
































































































































































































































































































































































































































































































































































































































Author: Гонсалес Р. Вудс Р. Эддинс С.
Tags: информатика программное обеспечение цифровая обработка изображений язык программирования matlab
ISBN: 5-94836-092-Х
Year: 2006




Text
МИР
цифровой обработки
Р. ГОНСАЛЕС, Р. ВУДС
С. ЭДДИНС
Цифровая
обработка
изображений
в среде MATLAB
Перевод с английского
В.В. Чепыжова
Гонсалес F., Вудс F., Эддинс С.
Цифровая обработка изображений в среде MATLAB
Москва:
Техносфера, 2006. - 616с. ISBN 5-94836-092-Х
Монография предназначена для тех. кто хочет в короткие сроки освоить
методы обработки изображений с использованием пакета MATLAB.
Книга разбита на 12 глав, охватывающих самые важные области обработки
изображений: градационные преобразования, линейную и нелинейную про-
странственную фильтрацию, вейвлеты, фильтрацию в частотной области, вос-
становление, регистрацию, сжатие, морфологическую обработку, сегментацию,
представление и описание областей и границ изображений, а также рас-
познавание объектов и обработку цветных изображений.
Книга будет полезна всем, кто хочет овладеть практическими навыками
работы с изображениями, особенно специалистам по дистанционному зон-
дированию, цифровому телевидению, компьютерной микроскопии, системам
безопасности, программистам и дизайнерам.
Digital
Image
Processing
using
MATLAB
Rafael C. Gonsales
Richard E. Woods
Steven L. Eddins
PEARSON
© 2004 Digital image processing using MATLAB,1-e Edition,
by WOODS, RICHARD E., published by Pearson Education,
Inc, publishing as Prentice Hall.
© 2006, ЗАО «РИЦ «Техносфера» перевод на русский язык,
оригинал-макет, оформление.
ISBN 5-94836092-Х
ISBN 0-13-008519-7 (англ.)
Содержание
Пролог 10
Благодарности.................................................. 12
Об авторах..................................................... 13
Глава 1
Введение 16
1.1. Некоторые основания....................................... 16
1.2. Что такое цифровая обработка изображений? 17
1.3. Система MATLAB и пакет Image Processing Toolbox........... 19
1.4. Задачи по обработке изображений........................... 20
1.5. О вебсайте этой книги..................................... 22
1.6. Обозначения............................................... 22
1.7. Рабочая среда системы MATLAB.............................. 23
1.7.1. Рабочий стол MATLAB................................... 23
1.7.2. Создание М-файлов в редакторе MATLAB.................. 24
1.7.3. Вызов справки......................................... 25
1.7.4. Сохранение и загрузка рабочего пространства........... 26
1.8. Как организованы ссылки 27
Выводы 27
Глава 2
Цифровые изображения в MATLAB.................................. 28
Введение.................................................. 28
2.1. Представление цифровых изображений........................ 28
2.1.1. Координатное соглашение 29
2.1.2. Изображение как матрица............................... 30
2.2. Загрузка изображений 31
2.3. Вывод изображения на дисплей.............................. 32
2.4. Сохранение изображений.................................... 34
2.5. Классы данных............................................. 39
2.6. Типы изображений.......................................... 40
2.6.1. Полутоновые изображения 41
2.6.2. Двоичные изображения.................................. 41
2.6.3. Еще раз о терминологии................................ 41
2.7. Конвертирование классов данных и типов изображений........ 42
2.7.1. Конвертирование классов данных........................ 42
2.7.2. Конвертирование классов и типов изображений........... 42
2.8. Индексирование массивов................................... 46
2.8.1. Индексирование векторов............................... 46
2.8.2. Индексирование матриц................................. 48
2.8.3. О размерности массивов................................ 52
2.9. Некоторые важные стандартные массивы...................... 52
Содержание
2.10. Введение в программирование М-функций..................... 53
2.10.1. М-файлы 54
2.10.2. Операторы............................................. 56
2.10.3. Управление вычислительными потоками 64
2.10.4. Кодовая оптимизация программ.......................... 70
2.10.5. Интерактивный ввод/вывод............................. 74
2.10.6. Краткое введение в смешанные массивы и структуры 77
Выводы 78
Глава 3
Преобразования яркости изображений и пространствен-
ная фильтрация 79
Введение................................................... 79
3.1. Некоторые основы........................................... 79
3.2. Преобразования яркости изображений 80
3.2.1. Функция imadjust....................................... 80
3.2.2. Логарифмические преобразования и преобразования растяже-
ния контрастности............................................. 82
3.2.3. Некоторые утилитные М-функции преобразования яркости.... 84
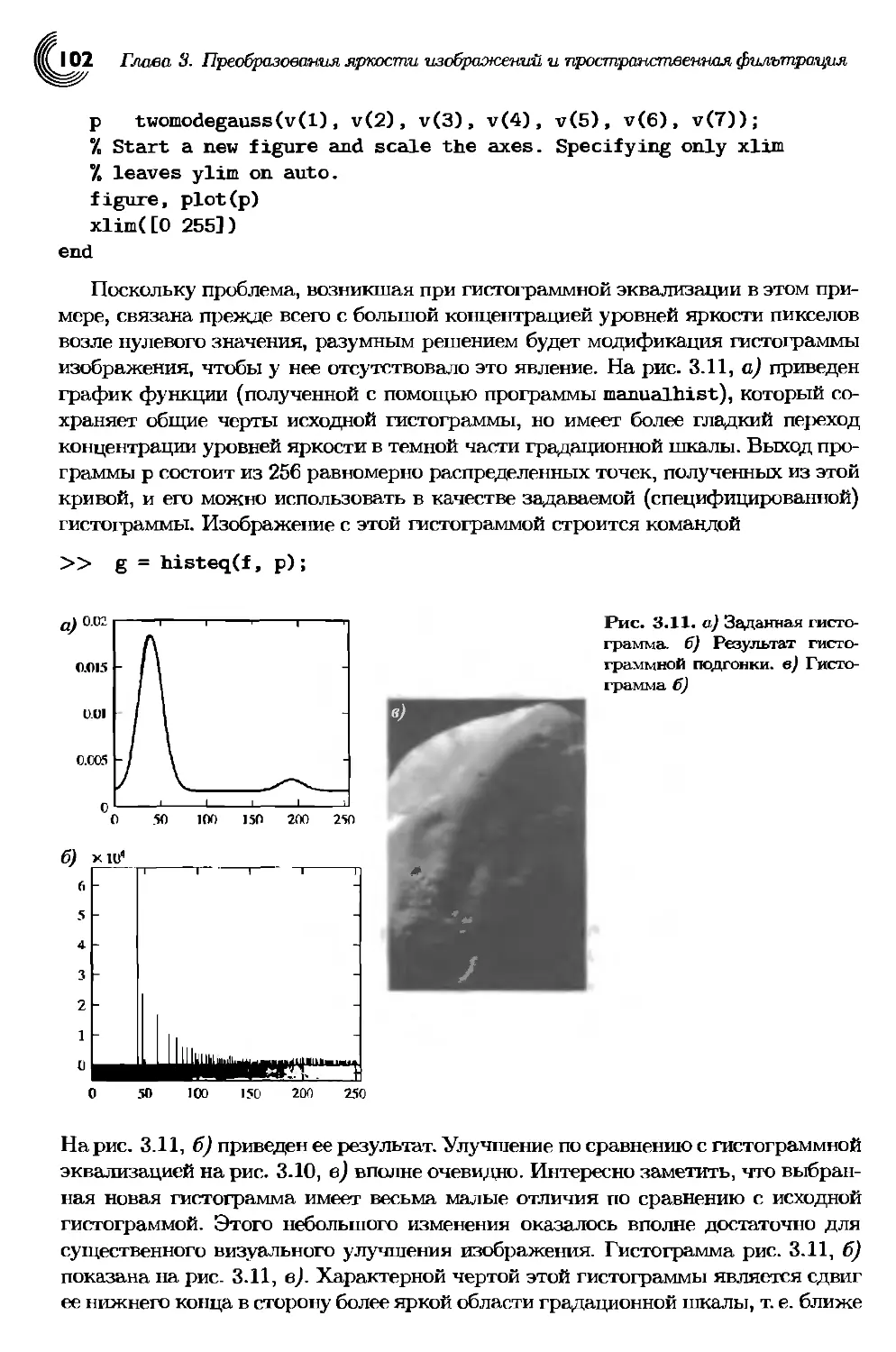
3.3. Обработка гистограмм и построение графиков функций......... 90
3.3.1. Нахождение и построение гистограмм..................... 90
3.3.2. Эквализапия гистограммы................................ 95
3.3.3. Гистограммная подгонка (спецификация) 98
3.4. Пространственная фильтрация.... 103
3.4.1. Линейная пространственная фильтрация...................103
3.4.2. Нелинейная пространственная фильтрация.................111
3.5. Стандартные пространственные фильтры из пакета IPT.........114
3.5.1. Линейные пространственные фильтры...... 114
3.5.2. Нелинейные пространственные фильтры....................118
Выводы 121
Глава 4
Обработка в частотной области...................................122
Введение...................................................122
4.1. Двумерное дискретное преобразование Фурье 122
4.2. Вычисление и визуализация двумерного DFT в MATLAB. 126
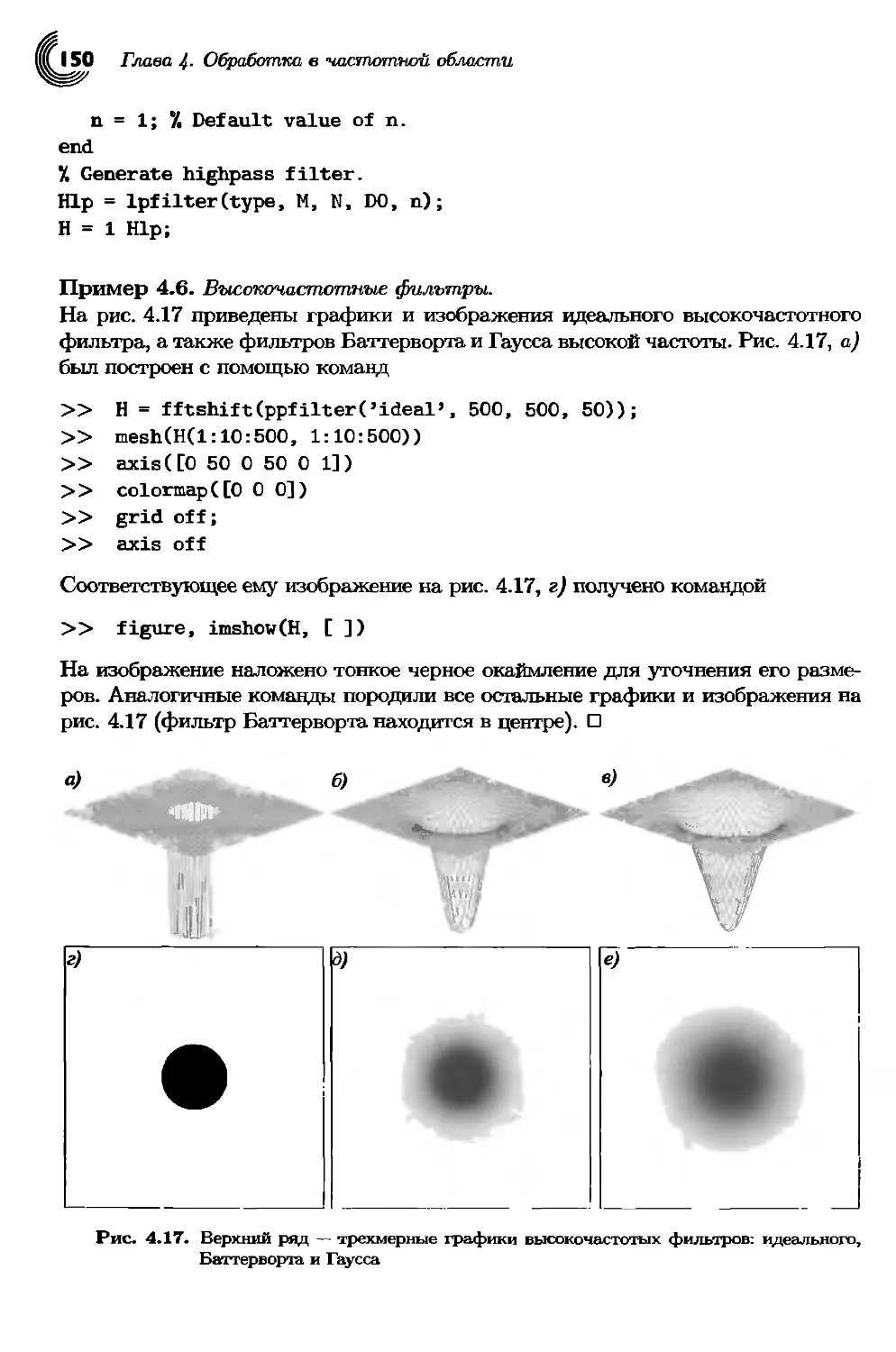
4.3. Фильтрация в частотной области.... 129
4.3.1. Базовые концепции......................................129
4.3.2. Основные шаги фильтрации в частотной области............134
4.3.3. М-функция для фильтрации в частотной области............136
4.4. Построение фильтров в частотной области
по пространственным фильтрам............................. 136
4.5. Прямое построение фильтров в частотной области.............141
4.5.1. Построение сеточных массивов для использования в фильтрах в
частотной области......................................141
Содержание S
4.5.2. Низкочастотные фильтры................................142
4.5.3. Построение графиков каркасных контуров и поверхностей.145
4.6. Повышение резкости при частотной фильтрации...............149
4.6.1. Основы высокочастотной фильтрации.....................149
4.6.2. Фильтрация с усилением высоких частот.................151
Выводы....................................................153
Глава 5
Восстановление изображений......................................154
Введение..................................................154
5.1. Моделирование процесса искажения/восстановления изображения.154
5.2. Модели шума...............................................156
5.2.1. Добавление шума функцией inmoise 156
5.2.2. Генерация случайного пространственного шума с заданным рас-
пределением ..................................................157
5.2.3. Периодический шум 165
5.2.4. Оценивание параметров шума.............................168
5.3. Восстановление в присутствии одного шума пространственная
фильтрация......................................................172
5.3.1. Фильтры для пространственного шума....................172
5.3.2. Адаптивные пространственные фильтры...................177
5.4. Подавление периодического шума с помощью фильтрации в частот-
ной области.....................................................179
5.5. Моделирование искажающих функций..........................180
5.6. Инверсная фильтрация......................................183
5.7. Винеровская фильтрация....................................183
5.8. Сглаживающая фильтрация методом наименьших квадратов со связью187
5.9. Алгоритм Люси-Ричардсона итерационного нелинейного восстанов-
ления...........................................................189
5.10. Слепая деконволюция.......................................192
5.11. Геометрические преобразования и регистрация изображений...195
5.11.1. Пространственные преобразования.......................195
5.11.2. Применение пространственных преобразований к изображениям . 200
5.11.3. Регистрация изображений 203
Выводы 205
Глава 6
Обработка цветных изображений...................................206
Введение..................................................206
6.1. Представление цветных изображений в MATLAB................206
6.1.1. RGB изображения.......................................206
6.1.2. Индексированные изображения...........................208
6.1.3. Функции IPT для обращения с RGB и индексированными изоб-
ражениями ....................................................211
6.2. Преобразования в другие цветовые пространства.............214
Содержание
6.2.1. Цветовое пространство NTSC..............................214
6.2.2. Цветовое пространство YCbCr.............................215
6.2.3. Цветовое пространство HSV...............................216
6.2.4. Цветовые пространства CMY и CMYK...................... 216
6.2.5. Цветовое пространство HSI...............................217
6.3. Основы обработки цветных изображений........................223
6.4. Цветовые преобразования.....................................236
6.5. Пространственная фильтрация цветных изображений.............243
6.5.1. Сглаживание цветных изображений..... ..243
6.5.2. Повышение резкости цветных изображений..................245
6.6. Обработка в векторном пространстве RGB напрямую.............246
6.6.1. Обнаружение контуров на цветных изображениях с помощью
градиента......................................................246
6.6.2. Сегментация в векторном пространстве RGB................250
Выводы.....................................................253
Глава 7
Вейвлеты.........................................................254
Введение...................................................254
7.1. Некоторые основы............................................254
7.2. Быстрое вейвлетное преобразование...........................257
7.2.1. Преобразования FWT в пакете Wavelet Toolbox.............258
7.2.2. Преобразования FW'T без использования Wavelet Toolbox...264
7.3. Работа со структурами вейвлетной декомпозиции...............272
7.3.1. Редактирование вейвлетных коэффициентов вне пакета Wavelet
Tollbox........................................................274
7.3.2. Отображение коэффициентов декомпозиции..................279
7.4. Быстрое обратное вейвлетное преобразование..................283
7.5. Вейвлеты при обработке изображений..........................289
Выводы.....................................................294
Глава 8
Сжатие изображений...............................................295
Введение...................................................295
8.1. Некоторые основы............................................296
8.2. Кодовая избыточность........................................299
8.2.1. Коды Хаффмана...........................................302
8.2.2. Кодирование Хаффмана....................................309
8.2.3. Декодирование Хаффмана..................................316
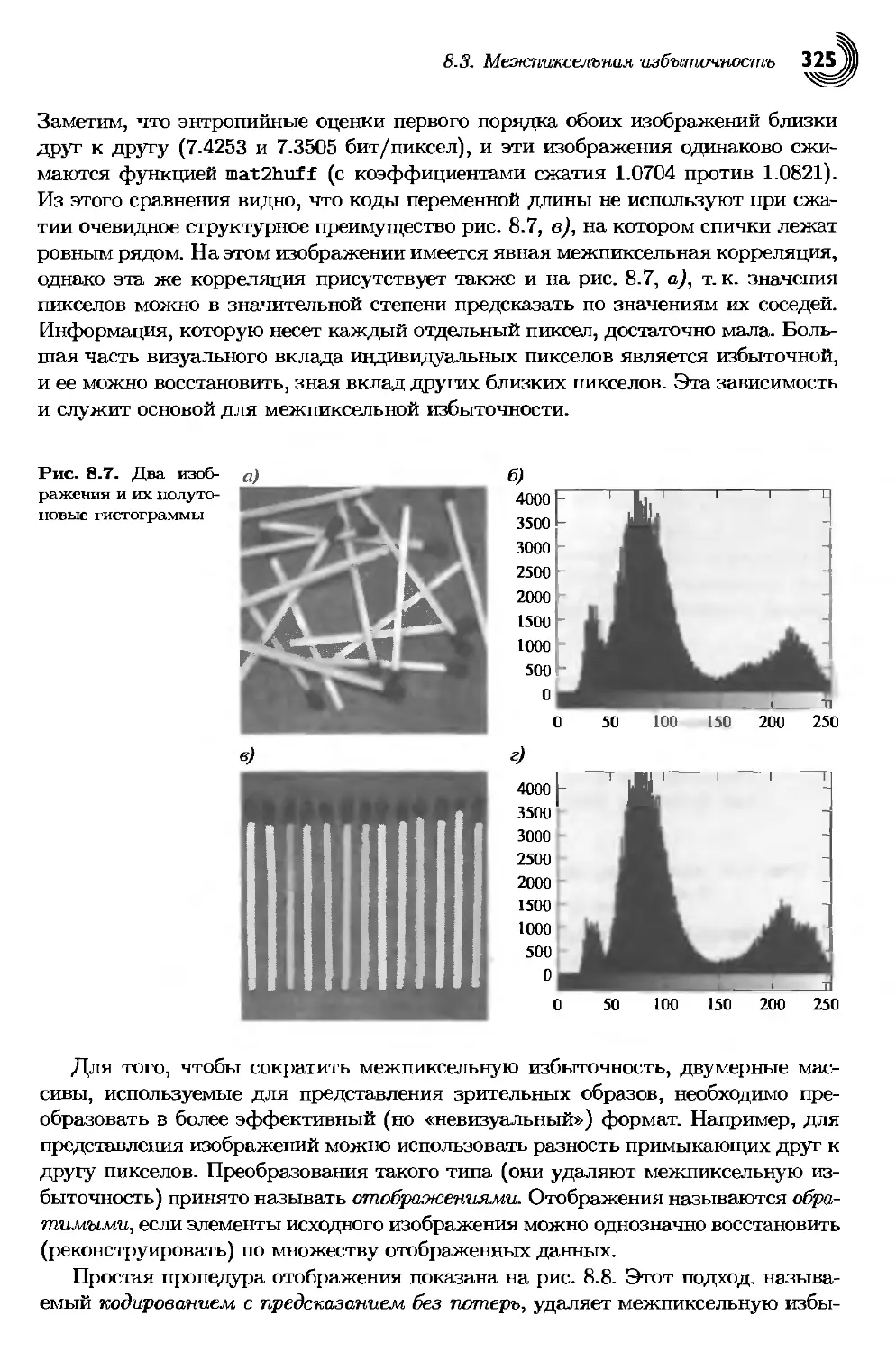
8.3. Межпиксельная избыточность..................................324
8.4. Визуальная избыточность.....................................330
8.5. Стандарты сжатия JPEG ......................................333
8.5.1. JPEG....................................................334
8.5.2. JPEG 2000 ............................................. 341
Выводы.....................................................349
Содержание 7
Глава 9
Морфологическая обработка изображений..........................351
Введение..................................................351
9.1. Предварительные сведения.................................352
9.1.1. Базовые понятия теории множеств.......................352
9.1.2. Двоичные изображения, множества и логические операции.354
9.2. Дилатация и эрозия.......................................355
9.2.1. Дилатация.............................................355
9.2.2. Разложение структурообразующих элементов..............358
9.2.3. Функция strel.........................................359
9.2.4. Эрозия................................................362
9.3. Комбинирование дилатации и эрозии........................364
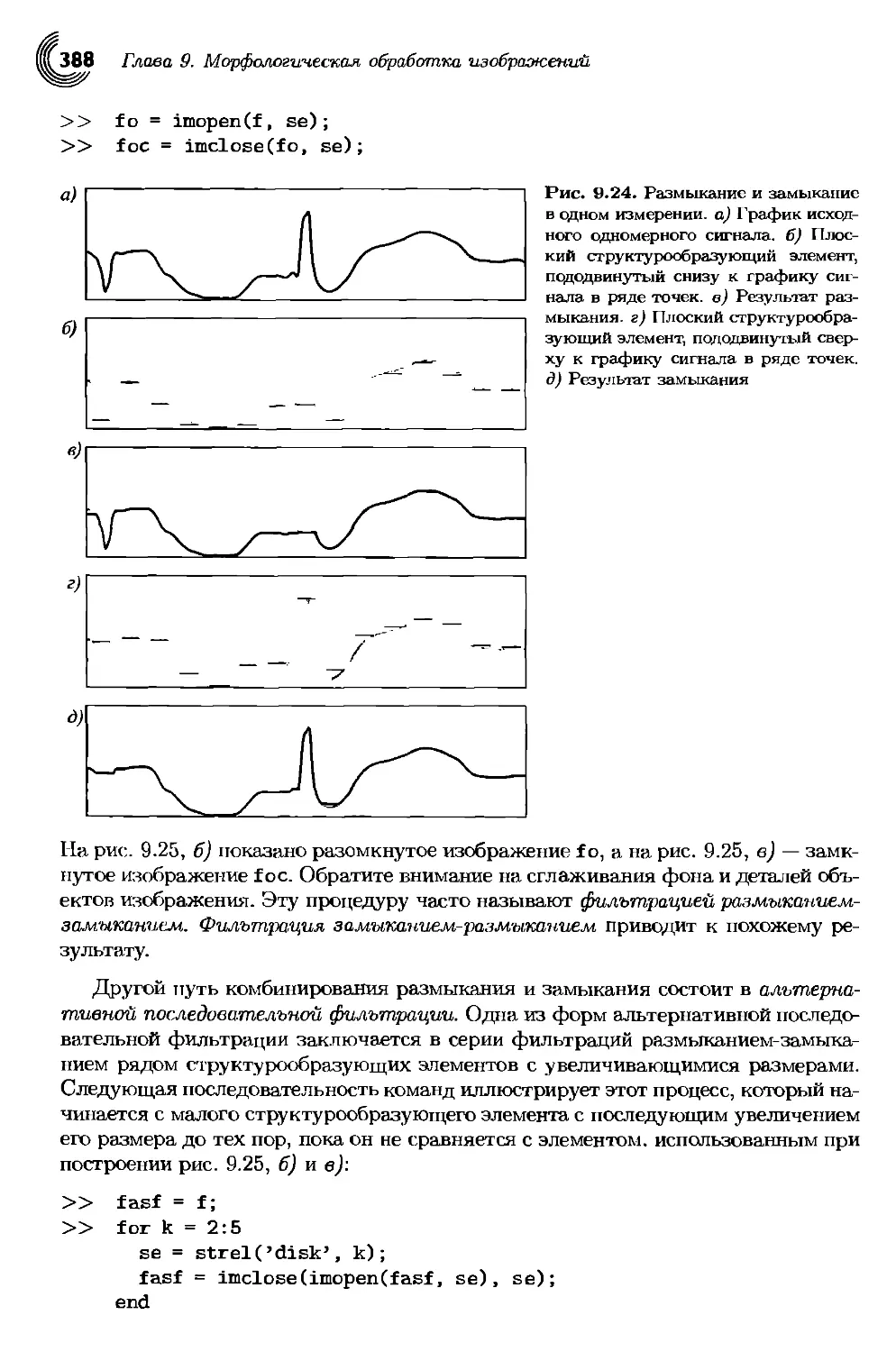
9.3.1. Размыкание и замыкание................................364
9.3.2. Преобразование успех, неудача.........................367
9.3.3. Использование поисковых таблиц........................370
9.3.4. Функция bwmorph.......................................373
9.4. Выделение компонент связности............................376
9.5. Морфологическая реконструкция............................380
9.5.1. Размыкание реконструкцией.............................381
9.5.2. Заполнение отверстий..................................383
9.5.3. Очистка от пограничных объектов.......................383
9.6. Полутоновая морфология...................................384
9.6.1. Дилатация и эрозия....................................384
9.6.2. Размыкание и замыкание................................387
9.6.3. Реконструкция.........................................392
Выводы....................................................395
Глава 10
Сегментация изображений........................................396
Введение..................................................396
10.1. Обнаружение точек, линий и перепадов.....................397
10.1.1. Обнаружение точек....................................397
10.1.2. Обнаружение линий....................................399
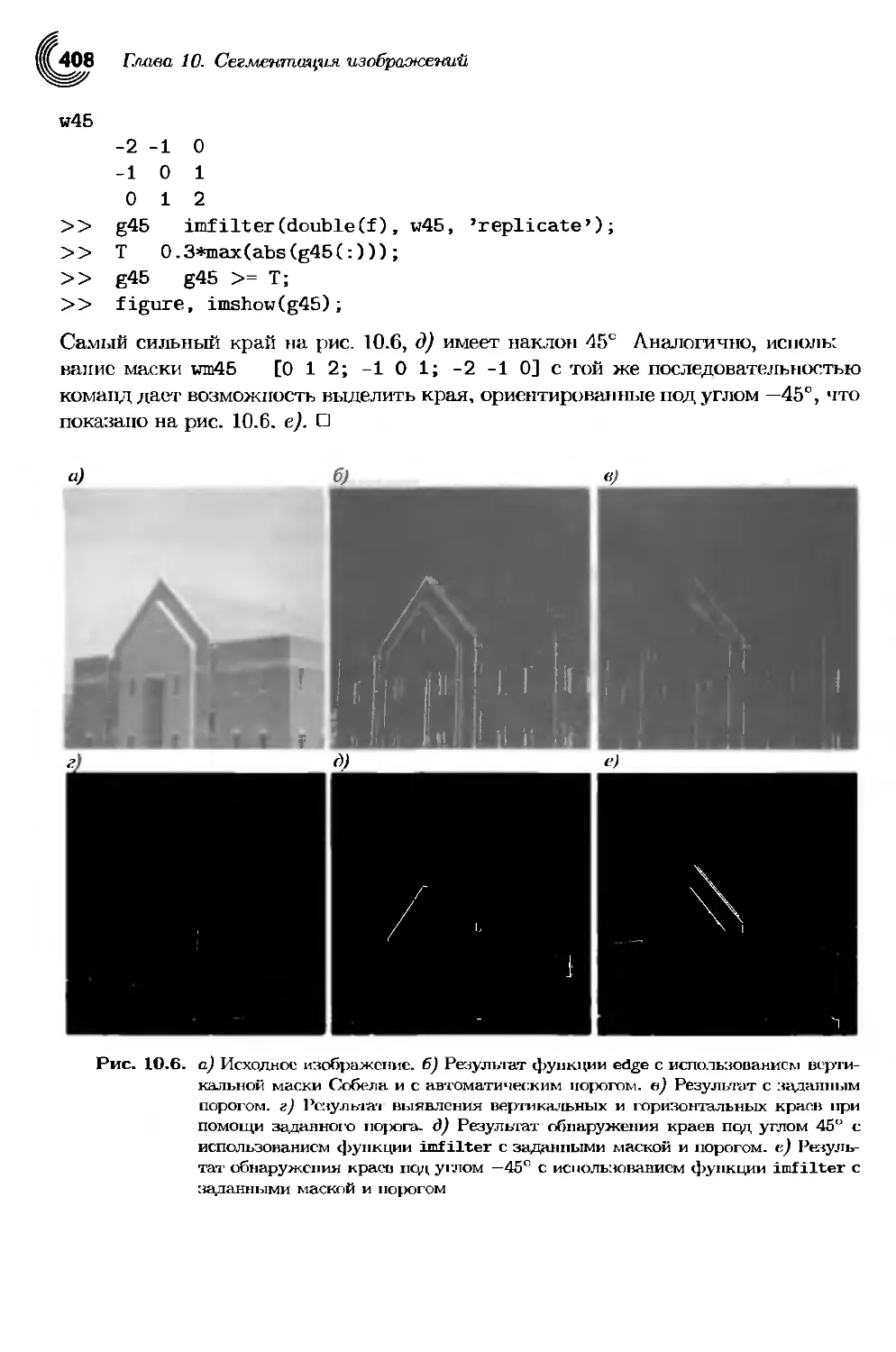
10.1.3. Обнаружение перепадов с помощью функции edge.........401
10.2. Обнаружение линий с помощью преобразования Хафа..........410
10.2.1. Нахождение максимумов преобразования Хафа............416
10.2.2. Преобразование Хафа при обнаружении линий и связывании.418
10.3. Пороговая обработка......................................421
10.3.1. Обработка с глобальным порогом.......................422
10.3.2. Обработка с адаптивным порогом.......................424
10.4. Сегментация на отдельные области.........................425
10.4.1. Постановка задачи....................................425
10.4.2. Выращивание областей.................................425
10.4.3. Разделение и слияние областей........................430
10.5. Сегментация преобразованием водораздела..................436
8
Содержание
10.5.1. Сегментация по водоразделам с помощью преобразования рас-
стояния.................................................436
10.5.2. Сегментация по водоразделам с помощью градиентов.......438
10.5.3. Использование маркеров при сегментации по водоразделам.440
Выводы.................................................... 443
Глава 11
Представление и описание.........................................444
Введение.................................................. 444
11.1. Предварительные сведения...................................444
11.1.1. Смешанные массивы и структуры..........................445
11.1.2. Некоторые дополнительные функции MATLAB и IPT..........450
11.1.3. Некоторые основные утилитные М-функции.................451
11.2. Представление..............................................454
11.2.1. Цепные коды............................................454
11.2.2. Приближение ломаной линией минимальной длины...........458
11.2.3. Сигнатуры..............................................466
11.2.4. Сегменты границы.......................................470
11.2.5. Остовы областей........................................470
11.3. Дескрипторы границ.........................................473
11.3.1. Некоторые простые дескрипторы..........................473
11.3.2. Нумерация фигур........................................474
11.3.3. Фурье-дескрипторы .....................................475
11.3.4. Статистические характеристики..........................480
11.4. Дескрипторы областей.......................................481
11.4.1. Функция regionprops....................................481
11.4.2. Текстура...............................................483
11.4.3. Инварианты моментов.................................. 488
11.5. Использование главных компонент при описании изображений...491
Выводы......................................................500
Глава 12
Распознавание объектов............. 501
Введение....................................................501
12.1. Некоторые основы...........................................501
12.2. Вычисление расстояний в MATLAB... 502
12.3. Распознавание с помощью теории решений.....................505
12.3.1. Формирование векторов признаков........................506
12.3.2. Сопоставление образов с помощью классификаторов по миниму-
му расстояния................................................506
12.3.3. Корреляционное сопоставление....................... 508
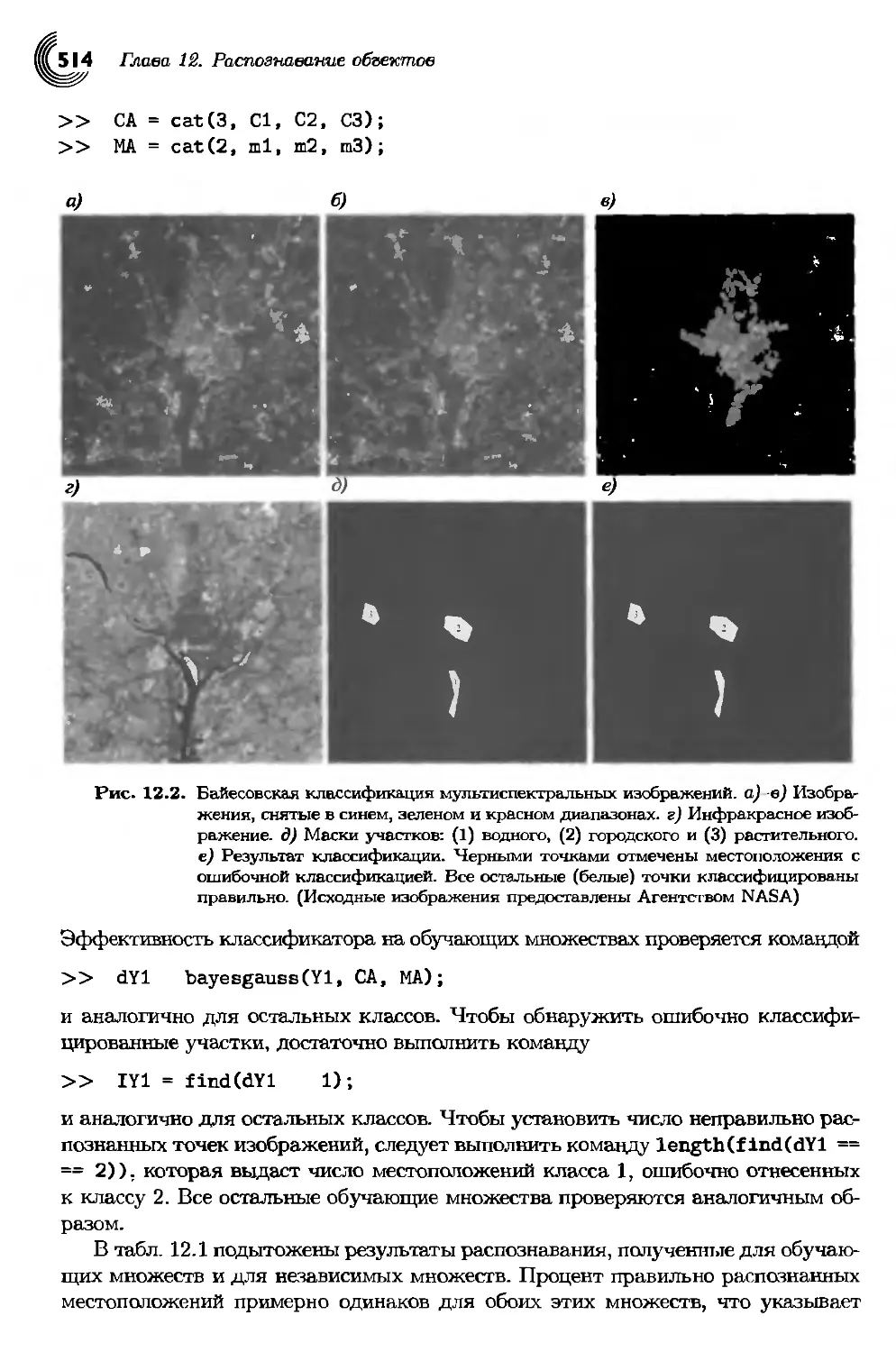
12.3.4. Статистически оптимальные классификаторы...............510
12.3.5. Адаптивные обучающиеся системы.........................515
12.4. Структурное распознавание..................................516
12.4.1. Работа со строками в MATLAB............................516
Содержание 9
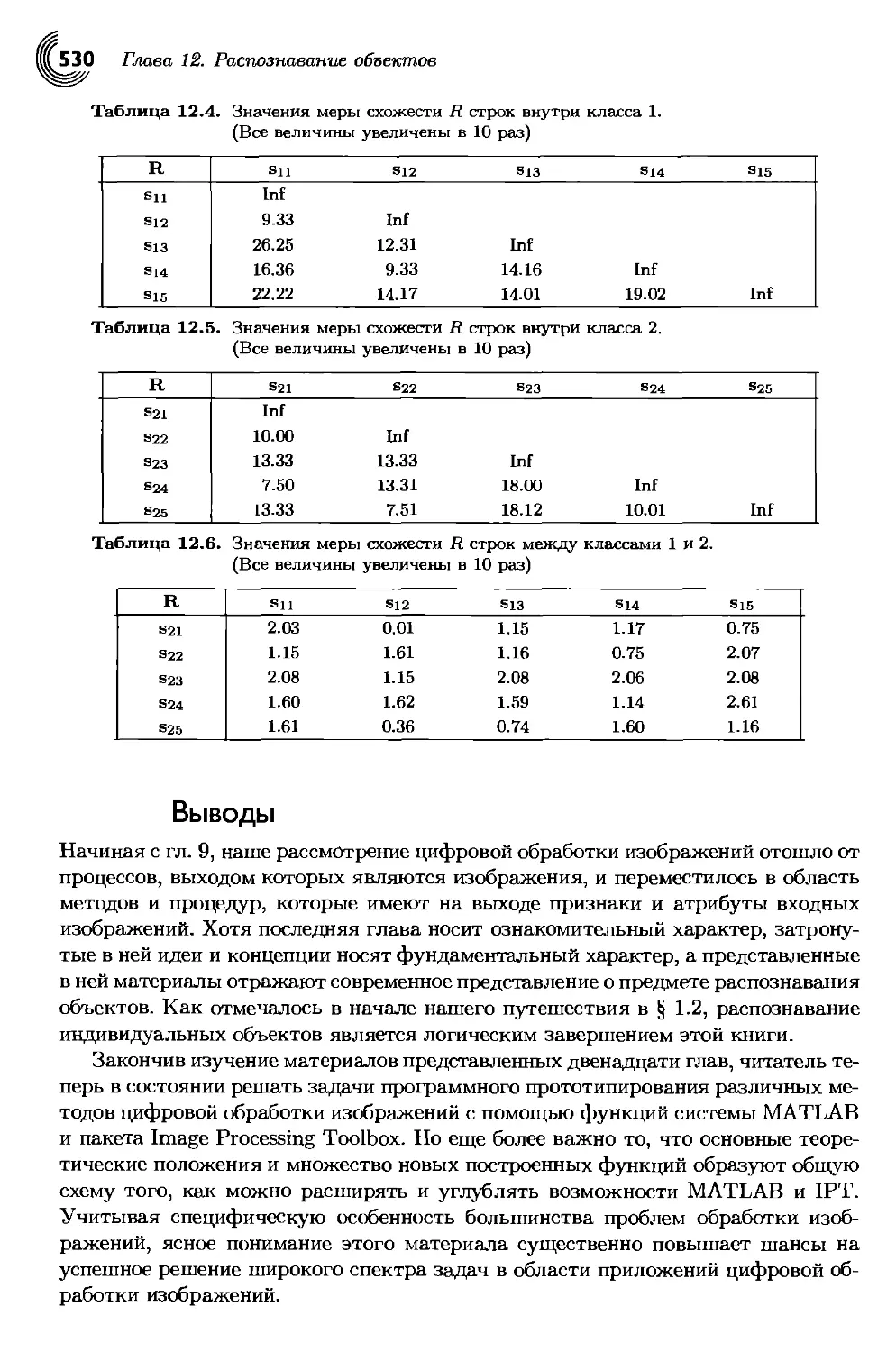
12.4.2. Сопоставление строк.............................526
Выводы...............................................530
Приложение А..............................................531
Введение.............................................531
А.1. Функции IPT и DIPUM..................................531
А. 2. Функции MATLAB......................................539
Приложение Б..............................................544
Введение.............................................544
Б.1. Построение графического интерфейса ICE...............544
Б.2. Программируемый интерфейс ICE........................547
Б.2.1. Программный код инициализации....................550
Б.2.2. Открытие окна и вывод функций....................552
Б.2.3. Функции вызовов окна.............................563
Б.2.4. Функции вызовов объектов.........................567
Приложение В..............................................570
Введение.............................................570
Литература................................................614
Пролог
Решение задач, возникающих в области цифровой обработки изображений, тре-
бует большой экспериментальной работы, в которой приходится использовать
специализированные алгоритмы и многократное тестирование с привлечением
обширной базы различных изображений. Разработка алгоритмов обычно опира-
ется на основательный теоретический фундамент; тем не менее, реальное при-
ложение этих алгоритмов почти всегда требует определения конкретных пара-
метров, редактирования отдельных частей алгоритмов и сравнения различных
конкурирующих версий искомого решения. Таким образом, выбор гибкой, все-
охватывающей и хорошо документированной среды для разработки конкретных
приложений является ключевым фактором, который влияет на цену и время
разработки программного обеспечения, а также на компактность конечного про-
граммного продукта.
Несмотря на очевидную актуальность предмета, было написано сравнительно
мало учебников и книг, в которых одновременно рассматривались бы теоретиче-
ские основы и практические программные аспекты решения основных задач в
области цифровой обработки изображения. Настоящая книга была написана как
раз с этой целью. Мы видели свою задачу в том, чтобы изложить фундаменталь-
ные алгоритмы обработки изображений с использованием самых современных
компьютерных программных инструментов. Одновременно с этим мы стреми-
лись к написанию самодостаточного учебника, который будет легко освоить всем,
кто имеет лишь общие представления о предмете цифровой обработки изображе-
ний, знаком с основами математического анализа и владеет минимальными на-
выками компьютерного программирования. Все эти необходимые знания обычно
приобретаются на первых курсах технических вузов и университетов. Желатель-
но (но не обязательно) также иметь элементарные сведения о системе MATLAB.
Для достижения поставленной цели нам потребовалось решить две ключевые
задачи. Первая задача — отобрать материалы по обработке изображений, кото-
рые в значительной степени покрывают стандартную программу учебных курсов
по данной теме. Вторая задача — выбрать подходящие программные инстру-
менты, хорошо документированные, с реальной поддержкой разработчиками, и
которые имеют широкий охват приложений в «реальном» компьютерном мире.
Для решения первой задачи мы воспользовались соответствующими главами
из монографии «Digital Image Processing», R.Gonzalez, R.Woods1, обновляющие-
ся издания которой считаются во всем мире основными базовыми учебниками по
этому предмету на протяжении более двадцати лет. А необходимые программные
инструменты были взяты из пакета MATLAB Image Processing Toolbox (IPT),
который одновременно занимает ведущие позиции и в образовательной, и в ин-
дустриальной сфере. Мы придерживались следующей стратегии при написании
данной книги: интегрировать хорошо разработанные теоретические конструкции
и их практические реализации на основе самого современного программного обес-
печения.
1 Имеется перевод этой монографии на русский язык: Р.Гонсалес, Р.Вудс «Цифровая обработка
изображений», М: Техносфера, 2005. — 1070 с. — Прим, перев.
Книга организована подобно монографии «Цифровая обработка изображе-
ний». При таком построении читателю будет весьма просто найти более деталь-
ное рассмотрение всех основных концепций, используемых в цифровой обработке
изображений. Там же можно обнаружить обширные ссылки на дополнительную
литературу по интересующему предмету. Кроме того, при таком подходе мож-
но весьма сжато представить теоретический материал и сфокусировать основ-
ное внимание на программном аспекте решения задач обработки изображений.
Отметим, что работа в среде системы MATLAB с пакетом IPT дает значитель-
ные преимущества, причем не только из-за широты и разнообразия предлага-
емых инструментов, но и в силу поддержки системы MATLAB подавляющим
большинством современных компьютерных платформ. Характерная особенность
этой книги состоит в последовательном акценте на том. как следует создавать
новый программный код, модифицируя и улучшая уже существующий функци-
ональный инструментарий MATLAB и IPT, который был разработан и оптими-
зирован настоящими профессионалами. Это очень важная черта при решении
задач обработки изображений, которые, как было отмечено выше, характеризу-
ются насущной необходимостью постоянного экспериментирования и внесения
изменений в отлаживаемый алгоритм.
После изложения основ системы MATLAB и описания основных его функ-
ций главным предметом книги будет исключительно цифровая обработка изоб-
ражений. Основные темы книги охватывают различные преобразования яркости
изображений, линейную и нелинейную пространственную фильтрацию, фильтра-
цию в частотной области, восстановление и регистрацию изображений, обработ-
ку цветных изображений, применение вейвлетов, сжатие изображений, морфо-
логическую обработку изображений, сегментацию изображений, представление
и описание областей и границ, распознавание объектов. Эти материалы сопро-
вождаются многочисленными иллюстрациями и примерами решения конкретных
задач обработки изображений с использованием функций MATLAB и IPT. В тех
случаях, когда необходимые функции отсутствуют в стандартном пакете, напи-
саны и документированы новые функции с учетом учебных целей данной книги.
В следующих главах имеется более 60 новых функций. Эти функции расширя-
ют пакет IPT, состоящий из 175 функций, примерно на 35 процентов, и, что
более важно, они показывают, как можно самостоятельно разрабатывать новые
эффективные приложения для обработки разнообразных изображений.
Все материалы книги представлены в формате учебника, а не в форме руко-
водства по написанию компьютерных программ. Несмотря на то, что эта книга
является вполне замкнутым и самодостаточным произведением, мы разместили
во всемирной паутине сопровождающий сайт (см. § 1.5), разработанный для осве-
щения некоторых дополнительных тем, который будет постоянно обновляться.
Для студентов, которые слушают общий курс по цифровой обработке изобра-
жений, а также для тех, кто изучает предмет самостоятельно, на нашем сайте
размещены учебные материалы и обзоры по основам предмета, включая базы
проектов и тестовых изображений, включая все изображения, использованные
в книге. Для преподавателей на сайте имеются материалы для презентаций в
учебных классах, включая слайды в системе PowerPoint всех изображений и гра-
фиков, представленных на страницах нашей книги. Читатели, уже знакомые с
12 Благодарности
обработкой изображений и с пакетом IPT, смогут найти на нашем сайте обнов-
ляющийся список литературы, новые технические решения, а также ссылки на
другие сайты в интернете, содержащие полезные материалы, которые не так про-
сто разыскать самостоятельно в этом море технической информации. Все поку-
патели данной книги имеют право загружать любые исполняемые программные
файлы всех новых функций, разработанных в тексте.
По природе любых писательских опытов подобного рода, прогресс продолжа-
ется и после написания манускрипта. По этой причине мы потратили много сил
на отбор фундаментального (по нашему мнению) материала, который, вероятно,
сохранит свое значение и применение в этой быстро развивающейся области зна-
ний. Мы верим, что читатели Оценят эти наши старания и обнаружат в нашей
книге материалы, нужные и полезные в их работе.
Мы глубоко признательны многим людям как из академических, так и из про-
мышленных и правительственных кругов, которые внесли значительный вклад
при приготовлении этой книги. Эта помощь была столь неоценимой и значитель-
ной, что нам трудно и невозможно кого-то выделить, поэтому мы всех их просто
перечисляем в алфавитном порядке. Мы выражаем нашу глубочайшую призна-
тельность Монги А.Абиди, Питеру Дж. Экламу, Сержу Бехеру. Эрнесто Брибес-
ка, Майклу У.Дэвидсону, Куртни Эспозито, Наоми Фернандес, Томасу Р. Гесту,
Роджеру Хиди, Бриану Джонсону, Лизе Кемплер, Рою Лурие. Эшли Мохаме-
ду, Джозефу Е. Пассенте, Дэвиду Р.Пикенсу, Эдгаро Фелипе Риверону. Майклу
Робинсону, Лорану Шуре, Джеку Склански, Салли Стоу, Крейгу Уотсону, Гре-
гу Володкину. Мы также благодарны организациям, упоминающимся во многих
подписях к фотографиям, за разрешение использовать эти материалы.
Особое спасибо Тому Роббинсону, Роуз Кернан, Алисе Дворкин. Хаоханг Жу,
Брюс Кенселаар и Джейн Конте из издательства Prentice Hall за их исключи-
тельные старания и постоянное стремление к совершенству во всем, связанном с
выпуском этой книги. Их творчество, поддержка и терпение были для нас просто
неоценимы.
Рафаэль С. Гонсалес
Ричард Е. Вудс
Стивен Л. Эддинс
Об авторах
Рафаэль С. Гонсалес
Р. С. Гонсалес получил степень бакалавра в университете штата Майами в 1965 г.,
а затем степени магистра и доктора философии по электротехнике в универси-
тете штата Флорида (г. Гейнсвилл) соответственно в 1967 и 1970 гг. В 1970 г. он
стал сотрудником факультета электронной и компьютерной техники университе-
та штата Теннеси (UTK) в г. Ноксвилл, где получил звание адъюнкт-профессора
в 1973 г., звание профессора в 1978 и звание заслуженного профессора в 1984 г.
С 1994 г. по 1997 г. профессор Гонсалес работал деканом факультета, а в насто-
ящее время он является почетным профессором UTK в отставке.
Профессор Гонсалес был основателем лаборатории анализа изображений и
образов, а также лаборатории роботехники и машинного зрения в университете
UTK. Он также основал в 1982 г. компанию Perceptics Corporation, и до 1992
года являлся ее президентом. Последние три года этого периода он также рабо-
тал в компании Westinghouse Corporation, которая купила Perceptics Corporation
в 1989 г. Под руководством Р. Гонсалеса компания Perceptics добилась больших
успехов в области обработки изображений, в машинном зрении и в технологии
хранения данных на лазерных дисках. В течение первых десяти лет своей ра-
боты компания Perceptics разработала и внедрила целый ряд инновационных
продуктов, в том числе: первую в мире коммерческую систему машинного зре-
ния для автоматического распознавания номерных знаков транспортных средств;
ряд крупномасштабных систем обработки и архивирования изображений, кото-
рые применяются на шести заводах ВМФ США при контроле реактивных двига-
телей баллистических ракет «Трайдент-2», размещенных на подводных лодках;
семейство видеоплат обработки изображений для модернизированных компьюте-
ров «Макинтош», занимающее лидирующие позиции на рынке; а также линейка
устройств хранения данных терабайтной емкости на основе лазерных дисков.
Профессор Гонсалес постоянно привлекается различными промышленными и
правительственными организациями в качестве консультанта по вопросам рас-
познавания образов, обработки изображений и обучающихся машин. Его ака-
демические заслуги в этих областях отмечены премией технического факульте-
та UTK за высокие достижения в 1977 г., премией ректора UTK для ученых-
исследователей в 1978 г., бруксовской премией выдающимся профессорам и по-
четным званием профессора Magnavox Engineering в 1980 г. В 1981 г. он стал
профессором IBM в университете Теннеси, а в 1984 г. Р. С. Гонсалес там же по-
лучил звание заслуженного профессора. Ему присуждено звание выдающегося
выпускника университета штата Майами (1985 г.), премия научного общества
«Фи-Каппа-Фи» (1986 г.) и премия им. Натана У.Догерти университета штата
Теннеси за выдающиеся инженерные достижения (1992 г.). Среди наград в обла-
сти техники — премия выдающемуся инженеру IEEE в 1987 г. за коммерческие
14 Об авторах
разработки в Теннеси; национальная премия 1988 г. им. Альберта Роуза за успе-
хи в создании промышленных систем обработки изображений; премия Б. Отто
Уили за достижения в переносе технологий и звание «предприниматель года»
агентства Купере и Либранд (1989 г.); премия выдающемуся инженеру IEEE за
1992 г. (по округу 3); национальная премия 1993 г. за развитие технологий от
ассоциации по автоматизированной обработке изображений.
Д-р Гонсалес является автором и соавтором более 100 научных и техниче-
ских статей, двух монографий и пяти учебников по распознаванию образов, об-
работке изображений и роботехнике. По его книгам учатся студенты более 500
университетов, работают исследователи во всем мире. Он включен в престиж-
ные справочники «Кто есть кто в Америке», «Кто есть кто в технике», «Кто
есть кто в мире». Его имя можно найти в десяти национальных и международ-
ных биографических перечнях. Он является совладельцем двух патентов США.
Профессор Гонсалес входит в редколлегию научных журналов «Труды по тео-
рии систем» (IEEE Transactions on Systems), «Человек и кибернетика» (Man and
Cybernetics), международного журнала по вычислительной технике и информа-
тике (International Journal of Computer and Information Sciences). Он является
членом IEEE и состоит во многих профессиональных и почетных обществах,
включая «Тау-Бета-Пи», «Фи-Каппа-Фи», «Эта-Каппа-Ню», «Сигма-Кси».
Ричард Э. Вудс
Ричард Э. Вудс получил степени бакалавра, магистра и доктора философии по
электротехнике в университете штата Теннеси (г. Ноксвилл). Сфера его профес-
сиональных интересов простирается от предпринимательской деятельности до
работы в традиционном академическом направлении исследователя и консуль-
танта в промышленных и правительственных организациях. Совсем недавно он
основал компанию MedData Interactive, работающую в сфере высоких техноло-
гий, которая специализируется в разработке портативных компьютерных систем
для нужд медицины. Он был также соучредителем и вице-президентом компа-
нии Perceptics Corporation, в которой он был ответственен за разработку многих
устройств для количественного анализа изображений и автономного принятия
решений роботизированными системами.
До работы в компаниях Perceptics и MedData Interactive д-р Вудс занимал
пост доцента по электронике и вычислительной технике в университете штата
Теннеси, а еще раньше он работал инженером по компьютеризации в компании
Union Carbide Corporation. В качестве консультанта он участвовал в разработке
различных процессоров специального назначения для решения задач распозна-
вания образов для ряда космических и военных организаций, включая агентство
NASA, Центра управления баллистическими ракетами и Национальную лабора-
торию Оук Ридж (Oak Ridge).
Д-р Вудс является автором множества публикаций по проблемам цифровой
обработки сигналов, а также соавтором монографии «Цифровая обработка изоб-
ражений», которая является одной из ведущих книг в это области. Он состоит во
многих профессиональных обществах, включая «Тау-Бета-Пи», «Фи-Каппа-Фи»
и IEEE. В 1986 г. он был признан выдающимся выпускником университета штата
Теннеси.
Об авторах
Стивен Л. Эдцинс
Стивен Л. Эддинс является менеджером по разработкам группы обработки изоб-
ражений компании MathWorks, Inc. Он руководил разработкой нескольких вер-
сий программного пакета Image Processing Toolbox этой компании. Его профес-
сиональная деятельность связана с созданием программных продуктов, основан-
ных на новейших алгоритмах обработки изображений, которые служат для ре-
шения широкого круга задач в научных и промышленных сферах.
До начала работы в MathWorks, Inc., в 1993 г., д-р Эддинс был сотрудником
факультета электроники и вычислительной техники университета Иллинойс в
Чикаго. Он является специалистом высочайшего класса в областях цифровой
обработки изображений, машинного зрения, распознавания образов, разработки
фильтров. Ему также приходилось выполнять исследования в области сжатия
изображений.
Д-р Эддинс имеет степень бакалавра (1986) и доктора философии (1990) по
электротехнике, которые он получил в технологическом институте штата Джор-
джия. Он является членом IEEE.
ГЛАВА I
ВВЕДЕНИЕ
Цифровая обработка изображений отличается необходимостью интенсивного экс-
периментирования для выяснения состоятельности предлагаемых решений дан-
ной задачи. В этой главе показывается, как теоретические основы и современ-
ное программное обеспечение можно интегрировать в некоторое единое макет-
ное окружение с целью разработки набора инструментов для решения широкого
круга проблем цифровой обработки изображений.
1.1. Некоторые основания
Разработка систем обработки изображений всегда тесно связана с большим объе-
мом тестирования и экспериментальной работы, который необходимо выполнить
для достижения приемлемого решения поставленной задачи. Эта особенность
означает, что умение строить прототипные модети возможных решений играет
важную роль для уменьшения денежных и временных затрат и для получения
конкурентоспособной реализации требуемой системы.
Отметим, что к настоящему времени опубликовано весьма мало книг и руко-
водств, которые помогают перекинуть мост через пропасть, разделяющую тео-
рию и конкретные компьютерные приложения на основе развитого программного
окружения. Главной целью этой книги является желание объединить под одной
обложкой широкий базис теоретических концепций и знаний, необходимых для
внедрения этих концепций в реальные программные продукты, написанные в сре-
де современного пакета обработки изображений. Материалы теоретических основ
следующих глав взяты из книги «.Цифровая обработка изображений», написан-
ной Р. Гонсалесом и Р. Вудсом и опубликованной издательством Prentice Hall.
Тексты компьютерных программ и базовых функциональных инструментов на-
писаны на основе популярного пакета Image Processing Toolbox, который работает
в среде MATLAB1, разработанной компанией MathWorks Inc. (см. § 1.3). Все ма-
териалы данной книги представлены в том же виде и с теми же обозначениями,
что и в книге Гонсалеса-Вудса. Это позволяет легко делать перекрестные ссылки
на родственные материалы.
Книга является совершенно самодостаточной. Для овладения ее содержанием
читателям достаточно иметь начальные сведения по цифровой обработке изоб-
ражений, полученные или на первых курсах университетов и вузов, или с по-
мощью самостоятельного изучения предмета. Предполагается также, что чита-
тели знакомы с системой MATLAB и имеют начальные навыки компьютерного
1В дальнейшем изложении мы для краткости будем ссылаться на книгу Р. Гонсалеса и Р. Вудса
«Цифровая обработка изображений», как на книгу Гонсалеса-Вудса, a Image Processing Toolbox
будем сокращенно обозначать IPT.
1.2. Что такое цифровая обработка изображений?
программирования, которые обычно приобретаются на первых стадиях обучения
на курсах по языкам программирования с технической ориентацией. Поскольку
MATLAB является матрично ориентированной системой, читателям будут по-
лезны некоторые базовые знания из матричного анализа.
Книга основана на правилах. Она организована в виде учебника, а не в виде
руководства по программированию. Таким образом, основные идеи по теории и
программированию объясняются до разработки новых концепций программиро-
вания. Материал книги иллюстрируется и объясняется с помощью множества
примеров, взятых из разных областей, от медицины и промышленности до уда-
ленного автоматического восприятия и астрономии. Такой подход позволяет ме-
тодично продвигаться от простых концепций до изощренных реализаций слож-
ных алгоритмов обработки изображений. Вместе с этим, читатели, уже знакомые
с MATLAB, IPT и с основами обработки изображений, могут прямо начать чте-
ние с интересующих их специфических приложений, в этом случае эту книгу
можно рассматривать как расширение пакета IPT. Все новые функции, приве-
денные в этой книге, полностью документированы. Программные коды новых
функций приведены или в соответствующей главе, или в приложении В.
В книге представлено более 60 новых функций. Эти функции расширяют при-
мерно на 35% набор из 175 функций исходного пакета IPT. Помимо конкретной
специализации, новые функции являются хорошим примером комбинирования
кода существующих функций MATLAB и IPT с новым программным кодом для
разработки прототипов решений для широкого спектра проблем цифровой обра-
ботки изображений. Функции пакета IPT, равно как и функции, разработанные в
этой книге, работают под управлением почти любой операционной системы. Чи-
татели могут найти полный список поддерживаемых компьютерных платформ
на сайте нашей книги (см. § 1.5).
1.2. Что такое цифровая обработка изображений?
Изображение представляет собой двумерную функцию f(x,y), где х и у это
пространственные координаты, а амплитуда f в любой точке с парой коорди-
нат (х,у) называется интенсивностью или уровнем серого цвета1 изображе-
ния в этой точке. Если переменные х, у и f принимают значения их конечного
(дискретного) множества, то говорят о цифровом изображении. Под цифровой
обработкой изображений подразумевается обработка цифровых изображений с
помощью цифровых вычислительных машин (компьютеров). Отметим, что циф-
ровое изображение состоит из конечного числа элементов, каждый из которых
расположен в конкретном месте и имеет определенное значение. Эти элементы
принято называть элементами изображения или пикселами?. Чаще всего эле-
менты цифрового изображения называют пикселами. Более строгое; определение
этого термина будет дано в гл. 2.
ХВ отечественной литературе этот термин принято называть яркостью, который мы будем
часто использовать, если это не приводит к разночтению. — Прим, перво.
2Слово pixel образовано из английского словосочетания picture element (элемент изображения).
В англоязычной литературе также принято сокращение pel для этого термина - Прим, персе.
Глава 1. Введение
Зрение является самым совершенным из наших органов чувств, поэтому зри-
тельные образы играют такую важную роль в человеческом восприятии. Однако
в отличие от людей, которые способны воспринимать лить электромагнитное
световое излучение видимого диапазона, машинная обработка изображений по-
крывает практически весь спектр электромагнитных волн от гамма-излучения
до радиоволн. Причем обрабатываемые изображения могут происходить от таких
источников, которые людям даже трудно ассоциировать с привычными наблюда-
емыми изображениями. Например, это ультразвуковые изображения, изображе-
ния, полученные в электронной микроскопии или искусственно сгенерированные
компьютером. Таким образом, цифровая обработка изображений имеет весьма
широкие сферы применения.
Не существует общепризнанной границы, которая разделяла бы область об-
работки изображений и другие смежные дисциплины, такие как анализ изобра-
жений или машинное зрение. Иногда такое разграничение делается по принци-
пу, что обработка изображений характеризуется присутствием изображений на
входе и выходе данной системы. Однако такое определение представляется нам
неоправданно ограничительным и искусственным. В самом деле, при таком под-
ходе даже такая простая задача, как опреде ление средней интенсивности по всему
полю изображения (требуется найти одно единственное число), не будет считать-
ся операцией по обработке изображения. С другой стороны, имеются такие об-
ласти, как машинное зрение, в которых конечной целью является компьютерная
имитация зрения человека, включающая способность к обучению, логическим
выводам и совершению определенных действий на основе обозреваемой инфор-
мации. Такие задачи относятся уже к области искусственного интеллекта, целью
которого является копирование и имитация интеллектуальной деятельности че-
ловека. Отметим, что эта отрасль искусственного интеллекта находится лишь
на начальной стадии развития, и приходится признать, что прогресс в этом на-
правлении идет значительно медленнее, чем это предполагалось ранее. Анализ
изображения (который иногда называют «интерпретацией» или «пониманием»
изображений) занимает некоторое промежуточное положение между обработкой
изображений и машинным зрением.
Во всем многообразии задач от обработки изображений ло машинного зрения
нет четких границ, однако здесь можно выделить компьютеризованные процессы
низкого, среднего и высокого уровня. Процессы низкого уровня включают лишь
примитивные операции над изображениями типа уменьшение шума, повышение
контрастности или улучшение резкости. Низкоуровневые процессы характери-
зуются тем, что на вход и выход поступают изображения. Процессы среднего
уровня связаны с такими задачами, как сегментация (разделение изображений
на области и выделение в них объектов), описание объектов и их сжатие для
придания им удобной формы для дальнейшей компьютерной обработки, а также
классификация (распознавание) выделенных объектов. В среднеуровневых про-
цессах на входе имеются изображения, а на выход поступают атрибуты и при-
знаки, извлеченные из этих изображений (например, границы, контуры и другие
отличительные признаки объектов). Наконец, процессы высокого уровня зани-
маются «осмыслением» множества распознанных объектов, как это делается в
анализе изображений, а еще далее стоят действия, связанные с когнитивными
функциями, обычно ассоциируемые с человеческим зрением.
1.3. Система MATLAB и пакет Image Processing Toolbox
Имея в виду перечисленные выше замечания, видно, что естественным полем
пересечения и перехода от обработки изображений к их анализу является область
распознавания отдельных фигур или объектов на изображениях. Таким образом,
в этой книге то, что называется цифровой обработкой изображений, связано с
процессами, имеющими изображения на входе и на выходе, а также с процесса-
ми извлечения определенных признаков изображений вплоть до распознавания
отдельных объектов. В качестве простой иллюстрации, проясняющей эти концеп-
ции, можно рассмотреть задачу автоматического анализа печатного или рукопис-
ного текста. Действиями по цифровой обработке изображений, которые рассмат-
риваются в данной книге, являются считывание области изображения с текстом,
предварительная обработка этого изображения, выделение (сегментация) отдель-
ных букв и знаков текста, описание этих символов в удобной компьютерной фор-
ме и, наконец, распознавание каждого индивидуального символа текста. Если же
говорить об осмыслении содержимого страницы, то эту задачу можно уже от-
нести к области анализа изображений или машинного зрения в зависимости от
уровня сложности информации, ожидаемой от прочитанного текста. Цифровая
обработка информации в том виде, как она была определена выше, успешно при-
меняется в широком круге областей, имеющих важное социально-экономическое
значение.
1.3. Система MATLAB и пакет Image Processing Toolbox
MATLAB является языком высокого уровня для выполнения технических и на-
учных вычислений. В нем интегрированы вычисления, визуализация и програм-
мирование в удобной пользовательской среде, в которой задачи и их решения вы-
ражаются с помощью привычных математических обозначений. Типичный набор
действий включает:
математические вычисления;
разработку алгоритмов;
моделирование и создание прототипных систем;
анализ данных, их исследование и визуализацию;
построение различных графиков;
разработку приложений и пользовательский интерфейс.
MATLAB представляет собой интерактивную систему, в которой базовым эле-
ментом выступает массив элементов, который не требует задания фиксированной
размерности. Это позволяет легко формулировать условия и решения многих вы-
числительных задач, которым требуется матричное представление объектов. При
этом необходимая работа займет лишь малую долю времени, которое потребова-
лось бы для написания аналогичных программ на скалярном и неинтерактивном
языке типа С или Fortran.
Название MATLAB происходит от английского словосочетания MATrix LABo-
ratory. Система MATLAB была написана для облегчения доступа к матричным
программным продуктам, разработанным в рамках проектов LINPACK (Linear
System Package) и EISPACK (Eigen System Package). В настоящее время яд-
ро MATLAB встроено в библиотеки LAPACK (Linear Algebra Package) и BLAS
Глава 1. Введение
(Basic Linear Algebra Subprograms), которые включают самое современное про-
граммное обеспечение для матричных вычислений.
В университетской среде MATLAB является стандартом вычислительных ин-
струментов для начальных и углубленных курсов по математике, технике и дру-
гим научным дисциплинам. В промышленности MATLAB широко используется
многими исследователями и разработчиками. Система MATLAB имеет расши-
рения в виде наборов специализированных программ, которые по-английски на-
зываются toolbox (набор инструментов). Пакет Image Processing Toolbox (IPT)
состоит из функций MATLAB (они называются M-функции или М-файлы), ко-
торые расширяют возможности стандартной среды MATLAB для решения задач
цифровой обработки изображений. Другие наборы toolbox, которые иногда ис-
пользуются в IPT, это Signal Processing Toolbox (пакет обработки сигналов),
Neural Network Toolbox (пакет для нейронной сети), Fuzzy Logic Toolbox (пакет
с нечеткой логикой) и Wavelet Toolbox (пакет для работы с вейвлетами).
Система MATLAB Student Version, предназначенная для студентов, вклю-
чает полную версию MATLAB. Ее можно купить со значительной скидкой в
университетских магазинах (в США), а также на вебсайте компании MathWorks
(www.mathworks.com). Вместе со студенческой версией системы можно приобре-
сти дополнительные продукты, включая пакет IPT.
1.4. Задачи по обработке изображений
В каждой главе этой книге даны подходящие функции из MATLAB и IPT, кото-
рые позволяют применять соответствующие теоретические построения. Если же
в системе MATLAB или в пакете IPT отсутствовали инструменты, необходимые
для реализации каких-то специфических функций, то были разработаны и до-
кументированы новые функции для решения этих задач. Как уже отмечалось,
полный текст всех таких функций приводится в книге. Ниже дано содержание
каждой последующей главы.
Глава 2: Цифровые изображения в MATLAB. В этой главе приводятся
основные сведения по системе MATLAB, включая обозначения, индексирование
массивов и основы программирования на языке MATLAB. Этот материал служит
фундаментом всей книги, поэтому читателю необходимо свободно овладеть всеми
этими понятиями.
Глава 3: Преобразование яркости изображений и пространственная
фильтрация. В этой главе рассказывается, как с помощью MATLAB и IPT со-
вершать преобразования яркости цифровых изображений. В ней также рассмат-
риваются методы линейной и нелинейной фильтрации с большим количеством
примеров и иллюстраций.
Глава 4: Частотные методы обработки изображений. В этой главе из-
лагаются основные подходы при реализации прямого и обратного быстрого пре-
образования Фурье (FFTs, Fast Fourier Transforms) и при визуализации спектра
Фурье с помощью функций IPT. Здесь также объясняется фильтрация в про-
странственной области. Рассматривается метод построения фильтров частотной
области из конкретных пространственных фильтров.
1-4- Задачи по обработке изображений
Глава 5: Восстановление изображений. В данной главе приводятся клас-
сические методы восстановления изображений, такие как винеровская фильтра-
ция. Обсуждаются и иллюстрируются также итеративные и нелинейные методы,
например, метод Ричардсона-Люси и метод оценивания по максимуму правдопо-
добия для слепых деконволюций. Разбираются методы регистрации изображений
и геометрической коррекции.
Глава 6: Обработка цветных изображений. Здесь рассматриваются под-
ходы при обработке псевдоцветных и полноцветных изображений. Обсуждаются
цветовые модели, применяемые при обработке цветных изображений. Функции
из IPT по обработке цветных изображений расширяются новыми инструментами
для обработки дополнительных цветовых моделей. В этой главе также рассмат-
ривается применение цвета при решении задач обнаружения границ и сегмента-
ции областей.
Глава 7: Вейвлеты. В текущей реализации пакета IPT отсутствуют вейвлет-
ные преобразования. В этой главе разработаны функции для вейвлетного анали-
за, совместимые с пакетом Wavelet Toolbox, которые дают возможность приме-
нять все концепции вейвлетных преобразований, изложенные в книге Гонсалеса-
Вудса.
Глава 8: Сжатие изображений. В пакете IPT нет функций сжатия изобра-
жений. В этой главе разработаны некоторые функции, которые можно применять
при решении задач компрессии изображений.
Глава 9: Морфологическая обработка изображений. Рассматривается
широкий спектр функций IPT, позволяющих делать морфологическую обработ-
ку изображений. Разбираются как двоичные изображения, так и полутоновые
изображения с градацией серого цвета.
Глава 10: Сегментация изображений. В этой главе описываются и иллю-
стрируются функции из пакета IPT, служащие для сегментации изображений.
Разработаны новые функции для применения преобразования Хуга и для метода
выращивания областей.
Глава 11: Представление и описание. Здесь разработаны некоторые но-
вые функции для представления объектов, включая цепные коды и представле-
ние ломаной линией. Даны также новые функции для описания объектов, на-
пример, Фурье-дескрипторы, текстурные дескрипторы и инварианты двумерных
моментов. Эти функции расширяют инструментарий пакета IPT для исследова-
ния свойств областей.
Глава 12: Распознавание объектов. Основным предметом данной главы
является эффективная реализация функции вычисления евклидова расстояния
и расстояния Махаланобиса. Эти функции играют ключевую роль в методах, ос-
нованных на сопоставлении образцов. В этой главе также делается обстоятельное
обсуждение методов манипуляции со строками символов в MATLAB. Манипуля-
ция и сравнение строк очень важны при распознавании структурных образцов.
Кроме этого материала, в книге имеется три приложения.
Приложение А. Здесь собраны все существующие в IPT и описанные в книге
новые функции для обработки изображений. Включены также соответствующие
базовые функции из MATLAB. Этот список представляет собой удобный обзор
всех полезных функции для выполнения работ по обработке изображений.
Глава 1. Введение
Приложение Б. Здесь обсуждаются методы разработки графических ин-
терфейсов пользователя (GUIs, Grafical User Interfaces) в среде MATLAB. Этот
материал весьма полезен, так как упрошает контроль и взаимодействие функций,
делает их более интуитивными.
Приложение В. В каждой главе приводятся тексты (листинги) всех новых
функций, разработанных в этой главе при объяснении соответствующих концеп-
ций. Для удобства читателя, все полные листинги помещены в это приложение.
Это относится, прежде всего, к листингам длинных функций, которые в тексте
были сокращены, чтобы не перегружать материал излишней детализацией.
1.5. О вебсайте этой книги
Важной особенностью настоящей книги является размещение соответствующих
и дополнительных материалов во всемирной паутине по адресу:
www.prenhall.com/gonzalezwoodseddins
На этом сайте имеются следующие материалы:
загружаемые М-файлы, включая М-файлы из книги;
- учебные пособия;
проекты;
— материалы для преподавателей;
- линки на другие базы данных, включая ссылки на все иллюстрации данной
книги;
- обновления книги;
список литературы.
Этот сайт интегрирован с вебсайтом книги Гонсалеса- Вудса
www.prenhall.com/gonzalezwoods ,
на котором размещены дополнительные учебно-справочные и исследовательские
материалы.
1.6. Обозначения
В этой книге все формулы набраны наклонным латинским шрифтом italic и греческим
шрифтом, например, f(x,y) = Asin(uT + vy) или </>(т, у) = tan-1 [I(u,v)/R(u,v)].
Все символы и имена функций системы MATLAB набраны шрифтом печатной
машинки, в котором все символы имеют одинаковую ширину, например, f f t2 (f ),
logical(A) или roipoly(f ,c,r) .
Если необходимо обозначить нажатие специальных клавиш на клавиатуре
компьютера, то будет использоваться жирный шрифт, например, Return или Tab.
Кроме того, жирный шрифт используется при обозначении пунктов экранного
меню, вроде File или Edit.
1.7. Рабочая среда системы MATLAB
1.7. Рабочая среда системы MATLAB
В этом параграфе делается краткий обзор некоторых важных действий и базовых
приложений в среде MATLAB.
1.7.1. Рабочий стол MATLAB
Рабочий стол MATLAB — это основное окно приложения MATLAB. Как пока-
зано на рис. 1.1, рабочий стол состоит из пяти подокон: окна команд (Command
Window), окна рабочего пространства (Workspace Browser), окна текущей папки
(Current Directory Window), окна совершенных команд (Current History Window)
и одного или нескольких окон графиков.
Рабочий стол MATLAB
Рис. 1.1. Рабочий стол MATLAB и его основные компоненты
Окно команд (Command Window) — это область, где пользователь набирает
команды и выражения MATLAB после приглашения системы (») (ввод) и где
система помещает свои отклики на команды пользователя (вывод). При каждом
сеансе работы MATLAB формирует рабочее пространство, т. е. множество пере-
менных, создаваемых пользователем. Окно рабочего пространства (Workspace
Browser) показывает эти переменные, а также сообщает некоторую информацию
о них. Двойное нажатие левой клавиши мыши на любую переменную в этом окне
Глава 1. Введение
вызывает окно Редактор массивов, в котором можно увидеть дополнительную
информацию о данном массиве, а также (во многих случаях) отредактировать
его содержимое.
Над заголовком окна рабочего пространства расположена метка Current Directory
(текущая папка), за которым расположено окно текущей папки (Current Directory
Window), отражающее ее полный системный путь, например, C:\MATLAB\Work.
Это означает, что папка «Work» является подпапкой главной папки «MATLAB»
приложения MATLAB, которое установлено на диск С. Если нажать левой кла-
вишей мьппи на треугольник справа от окна текущей папки, то раскроется спи-
сок путей недавно использованных папок, что позволяет пользователю быстро
менять текущую рабочую папку.
Система MATLAB использует переменную окружения путь поиска (Search
Path) для обнаружения М-файлов и файлов других типов, используемых в этой
системе, которые организованы в виде компьютерных папок. Любой исполняе-
мый файл должен располагаться или в рабочей папке, или в папке, на которую
указывает путь поиска. По умолчанию, файлы, поставляемые вместе с MATLAB
и MathWorks, помещаются в Search Path. Самый простой путь узнать, какие
папки помещены в Search Path, а также добавить, удалить или модифицировать
имеющиеся там записи, — это выбрать пункт Set Path в меню File рабочего сто-
ла и совершить необходимые действия в появившемся диалоговом окне Set Path.
В начале работы бывает удобно поместить ссылки на часто используемые папки
в путь поиска. В этом случае не придется часто менять текущую папку системы.
Окно совершенных команд (Current History Window) содержит записи всех
команд, которые пользователь вводил в окне команд, включая текущую и все
предыдущие сеансы работы с MATLAB. Ранее исполненные команды можно вы-
бирать и повторно исполнять из окна совершенных команд. Для этого достаточ-
но щелкнуть правой кнопкой мыши по команде или последовательности команд.
Такое действие активирует меню, из которого необходимо выбрать некоторые
дополнительные опции для выполнения этих команд. Такая организация хоро-
шо помогает при экспериментировании с разными командами в сеансе работы с
MATLAB.
1.7.2. Создание М-файлов в редакторе MATLAB
Редактор MATLAB является одновременно специализированным текстовым ре-
дактором для создания М-файлов и графическим отладчиком программ MATLAB.
Редактор может работать в своем собственном окне или может быть подокном
рабочего стола. M-файлы имеют расширение . ш. например, pixeldup. m. Окно ре-
дактора MATLAB имеет несколько выпадающих меню для выполнения действий
типа сохранить, посмотреть или отладить файл. Этот текстовый редактор вы-
полняет простейшие синтаксические проверки, а также использует разные цвета
для выделения различных элементов кода, поэтому его всегда обоснованно реко-
мендуют в качестве инструмента для написания и редактирования М-функций.
Для вызова редактора достаточно набрать edit после приглашения в окне ко-
манд. Аналогично командой edit filename открывается файл filename.m для
работы в редакторе. Как уже говорилось, этот файл должен располагаться в
текущей папке или на пути поиска Search Path.
1.1. Рабочая среда системы MATLAB 25
1.7.3. Вызов справки
Вызов окна онлайновой1 справки (Help Browser) в MATLAB производится или
нажатием мышью на знак вопроса (?) в строке инструментов рабочего стола, или
набором команды helpbrowser после приглашения в командном окне. Справоч-
ная система организована в виде веб-обозревателя, интегрированного в рабочий
стол MATLAB, который способен отображать документы, написанные на языке
HTML. Окно справки состоит из двух панелей: навигационной панели справки,
которая используется для поиска информации, и дисплейной панели, в которой
найденная информация отображается. На навигационной панели располагают-
ся кнопки, делающие процесс поиска вполне ясным. Например, чтобы получить
справку по некоторой функции, необходимо нажать кнопку Search (поиск), за-
тем выбрать Search Туре (тип поиска), Function Name (имя функции) и, на-
конец, набрать имя искомой функции в поле Search for (предмет поиска). Имеет
смысл вызывать окно справки в самом начале сеанса работы MATLAB, чтобы
иметь под рукой всю необходимую информацию о системе при написании новых
программ или выполнении иных действий в MATLAB.
Имеется другой путь получения справки по конкретной функции. Для этого
достаточно задать в командной строке команду doc, за которой поместить имя
нужной функции. Например, выполнив команду doc format, можно получить в
панели справки всю документацию, связанную с функцией format. Одновремен-
но эта команда открывает окно справки, если оно еще не было открыто.
М-функции имеют информацию двух типов, которая доступна пользовате-
лю. Первый тип информации называется Н1-строка, в которой содержится имя
функции и ее однострочное описание. А второй тип состоит из целого инфор-
мационного блока, который называется текстовым блоком справки. (Обе эти
справки будут подробно обсуждаться в § 2.10.1). Если набрать команду help,
а затем имя функции, то система отобразит в командном окне оба типа справ-
ки по данной функции. Отметим, что эта информация может оказаться более
свежей, чем предоставляемая справочной системой MATLAB, поскольку она из-
влекается непосредственно из заголовка данной М-функции. Если набрать коман-
ду lookf or, а далее некоторое ключевое слово, то это приведет к отображению
всех Hl-строк, в которых имеется данное ключевое слово. Поскольку каждая
Hl-строка содержит имя функции, это дает еще один альтернативный способ
получения справки про функции MATLAB. Например, если набрать команду
lookfor adge -all, то это даст список всех Hl-строк, в которых имеется слово
adge, которое находится и в Hl-строках, и в текстовых блоках. Будут обнаруже-
ны также все слова, в состав которых входит последовательность символов adge.
Например, если Hl-строка функции содержит слово polyedge где-то в Hl-строке
или в текстовом блоке, то все такие строки будут выведены на экран.
В MATLAB принято говорить о справочной странице, имея в виду инфор-
мацию об М-функциях, которую можно получить любым описанным способом,
исключая команду lookfor. Однако читателю рекомендуется использовать все
доступные способы получения справок, поскольку в следующих главах дается
ХВ данной книге под онлайновой информацией подразумеваются файлы помощи, имеющиеся
в данном локальном компьютере, а не в сети интернет.
Глава 1. Введение
только основные синтаксические формы функций MATLAB и IPT. Это связано
с ограниченностью объема книги и с нежеланием авторов часто отвлекаться от
обсуждения основных понятий. В этих случаях будет дан лишь основной син-
таксис функций в форме, которая необходима авторам в данный момент. Что-
бы оценить удобство, представляемое справочной системой MATLAB, читатель
может самостоятельно поупражняться в получении расширенной информации,
затратив минимальные усилия.
В заключение отметим, что вебсайт компании MathWorks, упомянутый в § 1.3,
содержит обширную справочную информацию по различным функциям, а так-
же по другим ресурсам, если встроенная система онлайновой справки не дает
исчерпывающий ответ по интересуемому вопросу.
1.7.4. Сохранение и загрузка рабочего пространства
Существует несколько способов сохранения и повторной загрузки всего сеанса
работы (т. е. содержимого окна рабочего пространства) или выбранных рабочих
переменных MATLAB. Самые простые из них состоят в следующем.
Чтобы сохранить все рабочее пространство целиком, достаточно щелкнуть
мышью в любом месте окна рабочего пространства, а затем выбрать в появив-
шемся меню строку Save Workspace As (сохранить рабочее пространство под
именем), в которой можно набрать имя и указать папку, в которой сохранить
этот файл. Для завершения команды следует нажать кнопку Save. Если тре-
буется сохранить одну переменную рабочего пространства, то ее надо сначала
выделить левой кнопкой мыши, а затем щелкнуть правой кнопкой по выделен-
ной переменной. В появившемся меню выбрать Save Selection As (сохранить
выделенное под именем) и сохранить данные под некоторым именем в подхо-
дящей папке. Если необходимо сохранить несколько переменных, то их следует
выделить левой кнопкой мыши, держа одновременно клавишу Shift или Ctrl,
а затем выполнить описанную выше процедуру для одной переменной. Все чис-
ловые данные сохраняются с двойной точностью в бинарном формате в файлах
с расширением .mat. Такие файлы принято называть МАТ-файлами. Например,
сеанс работы, названный именем mywork_2003_02_10, будет сохранен в виде фай-
ла mywork_2003_02_10.mat в соответствующей папке. Аналогично, сохраненное
изображение под именем final_image (которое является одной переменной ра-
бочего пространства) появится в файле под именем final „image .mat.
Для загрузки всего сохраненного рабочего пространства или части перемен-
ных необходимо щелкнуть мышью на значке папки на панели инструментов окна
рабочего пространства. Это вызовет окна с открытой папкой с МАТ-файлами,
из которых можно выбрать интересующий файл. Если щелкнуть по выбранному
файлу или нажать кнопку Open, то это действие откроет содержимое файла,
которое можно загрузить в окно рабочего пространства.
Все указанные действия можно также совершить из командной строки, если
набрать команды save и load, после которых поместить имена соответствующих
файлов с их путями. Этот способ не очень удобен, но им приходится пользо-
ваться, если нельзя вызвать соответствующее интерактивное меню (например,
в теле автоматически исполняемой программы MATLAB). Мы предлагаем чи-
1.8. Как организованы ссылки
тателю самостоятельно поупражняться в получении дополнительной справочной
информации по этим двум функциям.
1.8. Как организованы ссылки
Все ссылки на литературные источники в данной книге перечислены в библио-
графии в алфавитном и хронологическом порядке, например, [Soille, 2003]. Все
базовые теоретические ссылки взяты из книги [Gonzalez, Woods, 2002]. Неко-
торые новые ссылки делаются по мере необходимости при обсуждении соответ-
ствующего материала1. Ссылки на учебники и руководства по системе MATLAB,
используемые во всех главах, приведены в конце книги в библиографии.
Выводы
Материал данной главы вместе с кратким введением в основные понятия MATLAB
содержит аргументы в пользу важности создания прототипов решений задач по
обработке цифровых изображений. В следующей главе излагаются базовые зна-
ния, необходимые для понимания работы функций IPT, а также делается введе-
ние в основные приемы программирования. Материалы глав с 3 по 12 охватывают
широкий спектр тем и приложений, которые лежат в основе всех современных
методов обработки изображений. Тем не менее, при большом разнообразии вопро-
сов и задач основная нить обсуждения опирается на комбинирование функций
MATLAB и IPT с новыми программами, что дает возможность успешно решать
множество задач по обработке любых изображений.
гВ переводе книги Гонсалеса-Вудса на русский язык имеется дополнительный список русско-
язычной литературы по данной тематике. - Прим, перев.
ГЛАВА 2
ЦИФРОВЫЕ
ИЗОБРАЖЕНИЯ
В MATLAB
Введение
Как уже говорилось во введении, главное преимущество системы MATLAB при
ее использовании в качестве среды для работы с изображениями состоит в разно-
образном наборе функций обработки многомерных числовых массивов, а изоб-
ражения (двумерные числовые массивы) являются важным частным случаем
таких объектов. В пакете IPT (Image Processing Toolbox) собраны функции, рас-
ширяющие возможности вычислительной среды MATLAB. Эти функции, а так-
же широкие возможности языка MATLAB делают многие сложные операции по
обработке изображений вполне доступными; их можно записать в весьма ясной и
краткой форме, что делает систему MATLAB почти идеальной средой для напи-
сания модельных прототипов реальных приложений для решения задач обработ-
ки изображений. В этой главе вводятся базовые понятия MATLAB, обсуждаются
свойства и функции пакета IPT, даются основные концепции программирования,
которые существенно повышают мощь IPT. Материалы этой главы лежат в ос-
нове всех остальных разделов этой книги.
2.1. Представление цифровых изображений
Изображение можно определить как двухмерную функцию f(x.y), где х и у —
это пространственные (плоскостные) координаты, а амплитуда f для каждой
пары координат (х, у) называется интенсивностью или яркостью изображения
в точке с этими координатами. Словосочетание уровень серого часто использует-
ся для обозначения яркости монохромного изображения. Цветные изображения
формируются комбинацией нескольких монохромных изображений. Например, в
цветовой системе RGB цветное изображение строится из трех отдельных моно-
хромных компонент (красной, зеленой и синей). По этой причине многие методы
и приемы, разработанные для монохромных изображений, могут быть распро-
странены на цветные изображения путем последовательной обработки трех мо-
нохромных компонент. Обработка цветных изображений рассматривается в гл. 6.
Изображение может иметь непрерывные х- и у-координаты, а также непре-
рывную амплитуду /. Преобразование такого изображения в цифровую форму
требует представления координат и значений амплитуды некоторыми дискрет-
ными отсчетами. Представление координат конечным множеством отсчетов на-
зывается дискретизацией, а представление амплитуды значениями из конечного
2.1. Представление цифровых изображений
набора называется квантованием. Таким образом, если координаты х и у, а так-
же величины амплитуды / выбираются из фиксированных конечных наборов
элементов (дискретных величин), то изображение называется цифровым изобра-
жением
2.1.1. Координатное соглашение
Результатом дискретизации и квантования является матрица чисел. В этой кни-
ге используются два основных метода для представления цифровых изображе-
ний. Предположим, что изображение f(x, у) после дискретизации представлено
в виде матрицы, у которой имеется М строк и N столбцов. Тогда говорят, что
изображение имеет размер М х N. Значения координат (х, у) являются дискрет-
ными величинами. Для удобства и ясности значения этих дискретных координат
принимаются целочисленными. Во многих книгах по обработке изображений за
начало координат принимается верхний левый угол изображения, координатами
которого служит пара (х,у) = (0,0). Следующая точка в первой строке изобра-
жения имеет координаты (ж, у) = (0,1). Важно помнить, что пара (0,1) относится
ко второму пикселу (элементу изображения) вдоль первой строки изображения.
Это, однако, не обозначает настоящие физические координаты при регистрации
соответствующего изображения. На рис. 2.1, а) показано это координатное согла-
шение. Заметим, что координата х меняется от 0 до М — 1 с шагом 1, а координата
у меняется от 0 до Т — 1 с шагом 1.
Координатное соглашение, используемое в пакете IPT для обозначения мас-
сивов, отличается от описанного выше в некоторых деталях. Во-первых, вместо
(а:, у) используется пара (г, с) для обозначения номеров строк и столбцов. Отме-
тим, что порядок координат имеет тот же смысл, что и в предыдущем абзаце,
т. е. первая координата соответствует строке, вторая — столбцу. Другое отличие
состоит в том, что начало координат расположено в точке (г, с) — (1,1), т. е.
переменная г меняется от 1 до М, ас — от 1 до АГ с шагом 1. На рис. 2.1, б)
проиллюстрировано это координатное соглашение.
а)
Рис. 2.1. (а) Координатное
соглашение во многих кни-
гах по обработке изображе-
ний; (б) координатное согла-
шение в MATLAB и IPT
М- 1
0
1
2
пиксель
N. .1.
В документации пакета IPT соглашение из рис. 2.1, б) называется координа-
тами пикселов. Реже в этом пакете используется другое координатное соглашение,
которое называется пространственными координатами, при котором х называ-
ется столбцом, ay — строкой. Это противоречит нашим обозначениям для х и у.
Глава 2. Цифровые изображения в MATLAB
За малым исключением, мы не будем в этой книге использовать терминологию
пространственных координат из пакета, IPT, однако читателю наверняка придет-
ся встретиться с этим при изучении документации по IPT.
2.1.2. Изображение как матрица
Система координат из рис. 2.1, а) и предшествующее обсуждение приводит к
следующему представлению функции цифророго изображения:
/(г, у) = /(0,0) /(1,0) /(0,1) /(1.1) /(0,7V-1) /(1,7V-1)
_ /(М-1,0) /(М-1,1) /(М —1,7V —1) _
Здесь справа от знака равенства, по определению, стоит цифровое изображение.
Каждый элемент этого массива называется элементом изображения или пик-
селом. Термины изображение и пиксел будут применяться до конца этой книги
исключительно к цифровым изображениям и их элементам.
Цифровое изображение имеет естественное представление в виде матрицы
MATLAB1:
f(l,2) f(l.N) ’
f(2,1) f(2,2) f(2,N)
f(M,l) f(M,2) f(M, N)
где f (1,1) = /(0,0) (напомним, что шрифт печатной машинки используется для
обозначения величин MATLAB). Ясно, что оба зти представления изображений
являются эквивалентными с точностью до сдвига начала координат. Формула
f (р, q) обозначает элемент, расположенный в строке р и в столбце q. Например,
f(6,2) - это элемент шестой строки и второго столбца матрицы f. Обычно бу-
дут использоваться буквы М и N для обозначения, соответственно, числа строк
и столбцов матрицы f. Матрица размера 1XN называется вектором-столбцом, а
матрица размера Мх1 — вектором-строкой. Матрица 1x1 называется скаляром.
Матрицы в MATLAB хранятся в виде переменных с именами вроде A, a, RGB,
real_array и т. п. Имена переменных должны начинаться с буквы и могут состо-
ять из букв, цифр и знаков подчеркивания. Как уже говорилось в предыдущем
абзаце, в этой книге любые величины MATLAB набираются шрифтом печат-
ной машинки, в котором все символы имеют одинаковую ширину. Для матема-
тических формул и выражений будет использоваться стандартный наклонный
латинский шрифт italic.
*В документации по MATLAB и IPT оба термина, матрица и массив, часто являются сино-
нимами, однако стоит помнить, что матрица является двумерным массивом, а общий массив
может иметь произвольную размерность.
2.2. Загрузка изображений
2.2. Загрузка изображений
Для загрузки (чтения) изображений в рабочее пространство MATLAB исполь-
зуется функция imread со следующим синтаксисом:
imread(‘f ilename‘)
Здесь filename — это строка символов, образующих полное имя загружаемого
файла изображения (включая любое расширение). Например, командная строка
>> f=imread(‘chestxray.jpg‘);
присваивает изображение формата JPEG (см. табл. 2.1) с именем chestxray мат-
ричной переменной f. Заметим, что символ (‘) используется в качестве ограни-
чителя символьной строки filename. Точка с запятой в конце командной строки
означает инструкцию системе MATLAB не отображать вывод для данной коман-
ды. Если точка с запятой отсутствует, то MATLAB отображает результат (вывод)
выполнения операций в командной строке. Символ приглашения (>>) обозна-
чает начало командной строки, который появляется в окне команд MATLAB
(см. рис. 1.1).
Таблица 2.1. Некоторые графические форматы, распознаваемые командами immad и
imwrite, начиная с MATLAB 6.5. Более ранние версии поддерживали не
все форматы (см. подробную информацию в онлайновой справке)
Формат изображения Расшифровка сокращения Допустимые изображения
TIFF Tagged Image File Format • tif, .tiff
JPEG Joint Photographic Experts Group •jpg. -jpeg
GIF Graphics Interchange Format gif
BMP Windows Bitmap .bmp
PNG Portable Network Graphics png
XWD X Window Dump . xwd
Если в имя файла изображения не включена информация о пути к данному
файлу, как это имело место в последнем примере, то файл filename ищется в
текущей папке (см. § 1.7.1). А если его там нет, то делается поиск данного файла
во всех папках, пути к которым указаны в пути поиска MATLAB (см. § 1.7.1)1.
Самый простой способ прочесть изображение из некоторой конкретной папки —
это включить полный или относительный путь к этой папке в строке filename.
Например, команда
>> f imreadC‘D:\myimage\chestxray.jpg‘);
считывает изображение из папки myimage на диске D:, а команда
>> f imread(‘ \myimage\chestxray.jpg');
1В некоторых операционных системах вместо термина папка, применяемого в системе Windows,
используется термин директория.
Глава 2. Цифровые изображения в MATLAB
загружает изображение из подпапки myimage текущей рабочей папки. Текущая
рабочая папка MATLAB отображается в строке инструментов рабочего стола,
где ее легко поменять вручную. В табл. 2.1 перечислены некоторые популярные
форматы графических файлов, поддерживаемые командами imread и imwrite
(функция imwrite будет обсуждаться ниже в § 2.4).
Функция size (f) возвращает размер изображения, т. е. число строк и столбцов:
> > size(f)
ans
1024 1024
Эта функция будет особенно полезной при автоматическом определении размера
изображения, которое делается операцией2
> > [M.N] size(f);
При такой записи переменной М будет присвоено число строк изображения, а
переменной N — число столбцов.
Функция whos сообщает дополнительную информацию о массиве. Например,
строка
> > whos f
дает следующий результат;
Name Size Bytes Class
f 1024x1024 1048576 uint8 array
Grand total is 1048576 elements using 1048576 bytes
Запись uint8 означает один из классов данных MATLAB, которые будут об-
суждаться в § 2.5. Если в конце строки с командой whos поставить точку с запя-
той, то это не вызовет никакого эффекта, поэтому точку с запятой там можно не
ставить.
2.3. Вывод изображения на дисплей
Изображения можно вывести на дисплей компьютера с помощью функции imshow,
которая имеет следующий синтаксис:
imshow(f, G),
где f — это матрица изображения, a G — это число уровней яркости, используемое
при отображении этого изображения. Если аргумент G опущен, то по умолчанию
принимается 256 уровней яркости. Команда
imshow(f, [low high])
2О6ратите внимание на то, что, подобно функции size, многие функции MATLAB и IPT в ка-
честве своего вывода возвращают более одного значения. Поэтому при использовании операции
присвоения этот вывода следует заключать в квадратные скобки.
2.3. Вывод изображения на дисплей
означает, что все пикселы со значением не больше числа low надо показывать
черными, а все пикселы со значениями не меньше числа high — белыми. Все
промежуточные значения показываются с промежуточной яркостью с использо-
ванием числа уровней, принятому по умолчанию. Наконец, запись в командной
строке
imshow(f, [ ])
задает для переменной low минимальное значение массива f, а переменной high
присваивается его максимальное значение. Такая форма функции imshow бывает
полезной при показе изображений, имеющих узкий динамический диапазон зна-
чений пикселов, или когда среди них имеются положительные и отрицательные
значения.
Функция pixval часто используется для интерактивного определения зна-
чений яркости отдельных пикселов. Эта функция отображает курсор, располо-
женный поверх изображения. Курсор перемещается по изображению вместе с
мышью, а под окном изображения отображаются текущие координаты курсора
и значение интенсивности в этой точке. При работе с цветным изображением
вместе с координатами отображается интенсивность (яркость) красной, зеленой
и синей компоненты цветного пиксела. При нажатии и удержании левой кла-
виши мыши функция pixval показывает евклидово расстояние от исходного до
текущего положения курсора.
Синтаксическая форма этой команды имеет вид
pixval,
которая помещает курсор на последнее выведенное на дисплей изображение. На-
жатие кнопки X в окне курсора отключает курсор на изображении.
Пример 2.1. Чтение и вывод изображения.
(а) Следующая команда читает изображение rose_512.tif, выдает основную
информацию об этом изображении и отображает его с помощью функции imshow:
f=imread(‘rose_512.tif‘);
whos f
Name Size Bytes Class
f 512x512 262144 uint8 array
Grand total is 262144 elements using 262144 bytes
imshow(f,[ ] )
Знак точка с запятой в конце команды imshow не имеет никакого действия,
поэтому его можно опускать. На рис. 2.2 показано, как результат этой команды
выглядит на дисплее. Номер графика появляется в верхнем левом углу этого
окна. Обратите внимание на ниспадающие меню и кнопки инструментов С их
помощью выполняются такие действия, как смена масштаба, сохранение и пре-
образование графического содержимого этого окна. Так, например, меню Edit
содержит функции редактирования и форматирования перед печатью или со-
хранением на диске результатов работы.
Глава 2. Цифровые изображения в MATLAB
Если теперь показать другое изображе-
ние, скажем, g, с помощью функции imshow,
то MATLAB поместит его на место старого.
Чтобы сохранить на рабочем столе предыду-
щее изображение, можно использовать коман-
ду figure. Если набрать строку
>> imshow(f), figure, imshow(g)
то будут показаны оба изображения. Отметим,
что в MATLAB можно записывать несколько
команд, разделяя их запятыми или точками
с запятой. Как уже говорилось выше, точка с
запятой подавляет вывод на экран результа-
тов в командной строке.
(6) Предположим, что было загружено
изображение h, которое отображено на экране
командой imshow (h), результат которой пока-
зан на рис. 2.3, а). Видно, что это изображе-
ние имеет узкий динамический диапазон, ко-
торый можно расширить для улучшения его
визуализации командой
Рис. 2.2. Снимок экрана с окном изоб-
ражения на рабочем столе MATLAB.
Во всех следующих примерах в этой
книге будет отображаться только само
изображение без окна. Номер рисунка
указан в левом верхнем углу
>> imshow(h, [ ])
На рис. 2.3, б) показан результат этого действия, который, очевидно, выгля-
дит лучше для зрительного восприятия. □
Рис. 2.3. а) Изображение
h с узким динамическим
диапазоном. б) Результат
преобразования функцией
Imshow(h, [ ]). (Изображе-
ние предоставил д-р Дэвид
Р. Пикенс, Департамент par
диологии и радиологических
наук медицинского центраг
университета Вандербилта)
2.4. Сохранение изображений
Изображения записываются на диск функцией imwrite, которая имеет’ следую-
щий синтаксис:
imwrite(f, ‘filename^
При такой записи строка filename должна содержать расширение, поддержива-
емое системой MATLAB (см. табл. 2.1). Иначе желаемый формат можно задать
2.-4. Сохранение изображений
явно с помощью третьего аргумента функции. Например, следующая команда за-
писывает матрицу f в изображение с форматом TIFF с именем patientlO_runl:
>> imwrite(f, ‘patientlO_runl‘, ‘tif‘)
или, что эквивалентно,
» imwrite(f, ‘patientlO_runl.tif')
Если строка filename не содержит информацию о пути, то функция imwrite
записывает файл в текущую рабочую папку.
Функция imwrite может иметь другие параметры, зависящие от выбранного
формата. В следующих главах мы будем иметь дело в основном с двумя графи-
ческими форматами: JPEG или TIFF Рассмотрим их более подробно.
Более общий синтаксис функции imwrite, применяемый только к файлам в
формате JPEG, имеет следующий вид:
imwrite(f, ‘filename.jpg‘, ‘quality', q),
где q — это целое число в интервале от 0 до 100 (чем меньше это число, тем выше
степень искажения при сжатии файла в формате JPEG).
Пример 2.2. Сохранение изображения и применение функции imfinfo.
На рис. 2.4, а) приведено изображение f, которое весьма типично для некоторого
химического процесса. Предполагается передавать эти изображения по сети свя-
зи на центральный компьютер для визуального и/или автоматического контроля.
Чтобы сократить передаваемый объем данных, который влияет на время пере-
дачи и требуемую память для хранения этих данных, имеет смысл максимально
сжимать графические файлы, так, чтобы возникающие искажения при деком-
прессии (разжатии) не превосходили некоторого разумного порога или уровня.
В этом контексте «разумность» уровня означает отсутствие ложно воспринима-
емых контуров. На рис. 2.4 (б) (е) даны результаты, полученные при записи
на диск изображения f (в формате JPEG) при q 50, 25, 15, 10, 5 и 0 соот-
ветственно. Например, при q = 25 выполнялась команда
>> imwrite(f, ‘bubbles25.jpg‘; quality, 25)
Изображение при q = 15 [см. рис. 2.4, г)] имеет ложные контуры, которые ед-
ва различимы, однако этот эффект становится вполне ясным при q = 5 и q = 0.
Поэтому допустимым решением с некоторым крайним порогом ошибки будет
сжатие изображений при q = 25. Чтобы понять идею достигнутой компрессии
(сжатия) и получить другую информацию о файле изображения, можно исполь-
зовать функцию imfinfo. которая имеет вид
imfinfo filename,
где filename — это полное имя файла изображения, хранящегося на диске. На-
пример,
>> imfinfo bubbles25.jpg
выдает на выход следующую информацию (отметим, что для этого случая неко-
торые информационные поля остались пустыми):
Глава 2. Цифровые изображения в MATLAB
Filename:1bubbles25.jpg*
FileModeData:‘04-Jan-2003 12:31:261
FileSize:13849
Format:‘jpeg’
FormatVersion:<
Widht:714
Height:682
BitDepth:8
ColorType:‘grayscale‘
Formatsignature:<
Commnet :[}•
Рис. 2.4. а) Исходное изоб-
ражение. б)-е) Сжатие jpeg
со значениями параметра ка-
чества q = SO, 2Б, IS, S и О
соответственно. Ложные конту-
ры становятся различимыми
при q = 15 (изображение г)) и
совершенно явными при q =
5 и q = О1
где значение FileSize дано в байтах. Для нахождения числа байтов в исход-
ном (несжатом) изображении надо просто перемножить величины Widht, Height
’См. пример 2.11, в котором приводится функция, которая в одном цикле for генерирует все
изображения рис. 2.4.
2-4- Сохранение изображений
и BitDepth, а затем разделить полученное произведение на 8. Получится чис-
ло 486 948. Если его разделить на FileSize, то получится степень сжатия 4fgB9/g =
= 35.16. Эта степень сжатия была достигнута при качестве изображения, хоро-
шо согласующемся с требованиями конкретного приложения. Помимо очевидно-
го освобождения объема памяти компьютера, это сокращение дает выигрыш по
времени передачи сжатых изображений примерно в 35 раз.
Информационные поля, которые выводятся на экран функцией imfinfo, мож-
О
но ввести в т. н. структурные переменные , которые затем можно использовать
в последующих вычислениях. Беря в качестве примера предыдущее изображение
и присваивая имя К структурной переменной, можно дать команду
> > К imfinfo(‘bubbles25. jpg') ;
для сохранения в переменной К всей информации, генерируемой командой imfinfo.
Информация, полученная из функции imfinfo сохраняется в полях структурной
переменной К, которые отделяются от нее точкой. Например, высота и ширина
изображения теперь хранятся в структурных полях К.Height и К.Width.
Для иллюстрации рассмотрим следующее применение структурной перемен-
ной К для вычисления степени сжатия в изображении bubbles25.jpg:
> > К imfinfo(‘bubbles25.jpg');
» image_bytes = К.Width*K.Height*K.BitDepth/8;
> > compressed-bytes = K.FileSize;
> > compressed_ratio = image_bytes/compressed_bytes
compressed_ratio =
35.1612
Заметим, что в наших примерах функция imfinfo применялась двумя разными
способами. В первом случае была просто набрана команда imfinfo bubbles25. jpg
после приглашения, что отобразило информацию на дисплее. Во втором слу-
чае была исполнена команда К imfinfо('bubbles25.jpg'), в результате че-
го соответствующая информация была сохранена в структурной переменной К.
В этих двух различных способах применения функции imfinfo обнаруживает-
ся командно-функциональная двойственность3, которая является характерной
чертой системы MATLAB. Подробнее с этим можно ознакомиться в онлайновой
документации. □
Еще один синтаксис функции imwrite доступен при работе с форматом изоб-
ражений tif. Он имеет следующий вид:4
imwrite(g, 'filename.tif', 'compression',
'parameter', 'resolution', [colres rowres]),
2 Структуры будут обсуждаться подробно в §§ 2.10.6 и 11.1.1.
3 Чтобы узнать подробнее о командно-функциональной двойственности, посмотрите страницу
справки по этому вопросу. О том, как обратиться к справке, было рассказано в § 1.7.3.
4 Если последовательность команд не помещается в одной строке, можно использовать многото-
чие (...), после которого нажать Return или Enter. Это даст знак системе, что команды будут
продолжены на следующей строке. Между точками не нужно ставить пробелы.
38 Глава 2. Цифровые изображения в MATLAB
где ‘parameter' может иметь только следующие значения: 'попе' (отсутствие
компрессии), 'packbits' (компрессия packbits, используемая по умолчанию для
небинарных файлов) и 'ccitt' (компрессия ccitt, используемая по умолчанию
для бинарных файлов). Массив [colres rowres] размера 1x2 содержит две це-
лые переменные, которые сообщают разрешение, соответственно, по столбцам и
по строкам в точках на условную единицу (значение по умолчанию — [72,72]).
Например, если размер изображения указан в дюймах, то colres — это число
точек (пикселов) на дюйм (dpi, dot per inch) по вертикали, и, соответственно,
rowres — разрешение по горизонтали. Для того, чтобы задать одинаковое раз-
решение, например, res, и по вертикали, и по горизонтали, достаточно записать
[res res].
Пример 2.3. Использование параметров imwrite.
На рис. 2.5, а) показан 8-битовый тестовый рентгеновский снимок монтажной
платы. Изображение записано в формате jpg с разрешением 200 dpi. Изобра-
жение имеет размер 450x450 пикселов или 2,25x2,25 дюймов. Мы хотим его
сохранить в формате tit без сжатия и присвоить файлу имя sf. Кроме того, же-
лательно сократить размер изображения до 1,5 х 1,5 дюймов, сохранив при этом
пиксельный размер 450x450. Следующая строка дает решение этой задаче:
>> imwrite(f, 'sf.tif', 'compression', 'none', 'resolution',
[300 300])
Значение вектора [colres rowres] определено при умножении 200 dpi на
дробь 2,25/1,5, что дает число 300 dpi. Чтобы не делать ручных вычислений,
можно выполнить команду
>> res round(200*2.25/1.15);
» imwrite(f, 'sf.tif', 'compression', 'none', 'resolution', res)
0
Рис. 2.5. Эффекты изме-
нения разрешения dpi при
сохранении общего числа
пикселов- а) Изображение
450 х 450 пикселов с разреше-
нием 200 dpi (размер 2,25 х
х2,25 дюймов). 6) То же
изображение 450x450 пик-
селов с разрешением 300 dpi
(размер 1,5x1,5 дюймов).
(Исходное изображение пре-
доставлено кампанией Lixi,
Inc.)
Здесь функция round округляет значение аргумента до ближайшего целого
числа. Важно обратить внимание на то, что число пикселов изображения не из-
менилось при выполнении этих команд. Изменился лишь масштаб изображения.
2.5. Классы данных
Исходное изображение 450x450 при разрешении 200 dpi имело размер 2,25x2,25
дюймов, а в новом изображении с разрешением 300 dpi 450x450 пикселов рас-
пределены по площади 1,5x1,5 квадратных дюймов. Этой процедурой удобно
пользоваться для контроля размеров изображения при печати, когда оно имеет
неудовлетворительное разрешение. □
Часто бывает необходимо сохранить изображение на диске точно в том ви-
де, в каком оно отображено на экране. Особенно важно уметь это делать для
графиков и диаграмм, приведенных в следующей главе. Содержимое окна изоб-
ражений можно экспортировать на диск двумя способами. Первый способ — это
воспользоваться командой Export в ниспадающем меню File в окне изображе-
ний (см. рис. 2.2). Затем пользователь получает возможность выбрать папку на
диске, имя и формат файла. Еще большие возможности для выбора параметров
экспорта дает команда print:
print — fno —dfilefbrmat — rresno —filename,
где no — это номер окна интересующего изображения, Reformat — это один из
допустимых форматов изображения (см. табл. 2.1), resno — это разрешение в dpi,
a filename — это имя, под которым пользователь хочет сохранить изображение.
Например, чтобы экспортировать содержимое окна на рис. 2.2 в виде tif-файла
с разрешением 300 dpi под именем hi_res_rose, необходимо выполнить команду
>> print -fl -dtiff -гЗОО hi_res_rose
Эта команда поместит построенный файл hi_res_rose.tif в текущую папку.
Если просто набрать print после приглашения, то MATLAB напечатает
(на принтере, принятом по умолчанию) содержимое последнего выведенного на
экран окна изображений. Можно также указать другие опции команды print,
например, задать специфическое печатное устройство.
2.5. Классы данных
Несмотря на то, что приходится работать с целочисленными координатами, зна-
чения самих пикселов не обязательно должны быть целыми числами. В табл.
2.2 перечислены разные классы данных1, поддерживаемые системой MATLAB и
пакетом IPT. Первые восемь записей, приведенных в таблице, относятся к число-
вым классам данных. Девятая запись - это класс символов, а последняя запись
относится к логическому классу данных.
Все численные операции в MATLAB выполняются с двойной точностью в
классе данных double, который часто используется в приложениях по обработки
изображений. Класс uint8 тоже встречается весьма часто, особенно при считыва-
нии данных с запоминающих устройств, например, самых распространенных на
практике 8-битных изображений. Эти два класса данных, класс logical, а так-
же в меньшей степени класс uintl6, образуют первостепенные классы данных,
ХВ документации по MATLAB используются словосочетания классы данных и типы данных в
одном и том же смысле. В данной книге термин тип изображения зарезервирован для других
целей, которые будут обсуждаться в § 2.6.
Глава 2. Цифровые изображения в MATLAB
на которых будет сфокусировано внимание в нашей книге. Многие функции из
IPT поддерживают, однако, все классы данных, приведенные в табл. 2.2. Класс
данных double требует 8 байт для представления одного числа, класс uint8 ис-
пользует один байт на каждый элемент, типам uintl6 и intl6 необходимо по 2
байта, а типы uint32, int32 и single отнимают в памяти по 4 байта на каждый
элемент. Символьный класс данных char хранит буквы и символы в кодиров-
ке Unicode, в которой используется два байта на элемент. Символьная строка
представляет собой массив 1хп символов класса char. Массив logical состоит
из элементов, принимающих только два значения, 0 и 1. которые хранятся в
памяти, занимая по одному байту каждый. Логические массивы создаются с ис-
пользованием функции logical (см. § 2.6.2) или с помощью операций сравнения
(см. § 2.10.2).
Таблица 2.2. Классы данных. Первые восемь классов называются числовыми, девятый —
символьный класс, последний класс — логический
Имя Описание
double Вещественные числа с плавающей запятой двойной точности в диапазоне, примерно, от — Ю308 до 1О308 (8 байт на число).
Целые без знака в интервале [0,255] (1 байт на число).
uintl6 Целые без знака в интервале [0,65535] (2 байта на число).
uint32 Целые без знака в интервале [0,4294967295] (4 байта на число).
int8 Целые со знаком в интервале [—128,127] (1 байт на число)
intl6 Целые со знаком в интервале [—32768, 32767] (2 байта на число).
int32 Целые со знаком в интервале [—2147483648, 2147483647] (4 байта).
single Вещественные числа с плавающей запятой обычной точности в диапазоне, примерно, от —1038 до 1038 (4 байта на число).
char Символы (буквы и знаки) (2 байта на символ).
logical Значения 0 или 1 (1 байт на элемент).
2.6. Типы изображений
Пакет IPT поддерживает следующие типы изображений:
полутоновые изображения (изображения с градацией серого цвета);
двоичные изображения;
индексированные изображения;
цветные изображения RGB.
Большинство монохромных изображений обрабатывается операциями, которые
работают с двоичными и полутоновыми изображениями, поэтому вначале наше
внимание будет обращено именно на эти два типа изображений. Индексирован-
ный тип и тип изображений RGB будут обсуждаться в гл. 6.
2.6. Типы изображений
2.6.1. Полутоновые изображения
Полутоновое изображение это матрица, элементы яркости которой представ-
лены в виде числовых значений. Если элементы полутонового изображения при-
надлежат классу uint8 или uintl6, то они представлены целыми числами, со-
ответственно, в интервалах [0.255] и [0,65535]. Если изображение принадлежит
классу double, то его пикселы являются вещественными числами с плавающей
запятой. По общему соглашению, пикселы изображений double должны лежать
в интервале [0,1].
2.6.2. Двоичные изображения
Двоичные изображения имеют в MATLAB весьма специфический смысл. Они яв-
ляются логическими массивами, состоящими из 0 и 1. Поэтому массив элементов
0 и 1 других классов, например. uint8, двоичным изображением не считается.
Для преобразования числовых массивов в логические служит функция logical.
Если А числовой массив, состоящий из 0 и 1, то для построения логического
массива В с теми же элементами следует выполнить команду
В logical(А)
Если массив А имеет также другие элементы, отличные от 0 и 1, то функция
logical преобразует все его ненулевые единицы в логический элемент 1, а все
нулевые — в логический элемент 0. Операции сравнения (см. § 2.10.2) и логиче-
ские операторы тоже порождают логические массивы.
Чтобы проверить, является ли данный массив логическим, применяется функ-
пия islogical:
islogical(C)
Если С — логический массив, то эта функция возвращает 1, в противном случае — 0-
Для преобразования логических массивов в числовые применяются функции пре-
образования классов данных, которые будут обсуждаться в § 2.7.11
2.6.3. Еще раз о терминологии
В предыдущих параграфах большое внимание было уделено разъяснению поня-
тий класс данных и тип изображения. Теперь мы будем использовать выражения
вида «изображение типа image_type класса data_class», где слова data_class
даны в табл. 2.2, a image_type это один из типов изображений, перечисленных
в начале § 2.6. Таким образом, изображение характеризуется своим классом и
типом. Например, если обсуждается «полутоновое изображение класса uint8»,
то это означает, что речь идет об изображении, пикселы которого принадлежат
классу uint8. Многие функции пакета IPT поддерживают все классы данных, но
там имеются и специализированные инструменты, сконструированные для рабо-
ты с конкретными классами. Например, как говорилось выше, пикселы двоичных
изображений могут быть только из класса logical.
1См. табл. 2.9, в которой приведен список других функций, имеющих синтаксис вида is*.
^42 Глава 2. Цифровые изображения в MATLAB
T.J. Конвертирование классов данных и типов
изображений
Преобразование (конвертирование) изображений из одних классов и типов в дру-
гие классы и типы является самым распространенным действием в IPT. Совер-
шая конвертацию типов данных, следует помнить о диапазонах значений величин
каждого класса, приведенных в табл. 2.2.
2.7.1. Конвертирование классов данных
Классы конвертируются следующим образом:
В = data_class_name(A) ,
где data_class_name — это одно из имен классов данных из первого столбца
табл. 2.2. Например, пусть А — массив класса uint8. Массив двойной точности В
генерируется командой В double (А). Это преобразование будет весьма часто
применяться в книге, поскольку MATLAB предполагает, что операнды числовых
операций являются вещественными числами с двойной точностью. Если С — это
массив класса double, элементы которого лежат в интервале [0. 255], но среди них
могут встречаться дробные числа, то его можно преобразовать в массив uint8
командой D = uint8(C).
Если массив класса double имел элементы со значениями вне интервала [0, 255]
и он был конвертирован в класс uint8 описанным выше способом, то MATLAB
преобразует все отрицательные величины (меньшие 0) в 0. все величины, боль-
шие 255 — в 255, а у всех остальных элементов отбрасываются дробные части.
Это означает, что перед преобразованием массивов double в uint8 необходимо
совершить подходящую перенормировку (перемасштабирование) его элементов.
Как уже говорилось в § 2.6.2, преобразование любых числовых данных в логи-
ческие приводит к логическому массиву, в котором стоят логические 1 везде на
месте ненулевых элементов входного массива и 0 на месте тех элементов, которые
равны нулю.
2.7.2. Конвертирование классов и типов изображений
В пакете имеются специальные функции (см. табл. 2.31), которые совершают пе-
ренормировку (перемасштабирование) при конвертации одних классов и типов
изображений в другие. Функция im2uint8 сначала распознает класс данных на
входе и совершает все необходимые преобразования, чтобы выходное изображе-
ние имело правильный тип данных. Рассмотрим, к примеру, следующее изобра-
жение f размера 2x2 класса double, которое может являться результатом неко-
торых промежуточных вычислений:
>> f =
-0.5 0.5
0.75 1.5
1Функцию changeclass, которая рассматривается в § 3.2.3, можно использовать для изменения
класса входного изображения.
2.7. Конвертирование классов данных и типов изображений
Выполняя преобразование
>> g = im2uint8(f)
получаем результат
g =
О 128
191 255
Таблица 2.3. Функции IPT для конвертации классов и типов изображений. См. функции
из табл. 6.3 для конвертации цветных изображений
Имя Преобразует в Допустимый класс
im2uint8 uint8 logical,uint8,uintl6,double
im2uintl6 uintl6 logical,uint8,ulnt16,double
mat2gray double (в область [0,1]) double
im2double double logical,uint8,uintl6,double
im2bw logical uint8,uintl6.double
В последнем примере видно, что функция im2uint8 обнуляет все отрицатель-
ные значения входного изображения, ставит число 255 на место величин, боль-
ших 1, и умножает остальные значения на 255, после чего округляет результат до
ближайшего целого числа. Отметим, что функция im2uint8 делает округление
не так, как это совершает описанная в § 2.7.1 функция преобразования классов
данных uint8, которая просто отбрасывает дробную часть числа.
Преобразование произвольных массивов double в перенормированные масси-
вы (изображения) double со значениями в интервале [0,1] выполняется с помо-
щью функции mat2gray, имеющий следующий синтаксис:
g = mat2gray(A, [Amin, Атах])
где изображение g имеет значения пикселов в интервале от 0 (белый) до 1 (чер-
ный). Указанные параметры Amin и Атах имеют следующее действие: все элемен-
ты, меньшие Amin, обнуляются, а все элементы, большие Атах, заменяются на 1.
При выполнении команды
>> g = mat2gray(A);
значения Amin и Атах — это настоящие максимум и минимум массива А. Предпо-
лагается, что входной массив из класса double. Выходной массив также принад-
лежит классу double.
Функция im2double преобразует входной массив в класс double. Если входной
массив был из класса logical,uint8 или uintl6, то функция im2double преоб-
разует его в класс double с диапазоном [0,1]. Если входной массив был класса
double, то функция im2double оставляет его без изменений. Как уже объясня-
лось выше, для преобразования массивов double в массивы double со значениями
в интервале [0,1] применяется функция mat2gray.
В качестве иллюстрации рассмотрим изображение класса uint82
2В § 2.8.2 поясняется использование квадратных скобок и знака точка с запятой при задании
матриц.
Глава 2. Цифровые изображения в MATLAB
>> h = uint8([25 50; 128 200]);
Совершая преобразование
>> g = im2double(h);
получаем результат
» g =
0.0980 0.1961
0.4706 0.7843
из которого видно, что входной массив класса uint8 преобразуется делением
каждого его элемента на 255, а массив класса uintl6 будет делиться на 65535.
В заключение рассмотрим конвертацию двоичных и полутоновых изображе-
ний. Функция im2bw, имеющая синтаксис
g = im2bw(f, Т)
порождает двоичное изображение g из полутонового изображения f, используя
порог Т. Значения всех элементов f, меныпих Т, становятся логическим 0, а все
остальные — логическими 1. Значение порога Т должно находиться в интерва-
ле [0,1] независимо от класса входного изображения. Выходной массив авто-
матически делается логическим. Если написать g = im2bw(f), то в IPT будет
использоваться по умолчанию порог Т = 0.5. Если входное изображение было
класса uint8, то im2bw сначала делит его элементы на 255, а потом применяет
заданный порог или порог, принятый по умолчанию. Если входной массив был
класса uintl6, то деление производится на 65535. Если входное изображение
принадлежало классу double, то im2bw сразу применяет соответствующий порог.
Если входной массив был логическим, то выходной массив будет ему идентичен.
Логический (двоичный) массив можно преобразовать в числовой с помощью лю-
бой из первых четырех функций в табл. 2.3.
Пример 2.4. Конвертирование классов и типов изображений.
(а) Мы хотим преобразовать следующее изображение класса double
>> f [1 2; 3 4]
f
1 2
3 4
в двоичное изображение так, чтобы величины 1 и 2 стали 0, а все остальные
обратились в 1. Прежде всего, сделаем преобразование в область [0,1]
>> g = mat2gray(f)
g =
0 0.3333
0.6667 1.0000
Затем конвертируем эту матрицу в двоичную с помощью порога, например, Т = 0.26:
>> gb = im2bw(g, 0.6)
2.7. Конвертирование классов данных и типов изображений
gb =
О О
1 1
Как уже отмечалось в § 2.5, имеется возможность прямого построения двоич-
ных массивов с помощью операций сравнения (см. § 2.10.2). Мы получим тот же
результат, выполнив команду
» gb f > 2
gb
О О
1 1
Можно сохранить в некоторой переменной (например, в gvb) информацию о том,
что массив gb является логическим, используя функцию islogical, в следую-
щей команде:
>> gbv = islogical(gb)
gbv =
1
(б) Теперь мы хотим конвертировать массив gb в цифровой массив double, со-
стоящий из нулей и единиц. Это можно сделать командой
>> gbd im2double(gb)
gbd
О О
1 1
Если бы массив gb принадлежал классу uint8, то применение к нему im2double
привело бы к следующей матрице:
О О
0.0039 0.0039
так как функция im2double должна разделить все элементы на 255. Это не про-
изошло в предыдущей команде, так как im2double обнаружила, что входная мат-
рица была из класса logical, т. е. имеется всего два возможных значения: 0 или 1.
На самом деле, если бы исходная матрица была бы класса uint8 и требовалось
конвертировать ее в double, сохраняя значения 0 и 1, то такое действие можно
выполнить командной:
» gbd = double (gb)
gbd =
0 0
1 1
В заключение отметим, что MATLAB допускает вложенные команды, т. е. все
действия над входным изображением f можно выполнить в одну строчку
>> gbd = im2double(im2bw(mat2gray(f), 0.6));
Разумеется, весь этот процесс можно осуществить более простой командой
Глава 2. Цифровые изображения в MATLAB
>> gbd double(f > 2) ;
которая еще раз демонстрирует компактность языка MATLAB. □
2.8. Индексирование массивов
В системе MATLAB предусмотрено несколько мощных схем индексирования, ко-
торые сильно упрощают обращение с массивами и оптимизируют работу про-
грамм. В этом параграфе обсуждается и иллюстрируется базовое индексирова-
ние одномерных и двумерных массивов (т. е. индексирование векторов и матриц).
Более изощренные методы будут обсуждаться по мере необходимости.
2.8.1. Индексирование векторов
Как уже сообщалось в § 2.1.2, массив размера 1 хЛ' называется вектором-строкой.
Элементы таких векторов можно получить с помощью одномерного индексиро-
вания. Так, например, v(l) — это первый элемент вектора v, v(2) — это второй
элемент и т.д. При инициализации элементы векторов следует помещать в квад-
ратные скобки, разделяя их пробелами или запятыми. Например,
>> v = [1 3 5 7 9]
v =
1 3 5 7 9
» v(2)
ans =
3
Вектор-строку можно преобразовать в вектор-столбец с помощью оператора
транспонирования
>> W = V.
W =
1
3
5
7
9
Для доступа к блоку элементов в MATLAB принято использовать оператор
двоеточие. Например, чтобы получить вектор, состоящий из трех первых ком-
понент вектора V, пишем
» v(l:3)
ans
13 5
'Использование символа одинарный апостроф без точки означает операцию сопряженного
транспонирования комплексных данных. Если данные являются вещественными, то эта опе-
рация совпадает с обычным транспонированием матриц (см. табл. 2.4).
2.8. Индексирование массивов
Аналогичным образом можно получить элементы со второго по четвертый
» v(2:4)
ans
3 5 7
или, например, с третьего до последнего:
>> v(3: end)
ans =
5 7 9
где слово end означает последний элемент вектора. Запись
» v(:)
генерирует вектор-столбец, а команда
>> v(l:end)
дает вектор-строку.
Индексировать можно не только последовательные элементы. Например, мож-
но задать команду
>> v(l:2:end)
ans
15 9
Запись 1:2: end означает следующее: начать с 1, считать с шагом 2 и остановить-
ся, когда счетчик достигнет последнего элемента. Шаг может быть отрицатель-
ным:
>> v(end:-2:l)
ans =
9 5 1
Здесь счетчик индексов начинается от последнего элемента, уменьшается на каж-
дом шаге на 2 и останавливается, достигнув первого элемента.
Функция linspace, имеющая синтаксис
х = linspace(а, Ъ, п)
порождает вектор-строку х из п элементов, расположенных на равных расстоя-
ниях на отрезке от числа а до числа Ъ, включая их самих. Эта функция будет
иногда использоваться в следующих главах.
Векторы можно использовать в качестве индексов других векторов. Напри-
мер, можно выбрать первый, четвертый и пятый элементы v с помощью команды
» v([l 4 5])
ans
17 9
В следующем параграфе мы увидим, что использование векторов при индек-
сировании играет ключевую роль при работе с матрицами.
48 Глава 2. Цифровые изображения в MATLAB
2.8.2. Индексирование матриц
Матрицы в MATLAB можно представить в виде последовательности векторов-
строк, заключенных в квадратные скобки и разделенных точкой с запятой. На-
пример, набрав строку
» А = [1 2 3; 4 5 6; 7 8 9]
получаем матрицу 3x3
А =
12 3
4 5 6
7 8 9
Заметим, что в этой команде использование знака точка с запятой отличается
от его применения с целью подавления вывода или для записи нескольких команд
в одну строку.
Для выбора конкретного элемента матрицы следует действовать как и с эле-
ментами векторов, но здесь уже понадобятся два индекса: один для обозначе-
ния номера строки, а другой — для номера столбца, где располагается искомый
элемент. Например, чтобы извлечь элемент, находящийся во второй строке и в
третьем столбце, нужно написать
» А(2, 3)
ans =
6
Оператор двоеточие может использоваться при индексировании матриц для
выбора двумерных блоков их элементов. Например,
» СЗ = А(: 3)
СЗ =
3
6
9
Здесь можно также использовать эквивалентную запись А (1:3, 3). которая про-
сто выберет третий столбец матрицы. Аналогично, вторая строка извлекается
следующим образом:
» R2 А(2, :)
R2 =
4 5 6
Следующая команда извлекает верхние две строки:
» Т2 = А(1:2, 1:3)
Т2 =
12 3
4 5 6
2.8. Индексирование массивов
Чтобы получить матрицу В, совпадающую с А всюду, кроме последнего столб-
ца, куда следует поместить нули, можно записать
В А;
ВС:, 3)
О
12 0
4 5 0
7 8 0
Слово end можно использовать аналогично векторному индексированию. Сле-
дующие примеры являются простейшими иллюстрациями этого приема.
>> A (end, end)
ans
9
>> A(end, end 2)
ans
7
>> A(2:end, end:-2:1)
ans
6 4
9 7
С помощью векторов при индексировании матриц можно существенно расши-
рить конструкции отбора элементов. Например,
» Е АС[1 3] , [2 3])
Е
2 3
8 9
Обозначение А ( [а b] , [cd]) отбирает элементы матрицы А в следующем по-
рядке координат: (строка а, столбец с), (строка а, столбец d),(строка Ъ, столбец
с),(строка Ъ, столбец d). Значит, при присвоении Е АС [1 3] , [2 3]) выбира-
ются элементы матрицы А в следующем порядке: элемент в строке 1 и столбце 2,
элемент в строке 1 и столбце 3, элемент в строке 3 и столбце 2, элемент в строке
3 и столбце 3.
Более сложные схемы получаются при матричной адресации. Особенно полез-
ным является метод индексирования матриц вида A (D), где D — это логический
массив. Например, если
» D = logical([1 00; 001; 000])
D =
10 0
0 0 1
0 0 0
то
Глава 2. Цифровые изображения в MATLAB
» A(D)
ans =
1
6
Наконец, заметим, что подставление одного двоеточия в индекс матрицы при-
водит к формированию вектор-столбца, в котором следуют один за другим столб-
цы исходной матрицы. Например, обращаясь к матрице Т2, получаем вектор
» v = Т2(:)
v =
1
4
2
5
3
6
Такое применение символа двоеточие бывает полезным, например, если необхо-
димо найти сумму всех элементов числовой матрицы:
>> s = sum(A(:))
s =
45
В общем случае команда sum(v) суммирует все элементы заданного векто-
ра v. Если аргументом функции sum является матрица (в виде sum(A)), то вы-
ходом служит вектор-строка, элементами которого являются суммы по строкам
заданной матрицы (такое поведение свойственно многим функциям MATLAB,
которые встретятся в дальнейшем). При использовании символа двоеточие реа-
лизуется команда
>> sum(sum(A));
поскольку операция (:) преобразует матрицу в вектор.
Применение двоеточия, на самом деле, является не чем иным, как формой
линейного индексирования в матрицах или в многомерных массивах. MATLAB
хранит в памяти любой массив в виде столбца значений, которые могут иметь
произвольную размерность. Этот столбец состоит из столбцов массивов, состав-
ленных один за другим. Например, матрица А хранится в виде
1
4
7
2
5
8
3
6
9
2.8. Индексирование массивов
Обращение к А с помощью одномерного индексирования делается прямо к
этому столбцу. Например, А(3) обозначает третий элемент столбца, т. е. число 7;
А (8) это восьмое число, т. е. 6 и т.д. При использовании операции (:) мы просто
обращаемся ко всем элементам, A(l:end). Такой тип индексирования является
основой векторизации циклов при оптимизации программ, что будет обсуждать-
ся в § 2.10.4.
Пример 2.5. Некоторые простые операции над изображениями на основе ин-
дексирования массивов.
На рис. 2.6, а) представлено полутоновое изображение f размера 1024x1024 клас-
са uint8. Изображение на рис. 2.6, б) было получено из f зеркальным отраже-
нием по горизонтали с помощью команды
» fp = f(end:-1:1, :);
Рис. 2.6. Результаты приме-
нения операций над индекса-
ми массивов, а) Исходное изоб-
ражение. б) Зеркальное отра-
жение по горизонтали, в) Усе-
ченное изображение, г) Проре-
женное изображение, д) Гра-
фик средней линии изображения
б)
Изображение, показанное на рис. 2.6, в), является частью f, после выполне-
ния команды
» fc f(257:768, 257:768);
Аналогично, рис. 2.6, г) получается «прореживанием» из f, после применения
fs = f(1:2:end, 1:2:end);
Глава 2. Цифровые изображения в MATLAB
Наконец, на рис. 2.6, д) приведен график средней линии изображения f, постро-
енный командой
» plot(f(512, :))
Функция plot подробно рассматривается в § 3-3.1. □
2.8.3. О размерности массивов
Операции вида
operation(A, dim)
часто используются в книге. Здесь operation обозначает некоторую функцию
MATLAB, А - какой-то массив, a dim — некоторый скаляр. Например, пусть А -
матрица размера M>N Команда
>> k = size(A, 1);
сообщает размер матрицы А по первому измерению, которое называется в MATLAB
вертикальной размерностью. Т. е. эта команда выдает число строк матрицы А.
Аналогично, второе измерение массива называется горизонтальной размерно-
стью, т. е. команда size(A, 2) сообщает число столбцов матрицы. Размерность
dim, для которой size (A, dim) 1, называется точечной размерностью. Ис-
пользуя эти понятия, можно записать последнюю команду из примера 2.5 в сле-
дующем виде:
» plot(f(size(f, l)/2, :))
MATLAB не устанавливает ограничений на число размерностей массивов, что
является полезным свойством системы. В книге мы имеем дело, в основном, с
двумерными массивами, однако бывают случаи (например, при работе с цветны-
ми изображениями или с изображениями в нескольких спектрах), когда бывает
необходимо «укладывать» изображения вдоль третьего или еще большего изме-
рения. Такие случаи будут рассматриваться в гл. 6, 11 и 12. Функция ndim с
синтаксисом
d ndims(А)
возвращает число размерностей массива А. Эта функция всегда имеет значения
не меньше, чем 2, так как считается, что даже скаляры имеют размерность 2,
в том смысле, что их размер — это 1x1.
2.9. Некоторые важные стандартные массивы
Часто при исследовании конкретных алгоритмов полезно уметь строить про-
стые массивы для проверки идей и для тестирования разрабатываемых функций.
В этом параграфе рассматриваются семь стандартных функций, генерирующих
некоторые специальные массивы, которые будут использоваться в следующих
главах. Если аргументом рассматриваемых далее функций является одно число,
то результатом является квадратный массив.
2.10. Введение в программирование М-функций 53
Функция zeros (M,N) генерирует матрицу MxN из одних нулей класса
double.
Функция ones(M,N) генерирует матрицу MxN из одних единиц класса
double.
Функция true(M,N) строит логическую матрицу M'/.N из единиц (истина).
Функция false(M,N) строит логическую матрицу My.N из нулей (ложь).
Функция magic(M) порождает «магический квадрат» Му.М В этой квад-
ратной матрице суммы чисел по любой строке, по любому столбцу и по
главным диагоналям равны между собой. Магические квадраты бывают
полезными при тестировании, т.к. их легко строить и их элементами слу-
жат целые числа.
Функция rand(M,N) генерирует матрицу MxN, элементами которой явля-
ются нормально распределенные (гауссовы) случайные величины со сред-
ним 0 и с дисперсией 1.
Например,
5*ones(3,3)
5 5 5
5 5 5
5 5 5
magic(3)
ans =
8 1 6
3 5 7
4 9 2
>> В rand(2, 4)
В
0.2311 0.4860 0.7621 0.0185
0.6068 0.8913 0.4565 0.8214
2.10. Введение в программирование М-функций
Важнейшая отличительная черта пакета обработки изображений IPT состоит в том,
что в нем реализован прозрачный доступ к среде программирования MATLAB.
Как скоро будет видно, программирование функций MATLAB является доста-
точно гибким и его легко освоить для практических применений.
Глава 2. Цифровые изображения в MATLAB
2.10.1. М-файлы
Так называемые М-файлы являются или просто скриптами, т. е. состоят из после-
довательностей исполняемых команд MATLAB, или они являются функциями,
которые допускают использование аргументов и могут иметь выходные данные.
В этом параграфе мы займемся именно функциями. Эти функции расширяют
возможности MATLAB и IPT для выполнения специфических приложений, нуж-
ных конкретным пользователям.
М-файлы создаются в текстовом редакторе и сохраняются под именем f ilename. m,
например, average.m или fliter.m. Функции, задаваемые в М-файлах, состоят
из следующих компонент:
- заголовок функции;
- hl-строка;
текст справки;
тело функции;
- комментарии.
Заголовок функции имеет вид
function [outputs] = name(inputs).
Например, функция, которая вычисляет сумму и произведение (т. е. она имеет
два разных выходных параметра) двух изображений, может иметь следующий вид:
function [s, р] = sumprod(f, g),
где f и g — это два входных изображения, s — это их сумма, ар — произведе-
ние. Имя функции sumprod. может быть произвольным, но слева от него обяза-
тельно должно стоять слово function. Обратите внимание па то, что выходные
аргументы заключены в квадратные скобки. Если функция имеет единствен-
ный выходной параметр, то его можно не заключать в квадратные скобки. Если
определяемая функция не имеет выходных аргументов, то ставится одно слово
function без квадратных скобок и знака равенства. Имя функции должно начи-
наться с буквы, а остальные символы могут быть буквами, цифрами или знаками
подчеркивания. Пробелы в имени функции не допускаются. MATLAB различает
в начале имени функции 63 символа. Остальные символы игнорируются.
Функцию можно вызвать в командной строке после системного приглашения,
например,
>> [s,p] = sumprod(f, g);
а кроме того, функции могут являться элементами других функций, в этом слу-
чае они становятся подфункциями. Как уже отмечалось, если функция возвра-
щает только один аргумент, то квадратные скобки можно опускать, например,
>> у = sum(x);
Hl-строка — это первая текстовая строка функции. Она является первой
строкой комментария, который следует за заголовком функции. Между этой
2.10. Введение в программирование М-функций
строкой и заголовком не должно быть пустых строк. Примером Hl-строки может
служить следующая строка:
% SUMPROD вычисляет сумму и произведение двух изображений.
В § 1.7.3 указывалось, что Hl-строка отображается первой на экране, если поль-
зователь дает команду
» help function_name
В том же параграфе говорилось, что команда lookfor keyword выводит на экран
все Hl-строки, в которых содержится последовательность символов keyword. Та-
ким образом, Hl-строка несет важные сведения о данном М-файле, поэтому она
должна быть максимально информативной.
Текст справки является текстовым блоком, который размещается сразу после
Hl-строки без разделения пустой строкой. Текст справки используется для отоб-
ражения комментариев и онлайновой справки по данной функции. Если пользо-
ватель набирает в командной строке после приглашения help function_name, то
MATLAB выдает на экран все комментарии, расположенные между заголовком
функции и первой строкой, не являющейся комментарием (это или пустая строка,
или первая исполняемая строка данной функции). Справочная система игнори-
рует любые комментарии, которые могут стоять после блока справки функции.
Тело функции состоит из выполняемого кода MATLAB, который соверша-
ет некоторые действия или вычисления и присваивает определенные результаты
выходным аргументам. Далее в этой главе приводятся некоторые примеры ис-
полняемого кода MATLAB.
Все строки, перед которыми стоит символ «%» и которые не являются Hl-
строками или не входят в блок справки, рассматриваются в качестве строк ком-
ментария функции. Они не считаются частью справочной системы. Разрешается
также ставить комментарии в конце исполняемых команд.
М-файлы можно создавать и править в любом текстовом редакторе, сохранив
их с расширением .ш в соответствующей папке, для которой обычно указывают
путь поиска. Удобно также работать с М-файлами с помощью команды edit,
которая позволяет их создавать и редактировать. Например,
>> edit sumprod
открывает для редактирования файл sunprod, если он существует в рабочей пап-
ке или в папке, описанной в пути поиска MATLAB. Если файл с таким именем там
не обнаруживается, то MATLAB дает возможность пользователю создать новый
файл. Как подчеркивалось в § 1.7.2, окно редактора MATLAB имеет несколь-
ко ниспадающих меню для выполнения действий типа: сохранить, посмотреть и
отладить файлы. Этот редактор делает некоторые простейшие синтаксические
проверки и выделяет разными цветами различные элементы программного кода,
поэтому он весьма удобен для работы с М-файлами и его всегда рекомендуют в
качестве полезного системного инструмента.
Глава 2. Цифровые изображения в MATLAB
2.10.2. Операторы
Операторы MATLAB разделены на три основные категории:
арифметические операторы, совершающие стандартные арифметические дей-
ствия;
операторы сравнения, которые сравнивают операнды количественно;
логические операторы, которые выполняют действия И, ИЛИ и НЕ.
Рассмотрим каждую из этих категорий отдельно.
АргцДметггческие операторы
В MATLAB имеется два различных типа арифметических операторов. Матрич-
ные арифметические операторы определяются по правилам линейной алгебры.
Арифметические операторы с массивами выполняются поэлементно, и их можно
применять к многомерным числовым массивам. Для различения этих двух типов
операторов используется символ точка (.). Например, А * В обозначает обычное
произведение матриц, а действие А. * В обозначает операцию над массивами в том
смысле, что его результатом служит массив того же размера, что и у массивов А
и В, причем его элементами являются поэлементные произведения соответствую-
щих элементов А и В. Другими словами, если С = А. * В, тоС(1, J) = A(l, J) * B(l, J).
Отметим, что операции сложения и вычитания выполняются по одним и тем же
правилам для обоих типов арифметических операторов, поэтому команды (.+) и
(.—) не употребляются.
При выполнении действия вида В = А система MATLAB делает «заметку»,
что с этого момента массив В совпадает с А, однако при этом не происходит
немедленное «физическое» копирование всех элементов А в В. Это будет сделано
только при дальнейшем изменении содержимого массива А. Это обстоятельство
следует учитывать, поскольку «хранение» одной и той же информации в разных
переменных может иногда повысить доходчивость и читаемость программного
кода. Таким образом, MATLAB не дублирует информацию, пока в этом нет аб-
солютной необходимости. Это стоит помнить при написании программ на языке
MATLAB. В табл. 2.4 перечислены все арифметические операторы MATLAB.
В этой таблице заглавные А и В обозначают матрицы или массивы, а строчные
а и Ъ скалярные величины. Все операнды могут быть вещественными или
комплексными. Если операнды являются скалярными переменными, то знак (.)
можно не ставить. Следует помнить, что изображения являются двумерными
массивами, т. е. матрицами, поэтому все перечисленные операторы применимы к
изображениям.
В пакете IPT имеется несколько арифметических функций для работы с изоб-
ражениями (см. табл. 2.5). Разумеется, все эти действия можно выполнить, при-
меняя базовые арифметические операторы MATLAB напрямую. Однако преиму-
щество использования функций IPT заключается в том, что они учитывают класс
входного изображения, например, int8, а соответствующие математические опе-
раторы MATLAB требуют использование класса double.
2.10. Введение в программирование М-
Таблица 2.4. Операции с матрицами и массивами. Все действия можно выполнять или
непосредственно с помощью этих операторов, например, А + В, или с по-
мощью соответствующих функций, т. е. plus (А, В). Для простоты все дей-
ствия проиллюстрированы с использованием матриц, но все они очевидным
образом распространяются на массивы произвольных размерностей
Оператор Название Функция MATLAB Комментарии и примеры
+ Сложение матриц и массивов plus(A,B) a+b,A+B, или a+A.
Вычитание матриц и массивов minus(А,В) a-b,A-B, a-A или A-a.
.* Умножение массивов times(A.B) C=A.*B, C(I,J)=A(I,J)*B(I,J).
* Умножение матриц mtimes(A,B) A*B, стандартное произведение мат- риц, или а*А, умножение элемен- тов матрицы А на скаляр.
./ Деление на массив справа rdivide(A,B) C=A./B,C(I,J)=A(I,J)/B(I,J).
•\ Деление на массив слева ldivide(A,B) C=A.\B,C(I,J)=B(I,J)/A(I,J).
/ Матричное деление справа mrdivide(A,B) A/В, почти то же действие, что A*inv(B) в зависимости от точно- сти вычислений.
\ Матричное деление слева lrdivide(A,B) А\В, почти то же действие, что inv(A)*B в зависимости от точ- ности вычислений.
Возведение в степень массивов power(A.B) Если С=А."В, то C(I,J)=A(I,J)"B(I,J).
Матричное возведение в степень шроиег(A,B) См. онлайновую справку по это- му оператору.
Векторное или матрич- ное транспонирование transpose(A) А. ’ Стандартное транспониро- вание векторов или матриц
Векторное или матрич- ное комплексное сопря- жение и транспониро- вание ctranspose(A) А’ Стандартное комплексное со- пряжение векторов или матриц.
Унарный плюс uplus(A) +А. Эквивалентно 0+А.
Унарный минус uminus(A) -А. Эквивалентно 0-А. или -1*А.
Двоеточие Обсуждалось в § 2.8.
В примере 2.6 используются функции max и min. Эти функции имеют следу-
ющие синтаксические формы:
С = max(А)
С = max(А, В)
С = max(А, [ ], dim)
[С, I] тах(...)
В первом случае, если А — вектор, то max (А) возвращает его наибольший элемент;
если А - матрица, то max (А) рассматривает А как строку векторов-столбцов и воз-
вращает вектор-строку из максимальных элементов по всем столбцам. Во втором
случае функция max (А, В) возвращает массив размера, как было у А и В, элемен-
тами которого являются максимумы из пар соответствующих элементов из А и В.
Глава 2. Цифровые изображения в MATLAB
В третьем случае max(A, [],dim) возвращает максимальные элементы вдоль из-
мерения dim массива А. Например, тах(А, [ ], 1) находит максимальные элементы
по первому измерению (т. е. по строкам) массива А. Наконец, команда [С, I]
= тах(...) находит индексы (координаты) максимальных элементов А и поме-
шает их в выходной вектор I. Если имеется несколько одинаковых максимальных
элементов, то выбирается индекс первого из них. Многоточие в круглых скобках
обозначает использование любого из предыдущих аргументов. В этом контексте
также может использоваться функция min с очевидными изменениями смысла.
Таблица 2.5. Арифметические функции для обработки изображений из пакета IPT
Функция Описание
imadd imsubtract inimultiply Сложение двух изображений или прибавление константы. Вычитание двух изображений или вычитание константы. Умножение двух изображений, которое выполняется поэлементно между со- ответствующими парами элементов изображений, или умножение всего изоб- ражения на константу.
imdivide Деление двух изображений, которое выполняется поэлементно между соот- ветствующими парами элементов изображений, или деление всего изображе- ния на константу.
imabsdiff imcomplemeat imlincomb Вычисление модуля разности двух изображений. Дополнительное изображение (см. § 3.2.1). Нахождение линейной комбинации двух или более изображений. (См. по- дробнее в § 5.3.1.)
Пример 2.6. Иллюстрации для арифметических операторов и функций min и max.
Пусть требуется написать М-функцию, скажем, improd, которая перемножает два
входных изображения и возвращает изображение-произведение, максимальный
и минимальный элементы этого произведения, а также соответствующее норми-
рованное изображение со значениями в интервале [0,1]. С помощью текстового
редактора напишем следующую интересующую нас функцию.
function [р, ртах, pmin, pn] improd(f, g)
‘/.IMPROD Computes the product of two images1
'Z [P, PMAX, PMIN, PN] IMPROD(F, G)2 outputs the element-by-
% element product of two input images, F and G, the product
'Z maximum and minimum values, and a normalized product array with
‘Z values in the range [0, 1] The input images must be of the same
‘Z size. They can be of classes uint8, uintl6, or double. The outputs
°Z are of class double.
fd = double(f);
gd = double(g) ;
[При переводе данной книги Hl-строки и тексты справок всех функций приводятся как в ори-
гинале на английском языке. Это сделано для соблюдения авторских прав на функции и про-
граммы. Многие из этих функций можно найти на сайте авторов этой книги. (См. § 1.5.)
2В документации по MATLAB принято использовать заглавные буквы в именах функциях и
аргументах, которые отображаются в Hl-строках и в текстах справок. Это позволяет отличать
настоящие имена функций и аргументов от их смысловых разъяснений.
2.10. Введение в программирование М-функций
р fd.*gd;
ртах = maxСр (:)) ;
pmin = min(p(:));
pn = mat2gray(p);
Заметим, что конвертирование входных изображений в класс double сделано
с помощью функции double, а не im2double, так как в том случае, когда входное
изображение принадлежит классу uint8, функция im2double конвертирует его
значения в интервал [0,1]. Предположительно требовалось, чтобы изображение р
содержало произведение исходных изображений. Для нахождения нормирован-
ного массива рп с областью значений [0,1] была использована функция mat2gray.
Напомним, что особенности применения оператора (:) в индексах массивов объ-
яснялись в § 2.8.
Пусть теперь f = [12; 3 4] Hg = [12; 2 1]. Наберем следующую коман-
ду с использованием введенной выше функции:
[р, ртах, pmin, pn] = improdff, g)
Р =
1 4
6 4
ртах =
6
pmin =
1
рп =
О 0.6000
1.0000 0.6000
Если набрать после приглашения MATLAB команду help improd, то получим
следующий справочный текст:
> > help improd
IMPROD Computes the product of two images.
[P, PMAX, PMIN, PN] IMPROD(F, G) outputs the element-by-element
product of two input images, F and G, the product maximum and
minimum values, and a normalized product array with values in the
range [0, 1] The input images must be of the same size. They can
be of classes uint8, uintl6, or double. The outputs are of class
double. □
Операторы сравнения
Операторы сравнения MATLAB перечислены в табл. 2.6. Эти операторы срав-
нивают величины соответствующих элементов массивов, которые должны иметь
одинаковые размерности. Все операции делаются на поэлементной основе.
Глава 2. Цифровые изображения в MATLAB
Пример 2.7. Операторы сравнения.
Несмотря на то, что операторы сравнения в основном используются в программах
при управлении вычислительными потоками (например, в условных операторах
типа if), что будет обсуждаться в § 2.10.3, здесь мы кратко проиллюстриру-
ем прямое использование этих операторах при работе с массивами. Рассмотрим
следующие команды ввода-вывода:
» А = [1 2 3; 4 5 6; 7 8 9]
А =
12 3
4 5 6
7 8 9
» В = [0 2 4; 3 5 6; 3 4 9]
В =
0 2 4
3 5 6
3 4 9
» А == В
ans =
0 10
0 1 1
0 0 1
Таблица 2.6. Операторы сравнения
Оператор Название
< Меньше
<= Меньше или равно
> Больше
>= Больше или равно
Равно
-= Не равно
Значит, оператор == порождает логический массив с теми же размерами, что А
и В, причем единицы стоят там, где элементы А и В совпадают, и нули — там, где
они не совпадают. Вот еще одна иллюстрация. Команда
» А >= В
ans =
110
111
111
задает логический массив с единицами там, где элементы массива А больше или
равны соответствующих элементов массива В, и с нулями во всех остальных ячей-
ках массива. □
Для векторов и квадратных массивов оба операнда в логическом операто-
ре должны иметь одинаковые размеры, за одним исключением, когда один из
2.10. Введение в программирование М-функций
операндов — скаляр. В этом случае MATLAB сравнивает этот скаляр со всеми
элементами другого операнда и строит логический массив того же размера, в
котором единицы стоят там, где условие оператора выполнено, и нули — там,
где это условие нарушено. Если оба операнда являются скалярами, то резуль-
тат этого логического оператора равен 1, если сравнение истинно, и нуль — если
ложно.
Логические операторы и логические функции
В табл. 2.7 приведены логические операторы MATLAB, а в следующем приме-
ре проиллюстрированы некоторые свойства этих операторов. В отличие от об-
щепринятой интерпретации логических операций, операторы из табл. 2.7 могут
обрабатывать как логические, так и числовые данные. MATLAB трактует логи-
ческую 1 и любое ненулевое число как истина, а логический или числовой 0 —
как ложь. Например, логический оператор И, примененный к двум операндам, да-
ет 1, если оба операнда являются или логическими единицами, или ненулевыми
числами. Оператор И дает нуль, если один из операндов является или логическим
или числовым 0, а также когда оба операнда — нули.
Таблица 2.7. Логические операторы
Оператор Название
& и
1 или
- НЕ
Пример 2.8. Логические операторы.
Рассмотрим действие оператора И на следующем числовом массиве:
[12 0; 0 5 6];
[1 -2 3; 0 1 1] ;
А & В
ans
110
0 11
Видно, что оператор И порождает логический массив, имеющий размеры вход-
ных массивов, в котором единицы стоят на тех местах, где оба элемента, массивов
А и В являются ненулевыми, и нули — там, где имеется хоть один нулевой эле-
мент в массивах А и В. Напомним, что все операции совершаются поэлементно.
Оператор ИЛИ действует аналогичным образом. Выражение с ИЛИ есть истина,
если один из операндов является логической единицей или ненулевым числом, в
противном случае выражение есть ложь. Логический оператор НЕ имеет один опе-
ранд. Если этот операнд — логическая величина, то она обращается, т. е. истина
переходит в ложь, и наоборот. Результат этого оператора, примененного к число-
вой ненулевой величине, есть 0, а к числовому нулю — 1. □
MATLAB также поддерживает некоторые логические функции, приведенные
в табл. 2.8. Функции all и any бывают особенно полезными при написании про-
грамм.
Глава 2. Цифровые изображения в MATLAB
Таблица 2.8. Логические функции
Функция Комментарий
хог Возвращает логическую 1, только если оба операнда являются логически различными, иначе хог возвращает 0.
all Возвращает 1, если все элементы вектора являются ненулевыми, иначе возвращает 0. На матрицах действует по столбцам.
any Возвращает 1, если какой-то элемент вектора является ненулевым, иначе возвращает 0. На матрицах действует по столбцам.
Пример 2.9. Логические функции.
Рассмотрим простые массивы А = [123; 4 5б]иВ= [1-11; 00 2]. Под-
становка этих массивов в функции из табл. 2.8 приводит к следующим результатам:
>> хог(А, В)
ans =
10 0
110
» all(А)
ans =
111
>> any(A)
ans =
111
» all(B)
ans =
0 0 1
>> any(B)
ans =
0 1 1
Обратите внимание на то, что функции all и any действуют по столбцам
матриц А и В. Например, первые два элемента вектора, произведенного командой
all (В), равны 0, так как каждый из первых двух столбцов В имеет хоть один 0;
последний элемент равен 1, поскольку все элементы последнего столбца матрицы
В являются ненулевыми числами. □
В дополнение к перечисленным в табл. 2.8 функциям MATLAB имеет несколь-
ко других функций, которые проверяют некоторые специфические условия и
свойства, а также возвращают логические значения. Такие функции приведе-
ны в табл. 2.9. Некоторые из них связаны с понятиями и свойствами, которые
обсуждались ранее в этой главе (например, функция islogical рассматривалась
в § 2.6.2), другие функции встретятся в следующих главах. Обратите внимание на
то, что все эти функции возвращают логическую 1, когда проверяемое свойство
выполнено, в противном случае на выход поступает логический 0. Если аргумен-
том этих функций служит массив, то некоторые из них возвращают логический
массив тех же размеров, в котором единицы стоят на тех местах, где выполне-
но соответствующие условие у входного массива, в противном случае там стоят
нули. Например, если А = [12; 3 1/0], то функция isfinite(A) возвращает
матрицу [1 1; 1 0], где элемент 0 (ложь) указывает на то, что соответствующий
элемент А равен бесконечности (т. е. не является конечным).
Таблица 2.9. Некоторые функции, которые возвращают логические 1 или 0 в зависимости
от истинности или ложности аргументов. См. полный список функций в
онлайновой справке
Функция Описание
iscell(C) Истина, если С — матричный массив.
iscellstr(s) Истина, если С — матричный массив из строк.
ischar(s) Истина, если s — символьная строка.
isempty(A) Истина, если А — пустой массив, [ ] .
isequal(A, B) Истина, если А и В — тождественные массивы.
isfieldCS, ‘name*) Истина, если ‘паше1 является полем структуры S.
isfinite(A) Истина там, где элементы массива А конечны.
isinf(A) Истина там, где элементы массива А бесконечны.
isletter(A) Истина там, где элементы массива А являются буквами.
islogical(A) Истина, если А — логический массив.
ismember(A, B) Истина там, где элементы А есть также в В.
isnan(A) Истина там, где элементы А есть NaN (см. табл. 2.10).
isnumeric(A) Истина, если А — числовой массив.
isprime(A) Истина там, где элементы А — простые числа.
Isreal(A) Истина, если все элементы А не имеют мнимой части.
isspace(A) Истина там, где элементы А являются пробелами.
issparee(A) Истина, если А — разреженная матрица.
isstruct(S) Истина, если S — структура.
Некоторые важные переменные и константы
Элементы из табл. 2.10 весьма часто используются при программировании на
MATLAB. Например, число eps добавляется к числителям дробей, чтобы избе-
жать переполнения при вычислениях, даже если числитель равен нулю.
Таблица 2.10. Некоторые важные переменные и константы
Функция Возвращаемая величина
ans Самый последний ответ (переменная). Если выход команды не присвоен некоторой переменной, то MATLAB автоматически сохраняет результат в переменной ans.
eps Относительная точность вычислений с плавающей запятой. Равна рас- стоянию от числа 1.0 до следующего ближайшего числа, которое можно представить с плавающей запятой с двойной точностью.
i или j Nan или пап Мнимая единица, например, в выражении l+2i. Сокращение от Not-a-number (не число) (например, 0/0).
Pi realmax 3.14159265358979 Наибольшее вещественное число, которое компьютер может предста- вить с плавающей запятой.
realmin Наименьшее вещественное число, которое компьютер может предста- вить с плавающей запятой.
computer version Тип вашего компьютера. Версия MATLAB (строка).
Глава 2. Цифровые изображения в MATLAB
Представление чисел
MATLAB использует стандартное десятичное представление чисел с обычной де-
сятичной точкой. Перед числом ставится его знак, плюс или минус. Используется
также символ е для обозначения десятичного основания степени. В комплексных
числах используется суффикс i или j для обозначения мнимой единицы. Вот
некоторые примеры записи чисел
3 -99 0.0001
9.6397238 1.60210е - 20 6.02252е23
li —3.14159j 3e5i
Любые числа представляются в памяти компьютера в стандартном длинном фор-
мате IEEE (Institute of Electrical and Electronics Engeneers), предусмотренном для
хранения чисел с плавающей точкой. Числа с плавающей точкой имеют точность око-
ло 16 значащих десятичных цифр и область значений, примерно от 1О-308 до 1О308.
2.10.3. Управление вычислительными потоками
Возможность управления последовательностью операций с помощью предопре-
деленных условий лежит в основе любых языков компьютерного программиро-
вания. На самом деле, условное ветвление является одним из двух фундамен-
тальных принципов, которые были заложены в основание схемы универсальных
вычислительных машин в сороковых годах прошлого века (другой принцип за-
ключался в использовании памяти компьютера для одновременного хранения
выполняемых программ и используемых данных). В MATLAB предусмотрено
восемь операторов условных переходов, которые приведены в табл. 2.11. Следует
помнить, что MATLAB трактует логическую единиц} и любое ненулевое число
как истина, а логический или числовой нуль — как ложь.
Таблица 2.11. Операторы условных переходов
Оператор Описание
if if вместе c else и elseif совершает группу операций при выполнении предопределенных логических условий.
for Выполняет группу операций заданное число раз.
while Выполняет группу операций, число которых устанавливается на ос- нове предопределенных логических условий.
break Прерывает выполнение циклов операторов for или while.
continue Передает управление следующей итерации цикла for или while, про- пустив все оставшиеся операции в теле цикла.
switch switch вместе с case и otherwise выполняет разные группы операций в зависимости от предписанных значений или строк.
return Передает управление в вызвавшую функцию-
try...catch Изменяет управление вычислениями при обнаружении ошибок вы- числений.
Операторы If, else и elseif
Условный оператор if имеет следующий синтаксис:
if expression
statements
end .
2.10. Введение в программирование М-функций
Выражение expression вычисляется, и если оно истинно, то выполняются опера-
ции, перечисленные в statements, расположенные между строками if и end. Если
выражение expression ложно, то MATLAB пропускает все операции между стро-
ками if и end. Если имеются вложенные операторы if. то каждый из них обязан
иметь парное слово end.
Условные операторы else и elseif служат для дальнейшего условного раз-
ветвления оператора if. Общая форма этих операторов имеет следующий вид:
if expression!
statements!
elseif expressions
statemen ts2
else
statements3 end
Если expression! есть истина, то выполняется statements!, после чего контроль
передается на конец условного оператора (end). Если expression! есть ложь, то
выполняется expressions. Если оно есть истина, то выполняется statemen tsS, и
контроль передается на end. В противном случае (else) выполняется команда
(или группа команд) statementsS. Обратите внимание на то, что оператор else
не имеет условия. Операторы elseif и else могут появляться независимо друг от
друга после if. Они не обязаны быть в паре, как показано в общем виде условного
оператора if. Также допускается многократное присутствие операторов elseif.
Пример 2.10. Условные разветвления и появление функций error, length и
numel.
Пусть требуется написать функцию, которая вычисляет среднюю яркость изоб-
ражения. Как уже обсуждалось, двумерный массив f можно преобразовать в
вектор-столбец v, написав оператор v =f (:). Поэтому желательно, чтобы функ-
ция могла работать и с векторами, и с матрицами-изображениями. Программа
должна выдавать сообщение об ошибке, если входной массив не является одно-
мерным или двумерным.
function av average(А)
У,AVERAGE Computes the average value of an array
7, AV AVERAGE (A) computes the average value of input
7, array, A, which must be a 1-D or 2-D array.
% Check the validity of the input. (Keep in mind that
’/, a 1-D array is a special case of a 2-D array.)
if ndim(A) > 2
error(‘The dimension of the input cannot exceed 2/‘)
end
’/, Compute the average
av = sum(A(:))/length(A(:));
Заметим, что входной массив преобразуется в одномерный с помощью опера-
тора А(: ). В общем случае функция length (А) возвращает длину самого боль-
шого измерения массива А. В рассмотренном примере массив А( : ) является век-
тором, поэтому length(A(:) ) дает число элементов А. Это позволяет исключить
Глава 2. Цифровые изображения в MATLAB
проверку того, является ли входной массив вектором или матрицей. Другой спо-
соб прямого определения числа элементов массива заключается в использовании
функции numel, которая имеет следующий синтаксис:
n = numel(А)
Если А является изображением, то numel (А) дает число пикселов. Применяя эту
функцию, последнюю строку программы можно переписать в виде
av = sum(A(:))/numel(A(:));
Наконец, отметим, что функция error прерывает выполнение программы и
выдает на консоль сообщение, помещенное в круглые скобки (сообщение следует
помещать в апострофы, как это сделано в нашем примере). □
Оператор for
Как указано в табл. 2.11, цикл for выполняет группу операторов предписанное
число раз. Его синтаксис имеет вид
for index = start:increment:end
statements
end .
Циклы можно вкладывать один в другой следующим образом:
for index! = startl.’incrementl.endl
statements!
for index2 = start2:increment2:end2
statements2
end
statements3
end.
Например, следующий цикл исполняется И раз:
count = 1;
for k = 0:0.1:1
count = count + 1;
end
Если шаг цикла опущен, то он принимается за 1. Шаг цикла может быть отри-
цательным, например, for к = 0:-1:-10. Заметим, что в конце строки for не
нужно ставить точку с запятой. MATLAB автоматически подавляет выдачу на
печать значений индекса цикла. Как уже отмечалось в § 2.10.4, можно достиг-
нуть существенного повышения скорости выполнения программы, если заменить
цикл for везде, где это возможно, на так называемый векторизованный код.
2.10. Введение в программирование М-функций
Пример 2.11. Использование цикла for для записи нескольких изображений в
файлы.
В примере 2.2 сравнивалось несколько изображений с разными значениями каче-
ства сжатия JPEG. Покажем, как можно записать все эти изображения на диск
с помощью цикла for. Пусть имеется изображение f и требуется записать его в
ряд файлов формата JPEG со значениями коэффициента качества от 0 до 100 и с
шагом 5. Желательно также дать этим файлам имена вида series_xxx.jpg, где
ххх — это коэффициент качества изображения. Это можно сделать в следующем
цикле for:
for q = 0:5:100
filename = sprintf (‘ series_7«3d. jpg', q);
imwrite(f, filename, ‘quality', q) ;
end
В данном случае функция sprintf3, имеющая синтаксис
s = sprintf (‘characters 17,ndcharacters2‘, q)
записывает отформатированные данные в строку s. В этой синтаксической фор-
ме characters 1 и characters2 — это строки символов, a 7«nd — обозначает деся-
тичное число (для переменной q) с п цифрами. В нашем примере character si —
это series., величина п равна 3, строка characters2 — это . jpg, a q — это число,
определяемое в цикле. □
Оператор while
Цикл while выполняет группу операторов до тех пор, пока контролирующее цикл
условное выражение есть истина. Синтаксис имеет вид
while expression
statements
end
Как и в случае с циклом for, циклы while можно вкладывать друг в друга:
while expression!
statements!
while expression?
statements?
end
statemen ts3
end .
Например, следующие вложенные циклы while прерываются, когда обе вели-
чины а и b становятся равными нулю:
а = 10;
Ъ = 5;
3См. другие синтаксические формы sprintf на справочной странице этой функции.
Глава 2- Цифровые изображения в MATLAB
while а
а = а 1;
while Ъ
b = b 1;
end
end .
Здесь мы использовали соглашение MATLAB трактовать числовые величины в
логическом контексте как истина, когда они не равны нулю, и как ложь, когда
они равны нулю. Иными словами, while а и while Ъ истинны, пока а и Ъ оба не
равны нулю.
Как и в случае цикла for, существенного выигрыша производительности про-
грамм можно достигнуть, если заменить циклы while на векторизованный код
(см. § 2.10.4) везде, где это возможно.
Оператор break
Из названия этого оператора следует, что он осуществляет прерывание циклов
for и while. При обнаружении команды break выполнение программы продол-
жается со следующего оператора, находящегося вне цикла. Во вложенных циклах
оператор break вызывает прерывание лишь внутреннего цикла, в котором он на-
ходится.
Оператор continue
Оператор continue передает управление следующей итерации в циклах for или
while, в которых он обнаруживается, пропуская стоящие после него операции в
теле цикла и относящиеся к текущей итерации. Во вложенных циклах оператор
continue передает управление следующей итерации только внутреннего цикла,
в котором он стоит.
Оператор switch
С помощью этого оператора можно сделать выбор среди нескольких возможных
продолжений вычислительного процесса в М-функциях на основе различных ти-
пов входных данных. Синтаксис имеет вид
switch switch expression
case case_ expression
statements!
case {case_expression!, case_expression2, ...}
statements?
otherwise
statements3
end
Оператор switch строит группу выполняемых операторов, основываясь на вели-
чинах переменных и выражений. Ключевые слова case и otherwise очерчивают
эти группы. Выполняется лишь первый подходящий оператор case4. В конце
4В отличие от конструкции switsh языка С, в языке MATLAB этот оператор не «совершается
до конца». Т. е. switch выполняет только первое подходящее действие case. Все последующие
case игнорируются, так что не нужно прибегать к оператору break.
2.10. Введение в программирование М-
оператора switch должен обязательно находиться оператор end. Фигурные скоб-
ки используются, если несколько выражений включены в одну группу операций
case. В качестве простого примера предположим, что имеется М-функция, ко-
торая принимает изображение f и конвертирует его в некоторый класс, назовем
его newclass. Допускаются только три класса для конвертации: uint8, uintl6 и
double. Следующий программный фрагмент осуществляет такую конвертацию
и выдает сообщение об ошибке, если класс входного изображения не является
допустимым:
switch newclass
case ‘uint8‘
g im2uint8(f);
case ‘uintl6‘
g im2uintl6(f);
case ‘double'
g im2double(f);
otherwise
error(‘Unknown or improper image class.')
end
Конструкция switch будет интенсивно использоваться на протяжение всей
книги.
Пример 2.12. Извлечение подизображения из заданного изображения.
В этом примере мы напишем М-функцию (на основе цикла for) для извлече-
ния прямоугольного подизображения из исходного изображения. Несмотря на
то, что это действие можно осуществить с помощью одного оператора, который
будет рассмотрен в следующем параграфе, мы используем этот пример для срав-
нения скорости выполнения цикла и векторизованного кода. На вход этой функ-
ции подается изображение, размер (число строк и столбцов) извлекаемого поди-
зображения и координаты верхнего левого конца подизображения. Следует на-
помнить, что начало изображения в MATLAB имеет координаты (1,1) (см. § 2.1.1).
function s subim(f, m, n, rx, су)
7.SUBIM Extracts a subimage, s, fron a given image, f.
7, The subimage is of size m-by-n, and the coordinates
7. of its top, left corner are (rx, cy)
s zeros(m, n);
rowhigh = rx + m 1;
colhigh = су + n 1;
xcount = 0;
for r = rx:rowhigh
xcount xcount + 1;
ycount 0;
for c cy:colhigh
ycount = ycount +1;
s(xcount, ycount) f(r,c);
end
end .
Глава 2. Цифровые изображения в MATLAB
В следующем параграфе будет приведена более эффективная реализация этой
программы. В качестве упражнения предлагаем читателю самостоятельно напи-
сать программу, которая использует цикл while вместо цикла for. □
2.10.4. Кодовая оптимизация программ
Как уже говорилось в § 1.3, MATLAB представляет собой язык программирова-
ния, специально разработанный для выполнения операций над массивами. При-
нимая во внимание этот факт, можно существенно повысить скорость вычисле-
ний. В этом параграфе будут обсуждаться два важных подхода к оптимизации
кодов программ MATLAB: векторизация циклов и предварительное заполнение
массивов.
Векторизация циклов
Под векторизацией программ подразумевается преобразование циклов for и
while в эквивалентные векторные и матричные операции. Как скоро станет ясно,
векторизация может привести не только к существенному выигрышу по скорости
вычислений, но и повысить «читаемость» программного кода. Надо потратить
много времени, чтобы дать полное определение многомерной векторизации. Од-
нако можно достаточно легко описать векторизацию, которая используется при
обработке изображений.
Начнем с простого примера. Предположим, что нам требуется вычислить од-
номерную функцию вида
f(x) = Asin(a:/27r)
при х = 0,1,2,..., М — 1. С помощью цикла for это можно сделать следующим
образом:
for х = 1:М ’/Array indices in MATLAB cannot be 0.
f(x) = A*sin((x-l)/(2*pi));
end
Однако эти действия можно выполнить значительно быстрее с помощью векто-
ризации цикла, используя метод индексации в MATLAB:
х = 0:М-1;
f = A*sin(x/(2*pi));
В этом простейшем примере проиллюстрирован процесс общего одномерно-
го индексирования. Если функция, которую необходимо вычислить, имеет две
переменные, то оптимизация индексирования делается немного более хитроум-
но. В MATLAB имеется прямой путь для реализации двумерных вычислений с
помощью функции meshgrid, которая имеет синтаксис
[С, R] = meshgrid(c, г)
Эта функция преобразовывает область, обозначенную вектор-строками с и г, в
массивы С и R, которые можно затем использовать при вычислении функций двух
переменных и при построении трехмерных графиков поверхностей (заметим, что
2.10. Введение в программирование М-\
в функции meshgrid столбцы перечисляются, в первую очередь, как на входе, так
и на выходе функции).
Строки выходного массива С являются копиями вектора с, а столбцы выход-
ного массива R являются копиями вектора г. Пусть, к примеру, требуется сфор-
мировать двумерную функцию, элементами которой служат суммы квадратов
значений координат х и у при х 0, 1, 2 и у = 0, 1. Вектор г формируется
из компонент координат по строке: г = [0 1 2]. Аналогично, вектор с форми-
руется из компонент координат по столбцу: с = [0 1] (обратите внимание на то,
что здесь гис оба являются векторами-строками). Подставляя эти два вектора
в meshgrid, получаем следующий результат:
>> [С, R] = meshgrid(c, г)
С =
О 1
О 1
О 1
R =
О О
1 1
О 1
Нужная нам функции получается командой
» h = R.“2 + С.“2
которая приводит к результату
О О
1 2
4 5
Размер матрицы h равен length(r) xlength(c). Кроме того, заметим, напри-
мер, что h(l, 1) R(l,l)~2 + С(1,1)“2. Итак, MATLAB автоматически индек-
сирует h. В этом кроется потенциальный источник ошибок, когда 0 является
координатой, поскольку, как многократно отмечалось, в MATLAB индексы не
могут равняться нулю. Из этой простой иллюстрации видно, что при построении
массива h MATLAB использует в вычислениях содержимое массивов R и С. А ин-
дексы массивов h, R и С, как им положено, начинаются с 1. Достоинства такой
схемы индексирования видны из следующего примера.
Пример 2.13. Иллюстрация вычислительных преимуществ векторизации и
введение функций хронометрирования tic и toe.
В этом примере строится М-функция для сравнения двух реализаций вычисления
следующего двумерного изображения с помощью цикла for и на основе приема
векторизации:
f(x, у) = Asin(u0^ + voy)
при х = 0,1,2,...,М — 1 и у = 0,1,2,.. .,N — 1. В этом нам помогут две функции
хронометрирования tic и toe.
Глава 2. Цифровые изображения в MATLAB
Входными переменными функции являются величины A, uq,vq,M и N. Вы-
ходными переменными служат изображения, построенные двумя этими методами
(они должны быть идентичными), а также отношение времени, необходимое для
выполнения этих действий в цикле for, ко времени, затрачиваемом по методу
векторизации. Решение состоит в следующей М-функции:
function [rt, f, g] = twodsinfA, uO, vO, M, N)
XTWODSIN Compares for loops vs. vectorization.
*/, The comparison is based on implementing the functions
% f(x, y) Asin(uOx + vOy) for x = 0, 1, 2,... M 1 and
% у = 0, 1, 2,. N 1. The inputs to the function are
% M and N and the constants in the function.
% First implement using for loops.
tic % Start timing.
for r = 1:M
uOx = uO*(r 1);
for c = 1:N
vOy = v0*(c 1)
ycount = ycount +1;
f(r, c) AsinfuOx + vOy);
end
end
tl = toe 7. End timing.
% Now implement using vectorization. Call the imange g.
tic % Start timing.
r = 0:M 1;
c = 0:N 1;
[С, B] = meshgridCc, r);
g = Asin(uO*B + vO*C);
t2 = toe 7. End timing.
% Compute the ratio of the two times.
rt = tl/(t2 + eps); % Use eps in case t2 is close to 0.
Вызывая эту функцию после приглашения MATLAB,
» [rt, f, g] twodsind, l/(4*pi), l/(4*pi), 512, 512);
получаем следующее значение rt:
>> rt
rt
34.2520
Теперь мы преобразуем полученное изображение (матрицы f и g идентичны)
к виду, удобному для отображения на экране монитора, с помощью функции
mat2gray:
>> g = mat2gray(g) ;
и выведем его на экран командой Imshow
imshow(g)
На рис. 2.7 приведен результат этих действий. □
Итак, векторизованный код из примера 2.13
выполняется примерно в 30 раз быстрее, чем
программа, написанная на основе цикла for.
Это значительное вычислительное превосход-
ство становится еще более существенным фак-
тором при увеличении относительного времени
вычислений. Например, если числа М и N будут
большими, а время исполнения векторизован-
ной программы равно 2 минутам, то с помо-
щью цикла for компьютеру на это потребует-
ся потратить более часа. Все это убедительно
свидетельствует в пользу применения вектори-
зации циклов везде, где это только возможно,
особенно когда предполагается частое примене-
ние данной процедуры.
Обсуждение метода векторизации было сфо-
Рис. 2.7. Синусоидальное изображе-
ние, построенное в примере 2.13
кусировано на вычислениях, использующих ко-
ординаты изображений. Часто бывает необходимо выделить часть изображения
для дальнейшей обработки этой области. Векторизация такой программы делает-
ся особенно просто, если эта область является прямоугольной и соответствующая
процедура применяется ко всем пикселам этой области, что происходит весьма
часто при выполнении операций подобного типа. Фрагмент векторизованного ко-
да для выделения области, скажем, s, размера mxn, у которой верхний левый угол
имеет координаты (гх, су), имеет следующий вид:
rowhigh = гх + m -1;
colhigh = су + n -1;
s = f(rx:rowhigh; су:colhigh);
где f — это изображение, из которого извлекается нужная область. Цикл f or для
выполнения этой же процедуры был приведен в примере 2.12. Если сравнить два
этих метода наподобие примера 2.13, то обнаружится, что векторизованный код
работает примерно в 1000 раз быстрее программы с циклом for.
Предварительное заполнение массивов
Другой простой прием ускорения выполнения программ состоит в предваритель-
ном заполнении массивов, используемых в программах. При работе с числовыми
или логическими массивами эта процедура просто означает создание в памя-
ти компьютера массива из одних нулей подходящего размера. Например, если
работаем с двумя изображениями, скажем, f и g размером 1024x204 пикселов,
предварительное заполнение производится командами
>> f = zeros (1024); g = zeros (1024);
Глава 2. Цифровые изображения в MATLAB
Такое заполнение массивов позволяет также уменьшить фрагментацию памя-
ти при работе с большими массивами. Память компьютера становится сильно
фрагментированной при использовании процедур динамического распределения
и освобождения памяти. В этом случае может иметься достаточно доступной
физической памяти при выполнении вычислений, но может не хватить соседней
памяти для сохранения только что вычисленной большой переменной. Предвари-
тельное заполнение помогает исключить такие неприятности, позволяя системе
MATLAB зарезервировать достаточный объем памяти для больших массивов
данных в самом начале вычислений.
2.10.5. Интерактивный ввод/вывод
Часто бывает желательно написать М-функции в интерактивном виде5, т. е. так,
чтобы требуемая информация отображалась на дисплее и пользователь мог вво-
дить нужные данные непосредственно с клавиатуры компьютера. В этом пара-
графе мы разберем некоторые основные приемы при написании таких функций.
Функция disp применяется для отображения информации на экране дисплея.
Она имеет следующий синтаксис:
disp(argumnet)
Если argumnet является массивом, то disp показывает его содержимое. Если disp
является текстовой строкой, то disp отображает на экране последовательность
символов этой строки. Например,
>> А [1 2; 3 4] ;
disp(А);
1 2
3 4
> > sc ’Digital Image Processing.
> > disp(sc);
Digital Image Processing.
> > disp(’This is smother way to display text.’);
This is smother way to display text.
Заметим, что на экране отображается только содержимое переменной argumnet
без вывода слов типа sms =, которые мы привыкли видеть на экране, когда зна-
чение переменной появляется на экране при отсутствии в конце команды символа
точка с запятой.
Функция input применяется при вводе данных в М-функцию. Ее синтаксис
имеет вид
t input(’message’)
Эта функция выводит на экран слова, содержащиеся в message, а затем ожидает
ввода данных пользователем, в конце которых следует нажать клавишу Enter,
после чего она сохраняет введенные данные в переменной t. Входные данные мо-
гут быть одним числом, строкой символов (заключенных в апострофы), вектором
БСм. Приложение Б, посвященное созданию графических интерфейсов пользователя (GUI).
2.10. Введение в программирование М-функций
(элементы которого разделяются пробелами, и все они окружены квадратными
скобками), матрицей (строки которой разделяются символами точка с запятой,
и see они окружены квадратными скобками) или любой другой структурой дан-
ных, разрешенной в MATLAB. При выполнении команды
t = input(’message’, ’s’)
выдается содержимое message, а вход рассматривается как символьная строка,
элементы которой могут быть разделены запятыми или пробелами. Эта форма
ввода данных является достаточно гибкой, так как позволяет вводить отдельные
символы. Если предполагается, что вводимая строка (которая состоит из цифро-
вых символов) будет числом, то ее можно конвертировать в число класса double
с помощью функции str2num6, которая имеет синтаксис
n = str2num(t)
Например,
t = input(’Enter your data: ’s’)
Enter your data: 1, 2, 4
t =
12 4
>> class(t)
ans =
char
>> size(t)
ans =
1 5
>> n = str2num(t)
n =
12 4
>> size(n)
ans
1 3
>> class (n)
double
Итак, мы видим, что t — это символьный массив размера 1x5 (три цифры и
два пробела между ними), ап — это числовой вектор размера 1x3 класса double.
Если входные данные являются смешанными, т. е. состоят из символьных и
числовых данных, то можно использовать одну из функций MATLAB для об-
работки строк символов. Особый интерес в этом плане представляет функция
strread7, которая имеет следующий синтаксис:
[а, Ь, с, ...] = strread(cstr, ’format’, ’param’, ’value’)
6 См. в § 12.4 детальное обсуждение операций над строками.
7См. справочную страницу функции etrread, где приводятся разные синтаксические формы,
применяемые в этой функции.
Глава 2. Цифровые изображения в MATLAB
Эта функция читает данные из символьной строки cstr, используя специфиче-
ские комбинации параметров format, param/value. В этой главе нам понадобятся
форматы %f и 70q, которые обозначают соответственно числа с плавающей запя-
той и символьные строки. Параметр param совпадает со словом delimiter, если
необходимо обозначить, что элементы, описанные в format, будут разделяться
символами, заданными параметром value (обычно это пробел или запятая). На-
пример, пусть имеется строка
>> t ’12.6, х2у, z’;
Чтобы считать элементы этого входа в три переменные а, b и с, следует дать
команду
>> [a, b, с] strread(t, ’7»f7.q7.q’, ’delemiter’, ’,’)
а = 12.6000
b ’х2у’
с ’z’
Выход а принадлежит классу double; апострофы вокруг выходов х2у и z обо-
значают, что b и с являются неоднородными массивами, которые будут обсуж-
даться в следующем параграфе. Можно преобразовать их в символьные массивы,
просто положив,
>> d char(b)
d
х2у
и аналогичная команда выполняется для массива с. Число (и порядок) элементов
в строке format должно соответствовать числу и типу выходных переменных,
стоящих в правой части равенства. В приведенном выше примере использования
функции strread имеется три выходных переменных: одно число с плавающей
запятой и две символьные строки.
Функция strcmp применяется при сравнении строк8. Например, пусть задана
M-функция g imnorm(f, param), которая принимает изображение f, а пара-
метр param может иметь два значения: ’norml’ и ’norm255’ В первом случае
изображение f следует перенормировать в интервале [0,1], а во втором - в ин-
тервале [0,255]. В обоих случаях выходное изображение должно быть класса
double. Следующий программный фрагмент выполняет эти действия:
f double(f);
f f min(f(:));
f f./max(f(:));
if strcmp(param, ’norml’)
g f;
elseif strcmp(param, ’norm255’)
g 255*f;
^Функция strcmp(sl,s2) сравнивает строки si, s2 и возвращает логическую 1 (истина), если
строки совпадают; в противном случае возвращается логический 0 (ложь)
2.10. Введение в программирование М->
else
error(’Unknown value of param.’)
end .
Сообщение об ошибке будет выдаваться в том случае, если величина, указанная в
переменной param, не совпадаете’norml ’ или ’norm255’ Отметим, что это сооб-
щение будет появляться, если символы этих строк набраны заглавными буквами.
Эту функцию можно модифицировать, чтобы она принимала как строчные, так
и заглавные буквы. Для этого достаточно применить функцию lower, которая
преобразует заглавные буквы в строчные. Она имеет синтаксис
param lower(param)
Аналогично, для преобразования букв в заглавные можно воспользоваться функ-
цией upper:
param = upper(param)
2.10.6. Краткое введение в смешанные массивы
и структуры
При обращении с переменными разных типов (например, с числами и символьны-
ми строками), можно использовать т. н. смешанные массивы. В системе MATLAB
смешанным массивом? (cell array, массив ячеек) называется многомерный мас-
сив, элементами которого являются копии других массивов, которые могут при-
надлежать разным классам данных. Например смешанный массив
с = {’gauss’, [10; 01], 3}
состоит из трех элементов: символьной строки ’gauss’, числовой матрицы раз-
мера 2 х 2 и скаляра (обратите внимание на использование здесь фигурных скобок
при задании элементов массива). Для адресации элементов смешанного массива
используются целые индексы, заключенные в фигурные скобки. Например,
» с{1}
ans
gauss
» с{2}
ans =
1 0
0 1
» с{31
ans
3
Важная особенность смешанных массивов состоит в том, что в них хранятся
именно копии соответствующих аргументов, а не указатели на эти аргументы.
Например, при работе со смешанным массивом
с {А, В} ,
9Смешанные массивы и структуры обсуждаются в § 11.1.1.
Глава 2. Цифровые изображения в MATLAB
где А и В — это некоторые матрицы, которые в дальнейшем будут программно
изменяться, то содержимое массива с останется неизменным.
Понятие структура аналогично смешанному массиву в том смысле, что в
ней допускается группирование разнородных типов данных в одной переменной.
Однако в отличие от смешанных массивов, в которых индексами служат целые
числа, элементы структур арестуются именами, которые называются полями.
В зависимости от конкретного приложения, использование полей повышает по-
нимание смысла и читаемость М-функций. Например, пусть S — это структурная
переменная, в которой имеются поля с именами char_string, matrix и scalar.
Тогда в предыдущем примере можно идентифицировать структуру с помощью
следующих присвоений:
S.char_string = ’gauss’;
S.matrix = [10; 01];
S.scalar = 3;
Обратите внимание на использовании символа точка, который стоит между
именем структуры и соответствующим полем при обращении к его содержимому.
Например, задав команду S .matrix, получим в ответ
>> S. matrix
ans =
1 0
0 1
что согласуется с выходом соответствующего смешанного массива. Здесь оче-
видно преимущество использования выражения S.matrix по сравнению с запи-
сью с{2}. Такая адресация данных может быть особенно полезна при работе с
большим числом разнородных данных, которые должны легко распознаваться
пользователем.
Выводы
Материалы данной главы являются фундаментом всего последующего содержа-
ния книги. С этого места читатель должен уметь считывать изображения с дис-
ка, обрабатывать их с помощью простейших операций, отображать результаты
на экране и сохранять их на диске. Главным уроком этой главы является уме-
ние комбинировать разные функций MATLAB и IPT, а также основные приемы
программирования для решения конкретных задач, расширяющих возможности
этих стандартных функций. На самом деле, эти примеры служат моделью пред-
ставления новых материалов в следующих главах. Сочетая стандартные функ-
ции и новый программный код, можно получить прототипы решений для весь-
ма широкого спектра задач, которые возникают в области цифровой обработки
изображений.
ГЛАВА 3
ПРЕОБРАЗОВАНИЯ
ЯРКОСТИ
ИЗОБРАЖЕНИЙ
И ПРОСТРАНСТВЕННАЯ
ФИЛЬТРАЦИЯ
Введение
Термин пространственная область относится к плоскости изображения в целом,
и методы из этой категории основываются на прямых манипуляциях с пиксела-
ми изображений. В этой главе наше внимание будет сконцентрировано на двух
важных группах методов обработки пространственной области: преобразования
яркости (полутоновой градации) и пространственная фильтрация. Вторая груп-
па также иногда называется обработкой окрестностей или пространственной
фильтрацией. В следующих параграфах развиваются представления о техноло-
гиях обработки изображений из этих двух групп, которые будут иллюстрировать-
ся функциями MATLAB. Для лучшей согласованности разных тем большинство
примеров этой главы направлено на улучшение конкретных изображений. Такое
введение в пространственную обработку изображений является вполне продук-
тивным, поскольку визуальное оценивание качества изображений является, с од-
ной стороны, достаточно субъективным, а с другой стороны — привлекательным
для начинающих исследователей в данной области. Однако, как будет видно из
всего содержания книги, такой подход является достаточно общим, и он широко
применяется во многих других областях цифровой обработки изображений.
3.1. Некоторые основы
Как уже отмечалось, техника обработки пространственной области оперирует
напрямую с пикселами изображения. Процессы в пространственной области, об-
суждаемые в этой главе, можно обозначить уравнением
p(x,y) = T[f(x,y)] ,
где f(x,y) — входное изображение, д(х, у) — выходное (обработанное) изобра-
жение, а Г — некоторый оператор (преобразование) над f, который определен в
некоторой окрестности точки (х, у). Кроме того, оператор Т может обрабатывать
последовательность изображений, например, он может суммировать К входных
изображений для подавления шума.
80 Глава 3. Преобразования яркости изображений и •пространственная фильтрация
Рис. 3.1. Окрестность размера 3x3 во-
круг точки (х, у) изображения
Главный подход к определению про-
странственной окрестности вокруг точки
(х, у) состоит в использовании квадрат-
ной или прямоугольной области с центром
в точке (х, у), как показано на рис. 3.1.
Центр заданной шаблонной подобласти пе-
ремещается от пиксела к пикселу, начиная,
скажем, из верхнего левого угла, и на сво-
ем пути он накрывает различные окрест-
ности. Преобразование Т применяется в
каждой точке (ж, у), давая в результате вы-
ходное (обработанное) значение д для дан-
ной точки. В процессе вычислений исполь-
зуются только пикселы внутри заданной
окрестности с центром в (т, у).
Далее в этой главе будут рассмотрены
различные применения введенного уравнения. Несмотря на то, что это уравнение
выглядит концептуально весьма просто, его численная реализация на MATLAB
требует внимания и аккуратности, когда необходимо учитывать возможные клас-
сы данных и диапазонов значений величин.
3.2. Преобразования яркости изображений
Простейшая форма преобразования Т получается, когда окрестность на рис. 3.1
имеет размер 1x1 (т. е. состоит из одного пиксела). В этом случае значение д в
точке (х, у) зависит только от значения f в этой точке, и Т становится функ-
цией преобразования яркости (также называемой функцией градационного пре-
образования). Эти два термина эквивалентны применительно к монохромным
(полутоновым) изображениям. При обращении с цветными изображениями тер-
мин яркость используется для обозначения цветовой компоненты изображения
в конкретном цветовом пространстве (см. гл. 6).
Поскольку такие преобразования зависят только от значения яркости, но не
от (х, у), функцию преобразования яркости часто записывают в простой форме
s = Т(г),
где т обозначает яркость /, a s — яркость д в любой соответствующей точке (х, у)
изображения.
3.2.1. Функция imadjust
Функция imadjust является базовым инструментом пакета IPT при преобразо-
ваниях яркости полутоновых изображений. Она имеет следующий синтаксис:
g = imadjust(f, [low_in, high_in], [low_out, high_out] , gamma)
На рис. 3.2 проиллюстрировано отображение с помощью этой функции исходного
изображения f в новое изображение g, при котором значения яркости в интер-
3.2. Преобразования яркости изображений 81
вале [low_in, high_in] переходят в значения интервала [low_out, high_out],
а значения, меньшие порога low_in или большие порога low_in, обрезаются, т. е.
все, что меньше low_in. отображается в low_in, а все, что больше high_in, отоб-
ражаются в high_in. Входное изображение может иметь класс uint8, uintl6 или
double, а класс выходного изображения совпадает с классом входного. Все вход-
ные параметры функции imadjust, за исключением f, должны быть веществен-
ными числами в интервале от 0 до 1, независимо от класса f. Если f принадлежит
классу uint8, функция imadjust умножает эти параметры на 255 для задания
истинных величин, которые будут использоваться: если f — класса uintl6, то все
умножается на 65535. Если вместо векторов [low_in, high_in] или [low_out,
high_out] поставить пустой вектор ([ ]), то будут использоваться величины по
умолчанию, равные [О 1]. Если high_out меньше, чем low_out, то выходные
яркости симметрично переворачиваются.
Рис. 3.2. Различные отобра-
жения, допустимые в функции
imadjust
Параметр gamma служит для задания формы кривой, отображающей яркость f
в яркость g. Если gamma меньше 1, то яркость отображения смещается вверх в
сторону более ярких значений, как показано на рис. 3.2, а). Если gamma боль-
ше 1, то яркость отображения смещается вниз в сторону менее ярких значений.
Если параметр gamma опущен, то его значение по умолчанию равно 1 (линейное
отображение).
Пример 3.1. Применение функции imadjust.
На рис. 3.3, а) приведена цифровая рентгенограмма молочной железы f, демон-
стрирующая небольшое поражение ткани этого органа, а на рис. 3.3, б) дано его
негативное изображение, полученное по команде
» gl imadjust (f, [0 1], [10]);
Эта процедура, которая является цифровым эквивалентом получения фотонега-
тива, является весьма полезной для усиления белых или серых участков, окру-
женных большими, преимущественно темными, областями. Отметим, насколь-
ко легче в этом случае анализировать ткань грудной железы по рис. 3.3, б).
Негативное изображение можно легко построить также с помощью функции
imcomplement из пакета IPT:
g imcomplement(f)
На рис. 3.3, в) приведен результат команды
>> g2 = imadjust(f, [0.5 0.75], [1 0]);
Глава " Преобразования яркости изображений и пространственная фильтрация
которая растягивает шкалу градации между 0.5 и 0.75 на весь интервал [0,1].
Такое преобразование может быть полезным для выделения некоторой полосы
яркости. Наконец, по команде
» g3 imadjust(f, [ ], [ ], 2);
получается похожий результат (но с большими серыми тонами), как на рис. 3.3, в).
При этом производится сжатие нижнего и растяжения верхнего участка града-
ционной шкалы (см. рис. 3.3, г)). □
Рис. 3.3. а) Исходная рент-
генограмма молочной желе-
зы. б) Негативное изобра-
жение. в) Результат расши-
рения интенсивности из ин-
тервала [0.5,0.75]. г) Резуль-
тат улучшения изображения
с gamma = 2. (Предостав-
лено компанией G.E. Medical
System)
3.2.2. Логарифмические преобразования и
преобразования растяжения контрастности
Логарифмические преобразования и преобразования растяжения контрастности
являются основными инструментами манипуляций в динамическом диапазоне.
Логарифмические преобразования выполняются с помощью выражения
g = с* log(l + double(f))
где с некоторая константа. Форма этого преобразования похожа на гамма-
кривую, приведенную на рис. 3.2(a), где нижние величины отображаются в 0,
3.2. Преобразования яркости изображений
а верхние — в 1. Отметим, однако, что форма гамма-кривой является переменной,
в то время как форма функции log зафиксирована.
Основное применение логарифмического преобразования состоит в сжатии
динамического диапазона. Например, спектр Фурье часто имеет диапазон вели-
чин от 0 до 10S 6 и даже выше. Если линейно масштабировать этот диапазон в
интервал с 8-ми битной градацией, то при визуализации наиболее яркие пикселы
будут доминировать, что приведет к утере деталей менее ярких участков спек-
тра. Если применить функцию log, то динамический диапазон с амплитудой,
например, 106, сократится примерно до 14, что намного удобнее.
При выполнении логарифмических преобразований часто бывает необходи-
мо возвращать сжатый диапазон назад к исходному значению. Для 8 бит такое
действие в MATLAB можно совершить командой
>> gs im2uint8(mat2gray (g)) ;
Применение mat2gray переводит величины в диапазон [0,1], а функция im2uint8
преобразует их к диапазону [0,255]. В следующем параграфе мы обсудим функ-
цию масштабирования, которая автоматически определяет класс входных дан-
ных, а затем выполняет подходящее обращение.
Рис. 3.4. а) Преобразование рас-
тяжения контрастности, б) Поро-
говое преобразование
а) б)
Функция, показанная на рис. 3.4, а), называется функцией преобразования
растяжения контрастности, поскольку она сжимает входные величины, мень-
шие чем т, в более узкий поддиапазон темных уровней на выходном изобра-
жении, и, соответственно, величины, большие т, — в более узкую полосу яр-
ких уровней. В результате получается изображение с большей контрастностью.
На самом деле, в предельном случае, показанном на рис. 3.4, б), выходом слу-
жит двоичное (черно-белое) изображение. Эта предельная функция, называемая
пороговой, является простейшим инструментом при сегментации изображений,
которое обсуждается в гл. 10. Используя обозначение, введенное в начале пара-
графа 3.2, функцию на рис. 3.4, а) можно записать в виде
S = Т(~ГУ> = 1 + (т/г)Е ’
где 1— это яркость входного изображения, s — соответствующая яркость выход-
ного изображения, а параметр Е контролирует наклон функции. Это уравнение
Глава 3. Преобразования яркости изображений и пространственная фильтрация
реализуется на MATLAB в виде следующей команды обработки всего изображения:
g 1-/(1 + (m./(double(f) + eps)).~E)
Заметим, что использование величины eps (см. табл. 2.10) позволяет избежать
ошибки переполнения, если в f имеются нулевые величины. Поскольку верхнее
предельное значение функции Т(г) равно 1, выходные значения масштабированы
в диапазоне [0,1] при работе с этим типом преобразований. Форма кривой на
рис. 3.4, а) была получена при Е = 20.
Пример 3.2. Использование логарифмического преобразования для сокращения
динамического диапазона.
На рис. 3-5, а) показан спектр Фурье со значениями в диапазоне от 0 до 1.5х106,
который дан в линейном масштабе по 8-ми битной системе. На рис. 3.5, б) дан
результат применения команд
g im2uint8(mat2gray(log(l + double(f))));
imshow(g)
Визуальное улучшение изображения g по сравнению с исходным изображением
не вызывает сомнения. □
Рис. 3.5. а) Спектр Фурье.
б) Результат применения пре-
образования log
3.2.3. Некоторые утилитные М-функции
преобразования яркости
В этом параграфе мы построим две М-функции, в которых будут использованы
различные аспекты преобразования яркости, рассмотренные выше. Мы приведем
подробный код одной из этих функций для иллюстрации проверки ошибок, а так-
же для демонстрации возможности MATLAB описывать функции, допускающие
переменное число входных и выходных данных. Такие приемы часто используют-
ся при написании М-функций. С этого места детальные коды М-функций будут
приводи ться и обсуждаться только при необходимости объяснить новые специфи-
ческие конструкции программирования или при иллюстрировании новых функ-
ций MATLAB и IPT. Иногда это будет делаться при обзоре уже изложенного
материала. В противном случае будет приводиться лишь синтаксис рассматри-
ваемой функции, а ее полный код можно найти в приложении С. Кроме того, для
3.2. Преобразования яркости изображений
большей концентрации внимания на основных структурах, это будет последний
параграф, где разбираются приемы проверки возможных ошибок. Все эти проце-
дуры являются весьма типичными при программировании на языке MATLAB.
Использование переменного числа входных и выходных данных
Для определения числа входных аргументов М-функции используется функция
nargin,
и nargin,
которая возвращает фактическое число входных аргументов функции. Аналогично,
функция nargout определяет число выходных аргументов. Она имеет синтаксис
n = nargout.
Например, пусть выполнена команда со следующей М-функцией:
» Т testhv(4, 5);
Использование в теле этой функции команды nargin даст результат 2, а приме-
нение функции nargout выдаст 1.
Функцию nargchk можно применять в теле М-функций для проверки кор-
ректности числа передаваемых аргументов. Она имеет синтаксис
msg = nargchk(low, high, number).
Эта функция выдает сообщение Not enough input parameters, если number мень-
ше, чем low или Too many input parameters, если number больше, чем high.
Если параметр number находится между low и high (включая эти значения), то
nargchk возвращает пустую матрицу. Обычно функция nargchk используется для
остановки вычислений (через функцию error) при обнаружении неправильного
числа входных аргументов.Число фактических входных аргументов устанавли-
вается функцией nargin. Например, разберем следующий фрагмент кода:
function G = testhv2(x, у, z)
error(nargchk(2, 3, nargin));
Если теперь набрать команду
» testhv(6);
в которой имеется всего один входной аргумент, то это породит сообщение об
ошибке
Not enough input parameters,
и вычисления будут прерваны.
Часто бывает удобно писать функции с переменным числом входных и/или вы-
ходных данных. Для этого следует использовать аргументы varargin и varargout.
которые необходимо набирать строчными буквами. Например, запись
function [m, n] = testhv3(varargin)
86 Глава 3. Преобразования яркости изображений и пространственная фильтрация
допускает переменное число входных аргументов при вызове функции testhv3,
а запись
function [varargout] testhv4(m, n, p)
возвращает переменное число выходных аргументов для функции testhv4. Если
функция testhv3, скажем, имеет один фиксированный входной аргумент х, за
которым следует переменное число других входных аргументов, то запись
function [m, n] = testhv3(x, varargin)
позволит пользователю выбирать разное число входных аргументов по своему
усмотрению, начиная со второго аргумента. Допускается иметь функции, у ко-
торых переменно число и входных, и выходных аргументов.
При использовании varargin во входных аргументах функции MATLAB фор-
мирует соответствующий смешанный массив (cell array, см. § 2.10.5), который
допускает переменное число входных данных. Поскольку переменная varargin
является смешанным массивом, при вызове такой функции в ее аргументах могут
стоять данные разных типов. Например, при обращении к нашей гипотетической
функции testhv3, снабженной этой переменной, вполне допустимым будет обра-
щение типа
» [m, n] = testhv(f, [0 0.5 1.5], A, ’label’);
где f — это изображение, следующий аргумент — это вектор-строка длины 3, А —
матрица, а ’ label ’ — это строка символов. Такая организация данных является
очень мощным средством, которая позволяет существенно упростить структуру
функций, которым необходимо много входных аргументов. То же в полной мере
относится и к использованию переменной varargout.
М-функция преобразования яркости
В этом параграфе будет представлена функция, которая реализует следующие
преобразования: обращение, log, gamma и растяжение контрастности. Эти преоб-
разования нам еще понадобятся в дальнейшем изложении материала. Кроме того,
они прекрасно иллюстрируют процесс конструирования М-функций для преоб-
разования яркости. При написании этой функции мы воспользовались функцией
changeclass1, которая имеет синтаксис
g = cchangeclass(newclass, f)
Эта функция конвертирует входное изображение f в изображение g, класс ко-
торого предписан переменной newclass. Допустимые значения для newclass:
’uint8’, ’uintl6’ и ’double’
В следующей М-функции, которую мы назовем intrans. обратите внимание
на то, как ее использование описано в тексте справки, а также на то, как реали-
зуется возможность переменного числа входных аргументов, как закладывается
1 Функция chaageclass является недокументированной утилитой IPT. Ее код имеется в прило-
жении С.
3.2. Преобразования яркости изображений
проверка ошибок и как устанавливается согласование классов входных и выход-
ных изображений. Не забудьте, что переменная varargin является смешанным
массивом, поэтому его элементы следует окружать фигурными скобками.
function g intrans(f, varargin)
XlNTRANS Performs intensity (gray-level) transformations.
7. G = INTRANS(F, ’neg’) computes the negative of input image F.
7.
7. G = INTRANS(F, ’log’, C, CLASS) computes C*log(l + F) and
7. multiplies the result by (positive) constant C. If the last two
7, parameters are omitted, C defaults to 1. Because the log is used
7o frequently to display Fourier spectra, parameter CLASS offers the
7o option to specify the class of the output as ’uint8’ or
7, ’uintl6’ If parameter CLASS is omitted, the output is of the
7. same class as the input.
7.
7. G INTRANS(F, ’gamma’, GAM) performs a gamma transformation on
7. the input image using parameter GAM (a required input).
7.
% G = INTRANS(F, ’stretch’, M, E) computes a contrast-stretching
7. transformation using the expression l./(l + (M./(F +
7, eps)).~E). Parameter M must be in the range [0, 1]. The default
7. value for M is mean2(im2double(F)), and the default value for E
7. is 4.
7.
7, For the ’neg’, ’gamma’, and ’stretch’ transformations, double
7c input images whose maxi mum value is greater than 1 are scaled
7c first using MAT2GRAY. Other images are converted to double first
7o using IM2D0UBLE. For the ’log’ transformation, double images are
7c transformed without being scaled; other images are converted to
7c double first using IM2D0UBLE.
7.
7c The output is of the same class as the input, except if a
7c different class is specified for the ’log’ option.
7c Verify the correct number of inputs.
error(nargchk(2, 4, nargin))
7c Store the class of the input for use later.
classin = class(f);
7c If the input is of class double, and it is outside the range
7c [0, 1], and the specified transformation is not ’log’, convert the
7c input to the range [0, 1] .
if strcmp(class(f), ’double’) & max(f(:)) > 1 &
"strcmp(varargin{U, ’log’)
f = mat2gray(f);
else 7c Convert to double, regardless of class(f) .
f im2double(f);
end
88 Глава 3- Преобразования яркости изображений и пространственная фильтрация
7, Determine the type of transformation specified,
method = varargin{l};
% Perform the intensity transformation specified.
switch method
case ’neg’
g = imcomplement(f);
case ’log’
if length(varargin) 1
c = 1;
elseif length(varargin) 2
c = varargin{2};
elseif length(varargin) 3
c = varargin{2};
classin = varargin{3};
else
error(’Incorrect number of inputs for the log option.’)
end
g = c*(log(l + double(f)));
case ’gamma’
if length(varargin) < 2
error(’Not enough inputs for the gamma option.’)
end
gam = varargin{2};
g = imadjust(f, [ ], [ ], gam);
case ’stretch’
if length(varargin) 1
7, Use defaults.
m = mean2(f) ;
E = 4.0;
elseif length(varargin) 3
m = varargin{2};
E = varargin{3};
else error(’Incorrect number of inputs for the stretch option. ’)
end
g = l./(l + (m./(f + eps)).~E);
otherwise
error(’Unknown enhancement method.’)
end
% Convert to the class of the input image,
g = changeclass(classin, g) ;
Пример 3.3. Иллюстрация функции intrans.
Рассмотрим изображение на рис. 3.6, а), которое прекрасно подходит для приме-
нения преобразования растяжения контрастности для усиления структуры ске-
лета. Результат, приведенный на рис. 3.6, б), получен при следующем обращении
к функции intrans:
3.2. Преобразования яркости
>> g intrans(f, ’stretch’, mean2(im2double(f)), 0.9);
>> figure, imshow(g)
Здесь функция mean22 используется для вычисления среднего значения f пря-
мо в аргументе вызываемой функции. Найденное среднее используется в виде
аргумента ш. Изображение f было конвертировано в класс double с помощью
функции im2double для перемасштабирования значений в область [0,1], поэто-
му среднее значение будет также лежать в этих границах, что требуется для
входного аргумента ш. Величина Е была задана интерактивно. □
Рис. 3.6. а) Изображение
при сканировании скеле-
та. б) Улучшенное изобра-
жение после растяжения
контрастности. (Исходное
изображение предоставле-
но компанией G.E. Medical
Systems.)
М-функция масштабирования яркости
Часто приходится работать с изображениями, имеющими очень широкий диапа-
зон значений пикселов — от отрицательных до положительных. При выполнении
промежуточных вычислений это не порождает больших сложностей, однако про-
блемы возникают при желании сохранить или показать изображение в 8-и или
16-ти битном формате. Тогда следует перемасштабировать изображение на пол-
ный, максимальный интервал [0,255] или 0,65535]. Это делает функция gscale
Кроме того, эта функция может трансформировать выходные уровни в заданный
диапазон значений. Код этой функции не содержит новых концепций програм-
мирования на MATLAB, поэтому мы его здесь не приводим. Его листинг имеется
в приложении С.
Синтаксис функции gscale имеет следующий вид:
g gscale(f, method, low, high)
где f — это изображения для масштабирования. Значениями переменной method
могут быть ’full8’ (принято по умолчанию), которое масштабирует в полный
2 Функция ш = шеап2(А) вычисляет среднее значение элементов матрицы А.
Глава 3. Преобразования яркости изображений и пространственная фильтрация
интервал [0,255], и ’ full 16 ’, приводящее к интервалу [0,65535]. При этих значе-
ниях переменной method аргументы low и high игнорируются (их можно вовсе
опускать). Третьим допустимым значением переменной method служит ’minmax ’
В этом случае аргументы low и high обязаны присутствовать и должны на-
ходиться в диапазоне [0,1]. Итак, если выбрано значение ’minmax’, то изобра-
жение отображается в интервал [low, high]. Хотя эти значения имеют диапа-
зон [0,1], программа совершает подходящее масштабирование в зависимости от
класса входного изображения, а затем преобразует выходное изображение в тот
же класс, что и входное. Например, если f было класса uint8 и задан метод
’minmax’ с интервалом [0,0.5], то выходное изображение будет того же класса
uint8 в диапазоне [0,128]. Если же f было класса double, и диапазон его зна-
чений выходит за пределы [0,1], то программа сначала конвертирует его в этот
диапазон, а потом совершит требуемое перемасштабирование. Функция gscale
будет многократно использоваться на протяжении всей книги.
3.3. Обработка гистограмм и построение графиков
функций
Функции преобразования изображений, основанные на информации, которая из-
влекается из гистограмм яркости изображений, играют ключевую роль при об-
работке изображений, совершаемой при решении задач улучшения изображений,
их сжатия, сегментации и описания. В этом параграфе будут разобраны методы
нахождения, построения и использования гистограмм для улучшения изображе-
ний1 Другие применения гистограмм будут обсуждаться в следующих главах.
3.3.1. Нахождение и построение гистограмм
Гистограммой цифрового изображения, число возможных уровней яркости ко-
торого равно L, лежащих в диапазоне [0, G], называется дискретная функция
h(rk) = nk,
где rk — это /с-ый уровень яркости из интервала [0, G], а пк — число пикселов
изображения, уровень яркости которых равен гк. Значение G равно 255 для изоб-
ражений класса uint8, 65535 — для класса uintl6 и 1.0 — для класса double.
Напомним, что индексы в MATLAB начинаются с 1, а не с 0, поэтому Гх соответ-
ствует уровню яркости 0, Г2 соответствует уровню яркости 1 и так далее до г^,
что соответствует уровню G. Заметим, что G = L — 1 для изображений класса
uint8 и uintl6.
Часто бывает удобно работать с нормированными гистограммами, которые
получаются делением элементов /i(z>) на общее число пикселов изображения,
которое мы обозначим tv.
htrk) _ пк
§ 4.5.3 рассматривается техника построения двумерных графиков.
3.3. Обработка гистограмм и построение графиков функций
при к = 1,2, ., L. С точки зрения теории вероятностей, число р{г^) — это ве-
роятность (частота) появления (присутствия) уровня интенсивности в данном
изображении.
Стержневой функцией пакета для обращения с гистограммами служит функ-
ция imhist со следующим синтаксисом:
h imhist(f, b)
где f — это входное изображение, h - его гистограмма, Zi(rfc), и b — число корзин,
использованных при формировании гистограммы (если аргумент Ъ отсутству-
ет, то по умолчанию принимается b = 256). Корзиной называется подразделение
шкалы яркости. Например, если при работе с изображениями класса uint8 пере-
менная Ъ = 2, то шкала яркости делится на две подобласти (корзины): от 0 до 127
и от 128 до 255. Итоговая гистограмма будет иметь два значения: Л(1), равное
числу пикселов изображения, величины которых находятся в интервале [0,127],
и /г(2), которое равно числу пикселов со значениями в интервале [128,255]. Чтобы
получить нормированную гистограмму, надо просто выполнить действие
р = imhist(f, b)/numel(f).
Напомним, что numel(f) дает число элементов массива f, т. е. число пикселов
изображения (см. § 2.10.3).
Пример 3.4. Нахождение гистограмм и построение их графиков.
Рассмотрим изображение f на рис. 3.3, а). Простейший способ построения его
гистограммы состоит в применении функции imhist без обозначения выходного
аргумента:
>> imhist (f);
На рис. 3.7, а) показан результат этого действия. Такое построение гистограм-
мы заложено по умолчанию в пакете. Однако имеется много других способов по-
строения и графического отображения гистограммы. Мы воспользуемся этой воз-
можностью для объяснения некоторых опций построения графиков в MATLAB,
которые пригодятся в конкретных приложениях обработки изображений.
Гистограмму можно построить с помощью столбчатых диаграмм. Для этого
служит функция
bar(horz, v, width),
где v — это вектор-строка, график которого надо построить, horz — вектор того
же размера, что и вектор v, состоящий из приращений по горизонтальной шкале,
и width — число между 0 и 1. Если параметр horz опущен, то горизонтальная ось
делится с шагом 1 от 0 до length(v). Когда width равно 1. соседние столбики со-
прикасаются, когда width равно 0, столбики являются вертикальными линиями,
как на рис. 3.7(a). По умолчанию width равно 0.8. При построении столбчатых
диаграмм принято уменьшать разрешение по горизонтальной оси, деля ее на по-
лосы. Следующие команды приводят к построению столбчатой диаграммы, на
которой горизонтальная ось делится на группы по 10 уровней:
Глава 3. Преобразования яркости изображений и пространственная фильтрация
h = imhist(f);
hl h(l:10:256);
» horz = 1:10:256;
>> barfhorz, hl);
>> axis([0 255 0 15000]);
>> setfgca, ’xtick’, 0:50:255)
>> setfgca, ’ytick’, 0:2000:15000)
Рис. 3.7, б) дает результат этих команд. Высокий пик, расположенный на правом
конце шкалы яркости на рис. 3.7, а), отсутствует на столбчатой диаграмме в силу
большего шага приращения по горизонтали.
Рис. 3.7. Различные спосо-
бы построения графиков ги-
стограмм. a) imhist, б) bar,
в) stem, г) plot
в)
14000
12000
loooo
8000
0000
4000
2000
50 100 150 200 250
Пятая команда приведенного кода была использована для того, чтобы рас-
ширить нижнюю область вертикальной оси для визуального анализа, а также
для приведения горизонтальной оси к тому же масштабу, что и на рис. 3.7, а).
Функция axis имеет синтаксис
axis([horzmin horzmax vertmin vertmax]),
где устанавливаются минимальные и максимальные значения горизонтальных и
вертикальных координат. В последних двух командах gca означает фразу «get
current axis» (использовать текущие оси, т. е. оси ранее построенного графика), а
xtick и ytick устанавливают метки на горизонтальной и вертикальной оси через
заданные интервалы.
Возле горизонтальной и вертикальной оси графика можно поместить поясни-
тельные надписи с помощью функций
xlabelf’text string’, ’fontsize’, size)
ylabel(’text string’, ’fontsize’, size),
3.3. Обработка гистограмм и построение графиков функций
где size — это размер шрифта в пунктах. Текст можно также разместить прямо
на графике с помощью функции text следующим образом:
textfxloc, yloc, ’text string’, ’fontsize’, size),
где xloc и yloc — это координаты начала текста. Применение этих трех функций
будет проиллюстрировано в примере 3.5. Обратите внимание на то, что функции
оформления графика следует использовать после построения самого графика.
График можно снабдить заголовком с помощью функции title
title(’titlestring’)
где titlestring — это строка символов заголовка, которая будет размещена по
центру над графиком.
Стеблевая диаграмма строится аналогично столбчатой диаграмме. Ее син-
о
таксис имеет вид
stemfhorz, v, ’color_1inestyle_marker’, ’fill’),
где v — это вектор-столбец, график которого необходимо построить, а переменная
horz имеет тот же смысл, что и в функции bar. Аргумент color_linestyle_marker
состоит из комбинации символов, возможные значения которых приведены в
табл. 3.1. Например, команда stemfv, ’г--s’) построит стеблевую диаграм-
му, на которой вертикальные стебли будут проведены красными пунктирными
линиями, а головки стеблей будут квадратными. Если присутствует переменная
fill, а переменная marker обозначает круг, квадрат или ромб, то эти символы
внутри закрашиваются в цвет, предписанный переменной color. По умолчанию
цвет считается черным, линии стеблей сплошными, а головками служат круги.
Стеблевая диаграмма на рис. 3.7, в) получена с помощью команд
>> h = imhist(f);
» hl h(l:10:256);
» horz 1:10:256;
>> stem(horz, hl, ’fill’);
» axis([0 255 0 15000]);
>> set(gca, ’xtick’, 0:50:255)
>> setfgca, ’ytick’, 0:2000:15000)
Таблица 3.1. Атрибуты функций stem и plot. Атрибут none применяется только к функ-
ции plot, и его следует описывать отдельно (см. синтаксис функции plot)
Символ Цвет Символ Стебель Символ Головка
к черный сплошной + плюс
W белый пунктирный о круг
г красный точечный * звезда
Б зеленый штрихпунктирный точка
ь синий попе отсутствует X крест
с голубой S квадрат
У желтый d ромб
ш пурпурный none отсутствует
2Дополнительные опции функции stem см. на справочной странице этой функции.
Глава 3. Преобразования яркости изображений и пространственная фильтрация
В заключение рассмотрим функцию plot, которая строит график по точкам,
соединяя их отрезками прямых линий. Она имеет синтаксис3
plotfhorz, v, ’color_linestyle_marker’) ,
где аргументы имеют тот же смысл, что и у функции stem. Допустимые зна-
чения атрибутов color, linestyle и marker даны в табл. 3.1. Если переменная
linestyle или marker имеет значение попе, то все атрибуты должны быть зада-
ны индивидуально. Например, команда
>> plotfhorz, v, ’color’, g’, ’linestyle’, ’none’, ’marker’, ’s’)
построит график из зеленых квадратов и соединит их прямыми линиями. По умол-
чанию функция plot строит черный сплошной график без отметки узловых точек.
График на рис. 3.7, г) получен с помощью команд
> > h imhist (f ) ;
> > plot(h); 7, Use the default values.
» axis([O 255 0 15000]);
> > set(gca, ’xtick’, 0:50:255)
>> set(gca, ’ytick’, 0:2000:15000)
Функция plot часто используется для отображения функций преобразования
(см. пример 3.5). □
В рассмотренных нами примерах разметка осей координат на графиках произ-
водилась вручную. Однако это можно делать автоматически с помощью функций
ylim и xlim. Для наших целей достаточно использовать их синтаксис вида
ylim(’auto’)
xlim(’auto’).
Другой возможный вариант синтаксиса этих функций допускает ручное задание
опций
ylim([ymin ушах])
xlim([xmin xmax]).
(См. также справочные страницы). Если ограничения установлены только для
одной оси, то вторая ось оформляется по умолчанию. Эти функции будут ис-
пользоваться в следующих параграфах.
Если в командной строке набрать команду hold on, то текущий график будет
сохранен на экране, причем результаты выполнения последующих графических
команд будут отображаться в этом же окне. См. пример 10.6 для иллюстрации
команды hold on.
3 Дополнительные опции функции plot см. на справочной странице этой функции.
3.3. Обработка гистограмм и построение графиков функций
3.3.2. Эквализация гистограммы
Предположим на некоторое время, что уровни яркости являются непрерывными
величинами, распределенными в диапазоне [0,1]. Пусть рг(г) обозначает функ-
цию плотности распределения вероятности (PDF, probability density function)
уровней яркости данного изображения, где нижний индекс используется для раз-
личения PDF входного и выходного изображений. Рассмотрим следующее пре-
образование входных уровней для получения выходных (обработанных) уровней
яркости s
s — Т(г) — J Pr(w) dw,
о
где w — переменная, по которой ведется интегрирование. Можно показать (см.
[Gonzalez, Woods, 2002]), что функция распределения плотности выходных уров-
ней является равномерной, т. е.
. . (1 при 0 < s < 1,
P«(s) | Q иначе.
Другими словами, предыдущее преобразование порождает изображение, уровни
яркости которого являются равновероятными и покрывают весь интервал [0,1].
Результат этого процесса эквализации изображения состоит в увеличении дина-
мического диапазона уровней яркости, что обычно означает большую контраст-
ность выходного изображения. Заметим, что функция преобразования является
не чем иным, как функцией кумулятивного (накопленного) распределения (CDF,
cumulative distribution function).
Имея дело с дискретными величинами, нам приходится работать с гистограм-
мами, поэтому в этом случае описанная выше техника называется гистограмм-
ной эквализацией, хотя в общем случае гистограмма обрабатываемого изображе-
ния не будет равномерной в силу самой природы дискретных величин. Используя
обозначения, введенные в § 3.3.1, пусть pr(vj), j обозначает гистограм-
му уровней яркости некоторого исходного изображения. Напомним, что величи-
ны нормированной гистограммы являются приближениями вероятностей появ-
ления каждого уровня яркости на изображении. Для дискретных величин мы
делаем суммирование (вместо интегрирования), и преобразование эквализации
приобретает следующий вид:
к к
Sk = Т(гк) = ^2pr(rj) = 52 Э
J=1 J=1 п
при к = 1,..., L, где Sfc — величина яркости выходного (обработанного) изобра-
жения, соответствующая значению яркости тк входного изображения.
Эквализация гистограмм реализована в пакете IPT функцией hi st eq, которая
имеет синтаксис
g = histeqff, nlev),
Глава 3. Преобразования яркости изображений и пространственная фильтрация
где f — это входное изображение, a nlev — число уровней интенсивности, уста-
новленное для выходного изображения. Если nlev равно L (общему числу воз-
можных уровней входного изображения), то histeq просто реализует функцию
преобразования Т(г^)- Если число nlev меньше, чем L, то histeq стремится пе-
рераспределить уровни так, чтобы они приближали плоскую гистограмму. В от-
личие от imhist, значением nlev в histeq по умолчанию является 64. Обычно
мы будем использовать максимально возможное число уровней (например, 256)
для nlev, поскольку это дает истинную реализацию описанного выше метода
гистограммной эквализации.
Пример 3.5. Гистограммная эквализация.
На рис. 3.8, а) представлена фотография пыльцы, сделанная на электронном
микроскопе. Изображение увеличено примерно в 700 раз. Это изображение яв-
ляется весьма темным и у него имеется очень низкий динамический диапазон,
что необходимо улучшить. Гистограмма этого изображения дана на рис. 3.8, б),
на которой выявлена темная природа изображения, т.к. гистограмма целиком
расположена в темном участке спектра. Также очевиден низкий динамический
диапазон изображения, поскольку «ширина» гистограммы весьма мала по срав-
нению с шириной всего диапазона серых полутонов. Пусть f обозначает это изоб-
ражение, к которому применим следующую последовательность команд, которая
построит все изображения на рис. 3.8 от а) до г)\
> > imshow (f) ;
> > figure, imhist(f)
>> ylim(’auto’)
> > g = histeqff, 256);
> > figure, imshow(g)
> > figure, imhist(g)
>> ylim(’auto’)
Изображения были сохранены на диске в формате TIFF с разрешением 300
dpi с помощью функции imwrite, а построенные графики были аналогично экс-
портированы на диск с помощью функции print, которая обсуждалась в § 2.4.
Изображение на рис. 3.8, в) является гистограммной эквализацией исходно-
го изображения. Улучшение средней яркости и контрастности вполне очевидно.
То же можно заключить, изучив его гистограмму, приведенную на рис. 3.8, г).
Повышение контрастности вызвано существенным расширением динамического
диапазона на всю шкалу яркости. Повышение общей яркости изображения свя-
зано с тем, что средний уровень яркости на гистограмме эквализованного изоб-
ражения стал выше (ярче), чем на исходном изображении. Несмотря на то, что
обсуждаемый метод гистограммной эквализации не приводит к плоской гисто-
грамме, он обладает требуемыми характеристиками, позволяющими повышать
динамический диапазон уровней яркости изображений.
Как уже отмечалось, функция преобразования Т(т>) является кумулятивной
суммой величин нормированной гистограммы. Можно использовать функцию
cumsum4 и построить функцию преобразования следующим образом:
4Если А - вектор, то В = cumsum(A) — это сумма всех элементов А. Если А — многомерный
3.3. Обработка гистограмм и построение, графиков функций
hnorm = imhist(f)./numel(f);
> sdf cumsum (hnorm);
Рис. 3.8. Иллюстрация ihcto-
граммной эквализации. а) Ис-
ходное изображение. 6) Его
гистограмма, с) Изображение
после эквализации. г) Эква-
лизованная гистограмма. Оче-
видно улучшение от а) кв).
(Исходное изображение предо-
ставил д-р Роджер Хиди, Фа-
культет биологических иссле-
дований Австралийского наци-
онального университета, Кан-
берра, Австралия)
График sdf, приведенный на рис. 3.9, получен при выполнении следующих ко-
манд:
> > х = linspace(O, 1, 256); % Intervals for [О, 1] horiz scale.
% Note the use of linspace from § 2.8.1.
> > plot(x, cdf); % Plot sdf vs. x.
> > axis([O 101]); % Scale, settings, and labels:
» set(gca, ’xtick’, 0:.2:l)
» set(gca, ’ytick’, 0:.2:l)
> > xlabelC’Input intensity values’, ’fontsize’, 9)
>> ylabel(’Output intensity values’, ’fontsize’, 9)
» 7. Specify text in the body of the gragh:
>> text(0.18, 0.5, ’Transformation function’, ’fontsize’, 9)
Теперь мы можем визуально подтвердить, что эта функция преобразует узкий
входной диапазон яркости на всю шкалу яркости выходного изображения. □
массив, то В = ciunsiunCA, dim) — это сумма элементов вдоль размерности dim.
Глава 3. Преобразования яркости изображений и пространственная фильтрация
Рис. 3.9. Функция преобразования, исполь-
зованная при отображении уровней ярко-
сти входного изображения на рис. 3.8, а) на
уровни яркости выходного изображения на
рис. 3.8, в).
3.3.3. Гистограммная подгонка (спецификация)
Гистограммная эквализация совершается преобразованием, которое является адап-
тивным в том смысле, что оно зависит от гистограммы исходного изображения.
Однако если функция преобразования уже вычислена, то она не будет меняться,
пока не изменится само изображение. Как уже отмечалось в предыдущем па-
раграфе, гистограммная эквализация улучшает изображение путем расширения
диапазона его уровней до более широкой шкалы яркости. В этом параграфе бу-
дет показано, что такая процедура не всегда приводит к удовлетворительному
результату. Поэтому в конкретных приложениях полезно уметь задавать форму
гистограммы, которую желательно иметь для обработанного изображения. Ме-
тод построения обработанного изображения с заданной гистограммой называется
гистограммной подгонкой или гистограммной спецификацией.
Этот метод, в принципе, очень прост. Рассмотрим сначала непрерывные вели-
чины, распределенные на отрезке [0,1], и пусть гиг обозначают, соответствен-
но, уровни яркости входного и выходного изображений. Входные уровни имеют
функцию плотности вероятности рГ (г), а функция плотности вероятности выход-
ного изображения обозначается pz(z). Как было установлено, преобразование
Г
s = T(r) = jpr(w) dw
о
дает яркость уровней s, которые имеют равномерную плотность вероятности ps(s).
Зададим переменную z со следующим свойством:
X
H(z) = jPz(w) dw = s.
0
Следует иметь в виду, что полученные уровни яркости должны иметь предпи-
санную плотность pz(z). Из предыдущих двух уравнений следует, что
3.3. Обработка гистограмм и построение графиков функций
Функцию Т(г) можно вычислить по исходному изображению (это преобразо-
вание гистограммной эквализации, обсуждавшееся ранее), следовательно, преды-
дущее уравнение можно использовать для нахождения преобразованных уров-
ней z, для которых функция PDF была задана до тех пор, пока можно найти
функцию Н-1. При работе с дискретными величинами можно гарантировать,
что обратная к Н функция существует, если pz(z) — допустимая гистограмма
(т. е. она не отрицательна и имеет единичную область) и среди ее компонент нет
нулей (т. е., у pz(z) нет пустых корзин). Как и при гистограммной эквализации,
дискретная реализация этого метода дает лишь приближение заданной гисто-
граммы.
В пакете IPT метод гистограммной подгонки реализован в функции histeq
со следующим вариантом синтаксиса:
g = histeq(f, hspec)
где f — это входное изображение, hspec — заданная гистограмма (вектор-строка),
a g — выходное изображение, гистограмма которого близка к заданной гисто-
грамме hspec. Этот вектор должен состоять из целых чисел, соответствующих
одинаковым разбиениям (корзинами) диапазона уровней. Гистограмма изобра-
жения g, построенного функцией histeq, лучше приближается к hspec, когда
length(hspec) существенно меньше числа уровней яркости исходного изображе-
ния f.
Пример 3.6. Гистограммная подгонка.
На рис. 3.10, а) показано изображение! спутника Марса Фобоса, а на рис. 3.10, б)
приведена его гистограмма, полученная функцией imhist (f). На этом изобра-
жении доминируют темные области, что соответствует большой концентрации
яркости пикселов в темной части градационной шкалы. На первый взгляд, мож-
но было бы заключить, что гистограммная эквализация способна улучшить ка-
чество этого изображения, поскольку детали темных областей стали бы более
заметными. Однако результат на рис. 3.10, в), полученный командой
>> fl = histeq(f, 256);
показывает, что этот метод не дает существенного улучшения для этой фотогра-
фии. Причину этого можно объяснить, анализируя гистограмму эквализованного
изображения на рис. 3.10, г). Здесь видно, что уровни яркости были сдвинуты
в верхнюю половину градационной шкалы, что привело лишь к общему освет-
лению изображения, которое теперь выглядит как бы «вылинявшим». Причиной
такого сдвига является большая концентрация значений темных пикселов вблизи
нулевого уровня на исходной гистограмме. Оказывается, что функция кумуля-
тивного преобразования, построенная по этой гистограмме, имеет очень крутой
подъем. Это приводит к тому, что яркость пикселов, сконцентрированных возле
нижнего нулевого уровня, отображается в верхнюю часть яркостного диапазона.
Одним из возможных средств в такой ситуации может служить гистограмм-
ная подгонка с заданной гистограммой, которая имела бы меньшую концентра-
цию компонент в нижней части градационной шкалы, но при этом сохраняла бы
Глава 3. Преобразования яркости изображений и пространственная фильтрация
общую форму гистограммы исходного изображения. Заметим, что исходная ги-
стограмма (см. рис. 3.10, б)), в целом, является бимодальной, т. е. имеется одна
большая мода возле нулевого значения, а другая, меньшая мода, расположена в
верхней области градационной шкалы. Такой тип гистограмм можно смоделиро-
вать, например, с помощью нормированных мультимодальных гауссовых функ-
ций. Следующая М-функция вычисляет бимодальную функцию Гаусса, норми-
рованную на единичном отрезке, т. е. ее можно использовать в качестве гисто-
граммы.
Рис. 3.10. а) Изображение Фо-
боса, спутника Марса. 6) Гисто-
грамма. е) Гистограммно-эква-
лизованное изображение, г) Ги-
стограмма s). (Исходный сни-
мок предоставлен Агентством
NASA.)
function р twomodegauss(ml, sigl, m2, sig2, Al, A2, k)
YoTWOMODEGAUSS Generates a bimodal Gaussian function.
7. P = TWOMODEGAUSS(Ml, SIGI, М2, SIG2, Al, A2, K) generates a bimodal,
7o Gaussian-like function in the interval [0, 1]. P is a 256-element
7« vector normalized so that SUM(P) equals 1. The mean and standard
7, deviation of the modes are (Ml, SIGI) and (М2, SIG2), respectively.
7, Al and A2 are the amplitude values of the two modes. Since the
7. output is normalized, only the relative values of Al and A2 are
7» important. К is an offset value that raises the >floor> of the
% function. A good set of values to try is Ml 0.15, SIGI 0.05,
7. М2 = 0.75, SIG2 = 0.05, Al = 1, A2 = 0.07, and К = 0.002.
3.3. Обработка гистограмм и построение графиков функций
cl Al * (1 / ((2 * pi) *0.5) * sigl);
kl 2 * (sigl ~2);
c2 A2 * (1 / ((2 * pi) -0.5) * sig2);
k2 2 * (sig2 -2);
z linspace(0, 1, 256);
p к + cl * exp(((z ml) ~2) . / kl) +
c2 * exp(((z m2) ~2) ./ k2);
p p / sum(p(:));
Следующая интерактивная М-функция принимает входные данные с клави-
атуры и строит результирующую гауссову функцию. Мы отсылаем читателей к
§ 2.10.5, где объяснялись функции input и str2num.
function р manualhist
’/„MANUALHIST Generates a bimodal histogram interactively.
7. P MANUALHIST generates a bimodal histogram using
X TWOMODEGAUSS(ml, sigl, m2, sig2, Al, A2, k) ml and m2 are the means
X of the two modes and must be in the range [0, 1] sigl and sig2 are
X the standard deviations of the two modes. Al and A2 are
X amplitude values, and k is an offset value that raises the
X »floor> of histogram. The number of elements in the histogram
X vector P is 256 and sum(P) is normalized to 1. MANUALHIST
X repeatedly prompts for the parameters and plots the resulting
7c histogram until the user types an ’x’ to quit, and then it returns
7c the last histogram computed.
7.
7c A good set of starting values is: (0.15, 0.05, 0.75, 0.05, 1,
7. 0.07, 0.002) .
X Initialize.
repeats true;
quitnow = ’x’;
X Compute a default histogram in case the user quits before
X estimating at least one histogram.
p = twomodegauss(0.15, 0.05, 0.75, 0.05, 1, 0.07, 0.002);
X Cycle until an x is input.
while repeats
s input(’Enter ml, sigl, m2, sig2, Al, A2, k OR x to quit: ’s’);
if s == quitnow
break
end
% Convert the input string to a vector of numerical values and
X verify the number of inputs.
v str2num(s);
if numel(v) 7
disp(’Incorrect number of inputs.’)
continue
end
Глава 3. Преобразования яркости изображений и пространственная фильтрация
р twomodegauss(v(l), v(2), v(3), v(4), v(5), v(6), v(7));
7. Start a new figure and scale the axes. Specifying only xlim
7. leaves ylim on auto.
figure, plot(p)
xlim([O 255])
end
Поскольку проблема, возникшая при гистограммной эквализации в этом при-
мере, связана прежде всего с большой концентрацией уровней яркости пикселов
возле нулевого значения, разумным решением будет модификация гистограммы
изображения, чтобы у нее отсутствовало это явление. На рис. 3.11, а) приведен
график функции (полученной с помощью программы manualhist), который со-
храняет общие черты исходной гистограммы, но имеет более гладкий переход
концентрации уровней яркости в темной части градационной шкалы. Выход про-
граммы р состоит из 256 равномерно распределенных точек, полученных из этой
кривой, и его можно использовать в качестве задаваемой (специфицированной)
гистограммы. Изображение с этой гистограммой строится командой
» g = histeq(f, р);
Рис. 3.11. а) Заданная гисто-
грамма. б) Результат гисто-
граммной подгонки, в) Гисто-
грамма б)
На рис. 3.11, б) приведен ее результат. Улучшение по сравнению с гистограммной
эквализацией на рис. 3.10, в) вполне очевидно. Интересно заметить, что выбран-
ная новая гистограмма имеет весьма малые отличия по сравнению с исходной
гистограммой. Этого небольшого изменения оказалось вполне достаточно для
существенного визуального улучшения изображения. Гистограмма рис. 3.11, б)
показана на рис. 3.11, в). Характерной чертой этой гистограммы является сдвиг
ее нижнего конца в сторону более яркой области градационной шкалы, т. е. ближе
3-4- Пространственная фильтрация
к выбранной форме. Заметим, однако, что этот сдвиг вправо был не столь ради-
кальным, как на гистограмме, показанной на рис. 3.10, г), которая соответствует
очень слабому улучшению изображения, приведенного на рис. 3.10, в). □
3.4. Пространственная фильтрация
Как уже было отмечено в § 3.1 и проиллюстрировано на рис. 3.1, окрестностная
обработка изображений состоит из следующих действий:
(1) определение центральной точки (х, у)\
(2) совершение операции, которая использует лишь значения пикселов в зара-
нее оговоренной окрестности вокруг центральной точки;
(3) назначение результата этой операции «откликом» совершаемого процесса в
этой точке;
(4) повторение всего процесса для каждой точки изображения.
В результате перемещения центральной точки образуются новые окрестности,
отвечающие каждому пикселу изображения. Для описанной процедуры приня-
то использовать термины окрестностная обработка и пространственная филь-
трация, причем последний является более употребимым. Как будет объяснено в
следующем параграфе, если операции, совершаемые над пикселами окрестности,
являются линейными, то вся процедура называется линейной пространственной
фильтрацией (также иногда используется термин пространственная свертка),
в противном случае она называется нелинейной пространственной фильтрацией.
3.4.1. Линейная пространственная фильтрация
Понятие линейной фильтрации тесно связано с преобразованием Фурье при об-
работке сигналов в частотной области. Эта тематика будет рассматриваться в
гл. 4. В настоящей главе рассматриваются операции фильтрации, непосредствен-
но применяемые к пикселам изображения. Использование термина линейная про-
странственная фильтрация подчеркивает отличие этого процесса от фильтра-
ции в частотной области.
Линейные операции, рассматриваемые в настоящей главе, состоят из умноже-
ния каждого пиксела окрестности на соответствующий коэффициент и суммиро-
вание этих произведений для получения результирующего отклика процесса в
каждой точке (ж, у). Если окрестность имеет размер тхп, то потребуется тп ко-
эффициентов. Эти коэффициенты сгруппированы в виде матрицы, которая назы-
вается фильтром, маской, фильтрующей маской, ядром, шаблоном или окном,
причем первые три термина являются наиболее распространенными. По при-
чинам, которые скоро станут известны, мы также будем использовать термины
сверточный фильтр, маска или ядро.
Механизм линейной пространственной фильтрации проиллюстрирован на рис. 3.12.
Процесс заключается в перемещении центра фильтрующей маски w от точки
к точке изображения f В каждой точке (ж, у) откликом фильтра является сум-
ма произведений коэффициентов фильтра и соответствующих пикселов окрест-
ности. которые накрываются фильтрующей маской. Для маски размера тхп
104 Глава 3. Преобразования яркости изображений и пространственная фильтрация
обычно предполагается, что т = 2а + 1ип = 2Ь+1, где а и b — неотрицательные
целые числа, т. е. основное внимание уделяется маскам, имеющим нечетные раз-
меры, причем наименьшим содержательным размером маски считается размер
3x3 (маска 1x1 исключается как тривиальная). Преимущественное обращение
с масками нечетных размеров является вполне обоснованным, поскольку в этом
случае у маски имеется выраженная центральная точка.
Рис. 3.12. Механизм линейной пространственной фильтрации. Увеличенный рисунок по-
казывает маску 3x3 и соответствующий фрагмент изображения под ней, кото-
рый несколько смещен для удобства прочтения формул
Имеется две тесно связанные концепции, которые необходимо хорошо пони-
мать при совершении линейной пространственной фильтрации. Первая — это
3-4- Пространственная фильтрация
корреляция, а вторая — свертка. Корреляция состоит в прохождении маски w по
изображению /, показанному на рис. 3.12. С точки зрения механики процесса,
свертка делается так же, но маску w надо повернуть на 180° перед прохожде-
нием по изображению /. Две эти концепции лучше всего объяснить на простых
примерах.
На рис. 3.13, а) изображена одномерная функция f и маска w. Началом функ-
ции J считается ее самая левая точка. Чтобы совершить корреляцию этих двух
функций, перемещаем w так, чтобы ее самая правая точка совпала с началом У,
как показано на рис. 3.13, б). Заметим, что имеются точки на обеих функциях,
которые не перекрываются. Для решения этой проблемы предполагается, что
функция / равна нулю везде, где это необходимо, чтобы гарантировать наличие
соответствующих точек на f при прохождении над ней маски w. Такая ситуация
проиллюстрирована на рис. 3.13, в).
Свертка
w повернут
Начало f на 180 градусов
00010000 02321 и)
00010000 к)
0 2 3 2 1
0000000100000000 п)
0 2 3 2 1
0000000100000000 м)
0 2 3 2 1
0 0 Ь 0 о о1
0 0 0 0 0 0
Корреляция
Начало / w
а) 00010000 12320
I
0 0 0 10 0 0 0
б) 1 2 3 2 0
Подгонка начала
Заполнение ___________
। i нулями
в) 0 0 0 О1 0 0 0 1 0 0
1 2 3 2 0
г) 0000000100
1 2 3 2 0
t- Положение после одного сдвига
д) 0000000100000000
1 2 3 2 0
{.Положение после четырех
сдвигов
е) 0000000100000000
1 2 3 2 0
Окончательное положение 3
Результат корреляции 'full'
ж) 000023210000
Результат корреляции 'same’
з) 00232100
0000000100000000 н)
0 2 3 2 1
0000000100000000 о)
0 2 3 2 1
Результат свертки 'full'
000123200000 п)
Результат свертки ’same’
01232000 Р)
Рис. 3.13. Иллюстрация одномерной корреляции и свертки
Теперь все готово для совершения корреляции. Первым значением корреля-
ции является сумма поэлементных произведений двух функций в положении на
Глава 3. Преобразования яркости изображений и пространственная фильтрация
рис. 3.13, в). В этом случае сумма произведений равна 0. Затем маска w пере-
мещается на один шаг вправо и процесс вычисления повторяется [рис. 3.13, г)].
Сумма произведений опять равна 0. После четырех сдвигов [рис. 3.13, <?)] нам
встретится первое ненулевое значение 2x1 = 2. Продолжая тем же манером до
тех пор, пока w полностью пройдет f [последняя конфигурация показана на
рис. 3.13, е/[, мы получим результат, показанный на рис. 3.13, ж). Эта строка
чисел и является корреляцией w и /. Отметим, что если бы мы зафиксировали
w, а перемещали бы f, то результат был бы иным, так что порядок операции
здесь имеет значение.
Метка ’full’ над результатом корреляции на рис. 3.13, ж) является флагом
(он будет обсуждаться позже), который предписывает применение корреляции с
расширением изображения продемонстрированным выше методом. Пакет имеет
и другую опцию, ’вате’ [рис. 3.13, з)\, когда вычисляется корреляция, размер
которой совпадает с размером исходного изображения f. Эти вычисления так-
же используют расширение нулями, но начальная позиция центральной точки
маски (это точка с отметкой 3) совмещается с началом f. Последнее вычисление
производится, когда центральная точка маски совмещается с концом f.
Для совершения свертки необходимо повернуть маску w на 180° и совместить
ее самый правый конец с началом f [см. рис. 3.13, kJ]. Затем процесс скольже-
ния/вычисления совершается как при получении корреляции. Он проиллюстри-
рован на рис. 3.13 от л) до о). Результаты свертки с флагами ’full’ и ’same’
показаны, соответственно, на рис. 3.13, п) и р).
Функция / на рис. 3.13 является дискретным единичным импульсом, т. е. она
равна 1 только в одной координате, а во всех остальных она равна 0. Из ре-
зультатов на рис. 3.13, п) или р) видно, что свертка просто «копирует» w в то
место, Где был единичный импульс. Это простое свойство копирования (называ-
емое сдвигом) является фундаментальной концепцией теории линейных систем,
чем объясняется необходимость поворота одной из функций на 180° при выполне-
нии операции свертки. Заметим, что перестановка порядка функций при свертке
даст тот же самый результат, чего не происходит при корреляции. Если сдвигае-
мая функция является симметричной, то, очевидно, корреляция и свертка дают
одинаковые результаты.
Представленные концепции легко обобщаются на двумерные функции, т. е.
на изображения, что иллюстрируется на рис. 3.14. Начало находится в верхнем
левом углу изображения f(x,y) [см. рис. 2.1]. Для совершения корреляции на-
до поместить нижнюю правую точку w(x, у) так, чтобы она совпала с началом
f(x,y), см. рис. 3.14, в). Обратите внимание на использование расширения нуля-
ми, причина которого обсуждалась при рассмотрении рис. 3.13. Для совершения
корреляции надо перемещать w(x,y) по всем возможным положениям, так чтобы
хоть один пиксел маски перекрывался с пикселами изображения f{x,y). Резуль-
тат корреляции ’full’ показан на рис. 3.14, г). Чтобы получить корреляцию
’same’, приведенную на рис. 3.14, д), необходимо перемещать маску так, чтобы
ее центр перекрывал исходное изображение f(x, у).
Для совершения свертки необходимо сначала повернуть w(x, у) на 180° и со-
вершить ту же процедуру, что и при вычислении корреляции [см. рис. 3.14 от в)
до з)]. Как и в обсуждавшемся выше одномерном примере, свертка дает одинако-
3-4- Пространственная фильтрация
вый результат независимо от того, какая из двух функций подвергается переме-
щению. При нахождении корреляции порядок функций имеет значение. В пакете
IPT при реализации этих процедур всегда перемещается фильтрующая маска.
Заметим также, что результаты корреляции и свертки получаются друг из друга,
поворотом на 180° В этом нет ничего удивительного, так как свертка — это не
что иное, как корреляция с повернутой фильтрующей маской.
Рис. 3.14. Иллюстра- Расширение нулями f
ция двумерной корре- тяции и свертки. Нули показаны серым цве- том для лучшей на- f НачалоДх, у) гчядности 0 0 0 0 0 ооооо (*, у) 0 0 1 0 0 1 2 3 00000 456 00000 789 а) Исходное положение маски w 000000 0 00 00000000 0 0 00000000 000000000 0 00010000 0000000 0 0 0 00000000 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 б) Результат корреляции Результат корреляции ‘full’ 'same'
\1~2 31 0 0 0 0 0 0 000000000 00 0 00
'4 5 6; 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 9 8 7 0
|78_9'000000 00000000 0 06540
0 6 о' 0 0 0 0 0 0 000987000 03210
000010000 00 0 000000 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 000000000 в) 000654000 00000 000321000 000 0 0 0000 0 0 0 0 0 0 0 0 0 00 0 000000 г) д)
^Повернутая маска w Результат свертки 'full' Результат свертки 'same'
[9“8 71 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ооооо
6 5 4j 000000 0 0 000000 0 01230
(3 2 _1_' 0 0 0 0 0 0 0 0 0 0 00000 04560
0 6 О 0 0 0 0 0 0 0 0 0 1 2 3 0 0 0 0 7 8 9 0
0 0 0 0 1 0 0 0 0 000000 0 00 0 0 0 0 0 0 0 0 0 00000000 0 0 0 0 0 0 0 0 0 0 е) 0 0 0 4 5 6 0 0 0 00000 0 0 0 789000 0 0 0 000000 0 0 0 0 0 0 0 0 0 00 0 0000 0 0 ж) з)
В пакете IPT линейная пространственная фильтрация реализована функцией
imf liter, которая имеет следующий синтаксис:
>> g= imf ilter(f, w, filtering_mode, boundary_options, size_options);
где f — это входное изображение, w — фильтрующая маска, g — результат филь-
трации, а остальные параметры сведены в табл. 3.2. Параметр f iltering_mode
определяет, что совершает фильтр, корреляцию (’согг’) или свертку (’conv’).
Опция boundary.opt ions отвечает за расширение границ, причем размеры рас-
ширения определяются размерами фильтра. Подробнее этот параметр будет раз-
108 Глава 3. Преобразования яркости изображений, и пространственная фильтрация
бираться в примере 3.7. Опция size_options — это либо ’full’, либо ’same’,
смысл которых уже объяснялся на рис. 3.13 и 3.14.
Чаще всего функция imf liter применяется в виде команды
g = imfliter(f, w, ’replicate’)
Эта форма команды используется при реализации в IPT стандартных линейных
пространственных фильтров, которые будут обсуждаться в § 3.5.1. Эти фильтры
уже повернуты на 180°, поэтому можно делать процедуру корреляции, которая
задана в функции imf liter по умолчанию. А как уже обсуждалось при изуче-
нии рис. 3.14, совершение корреляции с перевернутым фильтром эквивалентно
свертке с исходным фильтром. Если фильтр симметричен относительно своего
центра, то обе опции дают одинаковые результаты.
Таблица 3.2. Опции функции imfilter
Опции Описание
Мода фильтрации ’согг’ ’conv’ Граничные опции Р ’replicate* ’symmetric’ ’circular’ Опции размера ’full’ ’same’ Фильтрация делается методом корреляции (см. рис. 3.13 и 3.14). Мода по умолчанию. Фильтрация делается методом свертки (см. рис. 3.13 и 3.14) Границы изображения расширяются значением Р (без апострофов). По умолчанию Р=0. Размер изображения увеличивается повторением величин на его бо- ковых границах. Размер изображения увеличивается путем зеркального отражения че- рез границы. Размер изображения увеличивается периодическим повторением дву- мерной функции. Выход имеет те же размеры, что и расширенное входное изображение. Выход имеет те же размеры, что и вход. Это достигается с помощью ограничения перемещения центра фильтрующей маски точками, при- надлежащими исходному изображению, (см. рис. 3.13 и 3.14). Опция по умолчанию.
При работе с фильтрами, которые не были предварительно перевернуты или
были несимметричными, когда требуется построить свертку, можно поступать
двумя способами. Один из них использует синтаксис
g = imfliter(f, w, ’conv’, ’replicate’).
Другой подход заключается в предварительной обработке маски w с помощью
функции rot90(w, 2)1, которая поворачивает w на 180° После этого приме-
няется команда imfliter(f, w, ’replicate’). Конечно, эти два шага можно
записать в одной формуле. В результате получится изображение, размер кото-
рого совпадает с размером исходного (т. е. по умолчанию принята опция ’same’,
которая обсуждалась ранее).
'Функция rot90(w, к) поворачивает w на угол fcx90°, где к — целое число.
3-4- Пространственная фильтрация
Каждый элемент фильтрованного изображения вычисляется с использовани-
арифметики двойной точности с плавающей запятой, но в конце работы функ-
ия imf liter конвертирует выходное изображение в класс исходного. Значит, ес-
f — это целый массив, то элементы обработанного массива, которые выходят
область целых чисел, будут обрезаться, а дробные величины округляться,
ели требуется результат с повышенной точностью, то необходимо предвари-
тыю перевести изображение в класс duble с помощью функций im2double или
’ouble перед применения imf liter
Рис. 3.15. а) Исходное изображение, б) Результат применения imf ilter с нулевым продол-
жением. в) Результат с опцией ’replicate’, г,) Результат с опцией ’symmetric’
д) Результат с опцией ’circular’ е) Результат конвертации исходного изобра-
жения в класс uint8 с последующей фильтрацией с опцией ’replicate’. Везде
использован фильтр размера 31x31 из одних единиц
Пример 3.7. Применение функции imf liter.
На рис. 3.15, а) дано изображение класса double, размера 512x512 пикселов. Рас-
лотрим простой фильтр размера 31 х31
>> w = ones (31) ;
.оторый пропорционален фильтру усреднения. Мы не делим коэффициенты на
’.1 х31, чтобы продемонстрировать в конце этого примера действие функции imf ilter
на изображениях класса uint8.
Свертка с фильтром w дает эффект размытия исходного изображения. По-
скольку фильтр симметричен, можно использовать моду корреляции, заданную
в imf ilter по умолчанию. На рис. 3.15, б) приведен результат выполнения сле-
1л Ющих действий:
gd imfilter(f, w);
imshow(gd, [ ])
10 Глава 3. Преобразования яркости изображений и пространственная фильтрация
где использовалась граничная опция, принятая по умолчанию, т. е. расширение
изображения нулями (черным цветом). Как и ожидалось, границы между белы-
ми и черными областями стали размытыми. Тот же эффект имел место на гра-
ницах изображения, к которым примыкают белые области, что вполне понятно в
силу расширения границ черным цветом. С этой трудностью можно справиться,
если использовать опцию ’replicate’
> > gr = imfilter(f, w, ’replicate’);
» figure, imshow(gr, [ ])
Из рис. 3.15, в) видно, что теперь границы фильтрованного изображения вы-
глядят так, как и ожидалось. Эквивалентный результат получается с опцией
’symmetric’
> > gs = imfilter(f, w, ’symmetric’);
> > figure, imshow(gs, [ ])
Результат показан на рис. 3.15, г). Однако, если применить опцию ’cirular’
> > gc = imfilter(f, w, ’cirular’);
» figure, imshow(gc, [ ])
(см. рис. 3.15, д)), то обнаружится та же проблема, что и при расширении нуля-
ми. Этому не стоит удивляться, ведь при периодическом повторении исходного
изображения черные квадраты примыкают к белым.
Наконец, проиллюстрируем эффекты, происходящие из-за сохранения клас-
са изображения функцией imfilter, который может привести к определенным
проблемам, если не обращать на это внимание:
> > f8 = im2uint8(f);
> > g8r = imfilter(f8, w, ’replicate’);
> > figure, imshow(g8r, [ ])
На рис. 3.15, e) изображен результат этих команд. Здесь при конвертации выход-
ного изображения в класс uint8 функцией imfilter произошло усечение части
изображения. Причина этого состоит в том, что сумма коэффициентов фильтра-
ции не принадлежит интервалу [0,1], в результате чего фильтрованные коэф-
фициенты вышли за допустимые пределы области определения [0,255] данного
класса. Чтобы избежать такой неприятности, следует делать нормировку коэф-
фициентов фильтра, чтобы их сумма принадлежала интервалу [0,1] (в рассмот-
ренном примере для этого необходимо разделить коэффициенты на 312, тогда
их сумма будет равна 1), или переводить изображение в класс double. Отметим,
однако, что даже во втором случае данные придется где-то перенормировать для
приведения их к нужному формату (например, при сохранении изображения на
диске). В любом случае, следует всегда помнить об области значений данных,
чтобы избегать неожиданных результатов. □
3-4- Пространственная фильтрация
3.4.2. Нелинейная пространственная фильтрация
Нелинейная пространственная фильтрация также основана на окрестностных
перациях, причем механизм определения окрестности размера тхп и сколь-
жения ее центра по изображению является таким же, как и в линейной филь-
грации, описанной в предыдущем параграфе. Однако там, где линейная филь-
грация использует сумму произведений (т. е. линейную операцию), нелинейная
фильтрация основана (что следует из ее названия) на нелинейных операциях, со-
вершаемых над пикселами текущей окрестности. Например, если положить, что
этклик фильтра в каждой центральной точке равен максимальному значению
ее окрестности, то это определит нелинейную операцию фильтрации. Другое
фундаментальное отличие состоит в том, что концепция маски не превалирует
в нелинейных процессах. Идея фильтрации остается, но сам «фильтр» следует
представлять себе в виде нелинейной функции, которая применяется к пикселам
крестности, и ее отклик состоит из отклика операции, примененной к централь-
ному пикселу окрестности.
В пакете предусмотрены две функции для совершения общей нелинейной
фильтрации: nlf ilter и coif ilt. Первая из них совершает операции непосред-
твенно в матричной форме, а функция coif ilt организует данные в форме
толбцов. Хотя coif ilt требует большего объема памяти, она выполняется су-
щественно быстрее, чем nlf ilter. В большинстве приложений обработки изобра-
жений скорость вычисления является первостепенным фактором, поэтому функ-
ция coif ilt является более предпочтительной при реализации общей нелинейной
пространственной фильтрации.
Для заданного входного изображения f размера MxN и для заданной окрест-
ности размера тхп функция coif ilt строит матрицу, назовем ее А, максималь-
ного размера mnxMN2, в которой каждый столбец соответствует пикселам,
круженным окрестностью с центром в некоторой точке изображения. Напри-
iep, первый столбец соответствует пикселам, окруженным окрестностью, центр
которой расположен в самом левом верхнем углу изображения f. Все необходи-
tbie расширения выполняются функцией coif ilt (с помощью нулевых добавок).
Синтаксис функции coif ilt имеет вид
g colfiltff, [m, n], ’sliding’, ©fun, parameters)
де, как и раньше, тип — это размеры области фильтра, ’sliding’ обозна-
чает, что процесс производится скольжением области тхп от пиксела к пик-
глу по входному изображению f, ©fun обозначает ссылку на функцию fun, а
parameters — это параметры (разделенные запятыми), которые могут потре-
□ваться функции fun. Символ © называется дескриптором функции, который
является особым типом данных MATLAB, содержащим информацию, которая
используется при вызове функции. Как скоро будет видно, эта конструкция яв-
тяется весьма плодотворной.
В силу организации матрицы А, функция fun должна обращаться к каждому
голбцу этой матрицы индивидуально, возвращая вектор-строку v, в которой
Матрица А всегда имеет тп строк, но число столбцов может меняться в зависимости от раз-
гра входного изображения. Выбор размера производится функцией colfilt автоматически.
I 12 Глава 3. Преобразования яркости изображений и пространственная фильтрация
записан результат для всех столбцов. В к-ом элементе вектора v стоит результат
применения операции fun к fc-ому столбцу матрицы А. Поскольку матрица А
может иметь до MN столбцов, максимальный размер v равен IxMN.
Обсуждавшаяся в предыдущих параграфах линейная фильтрация имеет сред-
ства для расширения изображений, чтобы разрешать граничные проблемы, при-
сущие пространственной фильтрации. Однако при использовании coif ilt необ-
ходимо заранее расширить входное изображение до его фильтрации. Для этого
служит функция padarray, которая в двумерном случае имеет синтаксис
fp padarray(f, [г с], method, direction)
где f — входное изображение, fp — расширенное изображение, [г с] дает число
добавляемых к f строк и столбцов, а параметры method и direction объясняются
в табл. 3.3. Например, если изображение f = [12; 3 4] , то команда
>> fp = padarray(f, [3 2], ’replicate’, ’post’)
дает результат
fP
12 2 2
3 4 4 4
3 4 4 4
3 4 4 4
3 4 4 4
Если среди аргументов отсутствует direction, то значение по умолчанию есть
’both’, а если отсутствует аргумент method, то расширение по умолчанию дела-
ется нулями. Если оба параметра опущены, то делается расширение нулями со
всех сторон изображения. В конце вычислений изображение обрезается до исход-
ного размера.
Таблица 3.3. Опции функции padarray
Опции Описание
Method
’symmetric’ Размер изображения увеличивается с помощью его зеркального отобра- жения через границы.
’replicate’ Размер изображения увеличивается с помощью продолжения пригранич- ными значениями.
’circular’ Расширение производится путем периодического повторения исходного изображения.
Direction ’pre’ ’post’ ’both’ Расширять перед первыми элементами по каждой размерности. Расширять после последних элементов по каждой размерности. Расширить в обе стороны по каждой размерности.
3-4- Пространственная фильтрация
Пример 3.8. Использование функции coif ilt при реализации нелинейной про-
странственной фильтрации.
В качестве иллюстрации применения функции coif ilt мы реализуем нелиней-
ный фильтр, отклик которого в любой точке совпадает со средним геометриче-
ским яркости пикселов в окрестности с центром в данной точке. Геометрическим
средним окрестности размера тхп называется произведение величин яркости
всех пикселов окрестности, возведенное в степень 1/ттт. Сначала построим нели-
нейную функцию, которую мы назовем gmean3:
function v = gmean(A)
mn size(A, 1); % The length of the columns of A is always mn.
v prod(A, l).'’(l/mn);
Для подавления граничных эффектов мы расширим изображение, например,
с помощью опции ’replicate’ в функции padarray:
>> f = padarray(f, [m n] , ’replicate’);
Наконец, вызываем функцию coif ilt
>> g = colfiltff, [m n] , ’sliding’, ©gmean);
В этих действиях имеется несколько важных моментов. Прежде всего отме-
тим, что несмотря на то, что матрица А является частью аргументов функции
gmean, сама она не включается в список аргументов функции coif ilt. Эта мат-
рица автоматически передается в gmean из coif ilt посредством дескриптора
функции. Кроме того, поскольку матрица А обрабатывается в coif ilt автома-
тически, число столбцов в А является переменным (но. как уже подчеркивалось,
число строк, т. е. длина столбца в А. всегда равна пт). Следовательно, размер
А должен вычисляться каждый раз при вызове функции аргумента функцией
coif ilt. Процесс фильтрации в нашем случае заключается в вычислении про-
изведения всех пикселов окрестности и возведения результата в степень 1/ттг.
Для каждой пары координат (х, у) результат фильтрации будет записан в со-
ответствующий элемент вектора v. Функция, обозначенная дескриптором ©, мо-
жет быть любой функцией, которую можно вызывать из того места, где этот
дескриптор был создан. Ключевое требование заключается в том, что нелиней-
ная функция оперирует над столбцами матрицы А и возвращает вектор-строку,
содержащую результат для каждого индивидуального столбца. Затем функция
coif ilt принимает эти результаты и группирует их в виде соответствующего
выходного изображения g. □
Некоторые часто встречающиеся нелинейные фильтры можно также постро-
ить на основе других функций MATLAB и IPT, например, imfilter и ordfilt2
(см. § 3.5.2). В частности, функция spf ilt из § 3.5 реализует фильтр геометри-
ческого среднего из примера 3.5 с помощью функции imfilter и стандартных
функций log и ехр системы MATLAB. При этом производительность вычис-
лений обычно повышается, а объем требуемой памяти становится меньше, чем
'^Функция prod(A) возвращает произведение элементов А, а функция prod(A, dim) вычисляет
произведение элементов А вдоль размерности dim.
I 14 Глава 3. Преобразования яркости изображений и пространственная фильтрация
у coif ilt. Тем не менее, функция coif ilt остается хорошим выбором при вы-
полнении операций нелинейной фильтрации, для которых нет альтернативных
реализаций.
3.5. Стандартные пространственные фильтры
из пакета IPT
В этом параграфе обсуждаются линейные и нелинейные пространственные филь-
тры, которые поддерживаются в пакете IPT. Дополнительные нелинейные филь-
тры будут реализованы в конце § 5.3.
3.5.1. Линейные пространственные фильтры
В пакете IPT имеются некоторые стандартные двумерные линейные простран-
ственные фильтры, которые можно получить из функции f special, которая ге-
нерирует маску фильтра w при выполнении команды
w = fspecial(’type’, parameters),
где ’ type ’ обозначает тип фильтра, а в аргументах parameters задаются пара-
метры выбранного фильтра. Пространственные фильтры, получаемые этой ко-
мандой, приведены в табл. 3.4 вместе с соответствующими параметрами каждого
фильтра.
Пример 3.9. Использование функции imfilter.
Проиллюстрируем использование fspecial и imfilter при улучшении изобра-
жения фильтром Лапласа. Оператор Лапласа изображения f(x,y) обозначается
V2/(r, у) и задается формулой
v2№ ) = gV(^/) + ^2/(M
л ,У) дх2 ду2
В качестве численных приближений вторых производных часто используются
выражения
d2f
^2 = /(г + 1,у) + f{x - 1, у) - 2/(г, у)
И
f
— = f(x,y + 1) + f(x,y - 1) - 2/(r,y),
поэтому
v2/ = [f(x + 1, у) + f (x - 1, у) + f(x, у + 1) + /(ж, у - 1)] - 4/(г, у).
Это выражение можно применить в любой точке (х, у) изображения, сделав
свертку со следующей пространственной маской:
О 1 О
1 —4 1
О 10
3.5. Стандартные пространственные фильтры из пакета IPT
Таблица 3.4. Пространственные фильтры функции fspecial
Тип Синтаксис и параметры
’average’ fspecial(’average’, [г с]). Прямоугольный усредняющий фильтр разме- ра гхс. По умолчанию 3x3. Одно число на месте [г с] означает квадрат- ный фильтр.
’disk' fspeclaK’disk’, г). Круговой усредняющий фильтр (внутри квадрата со стороной 2г+1) радиуса г. По умолчанию г = 5.
’gaussian’ f special (’gaussian’, [г с], sig). Низкочастотный гауссов фильтр разме- ра гхс со стандартным (положительным) отклонением sig. Значения но умолчанию 3x3 и О.Б, Одно число на месте [г с] означает квадратный фильтр.
’laplacian’ fspecial(’laplacian’, alpha), Фильтр Лапласа 3x3, форма которого за- дается параметром alpha из интервала [0,1]. По умолчанию alpha = 0.5.
’log’ fspecial( ’log’, [г с], sig). Лаплас от гауссова фильтра (LoG) размера гхс со стандартным (положительным) отклонением sig. Значения по умол- чанию 5x5 и 0.5. Одно число на месте [г с] означает квадратный фильтр.
’motion’ fspecial(’motion’, len, theta). Выдает фильтр, который, будучи сверну- тым с изображением, приближает линейное перемещение (видеокамеры по отношению к изображению) на 1еп пикселов. Направление перемещения за- дается углом theta, который измеряется в градусах от горизонтали против часовой стрелки. Значения по умолчанию 9 и 0, что соответствует переме- щению на 9 пикселов в горизонтальном направлении.
’prewitt’ fspecial(’prewitt’). Выдает 3x3 маску Превитта wv, которая аппрокси- мирует вертикальный градиент. Маску горизонтального градиента можно получить, транспонировав результат: wh = wv’
’sobel’ fspecial(’sobel’). Выдает 3x3 маску Собела sv, которая аппроксимиру- ет вертикальный градиент. Маску горизонтального градиента можно полу- чить, транспонировав результат: sh = sv’
’unsharp’ fspecial(’unsharp’, alpha). Выдает 3x3 маску нечеткого фильтра. Пара- метр alpha контролирует форму, он должен быть не меньше 0 и не больше 1.0. По умолчанию alpha = 0.2.
Альтернативное приближение вторых производных учитывает значения диа-
гональных элементов и дает маску
1 1 1
1 -8 1
1 1 1
Обе производные иногда определяются с противоположным знаком, что приво-
дит к смене знаков в приведенных выше формулах для масок.
Улучшение изображений с помошыо оператора Лапласа производится по фор-
муле
У) = ft?, у) + cV2f (ж, у),
где f (х, у) — это исходное изображение, д(х, у) — улучшенное изображение, а па-
раметр с равен 1, если центральный коэффициент маски положителен, и с — —1
в противном случае (см. [Gonzalez, Woods, 2002]). Поскольку оператор Лапласа
является дифференциальным, он повышает резкость изображения, но переводит
области с постоянными значениями яркости в 0. Добавление исходного изобра-
жения восстанавливает тональность уровней таких областей.
Глава 3. Преобразования яркости изображений и пространственная фильтрация
Функция fspecial(’laplacian’, alpha) реализует более сложную маску Ла-
пласа:
а 1 — а а
1 + а 1 + а 1 + о
1 — о — 4 1—0
1 + а 1 + а 1 + о
Ct 1—0 СЕ
1 + а 1 + о 1 + о’
которая позволяет тоньше подстраивать результат. Однако преобладающее ис-
пользование оператора Лапласа основано на приведенных выше двух масках.
Рис. 3.16. а) Снимок Север-
ного полюса Луны, б) Изобра-
жение, отфильтрованное лап-
ласианом в формате uint8.
б) Изображение, отфильтро-
ванное лапласианом в форма-
те double, г) Улучшение изоб-
ражения вычитанием б) из а)
(Исходное изображение предо-
ставлено Агентством NASA.)
Теперь рассмотрим улучшение изображения на рис. 3.16, а) с помощью филь-
тра Лапласа, который часто называется лапласианом. На этой фотографии дан
несколько расплывчатый снимок Северного полюса Луны. Улучшение в этом
случае заключается в подчеркивании перепадов уровней на изображении при со-
хранении, насколько это возможно, областей постоянной тональности. Сначала
мы генерируем и отображаем фильтр Лапласа:
>> w = fspecial(’laplacian’, 0) ;
w =
3.5. Стандартные пространственные фильтры из пакета IPT
О. ОООО
1.0000
0.0000
1.0000
-4.0000
1.0000
0.0000
1.0000
0.0000
Заметим, что фильтр принадлежит классу duobl е, и параметр формы alpha = 1
приводит к описанному выше фильтру. Такую форму можно легко задать вручную
>> w [0 1 0; 1 -4 1; 0 1 0] ;
Теперь применим фильтр w к изображению f, которое имеет класс uint8:
>> gl imfliter(f, w, ’replicate’);
>> imshow(gl, [ ])
На рис. 3.16, б) приведен результат этих команд. Этот результат представляет-
ся правдоподобным, но имеется одна проблема: все его пикселы положительны.
В силу отрицательности центрального коэффициента фильтра можно ожидать
появления фильтрованного изображения с отрицательными значениями пиксе-
лов. Однако в нашем случае исходное изображение было класса uint8, а, как
уже говорилось в предыдущем параграфе, фильтрация функцией imfilter про-
изводит на выходе изображение того же класса, что было на входе, поэтому
отрицательные величины будут обрезаны. Чтобы обойти эту проблему, следует
преобразовать изображение f в класс double перед фильтрацией:
» f2 im2double(f) ;
» g2 imfilter(f2, w, ’replicate’);
» imshow(g2, [ ])
Результат, показанный на рис. 3.16, в), является правильно обработанным изоб-
ражением при фильтрации с помощью лапласиана.
Наконец, для восстановления тонов областей, потерянных при выполнения
фильтрации лапласианом, следует вычесть (напомним, что центральный коэф-
фициент фильтра отрицателен) отфильтрованное изображение из исходного:
» g f2 g2;
>> imshow (g)
Окончательный результат приведен на рис. 3.16, г). Видно, насколько улучшен-
ное изображение является более резким по сравнению с исходным. □
Пример 3.10. Подбор параметров фильтров и сравнение разных техник улуч-
шения изображений.
Задача улучшения изображений часто требует подбора параметров фильтров из
имеющегося набора. Лапласиан является хорошим примером. В пакете имеется
фильтр-лапласиан 3x3 с числом —4 в центре. Как правило, еще большую рез-
кость изображения можно получить с лапласианом, в центре которого стоит чис-
ло —8, окруженное со всех сторон 1 (см. обсуждение выше). Целью следующего
примера является ручная реализация этого фильтра для сравнения результатов,
которые получаются с помощью двух форм фильтра лапласиана. Имеем следу-
ющую цепочку команд:
Глава 3. Преобразования яркости изображений и пространственная филътраи^ья
>> f imread(’moon.tif ’) ;
» w4 = fspecial(’laplacian’, 0); У, Same as Example 3.9.
» w8 [1 1 1; 1 -8 1; 1 1 1] ;
> > f im2double(f);
> > g4 = f imfilter(f, w4, ’replicate’);
> > g8 = f imfilter(f, w8, ’replicate’);
> > imshow(f)
> > figure; imshow(g4)
> > figure; imshow(g8)
На рис. 3.17, а) еще раз для удобства приведено исходное изображение f.
На рис. 3.17, б) дано g4, которое совпадает с рис. 3.16, г), а на рис. 3.17, б) изоб-
ражено g8. Как и ожидалось, оно еще более четкое, чем 3.17, б). □
Рис. 3.17. а) Снимок Северного полюса Луны, б) Изображение, улучшенное лапласианом
с —4 в центре, в) Изображение, улучшенное лапласианом с —8 в центре
3.5.2. Нелинейные пространственные фильтры
Наиболее употребительные нелинейные фильтры порождаются в пакете IPT функ-
цией ordf ilt2, которая строит фильтры порядковых статистик (их также на-
зывают ранговыми фильтрами). Отклики этих нелинейных пространственных
фильтров основаны на предварительном упорядочении (ранжировании) пиксе-
лов изображения из текущей окрестности, после чего центральному пикселу при-
сваивается значение, определенное в результате данного упорядочения. В этом
параграфе все внимание будет сосредоточено на фильтрах, получающихся при
помощи функции ordf ilt2. Несколько дополнительных нелинейных фильтров
будут рассмотрены в § 5.3.
Синтаксис функции ordf ilt2 имеет следующий вид:
g = ordfilt2(f, order, domain).
Эта функция создает выходное изображение g, заменяя каждый элемент f на
элемент номер order в упорядоченной последовательности ненулевых элементов
из окрестности, заданной параметром domain. Здесь domain — это матрица тхп,
3.5. Стандартные пространственные фильтры из пакета IPT
состоящая из нулей и единиц, которые обозначают позиции пикселов, участвую-
щие в вычислениях. В этом смысле матрица domain действует как маска. Пикселы
окрестности, которым соответствуют нули в domain, не участвуют в вычислени-
ях. Например, чтобы реализовать фильтр минимума (порядка 1) размера тхп,
применяется команда
g = ordfilt2(f, 1, ones(m, n)).
В такой записи order = 1 означает первый элемент в упорядоченной последова-
тельности из тпп пикселов, a ones(m, п) — это матрица тхп из одних единиц,
указывающая на то, что все элементы окрестности участвуют в вычислении от-
клика фильтра.
Используя терминологию статистик, фильтр минимума (первый элемент упо-
рядоченной по возрастанию последовательности) — это нулевой процентиль. Ана-
логично, сотый процентиль — это последний элемент упорядоченной последова-
тельности, имеющий номер тп. Он соответствует фильтру максимума, который
реализуется командой
g = ordfilt2(f, m*n, ones(m, n)).
Самым известным фильтром порядковых статистик в цифровой обработке изоб-
ражений является медианный1 фильтр, который соответствует 50-ому процен-
тилю. Можно использовать функцию median в ordfilt2 для построения этого
фильтра
g ordfilt2(f, median(l:m*n), ones(m, n)).
Здесь median(l:m*n) это медиана упорядоченной последовательности чисел
1,2,..., тп. Функция median имеет следующий общий синтаксис:
v median(A, dim),
где v — это вектор, элементы которого образуют медиану А вдоль размерности
dim. Например, если dim = 1, то каждый элемент v — это медиана элементов
вдоль соответствующих столбцов матрицы А.
В силу практической важности медианного фильтра в пакете IPT предусмот-
рена специальная реализация этого фильтра:
g = medfilt2(f, [m, n], padopt),
где пара [m, n] задает окрестность размера тхп, по которой вычисляется ме-
диана, а параметр padopt специфицирует три возможные опции расширения
границ изображения: опция по умолчанию ’zeros’ с нулевым расширением,
’symmetric’, при которой изображение f расширяется путем его зеркального
отражения через границы, и ’ indexed ’, при которой f расширяется значением
1, если f имеет класс double и значением 0 в противном случае. По умолчанию
эта функция имеет вид
g = medfilt2(f),
1 Напомним, что медиана некоторого множества величин — это такое число что половина
этих величин не больше £, а другая половина - не меньше £ .
Глава 3. Преобразования яркости изображений и пространственная фильтрация
при этом используется окрестность 3x3 для вычисления медианы, и входное изоб-
ражение расширяется нулевыми значениями пикселов.
Пример 3.11. Медианная фильтрация с функцией medfilt.
Медианная фильтрация весьма эффективна при удалении с изображений им-
пульсных шумов, которые иногда называют шумами «соль и перец». Борьбу с
различными шумами мы будем обсуждать подробно в гл. 5, однако здесь умест-
но проиллюстрировать эти действия с помощью медианного фильтра.
На рис. 3.18, а) представлен рентгеновский снимок f печатной платы, полу-
ченный на стадии автоматического контроля продукции производства. На рисун-
ке 3.18, б) дано то же изображение, сильно подпорченное шумом «соль и перец»,
при котором белые и черные точки имеют вероятность появления 0.2. Этот шум
был искусственно сгенерирован функцией inmoise, которая будет подробно об-
суждаться в § 5.2.1:
>> fn inmoise(f, ’salt & paper’, 0.2);
На рис. 3.18, в) дан результат медианной фильтрации этого искаженного изоб-
ражения при выполнении команды
gm = medfilt2(fn);
Рис. 3.18. Медианная фильтрация, а) Рентгеновский снимок, б) Изображение, испор-
ченное шумом «соль и перец», в) Результат медианной фильтрации функцией
medfilt2 с опциями, принятыми по умолчанию, г) Результат медианной филь-
трации с опцией расширения границ ’symmetric’ Обратите внимание на раз-
личие поведения границ изображений в) и г)
Выводы
При рассмотренном уровне шумов на рис. 3.18, б) медианный фильтр дает
хорошие результаты при использовании его настроек по умолчанию. Обратите,
однако, внимание на черные пятнышки на границах отфильтрованного изобра-
жения. Это произошло из-за расширения границ изображения черными пиксе-
лами (напомним, что по умолчанию изображение продолжается нулевыми, т. е.
черными пикселами). Такого рода артефакты часто можно избежать, используя
опцию ’symmetric’:
» gms = medfilt2(fn, ’symmetric’);
Результат, изображенный на рис. 3.18, г), похож на рис. 3.18, в), но эффект
почернения границ на нем не проявляется. □
Выводы
В этой главе, помимо обсуждения методов улучшения изображения, были зало-
жены основы многих концепций, которые будут изучаться в следующих главах.
Например, пространственная фильтрация снова встретится в гл. 5 в связи с по-
воротами изображений, где мы еще раз подробно рассмотрим задачу удаления
шумов и приведем функции MATLAB, моделирующие различные шумы. Некото-
рые пространственные маски лишь вскользь упоминались в этой главе, и они еще
будут подробным образом изучаться в гл. 10 при обнаружении границ в задачах
сегментации изображений. Концепции свертки и корреляции будут рассматри-
ваться вновь в гл. 4 применительно к частотной области. Базовые идеи обработ-
ки маской при использовании различных методов пространственной фильтрации
будут часто встречаться в дальнейшем. По ходу изложения нового материала бу-
дет продолжено обсуждение вопросов эффективной реализации пространствен-
ной фильтрации в среде MATLAB.
ГЛАВА 4
ОБРАБОТКА
В ЧАСТОТНОЙ
ОБЛАСТИ
Введение
Материал этой главы во многом параллелен обсуждавшимся в гл. 3 методам
фильтрации, однако здесь фильтрация будет производиться в частотной обла-
сти после выполнения преобразования Фурье. Находясь в основе методов ли-
нейной фильтрации, преобразование Фурье обеспечивает значительную гибкость
при разработке и реализации алгоритмов фильтрации при решении задач улуч-
шения, восстановления и сжатия изображений. Преобразование Фурье также ле-
жит в фундаменте великого множества других важный практических приложе-
ний. В этой главе внимание сфокусировано на основах фильтрации в частотной
области, реализуемой средствами MATLAB. Как и в гл. 3, мы проиллюстриру-
ем фильтрацию в частотной области примерами по улучшению изображений,
включая фильтры низких частот, базовую фильтрацию высоких частот, а также
фильтрацию с усилением высоких частот. Мы коротко остановимся на том, как
частотная и пространственная фильтрации, выполненные одновременно, могут
дать хорошие результаты, недоступные при использовании только одного типа
фильтрации. Концепции и методы, развиваемые в следующих параграфах, явля-
ются достаточно общими, поэтому они будут часто иллюстрироваться в других
приложениях, которым посвящены гл. 5, 8 и 11.
4.1. Двумерное дискретное преобразование Фурье
Пусть f(x, у), при а? = 0,1,2,..., — 1 и ?/ = 0,1,2,..., .А — 1, обозначает изобра-
жение MxN. Двумерное дискретное преобразование Фурье (DFT, Desrete Fourier
Transform) изображения /, которое обозначается F(u,v), задается уравнениями
М-1 TV-1
F(u,u) = ^2 12 f(x,y')e~j2^ux^M+vv^N'>
x=G у=0
при и = 0,1,2,..., М — 1 и и = 0,1,2,. ., N — 1. Мы могли бы разложить экспо-
ненту на синусы и косинусы от переменных ните соответствующими частотами
(переменные х и у уйдут после суммирования). Частотной областью называ-
ется координатная система, задающая аргументы F(u,v) частотными перемен-
ными и и и. Здесь можно обнаружить аналогию с заданием аргументов f(x, у)
пространственными переменными х тл у. Прямоугольную область размера МxN,
4-1. Двумерное дискретное преобразование Фурье 123
задаваемую при и = 0,1,2,..., М — 1 и v = 0,1,2, ., N — 1, принято называть
частотным прямоугольником. Видно, что частотный прямоугольник имеет те
же размеры, что и исходное изображение.
Обратное дискретное преобразование Фурье задается уравнениями
M-1N-1
F(x,y) = MN £ Е
u=0 w=0
при х = 0,1,2,..., М — 1 и у = 0,1,2,..., N — 1. Таким образом, зная F(u, v),
можно восстановить f(x,y) с помощью обратного DFT. Величины F(u,v) в этих
уравнениях принято называть коэффициентами разложения Фурье.
В некоторых определениях коэффициент 1/MN помещается в прямое преоб-
разование, а в других — в обратное. Для совместимости с реализацией преобра-
зования Фурье в системе MATLAB мы будем считать, что коэффициент 1/MN
расположен в формулах обратного преобразования, как это приведено выше. По-
скольку индексы массивов в MATLAB начинаются с 1, а не с 0, в MATLAB фор-
мулы F(l, 1) и f (1, 1) соответствуют математическим величинам F(0,0) и /(0,0),
которые стоят в прямом и обратном преобразованиях.
Значение преобразования Фурье в начале координат частотной области (т. е.
величина F(0,0)) называется коэффициентом или компонентой de преобразо-
вания Фурье. Эта терминология пришла из электротехники, где «de» означает
«direct current», постоянный электрический ток (ток с нулевой частотой). Лег-
ко показать, что величина F(0,0) равна числу MN, умноженному на среднее
значение функции f(x,y).
Даже если изображение f(x, у) вещественно, его преобразование Фурье яв-
ляется, как правило, комплексным. Основной метод визуального анализа этого
преобразования заключается в вычислении его спектра (т. е. абсолютной вели-
чины F(u,u)) и его отображения на дисплее. Пусть Д(ц,г>) и 1(и, и) обозначают
вещественную и мнимую компоненты F(u,u), тогда спектр Фурье задается вы-
ражением
|F(u,v)| = [Я2(и,г) +I2(u,u)]1/2
Фазовый угол (угол сдвига фазы) преобразования задается формулой
1(ц, и)
F(u, г>)
Введенные выше функции можно использовать для представления F(u, v) в стан-
дартных полярных координатах разложения комплексных величин
F(u,v) = \Р(и,и)\еЖи’^.
Энергетический спектр (или спектральная функция) равен квадрату модуля
F(u, v) = |F(u, п)|2 = Д2(ц, и) + /2(ц, и).
С точки зрения визуализации не принципиально, какую функцию отображать на
экране, |F(u,u)| или P(u,v).
ф(и,и) = arctg
124 Глава 4- Обработка в частотной области
Если f(x,y) вещественно, то его преобразование Фурье является сопряженно
симметричным относительно начала координат, т. е.
F(u, v) = F* (—и, —v),
что означает симметрию спектра Фурье относительно начала координат:
|F(u,v)| = |F(—и, -v)|.
Сделав прямую подстановку в уравнения для F(u/c), можно показать, что
F(u,v) = F(u + M,v) = F(u,v + TV) = F(u + M,v + N).
Другими словами, функция DFT является периодической по обеим переменным
и и V, периоды которой равны М и N соответственно. Обратное преобразование
Фурье также имеет свойство периодичности:
f(x, у) = f(x + М,у) = f(x, у + N) = f(x +М,у + N).
Это свойство часто приводит к затруднениям, так как интуитивно не очевидно,
что взятие обратного преобразования Фурье приводит к периодической функции.
Стоит помнить, что это обстоятельство просто является математическим свой-
ством прямого и обратного DFT. Заметьте также, что в конкретных реализациях
вычисляется только один период DFT, поэтому мы будем работать с массивами
размера MxN.
Рис. 4.1. а) Спектр Фурье
показан составлением рядом
двух полупериодов а интер-
вале [О, М 1]. б) Переме-
щение центра спектра в том
же интервале, которое дости-
гается умножением /(а?) на
(—1)® до взятия преобразова-
ния Фурье
(М точек)
Свойство периодичности весьма важно при изучении того, как данные DFT
связаны с периодами преобразования. Например, на рис. 4.1, а) показан спектр
F(u) одномерного преобразования Фурье. В этом случае свойство периодичности
выражается формулой F(u) = F(u + M'), откуда следует, что |F(u)| = |F(u +1И)|,
4-1. Двумерное дискретное преобразование Фурье
л из свойства симметрии заключаем, что F(u) = F(—u). Свойство периодичности
называет на то, что F(u) имеет период М, а свойство симметрии означает сим-
метрию функции относительно начала координат, как показано на рис. 4.1, а).
Этот график, а также предыдущие комментарии показывают, что модули вели-
чин преобразования от М/4 до М — 1 являются повтором величин из первой
половины слева от начала координат. Поскольку в одномерном DFT необходимо
вычислять М точек (т. е. для величин и из интервала [О, М—1]), то достаточно вы-
числить преобразование для первой половины точек. Нам нужен один, правильно
упорядоченный период на интервале [О, М — 1]. Нетрудно показать (см. [Gonzalez,
Woods, 2002]), что нужный период получается умножением /(х) на (—1)х до вы-
числения преобразования. На самом деле, все это означает перемещение начала
координат преобразования в точку и = М/2, как показано на рис. 4.1, б). Те-
перь величина спектра при и = 0 на рис. 4.1, б) соответствует |F(—Л//2)| на
рис. 4.1, а). Аналогично, величины |F(M/2)| и |F(A/ —1)| на рис. 4.1, б) соответ-
ствуют величинам |F(0)| и |F(A//2 — 1)|.
Похожая ситуация наблюдается для двумерных функций. Вычисление дву-
мерного DFT дает точки преобразования в прямоугольной области, показанной
на рис. 4.2, а), где затененная область показывает величины F(u,v), которые
вычисляются по формулам, указанным в начале этого параграфа. Пунктирные
прямоугольники получаются периодическим повторением, как на рис. 4.1, а). За-
тененная область показывает, что величины F(u, и) распадаются на 4 периодиче-
ских квадранта, которые соприкасаются в точке, указанной на рис. 4.2, а). Визу-
альный анализ спектра упрощается, если переместить начало координат преоб-
разования в центр спектрального прямоугольника. Это можно сделать, умножив
f(x.y) на (—1)х+2/ до вычисления преобразования Фурье. Тогда периоды выстраг
иваются так, как показано на рис. 4.2, 0). Как и при обсуждении одномерных
функций, значение спектра в точке (М/2,А/2) на рис. 4.2, б) совпадает со значе-
нием в (0, 0) на рис. 4.2, а), а значение в (0,0) на рис. 4.2, б) совпадает со значе-
нием в —N/2) на рис. 4.2, а). Аналогично, значение в точке (М — 1,АГ— 1)
на рис. 4.2, б) равно значению в (Af/2 — 1, N/2 — 1) на рис. 4.2, а).
Рис. 4.2. а) Спектр Фурье разме-
ра MxN (затененная область); по-
казан составлением 4 квадрантов.
б) Спектр, полученный умножением
f(x,y) на (—1)а‘+и до взятия преоб-
разования Фурье. Показан один пе-
риод (затененный), поскольку толь-
ко его необходимо вычислить по фор-
муле
[_ 1 Периоды двумерного DFT
| | Массив данных. M*N, который
получается при вычислении F[u, v)
Приведенные выше рассуждения о центрировании преобразования с помо-
щью умножения f(x,y) на (— 1)х+2/ представляют важную концепцию, которая
126 Глава 4- Обработка в частотной области
здесь приводится для полноты изложения. Однако при работе с MATLAB под-
ход заключается в вычислении преобразования без умножения на (—1)х+2/, после
чего данные передвигаются с помощью функции fftshift. Эта функция и ее
применение обсуждаются в следующем параграфе.
4.2. Вычисление и визуализация двумерного DFT в
MATLAB
Прямое и обратное DFT на практике вычисляются с помощью алгоритма быст-
рого преобразования Фурье (FFT, Fast Fourier Transform). Алгоритм FFT мас-
сива f изображения M'/N реализован в пакете функцией fft2, которая имеет
следующий синтаксис:
F fft2(f).
Эта функция возвращает преобразование Фурье размера MxN, причем данные
организованы в форме, представленной на рис. 4.2, а), т. е. начало данных нахо-
дится в верхнем левом угле, где имеется четыре четверть-периода (квадранта),
которые примыкают к центральной точке частотной области.
Как объясняется в § 4.3.1, необходимо дополнять входное изображение ну-
лями при использовании преобразования Фурье в фильтрации. В этом случае
синтаксис имеет вид
F = fft2(f, Р, Q).
В этом случае функция fft2 дополняет входное изображение нужным количе-
ством нулей, и результат ее выполнения имеет размер Px.Q.
Для получения спектра Фурье следует применить команду
S = abs(F),
которая вычисляет абсолютную величину (корень квадратный из суммы квадра-
тов вещественной и мнимой частей) каждого элемента массива.
Визуальный анализ спектра при отображении его в виде изображения яв-
ляется важным инструментом при работе в частотной области. В качестве ил-
люстрации рассмотрим простое изображение f на рис. 4.3, а). Мы вычисляем
преобразование Фурье и отображаем его спектр с помощью следующей последо-
вательности шагов:
» F = fft2(f) ;
» S = abs(F);
>> imshow(S, [ ]);
На рис. 4.3, б) приведен результат этих действий. Четыре яркие точки по углам
изображения появляются в силу свойства периодичности, объясненного в преды-
дущем параграфе.
Функцию fftshift пакета можно использовать для смещения начала коор-
динат преобразования в центр частотной области. Ее синтаксис имеет вид
Fc = fftshift(F) ,
Jf.&. Вычисление и визуализация двумерного DFT в MATLAB
де F — это преобразование, вычисленное с помощью f ft2, a Fc — отцентрован-
ое преобразование. Функция f ftshift переставляет квадранты F надлежащим
пособом. Например, если а [1 2; 3 4], то fftshift(а) [4 3; 2 1]. Если
рименять это действие после вычисления преобразования Фурье, то результат
удет в точности совпадать с умножением изображения на (—l)®4^ перед выпол-
ением преобразования. Заметим, однако, что эти два процесса нельзя переста-
ить, т. е., если обозначить оператор преобразования фурье через 9[-], который
рименяется к аргументу, то выражение S[(—l)3:+j'/(a?, у)] эквивалентно вычисле-
ию f ftshift (fft2(f)), но действие fft2(fftshift(f)) приведет к совершенно
ному результату.
В предыдущем примере, набрав команды
> Fc = fftshift(F);
>> imshow(abs(Fc), [ ]);
олучим рис. 4.3, в). Результат, очевидно, отвечает центрированию этого изоб-
ажения.
Рис. 4.3. а) Простое изоб-
ажение. б) Спектр Фурье.
Центрированный спектр.
Спектр, улучшенный функ-
:тй log для бблыпей нагляд-
-ости
Хотя сдвиг спектра был сделан корректно, динамический диапазон его значе-
ий весьма широк (от 0 до 204000) по сравнению с 8 битами дисплея, на котором
оминируют яркие значения в центре. Как уже обсуждалось в § 3.2.2, эту проб-
ему можно разрешить с помощью преобразования log, выполнив команды
> S2 = log(l + abs(Fc));
> imshow(S2, [ ]);
126 Глава 4- Обработка в частотной области
результат которых приведен на рис. 4.3, г). На этом изображении хорошо замет-
но визуальное улучшение отдельных деталей.
Функция if f tshift обращает центрирование спектра. Ее синтаксис имеет вид
F ifftshift(Fc).
Эту функцию можно использовать для приведения спектра к его первоначально-
му виду, т. е. когда центр спектра расположен в верхнем левом углу прямоуголь-
ника. Это свойство будет использоваться в § 4.4.
Обратите внимание на то, что центр частотного прямоугольника находится в
точке (AL/2,А/2), когда координаты пит пробегают интервал от 0 до М — 1 и
до N — 1 соответственно. Например, центр частотного квадрата 8x8 находится
в точке (4,4), т. е. в пятой точке по каждой оси, если считать от точки (0,0).
Если, как в системе MATLAB, эти переменные меняются от 1 до М и от 1 до
N соответственно, то центр квадрата имеет координаты [(М/2) + 1, (А/2) + 1].
В нашем примере с квадратом 8x8 цент находится в точке (5,5), если считать
от (1,1). Ясно, что эти два центра отвечают одной и той же точке, однако это
место может быть источником ошибок и разночтений при нахождении координат
центров DFT при вычислениях на MATLAB.
Если М и N — нечетные числа, то центр при вычислениях в MATLAB опре-
деляется округлением М/2п N/2 в сторону уменьшения до ближайшего целого.
Дальнейший анализ делается как в предыдущем абзаце. Например, центр обла-
сти 7x7 находится в точке (3,3), если считать от (0,0), и он имеет координаты
(4,4), если начало есть (1,1). В обоих случаях центр расположен в четвертой точ-
ке от начала отсчета. Если только одна из размерностей нечетна, то координаты
центра по этому направлению вычисляются округлением, как описано выше. Ис-
пользуя функцию floor1 из MATLAB и помня, что начало отсчета находится в
точке (1,1), центр частотного прямоугольника вычисляется по формуле
[floor(М/2) +1, floor(N/2) + 1],
которая дает правильный результат и для четных, и для нечетных величин М и N.
Наконец, укажем, что обратное преобразование Фурье вычисляется с помо-
щью функции ifft2, синтаксис которой имеет вид
f ifft2(F),
где F — это преобразование Фурье, a f - соответствующее изображение. Если
исходное изображение, использованное при вычислении F, было вещественным,
то и обратное преобразование, в теории, должно быть вещественным. Однако на
практике выход ifft2 часто имеет очень малую мнимую компоненту, которая
получается из-за ошибок округления при выполнении арифметических действий
с плавающей запятой. Поэтому хорошим практическим советом является выде-
ление вещественной части после выполнения обратного преобразования Фурье,
1 Команда В = floor (А) округляет каждый элемент массива А до ближайшего целого числа, не
превосходящего его по значению. Функция ceil округляет до ближайшего целого, большего
или равного заданному числу.
4-3. Фильтрация в частотной области
чтобы изображение имело вещественные пикселы. Эти два действия можно вы-
•* 2
полнить в одной команде :
>> f reaHif ft2(f)) ;
Как и в случае прямого преобразования, эта функция имеет альтернативную
форму ifft2(f, Р, Q), когда F расширяется нулями до размера РхQ до совер-
шения преобразования. Эта опция не будет использоваться в нашей книге.
4.3. Фильтрация в частотной области
Фильтрация в частотной области имеет весьма простую концепцию. В этом пара-
графе будет сделан краткий обзор понятий, связанных с фильтрацией, а также
будут приведены некоторые ее реализации на MATLAB.
4.3.1. Базовые концепции
Основой линейной фильтрации в частотной и пространственной области служит
теорема о свертке, которую можно сформулировать так3:
/(аг, у) * h(x,у) <=> Н{и, v)F(u, v),
и в обратную сторону
f(x, y)h(x, у) Н(u, v) * F(u, f).
Здесь символ «*» обозначает операцию свертки двух функций, а выражения по
обе стороны от двойных стрелок определяют соответствующие пары при преоб-
разовании Фурье. Например, первое выражение означает, что свертку двух про-
странственных функций можно получить, если вычислить обратное преобразова-
ние Фурье от произведения прямых преобразований Фурье этих двух функций.
Наоборот, прямое преобразование Фурье свертки двух пространственных функ-
ций дает произведение их прямых преобразований Фурье. Аналогичным образом
можно прокомментировать и второе утверждение.
Применительно к фильтрации нас интересует первое из приведенных выше
выражений. Фильтрация в пространственной области состоит из свертки изобра-
жения f(x,y) и маски h(x, у). Линейная пространственная свертка объяснялась
в § 3.4.1. В соответствии с теоремой о свертке, тот же результат можно полу-
чить в частотной области, умножив F(u, v) на Н(и, г) преобразование Фурье
пространственного фильтра. Принято называть Н(и, и) передаточной функцией
фильтра.
На самом деле, основная идея фильтрации в частотной области заключается
в подборе передаточной функции фильтра, которая модифицирует F(u, v) специ-
фическим образом. Например, фильтр на рис. 4.4. а) имеет передаточную функ-
^Функции real (arg) и image (arg) извлекают, соответственно, вещественную и мнимую части
arg.
Для цифровых изображений эти выражения выполняются строго, только когда функции
(х, у) и h(x,y) продолжены нулями правильным образом, что обсуждается позже.
Глава 4- Обработка в частотной области
цию, которая, будучи умноженной на центрированную функцию F(u, г>), ослабля-
ет высокочастотные компоненты F(u, v) и оставляет низкочастотные компонен-
ты относительно неизменными. Фильтр с такими характеристиками называется
низкочастотным. В § 4.5.2 показывается, что результатом низкочастотной филь-
трации является размытие (сглаживание) изображения. На рис. 4.4, б) приведен
тот же фильтр после его сдвига функцией fftshift. Такой формат фильтров
особенно часто используется в этой книге при фильтрации в частотной области,
когда преобразования Фурье не центруются.
Основываясь на теореме о свертке, мы знаем, что для получения соответству-
ющего отфильтрованного изображения в пространственной области нам следует
просто вычислить обратное преобразование Фурье от произведения Н{и, v)F(u, и).
Еще раз обращаем ваше внимание на то, что результат этих действий будет
идентичен выполнению операции свертки в пространственной области с маской
h(x, у), которая есть обратное преобразование Фурье от Н(и, и). На практике про-
странственная фильтрация сильно упрощается при использовании малых масок,
которые стремятся поймать выраженные характеристики их частотных двойников.
Рис. 4.4. Передаточные функ-
ции а) центрированного низко-
частотного фильтра; б) в фор-
мате, используемом при филь-
трации в DFT. Напомним, что
здесь изображены фильтры в
частотной области
Как отмечалось в § 4.1, изображения и их преобразования автоматически счи-
таются периодическими, если фильтрация реализована на основе DFT. Нетрудно
дать визуальные примеры свертки периодических функций, для которых возни-
кают эффекты интерференции между смежными периодами, если эти периоды
близко относительно длины ненулевых частей функций. Эту интерференцию,
которую принято называть ошибкой возврата или ошибкой перекрытия, можно
подавить, дополняя функции нулями следующим образом.
Предположим, что функции f(x,y) и h(x,y) имеют размеры Ах В и CxD
соответственно. Мы формируем две расширенные функции, обе имеющие разме-
ры PxQ, путем добавления нулей к / и д. Можно показать, что ошибка пере-
крытия не происходит, если выбрать
73 > А + С +1 и Q > В + D + 1.
В этой книге в основном рассматриваются функции одинаковых размеров MxN.
В этом случае сформулированное правило имеет следующий вид: Р > 2М — 1 и
Q > 2N - 1.
Следующая функция, называемая paddedsize, вычисляет минимальные чет-
ные4 значения для Р и Q, которые удовлетворяют этим условиям. Имеется также
4Принято работать с массивами четных размерностей для ускорения вычисления FFT.
4-3. Фильтрация в частотной области 131
опция, позволяющая дополнять входные данные до квадрата, длина стороны ко-
торого равна ближайшей степени числа 2. Время выполнения алгоритма FFT за-
висит, грубо говоря, от числа простых делителей Р и Q. Этот алгоритм работает
быстрее, когда Р и Q являются степенями двойки, чем когда Р и Q — простые
числа. Кроме того, на практике можно посоветовать работать с квадратными
изображениями и фильтрами, т. е. чтобы фильтрация имела одинаковые разме-
ры по обоим измерениям. Функция paddedsize позволяет делать такой выбор
достаточно гибко, исходя из входных параметров.
В функции paddedsize векторы АВ, CD и PQ имеют элементы [А В], [С D] и
[Р Q] соответственно (все эти числа были определены выше)5.
function PQ = paddedsize(АВ, CD, PARAM)
’/oPADDEDSIZE Computes padded sizes useful for FFT-based filtering.
7. PQ = PADDEDSIZE(AB), where AB is a two-element size vector,
7o computes the two-element size vector PQ = 2*AB.
7.
7o PQ PADDEDSIZE(AB, ’PWR2’) computes the vector PQ such that
7. PQ(D = PQ(2) = 2“nextpow2(2*m), where m is MAX (AB) .
7.
7. PQ = PADDEDSIZE(AB, CD), where AB and CD are two-element size
7o vectors, computes the two-element size vector PQ. The elements
7. of PQ are the smallest even integers greater than or equal to
7. AB + CD 1.
7.
7. PQ = PADDEDSIZE(AB, CD, ’PWR2’) computes the vector PQ such that
7. PQ(D = PQ(2) = 2“nextpow2(2*m), where m is MAX([AB CD])
if nargin == 1
PQ = 2*AB;
elseif nargin == 2 & “ischar(CD)
PQ = AB + CD 1;
PQ = 2 * ceil(PQ / 2);
elseif nargin == 2
m max (AB); 7« Maximum dimension.
7, Find power-of-2 at least twice m.
P = 2“nextpow2(2*m);
PQ = [P, P];
elseif nargin == 3
m max ([AB CD]); 7o Maximum dimension.
P 2“nextpow2(2*m);
PQ = [P, P] ;
else
error(’Wrong number of inputs.’)
end
5Функция p = nextpow2(n) возвращает наименьшую степень p числа 2, для которой 2Р не мень-
ше абсолютной величины п.
Глава 4- Обработка в частотной области
Определив PQ с помощью функции paddedsize, вычислим быстрое преобра-
зование Фурье по формуле
F = fft2(f, PQ(1), PQ(2)).
При этом к изображению f добавляется достаточное количество пулей, чтобы по-
лученное изображение имело размеры PQ(l)xPQ(2), а затем вычисляется FFT.
Отметим, что при использовании расширения функция фильтра в частотной об-
ласти должна иметь размеры PQ (1) xPQ(2).
Пример 4.1. Эффекты фильтрации с использованием и без использования про-
цедуры расширения.
Изображение f, приведенное на рис. 4.5, а), иллюстрирует фильтрацию с расши-
рением и без расширения. Здесь также используется функция Ipf ilter, которая
строит гауссов низкочастотный фильтр (подобный фильтру на рис. 4.4, б)) с за-
данным значением параметра сигма (sig). Эта функция и ее синтаксис будут
детально рассматриваться в § 4.5.2, но мы пока воспользуемся ею без пояснений.
Рис. 4.5. а) Простое изображение размера 256x 256. 6) Результат низкочастотной филь-
трации без расширения, в) Результат низкочастотной фильтрации с расширени-
см. Сравните вертикальные границы ярких областей б) и в)
Следующие команды совершают фильтрацию без расширения:
> > [М, N] size(f);
» F fft2(f);
> > sig 10;
> > Н Ipfilter(’gaussian’, M, N, sig);
» G H.*F;
> > g real(ifft(2(G));
> > imshow(g, [ ]);
На рис. 4.5, б) построено изображение g. Как и ожидалось, оно выглядит
размытым везде, кроме вертикальных границ. Объяснить это можно с помо-
щью рис. 4.6, а), на котором графически изображено воображаемое периодиче-
:кое повторение изображения при вычислении DFT. Тонкие белые линии между
изображениями проведены для удобства обзора. Они не являются частью дан-
ных. Пунктирные линии используются для обозначения (произвольного) ^x^
4-3. Фильтрация в частотной области
изображения, обрабатываемого fft2. Представьте себе свертку фильтра сгла-
живания с такой бесконечной периодической последовательностью. Очевидно,
что при прохождении фильтра сверху пунктирного изображения, он пересечет
верхнюю часть самого изображения, а также нижнюю часть периодической ком-
поненты, находящейся выше этого изображения. Таким образом, когда черная
и белая области смешиваются в фильтре, результатом будет серый (размытый)
вид. Это в точности то, что показано в верхней части рис. 4.5, а). С другой сторо-
ны, когда фильтр находится на границе яркой части пунктирного изображения,
му встретятся идентичные области, поэтому там размытия результата не будет.
Объяснение других частей изображения на рис. 4.5, б) делается аналогично.
Рис. 4.6. а) Бесконечное пе-
одическое повторение изоб-
ражения на рис. 4.5, а). Пунк-
тиром окружена область, к ко-
-•ий применяется fft2. 6) Та
лее периодическая последова-
тыюсть после расширения
тями. Тонкие белые линии
'троены для удобства, они
являются частью данных
Рассмотрим теперь фильтрацию с расширением:
> PQ paddedsize(size(f));
> Fp = fft2(f, PQ(1), PQ(2)); ’4 Compute the FFT with padding.
> Hp lpfilter(’gaussian’, PQ(1), PQ(2), 2*sig);
> Gp = Hp.*Fp;
Глава 4- Обработка в частотной области
» gp real(ifft(2(Gp));
>> gpc gp(l:size(f ,1), l:size(f,2));
>> imshow(g, [ ]);
В этом примере параметр сигма равен 2*sig, поскольку здесь размер фильтра в
два раза больше, чем у фильтра без расширения.
Рис. 4.7. Полное расширенное изоб-
ражение после фильтрации. Размер
этого изображения равен 512x512
На рис. 4.7 показано полное расширенное и
отфильтрованное изображение gp. Окончатель-
ный результат на рис. 4.5, в) был получен об-
резанием рис. 4.7 до исходных размеров (см.
предпоследнюю команду из приведенной вы-
ше последовательности). Этот результат можно
объяснить с помощью рис. 4.6, б), на котором
пунктиром выделено исходное изображение, про-
долженное нулями, что делается до выполне-
ния команды fft2(f, PQ(1), PQ(2)). Перио-
дическая последовательность строится как и на
рис. 4.6, а). Теперь изображение на границах
имеет одинаковое черное окружение, поэтому
свертка сглаживающего фильтра с этой беско-
нечной последовательностью даст одинаковые
размытия на границах всех светлых частей ис-
ходного изображения. Тождественный резуль-
тат получается при выполнении следующих ко-
манд пространственной фильтрации:
>> h = fspecial(’gaussian’, 15, 7);
>> gs = imf liter (f, h);
Напомним, что такая форма вызова функции imf ilter расширяет по умолчанию
границы изображения нулями (см. § 3.4.1). □
4.3.2. Основные шаги фильтрации в частотной области
Обсуждавшиеся в предыдущем параграфе действия можно формализовать в ви-
де следующей пошаговой процедуры с использованием функций MATLAB. Че-
рез f обозначим исходное изображение, а через g — результат фильтрации. Пред-
полагается, что передаточная функция H(u,v) имеет те же размеры, что и ис-
ходное изображение.
1. Получить параметры расширения с помощью paddedsize:
PQ paddedsize(size(f)) ;
2. Построить преобразование Фурье с расширением:
F fft2(f, PQ(1), PQ(2));
3. Сгенерировать функцию фильтра Н размера PQ(l)xPQ(2) одним из опи-
сываемых далее методов. Фильтр должен иметь формат, показанный на
рис. 4.4, б). Если он был центрирован, до использования его в фильтрации
следует выполнить команду Н = fftshift(H).
4-3. Фильтрация в частотной области
4. Умножить преобразование Фурье на передаточную функцию фильтра:
G H.*F;
5. Найти вещественную часть обратного преобразования Фурье от G:
g real(ifft2(G) ) ;
6. Вырезать верхний левый прямоугольник исходных размеров:
g g(l:size(f,1), l:size(f,2));
Эта процедура фильтрации схематически изображена на рис. 4.8. Предвари-
тельная стадия обработки может состоять из определения размеров изображения,
вычисления параметров расширения и генерации фильтра. Заключительная ста-
дия обработки состоит в выделении вещественной части результата, обрезания
изображения до исходного размера и его конвертации в класс uint8 или uintl6
для сохранения на диске.
fa, у) g(x, у)
Входное Улучшенное
изображение изображение
Рис. 4.8. Основные шаги фильтрации в частотной области
Передаточная функция фильтра Н(u, и) на рис. 4.8 умножается на веществен-
ную и мнимую части F(u, г). Если функция Н(и, v) была вещественной, то фазо-
вая часть произведения не меняется, что видно из фазового уравнения (см. § 4.1),
так как при умножении вещественной и мнимой части комплексного числа на од-
но и то же вещественное число фазовый угол не меняется. Такие фильтры приня-
то называть фильтрами с нулевым сдвигом фазы. В этой главе рассматриваются
только такие фильтры.
Из теории линейных систем хорошо известно, что при выполнении некоторых
слабых условий подача одиночного импульса в линейную систему полностью опи-
сывает характеристики этой системы. При работе с конечными линейными си-
стемами, что имеет место в данной книге, отклик линейной системы, включая
отклик на одиночный импульс, также является конечным. Если линейная си-
стема является пространственным фильтром, то можно полностью описать этот
фильтр, подавая на вход одиночный импульс и наблюдая соответствующий от-
клик. Такие фильтры называются фильтрами с конечной импульсной характери-
стикой (FIR, Finite Impulse Response). Все пространственные фильтры в данной
книге имеют тип FIR.
Глава 4- Обработка в частотной области
4.3.3. М-функция для фильтрации в частотной области
Последовательность описанных выше шагов фильтрации используется в этой гла-
ве и в части следующей, поэтому удобно иметь М-функцию, аргументами которой
являются изображение и передаточная функция фильтра, которая выполняет все
необходимые процедуры фильтрации и возвращает отфильтрованное и обрезан-
ное изображение. Следующая функция как раз совершает все эти действия.
function g = dftfilt(f, Н)
7DFTFILT Performs frequency domain filtering.
7. G = DFTFILT(F, H) filters F in the frequency domain using the
7o filter transfer function H. The output, G, is the filtered
7« image, which has the same size as F. DFTFILT automatically pads
7» F to be the same size as H. Function PADDEDSIZE can be used
7. to determine an appropriate size for H.
7.
7» DFTFILT assumes that F is real and that H is a real, uncentered,
circularly-symmetric filter function.
7» Obtain the FFT of the padded input.
F = fft2(f, size(H, 1), size(H, 2));
7. Perform filtering.
g = real(ifft2(H.*F)) ;
7. Crop to original size.
g = g(l:size(f, 1), l:size(f, 2));
Техника построения фильтров в частотной области обсуждается в следующих
трех параграфах.
4.4. Построение фильтров в частотной области по
пространственным фильтрам
В общем случае фильтрация в пространственной области является более эффек-
тивной с вычислительной точки зрения, чем фильтрация в частотной области,
когда используются «малые» фильтры. Точное определение этой малости яв-
ляется весьма трудным вопросом, ответ на который зависит от таких факторов,
как тип компьютера и выбор алгоритма, а также от многих других параметров,
например, от размеров буферов. Важную роль играет то обстоятельство, насколь-
ко удобно реализовано обращение с комплексными данными, а также множество
других факторов, которые выходят за рамки нашего обсуждения. Сравнение, вы-
полненное в (Brigham, 1988], для одномерных функций показало, что фильтрация
с использованием алгоритма быстрого преобразования Фурье FFT выполняется
быстрее, чем пространственная реализация этого процесса, когда функция имеет
примерно 32 точки, т. е. их число невелико. Поэтому полезно знать, как конвер-
тировать пространственные фильтры в эквивалентную частотную форму, чтобы
иметь возможность сравнивать эти два подхода.
Самый очевидный метод построения частотного фильтра Н, отвечающего простран-
ственному фильтру h, состоит в выполнении команды Н = fft2(h, PQ(1), PQ(2)),
4-4- Построение фильтров в •частотной области по пространственным
где значения вектора PQ зависят от размеров изображения, которое будет филь-
троваться (см. предыдущий параграф). Тем не менее, в этом параграфе мы будем
интересоваться следующими вопросами:
(1) как преобразовать пространственный фильтр в частотный;
(2) как сравнивать результаты, получаемые при пространственном фильтрова-
нии функцией imf ilter, с результатами фильтрования в частотной области,
которые обсуждались выше.
Как объяснялось в § 3.4.1, раз функция imf ilter использует корреляцию и на-
чало координат фильтра расположено в его центре, то для достижения эквива-
лентных результатов при обоих подходах необходимо выполнить определенную
предварительную обработку данных. В пакете имеется функция f reqz2, которая
в точности совершает эти действия, а выходом этой функции служит соответ-
ствующий фильтр в частотной области.
Функция freqz2 вычисляет частотный отклик фильтра FIR, а в этой книге
рассматриваются только такие фильтры. Тогда в результате получаем нужный
фильтр в частотной области. Интересующая нас команда выглядит следующим
образом:
Н freqz2(h, R, С),
где h — это двумерный пространственный фильтр, а Н — соответствующий ему
двумерный фильтр в частотной области. Здесь R обозначает нужное нам число
строк, а С — нужное число столбцов фильтра Н. Обычно полагается, что R =
PQ (1) и С PQ (2) (см. § 3.4.1). Если записать функцию f reqz2 без обозначения
выходной переменной, то абсолютная величина Н будет изображена на рабочем
столе MATLAB в виде трехмерного аксонометрического графика. Использование
в приложениях функции f reqz2 легко понять, разобрав следующий пример.
Пример 4.2. Сравнение фильтрации в пространственной и частотной обла-
стях.
Рассмотрим изображение f размером 600x600 пикселов, приведенное на рис. 4.9, а).
Сейчас мы сгенерируем фильтр Н в частотной области, соответствующий про-
странственному фильтру Собела, который улучшает вертикальные края изобра-
жения (см. табл. 3.4). Затем мы сравним результаты фильтрации f в простран-
ственной области с помощью маски Собела (используя imf ilter) с результата-
ми, полученными при совершении эквивалентного процесса в частотной области.
На практике фильтрация с малыми фильтрами вроде маски Собела может быть
реализована непосредственно в пространственной области, как говорилось рань-
ше. Однако мы выбрали этот фильтр в демонстративных целях, так как он имеет
простые коэффициенты, а результаты его фильтрации интуитивно ясны и легко
поддаются сравнению. С большими фильтрами можно обращаться аналогично.
На рис. 4.9, б) дан спектр Фурье f, полученный следующими командами:
F fft2(f);
S fftshift(log(l + abs(F));
S gscale(S);
imshow(S);
частотной области
Рис. 4.9. а) Полутоновое изоб-
ражение. 6) Ei-o спектр Фурье
Теперь строим пространственный фильтр функцией f special:
h f special(’sobel’);
h
1 0 -1
2 0-2
10-1
Чтобы увидеть график соответствующего фильтра в частотной области, надо
набрать
freqz2(h)
Рис. 4.10. а) Абсолютное зна-
чение частотного фильтра, со-
ответствующего вертикальной
маске Собела. 6) Тот же
фильтр после преобразования
fftshift. На рисунках е) и г)
эти же фильтры построены в
виде изображений
На рис. 4.10, а) приведен этот график с опущенными координатными осями (тех-
ника построения трехмерных аксонометрических графиков обсуждается в § 4.5.3).
Сам фильтр строится командами
Построение, фильтров в частотной области по пространственным
» PQ paddedsize(size(f));
» Н freqz2(h, PQ(1), PQ(2));
> > Hl ifftshift(H);
где команда if ftshift выполняется для перестановки данных так, чтобы начало
координат фильтра находилось в верхнем левом углу частотного прямоугольни-
ка. Па рис. 4.10, б) дан график abs(Hl). На рис. 4.10, в) и г) показаны абсолют-
ные значения Н и Н1 в виде полутоновых изображений, построенных командами
>> imshow(abs(Н) , [ ])
> > figure, imshow(abs(Hl), [ ])
Теперь строим отфильтрованное изображение. В пространственной области
используется команда1
> > gs imf ilter(double(f), h);
которая продолжает изображение за его границы по умолчанию нулями. Изоб-
ражение, отфильтрованное в частотной области, задается выражением
> > gf dftfilt(f, Hl);
На рис. 4.11, а) приведен результат команд
imshow(gs, [ ])
figure, imshow(gf, [ ])
Рис. 4.11. а) Результат филь-
трации рис. 4.9, а) в простран-
ственной области вертикаль-
ной маской Собела, б) Резуль-
тат фильтрации в частотной
области с помощью фильтра
показанного на рис. 4.10, б).
На рисунках е) и г) приведены
абсолютные значения а) и б)
1 Здесь используется функция double, чтобы иметь на выходе imfilter изображение этого клас-
са (см. § 3.4.1). Формат double понадобится в следующих вычислениях.
Глава i- Обработка в частотной области
Серый фон на этом рисунке объясняется тем, что оба изображения gs и gf име-
ют отрицательные значения, что приводит к изменению масштаба при выпол-
нении команды imshow. В §§ 6.6.1 и 10-1.3 маска Собела h будет использоваться
при решении задачи распознавания вертикальных краев изображения с помощью
абсолютной величины отклика этого фильтра. Поэтому имеет смысл построить
здесь абсолютные величины отфильтрованных выше изображений. Это сделано
на рис. 4.11, в) и г) посредством команд
>> figure, imshow(abs(gs), [ ])
>> figure, imshow(abs(gf) , [ ])
Края предметов можно выделить более отчетливо, если создать соответству-
ющие пороговые двоичные изображения:
>> figure, imshow(abs(gs) > 0.2*abs(max(gs(:))))
>> figure, imshow(abs(gf) > 0.2*abs(max(gf(:))))
где множитель 0.2 был выбран (достаточно произвольно) для того, чтобы выде-
лить участки изображений, на которых уровни пикселов больше 20% от макси-
мального значения изображений gs и gf. На рис. 4.12, а) и б) даны эти изобра-
жения.
Рис. 4.12. Пороговая обра-
ботка рис. 4.11, е) и г), соот-
ветственно, для более легко-
го выделения вертикальных
краев предметов
Изображения, построенные методами фильтрации в пространственной и ча-
стотной областях, являются практически идентичными. Этот факт можно про-
верить, вычислив их разность
d = abs(gs - gf)
и найдя максимальное и минимальное значения этой разности:
>> max(d(:))
ans =
5.4015е-012
>> min(d(:))
ans
О
4-5. Прямое построение фильтров в частотной области 141
Продемонстрированные подходы можно использовать при реализации любых
пространственных фильтров FIR произвольных размеров с помощью фильтров
в частотной области. □
4.5. Прямое построение фильтров в частотной области
В этом параграфе будет показано, как можно строить фильтры непосредственно
в частотной области. Мы будем работать с циклически симметричными филь-
трами, которые определяются как различные функции расстояния от начала ко-
ординат преобразования. Разработанные в качестве примеров М-функции могут
служить основой для построения других похожих функций. Мы начнем с реа-
лизации нескольких известных (низкочастотных) фильтров. Затем мы покажем,
как с помощью дополнительных средств визуализации и построения графиков в
MATLAB можно удобно отображать эти фильтры на экране компьютера. В конце
параграфа будут кратко обсуждаться (высокочастные) фильтры, повышающие
резкость изображения.
4.5.1. Построение сеточных массивов
для использования в фильтрах
в частотной области
В следующих М-функциях важную роль играет процедура вычисления расстоя-
ния между любыми точками частотного прямоугольника. Поскольку в MATLAB
при выполнении FFT предполагается, что начало отсчета находится в верхнем ле-
вом углу частотного прямоугольника, вычисления расстояния ведутся от этой точки.
Для лучшей визуализации центр данных можно смещать функцией fftshift.
Следующая функция dftuv создает сеточный массив, который используется
при вычислении расстояний и при других подобных действиях. (См. разбор функ-
ции meshgrid в § 2.10.4). Сеточный массивы, которые строит функция meshgrid,
уже приспособлены для применения в fft2 и ifft2 без дополнительного пере-
упорядочения1
function [U, V] dftuv(M, N)
7eDFTUV Computes meshgrid frequency matrices.
7» [U, V] DFTUV(M, N) computes meshgrid frequency matrices U and
7« V. U and V are useful for computing frequency-domain filter
% functions that can be used with DFTFILT. U and V are both
7. M-by-N.
7. Set up range of variables.
u 0:(M 1);
v = 0: (N 1) ;
7. Compute the indices for use in meshgrid.
idx find(u > M/2);
u(idx) u(idx) M;
idy find(v > N/2);
'Функция find обсуждается в § 5.2.2.
142 Глава 4- Обработка в частотной области
v(idy) = v(idy) N;
7. Compute the meshgrid arrays.
[V, U] = meshgrid(v, u);
Пример 4.3. Употребление функции dftuv.
В качестве иллюстрации рассмотрим следующие команды для вычисления квад-
рата расстояния от начала координат до всех точек частотного прямоугольника
размеров 8x5.
» [U, V] = dftuv(8, 5);
» D = U.“2 + V."2
D =
0 14 4 1
1 2 5 5 2
4 5 8 8 5
9 10 13 13 10
16 17 20 20 17
9 10 13 13 10
4 5 8 8 5
1 2 5 5 2
Обратите внимание на то, что расстояние до левой верхней точки равно 0, а
наибольшее расстояние — до центра прямоугольника, что соответствует фор-
мату, который объяснялся на рис. 4.2, а). Чтобы найти расстояния от центра
прямоугольника до всех его точек, достаточно применить к массиву D функцию
fftshift:
» fftshift(D);
ans =
20 17 16 17 20
13 10 9 10 13
8 5 4 5 8
5 2 1 2 5
4 1 0 1 4
5 2 1 2 5
8 5 4 5 8
13 10 9 10 13
Расстояние до точки (5,3) равно нулю, и массив симметричен относительно этой
точки. □
4.5.2. Низкочастотные фильтры
Идеальный низкочастотный фильтр (ILPF, Ideal Lowpass Filter) имеет переда-
точную функцию
1 при D(u, и) Do
0 при D(u, и) > Dq,
Н(и, г>) =
4-5. Прямое построение фильтров в частотной области 143
где Dq — это заданное неотрицательное число, a D(u,v) — расстояние от цен-
тра фильтра до точки (и, и). Геометрическое место точек (и,г>), для которых
D(u, г>) = Dq, является Окружностью. Помня о том, что фильтр Н умножается на
преобразование Фурье изображения, можно заключить, что идеальный фильтр
«срезает» (умножает на ноль) все компоненты F, лежащие вне этой окружности,
и оставляет неизменными (умножает на 1) все компоненты, находящиеся внутри
или на границе окружности. Несмотря на то, что этот фильтр невозможно реа-
лизовать на практике в аналоговой форме с помощью электронных компонент,
его, безусловно, можно смоделировать на компьютере с помощью заданной пере-
даточной функции. Свойства идеального фильтра часто бывают полезными при
объяснении таких явлений, как ошибки перекрытия.
Низкочастотный фильтр Баттерворта (BLPF, Butterworth LowPass Filter)
порядка п с обрезанием частот на расстоянии Do от начала координат имеет
передаточную функцию
= 1 + [P(u,u)/P0]2n ’
В отличие от идеального низкочастотного фильтра, функция фильтра BLPF не
имеет разрыва в пороговой точке Do- Для фильтров с гладкой передаточной
функцией принято задавать частоту срезания, которая определяется положени-
ем точек, для которых функция Н(и, г>) меньше определенной доли ее макси-
мального значения. В предыдущем уравнении значение Н(и, и) = 0.5 (т. е., 50%
от максимального значения, которое равно 1), когда D(u, и) = Dq.
Передаточная функция гауссова низкочастотного фильтра (GLPF, Gaussian
LowPass Filter) задается формулой
H(u,v) = e-D^u’v)/2a2
где а — это стандартное отклонение. Если положить а - Do, то получится сле-
дующее выражение в терминах срезающего параметра Do’.
H(u,v) = e~D2{u'vV2I%
При D(u, v) = Dq значение фильтра в этих точках меньше, чем 0.607 от макси-
мального значения, которое равно 1.
Пример 4.4. Низкочастотная фильтрация.
□дя пояснения введенных понятий мы применим гауссов низкочастотный фильтр
к изображению f размера 500x500 пикселов, приведенному на рис. 4.13, а). Мы
«зя.ти Dq, равное 5% от ширины расширения изображения. Совершая шаги филь-
рации, приведенные в § 4.3.2, имеем
> PQ = paddedsize(sized)) ;
> [U, V] = dftuv(PQ(l), PQ(2));
> DO 0.05*PQ(2);
> F fft2(f, PQ(1), PQ(2));
> H = exp(-(U.~2 + V.~2)/(2*(DO-2)));
Глава 4- Обработка в частотной области
» g = dftfilt(f, Н);
Построенный фильтр можно «увидеть» [см. рис. 4.13, б)], выполнив команду
» figure, imshow(fftshift(Н), [])
Рис. 4.13. Низкочастотная
фильтрация, а) Исходное изоб-
ражение. б) Гауссов низко-
частотный фильтр в вцде изоб-
ражения. в) Спектр а), г) Об-
работанное изображение
Аналогично, спектр Фурье можно отобразить на дисплее (см. рис. 4.13. в)), на-
брав на клавиатуре
>> figure, imshow(log(l + abs(fftshift(F))), [ ])
Наконец, на рис. 4.13, г)) приведено изображение, полученное командой
» figure, imshow(g, [ ])
Как и ожидалось, отфильтрованное изображение представляет собой размытый
образ исходного. □
Следующая программа генерирует1 передаточную функции всех перечислен-
ных выше низкочастотных фильтров.
function [Н, D] Ipfilter(type, М, N, DO, n)
7.LPFILTER Computes frequency domain lowpass filters.
7, H = LPFILTER(TYPE, M, N, DO, n) creates the transfer function of a low-
70 pass filter, H, of the specified TYPE and size (M-by-N). To view the
% filter as an image or mesh plot, it should be centered using
7o H = fftshift (H) .
^.5. Прямое построение фильтров в частотной области
% Valid values for TYPE, DO, and n are:
7.
"/, ’ideal’ Ideal lowpass filter with cutoff frequency DO. n need
7, not be supplied. DO must be positive.
7.
7, ’btw’ Butterworth lowpass filter of order n, and cutoff
7, DO. The default value for n is 1.0. DO must be
7, positive.
7.
7, ’gaussian’ Gaussian lowpass filter with cutoff (standard
7, deviation) DO. n need not be supplied. DO must be
7, positive.
7. Use function dftuv to set up the meshgrid arrays needed for
7. computing the required distances.
[U, V] dftuv(M, N);
7» Compute the distances D(U, V).
D sqrt(U.~2 + V.~2);
7. Begin filter computations.
switch type
case ’ideal’
H double(D <= DO);
case ’btw’
if nargin 4
n 1;
end
H l./(l + (D./DO).~(2*n));
case ’gaussian’
H exp( (D.~2)./(2*(DO-2)));
otherwise
error(’Unknown filter type.’)
end
Функция Ipf liter будет использоваться в § 4.6 как основа для построения
высокочастотных фильтров.
4.5.3. Построение графиков каркасных контуров и
поверхностей
Построение графиков функций одной переменной рассматривалось в § 3.3.1. В этом
параграфе мы обсудим методы построения трехмерных каркасных (сеточных)
контуров и поверхностей, которые могут быть полезными при визуализации пере-
даточных функций двумерных изображений. Самый простой способ нарисовать
сеточный график данной двумерной функции Н состоит в применении функции
mesh, которая имеет базовый синтаксис
mesh(H).
146 Глава 4- Обработка в частотной области
Эта функция рисует каркасный контур для точек х = 1: М и у = 1: N, где [М, N]
size (Н). Вид каркасного контура становится очень плотным и неудобным для
глаза, когда числа М и N — велики. В этом случае удобно строить только каждую
fc-ую точку по каждой оси с помощью команды
mesh(H(l:k:end, l:k:end))
Как правило, если использовать при построении каркасного контура от 40 до 60
точек по каждой оси, то результат будет вполне приемлемым компромиссом меж-
ду разрешением и внешним видом изображения.
По умолчанию MATLAB строит сеточные графики в цвете. Команда
colonnap([0 00])
устанавливает черную сетку (более подробно функция colonnap будет рассмат-
риваться в гл. 6). MATLAB также накладывает оси и линии координатной сетки
на сеточный график. Эти атрибуты отключаются командой
grid off
axis off
Снова включить их можно соответствующей командой, в которой off замене-
но на on. Наконец, точка обзора (местоположение наблюдателя) контролируется
функцией view, которая имеет синтаксис
view(az, el)
На рис. 4.14 показано, что az и el представляют собой, соответственно, азимут и
угол возвышения (измеренные в градусах). Стрелками обозначены положитель-
ные направления. Значения по умолчанию; az = -37.5 и el = 30, которые поме-
щают наблюдателя в квадрант, задаваемый полуосями —х и —у, откуда он смот-
рит на квадрант, определяемый положительными полуосями х и у на рис. 4.14.
Рис. 4.14. Геометрия функции view
Чтобы узнать текущее значение углов
обзора, следует набрать
>> [az, el] = view;
А чтобы присвоить этим параметрам зна-
чения по умолчанию, надо набрать
>> view(3)
Точку обзора можно менять интерактивно,
если нажать мышью на кнопку Rotate 3D
в строке инструментов окна графиков, а за-
тем действовать мышью в окне графика.
В гл. 6 будет показано, как можно зада-
вать точку обзора с помощью декартовых
координат, что весьма удобно при работе с
цветными данными в формате RGB. Однако при построении общих графиков
удобно использовать описанный выше метод, т. к. в нем используется всего два
параметра и он является более наглядным.
4-5. Прямое построение фильтров в частотной области
Пример 4.5. Построение сеточных графиков.
Рассмотрим гауссов низкочастотный фильтр из примера 4.4.
» Н = fftshift(lpfilter(’gaussian’, 500, 500, 50));
На рис. 4.15, а) показан сеточный (каркасный) график, построенный командами
» mesh(H(l:10:500, 1:10:500))
» axis([0 50 0 50 0 1])
Команда axis была описана в § 3.3.1 в двумерном случае. Здесь же обозначен
третий диапазон для координат по оси z.
Рис. 4.15. а) График, построенный функцией mesh, б) Удалены оси и координатная сет-
ка. г) Другая точка обзора, заданная функцией view, г) Третья точка обзора,
заданная той же функцией
Как уже ранее отмечалось, сеточный график по умолчанию рисуется в цвете,
причем цвета меняются от синего в основании до красного в вершине. Преобра-
зуем цвет линий графика в черный и отменим нанесение осей и координатных
линий командами
>> colormap ([0 0 0])
>> axis off
» grid off
На рис. 4.15, б) дан результат. На рис. 4.15, в) приведен результат выполнения
команды
view(-25, 30)
Глава 4- Обработка в частотной области
которая смещает наблюдателя немного вправо, оставляя неизменным угол возвы-
шения. Наконец, на рис. 4.15, в) при сохранении азимута -25 выбираем нулевой
угол возвышения:
» view(-25, 0)
Эти графики дают представление об удобных свойствах визуализации функции
mesh. □
Иногда бывает желательно построить график двумерной функции в виде по-
верхности, а не в виде сеточного контура. В этом поможет функция surf, имею-
щая следующий базовый синтаксис
surf(Н)
Эта функция строит трехмерный график подобно функции mesh, за тем исклю-
чением, что четырехугольники сетки заливаются цветом (это называется фасе-
точным тонированием). Для преобразования цветов в градацию серых тонов
используется команда
colormap(gray)
Функции axis, grid и view дают те же эффекты, что и при обращении к
функции mesh. Например, на рис. 4.16, а) дан результат выполнения следующей
последовательности команд:
» Н fftshift(lpfilter(’gaussian’, 500, 500, 50);
» surf(H(l:10:500, 1:10:500))
» axis([0 50 0 50 0 1])
» colormap(gray)
» grid off; axis off
Рис. 4.16. а) График, построен-
ный функцией surf, б) Резуль-
тат выполнения команды shading
interp
Можно удалить линии сетки и сгладить фасеточное тонирование по методу
интерполяции командой
shading interp
Вызов этой команды приводит к графику на рис. 4.16, б).
Если требуется построить некоторую функцию двух переменных, то исполь-
зуется функция meshgrid для создания матрицы значений координат, с помощью
которой порождается соответствующая матрица отсчетов. Эта матрица подстав-
ляется в функции mesh или surf. Например, пусть необходимо построить график
функции
f(x,y) = xe~(x2+yZ^
^.6. Повышение резкости при частотной фильтрации
в интервале от —2 до 2 с шагом 0.1 по обоим аргументам х и у. Пишем
» [Y, X] = meshgrid(-2:0.1:2, -2:0.1:2);
» Z = X.*ехр(-Х.“2-Y.~2);
после чего применяем mesh(Z) или surf (Z), как описано выше. Напомним, что
в выходных параметрах функции meshgrid сначала следует обозначать столб-
цы (Y), а затем строки (X).
4.6. Повышение резкости при частотной фильтрации
В противоположность низкочастотной фильтрации, которая приводит к размы-
тию изображений, высокочастотная фильтрация повышает резкость изобра-
жения, ослабляя низкие частоты и оставляя высокие частоты преобразования
Фурье относительно неизменными. В этом параграфе будут рассмотрены неко-
торые подходы к высокочастотной фильтрации.
4.6.1. Основы высокочастотной фильтрации
Имея передаточную функцию Н\р(и, и) низкочастотного фильтра, можно полу-
чить передаточную функцию соответствующего высокочастотного фильтра с по-
мощью формулы
Hhp(u.v) = 1 - Hip(u,v).
Значит, функцию Ipf liter, разработанную в предыдущем параграфе, можно
использовать для построения генератора высокочастотных фильтров:
function Н hpfliter(type, М, N, DO, n)
7. HPFILTER Computes frequency domain highpass filters.
7. H HPFILTER(TYPE, 14, N, DO, n) creates the transfer function of
7. a highpass filter, H, of the specified TYPE and size (M-by-N) .
7. Valid values for TYPE, DO, and n are:
7. ’ ideal ’ 7. •/ Ideal highpass filter with cutoff frequency DO. n need not be supplied. DO must be positive.
/• 7, ’btw’ 7. 7. •/ Butterworth highpass filter of order n, and cutoff DO. The default value for n is 1.0. DO must be positive.
/• 7, ’gaussian’ 7. 7. Gaussian highpass filter with cutoff (standard deviation) DO. n need not be supplied. DO must be positive.
7, The transfer 7. where Hip is function Hhp of a highpass filter is 1 Hip, the transfer function of the corresponding lowpass
7. filter. Thus, we can use function Ipfliter to generate highpass
7. filters.
if nargin == 4
n = 1; У, Default value of n.
end
% Generate highpass filter.
Hip = IpfilterCtype, M, N, DO, n);
H = 1 Hip;
Пример 4.6. Высокочастотные фильтры.
На рис. 4.17 приведены графики и изображения идеального высокочастотного
фильтра, а также фильтров Баттерворта и Гаусса высокой частоты. Рис. 4.17, а)
был построен с помощью команд
» Н = fftshift(ppfilter(’ideal’, 500, 500, 50));
» mesh(H(l:10:500, 1:10:500))
» axis([0 50 0 50 0 1])
> > colormap ([0 0 0])
» grid off;
> > axis off
Соответствующее ему изображение на рис. 4.17, г) получено командой
> > figure, imshow(H, [ ])
На изображение наложено тонкое черное окаймление для уточнения его разме-
ров. Аналогичные команды породили все остальные графики и изображения на
рис. 4.17 (фильтр Баттерворта находится в центре). □
Рис. 4.17. Верхний ряд — трехмерные графики высокочастотых фильтров: идеального,
Баттерворта и Гаусса
4-6. Повышение резкости при частотной фильтрации
Пример 4.7. Высокочастотная фильтрация.
На рис. 4.18, а) приведен тот же тестовый образец f, что и на рис. 4.13, а).
Рис. 4.18, б) получен с помощью следующих команд, результат которых демон-
стрирует применение высокочастотного гауссова фильтра к изображению f:
» PQ paddedsize(size(f));
» DO 0.05*PQ(l);
>> H = hpfilter(’gaussian*, PQ(1), PQ(2), DO);
» g = dftfilt(f, H);
>> figure, imshow(g, [ ])
На рис. 4.18, б) заметно повышение четкости границ и усиление других конту-
ров. Вместе с тем, поскольку средняя яркость изображения задается величиной
Е(0,0), а, как мы знаем, высокочастотная фильтрация гасит низкие частоты в
окрестности начала отсчета, то отфильтрованное изображение потеряло большую
часть фоновой тональности, имевшуюся на исходном изображении. Эта проблема
затрагивается в следующем параграфе. □
Рис. 4.18. а) Исходное изоб-
ражение. б) Результат высоко-
частотной фильтрации Гаусса
а)
4.6.2. Фильтрация с усилением высоких частот
Как уже отмечалось в примере 4.7, высокочастотные фильтры отбрасывают ко-
эффициент de, в итоге среднее становится равным нулю. Чтобы компенсировать
этот недостаток, необходимо добавить некоторое смещение к высокочастотному
фильтру. Если смещение комбинируется вместе с умножением фильтра на ко-
эффициент усиления, больший 1, то такая процедура называется фильтрацией
с усилением высоких частот. Поскольку этот коэффициент больше единицы, то
в результате происходит увеличение высоких частот. Конечно, амплитуда низ-
ких частот при этом тоже увеличивается, однако этот эффект меньше влияет
на низкие частоты, поскольку смещение мало по сравнению с коэффициентом
усиления. Высокочастотное усиление имеет передаточную функцию
ЙМе(щ п) = а + ЬНир(щ п),
где а — это смещение, Ь коэффициент усиления, a Н^р(и,и) передаточная
функция фильтра высоких частот.
Глава 4- Обработка в частотной области
Пример 4.8. Комбинированная фильтрация с усилением высоких частот и
гистограммная эквализация.
На рис. 4.19, а) представлен рентгеновский снимок грудной клетки f. Поскольку
рентгеновские лучи хуже поддаются фокусировке, как это делается со свето-
выми лучами при помощи линз, рентгеновские снимки, как правило, выглядят
расплывчато. Цель этого примера заключается в повышении резкости данного
изображения. В этом конкретном примере яркость изображения сдвинута в тем-
ную область градационной шкалы, поэтому мы воспользуемся этим обстоятель-
ством для демонстрации пространственной обработки, которая удачно дополняет
фильтрацию в частотной области.
Рис. 4.19. Фильтрация с усилением высоких частот, а) Исходное изображение, б) Резуль-
тат высокочастотной фильтрации, в) Результат повышения высоких частот.
г) Изображение в) после гистограммной эквализации. (Исходное изображе-
ние предоставлено д-ром. Томасом Р. Гестом, отделение анатомии медицинской
школы университета шт. Мичиган)
На рис. 4.19, б) изображен результат фильтрации рис. 4.19, а) с использова-
нием высокочастотного фильтра Баттерворта порядка 2 с частотой срезания Do,
равной 5% от вертикального размера расширенного изображения. Высокочастот-
ная фильтрация не очень сильно зависит от параметра Do, поскольку радиус
фильтра не так мал, чтобы пропускать частоты, расположенные возле начала
отсчета. Как и ожидалось, результат фильтрации не очень выразителен, одна-
ко на нем слабо различимы основные контуры изображения. Рис. 4.19, в) де-
монстрирует преимущество фильтрации с усилением высоких частот (в данном
случае, а = 0.5 и Ь - 2.0), при котором сохранен общий яркостной тон исход-
ного изображения. Следующая последовательность команд была использована
при построении изображений на рис. 4.19, где f обозначает входное изображение
[последняя команда строит рис. 4.19, г)].
» PQ = paddedsize(size(f));
» DO = 0.05*РП(1);
Выводы
HBW = hpfilter(’btw’, PQ(1), PQ(2), DO, 2);
>> H = 0.5 + 2*HBW;
> > gbw = HBW);
> > gbw = gscale(gbw);
» ghf = H);
> > gbf gscale(ghf) ;
> > ghe histeq(ghf, 256);
Как отмечалось в § 3.3.2, изображение, характеризующееся узким диапазоном
яркости, является идеальным кандидатом для гистограммной эквализации. Из
рис. 4.19, г) видно, что этот метод действительно продолжает улучшать изоб-
ражение. Обратите внимание на четкое выявление структур костей и других
деталей, которых даже не видно на трех предыдущих изображениях. В послед-
нем изображении можно обнаружить некоторое усиление шумов, но это явле-
ние весьма характерно для рентгеновских снимков при растяжении диапазона
их яркости. Результат, полученный при совместном использовании фильтрации
с усилением высоких частот и метода гистограммной эквализации, превосходит
любой результат, который можно было бы получить, применяя каждый из этих
методов по отдельности. □
Выводы
Материалы этой и предыдущей главы были проиллюстрированы приложениями
по улучшению изображений. Однако разработанные при этом методы и концеп-
ции можно с успехом применять и в других областях цифровой обработки изоб-
ражений, которые будут последовательно излагаться далее в этой книге. Преоб-
разования яркости будут часто использоваться при растяжении и сжатии диа-
пазонов яркости, пространственная фильтрация найдет применение в задачах
восстановления изображений в следующей гл. 5, а также при обработке цветных
изображений (гл. 6), при сегментации изображений (гл. 10) и при извлечении
дескрипторов изображений (гл. 11). Техника преобразования Фурье будет ин-
тенсивно применяться в следующей главе при изучении методов восстановления
изображений, в гл. 8 при сжатии изображений и в гл. 11 при описании изобра-
жений.
ГЛАВА 5
ВОССТАНОВЛЕНИЕ
ИЗОБРАЖЕНИЙ
Введение
Задача восстановления изображения заключается в улучшении данного изобра-
жения в некотором заранее оговоренном смысле. Несмотря на значительное пе-
ресечение областей применения этих двух методов обработки, улучшение изобра-
жений является достаточно субъективным процессом, в то время как процедуры
восстановления изображений носят вполне объективный характер. Целью восста-
новления является реконструкция или воссоздание изображения, которое ранее
было искажено или испорчено в результате явлений, про которые имеется доста-
точно определенная априорная информация. Поэтому методы восстановления
изображения основаны на моделировании процессов искажения и применении
обратных процессов для воссоздания исходного изображения.
При таком подходе важно уметь правильно формулировать критерии каче-
ства, которые позволят оценить результат восстановления. А при решении задач
улучшения изображений используется иная методология, основанная на эври-
стических процедурах, визуальный результат которых зависит от особенностей
человеческого зрения. Например, усиление контраста можно рассматривать как
процедуру улучшения изображения, поскольку после ее применения изображение
становится более приятным для глаза, а обработку смазанных изображений с по-
мощью соответствующих обратных процедур следует отнести к арсеналу средств
по восстановлению изображений.
В этой главе будут исследоваться возможности системы MATLAB и средства
пакета IPT при моделировании ухудшающих воздействий на изображения и при
решении задач компенсации этих искажений. Как и в гл. 3 и 4, одни методы
восстановления удобно применять в пространственной области, а другие лучше
проявляют себя в частотной области.
5.1. Моделирование процесса
искажения/восстановления изображения
На рис. 5.1 процесс ухудшения изображения смоделирован в виде функции иска-
жения, которая вместе с аддитивным шумом действует на исходное изображение
д(х, у) и порождает искаженное изображение д(х, у):
д(х, у) = H[f(x, ?/)] + 7?(ж, у).
5.1. Моделирование процесса искажения/восстановления изображения
Имея функцию д(х, у), обладая некоторой информацией об искажающем опера-
торе Н и зная основные характеристики аддитивного шума г)(х, у), можно по-
строить некоторое приближение f(x,y) исходного изображения. Целью восста-
новления изображения является построение приближения f(x,y)-, которое было
бы максимально близко к исходному изображению. При этом чем больше мы
знаем об операторе Н и шуме т](х, у), тем точнее (в принципе) мы сможем при-
близить изображение f(x,y) функцией f(x.y).
Рис. 5.1. Моделирование процесса искажеиия/восстановления изображения
Если известно, что Н — линейный трансляционно-инвариантный оператор,
то можно показать математически, что искаженное изображение представимо в
пространственной области в следующем виде:
д(х, у) = h(x, у) * f(x, у) + т](х, у),
где h(x, у) — это пространственное представление искажающего оператора, а сим-
вол с*»1 обозначает свертку, как и в гл. 4. Из материалов § 4.3.1 нам известно,
что свертка функций в пространственной области эквивалентна умножению в
частотной области преобразований Фурье этих функций, поэтому приведенное
выше уравнение модели искажения можно записать в эквивалентном представ-
гении в частотной области:
G(u,v) = H(u,v)F(u,v) + 7V(tz, v),
де заглавными буквами обозначены соответствующие преобразования Фурье
тункций из уравнения свертки. Функцию H(u,v') часто называют оптической
.ередаточной функцией (OTF, Optical Transfer Function). Этот термин заим-
гвован из анализа Фурье оптических систем. В пространственной области функ-
ия h(x, у) называется функцией разброса точек (PSF, Point Spread Function),
/гот термин возникает при действии функции h (х, у) на точки света для полу-
<• ния характеристик искажения разных типов входных данных. Функции h(x, у)
Н(и, и) переходят друг в друга под действием прямого и обратного преобразо-
аний Фурье, поэтому в пакете имеется две М-функции otf2psf и psf2otf для
< гих действий.
^ледуя общему соглашению, мы будем использовать символ «*» в строке уравнения для обо-
дачения свертки, а помещение его в верхний индекс формулы будет обозначать комплексное
• •пряжение. Кроме того, как это требует MATLAB, при написании программ звездочкой обо-
• •ч чается операция умножения. Поэтому следует быть внимательным, чтобы не перепутать эти
взличные использования одного и того же символа.
156 Глава 5. Восстановление изображений
В силу того, что оператор линейного трансляционно-инвариантного искаже-
ния Н можно смоделировать в виде свертки (конволюции), иногда этот процесс
искажения называют «конволюцией изображения с PSF или OTF». По аналогии,
обратный процесс восстановления называется деконволюцией.
В следующих трех параграфах предполагается, что Н — тождественный опе-
ратор, т. е. искажения вносятся исключительно шумом. Начиная с § 5.6. мы бу-
дем рассматривать модели, в которых искажения вносятся и оператором Н, и
шумом 7).
5.2. Модели шума
Возможность смоделировать шум является ключевым моментом восстановления
изображений. В этом параграфе рассматриваются два типа моделей шумов: шум
в пространственной области (характеризующийся функцией плотности вероят-
ности) и шум в частотной области, который описывается разными характеристи-
ками Фурье. За исключением § 5.2.3, везде в этой главе предполагается, что шум
не зависит от координат пиксела изображения.
5.2.1. Добавление шума функцией imnoise
В пакете имеется функция imnoise, которая моделирует искажение изображения
некоторым шумом. Синтаксис этой функции имеет вид
g imnoise(f, type, parameters),
где f — это исходное изображение, а смысл аргументов type и parameters бу-
дет объяснен позже. Функция imnoise сначала преобразует изображение в класс
double в диапазоне [0,1]. Это следует иметь в виду перед заданием параметров
шума. Например, чтобы прибавить шум со средним 64 и дисперсией 400 к изоб-
ражению класса uint8, следует сжать среднее до величины 64/256, а дисперсию
приравнять 400/(256)2, после чего эти параметры можно подставлять в функцию
imnoise. Рассмотрим различные синтаксические формы этой функции.
g imnoise(f, ’gaussian’, m, var) добавляет к изображению f гауссов
шум со средним m и дисперсией var. По умолчанию, m 0 и var 0.01.
g imnoise(f, ’localvar’, V) добавляет к изображению f локальный
гауссов шум с нулевым средним, дисперсия которого в каждой точке изоб-
ражения f задается матрицей V, размера как у f.
g imnoise(f, ’localvar’, image_intensity, var) добавляет к изобра-
жению f гауссов шум с нулевым средним, в котором локальная дисперсия
шума var является функцией значений яркости изображения f. Аргумен-
ты image_intensity и var являются векторами одинаковой размерности,
а функция plot(image_intensity, var) строит график зависимости дис-
персии var от яркости image_intensity. Вектор image_intensity должен
содержать нормированные значения яркости в диапазоне [0,1].
g imnoise (f, ’salt & paper’, d) портит изображение f шумом «соль и
перец», где d — это плотность шума (т. е. процент изображения, подвержен-
5.2. Модели шума
ного этому шуму). При этом приблизительно d*numel(f) пикселов будет
испорчено. По умолчанию, d = 0.05.
g = imnoise(f, ’speckle’, var) добавляет к f мультипликативный шум
по формуле g = f + n*f, где п это равномерно распределенный шум с
нулевым средним и дисперсией var. По умолчанию, var 0.04.
g = imnoise(f, ’poisson’) генерирует пуассоновский шум, зависящий от
исходных данных, вместо добавления искусственного шума. Чтобы согласо-
вываться со статистиками Пуассона, пикселы изображений uint8 и uintl6
должны соответствовать числу фотонов (или другим квантам информа-
ции). Используются изображения с двойной точностью, когда число фото-
нов на один пиксел больше, чем 65535 (но меньше 1012). Величины яркости
пикселов меняются в пределах от 0 до 1 и соответствуют числу фотонов,
деленному на 1012
Несколько иллюстраций использования функции imnoise дается в следующем
параграфе.
5.2.2. Генерация случайного пространственного шума
с заданным распределением
Часто бывает необходимо сгенерировать шум, тип и параметры которого охва-
тываются функцией imnoise. Значения пространственного шума являются слу-
чайными величинами, которые принято характеризовать функцией плотности
вероятности (PDF, Probability Density Function) или соответствующей функци-
ей (кумулятивного) распределения (CDF, Cumulative Distribution Function). По-
строение датчиков случайных чисел с интересующими нас распределениями де-
ается с помощью некоторых простых правил теории вероятностей.
Большинство генераторов случайных чисел основано на переформулирова-
нии задачи в терминах случайных чисел с равномерной функцией распределе-
ния в интервале [0,1]. В некоторых случаях таким базовым генератором может
т>жить генератор гауссовых случайных чисел с нулевым средним и единич-
ной дисперсией. Хотя оба этих генератора можно получить из функции imnoise,
<еет смысл сделать это с помощью функции rand для равномерных случайных
ясел и функции randn для нормальных (гауссовых) случайных чисел, которые
- ализованы в системе MATLAB. Эти функции будут описаны несколько позже
этом параграфе.
Основой описываемого здесь подхода является классический результат тео-
вероятностей (см., например, [Peebles, 1993]), который утверждает, что если
еется случайная величина w с равномерным распределением на отрезке [0,1],
случайную величину z с заданной функцией распределения Fz, можно постро-
по формуле
z = F~\w).
простой, но весьма полезный результат можно сформулировать в следую-
эквивалептной форме: решить уравнение F(z) = w относительно z.
158 Глава 5. Восстановление изображений
Пример 5.1. Использование равномерно распределенных случайных чисел в ге-
нераторе случайных чисел с заданной функцией распределения.
Пусть имеется генератор случайных чисел w с равномерным распределением в
интервале (0,1), и мы хотим построить случайную величину z с функцией рас-
пределения вероятностей Релея, которая имеет вид
Fz(z)=f 1~е (г~а?'Ъ ПРИ2^°’
( 0 при z < а.
Чтобы получить г, достаточно решить уравнение
1 — e~^z~a^ /ь = w или z = а + \/Ып(1 — ш).
Поскольку квадратный корень — положительная функция, то генерируемые слу-
чайные величины будут всегда больше а, что требуется в определении функции
Релея. Значит, равномерно распределенные случайные числа могут служить осно-
вой для генератора релеевских случайных чисел с заданными параметрами а и Ь.
В MATLAB это результат легко обобщить, но массив случайных чисел R раз-
меров МxN с помощью выражения
>> R = а + sqrt(b*log(l rand(M, N));
где log — это натуральный логарифм (см. § 3.2.2), а функция rand генерирует
равномерно распределенные случайные числа в интервале (0,1). Если положить
М = N = 1, то получится скалярная случайная величина с релеевским распреде-
лением и с параметрами а и Ь. □
Выражение вида z = а + -^/Ь1п(1 — и) иногда называют уравнением генера-
тора случайных чисел, поскольку в нем определяется, как вычислять требуемые
случайные величины. В этом случае имеется простая формула для решения урав-
нения. Однако это не всегда возможно, и проблему можно сформулировать сле-
дующим образом: как получить уравнение генератора случайных чисел, выход
которого хорошо приближает случайную величину с заданной функцией плотно-
сти вероятностей.
В табл. 5.1 перечислены полезные случайные величины в свете нашего обсуж-
дения. Для некоторых из них удается выписать формулу решения для обратной
функции распределения, например, для экспоненциального распределения или
для функции распределения Релея. В этих случаях имеется простая формула
для выражения требуемых случайных чисел в терминах равномерных случай-
ных чисел, как это проиллюстрировано в примере 5.1. В других случаях, как,
например, в случае гауссовой или логарифмически нормальной плотности, та-
кой простой формулы не существует. Тогда нужно искать альтернативный путь
для реализации требуемой случайной величины. Например, для случайной вели-
чины z с логарифмически нормальной плотностью можно воспользоваться тем
фактом, что величина ln(z) имеет гауссово распределение, и выписать выраже-
ние, приведенное в табл. 5.1, в терминах гауссовой случайной величины с нулевым
средним и единичной дисперсией. И в других случаях бывает полезно перефор-
мулировать задачу для нахождения более легкого решения. Например, можно
Таблица 5.1. Генераторы случайных величин
Имя Плотность
Среднее и Дисперсия Распределение Генератор1
Равно- мерная . Ч f гЦ?, а Z О 0, иначе
т = а±^, а2 (ь-°)2 2 12 Гг(г) = < 0, z < a TT^, a^z^b 0, z > b rand (MATLAB)
Гауссова рг(г)= 1 е-(^-“)2/2Ь2 V 27Г0 —оо < z < +оо
m = а, <т2 _ (,2 Z Fz(z) = f Pz(v) dv —ОО randn (MATLAB)
«Соль и перец»
pz(z) = < Pa, z = a Pb, z = b , (b> a) 0, иначе т = аРа + ЬРь <т2 = (а - т)2Ра -L (ь _ ту1рь Fz(z) = 0, z < a Pa, a z < b Pa + Pb, z > b rand (MATLAB)
Лога- рифми- чески нормаль- ная /2Ь г>0
т = са+(м/2) СТ2 = е2а+Ь2 z Fz(z)= f pz(v)dv — oo z = aebN^
Релея Pz(z)= f l(z - a)e~^-a'f/b, z^a, ( 0, z < a т = а + y/2irb/4, ст2 _ Ь(4-т) 4 О и-* 1 Л 'ТГ l * > II N N A W P © z = a + In [1 — (7(0,1)]
Экспо- ненци- альная , , f ае~аг, z > 0 Ps(z) = ) „ ( 0, z < 0
т = ±, ст2 — 1 а — т? а ( 1 - e-“z, z > 0 Fz(z) = < (0, z<0 z = -lln[l-C7(0,1)]
Эрланга Mz)=^-«z^0 т = £ , <Т2 ь а — т? а Fz(z) = [1 - e— E^o^]- z 0 z = E\ + £?2 + • • + Еъ, En — эксп. величины с параметром a.
1 Здесь 77(0. 1) нормальная (гауссова) случайная величина со средним ноль и дисперсией 1. (7(0,1) — равномерная случайная величина из
интервала (0, 1).
5.2. Модели шума 159
160 Глава 5. Восстановление изображений
показать, что случайные числа Эрланга с параметрами а и Ь можно построить,
складывая b независимых случайных величин с экспоненциальным распределе-
нием, имеющих параметр а (см. [Leon-Garcia, 1994]).
Генераторы случайных чисел, реализованные в imnoise и перечисленные в
табл. 5.1., играют важную роль при моделировании поведения случайного шума
в приложениях обработки изображений. Мы уже видели пользу от использования
равномерного распределения при генерации случайных чисел с заданной функ-
цией распределения. Гауссов шум используется в качестве естественного при-
ближения в тех случаях, когда сенсорные детекторы изображения работают на
пороге чувствительности. Шум типа «соль и перец» возникает в устройствах с
ошибочной коммутацией. Размеры зерен на фотоэмульсии являются случайными
величинами с логарифмически нормальным распределением. Шум Релея обра-
зуется при фиксации удаленных изображений, а экспоненциальный шум и шум
Эрланга используется при описании искажений на изображениях, полученных с
помощью лазерного излучения.
М-функция imnoise2, которая будет рассматриваться позже, генерирует слу-
чайные числа, которые имеют функцию распределения из списка в табл. 5.1.
Эта функция использует стандартную функцию rand, которая имеет следующий
синтаксис:
A rand(M, N).
Эта функция генерирует массив размера MxN, элементами которого служат рав-
номерно распределенные случайные величины в интервале (0,1). Если аргумент
N отсутствует, то по умолчанию он приравнивается к М. Если опущены оба ар-
гумента, то rand генерирует скалярную случайную величину, которая меняется
при каждом новом вызове функции rand. Аналогично, функция
A randn(M, N)
строит массив размера MxN с независимыми гауссовыми (нормальными) случай-
ными величинами с нулевым средним и единичной дисперсией. Если N отсут-
ствует, то по умолчанию N М. Если аргументов нет, то генерируется скалярная
случайная величина.
Функция imnoise2 использует функцию find из MATLAB, которая имеет
следующую синтаксические формы:
I find(А)
[г, с] find(А)
[г, с, v] find(A)
В первом случае в I записывается индексы массива А, которые обозначают нену-
левые элементы. Если таковые отсутствуют, то find возвращает пустую матрицу.
Вторая форма возвращает строку и столбец, состоящие из индексов элементов
матрицы А с ненулевым содержимым, а в третьей форме также возвращаются
ненулевые элементы А в виде отдельного векгор-столбца v.
В первой форме команды find матрица А трактуется в формате А(:), т. е.
I — это вектор-столбец. Такая форма очень удобна при обработке изображений.
5.2. Модели шума
Например, чтобы найти множество всех пикселов, меньших 128, и присвоить им
значение 0, достаточно выполнить команды
» I find(A < 128);
» ACT) 0;
Напомним, что логическая формула А < 128 возвращает матрицу, в которой
1-цы стоят там, где логическое условие выполнено и 0 — там, где оно не выполне-
но. Чтобы присвоить значение 128 всем пикселам, принадлежащих замкнутому
интервалу [64,192], можно записать
>> I f ind(A >= 64 & А <= 192) ;
>> А(1) 128;
Первые две формы команды f ind будут часто использоваться в дальнейшем.
В отличие от imnoise, следующая М-функция imnoise2 порождает шумовую
матрицу R размера MxN. которая не нормируется. Другое значительное отли-
чие от функции imnoise состоит в том, что выходом imnoise служит зашумлен-
ное изображение, a imnoise2 порождает только шумовую матрицу. Пользователь
должен сам задавать желаемые параметры шума. Заметьте, что шумовая матри-
ца, генерируемая по методу «соль и перец», принимает три возможных значения:
0 — это «перец», 1 — «соль», а 0.5 соответствует отсутствию шума. Эту матрицу
необходимо еще обрабатывать для дальнейшего использования. Например, что-
бы испортить изображение этим шумом, необходимо сначала найти (с помощью
функции find) все координаты шума R, равные 0, и присвоить соответствующим
пикселам изображения самое малое значение (обычно это 0). Затем следует най-
ти все координаты шума R, равные 1, и присвоить соответствующим пикселам
изображения самое большое допустимое значение (обычно это 255 для 8-ми бито-
вых изображений). Эта процедура моделирует практическое воздействие шума
<соль и перец» на изображение.
function R imnoise2(type, М, N, а, Ъ)
XIMNDISE2 Generates an array of random numbers with specified PDF
X R IMN0ISE2(TYPE, M, N, A, B) generates an array, R, of size
X M-by-N, whose elements are random numbers of the specified TYPE
X with parameters A and B. If only TYPE is included in the
X input argument list, a single random number of the specified
TYPE and default parameters shown below is generated. If only
TYPE, M, and N are provided, the default parameters shown below
X are used. If M N = 1, IMN0ISE2 generates a single random
number of the specified TYPE and parameters A and B.
Valid values for TYPE and parameters A and В are:
’uniform’ Uniform random numbers in the interval (A, B).
The default values are (0, 1).
’gaussian’ Gaussian random numbers with mean A and standard
deviation B. The default values are A = 0, В = 1.
162 Глава 5. Восстановление изображений
7. ’salt & pepper’
7.
7.
7.
7.
7.
7.
7.
7.
7.
7.
7.
7» ’lognormal’
7.
7.
7. ’rayleigh’
7.
7» ’ exponential ’
7.
7. ’erlang’
7.
7.
7.
7.
7.
if nargin 1
a = 0; b = 1;
M = 1; N = 1;
elseif nargin 3
a 0; b 1;
end
Salt and pepper numbers of amplitude 0 with
probability Pa = A, and amplitude 1 with
probability Pb = B. The default values are Pa
Pb = A = В 0.05. Note that the noise has
values 0 (with probability Pa = A) and 1 (with
probability Pb = B), so scaling is necessary if
values other than 0 and 1 are required. The noise
matrix R is assigned three values. If R(x, y)
0, the noise at (x, y) is pepper (black). If
R(x, у) 1, the noise at (x, y) is salt
(white). If R(x, y) 0.5, there is no noise
assigned to coordinates (x, y)
Lognormal numbers with offset A and shape
parameter B. The defaults are A 1 and В
0.25.
Rayleigh noise with parameters A and B. The
default values are A 0 and В 1.
Exponential random numbers with parameter A. The
default is A 1.
Erlang (gamma) random numbers with parameters A
and В. В must be a positive integer. The
defaults are A 2 and В 5. Erlang random
numbers are approximated as the sum of В
exponential random numbers.
Set default values.
7o Begin processing. Use lower(type) to protect against input
7« being capitalized.
switch lower(type)
case ’uniform’
R = a + (b a)*rand(M, N);
case ’gaussian’
R = a + b*randn(M, N);
case ’salt & pepper’
if nargin <= 3
a 0.05; b = 0.05;
end
7. Check to make sure that Pa + Pb is not > 1.
if (a + b) > 1
error(’The sum Pa + Pb must not exceed 1.’)
end
5.2. Модели шума 163
R(1:M, 1:N) = 0.5;
7о Generate an M-by-N array of uniformly-distributed random numbers
7. in the range (0, 1) Then, Pa*(M*N) of them will have values <=
7, a. The coordinates of these points we call 0 (pepper
7» noise). Similarly, Pb*(M*N) points will have values in the range
7. > a & <= (a + b) . These we call 1 (salt noise) .
X rand(M, N) ;
c find(X <= a);
R(c) 0;
u = a + b;
c = find(X > a & X <= u) ;
R(c) 1;
case ’lognormal’
if nargin <= 3
a 1; b 0.25;
end
R = a*exp(b*randn(M, N));
case ’rayleigh’
R = a + (-b*log(l rand(M, N))).~0.5;
case ’exponential’
if nargin <= 3
a 1;
end
if a <= 0
error(’Parameter a must be positive for exponential type.’)
end
к -1/a;
R = k*log(l rand(M, N));
case ’erlang’
if nargin <= 3
a 2; b = 5;
end
if (b “= round(b) | b <= 0)
error(’Param b must be a positive integer for Erlang.’)
end
к -1/a;
R = zeros(M, N);
for j l:b
R = R + k*log(l rand(M, N));
end
otherwise
error(’Unknown distribution type.’)
end
164 Глава 5. Восстановление изображений
Пример 5.2. Построение гистограмм данных, сгенерированных функцией imnoise2.
а)
8000
7000
6000
5000
4000
3000
2000
1000
0
54321012345
в)
10000
9000
8000
7000
6000
5000
4000
3000
2000
1000
б)
2500
2000
1500
1000
500
е)
9000
8000
7000
6000
5000
4000
3000
2000
1000
О
О 2 4 6 8 10 12
Рис. 5.2. Г истограммы случайных величин: а) гауссова, б) равномерная, в) логарифми-
чески нормальная, г) релеевская, д) экспоненциальная, е) Эрланга. В каждом
случае использовались параметры, принятые по умолчанию в imnoise2
На рис. 5.2 приведены гистограммы всех типов случайных чисел из табл. 5.1.
Данные для каждого из этих графиков были сгенерированы с помощью функции
imnoise2. Например, данные для рис. 5.2, а) получаются следующей командой:
>> г = inmoise2(’gaussian’, 100000, 1, 0, 1);
Эта команда порождает вектор-столбец г, содержащий 100000 элементов, каж-
дый из которых является случайной гауссовой величиной с нулевым средним и
5.2. Модели шума
единичным стандартным отклонением. После этого гистограмма строится функ-
цией hist, которая имеет синтаксис
р hist(r, bins),
где bins — это число корзин гистограммы. Чтобы построить гистограмму 5.2, а),
мы взяли число bins 50. Другие гистограммы строились аналогично. Во всех
случаях всем параметрам шумов присваивались значения по умолчанию, пере-
численные в соответствующих описаниях функции imnoise2. □
5.2.3. Периодический шум
Периодический шум весьма типичен для оцифрованных изображений. Он возни-
кает при интерференции различных электрических и электромеханических про-
цессов. В этой главе будет рассматриваться только такой тип шума, который
зависит от положения пиксела. Как будет обсуждаться в § 5.4, с таким шумом
можно справиться с помощью фильтрации в частотной области. Нашей моделью
периодического шума будет двумерная синусоида, задаваемая формулой
г(х, у) = Л sin [2тшо(х + В:с]/М + 2тгго(т + By)/N],
где А — это амплитуда, uq и гд определяют синусоидальные частоты, соответ-
ственно, по осям х и у, Вх и Ву — сдвиги фаз относительно начала отсчета.
Дискретным преобразованием Фурье (DFT) размеров MxN от т(х,у) является
функция
R(u, v) = ^Д2тги0Вх/М^ _|_ Uo, v _|_ _ ^^TrvoBy/N^ _ UQj v _ ,
которая имеет вид пары комплексно сопряженных единичных импульсов, нахо-
дящихся в точках (uo,vq) и (—ио, —vq) соответственно.
Следующая М-функция допускает произвольное число местоположений им-
пульсов (координат частот), каждый со своей амплитудой, частотой и сдвигом
фазы, и она вычисляет т(х, у) в виде суммы синусоид в форме, представленной в
предыдущем абзаце. Функция также возвращает преобразование Фурье R(u,v)
в форме суммы импульсов, а также спектр S(u,v). Синусовые волны строятся
по заданным положениям импульсов с помощью обратного DFT. Это позволя-
ет лучше понять и визуально представить частотное содержание пространствен-
ных шумов. Для определения положения импульса достаточно знать одну пару
координат. Программа строит сопряженно симметричные импульсы. (Обратите
внимание на использование здесь функции ifftshift для приведения R к виду,
подходящему для применения операции if ft2, что обсуждалось в § 4.2).
function [г, R, S] imnoise3(M, N, С, А, В)
7.IMN0ISE3 Generates periodic noise.
7. [г, R, S] IMN0ISE3(M, N, С, A, B), generates a spatial
7. sinusoidal noise pattern, r, of size M-by-N, its Fourier
7. transform, R, and spectrum, S. The remaining parameters are as
7. follows:
166 Глава 5. Восстановление изображений
7, С is а K-by-2 matrix containing К pairs of frequency domain coordi-
'k nates (u, v) indicating the locations of impulses in the frequency
7. domain. These locations are with respect to the frequency rectangle
7, center at (M/2 + 1, N/2 + 1). Only one pair of coordinates is requi-
7. red for each impulse. The program automatically generates the lo-
7. cations of the conjugate symmetric impulses. These impulse pairs
7. determine the frequency content of r.
7.
*Z A is a l-by-K vector that contains the amplitude of each of the
7. К impulse pairs. If A is not included in the argument, the
7. default used is A = ONES(1, К) . В is then automatically set to
7. its default values (see next paragraph) . The value specified
7, for A(j) is associated with the coordinates in C(j, 1:2).
7.
7. В is a K-by-2 matrix containing the Bx and By phase components
7. for each impulse pair. The default values for В are B(1:K, 1:2) = 0.
7. Process input parameters.
[K, n] = size(C);
if nargin == 3
A(1:K) = 1.0;
B(1:K, 1:2) = 0;
elseif nargin == 4
B(1:K, 1:2) = 0;
end
7. Generate R.
R = zeros(M, N);
for j = 1:K
ul = M/2 + 1 + C(j, 1); vl N/2 + 1 + C(j, 2);
R(ul, vl) i * (A(j)/2) * exp(i*2*pi*C(j, 1) * B(j, 1)/M);
’/, Complex conjugate.
u2 = M/2 + 1 C(j, 1); v2 = N/2 +1 C(j, 2);
R(u2, v2) -i * (A(j)/2) * exp(i*2*pi*C(j, 2) * B(j, 2)/N);
end
7. Compute spectrum and spatial sinusoidal pattern.
S = abs(R);
r = real(ifft2(ifftshift(R)));
Пример 5.3. Использование функции imnoise3.
На рис. 5.3, а) и б) построен спектр и пространственный синусовый шум с помо-
щью последовательности команд
>> С = [0 64; 0 128; 32 32; 64 0; 128 0; -32 32];
>> [г, R, S] = imnoise3(512, 512, С);
>> imshow(S, [ ])
>> figure, imshow(r, [ ])
5.2. Модели шума
Напомним, что порядок частотных координат (и, v). Эти две величины обо-
значены по отношению к центру частотного прямоугольника (см. § 4.2 для опре-
деления координат этой центральной точки). На рис. 5.3, в) и г) показан резуль-
тат повторения предыдущих команд, но с параметрами
>> С [0 32; 0 64; 16 16; 32 0; 64 0; -16 16];
Рис. 5.3. а) Спектр задан-
ных импульсов, б) Соответ-
ствующий синусовый шум. в)
и г) Аналогичная пара изоб-
ражений. д) и е) Два дру-
гих шумовых образца. Белые
точки на рис. а) и 6) бы-
ли увеличены для улучшения
ВИДИМОСТИ
Аналогично, рис. 5.3, д) построен при
» С [6 32;-2 2];
Рис. 5.3, е) получен с тем же вектором С, но с модифицированным вектором
амплитуд:
А
[1 5];
> [г, R, S] = inmoise3(512, 512, С, А);
168 Глава 5. Восстановление изображений
Из рис. 5.3, е) видно, что на изображении доминируют синусовые волны с низкой
частотой. Это легко понять, так как их амплитуда в пять раз больше амплитуды
высокочастотной компоненты. □
5.2.4. Оценивание параметров шума
Параметры периодического шума можно оценить, анализируя спектр Фурье изоб-
ражения. Периодический шум порождает частотные всплески, которые можно
обнаружить даже визуально. Автоматический анализ возможен в случаях, когда
эти всплески достаточно отчетливы или когда имеется дополнительная инфор-
мация о частотах интерференции.
В случае пространственного шума параметры PDF можно частично узнать
из спецификаций сенсоров, однако часто это делается с помощью анализа про-
стых тестовых изображений. Соотношения между средней величиной m и дис-
персией <т2 шума и параметрами а и Ь, которые описывают шум, перечислены в
табл. 5.1 для интересующих нас случайных величин. Поэтому задача заключает-
ся в оценивании среднего значения и дисперсии по тестовым образцам, которые
можно подставить в уравнения для нахождения параметров а и Ъ.
Пусть Zi — дискретная случайная величина, значениями которой являются
уровни яркости изображения. Обозначим через p(zj), i 1,2, ...,L — 1 соот-
ветствующую нормированную гистограмму, где L — это число возможных зна-
чений яркости. Таким образом, число р(гг) приближает вероятность появления
величины яркости Zi на изображении. Гистограмму можно рассматривать как
приближение PDF яркости.
Используя стандартный метод, форму гистограммы можно описать с помо-
щью статистических центральных моментов, которые вычисляются по формуле
L-1
Рп = тУПР^г),
i=0
где п — это порядок момента, ат — среднее значение,
L-1
т=^2 Zip^Zi).
г=0
Поскольку гистограмма была нормирована, сумма всех ее компонентов равна 1,
поэтому из приведенных формул следует, что ро — 1, Mi = 0. Второй момент
L-1
№ = - m)2p(zj)
г=0
равен дисперсии случайной величины z. В этой главе нам понадобятся лишь
среднее значение и дисперсия. Статистические моменты более высокого порядка
будут обсуждаться в гл. 11.
Функция statmoments вычисляет среднее и статистические моменты до по-
рядка п включительно и возвращает эти величины в виде вектора-столбца v.
Поскольку моменты нулевого и первого порядков равны, соответственно, 1 и О,
statmoments их игнорирует и присваивает v(l) = m и v(k) /j,k при к
= 2,3,..., п. Синтаксис имеет вид (см. приложение В):
[v, unv] statmoments(р, n),
где р — это вектор гистограммы, а п обозначает наибольший порядок моментов.
Требуется, чтобы число компонентов вектора р равнялось 28 для класса изоб-
ражения uint8, 216 для класса uintl6, а также 28 или 216 для класса double.
Выходной вектор v содержит нормированные моменты, вычисленные на основе
приведения случайных величин к диапазону [0,1]. Следовательно, все моменты
будут также принадлежать этому интервалу. Вектор unv содержит те же момен-
ты, что и v, но в диапазоне исходных данных. Например, если length (р) 256
и v(l) = 0.5,TOunv(l) 127.5, что равно половине от диапазона [0, 255].
Часто бывает необходимо оценить параметры шума непосредственно по за-
шумленному изображению или по набору таких изображений. В этом случае
следует выбрать на некотором изображении область, по возможности лишенную
характерных черт, чтобы распределение яркости на ней было бы произведено
главным образом шумом. Для выбора такой интересующей области (ROI, Region
Of Interest) можно воспользоваться функцией roipoly, которая строит много-
угольную область. Она имеет синтаксическую форму
В roipoly(f,с,г),
где f — интересующее нас изображение, а с и г — векторы, соответствующие
координатам (по столбцам и строкам) последовательных вершин многоугольни-
ка (заметьте, что в начале идут координаты по столбцам). Выходом функции
служит двоичный массив того же размера, что и f, с единицами внутри инте-
ресующей области и с нулями вне ее. Изображение В используется в качестве
маски для ограничения выполнения операций на выделенную область. Для ин-
терактивного задания области ROI можно использовать синтаксис
В roipoly(f).
В этом случае изображение f выводится на экран, и пользователю предлагается
обозначить интересующую область с помощью мыши. Если параметр f опущен,
функция оперирует с последним изображением на экране. Действуя левой кноп-
кой мыши, строим последовательные вершины многоугольника. Нажимая клави-
ши Backspace или Delete, можно удалить вершину, выбранную на предыдущем
шаге. Нажав левую кнопку мыши с одновременным удержанием клавиш Shift,
правую кнопку мыши или сделав двойной щелчок левой кнопкой, добавляем по-
следнюю вершину, после чего выбранный многоугольник заполняется единицами.
Если нажать Enter, то построение многоугольника завершается без добавления
последней вершины.
Чтобы получить бинарную маску и список вершин многоугольника, можно
использовать конструкцию
[В, с, г] = roipoly(. . .),
170 Глава 5. Восстановление изображений
где roipoly(. .) обозначает любой допустимый вид этой функции, а с и г —
векторы координат (по столбцам и строкам) вершин многоугольника, как было
описано раньше. Такой формат особенно удобен при интерактивном использова-
нии roipoly, так как он выдает информацию об области ROI. которую можно
копировать и использовать в последующих программах.
Следующая функция вьпшсляет гистограмму выбранной многоугольной об-
ласти ROI на изображении, вершины которой заданы парой векторов сиг, как
описано выше.
function [р, npix] = histroi(f, с, г)
7.HISTR0I Computes the histogram of an ROI in an image.
7. [P, NPIX] = HISTROI(F, C, R) computes the histogram, P, of a
7, polygonal region of interest (ROI) in image F. The polygonal
% vertices, which are specified (sequentially) in vectors C and R,
7o respectively. All pixels of F must be >=0. Parameter NPIX is the
% number of pixels in the polygonal region.
7o Generate the binary mask image.
В = roipoly(f, c, r);
7« Compute the histogram of the pixels in the ROI.
p = imhist(f(B));
% Obtain the number of pixels in the ROI if requested in the output.
if nargout > 2
npix = sum(B(:));
end
Пример 5.4. Оценивание параметров шума.
На рис. 5.4, а) показано изучаемое изображение f. В этом примере мы восполь-
зуемся представленными выше инструментами для определения типа шума и
оценивания его параметров. На рис. 5.4, б) изображена маска В, построенная ин-
терактивно командой
> > [В, с, г] roipoly(f);
Рис. 5.4, в) получен при выполнении команд
> > [р, npix] = histroi(f, с, г);
> > figure, bar(p, 1);
Среднее значение и дисперсия области исходного изображения, накрываемой
маской В, вычислены по формулам
> > [v, unv] statmoments(h, 2);
> > v
V =
0.5794 0.0063
unv
unv =
147.7430 410.9313
5.2. Модели шума
Рис. 5.4. а) Зашумленное изоб-
ражение. б) Область ROI, по-
строенная интерактивно, в) Ги-
стограмма ROI. г) Гистограмма
гауссова шума, сгенерированная
функцией imnoise2. (Исходное
изображение представлено ком-
панией Lixi, Inc.)
Из рис. 5.4, в) видно, что шум похож на гауссов. На самом деле, найти точное
значение среднего и дисперсии шума в области В не представляется возможным,
так как шум наложен на конкретное изображение. Тем не менее, выбирая одно-
родную область без фоновых деталей (как это было сделано выше) и полагая шум
гауссовым, можно считать, что средняя яркость изображения с шумом прибли-
зительно равна средней яркости этого изображения без шума (мы считаем, что
гауссов шум имеет нулевое среднее). Кроме того, поскольку выбранная область
достаточно однородна по яркости, разумно утверждать, что дисперсия яркости в
области В прежде всего определяется дисперсией шумового слагаемого. (Там, где
эго возможно, другой метод оценивания среднего и дисперсии шума состоит в
использовании тестового изображения постоянной яркости.) На рис. 5.4, г) при-
ведена гистограмма множества из npix (это число возвращает функция histroi)
случайных гауссовых величин со средним 147 и дисперсией 400, построенная ко-
мандами
>> X inmoise2(’gaussian’, npix, 1, 147, 20);
>> figure, hist(X, 130)
» axis([0 300 0 140)
где число корзин в hist выбрано так, чтобы результат можно было сравнить с
графиком на рис. 5.4, в). Эта гистограмма получена функцией histroi (см. преды-
дущий программный код), которая использует масштаб, отличный от масштаба
функции hist. Мы выбрали npix случайных гауссовых величин и записали их в
вектор X, чтобы иметь одинаковое число отсчетов на обеих гистограммах. Схо-
жесть графиков на рис. 5.4, в) и г) ясно указывает па то, что шум, и в самом
деле, хорошо аппроксимирован гауссовым распределением, параметры которого
взяты из оценок v(l) и v(2). □
Глава 5. Восстановление изображений
5.3. Восстановление в присутствии одного шума —
пространственная фильтрация
Если искажения вносятся в изображение исключительно шумом, то из модели
§5.1 вытекает, что
д(х,у) = f(x,y) +т](х,у).
В этом случае методом удаления шума может служить пространственная филь-
трация с использованием техники, описанной в §§ 3.4 и 3.5. В этом параграфе
мы суммируем эти подходы и построим несколько пространственных фильтров
для подавления шума. Дополнительные детали, характеризующие эти фильтры,
изложены в [Gonzalez, Woods, 2002].
5.3.1. Фильтры для пространственного шума
В табл. 5.2 перечислены пространственные фильтры, которые будут рассмотре-
ны в этом параграфе. В этой таблице Sxy обозначает подизображение (область)
размера тхп на зашумленном изображении д. Нижний индекс у S обозначает ко-
ординаты (х,у) центра подизображения. Через f(x,y) обозначается отклик филь-
тра (приближение изображения /) в точке (х, у). Линейные фильтры реализова-
ны с помощью функции imfilter, которая рассматривалась в § 3.4. Медианный,
минимальный и максимальный фильтры являются нелинейными фильтрами по-
рядковых статистик. Медианный фильтр можно непосредственно реализовать на
базе функции medf ilt2 из пакета IPT. Максимальный и минимальный фильтры
можно реализовать с помощью более общей функции ordf ilt2 для нахождения
порядковых статистик, которая обсуждалась в § 3.5.2.
Мы построим функцию spf ilt, которая совершает фильтрацию в простран-
ственной области с помощью любого фильтра из табл. 5.2. Обратите внимание
на использование функции imlincomb (упомянутой в табл. 5.2) при вычислении
линейной комбинации входных данных. Синтаксис этой функции имеет вид
В imlincomb(cl, Al, с2, А2, ck, Ak).
Она реализует формулу
В cl*Al + с2*А2 + + ck*Ak,
где ci - это скалярные величины двойной точности, a Ai — числовые масси-
вы одного класса и одинаковых размеров. Заметьте также, как в подфункции
gmean можно включить и выключить функцию warning. В этом случае имеется
возможность подавить предупреждение, которое выдает MATLAB, когда аргу-
мент функции log становится равен 0. В общем случае, функцию warning можно
использовать в любой программе. Ее базовый синтаксис имеет вид
warn ing(’message’)-
Эта функция ведет себя в точности, как и функция disp, за тем исключением,
что ее можно включать и выключать командой warning on или warning off.
function f = spfilt(g, type, m, n, parameter)
Таблиц» В.2. П|ик ipaiic 1НС1ШЫ1 фильтры. Переменные тип, соответственно, обозначают число строк и столбцов окрестности
фильтрации
Имя фильтра Уравнение Комментарии
Арифметическое среднее Геометрическое среднее Гармоническое среднее Контрагармони- ческое средне Медиана Максимум Минимум Срединная точка а-усеченное среднее (s,t) _Л f(?,y)= П 9(s,t) ,(attyG&xy f(x,y) = t E g(s,e>Q+1 в/ \ (s,t)GSxy Ё f(x, y) = median {g(s, t)} (s ,t) (sSiy f(x,y)= max {g(.5, £)} ( S , t ) C O x у f(x,y) = min {s(s,t)} №,!/)= 5 . max {s(s,t)} + min {s(s,f)} (Sit)€wap (s,t)£SXy Реализуется с помощью функций IPT v = fspecial(’average’, [m, nJ) и f = imfilter(g, «). Реализуется функцией gmean (см. функцию spf ilt в этом пара- графе). Реализуется функцией harmean (см. функцию spf ilt в этом паг раграфе). Реализуется функцией charmean (см. функцию spf ilt в этом параграфе). Реализуется с помощью функций IPT medfilt2: f = medfilt2(g, [m, nl). Реализуется с помощью функций IPT ordfilt2: f ordfilt2(g, m*n, ones(m,n)). Реализуется с помощью функций IPT ordfilt2: f - ordfilt2(g, 1, ones(m.n)). Реализуется в виде полусуммы фильтров максимума и минимума Из области Sxv удаляются d/2 наибольших и d/2 наименьших значений пикселов. gr(s, t) обозначает оставшиеся тп — d знаг чения окрестности. Реализуется с помощью функции alphatrim (см. функцию spfilt).
5.3. Восстановление в присутствии одного шума 173
Глава 5. Восстановление изображений
XSPFILT Performs linear and nonlinear spatial filtering.
% F = SPFILTCG, TYPE, M, N, PARAMETER) performs spatial filtering
7.
7.
7.
7.
7.
7.
7.
7.
7.
7.
7.
7o
7.
7.
7.
7.
7.
7.
7.
of image G using a TYPE filter of size M-by-N. Valid calls to
SPFILT are as follows:
F = SPFILTCG, ’amean’, M, N)
F = SPFILTCG, ’gmean’, M, N)
F = SPFILTCG, ’hmean’, M, N)
F = SPFILTCG, ’chmean’, M, N, Q)
F = SPFILT(G, ’median’, M, N)
F = SPFILTCG, ’max’, M, N)
F = SPFILTCG, ’min’, M, N)
F = SPFILTCG, ’midpoint ’, M, N)
F = SPFILTCG, ’atrimmed ’, M, N, D)
Arithmetic mean filtering.
Geometric mean filtering.
Harmonic mean filtering.
Contraharmonic mean
filtering of order Q. The
default is Q = 1.5.
Median filtering.
Max filtering.
Min filtering.
Midpoint filtering.
Alpha-trimmed mean filtering.
Parameter D must be a nonnega-
tive even integer; its default
value is D = 2.
The default values when only G and TYPE are input are M = N = 3,
7. Q = 1.5, and D = 2.
7, Process inputs.
if nargin == 2
m = 3; n = 3; Q 1.5; d 2;
elseif nargin 5
Q = parameter; d parameter;
elseif nargin == 4
Q = 1.5; d = 2;
else
error(’Wrong number of inputs.’);
end
7. Do the filtering.
switch type
case ’amean’
w = fspecial(’average’, [m n]);
f = imfilterCg, w, ’replicate’);
case ’gmean’
f = gmean(g, m, n);
case ’hmean’
f = harmean(g, m, n);
case ’chmean’
f = charmean(g, m, n, Q);
case ’median’
f = medfilt2(g, [m n], ’symmetric’);
case ’max’
5.3. Восстановление в присутствии одного шума
f = ordfilt2(g, m*n, ones(m, n), ’symmetric’);
case ’min’
f = ordfilt2(g, 1, ones(m, n), ’symmetric’);
case ’midpoint’
fl ordfilt2(g, 1, ones(m, n), ’symmetric’);
f2 ordfilt2(g, m*n, ones(m, n), ’symmetric’);
f imlincomb(0.5, fl, 0.5, f2);
case ’atrimmed’
if (d < 0) | (d/2 "= round(d/2))
error(’d must be a nonnegative, even integer.’)
end
f = alphatrim(g, m, n, d);
otherwise
error(’Unknown filter type.’)
end
7,- 7.
function f gmean(g, m, n)
7, Implements a geometric mean filter.
inclass = class(g);
g = im2double(g);
% Disable log(0) warning.
warning off;
f = exp(imfilter(log(g), ones(m, n), ’replicate’)).~(1 / m / n);
warning on;
f changeclass(inclass, f);
7.- 7.
function f = harmean(g, m, n)
7« Implements a harmonic mean filter.
inclass = class(g);
g im2double(g);
f = m * n ./ imfliter(1-/(g + eps) , ones(m, n), ’replicate’);
f changeclass(inclass, f) ;
7.- 7.
function f charmean(g, m, n, q)
7. Implements a contraharmonic mean filter.
inclass = class(g);
g im2double(g);
f = imfilter(g.~(q+l), ones(m, n), ’replicate’);
f = f ./ (imfilter(g.~q, ones(m, n), ’replicate’) + eps);
f = changeclass(inclass, f) ;
7.- ------- 7.
function f = alphatrim(g, m, n, d)
7. Implements an alpha-trimmed mean filter.
inclass = class(g);
g = im2double(g);
f = imfilter(g, ones(m, n), ’symmetric’);
Глава 5. Восстановление изображений
for к = l:d/2
f = imsubtract(f, ordfilt2(g, к, ones(m, n), ’symmetric’));
end
for к = (m*n (d/2) + 1):m*n
f = imsubtract(f, ordfilt2(g, k, ones(m, n), ’symmetric’));
end
f = f / (m*n d);
f = changeclass(inclass, f);
Рис. 5.5. а) Изображение, испорченное шумом «перец» с вероятностью 0.1. б) Изображе-
ние, испорченное шумом «соль» с вероятностью 0.1. в) Результат фильтрации
а) контрагармоническим фильтром размера 3x3 порядка Q = 1.5. г) Резуль-
тат фильтрации б) при Q = —1.5. д) Результат фильтрации а) максимальным
фильтром размера 3x3. е) Результат фильтрации б) минимальным фильтром
размера 3x3
5.3. Восстановление в присутствии одного шума
Пример 5.5. Использование функции spfilt.
На рис. 5.5, а) приведено изображение класса uint8, испорченное только шумом
«перец» с вероятностью 0.1. Это изображение построено следующими командами
[f, как всегда, обозначает исходное изображение, которое уже воспроизводилось
на рис. 3.18, а)]:
» CM, N] size(f);
> > R = imnoise2(’salt & paper’, М, N, 0.1, О);
> > с = f ind(R == О) ;
» gp = f;
> > gp(c) 0;
Рис. 5.5, б)), подпорченный только шумом «соль», получен командами
> > R inmoise2(’salt & paper’, М, N, 0, 0.1);
> > с find(R == 1);
> > gs f;
> > gs(c) 255;
Избавиться от шума «перец» можно с помощью контрагармонического фильтра
с положительным значением Q. Рис. 5.5, в) построен командой
>> fp spfilt(gp, ’chmean’, 3, 3, 1.5);
Аналогично, для борьбы с шумом «соль» можно воспользоваться контрагар-
моническим фильтром с отрицательным значением Q :
>> fs spfiltfgs, ’chmean’, 3, 3, -1.5);
На рис. 5.5, г) показан результат. Можно также действовать минимальным и
максимальным фильтрами. Например, рис. 5.5, д) и е) получены, соответственно,
из а) и б) с помощью следующих команд
>> fpmax spfiltfgp, ’max’, 3, 3);
>> fpmin spfilt(gs, ’min’, 3, 3);
Другие решения с использованием функции fpmin можно получать аналогич-
ным образом. □
5.3.2. Адаптивные пространственные фильтры
Приведенные выше фильтры применяются одинаково ко всем пикселам изобра-
жения независимо от их местоположения. В некоторых случаях результат филь-
трации можно улучшить, если фильтр имеет возможность менять свое действие
в зависимости от характеристик изображения в области фильтрации. В качестве
иллюстрации реализации адаптивной процедуры пространственной фильтрации на
MATLAB рассмотрим адаптивный медианный фильтр. Как и раньше, Sxy обоз-
начает окрестность фильтрации с центром в точке (гг, у) на изображении, подверга-
емом обработке. Алгоритм, который детально разобран в [Gonzalez, Woods, 2002|,
178 Глава 5. Восстановление изображений
действует следующим образом. Обозначим
^min минимум яркости в Sxy,
^max максимум яркости в Sxy,
^med медиана яркости в Sxy
Zxy яркость в точке (х, у).
Адаптивный алгоритм медианной фильтрации действует на двух уровнях, кото-
рые мы назовем уровень А и уровень В:
Уровень А Если zm-in < zmed < zmax, то перейти на уровень В,
иначе увеличить размер окна.
Если размер окна Smax, то повторить уровень А,
иначе подать на выход величину zme(j.
Уровень В Если zmin < zxy < zmax, то подать на выход zxy,
иначе подать на выход величину zmed-
Здесь Smax обозначает максимально допустимый размер окна адаптивного филь-
тра. Другая особенность последнего шага на уровне А состоит в возвращении
величины zxy вместо медианы. Это приводит к немного меньшему размытию
изображения, однако такая процедура может не заметить шум типа «соль» («пе-
рец») на постоянном заднем фоне, имеющем то же значение, что и шум «соль»
(«перец»).
М-функция, которая реализует этот алгоритм, называется admedian. Она вклю-
чена в приложение В и имеет синтаксис
f = adpmedianfg, Smax),
где g — это фильтруемое изображение, Smax — определенный выше максимально
допустимый размер окна адаптивной фильтрации.
Пример 5.6. Адаптивная медианная фильтрация.
В качестве примера рассмотрим снимок f монтажной платы на рис. 5.6, а), ис-
порченный шумом «соль и перец», который наложен на изображение командой
> > g = inmoiseff, ’salt & paper’, 0.25);
а на рис. 5.6, б) приведен результат выполнения следующей команды (см. § 3.5.2
по поводу использования функции medfilt2)
> > fl = medfilt2(g, [7 7], ’symmetric’);
Это изображение, очевидно, очищено от шума, но одновременно с этим оно стало
слишком расплывчатым и искаженным (обратите внимание на то, как выглядят
штырьки разъемов вверху изображения). Напротив, совершив действие
> > f2 = adpmedianfg, 7,);
мы получим изображение 5.6, е), на котором шум также отсутствует, но оно
существенно четче, чем рис. 5.6, б). □
5.^. Подавление периодического шума
Рис. 5.6. а) Изображение, испорченное шумом «соль и перец» с плотностью ошибок 0.25.
б) Результат применения медианного фильтра размеров 7x7. в) Результат адап-
тивной медианной фильтрации с Smax = 1
5.4. Подавление периодического шума с помощью
фильтрации в частотной области
Как отмечалось в § 5.2.3, периодический шум обнаруживается в ввде импульсно-
подобных всплесков, которые можно наблюдать в его спектре Фурье. Основной
метод борьбы с таким шумом основан на режекторной фильтрации. Передаточ-
ная функция режекторного фильтра Баттерворта порядка п имеет вид
Я(и,г>) =----f pg р,
(«,!>)]
где
£>1 (и, v) = [(а - М/2 - ио)2 + (« - АГ/2 - п0)2]1/2
И
D2(u, и) = [(а - М/2 + но)2 + (« - N/2 + п0)2]1/2
Здесь (uq, vq) и (в силу симметрии) (—по, —w) — центры расположения «выемок»,
радиус которых равен Dq- Обратите внимание на то, что фильтр задан относи-
тельно центра частотного прямоугольника, т. е. его следует обработать функци-
ей fftshift перед тем, как использовать в фильтрации средствами MATLAB
(см. пояснения в §§ 4.2 и 4.3).
Написание М-функции для режекторного фильтра основано на принципах,
изложенных в § 4.5. При этом полезно предусмотреть возможность многих «вы-
емок», как это было сделано в § 5.2.3 при построении функции, которая генери-
рует многократный синусоидальный шум. Имея функцию Н, можно совершать
фильтрацию с помощью функции dftfilf, которая объяснялась в § 4.3.3.
180 Глава 5. Восстановление изображений
5.5. Моделирование искажающих функций
Если имеется оборудование, генерирующее искаженные изображения, то можно
установить природу искажения, экспериментируя с различными установками и
параметрами этого оборудования. Однако доступность такого оборудования яв-
ляется скорее исключением, чем правилом. Более типичной является ситуация,
когда производятся эксперименты с различными функциями PSF, которые те-
стируются с разными алгоритмами восстановления изображений. Другой подход
состоит в математическом моделировании самих функции PSF. Такой подход вы-
ходит за рамки обсуждения в этой книге. Подробное изложение этого материала
имеется в [Gonzalez, Woods, 2002]. Наконец, если нет доступной информации про
PSF, можно прибегнуть к «слепой деконволюции» для каких-то заключений от-
носительно свойств PSF. Этот подход будет обсуждаться в § 5.10. Конец этого
параграфа будет посвящен различным методам моделирования функций PSF с
помощью функций imfilter и f special, которые были введены, соответственно,
в § 3.4 и 3.5, а также различным генераторам шума, рассмотренным ранее в этой
главе.
Одной из основных трудностей, с которой приходится сталкиваться при реше-
нии задач восстановления изображений, является проблема размывания и смазы-
вания изображений. Размывание, возникающее, когда сцена и регистрирующее
устройство находятся в покое по отношению друг к другу, можно смоделиро-
вать низкочастотными фильтрами в пространственной или частотной областях.
Другая важная модель искажения изображений смазыванием соответствует рав-
номерному прямолинейному перемещению сцены относительно регистрирующих
устройств и датчиков в процессе фиксирующей съемки. В этом случае размытие
изображений можно смоделировать с помощью функции f special из пакета IPT:
PSF fspecial(’motion’, len, theta)
Эта форма вызова f special возвращает PSF, которая аппроксимирует эффекты
линейного перемещения камеры на len пикселов. Угловой параметр theta изме-
ряется в градусах, причем он отсчитывается от положительной горизонтальной
полуоси против часовой стрелки. Значения по умолчанию: len 9 и theta = О,
что соответствует смещению на 9 пикселов в горизонтальном направлении.
Мы используем функцию imf ilter для построения изображения, искаженно-
го фильтром PSF, который или известен, или построен приведенной выше коман-
дой:
>> g imfilter(f, PSF, ’circular’);
где параметр ’circular’ (см. табл. 3.2) используется для подавления граничных
эффектов. После чего искажение вносится в изображение в виде аддитивного
шума по формуле
>> g = g + noise;
где noise — это случайное шумовое изображение, которое имеет тот же размер,
что и g, и строится одним из методов, изложенных в § 5.2.
5.5. Моделирование искажающих
При сравнении различных подходов, обсуждаемых в этом и следующем пара-
графах, полезно работать с одним и тем же тестовым изображением. Изображе-
ние, которое строится функцией checkerboard, особенно удобно в этом смысле,
поскольку у него очень просто изменять масштаб, не затрагивая его характерных
черт. Функция имеет следующий синтаксис
С checkerboard(NP, М, N),
где NP — это длина в пикселах каждой клетки, М это число строк, a N число
столбцов шахматной доски. Если параметр N опущен, то он по умолчанию при-
равнивается к М. Если они оба опущены, то строится классическая шахматная
доска 8x8. Наконец, если отсутствует NP, то по умолчанию NP 10 пикселов.
Светлые клетки в левой половине шахматной доски будут белыми, а в правой
половине они будут светло-серыми. Чтобы построить шахматную доску, у кото-
рой все светлые клетки будут белыми, следует дать команду1
» К im2double(checkerboard(NP, М, N) > 0.5);
Изображение, которое строит функция checkerboard, имеет класс double со зна-
чениями в интервале [0,1].
Многие алгоритмы восстановления изображений работают медленно с боль-
шими изображениями. Поэтому имеет смысл экспериментировать с малыми изоб-
ражениями для сокращения времени вычислений, что позволяет скорее оптими-
зировать алгоритм. В этом случае для целей визуализации полезно иметь воз-
можность увеличивать изображение посредством дублирования пикселов. Это
делается с помощью следующей функции (см. ее программный код в приложе-
нии В):
В pixeldup(A, ш, и).
Эта функция дублирует каждый пиксел ш раз по вертикали и и раз по горизон-
тали. Если и опущено, то по умолчанию и = ш.
Пример 5.7. Моделирование размытого зашумленного изображения.
На рис. 5.7, а) построено изображение с помощью команды
» f checkerboard^);
Испорченное изображение 5.7, б) получено командами
» PSF fspecial(’motion’, 7, 45);
» gb imfilter(f, PSF, ’circular’);
Заметьте, что PSF это пространственный фильтр. Он имеет следующие значения:
» PSF
PSF
00000 0.0145 0
0000 0.0376 0.1283 0.0145
3 Операция > производит результат класса logical; im2double используется для приведения
изображения к класса double, что согласуется с классом выхода функции checkerboad.
Глава 5. Восстановление изображений
0 0 0 0.0376 0.1283 0.0376 0
0 0 0.0376 0.1283 0.0376 0 0
0 0.0376 0.1283 0.0376 0 0 0
0.0145 0.1283 0.0376 0 0 0 0
0 0.0145 0 0 0 0 0
Шумовое изображение на рис. 5.7, в) сгенерировано командой
» noise inmoise(zeros(size(f), ’gaussian’, 0, 0.001);
Шум можно добавить к изображению прямо в комацце inmoise (gb, ’gaussian’,
0, 0.001). Однако это шумовое изображение нам еще понадобится в этой главе,
поэтому мы его здесь вычисляем отдельно.
Рис. 5.7. а) Исходное изобра-
жение. б) Изображение, размы-
тое функцией fspecial с па-
раметрами len = 7 и theta =
= -45. в) Шумовое изображе-
ние. г) Сумма б) и в)
Смазанное и зашумленное изображение на рис. 5.7, г) строится по команде
» gb = g + noise;
Этот шум трудно визуально обнаружить на этом изображении, так как его мак-
симальное значение имеет порядок 0.15, а максимальное значение пикселов изоб-
ражения равно 1. Однако в § 5.7 и 5.8 будет показано, что даже такой уровень
шума создает проблемы при восстановлении исходного изображения. Наконец,
отметим, что все изображения на рис. 5.7 были сжаты до размеров 512x512 и
отображены командой типа
imshow(pixeldup(f, 8), [ ]).
Изображение на рис. 5.7, г) будет восстановлено на рис. 5.8 и 5.9. □
5.6. Инверсная фильтрация
5.6. Инверсная фильтрация
Самый простой подход к восстановлению испорченного изображения состоит в
построении приближения вида
а, л G{u,v)
F(u,v) = —----
H{u,v)
после чего следует применить обратное преобразование Фурье к функции F(u, v)
(напомним, что G(u, и) — это преобразование Фурье испорченного изображения).
Этот подход удобно называть инверсной фильтрацией. Воспользовавшись моде-
лью из § 5.1, этот метод можно выразить в виде следующего приближения
F[u,v) = FM +
Это обманчиво простое выражение говорит нам о том, что даже если мы знаем
Н(и,и) точно, то мы не можем восстановить F(u, и) (а значит, и оригинальное,
неиспорченное изображение f(u, и)), поскольку шумовая компонента является
случайной величиной, преобразование Фурье которой N(u, и) остается неизвест-
ной. Кроме того, на практике обычно имеются большие проблемы с функцией
Н(и, и), которая может иметь нулевые значения. Даже если член N(u, и) прене-
брежимо мал, деление его на малые значения Н(и, и) может дать нежелательно
большую прибавку к приближению F(u, и).
Типичный подход к совершению инверсной фильтрации состоит в построении
частного F(u, и) = G(u, и)/Н{и, и), у которого необходимо ограничить частотный
диапазон «малой» окрестностью начала отсчета, а затем делать обратное преоб-
разование. Идея здесь заключается в том, что нули функции Н(и,и) с меньшей
степенью вероятности будут располагаться «близко» от начала частотных ко-
ординат, так как амплитуда преобразования в этой области равна наибольшему
значению этой величины. Имеется множество вариаций на эту тему, при которых
по-разному разбираются значения (и, и) функции Н в нуле или около нуля. Та-
кой подход иногда называется псевдоинверсной фильтрацией. Но, вообще говоря,
подходы, основанные на инверсной фильтрации такого типа, не очень точны, что
видно из примера 5.8 в следующем параграфе.
5.7. Винеровская фильтрация
Винеровская фильтрация (названная в честь Н. Винера, предложившего этот
;етод в 1942 г.) является одним из самых старых и хорошо известных подходов
в линейном восстановлении изображений. Винеровский фильтр ищет приближе-
ние /, которое минимизирует среднеквадратическое отклонение
е2 = E(f - /)2,
де Е — оператор математического ожидания, a f — неискаженное изображение.
Р шение этой экстремальной задачи в частотной области выражается формулой
F(u, v) =
1 ____________\Н(и,у)\2_____________'
H(u,v) H(u,v)\H(u,v)\2 + Stj[u, v)/Sf(u, и)
G(u, v),
184 Глава 5. Восстановление изображений
где Н(и, и) искажающая функция; \Н(и, г>)|2 = Н*(и, v)H(u, v); H*(u,v) —
комплексно-сопряженная функция H(u,v); S^fuju) = ^(u,г>)|2 — энергетиче-
ский спектр шума; Sf(u,v) = |F(u, г>)|2 — спектр неискаженного изображения;
частное S^iu, v)/Sf(u, v) называется энергетическим соотношением шум/сигнал
(NSPR, Noise-to-Signal Power Ratio). Видно, что если спектр шума равен нулю
для всех значений и и и, то это соотношение также равно нулю, и винеровский
фильтр приводится к инверсному фильтру, который обсуждался в предыдущем
параграфе.
Определим две полезные величины, которые называются средняя энергия шу-
ма и средняя энергия изображения, соответственно,
и V и V
Здесь М и N обозначают вертикальный и горизонтальный размеры массивов
изображения и шума. Эти величины являются скалярами, а их частное
которое также скалярно, иногда используется при построении постоянной матри-
цы, которая используется вместо S^(u, и)/ Sf(u, и). В этом случае, даже при неиз-
вестном истинном соотношении шум/сигнал, получается простой способ интерак-
тивного экспериментирования путем изменения этой константы и наблюдения ре-
зультатов восстановления. Конечно, такой метод является весьма грубым, когда
предполагается, что все функции являются константами. Замена Sj/u, v)/Sf(u, и)
на константу R в приведенной выше формуле для F(u, и) называется параметри-
ческим винеровским фильтром. В примере 5.8 показано, что даже такой простой
прием может привести к существенно более лучшему результату, чем при инверс-
ной фильтрации.
Винеровская фильтрация реализована в IPT с виде функции deconvwnr, кото-
рая имеет три возможные синтаксические формы. Во всех этих формах g обозна-
чает искаженное, a fr — восстановленное изображение. Первая синтаксическая
форма
fr deconvwnr(g, PSF)
предполагает, что соотношение шум/сигнал равно нулю. Следовательно, такая
форма винеровского фильтра совпадает с инверсным фильтром, рассмотренном
в § 5.6. Синтаксис
textfr = deconvwnr(g, PSF, NSPR)
предполагает, что соотношение шум/сигнал известно или в виде константы, или в
виде массива; годится и то и другое. Этот синтаксис используется для реализации
параметрической винеровской фильтрации. В этом случае аргумент NSPR может
служить интерактивным входным параметром. Наконец, команда вида
fr = deconvwnr(g, PSF, NACORR, FACORR)
5.7. Винеровская фильтрация
предполагает известными автокорреляционные функции NACORR и FACORR шума и
неискаженного изображения. Обратите внимание на то, что в функции deconvwnr
используются автокорреляции у и /, а не энергетический спектр этих функций.
По теореме о корреляции заключаем, что
|F(u,u)|2 = 3{f(x,y) о f(x,y)],
где «о» обозначает операцию корреляции, а 9 — преобразование Фурье. Это урав-
нение дает возможность вычислить автокорреляционную функцию f(x, y)of(x, у)
для использования в deconvwnr, находя обратное преобразование Фурье энер-
гетического спектра. То же можно сказать про автокорреляционную функцию
шума.
Если восстановленное изображение демонстрирует искажения типа «звоны»,
которые вносятся дискретным преобразованием Фурье, используемым в алгорит-
ме, то иногда с этим явлением позволяет справиться функция edgetaper, кото-
рую следует применить до выполнения функции deconvwnr. Ее синтаксис имеет вид
J = edgetaper(I, PSF).
Эта функция смазывает края входного изображения I, используя функцию раз-
броса точек PSF. Выходное изображение J есть взвешенная сумма I и его размы-
той версии. Весовая матрица, которая определяется автокорреляционной функ-
цией PSF, присваивает J значения I внутри изображения, а около границ J при-
равнивается размытой версии I.
Пример 5.8. Применение функции deconvwnr при восстановлении размытого
зашумленного изображения.
Рис. 5.8, а) совпадает с рис. 5.7, г), а рис. 5.8, б) получен командой
» frl deconvwnr(g, PSF);
где g — это искаженное изображение, a PSF — функция разброса точек, вычис-
ленная в примере 5.7. Как уже отмечалось выше, frl — это результат прямого
применения инверсной фильтрации, и, как ожидалось, на этом изображении пре-
обладают шумовые эффекты. (Как и в примере 5.7, все изображения были обра-
ботаны функцией pixeldup для их увеличения до размера 512x512 пикселов.)
Число R, которое обсуждалось ранее в этом параграфе, было получено с по-
мощью исходного и шумового изображений из примера 5.7 по формулам
abs(fft2(noise)).“2;
sum(Sn(:))/prod(size(noise));
abs(fft2(f)).-2;
sum(Sn(:))/prod(size(noise)) ;
nA/fA;
7» noise power spectrum
7. noise average power
7c image power spectrum
7o image average power
Для восстановления изображения с помощью этого соотношения R выполним
команду
>> fr2 = deconvwnr(g, PSF, R);
Глава 5. Восстановление изображений
Рис. 5.8. а) Размытое и зашумленное изображение, б) Результат инверсной фильтрации.
в) Результат винеровской фильтрации с постоянным соотношением шум/сигнал.
г) Результат винеровской фильтрации с использованием автокорреляционных
функций
Из рис. 5.8, в) видно, что такой подход дает существенное улучшение по срав-
нению с инверсной фильтрацией.
Наконец, используем автокорреляционные функции при восстановлении изоб-
ражения (напомним о необходимости использования функции fftshift при цен-
тровании).
>> NCORR = fftshift(real(ifft2(Sn)));
» IC0RR = fftshift(real(ifft2(Sf)));
» fr3 deconvwnrCg, PSF, NCORR, ICORR);
Из рис. 5.8, г) видно, что результат этих операций весьма близок к оригиналу, хо-
тя небольшой шум все еще проявляется. Поскольку нам известно само изображе-
ние и наложенный на него шум, мы можем оценить корректирующие параметры
и сделать заключение, что рис. 5.8, г) дает наилучший результат, который можно
достигнуть винеровской деконволюцией. На практике, когда одна (или более) из
этих величин неизвестна, приходится менять функции для экспериментирования
до тех пор, пока не будет достигнут удовлетворительный результат. □
5.8. Сглаживающая фильтрация методом наименьших квадратов
5.8. Сглаживающая фильтрация методом наименьших
квадратов со связью
Другой хорошо зарекомендовавший себя метод линейного восстановления заклю-
чается в фильтрации по методу наименьших квадратов с ограничениями, кото-
рый в документации IPT называется сглаживающей фильтрацией. Двумерная
дискретная свертка задается выражением
М-1 7V-1
h(x,y)* f(x,y) = -MN У7 У. f(m,n)h(x-m,y-n).
т=0 п=0
С помощью этой формулы можно выразить модель линейного искажения д(х, у) =
= h(x,y) * f(x,y) + г)(х,у), которая обсуждалась в § 5.1, в векторно-матричной
форме
g = Hf + rj.
Пусть, к примеру, д(х, у) имеет размеры MxN. Тогда можно сформировать пер-
вые N элементов вектора g из элементов изображения, которые располагаются
в первой строке д(х,у), следующие N элементов взять из второй строки д(х,у)
и т. д. В результате получится вектор размера MNyI. Такую же размерность
имеют векторы f и т], которые строятся по аналогичной схеме. В этом случае
матрица Н имеет размеры MNxMN. Ее элементы берутся из предыдущего урав-
нения свертки.
Логично заключить, что задача восстановления изображения может быть пе-
реформулирована в виде простых матричных действий. Однако в данном случае
это не так. Предположим, что мы имеем дело с изображением средних размеров,
например, у которого М = N — 512. Тогда векторы в описанных выше пред-
ставлениях будут иметь размерность 262144x1, а у матрицы Н будут размеры
262 144 х262 144. Обрабатывать векторы и матрицы таких размеров весьма непро-
сто. Проблема еще более усложняется тем обстоятельством, что для Н может не
существовать обратной матрицы в силу наличия нулей у передаточной функции
(см. § 5.6). Таким образом, формулировка задачи восстановления в матричной
форме не позволяет облегчить технику восстановления изображений.
Несмотря на то, что мы здесь не собираемся обосновывать метод наимень-
ших квадратов со связями, стоит отметить, что центральным местом этого ме-
тода является чувствительность к обращению матрицы Н, о чем говорилось в
предыдущем абзаце. Одним из возможных путей преодоления этой трудности
является оптимизация процедуры восстановления по сглаживающей мере, на-
пример, по вторым производным изображения (и, в частности, по лапласиану).
Такая процедура будет иметь смысл, если ограничения задачи являются доступ-
ными параметрами. Таким образом, требуется найти минимум целевой функции
С, которая определяется по формуле
М-1 7V-1
с= £ £[v7(t,<
:,;=0 у=0
при условии выполнения ограничения (связи)
II.?-н? ||2 = IM2,
188 Глава 5. Восстановление изображений
г ре ||w||2 = w7w — это евклидова норма вектора1, f — это приближение испор-
ченного изображения, а оператор Лапласа V2 был определен в § 3.5.1.
Решение этой задачи по оптимизации, записанное в частотной области, зада-
ется выражением
F(u, ц) = --------- -------------гту G(u, ц),
|_|Н(н,ц)|2 +7|F(u, ц)|2]
где 7 — это некоторый параметр, который следует подобрать так, чтобы выпол-
нялось уравнение связи (при 7 = 0 получаем решение для инверсного фильтра),
а Р(и, и) — преобразование Фурье функции
р(х, у) =
0 1 0
1 —4 1
О 10
В этой функции мы узнаем оператор Лапласа, введенный в § 3.5.1. В предыду-
щих формулах остались неизвестными две величины, 7 и ЦтуЦ2. Однако 7 можно
вычислить интерактивно, если известна скалярная величина ЦтуЦ2, которая про-
порциональна энергии шума.
Фильтрация методом наименьших квадратов со связями реализована в IPT в
виде функции deconvreg, которая имеет синтаксис
fr deconvreg(g, PSF, NOISEPOWER, RANGE),
где g — это искаженное изображение, fr — восстановленное изображение, NOISEPOWER
пропорционально Ц7Ц2, a RANGE - это диапазон для нахождения решения 7. По
умолчанию это интервал [10-9,109] (или в обозначениях MATLAB, [1е-10,1е10]).
Если два последних параметра в deconvreg отсутствуют, то эта функция совер-
шает обычную инверсную фильтрацию. Хорошим начальным приближением для
NOISEPOWER может являться число МАт[сг2 + о^], где М и N — размеры изобра-
жения, числа в квадратных скобках равны дисперсии и квадрату среднего зна-
чения шума. Эта величина является лишь первым приближением, в то время
как окончательное оптимальное значение может быть совсем иным, что видно в
следующем примере.
Пример 5.9. Использование функции deconvreg при восстановлении смазан-
ного зашумленного изображения.
Мы теперь восстановим изображение на рис. 5.7, г) с помощью функции deconvreg.
Это изображение имеет размеры 64x64, а из примера 5.7 нам известно, что его
шум имеет нулевое среднее и дисперсию, равную 0.001 Следовательно, наше на-
чальное приближенное значение для NOISEPOWER равно (64)2х [0.001 + 0| « 4.
На рис. 5.9, а) дан результат выполнения команды
» fr deconvreg(g, PSF, 4);
1Для вектор-сголбца w, имеющего п компонент, wTw = У”—, w^., где Wfc — fc-ая компонента
вектора w.
5.9. Алгоритм Люси-Ричардсона итерационного нелинейного восстановления
где g и PSF взяты из примера 5.7. Это изображение немного лучше исходно-
го, однако ясно, что выбранное значение NOISEPOWER не годится с практической
точки зрения. Если немного поэкспериментировать с этим параметром, а так-
же с параметром RANGE, то можно найти оптимальный результат, показанный на
рис. 5.9, б), который был построен командой
fr deconvregfg, PSF, 0.4, [1е-7 1е7]);
Итак, следует уменьшить величину NOISEPOWER на один порядок, а интервал
диапазона выбрать покомпактнее. Результат винеровской фильтрации того же
изображения приведен на рис. 5.8, г), однако он был получен при наличии пол-
ной информации о спектрах шума и исходного изображения. Без этих ключевых
сведений результаты, достигаемые при экспериментировании с этими фильтра-
ми, часто бывают вполне сравнимы друг с другом. □
Если в восстановленном изображении наблюдаются «звоны», наведенные д искрет-
ным преобразованием Фурье, то справиться с ними позволяет функция edgetaper
(см. § 5.7), которую следует применить до вызова deconvreg.
Рис. 5.9. а) Изображение из
рис. 5.7, г), восстановленное сгла-
живающим фильтром с пара-
метром NOISEPOWER = 4. б) То
же восстановленное изображе-
ния при NOISEPOWER = 0.4 и с
диапазоном RANGE [1е-7 1е7]
5.9. Алгоритм Люси-Ричардсона итерационного
нелинейного восстановления
Методы восстановления изображений, которые обсуждались в трех предыдущих
параграфах, являются линейными. Кроме того, они являются «прямыми» в том
смысле, что, как только соответствующий фильтр построен, решение задачи вос-
становления находится однократным применением этого фильтра. Эта простота
реализации вкупе со скромными требованиями к вычислительным ресурсам, а
также хорошо развитая теоретическая база, сделали линейные методы основны-
ми инструментами восстановления изображений на многие годы.
В последние два десятилетия нелинейные итерационные технологии стали за-
воевывать популярность в области восстановления изображений, приводя часто к
более лучшим результатам по сравнению с традиционными линейными методами.
Основными недостатками нелинейных методов являются недостаточная предска-
зуемость их поведения, а также использование значительных вычислительных
Глава 5. Восстановление изображений
ресурсов. Первый недостаток часто теряет свою актуальность, поскольку пока-
зано, что нелинейные методы превосходят линейные по широкому спектру прило-
жений (см. [Jansson, 1997]). Второй недостаток также постепенно преодолевается
в виду впечатляющего роста производительности вычислительной техники за по-
следние 10 лет. Нелинейные методы восстановления изображений, имеющиеся в
пакете IPT, разработаны независимо в [Richardson, 1972] и [Lucy, 1974]. В пакете
этот подход называется алгоритмом Люси-Ричардсона (L-R), однако в литера-
туре он также называется алгоритмом Ричардсона-Люси.
Алгоритм L-R формулируется в терминах метода максимального правдоподо-
бия (см. § 5.10), в котором изображение моделируется в виде статистик Пуассона.
Максимизация функции правдоподобия модели приводит к уравнению, которое
выполняется при условии сходимости следующих итераций
fk+i{x,y) = fk(x,y)
,, ч 9(х,у)
Щ—Х, —у) * --------Z------
h(x,y) * А(т,т/)
где, как обычно, «*» обозначает свертку, f — это приближение неиспорченного
изображения, а обе функции f и д определены в § 5.1. Алгоритм, очевидно,
является итерационным, а его нелинейность происходит из-за деления на / в
правой части уравнения.
Как и в любом нелинейном методе, здесь трудно в общем виде ответить на
вопрос: когда следует остановить алгоритм L-R? В конкретных приложениях этот
подход часто сопровождается выводом на экран промежуточных результатов, и
алгоритм останавливается при достижении приемлемых изображений.
Алгоритм L-R реализован в IPT функцией deconvlucy, которая имеет следу-
ющий синтаксис:
fr deconvlucy(g, PSF, NUMIT, DAMPAR, WEIGHT),
где fr — это восстановленное изображение, g — искаженное изображение, PSF —
функция разброса точек, NUMIT - число итераций (по умолчанию 10), а величины
DAMPAR и WEIGHT определяются следующим образом.
DAMPAR — это скаляр, который определяет порог отклонения полученного
изображения от g. Итерации останавливаются для пикселов, отклонение значе-
ний которых от исходных не превосходит этого порога. Это предотвращает обра-
зование шума в таких пикселах, сохраняя необходимые детали изображения. По
умолчанию DAMPAR = 0 (нет порога остановки).
WEIGHT — это массив размера, как у g, который каждому пикселу присваивает
некоторый вес, отражающий его качество. Например, «плохие» пикселы, кото-
рые получились из дефектных областей на изображения, можно исключить из
рассмотрения, присвоив им нулевой вес. Другое полезное применение этого мас-
сива состоит в подгонке весов пикселов для коррекции однородных областей при
наличии дополнительной информации. При моделировании смазывания конкрет-
ным PSF (см. пример 5.7) параметр WEIGHT можно использовать для исключения
из вычислений пикселов, которые расположены на границах изображения и ко-
торые размываются функцией PSF. Если PSF имеет размеры тгхтг, то в WEIGHT
5.9. Алгоритм Люси-Ричардсона итерационного нелинейного восстановления
используется обрамление из нулей ширины ceil(n/2) По умолчанию WEIGHT
состоит из одних единиц и имеет размеры, как у изображения g.
Рис. 5.10. а) Исходное
изображение. 6) Изобра-
жение, размытое и ис-
порченное гауссовым шу-
мом. в)-е) Изображения,
восстановленные по алго-
ритму L-R, соответствен-
но, после 5, 10, 20 и 100
итераций
Если в восстановленном изображении наблюдаются «звоны», производимые
дискретным преобразованием Фурье, то подавить их можно функцией edgetaper
(см. § 5-7), которую надо применять до вызова deconvlucy.
Пример 5.10. Использование функции deconvlucy при восстановлении смазан-
ного и зашумленного изображения.
На рис. 5.10, а) показано изображение, построенное командой
» f = checkerboard(8);
и имеющее размеры 64 x 64 пикселов. Как и раньше, его размеры были увели-
чены до 512x512 функцией pixeldup для лучшего визуального восприятия:
192 Глава 5. Восстановление, изображений
» imshow(pixeldup(f, 8));
Следующая команда создала гауссову PSF размера 7x7 со стандартным от-
клонением 10:
>> PSF = fspecial(’gaussian’, 7, 10);
Затем мы размыли изображение f с помощью функции PSF и прибавили к
нему случайный гауссов шум с нулевым средним и стандартным отклонением
0.01:
> > SD 0.01;
> > g= imnoise(imfilter(f, PSF), ’gaussian’, 0, SD~2);
На рис. 5.10, б) дан результат.
Остальная часть примера относится к восстановлению изображения g с помо-
щью функции deconvlucy. Зададим параметр DAMPAR:
> > DAMPAR = 10*SD;
Массив WEIGHT строится по описанной выше схеме:
» LIM = ceil(size(PSF), 1)/2);
» WEIGHT = zeros(size(g));
> > WEIGHT(LIM + l:end LIM, LIM + l:end LIM) 1;
Размеры массива WEIGHT равны 64 x64. На его границах располагается бордюр
нулевых пикселов ширины 4. а все остальные пикселы равны 1.
Остался неопределенным параметр NUMIT, который обозначает число итера-
ций. На рис. 5.10, в) приведен результат выполнения команд
» NUMIT = 5;
> > fr deconvlucy(g, PSF, NUMIT, DAMPAR, WEIGHT);
> > imshow(pixeldup(fr, 8))
Изображение немного улучшилось, но осталось достаточно размытым. Рис. 5.10, г)
и д) представляют результаты, полученные при NUMIT = 10 и 20. Последний из
них можно смело считать восстановлением исходного смазанного и зашумлен-
ного изображения. На самом деле, дальнейшее увеличение числа итераций не
приводит к значительным улучшениям. Например, рис. 5.10, е) получен после
100 итераций. Это изображение лишь чуть-чуть точнее и ярче результата после
20 итераций. Тонкий черный бордюр на всех восстановленных изображениях по-
лучился потому, что в массиве WEIGHT на соответствующих местах стоят нули. □
5.10. Слепая деконволюция
Одна из самых сложных проблем, возникающая при восстановлении изображе-
ний, состоит в получении подходящих приближений функции PSF для исполь-
зования в алгоритмах восстановления, которые обсуждались в предыдущих па-
раграфах. Как уже отмечалось ранее, методы восстановления изображений, в
5.10. Слепая деконволюция
которых не используется информация, характеризующая функцию PSF, называ-
ются алгоритмами слепой деконволюции.
Метод слепой деконволюции, к которому было обращено внимание исследова-
телей последние двадцать лет, основан на приближении по максимуму правдопо-
добия (MLE, Maximum-Likelihood Estimation) стратегии оптимизации при по-
строении приближений величин, искаженных случайным шумом. Вкратце можно
сказать, что в интерпретации MLE изображение считается случайно выбранным
с некоторой определенной вероятностью из семейства других возможных случай-
ных величин. Функция правдоподобия выражается через функции д(х, у), f(x,y)
и h(x, у) (см. § 5.1), и задача заключается в нахождении максимума функции
правдоподобия. При слепой деконволюции задача оптимизации решается итера-
тивно при выполнении соответствующих ограничений и при условии сходимости
всей процедуры. Максимизирующая пара функций f(x, у) и h(x, у) считается вос-
становленным изображением и соответствующей функцией PSF.
Вывод алгоритма слепой деконволюции выходит за рамки нашего обсужде-
ния, но читатель может найти основательное изложение этого материала в следу-
ющей литературе: основы приближений по максимуму правдоподобия изложены
в классической книге [Van Trees, 1968]. Обзор многих интересных работ по об-
работке изображений в этой области имеется в [Dempster et al., 1977], а также в
более позднем расширении этой работы в [Holmes, 1992]. Хорошим справочником
по деконволюции является книга [Jansson, 1997]. Подробные примеры по исполь-
зованию деконволюции в микроскопии и астрономии приведены, соответственно,
в работе [Holmes et al., 1995] и в [Hanisch et al., 1997].
В пакете слепая деконволюция представлена функцией deconvblind, которая
имеет синтаксис
[fr, PSFe] deconvblind(g, INITPSF),
где g — искаженное изображение, INITPSF - первое приближение функции PSF,
PSFe — конечное вычисленное приближение этой функции, a fr — восстановлен-
ное изображение на основе найденной функции PSF. Функция использует при
вычислениях итеративный алгоритм L-R, описанный выше. Приближение PSF
сильно зависит от размера начальной оценки и, в меньшей степени, от ее значе-
ний (массив из одних единиц является разумной начальной оценкой).
В этой форме функции число итераций равно 10 (принято по молчанию).
Дополнительные параметры, которые можно включить в аргументы функции
deconvblind контролируют число итераций и другие особенности процесса вос-
становления:
[fr, PSFe] deconvblind(g, INITPSF, NUMIT, DAMPAR, WEIGHT).
Параметры NUMIT, DAMPAR и WEIGHT объяснялись при описании алгоритма L-R в
предыдущем параграфе.
Если в восстановленном изображении имеются «звоны» от дискретного пре-
образования Фурье, то подавить их поможет функция edgetaper (см. § 5.7), ко-
торую надо вызвать до применения deconvblind.
Пример 5.11. Использование функции deconvblind при построении прибли-
жения PSF.
На рис. 5.11, а) изображена функция PSF, которая использовалась при построе-
нии искаженного изображения на рис. 5.10, б)-.
> > PSF = f special (’gauss ian’, 7, 10);
> > imshow(pixeldup(PSF, 73), [ ]);
Как и в примере 5.10, искаженное изображение, которое будет изучаться, полу-
чено командами
» SD 0.01;
» g = imnoise(imfilter(f, PSF), ’gaussian’, 0, SD~2);
В данном примере нас интересует использование функции deconvblind для по-
строения приближения PSF, если известно только искаженное изображение g. На
рис. 5.11, б) приведен результат следующих команд:
» INITPSF = ones(size(PSF));
» NUMIT = 5;
» [fr, PSFe] = deconvblind(g, INITPSF, NUMIT, DAMPAR, WEIGHT);
> > imshow(pixeldup(PSFe, 73), [ ]);
где значения DAMPAR и WEIGHT были взяты из примера 5.10.
Рис. 5.11. а) Исходная функция PSF. б)--г) Приближения PSF, соответственно, после 5,
10 и 20 итераций функции deconvblind
5.11. Геометрические преобразования и регистрация
Рис. 5.11, в) и г) показывают функции PSFe, построенные теми же командами,
но после выполнения, соответственно, 10 и 20 итераций. Последний результат
весьма близок к исходной PSF из рис. 5.11, а). □
5.1 I. Геометрические преобразования и регистрация
изображений
В завершении этой главы мы рассмотрим геометрические преобразования, кото-
рые используются при восстановлении изображений. Геометрические преобразо-
вания изменяют пространственные соотношения между пикселами изображения.
Их иногда называют преобразованиями куска резины, поскольку их можно себе
представить, если нанести изображение на кусок резины, а затем растягивать его
в соответствии с предписанными правилами.
Геометрические преобразования часто используются при регистрации изоб-
ражений. В этом процессе участвуют два изображения на одной сцене, которые
необходимо наложить друг на друга с целью визуализации или количественного
сравнения. В следующих подпараграфах обсуждаются:
(1) пространственные преобразования и способы их визуализации в MATLAB;
(2) применение пространственных преобразований к конкретным изображениям;
(3) задание пространственных преобразований для регистрации изображений.
5.11.1. Пространственные преобразования
Пусть изображение f, заданное в координатной система (w, z), подвергается гео-
метрической деформации, в результате которой получается изображение д в ко-
ординатной системе (х, у). Это (координатное) преобразование можно записать
в виде формулы
(х,у) = T{(w,z)}.
Например, если (х, у) = T{(w, z)} — (w/2, z/2), то «искажение» сводится к двой-
ному сжатию по обеим пространственным измерениям, как показано на рис. 5.12.
Чаще всего используется класс геометрических преобразований, представи-
тели которого называются аффинными преобразованиями (см. [Wolberg, 1990]).
Аффинное преобразование можно записать в матричной форме
[х у 1] = [w z 1]Т = [w z 1]
Hi
^21
*31
*12 0
^22 0
t32 1
Такой формулой можно задать сжатие, поворот, перенос или сдвиг, соответствую-
щим образом определяя элементы матрицы Т. В табл. 5.3 показано, как выбирать
эти величины для совершения различных преобразований.
Рис. 5.12. Простое простран-
ственное преобразование. (За-
метим, что оси ху на рисун-
ке не соответствуют коорди-
натной системе изображения,
заданной в § 2.1.1. Там же об-
ращалось внимание на то, что
IPT использует т. н. простран-
ственную координатную систе-
му, в которой у обозначает
строки, а х — столбцы. Далее
в этом параграфе используется
именно эта система для совме-
стимости с документацией IPT
по части геометрических пре-
образований.)
В пакете IPT пространственное преобразование задается в виде т. н. tform-
структуры1 Один путь определения структуры состоит в использовании функ-
хСм. §§ 2.10.6 и 11.1.1, где обсуждались структуры.
5.11. Геометрические преобразования и регистрация изображений
ции makef orm, вызов которой имеет вид
tform = maketform(transform_type, transform_parameters).
Первый входной аргумент transf orm_type может принимать значения ’affine’,
’projective’, ’box’, ’ composite’, или ’custom’ Эти типы преобразований объ-
яснены в табл. 5.4 в § 5.11.3. Остальные аргументы зависят от выбранного типа
преобразования, и они разъясняются на справочной странице функции makeform.
Рассмотрим некоторые аффинные преобразования. Например, можно опре-
делить аффинную tfonn-структуру, прямо описав ее матрицу Т следующим спо-
собом:
» Т = [2 0 0; 0 3 0; 0 0 1] ;
>> tform = maketform(’affine’, T)
tform =
ndims_in:2
ndims_out:2
f orward_f cn:@fwd_af f ine
inverse_fcn:@inv_affine
tdata:[1x1 struct]
Хотя пользователю не потребуется напрямую обращаться к полям структуры
tform, сообщим, что информация о матрице Т и о ее обратной Т-1 хранится в
поле tdata:
>> tform. tdata
ans
T:3 x 3 double
Tinv:3 x 3 double
>> tform. tdata.T
ans =
200
030
001
>> tform. tdata. Tinv
ans =
0.5000 0 0
00.3333 0
0 01.0000
В пакете IPT имеются две функции, с помощью которых пространствен-
ное преобразование применяется к точкам: tformfwd вычисляет прямое преоб-
разование T{(w,z)}, а функция tforminv вычисляет обратное преобразование
Т-1 {(ж, у)}. Форма вызова tformfwd имеет вид XY = tformfwd(WZ, tform). Здесь
WZ матрица Рх2, в каждой строке которой стоят пары w и z координат од-
ной точки из. Р. Аналогично, XY — это матрица, столбцы которой содержат х-
и у-координаты Р преобразованных точек. Например, следующие команды вы-
числяют прямое преобразование пары точек, после чего вычисляется обратное
преобразование для проверки, получаются ли исходные данные:
198 Глава 5. Восстановление изображений
» WZ [1 1; 3 2];
>> XY = tf ormfwd(WZ, tfonn)
XY
2 3
6 6
>> WZ2 tforminv(XY, tfonn)
WZ2
1 1
3 2
Чтобы лучше почувствовать то или иное пространственное преобразование,
полезно посмотреть на то, как оно действует на изображение, содержащее ко-
ординатную сетку. Следующая М-функция vistformfwd строит координатную
сетку, преобразует ее с помощью tf onnfwd, а затем размещает рядом графики
этой сетки и ее преобразования для удобства сравнения. Обратите внимание на
совместное употребление функций meshgrid (§ 2.10.4) и linspace (§ 2.8.1) при
построении сетки. Следующий программный код также иллюстрирует использо-
вание некоторых других функций, описанных ранее.
function vistformfwd(tform, wdata, zdata, N)
7»VISTF0RMFWD Visualize forward geometric transform.
7. VISTFORMFWD(TFORM, WRANGE, ZRANGE, N) shows two plots: an N-by-N
7, grid in the W-Z coordinate system, and the spatially transformed
7» grid in the X-Y coordinate system. WRANGE and ZRANGE are
7o two-element vectors specifying the desired range for the grid. N
7. can be omitted, in which case the default value is 10.
if nargin < 4
N = 10;
end
% Create the w-z grid and transform it.
[w, z] = meshgrid(linspace(wdata(l), zdata(2), N),
linspace(wdata(l), zdata(2), N));
wz = [w(:) zC:)] ;
xy = tformfwd([w(:) z(:)], tform);
% Calculate the minimum and maximum values of w and x,
7» as well as z and y. These are used so the two plots can be
7» displayed using the same scale.
x reshape(xy(: 1), size(w)); 7» reshape is discussed in Sec. 8.2.2.
у reshape(xy(:, 2), size(z));
wx = [w(:); x(:)];
wxlimits = [min(wx) max(wx)];
zy = [z(:); уC:)];
zylimits [min(zy) max(zy)];
7. Create the w-z plot.
subplot(l,2,1) 7o See Section 7.2.1 for a discussion of this function.
plot(w, z, ’b’), axis equal, axis ij
hold on
5.11. Геометрические преобразования и регистрация
plot(w’, z’, ’b’)
hold off
xlim(wxlimits)
ylim(zy1imit s)
vistformfwd
Пример 5.12. Визуализация некоторых аффинных преобразований функцией
vistformfwd.
В этом примере мы проиллюстрируем действие некоторых аффинных преобра-
зований с помощью функции vistf ormfwd. Кроме того, для создания аффинной
tf orm мы воспользуемся еще одним подходом использования функции maketf orm.
Начнем с аффинного преобразования, которое растягивает изображение в 3 раза
по горизонтали и в 2 раза по вертикали:
» II [3 0 0; 0 2 0; 0 0 1] ;
> > tforml = maketform(’affine’, Tl) ;
> > vistformfwd(tforml, [0 100], [0 100]);
На рис. 5.13, а) и б) даны результаты.
Эффекты сдвига наблюдаются, если элементы и ti2 в аффинной матрице
Т являются ненулевыми:
» Т2 [10 0; .2 1 0; 0 0 1] ;
> > tform2 = maketform(’affine’, T2);
> > vistformfwd(tform2, [0 100], [0 100]);
На рис. 5.13, в) и г) показаны эффекты сдвига применительно к координатной
сетке.
Важное свойство аффинных преобразований состоит в том, что любая их ком-
бинация снова является аффинным преобразованием. Математически матрица Т
этого аффинного преобразования получается перемножением соответствующих
аффинных матриц. Следующий блок команд генерирует и отображает аффин-
ное преобразование, которое получается комбинацией растяжения, поворота и
сдвига.
» Tscale [1.500; 020; 001];
> > Trotation = [cos(pi/4) sin(pi/4) 0;
-sin(pi/4) cos(pi/4) 0; 0 0 1];
» Tshear =[100; .2 1 0; 0 0 1];
> > T3 Tscale*Trotation*Tshear;
> > tform3 = maketform( ’ affine ’, T3) ;
> > vistformfwd(tform3, [0 100], [0 100]);
На рис. 5.13, д) и e) приведен результат. □
200 Глава 5. Восстановление изображений
Рис. 5.13. Визуализация аффинных преобразований с помощью сетки, а) Сетка 1. б) Сет-
ка 1, преобразованная с помощью tfonnl. в) Сетка 2. г) Сетка 2, преобразо-
ванная с помощью tfonn2. д) Сетка 3. е) Сетка 3, преобразованная с помощью
tf оппЗ
5.11.2. Применение пространственных преобразований
к изображениям
Большинство вычислительных методов пространственного преобразования изоб-
ражений можно разделить на две категории: методы, использующие прямое отоб-
5.11. Геометрические преобразования и регистрация
ражение, и методы, основанные на обратном отображении. Методы прямого
отображения берут каждый пиксел и копируют его в место на выходном изоб-
ражении, координаты которого вычисляются по формуле T{(w, z)}. При этом
возникает проблема: что делать с двумя или большим числом входных пикселов,
которые преобразуются в один и тот же пиксел, т. е. как скомбинировать крат-
ные величины входных пикселов для получения одного-единственного выходного
пиксела. Другая потенциальная сложность состоит в том, что на выходном изоб-
ражении могут оказаться точки, на которые не отобразился ни один входной пик-
сел. В более изощренной форме прямого отображения четыре вершины входного
пиксела отображаются в вершины неправильного четырехугольника на выход-
ном изображении. Входные пикселы распределяются среди выходных пикселов
в соответствии с тем, сколько раз накрывается каждый пиксел относительно пло-
щади каждого выходного пиксела. Такая форма прямого отображения является
более точной, однако она будет существенно сложнее и потребует больших вы-
числительных средств при реализации.
Функция IPT imtransf orm, напротив, использует обратное отображение. Про-
цедура обратного отображения берет поочередно пикселы выходного изображе-
ния и вычисляет координаты соответствующих точек — прообразов входного
изображения по формуле Т_1{(а:,у)}, а затем делает интерполяцию по ближай-
шим пикселам входного изображения для определения величины выходного пик-
села. Обратное преобразование бывает проще реализовать, чем прямое.
Основная форма вызова функции imtransf orm имеет вид
g = imtransform(f, tform, interp),
где interp — это строка символов, которая определяет метод интерполяции ближай-
ших пикселов для вычисления значения выходного пиксела. Переменная interp
имеет три возможных значения: ’nearest’, ’bilinear’ и ’bicubic’ Если interp
опущена, то по умолчанию используется ’bilinear’. Как и в предыдущих при-
мерах, в качестве тестового изображения при экспериментировании с простран-
ственными преобразованиями будет использоваться шахматная доска.
Пример 5.13. Пространственное преобразование изображений.
Мы воспользуемся функциями checkerboard и imtransform для исследования
некоторых аспектов преобразования изображений. Линейное конформное преоб-
разование является частным случаем аффинного преобразования, при котором
сохраняются формы и углы. Линейное конформное преобразование задается ко-
эффициентом растяжения/сжатия, углом поворота и вектором переноса. В этом
случае аффинная матрица имеет вид
s cos 0
— 8 sin в
<5х
з sin 0 О
8 COS 6 О
<5а 1
Следующая последовательность команд строит линейное конформное преобра-
зование и применяет его к тестовому изображению:
>> f = checkerboard(50);
>> s = 0.8;
Глава 5. Восстановление изображений
» theta = pi/6;
» Т [s»cos(theta) s»sin(theta) 0;
-s’sin(theta) s»cos(theta) 0;
0 0 1];
» tform = maketform(’affine’, T) ;
» g imtransform(f, tform);
На рис. 5.14, а) и б), показаны исходное и преобразованное изображения шахмат-
ной доски. Завершающий вызов функции imtransf orm использовал по умолча-
нию метод интерполяции ’ b ilinear ’ Как уже отмечалось, имеется возможность
выбрать другой метод интерполяции, например, по ближайшему соседу, который
задается явно при вызове функции imtransform:
>> g2 imtransform(f, tform, ’nearest’);
На рис. 5.14, в) показан результат этой команды. Интерполяция по ближай-
шему соседу выполняется быстрее, чем билинейная интерполяция, поэтому она
может оказаться более предпочтительной в определенных ситуациях, однако ре-
зультат бывает хуже по качеству, чем при билинейной интерполяции.
Рис. 5.14. Аффинные преобразования шахматной доски, а) Исходное изображение, б) Ли-
нейное конформное преобразование с использованием (по умолчанию) билиней-
ной интерполяции- в) Интерполяция по ближайшему соседу, г) Задание аль-
тернативного цвета для внешнего заполнения, д) Контролирование выходного
пространства для сохранения переносов
Функция imtransform имеет несколько опционных параметров, которые мо-
гут быть полезны. Например, параметр FillValue контролирует цвет, который
функция использует для пикселов, которые находятся вне входного изображения:
> > g3 imtransform(f, tform, ’FillValue’, 0.5);
Из рис. 5.14, в) видно, что внешняя часть изображения окрашена теперь в серый
цвет, а не в черный.
Другие дополнительные параметры помогают разрешить иной источник недо-
разумений, связанных с переносом изображений с помощью imtransf orm. Напри-
мер, следующие команды совершают обычный параллельный перенос:
> > Т2 [1 0 0; 0 1 0; 50 50 1] ;
> > tform2 maketform(’affine’, Т2) ;
> > g4 imtransform(f, tform2);
Однако результат будет идентичен исходному изображению на рис. 5.14, а). В этом
проявляется эффект функции imtransf orm, заложенный по умолчанию. А имен-
но: функция imtransf orm определяет ограничивающий прямоугольник (см. опре-
деление этого понятия в § 11.4.1) выходного изображения в выходной системе
координат, и по умолчанию обратное преобразование совершается только для
пикселов этого прямоугольника. При этом отменяются переносы. Задав пара-
метры XData и YData, можно точно указать функции imtransf orm, где именно
в выходном пространстве следует вычислять результат. XData — это вектор из
двух компонент, который обозначает координаты верхнего левого угла выходного
изображения, a YData содержит координаты нижнего правого угла. Следующая
команда совершает вычисления в выходной области, расположенной между точ-
ками (х,у) = (1,1) и (х,у) = (400,400).
> > g5 = imtransform(f, tform2, ’XData’, [1 400], ’YData’, [1 400],
’FillValue’, 0.5);
На рис. 5.14, д) приведен результат.
Другие настройки функции imtransf orm и связанные с ними функции IPT
обеспечивают дополнительные возможности воздействия на результат простран-
ственного преобразования, в частности, на совершение интерполяции. Относящу-
юся к этому вопросу информацию можно взять со справочной страницы функций
imtransf orm и makeresampler. □
5.11.3. Регистрация изображений
Методы регистрации изображений делают пригонку разных изображений од-
ной и той же сцены. Например, эти изображения могли быть получены пример-
но в одно и то же время, но разными регистрирующими устройствами, напри-
мер, сканированием магнитно-резонансным методом и одновременно позитронно-
эмиссионной томографией. Или, возможно, изображения были сняты одним и
тем же устройством, но в разные моменты времени. Например, фотоснимки со
спутника, сфотографированные через несколько дней, месяцев или лет. В лю-
бом случае, комбинирование изображений, количественный анализ и сравнение
требует компенсации геометрических аберраций, происходящих от разных углов
Глава 5. Восстановление изображений
наклона фотокамеры, разницы расстояния и особенностей ориентации объектов
съемки, а также из-за различия разрешения регистрирующих устройств, переме-
щения объектов и влияния других факторов.
В пакете поддерживается метод регистрации изображений на основе кон-
трольных точек, иногда называемых точками привязки. Контрольные точки
образуют подмножество пикселов, координаты которых на обоих изображениях
известны или могут быть выбраны интерактивно. На рис. 5.15 проиллюстрирова-
на идея контрольных точек на тестовом изображении и на измененном тестовом
изображении, подвергаутом проективному искажению. Если выбрано достаточ-
ное количество контрольных точек, функция cp2tform из IPT подбирает под-
ходящее преобразование предписанного типа по этим контрольным точкам (при
этом используется метод наименьших квадратов). Типы пространственных пре-
образований, которые распознаются функцией cp2tf orm, перечислены в табл. 5.4.
а)
Рис. 5.15. Регистрация изображений с помощью контрольных точек, а) Исходное изобра-
жение с контрольными точками (маленькие квадратики, наложенные на изоб-
ражение). б) Геометрически искаженное изображение с контрольными точка-
ми. в) Скорректированное изображение с помощью проективного преобразо-
вания, построенного по контрольным точкам
Пусть, к примеру, f обозначает изображение на рис. 5.15, a), a g это изоб-
ражение на рис. 5.15, б). Координаты контрольных точек на изображении f:
(83,81), (450,56), (43,293), (249,392) и (436,442). Соответствующие контрольные
точки на изображении g имеют координаты (68.66), (375,47), (42,286), (275,434),
и (523,532). Тогда команда по пригонке изображений f и g имеет вид:
» basepoints [83 81; 450 56; 43 293; 249 392; 436 442];
» inputpoints [68 66; 375 47; 42 286; 275 434; 523 532];
» tform cp2tform(inputpoints, basepoints, ’projective’);
>> gp imtransform(g, tform, ’XData’, [1 502], ’YData’, [1 502]);
На рис. 5.15, в) показано преобразованное изображение.
В пакете IPT также предусмотрен графический пользовательский интерфейс
для ручного выбора контрольных точек на паре изображений. Рис. 5.16 пред-
ставляет собой снимок с дисплея компьютера окна этого инструмента, который
вызывается командой cpselect.
Выводы
Таблица 5.4. Типы преобразований, которые поддерживают функпии cp2tform
и maketform
Тип преобразования Описание Функции
Affine Композиция растяжения/сжааия, поворота, сдвига и перено- са. Прямые линии остаются прямыми, параллельные линии остаются параллельными. maketform cp2tform
Box Независимое растяжение/сжатие и перенос по любой раз- мерности; подмножество аффинных преобразований. maketform
Composite Семейство пространственных преобразований, которые при- меняются последовательно. maketform
Custom Пространственное преобразование, заданное пользователем, который определяет функции для вычисления Т и Т—Ч maketform
Linear conformal Растяжение/сжатие (одинаковое по обеим размерностям), поворот и перенос; подмножество аффинных преобразований- cp2tform
LWM Локальное взвешенное среднее; локально варьируемое про- странственное преобразование. cp2tform
Piecewise linear Локально варьируемое пространственное преобразование. cp2tform
Polynomial Входные пространственные координаты выражаются в виде полиномиальных функций входных координат. cp2tform
Projective Как и при аффинных преобразованиях, прямые линии оста- ются прямыми, однако параллельные переходят в непарал- лельные с удаленной точкой пересечения. maketform cp2tform
Выводы
Материал этой главы является хорошим
примером того, как функции MATLAB
и IPT могут быть использованы при вос-
становлении изображений, а также то-
го, как на их основе можно строить мо-
дели, позволяющие описывать процес-
сы искажения, которым подвергаются
изображения. Возможности пакета IPT
при генерации шума были существен-
но расширены с помощью разработан-
ных в этой главе функций inmoise2 и
imnoise3. Кроме того, пространствен-
ные фильтры, получаемые функцией
spfilt [особенно нелинейные фильтры]
сильно расширяют возможности пакета
в этой сфере приложений. Эти функ-
Рис. 5.16. Интерактивный интерфейс для
выбора контрольных точек
ции являются замечательными приме-
рами того, как относительно простыми приемами можно внедрять функции
MATLAB и IPT в новый программный код для построения приложений, кото-
рые усиливают возможности существующего арсенала инструментов и средств
для обработки цифровых изображений.
ГЛАВА 6
ОБРАБОТКА
ЦВЕТНЫХ
ИЗОБРАЖЕНИЙ
Введение
В этой главе обсуждаются основы цифровой обработки цветных изображений
средствами пакета IPT, а также приводится ряд новых инструментов, расширя-
ющих функциональные возможности пакета. В этой главе предполагается, что
читатель знаком с базовыми принципами и с основной терминологией обработки
цветных изображений хотя бы на начальном уровне.
6.1. Представление цветных изображений в MATLAB
Как отмечалось в § 2.6, в пакете IPT цветные изображения представимы в двух
видах: в виде индексированных изображений или в виде RGB (Red, Green, Blue)
изображений. В этом параграфе подробно рассматриваются эти два типа изоб-
ражений.
6.1.1. RGB изображения
Цветным RGB изображением называется массив МхАхЗ, состоящий из цвет-
ных пикселов, причем каждый такой пиксел является триплетом, элементы кото-
рого соответствуют трем цветовым компонентам: красному, зеленому и синему.
Расположение этих пикселов на цветном RGB изображении показано на рис. 6.1
(стр. 224). RGB изображение можно представлять себе в виде «стека» трех моно-
хромных изображений с градацией серого цвета, которые подаются на красный,
зеленый и синий входы цветного монитора, в результате чего формируется цвет-
ное изображение на экране. Принято называть три монохромных изображения,
формирующих единое RGB изображение, красной, зеленой и синей составля-
ющей (компонентой) изображения. Класс компонент изображения определяет
область их значений. Если класс данных цветовой компоненты есть double, то
область значений — интервал [0,1|. Аналогично, области значений [0,255| или
[0,65535], соответственно, у RGB изображений класса uint8 и uintl6. Число
битов, используемых для представления величины цветного пиксела по всем со-
ставляющим RGB, называется глубиной цвета изображения. Например, если
каждая компонента является 8-ми битовым изображением, то соответствующее
RGB изображение имеет глубину 24 бита. Обычно, составляющие имеют оди-
наковое число битов. В этом случае число возможных цветов в палитре RGB
равно 236, где Ь — это число бит каждой цветной компоненты. В 8-ми битном
представлении всего имеется 16777216 цветов.
Пусть fR, fG и fB обозначают три составляющие RGB изображения. Соот-
ветствующее им цветное GRB изображение строится с помощью оператора cat
(concatination, соединение, сцепление):
rgb_image cat(fR, fG, fB).
Порядок расположения цветовых составляющих в этой формуле весьма важен.
В общем случае, оператор cat (dim, Al, А2, .) связывает массивы вдоль раз-
мерности, обозначенной в переменной dim. Например, если dim = 1, то массивы
располагаются по вертикали, если dim = 2. то — по горизонтали, а если dim = 3,
то они укладываются по третьему измерению в виде «стека», как показано на
рис. 6.1.
Если все три составляющие изображения идентичны, то в результате полу-
чается изображение в шкале градации (оттенков) серого цвета. Пусть rgb_image
обозначает некоторое RGB изображение. Следующие три команды извлекают
цветовые составляющие:
>> fR = rgb_image(: 1);
» fG = rgb_image(: 2);
>> fB = rgb_image(: 3);
Цветовое пространство RGB принято изображать графически в виде цветового
куба, как дано на рис. 6.2 (стр. 225). Вершины куба бывают первичными (крас-
ная, зеленая и синяя) и вторичными (голубая, пурпурная и желтая) цветами
яркости.
Иногда бывает необходимо рассмотреть цветовой куб с разных сторон. Для
этого используется функция rgbcube со следующим синтаксисом:
rgbcube(vx, vy, vz).
Набрав после приглашения MATLAB команду rgbcube ( vx, vy, vz ), можно уви-
деть на экране цветовой куб RGB из точки с координатами (vx, vy, vz). По-
лученное изображение можно сохранить на диске с помощью команды print,
которая обсуждалась в § 2.4. Далее приводится программный код этой функции,
который сам себя объясняет1
function rgbcube(vx, vy, vz)
’/.RGBCUBE Displays an RGB cube on the MATLAB desktop.
7, RGBCUBE(VX, VY, VZ) displays an RGB color cube, viewed from point
7, (VX, VY, VZ). With no input arguments, RGBCUBE uses (10, 10, 4)
*/, as the default viewing coordinates. To view individual color
7, planes, use the following viewing coordinates, where the first
7. color in the sequence is the closest to the viewing axis, and the
7. other colors are as seen from that axis, proceeding to the right
'Функция patch строит закрашенный многоугольник на плоскости, пользуясь заданными вели-
чинами/парами. См. дополнительную информацию об этой функции на справочной странице.
208 Глава 6. Обработка цветных изображений
7, right (or above), and then moving clockwise.
7.
7.
7.
7.
7.
7.
7.
7.
7.
7.
COLOR PLANE ( vx, vy, vz)
Blue-Magenta-White-Cyan
Red-Yellow-White-Magenta
Green-Cyan-White-Yellow
Black-Red-Magenta-Blue
Black-Blue-Cyan-Green
Black-Red-Yellow-Green
( 0, 0, 10)
( 10, 0, 0)
( 0, 10, 0)
( 0, -10, 0)
(-10, 0, 0)
( 0, 0, -10)
7» Set up parameters for function patch.
vertices_matrix = [0 0 0;0 0 l;0 1 0;0 1 1;1 0 0;l 0 1;1 1 0;l 1 1] ;
faces_matrix = [156 2;137 5;124 3;2 4 8 6;3 7 8 4;5 687];
colors vertices_matrix;
7. The order of the cube vertices was selected to be the same as
7, the order of the (R,G,B) colors (e.g. (0,0,0) corresponds to
7. black, (1,1,1) corresponds to white, and so on.)
7. Generate RGB cube using function patch.
patch(’Vertices’, vertices_matrix, ’Faces’, faces_matrix,
’FaceVertexCData’, colors, ’FaceColor’, ’interp’,
’EdgeAlpha’, 0)
7» Set up viewing point.
if nargin 0
vx 10; vy = 10; vz = 4;
elseif nargin “= 3
error(’Wrong number of inputs.’)
end
axis off
view([vx, vy, vz])
axis square
6.1.2. Индексированные изображения
Индексированное изображение имеет две компоненты: числовую матрицу дан-
ных X и матрицу цветовой карты тар. Матрица тар представляет собой массив
размеров тхЗ класса double, в котором записаны вещественные числа с плаваю-
щей запятой из интервала [0,1]. Длина т цветовой карты равна числу различных
цветов на данном изображении. Каждая строка матрицы тар2 обозначает крас-
ную, зеленую и синюю компоненту одного цвета. Индексированное изображение
использует «прямое отображение» величин яркости (насыщенности, цветного то-
на) пикселов в значения цветовой карты. Цвет каждого пиксела определяется с
2 Если все три столбца аар равны между собой, то цветовая карта превращается в карту града-
ций серого цвета.
6.1. Представление цветных изображений в MATLAB
помощью соответствующего числа, стоящего в матрице X, которое использует-
ся в виде указателя на шар. Если X имеет класс double, то все его компонен-
ты с величинами, меньшими или равными 1, указывают на первую строку шар,
все компоненты с величинами между 1 и 2 включительно указывают на вторую
строку и т. д. Если X принадлежит классу uint8 или uintl6, то все его компо-
ненты, равные 0, указывают на первую строку шар, все компоненты, равные 1,
указывают на вторую строку шар и т. д. Этот метод определения цвета пикселов
проиллюстрирован на рис. 6.3 (стр. 225).
Для отображения на дисплее индексированного изображения следует выпол-
нить команду
> > imshow(X, map);
или, что эквивалентно,
> > image (X)
> > colormap (map)
Цветовая карта хранится вместе с индексированным изображением, и она авто-
матически загружается, когда функция imread считывает изображение.
Иногда бывает необходимо аппроксимировать индексированное изображение
другим изображением с меньшим набором цветов. Для этой цели используется
функция imapprox, вызов которой имеет вид
[Y, newmap] imapprox(X, map, n).
Эта функция возвращает массив Y с цветовой картой newmap, который имеет не
более п цветов. Входной массив может принадлежать классу uint8, uintl6 или
double. Выход Y принадлежит классу uint8, если п не превосходит 256. Если п
больше 256, то Y принадлежит классу double.
Когда число строк матрицы тар меньше числа различных значений X, «лиш-
ние» значения в X отображаются с помощью одного и того же цвета в тар. На-
пример, пусть X состоит из четырех вертикальных полос одинаковой ширины со
значениями 1, 64, 128 и 256. Если мы определим цветовую карту
тар [0 0 0; 1 1 1],
то все элементы X со значениями 1 будут указывать на первую строку тар (чер-
ный цвет), а все остальные значения X будут указывать на вторую строку тар
(белый цвет). Таким образом, команда imshow(X, map) покажет изображение, на
котором за черной полосой следуют три белые полоски. На самом деле, это так и
будет до тех пор, пока длина карты не станет равна 65, в этот момент на дисплее
будет отображена черная полоска, затем серая полоска, за которыми следуют две
белые. В результате подобных действий на экране может появиться весьма стран-
ное изображение, если длина карты превосходит допустимый диапазон значений
элементов X.
Имеется несколько способов задания цветовой карты. Первый способ состоит
в применении команды
>> map(k, :) = [r(k) g(k) b(k)J;
210 Глава 6. Обработка цветных изображений
где [г (к) g(k) b(k)] — это RGB значения, которые определяют строку карты
с номером к. Карта будет заполняться при изменении параметра к.
В табл. 6.1 перечислены RGB значения некоторых основных цветов. Любой из
трех форматов, приведенных в таблице, может использоваться для обозначения
цвета. Например, цвет фона на изображении можно поменять на зеленый любой
из следующих трех команд:
whitebg(’g’)
whitebg(’green’)
whitebg([O 10])
Таблица 6.1. RGB значения некоторых основных цветов. Длинное или короткое имя (за-
ключенное в кавычки) может использоваться в приложениях наравне с чис-
ловым триплетом при обозначении RGB цвета
Длинное имя Короткое имя RGB значения
Black k [0 0 0]
Blue b [0 0 1]
Green g [0 1 0]
Cyan c [0 1 1]
Red r [1 0 0]
Magenta Ш [1 0 1]
Yellow У [1 1 0]
White w [1 1 1]
Для обозначения цветов, не представленных в табл. 6.1, используются дроб-
ные числа. Например, [. 5 .5 .5] — серый цвет, [. 5 0 0] — темно-красный,
а [. 49 1 .83] — аквамариновый.
В MATLAB имеется несколько стандартных цветовых карт, которые можно
загрузить командой
> > colormap (map_name);
В результате матрица цветовой карты становится равной map_name. Например,
> > colormap (copper);
где copper — одна из цветовых карт, имеющихся в MATLAB. Цвета в этой карте
гладко меняются от черного до светло-бронзового. Если последнее изображение,
выведенное на экран, было индексированным, то после этой команды цветовая
карта поменяется на copper. Кроме того, изображение с нужной картой можно
непосредственно вывести на экран командой
> > imshow(X, copper);
В табл. 6.2 перечислены некоторые цветовые карты MATLAB. Длины (число
цветов) этих карт можно ограничить, поставив в круглых скобках соответству-
ющее число. Например, gray(16) задает цветовую карту из 16 оттенков серого
цвета.
6.1.3. Функции IPT для обращения с RGB и
индексированными изображениями
В табл. 6.3 приведены функции IPT, которые совершают взаимную конверта-
цию RGB индексированных и монохромных изображений. Для ясности в этом
параграфе rgb_ image обозначает RGB изображение, gray_ image монохромное
изображение, bw — черно-белое изображение, а X — матрицу данных индексиро-
ванного изображения. Напомним, что индексированное изображение состоит из
матрицы данных и матрицы цветовой карты.
Таблица 6.2. Некоторые стандартные цветовые карты MATLAB
Имя Описание
autumn Плавный переход от красного, через оранжевый к желтому.
bone Шкала градации серого с усилением синей компоненты. Эта шкала придает дополнительный «электронный» вид полутоновым изображениям.
colorcube Содержит столько регулярно разделенных цветов в RGB цветовом про- странстве, сколько возможно, но обеспечивает дополнительные шаги серо- го, чисто красного, чисто зеленого и чисто голубого.
cool Состоит из оттенков голубого и пурпурного. Плавный переход от голубого к пурпурному.
copper Плавный переход черного к ярко бронзовому.
flag Состоит из красного, белого, синего и черного. Цвет меняется скачкообраз- но при увеличении индекса на один шаг.
gray Возвращает линейную серую шкалу.
hot Плавный переход от черного, через оттенки красного, оранжевого и жел- того к белому.
hev Цветонасыщенная цветовая модель. Цвет начинается с красного, переходит в желтый, зеленый, голубой, синий, пурпурный и возвращается снова в красный. Карта приспособлена для отображения периодических функций.
jet Простирается от синего до красного, проходит через голубой, желтый и оранжевый.
lines Строит цветовую карту, которая используется в функции ColorOrder (см. справочную страницу этой функции).
pink Состоит из пастельных тонов розового. Эта карта отображает тоны сепии, расцвечивающие полутоновые фотографии.
prism Повторяет шесть цветов: красный, оранжевый, желтый, зеленый, синий и фиолетовый.
spring Состоит из оттенков пурпурного и желтого.
Rummer Состоит из оттенков зеленого и желтого.
white Полностью белая монохромная карта.
winter Состоит из оттенков синего и зеленого.
Функцию dither (дрожать) можно применять как к монохромным, так и к
цветным изображениям. Этот процесс дрожания используется в печатном деле
для имитации градации серого цвета при печати черными точками. Для моно-
хромных изображений функция dither пытается передать градации серого цве-
та с помощью бинарной маски из черных точек на белом фоне (или наоборот).
Плотность точек уменьшается на ярких областях и увеличивается на более тем-
ных областях. Алгоритм, применяемый при дрожании, основан на компромиссе
между «точностью» зрительного восприятия и вычислительной сложностью. Ме-
тод дрожания, который заложен в IPT, использует алгоритм Флойда-Стейнберга
(Til 2 Глава 6. Обработка цветных изображений
(см. [Floyd, Steinberg, 1975]) и [Ulichney, 1987]). Синтаксис функции dither при
работе с монохромными изображениями имеет вид
bw = dither(gray_image),
где gray_ image — это, как и раньше, монохромное изображение, a bw — результат
дрожания (двоичное изображение).
Таблица 6.3. Функции IPT для преобразования RGB, индексированных и полутоновых
изображений друг в друга
Функция Назначение
dither Строит индексированное изображение из RGB изображения методом дрожания
grayscale Строит индексированное изображение из полутонового с помощью пороговых
величин.
gray2ind Строит индексированное изображение из полутонового.
ind2gray Строит полутоновое изображение из индексированного.
rgb2ind Строит индексированное изображение из RGB.
rgb2gray Строит полутоновое изображение из RGB.
При работе с цветными изображениями функция dither используется в соче-
тании с функцией rgb2ind, которая сокращает число цветов изображения. Эта
функция будет рассматриваться позже в этом параграфе.
Функция grayslice имеет синтаксис
X grayslice(gray_image, п).
Эта функция строит индексированное изображение с уменьшенным числом цве-
тов, которое определяется с помощью пороговых величин
1 £ п- 1
п п п '
Как уже отмечалось, полученное индексированное изображение можно увидеть
на экране после выполнения команды imshow (X, шар) с использованием карты
подходящей длины (например, jet(16)). Другая форма этой команды выгля-
дит так:
X grayslice(gray_image, v),
где v - это вектор, компоненты которого используются в качестве пороговых зна-
чений при разделении цветов в gray_image. В сочетании с цветовыми картами,
функция grayslice является основным инструментом при обработке псевдоцвет-
ных изображений, когда специальная шкала оттенков серого цвета используется
для обозначения цветов. Входное изображение может быть класса uint8, uintl6
или double. Пороговые величины вектора v должны лежать в интервале от О
до 1, даже если изображение имеет класс uint8 или uintl6. При этом функция
grayslice автоматически выполняет необходимую процедуру масштабирования.
Функция gray2ind, имеющая синтаксис
[X, map] = gray2ind(gray_image, и),
масштабирует, а затем округляет изображение gray_ image для получения индек-
сированного изображения X с цветовой картой gray (и). Если параметр и опущен,
то по умолчанию и 64. Входное изображение может быть класса uint8, uintl6
или double. Выходное изображение X принадлежит классу uint8, если и меньше
256, а если и больше этого числа, то оно имеет класс uintl6.
Функция ind2gray с синтаксисом
gray_image = ind2gray(X, map)
преобразует индексированное изображение, состоящее из пары матриц X и тар, в
монохромное. Массив X может иметь класс uint8, uintl6 или double. Выходное
изображение имеет класс double.
В этом параграфе нас также интересует функция rgb2ind, вызов которой
имеет вид
[X, map] = rgb2ind(gray_image, n, dither_option),
где и определяет длину (или число цветов) карты тар, а символьный параметр
dither_option может иметь одно из двух значений: ’dither’ (по умолчанию), ес-
ли необходимо получить лучшее цветовое разрешение за счет пространственного;
и, наоборот, ’nodither’, тогда каждый цвет исходного изображения отобража-
ется в ближайший цвет новой карты (зависящий от величины п). В этом случае
дрожание не делается. Входное изображение может иметь класс uint8, uintl6
или double. Выходное изображение X принадлежит классу uint8, если п мень-
ше 256, а если п больше 256, то X принадлежит классу uintl6. В примере 6.1
показано действие эффекта дрожания при сокращении цветовой палитры.
Функция
rgb_image ind2rgb(X, map)
преобразует матрицу X и соответствующую цветовую карту тар в формат RGB;
X может быть класса uint8, uintl6 или double. Выходное RGB изображение
является массивом MxNx3 класса double.
Наконец, функция rgb2gray, имеющая синтаксис
gray_image rgb2gray(rgb_image),
преобразует RGB изображение в монохромное. Входное изображение может при-
надлежать классу uint8, uintl6 или double, а выходное изображение принадле-
жит классу входного изображения.
Пример 6.1. Иллюстрации некоторых функций из табл. 6.3.
Функция rgb2ind бывает полезной, если необходимо уменьшить число цветов,
используемых в RGB изображении. В качестве такого действия функции rgb2ind,
при котором проявляется также преимущество метода дрожания, рассмотрим
рис. 6.4, а) (стр. 225), на котором дано RGB изображение f с глубиной цвета 24.
На рис. 6.4, б) и о). даны результаты следующих команд:
>> [XI, mapl] rgb2ind(f, 8, ’nodither’);
>> imshow(Xl, mapl)
214 Глава 6. Обработка цветных изображений
и
> > [Х2, map2] rgb2ind(f, 8, ’dither’);
> > imshow(X2, тар2)
Оба изображения имеют всего 8 цветов, т. е. было совершено значительное сокра-
щение числа возможных цветов в f, которое для 24-битового RGB изображения,
как уже отмечалось, превосходит 16 миллионов цветов. На рис. 6.4, б) заметны
ложные контуры, особенно в центре большого цветка. Изображение, построенное
с дрожанием, лучше передает цветовые оттенки; на нем имеется меньше ложных
контуров. В этом проявляется эффект «хаотичности», который вносится при дро-
жании. Изображение выглядит слегка размытым, однако для глаза оно будет
казаться более точным, чем рис. 6.4, б).
Эффект дрожания можно лучше проиллюстрировать на монохромных изоб-
ражениях. Рис. 6.4, г) и д) были получены командами
> > g rgb2ind(f ) ;
» gl dither(g);
> > figure, imshow(g);figure, imshow(gl).
Изображение на рис. 6.4, д) является двоичным, что опять-таки означает суще-
ственное сокращение объема данных. При взгляде на рис. 6.4, в) и д) становится
понятным, почему метод дрожания так важен в издательском и печатном деле
(особенно при выпуске газет), когда качество бумаги и разрешение печати может
быть достаточно низким. □
6.2. Преобразования в другие цветовые пространства
Как было объяснено в предыдущем параграфе, пакет IPT представляет цвета или
явно в виде RGB изображений, или косвенно в виде индексированных изображе-
ний, в которых цветовая карта также хранится в формате RGB. Однако имеет-
ся много других цветовых пространств (которые также называются цветовыми
моделями), использование которых может оказаться более предпочтительным
и/или удобным в некоторых приложениях. Речь идет о цветовых пространствах
NTSC, YCbCr, HSV, CMY, CMYK и HSI. В пакете имеются функции для пря-
мого и обратного преобразования их RGB в пространства NTSC, YCbCr, HSV
и CMY. Далее будет также построена функция для преобразования в формат HSI.
6.2.1. Цветовое пространство NTSC
Цветовая система NTSC используется в телевидении США. Основное преиму-
щество данного формата заключается в том, что в нем информация о яркости
(насыщенности), эквивалентная шкале серого цвета в черно-белом телевидении,
отделена от самих цветовых данных, что позволяет использовать один и тот же
сигнал в цветных и черно-белых телевизионных приемниках. В формате NTSC
пиксел представлен тремя компонентами: светлота (Y), цветовой тон (I) и на-
сыщенность (Q), где выбор букв YIQ является общепринятым. Светлота содер-
жит информацию о яркости в шкале градаций серого, а две другие компоненты
6.2. Преобразования в другие цветовые пространства
несут информацию о цвете в телевизионном сигнале. Компоненты YIQ получа-
ются из тройки RGB с помощью следующего преобразования:
Y ' ’ 0.299 0.587 0.114 ' ' R
I 0.596 -0.274 -0.322 G
Q 0.211 -0.523 0.312 В
Отметим, что сумма элементов первой строки матрицы, стоящей справа от знака
равенства, равна 1, а сумма элементов по остальным двум строкам равна 0. Это
легко понять, так как яркости всех трех компонент RGB монохромного изобра-
жения должны быть одинаковы, а значит, для такого изображения компоненты
I и Q равны нулю. Функция rgb2ntsc совершает это преобразование:
yiq_image = rgb2ntsc(rgb_image),
где входное RGB изображение может быть класса uint8, uintl6 или double. Вы-
ходом служит массив Мх.АхЗ класса double. Компонента светлота получается
командой у iq_image(: 1), цветовой тон — yiq_image(:, 2), а насыщен-
ность yiq_image(: 3).
Аналогично, компоненты RGB получаются из YIQ с помощью обратного пре-
образования
R ' 1.000 0.956 0.621 ' Y
G = 1.000 -0.272 -0.647 I
В 1.000 -1.106 1.703 . Q .
которое в IPT реализовано в виде функции
rgb_image ntsc2rgb(yiq_image).
Здесь и входное, и выходное изображения имеют класс double.
6.2.2. Цветовое пространство YCbCr
Цветовая модель YCbCr широко используется в цифровом видео. В этом формате
компонента светлота представлена единственной компонентой Y, а цвет хранится
в виде двух разностных цветовых компонент СЬ и Сг. Величина СЬ — это раз-
ность между голубой компонентой В и светлотой Y, а Сг — это разность между R
(красная компонента) и Y ([Polynton, 1996]). При конвертации из RGB в YCbCr
используются уравнения
Y
СЬ
Сг
16 65.481 128.553 24.966 R
128 + -37.797 -74.203 112.000 G
128 112.000 -93.786 -18.214 В
Функция преобразования имеет вид
ycbcr_image = rgb2ycbcr(rgb_image).
Входное RGB изображение может быть класса uint8, uintl6 или double. Выход-
ное изображение имеет тот же класс, что и входное. Обратное преобразование1
1 Чтобы получить матрицу преобразования из YCbCr в RGB, наберите команду
>> edit ycbcr2rgb.
216 Глава 6. Обработка цветных изображений
выполняется функцией
rgb_ image = ycbcr2rgb(ycbcr_image).
Входное YCbCr изображение может быть класса uint8, uintl6 или double, а
класс выходного изображения совпадает с классом входного.
6.2.3. Цветовое пространство HSV
Цветовая система HSV (Hue, Saturation, Value: цветовой тон, насыщенность, ве-
личина) представляет собой одно из цветовых пространств, в которых выбор
цвета похож на обращение с палитрой или гаммой цветов при работе художника
с красками или чернилами. Эта цветовая система стоит гораздо ближе к описа-
нию и восприятию цвета человеком, чем формат RGB. Пользуясь терминологи-
ей художников, термины цветовой тон, насыщенность и величина соответствуют
приблизительно таким словам, как окраска, оттенок и сила тона.
Цветовое пространство HSV можно увидеть, если посмотреть на цветовой куб
RGB вдоль его серой оси (которая соединяет черную и белую вершины). В резуль-
тате наблюдается цветовая палитра в форме шестиугольника, которая изображе-
на на рис. 6.5, а) (стр. 226). По мере движения вдоль серой оси на рис. 6.5, б),
размер шестиугольника в перпендикулярном сечении соответствует величине V
на рисунке. Цветовой фон Н выражается углом на цветовом шестиугольнике,
причем принято отсчитывать этот угол от луча, соединяющего центр и красную
вершину. Величина (V) измеряется вдоль оси конуса, вершина которого соответ-
ствует величине V = 0. Конец оси соответствует величине V = 1 (белый цвет),
и соответствующая точка располагается в центре полноцветного шестиугольни-
ка на рис. 6.5, а). Таким образом, на этой оси располагаются все оттенки серого
цвета. Насыщенность (чистота) S цвета измеряется расстоянием до оси V
Цветовая система HSV основана на цилиндрических координатах. Поэтому
преобразование из RGB в HSV осуществляется по стандартным формулам пе-
ресчета из прямоугольных в цилиндрические координаты. Эти уравнения мож-
но найти в большинстве учебников по компьютерной графике (см., например,
[Rogers, 1997]), поэтому мы их здесь не приводим.
Функция MATLAB для преобразования их RGB в HSV имеет вид
hBV_image = rgb2hsv(rgb_image).
Входное RGB изображение может иметь класс uint8, uintl6 или double, а вы-
ходное имеет класс double. Преобразование из HSV в RGB совершается функ-
цией
rgb_ image hsv2rgb(hsv_image).
Входное изображение должно принадлежать классу double, а выходное имеет
класс double.
6.2.4. Цветовые пространства CMY и CMYK
Голубой, пурпурный и желтый являются вторичными основными цветами све-
товых источников или, альтернативно, первичными цветами красителей. Напри-
мер, при освещении белым светом поверхности, покрашенной голубой краской,
красный цвет от нее не отражается. Значит, голубой краситель вычитает крас-
ную компоненту из отражаемого белого цвета, который состоит из равных частей
красного, зеленого и синего.
Большинство аппаратов для нанесения цветных красителей на бумагу, вроде
цветных принтеров и устройств копирования в цвете, либо требуют представ-
ления цветных данных в формате CMY, или автоматически совершают преоб-
разование из RGB в CMY. Это преобразование совершается по очень простым
правилам
1 R
1 G
1 В
С
м
Y
где предполагается, что все цветовые компоненты нормированы в диапазоне [0,1].
Эти уравнения демонстрируют эффект неотражения красного цвета от поверх-
ности, покрытой чисто голубой краской (из уравнений имеем С = 1 — R). Анало-
гично, чисто пурпурный цвет не отражает зеленый, а чисто желтый не отражает
синий. Из этих уравнений следует, что для получения RGB компонент из CMY
достаточно вычесть каждую из них из 1.
В теории равные количества первичных красителей голубого, пурпурного и
желтого должны давать черный цвет. На практике, при смешении этих цветов
на печати получается черный, который выглядит более осветленным, чем ори-
гинальный черный цвет. Поэтому, чтобы получить истинный черный цвет (кото-
рый часто доминирует при цветной печати), цветовая модель CMY расширяется
до модели CMYK четвертым цветовым компонентом — черным цветом. Таким
образом, когда издатели говорят о четырехцветной печати, они имеют в виду
трехцветную модель CMY плюс черный цвет.
Функцию imcomplement, введенную в § 3.2.1, можно использовать для преоб-
разования из RGB в пространство CMY:
cmy_image = imcomplement(rgb_image).
Эту же функцию можно использовать для обратного преобразования:
rgb image = imcomplement(cmy_image).
6.2.5. Цветовое пространство HSI
Если не брать HSV, все рассмотренные ранее цветовые модели плохо приспо-
соблены к описанию цветов, свойственному для человека. Например, говоря о
цвете автомобиля, человек никогда не скажет о процентном соотношении в нем
красного, зеленого и синего.
Описывая объект, мы скажем о его цвете (цветовом тоне), насыщенности
и светлости (светлоте). Цветовой тон сообщает собственно цвет и его чисто-
ту (чисто красный, оранжевый, желтый и т.п.), насыщенность дает меру того,
насколько чистый цвет разбавлен белым. Светлость или светлота является
характеристикой, которая практически не поддается точному измерению. Она
соответствует характеристике интенсивность (полутоновая яркость) в ахрома-
тическом (бесцветном) случае и является одним из ключевых параметров при
218 Глава 6. Обработка цветных изображений
описании цветового восприятия. Как известно, яркость (уровень серого цвета)
является основной характеристикой монохромных (полутоновых) изображений.
Эту величину можно легко мерить и интерпретировать.
В цветовом пространстве HSI (Hue, Saturation, Intensity: цветовой тон, на-
сыщенность, интенсивность), которое мы собираемся рассматривать, яркостная
информация (интенсивность) отделена от цветовой информации (цветовой тон и
насыщенность) цветного изображения. В результате модель HSI является идеаль-
ным инструментом в алгоритмах обработки цветных изображений, поскольку в
ее основе лежит описание цвета, интуитивно понятное человеку, а ведь именно он
является и разработчиком, и пользователем всех этих алгоритмов. В этом смысле
цветовое пространство HSV похоже на HSI. но оно сфокусировано на представ-
лении цветов в виде палитры художника, поэтому оно менее удобно в цифровых
приложениях.
Как уже говорилось в § 6.1.1, цветное RGB изображение состоит из трех моно-
хромных изображений, поэтому неудивительно, что компоненту интенсивности
можно выделить из RGB изображения. Это станет особенно ясно, если взять цве-
товой куб из рис. 6.2 и поставить его так, чтобы «черная» его вершина (0,0,0)
оказалась внизу, а «белая» (1,1,1) — прямо над ней, как показано на рис. 6.6, а)
(стр. 226). Как отмечалось при обсуждении рис. 6.2, все оттенки серого цвета
расположены на отрезке, соединяющем черную и белую вершины. На рис. 6.2, б)
этот отрезок (ось интенсивности) расположен вертикально. Значит, для опреде-
ления интенсивности в некоторой цветной точке необходимо провести через эту
точку плоскость, перпендикулярную оси. Координата пересечения этой плоско-
сти с осью даст значение интенсивности (яркости) в диапазоне [0,1]. Немного
подумав, становится ясно, что насыщенность (чистота цвета) увеличивается с
возрастанием расстояния от выбранной точки до оси интенсивности. На самом
деле, насыщенность цвета для точек на этой оси равна нулю, поскольку все эти
точки являются серыми.
Чтобы определить цветовой тон для некоторой заданной RGB точки, рассмот-
рим рис. 6.6, б). на котором выделена плоскость, проходящая через три точки
(черную, белую и голубую). Поскольку эта плоскость содержит черную и белую
вершины, то и вся соединяющая их (серая) прямая принадлежит выделенной
плоскости. Кроме того, ясно, что все точки треугольника, определяемого осью
интенсивности и двумя отрезками пересечения плоскости с гранями куба, имеют
один и тот же цветовой тон (в данном случае, голубой). Это объясняется тем,
что все цветовые точки этого треугольника являются всевозможными комбина-
циями или смешениями трех цветов вершин построенного треугольника. В самом
деле, если две точки являются белой и черной, а третья цветной, то первые две
не могут изменить тон любой цветной точки треугольника, которая получается
при смешивании трех указанных цветов. Черная и белая точки не вносят вклад
в цветной тон! (Однако они влияют на интенсивность и насыщенность цвета.)
Если теперь поворачивать выделенную плоскость вокруг вертикальной оси, то
будут получаться различные цветовые тона. Из этого умозрительного рассмот-
рения приходим к выводу, что значения цветового тона, насыщенности и интен-
сивности, необходимые для определения пространства HSI, можно получить из
цветовых координат модели RGB. Таким образом, точки RGB можно преобразо-
вывать в соответствующие точки HSI с помощью точных формул, описывающих
приведенные выше геометрические построения.
Из проведенных рассуждений следует, что пространство HSI состоит из вер-
тикальной оси интенсивности и цветных точек, которые располагаются на плос-
кости, перпендикулярной этой оси. При перемещении этой плоскости вверх и
вниз вдоль оси ее пересечение с цветовым кубом имеет форму треугольника или
шестиугольника. Это легче себе представить, если смотреть на куб сверху вдоль
оси интенсивности, как показано на рис. 6.7, а) (стр. 226). На этом рисунке вид-
но, что оси первичных цветов разделены углами в 120°. Оси вторичных цветов
расположены под углом 60° к первичным. Это означает, что вторичные цвета
также расположены под углом 120° друг к другу.
На рис. 6.7, б) изображена шестиугольная форма и некоторая цветная точка
(показанная черным цветом). Цветовой тон определяется углом между направле-
нием из центра шестиугольника в данную точку и некоторым опорным направле-
нием. Обычно (но не всегда) в качестве опорного выбирается направление крас-
ной оси, которое, по определению, имеет нулевой цветовой тон. Величина угла
цветового тона отсчитывается против часовой стрелки. Важными компонентами
пространства HSI являются: вертикальная ось интенсивности, длина вектора до
цветной точки и угол, который составляет этот вектор с красной осью. Поэтому
нет ничего необычного в том, что плоскость HSI может определяться с помощью
шестиугольника (как было выше), треугольника или даже круга, как это сдела-
но на рис. 6.7, в) и г). Выбор этой фигуры не столь важен, поскольку каждую
из них можно преобразовать в две другие с помощью простых геометрических
преобразований. На рис. 6.8 (стр. 227) даны модели HSI на основе цветового тре-
угольника и цветового круга.
Преобразование цветов из RGB в HSI
В этом параграфе приводятся уравнения преобразования из системы RGB в си-
стему HSI без их вывода. Подробное обоснование этих формул можно найти на
вебсайте нашей книги (см. адрес в Интернете в § 1.5). Для заданного цветного
RGB изображения компонента Н каждого RGB пиксела получается из уравнения
в
360-0
при В G,
при В > G,
в котором
в = cos
1[(Д-С)+(Д-В)]
[(Д - G)2 4- (Д - B)(G - В)]1/2
Компонента насыщенности вычисляется по формуле
5 = 1- —— ----------- [min (Д, G, В)].
(Д + G + B) v
Наконец, компонента интенсивности получается из уравнения
I = l(R+G + B).
О
220 Глава 6. Обработка цветных изображений
Эти формулы выписана в предположении, что величины RGB нормированы в
диапазоне [0,1], а угол в измеряется от красной оси пространства HSI, как пока-
зано на рис. 6.7. Цветовой тон можно нормировать, разделив его значения на 360.
Две другие компоненты HSI находятся в этом диапазоне, при условии, что GRB
величины уже были нормированы.
Преобразование цветов из HSI в RGB
Зная величины HSI в интервале [0,1], легко найти соответствующие значения
RGB в том же диапазоне. Применяемые уравнения зависят от величины Н. Име-
ются три сектора по 120°, разделенные первичными цветами (см. рис. 6.7), в ко-
торых применяются разные формулы. Сначала следует умножить Н на 360° для
приведения этой величины к исходному диапазону [0,360°].
Сектор RG (0 Н < 120°). Когда Н лежит в этом секторе, то RGB компоненты
вычисляются по формулам
В = 1(1 -5),
R / + cos(60° — II)
G = 3I — (R + В).
Сектор GB (120° С Н < 240°). Если Н находится в этом секторе, то сначала
следует вычесть 120° из Н:
Н = Н- 120°
После чего компоненты RGB вычисляются по формулам
R = 7(1-5),
S cos Н
cos(60° — Н)
B = 3I — (R + G).
G = I
Сектор BR (240° < Н С 360°). Наконец, если Н находится в этом секторе, то
сначала следует из Н вычесть 240°:
Н = Н- 240°
Затем компоненты RGB вычисляются по формулам
Чсоч Н
В = /[1+соб(60._д)], R = U-(C+B).
Эти уравнения будут использоваться далее при обработке цветных изображений.
М-функция для преобразования из RGB в HSI
Функция
hsi rgb2hsi(rgb)
реализует приведенные выше уравнения для конвертации из формата RGB в
формат HSI. Для простоты hsi и rgb обозначают, соответственно, HSI и RGB
изображения. Справочная документация детализирует синтаксические особенно-
сти данной функции.
function hsi rgb2hsi(rgb)
%RGB2HSI Converts an RGB image to HSI.
HSI RGB2HSI (RGB) converts an RGB image to HSI. The input image
7, is assumed to be of size M-by-N-by-3, where the third dimension
7, accounts for three image planes: red, green, and blue, in that
% order. If all RGB component images are equal, the HSI conversion
% is undefined. The input image can be of class double (with values
'Z in the range [0, 1]), uint8, or uintl6.
7.
7. The output image, HSI, is of class double, where:
7 hsi(: 1) hue image normalized to the range [0, 1] by
’Z dividing all angle values by 2*pi.
7. hsi(: 2) = saturation image, in the range [0, 1].
7, hsi(: :, 3) intensity image, in the range [0, 1].
QZ Extract the individual component immages.
rgb im2double(rgb);
r = rgb(: 1);
g = rgb(: 2);
b = rgb(:, :, 3);
7, Implement the conversion equations.
num = 0.5*((r g) + (r b));
den = sqrt((r g).~2 + (r b).*(g b));
theta = acos(num./(den + eps));
H = theta;
H(b > g) 2*pi H(b > g) ;
H = H/(2*pi);
num = min(min(r, g), b);
den = r + g + b;
den(den == 0) eps;
S 1 3.* num./den;
H(S == 0) 0;
I (r + g + b)/3;
’Z Combine all three results into an hsi image.
hsi cat(3, H, S, I);
M-функция для преобразования из HSI в RGB
Функция
rgb = hsi2rgb(hsi)
реализует обратное преобразование из HSI в RGB. Документация детализирует
входные и выходные аргументы данной функции.
function rgb = hsi2rgb(hsi)
’ZHSI2RGB Converts an HSI image to RGB.
7. RGB = HSI2RGB(HSI) converts an HSI image to RGB, where HSI
7» is assumed to be of class double with:
7. hsi(:, 1) hue image, assumed to be in the range
70 [0, 1] by having been divided by 2*pi.
7. hsi(:, :, 2) = saturation image, in the range [0, 1].
Глава 6. Обработка цветных изображений
‘A hsi(:, 3) = intensity image, in the range [О, 1].
7.
7. The components of the output image are:
% rgb(: 1) = red.
7. rgb(: 2) = green.
‘A rgb(:, 3) blue.
*A Extract the individual HSI component images.
H = hsi(: 1) * 2 * pi;
S = hsi(: 2);
I = hsi(:, :, 3);
% Implement the conversion equations.
R = zeros(size(hsi, 1), size(hsi, 2));
G = zeros(size(hsi, 1), size(hsi, 2));
В = zeros(size(hsi, 1), size(hsi, 2));
"A RG sector (0 <= H < 2*pi/3) .
idx find( (0 <= H) & (H < 2*pi/3));
B(idx) = I(idx) .* (1 S(idx));
R(idx) I(idx) .* (1 + S(idx) .* cos(H(idx)) ./
cos(pi/3 H(idx)));
G(idx) = 3*1(idx) (R(idx) + B(idx));
‘A BG sector (2*pi/3 <= H < 4*pi/3) .
idx = find( (2*pi/3 <= H) & (H < 4*pi/3) );
R(idx) = I(idx) .* (1 S(idx));
G(idx) = I(idx) .* (1 + S(idx) .* cos(H(idx) 2*pi/3) ./
cos (pi H(idx)));
B(idx) = 3*1(idx) (R(idx) + G(idx));
‘A BR sector.
idx = find( (4*pi/3 <= H) & (H <= 2*pi));
G(idx) = I(idx) .* (1 S(idx));
B(idx) = I(idx) .* (1 + S(idx) .* cos(H(idx) 4*pi/3) ./
cos(5*pi/3 H(idx)));
R(idx) = 3*I(idx) (G(idx) + B(idx));
‘A Combine all three results into an RGB image. Clip to [0, 1] to
‘A compensate for floating-point arithmetic rounding effects.
rgb = cat(3, R, G, B);
rgb = max(min(rgb, 1), 0);
Пример 6.2. Преобразование из RGB в HSI.
На рис. 6.9 (стр. 227) приведены компоненты цветового тона, насыщенности и
интенсивности изображения RGB куба на белом фоне, аналогичного его изобра-
жению на рис. 6.2, б). На рис. 6.9, а) дано изображение цветового тона. Самой
заметной деталью на этом изображении является разрыв величины вдоль ли-
нии под углом 45° на передней стороне (красной) плоскости куба. Чтобы понять
причину этого разрыва, обратимся к рис. 6.2, б), мысленно проведем прямую
линию, соединяющую красную и белую вершины куба, и выберем точку посе-
редине этой линии. Начав с этой точки, нарисуем кривую, двигаясь вправо и
6.3. Основы обработки цветных изображений
обходя куб по кругу, пока не вернемся в исходную точку. Основными цветами,
расположенными на этой кривой, будут желтый, зеленый, голубой, синий, пур-
пурный и, наконец, красный. В соответствии с рис. 6.7, величина цветного тона
должна увеличиваться вдоль этого пути от 0° до 360° (т. е. от минимального до
максимального значения цветового тона). А это в точности то, что мы имеем па
рис. 6.9, а), поскольку минимальное значение представляется черным цветом, а
максимальное — белым.
Изображение насыщенности на рис. 6.9, б) демонстрирует прогрессирующее
потемнение значений в направлении белой вершины RGB куба, что отражает все
меньшую насыщенность любого цвета при приближении к белому. Наконец, каж-
дый пиксел изображения интенсивности на рис. 6.9, в) является средним значе-
нием соответствующих RGB компонентов цветного пиксела на рис. 6.2, а). Заме-
тим, что фон на этом рисунке является белым, поскольку он был также белым на
исходном цветном изображении. А на двух предыдущих рисунках фон является
черным, так как цветовой тон и насыщенность белого цвета равны нулю. □
6.3. Основы обработки цветных изображений
В этом параграфе мы приступим к изучению методов, используемых при обра-
ботке цветных изображений. Хотя набор этих средств не является исчерпываю-
щим, эти методы являются хорошей иллюстрацией того, как следует обращаться
с цветными изображениями при решении широкого круга задач. Для удобства
изложения мы разделим подходы, используемые при обработке цветных изобра-
жений, на три большие категории:
(1) преобразования цветов (или отображения цветов)-,
(2) раздельная пространственная обработка цветовых плоскостей; и
(3) обработка цветовых векторов.
Первая категория обрабатывает пикселы каждой цветовой плоскости, основыва-
ясь исключительно на значениях пикселов, без учета их пространственных коор-
динат. Эти подходы аналогичны методам, рассмотренным в § 3.2 при изучении
преобразований яркости монохромных изображений. Методы второй категории
основаны на пространственной (окрестностной) фильтрации отдельных цвето-
вых плоскостей, и они аналогичны материалам §§ 3.4 и 3.5 по пространственной
фильтрации.
К третьей категории относятся методы, которые совершают обработку компо-
нент цветного изображения как единого целого. Поскольку полноцветные изобра-
жения имеют по крайней мере три компоненты, цветные пикселы являются трех-
мерными векторами. Например, в системе RGB каждую цветовую точку можно
рассматривать как вектор, проведенный из начала координат в соответствующую
точку цветового пространства, (см. рис. 6.2).
Пусть с — это произвольный вектор в цветовом пространстве RGB:
R
G
В
224 Глава 6. Обработка цветных изображений
Эти выражения показывают, что компонентами вектора с являются RGB коор-
динаты точки в цветовом пространстве. Если принять во внимание тот факт, что
цветовые компоненты являются функциями пространственных координат (х, у),
то последние уравнения можно переписать в виде
с(т,у)=
cr(x, у)
cg(x, у)
св(х,у)
R(x, у)
G(x,y)
В(х,у)
Для изображения с размером MxN имеется MN таких векторов с(т, у) при
х = 0,1,2,..., М - 1 и у = 0,1,2,..., N - 1.
В некоторых случаях можно получить эквивалентные результаты, если обра-
батывать цветное изображение или по отдельным плоскостям, или в векторном
представлении. Однако это можно сделать не всегда, о чем подробно говорится
в § 6.6. Для того, чтобы процессы обработки изображений по отдельным плос-
костям и в векторной форме давали одинаковые результаты, требуется выпол-
нение следующих условий: во-первых, процедура должна быть применима и к
векторам, и к скалярам, а во-вторых, операция над каждой компонентой век-
тора должна быть независимой от остальных компонент. В качестве иллюстра-
ции, на рис. 6.10 (стр. 228) показана пространственная окрестностная обработ-
ка монохромного и полноцветного изображения. Предположим, что процедура
заключается в окрестностном осреднении. На рис. 6.10, а) осреднение делается
суммированием всех полутоновых пикселов окрестности и делением полученной
суммы на общее число пикселов в окрестности, а на рис. 6.10, б) следует просум-
мировать все векторы окрестности и разделить каждую компоненту полученного
суммарного вектора на общее число векторов окрестности. Однако каждая ком-
понента осредненного вектора равна сумме пикселов изображения, соответствую-
щего данной компоненте, деленной на число пикселов окрестности, что совпадает
с результатом индивидуального окрестностного осреднения каждой компоненты
изображения, после чего можно строить цветной вектор.
Рис. 6.1. Схематически показан способ формирования цветного RGB пиксела из соответ-
ствующих пикселов цветовых составляющих
Рис. 6.3. Элементы индексированного изображе-
ния. Значения элементов числового массива X
определяют номер строки в цветовой карте. Каж-
дая строка карты содержит RGB триплет. L — это
общее число строк цветовой карты
Значение (индекс) обведенного
элемента равно к
Рис. 6.4. a) RGB изображе-
ние. 6) Число цветов сокра-
щено до 8 без метода дрожа-
ния. в) Число цветов сокра-
щено до 8 с методом дрожа-
ния. г) Черно-белый вариант
изображения а), д) Он же по
методу дрожания (это двоич-
ное изображение)
Глава 6. Обработка цветных изображений
Рис. 6.6. Соотно-
шения между мо-
делями RGB и HSI
Рис. 6.7. Цветовой тон и
насыщенность в модели HS1.
Черная точка обозначает
произвольный цвет. Угол
до красной оси определяет
цветовой тон, а длина век-
тора — насыщенность. Ин-
тенсивность любого цвета
на этих плоскостях опре-
деляется положением этих
плоскостей на вертикаль-
ной оси интенсивности
а)
Синий Пурпурный
Зеленый
г)
Зеленый
Синий
Желтый
Голубой
Пурпурный
Голубой
Синий
Желтый
Красный
Пурпурный
6.3. Основы обработки, цветных изображений
I
Красный
Рис. 6.8. Цветовая модель
HSI, основанная на а) цвето-
вом треугольнике и б) цве-
товом круге. Треугольник и
круг расположены перпендику-
лярно вертикальной оси ин-
тенсивности
Черный
Рис. 6.9. Компоненты HSI изображения цветового RGB куба, а) цветовой тон, б) насы-
щенность и а) интенсивность
Глава 6. Обработка цветных изображений
Рис. 6.10. Пространственные маски
для монохромного и цветного RGB
изображений
Полутоновое изображение
Рис. 6.11. Задание функций отображения по контрольным точкам: а) и в) линейная
интерполяция, б) и г) — кубическая сплайновая интерполяция
D й? й * А Л Z Р
Рис. 6.12. Типичный вид открытых окон в ice. (Изображение предоставлено компанией
G.E. Medical Systems)
6.3. Основы обработки цветных изображений
21
Рис. 6.13. а) Функция негатив-
ного отображения; б) ее дей-
ствие на монохромное изобра-
жение
а) б)
И JCF hrtetec>bn Cater Editor
Рис. 6.14. а) Полноцветное изоб-
ражение; б) его иегатив (допол-
нительное изображение)
Рис. 6.15. Использование функции ice для улучшения контрастности монохромных
полноцветных изображений: а) и г) - входные изображения с явлением в
мывания; б) и д) — результаты обработки; е) и е) — окна интерфейса i<
(Исходное полутоновое изображение предоставлено Агентством NASA)
Глава 6. Обработка цветных изображений
в)
Рис. 6.16. а) Рентгенограмма дефектного сварного шва; б) псевдоцветная версия снимка
сварного шва; в) и г) — функции отображений для зеленой и синей компонент.
(Исходное изображение предоставлено компанией Х-ТЕК Systems, Ltd.)
Рис. 6.17. Применение функции ice при балансировке цвета: а) исправляемое изображе-
ние; б) исправленное изображение; в) функция отображения, использованная
при балансировке
6.3. Основы обработки цветных изображений
w1
1
- pS
Component Мепей^
f-^vdr-cmTrfifif
BesecAll
И ££ - leteractiw Cetec E Ater
input
Output
EtarnpErufe
ShcwfOF
V Sbor'CDF
•* MqpBe«
•» Mapimage
Map Earn
«* WopSmage
fripji
OUffiur
I
□ia г)
Bl
И KE Cateracthe C*ter EAter
Рис. 6.18. Гистограммная эквализация интенсивности и подгонка насыщенности в цве-
товом пространстве HSI: а) входное изображение; б) преобразованное изобра-
жение; в) функция преобразования компоненты интенсивности с кумулятив-
ной функцией распределения; (г) функция преобразования компоненты насы-
щенности; д) гистограммы компонент исходного изображения; е) гистограммы
компонент преобразованного изображения
FiesertAf!
RetetAl
input
Outnit
* WopEcrs
* 44ap image
232 Глава 6. Обработка цветных изображений
Рис. 6.19. a) RGB изображение; б), е) и г) — красная зеленая и синяя компоненты изоб-
ражения
Рис. 6.20. Слева направо: цветовой тон, насыщенность и интенсивность изображения на
рис. 6.19, а)
6.3. Основы обработки цветных изображении
Рис. 6.21. а) Сглаженное RGB изображение, полученное раздельным сглаживанием плос-
костей R, G и В. 6) Результат сглаживания одной компоненты интенсивности
того же изображения в пространстве HSI. в) Результат одинакового сглажива-
ния всех трех компонент HSI
Рис. 6.22. а) Размытое изображение, б) Изображение, улучшенное с помощью лапласиа-
на; контрастность усилена функцией ice
а) б)
-2 -1 -1 0 1
0 0 0 —2 0 2
2 1 0
Рис. 6.23. а) Окрестность (маска), б) и в) Маски Собела, используемые при вычислении
частных производных, соответственно, по направлению х (вертикальному) и у
(горизонтальному) относительно центральной точки этой окрестности
Глава 6. Обработка цветнъа: зображений
Рис. 6-24. а -с) Изображения RGB компонентов (черный цвсг 0, белый — 255). г) Соот-
ветствующее цветное зображение. д) Градиент, вычисленный тюпосредствснно
в векторном пространстве RGB. с) (Составной градиент, вычисленный сложе-
нием двумерных гра^щентов каждой компоненты RGB
Рис. 6.25. a) RGB изоб-
ражение. б) Градиент,
вычисленный вектор-
ном пространстве RGB.
о) С Соответствующее цвет-
ное изображение. г) Гра-
диент, вы численный ана-
логично рис 6.25, е).
д) Модуль разности изоб-
ражений 6) и в), приве-
денный к интервалу [О,1]
6.3. Основы. обработки цвептъц жбра:
а) И
б) Я
Рис. 6.26. Два подхода к окружению данных и векторном пространстве RGB в задачах
сегментации изображений
Рис. 6.27. а) Псевдоцвстное изображение поверхности спутника Юпитера Ио. 6) Инте-
ресующая область, выделенная интерактивной функпией roipoly. (Исходное
изображение предоставлено Агентством NASA)
Рис. 6.28. а)— г) Сегментация рис. >.27, а) с опцией ’euclidean’ функции colorseg при
Т = 25,50,75,100
Глава 6- Обработка цветим: зображеимй
Рис. 6.29. а)-г) Сегмен-
тация рис. 6.27, а) с оп-
цией ’mahalanobis’ функ-
ции colorseg при Т — 25,
50, 75, 100. Сравните с:
рис. 6.28
6.4. Цветовые преобразования
Методы и процедуры, рассматриваемые в этом параграфе, основаны на обра-
ботке компонент цветного изображения или компоненты яркости полутонового
зображения в рамках единой цветовой модели. Для цветных изображений мы
ограничимся преобразованиями вида
зг = г = 1,2,
где г, и зг — это цветовые компоненты входного и выходного изображений, п
размерность (или число цветовых компонент) цветового пространства г, , а Д
обозначает функции полноцветного преобразования (или отображения).
Если входное изображение является монохромным, то эти уравнения следует
писать в виде
s, = Ti(r), г = 1,2, ., п,
где обозначает полутоновые величины, s.,,T, — то же, что и раньше, а п — число
цветовых компонент зг. Это уравнение описывает отображение полутоновых пик-
:елов в цветные. Такой процесс принято называть псевдоцветным преобразова-
нием или псевдоцветным, отображением. Отметим, что первое уравнение можно
использовать для воспроизведения монохромных изображений в RGB простран-
стве, если положить п з = г. В любом случае, приведенные здесь урав-
нения являются прямым расширением уравнений для преобразования яркости,
приведенным в § 3.2. Как и в том параграфе, все п псевдо- или полноцветных
функций преобразования {71,7г < , Тп} не зависят от пространственных коор-
динат (ж, у) изображения.
Некоторые М-функции преобразований полутоновых изображений, которые
рассматривались в гл. 3, например, функция imcomplement, вычисляющая допол-
нительное изображение, не зависят от содержимого полутонового изображения.
Другие, например, функция histeq, которая зависит от распределения серых
тонов, являются адаптивными, но само преобразование фиксируется, как толь-
ко вычислены необходимые параметры этого преобразования. А еще имеются
преобразования, вроде imadjust, для которых требуется сделать выбор подхо-
дящих параметров формы кривой, что лучше всего выполнить пользователю в
интерактивном режиме. Такая же си- уация возникает при работе с полноцвет-
ными и псевдоцветными изображениями, особенно когда приходится прибегать к
субъективному оцениванию изображений (например, при цветовой балансировке).
В таких приложениях имеет смысл отбирать подходящую функцию преобразо-
вания с помощью прямого графического манипулирования с потенциальными
функциями и наблюдения (в реальном времени) действия их комбинаций на об-
рабатываемое изображение.
На рис. 6.11 (стр. 228) иллюстрируется простой, но весьма эффективный ме-
тод задания функций отображения графическим путем. На рис. 6.11. а) пока-
зано преобразование, которое построено линейной интерполяцией по трем кон-
трольным точкам (маленькие кружки на графике); рис. 6.11, б) показывает ре-
зультат кубической сплайновой интерполяции по тем же трем точкам; наконец,
рис. 6.11, в) и г) дают примеры более сложный линейной и сплайновой интерпо-
ляции. Оба типа интерполяции реализованы в MATLAB. Линейная интерполя-
ция совершается функцией
z = interplqlx, у, xi).
которая возвращает вектор-столбец, состоящий из значений одномерной функ-
ции z в точках xi. В векторах-столбцах х и у записаны координаты по горизон-
тали и вертикали контрольных точек. Элементы вектора х должны монотонно
возрастать. Длина z должна быть равна длине xi. Так, например, команда
» z interplq![О 255]’, [0255]’, [0: 255]’);
строит взаимно однозначное отображение, состоящее из 256 элементов и соеди-
няющее контрольные точки (0,0) и (255,255), т. е. z [0 1 2 3 255].
Аналогичным образом кубическая сплайновая интерполяция задается функ-
цией
z spline(x, у, xi),
где переменные z, х, у и xi были объяснены при описании функции interplq.
Точки xi должны быть различными. Кроме того, если в массиве у число элемен-
тов на 2 больше, чем в массиве х, то его первый и последний элементы должны
быть коэффициентами наклонов касательных кубического сплайна в концевых
точках. Например, на рис. 6.11. б) кубический сплайн был построен с нулевыми
наклонами концевых каса тельных.
Функцию преобразования можно описать в интерактивном графическом ре-
жиме, манипулируя контрольными точками, которые являются входными дан-
ными функций interplq и spline, и получая на экране в реальном времени ре-
зультат преобразования данного изображения построенной функцией. Функция
ice (Interactive Color Editing, интерактивное цветное редактирование) совершает
Глава 6. Обработка цветных изображений
в точности эти действия. Она имеет следующий синтаксис:
g = ice(’Property Name’, ’Property Value’, ...),
где переменные ’ Property Name ’ и ’ Property Value ’ должны образовывать па-
ры. а многоточие означает дальнейшее повторение соответствующих входных
пар. В табл. 6.4 перечислены все допустимые входные пары функции ice. Неко-
торые примеры будут рассмотрены далее в этом параграфе.
Таблица 6.4. Допустимые входные аргументы функции ice
Property Name Property Value
’Image’ RGB или MOHOxjxDMHoe изображение f, которое будет преобразовано отоб- ражением, заданным интерактивно.
’space’ Цветовое пространство изображение, которое будет модифицировано. До- пустимые значения: ’rgb’, ’cmy’, ’hsi’, ’hsv’, ’ntsc’, (или ’yiq’) и ’ycbcr’ По умолчанию принято ’rgb’
’wait’ Если ’on’ (по умолчанию), то g — это преобразованное входное изобра- жение. Если ’off’, то g — это манипулятор преобразованного входного изображения.
Если первым аргументом пары стоит ’wait’, за которым следует явный ар-
гумент ’on’ (или он же принят по умолчанию), то выходом служит обработан-
ное изображение g. В этом случае функция ice принимает на себя контроль за
процессом, включая перемещение курсора, т. е. данные нельзя будет вводить с
клавиатуры в командном окне до тех пор. пока эта функция не будет закрыта, и
результатом будет являться изображение g. Если же выбран параметр ’off’, то
g является манипулятором1 обрабатываемого изображения, и управление сра-
зу передается окну команд, т. е. можно исполнять новые команды при активной
функции ice. Чтобы узнать свойства изображения с манипулятором g, достаточ-
но выполнить команду get
h get(g).
которая возвращает все свойства и текущие величины графического объекта,
обозначенного манипулятором g. Свойства хранятся в виде структуры h, поэтому
за вызовом в командной строке h последует список всех свойств обрабатываемого
изображения (см. §§ 2.10.6 и 11.1.1, где объясняются структуры). Чтобы получить
конкретное свойство, надо набрать h.PropertyName.
Пусть f обозначает монохромное или RGB изображение. Вот примеры неко-
торых синтаксических форм функции ice:
ice
g = ice(’image’, f);
% Показывает один графичес-
% кий интерфейс.
7, Показывает и возвращает
"X отображенное изображение g.
1При создании некоторого графического объекта MATLAB сопоставляет ему идентификатор,
называемый манипулятором, который обеспечивает доступ к свойствам этого графического
объекта. Графические манипуляторы полезны при изменении внешнего вида и оформления
графиков или при оформлении группы графических команд в виде отдельного М-файла, в
котором можно прямо создавать объекты и манипулировать ими.
6-4- Цветовые преобразования
g ice(’image’, f,
g = ice(’image’, f,
’waite’, ’off’); 7„ Показывает g
7. и возвращает манипулятор.
’space’, ’hsi’); 7. Преобразует GGB
7. изображение f в формат HSI.
Отметим, что при задании цветового пространства, отличного от RGB, входное
изображение конвертируется в это пространство до совершения преобразования.
После этого преобразованное изображение вновь конвертируется в RGB. Выхо-
дом функции ice всегда служит изображение RGB, а входом является моно-
хромное или RGB изображение. Если набрать команду g = ice (’image’, f),
то на рабочем столе MATLAB появится заданное изображение, а также окно
графического интерфейса пользователя (GUI, Graphical User Inerface), как это
показано на рис. 6.12 (стр. 228). В начале диалога кривая преобразования яв-
ляется прямой линией с двумя контрольными точками на концах. Контрольные
точки можно перемещать с помощью мыши в соответствии с правилами, приве-
денными в табл. 6.5. В табл. 6.6 перечислены функции других компонентов GUI.
В следующем примере рассматривается типичное применение функции ice.
Таблица 6.5. Манипулирование контрольными точками посредством мыши
Действие мыши Результат
Левая кнопка Перемещение контрольной точки при удержании кнопки и перетаскивании объекта..
Левая кнопка + Shift Создание новой контрольной точки. Ее положение можно изменять, перетаскивая мышью (при нажатой клавише Shift).
Левая кнопка 1 Ctrl Удаление контрольной точки.
Пример 6.3. Обратное (негативное) преобразование монохромного изображе-
ния и цветовых компонентов цветного.
На рис. 6.13, а) (стр. 229) приведен интерфейс ice после того, как заданная по
умолчанию кривая на рис. 6.12 была модифицирована и приведена к графику
функции обратного или негативного преобразования. Для этого контрольная точ-
ка (0.0) была перемешена (с помошью удержания левой клавиши мыши) в верх-
ний левый конец, а контрольная точка (1,1) была передвинута в точку с коорди-
натами (1.0). Обратите внимание на то, что координаты курсора отображаются
красным цветом в полях Input/Output. Изменяется только RGB отображение, а
отображения индивидуальных компонент R, G и В остаются в исходном состоя-
нии, принятом по умолчанию2 (см. элемент Component в табл. 6.6). Если входное
изображение было монохромным, то это гарантирует сохранение монохромно-
ти на выходе. На рис. 6.13. б) приведено негативно монохромное изображение,
которое получается при обратном преобразовании. Заметим, что оно идентично
рис. 3.3, б), который был получен с помощью функции imcomplement. Псевдо-
цветная полоса Pseudo-color Ваг на рис. 6.13, а) является «негативной фотогра-
фией» исходной полутоновой шкалы из рис. 6.12.
Отображения, принятые по умолчанию, в большинстве примеров не показываются.
Глава 6. Обработка цветных изображений
Функция обратного (негативного) отображения также полезна при обработке
цвета. Как можно увидеть на рис. 6.14, а) и б) (стр. 229), результат этого пре-
образования похож на обычный негатив цветной фотопленки. Например, крас-
ный мелок в нижнем ряду на рис. 6.14, а) стал голубым на рис. 6.14, б) (голубой
цвет дополнителен красному). Дополнением первичного цвета служит сметание
двух других первичных цветов (т. е. голубой это синий плюс зеленый). Как
и в монохромном случае, цветное дополнение удобно при усилении деталей на
темных цветовых участках, особенно если эти области превалируют на изобра-
жении. Заметьте, что цветная полоса Full-color Ваг на рис. 6.13, а) состоит из
дополнительных цветов исходной Full-color Ваг из рис. 6.12. □
Таблица 6.6. Функции кнопок и окошек отметок в GUI ice
Элемент GUI Функция
Smooth Если отмечено, то используется кубическая сплайновая (гладкая) интерполя- ция. Если отметка снята, то используется кусочно линейная интерполяция.
Clamp Ends Отметка означает начало и конец сплайновой кривой с нулевым наклоном. При линейной интерполяции не действует.
Show PDF Показывать функции плотности вероятностей (т. е. гистограммы) компо- нент изображений, подвергнутых преобразованию.
Show CDF Показывать функции распределения вероятностей вместо PDF. (Одновре- менно увидеть CDF и PDF нельзя.)
Map Image Map Bars Если отмечено, то разрешено отображение изображения, иначе — нет. Если отмечено, то разрешено отображение псевдо- и полноцветных полос цветового тона; иначе отображаются не преобразованные полосы.
Reset Инициализация последней отображенной функции преобразования и снятие всех отмеченных элементов.
Reset All Input/Output Инициализация всех функций преобразований. Показывают координаты выбранной контрольной точки на кривой преоб- разования. Input отвечает горизонтальной оси, a Output — вертикальной.
Component Выбор функции отображения для интерактивного манипулирования. В прост- ранстве RGB возможен выбор R, G, В или RGB (которая отображает все три цветные компоненты). В пространстве HSI доступны опции Н, S, I или HSI, и т. д.
Пример 6.4. Улучшение монохромной и цветной контрастности.
Теперь рассмотрим использование функции ice при улучшении монохромной и
цветной контрастности. На рис. 6.15 (стр. 229) с а) по в) продемонстрирована
эффективность этой функции при работе с монохромными изображениями. На
рис. 6.15 с г) по е) показан такой же хороший результат при работе с цветным
входом. Как и в предыдущем примере, непоказанные функции отображения со-
храняют свои установки по умолчанию. На обеих сериях иллюстраций отмечены
опции Show PDF Поэтому гистограмма аэрофотоснимка (рис. 6.15, а)) приведе-
на под функцией гамма-формы отображения на рис. 6.15, в) (см. § 3.2.1), а на
рис. 6.15, е) построено сразу три гистограммы рис. 6.15, г) — по одной на каждую
из цветных компонент. Несмотря на то, что S-образная функция преобразования,
приведенная на рис. 6.15. е), улучшает контрастность изображения 6.15, д) по
сравнению с рис. 6.15, г), оно также слегка действует и на компоненту цветного
тона. На рис. 6.15, д) небольшое изменение цвета почти не заметно глазу, но его
64- Цветовые преобразования 241
можно обнаружить на соответствующей полноцветной полосе рис. 6.15, е). На-
помним, что в предыдущем примере было продемонстрировано, что одинаковое
изменение цветных компонент может весьма существенно отразиться на цветах
RGB изображения (см. функцию дополнения цветов на рис. 6.14). □
Красная, зеленая и синяя компоненты входного изображения из примеров 6.3
и 6.4 отображались одинаково, т. е. с использованием одной и той же функции
преобразования. Чтобы избежать задания трех одинаковых функций, функция
ice позволяет определить функцию «для всех компонент» (кривую RGB при ра-
боте в RGB пространстве), которая одинаково отображает все компоненты вход-
ного изображения. В остальных примерах демонстрируются преобразования, ко-
торые по-разному действуют на разные цветовые компоненты.
Пример 6.5. Псевдоцветные отображения.
Как уже отмечалось ранее, когда монохромное изображение представлено в цве-
товом пространстве RGB и цветовые компоненты преобразуются независимо друг
от друга, результат такого преобразования называется псевдоцветным изобра-
жением, в котором входные полутоновые уровни заменены некоторыми цветами.
Такие преобразования могут быть полезными, т. к. глаз человека способен раз-
личать миллионы цветов, но он отличает лишь относительно малое число оттен-
ков серого тона. Поэтому псевдоцветные отображения часто используются при
желании сделать малые колебания яркости монохромного изображения более за-
метными и различимыми для глаза и для выделения важных областей на полу-
тоновых изображениях. На самом деле, основное применение псевдоцвета — это
зрительная визуализация, т. е. интерпретация черно-белых событий на изобра-
жениях или последовательности изображений с помощью монохромно-цветного
преобразования.
На рис. 6.16, а) (стр. 230) дана рентгенограмма сварного шва (горизонталь-
ная темная область), в котором имеются щели и раковины (яркие белые чер-
точки по середине изображения). Псевдоцветная версия этого изображения при-
ведена на рис. 6.16, б), которая была построена отображением зеленой и синей
компонент входного RGB-преобразованного изображения с помощью функции
из рис. 6.16, в) и г). Обратите внимание на существенное визуальное отличие
этих двух изображений. Псевдоцветная полоса в окне GUI дает представление
о составном цветовом отображении. Из рис. 6.16, в) и г) видно, что выбранная
интерактивно функция отображает черно-белую шкалу серого тона в цветную по-
лосу между синим и красным цветом, причем желтый зарезервирован за белым
цветом. Конечно, желтый цвет соответствует трещинам и раковинам, которые
являются главными характеристиками в данном примере. □
Пример 6.6. Балансировка цвета.
На рис. 6.17 (стр. 230) показано приложение с полноцветным изображением, в ко-
тором выгодно преобразовывать цветовые компоненты независимо друг от друга.
Отображения такого типа принято называть цветовой балансировкой или цвето-
вой коррекцией. Раньше для выполнения таких действий требовались высокока-
чественные цветовоспроизводящие системы, а теперь их можно совершить почти
на тюбом персональном компьютере. Эта процедура используется при улучшении
242 Глава 6. Обработка цветных изображений
цветных фотографий. Хотя разбалансировку цвета можно установить объектив-
но анализируя (с помощью цветного спектрометра) некоторый известный цвет на
изображении, аккуратное визуальное оценивание также возможно, если на изоб-
ражении имеются белые области, где RGB или CMY компоненты должны быть
равны между собой. Кроме того, как видно на рис. 6.17, оттенки человеческой
кожи могут служить отличным образцами для визуального оценивания, так как
человеческий глаз весьма восприимчив даже к малым отклонениям от истинного
цвета на этих участках.
На рис. 6.17, а) показано отсканированное CMY изображение матери с ребен-
ком с избытком пурпурного цвета (помните, что MATLAB может отображать
лишь RGB версии изображений). Для простоты и для совместимости с системой
MATLAB функция ice также допускает лишь RGB (и монохромные) изобра-
жения, однако она может обрабатывать входы различных цветовых форматов,
указанных в табл. 6.4. Например, чтобы интерактивно модифицировать CMY
компоненты RGB изображения fl, следует вызвать функцию ice в следующем
виде:
>> f2 = ice(’image’, fi, ’space’, ’CMY’);
Из рис. 6.17 видно, что небольшое уменьшение пурпурной компоненты произво-
дит ощутимое воздействие на цвет изображения. □
Пример 6.7. Отображения на основе гистограмм.
Гистограммная эквализации является процессом преобразования полутоновых
изображений, при котором получается монохромное изображение с гистограммой
яркости, близкой к гистограмме равномерного распределения. Как обсуждалось
в § 3.3.2, требуемая функция отображения является функцией распределения
уровней серых тонов входного изображения. Поскольку цветные изображения
состоят из нескольких компонент, монохромную процедуру необходимо приспо-
собить к обработке более одной компоненты и ассоциированной гистограммы.
Однако эти преобразования не следует делать независимо друг от друга, иначе
можно получить ложные цвета. Правильный подход заключается в приближении
к равномерному распределению для компоненты интенсивностей, оставляя сами
цвета (компоненты цветового тона) неизменными.
На рис. 6.18, а) (стр. 231) изображена вращающаяся стойка для специй и при-
прав. Преобразованное изображение на рис. 6.18, б) было получено HSI преоб-
разованием, приведенном на рис. 6.18, в) и г). Оно выглядит значительно ярче
исходного. Теперь стали хорошо различимы форма и текстура деревянного сто-
ла, на котором расположена стойка для специй. Компонента интенсивности была
преобразована функцией на рис. 6.18, в), которая хорошо аппроксимирует функ-
цию CDF этой компоненты (которая также построена на этом графике). Функция
отображения насыщенности на рис. 6.18, г) была выбрана так, чтобы улучшить
общее цветовое восприятие результата эквализации компоненты интенсивности.
Отметим, что гистограммы входных и выходных данных всех трех цветовых
компонент: цветового тона, насыщенности и интенсивности, приведены, соответ-
ственно, на рис. 6.18, д) и е). Компоненты цветовых тонов остались неизменны-
ми (как объяснялось выше), а компоненты насыщенности и интенсивности были
6.5. Пространственная фильтрация цветных изображений
исправлены. Осталось заметить, что для обработки RGB изображения в цвето-
вом пространстве HSI мы добавили в аргументы команды ice пару аргументов
’space’ и ’hsi’. □
Выходные изображения, построенные в предыдущих примерах этого парагра-
фа, имеют тип RGB и принадлежат классу uint8. Для монохромных результа-
тов, как в примере 6.3, все три RGB компоненты идентичны. Более компактную
форму представления таких изображений можно получить, применив функцию
rgb2gray из табл. 6.3, или воспользовавшись командой
» f3 = f2(:, ,1) ;
где £2 — это RGB изображение, построенное в ice, a f3 — стандартное моно-
хромное изображение в MATLAB.
6.5. Пространственная фильтрация цветных изображений
В § 6.4 рассматривались преобразования цветных изображений, которые приме-
няются к отдельным пикселам каждой цветовой плоскости (компоненты). Следу-
ющий уровень сложности соответствует обработке пространственных окрестно-
стей, которая также совершается на каждой цветовой плоскости. Для монохром-
ных изображений этот переходный момент уже обсуждался при рассмотрении
преобразований яркости в § 3.2 и при исследовании пространственной фильтра-
ции в §§ 3.4 и 3.5. Мы будем исследовать пространственную фильтрацию цветных
изображений в основном в пространстве RGB, однако базовая схема применима
к любой цветовой модели. Мы будем иллюстрировать методы пространственной
обработки цветных изображений на двух примерах процедур линейной фильтра-
ции: сглаживание изображений и повышение резкости изображений.
6.5.1. Сглаживание цветных изображений
Если обратиться к рис. 6.10, а) и к §§ 3.4 и 3.5, то сглаживание (пространствен-
ная фильтрация) монохромных изображений осуществляется умножением значе-
ний всех пикселов в пространственной маске на соответствующие коэффициен-
ты, суммированием и делением суммы на общее число элементов маски. Процесс
сглаживания полноцветных изображений с помощью пространственной маски по-
казан на рис. 6.19, б) (стр. 232). Этот процесс (например, в пространстве RGB)
определяется так же, как и при работе с монохромными изображениями, с той
лишь разницей, что вместо одиночных, скалярных пикселов приходится работать
с векторными величинами в представлении, изложенном в § 6.3.
Пусть Sxy обозначает множество точек окрестности (маски) с центром в точке
'х, у) некоторого цветного изображения. Среднее RGB векторов этой окрестности
задается формулой
с(х,у) = -^ 52
(s, t)esIW
где К — это число пикселов окрестности. Из свойства сложения векторов (см. § 6.3)
244 Глава 6. Обработка цветных изображений
следует, что
с(а:,у) =
7? 12(s, t)e.S3:„ -R(s>t)
Tc H^s,t)es^v
7c £(ММВ -B(s^)
Видно, что каждая компонента этого вектора получается при окрестностном
осреднении каждой отдельной цветовой компоненты, которую можно выполнять
по схеме стандартного осреднения монохромных изображений. Значит, сглажи-
вание пространственным осреднением можно выполнять независимо на покомпо-
нентной основе. Результат будет совпадать с осреднением в цветовом векторном
пространстве.
Как уже объяснялось в § 3.5.1, линейные пространственные фильтры для
сглаживания изображений строятся функцией f special, которая имеет три воз-
можные опции: ’average’, ’disk’ и ’gaussian’ (см. табл. 3.4). После того, как
фильтр сгенерирован, процедура фильтрации совершается функцией imfilter,
которая вводилась в § 3.4.1.
В идейном плане сглаживание цветных RGB изображений, скажем, f с линей-
ным пространственным фильтром, состоит из следующих шагов.
1. Выделить три компоненты изображения:
» fR = fc(: ,1); fG fc(:,
,2); fB = fc(: ,3);
2. Отфильтровать отдельно каждую компоненту. Например, пусть w обознача-
ет сглаживающий фильтр, построенный командой f special, тогда красная
компонента сглаживается следующим образом:
>> fR_filtered = imfilter(fR, w);
и аналогично обрабатываются остальные компоненты изображения.
3. Реконструировать отфильтрованное RGB изображение:
» fc_filtered = cat(3, fR_filtered, fG_filtered, fB_filtered);
Однако мы можем совершать линейную фильтрацию прямо RGB изображений
MATLAB с помощью того же синтаксиса, что и при обработке монохромных
изображений, что позволяет объединить описанные выше три шага в один:
» fc_filtered = imfilter(fc, w);
Пример 6.8. Сглаживание цветных изображений.
На рис. 6.19, а) (стр. 232) дано RGB изображение размерами 1197x1197, а на
рис. 6.19 с б) по г) — компоненты RGB этого изображения, извлеченные с помо-
щью описанной выше процедуры. На рис. 6.20 (стр. 232) с а) по в приведены три
компоненты HSI изображения на рис. 6.19, а), построенные с помощью функции
rgb2hsi.
Рис. 6.20, а) представляет результат сглаживания рис. 6.19, а) с помощью
функции imf ilter с опцией ’replicae’ ифильтром ’average’ размерами 25x25.
6.5. Пространственная фильтрация цветных изображений 245
Усредняющий фильтр является достаточно большим для достижения заметного
эффекта размытия. Такой размер фильтра был выбран для того, чтобы проде-
монстрировать разницу между сглаживанием в пространстве RGB и попыткой
достигнуть аналогичный результат, используя только компоненту интенсивно-
сти, которая получается после конвертации изображения в цветовое пространство
HSI. Рис. 6.21, б) (стр. 233) был получен с помощью команд:
> > h = rg2hsi(fc);
» Н = h(: ,1); S h(:, ,2); I h(:, ,3);
> > w = fspecial(’average’, 25);
> > I_filtered = imfilter(I, w, ’replicae’);
> > h = cat(3, H, S, I_filtered);
» f = hsi2rgb(h);
> > f = min(f, 1); */, RGB images must have values in the range [0, 1].
> > imshow (f)
Ясно, что результаты фильтрации существенно различаются. Например, кро-
ме меньшего размытия, можно заметить на изображении б) зеленые обводы по
верхним границам лепестков, чего нет на рис. а). Причина этого явления заклю-
чается в том, что компоненты цветового тона и насыщенности не изменялись, в
то время как перепады компоненты интенсивности были существенно сглажены.
Может показаться правильным сделать сглаживание по всем трем компонентам
с помощью одного и того же фильтра. Однако в такой процедуре существенно
изменятся соотношения между величинами цветового тона и насыщенности, что
дает ложные цвета, как это видно на рис. 6.21, в).
Общее правило таково: чем больше размер маски, тем больше разница меж-
ду результатами фильтрации компонент RGB и компоненты интенсивности HSI
эквивалентного изображения. □
6.5.2. Повышение резкости цветных изображений
Повышение резкости цветных RGB изображений с помощью линейного простран-
ственного фильтра выполняется теми же процедурами, что и в предыдущем пара-
графе, но с использованием фильтра, повышающего резкость. В данном парагра-
фе этот метод демонстрируется на примере лапласиана (см. § 5.5.1). Из векторно-
го анализа известно, что лапласиан вектора определяется как вектор, компонен-
ты которого равны лапласиану от соответствующих скалярных компонент вход-
ного вектора. В цветовом пространстве RGB лапласиан от вектора с (см. § 6.3)
равен
V2[c(x,y)] =
VW, 7/)]
V2[G(x,y)]
VW,7/)]
Как и в предыдущем параграфе, эта формула означает, что лапласиан от цветно-
го изображения можно находить с помощью вычисления лапласиана от каждой
отдельной цветовой компоненты.
246 Глава 6. Обработка цветных изображений
Пример 6.9. Повышение резкости цветных изображений.
На рис. 6.22, а) (стр. 233) приведен слегка размытый вариант bf изображения на
рис. 6.19, а), полученного усредняющим фильтром размерами 5x5. Чтобы повы-
сить резкость этого изображения, можно воспользоваться маской фильтра Ла-
пласа.
» lapmask [111; 1-81; 111];
Затем, как и в примере 3.9, улучшенное изображение вычисляется и отобража-
ется на дисплее командами
>> fen = imsubtract(fb, imfilter(fb, lapmask, ’replicate’));
>> imshow (fen)
Здесь два необходимых шага обработки выполнены в одной команде. Как и в
предыдущем параграфе, RGB изображение обрабатывалось как монохромное
изображение (т. е. с той же формой вызова) при исполнении команды imf ilter.
На рис. 6.22, б) показан результат. Обратите внимание на заметный эффект по-
вышения резкости отдельных деталей, например, капелек воды, прожилок ли-
стьев, желтого центра цветка и зеленой травы на заднем плане. □
6.6. Обработка в векторном пространстве RGB
напрямую
Как отмечалось в § 6.3, имеются случаи, когда раздельная обработка цветовых
плоскостей не эквивалентна прямой работе в векторном пространстве RGB. Это
демонстрируется в данном параграфе на примере двух важных приложений: об-
наружение контуров на цветных изображениях и сегментация областей.
6.6.1. Обнаружение контуров на цветных
изображениях с помощью градиента
Градиентом двумерной функции f(x, у) называется следующий вектор:
Г G 1 ££ 1
vf=kHs]
Модуль (длина) этого вектора равен
| V/| = mag(Vf) = [G2 + G£]1/2 = {(df/dx)2 + (df/ду)2]1'2.
Часто эту величину можно аппроксимировать с помощью суммы абсолютных
величин
|V/| « |GX| 4- IGJ.
Такое приближение позволяет избежать возведения в квадрат и извлечения квад-
ратного корня, но при этом оно ведет себя как производная (т. е. оно равно ну-
лю на областях с постоянным цветом пикселов, и его величина пропорциональна
степени изменения цвета на неоднородных областях). Общепринято называть мо-
дуль градиента просто «градиентом».
6.6. Обработка в векторном пространстве RGB напрямую
Основное свойство вектора-градиента состоит в том, что он направлен в сторо-
ну максимального роста / в точке с координатами (х, у). Угол этого направления
равен
а\х,у) = arctg I — I
\yy/
Производные принято аппроксимировать разностями значений пикселов в ма-
лой окрестности изображения. На рис. 6.23, а) (стр. 233) показана окрестность
размерами 3x3, где буквы z обозначают значения пикселов. Приближение част-
ной производной в (вертикальном) направлении х по отношению к центральной
точке окрестности (т. е. zg) определяется разностной формулой
Gx = (27 4- 2zg + Z9) — (zi + 2z2 4- Z3).
Аналогично, частная производная по направлению у приближается разностным
выражением
Gy = (гз 4- 2^6 4- 29) — (zi 4- 2z4 4- 27).
Обе эти величины легко вычисляются во всех точках изображения с помощью
свертки (функция imfilter) изображения с двумя масками, приведенными на
рис. 6.23, б) и в). После этого приближение градиентного изображения получа-
ется сложением абсолютных величин двух фильтрованных изображений. Указан-
ные выше маски являются масками Собела, приведенными в табл. 3.4, которые
строятся с помощью функции f special.
Описанный выше метод вычисления градиента часто используется в задачах
обнаружениях контуров на полутоновых изображениях, которые будут подробно
разбираться в гл. 10. В данный момент мы интересуемся вычислением градиента
в цветовом RGB пространстве. Однако приведенный метод применим только для
двумерных пространств, и его нельзя распространить на большие размерности.
Остается только подход, основанный на вычислении градиента для каждой цве-
товой компоненты изображения и сложении этих градиентов. К сожалению, как
скоро будет видно, такой путь не всегда приводит к решению задачи обнаруже-
ния контуров на цветных RGB изображениях.
Итак, проблема прежде всего заключается в том, чтобы определить градиент
(модуль и направление) вектора с, заданного в § 6.3. Приведем далее некоторый
вариант распространения понятия градиента на вектор-функции. Напомним, что
для скалярной функции /(т, у) вектор градиента указывает в направлении мак-
симального роста функции / в точке с координатами (х,у).
Пусть г, g и b — единичные векторы, направленные вдоль осей R. G и В
цветового пространства RGB (см. рис. 6.2). Зададим векторы
dR 9G дВъ
u=eT+&g+s?b
и
dR dG дВл
v = + Ъ“ь-
оу оу ду
248 Глава 6. Обработка цветных изображений
Пусть следующие величины дхх, дуу и дху задаются с помощью скалярных про-
изведений этих векторов:
и
дхх = и • u = u7u = dR dx 2 + dG dx 2 + dB dx 2
9уу = v ’ v = vTv = dR dy 2 + dG dy 2 + dB dy 2
T dR dR dG dG gxy-u v — u v - + + dx dy dx dy dB dB dx dy
Следует помнить, что величины R, G и В, а, следовательно, и все g являют-
ся функциями от х и у. С помощью введенных обозначений можно показать
(см. [Di Zenzo, 1986]), что угол направления максимального изменения (роста и
убывания) вектора с{х, у) как функции (.т, у) удовлетворяет уравнению
tg20 =
2 Уху
(9хх — дуу)
а величина скорости изменения (т. е. модуль градиента) в направлении этого угла
6 задается выражением
Г 1 1 1/2
у) = л 2 Kff®® 9уу) (.Ухх 9 у у) cos 20 4- 2дху sin 20] z
Напомним, что 0(х, у) и Fg(x, у) являются изображениями, размеры которых сов-
падают с размерами входного изображения. Элементами 0(ге, у) являются углы
градиентов в каждой точке исходного изображения, a Fg(x,y) — модуль этого
градиента.
Заметим, что tg(o) = tg(o ± л), поэтому если 0q является решением урав-
нения с tg, то и величина 0q + л/2 также является его решением. Кроме того,
Fe(x,y) = Fc+7r(.T, у), т. е. функцию Fg, достаточно вычислять лишь для тех ве-
личин 0, которые расположены в полуоткрытом интервале [0, л). Тот факт, что
уравнения для 0 имеет два решения, которые различаются на 90°, означает, что
с каждой точкой (х, у) изображения связаны два направления, расположенные
ортогонально друг к другу. Вдоль одного из этих направлений скорость измене-
ния функции F максимальна, а вдоль другого — минимальна, поэтому оконча-
тельный результат получается выбором максимума из этих двух чисел в каждой
точке изображения. Вывод этих формул занимает много места, но мало добавля-
ет к пониманию основных целей рассматриваемого предмета. Заинтересованный
читатель может найти весьма подробное изложение этого материала в работе
[Di Zenzo, 1986]. Частные производные, необходимые при решении приведенных
выше уравнений, можно вычислять, например, с помощью операторов Собела,
которые упоминались выше.
Следующая функция реализует вычисление градиента цветного RGB изобра-
жения (см. программный код в приложении В):
[VG, A, PPG] = colorgrad(f, Т) ,
6.6. Обработка в векторном пространстве RGB напрямую
где f — это RGB изображение, Т — порог (необязательный параметр) в интер-
вале [0,1] (по умолчанию равен 0); VG — модуль RGB градиента Fg(x, у); А —
это матрица углов 0(т, у) в радианах; a PPG — это градиент, полученный сложе-
нием двумерных градиентов отдельных цветовых плоскостей (вычисляется для
сравнения результатов). Эти последние градиенты равны, VR(t, у), VG(x,y) и
—г(х, у), где оператор V определялся ранее в этом параграфе. Все используемые
частные производные вычисляются функцией colorgrad с помощью операторов
Собела. Выходы VG и PPG нормированы в интервале [0,1], и, кроме того, функция
colorgrad осуществляет срезание больших значений VG в соответствии с поро-
говым значением Т: VG(x, у) 0 там, где вычисленное значение больше Т. Эти
же действия выполняются для выхода PPG.
Пример 6.10. Обнаружение контуров на цветных изображениях с помощью
функции colorgrad.
На рис. 6.24 (стр. 234) с а) по в) приведены три простых монохромных изобра-
жения, которые при использовании их в качестве RGB плоскостей дадут цветное
изображение, показанное на рис. 6.24, г). Целями этого примера являются:
(1) демонстрация функции colorgrad,
(2) иллюстрация того факта, что вычисление градиента цветного изображения
путем сложения градиентов отдельных цветовых плоскостей отличается от
результата нахождения градиента непосредственно в цветовом векторном
пространстве RGB с помощью описанного выше метода.
Пусть f обозначает RGB изображение на рис. 6.24, г). Команда
>> [VG, A, PPG] colorgrad(f);
строит изображения VG и PPG, которые приведены на рис. 6.24, д) и е). Самое
главное различие между этими двумя результатами заключается в том, что го-
ризонтальный контур на рис. 6.24, е) существенно слабее соответствующего кон-
тура на рис. 6-24, д). Причина очень проста: градиенты красной (R) и зеленой (G)
плоскостей (рис. 6-24, а) и б)) дают два вертикальных контура, а из градиента
синей плоскости выявляется всего один горизонтальный контур. При сложении
этих трех градиентов получается, что вертикальный контур имеет в два раза
большую интенсивность, чем горизонтальный.
С другой стороны, при вычислении градиента цветного изображения непо-
средственно в векторном пространстве (рис. 6.24, д)) отношение значений на вер-
тикальном и горизонтальном краях равно у/2, а не 2. Причина опять проста:
при обращении к цветовому кубу на рис. 6.2, а) и к рис. 6-24, г) видно, что вер-
тикальный контур на цветном изображении расположен между синим и белым
квадратами, а также между черным и желтым. Расстояние между этими цветами
на цветовом кубе равно у/2, а расстояние между черным и синим, а также между
желтым и белым (горизонтальный контур) равно 1. Поэтому отношение верти-
кального и горизонтального контура равно у/2- Если в конкретном приложении
важное значение имеет точность обнаружения контуров, особенно при использо-
вании срезающих порогов, то разница между результатами этих двух подходов
может быть неприемлемо большой. Например, если использовать порог 0.6, то
горизонтальная линия на рис. 6.24, е) просто исчезнет.
250 Глава 6. Обработка цветных изображений
На практике, если задача заключается в грубом определении контуров, то
оба подхода дают вполне сравнимые результаты. Например, рис. 6.25, б) и в)
(стр. 234) аналогичны рис. 6.24, д) и е). Они получены применением функции
colorgrad к изображению 6.25, а). На рис. 6.25, г) приведена разность этих двух
изображений, приведенная к шкале [0,1]. Максимальное значение модуля разно-
сти изображений равно 0.2. что соответствует 51 уровню градации серого цвета
на обычных 8-ми битовых изображениях. Однако при визуальном оценивании
эти два изображения выглядят весьма близкими, и лишь в некоторых местах
изображение на рис. 6.23. б) кажется более ярким (по причинам, разъясненным
в предыдущих абзацах). Значит, для грубого и субъективного анализа вполне
годится более простой метод вычисления градиента, основанный на сложении
градиентов отдельных плоскостей. В других случаях (например, при автомати-
ческом контроле расхождения цветов после окраски промышленной продукции)
может понадобиться более аккуратный векторный метод исследования. □
6.6.2. Сегментация в векторном пространстве RGB
Сегментацией называется процесс разделения изображения на области. Несмотря
на то, что этой теме посвящена гл. 10, мы кратко рассмотрим в этом параграфе
цветовую сегментацию, чтобы не прерывать логику изложения. У читателя не
должно возникнуть сложностей при ознакомлении с этим материалом.
Цветовая сегментация в векторном пространстве RGB заключается в следу-
ющем. Предположим, что наша цель состоит в выделении объектов на изобра-
жении RGB, цвет которых лежит в определенном диапазоне. Имея некоторую
репрезентативную выборку векторов, имеющих интересующий нас цвет, мы полу-
чаем оценку «среднего» цвета, который необходимо выделить. Пусть этот сред-
ний цвет обозначен RGB вектором-столбцом т. Задача сегментации состоит в
том, чтобы классифицировать каждый RGB пиксел изображения и определить,
принадлежит он выделенному «среднему» цветовому классу или нет. Чтобы вы-
полнять такое сопоставление, необходимо иметь некоторую меру сходства цветов.
Простейшей такой мерой может служить евклидово расстояние. Пусть z — про-
извольная точка пространства RGB. Мы скажем, что точка z схожа по цвету с
т, если расстояние между этими точками не превосходит некоторого порогового
значения Т. Евклидово расстояние между гит вычисляется по формуле1
D(z, m) = ||z — m|| = [(z — m)T(z — m)]1/2 =
= [(zr - mR)2 + (zG - mG)2 + (zB - mB)2]1/2,
где || || обозначает норму аргумента, а нижние индексы R, G и В используются
для обозначения RGB компонентов векторов гит. Геометрическое место точек,
для которых D(z, m) Т является шаром радиуса Т, который изображен на
рис. 6.26, а) (стр. 235). По определению, точки, лежащие внутри шара или на
его сферической поверхности, удовлетворяют заданному цветовому критерию,
1 Следуя общепринятым правилам, мы используем верхний индекс Т для обозначения операции
транспонирования матриц и векторов, а вне индексных полей буква Т обозначает пороговую
величину. При некоторой аккуратности такое совмещение обозначений не должно приводить к
ошибкам.
6.6. Обработка в векторном пространстве RGB напрямую 251 .
а точки, лежащие вне этого шара и его граничной сферы — не удовлетворяют.
Если присваивать двум соответствующим множествам изображения значения,
скажем, 1 (белое) и 0 (черное), то получится двоичное изображение, которое
является результатом сегментации изображения.
Полезным обобщением евклидова расстояния является расстояние, задавае-
мое выражением
£)(z, m) = [(z — m)TC-1(z — m)]1/2,
где С — это ковариационная матрица2 репрезентативной выборки векторов по от-
ношению к цвету, который необходимо сегментировать. Это расстояние принято
называть расстоянием Махаланобиса3. Геометрическое место точек, для кото-
рых D(z, m) Т представляет собой трехмерный эллипсоид (см. рис. 6.26, б),
который имеет следующее важное свойство: направления его главных осей сов-
падают с направлениями наибольшего разброса данных выборки. Если ковариа-
ционная матрица С является единичной, то расстояние Махаланобиса совпадает
с обычным евклидовым расстоянием. Процедура сегментации делается так же,
как описано в предыдущем абзаце, только данные теперь окружаются не шаром,
а эллипсоидом.
Сегментация по описанным выше правилам реализована в IPT функцией
colorseg (см. ее код в приложении В), которая имеет синтаксис
S = colorseg(method, f, Т, parameters),
где method — это или ’euclidean.’, или ’mahalanobis’, f — разделяемое RGB
изображение, а Т — пороговое значение, о котором говорилось выше. Входные
параметры — это либо вектор ш, если method = ’euclidean’, либо m и С, если
method = ’mahalanobis’ Здесь m — это в точности вектор ш, введенный выше,
который может быть вектором-строкой или вектором-столбцом, а С обозначает
ковариационную матрицу 3x3. Выходом функции служит двоичное изображение
S, размеры которого совпадают с размерами исходного изображения. В изобра-
жении S нули стоят там, где пороговый критерий нарушается, а единицы — на
тех местах, где этот критерий выполняется. Единицы определяют область, сег-
ментированную по заданному цветовому признаку.
Пример 6.11. Сегментация цветного RGB изображения.
На рис. 6.27, а) (стр. 235) приведено псевдоцветное изображение некоторой об-
ласти на поверхности спутника Юпитера Ио. На этом изображении красноватые
цвета выдают новые геологические образования, исторгнутые из недр действу-
ющего вулкана, которые окружены более древними осадочными сульфидными
породами. В этом примере иллюстрируется выделение красноватой области с
помощью обоих методов, заложенных в функцию colorseg.
Сначала необходимо получить репрезентативную выборку диапазона цветов,
по которым мы будем делать сегментацию. Простой способ выделения интере-
сующей области ROI (Region Of Interest) заключается в использовании функ-
2 Вычисление ковариационной матрицы по заданному множеству векторов детально рассмат-
ривается в § 11.5.
3В § 12.2 рассматриваются эффективные методы вычисления расстояний Евклида и Махаланобиса.
252 Глава 6. Обработка цветных изображений
ции roipoly, которая вводилась в § 5.2.4. Эта функция выдает двоичную мас-
ку многоугольной области, вершины которой выбираются в интерактивном ре-
жиме. Пусть f обозначает цветное изображение на рис. 6.27, а), а область на
рис. 6.27, б) была построена с помощью следующих команд:
> > mask = roipoly(f) ; 7. Select region interactively.
> > red = immultiply(mask, f(:, 1));
> > green = immultiply(mask, f(: 2));
> > blue = immultiply(mask, f(:, 3));
> > g = cat(3, red, green, blue);
> > figure, imshow(g),
где mask — это двоичное изображение (с теми же размерами, что и у f), в ко-
тором нули стоят на месте фона, а единицы соответствуют области, выбранной
интерактивно.
Теперь можно вычислять «средний» вектор и ковариационную матрицу точек
области ROI, но сначала необходимо получить координаты точек ROI.
» [М, N, К] = size(g);
» I = reshape(g, M*N, 3); X reshape is discussed in Sec.8.2.2.
> > idx = find (mask);
> > I = double(I(idx, 1:3);
> > [C, m] covmatrix(I) ; % See Sec.11.5 for details on covmatrix.
Команда во второй строке организует цветные пикселы g в виде строк матрицы
I, а третья команда находит индексы строк, где расположены не черные пикселы.
Это будут все пикселы интересующей нас области ROI на рис. 6.27, б).
В конце предварительных вычислений необходимо установить величину по-
рога Т Правильным решением будет присвоение Т значения, кратного стандарт-
ному отклонению одной из цветовых компонент. На главной диагонали матрицы
С расположены дисперсии RGB компонент, поэтому нам осталось лишь выбрать
эти элементы и извлечь из них квадратные корни:4
> > d = diag(C) ;
» sd sqrt(d)’
22.0643 24.2442 16.1806
Элементами вектора sd являются стандартные отклонения красной, зеленой и
синей компонент ROI.
Теперь приступим к сегментации изображения с использованием порогов Т,
равных кратным 25, поскольку это число приблизительно равно наибольшему
стандартному отклонению: Т = 25, 50, 75, 100. Выберем опцию ’euclidean’ и
положим Т = 25. Команда
> > Е25 = colorseg(’euclidean’, f, 25, m);
даст результат, показанный на рис. 6.28, а) (стр. 235), а на рис. 6.28 с б) по г)
даны результаты с порогом Т = 50, 75, 100. Аналогично рис. 6.29 (стр. 236) с а)
4Функция d = diag(C) возвращает вектор d, состоящий из элементов главной диагонали мат-
рицы С.
по г) представляет результаты, полученные с опцией ’mahalanobis’, при тех же
пороговых значениях.
Осмысленные результаты [зависящие от нашего выбора красноватой области
ROI на рис. 6.27, а)] получаются с опцией ’euclidean’ при Т = 25 и 50, а при
Т = 75 и 100 мы имеем явно лишние данные. С другой стороны, результаты
для опции ’mahalanobis’ демонстрируют большую надежность при росте по-
рога Т Это объясняется тем, что распределение трехмерных цветных данных в
ROI лучше отслеживается эллипсоидом, чем шаром. Заметьте, что для обоих ме-
тодов при увеличении Т проявляются слабые следы красноватых тонов, которые
включаются в выделяемую область, что вполне объяснимо. □
Выводы
Материал этой главы является введением в базовые концепции, которые исполь-
зуются при обработке цветных изображений, а также описанием реализации этих
концепций средствами MATLAB, IPT и некоторыми новыми разработанными
функциями. Область цветных моделей сама по себя является очень широкой и
может служить предметом рассмотрения отдельной книги. Изученные нами мо-
дели были отобраны по причине их полезности при решении различных задач
обработки изображений, и они могут служить прочным фундаментом для даль-
нейшего углубленного изучения этой сферы цифровых технологий.
Методы обработки псевдоцветных и полноцветных изображений, совершае-
мые на отдельных цветовых плоскостях, тесно связаны с техникой обращения
с монохромными изображениями, которая представлена в предыдущих главах.
Материал по векторной обработке отходит от подходов, изложенных в тех главах,
и обнаруживает определенные принципиальные различия между монохромными
и полноцветными изображениями и методами их обработке. В последнем пара-
графе этой главы рассмотрены некоторые векторные методы обработки полно-
цветных изображений, которые являются весьма характерными в этой области,
и к ним можно добавить медианную и другие порядковые фильтрации, адап-
тивную и морфологическую фильтрации, восстановление изображений, сжатие
изображений и многие другие методы обработки цветных изображений.
ГЛАВА 7
ВЕЙВЛЕТЫ
Введение
Если цифровые изображения необходимо обозревать или обрабатывать при раз-
личных увеличениях и разрешениях, то для этих целей чрезвычайно удобно
использовать дискретное вейвлетное преобразование DWT (Discrete Wawelet
Transform). Помимо того, что вейвлетное преобразование, будучи весьма эффек-
тивным и интуитивно понятным инструментом для представления и хранения
кратномасштабных1 изображений, оно обеспечивает глубокое проникновение к
основным пространственным и частотным характеристикам изображений. Отме-
тим, что обычное преобразование Фурье выявляет лишь информацию о частот-
ных характеристиках изображений.
В этой главе будут рассматриваться как вычислительные, так и пользователь-
ские аспекты дискретного вейвлетного преобразования. Мы будем изучать пакет
Wavelet Toolbox, набор функций MathWork, разработанный для выполнения вей-
влетного анализа, но не включенный в пакет Image Processing Toolbox (IPT) сис-
темы MATLAB. Кроме того, мы напишем ряд новых дополнительных программ,
которые позволят выполнять обработку изображений на основе вейвлетов с ис-
пользованием лишь функций из пакета IPT, т. е. без привлечения пакета Wavelet
Toolbox. Эти новые функции в сочетании с функциями IPT обеспечат полный ар-
сенал инструментов, необходимый для практической реализации всех концепций,
обсуждающихся в гл. 7 книги [Gonzalez, Woods, 2002]. Они применяются почти
так же и с тем же диапазоном возможностей, что и функции f ft2 и if ft2 для
совершения преобразования Фурье, изученные в гл. 2 настоящей книги.
7.1. Некоторые основы
Рассмотрим изображение f(x,y) размерами MxN, прямое дискретное преобра-
зование Т(и, v,...) которого можно выразить в общем виде следующим уравне-
нием:
T(u,v,...) = 52/(3;,y)ffu,^...(T,y),
х,у
где х и у — это пространственные переменные, а и, и,... — переменные в преобра-
зованной области. Зная Т(и, и,...), функцию f(x, у) можно построить с помощью
1В русскоязычной литературе принято переводить английский термин multiTesolution (кратная
или множественная разрешимость) словом кратномасштабностъ. Следует иметь ввиду, что
разные масштабы (разрешения) связаны между собой: они являются кратными друг друга,
причем соответствующий множитель обычно является степенью числа 2.
7.1. Некоторые основы
обобщенного обратного дискретного преобразования
Члены gu,v,...(x, у) и hu^^fx, у) в этих уравнениях называются прямым и обрат-
ным ядрами преобразования. Ядра полностью определяют природу, вычисли-
тельную сложность и реальную практическую пользу этой пары преобразований.
Коэффициенты преобразования Т(и, и,...) можно представлять себе в виде коэф-
фициентов разложения функции f в ряд по {hUiV> . (т, у)}. Значит, ядро обратного
преобразования определяет множество функций разложения для разложения в
ряды функций f.
Дискретное преобразование Фурье DFT, рассмотренное в гл. 4, хорошо впи-
сывается в эту схему разложения в ряды1 В этом случае
huA^y)=9*u,^y> = --^=e^^M+^N\
где j = у/—1, * обозначает оператор комплексного сопряжения, и = 0,1,..., 7И— 1
ин = 0,1,...,М — 1. Переменные в преобразованной области и и и представляют,
соответственно, горизонтальные и вертикальные частоты. Ядра являются разде-
лимыми, т. е.
h>u,v (•£, у) — (у),
где
/^(т) = -^=е^™х/м и hv(y) = -XeJ2^/^)
и ортогональнъьми, т. е.
= = рда--=«.
' [0,иначе,
где (•, •) обозначает операцию скалярного произведения. Разделимость ядер упро-
щает вычисление двумерных преобразований, поскольку позволяет выполнять
соответствующие одномерные преобразования по строкам и по столбцам; орто-
гональность означает, что ядра прямого и обратного преобразования являются
комплексно сопряженными друг к другу (в частности, они совпадают, если яв-
ляются чисто вещественными).
В отличие от преобразования Фурье, полностью определяемом парой простых
явных уравнений, и в котором все крутится вокруг описанных выше двух ядер,
термин дискретное вейвлетное преобразование обозначает целый класс преобра-
зований, которые различаются не только своими ядрами (а значит, и используе-
мыми функциями разложения), но и самой природой этих функций (например,
будут ли они образовывать ортогональный или биортогональный базис), а также
тем способом, как их следует применять (например, сколько различных разреше-
ний требуется вычислять). Поскольку DWT включают множество родственных,
1При задании преобразования DFT в гл. 4 в уравнение для обратного преобразования Фурье
помещался множитель 1/MN. Этот член можно также поместить только в уравнение прямо-
го преобразования Фурье, или разделить, как это сделано здесь, между прямым и обратным
преобразованиями в виде множителя 1/y/MN.
256 Глава 7. Вейвлеты
-ИЖ- ________________
Рис. 7.1. а) Семейство функций разложе-
ния Фурье является синусоидами с перемен-
ной частотой и с бесконечной длительно-
стью. б) Функции разложения DWT пред-
ставляют собой «маленькие волны» с пере-
менной частотой и с конечной длительно-
стью
но различных преобразований, мы не мо-
жем выписать одно уравнение, которое
полностью задало бы все эти преобра-
зования. Вместо этого мы можем оха-
рактеризовать каждое DWT с помощью
ядра преобразования или основываясь
на множестве параметров, которые од-
нозначно определяют пару ядер. Все эти
преобразования являются «родственны-
ми» в том смысле, что их функции раз-
ложения представляют собой «малень-
кие волны» или «вейвлеты» (от англий-
ского слова wavelet), которые имеют пе-
ременную частоту колебаний и ограни-
ченную длительность (см. рис. 7.1, б)).
Далее в этой главе мы введем множе-
ство ядер этих самых «маленьких волн».
Каждое из них будет иметь следующие
общие свойства.
Свойство 1: Разделимость, масштабируемость и переносимость. Ядра можно
представить в виде трех разделимых двумерных вейвлетов
фН(х,у) = ф(х)<р(у), ipV(x,y) = <^(т)^(у), ^D(x,y) = ф(х')ф(у'),
где (х,у) и фв(х, у) называются горизонтальным, вертикальным и
диагональным вейвлетами, а двумерная функция
99(2:, у) = <^(т)<^(у)
называется масшлгшбирующей функцией. Каждая из этих двумерных функций
является произведением двух одномерных интегрируемых в квадрате масштаби-
рующих вейвлетных функций
- k), ф^х) = 2j/2ip(2jx - k).
Параметры j и k являются целыми числами. Трансляция к определяет место-
положение этих одномерных функций на оси х, масштаб j задает их ширину,
т. е. насколько они широки или узки вдоль оси х, а множитель 2J/2 контролирует
их высоту или амплитуду. Заметим, что ассоциированные функции разложения
являются масштабированными по степени числа 2 и сдвинутыми на целые интер-
валы функциями, которые получаются из материнского вейвлета ?Дт) = tpo.o(x)
и из материнской масштабирующей функции <р(х) = <^о,о(^)-
Свойство 2: Кратномасштабная совместимость. Только что введенная мас-
штабирующая функция должна удовлетворять следующему требованию кратно-
масштабного анализа:
(а) каждая функция ^^(т) ортогональна любому своему целочисленному сдвигу
'1.2. Быстрое вейвлетное преобразование
(б) Множество функций, которые можно представить в виде рядов разложения
по <pj k(x) при малых масштабах или разрешения (т. е., когда j мало), при-
надлежит множеству функций, представимых в более высоких масштабах.
(в) Имеется единственная функция, которую можно представить во всех мас-
штабах, которая ес'ь тождественный нуль.
(г) Каждую суммируемую функцию можно представить с произвольной точ-
ностью при j —► оо.
Если выполнены все эти свойства, то существует парный вейвлет ipfx), кото-
рый вместе со всеми своими целочисленными сдвигами и масштабными преобра-
зованиями по всем степеням 2 охватывает (представляет в виде ряда) разность
между любыми двумя множествами функций, представимыми с помощью раз-
ложений по <pj,k(x) соседними масштабами j и j + 1.
Свойство 3: Ортогональность. Функции разложения {^^(т)} образуют орто-
гональный или биортогональный базис в пространстве одномерных измеримых,
суммируемых в квадрате функций. Базис обладает тем свойством, что каждая
представимая в этом базисе функция имеет единственный набор коэффициентов
разложения. Как уже отмечалось в этом параграфе, для вещественных ортого-
нальных ядер имеем равенство gu,v,... — hu,v,.... В биортогональном случае
(/гг,Зз)=<5™=П’ПрИГ=5’
rs (0, иначе,
и д называется двойственным ядром к h. Для биортогональных вейвлетных пре-
образований с масштабирующими функциями <pjk(x) и вейвлетами V'j.fcfa) двой-
ственные к ним функции обозначаются <Pj,h(x) и Дг.ДД-
7.2. Быстрое вейвлетное преобразование
Важным следствием из описанных выше свойств является возможность представ-
ления обеих функций <р(х) и ф(х) в виде линейной комбинации своих же копий
в масштабе с удвоенным разрешением, т. е. имеют место следующие разложения
в ряды:
99(2:) = hv(n)y/2<p(2x — п) ^(х) = Ьф(п)у/2ф(2х — п),
п п
где hv(n) и h^(n) — это коэффициенты разложения, которые принято называть,
соответственно, масштабным и вейвлетным векторами. Они являются коэффи-
циентами фильтрации при совершении быстрого вейвлетного преобразования
FWT (Fast Wavelet Transform). Итеративная процедура вычисления FWT по-
казана на рис. 7.2 в виде блок-схемы. На этом рисунке Wv(j, т, п) и {WJ,(j, т, п.)
при i = H,V,D} являются коэффициентами DWT с масштабом j. Блоки, со-
держащие перевернутые во времени масштабный и вейвлетный векторы ЕД—п)
и ЕД—т), представляют собой, соответственно, низкочастотный и высокоча-
стотный фильтры декомпозиции. Блоки, содержащие 2 со стрелкой |, осуществ-
Глава 7. Вейвлеты
ляют прореживающую выборку, т. е. они выбирают каждый второй элемент по-
следовательности. Математически последовательность шагов фильтрации и про-
реживания, используемых в этих вычислениях, можно записать в виде следую-
щей формулы, например, для вычисления т, п):
(j> т> П) = * [М-П) * + i, «)|n=2fe,fe>o]|m=2fe,fe>O,
где * обозначает операцию свертки. Вычисление свертки для отрицательных
нечетных индексов эквивалентно фильтрации и прореживанию с шагом 2.
Яф(/+7. т, п)
Рис. 7.2. Блок фильтров двумерного преобразования FWT. Каждый проход порождает
один масштаб DWT. При первой итерации Wv(j + 1, т, п) = f(x, у)
Каждый проход через блок фильтров на рис. 7.2 разлагает входные дан-
ные на четыре компоненты меньшего диапазона (или масштаба). Коэффициенты
получаются двумя проходами низкочастотной фильтрации (т. е. с фильтром
hv), и поэтому они называются коэффициентами приближения; коэффициенты
{И^, при г — Н, V, .О} называются, соответственно, коэффициентами горизон-
тальных, вертикальных и диагональных деталей. Поскольку само изображе-
ние f(x,y) представлено в наивысшем разрешении, то оно становится входом
ГРДу +1,тп, п) первой итерации процедуры. Обратите внимание на то, что в опе-
рациях на блок-схемы рис. 7.2 не используются ни вейвлетная, ни масштабная
функции, а только лишь ассоциированные с ними вейвлетный и масштабный век-
торы. Кроме того, здесь имеется три переменные преобразованного пространства:
масштаб j, горизонтальная трансляция п и вертикальная трансляция т. Эти пе-
ременные соответствуют обозначениям и, и,... в первых двух уравнениях § 7.1.
7.2.1. Преобразования FWT в пакете Wavelet Toolbox
В этом параграфе мы используем функции из пакета Wavelet Toolbox для вы-
числения преобразований FWT простого тестового изображения размера 4x4.
В следующем параграфе мы разработаем свою собственную функцию для вы-
полнения этих преобразований, не прибегая к Wavelet Toolbox (используя лишь
пакет IPT). Материал этого параграфа послужит основой для написания нужной
функции.
Пакет Wavelet Toolbox строит фильтры декомпозиции для широкого клас-
са быстрых вейвлетных преобразований. Доступ к фильтрам, осуществляющим
специфические вейвлетные преобразования, обеспечивается функцией wf ilters,
которая имеет следующий синтаксис:
[Lo_D, Hi_D, Lo_R, Hi_R] = wfilters(wname).
Здесь входной параметр wname определяет возвращаемые коэффициенты фильт-
ра в соответствии с табл. 7.1; выходные данные Lo_D, Hi_D, Lo_R и Hi_R являются
вектор-строками, в которых записаны коэффициенты фильтров, осуществляю-
щих, соответственно, высокочастотную декомпозицию, низкочастотную деком-
позицию, высокочастотную реконструкцию и низкочастотную реконструкцию.
(Фильтры реконструкции будут обсуждаться в § 7.4.) Соответствующие пары
фильтров можно также построить командой
[Fl, F2] wfilters(wname, type),
где переменная type принимает значения ’d’, ’г’, ’1’ или ’h’, что позволяет
получить пару фильтров декомпозиции, реконструкции, а также пару низкоча-
стотных и высокочастотных фильтров соответственно. При такой форме синтак-
сиса фильтр декомпозиции или низкочастотный фильтр записываются в пере-
менную F1, а их парные фильтры помещаются в F2.
Таблица 7.1. Фильтры FWT из пакета Wavelet Toolbox и имена семейств фильтров
Wavelet wfamily wname
Haar ’haar’ ’haar’
Daubechies db’ ’db2’, ’db3’,..., Jdb45’
Coiflets ’coif’ ’coifl’, ’coif2’,... ’coif5’
Symlets ’sym’ ’sym2’, ’sym3’,... ’sym45’
Discrete Meyer ’dmey’ ’dmey’
Biorthogonal ’bior’ ’biorl.l’, ’biorl.3’, ’biorl.5’, ’bior2.2’, ’bior2.4’, ’bior2.6’)
’bior2.8’, ’ЫогЗ.!’, ’bior3.3’, ’bior3.5’, ’bior3.7’, ’bior3.9’,
’bior4.4’, ’bior5.5’, ’bior6.8’
’rbio’ ’rbiorl.l’, ’rbiorl.3’, ’rbiorl.5’, ’rbior2.2’, ’rbior2.4’.
’rbior2.6*, ’rbior2.8’, ’rbior3.1', ’rbior3.3’, ’rbior3.5’,
’rbior3.7’, ’rbior3.9’, ’rbior4.4’j ’rbior5.5’, ’rbior6.8’
В табл. 7.1 перечислены все FWT фильтры, имеющиеся в Wavelet Toolbox
Свойства этих фильтров, а также другую полезную информацию относительно
их масштабирующих и вейвлетных функций можно узнать из многих книг по
цифровой фильтрации и по кратномасштабному анализу. Некоторые основные
свойства можно узнать из функций waveinfo и wavefun в самом пакете Wavelet
Toolbox. Чтобы получить описание семейства вейвлетов wfamily (см. табл. 7.1)
в окне команд MATLAB, следует набрать на клавиатуре
waveinfo(wfamily).
Чтобы получить численную аппроксимацию ортонормальных масштабирующих
и/или вейвлетных функций, воспользуйтесь командой
[phi, psi, xval] = wavefun(wname, iter),
260 Глава 7. Вейвлеты
которая выдаст аппроксимирующие векторы phi и psi, а также оценивающий
вектор xval. Целый положительный параметр iter контролирует точность при-
ближений, определяя число итераций, используемых при вычислениях этих век-
торов. Для биортогональных преобразований синтаксис имеет вид
[phil, psil, phi2, psi2, xval] wavefun(wname, iter),
где phil и psil — это функции декомпозиции, a phi2 и psi2 — функции рекон-
струкции.
Пример 7.1. Фильтры, масштабирующая и вейвлетная функции Хаара.
Самое известное и простое вейвлетное преобразование основано на масштабиру-
ющей и вейвлетной функциях Хаара. Фильтры декомпозиции и реконструкции
преобразования Хаара имеют длину 2, и их можно получить следующими командами:
>> [Lo_D, Hi_D, Lo_R, Hi_R] wfilters(’haar’)
Lo_D
0.7071 0.7071
Hi_D
-0.7071 0.7071
Lo_R =
0.7071 0.7071
Hi_R =
0.7071 -0.7071
Узнать ключевые свойства и построить графики масштабирующей и вейвлет-
ной функций этого преобразования можно с помощью команд:
>> waveinfo (’haar’ ) ;
HAARINFO Information on Haar wavelet.
Haar Wavelet
General characteristics: Compactly supported
wavelet, the oldest and the simplest wavelet.
scaling function phi 1 on [0 1] and 0
otherwise.
wavelet function psi 1 on [0 0.5] , -1
on [0.5 1] and 0 otherwise.
Family Haar
Short name haar
Examples haar is the same as dbl
Orthogonal' yes
Biorthogonal yes
Compact support yes
DWT possible
CWT possible
Support width 1
Filters length 2
Regularity haar is not continuous
7.2. Быстрое вейвлетное преобразование
Symmetry yes
Number of vanishing
moments for psi 1
Reference: I.Daubechies,
Ten lectures on wavelets,
CBMS, SIAM, 61, 1994, 194-202.
>> [phi, psi, xval] = wavefun(’haar’,
> > xaxis zeros(size(xval));
> > subplot(121); plot(xval, phi, ’k’,
>> axis([0 1 -1.5 1.5]); axis square;
>> title(’Haar Scaling Function’);
> > subplot(122); plot(xval, psi, ’k’,
>> axis([0 1 -1.5 1.5]); axis square;
>> title(’Haar Wavelet Function’);
10);
xval, xaxis, --k’);
xval, xaxis, ’--k’);
На рис. 7.3 приведен результат команд в последних шести строках. Функции
title, axis и plot описаны в гл. 2 и 3. Функция subplot используется для пред-
ставления окна графика в виде матрицы подграфиков, в которых можно строить
разные графики. Она имеет общий синтаксис
Н = subplot(m, п, р) или Н = subplot (mnp),
где тип — число строк и столбцов матрицы подокон. Оба числа тип должны
быть не меньше 1. Необязательный параметр Н является манипулятором под-
графика, выбираемого параметром р, который начинается с 1 (самый верхний
левый подграфик), а при увеличении на 1 обозначает следующий подграфик в
первой строке и т. д. до ее конца, потом первый подграфик во второй строке
и т. д. Таким образом, обращение subplot (122) из предыдущей последователь-
ности команд соответствует подграфику, расположенному в первой строке и во
втором столбце матрицы подграфиков 1x2, в котором и будет выполняться ко-
манда plot. Следующие за ней команды axis и title будут выполняться только
в этом подокне.
Рис. 7.3. Масштабирующая
и вейвлетная функции Хаара
Масштабирующая функция Хаара
Вейвлетная функция Хаара
Масштабирующая и вейвлетная функции Хаара, показанные на рис. 7.3, явля-
ются разрывными и имеют компактный носитель. Последнее свойство означает,
262 Глава 7. Вейвлеты
что они равны нулю вне некоторого конечного отрезка оси х, который называется
носителем. Для функций Хаара носителем служит отрезок [0,1]. Помимо всего
прочего, функция wave inf о сообщает, что функции разложения Хаара являют-
ся ортогональными, поэтому ядра прямого и обратного преобразования Хаара
совпадают. □
Имея фильтры декомпозиции, образованные функцией wf liters или получен-
ные иным путем, пользователь может легко вычислять соответствующее вейвлет-
ное преобразование с помощью функции wavedec2 из пакета Wavelet Toolbox.
Она вызывается командой
[С, S] wavedec2(X, N, Lo_D, Hi_D),
где X это изображение или матрица, N — число масштабов, которые следует
вычислить (т. е. количество проходов через блок фильтра DWT на рис. 7.2), а
Lo_D и Hi_D обозначают фильтры декомпозиции. Следующая форма обращения
к этой функции является немного более эффективной:
[С, S] wavedec2(X, N, wname),
в которой wname обозначает название фильтра из табл. 7.1. Выходные данные
оформлены в виде структуры [С, S], состоящей из вектора-строки С (класса
doble), в который записываются коэффициенты вычисленного вейвлетного пре-
образования входного изображения, и из вспомогательной управляющей матри-
цы S (также класса doble), которая определяет организацию коэффициентов век-
тора С. Связь между С и S станет понятной после изучения следующего примера,
а более подробная информация дается в § 7.3.
Пример 7.2. Простое преобразование DWT с помощью фильтров Хаара.
Рассмотрим одномасштабное вейвлетное преобразование Хаара:
>> f = magic(4)
f =
16 2 3 13
5 11 10 8
9 7 6 12
4 14 15 1
>> [cl, si] = wavedec2(f, 1, ’haar’)
cl =
Columns 1 through 9
17.0000 17.0000 17.0000 17.0000 1.0000
-1.0000 -1.0000 1.0000 4.0000
Columns 10 through 16
-4.0000 -4.0000 4.0000 10.0000 6.0000
-6.0000 -10.0000
si
2 2
2 2
4 4
1.2. Быстрое, вейвлетное
Здесь магический квадрат f размерами 4x4 преобразуется в вектор вейвлет-
ной декомпозиции cl размерами 1x16 с образованием управляющей матрицы
si размерами 3x2. Вейвлетное преобразование вычисляется за одну итерацию
(с использованием входа f) с помощью операций, изложенных в § 7.2. При этом
образуется четыре выходные матрицы размерами 2x2, а именно: одно прорежен-
ное приближение и три направленные (горизонтальная, вертикальная и диаго-
нальная) матрицы деталей. Точнее, с cl(l) по с1(4) записаны коэффициенты
приближения Wv(l, 0, 0), Wv(l, 1, 0), Wv(l, 0,1) и Wv(l, 1,1) из рис. 7.2, причем
исходный масштаб изображения f взяли равным 2; элементы с cl(5) по с1(8)
совпадают с коэффициентами W^(l, 0,0), W^(l, 1,0), W^(l, 0,1) и W®(1,1,1).
Например, матрица горизонтальных деталей равна
w¥ =
* * ф
1 -1,
-1 1.
В управляющей матрице si записаны размеры вычисленных матриц, которые
столбец за столбцом помещены в вектор cl плюс размер исходного изображе-
ния f [записанный в векторе sl(end, :)]. Векторы sl(l, :) и sl(2, :) содер-
жат, соответственно, размеры матрицы приближения и трех матриц деталей.
В первом элементе каждого из этих векторов записано число строк матрицы
приближения или матрицы деталей, а второй элемент число столбцов этих
матрицы.
Чтобы построить следующий, нулевой масштаб, необходимо выполнить ко-
манду
>> [с2, s2] wavedec2(f, 2, ’haar’)
cl
Columns 1 through 9
34.0000 0 -1.0000 -1.0000 0 1.0000 0.0000 4.0000 1.0000
Columns 10 through 16 -4.0000 -4.0000 4.0000 10.0000 6.0000
-6.0000 -10.0000
1 1
1 1
2 2
4 4
Заметьте, что c2(5:16) cl (5:16). Элементы cl (1:4), которые являются ко-
эффициентами приближения преобразования первого масштаба, были помещены
во вход блока фильтров рис. 7.2, что породило четыре выхода размерами 1x1:
Wv(0,0,0), (0,0,0), (0,0,0) и W? (0,0,0). Эти выходы были присоединены
по столбцам (они являются здесь матрицами 1x1) в том же порядке, что и при
вычислении первого масштаба, и подставлены на место коэффициентов прибли-
жения, по которым они вычислялись. Управляющая матрица s2 была обновлена,
чтобы в ней отражался тот факт, что единственная матрица приближения 2x2
в cl была заменена четырьмя матрицами 1x1: матрицей приближения и тремя
264 Глава 7. Вейвлеты
матрицами деталей в с2. Итак, s2(end, :) — опять размер исходного изображе-
ния, s2(3, :) — размер трех матриц деталей масштаба 1, s2(2, :) — размер
трех матриц деталей масштаба 0, a s2(l, :) — размер конечной матрицы при-
ближения. □
В заключение этого параграфа стоит заметить, что поскольку преобразова-
ния DWT основаны на технике цифровой фильтрации и свертки, на выходе
преобразования могут проявиться граничные искажения. Чтобы минимизиро-
вать эти артефакты, границы изображений следует обрабатывать отдельно от
остальных его частей. Если элементы фильтра выходят за пределы изображе-
ния в процессе свертки, необходимо присваивать некоторые значения областям,
лежащим вне обрабатываемого изображения. Многие функции пакета Wavelet
Toolbox осуществляют это расширение изображений с помощью глобального па-
раметра dwtmode. Чтобы узнать текущую моду расширения, наберите команду
dwtmode (’ status ’) или просто dwtmode после системного приглашения MATLAB
(т. е., >> dwtmode). Чтобы иметь текущую моду STATUS, выполните команду
dwtmode(STATUS). Поддерживаемые моды расширения и соответствующие зна-
чения переменной STATUS перечислены в табл. 7.2.
Таблица 7.2. Моды пакета Wavelet Toolbox для расширения изображений
STATUS Описание
’sym’ Изображение расширяется симметричным отражением относительно гра- ниц. Мода по умолчанию.
’zpd’ Изображение расширяется сплошными нулями.
’spd’, ’spl’ Изображение расширяется экстраполяцией первой производной или ли- нейным продолжением значений двух самых дальних границ.
>spO’ Изображение расширяется экстраполяпией граничных значений, т. е. их повторением.
>ppd> Изображение расширяется периодическим способом.
’per’ Изображение расширяется периодическим способом, после того, как оно будет (при необходимости) расширено до нечетного размера с помощью моды ’spO’
7.2.2. Преобразования FWT без использования
Wavelet Toolbox
В этом параграфе мы построим две функции wavefilter и wavefast, которые
смогут заменить функции wfilter и wavedec2 из пакета Wavelet Toolbox, рас-
смотренные в предыдущем параграфе. Наша цель состоит также в дополнитель-
ном рассмотрении алгоритма вычисления DWT, а также в разработке отдельного
пакета для обработки изображений на базе вейвлетного анализа без привлечения
пакета Wavelet Toolbox. Эта программа будет завершена в §§ 7.3 и 7.4, и полный
набор функций будет задействован в примерах § 7.5.
Прежде всего, необходимо написать функцию для построения фильтров вей-
влетной декомпозиции и реконструкции. Следующая функция, которую мы назо-
вем wavefilter, использует стандартную конструкцию switch вместе с операто-
рами сазе и otherwise и совершает эти действия. Несмотря на то, что функция
wavefilter строит фильтры, разобранные в гл. 7 и 8 книги [Gonzalez, Woods, 2002],
7.2. Быстрое вейвлетное преобразование 265
другие вейвлетные фильтры декомпозиции и реконструкции могут быть легко
добавлены (с помощью новых операторов case) к нашей функции. Описание эти
вейвлетов можно найти в разных книгах по кратномасштабному анализу.
function [varargout] = wavefilter(wname, type)
XWAVEFILTER Create wavelet decomposition and reconstruction filters.
’/, [VARARGOUT] WAVEFILTER(WNAME, TYPE) returns the decomposition
X and/or reconstruction filters used in the computation of the
'/„ forward and inverse FWT (fast wavelet transform)
7.
X EXAMPLES:
X [Id, hd, Ir, hr] wavefilter(’haar’) Get the low and highpass
X decomposition (Id, hd)
7. and reconstruction
X (Ir, hr) filters for
X wavelet ’haar’
7. [Id, hd] = wavefilter(’haar’
X
7. [Ir, hr] = wavefilter(’haar’
X
X
7. INPUTS:
7. WNAME
X
X ’haar’ or ’dbl’
X ’db4’
X ’sym4’
X ’bior6.8’
X ’jpeg9.7’
X
X TYPE
’d’) Get decomposition filters
Id and hd.
’r’) Get reconstruction
filters Ir and hr.
Wavelet Name
Haar
4th order Daubechies
4th order Symlets
Cohen-Daubechies-Feauveau biorthogonal
Antonini-Barlaud-Mathieu-Daubechies
Filter Type
Decomposition filters
Reconstruction filters
X
X ’d’ Decomposition filters
X ’r’ Reconstruction filters
X
X See also WAVEFAST and WAVEBACK.
X Check the input and output arguments.
error(nargchk(1, 2, nargin));
if (nargin 1 & nargout "= 4) | (nargin 2 & nargout 2)
error(’Invalid number of output arguments.’);
end
2 & nargout 2)
if nargin 1 & "ischar(wname)
error(’WNAME must be a string.’);
end
if nargin == 2 & "ischar(type)
error(’TYPE must be a string.’);
end
266 Глава 7. Вейвлеты
% Create filters for the requested wavelet,
switch lower(wname)
case {’haar’, ’dbl’}
Id = [1 l]/sqrt(2); hd [-1 l]/sqrt(2);
Ir = Id; hr -hd;
case ’db4’
Id = [-1.059740178499728e-002 3.288301166698295e-002
3.084138183598697e-002 -1.870348117188811e-001
-2.798376941698385e-002 6,308807679295904e-001
7.148465705525415e-001 2.303778133088552e-001];
t (0:7);
hd Id; hd(end:-l:l) cos(pi * t) .* Id;
Ir Id; Ir(end:-1:1) Id;
hr cos(pi * t) .* Id;
case ’sym4’
Id = [-7.576571478927333e-002 -2.963552764599851e-002
4.976186676320155e-001 8.037387518059161e-001
2.978577956052774e-001 -9.921954357684722e-002
-1.260396726203783e-002 3.222310060404270e-002];
t (0:7);
hd Id; hd(end:-l:l) cos(pi * t) .* Id;
Ir = Id; Ir(end:-1:1) = Id;
hr = cos(pi * t) .* Id;
case ’bior6.8’
Id = [0 1.908831736481291e-003 -1.914286129088767e-003
-1.699063986760234e-002 1.193456527972926e-002
4.973290349094079e-002 -7.726317316720414e-002
-9.405920349573646e-002 4.207962846098268e-001
8.259229974584023e-001 4.207962846098268e-001
-9.405920349573646e-002 -7.726317316720414e-002
4.973290349094079e-002 1.193456527972926e-002
-1.699063986760234e-002 -1.914286129088767e-003
1.908831736481291e-003];
hd [000 1.442628250562444e-002 -1.446750489679015e-002
-7.872200106262882e-002 4.036797903033992e-002
4.178491091502746e-001 -7.589077294536542e-001
4.178491091502746e-001 4.036797903033992e-002
-7.872200106262882e-002 -1.446750489679015e-002
1.442628250562444e-002 0000];
t (0:17);
Ir = cos(pi * (t + 1)) .* hd;
hr = cos(pi * t) .* Id;
case ’jpeg9.7’
Id = [0 0.02674875741080976 -0.01686411844287495
-0.07822326652898785 0.2668641184428723
0.6029490182363579 0.2668641184428723 ...
-0.07822326652898785 -0.01686411844287495
0.02674875741080976];
hd [0 -0.09127176311424948 0.05754352622849957
0.5912717631142470 -1.115087052456994
0.5912717631142470 0.05754352622849957
-0.09127176311424948 О 0];
(0:9);
t
1г = cos(pi * (t + 1)) .* hd;
hr cos(pi * t) .* Id;
otherwise
error(’Unrecognizable wavelet name (WNAME).’);
end
7, Output the requested filters.
if (nargin == 1)
varargoutd:4) {Id, hd, Ir, hr};
else
switch lower(type(l))
case ’d’
varargout = {Id, hd};
case ’r’
varargout = {lr, hr};
otherwise
error(’Unrecognizable filter TYPE.’);
end
end
Заметим, что для каждого ортонормированного фильтра в wavefilter (т. е.
’haar’, ’db4’ и ’sym4’) фильтр реконструкции получается из фильтра деком-
позиции отражением по времени, а высокочастотный фильтр декомпозиции яв-
ляется модулированной версией своей низкочастотной пары. Следовательно, в
программном коде достаточно дать численные значения лишь коэффициентов
низкочастотного фильтра декомпозиции. Все остальные коэффициенты получа-
ются из этих данных. В функции wavefilter обращение по времени осуществ-
ляется перенумерацией элементов векторов фильтров от последнего к первому
при выполнении команд вида lr(end:-l:l) = Id. Модулирование выполняется
умножением компонент известного фильтра на числа cos(pi*t), которые меня-
ются в интервале от —1 до 1 при возрастании t от 0 на целые шаги. Для каждого
биортогонального фильтра в wavefilter (т.е. ’Ыог6.8’ и ’jbeg9.7’), следует
численно задавать коэффициенты и высокочастотного, и низкочастотного филь-
тров, а фильтры реконструкции получаются из них модулированием. Наконец,
отметим, что все фильтры, генерируемые функцией wavefilter, имеют четную
длину. Кроме того, используется продолжение нулями, чтобы фильтры декомпо-
зиции и реконструкции для каждого вейвлета имели одинаковую длину.
Имея пару фильтров декомпозиции, построенных функцией wavefilter , лег-
ко написать процедуру общего назначения для вычисления соответствующего
268 Глава 7. Вейвлеты
быстрого вейвлетного преобразования. Наша цель состоит в разработке эффек-
тивного алгоритма на основе операций свертки и прореживания, изображенных
на рис. 7.2. Чтобы добиться совместимости с существующим пакетом Wavelet
Toolbox, мы воспользуемся той же структурой результата декомпозиции (т. е.
в виде [С, S], где С это вектор декомпозиции, aS — управляющая матрица).
Следующая программа, которую мы назвали wavefast, использует метод сим-
метричного дополнения изображений при борьбе с граничными искажениями,
возникающими при выполнении FWT:1
function [с, s] wavefast(х, и, varargin)
XWAVEFAST Perform multi-level 2-dimensional fast wavelet transform.
’/. EC, L] WAVEFAST(X, N, LP, HP) performs a 2D N-level FWT of
X image (or matrix) X with respect to decomposition filters LP and
7. HP.
X
7. [C, L] WAVEFAST(X, N, WNAME) performs the same operation but
% fetches filters LP and HP for wavelet WNAME using WAVEFILTER.
7.
7. Scale parameter N must be less than or equal to log2 of the
7. maximum image dimension. Filters LP and HP must be even. To
X reduce border distortion, X is symmetrically extended. That is,
7. if X = [cl c2 c3 cn] (in ID) , then its symmetric extension
7, would be [.. . c3 c2 cl cl c2 c3 cn cn cn-1 cn-2 ...]
X
7. OUTPUTS:
7, Matrix C is a coefficient decomposition vector:
%
X C - [ a(n) h(n) v(n) d(n) h(n-l) v(l) d(l) ]
7.
7. where a, h, v, and d are columnwise vectors containing
X approximation, horizontal, vertical, and diagonal coefficient
X matrices, respectively. C has 3n + 1 sections where n is the
X number of wavelet decompositions.
X
X Matrix S is an (n+2) x 2 bookkeeping matrix:
X
X S = [ sa(n, :); sd(n, :); sd(n-l, :); sd(l, :); sx ]
X
X where sa and sd are approximation and detail size entries.
X
% See also WAVEBACK and WAVEFILTER.
X Check the input arguments for reasonableness.
error(nargchk(3, 4, nargin));
if nargin == 3
1Функция rem(X, Y) возвращает остаток от деления X на Y. Функция С = conv2(A, В) совер-
шает двумерную свертку матриц А и В.
7.2. Быстрое вейвлетное преобразование 269
if ischar(varargin{l}-)
[Ip, bp] = wavefilter(varargin{l}, ’d’);
else
error(’Missing wavelet name.’);
end
else
Ip = varargin{l}; bp = varargin{2};
end
fl length(lp); sx = size(x);
if (ndims(x) "= 2) | (min(sx) < 2) | ~isreal(x) | "isnumeric(x)
error(’X must be a real, numeric matrix.’);
end
if (ndims(lp) "= 2) | "isreal(lp) | "isnumeric(Ip)
| (ndims(hp) "= 2) | "isreal(hp) | "isnumeric(bp)
| (fl "= length(hp)) | rem(fl, 2) 0
error([’LP and HP must be even and equal length real,
’numeric filter vectors.’]);
end
if "isreal(n) | "isnumeric(n) | (n < 1) | (n > log2(max(sx)))
error([’N must be a real scalar between 1 and ’
’log2(max(size((X))).’]);
end
7, Init the starting output data structures and initial approximation,
c = []; s = sx; app = double(x);
7. For each decomposition
for i = 1:n
7. Extend the approximation symmetrically.
[app, keep] = symextend(app, fl);
7. Convolve rows with HP and downsample. Then convolve columns
7. with HP and LP to get the diagonal and vertical coefficients.
rows = symconv(app, hp, ’row’, fl, keep);
coefs = symconv(rows, hp, ’col’, fl, keep);
c = [coefs(:)’ c]; s [size(coefs); s];
coefs = symconv(rows, Ip, ’col’, fl, keep);
c = [coefs(:) ’ c];
% Convolve rows with LP and downsample. Then convolve columns
7. with HP and LP to get the horizontal and next approximation
7. coefficients.
rows = symconv(app, Ip, ’row’, fl, keep);
coefs symconv(rows, hp, ’col’, fl, keep);
c [coefs(:)’ c];
app = symconv(rows, Ip, ’col’, fl, keep);
end
7. Append final approximation structures,
c = [app(:)’ c]; s = [size(app); s];
%------------------------------------------------------------%
270 Глава 7. Вейвлеты
function [у, keep] = symextend(x, fl)
% Compute the number of coefficients to keep after convolution
% and downsampling. Then extend x in both dimensions.
keep = floor((fl + size(x) 1) /2);
у = padarray(x, [(fl 1) (fl 1)], ’symmetric’, ’both’);
-%
function у = symconv(x, h, type, fl, keep)
*Z Convolve the rows or columns of x with h, downsample,
7. and extract the center section since symmetrically extended,
if strcmp(type, ’row’)
у = conv2(x, h);
у = y(: 1:2:end);
у y(: fl / 2 + l:fl / 2 + keep(2));
else
у = conv2(x, h’);
у = y(l:2:end, :);
у = y(fl / 2 + l:fl / 2 + keep(l), :);
end
Как видно из программного кода, в нем имеется всего один цикл for, кото-
рый совершается по уровням (масштабам) декомпозиции при выполнении прямо-
го преобразования. При совершении каждого шага цикла текущее приближение
изображения арр, которое в начале приравнивается к х, расширяется по методу
симметричного отражения с помощью внешней функции symextend. Эта функ-
ция вызывает процедуру padarray, которая рассматривалась в § 3.4.2. Функция
padarray расширяет изображение арр по обоим измерениям зеркальным отра-
жением через границы fl-1 его элементов (т.е. длина фильтра декомпозиции
минус 1).
Функция symextend возвращает расширенную матрицу коэффициентов при-
ближения и число пикселов, которое необходимо извлечь из центра любого по-
следовательно свернутого и прореженного результата. Строки расширенного при-
ближения затем сворачиваются с высокочастотным фильтром декомпозиции hp
и прореживаются функцией symconv. Эта функция определяется в следующем
абзаце. Свернутый выход rows затем подается на symconv для свертки и про-
реживания его столбцов с фильтрами hp и 1р для получения коэффициентов
диагональных и вертикальных деталей в соответствии с верхними двумя путя-
ми блок-схемы рис. 7.2. Эти результаты помещаются в вектор декомпозиции С
(от последнего элемента к первому). Далее весь процесс повторяется для вычис-
ления коэффициентов горизонтальных деталей и коэффициентов приближения
(нижние два пути на рис. 7.2).
Функция symconv использует функцию conv2 для выполнения основного объ-
ема вычислений при выполнении преобразования. Она совершает свертку филь-
тра h со строками или столбцами х (в зависимости от значения переменной type),
отбрасывает строки или столбцы с четными индексами (т. е. прореживает их с
шагом 2), а также извлекает центральные keep элементов из каждой строки или
столбца. Вызов функции conv2 с аргументами х (матрица) и вектором-строкой
7.2. Быстрое вейвлетное преобразование 271
фильтра h запускает вычисления строка за строкой, а использование вектора-
столбца h ’ приводит к вычислению свертки по столбцам.
Пример 7.3. Сравнение времени вычислений функциями wavedec2 и wavefast.
Следующая тестовая программа использует функции tic и toe для сравнения
скорости вычислений функцией wavedec2 из пакета Wavelet Toolbox и построен-
ной нами функцией wavefast.
function [ratio, maxdiff] = fwtcompare(f, n, wname)
'ZFWTCOMPARE Compare wavedec2 and wavefast.
% [RATIO, MAXDIFF] = FWTCOMPARE(F, N, WNAME) compares the operation
7. У of toolbox function WAVEDEC2 and custom function WAVEFAST
/о 7. INPUTS:
% F Image to be transformed.
% N Number of scales to compute.
7. WNAME Wavelet to use.
%
7. OUTPUTS:
% RATIO Execution time ratio (custom/toolbox)
7. MAXDIFF Maximum coefficient difference.
7. Get transform and computation time for wavedec2.
tic;
[cl, si] = wavedec2(f, n, wname);
reftime = toe;
XGet transform and computation time for wavefast.
tic;
[c2, s2] = wavefast (f, n, wname);
t2 = toe;
7, Compare the results.
ratio = t2 / (reftime + eps);
maxdiff = abs(max(cl c2));
Для изображения 512x512 на рис. 7.4 и для пятого масштаба вейвлетного
преобразования Добеши порядка 4 функция fwtcompare дает следующие резуль-
таты:
>> f imread (’Vase’, ’tif’);
>> [ratio, maxdifference] = fwtcompare(f, 5, ’db4’)
ratio =
0.5508
maxdifference =
3.2969e-012
Заметим, что функция wavefast выполнялась почти в два раза быстрее, чем
конкурирующая функция из пакета Wavelet Toolbox, выдавая при этом практи-
чески тождественный результат. □
Глава 7. Вейвлеты
7.3. Работа со структурами вейвлетной декомпозиции
Рис. 7.4. Изображение вазы разме-
ром 512x512
Функции вейвлетных преобразований из преды-
дущих параграфов порождают невоспроизводи-
мые на дисплее структуры данных вида {с, S},
где с — это вектор коэффициентов преобразо-
вания, aS — управляющая матрица, которая
определяет порядок расположения коэффици-
ентов в векторе с. Чтобы обработать изображе-
ние, мы должны уметь проверить и при необ-
ходимости изменить содержимое с. В этом па-
раграфе будет дано формальное определение
структуры {с, S}. Кроме того, мы рассмотрим
некоторые функции Wavelet Tools для обра-
щения с этими данными, а также разработаем
ряд независимых собственных функций, кото-
рые можно будет применять без использования
пакета Wavelet Tools. Эти функции будут по-
лезными при написании общих программ для
отображения с на экране дисплея. Схема представления данных, предложенная
в примере 7.2, интегрирует коэффициенты кратномасштабного двумерного вей-
влетного преобразования в едином одномерном векторе
с = [Aw(:yHw(-.y • - - пг(-.у ViO'DiC)' • • • ViC.yDiCn,
где Ajv это матрица коэффициентов приближения А-го масштаба декомпо-
зиции, а Ц, Vi и Di при i = 1,2,..., N — матрицы коэффициентов деталей по
горизонтали, вертикали и диагонали в масштабе г. Здесь, к примеру, Hi(:)'
вектор-строка, которая формируется последовательным присоединением один за
другим транспонированных столбцов матрицы Нг. Следовательно, если
3 -
1 6
то
и НД:)' = [ 3 1 -2 6 ]
Поскольку уравнение для с предполагает N декомпозиций (или проходов через
блок фильтров на рис. 7.2), то вектор с состоит из ЗА + 1 секции: одной секции
коэффициентов приближения и N групп по три секции коэффициентов горизон-
тальных, вертикальных и диагональных деталей. Заметим, что коэффициенты
наибольшего масштаба получаются при г — 1, а наименьший масштаб ассоции-
руется ci = N. Таким образом, коэффициенты в с упорядочены от наименьшего
к наибольшему масштабу.
7.3. Работа со структурами вейвлетной декомпозиции
Управляющая матрица S структуры декомпозиции представляет собой мас-
сив размерами (N + 2)х2 вида
S = [saw;sdw;sdw-i; • • sd2; -sdi;sf],
где saw, sd^ и sf — векторы 1x2, содержащие, соответственно, горизонтальные и
вертикальные размеры А-го уровня матрицы аппроксимации Aw, размеры г-го
уровня матриц деталей (Нг, V2 и D2 при i = 1,2,...,N) и размеры исходного
изображения F. Информация в S дает локализацию конкретных коэффициентов
приближения и деталей в векторе с. Обратите внимание на то, что использование
точки с запятой при разделении элементов матрицы S указывает на расположе-
ние этих данных в виде вектора-столбца.
Пример 7.4. Функции из пакета Wavelet Tollbox для обращения с вектором
декомпозиции с.
В пакете Wavelet Tollbox имеется множество функций для нахождения, извле-
чения, форматирования и изменения коэффициентов приближения и деталей,
расположенных в векторе с, которые действуют на заданном уровне или мас-
штабе. Мы приведем здесь эти функции для иллюстрации обсуждавшихся выше
понятий и для приготовления основы для написания альтернативных функций,
которые будут разрабатываться в следующем параграфе. Рассмотрим, к приме-
ру, следующую последовательность команд:
> > f = magic (8);
> > [cl, si] = wavedec2(f, 3, ’haar’);
> > size(cl)
ans
1 64
>> si
si
1 1
1 1
2 2
4 4
8 8
> > approx = appcoef2(cl, si, ’haar’)
approx =
260.0000
» horizdet2 detcoef2(’h’, cl, si, 2)
horizdet2 =
1.0e-013 ♦
0 -0.2842
0 0
> > newel = wthcoef2(’h’, cl, si, 2);
> > newhorisdet2 = detcoef2(’h’, newel, si, 2)
newhorisdet2 =
0 0
0 0
274 Глава 7. Вейвлеты
Здесь совершается трехуровневая (трехмасштабная) декомпозиция вейвлетным
преобразованием Хаара над магическим квадратом 8x8 с помощью функции
wavedec2. Результат декомпозиции записывается в вектор cl размерами 1x64.
Поскольку si имеет размеры 5x2, то коэффициенты cl соответствуют (п — 2) =
- (5 — 2) =3 масштабам декомпозиции. Значит, в нем располагаются элементы,
необходимые для заполнения 3N +1 = 3- 3 + 1 = 10 подматриц приближения
и деталей. Основываясь на информации, содержащейся в si, приходим к вы-
воду, что эти подматрицы суть: (а) одна подматрица приближения 1x1 и три
подматрицы деталей 1x1 масштаба 3 (см. sl(l,:) и sl(2,:)), (б) три подмат-
рицы деталей 2x2 масштаба 2 [см. sl(3,:)| и (в) три подматрицы деталей 4x4
масштаба 1 [см. si (4,:)]. Пятая строка матрицы si содержит размер исходного
изображения f.
Матрица approx 260 извлекается из cl с помощью функции пакета appeoef 2,
которая имеет следующий синтаксис:
а = appcoef2(c, s, wname).
Здесь а — это возвращаемая матрица приближения, a wname — имя вейвлета из
табл. 7.1. К коэффициентам деталей масштаба 2 можно обратиться с помощью
функции detcoef 2, которая имеет похожий синтаксис
d = detcoef2(o, с, s, n),
где о принимает одно из значений ’ h ’, ’ v ’ или ’ d ’, что соответствует деталям по
горизонтали, вертикали и диагонали, ап — это нужный масштаб декомпозиции.
В этом примере возвращается 2x2 матрица horizdet2. Затем коэффициенты
в cl, соответствующие horizdet2, обнуляются с помощью функции wthcoef2,
которая представляет собой вейвлетную срезающую функцию вида
пс = wthcoef2(type, с, s, n, t, sorh),
где type принимает одно из значений ’а’ (приближение), ’h’, ’v’ или’d’ (дета-
ли). Вход п обозначает уровень (масштаб) декомпозиции, который будет срезать-
ся с помощью пороговых значений, предписанных вектором t, а переменная sorh
принимает одно из двух значений ’s’ или ’h’, что соответствует мягкому (soft)
или жесткому (hard) решению при срезании. Если параметр t отсутствует, то все
коэффициенты, соответствующие значениям type и п, будут обнулены. Выход пс
представляет собой модифицированный (т. е. обрезанный) вектор декомпозиции.
Все три представленные функции пакета Wavelet Tollbox допускают и другие
синтаксические формы, о которых можно узнать, выполнив системный запрос
help. □
7.3.1. Редактирование вейвлетных коэффициентов вне
пакета Wavelet Tollbox
Не имея функций Wavelet Tollbox, всю информацию о коэффициентах декомпо-
зиции следует извлекать из управляющей матрицы S, которая поможет получить
доступ к конкретным коэффициентам приближения или деталей кратномасштаб-
ного вектора с. В этом параграфе мы разработаем несколько подпрограмм общего
7.3. Работа со структурами вейвлетной декомпозиции 275
применения для обработки вектора с с помощью информации, расположенной в
матрице S. Функция wavework является фундаментом всех этих подпрограмм,
которая является рутинной метафорой для действий при работе с современными
текстовыми процессорами типа «вырезать-скопировать-вставить»
function [varargout] = wavework(opcode, type, c, s, n, x) "/«WAVEWORK is used to edit wavelet decomposition structures.
% [VARARGOUT] WAVEWORK(OPCODE, TYPE, C, S, N, X) gets the
7. coefficients specified by TYPE and N for access or modification
7. •/ based on OPCODE.
% INPUTS:
7. 7- OPCODE Operation to perform
h 7. ’copy’ [varargout] = Y = requested (via TYPE and N)
7. coefficient matrix
7. ’cut’ [varargout] [NC, Y] New decomposition vector
7. (with requested coefficient matrix zeroed) AND
% requested coefficient matrix
7. ’paste’ [varargout] [NC] new decomposition vector with
% coefficient matrix replaced by X
%
7. 7- TYPE Coefficient category
ft 7, ’a’ Approximation coefficients
% ’h’ Horizontal details
7. ’v’ Vertical details
7. ’d’ Diagonal details
%
% [C, S] is a wavelet toolbox decomposition structure.
7. N is a decomposition level (Ignored if TYPE = ’a’).
7. X is a two-dimensional coefficient matrix for pasting.
%
7. See also WAVECUT, WAVECOPY, and WAVEPASTE.
error(nargchk(4. , 6, nargin));
if (ndims(c) ~= 2) | (size(c, 1) 1)
error(’C must ; be a row vector.’);
end
if (ndims(s) 2) | "isreal(s) | ~isnumeric(s) | (size(s, 2) 2)
error(’S must be a real, numeric two-column array.’);
end
elements = prod(s, 2); % Coefficient matrix elements.
if (length(c) < elements(end)) |
“(elements(1) + 3 * sum(elements(2:end 1)) >= elements(end))
error([’[C S] must form a standard wavelet decomposition ’ ...
’structure.’] );
end
if strcmp(lower(opcode(l:3)), ’pas’) & nargin < 6
276 Глава 7. Вейвлеты
error(’Not enough input arguments.’);
end
if nargin < 5
n = 1; У. Default level is 1.
end
nmax = size(s, 1) 2; % Maximum levels in [C, S].
aflag = (lower(type(1)) == ’a’);
if "aflag & (n > типах)
error(’N exceeds the decompositions in [C, S] . ’);
end
switch lower(type(1)) % Make pointers into C.
case ’a’
nindex = 1;
start = 1; stop = elements(l); ntst = nmax;
case {’h’, ’v’, ’d’}
switch type
case ’h’, offset = 0; ‘/, Offset to details.
case ’v’, offset = 1;
case ’d’, offset = 2;
end
nindex = size(s, 1) n; */. Index to detail info.
start = elements(l) + 3 * sum(elements(2:nmax - n + 1))
offset * elements(nindex) + 1;
stop = start + elements(nindex) 1;
ntst = n;
otherwise
error(’TYPE must begin with »a>, »h>, »v>, or »d».’);
end
switch lower(opcode) 7. Do requested action,
case -(’copy’, ’cut’}
у = repmat(0, s(nindex, :));
y(:) = c(start:stop); nc c;
if strcmp(lower(opcode(l:3)), ’cut’)
nc( st art-.stop) = 0; varargout = -(nc, y};
else
varargout = {y};
end
case ’paste’
if prod(size(x)) "= elements(end ntst)
error(’X is not sized for the requested paste.’);
else
nc = c; nc(start:stop) = x(:); varargout = {nc};
end
otherwise
error(’Unrecognized OPCODE.’);
end
При проверке корректности своих входных аргументов функция wavework
определяет число элементов каждой подматрицы с с помощью функции elements =
prod(s, 2). Напомним (см. § 3.4.2), что функция Y prod(X, DIM) из сис-
темы MATLAB вычисляет произведение элементов матрицы X вдоль измерения
DIM. Затем первое предложение в команде switch начинается вычислением пары
указателей на коэффициенты, ассоциированные с входными параметрами type
и п. Для случая коэффициентов приближения (т. е. case ’а’), вычисления явля-
ются тривиальными, т. к. эти коэффициенты всегда расположены в начале век-
тора с (т. е. начальный указатель start равен 1), а конечный индекс, указатель
stop, равен числу элементов матрицы приближений, т. е. elements (1). Если же
требуется найти коэффициенты деталей, то указатель start вычисляется сум-
мированием числа элементов всех уровней декомпозиции до масштаба п и сло-
жением offset*elements(nindex), где offset равен 0, 1 или 2, соответственно,
для коэффициентов деталей по горизонтали, вертикали и диагонали, a nindex —
указатель на строку в s, которая соответствует входному параметру п.
Второе предложение switch в функции wavework совершает операцию, за-
данную в opcode. Для случаев ’cut’ и ’сору’ коэффициенты с, расположенные
между start и stop, копируются в матрицу у, которая была заранее описана
как двумерная матрица, размер которой задан в s. Это действие совершается
командой у repmat (0, s(nindex, :)), где задействована стандартная функ-
ция MATLAB «тиражирования матриц» с синтаксисом repmat (А, М, N), кото-
рая создает большую матрицу В, составленную из копий матрицы А, размещен-
ных в ячейках таблицы MxN. Для случая ’paste’ элементы из х копируются
в вектор пс, который является копией с, на места между указателями start и
stop. Для обеих операций ’cut’ и ’paste’ функция возвращает новый вектор
декомпозиции пс.
Следующие три функции: wavecut, wavecopy и wavepaste используют в своих
манипуляциях с вектором с функцию wavework, но имеют более интуитивный
синтаксис.
function [пс, у] wavecut(type, с, s, п)
"/.WAVECUT Zeroes coefficients in a wavelet decomposition structure.
70 [NC, Y] WAVECUT (TYPE, C, S, N) returns a new decomposition
7. vector whose detail or approximation coefficients (based on TYPE
7, and N) have been zeroed. The coefficients that were zeroed are
7» returned in Y
7.
7. INPUTS:
% TYPE Coefficient category
7,-
7c ’a’ Approximation coefficients
7c ’h’ Horizontal details
7o ’v’ Vertical details
7. ’d’ Diagonal details
7.
% [C, S] is a wavelet data structure.
27В Глава 7. Вейвлеты
% N specifies a decomposition level (ignored if TYPE = ’a’).
7.
% See also WAVEWORK, WAVECOPY, and WAVEPASTE.
error(nargchk(3, 4, nargin));
if nargin == 4
[nc, y] = wavework(’cut’, type, c, s, n);
else
[nc, y] = wavework(’cut’, type, c, s);
end
function у wavecopy(type, c, s, n) VoWAVECOPY Fetches coefficients of a wavelet decomposition % Y WAVECOPY(TYPE, C, S, N) returns a coefficient array 7. TYPE and N. % 7» INPUTS: 7. TYPE Coefficient category %- 7, ’a’ Approximation coefficients 7» ’h’ Horizontal details 7. ’V Vertical details 7. ’d’ Diagonal details 7. structure based on
It % [C, S] is a wavelet data structure. % N specifies a decomposition level (ignored if TYPE = ; ’a’) .
4 See also WAVEWORK, WAVECUT, and WAVEPASTE,
error(nargchk(3, 4, nargin));
if nargin == 4
у = wavework(’copy’, type, c, s, n);
else
у = wavework(’copy’, type, c, s);
end
function nc = wavepaste(type, c, s, n, x)
XWAVEPASTE Puts coefficients in a wavelet decomposition structure.
% NC = WAVEPASTE(TYPE, C, S, N, X) returns the new decomposition
% structure after pasting X into it based on TYPE and N.
%
% INPUTS:
% TYPE Coefficient category
%-
% ’a’ Approximation coefficients
7. ’h’ Horizontal details
% ’ v’ Vertical details
% »d’ Diagonal details
%
7. [C, S] is a wavelet data structure.
7» N specifies a decomposition level (Ignored if TYPE = ’a’).
7. X is a two-dimensional approximation or detail coefficient
7. matrix whose dimensions are appropriate for decomposition
7. level N.
7.
% See also WAVEWORK, WAVECUT, and WAVECOPY.
error(nargchk(5, 5, nargin))
nc = wavework(’paste’, type, c, s, n, x);
Пример 7.5. Манипулирование с вектором с посредством функций wavecut и
wavecopy.
Функции wave cut и wavecopy можно применять для воспроизведения результатов
примера 7.4, полученных с использованием пакета Wave Toolbox.
> > f = magic (8) ;
> > [cl, si] wavedec2(f, 3, ’haar’);
> > approx wavecopy(’h’, cl, si, 2)
approx =
260.0000
> > horizdet2 = wavecopy(’h’, cl, si, 2)
horizdet2 =
1.0e-013 *
0 -0.2842
0 0
> > [newel, horizdet2] = wavecut(’h’, cl, si, 2);
> > newhorisdet2 = wavecopy(’h’, newel, si, 2)
newhorisdet2 =
0 0
0 0
Заметьте, что все извлеченные подматрицы идентичны соответствующим под-
матрицам, полученным в предыдущем примере. □
7.3.2. Отображение коэффициентов декомпозиции
Как указывалось в начале § 7.3, коэффициенты, расположенные в одномерном
векторе с вейвлетной декомпозиции, на самом деле являются коэффициентами
двумерного выходного массива, который получается из блока фильтров рис. 7.2.
При каждой итерации порождается четыре массива коэффициентов четвертно-
го размера от исходного (пренебрегая добавочным расширением, которое может
производиться при выполнении операции свертки). Их можно расположить в ви-
де массива 2x2 подматриц на месте двумерного входного массива, из которого
они образованы. Функция wave2gray совершает эту подматричную композицию.
Она меняет масштаб коэффициентов для более лучшего выявления их различий
и добавляет линии для очерчивания границ подматриц приближения и деталей.
280 Глава 7. Вейвлеты
function w = wave2gray(c, s, scale, border)
XWAVE2GRAY Display wavelet decomposition coefficients.
% W = WAVE2GRAY(C, S, SCALE, BORDER) displays and returns a
% wavelet coefficient image.
%
% EXAMPLES:
X wave2gray(c, s); Display w/defaults.
X foo = wave2gray(c, s); Display and return.
*A foo = wave2gray(c, s, 4); Magnify the details.
X foo = wave2gray(c, s, -4); Magnify absolute values.
’4 foo = wave2gray(c, s, 1, ’append’); Keep border values.
’/,
X INPUTS/OUTPUTS:
X
7.
7.
X
X
X
X
X
X
7.
7.
X
X
X
X
X
X
X
X
X
X
X
X
X
X
7,
X
X
X
7.
X
X
X
X
[C, S] is a wavelet decomposition vector and bookkeeping
matrix.
SCALE Detail coefficient scaling
0 or 1 Maximum range (default)
2, 3... Magnify default by the scale factor
-1, -2... Magnify absolute values by abs(scale)
BORDER
Border between wavelet decompositions
’absorb’ Border replaces image (default)
’append’ Border increases width of image
Image W:
III I
j a(n) | h(n) | j
h(n-l) |
| v(n) | d(n) | | h(n-2)
III I
| v(n-l) I d(n-l) I
I I I
I I
I v(n-2) I d(n-2)
Here, n denotes the decomposition step scale and a, h, v, d are
approximation, horizontal, vertical, and diagonal detail
coefficients, respectively.
7.3. Работа со структурами вейвлетной декомпозиции
7. Check input arguments for reasonableness.
error(nargchk(2, 4, nargin));
if (ndims(c) ~= 2) | (size(c, 1) 1)
error(’C must be a row vector.’); end
if (ndims(s) ~= 2) | “isreal(s) | “isnumeric(s) | (size(s, 2) ~= 2)
errorf’S must be a real, numeric two-column array.’); end
elements = prod(s, 2);
if (length(c) < elements(end)) |
“(elements(l) + 3 * sum(elements(2:end 1)) >= elements(end))
error([’[C S] must be a standard wavelet ’
’decomposition structure.’]);
end
if (nargin > 2) & (“isreal(scale) | “isnumeric(scale))
error(’SCALE must be a real, numeric scalar.’);
end
if (nargin > 3) & (“ischar(border))
error(’BORDER must be character string.’);
end
if nargin == 2
scale = 1; % Default scale.
end
if nargin < 4
border = ’absorb’; % Default border,
end
7. Scale coefficients and determine pad fill.
absflag = scale < 0;
scale = abs(scale);
if scale == 0
scale = 1;
end
[cd, w] = wavecut(’a’, c, s); w = mat2gray(w);
cdx = max(abs(cd(:))) I scale;
if absflag
cd = mat2gray(abs(cd), [0, cdx]); fill = 0;
else
cd = mat2gray(cd, [-cdx, cdx]); fill = 0.5;
end
% Build gray image one decomposition at a time.
for i = size(s, 1) 2:-1:1
ws = size(w);
h = wavecopy(’h’, cd, s, i);
pad ws size(h); frontporch = round(pad / 2);
h = padarray(h, frontporch, fill, ’pre’);
h = padarray(h, pad frontporch, fill, ’post’);
v = wavecopy(’v’, cd, s, i);
pad = ws size(v); frontporch = round(pad I 2);
v = padarray(v, frontporch, fill, ’pre’);
282 Глава 7. Вейвлеты
v = padarray(v, pad frontporch, fill, ’post’);
d = wavecopy(’d’, cd, s, i);
pad = ws - size(d); frontporch = round(pad / 2);
d = padarray(d, frontporch, fill, ’pre’);
d = padarray(d, pad frontporch, fill, ’post’);
% Add 1 pixel white border,
switch lower(border)
case ’append’
w = padarray(w, [1 1], 1, ’post’);
h = padarray(h, [10], 1, ’post’);
v = padarray(v, [01], 1, ’post’);
case ’absorb’
w(:, end) 1; w(end, :) 1;
h(end, :) 1; v(:, end) 1;
otherwise
error(’Unrecognized BORDER parameter.’);
end
w = [w h; v d] ; 7, Concatenate coefs.
end
if nargout == 0
imshow(w); % Display result,
end
В справочном разделе функции wave2gray детализируется структура генери-
руемого выходного изображения w. Например, подизображение в верхнем левом
углу является матрицей приближения, которая получается при выполнении по-
следнего шага декомпозиции. Она окружена, если смотреть по часовой стрел-
ке, матрицами горизонтальных диагональных и вертикальных деталей, которые
строятся при этой финальной декомпозиции. Полученный 2x2 массив подматриц,
в свою очередь, окружен (по часовой стрелке) коэффициентами деталей деком-
позиции предыдущего шага. Этот процесс, похожий на раскручивание спирали,
продолжается до тех пор, пока все коэффициенты одномерного вектора деком-
позиции с не будут размещены в соответствующих ячейках двумерной матрицы w.
Описанная только что процедура совершается в wave2gray с помощью все-
го одного цикла for. После проверки корректности входных данных, функция
wave cut вырезает данные коэффициентов приближения из вектора декомпози-
ции с. У этих коэффициентов меняется диапазон для дальнейшего отображения
на экране с помощью функции mat2gray. У модифицированного вектора деком-
позиции cd (т. е. вектора с с обнуленной областью, относящейся к коэффициентам
приближения) диапазон также меняется. Если входной параметр scale больше
нуля, то диапазон коэффициентов деталей меняется таким образом, что величина
О отображается средним серым уровнем; все необходимые действия расширения
осуществляются со значением fill, равным 0.5. Если параметр scale меньше
нуля, то абсолютные значения коэффициентов деталей отображаются со значе-
нием 0, что соответствует черному цвету, а переменная заполнения fill устанав-
ливается в 0. После того, как у коэффициентов приближения и деталей изменяет-
ся диапазон, первая итерация цикла for извлекает из cd коэффициенты деталей
7-4- Быстрое обратное вейвлетное преобразование
последнего шага декомпозиции и добавляет их в w (после расширения, которое
совершается для подгонки размеров всех четырех подизображений, и добавления
белой каймы шириной в один пиксел) с помощью команды w = [w h; v d]. Этот
процесс повторяется для каждого масштаба в с. Обратите внимание на исполь-
зование функции wave сору при извлечении различных блоков коэффициентов
деталей, необходимых для формирования изображения w.
Пример 7.6. Отображение на экране коэффициентов преобразования с помо-
щью функции wave2gray.
Следующая последовательность команд вычисляет двухмасштабное DWT изоб-
ражение на рис. 7.4 с использованием вейвлета Добеши четвертого порядка и
отображает на экране дисплея полученные коэффициенты:
> > f imread (’vase.tif’);
> > [с, s] = wavefast(f, 2, ’db4’);
> > wave2gray(c, s);
> > -figure; wave2gray(c, s, 8);
> > figure; wave2gray(c, s, -8);
Изображения, которые получаются при выполнении последних трех командных
строк, показаны на рис. 7.5 с а) по в). Без дополнительной смены диапазона зна-
чений пикселов различия коэффициентов деталей на рис. 7.5, а) едва видны. На
рис. 7.5, б) эти различия усилены с помощью увеличения в 8 раз. Обратите вни-
мание на добавление среднесерого цвета вдоль границ подизображений первого
уровня; это сделано для сглаживания вариаций размеров подматриц коэффици-
ентов преобразования. На рис. 7.5, в) показан эффект отображения абсолютных
величин деталей. В этом случае расширение у границ делается черным цветом. □
Рис. 7.5. Отображение двухмасштабного вейнлетного преобразования изображения на
рис. 7.4. а) Автоматический выбор диапазона, б) Дополнительное увеличение
диапазона в 8 раз. в) Взятие модуля и 8-ми кратное увеличение диапазона
7.4. Быстрое обратное вейвлетное преобразование
Как и соответствующее прямое преобразование, быстрое обратное вейвлетное
преобразование можно вычислять итеративным способом с использованием циф-
ровых фильтров. На рис. 7.6 изображен необходимый блок фильтров синтеза
284 Глава 7. Вейвлеты
или реконструкции, который обращает процесс блока фильтров анализа или
декомпозиции на рис. 7.2. При каждой итерации к четырем подизображениям
приближения и деталей масштаба j применяется процедура сгущающей выборки
с шагом 2 (т. е. производится вставка нулей между элементами), а затем выпол-
няется свертка с двумя одномерными фильтрами: одна операция по столбцам
подизображения и одна — по строкам. После сложения результатов этих свер-
ток получается приближение масштаба j + 1, и весь процесс повторяется вплоть
до полной реконструкции исходного изображения. Фильтры, используемые при
свертке, являются функциями вейвлетов, применяемых при прямом преобразо-
вании. Напомним, что их можно получить из функций wfilters и wavefilter,
описанных в § 7.2, с входным параметром type, который следует установить в ’г ’
(reconstruction, реконструкция).
При работе с пакетом Wavelet Toolbox функция waverес2 используется для
вычисления обратного преобразования FWT для структуры вейвлетной деком-
позиции [С, S]. Она вызывается следующим образом:
g = waverec2(C, S, wname),
где g — выходное реконструированное двумерное изображение (класса double).
Эта функция также имеет расширенный вариант синтаксиса
g = waverec2(C, S, Lo_R, Hi_R).
Следующую подпрограмму, которую мы назвали waveback, можно исполь-
зовать вместо waverec2, если пакет Wavelet Toolbox недоступен. Эта функция
завершает наш собственный пакет обработки изображений на базе вейвлетного
анализа в сочетании с функциями из IPT (и без использования Wavelet Toolbox).
т, п).--|~2f~[—| ----]
<(7. т, п).--
СТроки (+)— ^0+1- п)
т, п)»--|~2|]—| %,(т)|—J
С1роки
Щ G- т. ")•--[2f}—|/i<l(m)|—J столбцы
строки
Рис. 7.6. Блок двумерного
обратного преобразования
DWT. Квадраты со стрел-
кой вверх отвечают опера-
циям сгущающей выборки,
при которой вставляются ну-
ли между элементами
function [varargout] = waveback(c, s, varargin)
’/.WAVEBACK Performs a multi-level two-dimensional inverse FWT.
7. [VARARGOUT] WAVEBACK (C, S, VARARGIN) computes a 2D N-level
% partial or complete wavelet reconstruction of decomposition
% structure [C, S].
7.
7. SYNTAX:
7. Y = WAVEBACK(C, S, ’WNAME’); Output inverse FWT matrix Y
7.4- Быстрое обратное вейвлетное преобразование 285
7, Y WAVEBACK(C, S, LR, HR); using lowpass and highpass
У, reconstruction filters (LR and
% HR) or filters obtained by
% calling WAVEFILTER with ’WNAME’
7.
7o [NC, NS] = WAVEBACK(C, S, ’WNAME’, N); Output new wavelet
7. [NC, NS] = WAVEBACKCC, S, LR, HR, N) ; decomposition structure
7. [NC, NS] after N step
7c reconstruction.
7» See also WAVEFAST and WAVEFILTER.
7. Check the input and output arguments for reasonableness.
error(nargchk(3, 5, nargin));
error(nargchk(l, 2, nargout));
if (ndims(c) ~= 2) | (size(c, 1) 1)
error(’C must be a row vector.’);
end
if (ndims(s) 2) | ~isreal(s) | “isnumeric(s) | (size(s, 2) ~= 2)
error(’S must be a real, numeric two-column array.’);
end
elements = prod(s, 2);
if (length(c) < elements(end)) |
“(elements(l) + 3 * sum(elements(2:end 1)) >= elements(end))
error([’[C S] must be a standard wavelet ’
’decomposition structure.’]);
end
7 Maximum levels in [C, S] .
nmax = size(s, 1) 2;
7<, Get third input parameter and init check flags,
wname = varargin{l}-; filterchk = 0; nchk = 0;
switch nargin
case 3
if ischar(wname)
[Ip, hp] = wavefilter(wname, ’r’); n = nmax;
else
error(’Undefined filter.’);
end
if nargout 1
error(’Wrong number of output arguments.’);
end
case 4
if ischar(wname)
[Ip, hp] wavefilter(wname, ’r’);
n = varargin{2}-; nchk = 1;
else
Ip = varargin{l]-; hp = varargin{2}-;
Глава 7. Вейвлеты
filterchk = 1; n = итак;
if nargout “= 1
error(’Wrong number of output arguments.’);
end
end
case 5
Ip = varargin-tl}; hp varargin{2]-; filterchk = 1;
n = varargin{3}; nchk = 1;
otherwise
error(’Improper number of input arguments.’);
end
fl length(Ip);
if filterchk °k Check filters.
if (ndims(lp) “= 2) | “isreal(lp) | “isnumeric(lp)
| (ndims(hp) “= 2) | “isreal(hp) | “isnumeric(hp)
| (fl “= length(hp)) | rem(fl, 2) “= 0
error([’LP and HP must be even and equal length real,
’numeric filter vectors.’]);
end
end
if nchk & (“isnumeric (n) | “isreal(n)) 7, Check scale N.
error(’N must be a real numeric.’);
end
if (n > nmax) | (n < 1)
error(’Invalid number (N) of reconstructions requested.’);
end
if (n “= nmax) & (nargout 2)
error(’Not enough output arguments.’);
end
nc = c; ns = s; nnmax = nmax; 7, Init decomposition,
for i = l:n
% Compute a new approximation.
a = symconvup(wavecopy(’a’, nc, ns), Ip, Ip, fl, ns(3, :))
symconvup(wavecopy(’h’, nc, ns, nnmax),
hp, Ip, fl, ns(3, :)) +
symconvup(wavecopy(’v’, nc, ns, nnmax),
Ip, hp, fl, ns(3, :)) +
symconvup(wavecopy(’d’, nc, ns, nnmax),
hp, hp, f1, ns(3, : ) ) ;
% Update decomposition.
nc = nc(4 * prod(ns(l, :)) + l:end); nc = [a(:)’ nc];
ns = ns(3:end, :); ns [ns(l, :); ns];
nnmax = size(ns, 1) 2;
end
7 For complete reconstructions, reformat output as 2-D.
if nargout == 1
7.4- Быстрое обратное вейвлетное преобразование 2В1
а = nc; пс = repmat(O, ns(l, :)); пс(:) = а;
end
varargout{1} = пс;
if nargout == 2
varargout{2} = ns;
end
7.- -7.
function z symconvup(x, fl, f2, fin, keep)
70 Upsample rows and convolve columns with fl; upsample columns and
7. convolve rows with f2; then extract center assuming symmetrical
7. extension.
у = zeros([2 1] .* size(x)); y(l:2:end, :) = x;
у = conv2(y, f1’);
z zeros([l 2] .* size(y)); z(: 1:2:end) = y;
z conv2(z, f2);
z z(fln l:fln + keep(l) 2, fin l:fln + keep(2) 2);
Главные действия в функции waveback совершаются в цикле for, который
выполняет требуемое число шагов итерации, зависящее от уровня (масштаба)
декомпозиции. Можно видеть, что на каждом шаге четыре раза вызывается
внутренняя функция symconvup, и полученные матрицы складываются. Вектор
декомпозиции пс, который в начале приравнивается вектору с, обновляется на
каждом шаге итерации путем замены четырех подматриц коэффициентов, обра-
ботанных функцией symconvup, на одну вновь вычисленную матрицу приближе-
ния а. Управляющая матрица ns также параллельно изменяется, и в результате
получается структура декомпозиции [nc, ns] на единицу меньшего масштаба.
Эта последовательность действий слегка отличается от процесса, изображенного
на рис, 7.6, где верхние два входа комбинируются по правилу
т,п) Т2тп кф(т) + ?2m *hv(m)| T2n *Mn)-
Здесь f27” и f2n обозначают операции сгущающей выборки с шагом 2, соответ-
ственно, по т и zi. Функция waveback совершает эквивалентные вычисления по
формуле
[W^(j,m,n) Т2™ ^(тп)] ?2п + [W**M™)] fn
Функция symconvup производит требуемую свертку и сгущающую выборку
для вычисления вклада одного входа на рис. 7.6 в выход [^(j + 1, тп, тг) в соот-
ветствии с приведенным выше выражением. Сначала входной массив х сгущает-
ся по строкам, в результате чего образуется массив у, который сворачивается по
столбцам с фильтром fl, и результат записывается на место у. Затем у сгущает-
ся в направлении столбцов, сворачивается строка за строкой с фильтром f 2, и в
результате получается массив z. Наконец, центральные keep элементов z (окон-
чательная свертка) возвращаются в виде вклада входы х в новое приближение.
288 Глава 7. Вейвлеты
Пример 7.7. Сравнение времени вычислений waveback и waverec2.
Следующая тестовая программа сравнивает время выполнения функции waverес2
из Wavelet Toolbox и построенной нами функции waveback с помощью простой
модификации тестовой функции примера 7.3:
function [ratio, maxdiff] ifwtcompare(f, n, wname)
7.IFWTCOMPARE Compare waverec2 and waveback.
7. [RATIO, MAXDIFF] IFWTCOMPARE(F, N, WNAME)
7. compares the operation of toolbox function WAVEREC2
% and custom function WAVEBACK.
7.
7. INPUTS:
7. F Image to transform and inverse transform.
% N Number of scales to compute.
7» WNAME Wavelet to use.
7.
7. OUTPUTS:
7, RATIO Execution time ratio (custom/toolbox)
7. MAXDIFF Maximum genereted image difference.
7.
% Compute the transform and get output and computation
7. time for wavedec2.
[cl, si] = wavedec2(f, n, wname);
tic;
gl = waverec2(cl, si, wname);
reftime = toe;
7, Compute the transform and get output and computation
7. time for waveback.
[c2, s2] = wavefast(f, n, wname);
tic;
g2 = waveback(c2, s2, wname);
t2 = toe;
7c Compare the results.
ratio = t2 / (reftime + eps);
maxdiff = abs(max(gl g2));
Для изображения 512 x 512 на рис. 7.4, преобразованного до пятого масштаба вей-
влетным преобразованием Добеши порядка 4, получаем следующее:
>> f = imread (’Vase’, ’tif’);
» [ratio, maxdifference] ifwtcompare(f, 5, ’db4’)
ratio =
1.0000
maxdifference =
3.6948e-013
Отметим, что время работы обеих функций одинаково (частное ratio рав-
но 1), а максимум разности выходов равен 3.6948х10-13 Для любых практиче-
ски значимых целей обе функции выдают идентичные результаты, затрачивая
на вычисления одно и то же время. □
7.5. Вейвлеты при обработке изображений
Подобно преобразованию Фурье (см. § 4.3.2), вейвлетные преобразования приме-
няются при обработке цифровых изображений в следующем порядке:
1. Вычислить двумерное вейвлетное преобразование изображения.
2. Внести изменения в коэффициенты преобразования.
3. Вычислить обратное преобразование.
Поскольку масштаб в вейвлетной области аналогичен частоте области Фурье, боль-
шинство технологий, основанных на фильтрации в Фурье-переменных (см. гл. 4),
имеют похожие аналоги в «вейвлетных переменных». В этом параграфе, исполь-
зуя приведенную выше трехшаговую схему, мы приведем несколько примеров
использования вейвлетов при обработке конкретных изображений. Основное вни-
мание будет обращено на применение разработанных в этой главе процедур, при-
чем нам не потребуются ни функции из пакета Wavelet Toolbox, ни примеры из
гл. 7 книги [Gonzalez, Woods, 2002].
Пример 7.8. Вейвлетная направленность и обнаружение контуров.
Рассмотрим тестовое 500x500 изображение из рис. 7.7, а). Это изображение уже
использовалось в гл. 4 при иллюстрации процедур сглаживания и повышения
резкости на базе преобразования Фурье. Здесь мы продемонстрируем направ-
ленную чувствительность двумерных вейвлетных преобразований и их пользу в
задачах обнаружения контуров.
f imread(’A.tif’);
imshow(f);
[c, s] = wavefast(f, 1, ’sym4’);
figure; wave2gray(c, s, -6);
[nc, y] = wavecut(’a’, c, s);
figure; wave2gray(nc, s, -6);
edges abs(waveback(nc, s, ’sym4’));
figure; imshow(mat2gray(edges));
Горизонтальная, вертикальная и диагональная направленности одномасштаб-
ного вейвлетного преобразования рис. 7.7, а), выполненного вейвлетом ’sym4’,
отчетливо видна на рис. 7.7, б). Например, заметьте, что горизонтальные кон-
туры исходного изображения присутствуют на изображении горизонтальных де-
талей, расположенном в верхнем правом квадранте рис. 7.7, б). Вертикальные
контуры изображения также легко идентифицировать на изображении горизон-
тальных деталей, находящемся в нижнем левом квадранте. Чтобы объединить
Глава 7. Вейвлеты
эту информацию в одном общем изображении, достаточно обнулить коэффици-
енты приближения построенного преобразования, вычислить обратное преобра-
зование и взять абсолютное значение результата. Модифицированное преобра-
зование и результирующее изображение контуров показаны, соответственно, на
рис. 7.7, в) и г). Аналогичным образом можно выделить только горизонтальные
или только вертикальные контуры изображения. □
Вейвлеты при обнаружении контуров: а) Простое тестовое изображение; б) Его
вейвлетное преобразование; в) Модификация преобразования путем обнуления
коэффициентов приближения; (г) Контурное изображение, полученное вычис-
лением абсолютной величины обратного преобразования
Рис. 7.7.
Пример 7.9. Сглаживание и размытие изображений с помощью вейвлетов.
Вейвлеты, подобно их аналогам Фурье, являются эффективным инструментом
для сглаживания и размытия изображений. Еще раз рассмотрим тестовое изоб-
ражение на рис. 7.7, а), которое повторено на рис. 7.8, а). Его вейвлетное преоб-
разование четвертого масштаба с помощью ’sym4’ показано на рис. 7.8, б). Для
выполнения процедуры сглаживания мы воспользуемся следующей утилитной
функцией:
function [nc, g8] wavezero(е, s, 1, wname)
%WAVEZER0 Zeroes wavelet transform detail coefficients.
% [NC, G8] WAVEZERO(C, S, L, WNAME) zeroes the level
% L detail coefficients in wavelet decomposition
% structure [C, S] and computes the resulting inverse
% transform with respect to WNAME wavelets.
7.5. Вейвлеты при
[nc, foo] = wavecut (’h’, с, s, 1);
[пс, foo] = wavecut (’v’, nc, s, 1);
[nc, foo] = wavecut (’d’, nc, s, 1);
i = wavebaek (nc, s, wname);
g8 = im2uint8(mat2gray(i));
figure; imshow (g8);
. а а 3 й Э 3 &
Рис. 7.8. Сглаживание изображений на базе вейвлетов: а) Тестовое изображение; б) Его
вейвлетное преобразование; в) Обратное преобразование после обнуления коэф-
фициентов деталей первого уровня; г)-е) Аналогичные результаты после обну-
ления деталей второго, третьего и четвертого уровней
Используя функцию wavezero, можно построить целую серию изображений с
нарастающим сглаживанием, выполнив следующую последовательность команд:
» f = imread(’A.tif’);
» [с, s] = wavefast(f, 4, ’sym4’);
» wave2gray(c, s, 20);
» [c, g8] = wavezero(c, s, 1, ’sym4’);
» [c, g8] = wavezero(c, s, 2, ’sym4’);
» [c, g8] = wavezero(c, s, 3, ’sym4’);
» [c, g8] = wavezero(c, s, 4, ’sym4’);
Заметим, что сглаженное изображение на рис. 7.8, в) лишь слегка размыто. Оно
получено обнулением коэффициентов деталей вейвлетного преобразования пер-
вого уровня (масштаба) исходного изображения (взятием обратного преобразова-
ния от модифицированных данных). Уже большее размытие обнаруживается на
рис. 7.8, г), которое демонстрирует эффект обнуления коэффициентов деталей
Глава 1. Вейвлеты
первого и второго масштаба. Этот процесс продолжен на рис. 7.8, д), где допол-
нительно удалены коэффициенты третьего масштаба. Наконец, на рис. 7.8, е)
удалены все коэффициенты деталей. Градуированное повышение размытия от
рис. 7.8, в) до е) напоминает аналогичные результаты, полученные с помощью
преобразования Фурье. Это иллюстрирует близкую связь между масштабами
вейвлетной области и частотами в области Фурье-анализа. □
Пример 7.10. Прогрессивная реконструкция.
Теперь рассмотрим задачу передачи и реконструкции вейвлетного четырехмас-
штабного преобразования изображения на рис. 7.9, а) в контексте получения быст-
рого сетевого доступа к некоторой удаленной базе изображений. Здесь мы несколь-
ко отклонимся от нашей трехшаговой схемы, предложенной в начале этого пара-
графа, и рассмотрим приложение, у которого нет аналога на базе Фурье-анализа.
Пусть каждое изображение базы данных хранится в виде кратномасштабной вей-
влетной декомпозиции. Такая структура хранения весьма подходит для прило-
жений, которым нужна прогрессивная реконструкция данных, особенно если ко-
эффициенты декомпозиции хранятся в одномерном векторе, общий формат ко-
торого был представлен в § 7.4. Для преобразования четвертого масштаба этого
примера вектор декомпозиции имеет вид
[А4(:)'Н4(:)' -HiC/ViO'DiC)' УДО'ПД:)'],
где А4 это матрица коэффициентов приближения четвертого уровня деком-
позиции, а Н<, Vi, и Di при i = 4,3,2,1 — матрицы коэффициентов деталей по
горизонтали, вертикали и диагонали масштаба i. Если передавать этот вектор
по сети в порядке слева направо, то удаленное устройство отображения смо-
жет градуированно строить все более хорошие приближения конечного изобра-
жения высокого разрешения (в зависимости от потребностей пользователя) по
мере приема данных на станции обслуживания. Например, когда будут полу-
чены коэффициенты матрицы А4, станет доступна версия изображения самого
низкого разрешения, которое можно сразу отобразить на экране [рис. 7.9, б)\.
Когда поступят матрицы Н4, V4, и D4, можно будет реконструировать изобра-
жение с большим разрешением [рис. 7.9, б^] и т. д. На рис. 7.9 с г) по е) показаны
еще три реконструкции с возрастанием разрешения. Этот процесс прогрессивной
реконструкции легко смоделировать с помощью следующей последовательности
команд MATLAB.
f imread(’Strawberries.tif’);
[c, s] wavefast(f, 4, ’jpeg9.7’);
wave2gray(c, s, 8);
f = wavecopy(’a’ , с, s) ;
figure; imshow(mat2gray(f));
[c, s] waveback(c, s, ’jpeg9.7’, 1);
f = wavecopy(’a’, c, s) ;
figure; imshow(mat2gray(f));
7, Generate transform
70 Approximation 1
% Approximation 2
7.5. Вейвлеты при обработке изображений
Рис. 7.9. Прогрессивная реконструкция: а) Четырехмасштабное вейвлетное преобразова-
ние; б) Приближение четвертого уровня из верхнего левого угла; в) Улучшенное
изображение с использованием деталей четвертого уровня; г)-е) Дальнейшее по-
вышение разрешения с использованием деталей более высоких порядков
>> [с, s] = waveback(c, s, ’jpeg9.7’, 1);
» f = wavecopy (’a’, c, s);
> > f igure; imshow(mat2gray(f));
>> [c, s] = waveback(c, s, ’jpegS).?’, 1);
» f = wavecopy(’a’, c, s) ;
» figure; imshow(mat2gray(f));
>> [c, s] = waveback(c, s, ’jpeg9.7’, 1);
» f wavecopyf’a’, c, s);
» figure; imshow(mat2gray(f));
% Approximation 3
X Approximation 4
X Final image
294 Глава 7. Вейвлеты
Обратите внимание на то, что финальное, четвертое приближение использует
функцию waveback для совершения реконструкции первого масштаба. □
Выводы
В этой главе рассматриваются вейвлетные преобразования и обсуждается их ис-
пользование при обработке изображений. Подобно преобразованию Фурье, вей-
влетные преобразования могут применяться при решении задач широкого спек-
тра, от обнаружения контуров и до сглаживания изображений, что рассматри-
валось в материалах данной главы. Поскольку вейвлетный анализ глубоко про-
никает как в частотные, так и в пространственные характеристики изображе-
ний, вейвлетные преобразования могут найти применение в таких областях, где
анализ-Фурье уже не работает, например, в приложениях, требующих прогрес-
сивную реконструкцию данных (см. пример 7.10). По причине того, что стан-
дартный пакет IPT не содержит функции, совершающие вейвлетные преобразо-
вания, значительная часть главы посвящена разработке набора таких функций,
которые расширяют возможности IPT на базе вейвлетного анализа изображе-
ний. Разработанные функции полностью совместимы с возможностями пакета
Wavelet Toolbox системы MATLAB, обзор которого также делается в настоящей
главе, но который не является частью пакета IPT. В следующих главах вейвлет-
ный анализ будет использоваться в задачах сжатия изображений. К этой теме
обращено пристальное внимание авторов современных книг и учебников по об-
работке цифровых изображений.
ГЛАВА 8
СЖАТИЕ
ИЗОБРАЖЕНИЙ
Введение
Задача сжатия изображения заключается в сокращении объема данных, необхо-
димого для представления цифрового изображения. Эффект сжатия может быть
достигнут путем удаления одного из трех типов избыточности:
(1) кодовой избыточности, имеющей место, если используемые кодовые слова
не являются оптимальными (например, не имеют минимальную длину);
(2) межпиксельной избыточности, которая возникает при наличии определен-
ной корреляции между близкими пикселами;
(3) визуальной избыточности, содержащейся в информации, которая не вос-
принимается органами зрения человека (т. е. детали изображения, несуще-
ственные для глаза).
В этой главе рассматриваются все эти типы избыточности и описываются неко-
торые известные методы ее удаления или сокращения. Кроме того, мы изучим
два стандарта сжатия: JPEG и JPEG2000. Эти стандарты призваны унифици-
ровать основные концепции и подходы к сжатию изображений, излагаемые в
данной главе, путем комбинирования всех подходов, которые в итоге приводят к
сокращению всех трех типов избыточности.
Поскольку пакет IPT не содержит функции для сжатия изображений, основ-
ная цель данной главы заключается в обозначении эффективных путей исполь-
зования технологий сжатия в контексте системы MATLAB. В частности, мы раз-
работаем вызываемые в MATLAB С-функции, которые продемонстрируют идею
представления данных на битовом уровне с помощью кодов переменной длины.
Это весьма важно, так как именно коды переменной длины лежат в основе сжа-
тия изображений, в то время как эффективность и быстрота матричных опера-
ций в MATLAB определяется одинаковым форматом представления числовых
данных с помощью кодов фиксированной длины. При рассмотрении этих функ-
ций мы будем предполагать, что читатель знаком с основами программирования
на языке С, а наше внимание будет сконцентрировано на обсуждении механиз-
мов взаимодействия системы MATLAB с внешними программами (на языке С
или Fortran). Эти приемы являются весьма важными, когда возникает необходи-
мость наладить взаимодействие М-функций с уже существующими программами
на С или Fortran при сохранении преимуществ высокоскоростной векторизован-
ной техники MATLAB обработки матриц (например, когда цикл типа for не
поддается адекватной векторизации). Таким образом, семейство функций для
сжатия изображений, разработанное в этой главе, вместе со способностью си-
стемы MATLAB обращаться к программами на С или Fortran, как если бы они
296 Глава 8. Сжатие изображений
были обычными М-функциями, показывают, что MATLAB может стать весьма
эффективным инструментарием для создания прототипов алгоритмов и систем
сжатия изображений.
8.1. Некоторые основы
Как видно из рис. 8.1, системы сжатия изображений состоят из двух различных
структурных блоков: кодера и декодера. Изображение f(x,y) подается на вход
кодера, который преобразует входные данные в определенный набор символов и
использует его для представления исходного изображения. Пусть щ и пг обозна-
чают число элементарных носителей информации (например, битов) исходного
и закодированного изображения. Тогда меру сжатия можно выразить количе-
ственно с помощью коэффициента сжатия Cr = тц/п?- Коэффициент сжатия
10 (или 10 1) указывает на то, что исходное изображение имеет 10 элементов
хранения информации (т. е. битов) на каждый элемент хранения в сжатом на-
боре данных. В MATLAB частное числа битов, используемых для хранения и
представления двух файлов изображений и/или переменных, можно вычислять
с помощью следующей М-функции:
function cr = imration(f1, f2)
“ZIMRATIO Computes the ratio of the bytes in two images/variables.
“Z CR = IMRATIO(F1, F2) returns the ratio of the number of bytes in
7. variables/files Fl and F2. If Fl and F2 are an original and
* Z compressed image, respectively, CR is the compression ratio.
error(nargchk(2, 2, nargin)); Check input arguments
cr = bytes(fl) / bytes(f2); "Z Compute the ratio
• Z- -'Z
function b bytes(f)
°Z Return the number of bytes in input f. If f is a string, assume
* Z that it is an image filename; if not, it is an image variable.
if ischar(f)
info = dir(f); b = info.bytes;
elseif isstruct(f)
7. MATLAB’s whos function reports an extra 124 bytes of memory
7. per structure field because of the way MATLAB stores
7. structures in memory. Don’t count this extra memory; instead,
7. add up the memory associated with each field,
b = 0;
fields = fieldnames(f);
for k = 1:length(fields)
b = b + bytes(f.(fields{k}));
end
else
info = whos(’f’); b = info.bytes;
end
8.1. Некоторые основы
Рис. 8.1. Блок-схема модельной
системы сжатия изображений
Декодер источника
Например, коэффициент сжатия изображения на рис. 2.4, в) (стр. 36) при коди-
ровании JPEG можно вычислить с помощью команды
>> г imratio(imread(’bubbles25.jpg’), ’bubbles25.jpg’)
35.1612
Заметим, что в imratio внешняя функция b bytes (f ) написана так, чтобы
она возвращала число байтов
(1) в файле,
(2) в структурной переменной, и/или
(3) в переменной, не являющейся структурной.
Если f не является структурной переменной, то функция whos, введенная в § 2.2,
возвращает размер этой переменной в байтах. Если f — это имя файла, то ана-
логичное действие выполняет функция dir. В используемой форме синтаксиса
функция dir возвращает структуру (см. сведения о структурах в § 2.10.6), ко-
торая имеет поля name, date, bytes и isdir. В этих полях записаны, соответ-
ственно, имя файла, дата его последнего изменения, размер в байтах и инфор-
мация о том, является ли f папкой (директорией) (isdir = 1, если «да», иначе
isdir = 0). Наконец, если f является структурой, то функция bytes вызывает
рекурсивно сама себя для сложения числа байтов, используемых при хранении
каждого отдельного поля структуры. Это позволяет исключить объем служебной
информации, связанной с самой структурной переменной (124 байта хранения на
одно поле), когда возвращается только число байтов, необходимых для хранения
самих данных, записанных в полях. Функция fieldename1 используется для по-
лучения списка полей f, а операторы
for к 1:length(fields)
b b + bytes (f . (fields-tk») ;
осуществляют рекурсию. Обратите внимание на применение динамических имен
полей структур в рекурсивных вызовах функции bytes. Если S это структура,
1Функция names = f ieldnames(s) возвращает смешанный массив, состоящий из строк, в кото-
рых записаны имена полей структуры s.
298 Глава 8. Сжатие изображений
a F — переменная символьной строки, содержащая имя поля, то операторы
S.(F) foo;
field S.(F);
употребляют синтаксис динамических имен полей структур для присвоения и/или
прочтения содержимого поля F структуры S.
Чтобы увидеть и/или использовать сжатое (т. е. закодированное) изображе-
ние, его необходимо подать на декодер (см. рис. 8.1), который построит рекон-
струированное изображение f(x,y). В общем случае, изображение /(т, у) может
совпадать с исходным изображением f(x, у) или может от него отличаться. В пер-
вом случае система называется свободной от ошибок, или системой кодирования
или сжатия без потери информации. В противном случае в реконструированном
изображении присутствуют определенные искажения и потери и система назы-
вается кодированием или сжатием с потерей информации. Ошибку (невязку)
е(х, у) между f(x,y) и f(x,y) можно вычислить для любых пикселов (х,у) по
формуле
е(х,у) = f(x,y) - f(x,y),
а величина общей ошибки между двумя изображениями равна
M-1N-1
Е Е у) - fix, у)]
а?=0 у=0
Среднеквадратическое отклонение (root-mean-square) erms между f(x, у) и f(x, у)
равно квадратному корню из средней квадратичной ошибки по всей матрице
MxN, т. е.
^ГГПБ —
‘ 1 M-1N-1 2
mn 52 Е (/(мнм)
а;=0 у=0
1/2
Следующая М-функция вычисляет егтБ и строит (если егтБ 0) изображение
е(т, у) и его гистограмму. Поскольку матрица е(х, у) может содержать как по-
ложительные, так и отрицательные величины, вместо imhist (которая работает
только с изображения) используется функция hist для построения гистограммы.
function rmse = compare(f1, f2, scale)
^COMPARE Computes and displays the error between two matrices.
% RMSE = COMPARE(F1, F2, SCALE) returns theroot-mean-square error
4 between inputs Fl and F2, displays a histogram of the difference,
'k and displays a scaled difference image. When SCALE is omitted, a
"k scale factor of 1 is used.
У, Check input arguments and set defaults.
error(nargchk(2, 3, nargin));
if nargin < 3
scale = 1;
end
8.2. Кодовая избыточность 299
7, Compute the root-mean-square error,
e double(fl) double(f2);
[m, n] size(e);
rmse sqrt(sum(e(:) ~2) / (m * n));
7, Output error image & histogram if an error (i.e. rmse 0).
if rmse
% Form error histogram.
emax max(abs(e(:)));
[h, x] hist(e(:), emax);
if length(h) >= 1
figure; bar(x, h, ’k’);
7, Scale the error image symmetrically and display
emax emax / scale;
e = mat2gray(e, [-emax, emax]);
figure; imshow(e);
end
end
Заметим, что кодер на рис. 8.1 отвечает за сокращение всех трех типов избы-
точности (кодовой, межпиксельной и визуальной) исходного изображения. На пер-
вой стадии процесса кодирования преобразователь трансформирует входное изоб-
ражение в некоторый (невизуальный) формат, приспособленный для понижения
межпиксельной избыточности. На второй стадии блок квантователь понижает
точность выхода преобразователя в соответствии с ранее оговоренным критери-
ем точности. На этой стадии происходит сокращение визуальной избыточности,
т. е. некоторое огрубление изображения, почти незаметное, однако, для глаза. Эта
процедура является необратимой, поэтому не выполняется, если необходимо со-
вершить сжатие без потери информации. На третьей и последней стадии процесса
кодер символов строит оптимальный код (который сокращает кодовую избыточ-
ность) для выхода квантователя и преобразует выходную последовательность в
соответствии с построенным кодом.
Декодер на рис. 8.1 имеет только две компоненты: декодер символов и об-
ратный преобразователь. Эти блоки совершают действия, обратные действиям
блока кодера символов и блока преобразователя. Поскольку процедура кванто-
вания не является обратимой, блок обратного квантователя отсутствует в общей
схеме декодера.
8.2. Кодовая избыточность
Пусть дискретная случайная величина при к = 1,2,... ,L с вероятностями
Рт-(гк) соответствует распределению уровней полутонового изображения, общее
число которых равно L. Как и в гл. 3, предполагается, что Г\ соответствует ну-
левому уровню (напомним, что индексы массивов в MATLAB начинаются с 1, а
не с 0). Пусть также
Рг(гк) = —, k = l,2,...,L,
п
300 Глава 8. Сжатие изображений
где пк равно числу появлений на изображении пикселов fc-ro уровня серого цве-
та, а п — общее число пикселов изображения. Если число битов, используемых
в цифровом представлении каждой величины г^, равно /('/>), то среднее число
битов, необходимое для представления каждого пиксела, равно
L
Aavg = 1(Гк)Рг(Гк)
к=1
Таким образом, средняя длина кодовых слов, назначаемых различным значениям
уровней серого цвета, находится суммированием произведений числа битов пред-
ставления каждого уровня на вероятность появления этого уровня. Значит, общее
число битов для кодирования изображения размерами МxN равно MNL^g.
Таблица 8.1. Иллюстрация кодовой избыточности: LaVg = 2 для Кода 1 и Lavg — 1-81
для Кода 2
Tfc Рг(гк) Код 1 Z1 (г к) Код 2 hCk)
Т1 0.1875 00 2 011 3
Г2 0.5000 01 2 1 1
ГЗ 0.1250 10 2 010 3
Г4 0.1875 11 2 00 2
Если все уровни изображения представлены обычным m-битовым двоичным
кодом, то правая часть последнего равенства, очевидно, сводится к т битам. В са-
мом деле, /(?>) = тп для любого т>, и этот множитель выносится за знак сумми-
рования, а сумма всехрг(?>) равна 1, и в итоге Lavg = т- Из табл. 8.1 следует, что
кодовая избыточность почти всегда присутствует, когда уровни градации серого
цвета кодируются обычными двоичными кодами фиксированной длины. В этой
таблице даны обе схемы кодирования пикселов четырехуровневого изображения,
распределение уровней которого дано во втором столбце. Кодирование каждого
уровня двумя битами (Код 1 в третьем столбце таблицы) дает среднюю длину
кодового слова, равную 2 битам. А средняя длина кода пиксела при кодировании
Кодом 2 (пятый столбец таблицы) равна
4
bavg = 1(тк}Рг(тк) = з • 0.1875 + 1 • 0.5 + 3 • 0.125 + 2 • 1.875 = 1.8125,
fc=i
и достигнутый коэффициент сжатия равен Cr = 2/1.8125 ~ 1.103. Эффект сжа-
тия при использовании Кода 2 достигается за счет того, что кодовые слова имеют
переменную длину, и это позволяет назначать короткие коды значениям пиксе-
лов, чаще других появляющимся на изображении.
Тогда возникает естественный вопрос: сколько битов требуется для оптималь-
ного представления уровней пикселов изображения? Иными словами, какой ми-
нимальный объем данных является достаточным для полного описания изобра-
жения без потери информации? С математической точки зрения, ответы на по-
добные вопросы дает наука теория информации. Основная посылка этой теории
заключается в том, что информационный поток можно моделировать в виде веро-
ятностного процесса, измерение которого хорошо согласуется с нашей интуицией.
8.2. Кодовая избыточность
В соответствии с этим положением можно считать, что случайная величина Е,
наблюдаемая с вероятностью Р(Е), несет
/(F) = log-^ = -logF(E)
единиц информации. Если Р(Е) = 1 (событие всегда наступает), то 1(E) = 0 и
здесь нет никакой информации. В самом деле, в этом случае нет неопределенно-
сти в наступлении данного события, и поэтому нет необходимости сообщать или
передавать информацию о том, что событие имело место. При таком подходе,
чем реже наступает событие, тем оно «ценнее» и, следовательно, несет в себе
ббльшую информацию. Имея источник случайных событий из дискретного се-
мейства возможных исходов {«1, а-2, , o-j} и соответствующий набор вероятно-
стей этих исходов {F(ai), Р(а,2), , F(aj)}, средняя информация, приходящаяся
на один выход источника, называемая энтропией этого источника, вычисляется
по формуле
J
H = -^P(aj)iogP(aj).
1=1
Если интерпретировать изображение как выборку, порождаемую некоторым «по-
лутоновым источником», то можно моделировать вероятности символов этого
источника с помощью гистограммы наблюдаемого полутонового изображения.
Тогда строится число, называемое оценкой первого порядка Н для энтропии ис-
точника:
L
н = - ^2pr(rk) logpr(rfc).
1=1
Эту оценку можно вычислять с помощью следующей М-функции в предположе-
нии, что каждый уровень серого цвета кодируется независимо от других. В этом
случае в теории информации доказано, что энтропия задает нижнюю границу
сжатия, которую можно достигнуть путем удаления кодовой избыточности.
function h = entropy(х, n)
'/oENTROPY Computes a first-order estimate of the entropy of a matrix.
7. H = ENTROPY(X, N) returns the first-order estimate of matrix X
7. with N symbols (N = 256 if omitted) in bits/symbol. The estimate
7. assumes a statistically independent source characterized by the
7. relative frequency of occurrence of the elements in X.
error(nargchkd, 2, nargin)); 7« Check input arguments
if nargin < 2
n 256; 7. Default for n.
end
x = double (x); 7» Make input double
xh hist(x(:), n); 7. Compute N-bin histogram
xh xh / sum(xh(:)); 7» Compute probabilities
% Make mask to eliminate 0’s since log2(0) = -inf.
302 Глава 8. Сжатие изображений
i = find(xh);
h = -sum(xh(i) .* Iog2(xh(i))); % Compute entropy
Обратите внимание на употребление функции find из MATLAB для нахождения
индексов ненулевых элементов гистограммы xh. Оператор f ind(x) эквивалентен
команде find(x ~= 0). Функция entropy использует find при построении ин-
дексного вектора i гистограммы xh, который будет использоваться в дальней-
шем для удаления всех нулевых значений из формулы для вычисления энтропии
в последней строке функции. Если не сделать этого, функция log2 выдаст для
h значение NaN (результатом команды 0*-inf является не число), когда вероят-
ность символа равна нулю.
Пример 8.1. Вычисление оценки первого порядка для энтропии.
Рассмотрим простое изображение 4x4, гистограмма которого (см. вектор р в сле-
дующем программном фрагменте) моделирует вероятности символов из табл. 8.1.
Следующая последовательность команд строит одно такое изображение и вычис-
ляет оценку первого порядка для его энтропии.
» f = [119 123 168 119; 123 119 168 168];
» f = [f; 119 119 107 119; 107 107 119 119]
f =
119 123 168 119
123 119 168 168
119 119 107 119
107 107 119 119
p = hist(f(:) , 8);
p = p / sum(p)
P =
0.1875 0.5 0.125 0 0 0 0 0.1875
h = entropy(f)
h =
1.7806
Код 2 из табл. 8.1 имеет среднюю длину Lavg — 1-81, которая приближает оценку
первого порядка для энтропии, равной минимальной длине двоичного кода для
изображения f. Заметим, что уровень 107 соответствует элементу п и имеет
двоичный код 0112 в табл. 8.1, 109 это г2 с двоичным кодом 12, а 123 и 168
имеют коды 0102 и 002 соответственно. □
8.2.1. Коды Хаффмана
При кодировании уровней полутонового изображения или выхода некоторой опе-
рации полутонового отображения (разности пикселов, длин серий и т. д.) коды
Хаффмана назначают символам источника наименьшее возможное число кодо-
вых символов (например, битов) при условии, что символы источника (например,
пикселы) кодируются по отдельности.
Первый шаг метода Хаффмана состоит в построении серии редуцированных
источников путем упорядочивания вероятностей символов данного источника и
8.2. Кодовая избыточность
объединения символов с наименьшими вероятностями в один символ, который бу-
дет их замещать в редуцированном источнике следующего уровня. Этот процесс
проиллюстрирован на рис. 8.2, а) для распределения уровней из табл. 8.1. В двух
левых колонках исходный набор символов источника и их вероятности упорядоче-
ны сверху вниз по убыванию вероятностей. Для формирования первой редукции
источника два символа с наименьшими вероятностями — в данном случае это czi
и аз с вероятностями 0.125 и 0.1875 — объединяются в один «составной символ»
с суммарной вероятностью 0.3125. Этот составной символ и связанная с ним ве-
роятность помещаются в список первого редуцированного источника, который
также упорядочивается от наибольшей вероятности к наименьшей [см. третью
колонку рис. 8.2, &Д- Этот процесс повторяется до тех пор, пока не образуется
редуцированный источник всего с двумя символами [самая правая колонка на
рис. 8.2, а)].
а)
Исходный источник Редуцированный источник
Символ Вероятность 1 2
а1 0.5 0.5 0.5
Од 0 1875 ► 0.3125 г -0.5
«1 0.1875 — 0.1875 1
Оз 0.125 —
б)
Исходный источник Редуцированный источник
Символ Вероятность Код 1 2
«2 0.5 1 0.5 1 0.5 1
а4 0.1875 00 0.3125 01 1— 0.5 0
«1 0.1875 011 0.1875 00- 1
0.125 010
Рис. 8.2. Метод кодирования Хаффмана: а) Редуцирование источника; б) Назначение
кодовых слов
Второй шаг процедуры Хаффмана состоит в кодировании каждого редуциро-
ванного источника, начиная с источника с наименьшим числом символов и дви-
гаясь к исходному источнику. Наименьший двоичный код для источника с двумя
имволами состоит, конечно, из символов 0 и 1. Как показано на рис. 8.2, б), эти
символы приписываются к двум символам источника справа (порядок присвое-
ния не имеет значения перестановка 0 и 1 даст абсолютно тот же результат).
Поскольку второй символ редуцированного источника с вероятностью 0.5 был
получен объединением двух символов предыдущего редуцированного источника
(расположенного слева от него), кодовый символ 0 приписывается каждому из
объединенных символов, после чего коды этих символов дополняются слева сим-
волами 0 и 1 (в произвольном порядке) для отличия их друг от друга. Затем эта
304 Глава 8. Сжатие изображений
операция повторяется для редуцированных источников всех уровней вплоть до
исходного источника. Окончательные коды для символов исходного источника
приведены в третьей колонке на рис. 8.2, б).
Код Хаффмана на рис. 8.2, б) (и из табл. 8.1) является мгновенно и однознач-
но декодируемым блоковым кодом. Код называется блоковым, поскольку каждый
символ источника отображается в фиксированную последовательность кодовых
символов. Он является мгновенно декодируемым, так как каждое кодовое слово
в закодированной последовательности можно декодировать независимо от после-
дующих кодовых символов. Это связано с тем, что в любом коде Хаффмана каж-
дое кодовое слово не является префиксом (началом) никакого другого кодового
слова. По этой же причине код Хаффмана является однозначно декодируемым,
так как любая последовательность, состоящая из кодовых слов кода Хаффмана,
может быть декодирована единственным способом. Таким образом, любую после-
довательность кодированных по Хаффману символов можно декодировать, ана-
лизируя ее слева направо. Изображение размером 4x4, рассмотренное в приме-
ре 8.1, кодируется по Хаффману в порядке строк сверху вниз и по столбцам слева
направо с помощью кодов из рис. 8.2, б), в результате чего получается последо-
вательность из 29 кодовых символов 10101011010110110000011110011. Поскольку
мы использовали мгновенно и однозначно декодируемый блоковый код, нет необ-
ходимости ставить разделительные символы между закодированными пиксела-
ми. Анализ этой кодовой последовательности слева направо обнаруживает, что
первым допустимым кодовым словом является 1, которое является кодом сим-
вола й2> отвечающего уровню серого цвета 109. Следующее допустимое кодовое
слово — это 010, которое соответствует уровню 123. Продолжая этот анализ, мы
в итоге получим полностью декодированное изображение, которое эквивалентно
изображению f из рассматриваемого примера.
Построение редуцированных источников и назначение кодовых слов по опи-
санной выше схеме реализованы в следующей М-функции, которую мы назвали
huffтёш:
function CODE huffman(p)
‘/«HUFFMAN Builds a variable-length Huffman code for a symbol source.
‘A CODE = HUFFMAN(P) returns a Huffman code as binary strings in
7» cell array CODE for input symbol probability vector P. Each word
7. in CODE corresponds to a symbol whose probability is at the
'A corresponding index of P.
7.
7. Based on huffman5 by Sean Danaher, University of Northumbria,
7« Newcastle UK. Available at the MATLAB Central File Exchange:
7. Category General DSP in Signal Processing and Communications.
7» Check the input arguments for reasonableness.
error(nargchk(1, 1, nargin));
if (ndims(p) "= 2) | (min(size(p)) > 1) | “isreal(p) | “isnumeric(p)
error(’P must be a real numeric vector.’);
end
7. Global variable surviving all recursions of function ’makecode’
8.2. Кодовая избыточность 305
global CODE
CODE = cell(length(p), 1); % Init the global cell array
if length (р) > 1 р = р / sum(p); % When more them one symbol % Normalize the input probabilities
s = reduce(р); makecode(s, []); % Do Huffman source symbol reductions % Recursively generate the code
else CODE = {’I’}; end; 7, Else, trivial one symbol case!
%- function s = reduce(p); -7.
7, Create a Huffman source reduction tree in a MATLAB cell structure
% by performing source symbol reductions until there are only two
% reduced symbols remaining
s cell(length(p), 1);
7. Generate a starting tree with symbol nodes 1, 2, 3, to
7. reference the symbol probabilities.
for i l:length(p)
s{i} = i;
end
while numel(s) > 2
[p, i] sort(p); p(2) p(l) + p(2) ; p(l) □; s s(i); % Sort the symbol probabilities % Merge the 2 lowest probabilities % and prune the lowest one 7. Reorder tree for new probabilities
s{2} {s{l}, s{2}}; s(l) []; % and merge & prune its nodes % to match the probabilities
end 7.- -7.
function makecode(sc, codeword)
7, Scan the nodes of a Huffman source reduction tree recursively to
7, generate the indicated variable length code words.
7. Global variable surviving all recursive calls
global CODE if isa(sc, ’cell’) 7. For cell array nodes,
makecode(sc{l}, [codeword 0]); % add a 0 if the 1st element
makecode(sc{2}, [codeword 1]); 7» or a 1 if the 2nd
else C0DE{sc} = char(’O’ + end % For leaf (numeric) nodes, codeword); % create a char code string
Следующая последовательность команд использует кодирование Хаффмана для
построения кодов рис. 8.2:
»р [0.18750.50.1250.1875];
>> с = huffman(p)
306 Глава 8. Сжатие изображений
С =
’011’
’1’
’010’
’00’
Отметим, что выходом служит массив, состоящий из строк переменной длины, в
котором каждый элемент представляет собой строку из нулей и единиц, что яв-
ляется двоичным кодом соответствующего индексированного символа из р. На-
пример, символьная строка ’010’ (в массиве имеет индекс 3) является кодом
уровня серого цвета с вероятностью 0.125.
В первых строках функции huff man осуществляется проверка входного ар-
гумента р (вектора вероятностей входных кодируемых символов) на предмет его
корректности и производится инициализация глобальной переменной CODE в виде
смешанного массива MATLAB (см. § 2.10.6), который имеет length(p) строк и
один столбец. Все глобальные переменные MATLAB должны быть продеклари-
рованы в функциях, которые будут их использовать, с помощью команды
global X Y Z.
Эта команда делает переменные X, Y и Z доступными в тех функциях, в кото-
рых они будут продекларированы. Когда несколько функций декларируют одни
и те же глобальные переменные, они используют одну и ту же копию этих пе-
ременных. В функции huff man основная программа, а также внешняя функция
makecode используют общую глобальную переменную CODE. Обратим ваше вни-
мание на то, что общепринято писать имена глобальных переменных заглавными
буквами. Неглобальные переменные являются локальными переменными, и их
можно использовать лишь в тех функциях, где они объявлены (но не в других
функциях или в основном рабочем пространстве). Имена локальных переменных
принято писать строчными буквами.
В huf fman переменная CODE инициализируется с помощью функции cell, ко-
торая имеет следующий синтаксис1:
X cell(m, п).
При исполнении этой команды строится массив тхп матриц, к элементам кото-
рых можно обращаться как к смешанному массиву или по содержимому. Круглые
скобки «( )» используются для индексации смешанного массива; фигурные скоб-
ки «{ }» используются для индексации содержимого. Итак, команда Х(1) = []
индексирует и удаляет элемент 1 из смешанного массива, в то врем как Х{1} = []
присваивает первому элементу массива пустую матрицу. То есть, Х{ 1} обращает-
ся к содержимому первого элемента (массива), а Х(1) обозначает сам этот элемент
(а не его содержимое). Поскольку смешанные массивы могут находиться внут-
ри других смешанных массивов, синтаксис типа Х{1}{2} обращается ко второму
1 Эквивалентное выражение имеет вид X = cell([m, п] ). Другие формы вызова отображаются
командой
>> help cell
8.2. Кодовая избыточность
элементу смешанного массива, который является первым элементом смешанного
массива X.
После инициализации переменной CODE и нормирования входного вектора ве-
роятностей [по команде р = р / sum(p)] код Хаффмана для нормированного
вектора вероятностей р строится за два шага. На первом шаге, который начинает-
ся оператором s = reduce (р) основной программы, вызывается внешняя функ-
ция reduce, которая совершает редуцирование источника, проиллюстрированное
на рис. 8.2, а). В подпрограмме reduce элементы изначально пустого смешанного
массива s редуцированного источника, размер которого согласован с CODE, ини-
циализируются своими индексными значениями. Т. е. s{l} = 1, s{2} = 2 и т.д.
После этого в цикле while numel(s) > 2 создается двоичное дерево редуциро-
ванных источников, эквивалентное смешанному массиву. На каждом шаге цикла
вектор р упорядочивается в восходящем порядке вероятностей. Это совершается
функцией sort, имеющей синтаксис
[y,i] =sort(x),
где в выход у записывается вектор упорядоченных элементов вектора х, а ин-
дексный вектор i удовлетворяет соотношению у = x(i). После упорядочения
вектора р две наименьшие вероятности сливаются путем помещения их суммы
в р(2), а элемент р(1) выбрасывается. После этого смешанный массив реду-
цированного источника переупорядочивается, чтобы соответствовать р на базе
индексного вектора i с помощью операции s s(i). Наконец, s{2} заменяется
смешанным массивом из двух элементов, в котором записаны индексы слившихся
вероятностей по формуле s{2} = s{2}} (пример индексирования по со-
держимому), а индексирование по массиву используется для удаления первого из
двух слившихся элементов s(l) по правилу s(l) = [ ]. Процесс продолжается
до тех пор, пока в s не останется только два элемента.
Источник
символов
а)
Корень
Второе
редуцирование
источника
Первое
редуцирование
источника
в)
5{1}{1} = 4
S{1}{2}{1} = 3
s{l}{2}{2} = 1
s{2} = 2
Рис. 8.3. Редуцирование источника на рис. 8.2, а) с помощью функции Huffman: а) Экви-
валентное двоичное дерево; б) Изображение, построенное cellplot (в); в) Выход
команды celldiBp(e)
На рис. 8.3 показан результат процесса обработки вероятностей символов из
табл. 8.1 и рис. 8.2, а). Рис. 8.3, б) и в) были получены при подстановке пары
308 Глава 8. Сжатие изображений
команд
celldisp(s);
cellplot(s);
между двумя последними исполняемыми строками основной программы huffman.
Функция MATLAB celldisp рекурсивно печатает содержимое смешанного мас-
сива, а графическая функция cellplot представляет смешанный массив в виде
семейства вложенных прямоугольных блоков. Обратите внимание на взаимно од-
нозначное соответствие между элементами смешанного массива на рис. 8.3, б) и
узлами дерева редуцированного источника. На рис. 8.3, а)\
(1) каждая пара разветвляющихся ветвей дерева (которая обозначает редуци-
рование источника) соответствует двухэлементному смешанному массиву в s;
(2) каждый двухэлементный смешанный массив содержит индексы символов,
которые были слиты в один символ в процессе редуцирования.
Например, объединение символов аз и ai в основании дерева порождает двух-
элементный смешанный массив s{l}<2}, где s{ 1}{2}<1} = 3 и s{l}{2}{2} 1
(индексы аз и ai соответственно). Корень дерева, расположенный сверху, обра-
зует двухэлементный смешанный массив s самого верхнего уровня.
Последний шаг процесса построения кода (т. е. присвоение кодовых слов на основе
редуцированного источника) осуществляется вызовом функции makecode (s, [ ]).
Это обращение инициирует рекурсивную процедуру присвоения кода, основан-
ную на схеме рис. 8.2, б). Хотя рекурсивное задание не обеспечивает сохранение
в памяти (поскольку стек обработанных величин должен где-то храниться) или
увеличения скорости, оно имеет то преимущество, что код получается более ком-
пактным и его легче понять, особенно при работе с такой рекурсивно заданной
структурой данных, как дерево. Любую функцию MATLAB можно использовать
рекурсивно, т. е. она может вызывать сама себя явно или неявно. При использо-
вании рекурсии каждый вызов функции порождает новое множество локальных
переменных, которое не зависит от всех предыдущих подобных множеств.
Внешняя функция makecode принимает два входные параметра: codeword,
массив из нулей и единиц, и sc, элемент смешанного массива редуцированно-
го источника. Когда sc сам является смешанным массивом, он состоит из двух
символов источника (или составных символов), которые были объединены в про-
цессе редуцирования. Поскольку их необходимо кодировать раздельно, делается
два рекурсивных обращения (к функции makecode) наряду с двумя подходя-
щим образом обновленными кодовыми словами (0 и 1 добавляются к входному
codeword). Когда sc не содержит смешанный массив, он является индексом сим-
вола изначального источника и ему присваивается двоичная кодовая последова-
тельность, построенная по codeword с помощью операции
C0DE{sc} = char(’О’ + codeword).
Как отмечалось в § 2.10.5, функция MATLAB char преобразует массив, содержа-
щий положительные целые числа, представляющие коды символов в символьный
массив MATLAB (первые 127 кодов представляют собой стандартные ASCH коды
символов). Значит, к примеру, char (’O’ +[0 1 0] ) породит символьную строку
’010’, поскольку добавление 0 к ASCII коду нуля даст ASCII ’О’, а прибавле-
ние 1 к ASCII ’0’ даст ASCII код 1, а именно ’1’
Таблица 8.2. Процесс назначения кодов для смешанного массива редуцированного источ-
ника на рис. 8.3
Вызов Источник sc Кодовое слово
1 main routine {1x2 cell} [ ]
[2]
2 makecode [4] {1x2 cell} 0
3 makecode 4 0 0
4 makecode [3] [1] 0 1
5 makecode 3 0 10
6 makecode 1 Oil
7 makecode 2 1
Табл. 8.2 детализирует последовательность вызовов makecode, которые про-
изводятся в соответствии со смешанным массивом редуцированного источника
на рис. 8.3. Чтобы закодировать 4 символа изначального источника, потребова-
лось 7 вызовов этой функции. Первый вызов (строка 1 в табл. 8.2) совершается из
основной программы huffman. Он запускает процесс кодирования с присвоением
входам codeword и sc, соответственно, пустой матрицы и смешанного массива s.
В соответствии со стандартным обозначением MATLAB, {1x2 cell} обозначает
смешанный массив из одной строки и двух столбцов. Поскольку sc почти все-
гда является смешанным массивом при первом вызове (исключение составляет
источник, состоящий из одного элемента), совершаются два рекурсивных вызова
(см. строки 2 и 7). Первый из этих вызовов инициирует еще два вызова (строки 3
и 4), а второй инициирует два дополнительных вызова (строки 5 и 6). Во всех слу-
чаях, когда sc не является смешанным массивом, как это имеет место в строках
3, 5, 6 и 7 таблицы, дополнительные рекурсии не нужны; кодовая последователь-
ность строится по codeword и назначается символу источника, чей индекс был
передан как sc.
8.2.2. Кодирование Хаффмана
Построение кодов Хаффмана само по себе не является сжатием. Чтобы получить
эффект сжатия, заложенный в эти коды, символы соответствующего источника,
независимо от их природы (уровни серых тонов, длины серий или выходы иных
операций отображения уровней), необходимо преобразовать или трансформиро-
вать (т. е. закодировать) в соответствии с построенным кодом.
Пример 8.2. Отображение кодов переменной длины в MATLAB.
Рассмотрим простое 16-ти байтовое изображение размерами 4x4:
>>f2 uint8([2 34 2; 324 4; 2212; 112 2])
f2
2 3 4 2
3 2 4 4
310 Глава 8. Сжатие изображений
2 2 12
112 2
>> whos(’f2’)
Name Size Bytes Class
f2 4x4 16 uint8 array
Grand total is 16 elements using 16 bytes
Каждый пиксел в f 2 является байтом, состоящим из 8 битов. Для представ-
ления всего изображения используется 16 байтов. Поскольку уровни серых тонов
в f 2 не являются равновероятными, коды переменной длины (как отмечалось в
предыдущем параграфе) позволят сократить объем памяти, которая потребуется
для хранения этого изображения. Функция huf fman строит Один из таких кодов:
с = huffmanChist(double(f2(:)), 4))
’Oil’
’1’
’010’
’00’
Поскольку коды Хаффмана основаны на относительных частотах появления сим-
волов источника (но не на самих символах), которые требуется закодировать, код
с идентичен коду, построенному для изображения из примера 8.1. На самом деле,
изображение f2 можно получить из f (пример 8.1) путем отображения уровней
107,119,123 и 168 в числа 1, 2, 3 и 4. Оба изображения имеют одинаковый вектор
частот р = [0.1875 0.5 0.125 0.1875].
Простейший путь кодирования f 2 с помощью кода с заключается в соверше-
нии следующих операций:
»hlf2 = c(f2(:)) ’
hlf2 =
Columns 1 through 9
’1’ ’010’ ’1’ ’Oil’ ’010’ ’1’ ’1’ ’Oil’ ’00’
Columns 10 through 16
’00’ ’Oil’ ’1’ ’1’ ’00’ ’1’ ’1’
>> whos(’hlf2’)
Name Size Bytes Class
hlf2 1x16 1530 cell array
Grand total is 45 elements using 1530 bytes
Здесь изображение f2 (двумерный массив класса UINT8) преобразован в сме-
шанный массив hlf2 размерами 1x16 (операция транспонирования применена
для экономии бумаги). Элементами hlf 2 являются символьные строки перемен-
ной длины, а соответствующие пикселы f 2 расположены в порядке считывания
сверху вниз и слева направо (т. е. по столбцам). Как видно из этой распечатки,
закодированное изображение занимает 1530 байт, т. е. памяти требуется почти в
100 раз больше, чем при хранении самого изображения f 21
8.2. Кодовая избыточность
Использование смешанного массива hl 12 вполне логично, поскольку это один
из двух стандартных типов данных в MATLAB (см. § 2.10.6) для представле-
ния разнородных данных. В случае с hlf 2 эта разнородность означает различие
длин символьных строк, и платой за удобство обращения с ними посредством
смешанного массива служит существенное увеличение требуемой памяти (при-
сущее смешанным массивам), которое требуется для отслеживания положения
элементов переменной длины. Этот излишний расход памяти можно устранить
путем преобразования hlf 2 в обычный двумерный символьный массив:
»h2f2 = char(hlf2)’
h212 =
1010011000011011
1 11 1001 0
0 10 1 1
» whos(’h2f2’)
Name Size Bytes Class
h212 3x16 96 char array
Grand total is 48 elements using 96 bytes.
Здесь смешанный массив hlf 2 преобразован в символьный массив h2f 2 размера-
ми 3x16. Каждый столбец h2f2 соответствует пикселу в 12 в порядке сканирова-
ния сверху вниз и слева направо (т. е. по столбцам). Отметим, что в массиве h2f 2
вставлены символы пробелов для правильного соответствия битов по столбцам.
Поскольку два байта требуется для каждого символа ’ 0 ’ или ’ 1 ’ кодовых слов,
для хранения h2f 2 требуется 96 байт — все еще в 6 раз больше, чем исходные
16 байт, необходимые для хранения 12. Мы можем избавиться от вставки пустых
символов с помощью операций
»h212 = h2f2(:) ;
» h2f2(h212 == ’
’) [];
» whos(’h212’)
Name Size Bytes Class
h212 29x1 58 char array
Grand total is 29 elements using 58 bytes
Но требуемый объем памяти по-прежнему превосходит 16 байт для хранения 12.
Чтобы по-настоящему сжать 12, код с должен проявиться на битовом уровне,
когда несколько закодированных пикселов пакуются в один байт:
>>h312 = mat2huff(f2)
h312 =
size: [4 4]
min: 32769
hist: [3823]
code: [43867 1944]
» whos(’h312’)
Name Size Bytes Class
h312 1x1 518 struct array
Grand total is 13 elements using 518 bytes
312 Глава 8. Сжатие изображений
Несмотря на то, что функция mat2huff возвращает структуру h3f 2, которой тре-
буется для хранения 518 байт памяти, большая ее часть связана со служебной
информацией о структурной переменной (напомним,что в § 8.1 при обсуждении
функции imratio сообщалось, что MATLAB использует 124 дополнительные бай-
та на одно поле структуры), а также с тем, что mat2huf f генерирует некоторую
информацию, облегчающую будущее декодирование. Пренебрегая этими излиш-
ками памяти, которые пренебрежимо малы при работе с практически значимыми
изображениями (нормальных размеров), mat2huff сжимает f 2 с коэффициентом
4 1, а именно: 16 пикселов по 8 бит в f2 сжимаются до двух 16-ти битовых
слов — элементов поля code в h3f 2:
>>hcode = h3f2.code;
>>whos (’hcode ’)
Name Size Bytes Class
hcode 1x2 4 uintl6 array
Grand total is 2 elements using 4 bytes
>>dec2bin(double (hcode))
ans =
1010101101011011
0000011110011000
Отметим, что функция dec2bin2 была использована для отображения индивиду-
альных битов в h3f2.code. Пренебрегая завершающими тремя битами, которые
дополняют данные до объема, кратного 16, (т. е. нули в конце), можно сказать, что
это кодирование 32-мя битами эквивалентно кодированию 29 битами мгновенно
и однозначно декодируемым блоковым кодом 10101011010110110000011110011. □
Как было отмечено в предыдущем примере, функция mat2huff помещает ин-
формацию, необходимую для декодирования закодированного входного массива
(т. е. его исходные размеры и значения вероятностей символов), в одну структур-
ную переменную MATLAB. Сведения об этой переменной задокументированы в
справочной секции самой функции mat2huf f .3
function у = mat2huff(x)
7.MAT2HUFF Huffman encodes a matrix.
% Y = MAT2HUFF(X) Huffman encodes matrix X using symbol
7. probabilities in unit-width histogram bins between X’s minimum
7, and maximum values. The encoded data is returned as a structure
7. Y:
7. Y.code The Huffman-encoded values of X, stored in
7. a uintl6 vector. The other fields of Y contain
% additional decoding information, including:
7. Y.min The minimum value of X plus 32768
2Функция dec2bin преобразует десятичное целое число в двоичную строку. Для получения
большей информации наберите команду
>> help dec2bin.
3Функция histc аналогична функции hist. Для дополнительной информации выполните
» help histc
8.2. Кодовая избыточность 313
7. Y.size The size of X
7. Y.hist The histogram of X
7.
7, If X is logical, uint8, uintl6, uint32, int8, intl6, or double,
7. with integer values, it can be input directly to MAT2HUFF. The
7, minimum value of X must be representable as an intl6.
7.
7. If X is double with non-integer values- -for example, an image
7» with values between 0 and 1--first scale X to an appropriate
7» integer range before the call. For example, use Y
7o MAT2HUFF(255*X) for 256 gray level encoding.
7.
7» NOTE: The number of Huffman code words is round(max(X(:)))
7» round(min(X(:)) ) + 1. You may need to scale input X to generate
7. codes of reasonable length. The maximum row or column [dimension
7. of X is 65535.
7.
7» See also HUFF2MAT.
if ndims(x) ~= 2 | ~isreal(x) | ("isnumeric(x) & ~islogical<x))
error(’X must be a 2-D real numeric or logical matrix.’);
end
7, Store the size of input x.
y.size = uint32(size(x));
7. Find the range of x values and store its minimum value biased
7d by +32768 as a UINT16.
x = round(double(x));
xmin = min(x(:));
xmax = max(x(:));
pmin = double(intl6(xmin));
pmin = uintl6(pmin + 32768); y.min pmin;
7. Compute the input histogram between xmin and xmax with unit
7. width bins, scale to UINT16, and store.
x = x(:)’;
h = histc(x, xmin:xmax);
if max(h) > 65535
h 65535 * h / max(h);
end
h uintl6(h); y.hist h;
7. Code the input matrix and store the result.
map = huffman(double(h)); 7» Make Huffman code map
hx = map(x(:) xmin + 1); 7» Map image
hx = char(hx)’; 7» Convert to char array
hx hx(:)’; hx(hx == ’ ’) []; 7. Remove blanks
ysize ceil(length(hx) / 16); 7. Compute encoded size
hxl6 = repmat(’O’, 1, ysize * 16); 7« Pre-allocate modulo-16 vector
314 Глава 8. Сжатие изображений
hxl6(l:length(hx)) = hx; 7, Make hx modulo-16 in length
hxl6 = reshape(hxl6, 16, ysize); °k Reshape to 16-character words
hxl6 hxl6’ ’O’; 7, Convert binary string to decimal
twos = pow2(15:-1:0);
y.code = uintl6(sum(hxl6 .* twos(ones(ysize, 1), 2))’;
Обратите внимание на то, что команда у = mat2huf f (х) кодирует по Хаффману
матрицу х с помощью гистограммных корзин единичной длины, размещенных на
интервале от минимального до максимального значения матрицы х. При даль-
нейшем декодировании данных, закодированных в y.code, нужный код Хафф-
мана должен быть воссоздан по у.min, минимальному значению х, и по у.hist,
гистограмме х. Вместо того, чтобы хранить таблицу кода Хаффмана, функция
mat2huff сохраняет информацию о вероятностях символов, достаточную для вос-
становления этого кода. Имея эти данные, а также исходный размер матрицы х,
который записан в поле у.size, функция huff2mat, рассматриваемая в следую-
щем параграфе этой главы, сможет декодировать y.code и восстановить х.
Шаги при построении у. code можно резюмировать следующим образом:
1. Вычислить гистограмму h входа х между минимальным и максимальным
значениями х с помощью корзин единичной длины и нормировать ее так,
чтобы ее значения помещались в вектор UINT16.
2. Использовать функцию huff man для построения кода Хаффмана, который
называется тар, на основе гистограммы h.
3. Преобразовать х с помощью тар (при этом образуется смешанный массив) и
конвертировать результат в символьный массив hx, удаляя пустые символы,
которые были вставлены на манер примера 8.2 при обработке матрицы h2f 2.
4. Сконструировать вариант вектора hx, в котором символы организованы в
виде сегментов из 16-ти символов. Это делается разбиением hx на отрезки
по 16 символов (Ьх16 в программе) и приданием им формы матрицы из 16
строк и ysize столбцов, где ysize = ceil (length(hx) / 16). Напомним,
что функция ceil (см. §4.2) округляет число в сторону положительной бес-
конечности. Обобщенная функция MATLAB
у = reshape(х, т, п)
возвращает матрицу размерами ш на п, элементы которой взяты по столб-
цам матрицы х, и делает сообщение об ошибке, если в х нет m*n элементов.
5. Конвертировать элементы по 16 символов из hxl6 в 16-ти битовые числа
(т. е. в формате uintl6). Три завершающие операции выполняют действия,
эквивалентные одной компактной команде у = uintl6(bin2dec(hxl6’)).
Они являются ядром функции bin2dec, которая возвращает десятичный эк-
вивалент двоичной строки (например, bin2dec (’ 101 ’) дает результат 5), но
выполняется существенно быстрее. Функция MATLAB pow2(y) применяет-
ся для построения массива, равного числу 2, возведенному поэлементно в степе-
ни у; т.е. twos = pow2(15:-1:0) порождает массив [32768163848192.. .8421].
8.2. Кодовая избыточность
Пример 8.3. Кодирование с помощью mat2huff.
Чтобы проиллюстрировать степень сжатия при кодировании Хаффмана, рас-
смотрим 8-ми битовое монохромное изображение 512x512 на рис. 8.4, а). Сжатие
этого изображения функцией mat2huf f осуществляется посредством следующих
команд:
f
с =
crl
imread(’Tracy.tif’);
mat2huff(f ) ;
imratio(f, c)
crl =
1.2191
С помощью удаления кодовой избыточности, присутствующей в исходном изоб-
ражении, представленном обычными 8-ми битовыми кодами, нам удалось сжать
это изображение примерно до 80% от его исходного размера (даже при включе-
нии в сжатый файл служебной информации).
Рис. 8.4. Монохромное 8-ми
битовое изображение женщи-
ны размерами 512x512 и уве-
личенное изображение ее пра-
вого глаза
Поскольку выход mat2huff представляет собой структуру, мы запишем ее на
диск с помощью функции save:
» save SqueezeTracy с;
» cr2 = imratio(’Tracy.tif’, ’SqueezeTracy.mat’)
cr2 =
1.2365
Функция save4, аналогично командам Save Workspace и Save Selection As
из меню команд (см. § 1.7.4), добавляет расширение .mat к создаваемому файлу.
Полученный файл в нашем случае, SqueezeTracy.mat называется МАТ-
файлом. Он является файлом двоичных данных, в котором хранятся имена ра-
бочих переменных и их значения. В нашем случае в файле хранится всего одна
рабочая переменная с. Отметим, что небольшая разница в коэффициентах сжа-
тия crl и сг2 связана с размерами служебных данных файлов MATLAB. □
4 В синтаксической форме save file var эта функция записывает на диск рабочую переменную
var в виде файла данных MATLAB с именем ’file.mat’.
Глава 8. Сжатие изображений
8.2.3. Декодирование Хаффмана
Изображения, закодированные по Хаффману, будут бесполезными, пока их нель-
зя продекодировать и получить исходные изображения, по которым они были
построены. Для выхода у = mat2huff(х), описанного в предыдущем параграфе,
декодер должен сначала построить соответствующий код Хаффмана, по которо-
му кодировалось изображение х (по его гистограмме и связанной информации
в у), а затем сделать обратное отображение закодированных данных (которые
также извлекаются из у) для реконструкции х. Как видно из прилагаемого да-
лее листинга функции huff2mat, эти действия можно разложить на 5 основных
шагов:
1. Извлечь размеры m и п, а также минимальное значение xmin (возможного
выхода х) из входной структуры у.
2. Реконструировать код Хаффмана, которым было закодировано х, пропу-
стив его гистограмму через функцию huff man. Полученный результат в
программе носит имя тар.
3. Построить структуру данных (таблицу переходов и выходов link) для упро-
щения декодирования данных в у. code путем ряда эффективных процедур
двоичного поиска.
4. Пропустить построенную структуру и закодированные данные (т. е. link
и у. code) через С-функцию unravel. Эта функция минимизирует время
выполнения операций двоичного поиска и строит выходной декодированный
вектор х класса double.
5. Добавляет xmin к каждому элементу х и придает ему форму и размеры
исходного изображения х (т. е. форму матрицы с m строками и п столбцами).
Единственная особенность функции huf f2mat заключается в вызове С-функ-
ции unravel из тела М-функции MATLAB (см. шаг. 4), что делает декодирование
изображений нормального разрешения почти мгновенным.
function х huff2mat(y)
7»HUFF2MAT decodes a Huffman encoded matrix.
7. X HUFF2MATCY) decodes a Huffman encoded structure Y with uintl6
7» fields:
7» Y.min Minimum value of X plus 32768
7» Y.size Size of X
7. Y.hist Histogram of X
7. Y.code Huffman code
7.
7» The output X is of class double.
7.
7. See also MAT2HUFF.
if "isstruct(y) | ~isfield(y, ’min’) | ~isfield(y, ’size’) |
~isfield(y, ’hist’) | ~isfield(y, ’code’)
error(’The input must be a structure as returned by MAT2HUFF.’);
end
sz = double(y.size); m = sz(l); n = sz(2);
8.2. Кодовая избыточность
xmin = double (у. min) 32768; X Get X minimum
map = huffman(double(y.hist)); X Get Huffman code (cell)
7. Create a binary search table for the Huffman decoding process.
X ’code’ contains source symbol strings corresponding to ’link’
"X nodes, while ’link’ contains the addresses (+) to node pairs for
X node symbol strings plus ’0’ and ’1’ or addresses (-) to decoded
X Huffman codewords in ’map’ Array ’left’ is a list of nodes yet to
X be processed for ’link’ entries.
code = cellstr(char(>, ’O’, ’1’)); X Set starting conditions as
link [2; 0; 0]; left = [2 3]; 7» 3 nodes w/2 unprocessed
found = 0; tofind = length(map) ; Tracking variables
while length(left) Sc (found < tofind)
look = f ind(strcmp(map, code-Cleft(l))-)); X Is string in map?
if look
link(leftd)) = -look;
left left(2:end);
found found + 1;
else
len = length(code);
link(left(l)) = len + 1;
link [link; 0; 0];
X Yes
X Point to Huffman map
X Delete current node
X Increment codes found
X No, add 2 nodes Sc pointers
X Put pointers in node
X Add unprocessed nodes
code{end + 1} = strcat(code{left(l)}, ’O’);
code{end + 1} = strcat(code{left(l)}, ’1’);
left
left
end
left(2:end); X
[left len + 1 len + 2] ; X
Remove processed node
Add 2 unprocessed nodes
end
x = unravel(y.code’, link, m * n);
x x + xmin 1;
x = reshaped, m, n) ;
X Decode using C ’unravel
X X minimum offset adjust
X Make vector an array
Как уже отмечалось ранее, декодирование huff 2mat основано на сериях опе-
раций двоичного поиска с двумя исходящими решениями декодирования. Каж-
дый элемент последовательно просматриваемой строки символов, закодирован-
ной по Хаффману (т. е. О или 1), переключает двоичное решение декодирова-
ния, основанное на таблице переходов и выходов link. Построение link начи-
нается ее инициализацией командой link = [2; 0; 0]. Каждый элемент исход-
ного массива link, состоящего из трех элементов, соответствует закодирован-
ной двоичной последовательности в смешанном массиве code. В начале code
cell str (char (>, ’O’, ’1’)). Пустая строка code (1) является исходной точ-
кой (начальным состоянием) любого декодирования Хаффмана. Ассоциирован-
ное число 2 в link(l) обозначает два возможных состояния декодирования, кото-
рые следуют за добавлением к нулевой строке ’ 0 ’ или ’ 1 ’. Если следующий зако-
дированный бит равен ’О’, то следующее состояние декодирования есть link(2)
(поскольку code(2) ’0’ нулевая строка соединяется с ’О’); если этот бит ра-
вен ’ 1’, то новое состояние будет link(3) [с индексом (2+1) или 3, со значением
318 Глава 8. Сжатие изображений
code (3) ’ 1 Обратите внимание на то, что соответствующие значения в link
равны 0. Это означает, что они еще не были обработаны для получения подходя-
щих решений для кода Хаффмана тар. При построении link, если в тар найдена
строка (т. е. ’0 ’ или ’ 1 ’, что означает настоящее кодовое слово), то соответству-
ющий 0 в link заменяется на соответствующий индекс тар со знаком минус (это
декодированная величина). В противном случае новый (положительный) индекс
тар вставляется по указателю на два новые состояния (возможные кодовые слова
Хаффмана) в логической последовательности (или ’ 00 ’ и ’01’, или ’ 10 ’ и ’11’).
Эти новые и еще не обработанные элементы link увеличивают размер link (сме-
шанный массив code также необходимо обновить), после чего процесс построе-
ния продолжается до тех пор, пока в link остаются необработанные элементы.
Вместо того, чтобы непрерывно сканировать link на предмет необработанных
элементов, функция huff 2mat строит массив отслеживания с именем left, кото-
рый в начале процесса равен [2, 3], и каждый раз обновляет его, чтобы в нем
находились индексы неисследованных элементов link.
Таблица 8.3. Таблица декодирования смешанного массива редуцированного источника
нв рис. 8.3
Индекс i Значение link(i)
1 2
2 4
3 —2
4 —4
5 6
6 -3
7 -1
В табл. 8.3 показана таблица link, которая строится для кода Хаффмана из
примера 8.2. Если каждый индекс link рассматривать в качестве состояния деко-
дирования i, то каждое двоичное решение кодирования (при просмотре кодовой
последовательности слева направо) и/или выход декодера Хаффмана определя-
ется по link(i) по следующим правилам:
1. Если link(i) < 0 (отрицательно), то кодовое слово Хаффмана уже было
продекодировано. Выход декодера есть |link(i)|, где | | обозначает абсо-
лютную величину.
2. Если lirik(i) > 0 (положительно), и следующий обрабатываемый бит ра-
вен 0, то следующее состояние декодирования — это индекс link(i), т. е.
мы полагаем i lirik(i).
3. Если11пк(1) > 0 и следующий обрабатываемый бит равен 1, то следующее
состояние декодирования — это индекс link(i) + 1, т. е. мы полагаем i
lirik(i) + 1.
Как ранее отмечалось, положительные компоненты link соответствуют дво-
ичным переходам декодирования, а отрицательные компоненты определяют про-
декодированные выходные значения. После декодирования каждого кодового слова
Хаффмана начинается новый двоичный поиск с индексом link равным i 1.
При декодировании строки 101010110101... из примера 8.2 последовательность
8.2. Кодовая избыточность
состояний переходов: i = 1, 3, 1, 2, 5, 6, 1, .;а соответствующая после-
довательность выходов: -, |-2|, |-3|, . где знак обозначает
отсутствие выхода. Декодированные выходные значения 2 и 3 являются первыми
двумя пикселами из первого столбца тестового изображения f 2 в примера 8.2.
С-функция unravel принимает описанную выше структуру link и использует
ее в процедуре двоичного поиска, нужного для декодирования входа hx. Блок-
схема на рис. 8.5 отображает основные действия unravel, которые производятся
в процессе принятия решений, которые объяснялись вместе с табл. 8.3. Отметим,
что при написании программы на С потребовалось вносить некоторые поправки,
связанные с тем, что индексы массивов в С начинаются с 0, а не с 1.
Рис. 8.5. Блок-схема С-функ-
ции unravel
В систему MATLAB можно внедрять функции, написанные на языках С и
Fortran, что служит двум целям:
(1) появляется возможность вызывать в MATLAB огромное количество име-
ющихся программ на С и Fortran без необходимости их переписывания и
отлаживания в виде М-файлов, и
Глава 8. Сжатие изображений
(2) можно оптимизировать критически важные вычислительные процессы, т. е.
алгоритмы, реализации которых на MATLAB работают недостаточно быст-
ро, запрограммировать на С или на Fortran более эффективно, воспользо-
вавшись близостью этих языков к машинному коду.
При использовании С или Fortran, функции, написанные на этих языках, назы-
ваются МЕХ-файлами5 С ними можно обращаться как с обычными М-файлами
или М-функциями MATLAB, но сначала их надо откомпилировать с помощью
специальной программы MATLAB, которая называется тех. Например, для ком-
пиляции программы unravel при работе в операционной среде Windows необхо-
димо в командной строке MATLAB выполнить следующую команду:
» тех unravel.с
При этом образуется МЕХ-файл unravel.dll с расширением .dll. Функцию
МЕХ можно сопроводить любой справочной информацией, которую следует рас-
положить в отдельном М-файле с тем же именем (и с расширением .ш).
Следующий код функции на языке С для МЕХ-файла unravel имеет расши-
рение -с:
*================================================
* unravel.с
* Decodes a variable length coded bit sequence (a vector of
* 16-bit integers) using a binary sort from the MSB to the LSB
* (across word boundaries) based on a transition table.
*===================—============================ ====*/
#include >mex.h>
void unravel(unsigned short *hx, double *link, double *x,
double xsz, int hxsz)
int i 15, j 0, k = 0, n 0; /* Start at root node, 1st */
/* hx bit and x element */
while (xsz k) { /* Do until x is filled */
if (*(link + n) > 0) { /* Is there a link? */
if ((*(hx + j) >> i) & 0x0001) /* Is bit a 1? */
n *(link + n); /* Yes, get new node */
else n *(link + n) 1; /* It’s 0 so get new node */
if (i) i-; else <j++; i 15;} /* Set i, j to next bit */
if (j > hxsz) /* Bits left to decode? */
mexErrMsgTxt(>Out of code bits ???>);
)
else { /* It must be a leaf node */
*(x + k++) -*(link + n); /* Output value */
n = 0; } /* Start over at root */
5МЕХ-функция (Matlab External function) строится по программному коду С или Fortran. Ее
расширение зависит от компьютерной платформы. (Например, в Windows используется расши-
рение .dll)
8.2. Кодовая избыточность 321
if (к xsz 1) /* Is one left over? */
*(x + k++) -*(link + n);
void mexFunction(int nlhs, mxArray *plhs[],
int nrhs, const mxArray *prhs[])
{
double *link, *x, xsz;
unsigned short *hx;
int hxsz;
/* Check inputs for reasonableness */
if(nrhs != 3)
mexErrMsgTxt(>Three inputs required.>);
else if (nlhs > 1)
mexErrMsgTxt(>Too many output arguments.>);
/* Is last input argument a scalar? */
if (!mxIsDouble(prhs[2]) || mxIsComplex(prhs[2]) ||
mxGetN(prhs [2]) * mxGetM(prhs[2]) != 1)
mexErrMsgTxt(>Input XSIZE must be a scalar.>);
/* Create input matrix pointers and get scalar */
hx mxGetPr(prhs[0]); /* UINT16 */
link = mxGetPr(prhs [1]); /* DOUBLE */
xsz = mxGetScalar(prhs[2]); /* DOUBLE */
/* Get the number of elements in hx */
hxsz mxGetM(prhs[0]);
/* Create ’xsz’ x 1 output matrix */
plhs[0] = mxCreateDoubleMatrix(xsz, 1, mxREAL);
/* Get C pointer to a copy of the output matrix */
x = mxGetPr(plhs[0]);
/* Call the C subroutine */
unravel(hx, link, x, xsz, hxsz);
Сопроводительная справочная информация помещается в файле unravel.ш:
7UNRAVEL Decodes a variable-length bit stream.
7 X UNRAVEL(Y, LINK, XLEN) decodes UINT16 input vector Y based on
7 transition and output table LINK. The elements of Y are
7 considered to be a contiguous stream of encoded bits-i.e., the
7 MSB of one element follows the LSB of the previous element. Input
7 XLEN is the number code words in Y, and thus the size of output
7 vector X (class DOUBLE). Input LINK is a transition and output
7 table (that drives a series of binary searches):
7
7 1. LINK(O) is the entry point for decoding, i.e., state n 0.
7 2. If LINK(n) < 0, the decoded output is |LINK(n)|; set n = 0.
7 3. If LINK(n) > 0, get the next encoded bit and transition to
7 state [LINK(n) - 1] if the bit is 0, else LINK(n).
322 Глава 8. Сжатие изображений
Как и любой МЕХ-файл, построенный из программы на С, МЕХ-файл для unravel. с
состоит из двух частей: вычислительной программы и шлюзовой программы.
Вычислительная программа, которая также называется unravel, содержит про-
граммный код на С, реализующий процесс декодирования по схеме на рис. 8.5 с
использованием таблицы link. Шлюзовая программа, которая должна называть-
ся mexFunction, осуществляет интерфейс (обмен параметрами) вычислительной
программы и вызывающей ее М-функции huf f 2mat. Она использует стандартный
интерфейс МЕХ-файлов MATLAB, который включает следующие элементы:
1. Четыре стандартизованные параметра входа/выхода nlhs, plhs, nrhs и
prhs. Эти параметры являются, соответственно, числом выходных аргумен-
тов в левой части (целое), массивом указателей на выходные аргументы в
левой части (массивы MATLAB), числом входных аргументов в правой ча-
сти (другое целое) и массивом указателей на входные аргументы в левой
части (также массивы MATLAB).
2. Имеющееся в MATLAB семейство приложений программного интерфейса
API (Application Program Interface). Функции API имеют префикс mx. Они
предназначены для создания, доступа, манипулирования и/или удаления
структур класса шхАггау. Например,
mxCalloc осуществляет динамическое распределение памяти подобно
стандартной функции С calloc. Вместо соответствующих С-функций
malloc и realloc используются функции mxMalloc и mxRealloc;
mxGetScalar извлекает скаляры из входного массива prhs. Другие
функции mxGet. . ., например, mxGetM. mxGetN и mxGetString извле-
кают другие типы данных;
функция mxCreateDoubleMatrix создает выходной массив MATLAB
для plhs. Другие функции mxCreate. .., например, mxCreateString и
mxCreate-NumericArray создают другие типы данных.
Функции API с префиксом тех совершают действия в рабочем простран-
стве MATLAB. Например, mexErrMsgTxt выдает сообщение в рабочем окне
MATLAB.
Прототипы функций API тех и тх, приведенные в пункте 2 предыдущего пе-
речня, расположены в заголовочных файлах MATLAB mex.h и matrix.h соот-
ветственно. Оба эти файла размещаются в палке <matlab>/extern/include, где
<matlab> обозначает корневую установочную папку вашей системы MATLAB.
Заголовок тех. h, который должен быть включен в начало любого МЕХ-файла
(обратите внимание на присутствие в начале файла unravel. с записи #include
>mex.h>), содержит в себе также заголовочный файл matrix.h. Прототипы ин-
терфейсных программ тех и тх, которые хранятся в этих файлах, определяют
используемые параметры и придают смысл операциям над этими параметрами.
Дополнительную информацию по этому вопросу можно узнать из руководства
MATLAB по внешним интерфейсам (External Interfaces).
На рис. 8.6 приведенные выше сведения даны в компактной форме, из которой
видна структура МЕХ-файла unravel, а также обозначено направление потоков
информации между unravel и huf f 2mat. Несмотря на то, что эта концепция про-
иллюстрирована в контексте декодирования Хаффмана, ее легко распространить
на другие функции С или Fortran, если требуется их использование в MATLAB.
8.2. Кодовая избыточность
М-файл unravel.m
Справочная информация
для МЕХ-файла unravel:
Содержит текст,
отображаемый командой
» help unravel
ГмАТЬАВ передает параметры ]
I у, link и m*n в МЕХ-файл: I
I I
I prtisfO] = у I
| prtis[1 ] = link |
I prtis[2] = m*n I
I nrtis = 3 I
I nrtis = 1 ।
I Параметры nlhs и nrtis явля- !
ются целыми, обозначаклци- ।
I ми число аргументов слева и I
| справа, a prtis — вектор, со-
। держащий указатели на мае- ।
I сивы MATLAB у, link и Ш*п I
М-файл huff2mat
В М-файле huff2mat
команда
х = unravel(y,...
link, M*n)
говорит системе MATLAB
передать у, link и m*n в
МЕХ-файп функции unravel
Возвращаемая переменная
plhs(0) присваивается пере-
иенной х
MATLAB перелает выход
МАХ-файла plhs [0]
в М-файл huff2mat
С МЕХ-файл unravel.c
В МЕХ-файле unravel.c вычисления начинаются и заканчи-
ваются в шлюзовой программе mexFunction, которая вызы-
вает С-вычислительную программу unravel. Точка входа
интерфейса декларируется записью
include “mex.h"
С-функции mexFunction
Шлюзовая программа для МЕХ-файла
void mexFunction(
int nlhs, mxArray *plhs[ ],
int nrtis, const mxArray
*prtis[])
где целые nlhs и nrtis обозначают число аргументов слева
и справа, а векторы plhs и prtis содержат указатели на вход-
ные и выходные аргументы типа mxArray. Тип mxArray слу-
жит в MATLAB для внешнего представления массивов.
Пакет API MATLAB состоит из функций, которые обраба-
тывают типы данных, поддерживаемые этим пакетом.
Здесь мы:
1. Используем функции mxGetM, mxGetN, mxIsDoubl,
mxIsComplex и mexErrMsgTxt для проверки входных
и выходных аргументов.
2. Используем функцию mxGetPr для получения указате-
лей на prhs[O] (код Хаффмана) и на prtisfl ] (таблица деко-
дирования) и сохранения их в виде С-указателей hx и
link, соответственно.
3. Применяем mxGetScalar для получения размера выход-
ного массива и сохраняем его в переменной xsz.
4. Применяем mxGetM для определения числа элементов
prtlsfO] (кода Хаффмана) и сохраняем его в hxsz.
5. Используем mxCreateDoubleMatrix и mxGetPr для создания
указателя на выходной массив (для декодера) и присва-
иваем его plhs[OJ.
6. Вызываем вычислительную программу unravel, переда-
вая ее аргументы, сформированные при выполнении
шагов 1-5.____________________________________________
С-функция unravel
МАХ-файл вычислительной программы:
void unravel(
unsigned short *hx
double *1ink, double *x,
double xsz, int hxsz)
содержит исполняемый С-код для декодирования hx
на основе link и помещает результат в х.
Рис. 8.6. Взаимодействие М-функции huff2mat и вызываемой из MATLAB С-функции
unravel. Обратите внимание на то, что МЕХ-файл unravel состоит из двух
функций: шлюзовой программы mexFunction и вычислительной программы
unravel. Справочная информация для МЕХ-файла unravel располагается в от-
дельном М-файле, который также называется unravel
324 Глава 8. Сжатие изображений
Пример 8.4. Декодирование с помощью huf f2mat.
Изображение из примера 8.3 можно продекодировать следующей последователь-
ностью команд:6
> > load SqueezeTracy;
> > g = huff2mat(c);
> > f = imread(’Tracy.tif ’) ;
>> rmse = compare(f, g)
rmse =
0
Обратите внимание на то, что процесс кодирования-декодирования полностью
сохраняет информацию: среднеквадратическая ошибка между исходным и де-
кодированным изображением равна нулю. В силу того, что значительная часть
работы в функции huff2mat выполняется С-функцией unravel, время ее испол-
нения немного меньше времени кодирования функцией mat2huf f. Отметим также
использование функции load для повторной загрузки данных из МАТ-файла, в
котором были сохранен результат кодирования, полученный в пример» 8.3. □
8.3. Межпиксельная избыточность
Рассмотрим два изображения на рис. 8.7, а) и в), которые имеют практически
одинаковые гистограммы. На этих гистограммах можно выделить три определя-
ющие моды, которые означают присутствие на изображениях трех доминирую-
щих интервалов серых тонов. Поскольку здесь уровни серого цвета не являются
равномерно распределенными, можно использовать коды переменной длины для
сокращения кодовой избыточности, котор>ая будет присутствовать при кодирюва-
нии пикселов по обычной схеме кодами фиксированной длины:
» fl = imread(’Random Matches.tif’);
» cl = mat2huff(f1);
> > entropy (fl)
ans =
7.4253
> > imratio(fl, cl)
ans =
1.0704
> > f2 = imread(’Aligned Matches.tif’);
> > c2 = mat2huf f (f2) ;
> > entropy(f2)
ans =
7.3505
> > imratioff2, c2)
ans =
1.0821
6Функция load file считывает переменные MATLAB, хранящиеся надиске в файле ’file.mat’,
и загружает их в рабочее пространство. При выполнении команд save/load имена переменных
не изменяются.
8.3. Межпиксельная избыточность
Заметим, что энтропийные оценки первого порядка обоих изображений близки
друг к другу (7.4253 и 7.3505 бит/пиксел), и эти изображения одинаково сжи-
маются функцией mat2huff (с коэффициентами сжатия 1.0704 против 1.0821).
Из этого сравнения видно, что коды переменной длины не используют при сжа-
тии очевидное структурное преимущество рис. 8.7, в), на котором спички лежат
ровным рядом. На этом изображении имеется явная межпиксельная корреляция,
однако эта же корреляция присутствует также и на рис. 8.7, а), т. к. значения
пикселов можно в значительной степени предсказать по значениям их соседей.
Информация, которую несет каждый отдельный пиксел, достаточно мала. Боль-
шая часть визуального вклада индивидуальных пикселов является избыточной,
и ее можно восстановить, зная вклад других близких пикселов. Эта зависимость
и служит основой для межпиксельной избыточности.
Для того, чтобы сократить межпиксельную избыточность, двумерные мас-
сивы, используемые для представления зрительных образов, необходимо пре-
образовать в более эффективный (но «невизуальный») формат. Например, для
представления изображений можно использовать разность примыкающих друг к
другу пикселов. Преобразования такого типа (они удаляют межпиксельную из-
быточность) принято называть отображениями. Отображения называются обра-
тимыми, если элементы исходного изображения можно однозначно восстановить
(реконструировать) по множеству отображенных данных.
Простая пропедура отображения показана на рис. 8.8. Этот подход, называ-
емый кодированием с предсказанием без потерь, удаляет межпиксельную избы-
Глава 8. Сжатие изображений
точность с помощью вычитания и кодирования лишь новой (добавочной инфор-
мации) пикселов. Новая информация пикселов определяется как разность между
реальным значением пикселом и величиной его предсказания. Как видно, систе-
ма состоит из кодера и декодера, и каждый из них имеет один и тот же блок
предсказатель. Когда очередной пиксел входного изображения, обозначаемый fn,
поступает на вход кодера, предсказатель строит прогноз (оценку значения этого
пиксела), основанный на некотором наборе предыдущих входных пикселов. За-
тем выход предсказателя округляется до ближайшего целого, обозначаемого fn,
и используется для нахождения разности или ошибки предсказания
— fn fn.
Рис. 8.8. Модель кодирования с предсказанием без потери информации: а) кодер;
б) декодер
Эта ошибка кодируется кодом переменной длины (кодером символов), и тем самым
генерируется очередной элемент сжатого потока данных. Декодер на рис. 8.8, б)
восстанавливает значение еп по принятому кодовому слову переменной длины и
совершает обратное преобразование
fn ~ ^п "Ь fn-
Для построения предсказания fn могут использоваться различные локальные,
глобальные или адаптивные методы. Однако в большинстве случаев принято вы-
числять предсказание в виде линейной комбинации т предыдущих пикселов:
fn
= round
где т — это порядок линейного предсказания, операция round [| обозначает округ-
ление до ближайшего целого (наподобие функции round из MATLAB), а сц при
г = 1,2,..., т — коэффициенты предсказания. Для одномерного кодирования с
предсказанием это выражение можно переписать в виде
f&y)
=round
ТП
i=l
где каждая индексированная переменная теперь выражена явно в виде функции
пространственных координат хну. Отметим, что при таком подходе предсказа-
ние f(x, у) зависит лишь от значений пикселов одной текущей обрабатываемой
строки.
М-функции mat21pc и lpc2mat реализуют процедуру кодирования/декоди-
рования с предсказанием, описанную выше (за вычетом шагов символьного ко-
дирования/декодирования). Функция кодирования mat21pc использует цикл for
для построения одновременного прогноза всех пикселов входа х. На каждом ша-
ге итерации массив xs, который в начале равен х, сдвигается на одну позицию
вправо (с нулевым заполнением слева), умножается на соответствующие коэф-
фициенты предсказания и прибавляется к суммирующему массиву р. Поскольку
обычно число коэффициентов линейного предсказания мало, процедура работает
достаточно быстро. Отметим, что при исполнении следующей программы, если
фильтр предсказания f не задан на входе, то используется простейший фильтр,
состоящий из одного числа 1.
function у = mat21pc(x, f)
7.MAT2LPC Compresses a matrix using 1-D lossles predictive coding.
7, Y = MAT2LPC(X, F) encodes matrix X using 1-D lossless predictive
7, coding. A linear prediction of X is made based on the
7, coefficients in F. If F is omitted, F = 1 (for previous pixel
7. coding) is assumed. The prediction error is then computed and
7. output as encoded matrix Y.
7.
7. See also LPC2MAT.
error(nargchkd, 2, nargin)); % Check input arguments
if nargin <2 % Set default filter if omitted
f = 1;
end
x = double(x); 7» Ensure double for computations
[m, n] = size(x); 7. Get dimensions of input matrix
p = zeros(m, n); 7» Init linear prediction to 0
xs = x; zc = zeros(m, 1); 7» Prepare for input shift and pad
for j = l:length(f) 7. For each filter coefficient
xs = [zc xs(:, l:end -1)]; % Shift and zero pad x
p = p + f(j) * xs; % Form partial prediction sums
end
у = x round(p) ; 7. Compute the prediction error
Функция декодирования lpc2mat совершает действия, обратные преобразова-
ниям функции кодирования mat21pc. Как видно из следующего текста этой про-
граммы, она совершает п итераций цикла for, где п обозначает число столбцов
328 Глава 8. Сжатие изображений
закодированной входной матрицы у. На каждой итерации вычисляется только
один столбец выхода декодера х, поскольку для этого требуется знать все преды-
дущие столбцы. Для ускорения вычислений цикла for матрица х расширяется до
максимально необходимого размера перед началом цикла и заполняется нулями.
Заметьте также, что предсказания вычисляются здесь точно в том же порядке,
что и в функции lpc2mat. В этом случае удается избежать ошибок округления в
вычислениях с плавающей точкой.
function х lpc2mat(y, f)
XLPC2MAT Decompresses a 1-D lossless predictive encoded matrix.
7, X LPC2MAT(Y, F) decodes input matrix Y based on linear
7, prediction coefficients in F and the assumption of 1-D lossless
7. predictive coding. If F is omitted, filter F 1 (for previous
7. pixel coding) is assumed.
7.
7. See also MAT2LPC.
error(nargchk(l, 2, nargin)); 7. Check input arguments
if nargin < 2 % Set default filter if omitted
f = 1;
end
f = f(end:-1:1); 7« Reverse the filter coefficients
[m, n] = size(y); 7, Get dimensions of output matrix
order = length(f); % Get order of linear predictor
f = repmat(f, m, 1); % Duplicate filter for vectorizing
x zeros(m, n + order); 7« Pad for 1st ’order’ column decodes
7, Decode the output one column at a time. Compute a prediction based
7г on the ’order’ previous elements and add it to the prediction
7г error. The result is appended to the output matrix being built,
for j l:n
jj j + order;
x(:, jj) y(:, j) + round(sum(f (: , order:-l:l) .*
x(: (jj l):-l:(jj order)), 2));
end
x = x (: order + 1: end) ; 7c Remove left padding
Пример 8.5. Кодирование с предсказанием без потери информации.
Рассмотрим кодирование изображения на рис. 8.7, в) с помощью простого линей-
ного предсказателя первого порядка
/(х, у) = round [аУ(х, у - 1)].
Такую форму предсказания принято называть предсказанием по предыдущему
пикселу, а соответствующая схема кодирования называется дифференциальным
кодированием или кодированием по предыдущему пикселу. На рис. 8.9, а) приве-
дено изображение ошибки предсказания при а = 1. Здесь уровень яркости 128
8.3. Межпикселъная избыточность
соответствует нулевой ошибке предсказания, а ненулевые (положительные и от-
рицательные) ошибки усилены функцией mat2gray, что делает их более яркими
или более темными оттенками.
> > f imread(’Aligned Matches.tif ’) ;
> > e mat21pc(f);
» imshow(mat2gray(e));
> > entropy (e)
ans =
5.9727
Заметьте, что энтропия ошибки предсказания е существенно меньше энтропии
исходного изображения f. Энтропия уменьшилась с 7.3505 бит/пиксел (см. вы-
числения в начале этого параграфа) до 5.9727 бит/пиксел, и это при том, что для
т-битных изображений требуются (т + 1)-битные числа для корректного пред-
ставления полученной последовательности ошибок. Такое уменьшение энтропии
означает, что изображение, составленное из ошибок предсказания, можно коди-
ровать более эффективно по сравнению с исходным изображением, а как раз это
и является целью отображения. В итоге мы имеем
> > с = mat2huff(e);
» cr imratio(f, с)
cr =
1.3311
откуда видно, что коэффициент сжатия вырос, как и ожидалось, с 1.0821 (при
прямом кодировании уровней изображения по Хаффману) до 1.3311.
Рис. 8.9. а) Изображение ошибки предсказания для изображения на рис. 8.7, в)\
б) Гистограмма ошибки предсказания
б)
Гистограмма ошибок предсказания, приведенная на рис. 8.9, б), вычислена
командами
[h, х] hist(e(:) * 512, 512);
figure; bar(x, h, ’k’);
Глава 8. Сжатие изображений
Обратите внимание на высокий пик возле 0 и на относительно небольшую диспер-
сию гистограммы по сравнению с гистограммой распределения уровней исходно-
го изображения (см. рис. 8.7, г)). Все это означает удаление значительной части
межпиксельной избыточности в процессе дифференциального предсказания. Мы
завершим этот пример демонстрацией полного сохранения информации при ко-
дировании по этой схеме. Для этого мы декодируем с и сравниваем результат с
начальным изображением f:
>> Ipc2mat(huff2mat(c));
>> compare (f, g)
ans =
0 □
8.4. Визуальная избыточность
В отличие от кодовой и межпиксельной избыточности, визуальная избыточность1
связана с настоящей визуальной информацией, поддающейся количественному
измерению. Ее удаление желательно, поскольку эта информация сама по себе не
существенна для обычного визуального восприятия. Поскольку уменьшение ви-
зуальных избыточных данных приводит к потери части количественной инфор-
мации, этот процесс принято называть квантованием. Такая терминология хоро-
шо согласуется с обычным смыслом этого слова, которое означает представление
широкого набора величин с помощью ограниченного множества допустимых зна-
чений. Эта процедура не является обратимой (после ее совершения происходит
невосполнимая утрата части информации), т. е. квантование приводит к потере
части сжимаемых данных.
Пример 8.6. Сжатие посредством квантования.
Рассмотрим изображения на рис. 8.10. Рис. 8.10, а) показывает черно-белое изоб-
ражение с 256 возможными градациями яркости. На рис. 8.10, б) представлено то
же самое изображение после равномерного квантования на 16 уровней (4 бита).
Полученный в результате коэффициент сжатия равен 2 1. Заметим, что на
некоторых областях изображения, которые были гладкими, появились ложные
контуры. В этом проявляется обычный видимый эффект слишком грубого пред-
ставления уровней яркости изображения.
Рис. 8.10, в) иллюстрирует значительное улучшение изображения, возмож-
ное при использовании квантования, которое учитывает визуальные особенности
зрительного аппарата человека. Несмотря на то, что коэффициент сжатия при
этом квантовании также равен 2 1, ложные контуры значительно ослаблены за
счет некоторой дополнительной, но мало заметной зернистости. Заметим, что в
обоих случаях полное восстановление изображения после декодирования остается
невозможным (квантование является необратимым преобразованием). □
*В английском оригинале использовано словосочетание psychovisuai redundansy (психовизуалъ-
ная избыточность). Мы будем употреблять принятый в русскоязычной литературе термин
визуальная избыточность. Однако следует иметь в виду, что эта избыточность связана преж-
де всего с психофизическими особенностями зрения человека.
8-4- Визуальная избыточность
дифицированного квантования яркости IGS (Improved Gray-Scale quantization).
Он учитывает свойственную глазу чувствительность к контурам и борется с лож-
ными контурами с помощью добавления ко всем пикселам малых псевдослучай-
ных чисел, которые строятся по младшим битам значений окрестных пикселов до
из квантования. Поскольку младшие биты, как правило, достаточны случайны,
то это действие эквивалентно добавлению некоторого уровня случайности, зави-
сящего от локальных свойств изображения, что приводит к разрушению четкости
ровных перепадов, которые выглядят как ложные контуры. Ниже приводится
текст функции quantize, которая совершает оба типа квантования: метод IGS и
стандартное отсекание младших битов. Заметим, что реализация IGS векторизо-
вана так, что вход х обрабатывается по столбцам за один шаг. Чтобы построить
столбец результата по 4 бита на рис. 8.10, в), сумма по столбцам s (которая об-
нуляется в начале) вычисляется как сумма одного столбца х и четырех наименее
значимых битов существующей (ранее вычисленной) суммы. Если четыре самые
значимые бита некоторой величины х равны 1111г, то вместо этого добавляется
0000г- Затем четыре самые значимые бита полученной суммы используются для
кодирования значения пиксела обрабатываемого столбца2.
function у = quantize(х, b, type)
‘/«QUANTIZE Quantizes the elements of a UINT8 matrix.
% Y QUANTIZE(X, B, TYPE) quantizes X to В bits. Truncation is
% used unless TYPE is *igs’ for Improved Gray Scale quantization.
error(nargchk(2, 3, nargin)); % Check input arguments
if ndims(x) 2 | ~isreal(x) |
“isnumeric(x) | ~isa(x, ’uint8’)
error(’The input must be a UINT8 numeric matrix.’);
end
% Create bit masks for the quantization
lo uint8(2 "(8 b) 1);
2 Для сравнения строк si и s2 используется функция s = strcmpi(sl, s2).
Глава 8. Сжатие изображений
hi = uint8(2 "8 double(lo) 1);
7, Perform standard quantization unless IGS is specified
if nargin < 3 | “strcmpi (type, ’igs’)
у = bitand(x, hi);
"A Else IGS quantization. Process column-wise. If the MSB’s of the
•/. pixel are all l’s, the sum is set to the pixel value. Else, add
% the pixel value to the LSB’s of the previous sum. Then take the
% MSB’s of the sum as the quantized value.
else
[m, n] = size(x); s zeros(m, 1);
hitest double(bitand(x, hi) hi); x = double(x);
for j l:n
s x(: j) + hitest(:, j) .* double(bitand(uint8(s), lo));
y(:, j) bitand(uint8(s), hi);
end
end
Модифицированное квантование яркости является весьма типичным пред-
ставителем большого семейства процедур квантования, которые оперируют на-
прямую со значениями яркости пикселов сжимаемых изображений. Они часто
приводят к понижению как пространственного, так и яркостного разрешения
изображений. Если изображение сначала отображается с целью сокращения меж-
пиксельной избыточности, то дальнейшее квантование может привести к другим
типам искажения в виде размытия тонких контуров (т. е. к потере высокочастот-
ных деталей), когда двумерное преобразование в частотной области используется
для декорреляции данных.
Пример 8.7. Сочетание квантования IGS, кодирования с предсказанием без
потерь и кодирования Хаффмана.
Несмотря на то, что квантование, использованное при построении сжатого изоб-
ражения на рис. 8.10, в), удаляет большую часть визуальной избыточности с
весьма малым влиянием на воспринимаемое глазом качество изображения, даль-
нейшее сжатие можно получить, используя методы, изложенные в предыдущих
двух параграфах, которые позволяют уменьшить межпиксельную и кодовую из-
быточности. На самом деле, мы можем более чем вдвое повысить сжатие, достиг-
нутое при квантовании IGS. Следующая последовательность команд выполняет
квантование IGS, кодирование с предсказанием и кодирование Хаффмана, что
позволяет сжать изображение на рис. 6.10, а) в четыре раза и более от его исход-
ного размера:
> > f = imread(’Brushes.tif ’) ;
> > q = quantized, 4, ’igs’);
> > qs double (q) / 16;
> > e = mat21pc(qs);
> > c = mat2huff(e);
> > imratio(f, c)
ans
4.1420
8.5. Стандарты сжатия
Закодированное изображение с можно разжать с помощью обратной последова-
тельности операций (только без «обратного квантования»):
>> ne huff2mat(c);
>> nqs lpc2mat(ne);
>> nq = 16 * nqs;
>> compare (q, nq)
ans
0
>> rmse compare (f, nq)
rmse =
6.8382
Отметим, что среднеквадратическое отклонение разжатого изображения от ис-
ходного равно приблизительно 7 уровням яркости, что происходит исключитель-
но из-за процедуры квантования. □
8.5. Стандарты сжатия JPEG
Изложенные в предыдущем параграфе методы оперируют непосредственно с
пикселами изображения, поэтому Они называются методами квантования в про-
странственной области. В этом параграфе мы рассмотрим семейство популяр-
ных стандартов сжатия, которые основаны на модификациях преобразованного
изображения. Наше цель заключается в описании использования двумерных пре-
образований при сжатии изображений, а также в рассмотрении некоторых новых
приемов сокращения избыточности, которые обобщают подходы, изложенные в
§§ 8.2-8.4. Тогда читатель сможет оценить современное состояние дел в области
сжатия изображений. Представленные стандарты (на самом деле, мы рассмот-
рим лишь некоторые приближения к ним) разработаны для обработки широкого
круга изображений, которым требуются весьма различные условия сжатия.
При трансформационном кодировании используется некоторое обратимое линей-
ное преобразование, например, дискретное преобразование Фурье DFT (см. гл. 4)
или дискретное косинусное преобразование DCT (Descrete Cosinus Transform),
которое задается уравнениями
где
М-1 N — 1
T(u,v) = У? f(x,y)aM(u)aN(v) сов
х=0 у=0
(2х + 1)итг
2М
cos
(2у + 1)г>тг
2N
Ом(и) = <
при и = О,
при и = 1,2,..., М — 1
(и аналогичная формула для функции а^^у)). При этом изображение f(x,y)
отображается в некоторое множество коэффициентов преобразования, которые
334 Глава 8. Сжатие изображений
затем квантуются и кодируются. Для подавляющего числа естественных изоб-
ражений существенная часть коэффициентов преобразования имеет малую ам-
плитуду, и их можно грубо квантовать (или даже совсем отбросить), внеся тем
самым в изображение незначительные искажения, практически незаметные для
глаза.
8.5.1. JPEG
Одним из самых известных и широко применяемых универсальных стандартов
сжатия изображений с непрерывными тонами является стандарт JPEG (эта аб-
бревиатура образована из слов Joint Photographic Experts Group, объединенная
группа экспертов по фотографии). В базовой системе кодирования JPEG, осно-
ванной на дискретном косинусном преобразовании и годящейся для большинства
приложений сжатия, входные и выходные изображения ограничены 8-и битным
форматом представления компонент яркости и цветности, а длина представле-
ния коэффициентов DCT равна 11 битам. Как видно на упрощенной блок-схеме
рис. 8.11, а), само сжатие совершается за четыре шага: извлечение подизображе-
ний размерами 8x8, вычисление DCT, квантование и присвоение кодов перемен-
ной длины, т. е. кодирование.
а)
Входное
изображение
б)
Сжатое
изображение
Сжатое
изображение
Восстановленное
изображение
Рис. 8.11. Блок-схема JPEG: а) кодер; б) декодер
Первый шаг процесса сжатия JPEG заключается в разделении входного изоб-
ражения на непересекающиеся блоки пикселов размерами 8x8. Это выполняет-
ся последовательно в направлении слева направо и сверху вниз. Каждый блок
8x8 (подизображение) подвергается определенной обработке. Все его 64 пиксела
сдвигаются вычитанием числа 2т-1, где 2т — это число уровней яркости изоб-
ражения, после чего вычисляется дискретное косинусное преобразование DCT
блока. Полученные коэффициенты нормируются и квантуются по правилу
hatT(u,v) = round
T(u,v)
_Z(u,v)
где Т(и,и) при и,и — 0,1,2,...,7 обозначают нормированные и квантованные
коэффициенты, Т(и,и) — коэффициенты DCT текущего блока 8x8 изображения
/(ж,?/), a Z(u,v) — нормирующая матрица преобразования, предписанная стан-
дартом и приведенная на рис. 8.12, а). Если менять элементы матрицы Z(u,v)
пропорционально некоторому числу, то это позволяет варьировать коэффициент
достигаемого сжатия, что отражается на качестве реконструированного изобра-
жения.
8.5. Стандарты сжатия
16 11 10 16 24 40 51 61
12 12 14 19 26 58 60 55
14 13 16 24 40 57 69 56
14 17 22 29 51 87 80 62
18 22 37 56 68 109 103 77
24 35 55 64 81 104 113 92
49 64 78 87 103 121 120 101
72 92 95 98 112 100 103 99
0 1 5 6 14 15 27 28
2 4 7 13 16 26 29 42
3 8 12 17 25 30 41 43
9 11 18 24 31 40 44 53
10 19 23 32 39 45 52 54
20 22 33 38 46 51 55 60
21 34 37 47 50 56 59 61
35 36 48 49 57 58 62 63
Рис. 8.12. а) Нормировочная матрица JPEG; б) Последовательность упорядочения коэф-
фициентов по зигзагу в JPEG
После того, как коэффициенты DCT всех блоков будут проквантованы, эле-
менты двумерных матриц T(u, г) переупорядочиваются в зигзагообразном поряд-
ке, показанном на рис. 8.12, б) последовательными числами 0,1,2,..., 63, образуя
одномерный массив. Поскольку полученные одномерные векторы (квантованных
коэффициентов) упорядочены по возрастанию пространственной частоты, то са-
ми они уменьшаются в этом направлении, и кодер символов на рис. 8.11, а) опти-
мизирован с учетом вероятного появления длинных серий нулей, которые обычно
возникают после упорядочения зигзагом. В частности, ненулевые коэффициен-
ты АС [т. е. все T(u,v), кроме случая и = v = 0] кодируются с использованием
кодов переменной длины, которые определяют величины этих коэффициентов и
число следующих за ними нулей. Коэффициенты DC [т. е. Т(0,0)] кодируются
разностными кодами по отношению к коэффициентам DC предыдущих подизоб-
ражений. В стандарте имеются таблицы для кодов Хаффмана коэффициентов
DC и АС, которые используются при сжатии по умолчанию, но пользователь мо-
жет построить свои собственные таблицы, а также задать свою нормировочную
матрицу. В последнем случае всю эту информацию придется добавить к сжатым
данным в зарезервированную область параметров.
Хотя полная реализация стандарта JPEG выходит за рамки этой главы, сле-
дующая М-функция моделирует процесс базового кодирования:
function у im2jpeg(x, quality)
7ДМ2JPEG Compresses an image using a JPEG approximation.
7, Y = IM2JPEG(X, QUALITY) compresses image X based on 8 x 8 DCT
7. transforms, coefficient quantization, and Huffman symbol
% coding. Input QUALITY determines the amount of information that
7. is lost and compression achieved. Y is an encoding structure
% containing fields:
7.
7ч Y.size Size of X
7ч Y.numblocks Number of 8-by-8 encoded blocks
7ч Y.quality Quality factor (as percent)
336 Глава 8. Сжатие изображений
7„ Y.huffman Huffman encoding structure, as returned by
7 MAT2HUFF
7
7 See also JPEG2IM.
error(nargchk(1, 2, nargin)); 7 Check input arguments
if ndims(x) ~= 2 | “isreal(x) | “isnumeric(x) | “isa(x, ’uint8’)
error(’The input must be a UINT8 image.’);
end
if nargin < 2
quality = 1; 7 Default value for quality,
end
m = [16 11 10 16 24 40 51 61 7 JPEG normalizing array
12 12 14 19 26 58 60 55 7 and zig-zag redordering
14 13 16 24 40 57 69 56 7 pattern.
14 17 22 29 51 87 80 62
18 22 37 56 68 109 103 77
24 35 55 64 81 104 113 92
49 64 78 87 103 121 120 101
72 92 95 98 112 100 103 99] * quality;
order = [1 9 2 3 10 17 25 18 11 4 5 12 19 26 33
41 34 27 20 13 6 7 14 21 28 35 42 49 57 50
43 36 29 22 15 8 16 23 30 37 44 51 58 59 52
45 38 31 24 32 39 46 53 60 61 54 47 40 48 55
62 63 56 64];
[xm, xn] = size(x); 7 Get input size.
x = double (x) 128; 7. Level shift input
t dctmtx(8); 7 Compute 8x8 DCT matrix
7 Compute DCTs of 8x8 blocks and quantize the coefficients.
у blkproc(x, [88], ’Pl * x * P2’, t, t’);
у blkproc(y, [8 8], ’round(x ./ Pl)’, m);
у = im2col(y, [8 8], ’distinct’); 7 Break 8x8 blocks into columns
xb size(y, 2); 7 Get number of blocks
у y(order, :); 7 Reorder column elements
eob = max(x(:)) +1; 7 Create end-of-block symbol
r zeros(numel(y) + size(y, 2), 1);
count = 0;
for j l:xb 7 Process 1 block (col) at a time
i = max(find(y(: j))); 7 Find last non-zero element
if isempty(i) 7 No nonzero block values
i = 0;
end
p = count + 1;
q = p + i;
r(p:q) [y(l:i, j); eob]; 7 Truncate trailing 0’s, add EOB,
count = count + i + 1; 7« and add to output vector
end
r((count + l):end) [] ; % Delete unusued portion of r
y.size uintl6([xm xn]);
y.numblocks = uintl6(xb);
y.quality = uint16(quality * 100);
y.huffman = mat2huff(r);
В соответствии с блок-схемой на рис. 8.11. а), функция im2jpeg обрабатывает
отдельные подизображения или блоки 8x8 входного изображения х (последова-
тельно блок за блоком, но не все изображение сразу). Для упорядочения вычис-
лений используются две функции обработки блоков blkproc и 1ш2со1. Функция
blkproc имеет стандартный синтаксис
В = blkproc(A, [М N] , FUN, Pl, Р2, ...).
Эта функция унифицирует весь процесс поблочной обработки изображения. Она
принимает входное изображение А вместе с размерами блоков [М N], по которым
требуется обрабатывать изображение, а также функцию FUN, которая будет об-
рабатывать эти блоки, и некоторый опционный набор аргументов Pl, Р2,
функции FUN. Затем функция blkproc разделяет А на блоки MxN (используя за-
полнение нулями там, где блок выходит за рамки изображения), вызывает функ-
цию FUN для каждого блока с заданными параметрами Pl, Р2, . . ., и, наконец,
помещает результат в выходное изображение В.
Другой функцией поблочной обработки, используемой в процедуре im2jpeg,
является функция im2col. Если функция blkproc не годится для реализации
специфических поблочных действий, функция im2 col может использоваться для
переупорядочения входа так, чтобы операции можно было совершить проще и
эффективнее (например, применяя векторизацию). Выходом im2col служит мат-
рица, в которой каждый столбец состоит из элементов одного блока входного
изображения. Ее стандартизованный формат имеет вид
В im2col(A, [М N], ’distinct’),
где параметры А, В и [М N] имеют тот же смысл, что и в функции blkproc, а
строка ’distinct’ сообщает im2col о том, что обрабатываемые блоки не пересе-
каются; другая строка-параметр ’sliding’ сигнализирует о том, что необходимо
строить один столбец В для каждого пиксела в А (как если бы блок скользил по
изображению).
В процедуре im2jpeg функция blkproc применяется для облегчения вычис-
ления DCT, нормирования и квантования, а функция im2col упрощает упоря-
дочение квантованных коэффициентов и отслеживание серий нулей. В отличие
от стандарта JPEG, функция im2jpeg обнаруживает только последнюю серию
нулей в каждой упорядоченной последовательности коэффициентов квантован-
ного блока, заменяя всю эту серию одним символом eob (End Of Block). Наконец,
отметим, что в системе MATLAB имеется эффективная утилита, написанная на
базе FFT, которая выполняет DCT для больших изображений (см. справку для
функции dct2). Тем не менее, im2jpeg использует альтернативную матричную
338 Глава 8. Сжатие изображений
формулу1
Т = HFHT
где F - это блок 8x8 изображения Н — матрица преобразования DCT,
которая строится командой dctmtx(8), а Т — результат применения DCT к F.
Здесь верхний индекс Т обозначает операцию транспонирования. При отсутствии
квантования обратное преобразование DCT от Т вычисляется по формуле
F = НтТН.
Эта формула особенно эффективна при обработке малых квадратных изображе-
ний (подобно DCT 8x8 в JPEG). Таким образом, команда
у = Ыкргос(х, [8 8], ’Р1*х*Р2’, h, h’)
вычисляет преобразование DCT изображения х по блокам 8x8 с использованием
матрицы преобразования h и транспонированной матрицы h’ в качестве пара-
метров Р1 и Р2, которые являются множителями в формуле матричного произ-
ведения DCT Р1*х*Р2, играющего роль функционального параметра FUN.
Аналогичная поблочная обработка и преобразование на основе матричных
произведений (см. рис. 8.11, б)) применяются в процессе декодирования изобра-
жения, сжатого функцией im2jpeg. Приведенная ниже функция jpeg2im выпол-
няет всю необходимую последовательность обратных операций (за исключением
квантования). Она использует общую функцию
А = col2im(B, [И N], [ММ NN], ’distinct’)
для воссоздания двумерного изображения из столбцов матрицы В, где каждый
столбец по 64 элемента является блоком 8x8 реконструируемого изображения.
Параметры А, В, [М N] и ’distinct’ были определены при описании функции
im2col, а массив [ММ NN] обозначает размеры выходного изображения А.
function х = jpeg2im(y)
7.JPEG2IM Decodes an IM2JPEG compressed image.
7o X = JPEG2IM(Y) decodes compressed image Y, generating
7, reconstructed approximation X. Y is a structure generated by
7. IM2JPEG.
7.
7. See also IM2JPEG.
error(nargchk(l, 1, nargin)); X Check input arguments
m = [16 11 10 16 24 40 51 61 % JPEG normalizing array
12 12 14 19 26 58 60 55 % and zig-zag reordering
14 13 16 24 40 57 69 56 % pattern.
14 17 22 29 51 87 80 62
18 22 37 56 68 109 103 77
24 35 55 64 81 104 113 92
'Для вычисления DCT блока f размерами 8x8 с помощью матричной операции следует
взять h dctmtx(8).
8.5. Стандарты сжатия
49 64 78 87 103 121 120 101
72 92 95 98 112 100 103 99];
order = [1 9 2 3 10 17 25 18 11 4 5 12 19 26 33
41 34 27 20 13 6 7 14 21 28 35 42 49 57 50
43 36 29 22 15 8 16 23 30 37 44 51 58 59 52
45 38 31 24 32 39 46 53 60 61 54 47 40 48 55
62 63 56 64];
rev = order;
for к = 1:length(order)
rev(k) = find(order == k);
end
% Compute inverse ordering
m = double(y.quality) / 100 * m;
xb = double(y.numblocks);
sz = double(y.size);
xn = sz(2);
xm = sz(l);
x = huff2mat(y.huffman);
eob = max(x(:));
z = zeros(64, xb); к = 1;
for j l:xb
for i 1:64
if x(k) == eob
к = к + 1; break;
else
z(i, j) = x(k);
к = к + 1;
end
7, Get encoding quality.
‘X Get x blocks.
7, Get x columns.
7o Get x rows.
7, Huffman decode.
7, Get end-of-block symbol
7e Form block columns by copying
successive values from x into
% columns of z, while changing
7o to the next column whenever
7» an EOB symbol is found.
end
end
z z(rev, :); % Restore order
x = col2im(z, [8 8], [xm xn] , ’distinct’); 7» Form matrix blocks
x = blkproc(x, [8 8], ’x .* Pl’, m) ; 7o Denormalize DCT
t = dctmtx(8) ; 7o Get 8x8 DCT matrix
x blkproc(x, [8 8], ’Pl * x * P2’, t’, t) ; Compute block DCT-1
x = uint8(x + 128); 7« Level shift
Пример 8.8. Сжатие JPEG.
На рис. 8.13, а) и б), приведены два кодированные и декодированные изобра-
жения JPEG, которые являются приближениями одного и того же исходного
черно-белого изображения на рис. 8.4, а). Первый результат, имеющий коэффи-
циент сжатия примерно 18 к 1, получен прямым использованием стандартной
нормирующей матрицы на рис. 8.12, а). Второе изображение, имеющее коэффи-
циент сжатия 42 к 1, построено при умножении нормирующей матрицы на 4, что
соответствует более грубому квантованию.
Глава 8. Сжатие изображений
Разности между исходным изображением рис. 8.4, а) и восстановленными изоб-
ражениями рис. 8.13, а) и б) построены, соответственно, на рис. 8.13, в) и г).
Тоны обоих изображений были усилены для лучшей визуализации имеющихся
отклонений. Соответствующие средние ошибки RMS равны 2.5 и 4.4 уровней
яркости. Влияние этих ошибок на качество изображений видно более отчетли-
во на увеличенных участках изображений, приведенных на рис. 8.13, д) и е).
Эти изображения позволяют лучше оценить тонкие различия между обоими вос-
становленными изображениями [исходное увеличенное изображение имеется на
рис. 8.4, б)]. Обратите внимание на артефакты блочности, присутствующие на
обоих увеличенных приближениях.
Изображения на рис. 8.13 и обсуждавшиеся только что численные результаты
получены с помощью следующей последовательности команд:
f = imread(’Tracy.tif’);
cl im2jpeg(f);
fl = jpeg2im(cl) ;
ans
ans
ans
imratioff, cl)
18.2450
compare(f, fl, 3)
2.4675
c4 = im2jpeg(f, 4);
f4 = jpeg2im(c4);
imratio(f, c4)
41.7826
compare(f, f4, 3)
ans =
4.4184
Эти результаты отличаются от тех, которые получаются при сжатии насто-
ящим стандартом JPEG, поскольку наша программа im2jpeg лишь моделирует
процесс кодирования Хаффмана, заложенный в стандарт JPEG. Имеется два
принципиальных отличия, заслуживающих внимания:
(1) в стандарте все серии нулевых коэффициентов кодируются по Хаффману,
а в im2jpeg кодируется лишь завершающая серия нулей каждого блока;
(2) кодер и декодер стандарта используют (по умолчанию) предписанный код
Хаффмана, в то время как im2jpeg получает информацию, необходимую
для реконструкции таблицы кодовых слов из самого изображения.
Если использовать полный стандарт JPEG, то коэффициент сжатия повысится
еще примерно в два раза. □
8.5.2. JPEG 2000
Как и первоначальная реализация JPEG, рассмотренная в предыдущем парагра-
фе, алгоритм сжатия стандарта JPEG 2000 основан на идее, что коэффициенты
преобразования, которое декоррелирует пикселы изображения, можно кодиро-
вать более эффективно, чем сами исходные пикселы. Если базисные функции
преобразования — вейвлеты в случае JPEG 2000 — пакуют самую важную часть
визуальной информации в относительно малое число коэффициентов, то остав-
шиеся коэффициенты можно грубо проквантовать или вовсе обнулить, что при-
ведет лишь к малым искажениям сжатого изображения.
Рис. 8.14 показывает упрощенную систему кодирования JPEG 2000 (в ней от-
сутствует несколько опционных операций). Первый шаг процесса кодирования,
как и в исходном стандарте JPEG, состоит в сдвиге в нуль среднего уровня яр-
кости пикселов, которое достигается вычитанием из всех пикселов числа 2т-1,
где 2т — общее число возможных уровней яркости. Затем вычисляется одно-
мерное дискретное вейвлетное преобразование строк и столбцов изображения.
При сжатии без потерь используется биортогональное вейвлетное преобразова-
Глава 8. Сжатие изображений
ние 5 З2. В приложениях, которые допускают потерю информации, используется
вейвлетное преобразование 9 7 (см. функцию wavefilter в гл. 7). В обоих слу-
чаях первоначальным результатом декомпозиции изображения являются четыре
поддиапазона — одно низкочастотное приближение и три частные характеристи-
ки (детали) по горизонтали, вертикали и диагонали.
Сжатое
изображение
Восстановленное
изображение
Рис. 8.14. Блок-схема JPEG 2000: а) кодер и б) декодер
Рис. 8.15. Схема обозначений для ко-
эффициентов двухмасштабного вейв-
летного преобразования JPEG 2000 и
число дополнительных битов анализа
(в черных кружочках)
Повторяя процесс декомпозиции Nl раз
с последующими итерациями, применяемыми
к коэффициентам приближения предыдущей
декомпозиции, строится вейвлетное преобра-
зование масштаба N^. Пространственное раз-
решение соседних масштабов различается в
два раза, причем самый крупный масштаб об-
разует наиболее точное приближение исход-
ного изображения. Как можно предположить
из рис. 8.15, на котором приведена стандарт-
ная схема обозначений для случая масштаба
Nl = 2, преобразование масштаба обще-
го вида состоит из + 1 поддиапазона, ко-
эффициенты которых обозначаются индекси-
рованной буквой аь, где b N^LL, N^HL,
NlLH, NlLL, 1HL, 1LH, 1HH. Стандарт
не ограничивает число вычисляемых масштабов.
После того, как вейвлетное преобразование
масштаба NL вычислено, общее число коэффи-
циентов преобразования равно числу отсчетов
исходного изображения, но главная визуальная информация сконцентрирована
только в небольшом числе коэффициентов. Для уменьшения числа битов, требу-
емых для их представления, коэффициент аь(и, и) поддиапазона b квантуется на
величину §ь(и, г,') по формуле
Qb(w,n) = sign(ab(w, и))
floor
|аь(щ п)|
ДЬ
где sign( ) — это знак числа, floor[ ] — целая часть числа (подобно стандартным
2В обозначении вейвлетного преобразования а — Ь число а означает количество коэффициентов
низкочастотного, а Ъ — высокочастотного фильтров анализа.
8.5. Стандарты сжатия JPEG
функциям sign3 и floor в MATLAB). Шаг квантования Д(, задается выражением
Дь = 2«ь-еь (1 + ^т)
Здесь Rb — номинальный динамический диапазон поддиапазона Ь, а Еъ и (J-ь —
число битов, отводимых под величины порядка и мантиссы его коэффициентов.
Номинальный динамический диапазон b равен сумме числа битов, используемых
для представления исходного изображения, и числа дополнительных битов ана-
лиза поддиапазона Ь. Числа дополнительных битов анализа заключены в черные
кружочки на рис. 8.15. Например, для поддиапазона b = \НН отводится 2 до-
полнительных бита анализа.
Для сжатия без потерь используются следующие значения параметров: Дь = О,
Rb = Еъ, Ль = 1- Для необратимого сжатия в стандарте не предусмотрено никако-
го конкретного шага квантования. Вместо этого декодер должен знать число би-
гов порядка и мантиссы, которое или передается вместе с каждым поддиапазоном
(это называется явным квантованием), или же только с поддиапазоном NlLL
[неявное квантование). В последнем случае остальные поддиапазоны квантуют-
ся с использованием значений параметров, экстраполированных по параметрам
тоддиапазона N^LL. Полагая, что Eq и До — это известное число битов, отводи-
мых для поддиапазона N^LL, параметры для поддиапазона b вычисляются по
формулам
Иь = До, еь = Ео + nsdb — nsdo,
де nsdb обозначает число уровней декомпозиции от исходного изображения до
тоддиапазона Ь. Финальным шагом процесса сжатия является кодирование кван-
тованных коэффициентов с помощью метода арифметического кодирования на
основе битовых плоскостей. Мы здесь не обсуждаем метод арифметического ко-
пирования, который, подобно схеме Хаффмана, представляет собой эффектив-
1ый вариант кодирования кодами переменной длины, разработанный для сокра-
цения кодовой избыточности.
Приводимая далее функция im2 jpeg2k моделирует процесс кодирования JPEG 2000
ia рис. 8.14, а) за исключением этапа арифметического символьного кодирова-
гия. Как видно из текста этой функции, вместо этого для простоты используется
кодирование Хаффмана, расширенное кодированием длин нулевых серий.
:unction у = im2jpeg2k(x, n, q)
',IM2JPEG2K Compresses an image using a JPEG 2000 approximation.
Y IM2JPEG2K(X, N, Q) compresses image X using an N-scale JPEG
2K wavelet transform, implicit or explicit coefficient
quantization, and Huffman symbol coding augmented by zero
run-length coding. If quantization vector Q contains two
elements, they are assumed to be implicit quantization
parameters; else, it is assumed to contain explicit subband step
sizes. Y is an encoding structure containing Huffman-encoded
data and additional parameters needed by JPEG2K2IM for decoding.
Для любого числа x функция sign(x) возвращает 1, если х больше нуля, 0, если оно равно
улю и -1, если меньше нуля.
344 Глава 8. Сжатие изображений
7.
7. See also JPEG2K2IM.
global RUNS
error(nargchk(3, 3, nargin)); 7« Check input arguments
if ndims(x) 2 | ~isreal(x) | “isnumeric(x) | ~isa(x, ’uint8’)
error(’The input must be a UINT8 image.’);
end
if length(q) 2 & length(q) 3 * n + 1
error(’The quantization step size vector is bad.’);
end
% Level shift the input and compute its wavelet transform.
x = double(x) 128;
[c, s] wavefast(x, n, ’jpeg9.7’);
7, Quantize the wavelet coefficients.
q stepsize(n, q);
sgn sign(c); sgn(find(sgn == 0)) 1; c abs(c);
for к = l:n
qi 3 * к 2;
c wavepaste(’h’, c, s, k, wavecopy(’h’, c, s, k) / q(qi));
c wavepaste(’v’, c, s, k, wavecopy(’v’, c, s, k) / q(qi + 1));
c wavepaste(’d’, c, s, k, wavecopy(’d’, c, s, k) / q(qi + 2));
end
c wavepaste(’a’, c, s, k, wavecopy(’a’, c, s, k) / q(qi + 3));
c floor(c); с c .* sgn;
7. Run-length code zero runs of more than 10. Begin by creating
7. a special code for 0 runs (’zrc’) and end-of-code (’eoc’) and
7o making a run-length table.
zrc min(c(:)) 1; eoc zrc 1; RUNS = [655351;
7» Find the run transition points: ’plus’ contains the index of the
7» start of a zero run; the corresponding ’minus’ is its end + 1.
z c 0; z z [0 z(l:end 1)1;
plus find(z 1); minus find(z -1);
7. Remove any terminating zero run from ’c’
if length(plus) length(minus)
c(plus(end):end) [] ; c [c eoc];
end
7. Remove all other zero runs (based on ’plus’ and ’minus’) from ’c’
for i length(minus):-1:1
run = minus(i) plus(i);
if run > 10
ovrflo = floor(run / 65535); run run ovrflo * 65535;
c [c(l:plus(i) 1) repmat([zrc 1], 1, ovrflo) zrc
runcode(run) c(minus(i):end)J;
end
end
7. Huffman encode and add misc. information for decoding.
у.runs = uintl6(RUNS);
y.s = uintl6(s(:));
y.zrc = uintl6(-zrc);
y.q = uintl6(100 * q’);
y.n uintl6(n);
y.huffman = mat2huff(c);
%- 7.
function у = runcode(x)
7. Find a zero run in the run-length table. If not found, create a
7. new entry in the table. Return the index of the run.
global RUHS
у = find(RUNS == x);
if length(у) 1
RUNS = [RUNS; x];
у length(RUNS);
end
%- %
function q stepsize(n, p)
7. Create a subband quantization array of step sizes ordered by
7« decomposition (first to last) and subband (horizontal, vertical,
7. diagonal, and for final decomposition the approximation subband).
if length(p) == 2 7. Implicit Quantization
q П;
qn = 2 "(8 p(2) + n) * (1 + p(l) / 2 "11);
for к = l:n
qk = 2 ~-k * qn;
q [q (2 * qk) (2 * qk) (4 * qk)] ;
end
q = [q qk] ;
else % Explicit Quantization
q = p;
end
q = round(q * 100) / 100; % Round to 1/100th place
if any (100 * q > 65535)
error(’The quantizing steps are not UINT16 representable.’);
end
if any(q 0)
error(’A quantizing step of 0 is not allowed.’);
end
Декодер JPEG 2000 просто обращает описанные выше операции. После деко-
дирования арифметических кодов коэффициентов совершается восстановление
выбранного пользователем числа поддиапазонов изображения. Хотя кодер может
иметь Мь арифметически закодированных битовых плоскостей для конкретно-
го поддиапазона, пользователь — в силу вложенной природы кодового потока —
346 Глава 8. Сжатие изображений
может выбрать для декодирования только Nf, битовых плоскостей. Это равня-
ется квантованию коэффициентов с использованием размера шага 2Mb~Nb Д(,.
Все недекодируемые биты приравниваются нулю, и полученные коэффициенты,
обозначаемые ф>(гд ц), восстанавливаются по формулам
{(дь(и, у) +‘2Mb~Nb(u,v)) Д(, при Q(,(u, ц) > О,
(ёь(\ ц) - Дь при qt>(u, v) > О,
О при Q(,(u, ц) = О,
где /?9ь(и, ц) обозначает восстановленные значения коэффициентов, a Nb(u, v)
число декодируемых битовых плоскостей для qt>(u, ц). Затем полученные коэффи-
циенты подвергаются обратному преобразованию, а к результату прибавляется
величина 2П-1, где п число битов яркости пикселов. Функция jpeg2k2im мо-
делирует весь это процесс, обращая результат сжатия под действием функции
im2jpeg2k.
function х = jpeg2k2im(y)
7.JPEG2K2IM Decodes an IM2JPEG2K compressed image.
7« X = JPEG2K2IM(Y) decodes compressed image Y, reconstructing an
7o approximation of the original image X. Y is an encoding
7. structure returned by IM2JPEG2K.
7,
7. See also IM2JPEG2K.
error(nargchk(1, 1, nargin)); % Check input arguments
7. Get decoding parameters: scale, quantization vector, run-length
7e table size, zero run code, end-of-data code, wavelet bookkeeping
% array, and run-length table.
n = double(y.n);
q = double(y.q) / 100;
runs = double(y.runs);
rlen = length(runs);
zrc = -double(y.zrc);
eoc = zrc 1;
s = double(y.s);
s = reshape(s, n + 2, 2);
7o Compute the size of the wavelet transform.
cl = prod(s(l, :));
for i = 2:n + 1
cl cl + 3 * prod(s(i, :));
end
% Perform Huffman decoding followed by zero run decoding.
r = huff2mat(y.huffman);
c = []; zi = find(r == zrc); i 1;
for j = l:length(zi)
c = [c r(i:zi(j) 1) zerosd, runs(r(zi(j) + 1)))];
i = zi(j) + 2;
end
8.5. Стандарты сжатия JPEG
zi find(r == eoc); 7. Undo terminating zero run
if length(zi) 1 7» or last non-zero run.
c [c r(i:zi 1)];
c = [c zeros(l, cl length(c))];
else
c = [c r(i:end)];
end
7o Denormalize the coefficients.
с = c + (c > 0) (c < 0);
for к = 1 :n
qi = 3 * к 2;
c = wavepaste(’h’, c, s, k, wavecopy(’h’, c, s, k) * q(qi));
c = wavepaste(’v’, c, s, k, wavecopy(’v’, c, s, k) * q(qi + 1));
c = wavepaste(’d’, c, s, k, wavecopy(’d’, c, s, k) * q(qi + 2));
end
c = wavepaste(’a’, c, s, k, wavecopy(’a’, c, s, k) * q(qi + 3));
7. Compute the inverse wavelet transform and level shift.
x = waveback(c, s, ’jpeg9.7’, n) ;
x = uint8(x + 128);
Принципиальное отличие системы JPEG 2000 на основе вейвлетов (см. рис. 8.14)
от системы JPEG на базе преобразования DCT (см. рис. 8.11) заключается в
отсутствии этапа разделения изображения на маленькие подизображения. По-
скольку вейвлетные преобразования одновременно являются вычислительно эф-
фективными и локальными по своей природе (т. е. их базисные функции имеют
конечную длительность), нет необходимости делить сжимаемое изображение на
подблоки. Как видно в следующем примере, отсутствие стадии деления устраняет
артефакты блочности, которые являются неотъемлемыми спутниками приближе-
ния изображений на базе преобразования DCT при высокой степени сжатия.
Пример 8.9. Сжатие JPEG 2000.
На рис. 8.16 построены два приближения черно-белого изображения на рис. 8.4, а).
Рис. 8.16, а) является реконструкцией кодирования, которое сжало исходное изоб-
ражение в соотношении 42 1, а рис. 8.16, б) получен после сжатия 88 1. Оба ре-
зультата получены при преобразовании пятого масштаба и с параметрами цо = 8
и Ео = 8.5 и 7 соответственно. Поскольку наша функция im2jpeg2k лишь модели-
рует настоящее арифметическое кодирование по битовым плоскостям JPEG 2000,
коэффициент сжатия при использовании настоящего стандарта JPEG 2000 будет
отличаться от приведенных выше значений. На самом деле, степень сжатия воз-
растет почти в 2 раза.
Раз коэффициент сжатия 42 1, отвечающий левой колонке изображений
на рис. 8.16, практически совпадает с коэффициентом сжатия, достигнутым для
изображений в правой колонке на рис. 6.13 (пример 8.8), то рис. 8.16, а), в) и
д) можно сопоставить — качественно и количественно — с результатами сжа-
тия JPEG на рис. 8.14, б), г) и е). Визуальное сравнение обнаруживает заметное
снижение ошибок на изображениях JPEG 2000. На самом деле, ошибка RMS для
JPEG 2000 [рис. 8.16, а)] равна 3.7 уровня яркости, в отличие от 4.4 уровней для
Глава 8. Сжатие изображений
соответствующего изображения JPEG [рис. 8.13, б)]. Помимо уменьшения ошиб-
ки реконструкции, кодирование на базе JPEG 2000 значительно улучшает каче-
ство изображения (в субъективном смысле). Это становится особенно очевидным
при сравнении увеличенных фрагментов на рис. 8.16, д) и 8.13, е). Обратите вни-
мание на то, что на рис. 8.16, д) полностью отсутствуют артефакты блочности,
которые отчетливо видны на рис. 8.13, е).
Рис. 8.16. Левая колонка:
приближение JPEG 2000 для
рис. 8.4, а) с использовани-
ем 5 масштабов и при до =
= 8 и ео = 8.5. Правая ко-
лонка: аналогичные резуль-
таты с ео ~ 7
Когда степень сжатия повышается до значения 88 : 1 [см. рис. 8.16, б)], наблю-
дается некоторая потеря текстуры на одежде девушки, а также происходит раз-
мытие ее глаз. Оба эти эффекта можно обнаружить на рис. 8.16, б) и е). Ошибка
RMS для этих реконструкций равна 5.9 уровней яркости. Результаты на рис. 8.16
были получены с использованием следующей последовательности команд:
>> f = imreadC’Tracy.tif ’) ;
>> cl = im2jpeg2k(f, 5, [8 8.5]);
» fl jpeg2k2im(cl);
>> rmsl = compare(f, fl)
rmsl =
3.6931
>> crl imratio(f, cl)
crl
42.1589
> > c2 im2jpeg2k(f, 5, [8 7]);
> > f2 jpeg2k2im(c2);
> > rms2 compare (f, f2)
rms2 =
5.9172
> > cr2 imratio(f, c2)
cr2 =
87.7323
Обратите внимание на использование неявного квантования при задании третье-
го аргумента функции im2jpeg2k в виде вектора из двух компонент. Если же
число компонент этого вектора больше 2, функция подразумевает явное кванто-
вание, и размеры квантования всех SNl + 1 шагов должны быть заданы в этом
векторном аргументе (здесь Nl обозначает число требуемых масштабов). Все эти
числа необходимо упорядочить по уровням декомпозиции (первый, второй, тре-
тий, ...) и по типу поддиапазона (горизонтальный, вертикальный, диагональный
и приближенный). Например.
» сЗ im2jpeg2k(f, 1, [1111]);
вычисляет одномасштабное преобразование с явным квантованием, а все шаги
квантования всех поддиапазонов равны Aj = 1. Значит, все коэффициенты пре-
образования округляются до ближайшего целого. Это случай минимальной ошиб-
ки при реализации im2 jpeg2k. В этом случае ошибка RMS и коэффициент сжатия
равны
> > f3 jpeg2k2im(c3);
> > rms3 compare (f, f3)
rms3 =
1.1234
> > cr3 = imratio(f, c3)
cr3 =
1.6350 □
Выводы
Материал данной главы дает начальное представление об основах сжатия циф-
ровых изображений, которое достигается путем сокращения и удаления кодовой,
межпиксельной и визуальной избыточности. В ней также разработаны функции
Глава 8. Сжатие изображений
MATLAB, которые позволяют бороться со всеми типами избыточности и, тем са-
мым, расширяют возможности пакета IPT по обработке изображений. Наконец,
дается обзор популярных стандартов сжатия изображений JPEG и JPEG 2000.
За дополнительной информацией по методам сокращения избыточности изобра-
жений, которые здесь не рассматривались, а также по стандартам сжатия специ-
фических изображений (например, двоичных изображений) советуем обратиться
к гл. 8 книги [Gonzalez, Woods, 2002].
ГЛАВА 9
МОРФОЛОГИЧЕСКАЯ
ОБРАБОТКА
ИЗОБРАЖЕНИЙ
Введение
Словом морфология принято называть область биологии, которая изучает форму
и строение животных и растений. Мы будем использовать этот термин в контек-
сте математической морфологии, которая является инструментом для извле-
чения определенных компонентов изображения, полезных для представления и
описания форм объектов, например, их границ, остовов или выпуклых оболо-
чек. Мы будем также рассматривать морфологические методы, которые приме-
няются на этапах предварительной и заключительной обработки изображений,
например, морфологическая фильтрация, утончение и усечение.
В § 9.1 определяется базовый набор операций над множествами, вводятся дво-
ичные изображения, обсуждаются двоичные множества и логические операции
над ними. В § 9.2 вводятся две фундаментальные морфологические операции:
дилатация и эрозия, которые определяются с помощью операций объединения и
пересечения изображения и некоторой смещенной формы (структурообразующе-
го элемента). В § 9.3 понятия дилатации и эрозии используются для построения
более сложных морфологических операций. В § 9.4 вводятся методы маркировки
связных компонентов изображения. Эти действия являются весьма важным ша-
гом при распознавании и извлечении объектов изображения для их дальнейшего
анализа.
В § 9.5 рассматривается морфологическая реконструкция, которая представ-
ляет собой вид морфологического преобразования, в котором участвуют два
изображения, но не обязательно это изображение и некоторый структурообра-
зующий элемент, что является предметом изучения предыдущих параграфов.
В § 9.6 морфологические концепции обобщаются на полутоновые (монохромные)
изображения путем замены операций объединения и пересечения на операции
взятия максимума и минимума. Большинство двоичных морфологических опе-
раций имеет естественные расширения для их применения к полутоновым изоб-
ражениям. Однако имеются операции, которые применяются исключительно для
обработки полутоновых изображений, например, пиковая фильтрация.
С этой главы начинается переход от методов, сконцентрированных исклю-
чительно на обработке изображений (т. е. когда и входом, и выходом процесса
являются изображения), к методам анализа изображений, когда выходом про-
цессов уже являются описательные атрибуты, которые извлекаются из содер-
жания изображений. В этом смысле морфология служит краеугольным камнем
математических инструментов, которые используются при извлечении «смысла»
352 Глава 9. Морфологическая обработка изображений
изображения. Развитие этих и применение других подходов при решении подоб-
ных задач является предметом оставшихся глав книги.
9.1. Предварительные сведения
В этом параграфе вводятся некоторые основные понятия теории множеств, а
также обсуждаются способы реализации в среде MATLAB логических операций
над двоичными изображениями.
9.1.1. Базовые понятия теории множеств
Пусть Z обозначает множество целых чисел. Процесс дискретизации при фор-
мировании цифровых изображений можно представлять себе в виде разделения
плоскости ху координатной сеткой на ячейки, а координаты центров этих ячеек
являются парами декартова произведения1 Z2. Пользуясь терминологией теории
множеств, мы скажем, что функция /(т, у) называется цифровым изображени-
ем, если (а;, у) — это целые числа из Z2, a f — отображение, которое сопоставля-
ет значение яркости (которое принадлежит множеству вещественных чисел R)
каждой паре координат (я, у). Если значения яркости из R являются целыми чис-
лами (как это обычно предполагается в нашей книге), то цифровое изображение
становится двумерной функцией, координатами и амплитудами (т. е. значениями
яркости), которой служат целые числа.
Пусть А некоторое множество из Z2, элементами которого являются коор-
динаты пикселов (х, у). Если элемент w = (х,у) принадлежит А, то это принято
обозначать символической записью
w G А.
В противном случае, если го не принадлежит А, то принято писать
w А.
Множество пикселов В, удовлетворяющее некоторому условию, представляется
в виде
В = {w | условие}.
Например, множество всех пикселов, не принадлежащих множеству А, которое
принято обозначать Ас, задается формулой
Ас — {ю | w А}.
Это множество называется дополнением множества А.
Объединение двух множеств Аи В, которое обозначается
С = A U В,
1 Декартовым произведением множества Z на себя называется множество всех упорядоченных
пар где z, и z3 — любые целые числа. Его принято обозначать Z2
9.1. Предварительные сведения
есть по определению множество всех пикселов, которые принадлежат или мно-
жеству А, или множеству В, или одновременно обоим множествам. Аналогично,
пересечение двух множеств А и В состоит из всех элементов, которые одновре-
менно принадлежат и множеству А, и множеству В, и обозначается
С = АП В.
Разность двух множеств А и В обозначается А \ В. Оно состоит из пикселов,
которые принадлежат А, но не принадлежат В, т. е.
А \ В — {ю | w с A, w £ В}.
Рис. 9.1 иллюстрирует введенные выше операции над множествами, где резуль-
тат каждой операции обозначен темным цветом.
Рис. 9.1. а) Два множества
А и В. 6) Объединение мно-
жеств А и В. е) Пересечение
множеств А и В. г) Дополне-
ние множества А. д) Разность
множеств А п В.
Вместе с введенными базовыми понятиями нам понадобятся еще две опера-
ции, широко используемые при морфологическом анализе изображений и при-
меняемые ко множествам, элементами которых служат координаты пикселов.
Центральным отражением множества В называется множество В, определяе-
мое по формуле
В = {ю | w = —b, b С В}.
Параллельный перенос (или сдвиг) множества А в точку z = (zi, z?) обозначается
(A)z и задается формулой
(A)z = {c|c = a + z, а е А}.
Рис. 9.2 иллюстрирует эти две операции применительно к множествам из рис. 9.1.
Жирные точки обозначают начало координат для каждого множества.
Рис. 9.2. а) Сдвиг множества А в точку z.
б) Центральное отражение множества В. (Ис-
пользованы множества ЛиВиз рис. 9.1)
354 Глава 9. Морфологическая обработка изображений
9.1.2. Двоичные изображения, множества
и логические операции
Язык и теория математической морфологии позволяют взглянуть на двоичные
изображения как бы с двух сторон. С одной стороны, двоичное изображение (как
часто в этой книге) можно себе представлять в виде функции с двумя возмож-
ными значениями координат х л у. Теория морфологии рассматривает двоичное
изображение в виде множества его пикселов переднего плана (со значениями 1),
которое лежит в пространстве Z2. Введенные выше операции над множествами
типа объединение и пересечение можно напрямую применять к двоичным изоб-
ражениям. Например, если А и В — двоичные изображения, то С = A U В —
также двоичное изображение, причем пикселы на изображении С являются пик-
селами переднего плана, если соответствующие пикселы на А, на В или на обоих
этих изображениях принадлежат переднему плану. При первом, функциональ-
ном подходе, изображение С задается формулой
С{х, ?/)=(
1.если A(z, у} = 1, или В(х, у) = 1, или оба равны 1;
О в противном случае.
А, с точки зрения теории множеств, изображение С определяется выражением
С = {(т,у) | (х,у) С А, или (х,у) С В, или (х,у) е (А и В)}.
Операции над множествами, приведенные на рис. 9.1, можно совершать над дво-
ичными изображениями с помощью следующих логических операций MATLAB:
OR (I) (логическое сложение), AND (&) (логическое умножение) и NOT (~) (от-
рицание), как показано в табл. 9.1.
Таблица 9.1. Использование логических операций MATLAB для совершения операций
над двоичными изображениями
Операции Выражение MATLAB для двоичных изображений Имя
АЛБ A ft В AND
AUB А | В OR
Ас "А NOT
А\В A ft “В DIFFERENCE
В качестве простой иллюстрации рассмотрим рис. 9.3, на котором показа-
ны результаты применения ряда логических операций к двум двоичным изоб-
ражениям элементов текста. (Мы следуем правилу IPT, по которому пикселы
переднего плана (со значением 1) отображаются белым цветом.) Изображение
на рис. 9.3, г) является объединением изображений «UTK» и «GT»; на нем при-
сутствуют пикселы переднего плана обоих изображений. Наоборот, пересечение
этих двух изображений, показанное на рис. 9.3, д), состоит из пикселов, которые
принадлежат перекрытию букв «UTK» и «GT>>. Наконец, разность изображений,
приведенная на рис. 9.3, е), показывает части букв «UTK», из которых удалены
пикселы букв «GT».
9.2. Дилатация и эрозия
в)
итк
Рис. 9.3. а) Двоичное изображение А. 6) Двоичное изображение В» в) Дополнение ~А. г)
Объединение А | В. д) Пересечение А & В. е) Разность множеств A fc "В
9.2. Дилатация и эрозия
Операции дилатации и эрозии имеют основополагающее значение при морфоло-
гической обработке изображений. Многие алгоритмы, рассматриваемые в этой
главе, построены па этих операциях, которые далее определяются, иллюстриру-
ются и обсуждаются.
9.2.1. Дилатация
Операция дилатации «наращивает» или «утолщает» объекты на двоичных изоб-
ражениях. Способ и степень этого утолщения контролируется некоторой формой,
которая называется структурообразующим элементом. Рис. 9.4 иллюстрирует
работу дилатации. На рис. 9.4, а) задано простое двоичное изображение прямо-
угольника. На рис. 9.4, б) показан структурообразующий элемент, состоящий из
пяти пикселов, расположенных по диагонали. С точки зрения вычислений, струк-
турообразующий элемент представляется в виде матрицы из нулей и единиц, но
часто бывает удобно показывать только единицы, как изображено на рисунке.
Кроме того, центр структурообразующего элемента должен быть ясно выделен.
На рис. 9.4, б) его центр заключен в квадратик. Рис. 9.4, в) графически отобра-
жает операцию дилатации в виде процесса обноса центра структурообразующего
элемента по области изображения и отметки тех положений центра, когда со-
356 Глава, 9. Морфологическая обработка изображений
ответствующий элемент перекрывает некоторые пикселы переднего плана изоб-
ражения (со значением 1). Полученное изображение показано на рис. 9.4, г), на
котором значения 1 присвоены тем пикселам, которые соответствуют положени-
ям центра структурообразующих элементов, перекрывающих пикселы переднего
плана исходного изображения.
а) О оооо о о
о о о о о о о
() 0 0 0 0 о о
0 0 0 0 о о о
0 0 0 0 0 0 о
0 0 0 0 0 1 1
0 0 0 0 0 1 1
0 0 0 0 0 1 1
0 0 0 0 0 0 0
0 0 0 0 0 0 о
0 0 0 0 0 0 0
О 0 0 0 0 о о
0 0 0 0 0 0 о
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
1 1 1 1 1 0 0 0 0 0
1 1 1 1 1 0 0 0 0 0
1 1 1 1 1 0 0 0 0 0
0 0 00000000
0000000000
0 0 0 0000000
0000 0 00000
0000000000
б)
1
1
ш
1
1
Рис. 9.4. Иллюстрация при-
менения дилатации, а) Ис-
ходное изображение с прямо-
угольником. б) Структурооб-
разующий элемент из пяти пик-
селов по диагонали. Его центр
обведен кведратиком. е) Струк-
турообразующий элемент раз-
несен по нескольким положе-
ниям на изображении, г) Об-
работанное изображение
Структурообразующие элементы, перенесенные
в эти положения, не перекрывают ни одного единичного
пиксела исходного изображения.
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1 1 1 1 1 1 1 0 0 0
0 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 0
0 0 0 0 0 1 1 1 1 1 1 1 1 1 0 0 0
0 0 0 0 1 1 1 1 1 1 1 1 1 0 0 0 0
0 0 0 1 1 1 1 1 1 1 1 1 0 0 0 0 0
0 0 0 1 111 1 1 1 1 0 0 0 0 0 0
0 0 0 1 1 1 1 1 1 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Дилатацию можно строго определить математически в терминах операций
над множествами. Дилатация множества А по множеству В (или относительно
множества В) обозначается А ф В и определяется по формуле
А®В={г](В)гПА^0},
9.2. Дилатация и эрозия
где 0 обозначает пустое множество, а В — это структурообразующий элемент.
Другими словами, дилатация А относительно В является множеством, которое
состоит из всех положений центров
структурообразующего элемента, ко-
торый, будучи центрально отражен-
ным и сдвинутым, имеет частичное
перекрытие с множеством А. Заме-
тим, что процесс сдвига структуро-
образующего элемента похож на ме-
ханизм построения свертки, обсуж-
давшийся в главе 3. На рис. 9.4 не
видно действие центрального отра-
жения элемента В, так как сам он
центрально-симметричен. На рис. 9.5
изображен нецентрально-симметрич-
а) । Ф
1 1 1
1 1 1[Т|1 1 1 1[Т|1 1 1
1 11
1
Рис. 9.5. Центральное отражение структурооб-
разующего элемента, а) Несимметричный струк-
турообразующий элемент, б) Структурообразу-
ющий элемент, отраженный относительно своего
центра
ный структурообразующий элемент и его центральное отражение.
Операция дилатации является коммутативной, т. е. А ф В = В ф А. Однако
бывает удобно помещать на место первого операнда изображение, а на место
второго — структурообразующий элемент, который, обычно, существенно меньше
обрабатываемого изображения. Мы будем так их располагать и в дальнейшем.
Пример 9.1. Простое применение дилатации.
В пакете IPT операция дилатации реализуется функцией imdilate. Ее основная
форма вызова имеет вид
А2 = imdilate(А, В),
где А и А2 — это двоичные изображения, а В — матрица из нулей и единиц, которая
обозначает структурообразующий элемент. На рис. 9.6, а) дал пример двоичного
изображения, которое содержит текст с разорванными буквами. Мы хотим при-
менить дилатацию к этому изображению со структурообразующим элементом
О 1 О
1 Ш 1
О 1 О
Следующая последовательность команд считывает изображение из файла, стро-
ит матрицу структурообразующего элемента, совершает дилатацию и показывает
результат.
А = imread(’broken_text.tif’);
В
А2
[О 1 0; 1 1 1; 0 10];
imdilate(A, В);
imshow(А2)
На рис. 9.6, б) показано обработанное изображение. □
358 Глава 9. Морфологическая обработка изображений
б)
а)
Historic 'у, С'- tain с ггри ег р- gra $ weie wr’'txn u- ’ g or’y two cJiq:kj rather than four to clef ne t c appl<?lve yeai. Ac. rd ig у r;>e compa у s so t-.a«e r- ay recognize a date using '00' as 1900 rather than the year 2000 Historically, certain computer programs were written using only two digits rather than four to define the applicable year- Accordingly, the company's software may recognize a date using *00’ as 1900 rather than the year 2000.
Рис. 9.6. Простой пример ди-
латации. а) Исходное изобра-
жение, содержащее разорван-
ные символы, б) Изображение
после применения дилатации
9.2.2. Разложение структурообразующих элементов
Операция дилатации является ассоциативной, т. е. выполнено равенство
л®(веС) = (ЛбВ)ес.
Предположим, что структурообразующий элемент В можно представить в виде
дилатации двух других элементов Bi
В= В}& В2.
Тогда AQ В = А © (Bi ©В2) = (A Q Bi) & В2. Это означает, что дилатацию А по
В можно построить, выполнив сначала дилатацию А по Bi, а затем к результату
применить дилатацию по В2. Говорят, что В разложен на два структурообразу-
ющих элемента В] и В2.
Свойство ассоциативности весьма важно, потому что время вычисления дила-
тации пропорционально числу ненулевых пикселов структурообразующего эле-
мента. Рассмотрим, например, дилатацию с матрицей 5x5, состоящую из одних
единиц:
11111
11111
110 11
11111
11111
Этот структурообразующий элемент можно разложить на строку и столбец, со-
стоящие из пяти единиц:
1
[110 1
0
1
1
Число элементов исходного структурообразующего элемента равно 25, а общее
число элементов разложения строка-столбец равно 10. Это означает, что если к
9.2. Дилатация и эрозия
некоторому изображению применить дилатацию по элементу-строке, а затем — по
элементу-столбцу, то вся процедура будет работать в 2.5 раза быстрее, чем дила-
тация по целому массиву 5x5. На практике ускорение вычислений будет несколь-
ко меньшим, поскольку имеются некоторые дополнительные операции, которые
необходимо выполнять при каждой дилатации, а при использовании декомпози-
ции (разложения) требуется по крайней мере две дилатации. Однако выигрыш
по скорости при использовании этого приема все равно остается значительным.
9.2.3. Функция strel
В пакете IPT имеется функция strel, которая строит структурообразующие эле-
менты различных форм и размеров. Ее синтаксис имеет вид
se = strel(shape, parameters),
где shape — это строка, обозначающая желаемую форму структурообразующего эле-
мента, a parameters задают список параметров, которые уточняют информацию о
его форме, например, определяют его размер. Так, команда strel(’diamond’, 5)
строит структурообразующий элемент в форме ромба, который занимает ±5 пик-
селов по горизонтали и вертикали. В табл. 9.2 перечислены различные формы,
которые может строить функция strel.
Кроме того, для упрощения построения некоторых стандартных структурооб-
разующих элементов в функции strel предусмотрена возможность разложения
элементов там, где это допустимо. Функция imdelate автоматически использу-
ет информацию о разложении для ускорения процесса дилатации. В следующем
примере иллюстрируется выдача функцией strel информации, связанной с раз-
ложением структурообразующего элемента.
Пример 9.2. Иллюстрация разложения структурообразующего элемента с по-
мощью функции strel.
Рассмотрим еще раз процедуру построения структурообразующего элемента в
форме ромба с помощью strel:
se = strel(’diamond’, 5)
se
Flat STREL object containing 61 neighbors.
Decomposition: 4 STREL objects
Neighborhood:
000001000
000011100
000111110
001111111
011111111
111111111
011111111
001111111
000111110
000011 100
000001000
containing a total of 17 neighbors
0 0
0 0
0 0
0 0
1 0
1 1
1 0
0 0
о 0
о 0
о 0
360 Глава 9. Морфологическая обработка изображений
Таблица 9.2. Различные синтаксические формы функции strel. (Слово плоский означа-
ет, что структурообразующий элемент имеет нулевую высоту. Эта величи-
на осмыслена только для дилатации и эрозии полутоновых изображений.
См. § 9.6.1.)
Синтаксическая форма Описание
ве = strel(’diamond*, R) Строит плоский структурообразующий элемент в форме ромба, где R обозначает расстояние от центра структурообразующего элемента до крайней точки ромба.
se = strel(’disk’, R) Строит плоский структурообразующий элемент в форме круга с радиусом R. (Имеются дополнитель- ные параметры, которые описаны в справке по strel).
ве = strel(’line’, LEN, DEG) Строит плоский, линейный элемент, где LEN обозна- чает его длину, a DEG — угол (в градусах) наклона линии, измеренный против часовой стрелки от гори- зонтальной оси.
se strel(’octagon’, R) Строит плоский, шестиугольный элемент, где R обо- значает расстояние от центра элемента до стороны шестиугольника, измеренное вдоль горизонтальной или вертикальной оси. Число R должно быть поло- жительным и кратным 3.
se = strel(’pair’, OFFSET) Строит плоский структурообразующий элемент, со- стоящий из двух точек. Первая точка находится в центре, а вторая точка смещена от первой на вектор OFFSET, который должен иметь две целые компонен-
se = strel(’periodicline’, P, V) Строит плоский элемент, состоящий из 2*Р + 1 то- чек. V — это двумерный целочисленный вектор, в ко- тором записаны смещения по строке и столбцу. Одна точка элемента находится в его центре, а все осталь- ные имеют координаты 1*V, -1*V, 2*V, -2*V, , P*V и -P*V.
se strel(’rectangle’, MN) Строит плоский элемент в форме прямоугольника, где MN обозначает его размеры. МЯ — это двумерный вектор с неотрицательными целыми компонентами. Первый элемент MN обозначает число строк, а вто- рой — число столбцов.
ве « strel(’square’, W) Строит квадратный структурообразующий элемент ширины, где W неотрицательное целое.
ве Btrel(’arbitrary’, NHOOD) ве = strel(NHOOD) Строит элемент произвольной формы. NHOOD — это матрица из нулей и единиц, задающая его форму. Вторая, более простая синтаксическая форма, выпол- няет ту же операцию.
Видно, что strel не показывает обычную матрицу MATLAB. Вместо этого он
возвращает специальную величину, которая называется strel-объектом. В ко-
мандном окне MATLAB отображается следующая информация: окрестность (мат-
рица из единиц, обозначающая в нашем случае форму ромба), число единичных
пикселов структурообразующего элементы (их здесь 61), число структурообра-
зующих элементов в разложении (их 4) и общее число единичных пикселов всех
элементов разложения (17). Функцию getsequen.ce можно применять для извле-
чения и проверки отдельных структурообразующих элементов этого разложения.
9.2. Дилатация и
decomp = getsequence(se);
whos
Name Size Bytes Class
decomp 4x1 1716 strel object
se 1X1 3309 strel object
Grand- total is 495 elements using 5025 bytes
Функция whos сообщает, что переменные se и decomp обе являются strel-
объектами, а кроме того, decomp представляет собой четырехкомпонентный век-
тор strel-объектов. Все четыре структурообразующих элемента разложения мож-
но получить, индексируя переменную decomp:
>> decomp(l)
ans
Flat STREL object containing 5 neighbors.
Neighborhood:
0 10
111
0 10
>> decomp (2)
ans =
Flat STREL object containing 4 neighbors.
Neighborhood:
0 10
10 1
0 10
>> decomp(3)
ans =
Flat STREL object containing 4 neighbors.
Neighborhood:
0 0 10 0
0 0 0 0 0
1 0 0 0 1
0 0 0 0 0
0 0 10 0
>> decomp(4)
ans =
Flat STREL object containing 4 neighbors.
Neighborhood:
0 10
10 1
0 10
Функция imdilate автоматически использует форму разложения структуро-
образующего элемента, и при этом скорость вычисления возрастает примерно
в три раза по сравнению с прямым использованием элемента в неразложенной
форме (выигрыш по времени вычислений в ~ 61/17 раза). □
Глава 9. Морфологическая обработка изображений
9.2.4. Эрозия
Операция эрозия «ужимает» или «утончает» объекты двоичных изображений.
Как и при дилатации, вид и размер эрозии определяется структурообразую-
щим элементом. Рис. 9.7 иллюстрирует процесс эрозии. Рис. 9.7, а) совпадает
с рис. 9.4, а). На рис. 9.4, б) приведен структурообразующий элемент — корот-
кий вертикальный отрезок. Рис. 9.7, в) графически описывает эрозию как про-
цесс перемещения структурообразующего элемента по изображению и фиксации
положений его центра, в которых этот элемент целиком состоит из пикселов пе-
реднего плана изображения. Выходом операции эрозии служит изображение со
значениями 1 у тех пикселов, которые соответствуют положениям центра струк-
турообразующих элементов, целиком состоящих из пикселов переднего плана
исходного изображения (т. е. этим сдвигам элементов не принадлежат пикселы
изображения со значением 0).
а) б)
00000000000000000
0000 0 000000000000
000 0 0000000000000
000 0 0000000000000
00 0 0 0000000000000
00 0 0 0111111100000 1
0 0 0 00111111100000 Ш
0 0 000111111100000 1
0000000000000000 0
00000000000000000
00000000000000000
00000000000000000
00000000000000000
в) В этом положении выход равен нулю,
г)
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 1
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
о о о о о о
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
111111
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
о о о о о
0 0 0 0 0
Рис. 9.7. Иллюстрация применения эрозии, а) Исходное изображение с прямоугольником.
б) Структурообразующий элемент из трех пикселов по вертикали. Его центр об-
веден квадратиком, в) Структурообразующий элемент разнесен по нескольким
положениям на изображении, г) Обработанное изображение
9.2. Дилатация и эрозия
Математическое определение операции эрозии похоже на определение дила-
тации. Эрозией множества А по В называется множество
AGB = {z (В)2ГЛс = 0}.
Другими словами, эрозия А по В состоит из тех и только тех координат пиксе-
лов, для которых сдвиг- множества В в эту точку не пересекается с фоном изоб-
ражения А (напомним, что фон состоит из тех пикселов изображения, значения
которых равны 0).
Рис. 9.8. Иллюстрация эро-
зии. а) Эрозия с кругом ра-
диуса 10. б) Эрозия с кругом
радиуса 5. е) Эрозия с кру-
гом радиуса 20
Пример 9.3. Иллюстрация процесса эрозии.
Эрозия выполняется в IPT функцией imerode. Предположим, что нам необходи-
мо удалить тонкие провода с изображения на рис. 9.8, а), но с сохранением всех
остальных структур. Это можно сделать, выбрав достаточно малый структурооб-
разующий элемент, чтобы он помещался целиком внутри центрального квадрата,
а также внутри толстых полосок у границ, и достаточно большим, чтобы он не
помещался внутри удаляемых проводков. Рассмотрим следующие команды:
А = imread(’wirebond_mask.tif’);
se strel(’disk’, 10);
A2 imerode(A, se);
imshow(A2)
На рис. 9.8, б) видно, что эти команды успешно справились с задачей удаления
тонких проводов маски. На рис. 9.8, в) показано, что случится, если мы выберем
структурообразующий элемент слишком малым:
364 Глава 9. Морфологическая обработка изображений
se = strel(’disk’, 5);
АЗ = imerode(A, se) ;
imshow(АЗ)
Некоторые провода остались на изображении. Рис. 9.8, г) показывает, что будет,
если выбрать слишком большой структурообразующий элемент:
>> А4 = imerode(A, strel(’disk’, 20));
>> imshow(А4)
Удалены все провода, но одновременно исчезли толстые полоски возле границ. □
9.3. Комбинирование дилатации и эрозии
В конкретных приложениях обработки изображений операции дилатация и эро-
зия часто используются совместно. Обычно изображения подвергаются серии
операций дилатации и/или эрозии с одним и тем же, а иногда и с разными струк-
турообразующими элементами. В этом параграфе рассматриваются три часто
используемые комбинации дилатации и эрозии: размыкание, замыкание и преоб-
разование успех/неудача. Кроме того, вводятся операции с использованием по-
исковых таблиц, а также обсуждается функция bwmorph из пакета IPT, которая
выполняет различные морфологические действия.
9.3.1. Размыкание и замыкание
Морфологическое размыкание А по В обозначается А о В и определяется как
эрозия А по В, после которой выполняется дилатация результата по В:
А о В = (А 0 В) ф В.
Эту операцию можно также задать эквивалентной формулой
АоВ=и{(В)г | (В)2С Л},
где U{ } обозначает объединение всех множеств внутри фигурных скобок, а фор-
мула С С D означает, что множество С является подмножеством D. Такое пред-
ставление имеет простую геометрическую интерпретацию. На рис. 9.9, а) пока-
зано множество А и структурообразующий элемент В, имеющий форму круга.
На рис. 9.9, б) изображены некоторые сдвиги множества В, которые полностью
содержатся в А. Объединение всех таких сдвигов выделено темным цветом на
рис. 9.9, в/. Эта область и является размыканием А по В. На этом рисунке бе-
лым цветом показаны области, где структурообразующий элемент целиком не
поместился, поэтому они не принадлежат размыканию. Морфологическое раз-
мыкание удаляет те части объектов, в которых структурообразующий элемент
полностью не помещается. Оно также сглаживает контуры объектов, разрушает
тонкие соединения и удаляет острые выступы.
Морфологическое замыкание множества А по В обозначается А» В. Эта опе-
рация представляет собой эрозию, примененную к результату дилатации:
А • В = (Л ф В) ф В.
9.3. Комбинирование дилатации и
Геометрически множество А • В представляет собой дополнение к объединению
всех сдвигов множества В, которые не пересекаются с А. На рис. 9.9, г) постро-
ено несколько сдвигов множества В, которые не пересекаются с Л. Взяв допол-
нение к объединению всех таких сдвигов, мы получим область, затемненную на
рис. 9.9, д), которое есть искомое замыкание. Подобно размыканию, морфологи-
ческое замыкание приводит к сглаживанию контуров объектов. Однако в отличие
от размыкания, оно соединяет узкие разрывы, «заливает» длинные углубления
малой ширины и заполняет малые отверстия, диаметр которых меньше размеров
структурообразующего элемента.
Рис. 9.9. Размыкание и замыкание как объединение сдвигов структурообразующих эле-
ментов. а) Множество А и структурообразующий элемент В. б) Сдвиги В, ко-
торые полностью помещаются внутри А. в) Полное размыкание А (затемненная
область), г) Сдвиги В, которые лежат целиком вне А. д) Полное замыкание А
(затемненная область)
Операции размыкания и замыкания реализованы в пакете IPT с помощью
функций imopen и inclose. Обе эти функции имеют простые формы вызова
С = imopenfA, В)
и
С = imclosefA, В),
где А — это двоичное изображение, а В — матрица из 0 и 1, которая задает
структурообразующий элемент. Strel-объект SE можно использовать вместо ар-
гумента В.
Пример 9.4. Использование функций imopen и inclose.
Этот пример иллюстрирует применение функций imopen и inclose. Изображе-
ние shapes.tif, построенное на рис. 9.10, а), имеет ряд характерных особенно-
стей, которые помогут лучше понять действие размыкания и замыкания на такие
объекты, как: острые выступы, тонкие перемычки, длинные углубления, изоли-
рованные отверстия, маленькие одиночные объекты и зубчатые элементы грвг-
ниц. Следующая последовательность команд размыкает изображение с помощью
квадратного структурообразующего элемент 20x20:
f imread(’shapes.tif’);
se strel(’square’, 20);
fo imopen(f, se);
imshow(fo)
Рис. 9.10. Иллюстрация раз-
мыкания и замыкания, а) Ис-
ходное изображение, б) Раз-
мыкание. в) Замыкание, г) За-
мыкание б)
На рис. 9.10, б) показан результат этих действий. Видно, что при этом исчезли
тонкие выступы и острые зубцы, направленные во внешнюю сторону от границ
объекта. Тонкое соединение и маленький изолированный объект также исчезли.
Команды
fc = imclose(f, se);
imshow (f с)
произвели результат, приведенный на рис. 9.10, в). Здесь были удалены узкое
углубление, зубчатые неровности, направленные внутрь объекта, а также малень-
кое отверстие. Как будет показано в следующем абзаце, комбинация замыкания
и размыкания может весьма эффективно удалять шумы. Имея в виду рис. 9.10,
применение замыкания к предыдущему результату размыкания выглядит как
существенное сглаживание объектов изображения. Мы замыкаем разомкнутое
выше изображение следующим образом:
foe = imclose(fo, se);
imshow(foe)
На рис. 9.10, г) изображены полученные сглаженные объекты.
На рис. 9.11 приведена другая иллюстрация полезности операций замыка-
ния и размыкания при обработке нечетких и подпорченных отпечатков пальцев
[рис. 9.11, а)]. Команды
> > f imread(’fingerprint.tif ’) ;
> > se strel (’square ’, 3);
> > fo = imopen(f, se);
> > imshow(fo)
9.3. Комбинирование дилатации и эрозии
совершают действия, результат которых приведен на рис. 9.11, б). Заметим, что
случайные мешающие точки были удалены при размыкании изображения, одна-
ко одновременно с этим были внесены лишние разрывы и щели по краям отпе-
чатков. Многие из этих недостатков можно исправить последующим замыканием
результата размыкания:
>> foe = imclose(fo,se) ;
>> imshow (foe)
Рис. 9.11, в) показывает окончательный результат. □
Рис. 9.11. Изображение испорченных отпечатков пальцев, а) Размыкание изображения.
б) Замыкание после размыкания. (Исходное изображение предоставлено Наци-
ональным институтом стандартов и технологий США)
9.3.2. Преобразование успех/неудача
В приложениях часто бывает необходимо уметь распознавать определенные кон-
фигурации пикселов, например, изолированные пикселы переднего плана или
пикселы, которые являются концами сегментов линий. Преобразования успех/не-
удача1 помогают при решении подобных задач. Преобразование успех/неудача
множества А по множеству В обозначается через А® В. Здесь В обозначает
структурообразующую пару элементов В = (Дь-Вг), а не один элемент, как это
было раньше. По определению, преобразованием множества Л по В называется
множество
А ® в = (л е nJ п (лс е в2).
На рис. 9.12 показано, как преобразование успех/неудача можно использовать
для определения местоположений следующей конфигурации пикселов, имеющей
форму креста:
010
111.
010
На рис. 9.12, а) такие конфигурации пикселов встречаются в двух местах. Эрозия
по структурообразующему элементу Bi устанавливает положения пикселов пе-
реднего плана, у которых одновременно имеются северный, восточный, южный и
западный соседи переднего плана. Эрозия дополнения исходного изображения по
1В оригинале использован термин hit-or-miss transformation.
368 Глава 9. Морфологическая обработка изображений
элементу В% определяет положения всех пикселов, у которых одновременно име-
ются северо-восточный, юго-восточный, юго-западный и северо-западный соседи
заднего плана (фона). Рис. 9.12, ж) приводит результат пересечения (логическое
AND) этих двух действий. Каждый пиксел переднего плана на этом изображении
отвечает множеству пикселов, которое имеет искомую конфигурацию.
а) 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 б)
О 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0
и oloooiiiiooo о о о
0 111 0 0 0 0 0 0 0 11 0 0
0 0 1 0 0 0 0 0 0 0 0 11 1 0
0 0 0 0 0 1 0 0 6 0 0 0 0 1 0 0
0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0
0 0 0 0 1 0 0 0 О о 0 0 о о о
О 0 0 0 0 0 0 0 0 0 0 0 0 0 0
в)
О 0 0 0 0 О О О 0 0 0 0 0 0 о о
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
О О О О (> О О О О О О V о о о
0 0 1 0 0 0 0 0 0 0 0 0 и о о о
0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 о
О О О О о О О О 0 0 0 0 0 0 0 0
О О О О 0 1 0 0 0 0 О о о о о о
о о о о о о о о о о о о о о о о
О О 0 0 0 0 0 0 О О О О О О о о
г) 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 д)
110 1111111111111
1 1 0 1 1 1 0 0 0 0 1 1 1 1 1 1
1 0 0 0 1 1 1 1 1 1 1 1 0 0 1 1
1 1 0 1 1 1 1 1 1 1 1 1 0 0 0 1
111110 11111110 11
1111000111111111
1111101111111111
1111111111111111
I м
е)
10 10 111111111111 000 0 0 0 0 0 0 0 о о о о
1 о 1 О 1 О О О О О О 1 1 1 1 1 о О О О О О О О О о о о о о
О (>0 0 0 1 1 1 1 1 1 0 0 0 0 1 О о О О О 0 0 0 0 О О (> О О о
1 0 1 0 1 0 0 0 О О О О О О 0 0 0 1 0 0 0 О О О О О О 0 0 () о
О о 0 0 0 1 0 1 1 11 О О О О 1 (I О О (I О О О О О О О О О О (I
10 10 О 0 0 0 1 1 1 О О О О О ООО О О О О О О О О 0 () о
11110 16 111110 10 1 О О О 0 1 о о о о о о о о о о
1 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 О О О О о о о о о о о о о о о
11110 10 111111111 О О О О О О О О О О О о
Рис. 9.12. а} Исходное изображение А. б) Структурообразующий элемент В±. в) Эрозия
А по Bi. г) Дополнение исходного изображения Ас. д) Структурообразующий
элемент Вг. е) Эрозия Ас по Вг- ж) Результирующее изображение
Название операции «успех/неудача» происходит от результата двух эрозий.
Например, выходное изображение на рис. 9.12 состоит из всех позиций пикселов,
которые подходят под В± («успех») и полностью не подходят под В2 («неудача»).
9.3. Комбинирование дилатации и эрозии
Преобразование успех/неудача реализовано в IPT функцией bwhitmiss, ко-
торая имеет синтаксис
С bwhitmiss(A, Bl, В2),
где С - это результат операции, А исходное изображение, а В1и В2 — структуро-
образующие элементы, задействованные в преобразовании, которые обсуждались
выше.
Пример 9.5. Применение функции bwhitmiss.
Рассмотрим задачу обнаружения положений пикселов верхних левых углов объ-
ектов на изображении с помощью преобразования успех/неудача. На рис. 9.13, а)
приведено простое изображение, состоящее из квадратиков разных размеров. Мы
хотим выделить все пикселы переднего плана, которые имеют восточного и юж-
ного соседа (это «успех»), но не имеют ни северо-восточного, ни северного, ни
северо-западного, ни западного, ни юго-западного соседа (это «неудача»). Эти
условия приводят к следующим структурообразующим элементам:
В1
В2
strel([O 00; 01 1; 010]);
strel([l 11; 100; 100]);
Заметим, что оба элемента нс содержат юго-восточного соседа, который называ-
ется все равно каким пикселом. Мы применяем функцию bwhitmiss для выпол-
нения преобразования, где f обозначает входное изображение с рис. 9.13, а)'
g = bwhitmiss(f, Bl ,В2);
imshow(g)
Каждая однопиксельная точка на рис. 9.13, б) является пикселом верхнего лево-
го угла какого-то квадрата на рис. 9.13, а). Пикселы на рис. 9.13, б) были слегка
увеличены для лучшей видимости. □
Рис. 9.13. а) Исходное изоб-
ражение. б) Результат приме-
нения преобразования успех/
неудача (отмеченные точки бы-
ли увеличены для лучшей за-
метности)
370 Глава 9. Морфологическая обработка изображений
9.3.3. Использование поисковых таблиц
Когда структурообразующие элементы, используемые в операции успех/неудача,
малы, то это преобразование можно вычислить быстрее, если воспользоваться по-
исковой таблицей LUT (LookUp Table). Метод заключается в предварительном
вычислении значений выходных пикселов для всех окрестностных конфигура-
ций, а результаты сохраняются в некоторой таблице для дальнейшего исполь-
зования. Например, всего имеется 29 = 512 различных конфигураций значений
пикселов двоичного изображения 3x3.
Чтобы воспользоваться поисковой таблицей, необходимо присвоить уникаль-
ный индекс каждой возможной конфигурации пикселов. Простой способ сделать
это, скажем, для случая 3x3, заключается в умножении каждой конфигурации
3x3 поэлементно на матрицу
1 8 64
2 16 128
4 32 256
и в сложении полученных произведений. Эта процедура назначает уникальное
значение в интервале от 0 до 511 каждой двоичной окрестностной конфигурации
3x3. Например, окрестности
1 1 О
1 0 1
1 0 1
присваивается число 1(1)+2(1) +4(1) +8(1) +16(0)+32(0) +64(0)+128(1)+256(1) =
= 399, где первые множители являются коэффициентами из предыдущей матри-
цы, а в скобках стоят значения пикселов, взятые по столбцам.
В пакете IPT имеется две функции makelut и applylut (использование кото-
рых будет проиллюстрировано позже в этом параграфе), реализующие эти дей-
ствия. Функция makelut строит поисковую таблицу на основе некоторой функ-
ции, заданной пользователем, a applylut обрабатывает входное изображение с
помощью построенной таблицы. Если продолжить рассмотрение случая 3x3, то
использование makelut предполагает задание пользовательской функции, кото-
рая принимает на входе матрицы 3x3, а возвращает одно значение, обычно 0
или 1. Функция makelut вызывает эту заданную пользователем функцию 512 раз,
передавая ей все возможные окрестности 3x3. Она возвращает результат вычис-
лений в виде вектора из 512 элементов.
В качестве иллюстрации мы напишем функцию (назовем ее endpoints .m),
которая использует makelut и applylut для обнаружения концевых точек на
двоичном изображении. Концевой точкой мы будем называть пиксел передне-
го плана, у которого имеется в точности один сосед переднего плана. Функция
endpoints вычисляет, а затем применяет поисковую таблицу для обнаружения
концевых точек входного изображения. Строка программного кода
persistent lut,
которая используется в endpoints, определяет переменную с именем lut и объяв-
ляет, что она принадлежит типу persistent (устойчивый). MATLAB «помнит»
9.3. Комбинирование дилатации и эрозии
значения переменных типа persistent в промежутках между вызовами данной
функции. При первом вызове функции endpoints переменная lut автоматически
инициализируется пустой матрицей ([ ]). Когда lut пуста, то функция вызывает
makelut, передавая ее манипулятор подфункции endpoints_f сп. Затем функция
applylut находит концевые точки с помощью поисковой таблицы. Поисковая
таблица хранится в переменной lut типа persistent, поэтому при следующем
вызове функции endpoints не придется заново строить эту таблицу2.
function g = endpoints(f)
’/.ENDPOINTS Computes end points of a binary image.
7. G = ENDPOINTS (F) computes the end points of the binary image F
% and returns them in the binary image G.
persistent lut
if isempty(lut)
lut = makelut(Qendpoint_fcn, 3);
end
g = applylut(f, lut);
7.- -У.
function is_end_point = endpoint_fcn(nhood)
7. Determines if a pixel is an end point.
°k IS_END_POINT = ENDP0INT_FCN(NH00D) accepts a 3-by-3 binary
7. neighborhood, NHOOD, and returns a 1 if the center element is an
7. end point; otherwise it returns a 0.
is_end_point = nhood(2, 2) & (sum(nhood(:)) == 2);
Пример 9.6. Реализация игры Конвея «жизнь» на основе двоичного изображе-
ния и поисковой таблицы.
Интересным приложением поисковых таблиц может служить «игра жизнь» Кон-
вея, в которой участвуют «организмы», существующие на прямоугольной сетке
и эволюционирующие из поколения в поколение. Мы воспользуемся ею для ил-
люстрации достоинства и простоты метода поисковых таблиц. Имеются простые
правила, по которым организмы в игре Конвея рождаются, выживают и умирают
при переходе от одного «поколения» к следующему.
Генетические правила Конвея определяют метод вычисления следующего по-
коления (или следующего двоичного изображения) по текущему поколению:
1. Каждый пиксел переднего плана, имеющий двух или трех соседей передне-
го плана, выживает в следующем поколении.
2. Каждый пиксел переднего плана, имеющий ноль, один или не менее четы-
рех соседей, «умирает» в следующем поколении (т. е. становится фоновым
пикселом) по причине его «изоляции» или «перенаселенности».
3. Каждый фоновый пиксел, у которого имеется ровно три соседних пиксела
переднего плана, «рождает» пиксел, т. е. он становится пикселом переднего
плана.
2См. § 3.4.2, где обсуждается манипулятор функции ©.
Глава 9. Морфологическая обработка изображений
Все «рождения» и все «смерти» происходят одновременно в процессе вычис-
ления следующего двоичного изображения, определяя очередное поколение «ор-
ганизмов».
Рис. 9.14. а) Изображение мор-
фологического остова, б) Выход
функции endpoints. Пикселы это-
го изображения увеличены для
лучшей наглядности
Для реализации игры «жизнь» с помощью функций makelut и applylut мы
сначала напишем функцию, которая применяет генетические законы Конвея к
выделенному пикселу и его 3x3 соседям:
function out = conwaylaws(nhood)
7«CONWAYLAWS Applies Conway’s genetic laws to a single pixel.
% OUT = CONWAYLAWS(NHOOD) applies Conway’s genetic laws to a single
7. pixel and its 3-by-3 neighborhood NHOOD.
num_neighbors = sum(nhood(•)) nhood(2 2);
if nhood(2, 2) = 1
if num_neighbors <- 1
out 0; 7« Pixel dies from isolation.
elseif num_neighbors > = 4
out 0; 7» Pixel dies from overpopulation.
else
out 1; 7. Pixel survives.
end
else
if num_neighbors 3
out 1 % Birth pixel.
else
out 0; 7o Pixel remains empty.
end
end
9.3. Комбинирование дилатации и эрозии 373
Затем строится поисковая таблица вызовом функции makelut с манипулято-
ром функции conwaylaws в качестве аргумента:
> > lut = makelut (Qconwaylaws, 3);
Множество исходных изображений было придумано для демонстрации раз-
личных эффектов, возникающих в поколениях «организмов», подчиняющихся
законам эволюции Конвея (см. [Gardner, 1970, 1971]). Рассмотрим, к примеру,
начальное изображение, которое называется «конфигурацией чеширского кота»:
» bwl [0000000000
0000000000
0001001000
0001111000
0010000100
0010110100
0010000100
0001111000
0000000000
000000000 0];
Следующие команды совершают вычисления и показывают три поколения этого
изображения:
» imshow(bwl, ’n’), title(’Generation 1’)
» bw2 = applylut(bwl, lut);
> > figure, imshow(bw2, ’n’); title(’Generation 2’)
» bw3 applylut(bw2, lut);
> > figure, imshow(bw3, ’n’); title(’Generation 3’)
Мы оставляем читателям проверить, что после нескольких генераций от кота
остается одна улыбка, которая завершается отпечатком кошачьей лапки. □
9.3.4. Функция bwmorph
Функция bwmorph из пакета IPT выполняет ряд полезных действий, построен-
ных на основе операций дилатации, эрозии, а также с использованием поисковых
таблиц. Она имеет следующую синтаксическую форму вызова:
g = bwmorph(f, operation, n),
где f это входное двоичное изображение, operation символьная строка,
задающая конкретную операцию, а п обозначает, сколько раз необходимо вы-
полнить эту операцию. Входной аргумент п не является обязательным. При его
отсутствии операция выполняется только один раз. В табл. 9.3 перечислены все
допустимые операции функции bwmorph. В оставшейся части этого параграфа
мы сконцентрируем наше внимание на двух действиях, а именно: на утончении
и построении остова.
374 Глава 9. Морфологическая обработка изображений
Таблица 9.3. Операции, поддерживаемые функцией bwmorph
Операция Описание
bothat Совершает операцию «дно шляпы» с использованием структурообразующего элемента 3x3. Для других элементов применять imbothat (см. § 9.6.2).
bridge clean close Соединяет пикселы, разделенные промежутком в один пиксел. Удаляет изолированные пикселы переднего плана. Замыкает с использованием элемента 3x3. Для других структурообразующих элементов применять операцию imclose.
dlag dilate Делает заполнение вокруг диагонально связанных пикселов переднего плана. Совершает дилатацию с использованием элемента 3x3. Для других структу- рообразующих элементов применять операцию imdilate.
erode Выполняет эрозию с использованием элемента 3x3. Для других структуро- образующих элементов применять операцию imerode.
fill Заполняет однопиксельные «дырки» (фоновые пикселы, окруженные со всех сторон пикселами переднего плана).
hbreak majority Удаляет Н-связанные пикселы переднего плана. Делает пиксел р пикселом переднего плана, если не менее 5 пикселов в Ng(p) (см. § 9.4) являются пикселами переднего плана; в противном случае делает пиксел р фоновым.
open Размыкает с использованием элемента 3x3. Для других структурообразую- щих элементов применять операцию imopen.
remove Удаляет «внутренние» пикселы (пикселы переднего плана, у которых нет ни одного фонового соседа).
shrink Сжимает объекты без внутренних дыр в точки. Сжимает объекты с дырами в кольца.
skel Строит остов изображения.
spur thicken thin Удаляет отростки пикселов. Утолщает объекты без соединения несвязных частей. Утончает объекты без дыр до минимальной средней линии. Утончает объек- ты с дырами до колец.
tophat Совершает операцию «верх шляпы» с использованием структурообразующе- го элемента 3x3. Для других элементов применять imtophat (см. § 9-6.2).
Операция утончение сокращает двоичные объекты или формы изображения
до отдельных линий, которые имеют толщину всего в один пиксел. Например, по-
пилярные линии на отпечатках пальцев, показанные на рис. 9.22, в), являются
слишком толстыми. При анализе этих линий может потребоваться их утончение
вплоть до толщины в один пиксел. Каждое применение соответствующей опера-
ции утончения из bwmorph удаляет один или два пиксела из толщины объектов
двоичного изображения. Например, следующие команды демонстрируют резуль-
тат применения операции утончения один и два раза.
>> f = imreadC’fingerprint_cleaned.tif’);
>> gl = bwmorph(f, ’thin’, 1);
>> g2 = bwmorph(f, ’thin’, 2);
>> imshow(gl), figure, imshow(g2)
На рис. 9.15, а) и б), приведены соответствующие утонченные изображения. Име-
ется важный вопрос: сколько раз следует применять эту операцию? Для ряда
действий, включая утончение, функция bwmorph допускает для п значение Inf
9.S. Комбинирование дилатации и .грозии
(т. е. бесконечность). Вызов bwmorph с этим значением предписывает исполнение
операции до тех пор, пока изображение не перестанет изменяться. Иногда это
называют повторением операции до стабилизации. Например,
ginf = bwmorph(f, ’thin’, Inf);
imshow(ginf)
Как видно из рис. 9.15, в), это действие приводит к существенному улучшению
изображения по сравнению с рис. 9.11, в).
Рис. 9.15. а) Отпечатки пальцев из рис. 9-11, в) утончены один раз. б) Утончение изоб-
ражения произведено два раза, в) Утончение изображения до стабилизации
Построение остова представляет собой другой путь сокращения объектов
двоичного изображения для получения множества тонких линий, которое несет
важную информацию о формах исходных объектов. (Процесс построения осто-
ва детально описан в книге [Gonzalez, Woods, 2002]). Функция bwmorph строит
остов, когда параметр operation установлен в ’skel’ Пусть f обозначает изоб-
ражение объекта, похожего на кость, с рис. 9.16, а). Для получения его остова
мы вызываем bwmorph при n = Inf:
fs bwmorph(f, ’skel’, Inf);
>> imshow(f), figure, imshow(fs)
На рис. 9.16, б) приведен полученный остов, который вполне приемлемо отража-
ет основные формы исходного объекта.
Процедуры построения остова и утончения часто строят лишние короткие от-
ростки, которые иногда называются паразитическими компонентами. Процесс
подчищения (или удаления) этих компонент называется усечением. Для этих це-
лей можно использовать функцию endpoints (см. § 9.3.3). Метод заключается
в последовательном обнаружении концевых точек и их удалении. Следующие
простые команды делают завершающую обработку построенного остова f s изоб-
ражения, которые повторяются 5 раз, для удаления концевых точек:
» for к 1:5
fs fs & "endpoints(fs);
end
Рис. 9.16, в) показывает результат этих действий.
Глава 9. Морфологическая обработка изображений
Рис- 9.16. а) Изображение в виде кости, б) Остов, полученный с помощью функции
bwmorph. в) Окончательный остов после выполнения операции усечения функ-
цией endpoints
9.4. Выделение компонент связности
До этого момента все обсуждавшиеся операции применялись индивидуально к
пикселам переднего (или заднего) плана или к их ближайшим соседям. В этом
параграфе рассматриваются важные операции «среднего плана», которые зани-
мают промежуточное положение между обработкой отдельных пикселов и дейст-
виями над всеми пикселами переднего плана. Это приводит к понятию компо-
нент связности, которые мы будет также называть объектами.
Если предложить сосчитать объекты на рис. 9.17, а), то большинство людей
скажет, что их там десять: шесть букв и четыре геометрические фигуры. На
рис. 9.17, б) дан увеличенный прямоугольный фрагмент этого изображения. Ка-
кое отношение имеют 16 пикселов переднего плана на этом рисунке к десяти
выделенным объектам? Несмотря на то, что они разделены на две группы, все
эти 16 пикселов принадлежат букве «Е» на рис. 9.17, а). Чтобы написать ком-
пьютерную программу, которая обнаруживает объекты и оперирует с ними, нам
необходимо более точно определить ключевые понятия.
Пиксел р с координатами (т, у) имеет два горизонтальных и два вертикальных
соседа с координатами (,т + 1, у), (,т — 1, у), (,т, у 4- 1) и (.т, у — 1). Эта четверка со-
седей р обозначается ЛЦр). Она выделена на рис. 9.18, а) серым цветом. Четыре
диагональных соседа р имеют координаты (,т +1, у+ 1), (.т+1,р —1), (.т —1,р4 1)
и (.т — 1, у — 1). На рис. 9.18, б) изображены эти диагональные соседи; эта четвер-
ка обозначается ЛЪ(р). Объединение ЛЦр) и A'yj(p) на рис. 9.18. в) определяет
восьмерку соседей пиксела р. которая обозначается N%(p).
9-4- Выделение компонент связности
Рис. 9.17. а) Изображение, содержащее 10 объектов.
б) Подмножество пикселов изображения
Рис. 9.18. а) Пиксел р и его четвер-
ка соседей №д(р). б) Пиксел р и его
диагональные соседи Nd(p)- в) Пик-
сел р и его восьмерка соседей 7V«(p).
г) Пикселырид являются 4-смежны-
ми и 8-смежными. д) Пикселы р и q
являются 8-смежными, но не 4-смсж-
ными. е) Затемненные пикселы явля-
ются одновременно 4-связными и 8-
связными. :нс) Затемненные пикселы
являются 8-связными, но не 4-связ-
ными
г)
Р Ч
е)
Два пиксела р и q называются если q G N^p). Аналогично,
пикселы р и q называются 8-смежными. если q G Ав(р)- Рис. 9.18, г) и д), иллю-
стрируют эти понятия. Путем между пикселами р, и рп называется последова-
тельность пикселов pi,р2, iPn-hPn, такая, что р); является смежным для
при к — 1,2,. ,п — 1. Путь может быть ^-евлзяьш или 8-связным, в зависимости
от используемого определения смежности пикселов.
Глава 9. Морфологическая обработка изображений
Два пиксела переднего плана р и q называются 4-связными, если существует
4-связный путь между ними, который целиком состоит из пикселов переднего
плана [рис. 9.18, е)]. Пикселы р и q называются 8-связными, если между ними
имеется 8-связный путь [см. рис. 9.18, ж)]. Для любого пиксела переднего плана
р множество всех связанных с ним пикселов переднего плана называется компо-
нентой связности, содержащей р.
Понятие компоненты связности было определено в терминах путей, а поня-
тие пути, в свою очередь, зависит от определения смежности. Это означает, что
природа связных компонент зависит от понятия смежности, из которых наиболее
употребительными являются 4-связность и 8-связность. Рис. 9.19 иллюстрирует
влияние, которое определение смежности может произвести при подсчете числа
компонент связности изображения. На рис. 9.19, а) приведено маленькое двоич-
ное изображение с четырьмя 4-компонентами связности. Рис. 9.19, б) показывает,
что выбор 8-смежности сокращает число компонент 8-связности до 2.
Рис. 9.19. Компоненты связности, а) Четыре 4-связные компоненты. 6) Две 8-связные
компоненты, в) Размечающая матрица, полученная для 4-свяэности. г) Разме-
чающая матрица, полученная для 8-саязности
9-4- Выделение компонент связности
Функция bwlabel из IPT находит все компоненты связности двоичного изоб-
ражения. Форма ее вызова имеет вид
[L, num] bwlabel(f, conn),
где f — это входное двоичное изображение, а параметр conn обозначает желае-
мую связность (по 4- или 8-смежности). Выход L называется размечающей мат-
рицей, а в (необязательный) выходной параметр num записывается общее чис-
ло обнаруженных компонент связности. Если параметр conn опущен, то он по
умолчанию считается равным 8. На рис. 9.19, в) показана размечающая матри-
ца, отвечающая рис. 9.19, а) и вычисленная командой bwlabel (f, 4). Пикселам
каждой отдельной компоненты связности присваивается одинаковое число от 1
и до общего числа компонент связности. Другими словами, пикселы, помечен-
ные 1, принадлежат первой компоненте связности, пикселы, помеченные 2,
второй компоненте, и т. д. Фоновые пикселы помечены 0. На рис. 9.19, г) пока-
зана размечающая матрица, соответствующая рис. 9.19, а), которая построена
командой bwlabel (f, 8).
Пример 9.7. Нахождение центров масс компонент связности.
В этом примере показано, как можно найти центр масс каждой компоненты связ-
ности рис. 9.17, а). Прежде всего, мы воспользуемся функцией bwlabel для вы-
числения 8-связных компонент:
>> f imread(’objects.tif ’) ;
>> [L, n] bwlabel(f);
Функция find (cm. § 5.2.2) может быть полезной при работе с размечающими мат-
рицами. Например, следующий вызов функции find возвращает индексы строк
и столбцов всех пикселов, принадлежащих третьему объекту:
» [г, с] find(L == 3);
Функция mean с выходами г и с вычисляет центр масс этого объекта1.
» rbar = mean(r);
» cbar mean(с);
Для нахождения центров масс всех объектов изображения можно воспользовать-
ся циклом. Чтобы сделать центры масс объектов видимыми на изображении, мы
их обозначим символом «*» белого цвета, который разместим в центре черного
кружка. Для этого выполним следующую серию команд:
>> imshow(f)
>> hold on 7, So later plotting commands plot on top of the image.
>> for k = 1 :n
[r, c] = find(L == k);
'Если А является вектором, то tnean(A) вычисляет среднее значение его элементов. Если А —
матрица, то mean (А) трактует столбцы А как векторы и возвращает вектор-строку из средних
величин этих векторов. Форма вызова mean(A,dim) возвращает средние значения элементов
вдоль размерности dim.
Глава 9. Морфологическая обработка изображений
rbar = mean(г);
cbar = mean(с);
plot(cbar, rbar, ’Marker’, ’o’, ’MarkerEdgeColor’, ’k’,.
’MarkerFaceColor’, ’k’, ’MarkerSize’, 10)
plot(cbar, rbar, ’Marker’, ’MarkerEdgeColor’, ’w’)
end
Рис. 9.20 показывает результат этого программного кода. □
9.5. Морфологическая реконструкция
Рис. 9.20. Центры масс (белые звез-
дочки), наложенные на соответству-
ющие компоненты связности
Реконструкция является морфологическим пре-
образованием, в котором участвуют два изоб-
ражения и один структурообразующий элемент
(вместо одного изображения и одного структу-
рообразующего элемента, как это было в преды-
дущих параграфах). Одно изображение, ко-
торое называется маркером, является исход-
ной точкой преобразования. Другое изображение,
маска, накладывает определенные ограничения
(связи) на отображение. Используемый струк-
турообразующий элемент определяет связность.
В этом параграфе мы используем 8-связность
(задаваемую по умолчанию), которая означает,
что матрица В, используемая далее, есть 3x3
матрица из одних единиц, центр которой нахо-
дится в точке с координатами (2,2).
Если д — это маска, а / маркер, то рекон-
струкция д по /, которая обозначается Rs(/),
определяется следующей итеративной процедурой.
1. Инициализация: присвоить hi маркерное изображение /
2. Построить структурообразующий элемент В ones (3).
3. Повторять:
hk+i = (hkeB}Cg
до тех пор. пока не станет hk+i — hk.
Маркер / должен быть подмножеством д, . е.
fQs-
Рис. 9.21 иллюстрирует эту итеративную процедуру. Заметим, что, несмот-
ря на простоту и удобство итеративной формулировки процесса реконструкции,
существуют другие, более быстрые вычислительные алгоритмы, реализующие
9.5. Морфологическая реконструкция
это преобразование. Функция imreconstruct из пакета IPT выполняет «бысг
рую гибридную реконструкцию», описанную в [Vincent, 1993|. Эта функция име-
ет следующий синтаксис:
out imre construct (marker, mask),
где marker и mask это изображения, определенные в начале параграфа.
Рис. 9.21. Морфологическая реконстргкция. а) Исходное изображение (маска), б) Мар-
керное изображение. в)—д) Промежуточные результаты после 100, 200 и 300
итераций, соответственно, е) Окончательный результат. [Выделенные объекты
маски наложены на рис. б) д) для сравнения]
9.5.1. Размыкание реконструкцией
При морфологическом замыкании операция эрозия удаляет малые объекты,
последующая дилатация частично восстанавливает форму оставшихся объектов.
Однако точное- этою восстановления зависит от степени подобия форм объ-
ектов и структурооб азующего элемента. Метод размыкания рекстструкцией1,
обсуждающийся в этом парагр; фе, точности восстанавливает форму объектов,
которые остались после эрозии. Размыкание реконструкцией / с использованием
тгруктурообразующею элемента 13 определяется формулой Rj(f С 13).
1 Другие приложения морфологической реконструкции рассматриваются в §§ 10.4.2 и 10.4.3.
Глава 9. Морфологическая. обработка изображении
Пример 9.8. Размыкание реконструкцией.
Сравнение результатов морфологического размыкания и размыкания реконструкци-
ей для изображения, на котором имеется фрагмент текста, показало на рис. 9.22.
В этом примере мы хотим извлечь из рис. 9.22, а) символы, у которых имеют-
ся длинные вертикальные черточки. Поскольку для размыкания реконструкци-
ей требуется изображение, подвергнутое эрозии, мы выполним эту операцию па
первом шаге, -.пользуя тонкий, вертикальный структурообразующий элемен-
длина которого пропорциональна высоте букв:
f = imread(’book_text_bw.tif’);
fe = iroerodeCf, ones (51, 1));
d
fd
bl
tf th
fth
th
ponents or broken connection paths. I _ re is no p
tion past the level of detail required to identify those
Segmentation of nontrivial images is one of the m
processing. Segmentation accuracy determines the e-
of computerized analysis procedures. For this reason,
be taken to improve the probability of rugged segment,
such as industrial inspection applications, at least some
the environment is possible at times.The experienced
desi. ner invariabl p к s considerable attention to sun
th Th
dt
th
d t
F
patients er breken cannectian paths 1 -ere is ne pail
tian past the level af detail required te identify these
Segmentatien ef nentrivial images is ene ef the me
precessing. Segmentatien accuracy determines the ev
el computerized analysis precedures. Fer this reasen.
be laken te impi eve the probability ef rugged egment
such Os industrial inspection applications, at least seme
ihe envirenment is possible at times. Hie experienced
designer invariable p,iys uinsidciable attcntien te
ponents or broken connect on paths. There is no poi
tion past the level of detail required to identify those
Segmentation of nontrivial images is one of the mo
processing. Segmentation accuracy determines the vv
of computerized analysis procedures. For this reason,
be taken to improve the probability of rugged segment
such as industrial inspection applications, at least som
the environment is possible at times.The experienced
designer inv-.iri.ibly pays considerable attention to sue
Рис. 9.22. Морфологическая реконструкция, а) Исходное изображение, б) Эрозия по вер-
тикальной черточке, в) Размыкание по вертикальной черточке, г) Размыкание
реконструкцией по вертикальной черточке, д) Заполнение дыр. е) Символы,
соприкасающиеся с границей (см. правую границу). э+с) Пограничные символы
удалены
9.5. Морфологическая реконструкция
На рис. 9.22, б) приведен результат. Размыкание, показанное на рис. 9.22, в), бы-
ло выполнено функцией imopen:
>> fo imopen(f, ones(51, 1));
Отметим, что вертикальные черточки были обнаружены, но содержащие их сим-
волы целиком восстановлены не были. Теперь выполняем размыкание рекон-
струкцией по формуле
>> fobr = imreconstruct(fe, f) ;
Из результата, представленного на рис. 9.22, г), видно, что символы, содержащие
вертикальные черточки, были полностью восстановлены, а все остальные симво-
лы — удалены. Оставшиеся части рис. 9.22 иллюстрируют материалы следующих
двух параграфов. □
9.5.2. Заполнение отверстий
Морфологическая реконструкция имеет широкий спектр практических прило-
жений, которые определяются выбором маркера и маски. Например, пусть в ка-
честве маркерного изображения взято изображение /т, которое равно 0 везде,
кроме границ, а в точках границы оно равно 1 — /:
, , , f 1— f(x, у), если (х, и) лежит на границе,
Тогда операция д = [-R/c(/m)]c имеет эффект заполнения отверстий в /, как это
проиллюстрировано на рис. 9.22, д). Функция imf ill выполняет эти действия
автоматически при задании необязательного аргумента ’holes’ в команде
g = imfill(f, ’holes’).
Эта функция подробно обсуждается в § 11.1.2.
9.5.3. Очистка от пограничных объектов
Другое полезное приложение реконструкции заключается в очистке изображе-
ний от объектов, которые соприкасаются с границей. Опять ключевой момент
состоит в выборе подходящих маркера и маски для достижения желаемого ре-
зультата. В данном случае в качестве маски используется исходное изображение,
а маркерное изображение fm задается формулой
. , . _ ( f(x,y), если (х, у) лежит на границе,
МХ'У)~\ о
Рис. 9.22, е) показывает результат реконструкции Rf(jm), на котором остались
лишь объекты, касающиеся границы. Разность множеств /\ Rf(Jm), приведен-
ная на рис. 9.22, ж), состоит из объектов исходного изображения, которые не
касаются границы. Функция IPT imclearborder автоматически совершает эту
процедуру. Она имеет форму вызова
g = imclearborder(f, conn),
Глава 9- Морфологическая обработка изображений
где f — это входное изображение, a g - результат. Параметр сопл может быть
равным 4 или 8 (по умолчанию). Эта функция «гасит» структуры, которые ярче
своих окрестностей и которые примыкают к границам изображения. Изображе-
ние f может быть полутоновым или двоичным. Выходом служит или полутоно-
вое, или двоичное изображение соответственно.
9.6. Полутоновая морфология
Все двоичные морфологические операции, обсуждавшиеся в этой главе, за ис-
ключением преобразований «успех/неудача», имеют естественные расширения
для обработки полутоновых изображений. В этом параграфе, как и в двоичном
случае, мы начнем с рассмотрения операций дилатации и эрозии, которые для
полутоновых изображений формулируются в терминах минимума и максимума,
взятых по окрестностям пикселов.
9.6.1. Дилатация и эрозия
Полутоновая дилатация изображения f по структурообразующему элементу Ь
обозначается / 0 Ь и определяется формулой
(/ © Ь)(х, у) = max {f(x -х,у- у1) + Ь(х', у') | (х, у') е Db},
где Db обозначает область определения Ь, и предполагается, что f(x,y) равно
—оо вне области определения /. Это уравнение реализует процесс, аналогичный
процедуре нахождения пространственной свертки, которая объяснялась в § 3.4.1.
Для наглядности можно мысленно повернуть структурообразующий элемент на
180° вокруг его центра и разнести по всем точкам (х,у) изображения. В каждом
положении нужно сложить соответствующие пикселы изображения с пикселами
повернутого и перемещенного элемента, а затем вычислить максимум всех этих
величин. Получится значение дилатации в точке (ж, у).
Важное отличие полутоновой дилатации от пространственной свертки состоит
в том, что двоичная матрица Db определяет, какие точки из окрестности исполь-
зовать в операции взятия максимума. Другими словами, для любой пары коор-
динат (жо, уа) из области Db сумма величин f(x — xq, у — уо) 4- Ь(хо,уо) участвует
в вычислении максимума только в случае, если значение матрицы /Л в ячей-
ке (хо,Уо) равно 1. В противном случае, т. е. когда этот элемент матрицы равен
нулю, соответствующая сумма не участвует в операции взятия максимума. Это
действие повторяется для всех координат (ж',?/) Е Db, каждый раз, как только
меняется координата (ж, у). Построение графика величины Ь(х', у'), как функции
координат х и у', будет выглядеть как цифровая «поверхность», высота которой
в каждой точке задается значением изображения Ь в этой точке.
На практике полутоновая дилатация обычно выполняется с использованием
плоских структурообразующих элементов (см. табл. 9.2), для которых величина
(высота) Ь равна 0 в каждой точке, принадлежащей Db. То есть
Ь(х'тУ') = 0 при (х',у') Е Db.
9.6. Полутоновая морфология 385,
В этом случае операция взятия максимума полностью определяется конфигу-
рацией 0 и 1 двоичной матрица /Л, а уравнения ддя полутоновой дилатации
принимают более простой вид
(/ ® 6)(ж, у) = max {f(x - х ,у - у'} | (х', у'} G Db}
Таким образом, полутоновая дилатация является операцией взятия локального
максимума, в которой максимум вычисляется по множеству пикселов окрестно-
сти, форма которой задается областью Db.
Неплоские структурообразующие элементы можно строить с помощью функ-
ции strel, передавая ей две матрицы:
(1) одну матрицу из 0 и 1, которые обозначают область структурообразующего
элемента Db, и
(2) другую матрицу, в которой записаны значения высот Ъ(х',у').
Например, команда
» b strel ([1 11], [12 1])
Ь
Nonflat STREL object containing 3 neighbors.
Neighborhood:
111
Height:
12 1
создает структурообразующий элемент 1x3, значения высот которого равны Ь(0, —1) =
= 1, Ь(0,0) =2, Ь(0,1) = 1.
Плоские структурообразующие элементы для полутоновых изображений строят-
ся с использованием функции strel по тем же правилам, что и для двоичных
изображений. Например, следующие команды показывают, как совершать дила-
тацию изображения f на рис. 9.23, а) с помощью плоского 3x3 элемента:
>> se strel (’square ’, 3);
>> gd = imdilate (f, se) ;
На рис. 9.23, б) показан результат. Как и следовало ожидать, изображение полу-
чилось слегка размытым. Остальные части рис. 9.22 обсуждаются далее.
Полутоновая эрозия / по структурообразующему элементу b обозначается
/ 0 Ь и определяется формулой
(/ © Ъ)(х, у) = min {f(x + х',у+ у') - Ь(х', у') | (х', у') G Db} ,
где Db обозначает область определения b и предполагается, что f(x, у) равно +оо
вне области определения /. Опять эту процедуру можно мысленно представлять
в виде перемещения центра структурообразующего элемента во все точки изобра-
жения. В каждой точке изображения значения структурообразующего элемента
вычитаются из соответствующих значений пикселов изображения и берется ми-
нимум по всем таким разностям.
Глава 9. Морфологическая обработка изображений
Рис. 9.23. Дилатация и эро-
зия. а) Исходное изображение.
б) Изображение после дила-
тации. в) Изображение после
эрозии, г) Морфологический
градиент. (Исходное изображе-
ние предоставлено Агентством
NASA)
Как и с дилатацией, полутоновая эрозия чаще всего применяется по плоским
структурообразующим элементам. В этом случае уравнения для эрозии можно
упростить и привести их к виду
(/ ф Ь)(т, у) = min {f(x + х',у + у') | (х\ у') е А>}.
Значит, полутоновая эрозия является операцией локального минимума, в которой
минимум берется по множеству пикселов окрестности, форма которой задается
по Di,. Рис. 9.23, в) изображает результат применения функции imerode с тем
же структурообразующим элементом, что и на рис. 9.23, б)'.
» ge = imerode(f, se);
Дилатацию и эрозию можно сочетать для достижения различных эффектов.
К примеру, вычитание результата эрозии изображения из результата дилатации
задает «морфологический градиент»1, который представляет собой меру локаль-
ной полутоновой вариации изображения. Например, присвоив
» morph_grad = imsubtract(gd, ge) ;
получаем изображение на рис. 9.23, г), которое является морфологическим гра-
диентом рис. 9.23, а). На этом изображении подчеркнуто выделены граничные
*На самом деле, вычисление морфологического градиента использует другую процедуру для
несимметричных структурообразующих элементов. А именно: на шаге дилатации элемент сле-
дует симметрично отражать.
характеристики, подобно тому, как это делается операцией взятия градиента,
обсуждавшейся в § 6.6.1, и которая еще будет рассматриваться в § 10.1.3.
9.6.2. Размыкание и замыкание
Формулы размыкания и замыкания для полутоновых изображений имеют такой
же вид, что и для двоичных изображений. Размыкание изображения f по эле-
менту Ь обозначается / о Ь и определяется выражением
/о6= (/еб)©б.
Как и раньше, сначала выполняется эрозия / по Ъ, за которой следует дилатация
по Ь. Аналогично, замыкание / по 6, обозначаемое / • 6. есть дилатация, после
которой совершается эрозия:
/•б = (/Фб)еь.
Обе эти операции имеют простую геометрическую интерпретацию. Представим
изображение /(.т, у) в виде трехмерной поверхности, т. е. значения яркости пред-
ставляются высотами над координатной плоскостью ху. Тогда процесс размы-
кания / по Ь представляет собой перемещение (перекатывание) структурообра-
зующего элемента строго под трехмерной поверхностью изображения /, причем
поверхность размыкания получается как огибающая высшие точки, которые до-
стигает этот элемент.
Рис. 9.24 иллюстрирует эту процедуру в одномерном случае. Рассмотрим кри-
вую на рис. 9.24, а), которая представляет собой значения высот (яркости) вдоль
какой-то строки изображения. На рис. 9.24, б) показано несколько положений
плоского структурообразующего элемента при перемещении под кривой. Резуль-
тат замыкания дан на рис. 9.24, в) жирной линией над серой областью. Посколь-
ку структурообразующий элемент слишком велик, чтобы поместиться внутри
узкого пика, расположенного посередине исходного изображения, это iniK среза-
ется при размыкании. В общем случае процедура размыкания используется для
удаления узких всплесков яркости при сохранении среднего полутонового фона
и широких областей изменения яркости относительно неизменными.
Рис. 9.24, г) иллюстрирует процесс замыкания. Теперь структурообразующий
элемент перемещается сверху по поверхности кривой яркости. Результат замы-
кания, показанный на рис. 9.24, д), получается нахождением всех самых нижних
точек, которые достигаются элементом при движении по кривой. Видно, что за-
мыкание подавляет более темные малые колебания яркости, размеры которых
меньше размеров элемента.
Пример 9.9. Морфологическое сглаживание с помощью размыкания и замыкания.
Поскольку размыкание удаляет яркие детали, которых меньше, чем структуро-
образующих элементов, а замыкания, наоборот, подавляют аналогичные темные
детали малых размеров, то эти процедуры широко используются в различных
сочетаниях при сглаживании и удалении постороннего шума. В этом примере
мы применяем функции imopen и imclose для сглаживания изображения дере-
вянных шпонок на рис. 9-25, а):
» f imread(’plugs,jpg’);
>> se = strel(’disk’, 5);
388 Глава 9. Морфологическая обработка изображений
fo = imopen(f, se);
foe = imclose(fo, se);
На рис. 9.25, б) показано разомкнутое изображение f о, а на рис. 9.25, в) — замк-
нутое изображение foe. Обратите внимание на сглаживания фона и деталей объ-
ектов изображения. Эту процедуру часто называют фильтрацией размыканием-
замыканием. Фильтрация замыканием-размыканием приводит к похожему ре-
зультату.
Другой путь комбинирования размыкания и замыкания состоит в альтерна-
тивной последовательной фильтрации. Одна из форм альтернативной последо-
вательной фильтрации заключается в серии фильтраций размыканием-замыка-
нием рядом структурообразующих элементов с увеличивающимися размерами.
Следующая последовательность команд иллюстрирует этот процесс, который на-
чинается с малого структурообразующего элемента с последующим увеличением
его размера до тех пор, пока он не сравняется с элементом, использованным при
построении рис. 9.25, 6) и в):
» fasf = f;
>> for k = 2:5
se = strel(’disk’, k) ;
fasf = imclose(imopen(fasf, se), se);
end
9.6. Полутоновая морфология
Результат приведен на рис. 9.25, г). Он является более гладким по сравнением с
результатом простой фильтрации размыканием-замыканием, но платой служат
дополнительные вычислительные затраты. □
Рис. 9.25. Сглаживание
при помощи размыкания
и замыкания, а) Исходное
изображение деревянных
шпонок, б) Изображение,
разомкнутое с помощью
круга радиуса 5. в) Замы-
кание результата размы-
кания. г) Результат альтер-
нативной последователь-
ной фильтрации
Пример 9.10. Применение преобразования «верх шляпы».
Размыкание можно использовать для компенсации неравномерной яркости фона
изображения. На рис. 9.26, а) дано изображение f зерен риса, на котором фон
в нижней части темнее, чем в верхней части изображения. Неравномерный фон
создает трудности при пороговой обработке изображений (см. § 10.3). Например,
на рис. 9.25, б) приведен результат пороговой обработки, на которой зерна из
верхней части хорошо отделены от фона, а из нижней части - плохо. Размыкание
изображения может дать правильное приближение фона, если структурообразу-
ющий элемент достаточно велик, чтобы целиком поместиться внутри каждого
рисового зернышка. Например, командами
> > se = strelf’disk’, 10);
> > fo = imopen(f, se) ;
совершается размыкание изображения на рис. 9.26, в). Если вычесть это изобра-
жение из исходного, то получится изображение зерен на достаточно однородном
фоне:
> > f2 = imsubtract (f , f о) ;
Рис. 9.26, г) показывает результат этого действия, а на рис. 9.26, д) приведено
новое изображение после пороговой обработки. Налипо эффект улучшения.
Вычитание разомкнутого изображения из исходного называется преобразовани-
ем «верха шляпы». Функция IPT imtophat выполняет эти действия за один шаг:
> > 12 = imtophat(f, se) ;
Глава 9. Морфологическая обработка изображений
Функцию imtophat можно вызывать командой g imtophat(f, NHOOD), где
NHOOD это массив из нулей и единиц, которые обозначает размер и форму
используемого структурообразующего элемента. Этот синтаксис схож с вызовом
этой функции в виде imtophat (f, strel (NHOOD) ).
Сопряженная функция imbothat совершает преобразование «дно шляпы», ко-
торое по определению есть замыкание изображения минус само изображение.
Ее форма вызова подобна синтаксису функции imtophat Эти функции можно
употреблять в сочетании друг с другом, например, для усиления контрастности
командами вида
se strel(’disk’, 3);
>> g = imsubtract(imadd(f, imtophat(f, se)), imbothat(f se)); □
Рис. 9.26. Преобразование «верх шляпы», а) Исходное изображение, б) Изображение
после пороговой обработки, в) Разомкнутое изображение, г) Преобразование
«верх шляпы», д) «Верх шляпы» после пороговой обработки. (Изображение
предоставлено компанией The MathWorks, Inc)
Пример 9.11. Гранулометрия.
Методы определения размеров рассыпанных объектов на изображении составля-
ют важную часть гранулометрии. Для нахождения размеров объектов можно
воспользоваться неявным морфологическими подходом, т. е. без измерения раз-
меров каждого отдельного объекта. Для объектов с регулярными формами, ко-
торые ярче, чем фон изображения, метод заключается в применении морфологи-
9.6. Полутоновая морфология
ческого размыкания с увеличивающимися размерами. Для каждого акта размы-
кания вычисляется сумма всех значений пикселов. Эта сумма иногда называется
площадью поверхности изображения. Следующие команды реализуют размыка-
ние с помощью (структурообразующего элемента) круга, радиус которого меня-
ется от 0 до 35, применительно к изображению 9.25, а):
f imread(’plugs.jpg’);
sumpixels zeros(l, 36);
for k 0:35
se strel(’disk’, k);
fo imopen(f, se) ;
sumpixels(k + 1) sum(fo(:));
end
plot(0:35, sumpixels), xlabel(’k’)
ylabel(’Surface area’)
Рис. 9.27. Гранулометрия, а) Площадь поверхности как функция радиуса структурооб-
разующего элемента. 6) Уменьшение площади поверхности как функция ра-
диуса структурообразующего элемента, в) Уменьшение площади поверхности
как функция радиуса для сглаженного изображения
На рис. 9.27, а) приведен график зависимости sumpixels от радиуса к. Более
наглядным является график уменьшения площади поверхности между последо-
392 Глава 9. Морфологическая обработка изображений
О
вательными размыканиями:
>> plot(-diff (sumpixels))
>> xlabel(’k’)
>> ylabel(’Surface area reduction’)
Пики на рис. 9.27. б) говорят о присутствии большого числа объектов, имеющих
этот радиус. Поскольку исходное изображение является достаточно зашумлен-
ным, мы повторили эту процедуру применительно к его сглаженной версии на
рис. 9.25, г). Результат построен на рис. 9.27, в). Теперь имеется достаточно осно-
ваний, чтобы сделать вывод о присутствии двух характерных размеров объектов
на исходном изображении. □
9.6.3. Реконструкция
Рис. 9.28. Полутоновая морфологическая ре-
конструкция в случае одного измерения, а) Кри-
вые маски (сверху) и маркера, б) Итеративное
вычисление при реконструкции, в) Результат ре-
конструкции (черная кривая)
Морфологическая реконструкция по-
лутоновых изображений определяет-
ся с помощью итеративной процеду-
ры, описанной в § 9.5 для двоичных
изображений. Рис. 9.28 показывает, как
это преобразование работает в одно-
мерном случае. Верхняя кривая на
рис. 9.28, а) является маской, а ниж-
няя (серая) кривая служит маркером.
В этом примере маркер построен про-
стым вычитанием некоторой констан-
ты из маски, однако в общем случае
любой сигнал может служить марке-
ром при условии, что ни одно из его
значений не превосходит соответству-
ющей величины маски. Каждая ите-
рация процедуры реконструкции раз-
мазывает пики на кривой-маркере, по-
ка они усиливаются снизу кривой-
маской [см. рис. 9.28, б)\.
Окончательный результат рекон-
струкции показан на рис. 9.28, в). За-
метьте, что два малых пика исчезли
на реконструкции, в то время как два
высоких остались, но они стали ниже. Если маркерное изображение получается
путем вычитания константы h из изображения-маски, то такая реконструкция
называется преобразованием h-минимума. Преобразование /i-минимума выпол-
няется в IPT функцией imhmin. Она позволяет удалять малые локальные пики.
2Если v — это вектор, то diff(v) возвращает вектор короче исходного на один элемент, компо-
ненты которого равны разностям соседних элементе®. Если X — матрица, то diff (X) возвращает
матрицу разности строк X(2:end,:) - X(l:end-1,:).
9.6. Полутоновая морфология
Другая полезная техника реконструкции выполняется процедурой размыка-
ние реконструкцией, при которой исходное изображение сначала подвергается
эрозии, как при обычном морфологическом размыкании. Затем, однако, вместо
того, чтобы применять замыкание, полученное изображение используется в каче-
стве маркера при выполнении реконструкции. А в качестве маски используется
само исходное изображение. На рис. 9.29, а) показан пример размыкания рекон-
струкцией, полученный после выполнения команд
f
se
fe
imread(’plugs.jpg’);
strel(’disk’, 5);
imerode(f, se);
fobr
imreconstruct(fe, f );
Рис. 9.29. а) Размыкание ре-
конструкцией. 6) Размыкание
реконструкцией, после которо-
го выполняется замыкание ре-
конструкцией.
ау б)
Реконструкцию можно применять для дальнейшей подчистки изображения
fobr. применяя так называемую технику замыкания реконструкцией Замыка-
ние реконструкцией состоит из взятия дополнительного изображения, выполне-
ния размыкания реконструкцией и вычисления вновь дополнения. Эти шаги со-
вершаются командами
> > fobrc = imcomplement (fobr) ;
> > fobrce = imerode(fobrc, se) ;
> > fobrcbr = imcomplement(imreconstruct(fobrce, fobrc));
На рис. 9.29, б) показан результат размыкания реконструкцией, за которым при-
менено замыкание реконструкцией. Сравните его с результатами применения
фильтра размыкания-замыкания и альтернативного последовательного фильтра
на рис. 9.25.
Пример 9.12. Использование реконструкции для удаления сложного фона изоб-
ражения.
В заключение этой главы мы выполним несколько шагов полутоновой рекон-
струкции. Задача заключается в выделении текстовых символов па изображении
кнопок калькулятора, приведенного на рис. 9.30, а). Первый шаг состоит в уда-
лении линий горизонтальных отблесков наверху каждой кнопки. Для этого мы
воспользуемся тем фактом, что эти отблески длиннее, чем любой текстовый сим-
вол изображения. Мы выполняем размыкание реконструкцией, используя струк-
турообразующий элемент, представляющий длинный горизонтальный отрезок:
Глава 9. Морфологическая обработка изображений
f imread(’calculator.jpg’);
f_obr imreconstruct(imerode(f, ones(l, 71)), f);
f_o = imopen(f, ones(l, 71)); 7« For comparison.
Результат размыкания реконструкцией показан на рис. 9.30, б). Для сравнения
на рис. 9.30, в) приведен результат стандартного размыкания (f _о). Размыкание
реконструкцией лучше извлекает фон между соседними кнопками по горизон-
тали. Процесс вычитания результата размыкания реконструкцией из исходного
изображения называется преобразованием «верх шляпы» реконструкцией, и он
показан па рис. 9.30, г)
Рис. 9.30. Применение полутоновой реконструкции, а) Исходное изображение, б) Раз-
мыкание реконструкцией, в) Размыкание, г) «Верх шляпы» реконструкцией.
д) «Верх шляпы», е) Размыкание реконструкцией г) с использованием горизон-
тального отрезка, ж) Дилатация е) с использованием горизонтального отрезка.
з) Окончательный результат реконструкции
f_thr = imsubtract(f, f_obr);
f_th = imsubtract(f, f_o); 7, Or imtophat (f, ones(l, 71))
Выводы
На рис. 9.30, д) дан результат обычной операции «верх шляпы» (т. е. изображе-
ние f _th).
Теперь мы удалим линии вертикальных отблесков на правой стороне каждой
кнопки на рис. 9.30, г). Для этого мы воспользуемся размыканием реконструк-
цией с элементом, который есть короткий горизонтальный отрезок:
> > g_obr = imreconstruct(imerode(f_thr, ones(l, 11)), f_thr);
На полученном изображении [см. рис. 9.30, ц)] вертикальные отблески исчезли.
Однако это же случилось с символами, у которых имеются тонкие вертикальные
черточки, например, пропала косая черта у символа процента «%», и исчезла
вся буква «I» в слове ASIN. Тогда мы воспользуемся тем обстоятельством, что
буквы с удаленными по ошибке деталями будут близки к другим символам, если
сначала выполнить дилатацию [рис. 9.30,
> > g_obrd = imdilate(g_obr, ones(l, 21));
а затем уже совершить окончательную реконструкцию с изображением f_thr в
качестве маски и min(g_obrd) в качестве маркера:
> > f2 imreconstruct(min(g_obrd, f_thr), f_thr);
На рис. 9.30, з) приведен окончательный результат. Заметим, что на этом
изображении успешно удалены все тени на фоне изображения и все отблески
на кнопках. □
Выводы
Изложенные в этой главе понятия и методы, связанные с морфологическим ана-
лизом изображений, образуют весьма эффективный набор инструментов для из-
влечения различных свойств и характеристик изображений. Основные операции
дилатации, эрозии и реконструкции, определенные как для двоичных, так и для
полутоновых изображений, могут применяться в различных комбинациях для
решения весьма широкого спектра задач обработки изображений. В следующей
главе будет показано, как морфологический анализ используется при сегмента-
ции изображений. Кроме того, морфологические методы играют ключевую роль
в алгоритмах описания изображений, что будет обсуждаться в гл. 11.
ГЛАВА IО
СЕГМЕНТАЦИЯ
ИЗОБРАЖЕНИЙ
Введение
В прсдьщущей главе мы перешли от рассмотрения низкоуровневых методов об-
работки изображений, когда на входе и выходе присутствуют изображения, к
изучению методов среднего и высокого уровня, где иа вход подается изображе-
ние, а выходом процесса обработки служат некоторые свойства и атрибуты, из-
влеченные из изображения. Сегментация - это следующий важный шаг в этом
направлении.
Сегментация делит изображение на составные части и объекты. Степень де-
тализации этого деления зависит от решаемой задачи. Иными словами, сегмен-
тацию следует остановить, когда интересующие объекты уже выделены или изо-
лированы. Например, при осуществлении автоматического контроля при сборке
узлов радиоэлектронной аппаратуры важно уметь выявлять определенные де-
фекты изготавливаемых приборов, таких как отсутствие компонентов или на-
личие разрывов контактных дорожек на плате. Однако если такие дефекты уже
обнаружены, нет необходимости производить сегментацию более мелкого уровня.
Сегментация сложных изображений является весьма нетривиальной задачей
обработки изображений. Точность сегментации во многом определяет успех ко-
нечных компьютеризованных процедур анализа изображений. По этой причине
повышенное внимание должно быть уделено надежности первичной сегмента-
ции. В некоторых случаях, например, в приложениях контроля промышленных
изделий, можно в определенной степени управлять условиями текущей съем-
ки. В других прикладных задачах, например, при дистанционном зондировании,
разработчик может лишь сосредоточить свои усилия на выборе подходящих сен-
соров и детекторов.
Как правило, алгоритмы сегментации монохромных изображений основаны
на одном из двух базовых свойствах яркости изображения: разрывности и од-
нородности. В первом случае подход состоит в разбиении изображения на части
исходя из резких перепадов значений яркости, которые происходят, например,
на границах объектов. Вторая группа методов осуществляет разделение изобра-
жений на области, однородные в смысле определенных, заранее заданных кри-
териев.
В этой главе мы рассмотрим некоторые методы, основанные на этих двух
подходах, применительно к монохромным изображениям (обнаружение краев и
сегментация цветных изображений обсуждается в § 6.6). Мы начнем с представ-
ления методов, которые пригодны для обнаружения разрывов яркости, напри-
мер, точек, линий, краев и перепадов. Выделение контуров объектов долгие годы
10.1. Обнаружение точек, линий и
являлось основой алгоритмов сегментации. Помимо обнаружения перепадов яр-
кости как таковых, мы рассмотрим подход к обнаружению прямых участков,
основанный на преобразовании Хафа. После обсуждения выделения контуров мы
рассмотрим методы пороговых преобразований. Пороговая обработка также яв-
ляется одним из фундаментальных подходов к сегментации изображений, заво-
евавших популярность в приложениях, требующих быстрое принятие решения.
Затем будут изложены некоторые подходы к сегментации, ориентированные на
выделение областей. В конце главы мы рассмотрим морфологический подход к
сегментации, который называется сегментацией по водоразделам. Этот подход
особенно привлекателен, поскольку он приводит к замкнутым и четким облас-
тям. Кроме того, он является достаточно общим, а также позволяет использовать
априорную информацию об изображениях в конкретных приложениях для улуч-
шения результатов сегментации.
10.1. Обнаружение точек, линий и перепадов
В этом параграфе рассматривается техника обнаружения трех основных видов
разрывов яркости, встречающихся в цифровых изображениях: точки, линии и пе-
репады. Наиболее общий способ поиска таких разрывов заключается в обработке
изображения скользящей маской, подобно тому, как описывалось в §§ 3.4 и 3.5.
Для маски размерами 3x3 эта процедура использует вычисление линейной ком-
бинации коэффициентов маски со значениями яркости элементов изображения,
накрываемых маской. Отклик R этой процедуры в каждой точке изображения
задается выражением
9
R = WiZi + W121 +--h W9Z9 = WiZi,
i=l
где Zi — это значение яркости пиксела, соответствующего коэффициенту мас-
ки Wi. Как обычно, отклик маски присваивается элементу, над которым распо-
ложен центр маски.
10.1.1. Обнаружение точек
Обнаружение изолированных точек на изображении не
представляет большой сложности. Используя маску, пока-
занную на рис. 10.1, будем считать, что в пикселе под цен-
тром маски обнаружена точка, если
|Л| > Т,
где Т — это неотрицательное пороговое значение. Обна-
ружение точек реализовано в IPT с помощью функции
imfilter, которая использует маску на рис. 10.1 или дру-
гую похожую маску. Важное требование заключается в том,
что самый сильный отклик маски должен происходить, ко-
обнаружения точек
гда центр маски совмещен с изолированной точкой, а в областях постоянной
яркости отклик должен быть равен 0.
Глаоа 10. Сегментация изображений
Если порог Т задан, то следующая команда выполняет обнаружение изоли-
рованных точек в соответствии с описанным выше подходом:
>> g = abs(imf ilter(double(f) , w)) >= T;
где f — это входное изображение, w — подходящая маска для обнаружения точек
(например, маска с рис. 10.1), a g — результирующее изображение. Напомним,
что функция imf ilter возвращает результат в формате входного файла изоб-
ражения, поэтому мы воспользовались функцией double (f) в операции фильт-
рации для предотвращения преждевременного усечения значений, если изобра-
жение g было класса uint8, а кроме того, функция abs не допускает целых аргу-
ментов. Выходное изображение g принадлежит классу logical, т. е. его значения
есть 0 или 1. Если порог Т не задан, то его величина часто определяется по ре-
зультату фильтрации, и в этом случае приведенная выше команда разбивается
па три основных шага:
(1) вычисление фильтрованного изображения по команде
abs(imfilter(double(f), w)),
(2) нахождение значения Т по значениям фильтрованного изображения и
(3) сравнение результата фильтрации с порогом Т.
Этот подход иллюстрируется в следующем примерю.
Пример 10.1. Обнаружение точек.
На рис. 10.2, а) показано изображение с едва различимой изолированной черной
точкой на затемненной области в северо-восточном квадранте. Пусть f обознача-
ет это изображение. Мы обнаружим положение изолирюванной точки с помощью
следующих команд:
w = [-1 -1 -1; -1 8 -1; -1 -1 -1];
g = abs(imfilter(double(f), w));
Т max(g(:));
g g >= T;
imshow(g)
Рис. 10.2. а) Полутоновое
изображение с едва различи-
мой изолированной черной
точкой на затемненной обла-
сти в северо-восточном квад-
ранте. 6) Изображение, по-
казывающее обнаруженную
точку (опа увеличена для луч-
шей видимости)
10.1. Обнаружение точек, линий и
Здесь мы выбрали в качестве порога Т максимальное значение фильтрованного
изображения g, а затем нашли элементы g, для которых g >= Т, что отвечает
максимальному отклику. Мы исходили из предположения, что все такие точки
являются изолированными точками, расположенными на однородном (или почти
однородном) фоне. Заметим, что пороговый тест выполнен с помощью операции
>= для совместимости обозначений. Поскольку в данном случае порог Т является
максимальным значением g, нет точек из g, значение яркости которых больше,
чем Т. Из рис. 10.2, б) видно, что имеется ровно одна точка, которая удовлетво-
ряет условию g >= Т, где Т равно max(g(:) ). □
Другой подход к обнаружению точек заключается в поиске точек во всех
окрестностях тхп, для которых разность максимального и минимального зна-
чения превосходит некоторую заданную величину Т. Такой подход можно реали-
зовать с помощью функции ordf ilt2, введенной в § 3.5.2:
>> g = imsubtract(ordfilt2(f, m*n, ones(m, n)),
ordfilt2(f, 1, ones(m, n)));
» g = g >= T;
Легко проверить что выбор Т = max (g (: ) ) приводит к тому же результату, что и
на рис. 10.2, б). Предложенное решение является более гибким, чем использова-
ние маски из рис. 10.1. Пусть, к примеру, мы хотим вычислить разность между
самой большой величиной пиксела и следующей за ней по порядку. Для этого
достаточно заменить 1 в правой части выражения на m*n 1. Другие вариации
на эту тему можно сформулировать аналогичным образом.
10.1.2. Обнаружение линий
Следующий уровень сложности заключается в обнаружении линий. Рассмотрим
маски на рис. 10.3. Если первую маску перемещать по изображению, то наиболь-
ший отклик будет наблюдаться на горизонтальных линиях толщиной в один пик-
сел. Причем, если яркость фона одинакова, то отклик будет максимальным, ко-
гда линия проходит горизонтально через центр маски. Аналогично, вторая маска
на рис. 10.3 даст наибольший отклик на линиях, имеющих наклон +45°, третья
маска — на вертикальных линиях, а четвертая — на линиях, имеющих наклон
—45° Эти направления выделены на масках коэффициентами с наибольшим ве-
сом (в данном случае, равным 2). Сумма коэффициентов каждой маски равна
нулю, что дает нулевой отклик на областях постоянной яркости.
Обозначим через Ri, R%, R-t и R^ отклики масок, показанных на рис. 10.3 (сле-
ва направо), причем формулы для Ri аналогичны формуле для вычисления R в
параграфе § 10.1. Пусть изображение обрабатывается независимо каждой маской.
Если для некоторой точки изображения |2?j| > |Д| при всех j г, то эта точка,
по-видимому, лежит на линии, которое имеет направление маски г. Например,
если в какой-то точке |/?i| > |Д| для j = 2,3,4, то эта точка, скорее всего, при-
надлежит горизонтальной линии. Альтернативная задача заключается в поиске
линий, идущих в заданном направлении. В этом случае можно обработать все
изображение соответствующей маской, применяя пороговое преобразование, как
это делалось в предыдущем параграфе. Другими словами, если необходимо обна-
Глава 10. Сегментация изображений
ружить все линии на изображении, идущие в заданном направлении, достаточно
пройтись этой маской по всему изображению, сравнивая абсолютные значения
откликов с заданным порогом. Выделенные таким способом точки, отвечающие
наибольшим откликам, будут ближе всего примыкать к линиям (толщиной в один
пиксел), направление которых задано выбранной маской. Следующий пример ил-
люстрирует эту процедуру.
Рис. 10.3. Маски для обнаружения линий
Пример 10.2. Обнаружение линий заданного направления.
На рис. 10-4, а) дано двоичное изображение шаблона для изготовления выводов
кристаллов интегральных микросхем. Это изображение имеет размеры 486x486
пикселов. Предположим, что требуется найти все линии, имеющие толщину в
один пиксел и идущие под углом —45° Для этого мы воспользуемся последней
маской из рис. 10.3. Рис. 10.4 с б) по е) построены при выполнении следующих
команд применительно к изображению f на рис. 10.4, а)-.
w = [2 -1 -1 ; -12-1; -1 -1 2];
g imfilter(double(f), w);
imshow(g, [ ]) % рис. 10.4, 6)
gtop g(l:120, 1:120);
gtop = pixeldup(gtop, 4);
figure, imshow(gtop, [ ]) 7, рис. 10.4, в)
gbot g(end-119:end, end-119:end);
gbot pixeldup(gbot, 4);
figure, imshow(gbot, [ ]) 7« рис. 10.4, г)
g = abs(g);
figure, imshow(g, [ ]) % рис. 10.4, d)
T = max(g(:));
g = g >= T;
figure, imshow(g) % рис. 10.4, e)
Точки, более темные, чем общий серый фон на рис. 10.4, б), соответствуют отри-
цательным значениям. Имеется два сегмента, ориентированные под углом —45°,
один — вверх слева, а другой внизу справа. [На рис. 10.4, в) и г), показаны
увеличенные участки окрестностей этих двух сегментов]. Отметим, что прямой
участок на рис. 10.4, г) существенно ярче, чем сегмент на рис. 10.4, в). Причина
10.1. Обнаружение точек, линий и перепадов 4
заключается в том, что нижний правый сегмент на рис. 10.4, а) имеет толщ!
в один пиксел, а верхний левый сегмент толще. Отклики маски сильнее /
компонент, толщина которых равна в точности одному пикселу.
а) б) в)
Рис. 10.4. а) Двоичное изображение шаблона соединений, б) Результат обработки ма.
обнаружения линий под утлом —45° в) Увеличенная часть верхнего лев
угла изображения б), г) Увеличенная часть нижнего правого угла изобра
ния б), д) Модуль пикселов изображения б), е) Все точки (белые), знача
которых удовлетворяют условию g >= Т, где g — это изображение д) (То1
на е) слегка увеличены для лучшей видимости)
Рис. 10.4, д) отображает абсолютные значения рис. 10.4, б). Поскольку
ищем самые сильные отклики, положим порог Т равным максимальному зна
нию этого изображения. Белым цветом на рис. 10-4, е) показаны точки, значег
которых удовлетворяют условию g >= Т, где g — это изображение на рис. 10.4,
Ряд изолированных точек на этом изображении также имеет самые сильные
клики для данной маски. На исходном изображении эти точки и их ближайп
соседи ориентированы так, что процедура взятия маски выдает максимальг
значения в этих точках. Эти изолированные точки можно обнаружить с noi
щью маски на рис. 10.1, а затем удалить. Эти точки можно также удалит;
помощью морфологических операций, рассмотренных в предыдущей главе. С
10.1.3. Обнаружение перепадов с помощью
функции edge
Несмотря на то, что обнаружение точек и линий всегда приводится при обсу
дении сегментации изображений, методы нахождения краев являются едва ли
402 Глава 10. Сегментация изображений
самыми важными при обнаружении значимых разрывов яркости на изображе-
нии. При поиске таких перепадов используются производные первого и второ-
го порядка. Первые производные уже применялись при обработке изображений
градиентом в § 6.6.1. Мы напомним соответствующие уравнения для удобства
читателя. Градиентом двумерной функции f(x,y) называется вектор
Gx
Gy
Модуль вектора градиента равен
V/= m
ag(Vt) = [<£ + С?|,/2 = [(&У + Ш
1/2
Для упрощения вычислений эту функцию иногда приближают следующей фор-
мулой:
V/ « |G.| + |G,,|.
Эта величина ведет себя примерно как производные, т. е. она равна нулю в об-
ластях с постоянной яркостью и ее амплитуда пропорциональна скорости изме-
нения яркости там, где яркость пикселов непостоянна. Часто на практике эту
приближенную величину называют «градиентом», что не вполне строго.
Основное свойство вектора градиента заключается в том, что он указывает в
сторону максимального роста изменения функции / в точке (т,у). Угол наклона
этого вектора равен
, ч (Gy\
а(х,у) = arctgl —
Х*-7® /
Важно уметь приближать производные Gx и Gy численно. Различные подходы
приближения производных, заложенные в функцию edge, обсуждаются далее в
этом параграфе.
Вторые производные при обработке изображений работают при вычислении
оператора Лапласа, который вводился в § 3.5.1. Напомним, что лапласиан дву-
мерной функции f(x,y) равен
ох1 оу1
Сам лапласиан довольно редко используется при обнаружении перепадов, так как
он слишком чувствителен к шуму, кроме того, его амплшуда порождает сдвоен-
ные перепады, что не позволяет точно установить истинное направление перепа-
да яркости. Однако он является весьма полезным инструментом в сочетании с
другими приемами обнаружения перепадов, что будет видно из дальнейшего из-
ложения. Например, несмотря на наличие сдвоенных перепадов, которые не дают
прямо обнаружить соответствующий край, это свойство можно использовать при
локализации перепада.
После этого краткого напоминания отметим, что основная идея обнаружения
перепадов базируется на поиске мест изображения, где яркость меняется быстро,
с помощью следующих двух общих критериев:
1. Найти места, где первая производная яркости превосходит по модулю неко-
торый заранее заданный порог.
2. Найти места, где вторые производные яркости имеют пересечения нулевого
уровня.
Функция IPT edge реализует несколько оценок производных для использо-
вания в приведенных выше критериях. Для некоторых из этих оценок имеется
возможность указать, к каким именно перепадам чувствительна данная оценка: к
горизонтальным, вертикальным или к перепадам обоих типов. Общий синтаксис
этой функции выглядит следующим образом:
[g, t] = edge(f, ’method’, parameters),
где f — это входное изображение, method — одна из оценок, перечисленных в
табл. 10.1, a parameters — дополнительные параметры, которые объясняются
ниже. Выходом функции служит логический массив g, в котором стоят единицы
там, где обнаружены точки перепада на f, и нули там, где перепады не обна-
ружены. Аргумент t является необязательным, в него записывается значение
порога, которое функция edge использовала для сравнения с градиентами точек
изображения.
Таблица 10.1. Детекторы краев, доступные в функции edge
Детектор краев Основные свойства
Собела Обнаруживает края с помощью приближений Собела первых про- изводных, заданных на рис. 10.5, б).
Превитта Обнаруживает края с помощью приближений Превитта первых производных, заданных на рис. 10.5, в).
Робертса Обнаруживает края с помощью приближений Робертса первых производных, заданных на рис. 10.5, г).
Лапласиан гауссиана Обнаруживает края, выполняя поиск пересечений нулевого уров- ня после фильтрации /(я, у) гауссианом.
Пересечения нулевого Обнаруживает края, выполняя поиск пересечений нулевого
уровня уровня после фильтрации f(xty) фильтром, заданным пользова- телем.
Канни Обнаруживает края, выполняя поиск локальных максимумов гра- диента f(x,y). Градиент вычисляется от гауссиана. Метод исполь- зует два порога для нахождения сильных и слабых краев. Слабые края включаются в выход, если они связаны с сильными. Следо- вательно, этот метод с большей вероятностью обнаруживает на- стоящие слабые края.
Детектор Собела
Детектор Собела для обнаружения перепадов использует маски из рис. 10.5, б)
для численного приближения производных Gx и Gy. Другими словами, градиент
в центральной точке окрестности вычисляется по формуле
g=[G2x + G2]1/2 =
= {[(27 + 2^8 + гэ) — (г1 + 2^2 + 23)]2 + [(Z3 + 2^6 + ^э) — (г1 + 2^4 + Z7)]2 j
Глава 10. Сегментация изображений
Мы скажем, что пиксел с координатами {х, у) является пикселом перепада, если
для него д > Т, где Т — это выбранный порог.
а)
Окрестностные
маски детекторов
Рис. 10.5. Некоторые маски детекто-
ров и реализуемые ими формулы при-
ближения для первых производных
в)
1 1
0 0 0
1 I 1
-1 0
0 1
Из материалов § 3.5.1 известно, что обнаружение края методом Собела можно
реализовать фильтрацией изображения f (используя функцию imfilter) левой
маской на рис. 10.5, б), затем фильтрацией f правой маской, после чего следует
возвести результаты фильтраций в квадрат, все сложить и извлечь квадратный
корень из полученной суммы. Аналогичный комментарий можно составить для
второй и третьей записи в табл. 10.1. Функция edge всего лишь объединяет опи-
санные операции для их выполнения одним вызовом, а кроме того, добавляет
ряд дополнительных возможностей, а именно: задание порога или его автомати-
ческое определение самой функцией. Кроме того, функция edge имеет некоторые
технические особенности, которые не реализованы в функции imfilter.
Детектор Собела вызывается командой
[g, t] edged, ’sobel’, T, dir),
где f это входное изображение, Т заданный порог, а переменная dir обо-
значает предпочтительное направление для обнаружения края, которая имеет
следующие значения: ’horizontal’, ’vertical’, или ’both’ (принято по умол-
чанию). Как уже сообщалось, g — это логический массив, в котором 1 стоят там.
где обнаружен край, а 0 там, где его нет. Выходной параметр t не является
обязательным. Если он задан, то в него записывается значение порога, использо-
ванного функцией edge. Если входной параметр Т задан, то t Т. В противном
случае, если Т не задан (или пуст, т. е. равен [ ]), то t равен автоматически
выбранному порогу, который и использовался при обнаружении края. Одна из
причин включения выходного параметра t заключается в задании начального
значения для порога. Функция edge использует детектор Собела по умолчанию,
если применен синтаксис [g, t] edge(f) или просто g edge(f).
Детектор Превитта
Детектор Превитта использует маску из рис. 10.5, в) для численного приближе-
ния первых производных Gx и Gy. Его общая форма вызова имеет вид
[g, t] edge(f, ’prewitt’, T, dir).
Параметры этой функции имеют тот же смысл, что и в детекторе Собела. Де-
тектор Превитта немного легче реализовывать с вычислительной точки зрения,
чем детектор Собела, однако при этом возрастает невязка (ошибка) вычислений.
(Можно показать, что коэффициенты 2 в масках Собела обеспечивает некоторое
улаживание результата.)
Детектор Робертса
Цетектор Робертса основан на маске из рис. 10.5, г) для приближения Gx и Gy.
Зго форма вызова имеет вид
Eg, t] edge(f, ’roberts’, T, dir).
1араметры этой функции имеют тот же смысл, что и в детекторе Собела. Де-
тектор Робертса является одним из самых старых детекторов, используемых при
)бработке цифровых изображений, и из рис. 10.5, г) видно, что он устроен проще
фугих. Однако этот детектор используется существенно реже всех остальных,
гриведенных на рис. 10.5, по причине его ограниченной функциональности (на-
тример, он несимметричен, его нельзя обобщить для обнаружения краев, угол
гаклона которых является кратным 45° и т. д.). Тем не менее, он все еще исполь-
уется во многих аппаратных реализациях, где простота и скорость являются
>пределяющими факторами обработки.
Детектор лапласиан гауссиана (LoG)
’ассмотрим функцию Гаусса
г2
h(r) = ,
406 Глава 10. Сегментация изображений
где г2 = х2 + у2, а <т — это стандартное отклонение. Свертка этой сглаживающей
функции с изображением приводит к его расфокусировке. Степень расфокуси-
ровки определяется значением а. Лапласиан функции Гаусса (вторая производ-
ная по г) равен
г 2 21 2
V2/z(r) = — ----— е 2^
Эту функцию, по очевидным причинам, принято называть лапласианом гаусси-
ана (LoG). Поскольку взятие второй производной является линейной операцией,
то свертка (фильтрация) изображения с V2/i(r) — это то же самое, что свертка
функции со сглаживающей функцией, а затем применение оператора Лапласа к
результату. В этих действиях проявляются ключевые свойства детектора LoG.
Свертка изображения с V2/i(r) даст два эффекта: она сглаживает изображение
(сокращает шум) и вычисляет лапласиан, что выявляет сдвоенные края на изоб-
ражении. Окончательная локализация краев состоит в нахождении пересечений
нулевого уровня между двойными краями.
Общая форма вызова детектора LoG имеет вид
Eg, t] edge(f, ’log’, T, sigma),
где sigma — это стандартное отклонение, а остальные параметры объяснялись
выше. Значение sigma по умолчанию равно 2. Как и раньше, функция edge иг-
норирует перепады, значение которых меньше порога Т. Ркли Т не задано или
оно пусто, edge выбирает порог автоматически. Если положить Т 0, то функ-
ция edge построит замкнутые контуры, что является обычной характеристикой
метода LoG.
Детектор пересечения нулевого уровня
Этот детектор основан на том же принципе, что и метод LoG, но свертка выпол-
няется с фильтром Н, который задается пользователем. Он имеет синтаксис
Eg, t] edge(f, ’zerocross’, T, H).
Остальные параметры объяснены при описании детектора LoG.
Детектор Канни
Детектор Канни (см. [Саппу, 1986]) является самым мощным детектором, зало-
женным в функцию edge. Этот метод можно кратко описать следующим образом:
1. Изображение сглаживается гауссовым фильтром с заданным стандартным
отклонением ст для сокращения шума.
2. В каждой точке вычисляется градиент д(х, у) = [G2 + G2] и направле-
ние края а(х,у) = arctg (Gy/G^). Для нахождения Gx и Gy можно исполь-
зовать любой метод из табл. 10.1. Точки перепада определяются как точки
локального максимума градиента.
3. Точки перепада, определенные в п. 2, вызывают рост гребней на изобра-
жении модуля градиента. Затем алгоритм отслеживает верх этих гребней
и присваивает нулевое значение точкам, которые не лежат на гребне. В ре-
зультате на выходе строится тонкая линия, а весь этот процесс называется
немаксималъным подавлением. Затем пикселы гребня подвергаются поро-
говой обработке с использованием двух порогов Т1 и Т2, причем Т1 < Т2.
Пикселы гребня, величина которых больше Т2, называются «сильными»,
а пикселы, значения которых попадают в интервал [71, Т2], называются
«слабыми».
4. Наконец, алгоритм совершает соединение, добавляя к сильным пикселам
слабые, которые 8-связаны с сильными.
Синтаксис детектора Капни для обнаружения перепадов имеет вид
[g, t] edge(f, ’canny’, T, sigma),
де T — это вектор [Tl, Т2], состоящий из порогов, описанных в п.З, a sigma
бозначает стандартное отклонение сглаживающего фильтра. Если параметр t
ключей в выходные аргументы, то он является вектором из двух компонент, ку-
щ записаны два порога, использованные алгоритмом. Все остальные параметры
[меют обычный смысл, объясненный для других методов, включая автоматиче-
кое определение порогов, если вектор Т не задан. Значение sigma по умолчанию
>авно 1.
Тример 10.3. Извлечение краев с помощью детектора Собела.
Лы можем получить и отобразить вертикальные края на изображении f из
> ис. 10.6, а) с помощью следующих команд:
> > [gv, t] = edge(f, ’sobel’, ’vertical’);
> > imshow(gv)
> > t
0.0516
Сак показано на рис. 10.6, б), на результирующем изображении преобладают
1ертикальные края (отображены также некоторые края, которые имеют и вер-
тикальные, и горизонтальные компоненты). Мы можем подчистить слабые края,
1ыбрав более высокий порог. Например, рис. 10.6, в) построен командой
> > gv = edge(f, ’sobel’, 0.15, ’vertical’);
Тспользуя то же значение Т в команде
> > gboth edge(f, ’sobel’, 0.15);
юлучим результат на рис. 10.6, г), на котором доминируют как вертикальные,
так и горизонтальные края.
Функция edge с опцией sobel не позволяет обнаружить края под утлом ±45°
Лтобы выделить такие перепады, необходимо задать специальную маску и вос-
юльзоваться функцией imf ilter. Например, рис. 10.6, д) построен с помощью
соманд1
> > w45 = [-2 -1 0; -1 0 1; 0 1 2]
Величина порога Т подобрана экспериментально, чтобы результат можно было сравнить с
)ис. 10.6, в) и г).
Глава 10. Сегментация изображений
w45
-2 -1 О
-10 1
0 12
> > g45 imfilter(double(f), w45, ’replicate’);
> > T 0.3*max(abs(g45(:)));
> > g45 g45 >= T;
> > figure, imshow(g45);
Самый сильный край на рис. 10.6, д) имеет наклон 45° Аналогично, исполы
найме маски wm45 [0 12; -101; -2-10] с той же последовательностью
команд дает возможность выделить края, ориентированные под углом —45°, что
показано на рис. 10.6. е). □
Рис. 10.6. а) Исходное изображение. б) Результат функции edge с использованием верти-
кальной маски Собела и с автоматическим порогом, в) Результат с заданным
порогом, г) Результат выявления вертикальных и горизонтальных краев при
помощи заданного порога- д) Результат обнаружения краев под углом 45° с
использованием функции imfilter с заданными маской и порогом, е) Резуль-
тат обнаружения краев под углом —45° с использованием функции imfilter с
заданными маской и порогом
10.1. Обнаружение точек, линий и
Пример 10.4. Сравнение, результатов обнаружения краев с помощью детек-
торов Собела, LoC и Канни.
В этом примере мы сравним возможности детекторов Собела, LoG и Канни при
обнаружении краев и перепадов. Наша цель заключается в построении чистой
«карты» краев, выделив самые существенные детали на изображении здания f на
рис. 10.6, а) и удалив «несущественные» вроде особенности текстуры кирпичной
кладки стен или черепицы крыши. Основными линиями конструкции здания для
нас являются углы здания, вход, проемы окон, элементы окантовки окон и входа
из светлого кирпича, линии крыши, а также белая бетонная полоса, окружающая
здание примерно на расстоянии двух третей от его высоты.
Рис. 10.7. Левая колонка: результаты детекторов Собела, LoG и Канни с параметрами
по умолчанию. Правая колонка: результаты, полученные интерактивно, при
выявлении существенных деталей исходного изображения на рис. 10-6, а) и при
удалении липших деталей. Самый лучший результат получается у детектора
Канни
Левая колонка изображений на рис. 10.7 показывает результаты обнаружения
краев при использовании опций ’sobel’, ’log’ и ’canny’ в командах
[g_sobel_default, ts]
[g_log_default, tlog]
[g_canny_default, tc]
edge(f, ’sobel’);
edge(f, ’log’);
edge(f, ’canny’);
X рис. 10.7, a)
°/„ рис. 10.7, в)
% рис. 10 7, д)
Значения порогов в выходных аргументах при выполнении этих команд равня-
шсь следующим величинам: ts 0.074, tlog 0.0025, и tc [0.019,0.047] .
Значение параметра sigma для опций ’log’ и ’canny’ было, соответственно, 2
и 1. За исключением изображения детектора Собела, параметры по умолчанию
у других детекторов не дали желаемой чистой «карты» исходного изображения.
410 Глава 10. Сегментация изображений
Начав от значения по умолчанию, параметры для каждой опции были ин-
терактивно проварьированы для получения самого лучшего обнаружения ука-
занных выше деталей исходного изображения и удаления ненужных деталей,
насколько это было возможно. Результат показан в правой колонке изображений
на рис. 10.7. Он получен следующими командами:
g_sobel_best = edge(f, ’sobel’, 0.05);
g_log_best = edge(f, ’log’, 0.003, 2.25);
g_canny_best edge(f, ’canny’, [0.04 0.10],
7. рис. 10.7, 6)
7. рис. 10.7, г)
1.5); 7. рис. 10.7, е)
На рис. 10.7, б) видно, что результат Собела, на самом деле, только ухудшается
при попытке выявить бетонную полосу и левую сторону входа здания. Результат
LoG на рис. 10.7, г) немного лучше Собела и значительно превосходит результат
LoG с параметрами по умолчанию. Однако и здесь не удается выявить полно-
стью ни левую сторону входа, ни бетонную полосу. Результат детектора Канни на
рис. 10.7, е) превосходит все прочие результаты. Обратите внимание, что здесь
четко обозначен левый край входа в здание, видна бетонная полоса и другие
детали, например, контуры вентиляционной решетки над входом. Помимо выяв-
ления всех деталей, детектор Канни позволяет получить самую ясную «карту»
изображения. □
10.2. Обнаружение линий с помощью
преобразования Хафа
В идеале рассмотренные выше методы должны обнаруживать только пикселы,
принадлежащие краям и перепадам яркости. Однако на практике выделенные
пикселы редко относятся только к этой категории в силу многих причин: воз-
действия шума, разрыва краев из-за неравномерного освещения и других фак-
торов, которые вносят ложные перепады яркости в изображения. Поэтому за
алгоритмом обнаружения краев обычно следует процедура компоновки выделен-
ных пикселов краев в настоящие, осмысленные линии и краевые сегменты. Один
из подходов к выполнению подобных действий основан на преобразовании Хафа
[Hough, 1962]).
Имея некоторое множество точек изображения (обычно двоичного), предпо-
ложим, что требуется найти подмножества этих точек, которые лежат на пря-
мых линиях. Один возможный подход заключается в построении всевозможных
прямых, задаваемых парами этих точек, а потом в обнаружении точек, кото-
рые расположены близко к конкретным прямым. Проблема реализации такой
процедуры связана с необходимостью рассмотрения п(п — 1)/2 ~ п2 прямых, а
затем в выполнении порядка п (п(п — 1)) /2 ~ п3 операций сравнения всех точек
с каждой из этих прямых. Вычислительная сложность такого решения позволяет
применять его лишь в самых простых прикладных задачах.
Имея преобразование Хафа, возможен иной подход. Рассмотрим любую точку
(^iii/i) и все проходящие через нее прямые. Все такие прямые удовлетворяют
уравнению y-i = axi+b для произвольных значений а и Ъ. Однако если переписать
это уравнение в виде b = —ох,+уг и рассмотреть соответствующую ab-плоскость
10.2. Обнаружение линий с помощью преобразования Хафа
(называемую пространством параметров), то оно задаст единственную прямую
для каждой фиксированной координатной пары (т^, yi). Более того, другой точке
(т^,ул) соответствует своя прямая в пространстве параметров, и эти две прямые
пересекаются в некоторой точке (а', Ь'), где а' — это угловой коэффициент, а Ь' —
точка пересечения с осью у прямой, проходящей через точки (хг,уг) и (xj,yj)
на гсу-плоскости. На самом деле, у каждой точки этой прямой имеется прямая в
пространстве параметров, причем все такие прямые пересекаются в точке (а', V).
Рис. 10.8. а) Плоскость ху. б) Пространство параметров ab
В принципе, можно построить на графике все параметрические прямые, со-
ответствующие всем заданным точкам (хг,уг) изображения, а затем все линии
изображения можно идентифицировать с помощью точек пересечения парамет-
рических прямых. При этом возникает вычислительная трудность, связанная с
тем, что число а (угловой коэффициент) стремится к бесконечности, когда пря-
мая близка к вертикали. Один из способов справиться с этой проблемой состоит
в представлении уравнения прямой с помощью ее вектора нормали:
х cos 0 + у sin 0 = р.
На рис. 10.9, а) приведена геометрическая интерпретация параметров р и 0. Гори-
зонтальная прямая имеет 0 = 0°, а параметр р равен (положительной) координате
пересечения прямой с осью х. Аналогично, вертикальная прямая имеет 0 = 90°,
а р равно координате пересечения с положительной полуосью у или 0 = —90°,
ар — координате пересечения с отрицательной полуосью у. Каждая синусои-
дальная кривая на рис. 10.9, б) отвечает семейству прямых линий, проходящих
через некоторую точку (т^у^). Точка пересечения кривых (р',01) соответствует
прямой, проходящей через обе точки (xi,yi) и (х3,у3).
Привлекательность преобразования Хафа с точки зрения вычислений проис-
ходит из возможности разбиения пространства параметров р0 на так называемые
ячейки накопления, как показано на рис. 10.9, в), где (рГШ11, Ртах) и (0rnin, #тах) ' ’
предполагаемые диапазоны значений параметров. Обычно эти значения варьиру-
ются в интервалах —90е < 0 < 90° и — D < р < D, где D — это расстояние между
угловыми точками изображения. В ячейке с координатами (i,j) накапливается
Глава 10. Сегментация изображений
значение A(i, j) для квадрата в пространстве параметров, соответствующего точ-
ке (pi, Oj). Вначале значения всех ячеек накопления равны нулю. Затем для каж-
дой точки (хк,уь) выбранного множества на изображении полагаем параметр О
равным каждому разрешенному дискретному значению Oj в ячейках 0-оси и нахо-
дим соответствующее ему значение, решая уравнение р = Xk cos 0+ук sin 0. Затем
найденные величины р округляются до ближайшего разрешенного дискретного
значения р^ из ячеек p-оси. После этого значение соответствующей ячейки накоп-
ления увеличивается на единицу: Л(г, j) := A(i,j) +1. В конце процедуры ячейка
A(i, j) равна числу Q, которое означает, что Q точек плоскости ху лежат на пря-
мой xcosOj +ysin0j = р{. Точность попадания этих точек на прямую зависит от
числа ячеек накопления в пространстве р0.
а)
Рис. 10.9. а) Параметризация (pt0) прямых на плоскости ху. б) Синусоиды в плоско-
сти рО. Точка пересечения соответствует параметрам прямой, соединя-
ющей точки (хг^уг) и (ij, Уз), в) Разделение плоскости р0 на ячейки накопления
Далее рассматривается М-функция для вычисления преобразования Хафа.
Эта функция использует операции с разреженными матрицами, которые имеют
малое число ненулевых элементов. Свойство разреженности позволяет получить
выигрыш как при хранении данных, так и при вычислениях. Имея матрицу А,
преобразуем ее в разреженный матричный формат с помощью функции sparse,
которая имеет синтаксис
S sparse(А).
Например,
» А = [ О О 0 5
0 2 0 0
13 0 0
0 0 4 0 ] ;
>> S = sparse(A)
S =
(3,1) 1
(2,2) 2
(3,2) 3
(4,3) 4
(1,4) 5
10.2. Обнаружение линий с помощью преобразования Хафа
Здесь перечислены все ненулевые элементы S вместе с их индексами строк и
столбцов. Элементы упорядочены по столбцам.
Имеется форма обращения к функции sparse с пятью аргументами, которая
используется чаще всего:
S sparse(r, с, s, m, п).
Здесь гис это векторы индексов строк и столбцов ненулевых элементов мат-
рицы, которую мы хотим перевести в разреженный формат. Параметр s пред-
ставляет собой вектор значений, отвечающих индексным парам (г, с), a m и
п обозначают число строк и число столбцов построенной матрицы. Например,
матрицу S из предыдущего примера можно прямо построить командой
» S sparse([3 2 3 4 1], [1 2 2 3 4], [1 2 3 4 5] , 4, 4) ;
Существуют и другие синтаксические формы обращения к функции sparse, ко-
торые можно узнать из справочной информации по этой функции.
Имея разреженную матрицу S, порожденную любой формой функции sparse,
можно вернуться к стандартному матричному представлению, применяя функ-
цию full, синтаксис которой имеет вид
A full(S).
Чтобы использовать в MATLAB детектор линий на основе преобразования
Хафа, мы начнем с написания функции hough. ш, которая совершает это преоб-
разование.
function [h, theta, rho] hough(f, dtheta, drho)
7H0UGH Hough transform.
7. [H, THETA, RHO] H0UGH(F, DTHETA, DRHO) computes the Hough
7. transform of the image F DTHETA specifies the spacing (in
7o degrees) of the Hough transform bins along the theta axis. DRHO
7o specifies the spacing of the Hough transform bins along the rho
7. axis. H is the Hough transform matrix. It is NRHO-by-NTHETA,
7. where NRHO 2*ceil(norm(size(F))/DRH0) 1, and NTHETA
7, 2*ceil(90/DTHETA) Note that if 90/DTHETA is not an integer, the
7. actual angle spacing will be 90 / ceil (90/DTHETA)
7.
7. THETA is an NTHETA-element vector containing the angle (in
7. degrees) corresponding to each col nmn of H. RHO is an
7. NRHO-element vector containing the value of rho corresponding to
7. each row of H.
7.
7. [H, THETA, RHO] HOUGH(F) computes the Hough transform using
7, DTHETA 1 and DRHO 1.
if nargin < 3
drho 1;
end
if nargin < 2
414 Глава 10. Сегментация изображений
dtheta = 1;
end
f = double(f);
[M,N] = size(f);
theta = linspace(-90, 0, ceil(90/dtheta) + 1);
theta = [theta -fliplr(theta(2:end 1))];
ntheta = length(theta);
D = sqrt((M 1)“2 + (N 1)~2);
q = ceil(D/drho);
nrho = 2*q 1;
rho = linspace(-q*drho, q*drho, nrho);
[x, y, val] = find(f);
x = x 1; у = у 1;
7. Initialize output.
h = zeros(nrho, length(theta));
7. To avoid excessive memory usage, process 1000 nonzero pixel
‘Z values at a time.
for к = 1:ceil(length(val)/1000)
first = (k l)*1000 + 1;
last = min(first+999, length(x));
x_matrix repmat(x(first:last), 1, ntheta);
y_matrix = repmat(y(first:last), 1, ntheta);
val_matrix = repmat(val(first:last), 1, ntheta);
theta_matrix = repmat(theta, size(x_matrix, 1), l)*pi/180;
rho_matrix = x_matrix.*cos(theta_matrix) +
y_matrix.*sin(theta_matrix);
slope (nrho l)/(rho(end) rho(l));
rho_bin_index = round(slope*(rho_matrix - rho(l)) + 1);
theta_bin_index = repmat(1:ntheta, size(x_matrix, 1), 1);
7. Take advantage of the fact that the SPARSE function, which
7. constructs a sparse matrix, accumulates values when input
’Z indices are repeated. That’s the behavior we want for the
% Hough transform. We want the output to be a full (nonsparse)
7. matrix, however, so we call function FULL on the output of
7. SPARSE.
h = h + full(sparse(rho_bin_index(:), theta_bin_index(:),
val_matrix(:), nrho, ntheta));
end
Пример 10.5. Иллюстрация преобразования Хафа.
Здесь мы продемонстрируем использование функции hough при обработке про-
стого двоичного изображения. Прежде всего, построим изображение, у которого
имеется несколько изолированных точек переднего плана.
>> f = zeros(101, 101);
» f(1, 1) 1; f(101, 1) 1; f(l, 101) = 1;
» f(101, 101) = 1; f(51, 51) = 1;
Рис. 10.10, а) показывает наше тестовое изображение. Теперь мы выполним пре-
образование Хафа и отобразим результат на графике.
80 60 40 20 0 20 40 60 80
Рис. 10.10. а) Двоичное изображение с пятью точками (четыре точки находятся в уг-
лах изображения), б) Преобразование Хафа, показанное с помощью функции
imshow. в) Альтернативный график с размеченным осями. (Точки на рис. а)
были увеличен для лучшей видимосги)
416 Глава 10. Сегментация изображений
>> Н hough(f);
>> imshow(Н, [ ])
На рис. 10.10, б) приведен результат, отображенный на графике стандартной
функцией imshow. Однако более наглядная визуализация преобразования Ха-
фа получается на большем графике, на котором по осям отмечены координаты.
В следующем программном фрагменте функция hough вызывается с тремя аргу-
ментами. Два вторых выходных аргумента содержат величины 0 и р, отвечающие
каждой соответствующей паре индексов строки и столбца матрицы преобразова-
ния Хафа. Эти векторы theta и rho можно передавать функции imshow в виде
дополнителыгых аргументов для разметки горизонтальных и вертикальных осей
на графике. Функции imshow также передается опция ’notruesize’ Команда
axis подается для включения отображения осей и представления графика в пря-
моугольной форме. Наконец, функции xlabel и ylabel (см. § 3.3.1) используются
для помещения возле координатных осей греческих букв, представленных в стиле
ШЁХ.
>> [Н, theta, rho] hough(f);
>> imshow(theta, rho, H, [ ], ’notruesize’)
>> axis on, axis normal
>> xlabel(’\theta’), ylabel(’\rho’)
На рис. 10.10, в) показан результирующий график с соответствующей разметкой
осей. Пересечение трех синусоид в точках ±45с указывает на то, что на исходном
изображении f имеется два множества, состоящие из трех колинеарных точек.
Пересечение двух синусоид в точках (0, р) = (—90,0), (-90,-100), (0,0) и (0,100)
свидетельствует о присутствии четырех множеств колинеарных точек, которые
лежат вдоль вертикальных и горизонтальных осей. □
10.2.1. Нахождение максимумов преобразования Хафа
Первый шаг использования преобразования Хафа для обнаружения линий и свя-
зывания состоит в нахождении локальных максимумов преобразования. Поиск
множества максимумов преобразованием Хафа может быть вполне перспектив-
ным. В силу квантования пространства цифрового изображения и пространства
параметров, а также по причине того, что края и перепады на типичных изоб-
ражениях не являются совершенно прямыми, максимумы преобразования Хафа
могут достигаться более чем в одной ячейке накопления. Эту сложность можно
преодолеть с помощью следующей стратегии.
1. Найти ячейку преобразования Хафа, в которой лежит наибольшая величи-
на, и записать ее местоположение.
2. Опорожнить (обнулить) ячейки в ближайшей окрестности положения, най-
денного на шаге 1.
3. Повторять шаги 1 и 2 до тех пор. пока желаемое число максимумов не будет
найдено, или после достижения заданного порога.
Функция houghpeaks реализует эту стратегию.
function [г, с, hnew] = houghpeaks(h, numpeaks, threshold, nhood)
10.2. Обнаружение линий с помощью преобразования Хафа
’ZHOUGHPEAKS Detect peaks in Hough transform.
7, [R, C, HNEW] HOUGHPEAKS(H, NUMPEAKS, THRESHOLD, NHOOD) detects
7. peaks in the Hough transform matrix H. NUMPEAKS specifies the
"Z maximum number of peak locations to look for. Values of H below
7» THRESHOLD will not be considered to be peaks. NHOOD is a
7c two-element vector specifying the size of the suppression
7. neighborhood. This is the neighborhood around each peak that is
°Z set to zero after the peak is identified. The elements of NHOOD
7c must be positive, odd integers. R and C are the row and column
7. coordinates of the identified peaks. HNEW is the Hough transform
7c with peak neighborhood suppressed.
7.
7, If NHOOD is omitted, it defaults to the smallest odd values >=
7c size(H)/50. If THRESHOLD is omitted, it defaults to
7c 0.5*max(H(:)) If NUMPEAKS is omitted, it defaults to 1.
if nargin < 4
nhood size(h)/50;
"Z Make sure the neighborhood size is odd.
nhood = max(2*ceil(nhood/2) + 1, 1);
end
if nargin < 3
threshold 0.5 * max(h(:));
end
if nargin < 2
numpeaks = 1;
end
done false;
hnew h; r [] ; c [] ;
while “done
[p, q] find(hnew == max(hnew(:)));
p p(l); q q(l);
if hnew(p, q) >= threshold
r(end + 1) = p; c(end + 1) q;
7o Suppress this maximum and its close neighbors.
pl p (nhood(l) l)/2; p2 = p + (nhood(l) l)/2;
ql = q (nhood(2) l)/2; q2 = q + (nhood(2) l)/2;
[pp, qq] = ndgrid(pl:p2, ql:q2);
pp = pp(:); qq qq(:);
7o Throw away neighbor coordinates that are out of bounds in
7e the rho direction.
badrho = find((pp < 1) | (pp > size(h, 1)));
pp(badrho) []; qq(badrho) [];
7c For coordinates that are out of bounds in the theta
7c direction, we want to consider that H is antisymmetric
7. along the rho axis for theta = +/- 90 degrees.
theta_too_low = find(qq < 1);
Глава 10. Сегментация изображений
qq(theta_too_low) size(h, 2) + qq(theta_too_low);
pp(theta_too_low) size(h, 1) pp(theta_too_low) + 1;
theta_too_high = find(qq > size(h, 2));
qq(theta_too_high) = qq(theta_too_high) size(h, 2);
pp(theta_too_high) size(h, 1) pp(theta_too_high) + 1;
7. Convert to linear indices to zero out all the values.
hnew(sub2ind(size(hnew), pp, qq)) = 0;
done = length(r) == numpeaks;
else
done = true;
end
end
Функция houghpeaks иллюстрируется в примере 10.6.
10.2.2. Преобразование Хафа при обнаружении линий
и связывании
После обнаружения множества локальных максимумов преобразования Хафа
остается определить, есть ли сегменты краев, проходящие по соответствующим
линиям, а также где они начинаются и заканчиваются. Для каждого максимума
сначала следует найти положения всех ненулевых пикселов изображения, кото-
рые лежат на соответствующих прямых. Для этих целей написана следующая
функция houghpixels.
function [г, с] = houghpixels(f, theta, rho, rbin, cbin)
‘ZHOUGHPIXELS Compute image pixels belonging to Hough transform bin.
% [R, C] HOUGHPIXELS(F, THETA, RHO, RBIN, CBIN) computes the
°k row-column indices (R, C) for nonzero pixels in image F that map
% to a particular Hough transform bin, (RBIN, CBIN) RBIN and CBIN
7» are scalars indicating the row-column bin location in the Hough
% transform matrix returned by function HOUGH. THETA and RHO are
% the second and third output arguments from the HOUGH function,
[x, y, val] find(f);
x = x 1; у у 1;
theta_c theta(cbin) * pi / 180;
rho_xy x*cos(theta_c) + y*sin(theta_c);
nrho = length(rho);
slope = (nrho l)/(rho(end) rho(l));
rho_bin_index = round(slope*(rho_xy rho(l)) + 1);
idx = find(rho_bin_index rbin);
r = x(idx) + 1; с у(idx) + 1;
Пикселы, обнаруженные функцией houghpixels, необходимо сгруппировать в
сегменты. Для этого можно воспользоваться следующей стратегией:
1. Повернуть пикселы на угол 90° — 0 так, чтобы они легли примерно вдоль
вертикальной прямой.
10.2. Обнаружение линий с помощью преобразования Хафа 419
2. Упорядочить пикселы в порядке возрастания величин их повернутых аг-ко-
ординат.
3. Использовать функцию dif f для определения зазоров (щелей). Заполнить
малые зазоры. Это дает эффект слияния примыкающих сегментов линий,
которые разделены малыми промежутками.
4. Возвратить информацию о сегментах линий, которые длиннее некоторой
минимальной пороговой длины.1
function lines = houghlines(f,theta,rho,rr,cc,fillgap,minlength)
“XHOUGHLINES Extract line segments based on the Hough transform.
7. LINES = HOUGHLINES(F, THETA, RHO, RR, CC, FILLGAP, MINLENGTH)
‘X extracts line segments in the image F associated with particular
"X bins in a Hough transform. THETA and RHO are vectors returned by
7, function HOUGH. Vectors RR and CC specify the rows and columns
•/ of the Hough transform bins to use in searching for line
7. segments. If HOUGHLINES finds two line segments associated with
7. the same Hough transform bin that are separated by less than
7. FILLGAP pixels, HOUGHLINES merges them into a single line
'X segment. FILLGAP defaults to 20 if omitted. Merged line
‘X segments less than MINLENGTH pixels long are discarded.
7. MINLENGTH defaults to 40 if omitted.
7.
7. LINES is a structure array whose length equals the number of
7. merged line segments found. Each element of the structure array
7, has these fields:
%
7. pointl End-point of the line segment; two-element vector
7. point2 End-point of the line segment; two-element vector
7. length Distance between pointl and point2
7. theta Angle (in degrees) of the Hough transform bin
7, rho Rho-axis position of the Hough transform bin
if nargin < 6
fillgap = 20;
end
if nargin < 7
minlength = 40;
end
numlines = 0; lines = struct;
for k 1:length(rr)
rbin rr(k); cbin cc(k);
X Get all pixels associated with Hough transform cell.
[r, c] houghpixels(f, theta, rho, rbin, cbin);
if isempty(r)
continue
end
1Функция В = inv(A) вычисляет обратную матрицу для А.
420 Глава 10. Сегментация изображений
7, Rotate the pixel locations about (1,1) so that they lie
7, approximately along a vertical line.
omega = (90 theta(cbin)) * pi / 180;
T = [cos(omega) sin(omega); -sin(omega) cos(omega)];
xy = [r 1 c 1] * T;
x = sort(xy(:,1));
% Find the gaps larger than the threshold.
diff_x = [diff(x); Inf];
idx = [0; find(diff_x > fillgap)] ;
for p = 1:length(idx) 1
xl x(idx(p) +1); x2 x(idx(p + 1));
linelength = x2 xl;
if linelength >= minlength
pointl [xl rho(rbin)]; point2 [x2 rho(rbin)];
7» Rotate the end-point locations back to the original
7. angle.
Tinv = inv(T);
pointl = pointl * Tinv; point2 = point2 * Tinv;
numlines = muni inps + 1;
linns(niiml inns) .pointl = pointl + 1;
11nos(niiml inns) .point? = point2 + 1;
1 in os (niiml inos) . length = linelength;
lines(numlines).theta = theta(cbin);
1 inos(niiml inns) .rho = rho(rbin);
end
end
end
Пример 10.6. Использование преобразования Хафа для обнаружения линий и
связывания.
В данном примере вы воспользуемся функциями hough, houghpeaks и houghlines
для обнаружения сегментов линий на двоичном изображении f, приведенном
на рис. 10.7, е). Прежде всего, мы вычислим и покажем преобразование Хафа,
используя меньший шаг угловой дискретизации, чем принятый по умолчанию
(Д0 = 0.5 вместо 1.0).
>> [Н, theta, rho] hough(f, 0.5);
>> imshow(theta, rho, H, [ ], ’ notrues ize’), axis on, axis normal
>> xlabel( ’\theta’ ) , ylabel (’ \rho ’)
Затем с помощью функции houghpeaks мы находим 5 локальных максимумов
преобразования Хаф>а, которые, скорее всего, имеют существенный смысл.
>> [г, с] = houghpeaks(H, 5);
>> hold on
>> plot(theta(c), rho(r), ’linestyle’, ’none’, ...
’marker’, ’s’, ’color’, ’w’)
10.3. Пороговая обработка
На рис. 10.11. а) изображено преобразование Хафа с указанием положения най-
денных максимумов. Наконец, применяем функцию houghlines для нахождения
и связывания сегментов линий, а найденные сегменты помещаем на исходное
двоичное изображение с помощью функций imshow, hold on и plot:
• lines houghlines(f, theta, rho, r, c)
• figure, imshow(f), hold on
for k 1:length(lines)
xy [lines(k).pointl lines(k).point2];
plot(xy(:,2), xy(:,l), ’LineWidth’, 4, ’Color’, [.6 .6 .6]);
end
На рис. 10.11, б) показано результирующее изображение с обнаруженными сег-
ментами, которые обозначены жирными серыми линиями. О
Рис. 10.11. а) Преобразование Хафа с пятью локальными максимумами, б) Сегменты
линий, соответствующие максимумам преобразования Хафа
10.3. Пороговая обработка
Методы пороговой обработки занимают центральное место в прикладных зада-
чах сегментации изображений благодаря интуитивно понятным свойствам и про-
стоте реализации. Простое пороговое преобразование уже упоминалось в § 2.7.2
и обсуждалось в последующих главах. В этом параграфе мы рассмотрим методы
автоматического выбора пороговых величин, а также способы изменения порогов
в соответствии с локальными свойствами изображений.
Предположим, что гистограмма на рис. 10-12 соответствует некоторому изоб-
ражению /(а;, у), которое содержит светлые объекты на темном фоне, причем яр-
кости всех пикселов сосредоточены вблизи двух преобладающих значений. Оче-
видный способ выделения объектов из окружающего фона состоит в выборе по-
рога Т, который разделяет эти две моды яркости. Тогда любая точка (ж,?/), для
которой f(x, у) > Т, называется точкой объекта, а в противном случае она назы-
вается точкой фона. Иными словами, изображение д(х,у), которое получается в
результате этого порогового преобразования,
определяется следующим образом:
1
О
при f (х, у) > Т,
при/(х, у) < Т.
Рис. 10.12. Выбор порога на основа-
нии визуального анализа бимодаль-
ной гистограммы
Таким образом, пикселы со значениями 1 от-
вечают объектам, а пикселы, которым присво-
ено значение 0, соответствуют фону исходно-
го изображения. Если Т является константой
(т.е. не зависит от координат (ж, у)), то такой
порог называется глобальным. Методы выбо-
ра глобальных порогов обсуждаются в § 10.3.1.
В § 10.3.2 рассматриваются способы вариации
порогов, которые в этом случае называются ло-
кальными или адаптивными.
10.3.1. Обработка с глобальным порогом
Один способ выбора порога заключается в визуальном изучении гистограммы
изображения. Гистограмма на рис. 10.12 имеет две отчетливые моды, поэтому
легко выбрать разделяющий их порог. Другой подход к выбору Т основан на ме-
тоде проб и ошибок, когда выбираются различные пороги и проверяются до тех
пор, пока результат пороговой обработки не станет удовлетворять наблюдателя.
Такой метод особенно эффективен при наличии хорошей интерактивной среды
исследования, которая позволяет пользователю «двигать» параметры обработки
в ручном графическом режиме и наблюдать немедленный результат этих изме-
нений.
Для автоматического выбора порога в работе [Gonzalez, Woods, 2002] предло-
жена следующая интерактивная процедура:
1. Выбрать некоторую начальную опенку для значения порога Т (Предлагае-
мая величина равна среднему значению между максимумом и минимумом
яркости изображения).
2. Совершить сегментацию с помощью порога Т В результате образуются две
группы пикселов: Gi и G?. Область Gi состоит из пикселов, яркость кото-
рых больше или равно Т, а яркость пикселов из Gi меньше Т.
3. Вычислить среднюю яркость пикселов и Д2 по областям Gi и G?.
4. Вычислить новое значение порога:
т = 2 + ’
5. Повторять шаги с 2-го по 4-ый до тех пор, пока разность порогов Т для
соседних итераций не станет меньше наперед заданного значения То.
В примере 10.7 эта процедура реализуется средствами MATLAB.
10.3.
В пакете IPT имеется функция graythresh, которая вычисляет пороги по
методу Отсу из [Otsu, 1979]. Чтобы проверить этот метод, основанный на анализе
гистограмм, мы представим нормализованную гистограмму в виде дискретной
функции распределения вероятностей
Рг(гд) = q = 0,1,2,.. .,L - 1,
71
где 71 — это общее число пикселов изображения, nq обозначает число пикселов,
яркость которых равна величине rq, a L — число различных уровней яркости
изображения. Пусть теперь порог к выбран так, что Со обозначает множество
пикселов с уровнями яркости из [0,1,..., к — 1], а Со — это множество пикселов с
уровнями яркости из [fc, к+1,..., L — 1]. Метод Отсу заключается в выборе порога
к так, что он максимизирует межклассовую дисперсию <Тд, которая равна
СГд = и>о(до — Дт)2 + ^1(Д1 — дт)2,
где
fc-l L-1
w0 = 52pg(rg), WJ = 52рд(Гд),
д=0 q=k
к-1 к-1 L—1
ДО = 52 Д1 = 52 №ч(Гч)/^1, qPq(rq)/^Q.
q=0 q=0 q=0
Функция graythresh принимает входное изображение, вычисляет его гистограм-
му, а затем находит пороговую величину, которая максимизирует сг^. Функция
возвращает порог в нормализованном виде из интервала [0,1], поэтому его сле-
дует правильно масштабировать перед использованием. Форма вызова функции
имеет вид
Т = graythresh(f),
где f — это входное изображение, а Т — результирующий порог. При сегмента-
ции изображения мы используем порог Т в функции im2bw, введенной в § 2.7.2.
Поскольку величина порога отнормирована к диапазону от 0 до 1, ее следует пре-
образовать перед использованием. Например, если f — это изображение класса
uint8, то нужно сначала умножить Т на 255, а потом применять для пороговой
обработки.
Пример 10.7. Вычисление глобальных порогов.
В этом примере иллюстрируется описанная выше итеративная процедура, а так-
же метод Отсу применительно к полутоновому изображению f отсканированного
текста на рис. 10.13. Итеративный метод реализуется следующим способом:
>> Т = 0.5*(double(min(f(:))) + double(max(f(:))));
>> done = false;
>> while “done
g = f >= T;
Tnext = 0.5*(mean(f(g) ) + mean(f(~g)));
Глава 10. Сегментация изображений
done = abs(T Tnext) < 0.5;
Т = Tnext;
end
Для этого конкретного изображения цикл while совершается четыре раза и пре-
рывается, когда Т равно 101.47.
а>
ponents or broken connection pal .s. i - re is no M r
non past the level of detail required to identify those
Segmentation of nontrivial images is one of the m
processing. Segmentation accuracy determines the -
of computerized analysis procedures. For this reason,
be taken to improve the probability of rugged segment
such as industrial inspection application*!, at least «
the environment rs possible al times.The experienced
designer invarLihlv miss considerable attention to ч*
Рис. 10.13. а) Отсканирован-
ный текст, б) Результат поро-
говой обработки текста функ-
цией graythresh
Теперь вычислим порог с использованием функции graythresh:
>> Т2 graythresh (f)
Т2
0.3961
» Т2 * 255
ans
101
Результаты обработки этими двумя порогами практически неотличимы друг от
друш. На рис. 10.13, 6) приведено изображение после порогового преобразования
с величиной Т2. □
10.3.2. Обработка с адаптивным порогом
Глобальная пороговая обработка может не дать желаемого результата, если фон
изображения сильно неоднороден по яркости, например, как на рис. 9.26, а) и б).
В таких случаях необходимо применять предварительную обработку для компен-
сации перепадов фоновой яркости, после чего можно совершать глобальное поро-
говое преобразование. Результат улучшающей пороговой обработки на рис. 9.26, д)
был вычислен применением преобразования «верх шляпы», за которым исполь-
зовалась функция graythresh. Можно показать, что этот процесс эквивалентен
пороговому преобразованию с переменной пороговой функцией Т(х,у)-.
Г 1 при f(x,y) > Т(х,у),
( 0 при f(x,y) < Т(х,у),
где
Т(х,у) = fo(x,y)+To.
Изображение fo(x, у) представляет собой морфологическое размыкание /, а кон-
станта То равна результату применения функции graythresh к изображению /о.
10.4. Сегментация на отдельные области
Конечной целью процесса сегментации является разбиение изображения на обла-
сти. В §§ 10.1 и 10.2 эта задача решалась путем обнаружения границ областей на
основе разрывов яркости, а в § 10.3 для этой цели совершались пороговые пре-
образования, которые используют распределение определенных характеристик
пикселов, например, яркостей или цветов. В этом параграфе рассматриваются
методы сегментации, основанные на прямом поиске подходящих областей.
10.4.1. Постановка задачи
Пусть R обозначает всю область изображения. Сегментацией называется процесс
разбиения области R на п подобластей Ri, R?,..., таких, что
a) \JRi = R,
i=l
б) Ri является связной областью для любого г = 1, 2,..., п.
в) Ri Г) Rj — 0 для всех г и j, j.
г) P(Ri) = TRUE при i = 1,2,..., n.
д) P(Ri U Rj) = FALSE для любых двух смежных областей Ri и Rj1.
Здесь Р это некоторый логический предикат2, определенный на точках
множества Ri, а 0 обозначает пустое множество.
Условие (а) означает, что сегментация должна быть полной, т. е.- каждый пик-
сел изображения принадлежит какой-то области. Условие (б) говорит о том, что
точки каждой области должны быть связными в некотором оговоренном смыс-
ле (например, они 4- или 8-связны). Условие (в) указывает на то, что области
не должны пересекаться. Условие (г) относится к свойствам, которые должны
соблюдаться для каждого пиксела из одной области, например, P(Ri) — TRUE,
если все пикселы в Ri имеют одинаковую яркость. Наконец, условие (д) означает,
что прилегающие области Ri и Rj различаются в смысле предиката Р
10.4.2. Выращивание областей
Как ясно из названия, выращивание областей представляет собой процедуру, ко-
торая группирует пикселы или подобласти в более крупные области по заранее
заданным критериям роста. Основной подход состоит в том, что вначале берется
множество точек, играющих роль «центров кристаллизации», а затем на них
наращиваются области путем добавления к каждому центру тех соседних пик-
селов, которые по своим свойствам близки к центру кристаллизации (например,
имеют яркость или цвет в определенном диапазоне).
Выбор множества, состоящего из одной или более начальных точек, часто
зависит от природы задачи, как будет видно из примера 10.8. При отсутствии
априорной информации процедура состоит в вычислении одного и того же набо-
ра свойств для каждого пиксела. В конечном счете, эти свойства будут использо-
1В контексте § 9.4, две различные области Ri и Rj называются примыкающими, если их объе-
динение является компонентой связности.
2Логическим предикатом называется функция, принимающая только два значения: истина
(TRUE) и ложь (FALSE).
426 Глава 10. Сегментация изображений
ваться для отнесения пиксела к той или иной области в процессе выращивания.
Если в результате вычислений обнаруживаются кластеры значений, то пикселы,
близкие по своим свойствам к центроидам таких кластеров, могут выбираться в
качестве пентров кристаллизапии.
Выбор критериев сходства зависит не только от конкретной рассматривае-
мой задачи, но и от вида имеющихся данных, из которых состоит изображение.
Например, анализ данных спутниковой съемки земной поверхности основан на
цветовой информации, и он стал бы значительно затруднен или невозможен при
отсутствии цветовых данных. Если изображения монохромные, анализ областей
делается с использованием дескрипторов, которые основаны на значениях ярко-
сти и пространственных характеристиках (таких, как текстура или статистиче-
ские моменты). Дескрипторы, применяемые для описания областей изображения,
обсуждаются в гл. 11.
Использование при выращивании областей одних лишь дескрипторов может
привести к ошибочным результатам, если это делается в отрыве от информации о
смежности или связности областей. Например, представим себе случайную схему
расположения пикселов, принимающих только три значения яркости. Если стро-
ить «области», группируя вместе пикселы с одинаковой яркостью и не обращая
внимания на их связность, то это приведет к сегментации, лишенной смысла в
контексте нашего обсуждения.
Другая проблема при выращивании областей состоит в том, чтобы сформу-
лировать правило остановки этого процесса. По идее, выращивание некоторой
области следует прекратить, когда в изображении больше нет пикселов, удовлет-
воряющих критериям присоединения к данной области. Такие критерии, как яр-
кость, текстура и цвет, являются по своей природе локальными и не учитывают
«историю» выращивания области. Можно повысить производительность алго-
ритма выращивания областей за счет привлечения дополнительных критериев,
использующих, например, такие понятия, как размеры и форма выращиваемой
области, а также сходство между пикселом-кандидатом и пикселами, объеди-
ненными к данному моменту (скажем, путем сравнения значений яркости нового
кандидата и средней яркости уже выращенной области). Использование дескрип-
торов такого типа основано на предположении, что имеется хотя бы грубая мо-
дель ожидаемых результатов.
Чтобы проиллюстрировать основные принципы сегментации областей в систе-
ме MATLAB, мы напишем функцию regiongrow, которая делает выращивание
областей. Ее общий синтаксис имеет вид
textig, NR, SI, TI] regiongrow(f, S, T),
где f — это сегментируемое изображение, а параметр S может быть массивом
(с размерами как у f) или скаляром. Если S -- массив, то он должен содержать 1
в тех позициях, где расположены центры кристаллизации и 0 — во всех остальных
местах. Этот массив можно определить с помощью визуальной оценки изобра-
жения или применяя какую-то дополнительную внешнюю функцию построения
центров кристаллизации. Если параметр S является скаляром, то он задает зна-
чение яркости пикселов, которые становятся центрами кристаллизации. Анало-
гично, Т может быть массивом (с размерами, как у f) или скаляром. Если Т —
10.4- Сегментация на отдельные области
массив, то его элементы трактуются как локальные пороговые значения для f.
В противном случае, скаляр Т определяет глобальный порог. Значение(я) по-
рога(ов) применяется для проверки соседних (8-связных) пикселов для центров
кристаллизации на предмет того, достаточно ли они «похожи» на них.
Например, если S а и Т Ь, и мы сравниваем яркости, то пиксел называет-
ся похожим на а (в смысле прохождения данного теста), когда модуль разности
их значений не больше Ь. Кроме того, если рассматриваемый пиксел является
8-связным с одним или несколькими центрами кристаллизации, то этот пиксел
рассматривается как возможный элемент одного или нескольких областей. Такой
же подход применяется в случае, когда S и Т являются массивами, и сравнение
выполняется с привязкой центров кристаллизации и пороговых значений к кон-
кретным положениям тестируемых пикселов.
Выходом g служит сегментированное изображение, причем элементы каждой
области помечаются одним и тем же целым числом. Параметр NR равен числу
выделенных областей. Параметр SI является изображением, на котором отоб-
ражены центры кристаллизации, a TI — это изображение, содержащее пикселы,
которые прошли пороговый тест до их обработки на предмет связности. Оба
изображения SI и TI имеют размеры, как у f.
Текст программы regiongrow следующий. Обратите внимание на использова-
ние функции bwmorph из гл. 9 для сокращения до одного числа связных центров
кристаллизации в каждой области S (когда S есть массив), а также на примене-
ние функции imreconstruct для нахождения всех пикселов, связанных с каждым
q
центром кристаллизации.
function [g, NR, SI, TI] = regiongrow(f, S, T)
"/.REGIONGROW Perform segmentation by region growing.
7. [G, NR, SI, TI] = REGIONGROW(F, SR, T) . S can be an array (the
7. same size as F) with a 1 at the coordinates of every seed point
7. and Os elsewhere. S can also be a single seed value. Similarly,
7. T can be an array (the same size as F) containing a threshold
7. value for each pixel in F. T can also be a scalar, in which
7. case it becomes a global threshold.
7.
7. On the output, G is the result of region growing, with each
% region labeled by a different integer, NR is the number of
7. regions, SI is the final seed image used by the algorithm, and TI
7. is the image consisting of the pixels in F that satisfied the
7. threshold test.
f double(f);
7. If S is a scalar, obtain the seed image.
if numel(S) 1
SI = f == S;
SI = S;
else
7. S is an array. Eliminate duplicate, connected seed locations
3true эквивалентно loglcal(l), a false — это logical(O).
Глава 10. Сегментация изображений
7. to reduce the number of loop executions in the following
7i sections of code.
SI = bwmorph(S, ’shrink’, Inf);
J find(SI);
SI = f(J); 7i Array of seed values,
end
TI false(size(f));
for К l:length(Sl)
seedvalue SI(K);
S = abs(f seedvalue) <= T;
TI = TI | S;
end
7i Use function imreconstruct with SI as the marker image to
7i obtain the regions corresponding to each seed in S. Function
7i bwlabel assigns a different integer to each connected region,
[g, NR] bwlabel(imreconstruct(SI, TI));
Пример 10.8. Применение метода выращивания областей при контроле каче-
ства швов при сварке.
На рис. 10.14, а) приводится рентгеновское изображение сварного шва (горизон-
тальная темная область), в котором имеется несколько трещин и раковин (бе-
лые яркие полосы, идущие горизонтально посередине изображения). Мы хотим
воспользоваться методом выращивания областей для сегментации участков изоб-
ражения с дефектами сварки. Эти вьщеленные признаки могут применяться в
целях технического контроля, включаться в базу хронологических данных, ис-
пользоваться для управления автоматическим сварочным оборудованием и во
многих других прикладных задачах.
Рис. 10.14. а) Изображение де-
фсктного сварного шва. б) Цен-
тры кристаллизации, в) Дво-
ичное изображение, показываю-
щее (белым цветом) все пиксе-
лы, прошедшие пороговый тест.
г) Результат анализа всех пик-
селов на предмет 8-связности с
центрами кристаллизации. (Ис-
ходное изображение предостав-
лено компанией Х-ТЕК Systems
Ltd) в)
10-4- Сегментация на отдельные области
Прежде всего, необходимо определить исходные центры кристаллизации. В этой
конкретной задаче было установлено, что пикселы в районе дефектной сварки
имеют значения яркости, близкие к максимальному (в нашем случае это 255).
Исходя из этой информации, мы положим S 255. Следующий шаг состоит в
выборе скалярного порога или порогового массива. В данном примере мы поло-
жили Т = 65. Это число выбрано на основе анализа гистограммы изображения,
которая приведена па рис. 10.15, и оно равно разности между максимальным
значением 255 и положением ближайшей слева значительной впадины. Одно-
временно, эта точка отображает максимальное значение яркости в темной части
сварного шва. Как уже отмечалось ранее, пиксел должен быть 8-связным с неко-
торым пикселом области, чтобы попасть в эту область. Если оказывается, что
пиксел связан более чем с одной областью, то эти области автоматически слива-
ются в одну функцией regiongrow.
На рис. 10.14, б) показаны центры кристаллизации (изображение SI). Этих
точек оказалось много, так как в качестве центов были просто выбраны все точ-
ки изображения со значением яркости 255. На рис. 10.14, в) показано изображе-
ние TI. Ему принадлежат все точки, прошедшие пороговый тест: это все точки,
яркости которых Zi удовлетворяют неравенству \zi — S\ < Т На рис. 10.14, г)
показан результат выделения всех точек, которые связаны с центрами кристал-
лизации. Это и есть сегментированное изображение. При наложении этого изоб-
ражения на исходное можно убедиться в том, что процедура выращивания обла-
стей действительно приводит к сегментации дефектов сварки с хорошей степенью
точности.
Рис. 10.15. Гистограмма
рис. 10.14, а)
В завершение отметим, что изучение гистограммы на рис. 10.15 приводит к
выведу, что было бы невозможно получить то же или Эквивалентное решение
применением любого порогового метода, изложенного в § 10.3. В нашем случае
решающим оказалось применение свойства связности. □
430 Глава 10. Сегментация изображений
10.4.3. Разделение и слияние областей
Описанная только что процедура выращивает области из множества центров
кристаллизации. Альтернативный подход разделения на области состоит в том,
чтобы провести первичное разбиение изображения на множество произвольных
непересекающихся областей и в дальнейшем осуществлять слияние и/или раз-
деление этих областей, стремясь к выполнению условий, сформулированных в
§ 10.4.1. Далее излагается итеративный алгоритм разделения и слияния, кото-
рый соблюдает эти ограничения.
Пусть вся область изображения обозначена R и выбран предикат Р. Один
из возможных подходов к сегментации R состоит в том, чтобы последовательно
разбивать эту область на все более и более мелкие квадратные подобласти Ri,
пока выполняется условие P(Ri) = TRUE. Процесс начинается со всей области
изображения. Если P(R) = FALSE, то изображение делится на четверти вер-
тикальной и горизонтальной прямыми, проходящими через середину. Если для
какой-то четверти предикат Р принимает значение FALSE, то она аналогичным
способом делится на более мелкие четверти, и так далее. Такой метод разбие-
ния удобно представлять в форме так называемого квадродерева (т. е. дерева, у
которого вершины, не являющиеся листьями, имеют в точности четыре потом-
ка), как показано на рис. 10.16 (подизображения, которые соответствуют узлам
квадродерева, иногда называются квадрообластями или квадроиз обращениями).
Отметим, что корень дерева соответствует целому изображению, а каждая дру-
гая вершина — какой-то из его подобластей. В данном случае только область Ri
подверглась дальнейшему разбиению.
Если использовать только операцию разделения, то в окончательном разбие-
нии изображения могут присутствовать соседние области, имеющие одинаковые
свойства. Этот недостаток можно устранить, применяя наряду с разделением
также операцию слияния. Для соблюдения ограничений из § 10.4.1 требуется,
чтобы слиянию подвергались только соседние области, пикселы которых в сово-
купности удовлетворяют предикату Р. Другими словами, две соседних области
Rj и Rk сливаются только в том случае, если P(Rj U /Д) = TRUE.
а)
*1 Л2
*3 Л41 Л 42
Л44
Рис. 10.16. а) Деление изображения на части, б) Соответствующее квадродерево
Проведенное обсуждение можно кратко суммировать в виде процедуры, на
каждом шаге которой выполняются следующие действия:
10-4- Сегментация на отдельные области 431
1. Любая область Rj, для которой P(R3) = FALSE, разделяется на четыре
непересекающиеся четверти.
2. Любые две соседние области Rj и Rr, для которых P(Rj U Rr) = TRUE,
объединяются в одну.
3. Если невозможно выполнить ни одной операции слияния или разделения,
то процедура завершается.
Возможны различные варианты изложенной основной схемы. Например, изоб-
ражение вначале разбивается на множество блоков; дальнейшее разделение про-
водится, как описано выше, но слияние допускается только внутри группы из че-
тырех блоков, являющихся потомками в квадродереве и удовлетворяющих пре-
дикату Р. Когда дальнейшее слияние такого вида оказывается невозможным,
процедура заканчивается однократным слиянием областей, для которых соблю-
даются условия вышеуказанного шага 2; при этом объединяемые области уже
могут быть разных размеров. Главное достоинство такого подхода состоит в ис-
пользовании одного и того же квадродерева для разделения и слияния на всех
шагах, кроме заключительного шага слияния.
В пакете IPT выполнение разложения по квадродереву реализовано М-функ-
цией qtdecomp. Интересующая нас форма вызова этой функции имеет вид4
S = qtdecomp(f, Qsplit_test, parameters),
где f — это исходное изображение, aS — разреженная матрица, которая представ-
ляет структуру квадродерева. Если элемент S(k, m) не равен нулю, то (k, т)
является верхним левым углом квадратного блока в разложении и сторона это-
го блока равна S(k, m). Функция split_test (см. функцию splitmerge в сле-
дующем примере) определяет, надо ли разделять данную область на части, а
parameters — любые параметры, которые могут понадобиться функции split_test.
Механика обращения с такими параметрами аналогична той, которая рассмат-
ривалась в § 3.4.2 применительно к функции coltfilt.
Чтобы получить настоящие значения пикселов квадрообластей на квадроде-
реве разложения, применяется функция qtgetblk, которая имеет синтаксис
[vals, г, с] = qtgetblk(f, S, m),
где vals — это массив, содержащий величины блоков размерами mxm на дереве
разложения изображения f, a S — это разреженная матрица, которую возвращает
функция qtdecomp. Параметры тис являются векторами, в которые записаны
координаты строк и столбцов верхних левых углов этих блоков.
Проиллюстрируем использование функции qtdecomp, написав основную М-
функцию разделения и слияния, которая совершает упрощение, обсуждавшееся
ранее, когда две области сливаются в одну при выполнении предиката каждой
из них по отдельности. Функция, которую мы назвали splitmerge, имеет следу-
ющую форму вызова:
g = splitmerge(f, mindim, Qpredicate),
4 Другие формы функции qtdecomp обсуждаются в § 11.2.2.
Глава 10. Сегментация изображений
где f — это входное изображение, g - выходное изображение, в котором все связ-
ные области помечены разными целыми числами. Параметр mindim определяет
размер самого маленького блока, допускаемого при разложении; этот параметр
должен быть положительной степенью числа 2.
Функция predicate задается пользователем, и ее местоположение должно
быть известно системе (указано в переменной среды MATLAB). Она имеет син-
таксис
flag = predicate(region).
Эта функция должна возвращать значение true (логическую 1), когда пикселы
в области region удовлетворяют предикату, задаваемому этой функцией, в про-
тивном случае значение flag должно быть равно false (логическому 0). В при-
мере 10.9 имеется иллюстрация применения этой функпии.
Функция splitmerge имеет простую структуру. Вначале изображение делится
функцией qtdecomp. Функция split_test использует predicate для определе-
ния, нужно ли разделять область на части. Поскольку при разделении области
на четыре подобласти заранее неизвестно, какая из них индивидуально пройдет
тест предиката, далее выполняется этот тест. Здесь еще раз используется функ-
ция predicate. Каждая квадрообласть, прошедшая тест, заполняется единица-
ми. Этот массив используется вместе с разделенным изображением для опре-
деления связности (смежности) области. Для этих целей применяется функция
imreconstruct.
Далее приводится код функции splitmerge. Простая предикатная функция,
описанная в закомментированном справочном блоке функции, используется в
примере 10.9. Обратите внимание на то, что размеры входного изображения при-
водятся к наименьшему объемлющему квадрату, сторона которого есть степень
числа 2. В этом заключается требование функции qtdecomp гарантировать воз-
можность разделения изображения вплоть до единичного размера.5
function g = splitmerge(f, mindim, fun)
7.SPLITMERGE Segment an image using a split-and-merge algorithm.
7. G = SPLITMERGE(F, MINDIM, 0PREDICATE) segments image F by using a
7. split-and-merge approach based on quadtree decomposition. MINDIM
7. (a positive integer power of 2) specifies the minimum dimension
70 of the quadtree regions (subimages) allowed. If necessary, the
% program pads the input image with zeros to the nearest square
7. size that is an integer power of 2. This guarantees that the
7o algorithm used in the quadtree decomposition will be able to
7. split the image down to blocks of size 1-by-l. The result is
7o cropped back to the original size of the input image. In the
7. output, G, each connected region is labeled with a different
7. integer.
7.
7. Note that in the function call we use QPREDICATE for the value of
7» fun. PREDICATE is a function in the MATLAB path, provided by the
‘’Команда feval(fun, param) вычисляет функцию fun с параметрами param. См. другие формы
обращения к feval на справочной странице этой функции.
10.4- Сегментация на отдельные области 433
% user. Its syntax is
7.
7« FLAG = PREDICATE(REGION) which must return TRUE if the pixels
7o in REGION satisfy the predicate defined by the code in the
7» function; otherwise, the value of FLAG must be FALSE.
7c
7c The following simple example of function PREDICATE is used in
7c Example 10.9 of the book. It sets FLAG to TRUE if the
7c intensities of the pixels in REGION have a standard deviation
7c that exceeds 10, and their mean intensity is between 0 and 125.
7c Otherwise FLAG is set to false.
7.
7c function flag predicate (region)
7c sd std2 (region) ;
7c m = mean2 (region) ;
7c flag = (sd > 10) & (m > 0) & (m < 125) ;
7c Pad image with zeros to guarantee that function qtdecomp will
7c split regions down to size 1-by-l.
Q 2~nextpow2(max(size(f)));
[M, N] size(f);
f = padarray(f, [Q M, Q N], ’post’);
7c Perform splitting first.
S qtdecomp(f, @split_test, mindim, fun);
7c Now merge by looking at each quadregion and setting all its
7c elements to 1 if the block satisfies the predicate.
7c Get the size of the largest block. Use full because S is sparse.
Lmax full(max(S(:)));
7. Set the output image initially to all zeros. The MARKER array is
7o used later to establish connectivity.
g zeros(size(f));
MARKER zeros(size(f));
7c Begin the merging stage.
for К l:Lmax
[vals, r, c] qtgetblk(f, S, K);
if "isempty(vals)
7c Check the predicate for each of the regions
7c of size K-by-K with coordinates given by vectors
7c r and c.
for I l:length(r)
xlow = r(I); ylow = c(I);
xhigh xlow + К 1; yhigh ylow + К 1;
region = f(xlow:xhigh, ylow:yhigh);
flag = feval(fun, region);
if flag
g(xlow:xhigh, ylow:yhigh) = 1;
MARKER(xlow, ylow) = 1;
434 Глава 10. Сегментация изображений
end
end
end
end
7. Finally, obtain each connected region and label it with a
% different integer value using function bwlabel.
g = bwlabel(imreconstruct(MARKER, g));
7, Crop and exit
g = g(l:M, 1:N);
%- 7.
function v = split_test(B, mindim, fun)
7. THIS FUNCTION IS PART OF FUNCTION SPLIT-MERGE. IT DETERMINES
7c WHETHER QUADREGIONS ARE SPLIT. The function returns in v
7o logical Is (TRUE) for the blocks that should be split and
7 logical Os (FALSE) for those that should not.
7c Quadregion B, passed by qtdecomp, is the current decomposition of
7c the image into к blocks of size m-by-m.
7c к is the number of regions in В at this point in the procedure.
к = size(В, 3);
7e Perform the split test on each block. If the predicate function
7c (fun) returns TRUE, the region is split, so we set the appropriate
7c element of v to TRUE. Else, the appropriate element of v is set to
7. FALSE.
v(l:k) = false;
for I = l:k
quadregion = B(:, I);
if size (quadregion, 1) <= mindim
v(I) = false;
continue
end
flag = feval(fun, quadregion);
if flag
v(I) = true;
end
end
Пример 10.9. Сегментация изображения методом разделения и слияния.
На рис. 10.17, а) показан снимок в рентгеновском диапазоне так называемой Пет-
ли Лебедя6. Изображение имеет размеры 256x256 пикселов. Целью этого приме-
ра является выделение из этого изображения «кольца» менее плотной материи,
которая окружает плотную центральную часть. Интересующая нас область име-
ет несколько очевидных характеристик, которые могут помочь при сегментации.
Во-первых, данные имеют случайный характер, т. е. их стандартное отклонение
яркости будет больше стандартного отклонения фона (равного 0) и стандартного
6 Петля Лебедя представляет собой ударную волну от сверхновой в космосе, которая взорвалась
20000 лет назад в созвездии Лебедя.
10.4- Сегментация на отдельные области
отклонения большой яркой центральной области. Аналогично, среднее значение
(яркости) области с выделяемыми данными больше среднего значения фона (рав-
ного 0) и меньше среднего значения центральной области. Значит, можно попро-
бовать совершить сегментацию, основываясь на этих двух параметрах. На самом
деле, предикатная функция, приведенная в качестве иллюстрации в заголовоч-
ной документации функции splitmerge, использует именно эту информацию.
Параметры определяются при вычислении среднего значения и стандартного от-
клонения различных областей на рис. 10.17, а).
Рис. 10.17. Сегментация изображения методом разделения и слияния, а) Исходное изоб-
ражение. б)-е) Результаты сегментации функцией splitmerge со значениями
mindim, которые равны 32, 16, 8, 4 и 2 соответственно. (Исходное изображение
предоставлено Агентством NASA)
Рис. 10.17 с б) по е) показывают результаты сегментации рис. 10.17, а) с ис-
пользованием splitmerge со значениями параметра mindim, равными, соответ-
ственно, 32,16, 8, 4 и 2. Видно, что степень детализации на изображениях обратно
пропорциональна величине mindim.
Все результаты сегментации на рис. 10.17 вполне приемлемы. Если одно из
этих изображений нужно использовать в качестве маски для извлечения интере-
суемого объекта па исходном изображении, то наилучшим выбором будет изобра-
жение 10.17, г), поскольку оно представляет собой сплошную область с хорошей
детализацией границ- Важный критический момент этого метода заключается
в том, что функция predicate должна «поймать» адекватную информацию о
проблемной области, которая поможет при ее сегментации. □
Глава 10. Сегментация изображений
10.5. Сегментация преобразованием водораздела
В географии термин водораздел обозначает условную линию, которая разделя-
ет области водосборов разных речных систем. Водосборный бассейн определяет
географическую область, вода с которой собирается в одну реку или водохрани-
лище. Преобразование водораздела применяет эту идею к обработке монохромных
изображений при решении различных типов задач сегментации.
а) б) Рис. 10.18. а) Полутоновое изоб-
Линия водораздела ражения темных сгустков, б) Изоб-
\ражение, представленное в виде по-
верхности, на которой отмечены ли-
ния водораздела и водосборные бас-
сейны
Водораздельные бассейны
Чтобы понять преобразование водораздела, необходимо представить себе по-
лутоновое изображение в виде поверхности уровней, на которой величины /(яг, у)
интерпретируются как высоты. Например, простое изображение на рис. 10.18, а)
можно представить в виде трехмерной поверхности, показанной на рис. 10.18, б).
Если представить себе дождь, идущий над этой поверхностью, то, очевидно, вода
будет собираться в двух областях, помеченных как водосборные бассейны. Капли
дождя, падающие точно на линию, помеченную как линия водораздела, будут с
одинаковой вероятностью собираться и в левый, и в правый бассейн. Преобразо-
вание водораздела находит водосборные бассейны и строит линию водораздела
на полутоновом изображении. Если использовать терминологию по сегментации,
то ключевым моментом является изменение исходного изображения и преобра-
зование его в такое изображение, что водосборными бассейнами на нем являлись
как раз области и объекты, которые мы хотим сегментировать.
Метод вычисления преобразования водораздела детально обсуждается в кни-
гах [Gonzalez, Woods, 2002] и [Soille, 2003]. В частности, алгоритм, используемый
в IPT, взят из работы [Vincent, Soille, 1991].
10.5.1. Сегментация по водоразделам с помощью
преобразования расстояния
Инструмент, который часто используется при сегментации по водоразделу, назы-
вается преобразованием расстояния. Преобразование расстояния двоичного изоб-
ражения является довольно простой функцией: оно равно расстоянию от каждого
пиксела до ближайшего пиксела с ненулевым значением. На рис. 10.19 иллю-
стрируется это преобразование. На рис. 10.19, а) показана матрица маленького
двоичного изображения, а на рис. 10.19, б) приведено соответствующее преобра-
зование расстояния. Отметим, что ненулевые пикселы имеют нулевые значения
преобразования расстояния. Это преобразование вычисляется в пакете функцией
bwdist, которая имеет следующий синтаксис вызова:
D = bwdist(f).
10.5. Сегментация преобразованием водораздела 437
а) б)
1 1 0 0 0 0.00 0.00 1.00 2.00 3.00
1 1 0 0 0 0.00 0.00 1.00 2.00 3.00
0 0 0 0 0 1.00 1.00 1.41 2.00 2.24
0 0 0 0 0 1.41 1.00 1.00 1.00 1.41
0 1 1 1 0 1.00 0.00 0.00 0.00 1 00
Рис. 10.19. а) Маленькое двоичное изображе-
ние. б) Преобразование расстояния
Пример 10.10. Сегментация двоичного изображения по водоразделу с помощью
преобразования расстояния
В этом примере показывается, как пре-
образование расстояния может быть
использовано при сегментации в соче-
тании с преобразованием водораздела
в пакете IPT применительно к изоб-
ражению кругов, некоторые из ко-
торых касаются друг друга. Точнее,
мы хотим сегментировать изображе-
ние f деревянных шпонок, прошед-
шее предварительную обработку на
рис. 9.29, б). Сначала мы преобразу-
ем изображение в двоичный формат с
помощью функций im2bw и graythresh, как это описано в § 10.3.1.
>> g = im2bw(f, graythreshff));
Рис. 10 20. а) Двоичное изображение. 6) Дополнение изображения а), в) Преобразование
расстоянием г) Линии водораздела преобразования расстояния от дополнс
ния. д) Линии водоразделов, нанесенные черным цветом на исходное двоично
изображение. Видна некоторая избыточная сегментация
На рис. 10.20, а) показан результат. Следующий шаг состоит в получении нега
тивного (дополнительного) изображения, вычислении преобразования расстоя
ния и нахождении преобразования водораздела от изображения, полученного
помощью функции watershed. Эта функция вызывается командой
L = watershedff),
где L - это размечающая матрица (см. § 9.4). Положительные целые значения )
438 Глава 10. Сегментация изображений
соответствуют водосборным бассейнам, а нулевые значения обозначают пикселы
линий водоразделов.
» gc = ~g;
> > D = bwdist(gc);
> > L = watershed(-D) ;
> > w = L == 0;
На рис. 10.20, б) и в), приведено негативное изображение и его преобразова-
ние расстоянием. Поскольку нулевые значения в L обозначают линии водораз-
делов, в последней командной строке строит двоичное изображение w, выделя-
ющее только эти пикселы. Соответствующая картина водоразделов приведена
на рис. 10.20, г). Наконец, логическое AND исходного двоичного изображения с
дополнением к w дает полную сегментацию, которая показана на рис. 10.20, д).
» g2 = g & ~w;
Заметим, что некоторые объекты на рис. 10.20, д) разделены неправильно. Та-
кое явление называется избыточной сегментацией, которая часто проявляет-
ся при использовании метода сегментации по водоразделам. В следующих двух
параграфах рассматриваются различные подходы, позволяющие преодолеть эту
трудность. □
10.5.2. Сегментация по водоразделам с помощью
градиентов
Модуль градиента часто используется при предварительной обработке полуто-
новых изображений перед сегментацией по водоразделам. Пикселы изображе-
ния градиента с большими значениями располагаются вблизи границ объектов,
а остальным участкам соответствуют нулевые значения пикселов. В идеале, вы-
полняя затем преобразование водораздела, можно получить линии водоразделов
вдоль границ объектов. В следующем примере иллюстрируется этот подход.
Пример 10.11. Сегментация полутонового изображения с помощью градиента
и преобразования по водоразделу.
На рис. 10.21, а) приведено изображение f, которое содержит несколько затем-
ненных сгустков или пятен. Мы начнем с вычисления модуля градиента, исполь-
зуя или метод линейной фильтрации, описанный в § 10.1, или применяя морфо-
логический градиент, подобно тому, как это делалось в § 9.6.1.
» h = fspecial(’sobel’);
» fd = double(f);
>> g = sqrt(imfilter(fd, h, ’replicate’) .“2 +
imfilter(fd, h’, ’replicate’) . ~2);
Рис. 10.21, б) показывает изображение модуля градиента g. Затем мы вычисляем
преобразование по водоразделам от градиента и находим границы водоразделов.
>> L = watershed(g) ;
» wr = L == 0;
Рис. 10.21. а) Полутоновое изображение малых сгустков, б) Изображение модуля гра-
диента. в) Преобразование водораздела от б) с избыточной сегментацией.
г) Преобразование водоразделом от сглаженного изображения градиента. Из-
быточная сегментация уменьшена. (Исходное изображение представлено д-
ром С. Бёше, CMM/Ecole de Mines de Paris)
Как видно на рис. 10.21, в), результат такой сегментации не слишком хорош.
На нем имеется много линий водоразделов, которые не окружают интересующие
нас объекты. Это другой случай избыточной сегментации. Можно попытаться
справиться с этой проблемой, сгладив изображение градиента перед выполнением
преобразования водоразделов. Здесь мы применяем замыкание размыканием, как
описано в гл. 9.
» g2 imclose(imopen(g, ones(3,3)), ones(3,3));
» L2 = watershed(g2);
» wr2 = L2 == 0;
» f2 = f;
» f2(wr2) = 255;
Последние две строки программного кода помещают изображение wr2 линий во-
доразделов поверх исходного изображения. Результат показан на рис. 10.21, г).
Налицо улучшение по сравнению с рис. 10.21, в), хотя и здесь имеются лиш-
ние линии, поэтому трудно выделить водосборные бассейны интересующих нас
объектов. В следующем параграфе рассматривается дальнейшее усовершенство-
вание сегментации по водоразделам, которое поможет справиться с избыточной
сегментацией. □
440 Глава 10. Сегментация изображений
10.5.3. Использование маркеров при сегментации
по водоразделам
Непосредственное применение алгоритма сегментации по водоразделам в том ви-
де, как описывалось в предыдущем параграфе, обычно приводит к избыточной
сегментации, вызванной шумом или другими локальными неоднородностями на
градиентном изображении. Избыточная сегментация может быть настолько зна-
чительной, что сделает результат обработки практически бесполезным. В контек-
сте нашего обсуждения это означает огромное число областей, выделенных при
сегментации. Практическое решение этой проблемы состоит в том, чтобы огра-
ничить допустимое число областей путем включения в состав процедуры шага
предварительной обработки, служащего для привнесения добавочной информа-
ции в процедуру сегментации.
Подход, применяемый для управления избыточной сегментацией, основан на
идее маркеров. Маркер представляет собой связную компоненту, принадлежащую
изображению. Будем различать внутренние маркеры, относящиеся к интересу-
ющим пас объектам, и внешние маркеры, соответствующие фону изображения.
Затем эти маркеры используются для подправления градиентного изображения
при выполнении процедуры, описанной в примере 10.12. Разработаны различ-
ные методы для построения внутренних и внешних маркеров, многие из которых
используют линейную или нелинейную фильтрацию, а также морфологическую
обработку, описанную в предыдущих главах. Какой метод выбрать, зависит в
высокой степени от природы конкретных изображений, которые будут обраба-
тываться данной программой.
Пример 10.12. Иллюстрация использования маркеров при сегментации по во-
доразделам.
В этом примере рассматривается сегментация, контролируемая маркерами, кото-
рая применяется к изображению гели электрофореза на рис. 10.22, а). Сначала
приведем результат, который получается преобразованием водораздела от гра-
диентного изображения без предварительной обработки.
> > h fspecial(’sobel’);
> > fd doubled) ;
» g sqrt(imfilter(fd, h, ’replicate’) "2 +
imfilter(fd, h’, ’replicate’) ~2);
» L watershed(g);
» wr = L == 0;
Результат дан на рис. 10.22, б), на котором наблюдается избыточная сегмен-
тация, причина которой заключается в большом числе локальных минимумов.
Функция imregionalmin определяет все локальные минимумы изображения. Она
вызывается в виде
rm imregionalmin(f ),
где f это полутоновое изображение, a rm обозначает двоичное изображение, в
котором единицей отмечают положения локальных минимумов. Мы можем про-
верить функцию imregionalmin на градиентном изображении, чтобы понять,
почему функция watershed порождает такие маленькие водосборные бассейны:
10.5. Сегментация преобразованием водораздела
rm imregionalmin(g);
Большинство локальных минимумов, показанных на рис. 10.22, в), являются очень
мелкими. Они отображают маленькие детали, которые не играют роли в задаче
сегментации. Чтобы исключить такие дополнительные минимумы, используется
функция из IPT imextendedmin, которая находит «низкие» пятна на изображе-
нии, лежащие глубже некоторого заданного порогового уровня по сравнению с их
ближайшим окружением. (См. [Soille, 2003], где детально рассматривается преоб-
разование расширенного минимума и связанные с ним операции.) Эта функция
имеет форму вызова
im = imextendedmin(f, h),
где f — это полутоновое изображение, h — пороговый уровень, a im обозначает
двоичное изображение, на котором пикселы переднего плана отмечают положе-
ния глубоких минимумов. Теперь можно применить функцию imextendedmin,
которая задаст наше множество внутренних маркеров:
im = imextendedmin(f, 2);
fim = f;
fim(im) 175;
Последние две строки помешают положения расширенного множества миниму-
мов в виде сероватых пятен на исходное изображение [см. рис. 10.22. г)]. Видно,
что полученные пятна хорошо «отмечают» объекты, которые мы желаем сегмен-
тировать.
Теперь необходимо построить внешние маркеры или пикселы, про которые
мы уверены, что они принадлежат фону изображения. Здесь мы следуем подхо-
ду, согласно которому фон отмечается пикселами, которые расположены точно
посередине между внутренними маркерами. Как ни странно, но это можно сде-
лать, решив другую задачу водораздела, а именно: нужно вычислить преобра-
зования водораздела от преобразования расстояния изображения im внутренних
маркеров:
» Lim = watershed(bwdist(im));
> > em = Lim == 0;
Рис. 10.22, д) изображает результирующие линии водоразделов на двоичном изоб-
ражении em. Поскольку эти линии расположены посередине между темными пят-
нами, отмеченными im, они подходят для роли внешних маркеров.
Имея внутренние и внешние маркеры, мы их используем для модифициро-
вания градиентного изображения с помощью процедуры, которая называется
минимальным подъемом. Техника минимального подъема (см. подробности в
[Soille, 2003]) модифицирует полутоновое изображение так. что локальные мини-
мумы достигаются только в отмеченных положениях. Другие величины пикселов
повышаются для исчезания всех прочих точек локального минимума. Функция
IPT imimposemin реализует этот подход. Она вызывается командой
mp = imimposemin(f, mask),
Глава 10. Сегментация изображений
ж)
Рис. 10.22. а) Изображение гели, б) Избыточная сегментация в результате применения
преобразования водораздела к изображению модуля градиента, в) Локальные
минимумы модуля градиента, г) Внутренние маркеры, с) Внешние маркеры.
ж.) Модифицированный модуль градиента, з) Результат сегментации. (Исход-
ное изображение представлено д-ром С. Бёше, СММ/Ecole de Mines de Paris)
где f — это исходное полутоновое изображение, a mask двоичное изображе-
ние, пикселы переднего плана которого отмечают желаемое положение локаль-
ных минимумов на выходном изображении шр. Мы модифицируем градиентное
изображение, приподнимая локальные минимумы в положениях внутренних и
внешних маркеров:
g2 = imimposemin(g, im | em) ;
Выводы
Рис. 10.22, е) показывает результат. Наконец, мы готовы совершить преобразова-
ние водораздела отмеченного и модифицированного градиентного изображения
и взглянуть на полученные линии водоразделов:
» L2 = watershed(g2) ;
» f2 = f;
» f2(L2 == 0) = 255;
Последние две команды помещают линии водоразделов на исходное изображение.
В результате получается значительно улучшенная сегментация, как показано на
рис. 10.22, ж). □
Выбор подходящих маркеров может простираться от рассмотренных выше
простых процедур до существенно более сложных методов, которые вовлека-
ют размеры, форму, положение, относительные расстояния, текстуру и т. д. (см.
гл. 11 в связи с описаниями изображений). Ключевое место во всех этих методах
заключается в том, что использование маркеров добавляет априорную инфор-
мацию для облегчения задачи сегментации. Априорные знания часто помогают
при сегментации и при решении задач более высокого уровня, и самым попу-
лярным методом является использование контекста. Таким образом, тот факт,
что сегментация по водоразделам предлагает подход, который позволяет эффек-
тивно использовать этот тип информации, означает существенное преимущество
данного метода.
Выводы
Сегментация изображения является важным предварительным шагом большин-
ства задач автоматического распознавания зрительных образов и анализа сцен.
Как показывают рассмотренные в этой главе примеры, выбор того или иного
метода сегментации часто зависит от специфических особенностей изучаемой за-
дачи. Хотя набор методов, изложенных в этой главе, далек от исчерпывающего,
он является характерным инструментарием сегментации, применяемой на прак-
тике.
ГЛАВА 11
ПРЕДСТАВЛЕНИЕ
И ОПИСАНИЕ
Введение
После сегментации изображения на области, например, с помощью методов, опи-
санных в гл. 10, выделенные «грубые» совокупности пикселов обычно описыва-
ются и представляются в форме, удобной для последующей компьютерной обраг
ботки. При выборе способа представления имеется две возможности:
(1) область можно представить ее внешними характеристиками (т. е. границей)
или
(2) область можно представить внутренними характеристиками (т. е. совокуп-
ностью элементов изображения, составляющих эту область).
Однако выбор способа представления является только частью задачи преобра-
зования данных в форму, удобную для компьютерной обработки. Следующая
задача состоит в том, чтобы описать область, исходя из выбранного способа
представления. Например, область может быть представлена своей границей, а
граница — описана с помощью таких характеристик, как ее длина, направление
прямых, соединяющих угловые точки, и число вогнутостей границы.
Внешнее представление обычно выбирается в тех случаях, когда основное вни-
мание обращено на характеристики формы области. Внутреннее представление
выбирается, если интерес представляют свойства самой области, например, цвет
или текстура. Иногда приходится использовать оба способа представления од-
новременно. В любом случае, выбранные для описания признаки (дескрипторы)
должны быть как можно менее чувствительными к изменению размеров обла-
сти и ее перемещению по полю изображения (сдвигу или повороту). За редким
исключением, рассматриваемые в этой главе дескрипторы обладают одним или
несколькими из этих свойств.
I I. I. Предварительные сведения
Областью называется компонента связности, а границей области (называемой
также обводом или контуром) является множество пикселов этой области, ко-
торые имеют один или несколько соседних пикселов, не принадлежащих обла-
сти. Точки, не принадлежащие области или ее границе, называются фоновыми.
Сначала мы будем рассматривать только двоичные изображения, поэтому точки
области или ее границы имеют значение 1, а значение фоновых точек равно 0.
Позже в этой главе рассматриваются также недвоичные значения пикселов.
11.1. Предварительные сведения
Из приведенных выше определений следует, что граница образует замкнутое
множество точек. Точки границы называются ориентированными, если они об-
разуют последовательность, которая обходится по или против часовой стрелки.
Граница называется минимально связной, если любая из ее точек имеет в точ-
ности двух соседей величины 1, которые не являются 4-связными. Внутренней
точкой области является любая ее точка, не лежащая на границе.
Материал этой главы существенно отличается от материалов, обсуждавшихся
в предыдущих главах, в том смысле, что нам придется оперировать со смесью
различных типов данных, таких как области, границы, топологические формы
и так далее. Поэтому перед тем, как двигаться далее, мы сделаем отступление
и определим некоторые базовые понятия и функции MATLAB и IPT, которые
будут использоваться в дальнейшем.
11.1.1. Смешанные массивы и структуры
Мы начнем с обсуждения смешанных массивов и структур, которые были корот-
ко введены в § 2.10.6.
Смешанные массивы
Смешанные массивы позволяют комбинировать и смешивать объекты разных ти-
пов (как-то: числа, символы, матрицы и другие смешанные массивы), присваивая
таким переменным общие имена. Например, пусть мы работаем
(1) с некоторым изображением f класса uint8 размерами 512x512;
(2) с последовательностью Ъ двумерных вещественных координат, представлен-
ной в форме массива 188x2; и
(3) со смешанным массивом, который содержит две символьные строки
char_array = {’area’, ’centroid’}-.
Эти три непохожих объекта можно объединить в одну переменную С с помощью
особого типа данных, называемого смешанным массивом:
С = {f, b, char_array}-,
где фигурные скобки обозначают содержимое смешанного массива. Если в ко-
мандной строке набрать команду С, то это вызовет следующий отклик системы:
» С
С
[512x512 uint8] [188x2 double] {1x2 cell}-
Другими словами, выходом служат не значения различных переменных, а пе-
речисление некоторых их свойств. Чтобы обратиться к содержимому некото-
рого элемента массива, необходимо заключить индекс (числовое местоположе-
ние) этого элемента в фигурные скобки. Например, чтобы увидеть содержимое
char_array, следует набрать
» С{31
ans
’area’ ’centroid’
446 Глава 11. Представление и описание
или воспользоваться функцией celldiep:
» celldiep(С{ЗУ)
апв{1У
area
апв{2У
centroid
Если вместо фигурных скобок подставить круглые, то это вызовет описание этой
переменной, как было выше:
» С(3)
апв
{1x2 cell}
Мы можем работать с содержимым смешанного массива, преобразуя эти дан-
ные в числовую или другую уместную форму. Например, для извлечения f из С
мы выполним команду
» f = С{1У;
Функция Bize дает размер смешанного массива:
» Bize(C)
апв
1 3
Функция cellfun, имеющая синтаксис
D cellfun(’fname’ ,С),
применяет функцию fname к элементам смешанного массива С и возвращает ре-
зультат в виде массива D класса double. Каждый элемент D содержит величину,
которая возвращается функцией fname, примененной к соответствующему эле-
менту С. Размер D совпадает с размером С. Например,1
» D = cellfun(’length’, С)
D =
512 188 2
Другими словами, здесь отображены следующие величины: length(f) 512,
length(b) 188 и length(char_array) 2. Из материалов § 2.10.3 мы знаем,
что length (А) дает размер самой длинной размерности многомерного массива А.
Наконец, помните о комментарии, сделанном в § 2.10.6 о том, что смешанные
массивы содержат копии своих аргументов, а не указатели на них. Поэтому, ес-
ли любой из аргументов массива С в предыдущем примере был изменен после
создания переменной С, то это ие вызовет изменения в самой С.
хСм. справочную страницу для cellfun, где перечислены допустимые входные данные для
аргумента fname.
Пример 11.1. Простые иллюстрации работы со смешанным массивом.
Мы хотим написать функцию, выходом которой является средняя яркость изоб-
ражения, его размер, средняя яркость по строкам и средняя яркость по столбцам.
Это можно сделать, следуя «стандартным» путем, сконструировав следующую
функцию:
function [Al, dim, Alrows, Alcols] image_stats(f)
dim size(f);
Al = mean2(f);
Alrows = mean(f, 2);
AIcols = mean(f, 1);
где f — это исходное изображение, а выходные аргументы соответствуют опи-
санным выше величинам. Используя смешанный массив, можно написать так:
function G = image_stats(f)
G{1]- size(f);
G{2]- = mean2(f);
G{3]- = mean(f, 2);
G{4]- = meanff, 1);
Запись G(l) = {size(f)]- (и аналогично для других элементов) также допусти-
ма. Смешанные массивы могут быть многомерными. Например, предыдущую
функцию можно определить следующим образом:
function Н = image_stats2(f)
Н(1, 1) = {size(f)]-;
Н(1, 2) = {mean2(f)}-;
Н(2, 1) {mean(f, 2)У;
Н(2, 2) {mean(f, 1)}-;
Или можно использовать запись вида Н{1,1}- size(f) и аналогично для всех
других компонентов. Добавочные размерности обрабатываются совершенно ана-
логично.
Предположим, что f имеет размер 512x512. Набрав G и Н после системного
приглашения, получим
G = image_stats(f)
>> Н = image_stats2(f) ;
>> G
[1x2 double] [1] [512x1 double] [1x512 double]
» H
H =
[1x2 double] [1]
[512x1 double] [1x512 double]
Если необходимо работать с переменной, содержащейся в G, то мы ее извлекаем,
обратившись к нужному элементу смешанного массива, как раньше. Например,
если мы хотим получить размер f, то пишем
448 Глава 11. Представление и описание
» v = G{1}
или
» V = Н{1,1}-
где v — это вектор 1x1. Заметьте, что мы не воспользовались привычной коман-
дой [М, N] = G-[l)-для получения размера изображения. Это вызвало бы ошиб-
ку, поскольку только функции могут производить многомерные выводы. Чтобы
получить Ми N, следует написать М v(l) и N = v(2). □
Очевидная экономия в обозначениях предыдущего примера становится еще
более значительной, когда число выходных параметров велико. Однако при этом
наблюдается существенный недостаток, который заключается в потере ясности
и наглядности при использовании числовой адресации в отличие от присвоения
имен переменным. В этом месте могут помочь структуры.
Структуры
Структуры похожи на смешанные массивы в том смысле, что они позволяют
группировать данные различной природы, назначая им единую переменную. Од-
нако в отличие от смешанных массивов, к составляющим которых обращаются с
помощью числовых адресов, элементам структур присваиваются имена, которые
называются полями.
Пример 11.2. Простая иллюстрация структур.
Продолжение темы из примера 11.1 прояснит эту концепцию. С помощью струк-
тур можно написать
function s = image_stats(f)
s.dim size(f);
s.AI mean2(f);
s.Alrows = mean(f, 2);
s.AIcols = mean(f, 1);
где s — это структура. Полями этой структуры являются AI (скаляр), dim (век-
тор 1x2), Alrows (вектор Мх2) и AIcols (вектор 1x1V), где М и N обозначают
число строк и столбцов изображения. Обратите внимание на употребление точки
при отделении имени структуры от именем ее различных полей. Именем поля
может служить любая последовательность букв и цифр, начинающаяся с буквы.
Используя то же изображение, что и в примере 11.1, и набрав s и size(s)
после командного приглашения, получим следующие выходы:
» s
S
dim: [512 512]
AI: 1
Alrows: [512x1 double]
AIcols: [1x512 double]
» size(s)
ans
1 1
11.1. Предварительные сведения
Заметим, что сама переменная в является скаляром, с которым, в нашем случае,
ассоциированы еще четыре поля.
Из этого примера видно, что логика кода такая же, как и раньше, но орга-
низация вывода данных намного нагляднее. Как и со смешанными массивами,
преимущество использования структур становится еще яснее при большом числе
различных выходных данных. □
В предыдущем примере использовалась одна структура. Однако, если вместо
одного изображения их имеется Q штук, которые организованы в виде массива
размерами М х N х Q, то функция приняла бы следующий вид:
function в = image_BtatB(f)
К Bize(f);
for k = 1:K(3)
B(k).dim= Bize(f(: k));
в(к).А1 = mean2(f(:, k));
e(k).AIrowB = mean(f(: k), 2);
в(к).А1со1в = mean(f(: k), 1);
end
Другими словами, сами структуры можно индексировать. Несмотря на то, что
структуры, как и смешанные массивы, могут иметь произвольное число раз-
мерностей, наиболее употребительной формой является вектор, как показано в
предыдущей функции.
При извлечении данных из полей необходимо помнить размерность как пере-
менной s, так и ее полей. Например, следующая команда извлекает все перемен-
ные из Alrows и сохраняет их в v:
for k = l:length(s)
v(:, k) = в(k).Alrowe;
end
Отметим, что в v двоеточие стоит на первом месте, а индекс к на втором, посколь-
ку в имеет размерность IxQ, а размерность Alrowe равна MxQ. Тогда, раз к
пробегает от 1 до Q, размерность v будет Mx Q. Если бы нам потребовалось
извлекать данные из Alrowe, то мы бы написали в цикле v(k, :).
Квадратные скобки можно использовать при записи информации в вектор
или матрицу, если поля структуры содержат скаляры. Например, пусть D.Area
содержит площадь каждой из 20 областей изображения. Запись
» w [D.Area] ;
порождает вектор w размером 1x20, каждый элемент которого является площаг
дью одной области.
Как и в случае со смешанным массивом, когда величина присваивается полю
структуры, MATLAB помещает в структуру копию этой величины. Если исход-
ная величина меняется после этого действия, то это изменение не отражается в
поле структуры.
450 Глава 11. Представление и описание
11.1.2. Некоторые дополнительные функции
MATLAB и IPT
Функция imf ill кратко упоминалась в табл. 9.3 и в § 9.5.2. Эта функция действу-
ет по-разному на двоичные и полутоновые изображения, поэтому для лучшего
понимания обозначений этого параграфа мы обозначим через fB и fl, соответ-
ственно, двоичное и полутоновое изображение. Если выходом служит двоичное
изображение, то мы его обозначаем gB, а в противном случае оно обозначается
просто через g. Синтаксис
terrtgB imfill(fВ, locations, conn)
совершает операцию «затопления-заполнения» применительно к фоновым пик-
селам (т. е. она меняет значения этих пикселов на 1) входного двоичного изоб-
ражения fB, начиная от точек, позиции которых обозначены в locations. Этот
параметр может быть вектором nxl (п число позиций точек), и тогда в нем
записаны линейные индексы (см. § 2.8.2) координат начальных позиций точек.
Кроме того, параметр locations может быть матрицей пх2, в которой каж-
дая строка состоит из двумерных координат одной из начальных позиций точек
в fB. Параметр conn обозначает тип связности, который применяется к пиксе-
лам фона: 4 (по умолчанию) и 8. Если параметры location и conn опущены,
то команда gB = imf ill (fВ) отображает двоичное изображение fB на экране и
позволяет пользователю выбрать положение начальные позиции с помощью мы-
ши. Нажатие левой кнопки добавляет точку. Нажатие Backspace или Delete
удаляет точку, выбранную на предыдущем шаге. Нажатие левой кнопки мыши
с удерживаемой клавишей Shift, правой кнопки или двойной щелчок задает по-
следнюю точку и дает старт процедуре заполнения. Нажатие Return завершает
выбор точек без добавления последней точки.
Использование синтаксиса
gB = imfill(fB. conn, ’holes’)
приводит к заполнению дыр на двоичном изображении. Дырой называется мно-
жество фоновых пикселов, которых нельзя достигнуть путем заполнения фона,
начиная от края изображения. Как и раньше, conn обозначает тип связности: 4
(по умолчанию) и 8.
Синтаксис
g = imfillCfl, conn, ’holes’)
заполняет дыры на полутоновом изображении fl. В этом случае дырой считается
участок темных пикселов, окруженный более яркими пикселами. Параметр conn
обозначает то же, что и раньше.
Функция find может использоваться в сочетании с bwlabel2 для возвра-
щения векторов координат пикселов, которые образуют специфический объект.
Например, если [gB, num] = bwlabel (fB) выдает более одной связной области
(т. е. num > 1). то для получения, скажем, второй области, следует набрать
[г, с] find(g == 2).
2См. обсуждение функция find и bwlabel в § 5.2.2 и § 9.4 соответственно.
11.1. Предварительные сведения
Двумерные координаты областей или границ в этой главе представлены в
виде массивов прх2, где каждая строка - это пара координат (rr, у), а пр обозна-
чает число точек области или границы. В некоторых случаях бывает необходимо
упорядочить эти массивы. Для этой цели применяется функция
z sortrows (S).
Эта функция упорядочивает строки S по возрастанию. Аргументом S может слу-
жить или матрица, или вектор-столбец. В этой главе функция sortrows применя-
ется исключительно к массивам прх2. Если несколько строк имеют одинаковые
первые координаты, то они упорядочиваются по возрастанию второй координа-
ты. Если мы хотим упорядочить строки S и одновременно удалить повторные
строки, то следует применять функцию unique, которая имеет следующий син-
таксис:
[z, m, n] = unique(S, ’rows’),
где z — это отсортированный массив без повторов строк, a m и п имеют следующий
смысл: z S(m, :) и S = z(n, :). Например, если S = [12; 6 5; 1 2; 4 3],
то z = [1 2; 4 3; 6 5], m = [3; 4; 2] и n = [1; 3; 1; 2]. Заметим, что z
упорядочен по возрастанию, и m обозначает, какие строки исходного массива были
сохранены в новом массиве z.
Часто бывает нужно сдвинуть строки массива вверх, вниз или в сторону на
заданное число позиций. Для этого можно использовать функцию circshif t:
z = circshift(S, [ud Ir]),
где ud — это число элементов, на которое следует сдвигать вверх или вниз. Если ud
больше нуля, то все сдвигается вниз, а если меньше нуля, то — вверх. Аналогично,
если 1г положительно, то массив сдвигается вправо на 1г позиций, а в противном
случае он сдвигается влево. Если требуется сдвиг вверх или вниз, то имеется
упрощенная форма вызова функции
z = circshift(S, ud).
Если S — это изображение, то circshift — это не что иное, как обычная про-
крутка (вверх и вниз) или панорамирование (влево и вправо) зацикленного изоб-
ражения.
11.1.3. Некоторые основные утилитные М-функции
В этой главе будут часто использоваться следующие типичные операции: пре-
образование областей и границ, упорядочение граничных точек в смежные цепи
и подвыборка границы для упрощения ее представления и описания. Здесь мы
рассмотрим некоторые утилитные М-функции, которые применяются для этих
целей. Чтобы излишне не углубляться в особенности организации этих процедур
и не отвлекаться от основных идей главы, мы обсудим лишь основной синтак-
сис этих функций. Задокументированные коды всех этих функций имеются в
приложении В. Как отмечалось ранее, границы представляются в виде массивов
Глава 11. Представление и описание
прх.2, в которых каждая строка соответствует паре двумерных координат. Мно-
гие из этих функций автоматически конвертируют координатные массивы 2хпр
в массивы с размерами прх2.
Функция
В boundaries(f, conn, dir)
отслеживает внешние границы объектов изображения f, которое предполагается
двоичным с пулевым фоном. Параметр conn обозначает используемую связность
выходных границ: его значение может быть равно 4 или 8 (по умолчанию). Пара-
метр dir указывает направление, в котором отслеживаются границы: его значе-
ние может быть ’cw’ (по умолчанию) или ’ccw’, что, соответственно, означает
направление по часовой стрелке или против. Итак, если выбрана 8-связность и
направление ’ cw ’, то используется упрощенный синтаксис
В boundaries(f ).
Выходом обеих форм вызова функции является смешанный массив В, элементами
которого служат координаты точек обнаруженной границы. Первая и последняя
точки границы, возвращаемые функцией boundaries, совпадают. Этот приводит
к замкнутой границе.
Для закрепления этого материала предположим, что мы хотим найти границу
объекта с самой длинной границей на изображении f (для простоты предполо-
жим. что имеется единственная такая граница). Это можно совершить, применяя
следующую последовательность команд:
> > В = boundaries(f);
> > d cellfun(’length’, В);
> > [max_d, k] max(d);
» v = B{k(l)};
Вектор v содержит координаты самой длинной границы входного изображения,
а к соответствует номеру области. Массив v имеет размеры прх2. Последняя
команда просто выбирает первую границу максимальной длины, если таковых
имеется много. Как отмечалось в предыдущем абзаце, первая и последняя точ-
ки каждой границы, выделенной функцией boundaries, совпадают, т. е. строка
v(l, :) равна строке v(end, :).
Функция bound2eight, имеющая форму вызова
Ь8 bound2e ight(b),
удаляет из b пикселы, которые необходимы для 4-связности, но не нужны для 8-
связности, и оставляет границу, чьи пикселы являются только 8-связными. Вход-
ная матрица b должна иметь размер пр х 2, и в каждой ее строке записаны коор-
динаты (х, у) граничных пикселов. Требуется, чтобы граница b была замкнута,
связна, и необходимо, чтобы пикселы границы были ориентированы по часовой
стрелке или против. Те же условия применяются к функции bound2f our:
Ь4 bound2four(b).
3См. § 2.10.2, в котором объясняется такое использование функции шах.
Эта функция вставляет дополнительные пикселы в тех местах границы, где име-
ется диагональная связность, тогда получается выходная граница, в которой пик-
селы являются 4-связными. Листинги программ этих функций приведены в при-
ложении В.
Функция
g = bound2im(b, М, N, хО, уО)
строит двоичное изображение g размерами MxN, в котором 1 стоят на месте
точек границ и 0 на заднем плане. Параметры хО и уО обозначают положения
минимальных х- и y-координат b на изображении. Граница b должна быть ко-
ординатным массивом размерами прх2 (или 2хпр), где пр - это число точек.
Если параметры хО и уО опущены, то граница примерно центрируется в массиве
MxN. Если, в свою очередь, параметры М и N отсутствуют, то вертикальный и
горизонтальный размеры выходного изображения полагаются равными высоте и
ширине границы Ь. Если функция boundaries обнаруживает кратные границы,
то можно получить все эти координаты для использования в функции bound2im
путем связывания различных элементов смешанного массива В:4
b = cat(l, В{:}),
где 1 обозначает связывание вдоль первой (вертикальной) размерности массива.
Функция
[s, su] bsubsamp(b, gridsep)
совершает укрупняющую подвыборку (одинарной) границы b по решетке, линии
которой отстают друг от друга на gridsep пикселов. Выходом s является граница
с меньшим числом точек, чем было у Ь, число этих точек определяется значением
gridsep, a su это множество граничных точек, перемасштабированных так, что
перемещения их координат образуют единое целое. Такое представление полезно
при кодировании границы с помощью цепных кодов, что обсуждается в § 11.1.2.
Требуется также, чтобы точки b были упорядочены по или против направления
часовой стрелки.
После совершения подвыборки границы функцией bsubsamp ее точки пере-
стают быть связными. Их можно связать обратно, применив функцию
z connectpoly(s(:,1), s(:,2)),
где строки s являются координатами границы после подвыборки. Необходимо,
чтобы точки s были упорядочены по или против часовой стрелки. Строки выхо-
да z являются координатами связанной границы, которая получается соединени-
ем точек s самыми короткими путями, состоящими из 4- или 8-связных прямых
сегментов. Эта функция бывает полезной при построении связного граничного
многоугольника, который является более гладким (более простым) по сравне-
нию с исходной границей Ь, по которой он построен. Функция connectpoly так-
же довольно удобна при работе с функциями, которые строят только вершины
многоугольников, например, с функцией minperpoly, которая рассматривается в
§ 11.2.3.
4См. § 6.1.1 для объяснения оператора cat. См. также пример 11.13.
Глава 11. Представление и описание
Вычисление целочисленных координат отрезков, соединяющих две точки, являет-
ся базовым инструментом при работе с границами (например, функции connectpoly
требуется как раз такая подфункция). Для этих целей хорошо подходит функция
из IPT intline, которая имеет синтаксис5
[х, у] intline(xl, х2, yl, у2),
где (xl, yl) и (х2, у2) — это целочисленные координаты двух точек, которые
необходимо соединить прямой линией. Выходами х и у служат вектор-столбцы,
состоящие из целых х- и у-координат соединяющего отрезка.
11.2. Представление
Методы сегментации, обсуждавшиеся в гл. 10, дают на выходе необработанные
данные в форме множества пикселов, расположенных вдоль границы или внут-
ри области. Хотя эти данные иногда непосредственно используются для получе-
ния дескрипторов (например, при определении текстурных признаков области),
обычная практика состоит в применении методов компактного представления
данных сегментации. Полученные компактные представления оказываются зна-
чительно более эффективными для вычисления дескрипторов. В этом разделе
мы рассмотрим различные подходы к описанию областей.
11.2.1. Цепные коды
С помощью цепных кодов граница представляется в виде последовательности со-
единенных отрезков, для которых указаны длина и направление. Как правило,
такое представление основывается на отрезках с 4- или 8-связностью. Направ-
ление каждого отрезка кодируется числом в соответствии со схемой нумерации,
например, как изображено на рис. 11.1, а) и б). Коды, построенные по этой схеме,
называются цепными кодами Фримана.
Рис. 11.1. Номера направ-
лений а) для цепных кодов
с 4 направлениями и б) для
цепных кодов с 8 направле-
ниями
О
Цепной код границы области зависит от начальной точки, но с помощью
простой процедуры его можно сделать инвариантным к ее выбору. Для этого
8Функция intline является недокументированной утилитой IPT. Ее программный код приве-
ден в приложении В.
11.2. Представление
цепной код просто рассматривается как циклическая последовательность номе-
ров направлений отрезков, и исходная точка переопределяется таким образом,
чтобы при начале отсчета с нее получалась линейная запись, соответствующая
целому числу наименьшей величины. Цепной код также можно сделать инва-
риантным относительно поворота [на углы с шагом 90° или 45° как показано
на рис. 11.1, а) и б)], если вместо самого кода рассматривать его первую раз-
ность, которая формируется путем вычитания значений направления для всех
пар соседних элементов кодовой последовательности. Эта, разность определяется
подсчетом числа смен направлений (против часовой стрелки на рис. 11.1), ко-
торые разделяют два смежных элемента кода. Например, для цепного кода с 4
направлениями 10103322 первая разность задается последовательностью 3133030.
Инвариантность по отношению к поворотам достигается путем ориентирования
границы по отношению к некоторым доминирующим характеристикам описыва-
емого объекта, например, вдоль его главных осей, как это делается в § 11.3.2.
Функция f chcode с синтаксисом
с = fchcode(b, corm, dir)
вычисляет циклические коды Фримана для множества точек ориентированной
границы, которое хранится в виде массива Ь с размерами прх2. Выходом слу-
жит структура с со следующими полями, где числа внутри скобок определяют
размеры массивов:
с. f с с —цепной код Фримана (1 х пр)
с.diff -первая разность кода с.fee (Ixnp)
с.mm =целые числа наименьшей величины (1хпр)
с. diffmm—первая разность кода с .mm (1 хпр)
с. хОуО =координаты начала кода (1x2)
Параметр corm задает связность кода; его значения могут быть 4 или 8 (по умол-
чанию). Величина 4 допустима, только если граница не содержит диагональных
переходов.
Параметр dir обозначает направление выходного кода: если он равен ’ same ’
то код имеет то же направление, что и у точек Ь. Если dir равен ’reverse’, то
выбрано противоположное направление. По умолчанию принимается значение
’same’ Значит, при выполнении команды с = fchcode(b, corm) направление
выбирается по умолчанию, а команда с f chcode (b) определяет по умолчанию
и направление, и связность.
Пример 11.3. Цепной код Фримана и некоторые его вариации.
На рис. 11.2, а) приведено изображение f замкнутого обхода, на которое нало-
жен некоторый шум. Целью этого примера является построение цепного кода
и первой разности для границы объекта. При взгляде на рис. 11.2, а) становит-
ся очевидно, что шумовые фрагменты, касающиеся интересующего нас объекта,
приводят к весьма нерегулярной границе, которая не будет правильно отражать
общие формы объекта. Сглаживание является обычным процессом при работе с
зашумленной границей. На рис. 11.2, б) приведен результат g применения усред-
няющей маски 9x9 к исходному изображению:
Глава 11. Представление и описание
h = fspecial(’average’, 9);
g = imfilter(f, h, ’replicate’);
Двоичное изображение на рис. 11.2, в) получено последующей пороговой обра-
боткой:
>> g = im2bw(g, 0.5);
Граница этого изображения выделена с помощью функции boundaries, которая
обсуждалась в предыдущем параграфе:
» В boundaries (g);
Как и в иллюстрации к § 11.1.3, мы интересуемся самой длинной границей:
Рис. 11.2. а) Зашумленное изображение, б) Изображение, сглаженное усредняющей мас-
кой 9x9. в) Изображение после пороговой обработки, г) Граница двоичного
изображения, д) Укрупняющая подвыборка границы, е) Соединенные точки
из д)
d сеIlfun(’length’, В);
[max_d, k] = max(d);
b - B{1};
Граница изображения на рис. 11.2, г) построена следующими командами:
» [М N] = size(g);
» g = bound2im(b, М, N, min(b(:, 1)), min(b(:, 2)));
11.2. Представление
Если строить цепной код непосредственно для Ь, то это приведет к длинной
последовательности с малыми изменениями, которые не обязательно полезны
для общего представления формы объекта. Поэтому в качестве естественной и
типичной процедуры при построении цепных кодов совершается укрупняющая
подвыборка границы с использованием функции bsubsamp, которая вводилась в
предыдущем параграфе:
> > [s, su] bsubsamp (b, 50);
Здесь мы воспользовались разделяющей сеткой с шагом примерно в 10% от ши-
рины изображения, которое в нашем случае имеет размеры 570x570 пикселов.
Полученный результат отображен в виде белых точек на рис. 11.2, д):
» g2 bound2im(s, М, N, min(s(: 1)), min(s(: 2)));
или в виде соединяющих их отрезков на рис. 11.2, е), который получен командами
> > сп connectpoly(s(:, 1), s(:, 2));
> > g2 bound2im(cn, M, N, min(cn(: 1)), min(cn(: 2)));
Преимущество такого представления с точки зрения цепного кодирования ста-
новится очевидным при сравнении рис. 11.2, г) и е). Цепной код получается из
укрупненной последовательности su:
> > с fchcode(su);
Эта команда дает следующие результирующие выводы:
> > с.хОуО
ans
7 3
>> с.fee
ans
22022020000606666666644444424222
>> с .mm
ans =
00006066666666444444242222202202
>> c.diff
ans
06206260006260000000600000626000
>> c.diffmm
ans
00062600000006000006260000620626
Проверяя c. fee, рис. 11.2, e) и с. хОуО, видим, что код начинается слева от изоб-
ражения и обрабатывается в направлении по часовой стрелке, что совпадает с
направлением координат границы. □
Глава 11. Представление и описание
11.2.2. Приближение ломаной линией минимальной
длины
Дискретная граница может быть сколь угодно точно приближена ломаной лини-
ей. В случае замкнутой границы аппроксимация является точной, когда число
отрезков ломаной равно числу точек границы, и каждую пару соседних точек
соединяет свой отрезок. На практике цель аппроксимации ломаной состоит в
том, чтобы с помощью как можно меньшего числа отрезков приблизить «самое
существенное» в форме границы.
Хороший практический метод приближения заключается в нахождении ло-
маной линии минимальной длины МРР (Minimum-Perimeter Polygon) для гра-
ницы области. Теоретическое обоснование, а также алгоритм нахождения МРР
имеются в классической книге [Sklansky et al., 1972] (см. также [Kim, Sklansky,
1982]). В этом параграфе мы рассмотрим основы этого метода, а также приве-
дем реализацию алгоритма в виде М-функции. Метод ограничивается поиском
простых ломаных линий (т. е., не имеющих самопересечений) Кроме того, из
рассмотрения исключаются области, имеющие выступы и отростки шириной в
один пиксел. Такие аномалии можно отделить от области с помощью морфоло-
гических методов, а затем добавить к построенной аппроксимирующей линии в
соответствующих местах.
Некоторые основы
Основную идею аппроксимации мы рассмотрим на простом примере. Предполо-
жим, что граница области заключена внутри множества соединенных в цепочку
ячеек, как показано на рис. 11.3, а). Это позволяет визуально представить гра-
ницу области как резиновую ленту находящуюся между двумя стенками, соот-
ветствующими внутренней и внешней границам указанной цепочки ячеек. При
стягивании ленты она примет форму, приведенную на рис. 11.3, б), образуя мно-
гоугольник с минимальным периметром, который отвечает геометрической фор-
ме данной цепочке ячеек.
Рис. 11.3. а) Граница объ-
екта, заключенная в клетки.
б) Ломаная линия минималь-
ной длины
Подход Склански основан на так называемом клеточном комплексе (или кле-
точной мозаике), который в нашем случае является множеством квадратных
11.2. Представление
клеток, покрывающим границу изучаемой области, как показано на рис. 11.3, а).
На рис. 11.4, aj изображена (серая) область, заключенная в клеточный комплекс.
Отметим, что граница этой области образована 4-связными путями. При обхо-
де по этим путям в направлении по часовой стрелке мы отметим закрашенным
кружком (•) выпуклые углы (имеющие внутренний угол 90°), а незакрашенным
кружком (о) — вогнутые углы (имеющие внешний угол 270°). На рис. 11.4, б)
черные кружки помещены прямо на выпуклые вершины, а белые расположены
по диагонали рядом с вогнутыми вершинами. Такая картина соответствует кле-
точному комплексу и формулировке алгоритма с помощью вершин.
Рис. 11.4. а) Область, отнесенная внеш-
ней стенкой клеточного комплекса из
рис. 11.3, а), б) Маркеры выпуклых (•)
и вогнутых (о) вершин для границы об-
ласти из а). Маркеры вогнутых вершин
расположены по диагонали рядом с со-
ответствующими вершинами
Следующие свойства образуют основу подхода при построении МРР:
1. Ломаная МРР соответствует простому связному клеточному комплексу без
самопересечений. Пусть Р обозначает МРР.
2. Каждая выпуклая вершина Р совпадает с некоторым кружком • (но не
каждый кружок • является вершиной Р).
3. Каждая вогнутая вершина Р совпадает с некоторым кружком о (но не
каждый кружок о является вершиной Р).
4. Если кружок • принадлежит Р, но не является выпуклой вершиной Р, то
этот кружок лежит на стороне Р.
В нашем обсуждении вершина ломаной называется выпуклой, если величина
его внутреннего угла 6 лежит в диапазоне 0 < 6 < 180о1; в противном случае,
вершина называется вогнутой. Как и в предыдущем абзаце, выпуклость опреде-
ляется для внутренней области при обходе границы по часовой стрелке.
Алгоритм для нахождения МРР
Свойства с 1 по 4 являются основой при построении ломаной минимальной дли-
ны МРР. Имеется несколько способов сделать это построение (см., например,
[Sklansky et al., 1972] и [Kim, Sklansky, 1982]). Подход, которому мы здесь следу-
ем, разработан с учетом возможностей двух ключевых функций IPT/MATLAB.
Первая из них с именем qtdecomp выполняет разложение по квадродереву, кото-
рое приводит к окружению интересующих данных клеточным комплексом. Вто-
рая функция называется inpolygon. Она используется для определения точек,
гУгол 6 — 0° исключается, а случай в — 180° рассматривается как особый.
460 Глава 11. Представление и описание
которые лежат вне или внутри границы ломаной линии, заданной своими вер-
шинами.
Полезно разрабатывать процедуру построения МРР, имея перед глазами неко-
торую иллюстрацию. Для этого мы воспользуемся рис. 11.3 и 11.4. Построе-
ние 4-связной границы затемненной области на рис. 11.4, а) будет обсуждаться
несколько позже в этом параграфе. После того, как эта граница установлена,
следующий шаг заключается в нахождении ее вершин. Эта процедура делается
построением их цепного кода Фримана. Изменения кодовых направлений указы-
вают на углы границы. Анализируя изменения направлений, мы двигаемся по
часовой стрелке вдоль границы. Тогда достаточно несложно установить и раз-
метить выпуклые и вогнутые вершины, как это сделано на рис. 11.4, б). Особый
способ построения этих маркеров задокументирован в М-функции minperpoly,
которая будет обсуждаться далее в этом параграфе. Разметка вершин таким спо-
собом также отражена на рис. 11.4, б), которую мы повторяем на рис. 11.5, а).
Затемненная область, а также линии квадратной решетки добавлены для нагляд-
ности. Граница области не показана, чтобы избежать путаницы при построении
ломаных 1раниц на остальных схемах рис. 11.5.
Т еперь строим исходную ломаную линию, используя для этого только выпук-
лые вершины (черные кружки), как показано на рис. 11.5, б). Из свойства 2 мы
знаем, что множество выпуклых вершин МРР является подмножеством этого
исходного множества выпуклых вершин. Видно, что все вогнутые вершины (бе-
лые кружки), лежащие вне начального многоугольника, не образуют вогнутости
многоугольника. Чтобы эти особые вершины стали выпуклыми на следующих
стадиях алгоритма, ломаная должна пройти через эти точки. Но мы знаем, что
они никогда не смогут стать выпуклыми, поскольку все возможные выпуклые
вершины уже учтены к этому моменту (может случиться, что позже их углы
могут стать равными 180°, но это не скажется на форме многоугольника). Сле-
довательно, все белые кружки, расположенные вне исходного многоугольника,
можно удалить перед дальнейшем анализом, что и сделано на рис. 11.5, в).
Вогнутые вершины (белые кружки), расположенные внутри многоугольника,
ассоциированы с вогнутостями на границе, которые были проигнорированы на
первом проходе процедуры. Следовательно, их нужно добавить к ломаной, что
сделано на рис. 11.5, г). К этому моменту имеются черные вершины, которые
перестали быть выпуклыми в новом многоугольнике (они отмечены стрелками
на рис. 11.5, г)]. Имеется две причины для этого. Первая причина состоит в том,
что эти вершины являлись частью исходного многоугольника на рис. 11.5, б),
в который были включены все выпуклые (черные) вершины. Другая причина
состоит в том, что черные вершины стали вогнутыми в результате добавления
(белых) вершин, как это произошло на рис. 11.5, г). Значит, все черные кружки
многоугольника необходимо проверить, чтобы выяснить, не стали ли величины
соответствующих внутренних углов больше 180° Все такие вершины необходимо
удалить, а затем повторить процедуру.
На рис. 11.5, д) показана лишь одна черная вершина, которая потеряла вы-
пуклость на втором шаге обработки. Процедуру проверки и удаления следует
остановить, как только все вершины перестанут менять выпуклость. После этого все
вершины с углами 180° можно также удалить, поскольку они лежат на сторонах
Рис. 11.5. а) Выпуклые (черные) и вогнутые (белые) вершины границы на рис. 11.4, а),
б) Начальная ломаная, соединяющая все выпуклые вершины, в) Результат по-
сле удаления выпуклых вершин вне многоугольника, г) Присоединение остав-
шихся вогнутых вершин к многоугольнику (стрелками отмечены черные вер-
шины, которые стали вогнутыми; они будут удалены), д) Результат удаления
вогнутых черных вершин (стрелкой обозначена черная вершина, ставшая те-
перь вогнутой), е) Окончательный результат, отображающий МРР. э/с) Лома-
ная МРР, наложенная на клеточный комплекс границы
462 Глава 11. Представление и описание
ломаной и не влияют на форму окончательного многоугольника. Граница, изоб-
раженная на рис. 11.5, е), представляет собой ломаную минимальной длины МРР
нашего примера. Она же приведена на рис. 11.3, б). Наконец, на рис. 11.5, мс)
представлена МРР с наложением на исходный клеточный комплекс.
Предыдущие рассуждения суммируются в следующих шагах построения МРР
области:
1. Построить клеточный комплекс (метод построения будет изложен далее в
этом параграфе).
2. Выделить внутреннюю область комплекса.
3. Построить для выделенной на шаге 2 области ее границу с помощью функ-
ции boundaries, представив границу в виде 4-связной последовательности
координат с направлением обхода по часовой стрелке.
4. Для этой 4-связной последовательности получить цепной код Фримана с
помощью функции f chcode.
5. Отметить выпуклые (черные кружки) и вогнутые (белые кружки) вершины
на цепном коде.
6. Построить исходный многоугольник, используя все черные кружки как его
вершины. Удалить из дальнейшего анализа все белые кружки, лежащие
вне этого многоугольника (сохраняя белые кружки, лежащие на границе
многоугольника).
7. Построить многоугольник из оставшихся черных и белых кружков-вершин.
8. Удалить все черные кружки, которые стали вогнутыми.
9. Повторять шаги 7 и 8 до тех пор, пока не прекратятся изменения выпук-
лости вершин. После этого удалить все вершины с величиной угла 180°
Оставшиеся вершины образуют ломаную минимальной длины МРР.
Некоторые M-функции, используемые в алгоритме МРР
Функция qtdecomp, рассмотренная в § 10.4.2, используется на первом шаге при
построении клеточного комплекса, покрывающего границу. Как обычно, мы рас-
сматриваем область В, которая составлена из 1-иц и фоновых 0-ей. Мы восполь-
зуемся следующей формой вызова функции qtdecomp:
Q = qtdecomp(В, threshold, [mindim maxdim]),
где Q — это разреженная матрица, содержащая структуру квадродерева. Если
Q(k, ш) не равно нулю, то (к, ш) является верхним левым углом блока разло-
жения и размер блока равен Q(k, m).
Блок разделяется, если максимальное значение элементов блока минус их ми-
нимальное значение больше, чем threshold. Величина этого параметра заключе-
на между 0 и 1 независимо от класса входного изображения. При указанном син-
таксисе функция qtdecomp не производит блоки с размерами меньше, чем mindim
и больше, чем maxdim. Блоки, размеры которых превосходят maxdim разделяют-
ся, даже если они не удовлетворяют пороговому условию. Частное maxdim/mindim
должно быть степенью числа 2.
Если в аргументе функции qtdecomp в конце присутствует лишь одна вели-
чина (без квадратных скобок), то она считается равной maxdim. В таком виде
эта функция используется в данном параграфе. Изображение В должно иметь
размеры КхК, так что частное K/mindim является степенью числа 2. Ясно, что
наименьшее возможное значение К равно наибольшей размерности В. Для вы-
полнения этого требования обычно матрица В дополняется нулями с помощью
функции padarray при выборе опции ’post’ Например, пусть матрица В име-
ет размер 640x480 и задана величина mindim = 3. Параметр К должен удовле-
творять условиям К >= max(size(B)) и K/mindim = 2'р или К = mindim* (2'р).
Разрешая эти соотношения относительно р, получаем р = 8 и, следовательно,
К 768.
Для нахождения величин блоков при разложении на квадродерево мы вос-
пользуемся функцией qtgetblk, которая обсуждалась в § 10.4.2:
[vals, г, с] = qtgetblk(В, Q, mindim),
где vals — это массив, состоящий из значений mindimxmindim блоков разло-
жения по квадродереву матрицы В, a Q — разреженная матрица, возвращаемая
функцией qtdecomp. Параметры г и с являются векторами, в которые записаны
координаты сторон и столбцов верхних левых углов блоков.
Пример 11.4. Построение клеточной стенки границы области.
Чтобы увидеть реализацию шагов с 1 по 4 алгоритма МРР, рассмотрим изоб-
ражение на рис. 11.4, а) и предположим, что параметр mindim = 2. Пикселы
представлены маленькими квадратиками для облегчения объяснения функции
qtdecomp. Изображение имеет размер 32x32 пикселов, и легко проверить, что
для выбранного значения mindim не требуется делать расширение изображения.
4-связная граница этой области получается с помощью следующей команды2:
» В = bwperim(B, 8);
На рис. 11.6, б) показан результат. Отметим, что В стало изображением, на кото-
ром отображена только 4-связная граница (напомним, что маленькие квадратики
обозначают отдельные пикселы).
На рис. 11.6, в) показано разложение по квадродереву для В, которое получе-
но командой
» Q = qtdecomp(B, 0, 2);
Здесь 0 — это порог, который допускает разложение блоков вплоть до мини-
мального размера 2x2 независимо от расположения в них 0 и 1 (каждый из этих
блоков может содержать от 0 до 4 пикселов). Заметьте, что имеется много блоков,
размеры которых больше, чем 2x2, но все они образованы фоновыми пикселами.
Теперь мы воспользуемся командой qtgetblk(В, Q, 2) для извлечения вели-
чин и координат верхних левых углов для всех блоков с размером 2x2. После
2Синтаксис функции bwperim имеет вид g = bwperimCf, conn), где conn обозначает желаемую
связность: 4 (по умолчанию) или 8. Связность определяется относительно фоновых пикселов.
Поэтому, для получения 4-связной границы объекта мы выбрали conn = 8. Наоборот, для по-
строения 8-связной границы следует положить conn = 4. Выходом g служит двоичное изобра-
жение границ объектов изображения f. Эта функция рассматривается подробно в § 11.3.1.
Глава 11. Представление и описание
этого все блоки, содержащие не менее одного пиксела со значением I. полно-
стью заполняются единицами. Результат, который мы обозначили BF, показан на
рис. 11.6, г). Серые клетки на этом изображении образуют клеточный комплекс.
Другими словами, эти клетки покрывают границу на рис. 11.6, б).
а)
Рис. 11.6. а) Исходное изображение, где пикселы обозначены маленькими квадратами.
6) 4-связная граница, в) Разложение по квадродереву с использованием бло-
ков с минимальным размером сторон в 2 пиксела, г) Результат заполнения
1-ми всех блоков размерами 2x2, которые содержат не менее одного единич-
ного элемента. Это и есть клеточный комплекс, д) Внутренняя область для г),
е) 4-связные граничные точки, полученные с помощью функции boundaries.
Цепной код построен функцией f chcode
Область, ограниченная клеточным комплексом на рис. 11.6. г), построена ко-
мандой
» R = imfill(BF, ’holes’) & ~BF;
Рис. 11.6, д) дает результат. Теперь мы хотим выделить 4-связную границу этой
области, которая получается командами
Ъ
Ъ
boundaries(Ь, 4, ’cw’);
ЬШ;
Рис. 11.6, е) отображает результат. Цепной код Фримана, показанный на этом
рисунке, получен функцией f chcode. На этом завершаются шаги с 1 по 4 алго-
ритма МРР. □
Функция inpolygon используется функцией minperpoly (которая обсуждает-
ся в следующем параграфе) для выяснения, лежит ли точка внутри, на границе
или вне многоугольника. Она имеет синтаксис
IN inpolygon(X, Y, xv, yv),
где X и Y - это векторы, состоящие из х- и у-координат тестируемых точек, a xv
и yv — векторы, образованные из х- и у-координат вершин многоугольника, рас-
положенные в последовательности по или против направления часовой стрелки.
Массив IN является вектором, длина которого равна числу тестируемых точек.
Его значение равно 1 для точек, лежащих внутри или на границе многоугольни-
ка, и 0 для точек, расположенных вне границ многоугольника.
М-функция для построения МРР
Все шаги алгоритма с 1 по 9 реализованы функцией minperpoly, программный
код которой приведен в приложении В. Она имеет синтаксис
[х, у] minperpoly(В, cellsize),
где В — это входное двоичное изображение, содержащее единственную область
или границу, a cellsize — это размер квадратных ячеек клеточного комплек-
са для покрытия границы. Векторы-столбцы х и у содержат х- и ^-координаты
вершин МРР.
Пример 11.5. Использование функции minperpoly.
На рис. 11.7, а) показано изображение В кленового листа, а на рис. 11.7, б) при-
ведена его граница, выделенная командами
» b = boundaries(В, 4, ’cw’);
» Ъ = ЬШ;
» [И, N] size(В);
» xmin = min(b(: 1));
» ymin = min(b(:, 2));
> > bim = bound2im(b, M, N, xmin, ymin);
» imshow(bim)
С этой эталонной границей будут сравниваться различные ломаные МРР в дан-
ном примере. На рис. 11.7, в) приведен результат команд
> > [х, у] = minperpoly(B, 2);
> > Ь2 connectpoly(х, у);
> > В2 bound2im(b2, М, N, xmin, ymin);
» imshow(В2)
Аналогично, на рис. 11.7 с г) по е) показаны различные МРР, построенные по
квадратным ячейкам с размерами 3, 4 и 8 пикселов соответственно Тонкий сте-
бель был утрачен при использовании клеток, крупнее чем 2x2, в силу уменьше-
ния разрешения. Вторая основная характеристика формы листа связана с тремя
основными его долями. Эти особенности прослеживаются достаточно отчетливо
даже для ячеек со стороной 8, как показано на рис. 11.7, е). При дальнейшем
Глава 11. Представление и описание
увеличении размеров ячеек до 10 и даже до 16 эти характеристики все еще со-
храняются, как видно на рис. 11.8, а) и б). Однако на рис. 11.8, в) и г), видно,
что эти характерные черты теряются для 20 и для больших значений.
Стилками на рис. 11.7, в) и д), отмечены узлы, образованные самопересека-
ющимися линиями. Такие узлы могут возникать, если размер отступа на границе
по отношению к размеру ячейки такой, что при разметке вогнутых вершин их
положения «пересекают» друг друга, изменяя направление последовательности
по часовой стрелке. Один способ в разрешении этой коллизии состоит в уда-
лении одной из вершин. Другой путь — это увеличить или уменьшить размер
ячейки. Например, рис. 11.7, г), отвечающий размеру 3, не обнаруживает эту
особенность, которая проявилась для размеров ячеек 2 и 4. □
Рис. 11.7. а) Исходное изображение, б) 4-связная граница, в) Ломаная МРР, построенная
по ячейкам с размером сторон в 2 пиксела. г)-е) МРР, построенные, соответ-
ственно, по ячейкам со сторонами 3, 4 и 8
11.2.3. Сигнатуры
Сигнатура есть описание границы объекта с помощью одномерной функции, ко-
торая может строиться различными способами. Один из простейших методов
состоит в нахождении зависимости расстояния от центроида (т. е. от некоторой
средней точки объекта, например, от его центра тяжести) до границы объекта в
виде функции угла, что иллюстрирует рис. 11.9. Независимо от способа построе-
ния сигнатуры, основная идея состоит в том, чтобы свести представление грани-
11.2. Представление
цы к одномерной функции, которую предположительно описать легче, чем исход-
ную двумерную границу. Имейте в виду, что такой метод сигнатурного описания
годится, только если известно, что вектор, проведенный из начала координат до
границы, пересекает эту границу только один раз, что приводит к однозначно
определенной функции от возрастающего угла. Это условие исключает границы
с самопересечепиями, а также границы, имеющие глубокие узкие вогнутости или
тонкие длинные выступы.
Рис. 11.8. МРР, построен-
ные по еще большим ячей-
кам с размерами а) 10, б) 16,
в) 20 и г) 32
Сигнатуры, построенные описанным выше способом, инвариантны по отно-
шению к параллельному переносу, однако они зависят от поворота и изменения
масштаба. Инвариантности к повороту можно достичь, найдя способ выбора од-
ной и той же начальной точки для построения сигнатуры независимо от ориен-
тации фигуры. Один из способов сделать это заключается в выборе в качестве
начальной максимально удаленную от центроида точку (см. § 11.3.1) при усло-
вии, что такая точка единственна и не зависит от искажений, возникающих при
поворотах интересующих фигур.
Другой способ может заключаться в выборе максимально удаленной от цент-
роида точки па собственной оси фигуры (см. § 11.5). Такой метод требует больше-
го объема вычислений, но является и более устойчивым, поскольку направление
оси фигуры онределяется с учетом всех точек ее контура. Еще один способ осно-
ван на получении цепного кода границы и на последующем применении метода,
описанного в § 11.1.2, полагая, что поворот можно аппроксимировать дискрет-
ными углами в кодовых 11анравлепиях, определенных в § 11.1.
Если исходить из предположения, что изменение масштаба производится оди-
наково по обеим осям и дискретизация по углу в является равномерной, то
(468
Глеев 11. Представление и описание
масштабирование фигуры отражается на изменении амплитуды соответствую-
щей сигнатуры. Этот результат можно пронормировать путем масштабирования
функций сигнатуры таким образом, чтобы они всегда охватывали один и тот
же диапазон значений, например, [0,1]. Достоинством данного метода является
простота, однако его серьезный недостаток кроется в том, что масштабирование
всей функции определяется всего двумя значениями минимальным и макси-
мальным. Если в изображении присутствует шум, эта зависимость может стать
источником расхождений между объектами. Более устойчивый (но также требу-
ющий больших вычислений) метод состоит в делении каждого углового отсче-
та на дисперсию сигнатурной функции в предположении, что эта дисперсия не
равна нулю [как на рис. 11.9, а)] и не очень мала (тогда не возникнут вычис-
лительные трудности). Учет дисперсии приводит к переменному коэффициенту
масштабирования, который обратно пропорционален изменениям размеров и дей-
ствует аналогично автоматической регулировке расхождения. Какой бы способ
ни применялся, следует иметь в виду, что основная идея состоит в устранении
зависимости от масштаба при сохранении формы кривой в целом.
Рис. 11.9. Два объекта: о) круг
и б) квадрат, в) и г) — соответ-
ствующие сигнатурные функции
расстояния в зависимости от угла
| ।_I_। । । । । I । । । । । । । ।
ЕЕЗрр5рЗр7р2р ВрЗрр5рЗр7р2р
4 2 4 ц 4 2 4 4 2 4 ц 4 2 4
Функция signature, включенная в
ной границы. Она имеет синтаксис
приложение В, находит сигнатуру задан-
[st, angle, хО, уО]
signature(Ь, хО, уО),
где Ъ это массив прх.2, состоящий из зд/-координат границы, ориентирован-
ной по или против направления часовой стрелки. Сигнатура является функцией
угла angle, которая записывается в массив st. Координаты (хО, уО) обознача-
ют начало вектора, который продолжается до границы. Если эти координаты не
включены в аргументы, функция использует по умолчанию координаты цент-
роида границы. В любом случае, координаты начала использованного вектора
(хО, уО) включаются функцией в выходные данные. Размеры массивов st и
angle равны 360x1, т. е. разрешение составляет 1° Входом должна служить гра-
ница толщиной в один пиксел, которая получена, например, с помощью функции
boundaries (см. § 11.1.3). Как всегда предполагается, что граница является замк-
нутой кривой.
11.2. Представление
Рис. 11.10. Соотношение
декартовых и полярных ко-
ординат
Функция signature использует функцию MATLAB
cart2pol для перехода от декартовых координат к по-
лярным. Она вызывается командой
[THETA, RHO] = cart2pol(X, Y),
где X и Y — это векторы, содержащие декартовы ко-
ординаты точек, а векторы THETA и RHO образованы со-
ответствующими значениями угла и длины в полярных
координатах. Если X и Y являются векторами-строками,
то ими же являются векторы THETA и RHO. То же самое
относится и к векторам-столбцам. На рис. 11.10 показа-
но общепринятое соотношение для преобразования ко-
ординат, которое принято и в MATLAB. Обратите вни-
мание, что при таких обозначениях координаты (X, Y) связаны с координатами
нашего изображения по формулам: X = у и Y = -х [см. рис. 2.1, и)]. Функция
po!2cart совершает обратное преобразование в декартовы координаты:
[X, Y] = po!2cart(THETA, RHO).
Рис. 11.11. а) и 6) Грани-
цы искривленного квадрата
и треугольника, в) а г) Соот-
ветствующие им сигнатуры
а) б)
400
в)
400
350
300
ММ Г'
25011-----1---1---
0 100 200 300 400
1501-------1------l------------
0 100 200 300 400
Пример 11.6. Сигнатуры.
На рис. 11.11, а) и б), изображены границы bs и bt, соответственно, искривлен-
ного квадрата и треугольника, которые помещены в массив размерами 674x674
пиксела. На рис. 11.11, в) построена сигнатура квадрата, вычисленная парой ко-
манд
470 Глава 11. Представление и описание
» [st, angle, х0, уО] signature(bs);
>> plot (angle, st)
Координаты x0 и уО начала вектора определены функцией самостоятельно.
Они равны [342,326]. Аналогичные команды порождают график на рис. 11.11, г),
а центроид имеет координаты [416, 335]. Обратите внимание на то, что для раз-
личения этих двух границ достаточно просто подсчитать количество пиков на
графиках двух сигнатур. □
11.2.4. Сегменты границы
Часто оказывается полезным разбить границу на сегменты. При такой деком-
позиции уменьшается сложность границы и тем самым упрощается процесс ее
описания. Такой подход особенно привлекателен, когда граница содержит одну
или несколько хорошо выраженных выпуклых или вогнутых участков, несущих
информацию о форме объекта. В этом случае мощным инструментом для устой-
чивой декомпозиции границы является использование выпуклой оболочки обла-
сти, находящейся внутри границы.
Выпуклой оболочкой Н произвольного множества S называется наименьшее
выпуклое множество, содержащее S. Разность множеств Я \ S называется дефек-
том выпуклости D множества S. Чтобы проиллюстрировать, как эти понятия
могут использоваться для разбиения границы на содержательные сегменты, рас-
смотрим рис. 11.12, а), на котором изображен объект (множество S') со своим
дефектом выпуклости (он закрашен в темный цвет). Границу области S можно
разбить на части, обходя ее контур и отмечая точки входа в область и выхода из
области дефекта выпуклости. На рис. 11.12, б) показаны положения этих точек
в рассматриваемом случае. Заметим, что результат такого разбиения, в принци-
пе, не зависит от изменения размеров и ориентации области. При практической
реализации этот тип обработки предшествует существенному сглаживанию изоб-
ражения с целью удаления «несущественных» участков выпуклости/вогнутости
границы. Инструмент декомпозиции границы в MATLAB содержится в функции
regionprops, которая будет разбираться в § 11.4.1.
Рис. 11.12. а) Область S и ее
дефект выпуклости (темный).
6) Разбиение границы
11.2.5. Остовы областей
Важный подход представления формы плоской области основан на ее сведении к
графу. Такое сокращенное представление можно получить, выделяя остов обла-
11.2. Представление
сти с помощью подходящей процедуры утончения (этот процесс иначе называют
скелетонизацией).
Остов области можно определить с помощью преобразования к главным осям
MAT (Medial Axis Transformation). Преобразование МАТ области R с границей
Ъ выполняется следующим образом. Для каждой точки р области R находим
ближайшую к ней точку границы Ъ. Если таких точек имеется больше одной,
то говорят, что точка р лежит на серединной оси (т. е. она принадлежит остову)
области R.
Хотя понятие МАТ очень понятно и наглядно, прямое нахождение остова
сталкивается со значительными вычислительными трудностями, поскольку в этой
операции задействовано вычисление расстояния от каждой внутренней точки до
каждой точки границы области. Было предложено много разных алгоритмов
для повышения вычислительной эффективности МАТ. Одновременно с этим де-
лались попытки приближенного представления области ее остовом.
Как отмечалось в § 9.3.4, IPT позволяет строить остов всех областей, имею-
щихся на двоичном изображении В, с помощью функции bwmorph, которая имеет
следующий синтаксис:
S bwmorph(B, ’skel’, Inf).
Эта функция удаляет пикселы с границ объектов, но не дает им разваливать-
ся на части. Оставшиеся в результате пикселы образуют остов изображения.
Такой подход сохраняет эйлерову характеристику объекта (она определяется в
табл. 11.1).
Пример 11.7. Построение остова области..
На рис. 11.13, а) приведено изображение f хромосомы человека. Так она выгля-
дит после предварительной обработки фотографии, полученной на электронном
микроскопе с увеличением в 30000 раз. Целью данного примера является нахож-
дение остова хромосомы.
Ясно, что первым шагом процесса должно стать отделение хромосомы от фо-
на, содержащего несущественные детали. Подход заключается в сглаживании
изображения, а затем в совершении пороговой обработки. На рис. 11.13, б) дан
результат сглаживания f посредством гауссовой пространственной маски разме-
рами 25x25 с величиной sig = 15:
>> f = im2doubleCf);
» h = fspeciaH’gaussian’, 25, 15);
» g = imfilter(f, h, ’replicate’);
» imshowCg) 7. рис. 11.13, 6?)
На следующем шаге совершается пороговое преобразование изображения:
>> g = im2bwCg, 1.5*graythresh(g));
» figure, imshow(g) % рис. 11.13, в),
где автоматически вычисленный порог graythreshCg) увеличивается в полто-
ра раза для повышения на 50% доли отбракованных пикселов. Причина заклю-
чается в том, что повышение порога увеличивает долю выбрасываемых пиксе-
Глава 11. Представление и описание
лов границы, с помощью чего достигается дополнительное сглаживание. Остов
рис. 11.13, г) был получен командой
>> s = bwmorphfg, ’skel’, Inf); % рис. 11.13, г)
Лишние отростки па остове были отсечены командой
>> si bwmorph(s, ’spur’, 8); % рис. 11.13, д)
г) о> С] _
И
Рис. 11.13. а) Выделенная хромосома человека- б) Изображение, сглаженное гауссовой
маской 25x25 при sig = 15. в) Изображение после порогового преобразова-
ния. г) Остов, д) Остов после восьмикратного удаления отростков, е) Резуль-
тат еще 7 повторов операции удаления отростков
причем соответствующая операция повторялась 8 раз. что примерно равно по-
ловине величины sig фильтра сглаживания. Некоторые маленькие отростки все
еще остались на остове. Одпако если применить эту операцию еще 7 раз (пол-
ное значение sig), то в результате получится изображение на рис. 11.13, е), что
является вполне приемлемым остовом исходного изображения. Имеется эмпири-
ческое правило, по которому величина sig фильтра гауссовой маски является
хорошим приближением числа итераций алгоритма для полного удаления лиш-
них отростков. □
11.3. Дескрипторы границ
11.3. Дескрипторы границ
В этом параграфе рассматриваются некоторые подходы, применяемые для опи-
сания границы области. Ряд подходов в равной мере применим и к границам, и
к областям, поэтому при их группировании в пакете IPT в соответствующие М-
функции не делается разграничение между возможными приложениями. Неко-
торые из этих дескрипторов появятся вновь в § 11.4 при обсуждении описания
областей.
11.3.1. Некоторые простые дескрипторы
Одним из простейших дескрипторов границы является ее длина. Длиной 4-связ-
ной границы называется число пикселов этой границы. Для 8-связной границы
при подсчете ее длины для вертикальных и горизонтальных переходов к общей
сумме добавляются единицы, а для диагональных переходов добавляется \/2.
Чтобы выделить границы объектов на изображении f, следует воспользовать-
ся функцией bwperim, которая описана в § 11.2.2:
g bwperim(f, сопл),
где g — это двоичное изображение, в котором отображены границы всех объек-
тов из f. Для плоской связности, что является предметом нашего исследования,
параметр сопл принимает значения 4 или 8, в зависимости от типа связности (по
умолчанию используется 8-связность) (см. сноску в примере 11.4, где объясняет-
ся смысл этого параметра). Объекты на f могут иметь любые значения пикселов,
допустимые классом изображения, но фоновые пикселы должны иметь нулевые
значения. По определению, пикселы периметра объекта не равны нулю и связаны
по крайней мере с одним другим ненулевым пикселом объекта.
Связность можно определить в IPT более общим способом с помощью матри-
цы 3x3 из нулей и единиц, которая подставляется в аргумент сопл. Единичные
элементы задают окрестность относительно центрального элемента сопл. Напри-
мер, сопл = ones(3) задает 8-связность. Матрица сопл должна быть симмет-
ричной относительно своего центрального элемента. Входное изображение мо-
жет быть любого класса. Выходное изображение, содержащее границу каждого
объекта входного изображения, имеет класс logical.
Диаметр границы В определяется как евклидово расстояние между двумя
самыми отдаленными друг от друга точками границы. Эта пара точек не все-
гда определяется однозначно, как, например, для круга или квадрата, однако в
общем случае предполагается, что его наилучшее применение в качестве дескрип-
тора связано с описанием границ, у которых такая пара наиболее разнесенных
точек является единственной1 Отрезок, соединяющий две такие точки, называ-
ется большой осью границы. Малая ось границы определяется как отрезок, пер-
пендикулярный большой оси и имеющий такую (минимальную) длину, что про-
веденный через концы обеих осей прямоугольник со сторонами, параллельными
1Если имеется несколько таких пар, то они должны лежать близко друг от друга и служить
доминирующим фактором, позволяющим отличить форму границы.
474 Глава 11. Представление и описание
этим осям, полностью накрывает границу Упомянутый прямоугольник называ-
ется базовым прямоугольником, а отношение длины большой оси к длине малой
носит название эксцентриситета границы.
Функция diameter (см. ее листинг в приложении В) вычисляет диаметр, боль-
шую и малую оси, а также базовый прямоугольник границы или области. Она
имеет форму вызова
s = diameter(L),
где L это размечающая матрица (см. § 9.4), a s структура со следующими
полями:
s.Diameter
s.MajorАхis
s.MinorAxis
s.BasicRectangle
Скаляр, обозначающий максимальное расстояние меж-
ду любыми двумя пикселами соответствующей области.
Матрица 2x2, в которой по строкам записаны коорди-
наты концевых точек большой оси соответствующей об-
ласти.
Матрица 2x2, в которой по строкам записаны координа-
ты концевых точек малой оси соответствующей области.
Матрица 2x2, в которой по строкам записаны коорди-
наты четырех углов базового прямоугольника области.
11.3.2. Нумерация фигур
Цепной код: 0000 3 0032232221211
Разность: 300031033013003130
Номер фигуры: 0003 10330 13003 1303
Рис. 11.14. Шаги при вычислении номеров
фигур
номера фигур инвариантны относится
Номер фигуры границы строится на ос-
нове 4-направленного цепного кода Фри-
мана и определяется как первая раз-
ность с минимальным численным зна-
чением (см. [Bribiesca, Guzman 1980] и
[Bribiesca, 1981]). Порядком номера фи-
гуры по определению называется число
цифр в его записи. Таким образом, но-
мер фигуры границы задается парамет-
ром c.diffmmB функции fchcode, кото-
рая обсуждалась в § 11.2.1, а порядок
номера фигуры вычисляется по форму-
ле length(c.diffmm).
Как отмечалось в § 11.2.1, 4-направ-
ленный цепной код Фримана можно сде-
лать инвариантным относительно выбо-
ра начальной точки с помощью исполь-
зования целой минимальной величины.
А чтобы добиться инвариантности по
отношению к поворотам, надо, чтобы
они (повороты) были кратны 90° при ис-
пользовании первых разностей. Значит,
но начальной точки и относительно по-
воротов на углы, кратные 90° Один из часто используемых способов стандар-
тизации произвольных поворотов состоит в совмещении одной из координатных
11.3. Дескрипторы границ
осей с направлением главной оси, а затем строительстве цепного кода исходя из
повернутой фигуры. Эта процедура проиллюстрирована на рис. 11.14.
Инструменты, которые позволят реализовать в одной М-функции процеду-
ру определения номеров фитур, были разработаны нами ранее. Они состоят
из функции boundaries, которая находит границу, функции diameter, которая
определяет главную ось, функции bsubsamp, которая понижает разрешение ре-
шетки дискретизации и функции fchcode, которая вычисляет номера фигур.
Следует помнить, что при извлечении 4-связной границы функцией boundaries
входное изображение должно быть размечено функцией bwlabel, в которой за-
дана 4-связность. Как указано на рис. 11.14, компенсация движения основана
на совмещении одной из координатных осей области или границы с помощью
функции x2majoraxis. Эта функция имеет следующую форму вызова (ее про-
граммный код находится в приложении В):
[В, theta] x2majoraxis(A, В).
Здесь A s. Maj or Axis взято из функции diameter, а В входное (двоичное)
изображение или список точек границы (как обычно, мы предполагаем, что гра-
ница является связной замкнутой кривой). На выход В поступают данные в той
же форме, что и на вход (т. е. двоичное изображение или координатная последо-
вательность). В силу возможных ошибок округления, повороты могут привести
к разрывам границы, поэтому может потребоваться дополнительная обработка
для заполнения возникших разрывов (например, с помошью функции bwmorph).
11.3.3. Фурье-дескрипторы
На рис. 11.15 приведена К-точечная дискретная
граница на плоскости ху. Начиная с произволь-
ной точки (хи,уо), обойдем границу, скажем, про-
тив часовой стрелки, и обозначим координаты
встречающихся точек границы (зщЗ/о), (21,3/1),
(22,3/2), (хк-i, Ук-1)- Эти координаты мож-
но записать в форме х(к) = х^ и у(к) уь-
При использовании этих обозначений саму гра-
ницу можно представить в виде последователь-
ности координатных пар s(fc) [a:(fc), y(fc)], где
к = 0,1,2,..., К — 1. Далее, каждую пару коор-
динат можно представить комплексным числом
s(fc) = x(fc) + jy(k).
Как мы знаем из § 4.1, дискретное преобразование
Фурье (DFT) конечной последовательности s(k)
задается уравнением
К-1
а(и) = 52 з(к)е~^ик/К
fc=o
при и = 0,1,2,..., К — 1. Комплексные коэффициенты а(и) называются фуръе-
дескрипторами границы. Обратное преобразование Фурье, примененное к этим
1У
Уч
ъ
Рис. 11.15. Дискетная грани-
ца и ее представление в виде ком-
плексной последовательности. На-
чальная точка (хо»8/о) выбрана про-
извольно
*0*1
Действительная ось
Alb Глава 11. Представление и описание
коэффициентам, позволяет восстановить границу s(fc):
1 К~1
W = <^uk/K
u=0
при k = 0,1,2,.. ,K — 1. Предположим, однако, что вместо всех коэффициен-
тов Фурье используются только первые Р из них. Это равносильно тому, что в
последнем уравнении принимается а (и) = 0 при и > Р — 1. Результатом восста-
новления окажется следующее приближение последовательности s(fc):
W = ^£a(u^™k/K
и=0
при k 0,1,2, — 1. Несмотря на то, что при вычислении каждой ком-
поненты используется лишь Р членов, параметр к по-прежнему пробегает весь
диапазон от 0 до К — 1. Значит, в приближенной границе будет то же самое
число точек, хотя для восстановления их координат используется меньшее число
членов. Вспомним из рассмотрения преобразования Фурье в гл. 4, что высоко-
частотные составляющие описывают мелкие детали, тогда как низкочастотные
компоненты определяют общую форму границы. Следовательно, чем меньше Р,
тем больше деталей границы теряется.
Следующая функция frdescp вычисляет фурье-дескрипторы границы в. Ана-
логично, имея множество фурье-дескрипторов, исходная замкнутая простран-
ственная кривая получается с помощью обратной функции ifrdescp. В доку-
ментации каждой из этих функций объясняется их синтаксис.
function z frdescp(s)
7oFRDESCP Computes Fourier descriptors.
% Z FRDESCP(S) computes the Fourier descriptors of S, which is an
7» np-by-2 sequence of image coordinates describing a boundary.
7.
7o Due to symmetry considerations when working with inverse Fourier
% descriptors based on fewer than np terms, the number of
7» points in S when computing the descriptors must be even. If the
7. number of points is odd, FRDESCP duplicates the end point and
7. adds it at the end of the sequence. If a different treatment is
7» desired, the sequence must be processed externally so that it has
7. an even number of points.
7.
% See function IFRDESCP for computing the inverse descriptors.
7. Preliminaries
[np, nc] size(s);
if nc “= 2
error(’S must be of size np-by-2.’);
end
if np/2 "= round(np/2);
s(end +1, :) = s(end,
11.3. Дескрипторы границ
пр = пр + 1;
end
% Create an alternating sequence of Is and -Is for use in centering
the transform.
x O:(np 1);
m = ((-1) ~x)’;
% Multiply the input sequence by alternating Is and -Is to
% center the transform.
s(: , 1) =m .*s(: 1);
s (: , 2) =m . * s ( : , 2);
'X Convert coordinates to complex numbers.
s = s(:, 1) + i*s( : , 2) ;
% Compute the descriptors.
z = fft(s);
Функция ifrdescp имеет следующий текст:
function s = ifrdescp(z, nd)
"XIFRDESCP Computes inverse Fourier descriptors.
% I = IFRDESCP(Z, ND) computes the inverse Fourier descriptors of
7. of Z, which is a sequence of Fourier descriptor obtained, for
7. example, by using function FRDESCP. ND is the number of
% descriptors used to computing the inverse; ND must be an even
7» integer no greater than length(Z) If ND is omitted, it defaults
‘X to length(Z). The output, S, is an ND-by-2 matrix containing the
"X coordinates of a closed boundary.
“X Preliminaries.
np = length(z);
'X Check inputs.
if nargin == 1 | nd > np
nd = np;
end
7» Create an alternating sequence of Is and -Is for use in centering
7. the transform.
x = 0:(np 1) ;
m = ((-1) ~x) ’;
'X Use only nd descriptors in the inverse. Since the
7. descriptors are centered, (np nd)/2 terms from each end of
'X the sequence are set to 0.
d round((np nd)/2); 7« Round in case nd is odd.
z(l:d) = 0;
z(np d + 1:np) 0;
7. Compute the inverse and convert back to coordinates.
zz = ifft(z);
s(: 1) real(zz);
s(:, 2) imag(zz);
‘X Multiply by alternating 1 and -Is to undo the earlier
и тисание
*/, centering.
s(:, 1) = m.*s(:
s(: 2) = m.*s(:
1);
2);
Пример 11.8. Фурье-дескрипторы.
На рис. 11.16, а) приведено изображение f, похожее па рис. 11.13, в), но постро-
енткх: помощью гауссовой маски 15x15 с параметром sig 9 и с последующим
пороговым преобразованием с порогом 0.7. В этом случае мы хотели иметь не
очень гладкое изображение, чтобы было :гчс продемонстрировать эффекты,
возникающие при уменьшении числа дескрипторов и влияющие па форму гра-
ницы. Изображение на рис. 11.16, б) построено с помощью команд
b boundaries(f);
b b{l};
bim bound2imCb, 344, 270);
Рис. 11.16. а) Двоичное изоб-
ражение. б) Граница, получен-
ная функцией boundaries. Она
состоит из 1090 точек
где размеры изображения совпадают с размерами f. Рис. 11.16, б) дает изобра-
жение bim. Построенная граница содержит 1090 точек. Теперь мы вычисляем
фурье-дескрипторы
z = frdescp(Ь);
а затем применяем обратное преобразование, по с использованием примерно 50%
от 1090 возможных дескрипторов:
>> z546 ifrdescpCz, 546);
>> z546im = bound2im(z546, 344, 270);
Изображение z546im {рис. 11.17, aj] демонстрирует близкое соответствие с ис-
ходной границей па рис. 11.16, б). Некоторые слабоуловимые детали, например,
мельчайшая внадипка глубиной в 1 пиксел па пижпсй «йоге» хромосомы, были
утеряны, по с практической точки зрения эти два изображения идентичны. На
рис. 11.17 с б) по е) показаны результаты при использовании, юответственно,
11.3. Дескрипторы границ
ПО, 56, 28, 14 и 8 дескрипторов, что составляет примерно 10%, 5%, 2.5%, 1.25%
и 0.7% от 1090 имеющихся дескрипторов. Если использовать всего ПО дескрипто-
ров [рис. 11.17, б)], то наблюдается дальнейшее сглаживание границы, но общая
форма остается весьма близкой к исходной. Рис. 11.17, д) демонстрирует, что да-
же при 14 дескрипторах, что меньше 1.25% от общего их числа, сохраняются
характерные черты границы. Искажения, проявляющиеся па рис. 11.17, е), уже
становятся неприемлемыми, поскольку основные черты границы (четыре высту-
пающие «ноги») оказались почти утраченными. Дальнейшее уменьшение числа
дескрипторов до 4 и 2 приводит к эллипсу и, наконец, к окружности.
в!
Рис. 11.17. а) е) Границы, восстановленные по 546,110, 56, 28, 14 и 8 фурье-дескрипторам
из общего их числа в 1090 элементов
Некоторые границы па рис. 11.17 имеют однопиксельные щели, характерные
для фурье-дескрипторов, из-за ошибок округления, которые можно «заделать»
с помощью функции bwmorph, которая применяется с опцией ’bridge’ □
Как уже отмечалос >, дескрипторы должны быть инвариантными по отноше-
нию к переносам, поворотам и сжатию/растяжению. В тех случаях, когда резуль-
тат зависит от порядка обработки точек границы, дополнительное требование
480 Глава 11. Представление и описание
стоит в том, что дескрипторы не должны зависеть от выбора начальной точки.
Фурье-дескрипторы сами по себе не удовлетворяют этим условиям инвариантно-
сти, однако соответствующие измененные дескрипторы можно легко вычислить
по простым формулам (см. [Gonzalez, Woods, 2002]).
б) Рис. 11.18. а) Сегмент гра-
ницы. б) Представление в виде
одномерной функции
11.3.4. Статистические характеристики
Форму участков границы (или кривых сигнатуры) можно количественно описать
с помощью простых статистических характеристик, таких как среднее, дисперсия
и моменты более высокого порядка. Чтобы понять, как это делается, обратимся
к рис. 11.18, а), где показан участок границы, и к рис. 11.18, б), на котором этот
участок представлен в виде одномерной функции g(r) независимой переменной г.
Эта функция получается путем соединения двух крайних точек границы отрез-
ком и последующим поворотом его до горизонтального положения. Координаты
точек границы поворачиваются на тот же угол. Это преобразование выполняется
функцией x2majoraxis, которая обсуждалась в § 11.3.2.
Один возможный подход к описанию сегмента границы состоит в рассмотре-
нии самой функции g(r) как гистограммы, для чего она нормируется до единич-
ной площади. Другими словами, д(1\) теперь трактуется как вероятность появ-
ления значения г,. В этом случае г рассматривается как случайная величина с
моментами
К-I К-1
р-п = 52 (ri ~ т = 52 Ч5(ч).
г=0 i=0
В этой записи К это число точек границы, а i.in(r) непосредственно связано
с формой функции д(г). Например, второй момент рг(г) характеризует разброс
значений функции относительно среднего значения г, а третий момент дз(г)
является характеристикой симметричности кривой относительно среднего зна-
чения. Статистические моменты вычисляются функцией statmoments, которая
обсуждалась в § 5.2.4.
По существу, нам удалось свести задачу описания двумерной границы к опи-
санию одномерных функций. Хотя моменты — широко распространенные харак-
теристики, они не являются единственными дескрипторами, которые могут при-
меняться для этой цели. Например, другой метод основан на вычислении спек-
тра посредством одномерного дискретного преобразования Фурье и использова-
нии затем первых д составляющих спектра для описания функции д(г). Преиму-
щество моментов перед другими методами заключается в простоте реализации,
а также в том, что они позволяют «физически» интерпретировать форму гра-
ницы. Из рис. 11.18 становится ясно, что данный метод инвариантен к повороту
объекта, а нормировку по размерам можно получить путем масштабирования
диапазона значений д и г.
11.4. Дескрипторы областей
В этом параграфе мы рассмотрим некоторые функции из IPT, которые служат
для обработки областей, а также построим ряд других функций для вычисления
дескрипторов текстуры, инвариантов моментов и некоторых других характери-
стик областей. При этом будет часто использоваться функция bwmorph, которая
обсуждалась в § 9.3.4. Мы будем также часто обращаться к функции roipoly из
§ 5.2.4.
11.4.1. Функция regionprops
Функция regionprops является основным инструментом IPT при вычислении
дескрипторов областей. Она имеет синтаксис
D = regionprops(L, properties),
где L — это размечающая матрица, a D — массив структур, который имеет дли-
ну max(L(:)). Поля структур обозначают различные величины, вычисленные
для каждой области в соответствии со спецификацией properties. Параметр
properties может быть списком символьных строк, разделенных запятой, смешан-
ным массивом строк, а также одиночной строкой ’all’ или ’basic’ В табл. 11.1
перечислены все допустимые аргументы с объяснением их смысла и свойств. Ес-
ли параметр properties равен ’all’, то вычисляются все дескрипторы, перечис-
ленные в табл. 11.1. Если аргумент properties не задан или он равен ’basic’,
то функция вычисляет лишь дескрипторы ’Area’, ’Centroid’ и ’BoundingBox’
Имейте в виду (см. также обсуждение в § 2.1.1), что в IPT буквы х и у ис-
пользуются для обозначения, соответственно, горизонтальных и вертикальных
координат, причем начало координат помещается в верхнем левом угле. Коор-
динаты х и у увеличиваются, соответственно, вправо и вниз от этой начальной
точки. В контексте нашего обсуждения пиксел on имеет значение 1, а пиксел off
равен 0.
Таблица 11.1. Дескрипторы областей, вычисляемые функцией regionprops
Допустимые значения properties Объяснения и комментарии
1 2
’Area’ Число пикселов области, т. е. ее площадь.
’BoundingBox* Вектор 1x4, определяющий наименьший прямоу1\>льник, содержащий данную область. BoundingBox определяется через [ul.corner width], где ul_comer имеет вид [х у] и обозначает координаты верхнего левого угла прямоугольника, а параметр width имеет вид [x_width y_width], где записаны размеры прямоугольника вдоль соответству- ющих координатных осей. Отметим, что BoundingBox ориентирован вдоль координатных осей, и в этом смысле он является особым слу- чаем базового прямоугольника, который обсуждался в § 11.3.1.
482 Глава 11. Представление и описание
Таблица 11.1 (окончание).
1 ’Centroid’ 2 Вектор 1x2, определяющий центр масс области. Первый элемент Centroid — это горизонтальная координата (по оси х) центра масс, а второй — его вертикальная координата (по оси у).
’ConvexArea’ ’ConvexHull’ Скаляр, равный числу пикселов (площади) ’Convexlmage’. Матрица рх2, определяющая наименьший выпуклый многоугольник, содержащий данную область. В каждой строке матрицы записана пара координат (х, у) очередной вершины многоугольника-
’Convexlmage’ Двоичное изображение выпуклой оболочки с заполненными пикселами, принадлежащими оболочке (т. е. они установлены в on). (Для пикселов, через которые проходит граница оболочки, regionprops использует то же соглашение, что и roipoly, для определения положения пиксела внутри или вне оболочки). Изображение имеет размер объемлющего прямоугольника.
’Eccentricity’ Скаляр, равный эксцентриситету эллипса, который имеет те же вто- рые моменты, что и исходная область. Эксцентриситет равен частному расстояния между фокусами и длины большой оси. Эта величина из интервала [0,1], где 0 и 1 соответствуют вырожденным случаям. (Эл- липс с нулевым эксцентриситетом является окружностью, а единичный эксцентриситет соответствует отрезку прямой).
’EquivDiameter’ Скаляр, равный диаметру круга с той же площадью, что и данная об- ласть. Вычисляется по формуле sqrt(4*Area/pi).
’EulerNumber’ Скаляр, равный эйлеровой характеристике области, которая по опреде- лению есть число объектов в области минус число дыр в этих объектах.
’Extent’ Скаляр, пропорциональный части пикселов объемлющего прямоуголь- ника, которые принадлежат также и области. Вычисляется делением Area на площадь объемлющего прямоугольника.
’Extrema’ Матрица 8x2, состоящая из координат экстремальных точек области, которые записаны по строкам. Формат вектора [top-left,top-right, right-top, right-bottom, bottom-right, bottom-left, left-bottom, left-top].
’FilledArea’ ’Filledlmage’ Число пикселов (площадь) Filledlmage. Двоичное изображение с размерами как у объемлющего прямоугольни- ка. Пикселы on соответствуют области, в которой заполнены все дыры.
’Image’ Двоичное изображение с размерами как у объемлющего прямоуголь- ника. Пикселы on соответствуют области, а пикселы off — фону.
’Maj orAxisLength’ Длина (в пикселах) большой оси1 эллипсоида, который имеет те же вто- рые моменты, что и исходная область.
'MinorAxisLength’ Длина (в пикселах) малой оси эллипсоида, который имеет те же вторые моменты, что и исходная область.
’Orientation’ Угол между осью х и большой осью эллипсоида, который имеет те же вторые моменты, что и исходная область.
’PixelList’ Матрицы, строками которой являются пары [х, у] координат действи- тельных пикселов области.
’Solidity’ Скаляр, пропорциональный числу пикселов выпуклой оболочки, кото- рые лежат и в области. Вычисляется по формуле Area/ConvexArea.
1 Отметим, что в данном контексте использование большой и малой осей отличается от большой
и малой осей базового многоугольника, которые обсуждались в § 11.3.1. Подробнее о моментах
эллипса см. [Haralick, Shapiro, 1992].
11.4. Дескрипторы областей
Пример 11.9. Использование функции regionprops.
В качестве простейшей иллюстрации предположим, что нам необходимо найти
плотпядь и ограничивающий прямоугольник для каждой области на изображении
В. Тогда мы пишем команды
> > В = bwlabel(В); 7. Convert В to a label matrix.
> > D regionprops(В, ’area’, ’boundingbox’);
А для нахождения площадей и числа областей выполняем
» w = [D.Area] ;
> > NR = length(w) ;
где элементами вектора w служат площади областей, a NR обозначает количество
этих областей. Аналогично по следующей команде строится одна общая матрица,
в которой по строкам записаны ограничивающие прямоугольники для каждой
области:
> > V = cat(l, D.BoundingBox) ;
Этот массив имеет размер NR. Оператор cat объяснялся в § 6.1.1. □
11.4.2. Текстура
Важный подход к количественному описанию областей состоит в определении
их внутренней текстуры. В этом параграфе разбираются еще две функции для
нахождения текстуры, которые основаны на статистических и спектральных ха-
рактеристиках.
Статистические подходы
Часто используемый текстурный анализ основан на статистических свойствах ги-
стограмм яркости. Один класс таких мер строится по статистическим моментам.
Как объяснялось в § 5.2.4, формула для нахождения n-го момента относительно
статистического среднего имеет вид
Ь-1
Дп = 52 - m)np(Zi),
г=0
где Zi — это случайная величина, обозначающая яркость, p(z) — гистограмма
распределения уровней яркости в данной области, L обозначает число различных
значений яркости, а т задается выражением
Ь-1
т = 52 ziP(zi)
г=0
и является средней яркостью области. Эти моменты вычисляются функцией
statmoments, которая вводилась в § 5.2.4. В табл. 11.2 перечислены некоторые
основные дескрипторы, основанные на статистических моментах, а также постро-
енные по «однородности» и по энтропии. Напомним, что второй момент
является дисперсией ст2.
Глава 11. Представление и описание
Теперь все готово для написании М-функции, которая вычисляет величины,
перечисленные в табл. 11.2. Эта функция называется statxture и ее полный
текст приведен в приложении В. К ней можно обращаться по формуле
t statxture(f, scale),
где f — это входное изображение (или подизображение), a t — вектор-строка из 6
компонент, описанных в табл. 11.2 и расположенных в том же порядке. Параметр
scale также является 6-ти компонентным вектором-строкой, состоящим из мас-
штабных множителей, которые умножаются на элементы t. По умолчанию все
они равны 1.
Таблица 11.2. Некоторые текстурные дескрипторы, основанные на гистограмме яркости
области
Момент Выражение Мера текстуры
Среднее т = E,i=o zip(zi.) Мера средней яркости.
значение Стандартное сг = т/мг (z) = Мера средней контрастности.
отклонение Гладкость R = 1 - 1/ (1 + о2) Мера относительной гладкости яркости области.
Третий ДЗ = 52i=O — m)3p(zi) R равно 0 для областей с постоянной яркостью и близко к 1 для областей с большими отклонени- ями уровней яркости. На практике эту величину принято приводить к интервалу [0,1] делением на (L - I)2. Характеризует асимметричность гистограммы.
момент Равен 0 для симметричных гистограмм. Положи-
Однородность U = Efco1 p2W телен для гистограмм, скошенных вправо (по от- ношению к среднему значению) и отрицателен для скошенных влево. Для приведения этой меры к диапазону, сравнимому с другими пятью вели- чинами, следует разделить дз на (L — I)2. Этот же делитель используется при нормировке дис- персии. Мера равномерности. Эта величина максимальна
Энтропия е = - Efco1 ₽(z*) 1оВ2 ₽(zi) для постоянной яркости (максимальная однород- ность). Мера случайности.
Пример 11.10. Статистические меры, текстуры.
На рис. 11.19 белыми квадратами выделены области изображений, которые пред-
ставляют собой примеры гладкой, шероховатой и периодической текстуры. Ги-
стограммы этих областей, вычисленные функцией imhist, показаны на рис. 11.20.
Содержимое табл. 11.3 получено применением функции statxture к каждому
подизображению на рис. 11.19. Эти результаты согласуются с текстурным на-
полнением соответствующих подизображений. Например, энтропия шероховатой
области [рис. 11.19, б)] выше, чем у других областей, поскольку здесь значения
пикселов носят более случайный характер, чем у других областей. Это же отно-
сится к контрастности и к средней яркости. С другой стороны, эта область менее
всех гладка и однородна, что отражается на величине R и на значении одно-
родности. Гистограммы шероховатой области обнаруживают также отсутствие
11.4- Дескрипторы областей
какой бы то ни было симметрии по отношению к среднему значению, что оче-
видно следует из рис. 11.20, б), а также из большого значения третьего момента,
приведенного в табл. 11.3. □
Таблица 11.3. Текстурные меры для областей из рис. 11.19
Текстура Средняя яркость Средняя контрастность R Третий момент Однородность Энтропия
гладкая 87.02 11.17 0.002 -0.011 0.028 5.367
шероховатая 119.93 73.89 0.078 2.074 0.005 7.842
периодическая 98.48 33.50 0.017 0.557 0.014 6.517
Рис. 11.19. Выделенные подизображения отвечают, слева направо, гладкой, шерохова-
той и периодической текстуре. Здесь даны электронно-микроскопические фо-
тографии сверхпроводника, человеческого холестерина и микропроцессора.
(Изображения предоставил д-р Майкл У. Дэвидсон, университет шт. Флорида)
Спектральные меры текстур
Спектральные меры текстуры основаны на спектре Фурье, который идеально
подходит для описания направленности присутствующих в изображении пери-
одических или квазипериодических двумерных структур. Эти глобальные тек-
стурные образцы легко различаются на спектре в виде импульсов с высокой
энергией, однако их весьма непросто обнаружить с помощью прсхгграпствснных
методов обработки, которые являются локальными по своей природе.
Обнаружение и интерпретацию спектральных признаков можно упростить,
если перейти к полярным координатам, в которых спектральная функция вы-
ражается в виде S(r, 6), где г и 0 — переменные в этой системы координат. Для
каждого угла 6 функция S(r, 6) может рассматриваться как одномерная функция
Se(r). Аналогично, для каждого значения частоты г, Sr(6) является одномерной
функцией. Анализ функции Se(r) при фиксированном 6 дает картину поведения
486 Глава 11. Представление и описание
спектра (скажем, наличие пиков) по направлению радиуса из начала координат,
а исследуя Д.($) при фиксированном г, получаем поведение спектральной функ-
ции по окружности с центром в начале координат.
1800
1600
1400
1200
1000
800
600
400
200
О
Рис. 11.20. Гистограммы, отвечающие подизображениям на рис. 11.19
Глобальное описание получается при интегрировании (суммирований в дис-
кретном случае) этих функций:
я Ro
S(r) = ^Se(r) и 5(0) = £Я(0),
е=о т=1
где /?□ — это радиус круга с центром в начале координат.
Результатами вычислений по этим двум формулам являются пары значений
[S(r), б'(в)] для каждой точки спектра с координатами (г, 0). Варьируя эти коор-
динаты. можно построить две одномерные функции 5 (г) и S(6), описывающие
текстуру всего изображения или интересующей его части в терминах энергии
спектра. Затем можно вычислять те или иные дескрипторы самих этих функ-
ций. Для этих целей обычно используются такие дескрипторы, как положение
максимума, среднее значение и дисперсия, а также разность между средним и
максимальным значениями для амплитудной функции и для осевой функции.
Функция specxture (см. ее листинг в приложении В) может использовать-
ся для вычисления двух построенных текстурных характеристик. Ее синтаксис
имеет вид
[srad, sang, S] specxture(f),
где srad - это S(r), sang — S(0), aS обозначает изображение спектра (которое
строится в логарифмической шкале, как объяснялось в гл. 4).
Пример 11.11. Вычисление спектра текстуры.
На рис. 11.21, а) изображены случайно разбросанные предметы, а на рис. 11.21, б)
показаны те же предметы, но периодически упорядоченные. Соответствующие
спектры Фурье, вычисленные функцией specxture, приведены на рис. 11.21, в)
и г). Периодические энергетические всплески по двум направлениям спектра
Фурье обусловлены периодичностью текстуры шероховатой поверхности, на ко-
торой расположены спички. Другие компоненты спектра на рис. 11.21, в) несо-
мненно обусловлены случайной ориентацией прямолинейных сторон спичек на
11.4- Дескрипторы областей
рис. 11.21, а). В отличие от этого, основная энергия на рис. 11.21, г), не связан-
ная с фоном, расположена вдоль горизонтальной оси, что соответствует строго
вертикальным сторонам объектов па рис. 11.21, б).
Рис. 11.21. а) и 6) изоб-
ражение неупорядоченных и
упорядоченных объектов. &) и
г) Отвечающие им спектры
Фурье
в) г)
На рис. 11.22, а) и б), построены функции ,8'(г) и S(6) для случайно разбро-
санных спичек, а па рис. 11.22, в) и г) — для периодически разложенных. Они
вычислены функцией speexture. Эти графики были получены с помощью ко-
манд plot(srad) и plot (sang). Оси на рис. 11.22, а) по в) были приведены к
единому масштабу командой
>> axis ( [horzmin horzmax vertmin vertmax]),
которая обсуждалась в § 3.3.1, где максимальные и минимальные значения взяты
из графика па рис. 11.22, а).
График S(r), отвечающий случайно распределенным спичкам, демонстрирует
отсутствие явных периодических компонент (т. е. здесь нет всплесков, кроме од-
ного пика в окрестности начала координат, что отвечает компоненте DC). С дру-
гой стороны, график S(r), соответствующий упорядоченным спичкам, имеет явно
выраженный всплеск в окрестности точки г = 15 и еще один всплеск помень-
ше около г = 25. Аналогично, случайная природа энергетических всплесков па
рис. 11.21, в) с очевидностью проявляется на графике функции S(0) [рис. 11.22, б)].
И по контрасту с этим график на рис. 11.22, г) отображает сильные энергетиче-
ские компоненты области около начала координат и в близи углов 90° и 180°.
Все эти данные хорошо согласуются с распределением па. рис. 11.21, г). □
488 Глава 11. Представление и описание
а)
Рис. 11.22. Графики a) S(r) и б) S(0) для случайного изображения, в) и г) — графики
S(r) и S(0) для упорядоченного изображения
11.4.3. Инварианты моментов
Двумерный момент порядка {p+q) цифрового изображения /(ж, у) определяется
по формуле
тРЯ = '^J'^2xPyqf(.^y)
я у
прир, q = 0,1, 2,..., где суммирование производится по всем значениям простран-
ственных координат хну данного изображения. Соответствующий центральный
момент задается выражением
" ж)р (у ~ у)4 Кх' У)’
а: у
где
тлю _ moi
ж = ——, у =----.
moo moo
По определению, нормированным центральным моментом порядка (р + </) на-
зывается величина
11.Д Дескрипторы областей 489
при р, 5 = О,1,2,..., где
при р + q = 2, 3,....
Имея все эти моменты, можно определить следующие семь инвариантов мо-
ментов, которые инвариантны относительно переносов, осевой симметрии, пово-
ротов, а также растяжений и сжатий:
Ф1 = 520 + 502,
Ф% = (520 — 502)2 + 451!,
фз = (5зо - Зтдг)2 + (З521 — 5оз)2
</>4 = (5зо + 512)2 + (521 + 5оз)2
фз = (5зо — З512) (530 + 512) [(5зо + 512)2 — 3 (521 + 5оз)2] +
+ (З521 — 5оз) (521 + 5оз) [3 (530 + 512)2 — (521 + 5оз)2],
Фе = (520 ~ 502) [(530 + 512)2 — (521 + 5оз)2] + 4тд1 (530 + 512) (521 + 5оз),
Фт — (521 — 5оз) (5зо + 512) [(5зо + 512)2 [3 (530 + 512)2 — (521 + 5оз)2]-
М-функция invmoments для вычисления инвариантов моментов представляет
собой прямую реализацию всех этих формул (ее текст имеется в приложении В).
Она вызывается командой
phi invmoments(f),
где f это входное изображение, a phi — вектор-строка из 7 компонент, куда
записываются вычисленные инварианты.
Пример 11.12. Инварианты моментов.
Изображение на рис. 11.23, а) было получено из исходного изображения с разме-
ром 400x400 пикселов при помощи команды
> > fp = padarray(f, [84 84], ’both’);
Заполнение нулями совершено для совместимости с изображением, занимающим
большую область размером 568x568 пикселов, которое получается из исходного
поворотом на 45°, что будет совершаться далее. Заполнение нулями совершено
исключительно в демонстрационных целях и не используется при вычислении
инвариантов. Уменьшенное в два раза изображение было получено из расширен-
ного изображения с помощью команд
> > fhs f(l:2:end, l:2:end);
> > fhsp = padarray(fhs, [184 184], ’both’);
Зеркально симметричное изображение получено применением к f стандартной
функции fliplr2 из MATLAB:
2Функция В = fliplr (А) возвращает матрицу А, зеркально отраженную вокруг вертикальной
оси, а функция В = flipud(A) выполняет зеркальное отражение вокруг горизонтальной оси.
Глава 11. Представление и описание
fm fliplr(f);
fmp padarray(fm, [84 84], ’both’);
Для поворота изображения мы воспользовались функцией imrotate:
>> g imrotate(f, angle, method, ’crop’)
которая поворачивает f на угол angle против часовой стрелки. Параметр method
может иметь одно из следующих значений:
’nearest’
’bilinear’
’bicubic’
интерполяция по ближайшим соседям;
билинейная интерполяция (типичный выбор);
бикубическая интерполяция.
При повороте размеры изображения автоматически увеличиваются и происходит
заполнение пулями. Если в аргументах функции imrotate присутствует параметр
’ crop ’ то центральная часть повернутого изображения обрезается по краям для
получения размеров исходного изображения. По умолчанию для этой функции
необходимо задавать лишь угол поворота angle. Тогда используется интерполя-
ция ’nearest’ и совершается обрезание до исходных размеров.
Рис. 11.23. а) Исходное расширенное изображение, б) Уменьшенное в два раза изобра-
жение. в) Зеркально отраженное изображение, г) Изображение, повернутое
на 2° д) Изображение, повернутое на 45° Дополнение нулями выполнялось
с а) по г) для совместимости размеров с размером повернутого изображения
д) исключительно в демонстрационных целях
В нашем примере повороты изображения были выполнены следующими ко-
мандами:
fr2
fr2p
fr45
imrotate(f, 2, ’bilinear’);
padarray(fr2, [76 76], ’both’);
imrotate(f, 45, ’bilinear’);
Отметим, что при построении изображения fr45 дополнение нулями не потребо-
валось, так как оно было достаточно большого размера. Нули в обоих изображе-
ниях были вставлены в процессе поворота функцией IPT.
Все семь инвариантов моментов от пяти построенных изображений были вы-
числены командами
» phiorig abs(log(invmoments(f)));
» phihalf abs(log(invmoments(fhs)));
» phimirror abs(log(invmonients(fni)));
>> phirot2 abs(log(invmonients(fr2)));
» phirot45 = abs(log(invmonients(fr45)));
Отметим, что здесь найдены модули от прологарифмированных инвариантов
вместо самих инвариантов. Это сделано для сужения динамического диапазо-
на величин, а модуль применен, чтобы не иметь дело с комплексными числами,
которые возникают при взятии log от отрицательных инвариантов моментов.
Взятие модуля является распространенной практикой, поскольку нас интересует
инвариантность моментов, а не их знаки.
Таблица 11.4. Семь инвариантов изображений на рис. 11.23. Обратите внимание на ис-
пользование модуля логарифма в первом столбце
Инвариант (|l°g|) Исходное изображение У меньшенное в два раза Зеркально отраженное Повернутое на 2° Повернутое на 45°
Ф1 6.600 6.600 6.600 6.600 6-600
ф2 16.410 16.408 16.410 16.410 16.410
фз 23.972 23.958 23.972 23.978 23.973
фл 23.888 23.882 23.888 23.888 23.888
фз 49.200 49.258 49.200 49.200 49.198
фб 32.102 32.094 32.102 32.102 32.102
Ф7 47.953 47.933 47.850 47.953 47.954
Все семь инвариантов, вычисленных для исходного, уменьшенного, зеркально
отраженного и двух повернутых изображений, представлены в табл. 11.4. Обра-
тите внимание на исключительную близость соответствующих чисел. Все это го-
ворит о высокой степени инвариантности величин относительно перечисленных
выше преобразований исходного изображения. Эти замечательные результаты
объясняют, почему инварианты моментов являются основными инструментами
при описании изображений вот уже более сорока лет. □
11.5. Использование главных компонент при описании
изображений
Предположим, что у нас имеется п отобранных «родственных» изображений,
расположенных в одну «стопку» (стек), как показано на рис. 11.24. Для каж-
дой пары индексов (г,у) имеется п пикселов с этими координатами на каждом
492 Глава 11. Представление и описание
изображении. Из этих пикселов можно составить один вектор-столбец
Х1
Х2
Если изображения имеют размеры MxN, то определено MN таких п-мерных
векторов, построенных по пикселам всех п изображений.
Рис. 11.24. Выстраи-
вание соответствующих
пикселов в стеке изоб-
ражений, имеющих оди-
наковые размеры
Усредненный вектор тх для всего семейства изображений можно представить
в виде прос того среднего:
при К = MN. Аналогично пхп ковариационная матрица Сх семейства изобра-
жений задается формулой
1 К
сх = ——- УЛх/с - mx)(Xfc - mx)T,
IX — 1
k=l
где знаменатель К — 1 взят вместо К для получения несмещенной оценки для
Сх для заданного семейства изображений. Поскольку вещественная матрица Сх
является симметричной, всегда возможно построить ортонормированный базис,
состоящий из собст венных векторов этой матрицы.
Преобразование главных компонент (которое также называют преобразова-
нием Хотеллинга) определяется формулой
у = А(х-шх).
Нетрудно показать, что компоненты вектора у являются некоррелированными
величинами, и ковариационная матрица Су симметрична. Строками матрицы А
11.5. Использование главных компонент при описании
служат нормированные собственные векторы матрицы Сх, которые, как гово-
рилось выше, образуют ортонормированный базис в п-мерном евклидовом про-
странстве. Кроме того, элементы, стоящие на главной диагонали матрицы Су,
являются собственными числами матрицы Сх. Элемент главной диагонали, сто-
ящий в г-ой строке матрицы Су равен дисперсии элемента yi.
Раз строки матрицы А являются ортонормированными, то обратная к ней
матрица получается простым транспонированием матрицы А. Следовательно,
имеется возможность восстановить вектор х, совершив обратное преобразование:
х = Ату + пц,.
Важность преобразования главных компонент становится очевидной, когда ис-
пользуется лишь q собственных векторов. В этом случае матрица А становится
матрицей А9 с размером qxn. Теперь восстановленный вектор является лишь
приближением исходного вектора
х = А^у + шх.
Среднеквадратическое отклонение (ошибка) приближенного восстановленного век-
тора х от точного вектора х задается выражением
п Q п
бтв = — У2 ^з ~ У7 ^з
3=1 j=l j=g+l
Из первой строки этого выражения видно, что ошибка восстановления равна ну-
лю при q = п (т. е. когда в обратном преобразовании используются все собствен-
ные векторы). Из этого уравнения также следует, что ошибку можно миними-
зировать, выбрав для Ав собственные векторы, которые соответствуют q самым
большим собственным числам. Значит, преобразование главных компонентов яв-
ляется оптимальным в том смысле, что оно минимизирует среднеквадратическую
ошибку между вектором х и его приближением х. Название этого преобразова-
ния связано с выбором собственных векторов, имеющих наибольшие (главные)
собственные значения ковариационной матрицы. Пример, который будет рас-
сматриваться далее в этом параграфе, еще лучше прояснит эту концепцию.
Семейство из п выбранных изображений (каждое размером MxN) можно
поместить в «стопку» (стек), как показано на рис. 11.24, с помощью команды
» S cat(3, fl, f2,.. . fn);
Этот стековый массив изображений, имеющий размер MxNxn, преобразует-
ся с помощью функции imstack2vectors (см. ее код приложении В) в массив,
строками которого служат тг-мерные векторы. Функция imstack2vectors имеет
следующую форму вызова:
[X, R] imstack2vectors(S, MASK),
где S это стек изображений, а X — это массив векторов, извлеченный из S
по схеме, показанной на рис. 11.24. Входной аргумент MASK является логическим
494 Глава 11. Представление и описание
или числовым массивом размером MxN с ненулевыми элементами в тех пози-
циях, из которых выбираются элементы S для формирования X, и с нулями в тех
позициях, которые игнорируются. Например, если мы хотим использовать толь-
ко векторы из правого верхнего квадранта стека изображений, то матрица MASK
должна иметь единицы в этом квадранте и нули во всех остальных позициях.
Если переменная MASK не включена в список аргументов, то по умолчанию все
изображение целиком используется при формировании X. Наконец, по строкам
выходного массива R записаны двумерные координаты, соответствующие поло-
жениям векторов, которые использовались при построении X. Использование пе-
ременной MASK будет проиллюстрировано в примере 12.2, а до того момента будет
использоваться схема, принятая по умолчанию.
Следующая М-функция covmatrix вычисляет усредненный вектор, а также
ковариационную матрицу для векторов в X.
function [С, m] covmatrix(X)
‘/COVMATRIX Computes the covariance matrix of a vector population.
X [С, M] COVMATRIX(X) computes the covariance matrix C and the
7. mean vector M of a vector population organized as the rows of
7. matrix X. C is of size N-by-N and M is of size N-by-1, where N is
70 the dimension of the vectors (the number of columns of X) .
[K, n] = size(X);
X = double(X);
if n == 1 7. Handle special case.
C = 0;
m = X;
else
X Compute an unbiased estimate of m.
m = sum(X, 1)/K;
7. Subtract the mean from each row of X.
X = X m(ones(K, 1), :);
7o Compute an unbiased estimate of C. Note that the product is
7» X’*X because the vectors are rows of X.
C = (X’*X)/(K 1);
m = m’; 7» Convert to a column vector.
end
Следующая функция реализует концепцию, изложенную в этом параграфе.
Обратите внимание на использование структур для упрощения выходных аргу-
ментов.1
function Р = princomp(X, q)
7.PRINC0MP Obtain principal-component vectors and related quantities.
7. P = PRINCOMP(X, Q) Computes the principal-component vectors of
7. the vector population contained in the rows of X, a matrix of
1 Функция [V, D] = eig(A) возвращает собственные векторы матрицы А в виде столбцов мат-
рицы V, а соответствующие собственные значения записываются по главной диагонали диаго-
нальной матрицы D.
11.5. Использование главных компонент при описании изображений 495
7. size K-by-n where К is the number of vectors and n is their
7. dimensionality. Q, with values in the range [0, n] , is the number
7. of eigenvectors used in constructing the principal-components
7, transformation matrix. P is a structure with the following
7. fields:
7.
7, P.Y K-by-Q matrix whose columns are the principal-
"Z component vectors.
7. P.A Q-by-n principal components transformation matrix
7, whose rows are the Q eigenvectors of Cx corresponding
7, to the Q largest eigenvalues.
7o P.X K-by-n matrix whose rows are the vectors reconstructed
7. from the principal-component vectors. P.X and P.Y are
7. identical if Q n.
“Z P.ems The mean square error incurred in using only the Q
7. eigenvectors corresponding to the largest
7o eigenvalues. P.ems is 0 if Q = n.
°Z P.Cx The n-by-n covariance matrix of the population in X.
7. P.mx The n-by-1 mean vector of the population in X.
7. P.Cy The Q-by-Q covariance matrix of the population in
7. Y. The main diagonal contains the eigenvalues (in
7. descending order) corresponding to the Q eigenvectors.
[K, n] size(X);
X = double(X);
7. Obtain the mean vector and covariance matrix of the vectors in X.
[P.Cx, P.mx] covmatrix(X);
P.mx = P.mx’; °Z Convert mean vector to a row vector.
7. Obtain the eigenvectors and corresponding eigenvalues of Cx. The
7. eigenvectors are the columns of n-by-n matrix V. D is an n-by-n
7. diagonal matrix whose elements along the main diagonal are the
70 eigenvalues corresponding to the eigenvectors in V, so that X*V
% D*V.
[V, D] = eig(P.Cx);
7. Sort the eigenvalues in decreasing order. Rearrange the
7. eigenvectors to match.
d = diag(D);
[d, idx] sort(d);
d flipud(d);
idx = flipud(idx);
D = diag(d);
V V(:, idx);
7. Now form the q rows of A from first q columns of V.
P.A = V(:, l:q)’;
7. Compute the principal component vectors.
Mx repmat(P.mx, К, 1); 7. M-by-n matrix. Each row P.mx.
P.Y = P.A*(X - Mx)’; 7. q-by-K matrix.
496 Глава 11. Представление и описание
7, Obtain the reconstructed vectors.
P.X (P.A’*P.Y)’ + Mx;
7, Convert P.Y to K-by-q array and P.mx to n-by-1 vector.
P.Y = P.Y’;
P.mx = P.mx’;
7, The mean square error is given by the sum of all the
7, eigenvalues minus the sum of the q largest eigenvalues,
d = diag(D);
P.ems sum(d(q + l:end));
% Covariance matrix of the Y’s:
P.Cy P.A*P.Cx*P.A’;
Пример 11.13. Главные компоненты.
На рис. 11.25 приведены шесть спутниковых фотографий одной и той же мест-
ности, имеющие размеры 512x512, которые сняты в шести спектральных све-
товых диапазонах: видимом синем (длина волны 450-520 нм), видимом зеленом
(520-600 нм), видимом красном (600-690 нм), близком инфракрасном (760-900 нм),
среднем инфракрасном (1550-1750 нм) и тепловом инфракрасном (10400-12500 нм).
Целью этого примера является иллюстрация применения функции princomp для
работы с главными компонентами. Первый шаг состоит в формировании стека
из шести изображений размером 512x512x6, что обсуждалось ранее:
» S = cat(3, fl, f2, f3, f4, f5, f6);
где f l f2 соответствуют шести снимкам в разных спектральных диапазонах.
Далее этот стек загружается в массив X:
>> [X, R] imstack2vectors(S);
Теперь мы получаем 6 изображений главных компонент, применяя функцию
princomp при q = 6:
» Р princomp(X, 6);
Изображение первой компоненты строится и отображается на дисплее с помощью
команд
» gl P.Y(: 1);
>> gl = reshape(gl, 512, 512);
» imshow(gl, [ ])
Все другие компоненты получаются и отображаются аналогичным образом. Соб-
ственные значения расположены вдоль главной диагонали матрицы Р. Су, поэто-
му мы применяем команду
» d = diag(P.Cy);
где d — это 6-мерный вектор-столбец, поскольку в нашем примере параметр q = 6.
Рис. 11.25. Шесть снимков в разных частотных диапазонах: а) видимый синий свет, б) ви-
димый зеленый свет, в) видимый красный свет, г) близкое инфракрасное из-
лучение, д) среднее инфракрасное излучение, е) тепловое инфракрасное из-
лучение. (Изображение предоставлено Агентством NASA)
На рис. 11.26 показаны шесть вычисленных выше изображений главных ком-
понент. Самое очевидное наблюдение заключается в том, что наибольшая до-
ля деталей контрастности сконцентрирована на первых двух изображениях, а
далее происходит резкое снижение контрастности. Причину этого легко объ-
яснить, взглянув на собственные значения. Как показано в табл. 11.5. первые
два собственных значения являются достаточно большими по сравнению со все-
ми остальными. Поскольку собственные значения равны дисперсиями элементов
векторов у, а дисперсия является мерой контрастности, то нет ничего неожи-
данного в том, что изображения, отвечающие большей дисперсии, будут иметь
большую контрастность.
Таблица 11.5. Собственные значения Р.Су при q 6
10352
Аг
2959
Аз At Ав
1403 203 94
Пусть теперь используется малое число компонент, скажем, q 2. Тогда ре-
конструкция базируется лишь на двух изображениях главных компонент. При-
меняя команду
» Р = princomp(X, 2);
и описание
Рис. 11.26. Изображения главных компонент, соответствующие изображениям
на рис. 11.25
и выражения типа
hl = Р.Х(:, 1) ;
hl = reshape(hl, 512, 512);
для каждого результирующего изображения, получаем реконструированные изоб-
ражения на рис. 11.27. При визуальном сравнении эти изображения весьма близ-
ки исходным изображениям на рис. 11.25. На самом деле, и соответствующие раз-
ности изображений обнаруживают малое расхождение. Например, чтобы срав-
нить исходное и реконструированное изображение полосы 1, следует написать
DI = double(fl) double(hl);
DI = gscale(Dl);
imshow(DI)
На рис. 11.28, а) показан результат. Низкая контрастность этого изображе-
ния указывает на небольшую потерю данных при использовании только двух
изображений главных компонент при реконструкции исходного изображения. На
рис. 11.28, б) показана разность для изображений полосы 6. Здесь разность явля-
ется более резкой, поскольку исходное изображение полосы 6 было размытое, но
два изображения главных компонент, использованные при реконструкции, были
четкими, и они имели более сильное влияние на результат реконструкции. Сред-
11.5. Использование главных компонент при описании изображений
неквадратическая ошибка, возникающая при использовании только двух главных
компонент, равна
>> P.ems
ans
1.7311е+003
что есть сумма четырех наименьших собственных значений из табл. 11.5. □
Рис. 11.27. Изображения в разных спектральных диапазонах при использовании лишь
двух изображений главных компонент с наибольшими дисперсиями. Сравните
с оригиналами на рис. 11.25
Рис. 11.28. а) Разность меж-
ду рис. 11.27, а) и 11.25, а), б)
Разность между рис. 11.27, е)
и 11.25, е). Оба изображения
перемасштабированы к интерва-
лу [0,255] стандартных черно-
белых изображений
500 Глава 11. Представление и описание
Перед тем, как завершить материал данного параграфа, отметим, что функ-
ция princomp может использоваться для ориентации объектов (областей или их
границ) вдоль собственных векторов этих объектов. Для этого координаты объ-
ектов выстраиваются в столбцы массива X и применяется функция princomp с
аргументом q = 2. Преобразованные данные, выстроенные вдоль собственных
векторов, содержатся в поле Р. Y. В этом состоит грубая процедура выстраивания,
которая использует все координаты для вычисления матрицы преобразования и
располагает данные по направлению их основной концентрации.
Выводы
Представление и описание объектов или областей, полученных при сегментации
изображения, составляют первые шаги работы большинства автоматизирован-
ных процессов, в которых участвуют цифровые изображения. Такие описания,
например, являются входной информацией для алгоритмов распознавания объ-
ектов, обсуждаемых в следующей главе. Разрабатываемые в последующих пара-
графах М-функции представляют собой значительное расширение стандартных
функция пакета IPT для решения задач представления и описания изображений.
Не вызывает сомнения, что выбор того или иного типа дескрипторов в большой
степени диктуется исследуемой проблемой. Но тогда существенную помощь при
решении задач может оказать гибкая среда для моделирования и прототипиро-
вания, в которой уже имеющиеся функции могут быть интегрированы в новый
программный код, что расширяет рамки приложений при сокращении временных
затрат па их разработку. Материал данной главы является хорошим примером
построения основы для такой рабочей среды.
ГЛАВА 12
РАСПОЗНАВАНИЕ
ОБЪЕКТОВ
Введение
Мы завершаем нашу книгу разработкой и обсуждением ряда М-функций, реа-
лизующих некоторые методы распознавания областей и границ, которые в этой
главе будут называться объектами или образами. Подходы к компьютеризации
распознавания образов можно разделить на две основные категории: методы,
основанные на теории решений, и структурный анализ. Первая категория имеет
дело с образами, которые описываются количественными дескрипторами, такими
как длина, площадь, текстура и многими другими дескрипторами, рассмотренны-
ми в гл. 11. Вторая категория методов ориентирована на образы, которые можно
хорошо представить символьной информацией, например, символьными строка-
ми, и которые можно описать свойствами и взаимоотношениями между этими
символами, как объясняется в § 12.4. В теории распознавания образов ключевое
место занимает принцип «обучаемости» при исследовании выборки объектов. Да-
лее рассматриваются и иллюстрируются методы обучения, применяемые как в
теории решений, так и в структурном анализе.
12.1. Некоторые основы
Под образом подразумевается упорядоченная совокупность дескрипторов, подоб-
ных рассмотренным в гл. 11. В литературе по распознаванию образов дескрип-
торы принято также называть признаками. Классом образов называется сово-
купность образов, которые обладают некоторыми общими свойствами. Классы
образов будут обозначаться символами ищщг, • -, L’iy- где W — это число клас-
сов. Машинное распознавание образов предполагает отнесение образов к тем или
иным классам, что должно совершаться автоматически или с минимальным вме-
шательством человека.
В практических задачах распространены два типа упорядоченного представ-
ления признаков: в виде векторов (количественное описание) и в виде символь-
ных строк (структурное описание). Образы, представление которых основано
на векторах признаков, обозначаются жирными строчными буквами, например,
х, у, z и они имеют вид векторов-столбцов размера nx 1
3=1
3=2
хп
X =
502 Глава 12. Распознавание объектов
где каждая компонента х, представляет дескриптор с номером i, а п — это общее
число дескрипторов, ассоциированных с образом. Иногда в вычислениях бывает
удобно представлять образы в виде векторов-строк размера 1 хп, которые можно
получить простым транспонированием векторов-столбцов: хт
Природа компонент вектора образа х зависит от подхода, применяемого к
описанию самого физического объекта. Рассмотрим, к примеру, задачу автома-
тической классификации буквенно-цифровых символов. Дескрипторы, пригод-
ные для метода теории решений, могут включать такие величины, как двумер-
ные инварианты моментов или множество коэффициентов Фурье, описывающих
внешнюю границу символов.
В некоторых приложениях характеристики образов лучше всего описывать
с помощью структурных связей. Например, распознавание отпечатков пальцев
основано на взаимных связях отпечатка, которые называются мелкими дета-
лями1 Вместе с их относительными размерами и расположением эти признаки
играют роль примитивов, которые описывают свойства линий отпечатка, такие
как обрывы, ветвления, слияния и несвязные сегменты. Задачи распознавания
такого типа, в которых принадлежность образов определенному классу опреде-
ляется не только данными количественных измерений признаков, но также и
пространственным соотношениями между признаками, обычно лучше решаются
с использованием структурных методов.
Материал последующих параграфов представляет собой реализацию на базе
MATLAB некоторых методов распознавания образов. Основной принцип распо-
знавания, особенно в приложениях теории решений, состоит в сравнении обра-
зов с помощью измерения расстояния между векторами образов. Поэтому мы
начнем с обсуждения различных эффективных методов вычисления расстояний
средствами MATLAB.
12.2. Вычисление расстояний в MATLAB
Материал этого параграфа связан с векторизацией вычисления расстояний. Без
использования этой оптимизирующей возможности вычисления пришлось бы вы-
полнять на основе операторов цикла for или while. Некоторые из представлен-
ных ниже выражений с векторизацией являются еще более изощренными, чем
операторные формулы из примеров, рассмотренных в предыдущих главах, по-
этому мы советуем читателю детально разобраться в этих выражениях. Приводи-
мые далее формулировки основаны на аналогичных формулах, разработанных в
[Acklam, 2002].
Евклидовым расстоянием между двумя n-мерными векторами х и у (в виде
столбцов или строк) называется число
d(x,y) = ||х - у || = ||у - х|| = [(xi - У1)2 + • • + (х„ - у„)2]1/2
Это выражение представляет собой норму разности двух векторов, поэтому его
можно вычислять в MATLAB с помощью функции norm:
d = norm(x
у).
оригинале использован термин minutiae. — Прим, перев.
где х и у это векторы, соответствующие х и у из предыдущей формулы для
d(x, у). Часто бывает нужно вычислить множество евклидовых расстояний от
вектора у до каждого вектора некоторого семейства, состоящего из р векторов
размерности п, которые записаны в виде строк матрицы X размера рхп. Чтобы
размерности были правильно согласованы, вектор у должен иметь размер 1хп.
Тогда расстояние от каждого элемента X до у будет записано в вектор pxl
d sqrt(sum(abs(X repmat(у, p, 1)).~2, 2)),
где d(i) есть евклидово расстояние от у до г-ой строки матрицы X [т. е., до
X(i, : )]. Обращаем ваше внимание на употребление функции repmat, которая р
раз дублирует вектор-строку у и записывает результат в виде матрицы рхп для
приведения ее к размерам матрицы X. Значение 2 во втором аргументе функ-
ции sum означает, что следует вести вычисления вдоль второй размерности, т. е.
суммировать элементы по горизонтальной размерности.
Пусть имеется два семейства векторов X и Y размерами рхп и qxn соот-
ветственно. Матрицу, в которую записаны все расстояния между всеми парами
строк этих семейств, можно вычислить, применив оператор
D sqrt(sum(abs(repmat(permute(X, [1 3 2]), [1 q 1])...
-repmat(permute(Y, [3 1 2]), [p 1 1])).“2, 3)),
где D (i, j) — это евклидово расстояние между г-ым и у-ым векторами этих
семейств, т. е. между X(i, :) и Y(j , :).
Синтаксис функции permute в предыдущем выражении имеет вид
В = permute(A, order).
Эта функция перестраивает размерности массива А в соответствии с элементами
вектора order (элементы в этом векторе должны быть однозначными). Напри-
мер, если А является двумерным массивом, то выражение permute (А, [2 1] ) по-
просту переставляет строки и столбца матрицы А, что эквивалентно присвоению
матрице В результата транспонирования матрицы А. Если длина вектора order
больше, чем число размерностей А, то MATLAB обрабатывает компоненты век-
тора слева направо, пока не будут использованы все элементы. В предыдущем
выражении для D команда permute (X, [1 3 2]) порождает массивы в третьем
измерении, каждый из которых является столбцом (размерности 1) из X. Посколь-
ку в X имеется всего п столбцов, то создается п таких массивов, причем каждый
из них имеет размерность pxl. Следовательно, команда permute(X, [1 3 2])
создает массив размерности рх 1 хп. Аналогично, команда permute (Y, [3 12])
строит массив размерности Ixqxn. Наконец, команда
repmat(permute(X, [13 2]), [1 q 1] )
повторяет q раз каждый из п столбцов массива, порожденного командой permute,
и в результате образуется массив размерности pxqxn. Аналогичным образом
можно прокомментировать другие команды, в которые вовлечена матрица Y.
504 Глава 12. Распознавание объектов
На самом деле, рассмотренная формула для D является векторизацией выра-
жений, которые можно записать иначе с помощью «медленных» циклов for или
while.
В дополнение к рассмотренным выше выражениям в этой главе будет также
вычисляться взвешенное расстояние от вектора у до среднего вектора семей-
ства тх, причем вес расстояния задается матрицей, обратной ковариационной
матрице Сх этого семейства. Такая метрика, называемая расстоянием Махалан-
обиса, определяется выражением
d(y, mx) = (У - mx)TCx 1 (у - mx).
Операция взятия обратной матрицы является самой вычислительно затратной
при реализации расстояния Махаланобиса. Эту действие можно существенно
ускориг с помощью операции правого матричного деления (/), которая вво-
дилась в табл. 2.4 (см. также следующую сноску). Выражения для тх и Сх
приведены в § 11.5.
Пусть X обозначает семейство из р векторов размерности п, и пусть Y
это семейство из q векторов, причем в обоих матрицах векторы располагают-
ся по строкам. Следующая M-функция вычисляет расстояние Махаланобиса от
каждого вектора Y до mx'
function d mahalanobis(varargin)
"/.MAHALANOBIS Computes the Mahalanobis distance.
7. D = MAHALANOBIS(Y, X) computes the Mahalanobis distance between
7 each vector in Y to the mean (centroid) of the vectors in X, and
7 outputs the result in vector D, whose length is size(Y, 1). The
7 vectors in X and Y are assumed to be organized as rows. The
7 input data can be real of complex. The outputs are real
7 quantities.
7
7 D MAHALANOBIS(Y, CX, MX) computes the Mahalanobis distance
7 between each vector in Y and the given mean vector, MX. The
7 results are output in vector D, whose length is size(Y, 1). The
7 vectors in Y are assumed to be organized as the rows of this
7 array. The input data can be real or complex. The outputs are
7 real quantities. In addition to the mean vector MX, the
7 covariance matrix CX of a population of vectors X also must be
7 provided. Use function COVMATRIX (§ 11.5) to compute MX and
7. ex.
7 Reference: Acklam, P. J. [2002]. >MATLAB Array Manipulation Tips
7» and Tricks.» Available at
7 home.online.no/~pj acklam/matlab/doc/mtt/index.html
7 or at
7 www.prenhall.com/gonzalezwoodseddins
1Если матрица А квадратная, то матричная операция A/В является более точной (и более
быстрой) реализацией операции B*inv(A). Аналогично, операция А\В работает эффективнее
выражения inv(A)*B. См. табл. 2.4.
12.3. Распознавание с помощью теории решений
param = varargin; % Keep in mind that param is a cell array.
Y = param-Cl};
ny = size(Y, 1); 7, Number of vectors in Y.
if length(param) 2
X = рагат{2};
7. Compute the mean vector and covariance matrix of the vectors
7. in X.
[Cx, mx] covmatrix(X);
elseif length(param) 3 % Cov. matrix and mean vector provided.
Cx = param{2};
mx = param{3};
else
error(’Wrong number of inputs.’)
end
mx = mx(:)’; % Make sure that mx is a row vector.
% Subtract the mean vector from each vector in Y.
Yc = Y mx(ones(ny, 1), :);
% Compute the Mahalanobis distances.
d = real(sum(Yc/Cx.*conj(Yc), 2));
Вызов функции real в последней строке программы сделан для подавления
«численного шума», подобно соответствующей операции при фильтрации изобра-
жений в гл. 4. Если известно, что данные всегда вещественны, то для упрощения
кода функции можно опустить вызовы подфункций real и conj.
12.3. Распознавание с помощью теории решений
Подход к распознаванию образов на основе методов теории решений строится с по-
мощью решающих (или дискриминантных) функций. Пусть х =(хг,Х2,... ,хп)Т
обозначает п-мсрный вектор признаков объекта, который был определен в § 12.1.
Имея W классов образов • , сдг, задачу распознавания в теории реше-
ний можно сформулировать следующим образом. Требуется найти W решающих
функций ф (х), cfefx),. .., йцл(х), которые обладают следующим свойством: если
образ х принадлежит классу сщ, то
Ф(х) > d?(x), при всех j — 1,2,..., W, j =£ г.
Другими словами, неизвестный образ х относят к г-му классу, если при подста-
новке х во все дискриминантные функции наибольшее значение имеет величи-
на di(x). Неоднозначные решения разрешаются произвольным образом.
Разделяющей поверхностью между классами сщ и u>j называется множество
значений х, для которых ф(х) = ф,(х), или, что то же самое, множество векто-
ров х, для которых
Ф(х) - dj(x) = 0.
В теории решений принято описывать разделяющую поверхность между двумя
классами единой функцией фДх) dj(x) — ф,(х) 0. Тогда Ф7(х) > 0 для
образов класса щ и (ДДх) < 0 для образов из класса
506 Глава 12. Распознавание объектов
Как станет ясно из материала следующих параграфов, отыскивание решаю-
щих функций вызывает оценивание параметров образов, которые являются ре-
презентативными для данного класса. Образы, используемые при оценивании па-
раметров, называются обучающими образами или обучающими множествами.
Множества образов известного класса которые не используются для обучения, но
вместо этого используются для тестирования эффективности конкретного метода
распознавания, называются тестовыми или независимыми образами или мно-
жествами. В §§ 12.3.2 и 12.3.4 преследуется цель представить различные подходы
для нахождения решающих функций на основе оценивания параметров по обу-
чающим образам. В § 12.3.3 рассматривается корреляционное сопоставление —
подход, который можно сформулировать в терминах решающих функций, но по
традиции он излагается в форме прямого сопоставления образов.
12.3.1. Формирование векторов признаков
Как отмечалось в начале этой главы, векторы признаков можно строить на ос-
нове количественных дескрипторов, разные типы которых приводились в гл. 11,
для областей и/или границ. Например, предположим, что мы описываем гра-
ницу с помощью Фурье-дескрипторов. Величина г-го дескриптора становится
значением хг, т. е. г-ой компонентой вектора признаков. Кроме того, к Фурье-
дескрипторам можно добавить еще 6 дополнительных компонент, которые равны
мерам текстур из табл. 11.2.
Другой подход, который также весьма часто используется при работе с муль-
тиснектральными (регистрируемыми) изображениями, состоит в построении сте-
ка изображений, после чего строятся векторы по соответствующим пикселам
изображений, как показано на рис. 11.24. Изображения собираются в стек с по-
мощью функции cat:
S = cat(3, fl, f2, fn),
где S это стек, a fl, f2, ..., fn - изображения, формирующие этот стек. После
чего векторы строятся с помощью функции imstack2vectors, которая обсужда-
лась в § 11.5. См. иллюстрирующий пример 12.2.
12.3.2. Сопоставление образов с помощью
классификаторов по минимуму расстояния
Пусть каждый класс определяется его усредняющим вектором т7, т. е. мы ис-
пользуем среднее значение по обучающему множеству данного класса в качестве
представителя (прототипа') данного класса векторов:
у = 1,2,...,Щ
где Nj — это число обучающих образов класса причем суммирование ведется
по всем таким векторам. Как и раньше, W обозначает число классов образов.
Один способ отнесения неизвестного образа с вектором признаков х к некоторо-
му классу состоит в выборе того класса, чей прототип ближе всего к вектору х.
При использовании евклидова расстояния в качестве меры близости (т. е. схоже-
сти) образов задача заключается в вычислении расстояний:
£>3 (х) = ||х — m31| j = l,2,.. ,W.
После этого исследуемый образ относится к классу имеющему наименьшее
расстояние D3(x). Значит, в данной формулировке наилучшее совпадение опре-
деляется по минимальному расстоянию до прототипа.
Пусть все усредняющие векторы (прототипы) записаны в виде строк матри-
цы М. Тогда вычисление расстояния от произвольного вектора х до всех прото-
типов осуществляется с помощью формулы, обсуждавшейся в § 12.2:
d = sqrt(sum(abs(M repmat(x, W, 1)).“2, 2)).
Поскольку все расстояния неотрицательны, это выражение можно упростить, от-
бросив операцию sqrt. Минимум из d определит класс принадлежности вектора
признаков х:
>> class = find(d == min(d));
Другими словами, если минимум d достигается в позиции к (т. с. х принадлежит
к-му классу образов), то скаляр class будет равен к. Если имеется более одно-
го минимального элемента, то переменная class будет вектором, и каждый его
элемент укажет на разные позиции минимума.
Если вместо одного вектора у нас имеется множество векторов признаков,
представленных в виде строк матрицы X, то следует воспользоваться более длин-
ной формулой из § 12.2 для получения матрицы D, элемент D(I, J) которой равен
евклидову расстоянию от z-го вектора из X, до j-ro прототипа из М. Итак, чтобы
определить класс, скажем, z-го образа из X, достаточно найти номер столбца в
строке i матрицы X, имеющего минимальное значение. Кратные минимумы по-
родят кратные значения, как и в случае одного вектора из предыдущего абзаца.
Нетрудно показать, что выбор кратчайшего расстояния эквивалентен вычис-
лению функций
Ф (х) = хгт,----тУт, j = 1,2,..., W,
j v / j 2 j j ’’
и отнесение х к классу Wi происходит при наибольшем значении ф(х). Такая
формулировка согласуется с понятием дискриминантной функции, которое опре-
делялось раньше.
Разделяющая поверхность между классами а?; и ш3 в случае классификатора
по минимуму расстояния задается уравнением
ф3(х) = ф(х) - d3(x) = хг(гщ - m3) - i(mi - т3)г(т; + т3) = 0.
Заданная этим уравнением поверхность перпендикулярна отрезку, соединяюще-
му ш, и ш3, и проходит через его середину. При п = 2 это есть прямая линия,
при п = 3 — это плоскость, а при п > 4 она называется гиперплоскостью.
508 Глава 12. Распознавание объектов
12.3.3. Корреляционное сопоставление
Корреляция является достаточно простой концепцией. Имея изображение f(x, у),
корреляционная задача заключается в нахождении позиций на изображении, ко-
торые лучше всего соответствуют заданному подизображению w(x, у) (которое
называется маской или эталоном). Один подход к решению этой задачи состоит
в работе с эталоном w(x, у), как с пространственным фильтром, что означает вы-
числение суммы соответствующих произведений (или их нормированных значе-
ний) для каждой позиции ги в /, как это делалось в § 3.4.1. После этого, наилучшее
совпадение (или совпадения) ги(х, у) в f(x, у) считается там, где обнаруживается
точка (или точки) максимума результирующего изображения корреляции. Да-
же при малых и локализованных эталонов w(x, у) такой подход в общем случае
является ве :ьма вычислительно затратным. По этой причине практические ре-
ализации пространственной корреляции основываются на специализированных
аппаратных решениях.
Для целей прототипирования альтернативный подход заключается в реали-
зации корреляции в частотной области, где можно воспользоваться теоремой о
корреляции, которая, подобно обсуждавшейся в гл. 4 теореме о свертке, сводит
пространственную корреляцию к произведению преобразованных изображений.
Пусть «о» обозначает корреляцию, а «*» — комплексное сопряжение, тогда тео-
рема о корреляции утверждает, что
f(x,y) ow(x.y) <=> F(u. v)H*(u.v).
Другими словами, пространственную корреляцию можно получить с помощью
обратного преобразования Фурье, примененного к результата умножения пре-
образования одной функции на сопряженное преобразование второй функции.
Имеется также двойственное утверждение:
f(x, y)w*(x, у) <==> F(u,v) о Н(и, v).
Эта часть теоремы о корреляции приведена для полноты изложения. Она не
будет применяться в данной главе.
Реализация первого результата о корреляции в форме М-функции имеет сле-
дующий вид.
function g = dftcorr(f, w)
"/oDFTCORR 2-D correlation in the frequency domain.
7, G = DFTCORR(F, W) performs the correlation of a mask, W, with
7o image F. The output, G, is the correlation image, of class
"Z double. The output is of the same size as F. When, as is
°Z generally true in practice, the mask image is much smaller than
% G, wraparound error is negligible if W is padded to size(F).
[M, N] size(f);
f fft2(f);
w = conj(fft2(w, M, N));
g = real(ifft2(w.*f));
12.3. Распознавание с помощью теории решений
Пример 12.1. Использование -корреляции для сопоставления изображений.
На рис. 12.1, а) показан снимок урагана Эндрю, на котором отчетливо различим
его глаз. В качестве примера использования корреляции мы попробуем найти
наилучшее положение на а) изображения глаза (маски) из рис. 12.1, б). Исход-
ное изображение имеет размер 912x912 пикселов, а размер маски равен 32x32
пиксела. Рис. 12.1, в) получен в результате следующих команд:
g dftcorr(f, w);
gs gscale(g);
imshow(gs)
Очевидное размытие изображения корреляции на рис. 12.1, в) не должно удив-
лять, так как изображение на рис. 12.1, б) имеет две доминирующие, почти по-
стоянные области, и поэтому оно работает как низкочастотный фильтр.
Рис. 12.1. а) Мультиспек-
тральное изображение ура-
гана Эндрю, б) Маска, эта-
лон. в) Корреляция изобра-
жения и маски, г) Положе-
ние наилучшего совпадения.
(Изображение предоставле-
но метеорологической служ-
бой NOAA)
Нас интересует положение наилучшего совпадения, которое; для корреляции
означает нахождение точки (или точек), где значение корреляции максимально:
[I, Л
find(g == max(g(:)))
554
J
203
510 Глава 12. Распознавание объектов
В нашем случае такая точка единственна. Как объяснялось в § 3.4.1, коорди-
наты на изображении корреляции1 соответствуют перемещению маски, поэтому
координаты [I, J] отвечают положению нижнего левого угла этой маски. Ес-
ли теперь расположить маску поверх изображения в этом месте, то обнаружит-
ся близкое ее совпадение с глазом урагана. Другой подход к нахождению наи-
лучшего положения состоит в пороговой обработке изображения корреляции в
окрестности точки максимума или его копии gs с уменьшенным разрешением при
известном максимальном значении 255. Например, изображение на рис. 12.1, г)
получено командой
» imshow (gs > 254)
Совмещение нижнего левого угла эталона с маленькой белой точкой на рис. 12.1, г)
опять обнаруживает наилучшее совпадение для положения глаза урагана. □
12.3.4. Статистически оптимальные классификаторы
Хорошо известный классификатор Байеса для нуль-единичной функции потерь
(см. [Gonzalea, Woods, 2002]) имеет решающие функции вида
dj(x) =р(х|шДР(шД j = l,2,..,W,
где р(х | — функция плотности распределения вероятностей PDF для векто-
ров признаков из класса w,, a P(ujj) — вероятность обнаружения класса wj. Как и
раньше, имея неизвестный вектор признаков, процесс заключается в вычислении
всех W решающих функций и в назначении образу класса, решающая функция
которого имеет самое большое численное значение. Неоднозначные решения раз-
решаются произвольным образом.
Случай, когда функции плотности вероятностей являются (или предполага-
ются) гауссовыми, представляет особый интерес. Функция PDF для п-мерной
гауссовой случайной величины имеет вид
= ------------
И 1 3) (2л)"/2|С,-|1/2е
где Cj и пт, — это ковариационная матрица и усредняющий вектор семейства
образов класса w3-, a |CJ обозначает детерминант матрицы Су
Поскольку функция логарифма является монотонно возрастающей, то нахож-
дение максимума dj (х) по j эквивалентно максимизации In [ф (х)], и мы можем
выписать решающую функцию в виде
d,(x) = In [р(х | шДР(щД] = lnp(x| wj) + InP(wj),
где все логарифмы будут гарантированно вещественными, так как величины
р(х|шД и P(ujj) неотрицательны. Подставляя в эти формулы конкретную функ-
цию для многомерной гауссовой величины, получаем
d,-(x) = lnP(wJ - In2л - iIn |Су| - i [(x - nij)]
l £ £
1Cm. § 3.14, где объясняется схема корреляции.
Отбросив одинаковую для всех классов константу § In 2тг, приходим к следующим
решающим функциям
dj(х) = 1пР(и^) - | In |Cj| - [(х - mJ)rC71(x - ш3)]
при j = 1,2,... ,W Теперь видно, что в квадратных скобках стоит расстояние
Махаланобиса, (см. § 12.2) для которого имеется векторизованная реализация.
У нас также реализован эффективный метод для вычисления средних векторов
и ковариационных матриц (см. § 11.5). Поэтому мы можем построить байесовский
классификатор для многомерного гауссиана в виде следующей М-функции.2
function d = bayesgauss(X, СА, МА, Р)
XBAYESGAUSS Bayes classifier for Gaussian patterns.
% D = BAYESGAUSS(X, СА, MA, P) computes the Bayes decision
7, functions of the patterns in the rows of array X using the
% covariance matrices and and mean vectors provided in the arrays
7, CA and MA. CA is an array of size n-by-n-by-W, where n is the
% dimensionality of the patterns and W is the number of
7, classes. Array MA is of dimension n-by-W (i.e., the columns of MA
7» are the individual mean vectors). The location of the covariance
7, matrices and the mean vectors in their respective arrays must
7. correspond. There must be a covariance matrix and a mean vector
7c for each pattern class, even if some of the covariance matrices
7« and/or mean vectors are equal. X is an array of size K-by-n,
7c where К is the total number of patterns to be classified (i.e.
7c the pattern vectors are rows of X) . P is a 1-by-W array,
7c containing the probabilities of occurrence of each class. If
7c P is not included in the argument list, the classes are assumed
7c to be equally likely.
7c
% The output, D, is a column vector of length K. Its Ith element is
7c the class number assigned to the Ith vector in X during Bayes
7c classification.
d = [ ] ; 7c Initialize d.
error(nargchk(3, 4, nargin)) % Verify correct no. of inputs.
n = size(CA, 1); 7c Dimension of patterns.
7c Protect against the possibility that the class number is
7c included as an (n+l)th element of the vectors.
X = double(X(:, l:n));
W size(CA, 3); % Number of pattern classes.
К size(X, 1); 7» Number of patterns to classify.
if nargin == 3
2Функция eye(n) возвращает единичную матрицу размера nxn; обращение еуе(ш, и) или
еуе( [m в]) позволяет построить матрицу тпхп, в которой на главной диагонали стоят единицы,
а вне — нули. Синтаксис eye (size (А)) обеспечивает аналогичные результаты, где в качестве ш
и п используются, соответственно, числа строк и столбцов матрицы А.
512 Глава 12. Распознавание объектов
P(1:W) 1/W; 7. Classes assumed equally likely,
else
if sum(P) 1
error(’Elements of P must sum to 1.’);
end
end
7» Compute the determinants,
for J 1:W
DM(J) det(CA(: J));
end
7, Compute inverses, using right division (IM/CA), where IM
7» eye(size(CA, 1)) is the n-by-n identity matrix. Reuse CA to
°k conserve memory.
IM eye(size(CA,1));
for J 1:W
CA(:, J) IM/CA(: J);
end
7c Evaluate the decision functions. The sum terms are the
% Mahalanobis distances discussed in Section 12.2.
MA MA’; 7. Organize the mean vectors as rows,
for I 1:K
for J 1:W
m MA(J,
Y X m(ones(size(X, 1), 1),
if P(J) 0
D(I, J) Inf;
else
D(I, J) log(P(JB 0.5*log(DM(J))
0.5*sum(Y(I, :)*(CA(: J)*Y(I, :)’));
end
end
end
7o Find the maximum in each row of D. These maxima
7o give the class of each pattern:
for I 1: К
J find(D(I, :) == max(D(I, :)));
d(I, :) J(:);
end
7. When there are multiple maxima the decision is
7o arbitrary. Pick the first one.
d = d(:, 1);
Пример 12.2. Байесовская классификация мулътиспектралъных данных.
Байесовские классификаторы часто применяются при автоматическом распозна-
вании областей на мультиспсктральных изображениях. На рис. 12.2 даны пер-
вые четыре изображения из рис. 11.25 (три видимых спектральных диапазона и
один инфракрасный). В качестве простой иллюстрации мы применим байесов-
скую классификацию к трем типам (классам) участков земной поверхности на
этих изображениях: водному, городскому и растительному. Векторы признаков
в этом примере строятся по методу, который обсуждался в §§ 11.5 и 12.3.1, где
соответствующие пикселы выстраивались в стек. Мы работаем с четырьмя изоб-
ражениями. поэтому векторы признаков имеют размерность 4.
Чтобы вычислить средние векторы и ковариационные матрицы, нам нужны
образцы, представляющие каждый класс образов. Простейший способ получить
такие подизображения состоит в использовании интерактивной функции roipoly
(см. § 5.2.4), которая вызывается командой
>> В roipoly (f);
где f — это одно из мультиспектральных изображений, а В - двоичная маска.
В таком формате изображение В можно построить интерактивно на экране ком-
пьютера, перемещая курсор мыши. На рис. 12.2, д) приведены три маски Bl, В2
и ВЗ, построенные этим способом. Числа 1, 2 и 3 обозначают, соответственно,
водные, городские и растительные участки на снимках.
Теперь строятся векторы, отвечающие каждой подобласти. Четыре цифровых
изображения уже имеются, поэтому их осталось лишь «уложить» вдоль третьего
измерения и получить стековое изображение:
stack = cat(3, fl, f2, f3, f4);
где изображения с fl по f4 — это четыре снимка из рис. 12.2 с а) по г). Каждой
точке при взгляде сквозь эти изображения соответствует четырехмерный вектор
признаков (см. рис. 11.24). Нас будут интересовать векторы, отвечающие трем
выделенных областям, которые даны на рис. 12.2, д). Мы получим эти векторы,
применив функцию imstack2vectors, которая обсуждалась в § 11.5:
>> [X, R] imstack2ve ctors (stack, В);
где X — это массив, строки которого есть векторы, a R — массив, состоящий и:
положений (двумерных координат) векторов из массива X.
Использовав функцию imstack2vectors с тремя масками Bl, В2 и ВЗ. полу-
чаем три множества векторов XI, Х2 и ХЗ и три семейства координат Rl, R2 и R3.
Затем из множеств X извлекаются три подмножества Yl, Y2 и Y3, которые будут
служить обучающими образами для оценивания ковариационных матриц и сред-
них векторов. В качестве векторов для Y выбираются каждые вторые векторы
из множеств X. Ковариационная матрица и средний вектор для Y1 вычисляются
командой
[Cl, ml] covmatrix(Yl);
и аналогично для остальных классов. Теперь мы строим массивы СА и МА для их
использования в функции bayesgauss:
Гм1ва 12. Распознавание объектов
СА = cat(3, Cl, С2, СЗ);
МА = cat(2, ml, m2, m3);
Рис. 12.2. Байесовская классификация мультиспектральных изображений, а) в) Изобраг
женин, снятые в синем, зеленом и красном диапазонах, г) Инфракрасное изоб-
ражение. д) Маски участков: (1) водного, (2) городского и (3) растительного.
е) Результат классификации. Черными точками отмечены местоположения с
ошибочной классификацией. Все остальные (белые) точки классифицированы
правильно. (Исходные изображения предоставлены Агентством NASA)
Эффективность классификатора на обучающих множествах проверяется командой
>> dYl bayesgaussfYl, СА, МА);
и аналогично для остальных классов. Чтобы обнаружить ошибочно классифи-
цированные участки, достаточно выполнить команду
» IY1 = find(dYl 1);
и аналогично для остальных классов. Чтобы установить число неправильно рас-
познанных точек изображений, следует выполнить команду length (find (dYl ==
== 2)). которая выдаст число местоположений класса 1, ошибочно отнесенных
к классу 2. Все остальные обучающие множества проверяются аналогичным об-
разом.
В табл. 12.1 подытожены результаты распознавания, полученные для обучаю-
щих множеств и для независимых множеств. Процент правильно распознанных
местоположений примерно одинаков для обоих этих множеств, что указывает
12.3. Распознавание с помощью теории решений
на стабильность оценок параметров. Наибольшее число ошибок в обоих случаях
произошло при оценивании городских участков. Это неудивительно, так как там
тоже встречается растительность (заметим, что городские и растительные ме-
ста ни разу не классифицировались как водные). На рис. 12.2, е) черным цветом
отмечены точки, где произошла ошибочная классификация, а белый цвет соот-
ветствует правильной классификации. На области с номером 1 практически не
видно черных точек, поскольку все 7 ошибочно распознанных местоположений
находятся около границы или лежат на ней.
Таблица 12.1. Байесовская классификация мулътиспектралъных данных
и и S Число Обуч. мн-ва Назначенный класс % верных 8 2 Число Независ. мн-ва Назначенный класс % верных
и точек 1 2 3 И точек 1 2 3
1 484 482 2 0 99.6 1 483 478 3 2 98.9
2 933 0 885 48 94.9 2 932 0 880 52 94.4
3 483 0 19 464 96.1 3 482 0 16 466 98.7
Для построения завершенной системы распознавания для классификации муль-
тиспектральных изображений может потребоваться некоторая дополнительная
работа. Однако уже из этого примера видно, что прототип такой системы по-
строен на базе функций MATLAB и пакета IPT, которые дополнены некоторыми
новыми функциями, разработанными к этому моменту в данной книге. □
12.3.5. Адаптивные обучающиеся системы
Подход, изложенный в §§ 12.3.1 и 12.3.3, основан на оценке статистических пара-
метров некоторой выборки каждого класса образцов. Классификатор по мини-
мальному расстоянию полностью определяется средним вектором каждого клас-
са. Аналогично, байесовский классификатор для гауссовых величин однозначно
задается средним вектором и ковариационной матрицей множества образов каж-
дого класса.
В обоих случаях обучающие множества строятся достаточно просто. Обуча-
ющие образы каждого класса используются для вычисления параметров реша-
ющих функций, определяющих этот класс. После оценивания нужных парамет-
ров структура классификатора фиксируется, и далее его эффективность будет
зависеть от того, насколько хорошо реальные образы удовлетворяют базовым
статистическим предположениям, сделанным при выводе данного метода клас-
сификации.
Пока характеристики образов из рассматриваемых классов удовлетворяют,
хотя бы приблизительно, закону гауссова распределения, предложенные мето-
ды будут работать вполне удовлетворительно. Однако если эти допущения на-
рушаются, разработка подходящего статистического классификатора становится
более сложной задачей, поскольку оценивание многомерных функций распреде-
ления вероятностей является нетривиальным делом. На практике такие задачи
теории решений лучше преодолеваются с помощью методов, которые позволяют
строить решающие функции непосредственным обучением по доступным образ-
Глава 12. Распознавание объектов
цам. Тогда предварительные допущения относительно функций распределения
вероятностей для имеющихся классов образов становятся необязательными.
Основной подход, используемый в настоящее время для классификации тако-
го типа, базируется на нейронных сетях (см. [Gonzalea, Woods, 2002]). Реализация
нейронных сетей, годящихся для конкретных приложений обработки изображе-
ний, лежит не очень далеко от рамок возможностей MATLAB и IPT. Однако
такие действия были бы не вполне законными, поскольку уже имеется хороший
пакет по нейронным сетям, разработанный компанией The MathWorks несколько
лет назад.
12.4. Структурное распознавание
Техника структурного распознавания базируется на общем представлении инте-
ресующих объектов в виде символьных строк, деревьев или графов определении
набора дескрипторов и правил распознавания на основе выбранного представ-
ления объектов. Ключевое различие между подходами теории решений и струк-
турными методами заключается в том, что в теории решений количественные де-
скрипторы представляются в виде числовых векторов. В отличие от этого, струк-
турный метод принципиально работает лишь с информацией, представленной в
символьном виде. Например, пусть границы объектов в некотором приложении
представлены ломаными линиями минимальной длины. Подход теории решений
мог быть основан на построении векторов, элементами которых являются вели-
чины внутренних углов многоугольников, а структурный анализ может исходить
из задания символов для ряда величин углов, после чего строятся строки таких
символов для описания образа в целом.
Символьные строки являются самыми распространенным элементами пред-
ставления объектов, которые используются в структурном распознавании, поэто-
му мы сфокусируем наше внимание в этом параграфе именно на этом представ-
лении данных. Как скоро станет ясно, MATLAB имеет весьма солидный набор
специализированных функций для обращения со строками символов.
12.4.1. Работа со строками в MATLAB
В системе MATLAB символьные строки это одномерными массивы, элемен-
тами которых являются коды символов. Отображение символов на экране зави-
сит от таблицы символов, которая используется для кодирования данного шриф-
та. Длиной строки называется число ее символов, включая пробелы. Ее можно
узнать, воспользовавшись стандартной функцией length. Строка определяется
путем заключения ее символов в одинарные кавычки (текстовые кавычки внутри
строки обозначаются двойными кавычками).
В табл. 12.2 перечислены все основные функции MATLAB для работы со
строками.1 Первая функция blanks из этой категории имеет синтаксис
s = blanks(п).
1 Некоторые важные функции для обработки строк уже вводились в предыдущих главах.
12-4- Структурное распознавание
Она строит строку, состоящую из п пробелов. Функция cellstr создает смешан-
ный массив строк по массиву символов. Одно важное преимущество хранения
строк в виде смешанных массивов состоит в устранении необходимости допол-
нять строки пробелами, чтобы в символьном массиве все строки имели одинако-
вую длину (те. подравнивать строки). Обращение
с cellstr(S)
помещает строки символьного массива S в отдельные ячейки с. Функция char
конвертирует смешанный массив обратно в матрицу символов. Например, рас-
смотрим следующую матрицу строк:
S [’ abc’; ’defg’; ’hi ’] % Note the blanks.
abc
defg
hi
Таблица 12.2. Функции MATLAB для обработки строк
Категория Имя функции Объяснение
1 2 3
Общие blanks Строка пробелов.
функции cellstr Строит смешанный массив строк из символьно- го массива. Использовать функцию char для об- ратного преобразования в символьный массив.
char Строит символьный массив (строку).
deblaak Удаляет концевые пробелы.
eval Выполняет строковую команду MATLAB.
Проверки iscellstr Истина для смешанного массива строк.
строк ischar Истина для символьного массива.
isletter Истина для буквы.
isspace Истина для символов пробела.
Операции lower Преобразует буквы в строчные.
со строками regexp Отыскивает регулярные выражения.
regexpi Отыскивает регулярные выражения, игнорируя заглавные.
regexprep Заменяет строку на регулярное выражение.
strcat Соединяет строки.
strcmp Сравнивает строки (см. § 2.10.5).
strcmpi Сравнивает строки, игнорируя заглавные.
strf ind Ищет строку внутри другой.
strjust Выравнивает строку.
strmatch Находит совпадения строк.
stmcmp Сравнивает первые п символов строк.
strncmpi Сравнивает первые п символов строк, игнори- руя заглавные.
strread Читает форматированные данные в строке. См. подробности в § 2.10.5.
Глава 12. Распознавание объектов
Таблица 12.2 (окончание).
1 2 3
strrep Заменяет строку внутри другой.
strtok Ищет метку в строке.
strvcat Соединяет строки по вертикали.
upper Преобразует буквы в заглавные.
Преобразования double Преобразует из строки в число.
из строк в числа int2str Преобразует целое число в строку.
mat2str Преобразует матрицу в строку, годную для об- работки функцией eval.
num2str Преобразует число в строку.
sprintf Записывает форматированные данные в строку.
str2double Преобразует строку в число с двойной точно- стью.
str2num Преобразует строку в число (см. § 2.10.5).
s scant Читает строку с контролем формата.
Преобразования base2dec Преобразует строку в системе В в десятичное
систем счисления целое.
bin2dec Преобразует двоичную строку в десятичное целое.
dec2base Преобразует десятичное целое в строку в системе В.
dec2bin Преобразует десятичное целое в двоичную строку.
dec2hex Преобразует десятичное целое в шестнадцате- ричную строку.
hex2dec Преобразует шестнадцатеричную строку в деся- тичное целое.
hex2num Преобразует IEEE-шестнадцатеричное вещест- венное в число с двойной точностью.
Набрав в командной строке whos S, получим следующую информацию:
who в S
Name
S
Size
3x4
Bytes Class
24 char array
Заметьте, что в двух из трех строк массива S имеются по краям пробелы, посколь-
ку все строки символьной матрицы должны иметь одинаковое число символов.
Обратим также внимание на то, что в выходных данных отсутствуют ограничи-
вающие кавычки, так как мы имеем дело с символьным массивом. Следующая
команда возвращает смешанный массив размера 3x1
>> с = cellstr(S)
с
abc’
’defg’
’hi’
whos с
Name
с
Size
3x1
Bytes
294
Class
cell array
где, например, с Cl) abc’ Обратите внимание на появление одинарных ка-
вычек вокруг содержимого строк, а концевой пробел исчез. Для обратного пре-
образования смешанного массива в символьную матрицу выполним команду
>> Z char(c)
Z
abc
defg
hi
Функция eval выполняет команду MATLAB, записанную в виде стоки сим-
волов. Обращение eval (expression) выполняет команду-строку expression, ко-
торая может содержать любой допустимой текст MATLAB. Например, если t —
это строка символов t = ’ 3~2 ’, то набор на клавиатуре команды eval (t) выдаст
в ответ 9.
Следующая группа функций имеет дело с различными проверками строк. Ес-
ли результат есть истина, то возвращается значение 1; в противном случае — зна-
чение 0. Таким образом, в предыдущем примере команда iscellstr(c) выдаст
1, a iscellstr(S) — 0. Аналогичные комментарии относятся ко всем остальным
функциям этой группы.
Рассмотрим теперь операции со строками. Функции lower (строчные бук-
вы) и upper (заглавные буквы) говорят сами за себя. Они также обсуждались
в § 2.10.5. Следующие три функции относятся к регулярным выражениям2, ко-
торые представляют собой множество символов и синтаксических знаков, часто
используемых при сравнивании фрагментов текста. Простой пример регулярного
выражения — это символ «*», используемый при поиске файлов: поиск по вы-
ражению image*.ш через командное окно выдаст все М-файлы, имена которых
начинаются со слова «image». Другой случай применения регулярных выражений
встречается при поиске и замене фрагментов, когда в тексте ищется заданный
фрагмент и заменяется на другой. Регулярные выражения строятся с помощью
метасимволов, некоторые из которых перечислены в табл. 12.3. В этом контексте
«слово» — это подстрока, перед которой стоит пробел или начало новой строки,
а в конце стоит пробел или конец всей строки. В следующем абзаце приводятся
некоторые примеры регулярных выражений.
Функция regexp отыскивает регулярные выражения. Применение основного
синтаксиса
(er/idx = regexp(str, expr)
возвращает вектор-строку idx, которая содержит индексы (местоположения) под-
строк в строке str, которые подходят под регулярное выражение ехрг. Напри-
мер, пусть ехрг = ’Ь.*а’ Тогда команда idx regexp (str, ехрг) выполняет
поиск в строке str всех символов Ь, за которыми следуют любые символы (это
обозначает метасимвол «.») любое число раз, включая нулевое (что обозначено
символом «*»), после чего расположен символ «а». Индексы всех позиций в стро-
ке str, которые удовлетворяют этому условию, сохраняются в векторе idx. Если
2Понятие регулярного выражения возникло в работах американского математика Стефана
Клини в виде обозначений, которые он называл «алгеброй регулярных множеств».
520 Глава 12. Распознавание объектов
в str не найдено ни одной позиции с этим условием, то функция возвращает
пустой вектор.
Таблица 12.3. Некоторые метасимволы, используемые в регулярных выражениях при на-
хождении соответствий. См. справку для regular expressions
Метасимволы Использование
Подходит любой одиночный символ.
[аЬ...] Подходит любой одиночный символ из (ab...) внутри скобок.
ГаЬ...] Подходит любой одиночный символ, за исключением тех, что расположе- ны в скобках.
Подходит любой символ один или нуль раз.
* Подходит предыдущий символ нуль или больше раз.
+ Подходит предыдущий символ, един или больше раз.
{num} Подходит предыдущий символ num раз.
{min, max} 1 Подходит предыдущий символ не менее, чем min, и не более, чем max раз. Подходит выражение, стоящее до или после метасимвола |.
'chars Подходит, когда строка начинается на chars.
chars$ Подходит, когда строка кончается на chars.
\< chars Подходит, когда слово начинается на chars.
chars\> Подходит, когда слово кончается на chars.
\<word\> Подходит точное совпадение со словом word.
Еще несколько примеров регулярньгх выражений для переменной ехрг позво-
лят лучше понять эту концепцию. Регулярное выражение ’Ъ. + а’ имеет прак-
тически тот же смысл, что и ’Ъ.*а’, с одним отличием: вместо «любое число раз,
включая нулевое» следует читать «один раз или более». Выражение ’Ъ [0-9] ’
означает, что после Ъ должно идти любая цифра от 0 до 9; выражение ’Ъ [0-9] * ’
означает, что за Ъ следует любое число цифр от 0 до 9; а ’Ъ [0-9] + ’ означает
одна или более цифр от 0 до 9. Например, если str = ’b0123c234bcd’, то по-
следние три выражения для ехрг породят следующие результаты: idx = 1; idx
[1 10] ; и idx = 1.
Для примера использования регулярных выражений при распознавании сим-
вольно-звездочных объектов предположим, что граница объекта была закодиро-
вана 4-направленным цепным кодом Фримана [см. рис. 11.1, а)], который сохра-
нен в строке str, так что
>> str
str =
000300333222221111
Пусть наша цель состоит в нахождении всех местоположений в этой строке, где
направление движения меняется с восточного (0) на южное (3), а затем сохраня-
ет это направление не менее чем два шага, но не более, чем шесть шагов. В этом
заключается свойство объекта «спуск вниз», которое должно иметь больше од-
ного шага (один шаг мог быть вызван шумом). Это условие можно выразить с
помощью следующего регулярного выражения:
>> ехрг = ’0[3]{2, 6}’;
12.4- Структурное распознавание 521
Тогда
>> idx = regexp (str, ехрг)
idx =
6
В данном случае величина idx обозначает местоположение, где после 0 стоят
три цифры 3. Более сложные свойства и условия можно выразить аналогичным
образом.
Функция regexpi ведет себя подобным же образом, что и regexp, за тем лишь
исключением, что не делается различие между заглавными (upper) и строчными
(lower) буквами. Функция regexprep, имеющая форму вызова
s = regexprep(str, ехрг, replace),
заменяет на строку replace все обнаруженные регулярные выражения ехрг в
строке str. Преобразованная строка подается на выход s. Если не найдено ни
одного соответствия, то функция regexprep возвращает str без изменений.
Функция strcat имеет синтаксис
С = strcat(Sl, S2, S3, ..).
Эта функция соединяет (по горизонтали) соответствующие строки символьных
массивов SI, S2, S3 и т. д. Все входные массивы должны иметь одно и то же чис-
ло строк (или быть просто строками). Когда все входы являются символьными
массивами, то и выходом служит символьный массив. Если хоть один входной па-
раметр является смешанным массивом, то strcat возвращает смешанный массив
строк, который строится присоединением соответствующих элементов входов S1,
S2, S3 и т. д. При этом входы должны иметь одинаковый размер (или быть скаля-
рами). Любой вход может быть также символьным массивом. Концевые пробелы
символьных массивов игнорируются и не записываются в выход. Это не делается
для входов, которые являются смешанными массивами строк. Для сохранения
концевых пробелов можно использовать стандартный прием, основанный на вы-
ражениях в квадратных скобках типа [SI S2 S3 ...]. Например,
>> а = ’hello У, Note the trailing blank space.
>> b = ’goodbye’
>> strcat (a, b)
ans
hellogoodbye
[a b]
ans
hello goodbye
Функция strvcat, имеющая синтаксис
S strvcat(tl, t2, t3, .),
строит символьный массив S, состоящий из текстовых строк (или стоковых мат-
риц) tl, t2, t3, .... При необходимости, некоторые стоки дополняются пробелами
522 Глава 12. Распознавание объектов
для получения правильной матрицы. Пустые аргументы игнорируются. Так, ис-
пользование строк а и Ъ из предыдущего примера дает
>> strvcat(a, b)
ans =
hello
goodbye
Функция strcmp с вызовом
k strcmp(strl, str2)
сравнивает строки strl и str2 и возвращает 1 (true), если строки идентичны.
В противном случае она возвращает 0 (false). Более общая форма вызова имеет
вид
К strcmp(S, Т),
где или S, или Т является смешанным массивом строк, а К — это массив (с раз-
мерами как у S и Т), который содержит 1 на месте совпадающих элементов в S
и Т, а 0 — там, где совпадений нет. S и Т должны иметь одинаковые размеры (или
один из них может являться скалярным смешанным массивом). Они могут так-
же быть символьными массивами с подходящим числом строк. Функция strcmpi
совершает те же действия, но не различает строчные и заглавные буквы.
Функция strncmp с синтаксисом
k = strncmp(’strl’, ’str2’, n)
возвращает логическую 1 (true), если первые п символов строк strl и str2 сов-
падают, а в противном случае она возвращает логический 0 (false). Аргументы
strl и str2 также могут быть смешанными массивами строк. Команда
R = strncmp(S, Т, п),
где S и Т могут быть смешанными массивами строк, возвращает массив R, имею-
щий тот же размер, что и массивы S и Т, в котором записаны 1 на месте совпа-
дающих элементов S и Т (до п элементов включительно). Массивы S и Т должны
иметь одинаковые размеры (или один из них является скалярным смешанным
массивом). Кроме того, они могут быть символьным массивами с правильным
числом строк. Команда strncmp различает строчные и заглавные буквы. Все на-
чальные и конечные пробелы любой строки участвуют в процедуре сравнения.
Функция strncmpi совершает те же действия, что и strncmp, но не различает
строчные и заглавные буквы.
Функция, имеющая синтаксис
I = strfind(str, pattern),
ищет в строке str все вхождения более короткой строки pattern, возвращая
начальный индекс каждого такого вхождения в виде двойного массива I. Если
строка pattern не обнаружена в str, то strf ind возвращает пустой массив [ ].
12-4- Структурное распознавание
Функция str just допускает форму вызова
Q strjust(A, direction),
где А — это символьный массив, а параметр direction может иметь одно из трех
значений выравнивания: ’right’, ’left’ и ’center’ По умолчанию принято
значение ’right’. Выходной массив содержит все те же строки, что и А, но они
выровнены в соответствии с указанным параметром. Отметим, что выравнивание
строк предполагает наличие начальных или конечных пробелов при выполнении
предписанной операции. Например, пусть «□» обозначает символ пробела, тогда
строка ’□□abc’ с двумя начальными пробелами не меняется при выравнивании
’right’, превращается в строку ’аЬсПП’ при выравнивании ’left’ и стано-
вится строкой ’□abcQ’ при выравнивании ’center’ Ясно, что при отсутствии
начальных и конечных пробелов ничего не меняется.
Функция strmatch, имеющая синтаксис
m = strmatch(’str’, STRS),
просматривает строки символьного массива или смешанного массива строк STRS,
ища строки, которые начинаются на ’ str ’, и возвращая индексы найденных
строк. Альтернативная форма вызова имеет вид
m = strmatch(’str’, STRS, ’exact’).
В этом случае возвращаются лишь индексы, которым соответствуют строки с
полным совпадением по ’ str ’ Например, команда
> > m= strmatch(’max’, strvcat(’max’, ’minimax’, ’maximum’));
возвращает m = [1; 3], так как строки 1 и 3 массива, построенного функцией
strvcat, начинаются на ’max* С другой стороны, команда
> > m= strmatch (’max’, strvcat (’max ’, ’minimar’, ’maximum’), ’exact’);
возвращает m = 1, поскольку только строка 1 совпадает в точности с ’max’
Функция strrep с синтаксисом
г = strrep(’strl’, ’str2’, ’str3’)
заменяет’ в строке ’strl’ все вхождения подстроки ’str2’ на подстроку ’str3’
Если какая-то переменная из strl, str2 или str3 является смешанным массивом
строк, эта функция возвращает Смешанный массив того же размера, что и strl,
str2, str3, который получается поэлементным выполнением команды strrep.
Все входные данные должны иметь одинаковый размер (или могут быть скаляр-
ным смешанным массивом). Кроме того, любой из них может быть символьным
массивом с правильным числом строк. Например,
> > s = ’Image processing and restoration.
» str = strrep(s, ’processing’, ’enhancement’)
524 Глава 12. Распознавание объектов
str =
Image enhancement and restoration.
Функция strtok по команде
t strtok(’str’, delim)
возвращает первую метку в текстовой строке str. то есть первое множество сим-
волов до обнаружения ограничителя delim. Параметр delim является вектором,
состоящим из символов-ограничителей (т. е. пробелы, другие символы, строки).
Например,
> > str = ’An image is an ordered set of pixels’;
> > delim [’ ’] ;
> > t = strtok(str, delim)
t
An
Заметим, что функция strtok прерывает работу после обнаружения первого
ограничителя (в нашем случае это был пробел). Если мы заменим delim на delim
[ ’ х ’ ] , то получим
> > t strtok(str, delim)
t
An image is an ordered set of pi
Следующее семейство функций из табл. 12.2 совершает преобразования меж-
ду строками и числами. Функция int2str. имеющая синтаксис
str = int2str(N),
конвертирует’ целые числа в строки с форматом целых чисел. Вход N может быть
скаляром, вектором или матрицей целых чисел. Нецелые числа сначала округ-
ляются. Например. int2str(2 + 3) является строкой ’5’ Для входных матриц
или векторов функция int2str возвращает матрицу строк:
> > str = int2str(eye(3))
ans
10 0
0 10
0 0 1
>> class (str)
ans =
char
Функция mat2str, имеющая форму вызова
str = mat2str(A),
преобразует матрицу А в строку, которая годится быть входом функции eval
в представлении числовых данных с полной точностью. Расширенный вариант
вызова
str = mat2str(A, n)
преобразует матрицу с точностью с п цифрами. Например, рассмотрим матрицу
>> А [1 2;3 4]
А
1 2
3 4
Команда
» b = mat2str(A)
порождает
Ъ =
[1 2;3 4]
где Ъ — это строка из 9 символов, включая квадратные скобки, пробелы и точку
с запятой. Команда
> > eval(mat2str(A))
воспроизводит числовую матрицу А. Другие функции из этого семейства имеют
аналогичную интерпретацию.
Последняя группа функций из табл. 12.2 относится к преобразованиям систем
счисления. Например, функция dec2base, имеющая синтаксис
str = dec2base(d, base),
преобразует десятичные числа в числа с заданной системой счисления по основа-
нию base, где d — это неотрицательное целое меньше, чем 2’52, a base должно
быть целым между 2 и 36. Возвращаемый аргумент str является символьной
строкой. Например, следующая команда преобразует 23ю к числу по основанию 2
и возвращает результат в виде строки:
> > str = dec2base(23, 2)
str =
10111
> > class (str)
ans
char
Используя формулу
str = dec2base(d, base, n),
получаем представление не более чем с п цифрами.
Глава 12. Распознавание объектов
12.4.2. Сопоставление строк
Наряду с функциями сопоставления и сравнения из табл. 12.2, часто бывает по-
лезно уметь вычислять меру схожести символьных строк, которая вела бы себя
аналогично расстоянию, обсуждавшемуся в § 12.2. Мы проиллюстрируем такой
подход с помощью определяемой ниже меры близости.
Пусть имеется две границы областей а и Ь, которые закодированы, соответ-
ственно, с помощью строк aja? .. ат и b^bz. -. bn. Пусть а обозначает число сов-
падений между этими двумя строками, причем совпадение в некоторой А:-ой по-
зиции имеет место, если а*, = Ь^- Тогда число несовпадающих символов равно
/3 = тах(|а|, |Ь|) — а,
где | arg | обозначает длину (число символов) строки в аргументе. Можно пока-
зать, что /3 = 0, если, и только если а и b являются идентичными строками.
Простейшая мера схожести строк а и b равна дроби
/3 тах(|а|, ]Ь|) — а
Эта мера была предложена в работе [Sze, Yang, 1981]. Она равна бесконечности
при полном совпадении строк и равна 0, когда нет ни одного совпадения между
а и b (в этом случае а равно 0).
Поскольку сопоставление производится между соответствующими символами,
необходимо, чтобы все строки «регистрировались» некоторым общим способом,
не зависящим от положения символов, в противном случае такой метод сравне-
ния не будет иметь смысла. Один способ регистрации двух строк заключается в
сдвигах одной строки относительно другой до тех пор, пока величина R не станет
максимальной. Эту и некоторые другие похожие стратегии можно реализовать
на базе некоторых операций над строками, перечисленными в табл. 12.2. Обычно
более эффективный подход состоит в нахождении некоторой начальной точки
для каждой строки на основе нормировки границ относительно размера и ори-
ентации перед тем, как строить ее представление в виде строки символов. Такой
подход иллюстрируется в примере 12.3.
Следующая функция вычисляет предложенную выше меру схожести для двух
строк символов.
function R = strsimilarity(a, b)
XSTRSIMILARITY Computes a similarity measure between two strings.
% R = STRSIMILARITY(A, B) computes the similarity measure, R,
% defined in Section 12.4.2 for strings A and B. The strings do not
7, have to be of the same length, but if one is shorter than other,
"Z then it is assumed that the shorter string has been padded with
7, leading blanks so that it is brought into the necessary
"Z registration prior to using this function. Only one of the
*Z strings can have blanks, and these must be leading and/or
% trailing blanks. Blanks are not counted when computing the length
7, of the strings for use in the similarity measure.
7. Verify that a and. b are character strings.
if ~ischar(a) | ~ischar(b)
error(’Inputs must be character strings.’)
end
% Find any blank spaces.
I = find(a == ’ ’);
J = find(b == ’) ;
LI = length(I); LJ = length(J);
if LI ~= 0 & LJ ~= 0
error(’0nly one of the strings can contain blanks.’)
end
% Pad the end of the appropriate string. It is assumed
7, that they are registered in terms of their beginning
% positions.
a = a(:) ; b = b(:);
La = length(a); Lb = length(b);
if LI 0 & LJ == 0
if La > Lb
b [b; blanks(La Lb)’];
else
a = [a; blanks(Lb La)’];
end
elseif isempty(I)
Lb = length(b) length(J);
b = [b; blanks(La Lb LJ)’];
else
La length(a) length(I);
a [a; blanks(Lb La LI)’];
end
7„ Compute the similarity measure.
I = find(a == b);
alpha length(I);
den = max(La, Lb) alpha;
if den 0
R Inf;
else
R alpha/den;
end
Пример 12.3. Распознавание объектов на основе сопоставления строк.
На рис. 12.3, а) и г), показаны силуэты двух типов тарных банок, у которых
принципиальное отличие форм состоит в изгибе боковой поверхности. Чтобы
различать эти формы, мы будем относить объект с кривой боковой поверхностью
на рис. 12.3, а) к классу 1, а на рис. 12.3, г) — к классу 2. Оба изображения имеют
размеры 372x372 пиксела.
Глава 12. Распознавание объектов
Рис. 12.3- а) Объект, б) Его ломаная минимальной длины, полученная функцией
minperpoly с размером ячеек 8. в) Типичная зашумленная граница.
г) е) Те же изображения для другого объекта
Чтобы продемонстрировать эффективность меры 11 для дифференциации объ-
ектов классов 1 и 2, грани цы этих объектов приближаются ломаной минималь-
ной длины с помощью функции minperpoly (см. § 11.2.2) с размером ячеек 8. На
рис. 12.3, б) и д), показаны результаты. Затем к координатам каждой вершины
ломаной был добавлен некоторый шум с помощью функции randvertex (листинг
этой функции приведен в приложении В), которая имеет синтаксическую форму
[xn, yn] randvertex(х, у, npix),
где х и у являются векторами-столбцами, содержащими координаты вершин ло-
маной линии, хп и уп это соответствующие зашумленные координаты, a npix
это максимальное число пикселов, у которых разрешается поменять координату
по любому направлению. Для каждого класса были сгенерированы 5 зашумлен-
ных вершин при npix 5. На рис. 12.3, в) и е) показаны типичные результаты.
Строки символов для каждого класса были образованы кодированием внут-
ренних углов ломаных линий с помощью функции polyangles (см. программный
код в приложении В):3
> > angles = polyangles(x, у) ;
Тогда строка s строится по массиву angles квантованием с шагом 45° по команде
> > s = floor (angles/45) + 1;
Получается строка, элементами которой служат числа от 1 до 8, где 1 обозначает
диапазон 0° < 0 < 45°, 2 обозначает диапазон 45° < в < 90° и т. д. Здесь в это
внутренний угол многоугольника границы.
Поскольку первым элементом на выходе minperpoly всегда является самая
верхняя левая вершина входной границы В, то первый элемент строки s соот-
ветствует внутреннему углу этой вершины. В этом заключается автоматическая
регистрация строки (если не поворачивать объекты), поскольку все они начина-
ются с самого верхнего левого угла для всех изображений. Направление обхода
вершин на выходе minperpoly задано по часовой стрелке, поэтому и элементы s
следуют в этом направлении. Наконец, каждая строка s преобразуется из число-
вого формата в символьный с помощью команды
> > s int2str(s);
В этом примере объекты имеют сравнимые размеры, и они расположены вер-
тикально, поэтому нет необходимости нормировать или менять ориентацию. Если
бы объекты имели произвольный размер и ориентацию, то мы могли бы сори-
ентировать их вдоль их основных направлений, используя собственные векторы
соответствующих преобразований, которые обсуждались в конце § 11.5. После
чего мы могли бы использовать ограничивающий прямоугольник из § 11.4 для
определения размеров объектов для их нормирования.
Сначала функция strsimilarity использовалась для вычисления меры схо-
жести всех строк класса 1 между собой. Например, чтобы найти схожесть между
первой и второй строкой класса 1, выписываем команду
> > R = strsimilarity(sll, sl2) ;
где первый индекс обозначает класс, а второй — номер строки из этого класса.
Результаты, полученные для пяти типичных строк, суммированы в табл. 12.4, где
Inf обозначает бесконечность (т. е. полное совпадение, что объяснялось раньше).
Табл. 12.5 отображает аналогичные меры схожести для пяти строк класса 2.
Табл. 12.6 показывает величины меры схожести между строками разных клас-
сов 1 и 2. Отметим, что величины в этой таблице существенно меньше, чем числа
из предыдущих двух таблиц. Это указывает на то, что мера В, достигает высокой
степени различия между двумя классами объектов. Другими словами, измере-
ние схожести строк между членами одного класса дало существенно большие
значения, что означает их близкое совпадение по сравнению с членами противо-
положного класса. □
3Входы х и у функции polyangles являются векторами, состоящими из х- и ^/-координат вершин
многоугольника, упорядоченные по часовой стрелке. Выходом служит вектор, состоящий из
величин соответствующих внутренних углов, выраженных в градусах.
530 Глава 12. Распознавание объектов
Таблица 12.4. Значения меры схожести R строк внутри класса 1.
(Все величины увеличены в 10 раз)
R S11 S12 S13 S14 S15
S11 Inf
S12 9.33 Inf
S13 26.25 12.31 Inf
S14 16.36 9.33 14.16 Inf
S15 22.22 14.17 14.01 19.02 Inf
Таблица 12.5. Значения меры схожести R (Все величины увеличены в строк внутри класса 2. 10 раз)
R S21 622 S23 S24 S25
S21 Inf
S22 10.00 Inf
S23 13.33 13.33 Inf
S24 7.50 13.31 18.00 Inf
825 13.33 7.51 18.12 10.01 Inf
Таблица 12.6. Значения меры схожести R (Все величины увеличены в строк между классами 1 и 2. 10 раз)
R S11 S12 S13 S14 S15
S21 2.03 0.01 1.15 1.17 0.75
S22 1.15 1.61 1.16 0.75 2.07
S23 2.08 1.15 2.08 2.06 2.08
S24 1.60 1.62 1.59 1.14 2.61
S25 1.61 0.36 0.74 1.60 1.16
Выводы
Начиная с гл. 9, наше рассмотрение цифровой обработки изображений отошло от
процессов, выходом которых являются изображения, и переместилось в область
методов и процедур, которые имеют на выходе признаки и атрибуты входных
изображений. Хотя последняя глава носит ознакомительный характер, затрону-
тые в ней идеи и концепции носят фундаментальный характер, а представленные
в ней материалы отражают современное представление о предмете распознавания
объектов. Как отмечалось в начале нашего путешествия в § 1.2, распознавание
индивидуальных объектов является логическим завершением этой книги.
Закончив изучение материалов представленных двенадцати глав, читатель те-
перь в состоянии решать задачи программного прототипирования различных ме-
тодов цифровой обработки изображений с помощью функций системы MATLAB
и пакета Image Processing Toolbox. Но еще более важно то, что основные теоре-
тические положения и множество новых построенных функций образуют общую
схему того, как можно расширять и углублять возможности MATLAB и IPT.
Учитывая специфическую особенность большинства проблем обработки изоб-
ражений, ясное понимание этого материала существенно повышает шансы на
успешное решение широкого спектра задач в области приложений цифровой об-
работки изображений.
ПРИЛОЖЕНИЕ А
Введение
В § А.1 этого приложения перечислены все функции из пакета Image Processing
Toolbox, а также все новые функции, которые были разработаны в предыду-
щих главах данной книги. Последняя группа называется пакетом DIPUM. Эта
аббревиатура получится, если взять первые буквы слов из названия нашей кни-
ги на английском языке (Digital Image Processing Using Matlab). Все указанные
номера страниц относятся к тем местам книги, где эти функции появились в пер-
вый раз. В некоторых случаях для ряда функций имеется несколько ссылочных
страниц. Это означает, что данные функции прокомментированы и объяснены
по-разному в зависимости от возможных приложений. Некоторые функции IPT
не использовались в тексте книги. Это обстоятельство отмечено словом online
(оперативный доступ), что означает приглашение обратиться к справочной стра-
нице MATLAB по данной функции. Все функции MATLAB, использованные в
книге, перечислены в § А.2. В этом параграфе номера страниц соответствуют
первому упоминанию данной функции в тексте книги.
А. I. Функции IPT и DIPUM
Следующие функции достаточно условным образом объединены в группы, подоб-
но тому, как это сделано в документации по пакету IPT. Если в IPT отсутство-
вала соответствующая группа функций (например, для действий с вейвлетами),
то такую группу мы создали самостоятельно.
Группа и имя Описание Стр.
colorbar Вывод изображений на дисплей Отобразить панель цветов (MATLAB). online
get image Получить изображение по осям. online
ice (DIPUM) Интерактивное редактирование цветов. 238
image Создать и отобразить объект изображения (MATLAB). online
imagesc Поменять масштаб и показать изображение (MATLAB). online
immovie Построить мультфильм по последовательности кадров. online
imshow Показать изображение. 32
imview Показать изображение в Image Viewer. online
montage Показать несколько изображений в виде прямоугольных кад -online
movie ров. Показать записанный мультфильм (MATLAB). online
rgbcube (01РиМ)0тобразить цветовой куб RGB. 207
subimage Показать несколько изображений на одном графике. online
truesize Выровнять отображаемые размеры изображения. online
warp Показать изображение в виде текстуры поверхности. online
dicominfo Операции ввода/вывода файлов изображений Считать метаданные из DICOM-сообщения. online
dicomread Считать DICOM-изображение. online
dicomwrite Записать DICOM-изображение. online
dicom-dict.txt Текстовый файл, содержащий словарь DICOM-данных. online
dicomuid Построить однозначный DICOM-идентификатор. online
532 Приложение А
imfinfo Выдать информацию о файле изображения 35 (MATLAB).
imread imwrite Считать файл изображения (MATLAB). 31 Записать файл изображения (MATLAB). 34 Арифметика изображений
imabsdiff imadd Вычислить абсолютную разность двух изображений. 58 Сложить два изображения или прибавить константу к 58 изображению.
imcomplement imdivide Дополнительное (негативное) изображение. 58, 81 Разделить одно изображение на другое или разделить 58 изображение на константу.
imlincomb immultiply Вычислить линейную комбинацию изображений. 58, 172 Перемножить два изображения или умножить изобра- 58 жен не на константу.
imsubtract Вычесть одно изображение из другого или вычесть 58 константу из изображения. Геометрические преобразования
checkerboard f indbounds Построить изображение шахматной доски. 181 Найти выходные границы геометрического преобразо- online вания.
fliptform imcrop imresize imrotate imtransform Поменять местами вход и выход в структуре TFORM. online Обрезать изображение. online Изменить размеры изображения. online Повернуть изображение. 490 Применить геометрическое преобразование к изобра- 201 жению.
intline Алгоритм нахождения целочисленных координат ли- 454 нии (недокументированная функция IPT).
makeresampler maketform Создать повторную структуру. 203 Создать структуру геометрического преобразования 197 (TFORM).
pixeldup (DIPUM) Дублировать пикселы изображения по обоим иаправ- 181 лениям.
tformarray Применить геометрическое преобразование к N-мер- online ному массиву.
tformfwd tforminv Применить прямое геометрическое преобразование. 197 Применить обратное геометрическое преобразование. 197
vistformfwd (DIPUM)Сделать визуализацию прямого геометрического пре- 198
образования.
cpstruct2pairs Регистрация изображений Преобразовать CPSTRUCT в допустимую пару кон- online
cp2tform трольных точек. Построить геометрическое преобразование по контроль- 204
cpcorr ним точкам. Настроить положения контрольных точек с помощью online
cpselect normxcorr2 взаимной корреляции. Инструмент задания контрольных точек. 205 Нормализованная взаимная корреляция. online Значения пикселов и статистика
corr2 covmatrix (DIPUM) Вычислить двумерный коэффициент корреляции. online Вычислить ковариационную матрицу семейств векто- 494
imcontour ров. Построить контурный график данных изображения, online
А.1. Функции IPT и DIPUM
533
imhist
impixel
improfile
mean2
pixval
regionprops
statmoments (DIPUM)
std2
Построить гистограмму данных изображения. 91
Определить значения цветного пиксела. online
Вычислить значения пикселов пересечения вдоль от-online
резка прямой.
Вычислить среднее значение элементов матрицы. 89
Показать информацию о пикселах изображения. 33
Найти свойства областей изображения. 481
Вычислить статистические центральные моменты ги- 169
стограммы изображения.
Вычислить стандартное отклонение элементов матрицы. 433
Анализ изображений (включая сегментацию, описание и распознавание)
bayesgauss (DIPUM) Байесовский классификатор гауссовых образцов. 511
bound2eight (DIPUM) Преобразовать 4-связную границу в 8-связную. 452
bound2four (DIPUM) Преобразовать 8-связную границу в 4-связную. 452
bvboundaries Отследить границы области. online
bwtraceboundary Отследить единственную границу. online
bound2im (DIPUM) Преобразовать границу в изображение. 453
boundaries (DIPUM) Отследить границы области. 452
bsubsamp (DIPUM) Совершить укрупняющую подвыборку границы. 453
colorgrad (DIPUM) Вычислить векторный градиент RGB-изображения. 248
colorseg (DIPUM) Сегментировать цветное изображение. 251
connectpoly (DIPUM) Соединить вершины многоугольника. 453
diameter (DIPUM) Вычислить диаметр областей изображения. 474
edge Найти края на полутоновом изображении. 403
fchcode (DIPUM) Вычислить цепной кед Фримана границы. 455
frdescp (DIPUM) Вычислить Фурье-дескрипторы. 476
graythresh Вычислить глобальный порог изображения, исполь- 423
зуя метод Отсу.
hough (DIPUM) Преобразование Хафа. 413
houghlines (DIPUM) Выделить отрезки прямых с помощью преобразова- 419
ния Хафа.
houghpeaks (DIPUM) Найти локальные вершины преобразования Хафа. 416
houghpixels (DIPUM) Вычислить пикселы изображения, принадлежащие 418
корзине преобразования Хафа.
ifrdescp (DIPUM) Вычислить обратные дескрипторы Фурье. 477
imstack2vectors (П1РиМ)Изалечь векторы из стекового изображения. 493
invmoments (DIPUM) Вычислить инварианты моментов изображения. 489
mahal anobis (DIPUM) Найти расстояние Махаланобиса. 504
minperpoly (DIPUM) Найти ломаную минимального периметра. 465
polyangles (DIPUM) Вычислить внутренние углы многоугольника. 529
princomp (DIPUM) Получить векторы главных компонентов и связанные 494
величины.
qtdecomp Совершить разложение по квадродереву. 431
qtgetblk Получить величины блоков разложения по квадроде- 431
реву.
qtsetblk Задать величины блоков разложения по квадродереву. online
randvertex (DIPUM) Случайно переместить вершины многоугольника. 528
regiongrov (DIPUM) Совершить сегментацию выращиванием областей. 426
signature (DIPUM) Вычислить сигнатуру границы. 468
specxture (DIPUM) Вычислить спектральную текстуру изображения. 486
splitmerge (DIPUM) Сегментировать изображение по алгоритму разделе- 432
ние-слияние.
statxture (DIPUM) Вычислить статистические меры текстуры изображе- 484
strsimilarity (DIPUM) Мера схожести двух строк. 526
x2majoraxis (DIPUM) Совместить ось х с главной осью области. 475
534 Приложение А
Сжатие изображений
compare (DIPUM) Вычислить и отобразить ошибку между двумя мат- рицами. entropy (DIPUM) Вычислить оценку первого порядка для энтропии матрицы. buff2mat (DIPUM) Декодировать матрицу, закодированную по Хаффману. Huffman (DIPUM) Построить код Хаффмана переменной длины для ис- точника символов. im2jpeg (DIPUM) Сжать изображение, используя алгоритм, близкий JPEG. im2jpeg2k (ОТРиМ)Сжать изображение, используя алгоритм, близкий JPEG 2000. Imratio (DIPUM) Вычислить отношения числа байт двух изображе- ний / переменных. jpeg2im (DIPUM) Декодировать изображение, сжатое функцией IM2JPEG. jpeg2k2im (DIPUM) Декодировать изображение, сжатое функцией IM2JPEG2K. Ipc2mat (DIPUM) Декодировать матрицу, сжатую одномерными кодами с предсказанием. mat2buff (DIPUM) Закодировать матрицу по Хаффману. mat21pc (DIPUM) Кодировать матрицу одномерными кодами с предска- занием. quantize (DIPUM) Квантовать элементы матрицы класса UINT8. 271 301 316 304 335 343 296 338 346 328 312 327 331
Сжатие изображений
adaptbisteq decorrstretcb gscale (DIPUM) histeq intrans (DIPUM) imadjust stretcblim Линейная Адаптивная гистограммная эквализация. online Применить некоррелирующее растяжение к мульти-online канальным изображениям. Поменять масштаб входного изображения. 89 Улучшить контрастность с помощью гистограммной 95 эквализации. Совершить преобразования яркости. 87 Выровнять яркость или цветовые компоненты изоб- 80 ражения. Найти пределы для расширения контрастности изоб-опГте ражения. и нелинейная пространственная фильтрация
adpmedian (В1РиМ)Выполнить адаптивную медианную фильтрацию. 178 convmtx2 Вычислить двумерную свертку матриц. online dftcorr (DIPUM) Выполнить корреляцию в частотной области. 508 dftfilt (DIPUM) Выполнить фильтрацию в частотной области. 136 fspecial Построить стандартный фильтр. 114 medfilt2 Выполнить двумерную медианную фильтрацию. 119 imfilter Совершить фильтрацию двумерного или п-мерного 107 изображения. ordfilt2 Совершить двумерную фильтрацию по порядковым 118 статистикам. spfilt (DIPUM) Совершить линейную и нелинейную пространствен- 172
viener2
ную фильтрацию.
Совершить двумерную адаптивную фильтрацию дляопИпе
удаления шума.
Разработка линейных двумерных фильтров
freqspace Определить промежуток двумерного пространствен-online
ного отклика (MATLAB)
freqz2 Вычислить двумерный частотный отклик. 137
А.1. Функции IPT и DIPUM
f samp2 Построить двумерный FIR-фильтр с выборки. помощью частотнойопПпе
ftrans2 Построить двумерный FIR-фильтр с помощью частотногоопИпе преобразования.
fwindl Построить двумерный FIR-фильтр по окна. методу одномерногоопйпе
fwind2 Построить двумерный FIR-фильтр по окна. методу двумерногоопИпе
hpfilter (DIPUM) Вычислить высокочастотные фильтры. 149
Ipfilter (DIPUM) Вычислить низкочастотные фильтры. 144
Восстановление изображений
deconvblind Восстановить изображение с помощью слепой деконволюции. 193
deconvlucy Восстановить изображение по методу Люси—Ричардсона. 190
deconvreg Восстановить изображение с помощью регуляризующего фильтра. 188
deconvwnr Восстановить изображение с помощью винеровского фильтра. 184
edgetaper Смазать края с помощью функции разброса точек. 185
otf2psf Преобразовать оптическую передаточную функцию в функ- цию разброса точек. 155
pef2otf Преобразовать функцию разброса точек в оптическую пере- даточную функцию. 155
Преобразования изображений
dct2 Двумерное дискретное косинусное преобразование. 337
dctmtx Матрица дискретного косинусного преобразования. 338
fan2para Преобразовать центрально-лучевую проекцию в параллель-online
но-лучевую.
faiibeam Вычислить центрально-лучевую проекцию. online
fft2 Выполнить быстрое двумерное преобразование Фурье (MATLAB). 126
fftn Выполнить быстрое N-мерное преобразование Фурье (MATLAB). online
fftshift Перевернуть квадранты выхода FFT (MATLAB). 126
idct2 Двумерное обратное дискретное косинусное преобразование, online
ifanbeam Вычислить обратное центрально-лучевое преобразование. online
ifft2 Двумерное обратное быстрое преобразование Фурье (MATLAB). 128
ifftn N-мерное обратное быстрое преобразование Фурье (MATLAB). online
iradon Вычислить обратное преобразование Радона. online
para2fan Преобразовать параллельно-лучевую проекцию в централь-online
но-лучевую.
phantom Построить заглавное искусственное изображение. online
radon Вычислить преобразование Радона. online
Вейвлеты
wave2gray (DIPUM) Отобразить коэффициенты вейвлетного разложения. 280
waveback (DIPUM) Выполнить многоуровневое двумерное обратное FWT. 284
wavecopy (DIPUM) Извлечь коэффициенты из структуры вейвлетного разложения. 278
wavecut (DIPUM) Вырезать коэффипиенты из структуры вейвлетного разло- 277
жен ия.
wavefast (DIPUM) Выполнить многоуровневое двумерное быстрое вейвлетное 268
преобразование.
wavefilter (В1РиМ)Создать вейвлетное разложение и фильтры реконструкции. 265
uavepaste (DIPUM) Вставить коэффициенты в структуру вейвлетного разложения. 278
wavework (DIPUM) Редактировать структуру вейвлетного разложения. 275
536 Приложение А
vavezero (В1Р11М)Обиулить вейвлетные коэффициенты деталей. 290
Обработка областей и блоков
beetblk Выбрать блочный размер для обработки блока. online
blkproc Выполнить индивидуальную блочную обработку 337
изображения.
col2im Разместить столбцы матрицы в виде блока. 338
colfilt Окрестностные операции по столбцам. 111
im2col Разместить блоки изображений в виде столбцов. 337
nlfilter Выполнить общую нелинейную фильтрацию. 111
Морфологические операции (полутоновые и двоичные изображения)
conndef Связность по умолчанию. online
imbothat Выполнить преобразование «дно шляпы». 390
imclearborder Подавить светлые структуры, примыкающие к грани- 383
цам изображения.
imcloee Замкнуть изображение. 365
imdilate Выполнить дилатацию изображения. 357
imerode Выполнить эрозию изображения. 363
imextendedmax Расширенное преобразования максимума. online
imextendedmin Расширенное преобразования минимума. online
imf ill Заполнить области изображения и отверстия. 383
i mb max Н-максимум преобразование. online
imhmin Н-минимум преобразование. 392
imimpoeemin Выполнить процедуру минимального подъема. 441
imopen Разомкнуть изображение. 365
imreconstruct Морфологическая реконструкция. 381
imregionalmax Найти все локальные максимумы. online
imregionalmin Найти все локальные минимумы. 440
imtophat Выполнить преобразование «верх шляпы». 389
watershed Преобразование водораздела. 437
Морфологические операции (двоичные изображения)
applylut Выполнить окрестностные операции иа основе поиско- 370
вой таблицы.
bvarea Вычислить площадь объектов двоичного изображения, online
bwareaopen Разомкнуть двоичную область (удалить малые объек- online
ты).
bwdiet Вычислить преобразование расстоянием для двоичного 436
изображения.
bveuler Вычислить эйлерову характеристику двоичного изоб- online
ражения.
bvhitmiee Двоичная операция успех/неудача. 369
bvlabel Найти компоненты связности двумерного двоичного 379
изображения.
bvlabeln Найти компоненты связюститтгмернсятэ двоичного изображения. online
bwmorph Выполнить морфологические операции для двоичного 373
изображения.
А.1. Функции IPT и DIPUM
Создание структурообразующих элементов (STREL) и действия с ними
bwpack bwperim bvselect bwulterode bwimpack Запаковать двоичное изображение. online Вычислить периметр объектов двоичного изображения. 463 Выбрать объекты на двоичном изображении. online Окончательная эрозия. online Распаковать двоичное изображение. online
endpoints (Г)1РиМ)Вычислить концевые точки двоичного изображения. 371
makelut Построит ь поисковую таблицу для использования 370 в applylut.
getheight getneighbors Получить высоту strel. online Получить координаты смещения и высоту окрестностейопГше strel.
getnhood getsequence isflat reflect strel translate Получить окрестность strel. online Получить последовательность разложенных strels. 361 Вернуть «true» для плоских strels. online Симметрично отразить strel относительно его центра. online Создать морфологический структурообразующий элемент. 359 Сдвинуть strel- online Обработка на основе областей
histroi (DIPUM) poly2mask roicolor roifill roifilt2 roipoly Вычислить гистограмму области ROI изображения. 170 Преобразовать многоугольник ROI в маску. online Выбрать интересующую область (RIO) по цвету. online Гладкая интерполяция по произвольной области. online Фильтровать область RIO. online Выбрать RIO в форме многоугольника, отмечая интерак- 169 тивно его вершины. Действия с цветовой картой
brighten empermute cmunique colormap imapprox Изменить яркость цветовой карты (MATLAB). online Переставить цвета в цветовой карте. online Найти соответствие цветов карты и изображения. online Задать или получить цветовую таблицу (MATLAB). 146 Аппроксимировать индексированное изображение другим 209 изображением с меньшим набором цветов.
rgbplot Построить график компонент RGB цветовой карты (MATLAB).online Преобразования цветовых пространств
applycform Применить преобразование цветового пространства, незави-online симое от аппаратных средств.
hsv2rgb iccread lab2double Iab2uintl6 Iab2uint8 makeeform Преобразовать из HSV в RGB (MATLAB). 216 Считать цветовой профиль ICC. online Преобразовать L*a*b* цветовые значения в класс double, online Преобразовать L*a*b* цветовые значения в класс uintl6. online Преобразовать L*a*b* цветовые значения в класс uint8. online Создать структуру преобразования цветового пространства,online независимую от аппаратных средств.
Приложение А
ntsc2rgb rgb2hsv rgb2ntsc rgb2ycbcr ycbcr2rgb rgb2hsi (DIPUM) hsi2rgb (DIPUM) vhitepoint xyz2double xyz2uintl6 Преобразовать из NTSC в RGB. 215 Преобразовать из RGB в HSV (MATLAB). 216 Преобразовать из RGB в NTSC. 215 Преобразовать из RGB в YCBCR. 215 Преобразовать из YCBCR в RGB. 216 Преобразовать из RGB в HSI. 220 Преобразовать из HS1 в RGB. 221 Преобразовать из XYZ в пространство сгандартныхопбпе осветителей. Преобразовать величины из XYZ в класс double, online Преобразовать величины из XYZ в класс uintl6. online
Операции с массивами
circshift Сдвинуть массив циклически (MATLAB). dftuv (DIPUM) Вычислить сеточные массивы. padaxray Дополнить массив. paddedsize (П1РиМ)Вычислить минимальный размер расширения мас- сива для использования в FFTs. Типы изображений и преобразования типов 451 141 112 131
changeclass dither gray2ind grayslice im2bw im2double im2java im2java2d im2uint8 im2uint!6 ind2gray ind2rgb labe!2rgb mat2gray rgb2gray rgb2ind Сменить класс изображения (недокументированная 86 функция IPT). Преобразовать изображение с помощью алгоритма 212 дрожания. Преобразовать полутоновое изображение в индекси- 212 ро ванное. Создать индексированное изображение по монохром- 212 ному с помощью пороговой обработки. Преобразовать изображение в двоичное с помощью 43 пороговой обработки. Преобразовать массив изображения в изображение 43 с двойной точностью. Преобразовать изображение в изображение Javaonline (MATLAB). Преобразовать изображение в буферизованный ви-online зуальный объект Java. Преобразовать массив изображения в 8-ми битный 43 целый массив без знака. Преобразовать массив изображения в 16-ми битный 43 целый массив без знака. Преобразовать индексированное изображение в по- 213 лутоновое. Преобразовать индексированное изображение в изоб- 213 ражение RGB (MATLAB). Преобразовать размечающую матрицу в изображе-опНпе ние RGB. Преобразовать матрицу в полутоновое изображе- 43 ние. Преобразовать цветовое изображение RGB (или дру- 213 гое) в монохромное. Преобразовать изображение RGB в индексирован- 212 ное изображение. Различные действия
convaylavs (П1РиМ)Применить законы Конвея к выбранному пикселу. 372
manualhist (П1РиМ)Сгенерировать интерактивно двухмодовую гисто- 101
грамму.
A. 2. Функции MATLAB
twomodegauss (ПГРиМ)Сгенерировать двухмодовую функцию Гаусса. 100
uintlut Вычислить новые значения массива по поисковой таблице.опйпе
Пакетные предпочтения
iptgetpref Получить значение предпочтения пакета IPT. online
iptsetpref Установить значение предпочтения пакета IPT. online
А.2. Функции MATLAB
Ниже приводится алфавитный перечень функций MATLAB, использованных в
этой книге. Слева указан номера страниц, на которых имеются соответствующие
материалы.
Функция Описание Стр.
MATLAB
А abs Абсолютное значение или комплексный модуль. 126
all Проверить, все ли элементы ненулевые. 62
ans Последний результат (ответ). 63
any Проверить, есть ли ненулевой элемент. 62
axis Отображение и масштабирование осей. 92
В bar Столбчатая диаграмма. 91
bin2dec Преобразование из двоичного в десятичное. 314
blanks Строка пробелов. 516
break Оборвать выполнение циклов for или while. 64
C cart2pol Преобразовать декартовы координаты в полярные или цилиндри- 469
cat ческие. Соединить массивы. 207
ceil Округлить в сторону плюс бесконечности. 128
cell Построить смешанный массив. 306
celldisp Отобразить содержимое смешанного массива. 308, 446
cellfun Применить функцию к каждому элементу смешанного массива. 446
cellplot Отобразить графически структуру смешанного массива. 308
cellstr Построить смешанный массив по символьному. 517
char Построить символьный массив (строку). 76, 517
circshift Сдвинуть массив циклически. 451
colon Оператор двоеточие (:). 46, 57
colormap Задать и получить текущую цветовую карту. 146, 210
computer Идентифицировать информацию о компьютере, на котором дей- 63
continue ствует данная система MATLAB. Передать управление следующей итерации цикла for или while. 64
conv2 Двумерная свертка. 268
ctransposeKoMiineKCHOC транспонирование. 57
cumsum (См. транспонирование вещественных данных). Кумулятивная (накопленная) сумма. 97
D dec2base Преобразование из десятичной в другую систему счисления. 525
dec2bin Преобразование десятичного в двоичное. 312
diag Диагональные матрицы и диагонали матриц. 252
diff Разности и приближенные производные. 392
Приложение А
dir Отобразить список папок (директорий). 297
disp Отобразить текст или массив. 74
double Преобразовать в число с двойной точностью. 40
Е
edit Редактировать или создать М-файл. 55
eig Найти собственные значения и собственные векторы. 494
end Закончить оператор for, while, switch, try, if или обозна- 47
чить последний индекс.
eps Относительная точность вычислений с плавающей запятой. 63, 84
error Отобразить сообщение об ошибке. 65
eval Выполнить команду, записанную в виде символьной строки. 519
eye Единичная матрица. 511
F
false Создать логический массив из нулей (false). 52, 427
feval Вычисление функции. 432
fft2 Двумерное дискретное преобразование Фурье. 126
fftshift Переместить нулевую частотную компоненту DFT в центр 126
спектра.
fieldnamesBepuyrb имена полей структуры или названия свойств объ- 297
екта.
figure Закрепить текущий график. 34
find Найти индексы и значения ненулевых элементов. 160
f liplr Перевернуть матрицу слева направо. 489
f lipup Перевернуть матрицу сверху вниз. 489
floor Округлить в сторону минус бесконечности. 128
for Повторить группу операторов заданное число раз- 64
full Преобразовать разреженную матрицу в стандартную. 413
G
gca Использовать текущие оси. 92
get Получить свойства объекта. 238
getfield Получить поля массива структур. 558
global Задать глобальную переменную. 306
grid Координатные линии двумерного или трехмерного графика. 146
guidata Сохранить или восстановить данные приложения. 556
guide Запустить программу GUI Layout Editor. 544
Н
help Огобразить справку функции MATLAB в командном окне. 55
hist Вычислить и/или отобразить гистограмму. 165
histc Гистограммный счетчик. 312
hold on Сохранить текущий график и текущие свойства осей, 94
I
if Условная команда. 64
ifft2 Двумерное дискретное обратное преобразование Фурье. 128
ifftshift Обратное преобразования FFT со сдвигом. 128
imag Мнимая часть комплексного числа. 129
int 16 Преобразовать в целое со знаком. 40
inpolygon Обнаружить точки внутри многоугольной области. 465
input Запросить пользовательский ввод. 74
int 2st г Преобразование целого в строчное представление. 524
int32 Преобразовать в целое со знаком. 40
intB Преобразовать в целое со знаком. 40
interplq Быстрая одномерная линейная интерполяция. 237
inv Вычислить обратную матрицу. 419
is* См. табл. 2.9. 63
iscellstr Определить, является ли смешанным массивом строк. 63, 519
islogical Определить, является ли логическим массивом. 41
A.2. Функции MATLAB 541
L
Idivide Деление массива слева. (См. mldivide для деления матриц слева.) . 57
length Длина вектора. 65
linspace Построить вектор с равноотстоящими элементами. 47
load Загрузить переменные рабочего пространства с диска. 324
log Натуральный логарифм. 82
loglO Десятичный логарифм. 82
log2 Логарифм по основанию 2. 82
logical Преобразовать числовые значения в логические. 41
lookfor Найти ключевое слово на всех справочных страницах. 55
lower Преобразовать в строчные буквы. 77
M magic Построить магический квадрат. 52
mat2str Преобразовать матрицу в строку. 524
max Максимальный элемент массива. 57
mean Среднее значение массива. 379
median Значение медианы массива. 119
mesh Сеточный график. 145
meshgrid Построить матрицы X и Y для трехмерного графика. 70
mfilename Имя текущего выполняемого М-файла. 550
min Минимальный элемент массива. 57
minus Вычитание массивов и матриц. 57
mldivide Матричное деление слева. (См. Idivide для деления масси- 57
mpower вов слева). Матричная степень, (см. функцию power для степени мас- 57
mrdivide сивов). Матричное деление справа. (См. rdivide для деления мас- 57
mtimes сивов справа). Умножение матриц. (См. times для умножение массивов). 57
N nan or NaNHe число. 63
nargchk Проверить число входных аргументов. 85
nargin Число входных аргументов функции. 85
nargout Число выходных аргументов функции. 85
ndims Число размерностей массива. 52
nextpow2 Наименьшая степень числа два, большая данного числа. 131
norm Норма вектора или матрицы. 502
mimel Число элементов массива. 66
О
ones Построить массив из одних единиц. 52
Р
patch Закрасить графический объект по образцам. 207
permute Переставить размерности многомерного массива. 503
persistent Определить устойчивые переменные. 370
pi Отношение длины окружности к ее диаметру. 63
plot Линейный двумерный график. 94
plus Сложение массивов и матриц. 57
pol2cart Преобразовать полярные или цилиндрические координаты469
в декартовы.
pow2 Массив из упорядоченных степеней числа 2. 314
power Степень массивов. (См. mpower для степени матриц). 57
print Записать в файл или печатать на бумаге. 39
prod Перемножить элементы массива. 113
542 Приложение А
R
rand Случайные числа и массивы с равномерным распределением. 52, 160
randn Случайные числа и массивы с нормальным распределением. 52, 160
rdivide Деление массивов справа. (См. mrdivide для деления мат- 57
риц справа).
real Вещественная часть комплексного числа. 129
realmax Наибольшее число с плавающей точкой, которое представи- 63
мо на компьютере.
realmin Наименьшее число с плаваюшей точкой, которое представи- 63
мо на компьютере.
regexp Найти регулярные выражения. 519
regexpi Найти регулярные выражения, не различая строчные и за- 521
главные.
regexprep3aMeHHTb регулярное выражение на строку. 521
rem Остаток от деления. 268
repmat Тиражирование и повторение массивов. 277
reshape Переформировать массив. 314
return Вернуться назад в вызывающую функцию. 64
rot90 Поворот матрицы на угол, кратный 90 градусам. 108
round Округлить до ближайшего целого. 38
S
save Сохранить переменные рабочего пространства на диске. 315
set Задать свойства объектов. 92
setfield Задать поле структурного массива. 563
shading Задать параметры фасеточного тонирования. 148
(В данной книге используется мода interp.)
sign Функция знак числа. 343
single Преобразовать в данные с обычной точностью. 40
size Вернуть размеры массива. 32
sort Упорядочить элементы по возрастанию. 307
sortrows Упорядочить строки по возрастанию. 451
sparse Создать разреженную матрицу. 412
spline Кубическая сплайновая интерполяция данных. 237
sprintf Записать форматированные данные в строку. 67
stem Построить стеблевую диаграмму дискретных данных. 93
str* Операции со строками. См. табл.12.2. 517
str2num Преобразовать из строки в число. 75
strcat Присоединить строку. 521
strcmp Сравнить строки. 76, 522
strempi Сравнить строки, не различая строчные и заглавные. 522
strfind Найти одну строку внутри другой. 522
strjust Выровнять символьный массив. 523
strmatch Найти возможные соответствия (совпадения) строк. 523
strncmp Сравнить первые п символов двух строк. 522
stmempi Сравнить первые п символов двух строк, не различая строч- 522
ные и заглавные.
strread Считать форматированные данные из строки. 75
strrep Поиск и замена строк. 523
strtok Первая метка строки. 524
strveat Соединение строк по вертикали. 521
subplot Разделить окно графиков на несколько подокон или подгра- 261
фиков.
sum Суммировать элементы массива. 50
surf Трехмерный график поверхности. 148
switch Переключить выполнение действия при выполнении одного 64
из условий.
A.2. Функции MATLAB S43^
T
text Создать фрагмент текста. 93
tic, toe Функции хронометрирования. 72
хронометр Умножение массивов. (См. mtimes для умножения матриц). 57
title Добавить заголовок к текущему графику. 93
transpose Транспонирование матриц или векторов. (См. ctranspose 46, 57
для комплексных данных).
true Создать логический массив из одних единиц (true). 52, 427
try.. .catchCM. табл. 2.11 64
U
uicontrol Создать пользователем объект интерфейсного контроля. 551
uintl6 Преобразовать в целое без знака. 40
uint32 Преобразовать в целое без знака. 40
uint8 Преобразовать в целое без знака. 40
uiresume Контролировать исполнение программы. 557
uiwait Контролировать исполнение программы. 557
uminus Унарный минус. 57
uplus Унарный плюс. 57
unique Удалить повторные элементы вектора 451
upper Преобразовать в заглавные. 77
V
varargin Передать переменное число аргументов. 85
vararout Возвратить переменное число аргументов. 85
version Получить номер версии MATLAB. 63
view Задать точку обзора. 146
W
warning Показать предупреждающее сообщение. 172
while Повторять группу операций неопределенное число раз. 64
whitebg Поменять цвет фона. 210
whos Перечислить переменные рабочего пространства. 32
X
xlabel Разметить ось х. 92
xlim Задать или запросить пределы по оси х. 94
хог Исключающее ИЛИ. 62
xtick Разместить метки на горизонтальной оси. 92
Y
ylabel Разметить ось у. 92
у lim Задать или запросить пределы по оси у. 94
ytick Разместить метки на вертикальной оси. 92
Z
zeros Создать массив из одних нулей. 52
ПРИЛОЖЕНИЕ Б
Введение
В этом приложении будет подробно рассмотрена функция ice (Interactive Color
Editor, интерактивное редактирование цвета), которая была введена в гл. 6. При
этом предполагается, что читатель уже изучил материал § 6.4, где рассмотрено
много примеров использования функции ice применительно к обработке полно-
цветных и псевдоцветных изображений (примеры с 6.3 по 6.7), а также разобран
синтаксис вызова этой функции, описаны входные параметры и элементы гра-
фического интерфейса (они подытожены в табл. 6.4 6.6). Достоинство функции
ice состоит в том, что пользователь получает возможность интерактивно строить
кривые цветовых преобразований, наблюдая графический результат действия ва-
рьируемого преобразования в режиме реального (или почти реального) времени.
Б. I. Построение графического интерфейса ICE
Функциональный набор MATLAB GUIDE (Graphical User Interface Development
Environment, окружение для разработки графического интерфейса пользовате-
ля) имеет весьма богатый набор инструментов для внедрения графических поль-
зовательских интерфейсов (GUI, Graphical User Interfaces) в программный код
М-функций. С помощью GUIDE такие процессы, как:
(1) элементы GUI (т. е. разные кнопки, выпадающие меню и т. п.) и
(2) программирование действий GUI,
разделяются на две легко контролируемые и относительно независимые задачи.
Результирующая графическая М-функция состоит из двух файлов, имеющих
тождественные имена (если не учитывать их расширения):
1. Файл с расширением .fig, который называется FIG-файлом. В нем содер-
жится полное графическое описание всех объектов и элементов функций
GUI, а также их местоположений в окне программы. В файле .fig записа-
ны двоичные данные, которые не нужно анализировать при вызове ассоци-
ированного М-файла, написанного со встроенным GUI. FIG-файл для ICE
(ice.fig) описывается далее в этом параграфе.
2. Файл с расширением .ш. который называется GUI М-файлом. Он содержит
программный код, контролирующий операции GUI. В этом файле имеются
функции, которые вызываются при запуске и завершении основной про-
граммы, а также функции вызова, которые активируются при взаимодей-
ствии пользователя с объектами GUI например, при нажатии некоторой
кнопки. GUI М-файл для ICE (ice .m) разбирается в следующем параграфе.
Чтобы запустить GUIDE, в командном окне MATLAB следует набрать
guide filename,
Б.1. Построение графического интерфейса ICE
где filename обозначает имя существующего FIG-файла, который обнаружива-
ется по текущему пути. Если параметр filename опущен, то GUIDE открывает
новое (т. е. пустое) окно.
Редактор Редактор Контролер Просмотр
Рис. Б.1. Макет [СЕ GUI в редакторе раскладки GUIDE
На рис. Б.1 показано окно редактора раскладки GUIDE (который запускается
командой guide ice после стандартного приглашения MATLAB >>) для ком-
поновки элементов ICE (Interactive Color Editor, интерактивный редактор цве-
тов). Редактор раскладки позволяет выбирать и размещать графические объек-
ты, устанавливать их размеры, выравнивать и манипулировать этими объектами
на макете разрабатываемого пользовательского интерфейса. Кнопки слева обра-
зуют палитру компонентов, в которой отображены объекты, поддерживаемые
GUI: нажимаемые кнопки, переключаемые кнопки, кнопки настройки, окошки
меток, редактируемый текст, неизменяемый текст, слайды, рамки, окна спис-
ков, выпадающие меню и оси. Каждый объект ведет себя так, как и одноименный
объект операционной системы WINDOWS. Любую комбинацию объектов мож-
но добавить на рисунке объектов в области раскладки в правой части редакто-
ра раскладки. Отметим, что ICE GUI имеет окошки меток (Smooth, Clamp Ends,
Show PDF, Show CDF, Map Bars и Map Image), неизменяемый текст («Component:
«Curve», ), рамку, выделяющую контролируемые кривые, две нажимаемые
кнопки (Reset и Reset All), выпадающее меню для выбора кривой цветового
преобразования, а также три объекта axes для отображения выбранной кривой
Приложение Б
(вместе с наложенными контрольными точками), который действуют как для
монохромных, так и для цветных приложений. Иерархический список элемен-
тов, содержащихся в ICE (который появляется после нажатия мышью на кнопку
просмотр объекта, расположенную в полосе задач в верхней части редактора
раскладки), показан на рис. Б.2, а). Отметим, что каждому элементу присвое-
но уникальное имя или тэг. Например, объекту axes для отображения графи-
ка кривой (в самом вверху списка) приписано имя (идентификатор) curve_axes
[идентификатор отображается в первой записи после открытой круглой скобки
на рис. Б.2, а)].
«2.
6)
Heun (ICE • bd«MCth>« Colei Edrtor)
» Position
Render»
• RendererMode
Resize
RasizeFcn
SetertionMghlght
SetecfconType
ShareCotors
<KZ - XMZ
axes (cuive_axes)
JC*axes (gtey_axes)
axes (color_axes)
uicontrol (ftssel "")
ulcontrol (text-1 "Caaponent:")
ulcontrol (сояршепг_рорцр "RGB")
O’ ulcontrol (tsxtZ ’’Input:")
*1* ulcontrol (tcxt3 "Output:")
в uicontrol (s>ootb_checkbox "Ssooth")
Шuicontrol (resetjiusbbutton "Beset")
* ulcontrol (tect4 "Curve")
fc? ulcontrol (lnput_tert "”)
ulcontrol (oucput_t*xt "")
Й ulcontrol (slope_Cbeckbox "Clasp Ends")
ulcanttol (resetall_pusbbuczon "Reset All")
Й uicontrol (pd£_cbeckbox "Sbos PDF")
Q ulcontrol (cd£_cbeckbox "Sbov CDF")
Muicontrol (blue_text "”)
» ulcontrol (green_text "“)
M uicontrol (red_t«t "")
w uicontrol [textlO "Pseudo-color Bar")
Ж uicontrol (retell "Full-color Bar")
Q uicontrol (sapbar_checktiox "Bap Bars")
Q ulcontrol (aapraage_cbeckbox "Hap laage")
UiComadMenu
Units
UserData
Visible
- WlneowButtonOownFcn
WindowButtonMottoriFcn
Ad3
[OS 65 231 92 6 30 077]
Й painters
Gvl manual
ijjon
Ion
| normal
[•v|on
ri»
(* *j«None>
R characters
double array]
Qon
Ke(ice_VflndoweuttonDownFcn*,Qctro£iRjidata(gcbo))
tce(lce_vvMDw®uttonMcrtiorjFcn’QcboJLjRJidate(gcbo))
Рис. Б.2. а) Просмотр объекта в GUIDE и б) контролер свойств объекта figure из ICE
Тэги входят в набор свойств, который имеется у каждого объекта GUI. Про-
кручиваемый список свойств, которые характеризуют специфический объект,
можно получить, отметив этот объект [в списке просмотр объекта из рис. Б.2, а)
или в области раскладки на рис. Б.1 с помощью инструмента выбора], а за-
тем нажав на кнопку контролер свойств, расположенную в полосе задач ре-
дактора раскладки. На рис. Б.2, б) показан список, который формируется при
выборе объекта figure1 на рис. Б.2, а). Заметим, что свойством Tag [оно вы-
делено на рис. Б.2, а)] объекта figure является идентификатор ice. Это свой-
ство весьма важно, так как GUIDE использует его при автоматической гене-
рации имен функций вызова для figure. Таким образом, например, свойство
WindowButtonDownFcn внизу окна прокрутки контролера свойств получает имя
ice_WindowButtonDownFcn. Напомним, что функции вызова являются М-функ-
1 Сгенерированный GUIDE объект figure является оболочкой для всех других объектов интер-
фейса.
Б. 2. Программируемый интерфейс ICE
циями, которые выполняются при взаимодействии пользователя с объектом GUI.
Другими заметивши (и общими для всех объектов GUI) свойствами являются
Position и Units, которые задают размер и местоположение объекта.
Наконец, отметим, что некоторые свойства являются уникальными для ря-
да объектов. Например, объект «нажимаемая кнопка» имеет свойство Callback,
определяющее функцию, которая выполняется при нажатии данной кнопки, и
свойство String, которое обозначает метку кнопки. Свойством Callback кноп-
ки Reset из ICE является reset_pushbutton_Callback [обратите внимание на
вставку ее имени Tag из рис. Б.2, а) в имя функций вызова], а ее свойством
String является «Reset». Заметим, однако, что кнопка Reset не имеет свойства
WindowButtonMotionFcn, оно является специфическим для объекта figure.
Б.2. Программируемый интерфейс ICE
Когда FIG-файл для ICE из предыдущего параграфа сохраняется в первый раз
или совершается его первый вызов (например, при нажатии кнопки Run в по-
лосе задач редактора раскладки), то GUIDE генерирует стартовый GUI М-файл
с именем ice.m. Этот файл можно модифицировать в любом стандартном тек-
стовом редакторе или в редакторе М-файлов MATLAB, и в нем определяется
то, как интерфейс откликается на действия пользователя. GUI М-файл для ICE
имеет следующий вид:1
function varargout = ice(varargin)
7, Begin initialization code DO NOT EDIT
gui_Singleton = 1;
gui_State struct(’gui_Name’, mfilename,
’gui_Singleton’, gui_Singleton,
’gui_QpeningFcn’, 0ice_OpeningFcn,
’gui_QutputFcn’, 0ice_OutputFcn,
’gui_LayoutFcn’, [],
’gui_Callback’, [] ) ;
if nargin & ischar(vararginll})
gui_State.gui_Callback = str2func(varargin!1});
end
if nargout
[varargout!1:nargout}] gui_mainfcn(gui_State, varargin!:});
else
gui_mainfcn(gui_State, varargin!:});
end
7» End initialization code DO NOT EDIT
function ice_QpeningFcn(hQbject, eventdata, handles, varargin)
handles.output = hQbject;
guidata(hQbject, handles);
% uiwait(handles.figurel);
1 Начальный М-файл, генерируемый GUIDE.
548 Приложение Б
function varargout = ice_dutputFcn(hdbject, eventdata, handles)
varargout-fl} = handles.output;
function ice_WindowButtonDownFcn(hdbject, eventdata, handles)
function ice_WindowButtonMotionFcn(hdbject, eventdata, handles)
function ice_WindowButtonUpFcn(hdbject, eventdata, handles)
function component_popup_Callback(hdbject, eventdata, handles)
function smooth_checkbox_Callback(hdbject, eventdata, handles)
function reset_pushbutton_Callback(hdbject, eventdata, handles)
function slope_checkbox_Callback(hdbject, eventdata, handles)
function resetall_pushbutton_Callback(hdbject, eventdata, handles)
function pdf_checkbox_Callback(hdbject, eventdata, handles)
function cdf_checkbox_Callback(hdbject, eventdata, handles)
function mapbar_checkbox_Callback(hdbject, eventdata, handles)
function mapimage_checkbox_Callback(hdbject, eventdata, handles)
Этот автоматически генерируемый файл является хорошей отправной точкой
или прототипом для разработки полностью функционирующего интерфейса ice.
(Отметим, что здесь мы выбросили из файла множество комментариев, генери-
руемых GUIDE, для экономии места). В следующих параграфах мы разобьем
этот программный код на четыре основные раздела:
(1) код инициализации, расположенный между двумя строками комментариев
«Dd NdT EDIT»,
(2) открытие окна и вывод функций (ice_dpeningFcn и ice_dutputFcn),
(3) функции вызова окна (т. е., функции ice_WindowButtoriDownFcn,
ice_WindowButtonMotion-Fcnи ice_WindowButtonUpFcn), и
(4) функции вызова объектов (например, reset_pushbutton_Callback).
При рассмотрении каждого из этих разделов будут разработаны рабочие вер-
сии функций ice, относящихся к данному разделу. При этом будут обсуждаться
вопросы, которые будут интересны большинству разработчиков GUI М-файлов.
Программные коды каждого раздела (для краткости) не будут помещаться в
единый файл ice.m. Он будет представлен здесь по кускам.
Обращение к функции ice были описаны в § 6.4. Оно также кратко изложено
в приводимом ниже полном справочном разделе М-функции ice.m:2
7.ICE Interactive Color Editor.
7.
7. OUT = ICE(’Property Name’, ’Property Value’, ...) transforms an
7. image’s color components based on interactively specified mapping
7. functions. Inputs are Property Name/Property Value pairs:
7.
7. Name Value
%
7» ’image’ An RGB or monochrome input image to be
7» transformed by interactively specified
2Справочный раздел окончательной версии функции ice.
Б. 2. Программируемый интерфейс ICE
mappings.
'A 7. 7. 7. 7. 7. 7. 7. 7. 7. 7. 7. 7. 7. 7. 7, 7 ’space’ The color space of the components to be modified. Possible values are ’rgb’, ’cmy’, ’hsi’, ’hsv’, ’ntsc’ (or ’yiq’), ’ycbcr’ When omitted, the RGB color space is assumed. ’wait’ If ’on’ (the default), OUT is the mapped input image and ICE returns to the calling function or workspace when closed. If ’off’, OUT is the handle of the mapped input image and ICE returns immediately. EXAMPLES: ice OR ice(’wait’, ’off’) 7. Demo user interface ice (’image’, f) 7» Map RGB or mono image ice (’image’, f, ’space’, ’hsv’) 7. Map HSV of RGB image g = ice (’image’, f) 7« Return mapped image g = ice (’image’, f, ’wait’, ’off’); 7» Return its handle
/в 7. % 7. 7. 7. 7. 7. •/ ICE displays one popup menu selectable mapping function at a time. Each image component is mapped by a dedicated curve (e.g., R, G, or B) and then by an all-component curve (e.g. RGB). Each curve’s control points are depicted as circles that can be moved, added, or deleted with a two- or three-button mouse: Mouse Button Editing Operation
/• 7. 7. 7. 7. 7. •/ Left Middle Right Move control point by pressing and dragging. Add and position a control point by pressing and dragging. (Optionally Shift-Left) Delete a control point. (Optionally Control-Left)
/• 7« 7» 7. 7. •/ Checkboxes determine how mapping functions are computed, whether the input image and reference pseudo- and full-color bars are mapped, and the displayed reference curve information (e.g. PDF) :
Ze 7. •/ Checkbox Function
/« 7. 7. 7. 7. 7. 7. Smooth Clamp Ends Show PDF Checked for cubic spline (smooth curve) interpolation. If unchecked, piecewise linear. Checked to force the starting and ending curve slopes in cubic spline interpolation to 0. No effect on piecewise linear. Display probability density function(s) [i.e.,
histogram(s)] of the image components affected
Приложение Б
% by the mapping function.
7. Show CDF Display cumulative distributions function(s)
7. instead of PDFs.
Ч <Note: Show PDF/CDF are mutually exclusive.>
% Map Image If checked, image mapping is enabled; else
7. not.
7. Map Bars If checked, pseudo- and full-color bar mapping
7. is enabled; else display the unmapped bars (a
7. gray wedge and hue wedge, respectively).
7.
7« Mapping functions can be initialized via pushbuttons:
7.
7. Button Function
7.
7. Reset Init the currently displayed mapping function
7, and uncheck all curve parameters.
7. Reset All Initialize all mapping functions.
Б.2.1. Программный код инициализации
Открывающим разделом исходного GUI М-файла (см. начало § Б.2) являет-
ся стандартный GUIDE-блок инициализации. Его целью является построение и
отображение ICE GUI с использованием соответствующего парного FIG-файла
(см. § Б-1), а также контроль доступа ко всем внутренним функциям М-файла.
Как указано в окружающих строках комментариев «DO NOT EDIT», этот блок ини-
циализации нельзя изменять. При каждом вызове ice блок инициализации созда-
ет структуру с именем gui_State, которая содержит информацию для доступа к
функциям ice. Например, поле с именем gui_Name (т. е. gui_State. gui_Name) со-
держит функцию MATLAB mf ilename, которая возвращает имя текущего испол-
няемого М-файла. Аналогично, поля fields gui_OpeningFcn и gui_OutputFcn
загружаются вместе со сгенерированными GUIDE-ом именами открывающих и
выходных функций ice (они будут обсуждаться в следующем параграфе). Если
некоторый объект ICE GUI активируется пользователем (например, при нажа-
тии кнопки), то имя функции, вызывающий этот объект, добавляется в виде поля
gui_Callback [имя этой функции должно было быть передано в виде строки в
varargin (1)].
После формирования gui_State, эта структура передается в виде входного ар-
гумента вместе с vararginf:) в функцию gui_mainfcn. Эта функция MATLAB
отвечает за создание, компоновку и отправку вызова GUI. Для ice она строит и
отображает пользовательский интерфейс и генерирует все необходимые обраще-
ния для ее открытия, вывода и вызова функций. Поскольку предыдущие версии
MATLAB могли не иметь этой функции, GUIDE в состоянии построить независи-
мую версию нормального GUI М-файла (т. е. способного работать без FIG-файла)
с помощью выбора пункта Export... из меню File. В независимой версии функ-
ция gui_mainf сп и две подфункции, ice_LayoutFcn и local_openf ig, добавля-
ются к нормальному М-файлу, зависящему от FIG-файла. Задача ice_LayoutFcn
Б. 2. Программируемый интерфейс ICE
состоит в создании ICE GUI. Независимая версия ice начинается командами
hl figure! . .
’Units’, ’characters’,.
’Color’, [0.87843137254902 0.874509803921569 0.890196078431373],.
’Colormap’, [0 0 0.5625;0 0 0.625;0 0 0.6875;0 0 0.75;...
0 0 0.8125;0 0 0.875;0 0 0.9375;0 0 l;0 0.0625 1;...
0.125 l;0 0.1875 l;0 0.25 l;0 0.3125 l;0 0.375 1;...
0 0.4375 l;0 0.5 l;0 0.5625 l;0 0.625 l;0 0.6875 1;...
0 0.75 l;0 0.8125 l;0 0.875 l;0 0.9375 l;0 1 1;...
0.0625 1 l;0.125 1 0.9375;0.1875 1 0.875;...
0.25 1 0.8125;0.3125 1 0.75;0.375 1 0.6875;...
0.4375 1 0.625;0.5 1 0.5625;0.5625 1 0.5;...
0.625 1 0.4375;0.6875 1 0.375;0.75 1 0.3125;...
0.8125 1 0.25;0.875 1 0.1875;0.9375 1 0.125;...
1 1 0.0625;l 1 0;l 0.9375 0;l 0.875 0;l 0.8125 0;...
1 0.75 0;l 0.6875 0;l 0.625 0;l 0.5625 0;l 0.5 0;...
1 0.4375 0;l 0.375 0;l 0.3125 0;l 0.25 0;...
1 0.1875 0;l 0.125 0;l 0.0625 0;l 0 0;0.9375 0 0;...
0.875 0 0;0.8125 0 0;0.75 0 0;0.6875 0 0;0.625 0 0;...
0.5625 0 0] ,.. .
’IntegerHandle’, ’off’,...
’InvertHardcopy’, get(0, ’defaultfigurelnvertHardcopy’)....
’MenuBar’, ’none’,...
’Name’, ’ICE Interactive Color Editor’,...
’NumberTitle’, ’off’,...
’PaperPosition’, get(0, ’defaultfigurePaperPosition’),...
’Position’, [0.8 65.2307692307693 92.6 30.0769230769231],...
’Renderer’, get(0, ’defaultf igureRenderer’),...
’RendererMode’, ’manual’,...
’WindowButtonDownFcn’, ’ice(>ice_WindowButtonDownFcn”, gcbo, [],...
guidata(gcbo))’,...
’WindowButtonMotionFcn’, ’ice(>ice_WindowButtonMotionFcn>, gcbo,.
[], guidata(gcbo))’,...
’WindowButtonUpFcn’, ’ice(>ice_WindowButtonUpFcn>, gcbo, [],...
guidata(gcbo))’,...
’Handlevisibility’, ’callback’,...
’Tag’, ’ice’ ,..
’UserData’, zeros(l.O));
для создания основного окна программы. Затем объекты GUI добавляются one-
раторами типа
ЫЗ = uicontrol(..
’Parent’, hl,.
3Функция uicontroK’PropertyNamel', Valuel, _) задает пользовательское интерфейсное
управление с заданными свойствами и возвращает его манипулятор.
552 Приложение Б
’Units’, ’normalized’,..
’Callback’, ’ice(>reset_pushbutton_Callback>, gcbo, [],...
guidata(gcbo))’,...
’FontSize’, 10,...
’ListboxTop’, 0,...
’Position’, [0.710583153347732 0.508951406649616...
0.211663066954644 0.0767263427109974],...
’String’, ’Reset’,.
’Tag’, ’reset_pushbutton’);
которые добавляют кнопку Reset. Отметим, что эти команды явно описывают
свойства, которые изначально были определены с помощью контролера свойств
редактора раскладки GUIDE. Наконец, обратим ваше внимание на то, что функ-
ция figure была введена в § 3.2, а функция uicontrol обеспечивает пользова-
тельское управление интерфейсом (т.е. объектом GUI) в текущем окне программы, учи-
тывая свойства пар имя/значение (например, пары ’Tag’ и ’reset_pushbutton’),
и возвращает ее манипулятор.
Б.2.2. Открытие окна и вывод функций
Первые две функции, расположенные после блока инициализации в исходном
GUI М-файле, называются функциями открытия и вывода. Эти две функции вы-
полняются сразу после того, как GUI становится виден пользователю на экране, и
когда GUI возвращает свой вывод в командную строку или в вызвавшую его про-
грамму. Обеим функциям передаются аргументы hObject, eventdata и handles.
(Эти аргументы будут также входами вызывающих функций в следующих двух
параграфах). Аргумент hOb j ect является манипулятором графического объекта,
eventdata зарезервирован для будущего использования, a handles это струк-
тура, которая обеспечивает манипуляторы объектов интерфейса, а также любых
специфических данных пользователя или приложения. Чтобы реализовать заду-
манную функциональность интерфейса ICE (см. справочный текст), обе функ-
ции ice_0peningFcn и ice_0utputFcn должны быть расширением «скелетных»
версий исходного GUI М-файла. Вот этот расширяющий блок4:
% %
function ice_0peningFcn(hUbject, eventdata, handles, varargin)
% When ICE is opened, perform basic initialization (e.g. setup
% globals, ...) before it is made visible.
'X Set ICE globals to defaults.
handles.updown = ’none’; 7, Mouse updown state
handles.plotbox = [0011];% Plot area parameters in pixels
handles.setl = [0 0; 1 1]; % Curve 1 control points
handles.set2 = [00; 1 1]; % Curve 2 control points
handles.set3 = [00; 1 1]; % Curve 3 control points
handles.set4 =[00; 11];% Curve 4 control points
handles.curve = ’setl’; % Structure name of selected curve
4 Взято из окончательной версии М-файла
Б.2. Программируемый интерфейс ICE 553
handles.cindex = 1; 7, Index of selected curve
handles.node = 0; 7. Index of selected control point
handles.below = 1; 7. Index of node below control point
handles.above = 2; % Index of node above control point
handles.smooth = [0; 0; 0; 0]; 7» Curve smoothing states
handles.slope = [0; 0; 0; 0]; Curve end slope control states
handles.cdf = [0; 0; 0; 0]; % Curve CDF states
handles.pdf = [0; 0; 0; 0]; 7. Curve PDF states
handles.output = [] ; 7» Output image handle
handles.df = [] ; Input PDFs and CDFs
handles.colortype = ’rgb’; 7» Input image color space
handles.input = []; % Input image data
handles. imagemap = 1; 7» Image map enable
handles.barmap = 1; 7, Bar map enable
handles.graybar = [] ; 7. Pseudo (gray) bar image
handles. colorbar = [] ; 7» Color (hue) bar image
7. Process Property Name/Property Value input argument pairs,
wait = ’on’;
if (nargin > 3)
for i = 1:2:(nargin 3)
if nargin - 3 == i
break;
end
switch lower(varargin{i})
case ’image’
if ndims(varargin{i + 1}) == 3
handles.input = varargin{i + I};
elseif ndims(vararginfi + I}) 2
handles.input cat(3, varargin{i + 1},
varargin{i + 1}, varargin{i + 1});
end
handles.input = double(handles.input);
inputmax = max(handles.input(:));
if inputmax > 255
handles.input = handles.input / 65535;
elseif inputmax > 1
handles.input = handles.input / 255;
end
case ’space’
handles.colortype = lower(varargin{i + 1});
switch handles.colortype
case ’cmy’
list = {’CMY’ ’Cyan’ ’Magenta’ ’Yellow’};
case {’ntsc’, ’yiq’}
list = {’YIQ’ ’Luminance’ ’Hue’ ’Saturation’};
handles.colortype = ’ntsc’;
554 Приложение Б
case ’ycbcr’
list = {’YCbCr’ ’Luminance’ ’Blue’
’Difference’ 'Red Difference’};
case ’hsv’
list = {’HSV’ ’Hue’ ’Saturation’ ’Value’};
case ’hsi’
list = {’HSI’ ’Hue’ ’Saturation’ ’Intensity’};
otherwise
list = {’RGB’ ’Red’ ’Green’ ’Blue’};
handles.colortype = ’rgb’;
end
set(handles.component_popup, ’String’, list);
case ’wait’
wait = lower(varargin{i + 1});
end
end
end
7. Create pseudo- and full-color mapping bars (grays and hues). Store
% a color space converted 1x128x3 line of each bar for mapping.
xi = 0:1/127:1; x = 0:l/6:l; x = x’;
y = [1 10001 1; 011100 0; 000111 0]’;
gb = repmat(xi, [1 1 3]); cb = interplq(x, y, xi’);
cb reshape(cb, [1 128 3]);
if “strcnp (handles.colortype, ’rgb’)
gb = eval([’rgb2’ handles.colortype ’(gb)’]);
cb = eval([’rgb2’ handles.colortype ’(cb)’]);
end
gb = round(255 * gb); gb = max(0, gb); gb = min(255, gb);
cb = round(255 * cb); cb = max(0, cb); cb = min(255, cb);
handles.graybar = gb; handles.colorbar = cb;
7. Do color space transforms, clamp to [0, 255], compute histograms
7. and cumulative distribution functions, and create output figure.
if size(handles.input, 1)
if “strcmp(handles.colortype, ’rgb’)
handles.input = eval([’rgb2’ handles.colortype
’(handles.input)’]);
end
handles.input = round(255 ♦ handles.input);
handles.input = max(0, handles.input);
handles.input = min(255, handles.input);
for i = 1:3
color = handles.input(:, i);
df = hist(color(:), 0:255);
handles.df = [handles.df; df / max(df(:))];
df = df / sum(df(:)); df = cumsum(df);
handles.df = [handles.df; df];
end
Б.2. Программируемый интерфейс ICE 555
figure; handles.output = gcf;
end
7. Compute ICE’s screen position and display image/graph.
set(0, ’Units’, ’pixels’); ssz = get(O, ’Screensize’);
set(handles.ice, ’Units’, ’pixels’);
uisz = get(handles.ice, ’Position’);
if size(handles.input, 1)
fsz = get(handles.output, ’Position’);
be = (fsz(4) uisz(4)) / 3;
if be > 0
be = be + fsz(2);
else
be = fsz(2) + fsz(4) uisz(4) 10;
end
1c = fsz(l) + (size(handles.input, 2) / 4) + (3 ♦ fsz(3) I 4);
1c = min(lc, ssz(3) uisz(3) 10);
set(handles.ice, ’Position’, [1c be 463 391]);
else
be = round((ssz(4) uisz(4)) I 2) 10;
1c = round((ssz(3) uisz(3)) / 2) 10;
set(handles.ice, ’Position’, [1c be uisz(3) uisz(4)]);
end
set(handles.ice, ’Units’, ’normalized’);
graph(handles); render(handles);
7. Update handles and make ICE wait before exit if required.
guidata(hObject, handles);
if strempi(wait, ’on’)
uiwait(handles.ice);
end
7.- -7.
function varargout = ice_0utputFcn(h0bject, eventdata, handles)
7. After ICE is closed, get the image data of the current figure
7. for the output. If ’handles’ exists, ICE isn’t closed (there was
7o no ’uiwait’) so output figure handle,
if max(size(handles)) == 0
figh = get(gcf);
imageh = get(figh.Children);
if max(size(imageh)) > 0
image = get(imageh.Children);
varargout{l} = image.CData;
end
else
varargout{l} = hObject;
end
556 Приложение Б
Вместо того, чтобы вдаваться в детали этих функций (см. комментарии, прило-
жение А и справочные разделы конкретных функций), мы отметим некоторые
общие свойства функций открытия и вывода:
1. Структура handles (как видно из множества обращений к ней) играет цент-
ральную роль в большинстве GUI М-файлов. Она выполняет две основные
функции. Поскольку она обеспечивает манипуляторы для всех графических
объектов интерфейса, ее можно использовать для доступа к свойствам объ-
ектов и их модификации. Например, открывающая функция ice использует
команды
set(handles.ice, ’Units’, ’pixels’);
uisz = get(handles.ice, ’Position’);
для доступа к размеру и местоположению ICE GUI (которые даны в пик-
селах). Эти действия состоят в присвоении свойству Units окна ice, чей
манипулятор доступен в handles.ice, значения ’pixels’, после чего счи-
тывается свойство Position окна (с помощью функции get). Функция get,
которая возвращает значение свойства, ассоциированного с графическим
объектом, также используется для получения отображаемой на экране обла-
сти с помощью оператора ssz = get(0, ’Screensize’), который имеется
в конце открывающей функции. Здесь 0 является манипулятором дисплея
компьютера (т.е. корневого окна), a ’Screensize’ это свойство, содер-
жащее его размер.
Помимо обеспечения доступа к объектам GUI, структура handles является
мощным каналом для совместного использования данных в приложениях.
Отметим, что в ней хранятся значения по умолчанию двадцати трех гло-
бальных параметров ice (начиная состоянием мыши в handles.updown и
заканчивая всем входным изображением в handles, input). Эти парамет-
ры должны сохраняться при каждом вызове ice, поэтому они добавляются
к handles при запуске ice_OpeningFcn. Например, глобальная переменная
handles.setl создается командой
handles.setl [00; 11],
где setl — это имя поля, хранящего контрольные точки функции отображе-
ния цветов, которые надо сохранить в структуре handles, а [0 0; 1 1] —
их значения по умолчанию [координаты концевых точек кривой (0,0) и
(1,1)]. Перед тем, как завершить выполнение функции, в которой модифи-
цировалась структура handles, необходимо сделать вызов5
guidata(h0bject, handles)
и сохранить переменную handles в виде данных приложения в окне с ма-
нипулятором hObject.
5Функция guidata(H, DATA) сохраняет специфические данные в виде окна данных приложения.
Н — это манипулятор, который идентифицирует окно — он может быть самим окном или любым
объектом этого окна.
Б.2. Программируемый интерфейс ICE 557^
2. Как и многие встроенные графические функции, ice_OpeningFcn обраба-
тывает входные аргументы (за исключением hOb j ect, eventdata и handles)
по парам: имя и значение свойства. Если имеется более трех входных аргу-
ментов (т. е. nargin > 3), то выполняется цикл, который пропускает вход-
ные аргументы по парам [for i 1:2: (nargin 3)|. Для каждой входной
пары первый аргумент используется для управления конструкцией switch,
switch lower(varargin{i}),
которая обрабатывает второй аргумент соответствующим образом. Напри-
мер, в случае ’ space’, команда
handles.colortype = lower(varargin{i+l});
присваивает полю colortype значение второго аргумента входной пары.
Это значение затем используется для задания в ICE цветовых компонент
выпадающих опций (т. е. свойства String объекта component_popup). Позже
это значение используется для преобразования компонент входного изобра-
жения в желаемое пространство посредством команды
handles. input = eval( [’rgb2’
handles.colortype ’(handles.input)’ ] );
где встроенная функция eval(s) побуждает MATLAB выполнить строку s
как команду или оператор (см § 12.4.1). Если, к примеру, handles.input —
это ’hsv’, то eval от аргумента [ ’ rgb2 ’ ’hsv ’ ’ (handles. input) ’ ] , озна-
чающего соединенную строку ’rgb2hsv(handles. input) ’, выполняет стан-
дартную команду преобразования компонент входного RGB -изображения
в цветовое пространство HSV (см. § 6.2.3).
3. Команда
uiwait(handles.figure1);
в стартовом GUI М-файле преобразуется в условный оператор
if strcmpi(wait, ’on’) uiwait(handles.ice); end
в конечной версии функции ice_OpeningFcn. В общем случае команда
uiwait(fig)
блокирует выполнение кодового потока MATLAB до тех пор, пока выпол-
няется uiresume или пока окно fig не будет уничтожено (т. е. закрыто).
[При отсутствии входных аргументов uiwait эквивалентно uiwait(gcf),
где функция MATLAB gcf возвращает манипулятор текущего окна]. Когда
ice не занят выполнением преобразования входного изображения, но сразу
возвращает результат (до закрытия ICE GUI), входная пара имя/значения
’wait’/’off’ должна содержаться в обращении. В противном случае, ICE
не вернет управление вызвавшей ее программе или командной строке до
558 Приложение Б
тех пор, пока сама она не будет закрыта, т. е. до тех пор, пока пользователь
не закончит взаимодействовать с интерфейсом (и с функциями преобразо-
вания цвета). В этой ситуации функция ice_OutputFcn не может получить
преобразованное изображение из структуры handles, поскольку она уже не
будет существовать после закрытия GUI. Как можно обнаружить в оконча-
тельной версии функции, ICE извлекает данные изображения из свойства
CData сохраненного выходного окна преобразованного изображения. Если
выходное преобразованное изображение не должно возвращаться функцией
ice, оператор uiwait в ice_OpeningFcnHe выполняется, ice_OutputFcn вы-
зывается сразу после открывающей функции (задолго до закрытия GUI), и
манипулятор выходного окна преобразованного изображения возвращается
в вызвавшую программу или в командную строку.
Наконец, отметим, что ряд внутренних функций вызывается с помощью
ice_OpeningFcn. Все они являются внутренними функциями ice. Ниже приво-
дится их список. Обратите внимание на то, что эти функции дают дополнитель-
ные примеры использования структуры handles при работе с GUI MATLAB.
Например, команды
nodes = getfield(handles, handles.curve)
и
nodes = getfield(handles, [’set’num2str(i)])
из внутренних функций graph и render используются для доступа к заданным
интерактивно контрольным точкам различных кривых отображений ICE. В об-
щей форме
F = getfield(S, ’field’)
возвращает в F содержимое поля ’field’ структуры S.6
7. -7.
function graph(handles)
7о Interpolate and plot mapping functions and optional reference
7. PDF(s) or CDF(s) .
nodes = getfield(handles, handles.curve);
c = handles.cindex; dfx = 0:1/255:1;
colors = [’k’ ’r’ ’g’ ’b’];
7. For piecewise linear interpolation, plot a map, map + PDF/CDF, or
7. map + 3 PDFs/CDFs.
if “handles.smooth(handles.cindex)
if (“handles.pdf(c) & “handles.cdf(c)) |
(size(handles.df, 2) == 0)
plot(nodes(:, 1), nodes(:, 2), ’b-’,
nodes(:, 1), nodes(:, 2), ’ko’,
’Parent’, handles.curve_axes);
elseif c > 1
^Окончательная версия М-файла с внутренними функциями.
Б.2. Программируемый интерфейс ICE 559
i 2 * с 2 handles.pdf(с);
plot(dfx, handles.df(i, :), [colors(c)
nodes(: 1), nodes(: 2), ’k-’,
nodes(:, 1), nodes(: 2), ’ко’,
’Parent’, handles.curve_axes);
elseif c == 1
i = handles.cdf(c);
plot(dfx, handles.df(i +1, :), ’r-’,
dfx, handles.df(i +3, :), ’g-’,
dfx, handles.df(i +5, :), ’b-’,
nodes(:, 1), nodes(: 2), ’k-’,
nodes(:, 1), nodes(:, 2), ’ко’,
’Parent’, handles.curve_axes);
end
7. Do the same for smooth (cubic spline) interpolations,
else
x = 0:0.01:1;
if “handles.slope(handles.cindex)
у = spline(nodes(: 1), nodes(: 2), x);
else
у = spline(nodes(:, 1), [0; nodes(: 2); 0], x);
end
i find(y > 1); y(i) 1;
i = find(y < 0); y(i) = 0;
if (“handles.pdf(c) & “handles.cdf(c)) |
(size(handles.df, 2) == 0)
plot(nodes(:, 1), nodes(:, 2), ’ко’, x, y, ’b-’,,...
’Parent’, handles.curve_axes);
elseif c > 1
i = 2 * c 2 handles.pdf(c);
plot(dfx, handles.df(i, :), [colors(c)
nodes(:, 1), nodes(:, 2), ’ко’, x, y, ’k-’,
’Parent’, handles.curve_axes);
elseif c == 1
i = handles.cdf(c);
plot(dfx, handles.df(i +1, :), ’r-’,
dfx, handles.df(i +3, :), ’g-’,
dfx, handles.df(i +5, :), ’b-’,
nodes(:, 1), nodes(:, 2), ’ко’, x, y, ’k-’,
’Parent’, handles.curve_axes);
end
end
7, Put legend if more than two curves are shown.
s = handles.colortype;
if strcmp(s, ’ntsc’)
s ’yiq’;
end
if (с = 1) & (handles.pdf(c) | handles.cdf(с))
si = [’- ’ upper(s(l))];
if length(s) == 3
s2 = [’- ’ upper(s(2))]; s3 = [’- upper(s(3))];
else
s2 = [’- upper(s(2)) s(3)] ; s3 = [’- ’ upper(s(4)) s(5)] ;
end
else
si = >; s2 = >; s3 = >;
end
set(handles.red_text, ’String’, si);
set(handles.green_text, ’String’, s2) ;
set(handles.blue_text, ’String’, s3) ;
7.
function [inplot, x, y] cursor(h, handles)
7. Translate the mouse position to a coordinate with respect to
7. the current plot area, check for the mouse in the area and if so
7. save the location and write the coordinates below the plot.
set(h, ’Units’, ’pixels’);
p get(h, ’CurrentPoint’);
x = (p(l, 1) handles.plotbox(l)) / handles.plotbox(3);
у = (p(l, 2) handles.plotbox(2)) / handles.plotbox(4);
if x > 1.05 | x < -0.05 | у > 1.05 | у < -0.05
inplot 0;
else
x min(x, 1); x = max(x, 0);
у = min(y, 1); у = max(y, 0);
nodes = getfield(handles, handles.curve);
x = round(256 * x) / 256;
inplot = 1;
set(handles.input_text, ’String’, num2str(x, 3));
set(handles.output_text, ’String’, num2str(y, 3));
end
set(h, ’Units’, ’normalized’);
7.
function у = render(handles)
7 Map the input image and bar components and convert them to RGB
7. (if needed) and display.
set(handles.ice, ’Interruptible’, ’off’);
set(handles.ice, ’Pointer’, ’watch’);
ygb = handles.graybar; ycb = handles.colorbar;
yi = handles.input; mapon = handles.barmap;
imageon = handles.imagemap & size(handles.input, 1);
for i = 2:4
nodes = getfield(handles, [’set’ num2str(i)]);
t = lut(nodes, handles.smooth(i), handles.slope(i));
Б. 2. Программируемый интерфейс ICE 561
if imageon
yi(:, i 1) = t(yi(: i 1) + 1);
end
if mapon
ygb(:, i 1) = t(ygb(: i 1) + 1) ;
ycb(:, i 1) = t(ycb(: i 1) + 1);
end
end
t lut(handles.set1, handles.smooth(1), handles.slope(1));
if imageon
yi = t(yi + 1);
end
if mapon
ygb = t(ygb + 1); ycb = t(ycb + 1);
end
if “strcmp(handles.colortype, ’rgb’)
if size(handles.input, 1)
yi = yi / 255;
yi = eval([handles.colortype ’2rgb(yi)’]);
yi = uint8(255 * yi);
end
ygb = ygb / 255; ycb = ycb / 255;
ygb = eval([handles.colortype ’2rgb(ygb)’]);
ycb eval([handles.colortype ’2rgb(ycb)’ ] ) ;
ygb uint8(255 * ygb); ycb = uint8(255 * ycb);
else
yi = uint8(yi); ygb = uint8(ygb); ycb = uint8(ycb);
end
if size(handles.input, 1)
figure(handles.output); imshow(yi);
end
ygb = repmat(ygb, [32 1 1]); ycb repmat(ycb, [32 1 1]);
axes(handles.gray_axes); imshow(ygb);
axes(handles.color_axes); imshow(ycb);
figure(handles.ice);
set(handles.ice, ’Pointer’, ’arrow’);
set(handles.ice, ’Interruptible’, ’on’);
% -7.
function t lut(nodes, smooth, slope)
7. Create a 256 element mapping function from a set of control
% points. The output values are integers in the interval [0, 255].
X Use piecewise linear or cubic spline with or without zero end
7, slope interpolation.
t 255 * nodes; i = 0:255;
if “smooth
t = [t; 256 256]; t = interplq(t(:, 1), t(:, 2), i’);
562 Приложение Б
else
if "slope
t = spline(t(:, 1), t(: 2), i);
else
t = spline(t(: 1), [0; t(: 2) ; 0] , i) ;
end
end
t round(t); t = max(0, t) ; t = min(255, t);
7. -7.
function out spreadout(in)
7. Make all x values unique.
7, Scan forward for non-unique x’s and bump the higher indexed x-
7, but don’t exceed 1. Scan the entire range.
nudge 1 / 256;
for i = 2:size(in, 1) 1
if in(i, 1) <= in(i 1, 1)
in(i, 1) = min(in(i 1, 1) + nudge, 1);
end
end
7, Scan in reverse for non-unique x’s and decrease the lower indexed
’/, x but don’t go below 0. Stop on the first non-unique pair,
if in(end, 1) == in(end -1,1)
for i = size(in, 1):-1:2
if in(i, 1) <= in(i 1, 1)
in(i 1, 1) = max(in(i, 1) nudge, 0);
else
break;
end
end
end
% If the first two x’s are now the same, init the curve.
if in(l, 1) == in(2, 1)
in = [0 0; 1 1] ;
end
out in;
7. -7.
function g = rgb2cmy(f)
7, Convert RGB to CMY using IPT’s imcomplement.
g imcomplement(f);
7. -------------7.
function g = cmy2rgb(f)
7, Convert CMY to RGB using IPT’s imcomplement.
g = imcomplement(f);
Б.2.3. Функции вызовов окна
Сразу после функций открытия и вывода ICE в исходном GUI М-файле рас-
положены три функции вызова (см. начало § Б.2) ice_WindowButtonDownFcn,
ice.WindowButtonMotionFcn и ice_WindowButtonUpFcn. В автоматически гене-
рируемом М-файле они являются фиктивными функциями, т. е. одними заголов-
ками function, за которыми не следует никакой программный код. Полностью
разработанные коды этих трех функций, задачей которых является обработка
действий с мышью (нажатие кнопок, перетаскивание контрольных точек ICE-
объектов кривых curve_axes), приведены ниже.78
7. -7.
function ice_WindowButtohDownFcn(hObject, eventdata, handles)
7, Start mapping function control point editing. Do move, add, or
7. delete for left, middle, and right button mouse clicks (’normal’,
7o ’extend’, and ’alt’ cases) over plot area.
set(handles.curve_axes, ’Units’, ’pixels’);
handles.plotbox = get(handles.curve_axes, ’Position’);
set(handles.curve_axes, ’Units’, ’normalized’);
[inplot, x, y] cursor(hObject, handles);
if inplot
nodes = getfield(handles, handles.curve);
i find(x >= nodes(: 1)); below = max(i);
above = min(below + 1, size(nodes, 1));
if (x nodes (below, 1)) > (nodes (above, 1) x)
node = above;
else
node = below;
end
deletednode = 0;
switch get(hObject, ’SelectionType’)
case ’normal’
if node == above
above = min(above + 1, size(nodes, 1));
elseif node == below
below = max(below 1, 1);
end
if node == size(nodes, 1)
below = above;
elseif node == 1
above = below;
end
if x > nodes (above, 1)
x = nodes(above, 1);
7Функция S = setfieldCS, ’field’, V) присваивает обозначенным полям значения V. Затем
возвращается модифицированная структура.
®Функции вызовов окна ice.
elseif x < nodes(below, 1)
x = nodes(below, 1);
end
handles.node = node; handles.updown = ’down’;
handles.below = below; handles.above = above;
nodes(node, :) [x y];
case ’extend’
if “length(find(nodes(:, 1) == x))
nodes [nodes(l:below, [x y] ; nodes(above:end, :)];
handles.node = above; handles.updown = ’down’;
handles.below = below; handles.above = above + 1;
end
case ’alt’
if (node _= 1) & (node size(nodes, i))
nodes(node, :) [] ; deletednode = 1;
end
handles.node = 0;
set(handles.input_text, ’String’, >);
set(handles.output-text, ’String’, >);
end
handles setfield(handles, handles.curve, nodes);
guidata(hObject, handles);
graph(handles);
if deletednode
render(handles);
end
end
7.
function ice_WindowButtonMotionFcn(hObject, eventdata, handles)
% Do nothing unless a mouse ’down’ event has occurred. If it has,
% modify control point and make new mapping function.
if _strcmpi(handles.updown, ’down’)
return;
end
[inplot, x, y] cursor(hObject, handles);
if inplot
nodes = getfield(handles, handles.curve);
nudge = handles.smooth(handles.cindex) / 256;
if (handles.node ~= 1) & (handles.node _= size(nodes, 1))
if x >= nodes(handles.above, 1)
x = nodes(handles.above, 1) nudge;
elseif x <= nodes(handles.below, 1)
x = nodes(handles.below, 1) + nudge;
end
else
if x > nodes(handles.above, 1)
х = nodes(handles.above, 1);
elseif x < nodes(handles.below, 1)
x = nodes(handles.below, 1);
end
end
nodes(handles.node, :) [x y];
handles = setfield(handles, handles.curve, nodes);
guidata(hObject, handles);
graph(handles);
end
7. -7.
function ice_WindowButtonUpFcn(hObject, eventdata, handles)
% Terminate ongoing control point move or add operation. Clear
7o coordinate text below plot and update display.
update = strcmpi(handles.updown, ’down’);
handles.updown = ’up’; handles.node = 0;
guidata(hObject, handles);
if update
set(handles.input_text, ’String’, >);
set(handles.output_text, ’String’, >);
render(handles);
end
В общем случае вызовы окна совершаются в ответ на взаимодействия с объектами
или окном — неактивным объектом uicontrol. Более точно,
Выполняется WindowButtonDownFcnnpH нажатии кнопки мыши, когда кур-
сор стоит в окне, но не над разрешенным объектом uicontrol (например,
кнопка или выпадающее меню).
Выполняется WindowButtonMotionFcn при перемещении мыши с нажатой
кнопкой по рабочему окну.
Выполняется WindowButtonUpFcn, когда пользователь освобождает кнопку
мыши после нажатия этой кнопки в окне, но не над разрешенным объектом
uicontrol.
Задачи и поведение функций вызовов окна задокументированы (с помощью
комментариев) в программном коде. Сделаем некоторые общие вспомогательные
наблюдения по поводу окончательной реализации.
1. Поскольку функция ice_WindowButtonDownFcn вызывается при всех нажа-
тиях кнопок мыши в окне ice (за исключением расположения над актив-
ными объектами), первая задача вызываемой функции состоит в определе-
нии, находится ли курсор в пределах области графика ice (т. е. в объекте
curve_axes). Если курсор расположен вне этой области, то мышь должна
игнорироваться. Эта проверка совершается внутренней функцией cursor,
текст которой был приведен в предыдущем параграфе. В коде cursor ко-
МННДЗ,
р = get(h, ’CurrentPoint’);
Приложение Б
возвращает текущие координаты курсора. Переменная h передается из
ice_WindowBu.ttoriDown.Fcii и происходит из входного аргумента hObject. Во
всех вызовах окна hObject является манипулятором сервиса, запрашивае-
мого окном. Свойство ’CurrentPoint ’ содержит положение курсора в окне
в виде вектора-строки из двух компонент [х у].
2. Поскольку ice сконструирована для работы с двух- или трехкнопочной мы-
шью, функция ice_WindowButtonDownFcn должна определить, какая кнопка
активировала каждый вызов. Как видно из программного кода, это де-
лается с помощью конструкции switch с использованием свойства окна
’SelectionType’ События ’normal’, ’extent’ и ’alt’ обозначают, соот-
ветственно, нажатие левой, средней и правой кнопок трехкнопочной мыши
(или, соответственно, левой, левой+shift и левой+ctrl кнопки двухкнопоч-
ной мыши). Они используются для операций переключения добавленной
контрольной точки, ее перемещения и удаления.
3. Отображаемая в ICE функция преобразования обновляется (через внут-
реннюю функцию graph) каждый раз, когда изменяется контрольная точ-
ка, но выходное окно, чей манипулятор хранится в поле handles.output,
обновляется только при освобождении кнопки мыши. Это предусмотрено
по той причине, что вычисление выходного изображения, которое совер-
шается функцией render, может быть достаточно затратным по времени.
При этом совершается раздельное преобразование трех цветовых компонент
изображения, преобразование изображения по «всекомпонентной» кривой
и конвертирование результата в RGB-пространство для показа на дисплее.
Отметим, что без надлежащей осторожности контрольные точки отобра-
жающей функции могут быть случайно неправильно модифицированы в
процессе длительной обработки выходного изображения.
Чтобы избежать этой неприятности, ice контролирует возможные программ-
ные прерывания от разных вызывающих функций. Все графические объек-
ты MATLAB имеют свойство ’ Interruptible ’, которое установлено в ’ on ’,
что означает разрешение на прерывание объекта. Если оно переключено в
’off ’, то вызов, который совершается во время совершения теперь непре-
рываемой функции или игнорируется (т.е. отменяется), или помещается в
очередь событий для позднейшей обработки. Судьба прерывающих вызо-
вов определяется свойством ’BusyAction’ прерываемого объекта. Если оно
установлено в ’cancel’, то происходит отмена, если же оно равно ’queue’,
то вызов обрабатывается после завершения непрерываемого процесса.
Функция ice_WindowButtonUpFcn использует описанный выше механизм
для приостановки (на время вычисления выходного изображения) возмож-
ности пользователя манипулировать контрольными точками функции отоб-
ражения. Последовательность
set(handles.ice, ’Interruptible’, ’off’);
set(handles.ice, ’Pointer’, ’watch’);
set(handles.ice, ’Pointer’, ’arrow’);
set(handles.ice, ’Interruptible’, ’on’);
из внутренней функции render переключает свойство ’Interruptible’ ра-
бочего окна ice в положение ’off’ во время выполнения преобразования
входного изображения и изменения его (полных или псевдо) цветов. Это
предотвращает случайное изменение положения контрольных точек отоб-
ражающих функций при выполнении самого преобразования. Отметим так-
же, что свойство окна ’ Pointer ’ устанавливается в положение ’ watch ’, что
указывает на то, что ice занята, а положение ’arrow’ говорит о том, что
выходные вычисления завершены.
Б.2.4. Функции вызовов объектов
Последние девять строк исходного GUI М-файла из начала § Б.2 являются фик-
тивными функциями вызовов объектов. Подобно функциям вызовов окна из
предыдущего параграфа, в автоматически генерируемом макете функций вы-
зовов объектов отсутствует программный код. Далее приводится полностью раз-
работанный текст этих программ. Отметим, что каждая функция обрабатывает
взаимодействие пользователя с различными объектами ice uicontrol (нажима-
емые кнопки и т. п.), и ее имя получается присоединением к свойству Tag строки
’ -Callback ’ Например, вызов функции, ответственной за выбор функции отоб-
ражения имеет имя component_popup_Callback. Она вызывается, когда пользо-
ватель активирует (нажимает) соответствующий пункт меню. Отметим также,
что входной аргумент hOb j ect является манипулятором выпадающего графиче-
ского объекта, а не манипулятором окна ice (как это было для функций оконных
вызовов в предыдущем параграфе). Вызовы объектов ICE имеют небольшие про-
граммные коды и их документация является достаточно подробной.9
7. -7.
function component_popup_Callback(hObject, eventdata, handles)
7, Accept color component selection, update component specific
% parameters on GUI, and draw the selected mapping function,
c = get(hObject, ’Value’);
handles.cindex = c;
handles.curve = strcat(’set’, num2str(c));
guidata(hObject, handles);
set(handles.smooth-checkbox, ’Value’, handles.smooth(c));
set(handles.slope_checkbox, ’Value’, handles.slope(c)) ;
set(handles.pdf_checkbox, ’Value’, handles.pdf(c));
set(handles.cdf_checkbox, ’Value’, handles.cdf(c));
graph(handles);
7. -7.
function smooth_checkbox_Callback(hObject, eventdata, handles)
7i Accept smoothing parameter for currently selected color
7. component and redraw mapping function.
if get(hObj ect, ’Value’)
handles.smooth(handles.cindex) 1;
9Функции вызовов объектов ice.
568 Приложение Б
nodes = getfield(handles, handles.curve);
nodes = spreadout(nodes);
handles = setfield(handles, handles.curve, nodes);
else
handles.smooth(handles.cindex) = 0;
end
guidata(hObject, handles);
set(handles.ice, ’Pointer’, ’watch’);
graph(handles); render(handles);
set(handles.ice, ’Pointer’, ’arrow’);
7. -7,
function reset_pushbutton_Callback(hObject, eventdata, handles)
7, Init all display parameters for currently selected color
% component, make map 1:1, and redraw it.
handles = setfield(handles, handles.curve, [0 0; 1 1]);
c = handles.cindex;
handles.smooth(c) 0; set(handles.smooth_checkbox, ’Value’, 0);
handles.slope(c) 0; set(handles.slope_checkbox, ’Value’, 0);
handles.pdf(c) = 0; set(handles.pdf-Checkbox, ’Value’, 0);
handles.cdf(c) 0; set(handles.cdf_checkbox, ’Value’, 0);
guidata(hObject, handles);
set(handles.ice, ’Pointer’, ’watch’);
graph(handles); render(handles);
set(handles.ice, ’Pointer’, ’arrow’);
7. -7.
function slope_checkbox_Callback(hObject, eventdata, handles)
7. Accept slope clamp for currently selected color component and
7, draw function if smoothing is on.
if get(hObject, ’Value’)
handles.slope(handles.cindex) 1;
else
handles.slope(handles.cindex) 0;
end
guidata(hObject, handles);
if handles.smooth(handles.cindex)
set(handles.ice, ’Pointer’, ’watch’);
graph(handles); render(handles);
set(handles.ice, ’Pointer’, ’arrow’);
end
7. -7.
function resetall_pushbutton_Callback(hObject, eventdata, handles)
7. Init display parameters for color components, make all maps 1:1,
% and redraw display.
for c = 1:4
handles.smooth(c) = 0; handles.slope(c) = 0;
handles.pdf(c) = 0; handles.cdf(c) = 0;
Б.2. Программируемый интерфейс ICE
handles setfield(handles, [’set’ num2str(c)], [0 0; 1 1]);
end
set(handles.smooth-checkbox, ’Value’, 0);
set(handles.slope_checkbox, ’Value’, 0);
set(handles.pdf-Checkbox, ’Value’, 0);
set(handles.cdf-Checkbox, ’Value’, 0) ;
guidata(hObject, handles);
set(handles.ice, ’Pointer’, ’watch’);
graph(handles); render(handles);
set(handles.ice, ’Pointer’, ’arrow’);
7. -7.
function pdf_checkbox_Callback(hObject, eventdata, handles)
7. Accept PDF (probability density function or histogram) display
% parameter for currently selected color component and redraw
% mapping function if smoothing is on. If set, clear CDF display.
if get(hObject, ’Value’)
handles.pdf(handles.cindex) 1;
set(handles.cdf-checkbox, ’Value’, 0);
handles.cdf(handles.cindex) = 0;
else
handles.pdf(handles.cindex) 0;
end
guidata(hObject, handles); graph(handles);
7. -%
function cdf_checkbox_Callback(hObject, eventdata, handles)
7, Accept CDF (cumulative distribution function) display parameter
7o for selected color component and redraw mapping function if
7, smoothing is on. If set, clear CDF display.
if get(hObject, ’Value’)
handles.cdf(handles.cindex) 1;
set(handles.pdf-Checkbox, ’Value’, 0);
handles.pdf(handles.cindex) 0;
else
handles.cdf(handles.cindex) 0;
end
guidata(hObject, handles); graph(handles);
% -7.
function mapbar_checkbox_Callback(hObject, eventdata, handles)
7. Accept changes to bar map enable state and redraw bars.
handles.barmap = get(hObject, ’Value’);
guidata(hObject, handles); render(handles);
7. -7.
function mapimage_checkbox_Callback(hObject, eventdata, handles)
7. Accept changes to the image map state and redraw image.
handles.imagemap = get(hObject, ’Value’);
guidata(hObject, handles); render(handles);
ПРИЛОЖЕНИЕ В
Введение
Это приложение содержит тексты всех М-функций, которые не были приведены
ранее в этой книге. Функции упорядочены по алфавиту. Первые строки каждой
функции набраны жирным шрифтом, что дает краткое описание функции, а
также помогает при поиске нужной функции.
А
function f = adpmedian(g, Smax)
%ADPMEDIAN Perform adaptive median filtering.
% F = ADPMEDIAN(G, SMAX) performs adaptive median filtering of
7c image G. The median filter starts at size 3-by-3 and iterates up
7o to size SMAX-by-SMAX. SMAX must be an odd integer greater than 1.
7c SMAX must be an odd, positive integer greater than 1.
if (Smax <= 1) | (Smax/2 == round(Smax/2)) | (Smax "= round(Smax))
error(’SMAX must be an odd integer > 1.’)
end
[M, N] = size(g);
'X Initial setup.
f g;
f(:) = 0;
alreadyProcessed = false(size(g));
7c Begin filtering.
for k 3:2:Smax
zmin ordfilt2(g, 1, ones(k, k), ’symmetric’);
zmax = ordfilt2(g, k * k, ones(k, k), ’symmetric’);
zmed medfilt2(g, [kk], ’symmetric’);
processUsingLevelB = (zmed > zmin) & (zmax > zmed) &
"alreadyProcessed;
zB = (g > zmin) & (zmax > g) ;
outputZxy = processUsingLevelB & zB;
outputZmed = processUsingLevelB & "zB;
f(outputZxy) g(outputZxy);
f(outputZmed) zmed(outputZmed);
alreadyProcessed = alreadyProcessed | processUsingLevelB;
if all(alreadyProcessed(:))
break;
end
end
7c Output zmed for any remaining unprocessed pixels. Note that this
7c zmed was computed using a window of size Smax-by-Smax, which is
Приложение В 571
% the final value of к in the loop.
f(“alreadyProcessed) = zmed(~alreadyProcessed);
В
function rc_new = bound2eight(rc)
%BOUND2EIGHT Convert 4-connected boundary to 8-connected boundary.
7» RC_NEW = B0UND2EIGHT(RC) converts a four-connected boundary to an
% eight-connected boundary. RC is a P-by-2 matrix, each row of
7. which contains the row and column coordinates of a boundary
7o pixel. RC must be a closed boundary; in other words, the last
% row of RC must equal the first row of RC. B0UND2EIGHT removes
7d boundary pixels that are necessary for four-connectedness but not
% necessary for eight-connectedness. RC_NEW is a Q-by-2 matrix,
% where Q <= P.
if "isempty(rc) & "isequal(rc(l, :), rc(end, :))
error(’Expected input boundary to be closed.’);
end
if size(rc, 1) <= 3
7o Degenerate case.
rc_new = rc;
return;
end
% Remove last row, which equals the first row.
rc_new = rc(i:end 1, :);
% Remove the middle pixel in four-connected right-angle turns. We
7o can do this in a vectorized fashion, but we can’t do it all at
7. once. Similar to the way the ’thin’ algorithm works in bwmorph,
7. we’ll remove first the middle pixels in four-connected turns where
7. the row and column are both even; then the middle pixels in all
% the remaining four-connected turns where the row is even and the
7 column is odd; then again where the row is odd and the column is
7, even; and finally where both the row and column are odd.
remove_locations = compute_remove_locations(rc_new);
fieldi = remove_locations & (rem(rc_new(:, 1), 2) 0) &
(rem(rc_new(: 2), 2) == 0);
rc_new(fieldl, :) [] ;
remove_locations = compute_remove_locations(rc_new);
field2 = remove_locations & (rem(rc_new(: 1), 2) == 0) &
(rem(rc_new(:, 2), 2) 1) ;
rc_new(field2, :) [] ;
remove_locations = compute_remove_locations(rc_new);
field3 = remove_locations & (rem(rc_new(:, 1), 2) == 1) & ...
(,rem(rc newt,: , 2) , 2) == 0) ;
572 Приложение В
rc_new(field3, :) [] ;
reinove_locations = compute_remove_locations(rc_new);
field4 remove_locations & (rem(rc_new(: 1), 2) 1) &
(rem(rc_new(r 2), 2) 1);
rc_new(field4, :) [] ;
7, Make the output boundary closed again.
rc.new = [rc.new; rc_new(l, :)];
%- -7.
function remove = compute_remove_locations(rc)
7. Circular diff.
d [rc(2rend, r); rc(l, :)] rc;
70 Dot product of each row of d with the subsequent row of d,
7, performed in circular fashion.
dl [d(2rend, :); d(l, :)];
dotprod sum(d .* dl, 2);
7. Locations of N, S, E, and W transitions followed by
7c a right-angle turn.
remove “all(d, 2) & (dotprod == 0);
7o But we really want to remove the middle pixel of the turn.
remove = [remove(end, :); removed rend 1, :)];
if “any(remove)
done 1;
else
idx find(remove);
rc(idx(l), :) [] ;
end
function re new = bound2four(rc)
%BOUND2FOUR Convert 8-connected boundary to 4-connected boundary.
7c RC_NEW B0UND2F0UR(RC) converts an eight-connected boundary to a
7c four-connected boundary. RC is a P-by-2 matrix, each row of
7c which contains the row and column coordinates of a boundary
7c pixel. B0UND2F0UR inserts new boundary pixels wherever there is
7c a diagonal connection,
if size(rc, 1) > 1
7c Phase 1: remove diagonal turns, one at a time until they are
7» all gone.
done 0;
rcl [rc(end 1, :); rc] ;
while “done
d diff(rcl, 1);
diagonal-locations = all(d, 2);
double-diagonals = diagonal-locations(trend 1) &
(diff(diagonal-locations, 1) 0);
double_diagonal_idx = find(double_diagonals);
turns = any(d(double_diagonal_idx, :) “= ...
Приложение В 573
d(double_diagonal_idx + 1, :), 2);
turns_idx = double_diagonal_idx(turns);
if isempty(turns_idx)
done 1;
else
first_turn = turns_idx(l);
rcl(first_turn + 1, :) (rcl(first_tum, :) +
rcl(first-turn +2, :)) /2;
if first.turn == 1
rcl(end, :) rcl(2, :);
end
end
end
rcl rcl(2:end, ;);
end
% Phase 2: insert extra pixels where there are diagonal connections,
rowdiff diff(rcl(: 1));
coldiff diff(rcl(: 2));
diagonal-locations = rowdiff & coldiff;
num_old_pixels = size(rcl, 1);
num_new_pixels = num_old_pixels + sum(diagonal_locations);
rc_new = zeros(num_new_pixels, 2);
7, Insert the original values into the proper locations in the new RC
% matrix.
idx = (1:num_old_pixels)1 + [0; cumsum(diagonal_locations)];
rc_new(idx, :) rcl;
% Compute the new pixels to be inserted.
new_pixel_offsets = [0 1; -1 0; 1 0; 0 -1);
offset_codes = 2 * (1 (coldiff(diagonal-locations) + l)/2) +
(2 (rowdiff(diagonal-locations) + l)/2);
new_pixels = rcl(diagonal-locations, :) +
new_pixel_offsets(offset_codes, :);
7. Where do the new pixels go?
insertion-locations = zeros(num_new_pixels, 1);
insertion-locations(idx) 1;
insertion-locations = “insertion-locations;
7, Insert the new pixels.
rc_new(insertion_locations, :) new_pixels;
function В = bound2im(b, M, N, xO, yO)
%BOUND2IM Converts a boundary to an image.
7. В = B0UND2IM(b) converts b, an np-by-2 or 2-by-np array
7. representing the integer coordinates of a boundary, into a binary
7» image with Is in the locations defined by the coordinates in b
7, and Os elsewhere.
7.
Приложение В
’X
% В = B0UND2IM(b, М, N) places the boundary approximately centered
% in an M-by-N image. If any part of the boundary is outside the
% M-by-N rectangle, an error is issued.
7.
XB = B0UND2IM(b, M, N, XO, YO) places the boundary in an image of
’X size M-by-N, with the topmost boundary point located at XO and
7. the leftmost point located at YO. If the shifted boundary is
7, outside the M-by-N rectangle, an error is issued. XO and XO must
% be positive integers.
[np, nc] = size(b);
if np < nc
b = b’; 7. To convert to size np-by-2.
[np, nc] size(b);
end
7« Make sure the coordinates are integers.
x = round(b(: 1));
у = round(b(:, 2));
°X Set up the default size parameters.
x x min(x) + 1;
у = у min(y) + 1;
В = false(max(x), max(y));
C = max(x) - min(x) + 1;
D = max(y) min(y) + 1;
if nargin == 1
% Use the preceding default values.
elseif nargin == 3
if С > M | D > N
error(’The boundary is outside the M-by-N region.’)
end
"X The image size will be M-by-N. Set up the parameters for this.
В = false(M, N);
°X Distribute extra rows approx, even between top and bottom.
NR = round((M - C)/2);
NC round((N D)/2); % The same for columns.
x x + NR; 7. Offset the boundary to new position.
у = у + NC;
elseif nargin == 5
if хО < 0 | уО < 0
error(’xO and yO must be positive integers.’)
end
x x + round(xO) 1;
у = у + round(yO) 1;
С C + xO 1;
D = D + yO 1;
if С > M I D > N
Приложение В 575
error(’The shifted boundary is outside the M-by-N region.’)
end
В = false(M, N);
else
error(’Incorrect number of inputs.’)
end
B(sub2ind(size(B), x, y) ) = true;
function В = boundaries (BW, conn, dir)
%BOUNDARIES Trace object boundaries.
% В = BOUNDARIES(BW) traces the exterior boundaries of objects in
7. the binary image BW. В is a P-by-1 cell array, where P is the
7, number of objects in the image. Each cell contains a Q-by-2
7. matrix, each row of which contains the row and column coordinates
7. of a boundary pixel. Q is the number of boundary pixels for the
7» corresponding object. Object boundaries are traced in the
7. clockwise direction.
7»
7» В = BOUNDARIES(BW, CONN) specifies the connectivity to use when
7. tracing boundaries. CONN may be either 8 or 4. The default
7. value for CONN is 8.
7.
7, В = BOUNDARIES(BW, CONN, DIR) specifies the direction used for
% tracing boundaries. DIR should be either ’cw’ (trace boundaries
7. clockwise) or ’ccw’ (trace boundaries counterclockwise). If DIR
7. is omitted BOUNDARIES traces in the clockwise direction.
if nargin < 3
dir = ’cw’;
end
if nargin < 2
conn = 8;
end
L = bwlabel(BW, conn);
7. The number of objects is the maximum value of L. Initialize the
% cell array В so that each cell initially contains a 0-by-2 matrix.
numObjects = max(L(:));
if numObjects > 0
В = {zeros(0, 2)};
В repmat(В, numObjects, 1);
else
В = {};
end
7. Pad label matrix with zeros. This lets us write the
7. boundary-following loop without worrying about going off the edge
% of the image.
Lp = padarray(L, [1 1], 0, ’both’);
576 Приложение В
7» Compute the linear indexing offsets to take us from a pixel to its
% neighbors.
M = size(Lp, 1);
if conn == 8
7. Order is N NE E SE S SW W NW.
offsets = [-1, M 1, M, M + 1, 1, -M + 1. -M, -M-l];
else
7. Order is N E S W.
offsets = [-1, M, 1, -M];
end
'Z next_search_direction_lut is a lookup table. Given the direction
% from pixel к to pixel k+1, what is the direction to start with when
% examining the neighborhood of pixel k+1?
if conn == 8
next_search_direction_lut = [88224466];
else
next_search_direction_lut = [4123];
end
7» next.direction.lut is a lookup table. Given that we just looked at
7» neighbor in a given direction, which neighbor do we look at next?
if conn == 8
next_direction_lut = [23456781];
else
next_direction_lut = [2341];
end
7. Values used for marking the starting and boundary pixels.
START = -1;
BOUNDARY -2;
7» Initialize scratch space in which to record the boundary pixels as
% well as follow the boundary.
scratch = zeros(100, 1);
“Z Find candidate starting locations for boundaries.
[rr, cc] find((Lp(2:end-1, :) > 0) & (Lp(l:end-2, :) == 0));
rr = rr + 1;
for к = 1:length(rr)
r = rr(k);
c = cc(k);
if (Lp(r,c) > 0) & (Lp(r 1, c) 0) & isempty(B{Lp(r, c)})
‘Z We’ve found the start of the next boundary. Compute its
7. linear offset, record which boundary it is, mark it, and
'Z initialize the counter for the number of boundary pixels.
idx = (c-l)*size(Lp, 1) + r;
which = Lp(idx);
scratch(l) idx;
Lp(idx) = START;
numPixels = 1;
currentPixel = idx;
initial_departure_direction = [];
done = 0;
next_search_direction = 2;
while “done
% Find the next boundary pixel,
direction = next_search_direction;
found_next_pixel = 0;
for к = l:length(offsets)
neighbor = currentPixel + offsets(direction);
if Lp(neighbor) "= 0
7, Found the next boundary pixel.
if (Lp(currentPixel) START) &
isempty(initial_departure_direction)
7. We are making the initial departure from
7. the starting pixel.
initial_departure_direction = direction;
elseif (Lp(currentPixel) START) &
(initial_departure_direction == direction)
7. We are about to retrace our path.
% That means we’re done.
done = 1;
found_next_pixel = 1;
break;
end
% Take the next step along the boundary.
next_search_direction =
next_search_direction_lut(direction);
found_next_pixel = 1;
numPixels = numPixels + 1;
if numPixels > size(scratch, 1)
7. Double the scratch space.
scratch(2*size(scratch, 1)) =0;
end
scratch(numPixels) = neighbor;
if Lp(neighbor) ~= START
Lp(neighbor) = BOUNDARY;
end
currentPixel = neighbor;
break;
end
direction = next_direction_lut(direction);
end
if “found_next_pixel
7. If there is no next neighbor, the object must just
‘X have a single pixel.
578 Приложение В
numPixels = 2;
scratch(2) scratch(l);
done = 1;
end
end
% Convert linear indices to row-column coordinates and save
7. in the output cell array.
[row, col] = ind2sub(size(Lp), scratch(l-.numPixels)) ;
B-twhich} = [row 1, col 1];
end
end
if strcmp(dir, ’ccw’)
for к = 1:length(В)
B{k} = B{k}(end:-1:1, :);
end
end
function [s, su] = bsubsamp(b, gridsep)
%BSUBSAMP Subsample a boundary.
7, [S, SU] = BSUBSAMP(B, GRIDSEP) subsamples the boundary В by
7. assigning each of its points to the grid node to which it is
% closest. The grid is specified by GRIDSEP, which is the
7. separation in pixels between the grid lines. For example, if
7. GRIDSEP = 2, there are two pixels in between grid lines. So, for
% instance, the grid points in the first row would be at (1,1),
7. (1,4), (1,6), and similarly in the у direction. The value
7o of GRIDSEP must be an even integer. The boundary is specified by
7. a set of coordinates in the form of an np-by-2 array. It is
*Z assumed that the boundary is one pixel thick.
°Z
% Output S is the subsampled boundary. Output SU is normalized so
‘A that the grid separation is unity. This is useful for obtaining
7t the Freeman chain code of the subsampled boundary.
7» Check input.
[np, nc] = size(b);
if np < nc
error(’B must be of size np-by-2.’);
end
if gridsep/2 “= round(gridsep/2)
error(’GRIDSEP must be an even integer.’)
end
7» Some boundary tracing programs, such as boundaries.m, end with
*A the beginning, resulting in a sequence in which the coordinates
"A of the first and last points are the same. If this is the case
7. in b, eliminate the last point.
if isequal(b(l, :), b(np, :))
Приложение В
np = np 1;
Ь = Ъ (1: пр, :) ;
end
7. Find the max x and у spanned by the boundary.
xmax = max(b(:, 1));
ymax max(b(: 2));
7» Determine the number of grid lines with gridsep points in
% between them that can fit in the intervals [l.xmax], [l.yrnax],
7. without any points in b being left over. If points are left
7. over, add zeros to extend xmax and ymax so that an integral
7« number of grid lines are obtained.
7, Size needed in the x-direction:
L gridsep + 1;
n = ceil(xmax/L);
T (n 1)*L + 1;
7« Zx is the number of zeros that would be needed to have grid
7o lines without any points in b being left over.
Zx abs(xmax T L);
if Zx == L
Zx = 0;
end
7c Number of grid lines in the x-direction, with L pixel spaces
7o in between each grid line.
GLx = (xmax + Zx 1)/L + 1;
7c And for the y-direction:
n = ceil(ymax/L);
T = (n 1)*L + 1;
Zy = abs(ymax T L) ;
if Zy L
Zy = 0;
end
GLy = (ymax + Zy 1)/L + 1;
% Form vectors of x and у grid locations.
I l:GLx;
7c Vector of grid line locations intersecting x-axis.
X(I) gridsep*! + (I gridsep);
J l:GLy;
7c Vector of grid line locations intersecting y-axis.
Y(J) gridsep*! + (J gridsep);
‘A Compute both components of the cityblock distance between each
7c element of b and all the grid-line intersections. Assign each
7c point to the grid location for which each comp of the cityblock
7» distance was less than gridsep/2. Because gridsep is an even
7c integer, these assignments are unique. Note the use of meshgrid to
7c optimize the code.
DIST = gridsep/2;
580 Приложение В
[XG, YG] = meshgrid(X, Y);
Q = 1;
for k=l:np
[I,J] = find(abs(XG b(k, 1)) <= DIST & abs(YG - b(k, 2)) <=
DIST);
IL = length(I);
ord = k*ones(IL, 1); 7, To keep track of order of input coordinates
К = Q + IL 1;
dl(Q:K, :) = cat(2, X(I) , ord);
d2(Q:K, :) = cat(2, Y(J), ord);
Q = К + 1;
end
7c d is the set of points assigned to the new grid with line
’X separation of gridsep. Note that it is formed as d=(d2,dl) to
'Z compensate for the coordinate transposition inherent in using
7. meshgrid (see Chapter 2) .
d cat(2, d2(:, 1), dl); 7. The second column of dl is ord.
*Z Sort the points using the values in ord, which is the last col in
7. d.
d = fliplr(d); ‘X So the last column becomes first.
d sortrows(d);
d fliplr(d); 7. Flip back.
7. Eliminate duplicate rows in the first two components of
7c d to create the output. The cw or ccw order MUST be preserved.
s d(:, 1:2);
[s, m, n] = unique(s, ’rows’);
70 Function unique sorts the data-Restore to original order
7. by using the contents of m.
s [s, m] ;
s fliplr(s);
s sortrows(s);
s fliplr(s);
s = s(:, 1:2);
7. Scale to unit grid so that can use directly to obtain Freeman
7c chain code. The shape does not change.
su = round(s./gridsep) + 1;
c
function image = changeclass (class, varargin)
%CHANGECLASS changes the storage class of an image.
7c 12 = CHANGECLASS (CLASS, I);
7. RGB2 = CHANGECLASS (CLASS, RGB);
7c BW2 = CHANGECLASS (CLASS, BW);
Приложение В 581
7. Х2 = CHANGECLASS (CLASS, X, ’indexed’);
7. Copyright 1993-2002 The MathWorks, Inc. Used with permission.
7. $Revision: 1.2 $ $Date: 2003/02/19 22:09:58 $
switch class
case ’uint8’
image = im2uint8(varargin!:});
case ’uintl6’
image = im2uint 16 (varargin!:)-);
case ’double’
image = im2double(varargin!:));
otherwise
error(’Unsupported IPT data class.’);
end
function [VG, A, PPG| colorgrad(f, T)
%COLORGRAD Computes the vector gradient of an RGB image.
% [VG, VA, PPG] = C0L0RGRAD(F, T) computes the vector gradient, VG,
% and corresponding angle array, VA, (in radians) of RGB image
7. F. It also computes PPG, the per-plane composite gradient
% obtained by summing the 2-D gradients of the individual color
% planes. Input T is a threshold in the range [0, 1]. If it is
7. included in the argument list, the values of VG and PPG Eire
% thresholded by letting VG(x,y) = 0 for values <= T and VG(x,y)
7. VG(x,y) otherwise. Similar comments apply to PPG. If T is not
7. included in the argument list then T is set to 0. Both output
% gradients are scaled to the range [0, 1] .
if (ndims(f) "= 3) | (size(f, 3) "= 3)
error(’Input image must be RGB.’);
end
7. Compute the x and у derivatives of the three component images
% using Sobel operators.
sh fspecial(’sobel’);
sv = sh’;
Rx = imfilter(double(f(:, D), sh, ’replicate’);
Ry = imfilter(double(f(: D), sv, ’replicate’);
Gx = imfilter(double(f(:, 2)), sh, ’replicate’);
Gy = imfilter(double(f(:, 2)), sv, ’replicate’);
Bx = imfilter(double(f(: 3)), sh, ’replicate’);
By = imfilter(double(f(: 3)), sv, ’replicate’);
7. Compute the parameters of the vector gradient.
gxx = Rx.“2 + Gx.“2 + Bx.“2;
gyy = Ry."2 + Gy."2 + By."2;
gxy Rx.*Ry + Gx.*Gy + Bx.*By;
A = 0.5*(atan(2*gxy./(gxx gyy + eps)));
GI = 0.5*((gxx + gyy) + (gxx gyy).*cos(2*A) + 2*gxy.*sin(2*A));
7. Now repeat for angle + pi/2. Then select the maximum at each point.
Приложение В
А = А + pi/2;
G2 = 0.5*((gxx + gyy) + (gxx gyy).*cos(2*A) + 2*gxy.*sin(2*A));
Gl = GKO.5;
G2 = G2."0.5;
7. Form VG by picking the maximum at each (x,y) and then scale
*A to the range [0, 1] .
VG = mat2gray(max(Gl, G2));
% Compute the per-plane gradients.
RG = sqrt(Rx.~2 + Ry."2);
GG = sqrt(Gx.~2 + Gy."2);
BG = sqrt(Bx.~2 + By."2);
% Form the composite by adding the individual results and
7. scale to [0, 1] .
PPG = mat2gray(RG + GG + BG);
% Threshold the result.
if nargin == 2
VG = (VG > T).*VG;
PPG (PPG > T).*PPG;
end
function I = colorseg(varargin)
%COLORSEG Performs segmentation of a color image.
7. S = COLORSEG(’EUCLIDEAN’, F, T, M) performs segmentation of color
% image F using a Euclidean measure of similarity. M is a l-by-3
7o vector representing the average color used for segmentation (this
7. is the center of the sphere in Fig. 6.26 of DIPUM). T is the
7. threshold against which the distances are compared.
7.
7o S = COLORSEG(’MAHALANOBIS’, F, T, M, C) performs segmentation of
7. color image F using the Mahalanobis distance as a measure of
7o similarity. C is the 3-by-3 covariance matrix of the sample color
7o vectors of the class of interest. See function covmatrix for the
7. computation of C and M.
‘A
7. S is the segmented image (a binary matrix) in which Os denote the
"A background.
°A Preliminaries.
‘A Recall that varargin is a cell array.
f = varargin{2);
if (ndims(f) "= 3) | (size(f, 3) "= 3)
error(’Input image must be RGB.’);
end
M = size(f, 1); N = size(f, 2);
*A Convert f to vector format using function imstack2vectors.
[f, L] = imstack2vectors(f);
f = double(f);
Приложение В
583
7. Initialize I as a column vector. It will be reshaped later
7. into an image.
I = zeros(M*N, 1);
T = varargin{3)-;
m = varargin{4};
m = m(:)’; 7» Make sure that m is a row vector.
if length(varargin) == 4
method = ’euclidean’;
elseif length(varargin) == 5
method = ’mahalanobis’;
else
error(’Wrong number of inputs.’);
end
switch method
case ’euclidean’
7. Compute the Euclidean distance between all rows of X and m. See
% Section 12.2 of DIPUM for an explanation of the following
7o expression. D(i) is the Euclidean distance between vector X(i,:)
7. and vector m.
p = length(f);
D = sqrt(sum(abs(f repmat(m, p, 1))."2, 2));
case ’mahalanobis’
C = varargin{5};
D = mahalanobis(f, C, m);
otherwise
error(’Unknown segmentation method.’)
end
7o D is a vector of size MN-by-1 containing the distance computations
7» from all the color pixels to vector m. Find the distances <= T.
J = f ind(D <= T) ;
7. Set the values of I (J) to 1. These are the segmented
7. color pixels.
I(J) 1;
7. Reshape I into an M-by-N image.
I = reshaped, M, N);
function c = connectpoly(x, y)
%CONNECTPOLY Connects vertices of a polygon.
7» C = CONNECTPOLY(X, Y) connects the points with coordinates given
% in X and Y with straight lines. These points are assumed to be a
’/, sequence of polygon vertices organized in the clockwise or
7, counterclockwise direction. The output, C, is the set of points
7. along the boundary of the polygon in the form of an nr-by-2
7. coordinate sequence in the same direction as the input. The last
7. point in the sequence is equal to the first.
v = [x(:), y(:)J;
584 Приложение В
Close polygon.
if ~isequal(v(end, :), v(l, :))
v(end +1, :) = v(l, :);
end
7 Connect vertices.
segments cell(l, length(v) 1);
for I = 2:length(v)
[x, y] intline(v(I 1, 1), v(I, 1), v(I 1, 2), v(I, 2));
segments!! 1} [x, y] ;
end
c cat(l, segments!:});
D
function s = diameter(L)
%DIAMETER Measure diameter and related properties of image regions.
7 S DIAMETER(L) computes the diameter, the major axis endpoints,
7 the minor axis endpoints, and the basic rectangle of each labeled
7 region in the label matrix L. Positive integer elements of L
7 correspond to different regions. For example, the set of elements
7 of L equal to 1 corresponds to region 1; the set of elements of L
7 equal to 2 corresponds to region 2; and so on. S is a structure
7 array of length max(L(:)). The fields of the structure array
7 include:
7
7 Diameter
7 MajorAxis
7 MinorAxis
7 BasicRectangle
7
7 The Diameter field, a scalar, is the maximum distance between any
7 two pixels in the corresponding region.
7
7 The MajorAxis field is a 2-by-2 matrix. The rows contain the row
7 and column coordinates for the endpoints of the major axis of the
7 corresponding region.
7
7 The MinorAxis field is a 2-by-2 matrix. The rows contain the row
7 and column coordinates for the endpoints of the minor axis of the
7 corresponding region.
7
7 The BasicRectangle field is a 4-by-2 matrix. Each row contains
7 the row and column coordinates of a corner of the
7 region-enclosing rectangle defined by the major and minor axes.
Приложение В 585
7.
7» For more information about these measurements, see Section 11.2.1
7» of Digital Image Processing, by Gonzalez and Woods, 2nd edition,
7. Prentice Hall.
s = regionprops(L, {’Image’, ’BoundingBox’)-);
for к = l:length(s)
[s(k).Diameter, s(k).MajorAxis, perim_r, perim_c]
compute_diameter(s(k));
[s(k).BasicRectangle, s(k).MinorAxis]
compute_basic_rectangle(s(k), perim_r, perim_c);
end
7»- -7.
function [d, majoraxis, r, c] compute_diameter(s)
7, [D, MAJORAXIS, R, C] COMPUTE_DIAMETER(S) computes the diameter
7o and major axis for the region represented by the structure S. S
7. must contain the fields Image and BoundingBox. COMPUTE_DIAMETER
7» also returns the row and column coordinates (R and C) of the
7o perimeter pixels of s.Image.
7, Compute row and col vmn coordinates of perimeter pixels.
[r, c] find(bwperim(s.Image));
r r(:);
c = c(:);
[rp, cp] prune_pixel_list(r, c);
num_pixels = length(rp);
switch num_pixels
case 0
d -Inf;
majoraxis ones(2, 2);
case 1
d 0;
majoraxis [rp cp; rp cp];
case 2
d (rp(2) rp(l))~2 + (cp(2) cp(l))~2;
majoraxis [rp cp];
otherwise
7o Generate all combinations of 1 :num_pixels taken two at at time.
7. Method suggested by Peter Acklam.
[idx(: 2) idx(: 1)] find(tril(ones(num_pixels), -1));
rr = rp(idx);
cc cp(idx);
dist_squared = (rr(:, 1) rr(: 2))."2+
(cc(:, 1) cc(:, 2)).~2;
[max_dist_squared, idx] = max(dist_squared);
majoraxis [rr(idx,:)’ cc(idx,:)’];
d sqrt(max_dist_squared);
upper_image_row = s.BoundingBox(2) + 0.5;
586 Приложение В
left_image_col s.BoundingBox(l) + 0.5;
majoraxis(:, 1) = majoraxis(:, 1) + upper_image_row - 1;
majoraxis(:, 2) = majoraxis(: 2) + left_image_col - 1;
end
7.- -7.
function [basicrect, minoraxis] = compute_basic_rectangle(s,
perim_r, perim_c)
7. [BASICRECT,MINORAXIS] COMPUTE_BASIC_RECTANGLE(S, PERIM_R,
7. PERIM_C) computes the basic rectangle and the minor axis
% end-points for the region represented by the structure S. S must
7. contain the fields Image, BoundingBox, MajorAxis, and
7. Diameter. PERIM_R and PERIM_C Eire the row and column coordinates
7. of perimeter of s.Image. BASICRECT is a 4-by-2 matrix, each row
7. of which contains the row and column coordinates of one corner of
7. the basic rectangle.
7. Compute the orientation of the major axis.
theta = atan2(s.MajorAxis(2, 1) s.MajorAxis(l, 1),
s.MajorAxis(2, 2) s.MajorAxisd, 2));
7. Form rotation matrix.
T [cos(theta) sin(theta); -sin(theta) cos(theta)];
% Rotate perimeter pixels.
p [perim_c perim_r];
p P * T’;
7. Calculate minimum and maximum x- and у-coordinates for the rotated
7e perimeter pixels.
x = p(: 1) ;
У = P<: 2);
min_x = min(x);
max_x = max(x);
min_y = min(y);
max_y = max(y);
comers_x = [min_x max_x max_x min_x] ’;
comers_y = [min_y min_y max_y max_y] ’;
7. Rotate corners of the basic rectangle.
corners = [corners_x corners_y] * T;
7. Translate according to the region’s bounding box.
upper_image_row = s.BoundingBox(2) + 0.5;
left_image_col = s.BoundingBox(l) + 0.5;
basicrect = [cornersf:, 2) + upper_image_row 1,
corners(:, 1) + left_image_col 1];
7» Compute minor axis end-points, rotated.
x (min_x + max_x) / 2;
yl = min_y;
y2 = max_y;
endpoints = [x yl; x y2];
7« Rotate minor axis end-points back.
Приложение В 587
endpoints = endpoints * Т;
7 Translate according to the region’s bounding box.
minoraxis = [endpoints(:, 2) + upper_image_row 1,
endpoints(: 1) + left_image_col 1] ;
7-
-7.
function [r, c] = prune_pixel_list(r, c)
7. [R, C] = PRUNE_PIXEL_LIST(R, C) removes pixels from the vectors
7 R and C that cannot be endpoints of the major axis. This
7 elimination is based on geometrical constraints described in
7 Russ, Image Processing Handbook, Chapter 8.
top = min(r);
bottom = max(r);
left = min(c);
right = max(c);
7 Which points are inside the upper circle?
x = (left + right)/2;
У = top;
radius bottom top;
inside_upper = ( (c x) "2 + (r y).~2 ) < radius~2;
7 Which points are inside the lower circle?
у = bottom;
inside_lower = ( (c x).~2 + (r y) . "2 ) < radius"2;
7 Which points are inside the left circle?
x = left;
у = (top + bottom)/2;
radius right left;
inside_left = ( (c x) . "2 + (r y) . "2 ) < radius~2;
7 Which points are inside the right circle?
x = right;
inside_right = ( (c x).~2 + (r y) . "2 ) < radius"2;
7 Eliminate points that are inside all four circles.
delete_idx = find(inside_left & inside_right &
inside_upper tc inside_lower);
r(delete_idx) [];
c(delete_idx) [] ;
F
function c = fchcode(b, conn, dir)
%FCHCODE Computes the Freeman chain code of a boundary.
7 C = FCHCODE(B) computes the 8-connected Freeman chain code of a
7 set of 2-D coordinate pairs contained in B, an np-by-2 array. C
7 is a structure with the following fields:
7 c.fcc = Freeman chain code (1-by-np)
588 Приложение В
7 . с.diff First difference of code c.fcc (1-by-np)
% c.nnn = Integer of minimum magnitude from c.fcc (1-by-np)
% c.diffmm = First difference of code c.mm (1-by-np)
% c.xOyO = Coordinates where the code starts (l-by-2)
7.
% C FCHC0DE(B, CONN) produces the same outputs as above, but
% with the code connectivity specified in CONN. CONN can be 8 for
7. an 8-connected chain code, or CONN can be 4 for a 4-connected
7. chain code. Specifying C0NN=4 is valid only if the input
7. sequence, B, contains transitions with values 0, 2, 4, and 6,
7. exclusively.
7.
7» C = FHCODE(B, CONN, DIR) produces the same outputs as above, but
% in addition, the desired code direction is specified. Values for
% DIR can be:
7.
7. ’same’ Same as the order of the sequence of points in b.
7. This is the default.
7.
% ’reverse’ Outputs the code in the direction opposite to the
% direction of the points in B. The starting point
% for each DIR is the same.
7.
7, The elements of В are assumed to correspond to a 1-pixel-thick,
7e fully-connected, closed boundary. В cannot contain duplicate
7. coordinate pairs, except in the first and last positions, which
7> is a common feature of boundary tracing programs.
7.
7. FREEMAN CHAIN CODE REPRESENTATION
7. The table on the left shows the 8-connected Freeman chain codes
7. corresponding to allowed deltax, deltay pairs. An 8-chain is
% converted to a 4-chain if (1) if conn = 4; and (2) only
% transitions 0, 2, 4, and 6 occur in the 8-code. Note that
*Z dividing 0, 2, 4, and 6 by 2 produce the 4-code.
7.
7.
7. deltax | deltay | 8-code corresp 4-code
7.
7. 0 1 0 0
X -1 1 1
X -1 0 2 1
7. -1 -1 3
7. 0-142
X 1 -1 5
7. 1 0 6 3
X 1 1 7
7.---------------------
Приложение В
7с
7, The formula z = 4*(deltax + 2) + (deltay + 2) gives the following
7c sequence corresponding to rows 1-8 in the preceding table: z =
°k 11,7,6,5,9,13,14,15. These values can be used as indices into the
7L table, improving the speed of computing the chain code. The
% preceding formula is not unique, but it is based on the smallest
% integers (4 and 2) that are powers of 2.
7. Preliminaries.
if nargin 1
dir ’same’;
conn = 8;
elseif nargin == 2
dir = ’same’;
elseif nargin == 3
7c Nothing to do here.
else
error(’Incorrect number of inputs.’)
end
[np, nc] size(b);
if np < nc
error(’B must be of size np-by-2.’);
end
7c Some boundary tracing programs, such as boundaries.m, output a
7c sequence in which the coordinates of the first and last points are
7c the same. If this is the case, eliminate the last point.
if isequal(b(l, :), b(np, :))
np = np 1;
b = b(l:np, :);
end
7, Build the code table using the single indices from the formula
7c for z given above:
C(11)=O; C(7)=l; C(6)=2; C(5)=3; C(9)=4;
C(13)=5; C(14)=6; C(15)=7;
7c End of Preliminaries.
7c Begin processing.
xO b(l, 1);
yO b(l,2);
c.xOyO = [xO, yO];
% Make sure the coordinates are organized sequentially:
7c Get the deltax and deltay between successive points in b. The
7c last row of a is the first row of b.
a = circshift(b, [-1, 0]);
X DEL a b is an nr-by-2 matrix in which the rows contain the
7c deltax and deltay between successive points in b. The two
X components in the kth row of matrix DEL are deltax and deltay
X between point (xk, yk) and (xk+1, yk+1). The last row of DEL
590 Приложение В
7, contains the deltax and deltay between (xnr, ynr) and (xl, yl) ,
% (i.e., between the last and first points in b).
DEL = a b;
7, If the abs value of either (or both) components of a pair
7. (deltax, deltay) is greater than 1, then by definition the curve
‘k is broken (or the points are out of order), and the program
7» terminates.
if any(abs(DEL(: , 1)) > 1) | any(abs(DEL(: 2)) > 1);
error(’The input curve is broken or points are out of order.’)
end
7. Create a single index vector using the formula described above,
z 4*(DEL(:, 1) + 2) + (DEL(:, 2) +2);
7. Use the index to map into the table. The following are
7. the Freeman 8-chain codes, organized in a 1-by-np array,
fee = C(z);
% Check if direction of code sequence needs to be reversed,
if strcmp(dir, ’reverse’)
fee = coderev(fcc); 7o See below for function coderev.
end
7» If 4-connectivity is specified, check that all components
7, of fee are 0, 2, 4, or 6.
if conn == 4
val find(fcc 1 | fee == 3 | fee == 5 | fee ==7 );
if isempty(val)
fee = fee./2;
else
warning(’The specified 4-connected code cannot be satisfied.’)
end
end
7o Freeman chain code for structure output,
c.fcc = fee;
7. Obtain the first difference of fee.
c.diff = codediff(fee,conn); 7» See below for function codediff.
7e Obtain code of the integer of minimum magnitude,
c.mm = minmag(fcc); % See below for function minmag.
7o Obtain the first difference of fee
c.diffmm = codediff(c.mm, conn);
7.-
function cr = coderev(fee)
7. Traverses the sequence of 8-connected Freeman chain code fee in
the opposite direction, changing the values of each code
7, segment. The starting point is not changed, fee is a 1-by-np
% array.
7o Flip the array left to right. This redefines the starting point
7. as the last point and reverses the order of >travel> through the
7. code.
Приложение В
591
сг = fliplr(fcc);
7, Next, obtain the new code values by traversing the code in the
7. opposite direction. (0 becomes 4, 1 becomes 5, 5 becomes 1,
7. 6 becomes 2, and 7 becomes 3).
indl find(0 <= cr & cr <= 3) ;
ind2 find(4 <= cr & cr <= 7) ;
cr(indl) cr(indl) + 4;
cr(ind2) cr(ind2) 4;
7.- -7.
function z = minmag(c)
7.MINMAG Finds the integer of minimum magnitude in a chain code.
7, Z = MINMAG(C) finds the integer of minimum magnitude in a given
% 4- or 8-connected Freeman chain code, C. The code is assumed to
% be a 1-by-np array.
% The integer of minimum magnitude starts with min(c), but there
7. may be more than one such value. Find them all,
I findfc == min(c));
7 and shift each one left so that it starts with min(c).
J = 0;
A = zeros(length(I), length(c));
for к = I;
J J + 1;
A(J, :) = circshift(c,CO -(k-1)]);
end
% Matrix A contains all the possible candidates for the integer of
7. minimum magnitude. Starting with the 2nd column, succesively find
% the minima in each column of A. The number of candidates decreases
7, as the seach moves to the right on A. This is reflected in the
7, elements of J. When length(J)=l, one candidate remains. This is
% the integer of minimum magnitude.
CM, N] = size(A);
J (1:M)’;
for к 2:N
D(1:M, 1) = Inf;
D(J, 1) A(J, k);
amin = min(A(J, k));
J = find(D(: 1) amin);
if length(J)==l
z A(J, :);
return
end
end
7.- -7.
function d codediff(fee, conn)
7oCODEDIFF Computes the first difference of a chain code.
% D = CODEDIFF(FCC) computes the first difference of code, FCC. The
592 Приложение В
7, code FCC is treated as a circular sequence, so the last element
7, of D is the difference between the last and first elements of
7. FCC. The input code is a 1-by-np vector.
7.
7, The first difference is found by counting the number of direction
7. changes (in a counter-clockwise direction) that separate two
7o adjacent elements of the code.
sr = circshift(fcc, [0, -1]); 7» Shift input left by 1 location,
delta = sr fee;
d = delta;
I find(delta < 0);
type conn;
switch type
case 4 % Code is 4-connected
d(I) d(I) + 4;
case 8 '/• Code is 8-connected
d(I) = d(I) + 8;
end
G
function g — gscale(f, varargin)
%GSCALE Scales the intensity of the input image.
7o G = GSCALE(F, ’full8’) scales the intensities of F to the full
7. 8-bit intensity range [0, 255] . This is the default if there is
7 only one input argument.
7.
% G GSCALE(F, ’fulll6’) scales the intensities of F to the full
7. 16-bit intensity range [0, 65535] .
7.
7. G = GSCALE(F, ’minmax’, LOW, HIGH) scales the intensities of F to
% the range [LOW, HIGH]. These values must be provided, and they
7. must be in the range [0, 1], independently of the class of the
7, input. GSCALE performs any necessary scaling. If the input is of
7, class double, and its values are not in the range [0, 1] , then
% GSCALE scales it to this range before processing.
7.
% The class of the output is the same as the class of the input,
if length(varargin) == 0 7o If only one argument it must be f.
method = ’fu!18’;
else
method = varargin-[l)-;
end
if strcmp(class(f), ’double’) & (max(f(:)) > 1 I min(f(:)) < 0)
Приложение В 593
f = mat2gray(f);
end
7, Perform the specified scaling,
switch method
case ’fu!18’
g = im2uint8(mat2gray(double(f)));
case ’fu!116’
g = im2uintl6(mat2gray(double(f)));
case ’minmax’
low = varargin{2}; high = varargin{3]-;
if low > 1 | low < 0 | high > 1 | high < 0
error(’Parameters low and high must be in the range [0, 1].’)
end
if strcmp(class(f), ’double’)
low_in = min(f(:));
high_in = max(f (:));
elseif strcmp(class(f), ’uint8’)
low_in = double(min(f(:)))./255;
high_in = double(max(f(:)))./255;
elseif strcmp(class(f), ’uintl6’)
low_in = double(min(f(:)))./65535;
high_in = double(max(f(:)))./65535;
end
% imadjust automatically matches the class of the input.
g = imadjust(f, [low_in high_in], [low high]);
otherwise
error(’Unknown method.’)
end
I
function [X, R] = imstack2vectors(S, MASK)
%IMSTACK2VECTORS Extracts vectors from an image stack.
% [X, R] imstack2vectors(S, MASK) extracts vectors from S, which
7. is an M-by-N-by-n stack array of n registered images of size
7. M-by-N each (see Fig. 11.24). The extracted vectors are arranged
% as the rows of array X. Input MASK is an M-by-N logical or
7, numeric image with nonzero values (Is if it is a logical array)
7. in the locations where elements of S are to be used in forming X
7. and Os in locations to be ignored. The number of row vectors in X
7, is equal to the number of nonzero elements of MASK. If MASK is
7. omitted, all M*N locations are used in forming X. A simple way to
7. obtain MASK interactively is to use function roipoly. Finally, R
7. is an array whose rows are the 2-D coordinates containing the
594 Приложение В
7, region locations in MASK from which the vectors in S were
7. extracted to form X,
% Preliminaries.
CM. N, n] = size(S);
if nargin == 1
MASK = true(M, N);
else
MASK = MASK "= 0;
end
7. Find the set of locations where the vectors will be kept before
7o MASK is changed later in the program.
Cl, J] = find(MASK);
R = Cl, J] ;
7. Now find X.
7o First reshape S into X by turning each set of n values along the
7. third dimension of S so that it becomes a row of X. The order is
7, from top to bottom along the first column, the second column,
'k and so on.
Q M*N;
X = reshape(S, Q, n);
7. Now reshape MASK so that it corresponds to the right locations
7, vertically along the elements of X.
MASK = reshape(MASK, Q, 1);
% Keep the rows of X at locations where MASK is not 0.
X = X(MASK, :);
function Cx, y] intline(xl, x2, yl, y2)
'/INTLINE Integer-coordinate line drawing algorithm.
7, CX, Y] = INTLINE(X1, X2, Yl, Y2) computes an
7. approximation to the line segment joining (XI, Yl) and
7. (X2, Y2) with integer coordinates. XI, X2, Yl, and Y2
7» should be integers. INTLINE is reversible; that is,
7« INTLINE(X1, X2, Yl, Y2) produces the same results as
7. FLIPUD(INTLINE(X2, XI, Y2, Yl)).
7o Copyright 1993-2002 The MathWorks, Inc. Used with permission.
7, $Revision: 5.11 $ $Date: 2002/03/15 15:57:47 $
dx = abs(x2 xl);
dy = abs(y2 yl) ;
7. Check for degenerate case.
if ((dx == 0) & (dy == 0))
x = xl;
у = yi;
return;
end
flip = 0;
if (dx >= dy)
if (xl > x2)
Приложение В
X Always »draw> from left to right,
t xl; xl x2; x2 = t;
t = yl; yl = y2; y2 = t;
flip = 1;
end
m (y2 yl)/(x2 xl);
x = (xl:x2).’;
у = round(yl + m*(x xl));
else
if (yl > y2)
X Always »draw> from bottom to top.
t = xl; xl x2; x2 = t;
t = yl; yl = y2; y2 = t;
flip 1;
end
m = (x2 xl)/(y2 yl);
У (yl:y2).’;
x = round(xl + m*(y yl));
end
if (flip)
x flipud(x);
у = flipud(y);
end
function phi = invmoments(F)
XINVMOMENTS Compute invariant moments of image.
X PHI = INVMOMENTS(F) computes the moment invariants of the image
X F. PHI is a seven-element row vector containing the moment
X invariants as defined in equations (11.3-17) through (11.3-23) of
X Gonzalez and Woods, Digital Image Processing, 2nd Ed.
X
X F must be a 2-D, real, nonsparse, numeric or logical matrix.
if (ndims(F) “= 2) | issparse(F) | “isreal(F) | "(isnumeric(F) |
islogical(F))
error([’F must be a 2-D, real, nonsparse, numeric or logical
’matrix.’]);
end
F double(F);
phi compute_phi(compute_eta(compute_m(F)));
X- -X
function m = compute_m(F)
[M, N] = size(F);
[x, y] = meshgrid(l:N, 1:M);
X Turn x, y, and F into column vectors to make the summations a bit
X easier to compute in the following.
x = x(:);
у = y(=);
596 Приложение В
F = F(:);
% DIP equation (11.3-12)
m.mOO = sum(F);
Protect against divide-by-zero warnings.
if (m.mOO == 0)
m.mOO eps;
end
7. The other central moments:
m.mlO sum(x .* F);
m.mOl = sum(y .* F);
m.mll sum(x .* У •* F);
m.m20 = sum(x."2 .* F);
m.m02 = sum(y."2 .* F);
m.m30 = sum(x."3 .* F);
m.m03 sum(y."3 -* F);
m.ml2 sum(x .* y."2 .* F);
m.m21 sum(x."2 .* у .* F);
7.- -7.
function e compute_eta(m)
% DIP equations (11.3-14) through (11.3-16).
xbar = m.mlO I m.mOO;
ybar = m.mOl / m.mOO;
e.etall = (m.mll ybar*m.mlO) / m.m00"2;
e.eta20 = (m.m20 xbar*m.ml0) / m.m00"2;
e.eta02 = (m.m02 ybar*m.m01) / m.m00"2;
e.eta30 = (m.m30 3 * xbar * m.m20 + 2 * xbar"2 * m.mlO) / m.m00"2.5;
e. eta03 = (m.m03 3 * ybar * m.m02 + 2 * ybar"2 * m.mOl) / m.m00"2.5;
e. eta21 (m.m21 2 * xbar * m.mll ybar * m.m20 +
2 * xbar" 2 * m.mOl) t / m.m00"2.5;
e.etal2 = (m.ml2 2 * ybar * m.mll xbar * m.m02 +
2 * ybar" 2 * m.mlO' t / m.m00"2.5;
7.- -7.
function phi = compute_phi(e)
% DIP equations (11.3-17) through (11.3-23).
phi(l) = e.eta20 + e.eta02;
phi(2) (e.eta20 - e.eta02)"2 + 4*e.etall"2;
phi(3) (e.eta30 3*e.etal2)"2 + (3*e.eta21 e.eta03)"2;
phi(4) (e.eta30 + e.etal2)~2 + (e.eta21 + e.eta03)"2;
phi(5) (e.eta30 - 3*e.etal2) * (e.eta30 + e.etal2) *
( (e.eta30 + e.etal2)“2 3*(e.eta21 + e.eta03)"2 ) +
(3*e.eta21 e.eta03) * (e.eta21 + e.eta03) *
( 3*(e.eta30 + e.etal2)"2 (e.eta21 + e.eta03)"2 );
phi(6) (e.eta20 e.eta02) * ( (e.eta30 + e.etal2)"2
(e.eta21 + e.eta03)"2 ) +
4 * e.etall * (e.eta30 + e.etal2) * (e.eta21 + e.eta03);
phi(7) = (3*e.eta21 - e.eta03) * (e.eta30 + e.etal2) * ...
Приложение В 597
( (e.eta30 + e.etal2)"2 3*(e.eta21 + e.eta03)"2 ) +
(3*e.etal2 e.eta30) * (e.eta21 + e.eta03) *
( 3*(e.eta30 + e.eta!2)"2 (e.eta21 + e.eta03)"2 );
M
function [x, y] = minperpoly(B, cellsize)
%MINPERPOLY Computes the minimum perimeter polygon.
7 [x, Y] = MINPERPOLY(F, CELLSIZE) computes the vertices in [X, Y]
7 of the minimum perimeter polygon of a single binary region or
% boundary in image B. The procedure is based on Slansky’s
7 shrinking rubber band approach. Parameter CELLSIZE determines the
7 size of the square cells that enclose the boundary of the region
7, in B. CELLSIZE must be a nonzero integer greater than 1.
7
7 The algorithm is applicable only to boundaries that are not
7 self-intersecting and that do not have one-pixel-thick
7 protrusions,
if cellsize <= 1
error (’CELLSIZE must be an integer > 1.’);
end
7 Fill В in case the input was provided as a boundary. Later
7 the boundary will be extracted with 4-connectivity, which
7 is required by the algorithm. The use of bwperim assures
7 that 4-connectivity is preserved at this point.
В = imfilKB, ’holes’);
В = bwperim(В);
[M, N] = size(B);
7 Increase image size so that the image is of size K-by-K
7 with (a) К >= max(M,N) and (b) K/cellsize = a power of 2.
К = nextpow2(max(M, N)/cellsize);
К (2"K)*cellsize;
7 Increase image size to nearest integer power of 2, by
7 appending zeros to the end of the image. This will allow
7 quadtree decompositions as small as cells of size 2-by-2,
7 which is the smallest allowed value of cellsize.
M = К M;
N К N;
В = padarray(B, [M N] , ’post’); 7 f is now of size K-by-K
7 Quadtree decomposition.
Q = qtdecomp(B, 0, cellsize);
7 Get all the subimages of size cellsize-by-cellsize.
[vals, r, c] = qtgetblk(B, Q, cellsize);
7 Get all the subimages that contain at least one black
598 Приложение В
°!, pixel. These are the cells of the wall enclosing the boundary.
I = find(sum(sum(vals(: :)) >= 1));
x = r(I);
У = c(I);
X [x’, y’] is a length(I)-by-2 array. Each member of this array is
X the left, top corner of a black cell of size cellsize-by-cellsize.
% Fill the cells with black to form a closed border of black cells
X around interior points. These cells are the cellular complex.
for к = 1:length(I)
B(x(k):x(k) + cellsize-1, y(k):y(k) + cellsize-1) 1;
end
BF = imfill(B, ’holes’);
X Extract the points interior to the black border. This is the region
X of interest around which the MPP will be found.
В = BF & (~B);
X Extract the 4-connected boundary.
В boundariesCB, 4, ’cw’);
X Find the largest one in case of parasitic regions.
J = cellfun(’length’, B);
I = find(J == max(J));
В B{I(1)};
X Function boundaries outputs the last coordinate pair equal to the
X first. Delete it.
В = B(l:end-1,:);
X Obtain the xy coordinates of the boundary.
x = B(:, 1);
У = B(:, 2);
X Find the smallest x-coordinate and corresponding
X smallest y-coordinate.
ex = find(x == min(x));
cy = findfy == minCy(cx)));
X The cell with top leftmost corner at (xl, yl) below is the first
X point considered by the algorithm. The remaining points are
X visited in the clockwise direction starting at (xl, yl).
xl = x(cx(l)) ;
yl = y(cy(l));
X Scroll data so that the first point is (xl, yl).
I find(x == xl & у == yl);
x = circshift(x, [-(I 1), 0]);
у = circshift(y, [-(I 1), 0]);
X The same shift applies to B.
В circshift(B, [-(I 1), 0]);
X Get the Freeman chain code. The first row of В is the required
X starting point. The first element of the code is the transition
X between the 1st and 2nd element of B, the second element of
X the code is the transition between the 2nd and 3rd elements of B,
Приложение В 599
and so on. The last element of the code is the transition between
'f, the last and 1st elements of B. The elements of В form a cw
7, sequence (see above), so we use ’same’ for the direction in
% function fchcode.
code = fchcode(B, 4, ’same’);
code code.fee;
Follow the code sequence to extract the Black Dots, BD, (convex
'/„ corners) and White Dots, WD, (concave corners). The transitions are
7 as follows: 0-to-l=WD; 0-to-3=BD; l-to-0=BD; l-to-2=WD; 2-to-l=BD;
% 2-to-3=WD; 3-to-0=WD; 3-to-2=dot. The formula t 2*first second
7 gives the following unique values for these transitions: -1, -3, 2,
7 0, 3, 1, 6, 4. These are applicable to travel in the cw direction.
7 The WD’s are displaced one-half a diagonal from the BD’s to form
7 the half-cell expansion required in the algorithm.
7 Vertices will be computed as array »vertices> of dimension nv-by-3,
7 where nv is the number of vertices. The first two elements of any
7 row of array vertices are the (x,y) coordinates of the vertex
7 corresponding to that row, and the third element is 1 if the
7 vertex is convex (BD) or 2 if it is concave (WD). The first vertex
7 is known to be convex, so it is black.
vertices = [xl, yl, 1];
n = 1;
к = 1;
for к 2:length(code)
if code(k 1) "= code(k)
n = n + 1;
t = 2*code(k-l) code(k); 7 t = value of formula,
if t == -3 | t == 2 | t == 3 | t == 4 7 Convex: Black Dots.
vertices(n, 1:3) [x(k), y(k), 1];
elseif t == -1 | t == 0 | t == 1 | t == 6 7 Concave: White Dots,
if t == -1
vertices(n, 1:3) [x(k) cellsize, y(k) cellsize,2];
elseif t==0 vertices(n, elseif t==l 1:3) [x(k) - h cellsize, y(k) cellsize,2];
vertices(n, else 1:3) [x(k) н h cellsize, y(k) - h cellsize,2];
vertices(n, 1:3) [x(k) cellsize, y(k) - cellsize,2] ;
end
else
7 Nothing to do here,
end
end
end
7 The rest of minperpoly.m processes the vertices to
7 arrive at the MPP.
600 Приложение В
flag = 1;
while flag
У, Determine which vertices lie on or inside the
7, polygon whose vertices are the Black Dots. Delete all
У. other points.
I = find(vertices(: 3) 1);
xv = vertices(I, 1); % Coordinates of the Black Dots.
yv = vertices(I, 2);
X = vertices(:, 1); 7, Coordinates of all vertices.
Y = vertices(:, 2);
IN = inpolygon(X, Y, xv, yv);
I = find(IN "= 0);
vertices = vertices(I, :);
% Now check for any Black Dots that may have been turned into
7, concave vertices after the previous deletion step. Delete
% any such Black Dots and recompute the polygon as in the
"X previous section of code. When no more changes occur, set
% flag to 0, which causes the loop to terminate,
x = vertices (:, 1);
у = vertices(: 2);
angles = polyangles(x, y) ; % Find all the interior angles.
I = find(angles > 180 & vertices(: 3) 1);
if isempty(I)
flag = 0;
else
J 1:length(vertices);
for к = l:length(I)
К = find(J "= I(k));
J = J(K);
end
vertices = vertices(J, :);
end
end
% Final pass to delete the vertices with angles of 180 degrees,
x = vertices(: 1);
у = vertices(:, 2);
angles = polyangles(x, y) ;
I = find(angles “= 180);
У , Vertices of the MPP:
x = verticesCI, 1);
у = vertices(I, 2);
Приложение В
Р
function В = pixeldup(A, m, n)
%PIXELDUP Duplicates pixels of an image in both directions.
7. В = PIXELDUP(A, M, N) duplicates each pixel of A M times in the
7, vertical direction and N times in the horizontal direction.
% Parameters M and N must be integers. If N is not included, it
% defaults to M.
7. Check inputs,
if nargin < 2
error(’At least two inputs are required.’);
end
if nargin == 2
n = m;
end
7» Generate a vector with elements l:size(A, 1).
u = 1:size(A, 1);
7. Duplicate each element of the vector m times.
m = round(m); 7» Protect against nonintergers.
u = u(ones(l, m), :);
u = u(:);
7» Now repeat for the other direction.
v = l:size(A, 2);
n round(n);
v = v(ones(l, n), :) ;
v = v(:);
В A(u, v);
function angles = polyangles(x, y)
%POLYANGLES Computes internal polygon angles.
7» ANGLES = POLYANGLES(X, Y) computes the interior angles (in
7» degrees) of an arbitrary polygon whose vertices are given in
7. [X, Y] , ordered in a clockwise manner. The program eliminates
7. duplicate adjacent rows in [X Y], except that the first row may
7» equal the last, so that the polygon is closed.
7. Preliminaries.
[x y] dupgone(x, y) ; 7« Eliminate duplicate vertices,
xy = [x(:) y(:)l;
if isempty(xy)
7o No vertices!
angles zeros(0, 1);
return;
end
if size(xy, 1) 1 | “isequal(xy(l, :), xy(end, :))
% Close the polygon
xy(end +1, :) = xy(l, :);
end
602 Приложение В
% Precompute some quantities.
d = diff(xy, 1);
vl = -d(l:end, :);
v2 = [d(2:end, :); d(l, :)];
vl_dot_v2 = sum(vl .* v2, 2);
mag_vl = sqrt(sum(vl."2, 2));
mag_v2 = sqrt(sum(v2."2, 2));
% Protect against nearly duplicate vertices; output angle will be 90
7t degrees for such cases. The <real> further protects against
% possible small imaginary angle components in those cases.
mag_vl(~mag_vl) eps;
mag_v2(~mag_v2) = eps;
angles = real(acos(vl_dot_v2 ./ mag_vl ./ mag_v2) * 180 / pi);
% The first angle computed was for the second vertex, and the
% last was for the first vertex. Scroll one position down to
’A make the last vertex be the first.
angles = circshift(angles, [1, 0]);
‘A Now determine if any vertices are concave and adjust the angles
‘A accordingly.
sgn = convex_angle_test(xy);
"A Any element of sgn that’s -1 indicates that the angle is
7. concave. The corresponding angles have to be subtracted
7. from 360.
I = find(sgn == -1);
angles(I) = 360 angles(I);
‘A- -7.
function sgn = convex_angle_test(xy)
7. The rows of array xy are ordered vertices of a polygon. If the
7» kth angle is convex (>0 and <= 180 degress) then sgn(k)
°A 1. Otherwise sgn(k) = -1. This function assumes that the first
7. vertex in the list is convex, and that no other vertex has a
7. smaller value of x-coordinate. These two conditions are true in
"A the first vertex generated by the MPP algorithm. Also the
’A vertices are assumed to be ordered in a clockwise sequence, and
°A there can be no duplicate vertices.
7.
7, The test is based on the fact that every convex vertex is on the
7. positive side of the line passing through the two vertices
7, immediately following each vertex being considered. If a vertex
7. is concave then it lies on the negative side of the line joining
% the next two vertices. This property is true also if positive and
7. negative are interchanged in the preceding two sentences.
*A It is assumed that the polygon is closed. If not, close it.
if size(xy, 1) 1 | ~isequal(xy(l, :), xy(end, :))
xy(end +1, :) = xy(l, :);
end
Приложение В
7, Sign, convention: sgn = 1 for convex vertices (i.e, interior
7, angle > 0 and <= 180 degrees), sgn = -1 for concave vertices.
7. Extreme points to be used in the following loop. A 1 is appended
7. to perform the inner (dot) product with w, which is l-by-3 (see
7. below).
L 10'25;
top_left = [-L, -L, 1];
top_right = [-L, L, 1];
bottom_left = [L, -L, 1];
bottom_right = [L, L, 1];
sgn = 1; % The first vertex is known to be convex.
7. Start following the vertices.
for к = 2:length(xy) 1
pfirst= xy(k 1, :);
psecond = xy(k, :); % This is the point tested for convexity.
pthird = xy(k +1, :);
7. Get the coefficients of the line (polygon edge) passing
7. through pfirst and psecond.
w = polyedge(pfirst, psecond);
% Establish the positive side of the line wlx + w2y + w3 = 0.
7. The positive side of the line should be in the right side of the
7. vector (psecond - pfirst). deltax and deltay of this vector
7. give the direction of travel. This establishes which of the
7. extreme points (see above) should be on the + side. If that
7. point is on the negative side of the line, then w is replaced by -w.
deltax = psecond(: 1) - pfirst(:, 1);
deltay = psecond(:, 2) pfirst(: 2);
if deltax == 0 & deltay == 0
error(’Data into convexity test is 0 or duplicated.’)
end
if deltax <= 0 & deltay >= 0 % Bottom_right should be on + side.
vector_product = dot(w, bottom_right); 7« Inner product.
w = sign(vector_product)*w;
elseif deltax <= 0 & deltay <= 0 7» Top_right should be on + side.
vector_product = dot(w, top_right);
w = sign(vector_product)*w;
elseif deltax >= 0 & deltay <= 0 7. Top_left should be on + side.
vector_product = dot(w, top_left);
w = sign(vector_product)*w;
else 7. deltax >= 0 & deltay >= 0, so bottom_left should be on + side.
vector_product dot(w, bottom_left);
w = sign(vector„product)*w;
end
7. For the vertex at psecond to be convex, pthird has to be on the
% positive side of the line.
sgn(k) = 1;
Приложение В
if (w(l)*pthird(: 1) + w(2)*pthird(: 2) + w(3)) < 0
sgn(k) = -1;
end
end
7.- -7.
function w = polyedge(pl, p2)
°k Outputs the coefficients of the line passing through pl and
7. p2. The line is of the form wlx + w2y + w3 = 0.
xl = pl(:, 1); yl = pl(:, 2);
x2 = p2(:, 1); y2 = p2(: 2);
if xl==x2
w2 = 0;
wl = -1/xl;
w3 = 1;
elseif yl==y2
wl 0;
w2 = -1/yl;
w3 1;
elseif xl == yl & x2 == y2
wl 1;
w2 1;
w3 0;
else
wl (yl y2)/(xl*(y2 yl) yl*(x2 xl) + eps);
w2 -wl*(x2 xl)/(y2 yl);
w3 1;
end
w [wl, w2, w3] ;
7.- -7.
function [xg, yg] dupgone(x, y)
’X Eliminates duplicate, adjacent rows in [x y], except that the
% first and last rows can be equal so that the polygon is closed,
xg = x;
yg = y;
if size(xg, 1) > 2
I = find((x(l:end-l, :) == x(2:end, :)) &
(y(l:end-l, :) == y(2:end, :)));
xg(I) [];
yg(D [];
end
R
function [xn, yn] = randvertex(x, y, npix)
%RANDVERTEX Adds random noise to the vertices of a polygon.
7. [XN, YN] = RANDVERTEX[X, Y, NPIX] adds uniformly distributed
7, noise to the coordinates of vertices of a polygon. The
% coordinates of the vertices are input in X and Y, and NPIX is the
7c maximum number of pixel locations by which any pair (X(i), Y(i))
7c is allowed to deviate. For example, if NPIX 1, the location of
% any X(i) will not deviate by more than one pixel location in the
7c x-direction, and similarly for Y(i). Noise is added independently
7» to the two coordinates.
7c Convert to columns.
x x(:);
У = y(=);
7c Preliminary calculations.
L length(x);
xnoise rand(L, 1);
ynoise rand(L, 1);
xdev = npix*xnoise.*sign(xnoise 0.5);
ydev = npix*ynoise.*sign(ynoise 0.5);
7c Add noise and round.
xn round(x + xdev);
yn round(y + ydev);
7c All pixel locations must be no less than 1.
xn max(xn, 1);
yn max(yn, 1);
function [st, angle, xO, yO] = signature(b, varargin)
%SIGNATURE Computes the signature of a boundary.
7c [ST, ANGLE, XO, YO] SIGNATURE(B) computes the
7o signature of a given boundary, B, where В is an np-by-2 array
7 (np > 2) containing the (x, y) coordinates of the boundary
% ordered in a clockwise or counterclockwise direction. The
7c amplitude of the signature as a function of increasing ANGLE is
7c output in ST. (XO,YO) are the coordinates of the centroid of the
7. boundary. The maximum size of arrays ST and ANGLE is 360-by-l,
7c indicating a maximum resolution of one degree. The input must be
7c a one-pixel-thick boundary obtained, for example, by using the
% function boundaries. By definition, a boundary is a closed curve.
7.
7c [ST, ANGLE, XO, YO] SIGNATURE(B) computes the signature, using
7c the centroid as the origin of the signature vector.
7.
7c [ST, ANGLE, XO, YO] SIGNATURE(B, XO, YO) computes the boundary
7. using the specified (XO, YO) as the origin of the signature
7c vector.
606 Приложение В
7. Check dimensions of Ъ.
[np, nc] = size(b);
if (np < nc | nc _= 2)
error(’B must be of size np-by-2.’);
end
У, Some boundary tracing programs, such as boundaries.m, end where
% they started, resulting in a sequence in which the coordinates
% of the first and last points are the same. If this is the case,
% in b, eliminate the last point.
if isequal(b(l, b(np, :))
b = b(l:np 1, :);
np = np 1;
end
% Compute parameters.
if nargin == 1
xO = round(sum(b(: l))/np); % Coordinates of the centroid.
yO = round(sum(b(: 2))/np);
elseif nargin 3
xO varargin{U;
yO = varargin{2};
else
error(’Incorrect number of inputs.’);
end
% Shift origin of coord system to (xO, yO)).
b(:, 1) b(: 1) xO;
b(:, 2) b(: 2) yO;
7. Convert the coordinates to polar. But first have to convert the
% given image coordinates, (x, y), to the coordinate system used by
% MATLAB for conversion between Cartesian and polar cordinates.
7. Designate these coordinates by (xc, yc). The two coordinate systems
% are related as follows: xc = у and yc = -x.
xc = b(:, 2);
yc = -b(:, 1);
[theta, rho] cart2pol(xc, yc);
% Convert angles to degrees.
theta = theta.*(180/pi);
% Convert to all nonnegative angles.
j = theta == 0; 7. Store the indices of theta = 0 for use below.
theta = theta.*(0.5*abs(l + sign(theta)))...
0.5*(-l + sign(theta)).*(360 + theta);
theta(j) =0; 7. To preserve the 0 values.
temp = theta;
% Order temp so that sequence starts with the smallest angle.
7. This will be used below in a check for monotonicity.
I = find(temp == min(temp));
% Scroll up so that sequence starts with the smallest angle.
Приложение В 607
% Use 1(1) in case the min is not unique (in this case the
% sequence will not be monotonic anyway)
temp = circshift(temp, [-(1(1) 1), 0]);
% Check for monotonicity, and issue a warning if sequence
7, is not monotonic. First determine if sequence is
% cw or ccw.
kl abs(temp(l) temp(2));
k2 = abs(temp(1) temp(3));
if k2 > kl
sense = 1; 7» ccw
elseif k2 < kl
sense -1; 7» cw
else
warning([’The first 3 points in В do not form a monotonic
’sequence. ’ ] ) ;
end
7. Check the rest of the sequence for monotonicity. Because
7o the angles are rounded to the nearest integer later in the
7. program, only differences greater than 0.5 degrees are
% considered in the test for monotonicity in the rest of
7. the sequence.
flag = 0;
for к = 3:length(temp) 1
diff sense*(temp(k + 1) temp(k));
if diff < -.5
flag = 1;
end
end
if flag
waming(’Angles do not form a monotonic sequence.’);
end
% Round theta to 1 degree increments,
theta = round(theta);
7. Keep theta and rho together,
tr = [theta, rho];
7o Delete duplicate angles. The unique operation
7. also sorts the input in ascending order.
[w, u, v] = unique(tr(:, 1));
tr = tr(u,:); '/• u identifies the rows kept by unique.
7. If the last angle equals 360 degrees plus the first
% angle, delete the last angle.
if tr(end, 1) == tr(l) + 360
tr = tr(l:end 1, :);
end
% Output the angle values.
angle = tr(:, 1);
608 Приложение В
% The signature is the set of values of rho corresponding
% to the angle values,
st = tr(:, 2);
function [srad, sang, S] = specxture(f)
%SPECXTURE Computes spectral texture of an image.
7, [SRAD, SANG, S] = SPECXTURE(F) computes SRAD, the spectral energy
7L distribution as a function of radius from the center of the
7, spectrum, SANG, the spectral energy distribution as a function of
% angle for 0 to 180 degrees in increments of 1 degree, and S =
7. log(l + spectrum of f), normalized to the range [0, 1]. The
% maximum value of radius is min(M,N), where M and N are the number
of rows and columns of image (region) f. Thus, SRAD is a row
% vector of length = (min(M, N)/2) 1; and SANG is a row vector of
% length 180.
Obtain the centered spectrum, S, of f. The variables of S are
7. (u, v), running from 1:M and 1:N, with the center (zero frequency)
7o at [M/2 + 1, N/2 + 1] (see Chapter 4).
S = fftshift(fft2(f));
S = abs(S);
[M, N] = size(S);
xO = M/2 + 1;
yO = N/2 + 1;
7. Maximum radius that guarantees a circle centered at (xO, yO) that
% does not exceed the boundaries of S.
rmax = min(M, N)/2 1;
7o Compute srad.
srad = zeros(1, rmax);
srad(l) S(x0, yO);
for r = 2:rmax
[xc, yc] = halfcircle(r, xO, yO);
srad(r) sum(S(sub2ind(size(S), xc, yc)));
end
% Compute sang.
[xc, yc] = halfcircle(rmax, xO, yO);
sang = zeros(1, length(xc));
for a = l:length(xc)
[xr, yr] = radial(x0, yO, xc(a), yc(a));
sang(a) = sum(S(sub2ind(size(S), xr, yr)));
end
7. Output the log of the spectrum for easier viewing, scaled to the
% range [0, 1] .
S = mat2gray(log(l + S));
%- -%
function [xc, yc] = halfcircle(r, xO, yO)
7. Computes the integer coordinates of a half circle of radius r and
Приложение. В
7, center at (хО,уО) using one degree increments.
‘A
7. Goes from 91 to 270 because we want the half circle to be in the
‘A region defined by top right and top left quadrants, in the
% standard image coordinates.
theta=91:270;
theta = theta*pi/180;
[xc, yc] = pol2cart(theta, r);
xc round(xc) ’ + xO; 7« Column vector.
yc = round(yc)’ + yO;
%- -7.
function [xr, yr] = radial(x0, yO, x, y);
% Computes the coordinates of a straight line segment extending
‘A from (xO, yO) to (x, y).
7.
7, Based on function intline.m. xr and yr are
7. returned as column vectors.
[xr, yr] = intline(xO, x, yO, y);
function [v, unv] = statmoments(p, n)
%STATMOMENTS Computes statistical central moments of image histogram.
7, [W, UNV] STATMOMENTS (P, N) computes up to the Nth statistical
7. central moment of a histogram whose components are in vector
% P. The length of P must equal 256 or 65536.
7.
7. The program outputs a vector V with V(l) = mean, V(2) = variance,
7. V(3) = 3rd moment, V(N) = Nth central moment. The random
7. variable values are normalized to the range [0, 1] , so all
7, moments also are in this range.
7.
7, The program also outputs a vector UNV containing the same moments
% as V, but using un-normalized random variable values (e.g. 0 to
’A 255 if length(P) = 2'8). For example, if length(P) = 256 and V(l)
7. = 0.5, then UNV(l) would have the value UNV(l) 127.5 (half of
7, the [0 255] range) .
Lp = length(p);
if (Lp "= 256) & (Lp "= 65536)
error(’P must be a 256- or 65536-element vector.’);
end
G = Lp 1;
7, Make sure the histogram has unit area, and convert it to a
7. column vector.
p = p/sum(p); p = p(:);
7. Form a vector of all the possible values of the
7. random variable.
z = 0.-G;
610 Приложение В
7, Now normalize the z’s to the range [0, 1] .
z = z./G;
% The mean.
m = z*p;
7. Center random variables about the mean,
z = z m;
7. Compute the central moments.
v = zeros(1, n);
v(l) = m;
for j = 2:n
v(j) (z.~j)*p;
end
if nargout > 1
7. Compute the uncentralized moments,
unv = zeros(1, n);
unv(l)=m.*G;
for j = 2:n
unv(j) ((z*G)."j)*p;
end
end
function [t] — statxture(f, scale)
%STATXTURE Computes statistical measures of texture in an image.
7. T = STATXURE(F, SCALE) computes six measures of texture from an
7. image (region) F. Parameter SCALE is a 6-dim row vector whose
7« elements multiply the 6 corresponding elements of T for scaling
7. purposes. If SCALE is not provided it defaults to all Is. The
7. output T is 6-by-l vector with the following elements:
7» T(l) - Average gray level
7. T(2) Average contrast
7. T(3) = Measure of smoothness
7. T(4) = Third moment
7. T(5) = Measure of uniformity
7. T(6) = Entropy
if nargin == 1
scale(1:6) 1;
else % Make sure it’s a row vector,
scale = scale(:)’;
end
7. Obtain histogram and normalize it.
p = imhist(f);
p = p./numel(f);
L = length(p);
% Compute the three moments. We need the unnormalized ones
7, from function statmoments. These are in vector mu.
[v, mu] = statmoments(p, 3);
Приложение В
X Compute the six texture measures:
X Average gray level.
t(l) = mu(l);
X Standard deviation.
t(2) = mu(2).~0.5;
X Smoothness.
‘X First normalize the variance to [0 1] by
X dividing it by (L-l)~2.
van = mu(2)/(L 1)~2;
t(3) = 1 1/(1 + varn);
X Third moment (normalized by (L 1)~2 also).
t(4) = mu(3)/(L 1)~2;
X Uniformity.
t(5) = sum(p.~2);
X Entropy.
t(6) = -sum(p.*(log2(p + eps)));
X Scale the values,
t = t.*scale;
X
function [B, theta] = x2majoraxis(A, B, type)
%X2MAJORAXIS Aligns coordinate x with the major axis of a region
X [B2, THETA] = X2MAJ0RAXIS(A, B, TYPE) aligns the x-coordinate
7. axis with the major axis of a region or boundary. The у-axis is
X perpendicular to the x-axis. The rows of 2-by-2 matrix A are the
X coordinates of the two end points of the major axis, in the form
7. A = [xl yl; x2 y2] On input, В is either a binary image (i.e.
X an array of class logical) containing a single region, or it is
7, an np-by-2 set of points representing a (connected) boundary. In
X the latter case, the first column of В must represent
X x-coordinates and the second column must represent the
X corresponding y-coordinates. On output, В contains the same data
X as the input, but aligned with the major axis. If the input is an
X image, so is the output; similarly the output is a sequence of
X coordinates if the input is such a sequence. Parameter THETA is
X the initial angle between the major axis and the x-axis. The
X origin of the xy-axis system is at the bottom left; the x-axis is
X the horizontal axis and the у-axis is the vertical.
X
X Keep in mind that rotations can introduce round-off errors when
X the data are converted to integer coordinates, which is a
X requirement. Thus, postprocessing (e.g. with bwmorph) of the
X output may be required to reconnect a boundary.
‘k Preliminaries.
if islogical(B)
type = ’region’;
elseif size(B, 2) 2
type = ’boundary’;
[M, N] = size(B);
if M < N
error(’B is boundary. It must be of size np-by-2; np > 2.’)
end
'X Compute centroid for later use. c is a l-by-2 vector.
’X Its 1st component is the mean of the boundary in the x-direction.
X The second is the mean in the y-direction.
c(l) = round((min(B(:, 1)) + max(B(: l))/2));
c(2) = round((min(B(: 2)) + max(B(: 2))/2));
'X It is possible for a connected boundary to develop small breaks
X after rotation. To prevent this, the input boundary is filled,
X processed as a region, and then the boundary is re-extracted. This
X guarantees that the output will be a connected boundary.
m max(size(B));
X The following image is of size m-by-m to make sure that there
’X there will be no size truncation after rotation.
В = bound2im(B,m,m);
В imfill(B,’holes’);
else
error(’Input must be a boundary or a binary image’.)
end
X Major axis in vector form.
v(l) = A(2, 1) A(l, 1);
v(2) = A(2, 2) A(l, 2);
v v(:); 'X v is a col vector
X Unit vector along x-axis.
u = [1; 0] ;
X Find angle between major axis and x-axis. The angle is
X given by acos of the inner product of u and v divided by
X the product of their norms. Because the inputs are image
X points, they are in the f irst quadrant.
nv = nonn(v);
nu = norm(u);
theta = acos(u’*v/nv*nu);
if theta > pi/2
theta = -(theta pi/2);
end
theta = theta*180/pi; X Convert angle to degrees.
X Rotate by angle theta and crop the rotated image to original size.
В imrotate(B, theta, ’bilinear’, ’crop’);
X If the input was a boundary, re-extract it.
Приложение. В
if strcmp(type, ’boundary’)
В = boundaries(В);
В = B{1};
7. Shift so that centroid of the extracted boundary is
7, approx equal to the centroid of the original boundary:
B(: 1) B(: 1) min(B(:, 1)) + c(l);
B(:, 2) = B(:, 2) - min(B(:, 2)) + c(2);
end
Литература
Ссылки, применимые ко всем главам:
Gonzalez R. С., Woods R. Е. [2002]. Digital Image Processing, 2nd ed., Prentice
Hall, Upper Saddle River, NJ.
Hanselman D., Littlefield B. R. [2001]. Mastering MATLAB 6, Prentice Hall, Upper
Saddle River, NJ.
Image Processing Toolbox, Users Guide, Version 4- [2003], The MathWorks, Inc.,
Natick, MA.
Using MATLAB, Version 6.5 [2002], The MathWorks, Inc., Natick, MA.
Все остальные ссылки:
Acklam P. J. [2002]. "MATLAB Array Manipulation Tips and Tricks."
Можно загрузить co страницы
http://home.online.no/_pjacklam/niatlab/doc/mtt/ а также
www.prenhall.com/gonzalezwoodseddins.
Brigham E. O. [1988]. The Fast Fourier Transform and its Applications, Prentice
Hall, Upper Saddle River, NJ.
Bribiesca E. [1981]. "Arithmetic Operations Among Shapes Using Shape Numbers,"Pat-
tern Recog., vol. 13, no. 2, pp. 123-138.
Bribiesca E., Guzman A. [1980]. "How to Describe Pure Form and How to Measure
Differences in Shape Using Shape Numbers Pattern Recog., vol. 12, no. 2, pp.
101-112.
Canny J. [1986]. "A Computational Approach for Edge Detection,"IEEE Trans.
Pattern Anal. Machine Intell., vol. 8, no. 6, pp. 679-698.
Dempster A. P., Laird N. M., Ruben D. B. [1977]. "Maximum Likelihood from
Incomplete Data via the EM Algorithm,"J. R. Stat. Soc. B, vol. 39, pp. 1-37.
Zenzo S. [1986/ "A Note on the Gradient of a Multi-Image,"Computer Vision,
Graphics and Image Processing, vol. 33, pp. 116-125.
Floyd R. W., Steinberg L. [1975]. "An Adaptive Algorithm for Spatial Gray Scale,"In-
ternational Symposium Digest of Technical Papers, Society for Information Disp-
lays, 1975, p. 36.
Gardner M. [1970]. "Mathematical Games: The Fantastic Combinations of John
Conway’s New Solitaire Game ’Life’, "Scientific American, October, pp. 120-123.
Gardner M. [1971]. "Mathematical Games On Cellular Automata, Self- Reproduction,
the Garden of Eden, and the Game ’Life’, " Scientific American, February, pp. 112-117.
Hanisch R. J., White R. L., Gilliland R. L. [1997]."Deconvolution of Hubble Space
Telescope Images and Spectra,"in Deconvolution of Images and Spectra, P.A.
Jansson, ed., Academic Press, NY, pp. 310-360.
Haralick R. M., Shapiro L. G. [1992]. Computer and Robot Vision, vols. 1 & 2,
Addison-Wesley, Reading, MA.
Holmes T. J. [1992]. "Blind Deconvolution of Quantum-Limited Incoherent Imagery,
"J. Opt. Soc.Am.A, vol. 9, pp. 1052-1061.
um-pam fpa 615
Holmes T. J., et al. [1995]. "Ligh* AD • L”. R ' b Maximum
Likelihood Deconvolution."in Handbook of В u, r M~ro«“opy
2nd ed., J. B. Pawley, ed.. Plenum Pres? XY . pp o' 4-
Hough P. V.C. [1962]. "Methods and Means for Recogni? ig Сэпп <‘x Pat term "U S.
Patent 3,069,654.
Jansson P. A., ed. [1997]. Deconvolution of Images and Spectra. Academic Press. \Y.
Kim С. E. Sklansky J. [1982]. "Digital and Cellular Convexity."Pattern Recog., vol.
15, no. 5, pp. 359-367-
Leon-Garcia A. [1994]. Probability and Random Processes for Electrical Engineering,
2nd. ed.,Addison-Wesley, Reading, MA.
Lucy L. B. [1974]. "An Iterative Technique for the Rectification of Observed Dis-
tributions, "The Astronomical Journal, vol. 79, no. 6, pp. 745-754.
Otsu N. [1979] "A Threshold Selection Method from Gray-Level Histograms,"IEEE
Trans. Systems, Man, and Cybernetics, vol. SMC-9, no. 1, pp. 62-66.
Peebles P. Z. [1993]. Probability, Random Variables, and Random Signal Principles,
3rd ed., McGraw-Hill, NY.
Poynton C. A. [1996]. A Technical Introduction to Digital Video,Wiley, NY.
Richardson W. H. [1972]. "Bayesian-Based Iterative Method of Image Restoration, "J.
Opt. Soc.Am., vol. 62, no. 1, pp. 55-59.
Rogers D. F. [1997]. Procedural Elements of Computer Graphics, 2nd ed., Me- Graw-
Hill, NY.
Russ J. C. [1999]. The Image Processing Handbook, 3rd ed., CRC Press, Boca
Raton, FL.
Sklansky J., Chazin R. L., Hansen B. J. [1972]."Minimum-Perimeter Polygons of
Digitized Silhouettes,"IEEE Trans. Computers, vol. C-21, no. 3, pp. 260-268.
Soille P. [2003]. Morphological Image Analysis: Principles and Applications, 2nd ed.,
Springer-Verlag, NY.
Sze T. W. Yang Y. H. [1981]. "A Simple Contour Matching Algorithm,"IEEE Trans.
Pattern Anal. Machine Intell., vol. PAMI-3, no. 6, pp. 676-678.
Ulichney R. [1987], Digital Halftoning,The MIT Press, Cambridge, MA.
Van Trees H. L. [1968]. Detection, Estimation, and Modulation Theory, Part I,
Wiley,NY.
Vincent L. [1993], "Morphological Grayscale Reconstruction in Image Analysis:
Applications and Efficient Algorithms, "IEEE Trans, on Image Processing vol.
2, no. 2, pp. 176-201.
Vincent L., Soille P. [1991]. "Watersheds in Digital Spaces: An Efficient Algorithm
Based on Immersion Simulations, "IEEE Trans. Pattern Anal. Machine Intell.,
vol. 13, no. 6, pp. 583-598.
Wolbert G. [1990]. Digital Image Warping, IEEE Computer Society Press, Los Alami-
tos, CA.
Заявки на книги присылайте по адресу:
125319 Москва, а/я 594
Издательство «Техносфера»
e-mail: knigi@technosphera.ru
sales@technosphera.ru
факс: (495) 956 33 46
В заявке обязательно указывайте
свой почтовый адрес!
Подробная информация о книгах на сайте
http://www.technosphera.ru
Гонсалес Рафаэль С., Вудс Ричард Е., Эддинс Стивен Л.
Цифровая обработка изображений в среде MATLAB
Компьютерная верстка — С.А. Кулешов
Корректор — А.В. Бодрова
Дизайн — И.А. Куколева
Выпускающий редактор — О.Н. Кулешова
Ответственный за выпуск С.В. Зинюк
Формат 70x100/16. Печать офсетная.
Гарнитура Ньютон
Печ.л. 37,5. Тираж 2000 экз. Зак. № 4189
Бумага офсет №1, плотность 65г/м2,
цветная вклейка — бумага мелованная, плотность 115г/м2
Издательство «Техносфера»
Москва, Лубянский проезд, дом 27/1
Диапозитивы изготовлены ООО «Европолиграфик»
Отпечатано в ППП "Типография "Наука"
Академиздатцентра "Наука" РАН
121099 Москва, Шубинский пер., 6