — т)/2.
Проиллюстрируем доказанное на примере детерминированного конечно-
го автомата, изображенного на рис. 4.2. Представим отношение Dz- в виде
60
булевой матрицы размером 5X5, у которой /, £-й
элемент есть символ T^jD- к. Поскольку отноше-
ние Di симметрично и поскольку к ф. к, ддя по-
строения такой матрицы достаточно определить
лишь те ее элементы, которые находятся над глав-
ной диагональю. Последовательность матриц, соот-
ветствующих отношениям DQ, Dx, ., приве-
дена в табл. 4.1. Например, 1Z>i 2, поскольку Г(1,
b)DQt (2, b) и 2Dt 4, поскольку t (2, b)DQt (4, b). От-
Ta б л и ц а 4.1
/ftft\
.TFT
.TF
.Т
\ /
/ TTFT
.ттт
.TF
.Т
сюда видно, что пары состояний, помеченных символами 1 и 4, 3 и 5, нераз-
личимы.
Так как все неразличимые состояния детерминированного конечного ав-
томата найдены, то определить соответствующий минимальный автомат
очень просто. Известно, что состояния минимального конечного автомата
есть множества неразличимых состояний. Пусть К9 С К — одно из таких мно-
жеств, определим переходную функцию автомата ML следующим образом:
tL (К9, а) = К99 9 где К" — множество неразличимых состояний, содержащее
состояние t(k, а) для всех к^К9, Тогда, очевидно, начальным состоянием
автомата ML является множество неразличимых состояний, содержащее на-
чальное состояние автомата М9 конечными состояниями автомата ML являют-
ся те множества состояний автомата М, которые содержат конечные состоя-
ния автомата М. Вернемся к примеру. На рис. 4.3 приведен минимальный
детерминированный конечный автомат. В этом случае граф не содержит
узлов, которые не лежат на пути от начального узла до конечного.
Если исходный детерминированный конечный автомат имеет неполную
переходную функцию, то, определив ее на некотором фиктивном состоянии
Д, мы определим новый конечный автомат, равносильный исходному, кото-
рый имеет уже полную переходную функцию. Если в этом случае попытать-
ся определить минимальный конечный автомат, то окажется, что ни один из
путей от начального узла к любому конечному узлу не проходит через узел,
соответствующий состоянию из множества состояний неразличимых от
состояния Д. Таким образом, ни состояние Д, ни одно из неразличимых от
него состояний, не попадет в множество состояний минимального конечного
автомата.
61
АЛГОРИТМЫ ОПРЕДЕЛЕНИЯ РЕГУЛЯРНОСТИ ГРАММАТИКИ
Пусть L — произвольный регулярный язык, для которого определен та-
кой минимальный детерминированный конечный автоматML, что T(ML) =
= L. Предположим, что ML имеет множество состояний К = {&i,..., кп}9
где кг — начальное состояние, и рассмотрим строку z Е L, имеющую длину
Для того чтобы строка z была принята автоматом ML, достаточно,
чтобы t(ki, z)EF. Поскольку \z | > и, должно существовать некоторое
состояние кЕК такое, что z = wxy9 где |х| > 1 и t (к\, w) = к91 (к9 х) -к и
t (к9 у) G F. Но тогда t (кх, wxzj) G F для i > 0, а следовательно, wx\y Е
Е L для i > 0 и, следовательно, доказана приведенная ниже теорема.
ТЕОРЕМА 4.4
Если L — регулярный язык и z Е L имеет длину, большую или равную
числу состояний минимального конечного автомата , то z = wxy, где |х| >
> 1 и wxz\ Е L для i > 0.
Из этой теоремы можно сделать важный вывод: если£ ф, то, очевидно,
существует строка z Е L, имеющая длину < и, где п — число состояний ми-
нимального детерминированного конечного автомата ML. Тогда простой
алгоритм1 определения пустоты множества L ((7) может выглядеть следую-
щим образом: определим минимальный детерминированный конечный ав-
томат ML для L =L (G). Если ML имеет п состояний, то L = не при-
нимает ни одной строки, имеющей длину < п из множества Г*. Поскольку
число таких строк конечно, то выявить это можно за конечное время. При-
веденное рассуждение доказывает следующую теорему.
ТЕОРЕМА 4.5
Проблема непустоты регулярных грамматик разрешима, т. е. если задана
регулярная грамматика G, то существует алгоритм определения, пуст язык
L (G) или нет.
Сформулируем следующую теорему.
ТЕОРЕМА 4.6
а) Проблема равносильности регулярных грамматик разрешима, т.е.
если G\ и G2 — две регулярные грамматики, то существует алгоритм опре-
деления справедливости равенстваL(Gi) =L (G2).
б) Проблема конечности регулярных грамматик разрешима, т. е. если G -
регулярная грамматика, то существует алгоритм определения конечности
грамматики G.
Доказательство
a) L(Gi) =L (G2) ^минимальные детерминированные конечные автома-
ты, соответствующие грамматикам G^ и G2, совпадают с точностью до сим-
волов, помечающих состояния автоматов.
1 Алгоритмом решения некоторой проблемы я называют процедуру, с помощью
которой, использовав некоторые данные о проблеме я в качестве входных, можно полу-
чить ее гарантированное решение.
62
б) Вернемся к минимальному конечному автомату ML = (7Г, Г, t, ki9F),
определенному таким образом, чтобы он принимал язык L -L(G}. Если
ML имеет п состояний, то из теоремы 4.4 следует, что L — бесконечное
множество <=* существует строка г G L, имеющая длину > п. Пусть такие
строки существуют и пусть w — одна из них и I w| > и, если |z| > и, то
|z| > | w| , Покажем, что |и>| < 2и. Предположим, что это не так, тогда
можно написать где l<|w2|<« и t(ki9 wj -к9 t(k9 w2) =
= к9 t(k9 w3) G F для некоторого kE К. Значит, EF, w1w3E£)
но |w1w3| =|w| — |w2| > 2n — n = n и |w! w31 < |w|, следовательно, полу-
чаем противоречие. Таким образом, данный алгоритм позволяет опреде-
лить минимальный детерминированный конечный автомат, который прини-
мает языкL -L ((7) .
Если этот минимальный детерминированный конечный автомат имеет п
состояний, то необходимо выяснить, может ли он принять такую строку z,
что п < |z | < 2л. Множество таких строк конечно и L бесконечное множест-
во «=»хотя бы одна из таких строк принимается автоматом ML .
Внимательный читатель наверняка заметил, что доказательства теорем 4.5 и
4.6 в действительности не зависят от того, является конечный детерминирован-
ный автомат, принимающий строку z, минимальным или нет. Действитель-
но, все эти рассуждения справедливы для любого детерминированного ко-
нечного автомата, имеющего л состояний. Минимальный детерминированный
конечный автомат выгодно использовать потому, что число его состояний л —
минимально возможное число, и следовательно, число строк, которые не-
обходимо проверить, тоже минимально возможное число. И в заключение
докажем следующую теорему.
ТЕОРЕМА 4.7
Проблемы непустоты, равносильности и конечности разрешимы для де-
терминированных (или недетерминированных) конечных автоматов.
УПРАЖНЕНИЯ
4.1. Определите детерминированный конечный автомат, который принимает строки
а) а(Ъа + Ь) *+ Ь;
б) (ab + Ь”) *Ъа + Ь;
в) ((Ь%)*дЬ*>*.
4.2. Найдите регулярное выражение, соответствующее множеству T(Af), где М - не-
детерминированный конечный автомат, определенный в упражнении 3.4.
4.3. Покажите, что если Rx.Rn - регулярные выражения над множеством Т
и f (Rt,..., 7?w) - произвольная функция (в том числе функции вычисления суммы,
произведения, дополнения), то
а)/(Ях,...,Я„) + (Я, +R2 +... + Я„)*= (Л1 + ...+Л„)*;
6) (f(R*..Лп*))*=(Л1+...+Я„)».
4.4. Воспользуйтесь теоремой 4.4 и покажите, что следующие языки - регулярные
языки:
а) О};
б){х/|хе Г*}.
63
4.5. Определите детерминированный конечный автомат, принимающий язык L, ко-
торому соответствует регулярное выражение (ab)*+ (а) (Ьа + а) * Определите мини-
мальный детерминированный конечный автомат, который принимает язык L. Восполь-
зуйтесь этим автоматом для определения детерминированного конечного автомата, ко-
торый принимает язык L ={д, b} *\ L .
4.6. Пусть Rtf - отношение, ассоциированное с детерминированным конечным ав-
томатом М = (К, Т, Г, кх, F) таким, что Т(М) -L. Пусть х, у - два несовпадающих
класса эквивалентности отношения RПокажите, что если Г , х) = к и t , у) =
= к*, то xR^y <=► к и к* - неразличимы.
4.7. Вернитесь к решению у пр. 4.1 и определите, какой из построенных вами детер-
минированных конечных автоматов, минимальный.
ГЛАВА 5
КОНТЕКСТНО СВОБОДНЫЕ ЯЗЫКИ
’’Указать на форму - значило бы
скрыть остальное”
Вальтер Скотт ’’Лорд островов”
Во второй главе было приведено два эквивалентных определения кон-
текстно свободных грамматик. Сначала контекстно свободная грамматика
была определена как контекстная грамматика (7V, Г, Р, S ), каждая продук-
ция которой имеет вид А -+ a, A G N, (jVU Т) ♦. В этом случае контекстно
свободная грамматика может иметь произвольное число £-продукций. С дру-
гой стороны, если (G), и все продукции контекстно свободной грамма-
тики имеют вид А -+а9 N, (jVU7*)+, то такая грамматика, очевидно,
не имеет е-продукций. Снимем это последнее ограничение, пополнив набор
продукций рассматриваемой грамматики продукцией S -+ е при условии, что
нетерминальный символ S не будет содержаться ни в одной из правых частей
остальных продукций. В дальнейшем для упрощения доказательства некото-
рых теорем чаще будет использоваться второе определение контекстно сво-
бодной грамматики.
Если язык L порожден контекстно свободной грамматикой, то его назы-
вают контекстно свободным языком. Поскольку всякая регулярная грам-
матика является контекстно свободной, то всякий регулярный язык явля-
ется контекстно свободным. Обратное неверно, т. е. существуют такие
контекстно свободные языки, которые не являются регулярными языками.
В качестве примера рассмотрим язык {апЬп\п> 1}. Он не является регуляр-
ным языком и порожден контекстно свободной грамматикой, имеющей
продукции вида
S->aSb\ab.
Пусть G = (N, Т9 Р9 S) — контекстно свободная грамматика, предполо-
64
жим, что L(G) У (р. Тогда любому wGT+
можно поставить в соответствие дерево вы-
вода в грамматике G. Определим глубину
этого дерева равной длине самого длин-
ного пути по дереву от корня до узла, со-
ответствующего указанному терминально-
му символу w. Например, пусть контекст-
но свободная грамматика (71 имеет про-
дукции вида
8^ АВ,
А->аА |а,
Рис. 5.1
В^ЬВ\Ь.
На рис. 5.1 приведено дерево вывода для строки a3b2 G L ((7), которое в
данном случае имеет глубину 4.
Если мы говорим, что некоторое дерево вывода в контекстно свободной
грамматике G = (N, Т9 Р9 S) имеет глубину п, то это означает, что существу-
ет путь по графу, который проходит через узлы, помеченные символами A j,
Л2,... ,Ап, а9 где Л1,Л2,...,Лл6^аЕТ. Если п> , то два или бо-
лее узлов, через которые проходит указанный путь по графу, помечены од-
ними и теми же символами, например Aj = Ау, i < j Построим новое де-
рево вывода следующим образом: заменим в уже построенном дереве выво-
да поддерево с корнем в узле, помеченном символом Л 2- на поддерево с кор-
нем в узле, помеченном символом Aj . Пусть теперь w G L ((7) и соответст-
вующее ему дерево вывода имеет глубину п> #(7V), тогда, воспользовав-
шись описанным выше методом, можно добиться, чтобы для некоторого
и/ G£((7) дерево вывода имело глубину m<#(7V)« Докажем следующую
теорему.
ТЕОРЕМА 5.1.
Проблема непустоты разрешима для контекстно свободной грамматики.
То есть, если G - (jV, Г, Р9 S) — некоторая контекстно свободная граммати-
ка, то существует алгоритм, позволяющий определить, справедливо или нет
следующее утверждение: L ((7) = ф.
Доказательство
Функция алгоритма заключается в определении — имеет ли контекстно
свободная грамматика продукцию вида 5 -►€. Если продукция 5 являет-
ся элементом множества Р9 то поскольку eG L ((7), очевидно, что L ((7) ф.
Пусть продукция S не является элементом множества Р9 тогда построим
все возможные деревья вывода, имеющие глубину дерева, равную #(7V). Ес-
ли число таких деревьев конечно и ни одно из них не является деревом вы-
вода строки терминальных символов, тогда и только тогда справедливо
утверждение, что L (G) = ф.
Продукция контекстно свободной грамматики G = (jV, Г, Р9 S) тогда и
только тогда называется релевантной, когда существует вывод некоторо-
го xG L ((7), в котором эта продукция используется, т. е. А -+а — релевант-
65
ная продукция <=* существует xGZ (<7)|5*=>а1Ла2 =*^1^2 Всякая
продукция контекстно свободной грамматики, которая не является реле-
вантной продукцией, называется иррелевантной продукцией. Пусть теперь
некоторое A G Nt поставим ему в соответствие некоторую грамматику
GA = Г, Л Л). Если L (Ga) = 0, то вывести произвольную строку тер-
минальных символов из нетерминального символа А с помощью продукций
из множества Р невозможно, т. е. не существует такой сентенциальной формы
грамматики G, содержащей нетерминальный символ А, из которой можно
было бы вывести некоторую строку терминальных символов. Таким обра-
зом, если удалить из множества Р грамматики G все продукции, содержащие
в левой или правой своей части нетерминальный символ А, то на языке L (<7)
это никак не отразится. Помимо таких продукций грамматика G может,
вообще говоря, иметь иррелевантные продукции, т. е. такие продукции, с
помощью которых из некоторого A G N может быть выведена строка терми-
нальных символов, которая не входит ни в одну сентенциальную форму G.
Воспользовавшись теоремой 5.1, можно показать, что если существует сен-
тенциальная форма, содержащая нетерминальный символ А, то она может
быть выведена с помощью частичного вывода и соответствующее дерево
вывода будет иметь глубину < #(ЛГ). Такое дерево называют деревом
частичного вывода, так как его листья не помечены терминальными симво-
лами. Рассмотрев все такие деревья, можно выяснить, существует или нет
сентенциальная форма, содержащая нетерминальный символ А. Если такой
сентенциальной формы не существует, то все продукции, содержащие в ле-
вой и правой части нетерминальный символ А, могут быть исключены из рас-
смотрения как иррелевантные.
Далее будем предполагать, что любая контекстно свободная граммати-
ка имеет лишь релевантные продукции.
НОРМАЛЬНАЯ ФОРМА ХОМСКОГО
Формат рассмотренных выше продукций был чрезвычайно общим, что
значительно усложняет доказательство ряда важных теорем. К счастью, су-
ществует возможность существенно ограничить формат продукций, но так,
чтобы это не отразилось на выразительных свойствах грамматик.
ТЕОРЕМА 5.2. (НОРМАЛЬНАЯ ФОРМА ХОМСКОГО.)
Любой е-свободный контекстно свободный язык может быть порожден
некоторой контекстно свободной грамматикой в форме Хомского, т. е.
грамматикой, все продукции которой имеют вид
А^ВС, A9B9CeN
или вид
A->a9AeN9aeT
Доказательство
Пусть £ С Г* — е-свободный контекстно свободный язык, пусть G = (7V,
Г, Р9 S) — е-свободная контекстно свободная грамматика, порождающая
66
этот язык. Определим эквивалентную ей грамматику в нормальной фор-
ме Хомского, воспользовавшись следующим алгоритмом.
Шаг 1. Отметим все продукции вида А -+В9А9 BG N. (Будем называть та-
кие продукции первичными продукциями.) Пусть A Е N — некоторый не-
терминальный символ; обозначим U(A) множество первичных продукций,
содержащих в левой части нетерминальный символ А, а множество продук-
ций, не являющихся первичными, но содержащих в левой части нетерми-
нальный символ А9 обозначим N(A). Тогда множеству U(A) для каждого
AENt такого, что U(A)fi<p9 поставим в соответствие множество {А ->
->а|Л ^В и В ->а - элемент множества N(B)} .
Шаг 2. Отметим все продукции, правые части которых представляют стро-
ки длиной > 1 и включающие в себя подстроки терминальных символов.
Такие продукции будем называть вторичными продукциями.
Каждому терминальному символу а9 входящему в правую часть некото-
рой вторичной продукции, поставим в соответствие новый нетерминальный
символ Аа и новую продукцию вида Аа ~*а. В результате каждой вторичной
продукции вида А ->Xix2 . • .хт, Xj ENUT будет поставлена в соответст-
вие продукция видаЛ -> У1 У2 ... Ym, где
J Xi , если Xi G N\
Ха, если Xi =а9 где а Е Т.
Расширенное таким образом множество нетерминальных символов обозна-
чим V.
Шаг 3. Отметим все продукции, правые части которых представляют со-
бой строки, содержащие не менее трех нетерминальных символов. Такие
продукции мы будем называть третичными продукциями. Любой третичной
продукции, имеющей вид А ~+ВхВ2 .. .Вт9 т> 2, В19 В2,... ,ВтЕ N*, по-
ставим в соответствие совокупность продукций видаЛ -+ВВ\9В\ -+В2В2,...
... ,В'т_х ~+Вт[Вт9 где В\, В2,... ,В'т_х - новые нетерминальные сим-
волы, не содержащиеся более ни в одной продукции.
Теперь ясно, что грамматика, полученная в результате описанных выше
преобразований грамматики (7, эквивалентна последней и представляет со-
бой грамматику в нормальной форме Хомского. Рассмотрим пример. Пусть
контекстно свободная грамматика G2 имеет продукции вида
S->A\ABA,
А -> о Л | о | В,
В^ЬВ\Ь.
Шаг 1. Множество U(S) содержит продукцию вида 5->Л, множество
£7(Л) включает в себя продукцию вида Л->В, множество U(B) — пустое.
Поскольку S &А и S ^В, продукции S ->Л поставим в соответствие про-
67
дукцию S->aAlalbBlb, а поскольку А продук-
ции А^В поставим в соответствие продукцию
СУ J3) А^ЬВ\Ь. В результате такого преобразования по-
s-Yлучим эквивалентную грамматику, имеющую про-
Y у у у дукции вида
О О О (J S^aA\a\bB\b\ABAt
Рис. 5.2 А->аА\а\ЬВ\Ь,
В^ЬВ\Ь.
Шаг 2. Терминальным символом а и Ь, содержащимся в правых частях
вторичных продукции поставим в соответствие два новых нетерминальных
символа Аа и Аь и две новые продукции видаЛд и Аь ->Ь. Переписав та-
ким образом вторичные продукции, вновь получим эквивалентную грамма-
тику, имеющую продукции следующего вида:
S^AaA\a\AbB\b\ABA.
А-> АаА\а\АьВ\Ь,
В->АьВ\Ь,
Аа -*а,
АЬ^Ь.
Шаг 3. Единственная третичная продукция имеет вид S АВА. Поставим
в соответствие такой продукции совокупность двух продукций вида
В'-ВЛ,
получив таким образом эквивалентную G грамматику в нормальной форме
Хомского.
Пусть В СТ* — некоторый произвольный контекстно свободный язык, и
пусть £\{е} — язык, порожденный контекстно свободной грамматикой G в
нормальной форме Хомского. Если некоторому х Е L ((7) соответствует
дерево вывода, имеющее глубину дерева /и, то можно доказать, что |х| <
Это заключение — тривиально и следует из простого утверждения,
что каждый родительский узел дерева вывода может иметь не более двух
узлов-потомков, а родительские узлы для узлов, помеченных терминальны-
ми символами, могут иметь лишь по одному узлу-потомку. Для иллюстра-
ции сказанного рассмотрите дерево вывода глубины 3, приведенное на
рис. 5.2.
ТЕОРЕМА 5.3
Если L — контекстно свободный язык, тогда существуют целые числа
и It, такие, что для любого zEZ, удовлетворяющего условию |z| >/ь
справедливо утверждение: z = uvwxy, и при этом
(I) |uwx| < /2;
(II) VX J €
(III) для любого целого / > 0 справедливо uuzwx\yE Z.
68
Доказательство
Пусть £\{е}- язык, порожденный грамматикой G = (7V, Г, Р, S) в нор-
мальной форме Хомского. Положим п = #(ZV), l\ = 2”"1,12 = 2". Пусть z G L
и |z | > 2”"1, отсюда следует, что максимально длинный путь по любому де-
реву вывода строки z (обозначим его через Р) должен иметь длину > и, т. е.
проходить более чем через п + 1 узел графа, из которых лишь один помечен
терминальным символом.
Но тогда, очевидно, должны существовать два узла, через которые про-
ходит путь Р9 помеченные одним и тем же нетерминальным символом. Обоз-
начим эти узлы Ni и N2, и пусть узел jVi находится ближе к корню дерева,
чем узел N2. Если путь Р проходит через несколько таких пар узлов, выбе-
рем в качестве Nx и N2 тот из них, у которого узел находится на большей
глубине на дереве. Предположим теперь, что оба узла, jVi и N2, помечены
нетерминальным символом А. Поскольку путь Р был выбран как самый
длинный путь по графу, то очевидно, тот его отрезок, который принадле-
жит поддереву с корнем в узле jVi , тоже будет самым длинным на ука-
занном поддереве, следовательно, глубина этого поддерева равна, по край-
ней мере, п + 1. А это означает, что указанное поддерево может стать де-
ревом вывода из нетерминального символа А строки терминальных симво-
лов длиной 2”. Обозначим одну из таких строк zb Следовательно, |z j | <2"
и А z!. Если Т2 — поддерево с корнем в узле N2 и w — строка терминаль-
ных символов, выведенная из N29 то можно написать zx = uwx, где под-
строки v и w не могут одновременно быть пустыми, так как первая про-
дукция, использованная для вывода строки z1} должна иметь вид А -+ВС9
В9 СЕ N9 и не может быть пустой.
Далее, строка z i — подстрока строки z и, следовательно, справедлива сле-
дующая запись:
z = UZ} у = uvwxy.
Таким образом, мы показали, что существует вывод вида
S ^>uAy Z>uvAxy ^uvwxy,
где |uwx| <Z2. Поскольку A X vAx Xuwx, to A ^v‘wx‘ для любого i >0,
следовательно, 5 Z»uAy ^uv'wx'y — корректный вывод для любого i > 0
(рис. 5.3).
Проиллюстрируем теорему 5.3: пусть (73 — грамматика, имеющая про-
дукции вида
А -> BS\a9
В^АА\Ь
(в данном случае Zj =4). Рассмотрим дерево вывода строки а3Ь29 при-
веденное на рис. 5.4,а. Путь Р в нашем примере выделен как путь мак-
симальной длины по дереву и проходит через четыре узла, следовательно,
два из этих узлов должны быть помечены одним и тем же нетерминаль-
69
Рис. 5.3
Рис. 5.4
ным символом, в данном случае символом Л. Обозначим тот из узлов, ко-
торый находится ближе к корню дерева, , а другой N2. Пусть 1\ - под-
дерево исходного дерева вывода, имеющее корень в узле Nx и соответст-
вующее схеме вывода вида А ^>а3Ь. Обозначим zr строку а3Ь. Пусть Т2 -
поддерево, имеющее корень в узле N2 и соответствующее схеме вывода
вида А =>а. Тогда Zj = vwx9 где v=a9 w =а9 x = ab9 a z = uvwxy9 где u = e9
у = b. Из теоремы 5.3 следует, что для любого целого i > 0 строка ии*пх*у
является элементом языка Z, т.е. uv* ' wx*yE L. На рис. 5.4, б и 5.4, в при-
ведены деревья вывода для случаев i = 0 и i =2 соответственно. Рисунок
5.4, б отличается от рис. 5.4, а заменой поддерева на поддерево Т2, и
рис. 5.4, в отличается от рис. 5.4, а заменой поддерева Т2 на поддерево Л.
Особенно полезна теорема 5.3 бывает в тех случаях, когда необходимо
доказать, что рассматриваемый язык не является контекстно свободным
языком. Например, рассмотрим язык L{aP\p - простое число}. Предполо-
70
жим, что язык L — контекстно свободный язык, тогда согласно теореме 5.3
существует целое число к, 0 < к <р, такое, что р + 2ki — простое число для
любого i > 0. Очевидно, что это утверждение несправедливо и, следователь-
но, £ не является контекстно свободным языком.
Пусть G — произвольная контекстно свободная грамматика в нормаль-
ной форме Хомского. Предположим, что грамматика G имеет п нетерми-
нальных символов, 71 = 2”"1 и 12 =2п. Тогда по теореме 5.3 язык L (G) ко-
нечен «=> L(G) содержит строку длины большей, чем 1у. Действительно,
предположим, что L (G) — бесконечен, пусть z — самая короткая из его
строк, имеющих длину большую, чем 7j. Докажем методом ”от противно-
го”, что 71 < |z| <7i + 72. Предположим, что |z| >l\+l2 и, следовательно,
(по определению z) язык L(G) не содержит строки, меньшей по длине,
чем 71 +72, но большей, чем 71. Но по теореме 5.3 z = uvwxy и uwyE L —
строка длины |z| — l2>lx. С другой стороны, очевидно, что Iuwy\ < |z| , и
полученное противоречие доказывает неверность нашего предположения.
Итак, мы только что доказали, что L ((7) — бесконечное множество <=* су-
ществует zG£((7), такое, что < |z| <7i+72. Заметим, что число строк,
являющихся элементами языка L ((7) и удовлетворяющих указанному со-
отношению, конечно. Чтобы убедиться в этом, достаточно рассмотреть все
сентенциальные формы грамматики (7, имеющие длину к, 7i<fc<7i+72.
Таким образом, мы получили алгоритм определения конечности языка и
доказали следующую теорему.
ТЕОРЕМА 5.4
Проблема конечности разрешима для контекстно свободных грамматик,
т.е. существует алгоритм, позволяющий определить, конечный или беско-
нечный язык порождает контекстно свободная грамматика.
НОРМАЛЬНАЯ ФОРМА ГРЕЙБАХА
При рассмотрении регулярных грамматик в гл. 3 всякий раз нам уда-
валось каким-то чудесным образом найти способ ответить на вопрос: ’’яв-
ляется ли строка xG Г* элементом языка L ((7)?” Тем не менее формально
ответить на такой вопрос непросто, и он порождает проблему, называемую
’’проблемой принадлежности”. Для контекстно свободных грамматик эта
проблема разрешима приведенным выше способом — достаточно рассмотреть
все возможные сентенциальные формы грамматики (7, имеющие длину
|х|. Если ни одна из них не соответствует выводу строки х, то x$L ((7), в
противном случае наоборот. Однако отыскание всех сентенциальных форм
грамматики G, имеющих длину |х| — мало эффективный путь решения
проблемы принадлежности. Кроме того, интересно было бы решить еще
одну важную проблему — проблему построения реального дерева вывода
строки х (ее называют ’’проблемой выводимости”). Понятно, что если по-
строен эффективный алгоритм решения проблемы выводимости, то его
можно использовать и для решения проблемы принадлежности.
Практика показывает, что эффективное решение проблемы выводимос-
ти возможно лишь в случае наложения ряда ограничений на определение
71
контекстно свободной грамматики. При этом вид накладываемых ограни-
чений отразится на виде конкретных алгоритмов. К сожалению, эти ограни-
чения сформулированы так, что не всякий, порожденный контекстно сво-
бодной грамматикой язык, может быть порожден контекстно свободной
грамматикой, на которую наложены эти ограничения. (Этот вопрос будет
рассмотрен в гл. 6, 7 и 8.) Кроме того, чрезвьиайно важно, чтобы читатель
получил навыки осуществления процедуры вывода, изменения формата
продукций, не меняющего содержимого множества L ((7).
Один из рассматриваемых здесь приемов осуществления подобных ма-
нипуляций является результатом теоремы 5.5, доказательство которой мы
оставляем читателю.
ТЕОРЕМА 5.5
Если А -+ Qi Ва2 — продукция контекстно свободной грамматики G и В -+
-► 0! 1021 ... 10£ — все продукции этой грамматики, содержащие в своих ле-
вых частях нетерминальный символ В, тогда продукции видаЛ ->aiBa2 мож-
но поставить в соответствие продукцию видаЛ -*ai0iQ2 l<*i02I.. .1^10^21
и это никак не отразится на языке L .
Следующая теорема не столь очевидна, поэтому мы приведем ее доказа-
тельство. Теорема обращена к ’’проблеме удаляемости” из контекстно
свободных грамматик рекурсивных слева продукций, т.е. продукций ви-
даЛ ->Ла, Л Е N, (7VU7*)*.
ТЕОРЕМА 5.6
Если все продукции некоторой контекстно свободной грамматики явля-
ются рекурсивными слева продукциями,Л -+Ааг |Лаз I.. .|Лаш, Л ->0! |021...
... |0„ — оставшиеся продукции грамматики, имеющие нетерминальный сим-
вол А в своей левой части, то новая грамматика может быть построена до-
бавлением в множество N нетерминального символа Л и полной заменой
ее продукций исходной грамматики продукциями вида
Л'->а1|а2|...|ат|а1Л'|а2Л'|...|атЛ'.
Доказательство
В обоих случаях множество строк, которые могут быть выведены из Л,
имеет вид {01,02....0„} {ai,a2....
Для иллюстрации применения этой теоремы преобразуем продукции
грамматики <73 к виду Л ->аа, Л G7V, aG Г, (jVUT)*. Если все продук-
ции некоторой контекстно свободной грамматики имеют такой вид, то го-
ворят, что эта грамматика — контекстно свободная грамматика в нормаль-
ной форме Грейбаха. Для любого е-свободного контекстно свободного
языка L можно определить контекстно свободную грамматику в нормаль-
ной форме Грейбаха такую, что она порождает язык L . Вернемся к примеру.
Прежде всего переименуем нетерминальные символы грамматики G3
следующим образом: S переименуем в Л1,Л переименуем в А2,В переиме-
нуем в Л з. В результате продукции грамматики G3 будут иметь вид
72
Л] —► А2А11 ^2^3>
А2 Л3Л11 а,
А3 —► Л2Л2|Ь.
На первом шаге попытаемся преобразовать продукции грамматики G3 к ви-
ду Лz- ->Луа, где j >i, В данном случае из всех продукций грамматики G
продукция А3 ->А2А2 не имеет такого вида, поэтому, воспользовавшись
теоремой 5.5, преобразуем такую продукцию следующим образом:
Л3 —► Л3Л1Л21 аА 2,
а затем воспользовавшись теоремой 5.6, вновь преобразуем данную про-
дукцию. В результате продукции грамматики G3 примут вид
Л j -+ Л2Лj | Л2Л3,
Л2 —► Л3 А1 \at
Л3 ->аА2\Ь\аА2А'3\ЬА 3,
Л 3 -► Л j Л2| А{ Л2Л2.
Очевидно, что каждая продукция, содержащая в левой части нетерминаль-
ный символ А3, удовлетворяет условиям нормальной формы Грейбаха.
Вновь воспользуемся теоремой 5.5 и преобразуем продукции
А2 ->A3Alf
A} -^A2A1IA2A3t
в результате чего все полученные продукции грамматики G3f содержащие
в левых частях нетерминальные символы Alf А2 или А3, будут удовлетво-
рять условиям нормальной формы Грейбаха:
At -^аА2А1А11ЬА1А1\аА2А'3А1А11ЬА'3А1А1\аА1
|аЛ2Л1Л3|ЬЛ1Л3|аЛ2Л3Л1Л3|ЬЛ3Л1Л3|аЛ3;
A2-^aA2A1lbA1laA2A3A1lbA3A1la;
Л3 —► аЛ2|Ь|аЛ2Лз|ЬЛз ;
^3—>Л1Л2|Л1Л2Л3,
И наконец, преобразуем согласно теореме 5.5 все те продукции, в левых
частях которых содержатся символы А 3:
Л3->аЛ2Л1Л1Л2|ЬЛ1Л1Л2|аЛ2Л3Л1Л1Л2|ЬЛ3Л1Л1Л2|аЛ1 Л2
1^А2А1 Л3 А2 |ЬЛ| Л3 А2 \аА 2Л3 Л j Л3Л 2 |ЬЛ3 Л । Л3 Л2 |яЛ3 Л 2
МЛ2Л1Л1Л2Л3|ЬЛ1Л1Л2Л' 1аА2А3А1А1А2А3
|Ьл;41Л1Л2Лэ|аЛ1Л2Лз|аЛ2Л1Л3Л2Лз|5Л1Л3Л2Лз
\аА2А3А j Л3Л2Лз |ЬЛзЛ i Л3Л2Лз 1^^з
Итак, рассматриваемая нами контекстно свободная грамматика в нор-
мальной форме Грейбаха имеет 39 продукций. Покажем, что все выше-
73
приведенные преобразования справедливы и для общего случая, -а полу-
ченная в результате грамматика эквивалентна исходной.
Шаг 1. Пусть G — произвольная f-свободная грамматика. Преобразуем
G в эквивалентную ей грамматику G9 в нормальной форме Хомского.
Шаг 2. Определим множество нетерминальных символов грамматики
G9 как {Ль А2, • •• ,Ат}, т> 1, где Ai соответствует начальному нетер-
минальному символу.ПустьЛ={Яi,^2, • • • ,4т}.
Шаг 3. По теореме 5.5 каждую продукцию грамматики G9, содержащую
в левой части нетерминальный символ Aj, преобразуем к виду Aj ->аа, аЕ
G Т, или к виду AI -+Aja> где j>i, воспользовавшись следующим алго-
ритмом
begin
var i: integer;
i:=0;
while i(}m do
begin i: = i + 1;
while существует продукция вида Ai -+AjOt, j <i do подставить
вместо Aj соответствующее ему согласно теореме 5.5 выражение;
if существуют рекурсивные слева продукции, содержащие символ
Д- в левой части;
then ввести новый нетерминальный символ А\ и по теореме 5.6 за-
менить рекурсивную слева продукцию эквивалентным ей набо-
ром продукций.
end
end
Шаг 4. Пусть N — множество нетерминальных символов, введенных на
третьем шаге. Тогда справедливо следующее утверждение: после третьего
шага преобразования все продукции грамматики будут иметь видЛу -+Aj&,
j > f, aG (jVCLV' U7*)*; или вид Aj -ма, aG T, aG (NUN9 UT)*; или вид
A- ->Xa, Xe (NUT), aG (TVUjV’ U T)•.
Применим ко всем продукциям, имеющим первый из перечисленных ви-
дов, следующее преобразование:
begin
var i: integer;
i: = m;
while i<> 1 do
begin i: = i — 1;
while существует продукция видаЛу ->Л7-а, / > i do заменить Aj
согласно теореме 5.5
end
end
Шаг 5. Исключить продукции вида А\ ->Л7* а, заменив Aj согласно теоре-
ме 5.5. Полученная таким образом грамматика является грамматикой в
нормальной форме Грейбаха.
74
Понятно, что грамматика, полученная после второго шага, порождает
язык L ((7), если в качестве начального символа выбран символ A i. Чтобы
доказать, что шаг 3 выполняет свое назначение, воспользуемся методом ин-
дукции по параметру основного цикла, т. е. покажем, что после i итераций
будут преобразованы все продукции, содержащие в левой части нетерми-
нальный символ Аk<i. Для i =0 никаких преобразований не произво-
дилось и, следовательно, ни одна продукция не преобразована, значит, для
i =0 утверждение справедливо. Предположим, что утверждение верно для
всех i < п итераций и рассмотрим и-ю итерацию. Если существуют продук-
ции вида Ап -+Ajat где / < и, то по теореме 5.5 можно подставить вместо
символов Aj правые части тех продукций, которые содержат символ Aj в
левых частях.
Поскольку / < и, то согласно предположению индукции правые части та-
ких продукций должны начинаться либо с терминального символа, либо с
символа Ак, где k>j. Ясно, что продукции первого типа удовлетворяют
условиям нормальной формы Грейбаха, и потому интереса не представляют,
что касается продукций второго типа, для к < и, то после п — 1 итерации внут-
реннего цикла все продукции, левые части которых содержат символ Ап9 содер-
жат в правых частях в качестве первого символа либо терминальный символ,
либо нетерминальный символ где к> п. Следовательно, для i = п предпо-
ложение индукции справедливо, и алгоритм, реализуемый на 3-м шаге, вы-
полняет свое назначение, так как заканчивается при i = т и все продукции
имеют нужный вид.
Можно заметить, что правая часть каждой продукции, левая часть которой
содержит вновь введенный нетерминальный символ, должна содержать в ка-
честве первого символа элемент множества MJ Т\ и следовательно, шаг 3 вы-
полняет свое назначение. Из этого, в частности, следует, что правая часть про-
дукции, левая часть которой содержит символ A mt должна в качестве перво-
го символа содержать терминальный символ. Любая продукция, содержа-
щая в левой части символ Ат_{, содержит в правой части в качестве перво-
го символа либо терминальный символ, либо символ Ат. В то же время
все продукции вида Ат1 ~+Ата могут быть преобразованы по теореме
5.5, и тогда все продукции, содержащие в левой части символы Ат или
Лw , будут иметь в правой части в качестве первого символа терминаль-
ный символ. Этот процесс надо повторить для всех продукций, имеющих
в левой части один из символов Ат, Ат_19. .. ,Ai. Методом индукции по
числу итераций легко показать, что после п итераций цикла, на шаге 4, все
продукции, содержащие в левой части один из символов Ат, Am_it...
• • • ^т-п^ в правой части обязательно будут содержать в качестве первого
символа терминальный символ. Шаг 4 преобразования, таким образом, вы-
полняет свое назначение, так как описанный в нем алгоритм заканчивает-
ся после выполнения т - 1 итерации. Шаг 5 тривиален и доказательства не
требует. Следовательно, мы доказали следующую теорему.
75
ТЕОРЕМА 5.7. НОРМАЛЬНАЯ ФОРМА ГРЕЙБАХА
Для каждого е-свободного контекстно свободного языка существует
контекстно свободная грамматика в нормальной форме Грейбаха, такая,
что£ = Z(G).
КОНТЕКСТНО СВОБОДНЫЙ ЯЗЫК КАК РЕШЕНИЕ УРАВНЕНИЯ
Рассмотрим контекстно свободную грамматику, имеющую продукции
вида
5- АВ.
А->аА |а,
В->ЬВ\Ь.
Поставим в соответствие каждому нетерминальному символу множество
строк, которые могут быть из него выведены, например нетерминальному
символу А из рассмотренной выше грамматики соответствует множество
{ат1 т> 1}, нетерминальному символу В соответствует множество {bnln>
> 1}, а нетерминальному символу S соответствует множество {атЬп1т,
> 1}. Эти множества строк будем обозначать непосредственно теми символа-
ми, которым они соответствуют, например,
А ={ат \т>1}9В = {Ьп\п > 1}, S ={атЬп\т9 п > 1}.
С другой стороны, из определения продукции грамматики, множества S,
А9 В должны удовлетворять следующим условиям, имеющим вид уравнений:
S = AB9
А = {а}Аи{а}9
В = {Ь}Ви{Ь}.
Система таких уравнений может иметь бесконечное множество решений.
Например, уравнение
А = Ли{а}
имеет решение {а}, но в то же время любое множество, включающее мно-
жество {а}9 очевидно, также будет решением указанного уравнения. Вообще
говоря, далее мы будем называть решением уравнения минимальное из та-
ких множеств1.
Рассмотрим следующую систему уравнений:
Х1=/1(Х1,Х2....х„);
X 2 = 1’ ^2»* • • » *л) >
хя = Ж1,х2,...,хя),
1 Имеется в виду мощность множества. - Прим. ред.
76
где каждая функция /z- (Xi, Х2,..., — конечная функция, а каждое
множество Xj — конечное множество строк из множества Г*, причем на
множестве переменных Х^, Х2,..., Хп введены всего две операции — опе-
рация объединения и операция конкатенации. Такую систему уравнений
будем называть системой уравнений над множеством Г*. Совокупность
(Л\, Х2,..., Xw) будем обозначать символом X, а систему уравнений запи-
сывать в виде X =/(Х). Решение такой системы уравнений, очевидно, будет
совокупностью подмножеств множества Г* (обозначим его S = (Si, S2,...
..., Sw) ), следовательно,
S=/(S).
Если Т = (?!, Т2,,.., Tw), то будем считать, что
S С Т ~ S, cz S2 с Т2,..., Sn с Тп.
ТЕОРЕМА 5.8
Система уравнений X =/(Х) имеет решение
s= и Г(0),
i = 1
более того, если Т — некоторое другое решение, то S С Г.
Доказательство
Так как $) = (<£,$),..., (р), то по определению С/(<р). Воспользовавшись
решением упр. 1.11 можно показать, что если А С В, то / (А) С/ (В). Таким
образом, /(ф>) С/(f(<P)) =/2(<Р), и продолжая это рассуждение, получаем
неубывающую последовательность (рс/((р) С/2 (ф) С... . Пусть
S= и Л0)
i = 1
— предел этой последовательности; тогда можно показать, что f (S) = S, т. е.
S — решение системы уравнений.
Если Т — некоторое другое решение этой же системы уравнений, то Т =
= /(Т). По определению, ?>СТ, следовательно, /($)) С/(Т) =Т. Повторяя
это рассуждение, получим, что f (ф) СТ для всех i > 0. Таким образом,
и /'(0)с Т, т.е. S СТ.
/ = 1
Итак, всякой заданной контекстно свободной грамматике G = (N, T,P,S)
может быть поставлена в соответствие система уравнений множеств над
Г* и наоборот. Более того, если S = (Si, S2,... , S„) — единственное ми-
нимальное решение этой системы уравнений, и если первое уравнение ука-
занной системы уравнений соответствует тем продукциям, в левых частях
которых содержится символ S, то L (G) = S t.
Проиллюстрируем сказанное на следующем примере:
5= ЛВ = Л(5,А,В);
Л = {а}Ао{а}=/2(5,А,В);
B = {b}Bu{b}=f3(S,A,B).
f(0) = (Л(0), Л(0), f3(0))=(0, {«}. W);
77
= {«}, {b}), f2(0, {a}, {b}), /з(0, {a}, {*})) =
= ({ai>}, {a,aa}, {b,bb}),
= f({ab},{a,aa},{b,bb}) =
= ({ab, aab, abb, aabb}, {a, aa, aaa},{b,bb, bbb}).
Методом индукции no i можно показать, что
fi(0) = ({cimbn\i>m,n>\},{am\i>m^l}, {bn\i>n^l}\
и, следовательно, Q Д0) = ({ambn|m, и> 1}, 1}, {b"|n > 1}),а значит
L(G)={amb"|m,n>l}.
Представление контекстно свободного языка как решения системы
уравнений помогает лучше понять его природу. Кроме того, все элементы
множества L ((7) могут быть получены за конечное число шагов 0С/(ф) С
С/2 (Ф) • • •, следовательно, этот метод может быть использован для реше-
ния проблемы принадлежности.
УПРАЖНЕНИЯ
5.1. Опишите алгоритм, с помощью которого по заданной контекстно свободной
грамматике G и целому числу к > 0, можно построить все возможные деревья выво-
да глубины к.
5.2. Пусть L - контекстно свободный язык, покажите, что L *и Lr = {xz IxG L} кон-
текстно свободные языки.
5.3. Пусть Zj, Z2 - контекстно свободные языки, покажите, что Z, UZ2 и LXL2 -
тоже контекстно свободные языки.
5.4. Определите контекстно свободную грамматику в нормальной форме Хомского,
порождающую арифметические выражения над множеством {д, Ъ, с}.
5.5. Укажите, какие из приведенных ниже языков - контекстно свободные языки:
а) {а\У с^\0 < i < j < к},
б) { =/ =к],
в) / a\bJc^\0<i -j ,к> 0, i f к},
г){д*дЛЛ|0<1 =/,fc>0}.
5.6. Покажите, что если LeT*- контекстно свободный язык и 7\*-> Т2* - гомо-
морфизм, то <р (Z) - контекстно свободный язык.
5.7. Напишите формальное доказательство теорем 5.5 и 5.6.
5.8. Сформулируйте и докажите теорему, аналогичную теореме 5.6, для продукций
рекурсивных справа, т. е. для продукций, имеющих вид А -+аА, AeN, aE (TVuT)*
5.9. Приведите к нормальной форме Грейбаха грамматику, имеющую продукции
вида
Л, ->Л2Л3,
Л2-Л3Л,|Ь,
А 3 —* Л j Л 21 д.
5.10. Пусть G - контекстно свободная грамматика, имеющая продукции вида
78
S - Л5|В5|д,
A -*ВВ\а,
В-*АА\Ъ.
Выпишите систему уравнений множеств, решением которой является множество L (G),
и с ее помощью найдите все х G L (G) имеющие длину не более 5.
5.11. Воспользуйтесь решением упр. 5.5 и постройте контекстно свободные языки
L j, L 2, такие, что Z j n Z а не являются контекстно свободным языком.
5.12. Воспользуйтесь решением упр. _5.11 и покажите, что существует контекст-
но свободный язык Z с Г* такой, что Z = T*\L не является контекстно свободным
языком.
ГЛАВА 6
МАГАЗИННЫЙ АВТОМАТ
"Если кому-то чего-то не хватает,
он найдет это в той куче".
Уильям Шенк Гильберт "Колдунья"
Конечный автомат, рассмотренный в гл. 3 и гл. 4, служит прекрасным
инструментом для обработки регулярных языков. В этой главе мы рассмот-
рим и определим автомат для обработки контекстно свободного языка и
тем самым сделаем важный шаг по пути проектирования и практической
реализации синтаксических анализаторов, являющихся важной частью лю-
бого компилятора.
Прежде всего, определим, что такое стек. Стек - это специально органи-
зованная память, выборка и занесение данных в которую подчиняется дис-
циплине LIFO, т. е. ’’последним вошел — первым обслужен”. Подобная ор-
ганизация оперативной памяти ЭВМ, а также физические устройства, ее по-
рождающие, наверняка знакомы большинству читателей. Адрес памяти, по
которому может быть осуществлено запоминание в стеке очередного эле-
мента, называют вершиной стека, а операции запоминания в стеке и выбор-
ки из стека очередного элемента называют соответственно занесением в стек
и извлечением из стека, С помощью операции занесения в стек информа-
ционное слово может быть помещено в вершину стека, а с помощью опера-
ции извлечения из стека из его вершины может быть выбрано информацион-
ное слово, которое в таком случае и считается результатом операции извле-
чения из стека. В данном случае такими информационными словами, а сле-
довательно, и элементами стека, являются символы некоторого алфавита, а
размеры стека считаются неограниченными. Последнее требование исключа-
ет переполнение стека и делает, таким образом, всегда корректным выпол-
нение операции занесения в стек. Понятно, что для корректности выполне-
ния операции извлечения из стека стек должен содержать, по крайней мере,
один элемент.
79
Занести в
стек сим-
вол А
Занести в
стек сим-
вол В
в
А
Извлечь сим-
вол из стека
(извлечен ву- .
дет символв\—~
Извлечь сим-
вол из стека
(извлечен бу-
дет символ А)
Рис. 6.1
Пусть V обозначает множество символов, которые могут быть занесены и
соответственно извлечены из стека; в таком случае содержимое стека, оче-
видно, может быть представлено в виде строки — элемента множества К*.
При этом позиция первого символа строки соответствует вершине стека.
Например, последовательность преобразований стека, изображенную на
рис. 6.1, можно записать эквивалентным образом:
ВА ^АВА ^ВАВА =>АВА ^ВА.
Пустому стеку в таком случае соответствует строка <£, а операции занесения
в стек и извлечения из стека эквивалентны операциям над строками и могут
быть определены следующим образом:
PUSH (А9Х) = АХ,
т. е. символ A G V занести в стек, содержащий строку X = К*.
POP (и - J неопРеДелено> если X-е
1( } “ | А, еслиХ = ЛУ,Ле V, Y& V*,
т. е. извлечь символ из стека, содержащего строку XG. У*.
POP Г неопределено, еслиХ= е
2(Х) = | у, еслиХ = ЛУ,ЛЕ У, уе У*,
т. е. определить содержимое стека после одной операции извлечения из стека.
НЕДЕТЕРМИНИРОВАННЫЙ МАГАЗИННЫЙ АВТОМАТ
Недетерминированный магазинный автомат кратко можно определить
как такой недетерминированный конечный автомат, вид переходной функ-
ции которого зависит от содержимого вершины некоторого стека. Пояс-
ним это определение: набор возможных состояний недетерминированно-
го конечного автомата определяется его текущим состоянием и входным
алфавитом, аналогично набор возможных состояний недетерминированно-
го автомата определяется его текущим состоянием, входным алфавитом
и неким символом, который может быть в данный момент извлечен из не-
которого стека. Заметим, однако, что при переходе недетерминированного
магазинного автомата из одного состояния в другое в указанный стек мо-
жет быть занесено произвольное конечное число некоторых символов.
Приведем теперь строгое определение недетерминированного магазинно-
80
го автомата: недетерминированным магазинным автоматом называют сово-
купность семи объектов М = (Л*, Г, Vt p9kl9A19F), где
а) К — конечное множество состояний;
б) Г — конечный входной алфавит;
в) V — конечный стековый алфавит (его элементы обозначаются обычно
прописными буквами, имеющими, быть может, нижние индексы) ;
г) р — полная функция, называемая магазинной функцией и отображаю-
щая множество A’XKX(TU{e}) на множество конечных подмножеств
множества А* X К*;
д) кхЕ К - исходное состояние автомата;
е) A j G V - исходный символ (символ, инициализирующий стек);
ж) FE К — конечное множество конечных состояний.
Конфигурация недетерминированного магазинного автомата М = (К9 Т9
V9p9k19A19 F) в любой момент времени описывается элементом множества
А“Х К*, при этом первый элемент упорядоченной пары задает текущее сос-
тояние автомата, а второй элемент — текущее содержимое стека. Если не-
детерминированный магазинный автомат имеет в данный момент конфи-
гурацию с9 определим переходную функцию автомата tM следующим об-
разом: значением переходной функции tM(c9x) является множество кон-
фигураций, которые может иметь автомат М после ввода строкихб Г*, т. е.
Гм:(Кх И*)х(Ти{£})-2КхИ:
Наложим на определенную таким образом переходную функцию tM ог-
раничения: пусть с = (k9 Ах), кЕ К9 A G V9xE V* и cf = (k'9Yx)9k' Е К, YE
Е К*, xEV* — две конфигурации автомата М9 и пусть в результате одного
вычисления магазинной функции р при условии ввода входного символа
аЕ Ги {е} автомат М переходит из конфигурации с в конфигурацию с 1, и
c'G^(c,a).
Для определенной таким образом переходной функции справедливо сле-
дующее утверждение:
c' = (/cz, YX)etM((k, Л X), а) <=>(/<', Y)e р(к,А,а).
Заметим, что множество tM (с, г) имеет единственный элемент с, и лишь
в случае, если автомат М может перейти из одной конфигурации в другую
без ввода входного символа, множество tM (с, е) может иметь другие эле-
менты, иначе говоря, если конфигурация с = (к9 Ах) такова, что р (к9 А, е) £
£ ф. Такие перемещения автомата М называются ^-перемещениями. И, за-
вершая определение переходной функции tM9 сделаем еще одно замечание:
= 0 для всех кеК, аеТи {е},
tM((k9с),£) = {(/с,£)} для всех кеК,
т.е. пустота стека является достаточным условием невозможности каких-
либо перемещений автомата, кроме е-перемещений.
1 В процессе вычисления функции р (к, А, а) из стека будет извлечен элемент А, в
результате чего в вершине стека окажется элемент Y. - Прим. ред.
81
Расширим теперь функцию tM до функции, осуществляющей отображе-
ние вида (К х И*) х Т* ->2КхИ* следующим образом: ке К. Хе И*, а{,а2,...»
... ,апеТи{£}, тогда
tM((k,X),aia2...an) содержит (к’, Х')9к'ЕК9Х'Е V*
тогда и только тогда, когда
tM((k,X),a1a2...a„) содержит (к'9Х'),к'ЕК9Х'е И*
tM((k,X),ai) содержит (/с2,Х2),
^f((fc2>*2),a2) содержит (/с3,Х3),
^((fc^XJ,^) содержит (к'9Х’)
для некоторых к2,..., кпЕ К9 Х2,... ,XWG К*. Понятно, что некоторые
из входных символов в; могут быть равны е, и автомат М в этих случаях
будет выполнять е-перемещения.
Определим множество принимаемых автоматом М строк Т(М) следую-
щим образом:
Т(М) = {xeT*|tM((/c1, Л,),х) содержит элемент множества F х И*}.
Иначе говоря, Т(М) — множество таких строк, что в результате ввода лю-
бой из них автомат М перейдет из исходной конфигурации в конфигурацию
с конечным состоянием автомата.
Далее везде, где это не вызовет неопределенности, будем опускать у
функции tM ее нижний индекс и писать просто ’’функция Г”.
Приведем примеры магазинных автоматов. Построим магазинный авто-
мат Mi такой, что T(Mi) = {xxr |xG{a, b}*}. Пусть этот автомат решает
задачу последовательного ввода строки и сравнения первой половины стро-
ки со второй половиной и пользуется при этом следующим алгоритмом:
после занесения в стек первой половины строки продолжает посимволь-
ный ввод второй половины строки, одновременно извлекая из стека симво-
лы первой половины строки и сравнивая пары получаемых символов. По-
скольку строка вводится посимвольно, то длина ее заранее не известна, и
поэтому определить момент, когда необходимо прекратить занесение в стек
введенных входных символов, невозможно. Из этого следует, что построен-
ный автомат является недетерминированным магазинным автоматом. Пусть
при выполнении операции занесения в стек первой половины строки автомат
находится в исходном состоянии ki. В некоторый произвольный момент
времени он переходит в состояние к2, т. е. в состояние извлечения элементов
из стека и сравнения их с вводимыми символами. Запишем теперь формаль-
ное определение автомата Мх следующим образом: Mi = ({&i, к2, к3} ,{а, Ь},
{а9 Ь, -|}, р, ki, -| ,{fc3} } , где символ ” обозначает нижнюю границу сте-
ка. Ниже приведено формальное определение магазинной функции р (далее
при описании магазинной функции р соотношения, задающие значения мага-
82
зинной функции, совпадающие с пустым множеством будут опускаться).
Итак,
р{к1,а,а)= {(к1,аа),(к2,е)},
p(kt,b,a)= {(kltab)},
р(к^а, b)= {(k^ba)},
р(кг,Ь,Ь)= {(ki,bb),(k2,E)},
p(klt H,a) = {(fc1,aH)},
p(^i> H>b) = H)},
p(k2,a,a) = {(k2,e)},
p(k2,b,b}= {(k2,E)},
P(k2, H,£) = {(/C3,£)}.
Предлагаем читателю самостоятельно убедиться в том, что Т(Мх) =
= {xxr |xG{a, &}*}. Рассмотрим, например, строку abba, значением функ-
ции f((fci,4), abba), очевидно, может быть любая из конфигураций: (Аг1}
abba -|), (к2, -J) (к3, е), и, следовательно, abba G Т(Мi).
Согласно теореме 3,3 каждый регулярный язык LaT* может быть принят
некоторым недетерминированным конечным автоматом, например автома-
том М = (К, Г, t, klt F). Воспользуемся этим обстоятельством и построим
недетерминированный магазинный автомат М9 = (К, Т,{-|}, р, к19 -|, F) та-
кой, что Т(М9) = L. Фактически автомат М тождествен автомату М', ибо
стек не используется. Достичь этого можно следующим определением ма-
газинной функции р:
(^i > -I) Р (&i, —I, a) ^к9 G. t (к, а).
Таким образом, стек остается пустым для всех перемещений, выполняе-
мых автоматом М' и очевидно, что
хбТ(М') <=» —|),x)n(F х { -|})у=0 t(kl,x)r>F =/= 0<=>xeT(M)<=>
<=>xeL.
Приведенное рассуждение доказывает, что всякий регулярный язык может
быть принят некоторым недетерминированным магазинным автоматом.
Кроме того, из рассмотренного выше примера следует, что можно постро-
ить недетерминированный магазинный автомат, принимающий нерегулярный
язык {xxr |xG {а, b}♦}, поэтому можно утверждать, что недетерминирован-
ный магазинный автомат может принимать языки из более широкого клас-
са, нежели недетерминированный конечный автомат. На самом деле, и мы это
позже покажем, таким классом является класс всех контекстно свободных
языков. У читателя может возникнуть вопрос: необходимо ли условие не-
детерминированности магазинного автомата? К сожалению, необходимо
(в отличие от конечных автоматов, которые независимо от их детерминиро-
ванности принимают языки из одного и того же класса). В этом легко убе-
диться, если вернуться к примеру со строками {xxr |xG {а, Ь} ♦}. Позже мы
подробнее рассмотрим вопрос недетерминированности магазинного ав-
томата.
83
НЕДЕТЕРМИНИРОВАННЫЕ МАГАЗИННЫЕ АВТОМАТЫ И КОНТЕКСТНО
СВОБОДНЫЕ ЯЗЫКИ
Основным результатом этой главы является утверждение: для любого
контекстно свободного языка существует такой недетерминированный
магазинный автомат, который принимает его, и наоборот — если некоторый
недетерминированный магазинный автомат принимает некоторый язык, то
этот язык является контекстно свободным языком. Прежде чем приступить
к доказательству этого важного утверждения, приведем пример, с помощью
которого покажем, как может быть построен недетерминированный мага-
зинный автомат, принимающий простые арифметические выражения.
Пусть G = (Nt Т, Pt Е) — контекстно свободная грамматика, где N={E, Т,
F J, Т={а, bt ct (,) , +, —, X, /}, а множество продукций Р имеет элементы
Е-Т|Е + Т\Е —Т,
T^F\Tx F\T/F,
F^a\b\c\(E).
Из гл. 2 известно, что любой xEL ((7) может быть получен в результате
левостороннего вывода. Пусть недетерминированный магазинный авто-
мат, который мы хотим построить, эмулирует указанный левосторонний
вывод с помощью операций со стеком, например следующим образом:
пусть в исходном состоянии автомата содержимое стека имеет вид Е -|.
Поставим в соответствие продукциям вида Е^Т, Е^>Е+7\ Е^Е - Т сле-
дующие строки: Г—|, Е+Т-| и Е-Т-\ соответственно. При каждом пере-
мещении, выполняемом автоматом, из стека извлекается один символ;
если извлеченный символ оказывается нетерминальным, то ему в соответ-
ствие ставится некая продукция, правая часть которой в таком случае зано-
сится в стек. Если же извлеченный из стека символ оказывается терминаль-
ным, то он используется в качестве входного символа и, следовательно, оп-
ределяет следующее перемещение автомата.
Итак, мы определили недетерминированный магазинный автомат М =
= (К,Т,КрЛ>Ч {М.гае
= {^1
V=N<jTu{
а магазинная функцияр задана следующими соотношениями:
p(ki, -1,с)={(/с2,£-|)};
р(к2,Е,е) = {(Л2, Т),(к2,Е + Т),(к2,Е — Т)};
р(к2, Т,е) = {(k2,F),(k2, Тх F),(k2, T/F)}',
р(к2, F, £) = {(/с2, а), (к2, Ь),(к2, с),(к2,(£))};
р(к2, а, а) = {(к2, е) }, р(к2, Ь, Ь) = {(к2, е)};
р(к2, с,с) = {(/с2,е)};
р(к2, +, +) = {(к2,е)},р(к2,-) = {(/с2,£)}’,
84
р(к2, X, х) = {(/с2,£)},р(/с2,/,/) = {(/с2,£)};
Р(к2,(,() = {(к2,Е)},р(к2,),)) = {(/с2,£)};
р(к2, 4,£) = {(/с3,£)}.
В исходном состоянии автомата ki содержимое стека автомата принимает
вид Е -|, и переход к состоянию к3 возможен лишь в том случае, если стек
пуст (содержит лишь символ -|), следовательно, эмуляция левостороннего
вывода осуществляется автоматом лишь в состоянии кг. В табл, 6.1 приве-
дена последовательность конфигураций автомата М9 принимающего ариф-
метическое выражение вида а X (Ь +с).
В заключение заметим, что построить эффективный грамматический ана-
лизатор для разбора арифметического выражения с помощью определенно-
го выше недетерминированного магазинного автомата М — задача непростая.
Основная трудность заключается в том, что (как видно из определения ма-
газинной функции р) автомат М имеет три ^-перемещения. ЕслихЕ T(Af),
то может быть построена некоторая последовательность конфигураций авто-
мата М9 гарантирующая, что данная строка х действительно принимается ав-
томатом М\ однако такой строке может соответствовать целый ряд коррект-
ных перемещений автомата М9 не являющихся необходимыми для приема
Таблица 6.1
Невведенная часть входной строка Последовательность конфигураций
Состояние Содержимое стека
а х (Ь + с) н
а х (Ь + с) ^2 ЕН
а х (Ь + с) ^2 ГН
а х (Ь + с) ^2 ТхГ-|
а х (Ь + с) ^2 FxF-|
а х (Ь + с) ^2 а х F
х (Ь + с) ^2 xF-|
(Ь+с) ^2 ЕН
(Ь+с) ^2 (ЕН
Ь + с) ^2 Е)Н
Ь + с) ^2 # + Т)Ч
Ь + с) ^2 Т+7Н
b + с) ^2 Е + Т)Н
b + с) ^2 ь + тн
+ с) ^2 + TH
с) ^2 Е)Н
с) ^2 Е)Н
с) *2 с)Н
) ^2 Н
е ^2 И
£ £
85
строки х. В следующих главах мы покажем, что при наложении определен-
ных ограничении на грамматику, порождающую язык, последний приобре-
тет ряд свойств, благодаря которым принимающий его недетерминирован-
ный магазинный автомат будет лишен подобных неприятных особенностей.
В этом случае построение эффективного грамматического анализатора ста-
нет возможным.
ТЕОРЕМА 6.1
Для любого контекстно свободного языка L существует недетермини-
рованный магазинный автомат М такой, что L = Т(М).
Доказательство
Пусть язык L С Т* порожден контекстно свободной грамматикой G =
= (К9 Т9Р9 S) ; определим автомат М следующим образом:
М = (К,Т,КрЛ1,Ч{^з))>где
= {^15^2
v=NuTu{ Н),
p(fc2,A,£) = {(/с2,а)|Л->а-продукция из Р} для любого AeN;
p(k2,a,a) = {(fc2,c)} для любого аеТ;
P(k2, Н,е) = {(fc3,с)}.
Это определение гарантирует, что если х G Г*, aG (NU Г) ♦, то S =>ха — лево-
сторонний вывод тогда и только тогда, когда t ( (fci, -|), х) содержит конфи-
гурацию (к2> а -4). Следовательно, xG L <=►£ =>х <==>(^2» Ч) Е t ((^2, -1),х)**
~(*з, -|) Е t ((kx, Н), х) ~xg T(M).
Верна и обратная теорема, т. е. любой принимаемый недетерминирован-
ным магазинным автоматом язык является контекстно свободным языком.
Однако для доказательства этого утверждения нам понадобится один очень
важный результат. Пусть М = (/С, Г, V9 р9 kt, А1, F) — произвольный недетер-
минированный магазинный автомат. Построим новый недетерминированный
магазинный автомат М9 = (К9 9 Т9 V9 9 р , k\, -| , F) такой, что К9 =K*J{k\,
^2}, где к\, к92 Е К9 V9 = V U {} при -| К. Функция р9 задается теми же
соотношениями, что и функция р, за исключением соотношений, соответст-
вующих состояниям к\ и к2:
PX^i, Ч,с) = {(^iMi Н)}’,
р'(Л,Л,£) = {(к2,8)} длялюбых AeV'^keF',
р'(к'29А9е) = {(к'29е)} для любого AeV'}
F' = {k'2}.
Первое из этих соотношений гарантирует занесение в стек символа -| прежде
чем автомат М начнет осуществлять какие-либо перемещения, а это означает,
что даже если автомат М достигнет одного из состояний, являющихся элемен-
тами множества F99 в стеке останется один элемент. Второе из этих соотно-
86
шений указывает на возможность перехода автомата М9 в состояние к2 без
необходимого ввода одного из символов входного алфавита. Поскольку
k2EF9t то, очевидно, Т(М) = Т(М'). По определению автомат М имеет
единственное конечное состояние, после перехода в которое в соответствии
с третьим соотношением стек очищается.
ТЕОРЕМА 6.2
Если L — некоторый язык, принимаемый недетерминированным магазин-
ным автоматом М, то он может быть принят и недетерминированным мага-
зинным автоматом М\ имеющим единственное конечное состояние, при пе-
реходе в которое (и только в этом случае) стек автомата очищается.
Сформулировав эту теорему, мы можем перейти к доказательству второ-
го важного утверждения.
ТЕОРЕМА 6.3
Если L = Т(М), где М — некоторый недетерминированный магазинный ав-
томат, то L — контекстно свободный язык.
Доказательство
Пусть L — множество строк, принимаемых некоторым недетерминирован-
ным магазинным автоматом М = ({fci, к2,... 9кп}, Г, К,р, кх ,Ah {кп}), об-
ладающим указанными в теореме 6.2 свойствами, и пусть его состояния по-
мечены klt к2,... ,кп, где кг — исходное, акп — конечное состояния автома-
та. Определим контекстно свободную грамматику G такую, что Т(М) -L (G).
Поставим в соответствие каждому символу AEV такой нетерминальный
символ А^ определяемой грамматики G, что из него могут быть выведены
все строки, в результате ввода которых автомат переходит из состояния fcz-
в состояние kj и одновременно из стека автомата извлекается символ А.
В таком случае, Т(М) — язык, порождаемый грамматикой G = (TV, Г, Р, S),
где N={A^ |ЛЕ К, / Си} S =Л11", а множество продукций определя-
ется следующим образом: пусть р — магазинная функция, тогда если р (к^9А,
а), к^К9 ЛЕК, аЕ Г U {е} содержит (kjBxB2 .. .Вт}9 kj^K9 то A'i ->
аВ1”х ВГ2П2 ... В^т-17 — элемент Р для всех 1 Chj , п2,... ,иш-1 <и; если
р (fcz-, А, а), kj Е Kt А Е К, а Е TU {е} содержит (kj, f), kj Е К, то Aij -+а -
элемент Р, Следовательно,
хеТ(М)<=> (fcn,c) et((/cp Л1),х)<=>Л1пХх <=>xgL(G),
что и требовалось доказать.
Теперь можно определить контекстно свободный язык как язык, кото-
рый может быть принят некоторым недетерминированным магазинным ав-
томатом. Воспользуемся этим результатом и докажем ряд свойств контекст-
но свободных языков.
ТЕОРЕМА 6.4
Если L — контекстно свободный язык, a R — регулярное множество
строк, то L A R — контекстно свободный язык.
87
Доказательство
L = Т(М), где M = (Л*, Г, К, р, kx, Аj, F) - некоторый недетерминирован-
ный магазинный автомат и R = Т($), где Й = (/?, Г, t , к\, F) — некоторый
недетерминированный конечный автомат. Построим такой недетерминиро-
ванный магазинный автомат Л/ХЛ/, чтобы он принимал^язык £ АТ?. Прежде
всего, перемещения, осуществляемые автоматом Л/ХЛ/, соответствует, оче-
видно, одновременным перемещениям автоматов М и М, и строках будет
принята им в том и только том случае, если она может ^быть принята одно-
временно автоматами М и М. Формально автомат МХМ = (ТСХ??, Т, К, р9,
[fci, кх ], А1, FXF)1, где магазинная функция р определяется следующи-
ми соотношениями: для к,к'еК, eR, AeV,aeT, Хе V*
а)([/с/Л/],Х)бр'([^Д1 Л,а) <=► (/с', Х)ер(к, А,а) и Jc'Et(k,a).
б)( [к', £'],%) Ер'( [&,£], А,е) <=> (к',Х)ер(кч А, е) и f' = к.
Методом индукции по числу перемещений можно показать, что
([/с,£],ХИ tM х M((lk1,^Ai),x)^(k,X)e Л J, х) и е Г(£рх),
следовательно, хе Т(М х М)<=> ([/с,£],х)е tM ЛДх) для некото-
рых кеF, JceF, АгЕИ*<=>(/с,Лг)Е^((/с1,Л1),х),^еЛ АгеИ*и£еЦ^1,х)ЛеА=>
<=>хеТ(М) и хе Т(7ЙГ). Таким образом,Т(М х М) = Т(М)о Т(М) = LnR.
ДЕТЕРМИНИРОВАННЫЕ МАГАЗИННЫЕ АВТОМАТЫ
Если любой конфигурации магазинного автомата соответствует единст-
венное перемещение, то такой магазинный автомат называют детерминиро-
ванным магазинным автоматом. Приведем теперь строгое определение де-
терминированного магазинного автомата: магазинный автомат М = (ТС, Г,
И, р, ^i, Л1, F) называется детерминированным магазинным автоматом,
если для любых кЕК, аЕТ и АЕ V выполняются следующие условия:
1) р (к, А, а) имеет не более одного элемента;
2) р(к,А,в) имеет не более одного элемента;
3) еслир(£,Л,е) тор(к,А,а) = ф для любого а Е Т.
Поясним последнее условие — если из некоторой конфигурации автомат
может осуществить хотя бы одно е-перемещение, то оно является единствен-
ным перемещением, которое он может из этой конфигурации осуществить.
Из приведенного определения детерминированного магазинного автома-
та можно сделать вывод, что правые части всех соотношений, задающих
магазинную функцию такого автомата, определяют пустые множества или
синглетоны. Ниже соотношения, правые части которых определяют пустые
множества, мы не будем выделять, а потому можно утверждать, что магазин-
ная функция любого детерминированного автомата задается соотношения-
ми вида
f(k,A,a)={(k',X)}
1 Запись вида [fc, &] используется автором для обозначения такого состояния авто-
мата М ХМ^которое соответствует одновременно состоянию к автомата М и состоянию
к автомата М. - Прим. ред.
88
или, как это принято в теории формальных языков, соотношениями вида
/(/с,Л,а) = (/с',Х).
Язык, принимаемый детерминированным магазинным автоматом, назы-
вают детерминированным контекстно свободным языком, или просто
детерминированным языком. К сожалению, не всякий контекстно свобод-
ный язык является детерминированным языком, тем не менее детермини-
рованные языки составляют очень важный класс языков. Дело в том, что в
классе детерминированных языков значительно упрощается решение проб-
лемы выводимости. Синтаксические определения у большинства современ-
ных языков программирования сформулированы таким образом, что про-
цесс компиляции написанных на них программ весьма прост, так как в каж-
дом конкретном случае могут быть разработаны более или менее эффектив-
ные грамматические анализаторы. Ограничения же, накладываемые на ука-
занные синтаксические определения требованием детерминированности
языка программирования, являются при этом самыми слабыми (в следую-
щих двух главах мы покажем, почему). Приведем несколько примеров и
изучим еще несколько свойств детерминированных языков.
Сначала рассмотрим регулярные языки. Поскольку всякий регулярный
язык может быть принят некоторым детерминированным конечным авто-
матом и поскольку всякий такой автомат может быть представлен детер-
минированным магазинным автоматом, не использующим свой стек, то,
очевидно, всякий регулярный язык является детерминированным языком.
Обратное неверно: не всякий детерминированный контекстно свободный
язык является регулярным языком. Для иллюстрации сказанного обратим-
ся к примеру, и рассмотрим язык {anbn\n> 1}, не являющийся регулярным
языком, и детерминированный магазинный автомат М = ({fci, k2, k3}, {a, b},
{д, Ч},р,Л1,Ч,{Л3}),где
р(/сьа, а) = (/с15аа);
р(/с1,а,Ь) = (/с2,£);
р(/с2,а,Ь) = (/с2,е);
Ч,£) = (^3>£)-
Находясь в состоянии кх, автомат осуществляет занесение в стек всех вво-
димых входных символов а до тех пор, пока не будет введен символ Ь,
в результате чего автомат перейдет в состояние к2. В состоянии к2 автомат
ставит в соответствие каждому введенному символу Ъ извлеченный из сте-
ка символ а до тех пор, пока в стеке не останется только символ -|, после
чего автомат переходит в конечное состояние к3.
Любой детерминированный язык, очевидно, является контекстно сво-
бодным языком, так как по определению может быть принят некоторым
детерминированным магазинным автоматом, который, очевидно, является
ограничением недетерминированного магазинного автомата. Из у пр. 5.12 чи-
татель должен был узнать, что существует контекстно свободный язык
89
L СТ* такой, что его дополнение в L =T*\L не является контекстно сво-
бодным языком. Покажем, что дополнение всякого детерминированного
контекстно свободного языка в Г* является детерминированным контекст-
но свободным языком. Доказательство этого факта весьма сложно, и по-
этому, читая книгу первый раз, его можно пропустить, достаточно только
хорошо понимать один из промежуточных результатов доказательства, из
которого прямо вытекает возможность существования таких контекстно
свободных языков, которые не являются детерминированными языками.
Пусть LET* — детерминированный язык, принимаемый детерминиро-
ванным магазинным автоматом М = (К, Г, К, р, кх, А!, F). Построим де-
терминированный автомат М (при этом конечные и ”не” конечные состоя-
ния, очевидно, поменяются ролями) , который принимал бы язык! = T*\L.
На этом пути нас ожидает ряд непростых проблем, которые придется решить.
Первая из них заключается в том, что автомат М может иметь одно или
несколько ’’тупиковых” состояний, т. е. может существовать xG Т* такой,
что в результате ввода собственного префикса строки х, автомат М получит
конфигурацию, из которой не существует ни одного перемещения, кроме,
быть может, бесконечного числа е-перемещений. В любом случае xGZ, и
надо быть чрезвычайно осторожным при построении автомата М, если мы
хотим, чтобы он принимал такие строки. С такого рода трудностями мы
уже сталкивались при доказательстве теоремы 3.4, в которой утвержда-
лось, что дополнение регулярного языка есть регулярный язык. Возник-
шая проблема может быть решена удачной модификацией автомата М,
Построим некий детерминированный магазинный автомат М9 такой, что
T(Af) =Т(М ), но автомат М9 всегда использует все символы введенной
строки. Строго говоря, автомат М9 совпадает с автоматом М за исключе-
нием того, что его стек содержит маркер нижней границы -|, а сам авто-
мат имеет три дополнительных состояния s, d,fEK. Итак, s — исходное
состояние автомата М9, в котором стек автомата содержит символ -| G К,
и существует лишь е-перемещение, переводящее автомат М9 в состояние кг
(при этом в стек заносится символ Аj). Перейдя в состояние кг, автомат
М9 эмулирует автомат М, осуществляя при этом ряд важных дополнитель-
ных действий. Если автомат М перешел в состояние, в котором не сущест-
вует ни одного перемещения, то автомат М9 осуществляет переход в фиктив-
ное состояние d, игнорируя последующий ввод любых входных символов.
Аналогично новое конечное состояние автомата М9 используется для реше-
ния проблемы с бесконечным числом е-перемещений автомата М. Пусть
автомат М имеет конфигурацию с, в которой существует бесконечное чис-
ло е-перемещений автомата; тогда, очевидно, должна существовать конфи-
гурация с = (к, АХ), кЕК, АЕ Ки{—| }, ХЕ (К U {-| })*, которую будет
иметь автомат М9 в результате осуществления конечного числа е-перемеще-
ний, и при этом автомат М9, имеющий конфигурацию с9, может осуществить
бесконечное число ^-перемещений, не извлекая из стека более ни одного
элемента. После осуществления указанных е-перемещений автомат может
перейти или не перейти в конечное состояние. Определим автомат М9 таким
90
образом, чтобы в первом случае он имел бы конфигурацию (/, АХ), а во вто-
ром — конфигурацию (d9 АХ). И наконец, для того чтобы автомат М9 ис-
пользовал всю введенную строку, состояние f дополним ^-перемещением,
в результате осуществления которого автомат М9 переходит вновь в сос-
тояние d.
Приведем теперь формальное определение автомата М9 :
М' = (Х',Т,И',Р',5, H,F'), где
K' = Kv{s,d,f}> s,d9f$K,
г = Ио{Н},
F’ = Fu{f} , а магазинная функция р задается соотношениями
a) p'(s, —= —IK
б) для всех кЕ К9 A G УиаЕТ таких, что р(к9 А,а) = р(к9А9е) = ф9
p'(k9A9a) = (d9A);
в) pr (d9A9a) = (d9A) ддя всех А G У99аЕ Т\
г) для всех кЕК9 АЕ У таких, что бесконечная последовательность е-
перемещений может быть осуществлена автоматом, имеющим начальную
конфигурацию (к9А)9
{(d9 А), если ни одно из этих перемещений не переводит ав-
томат М в конечное состояние;
(/, А) в противном случае;
д) р (f9 А, е) = (d, А) для любых АЕ У9;
е) если р9 (к, А, а) не определена предыдущими соотношениями, то
р'(к, А,а)= р(к,А,а), кеК9 АеУ9 аеТи{г}.
Предоставляем читателю самостоятельно убедиться в том, что определен-
ный таким образом автомат М действительно использует всю введенную
строку и Т(М) = Т(М9). Особое внимание советуем обратить на то, как
была получена указанная конструкция. В частности, может возникнуть
вопрос: можно определить, является ли бесконечной последовательность
е-перемещений в конфигурации (к9 а) ? Если да, то есть ли среди них е-пе-
ремещения, переводящие автомат в конечное состояние? На оба эти вопро-
са следует ответить утвердительно (см. упр. 6.11).
Рассмотрим еще одну проблему: после ввода строки xG Т* автомат М9
осуществляет несколько е-перемещений. Допустим, что в результате осу-
ществления части из них автомат М9 переходит в конечное состояние, а в
результате осуществления остальных в ”не” конечное состояние и обмен
ролей конечных и ”не” конечных состояний ничего не изменит в этой си-
туации. Для решения этой проблемы построим еще один автомат — детер-
минированный конечный автомат М99 такой, что T(M9t) = Т(М9) =Т(М).
Автомат М9 9 имеет те же состояния, что и автомат М9, но помечены они
следующим образом: если в результате последнего непустого ввода автомат
М9 перешел в конечное состояние, то соответствующее состояние автома-
та М,г помечается так же, как и состояние автомата М99 но с присоединени-
ем индекса 1; в противном случае к обозначению состояния автомата М9 при-
соединяется индекс 2, и полученная таким образом запись является обозна-
91
чением соответствующего состояния автомата М". Приведем формальное
определение автомата М:
М' = (К', Г, И', р", 5," Н, Г'),
М" ={K\T,V\p\s\ —|,Г"),где
К” = {k^keK^i-l или 2);
„ _1\» если се Т(М),
\s2 в противном случае;
F" = {к^кеК'},
а магазинная функция р задается следующими соотношениями:
а) для кеК', AeV} если р'(к,А,е) = (к',Х), к'еК', Хе(И')*, то
f (fc'ls X) при k'eF',
p"(k2,4,£) = <'1 v
в противном случае;
б) для ке К’, AeV',aeT, если р’(к,А,а) = (к’,Х), к’еК’, Хе(И')*, то
л 1 "ib л ч f(ki>X) при k'eF'-
р"(к1,А,а) = р'(к2,А,а) = <
[ («2, X) в противном случае.
Теперь, наконец, стало возможным поменять ролями конечные и ”не” конеч-
ные состояния автомата М и получить, таким_образом, детерминирован-
ный магазинный автомат М, принимающий язык L.
ТЕОРЕМА 6.5
Если L С Г* - детерминированный язык, то L = T*\L — детерминирован-
ный язык.
ТЕОРЕМА 6.6
а) Любой регулярный язык является детерминированным языком, обрат-
ное неверно.
б) Любой детерминированный язык является контекстно свободным
языком, обратное неверно.
Свойства детерминированных языков отличаются от свойств контекстно
свободных языков, например класс детерминированных языков замкнут
относительно операции дополнения, т. е. если язык L принадлежит к клас-
су детерминированных языков, то язык L также принадлежит этому клас-
су. В табл. 6.2 приведены основные свойства некоторых классов языков.
Таблица 6.2
Операция Замкнутость относительно операции
Регулярное множество Детерминиро- ванный язык Контекстно свободный язык
Объединение Да Нет Да
Конкатенация »»
Дополнение ** Да Нет
92
Окончание табл. 6.2
Замкнутость относительно операции
Операция Регулярное множество Детерминиро- ванный язык Контекстно свободный язык
Пересечение Замыкание Клини Пересечение с регулярным множеством Гомоморфизм Да м Нет Да Нет Нет Да
УПРАЖНЕНИЯ
6.1. Пусть входная строка имеет вид 012345, 5 - стек. Какая из следующих строк
может быть получена в результате последовательного использования операций ’’занесе-
ние в стек” и ’’извлечение из стека”?
а) 543210, б) 534210, в) 431250, г) 415320, д) 542301.
6.2. Постройте детерминированные магазиные автоматы и покажите с их помощью,
что языки {wcwr |w G {a, b} ♦}, {albl\j > i} - детерминированные языки.
6.3. Докажите, что если L - детерминированный, a R - регулярный языки, то L п
n R - детерминированный язык.
6.4. Пусть недетерминированный магазинный автомат М(К, Т, К, р, kit Alt F) при-
нимает язык Е(М) С Г* где Е(М) = {х| существует кЕ К такое, что (к, £) Е tm((kit
А,), х)}. Покажите, что Е (М) - контекстно свободный язык (из теоремы 6.2 следует,
что обратное также верно).
6.5. Постройте недетерминированный магазинный автомат, принимающий язык,
порождаемый грамматикой, имеющей продукции вида
5 -+аА\аВВ,
A->Ba]Sb,
B^bAS\t.
6.6. Пусть L - детерминированный язык. Покажите, что min {х]хб L и не существу-
ет w G L - собственного префикса х}. - также детерминированный язык.
6.7. Используя то, что яэык {а/У\Л|/ и j ^&}не является контекстно свобод-
ным языком, докажите, что {а^ Ыc^\i -j или j =к} не является детерминированным
языком, т.е. существуют два детерминированных языка Zj и I, такие, что не
является детерминированным языком.
6.8. Используя результат упр. 6.7, покажите, что класс детерминированных языков
незамкнут относительно операции пересечения.
6.9. Покажите, что любой детерминированный контекстно свободный язык может
быть принят некоторым детерминированным магазинным автоматом М таким, что ни
на одном из перемещений автомат не осуществляет извлечения из стека более двух
символов.
6.10. Покажите, что каждый детерминированный контекстно свободный язык! с Т*
принимается некоторым детерминированным магазинным автоматом М = Т, V, р,
kl9 Alt F) таким, что если осуществляемое автоматом перемещение удовлетворяет
условию
р(£,Л,в) =(<Л),Л,*'ея,ае Ти{{},яе Г, Хе V*
93
то оно специфицирует одну из следующих операций:
а) извлечение из стека одного символа, т. е. X = f ;
б) занесение в стек одного символа, т. е. X =ВА, А, Ве V;
в) содержимое стека не изменяется, т. е. X = А;
6.11. Рассмотрим детерминированный магазинный автомат М = ({к^,.,. ,кп}, Т{А х . ..
... Ат), р, klt At, F), удовлетворяющий требованиям упр. 6.10, определим булевы
трехмерные массивы В,, В2, В3 следующим образом:
Bi [«./>*] = true~
В2 [/,/, fc] =true ^(kj,i)^tM((kitAk),e),
B3 [/,/,£] =true •«=• существует Хе K*[(Ay, X) e > £)
Разработайте итерационный алгоритм построения В2, В2 иВ3.
ГЛАВА 7
СИНТАКСИЧЕСКИЙ АНАЛИЗ ’’СВЕРХУ ВНИЗ”
lam nova progeniec caelo demittitur alto
(Все новое приходит к нам свыше)
Вергилий ’’Эклоги”
В гл. 6 мы показали, что любой контекстно свободный язык может быть
принят некоторым недетерминированным магазинным автоматом. Из не-
детерминированности указанного автомата, вообще говоря, следует, что
построенный на его основе синтаксический анализатор контекстно свобод-
ного языка может осуществлять возврат к предыдущему состоянию в про-
цессе функционирования. Сам алгоритм синтаксического разбора опреде-
ляет вполне однозначный процесс, поэтому при возникновении необходи-
мости выбора одной из возможных логических ветвей, алгоритм выбирает
и в дальнейшем следует всегда единственной из возможных логических
ветвей. Это означает, что, обнаружив ошибку выбора, необходимо вернуть-
ся к моменту осуществления выбора, вновь осуществить выбор и выпол-
нить другое перемещение. Однако если на порождающую язык граммати-
ку были наложены определенные ограничения, а автомат эффективно ис-
пользует свой стек, то становится корректным применение ряда хорошо
изученных и отработанных приемов, позволяющих построить эффективный
синтаксический анализатор для такого языка. На практике все реальные
проекты языков программирования, безусловно, содержат все необходи-
мые ограничения, поскольку они получат практическую ценность лишь в
том случае, если будут поддержаны достаточно эффективными компиля-
торами.
При решении задачи синтаксического разбора строки вида х -а1а2- •.
. .. апЕ L ((7) используют, как правило, один из двух основных методов.
Первый из них заключается в построении дерева вывода, корень которого
помечен символом S, а листьями являются узлы, помеченные символами
94
ai, а2,...,ап. Второй прием заключается в восходящем построении дере-
ва, листьями которого являются узлы, помеченные аг, а2, •. •, ап, а кор-
нем - узел, ^помеченный символом S. На рис. 7.1 применение обоих мето-
дов проиллюстрировано на примере строки abba$ и контекстно свободной
грамматики Gi, имеющей продукции вида
С -► ЬА | аВ,
А->а\аС,
В^Ь\ЬС.
В этой главе мы рассмотрим так называемый LL -разбор, который от-
носится к методам синтаксического разбора типа ’’сверху вниз”, отложив
знакомство с методами синтаксического разбора ’’снизу вверх” до следую-
щей главы. Для успешного LL -разбора предложений некоторого языка
95
на порождающую его грамматику должны быть наложены строгие ограни-
чения. И хотя практически это означает, что воспользоваться методом LL-
разбора можно лишь на подмножестве класса детерминированных языков,
он представляет значительный интерес, так как заложенные в нем принципы
использованы в большинстве современных компиляторов.
LL(K) -ГРАММАТИКИ
Снова рассмотрим грамматику Gx. Дерево синтаксического разбора
’’сверху вниз” строки abba$ показано на рис. 7.1, а. Рассмотрим подробно
его построение. Корень дерева помечен символом S, и, следовательно, един-
ственной продукцией грамматики G19 которая может быть использована
в данном случае, является продукция S -► С$; в результате будет получе-
но дерево
Перейдем теперь к узлу С. Мы можем воспользоваться продукциями
С^ЬА и С^аВ:
Поскольку рассматриваемая строка abba$ начинается с символа а, вос-
пользуемся второй из этих продукций, или, обобщая это рассуждение, ска-
жем, что ’’выбрана будет та продукция, правая часть которой начинается с
очередного введенного входного символа”. Итак, один из листьев дерева,
которое мы пытаемся построить, уже помечен символом а. Убедимся теперь
в том, что В=>ЬЬа. Воспользуемся для этого продукцией В ~+b\bС. В резуль-
тате получим два дерева:
На этот раз знать следующий введенный символ входной строки недоста-
точно для выбора одной из этих продукций. Тем не менее, если нам ста-
нут известны два очередных символа входной строки и если это символы
Ь$9 то следует воспользоваться первой продукцией, а если это символы Ьа
или bb, то второй продукцией. В данном случае очередные символы входной
строки — это символы bb, поэтому следует выбрать продукцию В -+bС. Убе-
димся в том, что С=*Ьа, для чего, согласно следующему символу входной
строки, воспользуемся продукцией С^ЬЛ9 а затем, согласно двум очеред-
96
ным символам входной строки, воспользуемся продукцией А~>а. В резуль-
тате будет получена левосторонняя схема вывода вида
S =>Ci$ =>аВ$ =>abC$ =>abba$ => abba$.
Грамматика Gx является примером LL (2)-грамматики, иначе говоря,
для однозначного определения дерева вывода достаточно знать не более
двух очередных символов входной строки на каждом этапе построения де-
рева. Вообще, LL (к)-грамматикой называют такую грамматику, что для
любой ее сентенциальной формы
w4y,weT*,/lejV,ye(jVu Т*),
полученной в результате некоторого левостороннего вывода для однознач-
ного выбора продукции, имеющей в левой части символ А, достаточно
знать к очередных символов входной строки. Аббревиатура ”ZZ” в назва-
нии грамматики означает ’’левосторонний ввод — левосторонний вывод”.
Заметим, что, строго говоря, вид следующей используемой для вывода про-
дукции определяется не только нетерминальным символом А и к очередны-
ми символами входной строки, но также возможно и видом сентенциаль-
ных форм и 7 Е Если вид следующей используемой для
вывода продукции однозначно определяется символом А и очередными к
символами входной строки, то такая LL (£)-грамматика называется стро-
гой LL (к)-грамматикой.
Введем следующее определение:
FIRST, где
f х, если I х I к
FIRST,(x) = < ,
[у, если х = у, уеТ, zeT*.
Определим функцию FIRST* на некотором языке L :
FIRST,(L) = {FIRST,(x)|xeZ} для любого Zcz Т*.
Приведем теперь формальное определение. Пусть G = (N, Т9 Р9 S) - контекст-
но свободная грамматика, ее называют LL (к)-грамматикой, если две лю-
бые левосторонние схемы вывода
S=> wAy =>way Xwye Т*,
S X wA у =>wfly ^>wze T*
связаны соотношением
если FIRST,(у) = FIRST,(z), то a = 0.
Кроме этого, грамматика G называется строгой LL (к)-грамматикой, если
любые две левосторонние схемы вывода
S =>wAy =>way ^>wye Т*,
sXxA<5 =>х@д =>xze Т*
связаны соотношением: если FIRST* (у) = FIRST* (z), то a = /?.
В общем случае определить, является ли некоторая грамматика однознач-
ной, невозможно, однако если можно показать, что рассматриваемая грам-
97
матика является строгой L L (к) -грамматикой, то из приведенной ниже тео-
ремы следует, что грамматика однозначная. На самом деле, теорема спра-
ведлива и для случая L L (к) -грамматики (см. упр. 7.7).
ТЕОРЕМА 7.1
Если G = (N9 T9P9S) — строгая L L (к)-грамматика (к> 1), то G — одно-
значная грамматика.
Доказательство
Предположим, что G — неоднозначная грамматика; тогда, очевидно, су-
ществует строка w Е L (G), которая может быть выведена из 5 двумя раз-
личными способами.
Пусть 7\ и Т2 — два различных дерева вывода, соответствующие двум
различным левосторонним схемам вывода строки w =аха2 .. .ап из нетерми-
нального символа 5. Оба дерева имеют общий корень 5 и внешние узлы ау,
^2, • • • >ап, но, по предположению, не совпадают. Осуществим одновремен-
ный обход узлов двух деревьев, используя для этого следующую рекур-
сивную процедуру: обход начинается с корня дерева, обход узлов данного
уровня осуществляется слева направо. Переходя таким образом с одного
уровня на другой, мы найдем два таких узла деревьев Ту и Т2, что они по-
мечены различными символами, например В и С (рис. 7.2). Очевидно, эти
узлы не являются корнями соответствующих деревьев, так как оба дере-
ва имеют один корень — узел 5. Из этого следует, что они, очевидно, имеют
родительские узлы и последние совпадают (пусть это будет узел, помечен-
ный символом А) .
Дерево Ту соответствует левосторонней схеме вывода
=>хаВ^1у1 Xxy1z1 = w,
а дерево Т2 схеме вывода
S^>xAy2 =>хаС02у2 =^ХУ2?2 =^хУ2г2 = w-
Рис. 7.2
98
Поскольку FIRSTk(71»21)= FIRSTk(y2,z2) и aB^1 ^аСД2, то, очевидно, G не
может быть строгой LL (к) -грамматикой, следовательно, теорема доказана.
По определению всякая строгая L L (к) -грамматика является LL(k)-
грамматикой, однако для 1 существуют грамматики, которые, являясь
L L (к} -грамматиками, в то же время не являются строгими L L (к) -грам-
матиками. Следует заметить, что при к = 1 определения LL (к) -грамматики
и строгой LL (к) -грамматики эквивалентны. Кроме того, как будет пока-
зано ниже, класс языков, порождаемых LL (к)-грамматиками, в точности
совпадает с классом языков, порождаемых строгими L L (к) -грамматика-
ми для всех к> 1.
ТЕОРЕМА 7.2
Контекстно свободная грамматика G = (N, Т9 Р, S) является строгой
L L (1) -грамматикой <=*G является L L (1) -грамматикой.
Доказательство
Необходимость этого условия теоремы следует непосредственно из опре-
деления строгой L L (1) -грамматики.
Докажем достаточность этого условия.
Пусть G — LL (1)-грамматика, не являющаяся строгой LL (1)-грамма-
тикой; тогда среди ее продукции есть две несовпадающие продукции вида
А -+а и А -»(3 такие, что для некоторых w, х, ylf у2, zif z2G Т* и у, 6G
G (7VU7*)*, и существуют две несовпадающие левосторонние схемы вывода
5 Xw4y =>way =>wy =>wy ty2 и 5 =>хАд =>xz{ д =>xzx z2, ТД£
FIRST1(y1,y2)=FIRST1(z1,z2).
Необходимо показать, что G не является LL (1)-грамматикой. Послед-
нее утверждение может быть справедливым в одном из следующих двух
случаев:
а)У1=^1=£;
б) У121 ^8.
Случай а) очевиден, а потому перейдем сразу к случаю б). Без потери
общности можно предположить, 4toji £. Следовательно, FIRSTi (yi ,у2 ) =
= FIRST! (ух) = FIRSTj (z, z2). Но в таком случае две левосторонние схе-
мы вывода
8^хА6=>хад^хух6=>ху^2 и 5 ^хАд =>xfi6 =>xzt 6 =>xzj z2
удовлетворяют условию
FIRST1(y1) = FIRSTi (zj,z2).
Однако и, следовательно, G не является LL (1)-грамматикой. Это
противоречие и доказывает теорему.
Следует заметить, что частный случай LL (к) -грамматики при к = 1 пред-
ставляет большой интерес при разработке компиляторов. Дело в том, что
очень часто разработчики языков программирования, формулируя синтак-
сические определения будущего языка, имеют в виду LL (1) -грамматику.
Даже если разработчик языка программирования не позаботился об этом,
99
то разработчик компилятора с этого языка программирования наверняка
исправит оплошность коллеги и соответствующим образом конвертирует
сформулированные синтаксические определения. Существует даже создан-
ный специально для этих целей конвертор SID (Syntax Improving Device)
(детальное описание конвертора SID можно найти в журнале Computer
Journal за 1968 год), который автоматически конвертирует произволь-
ную входную грамматику в эквивалентную LL (1) -грамматику, если это
возможно. Существуют, однако, некоторые синтаксические особенности,
присущие любому языку программирования, которые не могут быть сфор-
мулированы в виде синтаксических определений языка, порожденного
LL (1) -грамматикой. Они обрабатываются отдельно. Итак, если основная
часть синтаксиса некоторого языка программирования представляет собой
набор синтаксических определений языка, порожденного LL (1) -граммати-
кой, то для синтаксического разбора указанных синтаксических определе-
ний с помощью так называемого метода рекурсивного спуска, можно легко
разработать (или даже автоматически сгенерировать) эффективный анали-
затор. Осуществить разбор других синтаксических определений языка анали-
затором также можно, но с помощью более хитроумных методов. Пример-
но таким образом разработаны почти все существующие компиляторы с
языка программирования Паскаль. Метод рекурсивного спуска не следует
рассматривать только как средство построения синтаксических анализато-
ров для языка, порожденных LL (1) -грамматикой, фактически он пред-
ставляет собой формализацию принципов, использование которых дает
нам возможность строить эффективные и одновременно элегантные син-
таксические анализаторы в чрезвычайно широком классе детерминирован-
ных грамматик. Детали этой проблемы мы обсудим позднее.
Сформулируем теперь теорему, которая позволит нам построить ал-
горитм для определения того, является произвольная контекстно свобод-
ная грамматика G строгой LL (1)-грамматикой или нет. Для этого, преж-
де всего, понадобится определить контекстно свободную грамматику G'
такую, что L (Gz) = {x$|xG L (G)}, где $— специальный символ, который
будет введен сразу же за последним входным символом, или, как его еще
называют, ’’маркер конца ввода”. Итак, если G = (TV, Т, Р, 5) - произволь-
ная контекстно свободная грамматика, то пополненной грамматикой назы-
вают грамматику G' = (V, Т , Р , 5 ), где
/V' = /Vu{S'}l S'$Nt
г =Ти{$}\$фТ9
P' = Pu{S'-S$}.
Понятно, что L(G ) = {xS|xeL(Gz)}. Определим теперь на множестве N*UT
следующие функции:
(true. если X
EMPTY(X) = L ,
(false, в противном случае.
FIRST(X) = {а\аеТ и X ^>ах для некоторого хе(Т')*}.
FOLLOW(X) = {а\аеТ' и S'^>хХау для некоторого хеТ* и уе(Т')*}.
100
Таким образом, с каждым ХЕ N* UTf оказывается ассоциированным два
подмножества множества Т' : FIRST (Y) и FOLLOW (X).
Доопределим теперь функцию EMPTY на множестве (N‘ UT')* следую-
щим образом:
EMPTY(e) = true и
EMPTY(Xa) = EMPTY(Y) and EMPTY(a), Xe/V'u Г, ae(N’v T')*
Таким образом, если ye(N'u T')*, то EMPTY(y) = true <=> у Хе ** у Хе.
С G
И наконец, определим еще одну функцию:
LOOKAHEAD (А -Х|Х2...Л'Я) =
=u{FIRST(X,.)|l and EMPTYCX^-.X,. ,)}
u if EMPTY(Y1X2...Yn) then FOLLOW^) else 0.
Итак, сформулируем теорему.
ТЕОРЕМА 7.3
Контекстно свободная грамматика G = (N, Т, Р9 S) является строгой
LL (1)-грамматикой <=> для любой пары несовпадающих продукций грам-
матики вида А -► а и А -> (3, имеющих одинаковые левые части, справедли-
во следующее утверждение:
LOOKAHEADM ->a)n LOOK АН ЕА DM - 0) = 0.
Для иллюстрации использования только что сформулированной теоремы,
рассмотрим следующий пример: G2 = (А<, Т, Р, S) — контекстно свободная
грамматика, где N- {S, Л, В}9 Т = {а, b9 с, d}9 а множество Р содержит про-
дукции вида
A -►ale,
В^ЬА\сВ.
У соответствующей ей пополненной грамматики TV' = NО{S'} ={S,A,B, S'} ,
Tf = TU{$}={a, b, c, d, $}, а множество продукций P' имеет следующие
элементы:
S'^S$9
S ~>BA\AAd,
A -►ale,
В -> ЬА\сВ.
Кроме того, EMPTY (A) = true, но EMPTY (X) =false для всех X9 не совпа-
дающих с А. Как и для всякой пополненной грамматики, в данном слу-
чае очевидно, что для любых az- Е г', FIRST (az) ={az} и FOLLOW (S') =
= FOLLOW ($) = ф. Кроме того, нетерминальный символ S' не входит в
правую часть ни одной из продукций, и, следовательно, значение FIRST(S )
не участвует в вычислении функции LOOKAHEAD, а значит, можно огра-
ничиться рассмотрением следующих выражений:
101
FIRSTMjX^ieN и FOLLOW(X), XeNuT.
Значения функции FIRSTS,), AteN можно представить как систему
уравнений, построенную в соответствии со следующим правилом:
F1RSTG4 )= J{FlRST(X(j)| существует продукция
А^ХпХ12...Х1и и U= 1 или EMPTY Хг2 - - - 1))}-
В данном случае такая система уравнений записывается следующим об-
разом:
FIRST(S) = FIRST(B)o FIRST(4)o FIRST(/4)o {с/} =
= FIRST(B)o FIRSTS)о {d};
FIRST(4) = FlRST(a) = {a};
FIRST(B) = FIRST(b)o FIRST(c) = {b,c}.
В общем случае найти решение этой системы уравнений можно с помощью
итерационного метода, описанного в конце гл. 5. Однако в данном случае
решение очевидно и приведено в табл. 7.1.
Таблица 7.1
Содержимое множества N'uT' FIRST -множество FOLLOW-множество
f {$} 0
а {о) {а,</4}
b 4 М)
с W {М
d W
S' {a, b,c,d}1 0
S {a,b, c,d} {$}
А {«} 44$}
В М 4$}
1 FIRST(S') = FlRST(S)uif EMPTY(S) then {$} else 0.
Аналогичным образом может быть описано и множество значений функ-
ции FOLLOW. В этом случае, если ХЕ 7VU Г, то искомое множество значений
функции FOLLOW является решением следующей системы уравнений:
FOLLOW(X) = {FOLLOW(/4,)| существует продукция вида
Л,-аХ0 и EMPTY(/?)}u
{FIRST(X(J)| существует продукция
А^аХХiXXi2.. .Xin и j=i
или EMPTY^X^...*^-,)}-
И, следовательно, для данного примера справедлива следующая система
уравнений:
102
FOLLOW(a) = FOLLOWM);
FOLLOWS) = FOLLOW(B)u FIRSTM)
= FOLLOW(B)u {a};
FOLLOW(c) = FIRST(B) = {5, c};
FOLLOW W) = FOLLOW(S);
FOLLOW(S) = FIRSTS) = {$};
FOLLOWS) = FOLLOW(S)u FOLLOW(B)
о FIRSTS Ю FIRSTS)
= FOLLOW(S)u FOLLOW(B)u {a,d};
FOLLOW(B) = FOLLOW(S)u FOLLOW(B)u FIRSTS)
= FOLLOW(S)uFOLLOW(B)u{a}.
Таблица 7.2
Продукции LOOKAHEAD- множество
{Ь.с}
S->AAd М
А->а {«}
А — £ {a,4J}
В->ЬА W
В-+сВ Ю
Эта система уравнений также может
быть решена с помощью итерацион-
ного метода, описанного в гл. 5 (резуль-
тат решения приведен в табл. 7.1).
Вычислив значения функций FIRST и
FOLLOW для каждого элемента мно-
жества ЛЮТ, мы можем, наконец, найти
область значений функции LOOKAHEAD,
определенной на множестве продук-
ций грамматики (результат приведен в
табл. 7.2).
Поскольку LOOKAHEAD (А -+d) A LOOKAHEAD (А = Q грамматика
G2 не является LL (1)-грамматикой.
Рассмотренный выше пример показывает, что всегда возможно опреде-
лить, является ли произвольная контекстно свободная грамматика ТТ(1)-
грамматикой или нет. К сожалению, однозначно ответить на вопрос, сущест-
вует или нет LL (1) -грамматика, эквивалентная некоторой произвольной
контекстно свободной грамматике, в общем случае невозможно, так как
эта задача неразрешима. И потому из того, что произвольную контекстно
свободную грамматику невозможно конвертировать в эквивалентную ей
LL (1) -грамматику с помощью конвертора SID, не следует, что такой LL (1) -
грамматики не существует.
РЕКУРСИВНЫЙ СПУСК
Если контекстно свободная грамматика G является LL (к} -грамматикой,
то с помощью так называемого метода итерационного спуска можно постро-
ить синтаксический анализатор языка L ((7), который явно не использует
стек, однако алгоритм его функционирования включает ряд рекурсивных
процедур, которые обычно реализуют с помощью стека. Таким образом,
несмотря на внешние отличия алгоритма синтаксического анализа, получен-
ие
ного с помощью метода рекурсивного спуска, от алгоритма, описанного
в гл. 6, принципиально они не отличаются.
В простейшей форме метод рекурсивного спуска предоставляет удобную
возможность построения лексического анализатора (распознавателя симво-
лов) языка, порожденного LL (1)-грамматикой G = (7V, Г, Р, S). Такой лек-
сический анализатор каждому символу из множества NUT ставит в соот-
ветствие единственную процедуру, с помощью которой для любой строки
языка можно однозначно определить, выводима она из этого символа или
нет. Условимся обозначать рХ такую процедуру, соответствующую символу
ХЕ NUT. Так, если аЕ Т, то ра специфицирует ввод следующего входного
символа и сравнение его с символом а. Если А Е N и продукции граммати-
ки, содержащие символ А в левых частях, имеют вид А -><*!, А ->а2,...
... ,Л то, сравнив очередной входной символ с элементами области
значений функции LOOKAHEAD, можно определить, какой продукцией нуж-
но воспользоваться для осуществления следующего шага вывода. Если с
помощью процедуры рА и в зависимости от очередного входного символа
выбрана продукция A ->ау, и az =Xi{Xi2 . . .Xim, Хц ENUT, 1</ <m,
то имеет смысл говорить соответственно о процедурах рХ^; pXi2; ...
Таблица 7.3 • • • \pX-inv
Продукции LOOKAHEAD- множество — В качестве примера рассмотрим грамматику G3, которая, как вы сами можете убедиться, является
S->aAB {a} грамматикой, ее продукции имеют
S-bS w вид
A—>aAb w S^AB\bS,
A->bBc {b}
B^AB {a.fe} А->аА\ЬВ,
B-+c {<} В->АВ\с,
а значения функции LOOKAHEAD, приведены в табл. 7.3.
Представим себе, что функция nextsymbol определена таким образом, что
позволяет узнать вид очередного входного символа, не выполняя его реаль-
ного ввода из входного потока. Если оказывается, что такого очередного
входного символа нет, то управление передается специальной процедуре об-
работки аварийной ситуации. Воспользуемся этими рассуждениями и напи-
шем на языке программирования, подобном Паскалю, лексический анали-
затор языка L (<73):
begin pS; if ввод окончен then останов else авария end
procedure pS = case nextsymbol of
‘a’: pa; pA; pB;
'b': pb; pS;
‘c’:
end;
procedure pA = case nextsymbol of
wa’: pa; pA; pb;
104
*b'-. pb\ pBf pc\
V:
end;
procedure pB = case nextsymbol of
'a\ V: pA\pB\
‘c’: pc
end;
procedure pa = begin
ввести (символ) ; if символ # ’a’ then авария
end;
procedure pb = begin
ввести (символ)} if символ £ 'b* then авария
end;
procedure pc = begin
ввести (символ); if символ £ 'c' then авария
end.
He вдаваясь в подробности, скажем лишь, что в результате выполнения про-
цедуры авария осуществляется прекращение всех вычислений и вывод со-
ответствующего сообщения.
Следующим шагом введем в действия, выполняемые анализатором, се-
мантическую обработку, иначе говоря, потребуем от него ответа на вопрос,
можно ли считать некоторое внутреннее представление синтаксически кор-
ректной последовательности введенных входных символов верным резуль-
татом. Если это внутреннее представление введенной последовательности
входных символов можно рассматривать как дерево вывода, то мы столк-
немся здесь с проблемой выводимости. На практике разработчики компиля-
торов чаще всего именно так и поступают, используя внутреннюю форму
представления в виде семантического дерева, подобного тому, которое мы
описали в гл. 2 как наиболее подходящую форму. Покажем это на примере
грамматики, порождающей арифметические выражения, составленные из
переменных а, Ь, с и символа $ — последнего из вводимых входных симво-
лов. Пусть ее продукции имеют вид
S-E$,
Е-Т|Е + Т\Е-Т,
T^F\T х F\T/F,
F->a\b\c\(E).
Ясно, что такая грамматика не может быть ЕЕ (1)-грамматикой и вообще
ЕЕ (fc) -грамматикой для любого к, так как для любого к нетерминальному
символу Е может соответствовать арифметическое выражение вида (((.. .
... (а)...))) +а или вида (((.. .(а).. .))) -а, содержащее к + 1 пару ско-
бок, и следовательно просмотр этого выражения на к элементов вперед не
позволит однозначно определить, какой должна быть следующая продукция
(Е^>Е + Т илиЕ->Е - Т). Однако не будем отчаиваться. У нас есть несколь-
105
ко возможностей. Прежде всего попытаемся найти грамматику, эквивалент-
ную исходной, но являющуюся LL (1) -грамматикой. Понятно, что иско-
мая грамматика не должна содержать продукций рекурсивных слева (см.
упр. 7.2). Воспользуемся теоремой 5.6 и построим грамматику со следую-
щими продукциями:
S-E$,
Е-ТЛ,
Л —► с| + ТА\- ТА,
t->fb9
В^е\ х FB\/FBt
F -> а\Ь\с\(Е).
Построенная грамматика является ЕЕ (1)-грамматикой и, воспользовавшись
методом рекурсивного спуска, легко можно построить искомый синтакси-
ческий анализатор. К сожалению, добавить сементический разбор оказалось
возможным лишь благодаря ряду хитростей. Действительно, выбранная ис-
ходная грамматика была определена так аккуратно, что вид семантического
дерева следовал из вида дерева вывода. Например, арифметическое выраже-
ние а - b - с$ имеет соответственно дерево вывода, представленное на рис.
7.3, а, а семантическое дерево представлено на рис. 7.3, б (на рис. 7.3, в
представлено некорректное семантическое дерево).
Опишем теперь исходную грамматику с помощью синтаксических диаг-
рамм так, как это показано на рис. 7.4. Подобный подход избавляет нас от
необходимости вводить нетерминальные символы А и В и позволяет пост-
роить с помощью метода рекурсивного спуска лексический анализатор, в ко-
торый будет легко добавить функции семантического разбора. Действитель-
но, каждому нетерминальному символу, использованному в синтаксических
диаграммах, соответствует одна процедура (рЕ, рТ или pF). Как это приня-
то, вместо того, чтобы отдельно описывать процедуры (р+, р— и т. д.) для
Рис. 7.3
106
распознавания терминальных символов, присовокупим описание этих проце-
дур непосредственно к описаниям процедур рЕ, рТ и pF.
Вновь воспользуемся языком, подобным языку программирования
Паскаль, и запишем результат:
begin рЕ\ if nextsymbol = then останов else авария end
procedure рЕ = begin
PT;
while nextsymbol = ’+’ or nextsymbol = ’ do
begin
ввести (символ); pT\
end
end;
procedure pT= begin
РГ;
while nextsymbol = ’X’ or nextsymbol = 7’ do
begin
ввести (символ); pF
end
end;
procedure pF = begin
case nextsymbol of
’a’, 'b\ ’с’: ввести (символ);
'('’.ввести (символ)} рЕ\ ввести (символ)}
if символ /= ’) ’ then авария}
'$*'• авария
end
107
Добавим теперь функции семантического разбора, поставив в соответ-
ствие каждой процедуре рХ некоторую функцию fX, с помощью которой
станет возможным построить семантическое дерево арифметического выра-
жения, распознаваемого с помощью процедуры рХ. Предположим, что функ-
ция fX имеет три аргумента, символ 5 и деревья 1\ и Т2, а значением ее яв-
ляется некое дерево, корень которого помечен символом 5 и которое распа-
дается на два поддерева, 7\ и Т2. Обозначим пустое дерево nil. В резуль-
тате можно написать следующую программу:
begin var t: tree; t\=fE; if nextsymbol = then t else авария end
function/#: tree = begin
var Г:tree;
t:fT;
while nextsymbol=’+’ or nextsymbol =’—’ do
begin
ввести (символ) :f:=tree construct (символ, t,fT)
end;
fE\-t
end;
function fT: tree = begin
var t :tree;
t'--fF;
while nextsymbol=’X’ or nextsymbol=7’ do
begin
ввести (символ) ; t :=tree construct (символ't' fF)
end;
fT-=t
end;
function fF\ tree = begin
case nextsymbol of
'a't'b't *с'\ ввести (символ);
/F:=tree construct (символ, nil, nil)
ввести (символ);fF\=fE; ввести (символ);
if символ ’) ’ then авария;
’) ’, авария
end
Таким образом, метод рекурсивного спуска является одним из наиболее
эффективных способов создания компиляторов. Как мы показали, если рас-
сматриваемая грамматика является LL (1)-грамматикой, то для построения
лексического анализатора проще всего воспользоваться значениями функ-
ции LOOKAHEAD. Если затем к полученному лексическому анализатору
добавить функции семантического разбора, то мы получим искомый анали-
затор. Однако на практике синтаксис большинства языков программирова-
ния не может быть достаточно полно специфицирован LL (1)-грамматикой.
В таком случае разработчик компилятора с такого языка программирования
может, конечно, воспользоваться приведенными в этой главе результатами
108
и рекомендациями, однако их может оказаться недостаточно. Более того,
использование эквивалентной LL (1) -грамматики часто приводит к тому,
что добавление функций семантического разбора становится невозможным.
Заметим, что при необходимости анализировать к очередных входных сим-
волов перед разработчиком возникает задача обобщить решение на LL (к) -
грамматику. При желании читатель может детально ознакомиться с исполь-
зованием на практике метода рекурсивного спуска для построения компи-
ляторов с языка программирования Алгол; для этого достаточно обратить-
ся к книге Davie A. J. Т., Morrison R. Recursive Descent Compiling. - Ellis
Horwood, 1981.
Более полное теоретическое изложение проблемы LL (к} -грамматик,
метода рекурсивного спуска и ряда интересных исследований по вопросам
исправления ошибок читатель найдет в книге Backhouse R. С. Syntax of
Programming Languages: Theory and Practice. - Prentice-Hall International,
1979.
УПРАЖНЕНИЯ
7.1. Назовите, какая из описанных ниже грамматик является LL (1) -грамматикой,
и для каждой такой грамматики постройте с помощью метода рекурсивного спуска
лексический анализатор.
a) 5 -А\В,
А -+аА |д,
В^ЬВ\Ъ\
б) S ^АВ,
А-^Ва\г,
В^СЬ\С,
С->с|г;
в) S->аАаВ\ЬАЬВ,
A -+S]cb,
В^>сВ\а.
7.2. Покажите что LL (1) -грамматики не могут иметь леворекурсивных слева про-
дукций. Не забудьте, что в соответствии с принятым соглашением рассматриваемые
грамматики не имеют иррелевантных продукций. Справедливо ли это для LL(k)-
грамматик?
7.3. Обобщите теорему 7.3 и предшествующие ей определения на случай ZZ(2)-
грамматики в терминах fc-LOOKAHEAD-функций.
7.4. Воспользуйтесь решением упражнения 7.3 и покажите, что следующая грам-
матика является строгой LL (2) -грамматикой, а затем постройте методом рекурсив-
ного спуска соответствующий лексический анализатор:
А -+сЪА\а.
7.5. а) Покажите, что следующая грамматика, имеющая продукции
5 -+аАаа\ЬА Ьа,
А^Ь\е,
является LL (2)-грамматикой, но не является строгой LL (2)-грамматикой.
109
б) Покажите, что грамматика, имеющая продукции
S ^аВА\ЪВЪА,
А -+аЪА\с,
В -+a\ab,
является LL (3) -грамматикой, но не является строгой L L (к) -грамматикой для любо-
го к > 1.
7.6. Покажите, что если L - регулярный яэык, $$ L, то Z$={x$|xGZ} может
быть порожден строгой ££(1)-грамматикой (воспользуйтесь детерминированным ко-
нечным автоматом, принимающим яэык L).
7.7. Покажите, что если грамматика G= (N, Т, Р, S) неоднозначна, то существуют
w, хе Т* А е N, уЕ (NuT)* такие, что S - левосторонняя схема вывода, и
существуют две несовпадающие схемы вывода А => о =>х и А =>&=> х, где о, 0G (NuT) *
и Используя этот результат, покажите, что любая LL (к) -грамматика является
однозначной грамматикой.
7.8. Покажите, что грамматика, имеющая продукции вида
С^ЬА\аВ,
А ->д|дС|ЪАА,
В->Ь\ЬС\аВВ,
не является LL(k)-грамматикой для любого к. Можно ли для некоторого к построить
эквивалентную ей LL (к) -грамматику?
ГЛАВА 8
СИНТАКСИЧЕСКИЙ РАЗБОР ’’СНИЗУ ВВЕРХ”
’’Всегда стройте все снизу вверх”
Франклин Рузвельт
7 апреля 1932 г.
Вам должно быть понятно, что каким бы методом (’’сверху вниз” или
’’снизу вверх”) мы ни воспользовались для синтаксического разбора стро-
ки х G L (G), где G — контекстно свободная грамматика, результат дол-
жен быть один (это утверждение справедливо при условии допустимости
использования обоих методов), так как эти методы отличаются лишь спо-
собами построения деревьев1. Если метод синтаксического разбора ’’сверху
вниз”, описанный в гл. 7, рекомендует построение указанных деревьев на-
чиная с корня, то метод ’’снизу вверх” рекомендует строить их наоборот,
начиная с листьев и кончая корнем дерева. Введенные входные строки в
последнем случае анализируются слева направо; получаемые в процессе
подстроки сравниваются с правыми частями продукций грамматики, а при
совпадении заменяются или приводятся к нетерминальному символу, стоя-
1 Автор имеет в виду дерево вывода и семантическое дерево. - Прим. ред.
110
Рис. 8.1
щему в левой части таких продукций. В результате такой замены может
быть получена сентенциальная форма грамматики, а затем вся процедура
повторяется до тех пор, пока полученная сентенциальная форма не примет
вид 5, где символом 5 помечен корень дерева вывода. В результате будет
получена последовательность схем вывода и соответствующих им приведе-
ний, позволяющая построить дерево вывода от листьев до корня. Каждо-
му элементу этой последовательности, очевидно, соответствует один ро-
дительский узел дерева вывода.
Рассмотрим грамматику Gx, имеющую следующие продукции:
S-CJ,
С-*аВС\аВ\ЬАС\ЬА,
А —► ЬЛЛ|а,
В^аВВ\Ь.
Из результатов упр. 2.2, читателю должно быть известно, что Gi — одноз-
начная грамматика, и, следовательно, любой строке х£ L(GX} соответст-
вует единственное дерево вывода. Например, дерево вывода для строки х =
= bbaa$ приведено на рис. 8.1, д. Далее, каждому дереву вывода соответ-
ствует единственная правосторонняя схема вывода, т. е. такая схема вывода,
в которой всегда выводится самый правый нетерминальный символ. Так,
дереву вывода, рассмотренному в вышеприведенном примере, соответству-
ет правосторонняя схема вывода
5 =>С$ =>ЬА$ =>bbAA$ =>bbAa$ =>bbaa$.
Рассматриваемый метод синтаксического разбора ’’снизу вверх”, позволит
построить такую схему вывода справа налево. Пример построения дерева
вывода для строки b baa $ показан на рис. 8.1.
111
Подстроку, которая приводится, называют основой правосторонней сен-
тенциальной формы, или правосторонней простой фразой. Процесс построе-
ния дерева вывода для нашего примера иллюстрируется табл. 8.1.
Таблица 8.1
Правосторонняя сентенциальная форма Основа Замещающий символ
ЬЬаа$ а (левый символ) А
ЬЬАа$ а А
ЬЬАА$ ЪАА А
ЪА$ ЪА С
с$ с$ S
При использовании метода синтаксического разбора ’’снизу вверх” воз-
никает проблема поиска и своевременного приведения основы сентенциаль-
ной формы на каждом шаге построения дерева вывода.
ГРАММАТИКА ПРОСТОГО ПРЕДШЕСТВОВАНИЯ
Решим названную проблему прежде всего в небольшом классе грамма-
тик, называемых грамматиками с простым предшествованием.
Перечислим слева направо элементы правосторонней сентенциальной
формы, рассматривая пары смежных символов, в поисках самого правого
символа основы сентенциальной формы, а когда найдем его, то начиная с
него продолжим перечисление символов уже справа налево и найдем самый
левый символ этой сентенциальной формы.
Пусть G = (N, Т9 P,S) — контекстно свободная грамматика, и пусть
aXY(5 — правосторонняя сентенциальная форма, где а, 0G (TVUZ)*, X, YE
G jVU7\ В некоторый момент (на одном из этапов процесса последователь-
ных сокращений сентенциальной формы) возникает одна из следующих
возможных ситуаций:
а) X — часть основы сентенциальной формы, а У — нет. Таким образом,
X является окончанием основы сентенциальной формы. В этом случае гово-
рят, что X предшествует У и записывают это следующим образом: X •> У
б) И X, и У входят в основу сентенциальной формы. В этом случае гово-
рят, что X и У имеют равное предшествование и записывают это следующим
образом: Х=У.
в) У — часть основы сентенциальной формы, а X — нет. Таким образом,
У — заголовок основы сентенциальной формы. В этом случае говорят, что
У предшествует Х9 и записывают это следующим образом: Х<' У
Отношения, обозначенные символами •>, =, <•, называют отношениями
простого предшествования. Из вышеприведенных определений можно сде-
лать вывод, что
а) X > У *=► У — терминальный символ (напомним, что aXYQ — сентен-
циальная форма правостороннего вывода) и существует некоторая продук-
112
ция A у2> A, BE N, ZE ЛЮТ, у19 у2 G (ЛЮТ)* такая, что В 6\Х и
zXr62,5i,62G (ЛЮТ)*;
б) X = Y « существует некоторая продукция А -+ ?i XYу2, А Е N, у19
у2Е (NUT)*',
в) Х<- У <=* существует некоторая продукция А ~+ухХВу2, BEN, у1э
y2G (ЛЮТ)* такая, чтоВ^ (ЛЮТ)*.
Контекстно свободная грамматика G = (N, Т, Р, S) называется грамма-
тикой простого предшествования, если
1) никакие две продукции грамматики не имеют совпадающих правых
частей;
2) любые два символа, составляющие элемент множества (ЛЮ Т) X (NU Т),
связаны одним и тем же отношением предшествования.
Грамматика Gx удовлетворяет первому из этих условий, но не удовлет-
воряет второму. Действительно, одновременно выполняются а •>а (так как
А -+ЬАА,А нА =>а) иа<а (так как С->аВиВ^>аВВ).
Рассмотрим теперь грамматику простого предшествования G2, имеющую
продукции вида
R^Sa).
Предоставляем читателю самостоятельно проверить, что приведенные в
табл. 8.2 отношения являются отношениями простого предшествования.
Если G = (N, Т, Р, S) — грамматика простого предшествования, то найти
основу любой ее правосторонней сентенциальной формы очень просто. Для
этого достаточно перечислить элементы указанной сентенциальной формы
и найти самую левую пару символов Xj и Ау+1 таких, что Xj •> Х7+1 -Ау —
окончание основы сентенциальной формы. Перечислим теперь элементы
сентенциальной формы грамматики G справа налево начиная с символа
Xj и до тех пор, пока не будет найдена пара символов Xix и Xz- таких,
что Xj__x <Xj *Xj. Таким образом, будет найдена основа сентенциальной
формы, имеющая вид 0=Xj .. .Xj, а значит, должна существовать продук-
ция вида А •+ 0, т. е. основа сентенциальной формы может быть приведена к
символу А, Единственная трудность может возникнуть в случае, если окон-
чанием основы сентенциальной формы является последний символ этой
формы или же заголовок сентенциальной формы является ее первым симво-
лом. Чтобы преодолеть эту трудность, введем новый символ,’’маркер конца”,
$ENUT, который будем использовать для индикации обоих концов сен-
тенциальной формы. Далее, без ограничения общности, предположим, что
$ •>X, X- >S для всех ХЕ NUT и результатом последовательности приве-
дений входной строки $х $ (х Е L ((7) ) будет строка вида $.
Далее, язык L (<72) содержит строки вида а, (аа), ( (аа)а), ( ( (аа)а)а),... .
Синтаксический разбор строки $ (((аа)а)а) $, демонстрирующий исполь-
зование отношений предшествования, приводится в табл. 8.3. Процеду-
ра разбора соответствует правосторонней схеме вывода S =► (R =► (Sa) =*
=* ((Ла) => ((5а)а) => (((Ла) а) =* (((5а)а)а) =» (((аа)а)а).
113
Таблица 8.2
Таблица 8.3
S R а ( ) Сентенциальная
. -II А А V Д •II ОС а ~ — У ( < 9 ( < 9 ( < 9 ( 9 ( < 9 ( 9 ( ( < ( < ( < ( ( < S R ( ( ( < S < R а f а а)а )а) 9 < > S а ) а)а)9 < = = > R а)а )£ - > а ) а)9 а)9 ) 9 - > а Sa) (R Sa) (R Sa) (R
При реализации приведения основы сентенциальной формы удобными средствами является стек и входной буфер, для уп- равления которыми используют- ся следующие элементарные опе- рации: занесение в стек (т.е. по-
мещение в вершину стека оче- < = >
редкого входного символа). При- f S f
ведение (т.е. синтаксический ана-
лизатор), располагая информацией о том, что основа сентенциальной фор-
мы находится в стеке, осуществляет замену ее на соответствующий ей не-
терминальный символ. Синтаксический анализатор успешно осуществля-
ет разбор входной строки, если в результате его работы стек будет содержать
строку 5$ и входной буфер будет содержать символ $. Построенные на та-
ких принципах синтаксические анализаторы часто называют анализаторами
’’сдвига—приведения”1. В табл. 8.4 представлено содержимое стека и вход-
ного буфера на каждом шаге разбора рассмотренного выше примера.
Понятно, что при функционировании реального анализатора ’’сдвига-
приведения” очередная операция сдвига будет выполнена при условии, что
первый символ входного буфера предшествует последнему занесенному
в стек символу либо оба они имеют равное предшествование. В противном
случае анализатор будет извлекать символы из стека и искать основу и тем
самым выполнять операцию приведения. Если в последнем случае основа
не будет найдена, то возникнет аварийная ситуация.
Одной из основных проблем, возникающих при такой реализации син-
таксического анализатора, является вычисление отношений предшествова-
ния. Существует простой алгоритм, решающий эту проблему, однако здесь
надо быть осторожным во избежание трудностей с хранением данных. Ес-
ли грамматика имеет т терминальных и п нетерминальных символов, то,
очевидно, существует (ти+и)2 возможных отношений предшествования.
Можно хранить непосредственно множество этих отношений в виде так на-
зываемой матрицы предшествования, тем более, что многие элементы матри-
цы будут наверняка иметь вид что означает пустоту отношения. При
1 Операцию занесения в стек иногда называют сдвигом стека. - Прим. ред.
114
Таблица 8.4
Содержимое стека Входной буфер Выполняемое действие
$ (((аа)а)а)$ Сдвиг стека
$( ((аа)а)а)$ Сдвиг стека
$(( (аа)а)а)$ Сдвиг стека
$((( aa)a)a)f Сдвиг стека
^(((а a)a)a)f Приведение с помощью продукции S-v
W a)a)a)f Сдвиг стека
$(((Sa )a)a)f Сдвиг стека
$(((М a)a)f Приведение с помощью продукции R-*Sa)
a)a)f Приведение с помощью продукции 5 -► (R
?(($ a)a)f Сдвиг стека
$((Sa )a)f Сдвиг стека
$((Sa) a)f Приведение с помощью продукции R ->Sa)
W* a)f Приведение с помощью продукции 5 -► (R
$(5 a)f Сдвиг стека
$(Sa )f Сдвиг стека
flSo) f Приведение с помощью продукции R -+Sa)
$ Приведение с помощью продукции 5 -* (R
$ Строка принята
необходимости можно воспользоваться известными методами компактно-
го хранения рассеянных массивов или же решить эту проблему с помощью
так называемых функций предшествования. Пусть Р — матрица предшест-
вования; построим две целые функции / и g такие, что
ДО < 0(j), если <•;
7(0 = 00), если Pij= = ;
если pij= >
Если возможно найти такие функции, то вместо (т + п)2 элементов доста-
точно хранить лишь 2(/и + и) элементов. Однако при таком решении теря-
ется информация о несуществующих отношениях, которая может быть ис-
пользована, например, для обнаружения и исправления ошибок ввода вход-
ных символов.
В заключение отметим, что основным недостатком описанного в этом
параграфе метода разбора ’’снизу вверх” является применимость его лишь
в узком классе грамматик простого предшествования.
£7? (0)-ГРАММАТИКИ
Метод синтаксического разбора ’’снизу вверх”, наиболее широко исполь-
зуемый разработчиками компиляторов и называемый также LR -разбором,
был найден и разработан Кнутом (Knuth D. Е. On the Translation of Langua-
ges from Left to Right//Information and Control, 1965, № 8, Pl 607 - 639).
Аббревиатура LR означает ’’левосторонний ввод — правосторонний вывод”.
Как и в случае грамматики простого предшествования, LR-разбор может
115
быть реализован в виде анализатора ’’сдвига-приведения”, однако приме-
ним в более широком классе грамматик. В этом отношении LR-разбор пре-
восходит LL -разбор. Основным недостатком LR-разбора является то, что он
не поддается интуитивному восприятию, и поэтому труден для понимания.
К счастью, процедура LR-разбора может быть легко формализована, что
является веской причиной использования его на практике.
На каждом шаге функционирования анализатора ’’сдвига—приведения”
(см. табл. 8.4) содержимое стека анализатора аЕ (NUT)* и содержимое
его входного буфера z G Т* таковы, что строка az представляет собой право-
стороннюю сентенциальную форму. На каждом шаге такого разбора может
быть осуществлена либо операция сдвига, т. е. занесения в стек очередного
символа из входного буфера, либо операция приведения. Остается решить,
какая конкретно операция должна быть осуществлена на каждом конкрет-
ном шаге, и если осуществляется операция приведения, необходимо еще
выбрать продукцию грамматики, с помощью которой можно будет осущест-
вить приведение.
Однако, если рассматриваемая грамматика удовлетворяет ряду условий
(которые мы сформулируем позже), то на каждом шаге функционирования
анализатора можно по содержимому его стека однозначно определить, какое
перемещение анализатор должен совершить для построения обратной право-
сторонней схемы вывода.
Допустим, удовлетворяющая указанным условиям грамматика имеет
продукцию А -+Р и в данный момент содержимое стека а = у0‘, это означа-
ет, что в данный момент следует осуществить операцию приведения. Итак,
мы поставили в соответствие содержимому стека анализатора его переме-
щение. Требование однозначности этого соответствия означает, что выбран-
ное перемещение анализатора должно быть единственным возможным пе-
ремещением в данный момент. Другими словами, не может существовать
никакого другого перемещения анализатора (е-перемещения, или переме-
щения, соответствующего операции сдвига), в результате выполнения кото-
рого новое содержимое стека, ах, хЕ Т*9 оказалось бы таким, что после
осуществления некоторой операции приведения (допустим с помощью
продукции В^>р'), можно было бы получить правостороннюю сентенциаль-
ную форму грамматики. Сформулируем теперь это требование формально:
пусть существуют две правосторонние схемы вывода
S Z>yAxy=>yfixy и
sZ>SBy =>8Р'у = У$ху,
где у, 6, Р, 0* Е (NUT) *, A, BE N, х, уЕ Т*9 тогда они совпадают, т. е. 6 = у,
А =В, Р = Р' и х = е.
Множество строк, занесенных в стек к моменту осуществления опера-
ции приведения с помощью продукции А->Р, называют LRCONTEXT-mho-
жеством продукции А -> Р и обозначают LRCONTEXT (А -> Р). Формально
LRCONTEXT (А^Р) ={a|a=y0G (NUT)*, где S =>уАх=^у0х — правосто-
ронняя схема вывода, хЕ Т*, yE(NUT^}. Описанное выше условие не вы-
полняется, если существуют несовпадающие продукции А и В^р1, та-
116
кие, что уРЕ LRCONTEXT (А -+Р) и 8Р' G LRCONTEXT (В-»р')9 где 60' =
= уРх для некоторого х G Г*.
С другой стороны, даже если рассматриваемая грамматика удовлетворя-
ет этим условиям, существует еще проблема определения момента заверше-
ния приема. Рассмотрим, например, продукцию вида
S ->Sala,
тогда LRCONTEXT (S -+а) = {а} и LRCONTEXT(S->Sa) = {Sa} и, таким об-
разом, описанные выше условия удовлетворяются. Однако если S — единст-
венный символ, содержащийся в стеке, то анализатор, в принципе, может
закончить прием строки. В такой ситуации без дополнительной информации
нельзя определить, нужно ли осуществить ввод символа и завершить разбор,
или же осуществить операцию сдвига стека. Эту проблему легко решить
перейдя к пополненной грамматике, имеющей продукции
S'-S£,
S-► Sa| а,
где $ — маркер конца ввода. Тогда
LRCONTEXT(S' - S?) = {S£},
LRCONTEXT(S Sa) = {Sa},
LRCONTEXTfS- a) = {a}.
Подводя итоги, сформулируем следующее определение: контекстно сво-
бодная грамматика G- (N, Т, Р, S) называется LR (0) -грамматикой, если
а) ни одна из ее продукций не содержит в своей правой части исходного
символа;
б) если существует две правосторонние схемы вывода
S ^>уАху =>yflxy и
S ^дВу => 8 Ру = урху,
где у, 6, 0, р' Е (NUT)*, A, BE N и х9 уЕ Т*, то 6 = у, А =В, 0 = 0' и х = е.
ТЕОРЕМА 8.1
Контекстно свободная грамматика G = (N, Г, Р, S) является LR(0)-
грамматикой <=>
а) ни одна из ее продукций не содержит исходного символа в своей пра-
вой части;
б) если аЕ LRCONTEXT (A ->0') и ахЕ LRCONTEXT (В->0‘), где А -►
-+Р9В-»Р' ЕР,аЕ (NUT)*hxG Т*,тох=е,Л =В и 0 = 0'
Чтобы проверить, является ли грамматика, удовлетворяющая перво-
му условию этой теоремы, LR (0) -грамматикой, необходимо найти все
LRCONTEXT-множества. Каждая строка, являющаяся элементом множества
LRCONTEXT (А ->0), имеет, очевидно, вид уР, где yG (NUT)*. Определим
теперь функцию LEFT (Л) ={у|5=>уЛх — правосторонняя схема вывода,
хЕ Т*}.
117
ТЕОРЕМА 8.2
LRCONTEXT(4- Д) = LEFT(4){/?}.
Таким образом, чтобы найти LRCONTEXT-множества для грамматики,
достаточно найти все LEFT-множества для всех нетерминальных символов
грамматики. Если предположить, что ни одна продукция грамматики G = (7V,
Т, Р, S) не содержит в своей правой части исходного символа S, то утверж-
дение LEFT (S’) ={f} будет справедливо. Кроме того, если - про-
дукция грамматики G, то множество LEFT (В) • {у 1} С LEFT (А). Например,
пусть грамматика G3 имеет продукции вида
5-Л£,
А^АВ\В,
В^1А1\й.
Строки, порожденные этой грамматикой, представляют собой сбаланси-
рованные в обычном понимании последовательности квадратных скобок и
оканчиваются маркером конца строки, обозначенным символом
Воспользовавшись последним замечанием по поводу функции LEFT, вы-
пишем следующие уравнения:
LEFT(S) = {£},
LEFTM) = LEFT(S)u LEFT (Л LEFT (£){[},
LEFT(B)= ЕЕРТ(Л){ Л LEFTMk
Эти уравнения можно решить с помощью метода, обратного методу, описан-
ному в гл. 5, т.е. поставив в соответствие каждому уравнению некоторую
продукцию некоторой грамматики. Пусть при этом множеству LEFT(S) со-
ответствует нетерминальный символ S, множеству ЕЕЕТ(Л) — нетерминаль-
ный символ Л, а множеству LEFT (В) — нетерминальный символ В. Таким
образом, системе уравнений будет поставлена в соответствие грамматика G,
имеющая нетерминальные символы {S,A,B} и продукции вида
S—►£,
Л-5|В[ ,
В-ЛЛ|Л.
В общем случае LEFT-множества некоторой грамматики G = (N, T, P, S)
могут быть построены исходя из продукций грамматики G = (N,T, Р, S) при
условии, что jV=^HGjV}, TC7VUT. Продукции грамматики G имеют та-
кой вид, что грамматика G является линейной слева грамматикой, а следо-
вательно, все LEFT-множества — регулярны (см. упр. 3.1). Таким обра-
зом, в качестве следствия теоремы 8.2, можно сформулировать следующую
теорему.
ТЕОРЕМА 8.3
Пусть G= (N, Т Р, S) — произвольная контекстно свободная грамматика,
тогда ее LRCONTEXT-множества регулярны.
118
Это действительно важный результат! Регулярные множества представля-
ют собой довольно широкий класс множеств, их свойства хорошо изучены,
поэтому мы рассчитываем широко использовать их при проектировании
синтаксических анализаторов.
Структура конечного автомата М9 соответствующего линейной слева
грамматике (7, может быть описана следующим образом: каждой продук-
ции вида А -+Вх, A, BGN,xE Т соответствует путь, помеченный символом
х, из узла, помеченного символом Л, в узел, помеченный символом В, а каж-
дой продукции вида А ->х, A EN, xG Т*9 соответствует путь, помеченный
символом х, из узла, соответствующего исходному состоянию^ автомата
М (пусть он помечен цифрой 1) в узел, помеченный символом А. Каждый
из этих путей может, вообще говоря, включать одну или несколько дуг,
каждая из которых помечена символом, являющимся элементом множест-
ва Если путь содержит в себе более одной дуги, пометим промежу-
точные узлы цифрами 2, 3, 4 и т. д. Обозначим ? переходную функцию авто-
мата М\ тогда для всех Л G TV, LEFT (Л) ={хЕ Г*| ?(1, х) = Л}. На рис. 8.2, а
119
приведен автомат, построенный для грамматики предыдущего примера. Для
этого автомата справедливы следующие утверждения:
LEFT(S) = 1;
LEFTC4) = (C4 + 1)0*;
LEFT(B) = ((Л + 1)[)*(Л + 1),
и, следовательно,
LRCONTEXT(S ->• Л$) = ;
LRCONTEXTC4 - АВ) = ((Л + 1)[)* ЛВ;
LRCONTEXTU - В) = ((Л + 1)0*В;
LRCONTEXT(B-> [Л]) = ((Л + 1)[)*(Л + 1)[Л];
LRCONTEXT(B->[]) = ((/! + 1)[)*(Л + 1)[].
Из теоремы 8.1 следует, что грамматика G3 является LR (0)-грамматикой.
Воспользуемся теперь теоремой 8.2 и построим еще один конечный авто-
мат, такой, что каждой продукции исходной грамматики соответствует од-
но состояние автомата, а множество входных строк, переводящее автомат
из исходного состояния в состояние, соответствующее некоторой продук-
ции, совпадает с LRCONTEXT-множеством для этой продукции. На рис.
8.2, б приведен такой автомат для рассмотренного выше примера. Экви-
валентный ему детерминированный конечный автомат, не имеющий е-пере-
мещений, приведен на рис. 8.2, в. Такой детерминированный конечный ав-
томат называется характеристическим автоматом грамматики. Состояния
автомата, которым соответствуют продукции грамматики, называются
приводящими состояниями. Грамматика является LR (0) -грамматикой <=►
каждому приводящему состоянию ее характеристического автомата соот-
ветствует единственная продукция, и ни один из узлов автомата не помечен
терминальным символом.
Снова вернемся к примеру, и с помощью характеристического автомата
выясним, принадлежит языку L ((7) строка [[][]][]$ или нет. Пусть авто-
мат осуществляет последовательный ввод входной строки до тех пор, пока
не перейдет в приводящее состояние. Зная соответствующую этому состоя-
нию продукцию, осуществим сокращение входной строки, в результате че-
го будет получена новая правосторонняя сентенциальная форма. Пусть те-
перь автомат продолжит ввод префикса этой сентенциальной формы (после-
довательность действий автомата приведена в табл. 8.5).
Однако действия построенного в этом примере автомата были не самыми
эффективными (после каждой операции приведения строки автомат осу-
ществлял повторный ввод строки, начиная с ее первого символа). Напри-
мер, на ’’шаг 4” мы попадаем после только что осуществленной операции
приведения [] в В. Если на предыдущем шаге мы запомнили, что между
вводом и обработкой последовательности символов [А и вводом после-
довательности символов [] автомат находился в состоянии {3,В, 5} (см.
рис. 8.2, в), то можно заключить, что в результате ввода строки [АВ автомат
120
Таблица 8.5
Шаг Введенная часть входной строки — префикс сентен- циальной формы Невведенная часть входной строки — ос- тальная часть сентен- циальной формы Продукция, ис- пользованная для приведения Новая сентен- циальная форма
1 [□ []][]? в-П [«[]][]?
2 [В []][]? А^В
3 !»□ ][]? в-[]
4 [АВ ][]? А-+АВ to
5 М] []? В-[Л] В[]У
6 В []? л-в
7 У в-п АВ$
8 АВ 9 А-+АВ А?
9 AS е S-*AS S
перейдет в состояние t ({3, В, 5}, В). Прежде чем продолжить наши рассужде-
ния, переименуем состояния характеристического автомата, заменив поме-
чающую их последовательность символов на номера 1,2,..., сохранив ут-
раченную таким образом взаимосвязь между продукциями грамматики и
состояниями автомата в специально составленной таблице приведения (рис.
8.3). Если, например, к — приводящее состояние автомата и ему соответст-
вует, например, продукция то к-я строка таблицы содержит запись
видаЛ ->р.
Построим теперь эффективный алгоритм синтаксического разбора с ис-
пользованием стека состояний. На каждом шаге алгоритма этот стек будет
содержать те состояния характеристического автомата, через которые он
прошел бы, если бы был введен текущий префикс правосторонней сентен-
циальной формы. Например, если текущий префикс имеет вид [А [], стек
должен содержать последовательность 1, 2, 3, 2, 9 (элементы стека пере-
числены снизу вверх).
На каждом этапе автомат может осуществить одно из следующих четырех
перемещений:
а) перемещение приведения: если находящийся в вершине стека символ
к помечает приводящее состояние автомата, которому соответствует, напри-
Таблаца лрад'еденая
5 S-+A$
6 А—^АВ
7 А—^В
3 В—^[А]
9 8-+В1)
Рис. 8.3
121
мер, продукция А ^Х^Хг ... Хт и А J S, тогда, если стек содержит после-
довательность символов kQ, ,... ,кп = к (и> т), осуществим операцию
приведения с помощью продукции А . .Хт, в процессе чего из
стека будет извлечено т символов, а по завершении в стек будет занесен
символ, помечающий состояние t (кп_т, А) ;
б) перемещение сдвига: если находящийся в вершине стека символ к по-
мечает неприводящее состояние автомата, тогда необходимо осуществить опе-
рацию сдвига, введя из входного потока очередной входной символ, напри-
мер символ аб Т, а символ, помечающий состояние t (к, а), занести в стек;
в) перемещение приема: если находящийся в вершине стека символ по-
мечает приводящее состояние, которому соответствует единственная про-
дукция, имеющая в своей левой части исходный символ S, например S ->а,
тогда при условии, что в стеке находится ровно |а| + 1 символов, прием стро-
ки завершается и алгоритм заканчивает функционирование.
г) аварийное перемещение: если ни одно из вышеперечисленных переме-
щений осуществить невозможно, то ситуация считается аварийной, и либо
входная строка признается ошибочной и функционирование алгоритма
прекращается, либо предпринимаются попытки исправить ошибки.
Вернемся к примеру и проиллюстрируем сказанное, занеся предваритель-
но в стек последовательность [ [] [] ] [] $. Алгоритм разбора представлен
в табл. 8.6.
Таблица 8.6
Содержимое стека Выполняемое действие Содержимое стека Выполняемое действие
1 Сдвиг стека с занесением символа [ 1, 2, 3 Сдвиг стека с занесением символа ]
1,2 Сдвиг стека с занесением символа [ 1, 2, 3, 8 Приведение с помощью про- дукции В -► (А ]
1,2,2 Сдвиг стека с занесением символа ] 1,7 Приведение с помощью про- дукции А -► В
1,2, 2,9 Приведение с помощью про- дукции В -* [] 1,4 Сдвиг стека с занесением символа [
1,2,7 Приведение с помощью про- дукции А ->В 1,4, 2 Сдвиг стека с занесением символа ]
1,2,3 Сдвиг стека с занесением символа [ 1,4, 2, 9 Приведение с помощью про- дукции В -* []
1,2, 3,2 Сдвиг стека с занесением символа ] 1,4,6 Приведение с помощью про- дукции А -+АВ
1, 2, 3,2, 9 Приведение с помощью про- дукции В -* [] 1,4 Сдвиг стека с занесением символа $
1,2,3,6 Приведение с помощью про- дукции Л -+АВ 1,4,5 Строка принята
Если рассматриваемая грамматика является LR (0) -грамматикой, то
построение характеристического автомата грамматики легко поддается
формализации. Если формализация осуществлена, то задача разработки син-
122
таксического анализатора значительно упрощается. К сожалению, реаль-
ная грамматика редко удовлетворяет условиям, достаточным, чтобы быть
LR (0) -грамматикой. Тем не менее принципы LR-разбора успешно применя-
ются в самых сложных случаях, что делает этот метод поистине мощным
инструментом для программирования.
£7? (1)-ГРАММАТИКИ
Рассмотрим грамматику (74, которая имеет продукции вида
5-Е?,
Е-Е+Т|Т,
Т-Тх F|F,
F —а|(Е),
Характеристический автомат грамматики (74 показан на рис. 8.4.
Грамматика (74 не является LR (0) -грамматикой, так как, например,
ТЕ LRCONTEXT (Е-Т), но ТХa G LRCONTEXT(F->а) и TXF G
G LRCONTEXT (T-+TXF). Таким образом, если в данный момент в стеке
находится последовательность символов {1,6}, то однозначно указать, ка-
кое перемещение - приведения или сдвига — необходимо осуществить,
невозможно. Решить эту проблему можно, ’’заглянув на один символ впе-
ред”. Если очередной входной символ имеет вид х, то автомат должен выпол-
нить перемещение сдвига, в противном случае автомат должен осуществить
перемещение приведения. Грамматики, подобные грамматике (74, принято
называть LR (1) -грамматиками, для таких грамматик описанный синтакси-
ческий анализатор должен быть модифицирован (пополнен функцией анали-
Таблица. приведения
123
за и разрешения конфликтных ситуаций с помощью дополнительной инфор-
мации о виде очередного символа входной строки). Вообще, если граммати-
ка является LR (к) -грамматикой (к > 0 — целое число), конфликтные ситуа-
ции, возникающие при функционировании ее характеристического автома-
та, должны разрешаться с помощью дополнительной информации о виде к
очередных входных символов. Случай к = 1 очень важен, поэтому мы оста-
новимся на нем подробно.
Пусть G = (N, Т, Р, S) — произвольная пополненная грамматика. Единст-
венная продукция этой грамматики, содержащая символ $, имеет вид S -►
ЕЕ N. Определим ЬК(1)СО№ГЕХТ-множество для продукции А->(3:
LR( 1) CONTEXT(А-► Р) = {а|а = yf}ae(Nи Т)*Т, где№>уАах=>
=> урах — правосторонняя схема вывода;
aeT, хеТ*, ye(N\j Т)*}.
Если аЕ LRCONTEXT(A->0), то а = а а для некоторых аЕ LRCONTEXT(A->
и аЕ Т — символ, информация о виде которого так необходима анали-
затору. Обобщая теорему 8.1, сформулируем следующее определение:
пусть G = (N, Т, Pt 8) - пополненная контекстно свободная грамматика,
G называют LR (1)-грал<л<аликой <=> aeLR(l)CONTEXT(A->Р) и axe
eLR(l) CONTEXT(B-*P'), где А-Д B^fi'eP, ae(N^T)* и хе Г? то х=е,
А = В и Д = Д'.
Таким образом, для того чтобы проверить, является ли рассмотренная
грамматика G £ А (1)-грамматикой, необходимо найти LR(1)CONTEXT-
множества для каждой продукции этой грамматики. Пусть AEN и аЕ
Е FOLLOW (А), определим новую функцию:
LEFT/A, а) = {у|$ *>уАах - правосторонняя схема вывода, хеТ*}.
Из этого следует, что
LR (1) CONTEXT (А->Д) = |J LEFT/A, a)-{0a}.
a€F0LL0W(4)
Найдем теперь все LEFT!-множества. Сделать это можно аналогично тому,
как мы находили все LEFT-множества. Прежде всего, еслиВ->У1Ау2 - про-
дукция грамматики G, ЬЕ FOLLOW (В), а аЕ {FIRST(х) |y2Z?^x}, то, оче-
видно, а Е FOLLOW (А) и LEFTj (A, a) D LEFTj (В, b) -{у^ .
Таким образом, можно построить систему уравнений для LEFTi-множества
и, как в случае LEFT-множеств, полученные уравнения будут соответство-
вать линейной слева грамматике. Таким образом, LEFT j -множества регуляр-
ны, а следовательно, LR(1) CONTEXT-множества также регулярны. Исходя
из грамматики, определяющей LEFTj-множества, можно построить детер-
минированный конечный автомат, который, в свою очередь, будет опреде-
лять LR(l)CONTEXT-мнoжecтва. Если рассматриваемая грамматика явля-
ется LR (1) -грамматикой, то построенный детерминированный конечный
автомат можно использовать для построения синтаксического анализатора
аналогично тому, как был использован характеристический автомат LR (0) -
грамматики. К сожалению, автомат, полученный для £7? (1)-грамматики,
как правило, имеет очень много состояний, и потому построить его доволь-
124
но трудно. В связи с этим доказать, что данная пополненная грамматика яв-
ляется (или не является) LR (1) -грамматикой, иногда проще каким-либо
другим способом, например наложив на эту грамматику ряд довольно силь-
ных ограничений, называемых также условиями простоты LR (1) -граммати-
ки. Определим теперь функцию SLR(l)CONTEXT1 на множестве, состоя-
щем из продукции Л грамматики, следующим образом:
SLR (1) CONTEXT (Л - /}) = LRCONTEXT (Л - р) FOLLOW (Л).
Согласно определению, LR(1) CONTEXT-множество некоторой продукции
является подмножеством ее SLR(l)CONTEXT-мнoжecтвa.
Итак, пополненная грамматика G = (N, T,P,S) является простой LR (1)-
грамматикой SLR (1) CONTEXT (Л ->0) и ах G SLR (1) CONTEXT
->Pi), где В->р' ЕР, aG (MJT)*, xG Г», то х = Е, А = В,Р=р'.Не-
посредственным следствием этих определений является следующая теорема.
ТЕОРЕМА 8.4
Любая SLR(l)-грамматика является ЕЯ(1)-грамматикой. Обратное не-
верно (см. упр. 8.5). Пусть <74 — 5ЕЯ(1)-грамматика. С помощью методов,
описанных в гл. 7, легко найти соответствующие ей FOLLOW-множества:
FOLLOW(S) = 0,
FOLLOW(E) = { +,),$},
FOLLOW(T) = { x, + ,)J},
FOLLOW(F) = { x,+ ,),£}.
И, следовательно, SLR(1)CONTEXT-множества грамматики, характеристи-
ческий автомат которой изображен на рис. 8.4, удовлетворяют условиям
простоты. Воспользуемся этим выводом и построим LR-анализатор для
грамматики (74. Известно, что любой возникший при функционировании
характеристического автомата конфликт может быть разрешен знанием ви-
да очередного входного символа. Проиллюстрируем сказанное, осуществив
синтаксический разбор строки а + а Ха + а$ (табл. 8.7).
Итак, в результате разбора с помощью построенного синтаксического
анализатора будет получено дерево вывода. Дополнить анализатор функция-
ми семантического разбора можно без особого труда. Предположим, напри-
мер, что перед нами стоит задача получить семантические деревья, соответ-
ствующие арифметическим выражениям, порожденным грамматикой (74.
Это можно сделать, например, поставив в соответствие каждому элементу X
текущего префикса сентенциальной формы семантическое дерево, соответ-
ствующее поддереву дерева вывода, у которого символом X помечен корень
(обозначим его Тх). В таком случае после осуществления операции сдвига к
текущему префиксу присоединяется еще один символ, например а. Соот-
ветствующее этому символу дерево Та имеет, очевидно, лишь один узел ®.
Если же осуществлена операция приведения с помощью продукции А -►
• -Xfc, то самая правая подстрока текущего префикса сентенциаль-
1 В аббревиатуре SLR буква S от слова Symple - простой. - Прим. ред.
125
Таблица 8.7
Содержимое стека Выполняемое действие
1 1,4 1,3 1,6 Сдвиг стека с занесением символа а Приведение с помощью продукции F -> а Приведение с помощью продукции T^F Приведение с помощью продукции Е^Т (просмотр входной стро- ки на один символ вперед)
1, 2 1, 2, 8 1, 2, 8,4 1, 2, 8, 3 1, 2, 8, 11 Сдвиг стека с занесением символа + Сдвиг стека с занесением символа а Приведение с помощью продукции F ->а Приведение с помощью продукции T^F Сдвиг стека с занесением символа X (просмотр входной строки на один символ вперед)
1,2,8, 11, 10 1, 2, 8, 11, 10,4 1, 2, 8, И, 10, 13 1,2,8, 11 Сдвиг стека с занесением символа а Приведение с помощью продукции F Приведение с помощью продукции T^>TxF Приведение с помощью продукции Е -» Е+Т (просмотр входной строки на один символ вперед)
1,2 1,2,8 1, 2, 8,4 1,2, 8, 3 1, 2, 8, И Сдвиг стека с занесением символа + Сдвиг стека с занесением символа а Приведение с помощью продукции F ->а Приведение с помощью продукции T->F Приведение с помощью продукции Е Е + Т (просмотр входной строки на один символ вперед)
1,2 1, 2, 7 Сдвиг стека с занесением символа $ Строка принята
ной формы, совпадающая со строкой будет заменена на сим-
вол А. Семантическим правилом, ассоциированным с такой операцией приве-
дения, называют правило, описывающее дерево ТА как совокупность подде-
ревьев Тх^, Ту2,...,Ту£- Достаточным условием успешного завершения
синтаксического разбора является осуществление перемещения, в результа-
те которого текущий префикс сентенциальной формы грамматики будет со-
держать лишь один символ S, а одновременно с деревом вывода будет полу-
чено и семантическое дерево Ts.
В табл. 8.8 приведены семантические правила, ассоциированные с продук-
циями грамматики .
Таблица 8.8
Приведение Семантическое правило
S-+E$ TS- = TC
Е-+Е+Т Т£: = дерево(+ . ТЕ, Тт)
Е-*Т ТЕ: = Тт
Т-^Тх F Тт: = дерево (х, Тт, TF)
T-+F
F-+а TF- = Ta
F->(Е) tf- = te
126
ТЕОРЕТИЧЕСКИЕ РАССУЖДЕНИЯ
Синтаксический LR-разбор теоретически по своим возможностям превос-
ходит LL -разбор, поскольку, как было показано ранее, любая пополненная
LL (к) -грамматика является LR (к) -грамматикой. Однако существуют грам-
матики (см. упр. 8.6), которые, являясь LL (1)-грамматиками, не являются
SLR(\) -грамматиками. Любая LR (к) -грамматика обязательно порождает
детерминированный язык, но, кроме того, любой детерминированный язык
может быть порожден некоторой LR (1) -грамматикой. Таким образом,
язык порожден LR (к) -грамматикой <=► он порожден некоторой LR(1)-
грамматикой. Если язык удовлетворяет условию собственности префик-
сов, то он может быть порожден LR (0)-грамматикой. Условие собственнос-
ти префиксов означает, что если х — строка некоторого языка, то никакой
ее собственный префикс не принадлежит этому же языку. Таким образом,
если грамматика использует маркер конца ввода $, то всякий порожденный
ею язык удовлетворяет условию собственности префиксов и, следователь-
но, может быть порожден LR (0) -грамматикой. На практике разработчики
компиляторов, как правило, используют LR (1) -грамматики, предпочитая
им, однако, более простой случай SLR (1)-грамматики. Если у вас будет по-
требность убедиться в справедливости этих утверждений или вы захотите
заняться теоретическими исследованиями в этой области, обратитесь к кни-
ге Хопкрофт Дж. Е., Ульман Дж. Д. Формальные языки и автоматы: Пер. с
англ. — М.: Мир, 1982. — 346 с. или к книге Бекхауз Р. Ч. Синтаксис языков
программирования: Пер. с англ. — М.: Мир, 1986. - 281 с. Читателям, интере-
сующимся практической разработкой компиляторов, рекомендуем прочи-
тать книгу Ахо А. В., Ульман Дж. Д. Принципы машинного проектирования:
Пер. с англ. — М.: Мир, 1983. - 352 с. в которой обсуждается один из вариан-
тов грамматики, известный под названием LALR-грамматики.
УПРАЖНЕНИЯ
8.1. Пусть G = (А, Т, Р, S) - произвольная контекстно свободная грамматика, а £ и
F - некоторые отношения, определенные на Au Т следующим образом:
XFY *=> грамматика G имеет продукцию вида X -* Yy, уЕ (Аи Г) *,
XLY *=>грамматика G имеет продукцию вида X ~+yY, уЕ (Au Г) *
Пусть R+, R* и R"1 обозначают соответственно транзитивное замыкание отношения R,
рефлексивное замыкание транзитивного замыкания отношения R и отношение, обрат-
ное отношению R- Покажите, что (<•) = (i) (F+) и (• >) = (£+)"1 (=) (F*). Отношения
=, Fj.m L вычисляются легко. Вычислить отношения F+ и L+ можно с помощью алго-
ритма Уоршелла, опубликованного в журнале JACM за январь 1962 г. F* = F + и/, где
I - отношение тождественности. Исходя из этого легко вычислить отношения <• и •>).
8.2. Вычислить перечисленные в предыдущем упражнении отношения для граммати-
ки, имеющей продукции вида
S^AJ
А ^аАВС\СВ,
В^аВ\С,
С-+Ъ.
Является ли она грамматикой простого предшествования?
127
8.3. Покажите, что грамматика, описанная в упр. 8.2, является LR (0) -грамматикой,
для чего постройте ее характеристический автомат.
8.4. Покажите, что грамматика, имеющая продукции вида
S->А,
А ~^АЪ\ЬВа,
В -+аАс\а\аАЬ>
не является LR (0)-грамматикой, но является SLR (1) -грамматикой.
8.5. Пусть G = (N, Т, Р, S) - произвольная контекстно свободная грамматика ик -
положительное целое число. Предположим, что G - пополненная грамматика и каждая
строка языка L (<7) оканчивается к символами $. Определим следующую функцию:
FOLLOW^ (Л) = {х| длина (х) =к и S =>ухАху2 для некоторых yt, у2 G Т*}.
В таком случае, SLR (к) CONTEXT - множество продукций A -+Q грамматики G - мо-
жет быть определено следующим образом:
SLR(fc)CONTEXT (А ^0) = LRCONTEXT(Л 0) • FOLLOW*. (Л).
Используя эти определения, определите SLR (^)-грамматику, для чего покажите, что
грамматика, продукции которой имеют вид
5-Л$,
Л ^BaCD,
в-ь,
С-В\Еа>
D-*ba\Dba,
E^b,
для любого к > 0 является LR (1)-грамматикой, но не является SLR (к) -грамматикой.
8.6. Покажите, что грамматика, имеющая продукции вида
5-Л$,
Л -+ВаВЬ\СЬСа,
С —► Е
является LL (1)-грамматикой, но не является SLR (1)-грамматикой.
8.7. Обобщите определение LR (1)-грамматики на случай LR (к) -грамматики.
8.8. Напишите программу на языке программирования Паскаль, которая осуществ-
ляет синтаксический разбор простых арифметических выражений. Ваша программа
должна разбирать все корректные арифметические выражения, составленные из пере-
менных а, Ьу . . . , г ив качестве результата выдавать соответствующие им семантичес-
кие деревья. В случае некорректного арифметического выражения программа должна
выдавать соответствующее сообщение.
ОГЛАВЛЕНИЕ
Предисловие редактора перевода........................................ 5
Предисловие........................................................... 6
Введение ............................................................. 8
Глава 1. МАТЕМАТИЧЕСКОЕ ПРЕДИСЛОВИЕ...................................12
Множества..........................................................12
Мощность и счетность множества.....................................15
Произведения множеств..............................................17
Графы и деревья....................................................20
Строки.............................................................22
Упражнения.........................................................24
Глава 2. ВВЕДЕНИЕ В ГРАММАТИКИ........................................25
Контекстная грамматика.............................................27
Контекстно свободные грамматики....................................30
Грамматический раэбор арифметических выражений.....................33
Пустая строка в определении контекстно свободной грамматики........35
Упражнения.........................................................37
Глава 3. РЕГУЛЯРНЫЕ ЯЗЫКИ, I..........................................39
Регулярные грамматики..............................................40
Конечный автомат...................................................43
Конечный автомат с ^-переходами....................................51
Упражнения.........................................................53
Г л ав а 4. РЕГУЛЯРНЫЕ ЯЗЫКИ, II......................................54
Регулярные выражения...............................................54
Минимизация........................................................57
Алгоритмы определения регулярности грамматики......................62
Упражнения.........................................................63
Г л а в а 5. КОНТЕКСТНО СВОБОДНЫЕ ЯЗЫКИ...............................64
Нормальная форма Хомского..........................................66
Нормальная форма Грейбаха..........................................71
Контекстно свободный язык как решение уравнения....................76
Упражнения.........................................................78
Г л а в а 6. МАГАЗИННЫЙ АВТОМАТ.......................................79
Недетерминированный магазинный автомат.............................80
Недетерминированные магазинные автоматы и контекстно свободные языки. ... 84
Детерминированные магазинные автоматы..............................88
Упраженения........................................................93
Г л а в а 7. СИНТАКСИЧЕСКИЙ АНАЛИЗ ’’СВЕРХУ ВНИЗ”.....................94
LL (К)-грамматики..................................................96
Рекурсивный спуск.................................................103
Упражнения........................................................109
Глава 8. СИНТАКСИЧЕСКИЙ РАЗБОР ’’СНИЗУ ВВЕРХ”.........................110
Грамматика простого предшествования...............................112
LR (0) -грамматики................................................115
LRW -грамматики...................................................123
Теоретические рассуждения.........................................127
Упражнения........................................................127
р
: j|В.Дж.Рейуорд-Смит
Ш! ТЕОРИЯ В
ФОРМАЛЬНЫХ
га языков и
В Дж Рейуорд-Смит
ТЕОРИЯ
ФОРМАЛЬНЫХ
ЯЗЫКОВ
ВВОДНЫЙ КУРС
В книге автора из
Великобритании изложены
основы теории формальных
языков. Использован
математический аппарат
теории множеств, теории
графов и математической
логики. Все сведения,
необходимые для понимания
рассмотренных в книге
вопросов, приведены в
соответствующих главах.
Удачно подобранные задачи
в конце каждой главы нс
только поясняют, но и
дополняют основной
материал книги.
Для разработчиков
программного обеспечения
ЭВМ.