/
































































































































































































































Автор: Дорогов В.Г. Дорогова Е.Г.
Теги: языки программирования программирование язык программирования c
ISBN: 978-5-8199-0809-9
Год: 2020




Текст
В.Г. Дорогов
Е.Г. Дорогова
Основы
программирования
СРЕДНЕЕ ПРОФЕССИОНАЛЬНОЕ ОБРАЗОВАНИЕ
Серия основана в 2001 году
ВТ. Дорогой, Е.Г. Дорогова
основы
ПРОГРАММИРОВАНИЯ
НА ЯЗЫКЕ С
УЧЕБНОЕ ПОСОБИЕ
Под редакцией профессора Л,Г. Гагариной
Рекомендовано Межрегиональным учебно-методическим советом
профессионального образования в качестве учебного пособия
для учебных заведений, реализующих программу среднего
профессионального образования по укрупненным группам специальностей
09.02.00 «Информатика и вычислительная техника»,
10.02.00 «Информационная безопасность»
(протокол № 14 от 30.09.2019)
Москва
ИД «ФОРУМ» - ИНФРА-М
2020
УДК 004.43(075.32)
ББК 32.973-018.1я723
Д69
Рецензенты:
Нестеров А. Э., доктор технических наук;
Петров А.А>, кандидат технических наук
Дорогов В.Г.
Д 69 Основы программирован ия на языке С : учебное пособие / В. Г. До-
рогов, Е.Г. Дорогова ; иод ред. проф. Л,Г. Гагариной. — Москва :
ИД «ФОРУМ» : ИНФРА-М, 2020. — 224 с. — (Среднее профессио-
нальное образование).
ISBN 978-5-8199-0809-9 (ИД «ФОРУМ»)
ISBN 978-5-16-014137-4 (ИНФРА-М)
Учебное пособие является начальным курсом программирования
с примерами на языке С. Рассмотрены основы программирования, при-
емы и методы в стиле классического С. Может быть использовано как ру-
ководство по языку Приводятся многочисленные примеры, оттестирован-
ные на компьютере.
Соответствует требованиям федеральных государственных образова-
тельных стандартов среднего профессионального образования последнего
поколения.
Рекомендовано студентам, изучающим дисциплины «Основы програм-
мирования», «Языки высокого уровня», «Информатика».
УДК 004.43(075.32)
ББК 32.973-018.1я723
© Дорогов В.Г.,
ISBN 978-5-8199-0809-9 (ИД «ФОРУМ»)
ISBN 978-5-16-014137-4 (ИНФРА-М)
Дорогова Е.Г., 2020
© ИД «ФОРУМ», 2020
Введение
Язык С разработан и реализован в 1972 г. сотрудником фирмы
AT&T Bell Laboratories Деннисом Ритчи во время работы над опе-
рационной системой UNIX. При создании системных программ
программист обязан уделять особое внимание быстродействию,
надежности и эффективности программного кода, что обычно
достигается использованием ассемблера, но при решении таких
сложных задач, как разработка ОС, возникает желание использо-
вать более производительные средства программирования. Имен-
но так и возник язык С — объединил в себе гибкость ассемблера и
удобство языков высокого уровня.
Создатели языка С не стали разрабатывать абстрактную модель
языка, а просто реализовали в нем те возможности, в которых бо-
лее всего нуждались системные программисты — в первую очередь
это средства непосредственной работы с памятью, структурные
конструкции управления и модульная организация программы.
Как видите, создание универсального языка для широкого исполь-
зования не планировалось и долгое время язык С оставался инст-
рументальным языком операционной системы UNIX для сотруд-
ников фирмы AT&T.
Однако к концу 1980-х гг. язык С, оттеснив Fortran с позиции
лидера, приобрел массовую популярность среди программистов во
всем мире и стал использоваться в самых различных прикладных
задачах. Немалую роль здесь сыграло распространение Unix (а зна-
чит, и С) в университетской среде, где проходило подготовку но-
вое поколение программистов.
Рост популярности С, с одной стороны, и отсутствие утвер-
жденного стандарта — с другой, привели к тому, что в создании
компиляторов начали участвовать коллективы разработчиков, ра-
нее не причастных к проектированию языка, что привело к воз-
никновению проблемы совместимости программ. Программы, на-
писанные и отлаженные с применением средств программирова-
4
Введение
ния одного разработчика, могли не работать на компиляторе
другого разработчика.
В 1983 г. Американский институт национальных стандартов
(American National Standards Institute — ANSI) учредил комитет,
перед которым была поставлена цель выработать «однозначное и
машинно-независимое определение языка С», полностью сохра-
нив при этом его стилистику. Результатом работы, этого комитета
и явился стандарт ANSI языка С. Кроме того существует еще один
стандарт языка С — ISO (International Standart Organization).
Современные компиляторы обеспечивают поддержку значи-
тельной части обоих стандартов, приведем наиболее известные из
них: GNU компилятор, Intel C++, Borland C++, Visual C++.
Настоящее пособие предназначено для изучения программи-
рования на стандартном языке С. Большое внимание уделено как
ситаксису и конструкциям языка, так и их практическому исполь-
зованию при решении типовых задач. Наряду с простым перечис-
лением правил широко используется изучение, написание и про-
работка примеров.
Следует отметить, что изучать язык программирования только
по книге или лекциям — пустая трата времени. Для достижении
успеха в программировании необходима практика, поэтому пред-
полагается, что читатели будут выполнять упражнения, приведен-
ные в пособии, на компьютере. Все программы тестировались в
MS Visual C++ 6.0 под управлением Windows ХР.
Глава 1
БАЗОВЫЕ ПОНЯТИЯ ПРОГРАММИРОВАНИЯ
Под программированием чаще всего понимают процесс созда-
ния компьютерных программ с помощью языков программирова-
ния. Программирование сочетает в себе элементы математики и
инженерии. В узком смысле слова программирование рассматри-
вается как кодирование или реализация алгоритма на некотором
языке программирования.
Осваивая программирование, мы приобретаем два важных на-
выка:
1) изучаем синтаксис языка программирования — слова, грам-
матику и пунктуацию, узнаем значение каждой команды и каждой
функции, учимся правильно их использовать;
2) учимся логике программирования — как выполнить ту или
иную задачу, используя язык программирования. Это универсаль-
ный навык, который может быть применен для любого языка про-
граммирования.
Чтобы научиться программировать, необходимо освоить оба
эти навыка, в данном учебном пособии мы будем изучать их парал-
лельно.
Заметим, что если вы научитесь логике программирования и
получите практические навыки на одном из языков программиро-
вания, то для того, чтобы научиться работать с другим языком, ос-
танется лишь изучить его синтаксис.
Рассмотрим этапы создания программных систем.
На первом этапе происходит формализация задачи — это соз-
дание технического задания на проект.
Второй этап — разработка алгоритма решения.
Третий этап — программирование (создание текста програм-
мы, отладка, тестирование).
6
Глава 1. Базовые понятия программирования
Техническое задание (ТЗ) — это исходный документ для про-
ектирования разработки программы, он содержит основные тех-
нические требования, предъявляемые к программе и исходные
данные для разработки; в ТЗ указываются назначение, область
применения, сроки исполнения и многое другое. Как правило, ТЗ
составляют на основе анализа результатов предварительных иссле-
дований, расчетов и моделирования. Этот этап работы над про-
граммой относится к дисциплине «проектирование» и мы не будем
его подробно рассматривать.
1.1. Алгоритмизация задачи
Связь между алгоритмом решения и языком программирова-
ния очень тесная. Проводя аналогию с естественными языками,
заметим, что человек думает только о том, что можно воплотить в
слове, а программист решает задачи на компьютере только в тех
терминах и с использованием тех конструкций, которые есть в
языке программирования.
Алгоритм связан с языком программирования, но тем не менее
не зависит от него прежде всего потому, что в разных языках про-
граммирования есть общие, характерные для всех языков инстру-
менты, на которые и опирается алгоритм.
Заметим, что алгоритмизация задачи — это всегда сокращение
круга понятий, которыми можно оперировать при решении зада-
чи, это прежде всего переход от терминов и понятий естественного
языка к терминам и понятиям языка программирования. Что же
такое алгоритм? Приведем самое общее его определение.
Алгоритм решения — точные предписания (инструкции), ко-
торые определяют процесс, ведущий от исходных данных к требуе-
мому конечному результату.
Поскольку алгоритм — это «точная инструкция», а инструкции
встречаются практически во всех областях человеческой деятель-
ности, то возможны самые разнообразные алгоритмы, например
проведения физического эксперимента, сборки шкафа или теле-
визора, обработки детали. Однако следует заметить, что не всякая
инструкция есть алгоритм.
Инструкция становится алгоритмом, когда процесс преобразо-
вания исходной информации к требуемому конечному результату
1.3. Пример алгоритмизации
7
задается однозначно и выполняется за конечное число элементар-
ных дискретных шагов.
К основным способам описания алгоритмов можно отнести
следующие:
• словесно-формульный (на естественном языке);
• в виде схемы (схема алгоритма);
• с использованием специальных алгоритмических языков
(например язык UML).
1.2. Схема алгоритма программы
Схема алгоритма — это графическое представление программы
или алгоритма с использованием стандартных графических эле-
ментов (прямоугольников, ромбов, трапеций и др.), обозначаю-
щих команды, действия, данные и т. п.
Геометрические фигуры представляют блоки программы, ко-
торые связаны линиями со стрелками, указывающими направле-
ния потока управления. В блоках записывается последователь-
ность действий. Элементы схемы-алгоритма показаны на рис. 1.1.
1.3. Пример алгоритмизации
Составить алгоритм программы для расчета налога на прода-
жи. На первом этапе опишем задачу как можно подробнее. Боль-
шинство программ подчиняются алгоритму, включающему три
этапа: ввод данных, их обработку и вывод результата, например на
экран дисплея. Рассмотрим подробнее кажый из них.
Ввод данных: для расчета необходимы два параметра — объем
продаж и ставка налога, причем ставка налога — величина посто-
янная, объем продаж может меняться. Поскольку программа ис-
пользуется неоднократно, объем продаж следует вводить при каж-
дом новом расчете. Ставка налога может быть определена в тексте
программы. Опишем ввод короче:
во-первых, указать пользователю, что он должен ввести сумму
продаж (sum), показатель вводится с клавиатуры;
во-вторых, указать компьютеру величину налога на продажи
(rate), задать в виде константы в тексте программы.
8
Глава 1. Базовые понятия программирования
Начало или конец. Внутри фигуры пишут
«начало» или «конец» соответственно
Прямоугольником обозначается операция,
или группа операций. Например, присваивание
Внутри ромба пишутся проверяемые условия.
Например, «а < Ь»
Функция. Внутри указывают имя функции,
передаваемые параметры и возвращаемое значение
Параллелограмм обозначает операции
ввода-вывода данных
Начало цикла.
Внутри указывают параметры цикла.
Указание связи между прерванными линиями,
соединяющими блоки
Рис. 1.1. Основные элементы схемы-алгоритма
Обработка', чтобы рассчитать сумму налога (tax), необходимо
умножить сумму продаж на ставку налога.
Вывод данных', результат вычислений (tax) должен быть выве-
ден на экран дисплея.
На втором этапе рисуем схему алгоритма, используя принятые
обозначения (рис. 1.2).
Обратите внимание на блок обработки ошибок при вводе ин-
формации с клавиатуры — это необходимая часть любой про-
граммы, принимающей данные от человека, который является
источником потенциальных ошибок. Можно избежать проблем в
будущем, если на входе в обрабатывающие блоки отсекать некор-
ректные данные, в нашем случае — это простейшая проверка,
сумма не может быть отрицательным значением. Анализируя по-
1.4. Этапы трансляции программы
9
лученный алгоритм, отметим, что объем вспомогательной части
(ввод-вывод данных и контроль ошибок) намного превосходит
содержательную часть — обработку, ради которой и составлялся
алгоритм. Это типичная ситуация для задач, решаемых на компь-
ютере, в среднем половина программного кода посвящена вспо-
могательной части работы.
1.4. Этапы трансляции программы
По мере развития вычислительной техники увеличивалась па-
мять и быстродействие компьютеров, а значит, становилось воз-
можным создание все более длинных и сложных программ.
Самые первые программы писались в машинных кодах. Дан-
ные и программа составляли единое целое, структура такой про-
граммы была примитивна. Очень скоро появились первые языки
10 Глава 1. Базовые понятия программирования
программирования — так называемые ассемблеры, они отличают-
ся от машинных команд лишь заменой числовых кодов на сим-
вольные названия инструкций. Поэтому программирование на ас-
семблере мало отличается от программирования в машинных ко-
дах, это весьма трудоемкий процесс, требующий к тому же
довольно высокой квалификации программиста.
На следующем этапе развития программирования появились
языки высокого уровня — в них каждый оператор, написанный
программистом, при исполнении программы заменялся уже це-
лым набором машинных инструкций. Большим преимуществом
языков высокого уровня было то, что они позволяли забыть о том,
на каком именно компьютере программа исполняется, т. е. про-
граммы стали переносимы с одного компьютера на другой.
Для того чтобы исполнить программу, ее нужно разместить в
памяти компьютера (рис. 1.З.), но единственный язык, напрямую
выполняемый процессором, — это машинный код. Перевод исход-
ного текста на языке высокого уровня, написанного программи-
стом, в машинный код выполняют специальные программы, назы-
ваемые трансляторами.
Рис. 1.3. Размещение программы и данных в памяти компьютера
Транслятор — программа, которая принимает на вход про-
грамму на одном языке (он называется исходным языком) и пре-
образует ее в программу, написанную на другом языке (он называ-
ется целевым языком). В качестве целевого языка наиболее часто
выступает машинный код, так как он может непосредственно ис-
полняться компьютером.
Существуют две разновидности трансляторов.
1.4. Этапы трансляции программы
11
Компиляторы выдают результат в виде исполняемого файла.
Этот файл может быть исполнен самостоятельно без создавшего
его транслятора.
Интерпретаторы исполняют программу после построчного
разбора. Программа транслируется (интерпретируется) при каж-
дом запуске и требует наличия на компьютере как интерпретатора,
так и исходного кода.
В современных компьютерах трансляция исходного языка в
целевой язык проходит в несколько этапов, представленных на
рис. 1.4:
• компиляция (обработка исходного текста компилятором);
• компоновка (последующая обработка редактором связей).
Рис. 1.4. Этапы трансляции программы, состоящей из нескольких модулей
Компилятор — это программа, которая считывает текст про-
граммы на исходном языке (например, на С) из файла и преобразу-
ет его в последовательность команд на языке, понятном компьюте-
ру (этот процесс называется компиляция программы). Компилятор
преобразует сразу весь текст программы и сохраняет результат на
12
Глава 1. Базовые понятия программирования
диске, так что программу можно запустить в любое время. Основ-
ная задача компиляции — анализ исходного текста программы и
проверка возможных ошибок (компилятор проверяет только син-
таксические ошибки программирования, т. е. соответствие напи-
санной программы правилам языка программирования), затем соз-
дает промежуточную форму программы — объектный модуль.
Редактор связей выполняет дальнейшее преобразование про-
граммы, в результате которого объектный код превращается в ма-
шинный код, который называемый исполняемым модулем програм-
мы. Кроме того, на этом этапе происходит соединение нескольких
объектных модулей в единый исполняемый модуль и определяется
способ загрузки полученной программы в память.
Если текст программы состоит из нескольких частей, располо-
женных в различных файлах, говорят, что программа представляет
собой проект и состоит их нескольких модулей. В этом случае каж-
дый модуль компилируется отдельно, а затем полученные объект-
ные модули соединяются в единый исполняемый модуль.
Мы рассмотрели этапы трансляции, в результате которых про-
грамма преобразуется из исходного модуля в исполняемый модуль.
Результаты каждого этапа преобразования хранятся в соответст-
вующих файлах:
• исходный файл на С содержит текст, написанный программи-
стом, и имеет расширение .с или .срр. Исходный файл можно
распечатывать и читать так же, как любой текстовый файл.
Этот файл можно редактировать и тем самым изменять про-
грамму;
• объектный файл программы является результатом работы
компилятора и имеет расширение .obj, он содержит некий
промежуточный код, необходимый для редактора связей;
• исполняемый файл программы имеет расширение .ехе и содер-
жит последовательность машинных команд, которая может
быть выполнена компьютером.
Глава 2
ОБЗОР ЯЗЫКА С
2.1. Особенности языка
Выбирая язык программирования для решения конкретной за-
дачи, программист должен помнить, что он служит двум целям и
призван:
• во-первых, предоставить набор концепций и правил, кото-
рыми оперируют программисты, обдумывая решение постав-
ленной задачи;
• во-вторых, предоставить программисту инструмент для опи-
сания подлежащих выполнению действий.
Первая цель требует от языка быть наиболее близким к решае-
мой задаче, т. е. использовать ключевые слова в терминологии той
области деятельности, к которой относится задача, или, как гово-
рят, быть ближе к «предметной области». Вторая же цель требует
быть ближе к машинному коду. Язык С весьма удачно совместил
оба эти требования, кроме того, он хорош для обучения програм-
мированию, так как, несмотря на свою компактность, позволяет
использовать любые технологии и стили программирования, а так-
же доступен в различных операционных системах.
Следует также отметить, что С достаточно широко распростра-
нен, и приобретенные знания, и опыт могут пригодиться при ре-
шении самого широкого круга задач, используется сотнями тысяч
программистов, во многих прикладных областях, поддерживается
десятками независимых реализаций и сотнями библиотек, и все
это помогает программистам сделать свой выбор в пользу С.
Остановимся на характерных особенностях языка и постара-
емся понять, почему же он получил столь широкое распростране-
14
Глава 2. Обзор языка С
ние и динамичное развивитие? Рассмотрим главные отличия С от
других языков высокого уровня, которые и обеспечили столь за-
метный успех.
С — наиболее компактный из всех современных языков програм-
мирования. Вместе с тем следует отметить богатый набор операто-
ров, универсальность и возможность управления структурами дан-
ных. С не является языком «очень высокого уровня», он не рассчи-
тан и на какую-то конкретную область применения. Обладая
широкими возможностями и универсальностью, он гораздо эф-
фективнее, чем более мощные языки. Компактность С достигается
отсутствием некоторых механизмов программирования, традици-
онно включаемых во все языки высокого уровня.
В язык С включены только простые, последовательные конст-
рукции управления, такие как проверки, циклы, группирование и
функции. В языке отсутствуют:
• операции для работы с составными объектами, такими как
массивы, строки символов, множества, списки;
• операции ввода-вывода.
Следует отметить, что отсутствующие механизмы высокого
уровня, безусловно, необходимы для работы и обеспечиваются
многочисленными явно вызываемыми функциями. Такие «скром-
ные возможности» самого языка имеют реальные преимущества,
так как С относительно мал, описание языка также компактно и
его можно быстро изучить.
С не является языком со строгими типами данных. В отличие от
большинства языков он позволяет преобразование типов данных.
Эта особенность языка, с одной стороны, дает большие возможно-
сти и необыкновенную гибкость в программировании, но, с другой
стороны, потенциально опасна, так как является источником
ошибок и всякого рода несогласованностей.
С — современный язык. Средства языка позволяют использовать
все современные стили программирования, такие как:
• нисходящее проектирование;
• структурное программирование;
• пошаговую разработку модулей.
С — эффективный язык, легко переносимый (мобильный) язык.
Компилятор языка учитывает особенности и возможности совре-
менных компьютеров, и это обстоятельство делает программы
на С весьма эффективными, сравнимыми с ассемблерными про-
2.2. Элементы языка
15
граммами. Можно сказать, что С является языком, более близким
к ассемблеру, чем другие языки высокого уровня, и так как многие
его инструкции адресованы непосредственно аппаратной части
компьютера, программа на С выполняется очень быстро.
2.2. Элементы языка
Подобно естественному языку, любой язык программирова-
ния включает следующие понятия:
• алфавит — символы, которые можно использовать в про-
граммах;
• лексика — ключевые слова, идентификаторы, операторы;
• синтаксис — выражения, конструкции;
• пунктуация (или разделители): ( ) [] {}
• семантика (или смысловая составляющая) — это то, что мы
хотим сообщить компьютеру («что все это значит»), а также
то, как компьютер это понимает («что это обозначает для
компьютера»).
2.2.1. Алфавит
В алфавит языка С включены все символы, присутствующие на
клавиатуре персонального компьютера (не русифицированного),
кроме символов @ и $.
Все допустимые символы можно разделить на несколько групп:
• прописные латинские буквы: A...Z;
• строчные латинские буквы: a...z;
• арабские цифры: 0...9;
• символ подчеркивания _ (рассматривается как буква);
• спецзнаки: ”, {} | [ ] ( ) + - / % \;'. :?< = >_!&*#- А;
• управляющие символы;
• обобщенные пробельные символы.
Следует особо отметить две последние группы символов, вхо-
дящих в алфавит языка.
К первой группе относятся управляющие символы, которые ис-
пользуются для форматирования при вводе и выводе информации
на внешние устройства компьютера. К внешним устройствам мож-
16
Глава 2. Обзор языка С
но отнести клавиатуру, дисплей и принтер. Управляющие символы
выполняют служебные функции, они не отражаются на устройстве
ввода-вывода как обычные символы, а выполняют определенные
действия. Например, переводят курсор на новую строку, вставля-
ют табуляцию и т. п.
Управляющие символы иногда называют управляющими по-
следовательностями, наиболее часто используемые из них приве-
дены в табл. 2.1.
Таблица 2.1
Управляющая последовательность Наименование символа
\а Звонок
\ь Возврат на шаг
\t Горизонтальная табуляция
\п Новая строка
\v Вертикальная табуляция
\г Возврат каретки
V Новая страница
\” Кавычки
V Апостроф
\° Ноль-символ
\\ Обратная дробная черта
\ddd Восмеричное представление кода символа
\xdd Шестнадцатеричное представление кода символа
Ко второй группе относятся обобщенные пробельные символы,
которые используются для форматирования текста программы.
2.2. Элементы языка
17
Эти символы, не имеющие графического представления, имеют то
же назначение, что и пробелы между словами в тексте. К ним отно-
сятся: пробел, возврат каретки, новая строка, табуляция, верти-
кальная табуляция, новая страница. Пробельные символы часто ис-
пользуются для повышения читаемости (наглядности) программы.
Все остальные представимые символы (прописные и строчные
буквы русского алфавита, знаки @ и $, символы псевдографики
и др.) не включены в алфавит языка С, но могут содержаться в тек-
сте программы в качестве данных или комментария.
2.2.2. Лексемы
Программа на языке С состоит из элементов, называемых лек-
семами (token).
Лексема — это единица текста программы, которая имеет опре-
деленный смысл для компилятора и которая не может быть разби-
та на части в дальнейшем.
К лексемам следует отнести следующие понятия:
• идентификаторы (identifiers);
• ключевые слова (key words);
• литералы (literals) или константы (constans);
• операторы (operators);
• знаки пунктуации (punctuators).
Между лексемами могут вставляться разделители, в качестве
которых используются пробельные символы. Число пробельных
символов не ограничивается и зависит от предпочтений програм-
миста, основная цель которого — создать наглядный и легко чи-
таемый текст программы. Компилятор воспринимает текст как
сплошной поток символов, для него важно лишь определить гра-
ницу между лексемами, поэтому позиционирование операторов и
других лексем может быть произвольным.
Для лучшей читаемости программы текст необходимо структу-
рировать, т. е. делать отступы в строке, пропуски между строками
и т. п. Создание читаемой программы служит признаком хорошего
стиля программирования. Это приводит к облегчению понимания
смысла программы, поиска ошибок и в случае необходимости ее
модификации.
18
Глава 2. Обзор языка С
2.2.3. Идентификаторы
Идентификатором называется последовательность цифр и
букв, а также специальных символов (первой должна стоять буква
или специальный символ). Примеры правильного задания иденти-
фикаторов:
abc, ABC, А128В, Sa_128.
Идентификатор создается на этапе объявления программного
объекта. Идентификатор обозначают переменные, функции,
структуры, после объявления объекты можно использовать в по-
следующих операторах разрабатываемой программы. При выборе
идентификатора необходимо учитывать следующее:
• идентификатор не должен совпадать с ключевыми словами и
именами библиотечных функций языка С;
• следует обратить особое внимание на использование символа
«_» (подчеркивание) в качестве первого символа идентифи-
катора. Часто с одного или двух таких символов начинаются
имена системных функций и переменных, поэтому начинать
пользовательский идентификатор с символа «_» не рекомеду-
ется (хотя и не запрещается), надо помнить, что при игнори-
ровании этого совета могут возникнуть проблемы при пере-
носе программы из одной инструментальной среды в другую;
• компилятор допускает любое количество символов в иденти-
фикаторе, но значимыми являются первые 31 символ. При
программировании лучше выбирать названия покороче и на-
делять их некоторым смыслом;
• идентификаторы, используемые для связи между модулями,
имеют дополнительные ограничения, накладываемыми ре-
дакторами связей (отметим, что характер ограничений зави-
сит от конкретного редактора связей);
• так как прописные и строчные символы в языке С различа-
ются, следует учитывать регистр при обращении к перемен-
ным (с точки зрения компилятора, «х» и «X» — это два раз-
ных имени).
Пример идентификаторов:
i
count
Переменная цикла
Счетчик
2.2. Элементы языка
19
buff size Имя из двух слов (размер буфера)
name Имя со спецсимволом
Примеры ошибочного задания идентификаторов:
374q Идентификатор начинается с цифры
if Идентификатор совпадает с ключевым словом
2.2.4. Ключевые слова
Ключевые слова — это заранее определенные в языке иденти-
фикаторы, имеющие конкретное значение для компилятора. Час-
то ключевые слова называют зарезервированными, или служебными,
словами. Важно понять, что ключевые слова не могут быть исполь-
зованы в качестве свободных имен, выбираемых программистом,
так как компилятор придаст такому идентификатору зарезервиро-
ванный в языке смысл, а не тот, который подразумевает програм-
мист.
Ключевые слова можно разделить на группы, каждая из кото-
рых определяет некоторое понятие языка:
• объявление типов данных:
int char double float short long signed unsigned void enum
struct union volatile;
• создание языковых конструкций:
do while for if else goto switch case return default break continue;
• все остальные понятия (классы памяти, модификаторы
и т. д.:
const sizeof auto register extern near far huge typedef interrupt.
Обратите внимание на то, что ключевые слова всегда пишутся
строчными буквами! Если if — это ключевое слово для создания ус-
ловной конструкции, то IF — это свободно выбираемый иденти-
фикатор и потому может быть чем угодно (в зависимости от того,
в каком контексте эта лексема появилась в тексте программы, на-
пример, именем переменной или функции).
20
Глава 2. Обзор языка С
2.2.5. Переменные
Объектом языка С будем называть именованную область памя-
ти — это переменные и функции. Отметим, что в языке C++ поня-
тие объекта трактуется шире, и переменные рассматриваются как
частный случай объекта.
Данные, значения которых могут изменяться в процессе рабо-
ты программы, называются переменными. Переменную чаще всего
рассматривают как пару «имя—значение». Имени соответствует
адрес участка памяти, выделенный под переменную, а значением
является содержимое этого участка. Именем служит идентифика-
тор, а значение соответствует типу переменной, определяющему мно-
жество допустимых значении и набор применяемых операции.
Перед использованием переменная должна быть размещена в
памяти компьютера, или, как говорят, под нее должна быть выде-
лена память. Эти действия выполняются компилятором при опре-
делении переменной, размер выделяемой памяти определяется типом
переменной. Выделенная память (созданная переменная) имеет ад-
рес, который можно узнать, применяя специальную команду («по-
лучение адреса»).
Во избежание ошибок перед использованием переменной
должны присваиваться начальные значения. Важно понять, зачем
это нужно делать. Дело в том, что память компьютера устроена так,
что в ней всегда что-то записано, даже сразу после включения пи-
тания, когда содержимое памяти — это хаотичное чередование би-
тов-нулей и битов-единиц, этот «информационный мусор» можно
трактовать как информацию. Итак, сразу после определения пере-
менной ее значение (содержимое области выделенной памяти)
есть «информационный мусор», не имеющий отношения к решае-
мой задаче. Задавая начальные значения, программист «настраи-
вает» переменную на решаемую задачу. Очень часто для этой цели
используется инициализация.
Инициализация переменной — это одновременное выполнение
двух действий: выделение памяти и задание начальных значений
переменной.
2.2.6. Константы
Данные значения, которые программа не должна и не может
изменить, называются константами. Значения констант опреде-
2.3. Стандартные типы данных
21
ляются в исходном тексте программы до компиляции, они фикси-
рованы и неизменны на протяжении выполнения всей программы.
Так же как переменную, константу необходимо определить, после
чего под нее выделяется память в соответствии с заданным типом,
но в отличие от переменной адрес константы недоступен.
Так же как и переменные, константы могут иметь имена, в
этом случае их называют именованными константами. Традицион-
но принято обозначать именованные константы большими буква-
ми латинского алфавита, но это всего лишь общепринятая тради-
ция, облегчающая восприятие текста программы, а не правило
языка, поэтому, если программист не следует данной практике,
ошибок при компиляции не возникает.
2.3. Стандартные типы данных
Понятие «тип данных» было введено в предыдущем разделе,
оно связано со значением объекта, напрмер переменной. В языке
С каждая перменная должена иметь явно указанный (объявлен-
ный) тип, который определяет множество допустимых значений
переменной и набор операций, в которых переменная может ис-
пользоваться.
Стандартными типами данных называются типы, заранее оп-
ределенные в языке программирования, в отличие от пользова-
тельских типов, определяемых самим программистом в процессе
работы. В языке С стандартные типы данных разделяются на про-
стые и составные.
Данные простого типа не могут быть разделены на более мел-
кие составляющие. Для них четко определен размер (в соответст-
вии с типом) и способ размещения в памяти компьютера.
К простым типам данных относятся:
• числовые данные: целые и с плавающей точкой;
• символьные данные;
• указатели.
Подмножествами целых данных являются:
• данные перечислимого типа;
• битовые поля.
Составные типы можно разделить на две группы. К первой
группе относятся стандартный тип данных — массив.
22
Глава 2. Обзор языка С
Вторую группу образуют пользовательские типы данных; в язы-
ке С имеется четыре «базовых кирпичика», из которых строится,
вся работа по построению пользовательских типов:
• структуры (structures);
• объединения, или союзы (unions);
• битовые поля (bit fields);
• перечисления (enumerations).
2.3.1. Простые типы данных
Весь спектр типов данных представлен на рис. 2.1. К простым
данным относится пять стандартных типов:
• char — символ;
• int — целое число;
• float — число с плавающей точкой;
• double — число с плавающей точкой (двойная точность);
• void — отсутствие значения.
Дадим краткую характеристику каждому из них.
1. Переменная типа char имеет размер 1 байт, ее значениями
являются различные символы из кодовой таблицы, например: ’й',
Рис. 2.1. Типы данных
2.3. Стандартные типы данных
23
j’ (при записи в программе они заключаются в одинарные ка-
вычки).
2. Размер переменной типа int в стандарте языка С не опреде-
лен. В большинстве систем программирования ее размер соответ-
ствует размеру целого машинного слова. Например, в персональ-
ных компьютерах (PC) — это 32 разряда.
3. Ключевое слово float позволяет определить переменные ве-
щественного типа. Их значения имеют дробную часть, отделяемую
точкой, например: -5.6, 31.28. Вещественные числа могут быть за-
писаны также в форме с плавающей точкой, например: -1.09е+4.
Число перед символом «е» называется мантиссой, а после — по-
рядком. Переменная типа float занимает в памяти одно машинное
слово (32 бита в PC).
4. Ключевое слово double позволяет определить вещественную
переменную двойной точности. Она занимает в памяти в два раза
больше места, чем переменная типа float.
5. Ключевое слово void используется в различных целях, кото-
рые мы рассмотрим позднее, здесь же отметим его применение в
качестве «не имеющий значения», например при объявлении
функции, не возвращающей никаких значений.
2.3.2. Модификация типов данных
Объекты числовых типов могут быть модифицированы. Моди-
фикаторы не меняют тип данных, а лишь дают иную интерпрета-
цию выделенной памяти или изменяют ее размер. Для этой цели в
языке С имеются следующие ключевые слова:
• unsigned — беззнаковое;
• signed — знаковое;
• short — короткое;
• long — длинное.
Модификаторы следует записывать перед типом данных, на-
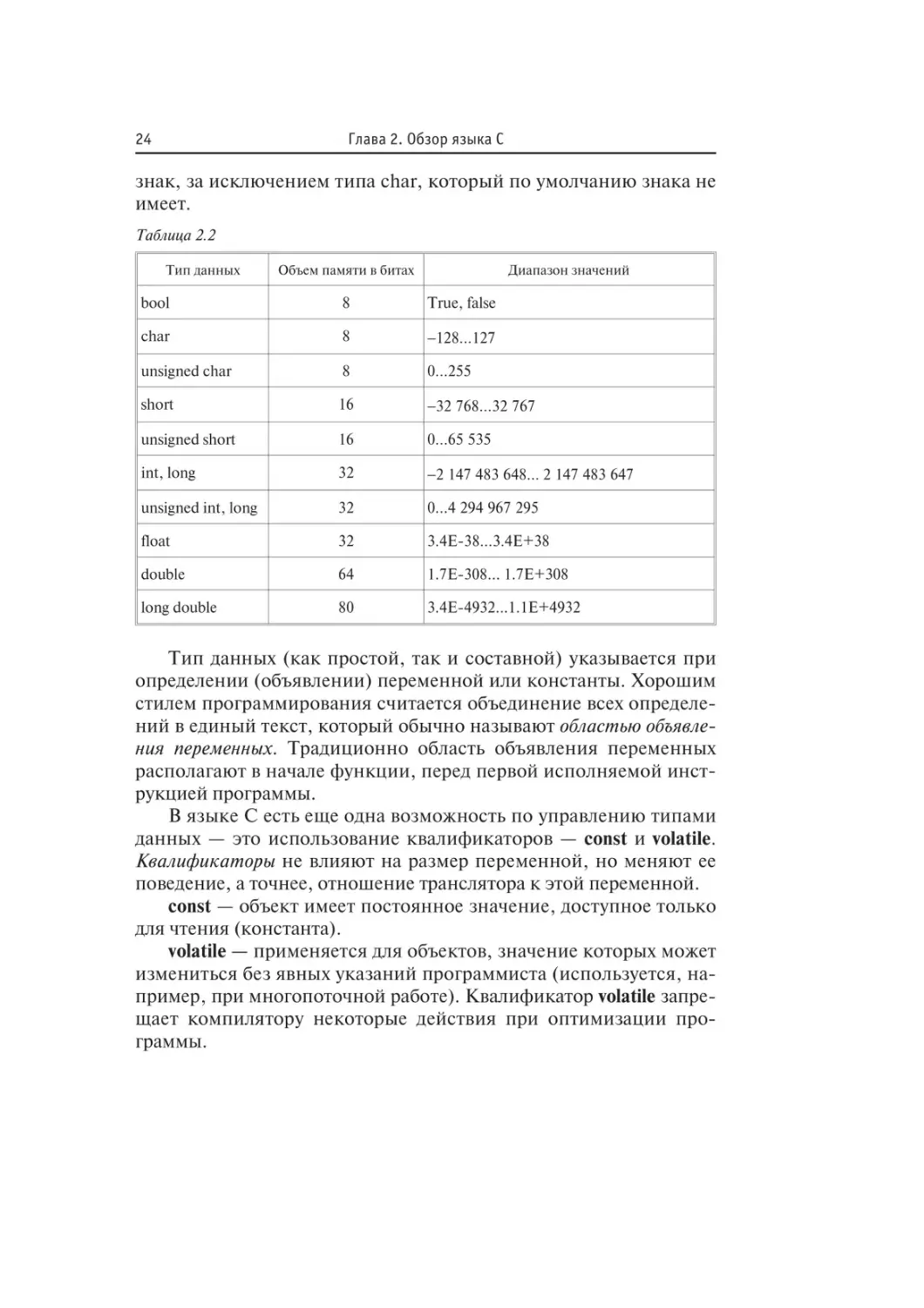
пример: unsigned char. Таблица 2.2 иллюстрирует возможные соче-
тания модификаторов (unsigned, signed, short, long) co специфика-
торами (char, int, float и double), а также показывает размер и диа-
пазон значений объекта (информация дана для 32-разрядных
компиляторов). Если модификатор не используется, то действуют
правила умолчания. По умолчанию все числовые типы имеют
24
Глава 2. Обзор языка С
знак, за исключением типа char, который по умолчанию знака не
имеет.
Таблица 2.2
Тип данных Объем памяти в битах Диапазон значений
bool 8 True, false
char 8 -128...127
unsigned char 8 0...255
short 16 -32 768...32 767
unsigned short 16 0...65 535
int, long 32 -2 147 483 648... 2 147 483 647
unsigned int. long 32 0...4 294 967 295
float 32 3.4Е-38...3.4Е+38
double 64 1.7Е-308... 1.7Е+308
long double 80 3.4Е-4932...1.1Е+4932
Тип данных (как простой, так и составной) указывается при
определении (объявлении) переменной или константы. Хорошим
стилем программирования считается объединение всех определе-
ний в единый текст, который обычно называют областью объявле-
ния переменных. Традиционно область объявления переменных
располагают в начале функции, перед первой исполняемой инст-
рукцией программы.
В языке С есть еще одна возможность по управлению типами
данных — это использование квалификаторов — const и volatile.
Квалификаторы не влияют на размер переменной, но меняют ее
поведение, а точнее, отношение транслятора к этой переменной.
const — объект имеет постоянное значение, доступное только
для чтения (константа).
volatile — применяется для объектов, значение которых может
измениться без явных указаний программиста (используется, на-
пример, при многопоточной работе). Квалификатор volatile запре-
щает компилятору некоторые действия при оптимизации про-
граммы.
2.3. Стандартные типы данных
25
Пример объявления переменных:
int count, sum;
charsim;
float sum=0;
// 2 переменные типа int с именами count, sum
// Переменная типа char с именем sim
// Определение и задание начального значения
// переменной sum
Пример объявления именованных констант:
#define МАХ 256 // константе МАХ присваивается значение 256
const double PI=3.14; // константе PI присваивается значение 3.14
2.3.3. Символьные данные
Значением переменной или константы типа char могут быть
только одиночные символы. Каждый символ кодируется числом
(код символа) — это машинное представление символа. Код сим-
вола — это целое число без знака в диапазоне от 0 до 255. Символь-
ные константы заключаются в апострофы.
Пример определения символьных переменных:
char dog, cat;
Примеры символьных констант:
’А’, ’а, 7’,
2.3.4. Целые числа
Типы int, short, long являются числами со знаками, т. е. значе-
ниями этих типов могут быть только целые числа — положитель-
ные, отрицательные и нуль.
Один бит используется для указания знака числа, поэтому диа-
пазон представления чисел без знака больше, чем со знаком.
Примеры:
signed int n; // Целое со знаком
unsigned int b; // Целое без знака
26
Глава 2. Обзор языка С
В языке С приняты следующие умолчания:
int с; // Подразумевается signed int с
unsigned d; // Подразумевается unsigned int d
signed f; // Подразумевается signed int f
Целые константы. Число без десятичной точки и без показате-
ля степени рассматривается как целое (соглашения языка С). Ком-
пилятор по внешнему виду константы определяет, целая она или ве-
щественная.
Примеры целых констант:
5 — целая десятичная константа;
61, 128L — целая десятичная константа двойной точности;
0105L — восьмеричная константа двойной точности;
0Х2А11 — шестнадцатеричная константа.
2.3.5. Данные плавающего типа (вещественные числа)
Числа могут быть представлены в разных видах. Например,
числа 5000 и 0.000077
в алгебраическом виде:
5.0* 103;
7.7* 10-5;
в экспоненциальном виде:
5.0еЗ;
7.7е-5.
В алгебраической записи числа хранятся в памяти в виде ман-
тиссы и порядка:
15 0 00 = 1.5*104,
где 1.5 — это мантисса; 4 — порядок.
В компьютере для определения вещественных чисел могут ис-
пользоваться типы:
float — одинарная точность представления;
double — двойная точность.
Данный формат представления вещественного числа показы-
вает в деталях расположение различных компонент числа:
float (4 байта): 1 бит — знака числа;
8 бит — порядок;
23 бита — мантисса;
2.4. Компоненты простой программы
27
double (8 байтов): 1 бит — знака числа;
16 бит — порядок;
47 бит — мантисса
Примеры определения переменных:
float f, а, b;
double х,у;
long float w;
// Вещественные числа одинарной точности
// Вещественные числа двойной точности
// Аналогично double
Напомним, что тип константы определяется по ее внешнему
виду. Наличие десятичной точки в числе указывает компилятору,
что перед ним — вещественная константа. Наличие модификато-
ра L или 1 увеличивает размер памяти, выделяемой под константу.
Примеры вещественных констант:
5. — десятичная константа;
123.456L, 1.31 — константы двойной точности.
2.3.6. Инициализация переменных
Инициализация — это выделение памяти с последующим задани-
ем начальных значений. Для этой цели могут использоваться кон-
станты.
Примеры инициализации переменных с использованием кон-
стант:
int web=5;
int rad=077;
int nina =0X99;
//Десятичная целая
// Восьмеричная
// Шестнадцатеричная
double sum=5.; // Десятичные вещественные
float bigword=5,77e+34;
char dog—b’; // Символьная
2.4. Компоненты простой программы
В этом разделе кратко разберем необходимые элементы, из ко-
торых состоит любая программа на языке С. Это позволит вам пи-
сать простейшие программы без подробного изучения соответст-
28
Глава 2. Обзор языка С
вующих разделов пособия. Прежде всего коснемся двух вопро-
сов — это структура программы, которая задает некие общие
правила для любой программы на С и средства ввода-вывода, без
которых не может обойтись ни одна программа, так как недоста-
точно произвести необходимые вычисления, желательно еще и по-
смотреть на результат.
2.4.1. Структура С-программы
Программа на С состоит из функций и переменных. Функции
содержат инструкции (операторы), описывающие вычисления,
которые необходимо выполнить, а переменные хранят значения,
используемые в процессе этих вычислений. Многие функции, ко-
торые могут понадобиться, уже написаны, откомпилированы и
помещены в библиотеки (их называют библиотечными или стан-
дартными функциями). Необходимость написания собственной
функции возникает только в том случае, если нет подходящей
библиотчной.
Традиционно, изучение языка программирования начинают с
программы, которая печатает текст на экране дисплея, например
фразу «hello, world!».
Текст программы имеет вид:
#include <stdio.h> // Включение файла в текст программы
void main ()// Головная функция, обязательна для любой программы
{
printff'hello, world!\n");// Библиотечная функция вывода на терминал
}
Первая строка программы: #include <stdio.h> сообщает компи-
лятору, что он должен включить в исходный текст программы
стандартную библиотеку ввода-вывода.
В библиотеке stdio находятся функции для работы с внешними
устройствами, такими как клавиатура, принтер или экран дисплея.
Какую бы задачу ни решал программист, ему понадобится ввести
данные в компьютер и вывести результат, т. е. использовать функ-
ции ввода-вывода. Одной из особенностей языка С является отсут-
ствие операторов ввода-вывода. В отличие от большинства языков
программирования, в которых операторы ввода-вывода встроены
2.4. Компоненты простой программы
29
и являются частью самого языка, С использует для этой цели биб-
лиотечные функции. Поэтому любая программа на С начинается с
директивы #include, так как обязана включить в текст ту или иную
библиотеку ввода-вывода.
Следующая строка программы — функция с именем main.
Обычно имена функциям даются произвольно, но main() — это
особая функция (ее называют главной или головной), любая про-
грамма на С начинает свои вычисления с первой инструкции этой
функции. В нашем примере головная функция не имеет аргумен-
тов, что указывается как (). Круглые скобки являются частью имени
функции, и ставить их надо обязательно, так как именно они ука-
зывают компилятору, что имеется в виду функция, а не перемен-
ная с именем main. Обычно одной функции main() недостаточно,
и программист пишет свои функции или же использует библио-
течные.
Следом за main() вводятся инструкции. Инструкции могут быть
представлены в виде стандартных команд и имен функций, содер-
жащихся в библиотеках или написанных программистом само-
стоятельно. Фигурные скобки { } отмечают начало и конец функ-
ции main(), тело функции. В нашей программе тело функции main()
состоит из одной инструкции — printf("hello, world\n"). Это вызов
библиотечной функции с именем printf и аргументом "hello,
world!\п". Функция printf является библиотечной, она выдает вы-
ходные данные на терминал, в данном случае печатается строка
hello, world!
Символ ’\п' в конце текста в кавычках сообщает компилятору,
что после вывода текста на экран нужно перейти на новую строку.
Функция printf не обеспечивает автоматического перехода на
новую строку, так что многократное обращение к ней можно ис-
пользовать для поэтапной сборки выходной строки. Наша первая
программа может быть переписана в следующем виде:
#include <stdio.h>
main()
printf(”hello,");
printf("world");
printfO");
}
30
Глава 2. Обзор языка С
Подчеркнем, что \п представляет собой только один символ.
Это пример «управляющей последовательности», символы, подоб-
ные \п, дают общий механизм для представления невидимых сим-
волов, которые не отображаются на экране, а выполняют некото-
рое действие.
2.4.2. Комментарии как средство облегчения понимания
программы
В программировании под комментариями понимают поясне-
ния к исходному тексту программы, оформленные по правилам,
определяемым языком программирования. Комментарии не ока-
зывают никакого влияния на результат компиляции, они лишь по-
могают человеку правильно понять текст программы.
До сих пор авторитеты в области программирования не при-
шли к общему мнению по вопросу комментирования программ.
Некоторые специалисты являются сторонниками минимизации
комментариев, они сходятся во мнении, что комментарии должны
объяснять намерения программиста, а не код программы. То, что
можно выразить на языке программирования, не должно выно-
ситься в комментарии, т. е. текст самой программы должен макси-
мально брать на себя функции комментариев. В частности, надо ис-
пользовать «говорящие названия» (названия, объясняющие назна-
чение) для переменных, функций и тому подобных, разбивать
программу на легкие для понимания части, стремиться к тому,
чтобы структура программы была максимально понятной и про-
зрачной. Есть даже ортодоксальное мнение, что если для понима-
ния программы требуются комментарии — значит, она плохо на-
писана.
Другая часть программистов придерживается противополож-
ного мнения и настаивает на включении комментариев в текст
программы, причем настолько подробных и продуманных, чтобы
исходный текст программы мог заменять сопроводительную доку-
ментацию к программе.
Авторы данного пособия предпочитают держаться «золотой се-
редины» и использовать краткий комментарий, который поможет
вспомнить алгоритм решения и назначение переменных после
окончания работы над программой.
2.4. Компоненты простой программы 31
Есть еще одна важная функция комментариев, которую часто
используют практикующие программисты — это временное ис-
ключение части кода программы из компиляции. Порой бывает
трудно определить местонахождение ошибки, это касается как
синтаксических ошибок, так и, в особенности, ошибок, возникаю-
щих при выполнении программы (ошибки времени выполнения).
Комментарии исключают сомнительные части программы из ком-
пиляции (а значит, и из выполнения), оставляя исключенный уча-
сток текста на своем месте, тем самым помогая программисту сде-
лать нужные выводы.
Итак, комментарии играют важную роль, они повышают на-
глядность и удобство чтения программ, помогают лучше понять
алгоритм выполнения программы. Комментарии пишутся для чело-
века и остаются после трансляции в неизменном виде, в отличие от
инструкций, которые транслятор преобразует в машинные команды.
Комментарии можно вставлять в любое место программы, где
допускаются пробелы, или в конце строки. Комментарии могут за-
нимать как одну, так и несколько строк. Следующие примеры по-
казывают правила синтаксического оформления комментариев:
И Это однострочный комментарий
/* Это многострочный комментарий, однако надо быть осторожным,
внутри комментария не должно быть операторов программы,
которые так же, как и этот текст, будут игнорироваться */
Длинные строки программы можно переносить. Для этой цели
служит символ «\» (обратная косая черта).
Пример текста с переносом:
printf ("Очень ддинные\
строки можно переносить:\п");
Эквивалентный текст:
рпшГС’Очень длинные строки можно переносить:\п");
Создание читаемой программы служит не только признаком
хорошего стиля программирования, но и приводит к облегчению
понимания смысла программы, поиска ошибок и в случае необхо-
32
Глава 2. Обзор языка С
димости ее модификации. Приведем несколько принципов для на-
писания хорошо читаемых программ.
1. Следует использовать «говорящие названия», т. е. все обо-
значения должны быть осмысленны.
2. Помещайте каждый оператор на отдельной строке.
3. Используйте пустые строки для отделения части программы,
имеющей некоторое семантическое значение. Например, отделяй-
те описательную часть программы от выполняемой части.
4. Текст программы должен коротко комментироваться, при
этом комментарии объясняют намерения программиста, а не код
программы.
Примеры, приводимые в дальнейшем, демонстрируют хоро-
ший стиль записи программ и рекомендуются для использования в
практических занятиях.
Пример. Программа снабжена комментариями, дающими по-
яснения к примеру.
// Подключение библиотеки ввода-вывода
#include <stdio.h>
void main(void)
{// Область определения переменных
int х=3,у;
double z;
// Выполняемая часть программы
у=2
z= х/у;
printf (”\пРезультат вычисления=%^\п",/ );
}
В результате выполнения программы на экране появится сле-
дующий текст:
Результат вычисления^. 5
2.4.3. Пример создания программы
Написать программу для расчета налога на продажи (алгоритм
решения рассмотрен выше). По условию задачи известны: общий
объем продаж в рублях, налоговая ставка в процентах. Требуется
рассчитать сумму уплачиваемого налога.
2.4. Компоненты простой программы
33
#include <stdio,h>
void main ()
{ /I Область определения данных
const double rate=0.2; // Константа rate
double sum , tax ; // Переменные tax и sum
// Команда printf имеет метку M для организации цикла
М: printf("\n input selling sum—’);
scanf (”%e’',&sum); // Ввод данных c Kia в натуры
if (sum >0) tax = rate * sum;
else { printf(" error input selling sum !!!");
goto M; // Переход на метку M
printf ("\ntax=%f rub", tax);
}
Вопросы для самопроверки
1. Какие символы не входят в алфавит языка С?
2. Для чего нужны «пробельные символы»?
3. Для чего нужны «управляющие символы»?
4. Поясните понятие «ключевые слова», назовите основные группы ключе-
вых слов.
5. Перечислите правила записи идентификаторов.
6. В чем заключается различие между константой и переменной?
7. Сохраняет ли переменная свое значение в ходе выполнения всей про-
граммы?
8. Как изменить значение константы?
9. Дайте определение термину «инициализация переменной».
10. Перечислите стандартные типы данных языка С.
11. Перечислите модификаторы типов данных.
12. Какие группы операторов языка С вы знаете?
13. Что такое тип данных char?
14. Какой тип данных нужно использовать для записи стоимости товара
(в рублях и копейках)?
15. Какова структура программы на языке С?
16. Какие функции выполняют комментарии в программе?
Глава 3
ВЫРАЖЕНИЯ И ОПЕРАЦИИ
Любое действие надданными, выполняемое программой мож-
но рассматривать как некоторое вычисление. На заре развития
электронной техники это свойство было отражено в самом назва-
нии компьютера, машины первого и второго поколения называ-
лись вычислительными устройствами, а позднее электронными
вычислительными машинами (ЭВМ).
Вычисляемое выражение состоит из операндов, соединенных
знаками операций.
Знак операции — это символ или группа символов, сообщаю-
щих компилятору о необходимости выполнения арифметических,
логических или других действий.
Операнд — это константа, литерал, идентификатор, вызов
функции, индексное выражение. Комбинацию операндов можно
также рассматривать как операнд. В простейшем случае операнд
это переменная или константа.
При вычислении выражения операции выполняются в строгой
последовательности, определяемой их приоритетом, или рангом.
Порядок выполнения операций может регулироваться с помощью
круглых скобок. Операции с более высоким рангом выполняются
до операций с более низким рангом, если часть выражения заклю-
чена в скобки, то вначале вычисляется выражение внутри скобок.
В зависимости от используемых операций выражения разделя-
ют на несколько видов:
• первичные (вызовы функций, индексные выражения и вы-
бор элементов);
• унарные (с одним операндом);
• бинарные (с двумя операндами);
• тернарные (с тремя операндами);
3.1. Операция и выражение присваивания
35
• выражения присваивания;
• выражения приведения типа.
Полный список операций языка С и их приоритетов приведен
в табл. 3.3 в конце главы.
ЗЛ. Операция и выражение присваивания
Операция присваивания обозначается символом «=», ее про-
стейший вид:
L = г
Операция присваивания выполняется справа налево, т. е. сна-
чала вычисляется значение выражения г, а затем это значение при-
сваивается операнду L, причем левый операнд должен быть адресным
выражением, т. е. объектом, размещенным в памяти компьютера.
Примером адресного выражения является имя переменной.
Примерами неадресного выражения могут быть выражения, на-
пример а+b, а также константы, которые могут стоять только спра-
ва. Также отметим, что в языке С возможна и такая запись:
a = b = c = d = e + 2;
Итак, результатом выражения присваивания является его ле-
вый операнд. Если же типы правого и левого операнда не совпада-
ют, то значение справа преобразуется к типу левого операнда, и
важно, чтобы при этом не произошло потери значения.
Примеры потери результата:
int i;
char ch;
i=3.14;
ch=777;
Здесь i получает значение 3, так как теряется дробная часть
числа 3.14, а значение 777 слишком велико, и потому не может
быть размещено в char-переменной, заметим, что максимальное
число, которое можно записать в один байт (размер char-перемен-
ной) — это 377.
36
Глава 3. Выражения и операции
Существует так называемая комбинированная операция при-
сваивания вида: а оп= Ь, здесь «оп» является знаком одной из би-
нарных операций:
+ -*/%»«<£! А<£<£||
Выражение а оп= b эквивалентно выражению а = а оп Ь.
Примеры:
а += 2 означает а = а+2;
s /= а означает s = s/a.
Выражение а += 2 выполняется быстрее, чем а = а+2 и пото-
му компактная запись предпочтительнее. Дело в том, что прежде,
чем приступить к вычислению, заданному операцией «+», необ-
ходимо вычислить адрес операнда а. В первом выражении адрес
вычисляется один раз, а во втором — дважды. Подобная «эконо-
мия» на вычислении адресов операндов является характерной
чертой языка С.
Следующий пример демонстрирует еще один прием компакт-
ной записи вычислений:
Выражение (а=Ь)+=с эквивалентно двум операторам:
а=Ъ;
а=а+с.
3.2. Бинарные арифметические операции
Бинарными арифметическими операциями являются:
• + сложение;
• — вычитание;
• * умножение;
• / деление;
• % деление по модулю (остаток отделения).
Рассмотрим выражения, в которых используются разнотипные
данные, именно в этом случае проявляются особенности вычисле-
ний при помощи компьютера. Как известно, данные (как операн-
ды, так и результат) должны быть размещены в памяти компьюте-
ра, причем объем занимаемой памяти зависит от типа данных.
3.3. Операции увеличения (++) и уменьшения (--)
37
Если при вычислении тип операндов отличается от типа результа-
та, то это следует учитывать при распределении памяти (объявле-
нии переменных).
Пример. Результат выражения i*f преобразуется к типу double
(к большему из двух типов), затем результат присваивается пере-
менной g.
int i=5;
double g, f=0.2;
g=f*i;
Пример. При делении двух целых чисел результат получается
дробный, если же результирующая переменная будет объявлена
как целая, то дробная часть результата будет потеряна.
int k=10,m=3,x;
x=k/m; // х=3
int 1=10;
double p=3,z;
z=l/p; //z=3.33333...
Пример. Операция a % b применяется только к целым операн-
дам и дает остаток от деления а на Ь.
х=10%3
у=2 % 3
z=12 % 2
//х=1
//У= 2
//z=0
3.3. Операции увеличения (++) и уменьшения (—)
Во многих алгоритмах в цикле требуется наращивание (или
уменьшение) значения переменных на единицу, такие перемен-
ные называют счетчиками. Назначение счетчиков различно и ис-
пользуются они настолько часто, что во многих языках програм-
мирования существует специальный оператор увеличения значе-
ния переменной на единицу, называемый инкрементом. Оператор
var++ выполняет то же действие, что и оператор var = var + 1.
Глава 3. Выражения и операции
Операции увеличения (инкремента) и уменьшения (декремента)
являются унарными операциями присваивания. Операнд может быть
целого или плавающего типа, а также указателем, но в любом слу-
чае он должен быть модифицируемым, т. е. не константным выра-
жением. Тип результата соответствует типу операнда.
В языке допускается префиксная или постфиксная формы опе-
раций инкремента и декремента, и от того, какая форма использу-
ется, зависит результат выражения.
В префиксной форме знак операции стоит перед операндом, и из-
менение значения операнда происходит до его использования в
выражении, В постфиксной форме знак операции стоит после опе-
ранда, и операнд вначале используется для вычисления выраже-
ния, а затем происходит его изменение.
Пример
int i=0, j=0, k, 1;
//k=l,i = 1
//1=0 J = 1;
//k=0;
//1=1
Последовательность выполнения оператора k = ++i:
i = i+1; k = i;
Последовательность выполнения оператора 1 = j++:
j=j+i;
Пример
int t=l, s=2, z, f;
z=(t++)*5; // z=5, t=2.
f=(++s)/3; //s=3, f=l
Вначале вычисляется t*5, а затем t++. Аналогично вначале вы-
числяется s++, а затем s/3.
3.4. Преобразования типов при вычислении арифметических выражений 39
Если операции увеличения и уменьшения используются как
самостоятельные операторы, префиксная и постфиксная формы
записи становятся эквивалентными:
z++; // Эквивалентно ++z
3.4. Преобразования типов при вычислении
арифметических выражений
3.4.1. Неявное преобразование типов
При вычислении выражений тип каждого операнда может
быть предварительно преобразован к типу другого операнда, необ-
ходимость такого преобразования диктует выполняемая операция,
это так называемое преобразование по умолчанию или автоматиче-
ское преобразование. Такое преобразование часто называют неяв-
ным, так как программист не дает никаких инструкций для прове-
дения действий по изменению типов данных.
Неявные преобразования типов данных происходит в следую-
щих случаях:
1) при выполнении арифметических вычислений;
2) при выполнении операции присваивания, если значение ле-
вой и правой части выражения различается по типу;
3) при передаче аргументов в функцию.
В независимости от причины, вызвавшей неявное преобразо-
вание, все они подчиняются общим правилам, которые состоят в
следующем:
1. Все операнды выражения преобразуются к типу операнда с
наибольшим размером памяти. Размеры для различных типов дан-
ных (в битах) приведены ниже:
long double 80
double 64
float 32
unsigned long 32
long 32
unsigned 32
int 32
short 16
char 8
40
Глава 3. Выражения и операции
Согласно этому правилу float преобразуется в double, long —
в unsigned long и т. д.
2. Операнд типа char всегда преобразуется к типу int по следую-
щим правилам:
• unsigned char преобразуется в int, у которого знаковый разряд
всегда нулевой;
• signed char преобразуется в int, у которого знаковый разряд
совпадает со знаком из char.
3. В выражении тип правой части преобразовывается к типу ле-
вой части выражения. Если размер результата в правой части больше
размера операнда в левой части, то часть результата будет потеряна.
Пример
double ft,sd;
unsigned char ch;
unsigned long in;
int i;
sd = ft*(i+ch/in);
В этом выражении преобразования типов данных будут выпол-
няться в следующей последовательности.
Операнд ch преобразуется к типу unsigned int (правило для типа
char).
Затем он преобразуется к типу unsigned long (к большему опе-
ранду выражения ch/in), по этой же причине i преобразуется к
unsigned long.
Результат операции, заключенной в круглые скобки, будет
иметь тип unsigned long.
Затем он преобразуется к типу double (к большему операнду
выражения ft*(i+ch/in)).
Результат всего выражения будет иметь тип double.
3.4.2. Явное преобразование типов
Явное приведение значения одного типа к другому выполняется
с помощью специальной операции. Допускается преобразования к
типу данных с меньшим объемом памяти, но следует помнить, что
в этом случае будет потеряна часть информации.
3.4. Преобразования типов при вычислении арифметических выражений 41
Формат операции приведения типа:
(имятипа) операнд.
Операндом может быть:
• переменная;
• константа;
• выражение в круглых скобках.
Примеры преобразования констант:
(long) 6 //Длина целой константы 6 равна 4 байта;
(char)6 //Длина целой константы 6 равна 1 байт.
Заметим, что при подобных преобразованиях значения кон-
стант и их внутреннее представление не меняется, так как типы
char, int, long являются целыми типами и отличаются только разме-
ром выделенной памяти.
(double)6 // Длина целой константы 6 равна 8 байт.
В данном случае значение константы не меняется, но меняется
ее внутреннее представление, так как целая константа 6 преобразу-
ется в вещественную константу 6, а следовательно, ей выделяется
память под мантиссу и порядок.
Примеры преобразования переменных:
int a,b,c;
double х;
/* Результат правой части выражения — целое, поэтому общий
результат будет округлен до ближайшего целого значения*/
х=(а+Ь)/с;
/* В обоих случаях результат правой части выражения —
вещественное значение, поэтому результат будет точным,
без округления*/
x=(double)(a+b)/c;
x=(a+b)/(double)c;
Заметим, что в нижеследующих примерах преобразования ти-
пов выполняются только в выражениях (т. е. носит временный ха-
рактер), ни тип, ни значение самих переменных i, 1, d не меняются.
int i=2;
long 1=2;
42
Глава 3. Выражения и операции
double d;
float f;
d=(double)i * (double)l; // i и 1 преобразуются в double
f=(float)d; // d преобразуются во float
3.5. Тернарная или условная операция
В языке С есть единственная операция с тремя операндами,
она обеспечивает выбор одного из двух выражении в зависимости от
условия, поэтому ее часто называют условной операцией (рис. 3.1).
Рис. 3.1. Схема условного оператора
Условная операция имеет следующую форму:
выражение! ? выражение?: выражениеЗ
Выражение 1 (первый операнд) может быть целого или пла-
вающего типа, а также указателем, ссылкой или элементом пере-
числения. Первый операнд является условием выбора последую-
щих операндов. Последовательность выполнения операции сле-
дующая:
• выражение! сравнивается с нулем;
• если выражение! не равно нулю, то вычисляется выражение?
и его значение является результатом операции;
• если выражение! равно нулю, то вычисляется выражениеЗ
и его значение является результатом операции.
Заметим, что всегда вычисляется какой-либо один операнд
(операнд? т&о операндЗ), но не оба.
З.б. Логические операции и операции отношения
43
Пример. Переменной max присваивается максимальное значе-
ние из двух переменных а и Ь.
max = a<=b ? Ь: а;
В примере используются две операции:
• тернарная операция а<=Ь ? Ь: а, ее результат есть максималь-
ное значение из а, Ь;
• операция присваивания заносит результат тернарной опера-
ции в переменную max.
Если в условной операции операнд2 и операндЗ являются адрес-
ными выражениями, то тернарная операция может стоять слева от
знака присваивания.
Пример. Значение выражения c*x+d присваивается меньшей
из переменных а и Ь.
а< b? a:b = c*x+d;
Если а<Ь, то вычисляется выражение а = c*x+d, иначе b = c*x+d.
З.б. Логические операции и операции
отношения
Операции отношения используются для проверки условий, это би-
нарные операторы (операторы с друмя операндами). В качестве
первого операнда может выступать переменная или константа, ко-
торая сравнивается со вторым операндом — литералом, перемен-
ной или константой. Результат сравнения всегда логический —
TRUE (истина —«да») либо FALSE (ложь — «нет»). В языке С
FALSE кодируется нулем, а все что не нуль, то TRUE. Поэтому ло-
гические переменные TRUE и FALSE можно заменять целыми пе-
ременными типа int.
К операциям отношения относятся:
• > больше;
• < меньше;
• >= больше или равно;
• <= меньше или равно.
44
Глава 3. Выражения и операции
Все они имеют одинаковый ранг. Непосредственно за ними по
уровню старшинства следуют операции сравнения на равенство и
неравенство:
= = равно (сравнение);
!= не равно.
Операции отношения ниже рангом, чем арифметические опе-
рации, поэтому выражение: i < lim+З понимается как i < (lim+3).
Примеры простых логических выражений:
3>7 результат О (FALSE);
8>1 результат 1 (TRUE );
3==6 результат О (FALSE);
2 !=0 результат 1 (TRUE).
Если нам необходимо проверить сложное условие, то нужно
объединить несколько простых логических выражений в единое
сложное выражение. Для этих целей служат логические связки, на-
зываемые также логическими операциями.
К логическим операциям относятся:
&& — логическое «И» (конъюнкция), бинарная операция;
|| — логическое «ИЛИ» (дизъюнкция), бинарная операция;
! — логическое «НЕ» (отрицание), унарная операция.
Операндами логических операций могут быть объекты различ-
ных типов: целых, плавающих и некоторых других, более сложных
типов данных, при этом операнды логических операций вычисляются
слева направо.
Так же как и у операций отношения, у логических операций
результат бинарный — FALSE или TRUE (0 или 1).
Легче всего результаты логических операций представить в
виде «таблиц истинности», которые можно сравнить с таблицами
умножения. Так же как в таблице умножения, в таблице истинно-
сти приводится результат операции при всех возможных значениях
операндов. Таблица 3.1 объединяет три таблицы истинности для
основных логических операций. Столбцы х&&у , х || у и !х соответ-
ственно дают результаты логических операций «И», «ИЛИ» и «НЕ»
при всех возможных сочетаниях операндов х и у.
Пример
(0&& 1) результат 0 (нет);
(0|| 1) результат I (да).
З.б. Логические операции и операции отношения
45
Таблица 3.1
X у Х&&У xh !х
0 0 0 0 1
0 1 0 1 1
1 0 0 1 0
1 1 1 1 0
(11) резул ьтат 0 (нет);
(!0) результат 1 (да).
Примеры сложных логических связок:
3 != 5 || 3==5 результат I (да);
3+4>5 && 3+5>4 && 4+5>0 результат 1 (да).
Как уже говорилось, логические связки используют для объе-
динения простых логических условий в единое, сложное условие,
характерным примером может стать проверка на принадлежность
переменной некоторому диапазону значений.
Пример. Записать условие принадлежности переменной х диа-
пазону Л, В (рис. 3.2).
А х В
Рис. 3.2. Диапазон значений интервала А—В
Искомое условие: (х>А && х<В).
В этом случае используется логическая связка «И», которая про-
веряет одновременное выполнение двух условий.
Пример. Записать условие, когда переменная х не принадлежит
диапазону Л, /?(рис. 3.3).
Искомое условие: (х<А || х>В).
Рис. 3.3. Значения, нс входящие в диапазон А—В
46
Глава 3. Выражения и операции
В этом случае используется логическая связка «ИЛИ», которая
проверяет выполнение хотя бы одного условия.
В логической связке «ИЛИ» не всегда вычисляются оба операнда,
если первое из логических выражений дает в результате TRUE, то
второе выражение не вычисляется, поскольку уже никак не может
повлиять на общий результат вычислений.
Также и в логической связке «И» оба операнда вычисляются не
всегда. Если первое из логических выражений дает в результате
FALSE, то второе выражение не вычисляется.
Подведем некоторые итоги, если арифметические операции в
выражении можно сравнить с утверждением факта. Например, х=5
(икс равняется пяти — это утверждение), дологическое выражение и
операции отношения можно сравнить с постановкой некоторого во-
проса.
Например:
(А==В)
(А > В)
(А>В)&&(А>С)
Равны ли переменные А и В?
Какая переменная больше?
Выполняется ли это условие?
Неудивительно, что ответ на вопрос будет «да» или «нет»,
TRUE или FALSE (0 или 1).
3.7. Поразрядные (побитовые) операции
Как извесно, на машинном уровне вся информация представ-
лена в виде нулей и единиц, но обычно для того, чтобы выполнять
вычисления, программисту не обязательно знать это представле-
ние, языки высокого уровня берут на себя эту рутинную работу, и
позволяют программисту оперировать данными в привычной для
себя форме.
Однако некоторые задачи требуют понимания происходящих
на машинном уровне процессов обработки информации. Напри-
мер, управление оборудованием (клавиатурой или принтером) за-
ключается в анализе и изменении отдельных битов регистра
управления, в этом случае необходимо использовать побитовые
операции.
Побитовые операции используются для анализа и изменения
отдельных битов числа и применяются только к переменным цело-
3.7. Поразрядные (побитовые) операции
47
го типа: int, char и их вариантам (long int, unsigned char и т. п.). По-
битовые операции нельзя применять к переменным типа: float,
double, void, а также к более сложным типам данных.
Отдельные биты переменной можно рассматривать как логи-
ческие значения, поскольку они могут принимать лишь два значе-
ния 0 или 1, которые в языке С можно рассматривать как FALSE
и TRUE.
К побитовым операциям относятся:
• ~ отрицание (или инверсия);
• & логическое И;
• | логическое ИЛИ;
• А исключающее ИЛИ (XOR, отрицание равенства).
Побитовые операции бинарные, т. е. оперируют с двумя опе-
рандами, поскольку по своей природе они являются логическими,
то могут быть заданы с помощью таблиц истинности (табл. 3.2).
В данном случае под х и у следует понимать отдельные биты пере-
менных х и у.
Таблица 3.2
X У (х&у) (х|у) (х А у) (~х)
0 0 0 0 0 1
0 1 0 1 1 1
1 0 0 1 1 0
1 1 1 1 0 0
Например, если д-й бит переменной х равен 0, и д-й бит пере-
менной у равен 1, то п-й бит (х Ау) равен 7, а п-й бит (х & у) равен 0.
Для полноценной работы с отдельными битами переменной
необходимы три функции:
1) установка бита (запись 1);
2) сброс бита (запись 0);
3) проверка бита.
Рассмотрим некоторые приемы работы с отдельными битами
переменной. В каждой операции участвуют два операнда:
первый операнд — это переменная, хранящая информацию;
второй операнд — это маска, отмечающая биты, участвующие
в операции.
48
Глава 3. Выражения и операции
Для того чтобы «пометить» бит, необходимо в соответствую-
щем разряде маски записать 1, например число 128 = 27 «помечает»
7-й бит (единица в седьмом разряде).
Двоичное представление числа 128: ...000000010000000.
В следующих примерах: действия проводятся с переменной i,
второй операнд — это маска.
i & 1; // Проверка i на четность
i | 128; // Установить 1 в 7-м бите i
i А 8; // Инвертировать 3-й бит i
~i; // Инвертировать все биты числа i
Операция & часто используется для маскирования некоторого
множества битов.
Например:
int C,N;
C=N&0377;
Выражение C=N&0377 передает в переменную С младший
байт (8 битов) переменной N, обнуляя все остальные разряды.
Двоичное представление константы 0377 будет выглядеть следую-
щим образом:
...000 000011 111 111.
Здесь наглядно видно, что «помечен» младший байт пере-
менной.
В следующем примере переменные инициализируются шест-
надцатеричными константами (в комментариях даны соответст-
вующие двоичные представления).
Результат формируется отдельно для каждого бита перемен-
ной г, используя в качестве операндов соответствующие биты пе-
ременных i nj, согласно таблице истинности логических операций
«ИЛИ-HE», «И», «ИЛИ»
Например, для г = iAj нулевой бит г равен 0, так как 1л 1 равно 0.
Пример. Вспомним, что тип константы определяется по ее
внешнему виду, если константа начинаются с нуля, то это восьме-
ричная константа, если же с 0Х (или Ох), то шестнадцатеричная.
3.8. Операции сдвига
49
int i=0x47F0;
int j=0xA0FF;
char r;
r = Kj;
r = i|j;
г = i&j
/ / i = OIOOO111 1111 0000
Ц j = 1010 0000 1111 nil
U
11 r=0xE70F = 1110 0111 0000 1111
//r=0xE7FF = 1110 0111 1111 1111
Ц r=0x00F0 = 0000 0000 1111 0000
3.8. Операции сдвига
Операции сдвига также оперируют с отдельными битами пере-
менной и являются бинарными операторами. В первом операнде
находится информация, которою необходимо сдвигать, во втором
размещается параметр — число сдвигов. Оба операнда должны
быть целыми величинами.
Существуют две операции сдвига:
<< — сдвиг влево;
>> — сдвиг вправо.
При сдвиге влево правые освобождающиеся биты устанавлива-
ются в нуль.
При сдвиге вправо метод заполнения освобождающихся левых
битов зависит от типа первого операнда. Если тип unsigned (беззна-
ковый), то свободные левые биты устанавливаются в нуль. В про-
тивном случае они заполняются копией знакового бита.
Например, X << 2 сдвигает переменную X влево на 2 разряда
(бита), заполняя освобождающиеся биты нулями, что эквивалент-
но умножению на 4. Сдвиг вправо переменной unsigned на п битов
эквивалентен целочисленному делению левого операнда на 2 в
степени п. Так 5 << 3 дает 40, а 7 >> 2 дает 1.
Пример
int i;
i«l;
i»2;
I/ Сдвиг влево на 1 бит (умножение i на 2)
// Сдвиг вправо на 2 бита (деление i на 4)
Отметим, что правый операнд должен быть константным выра-
жением. Если правый операнд отрицателен, а также больше или ра-
вен числу битов левого операнда, то результат сдвига не определен.
Типом результата операции сдвига является тип левого операнда.
50
Глава 3. Выражения и операции
3.9. Операция sizeof
Унарная операция sizeof() вычисляет размер памяти, занимае-
мой операндом, и имеет следующий формат:
sizeof (выражение)
В качестве выражения может быть использован любой иденти-
фикатор либо имя типа, а операндом sizeof() может быть только
объект, расположенный в памяти компьютера.
Например, нельзя использовать тип void (так как не существует
данных этого типа), также идентификатор не может быть именем
битового поля или функции.
Пример
int ij,k,n=15;
double х;
i = sizeof(n); // i=4
j = sizeof(int); //j=4
k = sizeof(double) // k=8
Чаше всего оператор sizeof() используется для определения
размеров пользовательских типов данных, например для определе-
ния размера массива или элемента структуры.
3.10. Операция следования
Символом операции следования является «,» (запятая). Выра-
жения, разделенные этим символом, выполняются слева направо
строго в том порядке, в котором они перечислены. Результатом
операции является результат последнего выражения. Поскольку
запятая может использоваться и в качестве разделителя, важно не
путать эти два ее назначения.
Пример
// В первой строке запятая — это разделитель, а не операция;
int а=3, Ь=8, с;
3.11. Сводная таблица операций языка С
51
//Две последующие строки содержат операцию следования
с=к++, к+Ь;
(Ь—,с)*=3;
Первую операцию следования можно заменить следующей по-
следовательностью команд:
с=к++; с=к+Ь;
В результате этого получим: с=12.
Вторую операцию следования можно заменить последователь-
ностью команд:
Ь-;с*= 3;
В результате получим: Ь=7, с=36.
В качестве разделителя запятая может применяться в следую-
щих случаях:
1) в функциях для разделения аргументов, если их более одно-
го. Например, П(х,у);
2) при объявлении переменных. Например, int q,w,e.
В качестве операции запятая часто используется в операторе
for. Примеры будут приведены в соответствующем разделе по-
собия.
3.11. Сводная таблица операций языка С
Операции приведены в табл. 3.3 в порядке уменьшения при-
оритета, т. е. имеют самый высокий ранг и выполняются в первую
очередь операции () | ] . и - >.
В последнюю очередь выполняются операции «присваивание»
и «запятая».
Естественный порядок выполнения выражений может быть
изменен с помощью круглых скобок. Например, выражение
6*r + k/s
интерпретируется как (6 *r) + (k/s), но можно изменить этот поря-
док, поставив скобки:
6 * (r+k)/s.
52
Глава 3. Выражения и операции
Таблица 3.3
Знак операции Название операции Ранг операции Порядок выполнения
0 II Вызов функции Индексная Выбор элемента 1 Слева направо
1 * & (тип) sizeof Отрицание арифметическое Отрицание логическое Двоичное дополнение Косвенная адресация Вычисление адреса Инкремент Декремент Приведение типа Вычисление размера 2 Слева направо
* / % Умножение Деление Остаток от деления 3 Слева направо
+ Сложение Вычитание 4 Слева направо
<< Сдвиг вправо Сдвиг влево 5 Слева направо
— II А V Л ч/ И II II II Больше Меньше Больше или равно Меньше или равно Равно Не равно 6 6 6 6 7 7 Слева направо
& 1 Поразрядное И Поразрядное исключающее ИЛИ Поразрядное ИЛИ 8 9 К) Справа налево
&& 1 Логическое И Логическое ИЛИ И 12 Справа налево
?• Условная 13 Справа налево
Присваивание 14 Справа налево
3.11. Сводная таблица операций языка С
53
Окончание табл. 3.3
Знак операции Название операции Ранг операции Порядок выполнения
" " || * е- < Составное присваивание 14 Справа налево
Последовательное вычисление 15 Справа налево
Вопросы для самопроверки
1. Поясните термин «унарная» (бинарная) операция.
2. Какие группы операций вы знаете?
3. Что такое ранг операции?
4. Какие выражения могут стоять слева от операции присваивания?
5. Какие выражения не могут стоять слева от операции присваивания?
6. Перечислите пять арифметических операций языка С.
7. Приведите алгоритм работы счетчика, для чего он используется?
8. Что общего и какая разница между счетчиком и аккумулятором.
9. Какая разница между префиксной и постфиксной формой операции ин-
кремента (декремента).
10. Изложите главное правило неявного преобразования типов при вычисле-
нии арифметических выражений.
11. Почему условную операцию называют тернарной?
12. Перечислите операции отношения.
13. Перечислите логические операции.
14. Для чего нужны логические операции?
15. Перечислите поразрядные операции. Для чего они используются?
16. Приведите пример использования операции sizeof.
Глава 4
ОПЕРАТОРЫ
Операторы языка программирования управляют процессом вы-
полнения программы, т. е. оператор сообщает компьютеру, как сле-
дует обрабатывать данные. Можно сказать, что программа состоит из
последовательности операторов с добавлением знаков пунктуации.
В составе языка С имеются операторы, обеспечивающие выполнение
всего набора конструкций структурного программирования.
Все операторы языка С (кроме составных) заканчиваются зна-
ком «;»(точкой с запятой).
Операторы языка С можно условно разделить на следующие
категории:
1. Структурные операторы — это наименьшая исполняемая
единица программы, они служат основными строительными бло-
ками программы. В конце каждого структурного оператора ставит-
ся «;», к ним можно отнести:
• операторы ветвления (if, switch);
• операторы цикла (for, while, do...while);
• операторы перехода (break, continue, return, goto);
• другие операторы (оператор «выражение», пустой оператор).
2. Операторы, используемые в выражениях.
• арифметические;
• сравнения;
• логические;
• битовые;
• специальные (присваивания, преобразования типов).
4.1. Оператор выражение
Любое выражение, которое заканчивается точкой с запятой,
является оператором. В языке С выражения могут входить в состав
4.2. Пустой оператор
55
различных операторов, либо использоваться самостоятельно. Вы-
полнение оператора выражение заключается в его вычислении.
Примеры
Ь=а+5; /* вичислить а+5 и присвоить b */
t++; /* к t прибавить 1 */
printf("\n %s’,,mes); /* Печать сообщения */
/* В следующем операторе результат не используется и потому
компилятор выдаст предупреждение*/
(а+5)/7;
4.2. Пустой оператор
Пустой оператор состоит из символа «;». Этот оператор ис-
пользуется в двух случаях.
Во-первых, в составе других операторов (например, в операто-
рах do, for, while, if) в том месте, где по синтаксису необходим опе-
ратор, но по смыслу программы он не требуется.
Во-вторых, при необходимости пометить закрывающуюся фи-
гурную скобку.
Синтаксис языка С требует, чтобы после метки обязательно
следовал оператор. Фигурная же скобка оператором не является.
Поэтому, если надо передать управление на фигурную скобку, не-
обходимо использовать пустой оператор.
Пример
int main ()
{ :
{if (...) goto F;
F:;}
return 0;
/* Переход на скобку */
/* Помеченый пустой оператор */
56
Глава 4. Операторы
4.3. Объявления и составной оператор
Каждая переменная перед использованием должна быть объявле-
на. Объявление не только вводит новое имя в программу, но и ко-
дирует разнообразную информацию о характеристиках перемен-
ной, связанной с этим именем, таких как тип, класс памяти, время
жизни и некоторые другие.
При объявлении переменной компилятор выделяет память в
соответствии с ее типом, в этот момент переменная создается.
Так как объявления являются операторами языка, то могут ис-
пользоваться там, где возможен любой другой оператор C++, на-
пример:
s = 0.3; d /= s;
char sim;
int k = 5;
d = s+2*k;
double f=s+d;
// Операторы-выражения
// Объявление переменной sim
// Объявление и задание начального значения
// переменной к
// Одновременное объявление и использование
// переменной f
Предполагается, что переменные s и d были объявлены ранее.
Составной оператор (или блок) представляет собой несколько
операторов и объявлений, заключенных в фигурные скобки.
Обычно составным оператором называют оператор, не содер-
жащий объявлений, а оператор с объявлениями называется блоком,
но синтаксических отличий между ними нет.
Составной оператор должен использоваться там, где синтаксис
языка требует наличия лишь одного оператора, а логика програм-
мы — сразу нескольких. Заметим, что в конце составного операто-
ра точка с запятой не ставится.
Пример составного оператора:
{i=5;
c=sin(i*x);
4.4. Условный оператор
57
Пример блока:
{double у;
у= i*sin(x);
printf ("\n %е",у);
}
4.4. Условный оператор
Оператор if позволяет разветвить вычислительный процесс на
два варианта в зависимости от значения некоторого условия.
Имеются две формы условного оператора (схемы представле-
ны на рис. 4.1):
• if (выражение) оператор! else оператор2;
• if (выражение) оператор!.
Рис. 4.1. Схемы условного оператора
Выполнение оператора if начинается с вычисления выраже-
ния. Далее выполнение осуществляется по следующей схеме:
1)если выражение истинно (отлично от 0), то выполняется
оператор!;
2) если выражение ложно (равно 0), то выполняется опера-
тор-2;
3) если выражение ложно и отсутствует конструкция со словом
else, то выполнение оператора if завершается.
Примеры
if (а > Ь)
с = а - Ь;
else с = b - а;
// Выполняется, если а > b
// Выполняется, если а < b
58
Глава 4. Операторы
if (i < j)
else
{j = i - 3; i ++;} // Выполняется блок операторов
В операторах if могут использоваться составные операторы
(блоки операторов) там, где логика программы требует последова-
тельности операторов. Допускается вложение оператора if как в
конструкцию if, так и в конструкцию else другого оператора if.
Если во вложенных конструкциях фигурные скобки отсутствуют,
то компилятор связывает каждое ключевое слово else с наиболее
близким if, для которого нет else.
Пример
int main ()
int t=2, b=7, r=3;
if (t>b)
else r=t;
return (0);
}
В результате выполнения этой программы г = 2, так как опера-
тор else связан с первым оператором if.
Если же в программе убрать фигурные скобки, стоящие после
оператора if, то логика программы изменится.
int main ()
int t=2, b=7, r=3;
if (t >b)
if (b<r) r=b;
else r=t;
return (0);
4.4. Условный оператор
59
В этом случае г = 3, так как ключевое слово else относится ко
второму оператору if, который не выполняется, поскольку не вы-
полняется условие, проверяемое в первом операторе if.
Количество вложенных операторов if не ограничено, следую-
щий фрагмент программы и схема (рис. 4.2) иллюстрирует это:
char ZNAC;
int x,y,z;
if (ZNAC == ’-')x = y-z;
else if (ZNAC == ’+’) x = у + z;
else if (ZNAC == ’*’) x = у * z;
else if (ZNAC == ’/') x = у / z;
else ....
Рис. 4.2. Схема вложенных операторов if
Пример показывает, что конструкции со вложенными опера-
торами if, фактически обеспечивают выбор одного варианта из
многих возможных, на блок-схеме каждая альтернатива выбо-
ра — это блок операторов. Однако такое решение представляется
довольно громоздким и не всегда достаточно надежным. Другим
способом организации выбора из множества различных вариан-
тов является использование специального оператора выбора
switch.
60
Глава 4. Операторы
4.5. Оператор выбора switch
Если в алгоритме присутствуют более трех вариантов (альтер-
натив) выбора, то следует использовать оператор switch. Его часто
называют селективным оператором, переключателем или операто-
ром выбора. Оператор switch передает управление одному из не-
скольких помеченных специальными метками операторов в зави-
симости от значения целочисленного выражения. Специальные
метки начинаются с ключевого слова case и являются целочисленны-
ми константами.
Оператор имеет следующий вид:
switch (целое_выражение )
{case константноевыражениек
операторы
case константное_выражение2:
операторы
default: операторы
}
Выражение в круглых скобках может быть любым допустимым
выражением языка С, значение которого должно быть целым.
Схема выполнения оператора switch представлена на рис. 4.3.
Рис. 4.3. Селективный оператор switch
4.5. Оператор выбора switch
61
Вычисляется выражение в круглых скобках (назовем его селек-
тором).
Значение селектора последовательно сравнивается со значе-
ниями case-меток в теле оператора switch, если селектор и кон-
стантное выражение метки равны, то управление передается опе-
раторам, помеченным данной меткой.
Если селектор не совпадает ни с одной меткой, то управление
передается на операторы, помеченные словом default.
Если default отсутствует, то управление передается следующему
за switch оператору.
Пример
int х;
switch (х)
{case 5: printf(”x равно 5\п");
break;
case 2:
case 10: printff’x равно либо 2, либо 10\п");
break;
default: rintff’x не равно 5, 2, 10\п");
break;
}
Каждый вариант оператора switch начинается меткой (case 5,
case 2, case 10 или default) и заканчивается оператором break. Ис-
ключение составляет вариант case 2: у которого нет «своих» опера-
торов. Дело в том, что switch, выбрав один из вариантов, не закан-
чивает автоматически выполнение, дойдя до следующего вариан-
та, — он исполняет все операторы, идущие дальше, вплоть до
конца своего блока или до ключевого слова break, которое прекра-
щает выполнение оператора. Если мы уберем, например, первый
break, то при х==5 увидим сначала сообщение от первого printf(),
затем от второго.
Следующий пример показывает, что оператор switch представ-
ляет собой структуру, построенную по принципу меню, он содер-
жит варианты условий и инструкции, которые следует выполнить
в каждом конкретном случае.
62
Глава 4. Операторы
Пример. Программа, реализующая функции калькулятора «+»,
«-», «*»,«/»
#include <iostream.h>
#include <stdio.h>
void main()
charznak;
double x, y, z;
do
{
cout«"Задайте знак операции + - * /\п";
cin>>znak;
со ut«" Задайте х и у \п";
cin»x>>y;
switch (znak)
{ case '+': z= x + у; break;
casez= x - y; break;
case z= x * y; break;
case if (у == 0 )
соиК<"Делить на нуль нельзя!\п";
else z = х / у;
break;
default: { сош<<"Неизвестная операциями";
continue;
}
}
cout<<x<<znak<<y<<’=’<<z<<endl;
}
while (znak!—&');
}
В данном примере использовалась библиотека ввода-вывода
языка C++ (iostream.h).
Оператор соиК<”Задайте знак операции + - * / \п", выводит
строку текста на экран дисплея. Оператор cin>>znak вводит дан-
ные с клавиатуры в переменную znak. Функции библиотеки
iostream проще в использовании (по сравнению с функциями
stdio), так как не требуют явного указания типов переменных,
типы, с которыми работают операторы cout<< и cin», определя-
ют те переменные, которые используются в текущий момент, на-
4.5. Оператор выбора switch
63
пример cin>>znak работает с типом char, а соиК<"Задайте х и у
\п" — с типом «строка».
Программа запрашивает информацию (знак операции и два
числа) и проводит соответствующую операцию, пока вместо знака
не введут символ &. Если вводится знак, отличный от разрешен-
ных («+», «-», «*», «/»), то программа выдает сообщение об ошибке
и начинает новый проход цикла (по директиве continue). При кор-
ректном вводе на экран выдается формула и результат вычисления.
Пример. Написать программу, которая вычисляет стоимость
междугородного телефонного разговора. Исходными данными для
программы являются код города, тариф звонка и длительность раз-
говора. Ниже в табл. 4.1 приведены коды некоторых городов.
Таблица 4. /
Город Код Цена минуты, руб.
Владивосток 423 2,2
Москва 095 1,0
Мурманск 815 1,2
Самара 846 м
#include <stdio.h>
#include <conio.h>
void main()
{
int kod; // Код города
float cena; // Цена минуты
int dlit; // Длительность разговора
float suram; // Стоимость разговора
printf(" Введите исходные данные:\п");
printf("Длительность разговора ->’’),
scanf(”%i", &dlit);
printff’Kofl города:’’);
рпп1Г("Владивосток\1432’’);
printff' MocKBa\t\t095’’);
printf("MypMaHCK\t8!5”);
64
Глава 4. Операторы
printf("CaMapa\t\t846");
PrintfC\n->”);
scanf("%i", &kod);
printf("Город: ");
switch (kod)
{
case 432: printf(" Влади восток"); cena = 2.2; break;
case 95: printf(" Москва"); cena = 1; break;
case 815: printff'Мурманск"); cena = 1.2; break;
case 846: printff'CaMapa"); cena = 1.4; break;
default: рпп1Г("неверно введен код.");
cena = 0;
}
if (cena != 0)
{
suram = cena * dlit;
printfC'UeHa минуты: %i руб.\п", cena);
printf("CTOHMOCTb разговора: %3.2f руб.\п", suram);}
}
4.6. Циклы
При программировании часто возникает потребность выпол-
нить несколько раз одни и те же действия, но с разными исходны-
ми данными. Чтобы решить эту проблему, программист организу-
ет цикл — многократное повторение какого-то участка кода, каж-
дый такой повтор называют итерацией. При этом необходимо в
той или иной форме задать условие выхода из цикла.
В общем случае можно организовать повтор выполнения уча-
стка программы с помощью оператора goto (безусловный переход
на метку), а условие выхода из цикла — с помощью оператора if.
Пример. Ввод чисел с клавиатуры и их суммирование до тех
пор пока сумма не превысит 100.
#include <stdio.h>
void main()
{int x,s=0;
4.6. Циклы
65
М: if(s<100)
{ printf("x=");
scanf("%d",&x);
s=s+x;
goto M; // Переход на следующий проход цикла
}
printf(("s=%d", s);
}
Такой подход не всегда удобен, противоречит принципам мо-
дульного программирования и чреват возможными ошибками, по-
этому в любом языке программирования предусматриваются спе-
циальные конструкции для организации циклов.
В языках C/C++ таких циклов три — это операторы while,
do-while и for. Кроме того, специально для расширения возможно-
стей этих трех операторов в языке предусмотрены еще два операто-
ра — continue и break (с оператором break мы уже познакомились,
рассматривая возможности оператора switch, по сути, в обоих слу-
чаях он делает одно и то же).
4.6.1. Цикл с предусловием white
Цикл while используется в том случае, когда не известно точное
число повторов (итераций). Оператор цикла с предусловием пред-
ставлен на рис. 4.4 и имеет вид:
while (выражение) тело цикла
Рис. 4.4. Схема цикла с предусловием
66
Глава 4. Операторы
В качестве выражения допускается использовать любое выраже-
ние языка С, а в качестве тела — любой оператор, в том числе пус-
той или составной. Схема выполнения оператора while следующая.
1. Вычисляется выражение.
2. Если выражение ложно, то выполнение оператора while за-
канчивается и выполняется следующий по порядку оператор. Если
выражение истинно, то выполняется тело цикла.
3. Процесс повторяется с пункта 1.
Важно отметить, что выражение вычисляется до начала и после
каждого прохода цикла. Цикл не выполняется ни разу, если выраже-
ние ложно (равно 0).
Поскольку в операторе while вначале происходит проверка ус-
ловия, его удобно использовать в ситуациях, когда тело оператора
не всегда нужно выполнять.
Пример. Вычисление суммы чисел от 0 до 9.
#include <stdio.h>
void main()
int i=0, sum=0;
while (i++ < 10) // Условие выполнения тела цикла
{ // Начало тела цикла
sum += i; //Аналог: sum= sum + i
} // Конец тела цикла
рпп1Г("Значение cyMMbi=%d\n",sum);
}
В выражении (i++ < 10) сначала выполняется операция инкре-
мент i++, а затем — проверка i< 10.
С помощью оператора while легко организовать бесконечный
цикл.
Пример. Бесконечный цикл.
while (1)
{ операторы цикла
break;
4.6. Циклы
67
Выражение в скобках (1) подразумевает проверку условия
(1==1), которое всегда истинно, поэтому естественного выхода из
цикла нет. Такие циклы следует использовать в тех случаях, когда
заранее не известно условие выхода из цикла, и оно формируется в
теле цикла в процессе работы программы.
4.6.2. Цикл с постусловием do—while
Этот оператор цикла проверяет условие окончания в конце
цикла, т. е. после каждой итерации, поэтому тело цикла выполня-
ется, по крайней мере, один раз. Схема оператора представлена на
рис. 4.5.
Рис. 4.5. Схема цикла с постусловием
Вид оператора:
do тело цикла while (выражение)
Последовательность выполнения оператора do—while:
1) выполняется тело цикла (которое может быть составным
оператором);
2) вычисляется выражение;
3) если выражение ложно, то выполнение оператора do—while
заканчивается и выполняется следующий по порядку оператор.
Если выражение истинно, то выполнение оператора продолжается
с пункта 1.
68
Глава 4. Операторы
Пример. Вывести на экран числа от 0 до 10.
int х=0;
do
{ printf("%d\t",x);
х++;
} while (х<10);
printf(" Вывод закончен!\п");
Пример. Вводить целые числа с клавиатуры пока их значения
лежат в диапазоне от 10 до 150. Вычислить сумму введенных чисел.
const int minvalue=10, maxvalue=150;
int input=0, s=0;
do
{ printff’Введите значение input->");
scanf("%d",&input);
s += input;
}
while (input < minvalue || input > maxvalue );
printf("s=%d\n",s);
Оператор const int minvalue=10, maxvalue=150; задает значение
именованным константам minvalue и maxvalue. Цикл do—while по-
вторяется до тех пор, пока вводимые с клавиатуры числа находятся
в диапазоне от minvalue до maxvalue.
4.6.3. Пошаговый цикл. Оператор for
Цикл for используется в том случае, когда известно точное ко-
личество итераций, которое нужно выполнить, — это наиболее об-
щий способ организации цикла.
Пошаговый цикл имеет следующий вид:
for ( выражение 1 ; выражение 2 ; выражение 3 ) тело цикла
69
4.6. Циклы
Выражение 1 обычно используется для установки начальных
значений переменных, использующихся в цикле, — это область
инициализации данных.
Выражение 2 — определяет условие, при котором тело цикла
будет выполняться.
Выражение 3 определяет изменение переменных цикла после
каждого прохода тела цикла — это область модификации данных.
Схема выполнения оператора for представлена на рис. 4.6, по-
следовательность действий такова.
1. Вычисляется выражение 1 (один раз перед входом в цикл).
2. Вычисляется выражение 2 (перед каждым проходом цикла).
3. Если значения выражения 2 — TRUE (отлично от нуля), то
выполняется тело цикла, иначе (если выражение FASLE) — цикл
прекращается и управление передается оператору, следующему за
оператором for.
4. Выполняется тело цикла.
5. Вычисляется выражение 3 — это модификация данных (по-
сле каждой итерации цикла)
6. Процесс повторяется с пункта 2.
Существенно то, что проверка условия выполняется в начале
цикла, это значит, что тело цикла может ни разу не выполниться
(если выражение ложно).
Любое из трех выражений может быть опущено, хотя точка с
запятой обязательно должна оставаться. Если отсутствует провер-
Рис. 4.6. Схема пошагового цикла
70
Глава 4. Операторы
ка (выражение 2), то считается, что оно истинно (отлично от нуля),
в этом случае цикл будет бесконечным.
Пример. Из бесконечного цикла можно выйти с помощью опе-
ратора break.
for (;;)
break;
Пример. Вычислить сумму квадратов целых чисел от 1 до 20.
main()
{ const int n=20 ; // Именованная константа n — счетчик цикла
// Начальное значение для суммы
int s=0; // На
int i;
for (i = 1; i <= n; i++ )
s += i*i;
printf(,’\ns=%d',,s);
В данном примере цикл управляется переменной i, значение
которой должно быть обязательно целым числом. Выражение в
круглых скобках имеет три составляющие:
i=l — инициализация переменной i путем присваивания ей на-
чального значения;
i <= п задает условие повтора цикла до тех пор, пока значение
переменной i остается меньше или равно л;
i++ — приращение значения переменной i после каждого про-
хода цикла.
Тело цикла состоит из одного простого оператора: s += i*i. По-
ка i<=n происходит накопление суммы в переменной s. После вы-
хода из цикла переменная s выводится на экран дисплея.
Часто в заголовке оператора for инициируют несколько пере-
менных, используя для этой цели операцию «запятая». В нашем
4.6. Циклы
71
примере нужно инициировать переменные i и s, в этом случае про-
грамма будет выглядеть следующим образом:
int s, i;
for (i = 1, s=0; i <= n; i++ )
Та же задача, выполненная с помощью оператора while, выгля-
дит следующим образом:
const int n=20 ;
int i=l,s=0;
while(i <= n)
{ s+=i*i;
}
Можно записать текст короче, и этот вариант программы будет
самым быстрым:
const int n=20 ;
int i=l,s=0;
while( i++ <= n) s += i*i;
Пример. Вычислить сумму геометрической прогрессии
1,1*0.85, 1*0.85*0.85 и т. д., пока ее очередной член не станет мень-
ше Ю’10.
double s, sum, den = 0.85, eps = le-10;
for (s= 1, sum=0; s>eps; s*=den )
sum += s;
printf(’,\nsum=%e\n,',sum);
В отличие от двух предыдущих примеров здесь число проходов
цикла заранее не известно, хотя управляющая переменная (s) име-
72
Глава 4. Операторы
ется. Обратите внимание на область инициализации — в ней зада-
ются начальные значения для двух переменных, используя, для
этой цели, операцию следования «,» (запятая). Количество опера-
торов, следующих через запятую, в области инициализации не ог-
раничено. То же самое можно сказать и об области модификации
переменных.
Использовать ли циклы while или for — это, в основном дело
вкуса. Цикл for предпочтительнее там, где имеется простая ини-
циализация и модификация, поскольку при этом управляющие
циклом параметры оказываются в заголовке цикла, что облегчает
понимание происходящего. Например, цикл for, применяемый
для обработки первых п элементов массива, наглядно демонстри-
рует начальное (i=0) и граничное (i<n) значение переменной цик-
ла, а также шаг итерации цикла (i++):
for (i = 0; i < n; i++)
Следует отметить, что управляющая переменная (i) сохраняет
свое значение после выхода из цикла, какова бы ни была причина этого
выхода.
Если один цикл выполняется внутри другого, то говорят, что
циклы вложенные. Внутренний цикл целиком выполняется во
время каждого прохода внешнего цикла.
Описание функции putchar(), используемой в следующем при-
мере, смотрите в разделе 11.1.2.
Пример. Вложенные циклы for:
main()
int row, col;
for (row = 1; row <= 10; row++)
{
for (col = 1; col <= 5; col++) printfC*");
putchar(’\n');
}
}
Программа выводит на экран монитора 10 рядов, состоящих
из пяти звездочек. Здесь используются две целочисленные пере-
4.7. Оператор break
73
менные row и col, управляющие соответственно внешним и внут-
ренним циклом. Во внешнем цикле переменная row увеличивает
свое значение на единицу при каждом проходе, при этом перемен-
ная col пробегает значения от I до 5 , т. е. внутренний цикл повто-
ряется 5 раз при каждом проходе внешнего цикла.
Тело внешнего цикла ограничено фигурными скобками и со-
держит два оператора — for и putchar, тогда как тело внутреннего
цикла — один оператор printf.
4.7. Оператор break
Оператор break используется для прерывания текущего операто-
ра, после его выполнения управление передается оператору, сле-
дующему за прерванным. Break может быть использован только
внутри операторов:
switch, for, while или do while.
Он обеспечивает прекращение выполнения самого внутренне-
го из содержащих его операторов. Подчеркнем, что break нельзя
использовать для выхода из нескольких вложенных циклов, а со-
ставной оператор, состоящий из нескольких операторов break, эк-
вивалентен одному break.
Пример. Ввести с клавиатуры х и у, суммировать числа начиная
отхс шагом у пока сумма меньше К, подсчитать количество итера-
ций. Повторять процессы вводах, у и суммирования поках нахо-
дится в диапазоне от А до В (см. раздел 11.1.5 — работа с функцией
scanf()).
#define А 10 // Задаются именованные константы
#define В 1 000
#define К 9999
// Выделяется память под переменные
int x,y,i,sum;
do
{printf("\n Ввести x, y\t"); // Приглашение для ввода данных
74
Глава 4. Операторы
// Ввод данных с клавиатуры в переменные х и у
scanf("%d%d",&x,&y);
for (i=x; sum=0; i=i+y)
{ sum += i;
if (sum>K) {break; break} // Выход из цикла for
}
/1 Цикл продолжается, если x — в диапазоне от А до В
while (х>А&&х<В)
При выполнении условия sum>K завершится выполнение толь-
ко внутреннего цикла for, а выполнение внешнего цикла do—while
продолжится, несмотря на то, что оператор break повторен дважды.
Для выхода из вложенных циклов используйте оператор goto.
Приведенная программа имеет один существенный недоста-
ток — общее приглашение для нескольких переменных, такой под-
ход провоцирует ошибки при вводе информации, к тому же дан-
ные на экране будут обезличены и лишены наглядности. Поэтому
хорошим тоном считается индивидуальное приглашение для каж-
дой переменной с необходимыми комментариями. В нашем при-
мере приглашение может выглядеть так:
// Общий заголовок при вводе данных
printf("\n Введите параметры суммированиями ");
printf("Начало суммирования : х—’); // Приглашение для х
scanf("%d",&x); // Ввод данных в х
printf("\nШаг суммирования : у—’); // Приглашение для у
scanf("%d",&y); // Ввод данных в у
4.8. Оператор безусловного перехода goto
Использование оператора goto всегда вызывало много споров.
Так, один из основоположников теоретического программиро-
вания Э. Дейкстра заметил, что качество программного кода об-
4.8. Оператор безусловного перехода goto
75
ратно пропорционально количеству операторов goto в нем, счита-
ется, что этот оператор затрудняет понимание программ, а также
их модификацию.
Тем не менее в практическом программировании применение
goto в некоторых случаях можно оправдать. Поскольку goto —
«простейший» оператор перехода, то его применение оправданно,
когда другие средства языка не позволяют достичь нужного резуль-
тата. К таким случаям можно отнести:
• выход из нескольких вложенных циклов сразу;
• обработка ошибок.
Настоятельно не рекомендуется использовать goto где-либо
еще!
Но если вы все же вводите этого изгоя в свой арсенал, то со-
блюдайте правила, вытекающие из структурного подхода к про-
граммированию, приведем некоторые из них:
• не следует использовать goto для перехода внутрь структур-
ных операторов, таких, как операторы цикла, условный опе-
ратор, оператор выбора;
• никогда не обходите инициализацию переменных, где бы
она ни использовались;
Игнорирование этих рекомендаций может привести к трудно-
обнаруживаемым ошибкам.
Оператор безусловного перехода имеет вид:
goto метка;
Метка — это имя, за которым следует Этот оператор передает
управление оператору, помеченному указанной меткой. Метка
должна быть уникальна, и находиться в той же функции, что и goto.
Пример. В программе осуществляется преобразование десяти
значений температуры, находящихся в пределах от I до 256. Значе-
ния вводятся с клавиатуры. Если оператор ошибся более 5 раз,
происходит аварийное завершение программы (выход сразу из не-
скольких вложенных циклов).
#include <stdio.h>
int main()
{ int temp, count, errc=0;
double Celsius;
76
Глава 4. Операторы
рпп1Г("Перевод температуры по Фаренгейту \
в температуру по ЦельсикДп");
for (count = 1; count <= 10; count++)
{ printf(("Введите значение температуры от 1 до\
256\п(значение по Фаренгейту):");
scanf("%d", &temp);
while (temp < 11| temp > 256)
{if (errc<5)
{print f('’Повторите ввод, ошибка №%d ",errc);
scanf("%d", &temp);
errc++;
}
else
goto exO; // Выход из вложенных циклов
Celsius = (5.0 / 9.0) * (temp - 32);
printf("%d градусов по Фаренгейту соответствуем
%6.2f градусов по ЦельсикДп",temp, Celsius);
}
printf("\nНормальное завершение \п");
return 0; // Штатный выход из программы
ехО: рпп1Г("\пАварийное завершение : оператор \
ошибся более 5 раз!!!\п");
return 1; // Выход из программы с признаком ошибки
}
4.9. Оператор continue
Оператор continue служит для изменения естественного хода
программы при работе циклических структур, он используется
только внутри операторов цикла: for, while или do—while. Оператор
continue позволяет перейти на очередной проход цикла, пропустив
оставшиеся после него операторы тела цикла. Обычно этот опера-
тор входит в одну из ветвей оператора if. Формат оператора:
continue;
Пример. Программа обрабатывает только четные суммы, про-
пуская остальные.
4.10. Оператор return
77
void main ()
{int i,a,sum;
for (i= 1, sum=0 ; a<100; a++)
{printff’a—');
scanf("%d", &a);
sum+=a;
if (sum%2 != 0) continue;
// Обработка четных сумм
ргпД1'("итерация %d:\tcyMMa=%d\n",i,sum);
Когда sum — нечетное, выражение sum % 2 получает значе-
ние 1 и выполняется оператор continue, который передает управле-
ние на следующую итерацию цикла for, тем самым «пропуская»
программу обработки четных сумм.
4.10. Оператор return
Оператор return завершает выполнение функции, в которой он
задан, и возвращает управление в вызывающую функцию в точку,
непосредственно следующую за вызовом.
Оператор return в функции main() прерывает выполнение про-
граммы и передает управление операционной системе.
Формат оператора:
return [выражение];
Значение выражения, если оно задано, возвращается в вызы-
вающую программу в качестве результата выполнения функции.
Если выражение опущено, то возвращаемое значение не определе-
но. Выражение может быть заключено в круглые скобки, хотя их
наличие не обязательно. Если в какой-либо функции отсутствует
оператор return, то передача управления в вызывающую программу
происходит после выполнения последнего оператора функции,
при этом возвращаемое значение не определено. Если функция не
должна иметь возвращаемого значения, то ее нужно объявлять с ти-
пом void.
78
Глава 4. Операторы
Таким образом, использование оператора return необходимо для
немедленного выхода из функции и передачи возвращаемого значения.
Пример. Функция вычисляет сумму двух чисел а и b и возвра-
щает результат.
int sum (int a, int b )
{renurn a+b;}
int x,y,z;
z= l/sum(x,y);
Более подробно оператор будет рассмотрен в главе 8, посвя-
щенной применению пользовательских функций.
Вопросы для самопроверки
1. Дайте определение простого и составного оператора.
2. В каких случаях используется пустой оператор?
3. Нарисуйте в виде блок-схемы две формы условного оператора.
4. Что общего у операторов if и switch? Какие между ними различия?
5. Напишите общую форму оператора for.
6. Будет ли работать оператор for, и если да то как, если:
в области инициализации нет ни одного оператора;
отсутствует условие выхода из цикла;
в области модификации переменных нет ни одного оператора.
7. Нарисуйте схему выполнения цикла с предусловием.
8. Нарисуйте схему выполнения цикла с постусловием.
9. Какой из операторов следует использовать для выхода из вложенных
циклов: break, goto или return.
10. Для какой цели используют оператор continue?
Глава 5
МАССИВЫ
Переменные, с которыми мы имели дело до сих пор, могут хра-
нить только одно значение в каждый момент времени, и поэтому
крайне неудобны в некоторых случаях. Примером может служить
следующая простая задача:
Вычислить сумму пяти чисел, введенных с клавиатуры.
int num , sum=0 , i;
for (i=0, sum=0 ; i<5 ; i++)
{ scanf("%d",&num);
sum += num;
}
В цикле 5 раз вводим значение переменной num и подсчитыва-
ем сумму sum.
Обратите внимание, что при вводе очередного значения num
предыдущее теряется (после ввода второго значения теряется пер-
вое, при вводе третьего— утрачивается второе, и т. д.). Сумма чи-
сел вычисляется верно, но исходные значения данных будут поте-
ряны. Если же требуется сохранить исходные данные, то потребу-
ется определить 5 переменных, при этом использование цикла
станет невозможным. Приведем программу, вычисляющую сумму
5 чисел с сохранением исходных данных.
Пример. Без использования массива данных.
int numl, num2, num3, num4, num5,sum=0;
scanf("%d",&num 1);
sum+=numl;
80
Глава 5. Массивы
scanf("%d",&num2);
sum+=num2;
scanf("%d",&num3);
sum+=num3;
scanf("%d",&num4);
sum+=num4;
scanf("%d",&num5);
sum+=num5;
Такой подход к решению данной задачи неэффективен, кроме
того, в некоторых случаях невыполним (допустим, нам нужно про-
суммировать тысячу чисел).
Для разрешения подобных трудностей в программировании
введено понятие массива.
Массив — это совокупность элементов одинакового типа (базо-
вого типа, такого как double, float или более сложного) с примене-
нием общего для всех имени.
Массив — это сложный (или структурированный) тип данных,
он представляет собой удобное средство группирования связанных
переменных. В C++ массивы могут быть как одномерными, так и
многомерными.
5.1. Одномерные статические массивы
Статическим называется массив, размер которого определяется
во время компиляции и не меняется во время исполнения программы.
Массивы предназначены для хранения набора единиц данных,
каждая из которых идентифицируется индексом или набором ин-
дексов.
Индекс — целое число, указывающее на конкретный элемент мас-
сива.
Перечислим свойства статических массивов:
• массив состоит из многих элементов одного и того же типа;
• число элементов назначается при определении массива и в
дальнейшем не меняется;
• ко всему массиву целиком можно обращаться по имени;
• выбор элемента массива производится по его индексу;
• первый элемент массива имеет индекс равный нулю;
5.2. Объявление массива. Обращение к элементу массива
81
• тип элемента массива не может быть void;
• элементами массива не могут быть функции.
Так же как и любую другую переменную, массив необходимо
объявить и инициализировать, после этого его можно использо-
вать в соответствии с требованиями решаемой задачи.
5.2. Объявление массива.
Обращение к элементу массива
В языке С имеется два формата для объявления массива:
Тип имямассива 1константное_ выражение];
тип имя массива [ ];
Тип в объявлении массива задает тип его элементов.
/Константное-выражение] — задает количество элементов мас-
сива, может быть опущено, если при объявлении массив инициа-
лизируется или если массив объявлен как формальный параметр
функции.
Так же как переменные, массивы должны быть определены до
их использования. Из объявления массива компилятор должен по-
лучить информацию о типе элементов массива и их количестве.
Примеры определения массивов:
int ter[ 100J; // Массив целого типа с именем ter в 100 элементов;
char string[20];// Символьный массив с именем string в 20 элементов;
float d[50]; // Массив из 50 вещественных чисел с именем d;
Для обращения к элементам массива следует указывать имя мас-
сива и индекс элемента заключенный в квадратные скобки.
В нашем примере обрашаються к первому элементу массива ter
следует ter[OJ, ко второму — ter[ 1], к третьему — ter|2] и т. д.
Число, заключенное в квадратные скобки, называется индексом.
Легко догадаться, что индекс необходим для работы, или, как чаще
говорят, для обращения к элементам массива.
Обратите особое внимание, что нумерация элементов массива
начинается с нуля, поэтому массив ter, содержит элементы от ter]0]
до ter[99], а элемента с номером 100 не существует.
82
Глава 5. Массивы
Элементы массивов могут участвовать в операциях как про-
стые переменные соответствующего типа, это могут быть любые
инструкции, где используется переменная: в процедурах ввода,
вывода и в выражениях.
Пример. Программа, вводит с клавиатуры одномерный массив
из пяти целых чисел, после чего выводит количество ненулевых
элементов. Перед вводом каждого элемента выводится подсказка с
номером элемента.
#include <stdio.h>
#include <conio.h>
#define SIZE 5
void main()
{
inta[SIZE];
int n = 0;
int i;
II Размер массива
// Массив
// Количество ненулевых элементов
// Индекс
printf(”Введите массив целых чисел.\п”);
for (i = 0; i < SIZE; i++)
{ printf("a[%i]->",i+l);
scanf(”%i”, &a[i]);
if <a[i] != 0)
11 « ,
}
printff'B массиве %i ненулевых элемента.\п", n);
printf("\nfljui завершения нажмите <Enter>");
getch();
Заметим, что в данном варианте программы размер массива
задан с помощью именованной константы SIZE. Такой подход
весьма распространен, так как позволяет при необходимости лег-
ко изменить размер массива. В самом деле, если мы захотим обра-
ботать массив из 100 элементов, то исправления следует внести в
одном месте при определении константы SIZE , а не в двух мес-
тах, как требовалось бы при использовании обычных числовых
констант.
5.3. Инициализация массива
83
При работе с именованными константами следует помнить, что
задавать их следует до момента первого использования.
Так, в нашем примере значение константы SIZE определено
раньше объявления массива int a[SIZE]; и использования в цикле
for (i = 0; i < SIZE; i++).
Обращение к элементам массива осуществляется по индексу,
так инструкция scanf("%i", &a[i]); в цикле последовательно вводит
данные в элементы массива, начиная от а[0] до a[SIZE -1] (так как
индекс i пробегает значения от 0 до SIZE -1).
5.3. Инициализация массива
После того как массив определен, в него можно вводить ин-
формацию. Как правило, перед тем, как начать работать с данны-
ми массива, требуется присвоить им начальное значение.
Начальные значения элементам статического массива можно
присвоить при его определении.
Формат определения массива с инициализацией демонстриру-
ет следующий пример: int temps[5] = {45, 56, 12, 98, 12};
Таким образом, создано пять элементов со следующими зна-
ченими:
temps[0] = 45;
temps[l ] = 56;
temps[2] = 12;
temps[3] = 98;
temps [4] = 12.
Пример показывает инициализацию массива, т. е. одновре-
менное определение и задание начальных значений массива.
При инициализации можно явно не указывать величину массива,
но следует обязательно перечислить начальные значения элемен-
тов массива. В следующем примере компилятор сам вычислит дли-
ну массива d по количеству элементов списка инициализации.
Пример. Автоматическое вычисление длины массива.
double d[l={ 1.5,2.0,3.75,5.0,3.1, 6.2};
84
Глава 5. Массивы
В результате такого определения создается массив и присваи-
ваются начальные значения, его элементам:
d[0]= 1.5;
d[l]=2.0;
d[2]=3.75;
d[3]=5.0;
d[4]=3.1;
d[5]= 6.2.
Если в определении массива указан его размер, то количество на-
чальных значений не может быть больше количества элементов,
меньше — может быть.
Если список инициализации меньше заявленной длины, то на-
чальные значения получают элементы с меньшими индексами, ко-
нец же массива остается неинициализированным. В этом случае
говорят, что массив заполнен не полностью.
Пример. Неполное заполнение созданного массива.
double d[8]={1.5,2.0,3.75,5.0,3.1};
Начальные значения получают элементы d[0]—d[4J, при этом
элементы d[5]—d[7] не определены.
После того, как массив задан (определен) и инициализирован
(элементы массива получили начальные значения), можно присту-
пать к работе с данными массива, т. е. считывать или записывать
информацию в массив.
5.4. Многомерные массивы
Следует отметить, что в языке С определены только одномер-
ные массивы, но элементом массива может быть массив.
Многомерный массив определяется как массив массивов, при
этом количество его индексов определяет размерность массива.
Количество используемых индексов может быть различным,
массивы с одним индексом называют одномерными, с двумя — дву-
мерными и т. д. Одномерный массив нестрого соответствует мате-
матическому вектору, двумерный — матрице. Чаще всего примени-
5.5. Выход индекса за границы массива
85
ются массивы с одним или двумя индексами, реже — с тремя, еще
большее количество индексов встречается крайне редко.
В следующем примере определен массив А из двух элементов,
каждый из которых в свою очередь состоит из трех элементов.
int А[2][3];
Это двумерный массив из двух строк и трех столбцов, который
можно представить в виде следующей матрицы:
А[0][0] А[0][1]А[0][2]
А[1][0]А[1][1]А[1][2]
Поскольку многомерный массив — это массив массивов, его
можно инициализировать следующим образом:
int w[3][3] = {
{2,3,4},
{3,4,8},
{1,0,9}
После чего элементы массива получают свои начальные зна-
чения:
w[0][0] =2
w[l][0]=3
w[2][0] =1
wl0J[l]=3
w[l][l]=4
w[2}fl]=0
w}0J[2]=4
w[lH2]=8
w[2][2]=9
Подобно одномерным массивам, многомерные массивы мож-
но инициализировать не полностью.
Пример. Присвоить начальные значения элементам первого
столбца матрицы.
double z[3][6]={ {1},{2},{3},{4}};
5.5. Выход индекса за границы массива
Что произойдет, если программист обратится к памяти за пре-
делами объявленного массива, т. е. если индекс массива превысит
максимально возможное значение? В большинстве языков про-
86
Глава 5. Массивы
граммирования подобные ошибки контролируются, например
программа, написанная на языке Паскаль, в этом случае выдаст
ошибку времени выполнения.
В языке C++ никакой проверки «нарушения границ» массивов не
выполняется!
Если происходит обращение к несуществующим элементам
массива, то программа просто считывает содержимое ячеек памя-
ти, никакого отношения к данному массиву не имеющих, либо за-
писывает туда какую-то информацию, портя содержимое других
переменных, возможно, в других программах. В этом случае ре-
зультат работы непредсказуем:
• возможно, произойдет ошибка времени выполнения;
• или программа выдаст неверные результаты;
• в худшем случае — компьютер зависнет и его придется пере-
загрузить.
Все эти действия происходят без каких-либо замечаний со сто-
роны компилятора при трансляции программы и без выдачи сооб-
щений об ошибке во время работы программы.
Пример. Выход за границу массива.
#include <iostream.h>
void main()
{
int err[ 10] ,i;
for (i=0;i< 10;i++) err[i]=i;
for (i=0;i<20;i++) cout«err[i]<<'\t'<<endl;
}
В примере объявлен массив из 10 элементов. В первом цикле
for при записи в массив нарушение границ не происходит, во вто-
ром же цикле на экран выводится 20 элементов. Этот пример не
приведет к сбою компьютера, так как ошибка происходит при чте-
нии данных, и мы лишь видим ошибочный результат на экране.
Если же выход за границы массива произойдет при записи дан-
ных, т. е. в первом цикле, то результат работы программы непред-
сказуем!
Этот пример демонстрирует, что вся ответственность за со-
блюдение границ массивов лежит на программисте. В программе
должны быть либо объявлены массивы достаточно больших раз-
5.6. Приемы работы с массивами в вычислительных задачах
87
меров, чтобы в них без осложнений помещались все необходимые
данные, либо предусмотрены проверки нарушения границ мас-
сивов.
Почему в языке С не предусмотрены столь необходимые с точ-
ки зрения надежности программного кода проверки? Дело в том,
что с самого начала проблема повышения эффективности про-
граммного кода имела наивысший приоритет при создании языка.
Любая проверка корректности доступа на уровне операторов язы-
ка, тем более динамическая проверка во время выполнения про-
граммы, значительно замедляет выполнение программы. Можно
сказать, что в С надежность была принесена в жертву эффектив-
ности.
Подводя итог всего сказанного, отметим, что вопрос о провер-
ке допустимости индексов массива оставлен на рассмотрение про-
граммиста, при необходимости можно определить пользователь-
ский тип «массив» и заложить в программу проверку пересечения
его границ.
5.6. Приемы работы с массивами в вычислительных
задачах
Пример. Задать сначала количество элементов массива, а затем
и сам массив (данные ввести с клавиатуры). Вычислить его сумму.
#include <stdio.h>
void main
int i ,j, n=l;
float s , b , x[ 100];
while (n>100)
{printf (”\n Введите количество элементов (меньше 100): ");
scanf ("%d ",&n);
}
printf ("Введите значение элементов: \п");
for (b=0.0 , i=0 ; i<n ; i++)
{printf ("x[%d]= ”,i);
scanf ("%f ",&x[i]);
88
Глава 5. Массивы
s=s+x[i] ; // Вычисление суммы массива
}
printf ("\п сумма массива=%Г",s);
}
Результат работы программы:
Введите количество элементов (меньше 100):
Введите значение элементов:
х[0] = 8
х[1] = 7
х[2] = 6
х[3] = 5
x[4J =4
Сумма массива=30
Пример. Ввести ежедневные данные о температуре в массив
(ввод с клавиатуры). Вычислить среднее арифметическое значение
элементов введенного массива.
void main()
// Количество дней в месяце (размер массива)
int month[31];
int i, sum;
float mid;
sum = 0.0;
for (i = 0; i < 31; i++) // Ввод значений температуры
рпп1Г("Введите значение температуры t%d= ", i);
scanf("%d", &month[i]);
/* Подсчет среднего арифметического */
for (i = 0; i < 31; i++)
sum += month [i];
mid = sum /31.0;
printf("CpeaHee значение температуры составляет: %f\n", mid);
}
В первом цикле for(...) вводятся данные в массив month[J. Об-
ратите внимание на то, что цикл содержит две строки, первая из
5.6. Приемы работы с массивами в вычислительных задачах
89
которых, функция printf(...) является так называемым приглаше-
нием — запросом на ввод данных, который выводится на экран
дисплея. Такая форма ввода данных с клавиатуры, с приглашени-
ем, является общепринятой и позволяет избежать ошибок при вво-
де информации. Приглашение обычно содержит информацию для
человека, работающего с программой, это может быть имя пере-
менной, в которую будет происходить ввод, комментарии о харак-
тере вводимой информации и т. п. В нашем примере на экран вы-
водится комментарий о характере вводимой информации и индекс
элемента, в который она будет записана.
Представленный алгоритм решения имеет один недостаток.
Как известно, количество дней в различных месяцах варьируется
от 28 до 31. Программа же не делает различий и всегда требует
ввести 31 значение, что не позволяет провести правильный ввод
данных, а следовательно, и расчет будет неверен. Этот недостаток
легко исправляется введением граничного значения при вводе
данных. В следующем примере процедура ввода прекратится, ко-
гда окажутся введены значения всех элементов массива или рань-
ше, если вы введете граничное значение 777. Такой алгоритм по-
зволяет использовать любое количество элементов массива от О
до 31.
Вместо цикла for предыдущей программы теперь используется
цикл do—while и инструкция i = 0;, которая выполняется в начале
каждого цикла, чтобы индекс массива всегда указывал на первый
элемент.
void main()
{
int month[31J;
int i, sum=0;
float mid;
/* Загрузка значений в массив */
i = 0;
do
printf(" Введите значение температуры t%d,\
для прекращения введите 777:", i);
scanf("%d", &month[i]);
}
90
Глава 5. Массивы
while (i < 31 && month[i-l] != 777);
/* Подсчет среднего арифметического */
index = 0;
do
{
sum += monthfi];
1“Ы”?
}
while (i < 31 && month[i-l] != 777);
mid = sum / i;
рпшЦ”Среднее значение температуры\ составляет: %f\n\n", mid);
}
Новым условием продолжения всех циклов do—while является
логическое выражение (i < 31 && monthfi-1 ] != 777), которое ис-
тинно, т. е. принимает ненулевое значение, если выполняется
одно из условий: i < 31 или monthfi-1] != 777.
Пример. В двумерный массив последовательно записываются
числа от 1 до 12.
#include <iostream.h>
void main()
{ int ij,mas[3][4],num=l;
for (i=0;i<3;i++)
{
for (j=0; j<4; j++,num++)
{ mas[i][j]=num;
cout «mas[i][i]<<’\t';
}
cout«'\n';
}
}
В двумерном массиве позиция любого элемента определяется
двумя индексами. Если представить его в виде матрицы, то один
индекс означает строку, другой — столбец. Если доступ к элемен-
там массива предоставлять в порядке, в котором они реально хра-
нятся в памяти, то правый индекс (j) будет изменяться быстрее,
чем левый (i).
5.7. Строка как массив символов
91
5.7. Строка как массив символов
Любая строка текста, например «чижик-пыжик, где ты был?»,
представляет собой массив символов. Во внутреннем представле-
нии компилятор завершает такой массив специальным граничным
символом «\0», благодаря чему любая программа может легко об-
наружить конец строки. Поэтому строка занимает в памяти на
один символ больше, чем записано между двойными кавычками. Сле-
дует учитывать это обстоятельство при определении длины строки,
а именно указывать количество элементов на единицу больше дей-
ствительной длины строки.
Все правила работы с массивами, рассмотренные ранее, рас-
пространяются и на строки, в частности:
• при определении строки вы присваиваете ей имя и указывае-
те максимальное количество символов, которое может в ней
содержаться;
• нумерация элементов строки, т. е. ее символов, начинается с
нуля.
Объявление массива для хранения строки из 10 символов.
char str[ 11J;
Объявленный размер 11 позволяет сохранить нулевой символ.
Мы с вами уже пользовались строками, при выводе текстов на
экран дисплея, например: printf(’’Hello, World!’’). «Hellow,
World!» — это строчная константа или литерал, который всегда за-
писывается в «двойных кавычках». Кавычки не являются частью
строки, а служат только для ее ограничения. Компилятор автома-
тически помещает в конец литерала нулевой символ.
Пример. Внутреннее представление литерала «константа» —
это массив символов с нулевым символом в конце.
I It II II II It II II II I l\ f\l
константа \0
He путайте символьную константу, например 'х', со строкой,
содержащей один символ — «х»:
’х’ — код символа х;
«х» — строка из двух символов (’х’ ’\0’).
92
Глава 5. Массивы
Литералы можно использовать для инициализации массива
типа char, т. е. строки текста, например: char str[] = "строка";
После чего элементы строки получают свои начальные зна-
чения:
st г[0] = ’с'
str[1J = 'т'
str[2] = ’р’
str[3] = о’
str[4J = ’к'
str[5] = ’а’
str[6]= *\0'
Средства языка С позволяют осуществлять ввод и вывод мас-
сива символов как единого целого, в виде строки. В то же время,
каждый символ является отдельным независимым элементом мас-
сива. В следующем примере мы введем строку, а затем отобразим
составляющие ее отдельные символы.
Пример. Ввод и отображение строки.
void main()
char str[60J;
int i;
printf(" Введите строку:");
scanf("%s", str);
for (i = 0; i < 60; i++)
11 Распечатать посимвольно
printf("%c\n", str[i]);
}
Формат %s функии scanf() позволяет вводить строку символов,
ввод заканчивается после нажатия клавиши <ENTER>. Формат %s
рассматривает строку как единое целое, поэтому не требует индек-
сации массива str[], напротив, формат %с в функции printf() рабо-
тает с отдельными символами, поэтому требует перебора элемен-
тов строки в цикле с индексацией каждого элемента.
5.7. Строка как массив символов 93
Если в действительности было введено меньше 60 символов,
элементы массива, следующие за нулевым символом, содержат
случайные величины.
Следующий пример выводит символы до ограничителя (’\0') ,
отсекая все остальное.
Пример. Ввод и отображение строки.
void main()
{ char str[60];
int i;
printf(" Введите строку:");
scanf("%s", str);
for (i = 0; str[i] != \0’; i++)
printf("%c\n", strfi]); // Распечатать посимвольно
}
Пример. Программа вычисляет среднюю (за неделю) темпера-
туру воздуха. Исходные данные должны вводиться во время рабо-
ты программы.
// Вычисление средней (за неделю) температуры воздуха
#include <stdio.h>
#include <conio.h>
void main ()
{
// Названия дней недели — массив строковых констант
char *day [ J = {"Понедельник","Вторник","Среда",
"Четверг","Пятница","Суббота","Воскресенье"};
float t[7]; 11 температура
float sum; // сумма температур за неделю
float sred; // средняя температура за неделю
int i;
printf("\nВведите температуру воздуха:\п");
for (i = 0; i <= 6; i++)
{printf("%s->", day[i]);
scanf("%f, &t[ij);
sum += t [i];
}
sred = sum / 7;
рпп1Й"\пСредняя температура за неделю: %2. If, sred);
94
Глава 5. Массивы
printf("\nAjiH завершения работы нажмите <Enter>");
getch();
Вопросы для самопроверки
1. Дайте общее определение массива данных.
2. Можетли массив содержать переменные нескольких типов?
3. Дайте определение статического массива данных.
4. Перечислите свойства статических массивов.
5. Приведите пример объявления статического массива.
6. Что такое индекс массива?
7. Приведите пример обращения к элементу массива.
8. Какова взаимосвязь между значением индекса и значением элемента
массива?
9. Для чего нужна инициализация массивов?
10. Можно ли инициализировать массив при его объявлении?
11. Расскажите об одномерных и многомерных массивах — их инициализа-
ция, обращение к элементам. Приведите примеры.
12. Что произойдет, если при обращении к элементу массива индекс превы-
сит максимально возможное значение?
13. Что такое строка с языке С?
14. Как присвоить значение строковой переменной?
Глава 6
УКАЗАТЕЛИ И ССЫЛКИ
Без преувеличения можно сказать, что невозможно написать
хорошую программу на С без использования указателей. Это одно
из самых мощных и в то же время самых опасных средств языка.
Неправильное использование указателей может быть причиной
трудно обнаруживаемых ошибок, сбоев в работе программы или
же операционной системы.
6.1. Понятие указателя
Определяя переменную, программист задает ее имя, которое
позволяет оперировать со значением переменной — это программ-
ный уровень работы. На машинном уровне компьютер имеет дело
с понятиями «адрес участка памяти», выделенный под переменную
и «содержимое участка памяти». Например, при определении пе-
ременной выделяется необходимая память (допустим, по адре-
су 100), а оператор присваивания заносит в нее некое значение.
int var = 1;
Программный уровень:
Имя Значение
var 1
Машинный уровень:
Адрес памяти Содержимое памяти
100 1
96
Глава 6. Указатели и ссылки
Можно сказать иначе, имя переменной var адресует участок
памяти, а константа 1 определяет значение, которое запишется по
этому адресу. Имея адрес переменной или другого объекта про-
граммы, необходимо с ним работать: сохранять, передавать и пре-
образовывать, для этой цели и служат указатели.
Указатели — это переменные, значениями которых являются ад-
реса других объектов — переменных, массивов, функции.
Указатель
Адрес X
Переменная X
Значение X
Рис. 6.1. Обращение к переменной через указатель
Указатели служат для обращения к области памяти, отведен-
ной под другую переменную. Подобно любой другой переменной,
указатель нужно создать (объявить) и задать начальное значение.
Термин «задать значение» применительно к указателю использует-
ся редко, вместо этого говорят, что нужно «установить» указатель,
после чего он будет «ссылаться», т. е. указывать на переменную.
Чтобы создать указатель следует определить тип данных, на ко-
торые он будет ссылаться. Символ «*» сообщает компилятору, что
вы создаете указатель, в конце указывается имя переменной.
Например, инструкция int *ptr; создает указатель, который бу-
дет ссылаться на данные целого типа.
Другие примеры объявления указателей:
II Переменная ptr_i — указатель на данные типа int
int *ptr_i;
// Переменная ptr c — указатель на данные типа char
char *ptr_c ;
// Переменная pt rd — указатель на данные типа double
double *ptr_d ;
6.2. Операция получения адреса &
После того, как указатель определен, его нужно установить на
какой-либо объект, размещенный в памяти компьютера, т. е. запи-
сать в него адрес этого объекта. Выражение &var позволяет полу-
чить адрес памяти, выделенный под переменную var. Следует от-
6.3. Операция разыменования (*)
97
метить, что операция & применима только к объектам, имеющим
имя и размещенным в памяти.
Операцию & нельзя применять к:
• выражениям;
• константам;
• битовым полям;
• регистровым переменным;
• внешним объектам (файлам).
Неправильными являются конструкции: &(х+7) и &28.
Первая пытается получить адрес выражения, а вторая — кон-
станты.
Установка указателя на объект — это обязательный этап рабо-
ты. Будьте внимательны неустановленный указатель — главный
источник неприятностей. Если переменная р объявлена как указа-
тель, то оператор присваивания р = &х означает: «получить адрес
переменной х и записать его в переменную-указатель р».
Пример
int var, *ptr_i;
double ss, *ptr_d;
ptr_i = &var;
pt r d = &ss ;
Определены два указателя:
• *ptr_i — указатель на переменную типа int;
• *ptr_d указатель на переменную типа double.
Указателю ptri присваивается адрес переменной var (говорят:
ptri указывает на переменную var), а указателю ptr d — адрес пе-
ременной ss.
После того, как указатель установлен, можно обращаться к
объекту, на который он указывает, для этой цели служит специаль-
ная операция «*».
63. Операция разыменования (*)
Унарная операция *, примененная к указателю, обеспечивает
доступ к содержимому ячейки памяти, на которую ссылается ука-
затель. Иными словами, операция * рассматривает свой операнд
98
Глава б. Указатели и ссылки
как адрес и позволяет обратиться к содержимому этого адреса.
Легко догадаться, что операндом операции * может выступать
только указатель. Приведем различные названия операции *, ис-
пользуемые в литературе по программированию:
• операция разыменования (или разадресации);
• операция раскрытия ссылки;
• косвенная адресация (или обращение по адресу).
Итак, для того чтобы работать с указателем, необходимы, по
крайней мере, две переменные — сам указатель и переменная, на
которую он будет ссылаться.
На рис. 6.2 схематично изображен участок памяти, в которой
располагаются две переменные — указатель ptr i и переменная var.
Если указателю присвоен адрес переменной var, то операция разы-
менования, примененная к указателю, вернет значение перемен-
ной var.
Указатель
i_ptr
Переменная
var
Операция
*i_ptr
Рис. 6.2. Косвенный доступ к переменной var через указатель ptr_i
Пусть указатель ptr i имеет тип int, тогда комбинация *ptr_i эк-
вивалентна произвольной переменной типа int. В этой связи важно
заметить, что привязка указателя к объекту (переменной) происхо-
дит лишь на начальной стадии работы (установка указателя), затем
идет безымянная работа с объектом через указатель, который на
определенной стадии работы может быть перенаправлен на другую
переменную типа int.
Указатели могут использоваться в выражениях, подобно лю-
бым другим переменным.
Пример
int х,у, *ptr;
ptr = &х;
* ptr= *ptr+ 1;
* ptr = *ptr*5;
ptr = &y;
* ptr= *ptr +1;
// ptr ссылается на x
/1 Аналог: x = x+1
// x=x*5
I/ ptr ссылается на у
// y=y+l
6.4. Арифметика указателей
99
В первой строке определен указатель ptr на переменную int, а
также и сама переменная х. Затем указатель устанавливается на пе-
ременную х, в дальнейшем он может использоваться в арифмети-
ческих выражениях вместо переменной х. Указатель в любой мо-
мент может быть перенаправлен на другую переменную, в примере
после вычислений с переменной х указатель устанавливается на
переменную у.
6.4. Арифметика указателей
В данном разделе рассмотрим арифметические операции, при-
менимые к указателям. Существует ряд ограничений и особенно-
стей при использовании арифметических операций над указателя-
ми, накладываемых компилятором языка С. Часто арифметиче-
ские операции над указателями называют адресной арифметикой,
основные элементы которой мы и рассмотрим ниже.
6.4.1. Операция присваивания
Операцию присваивания можно применять при занесении ад-
реса или нулевого значения в указатель. Два указателя можно при-
равнять друг другу, в этом случае значение указателя правой части
равенства заносится в левый указатель.
Пример
int *p,*k,*z,date=2007;
p=&date; // Установка указателя на переменную date
k=p; // Значение указателя р заносится в указатель к
z=NULL // Нулевое значение указателя
6.4.2. Унарные операции изменения указателя, инкремент
и декремент (++ --)
При выполнении операций инкремента и декремента значение
указателя увеличивается или уменьшается на длину типа, на кото-
рый ссылается используемый указатель.
100
Глава б. Указатели и ссылки
Если ptr — некоторый указатель, то ptr++ увеличивает его зна-
чение на такую величину, которая обеспечивает адресацию сле-
дующего (соседнего) однотипного объекта. Следовательно, опера-
ции ++ и -- изменяют числовые значения указателей по-разному,
в зависимости от типа данных, с которыми связан указатель.
Изменение числовых значений указателя:
для типа char: + (или -) 1;
для типа int: + (или -) 2;
для типа float: + (или -) 4;
для типа double: + (или - ) 8.
Пример
float *k;
char *s;
// +4(перемещение на следующее число)
к++;
//-1 (перемещение на предыдущий символ)
S--J
6.4.3. Аддитивные операции (сложение и вычитание)
Аддитивные операции имеют ограничения при работе с указа-
телями: два указателя нельзя складывать, однако к указателю мож-
но прибавить целую величину. При этом результат зависит не
только от значения слагаемого, но и от типа указателя.
Пример
float *k,*i;
intj;
char *s;
j= k+i // Ошибка, указатели нельзя складывать
k= k+2; // +8 к числовому значению указателя
s=s+2; // +2 к числовому значению указателя
Два указателя можно вычитать друг из друга, если они одного
типа. Эта операция дает расстояние между объектами. При этом
расстояние измеряется в единицах, равных размеру элемента дан-
ного типа.
6.5. Применение указателей в выражениях
101
Пример
int x[5],*i,*k, j;
i = &x[0];
k = &x[4];
j = k-i; // j = 4
Отметим, что j = 4, а не 8, как можно было бы предположить
исходя из того, что каждый элемент массива х|] занимает 2 байта.
6.4.4. Сравнение указателей
Если два указателя установлены на одинаковый тип данных, то
их можно сравнивать в операциях: == ,!=,<, <= , > , >=. При
этом значения указателей рассматриваются просто как целые чис-
ла, а результат сравнения равен 0 (ложь) или 1 (истина).
Пример
int *ptrl, *ptr2, а[ 10];
ptrl=a+5;
ptr2=a+7;
if (prt I >ptr2) a[3]=4;
В данном примере значение ptrl меньше значения ptr2, и по-
этому оператор а[3] =4 не будет выполнен.
Любой указатель можно проверить на равенство (==) или не-
равенство (!=) со специальным значением NULL, которое означа-
ет отсутствие адреса в указателе.
6.5. Применение указателей в выражениях
Как известно, приоритет операций имеет большое значение
при вычислении выражений. Унарные операции & и * имеют бо-
лее высокий приоритет, чем арифметические, и поэтому выполня-
ются раньше них. Унарные операции *(разадресация), ++ , -- име-
ют одинаковый приоритет и выполняются слева направо. Следую-
щий пример иллюстрирует взаимодействие унарных адресных
операций при вычислении выражений. Напомним, что операция
102
Глава б. Указатели и ссылки
присваивания — это, по сути, пересылка результата вычисления в
переменную, стоящую слева от знака равенства.
Пример
int xL4J = {0,2,4,6},*р , у ;
P = &х[01 ;
у = *р; И1
у = *р++ Ц 2
у=++*р //з
у=*++р //4
У=(*Р)++ //5
У = ++(*Р) //6
В данном примере к массиву, заданному при его определении,
происходит обращение с помощью указателя р. Пример хорошо
показывает двойственную природу указателя: с одной стороны,
указатель имеет свое собственное значение — адрес переменной, с
другой стороны, он дает возможность обращения к этой самой пе-
ременной. Поэтому, манипулируя указателем, мы имеем возмож-
ность, с одной стороны, «перебирать» элементы массива, изменяя
значение самого указателя (адреса, записанного в него), с дру-
гой — обращаться к элементам этого массива.
Каждая строка данного примера содержит действия как над
элементами массива, так и над указателем, последовательность
выполнения которых иллюстрируется текстом и рис. 6.3.
Строка 1.
Обращение к нулевому элементу (операция разыменования).
Пересылка нулевого элемента массива в у.
Строка 2.
Обращение к нулевому элементу (операция разыменования).
Пересылка элемента массива х[0] в у.
Инкремент указателя (перемещение на следующий элемент с
индексом 1).
Строка 3.
Инкремент текущего элемента массива (1-го элемента).
Пересылка элемента массива х[ 1 ] в у.
Строка 4.
Инкремент указателя (перемещение на следующий элемент).
Пересылка элемента массива х[2] в у.
6.6. Указатели и массивы
103
1. *Р(У=О)
2. *Р(У=О)
5. *Р(У=4)
6. х[2]++
Рис. 6.3. Обращение к массиву с применением указателей
Строка 5.
Пересылка элемента массива х[2J в у.
Инкремент элемента массива.
Строка 6.
Инкремент элемента массива.
Пересылка элемента массива х[2] в у.
6.6. Указатели и массивы
В языке С между указателями и массивами существует тесная
связь. Имя массива — это не что иное, как указатель на первый
элемент массива — элемент с индексом 0. Когда объявляется мас-
сив в виде int array[25], то компилятор не только выделяет память
104
Глава б. Указатели и ссылки
для 25 элементов массива типа int, но и создает указатель с именем
array, который ссылается на первый по счету элемент массива (эле-
мент с нулевым индексом). Сам массив остается безымянным,
а доступ к элементам массива осуществляется через указатель с
именем array. Следует отметить, что указатель array является кон-
стантным, значение которого можно использовать в выражениях,
но изменить нельзя.
Пример. Имя массива можно приравнять указателю, так как
оно также является указателем.
int аггау[25];
int *ptr;
ptr = array;
Здесь указатель ptr устанавливается на начало массива array,
причем присваивание ptr=array можно записать в эквивалентной
форме: ptr=&array[O].
Для доступа к элементам массива существует два различных
способа.
Первый способ связан с использованием обычных индекс-
ных выражений в квадратных скобках, например инструкция
array[10] = 35 записывает константу 35 в элемент с индексом 10,
а инструкция array[i+4] = rev записывает значение переменной rev
в (1+4)-й элемент массива array.
Второй способ доступа к элементам массива связан с примене-
нием указателей:
*(аггау+10) = 35
* (array+i+4)= 7.
Рассматривая имя массива как указатель, мы проделали те же
действие, что и в предыдущем примере. Операция * в данном слу-
чае — это «разыменование» или обращение к объекту через указа-
тель.
Подобным же образом можно обращаться к элементам масси-
ва с помощью независимого (переменного) указателя.
6.6. Указатели и массивы
105
Пример. Сравнение двух способов доступа к элементам мас-
сива.
// Определение массива mas и указателя q
char mas[ 100] , *q;
I/ Инициализация указателя — устаноска на нулевой элемент
// массива
// Ч
// *(q+10)
// *(q+n-l)
q = mas;
//Доступ к элементам массива (следующие записи эквивалентны):
mas[0j;
mas[10j;
mas[n-l];
Использование индексации для доступа к массиву более на-
глядно, но использование указателя более эффективно. При ин-
дексировании элемента массива его адрес каждый раз вычисляется
по начальному адресу (имени массива) и смещению (индексу), что
снижает эффективность полезных вычислений. Поскольку быст-
родействие программы — одно из важнейших ее свойств, предпоч-
тительнее использовать указатели-переменные.Сравним два вари-
анта работы с массивами на примере функции putstr().
Пример. Вывод строки символов на экран терминала.
// Создание строки (массив символов с именем s
// с нулевым элементом в конце)
char 5П="строка текста”,р;
int i;
for(i=0;s[i] !=0;++i)
putchar(s[ij);
/* Доступ с помощью указателя*/
p=s; // Установка указателя на начало массива
while (*р 1=0) putchar (*р++);
Первая часть примера работает с массивом при помощи индек-
сирования его элементов, инструкция putchar(s[i]) выводит один
106
Глава 6. Указатели и ссылки
символ на экран дисплея. В цикле перебираются элементы масси-
ва 5 до тех пор, пока не встретится элемент с нулевым значением.
Вторая часть примера делает ту же работу, рассматривая имя
массива как указатель.
Следующий пример демонстрирует особенности использова-
ния адресной арифметики при работе с указателями.
Пример. Обработка элементов массива.
char s[20]; // Определение массива типа char
// Определение и установка указателя на 0-й элемент массива
char *р = &s[0]; // Аналог *p=s
*(р+10)= 'Г; // Записываем символ 'Г в 10-й элемент
р++; // Установка указателя на 1 -й элемент
*(р+10) = ’к'; // Меняем значение 11-го элемента
if ( *(р-1) != ' \п') // Проверка 0-го элемента
В примере массив и указатель имеют тип char (размер элемен-
та = 1 байт). Прибавляя к адресу 1, мы сдвигаемся на один байт.
А как быть, если мы работаем, например, с типом int, у которого
размер — 4 байта? Оказывается, что и в этом случае все показан-
ные выше арифметические операции с указателями дадут правиль-
ный результат. Разумеется, к адресу будет добавляться не 1, а 4, но
нам об этом даже не придется думать.
Пример.
int s[20J; // Определение массива типа int
// Определение и установка указателя на 0-й элемент массива
int *р = &s[OJ;
*(р+10)= 1;
*(р+10) = 2;
if ( *(р-1) != 10)
// Аналог *p=s
// Записываем единицу в 10-й элемент
// Установка указателя на 1 -й элемент
// Меняем значение 11-го элемента
// Проверка 0-го элемента
Пример, приведенный ниже, отражает на экране абсолютные
значения адресов элементов массивов различных типов, что по-
зволяет наглядно увидеть особенности арифметики указателей.
6.7. Ссылочный тип данных
107
Пример. Вывести на экран элементы массива и их адреса.
#include <stdio.h>
void main()
char s[]—’string",*p; // Работа с массивом типа char
for (p=s; *p !=0; p++) // p+1 (в абсолютных значениях)
printff’s: %c\tp=%p\n",*p, p);
int qП={ 10,20,30,40,50,0},*p 1; // Работа с массивом типа int
for (p 1 =q; *pl !=0; pl++) // pl+4 (в абсолютных значениях)
printf("q[0]=%d\tpl=%p\n",*pl,pl);
}
Для вывода значения указателя (адреса элемента массива) на
экран дисплея в функции printf() используется спецификатор фор-
мата %р (тип укаазатель).
Итак, мы разобрали одно из назначении указателей — обращение
к элементам массивов (или других сложных типов данных).
Другое, не менее важное применение указателей — передача
параметров и возврат значений из функций.
Более подробно о применении указателей при работе с функ-
циями см. в разделе «Функции».
6.7. Ссылочный тип данных
Ссылочный тип (ссылки) иногда называют псевдонимом или
синонимом, и служит он для присвоения объекту дополнительно-
го имени. Ссылку можно рассматривать как константный указа-
тель. Ссылка связывается с конкретным объектом в момент ее
создания и в дальнейшем не может быть изменена, т. е. не может
быть перенаправлена на другой объект, подобно обычному указа-
телю.
Ссылка позволяет косвенно манипулировать объектом, точно
так же, как это делается с помощью указателя. Однако эта косвен-
ная манипуляция не требует специального синтаксиса (операции
разыменования «*»), необходимого для указателей.
Подводя итог вышесказанному, можно отметить, что ссылку
можно рассматривать как альтернативное имя объекта, а также как
безопасный вариант указателя.
108
Глава б. Указатели и ссылки
Ссылки имеют три особенности, отличающие их от указателей:
• при объявлении ссылка обязательно инициализируется,
т. е. должна быть направлена на уже существующий объект;
• ссылка всегда указывает на один и тот же объект;
• при обращении к объекту по ссылке не требуется указывать
операцию разыменования (*), так как она выполняется авто-
матически.
Создание ссылки похоже на создание обычной переменной —
тип, имя, инициализатор. Но справа от типа надо поставить сим-
вол &:
Пример
int i;
int& ref = i;
i nt & refl;
/1 Целая переменная
I/ Определение ссылки на переменную i
// Ошибка: ссылка должна быть инициализирована
После этого можно пользоваться ссылкой ref так же, как самой
переменной i:
i = 8;
ref = 8;
// «Прямой» доступ к i
// «Косвенный» доступ к i через ссылку
При работе со ссылками необходимо учитывать следующее:
• ссылка не может существовать сама по себе — она обязатель-
но связана с какой-либо переменной;
• у ссылки нет своего адреса — если взять адрес ссылки, то по-
лучим адрес связанной с ней переменной;
• все, что мы можем сделать со ссылкой, — это создать ее.
Ссылку нельзя уничтожить или перенаправить на другую пере-
менную. Она уничтожится автоматически при выходе из блока, в
котором была объявлена. Все операции со ссылками реально воз-
действуют на адресуемые ими объекты. В том числе и операция
взятия адреса.
Пример
int val = 1024;
int &refVal = val; // Ссылка на val
6.7. Ссылочный тип данных
109
refVal += 2; // val=val+2
int ii = refVal; // ii = val,
// Устанавливает указатель pi на переменную val
int *pi = &refVal;
Если несколько ссылок определяются в одной инструкции че-
рез запятую, перед каждой ссылкой должен стоять амперсанд (&)
int &rval3 = val3, &rval2 = val2;
Если указателю присвоить нулевое значение, это означает, что
указатель не установлен (не указывает ни на один объект), если же
нулевое значение присвоить ссылке, это будет означать, что ссыл-
ка связана с переменной, значение которой равно нулю.
Пример.
int *pi = 0; И pi не указывает ни на какой объект,
const int &ri = 0;
Означает примерно следующее:
int temp = 0;
const int &ri = temp;
Что касается операции присваивания, то работа с указателями
тоже отличается от аналогичной работы со ссылками, следующий
пример демонстрирует это:
// Работа с указателями
// Определение переменных val 1 и val2
int vail = 1024, val2 = 2048;
I/ Установка указателей
int *pil = &vall, *pi2 — &va!2;
pil = pi2;
110
Глава б. Указатели и ссылки
Переменная vail, на которую указывает pi 1, остается неизмен-
ной, а указатель pi 1 получает значение адреса переменной val2. Та-
ким образом, pi 1 и pi2 теперь указывают на один и тот же объект
va!2.
Проделаем подобные операции со ссылками.
int &ri 1 = val 1, &ri2 = val2; // Создание ссылок ri 1 и п2
ril = ri2;
Операция присваивания ril = ri2 меняет саму переменную vail
(записывает в нее значение из va!2), но ссылка ril по-прежнему ад-
ресует vail. Пример наглядно показывает, что с точки зрения син-
таксиса работа со ссылкой ничем не отличается от работы с пере-
менной, на которую она ссылается.
Следует отметить, что механизм ссылок отсутствует в класси-
ческом С, но все современные компиляторы C++ поддерживают
ссылки.
Ссылки редко используются как самостоятельные объекты,
обычно они употребляются в качестве формальных параметров и
возвращаемых значений функций.
Вопросы для самопроверки
1. Что такое указатель?
2. Что определяет тип указателя?
3. Для чего используется операция &?
4. Что означает операция «разадресации»? Какие синонимы этого понятия
вы знаете?
5. Приведите пример установки указателя на переменную.
6. Является ли обязательной инициализация указателя при его определе-
нии?
7. Приведите пример использования указателя в выражении.
8. Что означает термин «адресная арифметика»?
9. Какие особенности адресной арифметики вы знаете?
10. Поясните особенности применения операции инкремента и декремента к
указателю.
6.7. Ссылочный тип данных 111
11. Поясните особенности применения операции сложения к указателю.
12. Поясните особенности применения операции вычитания к указателю.
13. Можно ли сравнивать указатели?
14. Можно ли присвоить имя массива указателю?
15. Изложите методику обращения к элементам массива через указатель?
16. Приведите пример вывода на экран элемента массива и его адреса.
17. Что такое ссылка?
18. Является ли обязательной инициализация ссылки при ее определении?
19. Можно ли ссылку перенаправить с одной переменной на другую?
Глава 7
ВРЕМЯ ЖИЗНИ И ОБЛАСТЬ ВИДИМОСТИ
ПЕРЕМЕННОЙ
7.1. Общие понятия
При определении переменной компилятор выделяет для нее па-
мять, причем тип данных определяет размер выделенной памяти.
После того как переменная создана, в ней можно размещать
данные, но всегда ли к этим данным можно обратиться, или, как
говорят, всегда ли эти данные доступны? Чтобы ответить на этот
вопрос, необходимо рассмотреть несколько новых понятий.
Программным блоком будем называть часть программы, заклю-
ченную в фигурные скобки. Программируя на языке С, мы всегда
имеем дело с программными блоками, например тело функции
main(), тело цикла, одна из альтернатив оператора if — все это про-
граммные блоки.
Различают два вида блоков:
1 ) составной оператор;
2 ) определение функции.
Блоки могут быть вложенные, внутренний блок называется
вложенным, а внешний блок — объемлющим. При использовании
вложенных блоков следует соблюдать следующие правила:
• блоки могут включать в себя составные операторы;
• блоки не могут включать в себя определения функций.
Программный модуль — это файл с исходным текстом про-
граммы.
Время жизни программного объекта (объектом может быть
переменная, функция и т. п.) — это интервал времени выполне-
ния программы, в течение которого программный объект суще-
7.1. Общие понятия
113
ствует. Время жизни переменной может быть локальным или гло-
бальным.
Переменная с глобальным временем жизни существует, т. е. име-
ет распределенную для нее память и определенное значение, на
протяжении всего времени выполнения программы.
Переменная с локальным временем жизни существует только во
время выполнения блока, в котором эта переменная определена. При
каждом входе в блок для локальной переменной распределяется
новая память (переменная создается), которая освобождается при
выходе из блока (переменная уничтожается).
Область видимости объекта — это та часть текста программы, в
которой может быть использован данный объект. Объект считает-
ся видимым в блоке или модуле, если в этом блоке или модуле из-
вестны имя и тип объекта, в этом случае говорят, что объект досту-
пен и к нему можно обращаться.
Объект может быть видимым в пределах:
• блока;
• модуля (файла);
• во всех модулях (если программа располагается в нескольких
файлах).
Область видимости переменной зависит от того, в каком месте
программы (на каком уровне) она объявлена. Если переменная объ-
является вне всех блоков программы (обычно вначале программы, до
функции main()), то это внешнее объявление или глобальная пере-
менная.
Внутри блока или функции объявляются локальные переменные,
они видимы в том блоке, в котором объявлены, и во всех вложен-
ных блоках, если таковые есть.
В следующем примере переменная q существует на протяже-
нии всего времени выполнения программы, она видима во всех
блоках программы.
Переменная i существует на протяжении выполнения функции
main(), она видима внутри функции main(), т. е. в текущем модуле
программы.
Переменные к и 1 существуют на протяжении выполнения вло-
женного блока, они создаются при входе во вложенный блок и
уничтожаются при выходе из него. Переменная i видна как в своем
блоке (в функции main()), так и во вложенном блоке, переменные к
и 1 не видны вне «своего» блока (там их просто не существует).
114
Глава 7. Время жизни и область видимости переменной
Пример
int q; // Глобальная переменная
void main()
{//----------функция main(), объемлющий блок
int i; //Локальная переменная функции main()
{// ===================== вложенный блок
int k,l; //Локальные переменные вложенного блока
}//===================================
к++ // Ошибка, переменной к здесь не существует
}//-------------------------------------
7.2. Классы памяти
Класс памяти — очень важная характеристика, которая опреде-
ляет правила доступа к переменной, он определяет время жизни и
область видимости переменной, связанные с понятием блока про-
граммы.
Ключевые слова для обозначения классов памяти и их иерар-
хия в языке С представлены в табл. 7.1.
Таблица 7.7
Динамический класс памяти Статический класс памяти
Локальное время жизни Глобальное время жизни
Автоматический Регистровый Статический (внутренний) Статический (внешний)
auto register static extern
Обычно программа оперирует с множеством объектов: пере-
менных и функций. Все они по отношению к конкретной функции
делятся на внешние и внутренние объекты.
7.2. Классы памяти
115
Внешние переменные определяются вне функций. Сами функ-
ции друг для друга всегда являются внешними объектами, посколь-
ку в С запрещено определять функции внутри других функций.
Внутренние переменные определяются внутри функций.
Автоматический класс памяти
Ключевое слово «auto» указывает на то, что объект располага-
ется в локальной, автоматически распределяемой памяти, исполь-
зуется в операторах объявления в теле функций или внутри блоков
операторов.
Вне блоков и функций этот спецификатор не используется.
Время жизни объектов auto локально и равно времени выпол-
нения функции (или блока), auto-переменные существуют только
внутри функции, они создаются в момент входа в функцию и
уничтожаются при выходе из нее.
Область видимости автоматической переменной также локаль-
на и представляет собой функцию (или блок), в которой переменная
объявлена.
Инициализация автоматических переменных выполняется
всякий раз при входе в блок, в котором они объявлены.
Если инициализация переменных в объявлении отсутствует, то
их начальное значение не определено и содержат непредсказуемое
значение («информационный мусор»).
Спецификатор auto явно используется редко, он подразумева-
ется по умолчанию при любом объявлении в теле функции или в
блоке операторов.
Класс памяти register
Register — еще один спецификатор автоматического класса па-
мяти, применяется к локальным объектам и представляет собой
«пожелание» к транслятору по возможности размещать объект в
регистре, а не в оперативной памяти компьютера.
Если в момент начала выполнения кода в данном блоке опера-
торов все регистры заняты, транслятор обеспечивает обращение
как с объектами класса auto, т. е. располагает объекты в локальной
области памяти.
Класс static (внутренний статический класс памяти)
Спецификатор static относит переменную к внутреннему ста-
тическому классу памяти. Переменная, объявленная как static,
располагается по фиксированному адресу в памяти компьютера,
116 Глава 7. Время жизни и область видимости переменной
причем объявление может находиться как в теле функции или бло-
ке операторов, так и вне.
Область видимости у переменных класса static локальна, т. е. пе-
ременные доступны только в тех блоках или функциях, в которых
объявлялись.
Время жизни static-переменных глобально, т. е. они существуют с
момента определения до конца выполнения всех модулей про-
граммы.
В отличие от auto-переменных, static-переменные не уничто-
жаются, когда функция (или блок) завершает работу, и их значе-
ния сохраняются при последующих вызовах функции (или блока).
Переменная с классом памяти static может, подобно другим пере-
менным, получить начальное значение присваиванием констант-
ного выражения — это явная инициализация.
Сравнительная характеристика свойств переменных разных
классов памяти приведена в табл. 7.2. и 7.3.
Таблица 7.2
Инициализация Время жизни Область видимости
Нет начального значения Начальное значение задано
auto Нет инициализации. Значение не определено Задается при каждом входе в функцию Локально Локальна
static Автоматическая, ини- циализация нулем Задается один раз при первом обра- щении Глобально в пределах одного модуля Локальна
extern Автоматическая, ини- циализация нулем Задается один раз при первом обра- щении Глобально во всех модулях Глобальна во всех модулях
Таблица 7.3
Способ выделения памяти
auto Память выделяется динамически во время работы программы (адрес за- ранее не определен)
static Память выделяется один раз при компиляции программы (располагается по фиксированному адресу)
extern Память выделяется при компиляции программы (располагается по фик- сированному адресу)
7.3. Вложенные блоки в программе
117
Явная инициализация static-переменной выполняется один
раз при первом обращении, если же переменная не инициализиру-
ется, то ей присваивается нулевое значение.
Класс extern (внешний статический класс памяти)
Спецификатор extern делает переменную глобальной, т. е. отно-
сит ее к внешнему статическому классу памяти.
Время жизни глобальных объектов — с момента определения и
до конца выполнения программы. Переменные extern доступны
(видимы) во всем файле программы. Можно сделать переменную
видимой и в других исходных файлах, для чего в этих файлах ее
также следует объявить со спецификатором extern. Глобальные пе-
ременные всегда инициализируются, и если это не сделано явно,
то они инициализируются нулевым значением.
Сравнительная таблица свойств переменных разных классов
памяти приведена в табл. 7.2.
7.3. Вложенные блоки в программе
Программа может содержать блоки, вложенные друг в друга, но
вложенные друг в друга функции не допускаются, т. е. определение
функции не должно содержать определение другой функции.
Переменные из объемлющих блоков, включая переменные
объявленные на глобальном уровне, видимы во внутренних бло-
ках. Эту видимость называют вложенной.
Пример
#include <stdio.h>
int gp= 1; // Внешнее объявление переменной
void main()
{printf("\nmain\tgp=%d",gp);
{//+++++++++++++++++++++++++++ блок!
int 1р=0; // Внутреннее объявление переменной
{gp++;lp++; /у************** блок2
printf("\n blok2\tgp=%d\tlp=%d",gp,lp);
}
gp++; lp++;
118
Глава 7. Время жизни и область видимости переменной
printf(”\nblok\tgp=%d\tlp=%d”,gp,lp);
gp++;
lp++; 11 Ошибка’! здесь Ip не видна
printf("\nmain\tgp=%d\tlp=%d,’,gp,lp);
printf(’’\n");
}
Внешняя переменная gp видна в трех блоках — main, блоке!
и блоке?, а локальная переменная 1р видна в двух блоках — блоке!
и блоке?.
Поскольку переменная 1р объявлена во вложенном блоке 1, то
обращение к ней в теле функции main() приведет к ошибке, кото-
рая обнаружится на этапе трансляции.
Если переменная, объявленная внутри блока, имеет то же имя,
что и переменная, объявленная в объемлющем блоке, то это две
разные переменные, и переменная из объемлющего блока во внут-
реннем блоке будет невидимой.
Пример
int i= 1; // Внешние (глобальные) объявления
int k=5;
void ma in (void);
{ k++;
printf("%d %d\n", i, k); //i=l,k=6
{ /1 ++++++ объемлющий блок
int i=0;
printfl "%d %d\n", i, k ); // i=0 k=6
{ /I ******* вложенный блок
int i=2;
k++;
printfl ”%d %d\n", i, k); // i=2,k=7
I //***********
k++;
printfl ”%d %d\n”, i,k); //i=0,k=8
}//++++++++++
printfl "%d %d\n", i, k ); // i= I ,k=8
}
7.3. Вложенные блоки в программе
119
Обратите внимание, что имя i объявляется три раза, фактически
объявляются три разные переменные с одним и тем же именем:
• в глобальной области;
• в объемлющем блоке;
• во вложенном блоке.
Время жизни каждой из них — от объявления до выхода из бло-
ка, в котором переменная объявлена. Глобальная переменная к не
переопределяется во внутренних блоках и, поэтому существует в
единственном экземпляре, она видна во всех блоках.
Вопросы для самопроверки
1. Дайте определение следующим понятиям: программный блок, программ-
ный модуль, время жизни и область видимости переменной.
2. Объясните понятие «составной оператор», приведите пример.
3. Могут ли блоки включать в себя составные операторы?
4. Могут ли блоки включать в себя определения функций?
5. Какое время жизни у глобальной переменной?
6. Какое время жизни у локальной переменной?
7. Дайте определение понятию «класс памяти».
8. Класс памяти — это характеристика переменной, области памяти, блока
программы или функции?
9. Какие классы памяти вы знаете?
10. Какие классы памяти имеют локальное время жизни?
11. Какие классы памяти имеют глобальное время жизни?
12. К какому классу памяти относятся переменные, определенные в теле
функции?
13. Какой класс памяти используется для создания общих переменных не-
скольких модулей программы.
14. Могут ли быть программные блоки вложенными?
15. Могут ли быть определения функций вложенными?
Глава 8
ФУНКЦИИ
Как только программа приобретает большие размеры, работать
с ней становится все труднее. Для обеспечения действенного кон-
троля над алгоритмом и текстом программы в теории программи-
рования введено понятие «подпрограмма».
Подпрограмма — это часть компьютерной программы, имею-
щая имя и содержащая описание определенного набора дейст-
вий, она может быть многократно вызвана из разных частей про-
граммы.
Сначала подпрограммы использовались как средство оптими-
зации программ для уменьшения занимаемой памяти, но в настоя-
щее время данное свойство подпрограммы стало вспомогатель-
ным, уступив место другому — структуризации программы.
С помощью подпрограмм программу можно структурировать,
разделяя ее текст на блоки, каждый из которых выполняет ка-
кую-то одну вполне законченную задачу. Полученные блоки, в
свою очередь, также можно разделить на меньшие блоки. Такое
деление проводят многократно до тех пор, пока получающиеся
части все еще остаются самостоятельными задачами.
В языках программирования высокого уровня используется
два типа подпрограмм: процедуры и функции.
Функция — это подпрограмма специального вида, которая вы-
полняет следующие действия:
• получает параметры;
• выполняет инструкции, согласно заложенному алгоритму;
• может возвращать результат в вызывающую программу.
Процедура — это любая подпрограмма, которая не является
функцией.
Далее мы будем говорить только о функциях, так как в отли-
чие от других языков программирования в С нет деления на под-
8.1. Общие понятия
121
программы и функции, здесь вся программа строится только из
функций.
Самое общее определение функции таково — это совокупность
объявлений и операторов, обычно предназначенная для решения опре-
деленной задачи.
Подводя итоги сказанного можно отметить, что использование
функций дает много положительного:
• функции позволяют избежать дублирования кода в одной
программе. Кроме того, несколько программ могут совмест-
но использовать код функции;
• программы легче читаются, так как детали работы «скрыты»
внутри функций;
• программы приобретают структуру, и это облегчает работу
над текстом при программировании и отладке в процессе
разработки и в дальнейшем при внесении изменений в про-
грамму.
8.1. Общие понятия
С использованием функций в языке С связаны понятия, кото-
рые условно можно разделить на две группы.
В первую группу входят определение, прототип и вызов функ-
ции — все три понятия связаны с подготовкой функции к работе.
Определение функции — это описание действий, выполняемых
функцией согласно требованиям алгоритма. Именно эта часть
программы будет впоследствии многократно вызываться из других
частей программы.
Вызов функции обеспечивает выполнение действий, определен-
ных в функции. При вызове управление передается первой инст-
рукции в теле функции, а после завершения работы функции
управление возвращается строке, следующей за вызовом.
Объявление, или прототип, функции используется в том случае,
если вызов функции предшествует ее определению или если опре-
деление и вызовы функции находятся в разных файлах.
Ко второй группе следует отнести механизмы и связанные с
ними понятия, обеспечивающие связь функции с внешней про-
граммой, или, как чаще говорят, с вызывающей программой. Из вы-
зывающей программы в функцию необходимо передать необходи-
122
Глава 8. Функции
мне для работы данные, а по окончании работы из функции в вы-
зывающую программу возвратить результат.
Данные в функцию передаются при помощи параметров: фор-
мальных, описываемых в определении функции, и фактических,
задаваемых при вызове функции.
Данные из функции в вызывающую программу передаются
при помощи оператора return, который чаще всего завершает тело
функции.
8.2. Определение функции
Определение функции состоит из заголовка и тела и имеет сле-
дующий формат:
тип имя функции (тип имя_параметра_1, тип имя_параметра_2,...)
{тело функции};
Тип функции определяет тип значения, которое функция воз-
вращает.
Если тип не указан, то предполагается, что функция возвраща-
ет целое значение, типа int.
Если функция не должна возвращать значение, то используется
тип void, который в данном случае означает отсутствие значения.
Возвращаемое значение передается в точку вызова во внеш-
нюю по отношении к функции программу. В языке С функция мо-
жет возвращать только одно значение.
Следует подчеркнуть, что функция возвращает значение, только
если ее выполнение заканчивается оператором return, содержащим
некоторое выражение. Если оператор return не содержит выраже-
ния или выполнение функции завершается без выполнения опера-
тора return (в этом случае функция завершается после выполнения
последнего оператора), то возвращаемое значение функции не оп-
ределено. Когда функция объявлена как возвращающая некоторое
значение, а в ее теле отсутствует оператор return, поведение про-
граммы после выхода из функции может быть непредсказуемым.
В теле функции располагаются операторы, необходимые для
решения задачи. Могут быть объявлены и переменные.
8.3. Прототип функции
123
Параметры функции связывают ее с вызывающей программой.
Вызывающая программа через параметры передает данные в функ-
цию, которые та принимает и использует в своей работе. Чтобы от-
личать параметры функции, описанные в ее заголовке и теле, от
параметров, указываемых при ее вызове, первые принято называть
формальными параметрами, вторые — фактическими параметрами.
Пример. Функция находит максимальное значение из двух це-
лых чисел а и b и возвращает его в точку вызова.
// Определение функции max
int max(int a, int b) // a, b — формальные параметры
{int г; Ц Тело функции
if (a>=b) г=а;
else r=b;
return (r); // Возврат результата
}
void main()
{int x,y,big;
printf("\nx=); scanf("%d", &x);
printf("\ny=); scanf("%d", &y);
big=max(x,y); //Вызов функции max, x,y — фактические параметры
printf (,,big=%d\n",big);
}
Функция max() имеет два формальных параметра типа int а и b
и возвращаемое значение типа int. При вызове функции ей переда-
ются фактические параметры (х и у), в теле функции определена ло-
кальная переменная г для хранения и возврата результата. После
выполнения функции результат находится справа от знака присваи-
вания в выражении big=max(x,y), на месте выражения тах(х,у), по-
этому говорят, что результат передается в точку вызова.
8.3. Прототип функции
Определение функции шах() расположено до функции main(),
которая в данном случае является вызывающей функцией, т. е.
к моменту вызова функция тах() уже определена. В языке С нет
124
Глава 8. Функции
строгих требований к местоположению определения функции, оно
может располагаться:
• перед функцией main();
• после функции main();
• в другом модуле (файле) программы.
Вызов и определение функции могут находиться в разных час-
тях программы, но есть простое правило, относящееся к использо-
ванию функций, — к моменту вызова функция должна быть либо оп-
ределена, либо объявлена.
Если вызов функции предшествует ее определению, то перед
вызовом необходимо поместить объявление функции, которое чаще
называют ее прототипом. Это связано с тем, что компилятору не-
обходимо осуществить проверку соответствия количества и типов
передаваемых фактических параметров количеству и типам фор-
мальных параметров.
Прототип функции обладает следующими свойствами:
• прототип имеет такой же вид, что и заголовок определения
функции;
• тело функции отсутствует;
• имена формальных параметров могут быть опущены (типы
параметров опускать нельзя).
Приведем пример решения предыдущей задачи с использова-
нием прототипа функции шах().
В теле функции вместо оператора if будем использовать опера-
тор ?, что позволит записать алгоритм короче.
int max(int a, int b); // Прототип функции max
void main()
{int x,y,big;
printf("\nx=); scanf("%d", &x);
printf("\ny=); scanf("%d", &y);
big=max(x,y); // Вызов функции max()
printf ("big=%d\n’,,big);
}
int max(int a, int b) // Определение функции max
{ return (a>=b)? a: b;
}
Прототип функции max() может быть задан двумя способами:
int max (int a, int b); или int max (int, int);
8.4. Переменные в функции
125
Как видно, во втором случае опущены имена параметров функ-
ции, что не помешает транслятору проверить правильность ее вызова.
Практикующие программисты часто задают прототипы всех
используемых функций в начале программного модуля вне зависи-
мости от местоположения определения конкретной функции. Та-
кой подход дает возможность «охватить единым взглядом» все ис-
пользуемые функции и их параметры, что весьма удобно при раз-
работке и отладке больших программ.
Операторов return в функции может быть несколько, и тогда
они фиксируют несколько точек выхода.
Пример. Найти максимальное значение из двух целых чисел а и
Ь, отразить его на экране и вернуть в точку вызова.
int max(int, int); //Прототип функции max
void main()
{int x,y,big;
printf("\nx=); scanf("%d", &x);
printf(”\ny=); scanf("%d", &y);
big=max(x,y); // Вызов функции max()
int max(int a, int b)
{ if (a > b)
// Определение функции
{ printff’max = %d\n”, a);
return a;
printff'max = %d\n", b);
return b;
Предыдущий вариант данного примера, когда печать выполня-
ется в вызвающей программе, более компактный, но в данном слу-
чае демонстрируется возможность наличия нескольких выходов из
одной функции.
8.4. Переменные в функции
Переменные, определенные в функции, имеют класс auto, они ло-
кальны, т. е. создаются при входе в функцию и уничтожаются при
выходе из нее.
126
Глава 8. Функции
Область видимости такой переменной — функция, к ней могут
обращаться только операторы, принадлежащие определению
функции.
Время жизни переменной, определенной в функции — от входа до
выхода из функции. Из этих качеств локальных переменных функ-
ции вытекает одно интересное свойство — в определениях разных
функций переменным можно давать одинаковые имена.
Пример.
#include <stdio.h>
I/ Определение функции father_age()
int father_age()
{ int age; //Локальная переменная функции
рпп1Г("\пВведите возраст вашего отца:");
scanf (”%d",&age);
return (age);
}
// Определение функции your_age()
int your_age()
{ int age; //Локальная переменная функции
printf("\n В ведите ваш возраст:");
scanf (”%d",&age);
return (age);
void main()
{//Локальные переменные функции main()
int f a, y a, del;
f a = father_age(); // Вызовы функций
ya = your_age();
del = f a - y a;
printf ("\n ваш отец старше вас Ha%d лет\п", del);
В приведенном примере можно обойтись без переменных в
функции main(), если не требуется запоминать промежуточные
8.4. Переменные в функции
127
значения вычислений, само вычисление проведем при выводе ин-
формации на экран дисплея.
void ma in ()
printf ("\п ваш отец старше вас на%б лет\п", father_age()-your_age());
}
Статические переменные могут быть использованы в теле функ-
ции. Напомним, что статические переменные создаются и инициа-
лизируются при первом входе в функцию и сохраняются на протя-
жении выполнения всей программы.
Статические переменные в определении функции используют-
ся в том случае, если нужно сохранять результат вычислений меж-
ду ее вызовами.
Пример. Использование статических переменных в определе-
нии функции.
#include <stdio.h>
// Определение функции plusl ()
void plusl()
{static int x=0; // Инструкция выполняется один раз
int у=0; // Выполняется при каждом вызове
х=х+1;
у=у+1;
printf("x=%d , y=%d \n”,x,y);
}
void main()
{plusl ();
plusl();
y++;
plusl();
x++;
I/ Переменной у уже нет (будет ошибка!)
// Переменная х существует, но не видна здесь
// (будет ошибка!)
128
Глава 8. Функции
В программе функция plusl() вызывается три раза. Перемен-
ная х создается при первом вызове функции и сохраняется до кон-
ца выполнения программы. При втором и последующих вызовах
инициализация переменной х уже не проводится, т. е. инструкция
static int х=0 выполняется только один раз. Следует подчеркнуть,
что переменная х сохраняется между вызовами функции plusl(), по-
этому происходит ее увеличение на единицу при каждом вызове.
Переменная у создается каждый раз заново при входе в функ-
цию plusl(), при выходе она уничтожается, и поэтому ее значение
не сохраняется между вызовами.
В результате работы программы на экране будет напечатано:
При 1-м вызове:
х=1,у=1;
при 2-м вызове:
х=2,у=1;
при 3-м вызове:
х=3,у=1.
Рассмотрим использование глобальных переменных в функциях.
Подобно статическим переменным, глобальные переменные соз-
даются один раз в начале работы программы, по умолчанию ини-
циализируются нулем и существуют до конца выполнения про-
граммы. Но в отличие от статических переменных, которые видны
только в той функции, в которой определены, глобальные пере-
менные видны во всех функциях программного модуля.
Пример. Использование внешних (глобальных) переменных.
Переменная х доступна как в функции main(), так и во всех дру-
гих функциях программы.
// Внешнее (глобальное) объявление переменной
int х=3;
// Определение функции «увелечение х»
void plusl ()
{ intp=10; //Локальная переменная
х=х+1;
р=р+1;
8.4. Переменные в функции
129
рпгйГС’Плюс 1: x=%d\tp=%d\n",x,p);
}
// Определение функции «уменьшение х»
void minus 1 ()
{ int m; // Локальная переменная
х=х-1;
m=m+l;
printf("MHHyc 1: x=%d\tm=%d\n",x,m);
}
// Вызывающая программа
void main()
{ рпп(Г(”начало: x=%d\n",x);
x--;
p++; // Ошибка, нет доступа!
m++; // Ошибка, нет доступа!
plusl();
minusl();
minusl();
printff’KOHeu x=%d \n", x);
}
К глобальной переменной x можно обращаться из любой
функции программы, включая функцию main(). К переменным р и
m доступа из функции main() нет, этих переменных просто не су-
ществует в момент выполнения функции main().
Обратите внимание, что локальную переменную р иницииро-
вали прямо при создании и работа с ней не вызовет никаких про-
блем, переменную же m оставили без инициализации и это приве-
дет к получению непредсказуемого результата при выполнении
инструкции m=m+l и печати ш. Инициализация локальных пере-
менных — это не просто «правило хорошего тона», а совершенно
обязательная вещь.
Если внешняя переменная (в примере этох) не инициализиру-
ется явно, то по соглашениям языка С в ней будет записан нуль
(записывается автоматически при трансляции программы). Это
возможно сделать, так как внешние переменные создаются один
раз на все время работы программы.
У локальных переменных иная природа, поскольку они созда-
ются моногократно, инициализировать их автоматически («про
запас») слишком накладно. Поэтому под них просто отводится па-
130
Глава 8. Функции
мять с тем содержимым, которое в ней было до запуска програм-
мы. В результате в неинициализированных локальных перемен-
ных оказываются непредсказуемые значения, которые к тому же
могут меняться от вызова к вызову, поскольку местоположение
локальной переменной может меняться. Поясним вышесказанное
на примере.
int s;
int free()
{ int k;
return k;
}
// Глобальная переменная
// Определение функции free
//Локальная переменная
int main()
{
printf(”%d\n", s);
printf("%d\n", free());
return 0;
Обе переменные — s и k — не инициализируется, но если при
печати переменной s мы всегда получаем нуль, то значение пере-
менной к предсказать невозможно.
8.5. Передача параметров в функцию
Функция должна иметь доступ к данным в вызывающей про-
грамме. Эту проблему можно решить, сделав необходимые данные
глобальными. Но такой путь неудобен и чреват ошибками, так как
глобальные данные доступны всем функциям, поэтому лучше для
этой цели использовать механизм параметров.
Формальные параметры перечисляются при описании функции
в ее заголовке и могут использоваться внутри нее наряду с локаль-
ными переменными, описанными в теле функции.
При вызове фактические параметры пердаются в функцию и
используются в ее работе. Часто фактические параметры функции
называют ее аргументами. При вызове функции количество, поря-
8.5. Передача параметров в функцию
131
док и типы фактических параметров должны соответствовать фор-
мальным параметрам в определении функции.
Можно выделить следующие этапы вызова функции:
• проверка соответствия фактических и формальных парамет-
ров функции;
• присваивание фактических значений формальным парамет-
рам функции.
• передача управления на первый оператор функции.
Допускается использование функций без аргументов и функций,
не возвращающих никаких значений.
Пример. Вывести на экран дату в формате «Год: Месяц: День».
#include <stdio.h>
// Определение функции
void dateprint (int gg , int mm , int dd )
{ printf ("\n year: %d",gg);
printf ("\t month: %d",mm);
printf ("\t day: %d”,dd);
}
void main()
{
dateprint ( 1990 ,12,17); // Вызов (обращение к функции)
}
Результат выполнения:
Year: 1990 month: 12 day: 17
Функция не возвращает значения, поэтому ее тип — void. При
вызове происходит присваивание значений фактических парамет-
ров соответствующим формальным параметрам (gg= 1090, mm=12,
dd=17).
8.5.1. Передача параметров по значению
Во всех предыдущих примерах вызываемой функции передава-
лись не сами переменные, а лишь их значения, которые записыва-
лись во временные (локальные) переменные, являющиеся фор-
мальными параметрами функции.
132
Глава 8. Функции
При вызове функции для формальных параметров выделяется па-
мять, в которую копируются фактические параметры. Из этого
следует, что функция не может изменить переменную в вызываю-
щей программе, она может изменить лишь ее временную копию
(формальный параметр), значение которой теряется при выходе из
функции.
Пример, функция power() возводит base в д-ю степень.
int power(int base, int n)
{int p;
for (p = 1; n > 0; —n)
p = p * base;
return p;
}
void main()
{int i,p,dec;
for(i=l,dec=10, p=0 ; i<5 ; i++,dec=dec*i)
p=p+power(dec, i);
}
Обратите внимание на одноименные переменные р в вызы-
вающей программе и функции power(), это две разные перемен-
ные — локальные переменные функций main() и power(). Перемен-
ная р в функции power() «маскирует» (или исключает) переменную
р в вызывающей программе.
При вызове power(dec , i) создаются две локальные перемен-
ные для формальных параметров base и п, а также локальная пере-
менная р. Формальному параметру base присваивается фактиче-
ское значение dec, а формальному параметру п — фактическое зна-
чение i (base=dec, n=i). Формальный параметр п является
переменной для счета числа шагов цикла, что бы мы ни делали с п
внутри функции power(), это не окажет никакого влияния на саму
переменную i в вызывающей программе.
В следующем примере функция swap меняет местами перемен-
ные в локальной области, переменные во внешней вызывающей
программе остаются неизменными.
8.5. Передача параметров в функцию
133
Пример
// Определение функции swap
void swap (int x, int y)
{ int t = x;
x = y;
y = t;
printff’swap: x=%d\t y=%d",x,y);
}
void main()
{ inta = 3,b = 7;
swap (a, b);
printf("main: a=%d\t b=%d",a,b);
Результат выполнения программы:
swap: x=7 y=3
main: a=3 b=7
Итак, при передаче параметров по значению переменные в вызы-
вающей программе недоступны для функции. Если же требуется из-
менить переменную в вызывающей программе, следует передавать
параметры через указатель на переменную.
8.5.2. Указатель в качестве параметра функции
Когда управление передается в функцию, в распоряжении про-
граммиста оказываются ее параметры и внутренние переменные.
К внешним объектам функция не может обратиться прямо, ис-
пользуя имена переменных, но может использовать указатели для
косвенного обращения.
Следует отметить, что так же, как и обычные переменные, ука-
затели передаются по значению, внутри функции создается локаль-
ная переменная — указатель, в который записывается адрес пере-
менной из вызывающей программы при вызове функции. После
этого внешняя переменная становится доступной. В качестве,
примера рассмотрим уже известную нам функцию swap(), но в
134
Глава 8. Функции
данном случае в качестве формальных параметров используются
указатели.
void swap (int* х, int* у)
{ int t;
t = *x;
*x = *y;
*y = t;
}
void main()
{ int a=3,b=7,*pl,*p2;
I/ Вызов функции может происходить двумя способами:
// 1. передача адресов переменных
swap (&а, &Ь);
printff'l. main: a=%d\t b=%d",a,b);
I/ 2. передача указателей на переменные
pl = &а;
р2= &Ь;
swap (pl,p2);
printf("2.main: a=%d\t b=%d",a,b);
}
Результат выполнения программы:
l .main:a=7 b=3
2 . main: а=3 Ь=7
В новом исполнении функция swap() имеет два формальных
параметра — указатели на переменные типа int с именами х и у.
При первом вызове функции (swap (&а, &Ь)) передаются зна-
чения адресов переменных а и Ь, которые записываются в локаль-
ные переменные-указатели х и у, т. е. при вызове функции неявно
выполняются присваивания х=&а и у=&Ь. Таким образом, функ-
ция swap переставляет элементы а, Ь.
При втором вызове функции передаются указатели, иниции-
рованные адресами переменных а и Ь, т. е. при вызове неявно вы-
полняются присваивания х=р1 и у=р2.
В теле функции для доступа к переменным через указатели ис-
пользуется операция разыменования (*), инструкция *х = *у означа-
8.5. Передача параметров в функцию
135
ет следующее: переменную, адресуемую через указатель у (Ь), запи-
сать в переменную, адресуемую через указатель х (а), а инструкция
*у = t означает: переменную t записать в переменную, адресуемую
через указатель у.
Следующий пример демонстрирует совместное использование
индексирования и обращения через указатель.
Пример. Сортировка массива по убыванию, определенного в
вызывающей функции main().
#include <iostream.h>
#include <stdlib.h>
#include <time.h>
#define n 100 // Размер массива
#define col 10 // Печать no 10 элементов в строке
void swap (int *pl , int *p2)
{/* Создание локальной переменнрой f и записать в нее значение из
переменной указателя pl */
int f=*pl;
*pl=*p2;
*р2 =f;
void masprint (int *p_beg, int *p_end, int k)
{ int i=0; 11 Счетчик выведенных элементов
for (i=0 ; p_beg < p_end ; i++)
{ cout«*p_beg++;
if ((i+l)%k==0) cout«’\n';
else cout«'\t’;
}
void main()
{ int A[n],*p,i; // Определение массива и указателя
srand(time(0));
// Формирование исходного массива
for (р=А; p<&A[nJ ; p++)
*p=rand();
mas_print(A , &A[n] , col); // Печать массива до сортировки
cout«"\n!!l сортировка !!!!\n";
for (i=0 ; i<n ; i++) //Сортировка
136
Глава 8. Функции
for( р=А ; p<&A[n-i-l]; р++)
if (*р < *(р+1))
swap (р, (р+1)); //|
mas_print(A , &A[n] , col); // Печать отсортированного массива
Функция swap() переставляет местами переменные, адресуе-
мые параметрами pl и р2.
Функция mas_print() выводит массив на экран дисплея, первые
два параметра — начало и конец вывода заданы указателями, тре-
тий параметр задает количество элементов в строке при выводе.
В цикле for проходит формирование массива с помощью дат-
чика случайных чисел. При входе в цикл указатель р устанавлива-
ется на начало массива (р=А). Пока указатель р не равен адресу по-
следнего элемента (р<&А[п]) цикл продолжается.
Сортировка массива ведется методом «пузырька» по следую-
щему алгоритму:
1. Сравниваются два соседних элемента, и если текущий эле-
мент меньше последующего, элементы меняют местами. Текущий
элемент меняется в диапазоне от А[0| до А|п-1].
Эти действия называются одним проходом сортировки, в резуль-
тате которой наименьший элемент оказывается в конце массива
(внутренний цикл for).
2. Чтобы «поставить» на свои места все элементы массива, не-
обходимо выполнить п проходов сортировки, т. е. повторить алго-
ритм столько раз, сколько элементов в массиве (внешний цикл
for).
Обратите внимание на то, как передаются параметры в функции:
1. Прототип функции mas print ():
void mas_print (int *p_beg, int *p_end, int k)
Вызов функции:
mas_print(A , &A[n] , col)
Первый параметр передается с использованием указателя, на-
помним, что имя массива — это константный указатель на эле-
мент А|0], при вызове происходит присваивание p_beg=A (в ука-
затель p_beg записывается значение указателя А).
8.5. Передача параметров в функцию
137
Второй параметр — это адрес последнего элемента массива.
При вызове происходит присваивание p_end=&A[n] (адрес по-
следнего элемента &А[п] записывается в указатель ре nd).
Третий параметр передается по значению, переменная col со-
держит число, которое используется для определения числа коло-
нок при печати массива. При вызове функции происходит при-
сваивание k=col.
2. Прототип функции swap():
void swap (int *pl , int *p2)
Вызов функции:
swap (p, (p+1)
Оба параметра передаются с использованием указателей, пер-
вый параметр указывает на «текущий» элемент, а второй — на сле-
дующий элемент.
Для вывода на экран используется функция cout из библиотеки
iostream (см. раздел 11.20).
8,5,3, Передача параметров по ссылке
Параметры-ссылки преследуют ту же цель, что и парамет-
ры-указатели, а именно обращение к внешней памяти из вызываемой
функции.
Рассмотрим уже известную функцию swap, которая перестав-
ляет местами значения двух переменных, определенных во внеш-
ней функции main(). Имея транслятор языка С, эту задачу можно
решить только с применением указателей, в C++ можно использо-
вать еще и ссылки.
// Параметры функции заданы в виде ссылок
void swap(int& a, int& b)
int temp = a;
a — b;
b — temp;
}
138
Глава 8. Функции
void main()
{ inti=l,j = 2;
swap(ij); // После вызова: i=2 j=l
Как видно из примера, текст программы выглядит проще, чем
при работе с указателями. Напомним, что ссылка может рассмат-
риваться как синоним переменной, и обращение по ссылке синтак-
сически ничем не отличается от обращения к обычной перемен-
ной (не требуется использование операции разыменования). При
вызове функции неявно происходят операции присваивания &a=i
и &b=j, т. е. создаются ссылки на переменные i и j, с которыми в
теле функции можно работать так же, как с переменными i и j.
3.5.4. Передача массива в функцию
Использование массивов в качестве аргументов функции име-
ет некоторую особенность. Так как имя массива является указате-
лем на его первый элемент, то при передаче массива фактически
происходит передача указателя на начало массива, сам же массив,
объявленный в вызывающей программе, остается на своем месте.
Если аргументом функции является массив, то ее формальный
параметр можно объявить тремя способами.
1. Передача массива через указатель:
int func(char* s)
}
2. Передача массива определенного размера:
int func (char sf 100])
}
3. Передача массива неопределенного размера:
int func (char s[])
8.5. Передача параметров в функцию
139
Ниже приводится несколько примеров, демонстрирующих
различные приемы передачи массива в функцию.
Пример. Вычисление суммы массива.
В примере первый параметр определяет сам массив, а вто-
рой — его размерность.
int summa (int array[ ], int n)
{ int res=0;
for (int i = 0; i < n; i++)
res+ = array[i];
return res;
}
void main()
{// Определение массива в 100 элементов
int masllOO];
// Инициализация массива
for (int i = 0; i < 100; i++)
mas[i] = 2*i + 1;
// Создание переменной s и вычисление суммы
int s = summa (mas, 100);
При вызыове функции summa (mas, 100) происходит передача
лишь адреса массива mas. Этот процесс можно представить так:
массив mas[] получает новое имя аггау[ | .
Обратите внимание, что при вызове функции в аргументе ис-
пользуется только имя массива без индекса, так как передается ад-
рес массива. В формальном параметре функции используются
только пустые квадратные скобки, поскольку нет необходимости
задавать размерность при ожидании адреса массива.
Пример. Вычислить длину строки (массива типа char).
#include <stdio.h>
int length(char* s)
{ int i;
for(i=0; *s!=’\0’; s++,i++)
return(i);
140
Глава 8. Функции
void main()
{char *strl="KaKan длина у этой строки?’’;
printf("%s\njuiHHa=%d\n’’,strl ,le ngth(str 1));
}
Если формальный параметр в определении функции задан в
виде указателя, как в функции int length(char* s) , то фактическим
параметром при вызове функции может быть:
• имя массива, как в примере — length(str 1);
• адрес какого-либо элемента, например пятого элемента
строки, — length(&str 1 [4]), в этом случае началом строки бу-
дет символ «я»;
• или же указатель, инициированный ранее, например:
char *ptr;
ptr=&str[3];
length (ptr);
Пример. Копирование строки si в символьный массив s2.
void copy(char sl[], char s2[J)
{int i=0;
do I/ Бесконечный цикл
{if ((sl[i])=—\0') break; // Выход из цикла
s2[i]=sl[i];
1“Ы”,
}
while(true);
}
void main()
{ char strl []="Long string?’’;
char str2l80];
printf(”%s\n”,strl);
copy(str2 , strl);
printf(’'%s\n",str2);
}
Если формальный параметр в определении функции задан в
виде массива, как в функции — void copy(char si [], char s2[]) , то
8.5. Передача параметров в функцию
141
фактическим параметром при вызове функции может быть только
имя массива — copy(str2 , strl ).
Пример. Ввести с клавиатуры три массива, вычислить их сум-
мы, отобразить на экране результаты.
#include <stdio.h>
// Прототипы функций
double summa (double A[], int n )
void masinput (double A[], int n )
void main()
{// Определение трех массивов R,M и К
double R[1OJ,M115],K[5J,sum;
printf(” Введите массив R (10 элементов)\п");
mas_input (R, 10);
printf("Введите массив M (15 элементов)\п");
mas input (М,15);
printf("Введите массив К (5 элементов)\п”);
mas_input (К,5);
printf("CyMMa массива R[] =%5.2f\n", summa(R,10));
printf("CyMMa массива M[]=%5.2f\n",summa(M, 15));
printf("CyMMa массива K[] =%5.2f\n", summa(K,5));
} // Конец функции main()
// Область определения функций :
// Вычисление суммы массива типа double произвольной длины
double summa (double А[] , int n )
(double s;
int i;
for (i=0,s=0 ; i<n ; i++ )
s=s+A[i];
return s;
}
// Ввод с клавиатуры массива типа double произвольной длины
void mas input (double A| ], int n )
(int i;
for (i=0 ; i<n ; i++ )
scanf("%le",A[i]);
}
В примере определены две функции — mas_input() и summa()
для ввода с клавиатуры и подсчета суммы массива произвольной
142
Глава 8. Функции
длины. Обе функции имеют по два формальных параметра для пе-
редачи массива типа double и его длины.
В вызывающей функции main() определены три массива раз-
ной длины — R[ 10], М[15], К[5], которые задаются с клавиатуры,
для этого три раза вызывается функция mas_input().
Так как результат передается в точку вызова функции, мы мо-
жем использовать вызов функции summa() в качестве параметра
printf(). Приоритет оператора () «вызов функции» наивысший, по-
этому сначала выполняется вызов «вложенной функции» summa(),
а затем действия по обеспечению печати.
Как говорилось ранее, в языке С между указателями и масси-
вами существует тесная связь, следующий пример демонстрирует
их взаимозаменяемость.
Пример. Взаимозаменяемость указателя и массива.
#include <stdio.h>
// Формальный параметр функции — массив
void print 1 (char s[])
{ printf(s);
}
// Формальный параметр функции — указатель
void print2(char *s)
{ printf(s);
}
int main()
{// Определение строки как массива
char strl L]="String -massiv \n";
// Определение строки через указатель
char *p_str — ’ String -pointer \n";
/* Взаимозаменяемость массива и указателя при передаче
параметров*/
print l(p_str); I/ Параметр — указатель
print2(strl); // Параметр — массив
/* С индексами обе строки работают одинаково*/
for (int i=0 ; strl[i] ; i++) putchar(strl[i]);
for (int j=0 ; p_str[j] ; j++) putchar(p_str[i]);
// Работа с указателями возможна только c pstr
for (pstr; *p_str; p_str++) putchar (*p_str);
return 0;
}
8.5. Передача параметров в функцию
143
Несмотря на то что формальный парамерт функции print2 —
указатель, при вызове функции можно передавать имя массива.
Несмотря на то что формальный парамерт функции print 1 —
массив , при вызове функции можно передавать указатель.
Работа с индексами возможна для обеих строк:
• strl объявлен как массив типа char, а индексация — естест-
венная работа с массивами;
• р str — указатель на тип char, но тоже допускает индексиро-
вание.
По сути дела, в обоих случаях при индексировании происходит
одно и то же — вычисляется адрес очередного элемента строки, к
адресу, записанному в указателе (strl или p_str), прибавляется зна-
чение индекса.
Механизм работы с указателями возможен только для строки
p str, так как это полноценный указатель-переменная, значение
которой можно менять, что и делает инструкция p_str++ в заго-
ловке цикла for. Имя массива strl— это константный указатель,
который всегда указывает на начало массива, поэтому никакая мо-
дификация этого указателя недопустима, а без изменения значе-
ния адреса в указателе невозможно обращаться к разным элемен-
там массива.
Обратите внимание на необычную форму проверки условия в
заголовке цикла for (int i=0 ; strl [ij ; i++). Если условие не указано
явно, то по соглашению языка С проверяется условие !=0, поэтому
в нашем случае подразумевается strl [i] != 0.
Вопросы для самопроверки
1. Что такое функция и для чего она используется?
2. Определение, прототип и вызов функции: поясните эти понятия.
3. Что определяет тип функции?
4. Сколько значений может возвращать функция?
5. В каком случае можно обойтись без прототипа функции?
6. В каком случае нельзя обойтись без прототипа функции?
7. Что такое класс памяти, какие характеристики переменных он опреде-
ляет?
8. Какие классы памяти вы знаете?
144
Глава 8. Функции
9. Назовите основное отличие между статическим и автоматическим клас-
сом памяти.
10. К какому классу памяти относятся переменные, определенные в теле
функции?
11. Поясните понятия: формальные параметры функции, фактические пара-
метры функции.
12. Приведите пример передачи параметров в функцию по значению.
13. В каких случаях передача параметров по значению не дает нужного ре-
зультата?
14. В каких случаях в качестве формальных параметров функции нужно ис-
пользовать указатели?
15. Приведите два способа передачи массива в функцию.
16. Опишите механизм обращения из функции к переменной в вызывающей
программе.
17. Что такое «ссылочный тип» данных, для каких целей используются
ссылки?
18. Что общего можно найти между ссылкой и указателем?
19. Какие различия существуют между ссылкой и указателем?
20. Приведите пример передачи параметров в функцию по ссылке.
Глава 9
ПОЛЬЗОВАТЕЛЬСКИЕ ТИПЫ ДАННЫХ
Все переменные, которые мы использовали до настоящего мо-
мента, относились к одному определенному типу — числовому или
символьному, даже массивы содержали переменные только тако-
го-то одного типа. Все встречавшиеся нам переменные были про-
стыми.
В отличие от простых типов, которые заранее определенны в
языке С, сложные типы определяет сам пользователь (отсюда и на-
звание пользовательские типы). В стандарте языка С имеется четы-
ре «базовых кирпичика», из которых строится вся работа по по-
строению пользовательских типов:
• структуры (structures);
• объединения, или союзы (unions);
• битовые поля (bit fields);
• перечисления (enumerations).
Причем последний тип, перечисление, не очень популярен, так
как никаких дополнительных преимуществ, кроме улучшения чи-
таемости программы, он не дает. А наиболее распространен первый
пользовательский тип — структурный, с него и начнем изучение.
9.1. Структурный тип данных
Решая поставленную задачу, человек стремится максимально
полно отразить реальную ситуацию, когда некую информацию
нужно организовать и обработать систематически. Такая необхо-
димость возникает постоянно при создании современных про-
граммных систем вне зависимости от области применения, будь то
бухгалтерские, торговые или системы для решения инженерных
задач.
146
Глава 9. Пользовательские типы данных
В простейших программах, например в наших примерах, каж-
дый элемент данных представлен в виде переменной, определен-
ной простым типом float, int, char. Но при программировании бо-
лее сложных задач приходится иметь дело с объектами, которые
содержат не один, а несколько типов данных — в этом случае ис-
пользуется структурный тип данных.
Приведем простой пример использования структур. Если в
программе необходимо использовать дату, то под каждое поле дан-
ных необходимо выделить отдельную переменную, например так:
int day; //День
char month! 15]; //Месяц
int year; // Год
Однако этими тремя переменными мы собираемся пользовать-
ся не по отдельности, а как единым понятием «дата», т. е. требуется
объединить данные разных типов в единое множество, в нашем
случае — это две переменные типа int и текстовая строка, и такая
совокупность данных называется структурой. Дадим более точное
определение структурного типа данных.
Структура — это совокупность элементов, каждый из которых
может иметь любой тип кроме функции. В отличие от массива, ко-
торый состоит из элементов одинакового типа, структура может
состоять из элементов разных типов.
9.1.1. Определение структуры
Первым шагом в создании взаимосвязанного множества пере-
менных является определение структурного типа, тем самым поль-
зователь создает новый, до этого момента не существовавший тип
данных'.
• дает имя структуре, которое является идентификатором но-
вого типа данных;
• перечисляет имена и типы каждого элемента, из которых со-
стоит структура.
Определение структуры имеет следующий формат:
struct тип
{ тип элемента ! имя элемента !;
9.1. Структурный тип данных
147
тип элементап имя элементап;
Именем элемента может быть любой идентификатор.
Пример. Определение нового типа date, состоящего из трех по-
лей (элементов):
sruct date
{int day; //День
char monthf 15]; //Месяц
int year; //Год
Синтаксис определения элементов структуры аналогичен син-
таксису определения переменной. Необходимо указать типы дан-
ных каждого элемента и размер всех строк и массивов. Определе-
ние каждого элемента структуры заканчивается точкой с запятой.
Точка с запятой отмечает также и конец определения структуры.
Определение сообщает компилятору, сколько памяти следует за-
резервировать для каждого элемента новой структуры, сама же па-
мять не выделяется.
Написав определение структуры, можно пользоваться новым
типом данных — создавать переменные, указатели, массивы и т. п.
Название нового типа в нашем примере будет sruct date.
Память выделяется при создании объектов структурного типа,
т. е. при их объявлении.
Пример. Выделение памяти под переменную days типа struct
date.
struct date days;
После такого определения компилятор выделяет память под
структурную переменную days, которая состоит из двух перемен-
ных типа int и массива из 15 элементов типа char.
148
Глава 9. Пользовательские типы данных
Выделение памяти под структурные объекты можно совмес-
тить с определением структурного типа.
Пример
struct date
{ int day;
char month [15];
int year;
}a, b, c;
При этом выделяется соответствующая память под три пере-
менные структурного типа — а, b и с.
Введенное имя нового типа позже также можно использовать
для объявления разнообразных структурных объектов, можно соз-
дать переменную, массив или указатель структурного типа.
Пример. Объявляется указатель на структуру с имененм p date
и переменная birthday.
struct date *p_date, birthday;
Пример. Определить структуру (создать новый тип) и объявить
структуру (выделить память под переменные нового структурного
типа) для хранения информации о товаре на складе. Каждая пози-
ция склада содержит разнотипную информацию о товаре, напри-
мер: название, цену, количество, дату поступления.
struct tovar
{
char* name ;
double price;
int vol;
date in date;
} food;
11 Наименование
// Цена
/I Количество
//Дата поступления
Такое определение создает новый структурный тип tovar и вы-
деляет память под структурную переменную с именем food. Пере-
менные, подобные food, называют объектами структурного типа
или же структурными переменными, но чаще всего структурами.
Из-за этого может возникнуть некоторая терминологическая пута-
9.1. Структурный тип данных
149
ница, так как имя нового структурного типа тоже можно назвать
структурой. Эти два понятия различают по контексту, структур-
ный тип создается один раз и затем используется при создании
программных объектов. Сами же объекты (структуры) создаются
каждый раз, когда необходимо выделить память для размещения
данных.
Примеры использования нового типа struct tovar для создания
различных объектов:
struct tovar book; // Переменная-структура с именем book
struct tovar sklad2[ 1000]; // Массив структур с именем sklad2
struct tovar *poin_f; // Указатель на структуру tovar с именем point f
При необходимости структуры можно инициализировать, по-
мещая вслед за описанием список начальных значений элементов.
В следующем примере инициализируются переменные birthday
(тип sruct date) и food (тип sruct tovar).
charsname[]= "Масло растительное";
sruct date birthday={20, "февраля”, 1975};
sruct tovar food = {&sname, 20.6, 50, \
{11, "февраля",2011}
При определении разрешается вкладывать структуры друг в
друга. Следующий пример демонстрирует использование вложен-
ных структур.
Пример. В примере определяется структура man, для хранения
информации о человеке — имя, фамилия, дата рождения, ИНН.
struct man
{char name[20], fam[30];
struct date bd;
int inn;
};
Структура man включает четыре элемента name, fam, bd, inn.
Первые два — name[20] и fam|30] — это символьные массивы раз-
личной длины, переменная bd представлена составным элементом
150
Глава 9. Пользовательские типы данных
(вложенной структурой) типа date, а переменная inn — это целое
число (имеет тип int). Напомним, что определенный выше тип data
имеет три элемента: day, month, year. Теперь можно определить
объекты, значения которых принадлежат новому типу:
struct man list [ 100];
Здесь определен массив list, состоящий из 100 структур типа
man.
9.1,2. Оператор typedef
При работе со структурами очень полезен оператор typedef.
С его помощью в программу можно ввести новые имена, которые
затем используются для обозначения типов данных.
Синтаксис typedef-объявления:
typedefтип имя;
Пример. Введение нового имени типа для обозначения целого
числа.
typedef int INTEGER;
После такого объявления можно создавать целые числа, ис-
пользуя новое имя типа:
INTEGER а, Ь;
Оно будет выполнять то же самое, что и привычное объявление
int a,b;
Другими словами, INTEGER можно использовать как сино-
ним ключевого слова int.
При работе со структурами оператор typedef определяет струк-
турный тип и присваивает ему обозначение (имя):
typedef struct tovar
{ char* name;
double price;
int vol;
date in_date ;
} sklad_l ;
// Наименование
II Цена
II Количество
// Дата
9.1. Структурный тип данных
151
Ниже для одной и той же структуры введены два имени:
• tovar стандартным образом;
• skladl с помощью оператора typedef.
Теперь структурные объекты могут определяться как с помо-
щью типа skladl, так и с помощью обозначения struct tovar.
Пример.
// Три структуры (tea, meat, broad) типа sklad l
sklad l tea, meat, broad ;
// Две структуры (pen, book) типа struct tovar
struct tovar pen, book ;
Обратите внимание: при введении структурного типа с по-
мощью typedef в определении объектов не указывается специфика-
тор struct.
9.1.3. Определение структуры безымянного типа
Следующий вариант определения структур является некото-
рым упрощением приведенных выше вариантов. Можно опреде-
лять структуры, вводя «внутреннее строение» (т. е. элементы
структуры), но не вводя его имени. Такой безымянный структур-
ный тип используется для однократного определения структур.
Пример. Определить структуру для введения данных о компью-
тере.
struct
{ char processor [10] ;
int frequency;
int memory;
int disk;
} IBM , DEC, COMPAQ ;
После такого определения программист может работать со
структурными объектами IBM, DEC, COMPAQ, но не может вво-
дить в программу новые объекты. Если все же понадобится созда-
ние дополнительных объектов, придется полностью повторить
приведенное выше определение структурного типа.
152
Глава 9. Пользовательские типы данных
9.1.4. Доступ к элементам структуры
Итак, мы научились определять структуры, создавать и ини-
циализировать переменные структурного типа, осталось научиться
работать с ними.
Следует заметить, что элемент структуры называют полем или
компонентой. В языке С с каждым полем структуры приходится ра-
ботать как с самостоятельной переменной. Имя поля структуры
называется уточненным именем.
Для доступа к полям структуры используются два специальных
оператора:
. (точка), когда работают с именем структуры;
-> (минус и знак «больше»), когда работают с указателем на
структуру.
Заметим, что у операций доступа к структуре («точка», «стрел-
ка») самый высокий приоритет наряду со скобками, поэтому в вы-
ражениях сначала выполняется доступ к полю структуры, а затем
проводятся необходимые вычисления, иными словами, поля струк-
тур участвуют в вычислениях так же как обычные переменные.
Кроме участия в выражениях, поля структуры могут вводиться
с клавиатуры, их можно передавать функциям и т. д. При работе с
полями не должно возникнуть особых трудностей, поскольку мы
уже видели подобное поведение у элементов массива.
Пример. Обращение к полям структуры с использованием опе-
ратора «точка» и через указатель.
#include <stdio.h>
#include <string.h>
void main()
{struct date
{ int day;
char month[ 15];
int year;
// Объявление объектов структуры
sruct date s_day={10, ’’September", 1988}, e day, *pl, *p2;
/* Использование операции «точка» */
e_day. day = 22;
memcpy (e day.month, sday.month, 15);
9.1. Структурный тип данных
153
e day. year = s_day. year;
/* Использование указателей*/
pl = &s_day; // Установка указателей на
р2 = &e_day; // переменные sday и e day
p2->day = 22;
memcpy (p2->month, pl-> month,15);
p2-> year =pl->year;
printf("\ne_day: day=%d \t month=%s \t year=%d \n", /
e_day. day, e_day. month, e_day. year);
}
Определены следующие объекты структуры:
• переменные s day и e day, причем для s day одновременно с
созданием проведена инициализация;
• указатели на структуру с именами pl и р2;
В примере выполнены одинаковые действия двумя различны-
ми способами — с применением имен объектов и с безимянным
использованием через указатели. Оператор e_day.day=22 записы-
вавет число 22 в поле day переменной e day.
Обратите внимание, что перед точкой стоит не имя типа струк-
туры, а имя объекта, для которого выделена память.
В поле е day.year заносим элемент другой структуры — s day.
year. Третье поле e day.month представляет собой строку текста.
Как известно, в стандарте языка С нет встроенных средств работы
со строками, язык С позволяет работать только с отдельными сим-
волами строки, поэтому для работы с целыми строками приходит-
ся использовать библиотечные функции. В нашем примере ис-
пользуется функция memcpyO из библиотеки string.h, которая ко-
пирует 15 символов из строки s_day.month в строку eday.month.
Работа с полями структуры через указатель аналогична. Следу-
ет особо отметить, что правила работы с отдельными полями струк-
туры ничем не отличаются от правил работы с переменными, т. е. на
первом этапе следует определить указатель соответствующего
типа, установить его на объект, а затем обращаться к объекту через
указатель. Обращение к данным структуры выглядит следующим
образом:
• для обращения к полю day структуры e day:
p2->day = 22;
154
Глава 9. Пользовательские типы данных
• для копирования строки month из структуры s day в структу-
ру e_day:
memcpy(p2->month, pl-> month, 15).
При работе со структурами можно использовать комбинацию
доступа через указатель и операцию «точка».
(*р2). day = 22;
memcpy((*p2) .month, = (*р I) .month, 15);
(*p2). year = (*pl) .year;
Здесь используется операция разыменования указателя (*) для
доступа к переменной структурного типа, а затем через операцию
«точка» — получаем доступ к полю структуры.
Следующий пример демонстрирует доступ к вложенным
структурам. В структурном типе tovar поле in date представляет со-
бой элемент структурного типа date, т. е. структурный тип date вло-
жен в структурный тип tovar.
Пример
sruct tovar tea, skladl 1 000], *pt;
tea. in date, day = e day. day;
tea. in date, year = 1985;
// Установка указателя на 5 элемент массива
pt = &sklad[5];
pt->vol = 20;
pt->in_date.day =25;
(*pt). in date, year =2000;
Обращение к элементу внутренней (вложенной) структуры
типа date проходит в два этапа, сначала выбирается поле структуры
tea (в данном случае структура in date), а затем поле структуры
in date (например, day). Во вложенных структурах также возможна
работа с операцией «точка» и указателем. В нашем примере это:
tea. in date. day= e_day.day,
pt = &sklad[5];
pt ->in_date.day=25;
9.1. Структурный тип данных
155
Если отвлечься от формы записи, то очевидно, что поля струк-
тур ведут себя, как обычные переменные соответствующего типа.
Пример. Инициализация структуры с выводом на экран ее эле-
ментов.
#include < stdio.h >
void main()
11 Определение структурного типа
{struct tovar
{ char* name ; // Наименование
double price ; // Цена
int vol; // Количество
date in date ; // Дата
};
struct tovar meat={«6apaHHHa», 90.78 , 15,220 , {15, ’'января”, 2005}};
printf ("\пНаименование:\1%8", meat, name);
printf ("\пЦена nocTaBKH:\t%5.2f руб.", meat, price);
printf ("\пКоличество:\1%б кг" , meat, vol);
printf ("\пДата прихода:/
\t%d %s %d", meat, in date, day, meat, indate.month, meat.
in_date.year);
} ’
Результат выполнения программы:
Наименование: баранина
Цена поставки: 98.78 руб.
Количество: 220 кг
Дата прихода: 15 января 2005
Что еще можно делать со структурой? Разумеется, передавать в
функцию в качестве параметра и возвращать в качестве результата.
Однако здесь есть одна особенность — нельзя передавать в функцию
и возвращать из нее саму структуру, т. е. работать со структурой
«по значению», как с переменной. Параметр-структура может быть
передана только через указатель, и никаким другим образом,
т. е. нужно использовать адрес структурного объекта.
Связано это ограничение с желанием получить оптимальный
исполняемый код программы, действительно часто структура несет
156
Глава 9. Пользовательские типы данных
в себе большой объем данных, которые пришлось бы копировать
из оригинала в локальную копию (или из локальной копии в воз-
вращаемое значение) при передаче параметров по значению. Что-
бы избежать подобных накладных расходов и связанной с ними по-
тери эффективности программного кода, создатели языка потребо-
вали, чтобы для сложных типов данных в качестве параметров и
возвращаемых значений использовались только адреса объектов.
Но все-таки основное назначение структурного типа данных
мы пока не рассмотрели, ведь структуры задуманы прежде всего
для того, чтобы работать с разнородной информацией как с еди-
ным целым. В предыдущих примерах все, что мы видели, — это
разнотипные поля, сгруппированные в одном объекте и доступные
через имя этого объекта, теперь продвинемся немного дальше —
покажем, что структура может вести себя как единое целое.
В следующем примере создадим новый структурный тип для
работы с комплексными числами и несколько функций, позво-
ляющих совершать различные манипуляции с ними как с единым
целым.
Пример.
#include <stdio.h>
// Определение структурного типа COMPLEX
typedef struct
{ double re; // Действительная часть числа
double im; // Мнимая часть числа
} COMPLEX;
// Запись значений в структуру COMPLEX
void set_complex(COMPLEX* n,double re,double im)
{ n->re = re;
n->im = im;
}
/1 Сложение двух переменных COMPLEX
COMPLEX* add complex (COMPLEX* nl, COMPLEX* n2)
static COMPLEX result;
result.re = nl ->re + n2->re;
result.im = nl->im + n2->im;
return & re suit;
}
9.1. Структурный тип данных
157
// Печать переменной COMPLEX
void print_complex(COMPLEX* n)
{ рпгйГС'действительная часть:%Г\t мнимая часть: %f\n”, n->re,
n->im);
}
/1 Головная функция программы
void main()
{COMPLEX numl, num2, *ptr;
set_complex (&numl, 1.0, 1.0);
set_complex (&num2, 3.0, 0.0);
ptr=add_complex (&numl, &num2);
print_complex (ptr);
Новый структурный тип COMPLEX введен с помощью дирек-
тивы typedef, что позволяет в дальнейшем при обращении к новому
типу опускать ключевое слово struct. Определение структурного
типа включает два поля — для действительной и мнимой части
комплексного числа.
Функция set_complex() служит для записи данных в комплексное
число. Она не возвращает никакого значения и имеет три параметра.
Первый — это указатель на структуру типа COMPLEX (на комплекс-
ное число, в которое будет происходить запись). Второй и третий па-
раметры служат для передачи значений, записываемых соответствен-
но в действительную и мнимую части комплексного числа.
Функция add_complex(> складывает два комплексных числа и
возвращает их сумму в вызывающую программу. Оба параметра и
возвращаемое значение — указатели на структурные объекты типа
COMPLEX. Обратите внимание, что возвращаемое значение — это
указатель на переменную result, которая определяется в теле функ-
ции add_complex(). Для того чтобы переменная result была доступна
из вызывающей программы, она объявляется как статическая пе-
ременная и поэтому не уничтожается при выходе их функции. Опе-
ратор return возвращает адрес переменной result, при помощи яв-
ного обращения к оператору взятия адреса &.
Функция print_complex() выводит на печать комплексное число
и комментарий. Функция не возвращает никакого значения, а в
качестве параметра ожидает указатель на объект типа COMPLEX
(комплексное число).
158
Глава 9. Пользовательские типы данных
Обратите внимание, что когда в качестве формального пара-
метра функции объявлен указатель (в нашем примере на структу-
ру), то при вызове функции передается адрес переменной. В первом
случае, при вызове функций set_complex() и add_complex(), явно,
путем передачи адресов переменных numl и num2, а во втором
случае, при вызове функции print_complex(), — неявно, путем пе-
редачи указателя (в котором уже записан адрес переменной).
После того как новая структура данных и все необходимые
функции для работы с ней определены, приступаем к работе с ре-
альными объектами нового типа.
Для этого в функции main определяем две переменные для хра-
нения комплексных чисел numl, num2, и указатель *ptr для адреса-
ции результата. В дальнейшем для работы со сложным объектом,
каковым является комплексное число, будем использовать соот-
ветствующую функцию, в этом случае в вызывающей программе
«не видны» подробности строения структурного объекта, т. е. нет
обращения к отдельным элементам структуры, все эти подробно-
сти «спрятаны» внутри соответствующей функции.
Подобный подход рекомендован для работы со структурами
какой угодно сложности и демонстрирует работу со структурным
объектом как с единым целым.
9.1.5. Операции присваивания и сравнения
для структур
Сравнивая структуры с массивами, обратим внимание на раз-
личия в операции присваивания. Для массивов допустимо при-
сваивание значений только отдельным элементам. Для того чтобы
присвоить значения одного массива другому массиву, необходимо
в цикле выполнить присваивание для каждого элемента.
Пример. Использование имен массивов без индексации приве-
дет к ошибке.
float х[]={ 1.1 ,2.2, 3.3,4.4,5.5 }, z| 10] ;
intj;
for(j=0;j < 10;j++)
z U1 = x[j] ; // Правильное использование
9.1. Структурный тип данных
159
z — х; И Ошибка
При выполнении присваивания для структур разрешается исполь-
зовать имена без уточнения полей.
Разрешается следующее присваивание:
skladl tea, meat, bread ;
meat = tea ; // Ошибки нет
Напротив, операции сравнения для структур как единого целого не
определены, можно сравнивать лишь отдельные элементы структуры.
Напимер, возможны такие логические выражения:
tea.price > meat.price
meat. in_date. day != broad, in_date. day,
но ошибкой будет сравнивать структуры целиком:
meat > tea
9.1.6. Определение размера структуры.
Оператор sizeof
С помощью операции sizeof можно определить размер памяти,
которая необходима переменной или типу. Операция sizeof имеет
следующий формат:
sizeof (выражение).
В качестве выражения может быть использован любой иденти-
фикатор объекта либо имя типа, заключенное в скобки. Отметим,
что не может быть использовано имя типа void, а идентификатор
не может относиться к полю битов или быть именем функции.
Если в качестве выражения указанно имя массива, то результа-
том является размер всего массива, т. е. произведение числа эле-
ментов на длину типа.
Пример. Работа со структурами «Экзаменационная ведомость».
Вводятся экзаменационные оценки и распечатывается список сту-
дентов, получивших положительные оценки.
160
Глава 9. Пользовательские типы данных
#include < stdio.h >
void main()
// Определение структурного типа
{typedef struct ved
{ char* student; // Фамилия
int mark ; // Оценка
} vedom;
vedom grupl [25], grup2[ 15];
// Заполнение списков студентов grupl и grup2
cout<<”Введите оценки студентовgrupl: " << endl;
for (j=0; j < sizeof(grupl)/sizeof(grupl |0]); j++ )
{ cout<<endl« grupl [i]. student«"->";
cin>> grupl .markfil;
}
соШ<<"Список студентов grupl, сдавших экзамен:" « endl;
for (j=0; j < sizeof(grupl)/sizeof(grupl |0]); j++ )
if (grupl.mark[i]) >2)
cout<< grupl.student<<endl;
}
В примере создается структура для экзаменационной ведомо-
сти и два массива grupl и grup2 для хранения результатов, часть
программы, которая вводит фамилии студентов, не показана.
Выражение sizeof(grupl)/sizeof(grupl[0]) дает количество эле-
ментов массива (размер всего массива делим на размер одного эле-
мента).
Когда sizeof() применяется к пользовательским типам данных,
т. е. имени типа структуры или объединения или к идентификато-
ру, имеющему тип структуры или объединения, то результатом яв-
ляется фактический размер структуры или объединения, получен-
ный при компиляции. Этот размер может не совпадать с размером,
получаемым путем простого сложения размеров полей структуры,
потому что реально объект структуры может занимать большую
память из-за дополнительных участков памяти, образующихся в
результате выравнивания полей структуры.
9.2. Битовые поля
161
Пример
int al;
struct
{ charh;
intb;
double f;
} str;
al = sizeof (str);
Переменная al получит значение, равное 16 (байт), в то же вре-
мя если сложить длины всех используемых в структуре типов, то
длина структуры str будет равна 13.
Данное несоответствие наблюдается потому, что после разме-
щения в памяти первой переменной h длинной I байт добавляется
3 байта для выравнивания адреса переменной b на границу слова.
Кроме того, следует отметить, что понятия «слово» и «двойное
слово» зависят от разрядности компьютера, поэтому этот результат
верен только для 32-разрядных компьютеров.
Как видно из предыдущих примеров, размер структуры зави-
сит не только от образующих ее элементов, но и от самых различ-
ных факторов, в том числе и от оптимизатора, используемого при
компиляции. Поэтому если необходимо точно знать размер струк-
турного объекта, его необходимо явно вычислить с помощью опе-
рации sizeof(), которую можно применять в двух формах:
sizeof ( имя структуры).
sizeof ( имя структурного типа)
Для наших примеров одинаковые результаты дадут следующие
вызовы:
sizeof (struct tovar);
sizeof (meat);
sizeof (sklad l);
9.2. Битовые поля
Особую разновидность структур представляют собой битовые
поля. Битовое поле — это последовательность соседних битов внут-
ри переменной целого типа.
162
Глава 9. Пользовательские типы данных
Битовые поля применяются там, где необходимо манипулиро-
вать отдельными битами памяти. Для чего это нужно? В основном
для управления оборудованием. Например, внешним устройством
компьютера или автоматической линией на производстве. Чтобы
автоматизировать какой-либо процесс, необходимо управлять не-
стандартным оборудованием, всевозможными датчиками, мани-
пуляторами, моторами и т. д. Все эти устройства могут быть под-
ключены к компьютеру через устройства, называемые контролле-
рами.
Отдельные биты или группы бит контроллера служат для связи
внешнего устройства с компьютером, записывая и считывая от-
дельные биты контроллера, компьютер управляет внешним уст-
ройством. Поэтому неплохо было бы иметь возможность работать
с группами бит как с обычными переменными, для этого и преду-
смотрены битовые поля.
Битовое поле является элементом структуры и обеспечивает
доступ к отдельным битам памяти, при этом запрещается:
• объявлять битовые поля вне структур;
• организовывать массивы битовых полей;
• применять к полям операцию определения адреса.
Определение типа структуры с битовыми полями имеет сле-
дующий вид:
struct { unsigned имяполя 1: длина поля 1;
unsigned имя_поля2: длина_поля2;
Поля могут иметь тип signed int или unsigned int и занимать
от одного до 16 бит. В полях типа signed крайний левый бит явля-
ется знаковым.
Правила работы с битовыми полями:
• поля размещаются в машинном слове в направлении от
младших битов к старшим;
• длина определяет число бит, отведенное полю, и задается це-
лым выражением или константой;
• поле нулевой длины заставляет компилятор перейти к сле-
дующему слову (выравнивание на границу слова).
9.2. Битовые поля
163
Пример
struct prim
{ int a: 2; // 1 и 2 биты
unsigned b: 3; // 3—5 биты
int c: 5; // 6—10 биты
int d: 0; И Выравнивание на границу слова
unsigned e: 5; // 1 —5 биты второго слова
} i,j, k;
Данная структура обеспечивает размещение данных в двух сло-
вах. Последние 6 бит первого слова не определены'. В примере ис-
пользовано явное выравнивание на границу слова. В некоторых
случаях эта операция проводится компилятором автоматически.
Следующий пример демонстрирует это:
struct prim
{ int
unsigned
int
int
unsigned
а: 2; // 1 и 2 биты
Ь: 3; // 3—5 биты
с: 5; // 6— 10 биты
d: 1; // 11 бит
е: 6; // 1 —6 биты второго слова
} i,j, k;
Так как для размещения битового поля е в первом слове не хва-
тает места, компилятор проводим автоматическое выравнивание
на границу слова (переходит в следующему слову).
Пример. Описание работы контроллера абстрактного устройст-
ва, на основании которого требуется запрограммировать драйвер
этого устройства.
1. CSR (статусный регистр) доступен по адресу 0хС75000.
2. Для генерации цикла обмена данными требуется занести но-
мер функции (0...7) в биты 1—4 статусного регистра, а в бит 0 зане-
сти единицу.
3. После завершения цикла обмена бит 0 будет очищен кон-
троллером (установлен в нуль).
Создается три объекта (i, j, к), каждый из которых занимает два слова.
164
Глава 9. Пользовательские типы данных
Задача по программированию внешнего устройства может вы-
глядеть следующим образом: активизировать функцию контролле-
ра № 6, дождаться завершения цикла обмена.
Вариант решения 1. Проделаем это с помощью операций бито-
вой арифметики:
volatile char *csr = (char*)0xC7500;
*csr = (6<< 1)| I
while ((*csr & 1) != 0);
Первая строка программы создает указатель на статусный ре-
гистр. Обратите внимание на то, что:
во-первых, требуется преобразовать целую шестнадцатерич-
ную константу 0хС7500 к типу «указатель на char» для совмещения
типов правой и левой части выражения;
во-вторых, необходимо позаботиться о том, чтобы текст про-
граммы не претерпевал изменения при трансляции, что достигает-
ся использованием модификатора volatile, отменяющего оптими-
зацию этой части программы.
Вторая строка засылает код 6 в биты 1...4 (путем сдвига кон-
станты 6 на один разряд влево) и устанавливает, т. е. заносит 1,
в бит 0.
Третья строка реализует цикл ожидания до тех пор, пока кон-
троллер не очистит бит 0.
Такая программа будет работать, но читать ее текст сложно, так
как назначение отдельных битов никак не отражено в тексте про-
граммы. Использование битовых полей позволит избежать этих
недостатков.
Вариант 2. Применение битовых полей.
/* Определение структуры битовых полей*/
struct CSR
{ unsigned busy: 1; // Бит, запускающий цикл
unsigned func: 4 ; //4 бита под функцию
int unused: 3; //Три неиспользуемых старших бита
};
volatile struct CSR *mycsr = (struct CSR *)0xC7500;
mycsr->func = 6; // Занести код функции
9.3. Объединения или смеси
165
mycsr->busy = 1; // Запустить цикл
while ( mycsr->busy != О ); // Ожидание конца цикла
При определении структуры можно дать имена битовыми по-
лями, отражающие их назначение, что будет облегчать понимание
текста. Как видно из примера, использование битовых полей и
краткого комментария дают исчерпывающую информацию о на-
значении программы.
9.3. Объединения или смеси
Третий из определяемых пользователем типов данных — это
объединение, или союз. Объединение подобно структуре, однако в
каждый момент времени может использоваться (или, другими сло-
вами, быть ответным) только один из его элементов.
Объединение — это некоторая переменная, которая может хра-
нить (в разное время!) объекты различного типа и размера.
Общий вид определения объединения:
union имятипа { списокопределений }
имя_переменной[,имя_переменной];
Главной особенностью объединения является то, что для всех эле-
ментов списка определений выделяется одна и та же область памя-
ти, т. е. они перекрываются. Иными словами, объединение через
разные поля дает доступ к одному и тому же содержимому, т. е.
программа интерпретирует это содержимое по-разному.
Следует отметить, что хотя доступ к этой области памяти воз-
можен с использованием любого из элементов объединения, эле-
мент должен выбираться так, чтобы полученный результат не был
бессмысленным.
Пусть задано следующее определение объединения:
union range
{ int ir;
float fr;
char cr;
/1 Размеры переменных:
// 2 байта
// 4 байта
// 1 байт
166
Глава 9. Пользовательские типы данных
В данном объединении определены элементы разного типа.
Размер переменной z будет равен размеру самого большого из трех
приведенных типов, т. е. 4 байтам. В один и тот же момент времени
z может иметь значение только одной из переменных ir, fr или с г.
Доступ к элементам объединения осуществляется тем же спо-
собом, что и к структурам:
• z.ir — переменная z трактуется как int;
• z.fr — переменная z трактуется как float;
• z.cr — переменная z трактуется как char.
Элементом объединения может быть массив.
Пример
Ц Определение союза (объединения)
union tu
{ long а;
int b[2];
char k|4J;
};
union tu ul, *au, mu[5]; //Объявление трех переменных
// типа «union tu»
u 1 .a; j/ Обращение к u 1 как к типу long
u 1 .k[2]; j/ Обращение к u 1 как к типу char
// Установка указателя на массив объединений mu
au = mu;
au->b[ 1];
mu[2].k[3J ;
Здесь определение нового типа данных «union tu» и создание
объектов этого типа происходит раздельно. Объявлены следующие
объекты: переменная ul, указатель au на объединение и массив
объединений mu[5].
Обращения к элементам объединения:
ul .а — это «трактовка» переменной ul как типа long;
u1.k[2] — переменная ul имеет тип char, и значение к[2];
au->b[ 1 ] — указатель au установлен на первый элемент масси-
ва mu, а именно на mu[0] , именно в этом элементе выбирается
поле b[ 1 ];
9.3. Объединения или смеси
167
mu[2].k[3] — дает доступ к четвертому элементу массива к
(к элементу с номером 3) в третьем элементе массива объедине-
ний mu.
Пример. Рассмотрим число типа double в виде последователь-
ности байтов.
#include <stdio.h>
void main()
union DOUBLECHAR8 // Определение союза DOUBLECHAR8
{double d;
unsigned char byte[8];
};
int i;
union DOUBLE CHAR8 v; // Объявление переменной v
v.d = 2.71828;
printf("\n4Mcno=%f\n",v.d);
for (i=0; i<8; i++)
printf("byte[%d]= %d\n", i, v.byte[ij);
}
Результат на экране дисплея:
Число= 2.718280
byte[0]= 144
byte[l]= 247
byte[2J= 170
byte[3]= 149
byte [4] = 9
byte[5J= 191
byte [61= 5
byte[71= 64
При объявлении переменной v (тип переменной union
DOUBLE CHAR8) будет выделена память размером 8 байт, в ко-
торую и записывается число 2.71828, а затем в цикле информация
выводится в виде цепочки байтов. Союз тоже можно инициализи-
ровать при создании, правда, только значением для первого поля,
например:
union DOUBLE CHAR8 и = { 3.14 };
168
Глава 9. Пользовательские типы данных
Такой подход вполне естественен, так как память общая, то
инициализатор для второго поля испортил бы нам первое зна-
чение.
Объединения можно использовать для экономии памяти при
работе с большими объемами данных, следующий пример иллюст-
рирует такой подход.
Пример. Экономия памяти при работе с картотекой.
union
{ charfio[30];
char adres[8OJ;
int vozrast;
int telefon;
} inform;
inform.fio= base[k].fio
// Работа с полем fio
inform.adres= base[k].adress // Работа с полем adress
В приведенном примере данные из структуры base, хранящей
информацию, записываются в объект inform для текущей работы.
При этом отметим, что можно обрабатывать только тот элемент,
который получил значение, например, после присвоения значения
элементу inform.fio, не имеет смысла обращаться к другим элемен-
там до тех пор, пока они, в свою очередь, не будут определены. Ра-
зумеется, этот прием можно использовать только для текущей об-
работки информации, но никак не для ее хранения.
9.4. Перечисления
Этот пользовательский тип данных не создает дополнительных
возможностей в части программирования, он всего лишь улучшает
читаемость программы. Перечисления позволяют создавать сино-
нимы или имена для последовательности целых чисел, по умолча-
нию нумерация начинается с нуля и идет подряд. Для создания пе-
речисления используется ключевое слово enum.
9.4. Перечисления
169
Пример
enum BOOLEAN
{ FALSE,
TRUE
Данное перечисление можно заменить последовательностью
из двух строк:
const int FALSE = 0;
const int TRUE = 1;
To есть перечисление неявно задает символические константы
целого типа. После такого объявления имена FALSE и TRUE мож-
но использовать в качестве символических констант нуля и едини-
цы или использовать созданный тип при передаче параметров в
функцию «по значению».
Далее в примере показан прием для передачи параметров в
функцию, вместо того, чтобы использовать безликие константы 0
и 1, используются имена FALSE и TRUE, отражающие назначение
этих констант.
void f (enum BOOLEAN flag)
{ if(flag==FALSE)
printf ("ЛОЖЬ\п”);
else
printf ("ИСТИНА\п”);
}
void main()
{f (FALSE);
f(TRUE);
}
В таком виде программа лучше читается, но, к сожалению,
компилятор не проводит проверки правильности использования
типа enum BOOLEAN, например, если программист напишет не
имеющее смысла выражение f(25), ошибки не последует!
170
Глава 9. Пользовательские типы данных
Пример.
// Ввести новый тип данных seasons.
enum seasons (spring, summer, autumn, winter);
enum seasons a, b, с; // определить переменные
Каждая из переменных а, Ь, с может принимать одно из четы-
рех значений: spring, summer, autumn и winter.
Во всех предыдущих примерах нумерация выполнялась по
умолчанию, т. е. начиналась с 0, но можно проводить нумерацию
элементов в перечислении произвольно.
Пример. Задать имена для кодирования цветовой гаммы при
выводе графической информации на экран терминала.
enum COLOR
{ RED = 10,
GREEN,
BLUE,
MAGENTA = 16
};
// Начать нумерацию с 10
//GREEN == И
//BLUE == 12
В перечислении enum COLOR нумерация начинается с 10
(RED), а затем идет подряд (GREEN, BLUE), если нужно сделать
пропуск в нумерации, следует явно указать значение следующего
элемента (MAGENTA).
Пример. Создать несколько синонимов для одного и того же
числа, а также оставить «пустые места» в последовательности чисел:
enum PIXELCOLOR
{ BLACK,
BACKGROUND = 0,
RED,
GREEN,
BLUE = 4,
WHITE=7
//BLACK ==0
I/ Тоже 0 (синоним)
//RED== 1
//GREEN ==2
//Пропускаем число 3
// Пропускаем 5, 6
9.4. Перечисления
171
Вопросы для самопроверки
1. Какие разновидности пользовательских типов данных вы знаете?
2. Дайте определение структурного типа данных.
3. Приведите пример использования структур.
4. Назовите этапы создания структурного типа данных.
5. Чем отличается создание структурного типа данных от создания струк-
турного объекта данных?
6. Приведите пример создание структуры с помощью оператора struct.
7. Приведите пример создание структуры с помощью оператора typedef.
8. Покажите разницу между использованием структур, созданных с по-
мощью ключевых слов struct и typedef.
9. Назовите два оператора доступа к элементам структур, приведите при-
меры.
10. Допускается ли вложение одной структуры в другую? Если да, то как осу-
ществляется доступ к элементам вложенной структуры?
11. Допустимо ли использовать операцию присваивания целиком к структур-
ным объектам? Если да, то при каких условиях?
12. Допустимо ли использовать операции сравнения целиком к структурным
объектам? Если да, то при каких условиях?
13. С помощью какого оператора можно определить реальный размер струк-
туры?
14. Дайте определение понятию «битовые поля», для каких целей они ис-
пользуются?
15. Приведите пример определения битовых полей.
16. Дайте определение понятию «объединения», для каких целей оно исполь-
зуется?
17. Приведите пример определения объединения.
18. Можетли массив выступать в роли элемента объединения?
19. Для чего используются «перечисления»?
20. Приведите пример использования перечисления.
Глава 10
ДИНАМИЧЕСКАЯ РАБОТА
С ПАМЯТЬЮ
Все объекты, размещенные в памяти, — переменные, массивы,
структуры, указатели и т. п., можно разделить на две категории:
1) объекты, создаваемые до начала работы программы, при
компиляции;
2) объекты, создаваемые в процессе работы программы.
О первых говорят как о статических, постоянно размещенных
в памяти компьютера объектах, о вторых — как о динамических,
или временных, объектах, создаваемых и уничтожаемых в процес-
се работы программы.
К статическим объектам можно отнести глобальные перемен-
ные и static-переменные.
К динамическим объектам, с которыми мы уже успели познако-
миться, относятся локальные переменные функций и блоков опе-
раторов.
Ранее мы научились работать со статическими массивами, соз-
давали их, задавая размер либо явно, либо списком инициализа-
ции, в обоих случаях размер массива был известен и задавался до на-
чала выполнения программы, при компиляции.
На практике встречается очень много задач, когда заранее
нельзя определить, сколько элементов массива потребуется для ра-
боты, например:
• найти пересечение двух массивов;
• найти элементы массива, значения которых больше задан-
ного;
• базы данных для хранения информации;
• и т. п.
Такие задачи можно решить, создавая массивы или другие
структуры данных «с запасом», но этот способ, во-первых, неэко-
Глава 10. Динамическая работа с памятью
173
номно использует память и, во-вторых, не всегда решает постав-
ленную задачу.
Правильнее в такой ситуации создать массив нужного размера
динамически — непосредственно во время работы программы, когда
этот размер уже известен.
Как статические, так и динамические объекты размещаются в
памяти компьютера в строгой последовательности, определяемой
операционной системой компьютера и компилятором языка про-
граммирования. Распределение памяти в программах, написанных
на языке С, представлено на рис. 10.1.
(Верхние адреса памяти) СТЕК Локальные переменные и константы
Свободная память Динамическая память (куча)
Глобальные переменные и константы Фиксированое место в памяти (на все время работы программы)
Программа пользователя (нижние адреса памяти)
Рис. 10.1. Распределение памяти компьютера
Операционная система позволяет получать (а также возвра-
щать) память из кучи во время выполнения программы.
Для работы с динамической памятью в С предусмотрено четыре
функции из библиотеки stdlib.h:
• malloc(), calloc() — захватывают память или выделяют память
из кучи;
• геа11ос() — позволяет изменять (увеличивать или уменьшать)
размер уже выделенной памяти без потери ее содержимого;
• free() — освобождает уже ненужную память (возвращает па-
мять в кучу).
Функция mallocO захватывает область памяти, при этом размер
в байтах указывается в качестве аргумента, malloc() возвращает
указатель на захваченную память, т. е. ее адрес. При этом выделяе-
мая память не инициализируется, т. е. не очищается.
174 Глава 10. Динамическая работа с памятью
Пример. Создать динамический массив из 100 символов, а за-
тем заполнить его нулями:
#include <stdlib.h>
main()
{
int i;
char *p;
/* Резервируем 100 байтов под массив char */
р = malloc (100);
for (i=0; i< 100; i++)
p|i] = 0;
return 0;
}
Если нам нужен массив не char, а, например, int, то придется
определить размер памяти в байтах с помощью оператора sizeof(),
это можно сделать прямо при вызове функции:
/* Резервируем место под 100 элементов int */
р = malloc ( 100 * sizeof(int));
Функция calloc() не только захватывает память, но и очищает
ее (заполняет байты нулями), у нее два аргумента — количество
элементов и размер элемента в байтах:
#include <stdlib.h>
main()
{ inti;
char *cp;
int *ip;
/* Резервируем и очищаем 100 байтов под массив char */
ср = calloc (100, 1 );
/* Резервируем и очищаем 100 элементов int*/
ip = calloc (100, sizeof(*ip));
return 0;
Функция calloc(nelm, elmsize) выделит столько же байтов,
сколько и malloc(nelm*elmsize) и, кроме того, очистит выделенную
память.
Глава 10. Динамическая работа с памятью
175
В примерах выше мы пользовались динамической памятью
только для создания массивов, но таким же образом можно выде-
лять память и под структуры, переменные встроенных типов и т. п.
На самом деле все эти функции работают с «абстрактной» па-
мятью, и им абсолютно безразлично, как программист ее будет ис-
пользовать. А тот указатель (точнее тип указателя), в который вы
записываете адрес области, лишь помогает программе интерпрети-
ровать эту область нужным вам образом. Если поставить вместо
указателя на int указатель на структуру, то можно будет работать с
динамически созданной структурой или массивом структур:
#include <stdlib.h>
#include "compleh.h"
struct COMPLEX { double re, im;};
void main()
{ struct COMPLEX *ptr;
ptr=malloc(sizeof(struct COMPLEX));
ptr->re = 1.0;
ptr->im=0.0;
}
Функция realloc() позволяет изменять размер выделенного уча-
стка динамической памяти.
После создния динамического массива вы можете «увеличить»
или уменьшить его размер.
#include <stdlib.h>
void main()
{ int *ip;
/* Резервируем 100 элементов int */
ip = malloc(100*sizeof(*ip));
// He хватило памяти — наращиваем ее до 200 элементов
ip = realloc(ip, 200*sizeof(*ip));
/* Нам достаточно 150 элементов, убираем 50 лишних */
ip = realloc(ip, 150*sizeof(*ip));
return 0;
}
176
Глава 10. Динамическая работа с памятью
У функции геа11ос() два параметра:
1) указатель на уже имеющуюся область динамической памяти;
2) новый размер этой области;
Функция также использует возвращаемое значение — указа-
тель на захваченную область нужного размера в байтах.
Рассмотрим три особенности realloc():
1. Функция reallocf) может изменять размер только динамиче-
ского массива. В качестве первого аргумента ей можно передать
только указатель, который, как в примере выше, был получен от
malloc(X calloc() или от предыдущего вызова самой realloc(). Если
вы попытаетесь передать ей адрес статического массива, компиля-
тор выдаст ошибку:
char s[ 100];
char *р;
char*pl;
p=malloc(100);
pl=realloc(p, 150); //Так правильно
pl=realloc(s,150); //А так делать нельзя!!!
2. Обратим внимание на содержимое новой области. Если вы
увеличиваете размер массива с помощью realloc(), то содержимое
исходного массива у вас сохранится, новые же элементы будут со-
держать непредсказуемые значения или «информационный мусор».
int *ip;
ip=malloc(4*sizeof(*ip));
// Создали массив из четырех целых
ip[0]=0;
ipll]=l;
ip[2]=2;
ip[3]=3;
ip=realloc(ip, 5*sizeof(*ip)); // Добавляем еще один элемент.
ip = realloc(ip, sizeof(*ip)); // А теперь уберем два элемента
Естественно, вместе с элементом ip|3] мы потеряли и его со-
держимое.
3. И наконец, надо учитывать, что когда вы пользуетесь
realloc(), система не изменяет размер самой области, с которой вы
Глава 10. Динамическая работа с памятью
177
работали, а выделяет новую область памяти, копирует в нее инфор-
мацию, а исходную область освобождает (возвращает в кучу). А это
означает, что содержимое массива вы сохраняете, а вот адрес этого
массива становится другим, поэтому, передав realloc() указатель в
качестве первого аргумента, вы должны забыть о нем и в дальней-
шем использовать только тот новый указатель, который получите
от геа!1ос():
char *pl,*р2;
p2=malloc(100);
pl=realloc(p2, 1000);
/*После realloc() указатель pl скорее всего поменяется, поэтому
пользоваться указателем р2 нельзя, так как он указывает на память,
возвращенную в КУЧУ*/
pl [0] = с’; // Правильно
р2[0] = с'; // Ошибка. Эта память уже не наша
Во всех примерах, иллюстрирующих выделение памяти, пред-
полагалось, что программа эту память получает. Однако ресурсы
любого компьютера ограничены, и может оказаться, что в системе
не окажется нужного количества свободной памяти. В этом случае
все три функции сообщат вам об ошибке, вернув NULL. Так что
полезно после вызова любой из этих функций проверить, не воз-
никло ли ошибки при выделении памяти:
char *р;
// Хотим получить гигабайт памяти
р = malloc( 1024* 1024* 1024);
// Проверяем, удлосьли это?
if(p==NULL)
{ printf("HeT нужного объема памяти \п");
exit(l);
};
Если вы используете в программе динамический массив, рано
или поздно наступает момент, когда он перестает быть нужен.
Если этот момент совпадает с завершением задачи, можно особо
не беспокоиться на этот счет — современные системы, снимая за-
дачу с выполнения, заодно и освобождают отведенную ей память.
178
Глава 10. Динамическая работа с памятью
Однако чаще случается, что массив уже не нужен, а программа
продолжает работать. И в этом случае совсем не вредно освободить
выделенную память — во-первых, другим задачам может приго-
диться, а во-вторых, вашей же задаче может не хватить памяти для
другого массива.
Для того чтобы освободить динамическую память, надо вы-
звать функцию free(), передав ей в аргументе тот указатель, кото-
рый вы получили от mallocO, calloc() или геа11ос(). После вызова
free() этим указателем уже нельзя будет пользоваться.
int *р;
р = malloc(5 * sizeof(*p)); // Создаем динамический массив
р[0] = 1;
free(p); // Освобождаем память
р[0]=1; /* Ошибка! Массива, на который указывал р, уже нет ! */
/* Создаем, используем и уничтожаем еще один массив */
р = malloc(2 * sizeof(int));
р[0] = 7;
free(p);
Данный фрагмент программы показывает, что освободивший-
ся после возврата динамической памяти в кучу указатель р может
быть использован для создания нового массива или же для любых
других целей.
10.1. Универсальный указатель void
Если в программе необходимо работать с данными разных ти-
пов, то часто требуется преобразование указателей к различным
типам, например:
int *ip;
double *dp;
dp = ip; // Будет предупреждение транслятора
Предупреждение выдается не зря — подобные операции с ука-
зателями, если это сделано не осознанно, приводят к трудно выяв-
10.1. Универсальный указатель void
179
ляемым ошибкам. Поэтому и рекомендуют в подобных случаях
явно приводить один тип указателя к другому. Ошибку в предыду-
щем примере можно исправить следующим образом:
dp = (double*) ip;
Казалось бы, при таком внимательном отношении транслято-
ра к типам указателей примеры, приведенные выше, должны пест-
реть от операторов приведения типов, например таких:
char *ср;
double *dp;
ср = (char *) malloc(lOO);
dp= (double*)calloc(100, sizeof(double));
Однако во всех примерах работы с динамической памятью мы
ни разу не пользовались операторами приведения типов! Почему
это было возможно, и какой тип указателя используют функции
callocO, mallocO, геа!1ос()? Для ответа на этот вопрос рассмотрим
уже извесный нам тип void.
Свойства типа void:
• переменных этого типа не существует;
• первое применение void — отсутствие значения, указание
того, что функция ничего не возвращает или не содержит па-
раметров;
• второе применение типа void — указатели.
Для указателя void не работает арифметика указателей, по-
скольку отсутствует само понятие размера элемента. Транслятор
не позволит написать для такого указателя ptr[2] или р/г++.
Указатель void нужен для хранения значения указателей различ-
ных типов. По существу, транслятор позволяет использовать опе-
рации присваивания между указателем void и любыми другими ти-
пами указателей без явного приведения типов.
Пример. Присваивание между указателем типа void и любым
другим типом указателя.
void *vp;
char *ср;
180
Глава 10. Динамическая работа с памятью
double *dp;
/* Несмотря на отсутствие оператора приведения типа, ни одна из
следующих строк не даст предупреждения транслятора */
ср = vp;
vp = ср;
dp = vp;
vp = dp;
Теперь пришло время ответить на ранее поставленный вопрос
об указателях при работе с динамической памятью.
Функции работы с динамической памятью — calloc(), malloc(),
realloc() возвращают указатель типа void, который можно прирав-
нять к указателю любого типа, а значит, при выделении динамиче-
ской памяти указатели справа и слева от операции присваивания
могут иметь разные типы.
Прототипы функций имеют следующий вид:
void* malloc(int size);
void* calloc (int qu, int size);
void* free(void *p);
10.2. Принципы работы с динамическими массивами
В заключение перечислим правила «хорошего тона» при работе
с динамической памятью, соблюдение этих несложных правил по-
зволит избежать типичных ошибок, возникающих у начинающих
программистов, внесет в вашу работу систему и порядок, а про-
граммный код сделает более надежным.
1. Не забывайте об общих правилах работы с указателями, эти
правила желательно соблюдать всегда, где бы ни использовались
указатели:
• указатели должны содержать либо NULL, либо какой-нибудь
разумный адрес, т. е. адрес существующей переменной, при-
надлежащий выполняемой программе. В частности, освобо-
див память функцией free(), не забудьте стереть уже недейст-
вительный адрес, т. е. занести в указатель NULL, иначе вы
рискуете по ошибке использовать уже не принадлежащую за-
даче память;
10.2. Принципы работы с динамическими массивами
181
• почаще проверяйте значение указателя перед использовани-
ем, NULL должен сигнализировать о том, что указатель «сво-
боден», т. е. не указывает ни на один объект:
char *р = malloc(lOO);
char с;
free(p);
p=NULL;
/* Так легко ошибиться, так как р не установлен! */
с = *р;
/* А так безопасно, так как программа проверила, что р содержит
адрес переменной */
if(p!=NULL)
{ с = *р;
2. Всегда следует сохранять параметры выделенной динамиче-
ской памяти:
• не теряйте длину выделенной области — иначе вы не сможете
узнать, сколько же у вас элементов в динамическом массиве.
• не теряйте исходный адрес, который вам вернула malloc(),
calloc() или realloc() — без него вы не сможете освободить вы-
деленную область, а также организовать многопроходную ра-
боту с выделенной памятью.
Приведем пример, который иллюстрирует неправильную ра-
боту с динамической памятью.
char *р;
int size=k; // Размер требуемой памяти
р = malloc(size);
size=10;
р++;
После выполнения инструкции size=10 потерян размер выде-
ленной памяти, после инструкции р++ — потерян начальный ад-
рес выделенной памяти. После этих действий невозможно рабо-
тать с динамической памятью, так как неизвестен ни ее началь-
182
Глава 10. Динамическая работа с памятью
ный, ни конечный адрес, также невозможно будет вернуть память
в кучу.
Следующий пример демонстрирует стандартные подходы, по-
могающие избегать перечисленных проблем.
Рассмотрим сортировку динамического массива. Алгоритм
сортировки методом «пузырька» подробно рассмотрен в разделе
«Функции», где мы сортировали статический массив, воспользу-
емся этим же алгоритмом для решения поставленной задачи. Об-
ратите внимание, что определения функций swap() и mas_print() не
изменились. Так как после выделения памяти из кучи обращение к
отдельным элементам массива ничем не отличается от обращения
к статическому массиву через указатель.
Пример. Создать динамический массив, заполнить его случай-
ными числами и отсортировать по возрастанию.
#include <iostream.h>
#include <stdlib.h>
#include <time.h>
# define n 101 // Размер массива
# define col 10 // Печать no 10 элементов в строке
void swap (int *pl , int *p2)
{/* Создание локальной переменнрой f и записть в нее значение из
переменной указателя pl */
int f=*pl;
*pl=*p2;
*р2 =f;
}
void mas print (int *p_beg, int *p_end, int k)
{ int i=0; // Счетчик выведенных элементов
for (i=0 ; p_beg < p end ; i++)
{ cout<<*p_beg++;
if ((i+1 )%k==0) cout<<’\n';
else cout<<’\t’;
void main()
{ int *begin,*tek,i; // Определение указателей
10.2. Принципы работы с динамическими массивами
183
srand(time(0));
begin=(int*)rnalloc(n*sizeof(int)); // Выделение памяти из кучи
// Формирование исходного массива
for (tek=begin ; tek<(begin+n); tek++)
*tek=rand();
mas_print(begin , (begin+n), col); // Печать массива до сортировки
cout<<"\n!!! сортировка !!!!\n";
for(i=0 ; i<n ; i++) //Сортировка
for( tek=begin ; tek<(begin+n-i-l); tek++)
if (*tek > *(tek+1))
swap (tek , (tek+1)); //|
mas_print(begin , begin+n,col); // Печать отсортированного массива
free (begin); // Возвратить память в кучу
}
В функции main() работа идет по следующему сценарию.
Для полноценной работы с массивом через указатели необхо-
димо два указателя — один для хранения начала массива (begin),
второй для текущей работы (tek). Следует отметить, что требование
этого пункта относится равно как к статическим, так и к динами-
ческим массивам, работающим с указателями.
Проходом обработки массива (неважно, в чем эта обработка
заключается) называется последовательный «перебор» всех эле-
ментов массива (в нашем примере от начала к концу).
Перед каждым проходом обработки массива необходимо запи-
сывать адрес начала массива в текущий указатель, инструкция tek=
begin в заголовке цикла for выполняет эту работу.
Условие выполнения цикла for — tek<(begin+n) заключается в
следующем: пока адрес в текущем указателе не превышает адреса
последнего элемента массива (begin+n).
Переход к очередному элементу происходит по инструкции
tek++ в заголовке цикла for.
При выделении памяти из кучи некоторые компиляторы требу-
ют явного приведения типов указателей правой и левой части ра-
венства, что и сделано в примере:
begin=(int*) malloc(n*sizeof(int));
184
Глава 10. Динамическая работа с памятью
Вопросы для самопроверки
1. Чем отличаются статические переменные от динамических?
2. Какие программные объекты могут выступать в качестве динамических
объектов?
3. Поясните термин «куча». Для чего используется «куча»?
4. Какие функции динамического выделения памяти вы знаете?
5. Приведите примеры динамического выделения памяти.
6. Можно ли изменить размер динамического массива?
7. Какая из функций caLloc() или malloc() очищает память при создании ди-
намического массива?
8. Какая из функций caLLocQ или maLloc() не инициализирует (не очищает)
память при создании динамического массива?
9. Какая функция уничтожает динамический массив? Для чего это нужно?
10. Универсальный указатель void. Для чего он нужен?
11. Приведите схему многопроходной работы с динамической памятью.
Глава 11
ВВОД-ВЫВОД ДАННЫХ
Выводом называется процедура переноса данных из памяти
компьютера на внешние устройства. При вводе данных, напротив,
информация извне вносится в память компьютера.
Данные можно ввести с клавиатуры или из файла надиске, вы-
вести их на экран, отпечатать на принтере, кроме того, данные
можно сохранить на магнитном носителе или послать по линии
связи через модем. При выводе данные не удаляются из памяти
компьютера, не изменяется способ их хранения, компьютер про-
сто копирует данные и посылает их на соответствующие устройст-
ва. При вводе данные также копируются в память компьютера, а
информация на внешнем устройстве не претерпевает никаких из-
менений.
В языке С ввод и вывод данных осуществляется с помощью
библиотечных функций, которые работают как с консолью, так и
с файлами.
Консоль — это устройство для управления компьютерной сис-
темой, это может быть клавиатура, экран дисплея, принтер или
любое другое устройство, связывающее пользователя с компью-
тером.
Файл — это набор данных, хранящийся вне памяти компьюте-
ра. В настоящее время существует множество устройств для хране-
ния информации, в принципе можно сказать, что файловым мо-
жет быть любое устройство, на которое можно записывать, а в по-
следствии считывать данные. Но наиболее часто программист
работает с файлами на жестком диске компьютера. В отличие от
переменной файл (в частности, его имя) имеет смысл вне конкрет-
ной программы. Работа с файлами реализуется средствами опера-
ционных систем.
186
Глава 11. Ввод-вывод данных
Различают буферизованный и ^буферизованный (прямой)
ввод/вывод данных. Небуферизованный ввод/вывод характерен
тем, что символ немедленно доступен ожидающей программе. При-
мером могут служить функции ch=getch(), putch(ch) из библиотеки
conio.
При буферизованном вводе/выводе символы сначала помещаются
в специальную область памяти, называемую буфером. Здесь они на-
капливаются до тех пор, пока не будет нажата клавиша ENTER или
пока буфер полностью не заполнится. Только после этого накоплен-
ный блок данных становится доступным программе. Большинство
библиотечных функций языка С и C++ работают с буферизацией,
например getchar(), putchar(ch).
Зачем нужны буферы? Одни устройства производят запись
данных в буфер, а другие — чтение из него. Программа, выполнив-
шая запись в буфер, может немедленно продолжать работу, не
ожидая, пока данные будут обработаны внешним устройством.
Это очень важно для эффективной работы компьютера, так как
внешние устройства работают значительно медленнее памяти ком-
пьютера. Таким образом, буферизация позволяет выполнять парал-
лельно вывод и обработку данных.
Если необходимо передать данные между устройствами, рабо-
тающими с различными скоростями, также необходим буфер.
Каждое устройство работает с буфером со своей скоростью, в то
время как в буфере по необходимости накапливаются данные. Та-
кой метод работы называется синхронизацией передачи информации.
Термин буферизация чаще используется применительно к ком-
пьютерной технике, в программировании же чаще используется
термин поток данных.
В общем случае поток — это механизм преобразования значе-
ний различного типа в последовательность символов (вывод) и на-
оборот (ввод). Но можно рассматривать поток как синоним буфера
данных. Потоки могут быть буферизованные и небуферизованные,
форматированные и неформатированные.
Буфер, который поставляет данные компьютеру, называется
входным потоком, буфер, который выводит данные из компьюте-
ра, называется выходным потоком. При работе программы потоки
связываются с тем или иным физическим устройством, програм-
мист же, используя библиотечные функции, всегда работает с по-
током.
11.1. Ввод-вывод данных на консоль. Библиотека stdio
187
Отметим одно интересное свойство функций ввода языка С.
Когда данные вводятся с клавиатуры, они отображаются на экране
монитора, при этом в программе не используются никакие функ-
ции вывода на экран, это «явление» называется эхопечать. Эхопе-
чать используется в большинстве функций ввода, таких как
getchar(), gets(), scanf().
Мы рассмотрим наиболее простые и популярные из них, пол-
ный перечень библиотечных функций можно найти в справочни-
ках по библиотечным функциям языка С или C++. Таких справоч-
ников очень много как в электронном, так и в печатном виде, на-
пример книги известного автора, признанного специалиста по С
и C++ Герберта Шилдта [5].
11.1. Ввод-вывод данных на консоль.
Библиотека stdio
11.1.1. Стандартные потоки библиотеки stdio
Библиотека — это отдельный файл, прилагающийся к компи-
лятору языка С, содержащий функции для решения распростра-
ненных задач.
Функции ввода-вывода размещены в нескольких библиотеках,
наиболее популярные из которых stdio, conio, iostream.
Рассмотрим некоторые библиотечные функции библиотек
stdio и conio.
После подключения библиотеки stdio с помощью директивы
#include в начале работы программы автоматически открываются
три заранее определенных потока:
• stdin — входной поток данных;
• stdout — выходной поток данных;
• stderr — поток ошибок.
По умолчанию эти потоки связаны с консолью:
• stdin — с клавиатурой;
• stdout — с терминалом.
Следует отметить, что потоки можно перенаправить и на дру-
гие устройства, например в файл.
188
Глава 11. Ввод-вывод данных
11.1.2. Чтение и запись символов
Простейшими консольными функциями ввода-вывода явля-
ются функции getchar() и getch(), считывающие символ с клавиату-
ры, и функция putchar(), выводящая символ на экран. Все эти
функции имеют только один аргумент (параметр), а это означает,
что они могут отображать только один объект.
Функции getchar() и getch() возвращают целое число, в млад-
шем байте которого содержится код символа, соответствующего
нажатой клавише (старший байт содержит нулевое значение).
Если при вводе возникает ошибка, функции возвращают кон-
станту EOF (EOF равна -1).
Формат функций ввода выгладит так:
int getchar (void)
int getch (void)
Безразлично, к какому типу (char или int) вы отнесете вводи-
мый символ, что обусловлено двойственностью символьных дан-
ных в языке С (о двойственности смотрите ниже по тексту). Обра-
тите внимание на то, что для сохранения введенной информации
необходима операция присваивания, так как функции getch() и
getchar() рассматривается программой как значение введенной пе-
ременной.
Однако на этом сходство обеих функций кончается, далее ос-
тановимся на их отличиях. Прототип функции getchar() находится
в библиотеке stdio.h. Функция getchar() вводит символ из потока
stdin, который имеет буфер на одну строку, поэтому она ничего не
возвращает до тех пор, пока вы не нажмете клавишу ENTER, кро-
ме того, функция getchar() осуществляет эхопечать.
Прототип функции getch() находится в библиотеке conio.h.
Функция getch() вводит символ с консоли без буферизации и эхопе-
чати. Это означает, что символ доступен в программе сразу же по-
сле того, как он введен с клавиатуры.
Пример
#include <stdio.h>
#include <conio.h>
11.1. Ввод-вывод данных на консоль. Библиотека stdio
189
void main()
charsimboll;
char simbo!2;
simboll = getchar();
simbo!2 = getch();
printf ("\nsiml=%c sim2=%c\n",simboll,simbol2);
}
Для того чтобы записать информацию в переменную simbol 1,
после ввода первого символа необходимо нажать ENTER, второй
значащий символ запишется в переменную simbo!2 сразу после его
ввода с клавиатуры. Причем первый введенный символ мы увидим
на экране, а второй нет (мы не увидим simbo!2 при вводе), разуме-
ется, мы увидим оба символа после применения функции printf.
Следующий пример показывает посимвольную работу с тек-
стом.
Пример. Ввести текст с клавиатуры, признаком конца ввода
считать точку, подсчитать количество введенных символов.
#include <stdio.h>
void main()
{ char z[ 100];
int i;
printf("HanMiuMTe предложение с точкой в конце:\п")
for(i=0; z[i] != ’. i++)
z[i]=getchar();
ргппГ(«Количество CHMBonoB=%d»,i);
}
Следует обратить внимание на то, что при работе с текстом,
используя getchar(), мы не получаем строку символов, так как от-
сутствует признак конца строки ’\0’. Для того чтобы не нарушать
стандартов языка, следует добавить символ ’\0’ после окончания
ввода текстовой информации.
void main()
{
char z[ 100];
int i;
190
Глава 11. Ввод-вывод данных
рпп1Г("Напишите предложение с точкой в конце:\п")
for(i=0;z[i] i++)
z[i]=getchar();
рпп1Г(«Количество символов (без признака «конец строки») =%d»,i);
z[i] = ’\0';
}
Итак, добавление *\0* к массиву z| | превращает последователь-
ность символов в строку.
Остановимся на двойственности символьных данных. Функ-
ции ввода-вы вода для символьных данных были сконструированы
таким образом, чтобы они могли работать и с целочисленным ти-
пом данных. Компилятор самостоятельно преобразует данные
типа int в символы.
Пример. Двойственность символьных данных.
void main()
{
int letter;
letter='G’;
putchar(letter);
}
Несмотря на то что переменная letter определена как целочис-
ленная, ей может быть присвоен символ. Программа при этом бу-
дет компилироваться и выполняться без ошибок. Право выбора,
использовать ли переменные типа char или int, остается за про-
граммистом.
Рассмотрим функцию вывода символа на консоль — putchar().
Несмотря на то что эта функция наряду с символами может полу-
чать и целочисленный аргумент, ей можно передавать только сим-
вольные значения. Иначе говоря, целочисленные значения трак-
туются как коды символов, и, следовательно, на экран выводится
только младший байт аргумента.
Функция putchar() возвращает либо код символа, либо кон-
станту EOF, если произошла ошибка. Формат функции putchar()
выглядит так:
int putchar (int с)
11.1. Ввод-вывод данных на консоль. Библиотека stdio
191
Параметром функции может являться:
• символьный литерал;
• символьная константа;
• символьная переменная.
Пример. Составить слово из отдельных символов и вывести его
на экран.
#define sim2 ’Е' // Определение символьной константы
void main()
{ charsim3;
sim3='C’;
printf ("Составим слово Л EC из отдельных символов:")
putchar('JT); // Символьный литерал;
putchar(sim2); // Символьная константа;
putchar(sim3); // Символьная переменная
}
11.1.3. Чтение и запись строк
Консольные функции gets() и puts() позволяют считывать и за-
писывать строки.
Функция gets() считывает строку символов с клавиатуры, и
размешает ее по адресу, указанному в аргументе, ее прототип нахо-
дится в библиотеке stdio.
Поскольку функция работает с буфером, на время ее работы
выполнение программы приостанавливается, она ожидает ввода
текста с клавиатуры, признаком окончания ввода является клави-
ша ENTER, после чего строка, введенная пользователем, присваи-
вается переменной в качестве значения.
Следует обратить внимание на одну важную особенность
функции gets(), несмотря на то, что нажата клавиша ENTER, в ко-
нец строки ставится не символ перехода на новую строку, а нуле-
вой символ *\0* — признак конца строки.
При наборе строки допускается ее редактирование, ошибки
можно исправить с помощью клавиши BACKSPACE.
В качестве аргумента следует указывать массив символов, в ко-
торый и будут записаны символы, введенные пользователем.
192
Глава 11. Ввод-вывод данных
Пример. Ввести строку текста в массив, вывести строку на
экран.
#include <stdio.h>
void main()
{
char bufferfl 25];
printf("Ha6epnTe строку:");
gets(buffer);
printf("Bbwa введена строка: %s\n", buffer);
}
Функция gets() будет рассматривать символы, введенные с кла-
виатуры, как значение строковой переменной с именем buffer.
Следует помнить, что один элемент необходим для нулевого сим-
вола *\0’, поэтому указывайте длину массива на единицу больше
максимально возможной строки. Например, если вы хотите ввести
в переменную buffer строку, состоящую из 125 символов, то опре-
деляйте массив:
char bufferfl 26];
Функция puts() выводит на экран строку символов и переводит
курсор на следующую строку, ее прототип находится в библиотеке
stdio. Если при выводе возникла ошибка, то функция возвращает
константу EOF.
В качестве параметра могут выступать:
• строковый литерал;
• строковая константа;
• строковая переменная.
Хорошо известное приветствие можно записать с помощью
функции puts следующим образом:
puts("Hello world!!!"); // Это строковый литерал
Пример. Вывести фразу из нескольких строк на экран дисплея.
#define st г 1 "Чижик-пыжик, где ты был? "
void main()
{
char str2f ]="На Фонтанке водку пил...";
11.1. Ввод-вывод данных на консоль. Библиотека stdio
193
puts(strl);
puts(str2);
}
/1 Строковая константа
//Строковая переменная:
Отметим, что литерал — это конкретный набор символов, ко-
торый вводится непосредственно в инструкции языка С вместо
имени константы или переменной.
11.1.4. Обзор консольных функций ввода-вывода
Сведения об основных функциях ввода вывода приведены в
табл. 11.1.
Таблица 11.1
Функция Операция
getchar () Считывает символ с клавиатуры, выводит его на экран, ожи- дает перехода на новую строку
getche() Считывает символ с клавиатуры и выводит его на экран, не ожидает перехода на новую строку
getch() Считывает символ с клавиатуры и не выводит его на экран, не ожидает перехода на новую строку
putchar() Выводит символ на экран
gets() Считывает строку с клавиатуры, ожидает перехода на новую строку
puts() Выводит строку на экран и переводит курсор на следующую строку
11,1.5, Форматированный ввод-вывод данных
Функции printf() и scanf() выполняют форматированный ввод-
вывод на консоль, иначе говоря, они могут считывать и записы-
вать данные в заданном формате и с комментариями. Обе функции
могут оперировать любыми встроенными типами данных, включая
символы, строки и числа.
Функцию printf часто называют «выводом с форматирова-
нием».
194
Глава 11. Ввод-вывод данных
Формат вызова:
#include <stdio.h>
printf ("управляющая строка", аргумент !, аргумент _2,...);
Первый аргумент функции, в кавычках называют строкой фор-
матирования, так как она указывает «как нужно производить вы-
вод», т. е. определяет формат вывода, последующие аргументы
указывают «что нужно выводить».
Строка форматирования содержит элементы трех типов:
• обычные символы, которые просто копируются в стандарт-
ный выходной поток (выводятся на экран дисплея);
• команды форматирования, которые определяют тип отобра-
жаемого аргумента;
• управляющие символьные последовательности, которые осу-
ществляют форматирование.
Команда форматирования начинается с символа %, за кото-
рым следует код формата. Основные форматы представлены в
табл. 11.2 и 11.3.
Количество аргументов после строки форматирования должно
совпадать с количеством команд форматирования, причем совпа-
дение обязательно и в порядке их следования.
При форматировании необходимо не только выводить симво-
лы, но и управлять выводом, например переводить строки, делать
отступы и т. д. Для этой цели служат управляющие символы, уже
Таблица 11.2. Команды форматирования функции printf
%с Символ
%s Строка символов
%d, %i Десятичное целое со знаком
%u Десятичное целое без знака
%f Вещественное число (значение с плавающей точкой)
%e Экспоненциальное представление вещественного числа
%o Восьмеричное число без знака
%x Шестнадцатеричное число без знака
11.1. Ввод-вывод данных на консоль. Библиотека stdio
195
Таблица 11.3. Команды форматирования функции scanf()
%с Символ
%s Строка символов
%d,%i Десятичное целое со знаком
%u Десятичное целое без знака
%f, %е Вещественное число
%o Восьмеричное число
%x Шестнадцатеричное число.
рассмотренные нами ранее (см. табл. 2.1), часто их называют
escape-последовательностями. Напомним, что каждая последова-
тельность начинается с символа обратной косой черты (\), кото-
рый указывает на то, что символы, расположенные за ним, явля-
ются управляющими. Когда компилятор встречает обратную ко-
сую черту, он не отображает следующие символы, а выполняет
действие, на которое они указывают.
Пример. Вывод значений трех переменных на экран термина-
ла. Для большей наглядности различные элементы функции
printf() выделим различными шрифтами.
• вывод текста (комментарий)',
• управляющие последовательности;
• команды форматирования;
• имена переменных (объекты вывода).
printf ("Вывод трех целых чисел: \n\tx=%d\t v=%d\tz=%d". х , у , z):
Комбинация символов %d служит своего рода указателем мес-
та в строке, куда необходимо вставить значение переменной при
печати.
Пусть 5, 15, 25 — это значения переменных х, у, z, тогда на эк-
ране будет отображено следующее.
Вывод трех целых чисел:
х=5 у= 15 z=25
196
Глава 11. Ввод-вывод данных
Функция scanf считывает данные с клавиаруры и сохраняет ин-
формацию в переменных, заданных аргументами, перечисленны-
ми в списке аргументов.
Формат вызова:
#include <stdio.h>
scanf ("форматирование", аргумент !,...);
Аналогично функции printf() используются команды формати-
рования.
Пример. Ввод различных данных.
#include <stdio.h>
int i;
float fp;
chare, s[81 ];
scanf("%d %f %c %s", &i, &fp, &c, &s);
Чтобы ввести длинное целое поставьте перед форматом моди-
фикатор 1 или L, чтобы прочитать короткое целое — модификатор
h или Н.
Эти модификаторы можно использовать с форматами: d, i, о, и, х.
Пример
#include <stdio.h>
int х;
scanf ("%ld",&x);
В переменную x с клавиатуры будет введено длинное целое
число.
Пример. Пробельные символы (пробел, табуляция, новая стро-
ка и т. п.) используются для разделения полей при вводе данных.
scanf (”%d%d",&x,&y);
Если входной поток состоит из трех символов:
10 <пробел> 20 или 10 <табуляция> 20,
11.1. Ввод-вывод данных на консоль. Библиотека stdio
197
то:
• число 10 будет введено в переменную х;
• число 20 будет введено в переменную у.
Пример. Несмотря на то что пробельные символы используют-
ся для разделения полей, при вводе символьных данных они чита-
ются, подобно любому другому символу.
scanf (,’%c%c%c'\&x,&y,&z);
Если входной поток состоит из трех символов: а <пробел> б, то:
• символ а будет помешен в переменную х;
• <пробел> будет помещен в в переменную у;
• символ б будет помещен в переменную z.
11.1.6. Сравнительная характеристика консольных
функций ввода-вывода
Функции, используемые для ввода и вывода данных, зависят
от типа данных и способа их представления. Остановимся на свой-
ствах функций printf() и scanf(), главное из которых возможность
работать с самыми разнообразными данными. Например, с по-
мощью одной и той же функции scanf() можно вводить как число-
вые, так и символьные данные. Кроме того, функции printf() и
scanf() позволяют работать со списком из нескольких аргументов,
т. е. вводить (или выводить) сразу несколько переменных, а также
форматировать выводимые данные. Итак, функции printf() и scanf()
универсальны и это делает их привлекательными, но, с другой сто-
роны, следует отметить, что эти функции достаточно громоздкие
(занимают много места) и медленно работают. Поэтому для рабо-
ты с текстовой информацией в состав библиотек входят специаль-
ные функции для работы как с отдельными символами, так и с це-
лыми строками.
Если вы хотите работать с отдельными символами, то наиболее
удобно использовать функции getch, getchar() и putchar(). Для рабо-
ты с целыми строками используйте функции gets() и puts().
Все эти функции ввода-вывода текстовых данных имеют толь-
ко один аргумент (параметр), а это означает, что они могут отобра-
жать только один объект.
198
Глава 11. Ввод-вывод данных
11.2. Функции ввода-вывода библиотеки iostream
Хотя библиотека iostream относится к языку C++ и не является
темой нашего курса, все же мы бегло рассмотрим два потока этой
библиотеки — cin и cout. Дело в том, что большинство современ-
ных сред программирования поддерживают две полноценные сис-
темы ввода-вывода, одна из них относится к языку С, а другая —
к объектно-ориентированному C++. Многие программисты, не
выходящие в своей работе за рамки классического языка С, тем не
менее активно пользуются системой ввода-вывода C++, поэтому
целесообразно рассмотреть наиболее популярные средства этой
библиотеки.
Так же как в языке С, система ввода-вывода C++ оперирует
потоками. Поток в C++ — это логическое устройство, получающее
или передающее информацию. Поток связан с физическим устройст-
вом ввода-вывода. Все потоки функционируют одинаково, хотя фи-
зические устройства, с которыми они связаны, могут быть самыми
различными.
Потоки, определенные в языке C++:
cin — стандартный ввод;
cout — стандартный вывод;
сегг — стандартная ошибка;
clog — буферизованная версия сегг.
По умолчанию эти потоки связаны с консолью:
cin — с клавиатурой;
cout, сегг, clog — с терминалом.
Операции ввода-вывода языка C++:
вывод <<;
ввод ».
Пример. Напечатать на терминале строку текста:
«Пример вывода - 34»
cout << "Пример вывода - " « 34;
Пример. Ввести целое число с клавиатуры в переменную х (для
того, чтобы ввод произошел, на терминале нужно напечатать чис-
ло и нажать клавишу ENTER.)
11.2. Функции ввода-вывода библиотеки iostream
199
int х;
cin >> х;
Пример. Ввести строку текста в статический массив.
char str[8O];
cin »str;
Пример. Ввести строку текста в динамический массив и вывес-
ти его на терминал.
#include <iostream.h>
#include <stdlib.h>
void main()
{
char *ptr;
ptr=(char*)malloc(80);
cin » ptr;
cout<<endl<<"BBefleHa строка: "<<ptr<<endl;
free(ptr);
}
11.2.1. Форматирование ввода-вывода
Для форматирования текста и вывода спецсимволов следует
использовать манипуляторы, входящие в библиотеку iomanip.h,
наиболее популярные из них приведены в табл. 11.4.
Манипуляторы выводятся в выходной поток подобно всем ос-
тальным объектам вывода.
Пример. Вывести на терминал одно и то же число в разных сис-
темах счисления:
#include <iostream.h>
#include <iomanip.h>
int x = 53;
cout << "Десятичный вид:" << x « endl;
cout<< "Восьмеричный вид:"<< oct<<x<<endl;
cout<< "Шестнадцатеричный вид: "<< hex;
cout << x << endl;
200
Глава 11. Ввод-вывод данных
Таблица 11.4
endl Новая строка (символ '\n')
ends Конец строки (символ '\0')
setw (int n) Ширина поля вывода
setprecision(int n) Количество цифр после запятой
setfill (int n) Сим вол -запол н ител ь
flush Вывести и освободить все буферы
setbase(int n) Установить систему счисления (СС) для всей программы
dec Десятичная СС (только для открытого потока)
oct Восьмеричная СС (только для открытого потока)
hex Шестнадцатеричная СС (только для открытого потока)
Десятичная система счисления устанавливается по умолча-
нию, поэтому первый вывод не требует ее настройки.
Пример. Ввести шестнадцатеричное число с клавиатуры.
#include <iostream.h>
#include <iomanip.h>
int x;
cin >> hex >> x;
Аналогично используются манипуляторы с параметрами, та-
кие как setfill или setw.
Пример. Вывод числа с различной точностью.
#include <iostream.h>
#include <iomanip.h>
double x=123.4567;
cout<<setfill('*,)<<setw( 11 )<<setprecision(2)<<x;
cout<<setfill(,+,)«setw(l l)«setprecision(3)<<x;
Первое обращение к потоку cout определяет числовой формат
с двумя знаками числа в дробной части, также явно определен
символ-заполнитель «пустого» пространства вывода ('*').
11.2. Функции ввода-вывода библиотеки iostream
201
Форматы вывода при первом и втором обращении к потоку
cout выглядят следующим образом:
*****123 45
++++123.456
Те же манипуляторы, за исключением endl и ends, могут ис-
пользоваться и при вводе. В этом случае они описывают представ-
ление вводимых чисел. Кроме того, имеется манипулятор, рабо-
тающий только при вводе, это ws. Данный манипулятор переклю-
чает вводимый поток в такой режим, при котором все пробелы
(включая табуляцию, переводы строки, переводы каретки и пере-
воды страницы) будут вводиться в поток. В обычном режиме, по
умолчанию, эти символы воспринимаются как разделители между
объектами ввода.
Глава 12
ФАЙЛОВЫЙ ВВОД-ВЫВОД
Файл является набором данных, обычно на диске, со своим
именем.
Мы не будем рассматривать файл с точки зрения операцион-
ной системы, там это понятие трактуется более сложно. Нас же бу-
дет интересовать файл с точки зрения программы на языке С.
Компилятор языка С, а также функции и макрокоманды, работаю-
щие с файлом, рассматривают файл как структуру, предопределен-
ную в компиляторе, подобно стандартным типам данных, которая
содержит необходимую информацию для связи программы с
внешними устройствами и для работы с буфером.
Фрагмент файловой структуры:
struct iobuf
{ char*_ptr; /* Текущий указатель буфера*/
int_cnt; /* Текущий счетчик байтов*/
char*_base; /* Базовый адрес буфера ввода-вывода*/
char flag; /* Управляющий признак*/
char_file; /* Номер файла*/
}
#define FILE struct_iobuf/* краткая запись*/
Не будем разбираться детально в этом определении, для нас
главное отметить, что файл определяется структурой и что стан-
дартное (краткое) наименование этой структуры — FILE, таким
образом, любая программа, желающая работать с файлами, долж-
на использовать этот тип структуры. Для работы с файлами ис-
пользуются специальные файловые потоки, обмен с которыми осу-
ществляется с помощью функций потокового ввода-вывода. Пере-
чень файловый функций представлен в табл. 12.1, благодаря
работе этих функций алгоритм взаимодействия с файловой струк-
12.1. Четыре этапа работы с файлами
203
турой скрыт от пользователя, и мы получаем очередной запрошен-
ный элемент в качестве возвращаемого значения.
Остановымся подробнее на свойствах файлов:
• файлы могут изменять свой размер;
• обращение к элементам файла производится при помощи
специальных функций или макроопределений;
• доступ к элементу происходит в текущей позиции файла (по-
зиция чтения/записи);
• текущая позиция автоматически продвигается при операциях
чтения/записи, т. е. файл просматривается последовательно.
Для того чтобы изменить последовательный просмотр файла
(организовать произвольный доступ), существуют функции изме-
нения текущей позиции в файле.
12.1. Четыре этапа работы с файлами
Какие бы действия с файлами вы ни совершали, необходимо
выполнить четыре обязательных этапа:
Первый этап — определить указатель на файл.
Как мы уже говорили, при чтении/записи информации в файл
программа получает необходимую информацию из файловой
структуры, доступ к которой обеспечивается с помощью указателя.
Файловая структура определена как тип данных — FILE в сис-
темном файле stdio.h.
Пример. Определение указателя на файл.
#include < stdio.h >
FILE *file_pointer;
Ц Указатель на файл
После такого определения выделяется память под переменную
с именем file pointer.
Если вы собираетесь использовать одновременно несколько
файлов, вам нужны указатели для каждого из них.
Например, если необходимо скопировать содержимое одного
файла в другой, определяются два указателя на файл.
FILE *infile, *outfile;
204
Глава 12. Файловый ввод-вывод
Второй этап — открыть файл (функция fopen()).
На этом этапе устанавливается связь между именем файла и
определенным ранее указателем на файл, также задается режим
доступа к файлу. Режим доступа определяет, к какому файлу осу-
ществляется доступ: к текстовому или двоичному, а также способ
доступа: чтение или запись.
В общем виде функция fopen() выглядит следующим образом:
fp = ГорепС’имя файла", "режим доступа к файлу");
Здесь fp — указатель на файл.
Режимы доступа к файлу указаны в табл. 12.1.
Таблица 12.1
Режим Описание
Г Открыть файл для чтения
W Переписать или создать новый файл для записи
а Дополнить или создать файл для записи
г+ Открыть файл для чтения и записи
w+ Создать новый файл для чтения и записи
а+ Дополнить или создать файл для чтения и записи
Ранее мы говорили о возможности работы с двумя типами дан-
ных: текстовыми и двоичными. О каких же данных идет речь таб-
лице?
Тип файла определяет переменная fmode (из файла fcntl.h):
fmode = 0 BINARY — двоичный файл;
fmode = 0 TEXT— текстовый файл (по умолчанию).
Можно явно указать тип при открытии файла, для этого к обо-
значению режима доступа следует добавить:
b — для двоичного файла;
t — для текстового файла
По умолчанию работа идет с текстовыми файлами.
Пример. Работа с двумя текстовыми и одним двоичным фай-
лами.
fopen("c:\\my_progl.txt”, "г"); // Текстовый файл (для чтения)
fopen("c:\\my_prog2.txt", "w+"); // Текстовый файл (чтение/запись)
fopen("c:\\my_prog3.txt", "wb+"); //Двоичный файл (чтение/запись)
12.1. Четыре этапа работы с файлами
205
При ошибке доступа к внешнему устройству функция fopen()
возвращает нулевой указатель. Ошибка может возникать, когда не-
верно указан путь к файлу, файл отсутствует на указанном внеш-
нем устройстве или само устройство не готово к работе (неисправ-
но или не включено).
Пример. Контроль ошибок при открытии файла:
#include < stdio.h >
FILE *fp;
if ((fp = fopen("c:\\prog.txt", "r”)) == NULL)
{ putsC’OTKpbiTb файл не удалоеь\п”);
//Аварийное завершение программы
exit(l);
Третий этап — работа с данными файла (чтение/запись).
Применяются библиотечные функции для работы с данными
текстового файла (все они описаны в файле stdio.h) (табл. 12.2).
Таблица 12.2
Потоковая функция или макрокоманда Назначение
fopen Открывает поток для чтения и (или) записи
fclose Закрывает поток
fread Читает блок данных из потока
getc, fgetc Читает символ из потока
fgets Читает строку текста из потока
fscanf Читает форматированные данные из потока
fwrite Записывает блок данных в поток
putc, fputc Записывает символ в поток
fputs Записывает строку текста в поток
fprintf Записывает форматированные данные в поток
fseek Перемещает указатель позиции в потоке
ftell Возвращает текущую позицию в потоке. Возвращаемое значение — это смещение относительно начала потока (в байтах)
206
Глава 12. Файловый ввод-вывод
Окончание табл. 12.2
Потоковая функция или макрокоманда Назначение
feof Макрокоманда, которая возвращает ненулевое значе- ние, если в данном потоке обнаружен символ конца файла, в противном случае — нулевое значение
ferror Макрокоманда, возвращающая признак ошибки ( 0 — если ошибки не обнаружено, ненулевое значение в случае ошибки)
clearer Макрокоманда, сбрасывающая флаг наличия ошибок в данном потоке
fileno Макрокоманда, возвращающая дескриптор данного потокового файла
Четвертый этап — закрыть файл (функция fclose()).
После окончания работы с файлом он должен быть закрыт.
Функции fclose() записывает все оставшиеся в буфере символы
в файл, освобождает буфер и возвращает результат операции (нуль,
если файл закрыт успешно, любое другое значение свидетельствует
об ошибке).
Прототип функции:
int fclose(FlLE *fp);
Несколько примеров демонстрируют работу с файлами.
Пример. Посимвольное чтение файла и вывод его на экран:
#include <stdio.h>
main()
{ FILE*in; //Создаем указатель на файл
int ch;
{// открываем Text для чтения, проверяя, существует ли он
if ((in = fopen("Text", "г")) != NULL)
11 Указатель in ссылается на Text
while ((ch = getc(in)) != EOF) //получаем очередной символ
I/ Вывод ch на экран (в стандартный поток вывода)
putc(ch, stdout);
fclose(in); //закрываем файл
12.2. Файловые функции обработки строк
207
else
printf (" Файл \" Text\" не может быть открыт.\п");
Пример. Скопировать каждый пятый символ из файла Text в
файл Text5.
#include < stdio.h >
void main()
{char ch;
int count = 0;
FILE *f_in. *f_out;
if((f_in=fopen(,’Text.txt","r’’))!= NULL)
{ f ont = fopen("Text5.txt”, "w”);
while((ch = fgetc(fjn)) != EOF)
if (count++ % 5 == 0)
fputc(ch, f out);
fclose(f_in);
fclose(f_out);
else printf("Oaibi не открыт !\n");
}
// Счетчик символов
II Открыть файл лля чтения
// Открыть файл лля записи
// Чтение символа из файла
// Запись символа в файл
// Закрыть файлы
// Обработка ошибки
12.2. Файловые функции обработки строк
При работе со строками используются функции fgets(), fputs().
Необходимо помнить о нестандартном представлении строки в
языке С, который концом строки считает нулевой байт. Большин-
ство других программ, например текстовые редакторы, программы
отображения текстов и тому подобные системные программы,
концом строки считают ENTER (символ '\п'). Поскольку функции
ввода-вывод связывают программу на С с «внешней средой», то
необходимо выполнять перекодировку символа «конец строки».
Рисунок 12.1 показывает этот процесс.
Запись строк в файл — функция fputs.
Прототип функции:
int fputs (char* str, FILE *fp),
208
Глава 12. Файловый ввод-вывод
Здесь первый параметр — это указатель на строку, второй —
указатель на файл, возвращаемое значение — признак ошибки
(NULL — если ошибка, ненулевое значение в противном случае).
У функции fputs есть одна особенность, она не добавляет код \п
(ENTER), поэтому его необходимо вводить дополнительным дей-
ствием.
Пример. Создать текстовый файл. Ввод закончить при вводе
«пустой строки».
#include < stdio.h >
#include < stdlib.h >
#include < string.h >
void main()
{FILE*fp;
char name[20]; // Строка для имени
if((fp = fopen ("myfile",”w")) == NULL)
{ puts(" Невозможно открыть файл");
exit(l);
}
while (,t.) I/ Бесконечный цикл
{ printf("Введите имя:");
gets(name); // Ввод строки с клавиатуры
if (strlen(name) > 0) break; // Выход из цикла
fputs(name, fp); // Вывод строки в файл
fputs("\n", fp); // Записать «конец строки» в файл
}
fclose (fp);
}
12.2. Файловые функции обработки строк 209
Для того чтобы напечатать строку на принтере, вместо имени
файла используем стандартное имя для принтера «ргп»:
if ((fp = fopenf'pm", V)) == NULL)
Чтение строк из файла — функция fgets().
Функция вводит строку из файла до символа «конец строки»
(\п). Прототип функции:
char* fgets(char* strvar, int lenght, FILE *fp);
Здесь str var — указатель на строку, length — ограничитель дли-
ны строки, fp — указатель на файл.
Функция возвращает указатель на введенную строку в случае
успеха и нулевой указатель в противном случае.
Пример. Чтение строк из файла, созданного в предыдущем
примере.
#include <stdio.h>
void main()
{FlLE*fp;
char name[20];
if ((fp=fopen("MYFILE", ¥’))== NULL)
{рЩ8("Невозможно открыть файл");
exit(l);
while (fgets(name, 20, fp) != NULL)
printf(name);
fclose(fp);
}
Обратите внимание, что для указания конца файла использу-
ется:
• при построчном чтении fgets() — NULL;
• при посимвольном чтении getc, fgetc() — EOF.
210
Глава 12. Файловый ввод-вывод
Форматированный ввод-вывод, использование функции fprintf()
Формат функции fprintf() такой же, как у функции printf(), с той
разницей, что добавляется параметр для указания рабочего файла.
Пример
#include "stdio.h"
void main()
{FILE *fp;
char name[20];
int quantity;
float cost;
if ((fp=fopen("myflle", "w"))== NULL)
{puts("Omn6Ka при открытии файла");
exit(l);
printf("Наименование товара:");
gets (name); // Ввод с клавиатуры
while (strlen(name) > 0)
{ printf("HeHa товара: "); // Вывод на экран
// Вывод на экран
scanf("%f', &cost);
рптГ("Количество единиц товара:");
scanf("%d", &quantity);
I/ Форматированный вывод в файл
fprintf(fp,"%s\t%6.2f\t%d\n", name, cost, quantity);
рптГ("Наименование товара:");
gets(name);
fclose(fp);
Обратите внимание, что код «новая строка» записывается в
файл в конце каждой строки. Если просмотреть содержимое файла
с помощью текстового редактора, то каждая строка на экране будет
начинаться с новой строки:
дискеты 1.12 100
лента 7.34 150
картридж 75.00 3
12.3. Работа с двоичными данными
211
12.3. Работа с двоичными данными
Двоичное представление данных стирает различия между ти-
пами данных — это тип данных машинного уровня. На этом уров-
не функции ввода-вывода вместо понятия «тип данных» опериру-
ют понятием «блок данных», размер которого определяется в про-
грамме произвольно.
Функции для работы с двоичными файлами:
fread () — чтение данных, fwrite() — запись данных.
Прототипы функций:
int fread (void *pbuff, int qbyte, int qblock, FILLE *pf)
int fwrite (void *pbuff, int qbyte, int qblock, FILE *pf),
Здесь pbuff — указатель на данные для записи (чтения); qbyte —
размер блока (в байтах); qblock — количеситво блоков для записи
(чтения); pf — указатель на файл.
Возвращаемые значения — число блоков:
• считанных для fread(), может быть меньше заданного числа,
если обнаружен «конец файла»;
• записанных для fwrite(), если нет ошибки, это значение равно
параметру qblock.
Чаще всего fread() и fwrite() используются для работы со слож-
ными типами данных, например со структурами.
Пример. Записать в двоичный файл данные структурного типа.
// Объявление структуры
struct data
{ char name[40]; //Фамилия
int age; // Возраст
};
// Определение функции ввода с клавиатуры массива структур М[п]
void list ini (struct data M|], int n)
{int i;
212
Глава 12. Файловый ввод-вывод
printf ("\пВвод массива(размер %d)\n", п);
for(i=0; i<n; i++)
{рпп1Г(("Фамилия:");
scanf("%s", M[i].name); //ввести строку
printf ("Возраст:");
scanf("%d", &M[i].age);// ввести число
};
void main()
{ FILE *pf;
const int size =10;
struct data Listfsize], Rez[size], *pList;
list_ini (List, size); // Заполнить массив структур
pf = fopen("data.bin","wb"); // Зткрыть двоичный файл для записи
// Запись всего массива List [size]
fwrite (pList, sizeof(struct data),size, pf); // Записать данные в файл
fclose (pf);
pf = fopen ("data.bin", "rb"); // Открыть двоичный файл для чтения
// Чтение данных в цикле по 1 элементу массива List
for (pList=Rez; pList <List+size; pList++)
fread (pList, sizeof(struct data),!, pf);
fclose (pf);
I/ Вывести массив Rez на терминал
for (i=0; i<size; i++)
{ printf ("\n%s", Rez[i].name);
printf ("\tBO3pacT: %d", Rez[i].age);
}
}
Структура struct data предназначена для хранения информа-
ции о фамилии и возрасте человека и имеет два поля :
• char name[40] — строка текста;
• int age — целое число.
В функции main() создается массив структур List [size] для раз-
мещения информации в памяти компьютера. Функция list_ini()
позволяет ввести информацию с клавиатуры. В примере демонст-
рируется гибкость работы с двоичной информацией, запись мас-
сива List [size] в файл выполняется за одно обращение к функции
fwrite, чтение же проводится в цикле, из файла считывается по од-
ному элементу массива List.
12.4. Произвольный доступ к данным файла
213
12.4. Произвольный доступ к данным файла
Выше мы рассмотрели последовательный доступ к данным.
Все функции работы с файлами после выполнения действия (чте-
ния или записи) автоматически передвигают файловый указатель
на следующий элемент данных, таким образом обеспечивая после-
довательный «перебор» данных. Если требуется выборочная работа
с данными, необходимо использовать функции произвольного пере-
мещения файлового указателя. Для этой цели используются четыре
функции.
1. Функция rewindf) перемещает указатель (курсор) файла в на-
чало файла.
Прототип функции:
void rewind (FILE *fp);
2. Функция fseek() устанавливает курсор файла в заданную по-
зицию.
Прототип функции:
int fseek (FILE *fp, long delta, int begin)
Здесь fp — указатель на файл; delta — смешение относительно
«начала отсчета» (в байтах); begin — макрос, пределяющий «начало
отсчета».
Имена макросов представлены в табл. 12.3.
Таблица 12.3
Начало отсчета Имя макроса
Начало файла SEEK_SET
Текущая позиция SEEKCUR
Конец файла SEEKEND
3. Функция ftell() определяет текущую позицию файлового указа-
теля относительно начала файла.
Прототип функции:
long int ftell (FILE *fp)
214
Глава 12. Файловый ввод-вывод
4. Функция intfeof (FILE *fp) возвращает истинное значение, если
обнаружен «конец файла».
Несколько примеров ниже демонстрируют произвольный дос-
туп к массивам структур, расположенных в файле.
Пример. Работа с двоичным файлом. Используется структура
struct data, определенная в предыдущем примере. Создать исход-
ный массив структур List [size], прочитать каждый второй элемент
исходного массива в массив Rez и вывести его на экран.
#include <stdio.h>
#include <windows.h>
char msg[80];
// Прототип функции для ввода с клавиатуры массива структур data
void list_ini(struct data M[], int и);
void main()
{ FILE *pw,*pr;
const int size=5;
int i,k=l;
struct data List [size];
struct data *pList;
struct data Rez[size];
list_ini (List,size);
pw = fopen(’’data.bin","wb”);
// Исходный массив
// Массив результата
I/ Ввод массива с клавиатуры
//Двоичный файл для записи
fwrite (List,sizeof(struct data),size, pw); // Запись List[size] в файл
fclose (pw); // закрыть файл
pr = fopen ("data.bin","rb"); // Тот же двоичный файл для чтения
pList=Rez;
// Прочитать 1 структуру из файла в массив Rez
fread (pList, sizeof(struct data),l, pr);
while (!feof(pr))
{
printf ("\n%d : %d",i,pList->age); // Печать на экран
printf (”\t%s\t",pList->name);
// перемещение курсора файла на 1 позицию (пропуск 1-го элемента)
fseek (pr,sizeof(struct data),SEEK CUR);
pList++; // Перемещение указателя на следующий
// элемент массива Rez
fread (pList, sizeof(struct data), 1, pr); // Чтение из файла в массив
};
fclose (pr); // Закрыть файл
}
12.4. Произвольный доступ к данным файла
215
Пример. Прочитать п последних структур из файла.
#include <stdio.h>
#include <stdlib.h>
#define k 15
#define n 3
void main()
/* Объявление структуры balance и создание двух массивов:
mailfk] , buf_mail[n] */
{struct balance
{ float bal;
char namel25J;
} mail[k], buf_mail[n];
H
FILE *p_f;
int i;
// Заполнить массив структур
for (i=0 ; i<k ; i++)
{ printf ("bal=");
scanf (”%le",&mail[i].bal);
printf ("name—');
gets (mail[i].name);
}
// Открыть двоичный файл для чтения и записи
if ((p_f = fopen("mystruct", "wb+")) == NULL)
{рШзС'Невозможно открыть файл");
exit(l);
}
//Записать данные из mail[k] в двоичный файл
fwrite (mail, sizeof(struct balance), k, p_f);
// Установить курсор файла на n-ый элемент,
// считая от конца
fseek ( p_f, (-n)*sizeof(struct balance), SEEK END );
// Прочитать n эл-тов файла
fread ( buf mail ,sizeof(struct balance), n , p_f);
for (i=0; i < n ; i++)
printf ("bal=%f\t name=%s\n", buf_mail[i].bal, buf_mail[i].name);
}
216
Глава 12. Файловый ввод-вывод
Пример. Работа с текстовым файлом. Прочитать каждый вто-
рой символ файла.
void main()
{ inti;
FILE *fp;
const int n=50;
char sim;
if((fp = fopen("textl.txt","r"))== NULL)
{puts("Error open:text 1 .txt");
exit(l);}
// Вывод всего текста на экран (без пропусков)
while (!feof (fp))
{ sim=fgetc(fp);
putchar (sim);
};
putchar('\n');
rewind(fp);
sim=fgetc(fp);
while (!feof(fp))
{putchar(sim);
// Продолжить, пока не конец файла (==0)
// Чтение символа из файла
// Вывод символа на экран
// Переместить файловый указатель в начало
// Чтение символа из файла
//==0
// Переместить файловый указатель на одну позицию
fseek(fp, 1, SEEK CUR);
sim = fgetc (fp);
};
putchar('\n');
fclose (fp);
Пример. Построчная работа с текстовым файлом.
void main()
{int i;
FILE*fp;
const int n=50;
char name[n],*ps;
if((fp = fopen ("text.txt","r")) == NULL)
{putsf'Error open");
exit(l);}
12.4. Произвольный доступ к данным файла
217
while (!feof(fp)) // Аналог : feof(fp)==0
{if (fgets (name, n, fp)) // Аналог : fgets (name, n, fp) !=0
puts (name);
else puts( "error fgets");
};
fclose (fp);
}
Пример. Запись и чтение переменных различного типа в дво-
ичном формате.
#include <stdio.h>
#include <stdlib.h>
void main()
{ FILE*p_f;
double d =23.67, dl;
int i =12, il;
long h =1234567L, hl;
if ((p_f = fopen("myfile", ”wb+"))==NULL)
{puts("HeBO3MoxHo открыть файл");
exit(l);
}
// Запись данных из памяти (из переменных) в файл
fwrite (&d , sizeof(double), 1 , pf);
fwrite (&i, sizeof(int), 1 , p_f);
fwrite (&h , sizeof(long), 1 , p f);
rewind(pf); // Установить курсор в начало
// Чтение данных из файла в память
fread (&d 1 , sizeof(double), 1 , p f);
fread (&il , sizeof(int), 1 , pf);
fread (&hl , sizeof(long), 1 , p f);
printf ("dl=%fil= %d hl= %ld\n" , dl, il, hl);
fclose (p_f);
}
Литература
1. Керниган Б., Ритчи Д. Язык программирования С. М.: Вильямс,
2009.
2. Подбельский В.В. Программирование на Языке Си: учеб, пособие.
М.: Финансы и статистика, 2003.
3. Костюкова Н.И., Калинина Н.А. Язык Си и особенности работы с
ним: М.: Бином, 2006.
4. Самюэл П., Харбисон Г., Стил Л. Язык С с примерами. М.: Бином,
2011.
5. Шилдт Г. Полный справочник по С. М.: Вильямс, 2002.
6. Пауэрс Л., Снелл М. Microsoft Visual Studio 2008. СПб.: БХВ, 2009.
7. Бобровский С.И. Самоучитель программирования в системе Borland
C++ Builder 4.0. М.: Десс, 1999.
Оглавление
Введение................................................3
Глава 1. БАЗОВЫЕ ПОНЯТИЯ ПРОГРАММИРОВАНИЯ ..............5
1.1. Алгоритмизация задачи.....................6
1.2. Схема алгоритма программы ................7
1.3. Пример алгоритмизации.....................7
1.4. Этапы трансляции программы................9
Глава 2. ОБЗОР ЯЗЫКА С................................ 13
2.1. Особенности языка ...................... 13
2.2. Элементы языка.......................... 15
2.2.1. Алфавит ........................... 15
2.2.2. Лексемы ........................... 17
2.2.3. Идентификаторы .................... 18
2.2.4. Ключевые слова..................... 19
2.2.5. Переменные..........................20
2.2.6. Константы ..........................20
2.3. Стандартные типы данных..................21
2.3.1. Простые типы данных ................22
2.3.2. Модификация типов данных ...........23
2.3.3. Символьные данные...................25
2.3.4. Целые числа.........................25
2.3.5. Данные плавающего типа
(вещественные числа) ......................26
220
Оглавление
2.3.6. Инициализация переменных ............27
2.4. Компоненты простой программы..............27
2.4.1. Структура С-программы ...............28
2.4.2. Комментарии как средство облегчения
понимания программы ........................30
2.4.3. Пример создания программы............32
Глава 3. ВЫРАЖЕНИЯ И ОПЕРАЦИИ.......................... 34
3.1. Операция и выражение присваивания.........35
3.2. Бинарные арифметические операции .........36
3.3. Операции увеличения (++) и уменьшения (--) .... 37
3.4. Преобразования типов при вычислении
арифметических выражений ......................39
3.4.1. Неявное преобразование типов.........39
3.4.2. Явное преобразование типов ..........40
3.5. Тернарная или условная операция ..........42
3.6. Логические операции и операции отношения .43
3.7. Поразрядные (побитовые) операции .........46
3.8. Операции сдвига...........................49
3.9. Операция sizeof...........................50
3.10. Операция следования......................50
3.11. Сводная таблица операций языка С ........51
Глава 4. ОПЕРАТОРЫ..................................... 54
4.1. Оператор выражение........................54
4.2. Пустой оператор...........................55
4.3. Объявления и составной оператор ..........56
4.4. Условный оператор ........................57
4.5. Оператор выбора switch....................60
4.6. Циклы.....................................64
4.6.1. Цикл с предусловием while ...........65
Оглавление 221
4.6.2. Цикл с постусловием do—while ........67
4.6.3. Пошаговый цикл. Оператор for .......69
4.7. Оператор break ...........................73
4.8. Оператор безусловного перехода goto.......74
4.9. Оператор continue.........................76
4.10. Оператор return ..........................77
Глава 5. МАССИВЫ .......................................79
5.1. Одномерные статические массивы............80
5.2. Объявление массива. Обращение
к элементу массива.............................81
5.3. Инициализация массива.....................83
5.4. Многомерные массивы.......................84
5.5. Выход индекса за границы массива .........85
5.6. Приемы работы с массивами в вычислительных
задачах .......................................87
5.7. Строка как массив символов ...............91
Глава 6. УКАЗАТЕЛИ И ССЫЛКИ.............................95
6.1. Понятие указателя.........................95
6.2. Операция получения адреса &...............96
6.3. Операция разыменования (*)................97
6.4. Арифметика указателей.....................99
6.4.1. Операция присваивания ..............99
6.4.2. Унарные операции изменения указателя,
инкремент и декремент (++ —) ...............99
6.4.3. Аддитивные операции (сложение
и вычитание) ............................. 100
6.4.4. Сравнение указателей ............. 101
6.5. Применение указателей в выражениях...... 101
6.6. Указатели и массивы..................... 103
6.7. Ссылочный тип данных ................... 107
222
Оглавление
Глава 7. ВРЕМЯ ЖИЗНИ И ОБЛАСТЬ ВИДИМОСТИ
ПЕРЕМЕННОЙ ......................................... 112
7.1. Общие понятия......................... 112
7.2. Классы памяти ........................ 114
7.3. Вложенные блоки в программе........... 117
Глава 8. ФУНКЦИИ ................................... 120
8.1. Общие понятия......................... 121
8.2. Определение функции................... 122
8.3. Прототип функции ..................... 123
8.4. Переменные в функции ................. 125
8.5. Передача параметров в функцию ........ 130
8.5.1. Передача параметров по значению . 131
8.5.2. Указатель в качестве параметра
функции ........................... 133
8.5.3. Передача параметров по ссылке.... 137
8.5.4. Передача массива в функцию....... 138
Глава 9. ПОЛЬЗОВАТЕЛЬСКИЕ ТИПЫ ДАННЫХ............... 145
9.1. Структурный тип данных................ 145
9.1.1. Определение структуры............ 146
9.1.2. Оператор typedef................. 150
9.1.3. Определение структуры безымянного
типа.................................... 151
9.1.4. Доступ к элементам структуры......152
9.1.5. Операции присваивания и сравнения
для структур............................ 158
9.1.6. Определение размера структуры.
Оператор sizeof......................... 159
9.2. Битовые поля ......................... 161
9.3. Объединения или смеси ................ 165
9.4. Перечисления.......................... 168
Оглавление
223
Глава 10. ДИНАМИЧЕСКАЯ РАБОТА С ПАМЯТЬЮ....... 172
10.1. Универсальный указатель void ... 178
10.2. Принципы работы с динамическими
массивами............................. 180
Глава 11. ВВОД-ВЫВОД ДАННЫХ................... 185
11.1. Ввод-вывод данных на консоль.
Библиотека stdio............................... 187
11.1.1. Стандартные потоки библиотеки stdio ... 187
11.1.2. Чтение и запись символов.......... 188
11.1.3. Чтение и запись строк ............ 191
11.1.4. Обзор консольных функций
ввода-вывода ............................. 193
11.1.5. Форматированный ввод-вывод данных .. 193
11.1.6. Сравнительная характеристика
консольных функций ввода-вывода ...........197
11.2. Функции ввода-вывода библиотеки iostream .... 198
11.2.1. Форматирование ввода-вывода ...... 199
Глава 12. ФАЙЛОВЫЙ ВВОД-ВЫВОД ............ 202
12.1. Четыре этапа работы с файлами ........203
12.2. Файловые функции обработки строк......207
12.3. Работа с двоичными данными............211
12.4. Произвольный доступ к данным файла....213
Литература .................................................. 218
По вопросам приобретения книг обращайтесь:
Отдел продаж «ИНФРА-М» (оптовая продажа):
127214, Москва, ул. Полярная, д. 31 В, стр. I
Тел. (495) 280-33-86 (доб. 218, 222)
E-mail: bookwarc@infra-m.ru
Отдел «Книга—почтой»:
тел. (495) 280-33-86 (доб. 222)
Издание не подлежит маркировке
ФЗ Издание не подлежит маркиров
№ 436-ФЗ в соответствии с п. 1 ч. 4 ст. 11
Учебное издание
Дорогое Виктор Георгиевич,
Дорогова Екатерина Георгиевна
ОСНОВЫ ПРОГРАММИРОВАНИЯ
НА ЯЗЫКЕ С
УЧЕБНОЕ ПОСОБИЕ
Под редакцией Л.Г. Гагариной
ООО «Издательский дом ФОРУМ»
127247, Москва, ул. Софьи Ковалевской, д. 1, стр. 51
E-mail: forum2-book@yandcx.ru
Тел.: (495) 280-15-96
ООО «Научно-издательский центр ИНФРА-М»
127214, Москва, ул. Полярная, д. 31В, стр. 1
Тел.: (495) 280-15-96, 280-33-86. Факс: (495) 280-36-29
E-mail: books@infra-m.ru http://www.infra-m.ru
Подписано в печать 14.01.2020.
Формат 60x90/16. Бумага офсетная. Гарнитура Times.
Печать цифровая. Усл. печ. л. 14,0.
ППТ50. Заказ № 00000
ГК 684824-1082440-181119
Отпечатано в типографии ООО «Научно-издательский центр ИНФРА-М»
127214, Москва, ул. Полярная, д. 31В. стр, 1
Тел.: (495) 280-15-96, 280-33-86. Факс: (495) 280-36-29