/












































































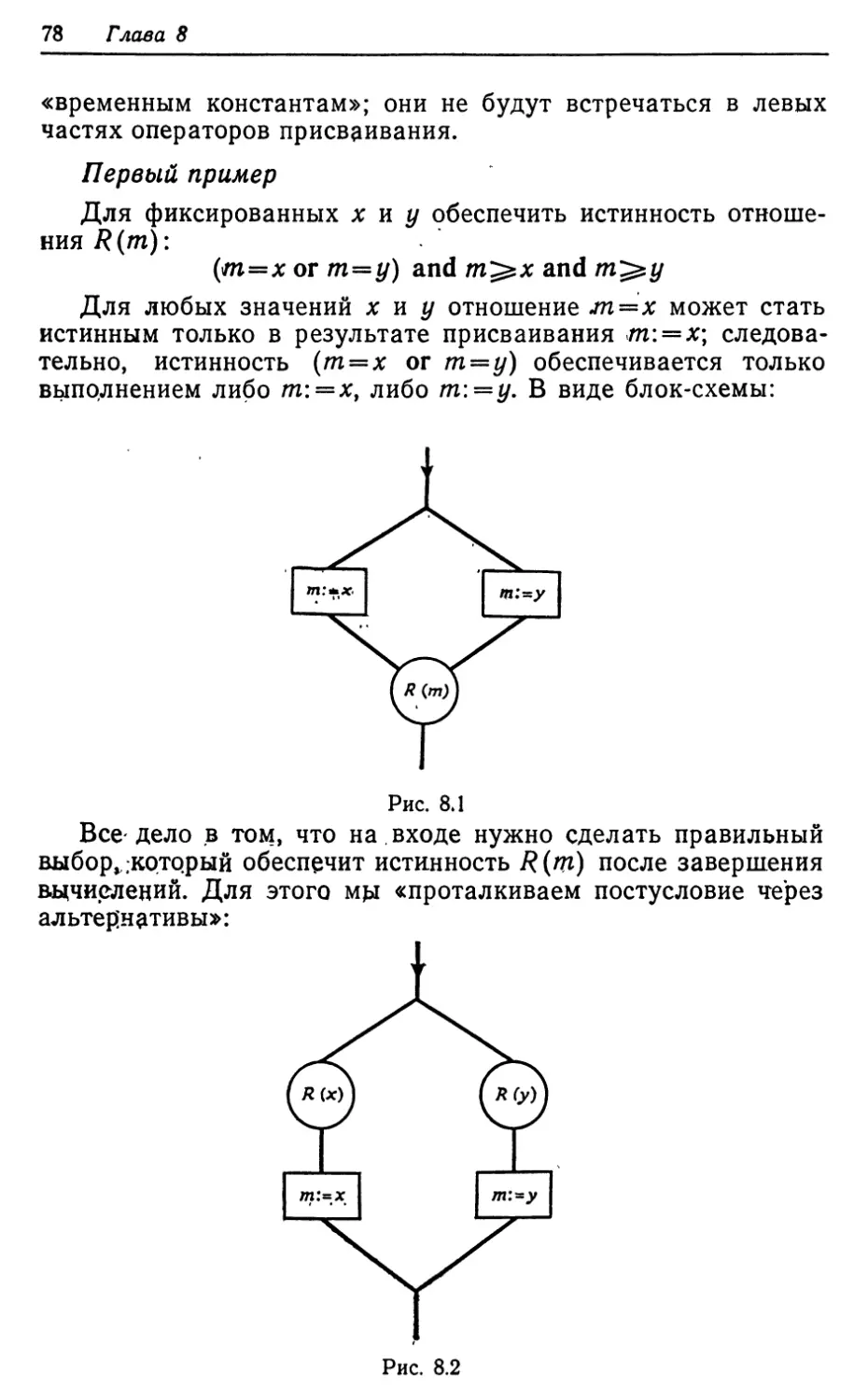











































































































































































































Текст
A DISCIPLINE OF PROGRAMMING
EDSGER W. DIJKSTRA
Burroughs Research Fellow,
Professor Extraordinarius,
Technological University, Eindhoven
PRENTICE-HALL, INC.
ENGLEWOOD CLIFFS, N. J.
1976
МАТЕМАТИЧЕСКОЕ
ОБЕСПЕЧЕНИЕ
ЭВМ
З.Дейкстра
ДИСЦИПЛИНА
ПРОГРАММИРОВАНИЯ
Перевод с английского
И. X. Зусман,
В. В. Мартынюка и
Л. В.' Ухова
Под редакцией
Э. 3. Любимского
ИЗДАТЕЛЬСТВО
«МИР»
Москва 1978
УДК 681.142.2
Книга написана одним из крупнейших зарубежных специа-
листов в области программирования, известным советскому чи-
тателю по переводам его книг на русский язык (например, «Струк-
турное программирование», «Мир», 1972). Она посвящена фунда-
ментальным вопросам конструирования корректных и изящных
программ для ЭВМ. В ней предлагается методика формального
вывода программы из математической» постановки задачи. При
этом прослеживается развитие алгоритмов вплоть до создания
программ. Материал излагается в форме остроумных и поучи-
тельных задач по программированию.
Книга представляет значительный интерес для широкого кру-
га программистов.
Редакция литературы по математическим наукам
Original English language edition published by Prenttee-
Hall Inc., Englewood Cliffs New Jersey USA Copyright
©1976 by Prentice-Hall Inc. All Rights Reserved
20204-033
Д-------------33-78
041(01)-78
©Перевод на русский язык, «Мир», 1978
ПРЕДИСЛОВИЕ РЕДАКТОРА ПЕРЕВОДА
Программирование богато и многообразно. Ведь кажется
яет такой- сферы человеческой деятельности, где нельзя было
бы с пользой применить вычислительную машину для оценки,
информационно-справочного обслуживания, планирования,
моделирования и т. п. И это многообразие задач переходит в
многообразие программ, которые должны разрабатывать
программисты. Они пытаются справиться с этим многообрази-
ем, «заключив» его в проблемно-ориентированные языки про-
граммирования. Языки вбирают в себя специфические черты
конкретных сфер программирования — характерные структу-
ры данных, принципы организации типичных процессов, соот-
ветствующую терминологию — и таким образом делают сам
процесс программирования более универсальным. Одновре-
менно они освобождают программистов от необходимости де-
тализировать программы до уровня слишком мелких машин-
ных команд и даже от необходимости знать особенности кон-
кретных вычислительных машин. Более того, операционные
системы призваны превратить вычислительные машины из
предмета постоянного беспокойства в «существа», которые
сами заботятся о программисте и готовы оказывать всяче-
ские услуги ему и его программе.
И тем не менее, после того, как любая более или менее
сложная задача сформулирована (пусть даже в адекватных
и удобных терминах) и машина выбрана (пусть даже в самом
деле готовая к всевозможным услугам), каждый программист
снова и снова остается один на один со своей собственной за-
дачей: ему нужно составить программу! Выбрать, как именно
следует расположить и связать данные в памяти, понять, ка-
кая именно последовательность операторов, — способных сде-
лать все что угодно и оттого одновременно и податливых и
опасных — выполнит поставленную задачу. И как организовать
эти операторы в цикл, который будет с каждым шагом при-
ближать машину к намеченной цели. Выбрать, понять, изо-
брести, проверить, усомниться и повторить все сначала.
6
Предисловие редактора перевода
Показательно, что хотя в таких «внешних» разделах про-
граммирования, как языки и трансляторы, операционные си-
стемы и базы данных, широко развивается и используется тео-
рия (от математической лингвистики и логики до статистики
и теории массового обслуживания), во внутренних, собствен-
ных разделах программирования господствуют умение и ин-
туиция или в лучшем случае «полезные советы». Есть, прав-
да, некоторые исследования, касающиеся уже готовых
программ, но нет никакой теории самого процесса программи-
рования.
Предлагаемая книга представляет собой один из первых
шагов в этом направлении. В ней с каждым оператором,
с их комбинациями и, в том числе, с циклами связываются
преобразования’предикатов, являющиеся формальным выра-
жением их свойств, и определение свойств программы
в целом превращается в задачу логического вывода. Особен-
но важно, что автор объясняет и демонстрирует на примерах,
как этим формализмом можно пользоваться для практическо-
го программирования. При этом он, разумеется, не дает отве-
та на вопрос о том, как написать любую программу, — ответа
на этот вопрос вообще не существует. Он предлагает нам ин-
струмент, позволяющий проверять наши гипотезы в процессе
проектирования программ, а иногда и подсказывающий те или
иные варианты решений.
А это совсем не мало. Представьте себе человека, живу-
щего в эпоху зарождения математического анализа, которо-
му нужно находить неопределенные интегралы от весьма гро-
моздких подынтегральных выражений и который знает толь-
ко определение первообразной функции и не знает никаких
приемов интегрирования. Каким для него было бы подспорь-
ем, если бы ему сообщили о правиле интегрирования по час-
тям или о таком приеме, как замена переменных! Его работа
не перестанет быть творческой, но насколько расширятся его
возможности и как много перейдет из области находок в об-
ласть техники. То, что было сложным, станет простым, то,
что было непосильным, станет только сложным. Систематиче-
ское использование, обобщение и расширение этих приемов
позволит постепенно перейти к формализации, алгоритмиза-
ции, а затем и к автоматизации отдельных этапов решения
или полного решения специальных классов задач.
Автор книги, Э. Дейкстра, не нуждается в представле-
нии,— его работы хорошо известны советским программистам.
Вместе с Ч. Хоар.ом они недавно совершили поездку по круп-
нейшим городам нашей страны, во время которой выступили
с лекциями перед многочисленными аудиториями.
Предисловие редактора перевода
7
О структуре и стиле книги достаточно полно сказано в
предисловии автора. Там же он предупреждает, чю чи ia н>
•его книгу трудно. Причина этого заключается в сложности
самих программ, послуживших для нее материалом Я хотел
бы добавить, что они сложны для нас только сейчас, когда
теория программирования делает свои первые шаги. Придет
время, и такие программы сможет составлять (или выводить)
прямо на уроке каждый школьник II чтобы это время при-
близить, надо осваивать, внедрять и ра шивать теорию Л этот
процесс легко не проходит.
Перевод предисловия и глав 1—7 выполнен В. В-Мар-
тынюком, глав 8—21 — И. X. Зусман, . глав 22—27—
Л. В. Уховым.
Э. 3. Любимский
ПРЕДИСЛОВИЕ
Историки таких древних интеллектуальных дисциплин,
как поэзия, музыка, живопись и наука, высоко оценивают
роль выдающихся практиков, чьи достижения обогатили опыт
и расширили представления поклонников этих дисциплин,
пробудили и укрепили таланты последователей. То новое, что
ими внесено, основывается на сочетании виртуозного практи-
ческого мастерства и проницательного осмысливания фунда-
ментальных принципов. Во многих случаях влияние этих лю-
дей усиливалось благодаря их высокой культуре, богатству
и выразительности их речи.
В этой книге в присущем ее автору утонченном стиле пред-
ставлена принципиально новая точка зрения на существо
программирования. Исходя из этой точки зрения, автор раз-
работал совокупность новых методов программирования и
средств обозначения, которые демонстрируются и проверяют-
ся на многочисленных изящных и содержательных примерах.
Этот труд, несомненно, будет признан одним из выдающихся
достижений в разработке новой интеллектуальной дисципли-
ны — программирования для вычислительных машин.
Ч. А. Р. Хоар
ОТ АВТОРА
Уже давно мне хотелось написать книгу такого рода. Я
знал, что программы мбгут очаровывать глубиной своего ло-
гического изящества, но мне постоянно приходилось убеж-
даться, что большинство из них появляются в виде, рассчитан-
ном на механическое исполнение, но совершенно непригодном
для человеческого восприятия — где уж там говорить об изя-
ществе. Меня не удовлетворяло и то, что алгоритмы часто пуб-
ликуются в форме готовых изделий, почти без упоминания
тех рассмотрений, которые проводились в процессе разработ-
ки и служили обоснованием для окончательного вида завер-
шенной программы. Сначала я задумал изложить некоторое
количество изящных алгоритмов таким способом, чтобы чи-
татель смог прочувствовать их красоту; для этого я собирался
каждый раз описывать истинный или воображаемый процесс
построения, который приводил бы к получению искомой про-
граммы. Я не изменил своему первоначальному намерению в
том смцсле, что основой этой монографии остается длинная
последовательность глав, в каждой из которых ставится и
решается новая задача. Тем не менее окончательный вариант
книги существенно отличается от ее первоначального замысла,
поскольку возложенная мною на себя обязанность представ-
лять решения в естественной и убедительной манере повлекла
за собой гораздо большее, чем я ожидал, и я навсегда сохраню
чувство благодарности еудьбе за то, что взялся за эту работу.
Когда начинаешь писать подобную книгу, сразу возникает
проблема: каким языком программирования пользоваться?
И это не только вопрос представления! Наиболее важным, но
в то же время и наиболее незаметным свойством любого инст-
румента является его влияние на формирование привычек
людей, которые имеют обыкновение им пользоваться. Когда
этот инструмент — язык программирования, его влияние, не-
зависимо рт нашего желания, сказывается на нашем способе
мышления. Проанализировав в свете этого влияния все извест-
ные мне языки программирования, я пришел,к выводу, что
ни они сами, ни их подмножества не подходят Для моих це-
лей. С другой стороны, я считал себя настолько не подготов-
10 От автора
ленным к созданию нового языка программирования, что дал
зарок не заниматься этим в ближайшее пятилетие, и я твер-
до знаю, что этот срок еще не вышел. (Прежде, помимо все-
го прочего, мне нужно было написать эту монографию.) Я по-
пытался выбраться из этого тупика, создав лишь подходящий
для моих целей мини-язык и включив в него только те элемен-
ты, которые представляются совершенно необходимыми и до-
статочно обоснованными.
Эти мои колебания и самоограничение, если их неправиль-
но понять, могут разочаровать многих потенциальных чита-
телей. Наверняка разочаруются все те, кто отождествляет
трудность программирования с трудностью изощренного ис-
пользования громоздких и причудливых сооружений, извест-
ных под назвацием «языки программирования высокого уров-
ня» или — еще хуже! — «системы программирования». Если они
сочтут себя обманутыми из-за того, что я вовсе не касаюсь всех
этих погремушек и свистулек, могу ответить им только одно:
«А вполне ли вы уверены, что все эти погремушки и свистуль-
ки, все эти потрясающие возможности ваших, так сказать,
«мощных» языков программирования имеют отношение к про-
цессу решения, а не к самим задачам?» Мне остается лишь на-
деяться, что, несмотря на употребление мною мини-языка, они
все же прочтут предлагаемый текст. ’ Тогда они, возможно,
признают, что помимо погремушек и свистулек имеется очень
богатое содержание и возникнет вопрос, стоило ли большин-
ство из них вообще придумывать. А всем читателям, интере-
сующимся преимущественно разработкой языков программи-
рования, я могу только принести извинения в связи с тем, что
еще не могу высказаться на эту тему более определенно. Тем
временем эта монография, возможно, наведет их на некото-
рые размышления и поможет им избежать ошибок, которые
они могли бы совершить, если бы не прочли ее.
Процесс работы над книгой, который явился для меня не-
прерывным источником удивления и'вдохновения, привел к
появлению текста, основательно отличающегося от первона-
чального замысла. Сначала у меня было вполне понятное на-
мерение представить построение программ с помощью аппа-
рата, чуть более формального чем тот, который я имел обык-
новение использовать в своих вводных лекциях, где семантика
обычно вводилась интуитивно, а доказательства правильности
представляли собой смесь строгих рассуждений, жестикуля-
ции и красноречия. Разрабатывая необходимые основы для
более формального подхода, я обнаружил два неожиданных
обстоятельства.
От автора
11
Первая неожиданность состояла в том, что так называемые
«преобразователи предикатов», выбранные мною в качестве
средства изъяснения, позволили прямо определять связь меж-
ду начальным и конечным состояниями без каких-либо ссылок
на промежуточные состояния, которые могут возникать во время
выполнения программы. Я обрадовался тому, что это дает
возможность провести четкое разграничение двух основных
проблематик программирования: проблематики математиче-
ской корректности (речь идет о проверке, определяет ли про-
грамма правильное соотношение между начальным и конеч-
ным состояниями — и преобразователи предикатов обеспечи-
вают нам формальное средство для такого исследования без
рассмотрения вычислительного процесса) и инженерной про-
блематики эффективности (благодаря разграничению стано-
вится очевидным, что последняя проблематика определена
только в связи с реализацией). Пожалуй, самое полезное
открытие состоит в том, что один и тот же текст программы
всегда допускает две (в известном смысле дополняющие друг
друга) интерпретации. Интерпретация в виде кода преобра-
зователей предикатов, Которая представляется более подхо'-
дящей для нас, противостоит интерпретации в виде кода для
выполнения — ее я предпочитаю оставлять машинам!
Второй неожиданностью оказалось то, что самые естест-
венные и систематизированные «коды преобразователей пре-
дикатов», какие я мог себе представить, потребовали бы не-
детерминированной реализации, если рассматривать их как
«коды для выполнения». Вначале я содрогался от мысли, что
придется ввести недетерминированность уже в однопрограм-
мном режиме (слишком хорошо мне были известны сложности,
возникающие из-за этого в мультипрограммировании); однако
потом я понял, что интерпретация текста как кода преобразо-
вателя предикатов имеет право на независимое существова-
ние. (Оглядываясь назад, мы можем отметить, что многие
проблемы мультипрограммирования, ставившие нас прежде
в тупик, являются всего лишь следствием априорной тенден-
ции придавать детерминированности слишком большое зна-
чение.) В конце концов я пришел к тому, что стал считать не-
детерминированность естественной ситуацией, при этом де-
терминированность свелась к довольно банальному частному
случаю.
Установив эти основы, я приступил, как и намеревался, к
решению длинной последовательности задач. Это занятие ока-
залось неожиданно увлекательным. Я убедился в том, что
формальный аппарат позволяет мне ухватывать существо дела
гораздо четче, чем-раньше. Я получил удовольствие, обнару-
жив, что явная постановка вопроса о завершимости может
12 От автора
иметь большое эвристическое значение; тут я даже начал со-
жалеть об излишне распространенной склонности к частичной
корректности. Но самое приятное состояло в том, что боль-
шинство решенных мною ранее задач теперь увенчалось более
изящными решениями. Я воспринял это как весьма ободря-
ющее свидетельство того, что разработанная методика и в са-
мом деле улучшила мои программистские возможности.
Как следует изучать эту монографию? Лучшёе, что я могу
посоветовать: прерывайте чтение, как только усвоите поста-
новку задачи, и пытайтесь сначала решить ее самостоятельно,
затем продолжайте чтение. Попытка самостоятельного реше-
ния задачи представляется единственным способом прочув-
ствовать, насколько она трудна; кроме того, вы можете срав-
нивать мое решение с вашим и получить удовлетворение, если
ваше окажется лучше. Предупреждаю заранее: не огорчай-
тесь, когда увидите, что этот текст читается отнюдь не легко.
Те, кто изучали его в рукописи, часто испытывали затруднения
(но вполне вознаграждались за это). Впрочем, каждый раз
при анализе их затруднений мы совместно убеждались в том,
что «виновным» оказывался вовсе не текст (т. е. способ из-
ложения), а сам излагаемый материал. Мораль этого может
быть только такова: нетривиальный алгоритм и вправду не-
тривиален, а его окончательная запись на языке программи-
рования слишком лаконична по сравнению с рассуждениями,
обосновывающими его разработку; эта краткость окончатель-
ного текста не должна нас дезориентировать. Один из моих
сотрудников внес предложение (а я довожу его до вашего
сведения, поскольку оно может оказаться полезным), чтобы
небольшие группы студентов изучали книгу вместе. (Здесь я
должен добавить в скобках замечание по поводу «трудности»
этого текста. Посвятив немало лет своей научной жизни тому,
чтобы прояснить задачи программиста и сделать их более
подвластными нашему интеллекту, я обнаружил с удивлением
(и раздражением), что мое стремление внести ясность приво-
дит к систематическим обвинениям в том, что я «внес в про-
граммирование трудности». Но эти трудности всегда в нем
были; и только сделав их видимыми, мы сможем надеяться,
что научимся разрабатывать программы с высокой степенью
надежности, а не просто «лепить команды», т. е. выдавать
тексты, основанные на неубедительных предположениях, не-
состоятельность которых может выявиться после первого
же противоречащего примера. Незачем и говорить, что ни
-одна программа из этой монографии не проверялась на ма*
.шине.)
От автора 13
Я должен объяснить читателю, почему я пользуюсь мини-
языком, столь ограниченным, что в нем нет даже процедур и
рекурсий. Поскольку каждое следующее расширение языка
добавляло бы к этой книге еще несколько глав, тем самым со-
ответственно увеличивая ее стоймюсть, отсутствие большинст-
ва возможных расширений (таких, как, например, мультипро-
граммирование) не нуждается в дополнительных оправданиях.-
Однако процедуры всегда занимали такое важное место, а ре-
курсия для вычислительной науки в такой степени считалась
признаком академической респектабельности, что некоторое
разъяснение представляется необходимым.
Прежде всего эта книга предназначена не для начина-
ющих, и я рассчитываю, что мои читатели уже знакомы с ука-
занными понятиями. Во-вторых, книга не является вводным
текстом по какому-то конкретному языку программирования,
такччто отсутствие в ней этих конструкций и примеров их
употребления не следует объяснять моей неспособностью или
нежеланием ими пользоваться или же воспринимать как на-
мек на то, что вообще лучше воздерживаться от их примене-
ния. Просто они не потребовались мне для разъяснения моей
главной мысли о том, насколько существенно тщательное раз-
граничение проблематик для разработки всесторонне высоко-
качественных программ; скромные средства мини-языка
предоставляют нам более чем достаточный простор для нетри-
виальных и в то же время вполне приемлемых разработок.
Можно обойтись этим объяснением, но оно все же не яв-
ляется исчерпывающим. Я все равно считал себя обязанным
ввести повторение как самостоятельную конструкцию, по-
скольку мне представлялось, что это следовало сделать уже
давно. Когда языки программирования зарождались, «дина-
мическая» природа оператора присваивания казалась не очень
приспособленной к «статической» природе традиционной ма-
тематики. Из-за отсутствия соответствующей теории мате-
матики ощущали некоторые затруднения, связанные с этим
оператором, а поскольку именно конструкция повторения соз-
дает необходимость в присваиваниях переменным, математики
ощущали затруднения и в связи с повторением. Когда были
разработаны языки без присваивания и без повторений — та-
кие, как чистый ЛИСП, — многие почувствовали значительное
облегчение. Они снова ощутили под ногами знакомую почву
и увидели проблеск надежды превратить программирование
в занятие с твердой и солидной математической основой. (До
сего времени среди склонных к теоретизированию специали-
стов по машинной математике все еще широко распростране-
но мнение, что рекурсивные программы «более естественны»,
чем программы с повторениями.)
14 Or автора
Другого выхода из положения путем надежного и дейст-
венного математического обоснования пары понятий «повто-
рение» и «присваивание переменной» нам предстояло ждать
еще десять лет. А выход, как показано в этой монографии,
заключался в том, что семантику конструкции повторения
можно описать с помощью рекуррентных отношений между
предикатами, тогда как для описания семантики общей ре-
курсии требуются рекуррентные отношения между преобра-
зователями предикатов. Отсюда совершенно очевидно, почему
я считаю общую рекурсию на порядок более сложной конст-
рукцией, чем простое повторение; и поэтому мне больно смот-
реть, как семантику конструкции повторения
«while В do S»
определяют как семантику обращения
«whiledo {В, S)»
к рекурсивной процедуре (описанной в синтаксисе языка
АЛГОЛ 60):
procedure whiledo (условие, оператор)-,
begin if условие then begin оператор-,
whiledo (условие, оператор) end
end
Несмотря на формальную правильность, это мне неприят-
но, потому что я не люблю, когда, из пушки стреляют по во-
робьям, вне зависимости от того, насколько эффективно пушка
может справляться с такой работой. Для поколения теорети-
ков машинной, математики, которые подключались к этой те-
матике в течение шестидесятых годов, приведенное выше ре-
курсивное определение часто является не только «естествен-
ным», но даже «самым правильным». Однако ввиду того, что
без понятия повторения мы не можем даже описать поведе-
ние машины Тьюринга, представляется необходимым произ-
вести некоторое восстановление равновесия.
По поводу отсутствия библиографии я не предлагаю ни
объяснений, ни извинений.
Благодарности. Следующие лица оказали непосредствен-
ное влияние на разработку этой книги, либо приняв участие в
обсуждении ее предполагаемого содержания, либо высказав
замечания относительно готовой рукописи или ее частей:
К. Брон, Р. Берсталл, У. Фейен, Ч. Хоар, Д. Кнут, М. Рем,
Дж. Рейнольдс, Д. Росс, К. Шолтен, Г. Зигмюллер, Н. Вирт и
От автора 15
М. Вуджер. Я считаю честью для себя возможность публично
выразить им мою признательность за сотрудничество. Кроме
того, я весьма обязан корпорации Burroughs, создавшей мне
благоприятные условия и предоставившей необходимые
средства, и благодарен моей жене за неизменную поддержку
и одобрение.
Э. В. Дейкстра
Нейен
Нидерланды
О АБСТРАКЦИЯ ИСПОЛНЕНИЯ
Абстракция исполнения лежит в основе всего понятия «ал-
горитма» настолько глубоко, что обычно ее считают само со-
бой разумеющейся и оставляют без внимания. Ее назначение
в том, чтобы сопоставлять между собой различные вычисле-
ния. Иначе говоря, она предоставляет нам способ осмыслива-
ния конкретного вычисления как элемента большого класса
различных вычислений; мы-можем отвлечься от взаимных от-
личий элементов такого класса и, руководствуясь определени-
ем класса в целом, высказывать утверждения, применимые к
каждому его элементу, а следовательно, справедливые и для
конкретного вычисления, которое мы хотим рассматривать.
Чтобы разъяснить, что подразумевается под «вычислени-
ем», я опишу сейчас невычислительную конструкцию «получе-
ния» (преднамеренно не употребляю термина «вычисление»),
например, наибольшего общего делителя чисел 111 и 259. Она
состоит из двух картонных карточек, расположенных одна по-
верх другой. На верхней карточке написан текст «НОД
(111,259)=». Чтобы получить от конструкции ответ, мы под-
нимаем верхнюю карточку и кладем ее слева от нижней, на
которой теперь можно прочесть текст «37».
Простота карточной конструкции является большим досто-
инством, но она омрачается двумя недостатками — мелким и
крупным. Мелкий недостаток состоит в том, что хотя эту кон-
струкцию можно в самом деле использовать для получения
наибольшего общего делителя чисел 111 и 259, но помимо
этого она мало на что пригодна. Однако крупный недостаток
в том, что, как бы тщательно мы ни проверяли устройство
конструкции, наша вера в то, что она вырабатывает правиль-
ный ответ, может основываться только на нашем доверии к ее
создателю: он мог ошибиться либо при проектировании своей
машины, либо при изготовлении нашего конкретного экземп-.
ляра.
Чтобы преодолеть меньшее затруднение, мы могли бы рас-
смотреть изображение на огромном листе картона большого
18 Глава О
прямоугольного массива из сетевых точек с целыми координа-
тами хи у, удовлетворяющими отношениям О^х^бОО в
0^t/^500. Для каждой такой точки (х, у) с положительны-
ми координатами (т. е. за исключением точек на осях) мы мо-
жем выписать в соответствующей позиции значение НОД (х, у);
предлагается двумерная таблица из 250 000 элементов. С точ-
ки зрения полезности это значительное усовершенствование:
вместо конструкции, способной выдавать наибольший общий
делитель единичной пары чисел, мы имеем теперь «конструк-
цию», способную выдавать наибольший общий делитель для
любой пары из 250 000 различных пар чисел. Это много, на
особенно радоваться нечему, так как указанный ранее второй
недостаток (почему мы должны верить, что конструкция вы-
дает правильный ответ?) помножился на те же самые 250 000,
и теперь от нас требуется уже совсем безграничное доверие к ее
изготовителю.
Поэтому перейдем к рассмотрению другой конструкции.
На таком же листе картона с сетевыми- точками написаны
только числа, пробегающие значения от 1 до 500 вдоль обеих
осей. Кроме того, начерчены следующие прямые линии:
1) вертикальные линии (с уравнением х=константа);
2) горизонтальные линии (с уравнением у=константа);
3) диагонали (с уравнением х+у=константа); •
4) «линия ответа» с уравнением х=у.
Чтобы работать на этой машине, мы должны следовать
следующим инструкциям («играть по следующим правилам»).
Когда хотим найти наибольший общий делитель двух чисел
X и У, мы помещаем фишку — также поставляемую изготови-
телем— в сетевую точку с координатами х=Х и y=Y. Коль
скоро фишка не находится на «линии ответа», рассматриваем
наименьший равнобедренный прямоугольный треугольник, у
которого вершина прямого угла совпадает с фишкой, а один
из концов гипотенузы (либо ниже фишки, либо слева от нее)
находится на одной из осей. (Поскольку фишка не лежит на
линии ответа, такой прямоугольный треугольник будет иметь
на осях только одну вершину.) Затем фишка перемещается в ,
сетевую точку, совпадающую с другим концом гипотенузы.
Такое перемещение повторяется до тех пор, пока фишка не
достигнет линии ответа. После этого х-координата (или «/-ко-
ордината) окончательного положения фишки является иско-
мым ответом. .
Как нам убедиться в том, что эта машина будет выдавать
правильный результат? Если (х, у\,— любая из 249 500 точек
не на линии ответа и (х', у') —точка, в которую передвинется
фишка за”один шаг игры, то либо х'=х и у'=у—х, либо
Абстракция исполнения 19
х' = х—у и у' = у. Нетрудно доказать, что НОД(х, у) =НОД
(х', у'). Важный момент здесь состоит в том, что одно и то же
рассуждение применяется одинаково верно к 'любому из
249 500 возможных шагов! Кроме того, — и опять-таки без тру-
да— Mbi можем доказать для любой точки (х, у), где х = у
(т. е. (х, у) является одной из 500 точек на линии ответа), что
НОД(х, у) = х. И снова важный момент в том, что одинаковое
рассуждение применимо к любой из 500 точек на линии отве-
та. В-третьих, — и вновь это не составит труда — нам нужно
показать, что при любом исходном положении (X, У) конеч-
ное число шагов в самом деле перенесет фишку на линию от-
вета, и опять важно отметить, что одно и то же рассуждение
одинаково применимо к любому из 250 000 исходных поло-
жений (X, У). Три простых рассуждения, пространность кото-
рых не зависит от *1исла сетевых точек: эта миниатюра пока-
зывает, насколько велики возможности математики. Если
обозначить через (х, у) произвольное положение фишки на
протяжении игры, начатой в положении (X, У), то первая на-
ша теорема позволяет утверждать, что во время этой игры
отношение
НОД(х, у)=НОД(Х, У)
будет всегда справедливо, или — выражаясь на соответству-
ющем жаргоне — «оно сохраняет инвариантность».. Далее, вто-
рая теорема гласит, что мы можем интерпретировать х-коор-
динату окончательного положения фишки как требуемый от-
вет, а третья теорема гласит, что такое окончательное
положение существует (т. е. будет достигнуто за конечное чис-
ло шагов). И этим завершается анализ того, что мы могли бы
назвать «нашей абстрактной машиной».
Теперь нам остается убедиться в том, что лист, поступив-
ший от изготовителя, является на самом деле правильной мо-
делью абстрактной машины. Для этого нужно проверить ну-
мерацию вдоль обеих осей, а также проверить, правильно ли
проведены все прямые линии. Это несколько затруднительно,
так как предстоит исследовать объекты, число который про-
порционально W, где N (в нашем примере 500) —длина сто-
роны квадрата, но все же предпочтительнее, чем N2, число воз-
можных вариантов вычисления.
Другая машина могла бы работать не с огромным листом
картона, а с двумя девятибитовыми регистрами, в каждом из
которых можно запомнить двоичное число от 0 до 500. При
этом мы могли бы использовать один регистр для запоминания
значения х-координаты, а другой — для запоминания значения
^-координаты, соответствующей «текущему положению фиш-
ки». Перемещение тогда соответствует уменьшению содержи-
20 Глава 0
мого одного регистра на содержимое другого. Мы могли бы
реализовать арифметику самостоятельно, но, разумеется, луч-
ше, если машина сможет делать это за нас. Если мы захотим
полагаться на полученный ответ, то нам нужно уметь убеж-
даться в том, что машина правильно выполняет операции
сравнения и вычитания. В уменьшенном масштабе повторяет-
ся та же история: мы выводим единожды и на все случаи, т. е.
для любой пары n-разрядных двоичных чисел, уравнения для
устройства двоичного вычитания, а затем удостоверяемся в
том, что наша физическая машина правильно моделирует это
абстрактное устройство.
Если это устройство параллельного вычитания, то число
проверок-—пропорциональное числу элементов и их взаимо-
связей — пропорционально значению n = log2M В последова-
тельной машине сделан еще один шаг .на пути упрощения обо-
рудования за счет расхода времени.
Теперь я попытаюсь, хоть бы для своего собственного про-
свещения, уловить основной смысл приведенного примера.
Вместо того чтобы рассматривать одиночную проблему
вычисления НОД (111, 259), мы обобщили ее и подошли к ней
как к частному случаю более широкого класса проблем вы-
числения НОД’ (X, У). Стоит отметить, что мы могли бы об-
общить проблему вычисления НОД(111, 259) по-разному:
можно было бы рассматривать эту задачу как частный случай
иного, более широкого класса задач, например вычисления
НОД(111,259), НОК(1И,259), 111X259, 111+259, 111/259.
111—259, 111 259, дня недели для llL-го дня 259-го года нашей
эры и т. д. В результате мог бы появиться «процессор для
111 и 259», и для того, чтобы он выдал упомянутый выше от-
вет, нам следовало бы дать на его вход команду «НОД.
пожалуйста». Вместо этого мы предложили «НОД-вычисли-
тель», которому для получения этого ответа потребуется за-
дать на вход пару чисел «111, 259», и это совсем другая ма-
шина!
Другими словами, когда требуется выработать один или
несколько результатов, обычная практика состоит в том, что-
бы обобщить проблему и рассматривать эти результаты как
частные случаи некоего более широкого класса. Однако мало
радости, если ограничиться* утверждением, что любой предмет
является частным случаем чего-то более общего. Если мы хо-
тим следовать этому подходу, то на нас возлагаются две обя-
занности:
1. Мы должны иметь полную ясность относительно способа
обобщения, т. е. должны тщательно выбрать и явно опреде-
Абстракция исполнения 2t
лить более широкий класс, поскольку наши рассуждения дол-
жны применяться ко всему этому классу.
2. Мы должны выбрать («изобрести», если вам угодно) та-
кое обобщение, которое окажется полезным для наших целей.
В нашем примере я, разумеется, отдаю предпочтение
«НОД-вычислителю», а не «процессору для 111 и 259», и срав-
нение этих двух конструкций дает нам намек на то, какие ха-
. рактеристики делают обобщение «полезным для наших целей».
Машина, которая по команде может вырабатывать в качестве
ответа значения всех видов забавных функций от 111 и 259,
становится все более неудобной для проверки по мере того,
как растет набор функций. В этом явный контраст с нашим
«НОД-вычислителем».
НОД-вычислитель был бы столь же плох, если бы он пред-
ставлял собой таблицу из 250 000 записей, содержащих «за-
готовленные» ответы. Его характерное отличие в том, что он
может быть задан в форме компактного набора «правил иг-
ры», который, если играть в соответствии с этими правилами,
обеспечит выдачу нужного ответа.
Огромный выигрыш состоит в том, что единое рассуждение
применительно к этим правилам позволяет нам доказывать
существенные утверждения о результатах любого варианта
игры. Это достигается ценой того, что при каждом из 250 000
конкретных применений этих правил мы получаем ответ «не
сразу»: каждый раз игра должна быть сыграна в соответствии
с правилами!
Тот факт, что мы в состоянии дать столь компактную фор-
мулировку правил игры, когда единое рассуждение позволяет
нам выводить заключения о любых вариантах игры, непосред-
ственно связан с систематизированным расположением
250 000 узловых точек. Мы оказались бы беспомощными, если
бы лист картона содержал беспорядочный случайный разброс
точек, исключающий какую-либо систематизацию. В нашем
же случае мы могли бы разделить свою фишку на две поло-
винки и двигать одну половинку вниз, пока она не ляжет на
горизонтальную ось, а другую половинку влево, пока она не
ляжет на вертикальную ось. Вместо того чтобы воспроизво-
дить с одной фишкой 250 000 возможных положений, мы мог-
ли бы добиться того же с двумя фишками, для каждой из ко-
торых нужно только 500 возможных положений, т. е. всего
1000 положений в общей сложности. Мы бы достигли того же
уровня в 2Й0 000 позиций, используя то обстоятельство, что лю-
бое из 500 положений одной половинки фишки может комби-
нироваться с любым из 500 положений другой половинки: чис-
ло положений неразделенной фишки равно произведению
22 Глава О
числа положений одной половинки на число положений дру-
гой. На принятом жаргоне мы говорим, что «общее простран-
ство состояний рассматривается как декартово произведение
пространств состояний переменных х и у».
Возможность замены одной фишки с двумерной свободой
выбора положения на две половинки с одномерной свободой
используется в предложенной выше двухрегистровюй машине.
С точки зрения технической реализации это представляется
весьма заманчивым: требуется только построить регистры, спо-
собные различать 500 разных случаев («значений»), а за счет
простого объединения этих двух регистров общее число разных
случаев возводится в квадрат! Это перемножительное правило
позволяет нам различать громадное число возможных общих
состояний с помощью ограниченного числа компонентов, у
каждого из которых только ограниченное число возможных
состояний. По мере добавления таких компонентов размер
пространства состояний возрастает экспоненциально, но нам
следует иметь в виду, что это допустимо только при условии,
что обоснование нашего нововведения Остается весьма компакт-
ным; если такое обоснование тоже возрастает экспоненциаль-
но, то вообще нет никакого смысла создавать такую машину.
Замечание. Убедительную иллюстрацию к сказанному вы-
ше можно найти в изобретении, возраст которого уже превы-
сил десять веков: в десятичной системе счисления! Она обла-
дает тем поистине пленительным свойством, что число необхо-
димых цифр возрастает всего лишь пропорционально
логарифму максимального из чисел, которые должны, быть
представлены. Двоичная система счисления — это то, что полу-
чается, когда вы забываете, что на каждой руке имеется по
пяти пальцев. (Конец замечания.)
Выше мы занимались одним аспектом множественности, а
именно большим числом позиций фишки ( = возможных со-
стояний). Имеется еще одна аналогичная множественность, а
имённо большое число различных игр ( = вычислений), кото-
рые могут состояться в соответствии с нашими правилами иг-
ры: по одной игре для каждого начального положения, если
говорить точнее. Наши правила игры являются очень общими
в том смысле, что они применимы к любому начальному поло-
жению. Но мы настаиваем на компактности обоснования пра-
вил игры, а это означает, что и сами правила должны быть
компактными. В нашем примере это достигалось следующим
приемом: вместо перечисления «сделай это, сделай то» мы
задали правила игры в виде правил для выполнения «шага» в
сочетании с критерием того, должен ли «шаг» быть выполнен
Абстракция исполнения 23
в следующий раз. (На самом деле шаг должен повторяться,
пока не будет достигнуто состояние, в котором он становится
неопределенным.) Иначе говоря, даже всю игру от научала до
конца можно произвести с помощью повторяемых применений
одного и того же «подправила».
Это очень продуктивный прием. Один алгоритм заключает
в себе проект определенного класса вычислений, которые мо-
гут выполняться под его управлением; благодаря условному
повторению «шага», вычисления из такого,класса могут иметь
весьма различные протяженности. Этим объясняется, как ко-
роткий алгоритм может занимать машину в течение длитель-
ного времени. С другой стороны, в этом можно усмотреть на-
чальный намек на то, зачем нам могут понадобиться особенно
быстрые машины.
Меня завораживает мысль, что эта глава могла писаться
еще в те времена, когда Евклид мог смотреть на нее из-за мо-
его плеча.
1 РОЛЬ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ
В главе «Абстракция исполнения» я дал неформаль-
ные описания различных «машин», предназначенных для вы-
числения наибольшего общего делителя двух положительных
(и не слишком больших) чисел. Одно описание было выраже-
но с помощью фишки, передвигаемой по листу картона, дру-
гое— с помощью двух половинок фишки, каждая из которых
двигалась вдоль своей оси, а- последнее — с помощью двух ре-
гистров, каждый из которых мог содержать целое число (не
превышающее некоторой границы). Физически эти три «ма-
шины» весьма различны, однако математически они очень
сходны: основная часть доказательства их способности вы-
числять наибольший общий делитель совпадает для всех трех
машин. Это объясняется тем, что они представляют собой
всего лишь различные воплощения одного и того же набора
«правил игры», и это именно тот набор правил, который со-
ставляет сущность реального изобретения, известного как «ал-
горитм Евклида».
В предыдущей главе алгоритм Евклида описывался сло-
весно, не совсем формальным образом. Однако мы отметили,
что число соответствующих ему возможных вычислений столь
велико, что нужно доказать его корректность. Коль скоро
алгоритм дан только не формально, он не является вполне
подходящим объектом для формального рассмотрения. Для
дальнейшего нам потребуется описание этого алгоритма в не-
которой удобной формальной записи.
Такая формальная запись может обладать многочислен-
ными преимуществами. Любой способ записи подразумевает,
что всякий описываемый с его помощью предмет задается как
конкретный представитель (часто бесконечного) класса объ-
ектов, которые могут быть описаны этим способом. Наш спо-
соб описания должен, разумеется, обеспечивать изящное и
точное описание алгоритма Евклида, но когда мы этого достиг-
нем, алгоритм Евклида окажется в действительности заданным
как представитель огромного класса всех видов алгоритмов.
Роль языков программирования 25
И в описаниях некоторых из этих других алгоритмов мы смо-
жем найти более интересные применения нашего способа за-
писи. В случае алгоритма Евклида есть основания утверждать,
что он настолько прост, что можно обойтись его неформаль-
ным описанием. Сила формальной записи должна проявиться
в таких достижениях, которых без нее мы никогда не смогли
бы добиться!
Второе преимущество формального способа записи состо-
ит в том, что он дает нам возможность изучать алгоритмы как
математические объекты; при этом формальное описание ал-
горитма служит основой, позволяющей нам интеллектуально
охватить этот алгоритм. Благодаря этому мы сумеем доказы-
вать теоремы о классах алгоритмов, например пользуясь тем,
что их описания обладают некоторым общим структурным
свойством.
Наконец, такой способ записи позволит нам описывать ал-
горитмы настолько точно, что если будет задан описанный так
алгоритм- и заданы значения аргументов (вход), то не будет
никаких сомнений относительно того, какими должны быть со-
ответствующие ответы (выход). При этом можно считать, что
вычисление выполняется автоматом, который, получив (фор-
мально описанный) алгоритм и аргументы, порождает ответы
без дальнейшего вмешательства человека: Такие автоматы,
способные обеспечивать взаимное воздействие алгоритма и
аргумента, и в самом деле были построены. Они называются
«автоматическими вычислителями». Алгоритмы, предназначен-
ные для автоматического выполнения такими вычислителями,
называются «программами», и с конца пятидесятых годов
формальные способы, используемые для записи программ,
называются «языками программирования». (Введение терми-
на «язык» применительно к способам записи программ вызы-
вает смешанные чувства. С одной стороны, оно оказалось весь-
ма полезным, поскольку существующая теория лингвистики
обеспечила естественную основу и устоявшуюся терминологию
(«грамматика», «синтаксис», «семантика» и т. д.) для рас-
смотрений применительно к этой новой тематике. С другой
стороны, необходимо отметить, что аналогия с (ныне имену-
емыми так) «естественными языками» часто оказывалась дез-
ориентирующей, так как для естественных языков, не формаль-
ных по существу, источником как их слабости, так и их силы
является присущая им неопределенность и неточность).
В историческом плане этот последний аспект, т. е. возмож-
ность использования языков программирования в качестве
средства .общения с существующими автоматическими вычис-
лителями, в течение долгого времени рассматривался как их
наиболее важное свойство. Эффективность, с которой сущест-
26 Глава 1
вующие автоматические вычислители могли бы выполнять
программы, написанные на конкретном языке, становилась
главным критерием качества этого языка. Как огорчительное
следствие мы нередко обнаруживаем, что аномалии существу-
ющих вычислительных машин старательно воспроизводятся в
языках программирования, причем это происходит в ущерб
интеллектуальной управляемости программ, выражаемых на
таком языке (как будто программирование и без этих анома-
лий не было уже достаточно трудным!). В рамках нашего
подхода мы постараемся восстановить равновесие и поэтому
будем относиться к возможности фактического выполнения
наших алгоритмов вычислительной машиной только как к
счастливой случайности, которая не должна занимать цент-
рального места в наших рассмотрениях. (В одном недавно
опубликованном учебном тексте по программированию на
PL/1 можно найти настойчивый совет избегать обращений к
процедурам, насколько это возможно, «потому что они делают
программу столь неэффективной». В свете того, что процедуры
в языке PL/1 являются одним из основных средств описания
структуры, этот совет выглядит ужасно, настолько ужасно, что
вряд ли можно называть упомянутый текст «учебным». Если
вы убеждены в полезности понятия процедуры и соприкаса-
етесь с приложениями, где дополнительные затраты на аппа-
рат процедур обходятся слишком дорого, то порицайте эти не-
подходящие приложения, а не возводите их на уровень стан-
дартов. Равновесие и в самом деле надлежит восстановить!)
Я рассматриваю язык программирования преимуществен-
но как средство для описания (потенциально весьма сложных)
абстрактных конструкций. Как показано в главе «Абстракция
исполнения», первейшим достоинством алгоритма является по-
тенциальная компактность рассуждений, на которых может
основываться наше проникновение в его сущность. Как толь-
ко эта компактность потеряна, алгоритм в значительной мере
теряет «право на существование», и поэтому мы будем стре-
миться к сохранению такой комрактности. Соответственно и
наш выбор языка программирования будет подчинен той же
цели.
2 СОСТОЯНИЯ И ИХ ХАРАКТЕРИСТИКА
В течение многих столетий человек оперирует натуральны-
ми числами. Мне представляется, что в доисторические вре-
мена, когда перед нашими предками впервые забрезжило по-
нятие числа, они изобретали индивидуальные имена для
каждого числа, на которое у них обнаруживалась потребность
сослаться. Им приходилось иметь имена для чисел точно так
же, как мы имеем имена «один, два, три, четыре и так далее».
• Это поистине «имена» в том смысле, что при исследовании
последовательности «один, два, три» никакое правило не по-
может нам умозаключить, что следующим -именем будет «че-
тыре». Вы, конечно же, должны это знать. (В том возрасте,
когда я вполне удовлетворительно умел считать — по-голланд-
ски,— мне пришлось учиться счету по-английски и во время
экзамена самое изощренное знание слов «семь» й «девять» не
смогло помочь мне установить, как писать слово «восемь», не
говоря уж о том, как произносить его.)
Очевидно, что такое несистематизированное разнообразие
позволяет нам выделять индивидуально только весьма ограни-
ченное количество различных чисел. Чтобы избежать подоб-
ного ограничения, каждый язык в цивилизованном мире вво-
дит (более или менее) систематизированное именование на-
туральных чисел, и обучение счету в значительной
степени сводится к обнаружению системы, лёжа-
щей в основе этого именования. Когда ребенок учится считать
до тысячи, ему не приходится заучивать наизусть эту тысячу
имен (в их точном порядке!); он руководствуется определен-
ными правилами: наступает момент, когда ребенок узнает, как
переходить от любого числа к следующему, например от «че-
тыреста двадцать девять» к «четыреста тридцать».
Легкость обращения с числами сильно зависит от выбран-
ной нами для них систематизации. Гораздо труднее устано-
вить, что
дюжина дюжин = гросс
одиннадцать плюс двенадцать = двадцать три
XLVII + IV=LI
28 Глава 2
чем установить, что
12X12=144
11 + 12 = 23
47 + 4 = 51
так как последние три ответа можно получить, применив про-
стой набор правил, которыми может руководствоваться любой
восьмилетний ребенок.
При механических манипуляциях над числами преимуще-
ства десятичной системы счисления проявляются гораздо бо-
лее отчетливо. Уже в течение столетий мы располагаем меха-
ническими сумматорами, показывающими ответ в окошке, по-
зади которого имеется несколько колес с десятью различными
положениями, причем каждое колесо в любом своем положе-
нии показывает одну десятичную цифру. (Теперь уже не яв-
ляется проблемой показать «00000019», прибавить 4 и затем
показать «00000023»; было бы проблемой — по крайней мере
если пользоваться чисто механическими средствами — пока-
зать вместо этого «девятнадцать» и «двадцать три».)
Существенное свойство такого колеса состоит в том, что оно
обладает десятью различными устойчивыми положениями.
Терминологически это выражается разными способами. На-
пример, колесо называется «переменной с десятью значения-
ми», и если мы хотим большей точности, то даже перечисля-
ем эти значения: от 0 до 9. Здесь каждое «положение» колеса
отождествляется со «значением» переменной. Колесо называ-
ется «переменной», потому что, хотя его положения и устой-
чивы, колесо может повернуться в другое положение: «значе-
ние^ может измениться. (Я вынужден отметить, что этот тер-
мин неудачен по крайней мере в двух отношениях. Во-первых,
такое колесо, которое (почти) всегда находится в одном из
своих десяти положений и, • следовательно, (почти) всегда
представляет некое значение, является понятием, весьма от-
личным от того, что математики называют «переменной», по-
скольку, как правило, математическая переменная вообще не
представляет какого-либо конкретного значения. Если мы го-
ворим, что для любого целого числа п утверждение п2^0
истинно, то здесь п является переменной совсем другого рода.
Во-вторых, в нашем контексте мы используем термин «пере-
менная» для того, что существует во времени и чье значение,
если его не трогать, остается постоянным! Термин «изменя-
емая константа» подошел бы лучше, но мы не станем вводить
его, а будем придерживаться прочно установившейся тради-
ции.)
Другой способ терминологически отразить сущность тако-
го колеса, которое (почти) всегда находится в одном из деся-
Состояния и их характеристика 29
ти различных положений или «состояний», состоит в том, что-
бы поставить этому колесу в соответствие «пространство со-
стояний из десяти точек». Здесь каждое состояние (положение)
связывается с «точкой», а собрание этих точек называется —
в соответствии с математической традицией — пространством
или, если мы хотим большей точности, «пространством состо-
яний». Вместо того чтобы говорить, что переменная обладает
{почти) всегда одним из своих возможных значений, мы можем
теперь выразить то же, сказав, что система, состоящая из
•единственной переменной, находится (почти) всегда в одной
из точек своего пространства состояний. Пространство состоя-
ний описывает степень свободы системы; больше ей некуда
переходить.
Отвлечемся теперь от отдельно взятого колеса и сосредото-
чим наше внимание на регистре с восемью такими колесами
в строке. Поскольку каждое из этих колес находится в одном
из десяти различных состояний, этот регистр, рассмотренный
как целое, находится в одном из 100 000 000 возможных раз-
личных состояний, каждое из которых естественно идентифи-
цируется числом (а точнее, строкой из восьми цифр), показы-
ваемым в окошке.
Если заданы состояния всех колес, то состояние регистра
в целом однозначно определено; и обратно, по любому состоя-
нию регистра в целом однозначно определяется состояние каж-
дого отдельного колеса. В этом случае мы говорим (в преды-
дущей главе нами уже использован этот термин), что получа-
ем (или строим) пространство состояний регистра в целом,
формируя «декартово произведение» пространств состояний
восьми отдельных колес. Общее число точек в этом простран-
стве состояний является произведением чисел точек в тех
пространствах состояний, из которых оно построено (именно
поэтому оно называется декартовым произведением).
В зависимости от .того, что нас интересует в этом предме-
те, мы либо рассматриваем такой регистр как единую пере-
менную с 108 различными возможными значениями, либо как
составную переменную/ составленную из восьми различных
переменных, называемых «колесами», с десятью значениями.
Если мы интересуемся только показываемыми значениями,
то будем, по-видимбму, рассматривать регистр как неделимое
понятие, тогда как инженер-эксплуатационник, которому нуж-
но заменить колесо со сломанным зубцом, будет, конечно, рас-
сматривать регистр как составной объект.
Мы наблюдали другой пример построения пространства
состояний как декартова произведения более мелких про-
странств состояний, когда обсуждали алгоритм Евклида и об-
наружили, что положение фишки где-то на листе можно пол-
30 Глава 2
ностью идентифицировать с помощью двух полуфишек, каж-
дая из которых находится где-то на своей оси, т. е. с помощью
комбинации (а точнее, упорядоченной пары) двух переменных
«х» и «у». (Идея идентификации положения точки на плоско-
сти значениями ее координат х и у идет от Декарта, который
разработал аналитическую геометрию и в честь которого на-
звано декартово произведение.) Фишка на листе была введена
для демонстрации того факта, что развивающийся вычисли-
тельный процесс — такой, как выполнение алгоритма Евкли-
да,— можно рассматривать как систему, движущуюся по
своему пространству состояний. В соответствии с этой метафо-
рой начальное состояние именуется также «исходной точкой».
В этой книге мы будем преимущественно — а может быть,.
даже исключительно — заниматься системами, пространства
состояний которых будут в конечном итоге рассматриваться
как некие декартовы произведения. Разумеется, не следует
усматривать в этом мое мнение, будто бы пространства состоя-
ний, построенные с помощью декартовых произведений, явля-
ются общим и окончательным решением всех наших проблем;
я отлично знаю, что это не так. Из дальнейшего станет очевид-
ным, почему они заслуживают столь большого нашего вни-
мания и в то же время почему это понятие играет столь гла-
венствующую роль во многих языках программирования.
Прежде чем продолжить рассуждения, отмечу одну проб-
лему, с которой нам придется столкнуться. Когда мы образу-
ем пространство состоянии, строя декартово произведение, то
вовсе не обязательно, что нам окажутся полезными все его
точки. Типичным примером этому является характеристика
дней данного года с помощью пары (месяц, день), где «ме-
сяц»— переменная с 12 значениями (от «янв» до «дек»), а
«день» — переменная с 31 значениями (от 1 до 31). В этом слу- *
чае мы образуем пространство состояний из 372 точек, тогда
как никакой год не содержит более чем 366 дней. Что нам де-
лать, скажем, с-парой (июн, 31)? Либо мы запрещаем ее, вво-
дя понятие «невозможных дат» и тем самым создавая в неко-
тором смысле возможность внутренних противоречий в систе-
ме, либо мы разрешаем ее как другой вариант имени для од-
ного из «истинных» дней, например, приравнивая ее к (июл, 1).
Феномен «неиспользуемых* точек пространства состояний» воз-
никает всякий раз, когда число различных возможных значе-
ний, которые мы желаем распознавать, оказывается простым
числом.
Систематизация, которая автоматически вводится, когда
мы строим пространство состояний как декартово произведе-
ние, позволяет нам идентифицировать отдельно взятую точку.
Например, я могу утверждать, что мой день рождения — это
Состояния и их характеристика 31
(май, И). Однако благодаря Декарту нам известен теперь и
другой способ фиксации этого факта: мой день рождения при-
ходится на ту дату (месяц, день), которая соответствует ре-
шению уравнения1)
(месяц=май) and (день=11)
Приведенное выше уравнение имеет только одно решение
и поэтому представляет собой несколько усложненный споссГб
указания этого единственного дня в году. Однако преимуще-
ство использования уравнения состоит в том, что оно позво-
ляет нам охарактеризовать множество всех его решений, и
такое множество может содержать значительно больше чем
одну точку. Тривиальным примером может служить определе-
ние рождества:
(месяц = дек) and ((день = 25) or (день = 26))
Более примечательным примером является определение мно-
жества дат, в которые выплачивается мое ежемесячное жа-
лованье:
(день = 23)
и разумеется, это гораздо более компактное описание, чем
перечисление вида «(янв, 23), (фев, 23), (мар, 23)» и т. д.
Из сказанного выше явствует, что степень легкости, с ко-
торой мы используем такие уравнения для характеристики
множеств состояний, зависит от того, насколько множества,
которые мы хотим охарактеризовать, «соответствуют» струк-
туре пространства состояний, т. е. «соответствуют» введенной
системе координат. Например, в рассмотренной выше системе
координат было бы несколько неудобно охарактеризовать мно-
жество дней,, которые приходятся на тот же день недели, что
и (янв, 1). Во многих случаях программисту приходится при
решении задач вводить пространства состояний с подходящи-
ми для его целей системами координат; причем дополнитель-
ные требования часто вынуждают его вводить также простран-
ства состояний, в которых число точек во много раз больше,
чем число различных возможных значений, которые он дол-
жен распознавать.
Другой пример использования уравнения для характери-
стики множества состояний встречался в нашем описании кар-
тонной машины для вычисления НОД (X, У), где
Здесь и далее в математических формулах используются для обозна-
чения логических операций символы and (конъюнкция), ог (дизъюнкция)
и поп (отрицание). — Прим, перев.
32 Глава 2
характеризует все точки того, что мы назвали «линией отве-
та»; это множество конечных состояний, т. е. вычисление
прекращается тогда и только тогда, когда достигнуто какое-
нибудь состояние, удовлетворяющее уравнению х=у.
Помимо координат пространства состояний, т. е. перемен-
ных, в терминах значений которых выражается ход вычисли-
тельного процесса, мы встречали в наших уравнениях констан-
ты (такие, как «май» или «23»), Кроме того, можно пользо-
ваться так называемыми «свободными переменными», которые
можно представить себе как «неспецифицированные констан-
ты». Мы применяем их специально для обозначения связей
различных состояний, которые могут встречаться на последо-
вательных шагах одного и того же вычислительного процесса.
Например, во время некоего конкретного выполнения алгорит-
ма Евклида с начальной точкой (X, У) все состояния (х, у>
будут удовлетворять формуле
НОД(х, у) =НОД(Х, У) and 0<x^X and 0<y^Y
Здесь X и У не являются такими переменными, как х и у.
Они представляют собой «их начальные, значения». Это кон-
станты с точки зрения конкретного вычисления', но они не
специфицированы в том смысле, что мы могли бы запустить
алгоритм Евклида с любой точкой сетки в качестве началь-
ного положения нашей фишки.
В заключение некоторые терминологические замечания.
Я буду называть такие уравнения «условиями» или «предика-
тами». (Я мог бы, а возможно, и должен бы различать эти
понятия, зарезервировав термин «предикат» для формального
выражения, обозначающего «условие». Тогда мы имели бы
возможность сказать, например, что два разных предиката
«х=у» и «у=х» обозначают одно и то же условие. Однако,
зная себя, я не надеюсь преуспеть в такой манере изложения.)
Я буду считать синонимичными такие выражения, как «состоя-
ние, для которого предикат истинен», . «состояние, которое
удовлетворяет условию», «состояние, в котором условие удов-
летворяется», «состояние, в котором условие справедлив^»,
и т. д. Если система заведомо достигнет состояния, удовлет*
воряющего условию Р, то мы будем говорить, что система
заведомо «обеспечит истинность Р».
Предполагается, что всякий предикат определен в каждой
точке рассматриваемого пространства состояний: в каждой
точке значением предиката является либо «истина», либо
«ложь», и предикат служит для характеристики множества
всех точек, для которых (или в которых) этот предикат
истинен.
Состояния и их характеристика 33
Мы будем называть два предиката Р и Q равными (фор-
мально «P=Q»), если они обозначают одно и то же условие,
т. е. характеризуют одно и то же множество состояний.
Два предиката будут играть особую роль, и мы резерви-
руем для них имена «Г» и «F».
Т — это предикат, который йстинен во всех точках рассмат-
риваемого пространства состояний; ему соответствует полное
множество состояний.
F — предикат, который ложен во всех точках пространства
состояний; он соответствует пустому множеству.
2-6
3 ХАРАКТЕРИСТИКА СЕМАНТИКИ
Нас интересуют преимущественно такие системы, которые,
приступив к работе в некоем «начальном состоянии», завер-
шат ее в каком-то «конечном состоянии», которое, как правило,
зависит от выбора начального состояния. Этот подход несколь-
ко отличается от концепции автомата с конечным числом со-
стояний, который, с одной стороны, воспринимает поток вход-
ных символов, а с другой стороны, порождает, поток выходных
символов. Чтобы перевести это в нашу схему, мы должны
предположить, что значение входа (т. е. аргумент) отража-
ется в выборе начального, состояния и что значение выхода
(т. е. ответ) отражается в выборе конечного состояния. Наш
подход избавляет нас от -всевозможных непринципиальных
сложностей.
Первая часть этой главы посвящена почти исключительно
так называемым «детерминированным машинам», тогда как
во второй части (которую можно пропустить при первом чте-
нии) речь идет о так называемых «недетерминированных ма-
шинах». Различие между этими двумя понятиями состоит
в том, что для детерминированной машины событие, которое
произойдет после запуска конструкции, полностью определя-
ется ее начальным состоянием. Если она запускается дважды
в одинаковых начальных состояниях, то произойдут одинако-
вые события: поведение детерминированной машины полностью
воспроизводимо. Для недетерминированной машины, напро-
тив, запуск в заданном начальном состоянии приведет к ка-
кому-то одному событию из класса возможных событий; на-
чальное состояние только фиксирует этот класс в целом.
Теперь я предполагаю, что проектирование такой систе-
мы является 'целенаправленной деятельностью, т. е. что мы
желаем достичь чего-то с помощью этой системы. Например,
если мы хотим создать машину, способную вычислять наиболь-
ший общий делитель, то можем потребовать, чтобы конечное
состояние удовлетворяло условию
х = НОД(Х, У) (1)
Характеристика семантики 35
-В рассмотренной ранее машине мы будем иметь также
у = НОД(Л’, У), потому что игра заканчивается при х=у, но
-вто отнюдь не часть наших требований, когда мы решаем при-
нять, конечное значение х в качестве ответа.
Мы называем условие (1) (желаемым) «постусловием» —
«пост», потому что оно налагается на то состояние, в котором
система должна оказаться после своей работы. Заметим, что
постуслов-ие может удовлетворяться многими возможными
состояниями. В таком случае мы естественно считаем каждое
из них.одинаково удовлетворительным, так что нет оснований
требовать, чтобы конечное состояние было однозначной функ-
цией от начального состояния. (Читатель увидит из дальней-
шего, что именно здесь проявляется потенциальная полезность
недетерминированного устройства.)
Для того чтобы использовать эту машину, когда мы хотим
получить от нее ответ (например, хотим «чтобы, она достигла
конечного состояния, удовлетворяющего постусловию (1) для
заданного'набора значений X и У»)/дам желательно зйать
множество соответствующих начальных состояний, а более
точно,, множество таких начальных состояний, при которых
запуск’обязательно приведет к событию правильного завер-
шения, причем система останется в конечном состоянии, удов-
летворяющем постусловию. Если мы можем привести систему
без вычислительных усилий в одно из таких состояний, то мы
уже знаем, как использовать эту систему для получения'же-
лаемого ответа. Приведем пример для евклидовой игры на
картоне: мы можем гарантировать конечное состояние, удов-
летворяющее постусловию (1) для любого начального состоя-
ния, удовлетворяющего условию
НОД(х, £/) = НОД(Х, У) and 0<х^500 and 0<у^500 (2)
(Верхние границы добавлены, чтобы учесть ограниченный
размер листа картона. Если мы начинаем с парой (X, У), та-
кой, что НОД(Х, У) =713, то не существует пары (х, у), удов-
летворяющей условию (2), т. е. для таких значений X и У
условие (2) сводится к предикату Е; а это означает, что рас-
сматриваемая машина не может быть использована для вычис-
ления НОД(Х, У) применительно к этой паре значений X и У)-.
При многих комбинациях (X, У) многие состояния удовлет-
воряют условию (2). В случае 0<Х^500 и 0<У^500 три*
виальным выбором является х = Х и у=У. Этот выбор может
быть произведен без какого-либо вычисления, функции НОД
и даже без учета того факта, что это симметричная функция
от своих аргументов.
Условие, характеризующее множество всех начальных со-
стояний, при которых Запуск обязательно приведет к событию
2*
36 Глава 3
правильного завершения, причем система останется в конеч-
ном состоянии, удовлетворяющем заданному постусловию,
называется «слабейшим предусловием, соответствующим это-
му постусловию». (Мы называем его «слабейшим», посколь-
ку, чем слабее условие, тем больше состояний удовлетворяют
ему, а мы стремимся здесь охарактеризовать все возможные
начальные состояния, которые неизбежно приведут к желае-
мому конечному состоянию.)
Если системаг(м'ашина^ конструкция) обозначается через
S, а желаемое постусловие — через 7?, то соответствующее сла-
бейшее предусловие мы обозначим ’>
wp(S, R)
Если начальное состояние удовлетворяет wp(S, R), то кон-
струкция обязательно обеспечит в конце концов истинность R.
Поскольку wp (S, R) — это слабейшее предусловие, мы знаем
также, что если начальное состояние не удовлетворяет
wp(S, R), то такой гарантии дать нельзя, т. е. ход событий
может привести к завершению работы в конечном состоянии,
не удовлетворяющем R, а может даже и вообще помешать
достижению какого бы то ни было конечного состояния (как
мы увидим далее, либо потому, что система оказывается во-
влеченной в выполнение незавершимого задания, либо потому,
что система попадает в тупик).
Мы считаем, что нам достаточно хорошо известно, как ра-
ботает конструкция S, если можем вывести для любого пост-
условия R соответствующее слабейшее предусловие wp (S, R),
поскольку тем самым мы уловили, что эта конструкция спо-
собна сделать для нас; это называется «ее семантикой».
Здесь уместны два замечания. Во-первых, множество воз-
можных постусловий,’ вообще говоря, столь огромно, что эта
информация в табличной форме (т. е. в виде таблицы, где
каждому постусловию 7? соответствует запись, в которой со-
держится соответствующее предусловие wp(S, 7?)), оказалась
бы совершенно необозримой, а следовательно, бесполезной.
Поэтому определение семантики той или иной конструкции
всегда дается другим способом — в виде правила, описываю-
щего, как для любого заданного постусловия 7? можно вывес-
ти соответствующее слабейшее предусловие wp(S, R). Для
фиксированной конструкции S такое правило, которое по за-
данному предикату R, означающему постусловие, вырабаты-
вает предикат wp(S, 7?), означающий соответствующее сла-
бейшее предусловие, называется «преобразователем предика-
П По начальным буквам- английских слов weakest pre-condition. —
Прим, перев.'
Характеристика семантики 37
тов». Когда мы просим, чтобы нам сообщили описание
семантики конструкции S, то в сущности речь идет о соответ-
ствующем этой конструкции преобразователе предикатов.
Во-вторых,— и я чувствую искушение добавить «благода-
рение судьбе» — часто нас не интересует полная семантика
конструкции. Это объясняется тем, что мы стремимся исполь-
зовать конструкцию S только для конкретной надобности, а
точнее, для того, чтобы обеспечить истинность весьма кон-
кретного постусловия /?, ради которого производилась разра-
ботка конструкции. И даже применительно к этому конкретно-
му постусловию R нас часто не интересует точный вид
wp(S, /?); зачастую мы удовлетворяемся более сильным усло-
вием Р9 т. е. таким условием, для которого можно показать,
что утверждение .
Р => wp (S, R) цля всех состояний (3)
справедливо. (Предикат «P=>Q» (читается «из Р следует Q»)
ложен только в тех точках пространства' состояний, где усло-
вие Р справедливо, a Q не справедливо; во всех остальных
точках он истинен. Требуя, чтобы утверждение «Р ==> wp(S, /?)»
было справедливо для всех состояний, мы тем самым требу-
ем, чтобы всякий раз когда Р — истина, условие wp(S, R)
тоже было истиной; тогда Р — достаточное предусловие.
В теоретико-множественной терминологии это означает, что
множество состояний, характеризуемое условием Р, является
подмножеством того множества состояний, которое характе-
ризуется условием wp(S, У?).) Если для заданных Р, S и R
отношение (3) выполняется, это часто можно доказать, не
прибегая к точной формулировке,— или, если вам так боль-
ше нравится, «вычислению» или «выводу» — предиката
wp(S, Р). И это отрадное обстоятельство, поскольку, за ис-
ключением тривиальных случаев, следует ожидать, что явная
формулировка условия wp(S, R) превысит по крайней мере
резерв нашей писчей бумаги, нашего терпения или нашей (ана-
литической) изобретательности (или какую-то комбинацию
этих резервов).
Смысл wp(S, /?), т. е. «слабейшего предусловия для на-
чального состояния, при котором запуск обязательно приведет
к событию правильного завершения, причем система S оста-
нется в конечном состоянии, удовлетворяющем постусловию
R», позволяет нам установить, что преобразователь предика-
тов, рассматриваемый как функция от постусловия /?, облада-
ет рядом определенных свойств.
Свойство 1. Для любой конструкции S мы имеем
wp(S, F)=F (4)
38 Глава 3
Предположим, что оказалось не так; при этом нашлось бы
хоть одно состояние, удовлетворяющее условию wp(S, F).
Возьмем такое состояние в качестве начального состояния
для конструкции S. Тогда, согласно нашему определению, за-
пуск привел бы к событию правильного завершения, причем
система осталась бы в конечном состоянии, удовлетворяющем'
предикату F. Но здесь возникает противоречие, так как по оп-'
ределению предиката F не существует состояний, удовлетворя-
ющих F; тем самым доказано отношение (4). Свойство 1 из-'
вестно также под названием «закон исключенного чуда».
.Свойство 2. Для любой конструкции S и любых постусло-
вий Q и R, таких, что
Q =?R для всех состояний (5)
справедливо также отношение
wp(S, Q) =>wp(S, R) для всех состояний (6)
В самом деле, при любом начальном состоянии, удовлетво-
ряющем wp(S, Q), согласно определению, по окончании раб®-'
ты .системы будет обеспечена истинность Q. С учетом отноше-
ния (5) тем самым будет обеспечена и истинность R. Следо-
вательно, данное начальное состояние будет одновременно
удовлетворять и условию wp(S, R), как записано в (6). Свой-
ство 2 — это свойство монотонности.
Свойство 3. Для любой конструкции S и для любых пост-
условий Q и R справедливо
(wp(S, Q) and wp(S,R)) =wp(S, Qand/?) (7)
В любой трчке пространства состояний из левой части от-
ношения (7) логически следует его правая часть, потому что
для любого начального состояния, удовлетворяющего и,
wp(S, Q), и wp(S, R), мы знаем в совокупности, что устано-
вится конечное состояние, удовлетворяющее и Q, и R. Далее,
поскольку, в силу определения,
(Q and R) => Q для всех состояний
свойство 2 позволяет нам заключить, что
wp(S, Q and 2?)=>wp(S, Q) для всех состояний
и аналогично
wp(S, Q and R) => wp (S, R) для всех состояний
Однако из А =£• В и Д=4>С, согласно исчислению предика-
тов, можно вывести, что А ==> (В and С). Поэтому правая часть
отношения (7) логически следует из его левой части в любой
Характеристика семантики 39
•точке пространства состояний. Поскольку обе части всюду
следуют друг из друга, они должны быть равны, а тем самым
доказано свойство 3.
Свойство 4, Для любой конструкции S и любых постусло-
вий Q и R справедливо
(wp(S, Q) or wp(S, /?))=» wp(S, Q or /?) для всех состояний
(8)
Поскольку, в силу определения,
Q (Q or /?) для всех состояний
свойство 2 позволяет нам прийти к заключению, что
wp(S, Q) =£> wp(S, Q or R) для всех состояний
и аналогично
)vp(S, 7?) =>wp(S, Q or R) для всех состояний
Но, согласно исчислению высказываний, из А =5 С и 2?==> €
.можно заключить, что (Д or В) => С, и этим доказана спра-
ведливость соотношения (8). Вообще говоря, следование
в обратном направлении не имеет места. Так про женщину,
которая ждет ребенка, неверно утверждение, что она родит
обязательно сына и неверно утверждение, что она родит обя-
зательно дочь; однако с абсолютной уверенностью можно ут-
верждать, что она родит сына или дочь. Впрочем, для детер-
минированных конструкций справедливо следующее, более
сильное свойство.
Свойство 4'. Для любой детерминированной конструкции S
< любых постусловий Q и R справедливо
(wp (S, Q) or wp (S, R)) = wp (S, Q or R)
Нам нужно показать, что следование выполняется и в ле-
вую сторону. Рассмотрим какое-то начальное состояние, удов-
летворяющее wp(S, Q or R); этому начальному состоянию со-
ответствует единственное конечное состояние, удовлетворяю-
щее либо Q, либо /?, либо обоим условиям; следовательно, дан-
ное начальное состояние должно удовлетворять либо wp(S, Q),
либо wp(S, /?), либо обоим условиям соответственно, т. е.
оно должно удовлетворять (wp(S, Q) or wp(S, /?)). И этим
доказано свойство 4'.
В этой книге я буду — и это может оказаться одной из ее
отличительных особенностей — рассматривать недетерминиро-'
ванность как правило, а детерминированность как исключе-
ние: детерминированная машина будет рассматриваться как
частный случай недетерминированной, как конструкция, для
40 Глава 3
которой справедливо свойство 4', а не только более слабое
свойство 4. Такое решение отражает коренное изменение в
моем мировоззрении. В 1958 г. я был одним из первых, кто
разрабатывал базовое программное обеспечение длй машины
с прерываниями ввода-вывода, и невоспроизводимость пове-
дения такой во всех отношениях недетерминированной машины
явилась горестным обстоятельством. Когда впервые была пред-
ложена идея прерываний ввода-вывода, меня настолько пуга-
ла сама мысль о необходимости разрабатывать надежное
программное обеспечение для такого неукротимого зверя,
что я оттягивал принятие решения о допущении таких преры-
ваний по крайней мере в течение трех месяцев. И даже после
того, как я сдался (мое сопротивление сломили лестью), чув-
ствовал я себя весьма неуютно: ведь ошибка в программе спо-
собна вызвать несуразное поведение системы, столь сходное
с невоспроизводимым машинным сбоем. Кроме того,— и это
в то время, когда для детерминированных машин мы все еще
полагались на «отладку»,— с самого начала было совершен-
но очевидно, что тестирование программ оказывалось теперь
совсем непригодным средством для достижения должного
уровня надежности.
В течение многих лет впоследствии q относился к невоспро-
-изводимости поведения недетерминированной машины как
к добавочному осложнению, которого следует избегать любы-
ми способами. Прерывания были для меня не чем иным, как
злыми кознями инженеров по аппаратуре против бедных
разработчиков программного обеспечения. Из этого моего
страха родилась дисциплина «гармонически взаимодействую-
щих последовательных процессов». Несмотря на ее успех, мои
опасения сохранялись, поскольку наши решения — хоть бы и
с доказанной правильностью — представлялись частными ре-
шениями проблемы «укрощения» (именно так мы это воспри-
нимали!) конкретных видов недетерминированности. Основа-
нием для моего страха было отсутствие общей методологии.
С тех пор два обстоятельства изменили картину. Первое
возникло с пониманием того, что даже в случае полностью
детерминированных машин полезность тестирования программ
оказывается сомнительной. Как я уже много раз говорил и во
многих местах писал: тестирование программы может вполне
эффективно служить для демонстрации наличия в ней оши-
бок, но, к сожалению, непригодно для доказательства их
отсутствия. Другим прояснившимся тем временем обстоятель-
ством явилось обнаружение необходимости того, чтобы вся-
кая дисциплина проектирования должным образом учитывала
тот факт, что само проектирование конструкции, предназначен-
ной для какой-то цели, тоже должно быть целенаправленной
Характеристика семантики 41
деятельностью. В нашем конкретном случае это означает ес-
тественность предположения, что отправной точкой для про-
ектных рассмотрений будет служить заданное постусловие.
В каком-то смысле мы будем «работать вспять». Действуя
так, мы обнаружим, что весьма существенным оказывается
следование из свойства 4, тогда как от равенства из свойства
4' мы получим очень мало пользы.
Как только мы разработали математический аппарат, по-
зволяющий проектировать недетерминированные конструкции,
достигающие цели, недетерминированная машина перестает
нас пугать. Напротив! Мы научимся даже ценить ее как важ-
ную ступень на пути разработки проекта в конечном итоге
полностью детерминированной конструкции.
(Последующая часть этой главы Может быть пропущена
при первом чтении.) Ранее мы договорились, что представля-
ем себе функционирование конструкции S достаточно хорошо,
если-толькб знаем, как соответствующий ей преобразователь
предикатов wp(S, /?) действует над любым постусловием /?.
Если нам известно также, что данная конструкция детерми-
нирована, то знание этого преобразователя предикатов пол-
ностью определяет возможное поведение конструкции. Для
детерминированной конструкции S и некоторого постусловия
R всякое начальное состояние попадает в.одно из трех непе-
ресекающихся множеств в соответствии со следующими вза-
имно исключающими возможностями:
(а) Запуск конструкции S приведет к конечному состоя-
нию, удовлетворяющему R.
(б) Запуск конструкции S приведет к конечному состоянию,
удовлетворяющему non R.
(в) Запуск конструкции S не приведет к какому бы то ни
было конечному состоянию, т. е. работа не сможет завершить-
ся правильным образом.
Первое множество характеризуется выражением wp(S, /?),
второе множество — выражением wp(S, non /?), их объедине-
ние— выражением
(wp(S, 7?) or wp(S, non /?)) =wp(S, R or non /?) =wp(S, T)
а следовательно, третье множество характеризуется выраже-
нием non wp(S, Т).
Труднее дать полную семантическую характеристику неде-
терминированной системы. По отношению к любому заданно-
му постусловию R мы снова имеем три возможных типа собы-
тий, как перечислено выше в пунктах (а), (б) и (в). Однако
в случае недетерминированной системы, одно и то же началь-
42 Глава 3
ное состояние не обязательно приводит к единственному со-
бытию, которое по определению относилось бы к одному из
трех взаимно исключающих типов; для любого начального
состояния возможные события могут теперь относиться к од-
ному, двум или даже ко всем трем типам.
Чтобы описывать такие ситуации, мы можем использовать
понятие «свободного предусловия». Ранее мы рассматривали
такие предусловия, при которых гарантировалась достижи-
мость «правильного результата», т. е. конечного состояния,
удовлетворяющего R. Свободное предусловие является более
слабым: оно гарантирует только, что система не выдаст не-
правильного результата, т. е. не достигнет такого конечного
состояния, которое не Удовлетворяло бы R, однако не исключа-
ется возможность незавершения работы системы. Аналогично
и для свободных предусловий мы можем ввести понятие «сла-
бейшего свободного предусловия»; обозначим его через
wlp(S, R). При этом пространство начальных состояний под-
разделяется в принципе на семь взаимно непересекающихся
областей, ни одна из которых не обязана быть пустой. (Их
семь, потому что из трех объектов можно сделать семь непус-
тых выборок.) Все они легко характеризуются тремя предиката-
ми: wlp (о, R), wlp (S, non R) и wp (S,‘ Г).
(a) wp (S, R) = (wlp (S, R) and wp (S, T))
Запуск обеспечит истинность R.
(6) wp(S, non R) — (wlp(S, non R) and wp(S, T))
Запуск обеспечит истинность non R.
(в) wlp (S, F) = (wlp (S, R) and wlp (S, non R))
Запуск не сможет привести к правильно завершаемой работе.
(аб) wp(S, Т) and non wlp(S, R) and non wlp(S, non R)
Запуск приведет к завершаемой работе, но по начальному со-
стоянию нельзя определить, будет ли конечное состояние удов-
летворять условию R или нет.
(ав) wlp(S, R) and non wp(S, У)
Если запуск приводит к какому-то конечному состоянию, такое
конечное состояние будет удовлетворять R, но по начальному
состоянию нельзя определить, завершится ли работа системы.
(бв) wlp (S, non R) and non wp (S, Г)
Если запуск приводит к какому-то конечному состоянию, такое
конечное состояние не будет удовлетворять R, но по начально-
Характеристика семантики 43
му состоянию нельзя определить, завершится ли работа си-
стемы.
(абв) non (wlp (8, 7?) or wlp (8, non R) or wp(8, 7))
По начальному состоянию нельзя определить, приведет ли
запуск к завершаемой работе, а в случае завершаемости нель-
зя определить, будет ли удовлетворяться условие R.
Последние четыре возможности существуют только для
недетерминированных машин.
Из определения tvlp (8, R) следует, что
wlp (8, Т) = Т
Ясно также, что
(wlp (8, F) and wp (8, Т)) = F
Если бы было не так, то существовало бы начальное со-
стояние, для которого можно было бы гарантировать и завер-
шимость, и незавершимость работы.
На рис. 3.1 дано гра-
фическое представление
пространства состояний,
причем внутренние части
прямоугольников удовлет-
воряют wlp (8, /?), wlp (8,
non У?) и wp(8, Т) соот-
ветственно.
Этот анализ приведен
для полноты, а также по-
тому, что на практике по-
нятие свободного предус-
ловия оказывается весьма
полезным. Если, напри-
мер, кто-то реализует
язык программирования, то он не станет доказывать, что при
этой реализации любая правильная программа выполняется
правильно. Он был бы удовлетворен и счастлив, если бы твер-
до знал, что никакая правильная программа не будет выпол-
няться неправильно без соответствующего предупреждения,—
разумеется, при условии, что класс программ, которые на са-
мом деле будут выполняться правильно, достаточно велик
для того, чтобы эта реализация представляла какой-то ин-
терес.
Однако пока мы не будем рассматривать понятие свобод-
ного предусловия, а сосредоточим свое внимание на способе
44 Глава 3
характеристики тех начальных состояний, которые гарантиру-
ют получение правильного результата. Когда такой способ бу-
дет разработан, мы посмотрим, как можно его видоизменить
таким образом, чтобы это позволило нам рассуждать о свобод-
ных предусловиях в той мере, в которой они нас интересуют.
4 СЕМАНТИЧЕСКАЯ ХАРАКТЕРИСТИКА
ЯЗЫКА ПРОГРАММИРОВАНИЯ
В предыдущей главе мы выдвинули тезис, что знаем семан-
тику конструкции S достаточно хорошо, если знаем ее «преоб-
разователь предикатов», т. е. правило, указывающее нам, как
вывести по любому постусловию 7? соответствующее слабейшее
предусловие (которое мы обозначили через wp(S, 7?)), харак-
теризующее те начальные состояния, при которых запуск при-
ведет к событию правильного завершения, причем система
останется в конечном состоянии, удовлетворяющем постусло-
вию 7?. Вопрос в том, как выводить wp(S, 7?) для задан-
ных S и 7?.
Оставим пока вопрос об одиночной конкретной конструк-
ции S. Программа, написанная на хорошо определенном язы-
ке программирования, может рассматриваться как некая кон-
струкция, такая конструкция, которую мы знаем достаточно
хорошо, если знаем соответствующий преобразователь преди-
катов. Однако язык программирования полезен только при
том условии, что его можно применять для записи многих
различных программ, и для всех этих программ нам жела-
тельно знать соответствующие им преобразователи предикатов.
Каждая такая программа задается своим текстом на хоро-
шо определенном языке программирования, и поэтому ее текст
должен служить для нас отправной точкой. Но теперь перед
нами неожиданно открываются два совершенно различных
назначения такого текста программы. С .одной стороны, текст
программы предназначен для машинной интерпретации, если
мы хотим, чтобы она могла выполняться автоматически, если
мы хотим, чтобы по ней для нас был произведен какой-либо
конкретный расчет. С другой стороны, желательно, чтобы
текст программы говорил нам о том, как строить соответству-
ющий преобразователь предикатов, как производить преобра-
зование предикатов, чтобы выводить предусловие wp(S, 7?)
для любого данного постусловия 7?, которое нас почему-либо
заинтересовало. Это замечание позволяет понять, что подра-
зумевается под «Хорошо определенным языком программиро-
46 Глава 4
вания». с нашей точки зрения. Когда семантика конкретной
конструкции (или программы) задается ее преобразрвателем
предикатов, мы рассматриваем" семантическую характеристику
языка программирования как набор правил, которые позволя-
ют любой программе, написанной на этом языке, поставить
в соответствие преобразователь предикатов. С такой точки
зрения мы можем рассматривать программу как «код» для
соответствующего преобразователя предикатов.
При желании можно подойти к проблеме проектирования
языка программирования с такой позиции. Можно руководст-
воваться (довольно формально) тем, что правила построе-
ния преобразователей предикатов должны быть такими, что-
б.ы, применяя их, нельзя было построить ничего другого, кро-
ме как преобразователя предикатов, обладающего свойствами
1—4 из предыдущей главы. В самом деле, если правила не да-
ют такой гарантии, то это означает, что вы деформируете пре-
дикаты таким образом, что они уже не могут интерпретиро-
ваться как постусловия и соответствующие слабейшие пред-
условия.
Сразу напрашиваются два примера весьма простых преоб-,
разо’ват^дей предикатов, которые обладают требуемыми свой-.
ствами.
Начнем с тождественного преобразования, т. е. с конструк-.
ции S, такой, что для любого постусловия 7? мы имеем
wp(S, )?)=i/?. Эту конструкцию знают и любят все програм-
мисты: она известна им под названием «пустой оператор»,
и в своих программах оцй часто используют ее», оставляя про-
пуск в том месте текста, где синтаксически требуется какой-
тр оператор. Это не слишком похвальный прием (компилятор
должен считать, что он «видит» этот оператор, на том основа-
нии, что он ничего не видит, и поэтому мы дадим этой кон-
струкции наименование,, скажем, «пропустить'». Итак, семан-
тика оператора «пропустить» определяется следующим об-
разом:
wp (пропустить, ;для любого постусловия R
(Как и все, я буду пользоваться термином «оператор»,.по-
тому что он прочно, вошел в жаргон. Когда.люди сообразили,
что «команда» могла, бы оказаться'более подходящим, терми-
ном, было уже слишком поздно Я)
По традиции мы переводим английский, термин «statement» (утверж-
дение, предложение) термином «оператору, введенным в программирование.
А. А. Ляпуновым, таким образом, русский читатель,оказывается в! более
выгодном положений/ чём' английский. — Прим. 'рёд. -
Семантической характеристика языка программирования 47
Замечание. Тем, кто считает расточительством символов
.введение явного имени «пропустить» для пустого оператора,
когда «йусто» столь красноречиво выражает его семантику,
следует осознать, что десятичная система счисления оказалась
возможной только благодаря введению символа «О» для поня-
тия «ничто». (Конец замечания.)
Прежде чем продолжить наши рассуждения, мне хотелось
бы не упустить возможность отметить, что тем временем мы
уже определили некий язык программирования. Остается до-
бавить только одно: это однооператорный язык, в котором
можно описать только одну конструкцию, причем единствен-
ное; что способна сделать для нас данная конструкция, это
«оставить, все, как есть» (или «ничего не делать», но такое
негативное употребление языка представляет опасность, см.
следующий абзац).
Другой простой преобразователь предикатов приводит к
постоянному слабейшему предусловию, которое вовсе не зави-
сит от постусловия R. Мы имеем два предиката-константы, Т
и F. Конструкция S, для которой wp(S, R) = T при всех R, не
может существовать, потому что она нарушила бы закон ис-
ключенного чуда. Однако конструкция S, для которой
wp(S, R)=F при всех R, обладает преобразователем преди-
катов, удовлетворяющим всем необходимым свойствам. Это-
му оператору мы тоже присвоим имя, назовем его «отказать».
Итак, семантика Оператора «отказать» задается следующим
образом:
wp (отказать, R)=F для любого постусловия У?
Этот оператор не может даже «ничего не делать» в смысле
«оставить все, как есть»; он вообще ни на что не способен.
Если мы полагаем R=T, т. е. не накладываем на конечное
состояние никаких дополнительных требований, кроме самого
факта его существования, даже тогда не найдется соответст-
вующего начального состояния. Если запустить конструкцию
по имени «отказать», она не сможет достичь конечного состоя-
ния: сама попытка ее запуска является гарантией неудачи.
(Нас не должно занимать теперь (а также и впоследствии)
то, что позднее мы введем структуру операторов, в которой со-
держатся как частные случаи семантические эквиваленты для
«пропустить» и «отказать».)
Теперь мы располагаем неким (все еще весьма зачаточным)
двухоператорным языком программирования, в котором можем
описать две конструкции; одна из них'ничего не делает, а вто-
рая всегда терпит неудачу. Со времени опубликования знаме-
нитого «Сообщения об алгоритмическом языке АЛГОЛ 60»
48 Глава 4
в 1960 г. никакой уважающий себя ученый, занимающийся
программированием, не позволит себе обойтись на этом этапе
без формального определения синтаксиса столь далеко про-
двинутого языка программирования в системе обозначений,
называемой «НФБ» (сокращение от «Нормальная форма
Бэкуса»), а именно:
<оператор>::=пропустить | отказать
(Читается так: «Элемент синтаксической категории, именуе-
мой «оператор» (именно это обозначают забавные скобки
«<» и «>»)% определяется как (это обозначает знак «:: = »)
«пропустить» или (это обозначает вертикальная черта «|»)
«отказать». Колоссально! Но не беспокойтесь; более впечат-
ляющие применения НФБ в качестве способа* записи последу-
ют в надлежащее время.)
Один класс безусловно более интересных преобразовате-
лей предикатов основывается на подстановке, т. е. на замене
всех вхождений некоей переменной в формальном выражении
для постусловия R на (одно и то же) «что-нибудь другое».
Если в предикате R все вхождения переменной х заменяются
некоторым выражением (Е), то мы обозначаем результат
этого преобразювания через Re-+x- Теперь мы можем рассмот-
реть для заданных х и Е такую конструкцию, чтобы для любых
постусловий R получалось wp(S, R) =Re-+x; здесь х — «коорди-
натная переменная» нашего пространства состояний, а Е —
выражение соответствующего типа.
Замечание. Такое преобразование путем подстановки удов-
летворяет свойствам 1—4 из предыдущей главы. Мы не ста-
нем пытаться демонстрировать это и предоставим самому чи-
тателю решать в зависимости от своего вкуса, будет ли он от-
носиться к этому как к тривиальному или же как к глубокому
математическому результату. (Конец замечания.)
Таким способом вводится целый класс преобразователей
предикатов, целый класс конструкций. Они обозначаются опе-
ратором, который называется «оператор присваивания»; такой ,
оператор должен определять три вещи:
1) наименование переменной, подлежащей замене;
2) тот факт, что правило, соответствующее преобразованию
предикатов, есть подстановка;
3) выражение, которым должно заменяться всякое вхожде-
ние этой переменной в постусловии.
Если переменная х должна быть заменена выражением
(Е), то обычная запись такого оператора выглядит следующим
Семантическая характеристика языка программирования 49
образом:
х : = Е
(где так называемый знак присваивания «: = » следует читать
$ак «становится»).
Сказанное можно суммировать, определив
wp («х: =£», 7?) =Re-+x для любого постусловия R
При желании это можно рассматривать как семантическое
определение оператора присваивания для любой координатной
переменной х и любого выражения Е соответствующего типа.
Наслаждаясь, по нашему обыкновению, употреблением
НФБ, мы можем расширить наш формальный синтаксис, что-
бы он читался так:
<оператор> :: = пропустить|отказать|
<оператор присваивания>
<оператор присваивания> :: = <переменная> : =
<выражение>
причем последнюю строчку следует читать так: «Элемент син-
таксической категории, именуемой «оператор присваивания»,
определяется как элемент синтаксической категорий, именуе-
мой «переменная», за которым следуют сначала знак присваи-
вания «: = », а затем элемент синтаксической категории, име-
нуемой «выражение».
Перед тем как продолжить рассуждение, представляется
разумным убедиться в том, что этим формальным описанием
семантики оператора присваивания в самом деле охватывает-
ся наше интуитивное понимание оператора присваивания —
если оно у нас есть! Рассмотрим пространство состояний с дву-
мя целыми координатными переменными «а» и «&». Тогда
wp(«a: = 7», а = 7) = {7=7}
и, поскольку логическое выражение в правой части является
истиной для всех значений а и Ь, т. е. для всех точек простран-
ства состояний, мы можем упрощенно записать это так:
wp(«a: = 7», а = 7) = Т
Иначе говоря, всякое начальное состояние гарантирует, что
присваивание «а: = 7» обеспечит истинность «а = 7». Аналогично
wp(«a: = 7», а = 6) = {7 = 6}
и, поскольку это логическое выражение является ложью для
всех значений а и Ь, мы получаем
wp(«a: = 7», а = 6) —F
-50 Глава 4
-Это означает, что не существует никакого начального состоя-
ния, для которого мы могли бы тарантировать, что присваива-
ние «а: = 7» обеспечит истинность «а=6». (Это находится в со-
ответствии с нашим предыдущим результатом, что все началь-
ные состояния обеспечат конечную истинность «а = 7», а
-следовательно, конечную ложность «а=/=7».) Далее,
wp(«a: = 7>, Ь = ЬО) = {b = bO}
т. е. если мы хотим гарантировать, что после присваивания
«а: = 7» переменная b имеет некоторое значение Ь0, то нужно,
чтобы b имела это значение еще в начальном состоянии. Дру-
гими словами,’все переменные, за исключением «а», не изме-
няются, они сохраняют те значения, которые имели раньше;
•присваивание «а: = 7» перемещает в пространстве состояний
точку, соответствующую текущему состоянию системы, парал-
лельно оси а так, что обеспечивается конечное выполнение
.равенства «а=7».
Вместо того чтобы брать в качестве выражения Е констан-
ту, мы могли бы взять какую-то функцию от начального со-
стояния. Это иллюстрируется следующими примерами:
wp(«a:=2*6 +1», а= 13) = {2*6 +1 = 13} = {6=6}
wp («а: = а+1», а> 10) = {а+1 > 10} = {а>9}
wp‘(«a: = a—6», a>b) = {а—b>b} = {а>2* Ь}
Возникает небольшое осложнение, если мы разрешаем вы-
ражению Е быть частично определенной функцией начально-
го состояния, т. е. такой функцией, попытка вычисления кото-
рой для начального состояния, не входящего в область опре-
деления, не приведет к правильно завершаемой работе. Если
мы хотим предусмотреть и эту ситуацию, то нам нужно уточ-
нить наше определение семантики оператора присваивания и
записать
wp («х: = Е», R) = {D (Е) cand Re-+x}
Здесь предикат D(E) означает «в области определения £»;
логическое выражение «В1 cand В2» (так называемая «услов-
ная конъюнкция») имеет то же значение, что и «В1 and В2»,
если оба операнда определены, но помимо этого по определе-
нию оно имеет значение «ложь», если В1 является «ложью»;
последнее справедливо вне зависимости от того, определен ли
операнд В2. Обычно условие D (£) не подчеркивается явно ли-
бо потому, что оно = Т, либо потому, что мы исходим из пред-
положения, что оператор присваивания никогда не будет за-
пущен в начальных состояниях, не принадлежащих области
определения выражения Е.
Семантическая характеристика языка программирования 51
Естественным обобщением оператора присваивания явля-
ется излюбленное некоторыми программистами так называе-
мое «одновременное присваивание». В этом случае возможна
одновременная* замена для нескольких различных переменных.
Оператор одновременного присваивания обозначается списком’
различных переменных), подлежащих замене (эти переменные
разделяются запятыми), слева от знака присваивания и столь-
же протяженным списком выражений (также разделяемых
запятыми) справа от знака присваивания. Итак, разрешается
писать
xl, х2: = £1, Е2
х1,х2, хЗ: = £1,£2, £3
Заметим, .что /-я переменная из списка левой части должна
быть заменена на i-e выражение из списка правой части, так
что, например, при заданных xl, х2, £1 и Е2 оператор
xl, х2: = £1, Е2
семантически эквивалентен оператору
х2, xl: = £2, £1
Одновременное присваивание позволяет нам предписать, что-
бы две переменные х и у обменялись своими‘значениями с по-
мощью оператора
х, */: = */, х
В иной записи эта операция выглядела бы более громоздкой.
Легкость реализации одновременного присваивания и воз-
можность с его помощью избёгать некоторой избыточности
записи являются причинами популярности таких операторов.
Заметим, что если списки становятся слишком длинными, то
получаемая программа становится весьма неудобочитаемой.
Истинный любитель НФБ расширит свой синтаксис, обеспе-
чив две различные формы для оператора присваивания, сле-
дующим образом:
<оператор присваивания^: = <переменная>: =
<выражение>| <пере-
менная>, < оператор
присваивания^ <выра-
жение>
. Это так называемое «рекурсивное определение», поскольку
одна из альтернативных форм для синтаксической единицы,
именуемой «оператор присваивания» (а именно вторая фор-
ма), содержит в качестве одного из своих компонентов снова
52 Глава 4
эту же синтаксическую единицу, именуемую «оператор при-
сваивания», т. е. ту самую синтаксическую единицу, которую
мы определяем! На первый взгляд такое циклическое опреде-
ление выглядит ужасающе, но после более внимательного изу-
чения мы можем убедиться в том, что, по крайней мере с син-
таксической точки зрения, в этом нет ничего неправильного.
Например, поскольку, согласно первой альтернативе,
х2: = Е1
является примером оператора присваивания, то формула
xl, х2:=Е1,£2
допускает разбор вида
xl, <оператор присваивания^ Е2
а следовательно, согласно второй альтернативе, также явля-
ется оператором присваивания. Однако с семантической точки
зрения это отвратительно, потому что получается, что Е2
ассоциируется с х! вместо того, чтобы ассоциироваться с х2.
В сравнении с двухоператорным языком, содержащим толь-
ко «.пропустить» и «отказать», наш язык с оператором при-
сваивания выглядит значительно более богатым: уже нет ка-
кой бы то ни было верхней границы для числа различных при-
меров синтаксической единицы «оператор йрисваивания». Но
он все же явно недостаточен для наших целей; нам нужна
возможность строить более изощренные программы, более
сложные конструкции. Для построения потенциально сложных
конструкций мы пользуемся схемой, которую можно рекурсив-
но описать так:
<конструкция>::= Спростая конструкция> |
<правильная композиция записей
вида: <конструкция>>
Для того чтобы эта схема могла принести хоть какую-ни-
будь пользу/необходимо выполнение двух условий: в нашем
распоряжении должны иметься «простые конструкции», что-
бы было с чего начать, и, кроме того, мы должны знать, как
строить «правильные композиции». Введенные раньше опера-
торы можно взять в качестве простых конструкций; оставшая-
ся часть этой главы посвящена именно процессу правильной
композиции некоей новой конструкции из заданных конструк-
ций. Новая конструкция в свою очередь может выступать в
роли части еще более сложного составного объекта.
После того как объект был образован композицией час-
тей, мы можем рассматривать его двумя способами. Во-пер-
Семантическая характеристика языка программирования 53
вых, мы можем считать его «нераздельным целым», восприни-
мая его свойства в большей или меньшей степени как маги-
ческие (или принимая их на веру или как постулаты). При
таком подходе существенны только свойства конструкции; не
имеет никакого значения, каким образом она образована из
своих частей. С такой точки зрения любые две конструкции,
обладающие одинаковыми свойствами, эквивалентны. Или же
мы рассматриваем конструкцию, как «составной объект», об-
разованный так, что мы можем понять, почему она обладает
объявленными свойствами. При этом мы воспринимаем части
как «малые» нераздельные целые, для которых принимаются
в расчет только их общие свойства. Второй подход вносит яс-
ность в то, что мы понимаем под «композицией». Композиция
должна определять, как свойства целого следуют из свойств
частей.
После этих общих замечаний вернемся к нашим конкрет-
ным конструкциям, свойства которых, как мы считаем, выра-
жаются их преобразователями предикатов. Точнее говоря,
если заданы две конструкции 51 и 52, чьи преобразователи
предикатов известны, можем ли мы представить себе правило
вывода нового преобразователя предикатов из двух заданных?
Если да, то мы можем считать результирующий преобразова-
тель предикатов описанием свойств составного объекта, по-
строенного специальным образом из частей 51 и 52.
Одним из простейших способов получения новой функции
из двух заданных является так называемая «функциональная
композиция», т. е. предоставление значения одной функции
в качестве аргумента для другой. Составной объект, соответ-
ствующий такому преобразователю предикатов, принято обо-
значать через «51; 52», и мы определяем
wp(«51; 52», 7?) = wp(51, wp(52, /?))
что при желании можно рассматривать как семантическое оп-
ределение точки с запятой.
Замечание. Из того факта, что преобразователи предика-
тов для 51 и 52 обладают свойствами 1—4 из предыдущей гла-
вы, можно заключить, что и определенный выше преобразова-
тель предикатов для «51; 52» также обладает этими четырьмя
свойствами. Например, поскольку для 51 и 52 справедлив
закон исключенного чуда:
wp(51,F)=F и wp(52, F)=F
54 Глава 4
мы заключаем, подставляя F вместо R в верхнее определе-
ние, что
wp(«51; 52», F) = wp(51, wp(52, F))
= wp(51, F)
=F
Читателю предоставляется в качестве упражнения прове-
рить, что остальные три свойства тоже сохраняются. (Конец
замечания.)
Перед тем как продолжить наши рассуждения, убедимся
в том, что этим формальным описанием семантики точки с за-
пятой охватывается наше интуитивное представление о. ней
(если оно у нас есть!), т. е. что составная конструкция «51;
52» может быть реализована по правилу «сначала запустить
конструкцию 51 и по окончании ее работы запустить 52». В са-
мом деле, в нашем определении wp(«51; 52», R) мы пред-
ставляем R — постусловие для составной конструкции — как
постусловие к преобразователю предикатов для 52, и этим
отражается то, что общая работа конструкции «51; 52» может
закончиться с окончанием работы 52. Соответствующее сла-
бейшее предусловие для 52, т. е. wp(52, R), представляется
как постусловие к преобразователю предикатов для 51; тем
самым мы явно отождествляем начальное состояние для 52
с конечным состоянием для 51. Однако именно так и бывает,
если работа'51 непосредственно предшествует во времени за-
пуску 52.
Чтобы удостовериться в этом, рассмотрим пример. Пусть
«51; 52» представляет собой
«а: = а+Ь; Ь: — а*Ь>
и пусть нашим постусловием является некоторый • предикат
R(a, b); в таком случае
wp(52, R(a, b)) =wp(«b:=a*6», R(a, b))
= R(a, a*b)
и
wp(«51; 52», R(a, b)) =wp(51, wp(52, R(a, b)))
=wp(51, R(a, a*b))
=wp («a: = a + t>», R(a, a *b))
~R(a+b, (a+b}*b)
т. e. мы можем гарантировать выполнение отношения R меж-
ду конечными значениями а и ft при условии, что первоначаль-
но то же отношение выполняется между а+b и (a + b)* b
соответственно.
Семантическая характеристика языка программирования 55
И наконец, поскольку функциональная композиция обла-
дает свойством ассоциативности, то не имеет значения, будем
ли мы разбирать «51; 52; 53» как «[51; 52]; 53» или же как
<51; (52; 53]». Иначе говоря, мы имеем полное право тракто-
вать точку с запятой как символ сочленения; поэтому не воз-
никает никакой неопределенности, когда мы выписываем опе-
раторный список вида «51; 52; 53; ...; 5П», и мы будем без
стеснения поступать так, когда для этого представятся подхо-
дящие случаи.
Упражнение
Проверьте, что конструкции
«х1 : = £1; х2:=£2» и «х2:=£2; х1: = £1»
семантически эквивалентны, если переменная х1 не встреча-
ется в выражении £2, а переменная х2 не встречается в выра-
жении £1. На самом деле, в таком случае обе эти конструкции
семантически эквивалентны одновременному присваиванию
х<х1, х2:=£1,‘ £2». (Эта эквивалентность является одним из ар-
гументов в пользу одновременного присваивания; ее примене-
ние позволяет нам избежать избыточности последовательной
записи,. более того, при одновременном присваивании стано-
вится очевидным, что два выражения £1 и £2 могут вычислять-
ся одновременно, и это последнее обстоятельство представляет
интерес при некоторых методиках реализации. Помимо того,
имеется, быть-может, более интересная возможность, что кон-
струкция «х1, х2: = £1, £2» не окажется семантически эквива-
лентной ни конструкции «х1: = £1; х2: = £2», ни конструкции
«х2: = £2; х/:=£1».) (Конец упражнения.)
До введения точки с запятой мы могли писать только одно-
операторные программы; с помощью точки с запятой мы обрели
способность писать программы в виде сочленения из п
г(п>0) операторов: «51; 52; 53; ...; 5/г». Если исключить про-
межуточную незавершенность, выполнение каждой программы
всегда означает временную последовательность выполнений п
операторов, сначала 51, потом 52 и так далее до Sn включи-
тельно. Однако из нашего примера игры на листе картона,
реализующей алгоритм Евклида, мы знаем, что должны уметь
описывать более широкий класс «правил игры»: всякая игра
будет состоять из последовательности перемещений, где каж-
дое перемещение имеет вид либо «х:=х—у», либо «У'.=у—х»,
но способ чередования этих перемещений во времени и даже
их общее число будут изменяться от игры к игре; он зависит от
начального положения фишки, он зависит от начального со-
стояния системы. Если точка с запятой является единственным
56 Глава 4
нашим средством для составления нового целого из заданных
частей, то мы не в состоянии этого выразить, и поэтому нам
необходимо искать нечто новое.
Пока точка с запятой остается единственным имеющимся
ь нашем распоряжении средством соединения, единственным
обстоятельством, при котором происходит запуск одной из со-
ставляющих конструкций Si (i>l), является правильное за-
вершение работы (лексикографически) предшествующей кон-'
струкции. Чтобы добиться нужной нам гибкости, необходимо
обеспечить возможность запуска той или йной (под) конструк-
ции в зависимости от текущего состояния системы. Для этого
мы введем — в два этапа — понятие «охраняемой команды»,
синтаксис которой задается следующим образом:
Сохраняющий заголовок>:: = <логическое выражение>->
<оператор>
Сохраняемая команда>:: = Сохраняющий заголовок> {;
Соператор>}
где фигурные скобки «{» и «}» следует читать так: «сопровож-
дается любым числом (быть может, нулем) экземпляров со-
держимого скобок».
(Другой вариант синтаксиса охраняемой команды moi бы
выглядеть так:
Ссписок операторов>::= <оператор> {;Соператор>}
Сохраняемая команда>:: = Слогическое выражение>->-
<список операторов>
Однако по причинам, которые не должны нас теперь интересо-
вать, я предпочитаю синтаксис, в котором вводится понятие
охраняющего заголовка).
В этом сочетании логическое выражение, предшествующее
стрелке, называется «предохранителем». Идея состоит в том,
что следующий за стрелкой список операторов будет выпол-
няться лишь при том условии, что обеспечена начальная
истинность значения соответствующего предохранителя. Предо-
хранитель позволяет нам избежать выполнения списка опера-
торов при тех первоначальных обстоятельствах, когда это вы-
полнение оказалось бы нежелательным или (если употребля-
ются частично определенные операции) невозможным.
Истинность значения предохранителя является необходи-
мым предварительным условием для выполнения охраняемой
команды как целого; это условие, разумеется, не является
достаточным, поскольку тем или иным способом — с двумя
такими способами мы встретимся —до него еще должна дойти
потенциальная «очередь». Именно поэтому охраняемая ко-
манда не рассматривается как оператор: оператор безогово-
Семантическая характеристика языка программирования 57
рочно выполняется, когда наступает его очередь, а охраняе-
мая команда может использоваться в качестве строительного
блока .для оператора. Если говорить точнее, мы предложим
два различных способа составления оператора из набора охра
няемых команд.
После некоторого осмысливания рассмотрение набора ох-
раняемых команд представляется вполне естественным. Пред-
положим, что нам требуется построить конструкцию, такую,
чтобы при условии, что начальное состояние удовлетворяет Q,
конечное состояние удовлетворяло Предположим далее, что
нам не удается найти единый список операторов, который вы-
полнял бы эту работу в любых случаях. (Если бы такой спи-
сок операторов существовал, то мы именно его бы и исполь-
зовали и не возникло бы потребности в охраняемых коман-
дах.) Однако нам может удасться найти несколько списков
операторов, каждый из которые будет выполнять нужную ра-
боту для некоего подмножества возможных начальных состоя-
ний. К каждому из этих списков операторов мы можем при-
соединить в качестве предохранителя логическое выражение,
характеризующее то подмножество, для которого этот список
подходит, и если у нас имеется вполне достаточный набор
предохранителей, такой, что из истинности Q всегда логически
следует истинность значения хотя бы одного предохранителя,
то для каждого начального состояния, удовлетворяющего Q,
мы располагаем конструкцией, которая переведет систему в
состояние, удовлетворяющее условию 7?, причем этой конструк-
цией служит одна из охраняемых команд, чей предохранитель
имел начальное значение «истина».
Чтобы выразить это, определим сначала
<набор охраняемых команд>:: = Сохраняемая команда>
{[] Сохраняемая команда^}
где символ «□» выступает в роли разделителя вариантов, в
остальном не упорядоченных. Один из способов формирова-
ния оператора из набора охраняемых команд состоит в том,
чтобы заключить такой набор в пару скобок «if ... И», при
этом наш синтаксис для синтаксической категории, именуемой
«оператор», пополняется следующей формой:
ConepaTop>:: = ifCHa6op охраняемых команд> fi
Таким образом, мы получаем возможность объединить нес-
колько охраняемых команд в новую конструкцию. Мы можем
представить себе работу, которая произойдет после запуска
этой конструкции, следующим образом. Выбирается одна из
58 Глава 4
охраняемых команд, чей предохранитель является истиной, П
запускается ее список операторов.
Прежде чем мы перейдем к изложению формального опи;
сания семантики нашей новой конструкции, уместно сделать
три замечания.
1. Предполагается, что все предохранители определены;
если это не так, т. е. вычисление какого-то предохранителя
может привести к работе без правильного завершения, то до-
пускается, что и вся конструкция не сможет правильно завер-
шить свою работу.
г. 2. Вообще говоря, наша конструкция приведет к недетер-
минированности при тех начальных состояниях, для которых
истинны значения 0олее чем одного предохранителя, посколь-
ку остается неопределенным, какой из соответствующих спис-
ков операторов будет тогда выбираться для запуска. Никакой
недетерминированности не возникает, если все предохранители
попарно исключают друг друга.
3. Если начальное состояние таково, что ни один из предо-
хранителей не является истиной, то мы встречаемся с началь-
ным состоянием, для которого не подходит ни один из вари-
антов, а следовательно, и вся конструкция в целом. Запуск
при таком начальном состоянии приведет к отказу.
Замечание. Если мы допускаем также и пустой набор охра-
няемых команд, то оператор «if fi» семантически эквивалентен
нашему прежнему оператору «отказать». (Конец замечания.}
(В следующем формальном определении слабейшего
предусловия для конструкции if-fi мы ограничимся случаем,
когда все предохранители являются полностью определенными
функциями. Если это не так, то нужно переписать выражение
с использованием символа capd при дополнительном требова-
нии, чтобы начальное состояние принадлежало области опре-
деления всех предохранителей.)
Обозначим через «IF» оператор О
if []B^SL2 □ ... О Bn-+SLn fi
Тогда для любого постусловия R
wp(IF, /?) = (Е j : : Bj) and
(A j : : Bj => wp(SLj, /?))
Эту формулу следует читать так: wp(IF, R) является исти-
ной для каждой такой точки в пространстве состояний, где
и SL — аббревиатура для Statement List — список операторов. —
Прим, перев.
Семантическая характеристика языка программирования 59
существует хотя бы одно значение / из отрезка 1^/^гг,
_такое, что Bj является истиной, и где, кроме того, для всех /
из отрезка таких, что Bj — истина, значение
wp(SLj, /?) также является истиной. Используя символ «...»,
какмы уже делали при описании самого оператора IF, мы мо-
жем предложить иную форму определения:
wp (IF, 7?) = (Bi or B2 or ... or Bn) and
(Bi ==> wp(SLi, /?)) and
(B2 => wp (SL2, #)) and ... and
(Bn => wp(SLn, /?))
Понимание этих формул не представляет особого труда.
Требованием, чтобы значение хотя бы одного предохранителя
являлось истиной, отражается факт отказа в случае, когда
значения для всех предохранителей ложны. Кроме того, мы
требуем для каждого начального состояния, удовлетворяющего^
wp(IF, 7?)/чтобы выполнялось Bj==>wp(SLj, R) для всех
Для тех значений /, при которых Bj — ложь, это следование
истинно независимо от значения wp(SLj, /?), т. е. для таких
значений /, разумеется, безразлично, что будет делать SLj.
При нашей реализации это учитывается в том, что для запуска
не берется SLj с ложным начальным значением предохрани-
теля Bj. При тех значениях /, для которых Bj — истина, данное
следование может быть истиной только в тОхМ случае, когда
wp (SLj, R) также является истиной. Поскольку наше формаль-
ное определение требует истинности следования при всех
значениях /, то реализация на самом деле имеет свободу вы-
бора, когда более чем один предохранитель является истиной.
- Конструкция if-fi представляет собой только один из двух
возможных способов построения оператора из набора охраня-
емых команд. В конструкции if-fi состояние,, при котором все
предохранители имеют ложные значения, ведет к отказу.
В нашей второй форме мы разрешаем, чтобы состояние, при
котором нет ни одного предохранителя с истинным значени-
ем, приводило к правильному завершению; поскольку в этой
ситуации не запускается никакой список операторов, вполне
естественно, что при этом возникает семантическая эквивалент-
ность с пустым оператором. Однако это разрешение на пра-
вильное завершение, когда нет ни одного предохранителя с
истинным значением, дополняется тем, что работе не разре-
шается завершаться, пока хотя бы один предохранитель явля-
ется истиной.'Итак, после запуска проверяются все предохра-
нители. Если нет ни одного истинного значения предохраните-
ля, то работа завершается; если же имеются предохранители
а истинными значениями, то один из соответствующих списков
60 Глава 4
операторов запускается, а после его завершения реализация
снова начинает общую проверку всех предохранителей. Эта
вторая конструкция обозначается путем заключения списка
охраняемых команд в пару скобок «do ... od».
Формальное определение слабейшего предусловия для кон-
струкции do-od является более сложным, чем для конструкции
if-fi; дело в том^ что первое выражается через второе. Мы,
сначала приведем это формальное определение, а затем объяс-
ним его. Обозначим через «DO» оператор
do B^-SLi □ B2-kSL2D ...□ Bn-+SLn od
и через «IF» оператор, получаемый путем заключения того же
набора охраняемых команд в пару скобок «if ... fi». Если ус-
ловия Hk (R) задаются в виде
7YO(7?) =7? and non (Е / : 1^/^n: В,)
и при fe>0
Hh(7?) = wp (IF, Hh-X (R)) or Яо (7?)
то
wp(DO, 7?) = (Е k: 7г>0: Hh(R))
Здесь интуитивно мы понимаем Яа(7?) следующим обра-(
зом: это слабейшее' предусловие, такое, что конструкция
do-od завершит свою работу после не более чем k выборок
охраняемых команд, причем система останется в конечном со-
стоянии, удовлетворяющем постусловию R.
При й = 0 требуется, чтобы конструкция do-od завершила
работу, не производя выборки какой-либо охраняемой коман-
ды, т. е. не допускается, существования какого-либо предохра-
нителя с истинным значением, что и выражено вторым логи-
ческим сомножителем. При этом начальная истинность R оче-
видным образом является необходимым условием для конечной
истинности 7?, что и выражено первым логическим сомно-
жителем.
При k>0 нам нужно различать два случая: либо ни один
из предохранителей не имеет истинного значения, но тогда
должно выполняться условие 7?, и это приводит нас ко второ-
му логическому слагаемому; либо хотя бы один предохрани-
тель'является истиной, и тогда события развиваются так, как
при однократном запуске оператора «IF» (в начальном состоя-
нии, которое не может привести к немедленному отказу вслед-
ствие отсутствия истинных значений предохранителей). Одна-
ко после такого выполнения, при котором производилась вы-
борка одной охраняемой команды, нам необходима гарантия
попадания в состояние, такое, чтобы потребовалось не более
Семантическая характеристика языка программирования 61
чем (&—1) дальнейших выборок для достижения завершения
работы в конечном состоянии, удовлетворяющем R. В соот-
ветствии с нашим определением, таким постусловием для
этого оператора «IF» служит Hk-\(R).
Согласно последней строке, определяющей wp(DO, /?),
должно существовать такое значение k, чтобы потребовалось
не более чем k выборок для обеспечения завершения работы
в конечном состоянии, удовлетворяющем постусловию R.
Замечание. Если мы допускаем также и пустой набор ох-
раняемых команд, то в силу сказанного оператор «do od»
семантически эквивалентен нашему прежнему оператору «про-
пустить». (Конец замечания.)
5 ДВЕ ТЕОРЕМЫ
В этой главе мы выводим две теоремы об операторах, ко-
•торые -строятся из наборов- охраняемых команд. Первая тео-
рема касается конструкции выбора if-fi, а вторая — конструк-
ции повторения do-od. В этой главе мы будем рассматривать
конструкции, выводимые из набора охраняемых команд
□ Br+SL2 □ ... □ Bn-+SLn
Будем обозначать через «IF» и «DO» операторы, получае-
мые заключением этого набора охраняемых команд в пары
•скобок «if ... fi» и «do ... od» соответственно. Мы будем также
использовать сокращение
ВВ= (Е /: 1=С/=С« Bj)
Теорема. (Основная теорема для конструкции выбора)
Используя введенные только 'что обозначения, мы можем
сформулировать основную теорему для конструкции выбора:
Пусть конструкция выбора IF и пара предикатов Q и R
таковы, что
Q^BB (1)
и
(А /: 1 : (Q and Bj) => wp(SLj, R)) (2).
одновременно справедливы для всех состояний. Тогда
Q=>wp(IF,/?) (3)
справедливо также для всех состояний.
Поскольку, в силу определения,
wp(IF, R) = ВВ and (А /: 1 : Bj=>wp (SLj, R))
и, согласно (1), из Q логически следует первый член правой
части, то отношение (3) доказывается, если на основании (2)
мы можем сделать вывод, что
Q =? (A j: 1 : Bj=± wp (SLj, R)) (4)'
справедливо для всех состояний. Для любого состояния, при
Две теоремы
63<
котором Q является ложью, отношение (4) истинно в силу оп-
ределения логического .следования. Для любого состояния»
.при котором Q является истиной, и для любого значения / мы
1^ожем различать два случая: либо Bj является ложью, но*
/тогда Bj=>wp(SLj, 7?) является истиной в силу определения
следования, либо Bj является истиной, но тогда, согласно (2),.
wp(SLj, R) является истиной, а следовательно, B?-=>wp (SLj, R)
тоже является истиной. В результате мы доказали отношение*
(4), а следовательно, и (3).
Замечание. В частном случае бинарного выбора (п = 2) и*
при В2 — non Bi мы имеем ВВ=Т, и слабейшее предусловие
Преобразуется так:
(В{ => wp (SLi, 7?)) and (non В{ => wp (SL2, R)) =
(non Bi or wp (SLi, R)) and (В{ or wp (SL2, R)) =
(#i and wp (SLi, 7?)) or (non Bi and wp (SL2, R)) (5)
Последнее преобразование возможно потому, что из четы-
рех перекрестных произведений член Bi and non B[ = F может
быть отброшен, а член wp (SLb 7?) and wp(SB2, 7?) тоже мо-
кнет быть отброшен по следующей причине: в любом состоя-
нии, где он истинен, обязательно является истиной какой-то-
один из двух членов формулы (5), и поэтому его самого мож-
но исключить из дизъюнкции. Формула (5) имеет прямое от-
ношение к предложенному Хоаром способу описания семан-
тики конструкции if-then-else из языка АЛГОЛ*60. Поскольку
здесь ВВ^Т логически следует из чего угодно, мы можем вы-
вести (3) при более слабом предположении:
((Q and BJ => wp (SLi, 7?)) and ((Q and non Bi) ==>wp (SL2, R))
(Конец замечания.)
Теорема для конструкции выбора представляет особую-
важность в случае, когда пара предикатов Q и R может быть
записана в виде
R — P
Q = P and ВВ
В этом случае предпосылка (1) выполняется автоматически,
а поскольку (ВВ and Bj)=Bj, предпосылка (2)' сводится
к виду
(A j : : (Р and Bj) =^wp(SLj, P)) (6)
из чего мы можем вывести, согласно (3),
(Р and ВВ) =^wp(IF, Р) для всех состояний (7)
64 Глава 5
Это отношение послужит предпосылкой для нашей следу-
ющей теоремы.
Теорема. (Основная теорема для конструкции повторения)
Пусть набор охраняемых команд с построенной для него
конструкцией выбора IF и предикат Р таковы, что
(Р and ВВ) -»wp(IF, Р) (7)
справедливо для всех состояний. Тогда для соответствующей
конструкции повторения DO можно вывести, что
(Р and wp (DO, Т)) =» wp (DO, P and non BB) (8)
для всех состояний.
Эту теорему, которая известна также под названием «ос-
новная теорема инвариантности для циклов», на интуитивном
уровне не трудно понять. Предпосылка (7) говорит нам, что
если предикат Р первоначально истинен и одна из охраняемых
команд выбирается для выполнения, то после ее выполнения
Р сохранит свою истинность. Иначе говоря, предохранители
гарантируют, что выполнение соответствующих списков опе-
раторов не нарушит истинности Р, если начальное значение Р
было истинным. Следовательно, вне зависимости от того, как
часто производится выборка охраняемой команды из имеюще-
гося набора, предикат Р будет справедлив при любой новой
проверке предохранителей. После завершения всей конструк-
ции повторения, когда ни один из предохранителей не явля-
ется истиной, мы тем самым закончим работу в конечном со-
стоянии, удовлетворяющем Р and non ВВ. Вопрос в том, за-
вершится ли работа правильно. Да, если условие wp(DO, Т)
справедливо и-вначале; поскольку любое состояние удовлет-
воряет Т, то wp(DO, Т) по определению является слабейшим
предусловием для начального состояния, такого, что запуск
оператора DO приведет к правильно завершаемой работе.
Формальное доказательство основной теоремы для конст-
рукции повторения основывается на формальном описании
семантики этой конструкции (см. предыдущую главу), из ко'-
торого мы выводим
Н0(Т)=попВВ (9)
при Л>0: Hk(T) =wp(IF, (Г)) or non ВВ (10)
Но (Р and non ВВ) =Р and non В В (11)
при Л>0: Hk (Р and non ВВ) =wp(IF, Hk-i (Р and
non BB)) or P and non BB (12)
Две теоремы
65
Начнем с того, что докажем посредством математической
индукции, что предпосылка (7) гарантирует справедливость
при k^O: (Р and Hk(T)) and non BB) (13)
для всех состояний.
В силу отношений (9) и (11) отношение (13) справедливо-
при & = 0. Мы покажем, что отношение (13) может быть дока-
зано при ^ = /С(/С>0) на основании предположения, ^то (13)
справедливо при /? = /(—1.
Р and НК(Т)=Р and wp(IF, HK_i(T)) or P and non BB
= P and BB and wp(IF, HK-i(T)) or P arid
non BB
==>wp(IF, P) and wp(IF, HK-X(T)) or P and
non BB
= wp(IF, P) and or P.and non BB
=>wp(IF, HK-X (P and non BB)) or P and
non BB
= HK (P and non BB)
Равенство в первой строке следует из (10), равенство во
второй строке следует из того, что всегда wp(IF, /?)
логическое следование в третьей строке вытекает из (7),
равенство в четвертой строке основывается на свойстве 3
преобразователей предикатов, следование в пятой стро-
ке вытекает из свойства 2 преобразователей предикатов и из
индуктивного предположения (13) для k = K—1, и последняя
строка следует из (12). Итак, мы доказали (13) для £ =
а следовательно, для всех значений k^Q.
Наконец, для любой точки в пространстве состояний мы
имеем, в силу (13),
Р and wp’(DO, Т) = (Е k : k^Q : Р and Hk{T))
=> (Е k : k^Q : Hh (P and non BB))
= wp(DO, P and non BB)
и тем самым доказана основная теорема (8) для~
конструкции повторения. Ценность основной, теоремы для
конструкции . повторения основывается на том, что ни в
предпосылке, ни в ее следствии не упоминается фактическое
число выборок охраняемой команды. Поэтому она применима
даже в тех случаях, когда это число не определяется началь-
ным состоянием.
3—6
6 О ПРОЕКТИРОВАНИИ
ПРАВИЛЬНО ЗАВЕРШАЕМЫХ КОНСТРУКЦИЙ
Основная теорема для конструкция повторения примени-
тельно к условию Р, сохраняемому инвариантно истинным, ут-
верждает, что
(P.and wp(DO, Т)) => (DO, Р and non ВВ)
Здесь член wp(DO, Т) представляет собой слабейшее
предусловие, такое} что конструкция повторения завершится.
Если задана произвольная конструкция DO, то в общем слу-
чае очень трудно (а может быть, невозможно} определить
wp(DO, Т). Поэтому я предлагаю проектировать нащи кон-
струкции повторения, постоянно помня о требовании заверши-
мости, т. е. предлагаю искать подходящее доказательство за-
вершимости и строить пррграмму таким способом, чтобы она
удовлетворяла предположениям, на которых основывается это
доказательство.
Предположим опять, что Р — отношение, которое сохраня-
ется инвариантно истинным, т. е.
(Р and ВВ) =» wp(IF, Р) для всех состояний (1}
Пусть t — конечная целочисленная функция от текущего со-
стояния, такая, что
(Р and ВВ) => (/>0) для всех состояний (2)
и, кроме того, для любого значения /0 и для всех состояний
(Р and ВВ and t</0+i) => wp (IF, t^t$). (3)
Тогда мы докажем, что
Р => wp (DO, Т) для всех состояний (4J
Сопоставив этот факт с основной теоремой для повторения,
мы можем заключить, что имеем для всех состояний
Р => wp (DO, Р and non ВВ) (5)
О проектировании правильно завершаемых конструкций SI
Мы покажем это, доказав сначала методом математиче-
ской индукции, что
(Р and t^k) =» Нь(Т) для всех состояний (6J
справедливо при всех k^O. Начнем с обоснования истинности
(6) при k = 0. Поскольку Н0(Т) =поп ВВ, нам требуется по-
казать, что
(Р and => non ВВ для всех состояний (7)
Одцако (7) —это просто другая форма записи выражения (2):
оба они равны выражению
non Р or поп ВВ or (/>0)
и поэтому (6) справедливо при k — 0.
Предположим теперь, что (6) справедливо при k = K; тогда
(Р and ВВ and /СК+1) => wp(IF, Р and
=> wp(IF, Як(О);
(Р and non ВВ and t^.K+1) => non ВВ
= H0(T)
И эти два логических следования можно объединить (из
А ==> С и D мы можем заключить, что справедливо
(А ог В) => (Сог £>)):
(Р and => wp(IF, НК(Т)) or HQ(T) = HK+i(T)
и тем самым истинность (6) доказана для всех k^>0. Посколь-
ку t — ограниченная функция, мы имеем
(Е6:£>0:^£)
и
(Е k-.k^Q.P and t^k)
=> (Е£:6>0:/Л(^))
= wp (DO, T)
и тем самым доказано (4).
Интуитивно теорема совершенно ясна. С одной стороны, Р
останется истиной, а следовательно, /^0 тоже останется исти-
ной; с другой стороны, из отношения (3) следует, что каждая
выборка охраняемой команды приведет к эффективному
уменьшению t по крайней мере на 1. Неограниченное количе-
ство выборок охраняемых команд уменьшило бы значение t
ниже любого предела, что привело бы к противоречию.
Применимость этой теоремы основывается на выполнении
условий (2) и (3). Отношение (2) является Достаточно про-
стым, отношение (3) выглядит более запутанным. Наша ос-
3*
68 Глава 6
новная теорема для конструкции повторения при
Q= (Р and BB and /^/0+1)
P=(t^tO)
(присутствие свободной переменной t0 в обоих предикатах
является причиной того, что мы говорили о «паре предика-
тов») позволяет нам заключить, что условие (3) справедливо,
если
(А/: 1^/^п: (Р and В; and /^70+1) =4wp (SLj,
Иначе говоря, нам нужно доказать для всякой охраняемой
команды, что выборка приведет к эффективному уменьше-
нию t. Помня о том, что t является функцией от текущего со-
стояния, мы можем рассмотреть
wp(SLj, (8)
Это предикат, включающий, помимо координатных перемен-
ных пространства состояний, также и свободную переменную
20. До сих пор' мы рассматривали такой предикат как преди-
кат, характеризующий некое подмножество состояний. Однако
для любого заданного состояния мы можем также рассматри-
вать предикат как условие, налагаемое на /0. Пусть t&=tmin
представляет собой минимальное решение уравнения (8) отно-
сительно /0; тогда мы можем интерпретировать значение tmin
как наименьшую верхнюю границу для конечного значения t.
Если вспомнить, что, подобно функции t, tmin также является
функцией от текущего состояния, то можно интерпретировать
предикат
tmin^t—1
как слабейшее Предусловие, при котором гарантируется, что
выполнение SLj уменьшит значение t по крайней мере на 1.
Обозначим это предусловие, где — мы повторяем — второй
аргумент является целочисленной функцией от текущего со-
стояния, через
wdec (SLj, t)
При этом инвариантность Р и эффективное уменьшение t га-
рантируются, если мы имеем при всех значениях /
(Р andBj) => (wp (SLj, Р) and wdec (SLj, t)) (9)'
Обычно практический способ отыскания подходящего пре-
дохранителя Bj состоит в следующем. Уравнение (9) отно-
сится к типу
(Р and Q) => R
О проектировании правильно завершаемых конструкций 69
где (практически вычислимое!) значение Q. нужно найти для
заданных значений Р и R. Мы замечаем, что
1. Q = R является решением.
2. Если Q=(Q1 and Q2) является решением и Р=» Q2,
то Q1 тоже является решением.
3. Если Q=(Q1 or Q2) является решением- и Р=М> non Q2
(или, что сводится к тому же самому, (Р and Q2) —F), то Q1
тоже является решением.
4. Если Q является решением и QI =»Q, то Q1 тоже явля-
ется решением.
Замечание 1. Если, действуя таким образом, мы приходим
к кандидатуре Q для Bj, такой, что Р=>поп Q, то эта канди-
датура может быть далее упрощена (в соответствии с преды-
дущим наблюдением 3; поскольку при любом Q мы имеем Q —
= (ложь or Q)) к виду ф = ложь; это означает, что рассматри-
ваемая охраняемая команда введена неудачно; ее можно иск-
лючить из набора, потому что она никогда не будет выбирать-
ся. (Конец замечания 1.)
Замечание 2. Часто на практике расщепляют уравнение (9)
на два уравнения:
(Р and Bj) =^wp (SLj, P) (9a)
и
(P and Bj) =»wdec(SLj, t) (96)
и рассматривают их по отдельности. Тем самым разделяются
две задачи: (9а) относится к тому, что остается инвариант-
ным, тогда как (96) относится к тому, что обеспечивает про-
движение вперед. Если, имея дело с уравнением (9а), мы при-
ходим к решению Bj, такому, что Р =$Bj, то тогда очевидно,
что это условие не будет удовлетворять уравнению (96), по-
скольку при таком Bj инвариантность Р привела бы к недетер-
минированности. (Конец замечания 2.)
Таким образом, мы можем построить конструкцию DO,
такую, что
Р=ф. wp (DO, Р and non В В)
Наши условия Bj должны быть достаточно сильными, чтобы
удовлетворялись следования (9); в результате этого новое га-
рантируемое постусловие Р and non ВВ может оказаться
слишком слабым и не обеспечить нам желаемого постусло-
вия R. В таком случае мы все-таки не решили нашу проблему
и нам следует рассмотреть другие возможности.
7 ПЕРЕСМОТРЕННЫЙ АЛГОРИТМ ЕВКЛИДА
Рискуя наскучить моим читателям, я посвящу еще одну
главу алгоритму Евклида. Полагаю, что к этому времени не-
которые из читателей уже закодируют его в виде
х,у.=Х, У;
do х>у'-+х:=х—у
□ у>х-+у;=у—х
fi
od;
печатать(х)
1
где предохранитель конструкции повторения гарантирует, что
конструкция выбор.а не, приведет к отказу. Другие читатели
обнаружат, что этот алгоритм можно закодировать более
просто следующим образом:
х, у.=Х, У;
do х> у^-х:=х—у
{\у>х-+у.=у—X
od;
печатать(х)
Попробуем теперь забыть игру на листе картона и попы-
таемся изобрести заново алгоритм Евклида для отыскания
наибольшего общего делителя, двух положительных чисел X
и У. Когда мы сталкиваемся с такого рода проблемой, в прин-
ципе всегда возможны два подхода.
Первый состоит в том, чтобы пытаться следовать опреде-
лению требуемого ответа настолько близко, насколько это
возможно. По-видимому, мы могли бы сформировать таблицу
делителей числа X; эта таблица содержала бы только конеч-
ное число элементов, среди которых имелись бы 1 в качестве
наименьшего и X в качестве наибольшего элемента. (Если
Х=1, то наименьший и наибольший элементы совпадут.) За-
Пересмотренный алгоритм Евклида 71
тем мы могли бы сформировать также аналогичную таблицу
делителей У. Из этих двух таблиц мы могли бы сформировать
таблицу чисел, присутствующих в них обеих. Она представля-
ет собой таблицу общих делителей чисел X и*У и обязательно
является непустой, так как содержит элемент 1. Следова-
тельно, из этой третьей таблицы мы можем выбрать (посколь-
ку она тоже конечная!) максимальный элемент, и он был бы
наибольшим общим делителем.
Иногда близкое следование определению, подобное обри-
сованному выше, является лучшим из того, что мы можем
сделать. Существует, однако, и другой подход, который стоит
испробовать, если мы знаем (или можем узнать) свойства
функции, подлежащей вычислению. Может оказаться, что мы
знаем так много свойств, что они в совокупности определяют
эту функцию; тогда мы можем попытаться построить ответ,
используя эти свойства.
В случае наибольшего общего делителя мы замечаем, на-
пример, что, поскольку делители числа — х те же самые, что
и для самого числа х, НОД(х, у) определен также для отри-
цательных аргументов и не меняется, если мы изменяем знаю
аргументов. Он определен и тогда, когда один из аргументов
равен нулю; такой аргумент обладает бесконечной таблицей
делителей (и поэтому нам не следует пытаться строить эту
таблицу!), но поскольку второй аргумент (=/=0) обладает ко-
нечной таблицей делителей, таблица общих делителей явля-
ется все же непустой и конечной. Итак, мы приходим к за-
ключению, что НОД (х, у) определен для всякой пары (х, у),
такой, что (х, у)=/=(0, 0). Далее, в силу симметрии понятия
«общий» наибольший общий делитель является симметричной
функцией своих двух аргументов. Еще одно небольшое умст-
венное усилие позволит нам убедиться в том, что.наибольший
общий делитель двух аргументов не изменяется, если мы за-
меняем один из этих аргументов их суммой или разностью.
Объединив все эти результаты, мы можем записать:
для (х, у)#= (0, 0)
(а) НОД(х, у) = НОД (у, х).
(б) НОД (х, у) =НОД(—х, у).
(в) НОД(х, у) = НОД(х+у, у) = НОД (х—у, у) и т. д.
(г) НОД(х, у) =n£s(x), если х = у.
Предположим для простоты рассуждений, что этими че-
тырьмя свойствами исчерпываются наши познания о функции
НОД. Достаточно ли их? Вы видите, что первые три отноше-
ния выражают наибольший общий делитель чисел х и у че-
рез’ НОД для другой пары, а последнее свойство выражает
72 Глава 7
его непосредственно через х. И в этом уже просматриваются
контуры алгоритма, который для начала обеспечивает истин-
ность
Р=(НОД(Х, У)=НОД(х, у))
(это легко достигается путем присваивания «х, у: =Х, У»),
после чего мы «утрамбовываем» пару значений (х, у) таким
образом, чтобы в соответствии с (а), (б) или (в) отношение
Р оставалось инвариантным. Если.мы можем организовать
этот процесс утрамбовки так, чтобы достигнуть состояния,
удовлетворяющего х=у, то, согласно (г), мы находим иско-
мый ответ, взяв абсолютное значение х.
Поскольку наша конечная цель состоит в том, чтобы обес-
печить при инвариантности Р истинность х=у, мы могли бы
испытать в качестве монотонно убывающей функции функцию
t=abs(x—у).
Чтобы упростить наш анализ (всегда похвальная цель!),
мы отмечаем, что если начальные значения х и у неотрица-
тельные, то ничего нельзя выиграть введением отрицательного
значения: если присваивание х:=Е обеспечило бы х<0, то
присваивание х: = —Е никогда не привела бы к получению
большего конечного значения t (потому что #^0). Поэтому
мы усиливаем наше отношение Р, которое должно сохранять-
ся инвариантным:
Р= (Pl and Р2)
при
Р1 = (НОД(Х, У)=НОД(х, у))
и
Р2= (х>0 and
Это означает, что мы отказываемся от всякого использования
операций х: = —х и у: = —у, т. е. преобразований, допусти-
мых согласно свойству (б). Нам остаются операции
из (а): х, у.—у, х
из (в): х:=х+у у:=у+х
х: = х—у у:—у—х
х:=у—х у:=х—у
Будем заниматься ими по очереди и начнем с рассмотре-
ния х, у '.—у, х:
wp («х, у. = у, х-», abs (х—у) /0) = (abs (у—х) t0)
поэтому
tmin(x, у) =abs(y—х)
Пересмотренный алгоритм Евклида 73
следовательно
wdec(«x, у.=у, х», abs (%—«/)) = (abs(y-x)^
^abs(x—у) — 1)=F
И здесь — для тех, кто не поверил бы без формального вы-
вода,— мы доказали (или, если угодно, обнаружили) с по-
мощью нашего исчисления, что преобразующая операция
х, У'—У> х не представляет интереса, так как она не может
привести к желаемому эффективному уменьшению выбранной
нами функции t.
Следующей испытывается операция х :=х+у, и мы нахо-
дим, снова применяя исчисление из предыдущих глав:
wp(«x: = x+z/», abs(x—у) ^/0) = (abs(x) ^tO)
tmin. (x, у) = abs (x) = x
(мы ограничиваемся состояниями, удовлетворяющими Р)
wdec(«x: = x+y», abs(x—у)) = (tmin(x, у) s^t(x, у)—1)
= (x^.abs(x—«/)“-!)
= (х-Ы^а&$(х—у))
= (x+1 ^x—у or x+1 ^.y—x)
Поскольку из P следует отрицание первого члена и к тому
же Р =^wp(«x:=x+t/», Р), то уравнение нашего предохра-
нителя
(Р and В,) => (wp(SL,-, Р) and wdec (SLj, t))
удовлетворяется последним членом, и мы нашли нашу первую,
а также (из соображений симметрии) нашу вторую охраняе-
мую команду:
х +1 У—х->х: = х+у
и
у+\^х—у-+у:=у+х
Аналогично мы находим (формальные манипуляции предо-
ставляются в качестве упражнения прилежному читателю)
1=Су and 3* у^2 * х—1-»-х:=х—у
и
' 1 ^х and 3 * х^2 * у—\-^у:=у—х
и
х+1 у—х-+х: = у—х
и
У +1 < X—у^у: = х—у
74 Глава 7
Разобравшись в том, чего мы достигли, мы вынуждены
прийти к досадному заключению, что способом, намеченным
в конце предыдущей главы, нам не удалось решить свою за-
дачу: из Р and non ВВ не следует, что х=у. (Например, при
(х, У) = (5,7) значения всех предохранителей оказываются
ложными.) Мораль сказанного, разумеется, в том, что наши
шесть шагов не всегда обеспечивают такой путь из начального
состояния в конечное состояние, при котором abs(x—у) моно-
тонно уменьшается. Поэтому нам нужно испытать другие
возможности.
Для начала заметим, что не повредит несколько усилить
условие Р2:
Р2= (х>0 and у>0)
так как начальные значения х и у удовлетворяют такому ус-
ловию, и, кроме того, нет никакого смысла в генерации рав-
ного нулю значения, поскольку это значение может возник-
нуть только при вычитании в состоянии, где х=у, т. е'. когда
уже достигнуто конечное состояние. Но это только малая мо-
дификация; основная модификация должна быть связана с
введением новой функции t, и я предлагаю взять такую функ-
цию t, которая только ограничена снизу в силу инвариантно-
сти Р. Очевидным примером является
Мы выясняем, что для одновременного присваивания
wdec(«x, y.=yi х», x+y)=F
и поэтому одновременное присваивание отвергается.
Мы находим для присваивания х := х+у
wdec(«x: = x+i/», х+у) = (у<0)
Истинность этого выражения исключается истинностью инва-
риантного отношения Р, а следовательно, такое присваивание
(наряду с присваиванием у:= у+х) также отвергается.
Однако для следующего присваивания х: — х—у мы нахо-
дим
wdec(«x:=x—у», х+у) = (t/>0)
т. е. условие, которое логически следует из условия Р (уси-
ленного мною ради этого).
Окрыленные надеждой, мы изучаем
wp(«x: = x—у», Р) = (НОД(Х, У) =
= НОД(х—у, у) and х—у>0 and у>0)
Пересмотренный алгоритм Евклида 75
Крайние члены можно отбросить, потому что они следуют из
Р, и у нас остается средний член; итак, мы находим
х>у-+х:=х—у
я
у>х-^у:=у—х
И на этом мы могли бы прекратить исследование, так как,
когда значения обоих предохранителей становятся ложными,
выполняется желаемое нами отношение х = у. Если мы продол-
жим, то найдем третий и четвертый варианты:
х>у—х and у>х-+х:=у—х
и
У>х—у and х>у-+у. =х—у
но не ясно, что можно выиграть их включением.
Упражнения
1. Исследуйте при том же Р выбор t=max(x, у).
2. Исследуйте при том же Р выбор t=x+2 * у.
3. Докажите, что при Х>0 и У>0 следующая программа,
оперирующая над четырьмя переменными,
х, у, u,v: = X, У, У, X;
do х>у-+х, v: = x—у, v+u
□ у>х-+у, и:=у—х, U+V
od;
печатать ((х+у)/2)-, печатать ((u+v)/2)
печатает наибольший общий делитель чисел X и У, а следом
за ним их наименьшее общее кратное. (Конец упражнений.)
Наконец, если наш маленький алгоритм запускается при
паре (X, У), которая не удовлетворяет предположению Х>0
and У>0, то произойдут неприятности: если (X, У) = (0, 0), то
получится неправильный нулевой результат, а если один из
аргументов отрицательный, то запуск приведет к бесконечной
работе. Этого можно избежать, написав
if Х>0 and У>0->
х, у:=Х, У;
do х>у-+х: =х—у □ у>х-+у: = у—х od;
печатать(х)
fi
76 Глава 7
Включив только один вариант в конструкцию выбора, мы
явно выразили условия, при которых ожидается работа этой
маленькой программы. В таком виде это хорошо защищенный
и довольно самостоятельный фрагмент, обладающий тем при-
ятным свойством, что попытка запуска вне его области опре-
деления приведет к немедленному отказу.
8 ФОРМАЛЬНОЕ РАССМОТРЕНИЕ
НЕСКОЛЬКИХ НЕБОЛЬШИХ ПРИМЕРОВ
В этой главе я проведу формальное построение несколь-
ких небольших программ для решения простых задач. Не сле-
дует понимать эту главу как предложение строить программы
только так и не иначе: такое предложение было бы довольно
смехотворным. Я полагаю, что многим из моих читателей зна-
комо большинство примеров, а если нет, они, вероятно, не за-
думываясь смогут написать любую из этих программ.
Следовательно, построение программ проводится здесь сов-
сем по другим причинам. Во-первых, это ближе познакомит
нас с формализмом, развитым в предыдущих главах. Во-вто-
рых, убедит нас в том, что по крайней мере в принципе, фор-
мализм способен сделать ясным и совершенно строгим то, что
часто объясняется при помощи энергичной жестикуляции.
В-третьих, многие из нас настолько хорошо знают эти про-
граммы, что уже забыли, каким образом давным-давно мы
убедились в их правильности: в этом отношении настоящая
глава напоминает начальные уроки планиметрии, которые по
традиции посвящаются доказательству очевидного. В-четвер-
тых, мы можем случайно обнаружить, к своему удивлению, что
маленькая знакомая задачка не такая уже знакомая. Нако-
нец, процесс построения программ может пролить свет на осу-
ществимость, трудности и возможности автоматического со-
ставления программ или использования машины в процессе
программирования. Это может оказаться важным, даже если
автоматическое составление программ не вызывает у нас ни
малейшего интереса, потому что может помочь нам лучше
оценить ту роль, которую могут или должны играть наши изо-
бретательские способности.
В моих примерах я буду формулировать требования зада-
чи в форме «для фиксированных х, у, ...», что является сокра-
щенной записью формы «для любых значений хО, уО, ... пост-
условие вида х=хО and y=z/O and ... должно вызывать пред-
условие, из которого следует, что х = хО and y = t/O and ...». Эта
связь между постусловием и предусловием будет гарантиро-
вана тем, что мы будем относиться к таким величинам как к
78 Глава 8
«временным константам»; они не будут встречаться в левых
частях операторов присваивания.
Первый пример
Для фиксированных х и у обеспечить истинность отноше-
ния R(m):
(т=х or т=у) and т^х and пг^у
Для любых значений х и у отношение лг=х может стать
истинным только в результате присваивания т\ = х\ следова-
тельно, истинность (т—х or т=у) обеспечивается только
выполнением либо т: = х, либо т:=у. В виде блок-схемы:
Рис. 8.1
Все-дело в том, что на . входе нужно сделать правильный
выбор.жоторый обеспечит истинность R(m) после завершения
вычислений. Для этого мы «проталкиваем постусловие через
альтернативы»:
Рис. 8.2
Формальное рассмотрение нескольких небольших примеров 79
и мы получили предохранители! Так как
7?(х) = ((*=* or x=r/)and х^х and х^у) = (х^>у)
и
Я (у) = ((у=х or у=у) and and у^у) = (у>х)
мы приходим к нашему решению:
if х'^у-^Ш'. — х П y^x-^m\=y fi
Поскольку (х^у ог у^х)=Т, отказа никогда не произойдет
(цопутно мы получили доказательство существования: для лю-
бых значений х и у существует т, удовлетворяющее /?(т)).
Поскольку (х^у and наша программа не обяза-
тельно детерминирована. Если первоначально х=у, то ока-
зывается неопределенным, какое из двух присваиваний будет
выбрано для исполнения; такая недетерминированность со-
вершенно корректна, так как мы показали, что выбор не имеет
значения.
Замечание, Если бы среди доступных примитивов имелась
функция «/пах», мы могли бы написать программу
т:= тах(х, у), поскольку /?(тах(х, у))=7\ (Конец замеча-
ния.)
Полученная программа не производит очень сильного впе-
чатления; с другой стороны, мы видим, что в процессе вывода
программы из постусловия на долю нашей изобретательности
почти ничего не осталось.
Второй пример
Для фиксированного значения п(п>0) задана функция
f (0 для 0^2i<n. Обеспечить истинность R:
and (A i: Ъ^л<п : f(k) ^f(i))
Поскольку наша программа должна работать при любом по-
ложительном значении п, трудно себе представить, как мож-
но обеспечить истинность /?, не прибегая к помощи цикла;
поэтому мы ищем отношение Р, которое легко можно сделать
истинным в начале программы и такое, что в конце (Р and поп
ВВ) =^R. Следовательно, отыскивая Р, мы ищем отношение,
более слабое, чем /?; иначе говоря, мы хотим получить обоб-
щение нашего конечного состояния. Стандартный способ обоб-
щения отношения — это замена константы переменной (воз-
можно, в ограниченном интервале), и здесь мой опыт подска-
зывает мне, что нужно заменить константу п новой
переменной, например /, и взять в качестве Р
O^k<j^Ln and (A i: Os£U</ : f (k) ^f(i))
80 Глава 8
где' условие добавлено для того, чтобы область опреде-
ления функции f была конечной. Теперь, имея такое обобще-
ние, мы легко получаем
(Р and j=n)
Чтобы подтвердить возможность использования таким об-
разом выбранного Р, мы должны располагать легким средст-
вом для обеспечения истинности Р в начале программы. По-
скольку
(A=0and/ = l) =>Р
мы отваживаемся предложить следующую структуру для на-
шей программы (комментарии даются в .скобках):
k, /: = 0, 1 {Р стало истинным};
do /=#«-> некий шаг к j=n при инвариантности Р od
{7? стало истинным}
Снова мой опыт подсказывает мне выбрать в качестве мо-
нотонно убывающей функции t текущего состояния функцию
t=(n—j), которая и в самом деле такова, что Р«= (/^0).
Чтобы гарантировать монотонное убывание t, я предлагаю
увеличивать j на 1, после чего мы можем написать
wp («/:=/+1», Р) =
0^А</+1^п and (Ai:0^i</ + l : f (k) ) =
0^&</+1 and (A i: 0^г</ : f (k) (i)) and
Первые два члена следуют из Р and /=/=п (потому что
(j^n and j^n)=^ и именно поэтому мы решили
увеличить j только на 1). Следовательно,
(Р and /¥=« and f (k) (/)) => wp(«/:=/ + l>, P)
и мы можем использовать последнее условие в качестве пре-
дохранителя. Программа
k, j: = 0, 1;
do /V=n-4-if f(^) (/)->/:=/+1 fi od
действительно даст правильный ответ, если она завершится
нормально. Однако нормальное завершение не гарантировано,
поскольку конструкция выбора может привести к отказу — и
это действительно так и будет, если k = 0 не удовлетворяет R.
Формальное рассмотрение нескольких небольших примеров 81
Если неверно, что f(&)^f(/), мы можем сделать это отноше-
ние верным при помощи присваивания k:= j и продолжить
наши исследования:
wp («£,/:=/,/+1», Р) =
Q^}<j+l^n and (At :0s^i</+l :/(/) >/(i)) =
0</<j + ls^n and (A
С огромным облегчением мы замечаем, что
(Р and /=#га and f(k) -=£-wp(«&, /:=/, / + 1», P)
и следующая программа будет работать, не подвергаясь опас-
ности отказа:
М: = 0, 1;
do/¥=n-Hf f (6) (/)->/: = /+1
= /+1 W od
Следует сделать несколько примечаний. Первое: посколь-
ку предохранители конструкции выбора не обязательно иск-
лючают друг друга, программа таит в себе внутреннюю неде-
терминированность того же типа, что и в первом примере. Эта
недетерминированность может проявиться и внешне. Функ-
ция f могла оказаться такой, что конечное значение k неодно-
значно; в этом случае наша программа может выработать лю-
бое допустимое значение!
Второе примечание: то, что мы построили правильную про-
грамму, не означает, что мы справились с задачей. Программи-
рование в равной степени является как математической, так и
инженерной дисциплиной; мы должны заботиться о правиль-
ности в той же мере, как скажем, и об эффективности. Исходя
из предположения, что на вычисление значения функции f
для данного аргумента затрачивается относительно много
времени, хороший инженер должен обратить внимание-на то,
что в программе, по всей вероятности, будет многократно вы-
числяться f (k) для одного и того же значения k. В этом случае
рекомендуется пойти на сделку и пожертвовать некоторым
объемом памяти, чтобы сэкономить час*гь времени, затрачи-
ваемого на вычисление. Но при этом наши усилия, направ-
ленные на повышение эффективности программы и уменьше-
ние затрат времени, ни в коей мере не должны служить изви-
нением за внесение беспорядка в программу. (Это очевидная
вещь, но я хочу подчеркнуть эту мысль, потому что очень час-
82 Глава 8
то запутанность программы оправдывается ссылками на эф-
фективность. Однако при ближайшем рассмотрении такое оп-
равдание всегда оказывается необоснованным, должно быть,
потому, что запутанность программы всегда неоправданна.)
Чтобы аккуратно реализовать обмен времени вычислений на
память, можно воспользоваться методом введения одной или
нескольких дополнительных переменных, чье значение можно
использовать, так как сохраняется инвариантным некоторое
отношение. В данном примере было замечено, что возможны
частые повторные вычисления f(k) для одного и того же k,
а это наводит на- мысль о введении дополнительной перемен-
ной, скажем-max,'и расширении инвариантного отношения за
счет дополнительного члена
max=f(k)
Это отношение должно стать истинные, когда k получит на-
чальное значение, и должно сохраняться инвариантным (при
помощи явного присваивания значения переменной max) пос-
ле изменения k. Мы приходим к следующей программе:
k, j, max;=0, 1, /(0);
do j=/=zi->-if max^f (/)->/:=/ +1
[] tnax^f(j) -+k, j, max: = j, /4-1, /(/) fi od
Вероятно, эта программа гораздо более эффективна, чем
наша предыдущая версия. В таком случае хороший инженер
на этом не остановится, потому что теперь он обнаружит, что
мог бы распорядиться повторными вычислениями /(/) для од-
ного и того же /. Для этого можно ввести дополнительную пе-
ременную, скажем А,' и обеспечить инвариантность отношения
А=/(/)
Однако мы не может сделать это на том же глобальном
уровне, как для нашего предыдущего члена: значение j=n не
исключено, а при этом значение /(/) не обязательно определе-
но. Следовательно, истинность отношения h=f(j) должна за-
ново обеспечиваться после каждой проверки, показывающей,
что /=/=п; по завершении внешней охраняемой команды (так
сказать, «как раз перед od») мы имеем h=f(j—1), но нас это
Формальное рассмотрение нескольких, небольших примеров 83
hq должно беспокоить, и пусть все остается так, как есть.
k, j, max: = 0, 1, f (0);
do /г: =/(/);
if max^h-*- j: = j+ 1
[] tnax^h-^k, j, max: = jt j+ 1, Л, fi od
Последнее примечание касается не столько нашего реше-
ния задачи, сколько наших соображений о подходе к реше-
нию. Мы говорили о математическом подходе, мы говорили об
инженерном подходе и провели разделение между этими под-
ходами, сосредоточивая внимание то на одном, то на другом
аспекте. Хотя разделение подходов абсолютно необходимо,
когда речь идет о более сложных задачах, я должен подчерк-
нуть, что, сосредоточивая внимание на одном из аспектов, не
следует полностью игнорировать другие аспекты. Разрабаты-
вая математическую часть проекта, мы должны помнить, что
даже математически правильная программа может погибнуть,
•если она плоха с инженерной точки зрения. Аналогично, осу-
ществляя .«сделку» между памятью и временем, мы должны
делать это аккуратно и систематически, чтобы по неряшли-
вости не внести ошибок в программу; кроме того, хотя пред-
варительно был проведен математический анализ, мы долж-
ны к тому же достаточно хорошо разбираться в задаче, чтобы
судить о том, приведут ли предполагаемые изменения к зна-
чительному улучшению программы.
Замечание. До того как я начал пользоваться этими фор-
мальными построениями, я всегда использовал «j<n» в каче-
стве предохранителя в этой конструкции повторения, теперь я
должен отучиться от этой привычки, так как в случае, подоб-
ном данному, конечно, предпочтительнее предохранитель
«уу=п». Для этого имеются две причины. Предохранитель
«/у=и» позволяет нам сделать вывод, что по завершении про-
граммы / = п, не ссылаясь при этом на инвариантное отноше-
ние Р; тем самым упрощается дискуссия о том, что дает нам
вся конструкция в целом по сравнению с предохранителем
«/<п». Гораздо важнее, однако, что предохранитель «/#=п»
ставит завершение программы в зависимость от (части) ин-
вариантного отношения, а именно j^n, и поэтому ему следует
отдать предпочтение, так как его использование приведет к
усилению конструкции. Если в результате выполнения /: =
/+1 значение / так возрастет, что станет справедливым отно-
шение j>n, предохранитель «/<п» не поднимет тревогу, тогда
84 Глава 8
как предохранитель «]'=£п» по крайней мере не допустит нор-,
мального завершения. Такой аргумент представляется вполне
весомым, даже если не принимать во внимание сбой машины.
Пусть в последовательности Xq, Xi, Х2, ... значение Хо задается,
а значение х< для :>0 определяется как Xi=f(x,-i), где f —
некоторая вычислимая функция. Будем внимательно и точно
следить за тем, чтобы сохранялось инвариантным отношение
X=xt. Предположим, что в программе имеется монотонно
возрастающая переменная п, такая, что для некоторых значе-
ний п нас интересуют хп. При условии что n^i, мы всегда
можем сделать истинным отношение Х=хп при помощи
do X: = i+l, f(X) od
Если же отношение n^i не обязательно имеет место (мо-
жет быть, последующие изменения в программе привели к то-
му, что в процессе вычислений п будет не только возрастать),
приведенная выше конструкция (к счастью!) не придет к за-
вершению, в то время как конструкция
do i<n->-i, X: = i+1, f(X) od
не обеспечит истинности отношения Х=хп. Мораль этой исто-
рии такова, что при прочих равных условиях мы должны вы-
бирать наши предохранители как можно более слабыми.
(Конец замечания.)
Третий пример
Для фиксированных а(а^О) и d(d>0) требуется обеспе-
чить истинность R:
0^r<d and d| (а—г)
(Здесь вертикальная черта «|» заменяет собой слова «являет-
ся делителем».) Иначе говоря, нам требуется вычислить наи-
меньший неотрицательный остаток г, полученный в результате
деления а на d. Чтобы эта задача действительно была задачей,
мы должны ограничить использование арифметических опе-
раций только операциями сложения и вычитания. Поскольку
условие d|(a—г) выполняется при г=а и при этом, так как
верно, что О^г, предлагается выбрать в качестве инва-
риантного отношения Р:
0=gV and d] (а—г)
В качестве функции t, убывание которой должно обеспе-
чить завершение работы программы, мы выбираем само г. По-
скольку изменение г должно быть таким, чтобы неизменно вы-
полнялось условие d \ (а—г), г можно изменять только на чис-
Формальное рассмотрение нескольких небольших примеров 85-
ло, кратное d, например на само d. Таким образом, нам, как
оказалось, предлагается вычислить
wp(«r:=r—d», Р) and wdec («г: = г—d», г) —
Osglr—d and d\ (a—r+d) and d>0
Поскольку член d>0 можно было бы добавить к инвари-
антному отношению Р, обоснования требует только первый
член; мы находим соответствующий предохранитель «r^d»
и пробуем составить такую программу:
if а^О and d>0->-
r:=a;
do r^d->-r: = r—d od
fi
По завершении программы стало истинным отношение
Р and non r2>d, из чего следует истинность R, и, таким обра-
зом, задача решена.
Предположим теперь, что нам, кроме того, потребовалось
бы присвоить q такое значение, чтобы по окончании програм-
мы было бы также верно, что
a=d*q+r
иначе говоря, требуется найти не только остаток, но и частное.
Попробуем добавить этот член к нашему инвариантному от-
ношению. Поскольку
(a = d * </ + г) => (a = d * (<7+ 1) + (г—d))
мы приходим к программе
if and d>0->
q, r: = 0, a;
do r~^d^>-q, r. = q+\, r—d od
fi
На выполнение приведенных выше программ будет, конечна,
затрачиваться очень много времени, если частное велико. Мо-
жем ли мы сократить это время? Очевидно, этого можно добить-
ся, если уменьшать г на величину, кратную и большую d. Вво-
дя для этой цели новую переменную, скажем dd, мы получаем
условие, которое должно неизменно выполняться на протяже-
нии всей работы программы:
d|dd and dd^d
86 Глава 8
Мы можем ускорить нашу первую программу, заменив
«г:= г—d» уменьшением, возможно повторным, г на dd, пре-
доставляя в то же время возможность dd, первоначально рав-
ному d, довольно быстро возрастать, например каждый раз
удваивая dd. Тогда мы приходим к следующей программе:
if а > О and d > 0 —►
г :=а;
do r^d—►
dd :—d;
do dd —*r’=r—dd', dd'—dd-\-dd od
od
fi
Ясно, что отношение O^r and d{(a—г) сохраняется инвари-
антным, и поэтому программа обеспечит истинность R, если
она завершится Иормально, но так ли это? Конечно, так, по-
скольку внутренний цикл, который завершается при dd>0,
возбуждается только при начальных состояниях, удовлетворя-
ющих условию r^-dd, и поэтому уменьшение г:=г—dd вы-
полняется по крайней мере один раз для каждого повторения
внешнего цикла.
Но такое рассуждение (хотя и достаточно убедительное!)
является весьма неформальным, а поскольку в этой главе мы
говорим о формальном построении программ, мы можем по-
пробовать сформулировать и доказать теорему, которой инту-
итивно пользовались.
Пусть IF, DO и ВВ понимаются в обычном смысле, и
Р — это отношение, сохраняющееся инвариантным, т. е.
(Р and ВВ) =» wp (IF, Р) для всех'состояний (1)
и пусть t — целочисленная функция, такая, что для любого
значения /0 и для всех состояний
(Р and BB and t </04-l)=^wp(IF, f</0) (2)
или, что то же,
(Р and 5В) => wdec (IF, /) для всех состояний (3)
Тогда для любого значения /0 и для всех состояний
(Р and BB and wp(DO, Г) and t </0+l)=>wp(DO, f</0) (4)
или, что то же,
(Р and BB and wp(DO, Г)) => wdec (DO, t) (5)
Формальное рассмотрение нескольких небольших примеров 87
В словесной формулировке: если сохраняемое инвариантным
отношение Р гарантирует, что каждая выбранная для испол-
нения охраняемая команда вызывает действительное умень-
шение t, то конструкция повторения вызовет действительное
уменьшение t, если она нормально завершится после по край-
ней мере одного выполнения какой-либо охраняемой команды.
Теорема настолько очевидна, что было бы досадно, если бы ее
доказательство оказалось трудным, но, к счастью, это не так.
Мы покажем, что из (1) и (2) следует, что для любого зна-
чения tO и для всех состояний
(Р and ВВ and Н6(Т) and t </04-1)=>//»(/</0) (6)
для всех k^sO. Это справедливо для k = 0, поскольку (ВВ
and H0(T))=F, и, исходя из предположения, что (6)
справедливо для k = K, мы должны показать, что (6) справед-
ливо и для k = K+1.
(Р and ВВ and Нк+г(Т) and /</04-1)
=» wp (IF, P) and wp (IF, HK (Г)) and wp (IF, t < /0)
=wp(IF, .P and HK(T) and t^tO)
=» wp ((IF, (P and В В and H K (T) and /</04-1) or (/ < /0
and non BB))
=4-wp(IF, //*-(/</0) or //0(/</0))
= wp(IF, ^(/</0))
=»wp(IF, HK(t </0)) or //0(/</0)
= Htf+i ^0)
Первая импликация следует из (1), определения НК+Х(Т)
и (2); равенство в третьей строке очевидно; импликация в чет-
вертой строке выводится при помощи присоединения
(ВВ or поп В В) и последующего ослабления обоих членов;
импликация в пятой строке следует из (6) при k = K и опреде-
ления Ho(t^tO)-, остальное понятно. Таким образом, мы до-
казали справедливость (6) для всех k~^0, а отсюда немедлен-
но вытекают (4) и (5).
Упражнение
Измените нашу вторую программу таким образом, чтобы
она вычисляла также и частное, и дайте формальное доказа-
тельство правильности вашей программы. (Конец упражне-
ния.)
88 Глава 8
Предположим теперь, что имеется маленькое число, ска-
жем 3, на которое нам позволено умножать и делить, и что эти
операции выполняются достаточно быстро, так что имеет
смысл воспользоваться ими. Будем обозначать произведение
«/и * 3» (или «3 * /и») и частное «m/З»; последнее выражение
будет использоваться только при условии, что первоначально
справедливо 3|/п. (Мы ведь работаем с целыми числами, не
так ли?)
И опять мы пытаемся обеспечить истинность желаемого от-
ношения R при помощи конструкции повторёния, для которой
инвариантное отношение Р выводится путем замены констан-
ты переменной. Заменяя константу d переменной dd, чьи зна-
чения будут представляться только в виде d * (степень 3), мй
приходим к инвариантному отношению Р:
0-^.r<dd and dd | (а—г) and (Ez tdd=d*3‘)
Мы обеспечим истинность этого отношения и затем, сохра-
няя его инвариантным, постараемся достичь состояния, при ко-
тором d=dd.
Чтобы обеспечить истинность Р, нам понадобится еще одна
конструкция повторения: сначала мы обеспечим истинность
отношения
О г and dd | (а —г) and (Ez: i : dd=d *3')
а затем будем увеличивать dd, пока его значение не станет
достаточно большим и таким, что r<dd. Получим следующую
программу:
if а>0 and z/>0—►
г, dd := a, d;
do г> dd—*dd'. = dd*3 od;
do dd=£ d — dd := dd/3;
do r^.dd ->r r — dd od
od
Упражнение
Измените приведенную выше программу таким образом,
чтобы она вычисляла* также и частное, и дайте формальное
доказательство правильности вашей программы. Это доказа-
тельство должно наглядно показывать, что всякий раз, когда
вычисляется dd/З, имеет место 31 dd. (Конец упражнения.)
Формальное рассмотрение нескольких небольших примеров 89
Для приведенной выше программы характерна довольно
распространенная особенность. На внешнем уровне две кон-
струкции повторения расположены подряд; когда две или
больше конструкций повторения на одном и том же уровне
следуют друг за другом, охраняемые команды более поздних
конструкций оказываются, как правило, более сложными, чем
команды предыдущих конструкций. (Это явление известно как
«закон Дейкстры», который, однако, не всегда выполняется.)
Причина такой тенденции ясна: каждая конструкция повто-
рения добавляет свое «and non ВВ» к отношению, которое она
сохраняет инвариантным, и это дополнительное отношение
следующая конструкция также должна сохранять инвариант-
ным. Если бы не внутренний цикл, второй цикл был бы в точ-
ности противоположен первому; и функция дополнительного
оператора
dor>aW — г : = r — dd od
именно в том и состоит, чтобы восстанавливать возможно на-
рушенное отношение r<dd, достигаемое при выполнении пер-
вого цикла.
Четвертый пример
Для фиксированных QI, Q2, Q3 и Q4 требуется обеспечить
истинность /?, причем R задается как and /?2, где
7?1: последовательность значений (<?1, q2, q3, q4) есть не-
которая перестановка значений (Q1, Q2, Q3, Q4)
R2: ql^q2^q3^q4
Если мы возьмем в качестве сохраняемого инвариант-
ным отношения Р, получим такое возможное решение:
ql, q2. ?3, ^4:=Q1, Q2, Q3, £4;
do ?1>?2—*q\, q2'.— q2, q\
[] q2>q3 —»<?2, q3:=q3, q2
□ <?3>?4 — <?3, q4\ = q4, q3
od
Очевидно, что после первого присваивания Р становится
истинным, и ни одна из охраняемых команд не нарушает его
истинности. По завершении программы мы имеем поп ВВ, а
это есть отношение R2. В том, что программа действительно
придет к завершению, каждый из нас убеждается по-разному
в зависимости от своей профессии: математик мог бы заме-
тить, что число перестановок убывает, исследователь операций
90 Глава 8
будет интерпретировать это как максимизацию tfl+2* q2 +
+ 3 *q3 + 4 *q4t а я — как физик — сразу «вижу», что центр тя-
жести смещается в одном направлении (вправо, если быть
точным). Программа примечательна в том смысле, что, какиё
бы предохранители мы ни выбрали, никогда не возникнет
опасности нарушения истинности Р: предохранители, исполь-
зуемые в нашем примере, являются чистым следствием необ-
ходимости завершения программы.
Замечание. Заметьте, что мы могли бы добавить также и
другие варианты, такие, как
tfl Z>q3-*q\,q3 := q3, q\
причем их нельзя использовать для замены одного из трех
перечисленных в программе. (Конец замечания.)
Это хороший пример того, какого рода ясности мы можем
достичь при нашей недетерминированности; излишне говорить,
однако, что я не рекомендую сортировать большое количест-
во значений аналогичным способом.
Пятый пример
Нам требуется составить программу аппроксимации квад-
ратного корня; более точно: для фиксированного п (п^О)
программа должна обеспечить истинность
/?: a2<n and(a+l)2>^
Чтобы ослабить это отношение, можно, например, отбро-
сить один из логических сомножителей, скажем последний, и
сосредоточиться на
Р: а2 < п.
Очевидно, что это отношение церно при а=0, поэтому вы-
бор начального значения не должен нас беспокоить. Мы ви-
дим, что если второй член не является истинным, то это вы-
зывается слишком маленьким значением а, поэтому мы могли
бы обратиться к оператору «а: = а+1». Формально мы полу-
чаем
wp(«a: = а-\-1», Р) = ((а + 1)2< п)
Используя это условие в качестве (единственного!) предо-
хранителя, мы получаем (Р and non ВВ) и приходим к
следующей программе:
if п>0—►
а:=0 {Р стало истинным};
Формальное рассмотрение .нескольких небольших примеров 91
do (л-|- I)2 п —: = а-\-1 [Р осталось истинным} od
{/? стало истинным}
fi {/? стало истинным}
При составлении.программы мы исходили из предположе-
ния, что она завершится, и это действительно так, Поскольку
корень из неотрицательного числа есть монотонно возрастаю-
щая функция: в качестве t мы можем взять функцию п—а2.
Эта программа довольно очевидна, к тому же она и не
очень эффективна: при больших значениях п она будет рабо-
тать довольно долго. Другой способ обобщения 7? — это вве-
дение другой переменной (скажем, Ь — и снова в ограничен-
ном интервале изменения), которая заменит часть 7?, на«-
пример,
Р- а2^п and b2 > п and 0 < а < b
Благодаря такому выбору Р обладает тем приятным свойст-
вом, что
(Р and (а+ 1== £))=> 7?
Таким образом, мы приходим к программе, представлен-
ной в такой форме (здесь и далее конструкция if п0fi
опускается):
а,Ь'. = 0,^+1 {Р стало истинным);
do а4-1 =/=£—>уменьшить Ь — а при инвариантности Pod
{Р стало истинным}
Пусть d будет ‘величиной, на которую уменьшается раз-
ность b—а при каждом выполнении охраняемой команды.
Разность может уменьшаться либо за счет уменьшения Ь,
либо за счет увеличения а, либо за счет и того и другого. Не
теряя общности, мы можем ограничиться рассмотрением таких
шагов, когда изменяется либо а, либо Ь, но не а и b одновре-
менно: если а слишком мало и b слишком велико и на одном
шаге только уменьшается Ь, тогда на следующем шаге можно
увеличить а. Эти соображения приводят нас к программе в
следующей форме:
а.Ь : = 0, п-\-1 (Р стало истинным};
do а-\-1#= Ь—>
d : = ... \d имеет соответствующее значение и Р по-преж-
нему выполняется};
if... —: = a-\-d {Р осталось истинным}
92 Глава 8
[]...—»b: = b — d {P осталось истинным)
fi {P стало истинным)
od {/? стало истинным)
Теперь
wp(«a:= а+flf», P)=((a-|-af)2-<n and 62>л)
Поскольку истинность второго члена следует из истинности Р,
мы можем использовать первый член в качестве нашего пер-
,вого предохранителя; аналогично выводится второй предохра-
нитель, и мы получаем очередную форму нашей программы:
a,&:=0,«+l;
do а-\- \ b —»d:=...;
if (a-\-d)2 —>a'-= a-\-d
□ (d —df)2> л—= b — d
fi {P осталось истинным)
od {/? стало истинным)
Нам остается еще соответствующим образом выбрать d.
Поскольку мы взяли b—а (на самом деле, b—а—1) в качестве
нашей функции t, эффективное убывание должно быть таким,
чтобы d удовлетворяло условию d>0. Кроме того, последую-
щая конструкция выбора не должна приводить к отказу, т. е.
по крайней мере один из предохранителей должен быть истин-
ным. Это значит, что из отрицания одного, (а+^)2>л, должен
следовать другой, (Ь—d)2>n; это гарантируется, если
a-[-d < b—d
или
2 * d ^.b—a
Наряду с нижней границей мы установили также и верхнюю
границу для d. Мы могли бы взять d=l, но чем больше d, тем
быстрее работает программа, поэтому мы предлагаем
а,b : — 0, п-\-1;
do а-|-1 =Н= b^~d(b — a) div 2;
if (a-j-d)2-^ п->-а : = a-^-d
□ (b-d)2>n^b:= b — d
fi
od
Формальное рассмотрение нескольких небольших примеров 93
где п div 2 есть п/2, если 21 и, и {п— 1) /2, если 21 {п— 1).
Использование действия div побуждает нас разобраться
в том, что произойдет, если мы навяжем себе ограничение на
b—а, полагая, что b—а четно при каждом вычислении d. Вво-
дя с = Ь—а и исключая 6, мы получаем инвариантное отно-
шение
Р: а2^п and {а-\-с)2>п and(Е/: / >0 : c = 2z)
и программу (в которой с играет роль d)
а, с := 0, 1; do п-^с : = 2 * с od;
do £ .=/= 1 : =г/2;
if (а ^)2 "С п а : = а + с
О (а~т пропустить
fi
od
Замечание, Эта программа очень похожа на последнюю
программу для третьего примера, где вычислялся остаток в
предположении, что мы имеем право умножать и делить на 3.
В приведенной выше программе можно было бы заменить кон-
струкцию выбора на
do{a-\-c)2^n->a: ==а-\-с od
Если, условие, которому должен удовлетворять остаток,
O^r<J, записать как r<d and (r + d)^d, сходство станет
еще более отчетливым. {Конец замечания.)
Понимая, что так можно окончательно «замучить» этот ма-
ленький пример, я бы хотел тем не менее предложить послед-
ний вариант преобразования программы. Мы написали про-
грамму/ исходя из предположения, что операция возведения
числа в квадрат входит в состав имеющихся операций; но
предположим, что это не так и что единственные операции
типа умножения, имеющиеся в нашем распоряжении,— это
умножение и деление на (малые) степени 2. Тогда наша ’по-
следняя программа оказывается не такой уж хорошей, т. е.
она нехороша, если мы предполагаем, что значения перемен-
ных, с которыми непосредственно оперирует машина, отож-
дествлены со значениями переменных аи с, как это было бы
при «абстрактных» вычислениях. Другими словами, мы мо-
жем рассматривать а и с как абстрактные переменные, чьи
значения представляются (в соответствии с соглашением, пре-
дусматривающим более сложные условия, чем просто тожде-
94 Глава 8
ственность) значениями других переменных, с которыми
в действительности оперирует машина при выполнении про-
граммы. Мы можем позволить машине работать не непосред-
ственно с а и с, а с р, q, г, такими, что
р=а*с
q=c2
г=п — а2
Мы видим, что это — преобразование координат, и каждой
траектории в нашем (а, с)-пространстве соответствует траек-
тория в нашем (р, q, г)-пространстве. Обратное не всегда вер-
но, так как значения р, q и г не независимы: в терминах
р, q и г мы получаем избыточность и, следовательно, потен-
циальную возможность, пожертвовав некоторым объемом
памяти, не только выиграть время вычислений, но
даже избавиться от необходимости возводить в квад-
рат! (Совершенно ясно, что преследовалась именно эта цель,
когда строилось преобразование, переводящее точку в (а, с)-
пространстве в точку в (р, q, г)-пространстве.) Теперь мы
можем попытаться перевести все булевы выражения и пере-
мещения в (а, с)-пространстве в соответствующие булевы вы-
ражения и перемещения в (р, q, г)-пространстве. Если бы нам
удалось сделать это в терминах допустимых операций, наша
задача/была бы успешно решена. Предлагаемое преобразова-
ние и в самом деле отвечает нашим требованиям, и результа-
том его является следующая программа (переменная h была
введена для очень локальной оптимизации):
p,q, г:=0,1,л; do q^n-+-q'—q*4 od;
do q ,=?= l-+q:=q/4;h:=p-[-q;p:=pl2{fi = 2*p-\-q];
ltr^>fi^>~p,r:=p-\-q,r — h
0 r пропустить
fi
od-(p имеет значение, требуемое для а]
Этот пятый пример был включен благодаря истории его
создания (правда, несколько приукрашенной).. Когда млад-
шей из двух наших собак было всего несколько месяцев, я
однажды вечером пошел погулять с ними обеими. Назавтра
мне предстояло читать лекции студентам, которые всего лишь
несколько недель назад начали знакомиться с программиро-
ванием, и мне нужна была простая задача, чтобы на ее при-
мере я мог «массировать» решения. В течение часовой прогул-
Формальное рассмотрение нескольких небольших примеров 95
ки я продумал первую, третью и четвертую^ программы, прав-
да, правильно ввести h в последней программе я смог только
при помощи карандаша и бумаги, когда вернулся домой. Ко
второй программе, той, которая оперирует с а и b и которая
была здесь представлена как переходная ступень к нашему
третьему решению, я пришел лишь несколько недель спустя —
и она была тогда в гораздо менее элегантной форме, чем пред-
ставлена здесь. Вторая причина для ее включения в число
представленных программ — это соотношение между третьей
и четвертой программами: по отношению к четвертой програм-
ме третья представляет собой наш первый пример так назы-
ваемой «абстракции представления».
Шестой пример
Для фиксированных Х(Х>1) и У(У^>0) программа долж-
на обеспечить истинность отношения
/?: z==XY
при очевидном предположении, что операция возведения в сте-
пень не входит в набор доступных операций. Эта задача может
быть решена при помощи «абстрактной переменной», скажем
Л; при решении задачи мы будем пользоваться циклом, для
которого инвариантным является отношение
Р: h*z=-XY
и наша (в равной степени «абстрактная») программа могла
бы выглядеть так:
h,z\=XY ,\[Р стало истинным);
do h Ф 1-f сжимать h при инвариантности Р od
{/? стало истинным)
Последнее заключение справедливо, поскольку (Р and
Л=1)=Ф/?. Приведенная выше программа придет к заверше-
нию, если после конечного числа применений операции «сжи-
мания» h станет равным 1. Проблема, конечно, в том, что мы
не можем представить значение h значением конкретной пере-
менной, с которым непосредственно оперирует машина; если
бы мы могли так сделать, мы могли бы сразу присвоить z
значение XY, не затрудняя себя введением h. Фокус в том, что
для представления текущего значения h мы можем ввести
две—на этом уровне конкретные — переменные, скажем х и
у, и наше первое присваивание предлагает в качестве согла-
шения об этом представлении
h = ху
96 Глава 8
Тогда условие «/г=И= 1» переходит в условие «г/=0=О», и наша сле-
дующая задача состоит в том, чтобы подыскать выполнимую
операцию «сжимания». Поскольку при этой операции произ-
ведение h *z должно оставаться инвариантным, мы должны
делить h на ту же величину, на которую умножается z. Исхо-
дя из представления й, наиболее естественным кандидатом на
эту величину можно считать текущее значение х. Без дальней-
ших затруднений мы приходим к такому виду нашей абстракт-
ной программы:
л, у, z: = X, К, 1 (Р стало истинным};
do y=#'O->z/, z: — y — 1, z*x\P осталось истинным} od
{Р стало истинным}
Глядя на эту программу, мы понимаем, что число выполне-
ний цикла равно первоначальному значению У, и можем за-
дать себе вопрос, нельзя ли ускорить программу. Ясно, что за-
дачей охраняемой команды является сведение у к нулю; не из-
меняя значения й, мы можем проверить, нельзя ли изменить
представление этого значения в надежде уменьшить значение
у. Попытаемся воспользоваться тем фактом, что конкретное
представление значения й, заданное как ху, вовсе не является
однозначным. Если у четно, мы можем разделить у на 2 и
возвести х в квадрат, при этом значение h совсем не изменит-
ся. Непосредственно перед операцией сжимания мы вставляем
преобразование, приводящее к наиболее привлекательному
представлению й, и получаем следующую программу:
х, У, — К, 1;
do r/.=7^0->do 2\у-+х, у:=х*х, у 12 od;
'У, z\=y—\y z* х
od {/? стало истинным}
Существует только одна величина, которую можно беско-
нечно делить пополам и она не станет нечетной, эта величи-
на —нуль; иначе говоря, внешний предохранитель гарантирует
нам, что внутренний цикл придет к завершению.
Я включил этот пример по разным причинам. Меня пора-
зило открытие, что если просто вставить в программу что-то,
что на абстрактном уровне действует как пустой оператор,
можно так изменить алгоритм, что число операций, которое
раньше было пропорционально У, станет пропорциональным
только log (У). Это открытие было прямым следствием того,
что я заставил себя думать в терминах отдельной абстрактной
Формальное рассмотрение нескольких небольших примеров 97
переменной. Программа возведения в степень, которую я знал,
была следующей:
х, у. z: — X, К, 1;
do 0->if non 2\у-+у, z:=y — l, z*x
□ 2[ у -^пропустить fi;
x, у :=x*x, y;2
od
Эта последняя программа очень хорошо известна, многие из
нас пришли к ней независимо друг от друга. Поскольку послед-
нее возведение х в квадрат, когда у стал равным нулю, уже
излишне, на эту программу часто ссылались как на пример,
подтверждающий необходимость иметь то, что мы назвали бы
«промежуточными выходами». Принимая во внимание нашу
вторую программу, я прихожу к заключению, что этот довод
слаб.
Седьмой пример
Для фиксированного значения п (п^О) задана функция
f(i) для 0^Л<п, Присвоить булевой переменной «всешесть»
такое значение, чтобы в конечном результате стало справед-
ливым
: всешесть = (A i: 0 < i < п : / (/) = 6)
(Этот пример обнаруживает некоторое сходство со вторым
примером данной главы. Заметим, однако, что в этом приме-
ре допускается равенство п нулю. В таком случае интервал
возможных значений для квантора «А» пуст и должно быть
верным,'что всешесть = истина.) По аналогии со вторым приме-
ром введем инвариантное отношение
Р: (всеьйестъ — ^Ьл: 0 • /(^)=‘б)) and 0 < j <; п
поскольку это отношение легко сделать истинным при / = 0
и к тому же (Р and j = n) =$>Р. Единственное, что, мы должны
сделать, это понять, как увеличивать / при инвариантности Р.
Поэтому берем
wp («у: =/4-1», Р)=
(всешесть = (A i: 0 I < j 4~ 1: f (i) — 6)) and 0 j 4-1 n
Справедливость последнего члена следует из справедливости
Р and j=^n; и в этом нет никакой проблемы, так Как мы уже
решили, что условие /=#я, взятое в качестве предохранителя,
является достаточно слабым, чтобы делать выводы о значе-
4—6
98 Глава 8
нии Р по завершении программы.,Слабейшим предусловием,
таким, что присваивание
всешесть '.—всешесть and/(У)==6
сделает истинным другой член, является
{всешесть and /(y)=6)=(AZ:0<i<y-|-1:/(i)=6)
условие, которое следует из Р. Таким образом, мы приходим
к программе:
всешесть, j :=истина, 0;
do j #=п -+ всешесть : = всешесть and /(у)=6;
(Мы не воспользовались одновременным присваиванием в ох-
раняемой команде просто так, без особых на то причин.)
К моменту чтения этой программы — или даже раньше —
у нас должно было возникнуть чувство беспокойства по пово-
ду того, что, как только будет найдено значение функции =/=6,
не будет смысла продолжать работу программы. И в самом
деле, хотя (Р and j=n) мы могли бы воспользоваться
более слабым утверждением
(Р and (j=n or non всешесть)) =? P
приводящим к более сильному предохранителю «]'=/= п and
всешесть» и к программе
всешесть, j ’.=истина, 0;
йо- j Ф п and всешесть-*-всешесть, j :=/(У) = 6, j-|-l od
(Отметим упрощение присваивания значения всешесть, упро-
щение, которое объясняется использованием более сильного
предохранителя.)
Упражнение
Для той же задачи дать доказательство правильности для
if n=Q-*-вс ешесть •. = истина
□ л>0->/:=0;
do УУ=л —1 and /(у) = 6-»-у : = у-|-1 od;
всешесть :=/(у)=б
fi
Формальное рассмотрение, нескольких небольших примеров 99
а также для более «хитрой» программы (которая избавилась
от необходимости обращаться к функции f более чем из одного
места в программе)
/:=0;
do j ;=£ п cand f (J) = 6->- j :—j -j-l od;
всешесть — j—n
(Операция условной конъюнкции, «cand» была здесь примене-
на для того, чтобы учесть тот факт, что значение f(n) не обя-
зательно должно быть определено.) Эта последняя програм-
ма некоторым очень нравится. (Конец упражнения.).
Восьмой пример
Прежде чем я смогу сформулировать нашу следующую за-
дачу, я должен дать некоторые определения и сформулировать
теорему. Пусть р= (ро, р\, ..., pn-i) обозначает перестановку
п (л>1) различных значений pi (0^i<n), т. е. (i¥=j) =»
(pi^pj). Пусть <7=(<7о, <7ь Qn-i) обозначает другую пе-
рестановку той же совокупности п значений. По определению
«перестановка р предшествует перестановке q в алфавитном
порядке» в том и только том случае, если для минимального
значения k, такого, что Pk=£qk, мы имеем рн<Яь-
Так называемый «алфавитный индексп» перестановки п
различных значений есть порядковый номер, сообщаемый пере-
становке, когда мы перенумеровываем п\ возможных переста-
новок, расположенных в алфавитном порядке, от 0 до п\—1.
Например, для п=3 и совокупности значений 2, 4, 7 мы имеем
индекс3 (2, 4, 7)=О
индекСз (2, 7, 4) = 1
индекс3 (4, 2, 7) —2
индекСз (4, 7, 2)=3
индекСз (7, 2, 4)=4
индекс3 (7, 4, 2)=5
Пусть (рб § pi § — § Pn-i) обозначает перестановку п раз-
личных значений в порядке их монотонного возрастания, т. е.
индексп((р0§ Pi§ ... § Pn-i))=0. (Например, (4 § 7 § 2) =
= (2, 4, 7), но и (7 § 2 § 4) = (2, 4, 7).)
4*
100 Глава 8
Пользуясь введенными выше обозначениями, мы можем
сформулировать следующую теорему для п> 1:
индекс,,(A). A.---» A»-i)=
индекс,,(р0>(А§Рч§• • • §А»-1)) + индекс„_1 (ри , A-i)
(например, индекс3(4, 7, 2) =индекс3(4, 2, 7)+индекс2(7,2) =
=2+1=3).
Словесная формулировка: индексп перестановки п различ-
ных значений есть индекс первой по алфавиту перестановки
с тем же самым левым значением, увеличенный на индексп-1
перестановки оставшихся правых п—1 значений. Следствие: из
Pn—k < Pn—k+l
•г^Рп—l
вытекает, что индекс,, (ро, Р\> Pn-i) кратен kl, и наоборот.
Теперь, после всех этих приготовлений, мы мо5кем изло-
жить нашу задачу. Имеется ряд из п позиций (и>1), перену-
мерованных слева направо с 0 до п—1; в каждой позиции
находится карточка, на которой написано некоторое число,
причем все эти числа различны.
Если в любой момент с,(0^/<п) обозначает число на
карточке, находящейся в позиции г, то в начальный момент
мы имеем
с0
Cl
Сп-1
(т. е. карточки разложены в порядке возрастания написанных
на них чисел). Для заданного значения г (0^г<п!) мы дол-
жны так переупорядочить карточки, чтобы выполнялось ус-
ловие
Я: индекс, (с0, сь..., c„_j)=r
Чтобы иметь возможность задавать действия над карточка-
ми, нам придется ввести оператор
переставить (I, /) при 0 < j п
который будет менять местами карточки в позициях i и /,
если i=^j (и ничего не будет делать, если i=j).
Чтобы выполнить заданное преобразование, мы должны
найти класс состояний (причем все они должны удовлетворять
соответствующему условию Р1), такой, что и начальное, и ко-
нечное состояния являются специфическими представителями
этого класса. Введем новую переменную, скажем s, и предста-
Формальное рассмотрение нескольких небольших примеров 101
вим в качестве очевидного кандидата для Р1 условие
индексЛ(с0, Сл_!) = 5
поскольку его легко удовлетворить в самом начале (а именно
при помощи «$: = 0») и поскольку (Pl and s — r)
Теперь мы можем подумать об ограничении интервала зна-
чений s, и, учитывая начальное значение s, можно было бы
попробовать
Р\: индексл(с0, rn..., and
что привело бы к программе в такой форме:
$:=0{Р1 стало истинным};
do $ #= r->(Pl and $<г)
увеличить $ на соответствующую
величину при инвариантности Р1
{Р1 остается истинным)
od {7? стало истинным}
Наша следующая забота — выбор «соответствующей вели-
чины». Поскольку увеличение s должно сопровождаться пере-
упорядочиванием карточек, призванным сохранить инвариант-
ность Р1, было бы благоразумным проверить, нельзя ли найти
такие условия, при которых отдельная операция переставить
соответствовала бы известному приращению $. Пусть для k,
такого, что l^ft<n, имеет место
С n—k <С с л-Л+1 сп-\
Это предположение эквивалентно предположению, что ft!|s
(т. е. s делится нацело на ft!). Пусть i = n—ft—1, т. е. сг- — это
значение на карточке, находящейся непосредственно слева от
этой последовательности. Далее, пусть сг<сп_ь и пусть Cj
будет минимальным значением для / в интервале и—ft^/<n,
таким, что Ci<j^ (т. е. q есть наименьшее значение справа от
С{, превосходящее Сг). В этом случае операция переставить
(i, j) оставляет правые ft' значений в том же самом порядке,
и наша теорема о перестановках и их индексах говорит о том,
что ft! есть соответствующее приращение 5. Она также говорит
нам, что когда, кроме ft! | s, мы имеем
$ < г $ + ft!
величины от с0 до сп-ь-\ достигли своих конечных значений.
Поэтому я предлагаю усилить наше первоначальное инва-
риантное отношение Р\ дополнительным отношением Р2
102 Глава 8-
(фиксируя функцию новой переменной k),
Р2-.
1 -С -С n and £!) s and г < s-j- А!
которое означает, что значения на правых k карточках еще
монотонно возрастают, и в то же время левые п—k карточек
уже находятся в своих окончательных позициях. Мы выбрали
«крупные шаги», которыми мы- будем двигаться к нашей це-
ли. Чтобы найти «соответствующую величину» для крупного
шага, машина сначала определяет самое маленькое значение
k, для которого условие r<s+kl уже не выполняется (это
означает, что с, при i=n—k—1 еще слишком мало, но слева
от него уже все в порядке), и затем увеличивает s на мини-
мальную величину, кратную k\, которая требуется для того,
чтобы условие г<$+&! опять выполнялось; для этого исполь-
зуются «мелкие шаги», равные А!, и одновременно увеличива-
ется Ct за счет карточек, находящихся справа. В следующей
программе мы вводим дополнительную переменную kfac,
удовлетворяющую условию
РЗ: kfac — k\
и для второго внутреннего цикла вводим переменные i и /,
такие, что i=n—k—1 и либо j=n, лцбо i<.j<n and cj>c<
and
s:=0{Pl стало истинным);
kfac, A: = l,l {РЗ тоже стало истинным);
do k =£n.^>-kfac, k: = kfac*{k-\-1), £-{-1 od
{P2 тоже стало истинным);
do s=/=r->{s<>, т. e. по крайней мере одна и, следователь-
но, по крайней мере две карточки еще не заняли
своих окончательных позиций)
do г <s-\-kfac^~kfac, k:=kfaclk, Л —1 od
{Pl и РЗ остались истинными, но в Р2 последний
член заменяется на
s-\-kfac г <$-{-(&-)-1) * kfac}-,
i, j -.—n — k — 1, n — k\
do s-\-kfac ^r-+\n, — k^i j <n)
s: =s-\-kfac\ [переставить{(i, /); j:=j-$-l
od {P2 опять восстановлено: Pl and P2 and P3)
od {P стало истинным)
Формальное рассмотрение нескольких небольших примеров
103
Упражнение
Убедитесь в том, что и следующая, довольно похожая на
предыдущую, программа справится с нашим заданием:
$:=0; kfac, k: = \, 1;
do k n-+-kfac, k:—kfac * (A-|- 1), й-|- 1 od;
do k =/= 1 —►
kfac, k : =k facfk, k — 1;
i, j = n — k — 1, n —k",
do s-\-kfac r —>
s \=s-\-kfac-, переставить (i, J); =
od
od
(Совет: в качестве монотонно убывающей функции /^0 для
внешнего цикла возьмите функцию t = r—s+k—1.) (Конец уп-
ражнения.)
9 КОГДА НЕДЕТЕРМИНИРОВАННОСТЬ ОГРАНИЧЕНА
Это опять очень формальная глава. В главе «Характеристи-
ка семантики» мы говорили о четырех свойствах, которыми
должно обладать условие wp(S, R), рассматриваемое как
функция для любой конструкции S, чтобы его можно было
интерпретировать как слабейшее предусловие, обеспечиваю-
щее истинность R. (Для недетерминированных конструкций
четвертое свойство было прямым следствием второго.)
В следующей главе «Семантическая характеристика языка
программирования» мы дали средства для построения новых
преобразователей предикатов, указав при этом, что такое по-
строение должно приводить только к преобразователям преди-
катов, обладающим вышеупомянутыми свойствами (т. е. чтобы
имело смысл продолжать всю эту процедуру). Для каж-
дого основного оператора («пропустить», «отказать» и опера-
торов присваивания) нужно получать подтверждение, что он
обладает упомянутыми свойствами; для каждого способа по-
строения новых операторов из составляющих операторов (точ-
ка с запятой, конструкции выбора и конструкции повторения)
нужно показывать, что полученные составные операторы так-
же обладают этими свойствами, при этом можно исходить из
предположения, что составляющие операторы этими свойст-
вами обладают. Мы проверили правильность этого предполо-
жения вплоть до закона исключенного чуда для точки с запя-
той, предоставив проверку остальных свойств читателям в каче-
стве упражнения. Оставим теперь эти свойства; в данной главе
мы'докажем, что наши конструкции обладают более глубоким
свойством, причем на этот раз явно проверим правильность
нашего утверждения и для конструкций выбора, и для кон-
струкций повторения. (Способом выполнения этих проверок
можно воспользоваться как образцом для проведения пропу-
щенных доказательств.) Свойство, о котором пойдет речь, из-
вестно как «свойство непрерывности».
Когда недетерминированность ограничена 105
Свойство 5. Для любой конструкции 5 и любой бесконеч-
ной последовательности предикатов Со, Сь С2, ..., таких, что
для г ^0: Cr=>Cr+1 для всех состояний (1)
мы имеем для всех состояний
wp (5, (Er : r>0 : Сг)) = (Es : s> 0 : wp (5, CJ). (2)
Для операторов «пропустить», «отказать» и для операторов
присваивания истинность (2) непосредственно вытекает из их
определений, и даже можно обойтись без предположения (1).
Для точки с запятой мы получаем
wp(«51; 52», (Er :г>0:Сг)) =
(по определению семантики точки с запятой)
wp (51, wp (52, (Е г : г > 0 : Сг))) =
(поскольку предполагается, что 52 обладает свойством 5)
wp(51, (Er': г' 0 : wp (52, СГ'))) =
(поскольку предполагается, что 52 обладает свойством 2, так
что wp(52, Сг/)=> wp(52, Cr/+i), и предполагается, что 51
обладает свойством 5)
(Е $: 0 : wp (51, wp(52, CJ)) =
(по определению семантики точки с запятой)
(Es:s>0 : wp(«51; 52», CJ) Ч.Т.Д,
Для конструкции выбора мы разбиваем доказательство
истинности (2) на два шага. Сначала легко показать, что ле-
вая часть (2) следует из его правой части. Для этого рассмот-
рим произвольную точку X в пространстве состояний, такую,
что правая часть (2) выполняется, т. е. существует неотрица-
тельная величина, скажем s', такая, что в точке X выполня-
ется условие wp(5, CS'). Но так как С> => (Е г : г2^0 : Сг) и
любая конструкция 5 обладает свойством 2, мы приходим к
выводу, что в точке X выполняется также
wp(5, (Er:r>0:Cr))
Поскольку X было произвольным состоянием, для которо--
го справедлива правая часть (2), значит, справедлива и левая
часть (2). В ходе этого рассуждения не использовалось пред-
положение (1), но оно понадобится нам для доказательства
того, что правая часть (2) следует из его левой части.
wp (IF, (Е г : г > 0 : Сг)) =
106 Глава 9
(по определению семантики конструкции выбора)
ВВ and (A j : 1 j п : Bj ==> wp (SLj, (Е г: г 0 : Сг))) =
(поскольку предполагается, что SLj обладает свойством 5)
ВВ and (Ay: 1<у</г:Ву=>(Е$:$>0: wp(S£y, С J)) (3)
Рассмотрим произвольное состояние X, для которого (3)
истинно, и пусть j' — это такое значение /, при котором
В (X) — истина; тогда в точке X мы имеем
(Es:s>0:wp(S£y,, CJ) (4)
Исходя из (1) и того факта, что SLj' обладает свойством 2, мы
приходим к выводу, что
wp(Sir, Cs)^wp(SLj', Cs+l)
и, учитывая (4), мы получаем, что в точке X справедливо
также
(Е s': s' > 0: (А $: s s': wp (SLj', С5))) (5)
Пусть s'=s'(/')—минимальное значение, удовлетворяющее
(5). Определим smax как максимальное значение s'(j') по
всем значениям /' (таких значений самое большее п, и, следо-
вательно, максимум существует!), для которых Bj>(X) = исти-
на. Тогда из (3) и (5) следует, что в точке X
В В and (Ay :l<y<«:5y=>wp(SZy, Csmax))=
(по определению семантики конструкции выбора)
wp(IF, Csmax)
Но отсюда следует, что для состояния X справедливо и
(Е $: s 0 : wp (IF, Csf
Но поскольку X было произвольным состоянием, удовлетворя-
ющим (3), то для S=IF доказано, что правая часть (2) сле-
дует из его левой части и тем самым что конструкция выбора
также обладает свойством 5. Заметим, что существенную роль
в доказательстве сыграли предположение (1) и тот факт, что
набор охраняемых команд является конечным набором охра-
няемых команд.
Для доказательства того, что конструкция повторения об-
ладает свойством 5, воспользуемся методом математической
индукции.
Когда недетерминированность ограничена 107
Основная предпосылка: HQ обладает свойством 5.
HQ (Е г : г 0 : Сг) =
(Er :r>0 :СГ) and non ВВ=
(Es:s>0:Cy and non BB) —
(Es:s>0://0(O- Ч. T. Д
Переход по индукции: из предположения, что Hk и Н$ об-
ладают свойством 5, следует, что им обладает и Нь+\-
Яй+1(Ег:г>0:Сг) =
(из определения Нк+\)
wp (IF, /УДЕ г : г 0 : СД) or //0 (Е г : г 0: Сг) =
(из предположения, что Нк и Но обладают свойством 5)
wp(IF, (Ег':г'>0://й(Сг))) or (Es: s>0 : HO(CS)) =
(поскольку конструкция выбора обладает свойством 5 и Hk
обладает свойством 2)
(Es:s>0: wp(lF, //ft(CJ)) or (Es: s>0 : HO(CS)) =
(E^:s>0: wp(IF, Hk(Cs)) or //0(CJ) =
(из определения Hk+i)
(Es:S>0:/7ft+1(G)) Ч. T. Д.
Таким образом, пользуясь методом индукции, мы показали, что
все Нк обладайте свойством 5, а отсюда
wp (DO, (Е г: г 0 : CJ) —
(по определению семантики конструкции повторения)
(Е^:^>0:Яй(Ег:г>0:Сг)) =
(поскольку все Нк обладают свойством 5)
(EA:A>0:(Es:s>0://ft(C4))) =
(поскольку этим выражается существование (k, $)-пары)
(Es:s>0:(EA:A>0://4 (CJ))=
(по определению семантики конструкции повторения)
(Е s: s> 0 : wp(DO, С,)) Ч. Т. Д.
Свойство 5 приобретает особое значение благодаря семан-
тике конструкции повторения
wp (DO, /?)= (Е k: k > 0 : Нк (/?))
108 Глава 9
в соответствии с которой предусловие могло бы быть посту-
словием для другого оператора. Поскольку
для k 0 : Hk (7?) => Hh+X (7?) для всех состояний
(это легко доказывается по индукции), условия, нужные для
существования свойства 5, удовлетворяются. Мы можем, на-
пример, доказать, что во всех начальных состояниях, для ко-
торых ВВ выполняется, конструкция
do ^->^0 □ ... □ Bn-+SLa od
эквивалентна конструкции
if B^SL, □ 52-S£2 □ ... Q Bn-*SLntV,
do В^ВЦ □ B2-*SL2 0 ... □ Bn-~ 5£„od
(В начальных состояниях, для. которых В В не выполняется,
первая программа будет действовать как «пропустить», вто-
рая— как «отказать».) Иначе говоря, мы должны доказать, что
(ВВ and wp(DO, R))=(BB andtwp(IF, wp(DO, 7?)))
BB and wp(IF, wp(DO, 7?))=
(из-за семантики конструкции повторения)
ВВ and wp (IF, (E k : k 0: Hk (7?))) =
(поскольку IF обладает свойством 5)
BB and (Es: s^. 0: wp(IF, HS(R)))=
(так как (BB and H0(R)) =F)
BB and (Es:s>0: wp(IF, /7Д7?)) or 7/0(/?)) =
(в силу рекуррентного отношения для Hk (7?))
ВВ and (Es:3>0://i+1(7?))=
(поскольку (ВВ and H0(R.)) = F)
ВВ and (Ek-.k^>Q-.Hk(R))=
(из-за семантики конструкции повторения)
ВВ and wp(DO, 7?) Ч. Т. Д.
В конце мне бы хотелось привлечь ваше внимание к совсем
другому следствию, вытекающему из того факта, что все наши
конструкции обладают свойством 5. Мы могли бы попробо-
вать составить программу S: «установить х равным любому
положительному целому», обладающую свойствами:
(a) wp(S, х>0) = Т
(б) (As : s^O : wp(S, 0<x<x<s) = F)
Когда недетерминированность ограничена 109
Здесь свойство (а) выражает требование, чтобы програм-
ма 3 пришла к завершению с х, равным некоторому положи-
тельному числу, а свойство (б) говорит о том, что 3 есть кон-
струкция неограниченной недетерминированности, т. е. что
a priori не существует верхней границы для окончательного
значения х. Для такой программы 3 мы могли бы, однако, по-
лучить теперь
Т= wp(3, х>0)
=wp(S, (Е г: г 0: 0 <^х <г))
= (Е s: $ 0: wp (3,0 < х < «))
= (Es:s>0:F)
=F
Мы пришли к противоречию; это означает, что для конст-
рукции 3 «установить х равным любому положительному це-
лому» не существует .никакой программы! •
Следовательно, любые попытки написать программу «уста-
новить х равным любому положительному целому» обречены
«а неудачу. Например, мы могли бы рассмотреть такую про-
грамму:
продолжение : = истина-, х: = 1;
do продолжение—>х:=х-)-1
□ продолжение —► продолжение : = ложь
od
Эта программа- будет продолжать увеличение х до тех пор,
пока действует первая альтернатива; как только произойдет
переход ко второй альтернативе, программа немедленно пре-
кратится. По завершении программы х действительно может
•быть «любым положительным целым» в том смысле, что мы не
можем представить себе такое положительное значение X,
для которого по завершении программы было бы невозможным
•отношение х=Х. Но завершение программы возсе не гаран-
тировано! Мы можем вызвать принудительное завершение:'
используя некоторую большую положительную константу N,
мы можем написать:
продолжение'— истина-, х: = 1;
do продолжение and x<^N —»х:=х4-1
П продолжение —♦продолжение : = ложь
od
«о тогда программа больше не обладает свойством (б).
То, что программы «установить х равным любому положи-
ПО Глава 9
тельному целому» не существует, успокаивает нас по двум
причинам. Во-первых, если бы такая программа могла сущест-
вовать, наше определение семантики конструкции повторения
следовало бы, мягко выражаясь, подвергнуть сомнению. Если
взять
<S; do x^>Q —>х'—х — 1
[] х 0 —»«установить х равным любому положительному
целому»
od
наш формализм для конструкции повторения приведет к тому»
что wp(S, Т) = (х^0), в то время как большинство моих чи-
тателей, я надеюсь, придет к заключению, что в предположе-
нии существования программы «установите х равным любому
положительному целому» для х<0 завершение программы бы-
ло бы гарантировано. Но тогда трактовка wp (S, Т) как слабей-
шего предусловия, гарантирующего завершение, перестает
быть справедливой. Однако, когда мы подставляем в качестве
программы нашу первую, так сказать, ее реализацию и полу-
чаем
S: do х>0—>х:—х— 1
Q х<^0продолжение := истина', х: = 1;
do продолжение —*х:=х-\-1
П продолжение —»продолжение : = ложь
od
od
то равенство wp(S, Т) = (х^О) абсолютно верно, как ин-
туитивно, так и формально.
Вторая причина имеет совсем другую природу. Конструк-
ция неограниченной недетерминированности, тем не менее за-
ведомо приходящая к завершению, могла бы за конечное вре-
мя производить выбор из бесконечно большого числа возмож-
ностей: если бы такую конструкцию можно было описать на
нашем языке программирования, то сам по себе этот факт
представлял бы непреодолимый барьер на пути к возможности
реализации этого языка программирования.
Благодарность. Я хотел бы выразить свою огромную при:
•знательность Джону К. Рейнольдсу за то, что он обратил мое
внимание на ту роль, которую играет свойство 5, и на то, что
несуществование конструкции «установить х равным любому
положительному целому» очень важно для интуитивного оп-
равдания семантики конструкции повторения. Естественно, что
он не несет никакой ответственности за все вышеизложенное.
(Конец благодарности.)
10 РАЗМЫШЛЕНИЯ НА ТЕМУ:
«ОБЛАСТЬ ДЕЙСТВИЯ ПЕРЕМЕННЫХ»
Прежде чем приступить к выяснению того, что могло бы
«ли должно было бы означать понятие «область действия пе-
ременных», имеет смысл поставить сначала предварительный
вопрос, а именно: «Почему мы вообще ввели понятие перемен-
ных?». Этот вопрос не так уж бессодержателен, как могло бы
показаться тому, кто имел дело только с программированием.
Например, когда разрабатывается последовательное соедине-
ние логических элементов машины, то довольно часто сначала
проектируется автомат с конечным числом состояний, причем
различные возможные состояния проектируемого автомата
просто перенумеровываются «0, 1, 2, ...» в том порядке, в ко-
тором конструктор обнаруживает желательность их включения.
В ходе проектирования конструктор строит так называемую
«таблицу переходов», которая определяет для каждого состоя-
ния переход к следующему состоянию в зависимости от вход-
ного символа, поступающего для обработки. Только когда фор-
мирование таблицы переходов закончено, конструктор вспоми-
нает, что в его распоряжении есть только.двоичные переменные
(он называет их триггерами) и что если число состояний ока-
залось между 33 и 64 (включая границы), то ему потребуется
по крайней мере шесть таких переменных. Эти шесть перемен-
ных охватывают пространство состояний из 64 точек, и конст-
руктор может по своему усмотрению выбирать способ пред-
<тавления различных состояний своего автомата в виде точек
в 64-точечном пространстве состояний. То, что этот выбор ска-
зывается на проектируемой конструкции, становится ясно сра-
зу же, $сак только мы поймем, что переходы автомата с конеч-
ным числом состояний из одного состояния в другое должны
представляться как перевычисление комбинаций булевых
переменных в зависимости от тех или иных булевых значений.
Конструкторам логических схем этот выбор известен как
«задача назначения состояний», и благодаря техническим огра-
ничениям или стремлению к оптимизации задача может Ока-
заться запутанной, столь,запутанной, что возникает искушение
112 Глава 10
усомниться в пригодности методологии проектирования, вызы-
вающей такие проблемы. Однако критическое обсуждение ме-
тодологии проектирования логических схем лежит за преде-
лами моей компетентности и, следовательно, выпадает из круга
вопросов, рассматриваемых в данной книге; мы упомянули об
этом только для того, чтобы показать, что существуют такие
традиции проектирования, для которых введение «переменных»
в самом начале разработки проекта не является, по-видимому,
естественным.
По двум причинам программист живет в другом мире, чем
конструктор логических схем, в особенности конструктор ста-
рой школы. Было время, когда технические соображения ока-
зывали очень сильное влияние на стремление конструкторов
минимизировать число используемых триггеров, и если при
создании механизма с конечным числом состояний, не превы-
шающим 64, использовалось больше шести триггеров, это
рассматривалось если не как преступление, то уж по меньшей
мере как полный провал. Поскольку триггеры дороги, конст-
рукторы логических схем занимаются проектированием
(под) механизмов, у которых число возможных состояний куда
более скромно, чем число внутренних состояний у конструк-
ций, предлагаемых здесь вниманию программистов. Програм-
мист живет в мире, где биты обходятся дешевле, и отсюда вы-
текают два следствия: во-первых, его конструкции могут иметь
во много раз больше внутренних состояний, во-вторых, «неис-
пользованная» часть пространства состояний у него может
быть большей, чем у конструктора логических схем. Вторая
причина, по которой мир программиста отличается от мира
конструктора схем, заключается в том, что большее число из-
менений (групп) битов приводит к большему времени вычис-
лений: самое дешевое средство, которое может в этом случае
прописать программист,— оставлять большие области памяти
незатронутыми!
Сравнивая мир программиста с миром конструктора схем,
который первоначально просто «именует» состояния своей кон-
струкции, сообщая им порядковые номера по мере ввода новых
состояний, мы сразу же понимаем, почему программисту хо-
чется с самого начала ввести переменные, которые он рассмат-
ривает как декартовы координаты в пространстве состояний
стольких измерений, сколько он чувствует необходимым ввес-
ти: число различных вводимых состояний так невероятно'
велико, что несистематизированная терминология сделала бы
проектирование совершенно не поддающимся контролю. Мож-
но ли (и если можно, то как?) сохранить «управляемость»
проектирования, вводя переменные посредством «номенклату-
ры»,— это, конечно, решающий вопрос.
Размышления на тему: «Область действия переменных» 113
Основным средством изменения состояния служит опера-
тор присваивания, устанавливающий (вплоть до следующего
присваивания) новое значение одной переменной. В простран-
стве состояний ему соответствует движение, параллельное
одной из осей координат. Его можно «принарядить», введя
одновременное присваивание; из небольшого числа операторов
присваивания мы можем таким образом сформировать про-
граммную компоненту, но число переменных, на которые будет
воздействовать эта компонента, оказывается всегда весьма
скромным. Чистый результат выполнения такой программной
компоненты можно описать в терминах движения в под-
пространстве, охватываемом несколькими переменными, на ко-
торые воздействует эта компонента (если угодно, в терминах
проекции на это подпространство). Тогда она становится абсо-
лютно независимой от всех остальных переменных в системе:
мы можем «понимать» ее, не принимая во внимание никакие
другие переменные, даже не сознавая их существования. Воз-
можность такого разделения, известного также как «фактори-
зация», неудивительна, если учесть, что наше полное простран-
ство состояний было построено прежде всего как декартово
«произведение». Важно заметить, что это разделение, так не-
обходимое нам, чтобы мы могли охватить (мысленно) всю
программу в целом, становится тем более нужным, чем больше
общее число переменных, используемых в программе. Вопрос
заключается в том, должно ли такое «разделение» (и если дол-
жно, то как?) отразиться более явно на текстах наших про-
грамм.
Наши первые «автокодировщики» (позже некоторые из них
были, неправильно названы «системами автоматического про-
граммирования» или — даже хуже — «языками программиро-
вания высокого уровня»), конечно, не обладали средствами
для реализации таких возможностей. Они были задуманы в то
время, когда, по общему мнению, программы были предназ-
начены для того, чтобы командовать машинами, тогда как в
наше время все больше и больше людей склоняются к мнению,
что это машины предназначены для выполнения программ.
В те далекие дни было вполне естественным, что разнообраз-
ные свойства машины находили непосредственное отражение
в записи программ. Так, например, поскольку машины имели
так называемые «команды передачи управления», в програм-
мах использовались «операторы перехода». Аналогично, по-
скольку машины располагали памятью постоянного размера,
считалось, что вычисления происходят в пространстве состоя-
ний с постоянным числом измерений, т. е. что в вычислениях
участвуют значения постоянного набора переменных. Анало-
гично, поскольку для памяти с произвольной выборкой каж-
114 Глава 10
дая ячейка памяти равнодоступна, программисту было позво-
лено ссылаться на любую переменную программы в любом,
месте текста программы.
Все это было хорошо в те далекие дни, когда из-за ограни-
ченных размеров памяти тексты программ были короткими и
число различных переменных, используемых в программе,
было невелико. Однако с ростом размеров и сложности про-
грамм стали возникать сомнения в достоинствах такой одно-
родности. Конечно, с точки зрения гибкости и широкой при-
менимости память с произвольной выборкой является блестя-
щим изобретением, но наступает момент, когда мы должны
ясно понять, что любая гибкость, любая общность наших
средств требует дисциплины для их использования. Этот мо-
мент настал. Давайте прежде всего примемся за «свободный
доступ».
В первой версии ФОРТРАН^ было два типа переменных,
целые переменные и переменные с плавающей запятой, тип
переменной определялся — в соответствии с фиксированным
соглашением — по первой букве ее имени, и любое появление
•имени переменной в каком-либо месте текста программы пред-
полагало постоянное существование переменной с этим име-
нем на протяжении всего времени выполнения программы. На
практике это оказалось очень опасным: если в программе, опе-
рирующей с переменной, названной «TEST», встречалась един-
ственная описка, где вместо имени «TEST»’ было написано
«TETS», никакого сигнала об ошибке не выдавалось, просто
заводилась другая переменная с именем «TETS». В АЛГОЛе
•60 была принята идея так называемых «описаний», и в том,
что касается ловли таких глупых описок, она оказалась крайне
ценной формой избыточности. Основная идея явного описания
переменных заключается в том, что операторы могут ссылать-
ся только на те переменные, о существовании которых было
явно объявлено; в' этом* случае ошибочное обращение к пере-
менной «TETS» обнаруживается автоматически, так как о су-
ществовании такой переменной не было объявлено. У описа-
ний АЛГОЛа 60 было и второе назначение: кроме того, что они
представляли собой «словарь» имен переменных, допустимых
для использования в операторах, они ставили в соответствие
каждому введенному имени тип переменной, отменяя тем
самым первоначальное соглашение, принятое в ФОРТРАНе,
что тип переменной определяется по первой букве ее имени.
Поскольку люди все больше и больше стремились использо-
вать мнемонику при выборе имен переменных, такая свобода
наименований была высоко оценена.
Еще большим отклонением от ФОРТРАНа была принятая
в АЛГОЛе 60 так называемая «концепция блока», которая
Размышления на тему: «Область действия переменных» 115
использовалась для установления границ так называемой
«текстуальной области действия» описаний. «Блок» в АЛГОЛе
60 простирается от открывающей скобки «begin» до соответ-
ствующей закрывающей скобки «end», и эта пара скобок
отмечает границы текстуального уровня перечня наименова-
ний. За открывающей скобкой «begin» следует описание одного
или более новых имен (когда имен больше одного, они все
должны быть' различными) с указанием того, что означает
каждое имя, и эти имена в их новом значении считаются
«локальными» для данного блока: употребление этих имен
в их новом значении должно быть сосредоточено в операторах,
находящихся между предшествующим «begin» и соответству-
ющим «end». Если вся наша программа — единственный блок,
к каждой переменной можно обратиться из любого места
текста, и единственная выгода от использования описаний —
это защита против описок (о чем говорилось в предыдущем
абзаце). Блок, однако,— это одна из возможных форм опера-
торов, следовательно, могут встречаться вложенные блоки, и
здесь описания дают возможность осуществить некоторую
защиту переменных, поскольку переменные, локализованные
во внутреннем блоке, недоступны для внешнего блока.
Правила области действия в АЛГОЛе 60 защищают ло-
кальные переменные внутреннего блока от внешнего воздейст-
вия; в другом направлении, однако, они не обеспечивают ни-
какой защиты. Для внутреннего блока в принципе доступно
все, что находится снаружи, т. е. доступно все, что находится
в текстуально объемлющем блоке. Я сказал «в принципе»,
потому что существует одно исключение,— исключение, кото-
рое в то время рассматривалось как крупное изобретение, а
теперь, 15 лет спустя, при ближайшем рассмотрении оказыва-
ется больше похожим на логическую заплату. Я имею в виду
так называемый «повторно описанный идентификатор». Если
в заголовке внутреннего блока описано имя — в АЛГОЛе
60 имена называются «идентификаторами»,— которое (слу-
чайно) уже было употреблено в объемлющем блоке, тогда
внешнее значение этого идентификатора остается текстуально
скрытым для внутреннего блока, чье локальное описание то-
го же идентификатора перекрывает его внешнее описание.
Идея, лежащая за этим «приоритетом самых внутренних опи-
саний», заключается в том, что составителю внутреннего бло-
ка нужно знать только те глобальные имена в окружающем
контексте, на которые он действительно ссылается, а все дру-
гие глобальные имена не должны ограничивать его свободу
выбора своих собственных имен с их локальным значением.
Тот факт, что благодаря этому соглашению вписывание внут-
ренних блоков в «разрастающееся» окружение проходило
116 Глава 10
гладко (например, программы пользователей целиком встав-
лялись в уже имеющийся внешний блок, содержащий обраще-
ние к стандартным библиотечным процедурам), в течение
длительного времени рассматривался как вполне достаточное
объяснение причин использования соглашения о приоритете
внутренних описаний. Оправданию этого соглашения способ-
ствовало и то, что незадолго до его принятия было обнаруже-
но, как однопроходный ассемблер может использовать стек
для обработки текстуально вложенных различных значений
одного и того же имени.
Однако, с точки зрения пользователя, это соглашение не
"так уж привлекательно, ибо делает переменные, описанные во
внешнем блоке, крайне уязвимыми. Если пользователь с ужа-
сом обнаруживает, что значение одной из этих переменных
испорчено, причем непонятно, когда и каким образом, он дол-
жен в принципе тщательно просмотреть все внутренние блоки,
включая и те, которые и вовсе не должны обращаться к этой
переменной, чтобы обнаружить то место, где происходит это
юшибочное обращение. Если предположить, что программисту
не. обязательно приходится обращаться из любого места к лю-
бой переменной, то лучше было бы предложить ему более
явные средства ограничения текстуальной области действия
имен, чем более или менее случайное повторное описание.
В качестве первого шага в этом направлении, сохраняюще-
го идею текстуально вложенных контекстов, предлагается сле-
дующее: для каждого блока мы постулируем для его уровня
(т. е. для его текста, за исключением входящих в него внут-
ренних блоков) текстуальный контекст, т. е. постоянную но-
менклатуру, в которой все имена имеют уникальное значение.
Имена, встречающиеся в текстуальном контексте блока, могут
быть либо «глобальными», т. е. доставшимися ему вместе с их
значениями по наследству от непосредственного окружения,
либо «локальными», т. е. имеющими смысл только для текста
данного блока. Предлагается помещать вслед за открывающей
скобкой блока перечень имен (с соответствующими раздели-
телями), составляющих вместе текстуальный контекст, напри-
мер, сначала перечислить.все глобальные имена (если таковые
имеются), затем все локальные (если они есть); очевидно, что
все имена должны быть различными.
Признание. Нужно сказать, что я решился на это предло-
жение после длительных колебаний и поисков альтернативных
предложений, которые позволили бы программисту вводить
в блок одно или больше локальных имен, не вынуждая его
при этом перечислять все используемые в блоке глобальные
имена, т. е. таких предложений, которые дали бы ему возмож-
Размышления на тему: «Область действия переменных» 117
«ость указывать (с той же компактностью) изменения в но-
менклатуре блока АЛГОЛа 60 (без «повторного описания
идентификаторов»), т. е. в чистом виде расширять номенкла-
туру. Это предоставило бы программисту возможность указы-
вать и на сужение номенклатуры, т. е. на ограниченное ис-
пользование имен из непосредственного окружения, но не вы-
нуждало бы его делать это в обязательном порядке. И
некоторое время такая позиция избавления программиста от
«отеческого попечения» казалась мне правильной для разра-
ботчика языка; я чувствовал также, что такая возможность
•сделает мои правила области действия более привлекатель-
ными, поскольку я опасался, что многие программисты будут
возражать против необходимости перечислять все используе-
мые глобальные переменные всякий раз, когда у них возникнет
потребность ввести локальную переменную. Так продолжа-
лось до тех пор, пока я страшно не рассердился сам на себя:
столько проектов языков загублено из опасения, что они не
найдут одобрения, а ведь я знаю только одного программис-
та, который собирается писать программы на этом языке, и
этот программист — я сам! А я в достаточной степени пурита-
нин и могу заставить себя явно указывать унаследованные
глобальные переменные. Более того, не только мои внутрен-
ние блоки будут ссылаться только на явно унаследованные
глобальные переменные, но и среди унаследованных перемен-
ных не будут упоминаться глобальные переменные, к-которым
во внутренних блоках нет обращения. Перечень унаследован-
ных переменных даст полное описание возможных нарушений,
вызываемых блоком в пространстве состояний, определенном
для окружения блока, не больше и не меньше! Когда я обна-
ружил, что мое желание «доставить удовольствие своей пуб-
лике»— желание, я считаю, вполне благородное — повлияло
•не только на способ представления, но и на существо дела,
я испугался, разозлился на себя и устыдился. (Конец при-
знания.)
Кроме имени переменные обладают уникальным свойством
иметь некоторое значение, которое может изменяться. Сразу
же возникает вопрос: каким будет значение локальной пере-
менной при входе в блок? Были предложены различные отве-
ты. АЛГОЛ 60 постулирует, что при входе в блок значения
его локальных переменных не определены,.т. е. для любой
попытки узнать их значение до того, как им будет присвоено
какое-то значение, результат не определен. Очень распростра-
ненной ошибкой является использование в цикле локальных
переменных, которым перед входом в цикл не было присвоено
начальное значение, поэтому контроль за использованием
118 Глава 10
неопределенных значений локальных переменных, осуществля-
емый во время выполнения программы, хотя и обходится доро-
го, во многих случаях оказывается отнюдь не роскошью.
Такой контроль является, конечно, прямой реализацией ответа
чистого математика на вопрос о том, что делать с переменной,
чье значение не определено, а именно дополнить интервал зна-
чений специальным значением, называемым «НЕОПРЕДЕ-
ЛЕННОЕ» и при входе в блок придавать это уникальное, спе-
циальное значение каждой локальной переменной. Тогда лю-
бая попытка использовать переменную с этим уникальным,
специальным значением приведет к прекращению работы про-
граммы й выдаче сообщения об ошибке.
Однако при ближайшем рассмотрении оказывается, что
это простое предложение приводит к логическим проблемам;
например, становится невозможным копировать значения лю-
бого набора переменных. Чтобы совладать с такой ситуацией,
можно, например, проверять, определено значение переменной
или нет. Но возможность манипулировать со специальным
значением, например со значением «НИЧТО» для указателя,
никуда не указывающего, легко приводит к неразберихе и про-
тиворечию: так и про двух холостяков можно сказать, что мы
имеем дело с двоемужием, поскольку можно считать, что у
них одна и та же жена — «никто».
Другим выходом из положения, упраздняющим перемен-
ные с неопределенными значениями, было неявное придание
переменным некоторого значения при входе в блок, причем не
очень специального, а очень распространенного, почти
«нейтрального» значения (скажем, «нуль» для всех целых и
«истина» для всех булевых переменных). Но это, конечно, все-
го лишь игра в прятки с самим собой; теперь обнаружить
очень распространенную программистскую ошибку стало не-
возможно, поскольку разнообразные лишенные смысла про-
граммы были искусственно превращены в программы дозво-
ленные. (Чтобы смягчить это предложение, было принято
соглашение о том, что «нейтральное» начальное значение
будет присваиваться переменной только «по умолчанию», т. е.
ёсли нет других указаний, однако ясно, что такое'соглашение
об умолчании —т это всего лишь латание дыр.)
Другой попыткой решить задачу обнаружения использова-
ния переменных с еще не определенными значениями была
проведение (автоматического) анализа текста, позволявшего
по крайней мере предупредить программиста, что в каких-то
местах переменные будут — или могут — использоваться до
того, как им будет присвоено некоторое значение. Можно
считать, что в каком-то смысле мое предложение было инспи-
Размышления на тему: «Область действия переменных» 119
рировано этим подходом. Я предлагаю такую жесткую дисци-
плину, что
1) анализ текста становится тривиальным;
2) ни в одном месте программы, где происходит обращение
к переменной, не может существовать неопределенности, каса-
ющейся того, было ли присвоено начальное значение этой пе-
ременной.
Одним из способов достижения этого была бы обязатель-
ная инициализация всех локальных переменных при входе в
блок; боюсь, что в сочетании с желанием не использовать
в качестве начальных значений «бессмысленные» значения,—
желанием, которое подразумевает, что локальные переменные
должны вводиться только на той стадии, когда доступны их
осмысленные начальные значения,— это приведет к слишком
уж глубокой вложенности текстуальных областей действия.
К тому же нам пришлось бы «распределять» вход в блок по
'различным охраняемым командам конструкции выбора всякий
раз, когда инициализация должна была бы выполняться одной
из охраняемых команд из некоторого набора. Оба эти сообра-
жения вынудили меня искать альтернативу, которая требо-
вала бы меньшего количества (и более однозначных) границ
блока. Следующее предложение, как мне кажется, отвечает
этим требованиям. z
Прежде всего мы настаиваем,^чтобы при входе в блок пере-
числялись все имена (как унаследованные, так и личные).
Кроме оператора присваивания, который уничтожает текущее
значение переменной, присваивая ей новое значение, у нас
будут инициализирующие операторы, которые распознаются
синтаксически и которые сообщают личной переменной ее
первое после входа в блок значение. (Если угодно, мы можем
считать, что выполнение инициализирующего оператора совпа-
дает по времени с «порождением» переменной; тогда более
раннее упоминание ее имени во входе в блок можно рассмат-
ривать как «резервирование идентификатора для пере-
менной».)
Иначе говоря, текстуальная область действия личной (т. е.
локальной) переменной блока — это область от открывающего
«begin» блока до соответствующего закрывающего «end», за
исключением текстов тех внутренних блоков, которые не на-
следуют эту переменную. Мы предлагаем разделить текстуаль-
ную' область действия переменной на «пассивную область
действия», где обращение к переменной не допускается и ее
нельзя рассматривать как координату в локальном простран-
стве состояний, и «активную область действия», где разрешено
обращение к переменной. Пассивная и активная области дей-
120 Глава 10
ствия переменной всегда будут отделены друг от друга Иници-
ализирующим оператором для этой переменной, и эти опера-
торы должны быть размещены таким образом, чтобы незави-
симо от значений предохранителей
1) после входа в блок и перед соответствующим выходом
из блока выполнялся в точности один инициализирующий опе-
ратор;
2) между входом в блок и выполнением инициализирующе-
го оператора не мог'выполняться ни один оператор из актив-
ной области действия переменной.
Выполнение вышеизложенных требований гарантирует
следующая дисциплина: прежде всего мы рассматриваем блок
как синтаксическую структуру, где за перечнем его личных
имен следует список операторов, отделенных друг от друга
точкой с запятой. Такой список операторов должен обладать
следующими свойствами:
(А) Он должен содержать единственный оператор, инициали-
зирующий данную личную переменную.
(Б) Операторы, предшествующие инициализирующему опера-
тору (если таковые имеются), находятся в пассивной об-
ласти действия этой переменной, и если они представляют
ёобой внутренние блоки; то они не имеют прара наследо-
вать эту переменную.
(В) Операторы, следующие за инициализирующим оператором
(если таковые имеются), находятся в активной области
действия переменной, и если они являются внутренними
блоками, могут наследовать эту переменную.
(Г) Для самого инициализирующего оператора имеются три
возможности:
(1) Это простой инициализирующий оператор.
(2) Это внутренний блок. В этом случае он наследует пе-
ременную, о которой идет речь, и список операторов,
следующий за перечнем имен внутренней номенклату-
ры, также обладает свойствами (А), (Б), (В) и (Г).
(3) Это конструкция выбора. В этом случае все списки
операторов, следующие за ее предохранителями, обла-
дают свойствами (А), (Б), (В) и (Г).
Для приверженцев НФБ может быть полезным следующий
синтаксис (где инициализация относится к одной личной пе-
ременной) :
•<блок>::=Ье?(п <номенклатура>; <список инициализи-
рующих операторов> end
<список инициализирующих операторов>:: = {<пассивный
оператор>; } <инициализирующий оператор>{; Актив-
ный оператор>}
Размышления на тему: «Область действия переменных» 121
<инициализирующий оператор>::= Спростой инициализи-
рующий оператор> |
begin <номенклатура>; <список инициализирующих
операторов> end|
if <предохранитель> -> <список инициализирующих опе-
раторов> { Q <предохранитель>-> <список инициали-
зирующих операторов>} fi
Замечание, При составлении программ на АЛГОЛе 60 не-
обходимость полностью выписывать скобки «begin» и «end»
вызывает неудобство; упраздняя составные операторы
АЛГОЛа 60, мы рассчитываем уменьшить потребность в этих
скобках. (Конец замечания,)
Соответствующая конструкция повторения не включена в
число допустимых форм инициализирующего оператора, по-
скольку ее включение привело бы к нарушению нашего пер-
вого требования: независимо от последовательности действий
-инициализация должна происходить в точности один раз. Та-
кое ограничение не встречается в языках программирования
типа АЛГОЛ 60, где просто (динамически) первое присваива-
ние рассматривается как «инициализация». За большую сво-
боду в языке типа АЛГОЛ нам приходится расплачиваться
тем, что для программ, написанных на таком языке, мы не
можем в каждом месте программы, где стоит точка с запятой,
решать статически (т. е. для всех вычислений), значения ка-
ких переменных определены, что видно из следующих при-
меров па языке АЛГОЛ 60.
Если В — глобальная булева переменная,
begin integer х, у\ if В then х: = 1 else у:=2;...
и если N— глобальная целая переменная,.
begin integer Z, х; for Z: = l step 1 until N do x: =
В первом примере значение х определено только при усло-
вии, что В — истина; во втором примере значение х определено
Только при Очевидно, что ни одна из этих двух конст-
рукций не может быть переведена на наш язык, и мы должны
убедить себя, что сможем жить при этих ограничениях, кото-
рые мы сами же себе и навязали, или даже что без таких начал
блоков, как в двух приведенных примерах, не только можно
обойтись, но в каком-то смысле они просто бесцельны. Ин-
туитивным обоснованием того, что внутри конструкции повто-
рения нам никогда не понадобится выполнять динамически
первое присваивание значения той переменной, чье >зна^ение
при завершении конструкции несущественно, может служить
следующее рассуждение: такая переменная должна входить
122 Глава 10
либо в инвариантное отношение, либо в предохранители, либо
и в отношения, и в предохранители, и поэтому лучше было бы
придать ей определенное значение и в начальном состоянии
конструкции повторения. (В следующей главе мы увидим, что
такая позиция заставит нас пересмотреть понятие «перемен-
ной».)
Поскольку мы ограничили себя рассмотрением такого язы-
ка, что при подходе к каждой точке с запятой статически из-
вестно, какие переменные составляют текущее пространство
состояний, нам нет нужды сомневаться — если мы пишем на-
ши программы на языке типа АЛГОЛа — в том, является
ли данное присваивание значения личной переменной динами-
чески первым с момента входа в блок, и поэтому требование,
чтобы синтаксическая форма <простой инициализирующий
оператор> отличалась от синтаксической формы обычного one-
ратора присваивания, не является дополнительным ограниче-
нием. По зрелом размышлении представляется, что было бы
даже нечестно использовать одинаковые обозначения, посколь-
ку эти операторы весьма различны: в то время как инициали-
зирующий оператор является в каком-то смысле созидающим
оператором (он порождает новую переменную с начальным
значением), обычный оператор присваивания является опера-
тором разрушающим в том смысле, что он уничтожает ин-
формацию, а именно предыдущее значение переменной.
Замечание. Нас не должна очень удивлять специальная
роль конструкции повторения, так как, если бы мы имели дело
с языком, в котором такая конструкция не предусмотрена,
нам никогда не понадобилось бы настоящее присваивание; мы
могли бы обойтись только’ инициализацией: без повторения мы
могли бы писать программы в терминах констант, которым
один раз придается начальное значение. Только с введением
повторения у нас возникает необходимость иметь* в полном
смысле слова переменные, т. е. нам нужно, чтобы на различ-
ных шагах процесса повторения при ссылке на одно и то же
имя мы получали разные значения. Именно понятие повторе-
ния влечет за собой понятие переменной, чье значение можно
изменять при помощи оператора присваивания. Именно в про-
цессе повторения нам действительно Нужно присваивать зна-
чения переменным, существующим вне данного блока, и имен-
но для повторения мы не можем разрешить инициализацию
таких переменных. {Конец замечания.)
Нам еще осталось решить несколько вопросов. Первый —
где и как указывать тип личных переменных. Представляются
возможными два места: либо — как в АЛГОЛе 60 — в начале
Размышления на тему: «Область действия переменных» 123
блока, для которого переменная является личной и ее имя
встречается где-то в перечне имен, либо в простом ини-
циализирующем операторе (или операторах).
Существуют, однако, две причины, по которым я чувствую
необходимость отойти от соглашения, принятого в АЛГОЛе 60,
и ограничить функцию перечисления имен в начале блока
только определением текстуальной области действия имен, не
отягощая этот перечень информацией о типе переменных. Мы
дадим обоснование этому отдельно для унаследованных и лич-
ных имен.
Если мы потребуем, чтобы каждое унаследованное имя в
номенклатуре сопровождалось явным указанием типа, во что
нам это обойдется и что мы выиграем? Нам придется распла-
чиваться не только удлинением текстов, но и тем, что характе-
ристика внешней среды, а именно тип глобальной переменной,
распространится по всему тексту. Во всех номенклатурах, со-
держащих унаследованное имя и рассеянных по всему тексту,
мы будем находить копию информации о типе переменной. Все
это выглядит особенно непривлекательно в случае необходи-
мости сменить тип такой глобальной переменной на другой,
для которого определен тот же набор функций и операций.
Кроме того, мы решили, что явное указание унаследованных
переменных выполняет функцию защиты от внешнего мира,
служит сжатым выражением того, как внутренний блок может
взаимодействовать со своим окружением, которое, как пред-
полагается, нам известно. Неоднократное повторение типа не
скажет нам в сжатой форме чего-нибудь нового или интерес-
ного о внутреннем блоке. .Единственный выигрыш, полученный
от включения в блок информации о типе глобальной перемен-
ной, по-видимому, состоит в том, что при изучении такого бло-
ка изолированно от всей программы в нем будет легче разо-
браться. Но я не совсем уверен, что нужная нам информация
об окружении может быть сведена только к типу глобальных
переменных: могут оказаться существенными и предполагае-
мые отношения между начальными значениями. Если мы хо-
тим понять, что делает какой-либо внутренний блок, нам нуж-
но более полное описание интерфейса, и до тех пор, пока мы
не собираемся автоматизировать доказательства правильно-
сти программы, более подходящим средством кажутся пред-
ставленные в удобной форме комментарии. (Читателя, кото-
рый сейчас восклицает: «А как же быть с независимой компи-
ляцией?»— мы просим понять, что это замечание относится
только к реализации очень специфического характера, и пред-
лагаем ему вообразить себя, как это делаю я, находящимся в
такой обстановке, когда этот вопрос абсолютно лишен
смысла.)
124 Глава 10
Вернемся теперь к личным переменным. Если тип перемен-
ной указывается в перечне имен, каждая активизация блока
вызовет инициализацию переменной этого типа. Мы видели,
однако, что если инициализирующий оператор является кон-
струкцией выбора, то при каждой активизации блока будет
выполняться один из множества простых инициализирующих
операторов. Я допускаю, что таким образом переменная мо-
жет получать начальные значения различных типов, и никто*
не будет возражать ^против этого, если только над такими ти-
пами определены одни и те же функции и рперации. Полезна
ли такая свобода выбора типа личной переменной или нет —
это довольно трудно обсуждать на данном этапе. Во всяком*
случае, было бы неразумно принять сейчас такое соглашение
об обозначениях, которое лишало бы нас возможности решить
этот вопрос в будущем. (Как заметит внимательный читатель,
возможность того, что тип личной переменной может быть
различным при разных активизациях блока, для которого эта
переменная является личной, служит еще одной причиной для
возражений против копирования информации о типах при
описании наследуемых переменных, т. е. во внутренних бло-
ках.)
Следующий вопрос, который мы должны решить, — это*
вопрос о том, нужно ли при входе в блок давать указания о
природе воздействия блока на унаследованные переменные.
Я напоминаю, что одной из причин включения в начало блока
перечня переменных из окружающего контекста, к которым
блок обращается, было стремление сократить объем текста,
который приходится изучать, когда одна из таких переменных
оказывается непостижимым образом испорченной. Если та-
кая переменная при каждой активизации внутреннего блока
действует как «глобальная константа», нам хотелось бы прямо
в начале блока видеть, что он не может испортить значение
этой переменной — более точно, что он может только выби-
рать, но не изменять это значение.
Давайте на минуту сосредоточим внимание на внутреннем
блоке (с контекстом «ВНУТРИ»), полностью находящемся в
активной области действия переменной, которую он наследует
от непосредственно объемлющего его блока (с контекстом
«ВНЕ»).
Если на уровне контекста ВНЕ переменная может изме-
няться, то, как мы видели, должно быть два возможных спосо-
ба наследования переменной: либо она может также изме-
няться и в контексте ВНУТРИ, т. е. внутренний блок может
содержать операторы присваивания, которые придают этой
переменной новые значения, либо внутренний блок получает
эту переменную как глобальную константу. Этот факт, однако,
Размышления на тему: «Область действия переменных» • 125»
имеет последствий для обоих контекстов. Для контекста ВНЕ
он означает, что, когда нам интересно узнать, что может воз-
действовать на значение переменной, мы можем пропустить,
текст внутреннего блока. Если, однако, мы хотим читать текст
внутреннего блока (более или менее в отрыве от его окруже-
ния) и при этом понимать, как рн будет выполняться, тогда
тот факт, что такая глобальная константа есть константа, а не
переменная, приобретает решающее значение. Уже в первом
примере главы «Формальное рассмотрение нескольких неболь-
ших примеров» мы начинали с такой постановки задачи: «Для
фиксированных х и у обеспечить истинность отношения R(m)-
(m—x or m=y) and and т>у»
То что хну считаются фиксированными, весьма сущест-
венно для данной задачи.
Если переменная является константой уже на уровне кон-
текста ВНЕ, тогда она может передаваться внутреннему бло-
ку только одним способом: тоже как константа. Для случая»,
когда внутренний блок целиком находится в активной области
действия наследуемой переменной, все обошлось благопо-
лучно.
Случай, когда внутренний блок целиком находится в пас-
сивной области действия переменной, также не представляет
никакой трудности: блок не может наследовать эту перемен-
ную из своего окружения.
Нашего внимания заслуживает третий случай, когда блок
начинается в пассивной области действия переменной, а кон-
чается в ее активной области действия; это означает не более
и не менее как то, что блок обязан инициализировать пере-
менную. Ему передали в наследство то, что мы могли бы на-
звать «нетронутой переменной», чтобы он выполнил инициали-
зацию. Как для контекста ВНУТРИ, так и для контекста ВНЕ
4iac может интересовать вопрос о возможности изменения, пе-
ременной в ее активной области. Когда наследуется нетрону-
тая переменная, эти два вопроса полностью независимы; то*
обстоятельство, что на текстуальном уровне контекста ВНЕ
.значение, полученное переменной после инициализации, не бу-
дет меняться, не исключает возможность, что сама инициали-
зация (во внутреннем блоке) представляет собой многошаго-
вую операцию, а это так и есть, когда мы рассматриваем ини-
циализацию не как единый, неделимый акт, но — интересуясь
деталями — как последовательный процесс формирования на-
чального значения.
После всех этих рассуждений пришла пора быть как можно
более точным. Напомним, что мы ввели название «тексту-
альный контекст» блока для постоянной номенклатуры (в ко-
126 Глава 10
торой все имена имеют единственное значение), принадлежа-
щей «уровню» блока, т. е. его тексту, за исключением его внут-
ренних блоков. Рассмотрим теперь два блока: внутренний
блок (с контекстом, называемым «ВНУТРИ») и объемлющий
его внешний блок (с контекстом, называемым «ВНЕ»). По
отношению к контексту ВНУТРИ контекст ВНЕ будет высту-
пать как «окружающий контекст».
Имена, используемые в контексте, могут быть двух типов:
либо они являются личной собственностью блока, т. е. не име-
ют отношения к тому, что расположено снаружи блока, либо
они «получены по наследству» от окружающего контекста.
В этом случае мы должны различать две возможности: имя
переменной может передаваться контексту ВНУТРИ от кон-
текста ВНЕ с обязательством или без обязательства инициа-
лизировать эту переменную при активизации блока. Мы бу-
дем различать все эти три вида переменных при помощи сле-
дующих обозначений:
pri («private» — личная переменная, т. е. переменная,
не имеющая отношения к окружающему контекс-
ту);
vir .(«virgin» — нетронутая переменная, т. е. перемен-
ная, полученная от окружающего контекста с обя-
зательством инициализировать эту переменную);
gio («global» — глобальная переменная, т. е. перемен-
ная, полученная от окружающего контекста без
обязательства и без разрешения ее инициализа-
ции).
Переменная может принадлежать более чем одному тек-
стуальному контексту: прежде всего она принадлежит тексту-
альному контексту того блока, для которого она является лич-
ной, и, кроме того, она принадлежит текстуальным контекс-
там всех внутренних блоков, которые наследуют ее от своих
окружающих контекстов. Область действия-переменной рас-
пространяется на уровни всех блоков, чьим текстуальным кон-
текстам принадлежит эта переменная. Область действия пе-
ременной всегда подразделяется на две части: на пассивную
область действия и активную область действия, и возможно-
сти размещения в тексте инициализирующих операторов для
переменных были ограничены таким образом, чтобы гаран-
тировать для каждой переменной своевременное выполнение
последовательности действий:
вход в блок, для которого переменная является личной;
нуль или более выполнений операторов из ее пассивной
области действия;
Размышления на тему: «Область действия переменных» 127
одна инициализация переменной;
нуль или более выполнений операторов из ее активной
области действия;
соответствующий выход из блока.
Когда речь идет о правах и обязанностях блока по отноше-
нию к некоторой переменной, не имеет значения, была она пе-
речислена под заголовком «pri» или под заголовком «vir»; в
обоих случаях блок обязан инициализировать эту перемен-
ную. Единственное различие между этими случаями состоит
в том, что переменная, перечисленная под заголовком «pri»,
не имеет отношения к контексту ВНЕ, в то время как пере-
менная, перечисленная под заголовком «vir», должна встре-
чаться в контексте ВНЕ, и внутренний блок должен начи-
наться в пассивной области действия этой переменной и кон-
чаться в ее активной области действия. Переменная, перечис-
ленная под заголовком «gio», должна встречаться в контексте
ВНЕ, и внутренний блок должен целиком находиться в актив-
ной области действия этой переменной.
Кроме внешних характеристик используемых в блоке пе-
ременных, которые задаются при помощи «pri», «vir» или
«gio», имеются и внутренние характеристики, а именно ука-
зания о том, может ли на уровне блока изменяться значение
переменной в ее активной области действия. Если значение
переменной может изменяться, это указывается при помощи
«var» («variable» — переменная); если нет — для указания ис-
пользуется «соп» («constant» — константа). Каждая из трех
внешних характеристик может комбинироваться с каждой из
двух внутренних характеристик, образуя шесть возможностей:
«privar», «pricon», «virvar», «vircon», «glovar» и «glocon». Для
шести заголовков в контексте ВНУТРИ мы приводим допу-
стимые заголовки в контексте ВНЕ:
ВНУТРИ
ВНЕ
privar, pricon glovar не применяется privar, virvar (только если внутренний блок целиком лежит в активной области действия) или glovar (без ограничений)
glocon privar, pricon, virvar, vircon (только если внут- ренний блок целиком лежит в активной обла- сти действия) или glovar, glocon (без ограни-
virvar, vircon чений) privar, pricon, virvar, vircon (только если внут- ренний блок начинается в пассивной области действия)
128 Г лава 10
Замечание 1. Из изложенного выше следует, что характе-
ристика «соп» в контексте ВНЕ исключает возможность изме-
нения значения этой переменной во внутренних блоках пос-
ле ее инициализации. (Конец замечания 1.)
Замечание 2. Характеристика «соп» в контексте ВНЕ не
исключает инициализацию переменной во внутреннем блоке,
на уровне которого переменная может обладать характери-
стикой «var»: в контексте ВНЕ мы можем иметь переменную
«pricon table», инициализация которой передается внутрен-
нему блоку, в чьем контексте будет создана переменная «vir-
var table» и будет сформировано ее значение. После того как
один раз выполнится такой инициализирующий, внутренний
•блок, значение переменной «table» останется постоянным на
протяжении выполнения внешнего блока (и других его внут-
ренних блоков, если таковые имеются). (Конец замечания 2.)
Решение оставшихся вопросов, хотя и достаточно важных
(они определяют, какими должны быть наши тексты, насколь-
ко легко писать их и читать), в меньшей степени чревато по-
следствиями; эти вопросы касаются только синтаксиса. Мы
должны представить синтаксические определения для поня-
тий <номенклатура> и <простой инициализирующий опера-
тор >. Я предлагаю дать определение номенклатуры, анало-
гичное определению понятия <заголовок блока> в АЛГОЛе
*60, — определению, к которому у меня никогда не возникало
никаких претензий.
<номенклатура>:: = <элемент номенклатуры^ {;<элемент
номенклатуры>}
<элемент номенклатуры> ::= <заголовок номенклатуры^
<переменная> {,<переменная>}
<заголовок номенклатуры^ ::=privar | -pricon | virvar |
vircon | glovar | glocon
Допуская возможность последующего расширения, я пред-
лагаю вывести определение инициализирующего оператора
из определения оператора присваивания, добавив после пере-
менной в левой части специальный символ «vir» — признак
того, что мы имеем дело с нетронутой переменной, — за кото-
рым следует наименование ее типа:
<простой инициализирующий оператор> ::= <переменная>
vir <тип> := <выражение>
Что касается типа, то до сих пор мы ограничивались толь-
ко целыми и булевыми переменными:
<тип>:: = | бул
Размышления на тему: «Область действия переменных* 129
Замечание 1. Расширение до одновременной инициализа-
ции нескольких переменных и одновременных инициализации
и присваивания предоставляется честолюбивому читателю.
(Конец замечания /.)
Замечание 2. Выражение (выражения) в правой части дол-
жно рассматриваться как еще находящееся в пассивной обла-
сти действия инициализируемых переменных. (Конец замеча-
ния 2.)
Приведем в качестве примера внутренний блок, который
инициализирует глобальную целую переменную х, придавая
ей значение НОД (X, У), где X и У по отношению к внутрен-
нему блоку являются положительными константами. Блок ис-
пользует личную переменную, называемую у.
begin glocon X, К; virvar х; privar у;
х vir цел, у vir цел : = X, У;
do х^>у —>х: = х — у
Q у Z = I/ —X
od
end
Хочу Заметить, что мое решение включать указатели «var»
или «соп» в номенклатуру было довольно произвольным. С од-
ной стороны, кому-то это указание может показаться излиш-
ним. Ну что же, если он захочет отменить это соглашение, он
волен это сделать; он может просто сократить заголовки до
«pri», «vir» и «gio», опустив все var и соп в моих программах.
Если мои программы были правильными в соответствии с мои-
ми соглашениями, его версии программ также будут правиль-
ными в соответствии с его соглашениями. С другой стороны,
у кого-то может появиться, желание дать более точную ин-
формацию, чем это дозволяют предлагаемые мной средства.
Он мог бы захотеть, например, указать,
1) что значение переменной может только возрастать;
2) что от начального значения глобальной переменной бу-
дет зависеть только ее собственное конечное значение, но не
значение других переменных;
3) что из всего набора способов изменения значения гло-
бальной переменной будет использоваться только его подмно-
жество.
Указание типа (1) представляется слишком специальным,
поскольку оно применимо только к тем переменным, чьи зна-
чения от природы упорядочены. Указание типа (2) тоже ка-
5—6
130 Глава 10
жется слишком специфическим. Как быть, например, с парой
глобальных переменных, чьи начальные значения влияют
только на собственные конечные значения и на конечные зна-
чения друг друга? А вот указание типа (3) могло бы иметь
смысл. В этом случае наше указание «соп» можно трактовать
как указание о том, что подмножество допустимых модифи-
каций пусто.
11 ВЕКТОРНЫЕ ПЕРЕМЕННЫЕ
Меня приучили рассматривать массив в смысле АЛГОЛа 60
как конечное множество одиночных, последовательно перену-
мерованных переменных, чьи «идентификаторы» могут «вы-
числяться». Однако такая точка зрения меня больше не удов-
летворяет, и объясняется это двумя причинами.
Первая причина — мое неприятие переменных с неопреде-
лейными значениями. В предыдущей главе мы разрешили эту
проблему, введя для каждой переменной пассивную и актив-
ную области действия, разделенные синтаксически распозна-
ваемой инициализацией этой переменной. Но когда мы рас-
сматриваем массив как совокупность переменных (с индек-
сами), это решение уже не годится.
Вторая причина носит комбинаторный характер и являет-
ся более основательной. В АЛГОЛе 60 составной оператор,
который заставляет переменные х и у обменяться своими зна-
чениями, нуждается в дополнительной переменной, скажем Л,
Л: = х;х: = у\у:= h
что выглядит громоздко и даже безобразно по сравнению с
одновременным присваиванием
х, у.= у, х
Мы потребовали, чтобы при одновременном присваивании
все переменные в левой части были различными: в самом де-
ле, глупо было бы вкладывать в «х, х: = 1, 2» какой-то иной
смысл, йем «ошибка». Тем не менее я не сразу решился при-
нять одновременное присваивание из-за проблем, возникаю-
щих в случаях, подобных такому:
л1*]> А [/]:= У
Следует ли считать такое присваивание допустимым, ког-
да но не когда /=/? Или, может быть, оно допустимо при
5*
132 Глава 11
i=j, если при этом х=у, так же, как, например, и в случае
Л [Z], Л[/]:=Л[Л ДИ
Если мы пойдем по такому пути, то, очевидно, будем гро-
моздить одну логическую заплату на другую. Однако я те-
перь пришел к заключению, что виновником всего этого яв-
ляется не одновременное присваивание, а понятие переменной
с индексом. В аксиоматическом определении оператора при-
сваивания через «подстановку переменной» нельзя позволить
себе — как, я полагаю, и во всех областях логики — никакой
неопределенности по поводу того, являются ли две переменные
одной и той же переменной или нет.
Мораль всего этого такова, что мы должны рассматривать
весь массив в целом как одну переменную, так называемую
«векторную переменную», в противоположность рассматри-
ваемым до сих пор «скалярным переменным». В дальнейшем
я ограничусь векторными переменными, являющимися анало-
гом одномерных массивов.
Мы можем рассматривать переменную (ее значение) це-
лого типа кай целочисленную функцию без аргументов (т. е.
как функцию, область определения которой состоит из един-
ственной безымянной точки), которая сохраняет свое значе-
ние, если не задано явно его изменение (обычно при помощи
присваивания). Вероятно, покажется необычным рассматри-
вать функцию без аргументов, но мы встали на такую точку
зрения ради проведения аналогии. Потому что подобным же
образом мы можем рассматривать переменную (ее значение)
типа «целый массив» как целочисленную функцию с одним
аргументом, определенную на множестве целых чисел, — функ-
цию, которая также сохраняет свое значение, пока не будет
явно задано его изменение.
Но значение переменной типа «целый массив» не может
быть любой целочисленной функцией, определенной на множе-
стве целых чисел, так как я ограничусь рассмотрением таких
типов, что для любых двух переменных этого типа мы можем
составить алгоритм, определяющий, имеют ли эти переменные
одно и то же значение. Если х и у являются скалярными пе-
ременными целого типа, тогда этот алгоритм сводится к бу-
левому выражению х—у, т. е. обе функции вычисляются в
единственной (безымянной) точке их области определения,
после чего сравниваются полученные Целочисленные значе-
ния. Аналогично, если ах и ау — две переменные типа «целый
массив», их значения равны тогда и только тогда, когда они
как функции имеют одну и ту же область определения и в
каждой точке этой области значения этих функций совпадают.
Чтобы можно было выполнить все эти сравнения, мы должны
Векторные переменные 133
ограничиться рассмотрением конечных областей определения.
Более того, эти области, кроме того, что они конечны, должны
быть тем или иным способом доступны для алгоритма срав-
нения значений векторных переменных ах и ау.
Из практических соображений я буду рассматривать толь-
ко области определения, состоящие из последовательных це-
лых чисел (когда область не пуста). Но и при таком ограни-
чении "возникает , по крайней мере две возможности.
В АЛГОЛе 60 область определения фиксируется при помощи
задания в описании нижней и верхней границ для значения
индекса, например boolean array А [1 : 10], В [1:5]». Так как
тип определяет класс возможных значений для переменной,
этого типа, мы должны сделать вывод, что в приведенном
примере массивы А и В являются массивами разных типов:
А может иметь 1024 различных значения, а В — только 32.
В АЛГОЛе 60 мы имеем столько различных типов булевых
массивов, сколько имеется граничных пар (а так как гранич-
ная пара может содержать выражения, то тип определяется,
вообще говоря, только при входе в блок). Кроме того, должны
существовать и другие средства, позволяющие получить не-
обходимые знания об области определения: не располагая до-
полнительной информацией, невозможно написать на языке
АЛГОЛ 60 внутренний блок, определяющий, равны ли два
глобальных булевых массива А и В!
В качестве альтернативы предлагается ввести только один
тип «целый массив» и только один тип «булев массив» и рас-
сматривать «область определения» как часть (аспект) любого
значения такого типа; тогда мы должны уметь извлекать этот
аспект из любого такого значения. Пусть ах — векторная пе-
ременная; в ее активной области действия я предлагаю извле-
кать из ее значения границы области определения при помощи
двух целочисленных функций, обозначаемых соответственно
через «ах.ниг» и «ах.вег», полагая при этом, что функция
«ах(0» определена для всех целых /, таких, что
ах.ниг^Л ^.ах.вег
Кроме этих двух функций, я предлагаю ввести третью (за-
висимую) функцию «ах.обл», равную числу точек в области
определения переменной. Три функции связаны соотношением
ах.обл=ах.вег-ах.ниг-{-1^0
(Заметим, что даже пустая область определения, обл = 0, за-
нимает свое место на числовой оси; ниг и вег по-прежнему оп-
ределены и удовлетворяют соотношению вег = ниг— 1.)
Мы применили здесь новое обозначение, использовав точку
в <<ах.ниг>\ «ах.вег» и «ах.обл», Имена, следующие за точкой,
134 Глава 11
называются именами, подчиненными типу той переменной, чье
имя предшествует точке. За точкой, следующей за именем пе-
ременной, могут следовать только имена, подчиненные типу
этой переменной, и их значение будет определяться по отно-
шению к этому типу.
Примечание 1. В других контекстах, т. е. не вслед за точ-
кой,, те же имена могут использоваться в совершенно другом
значении. Мы могли бы ввести векторную переменную с име-
нем «обл» и обращаться в ее активной области действия к
функциям «обл.ниг», «обл.вег» и даже «обл.обл»! Однако
подобные выкрутасы не рекомендуются, поэтому я старался
найти такие подчиненные имена, которые, хотя и имеют^неко-
торый мнемонический смысл, вряд ли могут быть придуманы
самим программистом. {Конец примечания /.)
Примечание 2. Еще одна причина, заставившая нас отка-
заться от обычного обозначения функции, например «обл{ах)>
и т. д., и воспользоваться точкой, заключается в том, что если
мы при этом не введем различные наборы имен для этих функ-
ций применительно к булевым массивам и целым массивам
(что выглядело бы довольно неуклюже), мы будем вынужде-
ны ввести функции от аргумента, который может быть вели-
чиной более чем одного типа, чего я хотел бы по мере возмож-
ности избегать. {Конец примечания 2.\
Примечание 3. Выражение «ax(t)» используется для обо-
значения значения функции в точке i. Необходимость в опре-
делении аргумента I возникает только тогда, когда нам тре-
буется значение «ах(/)», при этом должно выполняться соот-
ношение
ах.ниг^ах.вег
Исходя из обозначения функций с использованием точки,
мы могли бы рассматривать «ах (г)» как сокращение от
«ax.3Ha«(i)>, где «з«ач»— подчиненное имя, служащее ука-
занием, что нужно вычислить значение функции в точке, оп-
ределяемой значением последующего аргумента I. Для каж-
дого типа такое сокращение можно вводить только один раз!
Заметим, что тип «целый» тоже мог бы иметь подчиненное имя,
«з«ач», что позволило бы нам писать немного более явно
х'. = у.знач .
вместо обычной и несколько неаккуратной формы х.—у. {Ко-
нец примечания 3.)
Векторные переменные 135
Введем для удобства две дополнительные функции; для
векторной переменной ах они определены при ах.обл>0. Это
функции
ах.низ, равная по определению ах(ах.ниг)
и
ах.верх, равная по определению ах (ах.вег)
Они обозначают значения функции соответственно в самой
нижней и самой верхней точках области определения. Они не
представляют собой ничего действительно нового и определе-
ны в терминах уже известных понятий; при определении се-
мантики операций над значениями массивов не обязательно
явно упоминать об их влиянии на значения этих функций.
Как сказано выше, скалярную переменную можно рас-
сматривать как функцию (без аргумента), значение которой
можно изменить при помощи присваивания ей нового значе-
ния: такое присваивание полностью уничтожает информацию,
представлявшую собой «ее старое значение». Нам нужны
также операции, позволяющие изменять значение векторной
переменной (без таких операций мы всегда имели бы вектор-
ную константу!), но присваивание переменной нового значе-
ния, т. е. значения, совершенно не связанного с ее старым
значением, уже не будет играть такую центральную роль.
И не потому, что присваивание значения векторной перемен-
ной вызывает какие-то логические трудности — совсем наобо-
рот, мне хочется сказать — просто такая операция была бы
неэкономичной. Если область определения велика, объем ин-
формации, представляющей собой «значение векторной пере-
менной», может быть весьма значительным, и тогда ни копи-
рование, ни уничтожение информации такого объема нельзя
считать «хорошими» операциями.
С другой стороны, для многих з’адач программирования
суть проблемы состоит в том, что значение массива формиру-
ется постепенно, т. е. за ряд шагов, каждый из которых можно
считать «хорошей» операцией, «хорошей» в том смысле, что
новое значение массива можно рассматривать как «приятную»
производную от его старого значения. Будут ли такие опера-
ции «хорошими» или «приятными», существенно зависит от
двух моментов: во-первых, отношение между старым и новым
значениями должно поддаваться математическому выраже-
нию, иначе эти операции становятся слишком громоздкими
для использования; во-вторых, их реализация не должна быть
слишком дорогой для того оборудования, которое мы собира-
емся использовать для выполнения нашей программы. Вопрос
о том, в какой мере мы хотим учитывать накладываемые обо-
рудованием ограничения, является вопросом политики, а не
136 Глава 11
научным вопросом, и поэтому я не чувствую себя обязанным
давать развернутое обоснование своим предложениям. Из со-
ображений удобства я позволю себе быть более либеральным,
чем многие программисты, в особенности те, кому приходится
ежедневно работать на машине, которая создавалась десять
или больше лет тому назад; с другой стороны, мне кажется,
что, я сознаю возможные технические последствия своих пред-
ложений в достаточной степени, так что они остаются если не
реалистическими, то по крайней мере'не совсем нереальными.
Наша первая опер.ация над значением векторной перемен-
ной, скажем ах, не изменяет ни размера области определения,
ни набора значений функции, ни их порядка; она только сдви-
гает область определения на некоторое число позиций, ска-
жем k, вверх по числовой оси. (Если &<0, происходит сдвиг на
k позиций в другом направлении; если А=0, мы имеем тожде-
ственное преобразование, семантически эквивалентное опера-
ции «пропустить».) Обозначим нашу операцию как
ах: сдвинуть (k)
Мы ввели здесь двоеточие «:». Нижняя точка, как обычно,
указывает на то, что следующее имя является подчиненным
для типа упомянутой слева переменной; верхняя точка служит
просто украшением (на что нас вдохновила операция присва-
ивания «: = »), указывающим, что значение упомянутой слева
переменной подлежит переопределению.
Сразу же возникает вопрос, можем ли мы дать аксиомати-
ческое определение преобразователя предикатов wp(«ax: сдви-
нуть (Е)», R). Ясно, что это должен быть преобразователь
предикатов, аналогичный преобразователю из аксиомы о при-
сваивании значения скалярной переменной, но более слож-
ный; то же справедливо и для всех других операций над зна-
чением массива, поскольку значение скалярной переменной
полностью определяется одним (элементарным) значением,
в то время как значение векторной переменной включает в се-
бя и саму область определения, и значение функции для всех
точек этой области. Так как значение векторной переменной
ах полностью определяется
значением ах.ниг
значением ах.обл и
значением ax[i) для ах.ниг-^Л<^ах.ниг-\-ах.обл
мы можем, по крайней мере в принципе, ограничиться рас-
смотрением постусловий R., ссылающихся на значение массива
только в терминах «ах.ниг», «ах.обл» и «ах(арг)», где арг —
любое целочисленное выражение. Для такого постусловия R
Векторные переменные 137
соответствующее слабейшее предусловие
wp («ах: сдвинуть (£)», R)
выводится из R при помощи одновременной замены
1) всех вхождений ах.ниг.на (ахниг+ (Е)) и
2) всех вхождений' (под)выражений вида ах(арг) на
ах((арг) — (E)).
Замечание. Если Е само зависит от значения ах, самое бе-
зопасное— вычислить сначала для данного R, использовав
в нем совсем другое имя, скажем К, wp («ах: сдвинуть (К)»,
R), а затем подставить вместо К фактическое значение R.
Мы уже сталкивались с таким же осложнением, когда
применяли аксиому о присваивании к операторам вида
х:= x+f(x). (Конец замечания.)
Приведем несколько примеров. Пусть R — это отношение
ах.ниг= 10, тогда
wp («ах: сдвинуть (ах. ниг)», R)=(ах.ниг-|-ах. ниг=10)
= (ах .ниг—5)
Пусть R — это (Ai: 0^.1<^ах.обл: ах(ах.ниг-\-1) = i); тогда
wpj(«ax: сдвинуть (7)», R) — (Ai: 0<д <^ах.обл :ах(ах.ниг+
+ 7-}-i-7)=i)=R
Можно записать это слабейшее предусловие по-другому:
wp («ах: сдвинуть (£)», R)=Rax'^ax
(т. е. копия R, в которой каждое вхождение ах заменено на
ах'), где
ах'. ниг = ах. ниг + Е
ах’ ,обл=ах. обл
ах'(арг)=ах(арг — Е) для любого значения арг
Из трех этих определений следует, что
ах'. вег=ах. вег Е
ах' .низ=ах. низ
ах' .верх=ах.верх
Замечание. Из этих равенств следует, что, если правая
часть не определена, левая часть также не определена. (Конец
замечания.)
При определении дальнейших операций мы будем исполь-
зовать этот последний прием: он позволяет описать в более
138 Глава 11
ясной форме, как конечное значение ах' зависит от начального
значения ах.
Следующие операции расширяют область ойределения на
одну точку либо с верхнего, либо с нижнего ее конца. Значе-
ний функции в новой точке задается как параметр, тип кото-
рого должен быть так называемым «основным типом» масси-
ва, т. е. булевым для булева массива и т. д. Операции задают-
ся в виде
ах: вверх (х) или ах: вниз (х)
Семантическое определение вверх задается соотношением
wp («ах: вверх (х)», R)=Rax--ах
где
ах'. наг=ах. наг
ах'. вег—ах. вег -f-1
ax'. обл=ах. обл-\-1
ах'(арг)=х для арг=ах.вег4-1
=ах(арг) для арг =/=ах.вег-\-1
Семантическое определение вниз задается в виде
WP («ЯХ : вниз (Х)», R) = Rax'-ax
где
ах' .наг —ах.ниг — 1
ах' .вег = ах. вег
ах'. обл=ах.обл -j-1
ax'(арг)=х для арг=ах.ниг — 1
=ах(арг) для аргах.ниг— 1
Замечание. Наше предыдущее примечание о том, что и
пустая область определения имеет свое место на числовой оси,
должно служить гарантией, что операции расширения вверх
и вниз определены и для векторной переменной, для которой
обл = 0. (Конец замечания.)
Следующие две операции удаляют точку из области опре-
деления либо с верхнего, либо с нижнего ее конца. Они опре-
делены только в том случае, когда перед их выполнением
обл>0; когда они применяются к массиву, для которого
обл = 0, это вызывает отказ. Эти операции уничтожают ин«
формацию в том смысле, что одно из значений функции утра-
чивается.
Векторные переменные 139
Семантическое определение сверху задается соотношением
wp(«ах : сверху», R) = (ax.o6A>Q andRax'-^ax}
где
ах' .ниг—ах.ниг
ах'.вег = ах.вег — 1
ах' .обл=ах.обл— 1
ах'(арг) не определено для арг=ах.вег
= ах(арг) для арг^=ах.вег
Семантическое определение снизу задается соотношением
wp(«ax:снизу», К)=(ах.обл>Ъ and Raxr->ax}
где
ах'.ниг =ах.ниг-\-\
ах'.вег = ах. вег
ах'.обл =ах.обл—1
ах' (арг) не определено для арг=ах.ниг
=ах(арг) для арг=£ах.ниг
Введем для удобства еще две операции, семантика кото-
рых может быть выражена в терминах уже введенных функ-
ций и операций. Это операции
х, ах: векон, семантически эквивалентная «х: = ах. верх\
ах-.сверху»
и
х, ах: никои, семантически эквивалентная «х:= ах.низ-,
ах-.снизу»
Обозначение этих операций напоминает обозначение опе-
рации одновременного присваивания; имя, следующее за «:»,
должно быть подчиненным именем для типа переменной, имя
которой непосредственно предшествует «:». Очевидно, что дру-
гая. переменная х должна иметь основной тип векторной пе-
ременной ах.
Все описанные выше операции изменяют область определе-
ния функции, либо только смещая ее вдоль числовой оси, ли-
бо изменяя при этом и ее размер.,Будут введены еще две опе-
рации, которые сохраняют область определения и только воз-
действуют на одно или два‘значения функции.
Очень важной является операция, которая не порождает
новых значений функции, а только переупорядочивает имею-
140 Глава 11
щиеся значения. Операция задается в виде
ах- переставить^, J)
Если i и / не лежат аба в области определения функции,
операция вызовет отказ. Семантика операции задается соот-
ношением
wp(«ax:переставить (Z, /)», %)=(ах.ниг^Л^ах.вег and
ах.ниг^ j ^ах.вег and
Rax '—ox)
где
ах' .ниг = ах.ниг
ах'.вег = ах. вег
ах'. обл = ах. обл
ах' (арг) = ах (J) для арг=1
=ах(Г) для apz = j
=ах(ар?) для apz=£i and арг
Замечание. Не требуется, чтобы перед выполнением опера-
ции i^j: если i=j, значение векторной переменной останется
прежним. (Конец замечания.)
Наша последняя операция позволяет изменить одно зна-
чение функции; она задается в виде
ах: изм(1, х)
Операция приводит к отказу, если i не лежит в области опре-
деления; второй параметр х должен иметь основной тип век-
торной переменной. Семантика операции задается соотноше-
нием
wp («ах: изм (i, х)»,К)=(ах.ниг^1^,ах.вег and
Ках' —ах)
где
ах' .ниг =ах.ниг
ах'.вег = ах. вег
ах'. обл — ах. обл
ах' (арг)—х для apz=i
— ах (арг) для арг^1
Операция, обозначенная выше как «ах-, изм(i, х)>, семан-
тически эквивалентна операции, известной тем, кто програм-
мирует на ФОРТРАНе и АЛГОЛе 60, как «присваивание зна-
Векторные переменные • 141
чения переменной с индексом». (Они соответственно написали
бы в этом случае «XX(/)=X» и «ax[i]:= х».) Я ввел эту опе-
рацию в форме «ах: изм(1, х)», чтобы подчеркнуть, что такая
операция оказывает воздействие на массив ах в целом: если
две функции с одной и той же областью определения отлича-
ются хотя бы в одной точке этой области, то такие функции
различны. Однако «официальное» — или, если вам так больше
нравится, «пуританское» — обозначение «ах: изм(1, х)», даже
на мой взгляд, слишком громоздко и слишком непривычно,
поэтому я предлагаю (и у меня есть свои слабости!) исполь-
зовать вместо него обозначение
ах: (t)=x
которое и короче, и похоже на столь знакомый нам оператор
присваивания, и своим началом «ах:» говорит о том, что эта
операция направлена на векторную переменную ах. (Решение
использовать форму «ax:(i) — х» не очень отличается от реше-
ния использовать форму «ах (г)» вместо более помпезной фор-
мы «ах.знач (£)».)
Ни одна из предыдущих.операций не может быть исполь-
зована для инициализации. Эти операции -могут только изме-
нять значение массива при условии, что он уже обладает
каким-то значением; они могут встречаться только в активной
области действия векторной переменной. Мы еще не ввели
присваивание
ах: = Ьх
— конструкцию, которая могла бы выполнить инициализацию.
Я, однако, никак не могу на это решиться, потому что во всей
своей общности «присваивание значения» подразумевает обыч-
но «копирование значения», и если область определения функ-
ции Ьх велика, то при существующей технологии такую опера-
цию присваивания нельзя считать «хорошей». Не могу ска-
зать, что я абсолютно несклонен к введению «неприятных»
операций, но если уж я это делаю, то мне бы не хотелось, что-
бы на бумаге они выглядели как невинные операции. Язык
программирования, в котором операция «х:=у» считается
«хорошей», а операция «рх: = дх» расценивается как «непри-
ятная», ввел бы нас в заблуждение; по крайней мере он ввел
бы в заблуждение меня. Выход из этой дилеммы состоит в до-
пущении, что в правой части такого оператора присваивания
значения векторной переменной можно только перечислять
константы, например в форме
«целое^>{, ^значение основного типа>))
142 Глава 11
так что, например, в результате присваивания
Ьх:=(5, истина, истина, ложь, истина)
мы получим
Ьх.ниг=Г> Ьх (5) = истина
Ьх.вег=3 Ьх (6)=ис тина
Ьх.обл=4 Ьх (7)=ложь
Z>x(8)=истина
Вследствие такого ограничения использование при при-
сваивании или инициализации значения с областью определе-
ния большого размера не может пройти незамеченным.
Я предполагаю, что в большинстве случаев при инициализа-
ции будут использоваться значения, для которых обл=0.
Теперь несколько заключительных замечаний.
Начнем с вопроса об .экономичности операций. Я исхожу
из того, что выполнение всех упомянутых в этой главе опера-
ций стоит примерно одинаково. Нужно высказать некоторые
предположения о природе этих затрат, ибо без этого задача
программирования теряет смысл. Например, вместо
ах: (5) = 7
мы могли бы написать внутренний блок
begin glovar ах; privar Ьх;
if ах.ниг and Ъ^ах.вег-*-
Ьх vir цел array : = (0);
do ах.вег =/= 5-+Ьх:вверх(ах.верх); ах: сверху od;
ах : сверху, ах: вверх(7);
do Ьх.обл :вверх(Ьх.верх); Ьх: сверху od
й
end
но я бы забраковал этот внутренний блок, так как это худшая
замена, и не только из-за длинного текста, но и из-за неэффек-
тивности. Я даже не стану рассматривать «ах: (5) =7» как со-
кращенную запись этого внутреннего блока.
Я предполагаю, в частности, что стоимость выполнения
всех операций, за исключением, может быть, присваивания пе-
речисленных значений, не зависит от значений аргументов,
входящих в операцию: стоимость выполнения ах: сдвинуть (k)
Векторные переменные 143
не будет зависеть от значения k, стоимость выполнения ах : пе-
реставить (i, j) не будет зависеть от значений i и j и т. д. При
современной технологии такие предположения не так уж не-
реальны.
Принимая во внимание соображения эффективности, мне
следует дать обоснование моей готовности вводить дополни-
тельные избыточные имена; мы могли бы ограничиться функ-
циями ах.ниг и ах.обл, потому что всякий раз, когда нам пона-
добилась бы функция ах.вег, мы могли бы вместо нее писать
ах.ниг-]-ах.обл — 1
но тогда эффективное использование ах.вег обошлось бы
«вдвое дороже» эффективного использования ах.ниг, и то, что
мы осознаем это, легко можетшовлиять на наш способ мыш-
ления (и, что гораздо хуже, действительно, влияет).
Я говорил об одйнаковых затратах. При этом я имею в
виду, что они одинаковы по сравнению с затратами на опера-
ции, которые мы считаем примитивными. Если бы операции
над массивами обходились дороже, чем другие операции, мы
могли бы, например, заменить
ах: переставить^, /)
на
f i ах: переставить^, j) = / -^пропустить fi
и сразу перед нами возникла бы необходимость знать точное
соотношение затрат и очень хорошо оценить вероятность слу-
чая «i=j>, чтобы мы могли решить, действительно ли мы
получим повышение эффективности, если заменим ах: пере-
ставить (i, j) конструкцией выбора. Я знаю математиков, ко-
торые упиваются такими задачами оптимизации, полагая
иногда, что эти задачи занимают центральное место при со-
ставлении программ для вычислительных машин. Я с радо-
стью предоставляю им решение этих задач, раз уж они полу-
чают от этого такое удовольствие; операции, которые мы пред-
почитаем считать примитивными, не должны приводить нас
к таким конфликтам. Я полагаю, у нас есть более важные
проблемы, заслуживающие нашего внимания.
Последнее замечание о реализации. При инициализации
векторной переменной ах в принципе можно указывать неко-
торые ограничения: ограничение снизу для ах.ниг, или огра-
ничение сверху для ах.вег, или оба этих ограничения, или,
может быть, только ограничение сверху для ах.обл. Если та-
кие «подсказки компилятору» включаются в программу, то
становится возможным использовать все богатство традицион-
144 Глава 11
них приемов управления памятью. Я предпочитаю, однако, не
считать такие «подсказки компилятору» частью программы.
Они могут только удешевить реализацию (и то для какого-то
оборудования!); они разрешают (но не заставляют!) при кон-
кретных реализациях выдавать отказ, когда происходит на-
рушение указанных ограничений.
12 ТЕОРЕМА О ЛИНЕЙНОМ ПРОСМОТРЕ
Обозначим через В булеву функцию, определенную на мно-
жестве целых чисел, и рассмотрим следующее начало блока:
begin privar /;
i vir цел: =0;
do В(Z)->Z: = Z 1 od;
Для этой конструкции повторения мы можем сформули-
ровать инвариантное отношение
P(i): (Ay:O<y<Z:B(y))
Доказательство. Так как Р(0) истинно, Р(1) становится
истинным при инициализации. Далее,
(P(Z) and £(Z))=P(Z-f-l)
= wp(«Z :=/+ 1»,P(Z)) Ч.Т.Д.
Без дополнительных знаний о булевой функции В мы не
сможем доказать, что конструкция повторения завершится.
Если, однако,
(Е у •' у > 0 : поп В (у))
то, предположив, что конструкция не завершится, мы придем
к обычному противоречию: достаточно существования по край-
ней мере одного значения /^0, такого, что
поп В (у)
истинно, чтобы гарантировать завершение конструкции. Мы
знаем, однако, что по завершении
P(i) and non B(i) —
(Ay : 0 у < Z : В (у)) and поп В{1)
146 Глава 12
т. е. i является минимальным значением ^0; при котором
non B(i) истинно. Иначе говоря, когда мы ищем минимальное
значение (не меньшее, чем некоторая нижняя граница), удов-
летворяющее некоторому критерию, наша программа просмат-
ривает значения (начиная с нижней границы) в порядке их
возрастания. Такой просмотр превращает первое встретившее-
ся значение, удовлетворяющее данному критерию, в наимень-
шее из существующих значений, удовлетворяющих данному
критерию. Аналогично, когда мы ищем максимальное значе-
ние, мы ведем просмотр в порядке убывания значений.
Очень часто эти два оператора имеют форму
х:=хнуль;
doZ?(x)->x:=F(x) od
Такая программа осуществляет поиск среди последова-
тельности значений, определенной как
Хц=хнуль
для />0:
xz=F(xz_i)
такого значения х, с минимальным значением i(^0), при ко-
тором nonB(^z) истинно. (Более формальные доказательства
мы оставляем в качестве упражнения трудолюбивому чита-
телю, имеющему склонность к таким доказательствам.)
На результаты, полученные в этой главе, ссылаются как
на «теорему о линейном просмотре». В следующей главе мы
будем их использовать в наших рассуждениях, направленных
на решение реальных задач. Оказывается, что, несмотря на
свою простоту, теорема о линейном просмотре имеет большое
эвристическое значение.
13 ЗАДАЧА О СЛЕДУЮЩЕЙ ПЕРЕСТАНОВКЕ
Нам требуется написать внутренний блок, выполняющий
действие над глобальной целой векторной переменной, именуе-
мой с, при
с.ниг—1 и с.вег = п.
для некоторого постоянного значения п(п>1). Кроме того,
известно, что упорядоченная последовательность значений
с(1), с(2), с(п) является некоторой перестановкой значений
от 1 до п, но не последней в алфавитном порядке: п, п'—1,1.
Внутренний блок должен преобразовать последовательность
с(1), с(2), с(п) в последовательность, являющуюся ее не-
посредственным следующим по алфавиту преемником. (По
поводу понятия «алфавитный порядок» обратитесь к послед-
нему примеру в главе «Формальное рассмотрение нескольких
небольших примеров».) Например, при п = 9 последователь-
ность
146295.873
должна быть преобразована в последовательность
146297358
Как видно из приведенного примера, ряд значений функ-
ции на нижнем конце может остаться неизмененным. Выпол-
няемое преобразование сводится к перестановке значений на
верхнем конце, и первое, что мы должны сделать,— это найти
место раздела, т. е. определить значение I, такое, что
с [К} сохраняется для 1 < Л <7
c(k) изменяется для k=i
Значение i определяется как максимальное значение
*(<«), такое, что
c(/)<c(Z-|-l)
148 Глава 13
(Это значение не может быть большим, потому что тогда мы
были бы вынуждены переставлять значения в, первоначально
монотонно убывающей последовательности, а такая операция
не может привести к получению последовательности, стоящей
выше в алфавитном порядке; оно также не должно быть мень-
шим, так как в этом случае мы никогда бы не получили непо-
средственного следующего по алфавиту преемника.)
Замечание. Тот факт, что исходная последовательность не
является последней в алфавитном порядке, гарантирует нам
существование i (0<i<n), такого, чго с(i) <с(i+1). (Конец
замечания.)
После того как i найдено, мы должны отыскать в «хвосте»,
т. е. среди значений с(/) при новое значение c(i).
Так как мы ищем непосредственного преемника, мы должны
найти такое значение / в интервале что с(/) есть
наименьшее значение, удовлетворяющее условию
После того как / найдено, мы можем позаботиться о том,
чтобы с (i) получило свое новое значение, для чего используем
операцию «с: переставить (i, /)». Дополнительным преимуще-
ством этой операции является то, что после ее выполнения
вся последовательность продолжает оставаться перестановкой
чисел от 1 до п; заключает всю цепочку действий переупоря-
дочивание значений в хвосте последовательности, чтобы они
монотонно возрастали. Общая структура нашей программы
представляется теперь в таком виде:
определение г;
определение J;
с: переставить (Z, /);
сортировка хвоста
(В нашем примере i=6, /=8 и окончательный результат будет
достигаться через промежуточную последовательность 1 4 6
2 9 7 8 5 3.)
При определении i мы ищем максимальное значение i; тео-
рема о линейном просмотре говорит нам, что мы должны про-
сматривать потенциально возможные значения i в порядке
убывания.
При определении / мы ищем минимальное значение с(/);
теорема о линейном просмотре говорит нам, что мы должны
исследовать значения с(/) в порядке их возрастания. Посколь-
ку хвост представляет собой монотонно убывающую функцию
Задача о следующей перестановке 149
(из-за способа определения z), из этого следует, что мы долж-
ны будем вести просмотр значений с(/) в порядке убывания /.
Операция «с: переставить (z, /)» не нарушает монотонно-
сти значений функции в хвосте (докажите это!), и поэтому
«сортировка хвоста» сводится к расположению значений в
обратном порядке. (При выполнении сортировки наша про-
грамма пользуется переменными i и /, которые уже сослужи-
ли свою службу. Заметим, что способ сортировки одинаково
применим и для четного, и для нечетного числа значений в
хвосте.)
begin glovar с; privar z, у;
i vir цел\=с.вег — \\ do с (z) > с (z-f- 1) —> i := i — 1 ,od;
j vir цел : = с.вег\ do c (y)< (0 —* j< = j — 1 od;
с : переставить (z, y);
i := z-f- 1; j := с.вег\
do I <^j —* с : переставить^, у); z, y:=z-J-l, у —1 od
end
Примечание 1. Мы нигде не использовали тот факт, что все
значения с(1), с(2), ..., с(п) различны. Следовательно, можно
было бы предположить, что наша программа будет правильно
преобразовывать исходную последовательность в следующую
по алфавиту последовательность и в том случае, когда неко-
торые значения входят в последовательность более чем один
раз. И это действительно так, поскольку при определении i и
j мы формировали наши предохранители путем «механическо-
го» отрицания требуемых условий c(i)<c(i+l) и c(j)>c(i)
соответственно. Однажды в университете я продемонстриро-
вал эту программу аудитории, которая наотрез отказалась
принять мои предохранители с включенным в них равенством.
Слушатели настаивали на том, чтобы я писал
do <?(z)>t?(z-{-l)—*...
и
do с (у) <c(i)_...
если известно, что все значения в последовательности различ-
ны. Они были непоколебимы в своем убеждении, что проверка
также и равенства обойдется значительно дороже. Я уступил,
но при этом мне было интересно, каким же оборудованием
должен располагать университет, чтобы у студентов возникли
такие превратные представления. (Конец примечания 1.)
Примечание 2. Программисты, не знакомые с теоремой о
линейном просмотре, часто совершают ошибку, представляя
150 Глава 13
«определение /» в следующем виде:
j vir цел: do с (/+1) (/)—>/:=/-(-1 od
Они утверждают, что эта программа будет присваивать / зна-
чение /+1 только после того, как будет установлено, что это
новое значение допустимо с точки зрения c(/)>c(i). Проана-
лизируйте, почему их версия «определения /» может работать
неправильно. (Конец примечания 2.)
Примечание 3. Однажды мне пришлось выполнять непри-
ятную обязанность и экзаменовать студента, который, как мне
было известно, обладал весьма ограниченными изобретатель-
ными способностями. Так как он был знаком с описанной
выше программой, я попросил его написать программу, преоб-
разующую исходную последовательность, про которую изве-
стно, что она не. является первой в алфавитном порядке, в по-
следовательность, непосредственно предшествующую исходной
в алфавитном порядке. Я надеюсь, что время, которое вы
потратите на это упражнение, будет значительно меньше часа,
который потребовался моему студенту. (Конец примечания 3.)
Примечание 4. Эта программа мне особенно близка, пото-
му что я помню, как я бился над ней в мои студенческие годы,
в «каменном веке» программирования, когда программы пи-
сались в коде машины (даже без индекс-регистров: в добрых
старых традициях фон Неймана программы должны были
изменять свои собственные команды, хранящиеся в памяти
машины!). И я помню тадрке, что после тщетной борьбы, про-
должавшейся более двух часов, я сдался! И это в то время,
когда я уже был опытным программистом! Несколько лет
назад,- когда мне понадобился пример для моей лекции, я
вдруг вспомнил эту старую задачу и решил ее без всяких за-
труднений (и мог даже объяснить ее на следующее утро до-
вольно неопытной аудитории за двадцать минут). То обстоя-
тельство, что теперь можно за двадцать минут объяснить
неопытной аудитории решение задачи, которое двадцать лет
назад не мог найти опытный программист, свидетельствуем о
поразительных успехах искусства программирования (до та-
кой степени, что теперь даже трудно поверить, что тогда я не
мог решить эту задачу!). (Конец примечания 4.)
Примечание 5. Эквивалентом нашего критерия для i («мак-
симальное значение i (<п), такое, что c(i)<c(i+l)») явля-
ется критерий «максимальное значение i(<n), такое, что
(Е j : i<jt^.n : Однако последний критерий более
труден для применения, и тот, кто начнет с него, придет к
первому критерию (тем или иным путем). (Конец примеча-
ния 5.)
14 ЗАДАЧА О ГОЛЛАНДСКОМ НАЦИОНАЛЬНОМ
ФЛАГЕ
Имеется ряд сосудов, перенумерованных от 1 до N. Зада-
ны два условия Pl и Р2.
Р\: в каждом сосуде лежит один камень.
Р2: каждый камень либо красный, либо белый, либо си-
ний.
Перед сосудами расположена мини-машина, которую нуж-
но запрограммировать таким образом, чтобы она переложила
(если нужно) камни в порядке цветов голландского нацио-
нального флага, т. е. в сосудах в порядке возрастания их но-
меров должны располагаться сначала красные камни, затем
белые и, наконец, синие. Чтобы иметь возможность выполнить
эту программу, мини-машина должна быть снабжена одной
командой вывода, которая может воздействовать на располо-
жение камней, а именно
«сосуд: поменять (z, у)» для 1 i С N и 1
для l=j: камни остаются на прежних местах,
для i^j- две управляемые мини-машиной «руки» выни-
мают камни из сосудов с номерами z и j со-
ответственно и затем меняют их местами. (Эта
операция сохраняет отношения Р1 и Р2 инва-
риантными.)
и одной командой ввода, которая может проверять цвет кам-
ня, а именно
«сосуд (/)» для 1 С z 7V:
когда программа задает вычисление этой функции
типа «цвет», подвижный «глаз» направляется на
сосуд с номером z и передает мини-машине в ка-
честве значения функции цвет (т. е. красный, бе-
лый или синий) камня, лежащего в сосуде, содер-
жимое которого только что проверял «глаз».
Константа N — это глобальная константа из того контекс-
та, в который наша программа должна входить как внутрен-
152 Глава 14
ний блок. Наша программа, однако, должна отвечать трем
специальным требованиям:
1. Она должна уметь справляться со всеми возможными
формами «вырождения», т. е. отсутствия какого-то цвета: со-
суды могут быть наполнены камнями только двух цветов, или
только одного цвета, или вообще никакого цвета (если N — Q).
2. Мини-машина обладает очень малой памятью по срав-
нению с теми значениями N, с которыми она должна уметь
справляться, поэтому мы не разрешаем вводить какие бы то
ни было массивы, а только фиксированное число переменных
целого типа и/или переменных типа «цвет». (Под переменными
целого типа мы здесь будем понимать переменные, которые не
могут принимать много больше, чем jV различных значений.)
3^ Программа может направлять «глаз» на каждый камень
не более одного раза (предполагается, что на операцию ввода
затрачивается столько времени, что смотреть дважды на один
и тот же камень означает вызвать недопустимую трату вре-
мени).
Кроме того, среди программ одинаковой степени сложности
предпочтительней та, при выполнении которой происходит (в
среднем) меньше перекладываний камней.
Хотя все наши камни могут быть только трех различных
цветов, тот факт, что наш «глаз» может проверять только один
камень за один «взгляд», в сочетании с требованием (3) при-
водит к тому, что в процессе переупорядочивания камней мы
должны различать камни четырех различных категорий, а
именно: «оказавшийся красным» (ОК), «оказавшийся белым»
(ОБ), «оказавшийся синим» (ОС) и «еще не проверенный»
(X)..Требование (2) исключает возможность того, что камни,
относящиеся к этим различным категориям, могут лежать
вперемежку: мы не можем хранить в памяти мини-машины
информацию о том, «что есть что». Единственный выход —
разделить все сосуды на фиксированное число (может быть,
пустых) зон, состоящих из последовательно перенумерован-
ных сосудов, причем каждая зона отводится для камней опре-
деленной категории. Поскольку таких зон может быть мини-
мум четыре, попробуем для начала ввести ровно четыре зоны.
Но в каком порядке? Я обнаружил, что многие программисты
склонны, не особенно задумываясь, принять порядок «ОК»,
«ОБ», «ОС», «X», хотя такое решение явно опрометчиво. Как
только кому-нибудь покажется привлекательным расположить
зону «ОК» в нижнем конце, соображения симметрии сделают
таким же привлекательным расположение зоны «ОС» в верх-
нем конце. Придерживаясь нашего прежнего решения ввести
ровно четыре зоны, мы, таким образом, приходим к заключе-
Задача о голландском национальном флаге 153
нию, что зоны «ОБ» и «X» должны находиться в середине в
том или ином порядке (убедитесь, что в этом случае порядок
несуществен!), например,
«ОК», «X», «ОБ», «ОС»
Раз мы выбрали описанную выше «общую ситуацию», на-
ша задача в сущности решена, так как мы имеем общую си-
туацию, для которой как начальное состояние (все сосуды в
зоне «X»), так и конечное состояние (зона «X» пуста) являют-
ся особыми случаями! Мы можем принять эти условия, и тог-
да конструкция повторения должна уменьшать размер зоны
«X», сохраняя при этом общую ситуацию. В нашей мини-ма-
шине нам понадобятся три переменные целого типа, например
«к», «б» и «с», по которым можно будет следить за границами
зон:
1 1<^к: j-й сосуд находится в зоне «ОК» (число сосудов
«-1 >0)
б-. i-й сосуд находится в зоне «X» (число сосудов
б-«+1>0)
6<Zi-<c: i-й сосуд находится в зоне «ОБ» (число сосудов
с-б>0)
i-й' сосуд находится в зоне «ОС» (число сосудов
7V-c>0)
Обеспечить истинность отношения Р, которое должно со-
храняться инвариантным, значит придать трем этим перемен-
ным такие начальные 'значения, чтобы «все сосуды были в
зоне «Х>> », и наша программа могла бы иметь следующую
структуру:
begin glovar сосуд; glocon TV; privar к, б, с;
к vir цел, б vir цел, с vir цел: =1, N, N;
[Р стало истинным)
do б> к -> «уменьшить число сосудов в
зоне «X» при инвариантности /5»
od
end
Сразу же возникает вопрос: на сколько охраняемый опера-
тор должен уменьшать число сосудов в зоне «X»? Есть три
довода — и, как заметит читатель, довольно общего характе-
154 Глава 14
pa — в защиту того, чтобы сначала проверить возможность
«уменьшить число сосудов в зоне «X» на 1». Эти доводы та-
ковы:
1. Уменьшения на 1 достаточно.
2. Так как мы выбрали в качестве предохранителя условие
«б^к», мы можем гарантировать, что в зоне «X» находится
по крайней мере один сосуд. Чтобы гарантировать наличие
двух сосудов, нам понадобился бы предохранитель «б>к».
3. Проверка одного камня даст нам три различных резуль-
тата, проверяя два камня, мы получим уже девять различных
случаев; такое размножение числа подлежащих рассмотрению
случаев следует расценивать в принципе как высокую плату
за тот выигрыш, который мы можем получить, уменьшая зону
«X» больше чем на 1.
Следующий вопрос: на какой из еще не проверенных кам-
ней мы будем смотреть? Вопрос не такой уж праздный, по-
скольку за это время в расположений зон «ОК», «X», «ОБ»,
«ОС» возникла асимметрия. Ни один опытный программист
не станет проверять произвольный камень, а обратится к кам-
ням в нижнем или верхнем концах. При том, что все три цвета
равновероятны, проверяя камень в к-м сосуде, мы получим
число перекладываний, равное (0 4- 1 + 2)/3 = 1, проверяя же
камень в б-м сосуде,- мы получим только (1 + 0 + 1)/3 = 2/3,
что и определяет наш выбор. Таким образом, мы приходим к
следующей программе:
begin glovar сосуд-, glocon privar к, б, с;
к vir цел, б vir цел, с vir цел: =1, TV, TV;
do б^к-*-
begin glovar сосуд, к, б, с-, pricon цв-,
цв vir цвет := сосуд (б);
if цв=красный—* сосуд: поменять (к, б)-, «:=«4-1
[] цв=белый-+б-.= б— 1
[] цв—синий —»сосуд: поменять (б, с); б, с : — 6—1,
с— 1
fi
end
od
end
Замечание. Программа разумна в том смысле, что она при-
ведет к отказу, если ей придется работать с неправильными
данными, например если один из камней окажется зеленым.
(Конец замечания.)
Задача о голландском национальном флаге 155
В том случае, когда все камни красные и не требуется
никаких перекладываний, наша программа потребует выпол-
нения N перекладываний, и, как сознательные программисты,
мы должны провести исследования, чтобы понять, насколько
'более сложным окажется более утонченное решение: может
быть, отклонив его раньше, мы проявили трусость. (В качест-
ве общего подхода я бы рекомендовал не браться за более
утонченное решение, пока не испробовано более простое; та-
кой подход позволяет нам получить не только работающую
программу, но и довольно недорогое указание того, с чем
должна конкурировать такая утонченная программа.) Я всег-
да считал приведенное выше решение абсолютно удовлетвори-
тельным и до сих пор никогда не рассматривал более слож-
ного решения. Возьмемся же за него теперь!
Можно расширить проверку одного камня до «проверки
одного или двух» или до «проверки стольких камней, сколько
нам будет удобно расположить». Для случая «все камни крас-
ные» последний вариант оказывается в чем-то предпочтитель-
нее, Прежде чем проверять непроверенный камень в верхнем
конце, мы могли бы попытаться передвинуть границу, задан-
ную к, насколько возможно ближе к верхнему концу, не
перекладывая при этом камни, потому что было бы обидно
заменять один красный камень, находящийся в совершенно
правильной позиции, другим красным камнем. Внешняя конст-
рукция повторения могла бы тогда иметь следующее начало:
do б^к-+
begin glovar сосуд, к, б, с\ privar цвк\
цвк vir цвет : = сосуд (к);
do цвк=красны,й and б —*к '.=к-\-1; цвк : = сосуд (/с) od;
Внутренняя конструкция повторения прекращает работу
либо если проверены все камни (к = б), либо если мы наткну-
лись на некрасный камень. Случай к = б, где цвк может иметь
одно из трех различных значений, сводится к конструкции вы-
бора предыдущей программы, правда, благодаря тому, что
оператор «сосуд: поменять (к, б)» можно опустить, поскольку
к и б равны. Случай к<б означает, что цвк=£красный\ теперь
мы просто должны, проверить другой камень, иначе наше ре-
шение сведется к тому решению, при котором всегда проверя-
ется камень в нижнем конце зоны «X», а мы знаем, что такое
решение дает в среднем больше перекладываний, чем наш
первый вариант. Поскольку к<б, другой непроверенный ка-
мень действительно есть, и первым кандидатом на проверку
является, очевидно, камень в б*м сосуде.
И снова при цвк = белый кажется обидным менять местами
камень в я-м сосуде и белый камень в б-м сосуде, поэтому для
156 Глава 14
случая к<б предпочтительнее ввести новый внутренний блок
begin glovar сосуд, к, б, с; glocon цвк; privar цвб;
цвб vir цвет: —сосуд (б)-,
do цвб = белый and б^>к-{-1 —*б:=б— 1; цвб:= сосуд (б)
od;
Теперь мы имеем два возможных значения для цвк — бе-
лый или синий, три возможных значения для цвб — красный,
белый или синий и набор непроверенных камней, может быть,
пустой. На какое-то мгновение я испугался, что мне придется
разбирать 12 различных случаев! Но после длительного обду-
мывания (и после одного фальстарта) я понял, что сначала
надо поместить подлежащий сейчас проверке камень в б-й
сосуд и проследить за тем, чтобы во всех трех случаях камень,
первоначально находившийся в к-м сосуде, остался в (новом)
б-м сосуде. Тогда можно объединить три возможности и со-
ставить отдельную часть программы, выполняющую единооб-
разные действия над вторым камнем, цвет которого определя-
ется переменной цвк.
if цвб—красный—> сосуд: по ченять (к, б); /c:=k-|-1
цвб—белый —>б: = б— 1
Пцвб—синий —♦ сосуд : поменять (б, с); б, с: = б—\,
с — 1; сосуд: поменять (к, б)
fi;
if цвк=белый —>б:=б— 1
[] цвк=синий—> сосуд -.поменять (б, с); б, с: = б— 1,
с— 1
fi
Замечание 1. Мы получили приятный результат, состоящий
в том, что соединение двух конструкций выбора обеспечивает
работу программы для 2x3 комбинаций цветов! (Конец за-
мечания 1.)
Замечание 2. Убедитесь, что случай цвб=белый был разоб-
ран правильно, поскольку в этом случае первоначально
б = к+1. (Конец замечания 2.)
Примечание. Из педагогических соображений я немного
жалею, что случай «два проверенных камня лежат не в тех
сосудах» не оказался более сложным; может быть, я должен
был подавить искушение выполнить даже эту кропотливую
работу как можно лучше. (Конец примечания.)
Я предоставляю читателю довести до конца нашу вторую
программу, если ему еще не расхотелось (я надеюсь, что рас-
Задача о голландском национальном флаге 157
хотелось!); думаю, что мораль уже ясна. Я дбвел анализ воз-
можных случаев до этой стадии, чтобы стало ясно, что такого
анализа, известного также под названием «комбинаторный
взрыв», нужно всегда избегать, как чумы. Он удлиняет текст
программы и может легко привести к снижению эффективно-
сти! Такой анализ всегда ухудшает надежность программы,
потому что взваливает на плечи бедного программиста такую
тяжесть, которой тот обычно не выдерживает (не в последнюю
очередь из-за того, что работа становится очень нудной). Чи-
татель может рассматривать вышесказанное как намек руко-
водству на то, что не стоит оценивать труд программистов по
числу строк текста, которые они производят за месяц; я бы
скорее Заставил их оплачивать из своего кармана использован-
ные ими перфокарты.
Я часто разбирал эту задачу со студентами, располагая зо-
ны в порядке «ОК», «X», «ОБ», «ОС» или в порядке «ОК»,
«ОБ», «X», «ОС». Когда я спрашивал, какой камень нужно
проверять, они всегда предлагали «самый левый». У меня воз-
никла мысль, что такое предпочтение объясняется нашей при-
вычкой читать слева направо. Позже я столкнулся со студен-
тами, которые предложили начинать проверку с самого право-
го камня: один был специалистом по машинной математике
из Израиля, другой — сирийцем по происхождению. Есть
что-то пугающее в том, какими неисповедимыми путями наши
привычки влияют на наш способ мышления!
На этом я заканчиваю рассмотрение задачи о голландском
национальном флаге,— задачи, которой я обязан Фейену.
15 ОБНОВЛЕНИЕ ПОСЛЕДОВАТЕЛЬНОГО ФАрЛА
Когда появились охраняемые команды и о них заговорили,
один студент, занимавшийся главным образом решением ком-
мерческих задач на машине, выразил сомнение, имеет ли наш
подход какое-то значение вне (как он выразился) области на-
учных или технических прикладных задач. В подтверждение
своих сомнений он ссылался на задачу, которую считал типич-
ной коммерческой прикладной задачей, а именно на обновле-
нце последовательного файла. (Более точная формулировка
задачи будет приведена нйже.) Он показал нам блок-схему
программы, предназначавшейся для решения этой задачи, но
стрелки, которые вели от одного квадратика к другому, были
так беспорядочно расположены, что мы оба решили не рас-
сматривать это решение (если оно было решением, что мы так
и не смогли выяснить!). С некоторой гордостью он показал
нам таблицу решений — его таблицу, — которая, как он
считал, могла решить задачу, но размер этой таблицы
ужаснул нас. Однако, поскольку нам была брошена перчатка,
нам не оставалось ничего другого, как поднять ее. Наши пер-
вые два варианта, хотя и более аккуратные чем то, что мы ви-
дели, все же не удовлетворили Фейена, чье решение я приведу
в этой главе. Оказалось, что наши первые попытки были отно-
сительно безуспешными, потому что задача была представле-
на таким образом, что мы поверили, будто этот крепкий оре-
шек будет трудно расколоть. Но это совсем не так. Я включил
задачу об обновлении файла в настоящую книгу по трем при-
чинам. Во-первых, это дает мне возможность опубликовать
изящное решение, полученное Фейеном для задачи общего ти-
па, увешенной гроздьями весьма неаккуратных решений. Во-
вторых, потому что решение было найдено благодаря тем же
методам, которые привели к элегантному решению задачи о
голландском национальном флаге. Наконец, эта задача поз-
Обновление последовательного файла 159
воляет нам рассеять некоторые сомнения, вызванные тем, что
коммерческие программы являются чем-то особенным. (Если
уж говорить о чем-то особом, то, скорее, о характере коммер-
ческих программистов... )
Имеется файл, т. е. упорядоченная последовательность за-
писей, или, более точно, значений типа «запись». Если х —
переменная (ее значение) типа запись, тогда определены бу-
лева функция х.норм и целая функция х.ключ, такие, что для
некоторой константы инф
х.норм =$[х.ключ<^инф)
(поп X ,НОрм)=$>(х .КЛЮЧ = цнф)
Данный файл записей называется «старфайл», и записи в
нем располагаются в порядке монотонного возрастания зна-
чений их «ключей»', только для последней записи старого фай-
ла «х.норм» есть ложь.
Имеется, кроме того, еще один файл, называемый «измен-
файл» и представляющий собой упорядоченную последова-
тельность изменений, или более точно, значений типа «измене-
ние». Если у — переменная (ее значение) типа изменение,
определены булева функция у.норм и целая функция у.ключ,
такие, что для той же константы инф
у.норм =$(у.ключ<инф)
(поп у. норм) ==> (у. ключ = инф)
Изменения в файле располагаются в порядке монотонного
неубывания значений их «ключей», только последнее измене-
ние не является нормальным, и для него у.ключ = инф. Если
у.норм есть истина, определены еще три булевы функции, а
именно «у.обн», «у.искл» и «у.вкл», причем эти функции тако-
вы, что всегда в точности одна из них есть истина.
Далее, для переменной х типа запись и переменной у типа
изменение, такой, что у.норм есть истина, определены три опе-
рации, изменяющие х:
х: обновить (у) определена только в случае истинности
х.норм and у .обн and (х.ключ—у *ключ);
по завершении операции сохраняется истин-
ность х.норм ana (х.ключ—у .ключ)
х : исключить (у) определена только в случае истинности
• х.норм and у.искл and (х.ключ—
=у .ключ)', по завершении операции
х.норм=ложъ
160 Г лава 15
х : включить (у) определена только в случае истинности
поп х.норм and у.вкл-, по завершении
операции становится истинным х.норм and
(х. ключ—у. ключ)
Для переменной х типа запись имеется дополнительная опе-
рация «х: анорм», в результате которой х.норм=ложь.
Программа должна сгенерировать файл записей, называ-
емый «новфайл», окончательное значение которого зависит от
начального значения исходных файлов «старфайл» и «измен-
файл» следующим образом. Мы можем объединить записи
старого файла и изменения файла изменений, располагая их
в порядке неубывания ключей таким образом, что если данное
значение ключа встречается и в старом файле (один раз!), и
в файле изменений (может быть, больше одного раза), то в
объединенной последовательности запись с этим ключом пред-
шествует изменению (изменениям) с тем же ключом. В процес-
се объединения не должен нарушаться внутренний порядок сле-
дования изменений с одним и тем же ключом. Объединенная
последовательность подвергается описанному ниже преобра-
зованию до тех пор, пока в ней не останется ни одного измене-
ния; оставшаяся последовательность, состоящая только из за-
писей, и есть окончательное значение нового файла. Преобра-
зование выполняется следующим образом:
Пусть у — первое изменение в объединенной последователь-
ности и х — непосредственно предшествующая ему запись (ес-
ли она есть), тогда
если функция у.обн истинна и имеется предшествующая
у запись х, такая, что х.ключ=у.ключ, то запись модифициру-
ется при помощи операции х: обновить (у) и у удаляется из
последовательности;
если функция у.искл истинна и имеется предшествующая
у запись х, такая, что х.ключ=у.ключ, то и х, и у удаляются
из последовательности;
если функция у.вкл истинна и нет предшествующей у запи-
си х, такой, что х.ключ = у.ключ, то у заменяется записью, оп-
ределенной операцией включения записи;
если поп у.норм есть истина, изменение у удаляется US'
последовательности;
если первое изменение не удовлетворяет ни одному из пе-
речисленных четырех критериев, оно удаляется из последова-
тельности по операции «сообщение об ошибке», которую мы не
будем здесь описывать более подробно.
Представим модель программы в виде внутреннего блока,
оперирующего с тремя глобальными массивами:
Обновление последовательного файла 161
запись array старфайл, к которому можно обращаться
только по операции «никоя» и
который в конце концов стано-
вится пустым (т. е. старфайл.
обл = 0)
изменение array изменфайл, к которому можно обращаться
только по операции «никоя» и
который в конце концов стано-
вится пустым (т. е. изменфайл.
обл = 0)
запись array новфайл, к которому можно обращаться
только по операции «вверх» и
который первоначально пуст
(т. е. новфайл. обл = 0)
Мы видим, что задача усложняется, если объединенная по-
следовательность содержит последовательность изменений с
одинаковыми ключами и характеризующие изменения функ-
ции со значением «истина» следуют друг за другом, например,
в таком порядке:
вкл, вкл, обн, искл, искл, обн, вкл, обн, искл
В этом случае второе «вкл», второе «искл» и второе «обн»
приведут к сообщению об ошибке и вся последовательность
ничего не дает для получения окончательного значения нового
файла; за такой последовательностью может следовать и мо-
жет не следовать нормальная запись.
Поскольку длины файлов неизвестны, наша программа бу-
дет состоять из вступительной части, одной или нескольких
конструкций повторения и, может быть, части (не повторя-
емой), которая завершает новый файл записью, не являющей-
ся нормальной. В общем случае сгенерировать новую запись
для нового файла можно только при условии, что мы уже
«просмотрели» запись со следующим по порядку ключом из
старого файла и изменение со следующим по порядку ключом
из файла изменений. (Подумайте о возможности извлечения
следующей записи только из файла изменений.) В связи с
этим мы вводим переменную х типа «запись» и переменную у
типа «изменение», значением которых будут соответственно
запись и изменение с этими следующими по порядку ключа-
ми; после создания записи для нового файла «запись х и сле-
дующие за ней оставшиеся записи старого файла» означают
еще необработанные записи, а «изменение у и следующие за
ним оставшиеся изменения файла изменений» означают еще
необработанные изменения. Мы пользуемся этим, когда к но-
вому файлу добавляется новая нормальная запись; послед-
6-6
162 Глава 15
нюю, не являющуюся нормальной запись добавит к файлу за-
ключительная часть программы. Поскольку неизвестно, сколь-
ко будет сгенерировано новых записей, пока не исчерпается
один из исходных файлов, предлагается такая общая струк-
тура нашей программы:
begin glovar старфайл, изменфайл, новфайл-, privar х, у,
х vir запись, старфайл: никои-,
у vr изменение, изменфайл : никои-,
do х.норм or у. норм—>
«обработать по крайней мере одну запись или
одно изменение, такие, чтобы их обработка обес-
печивала продвижение в создании нового файла»
od;
«добавить к новому файлу запись, не являю-
щуюся нормальной»
end
При составлении конструкций повторения решающее зна-
чение имеет синхронизация прогресса в вычислениях с про-
движением по циклу, т. е. определение того, какой объем ра-
боты будет выполнен каждым списком охраняемых операто-
ров, выбираемым для исполнения. Если мы в этом примере
будем определять конец цикла по концу старого файла или
файла изменений, могут возникнуть неприятности, так как
один из файлов может уже быть исчерпанным; аналогичные
неприятности возникают и в том случае, когда мы считаем
концом цикла завершение генерации записей для нового файла,
потому что, хотя ни один из исходных файлов не исчерпан, мы
могли уже сгенерировать последнюю нормальную запись для
нового файла. Эта проблема должна решаться тем же спосо-
бом, как и для задачи о голландском национальном флаге,
когда нужно было определить, сколько камней подлежит про-
верке: охраняемый оператор будет выполнять в точности такой
объем работы — не больше и не меньше, — сколько нужно и
можно сделать, когда предохранитель имеет значение «исти-
на».
Если наш предохранитель х.норм or у.норм есть истина, мы
можем сделать единственное заключение, а именно что необ-»
работанные части исходных файлов содержат запись и (или)
изменения по крайней мере для одного значения ключа, тако-
го, что ключ<инф: следовательно, список охраняемых опера-
торов будет осуществлять обработку всех записей и (или) из-
менений с этим значением ключа!
Первый оператор — конструкция выбора — определяет это
значение ключа и присваивает его локальной константе «те-
ключ» (сокращение от «текущий ключ»). Кроме того, он ини-
Обновление последовательного файла 163
диализирует переменную «хх» типа запись; значение именно
этой переменной будет выбираться в качестве новой записи,
если потребуется сформировать такую запись. Если текущий
ключ извлекается из старого файла, обрабатывается единст-
венная запись с этим ключом, в противном случае старый
файл останется нетронутым.
Второй оператор — конструкция повторения — обрабаты-
вает все изменения с этим значением ключа; поскольку обра-
ботка изменений целиком выполняется этой конструкцией пов-
торения, в ней учтены различия между'разнообразными вида-
ми изменений.
Третий оператор — конструкция выбора — может добавлять
црвую запись к новому файлу.
begin glovar старфайл, изменфайл, новфайл*, privar х, у;
х vir запись, старфайл : никои*,
у vir изменение, изменфайл : никои*,
do х.норм or у.норм—>
begin glovar старфайл, изменфайл, новфайл, х, у;
pricon теключ; privar хх;
if х.ключ<у.каюч—> теключ vir цел: — х.ключ;
хх vir запись ; — х; х, старфайл-.никои* .
Q х.ключ>у.ключ —>теключ vir цел -.— у.ключ;
хх vir запись: анорм
fi [теключ <^инф and теключ <х. ключ and
теключ < у. ключ};
do у .ключ=теключ [у .ключ<^инф, т. е. у .норм]
if у.обн and хх.норм —: обновить (у)
Q у.искл and хх.норм—>хх: исключить (у)
О у. вкл and non хх.норм—► хх : включить {у)
О у.вкл—хх.норм—* сообщение об ошибке
fi; у, изменфайл *.никон
od [теключ <^х.ключ and теключ < у .ключ];
if хх.норм—► новфайл-. вверх (хх) [] поп хх.норм—*
пропустить
fi
end
od; новфайл; вверх (х) {новый файл замыкается не являю-
щейся нормальной записью}
end
Примечание 1. Избранный нами способ представления этой
задачи предусматривал в качестве одного из возможных зна-
чений переменной х типа запись такое значение, при котором
х.норм=ложь; при постановке задачи это значение использо-
валось в качестве маркера конца старого файла. Благодаря
6*
164 Глава 15
такому соглашению оказалось возможным ограничить обра-
щение к старому файлу операцией «никои»; если бы, однако,
нам была доступна также функция «старфайл. обл», такое ис-
пользование в качестве маркера конца файла записи, не явля-
ющейся нормальной, стало бы ненужным и вся задача могла
бы формулироваться в терминах переменных типа «нормаль-
ная запись». Тогда, чтобы составить такую программу, нам
понадобились бы языковые средства, позволяющие ввести тип
«запись» в том смысле, в каком он используется в нашем ре-
шении. Языки программирования, лишенные таких средств, вы-
нуждают своих пользователей удовлетворять эту потребность,
вводя, например, пару переменных, скажем переменную хх
типа «нормальная запись» и булеву переменную «ххнорм», и
затем в явном виде употреблять в программе эти переменные;
тогда ххнорм указывает, является ли значение хх осмыслен-
ным. Но такой «условный смысл» несовместим с нашей идеей
явного присвоения переменным осмысленных начальных зна-
чений. В случае х.ключ^у.ключ как хх, так и ххнорм могут
получить осмысленные начальные значения, в случае же
х.ключ>у.ключ, действительно имеет смысл только
ххнорм. vir бул'-= ложь
Но тогда наши соглашения заставляют нас присвоить пере-
менной хх в качестве начального значения некоторое пустое
значение. Предположив, что переменная типа запись может
иметь и значение, не являющееся нормальным, мы обошли эту
проблему, отсрочив тем самым дискуссию о языковых средст-
вах, необходимых для введения новых типов. (Конец примеча-
ния 1.)
16 ЕЩЕ РАЗ О ЗАДАЧАХ СЛИЯНИЯ
В двух предыдущих главах мы вели рассуждения в стиле,
несколько отличном от наших более ранних формальных рас-
суждений, когда мы получали предохранители, как только бы-
ли выбраны инвариантное отношение и изменяющаяся функ-
ция (для конструкции повторения) или постусловие (для кон-
струкции выбора) и список охраняемых операторов. Однако,
решая задачу о голландском национальном флаге и задачу об-
новления файла, мы начинали с рассуждения о конструкции
повторения с предохранителем и далее обсуждали, каким мо-
жет быть охраняемый оператор, т. е. придерживались более
классического подхода. Что касается программы обновления
файла, могу себе представить, что некоторые мои читатели,
изучив более ранние главы, стали настолько подозрительными,
что они удивляются, как это я осмеливаюсь верить в правиль-
ность программы, приведенной в последней главе; против всех
правил я даже не упомянул об инвариантном отношении! На-
стоящая глава призвана восполнить эти пробелы, и это одна
из причин ее включения в книгу; одновременно она пре-
доставит нам возможность решать более широкий класс за-
дач в более абстрактной форме.
Пусть х, у и z есть некоторые наборы (не теряя общности,
мы можем ограничиться наборами целых чисел — их вполне
достаточно!). Напомним, что из определения понятия «набор»
следует, что все его элементы отличны друг от друга; в этом
отношении «набор целых чисел» отличается от «совокупности
чисел, которая может содержать одинаковые числа». Два на-
бора равны (x = z/) тогда и только тогда, когда каждый эле-
мент одного набора входит в другой набор, и наоборот.
Обозначим объединение двух наборов символом « + », т. е.,
если z=x+f/, это значит, что набор z содержит некоторый
элемент тогда и только тогда, когда этот элемент входит либо
в набор х, либо в набор у, либо в оба набора.
Обозначим пересечение двух наборов символом « * », т. е.,
если z=x* у, это значит, что набор z содержит некоторый эле-
166 Глава 16
мент тогда и только тогда, когда этот элемент входит и в на-
бор х, и в набор у.
Обозначим пустой набор символом «0», т. е. z=0 тогда и
только тогда, когда z вообще не содержит элементов.
Рассмотрим теперь задачу вычисления для фиксированных
наборов X и У значения Z, такого, что
z=^+r
(В ходе обсуждения X и У, а следовательно, и Z рассматрива-
ются как константы: Z есть искомое окончательное значение
некоторой переменной, которая будет введена позже.) Наша
программа должна выполнить эту задачу, производя поэле-
ментно действия над наборами — проверку, изменение и т. д.
Прежде чем приступить к более детальному продумыванию
алгоритма, мы должны осознать, что в какой-то момент вы-
числительного процесса некоторые элементы Z уже будут най-
дены, а некоторые нет, т. е. существует разделение набора Z
на два поднабора zl и z2:
Z=zl + z2
Здесь символ «+» используется для сокращенной записи
Z=zl-\-z2 and zl*z2==0
(Мы можем рассматривать zl как набор элементов, чья при-
надлежность к Z уже установлена, и z2 — как набор остальных
элементов Z.)
Аналогично в некоторый момент вычислительного процес-
са наборы X и У могут быть представлены в виде
X=х1 + х2 и Y = y\ + у2
(Здесь мы можем рассматривать наборы xl и у\ как те эле-
менты X и У соответственно, которые больше не нужно при-
нимать во внимание, поскольку они уже были успешно обра-
ботаны.)
Такая интерпретация смысла разделения Z, X и У будет
интересовать нас позже, а сейчас мы сначала докажем, со-
вершенно независимо о^ того, что может произойти во время
выполнения нашей программы, теорему о таких разделениях.
Теорема
Если Z=X4-y (1)
Z=xl + х2 (2)
У=у1 +У2 (3)
zl=xl-i-yl (4)
z2=x2-\-y2 (5)
то Z=zl z2^=> (xl * y2 =0 and y\ *x2=0) (6)
Еще раз о задачах слияния 167
Доказательство. Чтобы показать, что правая часть (6)
следует из его левой части, воспользуемся тем, что
Z=zl + z2=^zl * z2= 0
Подставляя (4) и (5), получаем
(xl+yl)*{x2+y2)=
(xl *x2)-}-(xl *y2)-{-{yl *x2)-|-(t/l *t/2) = 0
откуда следует правая часть (6). Чтобы показать, что левая
часть (6) следует из его правой части, мы должны показать,
что из нее следует
zl*z2=0 and Z=zl-{-z2
z\ * z2 — {x\-\-y\)*{x2-\-y2)
= (xl * x2)-j-(xl * y2)-\-{y\ *x2) + (z/l * y2)
=0+0+0+0=0
z 14- z2=(x 1 + у 1) + (x2 4- у 2)
=x\-\-x2-±y\-\-y2
=X -\-Y=Z {Конец доказательства.)
Если имеют место отношения с (1) по (5), то правая часть
(6) и, следовательно, равенство
Z = z\ + z2
вытекают также из того, что
zl*x2=0 and z\* у2=0 (7)
и из отношений с (1) по (5) и (7) следует, что, если было
выбрано разделение Z, два других разделения однозначно
определены.
Вооруженные этими знаниями, мы возвращаемся к исход-
ной задаче, где наша программа должна обеспечить истин-
ность
/?: z=Z
Используя тот же подход, что и в предыдущих задачах,
введем две переменные х и у и попробуем взять в качестве
инвариантного отношения
Р: z-\-{x-\-y)=Z
которое обладает тем приятным свойством, что его истинность
тривиально обеспечивается при помощи
РО: г=0 and х=Х and y=Y
168 Глава 16
и в то же время при (х+у) =0 из него следует истинность R.
Наша теорема предлагает нам отождествить х с х2, у с у2
и z с zl (такая асимметрия вызвана тем, что X и У — извест-
ные наборы, a Z предстоит вычислить). После такого отожде-
ствления отношения с (2) по (5) определяют все наборы в
терминах х и у. Если мы теперь будем синхронно сокращать
х и у таким образом, чтобы неизменно сохранялась истинность
правой части (6) или
z*x=0 and z*y=0 (7')
то, как мы знаем,
Z=X -\-Y = z\ + z2
Так как z\+z2 есть разделение постоянного набора Z, то
добавление элемента е к z ( = zl) означает удаление этого
элемента е из х+у (=z2). Чтобы такой элемент существовал,
объединение не должно быть пустым, т. е. (х+у) =#0 или, что
то же, «х^0 or у=#0»; элемент е может принадлежать х, но
не принадлежать у, или он принадлежит у, но не принадле-
жит х, или принадлежит и х, и у и должен уда-
ляться соответственно либо из х, либо из у, либо и из х, и из у.
Структура программы представляется в следующем виде:
х, у, z\ — X, Y, 0;
dox+0 or у += 0 —»«перевести элемент из (х+у) в z» od
Предположим теперь, что элементы набора х представля-
ются значениями ах(1) при ах.ниг^а<ах.вег и элементы на-
бора у представляются значениями ау(1) при ау.ниг^Кау.вег,
где ах и ау — это монотонно возрастающие целые функции, и
ах.верх—ау.верх—инф. Использование дополнительной пере-
менной инф дает нам то преимущество,, что, даже если х или у
пусты, все равно определены ах.низ и ау.низ. Преимущество
от монотонного возрастания значений ах и ау состоит в том,
что для непустого набора х значение ах.низ равно минималь-
ному элементу х, и то же для у. В результате, если не оба на-
бора пусты, существует один элемент из их объединения, для
которого очень легко определить, принадлежит ли он х, у или»
обоим наборам, а именно
min(ах.низ, ау.низ)
Если, например, ах.низ< ау.низ, этот элемент равен ах.низ
и входит в х, но не может входить в у, так как все элементы
набора у больше, чем этот элемент; его удаление из набора х
осуществляется при помощи операции ах: снизу, при этом ос-
Еще раз о задачах слияния 169
давшиеся элементы набора х по-прежнему представляются
монотонно возрастающей функцией.
Если представление элементов набора z должно отвечать
тому же соглашению, мы выбираем для их представления зна-
чения az(i) прй аг.ниг^л^аг.вег; тогда последнее значение
инф можно добавить только в конце вычислений. Полученная
в результате функция az будет монотонно возрастающей, если
ее значение изменяется только при помощи операции
az:вверх {К) и при этом либо аг.обл=0, либо аг.обл>0 and
az.eepx<K. Наша программа будет удовлетворять этим огра-
ничениям.
Если ах и ау— это правильно инициализированные вектор-
ные переменные (т. е. ах.верх=ау.верх=инф) и az — вектор-
ная переменная с аг.обл = 0, то мы можем получить желаемое
преобразование при помощи следующих двух операторов:
do ах. низ #= инф or ау .низ=^инф—> {min {ах. низ, ау.низ) <
инф}
if ах.низ <^ау'низ —*az: вверх (ах. низ); ах'-снизу
□ ах.низ>ау .низ—az: вверх{(ау .низ); ау : снизу
[] ах. низ =ау .низ —»az; вверх (ах. низ); ах: снизу;
ау; снизу
fi {az.eepx<^tnin(ax.HU3, ау.низ)}
&1{аг.обл=0 cor (az.обл >0 and аг.верх<^инф)};
az -.вверх(инф)
Упражнения
1. Изменить эту программу таким образом, чтобы она обес-
печила также истинность u — U, где U=X* Y.
2. Составить аналогичную программу, которая обеспечит
истинность z—Z, где Z=W+X-}-Y.
3. Составить аналогичную программу, которая обеспечит
истинность z—Z, где Z.— W+ (X* Y).
4. Составить программу, обеспечивающую истинность
z=X+Y, но без предположения о наличии* (и без введения!)
значения «инф», отмечающего верхние концы областей опре-
деления; пустые наборы можно обнаруживать по ах.обл — 6 и
ау.обл = 0 соответственно. (Конец упражнений.)
Ценой еще большей формализации мы могли бы еще ус-
пешнее сыграть в нашу формальную игру.
Пусть для любого предиката P(z) семантика «г:=хц- у»
задается слабейшим предусловием
wp(«z:=x ц- у», P(z)) = (x*y—0 and Р(х-\-у))
170 Глава 16
где первый член означает, что пересечение хну должно быть
пустым, чтобы было определено х + у.
Пусть для любого предиката P(z) семантика «а: =х ^у»
задается слабейшим предусловием
wp(«z:=x~z/», P(z))=(x*у—у cand P(x~z/))
где первый член означает, что у должен целиком содержать-
ся в х, чтобы было определено х~у, и тогда х—у представ-
ляет собой единственное решение уравнения (хо~у) +у=х.
Исключая, xl, х2, yl, у2, zl и z2, мы получим следующие
отношения между х, у и z:
Pl: х *Х=х
Р2: у*у=у
РЗ: z=(X-x) + (K~i/)
Р4: x*(K~t/)=0
Р5: у*(Хс~х)—0
и мы можем задаться вопросом, при каких начальных услови-
ях выполнение операции
•S: z, х'- = z + {е},х^{е}
сохранит эти отношения инвариантными для некоторого эле-
мента е. Начнем с выяснения условий, при которых определе-
но это' одновременное присваивание, т. е.
wp(5, 7')=(z*{e) = 0 and х*{е} = {е))
Так как
(Pl and х*{е} = [е})’=^(Х~х)*{е] = 0
(Р2 and Р4 and х* [e} — [e})=$(Y’^y)* [е} = 0
Q=>wp(5, Т) при
Q=(P1 and Р2 and РЗ and Р4 and х*[е) = (е))
Теперь нетрудно установить следование
Q=^wp(S, Pl and Р2 and РЗ and Р4)
Однако
wp(<$, P5)=(wp(5, Г) and у * {£}))= 0)
= (wp(5, Т) and + (е})=0)
=(wp(5, Г) and Р5 and.y * (е] = 0)
Еще раз о задачах слияния 171
и, следовательно, предохранитель для S, обеспечивающий ин-
вариантность отношений с Pl по Р5, — это
х*{е) = (е) and у*{е} = 0
т. е. е должен быть элементом х, но не у, и т. д.
Вышесказанное завершает мою ревизию задач слияния. В
двух последних главах я проводил рассуждения с различной
степенью формальности, и какую из этих степеней предпочтет
мой читатель, зависит настолько же от его потребностей, на-
сколько и от его настроения. Но мне.казалось поучительным
проделать все это хоть один раз! (По всей вероятности, за-
метно, что при написании этой главы возникло гораздо боль-
ше трудностей, чем предполагалось заранее. Это по крайней
мере пятая версия, что само по себе служит достаточным ос-
нованием для ее включения в настоящую монографию.)
17 УПРАЖНЕНИЕ, ПРИПИСЫВАЕМОЕ Р. У. ХЭММИНГУ
Эта задача известна мне в такой формулировке: «Генери-
ровать в порядке возрастания последовательность 1, 2, 3, 4, 5,
6, 8, 9, 10, 12.состоящую из всех чисел, не делящихся ни
на какие простые числа, кроме 2, 3 и 5». Другое определение
того, какие значения являются элементами этой последова-
тельности, задается при помощи трех аксиом:
Аксиома 1. Значение 1 является элементом последователь-
ности.
Аксиома 2. Если х является элементом последовательности,
то 2* х, 3 и 5 * х также являются элементами
этой последовательности.
Аксиома 3. Последовательность не содержит других значе-
ний, кроме тех, которые принадлежат ей соглас-
но аксиомам 1 и 2.
(Предоставляем специалистам по теории чисел установить эк-
вивалентность двух этих определений.)
Мы включили это упражнение, потому что его структура
довольно типична для большого класса задач. Поскольку нас
интересуют только заканчивающиеся программы, будем со-
ставлять программу, генерирующую, скажем, лишь первые
1000 значений последовательности.
Пусть
P0(n, q) означает: значение «у» представляет упорядоченный
набор первых «п» значений последователь-
ности.
Тогда, согласно аксиоме 1, 1 входит в последовательность,
и так как 2*х, 3*хи5* х— это функции, чье значение боль-
ше х при х>0, то, согласно аксиоме 2, 1 есть минимальное из
всех значений, чья принадлежность к последовательности
может быть установлена на основании первых двух аксиом.
Согласно аксиоме 3, 1 есть минимальное значение, входящее
Упражнение, приписываемое Р. У. Хэммингу 173
в последовательность, и поэтому истинность P0(n, q) легко
обеспечивается для п=1: «<у» тогда содержит только значе-
ние 1. Очевидная структура программы такова:
«обеспечить истинность P0(n, q) для п=1»;
do п #= 1000 —►
«увеличить п на 1 при инвариантности P0(n, q)»
od
В предположении, что мы можем дополнить последова-
тельность значением «хслед», если это значение известно, ос-
новная проблема, возникающая при реализации операции
«увеличить п на 1 при инвариантности P0(n, q)», состоит в
том, как определить значение «хслед». Поскольку значение 1
уже принадлежит q, хслед>1 и принадлежность хслед после-
довательности должна обосновываться аксиомой 2. Назовем
максимальное значение, входящее в q, «q.eepx», тогда хслед —
это минимальное значение, большее q.eepx, которое можно
представить в виде 2 * х, 3* х и 5*х, где х — элемент после»
довательности. Но так как 2 * х, 3*х и 5* х — это функции,
чье значение больше х при х>0, то значение х должно удов-
летворять условию х<хслед; далее, х не может удовлетворять
условию x>q.eepx, так как мы тогда имели бы
q ,eepx<^x<i хслед
а это противоречит тому, что хслед есть минимальное значе-
ние, большее q.eepx, т. е. х должен уже входить в q. (Именно
ради проведенного анализа мы инициализировали Р0(«, <у)
для п=1; так же просто можно было сделать это для п = 0, но
тогда значение q.eepx не было бы определено.)
Если мы хотим получить простую реализацию описанного
выше анализа, мы можем ввести набор qq, состоящий из всех
значений хх> q.eepx, таких, что хх можно представить как
хх=2*х, где х— элемент q,
или как
хх=3*х, где х—элемент q,
или как
хх=5*х, где х—элемент q.
Набор qq не пуст, и хслед есть в этом случае минимальное
входящее в qq значение. Но при ближайшем рассмотрении та-
кой путь оказывается не очень привлекательным, так как кор-
ректировка qq могла бы привести (в терминах предыдущей
главы) к операции
qq .== {qqсх.\хслед\)-\-(2* хслед, 3*хслед, 5*хслед)
174 Глава 17
где «+» означает «образовать объединение двух наборов». Так
как мы должны определять минимальное значение, входя-
щее в qq, было бы хорошо, если бы элементы q были
упорядочены; но тогда образование объединения при такой
корректировке qq привело бы к значительной перетасовке
элементов, чего нам хотелось бы избежать.
Однако, поразмыслив немного, мы приходим к выводу, что
нам не нужно следить за всем набором qq, а можно выбрать
•в качестве хслед минимальное значение, входящее в гораздо
меньший набор
qqq—\х2\{хЗ\{х§\
где
х2 есть минимальное значение></.верх, такое, что
х2=2 * х и х входит в q, хЗ есть минимальное значение >q.eepx, такое, что
х3 = 3 * х и х входит в q, и х5 есть минимальное значение >q.eepx, х5=5 * х и х входит в q. такое, что
Этй отношения между q, х2, хЗ и х5 обозначаются как
P\(q, х2, хЗ, х5).
Поэтому очередной вариант нашей программы выглядит
так:
«обеспечить истинность P0(n, q) для п=1»;
do л^ЮОО->
«обеспечить истинность Pl (q, х2, хЗ, х5) для текущего
значения q»;
«увеличить п на 1 при инвариантности P0(n, q),.
т. е. добавить min, (х2, хЗ, х5) к q»
od
Такая программа была бы во всех отношениях правильной,
но теперь пришлось бы выполнять операцию «обеспечить ис-
тинность Pl (q, х2, хЗ, х5) для текущего значения q», опера-
цию весьма неприятную, даже если предположить, что мы име-
ем такой доступ к элементам упорядоченного набора q, какой
пожелаем. Справиться с этим можно' стандартным образом:
вместо того чтобы каждый раз, когда нам нужны х2, хЗ и х5,
заново вычислять их как функцию q, мы можем, понимая, что
значение q изменяется «медленно», пытаться «корректировать»
значения, являющиеся функцией q, только тогда, когда q из-
меняется. Этот прием настолько стандартен, что стоит дать
ему специальное название; назовем его «вынесением отноше-
ния *(из конструкции повторения)». Применение,этого приема
Упражнение, приписываемое Р. У. Хэммингу 175
отражено в следующей структуре программы:
«обеспечить истинность Р0(п, <?) для п = 1»;
«обеспечить истинность Pl (q, х2, хЗ, х5) для текущего значе-
ния q»',
do n=# 1000
«увеличить п на 1 при инвариантности P0(n, q), т. е.
добавить к q min (х2, хЗ, х5)»;
«восстановить истинность Pl (q, х2, хЗ, х5) для нового
значения q»
od
Теперь мы должны следить за тем, чтобы Pl (q, х2, хЗ, *5)
было истинным после расширения q, т. е. после добавления
q.eepx; в результате корректировка х2, хЗ и х5 есть либо пус-
тая операция, либо их увеличение, а именно замена соответст-
вующим кратным следующего значения х из q. Представляя
упорядоченный набор q в виде массива aq, т. е. в виде монотон-
но возрастающих значений а<?(1), aq(2), aq(n), мы вводим
три индекса i’2, i3 и /5 и расширяем Р1, добавляя к нему
...and x2=2*aq(i2) and х3=3*од(/3) and x3—5*aq{i3)
Тогда наш внутренний блок, придающий глобальной век-
торной переменной aq в качестве начального значения нужное
нам конечное значение, будет выглядеть следующим образом:
begin virvar aq', privar Z2, /3, Z5, x2, x3, x5;
'aq vir цел array :=(1, 1); (истинность P0 обеспечена}
12 vir цел, 13 vir цел, i5 vir цел:= 1, 1, 1:
x2 vir цел, хЗ vir цел, x5 vir цел-=2, 3, 5; (истин-
ность Pl обеспечена)
do aq-обл^ 1000—»
if x3 x2 < x5 —»aq: вверх (л2)
О л2 x3 < x5 —>aq-. вверх (x3)
U x2 x5 <x3 —»aq : вверх (x5)
fi {aq-обл увеличилась на 1 при инвариантности
Р0);
do x2<s^aq.eepx —>i2 :=Z2-|- 1; x2-—2*aq(i2'}o&,
do x3^aq.eepx—*i3 :=/3-j- 1; x3 - =3 *a^(/3)od;
do xS^aq.eepx —>15 :=/5-}-1; x5 :=5 *a^(i5)od
(вновь обеспечена истинность Pl)
od
end
В этой версии ясно выражено, что после того, как заново
обеспечена истинность Р1, мы имеем x2>aq.eepx and
x3>aq.eepx and x5>aq.eepx. Заметим, что мы могли бы с тем
же успехом использовать «... — aq.eepx>> вместо <c...^aq.eepx».
176 Глава 17
Замечание 1. В трех последних внутренних конструкциях
повторения каждый список охраняемых операторов будет вы-
бираться для выполнения самое большее один раз. Поэтому
мы могли бы представить их в таком виде:
if x2=aq .верх —*12: = Z2-|-l; х2 :=2*aq(i2)
О х2 > aq. ее рх —»п pony с тать
fi; и т. д.
Когда я начинаю думать о такой возможности, я прихожу
к выводу, что явно предпочитаю конструкции повторения, так
как не вижу ничего настолько особенного в том, что повторе-
ние может прекратиться после нуля шагов или одного шага,
чтобы ради этого стоило испрльзовать специальные синтакси-
ческие средства. Всякие колебания по поводу того, можно ли
считать «нуль или один раз» частным случаем «самое большое
k раз», вызываются, по-видимому, нашим языковым наследи-
ем, так как все западные языки делают различие между фор-
мами единственного и множественного числа. (Если бы мы
были классическими греками (т. е. мыслили бы также и кате-
гориями двойственного числа), мы, вероятно, чувствовали бы
себя обязанными ввести специальное дополнительное синтак-
сическое средство для выражения завершения конструкции
повторения после самое большее двух шагов!) В этом смысле
было бы, вероятно, «честнее» закончить главу «Обновление
последовательного файла» конструкцией
do хх .норм—* новфайл: вверх (хх); хх: анорм od
вместо
if хх.норм—*новфай.л'..вверх(хх) []поп хх.норм —
пропустить fi
так как при этом удовлетворяется условие завершения конст-
рукции, выраженное через хх.норм. (Конец замечания 1).
Замечание 2. Три последние внутренние конструкции пов-
торения можно было бы объединить в одну:
do x2-^aq.верх—*12 :=/2-(-1; x2*aq(i2)
□ x3-^.aq.верх—иЗ: = гЗ-(-1; x3*aq(i3)
Q х§ ^aq .верх—»i5 x5*aq(i5)
od
Однако я предпочитаю не делать этого и не объединять ох-
раняемые команды в один набор, когда выполнение одного
списка охраняемых команд не может повлиять на истинность
других предохранителей из этого набора. Тот факт, что при
этом три конструкции повторения, разделенные точкой с запя-
Упражнение, приписываемое Р. У. Хэммингу 177
той, предстают в порядке, выбранном произвольно, меня не
беспокоит: это обычная форма избыточной спецификации, с
которой мы всегда сталкиваемся в последовательных програм-
мах, описывающих последовательно’действия, которые могли
бы выполняться параллельно. (Конец замечания 2,)
Упражнение, разобранное в этой главе, является частным
случаем более общей задачи, а именно задачи о генерации
первых W значений последовательности, определенной следу-
ющими аксиомами:
Аксиома 1.
Аксиома 2.
Аксиома 3.
Значение 1 является элементом последователь-
ности.
Если х есть элемент последовательности, элемен-
тами последовательности являются также f(x),
g(x) и h(x), где /, g и h — монотонно возрастаю-
щие функции, такие, что f(x)>x, g(x)>x и
h(x)>x.
Последовательность не содержит других значе-
ний кроме тех, которые принадлежат ей согласно
аксиомам 1 и 2.
Заметим, что если бы о'функциях f, g и h не было ничего
известно, задача не могла бы быть решена!
Упражнения
1. Решить эту задачу, если аксиома 2 формулируется по-
дцугому:
Аксиома 2. Если х есть элемент последовательности, то
элементами последовательности являются
также f(x) и g(x), такие, что/(х)>х и
g(x)>x.
2. Решить задачу, если аксиома 2 формулируется так:
Аксиома 2. Если х и у принадлежат последовательности,
то ей принадлежит и f(x, у), где f обладает
свойствами:
1- f(x, у)>х
2. (yl>y2) =^f(x, yl)>f(x, у2)
(Конец упражнений.)
Пытливый читатель, который успешно справился с этими
упражнениями, может придумывать дальнейшие варианты сам.
18 ЗАДАЧА ПОИСКА ПО ОБРАЗЦУ
Задача, которая решается в этой главе, широко известна,
за ее решение принимались независимо многие программисты.
Однако мы надеемся, что наш подход доставит некоторое удо-
вольствие даже тем читателям, которые считают, что они до-
статочно хорошо знакомы с этой задачей и ее различными
решениями.
Даны две последовательности значений
д(0), р(1),..., р(ЛГ-1) при ЛГ>1
х(0), х(1),..., х(М— 1) при
(считается обычно, что М во много раз больше N).
Требуется определить, сколько раз «образец», заданный
первой последовательностью, входит во вторую последователь-
ность.
Используя форму
(Ni B(i))
для обозначения «числа различных значений I в интервале
0^i</n, для которых выполняется B(i)», мы получаем более
точное выражение конечного отношения В, истинность кото-
рого должна быть обеспечена нашей программой.
7?: счет = (N i :0 <;/ М — N: совпадение (/))
где функция совпадение (I) определяется следующим образом:
для —TV: совпадение(7) = (Ау :0<;у <N : p(j) =
для Z<0 or M — N‘.совпадение^) — ложь
(To что вне интервала —N мьг придаем функции
ложное значение, делая ее тем самым полностью определен-
ной, является вопросом удобства.)
Задача поиска по образцу 179
Если мы возьмем в качестве инвариантного отношения
Р1: счет = (N i: 0 i < г : совпадение (/)) and г О
то его истинность тривиально ’ обеспечивается оператором
«счет, г:=0, 0» и, кроме того, получаем, что
(Pl and
(Здесь мы опираемся на то, что выше было названо «вопро-
сом удобства»,.) Получаем некоторый набросок программы:
счет, г :=0, 0;
do г/И —7V->«увеличить г при инвариантности Р1» od
Ц читателю предлагается разработать для себя более деталь-
ный вариант, где г всегда увеличивается на 1; в самом плохом
случае время, потраченное на выполнение этой программы,
сбудет пропорционально М * 2V.
Однако в зависимости от образца иногда становится воз-
можным увеличивать г на число, гораздо большее чем 1; если,
например, образцом является последовательность (1, 2, 3, 4,
5) и функция совпадение (г) истинна, то операция «счет,
г\ = счёт+\, г + 5» сохранит инвариантность Р1! Рассматривая
инвариантное отношение
Р2: * (Ау : 0 < у <^k : р (у)=х (г-)-/)) ап(^ 0 < & < N
(которое, как можно предположить, сыграет роль в конструк-
ции повторения, вычисляющей совпадение^)), мы можем
посмотреть, что мы выиграем, если вынесем это условие из
конструкции повторения, для чего рассмотрим такой вариант
программы:
счет, г, k .’=0, 0, 0;
do г 7И — jV-> «увеличить г при инвариантности Pl and Р2»
od
(при k = 0 Р2 удовлетворяется из-за пустоты множества).
Исходя из истинности отношения Р2 и формулы для сов-
падение (г), самым естественным будет начать повторяемый
оператор с попытки определить значение функции совпадение
(г); так как истинность совпадение (г) следует из Р2 and
k=N, мы считаем, что нужно увеличивать k до тех пор, пока
это необходимо и возможно:
do k^N cand р(&)==л(г-4-&)“>&:==&+1 od (1)
180 Глава 18
По завершении этой конструкции, а завершение гарантирова-
но, мы имеем
Р2 and (k—N cor p(k) =#л (г-}-£))
откуда мы можем заключить, что совпадение (г) = (k — N).
Таким образом, известно, будет увеличение г на 1 сопро-
вождаться оператором «счет: — счет +1» или нет. Нам бы хо-
телось знать, насколько можно увеличивать г, не увеличивая
счет и не принимая во внимание последующие х-значения.
(Эти значения принимаются во внимание в операторе (1);
учитывать их является его специальным назначением! Мы же
хотим здесь использовать только свойства постоянного об-
разца.)
Если & = 0, мы делаем вывод (поскольку У>0), что совпа-
дение (г) = ложь-, отношение Р1 позволяет увеличить г на 1
(Р1 сохраняется инвариантным, поскольку счет не изменяет-
ся), но Р2 не допускает увеличения г больше чем на 1 и k
остается равным нулю (при этом Р2 истинно, так как соот-
ветствующее множество пусто).
Для любого k будем рассуждать следующим образом.
Определим для 0<k^.N.булеву функцию
dif (i, k)==(EJ :0 J <k — i: р (J) =£ p (i + /))
Отсюда следует, что dif(k, k) =мжь. Если, однако>,
dif (I, k) = истина,' мы заключаем — поскольку Q^i+j<k—
что благодаря истинности Р2
(EJ:O^j<k — i:p(j) =/= x(r-H + /))
т. е. dif (i, k)=$non совпадение (г-у Г). Следовательно, пере-
менная «счет» не нуждается в последующей корректировке
(кроме одного раза, что вызвано значением функции совпаде-
ние (г)), когда г увеличивается на d(k), где d(k) есть мини-
мальное решение для i (Q<i^k) уравнения dif (i, к)—ложь,
или
(А/ :0<j<k-i:p(j) = p(i + J)) (2)
Из того, что d(k) есть решение (2), следует
(Aj : 0 < j < k - d (k): p (j) = p(d (k) -|- /))
что с учетом P2 равносильно
(А/ : 0 < j < k-d (k) :p (j)=x(r-\-d(k)+j))
и в результате (помимо корректировки «счет», подразумевае-
мой значением совпадение (г)) при помощи «г, k:=r+d(k),
k—d(k)» обеспечивается сохранение инвариантности как Р\,
так и Р2.
Задача поиска па образцу 181
Поскольку минимальное решение (2) зависит только от k
и р, мы получаем:
begin glocon р, N, х, М; virvar счет; privar г, k; pricon d);
«инициализировать rf»;
счет vir цел., г vir цел, k vir цел\ = 0, 0, 0;
do г<7И-ДГ->
do k=^=N cand p (k)=x(r-\-k)->~k : =k-\-1 od;
if k=N -> счет счет1; r, k:—r-[-d(k),
k — d(k)
Q0< A<7V->r, A := r-|-d(A), k — d(k)
[]A = 0->r:=r-|-l
fi
od
end
Единственное, что нам осталось сделать,— это инициализи-
ровать векторную переменную d, т. е. найти для каждого
k минимальное решение уравнения (2) относитель-
но i. Согласно теореме о линейном просмотре, мы должны
проверять i-значения в порядке их возрастания. Полезно, од-
нако, ясно представлять себе, что это минимальное значение-
для i должно быть определено для всей последовательности
^-значений. Пусть А1>А2 и пусть d(kl)—минимальное ре-
шение уравнения (2) относительно i при k—kl. Из
(А/ : 0 < j < Al -d (Al): p(J)=p(d (Al) + /)) and A1>A2
следует
(A; : 0 < j < kZ - d (k 1): p ) = p (d (k 1) + j))
т. e. для k = kZ, d(kV) также является решением (2) относи-
тельно i, но не обязательно наименьшим! Отсюда мы заклю-
чаем, что d(k) есть монотонно неубывающая функция k. Сле-
довательно, мы должны исследовать значения i в порядке
возрастания и проверять каждый раз, выполняется ли условие
i=d(k) для одного или для нескольких значений k. Более
точно, пусть /(0 Для данного i будет максимальным значени-
ем —i, таким, что
(А/ : 0 < j < j (i): р (у)=р (Z + /))
тогда d(k)—i для всех А, таких, что А—(или
£=^/(t)+i), и для которых не существует решения d(A)<L
182 Глава 18
Так как мы будем исследовать все значения i в порядке их
возрастания и значение, являющееся минимальным решением,
будет представлять очередное значение монотонно неубыва-
ющей функции d, k удовлетворяет условию
d. вег < k < j (Z) + i
и мы получаем следующую программу
«инициализировать </»:
begin glocon р, jV; virvar d; privar i;
d vir цел array; i vir цел : = {l),0;
do d.eez=£ N->-
begin glocon p, N; glovar d, i; privar j;
J vir цел-=0; i :=Z-f
do j < N—i cand p (j) =p (i -|- /)->/ :=/-{-1 od;
do d.eez<^ j-[-i-+d: eeepx(i) od
end
od
«nd
-Упражнения
1. Дать формальное доказательство правильности приве-
денной выше инициа'лизации.
2. Используя «г, k: =r+d(k), г—d(k)» для 0<k, наш ал-
горитм корректирует г и k, не изменяя r+k. Исследуйте не-
значительный выигрыш, который можно получить, для
0<k<N, если известно, что все х могут иметь только два раз-
личных значения. (Конец упражнений.)
Примечание. Я считаю, что время выполнения нашего по-
следнего алгоритма будет расти пропорционально M+N.
Если задаться целью найтй, если возможно, алгоритм с такой
производительностью, то его действительная разработка не
потребует никаких чрезмерных усилий; решающим моментом
представляется отказ удовлетвориться (без дальнейших ис-
следований) очевидным алгоритмом, с временем выполнения,
.пропорциональным М *N, разработку которого я предоставил
читателям в качестве упражнения. Однако небольшое изме-
нение формулировки задачи позволит нам разглядеть здесь
использование общего принципа, который можно было бы
Задача поиска по образцу IS^
назвать «поиском малого супернабора». Предположим, что
нам нужно было не подсчитывать число вхождений одной по-
следовательности в другую, а сгенерировать последователь-
ность r-значений, для которых функция совпадение (г) истинна.
Когда программа должна генерировать элементы набора-
Л, возникают в первом приближении только две ситуации.
Либо мы располагаем простой и определенной «функцией сле-
дующего», при помощи которой можно получить следующий
элемент А,— и тогда генерация всего набора выполняется три-
виально посредством повторного применения этой функции —
либо мы не располагаем подобной функцией. В этом случае
обычно прибегают к генерации элементов некоторого набора
В, такого, что
1. Каждый элемент А является также элементом В.
2. Существует генератор последовательных элементов В.
3. Существует способ проверки, принадлежит ли элемент В
также и набору А.
Алгоритм генерирует и проверяет по очереди все эле-
менты В.
Чтобы, пользуясь этим методом, получить удовлетвори-
тельную производительность, необходимо выполнение трех
условий:
1. Генерация элементов набора В должна быть разумно
эффективной.
2. Проверка принадлежности элемента набора В набору А
также должна быть разумно эффективной (особенно в том
случае, когда элемент В не принадлежит А, так как В обычно
на порядок больше А).
3. Набор В не должен быть излишне большим.
Тот, кто.имеет большой опыт решения подобных задач, бу-
дет, исходя из вышесказанного, искать набор В, меньший, чем
это представляется очевидным. В данном примере такиДл оче-
видным набором является набор всех r-значений, удовлетворя-
ющих условию —7V. Заметим, что в предыдущей гла-
ве замена набора «qq» гораздо меньшим набором «qqq» была
еще одним применением принципа поиска малого супернабора.
И наряду с «вынесением отношения из конструкции повторе-'
ния» это иллюстрирует второе стратегическое сходство между
решениями, представленными в настоящей и предыдущей гла-
вах. (Конец примечания.)
19 ПРЕДСТАВЛЕНИЕ ЧИСЛА
В ВИДЕ СУММЫ ДВУХ КВАДРАТОВ
Предположим, что нам требуется составить программу, ко-
торая для любого заданного г^О будет получать все сущест-
венно различные формы представления г в виде суммы двух
квадратов, или, более точно, будет генерировать все пары
(х, у), такие, что
х2_|_у2_г an(j (1)
Ответом должны быть две векторные переменные xv и yv,
такие, что для i от ха.ниг ( = уу.ниг) до xv.eea (=yv.eee)
пары (xv(i), yv(i)) будут представлять все решения (1). Что-
бы быть уверенным, что наш последовательный алгоритм
получает все решения (1), воспользуемся стандартным спо-
собом упорядочивания решений по какому-либо признаку.
Я предлагаю располагать их в порядке возрастания значения
х (поскольку никакие два различных решения не имеют одно-
го и того же значения х, такое упорядочивание однозначно).
Мы предлагаем сохранять инвариантным следующее отно-
шение:
Pl: xv(i) будет монотонно возрастающей функцией с той же
областью определения, что и монотонно убывающая функ-
ция yv(i}, причем эти функции таковы, что пары (xv(i),
yv(i)) представляют собой все решения (1) при xv(i)<x
Начальная истинность Р1 легко обеспечивается, если ини-
циализировать xv и yv так, что их область определения пуста,
и выбрать х не слишком большим. Если пара (xv(i),
yv(i)) является решением (1), мы всегда будем иметь
2* xv(i)2'^xv(i)2+yv(i)2=r, и, следовательно, так как
xv(i)<x, наименьшее значение х^Э, такое, что 2
не слишком велико. Наименьшее значение х можно устано-
вить при помощи теоремы о линейном просмотре. Однако,
поскольку для каждого xv(i) будет выполняться условие
xv(i)2^r, мы знаем, что из истинности Pl and х2>г следует,
Представление числа в виде суммы двух квадратов 18&
что все решения получены. Поэтому наш первый вариант
может быть таким:
begin glocon г; virvar xv, yv, privar x;
x vir цел:—0\ do 2*x2<r-*-x: = x^-l od;
xv vir цел array, yv vir цел array: = (1), (1);
do x2< r->«увеличить x при инвариантности Р1» od
end
Из этой программы видно, что инвариантным отношением
является в действительности более сильное отношение
PV: Pl and 2*х2^г
Наивно было бы надеяться, что для каждого значения х
можно определить такое значение у, что х2+у2=г, так как
такое значение вовсе не обязательно'существует. Что мы дей-
ствительно можем сделать — это обеспечить истинность отно-
шения
x2-J-i/2<r and x2+(f/+1)2> г
Отсюда мы можем заключить не только то, что если
•*2+//2=Л значит решение (1) было найдено, но также и то,
что если х2+//2<г, значит для данного значения х не сущест-
вует значения.//, которое могло бы быть парой для х. Прини-
мая отношение
Р2: x2+^+i)2>r
в качестве инвариантного отношения для внутренней конструк-
ции повторения, получаем программу
«увеличить х при инвариантности РГ»:
begin glocon г; glovar xv, yv, x; privar y;
у vir цел:=х-, {благодаря истинности Pl' стало истин-
ным Р2)
do х2-\-у2>г-*-у: = у — 1 od; (x24-z/2<r and P2J
if x2+y2=r-+xv: вверх(х)-, yv: вверх (//); х:=х-{-1
П х2 -{- у2 <Z r^x: — х-\-1
fi
end
Замечая, однако, что последняя конструкция выбора не на-
рушит справедливости Р2, мы можем значительно повысить
186 Глава 19
эффективность этой программы, если вынесем отношение Р2
из внешней конструкции повторения:
«begin glocon г; virvar xv, yv; privar x, y;
x vir цел, у vir цел: = 0, 0;
do x*-\-y2<Zr-*-x, y.=zx-\-l, °d;
xv vir цел array, yv vir цел array := (1), (1);
do x2-C r->-do x2-|-y2>r-+y : = y— 1 od;
if x2-\-y2=r -+xv : вверх (x); yv: вверх (у);
0 x24-y2<r->x:=x-[-l
fi
od
«nd
Последнее усовершенствование есть результат применения-
поиска малого супернабора для у; оно было достигнуто бла-
годаря вынесению отношения из конструкции повторения, а
именно отношения Р2.
Замечание. В качестве упражнения предлагается внести
такие очевидные усовершенствования, как проверка справед-
ливости г mod 4=3 и использование рекуррентного отношения
(х-Н)2=х2+ (2* х+1). (Конец замечания.)
Примечание. Приведенная выше программа, которой мы
обязаны Фейену, явно превосходит программу, составленную
нами несколько лет назад, когда, например, чтобы показать,
что ни одного решения не пропущено, всегда требовалось при-
бегать к рисунку. (Конец примечания.)
20 ЗАДАЧА О НАИМЕНЬШЕМ ПРОСТОМ
МНОЖИТЕЛЕ БОЛЬШОГО ЧИСЛА
В этой главе мы займемся задачей определения наимень-
шего простого множителя большого числа (под «боль-
шим» я понимаю здесь число порядка, скажем, 1016), исходя
из предположения, что программа предназначается для малой
машины, которая выполняет операции сложения и сравнения
гораздо быстрее, чем произвольные операции умножения и
деления. (В наше время такое предположение вполне реально
для большинства так называемых «мини-машин?; описывае-
мый алгоритм был разработан несколько лет назад для устрой-
ства, которое, несмотря на его физический размер, сегодня
можно было бы назвать «микромашиной».)
Из непосредственного применения теоремы о линейном про-
смотре следует, что мы должны исследовать простые числа
в качестве возможных множителей в порядке их возрастания.
Поскольку составное число имеет по крайней мере один про-
стой множитель, не превосходящий корень квадратный из это-
го числа, наше исследование должно вестись не дальше этого
корня; если множитель еще не будет найден, это означает, что
число W простое. На этих рассуждениях основан следующий
алгоритм:
begin glocon N; virvar p; privar f;
f 'Л'Гцел: = 2;
do ATmod/ 0 and
«увеличить f до следующего простого числа»
od;
if Afmod/ =/=()-►/7 vir цел-. — N
0 ./Vmod/=0->p vir цел-.= f
fi
end
187
188 Глава 20
В этом алгоритме, однако, есть еще над чем подумать, по-
тому что пока неясно, как мы собираемся увеличивать f до
следующего простого числа.
Мы предположили, что составляем программу для малой
машины, а это исключает возможность хранения таблицы
последовательных простых чисел до 108. (Если хранить такую
таблицу, не прибегая ни к каким ухищрениям, потребовалось
бы 5 * 107 битов, а это совсем не то, что называется — даже
сегодня! — «малой памятью».) Вместо того чтобы определять
следующее простое число по хранящейся в памяти таблице,
•его можно было бы вычислять; но если идти обычным путем,
пришлось бы, вообще говоря, проверять последовательность
/+1, /+2,
пока не встретится первое простое число. Но проверка, явля-
ется ли числр простым, сводится обычно к вопросу о том, рав-
но ли оно своему наименьшему простому множителю!
Существует возможность очень просто разрешить эту ди-
лемму. Для 7V>1 наименьший простой множитель числа N
является также наименьшим натуральным числом ^s2, на ко-
торое делится N. Это свойство позволяет нам найти наимень-
ший простощмножитель числа N, не обращаясь больше к кон-
цепции «простого числа»:
begin glocon TV; virvar р; privar /;
f vir цел: = 2;
doNmod/=^0 and (/+1)2< AT->/: = /-{-1 od;
if JVmod f ,=#()—»p vir Цел :=N
□ N mod/=0 —»p vir цел: = /
fi
end
Основная неприятность, связанная с этим алгоритмом,
объясняется тем, что только операции сложения и сравнения
мы считали быстрыми, но допустили, что вычисления N mod f
и (f+1)2 могут быть такими медленными, что их по возмож-
ности следует избегать во внутреннем цикле.
Единственный выход из положения, как кажется, состоит
в том, чтобы найти способ применить прием «вынесения отно-
шения из конструкции повторения», т. е. попытаться хранить
такую информацию, чтобы после вычисления r=N mod f
можно было на ее основе вычислить следующее значение г
(для f+1). Что же мы можем хранить?
Для начала можно воспользоваться тем, что r=N mod f
есть решение уравнения
N=f *q-\-r and 0<г</
Задача о наименьшем простом множителе большого числа 189
и мы могли бы хранить q. Тогда мы знаем, что
ЛГ=(/+1)*<7 + (г-?)
и, вообще говоря, можем рассчитывать на «выигрыш» в том
смысле, что (г—q) будет ближе к нулю, чем исходное N, и,
следовательно, от него «легче» получить остаток по модулю
(f+1). Но для меньших значений f (и г) и, следовательно,
для больших значений q мы не можем рассчитывать на боль-
шой выигрыш.
Что касается нового значения г, а именно (г—q) mod (f+1),
то нас, оказывается, совсем .не интересует само значение
q\ Нам точно также подошло бы любое меньшее значение,
равное q’ по модулю (f+l), а уменьшение г на это значение
причинило бы нам меньшее беспокойство. Иначе говоря, мы
предпочли бы уменьшать г не на q, а, скажем, на q mod (f+1).
Тогда почему бы нам не хранить это значение? Повторяя наши
рассуждения, приходим к следующим уравнениям:
N—f* ^о+го 0<г,</-Н
?0 = (/+ 1) *<71 + г1 ДЛяО</<л
Я\ — (/+2) *?24"г2
^-i = (/4-«)*^4"^
<7«=0
Исключая все q, получаем
N=r0-\-
/*п+
/*(/4-1)* ^4-
/*(/+1)*(/4-2)*г3-|-
/*(/4-1)*(7+2)*...*(/4-«-1)*гя (1)
откуда ясно видно, как N полностью определяется через f и
конечную последовательность г.
Заменяя f на /+1 и компенсируя приращение, появляю-
щееся в каждой строке, уменьшением предшествующего ей
члена, мы получаем другое представление N:
^ = (Го-П)4-
(/4-1)*(П~2*г2) +
(/4-1)*(/+2)*(г2-3*г3) +
(/4-1)*(/+2)* (/+З)*(г;-4*г4)4-
(/4-1) * (/4-2) * (/4-3) *...*(/+«)* Гп
190 Глава 20
Этому преобразованию соответствует программа
/:=/+!; Z :=0;
do i<Zn—:= rz — od
но, однако, при этом могут нарушиться неравенства
так как г может стать отрицательным. Но это дело поправи-
мое, поскольку из (1) видно, что приращение ro- = ^o + f можно
компенсировать уменьшением п: = Г1—1. В общем случае
г<: = Гг+(/+0 компенсируется при помощи ri+1: = ri+1—1.
В результате полное преобразование правильно описывается
программой
/:=/+!; Z:=0;
do i <Z n —<
ri ri~ * rZ + b
do
^:=''/ + (/+0; rz+i:=z7+i—1
od;
i := t+ 1
od;
do r„=0 —• n := n— 1 od
В предположении, что умножение малых целых чисел не
представляет серьезной проблемы — оно может выполняться
путем повторного сложения,— вычисление последовательных
значений N mod f может быть реализовано при помощи набора
допустимых операций. Кроме того, проверка (f2<N в нашей
первой версии и (f-f- 1)2^ЛЛ в следующей версии), имеет ли
смысл продолжать поиск или мы уже достигли значения кор-
ня квадратного из N, может быть заменена проверкой п>1,
так как (п^1)=» (7V<(f+1)2).
Полагая ar(k)=rk для О^Л^аг.вег, мы приходим к сле-
дующей программе:
begin glocon N; virvar p; privar f, ar;
begin glocon A"; virvar ar; privar x, y;
ar vir цел array: = (0); x vir цел, у vir цел; =
N, 2;
do x =£0—>ar :вверх (x‘ mod y); x, y;= x div y,
y-fl od
Задача о наименьшем простом множителе большого числа 191
end {выполнена инициализация аг};
f vir цел'.—2 {отношение (1) стало истинным};
do аг (0) =Н= 0 ana аг. вег 1 —♦
begin glovar /, ar-, privar i\
f'-= /+1; i vir цел:—0;
do i =/=ar .вег—»
begin glocon /; glovar ar, i; pricon J;
j vir цел i-\- 1; ar: (i)—ar (/) —
J * ar (j);
do ar(i}<0->ar: (t)=ar(Z)-|-/-H;
ar :(/)=ar (/)—1
od;
*• = j
end
od
end;
do ar.eepx=0—> ar '.сверху od
od;
if ar(0)=0 —*p vir цел-. = f
[] ar (0),=£ 0—»p vir цел : = N
fi
end
Примечание 1. Некоторые могут подумать, что можно
вдвое ускорить программу, если рассматривать отдельно чет-
ные и нечетные значения N. Тогда для нечетных У мы могли
бы ограничиться последовательностью /-значений 3, 5, 7, 9,
11, 13, 15,операция
rt- G’+1) *ri+i
превращается тогда в операцию
rz:= rz — 2*(/4-l)*rm
и это насилие над гг- приведет к тому, что число прохождений
по следующему за операцией циклу, который вновь приводит
Г{ к нужному интервалу, возрастет в среднем в два раза. Так
что мы вряд ли получим улучшение программы, но зато ис-
портим формулу. (Конец примечания 1.)
Примечание 2. Хорошо известный способ обнаружения тех
мест в программе, где можно приложить энергию, направлен-
ную на оптимизацию программы, состоит в том, что при со-
ставлении программы в ней предусматриваются такие дейст-.
вия, которые позволят по завершении программы получить
распечатку полной гистограммы, указывающей, сколько раз
выполнялся каждый оператор; тем самым определяется, где
192 Глава 20
нужно оптимизировать программу. Если применить этот спо-
соб к нашей программе, мы увидим, что значительную часть
времени поглощает внутренний цикл, приводящий ar(i)
к нужному интервалу, особенно когда относительно много
времени уходит на операции над векторными переменными и
па получение значений функций от этих переменных. Для
данного примера такая информация не только тривиальна, hq
и вредна в том смысле, что этот внутренний цикл и не нужно
оптимизировать! (Оптимизируя его, сокращая количество
«индексов», что легко можно сделать, если ввести две скаляр-
ные переменные ari и arj, равные соответственно ar (Г) и аг(/),
мы получим более длинный и более беспорядочный текст.)
Дело в том, что вычисления поглощают много времени только
тогда, когда N— простое число или когда его наименьший
простой множитель близок к его квадратному корню. В этом
случае на протяжении основной части времени вычислений мы
будем иметь аг.вег = 2 (а именно начиная с того момента, ког-
да f минует значение корня кубического из N). Мы можем
заменить предохранитель внешнего цикла на
ar(0)=/=0 and аг.вег>2
и воспользоваться на заключительном этапе тремя скалярны-
ми переменными rO, rl и г2. В составление этой заключитель-
ной части программы можно вложить всю свою изобретатель-
ность. (Конец примечания 2.)
Примечание 3. Если вычисления дают нам p=N, этот ре-
зультат очень трудно проверить. Даже если программу вы-
полняет машина, которую нельзя назвать сверхнадежной, наш
алгоритм позволяет значительно повысить степень уверенно-
сти в полученном результате: после завершения вычислений
должно иметь место отношение N=f * ri + г0! Если какая-то из
арифметических операций была выполнена неверно, то очень
маловероятно, что, несмотря на это, последнее равенство бу-
дет иметь место. С точки зрения надежности этот алгоритм,
гДе новое значение г всегда вычисляется как функция старого
значения, имеет существенное преимущество перед алгорит-
мом, где очередное простое число, проходящее-проверку в ка-
честве возможного множителя, выбирается из таблицы: табли-
ца может испортиться, и, кроме того, каждая проверка на де-
лимость представляет собой совершенно отдельные вычисле-
ния. Стоит отметить, что такой огромный выигрыш в надеж-
ности стал возможным благодаря «вынесению отношения из,
конструкции повторения» и ничему больше. Алгоритм, опи-
санный в этой главе, использовался не только для получения
высоконадежного разложения на множители (типа p = N), но
Задача о наименьшем простом множителе большого числа 193
также и для проверки надежности арифметического устрой-
ства машины. (Конец примечания 3.)
Утешение. Тем из моих читателей, кому эта глава показа-
лась трудной, приятно будет узнать, что даже моим ближай-
шим сотрудникам понадобилось больше.часа, чтобы «перева-
рить» ее: программы могут быть очень компактными. (Конец
утешения.)
7—6
21 ЗАДАЧА О САМЫХ УДАЛЕННЫХ СЕЛЕНИЯХ
Рассмотрим п селений (п>1), перенумерованных с 0 до
а—1; для 0^i<n и 0^/<п задана вычислимая функция
f(t,удовлетворяющая для некоторой заданной положи-
тельной константы М условию
для i J)<M
для i=J:f(l, J)=M
Для. i-го селения степень его удаленности «id(i)> задается как
id (/)=минимум /(Z, у)=минимум /(Л J)
)+i i
(Здесь f(t, /) можно интерпретировать как расстояние от I До
/; правило /(i, j)=M было добавлено с целью упрощения.)
Требуется определить набор максимально удаленных селе-
ний, т. е. набор значений k, таких, что
(А А : О С /г<п: id (А) С id (£))
Предполагается, что программа представит этот набор значе-
ний в виде последовательности
mlv {miv. ниг),.... miv (miv. вег)
Заметим, что, вообще говоря, возможны все значения
1^т1и.обл^п.
Очень простая и бесхитростная программа вычисляет по-
следовательно п степеней удаленности и сохраняет максималь-
ное из полученных значений. В соответствии с границамй
f (i, /) мы можем взять в качестве минимума для пустого на-
бора значение М и в качестве максимума для пустого на-
бора — 0.
begin glocon п, Af; virvar mlv, privar max, I;
mlv vir цел array :=(0); max vir цел, i vir цел : = 0, 0;
do I a —*•
Задача о самых удаленных селениях 195
begin glocon п, М; glovar miv, max, i; privar min, 'J',
min vir цел, j vir цел := M, 0;
do j n—*~
do f(i, jXmin-* min:= f(i, j) od;
7 : = У + i
od id (/))•;
if max>min-► пропустить
□ max=min -> miv: вверх (i)
П maximin-*-miv := (0, f); max ;= min
fi;
i :=t’+1
end
od
end
Приведенная программа очень безыскусна: в самом внутрен-
нем цикле значение min при каждом прохождении по циклу
монотонно не возрастает, и следующая за ним конструкция
выбора будет одинаково реагировать на любое значение min,
удовлетворяющее условию min<max. Из двух этих замечаний
мы делаем вывод, что продолжать внутренний цикл имеет
смысл только до тех пор, пока minimax. Следовательно, мы
можем заменить строчку «do j^n-*» на
«do j п and tnin^max^-»
и комментарий, следующий за соответствующим od, на
or \6(i)=minimax]
Назовем эту модификацию «оптимизация 1».
Совсем по-другому можно оптимизировать программу,
если известно, что
/(Л /)=/(/,/)
и тогда, учитывая, что на вычисление f затрачивается много
времени, не будем вычислять f(i, j) для тех значений аргу-
ментов, для которых уже вычислено значение f(/, i). Мы мо-
жем так усовершенствовать первоначальную программу, что
для каждой неупорядоченной пары аргументов соответствую-
щее f-значение будет вычисляться только один раз. Мы достиг-
7м*
196 Глааа 21
нем этого,; если вместо начального значения, равного нулю,
будем каждый раз придавать / значение Z+1, т. е. будем, так
сказать, просматривать только верхний треугольник симмет-
ричной матрицы расстояний. В этом случае программа обе-
спечит правильное вычисление min только при условии, что
начальным значением min будет не М, а
минимум /(Z, Л)
0<Л</
Чтобы реализовать такую инициализацию, введем массив,
скажем Ь, такой, что для k, удовлетворяющего условию
i^k<n,
для i—0:b(f.)—M
для i 0: b (k) = минимум f(k, А)
0<Л</
(В словесной формулировке: b(k) есть минимальное из свя-
занных с селением k расстояний, вычисленных к настоящему
моменту.)
Программа, полученная в результате оптимизации 2, так-
же довольно бесхитростна.
qegin glocon п, М; virvar miv; privar .max, i, b;
miv vir цел array := (0); max vir цел, i vir цел := 0, 0;
Ъ vir цел array := (0); do Ь.обл =£n—>b' вверх(M) od;
do i n—*'
begin glocon n; glovar miv, max, i, b; privar min, J;
min vir цел, b: никоя; j vir =
do /-5^ n.—>
begin glocon i; glovar min, j, b; privar //;
ff vir цел ‘—f(i, J);
do ff <Zmin-^mint = ff od;
do ff<b(j)-b-. (j)=ff od;
end
od{mZn=id (Z)};
if maxf> min —> пропустить
[] max=min—»miv: вверх (i)
Q maximin—*miv := (0, i); max := min
fi;
Z: = Z-(-1
end
od
end
Задача о самых удаленных селениях 197
При попытке объединить обе эти оптимизации возникает
некоторая проблема. При оптимизации 1 сканирование строки
матрицы расстояний прекращается, когда min становится до-
статочно малым; при оптимизации 2, однако, сканирование
строки есть также сканирование столбца, и это сделано, чтобы
хранить последние полученные значения b(k). Давайте при-
меним оптимизацию 1 и заменим строчку «do/#=n-»> на
«do j =/= п and min max —♦»
Теперь самый внутренний цикл может завершиться при
j<n; значения b (Л) для j^k<n, изменение которых еще мо-
жет представлять интерес,— это значения, удовлетворяющие
-условию b(k)^max, остальные уже достаточно малы. Мы по-
лучим желаемый результат, если вставим в программу сле-
дующую конструкцию:
do / =# /г —
if b (/) тах —* J' '•= j + 1
О b (/) > max —>
begin glocon z; glovar j, b\ privar //;
ff vir цел\=/(1, /);
do ff<Mj}-*b:U) = ff od;
J '= 7+ 1
end
fi
od
Лучше всего вставить эту конструкцию непосредственно перед
«/: = i + 1», но после корректировки max; чем больше max,
тем больше вероятность, что корректировка b(k) больше не
потребуется.
Мы объединили две оптимизации, природа которых весьма
различна. Оптимизация 2 состоит в том, что мы избегаем по-
вторного выполнения работы, про которую известно, что она
уже'сделана, и эффективность этой оптимизации известна
заранее. Оптимизация 1, однако,— это прием, эффективность
которого зависит от неизвестных значений f; это один из мно-
гих возможных однотипных приемов.
Мы ищем те строки матрицы расстояний, чей минимальный
элемент S превосходит минимальные элементы остальных
строк, и идея оптимизации 1 состоит в том, что для этой цели
нам не нужно вычислять действительный минимум для осталь-
ных строк, если мы можем найти для каждой строки верхнюю
границу Вг ее минимума, такую, что Bi<S. На некоторой про-
межуточной стадии вычислений для некоторой строки (строк)
минимум S известен, поскольку все ее (их) элементы уже вы-
числены; для других строк известна только верхняя граница
7*—6
198 Глава 21
Bi. Теперь совершенно ясно, что нам нужно выработать опре-
деленную стратегию. Должны ли мы сначала вычислить наи-
меньшее число дополнительных элементов матрицы, которые
еще потребуются для определения нового минимума, в надеж-
де, что он окажется большим, чем тот минимум, которым мы
располагаем, и следовательно, превысит некоторые В? Или
мы должны сначала вычислить неизвестные элементы в стро-
ках с большим В в надежде добиться дешевой ценой снижения
этой верхней границы? Или нужно как-то объединить эти под-
ходы?
В моей первоначальной версии, объединявшей два подхода,,
«обновление оставшихся b (k)» откладывалось на некоторый
более поздний момент в надежде, что тем временем max ста-
нет больше, но сомнительно, чтобы эта программа была более
эффективной, чем та, которая приведена в настоящей главе.
Конечно, она была более сложной, ей требовался еще один
массив для хранения последовательности номеров селений. Я
пришел к публикуемой версии только тогда, когда уже писал
эту главу. j
Глядя в прошлое, я понимаю, что зря потратил свою изо-
бретательность на мою первоначальную программу: если она
и была «более эффективной», то это могло быть только «а
среднем». Но что значит в среднем? Определить это можно-
только при условии, что мы постулируем (совершенно произ-
вольно!) распределение вероятности для матрицы расстояний
f(i, j). Но в мои намерения*совсем не входила подгонка алго-
ритма под специальный подкласс матриц расстояний!
Мораль такова: составляя универсальную программу, мы
должны удерживаться от искушения применить хитроумную
стратегию, дающую повышение производительности в случаях,
которые могут никогда не встретиться, если такая стратегия
значительно усложняет программу: простота программы —это
гораздо менее расплывчатая цель. (Сложность в том, что мы
часто так гордимся своей хитроумной стратегией, что отказ
от нее причиняет нам боль.)
Примечание. Наша окончательная программа сочетает в
себе две идеи, и мы пришли к ней, рассматривая сначала, так
сказать, в качестве «переходных ступеней» две программы,
каждая из которых основывалась только на одной из идей. Во-
многих случаях я нахожу такие переходные ступени весьма
полезными. (Конец примечания.)
22 ЗАДАЧА О КРАТЧАЙШЕМ
ПОКРЫВАЮЩЕМ ДЕРЕВЕ
Две точки можно соединить одной простой связью; три
точки можно соединить вместе двумя простыми связями, в
общем случае N точек могут быть соединены в одно целое
N—1 простой связью. Такое множество взаимосвязей называ-
ется «деревом», или, если мы хотим подчеркнуть, что оно со-
единяет все N точек друг с другом, «покрывающим деревом»,
а сами связи называются «его ветвями». Кейли первым дока-
зал, что количество различных деревьев для заданных #
ргочек равно NN~2. (Проверьте истинность данного утвержде-
ния при #=4, не советую проверять для Af=5.)
Далее будем предполагать, что задана длина каждой из
возможных N* (N—1)/2 ветвей. Определив длину дерева как
сумму длин его ветвей, мы можем задать вопрос: как найти
самое короткое дерево для заданных N точек? (Пока будем
считать, что заданные длины таковы, что кратчайшее дерево
единственно.)
Замечание. Рассматриваемые точки не обязательно долж-
ны принадлежать евклидовой плоскости, а заданным длинам
разрешается не иметь никакого отношения к евклидову рас-
стоянию. (Конец замечания.)
Одно из очевидных и бесхитростных решений заключается
в том, чтобы последовательно получить все деревья для W
точек, определить их длину и отобрать самое короткое. Но,
согласно теореме Кейли, с увеличением N этот метод быстро
становится очень невыгодным, а затем и совершенно неприем;
лемым. Нам бы хотелось найти более эффективный алгоритм^
Сталкиваясь с проблемами, подобными этой (а нам с такой
проблемой уже пришлось иметь дело при решении задачи о
голландском национальном флаге), часто оказывается пло-
дотворным, учитывая то, что мы пытаемся построить последо-
вательный алгоритм, внимательно рассмотреть промежуточ-
ные состояния, которые могут возникнуть в процессе вычисле-
ния. Так как конечный результат является набором из N—1
ветвей, принадлежность которых самому короткому дереву
7**
200 Глава 22
будет — мы надеемся — устанавливаться поочередно, нам сле-
дует разобраться в том, что можно сказать, когда уже извест-
но некоторое количество ветвей искомого дерева.
Сразу же необходимо решить, будем ли мы иметь дело с
общим случаем, когда известно произвольное подмножество
этих ветвей, или ограничимся только некоторыми типами
подмножеств, надеясь, что они окажутся как раз теми под-
множествами, которые встретятся в наших вычислениях, и
надеясь также, что это ограничение упростит наш анализ.
Такой выбор представляется по крайней мере тогда, когда мы
имеем в виду «естественный» тип подмножеств. В нашем при-
мере напрашивается естественный тип подмножества, опреде-
ляемый так, что выбранные ветви распределены между точ-
ками не случайным образом, а тоже образуют дерево. Так как
этот специальный случай и на самом деле может оказаться
проще общего случая, мы зададим наш вопрос в другой форме.
Можно ли извлечь какую-нибудь пользу из того, что нам
известно некоторое поддерево искомого кратчайшего дерева?
В дальнейшем будем предполагать, что ветви уже опреде-
ленного поддерева и точки, связываемые ими, выкрашены в
красный цвет, а все оставшиеся точки выкрашены в синий
цвет. Можем ли мы найти еще одну ветвь, которая также
должна" принадлежать кратчайшему дереву? Так как резуль-
тирующее дерево соединяет все точки друг с другом, оно долж-
но содержать по крайней мере одну ветвь, соединяющую крас-
ную точку с синей. Назовем ветвь между красной и синей
точкбй «фиолетовой ветвью». Напрашивается очевидное пред-
положение о том, что кратчайшая фиолетовая ветвь принад-
лежит и кратчайшему дереву.
Правильность этого предположения нетрудно доказать.
Рассмотрим некоторое дерево Т для N точек, которое содер-
жит все эти красные ветви, но не содержит самую короткую
фиолетовую ветвь. Добавим к нему самую короткую фиоле-
товую ветвь. При этом образуется цикл, содержащий по край-
ней мере одну красную и одну синюю точку, т. е. цикл, кото-
рый, следовательно, содержит по крайней мере еще одну
(более длинную) фиолетовую ветвь. Удалим из цикла такую
более длинную фиолетовую ветвь. Получающийся в резуль-
тате граф также является деревом. В дереве Т мы заменили
некоторую фиолетовую ветвь более короткой, и поэтому де-
рево Т не могло быть кратчайшим. (Дерево для N точек есть
граф, обладающий следующими тремя свойствами:
1. Оно соединяет друг с другом JV точек.
2. У него N—1 ветвей.
3. У него нет циклов.
Задача о кратчайшем покрывающем дереве 201
Из любых этих двух свойств следует, что граф является дере-
вом и, следовательно, обладает и третьим свойством.)
Но теперь мы можем представить общий контур нашего
алгоритма, при условии, что нам удастся найти начальное крас-
ное дерево. Как только мы это сделаем, мы можем выбрать
самую короткую фиолетовую ветвь, покрасить ее и синюю
точку на ее конце в красный цвет и т. д. до тех пор, пока
красное дерево не станет таким большим, что не останется
ни одной синей точки. Чтобы начать этот процесс, достаточно
покрасить произвольную точку в красный цвет:
покрасить произвольную точку в красный цвет, а оставшие-
ся точки в синий;
do число красных точек
выбрать самую короткую фиолетовую ветвь;
покрасить ее и синюю точку на ее конце в красный цвет
od
Теперь нашей главной задачей становится «выбор самой
короткой фиолетовой ветви», так как число фиолетовых вет-
вей может быть очень большим, а именно k * (N—fe), где k —
число красных точек. Если «выбор самой короткой фиолето-
вой ветви» выполнять как отдельную операцию, потребуется
в среднем число сравнений, пропорциональное N2, и объем
работы, выполняемой всем алгоритмом, будет пропорционален
N3. Впрочем, замечая, что операция «выбрать самую короткую
фиолетовую ветвь» одна не встречается, а лишь как компонен-
та конструкции повторения, зададим себе вопрос, нельзя ли
применять метод «вынесения отношения из конструкции по-
вторения», т. е. нельзя ли организовать программу так, чтобы
последующие выполнения оператора «выбрать самую корот-
кую фиолетовую ветвь» могли воспользоваться результатом
предыдущего. Имеются веские соображения в пользу того, что
это возможно, так как каждое множество фиолетовых ветвей
тесно связано с последующим: множество фиолетовых ветвей
определяется тем, как были разделены точки на красные и
синие, и изменение этого разбиения каждый раз связано с
тем, что одна синяя точка делается красной.
Желание сильно сократить время поиска при выборе самой
короткой ветви из некоторого множества означает сокращение
объема этого множества; другими словами, мы ищем подмно^
жество фиолетовых ветвей — назовем их «ультрафиолетовы-
ми»,— которое будет содержать самую короткую ветвь и ко-
торое можно использовать для передачи полезной информации
от одного выбора к следующему. Мы представляем себе про-
грамму такой структуры:
202 -Глава 22
покрасить произвольную точку в красный цвет, а остальные
в синий;
определить множество ультрафиолетовых ветвей;
do количество красных точек =£N->-
выбрать самую короткую ультрафиолетовую ветвь;
покрасить ее и синюю точку на ее конце в красный цвет;
перевычислить множество ультрафиолетовых ветвей
od
где «ультрафиолетовый цвет» выбирается так, что
1. Гарантируется, что самая короткая фиолетовая ветвь
находится среди ультрафиолетовых.
2. Множество ультрафиолетовых ветвей в среднем гораздо
меньше множества фиолетовых.
3. Операция «перевычислить множество ультрафиолетовых
ветвей» относительно недорогая.
(Мы требуем выполнения первого свойства, поскольку тог-
да наш новый алгоритм будет Также правилен; мы требуем
выполнения второго и третьего свойств, так как хотим, чтобы
новый алгоритм был эффективнее прежнего.)
Можем ли мы найти такое определение понятия «ультра-
фиолетовый»? За неимением других сведений, я могу только
предложить попробовать. Учитывая, что множество фиолето-
вых ветвей, идущих из k красных точек в N—k синих точек,
содержит k * (N—k) элементов и что должен соблюдаться наш
первый критерий, немедленно напрашиваются такие два оче-
видных возможных подмножества:
1. Для каждой красной точки кратчайшую фиолетовую
ветвь, оканчивающуюся в ней, сделайте ультрафиолетовой;
следовательно, множество ультрафиолетовых ветвей имеет k
членов.
2. Для каждой синей точки кратчайшую фиолетовую ветвь,
оканчивающуюся в ней, сделайте ультрафиолетовой; следова-
тельно, множество ультрафиолетовых ветвей имеет N—k чле-
нов.
Нам нужно, чтобы ультрафиолетовое подмножество было
небольшим, но мы не можем сделать выбор исходя из размера:
в 'первом случае он будет меняться в пределах от 1 до N—1,
во втором — от N—1 до 1. Поэтому если мы и можем на что-то
решиться, то с учетом цены операции «перевычислить множе-
ство ультрафиолетовых ветвей».
Впрочем, не испытывая различные способы перевычисле-
Задача о кратчайшем покрывающем дереве 203
ния, можно сразу же высказать одно соображение в пользу
второго варианта. В первом варианте различные ультрафио-
летовые ветви могут идти к одной и той же синей точке, и
тогда мы знаем a priori, что самое большее одна из них будет
покрашена в красный цвет; во втором варианте каждая синяя
точка связана с красным деревом одним способом, т. е. крас-
ные и ультрафиолетовые ветви все время образуют покрываю-
щее дерево для N точек. Поэтому давайте внимательно рас-
смотрим следствия второго определения понятия «ультрафио-
летовый».
Рассмотрим состояние, когда у нас есть красное поддерево
и когда из множества соответствующих ультрафиолетовых
ветвей (в соответствии со вторым определением — я больше
не буду повторять это) самая короткая ветвь вместе со своей
первоначально синей точкой Р покрашены в красный цвет.
Число ультрафиолетовых ветвей, как и следовало ожидать,
уменьшилось на 1. Но правильны ли оставшиеся ветви? Для
каждой синей точки они представляют самую короткую связь
с первоначальным красным деревом R, и следовало бы пред-
ставлять самую короткую связь с новым красным деревом
R+P. Этот вопрос решается одним простым сравнением для
каждой синей точки В: если ветвь ВР короче ультрафиолето-
вой ветви, соединяющей В с R, последняя должна быть заме-
нена на ВР, в противном случае рост красного дерева не ведет
к новому кратчайшему пути между ним и точкой В. В резуль-
тате мы видим, что и выбор кратчайшей ультрафиолетовой
ветви, и перевычисление множества ультрафиолетовых ветвей
являются операциями, стоимость которых пропорциональна N,
стоимость всего алгоритма растет как N2, n введение понятия
«ультрафиолетовый» в самом деле позволило нам получить
экономию, на которую мы надеялись.
Упражнение
Убедитесь, что нерассмотренная альтернатива для понятия
«ультрафиолетовый» менее плодотворна. (Конец упражнения.)
Так как операция «перевычислить множество ультрафио-
летовых ветвей» предполагает для каждой ультрафиолетовой
ветви проверку, нужно ли эту ветвь заменить или сохранить,
заманчиво объединить этот процесс и выбор самой короткой
ветви нового множества ультрафиолетовых ветвей в одном
цикле. Вместо того чтобы передавать следующему повторению
модифицированное множество ультрафиолетовых ветвей, бу-,
дем передавать немодифицированное множество вместе с
204 Глава 22
спкц», номером точки, которая была последней выкрашена в
красный цвет. Задача инициализации может быть легко ре-
шена, если известна верхняя граница длин всех ветвей инф-,
будем считать, что эта константа нам известна, ультрафиоле-
товым ветвям немодифицированного множества зададим на-
чальную длину, равную инф (и соединим синие точки с вооб-
ражаемой точкой с номером 0).
Мы предполагаем, что заданные точки пронумерованы чис-
лами от 1 до N, а длина ветви между точками р и q задается
симметрической функцией «расст(р, q)». Ответ нужно полу-
чить в виде дерева, состоящего из N—1 ветвей, причем ветви
идентифицируются номерами своих конечных точек; то есть
ответ — это (неупорядоченное) множество (неупорядоченных)
пар чисел. Будем представлять их двумя массивами сиз» и
св» соответственно таким образом, что для —1
«из(Л)» и «в(й)» есть две конечные точки (их порядковые
номера) /г-й ветви. В нашем окончательном ответе все ветви
будут упорядочены (по Л); единственный порядок, который
имеет смысл,— порядок их окрашивания в красный цвет. Это
наводит на мысль во время вычисления использовать массивы
сиз» и св» для хранения и ультрафиолетовых ветвей с помо-
щью следующих условий:
для 1 -С h < k: h-я ветвь красная;
для : h-я ветвь ультрафиолетовая.
Чтобы не перевычислять длины ультрафиолетовых ветвей,
введем локальный массив уфд («ультрафиолетовая длина»),
т. е.
для k h С N: уфд (h.) — длина й-й ветви.
Далее, поскольку существует однозначное соответствие
между ультрафиолетовыми ветвями и синими точками, то для
того, чтобы определить, какие точки этих ветвей синие, можно
договориться, что h-я ультрафиолетовая ветвь соединяет крас-
ную точку сиз(И)» с синей точкой ce(h)».
В приводимой программе точка N — это произвольная точ-
ка, покрашенная вначале в красный цвет.
Замечание. По отношению к массиву сиз» и скалярной пе-
ременной скуф» можно сделать упрек, что нам не удалось
избежать бессмысленных инициализаций; однако они относят-
ся к виртуальной точке 0, находящейся на расстоянии синф»
от всех других точек, и к такой же виртуальной нулевой ульт-
рафиолетовой ветви. (Конец замечания.)
Задача о кратчайшем покрывающем дереве 205
begin glocon N, инф; virvar из, в; privar уфд, k, пкц;
из vir цел array := (1); в vir цел array :=(1);
уфд vir цел array :=(1);
do из.обл =/= N — 1 —>
из : вверх (0); в : вверх (из.обл)-, уфд : вверх (инф)
od;
k vir цел, пкц vir цел .=}., N;
do k =/= N —>
begin glocon N, инф; glovar из, в, уфд, k, пкц; privar
куф, min, h;
куф vir цел, min vir цел, h. vir цел:=0, инф, k\
do h=^N —>
begin glocon N, в, пкц; glovar из, уфд, куф, min, h;
privar длн;
длн vir цел.: = paccm (пкц, e(h));
if длн^,уфд(к)—*уфд :(Ь)=длн; из :(к)=пкц
О длн уфд(Н) —*длн: — уфд (h)
fi {длн—уфд (h)};
do длн < min —► min : = длн; куф : = h od (min=
уфд (куф)};
end
od {ветвь с номером куф есть кратчайшая ультра-
фиолетовая ветвь);
из ;nepecmaeumb(k, куф); в-, переставить (k, куф);
уфд: переставить (k, куф);
пкц:= e(k); k:=k-[-l; уфд-. снизу
end
od
end
Несмотря на простоту конечной программы — собственно
говоря, всего лишь цикл в цикле,— описываемый ею алгоритм
нельзя считать тривиальным. По существу это весьма эффек-
тивный алгоритм как в отношении использования памяти, так
и в отношении количества сравнений длин ветвей. Поэтому
стоит еще раз перечислить основные мбменты, приведшие к
его обнаружению.
Первый решающий шаг был сделан тогда, когда мы попы-
тались ограничиться такими промежуточными состояниями, в
которых красные ветви, т. е. ветви конечного результата, .сами
образуют дерево. Преимущественный выигрыш состоит в том,
что тогда количество красных точек превышает количество
красных ветвей ровно на единицу и мы имеем право сделать
206 Глава 22
вывод, что ветвь из одной красной точки в другую не может
никогда стать красной: произошло бы запретное замыкание
цикла. (А теперь становятся видны контуры еще одного алго-
ритма: рассортировать все ветви по возрастанию их длин и
обрабатывать их в этом порядке; причем обработка заклю-
чается в том, что, если обрабатываемая ветвь вместе с крас-
ными ветвями образует* цикл, ее надо отбросить, иначе ее
надо сделать красной. Очевидно, что этот алгоритм получает
элементы конечного результата в порядке увеличения длин
красных ветвей. Такой алгоритм менее привлекателен, по-
скольку, во-первых, нам нужно рассортировать все ветви, и,
во-вторых, проверка, не замыкает ли новая ветвь цикл, также
не слишком привлекательна. Эта проблема является темой
следующей главы.) Отсюда можно сделать вывод, что попыт-
ка достижения конечной цели посредством «простых» проме-
жуточных состояний обычно окупается!
Вторым решающим шагом явилась формулировка нашего
предположения, что самая короткая фиолетовая ветвь может
быть сделана красной. И здесь это предположение появилось
•не на пустом месте; если мы хотим «вырастить» красное дере-
во, нам нужно обращаться именно к фиолетовой ветви, а тогда
то, что вероятным кандидатом будет ветвь самая короткая,
вряд ли может показаться удивительным.
Наше решение не довольствоваться ^-алгоритмом — ре-
шение, которое привело к понятию «ультрафиолетовый»,—
может показаться самым неожиданным. Нам могут возразить:
«Предположим, что мне не пришло в голову исследовать, не
могу ли я найти алгоритм получше?» Что же, это решение
пришло тогда, когда у нас уже был алгоритм, и математиче-
ский анализ первоначальной задачи по существу завершен.
Мы занялись всего лишь оптимизацией, для которой никакого
более глубокого знания, например теории графов, не требо-
валось! Кроме того, эта оптимизация следовала хорошо из-
вестному образцу: вынесение отношения из цикла. Мораль
такова: когда алгоритм сделан, не считайте, что работа над
ним уже закончена, а проверьте, нельзя ли его еще утрамбо-
вать. Трудно представить, чтобы понятие «ультрафиолетовый»
могло ускользнуть от внимания тех, у кого вошло в привычку
проводить такую работу.
Замечание. Из анализа алгоритма следует, что самое ко-
роткое покрывающее дерево единственно, если длины любых
двух различных ветвей неодинаковы. Проверьте, что если су-
ществует более одного кратчайшего покрывающего дерева, то
наш алгоритм может построить любое из них. (Конец замеча-
ния.)
Задача о кратчайшем покрывающем дереве 207
Существует и совершенно другой алгоритм, который поме-
щает ветви в произвольном порядке, но каждый раз происхо-
дит проверка, не образуется ли при этом цикл, и тогда из него
удаляется самая длинная ветвь (или одна из самых длин-
ных) .
23 АЛГОРИТМ РЕМА ВЫДЕЛЕНИЯ КЛАССОВ
ЭКВИВАЛЕНТНОСТИ
В общем случае точки графа (не обязательно являющегося
деревом) называются «вершинами», а связи между ними —
«ребрами»,, а не ветвями. Граф называется «связанным» тог-
да и только тогда, когда он либо содержит только одну вер-
шину, либо между любыми двумя различными вершинами
существует по крайней мере один путь, проходящий по его-
ребрам. Так как многие из возможных ребер графа с N верши-
нами могут отсутствовать, граф не всегда связан. Но каждый
граф, как связанный, так и несвязанный, можно всегда одно-
значно разделить на связанные подграфы, т. е: все вершины
графа можно разделить на такие подмножества, что любая
пара вершин из одного и того же подмножества связана, а
для любых двух вершин, взятых из двух различных подмно-
жеств, связывающего их пути не существует. (Для математи-
ков: «связанность» есть рефлективное, симметричное и тран-
зитивное отношение, которое, следовательно, порождает клас-
сы эквивалентности.)
Мы будем рассматривать W вершин, занумерованных от О
до N—1, предполагая, что ЛГ достаточно велико (скажем,
10 000), и последовательность графов Gq, Gb G2, ..., которые
получаются при связывании этих вершин ребрами множеств
Ео, Еъ Е2, ..., где Ео пусто, a Ei+i = Ei+ {вг}; е0, еъ е2, ... — есть
некоторая заданная последовательность ребер. Ребра во^ь
... должны обрабатываться в данном порядке, и после обра-
ботки п ребер (т. е. когда последнее из обработанных ребер,
если такое было, есть ребро еп-\) для любой пары вершив
мы должны иметь возможность определить, является ли она
связанной в графе Gn или нет. Основная задача, которую
нужно решить в этой главе, заключается в следующем: «Как
хранить в памяти всю существенную для нас информацию,
которую мы получаем, когда знаем последовательность ребер
е0, ..., еп—1?»
Конечно, мы могли бы хранить саму последовательность
ребер «е0, вь ..., вп-1», но такое решение не очень хорошо с
Алгоритм Рема выделения классов эквивалентности 209
практической точки зрения, так как, во-первых, одновременно
мы запоминаем и много не относящейся к делу информации;
нацример, если мы уже обработали ребра {7, 8} и {12, 7}, то
новое ребро {12, 8} не говорит нам ничего нового! И, во-вто-
рых, ответ на вопрос: «Связаны ли вершины р и q?» — наш
главный вопрос!— спрятан слишком глубоко.
Как пример другой крайности мы могли бы хранить пол-
ностью всю матрицу связности, т. е. N2 битов (или, если ис-
пользовать то, что эта матрица симметрична, Л/* (М+1)/2 би-
тов), так что ответом на вопрос, связаны ли вершины р и q,
является булевское значение, хранимое как элемент матрицы
connp,g. (Нас не должно смущать то, что мы говорим о м*ат-
рице, хотя введенные нами векторные переменные более по-
хожи на векторы; мы могли бы ввести, скажем, переменную
«асоп» и воспользоваться следующим равенством:
соппА<7=ясо/г (N * p-^-q) и 0
Я назвал это другой крайностью, потому что здесь на са-
мом деле запоминаются готовые ответы, на все возможные
вопросы вида: «Связаны ли вершины р и #»?; но запоминает-
ся чересчур много, так как большинство из тех ответов, вооб-
ще говоря, зависят друг от друга. Решение хранить информа-
цию в такой избыточной форме — достаточно серьезное дело,
так как, чем больше избыточной информации мы храним, тем
большие преобразования информации могут потребоваться
при обработке нового ребра.
Более компактный способ представления того, какие вер-
шины связаны друг с другом, состоит в указании (например,
перечислении) тех подмножеств, которые соответствуют теку-
щему разделению. Тогда вопрос о том, являются ли связанны-
ми вершины р и q, сводится к вопросу об их принадлежности
к одному и тому же подмножеству, т. е. к вычислению значения
логического выражения
под множество(р) = под множество^
Так как имеется самое большее N различных подмножеств, по-
требуется не больше чем N * log2N битов (а не N2 битов пол-
ной матрицы связности).
Для ответа на вопрос о том, связаны ли вершины р и q,
было бы очень полезно ввести массив для хранения значений
функции «подмножество», но ... ее перевычисление может ока-
заться утомительной процедурой! В самом деле, предположим,
например, что подмножество(р) =Р, подмножество^) = Q и
P=/=Q, и предположим, далее, что очередное ребро, которое
нам нужно обработать, есть {р, q}. В конечном счете оба эти
подмножества должны быть объединены в одно, а это, если
210 Глава 23
сами подмножества уже достаточно велики, потребует значи-
тельных модификаций. Кроме того, если мы работаем только
с векторной переменной «.подмножество», то как нам найти,
например, все значения k, такие, что подмножество(к) = ()
(предполагая, что Р станет именем нового подмножества, по-
лученного в результате выполненного объединения), не пере-
бирая всю область определения функции «подмножество»?
Способ разрешения этой дилеммы заключается в том, что-
бы хранить не функцию «подмножество», а некоторую другую
функцию, скажем «f», обладающую следующими свойствами:
1. Для заданного значения р знание функции / позволяет,
по крайней мере в среднем, легко вычислить значение подмно-
жество (р).
2. При обработке нового ребра {р, q} обеспечена, по край-
ней мере в среднем, легкость перевычисления функции f.
Можно ли придумать такую функцию?
Учитывая, что основная информация, которая обрабатыва-
ется при введении ндвого ребра, состоит в том, что впредь обе
вершины 'будут принадлежать одному и тому же подмножест-
ву, напрашивается такое-определение функции f:
«вершина nr.k принадлежит тому же подмножеству, что и
вершина nr.f(k)»
т. е. как аргумент f, так и значение функции f интерпретируют-
ся как номера вершин.
Так как в начале работы Ео пусто, то каждая вершина яв-
ляется единственным членом подмножества, которому она при-
надлежит, и, следовательно, наша функция должна быть ини-
циализирована следующим образом:
f(k) = k для 0^k<N
и самым естественным наименованием каждого из N различ-
ных подмножеств будет, таким образом, номер той единствен-
ной вершины, которую это подмножество содержит. Очевидное
обобщение на случай подмножеств, состоящих из большего
числа вершин, заключается в отождествлении каждого под-,
множества с номером одной из содержащихся в нем вершин —
с которой именно, нас пока не интересует; принимая это усло-
вие, мы можем рассмотреть функцию f, такую, что '
если f(k)=k, то вершина nr.k принадлежит подмножеству
nr. k, и
если f~(k)=£k, то вершина nr.k принадлежит тому же под-
множеству, что и вершина nr.f(k).
Последовательно применяя вычисление функции f, будем
Алгоритм Рема выделения классов эквивалентности "211
переходить от одной вершины подмножества к некоторой дру-
гой вершине того же самого подмножества. Если мы будем
следить за тем, чтобы этот процесс не стал циклическим, преж-
де чем мы найдем «идентифицирующую вершину подмноже-
ства», т. е. ту вершину, номер которой унаследован самим под-
множеством, то знание функции f действительно позволит нам
вычислить под множество (р) для любого значения р.
Более точно, в формальных обозначениях:
/° (/>)=/>
и для />0
для каждой вершины р, принадлежащей подмножеству ps, су-
ществует значение j, такое, что
для i<j: f‘ (р) =/= ps
для i^j: fl' (p)=ps
Отсюда следует, что для 0^/1 </2^/ : fj'(p) =£fi2(p) и кон-
струкция
«ps vir цел:— p;do ps =£ f (ps)-*-ps\ — f(ps)od»
завершит свою работу при ps = под множество (р).
Тот факт, что функция f дает — возможно, после повторных
применений — для всех точек подмножества nr.qs одну и ту же
идентифицирующую вершину nr.qs, позволяет объединить это
подмножество с подмножеством nr.ps и идентифицировать
результат точкой nr.ps с помощью всего лишь очень неболь-
ших изменений в функции f: вместо равенства f(qs) =qs дол-
жно выполняться равенство f(qs)=ps. Обработка ребра
{р, q}, следовательно, может быть сделана следующим опера-
тором:
begin glocon р, q\ glovar /; privar ps, qs;
ps vir цел: = p; do ps=£ f (ps)-*-ps: = f (ps) od;
{ps—подмножество (/>)}
qs vir цел : — q; do <?s #= f (qs)-*-qs := f (qs) od; {<75=
подмножество (o)|
f:\qs) = ps
end
Приведенный выше способ обработки нового ребра, хотя и
правилен, но не очень привлекателен, поскольку в худшем слу-
.чае может стать слишком неэффективным: эти циклы может
потребоваться повторять очень много раз. Кажется полезным
212 Глава 23
произвести «чистку дерева»; как для вершины р, так и для
вершины q мы теперь знаем текущие идентифицирующие вер-
шины и было бы жалко вновь и вновь прослеживать связан-
ные с ними пути. Чтобы исправить эту ситуацию, предлагаем
следующий внутренний блок (мы также включили в'него по-
пытку уменьшить число вычислений функций f):
begin glocon р, q; glovar /; pricon ps;
begin glocon p, f; virvar ps; privar psO;
psO vir цел, ps vir цел:—р, f (p);
do psQ ps-*- psO, ps : = ps, f {ps) od
end {ps—подмножество (p)};
begin glocon p, ps; glovar f; privar psO, psi;
psQ vir цел, psi vir цел: — p, f (p);
do psO #= psi -*• f : (psO)=ps; psQ, psi: = psi, f (psi) od
end {«подчистка» вершин, которые встречаются после
пг.р\;
begin glocon q, ps; glovar f; privar <ysO, qsl;
qsQ vir цел, qsl vir цел:= q, f (q);
do qsQ =£qsl-*-f: (qsO)=ps; qsQ, qsl := qsl, f (^sl) od;
f:(qsQ)=ps
end {«подчистка» вершин, которые встречаются после
nr.q, й объединение всего подмножества с nr.ps}
end
Упражнения
1. Дайте более формальное доказательство правильности
приведенного выше алгоритма.
2. Мы совершенно произвольно решили, что подмножество
(р) не изменяется и что подмножество (q) переопределяется.
Можете ли вы с выгодой использовать эту свободу?
(Конец упражнений.)
Рассмотренный алгоритм был включен не из-за его красоты.
На самом деле, я бы не удивился, если бы большинство моих
Алгоритм Рема выделения классов зквивалентности 213
читателей остались им неудовлетворены. Например, очень не-
приятно, что совсем непросто произвести оценку т’ого, что мы
выиграли, заменив его первую версию второй. Этот алгоритм
был включен по двум другим причинам.
Во-первых, это дало мне прекрасную возможность обсу-
дить различные способы представления информации и проил-
люстрировать некоторые соображения экономичности. Во-вто-
рых, интересно отметить, что мы допускаем в качестве проме-
жуточного состояния неоднозначное представление текущего
разбиения (однозначного) и позволяем откладывать ликвида-
цию неопределенности и производить ее тогда, когда это будет
удобно. Я могу припомнить не один случай, когда использова-
ние неоднозначного представления приводило к находкам, ко-
торые вряд ли можно было обнаружить другим способом.
Когда Рем прочитал этот текст, он задумался — мое реше-
ние показалось ему далеко неудовлетворительным — и вскоре
-показал мне другое решение. В некоторых отношениях алго-
ритм Рема настолько красив, что я не избежал соблазна и
включил его также. (Следующие рассуждения являются ре-
зультатом совместного обсуждения, в котором принимал уча-
стие и Фейен.)
В первом решении плохо то, что, начиная с р, путь к вер-
шине дерева проходится дважды: один раз для определения ps
и второй раз для чистки дерева. Кроме этого, разрушается
симметрия между р и q.
Два просмотра пути из р были необходимы, так как мы хо-
тели произвести полную чистку дерева. Впрочем, не зная но-
мера идентифицирующей вершины, мы могли бы произвести
по крайней мере частичную чистку за один просмотр, если бы
знали направление в сторону «более чистого дерева». Поэто-
му предлагается использовать отношение порядка между но-
мерами вершин и для каждого подмножества выбрать в ка-
честве идентифицирующего номера, скажем, минимальное
значение; в таком случае, чем меньше /-значение, тем чище
дерево. Так как в начале f(k) =k для всех И, а наша задача
превратилась в задачу уменьшения f-значений, то нам следует
ограничиться представлениями разбиений, удовлетворяющим
неравенству
f(k)^k для 0<£<ЛГ
У этого ограничения есть еще одно преимущество, заклю-
чающееся в том, что становится очевидным, что единствейно
возможные циклы — это стационарные точки, для которых
f(k) =k (т. е. идентифицирующие вершины.).
Для того чтобы иметь возможность выражаться более точ-
но; введем функцию «разб» и двуместную операцию « $ ».
214 Глава 23
разб(1) обозначает разбиение, представляемое функцией f.
радб (f)$ (р, q) обозначает разбиение, получающееся из раз-
биения разб(1) в результате объединения в
одно подмножество подмножества, содержа-
щего р, и подмножества, содержащего q. Тог-
да и только тогда, когда в разбиении разб({)
вершимы р и q уже содержатся в одном и том
же подмножестве, справедливо
Pff.36(f)=^pa36{f) $(р, q)
Обозначая начальное значение f через /нач, обработку реб-
ра (р, q) можно описать как обеспечение истинности отноше-
ния
/?: разб(/) = разб(/нач)$(р, q)
Для этого (как обычно) вводятся две локальные перемен-
ные, скажем рО и qO (или, если вам больше нравится, локаль-
ное ребро), удовлетворяющие отношению
Р: разб(/)$(р0, q0)=pa36(f^)i(p, Я)
что тривиально обеспечивается при такай инициализации
рО vir цел, qO vir цел : = р, q
Далее, после обеспечения отношения Р, алгоритм должен
пересчитывать f, рО и qO при инвариантности Р, пока мы не
сможем заключить, что выполняется условие
Q: разб'(/) = разб(/)$(рО, <?0)
так как (Q and Р) R.
Уравнение R в общем случае относительно f имеет много
решений, нам бы хотелось получить «самое чистое»; поэтому
предлагается искать такой процесс, при котором на каждом
шаге уменьшается по крайней мере одно f-значение. В этом
случае гарантируется, что процесс завершится (в качестве
монотонно убывающей функции можно взять сумму ^-значе-
ний), и мы должны попытаться найти достаточное количество
шагов, таких, что. условие ВВ, дизъюнкция предохранителей,
настолько слабо; Что (non ВВ) Q.
Можно изменить значение функции f в точке рО, например,
так:
f; (р0)=нечто
но, чтобы обеспечить эффективное убывание вариантной функ-
ции, это «нечто» должно быть меньше первоначального значе-
ния f(pO), т. е. меньше чем pl, если мы введем
Pl: pl =f (рО) and q\=f (4О)
Алгоритм Рема выделения классов экс,валентности 215
(Введение второго члена объясняется соображениями симмет-
рии.)
Так как разб(]) $ (рО, qO) должно оставаться постоянным,
очевидными кандидатами на это «нечто» являются qO и ql\
но, учитывая, что ql^qO, выбор ql в общем случае более эф-
фективен, и нам нужно рассмотреть
pl<pl->/:(pO)=pl
где предохранитель полностью обеспечен требованием эффек-
тивного уменьшения вариантной функции. Следующий вопрос
такой: можем ли мы после изменения f воссоединить( рО, qO)
так, чтобы восстановилось, возможно нарушенное, условие Р.
Так как связь (из рО) с pl удалена, надежным воссоединением
будет возобновление (возможно) нарушенной связи с pl. Пос-
ле изменения f оператором f: (pO)=pl мы знаем, что
разб(/)$(р1, х)=раз^(/нач)$(р, q)
Для х, равных рО, qO или pl. Условие Р легко восстанавлива-
ется (так как в качестве х можно выбрать qO) с помощью опе-
ратора «рО: — pl», который с учетом Р1 кодируется как
рО, pl := pl,/(pl)
Таким образом, мы приходим к следующей программе, где
вторая охраняемая команда введена по соображениям сим-
метрии:
begin glocon р, q; glovar /; privar pO, pl, qO, ql-,
pO vir цел, qO vir цел :=p, q )P обеспечено);
pl vir цел, ql vir цел:=f (pO), /(рО){Р1 обеспечено)
do pl < pl->-/:(pO) = pl; pO, pl : = pl, /(pl)
□ pl<pl-?-/:(pO)=pl; qO, ql:=ql, /(pl)
od
end
Конструкция повторения построена таким образом, что ее
окончание не вызывает сомнений: при завершении мы можем
заключить, что pl — ql, откуда при учете Р1 вытекает f(pO) =
=f (рО) и откуда в свою очередь следует QI
Замечание. При «контролируемой» разработке этой про-
граммы— и даже при последующем доказательстве правиль-
ности— введение обозначений «разб», «$ » или других подоб-
ных обозначений, по-видимому, очень существенно. Тем читате-
216 Глава 23
лям, которые сомневаются в правильности этого утверждения,
предлагается попытаться самим провести это доказатель-
ство в^терминах N значений f(k), а не в терминах удачно под-
меченного свойства функции f как целого, как это сделали мы.
(Конец замечания.)
Совет. Те читатели, которые не вполне оценили все очаро-
вание алгоритма Рема, пусть очень внимательно прочтут эту
главу еще раз. ( Конец совета.)
24 ЗАДАЧА О ВЫПУКЛОЙ ОБОЛОЧКЕ
В ТРЕХМЕРНОМ ПРОСТРАНСТВЕ
Чтобы отвести от себя обвинение в том, что я привожу
только такие примеры, которые допускают простые и нагляд-
ные решения и в известном смысле не требуют сложной про-
граммы, сейчас мы займемся задачей, которая, как я уверен,
окажется значительно более трудной. (К сведению моих чи-
тателей: когда я начинал работать над этой главой, я еще не
видел ни одной программы, решающей задачу, которой мы со-
бираемся заниматься.)
Пусть на прямой линии задано несколько различных точек,
скажем с помощью их координат, и требуется выбрать такие
точки Р, что все остальные точки лежат по одну сторону от Р.
Эта задача проста: просмотрев один раз все координаты, мы
определим их максимальное и минимальное значения.
Когда несколько различных точек с помощью их коорди-
нат х, у заданы на плоскости, нас могут попросить выбрать те
точки Р, через которые можно провести прямые линии, такие,
что все остальные точки лежат по одну сторону от каждой из
этих-прямых. Такие.точки Р являются вершинами того, что
называют «выпуклой оболочкой заданных точек». Сама вы-
пуклая оболочка — это циклически упорядоченная последова-
тельность точек, обладающая тем свойством, что все осталь-
ные точки лежат по одну сторону от прямых, проходящих
через пары ее последовательных точек. Выпуклая оболочка —
это кратчайшая замкнутая линия, такая, про каждую точку
которой известно, что она лежит либо на этой, линии, либо
внутри нее.
В данной главе мы будем заниматься аналогичной задачей
в трехмерном пространстве. Своими координатами х, у и z за-
даются N различных точек (/V большое), таких, что никакие
четыре различные точки не лежат в одной плоскости. Требу-
ется выбрать все точки Р, через которые можно «провести»
плоскость, такую, что все остальные точки лежат по одну сто-
рону от этой плоскости. Эти точки являются вершинами вы-
пуклой оболочки для заданных N точек, т. е. минимальной
замкнутой поверхности, обладающей тем свойством, что каж-
8-6
218 Глава 24
дая точка лежит либо на ней, либо внутри нее. (Ограничение,
чтобы в каждой плоскости находилось не более трех точек,
введено для упрощения задачи; в результате все грани выпук-
лой оболочки будут треугольниками.)
На время мы оставим открытым вопрос о том, следует ли
получать выпуклую оболочку как объединение треугольников,
являющихся ее гранями, или как граф из ее вершин и ребер,
где ребро — это линия, проведенная через две различные вер-
шины, так что через эту линию можно провести плоскость,
причем все оставшиеся точки окажутся по одну сторону от
нее.
Причина, по которой мы откладываем принятие этого ре-
шения,— это та же самая причина, по которой задача,о трех-
мерной выпуклой оболочке является такой неудобной. В дву-
мерном случае выпуклая оболочка одномерна, и ее «обработ-
ка» (просмотр, формирование и т. д.) вполне естественно
выполняется последовательным алгоритмом над линейной па-
мятью. Однако в трехмерном случае ни представление «дву-
мерного» ответа с помощью линейной памяти, ни «установка
очередности» при работе с ним далеко не самоочевидны.
Все известные мне алгоритмы для решения соответству-
ющих двумерных задач можно считать частными случаями
такой абстрактной программы:
построить выпуклую оболочку для двух или трех точек;
do существует точка* вне текущей оболочкивыбрать.неко-
торую точку вне текущей оболочки;
модифицировать текущую оболочку так, чтобы она вклю-
чала и выбранную точку
od
Известные алгоритмы отличаются один от другого в не-
скольких отношениях. В одном из подклассов этих алгорит-
мов в операторе «выбрать некоторую точку вне текущей обо-
лочки» выбираются только такие точки, которые являются
вершинами конечного ответа. Эти алгрритмы разделяются на
два подподкласса: в одном цодподклассе конечному ответу
будет принадлежать не только новая вершина, но также и од-
но из новых ребер; во втором подподклассе новая вершина для,
ответа выбирается так, чтобы по возможности уменьшить чис-
ло точек, все еще находящихся вне оболочки. Эффективность
такой стратегии в худшем и .лучшем случаях зависит, однако,
от положения заданных точек, а их «средняя эффективность»
определяется только по отношению к совокупности множеств
точек, из которых наше входное множество является' случай-
ной выборкой. (Вообще говоря, алгоритм с резко различа-
ющейся производительностью в лучшем и худшем случаях не
Задача о выпуклой оболочке в трехмерном пространстве 219
очень привлекателен, беда состоит в том, что часто эти грани-
цы можно сблизить, лишь сделав эффективность одинаково
низкой во всех случаях.)
Второй^ аспект, по которому различаются известные алго-
ритмы для двумерного случая, — это вопр‘ос о том, какие точ-
ки лежат внутри текущей оболочки (и поэтому могут быть
исключены из рассмотрения). Чтобы определить, лежит ли
произвольная точка внутри текущей оболочки, мы можем про-
смотреть все ребра (например, последовательно): если для
всех ребер верно, что точка находится во внутренней полу-
плоскости, то точка находится внутри выпуклой оболочки.
Вместо того чтобы просматривать все вершины, можно ис-
пользовать то свойство, что точка лежит внутри выпуклой
оболочки; только когда она лежит внутри какого-либо тре-
угольника, вершины которого являются вершинами оболочки,
*и мы можем попытаться найти такую тройку вершин в соот-
ветствии с некоей стратегией «наибыстрейшего включения».
Некоторые из этих стратегий могут быть в среднем значитель-
но убыстрены с помощью хранения дополнительной информа-
ции и экономии вычислительного времени за счет памяти ма-
шины.
Из всего этого следует ожидать, что для трехмерного слу-
чая набор алгоритмов, заслуживающих определения «разум-
ный», будет достаточно разнообразен. Было бы тщетно пытать-
ся исследовать этот класс с достаточной полнотой, и уверяю
вас, что я буду более чем счастлив, если мне удастся найти
один, возможно, два «разумных» алгоритма, которые не по-
кажутся излишне запутанными.
Лично я считаю такое глобальное исследование потенци-
альных трудностей, как приведенное выше, очень полезным, так
как из него следует, что, решая задачу, я должен учитывать
свои скромные возможности. В данном случае из него следу-
ет, что я должен учитывать свои очень скромные возможности
и, по-видим'ому, не должен увлекаться сложными рассуждени-
ями, пока мы не обнаружим — если обнаружим! — что, в конце
концов, наша задача не так плоха, как показалось с первого
взгляда. Самое радикальное упрощение, которое я могу при-
думать,— это ограничиться топологией и воздержаться от
всех стратегических соображений, основанных на математи-
ческих ожиданиях числа точек внутри данных объемов.
По-видимому, самым разумным будет рассмотреть различ-
ные способы решения двумерной задачи и разобраться в спо-
собах их обобщения на случай трех измерений.
Одно из простых решений двумерной задачи связано с про-
извольно упорядоченными точками; начиная с выпуклой обо-
лочки для трех точек, последовательно получаются выпуклые
8*
220 Глава 24
оболочки для п первых точек. Всегда, когда в рассмотрение
включается следующая точка, необходимо решить две задачи:
1. Нужно узнать, где лежит новая точка: внутри или вне
выпуклой оболочки.
2. Если она лежит вне текущей оболочки, то последнюю
нужно модифицировать.
Один из способов состоит в нахождении множества k смеж-
ных (!) ребер, таких, что новая точка лежит вне их. Эти k ре-
бер (и k— 1 точек) должны быть удалены при модификации;
они будут заменены одной новой точкой и двумя ребрами. Ес-
ли в процессе поиска нам не удалось найти такое множество,
то новая точка лежит внутри.
Исходя из предположения, что текущие вершины цикличе-
ски упорядочены, т. е. для каждой вершины можно найти
предшествующую и последующую вершины, наименее «хит-
рая» программа будет исследовать ребра по порядку. В трех-
мерной задаче эквивалентом ребер являются грани-треуголь-
ники, эквивалентом множества смежных ребер — множество
связанных треугольников, которое топологически эквивалент-
но кругу. Будем называть его «шапкой».
Выпуклая, оболочка для двумерной задачи должна быть
разделена на две «секции»: множества ребер, которые отвер-
гаются и которые сохраняются соответственно; секции разде-
ляются двумя точками. В трехмерной задаче выпуклая обо-
лочка должна быть разделена на две шапки, разделенные
циклом из точек и ребер.
Мы можем начать с сопоставления выбранной новой точки
с произвольной гранью и считать ее начальной гранью одной
из двух шапок; к шапке может добавляться каждый раз не
более чем по одной грани, и процесс прекратится либо потому,
что шапка содержит все грани (а вторая шапка пуста; новая
точка лежит внутри выпуклой оболочки), либо потому, что она
полностью окружена гранями, принадлежащими второй
шапке.
Ключевая задача, состоит, по-видимому, в том, чтобы орга-
низовать изменяющийся набор граней таким образом, что ес-
ли нам-дана шапка, то мы всегда можем найти грань, присо-
единив которую, мы вновь получим шапку. Мы можем это сде-
лать, если будем хранить (в циклическом порядке) точки (и
ребра), принадлежащие границе шапки. У грани, которую
можно добавить к шапке, должны быть общее с границей шап-
ки ребро и, следовательно, две общие с ней точки: если в гра-
нице шапки окажется и третья точка этой грани, то в старой
границе -она должна быть соседней с одной из двух первых.
Задача о выпуклой оболочке в трехмерном пространстве 221
Мне бы не хотелось, чтобы поиск грани, расширяющей шап-
ку, включал в себя просмотр всех оставшихся граней, т. е.,
если мне задается ребро границы, я бы предпочел иметь воз-
можность быстрого доступа к необходимым данным, определя-
ющим другую грань, которой, принадлежит это ребро. Из на-
шего желания свести данные в таблицу — привычка работать
с массивами — вытекает, что нам нужно также вести учет и
группы перенумерованных ребер.
Тот факт, что ребро определяет две точки так же, как и
две грани, и что грань равно хорошо определяется своими тре-
мя точками и тремя ребрами, наводит нас на мысль постарать-
ся выбрать в качестве основных управляющих параметров
ребра. По-видимому, наиболее симметричным наш аппарат
будет тогда, когда мы занумеруем каждое неориентированное
ребро дважды, т. е. будем считать его суперпозицией двух за-
нумерованных, ориентированных ребер.
Пусть i — номер ориентированного ребра выпуклой обо-
лочки; тогда мы можем определить
UHe(i) = номер ориентированного ребра, которое соединя-
ет те же самые точки, что и ориентированное реб-
ро пгЛ, но в обратном направлении.
Далее, если мы связываем с каждой гранью три ориенти-
рованных ребра ее границы в порядке обхода по часовой
стрелке (правосторонней границы), то каждое ориентирован-
ное ребро является ребром в точности одной грани и вся топо-
логия полностью определяется с помощью еще одной функции
CAed(i) = номер ориентированного ребра, являющегося
следующим по часовой стрелке ребром той гра-
ни, к правосторонней границе которой принад-
лежит ребро гъгл; слово «следующий» означает,
что ребро «след(Г)» начинается там, где ребро
«^кончается.
В результате , мы имеем, что «г», «след(Г)» и «след
{след(1))» — это номера ребер, образующие в данном порядке
границу грани. Так как все грани — треугольники, справедливо
след [след (след(1))) = 1
Функции «инв» и «след» определяют полное топологиче-
ское описание выпуклой оболочки в терминах имен ориентиро-
ванных ребер. Если мы хотим перейти к номерам точек, мы
можем ввести третью функцию
конец(1) = номер точки, в которой оканчивается ориенти-
рованное ребро nr.i.
222 Глава 24
Тогда верно равенство конец (инв (/)) = конец (след (след
(/))), так как оба выражения обозначают номер точки, в ко-
торой начинается ориентированное ребро nr.i; левое выраже-
ние предпочтительнее не столько из-за того, что оно проще,
сколько потому, что оно не зависит от предположения, что все'
грани — треугольники.
Производить поиск множества ребер, которые оканчивают-
ся в точке, скажем rur.k, очень неудобно, и его следует избе-
гать. Вместо того чтобы запоминать значение <<k», нам нужно
запоминать «ей», такое, что конец (ek) =k. Тогда, например,
оператор
ek := инв (след (ek))
присвоит ek номер следующего ребра, оканчивающегося в й;
выполняя повторно данное преобразование, мы сможем «про-
крутить» ей по всем ребрам, которые заканчиваются в точке
ntr.k (и таким образом мы получим доступ ко всем граням, у
которых точка rur.k является вершиной).
Замечание. Так как инв (инв (Г)) = 1 и я думаю, что мы до-
статочно свободны в выборе номеров для ребер, мы можем вы-
бирать номера =#0 и ввести условие инв(1) =—г, в таком слу-
чае нам вообще не нужно хранить функцию инв. (Конец за-
мечания.)
Теперь мы попытаемся разделить текущую оболочку на две
шапки по отношению к новой вершине. Я стою на той точке
зрения, что обнаружение, по какую сторону грайи лежит новая
вершина, является трудоемкой операцией, и мне бы хотелось
сопоставлять новую точку с каждой гранью самое большее
один раз (а с некоторыми гранями, может быть, и не сопостав-
лять вообще).
Пользуясь языком метафор, мы можем считать новую точ-
ку лампой, освещающей все грани, на которые свет от нее па-
дает снаружи. Назовем их «светлыми» гранями, а все осталь-
ные «темными» гранями. Светлые грани должны быть удале-
ны; только тогда, когда точка находится внутри текущей
оболочки, все грани остаются темными.
После того как окрашена первая грань, мне, естественно,
хочется покрасить новые грани, являющиеся соседними к по-
крашенной. Теперь переда мной возникают два основных воп-
роса:
1. Считаем ли мы, что, пока мы обнаруживаем грани толь-
ко одного цвета, каждая следующая рассматриваемая грань
должна образовывать шапку с уже покрашенными гранями, или .
допускаем наличие «дыр»? Дело в том, что проверка, повлечет
Задача о выпуклой оболочке в трехмерном пространстве 223
ли добавление новой грани появление дыры, — операция, не
очень привлекательная.
2. После того как оказались использованными оба цвета,
мы знаем, что новая точка лежит вне текущей оболочки, и нам
также известно ребро, разделяющее две различно покрашен-
ные грани. Нужно ли нам изменить стратегию и отныне пы-
таться прослеживать границу между темными и светлыми гра-
нями, вместо того чтобы продолжать красить все грани пер-
воначальным цветом?
Мне потребовалось много времени, чтобы найти подходя-
щий ответ на эти вопросы. Так как мы встали на ту точку зре-
ния, что будем сопоставлять каждую грань с новой точкой са-
мое большее один раз, у нас в общем случае встречается три
вида граней: «темные», «светлые» и «еще неизвестно какие».
И нам необходимо запомнить определенное количество инфор-
мации об этом, чтобы не повторять сопоставления одних и тех
же граней с нашей новой точкой. Но у граней нет имен! Про
грань мы знаем только то, что «она расположена вдоль реб-
ра р>, т. е. у нее на границе при обходе по часовой стрелке име-
ется ребро г, а для каждой грани существует три таких реб-
ра. Поэтому кажется более выгодным в качестве основного
элемента- рассматривать не грани, а ребра; тем более что на
первом этапе мы ищем ребро между светлой и темной гранью.
Для того чтобы было удобнее сопоставлять, новую точку с
гранями, введем две константы: «правильный» и «неправиль-
ный»; «правильный» — это цвет (соответственно темный или
светлый) первой (произвольно выбранной) грани, которая со-
поставлялась с новой точкой, «неправильный» (соответствен-
но светлый или темный) —это противоположный ей цвет.
Пусть К — множество ребёр /, такое, что
1) грань вдоль ребра i правильная (и это уже установле-
но);
2) грань вдоль ребра — i еще не проверялась.
Таким образом, начальное состояние К содержит три реб-
ра правосторонней границы первой сопоставленной грани. Ког-
да множество К не пусто, мы выбираем из него произвольное
ребро, скажем ребро х, и грань вдоль ребра — х сопоставляем
(впервые, так как ребро х удовлетворяет критерию (2)) с но-
вой точкой. Если новая грань неправильная, то найдено пер-
вое ребро между двумя различно окрашенными гранями и мы
переходим ко второму этапу, обсуждать который будем позд-
нее. Если новая грань тоже правильная, мы выбираем ребра
у=—х, у = след(—х) и у = след(след(—х)), т. е. ребра право-
сторонней границы новой правильной грани, и для каждого из
224 Глава 24
этих трех значений выполняем следующие действия:
if ребро— у в /<—>удалить ребро — у из К
О ребро — у не в К -> добавить ребро у в К
fi
В первом случае ребро —у больше не удовлетворяет критерию
(2), во втором случае ребро у (которое не могло принадле-
жать К., так как не удовлетворяло критерию (1)) теперь удов-
летворяет критериям (1) и (2) (поскольку, если бы грань
вдоль —у была проверена раньше, ребро — у все еще было бы
в К).
Тем временем мы уже выработали некоторое мнение, по
крайней мере предварительное, по поводу вопросов 1 и 2: мы
не настаиваем на том, чтобы грани, правильность которых ус-
тановлена, всегда* образовывали шапку, и мы действительно
намереваемся менять стратегию при обнаружении первого реб-
ра, принадлежащего границе между шапками. (Эти решения
были приняты, когда я бросил писать и отправился на вечер-
нюю прогулку по нашему поселку. Сначала я заметил себе,
что прослеживание границы между двумя шапками, после то-
го как найдено одно из ее ребер, сводит двумерный . поиск к
одномерному и, следовательно, надо постараться использовать
эту возможность. Затем я осознал, что коль скоро я принял
эту стратегию, то, по-видимому, нет особого смысла добивать-
ся на первом этапе, чтобы грани, правильность которых уста-
новлена, всегда образовывали шапку. Далее некоторое время
я пытался представить себе, как выполнить первый этап в тер-
минах граней, являющихся правильными или непроверенны-
ми, пока не вспомнил то, что временно забыл, а именно что я
уже решил описывать структуру в терминах ребер. С уверен-
ностью, что теперь все должно получиться, я вернулся за стол
и написал то, что вы сейчас прочитали.)
Теперь нам нужно заняться вторым этапом. Пусть х—
ребро правосторонней границы правильной шапки .Как найти,
например, следующее ребро этой границы? Мы видели, как
можно перебирать грани с общей точкой; неизвестно одно —
достаточно ли знание множества К для соблюдения принципа,
что никакая грань не должна сопоставляться с новой точкой
больше одного раза.
Ну что ж, по-видимому, на это рассчитывать не приходит-
ся, так как когда мы находим какую-либо неправильную грань,
то, с одной стороны, мы не можем гарантировать, что мы уже
точно знаем, что надо делать с ней, т. е. со всеми соседними с
ней гранями, а с другой стороны, нам бы не хотелось сопостав-
Задача о выпуклой оболочке в трехмерном пространстве 225
лить эту неправильную грань с новой точкой более одного ра-
за. Простейший выход, вероятно, состоит в том, чтобы ввести
аналогичный аппарат для классификации ребер по отношению
к неправильным граням, а именно пусть Н — множество ре-
бер I, такое, что
1) установлено, что грань вдоль ребра i -неправильная;
2) грань вдоль ребра — t еще не проверялась.
Достаточно ли нам этого? Замечаем, что пересечение К и Н
пусто, так как никакое ребро I не может быть элементом и К,
и Н.
Можно ли перевычислить оба множества К и Н, когда но-
вая грань правильная и когда новая грань неправильная?
Пусть х — ребро из множества К, и снова рассмотрим три реб-
ра у, у= — ‘я, у=след(—х) и у= след (след (—х)). Пусть
в дальнейшем В — множество обнаруженных ребер правосто-
ронней границы правильной шапки.
Если новая грань правильная, то каждое из ее трех ребер у
обрабатывается так:
if ребро—у в ЛГ-► удалить ребро — у из К
□ ребро — у в Н удалить ребро — у из Н и
добавить ребро у к В
□ ребро — у не в (Н -|- К) добавить ребро у к. К
fi
Если новая грань неправильная, каждое из ее трех ребер у
должно быть обработано так:
if ребро — у в /С-> удалить ребро —у из К и
добавить ребро — у к В
О ребро — у в Н удалить ребро — у из Н
О ребро — у не в (Н добавить ребро у к Н
fi
Глядя на эти формулы, я делаю одно из удивительных от-
крытий, которыми так полна жизнь! Когда Н все еще пусто, а
новая грань правильная, перевычисление сводится — и это не
очень удивительно — к перевычислению из первого этапа. Но
мы же нигде не пользовались тем, что х — элемент К: если бы
х был элементом Н, этот алгоритм работал бы так же хорошо.
Мы требуем только, чтобы х был элементом объединения
Н-\-К, так как хотим избежать повторного сопоставления и
226 Глава 24
тем самым обеспечить завершаемость работы! С точки зрения
логики нам достаточно в качестве начального состояния К
выбрать ребра правосторонней границы первой грани, а в ка-
честве начального состояния Н и В — пустые множества. Тог-
да, до тех пор пока это возможно, мы будем выбирать произ-
вольное ребро х из объединения /f+A’ и подвергать последо-
вательные ребра у грани, расположенной вдоль ребра —%,
описанной выше обработке. Этот процесс заканчивается, ког-
да множество Н-\-К становится пустым; новая точка находится
внутри текущей оболочки тогда и только тогда, когда по окон-
чании работы В по-прежнему пусто!
Прежде чем продолжить рассуждения, мне кажется умест-
ным сделать несколько ретроспективных замечаний. Я ввел
ограничение, согласно которому каждая грань сопоставляется
с новой точкой только один раз, из соображений эффективно-
сти, сделав логически необоснованное предположение, что для
выполнения этой операции может потребоваться много време-
ни. Мне не следовало бы заботиться об эффективности еще на
первом этапе; мне следовало бы сосредоточить свое внимание
скорее на логических требованиях, гарантирующих окончание
работы. Если бы я это сделал, мне не пришлось бы так долго
возиться с «шапками» — этой навязчивой идеей — и я не стал
бы считать оба этапа логически различными! (Я должен был
бы более подозрительно отнестись к тому, что слишком долго
выбираю ответы на вопросы (1) и (2)!) К чему все сводится?
Мы замечаем, что если ребра в непустом множестве В образу-
ют цикл, то можно прекратить работу, даже если Н-\-К все
еще не пусто, и зная это, можно попытаться использовать наше
право выбора произвольного х из так чтобы найти по
возможности быстрее все ребра этого цикла. Поскольку мы
пытаемся сделать все как можно проще, естественно отложить
добросовестное прослеживание границы между двумя шапка-
ми как оптимизацию, которую мы, по всей видимости, можем
без труда ввести на более поздней стадии.
Введение понятий «правильный» и «неправильный», по-ви-
димому, также было ошибкой, если учесть то, как мы выбира-
ем ребро х из объединения /f+К. (Это было не’ только ошиб-
кой, это было глупой ошибкой. Я долго колебался, перед тем
как пойти на это, у меня были необычайные трудности с вы-
бором подходящих имен для них и с формулировкой их опре-
деления, но я не внял этим предостережениям, убеждая себя,
что я нашел нечто «хитрое».) Предадим забвению эти понятия
и будем работать с нашими первоначальными терминами
«светлый» и «темный». На этом пути у нас должна появиться
возможность сделать три упрощения:
Задача о выпуклой оболочке в трехмерном пространстве 227
1. Нам незачем по-особому обрабатывать первую прове-
ряемую грань; ее три ребра у могут обрабатываться так же,
как и ребра любой другой грани.
2. Обе приведенные выше различные конструкции обработ-
ки трех ребер новой проверяемой грани (для правильной гра-
ни и для неправильной грани соответственно) можно отобра-
зить на одну конструкцию выбора.
3. Нам не нужно менять направление ребер из множества
В, если оно окажется правосторонней границей темной
шапки.
Некоторые другие частности мы обсудим позднее, когда,
исследуем операцию модификации выпуклой оболочки для
включения новой точки.
После обнаружения непустой границы нахМ нужно удалить
внутренние ребра светлой шапки, если таковые имеются, и
добавить ребра, соединяющие новую точку с точками границы
этой шапки. Так как количество удаляемых ребер в общем
случае никак не связано с количеством добавляемых ребер,
мы предлагаем решать эти две задачи раздельно. В еще неде-
тализированный процесс поиска границы, при котором прове-
ряются все грани, нетрудно было бы ввести одновременное
удаление всех внутренних ребер светлой шапки. Но мне хо-
телось бы сохранить за собой право на оптимизацию поиска
границы, и поэтому нам йадо выбрать метод нахождения
множества внутренних ребер светлой шапки, когда задана ее
непустая правосторонняя граница В, независимо от того, как
эта граница была найдена.
В виду того что нахождение множества внутренних ребер
светлой шапки является частным случаем (не таким уж специ-
альным) более общей проблемы (ее более специальные слу-
чаи— это задача Хэмминга и обход двоичного дерева), мы
займемся сначала этой общей проблемой (которая по сущест-
ву является задачей о нахождении транзитивного замыкания).
Задано (конечное) множество элементов. Для каждого эле-
мента х определяются несколько (или ни одного) других эле-
ментов, называемых «преемниками х>>. Д«ля любого множест-
ва В множество S(B) задается следующими аксиомами:
Аксиома 1. Каждый элемент В принадлежит S(B).
Аксиома 2. Если х принадлежит S(B), то преемники х,
если таковые имеются, также принадлежат
5(B).
Аксиома 3. Множество S(B) содержит только те элемен-
ты, которые принадлежат ему согласно аксио-
мам 1 и 2.
228 Глава 24
Для заданного В требуется обеспечить истинность
R: У=5(В)
Идея алгоритма очень проста: инициализировать V: = B и
до тех пор, пока в V имеется элемент х, преемники которого
не принадлежат V, дополнять V этими элементами; когда все
такие элементы будут исчерпаны, остановиться. Алгоритм
можно улучшить, если учесть следующее: после того как ус-
тановлено, что для данного элемента у все его преемники уже
находятся в множестве V, такое положение будет сохраняться
и в дальнейшем. Это верно, потому что единственная модифи-
кация V состоит в расширении V новыми элементами. Следо-
вательно, оптимизация должна состоять в том, чтобы следить
за подмножеством из таких элементов у, поскольку их преем-
ников рассматривать больше не нужно. Таким образом, мно-
жество V разбивается на две части, которые мы назовем С
и1/~С. Здесь V~C содержит все элементы,-для которых бы-
ло установлено, что их преемники уже находятся в множестве
Vf а С содержит все оставшиеся элементы, у которых могут
найтись преемники, не содержащиеся в V. Алгоритм обраба-
тывает каждый раз один элемент из С. Пусть с — элемент
из С; он удаляется из С (и, следовательно, добавляется к
1/~С), а все его преемники, не принадлежащие V, заносятся
в V и С. Алгоритм прекращает работу, когда С пусто. Окон-
чание работы гарантируется конечностью множества 5(В)Г
так как, хотя число элементов С может и увеличиться, число
элементов У~С увеличивается на единицу на каждом шаге
работы, и это число ограничено сверху числом элементов
множества 5(B). (Количество шагов работы алгоритма не
зависит от порядка выбора элемента с из множества С!)
Данное неформальное описание предполагаемого вычисли-
тельного процесса может удовлетворить часть моих читате-
лей— меня оно удовлетворяло более пятнадцати лет. Я на-
деюсь, однако, что некоторые из читателей не будут удовлет-
ворены. Самое большее, что мы можем сказать, не формулируя
инвариантного отношения и не проводя четкого индуктив-
ного доказательства: «Я не понимаю, как этот вычислительный
процесс может не дать желаемого результата».
В доказательстве должно быть ясно выражено то, что под-
разумевается в интуитивном замечании о бессмысленности
обработки преемников данного элемента более чем один раз.
Для этого мы введем функции 5с (В), которые определяются
теми же самыми аксиомами^ что и множество 5(B), но для
другого множества преемников, а именно
если х принадлежит С, то у х нет преемников;
Задача о выпуклой оболочке в трехмерном.пространс!ее 229
если х не принадлежит С, то у х те же преемники, что и
в первоначальном определении.
Так как 3.0(B) =S(B), то в качестве инвариантных отно-
шений предлагается выбрать следующие отношения:
Pl : 1/=Зс(В) и Р2: С есть подмножество V
которые легко обеспечиваются с помощью присваивания
V, С: = В, В.
Функция .Sc (В) обладает следующими критическими свой-
ствами:-
1. Sc (В)—монотонная функция от С; это означает, что
если С2 есть подмножество С1, то Sci(B) есть подмно-
жество SC2(B).
2. Sc (В) не меняется, если С увеличивается за счет эле-
ментов, не принадлежащих Sc (В).
Пусть с — произвольный элемент С; расширение С преем-
никами с, не принадлежащими V, не изменяет истинности от-
ношения Р] ввиду второго свойства. Последующее удаление
с из С означает, что, в силу первого свойства, все элементы
V остаются в множестве V, которое (с учетом свойств Р1 и
Р2) модифицируется оператором:
V := V-J- (множество преемников с)
(где « + » означает объединение множеств). Образование это-
го объединения сводится к расширению V преемникам^ с, не
принадлежащими V, т. е. элементами, которые только что бы-
ли Добавлены к С; но, так как эти новые элементы «не имеют
преемников», модификация на этом заканчивается.
Замечание. Алгоритм транзитивного замыкания сам по
себе достаточно интересен, и не в последнюю очередь, из-за
того, что он показывает, почему обычное рекурсивное решение
задачи об обходе двоичного дерева является его частным
случаем. В роли С тогда выступает стек, и проверку, принад-
лежит ли V преемник с, можно опустить,.так как отсутствие
циклов в дереве обеспечивает то, что каждый узел будет
встречаться только один раз. В связи с этим наблюдением
возникают сомнения в правильности некоторых положений,
так высоко оцениваемых некоторыми специалистами, занима-
ющимися искусственным интеллектом. Одно из них заключа-
ется в том, что рекурсивные решения, которые считаются в не-
котором смысле «более основными», кажутся нам более ес-
тественными? чем решения с конструкциями повторения;
в связи с этим положением возникла область (полу) автома-
тических систем переделки программ, которые заменяют ре-
230 Глава 24
курсивные решения на (как считается, более эффективные)
конструкции повторения. Второе положение состоит в том, что
в случае поиска в конечной части потенциально бесконечного
множества необходимо лингвистическое средство рекурсивных
сопрограмм. Имеется в .виду, что из непустого множества С
в качестве с можно выбрать любой элемент, а каждый разра-
ботчик операционных систем знает, что стратегия «последним
пришел — первым ушел» чревата для индивидуального поль-
зования опасностью быть «замороженным»; каждый разработ-
чик операционных систем к тому же знает, как избежать этой
опасности. Не исключено, что будущие поколения решат, что
за последние пятнадцать лет рекурсивные решения были воз-
ведены на слишком высокий пьедестал. Если так и произой-
дет, то само это явление будет объясняться тем, что до послед-
него времени' у нас не было соответствующего математическо-
го аппарата для работы с повторениями и присваиваниями
переменным., {Конец замечания.)
В нашем примере в качестве В (из приведенной выше об-
щей трактовки) мы можем взять В, используемое при реше-
нии задачи о выпуклой оболочке, т. е. ребра правосторонней
границы светлой шапки. «Преемники ребра I» могут быть оп-
ределены так:
1) ничего, если след{1) принадлежит В;
2) след{1) и — след{1), если след{1) не принадлежит В.
Конечным значением V тогда будет В + {множество внутрен-
них ребер светлой шапки}.
Удаление внутренних ребер светлой шапки ставит перед
нами задачу меньшей трудности. Так как мы хотим иметь
таблицы функций след{1) и конец (i), нам бы хотелось зану-
меровать ребра выпуклой оболочки — исключая нуль — после-
довательными числами от —п до +п\ разумеется, мы можем
начать делать это (увеличивая массивы с обоих концов по ме-
ре роста и), но при удалении ребер в нашей системе номеров
начинают появляться «дыры». Представляется два пути вы-
хода из этого положения: либо мы перенумеровываем остав-
шиеся ребра выпуклой оболочки и в дальнейшем опять ис-
пользуем последовательные номера, либо мы ведем учет
«дыр» и используем их — когда они есть — как имена для до-
бавляемых ребер. Решение перенумеровывать оставшиеся реб-
ра,, в общем, не очень привлекательно, так как оно означает,
что нужно модифицировать все ссылки на перенумеровывае-
мые ребра. Хотя в нашем случае эта модификация, по-види-
мому, вполне осуществима, я бы предпочел воспользоваться
Задача о выпуклой оболочке в трехмерном пространстве 231
более общим методом учета «дыр», т. е. неиспользованных
имен в диапазоне от —п до + п.
Стандартным методом использования дыр является метод
типа «последним пришел — первым ушел»; для организации
стека дыр используется одна из имеющихся функций, напри-
мер след. Более точно:
i = 0 постоянно является самой ранней дырой;
если i(=/=0) есть дыра, то след (I) —следующая по возрас-
ту дыра.
И наконец, мы введем одну целую переменную, скажем пд
(«самая поздняя дыра»)/Удаление ребра Z, т. е. получение
вместо него дыры, выполняется следующими действиями:
след :(Г)—пд; пд : = Z;
если других дыр, кроме нуля, нет, то пд=0, иначе /г5#=0, и
присваивание i значения самой поздней дыры выполняется
операторами:
i: — пд;, пд : — след (Z)
Чтобы не усложнять управление данными, мы с одной ды-
рой i будем связывать пару ребер { + /, —I}.
По-видимому, наступила пора писать саму программу и
зафиксировать способы задания аргументов и формы получен-
ных ответов. Задается группа из точек с помощью трех
массивов констант х, у и z, так что
х.ниг = у.ниг = z.ниг=1
х.вег — у.вег=^.вег — М
и х((), */(0> г(0 Для есть соответственно координаты
х, у и z точки nr.i.
Выпуклую оболочку мы предлагаем описывать с помощью
двух массивов, «след» и «конец», и одной целой переменной
«старт» так, что
след .ниг —конец .ниг = — след.вег = —конец.вег
и
а) старт — это номер некоторого ориентированного ребра
выпуклой оболочки.
б) Если i — номер ориентированного ребра выпуклой обо-
лочки, то
(61) —i есть номер этого ориентированного ребра в об-
ратном направлении;
(62) конец (I) —номер точки, на которую указывает ори-
ентированное ребро i;
232 Глава 24
(63) след (I)—номер «следующего» ориентированного
ребра в правосторонней границе грани, расположен-
ной «вдоль» ребра i (определение понятий «следую-
щий» и «вдоль» дано гораздо раньше).
Допущение дыр предполагает, что, возможно, имеются (и да-
же должны быть) значения t, такие, что в конце работы
G^.abs(i) ^след.вег, но i не есть номер ребра из конечного
результата; введение переменной «старт» позволяет нам не
брать обязательств в отношении значения след (i) и конец (I)
для соответствующего значения i. Символически мы можем
теперь описать функцию внутреннего блока, который нам
предстоит разработать, следующим образом:
«(след, конец, старт) vir оболоч := выпуклая оболочка
(х, у, z)»
Если иметь в виду только наши внешние обязательства, то
мы могли бы ограничиться введением одной личной перемен-
ной, скажем п, инвариантного отношения
Р1: (след, конец, старт) = выпуклая оболочка первых п
точек (х, у, z)
и блока
«(след, конец,, старт) vir оболочка :=• выпуклая оболочка
(х, у, z)»
begin glocon х, у, z; virvar след, конец, старт1, privar п
«инициализировать Р\ при небольшом значении /г»;
do п ^=х.вег-+ «увеличить п на 1, соблюдая инвариант-
ность Р1» od
end
Но этого недостаточно по двум причинам. Во-первых, мы хо-
тим использовать дыры внутри повторяемого оператора, и по-
этому нам нужно ввести переменную пд для обозначения са-
мой последней дыры. Во-вторых, увеличение значения п пред-
полагает просмотр (вдоль граней) ребер выпуклой оболочки.
Мы могли бы ввести в повторяемый оператор массив, который
каждый раз мог бы инициализироваться некоторым специаль-
ным значением для каждого ребра, означающим «еще не сопо-
ставлялось с новой точкой». С логической точки зрения все
было бы совершенно правильно, но более эффективным ка-
жется вынесение этого массива за границы повторяемого опе-
ратора с последующим контролем того, чтобы просмотр кон-
чался теми же самыми нейтральными значениями, с которыми
он начался. Мы назовем этот массив «набор», а в качестве
нейтрального значения выберем 0. Обобщая сказанное, мы
вводим следующее инвариантное отношение:
Задача о выпуклой оболочке в трехмерном пространстве 233
Р2: (след, конец, с та рт)=выпуклая оболочка первых п
точек (х, у, z)
and пд = самая поздняя дыра
and (i есть дыра=^0)=> след (/) —следующая по
очередности дыра
and (/есть ребро (след, конец, старт)) =>набор (i) = Q
а вариант, с которого я предлагаю начать, имеет вид
«(след, конец, старт) vir оболоч : = выпуклая оболочка*
(х, у, г)»:
begin glocon х, у, z; virvar след, конещ старт', privar п,
пд, набор',
«инициализировать Р2 при небольшом значе-
нии /г»;
do пх.вег —> «увеличить п на 1, соблюдая
инвариантность Р2» od
end
Инициализация выполняется очень просто, так как доста-
точно сделать это для п = 3, треугольника с двумя грднями:
«инициализировать Р2 при небольшом значении /г»:
begin virvar след, конец, старт, п, пд, набор',
след vir цел array : = (— 3, — 2, — 1, — 3, 0, 2, 3, 1);
конец vir цел array : = ( — 3, 1, 3, 2, 0, 3, 1, 2);
старт vir цел := 1; п vir цел : = 3; nd vir цел : = 0;
набор v г цел array := ( — 3, 0, 0, 0, 0, 0, 0, 0)
end
Детализация оператора «увеличить и на 1, соблюдая инва-
риантность Р2» — единственное, что нам осталось сделать,—
более сложное дело. Увеличить п и выбрать точку п в качестве
новой точки (для ее координат будут введены переменные пх,
пу и nz) очень легко. Последующими шагами нужно опреде-
лить границу и, если она есть, модифицировать оболочку. На
первом шаге мы будем использовать значения набор (/) = ± 1
для обозначения «полуисследованных» ребер, т. е.
набор, (i) = + 1 означает: установлено, что грань вдоль ребра
i светлая, грань вдоль ребра —i еще
не сопоставлялась с текущей новой
точкой;
набор (i) = — 1 означает: установлено, что грань вдоль ребра i
темная, грань вдоль ребра —i еще
не сопоставлялась с текущей новой
точкой.
набор (i) = +2 означает: установлено, что ребро i принадлежит
правосторонней границе светлой
шапки.
234 Глава 24
Для ребер выпуклой оболочки, не принадлежащих ни к одной
из данных категорий, во время поиска границы набор (i)=0.
Когда этот поиск будет завершен, всем ребрам i, для которых
было набор (t) = ±l, будут снова соответствовать набор (t),
равные 0 или 2.
Кроме фиксирования границы как «ребра, у которых на-
бор (i)=2>, полезно иметь список номеров этих ребер в цик-
лическом порядке, чтобы они оказывались под рукой, когда
придется добавлять ребра, идущие в новую точку и выходящие
из нее. Поскольку нами принята оптимизация, состоящая
в переключении на линейный поиск после обнаружения первого
ребра границы и выборе ребер в циклическом порядке, в на-
шей версии такой список будет получаться автоматически.
Мы предлагаем фиксировать номера ребер правой границы
в некотором массиве, скажем «£>»; тогда условие Ь.обл — О
можно считать показателем того, что никакой границы не
найдено. Наш грубый набросок программы теперь имеет вид
«увеличить п на 1, соблюдая инвариантность Р2»:
begin glocon х, у, z; glovar след, конец, старт, п, пд,
набор',
pricon пх, пу, nz; privar b;
п :== п-\-1;
пх vir цел, пу vir цел, nz vir цел;=х(п}, y(n),z(n);
b vir цел, array := (0);
«занести границу в набор и /»>;
if Ь.обл=0—> пропустить
□ Ь. обл > 0 —♦ «модифицировать оболочку»
fi
end
Занесение границы в «набор» и «Ь» будет выполняться в
два шага: на первом шаге все грани сопоставляются с новой
точкой и граница фиксируется в массиве «набор»; на втором
шаге нам необходимо просмотреть границу и занести ее ребра
в список «Ь» в циклическом порядке. Сначала я намеревался
дойти до этого места и предоставить читателям как упражне-
ние по оптимизации переход к более линейному поиску при
нахождении первого ребра границы, теперь я изменяю свое
решение потому, что обнаружил трудность, о которой раньше
не подозревал: при первом исследовании какой-либо грани
для выбора ребра границы таких ребер может обнаружиться
несколько. Если грани — треугольники, то ребра будут смеж-
ными ребрами границы, но отсутствие граней с большим чис-
лом ребер объясняется лишь ограничением, что у нас никакие
четыре точки не лежат в одной плоскости. Я не придавал
этому ограничению большого значения и поэтому отказываюсь
Задача о выпуклой оболочке в трехмерном пространстве 235
использовать эту более или менее случайную смежность ребер
границы, которые могут быть обнаружены при исследовании
новой грани. А возможное «одновременное» обнаружение
несмежных ребер границы я как раз -и не учел; смежность
может иметь значение, если мы хотим выбирать ребра границы
в циклическом порядке, т. е. в циклическом порядке заносить
номера ребер в массив b («Ь : вверх»). Отсюда, видимо, сле-
дует, что нужно отделить «обнаружение» ребра границы при
просмотре ребер впервые исследуемой грани от построения
значения массива «Ь». Так как обнаруженные ребра границы
должны быть разделены на ребра «обработанные», т. е. заре-
гистрированные в массиве «6», и ребра еще не обработанные,
в массиве «набор» нужно хранить некоторую добавочную ин-
формацию. Я предлагаю следующее:
набор(1) = \ and набор(—‘i) = 0 установлено, что грань вдоль
ребра I светлая, грань вдоль
ребра —i еще не сопоставля-
лась с текущей новой точкой;
набор(1) =— 1апйнабор(—i) = Q установлено, что грань
вдоль ребра I темная, грань
вдоль ребра —i еще не со-
поставлялась с текущей но-
вой точкой;
набор (I) = 1 and набор (—i) = — 1 ребро i — это необработан-
ное ребро правосторонней
границы светлой шапки;
набор(1) =2 and набор(—Т) = 0 ребро i— это обработанное
ребро правосторонней грани-
цы светлой шапки;
набор(1) =0 and набор(—i) = 0 либо грани вдоль ребер /и
—I не исследовались, либо
установлено, что они одного
цвета.
Мы придерживаемся нашего первоначального принципа —
исследовать только грани вдоль (в обратном направлении)
полуисследованного ребра, скажем вдоль — хх (т. е. набор
(хх) = ± 1 and набор (—хх)=0); тогда мы можем использо-
вать значение хх = 0 как указание того, что проверки больше
не нужны. Отношение «Ь.обл = &» указывает, что к этому мо-
менту ребер границы не было обнаружено; первое обнаружен-
ное ребро границы будет помещено в b (и таким образом при-
ведет к Ь.обл=\), а остальные ребра границы будут затем по-
мещаться в осторожно увеличиваемый массив Ь. Первый
набросок программы (на этом уровне все еще слишком гру-
бый) имеет вид
236 Глава 24
«занести границу в набор и Ь-»:
begin glocon х, у, z\ след, конец, старт, пх, пу, nz-,
glovar набор, b\ privar хх-, хх vir цел := старт-,
do хх =/= О—»
«исследовать грань вдоль —хх»;
if Ь.обл^>0—» «расширить b и обновить хх»
О b. обл — 0 — «перевычислить хх»
fi
od
end
(Различные названия операторов «обновить хх» и «перевы-
числить хх» указывают на то, что при этом применяются раз-
личные стратегии.)
Этот набросок я назвал слишком грубым, так как опера-
тор «перевычислять хх» должен присваивать хх номер полу-
исследованного ребра (если таковое можно найти, в против-
ном случае — нуль). Было бы очень неприятно, если бы это
потребовало просмотра всей текущей оболочки и, следова-
тельно, введения аппарата, предотвращающего повторный
выбор одного и того же ребра во время поиска! Поэтому мы
введем массив с («кандидаты») и обеспечим следующее:
если i — номер полуисследованного ребра, то либо i
встречается среди значений векторной функции с, либо
t=xx.
(Заметим, что значения функции с —которые всегда будут
номерами ребер — могут также равняться номеру ребра, кото-
рое уже полностью обработано.) Принимая во внимание, что
последнее значение, присваиваемое величине хх, есть нуль,
удобно занести это значение в нижний конец с при инициали-
зации (это эквивалентно введению «виртуального ребра» с
номером нуль, что является обычной программистской улов-
кой). Наша новая версия принимает вид
«занести границу в набор и Ь»:
begin glocon х, у, z, след, конец, старт, пх, пу, nz-
glovar набор, b; privar хх, с;
хх vir цел старт-, с vir цел array := (0, 0);
do хх =/= 0—> «исследовать грань вдоль —хх»;
if Ь-обл>§ —««расширить b и обновить хх»
П/>.обл. = 0 —» «перевычислить хх»
fi
od
end
Поскольку при «перевычислить хх» ребро хх первоначаль-
но не полуиссл едокаиное (т. к. грань вдоль ребра — хх только
Задача о выпуклой оболочке в трехмерном пространстве 23Т
что была проверена!) и
abs [набор[хх))=\ and набор[ — хх)=0
есть условие полуисследованности, то последний подалгоритм
кодируется совсем просто:
«перевычислить хх»:
do хху= 0 and non [abs[Ha6op[xx))= 1 and
набор (~хх)~ 0) —>хх, с:векон
od
Алгоритм для «расширить b и обновить хх» более сложен..
Если мы сконцентрируем внимание на поиске ребра, которое
затем занесем в &, то обнаружим, что ищем ребро, скажем
хх, такое, что
Р1: оно начинается там, где кончается ребро Ь.верх, т. е. конец.
[Ь.верх) = конец (—хх)
Р2: установлено, что грань вдоль* ребра хх светлая
РЗ: установлено, что грань вдоль ребра — хх темная
Так как оператор хх: = след [Ь.верх) обеспечивает истин-
ность первых двух условий, мы выбираем в качестве инвари-
анта Р\ and Р2. Теперь можно выделить четыре (вот почему
этот алгоритм более сложный) различных случая.
1. набор (хх) = 1 and набор (—хх) =—1: в этом случае хх
есть'следующее ребро правосторонней границы светлой шап-
ки, которое должно'быть обработано; после его обработки
оператор хх\ = след [хх) восстанавливает условие Pl and Р2.
2. набор [xx)=Q and набор [—хх)=0: в этом случае, по-
скольку установлено, что грань вдоль ребра хх светлая, грань
вдоль ребра —хх также светлая; следовательно, оператор-
хх\ = след (—хх) определяет новое ребро хх, удовлетворяющее
условию Pl and Р2.
Операция (1) может встретиться только конечное число-
раз, так как существует лишь конечное число ребер правосто-
ронней границы светлой .шапки, которую нужно обработать.
Операция (2) повторится лишь конечное число раз, потому
что конец (—*хх) есть/ вершина грани, про которую известно,
что она темная. Когда ни одна из этих операций не имеет
места, может быть один из следующих двух случаев:
3. набор (хх) = 1 and набор [—хх)=0: в этом случае грань
вдоль ребра —хх еще не исследовалась и значение хх годится
для управления исследованием следующей грани.
4. набор (хх)=2 and набор (—хх)=0: в этом случае хх —
обработанное ребро границы и цикл должен быть уже закрыт..
238 Глава 24
у нас должно выполняться равенство хх=Ь.низ и, следователь-
но, поиск завершен, т. е.*хх = 0— это единственно приемлемое
конечное значение хх. Однако необходимо следить за тем, что-
бы не осталось ни одного ребра, у которого набор (i) = ± 1.
В следующей программе в целях безопасности выбраны бо-
лее сильные предохранители, чем это, строго говоря, необхо-
димо:
«расширить b и обновить хх»:
хх: = след )Ь. верх)-,
•do наборах) — 1 and набор) — хх) — — 1 —>
набор: (хх)=2; набор : ( — xx) = 0; b: вверх (хх);
хх: = след (хх)
[] набор(хх)—^ and набор) — хх)=0—»хх: = след)—хх)
od;
if набор (хх)=\ and набор) — хх)=0 —> пропустить
□ набор )хх)—2 and набор) — xx)=0 and хх=Ь.низ —>
хх, с: векон;
do хх=/= 0 —►
do abs (набор )хх))=1 —> набор-: )хх)=0 od;
хх, с: векон
od
fi
В предположении, что оператор «вычислить осе» инициали-
зирует осе значением +1, когда грань вдоль —хх светлая и
—1, когда она темная, кодирование оператора «исследов'ать
грань вдоль ребра —хх» становится совсем простым,
«исследовать грань вдоль ребра — хх»:
•begin glocon х, у, z, след, конец, пх, пу, nz, хх;
glovar набор, b, с, pricon осе; privar уу, круг;
«вычислить осе»;
уу vir цел: = — хх; круг vir бул := ложь;
do non круг—*
if набор) —у у)=0—* набор: (уу)—осе; с: вверх(уу)
О набор) — уу)—осе —> набор:)—у у)—О
□ набор ) — уу)= — осе —>
набор : (уу) — осе;
do b .обл=0 —» Ь : вверх (осе * уу) od
fi;
у у := след {уу); круг:= )уу= —хх)
od
«nd
Программирование вычисления «осе» несложно, но утоми-
тельно: оно сводится к вычислению объема (со знаком)
Задача о выпуклой оболочке в трехмерном пространстве 239
тетраэдра с вершинами и, конец (—хх), конец (след (—хх)) и
конец (след (след (—хх))). В нижеследующем мы учитываем,,
в какую сторону вращаются стрелки наших часов.
«вычислить осе»;
begin glocon х, у. г, след. конец, пх. пу. nz. хх;
vircon осе; privar тчк-.
pricon об. xl, yl. zl. х2.~у2. z2. хЗ, z/З, гЗ;
тчк vir цел := конец ( — хх);
xl vir цел. у\ vir цел. z\ vir цел: =
. х (тчк) — пх. у (тчк) — пу. z (тчк) — nz;
тчк: = конец (след (— хх));
х2 vir цел. у2 vir цел. z2 vir цел; =
х (тчк) — пх.у (тчк) — ny.z (тчк) — nz;
тчк: = конец (след (след (— хх)));
хЗ vir цел. уЗ vir цел. z3 vir цел; =
х (тчк) — пх.у (тчк) — ny.z (тчк) — nz;
об vir цел := xl *(y2*z3 —уЗ*г2)-|-
х2 * (уЗ * zl—yl * гЗ) +
x3*(yl * z2 — у2 * zl);
if об>0 —>осе vir цел;= — 1
□ о£<0—*осв vir цел;=-\-\
fi
end
Нам осталось детализировать оператор «модифицировать-
оболочку», причем ребра В правосторонней границы светлой
шапки заданы двумя способами:
1. В циклическом порядке как значение векторной функции
Ь; это представление позволяет прослеживать границу, выпол-
няя какую-нибудь работу для всех ребер В. и т. д.
2. набор (I) =2 выполняется тогда и только тогда, когда
ребро i принадлежит В; это позволяет нам быстро ответить на
вопрос: принадлежит ли В ребро i?
Так как число ребер, которые должны исчезнуть (внутрен-
ние ребра светлой шапки), и число добавляемых ребер (ребер,
соединяющих новую точку с вершинами правосторонней гра-
ницы) никак не связаны, представляется целесообразным раз-
делить эти два вида деятельности:
«модифицировать оболочку»:
«удаление ребер»;
«добавление ребер»
В первом операторе нам кажется не слишкОхМ привлекатель-
ным объединять идентификацию внутренних ребер и их уда-
ление: в процессе идентификации нужно просматривать свет-
лую шапку текущей оболочки, и я бы не стал изменять струк-
240 Глава 24
туру оболочки прежде, чем полностью закончится весь
просмотр. (Не следует считать, что это невыполнимо, я просто
хочу сказать, что у меня сейчас нет желания исследовать эту
возможность.)
Так как ввиду нашей концепции «дыр» внутреннее ребро i
и внутреннее ребро —I должны удаляться одновременно, до-
статочно построить список номеров «неориентированных» ре-
бер, т. е. значение i будет указывать, что должны исчезнуть
оба ребра i и —I. Назовем этот список ур (удаленные ребра);
мы получаем
«удаление ребер»:
begin glocon b; glovar след, nd, набор-, privar yp;
«инициализировать ур списком внутренних ребер»;
«удаление ребер, перечисленных в ур»
end
В соответствии с на'шей прежней договоренностью о дырах
второй оператор кодируется совсем просто:
«удаление ребер, перечисленных в ур»:
do ур.обл >0—»след: (ур. верх)=пд; пд, ур:векон od
С учетом нашего анализа инициализация ур не представ-
ляет трудности. Отношение набор (i) = набор (—0=3 будет
использоваться для представления того факта, что «было об-
наружено, что i и —i есть внутренние ребра»; это позволит
нам проверять, принадлежит ли ребро i множеству, которое
мы назвали V (граница+внутренние ребра), с помощью нера-
венства набор (t)J>2. Здесь мы снова используем векторную
переменную массива «с» для хранения списка кандидатов.
«инициализировать ур списком внутренних ребер»:
begin glocon b, след; glovar набор; virvar ур; privar с, k;
с vir цел array :== (0); k vir цел:—b.ниг;
do с .обл=^Ь.обл—>с -.вверх (b(k)); k :=£-}-l od;
yp vir цел array: — (0);
do с.обл^>0—►
begin glocon след; glovar набор, yp, c; pricon h;
h. vir цел : — след (с.верх); с-.сверху;
if набор(к)^2—>пропустить
[\набор (ti)=0 —> набор: (h)=3; набор: ( —й)=3;
ур: вверх (h); c:eeepx(h); с : вверх ( — h)
fi
end
od
•end
Задача о выпуклой оболочке в трехмерном пространстве 241
И наконец, нам нужно детализировать «добавление ребер».
Если мы будем обрабатывать по одному ребру границы, соеди-
няя его конец с новой точкой, то возникают трудности с обра-
боткой первого треугольника: номер ребра, соединяющий era
начало с новой точкой, еще не был определен. В начале мы
можем поступать так, как если бы это было виртуальное реб-
ро пг.нуль, и соответственно инициализировать t («проба»), а
в конце замкнуть цикл. Прежде чем локальная константа е
инициализируется значением номера самой ранней, дыры, ал-
горитм проверяет, есть ли такая дыра на самом деле, в про-
тивном случае такая дыра заводится путем расширения соот-
ветствующих массивов с обоих концов. В конце работы алго-
ритма* нужно удостовериться, что значение переменной «старт»
снова есть номер ребра выпуклой оболочки. (Вот типичный
пример оператора, который можно легко упустить из виду; и
это, между прочим, произошло со мной, так как вначале я на-
меревался включить данное переопределение в оператор
«удаление ребер», потому что это как раз то действие, при
котором величина «старт» может легко принять значение но-
мера ребра, не являющегося больше частью выпуклой оболоч-
ки. Мое внимание было привлечено к этому упущению, когда
я исследовал окружение «добавления ребер», которым явля-
ется окружение «модифицировать оболочку», где я обнару-
жил старт среди глобальных переменных', Так как мне было
лень вносить изменение в уже отпечатанную часть рукописи,
я поддался соблазну прибегнуть к типичной программистской
«заплате»!)
«добавление ребер» :
begin glovar след, конец, старт, пд, набор', glocon п, Ь;
privar t, k;
t vir цел, k vir цел:=0, Ь.ниг;
do k Ь.вег-+-
begin glovar след, конец, nd, набор t, k; glocon n, b;
pricon e;
do nd=0след : вверх (Q); след : вниз (0);
конец : вверх (0); конец : вниз (0);
набор : вверх (0); набор : в .из (0;;
пд : = след. вег
od;
242 Глава 24
е vir цел'.— пд; пд := след(е);
след :(b (k))=e; набор :(b(k))=O;
след :(е)—/; конец \(е}=п; набор :(^)==0;
след: t — b(t); конец .(1)—конец( — Ь(к)); набор :(/)=0;
t := — е; k:= k-\-1;
end
od;
след: (след (b .низ))=1;
след: (t) = b.низ; конец : (1)=конец ( — Ь.низ);
набор: И = 0;
след \ (Q)=Q; конец : (0)=0; набор : (0)=0;
старт : = Ь. низ
end
Этим завершается история создания первого алгоритма,
который'я написал для построения выпуклой оболочки в трех-
мерном пространстве. Это моя первая попытка, и алгоритм,
который получился в результате, по-видимому, не очень эф-
фективный;_.разумеется, причина его публикации заключается
не в его «качестве». (Я с удовольствием оставлю читателям
как упражнение разработку более эффективных алгоритмов.
Я же на этом останавливаюсь, так как, в конце концов, эта
книга не есть трактат по алгоритмам построения выпуклых
оболочек.) Включение этой главы в книгу связано с другими
причинами.
Первая причина была сформулирована в начале главы: из-
бежать обвинения в том, что я занимаюсь только легкими,
небольшими задачами.
Вторая причина состояла в том, что мне хотелось показать,
как к таким алгоритмам можно прийти при помощи процесса
пошаговой детализации. Если говорить совсем откровенно, я
хотел показать большее, а именно что метод пошаговой дета-
лизации является, по-видимому, наиболее многообещающим
способом разработки программ (весьма) значительной, но
еще преодолимой сложности. Надеюсь, что в разобранном при-
мере мне это удалось сделать. Я думаю, что этот пример за-
служивает того, чтобы его назвали примером «значительной,
но еще преодолимой сложности», так как конечная программа
состоит из тринадцати именованных блоков с «иерархией вло-
женности» (назовем это так), равной пяти! Это можно увидеть
Задача о выпуклой оболочке в трехмерном пространстве 243
из следующей таблицы; отступления в начале строк означают
новый уровень:
0) {след, конец, старт) vir {оболочка] := выпуклая оболоч-
ка {х, у, z}
1) инициализировать Р2 при небольшом значении п
1) увеличить п на 1, соблюдая инвариантность Р2
2) занести границу в набор и b
3) исследовать грань вдоль — хх
4] вычислить ос в
3) расширить b и обновить хх
3) пёревычислить хх
2) модифицировать оболочку
3) удаление ребер
4) инициализировать ур списком внутренних ребер
4) удаление ребер, перечисленных в ур
3) добавление ребер
Метод пошаговой детализации разработан как сознатель-
ная попытка учесть незначительность объема наших челове-
ческих черепов. Из него следует, что, когда нам нужно разра-
ботать алгоритм, который будет представлен большим
текстом, нам достаточно выработать * понятия, позволяющие
описывать алгоритм на таком уровне абстракции, на котором
описание становится достаточно коротким и, следовательно,
интеллектуально управляемым. И что касается этой цели, ме-
тод пошаговой детализации ей, по-видимому, соответствует.
Разумеется, он не дает гарантии получения программы, во
всех отношениях высококачественной!
Третья причина включения в книгу этой главы заключа-
лась в том, что мне-хотелось, по возможности, ничего не утаи-
вать и, следовательно, быть убедительным. Первым примером,
который я привел для демонстрации метода пошаговой дета-
лизации, была разработка программы получения таблицы
первой тысячи простых чисел. Хотя во многих отношениях это
был привлекательный и компактный пример, его убедитель-
ность снижалась тем, что каждый знал, что я уже умел гене-
рировать первую тысячу простых чисел, прежде чем начал
писать эссе на эту тему. Вот поэтому я и написал данную
главу; у меня не было ни малейшего представления, чем за-
"244 Глава 24
кончится моя попытка, когда я ее начал. Написав несколько
страниц, я их перепечатывал, прежде чем идти дальше.
Замечание 1. Когда были перепечатаны последние страни-
цы, мы обнаружили в тексте программы три ошибки: была
пропущена точка с запятой, в операторе «удаление ребер, пе-
речисленных в ур» я написал «след: (пд) =ур.верх» и в опе-
раторе «инициализировать ур списком внутренних ребер»
строка «с: вверх (h)-, с: вверх (—h)» была пропущена. Стоит
•обратить внимание на то, что только самая тривиальная из
них могла бы быть обнаружена при проверке синтаксиса.
Стоит также обратить внимание на то, что две другие ошибки
произошли в разделах, про которые я написал, что они «те-
перь программируются совсем легко» и «не представляет
больше трудности» соответственно! (Конец замечания 1.)
Замечание 2. Никоим образом не исключается, что эффек-
тивность моей программы может быть значительно увеличена
даже без привлечения стратегий, основанных на математиче-
ском ожидании числа точек внутри данного объема: если точка
уже находится внутрй выпуклой оболочки, ее не нужно сопо-
ставлять со всеми гранями; если она находится снаружи, то
должны быть (правда, в среднем!) более дешевые способы
нахождения первого ребра границы светлой шапки. Если, на-
пример, выпуклая оболочка содержит-более пяти точек, су-
ществует по крайней мере одна пара точек, связь между кото-
рыми проходит внутри, и мы могли бы попытаться найти
пересечение выпуклой оболочки и плоскости, проходящей че-
рез новую точку и две точки такой пары. В этом случае наши
просмотры стали бы линейными. (Конец замечания 2.)
25 НАХОЖДЕНИЕ МАКСИМАЛЬНО СИЛЬНЫХ
КОМПОНЕНТ В ОРИЕНТИРОВАННОМ ГРАФЕ
Задан ориентированный граф, т. е. множество вершин и
множество ориентированных ребер, идущих от-одной вершины
к другой; требуется разбить множество вершин на так назы-
ваемые «максимально сильные компоненты». Сильная ком-
понента— это множество таких вершин, что ребра между
ними обеспечивают ориентированный путь от произвольной
вершины множества ю любой другой вершине множества, и
наоборот. Одна-единственная вершина есть специальный слу-
чай сильной компоненты; следовательно, путь может быть
пустым. Максимально сильная компонента — это такая силь-
ная компонента, к которой нельзя добавить других вершин.
Чтобы производить описанное разбиение, нам необходимо
уметь доказывать два вида утверждений: утверждение, что
вершины принадлежат одной и той же сильной компоненте,
и — так как нам нужно найти максимально сильные компо-
ненты— утверждение, что вершины не принадлежат одной и
той же сильной компоненте.
Для первого типа утверждений нам может пригодиться
следующая теорема.
Теорема 1. Циклически связанные вершины принадлежат
одной сильной компоненте.
Кроме (ориентированных) связей между конкретными вер-
шинами мы можем говорить об ориентированных связях меж-
ду различными,сильными компонентами; мы говорим, что име-
ется связь от сильной компоненты А к сильной компоненте В,
если существует ориентированное ребро от некоторой верши-
ны А к некоторой вершине В. Так как А и В — сильные ком-
поненты, то, следовательно, имеется путь от любой вершины
А к любой вершине В. В результате обобщением теоремы 1
является
Теорема 1А. Вершины циклически связанных сильных ком-
понент принадлежат одной сильной компоненте.
246 Глава 25
Следствие 1. Непустой граф имеет по крайней мере одну
максимально сильную компоненту без выходящих ребер.
Достаточно о теоремах, утверждающих, что вершины при-
надлежат одной и той же сильной компоненте. Так как меж-
ду различными точками, принадлежащими одной и той же
сильной компоненте, должны существовать пути в обоих на-
правлениях, утверждения, что вершины не принадлежат одной
и той же сильной компоненте, могут быть сделаны с учетом
того, что утверждает
Теорема 2. Если вершины подразделены на два множества
мв А и мв В так, что не существует ребер, начинающихся
в вершине множества мв А и оканчивающихся в вершине мно-
жества мв В, то, во-первых, множество сильных компонент не
зависит от того, есть или нет ребра, начинающиеся в вершине
множества мв В и оканчивающиеся в вершине множества
мв Л, и, во-вторых, ни одна сильная компонента не содержит
вершин обоих множеств.
Из теоремы 2 следует, что, как только найдена сильная
компонента без выходящих ребер, мы можем взять ее верши-
ны в качестве множества мв А и заключить, что эта сильная
компонента является максимально сильной компонентой и что
все входящие в мв А ребра в дальнейшем могут не учитывать-
ся. Отсюда следует
Теорема 2А. Сильная компонента, у которой выходящие
ребра, если они есть, все являются входящими ребрами мак-
симально сильных компонент, сама является максимально
сильной компонентой.
Или, иначе говоря, как только найдена первая максимально
сильная компонента без выходящих ребер,— существование
которой обеспечивает следствие 1,— остальные максимально
сильные компоненты можно найти, решив нашу задачу для
графа, состоящего из оставшихся вершин и только тех ребер,
которые проходят между ними. Или, говоря еще иначе, макси-
мально сильные компоненты графа могут быть упорядочены
по «возрасту» так, что каждая максимально сильная компо-
нента обладает выходящими ребрами, идущими только к более
«старом» компонентам.
Чтобы иметь возможность делать несколько более строгие
утверждения, введем следующие обозначения:
мв\ заданное множество вершин (константа)
мр: заданное множество ребер (константа)
рзв: разбиение вершин множества мв
Нахождение максимально сильных компонент в ориентированном графе 247
Тогда отношение, которое должно выполняться в конечном
счете, можно записать так:
/?: рз# = МСК (мр),
где для фиксированного множества мв функция МСК, т. е.
разбиение на максимально сильные компоненты, рассматри-
вается как функция от множества ребер мр.
Соответствующее инвариантное условие получается при по-
мощи стандартной замены константы переменной, скажем
мру значением которой всегда будет подмножество множест-
ва мр\
Pi рзя = МСК (мр\)
Условие Р легко инициализируется при мр\, равном пусто-
му множеству, т. е. каждая вершина мв сама является макси-
мально сильной компонентой. Так как мр\ ограничено сверху
множеством мр, монотонный рост мрХ обеспечивает завершае-
мость процесса; если нам удастся сделать это, соблюдая инва-
риантность Р, то условие R выполнится, когда мр\=мр. В на-
ших рассуждениях мы будем использовать имя мр2 для обо-
значения множества оставшихся ребер, т. е. мр=мр\ + мр2.
Очевидно, что наша задача состоит в отыскании самого
удобного порядка добавления ребер к мру здесь под «удобст-
вом» понимается легкость, с которой обеспечивается выполне-
ние условия Р. Это, как мы знаем, можно выразить так: каково
наше общее промежуточное состояние, какие- типы рзв-зна-
чений мы допускаем? Для описания такого общего промежу-
точного состояния представляется практически удобным сгруп-
пировать вершины мв 'в непересекающиеся подмножества
(как мы сделали для ребер мр! и мр2). В конце концов, ведь
нас интересует разбиение вершин!
Общее промежуточное состояние должно быть обобщением
как начального, так и конечного состояний. В начале мы ни
про какую вершину не знаем, к какой максимально сильной
компоненте в МСК (мр) она принадлежит, в конце нам извест-
но это про любую вершину. Подобно множеству мрУ мы мо-
жем ввести (вначале пустое, а в конце содержащее все верши-
ны) множество мвУ где
мв1 содержит все вершины из мв, для которых уже извест-
на максимально сильная компонента в МСК(лф)^
которой они принадлежат.
Для определения того, что сильная компонента является
максимальной, мы будем использовать теорему 2А, т. е. будем
проверять все ее выходящие ребра. Если у нас
248 Глава 25
мр! — множество всех обработанных ребер и
мр2— множество всех необработанных ребер, т. е. ребер,
которые еще не принимались в расчет,
то мы имеем
Р1: все ребра, выходящие-из вершин, принадлежащих мв1,
принадлежат мр1.
Впрочем, группировать все оставшиеся вершины в одно
множество мв2 не очень выгодно. Из того, как определено
множество мв1, вытекает, что всякий раз, когда определяется
новая максимально сильная компонента МСК (мр), все верши-
ны этой максимально сильной компоненты должны быть одно-
временно перенесены в мв1. Между двумя такими перенесения-
ми, вообще говоря, должно быть обработано (т. е. перенесено
из мр2 в мр!) некоторое количество ребер, и для описания
промежуточных состояний с учетом «обработки по одному
ребру» все оставшиеся вершины должны быть разделены на
группы несколько более дифференцированно, а именно на
два непересекающихся подмножества, скажем мв2 и мвЗ
(мв = мв1± мв2±мвЗ), где мвЗ содержит никак не обработан-
ные вершины,
Р2: ни одно ребро из мр1 не начинается и не кончается в
вершине из мвЗ
(мвЗ в начале равняется мв, а в конце пусто).
Перенесение вершин из мвЗ в мв1 может выполняться в два
этапа: из мвЗ в мв2 (по одному) и из мв2 в мв1 (вместе со все-
ми другими вершинами из той же самой определенной мак-
симально сильной компоненты).
Другими словами, из вершины множества мв2 мы попыта-
емся построить (увеличивая мр!) следующую максимально
сильную компоненту МСК(-мр) для перенесения в мв1. Мак-
симально сильные компоненты в МСК(л/р1) (обратите внима-
ние на это рассуждение!) таковы, что они включат либо толь-
ко вершины из мв\, либо только вершины из мв2, либо одну
(единственную) вершину из мвЗ. Мы предлагаем пользовать-
ся следующим ограничением на связи, определяемые ребрами
из мр\ между максимально сильными компонентами в МСК
(лф1), которые содержат вершины только из мв2\ между эти-
ми максимально сильными компонентами ребра*из мр\ долж-
ны образовывать один и только один ориентированный путь,
ведущий из самой «старой» компоненты в самую младшую.
Мы будем называть такие максимально сильные компоненты
«элементами цепочки». Этот выбор объясняется следующими
соображениями.
Во-первых, мы ищем циклический путь, который позволит
Нахождение максимально сильных компонент в ориентированном графе 249
нам применить теоремы 1 или 1А к решению вопроса о том,
что некоторые различные вершины принадлежат одной и той
же максимально сильной компоненте. В предположении, что
мы имеем право предписывать порядок добавления следую-
щих ребер к мр1, по-видимому, не имеет большого смысла
вводить в МСК (мр!) разобщенные максимально сильные
компоненты, построенные из вершин множества мв2.
Во-вторых, направленный путь из «старейшей» в «самую
младшую» компоненту цепочки — как цикл «in statu nas-
cendi» — строится довольно легко, как показывает следующий
анализ.
Предположим, что в мр2 содержится ребро, выходящее из
одной из вершин самой младшей максимально сильной компо-
ненты цепочки. Тогда это ребро «е» переносится из мр2 в мр!
и «статус кво» легко поддерживается:
1. Если е ведет в вершину из мв1, то его можно игнориро-
вать на основании теоремы 2.
2. Если е ведет в одну из вершин из мв2, то самый млад-
ший элемент цепочки можно объединить с нулем или несколь-
кими более старшими элементами и получить новый, самый
младший элемент цепочки. Более точно, если е ведет в верши-
ну из самого младшего элемента, то его можно игнорировать;
если оно ведет к более старшему элементу цепочки, то обна-
руживается цикл между сильными компонентами, и тогда
теорема 1А говорит, что несколько младших элементов цепочки
нужно объединить в один элемент, уменьшая таким образом
длину цепочки, измеряемую числом входящих в нее элементов.
3. Если е ведет в вершину из лвЗ, то эта вершина перено-
сится в мв2 и как самый младший элемент (она сама по себе
является максимально сильной компонентой в МСК (лхр/))
добавляется к цепочке, длина которой таким образом увеличи-
вается на единицу.
Если ни одного такого ребра «е» не существует, имеется
две возможности. Либо цепочка не пуста, но тогда теорема
2А говорит, что максимально сильная компонента в МСК
(мр!) есть также максимально сильная компонента в МСК
(мр): самый младший элемент удаляется из цепочки и его вер-
шины переносятся из мв2 в мв1. Либо цепочка пуста: если мвЗ
не пусто, то в мв2 может быть перенесен произвольный эле-
мент из мвЗ, в противном случае вычисление закончено.
На рассматриваемом уровне детализации мы можем опи-
сать йаш алгоритм следующим образом:
мр\, мр2, л/el, мв2, мвЗ:— пусто, мр, пусто, пусто, ив;
do мвЗ^ пусто(цепочка пуста}
9-6
250 Глава 25
перенести некоторую вершину v из мвЗ в мв2 и
инициализировать цепочку начальным множеством {к);
do мв2=& пусто-> {цепочка не пуста}
do мр2 содержит ребро, начинающееся в одной из вер-
шин самого младшего элемента цепочки->
перенести это ребро е из мр2 в мр1;
if е ведет в вершину v из мв1-+ пропустить
О е ведет в вершину v из мв2-* объединение
[] е ведет в вершину v из .цвЗ -> расширить цепоч-
ку и перенести v из .ивЗ в мв2
fi
od; {цепочка не пуста}
удалить самый младший элемент и перенести его вер-
шины йз мв2 в мв1
od {цепочка снова пуста}
od
Замечание 1. После перенесения вершин из мв2 в мв! вхо-
дящие в них ребра (если таковые имеются), все еще находя-
щиеся в мр2, могут быть одновременно перенесены из мр2
в мр1, но ценой такой «улучшенной» обработки (выгода от ко-
торой несколько сомнительна) будет необходимость уметь вы-
бирать для любой вершины множество входящих в нее ребер.
Для описанного алгоритма нам нужно уметь находить для
каждой вершины только выходящие ребра. Отсюда и вытекает
описанная выше организация. (Конец замечания 1.)
Замечание 2. Завершаемость самой внутренней конструк-
ции повторения гарантируется уменьшением числа ребер в
мр2-, завершаемость следующей обрамляющей конструкции
повторения гарантируется уменьшением числа вершин в
мв2 + мвЗ\ завершаемость внешней конструкции повторения
гарантируется уменьшением числа вершин в мвЗ. Наше сме-
шанное рассуждение, иногда в терминах ребер и иногда в тер-
минах вершин, является показателем нетривиальности разра-
батываемого алгоритма. (Конец замечания 2.)
Нахождение максимально сильных компонент в ориентированном графе 251
На том уровне детализации, на котором мы описали наш
алгоритм, каждое ребро только один раз переносится из мр2
в мр! и каждая вершина только один раз переносится из мвЗ
через мв2 в мв1; пока что наш алгоритм предполагает объем
работы, линейно зависящий от числа ребер и вершин. При
дальнейшей детализации алгоритма мы попытаемся не нару-.
шить это приятное свойство, что мы сделали бы, например,
если бы проверка, принадлежит ли v мв1, мв2 или мвЗ (кото-
рая производится в самой внутренней конструкции повторе-
ния!), требовала поиска со временем, пропорциональным чис-
лу вершин. Для этой цели можно использовать тот факт, что
нам требуются только,ограниченные виды работ с нашими
множествами вершин, в частности, что вершины присоединя-
ются к цепочке и удаляются из нее в режиме «последним при-
шел — первым ушел».
Мы считаем, что наши вершины последовательно зануме-
рованы, и организуем табличную функцию ранг(и), где v
принимает значение всех номеров вершин; пусть КВ обозна-
чает количество вершин:
ранг(и)=0 означает: вершина nr.v принадлежит мвЗ
ранг (а)>0 означает: вершина nr.v принадлежит мв\+мв2
(Множества мв2 и мв1 для начала соединены: одна из воз-
можных форм объединения — пропуск!)
Если квц равняется «количеству вершин в цепочке», т. е.
количеству вершин в мв2, то
1 ^.pam(v) ^квц означает: вершина v в мв2;
ранг (а) ^КВ+ 1 означает: вершина v в мв\.
У всех вершин В мв2 значения функции ранг различны, и
что касается величин ранг и квц, перенесение вершины v из
мвЗ в мв2 кодируется так:
«квц := квц-\-1; ранг: (у) = квц»
т. е. вершины цепочки «ранжированы» в порядке уменьшения
«возраста в цепочке». Последняя договоренность позволяет
нам очень эффективно представлять то, как вершины мв2 раз-
делены на сильные компоненты: вершины, принадлежащие од-
ному и тому же элементу цепочки, имеют последовательные
значения функции ранг\ а если говорить о самих элементах, то
ранг самой старой вершины элемента есть убывающая функ-
ция его возраста. Введем cc(i) для обозначения ранга самой
старой вершины i-ro по старшинству элемента цепочки (тогда
у нас сс.обл = количество элементов в цепочке). Теперь что
касается величин ранг, квц и сс, то закодировать приведенную
9*
252 Глава 25
выше конструкцию выбора (объединяя первые две альтерна-
тивы) можно следующим образом:
if ранг (у) >0-*-do сс. верх>ранг(у)-*-сс-. сверху od
[] ранг(у) =0-*-квц : = квц+1; ранг: (у)=квц; сс:сверху (квц)
fi
Тем временем мы до некоторой степени перестали следить
за идентичностью вершин в цепочке. Если, например, мы за-
хотели бы перенести вершины самого младшего элемента це-
почки из мв2 в мв1, то нам пришлось бы просматривать зна-
чения функции ранг по всем вершинам в поисках таких зна-
чений о, которые удовлетворяют неравенствам сс.верх^
ранг (у)квц. Нам бы не хотелось этого делать, но бла-
годаря тому, что по крайней мере для вершин из мв2 все зна-
чения ранг (у) различны, мы можем хранить обратную функ-
цию для
ранг (у)=г<&гнар(г)=ъ
Пока хватит об организации работы с вершинами; обратим-
ся к ребрам. Здесь критическим вопросом является, безуслов;
но, вопрос о предохранителе самой внутренней конструкции
повторения: «лф2 содержит ребро, начинающееся в одной
из вершин самого младшего элемента цепочки». Этот предо-
хранитель легко вычисляется, если есть список ребер, принад-
лежащих мр2 и выходящих из вершин самого младшего эле-
мента цепочки. Однако одной из возможностей изменения
самого младшего элемента в цепочке является объединение;
чтобы поддерживать этот список, нам, таким образом, нужно
иметь также соответствующие списки и для старших элементов
цепочки. Поскольку для таких ребер нас интересует лишь их
«целевая вершина», в.аппарат управления цепочкой мы вво-
дим еще две векторные переменные — с областью определе-
ния, равной нулю, если цепочка пуста — «чв» (целевые вер-
шины») и «цег» (уцв-границыъ).
Область определения функции цвг содержит по одной точ-
ке для каждого элемента цепочки: ее значение равняется чис-
лу ребер, принадлежащих мр2 и выходящих из вершин более
старших элементов цепочки (область цвг все время равна об-
ласти сс, где также хранится одно значение для каждого эле-
мента цепочки). Каждый раз, когда новая вершина v перено-
сится из мвЗ в мв2, массив цвг расширяется вверх значением
цв.обл, после чего цв расширяется вверх целевыми вершинами
ребер, выходящих из и. Обозначая эту последнюю операцию
«расширить цв целями от о», мы получаем следующий вид
внутреннего цикла (с учетом гнар, цв и цвг):
Нахождение максимально сильных компонент в ориентированном графе 253
«внутренний цикл»:
do цв.обл~> цвг.верх-*-
v, цв: векон;
if ранг (х») > 0
do сс,верх^>ранг (v)-*-cc: сверху; цвг:сверху od
П ранг
квц : = квц-\-1; ранг : {^)=квц; гнар: вверху);
сс: вверх (квц); цвг : вверх (цв.обл);
«расширить цв целями от х»»
fi
od
Мы договорились, что для вершин v из мв1 ранг(р)>КВ.
Можно ввести и более сильную договоренность, а именно за-
нумеровать максимально сильные компоненты номерами 1, 2
и т. д. (в том порядке, в котором они отбираются) и условить-
ся, что для каждой вершины v из мв1 будет
ранг (u) — КВ + номер максимально сильной компоненты,
которой принадлежит v
Введя переменную «скном» (начальное значение 0), мы
можем теперь закодировать
«средний цикл»:
do сс.обл^>0-*-
«внутренний цикл»;
скном : = скном1;
do квц^ сс.верх
квц := квц — \; ранг: (гнар.верх)=КВ-\-скном\
гнар: сверху; мв1скет := мв1счет-\-1
od;
сс : сверху; цвг : сверху
od
(Переменная мв1счет, начальное значение = 0, является счет-
254 Глава 25
чиком числа вершин в juel; критерием конца работы будет
служить мв!счет=КВ.).
Мы предполагаем, что номера вершин меняются от 1 до
КВ, а ребра задаются двумя массивами констант «ребро» и
«реброг» таким образом, что для l^i^KB и; для реб-
рог (г) ^j<pe6 рог {1+1) значения ребро (/^являются номера-
ми вершин, в которые идут ребра, выходящие из вершины
Затем :мы кодируем:
«расширить цв целями от ть;
begin glocon ребро, реброг, p*t glovar цв; privar у;
j vir цел-.—реброг {v^-\);
do, /> реброг (т»)-»-у : = j —1;цв: в верх {ребро (Z))od
end
И последнее — это выбор произвольной вершины v из л1вЗ для
инициализации цепочки. Если каждый раз поиск будет начи-
наться . с ''Вершины, пг. 1Л время вычислений будет пропорцио-'
нально\КВ2, но и здесь этого можно избежать, если вынести
условие -за границы конструкции повторения и ввести на внеш-
нем уровне переменную «канд» (начальное значение=1), об-
ладающую свойством:
мвЗ не содержит вершин о, таких, что .о < канд
begin glocon ребро, реброг, КВ; virvar ранг; privar
мв1счет, канд, окном;
ранг vir цел, array: = (1); do ранг.обл =+КВ->ранг-.
вверх (0) od;
мвХсчет vir цел, канд vir цел, окном vir цел := 0,1,0;
do мвХскетф КВ^-
begin glocon ребро, реброг, КВ; glovar ранг,
мв\с'ч,ет, канд, окном;
privar V, со, цв, цвг, гнар, квц;
do ранг {канд) =/=0 канд: = канд 4-1 od;
“о vir цел-.= канд;
квц vir цел-. — \; ранг-.^ — Х; гнар vir цел
array :=(1, ®);
Нахождение максимально сильных компонент в ориентированном графе 255
сс vir цел array := (1, 1); цвг vir цел array : =
(1. 0);
цв vir цел array:—(1);
«расширить цв целями от и»;
«средний цикл»
end
od
end
Замечание I. Очень похожий алгоритм независимо был раз-
работан Робертом Тарьяном, (Конец замечания /.)
Замечание 2. Теперь мы видим, что переменная «.квц» из-
лишня, так как квц=гнар.обл. (Конец замечания 2.)
Замечание 3. Операция «расширить цв целями от о» ис-
пользуется дважды. (Конец замечания 3.)
Примечание 1. Читатель, должно быть, заметил, что в этом
примере фактическая разработка программы происходила в
порядке, обратном по сравнению с разработкой программы
для выпуклой оболочки в трехмерном пространстве. Я думаю,
что причина этого заключается в следующем. В случае выпук-
лой оболочки представление данных было исследовано очень
тщательно как часть логического анализа проблемы. В пос-
леднем примере логический анализ в основном был уже за-
вершен, когда перед нами встала задача выбора представле-
ния, допускающего эффективную реализацию предполагаемо-
го алгоритма. Поэтому было естественно сосредоточиться
сначала на самой существенной части, т. е. самом внутреннем
цикле. (Конец примечания 1.)
Примечание 2. Следует обратить внимание на отдельные
шаги получения нашего решения. На первом этапе нас бес-
покоило то, чтобы каждое ребро обрабатывалось только один
раз, и мы временно не учитывали зависимость времени обра-
ботки от числа вершин. И это совершенно правильно, так как
в общем случае следует ожидать, что число ребер на порядок
больше числа вершин. (Между прочим, первое решение этой
задачи, не приведенное в данной главе, линейно зависело от
числа ребер, но квадратично — от числа вершин.) И только на
втором этапе мы начали заботиться о линейной зависимости
от числа вершин. Насколько эффективным оказалось это «раз-
деление аспектов», убедительно показывает тот факт, что на
втором этапе нам совершенно не потребовалось обращаться
к теории графов! (Конец примечания 2.)
26 О РУКОВОДСТВАХ И РЕАЛИЗАЦИЯХ
В пятидесятых годах я написал для нескольких вычисли-
тельных машин голландского производства то, что я тогда на-
зывал «функциональными описаниями». Позднее документы
такого рода мне встречались под названием «справочных ру-
ководств». Отчетливо помню, с каким трудом я добивался то-
го, чтобы эти функциональные описания были недвусмыслен-
ны, полны и аккуратны: я считал своей обязанностью описы-
вать все свойства машины, которые существенны для про-
граммиста. Однако с тех пор моя оценка того, как соотносят-
ся машина и руководство по ее использованию, претерпела
изменение.
По существу, имеются две «машины». С одной стороны,
есть физическая машина, которая устанавливается в машин-
ном зале, может давать сбои, требует питания, кондициониро-
вания воздуха, обслуживания и которую показывают гостям.
С другой стороны, есть абстрактная машина, как она опреде-
лена 6 руководстве, та «воображаемая» машина, для которой
программист пишет программы и по отношению к которой ре-
шается вопрос о правильности программы.
В начале мне казалось, что главной функцией абстрактной
машины является правильное отображение физической реаль-
ности. Позднее, однако, я пришел к мысли, что именно абст-
рактная машина является «истинной», той единственной ма-
шиной, которую мы можем «вообразить»; назначение физи-
ческой машины — быть «работающей моделью», достаточно
(как мы надеемся) аккуратно имитировать истинную, абст-
рактную машину.
В соответствии с этим изменилась и терминология: вместо
«науки о вычислительных машинах» стали использовать тер-
мин «наука о вычислениях», и мы больше не читаем лекций по
курсу «Программирование для электронных вычислительных
машин» — нас совершенно не интересует, работает ли машина
электрически, пневматически или чудом! Но, конечно, это не
'только игра со словами; это показатель того, что программи-
рование как профессия постепенно взрослеет. Раньше казна-
О руководствах и реализациях 257
чение программ заключалось в управлении нашими вычисли-
тельными машинами, теперь назначение вычислительных ма-
шин состоит в исполнении наших программ.
Мы стали осознавать всю важность понятия интерфейса, и
несоответствие между абстрактной и физической машиной пе-
рестало рассматриваться как неточность в руководстве. На-
оборот, стали говорить, что работа физической модели не со-
ответствует спецификациям. Это, разумеется, предполагает,
что спецификации не только совершенно однозначны, но и
настолько «понятны» (и на много порядков проще инженер-
ной документации машины), что никто не сомневается, что они
описывают то, что нужно. Я помню время, когда по отноше-
нию к спецификации оборудования такие интерфейсы разра-
батывались с достаточной для всех ясностью: конструкторы
аппаратуры знали, что От них требуется, а программист мог
полностью владеть своим инструментом, не обращаясь к «экс-
периментальным» программам для обнаружения его свойств.
Такая необходимая всем ясность была присуща спецификаци-
ям не только оборудования, но и базового программйого обес-
печения, такого, как загрузчики, подпрограммы ввода и выво-
да и т. д., объемом не превышавшего нескольких сотен, воз-
можно, тысячи команд. (Если мне не изменяет память, кош-
марный термин «software» еще ждал своего изобретения.)
Печальное замечание. С тех пор мы были очевидцами быс-
трого размножения замысловатых, плохо определенных и по-
этому неустойчивых систем программного обеспечения. Те-
перь программисты лишены формального инструмента, кото-
рый требуется для решения их задач; они живут в мире мифой
и преданий, в неопределенном и полном неприятных неожи-
данностей мире, где они никогда не могут быть совершенно
уверенными в том, что сделает система с их программами.
В таких достоййых сожаления обстоятельствах само понятие
правильной программы — тем более программы, про которую
доказано, что она правильная, — становится пустым звуком.
Как появление множества таких систем повлияло на мораль
программистского общества, описать я уже не в силах. (Ко-
нец печального замечания.)
В предыдущих главах мы ввели предикаты для характе-
ристики множеств состояний и показали, каким образом тек-
сты программ могут интерпретироваться как коды преобразо-
вателей предикатов, устанавливающих связь между «коаеч,-
*> Software — программное обеспечение, буквально — бумажное обору-
дование (англ.). — Прим, перев.
258 Глава 26
ным и начальным состояниями». В соответствии с таким
подходом работа программиста представляется как построение
(кода) преобразователя предикатов, устанавливающего же-
лаемую связь между этими двумя состояниями.
Вводя различные способы построения новых преобразова-
телей предикатов из существующих (точку с запятой, кон-
струкции выбора и повторения), мы немного говорили о том,
как они могут быть реализованы. Впрочем, хотелось бы под-
черкнуть, что, хотя эти возможности реализации являлись
некоторым стимулом, они ни в коей мере не несли функций оп-
ределения. Утверждение, что тексты программ допускают раз-
личные интерпретации как «выполнимые коды», играло опре-
деленную роль при выборе направлений в нашей работе, но
никак не влияло на определение семантики языка программи-
рования: наши определения семантики не основываются на
какой-либо «модели вычислений».
Замечание 1. Стремясь к определению семантики, не зави-
сящей от «истории» вычислений, мы имели в виду совершенно
определенную цель, а именно «разделение аспектов», которое
кажется мне чрезвычайно важным для всей программистской
деятельности. Аспекты, которые нужно разделить, могут быть
названы «математическими аспектами» и «инженерными ас-
пектами». К математическим аспектам я отношу правильность
программы; к инженерным аспектам я отношу главным обра-
зом различные аспекты стоимости (такие, как память и
время вычисления), которые связываются с выполнением про-
граммы. Эти аспекты стоимости определяются лишь по отно-
шению к реализации, и наоборот, реализация (или, более стро-
го, интерпретация текста программы как выполнимого кода)
должна приниматься во внимание тогда, когда обсуждаются
аспекты стоимости. Если же нас интересует только правиль-
ность программ, то достаточно интерпретировать текст как код
преобразователя предикатов и не к чему учитывать, что он
может также интерпретироваться как выполнимый код. На-
оборот! Вот почему мы предпочли для семантики аксиомати-
ческую систему, не зависящую от какой-либо вычислительной
модели и не определяющую конечное состояние как «выход»
вычислительного процесса, которому на «входе» задано на-
чальное состояние. (Конец замечания /.)
Замечание 2. Простота представленной формальной систе-
мы и то обстоятельство, что до некоторой степени ее можно
рассматривать как средство формального вывода программ
определенного типа., являются для меня ее самой привлека-
тельной чертой. Вопрос о том, насколько широко {или узко)
О руководствах и реализациях 259
можно (или целесообразно) охватить на этом пути возможно-
сти вычислительных машин, выходит за рамки данной работы»
Пока что та часть, которую можно охватить, кажется нам до-
статочно богатой, чтобы продолжать ее исследование. (Конец
замечания 2.)
Определение семантики независимо от какой бы то ни было
вычислительной модели ставит вопрос о том, можно ли вообще
надеяться реализовать наш язык программирования. Мы мог-
ли бы воспарить в небеса и попросту отмахнуться от этого воп-
роса, объявив, что это не наше дело, что пусть об этом забо-
тятся те, кто занимается реализацией, и что поскольку мы не
требуем исполнения наших программ, то такой вопрос вообще
неуместен. Но отмахнуться от этого вопроса не входит в мои
намерения.
Реальные машины имеют память конечной емкости и, бу-
дучи предоставленными самим себе, в принципе ведут себя
как конечные автоматы, которые после достаточно большого
числа шагов возвращаются в состояние, в котором находились
прежде. (Если к тому же машина детерминированная, то весь
процесс с этого момента начнет повторяться.) Для полного
описания поведения современных вычислительных машин тео-
рия конечных автоматов, к сожалению, имеет лишь ограни-
ченное применение, так как число возможных состояний ма-
шины настолько громадно, что она может работать в течение
многих лет, не возвращаясь в состояние, в котором она была
прежде. Мы можем опустить требование конечного объема
памяти и взяться за изучение «бесконечных автоматов». По-
видимому, мы как раз так и поступили: мы ввели конечное
число переменных, но при введении переменных типа «integer»
не наложили .ограничения на число их возможных значений и,
следовательно, не ограничили числа возможных состояний. На-
ши программы написаны для Неограниченной Машины «НМ»,
а это то, что ни один инженер не может нам предоставить!
Впрочем, он может предоставить нам Достаточно Большую
Мащину «ДБМ». При загрузке в нее программы S она будет
имитировать поведение машины НМ,, когда та начнет выпол-
нять программу S с начального состояния, удовлетворяющего
условию wp(S, Т). Благодаря тому что для каждого началь-
ного состояния, удовлетворяющего условию 'Wp(S, Г), как
недетерминированность, так и количество шагов вычисления
ограничены, множество целых значений, с которыми имеет
дело машина НМ, конечно, и поэтому все они оказываются в.
конечной области. При условии что машина ДБМ может об-
рабатывать целые числа из этой конечной области, она сможет
имитировать поведение машины НМ в данном вычислитель*
260 Глава 26
ном процессе (мы надеемся, достаточно быстро, чтобы эта
имитация представляла интерес).
Замечание 3. Начиная с Тьюринга, у математиков вошло
в привычку рассматривать ДБМ, т. е. машину, выполняющую
вычислительные шаги с конечной скоростью в ограниченном
пространстве состояний, как «осуществимую». В этой связи
уместно вспомнить, что инженер должен моделировать ДБМ
с помощью аналоговых средств, и самые теоретические физи-
ки, по-видимому, полагают, что вероятность ошибок при таком
моделировании отлична от нуля и увеличивается с увеличени-
ем скорости выполнения операций. (Конец замечания 3.)
Реализация недетерминированности требует специального
рассмотрения. Возьмем такую часть программы:
S : do продолжение х: = х 1
[^продолжениепродолжение := ложь
od
Для всех наш формализ дает Нь(Т) =по« продолжение
и, следовательно,
wp(S, Г)=поп продолжение
Мы представляем себе, что наша гипотетическая машина
НМ при выполнении этой конструкции повторения вычисляет
все предохранители и останавливается, если они ложные; в
противном случае она выбирает одну из альтернатив с истин-
ным предохранителем и выполняет ее. Затем, т. е. после ус-
пешного завершения этой операции, процесс повторяется. Ес-
ли в начале выполняется условие поп продолжение, т. е. про-
должением ложь, то наш формализ говорит, что вначале пре-
дикат wp (S, Т) удовлетворяется, и это полностью согласуется
с нашим желанием гарантировать окончание работы: собст-
венно говоря, машина НМ немедленно прекратит выполнять
повторения. Если, однако, в начале продолжение = истина, то
предикат wp(S, Т) не удовлетворяется, и если мы хотим ин-
терпретировать wp(S, Т) как слабейшее предусловие, гаран-
тирующее завершение, мы должны отвергнуть любую пред-
лагаемую НМ, в которой свобода выбора в отношении раз-
личных вариантов обеспечивается настолько, что каждый
возможный вариант будет рано или поздно выбран. Мы могли
бы представить себе какое-нибудь игральное устройство, на-
пример бросание монеты: герб для первой и решка для второй
альтернативы. Так как никакая «правильная» монета не обя-
зана когда-нибудь упасть гербом, наше требование было бы
О руководствах и реализациях 261
удовлетворено. Но теперь мы в некотором смысле переопреде-
лили НМ. Беда в том, что первоначально естественное пред-
положение о монете заставит нас заключить, что, хотя завер-
шаемость не полностью гарантирована, вероятность незавер-
шаемости равна нулю и что математическое ожидание
величины, на которую увеличится х, равно 1. Такие вероят-
ностные расчеты довольно скоро становятся очень трудными,
но, к счастью, мы ими и не будем заниматься, так как весь
подход не совсем верен: мы допускаем недетерминированность
в тех случаях, когда нам безразлично, какой выбор сделает
НМ, но тогда нам и не следует беспокоиться о том, какой она
сделает выбор! Самый эффективный способ выйти из этого
положения заключается в предположении, что НМ снабжена
не правильной монетой, а очень вредным демоном; наличие
такого демона превращает все вероятностные вопросы a priori
в пустой звук. (Машина с таким демоном нас вполне устраи-
вает; если нам существенно, какой из вариантов будет выбран
и когда, то нам лучше усилить предохранители.)
Можно подумать, что моделирование НМ с ее вредным де-
моном представляет серьезную трудность для инженера, кото-
рый разрабатывает моделирующую ДБМ. Это действительно
было бы трудно, если бы требовалось реализовать истинно
вредный выбор — в чем бы он ни состоял. Но так как демон
всего лишь метафора, символизирующая наше незнание, его
реализация не должна представлять ни малейшей трудности.
Если у нашего конструктора ДБМ на полке десять различных
«квазидемонов», то мы предоставляем ему полную свободу
вмонтировать в ДБМ любой из них, и не будем возражать,
если он вмонтирует в нее некий одиннадцатый, коФорый он за
это время придумает. Пока мы не знаем и отказываемся знать
его свойства, все обстоит так, как надо.
Теперь мы достигли такой стадии, что если у нас есть про-
грамма и начальное состояние, то мы можем, по крайней мере
в принципе, выбрать достаточно большую машину ДБМ. Но
такой порядок действий не совсем реалистичен по двум при-
чинам. Во-первых, непрактично держать на складе всю после-
довательность увеличивающихся по мощности ДБМ; во-вто-
рых, в общем случае определение для произвольной програм-
мы и данного начального состояния размера ДБМ, удовлетво-
ряющей нашим требованиям, является достаточно трудным
делом. Легче «попробовать».
Более реальной является такая ситуация, когда вместо по-
следовательности ДБМ у нас имеется одна «по-видимому до-
статочно большая машина» ПДБМ. ПДБМ выполняет две
функции. Кроме того, что она является наибольшей ДБМ, ко-
торую мы можем себе позволить, она может проверять во вре-
262 Глава 26
мя выполнения программы, является ли эта ДБМ достаточно
большой для выполнения текущих вычислений. Если так, то
она продолжает имитировать поведение НМ, в противном слу-
чае она отказывается их продолжать. Машина ПДБМ позво-
ляет нам «пробовать», т. е. экспериментально определять, яв-
ляется ли реализуемая ею ДБМ на самом деле достаточно
большой для выполнения текущих вычислений. Если ПДБМ
доводит вычисления до конца, то мы можем заключить, что
выбранная ДБМ оказалась достаточно большой.
Отсюда ясно, что самой существенной особенностью ПДБМ
является умение явно отказываться выполнять работу, пре-
вышающую ее возможности: это необходимо, чтобы мы могли
провести наш эксперимент. К большому сожалению, существу-
ют машины, в которых постоянная проверка того, что имита-
ция поведения НМ не выходит за границы их возможностей,
не производится: из предполагаемых соображений эффектив-
ности, даже когда ее возможности не позволяют- правильно
продолжить вычисления, машина йродрлжает работать — хотя
и неправильно. Очень трудно пользоваться такой машиной как
надежным инструментом, так как подтверждение правильно-
сти получаемых ответов требует, кроме доказательства пра-
вильности программы, доказательства того, что машина спо-
собна выполнить заданные вычисления', по сравнению с пер-
вым второе доказательство во много раз сложнее и труднее.
Нам бы потребовалось (аксиоматическое) определение воз-
можных событий в НМ, тогда как до сих пор было достаточно
предписывать только результаты; кроме того, часто очень
трудно сформулировать точные ограничения, накладываемые
конечностью конкретной машины. Поэтому машины, которые
не контролируют свою возможность правильной имитации
НМ, мы считаем непригодными и в дальнейшем исключаем
из рассмотрения.
Благодаря тому что машина явно сообщает о своем отказе
продолжать работу, ПДБМ является надежным средством, но
это средство окажется не очень полезным, если отказы будут
происходить слишком часто! На практике программист не толь-
ко.хочет написать программу, исполняя которую НМ вырабо-
тает желаемый результат, но он также хочет уменьшить веро-
ятность (или даже исключить возможность) получения отка-
за от ПДБМ, моделирующей НМ. Если конкретная ПДБМ
накладывает в связи с этим на программиста большие обяза-
тельства (или, наприцер, программисту очень трудно оценить,
насколько эффективным окажутся меры, которые он собира-
ется принять),.то такая ПДБМ просто неудобна в работе.
Теперь мы обратимся к понятию так называемого «свобод-
ного» предусловия, которое обсуждалось в конце главы «Ха-
О руководствах и реализациях 2G3
рактеристика семантики». Свободное предусловие гарантирует
выполнимость постусловия, если известно, что вычислительный
процесс завершится правильно, но не гарантирует самого пра-
вильного завершения. В последующих главах нам не приш-
лось пользоваться этим понятием, ввиду того что мы опреде-
лили семантику Как отношение между начальным и конечным
состояниями независимо от выполнения программы; только
в связи с выполнением программы это понятие становится со-
держательным. Понятие выполнения программы нам понадо-
билось лишь тогда, когда мы ввели неограниченную машину
НМ. Но от'НМ мы требовали только выполнения наших про-
грамм, т. е. чтобы для любого (неупомянутого) постусловия
R машина перешла в состояние, удовлетворяющее R, при ус-
ловии, что мы запустили ее в начальном состоянии, удовлет-
воряющем предикату wp(S, R). В частности, мы требуем пра-
вильного завершения, только если при запуске удовлетворя-
лось wp(S, Г). Мы не позаботйлись предписать поведение НМ
для начальных состояний, которые не удовлетворяют wp(S,
Т), и поэтому понятие свободного предусловия к НМ не
приложимо. Но мы ввели это понятие по отношению к ПДБМ,
когда потребовали, чтобы она прекратила работу, если ее воз-
можности оказались, недостаточными. Другими словами, мы
принимаем ПДБМ, умеющую правильно имитировать только
некоторое подмножество вычислений, для которого гарантиру-
ется правильное завершение на НМ.
Замечание 4. Понятие свободного предусловия введено
здесь в связи с ограниченностью ПДБМ. Оно резко контрасти-
рует с очень похожим понятием «частичной правильности», ко-
торое было введено по отношению к неограниченным машинам
(таким, как машины Тьюринга) в связи с неразрешимостью
проблемы применимости. {Конец замечания 4.)
Можно задать вопрос — но я на него отвечать не буду — о
том, как будет вести себя НМ, когда она начнет работать с на-
чального состояния, про которое мы не знаем, удовлетворяет
ли оно предикату wp(S, Т), Моя позиция (с философской точ-
ки зрения, по-видимому, о^ень шаткая) состоит в том, что, по-
скольку мы не доказали, что начальное состояние удовлетво-
ряет wp(S, 71), НМ может вести себя как угодно в том смысле,
что мы не имеем права предъявлять ей какие-либо претензии.
(Представим следующую ситуацию. Чтобы НМ начала рабо-
тать, пользователь должен нажать на кнопку «пуск», но чтобы
иметь возможность сделать это, он должен находиться в ма-
шинном зале. В связи с режимом кондиционирования НМ мо-
жет начать работу только тогда, когда все двери машинного
зала закрыты, и в целях безопасности НМ (у которой нет
264 Глава 26
кнопки «стоп») во время работы не допускает, чтобы двери
открывались. Тайая ситуация показывает, насколько опасно
запускать машину, не доказав, что она завершит работу!)
Если мы разрешаем НМ вести себя как угодно, коль скоро
не доказана истинность wp(S, 7') в начальном состоянии, то из
самого факта окончания работы мы не можем вывести каких-
либо следствий. Мы можем попытаться с помощью машины
найти опровержение предположения Гольдбаха, что каждое
натуральное число есть среднее двух простых чисел. Но
можно ли это сделать с помощью следующей программы:
begin privar п, опровергнуто-,
п vir цел-.— 1; опровергнуто vir б[Лев-. — ложь-,
do non опровергнуто ->•
begin glovar п, опровергнуто-, privar х, у,
п:= п-\-1;
х vir цел, у vir цел-.— 2, 2*п;
do x<Zy and х-\-у<^2, 2*п-^
x-. —наименьшее простое, большее (х)
□ х < у and х1/> 2 * л
у := наибольшее простое, меньшее (у)
od;
опровергнуто-. — {х-\-у ^=2*п)
end
od;
печатьбулев {опровергнуто)
end
Так как я не доказал, что предположение Гольдбаха не
верно, я не доказал, что первоначальное значение wp(S, Т)
истинно; следовательно, НМ может поступать, как ей нравит-
ся, а, следовательно, я не могу заключить, что предположение
Гольдбаха не верно из того, что машина напечатала «истина»
и остановилась. Я бы мог сделать это удивительное заключе-
ние, впрочем, если бы третья строка программы имела вид
«do non опровергнуто and 1000000->-»
Немного подумав, я даже предпочитаю модифицированную
программу первому варианту, так как она выглядит более
«честной»: никто не начинает вычислений, не установив верх-
ней границы для времени, в течение которого он готов ожи-
дать ответ.
27 РЕТРОСПЕКТИВЫ
Появление автоматических вычислительных машин озна-
чало появление не только нового средства, но и новых проб-
лем; и поскольку это средство оказалось беспрецедентным, та-
кими же оказались и проблемы. Эти проблемы имели (и до
сих пор имеют) два аспекта.
Во-первых, перед нами стоит задача поиска новых (разум-
ных) сфер применения; это не так просто, потому что сфера
применения может быть такой же революционизирующей, как
и само средство. Спросите любого специалиста в области про-
граммирования: «Если бы в вашем распоряжении оказалась
машина стоимостью в 10 миллиардов долларов, какие проб-
лемы во имя блага человеческого стали бы вы на ней ре-
шать?», — и вы обнаружите, что специалисту понадобится мно-
го времени, чтобы найти сколько-нибудь разумный ответ. Эта
серьезная задача требует от нас большой фантазии и всей си-
лы воображения. Мы говорим о ней здесь для полноты кар-
тины; в данной книге она не рассматривается.
Во-вторых, когда (будем надеяться, разумная) сфера при-
менений определена, мы сталкиваемся с задачей программи-
рования, т. е. с задачей приспособления нашего общего сред-
ства к данной специфической цели. Для сравнительно неболь-
ших и медленных машин задача программирования не
являлась слишком серьезной, но когда широко доступными
стали машины, в тысячи раз более мощные, соответственно
возросли и запросы общества по их применению и задача
программирования переросла в беспрецедентную интеллекту-
альную проблему. Именно это и явилось побудительным сти-
мулом для написания настоящей книги.
< С одной стороны, математическая основа программирова-
ния очень проста. Конечная последовательность нулей и еди-
ниц подвергается конечному числу простых операций, и в не-
котором смысле программирование должно быть тривиаль-
ным. С другой стороны, память объемом в много миллионов
битов настолько велика, а обработка этих битов происходит
266 Глава 27
с такой невообразимо большой скоростью, что возможные вы-
числительные процессы — т. е. те процессы, которые мы изоб-
ретаем,— превосходят уровень тривиальностй на несколько
порядков. Именно это уникальное единство простоты и изощ-
ренности характерно для задачи программирования.
Что означает это единство, можно понять, если сравнить
программиста, например, с хирургом, делающим сложную опе-
рацию. Оба должны быть в высшей степени аккуратны и вни-
мательны. Однако в этом отношении хирург выполнил свои
обязанности, если принял все известные меры предосторожно-
сти, и затем ему позволено уповать на то, что внешние обстоя-
тельства, не находящиеся под его контролем, не испортят его
работу. Хирурга не порицают за то, что его умение ограниче-
но: неисчерпаемая сложность человеческого тела — общепри-
знанный факт. Но программист едва ли может аппелировать
к неисчерпаемой сложности своей программы, так как она соз-
дана им самим! Программист должен платить за то, что все
находится в его полном распоряжении; это следствие элемен-
тарности основ программирования.
Здесь следует упомянуть одно из следствий возросшей мо-
щи современных вычислительных машин. В иерархических си-
стемах нечто, рассматриваемое как неделимое и неанализируе-
мое на одном уровне, считается составным на следующем, бо-
лее низком уровне детализации; следовательно, естественная
единица времени или пространства, соответствующая каждому
уровню, уменьшается на порядок каждый раз, когда мы пере-
ходим с одного уровня на другой, более низкий. ОтсюДа мак-
симальное число уровней, которые содержательно можно
выделить в иерархической системе, более или менее пропор-
ционально логарифму отношения между единицами самого
высшего и самого низшего уровней, и, следовательно, много
уровней можно ожидать только тогда, когда это отношение
очень велико. В программировании наш основной строитель-
ный блок, команда, выполняется меньше чем за микросекунду,
а наша программа может потребовать часы и часы машинного
времени. Кроме программирования, я. не знаю другой техно-
логии, имеющей дело с отношением 1010 или даже большим.
Автоматическая вычислительная машина из-за своей фанта-
стической скорости явилась первым устройством, предоставля-
ющим достаточно «места» для развитой иерархической
системы. И в этом отношении проблема программирования,
по-видимому, на самом деле не имеет прецедента. Для инте-
ресующихся способностями человека решать трудные интел-
лектуальные задачи (избегая непреодолимую сложность) за-
дача программирования является идеальным испытательным
стендом.
Ретроспективы 267
Когда неспециалист просит объяснить, что в программиро-
вании понимается под «модуляризацией», самое первое, что
приходит в голову, — это, по-видимому, то, как в мире науки
из всей суммы знаний и умений выкристаллизировались от-
дельные научные дисциплины. Научные дисциплины имеют не-
который «размер», определяемый человеческими константами:
необходимая сумма знаний должна умещаться в человече-
ской голове, число необходимых умений должно быть не боль-
ше того, чему человек может научиться и в дальнейшем не
терять полученных навыков. С другой стороны, научная дис-
циплина не должна быть слишком маленькой или слишком уз-
кой, так чтобы она не исчерпалась в течение по крайней мере
одного поколения. Но не любой набор отрывочных фактов
и небывалых умений, даже достаточного размера, составляет
живую научную дисциплину! Есть еще два требования.
Внутреннее требование соответствия: умение должно позво-
лять накапливать знания, а знания должны позволять совер-
шенствовать умение. И, наконец, есть внешнее требование —
мы назовем его «узким интерфейсом» — это чтобы сущность
дисциплины можно было изучать в достаточно высокой сте-
пени изолированности, чтобы она не зависела в каждый
момент критически от развития других областей науки.
Эта аналогия не только полезна при объяснении термина
«модуляризация», но она дает нам и ключ к пониманию
того, как мы должны пытаться думать во время программи-
рования. При программировании перед нами встают те же
самые проблемы размера и разнообразия. (Даже программи-
руя на самом высоком уровне наших способностей, мы иногда
ничего не можем поделать с текстом программы, он стано-
вится таким большим, что проблемой становится сама его
длина. Возможные варианты вычислений могут стать такими
длинными или настолько изменчивыми, что нам трудно их
представить. У нас могут быть конфликтующие цели, такие,
как высокая скорость прохождения задачи и маленькое время
реакции, и т. д.). Мы не можем решить эти проблемы, просто
решив, что программа будет разбита на «модули».
Главная характерная черта культурного мышления, по
моему мнению, заключается в том, что человек может и хочет
глубоко изучать некоторый аспект изолированно, ради его
собственного содержания, сознавая в то же самое время, что
он занимается только одним из аспектов. Другие аспекты
должны ждать своей очереди, потому что наши головы так
малы, что не могут без путаницы работать со всеми аспектами
одновременно. Именно это я понимаю под «фиксацией вни-
мания на определенном аспекте»; это не значит, что другие
аспекты полностью игнорируются, но временно мы про них
268 Глава 27
забываем настолько, насколько они не существенны для теку-
щей темы. Такое разделение, даже если оно и не полностью
осуществимо, есть единственно доступный нам метод эффек-
тивного упорядочивания наших мыслей, который мне извес-
тен.
Обычно я называю этот метод «разделением аспектов», так
как мы пытаемся поочередно разделаться с нашими трудно-
стями, обязанностями, желаниями и ограничениями. Когда
это достижимо, то мы добиваемся более или менее полного
разделения объектов рассуждения — и это разделение находит
свое отражение в результирующем разделении программы на
«модули», — но мне бы хотелось отметить, что это разделение
объектов рассуждения является только результатом, а не
целью. Цель мышления заключается в уменьшении детализо-
ванных рассуждений до выполнимого количества, и разделе-
ние аспектов —это способ, с помощью которого мы собира-
емся добиться этого уменьшения.
Критическим моментом здесь является, конечно, выбор тех
аспектов, которые подлежат «изолированному» изучению; как
распутать аморфный клубок обязанностей, ограничений и це-
лей и выделить множество «аспектов», допускающих разумное
и эффективное разделение. Чтобы успешно разделить аспекты
в области новых и трудных проблем, почти всегда потребуется
долгая и кропотливая работа; по-видимому, нереально наде-
яться на другое. Но даже если мы не располагаем простыми
правилами, по которым производится это разделение (мы ведь
не пишем брошюру на тему «Как научиться принимать важные
решения за десять простых уроков»), знание цели «разделе-
ния* аспектов» очень полезно: по крайней мере мы начинаем'
понимать, что нам нужно.
К тому же у нас есть одно простое правило! Оно говорит:
не смешивайте аспекты, которые были разделены в начале!
Этим правилом мы воспользовались, когда начали работать
над данной книгой. Вначале мы боялись, как бы у нас не по-
лучилась такая ненадежная система, которая либо будет про-
изводить неверные результаты, либо вообще не будет рабо-
тать. Если такая система является комбинацией оборудования
и программного обеспечения, то в идеале программное обес-
печение будет безошибочным, оборудование безупречным и
работа системы совершенной. Если это не так, то либо невер-
но программное обеспечение, либо неверно функционирует
оборудование, либо и то и другое. Оба этих различных источ-
ника ошибок могут вызвать почти одинаковые эффекты: если
из-за случайной ошибки испорчена команда в памяти машины
или из-за постоянной неправильной работы все время непра-
вильно интерпретируется некоторая команда, конечный ре-
Ретроспективы 269
зультат очень похож на работу с неотла^кенной программой.
И все же причины этих двух неправильностей весьма различ-
ны. Даже совершенное оборудование подвержено износу и
нуждается в обслуживании; программное обеспечение нужда-
ется в исправлениях (но тогда оно было неправильно с самого
начала) или модификациях, если изменились наши требова-
ния к программе. Наше простое правило требует, чтобы мы не
смешивали эти два момента. С одной стороны, мы можем за-
ниматься повышением уровня надежности наших программ
(предполагая, что они выполняются совершенной машиной).
С другой стороны, можно исследовать вопрос о вычислениях
на не вполне надежной машине, и тогда нам лучше предпо-
ложить, что наши программы совершенны. В данной книге
мы имеем дело с первым из этих аспектов.
В упомянутом случае наше простое правило, по-видимому,
корректно: не разделив оборудование и программное обеспе-
чение, нам бы пришлось прибегнуть к статистическим методам,
возможно с использованием понятия СВМС («среднее время
между сбоями», где «среднее время между очевидными ошиб-
ками» было бы более правильным), и описанная в книге тео-
рия никогда не могла бы быть разработана.
Прежде чем взяться за эту работу, я провел дальнейшее
разделение аспектов. Цитирую отрывок из письма одного из
моих коллег:
«В программировании имеется еще и третий момент: после подготовки
«текста программы как статического, в некотором смысле формального,
математического объекта» и после того как рассмотрена инженерная сто-
рона вычислительных процессов, определяемых программой в конкретной
ситуации, лично для меня самым трудным является фактический переход
к выполнению программы: перевод удобного для чтения человеку текста,
содержащего труднообнаруживаемыё глазом (который «видит то, что хо-
чет видеть») ошибки и описки, в текст, удобный для чтения машине; и за-
тем еще нужно как-то убедиться, что мы при этом ничего не потеряли».
(Из того, что мой коллега называет этот третий момент «са-
мым трудным», можно заключить, что он очень опытный про-
граммист, а также и честный! Я мог бы добавить, хотя и не
знаю, имеет ли это какое-нибудь отношение к делу, что его
почерк оставляет желать лучшего.) Этот третий момент в дан-
ной книге не обсуждается не потому, что мы считаем его не-
важным, а потому, что его можно (и поэтому нужно) отделить
от других аспектов; здесь применяются совсем другие, специ-
фические средства (считывание, многократное дублирование
и другие формы избыточности). Я упомянул этот третий^ мо-
мент, потому что обнаружил, что другой мой коллега — инже-
нер по профессии — настолько им одержим, что не может за-
ставить себя рассматривать два другие аспекта изолированно
27.0 Глава 27
и поэтому отбрасывает саму идею доказательства' правильно-
сти программы как совершенно несущественную. Следует от-
четливо сознавать, что действия, направленные на разделение
аспектов, почти всегда вызывают противодействие, часто со-
провождаемое замечанием, что «решаются не настоящие за-
дачи». Мы не будем пытаться понять или объяснить это явле-
ние. Такое сопротивление присуще, разумеется, не только
инженерам-практикам, как показывает следующее высказы-
вание Бертрана Рассела: «Преимущества метода постулиро-
вания огромны — это те же преимущества, что у воровства
перед честным трудом».
Следующее разделение аспектов осуществляется в самой
книге: это разделение математической стороны дела, относя-
щейся к правильности, и инженерной стороны, относящейся к
выполнению. И мы провели это разделение настолько полно,
что дали аксиоматическое определение семантики наших язы-
ков программирования, что позволяет нам, если мы этого хо-
тим, игнорировать возможность выполнения программы. Это
сделано в самой книге по той простой причине, что, историче-
ски говоря, такое разделение не следовало из нашего простого
правила; наоборот, в шестидесятых годах доминировал опера-
ционный подход, характеризуемый тем, что «сама семантика
задается некоторым интерпретатором, который описывает»
как изменяется вектор состояния во время вычисления».
(Джон Мак-Карти, 1965.) Первыми от этого метода начали
отходить Р. У. Флойд (1967) и Ч. Хоар {1969).
Такое разделение требует гораздо больше времени, потому
что даже после того, как становится очевидным его возмож-
ность и желательность, существует много путей его реализа-
ции. В зависимости от темперамента, способности, оценки
предстоящих трудностей можно либо загореться желанием
аксиоматизировать как можно более универсальный язык
программирования, либо осторожно попытаться найти самые
эффективные ограничения. Я безоговорочно выбрал второе, и
отказ от процедур (и в чистом виде, а также от таких поня-
тий, как параметры, и даже — результат) является, по-види-
мому, эффективным упрощением, настолько решительным, что
некоторые из моих читателей могут потерять интерес к остав-
шимся «тривиальным» деталям.
Оставалось решить следующие главные вопросы:
1) выводить ли слабейшее предусловие из желаемого постус-
ловия или выводить сильнейшее постусловие из данного
предусловия;
2) взять за основу слабейшее предусловие — как сделали
мы — или слабейшее свободное предусловие;
3) включить ли недетерминированность;
Ретроспективы, 271
4) должен ли -«демон» быть вредным или в некотором смысле
«справедливым».
Как решать эти вопросы? То что вывод слабейшего пред-
условия вместо сильнейшего постусловия ведет к более глад-
кому формализму, возможно, для многих и очевидно, я же
дошел до этого, только испытав оба варианта. Более естест-
венным казалось начинать с желаемого постусловия, на что
я и решился, тем более’что в этом отражался тот факт, что
программирование — это целенаправленная деятельность.
Мне потребовалось больше времени, чтобы остановиться
просто на предусловиях, а не на свободных предусловиях. Мне
хотелось этого, так как до тех пор, пока вывод преобразова-
телями предикатов слабейшего свободного предусловия яв-
ляется для нас единственным путем определения семантики,
нам никогда не удастся гарантировать завершаемости, но
такая система не может привлечь нас, так как она слишком
слаба. Вопрос был решен, #когда выяснилась возможность оп-
ределения wp (DO, jR) в терминах wp (IF, /?).
К решению ввести недетерминированность я пришел посте-
пенно. Аналогия между синхронизирующими условиями в
мультипрограммировании и упорядочивающими условиями в
последовательном программировании подсказала переход к
охраняемым наборам команд и подготовила меня к введению
недетерминированности в последовательные программы; моя
растущая неудовлетворенность асимметричностью выражения
«if В then SI else S2 fi», в котором S2 трактуется как умол-
чание,— а я научился не доверять умолчанию — доделала
остальное. Симметрия и элегантность-выражения
if у -+т: = х □ х-+т: = у fi
и то, что я смог систематично вывести эту программу, явилось
последним аргументом при решении этого вопроса.
Некоторое время (и в непосредственной связи с моими опы-
тами мультипрограммирования, где обычно стараются не
допускать «замораживания отдельных процессов») я считал
необходимым постулировать, что демон должен работать
«справедливо случайно», т. е. не допуская постоянного игнори-
рования одной из возможных альтернатив. Этот «справедливо
случайный порядок» постулировался на этапе, когда я только
вырабатывал операционное описание того, как я намеревался
реализовать конструкцию повторения. На следующий день,
когда я рассмотрел формальное описание ее семантики, я уви-
дел свою ошибку и демон окончательно был объявлен совер-
шенно вредным.
Короче говоря, после необходимых исследовательских экс-
272 Глава 27
периментов вопросы (1) — (4) были решены в основном с по-
мощью одного и того же критерия: формальной простоты.
Мой интерес к формальным доказательствам правильно-
сти был и остается вторичным. Я был свидетелем многих об-
суждений языков программирования и стиля программирова-
ния, которые были удручающе неубедительными. Причина, по
которой спорящие с большим трудом приходили к соглашени-
ям, заключалась в том, что не было эффективных критериев,
в уместность которых мы бы все верили. (Слишком много мы
пытались решить во имя удобства пользователя, но слишком
часто мы путали «удобное» с «привычным», а этот последний
критерий в слишком большой степени зависит от лйчного кон-
кретного опыта.) Во время этой неразберихи как дар с небес
к нам пришла такая мысль: «элегантным» мы почти всегда
называли то, что допускало красивое короткое доказательст-
во; это было немедленно принято как разумная гипотеза, а
эффективность этой гипотезы превратила ее в лелеемый кри-
терий. И, помимо всего прочего, длина формального доказа-
тельства— это объективный критерий; эта объективность,
по-видимому, стала тем средством, которое позволило нам
быстрее приходить к взаимопониманию, гораздо быстрее, чем
под влиянием только красноречия. Главным для меня было не
формальное доказательство правильности, а научная дисцип-
лина, которая помогала бы нам делать наши программы ра-
зумными, понятными и разумно управляемыми.
С разными примерами я работал с разной степенью фор-
мальности. Эти отклонения были преднамеренными, так как
мне не хотелось, чтобы мои читатели думали, что некая опре-
деленная, фиксированная степень формальности является
«правильной». Я предпочитаю смотреть на формальные мето-
ды как на средство, использование которого может оказаться
полезным.
Я попытался представить программирование скорее как на-
учную дисциплину, а не как ремесло. С давних времен нам
известны два главных способа передачи знаний и умений сле-
дующим поколениям. Один метод цеховой: молодой ученик
семь лет работает с мастером, знание передается неявно, уче-
ник поглощает его, так сказать, осмотически, пока сам не ста-
новится мастером. (Эта неявная передача для знания невы-
годна: потеряно столько старых ремесел!) Второй метод при-
меняется в университетах, расцвет которых совпал (не
случайно!) с распространением книгопечатания; здесь мы
пытаемся формулировать наши знания и тем самым делаем
их общественным достоянием. (Наше фактическое обучение
в университетах часто занимает промежуточное место: в мате-
матике, например, результаты публикуются и им учат вполне
Ретроспективы 273
явно; обучение же тому, как делать математику, часто остав-
ляется осмосу. И причина заключается не в нашей скрытности,
а в том, что мы чувствуем себя неспособными сказать про это
«как» что-нибудь более научное, чем обычные родительские
пожелания.)
Разбирая примеры, я старался как можно более ясно пе-
редать весь ход своих размышлений (хотя, конечно, мне не
всегда удавалось плавно объяснить неожиданную находку);
все примеры были лишь средством для демонстрации этой
ясности.
Мы сформулировали ряд теорем о конструкциях выбора и
повторения. Это была самая легкая часть, так как она каса-
ется знания. С помощью примеров мы попытались показать,
как целенаправленная попытка применить это знание может
помочь нам в процессе программирования; это было трудной
частью, так как она относится уже к умению. (Я думаю, на-
пример, о том, как знание теоремы о линейном просмотре по-
могало нам решать задачу о следующей перестановке.) Мы
попытались четко описать несколько стратегий, таких, как
Поиск Малого Супе’рмножества, и несколько методов «утрам-
бовки» программы, таких, как вынесение условия из конст-
рукции повторения. Но эти методы тесно связаны с програм-
мированием (нашей формой программирования).
Возможно, что читатель уловил между строк несколько бо-
лее общих соображений. Первое соображение заключается в
том, что не достаточно разработать механизм, который, как
мы надеемся, будет отвечать нашим требованиям; надо раз-
работать его в таком виде, чтобы мы могли убедить себя (и во-
обще говоря, любого другого), что он на самом деле будет им
отвечать. И, следовательно, вместо того, чтобы сначала напи-
сать программу, а лотом пытаться доказывать ее правиль-
ность, мы одновременно разрабатываем и программу, и до-
казательство ее правильности. (Фактически доказательство
правильности несколько опережает программу: выбрав форму
доказательства правильности, мы пишем программу так, что-
бы она удовлетворяла требованиям доказательства.) Из этого
следует, что если все идет по составленному плану, то разра-
ботка остается «интеллектуально управляемой». Второе сооб-
ражение состоит в том, что, если этот конструктивный подход
к проблеме правильности программы мы берем как основу
нашего планирования, нам следует проследить за тем, чтобы
соответствующая ей интеллектуальная работа не превысила
наших ограниченных возможностей; следует заметить, что
немногие разработки удовлетворяют этому требованию. В за-
даче о голландском национальном флаге, например, мы чуть
не увлеклись анализом вариантов, где число вариантов, кото-
274 Глава 27
рые необходимо различать, росло экспоненциально: если бы
мы пошли по этому пути, то быстро пришли бы к такому числу
вариантов, проанализировать которые были бы уже не в си-
лах. В задаче о кратчайшем покрывающем дереве мы видели,
как ограничение класса допустимых промежуточных состоя-
ний («красные» ветви всегда образуют дерево) может значи-
тельно упростить анализ. Но самым полезным — его можно
считать примером разделения аспектов — является метод по-
шаговой детализации, когда мы пытаемся преодолевать воз-
никающие перед нами препятствия по очереди. В задаче о
кратчайшем покрывающем дереве к тому времени, когда нас
начало беспокоить время вычисления, №-алгоритм мы нашли
как оптимизацию №-алгоритма. В задаче о максимально
сильной компоненте мы сначала нашли алгоритм, линейно за-
висящий от числа ребер, и только следующее уточнение га-
рантировало нам и фиксированное максимальное время
обработки каждой вершины. В задаче о самых удаленных се-
лениях наше грубое решение было подвергнуто двум незави-
симым сильно отличающимся оптимизациям, их объединение
после этого уже не представляло труда.
Как было замечено выше, цель мышления состоит в умень-
шении детализированных рассуждений до выполнимого коли-
чества. Наиболее волнующий вопрос здесь: можно ли понимае-
мому в этом смысле «мышлению» научить? Если я отвечу на
этот вопрос: «Нет», — то меня сразу же могут спросить, зачем
я стал писать эту книгу; если на этот вопрос я отвечу:
«Да», — то буду выглядеть дураком, и мне остается ответить
одно: «До некоторой степени...» По-видимому, мягко выража-
ясь, тщетно надеяться написать книгу, которую можно дать
молодому человеку со словами: «Прочти ее, и ты сможешь
мыслить эффективно». Наша надежда остается столь же тщет-
ной, если, заменить такую книгу красивой диалоговой системой
обучения с помощью машины.
Но когда люди пытаются понять (сначала подсознатель-
но) , выявить и обойти непреодолимую сложность, я верю, что
им можно помочь. Прежде всего им нужно объяснить, что че-
ловек неспособен «заниматься всем: королями и капустой»
(по крайней мере в каждый конкретный момент), и нужно
научить их видеть, в чем и когда сложность проявляется.
В той же мере, в какой профессор консерватории помогает
своим ученикам знакомиться с элементами гармонии и ритма
и с тем, как их можно комбинировать, вполне возможно нау-
чить студентов чувствовать образцы рассуждений и способы
их комбинирования. Эта аналогия вовсе не притянута за во-
лосы: четко проведенным рассуждением можно востор1аться
так же, как и адажио Моцарта.
ОГЛАВЛЕНИЕ
Предисловие редактора перевода ............................... 5
Предисловие .................................................. 8
От автора....................................................... 9
0. Абстракция исполнения......................................17
1. Роль-языков программирования.............•.................24
2. Состояния'и их характеристика..............................27
3. Характеристика семантики...................................34
4. Семантическая характеристика языка программирования . . . 45
5. Две теоремы.............................................. 62
6. О проектировании правильно завершаемых конструкций........66
7. Пересмотренный алгоритм Евклида............................70
8. Формальное рассмотрение нескольких небольших примеров ... 77
9. Когда недетерминированность ограничена ...................104
10. Размышления на тему: «Область действия переменных» . . . .111
11. Векторные переменные...........’.........................131
12. Теорема о линейном просмотре.............................145
13. Задача о следующей перестановке..........................147
14. Задача о голландском национальном флаге..................161
15. Обновление последовательного файла.......................168
16. Еще раз о задачах слияния................................165
17. Упражнение, приписываемое Р. У. Хэммингу.................172
18. Задача поиска по образцу.................................178
19. Представление числа в виде суммы двух квадратов..........134
20. Задача о наименьшем простом множителе большого числа . . .187
21. Задача о самых удаленных селениях........................194
22. Задача о кратчайшем покрывающем дереве...................199
23. Алгоритм Рема выделения классов эквивалентности..........208
24. Задача о выпуклой оболочке в трехмерном пространстве .... 217
25. Нахождение максимально сильных компонент в ориентированном
графе.............................................ч..........245
26. О руководствах и реализациях.............................256
27. Ретроспективы............................................265
УВАЖАЕМЫЙ ЧИТАТЕЛЬ!
Ваши замечания о содержании книги, ее оформ-
лении, качестве перевода и другие просим присылать
по адресу: 129820, Москва, И-110, ГСП, 1-й Рижский
пер., д. 2, издательство «Мир>.
Э. Дейкстра
ДИСЦИПЛИНА
ПРОГРАММИРОВАНИЯ
Редактор Л. Н. Бабынина
Художник В. М. Новоселова
Художественный редактор В. И. Шаповалов
Технический редактор Н. И. Борисова
Корректор В. И. Киселева
ИБ № 1232
Сдано в набор 21.12.77. Подписано к печати 22 08.78
Формат 60 X90’/ie Бумага типографская № 1.
Гарнитура латинская. Печать высокая.•
Объем 8,75 бум. л. Усл. печ. л. 17,50 Уч.-изд. л. 14,03
Изд. № 1/9552 Тираж 25 000 экз. Зак. 6. Цена 1 р. 20 к.
Издательство «МИР>
Москва, 1-й Рижский пер., 2
Московская типография № 8 Союзполиграфпрома
при Государственном комитете Совета Министров СССР
по делам издательств, полиграфии и книжной торговли,
Хохловский пер., 7.