/





























































































































































































































































































































































































































































































































































Автор: Моли Б.
Теги: программирование операционная система unix операционная система linux
ISBN: 0-13-008396-8
Год: 2004




Текст
Брюс Моли
Unix/Linux
Теория и практика программирования
Перевод с английского
КУДИЦ-ОБРАЗ
МОСКВА • 2004
ББК 32.973-018.2
Моли Б.
Unix®/Linux: теория и практика программиррвания. Пер. с англ. - М: КУДИЦ-ОБРАЗ,
2004. - 576 с.
Книга посвящена вопросам системного программирования в среде Unix.
Излагаемый материал является общим для всех разновидностей систем Unix.
Теоретический материал сопровождается примерами реальных программ и большим
количеством тем для обсуждения и самостоятельной разработки. Книга будет полезна
прежде всего студентам, а также всем, кто программирует в среде Unix и хочет
наилучшим образом использовать инструментальные возможности системы.
ISBN 0-13-008396-8
ISBN 5-93378-087-1
Брюс Моли
Unix®/Linux: теория и практика программирования
Учебно-справочное издание
Корректор М. Матёкин
Перевод с англ. В. Д. Никитин
Научный редактор Л. И. Шустова
Лицензия ЛР № 071806 от 02.03.99. НОУ «ОЦ КУДИЦ-ОБРАЗ»,
119034, Москва, Гагаринский пер., д. 21, стр. 1. Тел.: 333-82-11, ok@kudits.ru
Подписано в печать 12.02.2004.
Формат 70x100/16. Печать офсетная.
Усл. печ. л. 46,4. Тираж 2000. Заказ 4227
Отпечатано с готовых диапозитивов в ООО «Типография ИПО
профсоюзов Профиздат», 109044, Москва, Крутицкий вал, 18.
ISBN 0-13-008396-8
ISBN 5-93378-087-1 © НОУ «ОЦ КУДИЦ-ОБРАЗ», 2004
Авторизованный перевод с англоязычного издания, озаглавленного UNDERSTANDING UNIX/LINUX
PROGRAMMING, 1st Edition by MOLAY, BRUCE, опубликованного Pearson Education, Inc, под
издательской маркой Prentice Hall, Copyright © 2003 by Pearson Education, Inc.
All rights reserved. No part of this book may be reproduced or transmitted in any forms or by any means,
electronic or mechanical, including photocopying, recording or by any information storage retrieval system,
without permission from Pearson Education Inc.
Все права защищены. Никакая часть этой книги не может воспроизводиться или распространяться
в любой форме или любыми средствами, электронными или механическими, включая фотографирование,
магнитную запись или информационно-поисковые системы хранения информации без разрешения от
Pearson Education, Inc
Русское издание опубликовано издательством КУДИЦ-ОБРАЗ, © 2004
Предисловие
Понимание Unix программирования
Что такое UNIX?
Я написал эту книгу, чтобы объяснить, как работает Unix, и показать, как нужно писать
системны^ программы для Unix. Unix, развиваясь более тридцати лет, стал богаче, но
ненамного сложнее. Дли нее всё также остаются справедливыми фундаментальная
структура и принципы проекта. Помимо того, что вам станут понятны структура, принципы и
история системы, вы можете читать, расширять и добавлять знания, касающиеся
программирования в Unix, знания, которые рассредоточены в обширной литературе. Вам будет
представлена возможность и немного поразвлечься.
Для того, чтобы донести суть идей я преподношу их в книге в различных формах:
в форме картинок, используя аналогии, применяя псевдокод и реальный код, используя
эксперименты, упражнения, и анекдоты. Эти объяснения и факты брались из реальных,
полезных задач и проектов.
Кому будет полезна эта книга?
Вы должны иметь навык программирования в С. Если Вы обладаете навыком работы в C++,
то вы быстро адаптируетесь и будете отслеживать предлагаемые коды. Вы должны знать о
массивах, структурах, указателях, связанных списках и должны понимать как использовать эти
элементы при написании программных кодов.
От вас не требуется знания особенностей использования Unix или знания внутренней
структуры Unix. Каждую главу мы будем начинать с представления Unix с
пользовательского уровня. Вопрос "Что делает этот механизм?", поставленный на пользовательском
уровне, неизбежно приводит к вопросу системного уровня "Как это работает?"
Вам нужно иметь доступ к системе Unix и подготовиться к тому, что потребуется иногда
рисковать. >
Зачем это мне?
Эта книга дает теоретическое представление о компонентах системы Unix с позиций, что
они делают, дает теорию с позиций, как они работают, и как следует программировать,
используя эти компоненты. Вы также увидите, как можно объединять все эти компоненты,
чтобы получить понятную и ясную операционную систему.
6
Благодарности
Эта книга базируется на материале,курса лекций Системное Программирование в Unix,
который я читал с 1990 в Harvard Extension School. Студенты, как при оценках курса, так
и позже, по электронной почте писали, что дал им этот курс. Так один студент сообщил,
что курс дал ему " ключи к королевству." Он понял Unix на пользовательском,
программистском и теоретическом уровнях в достаточной степени для того, чтобы почувствовать
все это вместе и применить в отношении большинства из возникающих проблем. Это
напоминает подготовку врачей, когда студенты медики учатся работать с реальными
проблемами.
Другой студент, один из тех , кто он поставил целью стать лидером проекта OSF (Open
Software), сказал, что курс научил его идеям и позволил получить профессиональную
подготовку, необходимую для этой работы.
В отношении какой версии Unix написана книга?
Материал распространим по отношению большинства систем Unix, включая GNU/Linux.
В книге внимание сосредоточено на структуре и подходах, из которых сформированы
основы всех версий Unix. Изложение не фокусируется на специфичных отличиях между
отдельными диалектами. Если были поняты основные идеи, то можно легко изучить и эти
детали. /
Благодарности
Появление этой книги стало возможным благодаря помощи многих людей.
Я благодарен Петра Рехтеру (Prentice-Hall) за предоставление возможности издания и
руководство проектом, а также благодарен Грегори Даллесу за работу со мной по иллюстрации
книги, предложения этой возможности и для руководства
Я благодарен рецензентам книги за их внимательную работу, за замечания,
способствующие улучшению книги, и конкретные предложения: Бену Абботу, Джону Б. Коннели,
Геофу Сацлайфу, Луису Таберу, Сэму Р. Тангиаху и Лоуренсу Б.Уэлсу. Я благодарен Пегги
Бастаманту и Амит Чаттержи за предоставление кардинальной информации о
графическом программном обеспечении. Я благодарю Юрико Кувабара за несчетное число бесед,
за моральную и практическую поддержку в этом проекте.
Я благодарен тем многим студентам и преподавателям, которые были заняты в курсе
Системное Программирование в Unix, чьи вопросы и замечания в аудиторных дискуссиях
и при проведении консультаций помогли оформлению схем, объяснений, метафор
и образов, использованных в этой книги. Особую благодарность выношу Ларри деЛюка,
который работал в качестве ассистента по курсу, и за материал, который был изложен
в главе 13.
Содержание
Глава 1 Системное программирование в Unix.
Общие представления > 24
1.1. Введение . 24
1.2. Что такое системное программирование? ........24
1.2.1. Простая модель программы 24
1.2.2. Реальность 25
1.2.3. Роль операционной системы 26
1.2.4. Поддержка сервиса для программ 27
1.3. Понимание системного программирования 28
1.3.1. Системные ресурсы 28
1.3.2. Наша цель: понимание системного программирования 29
1.3.3. Наш метод: три простых шага ... 29
1.4. UNIX с позиций пользователя 30
1.4.1. Что делает Unix? 30
1.4.2. Вхождение в систему — запуск программ—выход из системы 30
1.4.3. Работа с каталогами 32
1.4.4. Работа с файлами 34
1.5. Расширенное представление об UNIX 36
1.5.1 Взаимодействие (связь) между людьми и программами 36
1.5.2.Турниры по игре в бридж через Интернет ..37
1.5.3. be: секреты настольного калькулятора в Unix 38
1.5.4. От системы bc/dc к Web .41
1.6. Могу ли я сделать то же самое? 41
1.7. Еще несколько вопросов и маршрутная карта ...49
1.7.1. О чем пойдет теперь речь? 49
1.7.2. А теперь - карта 49
1.7.3 Что такое Unix? История и диалекты 50
Заключение 51
Глава 2 Пользователи, файлы и справочник.
Что рассматривать в первую очередь? 52
2.1. Введение 52
2.2. Вопросы, относящиеся к команде who 53
2.2.1. Программы состоят из команд , 53
2.3. Вопрос 1: Что делает команда who? 54
2.3.1. Обращение к справочнику 54
2.4 Вопрос 2: Как работает команда who? v56
2.4.1. Мы теперь знаем, как работает who 60
8 Содержание
2.5 Вопрос 3: Могу ли я написать who? . 60
2.5.1. Вопрос: Как я буду читать структуры из файла? ...61
2.5.2. Ответ: Использование open, read и close 62
2.5.3. Написание программы whol.c 65
2.5.4,Отображение записей о вхождениях в систему 65
2.5.5. Написание версии who2.c 67
2.5.6. Взгляд назад и взгляд вперед 72
2.6. Проект два: Разработка программы ср (чтение и запись) .....73
2.6.1. Вопрос 1: Что делает команда ср? 73
2.6.2. Вопрос 2: Как команда ср создает файл и как пишет в него? 73
2.6.3. Вопрос 3: Могу ли я написать программу ср? : 74
2.6.4. Программирование в Unix кажется достаточно простым 77
2.7. Увеличение эффективности файловых операций ввода/вывода:
Буферирование 77
2.7.1. Какой размер буфера следует считать лучшим? 77
2.7.2 Почему на системные вызовы требуется тратить время? .78
2.7.3. Означает ли, что наша программа who2.c неэффективна? 79
2.7.4. Добавление буферирования к программе who2.c 80
2.8. Буферизация и ядро 83
2.8.1. Если буферизация столь хороша, то почему ее не использует ядро? 83
2.9. Чтение файла и запись в файл 84
2.9.1. Выход из системы: Что происходит? : 84
2.9.2. Выход из системы: Как это происходит 85
2.9.3. Смещение текущего указателя: lseek 86
2.9.4. Кодирование выхода из системы через терминал 87
2.10. Что делать с ошибками системных вызовов? 88
Заключение 90
Исследования ..9J
Программные упражнения 92
Проекты 93
Глава 3 Свойства каталогов и файлов при просмотре
с помощью команды Is 95
3.1. Введение 95
3.2. Вопрос 1: Что делает команда Is? 96
3.2.1. Команда Is выводит список имен файлов и оповещает об атрибутах
файлов 96
3.2.2. Получение листинга о других каталогах, получение информации
о других файлах .; 96
3.2.3. Наиболее употребимые опции 97
3.2.4. Первый ответ: Итоговые замечания 97
3.3. Краткий обзор дерева файловой системы 97
Содержание 9
3.4. Вопрос 2: Как работает команда Is? ;.,• 98
3.4.1. Что же такое каталог, в конце концов? , 98
3.4.2. Работают ли системные вызовы open, read и close в отношении
каталогов? 99
3.4.3. Хорошо, хорошо. Но как же мне прочитать каталог? 100
3.5. Вопрос 3: Могу ли я написать Is? ....102
3.5.1. Что еще нужно делать? 103
3.6. Проект 2: Написание версии Is -.1 ¦, 104
3.6.1. Вопрос 1: Что делает Is -1? , 104
3.6.2. Вопрос 2: Как работает Is -1? 105
3.6.3. Ответ: Системный вызов stat получает информацию о файле ...105
3.6.4. Какую еще информацию можно получить с помощью системного
вызова stat? 106
3.6.5. Чего мы достигли? ,.,....., 108
3.6.6. Преобразование числового значения поля mode в символьное
значение 108
3.6.7. Преобразования числового представления идентификаторов
собственника/группы в строковое представление .112
3.6.8. Объединение всего вместе: ls2.c 115
3.7. Три специальных разряда , 119
3.7.1. Разряд Set-User-ID 119
3.7.2 Разряд Set-Group-ID 121
3.7.3 Разряд Sticky Bit 121
3.7.4. Специальные разряды и Is -1 122
3.8. Итоги для команды Is 122
3.9. Установка и модификация свойств файла 123
3.9.1. Тип файла 123
3.9.2. Разряды прав доступа и специальные разряды 123
3.9.3. Число ссылок на файл 124
3.9.4. Собственники группа для файла 125
3.9.5. Размер файла 126
3.9.6. Время последней модификации и доступа 126
3.9.7. Имя файла * 127
Заключение 127
Исследования -. 128
Программные упражнения 130
Проекты 132
Глава 4 Изучение файловых систем. Разработка версии pwd 133
4.1. Введение 133
4.2. Пользовательский взгляд на файловую систему 134
4.2.1. Каталоги и файлы ., 134
4.2.2. Команды для работы с каталогами 134
10 Содержание
4.2.3. Команды для работы с файлами 135
4.2.4. Команды для работы с деревом 136
4.2.5. Практически нет пределов на древовидную структуру 137
4.2.6. Итоговые замечания по файловой системе Unix 137
4.3. Внутренняя структура файловой системы UNIX 137
4.3.1. Абстракция 0: От пластин к разделам ; 138
4.3.2. Абстракция 1: От плат к массиву блоков 138
4.3.3. Абстракция 2: От массива блоков к дереву разделов 138
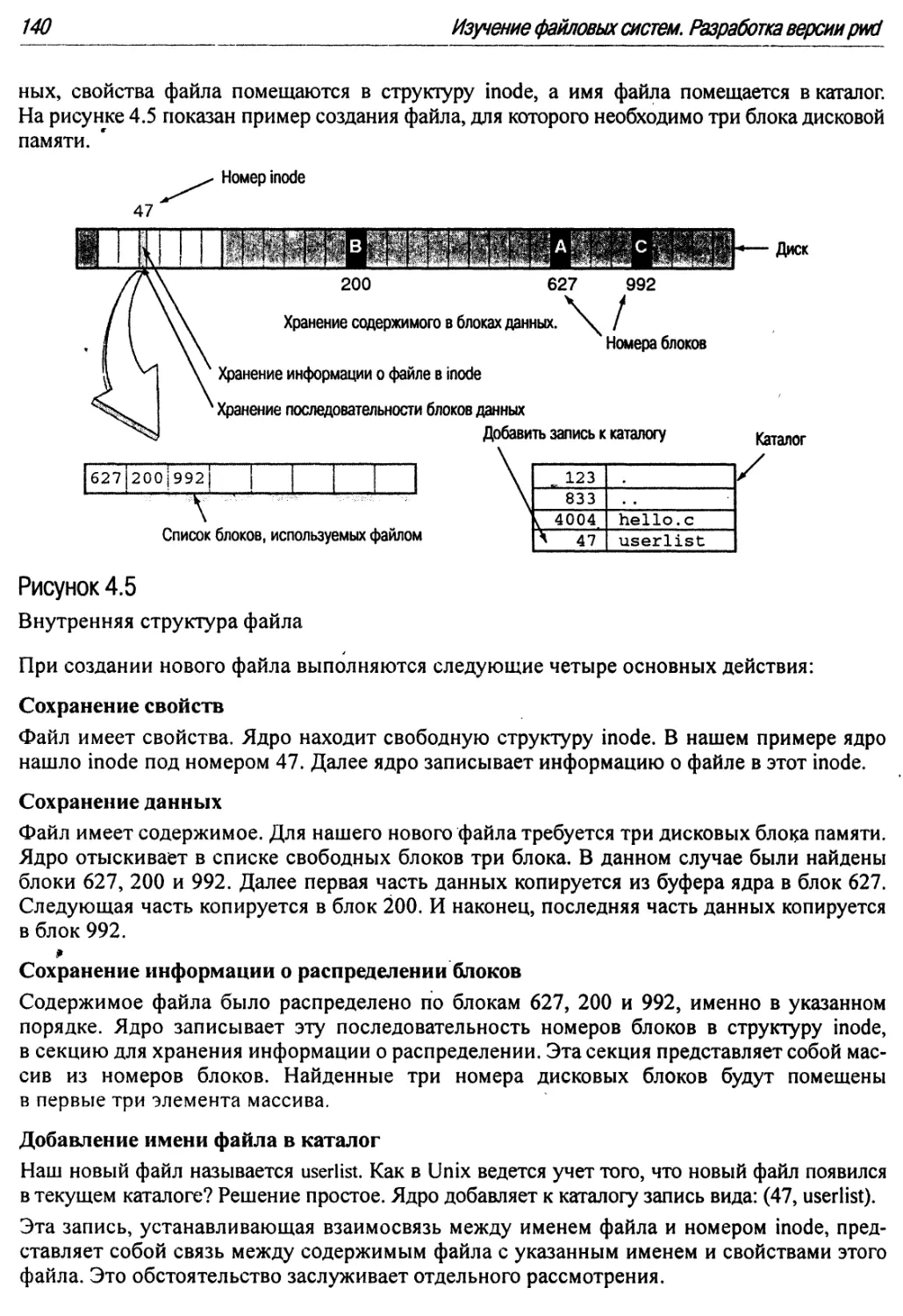
4.3.4. Файловая система с практических позиций: Создание файла ...139
4.3.5. Файловая система с практических позиций:
Как работают каталоги 141
4.3.6. Файловая система с практических позиций:
Как работает команда cat 142
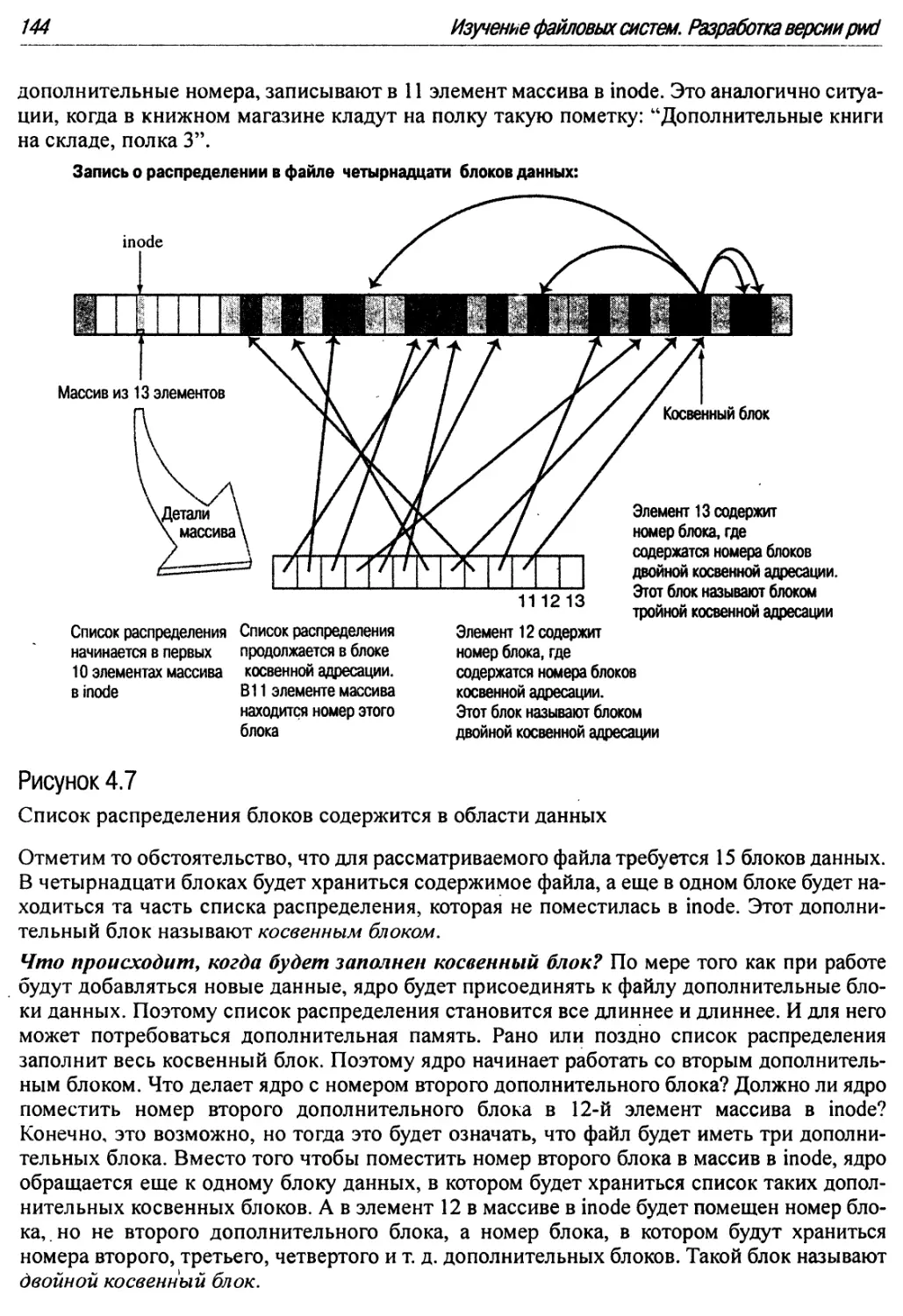
4.3.7 Inodes и большие файлы : 143
4.3.8. Варианты файловых систем в Unix 145
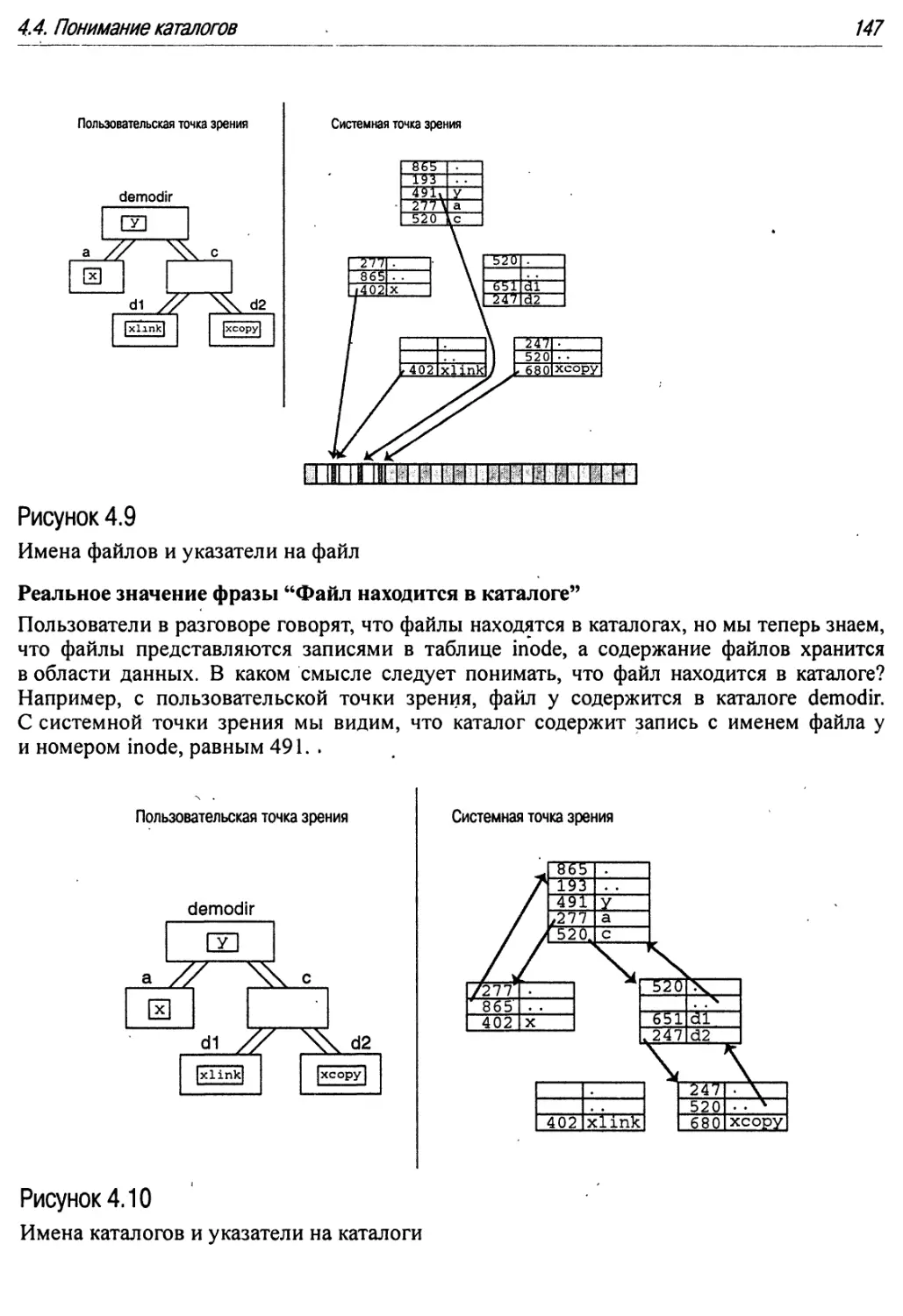
4.4. Понимание каталогов 145
4.4.1. Понимание структуры каталога 146
Реальное значение фразы "Каталог содержит подкаталоги" 148
4.4.2. Команды и системные вызовы для работы с деревьями каталогов. 149
4.5. Разработка программы pwd ;. 153
4.5.1. Как работает команда pwd? 153
4.5.2. Версия команды pwd 154
4.6. Множественность файловых систем: Дерево из деревьев 156
4.6.1 Точки монтирования 157
4.6.2. Дублирование номеров Inode и связей между устройствами ....158
4.6.3. Символические ссылки: Панацея или блюдо спагетти? 159
Заключение ».. 160
Исследования 161
Программные упражнения 164
Проекты 164
Глава 5 Управление соединениями. Изучение stty 165
5.1. Программирование устройств 166
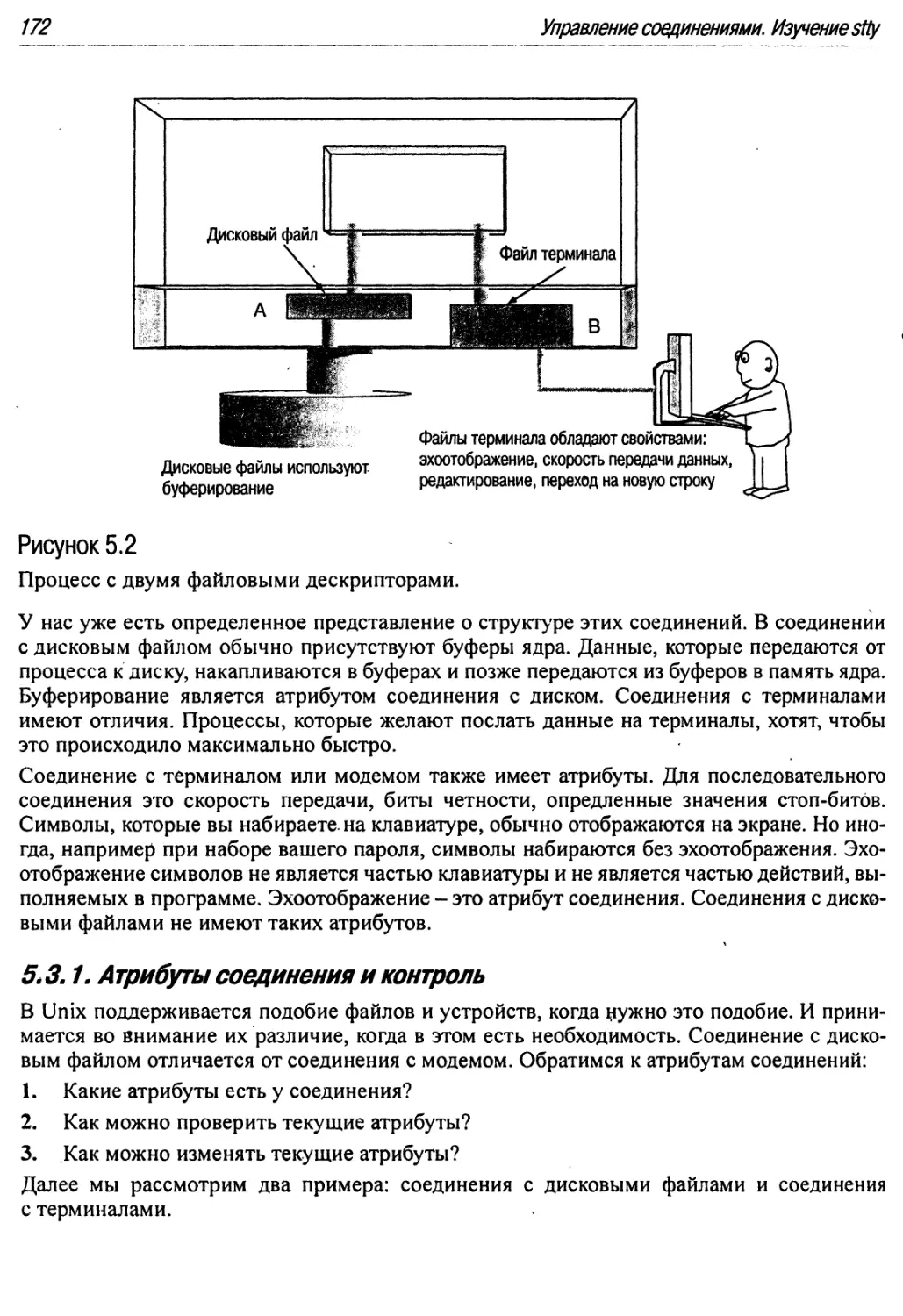
5.2. Устройства подобны файлам 166
5.2.1. Устройства имеют имена файлов 166
5.2.2. Устройства и системные вызовы 167
5.2.3. Пример: Терминалы аналогичны файлам k 167
5.2.4 Свойства файлов устройств 168
5.2.5. Разработка команды write 169
5.2.6. Файлы устройств и Inodes 170
5.3. Устройства не похожи на файлы 171
5.3.1. Атрибуты соединения и контроль 172
Содержание 11
5.4. Атрибуты дисковых соединений 173
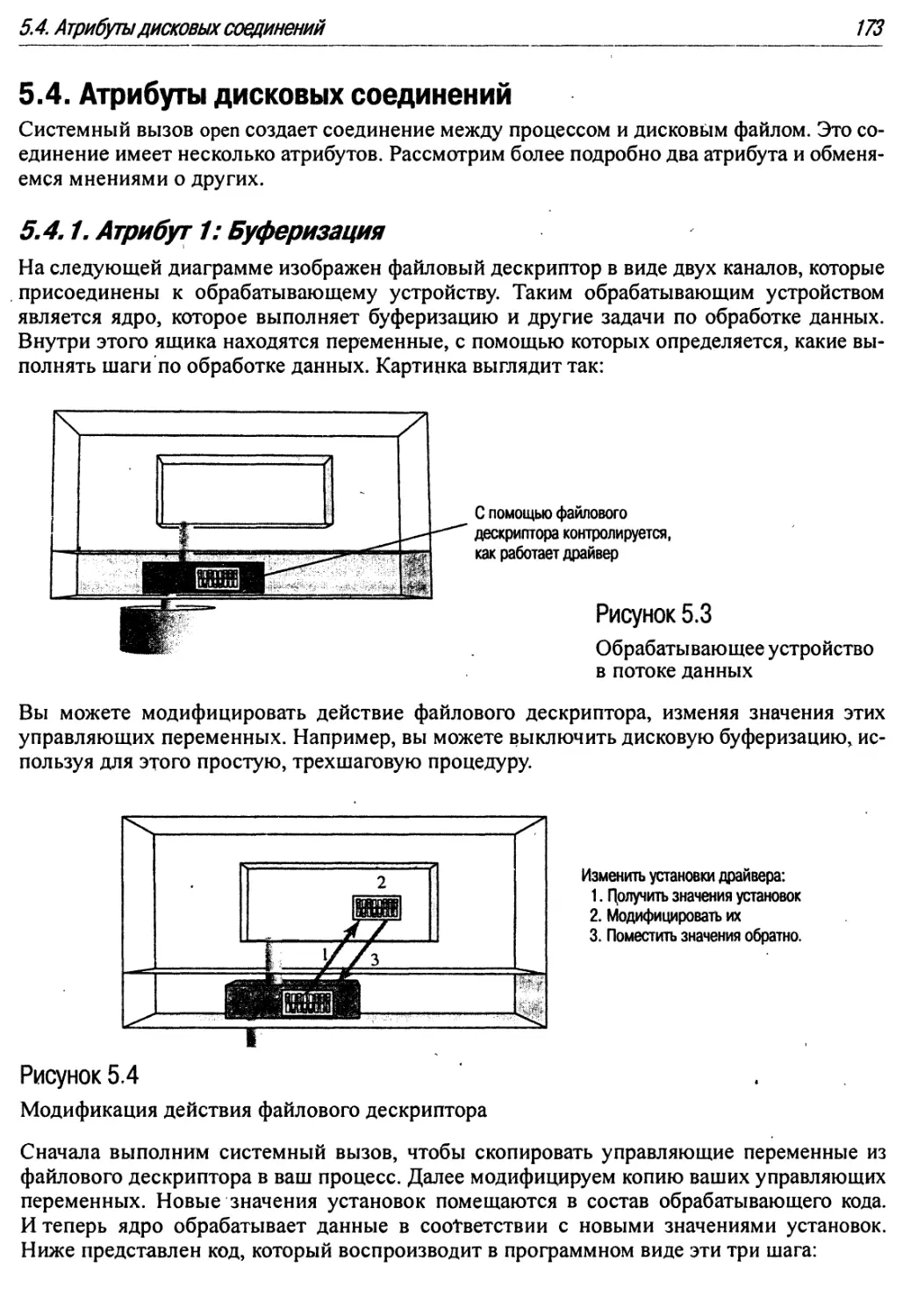
5.4.1. Атрибут 1: Буферизация : » 173
5.4.2. Атрибут 2: Режим Auto-Append 174
5.4.3. Управление файловыми дескрипторами с помощью системного
вызова open '..< 177
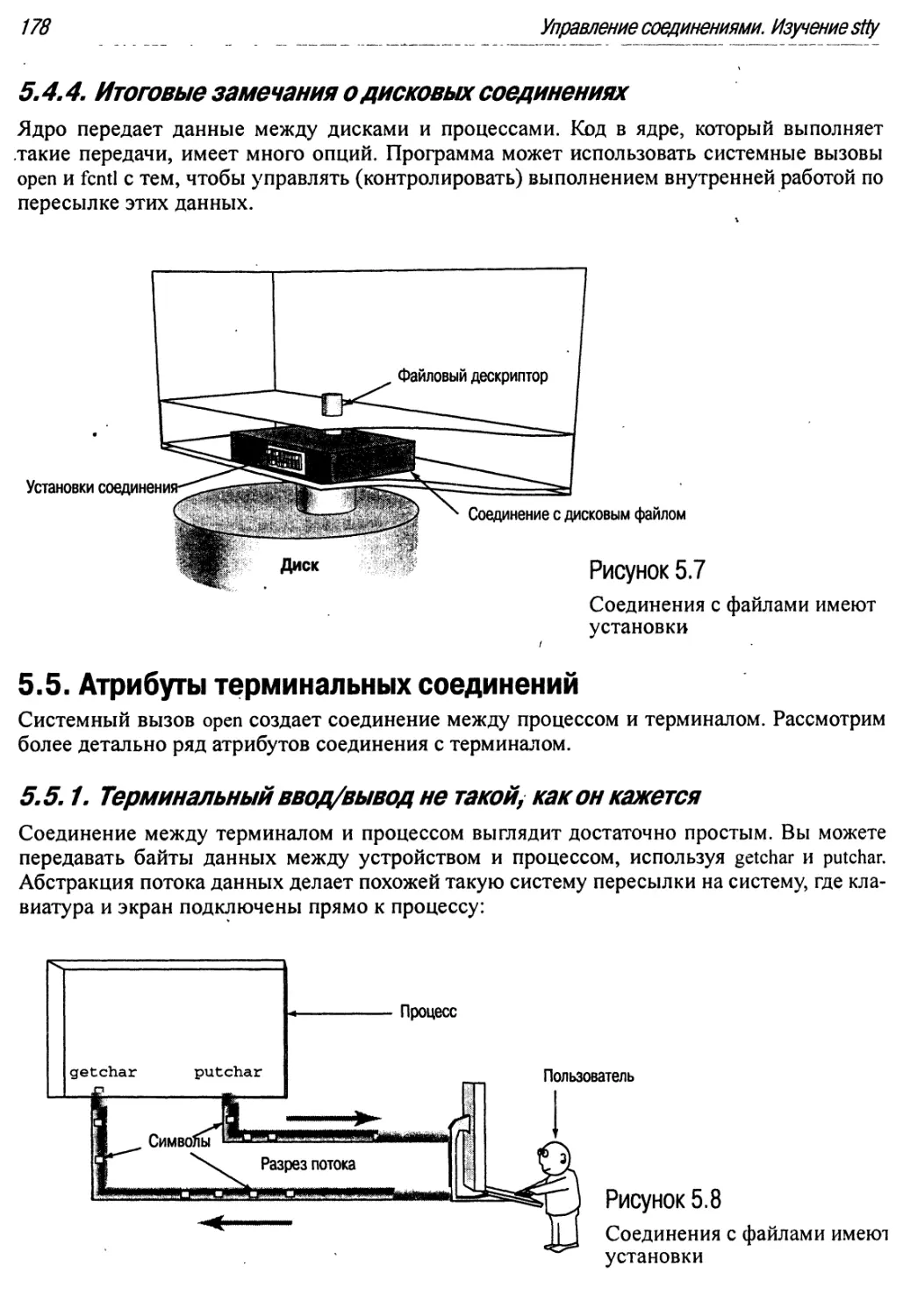
5.4.4. Итоговые замечания о дисковых соединениях 178
5.5. Атрибуты терминальных соединений 178
5.5.1. Терминальный ввод/вывод не такой, как он кажется 178
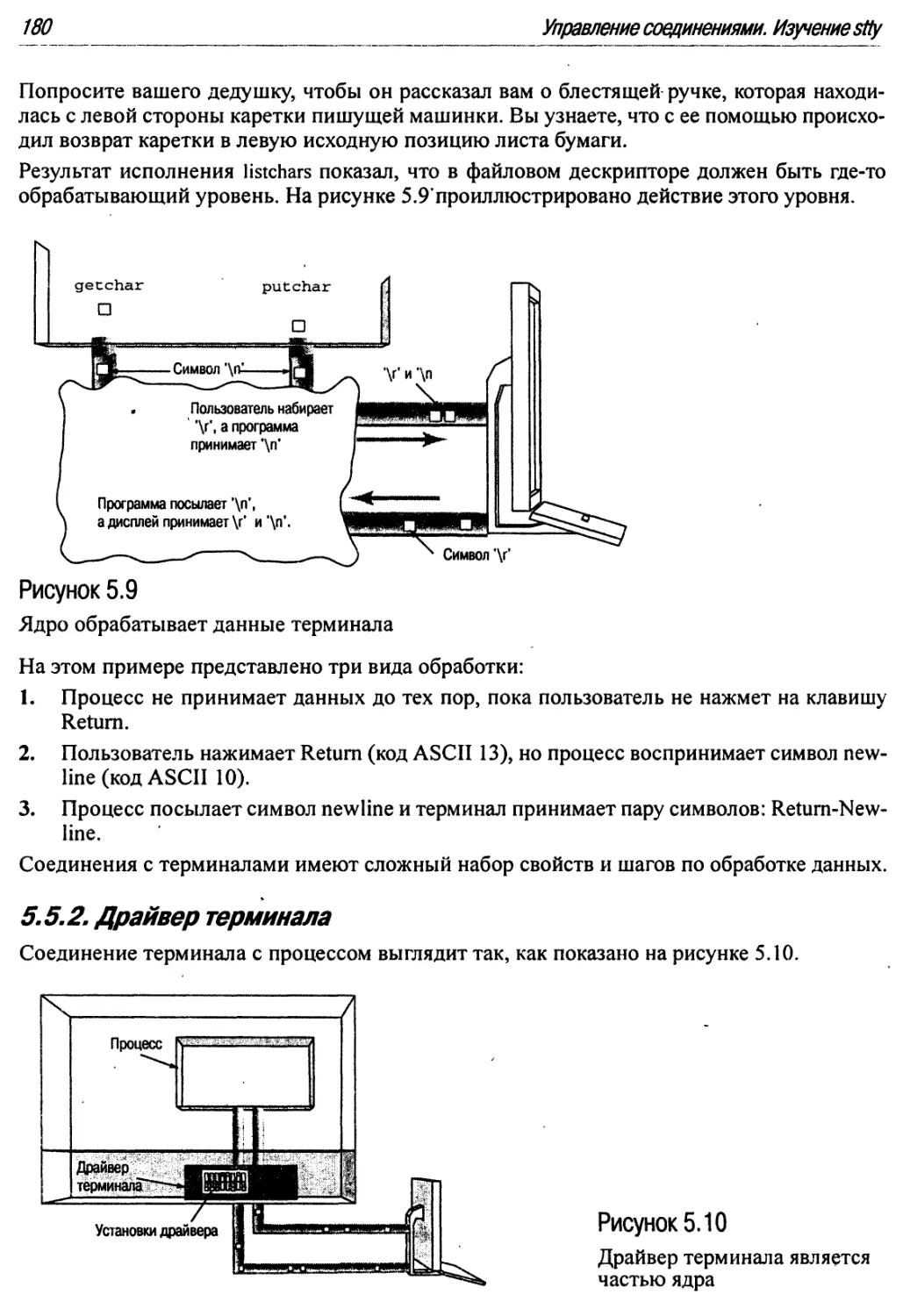
5.5.2. Драйвер терминала ;180
5.5.3. Команда stty 181
5.5.4. Программирование драйвера терминала: Установки 182
5.5.5. Программирование драйвера терминала: Функции 182
5.5.6. Программирование драйвера терминалов: Флаги 184
5.5.7. Программирование драйвера терминала: Примеры программ ..186
5.5.8. Итоговые замечания по соединениям с терминалами 189
5.6. Программирование других устройств: ioctl .......190
5.7. О небо! Это файл, это устройство, это поток! 190
Заключение 191
Исследования 193
Программные упражнения , .195
Проекты 197
Глава 6 Программирование дружественного способа управления
терминалом и сигналы 198
6.1. Инструментальные программные средства 198
6.2. Режимы работы драйвера терминала 200
6.2.1. Канонический режим: Буферизация и редактирование 200
6.2.2. Неканоническая обработка .202
6.2.3. Итоговые замечания по режимам терминала 203
6.3. Написание пользовательской программы: play_again.c 204
6.3.1. Неблокируемый ввод: play__again3.c .210
6.4. Сигналы ., 214
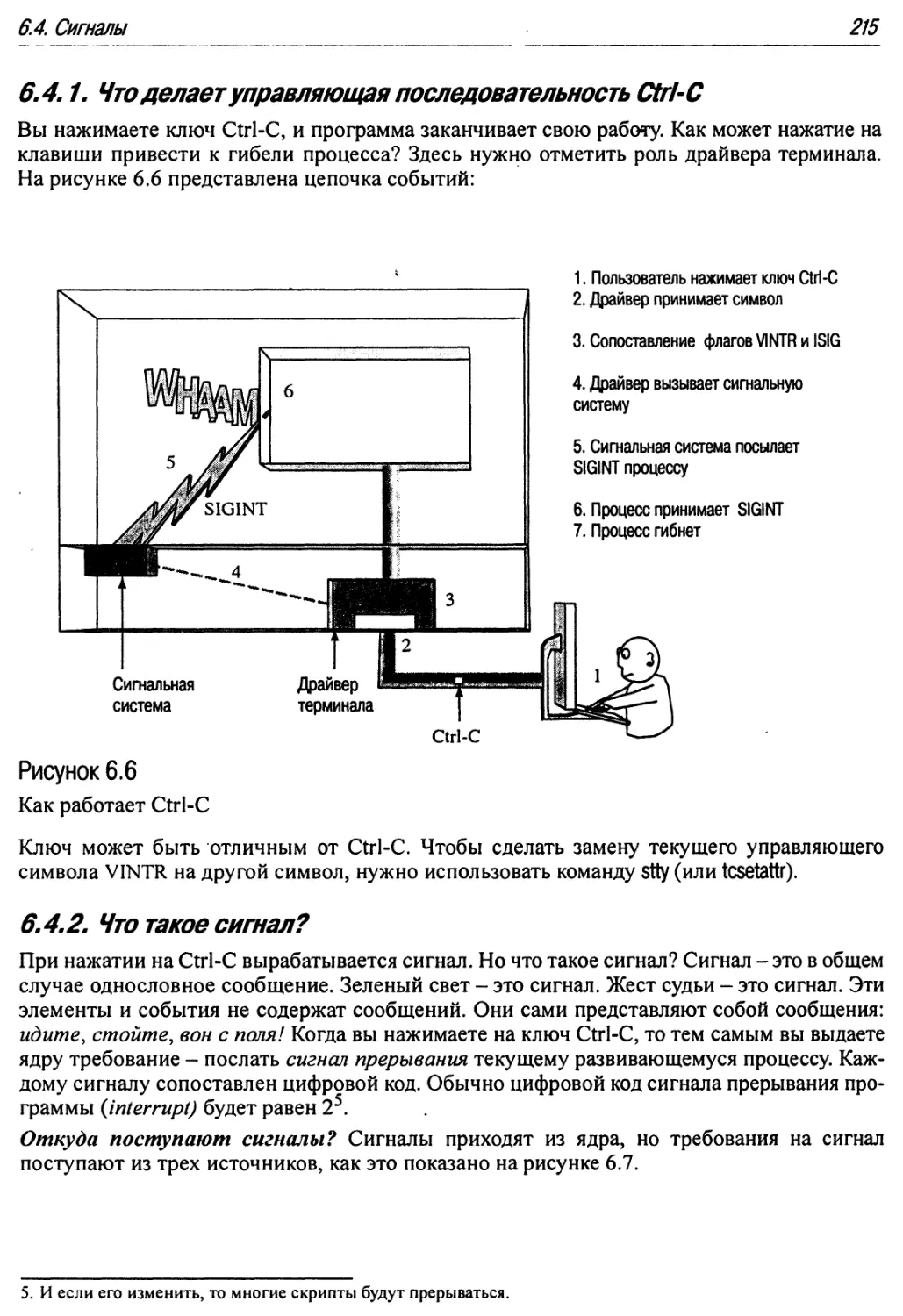
6.4.1. Что делает управляющая последовательность Ctrl-C 215
6.4.2. Что такое сигнал? 215
6.4.3. Что может процесс сделать с сигналом? 217
6.4.4. Пример обработчика сигнала , 218
6.5 Подготовка к обработке сигналов: play__again4.c ...221
6.6. Процессы смертны ., 223
6.7. Программирование для устройств ,.. 223
Заключение 224
Исследования .224
Программные упражнения .225
12 Содержание
Глава 7 Событийно-ориентированное программирование.
Разработка видеоигры.... ....228
7.1. Видеоигры и операционные системы 228
7.2 Проект: Разработка pong-игры в настольный теннис
для одного игрока , 231
7.3. Программирование пространства: Библиотека curses 231
7.3.1. Введение в curses 231
7.3.2. Внутренняя архитектура curses: Виртуальный и реальный экраны 234
7.4. Программирование времени: sleep ....: 235
7.5. Программирование времени .1: ALARMS .238
7.5.1. Добавление задержки: sleep 238
7.5.2. Как работает sleep(): Использование alarms в Unix 238
7.5.3. Планирование действий на будущее 241
7.6. Программирование времени II: Интервальные таймеры 241
7.6.1. Добавление улучшеной задержки: usleep 241
7.6.2. Три вида таймеров: реальные, процессные и профильные ........241
7.6.3. Два вида интервалов: начальный и период .......242
7.6.4 Программирование с помощью интервальных таймеров 243
7.6.5. Сколько часов можно иметь на компьютере? 246
7.6.6. Итоговые замечания по таймерам 248
7.7. Управление сигналами I: Использование signal 248
7.7.1. Управление сигналами в старом стиле 248
7.7.2. Управление множеством сигналов 249
7.7.3. Тестирование множества сигналов 251
7.7.4. Слабые места схемы управления множеством сигналов 253
7.8. Управление сигналами II: sigaction 254
7.8.1. Управление сигналами: sigaction 254
7.8.2. Заключительные замечания по сигналам 257
7.9. Предотвращение искажений данных 257
7.9.1. Примеры, иллюстрирующие искажение данных 258
7.9.2. Критические секции 258
7.9.3. Блокирование сигналов: sigprocmask и sigsetops 259
7.9.4. Повторно входной код: Опасность рекурсии .....260
7.9.5. Критические секции в видеоиграх 261
7.10. kill: Посылка сигнала процессом 261
7.11. Использование таймеров и сигналов: видеоигры 262
7.11.1. bounceld.c: Управляемая анимация на строке 263
7.11.2. bounce2d.c: Двухмерная анимация 266
7.11.3. Вся игра целиком , 271
7.12. Сигналы при вводе: Асинхронный ввод/вывод 271
7.12.1. Организация перемещения с помощью асинхронного
ввода/вывода ; 272
7.12.2 Метод 1: Использование 0_ASYNC 272
Содержание 13
7.12.3. Метод 2: Использование aiojread ....274
7.12.4. А нужно ли нам производить асинхронное чтение для
организации перемещения? 277
7.12.5. Асинхронный ввод, видеоигры и операционные системы 277
Заключение 278
Исследования 278
Программные упражнения 280
Проекты .. : 282
Глава 8 Процессы и программы. Изучение sh 283
8.1. Процессы = программы в исполнении ..,..; 283
8.2. Изучение процессов с помощью команды ps 284
8.2.1. Системные процессы 286
8.2.2. Управление процессами и управление файлами 287
8.2.3. Память компьютера и память для программ ..288
8.3. SHELL: Инструмент для управления процессами и программами .289
8.4. Как SHELL запускает программы на исполнение ...290
8.4.1. Основной цикл shell 290
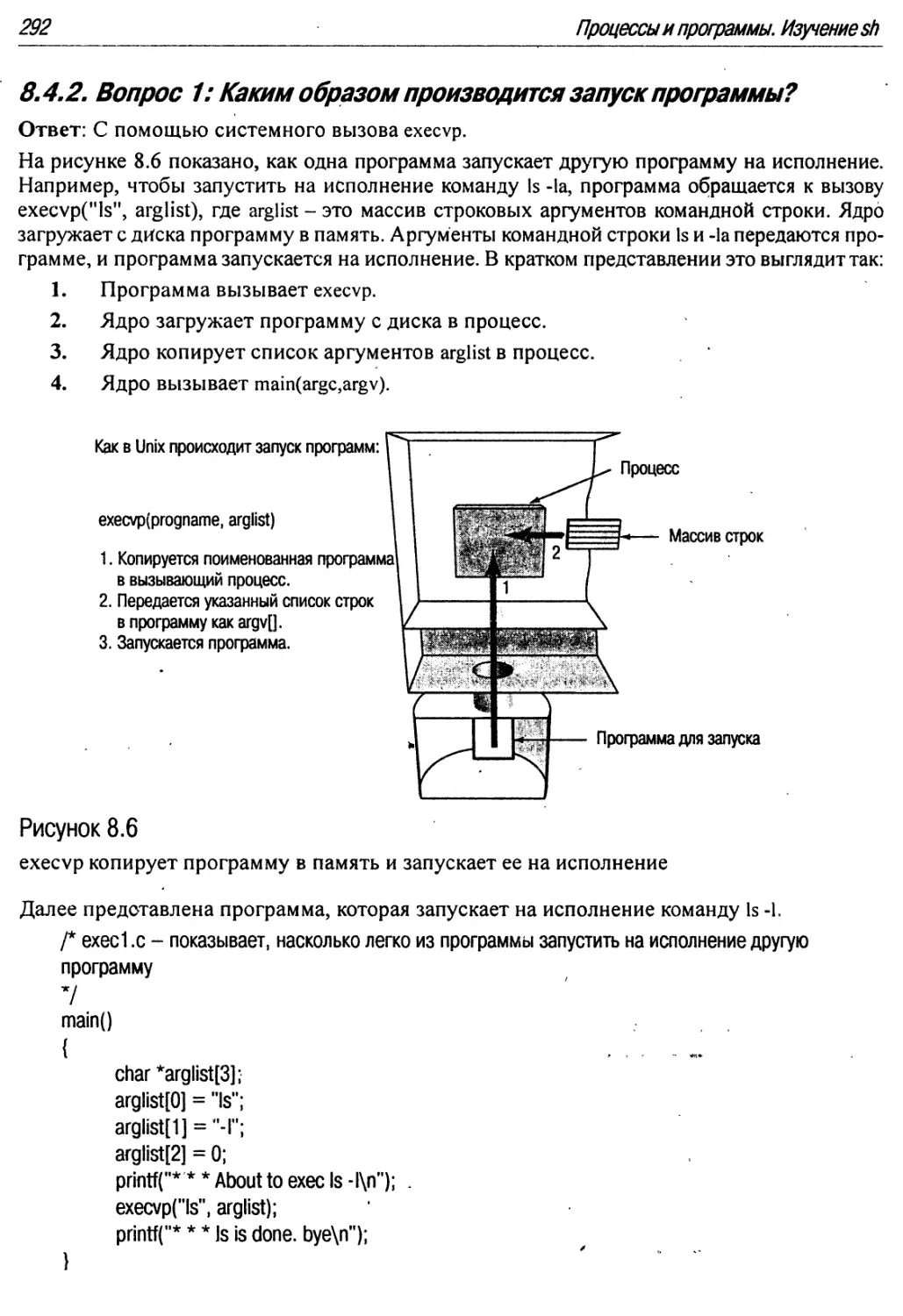
8.4.2. Вопрос 1: Каким образом производится запуск программы? ....292
8.4.3. Вопрос 2: Как получить новый процесс? 296
8.4.4. Вопрос 3: Как процесс-отец ожидает окончания дочернего
процесса? 300
8.4.5. Итог: Как Shell запускает программы на исполнение 306
8.5. Создание shell: psh2.c 307
8.5.1. Сигналы и psh2.c 310
8.6. Защита: программирование процессов 311
8.7. Дополнение относительно EXIT и EXEC 312
8.7.1. Окончание процесса: exitH_exit 312
8.7.2. Семейство вызовов exec 313
Заключение 314
Исследования , 315
Программные упражнения 317
Глава 9 Программируемый shell. Переменные и среда shell 318
9.1. Программирование в среде SHELL 318
9.2. SHELL-скрипты: что это такое и зачем? 319
9.2.1. Shell скрипт - это пакет команд ...319
9.3. smshl-Разбор текста командной строки . 321
9.3.1. Замечания относительно smshl 328
9.4. Поток управления в SHELL: почему и как? 328
9.4.1. Что делает if? 328
9.4.2. Как работает if.... 329
9.4.3. Добавление if к smsh 330
9.4.4. smsh2.c: Модифицированный код 331
14 Содержание
9.5. SHELL-переменные: локальные и глобальные 336
9.5.1. Использование переменных shell ...J 337
9.5.2. Система памяти для переменных 338
9.5.3. Команды для добавления переменных: встроенные команды ...339
9.5.4. Как все работает? 341
9.6. Среда: персонализированные установки 342
9.6.1. Использование среды 343
9.6.2. Что собой представляет среда? Как она работает? 344
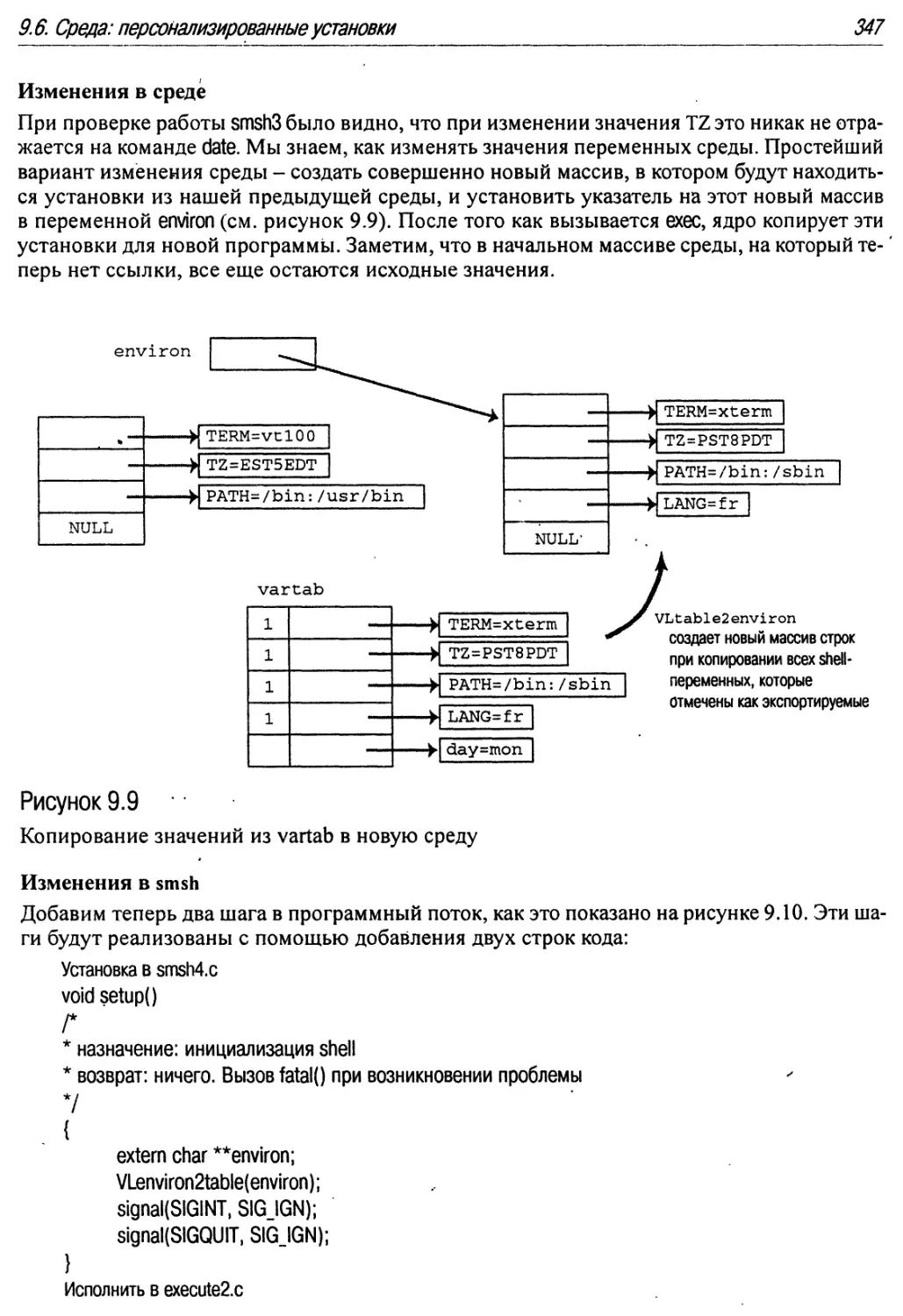
9.6.3. Добавления средств по управлению средой в smsh 346
9.6.4. Код varlib.c ...349
9.7. Общие замечания о SHELL 353
Заключение ........ 353
Исследования ,.. 354
Программные упражнения .i. 354
Глава 10 Перенаправление ввода/вывода и программные каналы 356
10.1. SHELL-программирование 356
10.2. Приложение SHELL: наблюдение за пользователями 357
10.3. Сущность стандартного ввода/вывода и перенаправления 359
10.3.1. Фактор 1: Три стандартных файловых дескриптора 359
10.3.2. Соединения по умолчанию: терминал 360
10.3.3. Вывод происходит только на stdout 360
10.3.4. Shell, отсутствие программы, перенаправление ввода/вывода 360
10.3.5. Соглашения по перенаправлению ввода/вывода 362
10.3.6. Фактор 2: Принцип "Первый доступный,самый малый
по значению дескриптор" 362
10.3.7. Синтез 363
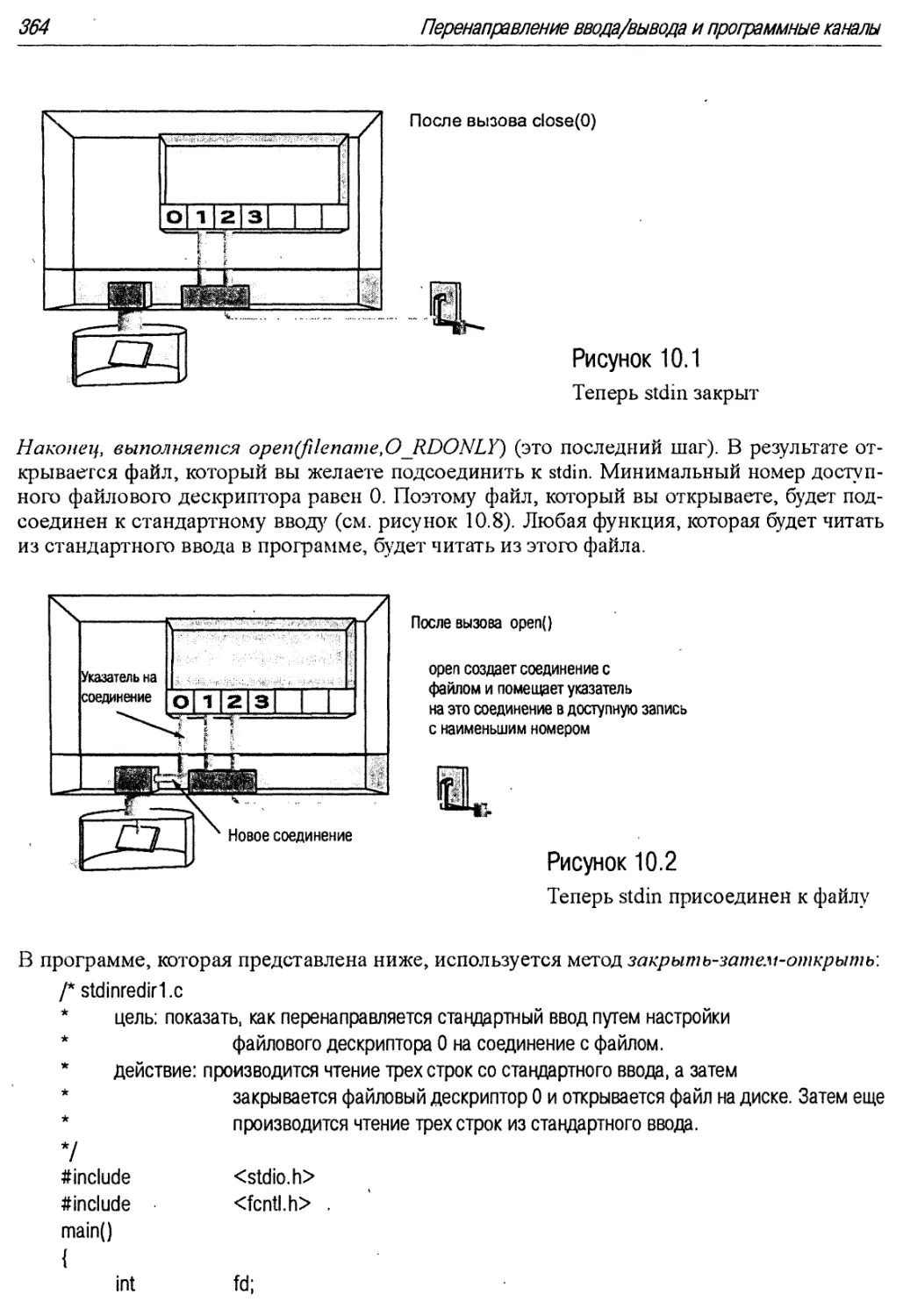
10.4. Каким образом можно подключить stdin к файлу 363
10.4.1. Метод 1: Закрыть, а затем открыть 363
10.4.2. Метод 2: open..close..dup..close 365
10.4.3. Обобщенная информация о системном вызове dup 367
10.4.4. Метод 3: open..dup2..close 368
10.4.5. Shell перенаправляет stdin не для себя, а для других программ ... 368
10.5. Перенаправление ввода/вьюода для других программ: who > userlist 368
10.5.1. Итоговые замечания по перенаправлению стандартных потоков
в файлы 372
10.6. Программирование программных каналов 372
10.6.1. Создание программного канала 373
10.6.2. Использование fork для разделения программного канала 375
10.6.3. Финал: Использование pipe, fork и exec 377
10.6.4. Технические детали: Программные каналы
не являются файлами 379
Содержание 15
Заключение 381
Основные идеи 381
Исследования 381
Программные упражнения * 382
Глава 11 Соединение между локальными и удаленными процессами.
Серверы и сокеты 384
11.1. Продукты и сервисы 385
11.2. Вводная метафора: интерфейс автомата для получения напитка ..385
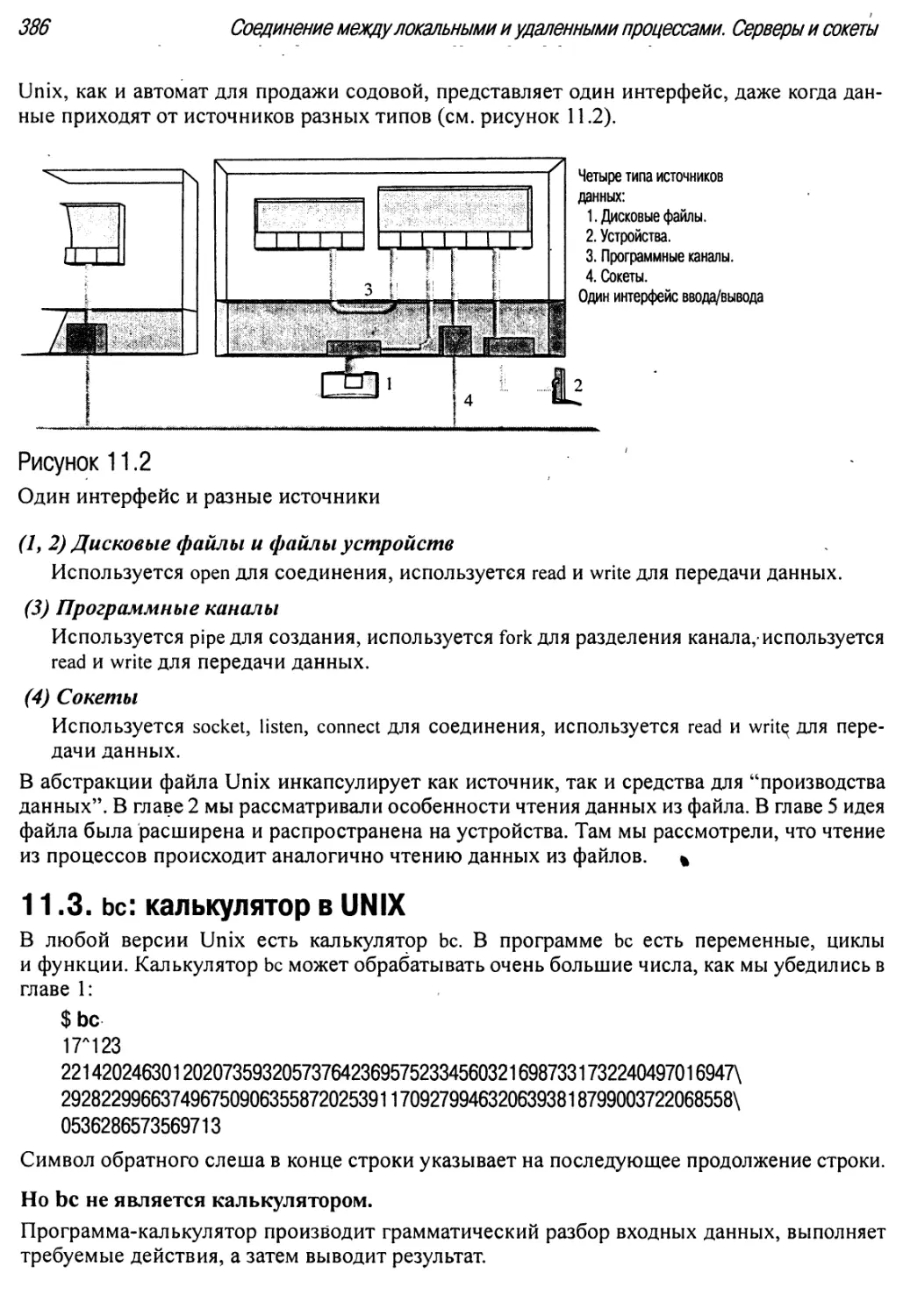
11.3. be: калькулятор в UNIX .: 386
11.3.1. Кодирование be: pipe, fork, dup, exec 388
11.3.2. Замечания, касающиеся сопрограмм ....: 39Г
13.3.3. fdopen: файловые дескрипторы становятся похожими на файлы . 392
11.4. рореп: делает процессы похожими на файлы 392
11.4.1. Что делает функция рореп 392
11.4.2. Разработка функции рореп: использование fdopen 394
11.4.3. Доступ к данным: файлы, программный интерфейс API
и сервера '. 396
11.5. Сокеты: соединения с удаленными процессами 397
11.5.1. Аналогия: "....время равно..." 397
11.5.2. Время Internet, DAP и метеорологические серверы 401
11.5.3. Списки сервисов: широко известные порты 402
11.5.4. Разработка timeserv.c: сервер времени 403
11.5.5. Проверка работы программы timeserv.c 407
11.5.6 Разработка программы timeclnt.c: клиент времени 408
11.5.7. Проверка работы программы timeclnt.c 410
11.5.8. Другие серверы: удаленный Is 411
11.6. Программные демоны 416
Заключение 416
Исследования 417
Программные упражнения 417
Глава 12 Соединения и протоколы. Разработка Web-сервера 421
12.1. В центре внимания - сервер 421
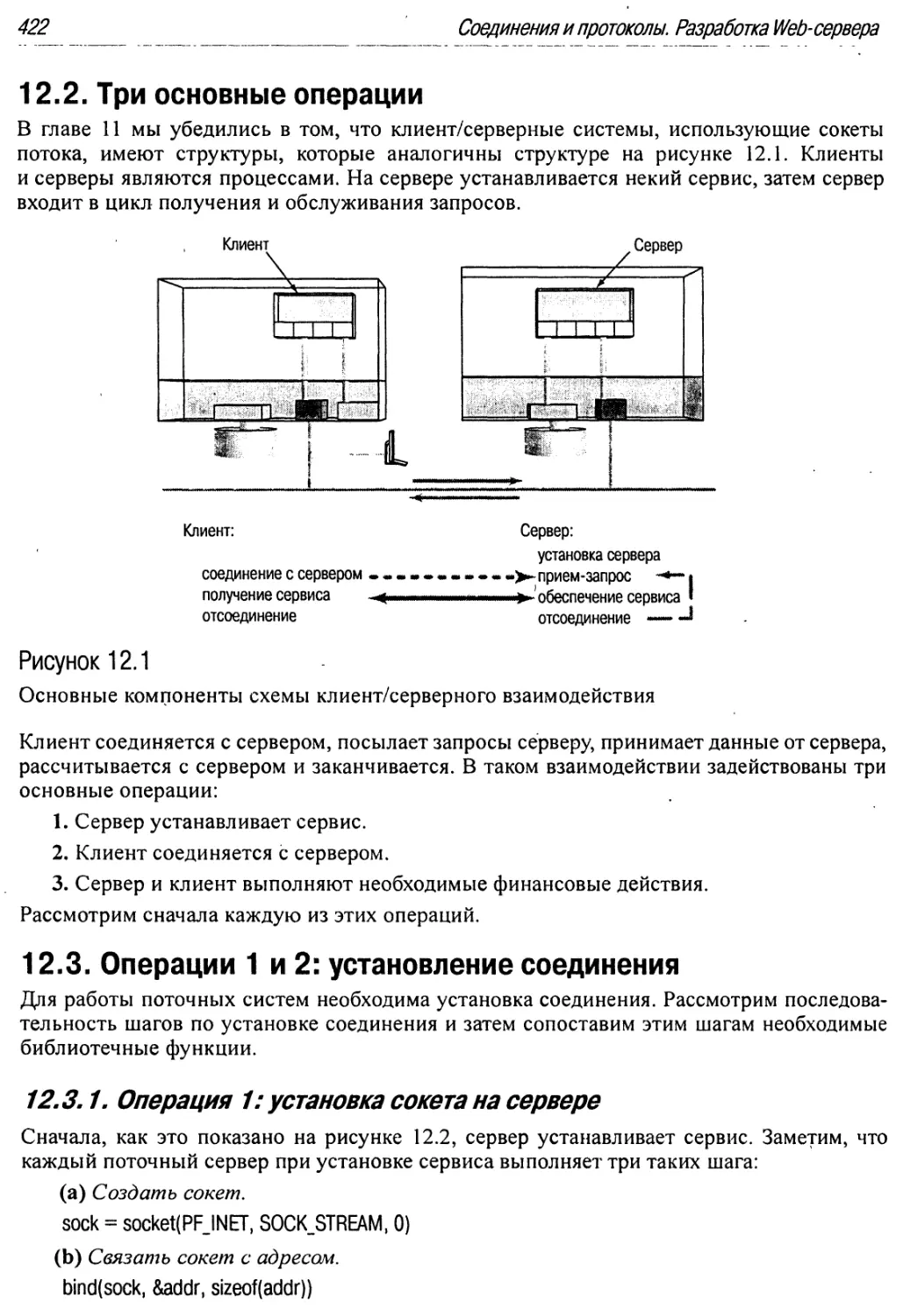
12.2. Три основные операции 422
12.3. Операции 1 и 2: установление соединения 422
12.3.1. Операция 1: установка сокета на сервере 422
12.3.2. Операция 2: соединение с сервером 423
12.3.3. socklib.c 424
12.4. Операция 3: взаимодействие между клиентом и сервером 425
12.4.1. timeserv/timeclnt, использующие socklib.c 426
12.4.2. Вторая версия сервера: использование fork 427
16 Содержание
12.4.3. Вопрос по ходу проектирования: делать самому и делегировать
работу другому? .428
12.5. Написание Web-сервера 430
12.5.1. Что делает Web-сервер .. 430
12.5.2. Планирование работы нашего Web-сервера 431
12.5.3. Протокол Web-сервера 431
12.5.4. Написание Web-сервера 433
12.5.5. Запуск Web-сервера 435
12.5.6. Исходный код webserv 436
12.5.7. Сравнение Web-серверов .440
Заключение .. 440
Исследования ....441
Программные упражнения 441
Проекты , 442
Глава 13 Программирование с использованием дейтаграмм.
Лицензионный сервер 443
13.1. Программный контроль 444
13.2. Краткая история лицензионного контроля .445
13.3. Пример, не связанный с компьютерами: управление использованием
автомобилей в компании 445
13.3.1. Описание системы управления ключами от автомобилей 446
13.3.2. Управление автомобилями в терминах модели клиент/сервер 446
13.4. Управление лицензией 447
13.4.1. Система лицензионного сервера: что делает сервер? 447
13.4.2. Система лицензионного сервера: как работает сервер? 448
13.4.3. Коммуникационная система 450
13.5. Сокеты дейтаграмм 450
13.5.1 Потоки (streams) и дейтаграммы ....450
13.5.2. Программирование дейтаграмм 452
13.5.3. Обобщение информации о sendto и recvfrom 457
13.5.4. Ответ на принятые дейтаграммы 458
13.5.5. Итог по теме дейтаграмм 459
13.6. Лицензионный сервер. Версия 1.0 .'. 460
13.6.1. Клиент. Версия 1 461
13.6.2. Сервер. Версия 1 465
13.6.3. Тестирование Версии 1 469
13.6.4. Что еще нужно сделать? 470
13.7. Программирование с учетом существующих реалий 470
13.7.1. Управление авариями в клиенте 470
13.7.2. Управление при возникновении аварийных ситуаций на сервере 473
13.7.3. Тестирование версии 2 476
Содержание . 17
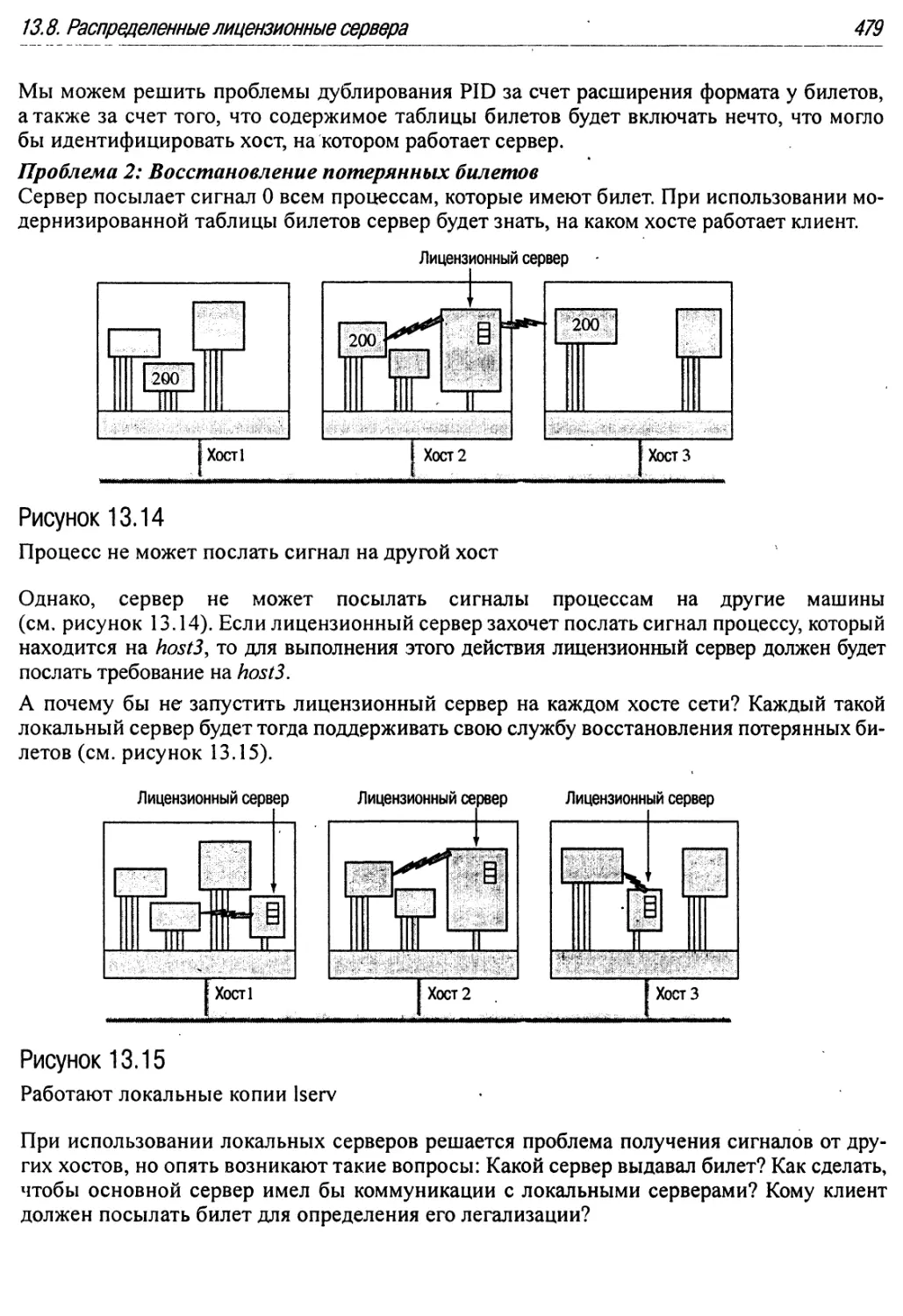
13.8. Распределенные лицензионные сервера 478
13.9. UNIX-сокеты доменов 480
13.9.1. Имена файлов, как адреса сокетов 480
13.9.2. Программирование с использование сокетов доменов 481
13.10. Итог: сокеты и сервера ! 483
Заключение 484
Исследования 484
Программные Упражнения 486
Проекты 487
Глава 14 Нити. Параллельные функции .488
14.1. Одновременное выполнение нескольких нитей 488
14.2. Нить исполнения 489
14.2.1. Однонитьевая программа 489
14.2.2. Мультинитьевая программа .....491
14.2.3 Обобщенная информация о функции pthreadcreate 493
14.3. Взаимодействие нитей .. 494
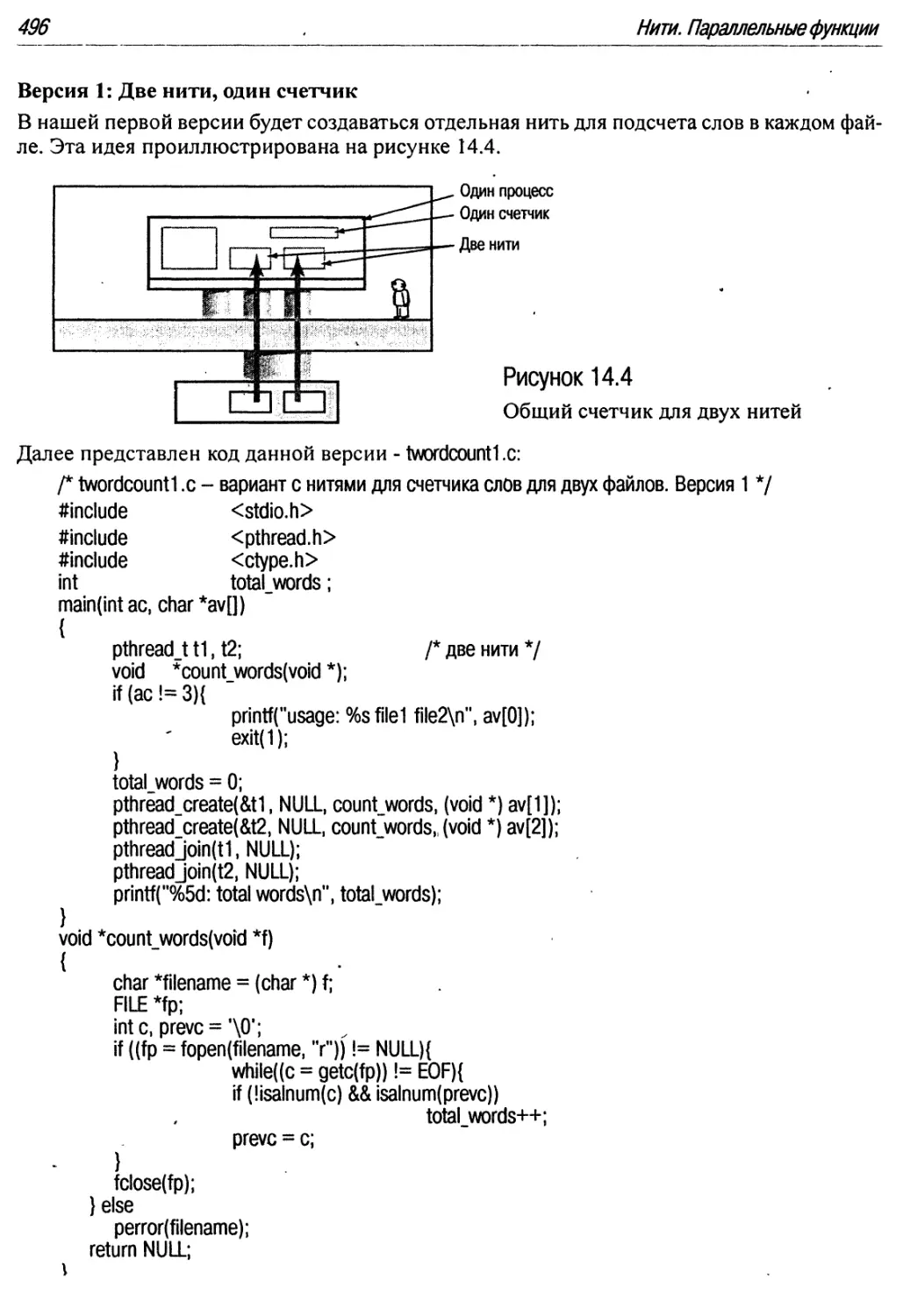
14.3.1. Пример 1: incrprint.c 494
14.3.2. Пример 2: twordcount.c 495
14.3.3. Взаимодействие между нитями: итог 502
14.4. Сравнение нитей с процессами 503
14.5. Уведомление для нитей 504
14.5.1. Уведомление для центральной комиссии о результатах выборов .505
14.5.2. Программирование с использованием условных переменных 506
14.5.3. Функции для работы с условными переменными 510
14.5.4. Обратимся опять к Web 510
14.6. Web-сервер, который использует механизм нитей 511
14.6.1 Изменения в нашем Web-сервере 511
14.6.2. При использовании нитей появляются новые возможности ....511
14.6.3 Предотвращение появления зомби для нитей:
отсоединение нитей 511
14.6.4. Код 512
14.7. Нити и анимация 516
14.7.1. Преимущества нитей 517
14.7.2 Программа bounceld.c, построенная с использованием нитей .518
14.7.3. Множественная анимация: tanimate.c 519
14.7.4. Mutexes и tanimate.c 523
14.7.5. Нить для curses 524
Заключение 525
Исследования • , ....526
Программные упражнения 526
18 Содержание
Глава 15 Средства межпроцессного взаимодействия (IPC).
Как можно пообщаться? 529
15.1 Выбор при программировании ...530
15.2. Команда talk: Чтение многих входов 530
15.2.1. Чтение из двух файловых дескрипторов .:....531
15.2.2. Системный вызов select 532
15.2.3. select и talk 535
15.2.4. select или poll 535
15.3. Выбор соединения 535
15.3.1. Одна проблема и три ее решения 535
15.3.2. Механизм IPC на основе использования файлов 536
•15.3.3. Именованные программные каналы 537
15.3.4. Разделяемая память , 539
15.3.5. Сравнение методов коммуникации 541
15.4. Взаимодействие и координация процессов 543
15.4.1. Блокировки файлов ...543
15.4.2. Семафоры , ;.546
15.4.3. Сравнение сокетов и каналов FIFO с разделяемой памятью ...554
15.5. Спулер печати 554
15.5.1. Несколько писателей, один читатель 554
15.5.2. Модель клиент/сервер 556
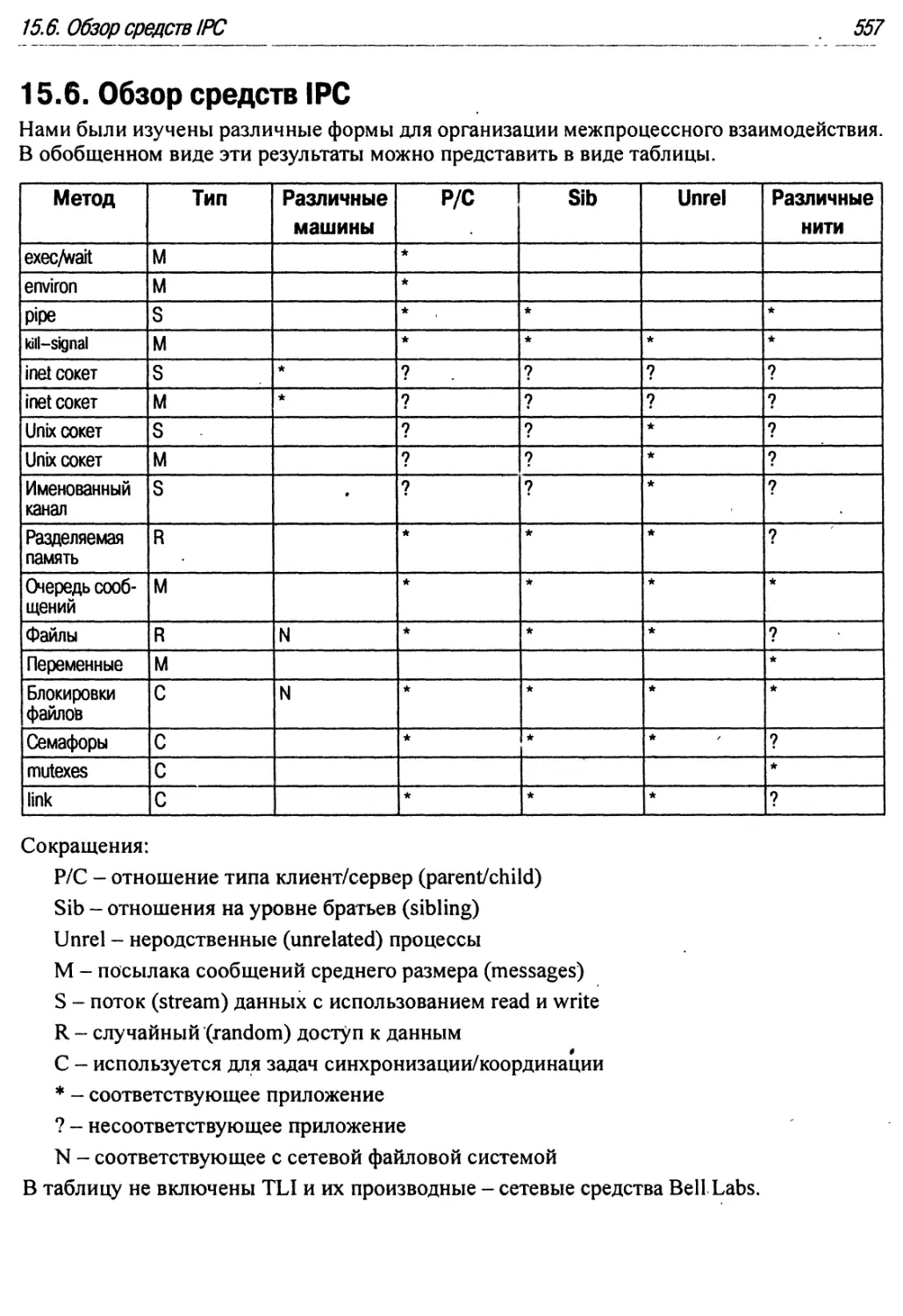
15.6. Обзор средств IPC .557
15.7. Соединения и игры ...560
Заключение 561
Исследования ! ..562
Программные упражнения 562
Предметный указатель 563
Список иллюстраций
1.1 Прикладная программа в компьютере 25
1.2 Как прикладные программы рассматривают пользовательский ввод/вывод 25
1.3 Реальность: много пользователей, программ и устройств 26
1.4 Как все это соединено? . 26
1.5 Операционная система - это программа 27
1.6 Ядро управляет всеми соединениями 27
1.7 Вхождение пользователя в систему 31
1.8 Часть дерева каталогов 32
1.9 Четыре человека играют в бридж через Интернет 37
1.10 Стол для бриджа на серверном компьютере 37
1.11 Отдельные программы посылают сообщения друг другу 38
1.12 Программы посылают сообщения друг другу 40
1.13 Отдельные программы посылают сообщения друг другу 41
1.14 more читает со стандартного ввода 45
1.15 Программа who читает пользовательский ввод с терминала 46
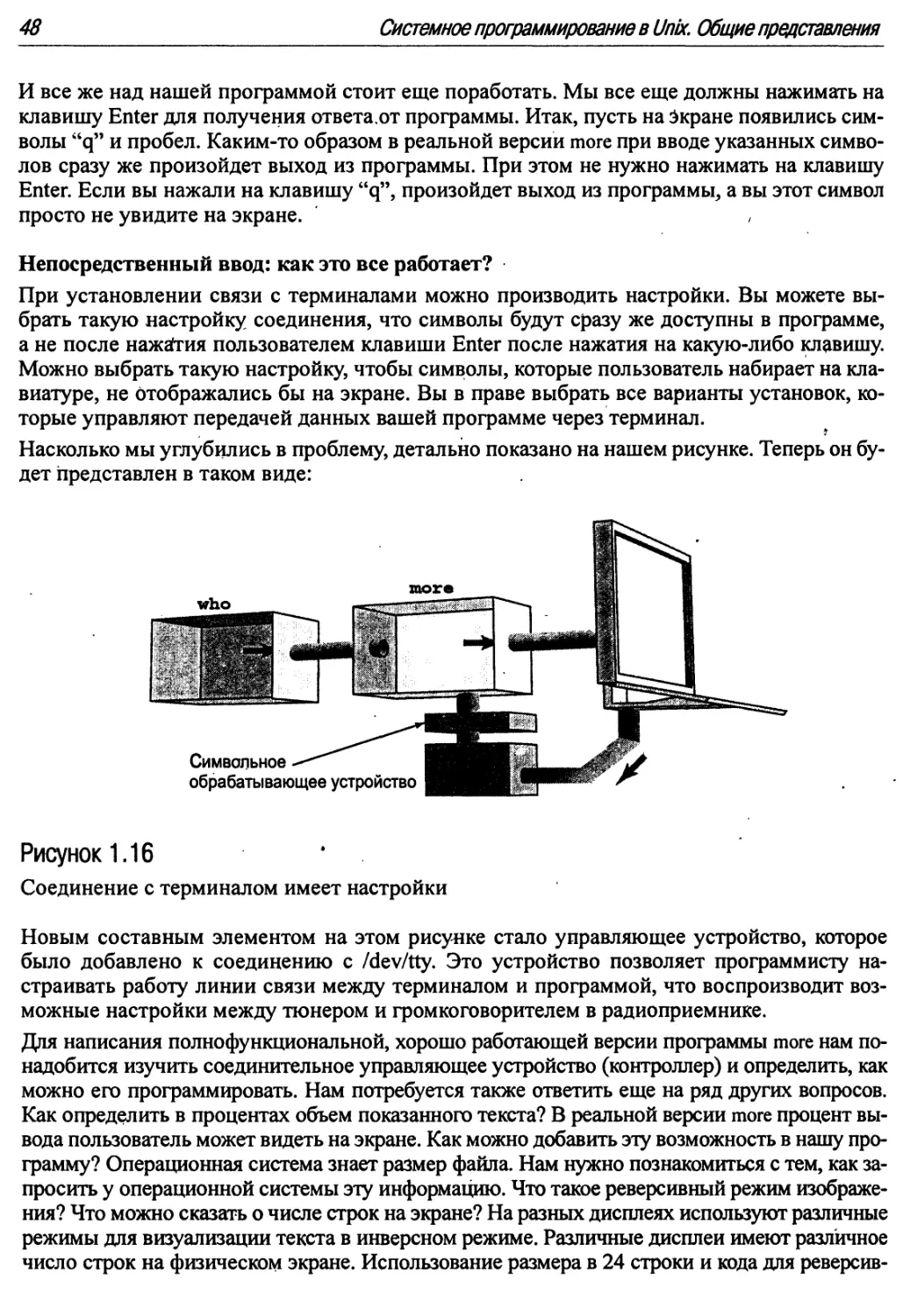
1.16 Соединение с терминалом имеет настройки 48
1.17 Диаграмма основной структуры системы Unix 49
2.1 Пользователи, файлы, процессы и ядро ; 53
2.2 Поток данных для команды who 60
2.3 Дескриптор файла - это соединение с файлом 63
2.4 Копирование файлов посредством чтения и записи 75
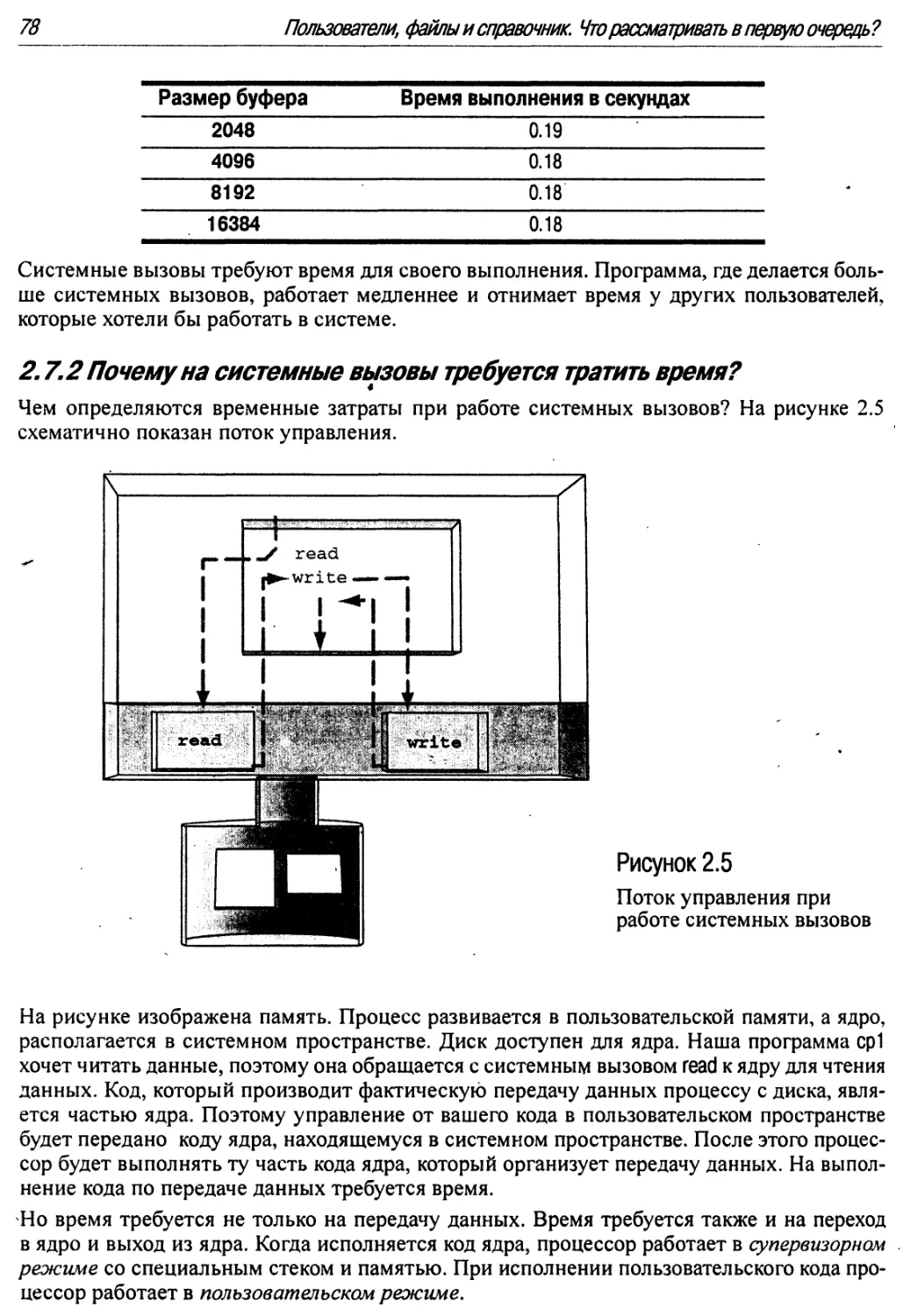
2.5 Поток управления при работе системных вызовов 78
2.6 Поток управления при работе системных вызовов ;.... 80
2.7 Буферизация дисковых данных в ядре 83
2.8 Каждый открытый файл имеет текущий указатель 86
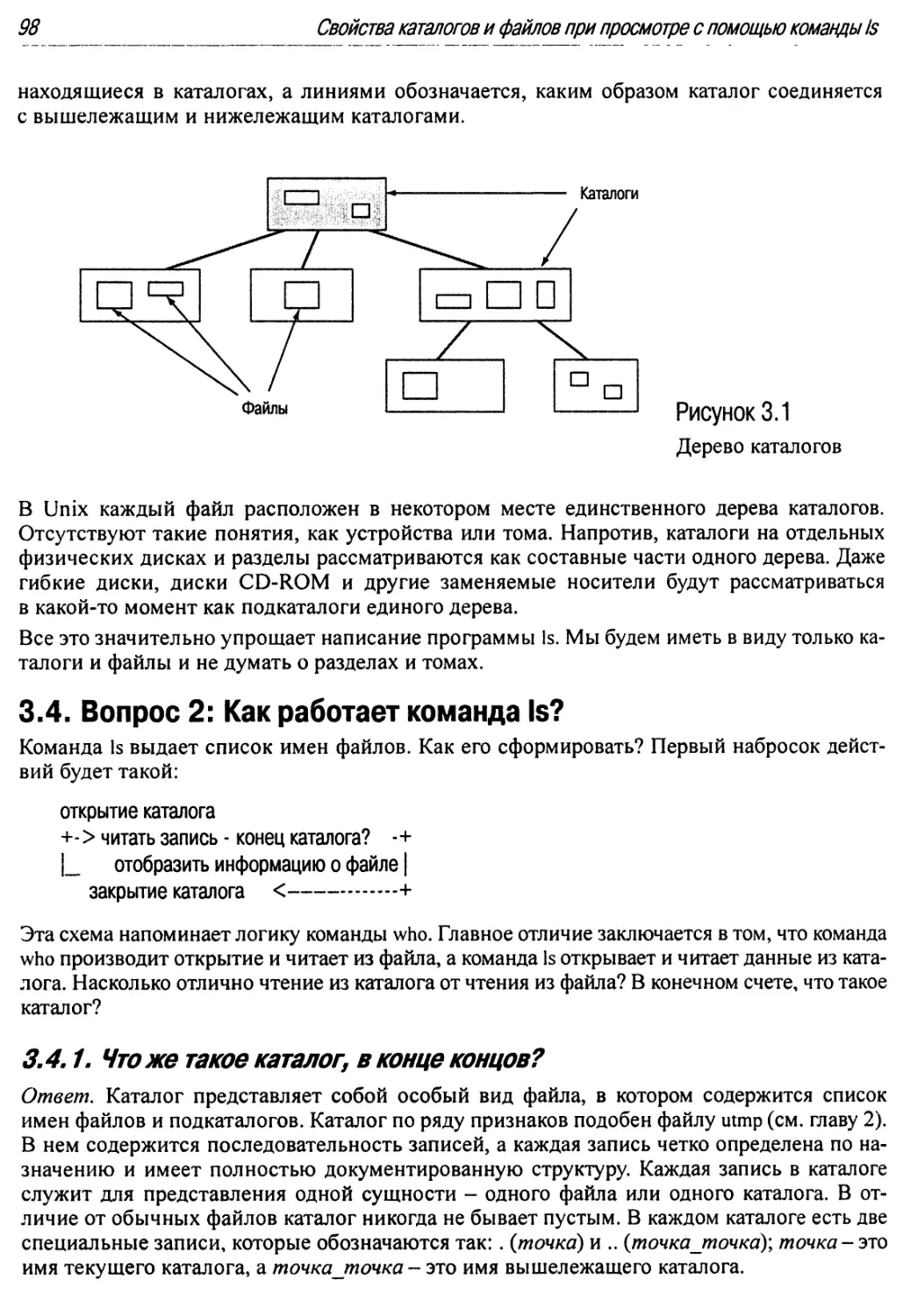
3.1 Дерево каталогов 98
3.2 Чтение содержимого каталога 101
3.3 Чтение статусной информации о файле с помощью stat 105
3.4 Представление кодов типа файла и прав доступа 108
3.5 Преобразования десятичного представления в двоичное 109
3.6 Использование двоичной маски 110
3.7 Диск содержит файлы, каталоги и статусную информацию о них 128
4.1 Дерево каталогов 134
4.2 Две связи к одному и тому же файлу 136
4.3 Нумерация дисковых блоков 138
4.4 Три области файловойгсистемы 139
4.5 Внутренняя структура файла 140
4.6 От имени файла к дисковым блокам 142
4.7 Список распределения блоков содержится в области данных 144
20
Список иллюстраций
4.8 Две точки зрения относительно дерева каталогов 146
4.9 Имена файлов и указатели на файлы 147
4.10 Имена каталогов и указатели на каталоги 147
4.11 Перемещение файла в новый каталог 151
4.12 Составление пути текущего каталога 153
4.13 "Прививка" деревьев 157
4.14 Номера inode и файловые системы 158
4.15 Inodes, блоки данных, каталоги, указатели 161
.5.1 Inode ссылается на блоки данных или на код драйвера 171
5.2 Процесс с двумя файловыми дескрипторами 172
5.3 Обрабатывающее устройство в потоке данных 173
5.4 Модификация действия файлового дескриптора 173
5.5 Присоединение записей с помощью lseek и write 175
5.6 Чередующиеся lseek и write = хаос 175
5.7 Соединения с файлами имеют установки 178
5.8 Соединения с файлами имеют установки 178
5.9 Ядро обрабатывает данные терминала 180
5.10 Драйвер терминала является частью ядра : 180
5.11 Управление драйвером терминала с помощью tcgetattr и tcsetattr 183
5.12 Разряды и символы в составе членов termios 185
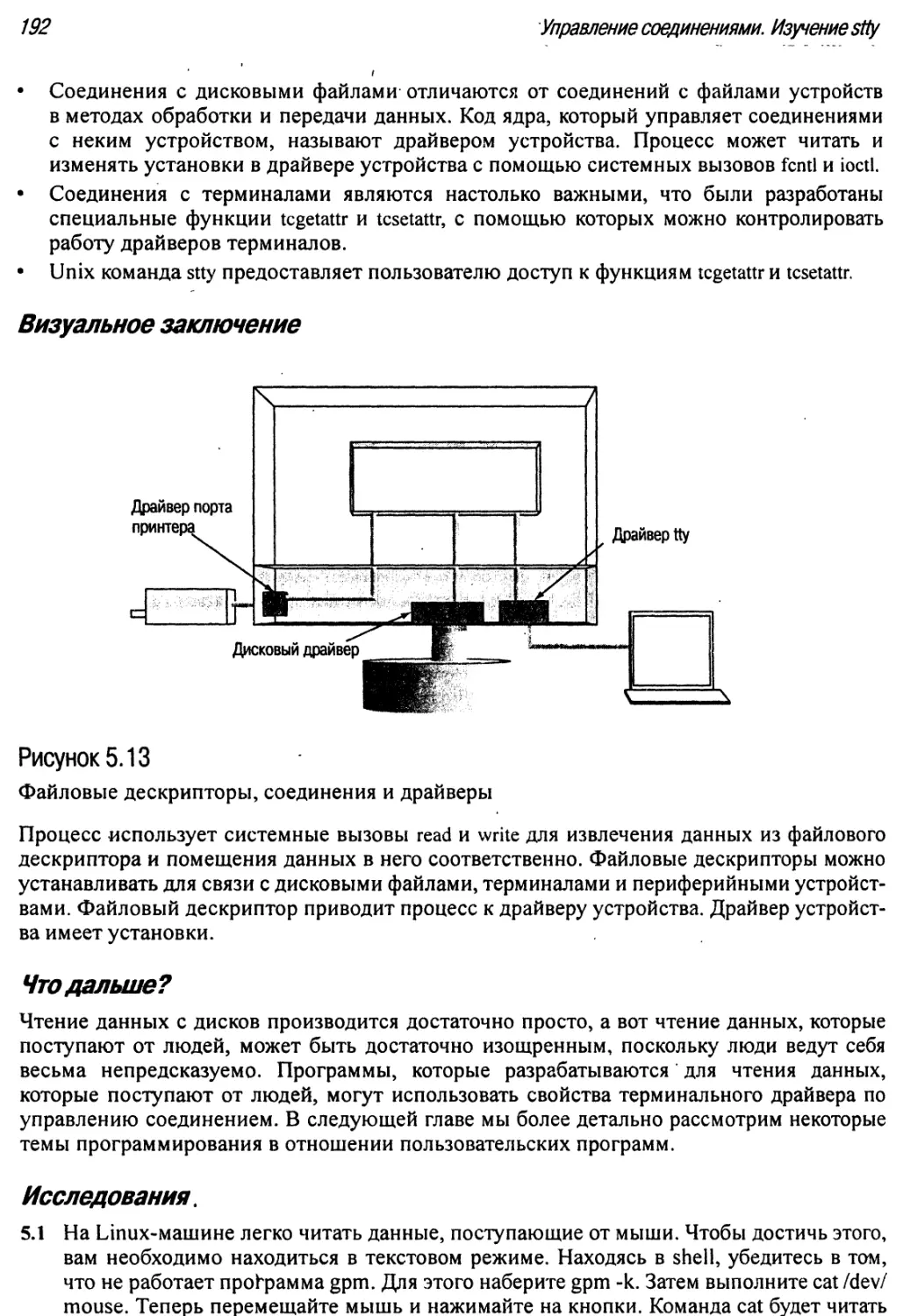
5.13 Файловые дескрипторы, соединения и драйверы 192
6.1 Три стандартных файловых дескриптора 199
6.2 То, что вы набираете, и то, что получает программа 201
6.3 Обрабатывающие уровни в драйвере терминала 202
6.4 Основные компоненты драйвера терминала 204
6.5 Ctrl-C убивает процесс исполнения программы. Программа заканчивается
без восстановления 214
6.6 Как работает Ctrl-C 215
6.7 Три источника сигналов ...216
6.8 По сигналу происходит обращение к подпрограмме 219
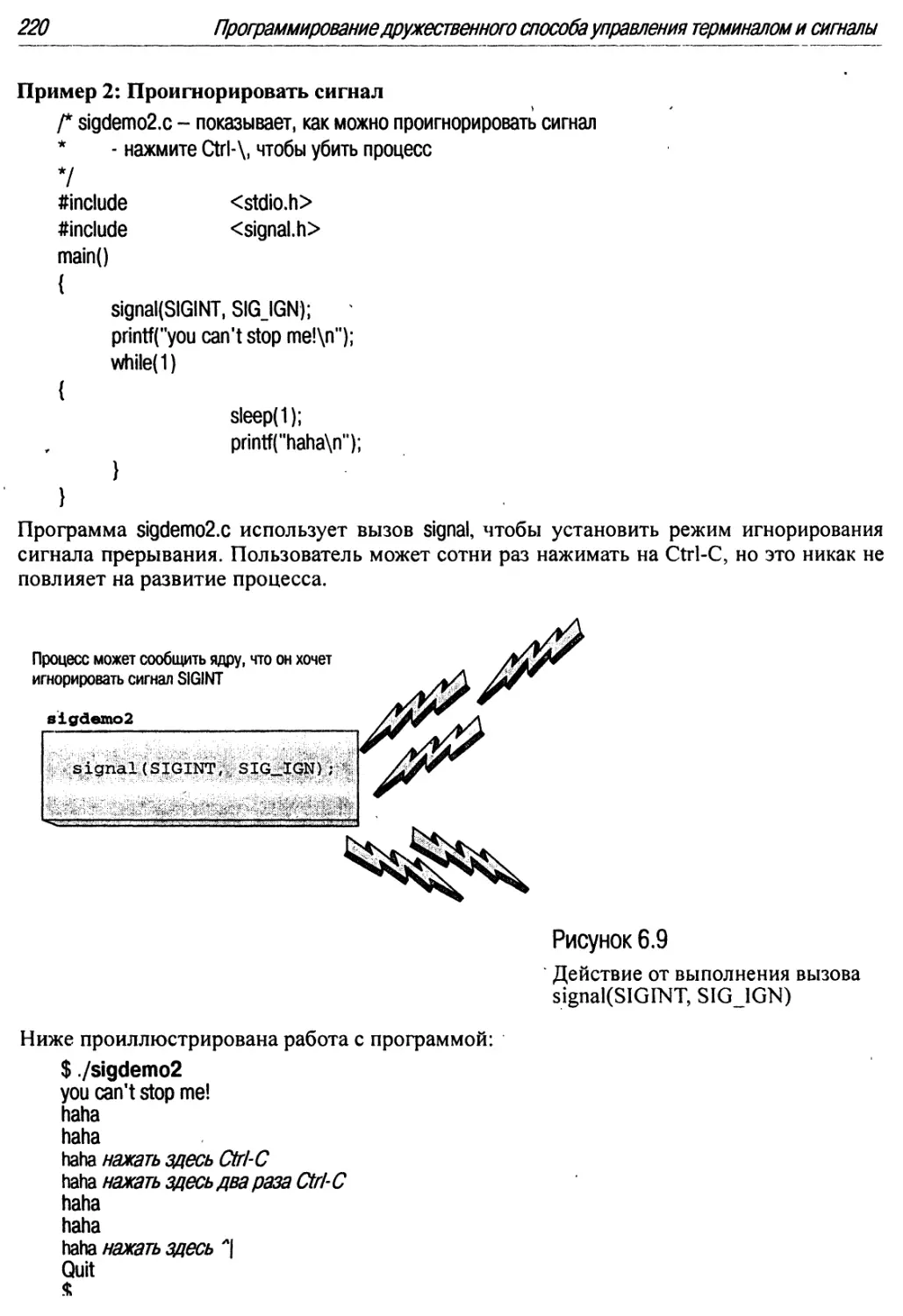
6.9 Действие от выполнения вызова signal(SIGINT, SIGJK3N) 220
7.1 Видеоигра для одного игрока 231
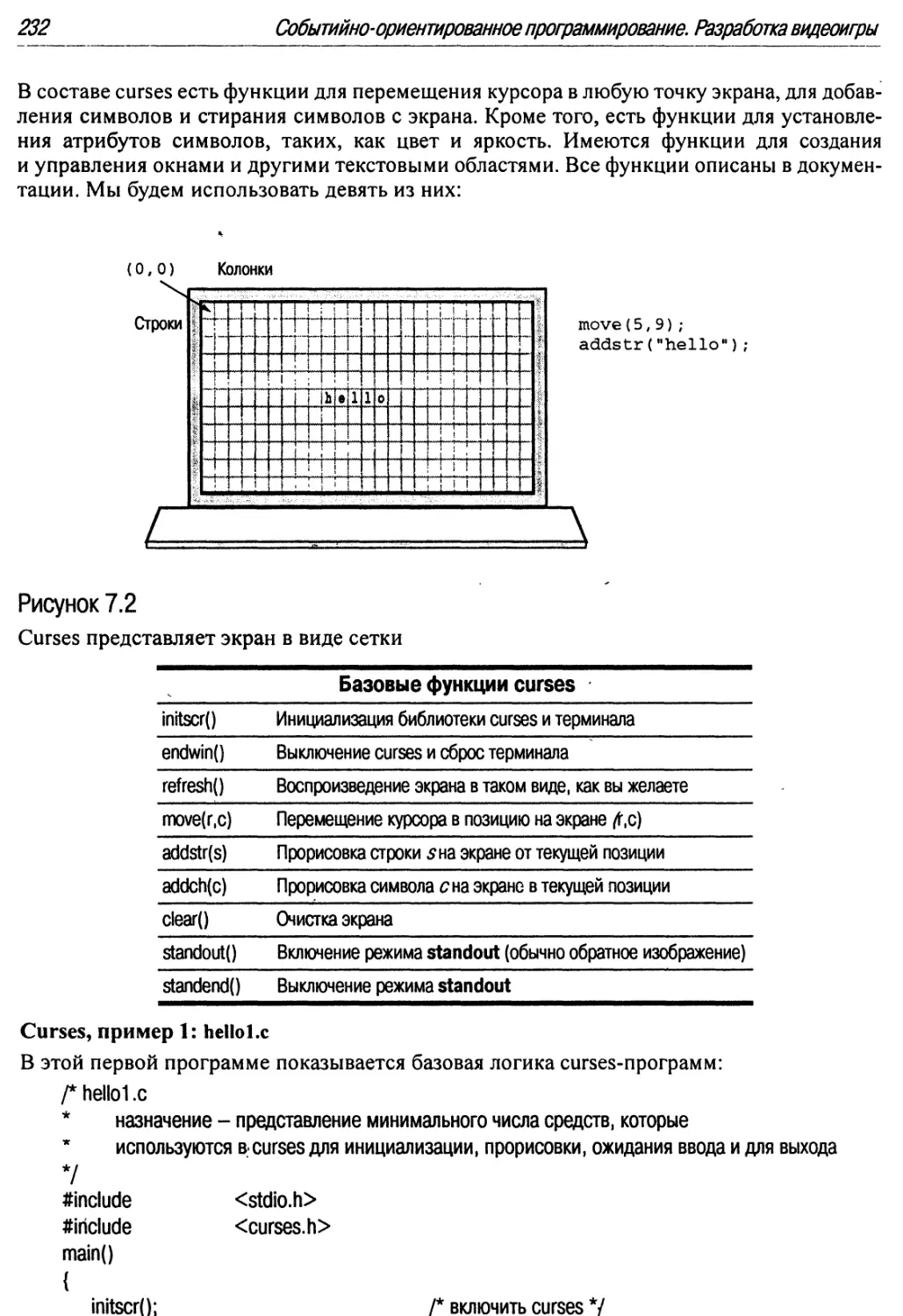
7.2 Curses представляет экран в виде сетки 232
7.3 Наша первая программа с использованием curses 233
7.4 Curses поддерживает копию реального экрана 234
7.5 Изображение медленно перемещается вниз по экрану 236
7.6 Сообщение движется вперед и назад 237
7.7 Процесс устанавливает alarm, в течение которого он приостанавливает
свое развитие 238
7.8 Поток управления в обработчике сигнала .. 240
7.9 Каждый процесс имеет три таймера 241
7.10 Как распределяются действия во времени? 242
7.11 Чтение и запись установок для таймера 243
7.12 Внутреннее представление интервальных таймеров ..245
Список иллюстраций 21
7.13 Секунды и микросекунды * 246
7.14 Два таймера, одни часы 247
7.15 Процесс принимает несколько сигналов : 250
7.16 Прохождение потока управления через эти функции 252
7.17 Процесс для посылки сигнала использует kill() 261
7.18 Сложное использование сигналов 262
7.19 bounceld в действии: анимация, управляемая пользователем : 263
7.20 Изменение значений через пользовательский ввод.
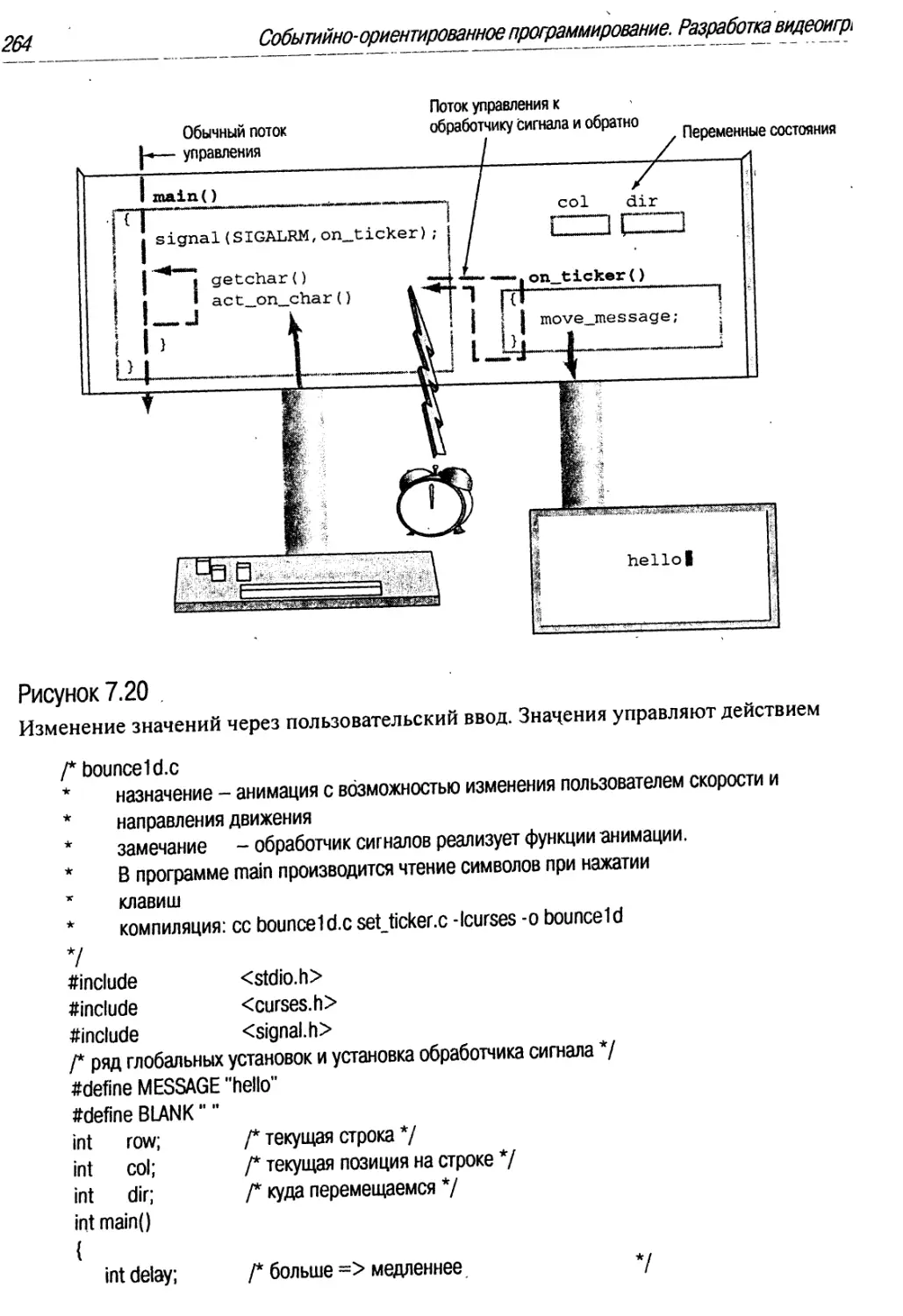
Значения управляют действием ....; 264
7.21 Двухмерная анимация ...266
7.22 Траекториядодуглом 1/3 267
7.23 Перемещение по наклонной на один шаг за такт выглядит лучше 268
7.24 Сигналы поступают от клавиатуры и таймера 272
8.1 Процессы и программы 284
8.2 Команда ps выводит список текущих процессов 284
8.3 Три модели памяти в компьютере , 288
8.4 Пользователь обращается к shell для выполнения запуска программы 290
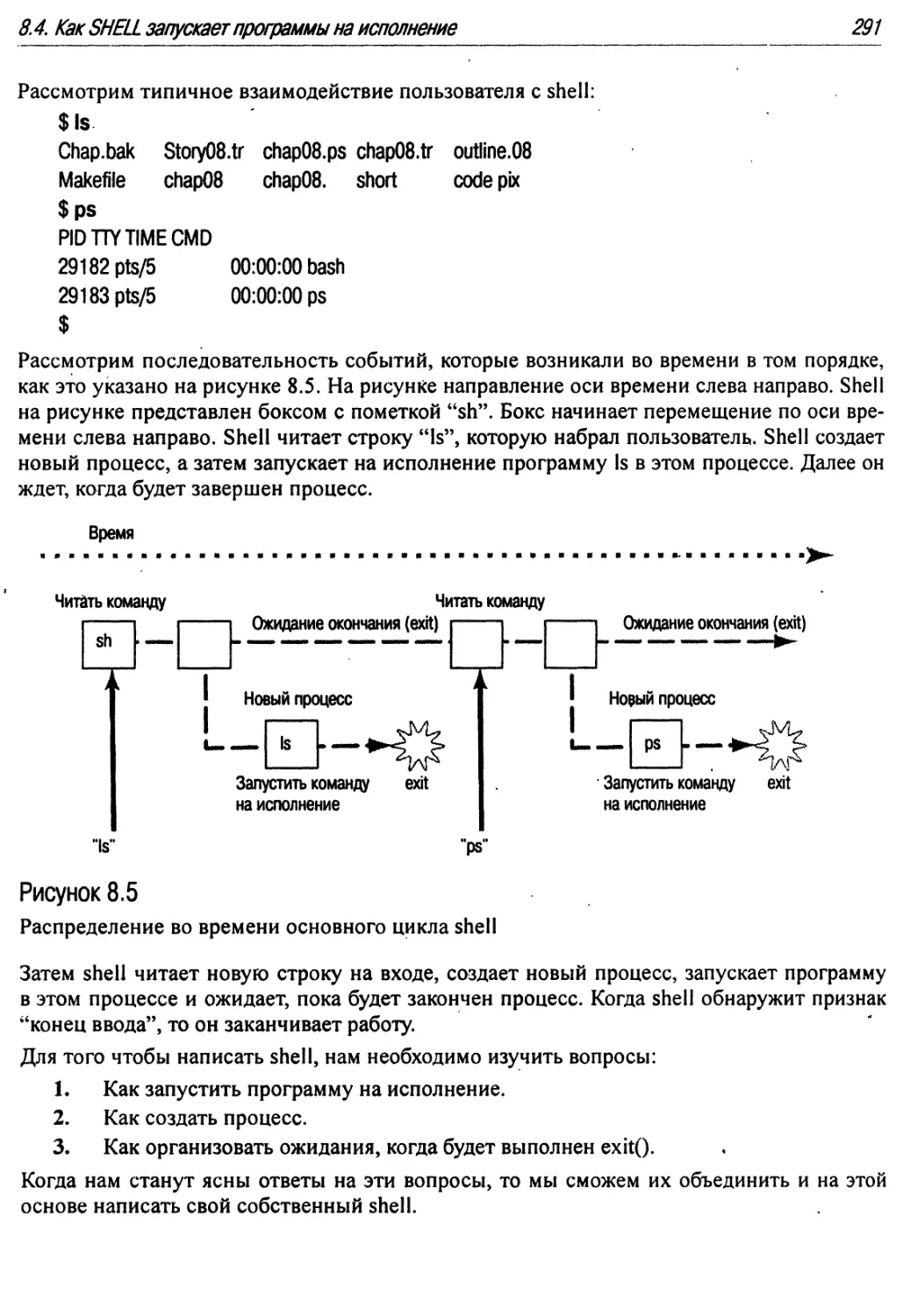
8.5 Распределение во времени основного цикла shell 291
8.6 execvp копирует программу в память и запускает ее на исполнение 292
8.7 Построение однострокового списка аргументов 295
8.8 fork() выполняет копирование процесса 297
8.9 Дочерний процесс исполняет код после fork() ... 298
8.10 Вызов wait переводит порождающий процесс в ожидание,
пока не закончится дочерний процесс 301
8.11 Управляющий поток и коммуникация с wait() 302
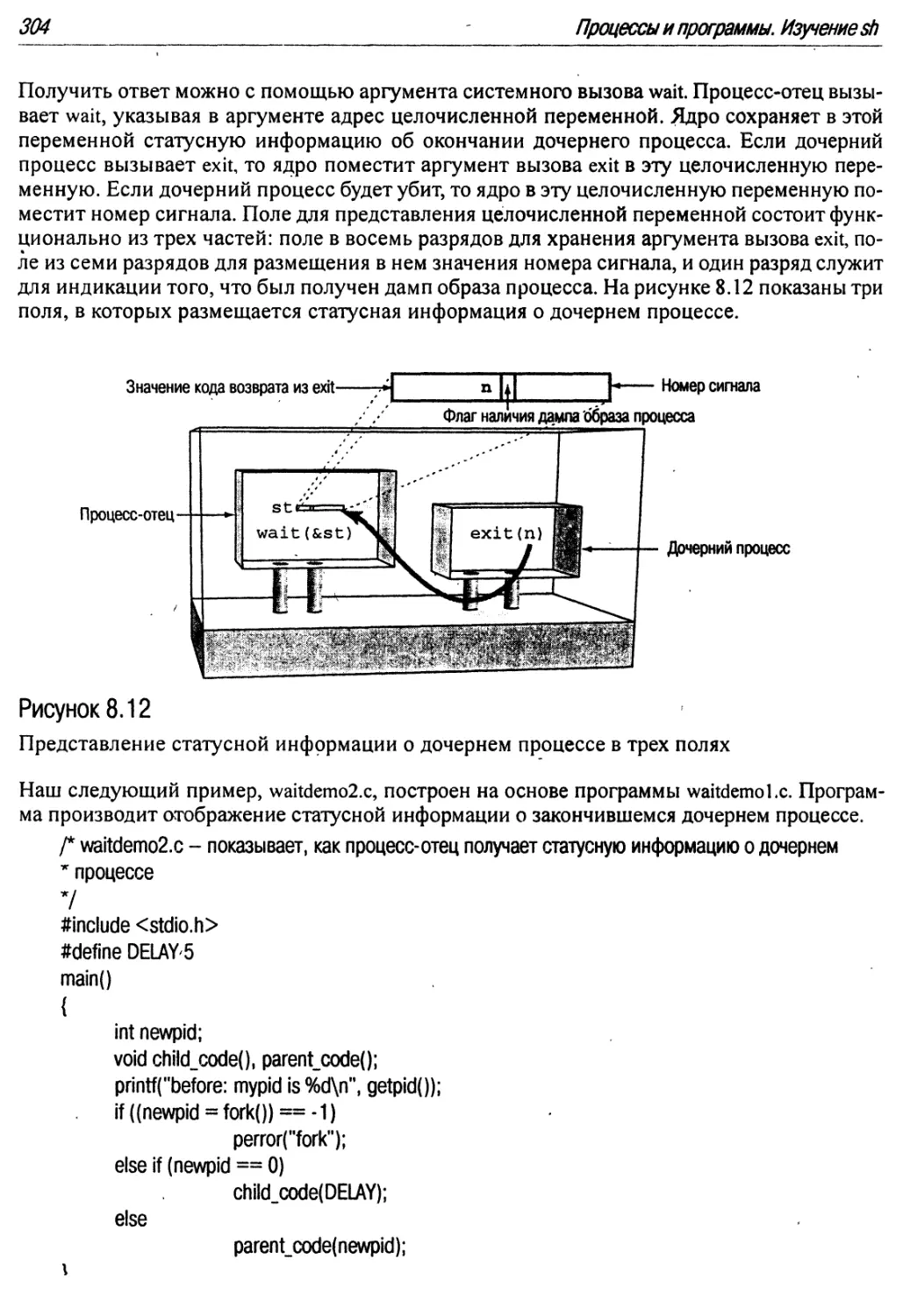
8.12 Представление статусной информации о дочернем процессе в трех полях 304
8.13 Последовательность шагов в цикле shell с выполнением fork(), exec(), wait() .... 306
8.14 Логика shell в Unix 307
8.15 Сигналы от клавиатуры поступают на все присоединенные процессы .310
8.16 Вызов функций и вызов программ 312
9.1 Shell с сигналами, exit и разбором командной строки 322
9.2 Добавление потока управления командами в smsh * '. 330
9.3 Скрипт, состоящий из различных областей 331
9.4 Система памяти для переменных shell 338
9.5 Добавление к smsh встроенных команд 339
9.6 Среда - это массив указателей на строки 344
9.7 Строки из среды копируются при выполнении ехес() 345
9.8 Копирование значений из среды в переменную vartab 346
9.9 Копирование значений из vartab в новую среду 347
9.10 Добавление средств управления средой в smsh 348
10.1 Соединение вывода команды who со входом команды sort 357
10.2 Команда comm сравнивает два списка и выводит три набора строк 358
10.3 Программное средство читает входные данные и записывает результаты
и сообщения об ошибках \ , 359
22 Список иллюстраций
10.4 Три специальных файловых дескриптора 360
10.5 Принцип "Первый доступный, самый малый по значению дескриптор" 362
10.6 Типичная начальная конфигурация 363
10.7 Теперь stdin закрыт . 364
10.8 Теперь stdin присоединен к файлу 364
10.9 Использование dup для перенаправления 366
10.10 Shell перенаправляет вывод у дочернего процесса ¦. 368
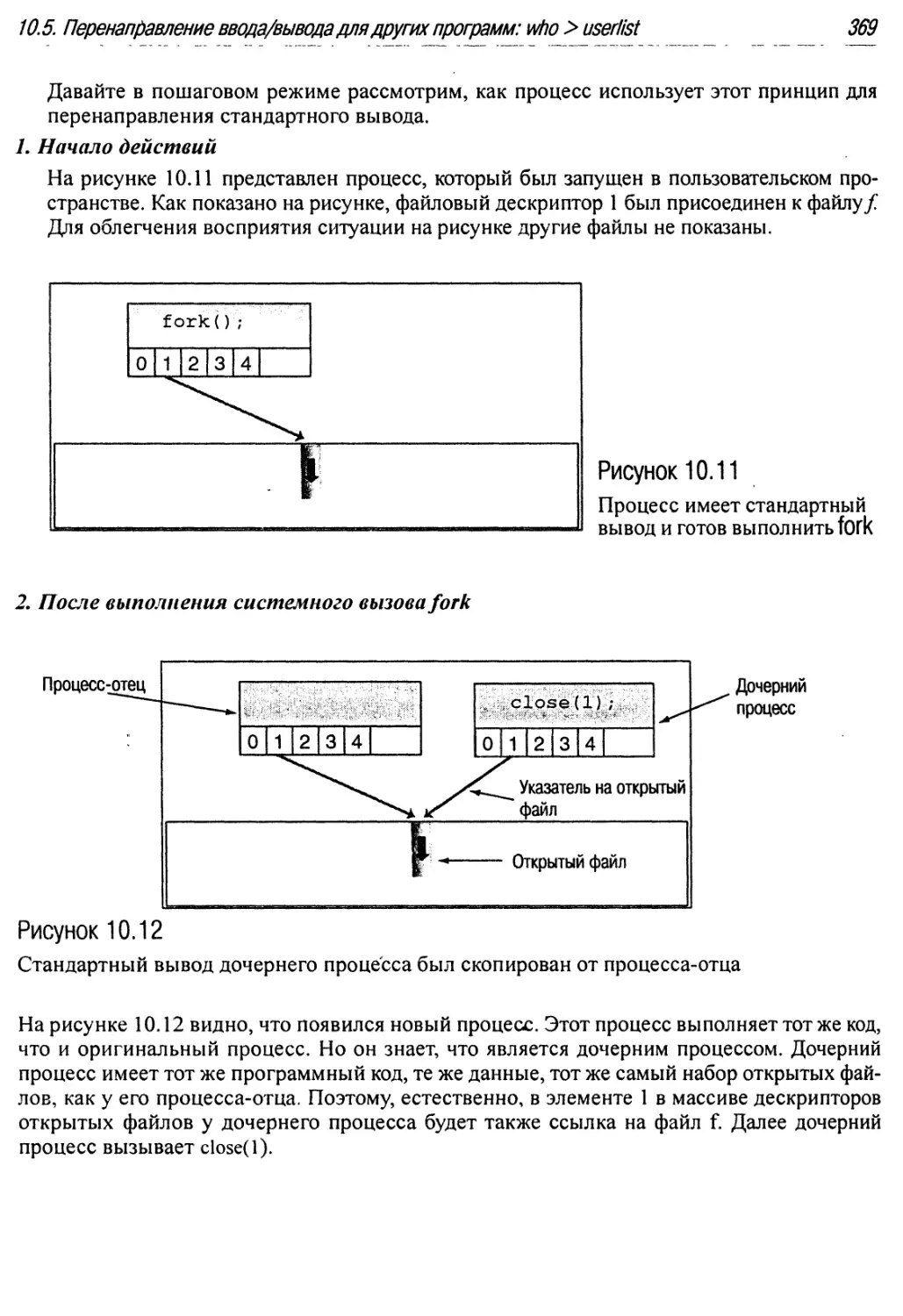
10.11 Процесс имеет стандартный вывод и готов выполнить fork 369
10.12 Стандартный вывод дочернего процесса был скопирован от процесса-отца 369
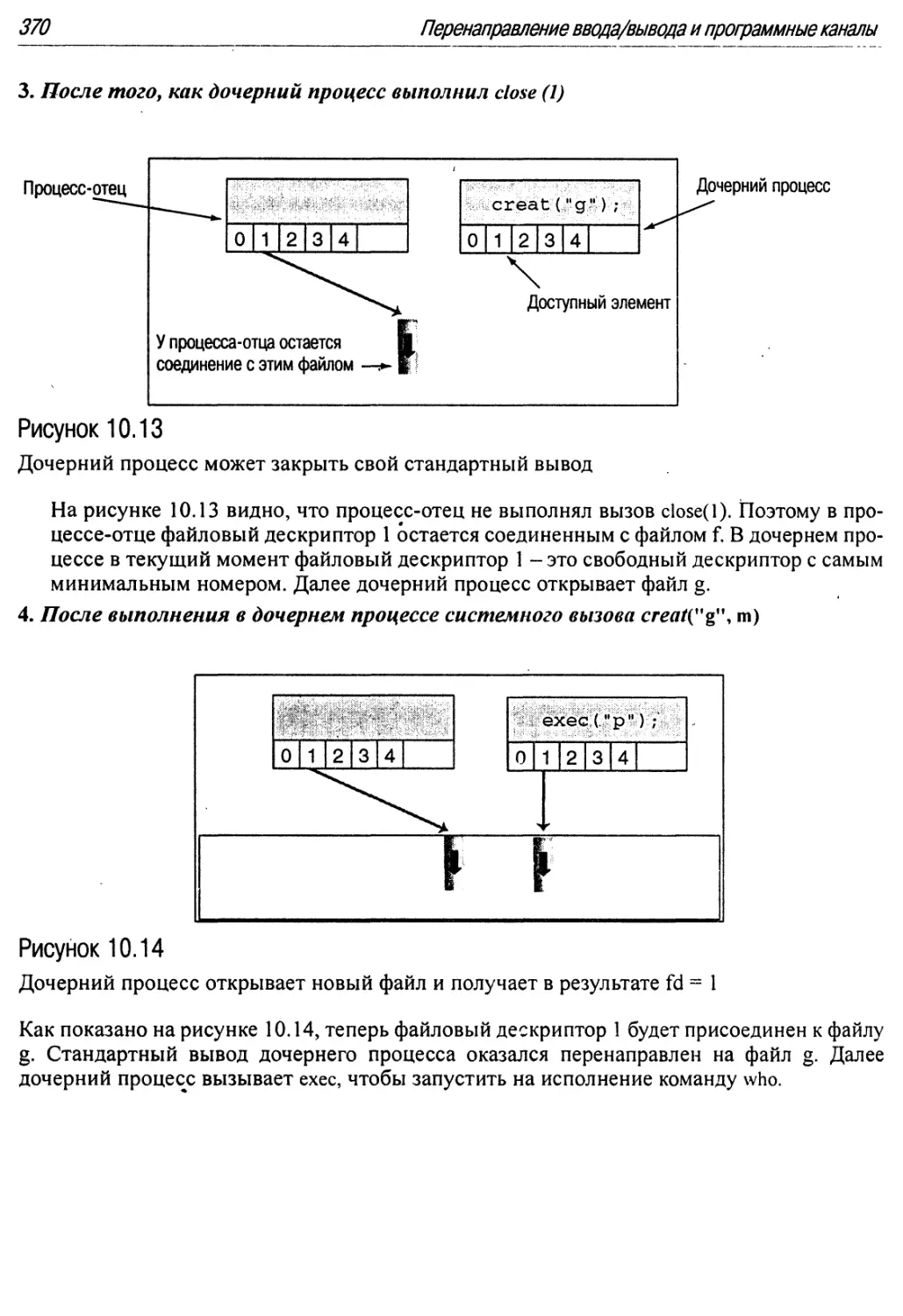
10.13 Дочерний процесс может закрыть свой стандартный вывод 370
10.14 Дочерний процесс открывает новый файл и получает в результате fd = 1 370
10.15 Дочерний процесс запускает на исполнение программу с новым стандартным
выводом 371
10.16 Два процесса соединены с помощью программного канала 372
10.17 Программный канал 373
10.1.8 Процесс создает программный канал 374
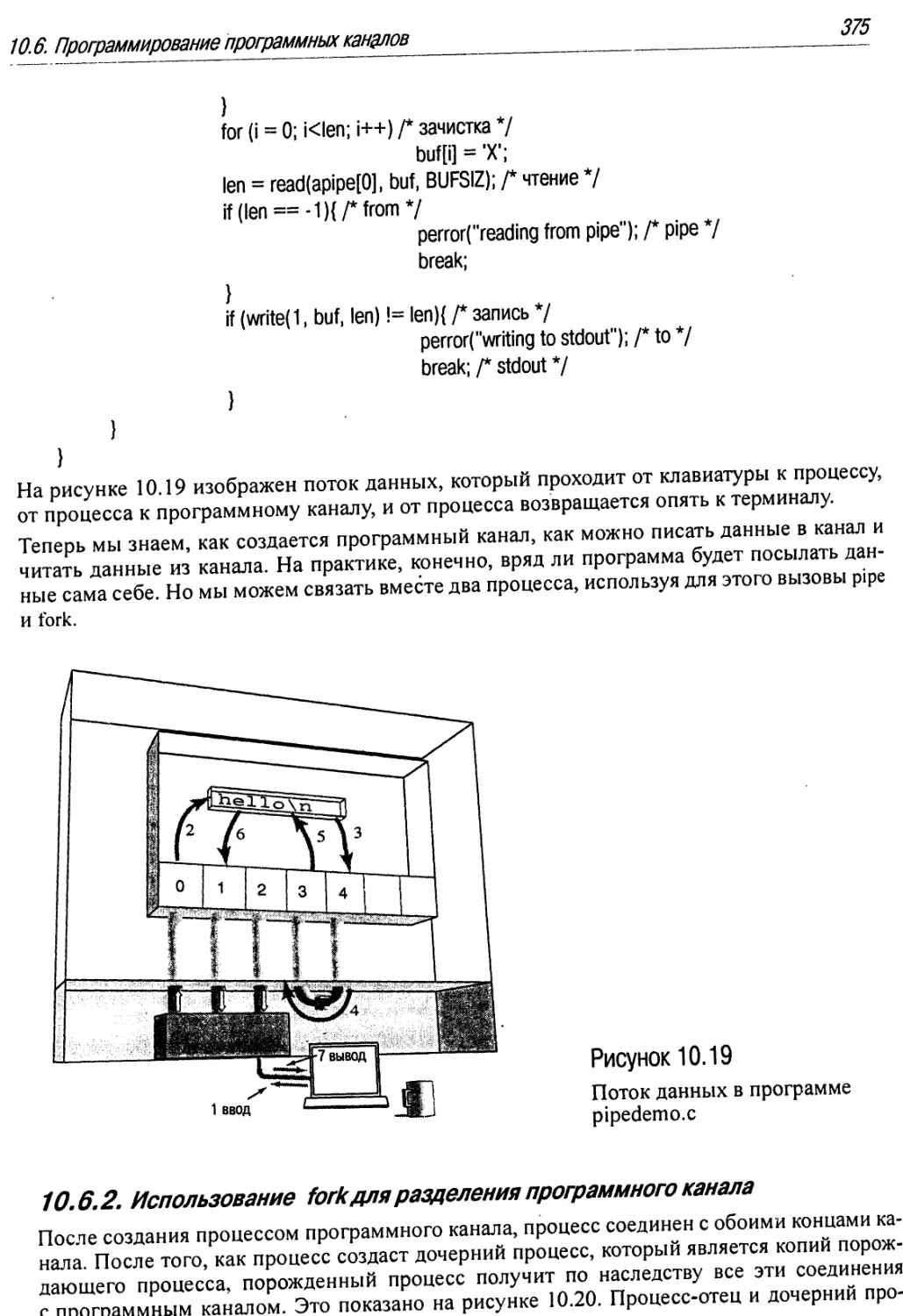
10.19 Поток данных в программе pipedemo.c 375
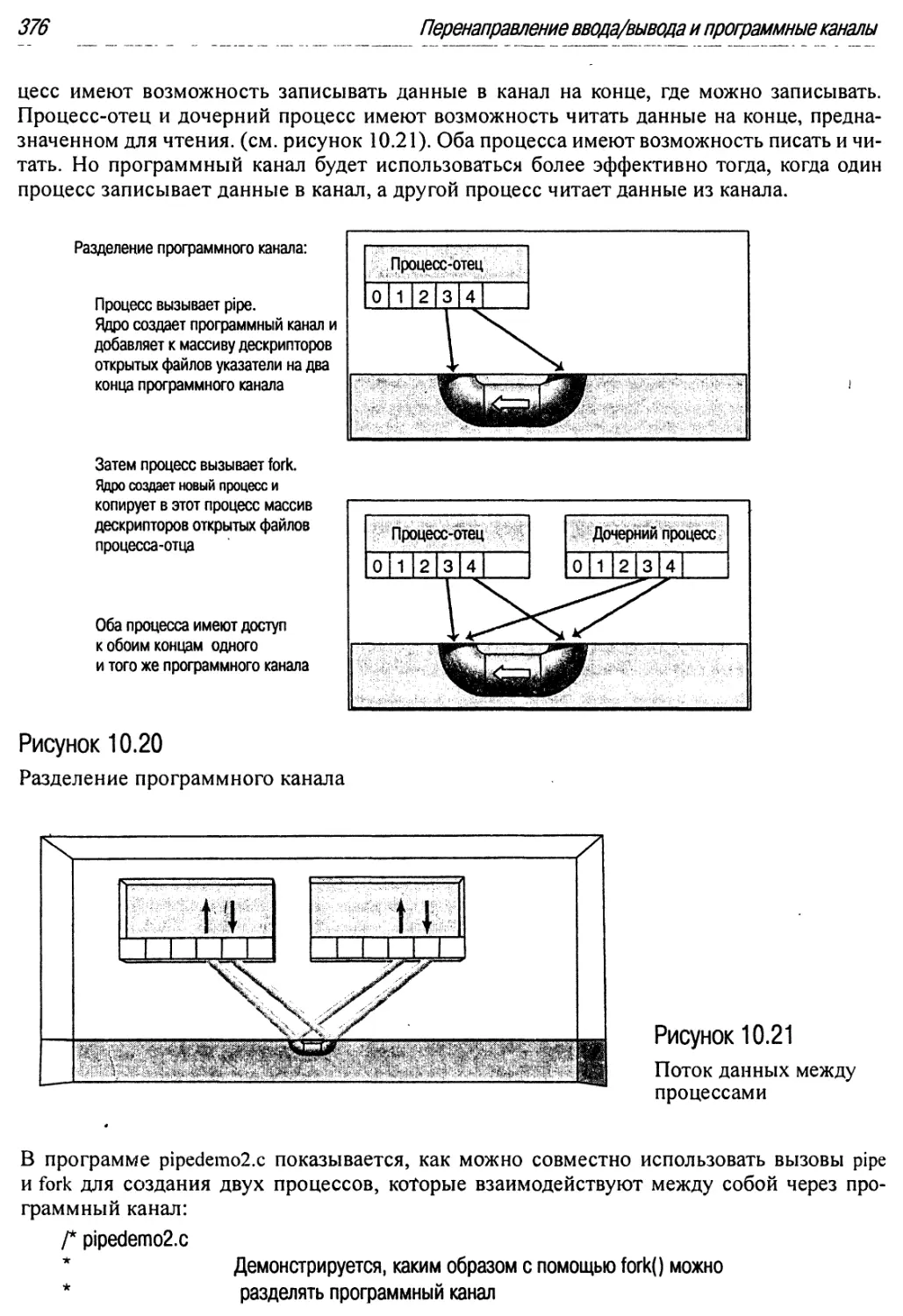
10.20 Разделение программного канала 376
10.21 Поток данных между процессами 376
11.1 Напиток, который готовится сейчас или заранее? 385
11.2 Один интерфейс и разные источники 386
11.3 be и dc, работающие как сопрограммы 387
11.4 be, dc и ядро 388
11.5 fopen и рореп 393
11.6 Чтение из команды 394
11.7 Соединение с удаленным процессом 397
11.8 Служба времени 398
11.9 Процессы на различных машинах 410
11.10 Система remote Is 411
11.11 Использование рореп ("Is") для получения списка файлов из удаленных каталогов .413
12.1 Основные компоненты схемы клиент/серверного взаимодействия 422
12.2 Создание сокета на сервере 423
12.3 Соединение с сервером 423
12.4 Сервер и клиент для службы времени (версия 1) 426
12.5 Сервер выполняет fork для запуска программы date 427
12.6 Web-сервер обеспечивает удаленное выполнение Is, cat, exec 430
13.1 Лицензионный сервер дает разрешение , 444
13.2 Управление доступом к автомобилям 446
13.3 Управление доступом к программному обеспечению , 448
13.4 Передача данных с помощью пакетов в Internet 450
13.5 Коммуникации можно устанавливать либо с помощью соединения,
либо без соединения 451
13.6 Три составные части дейтаграммы 452
13.7 Использование sendto и reevfrom 453
Список иллюстраций 23
13.8 Клиент уносит билет с собой в могилу 470
13.9 Использование alarm для планирования процедуры восстановления билетов ... 471
13.10 Сервер повторно стартует после своего краха 474
13.11 Клиент проверяет легальность билета 474
13.12 Клиент проверяет легальность вначале и далее 475
13.13 Идентификаторы процессов (PIDs) не являются уникальными в сети 478
13.14 Процесс не может послать сигнал на другой хост 479
13.15 Работают локальные копии lserv 479
14.1 Единственная нить исполнения 490
14.2 Несколько нитей исполнения , 491
14.3 Две нити разделяют глобальную переменную 495
14.4 Общий счетчик для двух нитей 496
14.5 Две нити инкремёнтируют один и тот же счетчик 497
14.6 Две нити используют mutex для разделения счетчика 499
14.7 Каждая нить имеет указатель на собственную структуру •...;.... 502
14.8 Использование почтового ящика с замком для передачи данных 505
14.9 Использование блокируемой переменной для передачи данных 507
14.10 Анимируемое изображение и управление с помощью клавиатуры 517
14.11 Нить анимации и нить клавиатуры , 517
14.12 Множество сообщений с изменением направления 520
14.13 Отдельная нить взаимодействует с curses 524
15.1 Команда talk при работе в сети .... 530
15.2 Команда talk 531
15.3 Три файловых дескриптора \ 535
15.4 У одного процесса есть информация, которая необходима другому процессу ... 536
15.5 Три пути для передачи данных 536
15.6 Каналы FIFO являются независимыми от процессов 537
15.7 Два процесса разделяют блок памяти ...539
15.8 Семафорный набор: num_readers 547
15.9 Несколько источников данных, один принтер 554
15.10 Получение файла для принтера .....555
15.11 Клиент/серверная система печати. 556
Глава 1
Системное программирование в Unix.
Общие представления
ЦЕЛИ
Идеи
Система Unix содержит пользовательские программы и системное ядро.
Ядро Unix - это набор специальных подсистем.
Ядро управляет всеми программами и организует доступ к ресурсам.
Коммуникации между процессами являются важнейшим аспектом для Unix - программ.
Что такое системное программирование?
Команды
be
more
1.1. Введение
Что такое системное программирование? Что такое системное программирование в Unix?
Что мы будем рассматривать в этой книге? В этой главе мы, образно говоря, нарисуем
общую картину в соответствии с поставленными вопросами.
Начнем с выяснения роли операционной системы и определения того, что означает
процесс написания программ, которые работают непосредственно с операционной системой.
После краткого представления общих положений мы рассмотрим Unix - программы,
которые используют услуги операционной системы, и затем перейдем к написанию наших
собственных версий программ. Наконец, мы рассмотрим схему, на которой представлен
Unix - компьютер. Схематические представления и техника раскрытия сути программ
составляют основу этой книги.
1.2. Что такое системное программирование?
1.2./. Простая модель программы
Возможно, вы писали научные программы, либо финансовые программы, либо
графические программы, либо программы текстовой обработки. Существуют много
разновидностей программ. Большая часть программ строится в соответствии с моделью,
представленной на рисунке 1.1.
1.2. Что такое системное программирование?
25
Компьютер
Программа
Рисунок 1.1
Прикладная программа
в компьютере
Программа - это некоторый код, который исполняется на компьютере. Данные.поступают
на вход программы, программа выполняет некоторую обработку данных, и
результирующие данные выводятся из программы. Человек может набирать данные на
клавиатуре и анализировать их на экране терминала, программа способна читать данные с диска
или записывать на диск, программа может посылать данные на печать на принтер.
Возможны и другие варианты. В этой модели программы, которая достаточно очевидна, код
выглядит следующим образом:
Г копирование со стандартного ввода на стандартный вывод */
main()
{
int с;
while((c = getchar())!=EOF)
putchar(c);
}
Этот код соответствует визуальной модели, представленной на рисунке 1.2.
'-'; ¦« "*^Л."
'^ш!^
getchar()
Рисунок 1.2
Как прикладные программы
рассматривают
пользовательский ввод/вывод
Рисунок подчеркивает то обстоятельство, что клавиатура и экран имеют связь с
программой. В отношении обыкновенного персонального компьютера такая модель достаточно
точно воспроизводит реальность. Клавиатура и дисплей подсоединены к материнской
плате. Эти компоненты соединяются с помощью обыкновенных металлических
проводников. Вы можете при случае увидеть на печатной плате эти проводники, которые
соответствуют направлениям линий связи на рисунке.
1.2,2. Реальность
Что происходит, когда вы входите в многопользовательскую систему, подобную типичной
Unix - машине? В этом случае простая модель, где клавиатура и монитор связаны с
процессором (CPU), не соответствует действительности. Реальность более близка тому, что
изображено на рисунке 1.3.
26
Системное программирование в Unix. Общие представления
Рисунок 1.3
Реальность: много
пользователей, программ
и устройств
В данном случае есть несколько клавиатур и дисплеев, несколько дисков, один или более
принтеров, а также есть несколько программ, исполняемых одновременно. При этом
программы, которые получают данные, вводимые с клавиатуры, и передают данные на дисплей
или на диск, прекрасно работают. Программы могут предполагать использование простой
модели и получать правильные результаты.
На самом деле все гораздо сложнее. Каким-то способом все эти различные клавиатуры
соединяются с различными программами. Каким-то образом строится множество связей
внутри машины. Если у вас появится возможность рассмотреть материнскую плату,
то увидите ли вы то, что представлено на рисунке 1.4?
Вряд ли. Такие соединения были бы кошмарными. Это все просто не будет работать,
поскольку различные программы сменяют друг друга по мере вхождения различных
пользователей в систему и выхода их из системы. Для данного случая должна существовать
другая модель, которая соответствовала бы мультипользовательскому, мультизадачному
компьютеру.
Рисунок 1.4
Как все это соединено?
1.2.3. Роль операционной системы
Роль операционной системы сводится к управлению и защите всех ресурсов, а также к
присоединению устройств к различным программам. Физический смысл этого заключается
в том, что операционная система, которая реализована программно, делает то же, что и
материнская плата персонального компьютера, которая реализована аппаратно. Сплетение
проводов, которое было на предшествующем рисунке, заменяется моделью на рисунке 1.5.
1.Z Что такое системное программирование?.
27
тт
Пользавательсков
пространство
Системное
Рисунок 1.5
Операционная система - это
программа
Операционная система - это программа. Код операционной системы, аналогично коду
любой исполняемой программы, располагается в памяти компьютера. В памяти находятся
также и другие программы - программы, которые были написаны пользователями и
запущены на исполнение. Операционная система соединяет эти программы с внешним миром.
1.2.4. Поддержка сервиса для программ
После того как мы рассмотрели проблему (как можно связать множество пользователей
с множеством процессов?) и возможное решение проблемы (иметь основную
управляющую программу для установления всех соединений), приступим к ее рассмотрению.
Начнем сначала с некоторых определений. Память компьютера предназначена для
поддержания некоторого пространства для хранения программ и данных. Часть памяти
компьютера, где размещается операционная система, называется системным
пространством, а другая часть, где хранятся пользовательские программы, называется
пользовательским пространством.
Операционная система называется ядром; клавиатуры и экраны подсоединяются к
компьютеру (см. рисунок 1.6).
Рисунок 1.6
Ядро управляет всеми
соединениями
Заметим, что местом подсоединения устройств является системное пространство; таким
образом, ядро является единственной программой, которая имеет доступ к этим
устройствам.
Пользовательские программы получают данные, обращаясь для этого к ядру. Ядро
передает данные от клавиатуры к программе и пересылает данные от программы через
установленное соединение на дисплей. Аналогично ядро может обеспечивать доступ к
твердому диску, принтерам, сетевым картам и другим периферийным устройствам. Если
программе понадобится подсоединение или управление этими устройствами, то ей
необходимо обратиться с запросом к ядру.
28
Системное программирование в Unix. Общие представления
Линии связи на рисунке представляют собой виртуальные соединения, которые
поддерживает ядро. Ядро обеспечивает для пользовательских программ доступ к этим
внешним объектам, что рассматривается как отдельные службы (сервисы).
Мы теперь представляем контекст, в котором будет проходить объяснение системного
программирования. Это и будет содержанием данной книги. Обычные прикладные
программы могут быть написаны так, как будто они имеют непосредственное соединение
с терминалами, дисками, принтерами. В этой расширенной модели работают системные
программы, обеспечивая ресурсы и поддерживая службы. Мы будем изучать службы,
которые поддерживает ядро, структуру этих служб, а также рассматривать, как писать
программы, которые работают в этом расширенном контексте.
1.3. Понимание системного программирования
Ядро обеспечивает доступ к системным ресурсам. Системные программы используют эти
службы непосредственно. Что представляют собой эти службы и как мы будем изучать
способы их использования?
1.3.1, Системные ресурсы
Процессоры
Программа представляет собой набор команд; процессор - это аппаратное устройство,
которое выполняет команды. Процессор также называют обрабатывающим устройством.
Некоторые компьютеры имеют несколько процессоров. Ядро назначает программы для
исполнения на процессорах. Оно начинает исполнение, приостанавливает, возобновляет
и заканчивает исполнение программы на процессоре.
Ввод/Вывод
Все данные, которые поступают на входы программ и которые вырабатываются как
выходные данные программ, проходят через ядро. Данные, поступающие от пользователей,
и данные, которые поступают на терминалы пользователей, также проходят через ядро.
Данные, которые читаются с дисков и которые записываются на диск, проходят через
ядро. Такая централизация гарантирует, что передача данных будет происходить
правильно - данные попадают в необходимое место. Гарантируется эффективность - не требуется
дополнительного времени, необходимого для передачи информации с одного места в
другое. Гарантируется безопасность - ни один из процессов не может увидеть информацию,
которая ему не предназначена.
Управление процессами
В Unix термин "процесс" используется для обозначения программы при ее исполнении.
Процесс состоит из памяти, открытых файлов, других системных ресурсов, необходимых
программе при исполнении. Новые процессы создает ядро. Ядро управляет процессами
и организует их совместную работу.
Память
Память компьютера является ресурсом. Программы могут потребовать некую
дополнительную память для хранения информации. Ядро следит за тем, какие секции памяти
используют процессы, и защищает память одного процесса от возможного доступа со
стороны других процессов.
1.3. Понимание системного программирования
29
Устройства
К компьютеру могут быть присоединены самые разнообразные устройства. Ленточные
устройства, CD-плееры, мышь, сканеры, видеокамеры - все это примеры устройств. Ядро
обеспечивает доступ к устройствам и заботится обо всех сложностях управления. Когда
программе необходимо получить картинку с видеокамеры, подсоединенной к
компьютеру, она обращается к ядру, чтобы обеспечить доступ к этому ресурсу.
Таймеры
Некоторые программы зависят от времени. Они могут выполнять действия по установке
временных интервалов; им может потребоваться ожидать наступления некоторого
момента времени, после которого они будут что-то делать. Программам может потребоваться
определение длительности выполнения неких действий. Ядро предоставляет для
использования процессоров определенное число таймеров.
Межпроцессные коммуникации
В повседневной жизни у людей возникает потребность в установлении коммуникаций
между собой. Для этого они используют телефоны, электронную почту, обыкновенную
почту, радио, телевидение и другие средства для передачи информации. В
вычислительной системе дри одновременном исполнении нескольких программ у процессов возникает
потребность взаимодействия. Ядро поддерживает несколько способов межпроцессных
коммуникаций. Такие коммуникационные системы, как телефонная сеть и почтовая
служба, являются системными ресурсами.
Сети
Сеть, связывающая компьютеры, является расширенной формой межпроцессных
коммуникаций. Сеть предоставляет возможность процессам на различных машинах
обмениваться данными, даже если на этих машинах работают различные операционные системы.
Сетевой доступ является службой ядра.
/. 3.2. Наша цель: понимание системного программирования
Мы только что ознакомились с некоторыми типами сервисов (служб) и с механизмами
доступа к ресурсам в ядре, которые реализуются системными программами. Каково
детальное представление каждого из типов служб? Как передавать данные от устройства
к программе и обратно? Хотелось бы узнать, как работает ядро, как оно выполняет
сервисные действия и как писать программы, которые могли бы использовать такие службы.
1.3.3. Наш метод: три простых шага
Мы будем изучать службы Unix, используя:
1. Просмотр "реальных" программ.
Мы будем изучать стандартные Unix - программы, чтобы посмотреть, что они делают и
каким образом программы используются на практике. Мы посмотрим, какие системные #
службы будут использоваться этими программами.
2. Изучение системных вызовов.
Мы будем далее изучать системные вызовы, которые можно использовать при работе
с упомянутыми службами.
3. Написание наших собственных версий.
После того как поймем, как работает программа, какие системные службы она
использует и как используются эти службы, мы будем способны писать наши собственные
системные программы. Эти программы является расширением существующих про-
гпяма/Г ним fwnrvr игттптттлпрятт. ппи ттпг/rnriftwwi* пяггмптпрнш.т<» ттпиниипи
30
Системное программирование в Unix. Общие представления
Мы будем изучать системное программирование в Unix, задавая себе многократно
следующие три вопроса:
Кто выполняет это действие?
Как выполняется это действие?
Могу ли я попытаться сделать то же?
1.4. UNIX с позиций пользователя
1.4.1. Что делает Unix?
Первым нашим шагом при изучении любого аспекта Unix будет получение ответа на
вопрос - что делает система? Сначала ответ на этот вопрос будет относительно UNIX в
целом. Как пользователь воспринимает Unix? Как система воспринимается пользователем,
который садится за Unix - терминал?
После беглого рассмотрения этих вопросов у нас возникнут вопросы относительно того,
как это все работает.
1.4.2. Вхождение в систему—запуск программ—выход из системы
Работать в Unix просто. Вы входите в систему, запускаете какие-то программы и выходите
из системы. При вхождении в систему вы набираете пользовательское имя и пароль:
Linux 1.2.13 (maya) (ttypl)
maya login: betsy
Password: _
После вхождения в систему вы запускаете программы на исполнение. Вы можете запускать
различные виды программ. Можете запустить программу дня чтения и посылки электронной
почты. Можете запустить программу дня расчета места расположения планет или определения
фондовых показателей. Можно запускать игровые программы. Запуск программ выполняется
чрезвьиайно просто. Система выводит на экран приглашение. В ответ вы набираете и вводите
имя программы, которую хотели бы запустить на исполнение. Компьютер запускает
программу. После выполнения этой программы система выводит на экран следующее приглашение.
Даже изощренные графические десктопы следуют такому порядку действий. Приглашением
является экран с иконками и меню, а нажатие кнопкой мышки на иконке или пункте меню
эквивалентно набору имени команды. За графическим интерфейсом стоит программное
обеспечение, которое связывает текстовые имена файлов изображений с именами программ.
После окончания запущенных программ вы выполняете выход из системы (log out):
$exit
В зависимости от проведенных предварительно настроек для вашего входа в систему вы
можете выйти из системы с помощью команды logout или при наборе на клавиатуре
последовательности Ctrl-D.
Как все это работает?
Все выглядит достаточно просто, но что за этим стоит? Как это все работает?
Что означает войти в систему! При работе с персональным компьютером используется идея
персонального использования компьютера, что сравнимо с использованием семейного
автомобиля. На Unix - машине в одно и то же время в систему могут входить несколько человек,
даже сотни человек. Как система узнает, кто вошел в систему и где это произошло?
1.4. UNIX с позиций пользователя
31
Рассмотрим этот процесс более детально. Если ваше входное имя и пароль были восприняты
при входе, то система стартует программу, которая называется shell, и свяжет вас с ней.
Каждый пользователь, вошедший в систему, связывается с собственным shell-процессом.
На рисунке 1.7 представлена иллюстрация вхождения пользователя в Unix - систему.
Компьютер изображен в форме ящика слева, а пользователь сидит и работает с
клавиатурой и экраном. Внутри компьютера находится память, где хранится ядро и
пользовательские процессы. Ядро производит контроль и управление за соединением пользователя
с системой. Также оно передает данные между пользователем и shell.
Shell выводит на экран приглашение, по которому пользователь оповещается о готовности
запустить для него некую программу. В данном примере в качестве приглашения
использован знак доллара. В качестве приглашения может быть использована любая текстовая
строка. Пользователь набирает имя программы, и ядро пересылает его на вход shell.
Рисунок 1.7
Вхождение пользователя
в систему
Например, чтобы запустить программу, которая выводит на экран текущее время и дату,
пользователь должен набрать такую командную строку:
$
$ date
Sat Jul 121:34:10 EDT 2000
Запускается программа date, она выводит дату, а затем shell выводит новое приглашение.
Для запуска другой программы достаточно набрать ее имя. Во многих Unix - системах
имеется программа, которая называется fortune. Вот пример ее вызова:
$ fortune
Algol-60 surely must be regarded as the most important
programming language yet developed.
-- T. Cheatham
$-
Когда вы выйдете из системы, ядро уничтожит shell-процесс, который был вам ассоциирован.
Каким образом ядро создает такой shell-процесс? Каким образом shell-процесс получает
имя программы и запускает на исполнение эту вашу программу? Как shell узнает о том,
что программа закончилась? Процедура вхождения в систему и запуски программ не так
просты, как это может вначале показаться. Мы будем изучать детали в главе 8.
32
Системное программирование в Unix. Общие представления
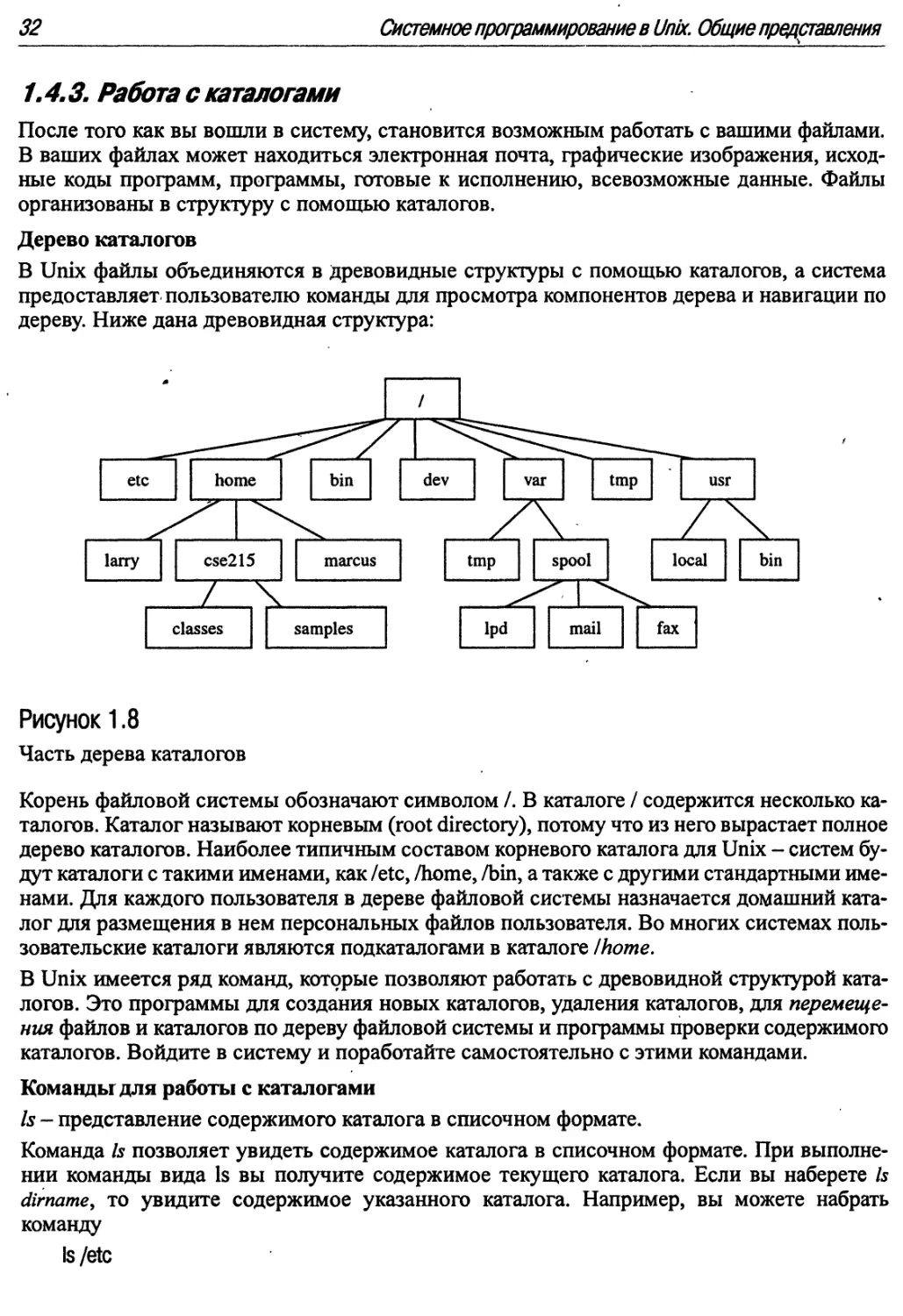
1\4.3. Работа с каталогами
После того как вы вошли в систему, становится возможным работать с вашими файлами.
В ваших файлах может находиться электронная почта, графические изображения,
исходные коды программ, программы, готовые к исполнению, всевозможные данные. Файлы
организованы в структуру с помощью каталогов.
Дерево каталогов
В Unix файлы объединяются в древовидные структуры с помощью каталогов, а система
предоставляет пользователю команды для просмотра компонентов дерева и навигации по
дереву. Ниже дана древовидная структура:
*
etc
larry
home
cse215
/
classes
\
^V
bin
/
/
marcus
samples
dev
var
/\
tmp
lpd
tmp
spool
mail
usr
/
local
fax
\
bin
Рисунок 1.8
Часть дерева каталогов
Корень файловой системы обозначают символом /. В каталоге / содержится несколько
каталогов. Каталог называют корневым (root directory), потому что из него вырастает полное
дерево каталогов. Наиболее типичным составом корневого каталога для Unix - систем
будут каталоги с такими именами, как /etc, /home, /bin, а также с другими стандартными
именами. Для каждого пользователя в дереве файловой системы назначается домашний
каталог для размещения в нем персональных файлов пользователя. Во многих системах
пользовательские каталоги являются подкаталогами в каталоге /home.
В Unix имеется ряд команд, которые позволяют работать с древовидной структурой
каталогов. Это программы для создания новых каталогов, удаления каталогов, для
перемещения файлов и каталогов по дереву файловой системы и программы проверки содержимого
каталогов. Войдите в систему и поработайте самостоятельно с этими командами.
Команды для работы с каталогами
Is - представление содержимого каталога в списочном формате.
Команда Is позволяет увидеть содержимое каталога в списочном формате. При
выполнении команды вида Is вы получите содержимое текущего каталога. Если вы наберете Is
dirname, то увидите содержимое указанного каталога. Например, вы можете набрать
команду
Is /etc
1.4. UNIX с позиций пользователя
33
с тем, чтобы посмотреть, какие файлы и каталоги находятся в каталоге /etc. Если же вы
наберете команду
Ь/
то увидите файлы и каталоги, которые находятся в корневом каталоге,
cd - сменить каталог.
При выполнении команды cd происходит переход в указанный каталог. Когда вы входите
в систему, то попадаете в ваш домашний каталог. Далее вы можете покинуть свой
домашний каталог и перейти в другую часть дерева файлов с помощью команды изменения
каталога. Например, после выполнения команды
cd /bin
вы попадаете в каталог, в котором содержится много системных программ. Когда вы
перешли в этот каталог, то можете выполнить команду Is, чтобы посмотреть, какие файлы и
каталоги здесь находятся. Из любого каталога можно переместиться по дереву на уровень
вверх после набора и выполнения команды
cd..
Независимо от того, куда вы переместились по дереву, вы в любом месте можете
вернуться в свой домашний каталог после выполнения команды
cd
pwd - вывести (распечатать) маршрутное имя текущего каталога.
Команда/?wrf информирует вас о том, в каком каталоге дерева вы сейчас находитесь. Она
выводит на экран путь от корня системы каталогов до вашего текущего каталога.
Например, команда
$pwd
/home/cse215/samples
показывает, что путь от корня дерева до нашего текущего каталога проходит через каталог
home, затем через подкаталог cse215 и т. д.
mkdir, rmdir - создание и удаление каталогов.
Для создания каталога следует использовать команду mkdir. Например, после выполнения
команд
$cd
$ mkdir jokes
будет создан каталог jokes, который размещается в домашнем каталоге. Вам не
разрешается создавать новые каталоги в каталогах других пользователей.
Для удаления каталога следует использовать команду rmdir. Например, после выполнения
команды
$ rmdir jokes
будет удален каталог jokes, если он не содержит файлов или каталогов. Вы должны
удалить или переместить содержимое каталога перед тем, как попытаться его удалить.
Команды для работы с каталогами: как они работают? Мы рассмотрели, как может
выглядеть твердый диск в форме дерева каталогов, где каждый каталог соединен с одним
вышележащим и каждый каталог может содержать некоторое количество каталогов,
которые находятся на уровнях ниже текущего. Каждый каталог может содержать файлы.
Пользователь имеет возможнось перемещаться по этой древовидной структуре, переходя
от одного каталога к другому, создавая при этом новые каталоги здесь и там или удаляя
старые каталоги.
34
Системное программирование в Unix. Общие представления
А как это все работает? Твердый диск - это просто набор металлических пластин, которые
способны хранить намагниченные элементы. А где же здесь каталоги? Что для вас
означает выражение "находиться в вашем домашнем каталоге"? Что для вас значит переход
в другой каталог?
Какое-то число пользователей могут войти и работать одновременно на одной Unix -
машине. При этом эти пользователи могут находиться в различных каталогах или все сразу
в одном и том же каталоге, если они этого пожелают. Что будет с такими пользователями,
если они все обратятся к одному каталогу?
Как можно писать программы, которые будут выполнять навигационные действия по
дереву каталогов? Какую роль играет ядро в создании такой древовидной модели?
/. 4.4. Работа с файлами
Каталоги играют роль, системной памяти для файлов. Пользователи имеют персональные
файлы, которые хранятся в домашнем каталоге и в нижележащих каталогах. Система
хранит свои файлы в системных каталогах. Что может делать с файлами пользователь?
Мы начинаем рассмотрение некоторых базовых действий.
Команды для работы с файлами
Имена файлов - краткое представление.
Файлы имеют имена. В большинстве версий Unix имена файлов могут быть достаточно
длинными - иметь до 250 символов.(Чаще всего указывают максимальную длину, равную
255 символов.- Примеч. пер.) Имена файлов могут быть составлены из любых символов,
за исключением символа "/". Символы могут быть набраны в верхнем и нижнем
регистрах. В именах можно использовать знаки пунктуации, пробелы, знаки табуляции и даже
символы перевода строки.
cat, more, less, pg - команды для представления содержимого файлов.
Файл содержит данные. Для просмотра содержимого файла можно использовать команды
cat, more или less.
Команда cat служит для отображения содержимого всего файла целиком:
$ cat shopping-list
soap
cornflakes
milk
apples
jam
$
Если файл имеет большее число строк, чем размер экрана, то можно использовать
команду щоге для организации постраничного вывода содержимого файла на экран.
$ more longfile
После вывода каждой очередной порции на экран вы должны нажать на клавишу
"Пробел", чтобы вывести следующую страницу, или нажать на клавишу Enter для смещения
текущего вывода на одну строку или нажать на клавишу "q" для выхода из просмотра
файла. На некоторых системах доступны для использования команды less и pg. Они работают
аналогично команде more.
1.4. UNIX с позиций пользователя
35
ср - копирование файла.
Для выполнения копирования файла следует использовать команду ср. Например, при
выполнении команда
$ ср shopping-list last.week.list
будет создан новый файл last.week.list, и в этот новый файл будет копироваться
содержимое файла shopping-list.
rm - удаление файла.
Для удаления файла из каталога следует использовать команду rm. Например, после
выполнения команды
$ rm old.data junk shopping.junel 992
будут удалены три файла.
В Unix не поддерживается действие восстановления (undelete). В одно и то же время
систему могут использовать сразу несколько пользователей. Когда вы удаляете файл,
то система может немедленно выделить освободившееся место на диске для другого
пользователя. Дисковое пространство, в котором всего секунду назад находилась ваша
курсовая работа, может теперь содержать исходный код программы на С другого пользователя.
mv - переименование или перемещение файла.
Для переименования файла или для перемещения файла в другой каталог следует
использовать команду mv. Например, после выполнения команды
$mvprog1.cfirst_program.c
будет изменено имя файла prog 1.с: новым именем будет first_program.c. Можно теперь
переместить эту программу в другой каталог, задавая имя каталога в качестве последнего
аргумента при обращении к команде:
$ mkdir mycode
$ mv first_program .с mycode
Ipr, Ip - распечатать содержимое файла.
Вы можете распечатать содержимое файла при помощи команды Ipr. В самом простом
варианте команда имеет вид:
$ Ipr filename
На принтер по умолчанию будет передан для печати файл с указанным именем. На многих
системах используют более одного принтера. Тогда команда Ipr применяется в более
сложном варианте, с тем чтобы выбрать для использования конкретный принтер. Пожалуйста,
обратитесь к документации на вашей локальной системе, чтобы ознакомиться с деталями
печати. На некоторых системах для печати используется команда 1р.
Файловые команды: как они работают? Пользователи воспринимают файл как некое
объединение информации, обычно в форме документа. Документ рассматривается как
совокупность страниц, состоящих из символьных строк. Как файлы хранятся на диске?
Каким образом происходит копирование файлов? Как можно перемещать файл из одного
каталога в другой? Как система производит переименование файлов? И вообще, как
система производит именование файлов? Вы, читатель, имеете имя; где оно хранится? В Unix
все эти вопросы разрешены. Вам, как системному программисту, необходимо понимать,
как это все работает.
36
Системное программирование в Unix. Общие представления
Атрибуты прав доступа к файлам
У вас есть некоторые файлы, у других пользователей есть свои файлы. У тех, кто
запускает систему, имеются свои системные файлы. Вы можете не предоставлять всем
окружающим право на изменение или даже право на чтение ваших файлов.
Для тех лиц, которые будут запускать систему, требуется, чтобы пользователи не изменяли бы
системные файлы или не вызвали бы беспорядок при работе с системными каталогами.
Для контроля за доступом пользователей к их файлам в Unix для каждого файла
устанавливаются несколько атрибутов. Файл имеет собственника, и файл имеет атрибуты прав
доступа к нему. Собственник файла является пользователем в системе. Вы становитесь
собственником файла, когда его создаете. Другие пользователи становятся
собственниками при создании их собственных файлов.
Каждый файл имеет три группы атрибутов прав доступа к файлу. Команда Is -1 показывает
значения атрибутов файла:
$ Is -I outline.01
-rwxr-x— 1 molay users 1064 Jun 29 00:39 outline.01
Это расширенный вариант вывода по команде Is. Символы -1 называются опцией в
командной строке. Вы можете менять поведение Unix - команд с помощью указания значений
этих опций при запуске команды. При расширенном варианте вывода команда Is выводит
информацию о правах доступа, имя собственника файла, размер файла, дату и время
последней модификации файла. Подстрока в левой части строки вывода команды Is -1,
состоящая из символов и знаков пунктира, отображает состояние разрядов прав доступа.
Каждый файл имеет собственника и три группы атрибутов доступа к файлу:
г w х г w х г w х г: чтение, w: запись, х: исполнение
user group other (собственник группа все_остальные).
Весь мир пользователей делится на три категории: пользователь, являющийся
собственником файла, группа, к которой принадлежит пользователь, и все другие пользователи.
Пользователям в каждой из этих трех категорий может быть предоставлено право на
чтение из файла, на запись в файл или на исполнение файла. Эти девять атрибутов являются
независимыми. Вы можете, например, дать право на модификацию файла и не разрешить
читать из файла всем пользователям из категории все_остальные. Вы даже себя можете
лишить возможности читать собственные файлы.
Права доступа к файлу: каким образом это все работает? Каково назначение разрядов
прав доступа? Как установить указанные атрибуты прав доступа? Какие стратегии при
управлении правами поддерживаются в Unix? Где хранятся эти разряды прав доступа?
Мы изучим эти темы в последующих главах.
1.5. Расширенное представление об UNIX
/. 5.1 Взаимодействие (связь) между людьми и программами
В предшествующем разделе мы рассмотрели, что делает Unix с позиций пользователя,
и начали рассмотрение вопроса, как работает система. Пользователь входит в систему,
запускает программы на исполнение, работает с файлами и каталогами и выходит из
системы. Возможно, что в то же самое время в систему могут входить еще какие-то
пользователи, запускать на исполнение свои программы, работать с их файлами и каталогами и вы*
ходить из системы. Пользователи могут работать с одними и теми же файлами и
каталогами, они могут посылать электронную почту или разовые сообщения друг другу. Каждый
пользователь работает в собственном пространстве, но это пространство является частью
большой системы.
1.5. Расширенное представление об UNIX
37
Мы изучим, как все это работает, и рассмотрим, как писать программы, которые работают
в этой большой системе. Что представляет собой эта большая система? Большая система
представляет собой систему, в которой работают более одного пользователя, исполняются
более одной программы, работают более одного компьютера, производится
взаимодействие (связь) между людьми, программами и компьютерами.
Рассмотрим три примера, с тем чтобы обсудить некоторые идеи и вопросы, которые
возникают при программировании в этой большой системе.
1.5.2.Турниры по игре в бридж через Интернет
Много людей играют в бридж через Интернет. Люди садятся за свои компьютеры,
соединяются с сайтом для игры в бридж и ищут игру. Как только игроки подсоединились к игре,
возникает ситуация: четыре человека сидят за компьютерами в разных частях света.
Каждый из них видит на своем экране общий стол, каждый из них разделяет с другими
игроками одну и ту же колоду карт, и каждый может видеть, что делают другие игроки.
Упрощенная картинка этой игры будет такой:
Рисунок 1.9
Четыре человека играют в бридж через Интернет
На рисунке 1.9 изображены четверо игроков, каждый из которых работает со своим
компьютером, каждый компьютер соединен через линию связи с Интернет.
На этом рисунке не представлен стол для бриджа, который добавлен на рисунке 1.10.
§д
ЕШЭ %%
Рисунок 1.10
Стол для бриджа на серверном компьютере
Теперь мы имеем дело с сетью, в которой появляется пятый компонент. На столе для
бриджа находятся карты, которые используются в игре. Стол представлен как
поверхность, на которой отображаются образы карт. Стол - это место, вокруг которого
собираются люди, чтобы сыграть в игру. В реальной игре игроки могут передавать карты от одного
игрока другому. Каким образом сделать то же самое при ведении виртуальной игры?
38
Системное программирование в Unix. Общие представления
Где расйолагаются карты? Как представить карты, которые находятся у вас на руках? Как
программа может предотвратить "использование двумя игроками одних и тех же карт?
В реальном мире это не является проблемой. В виртуальном мире каждая карта не
представляет собой отдельную физическую целостность, что предотвращает возможность ее
одновременного пребывания сразу в двух местах.
На рисунке 1.11 изображены некоторые коммуникационные маршруты:
8А
о
Рисунок 1.11
Отдельные программы посылают сообщения друг другу
При рассмотрении примера с игрой в бридж возникли три новые темы, которые весьма
важны в системном программировании в среде Unix.
Коммуникации
Каким образом один пользователь или процесс связывается с другим пользователем или
процессом?
Координация
Одновременно два игрока не могут выбирать карты из колоды. Каким образом программа
должна координировать действия между процессами, чтобы они правильно разделяли
ресурсы?
Сетевой доступ
В данном примере программы на каждом из компьютеров пользователей
взаимодействуют через Интернет. Как программа может связаться с другой программой, используя
Интернет? Каким образом обеспечивается программный доступ к Интернет?
/. 5.3, be: секреты настольного калькулятора в Unix
В каждой версии Unix имеется программа be, которая выполняет функции простого,
текстового калькулятора с двумя привлекательными характеристиками. Чтобы запустить
программу на исполнение, нужно набрать:
$Ьс
В ответ не появится ни приглашения, ни указания номера версии, ни требования набрать
пароль. Программа просто будет ждать возможности выполнить некие вычисления.
Наберите арифметическое выражение и нажмите на клавишу Enter.
2+3*4+5*10
1.5. Расширенное представление об UNIX
39
Программа be выведет на экран правильный результат. Программе известно, что в
выражении следует сначала выполнить умножение, а затем сложение. Для выхода из
программы be следует нажать на клавиши Ctrl-D.
Одним из достоинств программы be является возможность работать с очень большими
целыми числами, такими, как:
99999999999999999999 * 88888888888888888888
8888888888888888888711111111111111111112
Для представления больших чисел можно использовать экспонентную форму записи
чисел:
3333 Л 44
10110061584495640995005898489182285794822405288498070703365111794769\
43890411064925291154381468890721948142209004688381870355409155411563\
21805747562427309521
Для обычного представления числа 3333 с десятичным порядком 44 понадобилось две
с половиной строки десятичных цифр. Поэкспериментируйте с be, чтобы посмотреть, как
программа работает с большими числами. Программа be поддерживает также свой язык
программирования, где используются переменные, циклы и С-образный синтаксис.
Например, следующий ниже код (будет восприниматься для выполнения программой be:
х = 3
if (х == 3){
у = х*3;
}
У
Вот еще одно интересное свойство программы be. Программа be не является'
калькулятором. Она не производит вычислений. Чтобы посмотреть, что делает программа, давайте
попытаемся выполнить следующее:
$Ьс
2 + 3
5
<-- Нажмите здесь Ctrl-Z
Приостанов процесса
$ps
PIDTTYSTIMECMD
25102 ttyp2T 0:00.02 be
27081 ttyp2 T 0:00.01 dc-27560
ttyp210:00.59-bash
27681 ttyp2T 0:00.00 be
$fg
<- Нажмите здесь Ctrl- D
Программа ps выводит информацию о запущенных вами процессах. В данном листинге
представлена информация о четырех процессах. Для одного из процессов указана в
качестве имени исполняемой программы строка в виде "-bash," что говорит о том, что это
информация о "входном shell" (log-in shell). В листинге представлены еще два процесса,
в которых исполняется программа be, и один процесс, в котором исполняется программа dc.
Что представляет собой программа dc?
40
Системное программирование в Unix. Общие представления
В большинстве версий Unix есть электронный справочник. Для прочтения документации
по команде dc следует набрать такую команду:
$mandc
User Commands dcA)
NAME
dc - desk calculator
SYNOPSIS
dc [ filename ]
DESCRIPTION
dc is an arbitrary precision arithmetic package. Ordinariiyit operates on decimal integers, but one may
specify an input base, output base, and a number of fractional digits to be maintained. The overall
structure of dc is a stacking (reverse Polish) calculator. If an argument is given, input is taken from
that file until its end, then from the standard input.
Это страничка из электронного справочника системы SunOS 5.8; в большинстве версий
Unix описания команд представлены в аналогичном виде. В этом тексте из документации
говорится о том, что dc - это команда, которая выполняет функции калькулятора. Более
того, здесь указывается, что эта команда работает как калькулятор с использованием стека и
обратной польской записи. Предполагается, что она начинает работать после набора
пользователем чисел. Выполним сложение следующего вида: 2+3.
2
3
+
Р
5
Этот протокол означает, что сначала в стек заносится 2, затем 3, далее производится
сложение двух чисел, которые находятся в головной части стека, затем происходит выдача
полученного результата, который будет размещен в голове стека. Возникает вопрос - если
программа dc представляет собой калькулятор, причем калькулятор, использующий
стековую память, то чем же тоща является программа 1?с и почему она тоже исполняется?
Ответ мы получим после прочтения документации в электронном справочнике
относительно команды be. В документации сказано о том, что команда be является препроцессором
относительно команды dc1. Программа be является синтаксическим анализатором. Она
взаимодействует с процессом, где выполняется программа dc через коммуникационное средство,
которое называется pipes (программные каналы)^ как показано на рисунке 1.12.
Данные, которые вводит пользователь в формате +2", поступают на вход процесса be.
В этом процессе происходит преобразование данных в соответствии со стековым
представлением, после чего данные передаются процессу dc. Процесс dc выполняет
необходимые вычисления и отправляет полученный результат обратно процессу be. Процесс be
производит форматирование этого результата для оконечного пользователя. Пользователь
воспринимает программу be как калькулятор.
22+р 2 + 2
4
Рисунок 1.12
Программы посылают сообщения друг другу
» I I
1. В версии GNU команды be вместо dc используется внутренний стековый калькулятор.
1.6. Могу ли я сделать тожесамое?
41
В данном примере с программами bc/dc показано наличие программ, которые, аналогично
случаю использования стола для бриджа в Интернете, включают в себя различные
процессы, а также некоторые разновидности средств коммуникации и кооперации. Отдельные
программы при совместной работе образуют систему. Каждая часть системы выполняет
свою задачу и достаточно наглядно выделена. Значимую часть системы составляют
средства межпроцессных коммуникаций, которые используются отдельными программами.
Сходство между примером с игрой в бридж через Интернет и примером с системой и bc/dc
является фундаментальным принципом системного программирования в Unix. Поэтому
изучение системного программирования в Unix сводится к изучению того, как нужно писать
отдельные программы и каким образом необходимо построить связи и обеспечить совместную работу
программ.
1.5.4. От системы bc/dc к Web
Систему из программ bc/dc отделяет от World Wide Web всего один небольшой шаг. В
системе в паре bc/dc программа be выполняет функции пользовательского интерфейса, а
программа dc выступает в роли программы, выполняющей заданную работу. При
рассмотрении World Wide Web видно, что броузер выполняет функции пользовательского
интерфейса, а Web-сервер выполняет конкретную работу. Архитектура при этом одна и та же.
(http://www.xyz.com/info
<htmlxhead><title>...|| Шйашй _l—server
Рисунок 1.13
Отдельные программы
посылают сообщения друг другу
Пользователь взаимодействует с броузером. Броузер располагается не в том месте, где
находятся Web-страницы. Эти страницы находятся на серверах. Совсем коротко можно
сказать, что серверы поддерживают текстовый язык нттр, а программа dc разговаривает
на текстовом языке, который называется rpn. Пользовательский агент (be или броузер)
транслирует пользовательский ввод B+3 или нажатия кнопок мыши) в краткий текстовый
язык и посылает требование на обслуживание (программа dc или Web-сервер).
Пользовательский агент (be или броузер) принимает ответ от сервера и форматирует его для
пользователя. Между моделью системы программ bc/dc и World Wide Web
принципиальная разница отсутствует. Вероятно, не является неожиданным, что Web выросла благодаря
Unix - системам2.
1.6. Могу ли я сделать то же самое?
У нас теперь появилось представление о сути проблем, которые были обозначены ранее
в двух первых вопросах. Мы рассмотрели несколько аспектов системы Unix, с тем чтобы
ответить на вопрос "Что делает система?". Перед нами стоял вопрос "Как выполняется эта
работа?"
2. Между прочим, студент моего курса Ами Чусед был первым, кто отметил связь между системой bc/dc и
клиент-серверным программированием на основе TCP/IP.
42
Системное программирование в Unix. Общие представления
По таким примерам, как система bc/dc, мы получили частично ответ на этот вопрос.
Согласно нашему методу есть и третий вопрос: "Могу ли я сделать то же самое?" В этом
разделе мы напишем версию Unix программы more.
Во-первых, определим, "Что делает команда more"?
Команда more служит для поэкранного вывода содержимого файла. В большинстве Unix
систем есть большой текстовый файл, который называется /etc/termcap и используется
некоторыми редакторами и видеоиграми. Если вы захотите постранично просмотреть
содержимое этого файла, то вы должны будете набрать следующую команду:
$ more /etc/termcap
В начале работы программы вы увидите первый экран текста файла. В нижней части
экрана программа more будет выводить в инверсном режиме отображения процент
просмотренного объема текста. Для просмотра следующей страницы следует нажать на
клавишу пробела, для смещения просматриваемого текста на одну строку необходимо нажать
на клавишу Enter, для выхода из просмотра следует нажать на клавишу "q", для получения
текста помощи вы должны нажать на клавишу "h".
Заметим, что не следует нажимать на клавишу Enter после нажатия на клавишу пробела
или на клавиши "q" или "h". Программа сразу отвечает на нажатие указанных клавиш.
Есть три варианта использования команды more на уровне командной строки:
$ more filename
$ command | more
$ more < filename
В первом случае команда more будет отображать содержимое файла с указанным именем.
Во втором случае запускается на исполнение программа с именем command и ее вывод
постранично отображается на экране. В третьем случае команда more отображает тот
текст, который эта программа читает из стандартного ввода. Вместо стандартного ввода
был присоединен указанный файл.
Во-вторых, определим, "Как это все работает"?
После неоднократного запуска команды more можно заметить, что ее логика работы
вполне вероятно описывается следующей последовательностью шагов:
+—-> вывод 24 строк из файла
| +- - > вывод сообщения [more?]
| Нажатие на клавиши Enter, SPACE или q
j +-- если Enter вывод одной очередной строки
+—- если SPACE
если q--> выход
Наша программа должна быть гибкой в части организации ввода и быть похожей в этом на
реальную программу more. Это означает, что если пользователь указывает для нашей
программы в командной строке имя файла, то программа должна читать этот файл. Если в
командной строке при обращении к программе имя файла не задано, то программа должна
будет читать со стандартного ввода.
Ниже представлен первый вариант нашей версии программы more:
/* moreOI .с - версия 0.1 программы more
* читает и выводит на экран 24 строки, затем следуют несколько
* специальных команд */
#include <stdio.h>
?. Могу ли я сделать то же самое?
#define PAGELEN 24
«define UNELEN 51.2
void do_more(FILE *);
intsee_more();
int main(int ac, char*av[])
{
RLE *fp;
if (ac == 1)
do_more(stdin);
else
while (--ac)
if (ft> = fopen(*++av, T)) != NULL)
{
do_more(fp);
fclose(fp);
} "
else
exitA);
return 0;
}
void do more(FILE *fp)
Г
* читает PAGELEN строк, затем вызывает see more() для получения дальнейших инструкций
7
{
charline[UNELEN];
int numjrfjines = 0;
int seejnoreQ, reply;
while (fgets(line, UNELEN, fp)){ /* ввод для more 7
if*(numj)fJines == PAGELEN) {/* весь экран? 7
reply = see_more(); /* у: ответ пользователя 7
if (reply == 0) Г п: завершить7
break;
num of lines -= reply; /* переустановка счетчика 7
}
if (fputs(line, stdout) == EOF) /* показать строку 7
exitA );/* или закончить */
num of lines++; /* учесть очередную строку 7
}
}
intseemore()
Л
* выдать сообщение, ожидать ответа, возвратить значение числа строк
* q означает по, пробел означает yes, CR означает одну строку
7
{
int с;
printf(H\033[7m more? \033[mM); /* реверс изображения для vt100 7
while((c=getchar()) != EOF) /* получение ответа 7
44
Системное программирование в Unix. Общие представления
if (с == -Q-) */
return 0;
if (с ==' ')Г'' => следующая страница 7
return PAGELEN; /* сколько показывать */
if (с == '\п*) /* Требование на 1 строку */
return 1;
}
return 0;
}
Код программы состоит из трех функций. В функции main определяется, откуда
производится ввод информации - из файла или со стандартного ввода. Выяснив вопрос
относительно входного потока; функция main передает этот входной поток функции, которая
называется do_jnore и которая должна будет поэкранно отображать этот поток. В свою
очередь функция do_more отображает экран текста и затем обращается к функции see_more,
которая должна запросить у пользователя, что делать дальше.
Для компиляции и запуска нашей программы следует выполнить:
$ ее moreOI .с -о moreOI
$ moreOI moreOI .с
Полученная программа работает достаточно хорошо. Программа выводит 24 строки
текста и далее выводит заметное для плаза приглашение тоге? в реверсном изображении.
При нажатии на клавишу Enter будет выведена следующая строка текста. Над этой
программой необходимо будет еще поработать.
В частности, после вывода сообщения more? оно остается на экране и смещается (скрол-
лируется вверх) вместе с текстом. Кроме того, если вы нажмете клавишу пробела или
клавишу "q", ничего не произойдет, если вы не нажмете после этого на клавишу Enter. Это
решение нельзя признать хорошим. Итак, на экране остается приглашение more?. Создание
данной версии программы more иллюстрирует основополагающий фактор относительно
программирования в Unix:
Программирование в Unix не так трудно, как вы думали, но и не так просто,
как можно судить по первому опыту.
Программа выполняет четко заданную задачу. Логика этой задачи достаточно ясна. При
^ разработке алгоритма, который реализует действия, выполняемые задачей, не
использовались всяческие ухищрения.
Мы отметили ряд тонкостей в работе программы. Как модифицировать программу,
которая реагировала бы сразу же на нажатие клавиш без последующего нажатия на клавишу
Enter? Как можно вычислить процент объема просмотренного текста из файла? Как
удалить с экрана текст приглашения more? после того, как будет нажата клавиша?
Это не должно быть слишком сложным. Но прежде всего нам нужно закончить с другими
характеристиками программы, которые должны быть сравнимы с оригинальной программой.
Насколько хорошо наша программа справляется с управлением входными потоками?
Функция main выполняет проверку числа аргументов в командной строке. Если в
командной строке имена файлов отсутствуют, то программа будет производить чтение со
стандартного входа. Тем самым обеспечивается возможность помещать программу more в
конец конвейера, как показано ниже:
$who|more
1.6. Могу ли я сделать то же самое?
45
В этом конвейере запускается команда who, которая отображает список всех
пользователей, работающих в текущий момент в системе, и посылает этот список пользователей
команде more. Поскольку наша программа more отображает за раз 24 строки, то она будет
полезна, если число пользователей будет превышать 24. Давайте проверим работу нашей
программы, но при работе не с программой who, а при работе с командой Is:
$ Is/bin | moreOl
Мы предполагаем увидеть содержимое каталога /bin страницами по 24 строки.
Когда вы запустите нашу программу, то увидите, что moreOl не приостанавливается после
вывода 24 строк. Что привело к ошибке? Причина заключается в следующем. Наша
программа moreOl читает и выводит по 24 строки из входного потока, который она получает
от команды Is. Когда программа moreOl будет читать двадцать пятую строку, она выведет
приглашение more? и будет ожидать ответа пользователя. Наша программа ждет, что
пользователь нажмет либо на клавишу пробела, либо на клавишу Enter, либо на клавишу "q".
Где в программе принимается информация от пользователя? В программе используется
для чтения из стандартного ввода getchar. Но в таком представлении конвейера:
$ Is/bin | moreOl
происходит перенаправление стандартного вывода команды Is на стандартный ввод
программы moreOl. Наша версия программы more пытается читать команды пользователя из
того же потока, откуда поступают данные из файла. На следующем рисунке показана
ситуация:"*
Рисунок 1.14
more читает со стандартного
ввода
Каким образом решается эта проблема в реальной программе more? To есть, как программа
может читать данные со стандартного ввода и одновременно вводить информацию от
пользователя с клавиатуры? Решением будет чтение данных непосредственно с
клавиатуры. На рисунке 1.15 показано, как это делается в реальной версии.
В каждой системе Unix есть специальный файл, который называется /dev/tty. Этот файл
обеспечивает соединение с клавиатурой и экраном. Даже если пользователь с помощью
символов < или > перенаправит в программе стандартный вход или стандартный вывод,
программа остается связанной с терминалом, чтение и запись с которым производится
через файл/dev/tty.
46
Системное программирование в Unix. Общие представления
Рисунок 1.15
Программа who читает
пользовательский ввод
с терминала
На рисунке показано, что more имеет два источника ввода. Стандартный ввод
программы подсоединен к выводу программы who. Но программа more также читает данные из
файла /dev/tty. Программа читает строки файла и отображает их на экране. Когда
необходимо запросить у пользователя, следует ли выводить более одной строки, более
одной страницы или следует выйти из просмотра, программа читает ответ от
пользователя из файла /dev/tty.
В соответствии с полученными новыми знаниями расширим вариант программы moreOl.c
и создадим вариант more02.c:
Г more02.c - версия 0.2 программы more
* чтение и выдача 24 строк, затем следуют несколько
* специальных команд
* особенность версии 0.2: чтение команд из файла /dev/tty
7
#include <stdio.h>
#define PAGELEN 24
#defineUNELEN512
void do_more(FILE *);
intsee_more(FILE*);
int main(int ac, char *av[])
{
FILE *fp;
if(ac==1)
dojnore(stdin);
else
while (--ac)
if ((fp = fopen(*++av, Г)) != NULL)
{
do_more(fp);
fclose(fp);
}
else
exitA);
return 0;
}
void do_more(FILE *fp)
Г
1.6. Могу ли я сделать то же самое?
47
* команд
7
{
charline[UNELEN];
int nunrurfjines = 0;
int see more(FILE *), reply;
FILE *fp_tty;
fpjty = fopen('7dev/tty", V); /* НОВОЕ: команда потока 7
if (fpjty == NULL) /* если открытие неудачно 7
exitA); Г не используется при запуске программы no use in running*/
while (fgets(line, LINELEN, fp)){ /* ввод для more 7
if (num_qfjines == PAGELEN) {/* весь экран? 7
reply = see_more(fp_tty); /* НОВОЕ: передача FILE * 7
if (reply == 0) /* n: завершить 7
¦ f v break;
num of lines -= reply; /* переустановить счетчик 7
}
if (fputs(line, stdout) == EOF) /* показать строку 7
exitA); /* или закончить вывод 7
num of lines++; /* учет выведенной строки 7
}
}
int see_more(FILE *cmd) /* НОВОЕ: прием аргументов 7
Г
* выдать сообщение, ожидать ответа, возвратить значение числа строк
* q означает по, пробел означает yes, CR означает одну строку
7
{
int с;
printf("\033[7m more? \033[m"); /* реверсировать текст для vt100 7
while((c=getc(cmd)) != EOF) /* НОВОЕ: читать из tty 7
{
if (с == -q*) /*q->N7
return 0;
If (C ==f ¦) /*•¦•=> следующая страница 7
return PAGELEN; /* сколько показывать 7
if (с == f\n') /* Enter => 1 строка 7
return 1;
}
return 0;
}
Компиляция и проверка этой версии производятся с Помощью команд:
$s ее -о more02 more02.c
$ Is /bin | more02
Эта версия more02.c может читать данные со стандартного ввода, а команды - с
клавиатуры. Заметим, что стремление написать стандартную Unix - программу привело нас
к необходимости изучить файл /dev/tty и определить его роль в качестве связующего файла
с пользовательским терминалом.
48
Системное программирование в Unix. Общие представления
И все же над нашей программой стоит еще поработать. Мы все еще должны нажимать на
клавишу Enter для получения ответа.от программы. Итак, пусть на Экране появились
символы "q" и пробел. Каким-то образом в реальной версии more при вводе указанных
символов сразу же произойдет выход из программы. При этом не нужно нажимать на клавишу
Enter. Если вы нажали на клавишу "q", произойдет выход из программы, а вы этот символ
просто не увидите на экране. ,
Непосредственный ввод: как это все работает?
При установлении связи с терминалами можно производить настройки. Вы можете
выбрать такую настройку соединения, что символы будут сразу же доступны в программе,
а не после нажа(тия пользователем клавиши Enter после нажатия на какую-либо клавишу.
Можно выбрать такую настройку, чтобы символы, которые пользователь набирает на
клавиатуре, не отображались бы на экране. Вы в праве выбрать все варианты установок,
которые управляют передачей данных вашей программе через терминал.
Насколько мы углубились в проблему, детально показано на нашем рисунке. Теперь он
будет представлен в таком виде:
Рисунок 1.16
Соединение с терминалом имеет настройки
Новым составным элементом на этом рисунке стало управляющее устройство, которое
было добавлено к соединению с /dev/tty. Это устройство позволяет программисту
настраивать работу линии связи между терминалом и программой, что воспроизводит
возможные настройки между тюнером и громкоговорителем в радиоприемнике.
Для написания полнофункциональной, хорошо работающей версии программы more нам
понадобится изучить соединительное управляющее устройство (контроллер) и определить, как
можно его программировать. Нам потребуется также ответить еще на ряд других вопросов.
Как определить в процентах объем показанного текста? В реальной версии more процент
вывода пользователь может видеть на экране. Как можно добавить эту возможность в нашу
программу? Операционная система знает размер файла. Нам нужно познакомиться с тем, как
запросить у операционной системы эту информацию. Что такое реверсивный режим
изображения? Что можно сказать о числе строк на экране? На разных дисплеях используют различные
режимы для визуализации текста в инверсном режиме. Различные дисплеи имеют различное
число строк на физическом экране. Использование размера в 24 строки и кода для реверсив-
/. 7. Еще несколько вопросов и маршрутная карта
49
ного изображения в стиле vtlOO представляется недостаточно гибким. Как можно написать
версию программы more, которая работала бы с любым типом терминала и с любым числом
строк на экране? Для ответа на эти вопросы нам необходимо будет изучить особенности
управления экраном терминала и его атрибуты.
1.7. Еще несколько вопросов и маршрутная карта
/. Z /. О чем пойдет теперь речь?
Мы оговорили целевое назначение этой книги. Unix - это операционная система, которая
предоставляет нескольким пользователям возможность одновременной работы.
Пользователи могут запускать программы на исполнение и работать с файлами и каталогами. Эти
программы могут взаимодействовать между собой, с другим компьютером, а также
взаимодействовать через сеть. Пользователи запускают программы для управления своими
файлами, для обработки данных, для передачи и преобразования данных и для
установления связи с другими пользователями.
Что нужно сделать, чтобы все эти программы работали? Что делают программы? Что
делает операционная система? По мере изучения основных свойств системы мы ответили на
многие вопросы.
Давайте продолжать отвечать на вопросы. Наша разработка команды more
продемонстрировала метод, который мы возьмем для последующего использования. Мы
анализируем реальную программу, изучаем, что она делает, а затем пытаемся написать нашу
собственную версию такой программы. По мере разработки мы изучаем все более детально, как
работает Unix, и учимся, как использовать ее принципы работы.
1.7.2. А теперь - карта
Нам понадобится карта для нашего продвижения вперед. Вот она.
(ммЛ [
1 Ifr- 1
Ш
Ш ! U ;
?]^{V/±;\^YJ*?T~'*'r*''-
-[ШЗ
г —г-
L
i-i. t
fir if
Ц^ЩуЩр^ТТТ
;<-.. > < *СП?||
ЛЕ
D
Рисунок 1.17
Диаграмма основной структуры системы Unix
На этой диаграмме представлена основная структура любой системы Unix. Память
разделяется на системное пространство и на пользовательское пространство. В системном
пространстве находится ядро и его структуры данных. Пользовательские процессы
размещаются в пользовательском пространстве. Некоторые пользователи взаимодействуют
с системой через терминалы. Линии связи этих терминалов присоединены к ядру. Файлы
50
Системное программирование в Unix. Общие представления
хранятся в файловой системе на диске. К ядру подсоединяются различные типы
устройств, которые становятся доступными пользовательским процессам. Наконец, есть
средства для поддержки сетевых коммуникаций. Пользователи могут работать с
системой, используя сетевые средства.
В каждом разделе этой книги мы рассматриваем отдельные элементы этой диаграммы.
Каждый компонент будет рассмотрен более детально, чтобы, изучить службы ядра,
которые их поддерживают, и объяснить догику и структуры данных ядра, которые
используются для обеспечения этих служб.
В конце книги мы изучим каждую часть представленной диаграммы и рассмотрим все
идеи и средства, которые необходимы для написания сложных системных программ для
Unix (например, для разработки версии игры в бридж через Интернет).
/. 7.3 Что такое Unix? История и диалекты
В этой книге объясняются базовые идеи и структуры Unix и рассматривается, как следует
писать программы, которые будут работать в системе Unix. Но что же представляет собой
система Unix? Откуда она появилась? Что в этой части можно ожидать от этой книги?
Прежде всего, откуда появилась система Unix? Система Unix была разработана в Bell
Laboratories в 1969 году несколькими компьютерными специалистами для решения
специальных технических проблем и состояла из ядра и набора инструментальных средств.
Система Unix не была коммерческим продуктом. В самом деле, в течение семидесятых годов
Bell Labs распространяла программное обеспечение Unix, включая исходный код, в
школы и научные центры за номинальную цену. Специалисты из Bell Laboratories и многие
другие компьютерщики потратили много времени на изучение системы, ее улучшение
и добавление новых оригинальных программ. В восьмидесятых годах несколько
компаний лицензировали исходный код Unix и создали несколько версий Unix,
ориентированных на потребителей. Двумя основными центрами по развитию системы стали AT&T
и университет Беркли в штате Калифорния (UCB). AT&T разработала версию, которая
была названа System V, а специалисты UCB разработали версию, которая была названа
BSD. Большинство версий Unix были разработаны на основе одной из этих базовых
систем или на основе использования той и другой системы. С годами менялась собственность
на систему, прошла серия продаж системы от AT&T ряду компаний, коллектив UCB
перестал работать над Unix, появились различные группы, которые пытались выверять и
стандартизировать систему.
Независимо от курсов и стандартов основной проект и принципы Unix распространяются
через университетские и коммерческие компьютерные сферы. Развиваются различные
диалекты и модели системы. В некоторые версии были включены специальные средства,
например, обработка в режиме реального времени. При всех этих адаптациях и
изменениях в системе всегда оставались архитектура ядра и постоянный набор функций. Хотя
точная внутренняя структура и набор инструментальных средств для версии Unix от
AT&T времен восьмидесятых годов будут отличаться для варианта,,написанного в 1991
году в Хельсинки, но программы, которые были написаны для версии восьмидесятых,
можно будет с минимальными изменениями откомпилировать и запустить на исполнение
в среде финской версии.
Что же, в конце концов, представляет собой Unix? Термин система Unix чаще всего
используется при ссылке на системы, которые построены на основе ядерной модели и
поддерживают определенные функции, которые являются общими для всех этих
вариантов систем. Некоторые системы работают и выглядят аналогично Unix, но построены они
были не на основе кодов версий AT&T или UCB. Комбинация инструментальных средств
Заключение
51
и ядра вида GNU/Linux известна под названием Unix - подобная система. Одно из
формальных определений системного интерфейса называется POSIX. Для понимания,
чтения и написания Unix - программ вам понадобится знание более одного стандарта.
Unix имеет длинную, многовариантную историю. Какое число систем Unix
предполагается изучить в этой книге? Мы сосредоточим свое внимание на структуре, принципах и
средствах, которые являются общими для всех систем Unix. Некоторые детали будут
опущены, некоторые операции дублируются, а все идеи рассматриваются с практических
позиций.
Некоторые детали я не включаю в рассмотрение, и иногда я предлагаю вам обратиться
к документации. Эта книга не является исчерпывающим руководством по любому аспекту
относительно любой версии Unix. Существенная часть знаний об Unix должна быть
получена по мере изучения и использования электронной документации на вашей системе.
Иногда я описываю различные функции, которые производят одно и то же действие. Это
обусловлено тем, что имеет место дублирование функций при децентрализованном
процессе развития Unix. Различные группы, подобные AT&T и UCB, иногда предлагают
различные решения одной и той же проблемы. Другая причина дублирования функций
объясняется обычными издержками роста. Когда разработчики заменяют в более развитой
версии какую-либо службу в Unix, например, такую, как аварийные таймеры, они не хотят
выкидывать существующие программы. Поэтому они редко удаляют старый, упрощенный
интерфейс. Иногда я привожу одно решение, а иногда несколько. Если вы будете изучать
программы Unix, то будете встречать такие варианты решений. Изучение различных
методов может помочь разобраться в фундаментальных идеях и помочь вам адаптироваться
к локальным особенностям системы.
Наконец, я представляю Unix в контексте действующих программных проектов. Unix -
это система идей и средств, созданных людьми, которые искали решение реальных
проблем. Мы начали рассмотрение с реальных проблем и наблюдали, как идеи приводят к
нахождению решений. Unix воспринимается осмысленно, когда вы видите, что составные
части работают совместно, как система.
Заключение
• Вычислительная система состоит из нескольких типов ресурсов, таких, как дисковая
память, память, периферийные устройства и сетевые средства. Программы
используют эти ресурсы для хранения, пересылки и обработки данных.
• Вычислительные системы, где одновременно работают несколько программ
нескольких пользователей, требуют наличия централизованной управляющей программы.
Ядро Unix представляет собой программу, которая планирует исполнение программ и
управляет доступом к ресурсам.
Пользовательские программы обращаются к ядру за ресурсами.
Некоторые Unix - программы состоят из отдельных программ, которые разделяют
или обмениваются данными.
Написание системных программ требует понимания структуры и использования
служб ядра.
Глава 2
Пользователи, файлы и справочник.
Что рассматривать в первую
очередь?
В-г
шв-
fie
шртшё
4L
Цели
Идеи и средства
Роль и использование электронной документации.
Файловый интерфейс Unix: open, read, write, lseek, close.
Создание и чтение файлов, запись в файлы.
Дескрипторы файлов.
Буферирование: пользовательский уровень и уровень ядра.
Режим ядра, пользовательский режим и назначение системных вызовов.
Как в Unix представлено время, как форматировать изображения времени в Unix.
Использование файла utmp для определения списка текущих пользователе.
Обнаружение ошибок в системных вызовах,и оповещение об ошибках.
Системные вызовы и функции
open, read, write, creat, lseek, close
perror
Команды
man
• who
• cp
• login
2.1. Введение
Кто же использует систему? Не много ли пользователей? Вошел ли в систему мой друг?
В каждой многопользовательской вычислительной системе есть команда who. Команда
сообщает, кто работает на компьютере. Как работает эта команда?
В этой главе мы будем изучать работу команды в Unix. По мере изучения мы узнаем, как
в Unix можно вести обработку файлов. Дополнительно к информации об Unix, которую мы
получаем при изучении, рассмотрим, как использовать систему Unix в качестве справочника
об этой системе.
2.2. Вопросы, относящиеся к команде who
53
2.2. Вопросы, относящиеся к команде who
Обратимся снова к представлению системы Unix.
Рисунок 2.1
Пользователи, файлы,
процессы и ядро
Большой ящик ни рисунке представляет память компьютера. Он разделен на
пользовательское и системное пространство. Пользователи соединены с системой через
терминалы. В этой системе есть два твердых диска, изображенное в виде больших цилиндров,
и один принтер. В пользовательском пространстве исполняются различные программы.
Они связываются с внешним миром через ядро. Эти коммуникационные каналы на
рисунке представлены в виде линий связи процессов с ядром.
По нашему плану мы будем изучать команду who. Поэтому возникают вопросы:
1. Что делает команда who?
2. Как работает команда who?
3. Могу ли я написать программу who?
2.2.1. Программы состоят из команд
Прежде чем начинать рассмотрение, важно отметить, что почти все команды Unix типа
who и Is - это просто программы, которые были написаны некоторыми программистами,
обычно на С. Когда вы набираете на клавиатуре Is, то обращаетесь к командному
интерпретатору shell, чтобы он запустил на исполнение программу с именем Is. Программа Is
при исполнении выводит список файлов в каталоге. Если вы не удовлетворены тем, что
делает команда Is, то можете написать собственную версию этой команды и использовать
ее вместо исходной версии.
Добавить новые команды в Unix очень просто. Вы пишете новую программу и должны
поместить исполнимый файл для хранения в один из стандартных каталогов, таких, как
/bin, /usr/bin, /usr/local/bin. Многие команды в Unix появились как программы, которые кто-
то написал для решения некоторой частной задачи.
Другие пользователи сочли такие программы полезными. И тогда такие программы
можно встретить на каком-то числе Unix - машин. Поэтому у вашей версии программы who
есть шанс стать когда-нибудь стандартной.
г^. к
54
Пользователи, файлы и справочник. Что рассматривать в первую очерщь?
2.3. Вопрос 1: Что делает команда who?
Если нам нужно узнать, кто в текущий момент работает в системе, то мы должны набрать
команду who:
$who
heckerl
nlopez
dgsulliv
one.net)
ackerman
wwchen
barbier
ramakris
czhu
bpsteven
molay
$
ttypl
ttyp2
ttyp3
ttyp4
ttyp5
ttyp6
«УР7
ttyp8
ttyp9
ttypa
Jul 21 19:51
Jul 21 18:11
Jul 21 14:18
Jul 15 22:40
Jul 21 19:57
Jul 8 13:08
Jul 13 08:51
Jul 21 12:47
Jul 21 18:26
Jul 21 20:00
(tide75.surfcity.com)
(roam163-141.student.ivy.edu)
(h004005a8bd64.ne.media-
r
(asd1-254.fas.state.edu)
(circle.square.edu)
(labpcl 8.elsie.special.edu)
(roaml 57-97.student.ivy.edu)
(spa.sailboat.edu)
B07.178.203.99)
(xyz73-200.harvard.edu)
Каждая строка этого протокола представляет одну сессию (одно вхождение в систему).
В начале строки расположено пользовательское имя (usemame). Далее выводится имя
терминала, через который пользователь вошел в систему. В следующей части строки
выводится информация о том, когда пользователь вошел в систему. Последняя часть строки
предназначена для обозначения, где находится пользователь, вошедший в систему. В некоторых
версиях команды who информация об имени удаленного компьютера не выводится, если вы
ее явно не затребовали. '
2.3.1. Обращение к справочнику
При запуске команды who мы получаем определенную информацию о том, что эта команда
делает. Для более подробного изучения вопроса о назначении команды можно обратиться
к электронному справочнику. Каждая из систем Unix поступает с документацией обо всех
командах. Иногда система Unix Поступает с печатным справочником, где для каж-дой
команды представлена документация в одну или две страницы. Чаще всего теперь
справочник расположен на диске. Команда для чтения информации из справочника - man1. Для
получения описания команды who следует выполнить команду:
$ man who
whoA) whoA)
NAME
who - Identifies users currently logged in
SYNOPSIS
who [-a] |[-AbdhHlmMpqrstTu] [file]
who am i
who am I
whoami
The who command displays information about users and processes on the local system.
1. В некоторых версиях Unix реализована традиционная man-документация со ссылками на основе использования
системы info или справочник представлен как набор взаимосвязанных страниц HTML.
2.3. Вопрос 1: Что делает команда who?
55
STANDARDS
Interfaces documented on this reference page conform to industry standards as follows:
who:XPG4,XPG4-UNIX
Refer to the standardsE) reference page.for more information about industry standards and associated
tags.
OPTIONS
-a Specifies all options; processes /var/adm/utmp or the named file
with all options on. Equivalent to using the -b, -d, -I, -p, -r,
-t,-T, and-u options.
more A0%)
Все страницы руководства, которые часто называют manpages, имеют одинаковый
базовый формат. Заголовок служит для представления имени команды и обозначает раздел
справочника, в котором находится данный документ. В данном примере это изображается
как who A), что обозначает команду who и раздел 1. В разделе 1 содержится документация
обо всех пользовательских командах. Обратитесь к справочнику на вашей системе и
посмотрите, что находится в других разделах справочника.
Секция name на странице документации содержит имя команды и однострочное
представление назначения команды. * . .
Секция synopsis представляет, как можно использовать команду. Здесь показано, что
следует набирать при вызове команды, список аргументов и опций, которые возможно
использовать при вызове команды. Каждая опция обычно начинается со знака дефиса,
за которым следуют один или более символов. С помощью опций можно указывать
вариант исполнения команды.
В тексте страницы справочника можно использовать квадратные скобки ([-а]), чтобы
показать, что данный элемент не является обязательным для команды, но может быть при
необходимости включен в текст командной строки при вызове команды. В примере
страницы документации для команды who показано, что вы можете обращаться к команде просто
набором ее имени who, или можете набрать: who -а (произносится who минус я), или вы
можете набрать who с последующим набором знака "минус" и некоторой комбинации
символов, затем указать имя файла, которое вам понравится.
На странице документации для команды who представлены еще три формы обращения
к команде:
who ami
who am I
whoami
Вы можете прочитать о назначении этих альтернативных форм вызова команды в
справочнике или попытаться поработать с ними.
В секции description находится описание того, что делает команда. Эти описания весьма
сильно варьируются от команды к команде, от одной версии Unix к другой. Некоторые
тексты описаний краткие, но точные. В некоторых описаниях представлено большее
число деталей и несколько примеров. В любом случае описания представляют все свойства
команды и содержат надлежащие авторитетные ссылки.
В секции options представлен список допустимых опций и описание, для чего
предназначена каждая опция. В давние времена каждая команда в Unix была простой. Каждая
выполняла некоторое действие и имела одну или две опции. С годами многие команды были
vcoRenuieHCTRORaHbi за счет введения в их состав новых возможностей, каждая из котооых
56 Пользователи, файлы и справочник. Что рассматривать в первую очередь?
может быть активизирована с помощью опций при обращении к команде с уровня
командной строки. Некоторые команды, подобные рассматриваемой версии команды who, имеют
весьма много опций.
В секции see also представлен список тем в справочнике, связанных с командой. В
некоторых страницах справочника есть еще секция bugs.
2.4. Вопрос 2: Как работает команда who?
Нами было установлено, что команда who отображает информацию о тех пользователях,
которые к текущему моменту вошли в систему. На странице документации для команды
who дано описание того, что может делать эта команда и каким образом заставить ее
выполнить допустимое для нее действие. Как работает команда who? Как она выполняет
допустимые для нее действия?
Можно предположить, что системные программы, подобные who, используют
специальные системные функции. В том числе, возможно, они включают расширенные привилегии
администратора. Вам может потребоваться получить доступ к средствам системного
разработчика, включая доступ к CD-ROM, толстым книгам и секретным кодам. Все это
может потребовать каких-то расходов.
Вся документация о функционировании команды who находится в самой системе. Вам
только нужно знать, где следует искать документацию.
Изучение Unix из Unix
Вы можете изучать принципы работы любой команды, используя для этого четыре
возможности:
• Чтение справочника. > , ¦
Поиск в справочнике..
• Чтение файлов с именами, имеющими расширение .h.
Использование ссылок из секции see also.
Мы будем далее использовать эти возможности для изучения команды who.
Чтение из справочника
Для изучения команды who следует набрать
$ man who
и обратиться к секции DESCRIPTION. В справочнике для SunOS текст этой секции будет
иметь такой вид:
. DESCRIPTION
The who utility can list the user's name, terminal line,
login time, elapsed time since activity occurred on the
line, and the process-ID of the command interpreter (shell)
for each current UNIX system user. It examines the
/var/adm/utmp file to obtain its information. If file is
given, that file (which must be in utmpD) format) is exam-ined.
Usually, file will be /var/adm/wtmp, which contains a
history of all the logins since the file was last created.
2.4 Вопрос 2: Как работает команда who?
57
Из данного документа мы получаем полную информацию о команде. Команда who
проверяет файл /var/adm/utmp для извлечения для себя из него необходимой информации.
Из текста описания следует, что список текущих пользователей хранится в этом файле.
Команда читает файл. Что нам следует знать об этом файле? Для этого мы можем
обратиться к справочнику и найти необходимую информацию.
Поиск в справочнике
Команда man допускает возможность обращения к справочнику для организации поиска
по ключевым словам. Для организации поиска следует использовать опцию -к. Чтобы
получить информацию о 'utmp', следует выполнить:
$ man -к utmp
-access utmp file entry
-access utmpx file entry
-access utmp file entry
-access utmp file entry
-access utmp file entry
-access utmpx file entry
-access utmpx file entry
-access utmpx file entry
-access utmpx file entry
-access utmpx file entry
-access utmp file entry
-access utmpx file entry
-access utmp file entry
-access utmpx file entry
-find the slot in the utmp file of the
current user
-access utmpx file entry
-access utmpx file entry
utmp and wtmp entry formats
overview of accounting and
miscellaneous accounting commands
-utmp and utmpx monitoring daemon
-access utmp file entry
utmpx and wtmpx entry formats
-access utmpx file entry
utmp and wtmp entry formats
utmpx and wtmpx entry formats
Полученный результат работы команды был получен на SunOS. Такой вывод будет
представлен в аналогичном виде и на других инсталляциях. Каждая строка в этом выводе
содержит тему, название страницы справочника и краткое описание. Те строки, которые
помечены метками utmp и wtmp, возможно, представляют то, что нам необходимо. Другие
записи с похожими метками могут нам понадобиться позже.
Нотация utmp D) означает, что документация по utmp находится в разделе 4 справочника.
Этот номер раздела следует использовать при обращении к команде man:
endutent
endutxent
getutent
getutid
getutline
getutmp
getutmpx
getutxent
getutxid
getutxline
pututline
pututxline
setutent
setutxent
ttyslot
updwtmp
updwtmpx
utmp
utmp2wtmp
utmpd
utmpname
utmpx
utmpxname
wtmp
wtmpx
$
getutent Cc)
getutxent Cc)
getutent Cc)
getutent Cc)
getutent Cc)
getutxent Cc)
getutxent Cc)
getutxent Cc)
getutxent Cc)
getutxent Cc)
getutent Cc)
getutxent Cc)
getutent Cc)
getutxent Cc)
ttyslot Cc)
getutxent Cc)
getutxent Cc)
utmp D)
acctAm)
utmpd Am)
getutent Cc)
utmpx D)
getutxent Cc)
utmp D)
utmpx D)
58
Пользователи, файлы и справочник. Что рассматривать в первую очередь?
$ man 4 utmp
utmpD) utmpD) *
NAME
utmp, wtmp - Login records
SYNOPSIS
#include <utmp.h>
DESCRIPTION
The utmp file records information about who is currently using the
system.
The file is a sequence of utmp entries, as defined in struct utmp in the
utmp.h file.
The utmp structure gives the name of the special file associated with
the user's terminal, the user's login name, and the time of the login
in the form of timeC). The utjype field is the type of entry, which
can specify several symbolic constant values. The symbolic constants
are defined in the utmp.h file.
The wtmp file records all logins and logouts. A null user name
indicates a logout on the associated terminal. A terminal referenced
with a tilde (~) indicates that the system was rebooted at the
indicated time. The adjacent pair of entries with terminal names
referenced by a vertical bar (|) or a right brace (}) indicate the
system-maintained time just before and just after a dale command has
changed the system's time frame.
The wtmp file is maintained by loginA) and init(8). Neither of these
pro-grams creates the file, so, if it is removed, record keeping is
turned off. See ac(8) for information on the file.
FILES ' '
/usr/include/utmp.h
/Var/adm/utmp
more (88%)
Мы достаточно быстро ответили на вопрос, как работает команда who. На первой
странице документации по команде who сказано, что команда читает файл utmp. Здесь сказано,
что файл utmp представляет собой последовательность записей utmp, которые
определены в структуре utmp в файле utmp.h. Где же находится этот файл utmp.h?
Нам повезло. В разделе FILES на странице документации есть нужная информация. Там
указано маршрутное имя файла /usr/include/utmp.h.
Прежде чем перейти к рассмотрению следующей возможности для работы со
справочником (чтение файлов с расширением имен .h), обратимся еще к некоторой информации на
данной странице документации. Речь идет о файле wtmp, куда происходит запись обо всех
входах в систему и выходах из системы. Для работы с файлом указаны ссылки на команды
login(l), init(8) и ас(8). Их рассмотрение будет интересно при изучении тем, которые будут
представлены позже.
Изучение Unix по справочнику аналогично поиску информации о каком-то объекте в Web.
По мере чтения различных страниц справочника вы находите дополнительные ссылки,
с помощью которых можете обратиться к интересующим вас и полезным для вас темам.
Именно так, в соответствии с нашими задачами, мы подошли к изучению файла <utmp.h>.
2.4. Вопрос 2: Какработаеткоманда who?
59
Чтение файлов .h
В документации по utmp сказано, что структура записей в файле utmp описана в файле
/usr/include/utmp.h. В большинстве Unix - машин заголовочные файлы для системной
информации хранятся в каталоге, который называется /usr/include. Когда С - компилятор
обнаруживает в тексте программы строку вида:
#include <stdio.h>
он предполагает, что этот файл находится в каталоге /usr/include. Используем команду more
для прочтения содержимого этого файла:
$ more /usr/include/utmp.h
4 «define ШМР_Н1?иАаг/Мя0Лпр"
«define WTMPJILE >ar/adm/Wtmp"
«include <sysAypes.h> Г for pid t, time 17
Г
* Структуры файлов utmp и wtmp.
«define ut_name ut_user
struct utmp {
charut_user[32];
charutjd[14];
«charutjine[32];
shortutjype;
pidj utj)id;
struct exit_status {
short extermination;
short e_exit;
} ut_exit;
time J utjime;
char ut_host[64];
/* совместимость */
/* Пользовательское входное имя 7
Л /etc/inittab id- IDENT^LEN в
* init */
Г имя устройства (console, Inxx) 7
Г тип записи 7
Г идентификатор процесса 7
/* статус окончания процесса 7
/* статус процесса при выполнении exit 7
Г Статус exit процесса, помеченного как
* DEAD PROCESS. '
7
Г временная отметка о сделанной записи 7
Г имя хоста, такое же как
¦* MAXHOSTNAMELEN 7
};
Г Определения для utjype 7
utmp.hF0%)
В начале в данном выводе пропущен ряд сообщений и другой вводный материал. Далее
мы обнаруживаем определение структуры. Оказывается, записи о вхождениях в систему
состоят из восьми элементов. Поле ut_user предназначено для хранения
пользовательского имени. В массиве ut_line помещается информация об устройстве, что в данном случае
будет означать терминал, через который пользователь соединен с системой. Через
несколько строк в структуре представлено поле utjime, где хранится время вхождения
в систему, а поле ut__host предназначено для хранения имени удаленного компьютера.
60
Пользователи, файлы и справочник. Что рассматривать в первую очередь?
В рассматриваемой структуре есть еще и другие элементы. Они напрямую не
используются для отображения информации командой who, но могут быть полезными в других
ситуациях.
Структура записи utmp на вашей системе может отличаться от рассмотренной. Но файл ut-
mp.h на вашей системе будет описывать формат данных utmp для вашей системы. Имена
полей обычно одинаковы для различных версий Unix, но наличие поля, которое имеет
комментарий "совместимость", показывает, что они иногда могут и отличаться.
Заголовочные файлы обычно снабжены хорошими комментариями, которые содержат полезную
информацию.
2.4.7. Мы теперь знаем, как работает who
При чтении электронной документации по темам who и utmp и просмотре заголовочного
файла /usr/include/utmp.h, мы изучили, как работает команда who. Команда who читает
структуры из файла. Файл содержит для каждой сессии по одной структуре. Мы изучили
формат структуры. Поток информации изображен на рисунке 2.2.
Рисунок 2.2
Поток данных для команды who
Файл - это массив, откуда who может читать записи и выводить требуемую информацию.
По самой простой логике следовало бы читать и выводить записи по одной. Было бы это
проще? Мы не рассматривали исходный код для версии команды who, но у нас была
возможность изучить все, что касается команды, из электронной документации. Из
справочника мы узнали, что делает команда, и также рассмотрели, как используется структура
данных в заголовочном файле. Единственная возможность проверить, действительно ли
вам все понятно, — это попытаться сделать что-то самому.
2.5. Вопрос 3: Могу ли я написать who?
В следующей части этой главы мы попытаемся создать программу, которая должна
работать аналогично стандартной команде who. Мы продолжим обучение, используя
обращение к справочнику, и проверим нашу программу, сверяя ее вывод и вывод из версии
команды who на нашей системе. Проведенный анализ программы who показал, что есть только
две задачи, которые необходимо выполнять в программе:
• Чтение структур из файла.
• Отображение инсЬоомашш. котооая хоанится в стоуктуое.
2.5 Вопрос 3: Могу ли я написать wfio? 61
2.5./. Вопрос: Как я буду читать структуры из файла?
Для чтения символов и строк из файла вы можете использовать getc и f gets. Что
представляют собой структуры с позиций данных? Мы можем использовать getc для
посимвольного чтения, но это довольно скучное занятие. Хотелось бы читать сразу всю
структуру с диска.
Давайте почитаем справочник!
Нам необходимо найти страницы справочника, относящиеся к file и read. С помощью
опции -к можно задавать только одно ключевое слово, поэтому мы укажем только одно из
ключевых слов и выполним.
$ man -k file
для просмотра предлагаемых тем. Нам будет выдан перечень тем, касающихся файлов.
На моей системе по этой команде был получен результирующий вывод из 537 строк.
Из этих строк нам нужно выбрать строки, где содержится слово "read". В Unix есть
команда grep, * которая будет выводить строки, где содержится заданный шаблон. Используем
в конвейере команду grep следующим образом:
$ man -k file | grep read
JlseekB) - reposition read/Write file offset
fileevent(n) - Execute a script when a channel becomes readable
or writable
gftype A) - translate a generic font file for humans to read
lseekB) - reposition read/Write file offset
macsaveA) - Save Mac files read from standard input
read B) - read from a file descriptor
readprofile A) - a tool to read kernel profiling information
scr_dump, scrjestore, sennit, scr_set C) - read (write) a curses
screen from (to) a file
tee A) - read from standard input and write to standard
output and files
$
Наиболее значимую информацию среди этих строк содержит readB). В других строках
речь идет о других темах.
Выберем страницу документации в разделе 2 относительно read:
$ man 2 read
READB) System calls READB)
NAME
read - read from a file descriptor
SYNOPSIS
#include <unistd.h>
ssizej read(int fd, void *buf, sizej count);
DESCRIPTION
read() attempts to read up to count bytes from file
descriptor fd into the buffer starting at buf.
If count is zero, read() returns zero and has no other
62
Пользователи, файлы и справочник. Что рассматривать в первую очередь?
results. If count is greater than SSIZE_MAX, the result
is unspecified.
RETURN VALUE
On success, the number of bytes read is returned (zero
indicates end of file), and the file position is advanced
by this number. It is not an error if this number is
smaller than the number of bytes requested; this may hap-pen
for example because fewer bytes are actually available
right now (maybe because we were close to end-of-file, or
because we are reading from a pipe, or from a terminal),
or because read() was interrupted by a signal. On error,
-1 is returned, and errno is set appropriately. In this
case it is left unspecified whether the file position (if
any) changes.
С помощью этого системного вызова мы можем прочитать заданное число байт из файла
в буфер. Нам необходимо считать за один раз. одну структуру, поэтому мы можем
использовать sizeof (struct utmp) для определения того числа байтов, которое необходимо
прочитать. В найденной документации сказано, что системный вызов read производит
чтение из файлового дескриптора. Как мы можем получить один из них? При просмотре
страницы документации относительно read мы обнаружим в последней ее части
следующее:
RELATED INFORMATION (called SEE ALSO in some versions)
Functions: fcntlB), creatB), dupB), ioctlB), getmsgB), lockfC),
lseekB), mtioG), openB), pipeB), pollB), socketB), socketpairB),
termiosD), streamioG), opendirC) lockfC)
Standards: standardsE)
Здесь мы обнаруживаем ссылку на орепB). Запускаем на исполнение команду:
man 2 open,
чтобы прочитать, как работает open. Из этой страницы документации есть ссылка на close.
Итак, при работе с электронным справочником мы нашли три части, которые необходимы
нам для чтения структуры из файла.
2.5.2. Ответ: Использование open, read и close
Мы можем использовать эти три системных вызова для извлечения из файла utmp записей
о вхождениях в систему. Страницы справочника, касающиеся этих тем, могут быть весьма
краткими по содержанию. Эти системные в!ызовы имеют много опций и достаточно
сложны в своем поведении, когда они используются в отношении программных каналов,
устройств и других источников данных. Основополагающие факторы выделяются и
рассматриваются далее.
Открытие файла: open
Системный вызов open создает связь между процессом и файлом. Эта связь называется
дескриптором файла и изображается на рисунке 2.3 в виде туннеля от процесса к ядру.
2.5 Вопрос 3: Могу ли я написать who?
63
Процесс
Дескриптор файлов
^:
^
JT
1
¦ »
':. :'.¦¦'¦'•*.
k h
¦ Щ%. <* -у-.:-,--^^-<:Л:
7
Массив символов
Рисунок 2.3
Дескриптор файла - это соединение с файлом.
Основные свойства системного вызова open:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
open
Создания связи с файлом
#include <fcntl.h>
Int fd = open(char *name, int how)
name - имя файла
how - 0_RDONLY, O.WRONLY или 0_RDWR
-1 -при ошибке
Целое число - при успехе
Для открытия файла необходимо определить имя файла и тип желаемой связи.
Существуют три типа связей - соединение для чтения, соединение для записи и соединение для
чтения и записи. В заголовочном файле /u$r/include/fcntl.h находятся определения для
макросов 0_RDONLY, OJ/VRONLY и OJTOWR.
Открытие файлов - это служба ядра. Системный вызов open - это требование, которое
выдает ваша программа ядру. Если ядро обнаружит ошибку при обращении к нему, то оно
вернет код возврата, равный -1.
Есть несколько видов ошибок. Может случиться, что указанный файл не существует. Файл
может существовать, но у вас нет прав доступа на чтение из этого файла. Файл может
находиться в каталоге, к которому у вас нет доступа. В странице документации по
системному вызову open приведен список подобного рода ошибок. Способы обработки ошибок
будут изучены далее в этой главе.
Что происходит, если файл уже был открыт? То есть что будет в ситуации, когда другой
процесс уже работает с файлом? В Unix не устанавливается запрета на одновременное
открытие несколькими процессами одного и того же файла. Если бы такое ограничение
существовало, то двум различным процессам нельзя было бы запустить одновременно одну
и ту же команду who. Если открытие происходит успешно, то ядро возвращает процессу
небольшое по значению целое положительное число. Это число называют дескриптором
файла, который является по смыслу идентификатором соединения процесса с файлом.
64 Пользователи, файлы и справочник. Что рассматривать в первую очередь?
Вы можете одновременно открыть несколько файлов. При этом для каждого соединения
будет установлен уникальный дескриптор файла. Ваша программа даже может
многократно отрыть один и тот же файл. При этом для каждого соединения будет установлен свой
дескриптор файла.
Вы можете использовать дескриптор файла для всех операций с установленным
соединением.
Чтение данных из файла: read
Вы можете в процессе производить чтение данных, используя дескриптор файла:
НАЗНАЧЕНИЕ
INCLUDE
read
Пересылка qty байт из файлового дескриптора fd i
#include <unistd.h>
ИСПОЛЬЗОВАНИЕ ssizej numread = read(int fd, void *buf,
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
fd-источник данных
buf - место для сохранения данных
qty - количество байт для передачи
-1 -при ошибке
Целое число - при успехе
sizej qty)
з буфер
С помощью системного вызова read происходит обращение к ядру для передачи qty байтов
данных из файлового дескриптора fd в массив buf, который находится в пространстве
памяти вызывающего процесса. Ядро выполняет действие по запросу и возвращает
информацию о результате выполнения. Если требование не было выполнено, то код
возврата будет равным -1. В противном случае в качестве кода возврата будет число байтов,
переданных при чтении.
Почему можно получить в ответ меньшее число байтов, чем было запрошено? В файле
может не быть столько байтов, сколько вы указали при обращении к системному вызову.
Например, если вы запросили 1000 байтов, а в файле содержится только 500 байтов, то
после выполнения вызова вы увидите в качестве результата 500 байтов. При достижении
конца файла системный вызов вырабатывает код возврата, равный нулю, поскольку нет
данных для чтения.
Какового сорта ошибки может фиксировать системный вызов read? Ответ можно найти на
странице документации в вашей системе, где приведен перечень ошибок.
Закрытие файла: close
Когда вы прочитали данные или записали данные через файловый дескриптор, то вы
можете закрыть его. Системный вызов close представлен такими характеристиками:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
close
Закрытие файла
#include <unistd.h>
int result = close(intfd)
fd - дескриптор данных
buf - место для сохранения данных
qty - количество байт для передачи
КОДЫ ВОЗВРАТА -1 - при ошибке
О - при успехе
2.5Вопрос3: Могу ли я написать who?
65
Системный вызов close отключает соединение, которое было определено с помощью
файлового дескриптора fd. При обнаружении ошибки системный вызов close возвращает код
возврата -1. Например, при попытке закрыть файловый дескриптор, который не ссылается на
открытый файл, будет выработана ошибка. Другие виды ошибок описаны в справочнике.
2.5.3. Написание программы who 1. с
Итак, мы почти у цели. Мы знаем суть работы команды who, мы знаем о существовании
трех системных вызовов, необходимых для установления связи с файлом, выбора данных
из файла и для закрытия файла. Ведущая часть кода программы будет выглядеть так:
Г whol .с - первая версия программы who
* выполнить open, прочитать файл UTMP и показать результаты
7
#include <stdio.h>
#include <utmp.h>
#include <fcntl.h>
tinclude <unistd.h>
#define SHOWHOST /* подключить удаленную машину для вывода */
int main()
{
struct utmp current jecord; /* считывать сюда данные 7
int utmpfd; /* читать из этого дескриптора 7
int reclen = sizeof(current record);
if ((utmpfd = open(UTMP>ILE, O.RDONLY)) ==-1){
perror(UTMPJILE); /* UTMP_RLE - описание в utmp.h 7
exitA);
} -
while (read(utmpfd, «currentjecord, reclen) == reclen)
show_info(¤tjecord);
close(utmpfd);
return 0; /* все нормально 7
}
В этой программе реализована логика, которая была рассмотрена выше в этой главе.
В цикле while производится последовательное чтение записей из файлового дескриптора
current jecord. Функция showjnfo отображает информацию о вхождениях в систему.
Программа работает в цикле до тех пор, пока системный вызов read в состоянии читать записи
из файла. Наконец, происходит закрытие файла и выход из программы.
Системный вызов perror является удобным средством для оповещения о наличии
системных ошибок. Мы рассмотрим его далее в этой главе.
2.5.4. Отображение записей о вхождениях в систему
Далее приведен код первого наброска функции show_info, которая производит
отображение информации из файла utmp.
Г
* show infoO
66
Пользователи, файлы и справочник. Что рассматривать в первую очередь?
отображает содержимое структуры utmp в формате, удобном для восприятия
* эти размеры аппаратно не зашиты
7
show info(struct utmp *utbufp)
{
printf("%-8.8s",utbufp->ut_name);
printfC");
printfC^-e.es", utbufp->utjine);
printf("");
printf(H%1 Old", utbufp->utjime);
printf("");
#ifdefSHOWHOST
printf(M(%s)"f utbufp->utjwst);
#endif
printf("\n");
}
Мы выбрали в этой программе ширину полей для printf так, чтобы было соответствие
с длинами строк вывода системной версии программы who. Программа выводит элемент
utjime в формате long int. Значение time_t определено в заголовочном файле, но мы пока
ничего об этом не знаем.
Компилируем и запускаем программу на исполнение:
I* входное имя */
Г пробел 7
/* терминал 7
Л пробел 7
Г время вхождения 7
/* пробел 7
/* ххт 7
Г перевод на новую строку */
$ccwho1.c-o
$who1
system b
run-leve
whol
LOGIN console
ttypl
shpyrko ttyp2
acotton ttyp3
ttyp4
spradlin ttyp5
dkoh ttyp6
spradlin ttyp7
king ttyp8
berschba ttyp9
rserved ttypa
riahpl ttvnh
952601411()
9526014110
952601416 0
952601416 0
952601417 0
952601417 0
952601419 0
952601419 0
952601423 ()
952601566 0
952601566 0
958240622 ()
964318862 (nas1-093.gas.swamp.org)
964319088 (math-guest04.williams.edu)
964320298 0
963881486 (h002078c6adfb.ne.rusty.net)
964314388A28.103.223.110)
964058662 (h002078c6adfb.ne.rusty.net)
964279969 (blade-runner.mit.edu)
964188340 (dudley.learned.edu)
963538145 (gigue.eas.ivy.edu)
Qfi431 QARR /rnamlQ3-97 student state erin\
2.5 Вопрос 3: Могу ли я написать who?
67
ttypc
rserved ttypd
dkoh ttype
ttypf
molay' ttyqO
ttyql
ttyq2
ttyq3
ttyq4
ttyqS
ttyq6
ttyq7,
cweiner ttyq8
964319645 0
963538287 (gigue.eas.ivy.edu)
964298769A28.103.223.110)
964314510 0
964310621 (xyz73-200.harvard.edu)
964311665 0
964310757()
964304284 0
964305014 0
964299803 ()
964219533 0
964215661 ()
964212019 (roam175-157.student.stats.edu)
ttyqa 964277078 0
ttyq9 964231347 0
$
Давайте сравним вывод нашей программы с выводом системной версии команды who:
$who
shpyrko ttyp2 Jul
acotton ttyp3 Jul
spradlin ttypS Jul
. dkoh ttyp6 Jul
spradlin ttyp7 Jul
king ttyp8 Jul
berschba ttyp9 Jul
rserved ttypa Jul
dabel ttypb Jul
rserved ttypd Jul
dkoh ttype Jul
molay ttyqO Jul
cweiner ttyq8 Jul
$
22 22:21 (nas1-093.gas.swamp.edu)
22 22:24 (math-guest04.williams.edu)
17 20:51 (h002078c6adfb.ne.rusty.net)
22 21:06 A28.103.223.110)
19 22:04 (h002078c6adfb.ne.rusty.net)
2211:32 (blade-runner.mit.edu)
21 10:05 (dudley.learned.edu)
13 21:29 (gigue.eas.ivy.edu)
22 22:30 (roam193-27.student.state.edu)
13 21:31 (gigue.eas.harvard.edu)
2216:46 A28.103.223.110)
22 20:03 (xyz73-200.harvard.edu)
21 16:40 (roam175-157.student.stats.edu)
Наша версия выглядит как перспективная, но все еще не в полном виде. Есть еще
шероховатости, которые следует ликвидировать. У нас выводятся те же пользовательские имена,
как и в who. У нас выводятся Правильные имена терминалов, правильно указываются
имена удаленных машин. Но есть две проблемы.
Что нам следует еще сделать:
Подавить пустые записи.
Получить корректное представление времени вхождения в систему.
2.5.5. Написание версии who2. с
В версии 2 нашей программы who внимание уделяется двум проблемам, о которых шла
речь в версии 1.
И вновь мы будем решать эти проблемы, обращаясь к необходимым документам
справочника и заголовочным файлам.
68
Пользователи, файлы и справочник. Что рассматривать в первую очередь?
Подавление пустых записей
В реальной версии команды who выводится список пользовательских имен тех
пользователей, которые входили в систему. В нашей версии программы выводится список из того,
что программа находит в файле utmp. Файл utmp содержит записи, касающиеся всех
терминалов, даже тех, которые не используются. Необходимо изменить нашу программу так,
чтобы она не выводила записи о неиспользуемых терминальных линиях. Но как
определить, какая из utmp - записей не представляет активную сессию?
Самое простое решение (которое не работает) - пропускать записи с пробелами в поле
пользовательского имени. Это будет работать в большинстве случаев, но на экран не будет
выводиться запись с полем LOGIN в строке, которая относится к консоли. Лучшим
решением (которое работает) будет, если выбирать для вывода только те utmp - записи,
которые соответствуют пользователем, вошедшим в систему.
Обратимся к файлу /usr/include/utmp.h и мы обнаружим там следующее:
Г Определения для ut type
#define EMPTY
#defineRUN LVL
#define BOOT TIME
#defineOLDTlME
#define NEW TIME
•define INIT PROCESS
•define LOGIN PROCESS
•define USER PROCESS
•define DEADPROCESS
Этот список весьма полезен. В каждой записи есть поле с именем utjype. Значения,
которые могут находиться в этом поле, и их символические имена представлены в
приведенном выше списке. Тип 7 будет для нас счастливым номером. Если теперь мы сделаем
нижеследующие небольшие изменения в нашей функции showjnfo, то пробельные записи'
должны исчезнуть:
show info(struct utmp *utbufp)
{
if (utbufp->utjype != USER.PROCESS) /* только пользователи! */
return;
printf("%-8.8s", utbufp->ut_name); /* имя пользователя */
Отображение времени вхождения в систему в удобном для прочтения виде
Теперь решим проблемы представления времени в формате, который воспринимаем
людьми. Начнем поиск в справочнике и поиск заголовочных файлов. Страниц по теме
"time" во всех версиях Unix весьма много, и они разнообразны.
После набора
$ man-k time
получим много записей. На одной своей машине я получил 73 записи, а на другой машине
получил 97. Вы можете просмотреть этот длинный список или можете отфильтровать
полученный вывод. Следующие ниже конвейеры прекрасно проведут фильтрацию:
$ man -k time | grep transform
$ man -к time j grep -i convert
7
о
1
2
3
4
5 /* Процесс был порожден процессом "init" 7
6 Г Процесс "getty" ждет login 7
7 /* Пользовательский процесс 7
8
2.5 Вопрос 3: Могу ли я написать who? / 69
Через справочник выходим на необходимые заголовочные файлы. Файл /usr/include/time.h есть
на ряде систем Unix. Проверьте вашу систему относительно информации, касающейся темы
*4ime". Нам же нужно обсудить вопрос
Как в Unix хранится значение времени: тип данных time J
В Unix значение времени представляется целым числом, которое измеряет в секундах
интервал времени с полуночи первого января 1970 года по Гринвичу. Тип данных timej -
это целочисленное представление времени в секундах. Этот формат в Unix используется
во многих приложениях. Поле ut_time в utmp записях содержит время вхождения в
систему, которое представлено числом секунд с начала Эпохи.
Преобразование timej в читаемый формат: ctime
Есть функция ctime, которая преобразует значение времени в секундах от начала работы
системы Unix в значение времени в читабельном формате. Функция описана в разделе 3
электронного справочника.
$ man 3 ctime
CTIMEC) Linux Programmer's Manual CTIMEC)
NAME
asctime, ctime, gmtime, localtime, mktime - transform
binary date and time to ASCII
SYNOPSIS
#include <time.h>
char *asctime(const struct tm *timeptr);
char *ctime(const timej *timep);
struct tm *gmtime(const timej *timep);
struct tm *localtime(const timej *timep);
timej mktime(struct tm *timeptr);
extern char *tzname[2];
long int timezone;
extern int daylight;
DESCRIPTION
The ctime(), gmtimeQ and localtime() functions all take
an argument of data type timej which represents calendar
time. When interpreted as an absolute time value, it rep-resents
the number of seconds elapsed since 00:00:00 on
January 1,1970, Coordinated Universal Time (UTC).
The ctime() function converts the calendar time timep into
a string of the form
4№киип3021:49:081993\пи
The abbreviations for the days of the week are Sun,
Mon, Tue, Wed, Thu, Fri, and Sat. The abbre-viations
for the months are Jan, Feb, Mar, Apr,
May, Jun, Jul, Aug, Sep, Oct, Nov, and
Dec. The return value points to a statically allocated
string which might be overwritten by subsequent calls to
any of the date and time functions. The function also
70 Пользователи, файлы исправочник. Чторассматривать в первую очередь?
Вот это то, что нам необходимо. Мы имеем значение time_t в записях utmp. А нам
требуется строка в формате, подобном такому:
Jun 30 21:49
Функция ctimeC) выбирает указатель на timej, а при окончании возвращает указатель на
строку, которая будет выглядеть примерно так:
Wed Jun 30 21:49:08 1993\n
Заметим, что строка, которая нам нужна для работы who, вставляется в строку возврата
функции ctime. Это позволяет достаточно просто производить кодировку даты для who.
Мы обращаемся к функции ctime и получаем после ее работы строку из 12 символов
со смещением, равным 4. Это выполняется при выполнении оператора printf(a%12.12s",
ctime(&t)+4).
Одновременный вывод всего сразу
Теперь мы знаем, как подавить пустые записи, и знаем, как отобразить значение utjime
в читабельном виде. Далее представлена окончательная версия программы who2.c:
Г who2.c - читает файл /etc/utmp и выводит список информации из него
* - подавляет пустые записи v
* - правильно форматирует время
7
#include <stdio.h>
#include <unistd.h>
#include <utmp.h>
#include <fcntl.h>
#include <time.h>
r#defineSH0WH0ST7
void showtime(long);
void showJnfo(struct utmp *);
int main()
{
struct utmp utbuf; /* сюда читается информация */
int utmpfd; /* чтение происходит из этого дескриптора 7
if((utmpfd = open(UTMP FILE, O.RDONLY)) == -1){
perror(UTMP_FILE);
exitA);
}
while(read(utmpfd, &utbuf, sizeof(utbuf)) == sizeof(utbuf))
showJnfo(&utbuf);
close(utmpfd);
return 0;
}
Г
showinfo()
* отображает содежимое структуры utmp
2.5 Вопрос 3: Могу ли я написать who?
71
* в удобном для восприятия виде
* * ничего не отображает, если в записи нет имени пользователя*/
void show_info(struct utmp *utbufp)
{
if (utbufp->ut_type != USER_PROCESS)
return;
printf("%-8.8s", utbufp->ut_name); /* входное имя */
printf(,,M); /* пробел*/
printf("%-8.8s'\ utbufp->utjine); /* терминал */
printff'"); /* пробел*/
showtime(utbufp->utjime); /* отображение времени */
#ifdef SHOWHOST
if (utbufp->ut_host[0] != ЛО')
printff' (%s)"f utbufp->ut_host); /* хост */
#endif
printf("\nn); /* перевод на новую строку */
}
void showtime(long timeval)
Г
* отображает время в формате, удобном для восприятия
" использует функцию ctime для формирования строки с изображением времени
* Замечание: посредством формата %12.12s выводится строка из 12 символов,
* при значении LIMITS, равно 12 символов.
v ¦
{
char*cp; /* адрес со значением времени 7
ср = ctime(&timeval); /* преобразование значения времени в строку */
Г строка должна иметь приблизительно такой вид */
Л Mon Feb 4 00:46:40 EST 1991 */
Л 0123456789012345. */
printf("%12.12s", cp+4); /* вывести 12 символов с позиции 4 */
)
Тестирование программы who2.c
Рткомпилируем и запустим на исполнение программу who2.c. Для разнообразия
выключим настройку SHOWHOST. Далее запустим на исполнение системную версию команды
who и сравним полученные результаты:
$ccwho2.c-owho2
$who2
rlscott ttyp2 Jul 23 01:07
acotton ttyp3 Jul 22 22:24
spradlin ttyp5 Jul 17 20:51
spradlin ttyp7 Jul 19 22:04
king ttyp8 Jul 2211:32
72
Пользователи, файлы и справочник. Что рассматривать в первую очередь?
berschba ttyp9
rserved ttypa
rserved ttypd
molay ttyqO
cweiner ttyq8
mnabavi ttyx2
$who
rlscott ttyp2
acotton ttyp3
spradlin ttyp5
spradlin ttyp?
king ttyp8
berschba ttyp9
rserved ttypa
rserved ttypd
molay ttyqO
cweiner ttyq8
mnabavi ttyx2
Jul 21 10:05
Jul 1321:29
Jul 13 21:31
Jul 22 20:03
Jul 21 16:40
Apr 10 23:11
Jul 23 01:07
Jul 22 22:24
Jul 17 20:51
Jul 19 22:04
Jul 22 11:32
Jul 21 10:05
Jul 13 21:29
Jul 13 21:31
Jul 22 20:03
Jul 21 16:40
Apr 1023:11
$
Есть некоторое отличие в форматировании результатов. В различных версиях команды
who используются различные по ширине колонки при выводе результатов. При изменении
размеров колонок протокола вывода мы можем в точности добиться совпадения формата
вывода по отношению к стандартному варианту. Можете заняться этим на своей системе.
В некоторых версиях команды who производится вывод имени хоста для удаленной
системы, если такая система была зафиксирована. В других же версиях такое имя не выводится.
Программа выдает точный список пользователей, имена их терминальных линий и
времена вхождения пользователей в систему.
2.5.6. Взгляд назад и взгляд вперед
Мы начали эту главу с постановки простого вопроса: "Как работает в Unix команда who?"
Мы следовали в тексте трем сформулированным шагам. Во-первых, мы изучили, что
делает команда. Затем мы разобрались, посредством детального изучения технической
документации, как работает команда. Далее написали собственную версию программы, чтобы
убедиться в том, что мы действительно понимаем, к^к работает команда.
По мере нахождения решений на каждом из трех шагов мы научились использовать
электронный справочник Unix и заголовочные файлы. Написание собственной версии
программы привело к закреплению рассмотренного материала. Стала ясной структура файла utmp.
Мы убедились в том, что каждое вхождение в систему приводит к появлению записи
в журнале. Мы изучили, каким образом в Unix представляются временные величины.
Это будет полезно при работе с другими частями Unix.
Наконец, мы почитали документацию по надлежащим темам. На страницах справочника
для файла utmp были найдены ссылки на файл wtmp. А со страниц справочника для
функции ctime есть ссылки на другие функции, которые связаны со временем. Эти ссылки дают
дополнительное представление о структуре системы.
2.6. Проект два: Разработка программы ср (чтение и запись)
73
2.6. Проект два: Разработка программы ср (чтение и запись)
В программе who мы только читали из файла. А как можно будет записывать в файл? Для
изучения возможности записи в файлы мы разработаем версию Unix команды ср.
2.6.1. Вопрос 1: Что делает команда ср?
Команда ср выполняет копирование файла. Типичное обращение к команде будет таким:
$ ср исходный _файл целевой_файл
Если нет целевого файла, то команда ср создает его. Если целевой файл есть, то команда ср
заменяет содержимое этого файла содержимым исходного файла.
2.6.2. Вопрос 2: Как команда ср создает файл и как пишет в него?
Создание/транкатенация файла
Один из способов создания файла или перезаписи файла является использование для
этого системного вызова creat. Обобщенные характеристики системного вызова:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
creat
Создание или уничтожение файла
tlnclude < fcntl.h >
int fd = creat(char *filename, modej mode)
filename: имя файла
mode: права доступа
-1-при ошибке
fd - при успехе
Системный вызов creat открывает файл с именем filename на запись. Если до этого не было
файла с таким именем, то ядро создает файл. Если же есть файл с таким именем, то ядро
уничтожает его содержимое, сокращая (транкатинируя) его размер до нуля.
Если ядро создает файл, то оно устанавливает разряды прав доступа к файлу в
соответствии со значением второго аргумента2, который задается при обращении к системному
вызову. Например:
fd = creatf'addressbook", 0644);
Будет создан или транкатенирован файл с именем addressbook. Если до этого файл не
существовал, права доступа будут такими: rw-r-r-: (Смотри детали в главе 3.) Если же файл
с указанным именем существовал, то он становится пустым, а права доступа не меняются.
В любом случае через файловый дескриптор fd файл будет открыт только на запись.
2. На самом деле разряды прав доступа модифицируются процессом с помощью системного вызова umask.
См. главу 3.
74
Пользователи, файлы и справочник. Что рассматривать в первую очередь?
Запись в файл
Передача данных в открытый файл производится с помощью системного вызова write:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
write
#inc!ude < unistd.h >
ssizej result = writefint fd, void *buf, size J amt)
fd - файловый дескриптор
but - массив
amt - количество байт для записи
-1 - при ошибке
Количество записанных байт - при успехе
Системный вызов write копирует данные из памяти процесса в файл. Если ядро не может
ил и.не хочет копировать данные, то системный вызов write возвращает код -1. Если ядро
переслало данные в файл, то системный вызов возвращает в качестве кода возврата
количество байтов, переданных в файл.
Почему может быть различие между количеством переданных байтов и тем значением,
которое было заказано для передачи? Есть несколько обстоятельств, которые могут это
прояснить. В системе может быть установлен предел на максимальный размер файла,
который может создавать пользователь, или может быть недостаточно места на диске по
отношению к затребованному значению. Если в системном вызове будет записано
требование на размер, которое превышает предел или размер свободного пространства на
диске, то системный вызов write запишет столько байтов, сколько он сможет, а затем
остановится. В вашей программе всегда необходимо сравнивать количество байтов, которое вы
запрашиваете для пересылки в файл, с числом байтов, которое действительно туда было
передано. Если эти значения оказываются разными, то программа должна
предусматривать реакцию на эту ситуацию.
2.6.3. Вопрос 3: Могу ли я написать программу ср?
Проверим, насколько было все понятно, путем создания версии программы ср. Схема
работы программы будет такой:
открытие исходного файла для чтения
открытие целевого файла на запись
+- > чтение из исходного файла в буфер - - eof? -+
!_ запись из буфера в файл |
закрыть исходный файл < +
закрыть целевой файл
На рисунке 2.4 показаны потоки данных при копировании:
2.6. Проектдва:Разработкапрограммыср(чтениеизапись)
• 75
Рисунок 2.4.
Копирование файлов посредством чтения и записи
Файлы расположены на диске. Исходный файл находится слева на схематическом
изображении диска, а целевой файл - справа. Буфер представляет собой область памяти в
пределах среды процесса. Процесс располагает двумя файловыми дескрипторами. Данные
читаются из исходного файла в буфер, а затем записываются из буфера в целевой файл.
Наконец, программный код, который соответствует изображению на рисунке, будет
таким:
/**ср1.с
* версия 1 программы ср - использует read и write при работе с буфером с
* настраиваемым размером
*
* usage: cp1 srcdest
7
#include <stdio.h> ,
#!nclude <unistd.h>
#include <fcntl.h>
#defineBUFFERSIZE4096
#defineCOPYMODE0644
void oops(char *, char *);
main(intac, char*av[])
{
int in fd, out fd, n chars;
charbuf[BUFFERSIZE];
Г проверка аргументов */
if (ас != 3){
fprintf(stderr, "usage: %s source destination^", *av);
exitA);
}
Г открытие файлов */
if ((in_fd=open(av[1 ], O.RDONLY» == -1)
oopsfCannot open", av[1]);
76 . Пользователи, файлыисправочник. Чтоу рассматривать впервуюочередь?
if ((out.fd=creat(av[2], COPYMODE)) == -1)
oops("Cannot creaf, av[2]);
/* копирование файлов */
while ((n_chars = read(injd, buf, BUFFERSIZE)) > 0)
if (write(out_fd, buf, n_chars) != n_chars)
oops("Write error to", av[2]);
if (n^chars == -1)
oops("Read error from.", av[1]);
Г закрытие файлов */
if (close(injd) == -11| close(out_fd) == -1)
oopsf'Error closing files",'"*);
}
void oops(char *s1, char *s2)
{
fprintf<stderr/,Error:%s"ls1);
perror(s2);
exitA);
}
Откомпилируем и проверим работу программы:
$ ее ср1 .с-о ср1
$ ср1 ср1 copy.of.cp1
$ Is -I cp1 copy.of.cp1
-rw-r-r- 1 bruce bruce 37419 Jul 23 03:12 copy.of.cp1 •
-rwxrwxr-x 1 bruce bruce 37419 Jul 23 03:08 cp1
$ emp cp1 copy.of.cp1
$
С первого взгляда кажется, что все работает. Утилита стр сравнивает два файла и при
обнаружении несовпадения по содержанию оповещает об этом. Поскольку разницы между
указанными файлами нет, то нет и сообщения о несовпадении.
А как наша программа будет реагировать на ошибочные ситуации? Сначала попытаемся
снять копию с несуществующего файла, а затем записать копию в каталог. Получим такой
результат:
$ср1 xxx123file1
Error: Cannot open xxxl 23: No such file or directory
$ cp1 cp1 /tmp
Error: Cannot creat Amp: Is a directory
Проверим другие ошибочные ситуации. Следует обратиться к документации по
системному вызову и посмотреть там, какие ошибки могут возникать при его выполнении. Затем
нужно попытаться воспроизвести ошибочные ситуации. При этом проверяйте - не
затираете ли вы файлы, с которыми вам будет необходимо работать.
2.7. Увеличение эффективности файловых операций ввода/вывода: Буферирование
77
2.6.4. Программирование в Unix кажется достаточно простым
Программа who - это программа, которая читает из файла и форматирует данные.
Программа ср - это программа, которая читает один файл и производит запись в другой файл.
Обе программы используют одни и те же базовые системные вызовы для установления
связей с файлами и организации передачи данных в файлы и из файлов. Из справочника
и из текстов заголовочных файлов мы будем извлекать всю информацию, которая будет
необходима, чтобы понять, как писать такие программы.
Программирование в Unix не выглядит слишком затруднительным. Следует ли
пропускать некоторые основополагающие вопросы? Давайте разберемся. Помимо трех вопросов,
которые мы сформулировали в отношении Unix и программирования в Unix, есть еще
один важный вопрос: что можно сделать, чтобы это работало лучше?
2.7. Увеличение эффективности файловых операций ввода/
вывода: Буферирование
В программе ср1 содержится символьная константа BUFFERSIZE, которая задает размер
массива в байтах, где содержатся данные по мере их передачи от исходного файла к целевому
файлу. Это значение равно 4096. Возникает важный вопрос: какой размер буфера следует
считать лучшим?
2.7.1. Какой размер буфера следует считать лучшим?
Давайте порассуждаем. Если вы используете половник для разлива супа по тарелкам,
то чем больше будет этот половник, тем меньше вам потребуется манипуляций с разливом
и меньше времени.
Рассмотрим файл длиной в 2500 байт. Можно выделить некоторые особенности при
работе с ним:
Ех: Размер файла = 2500 bytes
Если buffer = 100 байт, тогда
для копирования потребуется 25 системных вызовов read() и 25 write()
Если buffer = 1000 байт, тогда
для копирования потребуется 3 системных вызова readQ и 3 write))
При изменении размера буфера со 100 байт до 1000 байт сокращается число системных
вызовов read и write с 50 до 6.
В следующей ниже таблице показано время выполнения программы ср1 при копировании
файла размером в 5 Мбайт при различных значениях BUFFERSIZE.
Размер буфера
1
4
16
64
128
256
512
Время выполнения в секундах
50.29
12.81
3.28
0.96
0.56
0.37
0.27
1024.
0.22
78
Пользователи, файлы и справочник Что рассматривать в первую очередь?
Размер буфера
2048
4096
8192
16384
Время выполнения в секундах
0.19
0.18
0.18
0.18
Системные вызовы требуют время для своего выполнения. Программа, где делается
больше системных вызовов, работает медленнее и отнимает время у других пользователей,
которые хотели бы работать в системе.
2.7.2 Почему на системные вызовы требуется тратить время?
Чем определяются временные затраты при работе системных вызовов? На рисунке 2.5
схематично показан поток управления.
Рисунок 2.5
Поток управления при
работе системных вызовов
На рисунке изображена память. Процесс развивается в пользовательской памяти, а ядро,
располагается в системном пространстве. Диск доступен для ядра. Наша программа ср1
хочет читать данные, поэтому она обращается с системным вызовом read к ядру для чтения
данных. Код, который производит фактическую передачу данных процессу с диска,
является частью ядра. Поэтому управление от вашего кода в пользовательском пространстве
будет передано коду ядра, находящемуся в системном пространстве. После этого
процессор будет выполнять ту часть кода ядра, который организует передачу данных. На
выполнение кода по передаче данных требуется время.
Но время требуется не только на передачу данных. Время требуется также и на переход
в ядро и выход из ядра. Когда исполняется код ядра, процессор работает в супервизорном
режиме со специальным стеком и памятью. При исполнении пользовательского кода
процессор работает в пользовательском режиме.
2\7. Увеличениеэффективностифайловыхоперацийввода/вывода: Буферирование 79
Функции ядра должны иметь доступ к диску, терминалам, принтерам и другим ресурсам.
А вот пользовательские функции не должны иметь доступа к этим ресурсам. Поэтому
и организуется работа компьютера в различных режимах. Когда компьютер работает
в пользовательском режиме, он имеет ограничение на доступ к памяти - возможен доступ
только к определенному сегменту памяти в пользовательском пространстве. Когда
происходит работа в режиме ядра, компьютер имеет доступ ко всей памяти. Особенности смены
режимов работы зависят от вашего процессора. У каждого процессора имеются
собственные схемы по поддержке супервизорного и пользовательского режимов. Каждая версия
Unix адаптируется к той модели поддержания супервизорного и пользовательских
режимов, которые обеспечиваются данным процессором.
Рассмотрим Кларка Кента и Супермена. Когда происходит переход от пользовательского
режима (Кларк Кент) в режим ядра (Супермен), то Кларк находит телефонную будку, там
переодевается, снимает очки и меняет прическу. Далее Супермен выполняет
определенные действия, на что требуется время. И на переход обратно в пользовательский режим
также требуется время. Чем чаще Кларк Кент выполняет такие смены образов (режимов),
тем больше времени у него на это уходит и меньше времени остается на работу
репортером или на борьбу с преступностью.
Ваша программа не является исключением. Чем больше времени процессор затрачивает
на исполнение кода ядра и на вход в режим ядра и на выход из него, тем меньше времени
у него остается для работы над вашим кодом или на обеспечение неких системных
сервисов. Поскольку за время следует платить, то системные вызовы называют do/югиш/. Что
приводит к удорожанию при чтении и записи данных в нашей версии программы who?
2. Z 3. Означает ли, что наша программа who2.c неэффективна?
Да! Выполнение для каждой записи utmp одного системного вызова выглядит также
неэффективно, как если бы мы покупали пиццу слоями или покупали бы яйца поштучно. Если вы
собрались приготовить на завтрак яичницу из трех яиц, то вы должны будете поехать
в магазин, купить одно яйцо, возвратиться обратно, поджарить яйцо, затем съесть его. После
того как вы разделались с первым яйцом, должны будете поехать в магазин, купить другое
яйцо, приехать обратно, поджарить яйцо и съесть его. Наконец, вы должны будете поехать
и купить третье яйцо и понять, почему же яйца упаковывают в эти удобные коробки.
Хорошая идея состоит в том, чтобы читать сразу несколько (связку) записей. Тогда (как
в случае приобретения яиц в упаковке) связка записей помещается в локальную память.
Упаковка с яйцами является по смыслу буфером. Далее показан псевдокод для метода
getegg, где будет использована буферизация при покупке яиц.
getegg(){
if (eggsjeft_in_carton == 0){
вновь упаковать коробку с яйцами в магазине
if (eggs_at_store == 0)
return EndOfEggs
eggs left in carton = 12
}
eggsJeftJn_carton--;
return one egg;
v
80 Пользователи, файлыисправочник. Что рассматривать впервую очередь?
При каждом обращении к getegg выбирается одно яйцо, но не из магазина. Когда упаковка
с яйцами опустеет, то по алгоритму функции следует ехать в магазин. Но какое отношение
все это имеет к программированию в Unix?
Ознакомьтесь с содержанием заголовочного файла /usr/include/stdio.h для getc. В некоторых
версиях Unix функция getc, реализованная как макрос, использует ту же логику, что и
функция getegg.
2.7.4. Добавление буферирования к программе who2.c
Мы создадим версию программы who2.c, которая будет работать более эффективно за счет
введения буферирования, что должно уменьшить число используемых системных
вызовов. Идея, которая была представлена на примере функции getegg, может быть
представлена в программном виде. На рисунке 2.6 показано, как будет работать программа с
буферизацией.
main
Буфер
Файл utmp
Буферирование файла с utmplib
Функция main обращается
в utmplib.c для получения
следующей utmp структуры
Функция из utmplib.c читают
эти структуры 16 раз
с диска в массив
Ядро будет вызвано,
только когда отработают
все 16 чтений
Рисунок 2.6
Поток управления при работе системных вызовов
Мы создаем массив, который может содержать 16 utmp структур. Этот массив именуется
как буфер в нижней части схематического изображения процесса. Массив содержит
последовательность структур в пространстве процесса, что аналогично случаю с коробкой
для яиц, в которой находились яйца у вас дома. Напишем функцию с именем utmpjiext,
которая будет извлекать записи из буфера.
Модифицируем функцию main так, чтобы получать структуры из нашего буфера в
пользовательском пространстве. Это будет сводиться к вызову нашей собственной функции
utmp_next в пользовательском пространстве. После того как будут обработаны все
структуры из буфера, функция utmp_next обратится к системному вызову read, чтобы потребовать
от ядра считать очередные 16 записей. Эта новая модель уменьшает число системных
вызовов read в 16 раз.
2.7. Увеличениеэффективности файловыхоперацийввода/вывода: Буферироваиие 81
Такой буфер для размещения в нем 16 структур и функции для загрузки в буфер данных
с диска и для извлечения из него структур для функции main помещены в файл utmplib.c.
Код utmplib.c
Файл utmplib.c, содержимое которого здесь приведено, реализует алгоритм буферирования
записей:
/* utmplib.c - функции для чтения в буфер из файла utmp
* функции:
* utmpj)pen(filename) - открытие файла
*¦ возвращает -1 при ошибке
* utmp_next() - возвращает указатель на следующую структуру
* возвращает NULL при достижении конца файла eof
* utmp_close() - закрытие файла
* при одной операции чтения происходит чтение NRECS записей и затем они
* извлекаются из буфера
7
#include <stdiorh>
#include <fcntl.h>
#include <sys/types.h>
«include <utmp.h>
«define NRECS 16
«define NULLUT ((struct utmp *)NULL)
«define UTSIZE (sizeof(struct utmp))
static char utmpbuf[NRECS * UTSIZE];
static int numjecs;
static int cur jec;
static int fdjjtmp = -1;
utmp open(char *filename)
{
fd_utmp = open(filename, 0_RDONLY);
curjec = numjecs = 0;
return fd_utmp;
}
struct utmp *utmp next()
{
struct utmp *recp;
if(fdutmp==-1)
return NULLUT;
if (curjec==numjecs && utmpjeload()==0) /* еще? 7
returnNULLUT;
/*получить адрес следующей записи */
recp = (struct utmp *) &utmpbuf [curjec * UTSIZE];
curjec++;
return recp;
}
intutmo reloadM
/* место хранения */
/* количество хранимых элементов 7
/* переход 7
I* чтение из */
/* открытие 7
/* пока нет записей */
Г сообщение 7
/* ошибка? 7
82
Пользователи, файлы и справочник. Что рассматривать в первую очередь?
Г
* Читать следующую последовательность записей в буфер
7
{
intamtjead;
/* чтение записей в буфер */
amtjead = read(fd_utmp, utmpbuf, NRECS * UTSIZE);
/* сколько было получено? 7
numjecs = amtjead/UTSIZE;
/* сброс указателя */
curjec = 0;
. return num recs;
}
utmp_close()
{
if (fd_utmp != -1) /* не закрывать, если не было 7
closeffd utmp); /* открыто 7
}
utmplib.c содержит буфер, переменные и функции для управления потоком данных,
который проходит через буфер. Значения переменных num_recs и curjec определяют,
сколько структур находится в буфере и сколько из них было использовано.
Каждый раз при выборке записи функция utmp_next определяет с помощью проверки
переменной curjec - не достигли этот счетчик значения, равного числу записей в буфере. Если
не осталось неиспользованных записей, то функция utmpjext производит перезагрузку
буфера с диска. Прежде чем передать запись на использование, функция инкрементируеТ
счетчик curjec.
utmplib.c поддерживает ясный интерфейс в отношении вызываемых функций, скрывая
внутренние детали расположения в памяти и формат utmp записей. Функция utmpjext
просто возвращает указатели на структуры.
Далее представлена модифицированная версия функции main:
/* who3.c - who с буферируемым чтением
* - подавление пустых записей
* - форматирование времени
* - буферирование ввода (используя utmplib)
7
#include <stdio.h>
#include <sys/types.h>
#include <utmp.h>
#include <fcntl.h>
#include <time.h>
#defineSHOWHOST
void showjnfo(struct utmp *);
void showtime(timej);
intmain()
{
struct utnrm *utbufo. /* vкaзaтeль на следоюимо запись */
2.8. Буферизация и щю
83
}
Г
*utmp_next(); /* возвращаемый указатель на следующую запись */
if (utmp_open(UTMP_FILE) == -1){
perror(UTMP_FILE);
exitA);
}
while ((utbufp = utmpjiextQ) != ((struct utmp *) NULL))
showjnfo(utbufp);
utmp_close();
return 0;
showinfo()
В данной версии вместо системных вызовов open, read, close будут вызываться
эквивалентные функции в модуле буферизации. Функции для отображения находятся в showjnfo.
2.8. Буферизация и ядро
Буферизация - чрезвычайно полезная идея: читать данные в большие области памяти,
которые находятся в вашем пространстве. Затем процесс выбирает из этих областей более
мелкие части - те, которые ему необходимы.
2.8,/. Если буферизация столь хороша, то почему ее не использует ядро?
Использует. При переходе в режим ядра и при возврате из него затрачивается время, но на
передачу данных между твердым диском требуется несравненно больше времени. Для
экономии времени ядро хранит копии блоков с диска в памяти. На рисунке 2.7 это
проиллюстрировано.
Буферы ядра
(в системном пространстве)
Рисунок 2.7
Буферизация дисковых данных в ядре
84 Пользователи, файлы и справочник. Чторассматривать впервую очередь?
Диск представляет собой объединение блоков данных аналогично тому, как файл utmp
представляет собой объединение записей о входах в систему. Буферы ядра содержат
копии некоторых блоков диска, точно так же, как наши utmp буферы содержат копии utmp
записей.
Ядро копирует блоки с диска в буферы ядра. Когда процессу становятся нужны данные из
определенного файла, то ядро копирует данные из буфера ядра в буфер процесса. Ядро не
копирует непосредственно с диска в пользовательское пространство памяти.
Что происходит, если обнаруживается, что требуемой части данных нет в буфере ядра?
Ядро приостанавливает процесс, который к нему обратился, и выставляет заявку на
требуемый блок в свой "список покупок". Ядро затем находит другие процессы, которые
готовы к выполнению некой работы и позволяет этим процессам развиваться.
Через какое-то время ядро переместит требуемые данные с диска в буфер ядра. Теперь
ядро может копировать данные в буфер пользовательского пространства, после чего
разбудит спящий процесс.
Понимание принципов буферированш в ядре изменяет наше восприятие системных
вызовов read и write. Системный вызов read копирует данные для процесса из буфера ядра, а
системный вызов write копирует данные из процесса в буфер ядра. Передача данных между
буферами ядра и диском происходит не так, как при работе системных вызовов read и write.
Ядро может копировать данные на диск всякий раз, когда возникает в этом потребность.
Возникает ситуация, аналогичная тому, как вы складываете почтовые конверты на столе
в прихожей, чтобы потом их сразу переслать по почте. В нашем случае данные, которые
обозначены процессом для записи, накапливаются в буферах ядра, ожидая момента, когда
ядро скопирует их на диск. Если в системе внезапно произойдет отказ, который не
позволяет ядру скопировать блоки из буфера на диск, то изменения в файле или добавления
данных в него произведены не будут. ,
Последствия буферизации в ядре:
Более быстрый "дисковый " ввод/вывод.
Оптимизированные записи на диск.
Необходимость записи буферов на диск перед остановом системы.
2.9. Чтение файла и запись в файл
Наша первая программа who читала из файла. Наша вторая программа ср читала из одного
файла и писала в другой файл. А есть ли программы, которые читают из файла и пишут
в тот же файл?
2.9.1. Выход из системы: Что происходит?
Что происходит, когда вы выходите из системы? Прежде всего, в системе происходит
изменение записи в файле utmp. По полученному результату работы whol можно было
заметить, что в файле utmp могут содержаться записи для неиспользуемых терминальных
линий. Поэкспериментируйте и попытайтесь выполнить следующее:
1. Войдите в систему дважды, используя для этого два окна telnet к одной машине.
2. Используйте программу whol, которую мы написали, чтобы посмотреть содержимое
файла utmp. Посмотрите, какие терминальные линии используются.
3. Выполните однократный выход из ваших сессий.
4. Запустите повторно на исполнение whol, чтобы посмотреть, что произошло с нашими
двумя utmp записями.
2.9. Чтение файла и запись в файл 85
Вы увидите, что одна из записей, которая содержит ваше входное имя, изменилась.
Обратите внимание, что изменилось значение поля utjime. Какое будет новое значение времени
в этом поле? На некоторых системах поле с входным именем очищается. Будут ли еще
какие-то изменения в записи? Что произойдет с именем удаленной машины?
2.9.2. Выход из системы: Как это происходит
Давайте обратимся к простому примеру. Программа, которая удаляет ваше имя из
журнала, должна выполнять следующие действия:
1. Открыть файл utmp.
2. Читать файл utmp до обнаружения записи о вашем терминале..
3. Сместить модифицированную запись utmp на ее место.
4. Закрыть файл utmp.
Рассмотрим эти четыре шага, один за другим.
Шаг 1: Открытие файла utmp
Программа выхода читает из файла utmp (она способна найти запись о вашем терминале),
а также производит запись в файл utmp (чтобы заменить запись). Поэтому программа
выхода должна открыть файл utmp на чтение и запись:
fd = openfUTMP.FILE, CLRDWR);
Шаг 2: Поиск записи о вашем терминале
Все происходит просто. В цикле while будут по одной читаться utmp записи (или будет
использовано буферирование), будет производиться сравнение значения utjine с именем
вашего терминала. Это может происходить так:
while(read(fd, rec, utmplen) == utmplen) /* получить следующую запись*/
if (strcmp(rec.utjine, myiine) == 0) /* это моя линия? */
revise_entry(); /* удалить мое имя 7
ШагЗ: Запись модифицированной записи на место
Программа выхода модифицирует запись и помещает эту запись обратно в файл.
Программа изменяет значение USER_PROCESS, которое находится в utjype, на значение
DEAD_PROCESS. В некоторых версиях программ выхода может производиться очистка поля
с входным именем пользователя и поля с именем хост-машины, а значение, которое было
в поле utjime заменяется на время выхода. Описанные действия легко запрограммировать.
Теперь возникает такой большой вопрос: как же мы запишем модифицированную запись
обратно в файл? Если просто вызвать системный вызов write, то произойдет модификация
следующей записи. Это произойдет потому, что ядро поддерживает понятие текущей
позиции в файле и смещает текущую позицию после каждого прочтения некого числа байтов
или при записи в файл. При организации поиска utmp записи о нашем терминале текущая
позиция была выставлена на следующую запись. Тогда возникает важный вопрос.
Вопрос: Как программа может изменить текущий указатель чтения-записи в файле?
Ответ: С помощью системного вызова lseek.
Мы рассмотрим lseek в следующем разделе.
Шаг 4: Закрытие файла
Следует вызвать close(fd).
86 Пользователи, файлы и справочник. Что рассматривать в первую очередь?
2.9.3. Смещение текущего указателя: Iseek
Unix управляет текущим указателем в каждом открытом файле, как это показано на
рисунке 2.8.
Каждый раз, когда вы читаете байты из файла, ядро будет читать данные с текущей
позиции и затем смещать текущий указатель на то число байтов, которое было прочитано.
Указатель используется и при записи данных в файл. Каждый раз, когда вы производите
запись байтов в файл, ядро помещает их в файл, начиная с текущей позиции, а затем
корректирует значение текущей позиции - увеличивает ее на число записанных байтов.
Начало файла
Текущая позиция
Рисунок 2.8
Каждый открытый файл имеет текущий указатель
Системный вызов read
получает данные от текущей
позиции и до места
расположения новой текщей
позиции, которое смещено
относительно текущей
позиции на количество
прочитанных символов
Конец
Текущий указатель позиции привязан к соединению с файлом, а не к самому файлу.
Например, если две программы открыли один и тот же файл, то после открытия для каждого
соединения будет поддерживаться собственный указатель позиции. Программы могут
читать или записывать в разных местах файла. Системный вызов Iseek дает вам возможность
изменять текущую позицию в открытом файле и имеет такие характеристики:
Iseek
НАЗНАЧЕНИЕ Устанавливает файловый указатель с определенным
смещением в файле
INCLUDE «include < sysAypes.h >
«include < unustd.h >
ИСПОЛЬЗОВАНИЕ off J oldpos = lseek(int fd, off J dist, int base)
АРГУМЕНТЫ fd - дескриптор файла
dist: смещение в байтах base:
base:
SEEK_SET => от начала файла
SEEK_CUR => от текущей позиции
SEEKJEND => от конца файла
КОДЫ ВОЗВРАТА -1 -приошибке
Или предшествующая позиция в файле
2.9. Чтение файла и запись в файл
87
Iseek устанавливает текущий указатель через дескриптор открытого файла fd в то место
в файле, которое задается парой значений - dist и base. Значением base (база) можно
задавать начало файла @), текущую позицию в файле A) или конец файла B). Смещение - это
число байтов относительно базы.
Например, при таком обращении к системному вызову:
lseek(fd, -(sizeof(struct utmp)), SEEK_CUR);
произойдет смещение текущего указателя на sizeof(struct utmp) байтов относительно
текущей позиции. При обращении вида:
lseek(fd, 10 * sizeof(struct utmp), SEEK.SET);
текущий указатель будет установлен на начало одиннадцатой utmp записи в файле. А при
обращении вида:
lseek(fd, О, SEEK.END);
write(fd, "hello", strlenfhello"));
текущий указатель будет установлен в конец файла и там будет записана текстовая строка.
Наконец, нотация вида: lseek(fd, О, SEEK_CUR) означает возврат в текущую позицию.
2.9.4. Кодирование выхода из системы через терминал
Теперь у нас есть все, что необходимо для написания функции, которая будет делать
отметку в файле utmp при выходе из системы:
Г
* logout_tty(char *line) .
* производит отметки в utmp - записи при выходе из системы
* не затирает имени пользователя и удаленной машины
* возвращает -1 - при ошибке, 0 - при успехе
int logout tty(char *line)
{
intfd;
struct utmp rec;
int len = sizeof(struct utmp);
int retval = -1; Г пессимизм*/
if ((fd = open(UTMPTILE,0_RDWR)) == -1) /* открытие файла 7
return-1;
/* поиск и замена */
while (read(fd, &rec, len) == len)
if (strncmp(rec.ut_line, line, sizeof(rec.ut line)) == 0)
{
rec.uUype = DEAD.PROCESS; /* установка типа 7
if (time(&rec.ut time) != -1) /* и времени 7
if (lseek(fd,-len, SEEK.CUR)!= -1) Л откат 7
if (write(fd, &rec, len) == len) /* модификация7
retval = 0;/* успех! 7
88
Пользователи, файлы и справочник. Чторассматривать\в первую очерщь?
break;
}
/* закрытие файла */
if(close(fd)==-1)
retval = -1;
return retval;
}
В этом программном коде производится проверка возникновения ошибок для каждого
системного вызова. В ваших системных программах следует всегда проверять наличие
ошибок при каждом системном вызове. Такие программы в состоянии модифицировать
файлы и данные, от которых зависит работа системы. Могут возникнуть серьезные
последствия, если оставлять файлы в некотором противоречивом состоянии или оставлять
их, не закончив с ними работу. С другой стороны, в ряде простых программ в данном
тексте были опущены проверки на наличие ошибок. Это сделано было для того, чтобы
оставить наглядной и ясной логику работу самих системных вызовов.
Упомянув об ошибках, теперь посмотрим, как управлять ими и как оповещать об их
наличии.
2.10. Что делать с ошибками системных вызовов?
Если системный вызов open не может открыть файл, то он возвращает -1. Если системный
вызов read не может прочитать данные, то он возвращает -1. Если системный вызов Iseek не
может отыскать нужную позицию, то он возвращает-1. Системные вызовы возвращают-1,
когда что-то выполняется неправильно. Ваши программы должны проверять код возврата
каждого системного вызова, которые делаются в вашей программе, и предусматривать
выполнение необходимых действий в случае возникновения ошибок.
Что следует считать неправильным? Для каждого системного вызова установлен
собственный перечень ошибок. Рассмотрим системный вызов open. Файл может не
существовать, вы можете не иметь прав на открытие файла или у^ке открыли слишком много
файлов. Как же ваша программа сообщит вам, какая и^з нескольких возможных ошибок
возникла?
Как идентифицировать ошибочную ситуацию: errno
Ядро оповещает вашу программу при возникновении ошибки с помощью определенного
кода ошибки, который ядро записывает в глобальную переменную errno. Каждая
программа имеет доступ к этой переменной.
На странице документации еггпо(З) и в заголовочном файле <errno.h> находятся
символьное и числовое представление кодов ошибок. Вот несколько примеров:
#define EPERM 1 /* Отсутствие прав на действие 7
#define EN0ENT 2 /* Нет такого файла или каталога */
#define ESRCH 3 •/* Нет такого процесса */
#define EINTR 4 /* Прерываемый системный вызов */
#define ЕЮ 5 /* Ошибка ввода/вывода 7
Различные ответы на различные ошибки
Вы можете использовать эти символические коды ошибок в вашей программе, когда
будете программировать распознавание ошибочных ситуаций и действий, которые нужно
предпринимать при ошибках. Это иллюстрируется в следующем программном коде:
2.10. Что делать с ошибками системных вызовов?
89
#include <errno.h>
extern int errno; '
int sample()
{
intfd;
fd = open("file",ORDONLY);
if(M==-1)
{
printff'Cannot open file:");
if (errno ==ENOENT)
printffThere is no such file.");
else if (errno == EINTR)
printff'lnterrupted while opening file.");
else if (errno == EACCESS)
printffYou do not have permission to open file.");
Действия вашей программы будут зависеть от того, что вы будете считать ошибочным
действием. Например, если системный вызов open заканчивается неуспешно, поскольку
указанный файл не существует, вы можете запросить у пользователя другое имя файла.
С другой стороны, если программа открыла слишком много файлов (EMFILE), то можно
закрыть некоторые из них и вновь попытаться открыть нужный файл. В данном случае
пользователю нет необходимости знать о возникновении такой ошибки и выполненных
действиях при ее возникновении.
Сообщения об ошибках: реггог(З)
Если вы хотите выдать сообщение, которое описывает ошибку, то требуется проверить
значение переменной errno и вывести то или иное сообщение в зависимости от значения
переменной. В функции sample, которая была приведена выше, это. выполняется. Вместе
с тем вместо указанных действий представляется удобным использовать библиотечную
функцию perror(string). Функция perror(string) выбирает код ошибки и выводит в
соответствии с возникшей стандартной ошибкой строку, которую вы ей передаете, вместе с кратким
сообщением об ошибке.
В модифицированной версии программы sample используется perror:
int sample()
{
intfd;
fd = open("file", 0 RDONLY);
if (fd == -1)
{
perrorf'Cannot open file");
return;
}
Если возникает ошибка при работе системного вызова open, то вы увидите такого рода
сообщения:
Cannot open file: No such file or directory
Cannot ooen file: Interrupted svstem call
90 Пользователи, файлы и справочник. Что рассматривать в первую очередь?
В первой части диагностического вывода находится строка, которую вы передаете при
обращении к функции perror, а во второй части вывода находится текст, который
соответствует коду ошибки в переменной errno.
Заключение
Основные идеи
• Команда who выводит список текущих пользователей после чтения его из системного
журнала.
• В системах Unix данные хранятся в файлах. Unix - программы организуют передачу
данных в файлы и из файлов с помощью шести системных вызовов:
open(filename, how)
creat(filename, mode)
read(fd, buffer, amt)
write(fd, buffer, amt)
lseek(fd, distance, base)
close(fd)
• Процесс читает данные и записывает их с помощью файловых дескрипторов.
Файловый дескриптор определяет соединение между процессом и файлом.
• Каждый раз, когда программа выполняет системный вызов, компьютер переключается
из пользовательского режима в режим ядра. Далее исполняется некоторый код в ядре.
Программы будут работать более эффективно, если в них будет произведена
минимизация числа системных вызовов.
Программы, которые читают и пишут данные, могут сократить число системных
вызовов, размещая данные в буферах и обращаясь к ядру, когда необходимо записать
заполненный буфер или поместить данные в буфер при его опустошении.
Ядро Unix использует буферы, которые располагаются в памяти ядра для того, чтобы
сократить время на пересылку данных между системой и диском.
В Unix значение времени хранится в форме целого числа секунд, прошедших
с момента начала работы Unix.
Когда в Unix системный вызов обнаруживает ошибку, система устанавливает
определенное значение в глобальной переменной errno и возвращает код возврата,
равный -1. Системные программы могут использовать значение errno для
диагностирования ошибок и выполнения необходимых действий при возникновении
ошибок.
Большая часть информации, которая была представлена в этом разделе, доступна
в системе. Расширенные тексты документации представляют описание команд, что
они делают, а в ряде случаев описывают, и как они работают. В заголовочных файлах
содержатся определения структур данных, значения символических констант,
прототипы функций, используемые для создания системных средств.
Заключение
91
Исследования
2.1 Команда W. В Unix есть команда, которая называется w и которая имеет отношение
к команде who. Попытайтесь выполнить команду и прочитайте документацию для нее.
Какие действия поддерживаются в команде w и не поддерживаются в команде who?
Какая при этом используется информация в файле utmp? Каково назначение
дополнительной информации? Попытайтесь найти источники, объясняющие смысл
дополнительной информации.
2.2 Авариии utmp. Когда вы входите в систему, то ваше входное имя, имя терминала, время,
имя вашего удаленного хоста записываются в файл utmp. Когда вы выходите из
системы, то запись зачищается. Что происходит, если в системе произойдет некая авария?
Очевидно, что в файле utmp останется список пользователей, которые были в системе
во время аварии. Когда система вновь стартует, то информация в файле utmp не будет
верной. Что в системе Unix делается с файлом utmp, когда система стартует?
Создаются ли записи для всех доступных терминальных линий? Может быть, создается
пустой файл, в котором будут накапливаться записи о терминальных линиях? Для ответа
на эти вопросы обратитесь к справочнику, заголовочным файлам и стартовым
скриптам. Вы можете поэкспериментировать на собственных машинах.
2.3 Проверьте, как работает программа ср1, копируя некий файл на /dev/tty:
Ср1 ср1 .с /dev/tty. Здесь целевым файлом является терминал. Наша программа будет
открывать терминал, производить запись и закрывать терминал, используя для этого те
же системные вызовы, которые она использовала при посылке данных в файл на
диске. Далее скопируйте данные с терминала в дисковый файл, используя такую
нотацию: ср1 /dev/tty filyl. Теперь ваша клавиатура становится входным файлом. Следут
отметить, что после набора строк вы должны нажимать на клавишу Enter, а в конце
следует набрать Ctri-D.
2.4 Стандартные С - функции для работы с файлами fopen, getc, fclose, fgets представляют
собой часть системы буферированного ввода и вывода файлов. Эти функции
используют структуру типа RLE, которая является промежуточным уровнем и подобна по
назначению модулю utmplib. Найдите определение FILE в заголовочных файлах, описание
структур и сравните их с переменными в utmplib.c.
2.5 Запись в буферы ядра. Как убедиться в том, что данные, которые вы пишете на диск,
действительно туда были записаны? Мы отмечали, что ядро будет копировать
данные, когда оно в них нуждается. Изучите справочный материал, где говорится, как
системные вызовы и программы отслеживают состояние буферов при копировании на
диск.
2.6 Многократное открытие одного и того же файла. В Unix допускается открытие
одного файла несколькими процессами. В Unix возможно, что один и тот же процесс
может многократно открывать один и тот же файл. Поэкспериментируйте с
многократным открытием одного и того же файла, предварительно создав файл с
некоторым произвольным текстом. Затем напишите программу, которая выполняет
следующие действия:
(a) Открывает файл для чтения.
(b) Еще раз открывает этот же файл на запись.
(с) Еще раз открывает этот же файл на чтение.
92 Пользователи, файлы и справочник. Что рассматривать в первую очередь?
Вы должны получить три файловых дескриптора. После этого программа должна:
(d) Прочитать 20 байтов, используя для этого первый дескриптор fd, и вывести на экран
то, что прочитали.
(e) Записать строку ''testing 12 3", используя для этого второй дескриптор fd.
@ Прочитать 20 байтов, используя для этого третий дескриптор fd и вывести на экран
то, что прочитали.
2.7 Изучение электронного справочника. Команда man предоставляет вам информацию о
командах Unix, системных вызовах, системных устройствах и информацию по
другим темам. Какую команду следует использовать, чтобы изучить свойства самой
команды man? Сколько разделов содержится в электронном справочнике в вашей версии
Unix? Для чего они предназначены?
2.8 Изучение файла utmp. Файл utmp, о котором шла речь в предшествующих
экспериментах, содержит записи, которые соотнесены текущим сессиям. Какие еще виды
записей содержатся в этом файле? Для чего они предназначены?
2.9 Переход в конец файла. Системный вызов Iseek позволяет вам выставить текущий
указатель в файле на позицию, которая будет располагаться за концом файла. Например,
системный вызов:
lseek(fd,100,SEEKEND)
установит текущий указатель в позицию, которая смещена на 100 байтов от конца
файла.
Что произойдет, если после этого вы попытаетесь читать данные сразу за концом
файла? Что произойдет, если после этого вы попытаетесь писать данные сразу за концом
файла? Попытайтесь записать некоторую строку, типа "hello", совмещением на
большую величину относительно конца файла (например, 20 000 байтов). Проверьте,
каков будет размер файла с помощью команды Is -1 и с помощью команды Is -s. Что
в результате получили?
Программные упражнения
2.10 Идентификация личности. В документации для команды who упоминается о
возможности использования для этой команды такой нотации: who am i. Кроме того, допустим
и вариант: whoami. Модифицируйте программу who2.c так, чтобы она поддерживала
вариант вызова команды who am i. Поэкспериментируйте с командой whoami и
почитайте документацию по ней. Чем этот вариант отличается от варианта who am i? Напишите
программу, которая работала так же, как и whoami.
2.11 Что сделает стандартная программа ср, если вы попытаетесь с ее помощью
копировать из файла в этот же файл? Например: ср filel filel. Насколько это корректно?
Модифицируйте программу ср1 .с, которая управляла бы данной ситуацией.
2.12 Файлы и API. Мы создали utmplib.c, чтобы увеличить эффективность, но при этом
достигается еще и дополнительный эффект. Этот дополнительный эффект заключается
в том, что была произведена замена файла данных на набор функций, который
представляет собой программный интерфейс (API). С помощью этого API программа по-
Заключение
93
лучает все структуры utmp, даже те, которые не представляют входы пользователей.
Программе who необходимо только получить для рассмотрения те записи, которые
представляют активные сессии. Модифицируйте utmplib.c так, чтобы она возвращала
только записи об активных сессиях. Как такие изменения подействуют на остаток
кода who3.C? Хороша ли эта идея с изменениями? Почему да или почему нет?
2.13 Буферирование и поиск. Функция logout Jty, которая была приведена ранее, использует
системный вызов Iseek. Она производит откат на одну запись и может быть применена
для перезаписи. Заметим, что функция logout_tty не использует буферирования для
чтения файла utmp. Программа магла более эффективно работать, если бы
использовалось буферирование.
(a) Рассмотрите те проблемы, которые могут возникнуть, если мы соединим вместе
системный вызов и обращения к функциям в utmplib.c.
(b) Добавьте новую функцию в utmplib.c, которая должна будет вызываться так:
utmp_seek(record_offset,base)
и которая изменяет текущий указатель для utmp_next таким же образом, как это делает
Iseek
при изменении текущего указателя при вызове read. Эта новая функция должна
передвигать текущий указатель на record_offset записей относительно базы base, где
значениями base могут быть seek_set, seek_cur или seek_end. Заметьте, что значение
аргумента представляется в количестве записей, а не в количестве байтов.
(c) Модифицируйте logout Jty так, чтобы в этой версии можно было использовать
utmplib.c.
2.14 Эксперименты с utmp. Программа whol пролистывает каждую запись в файле utmp.
Хотя это и не входило в наши намерения, но программа тем самым предоставляет
удобное средство для проверки содержимого файла utmp. Сделайте программу whol
еще более полезной, добавив некий код к ней, который будет выводить все другие
поля в структуре. В частности, полезно поле litjype. Модифицируйте программу так,
чтобы она позволяла пользователю заменить файл utmp (файл по умолчанию)на файл,
имя которого задается в командной строке. Теперь можно будет использовать это
средство для проверки файла wtmp.
2.15 Предотвращение разрушений файлов. В стандартной версии команды ср безусловно
происходит перезаписывание существующих файлов. То есть, если у вас есть файл
file2, и вы будете выполнять команду:
$ ср filel file2
то вы уничтожите оригинальное содержание файла file2. В стандартной версии ср
поддерживается опция -i, которая заставляет команду запрашивать у пользователя
подтверждение на перезапись файла. Добавьте это свойство в программу ср1.с.
Проекты
Взяв за основу материал этой главы, вы можете изучить и написать собственные версии
следующих команд Unix:
ас, last, cat, head, tail, od, dd
94 Пользователи, файлыи справочник. Чторассматривать впервую очередь?
Последняя трудная задача: Команда tail
Мы многое узнали при ознакомлении с рядом команд. Рассмотрите еще одну команду. У нас
нет возможности ее изучать, поэтому вы должны будете сделать это самостоятельно.
Системный вызов Iseek позволяет вам передвигать текущий указатель по файлу. Вызов
Iseek(fdASEEKEND)
переместит текущий указатель в конец файла.
Команда tail позволяет отобразить последние десять строк файла. Попытайтесь ее
выполнить. Команда tail будет выводить не от конца файла и вперед, а десять строк, которые
располагаются перед концом файла. Заметим, что аргумент distance в системном, вызове Iseek
измеряется в количестве символов.
Как работает команда tail? Разработайте собственную версию. Подумайте о буферирова-
нии, чтобы ваша программа работала эффективнее. Изучите документацию и
познакомьтесь со всеми опциями, которые поддерживаются в команде tail. Как они работают?
Разработка такой программы в отношении программ who и ср выглядит гораздо более простым
проектом.
Исходный код двух версий tail доступен на Web-сайте книги. Одна версия - это gnu версия,
другая - версия bsd. В них используются различные средства. Прежде чем обратиться
к этим решениям, попытайтесь написать одну из версий самостоятельно.
Глава 3
Свойства каталогов и файлов при
просмотре с помощью команда Is
Цели
Идеи и средства
• Каталог - это список файлов.
• Как прочитать каталог.
• Типы файлов и как определять тип файла.
• Свойства файлов и как определять свойства файл.
• Битовые наборы и биты маскирования.
• Идентификаторы пользователя, идентификаторы группы и база данных passwd.
Системные вызовы и функции
• opendir, readdir, closedir, seekdir
• stat
• chmod, ehown, utime
• rename
Команды
• Is
3.1. Введение
Мы знаем, как прочитать содержимое файла и как записать данные в файл. Помимо
содержания, файл имеет еще ряд атрибутов. Файл имеет собственника, у файла есть время
его последней модификации, размер, тип и другие атрибуты. Как мы можем посмотреть
имена файлов и определять свойства файлов? С помощью команды Is можно получать
списки имен файлов в каталоге и информацию о файлах. Мы изучим команду Is, чтобы
больше узнать о каталогах и типах файлов, узнать о свойствах файлов.
96
Свойства каталогов и файлов при просмотре с помощью команды Is
3.2. Вопрос 1: Что делает команда is?
3.2.1. Команда Is выводит список имен файлов и оповещает об атрибутах файлов
Наберите команду Is, чтобы посмотреть, что она делает.
JJ Is
Makefile docs Is2.c s.tar statdemo.c taill .c
chap03 Is1 .c old_src statl x taiM
$
Действие команды Is по умолчанию ~ вывод списка имен файлов в текущем каталоге. При
выводе имена файлов сортируются командой Is в алфавитном порядке. В одних версиях
команда располагает список имен поколонно, в других версиях такой вывод выполняется с
помощью опции (используя опцию -С). Помимо имен файлов, команда Is может выводить еще
дополнительную информацию о файлах. Если при обращении к команде задается опция -1,
то команда представляет информацию о каждом файле, используя длинный формат:
S Is -1
total 108
-rw-rw-r--
-rw-rw-r--
drwxrwxr-x
-rw-r-r--
-rw-r-r-
drwxrwxr-x
-rw-rw-r--
-rw-r-.-r--
-ПЛИ--Г--
-rwxrwxr-x
-rw-r-r-
$
2bruce
1 bruce
2 bruce
1 bruce
1 bruce
2 bruce
1 bruce
1 bruce
1 bruce
1 bruce
1 bruce
users
users
users
users
users
users
users
support
support
users
users
345 Jul 29 11:05 Makefile
27521 Aug 1 12:14 chap03
1024 Aug 1 12:15 docs
723 Feb 91998 Is1.с
3045 Feb15 03:51 Is2.c
1024 Aug 1 12:14oldsrc
30720 Aug 1 12:05 s.tar
946 Feb18 17:15 stall.с
191 Feb 9 1998 statdemo.c
37351 Aug 1 12:13 taih
1416 Aug 1 12:05 taill.с
Каждая строка вывода представляет один файл и содержит несколько атрибутов для
каждого файла.
3.2.2. Получение листинга о других каталогах, получение информации
о других файлах
В системе Unix находится много каталогов, в каждом из которых собраны собственные
наборы файлов. Как быть, если вам понадобится информация о других каталогах и о файлах
в этих каталогах? Можно обратиться к команде Is для получения информации о файлах из
других каталогов, указывая имена каталогов и имена файлов в командной строке:
Запрос на получение информации по Is из других каталогов и об их файлах
Пример
Действие
Is Дтр
Список имен файлов в каталоге Дтр
Is -I docs
Показать атрибуты файлов в каталоге docs
Is -l./Makefile
Показать атрибуты. /Makefile
Is ".с
Список файлов, имена которых удовлетворяют шаблону *.с
3.3. Краткий обзор дерева файловой системы
97
Если в качестве аргумента задан каталог, то команда Is выводит в виде списка его
содержимое. Если в качестве аргумента задан файл, то команда Is выводит его имя и, возможно,
атрибуты. На то, что может выполнить Is и как будет выглядеть вывод команды Is,
указывают опции, которые задаются при обращении к команде.
3.2.3. Наиболее употребимые опции
В документации команды Is приводится большой список опций этой команды. Наиболее
популярные представлены в таблице.
Команда
Is-а
Is-lu
Is-s
Is-t
Is-F
Действие
Показать скрытые файлы
Показать время последнего чтения
Показать размер в блоках
Сортировка по времени
Показать типы файлов
Ремарка относительно имен файлов с начальной точкой
Опция -а требует пояснения, если вы новичок в Unix. Unix реализует концепцию скрытых
файлов на основе использования простого соглашения. Соглашение заключается в том,
что команда Is не включает в список вывода имена файлов, если они начинаются с точки.
Нечто в операционной системе (а именно ядро) знает и поддерживает концепцию скрытых
файлов. Это соглашение, которому следуют команда Is и пользователи.
Некоторые программы используют имена с начальной точкой для файлов в
пользовательском домашнем каталоге, чтобы указать неопределенные пользовательские предпочтения.
Такие конфигурационные файлы легко редактировать. Но их имена в листинге о
содержании каталога чаще всего не выводятся.
3.2.4. Первый ответ: Итоговые замечания
В результате проведения экспериментов с командой Is и после изучения соответствующей
документации мы обнаружили, что команда Is выполняет две функции:
Выводит в виде списка содержимое каталогов.
Отображает информацию о файлах.
Отметим, что команда Is выполняет различную обработку каталогов и файлов. При
обращении команда Is определяет, что задано в качестве аргумента - файл или каталог. Как это
делается? Если мы будем писать версию программы Is, то нам потребуется ответить на три
вопроса:
• Как вывести в форме списка содержимое каталога?
• Как получить и отобразить свойства файла?
• Как различить имя файла и имя каталога?
3.3. Краткий обзор дерева файловой системы
Прежде чем отвечать на сформулированные вопросы, давайте рассмотрим картину
распределения файлов на диске, которая поддерживается в Unix.
Информация на диске представлена как дерево каталогов, каждый из которых содержит
файлы и/или каталоги. На рисунке 3.1 небольшие прямоугольники обозначают файлы,
98
Свойства каталогов и файлов при просмотре с помощью команды Is
находящиеся в каталогах, а линиями обозначается, каким образом каталог соединяется
с вышележащим и нижележащим каталогами.
Каталоги
Файлы
Рисунок 3.1
Дерево каталогов
В Unix каждый файл расположен в некотором месте единственного дерева каталогов.
Отсутствуют такие понятия, как устройства или тома. Напротив, каталоги на отдельных
физических дисках и разделы рассматриваются как составные части одного дерева. Даже
гибкие диски, диски CD-ROM и другие заменяемые носители будут рассматриваться
в какой-то момент как подкаталоги единого дерева.
Все это значительно упрощает написание программы Is. Мы будем иметь в виду только
каталоги и файлы и не думать о разделах и томах.
3.4. Вопрос 2: Как работает команда Is?
Команда Is выдает список имен файлов. Как его сформировать? Первый набросок
действий будет такой:
открытие каталога
+- > читать запись - конец каталога? -+
|__ отобразить информацию о файле |
закрытие каталога < +
Эта схема напоминает логику команды who. Главное отличие заключается в том, что команда
who производит открытие и читает из файла, а команда Is открывает и читает данные из
каталога. Насколько отлично чтение из каталога от чтения из файла? В конечном счете, что такое
каталог?
3.4.1. Что же такое каталог, в конце концов?
Ответ. Каталог представляет собой особый вид файла, в котором содержится список
имен файлов и подкаталогов. Каталог по ряду признаков подобен файлу utmp (см. главу 2).
В нем содержится последовательность записей, а каждая запись четко определена по
назначению и имеет полностью документированную структуру. Каждая запись в каталоге
служит для представления одной сущности - одного файла или одного каталога. В
отличие от обычных файлов каталог никогда не бывает пустым. В каждом каталоге есть две
специальные записи, которые обозначаются так: . (точка) и .. {точка_точка)\ точка -это
имя текущего каталога, а точкаjno4Ka - это имя вышележащего каталога.
ЗА Вопрос 2: Как работает команда Is?
99
3.4.2. Работают ли системные вызовы open, read и dose в отношении каталогов?
Ответ 1. В Olden Days ®#Что это такое? нет упоминаний о таких возможностях.
Поработайте с такими командами на вашей системе:
Scat/
as'.a'asa.-a'bw.tagsb'cf
quota.userc'{
quota.group,esbetce,,sbtmp,"sbdevM sbmnt' wcsbin '2
sbopt2
¦8
sbusr8
¦9
sbvar9
(many lines of hard-to-read data omitted)
$ more /tmp
/tmp is a directory
$ od -c /dev
0000000
0000020
0000040
0000060
0000100
0000120
0000140
0000160
0000200
0000220
0000240
360 001
001 200
002 \0
M A
362 001
362 001
k с
364 001
364 001
k m
366 001
\o
\o
\o
К
\o
\o
0
\o
\o
e
\o
\0 024 \0
\0 002 \0
\0 001 200
E D E
\0 030 \0
\0 001 200
n \0 \0
\0 030 \0
\0 001 200
m \0 \0
\0 024 \0
001
\o
\o
V
004
\o
\o
\a
\o
\o
003
\0
\0 024
\0 361
\0 361
\0 k
\0 363
\0 363
\0 k
\0 365
\0 365
\0 m
\o
\o
001
001
I
001
001
b
001
001
e
\0
002
\o
\o
0
\o
\o
i
\o
\o
m
\0 360
\o .
\0 030
\0 001
g о
\0 030
\0 001
n i
\0 030
\0 001
\0 366
001
.
\o
200
\o
\o
200
0
\0
200
001
\0
\o
\a
\o
\o
004
\o
g
004
\o
\o
\o
\o
\o
\o
\o
\o
\o
\o
\o
\o
\o
Из этих примеров следует ряд интересных результатов. Во-первых, команды cat и od могут
читать каталоги так же, как они читают обыкновенные файлы. В этих командах
используются стандартные системные вызовы для работы с файлами: open, read и close. Поэтому
каталоги можно читать как обыкновенные файлы.
Во-вторых, команда more отказывается показывать вам содержимое каталога. Она
распознает, что в качестве аргумента задан каталог, и не будет отображать его содержимое.
Команда more смогла бы отображать содержимое каталога, но не думаю, что вам
захотелось бы его рассматривать. Некоторые версии команды cat, подобно команде more,
распознают каталог при обращении и не отображают его содержимое.
Наконец, примеры показывают, что каталоги не содержат однородного текста. Каталог
состоит из последовательности структур.
Ответ 2. Использование системных вызовов open, read и close для получения списка
содержимого каталогов является плохой идеей. В Unix поддерживается много типов
каталогов. Допускается читать диски, используя форматы Apple HFS, ISO9660, VFAT. Можно
читать каталоги NFS и различные обыкновенные каталоги. При использовании
системного вызова read потребуется знание формата записей для обработки каждого типа каталога.
100
Свойства каталогов и файлов при просмотре с помощью команды Is
3.4.3. Хорошо, хорошо. Но как же мне прочитать каталог?
Обратимся к электронному справочнику. Поищем информацию по ключевому слову
direct:
$ man-k direct
В одной из систем по этому слову была найдена 81 запись. Отфильтруем этот вывод по
слову read:
$ man -к direct | grep read
DXmHelpSystemDisplay CX) - Displays a topic or directory of the
help file in Bookreader.
opendir, readdir, readdirj, telldir, seekdir, rewinddir, closedir C) -
Performs operations on directories
$
Первый экран документации будет выглядеть так:
$ man 3 readdir
opendirC) opendirC)
NAME
opendir, readdir, readdirj, telldir, seekdir, rewinddir, closedir-Performs
operations on directories
LIBRARY
Standard С Library (libc.a)
SYNOPSIS
#include <sys/lypes.h>
tinclude <dirent.h>
DIR*opendir(
const char *dirjame);
struct dirent *readdir (
DIR *dir_pointer);
int readdirj (
DIR *dirj)ointer,
struct dirent *entry,
struct dirent **result);
long telldir (
DIR *dirj)ointer);
void seekdir(
DIR *dirj)ointer,
long location);
void rewinddir (
DIR *dir_pointer);
int closedir(
DIR *dir_pointer);
[more] A1%)
3.4. Вопрос 2: Как работает команда Is?
101
Согласно этой странице документации мы убеждаемся в том, что данные из каталога
получают аналогично тому, как получают данные из файла. Сначала с помощью opendir
открывается соединение с каталогом, а далее readdir возвращает указатель на следующий
элемент в каталоге. Наконец, closedir разрывает соединение. Системные вызовы: seekdir,
telldir и rewinddir по назначению подобны lseek. На рисунке 3.2 показано, как происходит
чтение.
struct dirent
opendir(char *)
Создание соединения,
возвращения указателя DIR *
readdir(DIR *)
Чтение следующей записи,
возврат указателя
на структуру struct dirent
cJosedir(DIR *)
Закрытие соединения
Рисунок 3.2
Чтение записей из каталога
Чтение содержимого каталога
Каталог - это список файлов, а более точно, это последовательность записей, каждая из
которых есть запись о каталоге. Мы читаем записи с помощью вызова readdir. После
работы каждого вызова readdir возвращается указатель на очередную запись типа struct direntn.
Компоненты структуры описаны в соответствующей документации и в заголовочном
файле /usr/include/dirent/h. Например, начало документации по dirent, которая была взята в
системе Sun OS, будет таким:
File Formats direntD)
NAME
dirent - file system independent directory entry
SYNOPSIS
tinclude <dirent.h>
DESCRIPTION
Different file system types may have different directory
entries. The dirent structure defines a file system
independent directory entry, which contains information com-mon
to directory entries in different file system types. A
set of these structures is returned by the getdentsB) sys-tem
call.
The dirent structure is defined:
struct dirent {
inoj djno;
off J <foff;
unsigned short djeclen;
chardjiame[1];
102
Свойства каталогов и файлов при просмотре с помощью команды Is
Каждая структура dirent содержит элемент с именем djrame. Это элемент для хранения
имени файла. Заметьте, что длина массива d_name в этой системе равна 1. Что означают
такие установки? Один символ char задает пространство для сохранения в поле одиночного
терминального нулевого символа.
3.5. Вопрос 3: Могу ли я написать Is?
Логика получения содержимого каталога будет такой:
main()
opendir
while (readdir)
print d_name
closedir
Полный код программы lsl.c будет таким:
Л* Isl.c
** цель - вывод списка содержимого каталога или каталогов
при отсутствии аргументов используется., в противном случае
используется список имен файлов через список аргументов
У
#include <stdio.h>
#include <sys/types.h>
#include <dirent.h>
void doJs(char []);
main(intac,char*av[])
{
if (ac == 1)
doJs(".M);
else
while (--ac){
printf("%s:\n", *++av);
do ls(*av);
>
}
void do ls(char dirname[])
Л
list files in directory called dirname
7
{
DIR *dir_ptr; /* каталог */
struct dirent *direntp; /* каждая запись 7
if ((dir_ptr = opendir(dirname)) == NULL)
fprintf(stderr,Mls1: cannot open %s\nM, dirname);
else
{
while ((direntp = readdir(dir_ptr)) != NULL)
printf(,,%s\n,,1 direntp->d_name);
3.5. Вопрос 3: Могу ли я написать Is?
103
closedir(dir ptr);
}
}
Откомпилируем и запустим этот код, а затем сравним полученный результат с выводом
команды Is, которая работает на вашей системе:
$ ее -о Is1 Is1 .с
$ls1
s.tar
tain
Makefile
Isl.c
Is2.c
chap03
old_src
docs
Is1
statl.c
statdemo.c
taill.c
$ls
Makefile docs Isl.c old_src statl.c taiM
chap03 Is1 Is2.c s.tar statdemo.c tail 1.с
$
3.5.1. Что еще нужно делать?
Неплохо для первой попытки. Эта версия 1.0 Is выводит список файлов в каталоге, но в
данной версии не поддерживаются следующие возможности:
(a) Нет сортировки вывода.
Наш список имен файлов не отсортирован в алфавитном порядке. Устранение. Мы можем
считать все имена файлов в массив, а затем использовать команду qsort для сортировки
этого массива.
(b) Нет поколонного вывода.
Стандартная версия команды Is поддерживает возможность вывода списка имен файлов
поколонно. В некоторых версиях расположение имен поколонно происходит сверху вниз,
слева направо, а в других системах - слева направо, сверху вниз.
(c) Вывод файлов с именами с лидирующей точкой.
В этой версии отображаются имена файлов с точкой. В стандартной версии команды
Is имена файлов с лидирующей точкой отображаются, только если используется опция -а.
Устранение: Подавить вывод имен с лидирующей точкой достаточно просто и обеспечить
их вывод по опции -а.
(d) He работает опция -I.
104
Свойства каталогов и файлов при просмотре с помощью команды Is
В стандартной версии is производится вывод статусной информации о файле, если
пользователь задает при обращении к команде опцию -I. В нашем варианте такой возможности
нет. Устранение: Добавить отработку опции -I непросто. В структуре dirent, которая
определена в заголовочном файле <dirent.h>, есть только несколько необходимых элементов.
В структуре dirent отсутствует информация о размере файла, о собственнике, а также
данные о других характеристиках файла. Если этой информации нет в каталоге, то где же она
хранится?
3.6. Проект 2: Написание версии Is -I
Мы уже заметили, что команда Is выполняет два вида действий: выводит список
содержимого каталогов, а также отображает статусную информацию о файлах. Далее мы увидели,
что эти два аспекта не связаны между собой. В каталоге содержатся не только имена
файлов. Нахождение и отображение статусной информации о файлах - это отдельный
сложный проект. Мы будем его реализовывать, отвечая на три стандартных вопроса.
3.6.1. Вопрос 1: Что делает Is -I?
Рассмотрим вывод команды:
$ Is -I
total 108
-rw-rw-r- 2 bruce users 345 Jul 29 11:05 Makefile
-rw-rw-r- 1 bruce users 27521 Aug 1 12:14 chap03
drwxrwxr-x 2 bruce users 1024 Aug 1 12:15 docs
-rw-r-r- 1 bruce users 723 Feb 9 1998 Is1 .c
-rw-r--r- 1 bruce users 3045 Feb 15 03:51 Is2.c
drwxrwxr-x 2 bruce users 1024 Aug 1 12:14 old_src
-rw-rw-r- 1 bruce users 30720 Aug 1 12:05s.tar
-rw-r-r- 1 bruce support 946 Feb 18 17:15 statl .c
-rw-r-r- 1 bruce support 191 Feb 9 1998 statdemo.c
-rwxrwxr-x 1 bruce users 37351 Aug 1 12:13 taiM
-rw-r-r- 1 bruce users 1416 Aug 1 12:05taiM.c
-rw-r-r- 1 cse215 cscie215 574 Feb 9 1998 writable.c
$
В каждой строке содержатся следующие семь полей:
Режим. Первый символ в каждой строке предназначен для обозначения типа файла.
Символ ;i-" показывает, что это обычный файл, а символ "d" показывает, что это каталог.
Есть еще и другие типы файлов. Вы должны еще немного изучить свойства и возможности
Unix с тем, чтобы было понятно назначение других типов файлов.
Последующие девять символов в первой колонке предназначены для обозначения прав
доступа. Могут быть установлены или сброшены права на чтение, запись, исполнение
в отношении файла для трех категорий пользователей: собственник, группа, все
остальные. В предшествующем примере вывода все файлы и каталоги были доступны для
чтения в каждом из классов пользователей, но файлы были доступны на запись только
собственнику файлов. Откомпилированный файл taill доступен на исполнение для всех
категорий пользователей.
Ссылки. Ссылки указывают на файл. Эта тема будет обсуждаться в следующей главе.
3.6. Проект 2: Написание версии Is -/
105
Собственник. Каждый файл принадлежит пользователю собственнику. В данной колонке
указывается пользовательское имя собственника.
Группа. Каждый файл принадлежит также группе пользователей. В ряде версий команды
Is в колонке указывается имя группы.
Размер. В пятой колонке находится целое число, которое обозначает число байтов в
файле. Заметим, что в этой колонке каталоги в нашем примере имеют один и тот же размер.
Память под каталоги выделяется блоками, поэтому размер каталога всегда кратен 512.
(Это зависит от конкретной версии Unix. Так, в HP UX под каталог выделяются блоки
размером 1024 байта. - Примеч.ред.) Для обычных файлов размер указывается в количестве
байтов данных, которые хранятся в этом файле.
Время последней модификации. Следующее поле состоит из трех подстрок, где
размещается время последней модификации. Для сравнительно новых файлов в подстроки
заносится месяц, день и время. Для более старых файлов заносится месяц, день и год. Почему
такие отметки будут полезны в системе? Насколько должен быть "старым" файл, чтобы
выводить в колонку год, а не время?
Имя. В этой колонке изображается имя файла.
3.6.2. Вопрос 2: Как работает Is -I?
Как мы можем получить информацию о файле? Давайте обратимся к электронному
справочнику. При таком обращении:
$ man -k file | grep -i information
должна быть найденаполезная информация о файле, но она по-разному называется в
различных версиях Unix. Многие версии вместо термина информация о файле используют
термин статусная информация о файле, или свойства файла. Для извлечения статусной
информации о файле используется системный вызов stat.
3.6.3. Ответ: Системный вызов stat получает информацию о файле
На рисунке 3.3 изображено, как работает системный вызов stat.
stat(name,ptr)
Копирование информации о
файле 'name" с диска в
структуру, которая находится в
вызывающем процессе.
Статусная информация
Содержимое файла
Рисунок 3.3
Чтение статусной информации о файле с помощью stat
Файл хранится на диске. Файл имеет содержимое и набор атрибутов: размер,
идентификатор собственника и т. д. Процессу необходимо получить статусную информацию о файле.
Процесс должен определить место, куда будет помещена статусная информация о файле.
106
Свойства каталогов и файлов при просмотре с помощью команды Is
Поэтому он определяет буфер типа struct stat, а затем процесс обращается к ядру с
требованием скопировать статусную информацию с диска в этот буфер.
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
stat
Получение статусной информации о файле
#include < sys/stat.h >
int result = statfchar *fname, struct stat *bufp)
fname - имя файла
bufp - указатель на буфер
-1-при ошибке
0 -при успехе
Системный вызов stat копирует статусную информацию о файле с именем fname в
структуру, на которую выставлен указатель bufp. В следующем ниже примере показывается, как
используется системный вызов stat для получения размера файла.
Г filesize.c - выводит размер файла passwd */
#jnclude <stdio.h>
#include <sys/stat.h>
intmain()
{
struct stat infobuf; /* место хранения статусной информации */
if (statf/etc/passwd", &infobuf) — -1) /* получить информацию 7
perrorGetc/passwd");
else
printff* The size of /etc/passwd is %d\nM, infobuf.st size);
}
Системный вызов stat копирует статусную информацию о файле в структуру infobuf, после
чего программа читает размер файла из поля st_size в этой структуре.
3.6.4. Какую еще информацию можно получить с помощью системного
вызова stat?
Документация для stat и заголовочный файл /usr/include/sys/stat.h представляют описание
перечня полей в структуре struct stat.
stjnode - тип и права доступа
st_uid - идентификатор собственника
st_gid - идентификатор группы
st„size - количество байтов в файле
stjilink - число ссылок на файл
stjntime - время последней модификации содержимого файла
st_atime - время последнего доступа
st_ctime - время последнего изменения статусной информации
В структуре содержатся еще и другие поля. Но именно указанные поля отображаются при
работе команды Is -1.
Следующая далее простая программа fileinfo.c извлекает и выводит эти атрибуты.
3.6. Проект 2: Написание версии Is -/
107
Г fileinfo.c - использует stat() для получения и вывода статусной
информации о файле
* - некоторые поля просто содержат числа...
7
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
intmain(intac, char*av[])
{
struct stat info; /* буфер для статусной информации */
if (ac>1)
if(stat(av[1],&info)!=-1){
show_stat_jnfo(av[1], &info);
return 0;
}
else
perror(av[ 1 ]); /* сообщения об ошибках stat( )*/
return 1;
}
show_stat info(char *fname, struct stat *buf)
Г
* отображение информации из stat в формате a name=value
7
{
printff mode: %o\n", buf->st_mode); /* тип + доступ 7
printff links: %d\n", buf->st_niink); /* количество ссылок 7
printff" user: %d\n", buf->st_uid); /* id пользователя */
printff group: %d\n", buf->st_gid); Г id группы 7
printff size: %d\n", buf->st_size); /* размер файла 7
printff modtime: %d\n", buf->stmtime); Л время модификации 7
printff name: %s\n", fname); /* имя файла 7
}
Откомпилируем и запустим на исполнение программу fileinfo, а затем сравним
полученный вывод с выводом, который получается при работе стандартной версии Is -1:
$ ее -о fileinfo fileinfo.c
$ /fileinfo fileinfo.c
mode: 100664
links: 1
user: 500
group: 120
size: 1106
modtime: 965158604
name: fileinfo.c
$ Is -I fileinfo.c
-rw-rw-r-- 1 bruce users 1106 Aug 1 15:36 fileinfo.c
108
Свойства каталогов и файлов при просмотре с помощью команды Is
3.6.5. Чего мы достигли?
Мы достигли того, что правильно отображаются такие атрибуты, как ссылки, размер, имя.
Вывод значения времени модификации представлен в формате timej. Мы можем
использовать ctime, чтобы конвертировать это значение в строку, где будет содержаться месяц,
день, время или год. В поле mode в нашем выводе выводится значение режима в числовом
виде, а при работе Is вывод будет символьным:
-rw-rw-r--
Вывод в полях user и group представлен в числовом виде, а в команде Is в этих полях
выводятся символьные имена собственника и имя группы. Для окончания работы над нашим
вариантом по написанию Is -l нам необходимо еще ознакомиться, как конвертировать
числовые значения полей mode, user и group в символьные представления значений.
3.6.6. Преобразование числового значения поля mode в символьное
значение
Каким образом представлены разряды, соотнесенные типу файла и правам доступа, в поле
stjnode? Как нам выбрать эти атрибуты и представить их как последовательность из
10 символов? Какая связь между восьмеричным числом 100664 и строкой rw-rw-r-?
Ответ: поле st mode шестнадцатиразрядное. Отдельные атрибуты закодированы в
соответствующих подстроках в этом 16-разрядном поле. На рисунке 3.4 показано назначение
пяти таких подстрок.
Тип ~. ^ i? Собственник Группа Остальные
3
ел
U
ел
д
sti
s
г
W
X
г
W
X
г
W
X
Рисунок 3.4
Представление кодов типа файла и прав доступа
Подстрока из первых четырех разрядов предназначена для представления типа файла.
В четырехразрядном поле можно хранить 16 возможных комбинаций из 1 и 0. Каждый из
этих двоичных кодов может служить для представления отдельного типа файла. В
настоящее время используется семь типов файлов.
Следующая подстрока из трех разрядов предназначена для хранения специальных
атрибутов файла. Каждый разряд в этой подстроке соответствует специальному атрибуту. Если
любой разряд установлен в Ч \ то соответствующий ему атрибут установлен. Если разряд
установлен в '0', то соответствующий ему атрибут не установлен. Эти специальные
атрибуты называются set-user-ID, set-group-ID и sticky bits. Они будут рассмотрены позже.
Наконец, далее расположены три последовательности трехразрядных подстрок для
представления прав доступа к файлу. Первая подстрока - для хранения прав доступа
собственника, вторая подстрока - для хранения прав доступа группы и последняя подстрока - для
хранения прав доступа всех остальных пользователей. Для каждого класса пользователей
в подстроке из трех разрядов можно задать наличие или отсутствие прав на чтение, запись
и исполнение. Значение какого-либо разряда в любой из подстрок, равное 4Г, означает,
что соответствующий вид доступа разрешен. Значение какого-либо разряда в любой из
подстрок, равное '0', означает, что соответствующий вид доступа запрещен.
3.6. Проект2: Написание версии Is -I
109
Секреты кодировки подполей
Весьма распространенным приемом является упаковка специальных значений в подполя
больших строк. Эта идея иллюстрируется на таких примерах:
Примеры кодирования подстрок
617-495-4204 Область, коммутатор, линия
027-93-1111 Личный социальный номер
128.103.33.100 IP-адрес
Как читать подполя: Маскирование
Как можно определить - принадлежит ли телефонный номер 212-333-4444 кодовой
области 212? Очень просто. Вы берете три первых числа из номера и сравниваете их подстрокой
212. Другой подход будет заключаться в том, что вы обнуляете все цифры в телефонном
номере, кроме первых трех, и затем сравниваете результат с 212-000-0000.
Техника обнуления указанных подполей называется маскированием. Подход напоминает
о маске на лице, которая все скрывает, за исключением ваших глаз и, возможно, ушей
и рта. Мы можем использовать набор масок для преобразования значения поля stmode
в символьную строку, которая выводится стандартной командой Is -1.
Кодирование подполей является общим и важным методом системного
программирования. Вам будет необходимо помнить о четырех моментах для понимания кодирования
и маскирования подполей.
Первый момент: Концепция маскирования
Маскирование значения - это обнуление установленных значений разрядов в числе при
условии, что остальные разряды остаются неизменяемыми.
Второй момент: Целое число - это битовая строка
Целые числа хранятся в компьютере как последовательность двоичных разрядов. На
рисунке 3.5 показано, как десятичное значение числа 215 выражается как
последовательность единиц и нулей, используя двоичную нотацию (основание 2). Каково будет
десятичное значение, которое соответствует двоичному значению 00011010?
100's 10's l's
\ / / 128 64 32 16 8 4 2 1
215 = oiioioiii
128 64 32 16 8 4 2 1
ooooiioilo
Рисунок 3.5
Преобразования десятичного представления в двоичное
Третий момент: Техника маскирования
Операция поразрядного "И"(т. е. &) дает возможность маскировать одно значение с
помощью другого значения. На рисунке 3.6 показано восьмеричное значение 100664
(основание 8), которое маскируется кодом, составленным пользователем. Отметьте, как
некоторые единичные разряды в исходном числе будут преобразованы в 0 с помощью
определенных разрядов маски.
/10 Свойства каталогов и файлов при просмотре с помощью команды Is
1000000110110100
0
0
0
0
0
0
0
0
1
0
1
1
0
0
0
0
0
0
0
0
0.
0
0
0
1
0
1
1
0
0
0
0
Рисунок 3.6
Использование двоичной маски
Четвертый момент: Использование восьмеричного основания
Использование масок в двоичном формате является достаточно утомительным, особенно
для слов длиной в 16 или 32 разряда. Поэтому произведем группировку больших
десятичных чисел в трехсимвольные "связки" (например, 23,234,456,022) для более простого
прочтения значения числа, а также сгруппируем двоичные представления больших чисел
в трехсимвольные "связки" и преобразуем каждую "связку" в одно восьмеричное число
(значение от 0 до 7).
Например, мы можем произвести группировку по связкам в двоичном числе
1000000110110100 и получить такое представление: 1,000,000,110,110,100. После чего
преобразуем каждую связку и получим такое представление числа: 0100664, которое легче
воспринимается.
Использование маскирования для декодирования значения типа файла
Тип файла кодируется в первом четырехразрядном поле mode. Для декодирования
информации в этом поле мы можем использовать маскирование. Прежде всего, мы
используем маску для обнуления всех разрядов, кроме первых четырех разрядов. Затем сравним
полученный результат с кодами для каждого из типов:
Определения этих кодов находятся в заголовочном файле <sys/stat.h>:
#define
#define
#define
#define
#define
#define
#define
#define
SIFMT 0170000
SIFREG 0100000
S IFDIR 0040000
SIFBLK 0060000
SIFCHR 0020000
SJFIFO 0010000
SIFLNK 0120000
SJFSOCK 0140000
/* тип файла 7
/* обычный */
Г каталог */
/* специальный блочный */
/* специальный символьный */
/* программный канал fifo */
/* символическая ссылка */
Г сокет */
Символьная константа SJFMT - это маска, с помощью которой выбираются первые
четыре разряда. Значением маски является число 0170000. Убедитесь в том, что эта маска
выбирает правильный набор разрядов с помощью обратного преобразования каждого
восьмеричного представления цифры в трехразрядный двоичный эквивалент. Код типа для
обычного файла (SJFREG) равен 0100000. Значение кода типа для каталога равно 0040000.
Например, во фрагменте кода:
if ((info.stjnode & 0170000) = 0040000)
printf("this is a directory.");
будет проводиться проверка на тип каталога, что делается с помощью маскирования всех
полей, кроме поля типа, и последующего сравнения результата с кодом типа каталога.
3.6. Проект 2: Написание версии Is -/
///
Если вы пожелаете написать код для маскирования и проверки, вы можете использовать
при этом макросы из заголовочного файла <sys/stat.h>:
/*
•
7
#define
#define
#define
#define
#define
Макросы для типов файла
S ISFIFO(m) (((m)&@170000)) == @010000))
SJSDIR(m) (((m)&@170000)) == @040000))
SJSCHR(m) (((m)&@170000)) == @020000))
S ISBLK(m) (((m)&@170000)) == @060000))
S ISREG(m) (((m)&@170000)) == @100000))
С помощью этих макросов можно так написать наш код:
if (S_ISDIR(info.st_mode))
printffthis is a directory.");
Использование маскирования для декодирования разрядов прав доступа
Последние девять разрядов в mode предназначены для представления прав доступа на
выполнение операций чтения, записи и исполнения с файлом для каждого класса
пользователей. В стандартной версии команды Is производится преобразование этих девяти
двоичных разрядов, каждый из которых установлен в 1 или 0, в строку, которая состоит из
последовательности символов и прочерков.
Назначение каждого разряда маски можно посмотреть в файле <sys/stat.h>. Следующая
программа представляет собой простое, читабельное приложение, которое проверяет
отдельно каждый разряд:
Л
* В этой функции извлекается значение mode и формируется символьный массив.
* В символьный массив помещается значение типа файла и
* девять символов для представления прав доступа.
* ЗАМЕЧАНИЕ: Коды setuid, setgid sticky
* не рассматриваются
7
void mode_to_letters( int mode, char str[])
{
strcpy(str,"- —");
if(SJSDIR(mode))str[0] = 'd';
if(SISCHR(mode))str[0] = ,c';
if(SJSBLK(mode))str[0] = ,b*;
if(mode&SIRUSR)str[1] = r;
if(mcxie&SJWUSR)str[2] = W;
if(mode&SJXUSR)str[3] = V;
if(mode&SJRGRP)str[4] = Y;
if(mode&SIWGRP)str[5] = 'w';
if(mode&SIXGRP)str[6] = Y;
if(mode&SIROTH)str[7] = r;
/* по умолчанию - отсутствие всех прав */
/* каталог */
/* символьные устройства */
/* блочное устройство */
/* 3 разряда для собственника */
Г 3 разряда для группы */
/* 3 разряда для всех остальных */
/12 Свойства каталогов и файлов при просмотре с помощью команды Is
if (mode & SJWOTH) str[8] = V;
iffmode&SIXOTHlstr^Y;
}
Декодирование разрядов и написание версии Is
У нас накопилось достаточно знаний для написания версии команды Is, которая может
правильно работать с длинным форматом вывода. Мы можем правильно выводить
значения таких атрибутов файла, как размер, ссылки и имя файла. Мы имеем возможность взять
значение поля mode и преобразовать его значение в стандартную последовательность
из символов и прочерков. Можно преобразовать с помощью ctime значение времени из
формата time_t в строковый формат. А каковы соображения по строчному представлению
имен собственника и группы?
3.6. Z Преобразования числового представления идентификаторов
собственника/группы в строковое представление
В нашем варианте в выводе для представления собственника и группы выдаются числа.
В стандартном выводе команды Is выводится символьное пользовательское имя и имя
группы. Какая связь между числовым идентификатором пользователя ию и
пользовательским именем?
При обращении к документации для поиска по ключевым словам usemame, w/d и group
будет получен весьма различный по составу результат поиска, который будет зависеть от
версии Unix. Посмотрим, что можно найти. Есть несколько интересующих нас факторов.
Фактор первый: Файл /etc/passwd содержит список пользователей
Как производится ваш вход в Unix - машину? Сначала система запросит у вас входное
пользовательское имя, а затем пароль. Далее система определяет, верны ли указанные
значения входного пользовательского имени и пароля. Как она узнает об их
правильности?
Традиционная система для учета пользовательских имен и паролей состоит из файла /etc/
passwd. В этом поле находится список всех пользователей данной системы. Содержимое
файла выглядит так:
root:WPA4d1 OwUxypE:0:0:root:/root:/bin/bash
bin:*: 1:1 :bin:/bin:
daemon:*:2:2:daemon:/sbin:
smith:x1 mEPcp4TNokc:9768:3073:James Q Smith:/home/s/smJth:/shellsAcsh
fred:mSuVNOF4CRTmE:20359:550:Fred:/homeAAred:/shellsAcsh
diane:7oUS8f 1 PsrccY:20555:550:Diane Abramov:/home/d/diane:/shellsAcsh
ajr:WitmEBWylar1 w:3607:3034:Ann Reuter:/home/a/ajr:/shells/bash
Этот последовательный текст представляет собой список пользователей и информации
о каждом из пользователей. Каждая строка в файле представляет одного пользователя.
Поля в каждой строке разделяются знаком двоеточия. Первое поле предназначено для
хранения пользовательского имени. Второе поле содержит зашифрованный пароль. Третье
поле хранит значение пользовательского идентификатора, четвертое поле предназначено
для хранения идентификатора группы, членом которой является пользователь.
Следующие поля: поля для представления фактического имени пользователя, поле для
указания домашнего каталога пользователя, поле для хранения маршрутного имени
программы, которую пользователь использует в качестве shell. (Речь идет о произвольной про-
3.6. Проект 2: Написание версии Is -/
113
грамме, которая запускается в начале сессии пользователя. - Примеч. пер.) Файл passwd
доступен для чтения для всех категорий пользователей. Для более детального
ознакомления с файлом обратитесь к электронному справочнику с аргументом passwd.
Все выглядит вполне оптимистично. Достаточно найти в файле запись, которая содержит
необходимый идентификатор пользователя, а далее необходимо прочитать первое поле
в выбранной строке. Но этот метод не перспективен и вот почему: поиск в файле /etc/passwd -
достаточно скучное занятие, кроме того метод не работает во многих сетевых системах.
Фактор второй: В файле /etc/passwd не всегда содержится полный список пользователей
В каждой системе Unix есть файл /etc/passwd, но во многих системах Unix в этот файл
включаются не все пользователи. В сетевых реализациях систем предполагается регистрация
пользователей на любой машине в сети с одним и тем же именем пользователя и паролем.
Чтобы достигнуть такой возможности, используют файл /etc/passwd1. Системный
администратор должен будет добавить в этот файл на каждой машине в сети одно и то же
пользовательское имя и текущий пароль. Когда пользователь захочет изменить на какой-то машине пароль,
то это изменение должно быть сделано в каждом файле /etc/passwd сети. Если одна из машин
будет недоступна, то это может привести к нарушению процесса синхронизации в отношении
оставшихся машин.
Одно из решений - инсталлировать минимально файл /etc/passwd на каждой машине для
автономных действий, но поддерживать полный список пользователей в базе данных,
которая доступна в сети. Все новые пользователи и изменения паролей записываются
в эту центральную базу данных. Все программы, которым необходима информация
о пользователе, будут обращаться к центральной базе данных. Система с
централизованной сетевой информацией называется nis. В электронном справочнике можно получить
дополнительную информацию по этому поводу.
Фактор третий: Доступ к полному списку пользователей обеспечивает функция getpwuid
Библиотечная функция getpwuid предоставляет доступ к пользовательской информации
в базе данных. Если в вашей системе используется файл passwd, то функция будет работать
с этим файлом. А если используется центральная база данных, то функция getpwuid будет
работать с этой базой. При использовании функции getpwuid в качестве аргумента задается
идентификатор пользователя, а в результате функция возвращает указатель на структуру
struct passwd, которая описана в файле /usr/include/pwd.h так:
Г Структура passwd. */
struct passwd
{
char *pw_name; Л Пользовательское имя. */
char *pw_passwd; /* Пароль. */
_uidj pw_uid; /* Пользовательский ID. */
__gid_t pw_gid; /* Групповой ID. */
char *pw_gecos; /* Реальное имя. */
char *pw_dir; /* Домашний каталог. */
char *pw_shell; /* Программа Shell. 7
};
1. Во многих системах пароли хранятся в зашифрованном виде в файле shadow, чтобы увеличить степень
безопасности системы.
114
Свойства каталогов и файлов при просмотре с помощью команды Is
Эта функция и описание этой структуры дают нам возможность организовать вывод поля
с пользовательским именем в длинном формате. Вот таким может быть простое решение:
Г
* возвращается пользовательское имя, соотнесенное uid
* ЗАМЕЧАНИЕ: код не работает, если нет пользовательского имени
7
char *uid to name(uid t uid)
{
return getpwuid(uid)->pw name;
}
Эта функция проста, но ненадежна. Если значению uid не найдено соответствующее
пользовательское имя, то функция getpwuid возвращает указатель NULL. В этом случае нечего
разыменовывать в pw_name. Как это может произойти? В стандартной версии команды Is
приводится решение этой проблемы.
Фактор четертый: Для некоторых UID нет входных имен
Скажем, что вы зарегистрированы на некоторой Unix-машине и вам присвоено
пользовательское входное имя pat, значение идентификатора пользователя равно 2000. Когда вы
создаете файлы, то будете собственником этих файлов. То есть системный вызов stat будет
возвращать в качестве результата структуры для ваших файлов, где в поле st_uid будет
находиться 2000. Это число является атрибутом файла.
Далее вы уехали в другой город. Системный администратор удалит учетную запись о вас
из файла passwd. Тем самым удаляется связь между числом 2000 и пользовательским
именем pat. Если программа будет передавать число 2000 при обращении к системному
вызову getpwuid, то системный вызов будет возвращать null.
В стандартной версии Is происходит обработка данной ситуации - будет выводиться uid,
если нет соответствующего пользовательского имени.
Что произойдет, если в системе будет зарегистрирован новый пользователь и ему будет
присвоено значение старого UID? В системе могли остаться файлы, у которых теперь
собственником становится этот новый пользователь. Этот пользователь имеет права на
чтение, запись и удаление этих файлов.
И наконец, как мы можем преобразовать идентификатор группы в имя группы? Что такое
группа? Что такое идентификатор группы?
Фактор пятый: Файл /etc/group содержит список групп
Рассмотрим Unix-машину, которая используется в сфере бизнеса. В этой области все
работники сгруппированы по отделам и отдельным проектам. Может быть группа людей,
которые занимаются продажами, группа менеджмента и т. д.
Рассмотрим школу. Весь состав людей в школе можно представить так: учителя,
школьники, администрация. Людей можно сгруппировать и по другим признакам - по
принадлежности студентов к одному и тому же курсу, по месту работы в одном и том же отделе.
В Unix имеется система для регистрации групп и введения пользователей в состав групп.
Имеется файл /etc/group, который является обыкновенным текстовым файлом и который
выглядит примерно так:
3.6. Проект 2: Написание версии Is 7
115
root::0:root
other:: 1:
bin::2:root,bin,daemon
sys::3:root,bin,sys,adm
adm::4:root,adm,daemon
uucp::5:root,uucp
mail::6:root
tty: :7: root, tty,adm
lp::8:root,lp,adm
Первое поле предназначено для хранения имени группы, во второе поле записывается
пароль группы (редко используется на практике), в третье поле записывается
идентификатор группы, в четвертом поле хранится список пользовательских имен. Элементы списка
разделяются запятыми. Эти пользователи составляют группы.
Фактор шестой: Пользователь может быть членом более чем одной группы
В файле passwd для каждого пользователя заведены поля ию и gid. Идентификатор группы
в файле passwd указывает первичную группу для пользователя, но пользователь может
быть также зарегистрирован в составе других групп. В примере, приведенном выше, вы
можете заметить, что пользователь adm находится в группах с именами sys, adm, tty, lp. Этот
список используется при работе с разрядами прав доступа для группы. Например, если
файл принадлежит группе с именем 1р и для группы установлены права на запись, тогда
пользователь adm может модифицировать этот файл.
Фактор седьмой: Системный вызов getgrgid предоставляет доступ к списку групп
В сетевом варианте системы данные, которые размещаются в файле /etc/group, также
можно переместить в центральную базу данных. Аналогично работе со статусной
информацией для файлов в Unix есть возможность получать доступ к списку групп независимо
от реализации системы. В документации на getgrgid приведены детали и необходимая
информация. Для наших целей будем использовать код, подобный приведенному ниже.
Л
* возвращает имя группы, которое соотнесено указанному gid
* ЗАМЕЧАНИЕ: не работает, если нет имени группы
7
char *gid_to name(gid t uid)
{
return getgrgid(gid)->gr name;
}
3.6.А Объединение всего вместе: Is2. с
Мы проверили каждый компонент в выводе Is -1. Для каждого из них мы знаем, что
означает каждое поле и как можно преобразовать значение поля в форму, наиболее понятную для
пользовательского восприятия. В результате программа ls2.c будет такой:
Г Is2.c
* цель - вывод списка содержимого каталога или каталогов
* при отсутствии аргументов используется., в противном случае
6
Свойства каталогов и файлов при просмотре с помощью команд^
* используется список имен файлов через список аргументов
* замечание - использует stat, pwd.h и grp.h
* BUG: попробуйте Is2 Дтр
7
#include <stdio.h>
«include <sys/types.h>
«include <dirent.h>
«include <sys/stat.h>
voiddo_ls(char[]);
void dostat(char *);
void show_fileJnfo(char *, struct stat *);
void modeJoJetters(int, char []);
char *uid_to_name(uidJ);
char *gid_to_name(gidJ);
main(intac, char*av[])
{
if (ac == 1)
doJs('V');
else
while (--ac){
printf(,,%s:\n,,J *++av);
doJs(*av);
}
}
void do_ls(char dimamefl)
Г
* перечисляет файлы в каталоге с именем dirname
7
{
DIR *dirj>tr;
struct dirent *direntp;
if ((dir_ptr = opendir(dirname)) == NULL)
fprintf(stderr,"ls1: cannot open %s\n", dirname);
else
{
while ((direntp = readdir(dir_ptr)) != NULL)
dostat(direntp- >d_name);
closedir(dir ptr);
}
}
void dostat(char *filename)
{
struct stat info;
if (stat(filename, &info) == -1)
perror(filename);
else
/* каталог */
/* какая запись */
Г неудача у stat 7
Г посмотреть почему 7
/* иначе показать информацию 7
7. Проект 2: Написание версии Is -I
show file info(filename, &info);
}
void showfile_info(char *filename, struct stat *info_p)
Г
* выводит информацию о 'filename'. Эта информация записана в структуре
*info_p
7
{
char *uidJo_name(), *ctime(), *gid_to_name(), *filemode();
voidmode_to_letters();
charmodestr[11];
modeJo_letters(info_p->st,mode, modestr);
printfp/os", modestr);
printf("%4d", (int) info_p->st_nlink);
printf("%-8s", uid_to_name(info_p->st_uid));
printf("%-8s", gid_to_name(info_p->st_gid));
printf(M%8ld", (long)info_p->st_size);
printf("%.12s", 4+ctime(&info_p->st_mtime));
printf("%s\n", filename);
}
Г
* utility functions
7
Л
* В этой функции извлекается значение mode и формируется символьный масси
* В символьный массив помещается значение типа файла и
* девять символов для представления прав доступа.
ж ЗАМЕЧАНИЕ: Коды setuid, setgid sticky
* не рассматриваются
7
void mode_to_letters(int mode, char str[])
{
strcpy(str," "); /* по умолчанию отсутствие прав */
if (SJSDIR(mode)) str[0] = 'd'; /* каталог? 7
if (SJSCHR(mode)) str[0] = 'с'; /* символьные устройства 7
if (SJSBLK(mode)) str[0] = 'b'; /* блочное устройство 7
if (mode & SJRUSR) str[1 ] = 'r'; /* 3 разряда для собственника 7
if (mode & SJWUSR) str[2] = 'w';
if(mode&SJXUSR)str[3] = *x';
if (mode & SJRGRP) str[4] = V; /* 3 разряда для группы 7
if(mode&SIWGRP)str[5] = 'w';
if(mode&S_IXGRP)str[6] = 'x';
if (mode & SJROTH) str[7] = 'r'; /* 3 разряда для остальных 7
if(mode&SJWOTH)str[8] = W;
if(mode&SJXOTH)str[9] = 'x';
/18 Свойства каталогов и файлов при просмотре с помощью команды Is
)
#include <pwd.h>
char *uid to name(uid t uid)
Г
* возвращается указатель на пользовательское имя, соотнесенное
ж идентификатору uid, используется getpw()
7
{
struct passwd *getpwuid(), *pw_ptr;
static char numstr[10];
if ((pw_ptr = getpwuid(uid)) == NULL){
sprintf(numstr,"% d", uid);
return numstr;
}
else
return pw ptr->pw name;
}
#include <grp.h>
char *gid to name(gid t gid)
Г
* возвращается указатель на имя группы, используется getgrgidC)
7
{
struct group *getgrgid(), *grp_ptr;
static char numstr[10];
if ((grpjrtr = getgrgid(gid)) == NULL»
sprintf(numstr,"% d", gid);
return numstr;
}
else
return grp ptr->gr name;
}
И вот теперь запустим нашу программу и получим также для сравнения стандартный вывод:
$ls2
drwxrwxr-x
drwxrwxr-x
-rw-rw-r--
-rwxrwxr-x
-rw-rw-r--
-rw-r-r-
-rw-r-r--
-rw-rw-r-
drwxrwxr-x
drwxnvxr-x
4bruce
5 bruce
1 bruce
1 bruce
2 bruce
1 bruce
1 bruce
1 bruce
2 bruce
2 bruce
bruce
bruce
users
users
users
users
users
users
users
users
1024 Aug
1024 Aug
30720 Aug
37351 Aug
345 Jul
723 Aug
3045 Feb
27521 Aug
1024 Aug
1024 Aug
218:18.
218:14..
1 12:05 s.tar
1 12:13 taih
2911:05 Makefile
1 14:26ls1.c
1503:51 Is2.c
1 12:14 chap03
1 12:14 old.src
1 12:15docs
3.7. Три специальных разряда
119
-rwxrwxr-x
-rw-r--r--
- rwxrwxr-x
-rw-r--r--
-rw-r-r-
$ Is -1
total 189
-rw-rw-r-
-rw-rw-r--
drwxrwxr-x
-rwxrwxr-x
-rw-r-r-
- rwxrwxr-x
-rw-r-r--
drwxrwxr-x
-rw-rw-r-
-rw-r-r-
-rw-r-r-
- rwxrwxr-x
-rw-r-r-
1 bruce
1 bruce
2 bruce
1 bruce
1 bruce
2 bruce
1 bruce
2 bruce
1 bruce
1 bruce
2 bruce
1 bruce
2 bruce
1 bruce
1 bruce
1 bruce
1 bruce
1 bruce
bruce
support
bruce
support
users
users
users
users
bruce
users
bruce
users
users
users
support
support
users
users
37048 Aug
946 Feb
42295 Aug
191 Feb
1416 Aug
345 Jul
27521 Aug
1024 Aug
37048 Aug
723 Aug
42295 Aug
3045 Feb
1024 Aug
30720 Aug
946 Feb
191 Feb
37351 Aug
1416 Aug
1 14:26 Is1
1817:15stat1.c
218:18ls2
9 21:01 statdemo.c
1 12:05 taill. с
29 11:05 Makefile
1 12:14chap03
1 12:15 docs
1 14:26 Isl
1 14:26 Is1. с
2 18:18 Is2
15 03:51 Is2.c
1 12:14old_src
1 12:05 s.tar
1817:15stat1.c
9 1998 statdemo.c
1 12:13 taiM
1 12:05 taill.с
$
Чего мы достигли?
Программа ls2 отображает информацию о файлах в стандарте вывода команды Is -1. Вывод
выглядит хорошо. Он происходит поколонно, производится преобразование из
внутреннего представления разрядов доступа и числовых значений идентификатора в читабельные
строки.
Но программа все же нуждается в доработке. В реальной версии в самой первой строке
вывода печатается строка total. Зачем нужна эта строка? Кроме того, в нашей программе
все еще нет сортировки имен файлов, не работает опция - а, не производится
упорядочения имен файлов по колонкам, программа рассматривает каждый аргумент при
обращении к ней в качестве имени каталога.
В программе ls2 есть еще более серьезные проблемы. Она не будет корректно выдавать
информацию о файлах, которые находятся в других каталогах. Для рассмотрения проблемы
попытайтесь выполнить команду ls2 /tmp. Следует решить эту проблему, что вы должны
сделать в качестве упражнения.
3.7. Три специальных разряда
Поле st_mode в структуре stat содержит шестнадцать разрядов. Четыре разряда
используются для хранения типа файла, девять - для хранения прав доступа. Три оставшихся
разряда используются для организации действий со специальными атрибутами файла.
3.7.1. Разряд Set-User-ID
Первый из трех специальных разрядов называется set-user-ID. Он используется для
решения важного вопроса:
120
Свойства каталогов и файлов при просмотре с помощью команды Is
Как может обычный пользователь изменить его или ее пароль?
Это легко сделать, используя команду passwd. Но как работает команда passwd? Заметьте -
кто является собственником и каковы права доступа к файлу паролей.
$ Is-I/etc/passwd
-rw-r-Г" 1 root root 894 Jun 2019:17/etc/passwd
Изменение вашего пароля означает изменение вашей учетной записи в этом файле, но вы
не имеете прав доступа на запись в этот файл. Права на запись имеет только
пользователь с именем root. Как добиться при использовании программы passwd, чтобы вы
получили бы право на изменение файла, который не имеете права изменять? Почувствовали
проблему?
Решением будет предоставление прав на запись программе, но не вам. Вы используете
программу /usr/bin/passwd или /bin/passwd для изменения вашего пароля, собственником
которой является root и для которой установлен разряд set-user-ID. Права доступа будут
выглядеть так:
$ Is -I /usr/bin/passwd
-r-sr-xr-x 1 root bin 15725 Oct 31 1997/usr/bin/passwd
Установленный разряд suid сообщает ядру о необходимости запускать программу так, что
предполагается, что программу запустили не вы, а собственник этой программы.
Название разряда set-user-ID (Буквальный перевод - установить идентификатор пользователя.
Но в русскоязычной литературе название этого разряда не переводится. - Примеч. пер.)
подчеркивает тот факт, что этот разряд требует у ядра присвоения эффективному
пользовательскому идентификатору значения пользовательского идентификатора
собственника программы. Пользователь root является собственником файла /etc/passwd. Поэтому
программа, которая запускается в статусе root, может модифицировать учетный файл.
Не означает ли это, что я могу изменять пароли других пользователей?
Нет. Программа passwd знает, кто вы такой. Она использует системный вызов getuid, чтобы
узнать с помощью ядра- какой был у вас UID, когда вы вошли в систему. Программе
passwd предоставлена возможность перезаписывать любые записи в учетном файле, но она
будет изменять только запись, которая принадлежит пользователю, который запустил
программу passwd.
Другие случаи использования разряда Set-User-ID
Разряд suid может быть использован некой программой, которая должна контролировать
доступ к файлу или к каким-то другим ресурсам. Рассмотрим систему печати с
буферизацией (систему спулинга). Для многих пользователей возникает необходимость
распечатать свои файлы, но принтер может печатать в каждый момент времени только один файл.
В Unix есть команда 1рг. (В HP-UX утверждается, что 1рг - это команда печати для Linux,
а для Unix - 1р. - Примеч. ред.) Команда копирует ваш файл в каталог, где он будет ждать,
когда он будет распечатан. Но было бы рискованным разрешить всем пользователям
копировать свои файлы в этот каталог для спулинга и разрешать им модифицировать списки
имен файлов, которые ждут в очереди на печать. Реально все происходит так. У
программы 1рг собственником является root или 1рг, и для нее установлен разряд set-uid. Когда вы,
обычный пользователь, используете команду 1рг, то программа будет запущена с
установленным значением root или 1рг для эффективного UID и может теперь модифицировать
содержание каталога для спулинга и соответствующих файлов в нем. Программы для
удаления заданий на печать из очереди на печать также имеют установленные разряды
set-uid.
3.7. Три специальных разряда
121
Компьютерные игры, которые модифицируют базы данных со счетчиками для игроков
или читают файлы с секретными планами, будут маркироваться так, что они будут
запускаться пользователем и работать в статусе собственника базы данных или секретных
файлов. Любой пользователь может играть, но только программа игры может
модифицировать списки со счетом или читать секретные планы.
Маска для определения значения разряда sum
Программа может проверить, установлен ли разряд set-user-ID для файла, с помощью
маски, которая определена в заголовочном файле: <sys/stat.h>. Определение такое:
#define SJSUID 0004000 /* set user id на исполнение 7
Вы можете убедиться, что маска выбирает первый из трех специальных битов.
3.7.2 Разряд Set-Group-ID
Второй специальный разряд используется для установки эффективного группового
идентификатора программы. Если программа принадлежит группе g и установлен разряд
set - group ID, то программа будет запускаться так, если бы она запускалась на
исполнение членом группы g. Этот бит предоставляет программе права доступа, которые
приписаны членам группы.
Программист может проверить значение данного разрядах помощью такой маски:
#define SJSGID 0002000 /* установить group id на исполнение 7
3.7.3 Разряд Sticky Bit
Этот разряд имеет две различные области использования - для работы с каталогами и для
работы с файлами. Поговорим сначала о файлах. В Olden Days ®#.Что это такое? Unix
разрешала проблему одновременного исполнения нескольких программ с помощью
техники, которая называется своппированием. Рассмотрим следующую ситуацию. На вашем
компьютере есть 1 мегабайт пользовательского пространства памяти, и вы запускаете на
исполнение три программы, каждая из которых использует 0,5 мегабайта памяти.
Очевидно, что только две программы из них могут одновременно находиться в памяти. Куда ядро
поместит те программы, которые в текущий момент не могут быть исполнены? В Olden
Days ®. Что это такое? было решено, что ядро может размещать сразу всю программу в
разделе твердого диска, который резервируется специально для своппирования. В некоторый
момент эта программа может быть повторно запущена на исполнение. Тогда ядро
выгружает эту программу из области своппирования, а помещает туда одну из исполняемых до
этого момента программ.
Загрузка программы, которая хранилась на устройстве для своппинга, будет происходить
более быстро, чем загрузка программы из обычного раздела диска. При хранении
программы в обычном разделе на диске текст программы может быть фрагментирован, т. е.
разбит на много малых секций, которые разбросаны по диску. При хранении программы
на устройстве для своппирования текст программы не фрагментирован.
Рассмотрим теперь такие программы, которые интенсивно используются. Это редакторы,
компиляторы или компьютерные игры. Если копии таких программ поместить для
хранения на устройстве для своппирования, то ядро будет загружать эти программы быстрее.
Установленный разряд sticky bit (Название этого бита принято не переводить. - Примеч.
пер.) для какой-либо программы говорит ядру о необходимости хранить эту программу на
устройстве для своппинга, даже если никто эту программу в текущий момент времени не
122
Свойства каталогов и файлов при просмотре с помощью команды Is
вызывает. Название разряда (sticke — приклеивать) обусловлено тем фактом, что
программа "приклеивается " к устройству для своппирования так же, как жевательная резинка
приклеивается к вашему ботинку.
К настоящему времени признано, что своппировать полностью тексты программ (туда
и обратно) больше нет необходимости. Теперь используется механизм виртуальной
памяти, который позволяет ядру выгружать и загружать программы в память небольшими
частями, которые называются страницами. У ядра отпадает необходимость загружать
полностью блок кода, чтобы запустить программу на исполнение.
Разряд sticky bit имеет другой смысл, если он установлен для каталога. Это значение
также относится к проблеме "приклеивания". Некоторые каталоги создаются для хранения
в них временных файлов. Эти временные каталоги, и прежде всего /tmp, доступны всем
для записи, что дает возможность любому пользователю создавать и удалять любые
файлы в таком каталоге. Sticky bit, который может быть установлен для каталога, аннулирует
возможность доступа на запись для всех в этом каталоге. В таком случае файлы в каталоге
могут удалять только их собственники.
3. Z 4. Специальные разряды и Is -/
Как мы убедились, каждый файл имеет атрибут типа и 12 разрядов для других атрибутов,
но команда Is резервирует для вывода только девять знакомест для изображения в них этих
12 атрибутов. Как происходит отображение этих значений?
В документации команды Is приведены детали. Пример
- rwsr- sr-t 1 root root 2345 Jun 1214:02 sample
показывает, что символ s используется в тех же местах, где может быть символ х для
пользователя и группы. Символ s показывает, что произошла замена символа х на символы s,
для обозначения установленных разрядов set-user and set-group-ID. Символ t
свидетельствует об установленном разряде sticky bit.
3.8. Итоги для команды is
Мы теперь имеем работающую версию команды Is, которая выводит список файлов в
каталоге и отображает статусную информацию об этих файлах. По мере того как мы
рассматривали возможности команды Is, рассматривали, как работает эта команда и при
написании нашей собственной версии программы, у нас сложилось, в некотором смысле,
определенное представление об Unix. Далее следует список основных тем.
Каталоги и файлы
В Unix данные хранятся в файлах. Каталог- это специальный тип файла. В каталоге имеется
список имен файлов. В каталоге содержится также его собственное имя. В Unix есть набор
функций, которые позволяют открывать, читать, искать и закрывать каталоги. Функции для
записи в каталог отсутствуют.
Пользователи и группы
Каждому, кто использует систему, присваивается имя пользователя и числовое значение
идентификатора пользователя. Пользовательские имена используются людьми для
вхождения в систему и установления связей с другими людьми. Система использует значения
UID для идентификации собственника файла. Люди принадлежат различным группам.
Каждая группа имеет имя и числовой идентификатор группы.
3.9. Установка и модификация свойств файла
123
Атрибуты файла
Каждый файл имеет набор свойств. Программа может получить список свойств файла
с помощью системного вызова stat.
Собственник файла
У каждого файла есть собственник. UID собственника в Unix записывается в качестве
свойства файла. Файл принадлежит группе. GID группы в Unix записывается в качестве
свойства файла.
Права доступа
Пользователи могут читать файлы, писать в файлы и исполнять файлы. Каждый файл
имеет набор разрядов, которые определяют, какие пользователи могут выполнять эти
операции. Права на чтение, запись и исполнение могут контролироваться на трех уровнях:
собственник, группа, остальные.
3.9. Установка и модификация свойств файла
Команда Is -l отображает несколько свойств файла. Как можно устанавливать эти
свойства? Можно ли изменять их значения? Если да, то как это делать? Если нет, то почему?
Проверим установленные значения свойств в выводе в длинном формате:
-rw-r-r-- 1 bruce users 3045 Feb 1503:51 Is2.c
Рассмотрим слева направо каждый из атрибутов.
3.9.1. Тип файла
Файл имеет тип. Могут быть обычные файлы, каталоги, файлы устройств, сокеты,
символические ссылки и именованные программные каналы.
Установка типа файла. Тип файла устанавливается при создании файла. Например,
с помощью системного вызова creat создается обычный файл. Для создания каталогов,
файлов устройств и других типов файлов используются другие системные вызовы.
Изменение типа файла. Тип файла изменить невозможно. В сказках тыквы
превращаются в кареты, но никто не объясняет, куда девать семечки и мякоть тыкв.
3.9.2. Разряды прав доступа и специальные разряды
Каждый файл имеет девять разрядов прав доступа и три специальных разряда. Эти
разряды устанавливаются при создании файла и могут быть модифицированы с помощью
системного вызова chmod.
Установка режима файла. Второй аргумент, который задается в системном вызове creat,
служит для задания значений прав доступа, которые будут установлены при создании
файла. Например:
fd = creatrnewfile", 0744);
Будет создан файл newfile, для которого требуется установить начальный набор таких прав
доступа: rwxr—г—.
Второй аргумент в creat - это требование на установку доступа. Ядро будет выбирать это
требуемое значение и далее накладывать на него маску. В результате получается
двоичный код, который и будет окончательным для установки прав доступа. Маска
называется маска на создание файлов и определяет, какие разряды в исходном требовании на права
доступа должны быть сброшены. Например, если вы хотите запретить программам созда-
124
Свойства каталогов и файлов при просмотре с помощью команды Is
вать файлы в системе, которые можно было бы модифицировать группе и остальным
пользователям, то вы должны будете сбросить разряды: —w--w-, что соответствует
восьмеричному коду 022. Системный вызов umask в таком варианте:
umask@22);
установит маску на создание файлов, по значению которой будет происходить сброс этих
двух разрядов. В общем случае маски используются для включения и выбора разрядов.
В данном случае маска определяет, какие разряды следует сбросить. Да, такая вот
обратная трактовка смысла.
Изменение режима файла. Программа может модифицировать значения прав доступа
и значения специальных разрядов с помощью системного вызова chmod. Два примера:
chmodCytrnp/myfile", 04764);
и
chmodC'/tmp/myfile", SJSUID | SJRWXU | SJRGRP|SJWGRP | SJR0TH);
имеют один и тот же результат. В первом случае указывается новый двоичный код,
выраженный в восьмеричном формате, а во втором случае указываются маски, которые
определены в файле <sys/stat.h>, комбинируются в один двоичный набор или оператор.
Во втором случае можно изменять значение разрядов доступа в будущей работе,
не прерывая для этого вашу программу. Количество существующих программ, которые
используют точное восьмеричное представление, таково, что можно говорить о меньшей
привлекательности этого варианта для тех, кто собирается менять значения разрядов
доступа. Значение маски на создание файлов не влияет на значение режима, которое задается
при обращении к системному вызову chmod.
В заключение суммируем свойства в данной таблице:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
chmod
Изменение прав доступа и специальных разрядов для файла
#include < sys/types.h >
#include <sys/stat.h>
int result = chmod(char *path, modej mode);
path - путь к файлу
mode - новое значение режима
-1 -при ошибке
0 - при успехе
Команда Shell для изменения прав доступа и специальных разрядов.
Для модификации прав доступа и специальных разрядов используется обычная
Unix-команда chmod. Команда chmod допускает возможность для пользователя задавать двоичный
код режима в восьмеричном представлении (например, 04764) или в символьной нотации
(например, и -rws g =rw о =r).
3.9.3. Число ссылок на файл
Назначение этого атрибута будет рассмотрено в следующей главе. Если говорить кратко,
то число ссылок соответствует числу обращений к файлу в разных каталогах. Если файл
оказывается представлен в трех местах, в различных каталогах, то число ссылок будет
равно 3.
3.9. Установка и модификация свойств файла
125
Для увеличения значения счетчика ссылок нужно создать новые ссылки. (Вы можете
использовать для этого системный вызов link.) Для уменьшения значения счетчика ссылок,
необходимо удалить какое-то число ссылок. (Вы можете использовать для этого
системный вызов unlink.)
3.9.4. Собственник и группа для файла
У каждого файла есть собственник. Для внутреннего представления в Unix собственник
представлен числовым значением UID, а группа, использующая файл, представлена
числовым значением GID.
Установление собственника файла. В самом простом толковании собственник файла -
это пользователь, который создал файл. Но файлы создают не люди, а ядро. Ядро создает
файл, когда в процессе выполняется системный вызов creat. Когда ядро создает файл, оно
устанавливает в качестве собственника файла эффективный UID процесса, который
выполнял вызов creat. Значение эффективного UID процесса обычно равно значению UID
того, кто породил процесс. Если в программе процесса был установлен разряд set-user-ID,
то эффективный UID будет равен значению того пользователя, кто является
собственником этой программы. Все ясно?
Установление группы для файла. Обычно в качестве группы для файла устанавливается
эффективный GID процесса, который создает файл. Но иногда значением GID для файла
становится значение GID родительского каталога.
Ну, как? Такие действия напоминают процедуру, как если бы национальность
устанавливалась по месту вашего рождения и не принимались во внимание ваши родители, которые
вас и создали. В системе делается нечто напоминающее эту процедуру.
Изменение собственника и группы для файла. Программа может изменять собственника
и группу для файла с помощью системного вызова chown. Например:
chownC'filel", 200,40);
Здесь происходит изменение пользовательского ID на 200, значение группового ID
заменяется на 40 для файла с именем filel. Если какой-либо аргумент будет иметь значение -1,
то этот атрибут не модифицируется. Обычно пользователи не меняют собственника
файла. Суперпользователь может установить в любой момент и для любого файла требуемое
значение пользовательского ID и группового ID. Этот вызов обычно используется для
установки и управления пользовательскими входами в систему. Собственник файла может
изменить групповой ID файла в любой группе, к которой он принадлежит.
В итоге мы имеем следующую таблицу с характеристиками вызова:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
chown
Изменение собственника или группового ID для файла
#include < unistd.h >
int chown(char *path, uidj owner, gidJ group)
path - путь к файлу
owner - пользовательский ID для файла
КОДЫ ВОЗВРАТА group - групповой ID для файла
-1-при ошибке
0 - при успехе
126
Свойства каталогов и файлов при просмотре с помощью команды Is
Команды Shell для изменения идентификаторов пользователя и группы для файлов
В shell есть обычные команды chown и chgrp, с помощью которых программы могут
модифицировать пользовательский ID и групповой ID для файлов. В одной команде с помощью
этих команд можно изменять UID и GID для нескольких файлов. В документации
изложены все детали. В командах chown и chgrp пользователи могут задавать идентификаторы или
в числовом варианте, или в символьном - как имена пользователей и имена групп.
3.ft5. Размер файла
Размер файла, каталога и именованного программного канала представляется в выводах
числом хранимых байтов в таких файлах. Программы могут увеличить размер файла
добавлением в него данных. Программы могут обнулить размер файла с помощью
системного вызова creat. Программы не могут сокращать размер файла до некоторой ненулевой
длины. (Утверждение слишком категорично. Для сокращения размера можно
использовать системный вызов truncate. - Примеч. ред.)
3.Л6. Время последней модификации и доступа
Каждый файл имеет три временных отметки: время последней модификации файла, время
последнего чтения из файла и время последней модификации статусной информации
файла (таки,е как идентификатор собственника или права доступа). Ядро автоматически
модифицирует значения этих времен, когда программы пишут в файлы или читают из файла.
Это может показаться странным, но вы можете написать программы, которые
устанавливали бы произвольные значения для времени последней модификации и времени
последнего доступа.
Изменение значений времен последней модификации и последнего доступа к файлу
С помощью системного вызова utime можно устанавливать время последней модификации
и время последнего доступа к файлу. Для того чтобы использовать системный вызов utime,
создается структура, в которой находятся два элемента time_t, один для хранения времени
доступа, а другой - для времени модификации. Затем происходит вызов utime, где задается
имя файла и указатель на эту структуру. Ядро устанавливает в этой структуре значения
времени доступа и времени модификации для этого файла.
В итоге сведем свойства вызова в таблицу:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
utime
Изменение времени модификации и доступа к файлу
#include < sys/time.h >
#include <utime.h>
tinclude <sys/types.h>
int utime(char *path, struct utimbuf *newtimes)
path - путь к файлу
newtimes - указатель на структуру utimbuf
См. более детально в utime. h
-1 -при ошибке
0 - при успехе
Почему у вас может появиться желание изменить время последней модификации или
последнего доступа? Использование системного вызова utime будет полезно, в частности,
когда вы извлекаете файлы из копий (backups) и архивов. Рассмотрим набор файлов,
который был сброшен в backup. При хранении этого набора на диске или на ленте эти
Заключение
127
файлы будут иметь свои первоначальные значения времен модификации. Когда
программа восстанавливает файлы из backup, то она гарантирует, что получит файл назад с
правильным временем модификации.
Программа, которая копирует файлы из места хранения backup, выполняет два действия.
Во-первых, она копирует данные в новый файл. Затем она изменяет время модификации
и время доступа так, чтобы они были равны значениям для оригинальных файлов,
которые остались в backup на диске. Таким образом, ваши восстановленные файлы имеют
то же содержимое и те же свойства, что и оригинальные файлы.
Команды Shell для изменения времени модификации и времени доступа. Обычная
Unix-команда touch выполняет установку значений времени модификации и времени доступа
к файлам. В документации приведены подробности об этой команде.
3.9.7. Имя файла
Когда вы создаете файл, вы присваиваете ему имя. С помощью команды mv можно
изменять имя файла. Кроме того, команда mv может перемещать файл из одного каталога
в другой. >*
Установление имени файла. Системный вызов creat устанавливает имя и начальный
режим для файла.
Изменение имени файла. Системный вызов rename изменяет имя файла. При обращении
к вызову задаются два аргумента, старое и новое имя:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
rename
Изменение имени и/или перемещение файла
#include < stdio.h >
int result = rename(char *okJ, char *new)
old - старое имя файла или каталога
new - новое маршрутное имя для файла или каталога
-1 -при ошибке
0 - при успехе
Заключение
Основные идеи
• На диске находятся каталоги и файлы. Файлы имеют содержимое и свойства. В файле
могут содержаться данные некоторого типа. Каталог может содержать только список
имен файлов.
• Имена в каталогах соотнесены файлам и другим каталогам. В ядре есть системные
вызовы для чтения содержимого каталогов, для чтения свойств (атрибутов) файлов и
для модификации большинства атрибутов файлов.
• Тип файла, права доступа и три специальных атрибута хранятся как двоичный код
некоторого целого числа. Для выборки определенных разрядов используется техника
поразрядного маскирования.
• Собственник и группа файла хранятся в числовом представлении. Соответствие
между этими числами и символьными именами собственника и группы устанавливается
через базы данных passwd и group.
128
Свойства каталогов и файлов при просмотре с помощью команды Is
Что дальше?
Каталог - это список файлов и каталогов. Каталоги связаны между собой в древовидную
структуру. Как происходит работа с этим деревом? Как связываются между собой
каталоги? В следующей главе мы рассмотрим внутреннюю структуру дерева.
Визуальнй итог
Свойства
(соседа ифРОДя}
Обычные файлы
Рисунок 3.7
Диск содержит файлы, каталоги
и статусную информацию о них
Исследования
3.1 Длина d_name[ ]. В определении структуры struct dirent длина символьного массива
d_name[] была указана равной 1 для некоторых систем и может быть 255 символов
для других систем. Какова будет фактическая длина? Почему приведены такие
странные числа? Почему не использована нотация вида: char *?
3.2 Защита файлов от самого себя. Режим доступа вида: rwx, который вы можете
установить с помощью команды chmod 007 filename, вполне допустим, но явно
весьма эксцентричен. Он гарантирует все остальным пользователям право на чтение,
запись и исполнение в отношении файла filename, но не предоставляет таких прав ни
собственнику, ни группе. Установите такой режим для некоторого файла. Смогли ли
вы прочитать такой файл? Поэкспериментируйте с различными комбинациями, чтобы
представить себе логику ядра, которая используется при определении прав доступа
при работе системного вызова open. Если у вас есть возможность доступа к исходным
Заключение
129
кодам ядра, найдите ту часть кода, которая отвечает за права доступа, и проверьте -
правильны ли ваши догадки относительно логики работы.
3.3 Идентификаторы и пользовательские имена. Каждый пользователь имеет
пользовательское имя и каждому имени сопоставлен пользовательский числовой
идентификатор. Возможен ли случай, когда двум различным пользовательским именам
сопоставлен один и тот же числовой идентификатор пользователя? Возможен ли случай, когда
одному и тому же пользовательскому имени сопоставлены два различных числовых
идентификатора пользователя? Если у вас есть права доступа root на машине, то
попробуйте поэкспериментировать с различными комбинациями. Заведите учетные
записи на двух различных пользователей, для которых укажите один и тот же UID, но
для каждого пользователя должны быть установлены свое пользовательское имя
и свой пароль. Могут ли каждый из пользователей модифицировать файлы у другого?
Что должна показать при выводе команда who? Что покажет команда Is -l? Что
покажет команда id? А как быть с электронной почтой? Что дал вам эксперимент для
понимания того, как работают эти команды?
Можете ли придумать ситуации, где было бы полезным использовать множество
пользовательских имен при одном и том же пользовательском идентификаторе?
3.4 Специальные разряды и каталоги. Каталоги, как и все файлы в Unix, имеют полный
набор разрядов для определения прав доступа, включая разряды set-user-ID, set-
group-ID. Возникает вот какая задача. Если вы установите в отношении каталога
pKspnnset^roup-ID, то повлияет ли он на работу с каталогом? Если да, то как и
почему? Если нет, то подумайте, как можно будет использовать этот разряд?
3.5 Исполнимый код и права на исполнение. У каждого файла есть три разряда для
установки права на исполнения для собственника, группы и для всех остальных
пользователей. Вы можете установить право на исполнение для любого файла, для
обыкновенных текстовых файлов, даже для тех, которые содержат перечень товаров в
продовольственном магазине.
Но, с другой стороны, может быть файл, который содержит исполнимый код,
например, a.out, и который получен после компиляции С-программы. Для этого файла
может быть сброшен разряд на исполнение. Объясните разницу между идеями
исполнимого кода и правами на исполнение для файла. Связаны ли эти идеи между собой?
Почитайте документацию по команде file.
3.6 Входные имена и пользовательские ID. Каждый пользователь имеет символьное
пользовательское имя и числовой идентификатор — UID. Зачем? Не было бы более
простым указывать в качестве владельца файла символьное имя пользователя? Почему
бы для каждого пользователя не завести только один числовой идентификатор? В чем
проблемы с двумя системами идентификации? Какие преимущества предоставляют
две системы идентификации? Если бы вы проектировали собственную операционную
систему, то как бы вы поступили в отношении этого вопроса?
3.7 В документации на dirent, текст которой был приведен, была сделана ссылка на
системный вызов getdentsB). Что делает этот вызов и какое отношение он имеет к readdir?
3.8 Обычно в листинге команды Is -l каталоги представлены с такими правами доступа:
drwxr-xr-x.
130 Свойства каталогов и файлов при просмотре с помощью команды Is
При посимвольном разборе этого поля слева направо обнаруживаем: тип файла -
каталог, собственник каталога может выполнять операции чтения, записи и
исполнения в отношении каталога, члены группы и все остальные пользователи могут
выполнять только операции чтения и исполнения в отношении каталога.
Что означает право на "исполнение" в отношении каталога? Файл может содержать
код, составленный из команд конкретной машины, или код, составленный на "скрип-
товом" языке. Имеет смысл маркировать такой файл как "исполняемый", поскольку
компьютер может непосредственно исполнять программу на машинном языке или
запустить интерпретатор для исполнения скрипта. Каталог же - это просто список имен
файлов, и он не может быть запущен на исполнение. Так что же означает разряд,
дающий право на исполнение каталога? Почему он полезен? Поэкспериментируйте
с командной chmod и выключите разряд на исполнение для каталога и посмотрите,
что получится в данной ситуации.
3.9 Работа с вашим терминалом. Пользователи связываются с системой с помощью
терминалов или терминальных эмуляционных программ. Каждый терминал представлен
как файл в каталоге /dev. Выполните следующие команды: Is -l /dev/tty* \ more.
В результате получим вывод списка всех терминальных устройств и их свойств.
Файлы, которые представляют терминалы, как и обычные файлы, имеют собственника.
Собственником терминала будет тот пользователь, который вошел в систему через
этот терминал. Терминальные устройства не используют root в качестве
собственника. Собственник терминала изменяется программой login. Обратитесь к исходному '
коду программы login и отыщите в ней код, где происходит изменение собственника.
Что изменяет программа, когда собственность возвращается опять в root, когда вы
будете выходить из системы?
Программные упражнения
3.10 Добавьте возможность многоколонного вывода в версии программы Is 1 .с.
Поэкспериментируйте со стандартной версией команды Is с тем, чтобы посмотреть, что она
делает. Вы можете увидеть, что она выводит поколонно в зависимости от длины
текущего списка имен файлов. Колонки по возможности строятся в выводе равной длины.
Наконец, ширина для отображения при выводе. Как команда Is конструирует такой
вывод?
3.11 Модификация ls2. Следует модифицировать ls2.c так, чтобы она правильно работала,
когда имя каталога задается как аргумент при обращении к программе.
3.12 Модифицируйте программу ls2.c так, чтобы ею можно было корректно управлять
с помощью разрядов suid, sgid, sticky bit. Почитайте документацию, чтобы убедиться,
что вы учли все возможные комбинации.
3.13 Стандартная утилита ср допускает использование имени каталога в качестве второго
аргумента. В таком случае файл будет копироваться в этот каталог и получать имя
оригинала. То есть, команда:
$ cpfilel /tmp
Заключение
131
будет работать так же, как и команда:
$cpfile1/tmp/fjle1
Модифицируйте программу cpl.c в главе 2, чтобы реализовать такой вариант
обращения.
3.14 Иногда вам необходимо скопировать в некоторый каталог сразу все файлы. Просто
вам требуется сделать "сброс" (backup) всех файлов. Модифицируйте программу
cpl .с в главе 2 так, чтобы при задании двух имен каталогов в качестве аргументов
программа копировала бы все файлы из первого каталога во второй, присваивая каждой
копии имя оригинала.
3.15 Модифицируйте программу Isl.c так, чтобы она производила бы сортировку списка
имен файлов. В стандартной версии команды Is поддерживается опция -г, с помощью
которой можно выдавать список в обратном порядке. Добавьте возможность
отработки этой опции.
В некоторых версиях команды Is поддерживается опция a -q для "quick" (быстрого)
вывода. При использовании такой опции команда Is не производит сортировки списка
имен файлов. Эта опция полезная, когда каталог содержит слишком большое число
файлов. Их так много, что даже при быстрой сортировке на вывод тратится
значительное время.
3.16 Нарисуйте строку, содержащую 16 знакомест, и заполните требуемые знакоместа
единицами и нулями с тем, чтобы они соответствовали такому праву доступа к каталогу:
rwxr-x—х.
3.17 Блокировка сарая. Если вы выключили право чтения на файл, то вы не сможете
открыть файл на чтение. Что будет, если вы открыли файл на чтение, а затем с другого
терминала сбросили право на чтение для этого файла? Выполнится ли успешно
следующий системный вызов read? Напишите программу, которая открывает файл на
чтение, далее читает из него несколько байтов, затем выполняет системный вызов
sleepB0) и находится в состоянии ожидания 20 секунд, а далее опять пытается
прочитать из файла. В течение этих 20 секунд сбросьте для файла право на чтение. Что
произойдет далее? Объясните истинный смысл прав доступа на чтение.
3.18 Рекурсия для Is. Стандартный вариант команды Is поддерживает опцию -R. Эта опция
позволяет получить содержимое каталога и содержимое всех подкаталогов под ним.
Попытайтесь выполнить такую команду. Модифицируйте вариант программы ls2.c,
чтобы работала опция -R.
3.19 Вывод времени последнего доступа. В стандартном варианте команды Is
поддерживается опция -и, с помощью которой можно отображать в длинном листинге время
последнего доступа вместо времени последней модификации. Что произойдет, если
будет использована опция -и без использования опции -1? Намек: почитайте
документацию относительно опции -1
3.20 Напищите простую версию программы chown, которая при обращении должна
воспринимать из командной строки пользовательское имя или пользовательский ID
и произвольное имя файла. Как вы будете преобразовывать пользовательское имя
в пользовательский идентификатор? Что будет, если не будет обнаружен
пользователь с указанным пользовательским именем? Замечание. Чтобы проверить работу
вашей программы, вам понадобится стать суперпользователем.
132
Свойства каталогов и файлов при просмотре с помощью команды Is
3.21 Время последнего доступа к файлу - это полезная информация. Получение backup для
файлов - это хорошая идея. Но когда происходит восстановление (чтение) файлов из
backup, то изменяется время последнего доступа для каждого восстановленного
файла. Было бы очень хорошо, если бы программа для восстановления из backup при
восстановлении файла оставляла для него неизменяемым время последнего доступа.
Кроме того, не менее приятно было бы, если бы копия файла имела такие же времена
последней модификации и последнего доступа, как у оригинала. Напишите версию
программы ср, которая выполняла эти два действия.
3.22 Ваше терминальное устройство - это файл, который программа использует, чтобы
получать из него данные для вас и посылать от вас данные на него. Когда программа
читает с терминального устройства, то она получает данные с вашей клавиатуры.
Когда программа выдает данные на терминальное устройство, то они передаются на
экран. Для установления времени последней модификации в терминальном файле
используется stjfitime. Напишите программу с именем lastdata, которая выводит список
всех текущих пользователей и отображает для каждого пользователя время, когда
была последняя модификация терминала. Используйте тот же формат, как в команде
who.
Проекты
Основываясь на материале этой главы, вы можете изучить справочный материал и
написать версии следующих Unix программ:
Ghmod, file, chown, chgrp, finger, touch .
Глава 4
Изучение файловых систем.
Разработка версии pwd
Цели
Идеи и сродства
• Пользовательское восприятие дерева файловой системы в Unix.
• Внутренняя структура файловой системы Unix: структуры inodes и блоки данных.
• Как связаны между собой каталоги.
• Твердые ссылки, символические ссылки: идеи и системные вызовы.
Как работает команда pwd.
• Монтирование файловых систем.
Системные вызовы и функции
• mkdir, rmdir, chdir
• link, unlink, rename, symlink
Команды
• pwd
4.1. Введение
Файлы содержат данные. В каталогах содержится список имен файлов. Каталоги
организованы в древовидную структуру. В них могут содержаться имена других каталогов.
Что для файла значит "быть в каталоге"? Когда вы сходите в Unix-машину, то вы
попадаете в ваш "домашний каталог". Что означает для пользователя выражение "находиться
в каталоге"?
Древовидная структура является иллюзией. Твердый диск-это набор металлических
пластин, на каждой из которых нанесено магнитное покрытие. Как сделать, чтобы этот набор
связанных металлических пластин представлялся бы нам как дерево файлов, свойств и
каталогов?
134
Изучение файловых систем. Разработка версии pwd
Чтобы найти ответ на вопрос, напишем версию команды pwd. Эта команда сообщает
о вашем текущем расположении в дереве каталогов. Последовательность каталогов и
подкаталогов от корня дерева до места вашего расположения называют путем к вашему
рабочему каталогу. Чтобы написать версию pwd, нам следует понять, как организованы
и хранятся файлы и, каталоги. Мы будем изучать файловую систему, начиная с
рассмотрения ее с позиций пользователя. Далее рассмотрим ее внутреннюю структуру. И наконец,
изучим системные вызовы и способы их использования.
4.2. Пользовательский взгляд на файловую систему
4.2.1. Каталоги и файлы
Пользователи воспринимают диск в Unix как дерево каталогов. В каждом каталоге могут
содержаться файлы и другие каталоги. На рисунке 4.1 представлена схема небольшой
части дерева.
СО® ПЛЮСОВ IT
GD
d1
jclink
d2
xcopy
Рисунок 4.1
Дерево каталогов
Начнем со строительства этой древовидной структуры и по мере строительства введем
в использование ряд Unix-команд для управления такими деревьями файлов и каталогов.
4.2.2. Команды для работы с каталогами
Дерево можно создать с помощью последовательности таких команд:
$ mkdir demodir
$ cd demodir
$pwd
/home/yourname/experiments/demodir
$ mkdir b oops
$mvbc
$ rmdir oops
$ cd с
$ mkdir d1 d2
$cd../-.
$ mkdir demodir/a
Мы будем использовать много других команд. Та последовательность команд, что была
только что приведена, преднамеренно усложнена и включает в себя несколько методов.
4.2. Пользовательский взгляд на файловую систему
135
Прочтите текст этого примера и нарисуйте дерево таким, как оно вам представляется.
Пример использует несколько базовых команд. Команда mkdir создает новый каталог или
каталоги с заданными именами. Что произойдет, если вы попытаетесь создать каталог
и укажете при этом имя, которое уже присвоено файлу или каталогу? Команда rmdir
удаляет каталог или каталоги. Что произойдет, если вы попытаетесь удалить каталог, в котором
содержатся подкаталоги? Команда mv переименовывает каталог. С ее помощью можно
также перемещать каталог с одного места в другое.
Команда cd несколько отличается. Она ничего не делает с каталогом. Эта команда влияет
на вас, на пользователя. Команда cd перемещает вас из одного каталога в другой, как если
бы вы переходили из одной комнаты в другую. Команда pwd выводит путь к текущему
каталогу. В примере мы начали работу в подкаталоге с именем demodir. Это подкаталог для
каталога experiments, который в свою очередь находится в каталоге yourname. Каталог your-
name расположен под каталогом home, а он в свою очередь находится под корневым
каталогом, который обозначается символом слеша (/).
4.2.3. Команды для работы с файлами
Теперь мы создадим несколько файлов в дереве каталогов:
$ cd demodir
$ ср/etc/group x
$catx
root::0:
bin::1:bin,daemon
users: :200:
$ cp x copy.of.x
$ mv copy .of .x у
$mvxa
$cdc
$cp../a/xd2/xcopy
$ln../a/xd1/xlink
$ Is > d1/xlink
$cpd1/xlinkz
$ rm../. ./demodir/c/d2/. ./z
$cd../-
$ cat demodir/a/x
(что здесь произойдет?)
Эта последовательность команд для работы с файлами также намеренно усложнена, чтобы
показать различные команды и проиллюстрировать их действие. Пройдите в пошаговом
режиме по этой последовательности команд и нарисуйте файлы по мере их возникновения.
Предскажите, каков будет результат выполнения последней команды в данной
последовательности. В этом примере использована большая часть команд для управления файлами.
Команда ср выполняет копирование файла. Мы разработали версию команды ср в
предшествующей главе. Команда cat копирует содержимое файла на стандартный вывод. Команда mv
переименовывает файл, как показано в первом примере, и перемещает файл в другой каталог,
как показано во втором примере. Команда rm удаляет файл. Заметьте, что в пути может быть
использована нотация вида "..". Такая нотация обозначает каталог, который расположен на
136
Изучение файловых систем. Разработка версии pwd
уровень выше. Его называют родительским каталогом. Последовательность имен каталогов,
с символами / в качестве разделителей в последовательности, определяет путь, который ведет
к именованному объекту. В частности, заметьте* что используется окольный путь для
удаления файла с именем z.
Cfl<?$ OTDOCfl 0 D"
¦ Фактический файл
Рисунок 4.2
Две связи к одному и тому же
файлу
Копирование, проверка наличия, переименование - это все стандартные операции,
которые имеются на многих компьютерных системах. Команда In носит не столь общий
характер, а является неотъемлемой частью Unix. В данном примере мы взяли
существующий файл../а/х и сделали на него ссылку. Ссылка была названа dl/xlink. Обратитесь
к рисунку 4.2 и найдите эти два элемент а. Элемент, который называется х, находится
в каталоге demodir/a, а элемент с именем xlink находится в каталоге demodir/c/dl. Как х, так
и xlink называют ссылками. Ссылка - это указатель на файл. Как../а/х, так и dl/xlink
указывают на одни и те же данные на диске. В соответствии с нашим примером следующая
команда Is > dl/xlink заменяет содержимое xlink выводом от команды Is. Что получится,
если с помощью cat вывести содержимое файла../а/х?
4.2.4. Командыдляработы сдеревом
Несколько команд в Unix предназначены для работы с древовидными структурами.
Вот несколько примеров:
Is-R
Команда Is может выводить в списочном формате содержимое всего дерева. С помощью
опции -R задается такой режим отображения, когда будет выводиться содержимое
указанного каталога и всех подкаталогов под ним. В предшествующей главе мы разработали
версию команды Is. Что еще необходимо сделать в нашей версии, чтобы добавить эти
рекурсивные возможности.
chmod-R
Команда chmod изменяет права доступа у файлов. С помощью опции -R в этой команде
можно производить изменения прав доступа у всех файлов в подкаталогах.
du
Команда du (имя является сокращением от disk usage - использование диска) сообщает
о числе дисковых блоков, которые используются каталогом, указанным в команде, и всеми
входящими в него файлами и подкаталогами с их файлами - т. е. рекурсивный спуск до
листьев данного поддерева
4.3. Внутренняя структура файловой системы UNIX
137
find
Команда find ищет в каталоге и во всех вложенных подкаталогах файлы и каталоги,
которые удовлетворяют критерию поиска, заданному в команде. Например, вы можете
искать файлы с размером большим одного мегабайта, которые не были модифицированы
в течение последней недели и которые доступны на чтение всем пользователям.
Бще немного о командах
Поддеревья каталогов составляют существенную часть файловой системы. В Unix
имеется много команд для работы с деревьями. Вы многое можете обнаружить в этой области.
4.2.5. Практически нет пределов на древовидную структуру
В каталогах может находиться большое количество файлов и большое число
подкаталогов. Внутренняя структура системы не накладывает ограничений на глубину дерева
каталогов. Можно создавать каталоги с такой глубиной, чтобы они удовлетворяли
возможностям большинства команд для работы с деревьями.
Предупреждение. Если вы пожелаете, то проведите такой эксперимент на вашей
собственной машине. Системный администратор в вашей школе или на вашей работе вряд ли
обрадуется, если вы попытаетесь провести эксперимент на его машине.
Простой shell-скрипт (Этот термин все более часто используют при переводе литературы
по Unix. Хотя вполне допустимо использование эквивалентного термина -
shell-процедура. - Примеч. пер.) (см. главу 8).
while true
do .
mkdir deep-well
cd deep-well
done
создаст связанный список каталогов очень большой глубины, даже если вы нажмете на
Ctrl-C сразу через одну или две секунды после запуска скрипта на исполнение. Что
покажет утилита du при обработке этого "туннеля"? А как будут вести себя команды find и Is -R?
Во многих версиях Unix команда rm -r deep-well не работает. Как можно удалить такие
структуры с большой глубиной?
4.2.6. Итоговые замечания по файловой системе Unix
В этом разделе мы рассмотрели файловую систему Unix с позиций пользователя. С этих
позиций диск представляется в виде дерева каталогов, которое может расширяться как
вглубь, так и вширь. В Unix имеется много программ для работы с объектами такой
структуры. Все файлы в системе Unix располагаются в составе этой структуры.
Как это все работает? Что такое каталог? Как узнать, в каком каталоге мы находимся? Что
означает для вас, для человека, смена одного каталога на другой? Как команда pwd
определяет, где вы находитесь в дереве?
4.3. Внутренняя структура файловой системы UNIX
Диск представляет собой набор металлических пластин. Несколько уровней абстракции
преобразуют наше представление физического диска в файловую систему, которую мы
рассматривали в предшествующем разделе.
138
Изучение файловых систем. Разработка версии pwd
4.3.1. Абстракция О: От пластин к разделам
Диск может хранить набор данных. Как страна разделяется на штаты или округа, так и
диск может быть разделен на разделы для создания отдельных регионов с определенной
однородностью содержания. Мы будем рассматривать каждый раздел как отдельный диск.
4.3.2. Абстракция 1: От плат к массиву блоков
Диск - это набор магнитных плат. Поверхность на каждой магнитной плате представляет
собой структуру из концентрических окружностей, которые называют треками. Каждый
из таких треков разделен на секторы, как пригородная улица разделяется на жилые
массивы. Каждый их этих секторов хранит некоторое число байтов данных, например 512.
Сектор - это основная единица хранения данных на диске. На современных дисках
количество секторов очень большое. На рисунке 4.3 представлена схема нумерации для
дисковых блоков.
Рисунок 4.3
Нумерация дисковых блоков
А теперь рассмотрим важную идею: нумерацию дисковых блоков. Присвоение номеров
дисковым блокам в последовательном порядке дает возможность системе вести учет
каждого блока на диске. Можно проводить нумерацию блоков в нисходящем порядке, от
платы к плате, а можно нумеровать вовнутрь каждой платы - нумеровать блоки от трека
к треку на плате. Подобно почтальону, который устанавливает соответствие каждому
письму дома и улицы, должно быть программное обеспечение, которое управляет
хранением данных на диске по адресам, которые назначаются отдельным блокам на некотором
треке на диске.
Система нумерации на диске по схеме разбиения на секторы дает вам возможность
рассматривать диск как массив из блоков.
4.3.3. Абстракция 2: От массива блоков к дереву разделов
Файловая система хранит файлы. Более точно, файловая система хранит содержимое
файлов, атрибуты файла (собственник, временные отметки и т. д.) и каталоги, в которых
находятся такие файлы. А где находятся в однородной последовательности блоков содержимое
файла, атрибуты файла и каталоги?
В Unix используется простой метод. Массив блоков разделяется на три секции, как
показано на рисунке 4.4.
4.3. Внутренняя структура файловой системы UNIX
139
Суперблок
I Таблица inode Власть данных
ш\ \
'' '-
г'
'"
ш
т?>
f <
щ
•/*
Ь*
М
'f-
г.
ЕЕ
^;|*Н?*|
Здесь Здесь содержимое файла
свойства файла
Рисунок 4.4
Три области файловой системы
В одной из секций, которая называется областью данных, находятся данные файлов,
являющиеся их содержимым. В другой секции, которая называется таблицей inode,
содержатся свойства (атрибуты) файлов. И в третьей секции, которая называется суперблоком,
находится информация о самой файловой системе. Трехэлементная структура, которая
распространяется на пронумерованную структуру блоков, и называется файловой системой.
Суперблок. Первый блок в составе файловой системы называется суперблоком. В этом
блоке содержится информация об организации самой файловой системы. Например,
в суперблок записываются размеры каждой из областей файловой системы. В суперблоке
также находится информация о неиспользуемых блоках данных. Конкретное содержание
и структура суперблока зависит от версии Unix. Обратитесь к электронному справочнику
и к заголовочным файлам, чтобы узнать, что содержится в вашем суперблоке.
Таблица inode. Следующая часть файловой системы называется таблица inode. Каждый
файл имеет набор свойств, таких, как размер, пользовательский идентификатор
собственника, время последней модификации. Эти свойства записываются в структуру, которая
называется inode. Все эти структуры имеют один и тот же размер, а таблица inode представляет
собой просто массив из таких структур. Каждый файл, который "находится в файловой системе,
имеет один inode в этой таблице. Если вы обладаете правами суперпользователя, то можете
открыть раздел как файл, почитать и распечатать содержимое таблицы inode. Это
аналогично варианту обращения к файлу utmp для чтения и вывода его содержимого.
Важно следующее: Каждый inode идентифицируется в системе своей позицией в таблице
inode. Например, inode 2 будет третьей структурой в таблице inode файловой системы.
Область данных. Третьей частью файловой системы является область данных. Здесь
хранится содержимое файла. Все блоки на диске имеют один и тот же размер. Если.в файле
содержатся данные, для хранения которых необходимо более одного блока, то содержимое
такого файла будет располагаться в нескольких блоках. Количество блоков определяется
размером файла. Большие файлы могут состоять из тысяч отдельных дисковых блоков. Каким
образом система учитывает наличие цепочек из таких отдельных блоков?
4.3.4. Файловая система с практических позиций: Создание файла
Идея поддержки одной области для хранения содержимого файла и другой области для
хранения файловых характеристик выглядит достаточно простой, но как это будет
работать на практике? Что происходит, когда вы создаете новый файл? Рассмотрим простую
команду:
$ who > userlist
Когда команда будет выполнена, то, как результат, в файловой системе появится новый файл,
в котором будет находиться вывод команды who. Как это все происходит? У файла есть
содержимое, у файла также есть свойства. Ядро поместит содержимое файла в область дан-
140
Изучение файловых систем. Разработка версии pwd
ных, свойства файла помещаются в структуру inode, а имя файла помещается в каталог.
На рисунке 4.5 показан пример создания файла, для которого необходимо три блока дисковой
памяти.
Номер inode
Диск
200 627 992
Хранение содержимого в блоках данных. \ /
Номера блоков
Хранение информации о файле в inode
Хранение последовательности блоков данных
Добавить запись к каталогу
\Ь21
200J992
гт
123
т
833
Список блоков, используемых файлом
4004
47
Каталог
hello.с
userlist
Рисунок 4.5
Внутренняя структура файла
При создании нового файла выполняются следующие четыре основных действия:
Сохранение свойств
Файл имеет свойства. Ядро находит свободную структуру inode. В нашем примере ядро
нашло inode под номером 47. Далее ядро записывает информацию о файле в этот inode.
Сохранение данных
Файл имеет содержимое. Для нашего нового файла требуется три дисковых блока памяти.
Ядро отыскивает в списке свободных блоков три блока. В данном случае были найдены
блоки 627, 200 и 992. Далее первая часть данных копируется из буфера ядра в блок 627.
Следующая часть копируется в блок 200. И наконец, последняя часть данных копируется
в блок 992.
Сохранение информации о распределении блоков
Содержимое файла было распределено по блокам 627, 200 и 992, именно в указанном
порядке. Ядро записывает эту последовательность номеров блоков в структуру inode,
в секцию для хранения информации о распределении. Эта секция представляет собой
массив из номеров блоков. Найденные три номера дисковых блоков будут помещены
в первые три элемента массива.
Добавление имени файла в каталог
Наш новый файл называется userlist. Как в Unix ведется учет того, что новый файл появился
в текущем каталоге? Решение простое. Ядро добавляет к каталогу запись вида: D7, userlist).
Эта запись, устанавливающая взаимосвязь между именем файла и номером inode,
представляет собой связь между содержимым файла с указанным именем и свойствами этого
файла. Это обстоятельство заслуживает отдельного рассмотрения.
4.3. Внутренняя структура файловой системы UNIX , 141
4.3.5. Файловая система с практических позиций: Как работают каталоги
Каталог - это специальный тип файла, который предназначен для хранения списка имен
файлов. Внутренняя структура каталога может быть разной в разных версиях Unix, но
абстрактная модель остается всегда одной и той же - это таблица номеров inode и имен файлов:
Номер inode #
2342 ,.'
43989
3421
533870
Имя файла
hello.c
myls.c
Представление внутреннего содержимого каталога
Вы можете посмотреть содержимое каталога с помощью команды Is -lia (первая опция -
это цифра 1):
$ Is-liademodir
177865.
529193..
588277 а
200520 с
204491 у
$
В этом выводе представлен список из имен файлов и соответствующих им номеров
inode. Например, файлу с именем у соответствует номер inode 204491. Текущий каталог,
который обозначается символом ".", имеет номер inode 177865. Это означает, что
информация о размере, собственнике, группе и т, д., расположена в таблице inode,
в структуре с номером 177865.
Опции -i и -1 (единица, а не 1) для команды Is могут быть для вас новыми. При
использовании опции -i команда Is будет включать в вывод номер inode, при указании опции -1
команда будет производить одноколонный вывод. Постройте на вашей машине
собственную версию поддерева demodir, а потом посмотрите номера inode в поддереве.
Множественность ссылок на один и тот же файл
Вы можете использовать команду ls-i, чтобы получить номера inode для файлов в системе.
Например, вы можете посмотреть номер inode для всех элементов в корневом каталоге
вашей системы:
ls-ia/
2
2 ..
3 auto
26625 bin
403457 boot
225281 dev
28673 etc
311297 home
8832 home2
24646 initrd
24579 install
161797 lib
11 lost+found
4097 mnt
108545 opt
1 proc
24681 root
233473 sbin
43829 shlib
2
40961 tmp
18433 usr
10241 var
183 xfer.log
183 transfers
142 Изучение файловых систем. Разработка версии pwd
В этом листинге следует обратить внимание на две вещи. Bq-первых, в конце самой правой
колонки представлены два файла с именами xfer.log и transfers. У этих файлов один и тот же
номер inode, равный 183. Следовательно, оба из этих имен файла ссылаются на один и тот
же inode. Структура inode представляет отдельный файл. Эта структура содержит свойства
файла и список блоков данных для файла. Поэтому xfer.log и transfers - это два имени одного
и того же файла. Короче говоря, это напоминает ситуацию, когда в телефонной книге один
и тот же телефонный номер представлен в двух различных разделах. Но в обоих случаях - это
ссылки на один телефонный номер1.
Другая важная вещь, которую следует подчеркнуть в листинге содержимого корневого
каталога - это изображение точки и двух точек в начале колонки слева. В этих записях указан
один и тот же номер inode, равный 2, что говорит о том, что имена "." и ".." ссылаются на
один и тот же каталог. Как может текущий каталог одновременно быть и родительским
каталогом?2 Когда с помощью команды mkfs создается файловая система, то команда mkfs в
качестве родительского каталога для корневого каталога указывает сам корневой каталог.
4.3.6. Файловаясистемаспрактических позиций: Как работает команда cat
Мы рассмотрели, что делается внутри системы, когда вы пишете в новый файл, как это
было в примере с командой who > userlist. А что будет происходить, когда вы будете
пытаться прочитать что-то из файла. Например, как будет работать такая команда:
$ cat userlist
Проследуем через указатели от каталога к данным.
Поиск в каталоге указанного имени файла
Имена файлов хранятся в каталогах. Ядро ищет в каталоге запись, в которой содержится
тюле со значением userlist.
$ cat userlist
От имени файла к содержимому файла:
Поиск в каталоге имени файла,
определение соответствующего номера inode,
использование номера inode для локализации inode,
inode содержит список блоков данных.
т
47
ЬеШо.с
userlist
Рисунок 4.6
От имени файла к дисковым блокам
Локализация и чтение inode 47
Ядро находит inode 47 в области, где расположена таблица inode в файловой системе. Для
обнаружения inode требуется провести простой расчет. Все структуры inode имеют один
и тот же размер, и в каждом дисковом блоке содержится фиксированное число таких
структур. Структура inode может уже быть в буфере в ядре. В inode находится список
блоков данных.
1. Пример с телефонным справочником не совсем точен, поскольку два различных человека могут проживать
в одном и том же доме. См. концепцию порта в главе, посвященной вопросам сетевого программирования.
2. Послушайте I'm My Own Grandpa, 1947, by Latham & Jaffe для продолжения дискуссии по данной теме.
4.3. Внутренняя структура файловой системы UNIX
143
Обращение к блокам данных в последовательном порядке, один за другим
Ядро теперь знает, в каких блоках данных находятся данные, в каком порядке было
распределение данных по этим блокам. По мере того как команда cat многократно вызывает
read, ядро обращается пошагово в заданном порядке к блокам данных, копируя данные
с диска в буферы ядра и оттуда в массив пользовательского пространства.
Все команде, которые читают из файла, такие, как cat, cp, more, who и тысячи других
команд, передают имя файла системному вызову open для получения доступа к
содержимому файла. При каждом вызове open отыскивает в каталоге имя файла, затем использует
номер inode в каталоге, чтобы получить доступ к атрибутам файла и локализовать место
нахождения содержимого файла.
Рассмотрим теперь ситуацию, когда вы пытаетесь выполнить open в отношении файла,
к которому у вас нет прав на запись и чтение. Ядро использует имя файла, чтобы по нему
найти номер inode, затем использует этот номер inode для локализации структуры inode.
В этой структуре ядро находит разряды, определяющие права доступа к файлу, и
пользовательский ID собственника файла. Если ваш UID и UID для файла совпадают, а
необходимые разряды доступа не установлены, то системный вызов заканчивается с кодом
возврата -1 и в переменной errno устанавливается значение EPERM
На основе рассмотренного представления схемы из каталогов, таблицы inode, блоков
данных вы теперь должны прочувствовать смысл работы других файловых операций.
Обратившись к исходному коду на какой-либо версии Unix, вы можете посмотреть, как
работает системный вызов close.
4.3. 7. I nodes и большие файлы
Каким образом файловая система Unix учитывает распределение по блокам для больших
файлов? Те пояснения, которые были представлены в предшествующем разделе,
недостаточны. Кратко проблему можно представить так:
Фактор 1 Для большого файла необходимо много дисковых блоков
Фактор 2 В структуре inode хранится список распределения дисковых блоков
Проблема Как можно сохранять в Inode, который имеет фиксированный
размер, длинный список распределения блоков?
Решение Сохранять большую часть списка распределения в области блоков
данных, а в inode установить указатели на эти блоки
Рассмотрим ситуацию, изображенную на рисунке 4.7. Для файла необходимо выделить
четырнадцать блоков для хранения его содержимого. Поэтому в списке распределения
будет расположено четырнадцать номеров блоков. Печально, но факт: inode файла имеет
область для хранения массива распределения блоков, в которую можно записать только
тринадцать элементов массива. Звучит зловещая музыка! Как поместить список из 14
элементов в область, рассчитанную на хранение только 13 элементов? Да легко. Поместим
первые 10 номеров из списка распределения в область распределения в inode. Далее
поместим оставшиеся 4 номера дисковых блоков из списка распределения в какой-либо блок
данных. Это — своего рода проведение инвентаризации на полке и перемещение всего
лишнего с полки на склад.
А теперь поговорим о деталях. В inode находится массив, в который можно записать 13
номеров блоков. Первые 10 элементов массива подобны "пространству на полке". Здесь
хранятся в 10 элементах номера тех блоков, которые действительно содержат данные файла. Если
реальный список распределения номеров содержит более 10 элементов, то заводится
дополнительный блок для хранения номеров блоков. Но располагается дополнительная область не
144
Изучение файловых систем. Разработка версии pwd
дополнительные номера, записывают в 11 элемент массива в inode. Это аналогично
ситуации, когда в книжном магазине кладут на полку такую пометку: "Дополнительные книги
на складе, полка 3".
Запись о распределении в файле четырнадцати блоков данных:
Список распределения Список распределения Элемент 12 содержит
начинается в первых продолжается в блоке номер блока, где
10 элементах массива косвенной адресации. содержатся номера блоков
в inode B11 элементе массива косвенной адресации.
находится номер этого Этот блок называют блоком
блока двойной косвенной адресации
Рисунок 4.7
Список распределения блоков содержится в области данных
Отметим то обстоятельство, что для рассматриваемого файла требуется 15 блоков данных.
В четырнадцати блоках будет храниться содержимое файла, а еще в одном блоке будет
находиться та часть списка распределения, которая не поместилась в inode. Этот
дополнительный блок называют косвенным блоком.
Что происходит, когда будет заполнен косвенный блок? По мере того как при работе
будут добавляться новые данные, ядро будет присоединять к файлу дополнительные
блоки данных. Поэтому список распределения становится все длиннее и длиннее. И для него
может потребоваться дополнительная память. Рано или поздно список распределения
заполнит весь косвенный блок. Поэтому ядро начинает работать со вторым
дополнительным блоком. Что делает ядро с номером второго дополнительного блока? Должно ли ядро
поместить номер второго дополнительного блока в 12-й элемент массива в inode?
Конечно, это возможно, но тогда это будет означать, что файл будет иметь три
дополнительных блока. Вместо того чтобы поместить номер второго блока в массив в inode, ядро
обращается еще к одному блоку данных, в котором будет храниться список таких
дополнительных косвенных блоков. А в элемент 12 в массиве в inode будет помещен номер
блока,, но не второго дополнительного блока, а номер блока, в котором будут храниться
номера второго, третьего, четвертого и т. д. дополнительных блоков. Такой блок называют
двойной косвенный блок.
4.4. Понимание каталогов
145
Что происходит, когда будет заполнен двойной косвенный блок? Когда будет заполнен
двойной косвенный блок, ядро начинает работать с новым двойным косвенным блоком.
Ядро не помещает номер этого нового косвенного блока в область inode. Вместо этого
ядро создает тройной косвенный блок, где будут размещаться номера нового двойного
косвенного блока и всех последующих двойных косвенных блоков, которые понадобятся
файлу. Номер этого тройного косвенного блока запоминается в последнем элементе в
массиве в области inode.
Что происходите, когда будет заполнен тройной косвенный блок? В данной ситуации
предполагается, что файл достиг по размеру своего предела. Если вам требуется
использовать файлы большого размера, то можно установить файловую систему с большими
размерами дисковых блоков. Когда вы создаете такую файловую систему, то вы можете
определять не только размер таблицы inode и области данных, но вы можете задавать и размер
дискового блока. Размер дискового блока не обязательно должен совпадать с размером
сектора на поверхности диска. Часто в одном дисковом блоке содержится несколько
дисковых секторов.
Большие файлы требуют больших системных затрат. Система распределения дисковой
памяти является быстрой и эффективной для маленьких файлов. По мере роста размера
файла ядро использует все больше и больше дискового пространства для хранения списка
распределения. При поиске конкретного элемента в файле может потребоваться
обращение к нескольким косвенным блокам, чтобы получить номер нужного блока данных.
4.3.8. Варианты файловых систем в Unix
В предшествующем разделе было дано описание структуры файловой системы Unix.
В различных версиях Unix используются различные версии этой модели. Из-за простоты
этого классического метода возникает ряд важных слабых мест. Например, уязвимым
местом в системе является суперблок. Если блок будет разрушен каким-то образом,
то будет потеряна информация обо всей файловой системе. В некоторых версиях Unix
сохраняют копии суперблока в самой файловой системе.
Другой проблемой является фрагментация» По мере создания и удаления файлов
свободные блоки распределяются в произвольном порядке по диску. Одно из решений -
создавать небольшие файловые системы, которые будут называться группы цилиндров.
Классическая модель не устарела. Файлы создаются и удаляются в области данных
поблочно. Атрибуты файлов также хранятся в inode в таблице inode, а в составе inode
содержится массив распределения блоков диска для файла. Каталоги содержат списки из
имен файлов и номеров inode. Мы можем теперь возвратиться к небольшому поддереву,
которое мы построили и изучили в начале главы. Обогащенные знанием внутренней
структуры файловой системы, мы получим и рассмотрим "рентгеновский снимок"
каталогов и файлов.
4.4. Понимание каталогов
Теперь, когда мы знаем внутреннюю структуру файловой системы Unix, мы можем
рассмотреть, что реально происходит с нашим поддеревом demodir. И при этом мы сможем
разобраться, как работают различные команды для обработки каталогов.
4.4.1. Понимание структуры каталога
Пользователи воспринимают файловую систему как набор каталогов и подкаталогов.
Каждый каталог содержит файлы, в каждом каталоге могут находиться подкаталоги. Каж-
пктй полк-ятя ттг имррт пилите пкпк-ий кятяппг Тякпе пепеко w\ кятяппгпр и (Ьяйлгт чягугп
146
Изучение файловых систем. Разработка версии pwd
изображают как набор прямоугольников (боксов), соединенных линиями связи. В каком
смысле следует понимать выражение, что файл находится в каталоге! Что означает в
техническом смысле термин "dl является подкаталогом с"? Что обозначают соединительные
линии на таких рисунках?
В содержательном смысле каталог - это файл, который содержит список. Список состоит
из таких пар: имя файла и номер inode. Более того, пользователи видят список из имен
файлов, в то время как Unix видит список поименованных указателей.
Пользовательская точка зрения
demodir
| ш
а //
I и Г
d1
\s
//
jxlink)
С
^S «2
|хсору)
Системная точка зрения
У
а
с
х
dl
62
xlink
хсору
Рисунок 4.8
Две точки зрения относительно дерева каталогов
Как преобразовать одну диаграмму в другую? Используя номера inode, мы можем точно
представить структуру дерева. Используем команду Is -iaR, чтобы получить рекурсивно
список номеров inode для всех файлов.
520 с 491 у
$ Is -iaR demodir
865. 193..
demodir/a:
277. 865..
demodir/c:
520. 865..
demodir/c/dl:
651. 520..
demodir/c/d2:
247. 520..
$
277 a
402x
651 d1
402 xlink
680 xcof
247 d2
На рисунке 4.9 представлена диаграмма с указанием номеров inode в каталогах.
4,4. Понимание каталогов
147
Пользовательская точка зрения
demodir
га
/Z ^
S
d1_^-^d2
|xlink|
Системная точка зрения
865
153
4$1*
Й7?\
520 ]
У
а
LC
277
865
140,2
X
520
651
247
di
d2
1 247
520
L 680lxcopy
mum и him
И И111ИI
Рисунок 4.9
Имена файлов и указатели на файл
Реальное значение фразы "Файл находится в каталоге"
Пользователи в разговоре говорят, что файлы находятся в каталогах, но мы теперь знаем,
что файлы представляются записями в таблице inode, а содержание файлов хранится
в области данных. В каком смысле следует понимать, что файл находится в каталоге?
Например, с пользовательской точки зрения, файл у содержится в каталоге demodir.
С системной точки зрения мы видим, что каталог содержит запись с именем файла у
и номером inode, равным 491. .
Пользовательская точка зрения
demodir
1 и 1
а // Ч\
| ш | |
d1 //
|xlink(
С
(\Ч *
|хсору|
Системная точка зрения
Рисунок 4.10
Имена каталогов и указатели на каталоги
865
193
491
,277
Г 52 0^
у
а 1
_с 1
1/277
Г8б5'
402
X
Г5Щ
651
.247
кл
X
di
d2
S 402
xlink
X
T47
520
Sv
.?80
xcopy
148
Изучение файловых систем. Разработка версии pwd
Аналогично, фраза "файл х находится в каталоге а" означает, что существует ссылка на
inode 402 в каталоге с именем а, и х - это имя файла, которое соответствует этой ссылке.
Также заметим, и это важно, что каталог с именем dl внизу, слева на диаграмме, имеет
ссылку на inode 402 и что эта ссылка имеет имя xlink. Таким образом, имеются две ссылки
на узел 402. Одна из них называется demodir/a/x, а другая - demodir/c/dl/xlink. Обе ссылки
обращены к одному и тому же файлу.
Короче говоря, каталоги содержат ссылки на файл. Каждая из таких ссылок называется
link (связь). Содержимое файла находится в блоках данных, атрибуты файла записаны
в структуре в таблице inode, а номер inode и имя файла хранятся в каталоге. Этот
же принцип можно использовать для раскрытия смысла выражения "каталог содержит
подкаталог".
Реальное значение фразы "Каталог содержит подкаталоги"
С точки зрения пользователя, каталог с именем а является подкаталогом каталога demodir.
А как это выглядит изнутри? Опять же, это означает, что каталог demodir имеет ссылку на
inode подкаталога. В верхней части диаграммы, рассматриваемой с системных позиций, есть
ссылка с именем а, для которой inode имеет номер 277. Как мы узнаем, что 277 - это номер
inode для каталога, изображенного слева на диаграмме? Каждый каталог имеет inode. Ядро
в каждом каталоге устанавливает запись, которая относится к собственному inode каталога.
Эта запись имеет имя ".". В маленьком прямоугольнике слева точка ссылается на inode 277,
поскольку каталог в левой части диаграммы имеет inode 277.
Посмотрите на диаграмму и убедитесь в том, что каталог, для которого заведен inode 520,
содержится в каталоге demodir. В списке имен он представлен под именем с. Аналогично,
другой каталог, у которого номер inode равен 247, будет подкаталогом каталога с inode
520, и который имеет имя d2.
Реальный смысл фразы "У каталога есть родительский каталог"
Посмотрите с пользовательских позиций на диаграмму и найдите каталог d2. У него есть
родительский каталог с именем с. Чтобы все это отобразить, опять используется простая
ссылка на inode. Для каталога номер inode равен 520. А в каталоге d2 есть запись,
в котором используется имя ".Л В этой записи указан номер inode 520. Двумя точками
принято обозначать родительский каталог. Таким образом, inode 520 является
родительским для inode.
Заполнение пустых полей для записей, которые имеют в качестве имен точки
Если вам стало все понятно при рассмотрении предыдущего раздела, то вы будете
в состоянии заполнить пропущенные значения номеров inode на рисунке 4.10. Если вы не
уверены, что нужно поместить в эти пустые поля, обратитесь к выводу команды Is,
который был приведен ранее, и просмотрите еще раз текст предшествующего раздела.
Множественные ссылки, счетчик ссылок
В дереве demodir для inode 402 установлены две ссылки. Одна имеет имя х и находится
в каталоге а, вторая называется xlink и находится в каталоге dl. Можно ли определить,
какое из этих имен - имя оригинального файла, а какое имя - это имя ссылки? В структуре
каталога в Unix эти две ссылки имеют одинаковый статус. Их называют твердыми
ссылками на файл. Файл - это inode и "связка" блоков данных. Ссылка указывает на inode.
Вы можете создать много ссылок на файл, если вам это необходимо.
4.4. Понимание каталогов U9
Ядро записывает значения числа ссылок к файлу. В случае для inode 402 это значение
будет не меньше 2. К inode могут быть установлены и другие ссылки из других частей
файловой системы. Счетчик ссылок хранится в inode. Счетчик ссылок - один из
элементов структуры struct stat, которая возвращается в результате работы системного вызова stat.
Имена файлов
В файловой системе Unix файлы не имеют имен. Имена присваиваются ссылкам.
А файлам соответствуют номера inodes. Полезность этого факта мы обсудим позже.
4.4.2. Команды и системные вызовы для работы с деревьями каталогов
Внутренняя структура файловой системы Unix проста. Это большая структура из
совместно связанных данных. Узлы в данной структуре называют inodes (индексные узлы),
наборы указателей называются каталогами, и оконечные узлы называют файлами.
Мы имеем возможность управлять таким деревом с помощью стандартных команд Unix,
таких, как mkdir, rmdir, mv, In и rm. Как работают эти команды? В частности, какие
системные вызовы используются при работе этих команд?
mkdir
Команда mkdir служит для создания новых каталогов. При обращении к команде можно
задавать одно или более имен каталогов. В команде mkdir используется системный вызов mkdir:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
mkdir
Создание каталога
#inciude < sys/stat.h >
«include <sys/types.h>
int result = mkdir(char "pathname, modej mode)
pathname - имя нового каталога
mode - маска для разрядов прав доступа
-1 - при ошибке
0- при успехе
Системный вызов mkdir позволяет создавать и устанавливать ссылку на новый узел
каталога в дереве файловой системы. То есть mkdir создает inode для каталога, выделяет
дисковый блок для хранения его содержимого, записывает в каталоге две записи с именами,
и.., с необходимыми для них номерами inode. Затем добавляется ссылка на новый узел из
родительского каталога.
rmdir
Команда rmdir позволяет удалять каталог. При обращении к команде можно задавать одно
или более имен каталогов. В команде rmdir используется системный вызов rmdir:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
rmdir )
Удаление каталога. Каталог должен быть пустым.
#inciude < unistd.h >
int result = rmdir(const char *path);
path - имя каталога
КОДЫ ВОЗВРАТА -1 - при ошибке
0 - при успехе
150
Изучение файловых систем. Разработка версии pwd
Системный вызов rmdir удаляет узел каталога из дерева каталогов. Каталог должен быть
пустым, т. е. в нем не должно содержаться записей о файлах и подкаталогах, кроме
записей с именем точкам, точкаточка. Удаляется ссылка из родительского каталога. Если при
этом обнаруживается, что удаляемый каталог не используется другими процессами, то
освобождаются также его inode и блоки данных.
rm
Команда rm позволяет удалять записииз каталога. При обращении к команде можно
задавать одно или более имен каталогов. В команде rm используется системный вызов unlink:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
unlink
Удаление записи в каталоге
#include < unistd.h >
int result = unlink(const char *path);
path - имя записи в каталог для удаления
-1 -при ошибке
0 - при успехе
Системный вызов unlink удаляет запись в каталоге. В соответствующем inode уменьшается
на 1 счетчик ссылок. Если счетчик ссылок становится равным нулю, то освобождаются
блоки данных и inode. Если после декремента счетчика остаются еще ссылки на inode,
то блоки данных и inode не отсоединяются. Системный вызов unlink нельзя использовать
для аналогичных действий в отношении каталогов.
In
Команда In позволяет создавать ссылку на файл. Команда In использует при работе
системный вызов link:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
link
Установление новой ссылки на файл
#include < unistd.h >
int result = linkfconst char *orig, const char *new);
orig - имя оригинальной ссылки
new - имя новой ссылки
-1 -при ошибке
0-при успехе
С помощью системного вызова link устанавливается новая ссылка на inode. В новую
ссылку записывается новое имя ссылки и номер inode оригинальной ссылки. Если при
обращении к вызову было указано уже существующее имя, то фиксируется ошибка выполнения
системного вызова link. Использовать link для создания новых ссылок на каталоги нельзя.
mv
Команда mv позволяет изменять имя или расположение файла или каталога в дереве
каталогов. Команда mv является более гибкой командой, нежели другие команды, которые
были представлены в этом разделе. Ряд ее внутренних деталей мы рассмотрим позже.
Во многих случаях при работе этой команды используется системный вызов rename:
4.4. Понимание каталогов
151
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
rename
Переименовать или переместить ссылку
#include < unistd.h >
int result = renamefconst char *from, const char *to);
from - имя оригинальной ссылки
to - имя новой ссылки
-1 -при ошибке
0 - при успехе
Системный вызов rename изменяет имя или место расположения файла или каталога.
Например, при вызове rename(MyM,"y.oldn) будет изменено имя файла, а при вызове
renarne("yV'c/(J2/y.old") будет изменено имя и место расположения файла. Системный
вызов rename можно использовать как в отношении файлов, так и в отношении
каталогов. Но существует ряд ограничений при работе с перемещением каталогов. Например,
вы не сможете переместить каталог в один из его подкаталогов. Попробуйте
предсказать результат работы вызова rename("demodir/c","demodir/d2/c") и посмотреть, какой
опустошительный будет результат. В отличие от link системный вызов rename удаляет
существующий файл или пустой каталог с именем to.
Как работает rename, зачем существует rename?
Как rename перемещает файл в другой каталог? Файлы реально в каталогах не находятся.
В каталогах находятся ссылки на файлы. Поэтому rename перемещает ссылку из одного
каталога в другой. Схема действий при переименовании у на c/d2/y.old представлена на
рисунке 4.11.
Перед переименованием
865
Ш
1 49iv
1 277\
1 520
У
а
\с
ТГГ
865
402
X
5ЯГ
651
J 247l
dl
LU2 1
402
xlink:
Т7"
520
680
хсору
L
После переименования ("yYc/cM/y.olcr;
~g-5F
193
\211
1 520
a
с
~ТГГ
8б5
402
X
520
651
247
di ;
_d2 |
402
xlink
TT7"
520
680
,491
XCODV
y.old
NH№
inode491
Рисунок 4.11
Перемещение файла в новый каталог
152
Изучение файловых систем. Разработка версии pwd
Перед переименованием ссылка на inode 491 с именем у находилась в каталоге demodir.
После переименования ссылка на 491, которая стала называться y.old, будет находиться
в каталоге c/d2, а оригинальная ссылка пропадает. Как ядро перемещает ссылку?
В ядре Linux базовый алгоритм системного вызова rename такой:
скопировать оригинальную ссылку в соответствии с новым именем и/или местом расположения
удалить оригинальную ссылку
В Unix есть два системных вызова link и unlink,c помощью которых можно выполнить эти
два действия. Поэтому вызов rename("xM,"z") будет работать так:
if (!ink("x"/z")
unlink("x");
В Olden Days ®не было системного вызова rename. Поэтому команда mv использовала
вызовы link и unlink. С добавлением в ядро вызова rename были решены две проблемы.
Во-первых, вызов rename делает возможным благополучно переименовывать или
перемещать каталоги. Раньше, в более старых системах, обычным пользователям не разрешалось
выполнять вызовы link или unlink в отношении каталогов. Поэтому они могли быть
использованы для переименования каталогов.
Еще одно важное преимущество системного вызова rename - поддержка файловых систем
не для Unix. При работе в Unix переименование файла или каталога сводится к изменению
ссылки, но в других системах эта схема может не работать. Добавляя к ядру общий метод,
который был назван rename, добиваются скрытия деталей реализации, что обеспечивает
возможность работы с одним и тем же кодом на все типах файловых систем.
cd
Команда cd изменяет текущий каталог для процесса. Команда cd влияет на процесс, а не на
каталог. Пользователь может сказать "Я перешел в каталог /tmp и нашел там много моих
рабочих файлов". Это по сути то же, что сказать "Я отправился на чердак и обнаружил там
много моих старых книг". При работе команды cd используется системный вызов chdir:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
chdir
Изменить текущий каталог у вызывающего процесса
#include < unistd.h >
int result = chdirfconst char *path);
path - путь к новому каталогу
-1 -при ошибке
0- при успехе
Для каждой исполняемой программы в Unix устанавливается ее текущий каталог.
Системный вызов chdir позволяет изменять текущий каталог процесса. После этого говорят, что
'"процесс находится в этом каталоге". В процессе поддерживается переменная, в которой
хранится номер inode текущего каталога. Когда вы выполняете "переход в новый каталог",
то вы заставляете изменить значение этой переменной.
Важное упражнение. Как работает команда cd..? Обратитесь к примеру поддерева
demodir и представьте, что вы находитесь в каталоге с именем с. Какой номер inode у
вашего текущего каталога? Далее выполните команду cd dl. Каким стал теперь номер inode
вашего текущего каталога? Каким образом ядро получает значение этого номера? Если вы
4.5. Разработка программыpwd
153
теперь выполните команду cd../.., то какой будет номер inode вашего текущего каталога?
Какие шаги выполняет ядро, чтобы получить значение этого номера? Если вы
разобрались, какие действия происходят при выполнении этого важного упражнения, то вы
поняли, как работает команда pwd.
4.5. Разработка программы pwd
Команда pwd выводит путь для текущего каталога. Например, если вы спустились по
дереву вниз в каталог demodir/c/d2 и далее выполнили команду pwd, то вы увидите нечто
похожее на следующее:
$pwd
/home/yourname/experiments/clemoclir/c/d2
Где хранится такой длинный путь? Он не хранится в текущем каталоге. Текущий каталог
обращается сам к себе с помощью ссылки ."." и имеет номер inode. Каталог - это просто
узел среди набора узлов, соединенных между собой. Каким образом команда pwd узнает,
что каталог называется d2, как она узнает, что у текущего каталога родительским будет
каталог с, как узнает, что у каталога с родительским каталогом будет demodir и т. д.?
4.5.1. Как работает команда pwd?
Ответ на этот вопрос, как и ответы на все вопросы этой главы, будет простым. Команда,
следуя по указателям, читает содержимое каталогов. На самом деле команда pwd
поднимается вверх по дереву, от каталога к каталогу, отмечая для каждого шага перемещения
номер inode для имени "точка". Затем через родительский каталог выбирается имя,
которое установлено для этого номера inode. Это делается до тех пор, пока не будет
достигнута вершина дерева. Рассмотрим, например, рисунок 4.12:
Computing pwd:
1. Для"." номер
равен 247
2. Для номера 247
имя ссылки "d2"
3. Дляп." номер равен 520
4. Для номера 520
имя ссылки "с.
5. Для"." номер равен 865
6. Для номера 865
имя ссылки "demodir"
7. Для"." номер равен 193
Рисунок 4.12
Составление пути текущего каталога
Наше восхождение по дереву начинается в текущем каталоге. Он обозначен на рисунке
индексом 1 в нижнем правом углу. В этом каталоге для ячейки с именем "." номер inode
равен 247. Теперь с помощью chdir переместимся в родительский каталог, где найдем
i 865
193
I 491
277
1 520
у !
а
с
! 520
651
| 247
dl
62
277
865
402
х
402
xlink
247
520
680
хсору
154
Изучение файловых систем. Разработка версии pwd
запись, содержащую номер inode 247. Для этого номера в этой записи указано имя d2.
Поэтому имя последнего компонента в пути будет d2. А какое имя у родительского
каталога? В родительском каталоге обращаемся к записи, содержащей имя ".", и выбираем его
номер inode 520. Далее с помощью chdir переходим еще на шаг вверх по дереву. И уже
в этом родительском каталоге находим запись с номером inode 520. Из нее узнаем имя
каталога - с. Поэтому последние два элемента пути будут теперь такими: c/d2. Алгоритм для
повторения этих трех шагов можно выразить так:
1. Выбрать номер inode для имени"'.", назовем его п (использовать stat).
2. chdir... (использовать chdir).
3. Найти имя для ссылки с номером inode п (.использовать opendir, readdir, closedir).
Повторить (до тех пор, пока не достигнете вершины дерева).
Все выглядит достаточно просто. Но остались два вопроса.
Вопрос 1: Как мы узнаем, что достигли вершины дерева? В корневом каталоге
файловой системы Unix в записях с именами ссылок "." и ".." указан один и тот же inode.
Программисты часто отмечают конец связанных структур указателем NULL. Разработчики
Unix могли бы использовать нулевой указатель в записи корневого каталога, содержащего
имя "..". Но вместо этого было принято решение "зациклиться на себя". В чем
преимущество такого решения? В нашей версии pwd повторение при составлении пути будет
происходить до тех пор, пока не будет достигнут каталог, в котором в записях с именами ссылок
"." и ".." записан один и тот же inode.
Вопрос 2: Как нам вывести имена каталогов в пути в правильном порядке? Мы
напишем цикл и построим строку, состоящую из имен каталогов, с помощью strcat или sprintf.
Мы не будем использовать при составлении строки с рекурсивной программой, которая
разворачивается к вершине дерева и выводит по одному имена каталогов, по мере
продвижения по дереву.
4.5.2. Версиякомандыpwd
/* spwd.c: упрощенная версия pwd
* начало работы в текущем каталоге и
* последующее восхождение по дереву файловой системы к ее корню.
* При этом сначала выводится головной элемент, а затем текущая часть пути
*
* Используется readdir() для получения информации об элементах каталога
* . .
* Нештатная ситуация: Вывести пустую строку, если достигли"/"
**/
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <dirent.h>
inoj getJnode(char *);
void printpathto(inoj);
void inum_tojiame(inoJ, char *, int);
intmainQ
I Разработка программы pwd
printpathto(get_inode("."));
putGhar('\n');
return 0;
/* здесь вывод пути 7
/* затем добавить новую строку 7
}
void printpathto(ino_t thisjnode)
Г
* вывод пути, ведущего к объекту с этим inode,
* как будто рекурсивно
7
{
inoj myjnode;
char its_name[BUFSIZ];
if (getJnode("..M) != thisjnode)
chdirf'.."); /* перемещение вверх на каталог */
inumJo_name(thisJnode,its_namefBUFSIZ);/* получить имя каталога*/
myjnode = getJnode(M.");
printpathto(myjnode);
printfG%s", its_name);
/* name of this 7
}
}
void inum to name(inoJ inodejo find, char *namebuf, int buflen)
/*
* Найти в текущем каталоге файл с этим номером inode
ж и скопировать его имя в namebuf
7
/* печать головной чаете
Г рекурсия 7
/* теперь печать 7
{
DIR *dir_ptr;
struct dirent *direntp;
dirj)tr = opendir(".");
if(dirj>tr==NULL){
perror(".M);
exitA);
/* каталог 7
Г каждая запись 7
}
Л
* поиск каталога для файла с заданным inum
7
while ((direntp = readdir(dirjrtr)) != NULL)
if (direntp->d ino == inode to find)
{
strncpy(namebuf, direntp->d_name, buflen);
namebuf[buflen-1] = '\0';
closedir(dir_ptr);
return;
/* на всякий случай 7
156 Изучение файловых систем. Разработка версии pwd
fprintf(stderr, "error looking for inum %d\n", inodejojind);
exitA);
}
inaj get inode(char *fname)
r~
* возвратить номер inode файла
7
{
struct stat info;
if (stat(fname, &info) == -1){
fprintf(stderr, "Cannot stat");
perror(fname);
exitA);
}
return info.st ino;
}
Работает ли наша программа? Вот реальный вывод после запуска программ:
$ /bin/pwd
/home/bruce/experiments/demodir/c/d2
$spwd
/bruce/experiments/demodir/c/d2
$
Все закончилось красиво. В реальной версии команды pwd в составе пути выводятся все
каталоги до корня дерева. Но и наша версия останавливается, когда она достигает
вершины дерева. Так в чем проблема? Есть ли ошибки? Нет. Программа на самом деле работает
правильно. Она действительно останавливается, когда достигает корня файловой
системы. Но корень этой файловой системы не является корнем всего дерева, которое
поддерживается на компьютере.
В Unix можно построить на одном диске дерево, состоящее из деревьев. Каждый диск, или
каждый раздел на диске, содержит дерево каталогов. Эти отдельные деревья соединяются
вместе и составляют одно единое дерево. Наша версия pwd столкнулась с одним из
ограничений такого построения.
4.6. Множественность файловых систем: Дерево из деревьев
Что происходит, когда в системе Unix используется два диска или раздела? Мы
наблюдали, как происходит работа в системе. Мы смогли организовать один раздел, в котором
разместилось дерево каталогов. А если у вас имеется два раздела, то можем ли мы получить
два отдельных дерева?
Как организуется работа с разделами в других системах? В некоторых операционных
системах каждому диску или разделу назначается символ дисковода или имя тома. Этдт
символ устройства или имя тома становится частью полного пути к файлу. Есть
экстремальные схемы, когда в системах назначаются номера блоков по всем дискам, с тем чтобы
создать один виртуальный диск. .
В Unix есть еще одно, третье преимущество. В каждом разделе хранится дерево
собственной файловой системы. Но поскольку на компьютере существуют более одной файловой
4.6. Множественность файловых систем: Дерево из деревьев
157
Пользовательская позиция: одно дерево Системная позиция: два диска
ЛЬ
da
en cm
Рисунок 4.13
"Прививка" деревьев
Пользователь видит одно полное дерево каталогов. Действительно же существуют два
дерева - одно на диске 1, а другое на диске 2. Каждое дерево имеет корневой каталог. Одна из
файловых систем выступает в роли корневой файловой системы. Вершина этого дерева
является одновременно вершиной единого дерева. Другая файловая система присоединяется к
некоторому подкаталогу корневой файловой системы. С позиций системы ядро устанавливает
ссылку на другую файловую систему из каталога в корневой файловой системе.
4.6ш1ш Точкимонтирования
В Unix используется выражение монтировать файловую систему со смыслом, который
аналогичен выражению пришпилить бабочку или приклеить картину на картону, е.
необходимо что-то к чему-то прикрепить. Корневой каталог поддерева прикрепляется к
каталогу в составе корневой файловой системы. Каталог, к которому присоединяется
поддерево, называется точкой монтирования для этой второй системы.
Команда mount выводит список файловых систем, которые в текущий момент примон-
тированы в системе, и их точки монтирования:
$ mount
/dev/hda1 on / type ext2 (rw)
/dev/hda6 on /home type ext2 (rw)
none on /proc type proc (rw)
none on /dev/pts type devpts (rw,mode=0620)
В первой строке выводится информация о том, что раздел 1 на устройстве /dev/hda (первый
IDE дисковод) смонтирован в корневой вершине дерева. Этот раздел является корневой
файловой системой. Во второй строке сообщается о том, что файловая система на
устройстве /dev/hda6 присоединена к корневой файловой системе к каталогу /home. Таким
образом, когда пользователь переходит с помощью chdir из каталога / в каталог /home, to
происходит переход от одной файловой системы в другую. Когда наша версия pwd будет
проходить по дереву, то она остановится в каталоге /home, поскольку она достигнет вершины
своей файловой системы. » ' .
158
Изучение файловых систем. Разработка версии pwd
Плюрализм Unix
В Unix допускается монтировать к корневой файловой системе файловые системы
различных типов. Например, на Unix машине, где есть корневая файловая система, можно
смонтировать а файловую систему ISO9660 на CD-ROM. Файлы и каталоги этого диска
становятся после этого частью единого дерева. Если в ядре есть подпрограммы, которые
могут работать со структурой файловой системы Macintosh, то можно примонтировать
файловую систему Macintosh, расположенную на каком-то диске. Можно даже
монтировать файловые системы, которые расположены на других компьютерах, используя сетевые
средства.
4.6.2. Дублирование номеров /node и связей между устройствами
Объединение нескольких файловых систем в составе одного дерева имеет ряд
преимуществ. Однако есть один небольшой нюанс. При работе в Unix каждый файл в файловой
системе имеет номер inode. Аналогично тому, как могут быть расположены на двух
различных улицах дома с одним номером 402, так и на двух различных дисках могут быть
файлы, каждый из которых имеет inode под номером 402. В каких-то каталогах могут быть
записи, где для файлов с некоторыми именами указан номер inode 402. Как ядро может
узнать, какой номер inode следует использовать?
,'fltl\ .
Рисунок 4.14
Номера inode и файловые
системы
Рассмотрите внимательно на увеличенной части рисунка два каталога. Один из них
находится в корневой файловой системе, а другой в примонтированной файловой системе.
В каждом каталоге есть ссылка на inode 402. Имена ссылок myls.c и y.old соотнесены
одному и тому же номеру inode. Но где расположен этот inode? В файловой системе на диске 1
есть inode с номером 402, а на диске 2 в файловой системе есть другой inode с номером
402. Это означает, что эти ссылки вовсе не ведут к одному и тому же файлу.
На этом примере иллюстрируется проблема, которая возникает при создании дерева
деревьев. Как оказалось, номер inode идентифицирует файл совсем не однозначно. Как мы
только что убедились, один и тот же номер inode 402 находится в двух различных
каталогах, но каждый из них ссылается на разные файлы. При этом все выглядит так, будто
ссылки установлены на один и тот же файл. Но это не так.
Как мне сослаться на один и тот же файл из различных файловых систем? Вы не
сможете этого сделать. Файл существует как набор блоков данных и inode на диске. В каталоге
на этот inode есть ссылка. Что должно произойти, если ссылка на одном диске будет
указывать на inode, который находится на другом диске? Если другой диск был размонтиро-
4.6. Множественность файловых систем: Дерево из деревьев
159
ван, то файл будет потерян. Еще хуже случай, если будет примонтирован совсем другой
диск, на котором окажется файл с номером inode 402. Но содержание этого другого файла
будет совершенно другим, чем нам нужно. Существует еще ряд проблемных ситуаций,
над которыми вы можете подумать.
Знают ли системные вызовы link и rename о том, что было рассмотрено выше? Да.
Системный вызов link отказывается создавать связи между устройствами, а системный
вызов rename отказывается перемещать номер inode по файловым системам. Читайте
документацию в справочнике для изучения того, какими могут быть коды ошибок.
4.6.3. Символические ссылки: Панацея или блюдо спагетти?
Твердые ссылки по сути являются указателями, с помощью которых каталоги
объединяются в дерево. Такие ссылки являются указателями, которые связывают имена файлов
с собственно файлами.
Твердые ссылки не могут указывать на inodes в других файловых системах. И даже root не
может сделать твердую ссылку на каталог. Однако есть достаточно причин, чтобы иметь
возможность ссылаться на каталоги или файлы в других файловых системах. Для
удовлетворения таких требований в Unix поддерживается еще один тип ссылок - символические
ссылки. Символическая ссылка производит обращение к файлу по имени, а не по номеру
inode. Сделаем такое сравнение:
$ who > whoson
$ In whoson ulist
$ Is-li whoson ulist
377 -rw-r--r-- 2 bruce users 235 Jul 16 09:42 ulist
377 - rw- r- - r- - 2 bruce users 235 Jul 16 09:42 whoson
$ In-s whoson users
$ Is -li whoson ulist users
377 - rw- r- - r- - 2 bruce users 235 Jul 16 09:42 ulist
289 Irwxrwxrwx 1 bruce users 6 Jul 16 09:43 users -> whoson
377 - rw- r- r- 2 bruce users 235 Jul 16 09:42 whoson
Файлы whoson и ulist ссылаются на один и тот же файл. Для обоих файлов указаны одни и
те же характеристики: они имеют номер inode 377, у каждого указан один и тот же размер
файла, одно время модификации файла и одно и то же значение числа ссылок. Твердая
ссылка ulist была создана с помощью команды In.
С другой стороны, с помощью команды In -s создается символическая ссылка на файл
whoson, которая будет называться users. С помощью команды Is -li обнаруживаем, что ссылка
users имеет inode 289. Символ 1 в позиции для указания типа файла свидетельствует о том,
что это символическая ссылка. Число ссылок, время модификации и размер имеют
значения, отличные от значений этих же характеристик у оригинального файла. Файл users не
является оригинальным файлом whoson, но ведет себя в точности так, как ведет себя
оригинальный файл при обращении к нему на чтение или запись. Например:
$wc-I whoson users
5 whoson
5 users
10 total
$ diff whoson users
160
Изучение файловых систем. Разработка версии pwd
С помощью команд wc и diff производится обращение к файлам и подсчет строк в этих
файлах. Потом производится сравнение содержимого этих файлов. В рассмотренном
случае ядро использует имя для обращения к оригинальному файлу. Но, с другой стороны,
при выполнении вызова stat будет получена информация о ссылке, а не об оригинальном
файле. Символические ссылки могут действовать в составе различных файловых систем,
потому что они не хранят inode оригинального файла. Такие ссылки можно также
устанавливать на каталоги. Это свойство значительно отличает этот вид ссылок от других ссылок
и позволяет рассматривать в качестве средства "связывания" файловых систем для
получения единого целого3.
Символическим ссылкам свойственны те проблемы, о которых шла речь при обсуждении
связей между устройствами. Если удаляется файловая система, содержащая
оригинальный файл, или оригинальный файл получит новое имя, или будет инсталлирован в
системе новый файл с таким же именем, как у оригинального, то символическая ссылка будет
ссылаться (в соответствии с порядком перечисления этих вариантов): в никуда, в никуда,
на совсем другое содержание, чем у оригинального файла. Символические ссылки могут
указывать на родительские каталоги, тем самым создавая циклы в дереве каталогов.
С помощью символических ссылок можно превратить вашу файловую систему в "порцию
спагетти". Но ядро признает только такие символические ссылки и никакие другие.
Поэтому ядро может проверять ссылки на наличие потери объектов, на которые
производится ссылка, а также на наличие бесконечных циклов.
Системные вызовы для символических ссылок
Системный вызов symlink создает символическую ссылку. С помощью системного вызова
readlink можно получить имя оригинального файла. С помощью системного вызова Istat
получают статусную информацию об оригинальном файле. Обратитесь к справочнику
и прочтите документацию относительно вызовов unlink, link, чтобы узнать, как они
работают с символическими ссылками.
Заключение
Основные идеи
• Unix организует на дисковой памяти файловые системы. Файловая система - это
объединение файлов и каталогов. Каталог - это список имен и указателей. Каждая
запись в каталоге указывает на файл или каталог. В каталоге находятся записи,
которые указывают на его родительский каталог и его подкаталоги.
• Файловая система в Unix состоит из трех основных частей: суперблок, таблица inode,
область данных. Позиция inode в таблице называется номером inode файла. Номер
inode является уникальным идентификатором файла.
• Один и тот же номер inode может находиться в различных каталогах, но для каждого
такого номера будут разные имена файлов. Каждая такая запись называется твердой
ссылкой. Символическая ссылка - это ссылка, которая обеспечивает обращение
к файлу по имени, а не номеру inode.
• Несколько файловых систем могут быть объединены в одно дерево. Операция,
с помощью которой ядро связывает каталог одной файловой системы с корнем другой
файловой системы, называется монтированием.
• В Unix имеются системные вызовы, с помощью которых программист может
создавать и удалять каталоги, дублировать указатели, перемещать указатели, изменять
имена, которые ассоциированы указателям, присоединять и отсоединять другие
файловые системы.
3. Вызов Istat разыменовывает ссылку.
Заключение
161
Визуальное заключение
Запись в каталоге состоит из имени файла и номера inode. Номер inode указывает на
структуру на диске. Эта структура содержит информацию о файле и о распределении
блоков данных файла.
Каталог
Запись в каталоге
Таблица inode
Рисунок 4.15
Inodes, блоки данных,
каталоги, указатели
Что дальше?
Файлы - это только один из источников данных. Программы также обрабатывают данные,
которые поступают с устройств, таких, как терминалы, видеокамеры, сканеры. Kajc
программы в Unix получают данные от устройств и как посылает на них данные?
Исследования
4.1 Команда pwd выводит путь к текущему каталогу в файловой системе. В определенном
смысле каталог - это ваше место расположения в дереве. На самом деле такой каталог
представляет собой некоторое объединение байтов, которые расположены на диске в
каком-то месте. Это место можно определить с помощью указания головки, дорожки,
сектора и байта. Или можно указать с помощью цилиндра, головки сектора и байта. Какие
имеются возможности для преобразования имени текущего каталога в термины
аппаратных средств, с помощью которых производится указание места расположения?
4.2 Исследуйте один из твердых дисков в системе, которую вы используете. Определите,
сколько разделов на этом диске. Определите для каждого раздела число inodes и число
блоков данных.
4.3 Абстракцию типа "диск как массив" использует не только система Unix при создании
файловой системы. Ее вправе использовать любой, кто имеет необходимые права доступа
Чтобы реализовать такой проект, вам необходимо иметь права доступа root.
Каталог /dev содержит файлы, с помощью которых вы можете читать байты данных
размещаемые в блоках на диске так, будто эти байты находятся в файле. В система>
Linux с IDE-дисководами вы можете найти файлы, которые называются /dev/hda, /dev
. «. /j-./lj^ ia^.iuaa cw„ Ллойгпл vrxnnMrTR не являются обычными файлам*
162
Изучение файловых систем. Разработка версии pwd
данных, аналогичные файлам /etc/passwd или /var/adm/utmp. Эти файлы устройств
предоставляют возможность доступа к необработанным (raw) данным на диске.
Вы можете использовать команды cat, more, cp и любые другие команды для работы
с файлами для чтения содержимого, которое расположено на диске. Диск, подобно
файлу utmp, имеет вполне очевидную структуру. Одна из возможностей получить
поблочное содержимое диска - выполнить команду od -с /dev/hda | more. По мере
выполнения такого постраничного вывода вы будете читать содержимое диска так,
как будто вы читаете одну непрерывную последовательность из дисковых блоков.
Для каждого раздела представлен один из таких специальных файлов устройств.
Например, первый раздел на/dev/hda называется /dev/hdal.
Исследуйте ваш каталог /dev и определите, какие специальные файлы в этом каталоге
соотнесены твердым дискам, гибким дискам, CD-ROM или другим дисковым
устройствам в системе.
4.4 В ядре имеется кодовый текст, который определяет место расположения свободного inode
и находит свободные дисковые блоки. Это делается, когда ядро создает новый файл. Как
ядро узнает, какие из блоков являются свободными? Как ядро узнает, какие из inode
являются свободными? Какой метод используется в файловой системе на вашей машине
для учета последовательности неиспользуемых блоков и inodes?
4.5 В Unix можно читать и монтировать диски (такие как PC-DOS и Macintosh диски), на
которых находятся non-Unix-файловые системы. В этих файловых системах нет inodes. Тем
не менее, если вы используете команду mount, для присоединения одного из таких дисков
к системе Unix, то после выполнения команды Is -i вы обнаружите вывод списка inode для
таких систем.
Обратитесь к исходному коду Linux и поищите там ответ на вопрос: откуда берутся
эти номера? Зачем в Linux происходит добавление этих номеров?
4.6 Текст, предназначенный для описания списка распределения блоков в составе inode,
представляет собой описание десяти прямых блоков, одного косвенного блока, одного
двойного косвенного блока и одного тройного косвенного блока. В некоторых версиях Unix
используют другие номера для представления прямых и косвенных блоков.
(а) Какой формат списка распределения в inode используется в вашей системе?
Детали можно найти при рассмотрении заголовочных файлов.
(в) Какой размер блока данных на вашей системе?
(c) Какой самый большой файл в вашей системе не использует косвенные блоки?
(d) Какой самый большой файл в вашей системе не использует двойные косвенные
блоки? Сколько реально использует блоков этот самый большой файл?
4.7 Счетчик ссылок для каталогов. Файл может иметь много ссылок. Число таких ссылок
записывается в счетчик ссылок для файла. А как обстоят дела в отношении каталогов?
Используйте в вашей версии дерева demodir команду Is -l, чтобы посмотреть на значения счетчика
ссылок для каталогов. Сравните эти значения счетчиков с числом дуг (Для каждого
каталога. - Примеч. пер.) на диаграмме. Объясните значение счетчика ссылок для каталога.
Почему каждый каталог имеет значение счетчика ссылок, которое будет не меньше 2?
4.8 Ссылки на каталоги. Использовать вызов link для образования новой ссылки на
каталог нельзя. В Olden Days ® делать ссылки на каталоги разрешалось
суперпользователю. В примере demodir проследите действие системного вызова link("demodir/c","de-
modir/d2/e") в пользовательском и системном режимах. Затем поясните результаты
работы команды Is -iaR demodir.
Заключение
163
4.9 Скрытые поддеревья. Когда вы с помощью команды mount присоединяете одну файловую
систему к другой файловой системе, то точка монтирования должна быть каталогом в
оригинальной файловой системе. Например, вы можете присоединить файловую систему на
диске /dev/hda4 к каталогу /home2. Ответьте на следующие два вопроса:
(а) Что произойдет, если точки монтирования (в данном случае /Ьоте2)не существует?
(в) Что произойдет, если точка монтирования существует и содержит файлы и
подкаталоги?
4.10 Команда rmdir не удаляет каталог, в котором содержатся файлы и подкаталоги. Почему
такое решение можно считать хорошим?
Но, с другой стороны, вы можете удалять каталог, в котором находится пользователь.
Сделайте следующее и удивите ваших друзей: образуйте новый каталог с
произвольным именем, перейдите в этот каталог. Далее откройте еще одно shell-окно и удалите
этот каталог. Закройте второе shell-окно и выполните команду /bin/pwd. Объясните,
что произойдет.
4.11 Что означает термин цилиндр для твердого диска? Какая физическая конструкция твердого
диска, которая делает концепцию цилиндров важной с позиций эффективного
использования диска? Найдите через Web пояснения термина группа цилиндров. Объясните связь
между этой идеей и моделью файловой системы, которая была представлена в тексте.
4.12 Нехватка пространства на диске. Для большинства людей знакома проблема нехватки
пространства на диске. В файловой системе Unix имеется область для inodes и область для
данных. Поэтому возможно, что все пространство в области для inode будет
использовано, хотя еще есть свободное пространство в области данных. Когда вы инсталлируете
новый диск в Unix, то вам необходимо выделить на диске область для расположения в ней
таблицы inode и выделить область данных. Для каждого файла в файловой системе
необходим один inode. Чем больше места будет отведено под таблицу inode, тем меньше
пространства останется для хранения содержимого файлов.
Пускай вы собираетесь устанавливать новый твердый диск. Команда mkfs позволяет
образовать новую файловую систему и дает вам возможность определить размер
таблицы inode. Почитайте документацию по этой команде. Почему вам может
потребоваться много inodes? Почему у вас может появиться необходимость запросить
меньшее их число, чем обычно?
4.13 Системному вызову stat передается имя файла и указатель на структуру, которую он
заполняет информацией о файле. Объясните, как работает системный вызов stat, используя для
этого модель каталога, inode и данных. Где системный вызов находит данные о файле,
которые он копирует в структуру stat?
Программные упражнения
4.14 Напишите текст одной командной строки в Unix, чтобы можно было построить дерево
каталогов
demodir.
4.15 В Unix-команде mkdir можно использовать опцию -р. Напишите версию команды mkdir,
в которой можно использовать эту опцию.
4.16 Команда mv - это всего лишь обертка системного вызова rename. Напишите версию
команды mv, для которой при обращении потребуется указывать два аргумента. Первый
аргумент должен быть именем файла, а второй аргумент должен быть именем файла или
164
Изучение файловых систем. Разработка версии pwd
именем каталога. Если вторым аргументом указано имя каталога, то команда mv
перемещает файл в этот каталог. В противном случае команда mv переименовывает файл, если
это возможно.
4.17 Текст версии rename написан с использованием link и unlink. В этом кодовом фрагменте
производится проверка кода возврата из link, но не проверяется код возврата из unlink.
Расширьте возможности этого кода с целью достижения корректной реакции при ошибках
исполнения unlink.
4.18 Ознакомьтесь с документацией в справочнике и с содержанием заголовочных файлов,
чтобы разобраться со структурой суперблока на вашей системе. Напишите программу,
которая открывает файловую систему, читает содержимое суперблока, и отображает ряд
характеристик файловой системы в ясном, читабельном формате. Это упражнение
аналогично составлению тех программ, которые были написаны для отображения содержимого
utmp записей и stat структур.
4.19 Процедура создания нового файла включает четыре основные операции. Все они должны
быть успешно завершены для того, чтобы файл был правильно включен в состав
файловой системы. Что случится, если вдруг будет выключено питание компьютера где-либо
при выполнении этих действий по созданию файла? Например, что произойдет, если
данные были размещены в области данных, но inode сформировать не успели?
(a) Определите порядок, в котором должны выполняться эти четыре основные
операции. Аргументируйте ваш выбор.
(b) Предположите, что система будет построена и работает в соответствии с тем, как
вы ответили на вопрос (а). Что будет, если авария произойдет между какими-то двумя
шагами в вашей процедуре? Например, если ваш процедура состоит из четырех
шагов, то таких точек между шагами будет три. Объясните, какие некорректности
возникнут в системе при возникновении аварии в каждой из этих трех точек?
(c) Почитайте документацию по Unix-команде fsck. Насколько похож ваш ответ на
вопросы пункта (Ь) на те действия, которые выполняет команда fsck?
4.20 В главе 3 мы разработали версию команды Is -1. Модифицируйте эту программу таким
образом, чтобы она выводила бы номер inode дополнительно к той информации, которую
она до того выводила. Где будет производиться поиск номера inode в модифицированном
варианте вашей версии?
Проекты
На основе материала этой главы вы можете изучить дополнительный материал и
разработать на его основе следующие Unix-программы:
find, du, Is -R, mount, dump
Глава 5
Управление соединениями.
Изучение stty
Цели
Идеи и средства
• Подобие файлов и устройств.
• Отличие между файлами и устройствам.
• Атрибуты соединений.
• Условия гонок и атомарные операции.
• Драйверы устройств.
• Потоки
Системные вызовы и функции
• fcntl, ioctl
• tcsetattr, tcgetattr
Команды
• stty
• write
166
Управление соединениями. Изучение stty
5.1. Программирование устройств
% В нескольких главах мы рассмотрели программы, которые работают с файлами и
каталогами. В компьютере есть еще один источник данных — периферийные устройства. Это
модемы, принтеры, сканеры, мыши, громкоговорители, видеокамеры, терминалы. В этой
главе мы рассмотрим сходство и различие между файлами и устройствами. Рассмотрим,
каким образом можно использовать такие свойства при управлении соединениями
с устройствами.
В этой главе мы напишем версию команды stty. Команда stty дает возможность
пользователям проверять и модифицировать установки, с помощью которых производится
управление соединением клавиатуры и экрана.
5.2. Устройства подобны файлам
Многие считают, что файл представляет собой "связку" данных, хранимых на диске.
Но в Unix поддерживается более абстрактное представление файла. Прежде всего
рассмотрим несколько характеристик, касающихся файлов. Файлы содержат данные, у
файлов есть свойства, файлы идентифицируются с помощью имен в каталогах. Вы можете
побайтно читать данные из файла, а также побайтно записывать данные в файл. Ну а теперь
заметьте: эти же самые характеристики и действия применимы и в отношении устройств.
Рассмотрим звуковую карту, к которой присоединен микрофон и громкоговоритель.
Вы говорите что-либо в микрофон, звуковая карта преобразует сигналы вашего голоса
в поток данных, а программа может читать этот поток данных. Когда программа
записывает поток данных на карту, то полученный звук передается на громкоговорители. Для
программы звуковая карта является источником данных и местом, куда можно передавать
данные.
Терминал, имеющий клавиатуру и дисплей, также аналогичен файлу. Значения клавиш, на
которые вы нажимаете, считываются программой и воспринимаются как входные данные
для нее. А символы, которые процесс передает на терминал, отображаются на экране.
Для Unix звуковые карты, терминалы, мышь и дисковые файлы - все это рассматривается
как один и тот же тип объектов. В системе Unix каждое устройство трактуется как файл.
Каждое устройство имеет имя, номер inode, собственника, разряды прав доступа и время
последней модификации. Каждый, кто знает, как можно работать с файлами,
автоматически может использовать эти знания при работе с терминалами и другими устройствами.
5.2.1. Устройства имеют имена файлов
Каждое устройство (терминал, принтер, мышь, диск и т. д.), которое присоединено к Unix
машине, представлено в системе именем файла. По традиции файлы, которые
представляют устройства, помещены в каталоге /dev, но вы вправе создавать файлы устройств
в любом каталоге. Рассмотрите состав каталога /dev на различных Unix-машинах. Ниже
показан фрагмент листинга для машины, на которой я сейчас работаю:
$ Is-C/dev | head-
XOR fd1u720
agpgart fd1u800
apm_bios fd1u820
arcd fd1u830
dsp flashO
5
loopl
IpO
Ipl
Ip2
mcd
ptyqf
ptyrO
ptyrt
ptyr2
ptyr3
sda7
sda8
sda9
sdb
sdM
stderr '
stdin
stdout
tape
tcp
' ttysd
ttyse
ttysf
ttytO
ttytl
5.2. Устройства подобны файлам
167
На этом листинге представлено несколько типов устройств. Файлы с именами lp* в
третьей колонке - это принтеры. Файлы с именами fd* во второй колонке - это дисководы
гибких дисков. Файлы с именами sd* — это разделы SCSI-устройств. Имя файла /dev/tape
присвоено ленточному устройству, предназначенному для построения на нем системных
копий (backup). Файлы с именами tty* в последней колонке — это терминалы. Программы
при чтении из таких файлов получают значения символов при нажатии клавиш на
клавиатуре. По мере записи данных в эти файлы программы посылают данные на экраны
терминалов.
Файл dsp представляет собой соединение со звуковой картой. Процесс проигрывает
звуковой файл путем записи данных из звукового файла в этот файл устройства. Процесс может
открыть файл /dev/mouse и далее воспринимать события, связанные с нажатием на кнопки
мыши и со всеми изменениями расположения курсора мыши.
5*2.2. Устройства и системные вызовы
Устройствам можно не только присваивать имена файлов. В их отношении можно
использовать все системные вызовы, предназначенные для работы с файлами: open, read, write,
lseek, close, stat.
Например, фрагмент программы для чтения данных с магнитной ленты будет иметь такой
вид:
intfd;
fd = openGdev/tapeH, 0_RDONLY); Г связаться с ленточным устройством */
lseek(fd, (long) 4096, SEEKJJET); /* перемотка ленты на 4096 байтов */
n = readffd, buf, buflen); /* чтение Данных с ленты */
close(fd); /* разрыв связи с устройством */
Для работы с устройствами можно использовать те же системные вызовы, которые вы
использовали для работы с дисковыми файлами. В Unix фактически нет других средств
для связи с устройствами.
Некоторые устройства не поддерживают все файловые операции
Когда вы перемещаете мышь и нажимаете на кнопки мыши, то от мыши в систему
поступают байты данных, которые процесс может читать с помощью вызова read. Ну а что
произойдет, если процесс попытается выполнить вызов write в отношении мыши? Передачи
данных на мышь не произойдет. Мышь можно только перемещать и нажимать на ней
кнопки. Для файла /dev/mouse не поддерживается системный вызов write. Конечно, кто-то
может придумать мышь с моторчиком и написать для нее усовершенствованный драйвер,
который будет способен как принимать события от мыши, так и вырабатывать их.
Для терминалов поддерживаются системные вызовы read и write, но не поддерживается
вызов lseek. А почему?
5.2.3. Пример: Терминалы аналогичны файлам
Большая часть пользовательских входов для Unix производится через терминалы. Файлы
ttysd, ttyse и т. д. в приведенном листинге представляют собой терминалы. Терминалом
называют все, что ведет себя аналогично классической клавиатуре с устройством
отображения. Сюда можно отнести печатающий терминал 70-х годов, и клавиатуру с экраном,
которые подсоединены к последовательному порту, и ПК с модемом и программой
эмуляции терминала, которая связана с системой через телефонную линию. Окна telnet или ssh,
168
Управление соединениями. Изучение stty
через которые можно входить в систему через Интернет, ведут себя как терминалы.
Основными компонентами терминала являются источник ввода символов от пользователя
и любое устройство отображения для вывода данных пользователю. Устройство
отображения может даже выдавать тексты для слепых в кодах Брайля или воспроизводить
данные в звуковом виде.
С помощью команды tty можно узнать имя файла, который представляет ваш терминал.
Давайте поэкспериментируем с терминальными файлами:
$tty
/dev/pts/2
$ ср/etc/motd/dev/pts/2
Today is Monday, we are running low on disk space. Please delete files.
- your sysadmin
$ who >/dev/pts/2
bruce pts/2 Jul 17 23:35 (ice.northpole.org)
bruce pts/3 Jul 18 02:03 (snow.northpole.org)
$ Is -li /dev/pts/2
4 crw--w--w-1 bruce tty 136,2 Jul 18 03:25 /{Jev/pts/2
Команда tty сообщает, что мой терминал подсоединен к файлу /dev/pts/2, т. е. оконечное имя
файла 2, файл находится в подкаталоге pts для каталога /dev. Мы можем использовать
произвольные файловые команды и операции для работы с этим файлом: ср, перенаправление
вывода с помощью операции >, mv, In, rm, cat, Is.
Команда ср читает данные из обычного файла /etc/motd и записывает их на устройстве /dev/
pts/2, что приводит к отображению содержимого исходного файла на экране. При записи
данных в файл устройства происходит передача данных на устройство. На следующей
строке в данном примере показывается, как производится передача результатов работы
команды who с помощью оператора перенаправления > в файл /dev/pts/2. После этого
данные отображаются в символьном виде на указанном экране1.
5.2.4 Свойства файлов устройств
У файлов устройств имеется большая часть тех же свойств, что есть у дисковых файлов.
В выводе результатов работы команды Is, что представлен выше, видно, что файл /dev/pts/
2 имеет inode 4, права доступа: rw--w—w-, счетчик ссылок равен 1, собственник файла -
bruce, группа-tty, время последней модификации Jul 18 03:25. Обозначение типа файла-
"с". Этим обозначением показывается, что такой файл в действительности является
устройством, относительно которого происходит побайтная пересылка данных. Права
доступа выглядят несколько странными, а вместо размера файлов мы видим выражение
136,2. Что означает это выражение?
Файлы устройств и размер файла. Обычные дисковые файлы содержат какое-то
количество байтов данных. Число байтов в дисковом файле называют размером файла. Файл
устройства - это соединение, а не контейнер. Клавиатуры и мышь не хранят, сколько было
нажатий на клавиши или на кнопки мыши. В inode файла устройства хранится не размер
файла и распределение его по памяти, а указатель на подпрограмму в ядре. Такая
подпрограмма ядра, которая получает данные от устройства и передает данные на устройство,
называется драйверам устройства.
1. Или в коде Брайля, или воспроизводится звук.
5.2. Устройства подобны файлам
169
В нащем примере с файлом /dev/pts/2 программный код, который перемещает данные
между системой и терминалом (туда и обратно). Это подпрограмма под номером 136 в
таблице драйверов. Для этой подпрограммы при вызове задается целочисленный аргумент.
В случае работы с файлом /dev/pts/2 значением аргумента будет 2. Эти два номера, 136 и 2,
называют старший номер и младший номер устройства. Старший номер определяет, какая
подпрограмма будет управлять конкретным устройством. Значение младшего номера
будет передаваться этой подпрограмме.
Файлы устройств и права доступа. У каждого файла имеются разряды, с помощью
которых задаются права на чтение, запись и исполнение. Какой смысл будет в
использовании этих разрядов прав доступа, когда речь идет не о файле, а о файле устройства? При
попытке записи данных в файл устройства данные передаются устройству. Поэтому право на
запись означает право на передачу данных устройству. В нашем текущем примере
собственник файла и члены группы tty имеют право писать на терминале, но только
собственнику файла разрешено читать данные с терминала. При чтении из файла устройства,
аналогично чтению из обычного файла, получают данные из файла. Ввод данных с
терминала заключается в нажатии пользователем на клавиши клавиатуры. Если пользователи,
не являясь собственниками файла терминала, получат право на чтение из файла /dev/pts/2,
то они смогут читать символы, которые будут нажиматься на клавиатуре.
Но при чтении данных с клавиатуры другого пользователя могут возникнуть проблемы.
С другой стороны, запись символов на терминал другого пользователя является целью
команды write.
5.2.5. Разработка команды write
Еще задолго до появления средств обмена сообщениями и всевозможных chat rooms
(Без перевода! - Примеч. пер.) Пользователи в Unix беседовали с друзьями, которые
находились за другими терминалами, с помощью команды write:
$ man 1 write
WRITE) 1) Linux Programmer's Manual WRITE( 1)
NAME
write - send a message to another user
SYNOPSIS
write user [ttyname]
DESCRIPTION
Write allows you to communicate with other users by copy-ing
lines from your terminal to theirs.
When you run the write command, the user you are writing
to gets a message of the form:
Message from youmame@yourhost on yourtty at hh:mm
Any further lines you enter will be copied to the speci-fied
user's terminal. If the other user wants to reply,
they must run write as well.
When you are done, type an end-of-file or interrupt char-acter.
The other user will see the message EOF indicating
that the conversation is over.
170
Управление соединениями. Изучение stty
Версия команды write, следующая далее, не будет посылать сообщение "Message from"
и требует имени файла для терминала (ttyname), а не пользовательского имени собеседника:
Г writeO.c
* цель: посылка сообщений на другой терминал
* метод: открыть другой терминал для вывода, затем
* произвести копирование stdin на другой терминал
* представление: терминал, который воспринимается как файл и поддерживает
* обычный ввод/вывод
* обращение: writeO ttyname
7
#include <stdio.h>
#include <fcntl.h>
main(intac, char*av[])
{
intfd;
charbufpUFSIZJ;
/* проверка аргументов */
if (ас != 2){
fprintf(stderr,Husage: writeO ttyname\n");
exitA);
}
Г открытие устройств */
fd = open(av[1],OWRONLY);
lf(W —1){
perror(av[1));exitA);
}
/* цикл, пока не будет признак EOF на входе */
while(fgets(buf, BUFSIZ, stdin) != NULL)
if (write(fd, buf, strien(buf)) == -1)
break;
close(fd);
}
Тщательно проанализируйте эту программу и попытайтесь найти в ней специальные
средства для установления соединения вашей клавиатуры с экраном другого пользователя.
Их нет. В этом примере программы write производится копирование строк из одного файла
в другой. Эта простая программа и примеры в предшествующем разделе показывают, что
к терминалам, а также ко всем устройствам, которые присоединены к Unix-машине,
можно обращаться точно так же, как к дисковым файлам.
5.2.6. Файлы устройств и Inodes
Как работать с файлами устройств? Как в файловой системе Unix inodes и блоки данных
поддерживают идею файлов устройств? На рисунке 5.1 показаны соединения.
5.3. Устройства не похожи на файлы
171
Inode для дискового
файла содержит список
указателей на блоки
в области данных
Inode для файла устройства
содержит указатель на драйвер
устройства в ядре
Пластины
Каталог
tty02
utmp
Рисунок 5.1
Inode ссылается на блоки данных или на код драйвера
Каталог - это список имен файлов и номеров inode. В каталоге нет ничего такого, что
говорило бы о принадлежности имени дисковому файлу или принадлежности имени
устройству. Разница между типами файлов проявляет себя на уровне inode.
Каждый номер inode - это ссылка на структуру в таблице inode. Каждая такая структура
может быть либо inode дискового файла, либо inode файла устройства. Тип inode
записывается в поле типа в элементе stjnode структуры struct stat.
В inode дискового файла находятся указатели на блоки на диске, где содержатся данные.
В inode файла устройства находится указатель на таблицу подпрограмм ядра. С помощью
старшего номера указывается, где нужно искать программный код, с помощью которого
можно будет получать данные от устройства.
Рассмотрим, например, как работает системный вызов read. Ядро находит inode для
файлового дескриптора. С помощью inode ядро узнает о типе файла. Если это дисковый файл,
то ядро будет получать данные с использованием списка распределения блоков. Если это
файл устройства, то ядро читает данные с помощью обращения к коду read в составе
драйвера для этого устройства. Подобная логика поддерживается и в отношении других
операций - open, write, lseek, close.
5.3. Устройства не похожи на файлы
Внешне дисковые файлы и файльгустройсхв похожи. Оба имеют имена и обладают
свойствами. Системный вызов open создает соединение файлами и с устройствами. Но
соединение с дисковыми файлами отличается от соединения с терминалом. На рисунке показан
процесс, у которого имеются два файловых дескриптора. Один определяет соединение
с дисковым файлом, а другой определяет соединение с пользователем за терминалом.
172
Управление соединениями. Изучение^
Дисковый
Файл терминала
Дисковые файлы используют
буферирование
Файлы терминала обладают свойствами:
эхоотображение, скорость передачи данных,
редактирование, переход на новую строку
Рисунок 5.2
Процесс с двумя файловыми дескрипторами.
У нас уже есть определенное представление о структуре этих соединений. В соединении
с дисковым файлом обычно присутствуют буферы ядра. Данные, которые передаются от
процесса к диску, накапливаются в буферах и позже передаются из буферов в память ядра.
Буферирование является атрибутом соединения с диском. Соединения с терминалами
имеют отличия. Процессы, которые желают послать данные на терминалы, хотят, чтобы
это происходило максимально быстро.
Соединение с терминалом или модемом также имеет атрибуты. Для последовательного
соединения это скорость передачи, биты четности, опредленные значения стоп-битов.
Символы, которые вы набираете, на клавиатуре, обычно отображаются на экране. Но
иногда, например при наборе вашего пароля, символы набираются без эхоотображения. Эхо-
отображение символов не является частью клавиатуры и не является частью действий,
выполняемых в программе. Эхоотображение - это атрибут соединения. Соединения с
дисковыми файлами не имеют таких атрибутов.
5,3.1. Атрибуты соединения и контроль
В Unix поддерживается подобие файлов и устройств, когда нужно это подобие. И
принимается во внимание их различие, когда в этом есть необходимость. Соединение с
дисковым файлом отличается от соединения с модемом. Обратимся к атрибутам соединений:
1. Какие атрибуты есть у соединения?
2. Как можно проверить текущие атрибуты?
3. Как можно изменять текущие атрибуты?
Далее мы рассмотрим два примера: соединения с дисковыми файлами и соединения
с терминалами.
5.4. Атрибуты дисковых соединений
173
5.4. Атрибуты дисковых соединений
Системный вызов open создает соединение между процессом и дисковым файлом. Это
соединение имеет несколько атрибутов. Рассмотрим более подробно два атрибута и
обменяемся мнениями о других.
5.4.1. Атрибут i: Буферизация
На следующей диаграмме изображен файловый дескриптор в виде двух каналов, которые
присоединены к обрабатывающему устройству. Таким обрабатывающим устройством
является ядро, которое выполняет буферизацию и другие задачи по обработке данных.
Внутри этого ящика находятся переменные, с помощью которых определяется, какие
выполнять шаги по обработке данных. Картинка выглядит так:
к
V . i ¦• i i I ,' - ¦ ZD
-
У\
Щ
С помощью файлового
дескриптора контролируется,
как работает драйвер
Рисунок 5.3
Обрабатывающее устройство
в потоке данных
Вы можете модифицировать действие файлового дескриптора, изменяя значения этих
управляющих переменных. Например, вы можете выключить дисковую буферизацию,
используя для этого простую, трехшаговую процедуру.
^:
L-i
iffiflinflffil 1
1 ff { 1
I //
л
|^*-|
^¦ч^
Изменить установки драйвера:
1. Получить значения установок
2. Модифицировать их
3. Поместить значения обратно.
Рисунок 5.4 *
Модификация действия файлового дескриптора
Сначала выполним системный вызов, чтобы скопировать управляющие переменные из
файлового дескриптора в ваш процесс. Далее модифицируем копию ваших управляющих
переменных. Новые значения установок помещаются в состав обрабатывающего кода.
И теперь ядро обрабатывает данные в cooteeTCTBHH с новыми значениями установок.
Ниже представлен код, который воспроизводит в программном виде эти три шага:
174 Управлениесоединениями. Изучение^
#include <fcntl.h>
ints;//установки
s = fcntl(fd, F_GETFL); // получить флаги
s |= O.SYNC;//установить бит SYNC
result = fcntl(fd, F.SETFL, s); // установить флаги
if (result ==-1)//если ошибка
perror( "setting SYNC"); // отчетность
Атрибуты файлового дескриптора кодируются с помощью битового представления целого
числа. Системный вызов fcntl позволяет вам получить контроль над файловым
дескриптором с помощью операций чтения и записи этого целого числа:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
fcntl
Управление файловыми дескрипторами
«include < fcntl.h >
«include <unistd.h>
«include <sys/types.h>
int result = fcntl(int fd, int cmd);
int result = fcntl(int fd, int cmd, long arg);
int result = fcntl(int fd, int cmd, struct flock *lockp);
fd - файловый дескриптор.который контролируется
cmd - операция, которую нужно выполнить
arg - аргументы для операции
lock - информация о блокировке
•1-при ошибке
Другие значения зависят от операции
Системный вызов fcntl выполняет действие cmd над открытым файлом, который
определен дескриптором fd. Для действия cmd можно задавать аргументы arg. В нашем примере
с помощью действия f_getfl получаем текущий набор битов (также называют флаги).
Этот набор флагов помещается в переменную s. Оператор поразрядного или устанавливает
бит OSYNC. Тем самым с помощью этого бита устанавливается требование к ядру о том,
что возврат из вызова write должен произойти только после окончания записи на реальное
устройство. Следовательно, действие по умолчанию не выполняется, когда возврат из
вызова происходит сразу после того, как данные будут скопированы в буфер ядра.
Наконец, мы должны передать модифицированные значения установок обратно ядру. Мы
определяем действие F_SETFL как второй аргумент в системном вызове и указываем с
помощью третьего аргумента, какие модифицированные значения следует установить в ядре.
Такая трехшаговая процедура - чтение текущих установок из ядра в переменную, изменение
значений считанных установок, помещение этих установок обратно в ядро - является
стандартным средством для чтения и модификации атрибутов соединений в Unix.
При установке 0_SYNC снижается эффективность от буферирования в ядре. Поэтому
необходимы убедительные причины, которые вынуждают отключить буферирование.
5.4.2. Атрибут2: Режим Auto-Append
Другим атрибутом файлового дескриптора является режим auto-append. Режим
auto-append полезен для файлов, в которые производится одновременная запись несколькими
процессами.
5.4. Атрибуты дисковых соединений
175
Почему полезен режим Auto-Append
Рассмотрим журнал wtmp. В журнале wtmp сохраняется история всех вхождений в систему
и выходов из системы. Когда пользователь входит в систему, то программа login добавляет
запись в конец файла wtmp. Когда пользователь выходит из системы, то система добавляет
запись о выходе в конец файла wtmp, этого своеобразного дневника системы. Как в
дневнике человека, так и здесь каждая новая запись должна добавляться в конец имеющегося
текста.
А не можем ли мы использовать Iseek, чтобы добавлять записи в конец файла?
Рассмотрим следующую логику для login:
Присоединение данных к
файлу с помощью двух системных
вызовов:
lseek(fd,0,SEEK__END) ;
write(f d,&rec,len)
Рисунок 5.5
Присоединение записей
с помощью lseek и write
Системный вызов lseek устанавливает текущую позицию на конец файла, а затем
системный вызов write добавляет входную запись к файлу. Что плохое может здесь произойти?
Что будет, если два человека входят в систему в одно и то же время? Обратимся к
рисунку 5.6, на котором изображено распределение времени обработки.
Время
I Вхождение пользователя А
*
1 -
2 ; lseek(fd,0,SEEKJ2ND);
4* write(fd,&rec;len);
Вхождение пользователя В
lseek(fd,0,SEEKJEND);
write(fd,&rec,len);
Рисунок 5.6
Чередующиеся lseek и write = хаос
Файл wtmp изображен в середине рисунка. Слева изображена временная ось, на которой
находятся четыре временных отметки. Последовательность действий при вхождении
пользователя А представлена слева, а последовательность действий при входе пользова-
176 Управление соединениями. Изучение stty
теля В приведена справа. Пока все нормально? Важным обстоятельством является тот
факт, что Unix является системой разделения времени, и что в этой процедуре требуется
выполнение двух отдельных шагов: lseek и write.
Теперь посмотрим в замедленном темпе, как все будет происходить:
time 1 — Процесс В ищет конец файла.
time 2 — Интервал времени для В закончился. Процесс А ищет конец файла.
time 3 — Интервал времени для А закончился. Процесс В производит запись.
time 4 — Интервал времени для В закончился. Процесс А производит запись.
Таким образом, запись от процесса В будет потеряна, поскольку произойдет ее перезапись
процессом А.
Такая ситуация называется условием гонок. (Иногда называют условием состязаний. -
Примеч. пер.) Окончательный результат обработки файла, который разделяется этими
двумя процессами, будет зависеть от того, как будет спланировано развитие этих процессов.
Если выполнить даже небольшие изменения в распределении действий во времени, то это
может привести к потере записи о входе пользователя А. Или все может произойти так,
что ничего не будет потеряно.
Как можно аннулировать это условие гонок? Есть множество вариантов, чтобы
избежать условий гонок. Условия гонок представляют собой критическую проблему в области
системного программирования. Мы будем многократно возвращаться к этой теме.
В нашем конкретном случае можно воспользоваться средством, которое находится в ядре
и которое обеспечивает простое решение проблемы: поддержка режима auto-append. Если
будет установлен бит 0_APPEND для файлового дескриптора, то это приведет к тому, что
в системном вызове write автоматически будет включен lseek для выставления на конец
файла.
В этом фрагменте кода устанавливается режим auto append и затем вызывается write:
#include <fcntl.h>
ints;//установки
s = fcntl(fd, FJ3ETFL); // получить флаги
s |= 0_APPEND; // установить бит APPEND
result = fcntl(fd, FJ5ETFL, s); // установить флаги
if (result — -1) // если ошибка
perrorf'setting APPEND"); // сообщение
else
write(fd, &rec, I); // записать в конец файла
Атомарные операции. С важным термином условия гонок связан другой важный
термин-атомарная операция. Вызовы lseek и write представляют собой раздельные
во времени системные вызовы. Ядро может прервать процесс в точке, которая
расположена между этими двумя вызовами. Когда установлен бит 0_APPEND, то ядро
комбинирует одну атомарную операцию из lseek и write. Две операции объединяются в одну
неделимую операцию. (При выполнении неделимой операции ядро уже не может ее
прервать. -Примеч. пер.)
5.4. Атрибуты дисковых соединений
177
5А. 3. Управление файловыми дескрипторами с помощью системного
вызова open
OSYNC и 0_APPEND - два атрибута файлового дескриптора. Но их гораздо больше. Мы
рассмотрим другие установки в последующих главах. В документации системногр вызова
fcntl представлен список всех опций и операций, которые поддерживаются для вызова
в вашей системе.
Установка атрибутов файлового дескриптора с помощью fcntl не является единственной
возможностью. Часто при открытии файлов вам известно, какие нужно сделать установки.
Системный вызов, open дает вам возможность определить биты атрибутов файлового
дескриптора, используя для этого часть второго аргумента при обращении к вызову.
Например, с помощью вызова,
fd = open(WTMP_FILE, OJ/VRONLY|0>PPEND|0„SYNC);
будет открыт на запись файл wtmp (В примере, в системном вызове open указано имя файла
WTMP_FILE. - Примеч. пер.) с установленными битами 0_APPEND и 0_SYNC. Второй
аргумент в системном вызове open используется не только для указания режима открытия:
на чтение, на запись, на чтение/запись. Например, вы можете запросить при выполнении
open, чтобы файл был предварительно создан. Это делается с помощью флага 0_CREAT.
Следующие два вызова будут эквивалентны:
fd = creat(filename, permission bits);
fd = open(filename, O^CREAT|OJRUNC|0_WRONLY, permission _bits);
Почему существует системный вызов creat, если ту же работу можно выполнить с
помощью системного вызова open? В старых системах с помощью open происходило только
открытие файлов, а с помощью creat создавался новый файл. Позже системный вызов open
был модифицирован и стал поддерживать большее количество флагов, в том числе и
опцию по созданию файла.
Другие флаги, которые поддерживаются в open
O.CREAT Создать файл, если он не существовал. Смотри 0_EXCL
OJRUNC Если файл существует, то следует уничтожить его содержимое -установить
размер файла равным 0 (транкатенировать).
0_EXCL Флаг 0_EXCL предполагает предотвращение попытки создания одного и того
же файла двумя процессами. Если указанный файл существует и установлен
флаг 0_CREAT, то системный вызов возвратит-1.
Комбинация флагов 0„CREAT и 0_EXCL может быть использована для устранения
следующей ситуации гонок. Что произойдет, если два процесса попытаются одновременно
создать один и тот же файл? Например, что будет, если два процесса пожелают вести
записи в файл wtmp, но потребуется создать этот файл, если он до этого не существовал?
Программа определяет, существует ли файл с помощью вызова stat. Затем вызывается creat,
если обнаруживается, что файл не существует. Проблема может возникнуть тогда, если
процесс будет прерван в точке между stat и creat. Флаги 0_EXCL/0_CREAT позволяют
объединить эти два системных вызова в атомарную операцию.
Несмотря на наши старания, в ряде важных случаев эта комбинация работать не будет.
Надежным альтернативным решением будет использование link. В упражнениях есть
пример на эту тему.
178
Управление соединениями. Изучение stty
5.4.4. Итоговые замечания о дисковых соединениях
Ядро передает данные между дисками и процессами. Код в ядре, который выполняет
.такие передачи, имеет много опций. Программа может использовать системные вызовы
open и fcntl с тем, чтобы управлять (контролировать) выполнением внутренней работой по
пересылке этих данных.
Установки соединены!
Соединение с дисковым файлом
Рисунок 5.7
Соединения с файлами имеют
установки
5.5. Атрибуты терминальных соединений
Системный вызов open создает соединение между процессом и терминалом. Рассмотрим
более детально ряд атрибутов соединения с терминалом.
5.5.1. Терминальный ввод/вывод не такой, как он кажется
Соединение между терминалом и процессом выглядит достаточно простым. Вы можете
передавать байты данных между устройством и процессом, используя getchar и putchar.
Абстракция потока данных делает похожей такую систему пересылки на систему, где
клавиатура и экран подключены прямо к процессу:
getchar
putchar
Симво)
>лы I
Шруср
Процесс
Разрез потока
mctmmcm
Пользователь
Рисунок 5.8
Соединения с файлами имеют
установки
5.5. Атрибуты терминальных соединений
179
Простой эксперимент показывает, что эта модель не является полной. Рассмотрим программу:
/* listchars.c
* цель: представление в списке тех символов, которые
* поступают на вход программы
* вывод: одна пара в строке, значения символа в формате char и в ascii коде
* ввод: stdin,noKa не появится на входе символ Q
* замечание: программа полезна для показа, что присутствуют средства
* буферирование/редактирование
7
#include <stdio.h>
main ()
{
int с, п = 0;
while((c = getchar())!=,Q')
printff'char %3d is %c code %d\n", n++, с, с);
}
Программа производит посимвольную обработку, т. е. читает очередной символ, а затем
выводит значение счетчика цикла, сам символ и его внутренний код. Откомпилируйте
и запустите программу на исполнение. После запуска вы можете получить такой результат:
$ /listchars
hello
char 0 is h code 104
char 1 is e code 101
char 2 is I code 108
char 3 is I code 108
char 4 is о code 111
char 5 is
code 10
Q
$
Что происходит? Если коды символов поступают непосредственно с клавиатуры на get-
char, то мы должны были бы получать желаемый результат сразу после нажатия на каждую
клавишу. Но вместо этого нам придется нажать на пять клавиш при наборе слова hello,
а потом нажать на клавишу Enter. Только тогда программа обработает введенные
символы. Ввод оказался буферируемым. Подобно данным, которые передаются на диск, поток
байтов при передаче с терминала сохраняется в каком-то месте.
Иногда listchars может вести себя по-другому. При нажатии на клавиши Enter или Return
обычно посылается код ASCII, равный 13, что соответствует символу возврат каретки
{carriage return). Из вывода программы listchars следует, что код ASCII, равный 13, при
передаче был заменен на код 10, который соответствует символу line feed или newline
(перевод строки).
Третий вид обработки, который влияет на программный вывод. Программа listchars при
выводе посылает символ перехода на новую строку (\п) в конце каждой строки. Код
перехода на новую, строку указывает на необходимость перемещения курсора на одну строку,
но не указывает на необходимость возврата курсора в самую левую колонку строки.
Код 13 (carriage return, т. е. возврат каретки) требует возврата курсора в самую левую
колонку.
180
Управление соединениями. Изучение^
Попросите вашего дедушку, чтобы он рассказал вам о блестящей ручке, которая
находилась с левой стороны каретки пишущей машинки. Вы узнаете, что с ее помощью
происходил возврат каретки в левую исходную позицию листа бумаги.
Результат исполнения listchars показал, что в файловом дескрипторе должен быть где-то
обрабатывающий уровень. На рисунке 5.9'проиллюстрировано действие этого уровня.
L^^
Символ V'
Рисунок 5.9
Ядро обрабатывает данные терминала
На этом примере представлено три вида обработки:
1. Процесс не принимает данных до тех пор, пока пользователь не нажмет на клавишу
Return.
2. Пользователь нажимает Return (код ASCII 13), но процесс воспринимает символ new-
line (код ASCII 10).
3. Процесс посылает символ newline и терминал принимает пару символов: Return-New-
line.
Соединения с терминалами имеют сложный набор свойств и шагов по обработке данных.
5.5.2. Драйвертерминала
Соединение терминала с процессом выглядит так, как показано на рисунке 5.10.
Рисунок 5.10
Драйвер терминала является
частью ядра
5.5. Атрибуты терминальных соединений
181
Набор подпрограмм ядра, которые обрабатывают данные, передаваемые между
процессом и внешним устройством, называют драйвером терминала или драйвер tty 2. Драйвер
содержит много установок, с помощью которых производится управление его работой.
Процесс может читать, модифицировать и сбрасывать значения этих управляющих
флагов драйвера.
5.5.3. Команда stty
Команда stty предоставляет пользователю возможность читать и изменять значения
установок в драйвере терминала.
Использование команды stty для работы с установками драйвера дисплея. Выходные
результаты работы команды stty будут выглядеть приблизительно так:
$stty
speed 9600 baud; line = 0;
$ stty —all
speed 9600 baud; rows 15; columns 80; line = 0;
intr = AC; quit = Л\; erase =л?; kHI = TJ; eof = AD; eol = <undef>;
eol2 = <undef>; start = AQ; stop = AS; susp = AZ; rprnt = AR; werase = AW;
Inext = AV; flush = A0; min = 1; time = 0;
-parenb -parodd cs8 -hupcl -cstopb cread -clocal -crtscts
-ignbrk brkint ignpar -parmrk -inpck -istrip -inlcr -igncr icml ixon -ixoff
-iuclc -ixany imaxbel
opost -olcuc -ocrnl onlcr -onocr -onlret -ofill -ofdel nIO crO tabO bsO
vtOffO
isig icanon iexten echo echoe echok -echonl -nofish -xcase -tostop -echoprt
echoctl echoke
По умолчанию команда выдает короткий листинг. При использовании опции -all выдается
список, в котором представлено много установок. Некоторые установки представлены как
переменные, имеющие некоторые значения. Некоторые же установки являются
булевскими константами. Например, установки baud rate (скорость в бодах), число строк и колонок
на экране имеют числовые значения. А такие установки, как intr, quit и eof, имеют
символьные значения. Наконец, такие значения, как icrnl, -olcuc и onlcr, представляют собой флаги,
которые либо установлены, либо сброшены.
Каково назначение всех этих установок? Установка icrnl является аббревиатурой от Input:
convert Carriage Return to NewLine (Ввод: преобразование Carriage Return в NewLine). Она
обозначает действие, которое выполнял драйвер в нашем предшествующем примере.
Аббревиатура onlcr означает Output: add to NewLine a Carriage Return (Вывод: добавить
Carriage Return к NewLine). Знак минус, который стоит перед атрибутом, указывает на то,
что данная операция выключена. Например, установка -olcuc означает невозможность
выполнения действия типа Output: convert LowerCase to UpperCase (Вывод:
преобразование из нижнего регистра в верхний). Многие старинные терминалы печатали только
заглавными символами, поэтому преобразование вывода в заглавные символы было для
них полезным.
Изменение установок драйвера с помощью команды stty. Вот несколько примеров
использования команды stty по изменению установок драйвера:
2. tty - это осталось от ссылок на первые'печатающие терминалы, которые производились Teletype Corporation.
182
Управление соединениями. Изучение stty
$ stty erase X # сделать X клавишей стирания
$ stty -echo # набор без эхо отображения
$ stty erase @ echo # несколько установок терминала
В первом примере мы используем команду stty для изменения клавиши, с помощью
которой можно корректировать ошибки при вводе. Обычно такое действие по стиранию
введенного символа закреплено за клавишей backspace или delete. Но вы можете
закрепить выполнение такого действия за любой клавишей. Во втором примере мы отключили
воспроизведение символа при нажатии на клавишу. Когда вы набираете пароль при входе
в систему, то при наборе символов пароля эти символы не воспроизводятся на вашем
экране. А дальше, при нажатии на клавиши, символы опять будут отображаться.
Выключение отображения символов приводит к тому, что при наборе вы не будете видеть
на экране, что набираете. В третьем примере мы используем команду stty для изменения
сразу нескольких установок. Мы заменили символ стирания на символ 4@' и опять
включили режим echo (режим с эхоотображением при наборе).
Как работает команда stty? Можем ли мы написать команду stty?
5.5.4. Программирование драйвера терминала: Установки
Драйвер терминала поддерживает дюжины операций, которые он может выполнить над
данными, передаваемые с его помощью. Эти операции сгруппированы по четырем
категориям:
Входная Задается, что драйвер делает с символами, которые поступают к нему с терминала
Выходная Задается, что драйвер делает символами, которые он выдает на терминал
Управляющая Задается, как представлены символы - число разрядов, четность, стоп-биты и т. д.
Локальная Задается, что драйвер делает, когда символы находятся внутри драйвера
Входная обработка включает в себя преобразования представления символов из нижнего
регистра в верхний, сбрасывание high bit, преобразование управляющего символа carriage
returns в newlines. При выходной обработке символы табуляции заменются на
последовательность из пробелов, происходит преобразование управляющего символа newlines в
carriage returns, происходит преобразование символов из нижнего регистра в верхний.
Управляющая обработка включает в себя even parity, odd parity (проверку на четность или
нечетность), работу со стоп-бйтами. Локальная обработка включает в себя установление для
пользователя режима эхо отображения и буферирование ввода до тех пор, пока
пользователь не нажмет на клавишу Return.
Кроме включений/выключений установок, драйвер поддерживает список ключей
(клавиш) со специальным назначением. Например, пользователи могут для удаления
символа нажимать на клавишу backspace. Драйвер отслеживает нажатия на эту клавишу
и производит действие по этому ключу стирания. Кроме того, драйвер отслеживает
нажатия еще ряда других управляющих символов.
В документации на команду stty приводится список большинства установок и
управляющих символов.
5.5.5. Программирование драйвера терминала: Функции
Изменение установок в драйвере терминала производится аналогично тому, как делаются
изменения установок для соединений с дисковым файлом:
(a) Получить атрибуты от драйвера.
(b) Модифицировать какие-то атрибуты, которые вы желаете.
(c) Пеоелать эти молиАипиоованные атоибуты обоатно лпайвеоу.
5.5. Атрибуты терминальных соединений
183
Например, в последующем программном коде включается режим эхоотображения для
соединения:
#include <termios.h>
struct termios attribs; •/* структура, где хранятся атрибуты */
tcgetattr(fd, Ssettings); /* получить атрибуты драйвера */
settings.cjflag |= ECHO; /* включить бит ECHO в наборе флагов */
tcsetattr(fd, TCSANOW, &settings); /* передать атрибуты обратно драйверу */
Общая процедура изменения атрибутов изображена на рисунке 5.11:
#include <termios.h>
struct termios settings;
tcgetattr(fd,&settings);
/* проверака, установка или
сброс битов */ */
tcsetattr(fd, how.&settings);
Рисунок 5.11
Управление драйвером терминала с помощью tcgetattr и tcsetattr
Библиотечные функции tcgetattr и tcsetattr обеспечивают доступ к драйверу терминала. Обе
функции работают с установками в структуре struct termios. Детали функций следующие:
tcgetattr
НАЗНАЧЕНИЕ
Чтение атрибутов драйвера терминала
INCLUDE
#include <termios.h>
#include < unistd.h >
ИСПОЛЬЗОВАНИЕ int result = tcgetattrfmt fd, struct termios *info);
АРГУМЕНТЫ fd - файловый дескриптор для терминала
info - указатель на структуру termios
КОДЫ ВОЗВРАТА
-1 при ошибке
О - при успехе
Функция tcgetattr копирует текущие установки драйвера терминала, которому сопоставлен
дескриптор открытого файла устройства/^, в структуру info.
tcsetattr
.НАЗНАЧЕНИЕ
Установить атрибуты драйвера терминала
INCLUDE
#include <termios.h>
tinclude < unistd.h >
ИСПОЛЬЗОВАНИЕ int result = tcsetattr(int fd, int when, struct termios *info);
184
Управление соединениями. Изучение stiy
tcsetattr
АРГУМЕНТЫ fd - файловый дескриптор для терминала
info - указатель на структуру termios
when - когда изменять установки
КОДЫ ВОЗВРАТА -1-при ошибке
О-при успехе
Функция tcsetattr копирует установки драйвера из структуры, на которую указывает info,
и передает их драйверу терминала, которому сопоставлен файловый дескриптор fd. С
помощью аргумента when при обращении к функции указывается, когда следует
модернизировать установки драйвера. Допустимы следующие значения для аргумента when:
TCSANOW
Немедленно модернизировать установки драйвера.
TCSADRAIN
Ждать, пока все выходные данные, которые собраны в очереди в драйвере, не будут
переданы на терминал.
TCSAFLUSH
Ждать, пока все выходные данные, которые собраны в очереди в драйвере, не будут
переданы на терминал. Далее сбросить все поступившие входные данные. Затем выполнить
изменения установок.
5.5.6. Программирование драйвера терминалов: Флаги
В типе данных struct termios содержится несколько наборов флагов и массив управляющих
символов. Во всех версиях Unix включены следующие поля:
. struct termios
{
tcflagj cjflag; /* флаги режима ввода */
tcflagj c_pflag; /* флаги режима вывода */
tcflagj c.cflag; /* флаги управляющего режима 7
tcflagj cjflag; /* флаги локального режима */¦
ее J c_cc[NCCS]; /* управляющие символы */
speedj cjspeed;/* скорость ввода 7
speed t с ospeed; /* скорость вывода 7
};
Скорость передачи в бодах для входных и выходных потоков данных хранится в полях
cjspeed и c_ospeed.
Распределение разрядов в каждом из наборов флагов показано на рисунке 5.12.
Первые четыре члена - это наборы флагов. Каждый набор флагов состоит из разрядов,
которым сопоставлены операции в этой группе. Например, член cjflag содержит разряд
со значением INLCR. Член c_cflag содержит бит проверки на нечетность (odd parity),
который называется маской PARODD. Все эти маски определены в termios.h. Когда вы
обращаетесь к текущим атрибутам из драйвера в struct termios, то все значения в этой
структуре вам доступны для проверки и модификации.
5.5. Атрибуты терминальных соединений
185
c_iflag I I I I I I IT
Mill
c__of lag
en
1 I I I I 1 I I I I [ I I
3 3
^ О 2
68R
О Г f
t- к; к;
OFD
m
r
OFI
r»
r«
ONL
50
И
>3
О
О
*
OLC
G
О
ONL
о
я
c_cflag
I i I I I I I I I I I l 1ТЛ
под
SO It» G
Ч О >0
woo
3 P^
ТЭ ТЭ О
egg
g § s
D CD
О О
w w
•-Э и
О N
тэ и
ш
c_lflag I 1 I II I I I I I I I I 1 I I I
§OOMOOOOOOOW
1ПЧХ'Ж«ЯЯДИ>Н
2
о
r
о
3 3
M О
ana
о
73
^ <
О н
s §
Рисунок 5.12
Разряды и символы
в составе членов termios
Член с__сс-это массив управляющих символов. В этом массиве хранятся символы тех
клавиш, при нажатии на которые выполняются различные управляющие функции. Каждый
элемент в массиве определяется константой из файла termios.h. Например, присвоение
значения вида attribs.c_cc[VERASE]-\b' будет означать для драйвера, что он будет
рассматривать ключ backspace как символ стирания.
Программирование драйвера терминала: Битовые операции
Теперь мы знаем, как получить установки драйвера и как их передать драйверу обратно.
Рассмотрим теперь технику модификации атрибутов драйвера.
Каждый атрибут - это бит в составе набора флагов. Маски для атрибутов определены
в файле termios.h. Для проверки значения некоторого атрибута вы должны замаскировать
набор флагов маской для этого бита. Для установления значения некоторого атрибута вы
должны установить соответствующий бит. Для сброса значения атрибута, вы должны
сбросить соответствующий бит. В таблице показаны эти действия.
Действие
Проверка бит
Установка бита
КОД
if(flagest&MASK)...
flagset | = MASK
Очистка бита
flagset &= -MASK
186
Управление соединениями. Изучение stty
5.5.7. Программирование драйвера терминала: Примеры программ
Пример: echostate.c - показать состояние бита echo
Наша первая программа будет сообщать нам об установке символов режима эхо
отображения. Производится чтение установок, проверка бита и вывод результатов проверки.
Г echostate.c
* сообщает, установлен ли бит echo у драйвера терминала, файловый дескриптор fd которого
равен О
* показывает, как читаются атрибуты из драйвера терминала и как проверяются значения бита
7
#include <stdio.h>
#include <termios.h>
main()
{
struct termios info;
intrv;
rv = tcgetattr@, &info); /* читать значения атрибутов драйвера 7
if (rv ==-!){
perrorftcgetattr");
exitA);
}
if (info.c_Iflag & ECHO)
printf(" echo is on, since its bit is 1\n");
else
printfC echo if OFF, since its bit is 0\n");
}
В этой программе читаются атрибуты терминала через файловый дескриптор 0. Нулевой
файловый дескриптор принадлежит стандартному вводу, т. е. такой файловый дескриптор
обычно устанавливается для клавиатуры. Далее показаны команды компиляции и запуска
программы на исполнение:
$ ее echostate.c -о echostate
$./echostate
echo is on, since its bit is 1
$ stty -echo
$./echostatr: not found
$ echo is OFF, since its bit is 0
Пример показывает нам, что по команде stty -echo устанавливается запрет на эхоотображе-
ние в драйвере. Если пользователь будет набирать тексты двух каких-то команд после
указанной команды, то тексты этих команд отображаться на экране не будут. Но при этом
результаты выполнения этих команд отображаются на экране.
Пример: setecho.c - изменить состояние бита echo
Наша вторая программа может переключать режим эхоотображения для клавиатуры. Если
при обращении к программе аргумент будет начинаться с символа "у", то флаг терминала
echo должен быть установлен. В противном случае флаг echo будет сброшен. Программа
выглядит так:
5.5. Атрибуты терминальных соединений
187
Г setecho.c
* обращение: setecho [y|n]
х показывает, как читать, изменять и переустанавливать атрибуты терминала
7
#include <stdio.h>
#include <termios.h>
#define oops(s,x) {perror(s); exit(x);}
mainfintac, char*av[])
{
struct termios info;
if(ac==1)
exlt(O);
if (tcgetattr@,&info) == -1) /* получить атрибуты */
oops("tcgettattrM, 1);
if(av[1][0]==V)
info.cjflag |= ECHO; Г включить бит */
else
info.cjflag &= -ECHO; /* выключить бит */
if (tcsetattr@,TCSAN~OW,&info) == -1) /* установить атрибуты */
oops("tcsetattr",2);
}
Проверим и запустим на исполнение наши две программы и выполним обычную команду
stty:
$ echostate; setecho n; echostate; stty echo
echo is on, since its bit is 1
echo is OFF, since its bit is 0
$ stty -echo; echostate; setecho y; setecho n
echo is OFF, since its bit is 0
В первой командной строке мы использовали программу setecho для выключения режима
эхоотображения. Далее мы использовали команду stty, чтобы восстановить режим
эхоотображения. Драйвер и установки драйвера хранятся в ядре, а не в процессе. Процесс может
изменять установки драйвера. Другой процесс также может читать или изменять установки.
Пример: showtty.c - отобразить набор атрибутов драйвера
Мы можем применить технику, которая была использована в программах setecho.c и echos-
tate.c и разработать полную версию команды stty. Драйвер терминала обрабатывает три
вида установок: специальные символы, числовые значения и битовые значения. В
программе showtty находятся функции для отображения каждого из этих типов данных. Далее
следует код программы:
Г showtty.c
* отображает некоторые текущие установки терминала
7
#include <stdio.h>
#include <termios.h>
main()
8
Управление соединениями. Изучение stty
struct termios ttyinfo; /* эта структура содержит информацию о терминале 7
if (tcgetattr@, &ttyinfo) == -1){/* получить информацию 7
perrorfcannot get params about stdin");
exit(l);
}
Г show info 7
showbaud (cfgetospeed(&ttyinfo)); /* получить + показать baud rate*/
printf(The erase character is ascii %d, Ctrl-%c\n",
ttyinfo.c_cc[VERASE]lttyinfo.cxc[\/ERASE]-H-,A,);
printf('The line kill character \s ascii %d, Ctrl-%c\n",
ttyinfo.c_cc[VKILL]>ttyinfo.c-.cc[VKIЩ-1+,A,);
show some flags(&ttyinfo); /* nc
}
showbaud(int thespeed)
Г
* вывод скорости по-английски
7
{
printf("the baud rate is");
switch (thespeed){
case B300:
case B600:
case В1200:
case В1800:
case B2400:
case B4800:
case B9600:
default:
}
}
struct flaginfo {int fl_value; char *fl_name;};
struct flaginfo input flags[] = {
" IGNBRK,
BRKINT,
I6NPAR,
PARMRK,
INPCK,
ISTRIP,
INLCR,
IGNCR,
ICRNL,
IXON,
Г IXANY,
IXOFF,
O.NULL};
struct flaginfo localjagsn = {
misc. flags 7
рппИС'ЗОО^"); <
printf(M600\nM);
рппй(200\пн);
printf(M1800\nn);
prirrtfl,,2400\n");
printf<800\nM);
printfC^eOOXn");
printf("Fasl\n");
break;
break;
break;
break;
break;
break;
break;
break;
"Ignore break condition",
"Signal interrupt on break", ч
"Ignore chars with parity errors",
"Mark parity errors",
"Enable input parity check",
"Strip character",
"Map NLtoCR on input",
"Ignore CR",
"Map CR to NL on input",
"Enable start/stop output control",
¦ "разрешить некоему символу производить рестарт вывода", */
"Enable start/stop input control",
5.5. Атрибуты терминальных соединений
189
ISIG, "Enable signals",
ICANON, "Canonical input (erase and kill)",
Г _XCASE, "Каноническое проявление upper/lower", */
ECHO, "Enable echo",
ECHOE, "Echo ERASE as BS-SPACE-BS",
ECHOK, "Echo KILL by starting new line",
O.NULL};
show some flags(struct termios *ttyp)
Г
* показывает значения двух флагов в наборе: c_iflag и c_lflag
* добавление флагов c_oflag и c_cflag - это подпрограмма, которая
* добавляет новую таблицу, указанную выше, и биты, как это показано ниже
7
{
showJagset(ttyp->c_iflag, inputjlags);
show flagset(ttyp->c Iflag, local flags);
}
show flagset(int thevalue, struct flaginfo thebitnamesf])
I*
* проверят каждый битовый шаблон и выводит краткое сообщение
7
{
inti;
for (i=0; thebitnames[i].f Ualue; i++) {
printff %s is", thebitnamesp] .fl_name);
if (thevalue & thebitnamesp] .fhralue)
printf("ON\n");
else
printf("OFF\n");
}
}
Программа showtty выводит текущее состояние семнадцати атрибутов драйвера, сопровождая
вывод разъяснительным текстом. Наша программа использует массив структур для
упрощения кода. При вызове функция showjlagset задается целое число и набор флагов драйвера.
В функции show_flagset циклически проверяются все биты и отображается статус каждого из
них. Что потребуется добавить в нашей программе для работы с другими наборами флагов?
Что еще нужно добавить в эту программу, чтобы она работала как полная версия stty?
5.5.8. Итоговые замечания по соединениям с терминалами
Терминал - это устройство, которое используется человеком для связи с процессами Unix.
Терминал имеет клавиатуру, с которой процесс читает символы, и дисплей, на котором
отображаются символы, выдаваемые процессом. Терминал - это устройство. Поэтому он
представлен как специальный файл в дереве каталогов. Обычно он заносится в каталог /dev.
Передача и обработка данных между процессом и терминалом происходит под
управлением драйвера терминала, который является частью ядра. Этот код ядра поддерживает
буферирование, редактирование и преобразование данных. Программы могут проверять
значения и модифицировать значения установок этого драйвера с помощью функций
tceetattr и tcsetattr.
190
Управление соединениями. Изучение stty
5.6. Программирование других устройств: ioctl
Соединение с дисковым файлом имеет один набор атрибутов, а соединение с терминалом
имеет другой набор. А что можно сказать относительно соединений с другими типами
устройств?
Рассмотрим пишущие CD. Перезаписываемые CD можно стирать. На CD можно
проводить запись с разными скоростями. Сканеры имеют собственный набор установок, таких
как разрешение при сканировании и глубина цвета. У других типов устройств также
имеются собственные наборы установок. Как прбграммист может проверять и управлять
установками для устройств?
С каждый файлом устройства может работать системный вызов ioctl:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
ioctl
Управление устройством
#include < sys/ioctl.h >
int result = ioctl (intfd, int operation [, arg..])
fd - файловый дескриптор устройства
operation - операция, которую необходимо выполнить
arg... - аргументы, необходимые для выполнения операции
-1 - при ошибке
Другие значения зависят от устройства
Системный вызов ioctl позволяет получить доступ к атрибутам драйвера устройства
и к операциям над атрибутами. Драйверу соответствует файловый дескриптор/^. Каждый
тип устройства имеет собственный набор свойств и ioctl операций.
Например, экран терминала имеет размер, который измеряют числом строк и числом
колонок в строке или в пикселях. Следующий ниже код.
#include <sys/ioctl.h>
. void print screen_dimensions()
{
struct winsizewbuf;
if (ioctl@, TIOCGWINSZ, &wbuf) != -1){
printf("%d rows x %d cols\n", wbuf.wsjow, wbuf.ws_col);
printf("%d wide x %d tall\n", wbuf.ws xpixel, wbuf.ws ypixel);
}
}
выполняет вывод значения размера экрана. Здесь TIOCGWINSZ - это имя кода функции,
а адрес wbuf является аргументом при обращении к этой функции управления устройством.
Лучшим способом изучения типов устройств и их функций является чтение заголовочного
файла. В документации на устройства также приведены списки свойств и функций.
Например, при обращении к справочнику Linux за документом stD), получим детальное
описание вариантов использования ioctl для управления ленточным устройством SCSI.
5.7. О небо! Это файл, это устройство, это поток!
В Unix файл рассматривается либо как источник данных, либо как приемник данных.
Основные системные вызовы применимы в равной степени как к дисковым файлам, так
и к файлам устройств. Различия возникают в действиях, которые происходят в
соединениях. В файловом дескрипторе для дискового файла содержится код для буферирования
Заключение
191
и присоединения данных. Файловый дескриптор для терминала содержит код, который
производит редактирование, поддерживает эхоотображение, преобразование символов,
а также другие операции.
Мы описали каждый шаг по обработке, как атрибут соединения. Но вместо этого можно
также сказать, что соединение - это просто комбинация шагов по обработке. System V Unix,
являющаяся одним из вариантов Unix, была разработана AT&T в 80-х годах. В этой системе
была предложена модель потока данных. Основаная идея модели - построение
последовательности шагов обработки. Это напоминает последовательность действий при мытье
автомобиля. Сначала ваш автомобиль обрызгивают моющим раствором. Затем смывают грязь
с помощью больших щеток. Далее смывают грязь с поверхности, что делают с помощью
мыльного раствора из шлангов с высоким давлением. Накладывается антикоррозийный
ингибитор, набрызгивается горячий воск и накладывается полировка для хромированных
колпаков. Наконец, обрабатывают поверхность мягкой тканью и горячим воздухом. Все,
дело сделано!
Конечно, каждый этап является отдельной операцией, которую захотел выполнить
владелец автомобиля. Владелец выбрал их из последовательности тех операций, на которые
в данной компании был разбит процесс помывки машины. Кроме того, вы можете
отказаться от некоторых конкретных шагов. (Но, пожалуйста, не отказывайтесь от шага
нанесения горячего воска!)
То, что было описано, представляет собой в огрубленном виде идею модели ПОТОКОВ
(STREAMS) относительно данных и атрибутов соединений. Элегантной частью
потоковой "модели является модульность обработки. Если вы не удовлетворены драйвером
терминала, который поддерживает только такие скучные операции как преобразование
символов из нижнего регистра в верхний и наоборот, то вы можете разработать и
инсталлировать модуль для перевода цифр в римские цифры. Итак, вы должны написать
обрабатывающий модуль, который выполняет преобразования арабских цифр в римские.
Вы должны были написать его в соответствии со спецификациями модуля STREAMS.
Затем следует использовать специальные системные вызовы для правильной инсталляции
этого модуля между шагом отделки колпака и шагом протирки мягкой тканью. Когда ваш
автомобиль достигнет конца мытья, то все цифры на приборном щитке будет заменены на
римские.
Обратитесь к вашему справочнику за документами по теме streamio, чтобы более
подробно изучить вопросы управления свойствами соединений. ПОТОКИ используются в
некоторых версиях Unix для реализации сетевых служб.
Заключение
Основные идеи
• Ядро передает данные между процессами и теми объектами, которые находятся извне.
Такими внешними объектами могут быть дисковые файлы, терминалы и периферийные
устройства (принтеры, ленточные устройства, звуковые карты, мыши). Соединения
с дисковыми файлами и соединения с устройствами имеют как подобия, так и отличия.
• Дисковые файлы и файлы устройств имеют имена, свойства и разряды прав доступа.
Как для файлов, так и для устройств можно использовать стандартные файловые
системные вызовы: open, read, write, close и Iseek. Управление доступом к устройствам
происходит с помощью разрядов прав доступа к файлам. Управление происходит
точно так же, как это происходит при работе с дисковыми файлами.
192
Управление соединениями. Изучение stty
• Соединения с дисковыми файлами отличаются от соединений с файлами устройств
в методах обработки и передачи данных. Код ядра, который управляет соединениями
с неким устройством, называют драйвером устройства. Процесс может читать и
изменять установки в драйвере устройства с помощью системных вызовов fcntl и ioctl.
• Соединения с терминалами являются настолько важными, что были разработаны
специальные функции tcgetattr и tcsetattr, с помощью которых можно контролировать
работу драйверов терминалов.
• Unix команда stty предоставляет пользователю доступ к функциям tcgetattr и tcsetattr.
Визуальное заключение
Драйвер порта
принте|
Рисунок 5.13
Файловые дескрипторы, соединения и драйверы
Процесс использует системные вызовы read и write для извлечения данных из файлового
дескриптора и помещения данных в него соответственно. Файловые дескрипторы можно
устанавливать для связи с дисковыми файлами, терминалами и периферийными
устройствами. Файловый дескриптор приводит процесс к драйверу устройства. Драйвер
устройства имеет установки.
Что дальше?
Чтение данных с дисков производится достаточно просто, а вот чтение данных, которые
поступают от людей, может быть достаточно изощренным, поскольку люди ведут себя
весьма непредсказуемо. Программы, которые разрабатываются для чтения данных,
которые поступают от людей, могут использовать свойства терминального драйвера по
управлению соединением. В следующей главе мы более детально рассмотрим некоторые
темы программирования в отношении пользовательских программ.
Исследования.
5.1 На Linux-машине легко читать данные, поступающие от мыши. Чтобы достичь этого,
вам необходимо находиться в текстовом режиме. Находясь в shell, убедитесь в том,
что не работает программа gpm. Для этого наберите gpm -k. Затем выполните cat /dev/
mouse. Теперь перемещайте мышь и нажимайте на кнопки. Команда cat будет читать
Заключение
193
данные из файла устройства. Те байты, которые будут прочитаны, будут
соответствовать сообщениям о таких событиях, как нажатия на кнопки и перемещение мыши.
5.2 Каково назначение бита, разрешающего исполнение для файла устройства? Изучите
команду biff, чтобы получить представление об использовании этого бита.
5.3 Операции над каталогами и файлы устройств. Мы обсудили, как работают операции
ввода/вывода для файлов устройств. А что можно сказать относительно операций над
каталогами типа In, mv, rm и т. д. Используя рисунок 5.1, объясните, каким образом
будут воздействовать эти три команды на каталоги, inodes и на драйверы.
5.4 rm и специальные файлы. Команда rm и лежащий в ее основе системный вызов unlink
удаляют ссылку на inode. Если число ссылок на inode достигнет нуля, то ядро
освобождает дисковые блоки и inode (Которые относятся к файлу, имя которого указано в
команде. -Примеч. пер.) В inode устройства нет списка распределения. Файл
устройства не содержит блоков данных. Вместо этого в inode для файла устройства содержится
указатель на подпрограмму устройство-драйвер в ядре. Если вы удалите имя файла
для устройства и ядро отметит соответствующий inode как свободный, то драйвер при
этом останется в ядре. Как можно будет создать новый файл устройства и соединить
его с устройством?
(Подсказка: почитайте документацию о системном вызове mknod.)
5.5 Рассмотрим условия гонок, которые возникают при присоединении данных к файлу.
В обсуждении проблемы, которое было представлено в тексте книги,
рассматривалась одна из возможных последовательностей планирования. Сколько можно
составить управляющих последовательностей в отношении двух операций для двух
процессов? Что должно происходить при выполнении каждой их этих
последовательностей?
5.6 Обратитесь к коду ядра Linux и найдите там место, где можно увидеть, как
проверяется бит 0_APPEND. Как реализуется автоматический переход в конец файла?
5.7 Как работает системный вызов rename? Системный вызов rename является
атомарной операцией. Из каких шагов состоит этот целостный вызов? Найдите код в ядре
некоторого варианта Unix и рассмотрите все условия гонок и возможные конфликты,
которые могут возникнуть при управлении. Комментарии, которые вы можете найти
в ядре Linux, выглядят весьма неряшливо и забавно.
5.8 Стандартная библиотечная функция fopen поддерживает открытие файла в режиме
append (режим добавления в конец файла). Например, fopen ("data","a"). Как
устанавливается на вашей системе режим append - с помощью OAPPEND или с помощью
lseek выполняется переход в конец файла после его открытия? Найдите исходный код
для функции fopen или проведите эксперимент и напишите программу, которая
дважды открывает один и тот же файл в режиме присоединения, а затем поочередно
производит запись в два потока.
5.9 Проверка работы программы echostate с другими устройствами. Программа echos-
tate.c оповещала о состоянии бита echo в драйвере для файлового дескриптора 0.
Используйте оператор перенаправления < для присоединения стандартного ввода
к другим файлам или устройствам. Проведите такой эксперимент:
echostate < /dev/tty
echostate </dev/lp
echostate < /etc/passwd
echostate < 'tty
Объясните результаты, которые будут получены после работы каждой их этих команд.
194
Управление соединениями. Изучение stty
5.10 Изменение атрибутов других терминалов. Программа setecho позволяла изменять
бит echo в драйвере, присоединенном к стандартному вводу. Если вы перенаправите
стандартный ввод на другой терминал, то вы можете изменить бит echo для этого
терминала.
Проведите такой эксперимент:
(a) Войдите дважды в систему на одной и той же машине (или сразу откройте два окна).
(b) Выполните в каждом окне команду tty, чтобы определить имена файлов устройств
для этих двух окон. Скажем, одно из них будет связано с файлом устройства /dev/
ttyp 1, а другое - с файлом устройства /dev/ttyp2.
(c) В окне ttypl выполните setecho n < /dev/ttyp2
(d) В окне ttyp2 выполните команду echostate
(e) Теперь в ttypl выполните команду echostate < /dev/ttyp2
@ Объясните эффект от того, что в результате получилось,
(g) Попытайтесь выполнить то же с обычной командой stty.
Вы когда-нибудь поймете, что полученные результаты чрезвычайно полезны.
5.11 Файлы устройств и управление терминалом. Примеры в тексте использовали
значение 0 для файлового дескриптора в вызовах tcgetattr и tcsetattr. Первый аргумент при
обращении к вызову - это файловый дескриптор. Он может быть любым значением,
с помощью которого производится ссылка на связь с терминальным устройством.
Файловый дескриптор 1 ссылается на стандартный вывод. Модифицируйте
программы echostate и setecho так, чтобы использовать файловый дескриптор 1 вместо 0. Как
это повлияет на работу программ? Часто стандартный ввод и стандартный вывод
ссылаются на терминал. Объясните, что будет при таком перенаправлении: echostate »
echostate.log. Какие преимущества от использования файлового дескриптора 0?
5.12 Если вы хотите установить систему с присоединением ррр соединений, то вам
понадобится инсталлировать модем и произвести конфигурацию последовательного
порта. Терминальный драйвер для последовательного порта может быть
сконфигурирован для работы с модемом. Почитайте документацию о файлах /etc/gettydefs и
/etc/inittab, чтобы понять, как Unix определяет терминальные установки для
вхождений по последовательным линиям связи.
5.13 В некоторых версиях Unix поддерживаются три варианта использования OSYNC:
только для блоков данных, только для inodes, то и другое вместе. Почему вам может
потребоваться использовать одну из версий? Как называются флаги, которые
контролируют работу в каждой из этих версий?
5.14 Каково назначение прав на чтение и запись при управлении терминальным
специальным файлом? Используйте tty, чтобы определить имя вашего терминала, а потом
выполните команду chmod 000 /dev/yourtty, чтобы сделать ваш терминал недоступным
на чтение даже для вас. Что после этого произойдет? Почему?
5.15 Обратитесь к каталогу /dev на вашей системе и найдите там файлы, которые не
поддерживают read, файлы, которые не поддерживают write, файлы, которые не
поддерживают Iseek.
5.16 Используйте Is -I в каталоге /dev, чтобы посмотреть на старшие и младшие номера
различных устройств. Какой формат вы видите? Какие устройства разделяют один и тот
же главный номер? Что общего у этих устройств, в чем они различаются?
5.17 Назовите имя для каждой из четырех групп установок для tty драйвера, объясняет
назначение каждой группы и назовите имя двух бит в каждой группе.
Заключение
195
5.18 Программа использует stcsetattr для выключения режима echo для текущего
терминала. Когда эта программа заканчивается, то терминал остается в режиме с
отключенным echo. Но с другой стороны, когда программа открывает файл и использует fcntl
для установке дескриптора в режим OAPPEND, то следующая программа, которая
открывает этот файл, не получает возможности установить режим auto-append.
Объясните эту явную несовместимость.
5.19 Соединением с терминалом является обыкновенный файловый дескриптор. Можно ли
использовать вызов fcntl для установки атрибута OAPPEND в файловом
дескрипторе? Что означает режим auto-append для устройств?
5.20 В чем заключается разница между ioctl и fcntl?
5.21 В каталоге /dev содержатся файлы /dev/null и /dev/zero. Эти файлы не представляют
собой реальное соединение с устройствами, но это также и не дисковые файлы.
Каково назначение этих файлов и для чего они могут быть полезны? Можно ли найти
в каталоге /dev еще файлы, которые являются виртуальными устройствами, как эти
два файла?
Программные упражнения
5.22 Расширьте версию программы write, которая была представлена в главе.
Представленная версия требовала, чтобы пользователь указывал имя файла устройства. В этой
версии не выводились начальные идентификационные приветствия. Напишите новую
версию, для которой при обращении можно будет указывать в качестве аргумента имя
пользователя. Эта версия будет выводить на экран сообщение о том, какой
пользователь приглашает вас к взаимодействию. Посмотрите, как это делается в обычной
версии команды write.
Ваша программа должна предусматривать обработку при возникновении ряда особых
ситуаций. Например, лицо, с которым вы хотели бы вступить во взаимодействие,
может просто не работать в системе. Другая ситуация, когда лицо, с которым вам
хотелось бы взаимодействовать, могло войти в систему сразу с нескольких терминалов.
5.23 Пользователи, которые не хотят, чтобы им мешали другие пользователи,
выполняющие команду write, могут использовать команду mesg. Почитайте документацию
по этой команде. Поэкспериментируйте с командой и посмотрите, как она работает.
Затем напишите версию этой программы.
5.24 Использование linkQ для блокировки. Условие гонок возникает в ситуации, когда два
процесса пытаются одновременно модернизировать один и тот же файл. Например,
когда вы изменяете ваш пароль на некоторой системе, то программа passwd
перезаписывает некоторую информацию в файле /etc/passwd. А что произойдет, если два
пользователя попытаются одновременно изменить свои пароли? Один из подходов по
предотвращению одновременного доступа к файлу заключается в использовании
важного свойства системного вызова link. Рассмотрим код:
Г
* Программа пытается построить ссылку /etc/passwd.LCK
* После выполнения программы код возврата равен 0, если ссылка была построена,
* 1 - если уже есть блокировка, 2 - если возникли другие проблемы
7
int lock passwd()
{
int rv = 0; Г код возврата по умолчанию */
196
Управление соединениями. Изучение stty
if (link("/etc/passwd", "/etc/passwd.LCK") == -1)
rv = (errno==EEXISTS?1 :2);
return rv;
}
(a) Если два процесса попытаются одновременно выполнить этот код, только одному
из них удастся достичь успешного решения. Что вы можете сказать о системном
вызове link, который может служить полезным средством для установления
блокировки доступа к файлам?
(b) Напишите короткую программу, которая использует метод присоединения строки
текста к файлу. Ваша программа должна попытаться построить ссылку с помощью
link. Если попытка создания ссылки будет успешной, то программа может далее
открыть файл, присоединить строку, а затем удалить связь. Если попытка построения
ссылки будет неуспешной, то программа должна использовать системный вызов sleep
A), чтобы подождать одну секунду и потом повторить попытку построения ссылки.
При программировании требуется позаботиться о гарантии, чтобы ваша программа не
ждала бы бесконечно долго.
(c) Напишите функцию unlock_passwd, которая отменяет действие lock_passwd.
(d) В примере показан способ, как процессы могут блокировать доступ к
существующему файлу. Но как может программа, где используется link, предотвратить
возможность попытки одновременного процесса одного и того же файла?
(e) Изучите команду vipw. Может ли vipw использовать links для установления
блокировок?
5.25 Связи и блокировки, часть II В предшествующей задачи показано, как при
возникновении проблемы гонок можно использовать связи для установления блокировок на
файлы. Блокировка на файл должна быть снята, когда программа, которая установила
блокировку, закончит модификацию файла. Если программа не снимет блокировку
файла, то другие программы будут ждать доступа к этому файлу неопределенно
долго. А что будет, если в программе (Которая установила блокировку - Примеч. пер.)
есть ошибки и она аварийно закончилась или она была "убита" пользователем,
который нажал на клавиши Ctrl-C? И все это произошло до сброса программой
блокировки на файл.
Один из вариантов решения проблемы - в программе, которая установила
блокировку, выполнять модификацию файла каждые п секунд. Для этого программа моэкет
использовать utime. Программы, которые ожидают по условию блокировки, могут
проверять время модификации, чтобы убедиться - находится или нет файл в "теплом
"состоянии. Если блокировка не была модифицирована на установленном временном
интервале, то другие программы будут в праве удалить связь с тем, чтобы потом
повторно ее установить.
Напишите новую версию функции lock_passwd, которая при вызове получает в
качестве аргумента значение длительности интервала в секундах. Эта новая версия
должна реализовать логику, которая была описана в предыдущем параграфе.
Заключение
197
5.26 Как скажется на производительности, если вы отключите механизм буферизации?
Напишите программу, которая производит запись в большой файл. Запись
производится небольшими порциями. Например, запись производится частями в 16 байт
в файл размером 2 Мегабайта. Попытайтесь писать в файл в ситуациях, когда
установлен атрибут 0_SYNC и когда атрибут 0__SYNC не установлен.
Поэкспериментируйте с размерами файла и размерами записываемых порций. Посмотрите, как это
будет влиять на результаты работы.
5.27 В рассмотренном ранее тексте есть программный код, где выключается дисковая
буферизация для файлового дескриптора. Напишите функцию, которая включала бы
механизм буферизации.
5.28 Напишите программу uppercase.c, которая могла бы переключать бит OLCUC в
драйвере терминала и оповещала бы о текущем состоянии этого бита.
5.29 Размер окна u ioctl В выводе команды stty -а есть информация о числе строк и
колонок в терминальном окне. Эти значения исходят не от tcgetattr, исходят ioctl.
Используйте этот системный вызов для модификации версии программы more из главы 1
с тем, чтобы программа использовала устанавливаемый размер экрана терминала
вместо фиксированного значения 24.
Проекты
На основе материала этой главы вы можете изучить документацию и написать версию
следующих программ Unix:
write, stty, passwd, wall, biff, mt (программа управления ленточным устройством; может
отсутствовать на вашей системе).
Глава 6
Программирование дружественного
способа управления терминалом
и сигналы
Цели
Идеи и средства
• Инструментальные программные средства или пользовательские программы.
• Чтение и изменение установок драйвера терминала.
• Режимы работы драйвера терминала.
• Неблокируемый ввод.
• Таймауты на пользовательский ввод.
• Введение по теме сигналов: Как работает Ctrl~C.
Системные вызовы
• fcntl
• signal
6.1. Инструментальные программные средства
В системе Unix устройства во многом выглядят аналогично дисковым файлам. Но
устройства - это не то же, чем является дисковый файл. В главе 5 нами была рассмотрена
возможность использования системных вызовов open, close, read, write, lseek в отношении
устройств. Но мы также видели, что устройства имеют драйверы, и эти драйверы имеют
большое число атрибутов и средств управления устройствами. Как программам относиться
к этой двойственности?
6.1. Инструментальные программные средства
199
Инструментальные программные средства:
в stdout
Чтение из stdin или из файлов, запись
Программы, которые не ощущают разницы между дисковыми файлами и устройствами,
называют инструментальными программными средствами (Эти средства чаще всего
называют утилитами. - Примеч. пер.) В системах Unix используют сотни инструментальных
программных средств таких, как who, Is, sort, uniq, grep, tr, du. Эти средства построены на основе
модели, которая представлена на рисунке 6.1.
Стандартный
ввод
Особенность: большинство процессов
автоматически получают открытыми
первые три файловых дескриптора.
Процессам не нужно выполнять
системный вызов ореп()
для получения таких дескрипторов
Рисунок 6.1
Три стандартных
файловых дескриптора
Инструментальные программные средства читают данные со стандартного входа,
производят некоторую обработку данных, записывают результирующий выходной поток
байтов на стандартный вывод. Утилита посылает сообщения об ошибках, которые опять
же рассматриваются как поток байтов, на стандартный вывод сообщений об ошибках.
С файлами, терминалами, мышью, фотоэлементами, принтерами, программными
каналами должны быть соединены три файловых дескриптора. Утилиты не обращают
внимания на то, каков источник поступления данных на обработку и каков приемник
полученных результатов обработки. Многие из таких программ читают информацию из
файлов, имена которых задаются при обращении к команде в командной строке.
Ввод и выход для таких программ может быть присоединен ко всем типам соединений:
$ sort > outputfile
$ sort x > /dev/lp
$who|tr,[a-z],,[A-Z]f
Программы, ориентированные на устройства: Управление устройством в конкретном
применении
Однако есть и другие программы, которые написаны для взаимодействия с конкретными
устройствами. В качестве примера можно назвать программы для управления сканерами, для
записи компакт дисков, для работы с ленточными накопителями, для производства цифровых
фотографий. В этой главе мы изучим идеи и средства написания программ, ориентированных
на конкретные устройства. Мы познакомимся с наиболее общими типами таких программ.
Это программы, которые взаимодействуют с терминалами, которые разработаны специально
для удобного использования человеком. Мы будем далее называть такие терминально
ориентированные программы пользовательскими программами.
200 Программирование дружественного способа управления терминалом и сигналы
, Пользовательские программы: Общий тип программ, ориентированных на устройства
Примерами пользовательских программ являются vi, emacs, pine, more, lynx, hangman, robots
и многие игры, которые были разработаны в University of California at Berkeley1 Такие
программы управляют установками в драйвере терминала. После чего могут отслеживать
нажатия на клавиши и контролировать вывод..
При работе.с драйвером можно использовать большое количество установок. Но для
пользовательских программ, прежде всего, необходимы такие:
(a) Немедленный отклик на нажатие ключей (клавиш).
(b) Лимитированный входной набор.
(c) Таймаут на входе.
(d) Защита от нажатия на клавиши Ctrl-C.
Мы изучим эти темы при написании программы, где будут реализованы все эти свойства.
6.2. Режимы работы драйвера терминала
В предшествующей главе было начато обсуждение, касающееся драйвера терминала.
Теперь мы изучит драйвер более детально, что будет сделано с помощью эксперимента
с короткой программой преобразованиям
/* rotate.c: map a- >b, b- >c,.. z- >a
* назначение: полезна для показа режимов работы tty
7
#include <stdio.h>
#include <ctype.h>
intmain()
{
int c;
while ((c=getchar()) != EOF){
if(c —?)
c = ,a';
else if (islower(c))
C++;
putchar(c);
}
}
6.2,1. Канонический режим: Буферизация и редактирование
Запустите приведенную программу, в которой используются установки по умолчанию
(<- это клавиша backspace):
$ сс rotate.c -о rotate
$./rotate
abx<-cd
1. Исходные коды таких программ можно найти через Web. Следует искать bsdgames.
6.2. Режимы работы драйвера терминала
201
bcde
etgCtr/'C
$
На рисунке 6.2 показаны терминал, ядро, программа rotate и потоки данных.
Драйвер
терминала
[тт
ж
Программа
rotate
штитжкююттклжттт^
Рисунок 6.2
То, что вы набираете, и то,
^ что получает программа
В ходе нашего эксперимента обнаружились следующие свойства обработки стандартного
ввода:
(a) Программа никогда не сможет воспринять символ "х". Символ стирается при
вводе ключом backspace.
(b) Символы воспроизводятся на экране по мере того, как вы их набираете на
клавиатуре.
(c) Символы, набираемые на входе, не поступают в программу до тех пор, пока не
будет нажата клавиша Enter.
(d) Ключ Ctrl-C прерывает ввод и останавливает программу.
В программе rotate нет перечисленных операций. Буферирование, эхоотображение,
редактирование и обработка управляющих ключей - все это делается терминальным
драйвером. На рисунке 6.3 изображены эти операции в виде уровней в драйвере.
Буферирование и редактирование совместно составляют каноническую обработку. Когда
эти возможности установлены, то говорят, что терминальное соединение работает
в каноническом режиме.
202
Программирование дружественного способа управления терминалом и сигналы
Обработка ввода:
редактирование
преобразование
У в У
echo —
Отработка
управляющих символов
Программа
rotate
Выходная обработка
Рисунок 6.3
Обрабатывающие уровни
в драйвере терминала
6.2.2. Неканоническая обработка
Проведем теперь такой эксперимент (опять вводим: abx<-cd, затем вводим efg Ctrl-C):
$ stty -icanon;. /rotate
abbcxyA?cdde
effggh
$ stty icanon
Команда stty -icanon выключает канонический режим обработки в драйвере. На печатной
странице трудно в полной мере ощутить особенности неканонического режима. Вывод
выше показывает, как изменится обработка на входе. (В протоколе результатов жирным
шрифтом выделено то, что вводит пользователь, а не жирным - результат работы
программы. -Примеч. пер.)
В неканоническом режиме, в частности, нет буферирования. Когда вы нажимаете на клавишу
"а", то драйвер обходит уровень буферирования и доставляет этот символ программе rotate,
которая выведет на экран символ "Ь". При использовании небуфери-рованного
пользовательского входа могут возникнуть неприятности. Когда пользователь попытается
стереть введенный символ, то драйвер в ответ не может этого сделать. Символ уже был
размещен в пользовательскую память.
Для окончания эксперимента выполните командные строки, которые следуют ниже, и опять
наберите abx<-cd, а затем efg Ctrl-C.
$ stty -icanon -echo; ./rotate
bcyA?de
fgh
$ stty icanon echo (Замечание: Вы этого не увидите. Почему?)
В этом примере мы выключили канонический режим, а также выключили режим эхоотобра-
жения. После этого драйвер не будет отображать те символы, которые мы набираем. Будет
отображаться только вывод из программы. Когда вы закончите исполнение программы,
то драйвер останется в режиме без эхоотображения, в неканоническом режиме. Драйвер
остается в этом состоянии до тех пор, пока программа не изменит его установки.
Интерпретатор shell выводит приглашение и ждет ввода от вас текста очередной командной
строки. Некоторые интерпретаторы сбрасывают установки драйвера, а некоторые не делают
этого. Если ваш shell не сбрасывает установки драйвера, то вы будете продолжать работу без
эхоотображения и в неканоническом режиме.
6.2. Режимы работы драйвера терминала
203
6.2.3. Итоговые замечания по режимам терминала
Если вы еще не потренировались с примерами на терминале, то сделайте это теперь. Эти
примеры показывают, что драйвер терминала может работать в различных режимах. Когда
вы разрабатываете программу для Unix, то вам необходимо решить - какой терминальный
режим для приложения вы выбираете.
канонический режим
Канонический режим, который называют еще cooked режим, - это режим, в котором чаще
всего будут работать пользователи.
Драйвер накапливает входящие символы в буфер. Он посылает эти символы из буфера
программе, когда определит, что нажат ключ Enter2. Буферирование данных позволяет
драйверу выполнять базовые функции редактирования, такие, как удаление символа, слова
или целой строки. Эти функции начинают выполняться, когда пользователь нажимает
соответственно на ключи: erase, word-erase или kill.
Вызов этих трех функций закрепляется за специальными клавишами, что записано
в драйвере в качестве установок. Эти установки можно изменить с помощью команды stty
или системного вызова tcsetattr.
неканонический режим или crmode
Когда выключено действие функций буферирования, а следовательно, и функций
редактирования, то говорят, что соединение работает в неканоническом режиме. Но драйвер
терминала все также поддерживает обработку специальных символов, таких, как Ctrl-C,
поддерживает преобразование символов newline в carriage return. Однако клавиши erase,
word-erase, kill утрачивают свой специальный смысл. Поэтому коды этих клавиш будут
рассматриваться драйвером как обычные данные.
Если вы пишете программу, которая использует неканонический режим, и вы захотите
использовать редактирование при вводе, то вам придется написать в вашей программе
функции редактирования.
"никакой" режим или raw mode
Также для управления каждым шагом обработки используются отдельные биты.
Например, бит ISIG указывает на то, что нажатие на ключ прерывания (обычно это Ctrl-C)
приведет к обычному действию - программа будет "убита". В программе можно выключить
все шаги по обработке.
Когда выключены все шаги обработки, то драйвер передает ввод непосредственно программе.
В таком случае говорят, что драйвер работает в raw режиме (Буквально - в сыром режиме. -
Примеч. пер.) Этот режим был впервые использован в Olden Days ® когда драйвер терминала
был гораздо проще. Там он и получил название raw-режим. В команде stty установка raw
режима производится с помощью определенной опции. Назначение raw режима для команды stty
представлено в документации.
Драйвер терминала - это набор подпрограмм в ядре. Роль различных компонентов
драйвера становится все более ясной по мере изучения и проведения экспериментов с
драйвером. На рисунке 6.4 представлены наиболее важные части.
2. Или при нажатии на ключ, обозначающий конец файла. Обычно это Ctrl-D.
204 Программирование дружественного способа управления терминалом и сигналы
¦ Обработка вывода
Буфер чтения.
Буфер
редактирования
Канонический?
Преобразование
Рисунок 6.4
Основные компоненты
драйвера терминала
Несколько режимов работы терминала были разработаны потому, что каждый из них по-
своему полезен. Для понимания практической значимости этих режимов мы разработаем
пользовательскую программу, которая использует различные режимы работы драйвера.
6.3. Написание пользовательской программы: piay_again.c
Во многих пользовательских приложениях, таких как приложения для банкоматов или
в видео играх, пользователю задают вопросы, предполагающие ответы в форме yes/no.
Следующий ниже shell-скрипт является главным циклом обработки при работе банкомата:
#!/bin/sh
#
# atm.sh - это "обертка" для двух программ
#
while true
do
do_aJransaction # запустить программу
if play_again # запустить нашу программу
then
continue # если "у", то повторить цикл
fi
break # если "п", то прервать цикл обработки
done
Используя типичный стиль Unix, работу с банковской машиной можно представить как
скрипт, который содержит отдельные компоненты. Первым компонентом является
программа do_a_transaction, которая воспроизводит работу банкомата (ATM). Вторым
компонентом является программа play_again, которая получает от пользователя ответы - либо
yes, либо по. Мы напишем эту вторую программу. Такая компонентная архитектура
позволяет нам легко присоединить playagain к последующим реализациям.
6.3. Написание пользовательской программы: play_again.c
Логика play_again.c проста:
обращение к пользователю с вопросом,
получение ответа,
если "у", то возвратить О,
если un", то возвратить 1.
Пример: play_again0.c - выполнение задания
Г play_again0.c
* назначение: обращение к пользователю с вопросом - хочет ли он получить
* некую транзакцию
* метод: задать вопрос, ожидать ответа yes/no
* коды возврата: 0=>yes, 1=>no
* усовершенствования: устраняется потребность в нажатии на клавишу return
7
#include <stdio.h>
#include <termios.h>
tdefine QUESTION "Do you want another transaction"
int get_response(char *);
intmain()
{
int response;
response = getjesponse(QUESTION); /* получить какой-то ответ */
return response;
}
int get response(char *question)
Г
* назначение: задать вопрос и ждать ответа у/п
* метод: использовать getchar и игнорировать ответы, которые не отвечают
- * форме у/п
* коды возврата: 0=>yes, 1=>no
7
{
printff %s (у/п)?", question);
whileA){
switch(getchar()){
case у:
case Y: return 0;
case 'n':
case'N':
case EOF: return 1;
206 Программирование дружественного способа управления терминалом и сигналы
Эта программа выводит вопрос и далее переходит в цикл, считывая ввод от пользователя
до тех пор, пока пользователь не наберет какой-либо из симоволов: "у" или "n", "Y" или
"N". В программе play_againO есть две проблемы, которые явились следствием
использования канонического режима. Во-первых, пользователь нажимал на ключ Enter для того,
чтобы программа play_againO могла бы приступить к обработке ввода. Во-вторых,
программа принимала и обрабатывала всю строку данных после того, как пользователь нажимал
на Enter. Поэтому программа play_agaipO после такого с ней взаимодействия:
$ play_againO
Do you want another transaction (y/n)? sure thing!
сочтет, что ответ на ее вопрос был отрицательный. Нашим первым улучшением этой
версии программы явился отказ от канонического режима ввода для того, чтобы
программа принимала и обрабатывала символы по мере нажатия пользователем на клавиши.
Пример: play_again1 .с - немедленный ответ
/*play_again1.c
назначение: обращение к пользователю с вопросом - хочет ли он получить
* некую транзакцию
* метод: установить терминал в посимвольный режим (char-by-char), читать
* символ, возвратить результат
* коды возврата: 0=>yes, 1=>no
* усовершенствования : не отображать неподходящий ввод
7
#include <stdio.h>
#include <termlos.h>
#define QUESTION "Do you want another transaction"
maln()
{
int response;
ttyjnode(O); /* сохранить режим терминала */
set_crmode(); /* установить режим chr-by-chr */
response = getjesponse(QUESTION); /* получить некий ответ */
tty_mode( 1); /* восстановить режим терминала */
return response;
}
int get response(char ^question)
Г
* назначение: задать вопрос и ждать ответа у/п
* метод: использовать getchar и выражать недовольство по поводу ответов,
* представленных не в форме у/п
* коды возврата: 0=>yes, 1 =>по
7
{
int input;
printf("%s (у/п)?", question);
whileA){
switch(input = getchar()){
6.3. Написание пользовательской программы: р/ау_ада/п. с
207
case У:
case T: return 0;
case 'n':
case'N':
case EOF: return 1;
default:
printf("\ncannot understand %c,", input);
printff'Please type у or no\n");
}
}
}
set crmode()
Г
* назначение: получить файловый дескриптор 0(т. е. stdin)B режиме chr-by-chr
* метод: использовать разряды в структуре termios
7
{
struct termios ttystate;
tcgetattr@, &ttystate); /* читать текущие установки */
Jtystate.cjflag &= - ICANON; /* без буферизации */
ttystate.c_cc[VMIN] = 1; /* получать за раз 1 символ */
tcsetattr@, TCSANOW, &ttystate); /* инсталляция установок */
}
/* how == 0 => save current mode, how == 1 => restore mode 7
tty_mode(int how)
{
static struct termios original_mode;
if (how ==0)
tcgetattr@, ioriginaLrnode);
else
return tcsetattr@, TCSANOW, &original mode);
}
В программе play_again1 прежде всего выполняется перевод терминала в посимвольный
(character-by-character) режим. Затем вызывается функция для вывода приглашения и для
получения ответа. Наконец, производится восстановление режима работы терминала.
Заметим, что в конце мы не переводим драйвер в канонический режим. Вместо этого мы
сначала копируем первоначальные установки в структуру originaljnode, а потом эти
установки восстанавливаются.
Перевод терминала в посимвольный режим состоит из двух частей. Мы сбрасываем бит
ICANON и устанавливаем в 1 элемент VMIN в массиве управляющих символов. Такое значение
VMIN указывает драйверу, сколько символов он должен однократно считывать при вводе.
Мы хотим производить посимвольное считывание, поэтому было установлено значение 1.
Если бы нам потребовалось читать по три символа3, то нужно было бы установить число 3.
3. Я это использовал для управления функциональными ключами. На моей клавиатуре функциональные ключи
посылают многосимвольные последовательности, такие, как escape-[-l-l- ~. Когда моя программа читает символ
escape (код ASCII равен 27), то она предполагает три или четыре символа в строке.
208 Программирование дружественного способа управления терминалом и сигналы
Откомпилируем и запустим эту программу. В качестве ответа будем набирать слово sure:
$ make play_again1
ее play_again1 .с -о play_again1
$/play_again1
Do you want another transaction (y/n)?
s
cannot understand s, Please type у or no
u
cannot understand u, Please type у or no
r
cannot understand r, Please type у or no
e
cannot understand e, Please type у or no
У$
Как и предполагалось, программа play_againl принимает и обрабатывает символы по мере
их набора на клавиатуре без ожидания нажатия на клавишу Enter. Но раздражает вывод
негативной реакции программы на каждый символ. Более очевидным решением было бы
отключение режима эхо отображения и тем самым игнорирование неприемлемых
символов, пока не будут введены ожидаемые символы.
Пример: play_again2.c - игнорирование недопустимых ключей
Г play_again2.c
* назначение: обращение к пользователю с вопросом - хочет ли он получить некую транзакцию
* метод: установить терминал в посимвольный режим (char-by-char)n погасить
* эхоотображение, читать символ, возвратить результат
* коды возврата: 0=>yes, 1 =>по
* усовершенствования : таймаут, если пользователь уходит
7
#include <stdio.h>
#include <termios.h>
#define QUESTION "Do you want another transaction"
main()
{
int response;
tty_mode@); /* сохранить режим */
setterjioecho_mode(); /* установить -icanon, -echo */
response = getjesponse(QUESTION); /* получить некий ответ */
tty_mode( 1); /* восстановить состояние терминала 7
return response;
}
int get response(char *question)
/*
* назначение: задать вопрос и ждать y/n ответа
* метод: использовать getchar и игнорировать ответы, которые не в формате у/п
* коды возврата: 0=>yes, 1=>no
*/
6.3. Написание пользовательской программы: play_again.с
209
{
printf("%s (у/п)?и, question);
whileA){
switch(getchar()){
case у:
case Y: return 0;
case *n':
case 'N':
case EOF: return 1;
}
}
}
set cr noecho mode()
Г
* назначение: установить для файлового дескриптора 0 посимвольный режим и
* сброс эхоотображения
* метод: использование разрядов в структуре termios
7
{
struct termios ttystate;
tcgetattr@, &ttystate); /* читать текущие установки 7
ttystate.cjflag &= - ICANON; /* без буферирования 7
ttystate.c_lflag &= - ECHO; /* также без echo 7
ttystate.c_cc[VMIN] = 1; /* получать при чтении однократно 1 символ 7
tcsetattr@, TCSANOW, &ttystate); /* инсталляция установок 7
}
/* how == 0 => сохранить текущий режим, how == 1 => восстановить режим */
tty mode(int how)
{
static struct termios originaljnode;
if (how ==0)
tcgetattr@, &originaLmode);
else
return tcsetattr@, TCSANOW, &original mode);
}
Эта программа отличается от предшествующей версии двумя особенностями. Есть
функция, которая сбрасывает бит echo при установке режима работы драйвера терминала.
Заметим, что функция восстановления не включает этот бит. Другой особенностью
является то, что функция getjesponse больше не выводит предупредительных сообщений, когда
получает недопустимые символы. Драйвер просто их игнорирует.
Откомпилируйте и выполните эту программу. Если при работе вы наберете слово sure,
то ничего не увидите на экране. Только когда вы наберете у или п, то программа будет на
это явно реагировать.
Программа play_again2 делает то, что мы предполагали. Но у нее есть еще одна
особенность. Что, если эта программа будет использована в реальном банкомате (ATM) и
покупатель ушел по рассеянности без нажатия на клавиши у или п. Тогда следующий покупа-
210 Программирование дружественного способа управления терминалом и сигналы
тель может нажать на>> и получить доступ к счету покупателя, который ушел.
Пользовательские программы имеют больший уровень защищенности, когда в них есть средства
поддержки таймаута.
6.3.1. Неблокируемый ввод: play__again3.c
В следующей версии нашей программы включена возможность таймаута. Мы создадим
средство таймаута, которое должно будет сообщать драйверу терминалу о том, что далее
не следует ожидать ввода. Если мы не обнаруживаем ничего на входе, то мы должны
будем перейти в состояние ожидания на несколько секунд и опять проверить состояние
входа. После трех неуспешных попыток происходит отказ от дальнейших проверок.
Блокируемый и неблокируемый ввод
Когда вы обращаетесь к getchar или к read, чтобы читать данные через файловый
дескриптор, то обычно системный вызов ожидает ввода. В примере play_again при обращении к
getchar программа ждала до тех пор, пока пользователь не нажмет на клавишу. Программа
блокировалась аналогично тому, как блокируется автомобиль на железнодорожном
переезде. Программа блокируется, пока на ее входе не появится какой-либо символ или не
будет обнаружено поступление признака конца файла. А как отключить блокировку ввода?
Блокировка является свойством любого открытого файла, а не только соединений с
терминалами. Программы могут использовать системные вызовы fcntl или open для того, чтобы
установить неблокируемый ввод для файлового дескриптора. Программа play_again3
использует системный вызов fcntl, чтобы установить флаг 0_NDELAY4 для файлового
дескриптора. Мы выключили блокировку файлового дескриптора и обратились к вызову
read. Ну и что произойдет? Если ввод доступен, то вызов read получает входные данные
и возвращает, как результат, количество прочитанных символов. Если символов на входе
не было, то вызов read возвращает 0, как это делается в случае приема на входе символа
конца файла.
Вызов read возвращает -1, если была обнаружена ошибка. В непосредственной
реализации неблокируемое действие является весьма простым. Для каждого файла имеется
пространство для хранения допустимых непрочитанных данных, что изображено на рисунке
6.4 в верхней части бокса внутри драйвера. Если файловый дескриптор имеет
установленный бит 0_NDELAY и это пространство пустое, то системный вызов read возвратит 0. Если
вы обратитесь к исходному коду Linux с командной grep для поиска места использования
OJNDELAY, то там вы найдете детали реализации.
Пример: play_again3.c - использование неблокируемого режима для таймаутов
Г play_again3.c
* назначение: обращение к пользователю с вопросом - хочет ли он получить
* некую транзакцию
* метод: установить терминал в посимвольный режим (char-by-char)n погасить
* эхоотображение, установить терминал в режим no-delay, читать символ,
* возвратить результат
* коды возврата: 0=>yes, 1=>no 2=>таймаут
* усовершенствования: сброс режима терминала по прерыванию
7
#include <stdio.h>
4. Вы можете также использовать бит 0_NONBLOCK; обратитесь к документации.
I Написание пользовательской программы: play_again.с
#include <termios.h>
#include <fcntl.h>
#include <string.h>
«define ASK
#define TRIES 3
#defineSLEEPTIME 2
#define BEEP putchar('\a*)
main()
{
int response;
ttyjnode(O);
set_cr_noecho._mode();
set_nodelay_mode();
"Do you want another transaction"
/* максимальное число попыток 7
Г время на одну попытку 7
/* предупреждение пользователя 7
Г сохранить текущий режим */
Г установить -icanon, -echo 7
Г noinput => EOF 7
response = getjesponse(ASK, TRIES); /* получить некий ответ 7
tty_mode( 1); /* восстановить исходный режим */
return response;
}
get response(char *question, int maxtries)
r~
* назначение: задать вопрос и ждать ответа у/n или ждать в течение
* указанного максимального времени
* метод: использовать getchar и реакцию на non-y/n ввод
* returns: 0=>yes, 1 =>no, 2=>таймаут
7
{
int input;
printf("%s (y/n)?", question);
fflush(stdout);
while A){
sleep(SLEEPTIME);
input = tolower(get_ok_char());
if (input == 'y')
return 0;
return 1;
Г задать вопрос 7
Г обеспечить вывод 7
Г ожидать указанное время 7
/* получить следующий символ *
if (input == fn')
if (maxtries- == 0)
BEEP;
return 2;
/* вышло время? 7
Лда7
}
Г
* пропустить недопустимые символы и возвратить y,Y,n,N или EOF 7
get ok char()
{
int с;
2 Программирование дружественного способа управления терминалом и сигналы
while((c = getchar()) != EOF &&strchr("yYnN",c) == NULL)
return с;
}
set_cr noecho_mode()
Г~ "
* назначение: установить для файлового дескриптора 0 посимвольный режим и
* режим без эхоотображения
* метод: использовать биты в структуре termios
7
{
struct termios ttystate;
tcgetattr@, &ttystate);
ttystate.cjflag &= - ICANON;
ttystate.cjflag &= - ECHO;
ttystate.c_cc|VMIN] = 1;
tcsetattrF, TCSANOW, Mtystate);
/* читать текущие установки */
Г не буферировать */
/* также без echo */
/* получать однократно по 1 символу */
/* инсталлировать установки */
}
set nodelay mode()
Г
* назначение: установить файловый дескриптор 0 в режим no-delay
* метод: использовать fcntl для установки разрядов
* . замечания: подобное выполняет tcsetattr(), но она более сложна
7
{
int termflags;
termflags = fcntl@, F GETFL);
termflags |=0_NDELAY;
fcntl@, F_SETFL, termflags);
/* читать текущие установки */
/* переустановить бит nodelay */
/* и инсталлировать установку в ядре 7
}
Г how == 0 => сохранить текущий режим, how == 1 => восстановить режим */
Г В этой версии происходит управление структурой termios и флагами fcntl */
tty mode(int how)
{ "
static struct termios originaLmode;
static int originaLflags;
if(how==0){
tcgetattr@, &originaLrnode);
original Jags = fcntl@, F^GETFL);
}
else{
tcsetattr@, TCSANOW, &originaLmode);
fcntl@, F^SETFL, originalJlags);
6.3. Написание пользовательской программы: play_again. с
213
Новые свойства в этой версии программы - использование системного вызова fcntl для
включения и выключения режима неблокируемого ввода и использование sleep, а также
счетчика maxtries в getjesponse.
Небольшие проблемы с программой play_again3
Программа play_again3 не идеальна. При запуске в неблокируемом режиме программа
засыпает на две секунды, прежде чем обратиться к getchar и дать пользователю шанс набрать
что-нибудь. Если пользователь справится с набором за одну секунду, то программа не
получит этот символ, пока не истекут две секунды. Возможно, это запутает пользователей.
Можно ли написать программы с более быстрой реакцией? Мы можем сократить время на
ожидание перед вызовом getchar и компенсировать это уменьшение'за счет увеличения
числа итераций. Во-вторых, обратим внимание на вызов fflush после вывода приглашения.
Без этой строки приглашение не появится, пока в программе не будет вызова getchar. И вот
почему. Драйвер терминала не только производит буферирование ввода на основе
построчного принципа он также поддерживает и построчное буферирование вывода.
Драйвер буферирует вывод до тех пор, пока он не получит символ newline или пока программа
не сделает попытку чтения с терминала. В этом примере, где пользователю дается шанс
для прочтения приглашения на основе метода откладывания обращения к вводу, нам
понадобится добавить вызов fflush.
Другие методы реализации таймаутов
В Unix есть более хорошие методы для реализации таймаутов для пользовательского
ввода. Элемент VTIME в массиве управляющих символов с_сс[] драйвера терминала позволяет
устанавливать значение таймаута в драйвере терминала. Детали представлены в
упражнении (в конце главы). Устанодление значения таймаута можно сделать с помощью
системного вызова select. Вызов select мы обсудим в следующей главе.
Большая проблема с play_again3
Программа play_again3 игнорирует символы, которые ей не нужны, идентифицирует и
обрабатывает допустимые входные символы и выполняет exit, если не поступили допустимые
символы в течение установленного временного интервала. Что произойдет, если
пользователь нажмет на Ctrl-C? Вот простой пример работы:
$ make play_again3
ее play_again3.c -о play_again3
$ /play_again3
Do you want another transaction (y/n)? press Ctrl-C now
$ logout
Connection to host closed.
bash$
Когда мы нажимаем на Ctrl-C, то будет убит процесс исполнения программы. Убивается
не только процесс исполнения программы, но убивается также и вся login сессия (Ранее
автор не давал четкого определения login сессии. Это совокупность процессов, которые
имеют один и тот же идентификатор пользователя. Они были порождены по инициативе
пользователя, вошедщего в систему. - Примеч. пер.) Как это могло случиться? При работе
программы можно выделить такие шаги. Программа play_again3 состоит из трех частей-
инициализация, получение ввода от пользователя, восстановление установок. Это
показано на рисунке 6.5.
214 Программирование дружественного способа управления терминалом и сигналы
Начальный поток управления
Выход из нормального
потока управления
set 0_NDELAY
set crmode
print prompt Прерывания потока при чтении
.wait Jor user input_J__^ ^^ Ьш ^
user types input
restore tty settings
restore fcntl flags
exit
T
Выход из процесса нормальный
Рисунок 6.5
Ctrl-C убивает процесс исполнения программы. Программа заканчивается без восстановления
В инициализирующей части производится установка терминала в неблокируемый режим
ввода.
Затем программа входит в основной цикл ввода, где выводится приглашение, переход
в состояние ожидания и ввод данных. Затем процесс исполнения программы был убит
с помощью ключа Ctrl-C. А в каком состоянии остался драйвер терминала?
После того, как исполнение программы было закончено, не существует какой-то части
программы, которая могла бы сбросить установки драйвера в исходное состояние. К моменту,
когда shell выведет на экран новое приглашение и будет готов получать текст командной
строки от пользователя, терминал остается в неблокируемом режиме ввода. В shell запускается
команда read для чтения текста командной строки. Но работа read будет проходить в
неблокируемом режиме ввода и поэтому сразу будет возвращено значение 0. Таким образом,
программа оставила файловый дескриптор и соответствующий драйвер с неправильными
атрибутами. В нашем следующем проекте мы поучимся, как защитить нашу программу от
действия ключа Ctrl-C.
Когда я это попробовал сделать, то не мог выйти из системы!
Во многих системах Unix командные интерпретаторы обладают возможностями по
редактированию. Такими, например, как использование клавишей со стрелками для скроллиро-
вания по списку введенных ранее команд. Командные интерпретаторы bash и tcsh
сбрасывают терминальные атрибуты после того, как произойдет выход из вашей программы или
она будет досрочно окончена.
6.4. Сигналы
Ключ Ctrl-C прерывает исполнение текущей программы. Это прерывание производится
с помощью механизма ядра, который называют механизмом сигналов. Сигналы - это
простая и продуктивная идея. Мы изучим основные идеи механизма сигналов и узнаем, как
можно использовать сигналы, по мере решения нашей проблемы в версии play_again3.
В следующей главе мы рассмотрим сигналы более детально.
6.4. Сигналы
215
6.4.1. Что делает управляющая последовательность Ctrl-C
Вы нажимаете ключ Ctrl-C, и программа заканчивает свою работу. Как может нажатие на
клавиши привести к гибели процесса? Здесь нужно отметить роль драйвера терминала.
На рисунке 6.6 представлена цепочка событий:
1. Пользователь нажимает ключ Ctrl-C
2. Драйвер принимает символ
3. Сопоставление флагов VINTR и ISIG
4. Драйвер вызывает сигнальную
систему
5. Сигнальная система посылает
SIGINT процессу
6. Процесс принимает SIGINT
7. Процесс гибнет
Сигнальная
система
терминала
Ctrl-C
Рисунок 6.6
Как работает Ctrl-C
Ключ может быть отличным от Ctrl-C. Чтобы сделать замену текущего управляющего
символа VINTR на другой символ, нужно использовать команду stty (или tcsetattr).
6.4.2. Что такое сигнал?
При нажатии на Ctrl-C вырабатывается сигнал. Но что такое сигнал? Сигнал -это в общем
случае однословное сообщение. Зеленый свет - это сигнал. Жест судьи - это сигнал. Эти
элементы и события не содержат сообщений. Они сами представляют собой сообщения:
идите, стойте, вон с поля! Когда вы нажимаете на ключ Ctrl-C, то тем самым вы выдаете
ядру требование - послать сигнал прерывания текущему развивающемуся процессу.
Каждому сигналу сопоставлен цифровой код. Обычно цифровой код сигнала прерывания
программы (interrupt) будет равен 25.
Откуда поступают сигналы? Сигналы приходят из ядра, но требования на сигнал
поступают из трех источников, как это показано на рисунке 6.7.
5. И если его изменить, то многие скрипты будут прерываться.
216
Программирование дружественного способа управления терминалом и сигналы
Сигналы от
других процессов
Сигналы при
возникновении исключений
Сигналы от нажатий
клавиш пользователем
Рисунок 6.7
Три источника сигналов
Пользователи Пользователь может нажать на ключи (клавиши) Ctrl-C, CtrlA или нажать на
любой другой ключ, который поддерживает драйвер терминала и
используется в качестве средства для выработки сигнала.
Ядро Ядро посылает процессу сигнал, когда процесс делает что-либо
неправильно. Например, фиксируются такие ошибки: происходит нарушение
сегментации памяти, возникает ситуация исключения при выполнении операции
с плавающей точкой, делается попытка выполнить недопустимую
машинную команду. Таким образом, ядро использует сигналы, чтобы оповещать
процесс о возникновении определенных событий.
Процессы Процесс может посылать сигналы другому процессу с помощью системного
вызова kill. Посылка сигнала - это один из возможных способов для процесса
установить связь с другими процессами.
Сигналы, которые возникают в результате деятельности процесса (например, деление на
ноль) называют синхронными сигналами. Сигналы, которые возникают при
возникновении внешних событий в отношении процесса (например, нажатие пользователем на ключ
прерывания) называют асинхронными сигналами.
Где можно найти список сигналов? Номера сигнагюв и их символические имена чаще всего
находятся в файле /usr/include/signal.h. Ниже приведен фрагмент текста из этого файла:
Г hangup, generated when terminal disconnects 7
Г interrupt, generated from terminal special char */
Г (*) quit, generated from terminal special char */
Г (*) illegal instruction (not reset when caught)*/
Г (*) trace trap (not reset when caught) 7
Г (*) abort process 7
Г (*) EMT instruction */
Г (*) floating point exception 7
/* kill (cannot be caught or ignored) 7
Г (*) bus error (specification exception) */
Г (*) segmentation violation */
Г (*) bad argument to system call 7
/* write on a pipe with no one to read it 7
/* alarm clock timeout */¦
Г software termination signal 7
#define SIGHUP
«define SIGINT
«define SIGQUIT
«define SIGILL
«define SIGTRAP
«define SIGABRT
«define SIGEMT
«define SIGFPE
«define SIGKILL
«define SIGBUS
«define SIGSEGV
«define SIGSYS
«define SIGPIPE
«define SIGALRM
«define SIGTERM
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
6.4. Сигналы
217
Например, сигнал прерывания {interrupt signal) называется SIG1NT, сигнал выхода (quit)
называется SIGQUIT, а сигнал по ошибке "нарушение сегментации памяти" называется
SIGSEGV. В каждой версии Unix есть документация, в которую включена более детальная
информация. В Linux следует обратиться к документу signalG).
Что делают сигналы? Результат зависит от обстоятельств. Многие сигналы приводят
к гибели процесса. Процесс развивался, а затем умирает, что проявляется в освобождении
памяти, закрытии всех дескрипторов, удалении процесса из таблицы процессов. Для
уничтожения процесса мы будет использовать сигнал SIGINT. Но процесс может
защититься от воздействия сигнала.
6.4.3. Что может процесс сделать с сигналом?
Процесс может и не погибнуть, когда он получит сигнал SIGINT. Процесс может
обратиться к ядру с помощью системного вызова signal и сообщить ядру, как он желал бы
реагировать на сигнал. Для процесса есть три варианта действий:
согласиться с действием по умолчанию (обычно гибель процесса)
В документации для каждого процесса указано действие по умолчанию. Действием по
умолчанию для сигнала SIGINT является гибель процесса. Процесс может восстановить
действие по умолчанию с помощью такого вызова:
signal(SIGINT, SIG.DFL);
проигнорировать сигнал
Процесс может создать защиту от поступающих сигналов. Программа сообщает ядру, что
она хочет игнорировать поступление сигнала SIGINT с помощью системного вызова:
signal(SIGINT, SIGJGN);
вызов функции
Этот вариант наиболее мощный из трех возможных вариантов. Рассмотрим пример
play__again3. Когда пользователь нажимает ключ Ctrl-C, то программа, находясь в том виде,
как она сейчас представлена, будет прервана. При этом не производится вызов функции
по восстановлению установок драйвера. Программу можно улучшить, если при
поступлении сигнала SIGINT будет вызвана функция по восстановлению установок терминала,
а затем будет выполнен вызов exit.
Третий вариант работы системного вызова signal в полной мере решает проблему. Профамма
может сообщить ядру, какую функцию следует вызвать при поступлении сигнала. Функция,
которая вызывается при поступлении сигнала, называется обработчиком сигнала. Для
инсталляции обработчика сигнала программа обращается к вызову:
signal(signum, functionname);
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
signal
Управление сигналом
#include < signal, h >
result = signal (int signum, void (*action)(int))
signum - сигнал
action - каким образом реагировать
КОДЫ ВОЗВРАТА -1 - при ошибке
При успехе - предыдущая реакция на сигнал
218 Программирование дружественного способа управления терминалом и сигналы
Системный вызов signal инсталлирует новый обработчик сигналов в отношении сигнала
с указанным номером signum. В качестве аргумента action может быть задано имя функции
или одно из двух специальных значений:
SIGJGN - проигнорировать сигнал;
SIGJDFL - восстановить действие сигнала по умолчанию.
Системный вызов signal возвращает, как результат выполнения вызова, предшествующую
установку для обработчика сигнала. Этим значением будет указатель на функцию
обработки сигнала.
6.4.4. Пример обработчика сигнала
Пример 1: Перехват сигнала
Г sigdemol .с - показывает, как работает обработчик сигнала
* - запустите программу и нажмите несколько раз Ctrl-C
7
«include <stdio.h>
«include <signal.h>
main()
{
void f(int); /* декларирование обработчика */
inti;
stgnal(SIGINT, f); /* инсталляция обработчика */
for(i=0; i<5; i++){ Г выполнение некой работы */
printf("heHo\nM);
sleepA);
}
}
void ffint signum) /* вызывается эта функция 7
{
printf(nOUCH!\nH);
}
Функция main состоит из двух частей - из вызова signal и цикла. В программе sigdemol.c
при обращении к signal производится инсталляция функции f, которая должна управлять
сигналом SIGINT. Если процесс принял сигнал SIGTNT, то ядро заставит программу
вызвать функцию f. В программе управление передается этой функций, функция
выполняется, и управление передается обратно программе. Вся эта последовательность действий
такая же, как при обращении к подпрограмме.
На рисунке 6.8 показаны два независимых потока управления: обычный, который
проходит по функции main, через цикл и к выходу из main. Другой поток проходит через
функцию f и возникает по мере появления сигнала.
6.4. Сигналы
219
| main()
Обычный поток управления
{l
(}
signal(SIGINT, f)
for(i=0; i<5; 1++){
#—* printf ("hello\n") ;
%m ~—.I sleep A) ;
* }
По прибытии сигнала SIGINT поток управления
перенаправляется к обработчику сигнала. После
возврата управления возобновляется обычный
поток управления
Переход к обработчику сигналов
и возврат назад
I fit-
| I printf("OUCH! и) ; I
Ш I
Рисунок 6.8
По сигналу происходит
обращение к подпрограмме
Ниже приведена иллюстрация работы программы:
$ /sigdemol
hello
hello нажать здесь Ctrl-C
OUCH!
hello нажать здесь Ctrl-C
OUCH! ,
hello
hello
$
Откомпилируйте программу и попытайтесь выполнить все это сами. В программе нет
явного вызова функции ? Обращение к функции происходит по мере прихода сигнала.
(Указанная в примере логика выполнения системного вызова signal справедлива для Linux, *
но может быть несправедлива для других версий ОС Unix. Например, в System V, если
в системном вызове signal указывается функция обработки сигнала, то первое, что
выполняется в этой функции при поступлении сигнала, - будет восстановлена стандартная
реакция на сигнал. Для Ctrl-C реакция по умолчанию - завершение процесса. Поэтому при
повторном поступлении этого же сигнала процесс завершится:
$./sigdemo1
hello
hello нажать здесь Ctrl-C
OUCH! Здесь будет восстановлена Стандартная реакция на сигнал
hello нажать здесь Ctrl-C; программа будет завершена
%
При использовании системного вызова sigaction, который соответствует стандарту POSIX,
установленная функция обработки сигнала сохраняется до переустановки реакции на
сигнал. Автор рассматривает особенности этого системного вызова в главе 7. - Примеч. ред.)
220
Программирование дружественного способа управления терминалом и сигналы
Пример 2: Проигнорировать сигнал
Г sigdemo2.c - показывает, как можно проигнорировать сигнал
* - нажмите Ctrl-\, чтобы убить процесс
7
#include
#include
main()
{
<stdio.h>
<signal.h>
signal(SIGINT, SIGJGN); *
printf(Myou can't stop me!\nM);
whileA)
}
sleepA);
printf("haha\n");
}
Программа sigdemo2.c использует вызов signal, чтобы установить режим игнорирования
сигнала прерывания. Пользователь может сотни раз нажимать на Ctrl-C, но это никак не
повлияет на развитие процесса.
Процесс может сообщить ядру, что он хочет
игнорировать сигнал SIGINT
Рисунок 6.9
Действие от выполнения вызова
signal(SIGINT, SIGJGN)
Ниже проиллюстрирована работа с программой:
$ /sigdemo2
you can't stop me!
haha
haha
haha нажать здесь Ctrl-C
haha нажать здесь два раза Ctrl-C
haha
haha
haha нажать здесь Л\
Quit
6.5. Подготовка к обработке сигналов: play_again4.c
221
При нажатии на ключ Ctrl-\ возникает уже другой сигнал, сигнал quit (выход). А в данной
программе не было выполнено никаких приготовлений для игнорирования или перехвата
сигнала SIGQUIT.
6.5. Подготовка к обработке сигналов: piay_again4.c
Мы теперь знаем, как нужно модифицировать программу play_again3.c, чтобы было можно
управлять сигналами. Но мы теперь должны найти проектное решение. Будем ли мы
игнорировать сигналы и требовать, чтобы пользователь набирал yes или по в ответ на
вопрос? Следует ли перехватывать сигналы от клавиатуры и организовывать выход из
программы, если пользователь наберет ответ по? Или следует выполнить exit и с помощью
кода возврата сообщить, что процесс исполнения программы был убит?
В представленной версии программы происходит перехват сигнала SIGINT,
восстановление установок драйвера, и возврат кода по:
Г play_again4.c
* назначение: запросить, не желает ли пользователь выполнить некую транзакцию
* метод: установить посимвольный режим терминала, режим no-echo,
* установить no-delay режим терминала
* читать символ, возвратить значение результата
* восстановить режимы терминала при поступлении
* сигнала SIGINT, проигнорировать поступление
сигнала SIGQUIT
* коды возврата: 0=>yes, 1=>no, 2=>таймаут
* усовершенствования: сброс терминального режима при прерывании
7
#include <stdio.h>
#include <termios.h>
#include <fcntl.h>
#include <string.h>
#include <signal.h>
#define ASK "Do you want another transaction"
#define TRIES 3 /* максимальное число попыток */
#defirie SLEEPTIME 2 /* время на одну попытку */
#define BEEP putchar('\a') /* оповещение пользователя */
main()
{
int response;
void ctrLc_hand!er(int);
tty_modeF); /* сохранение текущего режима */
sef_cr_noecho_mode(); Л установить -icanon, -echo 7
sefnodelayjnbdeQ; .' Л noinput => EOF */
signal(SIGINT, Ctrl с handler); /* обработка сигнала INT */
signal(SIGQUIT, SIGJGN); Л игнорировать сигналы QUIT */
response = getjesponse(ASK, TRIES); Г получить некий ответ */
tty_mode( 1); /* восстановить оригинальный режим 7
return response;
}
get response(char ^question, int maxtries)
Л"
* назначение: задать вопрос и адать у/п ответа или таймауг
* метод: использование getchar и предостережений о вводе символов, отличных от у/п
* коды возврата: 0=>yes, 1 =>по
*/
2 Программирование дружественного способа управления терминалом и сигналы
{
int input;
printf("%s (у/л)?", question); /* вопрос */
fflush(stdout); /* форсировать вывод */
while A){
sleep(SLEEPTIME); /* ожидание */
input = tolower(get_ok_char()); /* получить следующий символ */
if (input == У)
return 0;
if (input == 'n')
return 1;
if (maxtries-- == 0) /* истекло время? */
return 2; /* такой выход */
BEEP;
}
}
Л
* пропускать недопустимые символы и возвращать y.Y.n.N или EOF
7
get ok char()
{ " " .
int с;
while((c = getchar()) != EOF &&strchr(nyYnN,,,c) == NULL)
return c;
}
set cr noecho mode()
/*"¦"
* назначение: перевод файлового дескриптора 0 в посимвольный режим и режим
* noecho
* метод: использование разрядов в структуре termios
7
{
struct termios ttystate;
tcgetattr@, &ttystate); /* читать текущие установки */
ttystate.cjflag &= - ICANON; /* отказ от буферирования 7
ttystate.cjflag &= - ECHO; /* а также отказ от echo */
ttystate.c_cc|VMIN] = 1; /*получение при однократном вводе одного символа *
tcsetattr@, TCSANOW, &ttystate); /* инсталляция установок */
)
set nodelay mode()
Г'
* назначение: установка файлового дескриптора 0 в режим no-delay
* метод: использование fcntl для установки управляющих разрядов
* замечания: нечто подобное выполняет tcsetattr(), но она более сложна
7
{
int termflags;
termflags = fcntl@, F_GETFL); /* читать текущие установки 7
termflags |= 0_NDELAY; /* переустановка разряда nodelay */
fcntl@, F SETFL, termflags); /* и его инсталляция */
)
/* how == 0 =>сохранение текущего peжимalhow == 1 =>восстановление режима 7
/* В этой версии происходит управление с помощью структуры termios и флагов * fcntl
*/
6.6. Процессы смертны 223
tty_mode(int how)
{ "
static struct termios original_mode;
static int originaljags;
static int stored = 0;
if(how==0){
tcgetattr@, &original mode);
originaljlags = fcnt!@, F_GETFL);
stored = 1;
}
else if (stored) {
tcsetattr@, TCSANOW, &original_rnode);
fcntl@, F SETFL, original flags);
}
}
void Ctrl c_handler(int signum)
/*
* назначение: вызывается, если поступит сигнал SIGINT
* действие: сброс tty и scram
7
{
tty_modeA);
exit(l);
}
Другие проекты на эту тему остаются в качестве упражнений.
6.6. Процессы смертны
Программа использует системный вызов signal для передачи ядру требования, что она
хотела бы игнорировать сигнал. А что произойдет, если кто-либо напишет программу, где
будет установлена диспозиция SIG_IGN для всех процессов и если в программе будет
исполняться бесконечный цикл?
К радости системного администратора (и программистов), в Unix невозможно сделать
программу бессмертной. Есть два сигнала, которые нельзя перехватить или
проигнорировать. Почитайте документацию или список сигналов в заголовочном файле, чтобы
определит, какие сигналы проходят через любые преграды.
6.7. Программирование для устройств
Мы рассмотрели три аспекта написания программы, которая управляет терминалом.
Сначала мы изучили атрибуты драйвера и возможности по управлению соединениями.
Затем мы рассмотрели конкретные потребности приложений и разработали драйвер,
который удовлетворял бы этим требованиям. Наконец, мы изучили, как можно управлять
сигналами, которые являются одной из форм прерывания процессов.
Эти три аспекта применимы ко всем устройствам. Рассмотрим звуковую карту или
дисковод. Устройство имеет различные установки, которые контролируются драйвером
устройства. Вам необходимо изучение материала, касающегося этих установок. Итак, есть
программа, которая работает определенным образом. Наконец, многие драйверы устройств
вырабатывают сигналы, когда возникают ошибки или определенные ситуации. Дисковод
может послать сигнал, когда заканчивается копирование блока данных с диска в память.
Программа должна реагировать на поступление этих сигналов.
224 Программирование дружественного способа управления терминалом и сигналы
Заключение
Основные идеи
• Некоторые программы обрабатывают данные, поступающие от конкретных устройств.
Эти программы, ориентированные на работу с устройствами, могут управлять
соединениями с такими устройствами. Наиболее общим устройством для систем Unix
является терминал.
• Драйвер терминала имеет много установок. Набор установок образует режим работы
драйвера терминала. Программы пользователей часто устанавливают требуемые
режимы драйвера терминала.
• Клавиши, на которые нажимают пользователи, можно сгруппировать по трем
категориям. Драйвер терминала управляет этими категориями по-разному.
Большинство клавиш служат для представления обычных данных. При нажатии на эти
ключи драйвер передает эти данные программе. Некоторые клавиши служат для
инициализации функций редактирования в самом драйвере. Если нажать на клавишу
erase, то драйвер удалит набранный предшествующий символ из его буфера строки и
пошлет необходимый код на экран терминала для удаления этого символа с экрана.
Наконец, при нажатии на некоторые ключи вызываются функции управления
процессом. Ключ Ctrl-C при нажатии требует от ядра вызвать некоторую функцию
ядра, а эта функция пошлет сигнал процессу. В драйвере терминала поддерживается
ключи для вызова нескольких функций управления процессами. Все они
предполагают посылку сигналов процессу.
• Сигнал является коротким сообщением, которое передается от ядра процессу.
Инициировать появление сигнала могут пользователи, другие процессы и само ядро.
Процесс сообщает ядру, как он хотел бы реагировать на появление сигнала.
Что дальше?
Unix-машина все время принимает данные от многих терминалов и других устройств.
Пользователи производят данные, передаваемые через терминал, в непредсказуемые
моменты времени. Ядро должно обрабатывать данные, которые возникают при нажатии
на клавиши. На Unix-машине сразу исполняется несколько программ. Как ядро
поддерживает одновременно развитие программ и правильно реагирует на множество
непредсказуемых во времени прерываний? Мы изучим эти вопросы при написании видеоигры.
Исследования
6.1 Многие программные инструментальные средства в Unix читают данные из файлов,
имена которых задаются в командной строке. В команде tr этого нет. Каково
назначение команды tr? Каковы причины, на ваш взгляд, того, что в этой команде явно не
указываются имена файлов? Есть ли еще другие средства в Unix, где чтение происходит
только из стандартного ввода, а не из поименованных файлов? Большинство команд
в Unix находятся в каталогах, которые называются /bin, /usr/bin и /usr/local/bin.
Заключение
225
6.2 Реэюим без блокирования для других файлов. Атрибут 0J4DELAY можно,
использовать для произвольного дескриптора, а не только для драйвера терминала. Это
означает, что такой атрибут может быть использован в отношении дисковых файлов, а также
в отношении файлов устройств.
Что будет означать режим без блокирования при работе с дисковым файлом? Что
будет означать режим без блокирования при работе с устройствами, которые не
являются терминалами?
Программные упражнения
6.3 Реэюим some-delay. Файловый дескриптор можно установить в блокированный режим
или в режим no-delay. Драйвер терминала обеспечивает прекрасный контроль. Он
позволяет вам установить величину таймаута на ввод данных. В массиве управляющих
символов с_сс[], который находится в структуре struct termios драйвера, есть элемент
в позиции VTIME. В нем устанавливается значение периода таймаута в десятых
долях секунды. Таким образом, присвоение значения вида s.c_cc[VTIME] = 20 означает
установку для драйвера таймаута в две секунды. Модифицируйте play_again3.c так,
чтобы программа использовала средство таймаута в драйвере, а не переводила бы
файловый дескриптор в неблокируемый режим.
6-4 Управление сигналами в программе playjxgain.
(a) Модифицируйте программу play_again3.c так, чтобы сигналы от клавиатуры
игнорировались, а программа реагировала бы только на ввод сообщений вида: yes или по.
(b) Модифицируйте программу play_again3.c так, чтобы по мере приема сигнала от
клавиатуры она переустанавливала бы установки терминала и осуществляла выход
с кодом возврата 2.
6.5 Модифицируйте программу rotate, с так, чтобы она сама изменяла бы режимы
терминала. Модифицированная программа должна выключать канонический режим и
выключать режим эхоотображения. Затем она должны читать символы и для каждого
введенного символа выводить следующую по алфавиту букву. При нажатии
пользователем на клавишу "Q" программа должна восстановить установки терминала и
закончить работу.
Ваша программа должна игнорировать сигналы от клавиатуры и управлять ими
посредством переустановки^ драйвере перед выходом.
6.6 Напишите строковый редактор. Одна из проблем при написании программы, которая
работает в неканоническом режиме, заключается в следующем. Становится невозможным
вести редактирование при вводе данных. Модифицируйте вашу измененную версию
программы rotate.c так, чтобы можно было вести посимвольное и построчное
редактирование. В частности, когда программа принимает символы backspace или delete, то она
должна стирать предшествующий символ с экрана. Для стирания символа ваша программа
должна вывести символ backspace, символ пробела и опять символ backspace.
Также модифицируйте программу с тем, чтобы она отрабатывала бы символ
уничтожения строки (line-kill) так же, как это делает драйвер терминала, т. е. программа
должна уничтожать на экране все символы, которые были набраны в текущей строке.
Что вам потребуется, чтобы реализовать функцию удаления слова, которая
поддерживается в драйвере?
226 Программирование дружественного способа управления терминалом и сигналы
6.7 Модифицируйте программу sigdemol .с так, чтобы она производила бы подсчет числа
нажатий пользователем на ключ Ctrl-C. Модифицированная версия должна выводить
сообщение OUCH!, затем OUCH!! и т. д., где число восклицательных знаков равно
числу нажатий на ключ в данный момент.
Кроме вывода на экран возрастающего числа восклицательных знаков программа
должна воспринимать целочисленный аргумент, значение которого задается при
обращении к программе. После того как пользователь нажал на ключ Ctrl-C столько
раз, сколько было задано с помощью аргумента, программа должна закончить работу.
6.8 Вы уверены? Модифицируйте программу sigdemol .с так, чтобы она запрашивала бы у
пользователя ответ, на самом ли деле он хочет завершить программу. Результат
работы с программой может выглядеть так:
hello
hello
Interrupted! OK to quit (y/n)? n
hello
hello
Interrupted! OK to quit (y/n)? у
$
Что произойдет, если пользователь нажмет ключ Ctrl-C, когда программа находится
в ожидании ответа на вопрос OKto quit (y/n)? Напишите код и посмотрите, что
происходит при его работе. (Данное упражнение не своевременно. В тексте еще не
говорилось о том, что происходит, если во время обработки сигнала этот же сигнал
поступает еще раз. Причем, и решение может быть разным - в зависимости от того, как
реализована логика системного вызова signal. - Примеч. ред.)
6.9 Программа может использовать системный вызов signal, чтобы сообщить ядру, что
она хотела бы проигнорировать определенные сигналы, такие как SIGINT и SIGQUIT.
Есть разные стратегии по предотвращению выработки этих сигналов. Драйвер
терминала имеет флаг ISIG. Обратитесь к документации и ознакомьтесь с назначением
этого флага. Затем перепишите программу sigdemo2.c так, чтобы она использовала бы
этот флаг. Что будет делать модифицированный вариант программы, если при ее
исполнении будет принят сигнал SIGINT, который поступил откуда-то, а не с
клавиатуры? Ознакомьтесь с командой kill и используйте команду kill для посылки сигнала
SIGINT процессу, где выполняется версия программы, в которой сброшен флаг ISIG.
6.Ш Прерывания не всегда являются деструктивными. Представьте себе, что вы работаете
над проектом в течение нескольких дней. Вы можете получать телефонные звонки от
вашего босса, который интересуется, как у вас идут дела. Такого рода прерывания
разработаны с целью запуска подпрограммы оповещения о состоянии, а не с целью
убить процесс. Напишите программу на С, которая выполняет задачу, требующую
много времени. Например, напишите программу, которая находит простые числа с
использованием некоторого медленного метода. Программа должна отслеживать
получение самого большого простого числа на текущий момент. Добавьте к этой
программе функцию обработки сигнала SIGINT, которая выводит краткий отчет, где
показывается, сколько чисел она проверила и самое большое простое число, которое
она обнаружила.
Как может быть использована эта идея в системных программах?
Заключение
227
6.11 Возврат к программе more. В главе 1 мы написали несколько версий утилиты more.
В тот момент мы не знали, как работает драйвер терминала. Усовершенствуйте эту
программу так, чтобы она работала в режиме no-echo, в неканоническом режиме
и правильно реагировала бы на сигнал прерывания и сигнал kill.
6.12 Сигналы и окна. Пользователь может вырабатывать сигналы не только по мере
нажатия на определенные ключи, но также и при изменении размера окна терминала.
Каждый раз, когда меняется размер окна, процессу посылается сигнал SIGWINCH.
' По умолчанию процесс игнорирует сигнал SIGWINCH. Напишите программу,
которая заполняет экран терминала выводом большого количества символов аА" в
отдельные позиции экрана. Например, если окно имеет десять строк и двадцать
колонок, то программа должна вывести символ "А" двести раз. Когда будут изменены
размеры окна, то программа должна будет заполнить окно символами "В". При
следующем изменении размера следует использовать символ "С" и т. д. Когда
пользователь нажмет на клавишу "Q", то окно должно быть очищено, а программа должна
быть закончена. Когда пользователь нажмет любую клавишу, то программа начнет
заполнять окно символом "А".
Глава 7
Событийно-ориентированное
программирование.
Разработка видеоигры
1~™~j
Цели
Идеи и средства
• Профаммы управляют асинхронными событиями.
• Библиотека curses: назначение и использование.
• Интервальные таймеры и будильник.
• Управление надежными сигналами.
• Повторно входной код, критические секции.
• Асинхронный ввод.
Системные вызовы и функции
• alarm, setitimer, getitimer
• kill, pause
• sigaction, sigprocmask
• fcntl, aio_read
7.1. Видеоигры и операционные системы
Деннису Ричи и Кену Томпсону из Bell Labs захотелось поиграть в видеоигру Space Travel
(Космическое путешествие). Поэтому они и создали Unix. Ричи писал:
Да, в течение 1969 года Томсон разработал игру Space Travel. Сначала игра была
написана в среде Multics, а затем была переписана на Фортране в среде GECOS
(операционная система для машины GE, позже - Honeywell 635). Игра была ничем иным, как эму-
Z /. Видеоигры и операционные системы
229
ляцией движения крупных тел в Солнечной системе, где под управлением игрока
перемещался космический корабль в соответствии со сценарием, и который нужно
попытаться посадить на различные планеты и луны. Версия GECOS была
неудовлетворительной в части двух важных позиций: во-первых, отображение состояний в игре
происходило скачкообразно, а дисплей был слишком грубым для управления, поскольку для
этого использовались команды; эо-вторых, для ведения игры нужно было заплатить
около $75 за время использования центрального процессора большого компьютера.
Но это продолжалось недолго, т. к. Томпсон нашел почти неиспользуемый компьютер
PDP-7 с прекрасным дисплейным процессором, где была установлена система Graphic-
II terminal. Он и я переписали Space Travel с тем, чтобы можно было работать на этой
машине. Сделанное оказалось по значимости большим, чем вначале казалось.
Поскольку мы отказались от всего имеющегося программного обеспечения, то вынуждены были
написать пакет для плавающей арифметики, спецификацию графических символов для
дисплея и подсистему отладки, которая постоянно выводила содержимое в области для
отображения в углу экрана. Все это было написано на ассемблере для кросс-ассемблера,
который работал под GECOS и выдавал результат на перфоленты, которые можно был
переносить на PDP-7. Программа Space Travel, хотя и была сделана как весьма
привлекательная игра, рассматривалась в основном как нововведение в неуклюжую
технологию подготовки программ для PDP-7.
Вскоре Томпсон начал реализацию "бумажной" файловой системы (возможно, более
точно было бы ее назвать ''меловой" файловой системой), которая была разработана
ранее.
Файловая система без экспериментального использования - это всего лишь чистое
предположение. Так что он реализовал во плоти то, что удовлетворяло различным
требованиям работающей операционной системы, в частности удовлетворяло
введенному понятию процесса. Затем появился небольшой набор утилит пользовательского
уровня (средства для копирования, печати, удаления и редактирования файлов), и,
естественно, появился простой командный интерпретатор (shell). До этого момента
все программы писались в среде GECOS, а файлы переносились на PDP-7 с помощью
перфоленты. Но поскольку была завершена разработка ассемблера, то система стала
в состоянии поддерживать сама себя. Несмотря ни на что, но после того как в 1970
году, Brian Kernighan предложил имя "Unix", в определенном смысле язвительный
каламбур в отношении "Multics", система, которую мы сегодня знаем, родилась1.
Видеоигры и операционные системы имеют много общего. В этой главе мы напишем
простую видеоигру. При разработке этой игры нам потребуется использовать определенные
виды Unix-сервисов, а также использовать базовые принципы и средства, свойственные
собственно проекту операционных систем.
Что делает видеоигра
Рассмотрим видеоигру space travel (космическое путешествие) с двумя игроками.
Программа создает образы планет, астероидов, космических кораблей и поддерживает ряд
образов перемещений. Каждый объект характеризуется скоростью, положением,
направлением движения, моментом движения и другими атрибутами. Астероид может
столкнуться с космическим кораблем или с другим астероидом.
1. AT&T Bell Laboratories Technical Journal 63 No. 6 Part 2, October 1984, p.. 1577-1593.
230 Событийно-ориентированное программирование. Разработка видеоигры
В игре также поддерживается ввод информации от пользователя. Игроки оперируют
кнопками, мышью и трек-боллами. При этом в непредсказуемые моменты времени поступают
входные данные, а программа должна быстро на это реагировать. Такие входные события
действуют на атрибуты объектов в игре. При нажатии на кнопку пользователь может
увеличить скорость и уменьшить массу корабля. От изменений атрибутов корабля будет
зависеть, как он будет взаимодействовать с другими объектами.
Как работает видеоигра
В видеоигре реализуется несколько базовых идей и принципов:
Пространство В игре можно перемещать образы в определенные места на экране
компьютера. Как программа выполняет управление дисплеем?
Время Образы могут перемещаться по экрану с различными скоростями.
Изменение положения производится с определенной периодичностью. Как
программа отслеживает течение времени и планирует выполнение
определенных действий в определенное время?
Прерывания Программа непрерывно перемещает объекты по экрану, но пользователи
могут посылать свои входные данные тогда, когда они пожелают. Как
программа реагирует на прерывания?
Выполнение нескольких действий
В игре поддерживается перемещение нескольких объектов и одновременно
поддерживается обработка прерываний. Как программа может управлять множеством активностей
и при этом не запутаться?
В операционных системах решаются те же вопросы
В операционных системах возникают те же самые четыре проблемы. Ядро загружает
программы в пространство памяти и учитывает места распределения для каждой программы. Ядро
планирует порядок выполнения программ на коротких интервалах времени, а также планирует
выполнение ряда внутренних задач, которые должны быть выполнены к определенному
моменту времени. Пользователи и другие внешние устройства посылают свои входные данные
в непредсказуемые моменты времени, а ядро должно быстро реагировать на их появление.
Одновременное выполнение нескольких работ может быть весьма сложным. Как ядро
предохраняет обработку данных от возможности наступления беспорядка и хаоса?2
Управление экраном, время, сигналы, разделение ресурсов
В этой главе мы будем изучать вопросы управления экраном, временем, сигналами, а
также вопросы, которые связаны с успешным выполнением нескольких параллельных работ.
Мы напишем ряд анимированных игр для текстового терминала, чтобы изучить
проблематику указанных ранее четырех фундаментальных тем.
Почему символьно ориентированная графика?
Почему не используется более мощное программирование в среде XII или графические
средства Java? Есть несколько-соображений по этому поводу. Во-первых, символьно
ориентированные игры аналогичны по сути графическим играм с высоким разрешением. Они
отличаются лишь "более объемными" пикселями. Следующее соображение -
перемещаемость. Символьно ориентированные игры требуют только терминального эмулятора и
соединения с ним, что является доступным на любой вычислительной системе. В-третьих,
2. Обратитесь к Web для поиска тем по ключевым словам DEC Wars и Unix Wars. После чего вы можете
ознакомиться с информацией, где прослеживается аналогия между Unix и космическими кораблями.
7.2. Проект: Разработка pong-игры в настольный теннис для одного игрока
231
при сокращении времени на рассмотрение графических вопросов увеличивается время на
рассмотрение вопросов системного программирования. Если вам это необходимо, то
можно обратиться к Web-сайту, где есть версии программ, которые работают с графической
системой X windows.
7.2. Проект: Разработка pong-игры в настольный теннис для
одного игрока
ракетка: пользовательский контроль
шарик: перемещается по экрану
цель: поддерживать шар в игре
Рисунок 7.1
Видеоигра для одного игрока
Давайте начнем. Основной проект в этой главе - игра pong, которая является версией с
одним игроком из набора классических аркадных и развлекательных игр. На рисунке 7.1
изображены три основных элемента: стенки, шарик и ракетка. Обобщенная схема работы
программы такая:
(a) Шарик движется с некоторой скоростью.
(b) Шарик отскакивает от стенок и ракетки.
(c) Пользователь, нажимая на ключи, может перемещать ракетку вверх и вниз.
Разработка такой игры потребует-понимания Вопросов управления экраном, временем,
прерываниями, а также потребует решения вопросов одновременного выполнения
нескольких действий. Каждая из названных тем будет изучена позже.
7.3. Программирование пространства: Библиотека curses
Библиотека curses - это набор функций, с помощью которых программист может
устанавливать положение курсора и управлять выводом текста на экране терминала. Библиотека curses
или просто curses, как она была вначале названа, была разработана в UCB Olden Days ®.
Большая часть программ, которые управляют экраном терминала, используют curses. Изначально
это был просто набор функций. Теперь curses обладает многими изощренными средствами.
Мы будем использовать лишь небольшую часть этих средств.
7.3.1. Введение в curses
Curses поддерживает представление терминального экрана в виде двумерного массива,
состоящего из символьных ячеек, каждая из которых идентифицируется на экране парой
(строка, колонка). Началом координат является верхний левый угол экрана. Номера строк
возрастают в направлении сверху вниз, а номера колонок возрастают в направлении слева
направо. На рисунке 7.2 представлен экран, образ которого поддерживает curses.
232
Событийно-ориентированное программирование. Разработка видеоигры
В составе curses есть функции для перемещения курсора в любую точку экрана, для
добавления символов и стирания символов с экрана. Кроме того, есть функции для
установления атрибутов символов, таких, как цвет и яркость. Имеются функции для создания
и управления окнами и другими текстовыми областями. Все функции описаны в
документации. Мы будем использовать девять из них:
@,0) Колонки
\
Строки
?
р
1
1
-1
—
I™
тгг
! ! 1
« : . '
i lb
!
_
e
1
i |
! '
s...i
""! i | |
1
-.
0
"
4"
•
F-p
1 !
г f
...» ;
| j
!
i
i
"ТТГ
1 1 i
""
™]
moveE,9);
addstr("hello")j
л
Рисунок 7.2
Curses представляет экран в виде сетки
initscr()
endwinQ
refresh()
move(r.c)
addstr(s)
addch(c)
clear()
standout()
standendf)
Базовые функции curses
Инициализация библиотеки curses и терминала
Выключение curses и сброс терминала
Воспроизведение экрана в таком виде, как вы желаете
Перемещение курсора в позицию на экране /f,c)
Прорисовка строки s на экране от текущей позиции
Прорисовка символа ?на экране в текущей позиции
Очистка экрана
Включение режима standout (обычно обратное изображение)
Выключение режима standout
Curses, пример 1: hellol.c
В этой первой программе показывается базовая логика curses-программ:
I* hellol.c
* назначение - представление минимального числа средств, которые
* используются в curses для инициализации, прорисовки, ожидания ввода и для выхода
7
#iriclude <stdio.h>
<curses.h>
#iriclude
main ()
{
initscrt);
Г включить curses 7
7.3. Программирование пространства: Библиотека curses
233
clear();
addstrfHello, world");
move(UNES-1,0);
refresh();
getch();
endwin();
Г послать запросы */
/*. очистить экран */
/* добавить текст строки */
Г переход к LL.*/
/* обновить экран */
/* ожидать ввода от пользователя 7
/* выключить curses 7
}
Компиляция и запуск программы на исполнение г.: шолняются весьма просто:
$ ее hellol .с-Icurses-о hellol
$/hello1
Выходной экран показан на рисунке 7.3. Программа работает с любым терминальным
соединением на любом компьютере с любой версией Unix
Hello, world
Рисунок 7.3
Наша первая программа
с использованием curses
Curses, пример 2: hello2.c
Построение более сложных изображений достигается совместным использованием циклов,
переменных и различных функций curses. Попробуйте предугадать - какой будет результат
работы вот такого второго примера:
Г hello2.c
* назначение - представление использования функций curses совместно с
* циклами при инициализации, прорисовке, завершении
7
#include
#include
main()
{
<stdio.h>
<curses.h>
int
initscr();
move(i, i+i);
if(i%2==1)
addstrfHello, world");
jf(i%2==1)
/* включение curses 7
clear(); /* прорисовка чего-либо 7
for(i=0; KLINES; i++){ Л в цикле 7
standout!);
234
Событийно-ориентированное программирование. Разработка видеоигры
standend();
refresh();
getch();
endwin();
Г обновить экран */
/* ожидать ввода от пользователя */
/* сброс tty и прочее 7
}
Откомпилируйте и запустите программу на исполнение. Насколько правильными
оказались ваши прогнозы?
7. 3.2. Внутренняя архитектура curses: Виртуальный и реальный экраны
Что делает функция refresh? Поэкспериментируем. Закомментируйте эту строку (В
примере Ье11о2.с строка refresh(). - Примеч. пер.), повторно откомпилируйте и запустите
программу. На экране ничего не появится.
Curses был разработан так, чтобы можно было изменять содержимое текстового экрана
без "засорения" коммуникационной линии. Curses минимизирует поток данных за счет
того, что работает с виртуальными экранами (смотри рисунок 7.4).
Функция addstr записывает буфер экрана Буфер экрана
addstrt) | Hello
refresh()
Функция refresh модифицирует реальный экран
[
/
Реальный экран
Hello
Л
Рисунок 7.4
Curses поддерживает копию реального экрана
Реальный экран - это массив символов, который находится непосредственно перед
глазами пользователя. В curses поддерживаются две разновидности экрана. Первый
внутренний экран - это копия реального экрана. Второй внутренний экран - это рабочее
пространство, где записываются изменения на экране. Каждая из функций move, addstr и т. д.
модифицирует символы, находящиеся в пределах экрана рабочего пространства. Большинство
функций библиотеки curses действует только в отношении рабочего пространства, что
напоминает буферирование для диска.
Функция refresh сравнивает экран рабочего пространства с копией реального экрана.
Функция refresh помимо этого выдает с помощью драйвера терминала символы и коды по
управлению экраном, которые необходимы для установления соответствия между
реальным экраном и рабочим экраном. Пусть, например, в левом верхнем углу на реальном
экране в текущий момент визуализирована строка Smith, James. Если вы затем
используете функцию addstr, чтобы поместить на это же место строку Smith, Jane, то вызов функции
refresh приведет только к тому, что в слове James будет заменен символ т на символ п,
а символ s будет заменен пробелом. Такая техника, когда происходит передача не самих
образов* а только изменений в образах, используется в потоковом видео.
7.4. Программирование времени: sleep
235
7.4. Программирование времени: sleep
При разработке видеоигры будем помещать образы в определенные места и будем делать
это в определенное время. Для размещения образов в определенных местах мы будем
использовать curses. Добавим теперь в наши программы средства, которые позволяют
разрешать временные вопросы. Сначала используем системную функцию sleep.
Анимация, пример 1: ИеПоЗ.с
ЛпеНоЗ.с
* назначение - использование refresh и sleep для поддержки анимационных эффектов
* представление инициализации, прорисовки, завершения
7
#include <stdio.h>
«include <curses.h>
main()
{
int i;
initscr();
clear();
for(i=0; KLINES; i++){
move(i, i+i);
if(i%2==1)
standout();
addstr( "Hello, world");
if(i%2==1)
standend();
sleepA); *
refresh();
}
endwin();
}
После компиляции и запуска этой программы вы увидите приветственное сообщение,
которое каскадно будет перемещаться вниз по экрану со скоростью одна строка в секунду.
Сообщение будет отображаться в инверсном режиме. Зачем нам необходимо вызывать
refresh в каждой итерации цикла?
Анимация, пример 2: heIIo4.c
/* hello4.c
* назначение - показать, как используются erase, time и draw при анимации
.*/
«include <stdio.h>
«include <curses.h>
Hello, world
main()
{
int i;
initscr();
clean!);
236
Событийно-ориентированное программирование. Разработка видеоигры
for(i=0; KLINES; i++){
move(i, i+i);
jf(i%2==1)
standout);
addstif'Hello, world");
if(i%2==1)
standend();
refresh();
sleepA);
move(i,i+i);
addstrf");
}
endwin();
}
Л переместиться обратно в ту же позицию 7
Г стереть строку 7
Программа hello4 создает иллюзию движения. Сообщения выводятся постепенно, в
направлении вниз по диагонали. Наш секрет заключается в том, что происходит прорисовка
сообщения в одном месте, затем визуализируется состояние экрана в течение одной
секунды, потом на место, где было выведен текст сообщения, выводится пустая строка, чтобы
стереть это сообщение. Затем происходит смена места вывода сообщения. Заметим, что
вызовом refresh после двух запросов (Запросов на включение режима. - Примеч. пер.), мы
гарантируем, что старое сообщение исчезнет и появится новое сог ицение в одном
проходе. На рисунке 7.5 приведен "snapshot" (мгновенный снимок) экрана.
Рисунок 7.5
Изображение медленно
перемещается вниз по экрану
В следующем примере текст сообщения отражается от границы экрана и далее опять
движется по экрану.
Анимация, пример 3: hello5.c
/* heilo5.c
* назначение - показать, как сообщение отражается от границы и опять
ж движется по экрану
* компиляция: ее helloS.c -leurses -о hello5
7
#include <curses.h>
#define LEFTEDGE
#define RIGHTEDGE
10
30
7.4. Программирование времени: sleep 237
#defineROW10
main()
{
char message[] = "Hello";
char blank[] ="";
intdir = +i;
int pos = LEFTEDGE;
initscr();
clear();
while) 1){
move(ROW,pos);
addstr(message); /* прорисовать строку */
move(UNES-1 rCOLS-1); /* "парковка" курсора */
refresh(); /* показать строку */
sleepA);
move(ROW,pos); /* стереть строку */
addstr(blank);
pos += dir; /* сменить позицию для вывода */
if (pos >= RIGHTEDGE) /* проверить на необходимость отражения */
dir = -1;
if(pos<=LEFTEDGE)
dir = +1;
}
>¦
Переменная dir используется для управления скоростью вывода сообщения. Если
значение переменной dir равно +1, то изображение текста сообщения смещается каждую
секунду на одну позицию вправо. Когда значение переменной dir равно -1, то изображение
текста сообщения смещается каждую секунду на одну позицию влево. При изменении знака
у значения переменной dir происходит и смена направления перемещения текста
сообщения. На рисунке 7.6 показан "снимок" экрана в некоторый момент времени.
>Hello, world
Рисунок 7.6
Сообщение движется
вперед и назад
Как мы все делали?
Достаточно ли мы узнали, для того чтобы написать видеоигру со скромным перечнем
действий? Мы узнали, как воспроизвести символ в указанном месте строки на экране.
Мы знаем, как добиться анимационного эффекта с помощью введения временных
задержек между прорисовками, стираниями и перерисовками. Наша программа хороша, но:
238 Событийно-ориентированное программирование. Разработка видеоигры
(a) Односекундные задержки являются слишком большими. Нам требуется более
лучший способ управления временем.
(b) Нам необходимо добавить средство ввода информации от пользователя.
Эти две проблемы приводят нас к рассмотрению двух новых тем: программирование
времени и техника расширенных сигналов. Через несколько страниц текста мы вернемся
к игре.
7.5. Программирование времени 1: ALARMS
(Перевод alarm далее сознательно не делается, хотя часто встречается буквальный перевод
"аларм" или "сигнал тревоги" или "будильник". - Примеч. пер.) Работа со временем
может проводиться в программах по-разному. В программе в поток управления может быть
введена временная задержка. В последних трех примерах для введения задержки была
использована функция sleep. Другая возможность использовать время - планирование
выполнения некоторого действия через некоторое время. Это техника, которая базируется на
бытовом использовании таймера при варке яиц. Вы можете заниматься какими-то своими
делами до тех пор, пока таймер не подаст звуковой сигнал. В Unix для этой цели
используют системный вызов alarm.
7.5. 1. Добавление задержки: sleep
Для того чтобы добавить в программу временную задержку, используют функцию sleep:
sleep(n)
Функция sleep(n) обеспечивает задержку развития текущего процесса на п секунд или до
момента, когда процессу будет передан сигнал, который не будет им проигнорирован.
7.5.2. Какработает sleep(): Использование alarms в Unix
Функция sleep работает по сценарию, которым вы пользуетесь, когда ложитесь спать и
хотите проснуться через установленное время:
(a) Следует установить будильник на выдачу сигнала побудки через желаемое число
секунд, в течение которых вы будете спать.
(b) Наступает пауза до тех пор, пока не истечет временная уставка будильника.
На рисунке 7.7 проиллюстрирована основная идея. Каждый процесс в системе имеет
собственный будильник. Этот будильник, аналогичный кухонному таймеру, можно заставить
зазвонить после того, как истечет заказанный временной интервал в секундах.
Как работает функция sleep:
signal(SIGALRM,handler);
alarm(n);
pause();
Каждый процесс имеет собственный таймер
Рисунок 7.7
Процесс устанавливает alarm, в течение которого он приостанавливает свое развитие
7.5. Программирование времени 1: ALARMS
239
Когда истечет установленное время, будильник посылает процессу сигнал SIGALRM. Если
в процессе не был установлен обработчик сигнала SIGALRM, то этот сигнал убьет
процесс. Таким образом, функция sleep состоит из трех шагов:
1. Установка обработчика сигнала SIGALRM.
2. Вызов alarm(num_seconds).
3. Вызов pause.
Системный вызов pause приостанавливает процесс до тех пор, пока процесс не примет
сигнал. Причем любой сигнал, а не обязательно сигнал SIGALRM. Теперь соединим воедино
эти идеи и напишем такой код:
' Л sleep 1.с
* назначение - показать, как работает sleep
* обращение - sleep 1
* Программа представляет, как устанавливается обработчик сигналов, как
* устанавливается alarm, как устанавливается пауза, а затем происходит
* * продолжение действия.
7
#include
#include
//#define
main()
\
<stdio.h>
<signal.h>
SHHHH
void wakeup(int);
printff'about to sleep for 4 seconds\n"):
signal(SIGALRM, wakeup);
alarmD);
pause();
printf("Morning so soon?\n");
/* перехватить сигнал */
/* установить будильник */
/* здесь замереть 7
Г возобновить работу */
)
voidwakeup(intsignum)
{
tifndef SHHHH
printff'AIarm received from kernel\nn);
#endif
}
Мы обратились к signal, чтобы установить функцию обработки сигнала SIGALRM. Затем,
с помощью обращения к alarm, была установлена уставка таймера, равная четырем
секундам. Наконец, при обращении к pause произведена задержка развития процесса до момента
поступления сигнала от таймера. По мере истечения интервала в четыре секунды, что
контролируется таймером, ядро пошлет процессу сигнал SIGALRM. В результате происходит
передача управления от строки pause на обработчик сигнала. После выполнения кода
обработчика сигналов происходит возврат управления. Выполнение действий по перехвату
сигнала приводит к выходу из pause, и процесс возобновляет свое развитие. На рисунке 7.8
иллюстрируется обобщенное представление о работе системного вызова pause.
240
Событийно-ориентированное программирование. Разработка видеоигры
Нормальный поток управления
Системный вызов pause()
приводит к блокировке процесса
до тех пор, пока не произойдет
обработка сигнала
&^
А
И
signal
alarm
pause
И
V
х&пщ
Передача управления
обработчику и возврат
управления
Рисунок 7.8
Поток управления
в обработчике сигнала
Ниже приводится более детальная информация, относящаяся к alarm и pause:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
alarm
Установить уставку таймера для выдачи сигнала
#include < unistd.h >
unsigned old = alarm(unsigned seconds)
seconds - длительность интервала ожидания
-1 при ошибке
остаток времени до окончания предшествующей уставки
С помощью alarm вызывающий процесс производит установку таймера на указанное число
секунд seconds. Когда это время истечет, ядро пошлет процессу сигнал SIGALRM. Если
таймер уже был установлен, то после выполнения вызова alarm возвращается число оставшихся
секунд до истечения установленного ранее интервала. (Замечание. При обращении вида
alarm(O) имеющаяся на таймере уставка сбрасывается.)
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
pause
Ожидать прихода сигнала
#include < unistd.h >
result = paused
Нет аргументов
Всегда -1
Системный вызов pause задерживает вызывающий процесс до момента поступления
сигнала. Если вызывающий процесс будет закончен при поступлении сигнала, то возврата из
pause не произойдет. Если вызывающий процесс перехватывает сигнал с помощью
обработчика, то после обработки сигнала управление передается на команду, которая следует
за pause. В этом случае значение переменной errno становится равным EINTR.
7.6. Программирование времени II: Интервальные таймеры
241
7.5.3. Планирование действий на будущее
Другой вариант использования времени - произвести планирование выполнения действия
через какое-то время, а пока заняться чем-либо. Планирование выполнения действия в
будущем выполняется весьма просто. Достаточно установить требуемое время начала выполнения
действия на таймере с помощью обращения к alarm, а затем выполнять какую-либо работу.
Когда время, отслеживаемое таймером, истечет, т. е. достигнет нуля, то процессу будет послан
сигнал. Далее будет произведена передача управления обработчику сигнала.
7.6. Программирование времени II: Интервальные таймеры
Системные вызовы sleep и alarm были включены в Unix очень давно. Они обеспечивают
временное разрешение с точностью в одну секунду, что является весьма грубым для
многих приложений. По мере развития Unix была добавлена более мощная и всеобъемлющая
таимерная система. Эта новая система, где была использована концепция интервального
таймера, имеет более высокое разрешение и допускает использование не одного, а трех
таймеров для каждого процесса. И это еще не все. Для каждого из этих таймеров
допустимо использовать две установки: установка режима единичного alarm и установка режима
периодичного использования (зацикливания) таймера. Кроме того, все еще
поддерживается системные вызовы alarm и sleep, поскольку они вполне удовлетворяют по своим
возможностям многие приложения. Идея иллюстрируется на рисунке 7.9.
ч>)
Ъ?Л^;"-.^
\ \
S
W'
^т^
1
Каждый процесс
имеет три таймера
Для каждого таймера
допустимы две установки:
время до момента выдачи
первого alarm и интервал
между повторяющимися
alarms
Рисунок 7.9
Реальный Виртуальный Профильный
Каждый процесс имеет три
таймера
Мы можем использовать эту новую систему для добавления задержек и для планирования
событий.
7.6.1. Добавление улучшеной задержки: usleep
В программе можно использовать возможности улучшенной задержки usleep:
usleep(n)
При использовании usleep(n) происходит задержка текущего процесса на п микросекунд
или до момента поступления не перехваченного сигнала.
7.6.2. Три вида таймеров: реальные, процессные и профильные
Процессы имеют возможность измерять три вида времени. Рассмотрим программу,
которая заканчивается через 30 секунд после своего запуска на исполнение. Программа не
будет исполняться в течение всего этого интервала времени, если она исполняется в
системе разделения времени. Процессор будут исполнять также и другие программы,
исполнять в определенной очередности во времени. На рисунке 7.10 показана диаграмма
развития событий, которые могли произойти в течение этих 30 секунд:
242 Событийно-ориентированное программирование. Разработка видеоигры
О 5 10 15 20 25
Пользовательский ^^^^^^^^
«од: ¦¦¦¦¦ шжж:-длмжш "
Состояние сна:
I Время: реальные 30 секунд Виртуальные 10 секунд Профильные 15 секунд I
(пользовательский режим работы) (режим пользователь+ядро)
Рисунок 7.10
Как распределяются действия во времени?
На диаграмме показано, что на интервале от 0 до 5 секунд процесс работает в
пользовательском режиме. Затем он переходит в состояние ожидания и спит на интервале от 5 до
15 секунд. После происходит переход в режим ядра на интервале, который длится до 20
секунд. Далее происходит возврат в режим ожидания и т. д. На этом интервале в 30 секунд
от начала программы до ее окончания программа использовала 10 секунд
пользовательского времени и 5 секунд системного времени. На диаграмме представлены три
разновидности времени: реальное, пользовательское и пользовательское+системное. Ядро
позволяет измерять время для каждой из этих трех разновидностей. Имена этих трех таймеров
такие:
lTIMERJtEAL
Этот таймер "тикает" в реальном времени, т. е. просто измеряет время независимо от того,
сколько при этом процесс использовал времени процессора, находясь в пользовательском
или системном режимах. По истечении утановлепного временного значения для этого
таймера он посылает сигнал SIGALRM.
ITIMER^VIRTUAL
Этот таймер работает аналогично использованию часов во время футбольного матча. Он
"тикает" только, когда процесс находится в пользовательском режиме. Тридцать секунд,
которые будут отсчитаны на виртуальном таймере, будут длиннее, чем тридцать секунд
реального времени. Виртуальный таймер посылает сигнал SIGVTALRM по истечении
установленного для него значения временного интервала.
ITIMERJPROF
Этот таймер работает и измеряет время, когда процесс находится в пользовательском
режиме, а также, когда ядро исполняет системные вызовы, которые были запущены по
инициативе процесса. Когда для этого таймера будет исчерпано установленное значение
временного интервала, то таймер посылает сигнал SIGPROF.
7.6.3. Два видаинтервалов: начальный ипериод
Доктор дает вам пилюлю и говорит "примите лекарство через час и далее будете
принимать через каждые четыре часа". В ответ на это вам нужно установить таймер так, чтобы
он сработал через час, а затем, когда он в очередной раз сработает, вы будете
переустанавливать его каждые четыре часа. В каждом интервальном таймере можно выполнить
установку этих двух временных значений: начальное значение интервала и значение периода
зо
7.6. Программирование времени II: Интервальные таймеры
243
повторения. В структуре, которая используется интервальным таймером, начальный
интервал задается с помощью члена структуры it__value, а значения периода задаются с
помощью члена структуры itjnterval. Если вам не нужна последующая периодичность работы
терминала, то нужно установить значение itjnterval в ноль. Для сброса обоих уставок
нужно установить в ноль значение it_value.
7. 6.4. Программирование с помощью интервальных таймеров
Программировать на основе использования alarm достаточно легко. Вы просто задаете при
вызове alarm требуемое число секунд. Программирование с помощью интервального
таймера является более сложным. Вам будет необходимо выбрать вид времени, а затем
решить, каково должно быть значение начального интервала и значение периода. Кроме
того, вы должны будете записать выбранные значения времен в структуру struct itimerval.
Например, чтобы интервальный таймер напоминал бы вам о порядке приема лекарства
в соответствии с планом, который был описан в предшествующем параграфе, нужно будет
присвоить члену структуры it_value значение, равное одному часу, а члену структуры
itjnterval присвоить значение 4 часа. Затем следует переслать эту структуру таймеру,
используя для этого setitimer. Для того чтобы прочитать значения установок таймера,
Следует обратиться к getitimer. Иллюстрация этой концепции представлена на рисунке 7.11.
Рисунок 7.11
Чтение и запись установок для таймера >
Пример использования интервального таймера: ticker_demo.c
В программе ticker_demo.c показывается, как можно использовать интервальный таймер:
Г tickerjlemo.c
* демонстрируется использование интервального таймера для выработки
* последовательности сигналов, которые в свою очередь перехватываются и
* используются для декремента счетчика
7
#include <stdio.h>
#include <sysAime.h>
#include <signal.h>
int main()
{
void countdown(int);
signal(SIGALRM, countdown);
if(settickerE00)==-1)
244
Событийно-ориентированное программирование. Разработка видеоигры
else
return 0;
perrorf'seUicker");
whi!eA)
pause();
}
void countdown(int signum)
{
static intnum = 10;
printtp/od..", num--);
fflush(stdout); -
if(num<0){
printf(,,DONE!\nM);
exit@);
}
/* [из setjicker.c]
* setJicker(numberj)f_milliseconds)
*' настраивает интервальный таймер на выдачу сигнала SIGALRM с
* установленной периодичностью
* код возврата -1 - при ошибке, 0 - при успешном окончании
* Значение аргумента, которое задается в миллисекундах, преобразуется в
* секунды и микросекунды
* Замечание: обращение вида setJicker(O) сбрасывает установки для ticker
7
int set_ticker(int n_msecs)
{
struct itimerval newjimeset;
long n_sec, n_usecs; %
n_sec = n_msecs /1000; /* целая часть */
n_usecs = (n_msees % 1000) * 1000L; /* остаток */
newjimeset. it interval, tv^sec = n_sec; /* установка перезагрузки */
new_timeset.it_value.tv_sec = n_sec; /* сохранить это 7
new_timeset.it_value.tv_usec = n_usecs; /* и это */
return setitimer(ITIMER_REAL, &newjimeset, NULL);
}
Отследим поток управления для программы ticker_demo.c. Сначала мы использовали signal
для установки функции countdown, которая должна обрабатывать сигнал SIGALRM. Сигнал
должен возникнуть по истечении интервала, длительность которого задается при
обращении к setjicker.
Функция set_ticker устанавливает интервальный таймер, что делается загрузкой значения
начального интервала и значения периода. Каждый из этих интервалов представлен
значениями, каждое из которых хранится в двух разных видах: значение, измеряемое в
секундах, и значение, измеряемое в микросекундах, что эквивалентно представлению
вещественного числа с помощью целой и дробной частей. После того как таймер "затикает",
управление передается в функцию main.
7.6. Программирование времени II: Интервальные таймеры
245
После передачи управления в main программа ticker_demo.c входит в бесконечный цикл,
в котором вызывается pause. После окончания каждого интервала в 500 миллисекунд
происходит передача управления на функцию countdown. Функция countdown производит
декремент статической переменной, печатает сообщение и передает управление обратно
тому, кто эту функцию вызвал. Когда значение переменной num достигнет нуля, то
функция countdown выполняет exit.
Естественно, функция main не обязана выполнять вызов pause. Вместо этого основная
программа может делать что-либо более интересное для себя. При этом после каждого тика
таймера управление будет передаваться функции countdown.
Детали структуры данных. Внутренние установки таймера передаются в структуру
struct itimerval. Эта структура содержит значение начального интервала и значение периода
повторения. Оба значения хранятся в структуре struct timeval:
struct itimerval
{
struct timeval it_value; /* время, когда должен кончиться интервал */
struct timeval itjnterval; /* это значение загружается в it_value */ •
struct timeval {
timej tv_sec;
susecondsj tv_usec;
/* секунды */
/* и микросекунды */
Детали в представлении структуры struct timeval могут быть разными от одной версии Unix
к другой. Поэтому обратитесь к документации и заголовочным файлам на вашей системе.
На рисунке 7.12 изображены структуры внутри структур, а на рисунке 7.13 показано, как
будет произведена загрузка структуры так, чтобы первый alarm возник через 60.5 секунды,
а затем повторялся через каждые 240.25 секунды.
ITIMER_REAL
it_value
:t_intervai
33;
РЗ^РЗ
ITIMER_VIRTUAL
it_value [_
it_interval Г
ITIMER_PROF
it_value I
it_intervalJ~
struct itimerval
Каждый таймер имеет две установки: остаток времени
на таймере и интервал для повторения выдачи сигнала.
Каждая из этих установок представлена в качестве члена
в структуре типа struct timeval
Рисунок 7.12
struct timeval
Структура struct timeval имеет два члена: число секунд
и число микросекунд
Внутреннее представление интервальных таймеров
246
Событийно-ориентированное программирование. Разработка видеоигры
ITIMER_REAL
it_value
it__interval
60
240
tv_sec
500000
250000
tv_usec
В этом примере показана установка
интервального таймера реального времени,
который должен выдать сигнал
через 60.5 секунды, а далее выдавать
сигнал через каждые 240.25 секунды
Рисунок 7.13
Секунды и микросекунды
Обобщение fio системным вызовам
getitimer,setitimer
НАЗНАЧЕНИЕ
Получить или установить значение уставки интервального таймера
INCLUDE
#include < sysAime.h >
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
result = getitimerfjnt which.struct itimeival *val);
result = setitimer(int which.const struct itimerval *newval, struct itimerval *oldval);
which - таймер, который устанавливается или установки которого читаются
val - указатель на текущие установки
newval - указатель на установки, которые будут инсталлированы
oldval - указатель для установок, которые будут заменены
-1 -при ошибке
О - при успехе
Системный вызов getitimer позволяет читать значения текущих установок для конкретного
таймера и помещать считанные значения в структуру, на которую направлен указатель val.
Системный вызов setitimer позволяет производить установку таймерных значений, на
которые направлен указатель newval. Если указатель oldval ненулевой, то предшествующие
значения установок для этого таймера копируются в структуру, на которую направлен
указатель oldval. *
С помощью значения аргумента which определяется таймер, который будет
устанавливаться или у которого будут прочитаны его установки. Коды для таймеров таковы:
ITIMER_REAL, ITIMERJ/IRTUAL, ITIMER_PROF.
Z 6.5. Сколько часов можно иметь на компьютере?
Что нужно сделать в системе, чтобы каждый процесс в системе имел бы в своем
распоряжении трое отдельных часов? Ведь в некоторых системах одновременно развиваются
сотни процессов. Означает ли это, что на компьютере следует поддерживать сотни отдельных
часов? Нет, в системе необходимы только одни часы для поддержки общей синхронизации
(для задания темпа работы): Подобно постоянному тиканью только одного метронома,
задающего такт для струнного квартета, или подобно только одному маятнику, который
7.6. Программирование времени II: Интервальные таймеры
247
двигает стрелки на старинных часах, так и тиканье (пульсация) одних аппаратных часов
будет достаточным для реализации на компьютере только одного таймера. Но при
наличии только одного таймера, каким образом сможет один процесс установить
собственный таймер на выработку сигнала через 5 секунд, а при этом другой процесс сможет
установить собственный таймер на выработку сигнала через 12 секунд?
А как все происходит в старинных часах, где часовая стрелка движется с одной скоростью,
минутная стрелка движется с другой скоростью, секундная стрелка движется с третьей
скоростью, а индикатор лунных фаз движется с четвертой скоростью? Ответ на все
поставленные вопросы будет один и тот же. Для каждого исполнителя в квартете, для
процесса и для шестеренки часов необходима установка личного счетчика. Операционная
система должна будет декрементировать все эти счетчики после каждого тика системных
часов. Идею поможет пояснить следующий пример.
Конкретный пример. Рассмотрим два процесса, процесс А и процесс В. Процесс А
установил свой реальный таймер на срабатывание через 5 секунд, а процесс В установил свой
реальный таймер на срабатывание через 12 секунд. Для того чтобы иметь дело с более
простыми числами, представим, что системные часы тикают в темпе 100 тиков в секунду.
Когда процесс А установил свой таймер, ядро установило значение счетчика этого
процесса равным 500. Когда процесс В установил свой таймер, то ядро установило
значение счетчика для этого процесса равным 1200. Пока все хорошо, не так ли? Взгляните на
рисунок 7.14.
Интервальные таймеры для процессов
Одни настоящие часы
Каждый процесс устанавливает собственный таймер с помощью alarm. Ядро модифицирует все таймеры процессов после
каждого сигнала от часов
Рисунок 7.14
Два таймера, одни часы
При каждом тике системных часов ядро обращается к набору интервальных таймеров и
уменьшает значение каждого счетчика на единицу. Когда значение счетчика процесса А
достигнет нуля (это произойдет после того, как от часов поступит 500 тиков), ядро пошлет
процессу А сигнал S1GALRM. Если процесс А установил значение itjnterval для этого
таймера, то ядро скопирует это значение в счетчик it_value. В противном случае ядро сбросит
таймер. *
248 Событийно-ориентированное программирование. Разработка видеоигры
Несколько позже ядро декрементирует значение счетчика процесса В на 1200-м тике и
обнаружит, что значение счетчика стало равным нулю. Это заставит ядро послать сигнал процессу В.
Если в процессе В была запланирована переустановка значения таймера, то ядро выполнит
перезагрузку значения it_value и перейдет к обслуживанию следующего таймера.
Такой простой механизм позволяет каждому процессу установить собственный
будильник. Даже когда процесс спит, таймер будет "тикать" - декрементировать счетчик
времени, оставшегося до побудки.
А как работают оставшиеся два вида таймеров? Они декрементируют значение счетчика
не постоянно, а делают это только тогда, когда процесс будет находиться в нужном
состоянии. По исходному коду Linux ясно видно, как работают эти таймеры.
7. 6.6. Итоговые замечания по таймерам
Программа в Unix использует таймеры для приостановки своего исполнения и для
планирования выполнения действий в будущем. Таймер представляет собой механизм ядра,
который посылает сигнал процессу после того, как истечет заданный интервал времени.
С помощью системного вызова alarm процессу посылается сигнал SIGALRM после того,
как пройдет заданное число секунд реального времени. Системный вызов setitimer
позволяет управлять таймером с высоким временным разрешением и использовать
возможность вырабатывать сигналы через регулярные интервалы времени.
Мы знаем теперь, как можно использовать время в наших программах. В видеоигре
требуется использование еще одного механизма: управление прерываниями.
7.7. Управление сигналами I: Использование signal
Наша игра должна управляться с помощью прерываний. Игра может быть в таком
состоянии: образ перемещается по экрану, а в это время пользователь нажал на клавишу. Или
может случиться, что игра находится в таком состоянии, что производится обработка
пользовательского ввода, и в это время приходит сигнал от таймера. Если в игре могут
принимать участие два игрока, то может случиться, что при отработке ответа одному игроку
другой игрок нажал на клавишу.
Управление прерываниями является существенной частью операционной системы и
системных программ. В Unix прерывания, вызванные программным образом, воспринимаются как
сигналы. Рассмотрим теперь более детально тему управления сигналами. Сначала сделаем
обзор начальной модели управления сигналами в Unix. Затем определим проблемы,
свойственные этой модели. Наконец, мы изучим POSIX-модель управления сигналами.
Z Z /. Управление сигналами в старом стиле
Ядро посылает сигналы процессу в ответ на некоторые события, включая нажатия на
клавиши, недопустимое поведение процесса, окончание отсчета времени на таймере. В главе
6 была введена для рассмотрения начальная модель управления сигналами. Процесс
обращается к signal для выбора одного из трех возможных вариантов реакции на сигнал:
(a) Действие по умолчанию (обычно это окончание процесса).
Например, signal (SIGALRM, SIGJDFL).
(b) Игнорирование сигнала. Например, signal(SIGALRM, SIGJGN).
(c) Введение функции для обработки сигнала. Например, signal (SIGALRM, handler).
Z Z Управление сигналами I: Использование signal
.249
7.7.2, Управление множеством сигналов
Базовая модель управления сигналами прекрасно работает, если будет поступать только
один сигнал. А что будет происходить, если процессу будет посылаться множество
сигналов? С реакцией типа окончание процесса и типа игнорирование все ясно. А вот с реакцией
типа перехват сигнала для последующей обработки с помощью функции ответ не ясен
и не очевиден.
Проблема мышеловки
Обработчик сигнала подобен мышеловке. Сигнал появляется, чтобы известить о
возникновении некоторой опасности. И щелк! Мышь или сигнал перехватываются. Но такая
обработка сигналов неэффективна.
В Olden Days ® механизм перехвата сигналов был похож на мышеловку еще и в другом
смысле: вы должны были восстанавливать этот механизм в исходное состояние после
каждого перехвата сигнала. Например, обработку сигнала SIGINT можно было выполнить так:
void handler(int s)
{
Г процесс в этом месте уязвим */
signal(SIGINT, handler); /* восстановление обработчика */
... /* здесь все работает 7
}
Даже если вы все будете делать быстро, все равно пройдет какое-то время от начала
процесса до восстановления обработчика, т. е. до момента, когда мы могли бы поймать
другую мышь. Это зона уязвимости делает начальную модель управления сигналами нена-
дежной. Как это ни странно, но многие используют термин ненадежные сигналы. Это
звучит так же неправильно, как если бы мы говорили - ненадежные мыши.
Планирование работы в улучшенной системе
Проблема мышеловки - это только одно из слабых мест начальной модели управления
сигналами. Для понимания сложности этой темы рассмотрим реальные примеры:
Множество сигналов, предназначенных человеку
В реальном мире существует множество сигналов, т. е. непредсказуемых прерываний.
Представьте себе, что вы работаете в вашем офисе. Может зазвонить телефон, кто-то
может постучать в дверь, может зазвучать сирена пожарной тревоги. Каждое из этих
событий является для вас требованием на прерывание вашей работы. Каждое такое требование
можно или проигнорировать, или как-то на него отреагировать. Управление, связанное
с телефонным звонком, сводится к тому, что вы должны будете отложить на время вашу
текущую работу, ответить на звонок абонента, поговорить с ним, положить трубку и затем
продолжить вашу работу. Ваша реакция на стук в дверь, по сути, приведет к выполнению
действий по той же схеме.
А что произойдет, если к вам стучатся, когда вы отзечаете на телефонный звонок? Вы на
момент прервете разговор по телефону, отложите трубку, ответите на стук в дверь,
поговорите с визитером и вновь продолжите разговор по телефону. Потом, когда вы закончите
телефонный разговор, вы опять продолжаете свою работу за столом. В данном случае мы
говорим, что второй сигнал прервал обработку первого сигнала. Далее. А что случится,
если появится еще один визитер, когда вы разговариваете с первым визитером? Часто
происходит так, что первый визитер закрывает дверь. Поэтому второй визитер будет
вынужден ожидать, пока вы не поговорите с первым. Когда вы закончите переговоры с первым
250
Событийно-ориентированное программирование. Разработка видеоигры
визитером, то второй визитер может постучать в дверь. В этом случае мы будем говорить,
что второй визитер был блокирован до того момента, пока не заканчивается беседа
с первым визитером.
Итак, вернемся к вопросу что, если визитер прерывает вас, когда вы разговариваете с кем-
либо по телефону? Когда визитер выходит из комнаты, то сможете ли вы правильно
восстановить (или вспомнить), на чем прервался ваш разговор по телефону, или же вы
скажете абоненту, что забыли, о чем вы говорили с ним?
Наконец, ваша жизнь может зависеть от понимания следующего примера. Что случится,
если зазвонил телефон или кто-то постучад в дверь в момент возникновения сигнала
пожарной тревоги?
При возникновении критического сигнала пожарной тревоги вы, вероятно, блокируете
другие сигналы, такие, как телефон и дверь, когда будете что-то делать по сигналу
пожарной тревоги. Наверное, могут быть и другие случаи, когда возникает потребность
блокировать все сигналы, хотя и нет необходимости отрабатывать действия по сигналу
пожарной тревоги.
Множество сигналов для процесса
Жизнь ваших процессов мало отличается от вашей жизни. Представьте себе процесс, который
развивается в своей маленькой виртуальной клетушке где-то в памяти компьютера (см.
рисунок 7.15). Пользователь может нажать ключ Ctrl-C и выработать сигнал SIGINT. Или нажать на
ключ CtrIA и выработать сигнал SIGQUIT. Или поступит сигнал от таймера SIGALM, когда
закончится установленный интервал времени. Все эти сигналы могут одновременно поступить
процессу, что аналогично ситуации с телефонным звонком и со стуком поситителей в дверь.
Как в Unix процесс будет производить обработку сразу нескольких сигналов?
Обработчик SIGINT
Обработчик SIGQUIT
Обработчик SIGALRM
Рисунок 7.15
Процесс принимает
несколько сигналов
1. Нужно ли восстанавливать работоспособность обработчика после каждого его
использования? (Модель мышеловки)
2. Что произойдет, если поступит сигнал SIGY, когда процесс занят обработкой сигнала
SIGX?
3 Что произойдет, если поступает второй сигнал SIGX, когда процесс занят обработкой
предшествующего сигнала SIGX? Или что будет, если поступит в этот момент еще и
третий сигнал SIGX?
4. Что произойдет, когда поступает сигнал, а программа блокирована по входу, поскольку
быполняет getchar или read?
В различных версиях Unix ответы на эти вопросы будут разными. Написать программу,
в которой работали бы все возможные варианты, трудно.
7. 7. Управление сигналами I: Использование signal
251
7.7.3. Тестирование множества сигналов
Как в вашей системе решаются указанные выше задачи? Скомпилируем и запустим на
исполнение программу sigdemo3.c для того, чтобы ответить на вопрос, как процессы вашей
системы будут реагировать на различные комбинации сигналов:
/* sigdemo3.c
* назначение: иллюстрация ответов на вопросы о сигналах
вопрос 1: остается ли в рабочем состоянии обработчик после того, как был
* принят сигнал?
* вопрос 2: что происходит, если сигнал signalX приходит, когда происходит
* обработка предшествующего сигнала signalX?
вопрос 3: что произойдет, если сигнал signalX поступает, когда процесс
занят обработкой сигнала signalY?
вопрос 4: что произойдет с выполнением read(), если поступает сигнал?
7
#jnclude <stdio.h>
#include <signal.h>
#define INPUTLEN 100
main(intac, char*av[])
{
void inthandler) int);
void quithandler(int);
charinputflNPUTLEN];
intnchars;
signal(SIG!NT, inthandler); /* установка обработчика 7
signal(SIGQUIT, quithandler); /* установка обработчика */
do{ ".. .
printf("\nType a message\n");
nchars = read@, input, (INPUTLEN-1));
if (nchars == -1)
perrorf'read returned an error");
else{
input[nchars] = '\0*;
printf("You typed: %s", input);
}
}
while(strncmp(input, "quit", 4) != 0);
}
void inthandlerfint s)
{
printff Received signal %d.. waiting\n", s);
sleepB);
printf(" Leaving inthandler \n");
}
void quithandler(int s)
252
Событийно-ориентированное программирование. Разработка видеоигры
printf(" Received signal %d.. waiting\n", s);
sleepC);
printf(" Leaving quithandler \nn);
}
Поэкспериментируйте с выполнением некоторых тестовых последовательностей, что
сводится к обычному вводу текста и нажатию в определенном порядке на два ключа: Ctrl-C
и CtrlA. В частности, проверьте действие следующих далее комбинаций, используя
различные задержки между нажатиями на ключи. Проследите трассу потока управления
через функции обработки сигналов, как показано на рисунке 7.16.
(a) АСЛСЛСАС
(b) Л\ЛСЛ\ЛС
(c) heIloAC Return
(d) hello Return ЛС
(e) A\A\helloAC
Основной цикл -
Обработчик ЛС
whileA) {
n = read@,buf,len)
writeA, buf, n);
}
обработчик л—4-| | [;| ^^ Рисунок 7.16
Прохождение потока
управления через эти функции
Результаты этих экспериментов покажут, как ваша система управляет комбинацией
сигналов: .%
1. Ненадежные сигналы (мышеловка).
Если посылка двух сигналов SIGINT приведет к уничтожению процесса, то вы имеете дело
с ненадежными сигналами: после очередной обработки сигнала обработчик должен быть
восстановлен. Если при поступлении нескольких сигналов SIGINT процесс не будет убит,
то это означает, что обработчик остается в рабочем состоянии после очередной обработки
сигнала. В современных механизмах обработки сигналов можно встретить тот и другой
вариант обработки.
2. Сигнал SIGY прерывает работу обработчика сигнала SIGX (сначала телефонный
звонок, потом стук в дверь).
Когда вы нажали на ключ Ctrl-C, а потом нажали на ключ Ctrl-\, то можете заметить, что
сначала в вашей программе было передано управление на обработчик inthandler, затем
управление будет передано на quithandler, а затем опять управление будет передано
функции inthandler. И, наконец, управление будет передано опять в цикл функции main. А что
показал ваш эксперимент?
3. Сигнал SIGX прерывает работу обработчика сигнала SIGX (в дверь постучали дважды).
7.7. Управление сигналами I: Использование signal 253
Этот случай аналогичнен той ситуации, когда двое человек подряд хотят к вам войти.
Рассмотрим три возможные метода решения этой проблемы:
1. Рекурсивный, вызывается один и тот же обработчик3.
2. Проигнорировать второй сигнал, что аналогично ситуации, когда телефон занят.
3. Блокировать второй сигнал, пока не будет закончена обработка первого сигнала.
В первоначальных системах по обработке сигналов использовался первый метод, где
допускались рекурсивные вызовы. Метод 3 является методом защиты. Все происходит так,
как в ситуации со вторым посетителем у двери. Второй сигнал блокируется, а не
игнорируется. Блокируется до тех пор, пока обработчик не закончит обработку, связанную
с появлением первого сигнала. В вашей системе происходила блокировка второго прихода
сигнала или производился рекурсивный вызов обработчика? Может ли ваша система
ставить несколько сигналов в очередь на обработку?
4. Прерываемые системные вызовы (стук в дверь во время телефонного разговора)
Это один из вероятных случаев. Программы часто принимают сигналы во время ожидания
ввода. В тестовой программе, которая была приведена выше, основной цикл
блокировался, когда системный вызов read ожидал ввода данных с клавиатуры. Если при этом вы
нажмете на ключ прерывания или на ключ выхода (ключ quit), то управление в программе
будет передано соответствующему обработчику сигнала. После того, как обработчик
закончит работу, управление вновь будет передано в функцию main, предположительно в то
место, где функция была прервана. Правильно ли это? Что произойдет, если вы набрали на
клавиатуре "hel", затем нажали ключ Ctrl-C, потом дополнительно набрали о" и нажали
Enter? Как поступит программа - произведет рестарт read или будет закончено
выполнение read и в переменную errno будет занесено значение EINTR?
Этот вопрос, рестарт или return, может быть решен двумя способами. Либо по схеме
AT&T (возврат из read с кодом -1 и со значением в errno, равным EINTR. Это классическая
модель), либо по схеме UCB (автоматический рестарт).
7.7.4. Слабые места схемы управления множеством сигналов
В начальной схеме управления сигналами есть еще два слабых места;
Вы не знаете - почему был послан сигнал.
Обработчик сигнала - эта функция, которая вызывается, когда поступает сигнал. Ядро
передает обработчику номер сигнала. В программе sigdemo3.c функция inthandler
вызывается с аргументом SIGINT. Получение через аргумент номера сигнала позволяет одной
функции управлять обработкой нескольких сигналов. Например, в программе sigdemo3.c мы
можем заменить два обработчика одним обработчиком, который будет использовать
аргумент для определения, какое сообщение вывести на печать. В первоначальной модели
обработчик извещается, какой сигнал он принял, но обработчику ничего не сообщается,
почему был выработан сигнал. Например, возникшая ситуация исключения по плавающей
точке (floating-point exception) может привести к выработке сигнала, когда происходят
любая из нескольких видов арифметических ошибок - таких как деление на ноль,
целочисленное переполнение, потеря значимости. Обработчику необходимо знать о
причине возникновения данной проблемы, т. е. о причине исключения.
3. Это - непреднамеренная рекурсия, поскольку обработчик сам себя не вызывает, но проявление будет
аналогично обычной рекурсии.
254 Событийно-ориентированное программирование. Разработка видеоигры
Вы не можете надежно произвести блокирование других сигналов, когда происходит
работа обработчика сигналов.
Когда вы что-либо делаете в ответ на сигнал пожарной тревоги, то обычно вы игнорируете
звонки телефона. Пусть мы решили, что наша программа будет игнорировать сигнал
SIGQUIT, если он приходит при обработке сигнала SIGINT. Используя классические
сигналы, модифицируем обработчик inthandler, который теперь будет выглядеть так:
void inthandlerfint s)
{
intrv;
void (*prev,qhandler)(); . /^сохранить связь с обработчиком */
prev_qhandler = signal(SlGQUIT, SIGJGN); /* игнорировать сигналы QUIT */
signal(SlGQUIT, prev qhandler); /* восстановить действие обработчика */
. }
To есть мы отключаем обработчик сигнала выхода (quit handler) при входе в обработчик
сигнала прерывания (interrupt handler) и восстанавливаем доступность к обработчику
сигнала выхода при окончании работы обработчика сигнала прерывания. В связи с таким
решением возникают две проблемы. Во-первых, возникает уязвимое пространство, которое
расположено от момента начала исполнения inthandler до вызова signal. А нам хотелось,
чтобы одновременно был бы и вызов обработчика inthandler, и было бы установлено
игнорирование сигнала SIGQUIT.
Во-вторых, мы не хотели бы просто проигнорировать сигнал SIGQUIT. Мы хотели бы
только блокировать этот сигнал до тех пор, пока не будут выполнены действия по сигналу
пожарной тревоги. Нам хотелось бы благополучно получить опять возможность обработки
сигнала SIGQUIT, когда закончится критическое событие.
7.8. Управление сигналами II: sigaction
В течение ряда лет различные группы разработали варианты решения вопросов и
проблем, которые были связаны с первоначальной моделью управления сигналами. Мы
будем изучать только POSIX-модель и набор необходимых для нее системных вызовов.
Между тем классический системный вызов signal все еще поддерживается. Он вполне
приемлем для некоторых приложений.
Z 8.1. Управление сигналами: sigaction
В POSIX системный вызов signal заменен системным вызовом sigaction. При этом
назначение аргументов осталось практически тем же. Вы определяете, какой сигнал будет
обрабатываться и как вам хотелось бы управлять этим сигналом. При желании вы можете
узнать, каковы были предшествующие установки по обработке сигнала.
int sigaction(signalnumber, action, prevaction)
Обобщенно характеристики будет выглядеть так:
sigaction
НАЗНАЧЕНИЕ Определить способ управления сигналом
INCLUDE
#include < signal.h >
7.8. Управлениесигналами II: sigaction
255
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
sigaction
res = sigactionflnt signum,
const struct sigaction 'action,
struct sigaction *prevaction)
signum - сигнал, которым следует управлять
action - указатель на структуру, где описано действие по управлению
prevaction - указатель на структуру, куда помещается описание
старого действия по управлению
-1 -при ошибке
0-при успехе
Первый аргумент signum служит для задания сигнала, которым следует управлять. Второй
аргумент action указывает на структуру, где описано, как следует реагировать на
появление сигнала. Третий аргумент prevaction, если он не равен нулю, указывает на структуру,
куда будут помещены старые установки по обработке сигнала. Системный вызов
возвращает 0, если новое действие было успешно инсталлировано, и -1 в случае неудачи.
Настройка процедуры обработки сигналов: struct sigaction
На ранних этапах развития Unix ваш выбор варианта по управлению сигналами был
прост: SIG_DFL, SIGJGN или функция обработки. В новой модели за вами сохраняется
выбор варианта управления. Но это лишь часть возможностей структуры struct sigaction,
с помощью которой задается, как будет обрабатываться сигнал. Далее представлена эта
структура полностью:
struct sigaction {
Г используется только одна из этих двух возможностей */
void (*sa_handler)(); /* SIG_DFL, SIGJGN или функция обработки */
void (*sa_sigaction)(int, siginfot *, void *); /* НОВЫЙ обработчик 7
sigsetj sa.mask; /* сигналы, которые будут блокированы во время обработки*/
int sajlags; /* установка различных режимов поведения */
}
sajiandler //y7#sa_sigaction
Прежде всего вам необходимо принять решение и выбрать либо старый метод управления
сигналами, либо новый, более мощный. Если вы выбрали старый метод - SIG_DFL,
SIGJGN, функция обработки, то следует установить в sajiandler одну из трех,
перечисленных выше установок. Естественно, если вы выбрали старый стиль управления сигналами,
то вам будет достаточно сообщить о номере управляемого сигнала. Если же вы вместо
этого варианта указываете в sa_sigaction имя обработчика, то это будет обработчик,
который получит номер сигнала, а также получит информацию о причине и о проблемном
контексте. Различие между этими двумя видами обработчиков можно в целом выразить
так:
Использование обработчика старого стиля Использование обработчика нового стиля
struct sigaction action; struct sigaction action;
action.sajiandler = handler_old; action.sa_sigaction = handler_new;
А как сообщить ядру о том, чтовы хотели бы использовать обработчик нового стиля?
Легко. Надо установить бит SA_SIGINFO в члене структуры sajlags.
sajlags
256
Событийно-ориентированное программирование. Разработка видеоигры
Вы должны решить, как ваш обработчик будет отвечать на четыре вопроса,
сформулированные в предшествующем разделе. Член sa_flags представляет собой битовый набор.
С его помощью и происходит управление режимами работы обработчика так, что" можно
ответить на эти четыре вопроса. Обратитесь к вашему справочнику для получения полной
информации по этому поводу. Вот некоторая часть информации об этом битовом наборе:
Флаг
SA RESETHAND
SA NODEFER
SA RESTART
SA SIGINFO
Назначение
Сброс обработчика после вызова. Этим достигается режим мышеловки.
Выключение автоматической блокировки сигнала, когда он будет
обрабатываться. Этим обеспечивается возможность рекурсивных обращений
к планировщику
Рестарт, а не return, выполнения системных вызовов в отношении медленных
устройств и необходимые для этого системные вызовы. Этим обеспечивается
поддержка режима BSD
Использование значения в sa_sigaction в качестве функции обработчика. Если
этот бит не установлен, то используется значение sa_handler. Если
используется значение sa_sigactionjo этой функции обработчика будет
передаваться не только номер сигнала, но также указатели на структуры, где
содержится информация, которая позволяет определить, почему и как был
выработан сигнал
sa_mask
Наконец, вы должны решить, нужно ли блокировать другие сигналы, которые могут
появиться при работе обработчика. Указать сигналы, которые требуется блокировать, можно
с помощью разрядов в sa_mask. С помощью sa_mask вы можете блокировать телефонные
звонки и стуки в дверь визитеров до тех пор, пока не ликвидируете пожарную ситуацию.
Значением sajnask будет набор сигналов, которые необходимо блокировать.
Блокирование сигналов - это средство для предотвращения искажений данных. В следующем
разделе мы рассмотрим эту тему более детально.
Пример: Использование sigaction
В данной программе демонстрируется использование sigaction (заметьте, как производится
блокирование сигнала SIGQUIT на периоде обработки сигнала SIGINT).
Г sigactdemo.c
* назначение: показывает, как используется sigaction()
свойство: блокирование нажатия на ключ \ когда обрабатывается сигнал от нажатия ЛС
* Обработчик ЛС не восстанавливается, поэтому второй сигнал
* убивает процесс
*/
#include <stdio".h>
#include <signal.h>
#define INPUTLEN 100
main()
struct sigaction newhandler;
sigseU blocked;
void inthandler();
charx
/* новые установки */
/* набор блокированных сигналов */
Г обработчик 7
[INPUTLEN];
Г сначала загружаются эти два члена 7
7Л Предотвращение искажений данных
257
m&4l^<№mjmti\er = inthandler; /* функций обработчика */
newhandter.sajags = SA_RESETHAND | SA.RESTART; /* опции */
/* затем строится список блокируемых сигналов */
sigemptyset(&blocked); /* очистить все разряды */
sigaddset(&blocked, SIGQUIT); /* добавить в список сигнал SIGQUIT */
newhandier;sa_mask = blocked; /* сохранить маску блокирования сигналов */
if (sigaction(SIGINT, &newhandler, NULL) == -1)
perrorf'sigaction");
else
whileA){
fgets(x, INPUTLEN, stdin);
printff'input: %s", x);
}
}
void inthandler(int s)
{
printf("Called with signal %d\n"J s);
sieep(s);
printffdone handling signal %d\n", s);
}
Попробуйте поработать с этой программой. Если вы нажмете на ключ Ctrl-C, а затем
быстро на ключ CtrlA, то сигнал quit будет блокирован до тех пор, пока обработчик не
завершит обработку сигнала interrupt. Добейтесь того, чтобы вы получили на практике то,
что хотели бы видеть. Если дважды нажать на ключ Ctrl-C, то по второму сигналу процесс
исполнения нашей программы будет убит. Если вы предпочтете перехват всех сигналов,
которые поступят при нажатии ключа Ctrl-C, то следует убрать маску SARESETHAND из
члена saflags.
7, 8.2. Заключительные замечания по сигналам
Процесс может быть прерван сигналами, которые поступают из разных источников.
Сигналы могут поступать в произвольном порядке и в произвольное время. Системный вызов
signal предоставляет возможность использовать простой, неполно определенный метод
управления сигналами. В POSIX интерфейс sigaction предоставляет исчерпывающий, ясно
определенный метод для управления реакциями процессов при поступлении различных
комбинаций сигналов.
Мы знаем теперь, как управлять временными интервалами и прерываниями в наших
программах. Наша видеоигра требует рассмотрения последнего вопроса: предотвращение
неразберихи.
7.9. Предотвращение искажений данных
Когда вы одновременно заняты исполнением сразу нескольких дел, то не приводит ли это
вас к неразберихе и не делаете ли вы при этом ошибки? Представьте, что вы готовите к
отправке письмо и ищете марку для письма. В это время раздается звонок в дверь. В
результате такой помехи вы можете забыть, чем вы занимались до звонка, и отправить письмо
без марки. В программах может произойти то же. Если программа находилась где-то на
половине выполнения некой работы и неожиданно ее прерывают. Программа от такой
плмргуи мпжрт г.бмткг.яг что ппиир.пет к игкяж^ниш пяннму
258
Событийно-ориентированное программирование. Разработка видеоигры
Обратимся к бытовым примерам, чтобы проиллюстрировать, как прерывания могут
Привести к ошибкам в данных. Потом обратимся к программистским идеям и средствам,
с помощью которых можно предотвратить появление проблемы.
7.9.1. Примеры, иллюстрирующие искажение данных
Продолжим рассмотрение ситуации, которая может сложиться в вашем офисе, когда вашу
работу прерывает телефонный звонок и стук в дверь. Пусть посетители, которые стучат
в дверь офиса, будут заносить свои фамилии и адреса в список. Каждый посетитель
должен заносить в конец списка три строки: фамилия, улица, город, штат и индекс (zip).
Рассмотрим две проблемы.
Во-первых. Визитер в текущий момент занят тем, что добавляет в список информацию
о себе. В это время кто-то звонит по телефону и запрашивает фамилии и адреса из списка.
Если вы в ответ возьмете список и прочтете своему телефонному абоненту список, то вы
предоставите ему данные, которые полностью не сформированы. Вы можете
предотвратить появление ошибок такого рода, если блокируете телефонные звонки на время, пока
происходит оформление посетителей.
Далее. Рассмотрим другую проблему. Пусть один из посетителей только что добавил
в список одну строку о себе, и в этот момент поступил второй сигнал SIGKNOCK. Если
вами используется рекурсивный метод управления сигналами, то вы приостанавливаете
оформление первого посетителя и допускаете к оформлению второго, который записывает
три строки в список о себе, а затем уходит. После этого первый посетитель продолжает
регистрацию, дописывая свои данные к концу имеющегося списка. Он добавляет записи
об улице, городе, штате и индексе. После этого в учетном списке будут содержаться
неправильные данные. Получилось, что одна учетная запись попала внутрь другой.
Вы можете предотвратить появление этого типа ошибок за счет последовательного, а не
рекурсивного обслуживания при оформлении.
Эти два примера продемонстрировали, что необходимо предотвращение прерывания
одним действием другого действия. Структура данных (это в нашем случае список учета)
модифицировалась, когда производилась работа с этой структурой. До тех пор, пока не
будут выполнены все изменения в структуре, все другие функции не должны читать и
изменять структуру данных. Естественно, средство отработки сигнала пожарной опасности
сохраняет свою работоспособность, поскольку этот обработчик не читает и не пишет
в список учета.
7.9.2. Критические секции
Секцию кода, где производится модификация структуры данных, называют критической
секцией, если прерывания кода в этой секции могут привести к появлению неполных или
"опасных" данных. Когда ваша программа работает с сигналами, то вы должны
определить, какие части вашего кода принадлежат критическим секциям, и предпринять меры по
защите этих секций. Критические секции не обязательно должны быть в составе
обработчиков сигналов. Многие из них находятся в обычном потоке управления программы.
Самый простой способ защиты критических секций заключается в блокировке или
игнорировании сигналов, по которым происходит обращение к обработчикам сигналов,
где используются или изменяются данные.
7.9. Предотвращение искажений данных 259
7. 9.3. Блокирование сигналов: sigprocmask и sigsetops
Вы можете блокировать сигналы как на уровне обработчика сигналов, так и на уровне
процесса.
Блокирование сигналов в обработчике сигналов
Для блокирования сигналов по мере обработки сигнала следует установить член sa mask
в структуре struct sigaction. Это выполняется при передаче структуры для использования в sigac-
tion, когда производится инсталляция обработчика. Член sa_mask имеет тип sigset_t. Здесь
хранится набор сигналов. Мы кратко рассмотрим назначение этого набора.
Блокирование сигналов в процессе
Для процесса можно установить набор сигналов, которые для процесса будут
блокированы в любой момент его развития. Это не игнорируемые сигналы, а блокируемые. Такой
набор блокируемых сигналов называют маской сигналов. Чтобы модифицировать этот
набор блокированных сигналов, необходимо использовать sigprocmask. Вызов sigprocmask
выбирает набор сигналов и использует этот набор (выполняет это как атомарное действие)
для изменения текущего состава блокированных сигналов:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
sigprocmask
Модифицировать текущую маску сигналов
«include < signal.h >
int res = sigprocmask(Jnt how,
const sigsetj *sigs,
sigsetj *prev);
how - как модифицировать маску сигналов
sigs - указатель на список сигналов, которые будут использованы
prev - указатель на предшествующую маску сигналов (или NULL)
-1 - при ошибке
0 - при успехе
С помощью sigprocmask модифицируется текущая маска сигналов - или добавляются, или
удаляются, или замещаются сигналы в *sigs. Действие определяется с помощью значения
how, которое может быть одним из значений: SIG_BLOCK, S1GJJNBLOCK, SIG_SET. Если
значение prev не равно нулю, то в *prev копируется предшествующая сигнальная маска.
Создание сигнальных наборов с помощью sigsetops
sigsetj - это абстрактный набор сигналов, который можно обрабатывать определенным
образом - добавлять и удалять сигналы. Основные возможности:
sigemptyset(sigseU *setp)
Очистка всех сигналов в списке, на который указывает setp.
sigfillset(sigsetj *setp)
Добавление всех сигналов к списку, на который указывает setp. (Более точно - включение
всех сигналов, известных системе. - Примеч. пер.)
sigaddset(sigset_t *setp, int signum)
260
Событийно-ориентированное программирование. Разработка видеоигры
Добавление signum к набору, на который указывает setp. , 14 ., ^ ,4V ¦ *. ~
sigdelset(sigsetj*setp, int signum)
Удаление signum из набора, на который указывает setp.
Детали можно найти в справочнике по ключу sigsetops.
Пример: Временное блокирование пользовательских сигналов
Программа может временно блокировать сигналы SIGINT и SIGQUIT с помощью такого
кода: .
sigsetj sigs, prevsigs; /* определение двух наборов сигналов */
sigemptyset( &sigs); /* сбросить все биты в наборе */
sigaddset(&sigs, SIGINT); /* включить бит SIGINT 7
sigaddset(&sigs, SIGQUIT); /* включить бит SIGQUIT 7
, sigprocmask(SIG_BLOCK, &sigs, &prevsigs); /*добавить это к маске процессе/
//.. здесь производится модификация структуры данных.
sigprocmask(SIG_SET, &prevsigs, NULL); /*восстановить предшествующую маску7
Заметьте, что метод блокирования сигналов реализован по той же схеме, какая была
использована при изменении установок в драйвере терминала или для файлового
дескриптора. Мы сохраняем предшествующие установки и потом используем эти значения
установок для восстановления маски сигналов. Это хороший стиль. Необходимо оставлять
программный ресурс таким, каким вы его застали в начале работы.
Z 9.4. Повторно входной код: Опасность рекурсии
Пример с одним посетителем, прерывающим процедуру учета другого посетителя, и
помещение фамилии и адреса в середину учетной записи первого посетителя - все это
приводит нас еще к одной концепции, касающейся искажения данных: повторно вызываемая
функция.
Обработчик сигнала или любая функция, которые могут быть повторно вызваны, когда
они уже активны, и которые при повторном вызове не создадут каких-либо проблем,
называют повторно входными. (В ранних переводах по тематике ОС функции или
программы с такими свойствами так и называли - реентерабельными. - Примеч. пер.)
С помощью sigaction можно включить рекурсивный режим управления. Это делается с
помощью установки флага SA_NODEFER. Или можно включить блокировку, что делается
с помощью сброса флага. Что вы из этого выберете?
Если обработчик не является повторно входным, то вы должны использовать блокировку.
Но если вы блокировали сигналы, то можете их потерять. Сигналы не заносятся в
стековую память, подобно свойству телефона while you were out (режим ипока вас не было").
Потерянные сигналы могут быть важными. Сохранять или пропускать что-то?
Что выбрать - потерю сигналов или возможность смешения данных? Что из этого хуже?
Нет ли возможности избежать возникновения этих проблем? Когда вы разрабатываете
программу, где используются сигналы, то эти вопросы необходимо принимать во
внимание. Ошибки, допущенные при управлении сигналами, проявляют себя нерегулярно.
Обычно они возникают, когда система очень сильно занята и необходимо тщательно
учитывать возможности по производительности. Отладка таких систем требует понимания
особенностей работы обработчиков сигналов и понимания, где в них могла возникнуть
проблема.
7/10. kill: Посылка сигнала процессом 261
7. SL 5. Критические секции в видеоиграх
Шарик движется по экрану с постоянной скоростью, отталкиваясь от стенок и ракетки.
Пользователь, нажимая на клавиши, перемещает ракетку вверх и вниз. Поддержка
постоянного перемещения шарика - это задание, которое исполняется под управлением
интервального таймера. Пользовательский ввод, который управляет перемещением ракетки,
происходит как последовательность непредсказуемых событий, как последовательность
сигналов. В какие моменты нам нужно будет блокировать пользовательский ввод? Где
находятся критические секции в игре, когда ракетка не должна перемещаться? Прежде чем
мы применим все эти новые знания к нашему проекту видеоигры, рассмотрим еще один
источник сигналов: другие процессы.
7.10. kill: Посылка сигнала процессом
Сигналы приходят процессу от интервальных таймеров, драйвера терминала, ядра и от
процессов. Процесс может послать сигнал другому процессу с помощью системного
вызова kill:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
kill
Посылка сигнала процессу
«include < sys/types.h >
«include < signal.h >
int kill(pidj pid, int sig)
pid - идентификатор целевого процесса
sig - сигнал, который передается
-1 -при ошибке
0 - при успехе
Системный вызов kill посылает сигнал процессу. Процесс, который посылает сигнал,
должен иметь тот же пользовательский идентификатор (UID), что и у целевого процесса. Или
собственником посылающего процесса должен быть суперпользователь. Процесс может
послать сигнал сам себе.
Процесс может посылать другим процессам любые сигналы, в том числе сигналы,
которые обычно приходят от клавиатуры, интервальных таймеров или ядра. Например,
процесс может послать другому процессу сигнал SIGSEGV, что равносильно ситуации, когда
в процессе-адресате была попытка недопустимого обращения к памяти.
Рисунок 7.17
Процесс для посылки сигнала
использует kill()
В Unix команде kill используется системный вызов kill (см. рисунок 7.17).
killA2?,SIGINT) J
г г г
_JJ-J
SIGINT
'* PID 129 I
—JJ-—-I
262
Событийно-ориентированное программирование. Разработка видеоигры
Возможности использования механизма передачи сигналов для межпроцессных
коммуникаций • ч •
Принимающий процесс может установить обработчики сигналов почти для всех
сигналов. Рассмотрим наш пример с программой, которая выводит сообщение OUCH! при
поступлении сигнала SIGINT. Что произойдет, если какая-то другая программа пошлет
программе OUCH! сигнал SIGINT? Наша программа перехватит сигнал, будет передано
управление обработчику сигнала и будет выведено сообщение OUCH!, (см. рисунок 7.18).
Продолжим далее рассмотрение сути этой идеи. Пусть в первой программе установили
интервальный таймер, который в некоторый момент вызывает обработчик сигнала от
таймера в этой программе, а обработчик посылает сигнал SIGINT программе OUCH!. Этот
сигнал будет передан обработчику сигнала другой программы. В данном случае таймер
одного процесса может управлять действием другого процесса. По сути, происходит то же, что
и в футбольном матче, когда игроки перемещаются по полю и борются за мяч. Игроки -
это процессы, которые могут выдавать сигналы.
Рисунок 7.18
Сложное использование сигналов
Сигналы, предназначенные для IPC (Это краткое, стандартное обозначение механизма
межпроцессных взаимодействий - InterProcess Communication, IPC- Примеч. пер.) SIGUSR1,
SIGUSR2
В Unix есть два сигнала, которые вы можете использовать для заказных приложений. Для
сигналов SIGUSR1 и SIGUSR2 не установлено определенное функциональное назначение.
Вы можете использовать эти сигналы вместо тех сигналов, для которых определенное
функциональное значение уже установлено.
Мы рассмотрим технику межпроцессных взаимодействий в следующих главах.
Комбинация системных вызовов kill и sigaction предполагает достижение с их помощью многих
заманчивых программистских возможностей.
7.11. Использование таймеров и сигналов: видеоигры
Теперь вернемся к проекту видеоигры. В играх есть два главных элемента: анимация
и пользовательский ввод. Средства анимации должны обеспечивать "гладкое" преобразование
изображения, а пользовательский ввод должен предоставлять возможность изменять
движение. В программе bounceld.c пользователь может управлять текстом сообщения: он может
изменять перемещение текста в прямом или в обратном направлениях.
7.11. Использование таймеров и сигналов: видеоигры
263
Z / /, /. bounce1d. с: Управляемая анимация на строке
Сначала рассмотрим, что и как делает программа bounceld. Изображение на экране будет
выглядеть аналогично тому, что приведено на рисунке 7.19. Программа bounceld.c плавно
перемещает по экрану одно слово. Когда пользователь нажмет клавишу пробела, то это
слово станет перемещаться в обратном направлении. При нажатии на клавишу "s" или на
ktf' произойдет увеличение скорости перемещения и уменьшение скорости перемещения
слова соответственно. При нажатии на клавишу "Q" игра будет закончена.
ВыхоДч
rihellol
^?^ж.^^ш^щъ<,гт#ш^^^^ш.
rg>^B)
Медленнее Быстрее
Переключение
Рисунок 7.19
bounceld в действии: анимация,
управляемая пользователем
Как построить такую программу? Мы знаем, как достигается анимационный эффект.
Строка воспроизводится в одном месте экрана. Воспроизведение длится несколько
миллисекунд, а затем изображение затирается. После чего изображение строки
перерисовывается слева или справа относительно первоначального места воспроизведения. Нам
потребуется стирать изображение и перерисовывать его через регулярные интервалы времени.
Поэтому мы используем интервальный таймер, который будет посылать сигналы
обработчику.
Введем две переменные, значения которых будут определять направление и скорость
перемещения. Значением переменной направления может быть +1 или -1. Это означает
соответственно, что сообщение движется влево или вправо. Более длинные задержки
между тиками таймера будут приводить к более медленному перемещению слова, а более
короткие задержки между тиками будут приводить к более быстрому перемещению.
Добавим теперь в программу возможность для пользователя управлять направлением
и скоростью перемещения слова. Мы будем читать символы при нажатии клавиш
пользователем и в зависимости от значения введенного символа будем модифицировать
переменную направления или переменную скорости перемещения. Логика программы
изображена на рисунке 7.20. В алгоритме программы bounceld поддерживаются две важных идеи:
переменные состояния и управление событиями. Состояние анимации описывается
с помощью переменной положения, переменной направления движения и переменной
задержки. Ввод символов от пользователя (пользовательский ввод) и тики от таймера -
это события, при наступлении которых происходит модификация этих переменные
состояния. После каждого тика таймера вызывается код, который должен изменять
положение слова на экране. При каждом нажатии пользователем на клавиши.вызывается код,
который изменяет значение переменнойГнаправления или значение переменной скорости
перемещения. Этот код имеет вид:
264 Событийно-ориентированное программирование. Разработка видеоигр^
Обычный поток
J-«— управления
Поток управления к
обработчику сигнала и обратно
/
Переменные состояния
main()
signal(SIGALRM,on_ticker)
getchar()
act__on_char ()
11
i
чэЁП
*»r ,jm**v^№wm
col dir
*—»on ticker()
i jci
| I | move_message;
Рисунок 7.20
Изменение значений через пользовательский ввод. Значения управляют действием
/*bounce1d.c
* назначение - анимация с возможностью изменения пользователем скорости и
* направления движения
* замечание - обработчик сигналов реализует функции анимации.
* В программе main производится чтение символов при нажатии
клавиш
* компиляция: ее bounceld.c set ticker.c -leurses -о bounceld
7
#include <stdio.h>
#include <curses.h>
#include <signal.h>
Г ряд глобальных установок и установка обработчика сигнала 7
«define MESSAGE "hello"
#define BLANK""
Г текущая строка 7
/* текущая позиция на строке 7
Г куда перемещаемся 7
int row;
int col;
int dir;
int main()
{
int delay;
/* больше => медленнее
7
' /. Использование таймеров и сигналов: видеоигры
int ndelay;
intc; .
void move_msg(int);
initscr();
crmode();
noecho();
c!ear();
row= 10;
col = 0;
dir=1;
delay = 200;
move(row,col);
addstr(MESSAGE);
signal(SIGALRM, move_msg);
setjicker(delay);
" while( 1)
1
ndelay = 0;
c = getch();
if (c == *Q') break;
if(c==' *)dir = -dir;
if (с == Т&& delay > 2) ndelay
if (c == 's') ndelay = delay * 2;
if (ndelay >0)
setjicker( delay =
endwinQ;
return 0;
)
void move_msg(int signum)
signal(SIGALRM, move_msg);
move(row, col);
addstr(BLANK);
col += dir;
move(row, col);
addstr(MESSAGE);
refresh();
r
Г новая задержка 7
/* пользовательский ввод */
/* обработчик сигнала от таймера */
Г отсюда происходит старт */
Г добавить 1 к счетчику строк */
Г 200ms = 0.2 секунды */
/* перейти в позицию */'
Г нарисовать сообщение */
= delay/2;
ndelay);
/* сразу же восстановление */
/* перейти в новую позицию на строю
1* затем установить курсор */
/* перерисовать изображение 7
/* и показать его */
* теперь управление на границах
*/
/
if (dir ==-1 &&col<=0)
dir = 1;
else if (dir == 1 && col+strlen(MESSAGE) >= COLS)
dir = -1;
266
Событийно-ориентированное программирование. Разработка видеоигры
Рекурсия или блокировка: Реальный пример
Когда мы рассматривали пример с искажением данных при использовании обработчиков
сигналов, мы упоминали о повторно входных функциях. Программа bounceld заставляет
вспомнить о таких функциях.. В начале обработчик сигнала move_msg вызывается пять раз
за секунду. При нажатии на клавишу "f' скорость анимации возростает, поскольку
уменьшается значение временного интервала таймера. Если нажимать на клавишу "f" много раз
подряд, то интервал между сигналами может стать короче интервала времени, в течение
которого выполняется обработчик. А что произойдет, если следующий сигнал от таймера
будет поступать тогда, когда обработчик будет занят стиранием и/или перерисовкой
текста сообщения и/или модификаций переменной положения?
Проведение такого анализа остается в качестве упражнения. Мы использовали в
программе интерфейс signal. Поэтому, произойдет ли вызов обработчика по рекурсивной схеме или
по схеме с блокировкой - все будет зависеть от конкретной реализации на вашей системе.
Что дальше?
Как нам преобразовать программу bounceld в игру пинг-понг? Прежде всего мы можем
заменить строку "hello" символом "О", который будет заменять изображение шарика. Во-
вторых, нам необходимо, чтобы шарик мог перемещаться вверх и вниз, а также влево и
вправо. Добавление возможности перемещения вверх и вниз потребует введения
дополнительных переменных состояния. Мы уже имеем две переменные col и row, с помощью
которых описывается положение шарика, а также переменную dir, значение которой
задает направление перемещения по горизонтали. Какие новые переменные следует нам
добавить для обеспечения перемещения по вертикали?
7. /1.2. bounce2d. с: Двухмерная анимация
В следующей программе bounce2d.c воспроизводится двухмерная анимация с
предоставлением пользователю возможности менять горизонтальную и вертикальную скорость.
На рисунке 7.21 приведена соответствующая иллюстрация.
Выхода
L
г *'v&-'-ff ? r-'btf^- Н» t ^yfify' j1 jfWP^"' * ¦ fj i
Ш
I UK Переключение
Jz\ (не реализовано)
Медленнее быстрее
Рисунок 7.21
Двухмерная анимация
Программа bounce2d использует тот же трехшаговый проект, какой был использован при
построении программы bounceld:
7.11. Использование таймеров и сигналов: видеоигры
267
Управление таймером
Производится установка интервального таймера, который должен посылать постоянно
процессу поток сигналов SIGALRM. При поступлении очередного сигнала шарик необходимо
переместить.
Блокирование клавиатуры
Программа блокирует ввод с клавиатуры. Она сразу воспринимает и обрабатывает
символы по мере их набора.
Переменные состояния
Место расположения шарика и его скорость хранятся в качестве значений в переменных.
С помощью пользовательского ввода производится модификация переменных, значения
которых представляют скорость. Значения скорости и места расположения используются
обработчиком сигнала от таймера для управления шариком.
Эта схема выглядцт аналогично bounceld, но появился один новый, важный вопрос:
Как будет происходить перемещение шарика по диагонали?
Воспроизведение движения по диагонали - это новая проблема. В одномерной программе
при каждом очередном тике происходило перемещение образа на один шаг. Все
происходило очень просто: один тик - один шаг смещения. Но при двухмерном перемещении дело
обстоит уже не так просто. Рассмотрим траекторию, изображенную на рисунке 7.22. Эта
траектория состоит из смещения на одну строку вверх и одновременно смещения вправо
на три позиции на строке. Данная техника перемещения из точки А в точку В должна быть
использована при возникновении каждого очередного тика. Переход из одной точки в
другую может оказаться достаточно большим и зависит от размеров сторон треугольника.
Например, при соотношении сторон 3/4 перемещение по наклонной линии будет равно
пяти позициям.
Вопрос: Как обеспечить
"гладкое" перемещение
символа '0* из точки
А в точку В?
Рисунок 7.22
Траектория под углом 1/3
При перемещении от одной точки к другой по наклонной линии маршрут будет выглядеть
аналогично тому, как это изображено на рисунке 7.23. Заметим, что для перехода по
наклонной траектории из точки А в точку В образ должен быть перемещен на три шага по
горизонтали и на один шаг по вертикали. Горизонтальная скорость должна быть в три раза
большей, чем вертикальная.
А
0"
ч
в
268 Событийно-ориентированное программирование. Разработка видеоигры
Для аппроксимации диагонального перемещения нужно:
переместиться вправо на каждые два таймерных тика;
переместиться вверх на каждые шесть таймерных тиков.
Эта техника предполагает использование двух счетчиков,
один из них считает тики для горизонтального перемещения,
другой считает тики для вертикального
перемещения РИСУНОК 7.23
Перемещение по наклонной на
один шаг за такт выглядит лучше
Схема выглядит так, будто используются два таймера. Так оно и есть. Понаблюдаем
за одним работающим таймером. После каждых двух тиков программа перемещает образ
на один шаг вправо. После каждых шести тиков программа перемещает образ на один шаг
вверх. Шарик будет перемещаться по этой же траектории, если интервалы были указаны
в 10 и 30 тиков. Но движение при этом будет более медленным.
Программа имеет только один интервальный таймер реального времени. Поэтому нам
нужно построить два интервальных таймера и один интервальный таймер, который будет
использоваться для управления этими таймерами. Мы будем использовать логику,
изображенную на рисунке 7.23 для организации двухмерной анимации.
Код
Для организации двухмерного перемещения заведем два счетчика, которые будут
выступать в роли таймеров. Каждый из этих счетчиков будет характеризоваться двумя
составляющими ~ значением и интервалом. Работа с ними будет выглядеть так же, как при
работе с системными интервальными таймерами. Значение счетчика - это число тиков, ко-
торое осталось до наступления следующей перерисовки. Значения интервального
счетчика - это число тиков между очередными перерисовками. Для изображения этих
двух элементов будут использованы аббревиатуры ttg и ttm. Код программы будет
выглядеть так:
Г bounce2d 1.0
* перемещение символа (по умолчанию это 'о') по экрану, которое
задается с помощью определенных параметров
*
ж пользовательский ввод: s - замедлить перемещение по оси х, S: замедлить
* перемещение по оси у
f - ускорить перемещение по оси х, F: ускорить
* перемещение по оси у
* Q: выход
* блокируется чтение, но таймер посылает сигнал SIGALRM, который
* перехватывается функцией ball_move
* трансляция: ее bounce2d.c set ticker.c -leurses -o bounce2d
7
#include <curses.h>
#include <signal.h>
#jnclude "bounce, h"
struct ppball the_ball;
/** основной цикл **/
A „
о".
1?.
.**
\
I
11. Использованиетаймеровисигналов:видеоигры
voidset_up();
void wrap_up();
intmaih()
{
int с;
setjjp();
whHe((c = getchar())!=,Q,){
И(с==Т)Ше^ЬаН.х^т-;
else if (c == 's') the_ball.x_ttm++;
else if (c == T) the~ball.y_.ttm--;
else if (c == 'S') the_ball.y_ttm++;
}
wrap up();
}
void set up()
Г
* инициализация структуры и других элементов
7
{
void ball_move(int);
the ball.y pos = Y_INIT;
the ball.x pos = X INIT;
the.ball.yjtg = the ball.y ttm = YJTM;
the_ball.xjtg = the_ball.x_ttm = XJTM;
the__ball.y_.dir
the ball.x dir = 1;
the>all.symbol = DFL.SYMBOL;
initscr();
noecho();
crmode();
signal(S!GINT, SIGJGN);
mvaddch(the_ball.y_pos, the_ball.x_pos, the_ball.symbol);
refresh();
signal(SIGALRM, bali_move);
set_ticker( 1000 / TICKS_PER_SEC); /* установить значение в *
/* миллисекундах на один тик */
}
void wrap up()
{
set_ticker@);
endwin(); /* нормальный возврат 7
}
void ball move(int signum)
{
inty_cur.x_.cur, moved;
signal(SIGALRM, SIGJGN); /* после этого не перехватывать *
y_cur = the_ball.y_pos; /* старое расположение 7
x_cur = the_ball.x_pos;
moved = 0;
if (the ball.y ttm > 0 && the ball.y_.ttg- == 1){
270
Событийно-ориентированное программирование. Разработка видеоигры
the_ball.y_pos += the_ball.yjlir; /* перемещение */
the_ball.y_ttg = the_ball.yjtm; /* переустановка*/
moved = 1;
if (the_ball.xjtm > 0 && the_ball.xJtg- == 1){
the_ball.x_pos += the_ball.x_dir; /* перемещение */
the_ball.xjtg = the_ball.xjtm; /* переустановка*/
moved = 1;
}
If (moved){
mvaddch(y_cur,.x_cur, BLANK);
mvaddch(y_cur, x_cur, BLANK);
mvaddch(the_ball.y.pos,the_ball.x_posJ the_ball.symbol);
bounce or_lose(&the ball);
move(LrNES-1,COLS:1);
refresh();
}
signal(SIGALRM, ball move); /* для систем с ненадежными сигналами */
}
int bounce or lose(struct ppball *bp)
{
int return val = 0;
if(bp->yj>os==TOP_ROW){
bp->y_dir=1;
retum_val = 1;
} else if (bp- >y_pos == BOT_ROW){
bp->y_dir = -1;
return val = 1;
}
if (bp->x_pos === LEFTJDGE){
bp->x_dir=1;
return val = 1;
} else if (bp->x^pos == RIGHT_EDGE){
bp->x_dir = -1;
return val = 1;
}
return return_val;
Заголовочный файл будет иметь вид:
Г bounce.h */
Г некоторые установки для игры */
#define BLANK''
#define DFL SYMBOL 'о'
#defineTOPROW 5
#define ВОТ ROW 20
#define LEFf EDGE 10
#define RIGHT EDGE 70
7.12. Сигналы при вводе: Асинхронный ввод/вывод N - 271
Г начальная позиция на строке */
/* начальная строка 7
/* составляющие'скорости */
«define XINIT
«define YINIT
«define TICKS PER SEC
«define X ИМ
«define YTTM
/** шарик для пинг-понга
struct ppball {
int
char
10
10
50
5
8
•*/
y_pos, x_pos,
yjtm, xjtm,
yjtg, xjtg,
y_dir, xjjir;
symbol;
};
Z / /. 3. Вся игра целиком
Оставшуюся часть работы по созданию игры следует выполнить в качестве упражнения.
Вам необходимо добавить механизм управления ракеткой, логику для описания
отскакивания шарика от ракетки, логику для определения выхода шарика из игры.
Мы детально рассмотрели все идеи, которые необходимы для завершения проекта.
Подумайте о возможное;™ использования повторно входного кода. Где можно было бы
использовать такой код? Какой режим управления таймером вы предпочитаете - блокирование
или рекурсивный?
7.12. Сигналы при вводе: Асинхронный ввод/вывод
При рассмотрении средств анимации и игры в этой главе были использованы два типа
событий: тики от таймера и ввод с клавиатуры. Мы настроили обработчик так, чтобы он
управлял анимационными эффектами с помощью тиков от таймера, а также блокировали
ввод с клавиатуры с помощью getch. Нельзя ли вместо блокировки использовать
пользовательский ввод с помощью сигналов аналогично тому, как это делается при работе с
сигналом от таймера?
Да, можно. Программы могут затребовать, чтобы ядро присылало процессу сигнал тогда,
когда произойдет событие на входе. Это будет аналогично ситуации, когда почтальон
будет звонить в вашу квартиру, если он принес вам письмо. В этом случае вам не
понадобится садиться в прихожей и часами пристально наблюдать за почтовым ящиком. Вы можете
заниматься чем угодно или даже лечь поспать. Когда придет почтальон с письмом, то вы
услышите сигнал от дверного звонка.
В Unix есть две системы для поддержки асинхронного ввода. В одной системе
используется метод, когда сигнал посылается, если на входе появились данные, готовые для чтения.
В другой системе сигнал будет послан после прочтения входных данных. Для
использования первого метода необходимо установить в файловом дескрипторе бит 0_ASYNC. Эта
методика была принята для использования в UCB. Во втором методе, который
удовлетворяет стандарту POSIX, необходимо использовать aioj-ead. Мы далее
продемонстрируем возможности двух этих методов. Но сначала рассмотрим идею.
272 Событийно-ориентированноепрограммирование. Разработка видеоигры
7.12. /. Организация перемещения с помощью асинхронного ввода/вывода
Новый проект программы перемещения образа схематически иллюстрируется на рисунке 7.24.
Поскольку предполагается использование сигналов двух видов: SIGIO и SIGALRM, то мы
создадим два обработчика сигналов. Обработчик сигнала SIGIO читает данные, которые
поступают от клавиатуры, и обрабатывает эти данные. Обработчик сигнала SIGALRM управляет
анимацией и отвечает за организацию перемещений в разных направлениях. Для упрощения
программы удалим из нее управление скоростью перемещения.
col dir
| main ()
¦ signal (SIGALRM, on_alarm);
I signal (SIGIO, on_JLnput) ;
! * pause(>
/
функция
7
процесс
SIGIO
EZZD'
г,«—^ on^lnput ()
, данные
Igetchar();
act_on_char()
| \-J I hellol I
Рисунок 7.24
Сигналы поступают от клавиатуры и таймера
7. 12.2. Метод 1: Использование OJISYNC
Использование бита 0_ASYNC требует внесения четырех изменений в программу
перемещений. Во-первых, необходимо создать и инсталлировать обработчик, который будет
вызываться в момен!, когда становится доступным ввод с клавиатуры. Во-вторых,
необходимо использовать команду FJSETOWN в системном вызове fcntl, чтобы потребовать от ядра
передать установленные входные сигналы нашему процессу. С клавиатурой могут быть
связаны и другие процессы, но мы не хотим, чтобы этим процессам ^акже посылались бы
эти входные сигналы. В-третьих, необходимо включить входные сигналы посредством
обращения к fcntl и установления с его помощью атрибута 0_ASYNC в файловом
дескрипторе 0. Наконец, необходимо выполнение системного вызова pause в цикле для того, чтобы
обеспечить ожидание поступления сигналов от таймера или от клавиатуры. Когда от
клавиатуры поступает символ, то ядро посылает процессу сигнал SIGIO. Обработчик сигнала
SIGIO использует стандартную curses функцию getch для чтения символа. Когда истечет
интервал времени таймера, ядро посылает сигнал SIGALRM, управление которым будет
происходить так, как было рассмотрено ранее. Вот какой будет исходный код:
Г bounce_async.c
* Назначение - анимация с возможностью управления со стороны пользователя.
* Это делается с помощью установки в файловом дескрипторе fd бита 0.ASYNC
* Замечание: set_ticker() посылает сигнал SIGALRM, а обработчик организует
!2. Сигналы при вводе: Асинхронный ввод/вывод
7
действия ro анимации.
Клавиатура посылает сигнал SIGIO.a в main только происходит
вызов pause()
Компиляция: се bounce_async.c seUieker.c -leurses -о bounce_async
#include.
#include
#indude
#include
Л Состояние игры
#define MESSAGE "hello"
«define BLANK""
int row =10;
int col = 0;
int dir = 1;
int delay = 200;
int done = 0;
main()
{
void on_alarm(int);
void on jnput(int);
void enable_kbd_signals();
initscr();
crmode();
noecho();
clear();
signal(SIGIO, onjnput);
enable_kbd_signals();
signal(SIGALRM, on_alarm);
setjicker(delay);
move(row,col);
addstr(MESSAGE);
while(ldonq)
pause();
endwin();
}
void on input(int signum)
{
intc = getch();
if(c=='Q,||c==EOF)
done = 1;
else if (c =='
dir = -dir;
}
void on_aiarm(int signum)
<stdio.h>
<curses.h>
<signal.h>
<fcntl.h>
7
/* текущая строка */
Г текущая позиция на строке */
/* где мы находимся */
Г и как долго ждем */
/* обработчик сигнала от таймера */
Г обработчик сигнала от клавиатуры */
/* установка экрана */
/* инсталляция обработчика */
Г разрешение на включение сигналов от клавиатуры
/* инсталляция обработчика сигналов таймера */
/* начало отсчета времени на таймере 7
/* позиционирование 7
/* начальная прорисовка образа */
Г основной цикл 7
Г захватить символ 7
274 Событийно-ориентированное программирование. Разработка видеоигры
sighal(SIGALRM, on_alarm); /* сразу же восстановление реакции */
mvaddstr(row, col, BLANK); /* обратиться к mvaddstr() */
col += dir; /* перемещение в новую позицию на строке */
mvaddstr(row, col, MESSAGE); /* перестроить образ сообщения */
refiresh(); /* и показать этот образ 7
/*
* здесь управление на границах
7
if (dir ==-1 &&coK=0)
dir = 1;
else if idir = 1 && col+strlen(MESSAGE) >= COLS)
.dir = -1;
}
Г
* инсталляция обработчика, обращение к ядру для установки уведомления сигнала
* на входе, установление разрешения на поступление сигналов
7
void enable kbd_signals()
{
intfdjlags;
fcntl@, F.SETOWN, getpid());
fd flags = fcntl@, F GETFL);
fcntl@, F SETFL, (fd~ flagsp ASYNC));
}
7.12.3. Метод 2: Использование aiojead
Метод использования aio_read является более сложным, но и более гибким, чем метод
установки бита 0_ASYNC в файловом дескрипторе. Сделаем четыре изменения в
программе перемещения. Во-первых, инсталлируем onjnput, поскольку мы предполагаем, что
обработчик будет вызываться, когда уже произошло чтение ввода.
Во-вторых, установим необходимые значения в структуре struct kbcbuf, чтобы описать,
какой ожидается ввод и какой сигнал следует послать, когда будет прочитан этот ввод.
В нашем простом приложении нужно ждать поступления только одного символа от
файлового дескриптора 0. Мы хотели бы получать в программе сигнал SIGIO после того, как
этот символ будет прочитан. Мы может задать любой сигнал о наступлении этого
события. Даже SIGARLM или SIGINT.
В-третьих, мы выставляем требование на чтение посредством передачи этой структуры
при вызове aio_read. В отличие от обычного системного вызова read при использовании
aio_read процесс не блокируется. Вместо этого происходит посылка сигнала после
завершения aiojead.
Наша программа теперь свободна делать все, что ей необходимо (А не следить
непрерывно за появлением данных на входе, как в случае с почтовым ящиком. -Примеч. пер.).
В данном случае мы будем просто вызывать pause, чтобы в паузе ожидать поступление
сигнала. Когда пользователь нажмет на клавишу клавиатуры, то aio_read пошлет процессу
сигнал SIGIO, который приведет к вызову обработчика.
7.12. Сигналы при вводе: Асинхронный ввод/вывод
275
Наконец, мы напишем обработчик, чтобы он мог получать входной символ при вызове
aioreturn, а затем смог бы обрабатывать его.
Г bounce_aio.c '
* Назначение - анимация с возможностью управления со стороны пользователя
* посредством обращения к aiojead() и т. д.
* Замечание: setjickerf) посылает сигнал SIGALRM, а обработчик организует
действия по анимации.
Клавиатура посылает сигнал SIGIO, а в main только происходит
* вызов pause()
* Компиляция:
* ее bounce_aio.c set ticker.c -Irt -leurses -о bounce aio
7
#incfude <stdio.h>
#include <curses.h>
«Include <signal.h>
#include <aio.h>
Г Состояние игры */
#define MESSAGE "hello"
#define BLANK""
int row =10;
int col = 0;
int dir = 1;
int delay = 200;
int done = 0;
struct aiocb kbcbuf;
main()
{
void on_alarm(int);
void on jnput(int);
void setup_aio_buffer();
initscr();
crmode();
noecho();
clear();
signal(SIGIO, onjnput);
setup_aio_bufferO;
aiojead(&kbcbuf);
signal(SIGALRM, on_alarm);
set ticker(delay);
mvaddstr(row, col, MESSAGE);
while(ldone)
pause();
endwin();
Г текущая строка */
/* текущая позиция на строке 7
/* где мы находимся */
/* сколько, необходимо ждать */
/* управляющий буфер aio */
/* обработчик сигнала от таймера */
Г обработчик сигнала от клавиатуры */
/* установка экрана 7
/* инсталляция обработчика 7
/* инициализация управляющего буфера aio */
/* выдача требования на чтение 7
/* инсталляция обработчика сигнала от таймера */
/* начало отсчета временного интервала */
Г прорисовка начального образа 7
/* основной цикл 7
Обработчик, который вызывается, когда aio_read() что-либо прочитал
Сначала проверяется наличие ошибок, и если их нет, то получаем код возврата
7
void on input()
{
int с;
char *cp = (ch'ar *) kbcbuf .aio_buf; /* обращение к char'
9
Событийно-ориентированное программирование. Разработка видео
Г проверка наличия ошибок */
if (aio_error(&kbcbuf) != 0)
perrorfreading failed");
else
Г получить число прочитанных символов */
if (aiojeturnf&kbcbuf) == 1)
{
с = *ср;
if (с == -Q* || с == EOF)
done = 1;
elseif(c==")
Г установка нового требования */
aio_read(&kbcbuf);
dir = -dir;
}
void on_alarm()
{
signal(SIGALRM, on_alarm);
mvaddstr(row, col, BLANK);
col += dir;
mvadcfetr(row, col, MESSAGE);
refresh( )¦;
Л
* теперь управление на границах
7
if (dir ===-1 &&coK=0)
dir = 1;
else if (dir == 1 && col+strlen(MESSAGE) >= COLS)
dir = -1;
Г сразу же здесь переустановка реакции */"
Г очистка старой строки */
/* перемещение в новую позицию */
/* прорисовка новой строки */
/* и показ ее */
/*
* Установление значений членов структуры.
* Сначала определить аргументы, как это делается при вызове
* read(fd, buf, num), и потом - смещение.
* Затем определить, что нужно делать (послать сигнал) и какой сигнал
* послать (S16I0)
7
void setup_aio buffer()
{
static char input[1];
/* описание того, что нужно читать */
kbcbuf.aio.fildes = 0;
kbcbuf .aio_buf = input;
kbcbuf.aio.nbytes = 1;
kbcbuf .aioj)ffset = 0;
/* описание того, что нужно делать, после того, как произойдет чтение */
kbcbuf.aio__sfgevent.sigev_notify = SIGEV_SIGNAL;
kbcbuf.aio_sigevent.sigev_signo = SIGIO; Л послать SIGIO 7
\
/* 1 символ на входе */
/* стандартный ввод */
Г буфер 7
/* количество читаемых символов 7
/* смещение в файле 7
7.12. Сигналы при вводе: Асинхронный ввод/вывод
277
7. 12.4. А нужно ли нам производить асинхронное чтение для организации
перемещения?
Нет. Программы, в которых организуется перемещение, прекрасно работают, используя
блокировку пользовательского ввода и организуя перемещение с помощью тиков интервального
таймера. Преимущество асинхронного чтения заключается в том, что программа не
блокирует ввод и может заниматься чем угодно, пока не наступят входные события.
Например, в более изощренных играх программа может воспроизводить музыку,
порождать какие-то звуковые эффекты, рассчитывать какой-то усложненный фоновый образ,
даже может выполнять некую общественную работу. Компьютеры все больше и больше
привлекают для того, чтобы их свободное время использовать для выполнения больших
вычислительных проектов в областях математики, астрономии и медицины.
Программа перемещения может потратить свое свободное время для подсчета значения
р/, которое содержало бы произвольное число десятичных знаков. При этом программа
будет использовать асинхронный пользовательский ввод, чтобы определить, когда
пользователь нажмет на клавишу. Изменим цикл в функции main следующим образом:
До: После:
while(ldone) compute_pi();
pause(); endwin();
endwin();
В модифицированной программе происходит вызов функции, которая подсчитывает
значение pi. Когда на входе программы появится символ, то происходит передача
управления обработчику, происходит обработка входных данных, а затем происходит возврат
и продолжение расчетов значения pi. Когда возникает сигнал от таймера, то программа
передает управление обработчику этого сигнала, происходит обработка таймерного тика,
а затем опять передается управление на продолжение вычислений.
В программе необходим другой способ обработки ключа "Q". Как нужно модифицировать
программу, чтобы достичь этого?
7.12.5. Асинхронный ввод, видеоигры и операционные системы
Мы начали эту главу со сравнения видеоигры и операционной системы. В нашей
программе перемещения не был задействован асинхронный ввод, в операционной системе он
используется. Ядро запускает программы на исполнение и не может тратить время
процессора на ожидание ввода от пользователя. Ядро устанавливает обработчики, которые будут
вызываться, когда будут обнаружены входные данные от клавиатуры, последовательных
линий или от сетевой карты. Тогда ядро передаст управление от исполняемой программы
к обработчику, далее происходит обработка ввода, а затем управление возвращается
обратно и возобновляется исполнение программы, Ядро блокирует сигналы в пределах
критических секций.
Ядро использует аппаратные версии асинхронного ввода, а процессы используют
программные версии. Какая связь между этими версиями? Пусть исполняется программа
видеоигры. Если пользователь нажмет на клавишу, то это приведет к посылке
электрического сигнала в порт клавиатуры. Порт клавиатуры вырабатывает реальный, аппаратный
сигнал, который приводит к передаче управления из некоторого места видеоигры к
драйверу клавиатуры.
278
Событийно-ориентированное программирование. Разработка видеоигры
Код драйвера находится в ядре. Драйвер читает символ на входной линии, передает
символ на многошаговую обработку в драйвере терминала. Если файловый дескриптор,
присоединенный к этому драйверу, установлен в режим асинхронного ввода, то ядро пошлет
процессу Unix сигнал. Когда процесс становится активным, то управление будет передано
обработчику сигнала в составе этого процесса.
Заключение
Основные идеи
• В некоторых программах поддерживается простой поток управления. В некоторых
программах отслеживаются моменты наступления внешних событий. В видеоигре
отслеживается изменение времени и появление пользовательского ввода.
Операционная система также отслеживает изменение времени и поступление входных данных от
внешних устройств.
• Библиотека curses представляет собой набор функций, которые программа может
вызывать для управления текстовым выводом на экране.
• Процесс планирует обслуживание событий с помощью установок таймеров. Каждый
процесс может использовать три различных вида таймеров. Когда таймер "зазвенит",
то он посылает сигнал. Каждый таймер может "звонить" или однократно, или
периодически, через установленный интервал времени.
• Управление одним сигналом производится достаточно просто. Управление
несколькими сигналами, которые возникают одновременно, уже более сложное.
Процесс может принять решение об игнорировании сигналов или о блокировании
сигналов. Кроме того, он может указать ядру, какие сигналы требуется блокировать
или игнорировать на некоторое время.
• Ряд функций выполняют сложные действия, которые не должны прерываться.
Программа может защитить эти критические секции от прерываний с помощью
правильного использования масок сигналов.
Что дальше?
В этой главе мы рассмотрели, как видеоигра выполняет сразу несколько действий. Это
достигается за счет использования техники приема и обработки сигналов. В Unix можно
запускать на исполнение сразу несколько программ. Как происходит развитие процессов?
Где находятся процессы? Далее переключим наше внимание с базовых вопросов в
области операционных систем и с общих принципов на конкретные вопросы, касающиеся
построения и управления процессами в Unix.
Исследования
7.1 При выполнении системного вызова pause происходит ожидание поступления любого
сигнала, включая сигналы, которые вырабатываются при нажатии ключей
клавиатуры, таких как, SIGINT.
(a) Запустите sleep 1 и нажмите на ключ Ctrl-C. Что происходит? Почему?
(b) Модифицируйте программу sleepl, чтобы было бы можно управлять сигналом
SIGINT.
(c) Запустите теперь программу на исполнение и нажмите на ключ Ctrl-C. Что
происходит? Почему?
Заключение
279
12 Медленные устройства. Системный вызов read может быть в ряде случаев прерван.
Например, пользователь может нажать ключ Ctrl-C, когда в программе происходило
чтение ввода с клавиатуры. Но, с другой стороны, когда программа выполняет вызов
read для чтения данных с диска, то при нажатии на ключ Ctrl-C прерывания
системного вызова не произойдет.
Обратитесь к электронному справочнику или поищете с помощью Web материал,
используя для поиска термин медленное устройство (slow device). Какие обращения к
read могут быть прерваны, а какие не могут быть прерваны? Почему?
7.3 Сравнение sigprocmask с ISIG. Другой вариант достижения гарантии непрерываемой
работы критической секцией в коде при поступлении сигнала клавиатуры -
выключение в драйвере терминала флага ISIG. Насколько это решение отличается от варианта,
когда необходимые сигналы устанавливаются с помощью маски сигналов?
7.4 Разработайте повторно входную систему для посетителей, которая обеспечивает
добавление их имен и адресов к учетному списку в вашем офисе. Сможете ли вы
преобразовать эту систему в алгоритм для добавления трех строк данных в конец
текстового файла при каждом вызове обработчика? Обратитесь к секции в главе 5, где
рассмотрен режим auto-append, и поэкспериментируйте с блокировками файла при
использовании link.
7.5 Рассмотрите, каково будет поведение программы bounceld.c, если длина таймерного
интервала оказывается короче, чем время, которое необходимо для исполнения
move_msg.' Что произойдет со значением переменной pos? Что произойдет с экраном?
Найдите ответы на эти вопросы при использовании режима блокирования и режима
рекурсии. Есть ли возможность предотвратить искажение данных и не потерять
сигналы?
7.6 Прерываемые системные вызовы. В некоторых версиях Unix выполнение getch
прерывается, когда поступает на обработку сигнал от таймера. В таких системах
вызов getch после каждого таймерного тика возвращает EOF. Для чего это делается
в программе? В чем проблема? Можно ли как-то изменить ситуацию?
7.7 Режим блокирования и режим рекурсии с асинхронным вводом/выводом. В версии
программы перемещения, которая использует асинхронный ввод, необходимо
использовать два обработчика сигналов. Что произойдет, если приходит сигнал S1G10
в тот момент, когда в программе исполняется обработчик сигнала SIGALRM? Что
произойдет в противоположной ситуации? Может ли каждый из этих двух
обработчиков повлиять на работу другого обработчика? Следует ли блокировать сигналы, когда
в текущий момент происходит обработка сигналов? Каково ваше мнение о
возможности использования рекурсивных вызовов? Возникнет ли проблема, если на вход
программы поступает новый символ, когда программа занята обработкой сигнала SIGIO?
Просмотрите все возможные комбинации и составьте список проблем, которые при
этом могут возникнуть.
280
Событийно-ориентированное программирование. Разработка видеоигры
Программные упражнения
7.8 Мерцающий текст. В некоторых Web-броузерах поддерживается вывод мерцающего
текста и возможность вывода текста в режиме theater-marquee. Модифицируйте
программу hellol.c так, чтобы она отображала, мерцающее сообщение. Если
пользователь передает сообщение через командную строку, то ваша программа должна
отображать это сообщение. В противном случае программа должна отображать сообщение
по умолчанию. Используйте функцию sleep для реализации паузы в программе между
выводом сообщения и последующим стиранием его.
7.9 Режим Theater Marquee, или режим Телеграфной ленты. Напишите программу, которая
использует curses для создания режима отображения theater-marquee. Этот режим должен
использоваться для отображения содержимого файла. В режиме Theater Marquee (или
отображения в режиме телеграфной ленты) используется горизонтальная область для
отображения текста. В области возможно горизонтальное скроллирование в режиме
посимвольного перемещения по экрану. Ваша программа должна через командную
строку принимать имя файла и его длину, позицию и скорость отображения.
7.10 Модифицируйте программу hello5.c так, чтобы заменить в ней вызов sleep на вызов
usleep. Выберите интервал, который задает сглаженное, но не очень быстрое
действие. Модифицируйте программу так, чтобы сообщение замедлялось бы при
достижении левой или правой границы по пути перемещения, и так, чтобы сообщение
ускорялось бы при перемещении к середине экрана.
Представьте себе, что правая сторона экрана ~ планета, а сообщение падает из космоса на
ее поверхность. Модифицируйте программу так, что при падении имитируется
гравитационное ускорение. Для усиления эффекта промоделируйте аварийную посадку, когда
сообщение достигнет поверхности планеты. Выполните это с помощью слов, которые
расщепляются на отдельные буквы.
7.11 В программе ticker_demo.c выход производится из обработчика сигнала. Можно ли
сделать выход из функции main, а не из обработчика сигнала? Добавьте в программу
глобальную переменную done. Далее сделайте два изменения в программе с тем,
чтобы был обеспечен выход из main. Какие преимущества и недостатки первого варианта
решения и этого нового варианта?
7.12 Аргумент для обработчика сигнала. Модифицируйте программу sigdemo3.c так,
чтобы объединить два обработчика сигналов в один обработчик, который проводит
проверку значения аргумента, для определения, какой сигнал поступил на обработку. Как
это изменение повлияло на поведение программы в вашей системе?
1.13 Автоматическое окончание сессии. Случалось ли вам забывать о выходе из сессии
при работе с удаленной машиной? Было бы полезным иметь программу, которая
работала бы в фоновом режиме и которая после окончания установленного периода
времени посылала бы сигнал SIGKILL вашему log-in shell.
Заключение 281
Напишите программу timeout.c, которой передаются через аргументы командной строки
идентификатор процесса (PID) и число секунд. Программа переходит в состояние сна
в течение указанного числа секунд, а затем посылает сигнал SIGKILL процессу с
заданным значением P1D. Вы можете запустить программу из вашего log-in shell по команде
timeout $$ 3600 &. Здесь символ $$ обозначает идентификатор процесса shell.
Проблема, которая возникает при работе с программой timeout.c заключается в том,
что для вас закрывается сессия, даже если хотели бы продолжать работать дальше.
Измените программу так, чтобы она заканчивала бы вашу сессию, если только не
будет производиться ввод или вывод с вашего терминала в течение десяти минут.
(Подсказка: время модификации для файла устройства /dev/ttyxx обозначает время,
когда были прочитаны или записаны туда данные. Измените программу так, чтобы
она воспринимала имя терминала через аргумент при обращении к программе.)
7.14 Для этого упражнения вы должны смоделировать на пользовательском уровне
ситуацию, изображенную на рисунке 7.14.Там показано, как с помощью одних реальных
часов происходит управление двумя различными таймерами.
Сначала напишите программу ouch.с на основе программы sigdemol.c, которая в
главе 6 была названа программой OUCH.
При запуске программы ouch.c ей будут передаваться через аргументы командной
строки два аргумента: сообщение, которое обработчик сигналов будет выводить,
и значение интервала времени, по истечении которого периодически должен быть
вызван обработчик сигнала для вывода сообщения. Например, при обращении:
$ ouch hello 10 &
программа будет запущена на исполнение в фоновом режиме. Программа будет
выводить сообщение "hello" каждые десять единиц времени после приема сигнала SIGINT.
Затем напишите программу-метроном, которая будет называться metronome.c.
Программа принимает из командной строки список идентификаторов процессов. Эта программа
должна использовать интервальный таймер, чтобы вырабатывать каждую секунду
сигнал SIGALRM. Обработчик этого сигнала должен использовать системный вызов kill для
посылки сигнала SIGINT всем процессам, идентификаторы которых были заданы при
обращении к программе в командной строке. Например, при обращении вида:
$ metronome 1 3456 7777 2345
будет каждую секунду посылаться сигнал SIGINT процессам 3456, 7777 и 2345.
Запустите на исполнение в фоновом режиме три раза программу ouch. При каждом
запуске указывайте через аргументы различные сообщения и различное значение
интервала. Запомните идентификаторы этих трех процессов. Затем запустите
программу metronome, передавая ей в качестве аргумента число 1 и три запомненных
идентификатора процессов.
7.15 Блокирование на usleepQ, управление вводом. В программе bounceld.c основной цикл
блокировался на getch, а программа управляла анимационными действиями в
обработчике сигнала. Измените роли пользовательского ввода и анимации в новой версии
программы, в которой главный цикл должен блокироваться на usleep, а программа
должна управлять пользовательским вводом в обработчике сигнала.
282
Событийно-ориентированное программирование. Разработка видеоигры
7.16 Тестер времени реакции. Напишите программу, которая проводит измерение, насколько
быстро отвечает пользователь. Программа ожидает в течение случайного интервала
времени и затем выводит на экране одну цифру. Пользователь должен быстро, насколько это
возможно, набрать на клавиатуре эту же цифру. Программа должна записывать, сколько
времени она ожидала ответа от пользователя. Программа должна выполнить десять
таких тестов и выдать значения минимального, максимально и среднего времени ответа.
(Подсказка: обратитесь к справочной странице gettimeofday).
7.17 Завершите разработку игры в пинг-понг, которая была начата в предшествующем
тексте. Добавьте возможность вести счет, возможность игры нескольких игроков,
ограничители и все, что считаете нужным для того, чтобы сделать игру более
привлекательной.
Проекты
На основе материала, который был представлен в этой главе, вы можете изучить и
написать версии следующих Unix-программ:
snake, worms
Глава 8
Процессы и программы.
Изучение sh
Цели
Идеи и средства
• Что делает Unix shell.
• Модель процесса в Unix.
• Как программа запускается на исполнение.
• Как создается процесс.
• Как взаимодействуют родительский и дочерний процессы.
Системные вызовы и функции
• fork
• exec
• wait
exit
Команды
• sh
ps
8.1. Процессы = программы в исполнении
Как в Unix происходит запуск программы на исполнение? Все происходит достаточно
просто. Вы входите в систему, ваш shell выводит приглашение (prompt), вы набираете
текст команды и нажимаете на Enter. В результате будет запущена на исполнение
желаемая программа. После того как закончится исполнение программы, ваш shell выведет
новое приглашение. А как это все работает? Что такое shell? Что делает shell? Что делает
ядро? Что такое программа и что подразумевается, когда требуется запустить программу
на исполнение?
284
Процессы и программы. Изучение sh
Программа - это последовательность команд машинно-ориентированного языка. Эта
последовательность хранится в файле, который обычно получается в результате компиляции
исходного кода в двоичный код. Запуск программы на исполнение - это загрузка этого
списка машинно-ориентированных команд в память, после чего процессор (CPU)
начинает покомандно выполнять этот список.
В терминологии Unix список из машинно-ориентированных команд и данных называют
исполняемой программой. А процесс - это пространство в памяти и установки, в
соответствии с которыми происходит выполнение программы. На рисунке 8.1 показаны
программы и процессы.
Рисунок 8.1
Процессы и программы
Данные и программы хранятся в файлах на диске. Программы выполняются в составе
процессов. Мы будем изучать концепцию процесса в нескольких главах. Начнем
исследование с эксперимента - рассмотрим возможности команд ps и sh. Далее разработаем нашу
собственную версию Unix shell.
8.2. Изучение процессов с помощью команды ps
Процесс "живет" в пользовательском пространстве, которое представляет собой часть
памяти компьютера, где находятся исполняемые программы и их данные (см. рисунок 8.2).
Мы можем получить информацию о процессах в пользовательском пространстве с помощью
команды ps (сокращение от process status, т. е. статус процесса), которая предоставляет список
текущих процессов.
ps
ps -a
ps -1
Рисунок 8.2
Команда ps выводит список
текущих процессов
Процессы
****Р.
шт
Файлы:
иьо
В пользовательском
пространстве
содержатся процессы
В файловой системе
находятся
файлы и каталоги
8.2. Изучение процессов с помощью команды ps
285
$ ps
RDTTY TIMECMD
1755pts/1 00:00:17 bash
1981 pts/1 00:00:00 ps
Я запустил два процесса: bash (т. е. shell) и команду ps. Каждый процесс имеет уникальный
идентификатор, который называется идентификатором процесса (process ID), или наиболее
часто - просто PID. Все эти процессы соединены с терминалом. В данном случае терминал
/dev/pts/1. Для каждого процесса указано время его работы. Заметим, что время работы для
процесса ps указано в краткой форме и равно нулю секунд. В команде ps используется много
опций. В команде , как и в команде Is, используется опция -а:
$ps-a
PIDTTY
1779 pts/0
1780 pts/0
1781 pts/0
2013 pts/2
2017 pts/2
2018 pts/1
TIMECMD
00:00:13 gv
00:00:07 gs
00:00:01 vi
00:00:23 xpaint
00:00:02 mail
00:00:00 ps
При использовании опции -а выводится список, где содержится большее число процессов,
в том числе выводится информация о тех процессах, которые были запущены другими
пользователями и с других терминалов. Однако в списке, который выдается при работе
с опцией -а, не выводится информация о командных интерпретаторах shells. В команде ps
также можно использовать опцию -I для получения более длинного, более
информативного представления строк в выводимом списке:
$ps-la
F S
000 S
000 S
000S
000 S
000 S
000 R
UID
504
504
504
519
519
500
PID PPID
1779 1731
1780 1779
1781 1731
2013 1993
2017 1993
2023 1755
С
0
0
0
0
0
0
PRI
69
69
72
69
69
79
Nl
0
0
0
19
0
0
ADDR SZ
1086
2309
1320
1300
363
750
WCHAN
do_sel
do_sel
do_sel
do.sel
read_c
-
TTY
pts/0
pts/0
pts/0
pts/2
pts/2
pts/1
TIME CMD
00:00:13 gv
00:00:07 gs
00:00:01 vi
00:00:23 xpain
00:00:02 mail
00:00:00 ps
В колонке, которая помечена символом S, показывается статус (состояние) каждого процесса.
Для команды ps процесс развивается (running), о чем и свидетельствует символ R в этой
колонке. Остальные процессы находятся в пассивном состоянии (состоянии сна - sleeping),
о чем свидетельствует символ S в этой колонке. Каждый процесс принадлежит какому-то
пользователю. Для каждого процесса в выводимом списке указывается идентификатор
пользователя UID. Каждый процесс имеет PID. Кроме того, как мы видим, для каждого процесса
указывается идентификатор родительского процесса (PPID - parent process ID).
В колонках, которые помечены обозначениями PRI и N1, содержится приоритет и
поправка к приоритету niceness, с помощью чего обозначаются уровни процессов. Ядро
использует эти значения, чтобы выбрать в определенные моменты времени процессы, которым
следует предоставить процессор (т. е. сделать процесс активным). Процесс может
увеличить значение свого niceness уровня. Это аналогично ситуации, когда вы стоите
в очереди и разрешаете кому-то становиться в очереди перед вами. Только
суперпользователю разрешено уменьшать значение niceness уровня. Это равносильно тому, что вам
предоставляется право переместиться ближе к голове очереди.
286
Процессы и программы. Изучение sh
В колонке SZ указывается размер процесса. Это значение, которое показывает объем
памяти, которую использует процесс. В данном примере программа mail использует много
меньше памяти, чем программа xpaint, в которой необходимы большие объемы памяти для
хранения изображений. Значение размера процесса может меняться по мере развития
процесса.
В колонке WCHAN представлена информация о причине, по которой процесс находится
в состоянии сна. В данном примере все процессы ожидают ввода. Обозначения в колонке
вида readjc и dojsel- это адресные ссылки к ядру. Значения в колонках ADDR и F больше
не используются, но выводятся в листинг для обеспечения совместимости с программами,
которые предполагали вывод значений в этих колонках. При использовании опции -1у
получается листинг с набором значений, которые используются в более современных
версиях систем.
Опции, которые используются в команде ps, значительно разнятся от одной версии Unix
к другой. Опции -а и -1, о которых шла речь в предшествующем параграфе, могут на вашей
системе не работать или работать, но не так, как было представлено. Следует поэтому
прочитать документацию по этой команде на вашей системе. Примеры, которые были
здесь приведены, получены при работе с версией, которая называется procps 2.O.6.
Примеры лишь иллюстрируют большой объем информации, который можно получить с
помощью команды ps.
Команда ps весьма разносторонняя. При использовании опций -fa можно получить такой
результат:
$ ps -fa
UID PID
betsy1779
betsy 1780
betsy 1781
yuriko2013
yuriko2017
bruce 401
РРЮ
1731
1779
1731
1993
1993
1755
С
0
0
0
0
0
0
STIME TTY
19:53 pts/0
19:53 pts/0
19:54 pts/0
20:15 pts/2
20:16 pts/2
20:36 pts/1
TIME CMD
00:00:01 gvdinner.ps
00:00:07 gs-dNOPLATFONTS
00:00:02 vi dinner
00:00:00 xpaint
00:00:00 mail bruce
00:00:00 ps -afGh
При использовании опции -f получаем листинг в формате, который легче читать. Здесь
вместо UID отображается пользовательское имя. В колонке CMD выводится полный текст
командной строки.
8.2.1. Системные процессы
Помимо процессов, которые были запущены пользователями, вы можете обнаружить
в Unix процессы, которые выполняют системные функции.
$ps
PID
1
2
3
4
5
35
36
420
423
437
-ax|head-25
TTY STAT
? S
? SW
? SW
? SW
? SW
? SW
? SW
? S
? s
? SW
TIME
0:05
3:54
0:38
0:00
2:13
0:00
0:00
0:25
0:36
0:00
COMMAND
init
' [kflushd]
[kupdate]
[kpiod]
[kswapd]
[uhci-control]
[khubd]
syslogd
klogd -k/boot/System.map-2.2.14
[inetd]
8.2. Изучение процессов с помощью командыps
287
449 ?
461 ?
466 ?
471 ?
476 ?
484 ?
500 ? <
504 ?
506 ?
512 ?
514 ?
561 ttyl
562 tty2
563 tty3
$ ps -ax| wc
82
S
SW
S
S
S
SW
S
SW
SW
SW
SW
SW
SW
SW
-1
0:02
0:00
0:00
0:00
0:00
0:00
0:46
0:00
0:00
0:00
0:00
0:00
0:00
0:00
amd-F/etc/am.d/conf
[rpciod]
cron
atd
sendmail: accepting connections on port 25
[rpc.rstatd]
sshd
[calserver]
[keyserver]
[portsentry]
[portsentry]
[getty]
[getty]
[getty]
В приведенном выше примере показаны первые 24 из 82 процессов, которые были
запущены к текущему моменту в системе. Некоторые из них являются системными
процессами. У большинства системных процессов нет связи с терминалом. Они были порождены
при старте системы и недоступны пользователю с уровня командной строки. Что делают
все эти системные процессы?
Несколько первых процессов в списке управляют различными частями памяти, в том
числе буферами ядра и страницами виртуальной памяти. Другие процессы (klogd, syslogd)
в этом списке управляют системными учетными файлами (logfiles). Процессы cron, atd
предназначены для управления пакетными заданиями (batch jobs). Процесс portsentry
должен выявлять потенциальных злоумышленников. Процессы sshd, getty предоставляют
обычным пользователям возможность входа в систему. Вы сможете больше узнать о
возможностях системы Unix, если изучите результаты работы команды ps -ax и прочтете
соответствующие документы в электронном справочнике. Использование команды ps
напоминает ситуацию с разглядыванием через микроскоп капельки воды из озера. Вы можете
вести наблюдение как за составом, так и за определенным разнообразием процессов,
которые "живут" в вашем компьютере.
8.2.2. Управление процессами и управление файлами
Наши эксперименты с командой ps показали, что процессы имеют много атрибутов. У каждого
процесса есть UID, процесс имеет размер, для процесса отмечается, когда он начал работать и
сколько времени уже работает. Кроме того, у него есть приоритет и текущее значение niceness-
уровня. Некоторые процессы имеют присоединенный терминал, а некоторые не имеют. Где
должны храниться все эти свойства процесса? Мы должны отвечать нате же вопросы, которые
ставились при рассмотрении файлов. Ядро управляет процессами в памяти и файлами на
диске. Насколько похожи эти управляющие действия?
В файлах содержатся данные, а в процессах находится исполняемый код. Файлы имеют
атрибуты, и процессы имеют атрибуты. Ядро создает и уничтожает файлы. То же самое
справедливо и в отношении процессов. Ядро хранит несколько процессов в памяти, что
аналогично ситуации хранения ядром ряда файлов на диске. Ядро учитывает, какие блоки
находятся в памяти. Это необходимо для распределения пространства памяти и
поддержания порядка вызова процессов при их работе. Насколько похожи методы управления
оперативной памятью с методами управления дисковой памятью?
288
Процессы и программы. Изучение sh
8.2.3. Память компьютера и память для программ
Концептуально процесс представляет собой абстракцию. Но иногда данное понятие
носит весьма конкретный смысл: это объединение некоторого числа байт в памяти.
На рисунке 8.3 показаны три модели памяти в компьютере.
Память может быть рассмотрена
как некоторое протяженное
пространство, в котором
располагаются ядро и процессы
Многие системы рассматривают
память как массив из "страниц",
в котором каждому процессу
выделяются определенные
страницы
Массив страниц можно физически
сохранить на чипах памяти
Ядро Процесс А Процесс В
^СЬ-
Рисунок 8.3
Три модели памяти
в компьютере
Память в Unix разделяется на пользовательское пространство и пространство ядра.
Процессы развиваются в пользовательском пространстве. Память - это, прежде всего,
последовательность байтов, но это также и большой массив. Если на вашей машине есть
64 Мбайт памяти, то в таком массиве памяти будет находиться около 67 миллионов ячеек
памяти. В некоторых из этих ячеек памяти находятся машинно-ориентированные
команды и данные, которые и составляют ядро.
В определенных ячейках памяти находятся команды и данные процесса. Процесс не
обязательно занимает один участок (chunk) памяти. Обычно процессы состоят из более мелких
участков, аналогично тому, как дисковые файлы состоят из дисковых блоков. И опять же
аналогично тому, как для файла поддерживается список распределенных блоков на диске, для
процесса заводится структура, где содержится список распределения страниц памяти.
Поэтому абстрактным будет такое представление, где каждый процесс представлен как
некоторый бокс в составе пользовательского пространства.
Абстрактным представление памяти можно считать непрерывный байтовый массив. При
этом известно, что современная память обычно представляет собой ряд чипов памяти,
которые расположены на небольшой плате.
Создание процесса аналогично созданию файла. Ядро должно найти сначала
необходимое число свободных страниц в памяти, чтобы разместить в них коды команды и данные
программы. Ядро также создает в памяти некоторые структуры данных, в которых
содержится информация о распределении пространства памяти и атрибуты процесса.
Магическим свойством операционной системы является то, что она преобразует
структуру файловой системы в последовательность секторов, расположенных на поверхностях
наборов пластин. В результате файловая система предстает в виде дерева с определенным
составом взаимосвязанных каталогов. Таким же образом ОС поступает и при управлении
процессами. Производится некое преобразование последовательностей битов памяти,
8.3. SHELL: Инструмент для управления процессами и программами
289
которые расположены в чипах памяти. В результате получается нечто, воспринимаемое
как некое сообщество процессов, в котором каждому процессу присущи такие свойства,
как развитие, взаимодействие, сотрудничество, порождение, возможность выполнять
определенные задания, гибель. Полная аналогия с муравейником.
Для того чтобы понять свойства процессов, мы изучим и разработаем Unix shell, т. е.
программу, которая управляет процессами и запускает программы на исполнение.
8.3. SHELL: Инструмент для управления процессами
и программами
Shell - это программа, которая управляет процессами и запускает программы на
исполнение. Существуют несколько shell, которые могут работать в Unix. Это напоминает
ситуацию с использованием различных языков программирования. Каждый из них
отличается стилем и возможностями. Во всех популярных shell поддерживаются три
основные функции:
(a) Каждый shell запускает программы на исполнение.
(b) Каждый shell управляет вводом и выводом.
(c) В каждом shell можно вести программирование.
Рассмотрим последовательность команд shell:
$ grep lp /etc/passwd
lp:x:4:7:lp:/var/spool/lpd:
$TZ=PST8PDT; export TZ; date; TZ=EST5EDT
Sat Jul 28 02:10:05 PDT 2001
$date
SatJul 28 05:10:14 EDT 2001
$ Is-I/etc > etc.listing
$ NAME=lp
$ if grep $NAME /etc/passwd
>then
> echo hello | mail $NAME
>fi
lp:x:4:7:lp:/var/spool/lpd:
$
*
Запуск программ на исполнение
Команды grep, date, Is, echo, mail - это обычные программы, которые написаны на языке С
и были оттранслированы в коды машинного языка. Командный интерпретатор shell
загружает эти программы в память и затем запускает их на исполнение. Многие пользователи
рассматривают shell в качестве программы-стартера.
Управление вводом и выводом
Shell делает гораздо больше, чем просто запуск программ на исполнение. Когда
пользователь в командной строке набирает символы >, <, |, чтобы указать на необходимость
перенаправления ввода/вывода, то shell воспринимает эти символы как требование
присоединения ввода и вывода процессов к дисковым файлам или к другим процессам.
290
Процессы и программы. Изучениев!}
Программирование ,
Shell можно рассматривать и как язык программирования, в котором используются
переменные и средства управления потоком (if while и т. д.). В предшествующем примере
было продемонстрировано два случая использования переменных. Во-первых, было
присвоено значение переменной TZ. Это значение определяло временную зону для западной
части U. S. и было использовано командой date при выводе текущей даты и времени.
Далее в примере мы видим использование оператора if .then. Переменной NAME в
качестве значения присваивается строка р". Значение этой переменной, т. е. SNAME,
используется в команде grep, а результат этой команды проверяется в операторе // Если команда
выполнилась успешно при организации поиска строки р" в файле /etc/passwd, то shell
выполнит команду echo hello | mail $NAME. В противном случае управление будет передано
следующей команде.
В этой главе мы рассмотрим, как shell запускает программы на исполнение. В
последующих главах обсудим вопрос использования переменных в shell, а также вопросы
управления порядком выполнения, вопросы перенаправления ввода и вывода.
8.4. Как SHELL запускает программы на исполнение
Shell выводит приглашение, вы набираете текст команды, shell запускает команду на
исполнение, а затем shell опять выводит приглашение. И далее все повторяется. А что
происходит за кулисами?
Новый процесс
Система управления
процессами
shell
Программа | 4"П II Ч-^Г Пользователь
Рисунок 8.4
Пользователь обращается к shell для
выполнения запуска программы
Shell выполняет следующие шаги, которые составляют основной цикл работы shell (см.
рисунок 8.4).
A. Пользователь набирает a.out.
B. Shell создает новый процесс для запуска программы на исполнение.
C. Shell загружает программу с диска в пространство процесса.
D. Программа исполняется в своем процессе, пока не закончится.
8.4.1. Основной цикл shell
Shell работает в таком цикле:
while (! end.ofjriput)
получить команду
выполнить команду
ожидать, когда закончится команда
8.4. Как SHELL запускает программы на исполнение
291
Рассмотрим типичное взаимодействие пользователя с shell:
$ls
Chap.bak Story08.tr chap08.ps chap08.tr outline.08
Makefile chap08 chapOff. short codepix
$ps
PIDT7YTIMECMD
29182 pts/5 00:00:00 bash
29183 pts/5 00:00:00 ps
$
Рассмотрим последовательность событий, которые возникали во времени в том порядке,
как это указано на рисунке 8.5. На рисунке направление оси времени слева направо. Shell
на рисунке представлен боксом с пометкой "sh". Бокс начинает перемещение по оси
времени слева направо. Shell читает строку "Is", которую набрал пользователь. Shell создает
новый процесс, а затем запускает на исполнение программу Is в этом процессе. Далее он
ждет, когда будет завершен процесс.
Читать команду
sh \ —
Ожидание окончания
Читать команду
Новый процесс
Запустить команду exit
на исполнение
}
Ожидание окончания (exit)
>
Норый процесс
ps
Запустить команду exit
на исполнение
ps"
Рисунок 8.5
Распределение во времени основного цикла shell
Затем shell читает новую строку на входе, создает новый процесс, запускает программу
в этом процессе и ожидает, пока будет закончен процесс. Когда shell обнаружит признак
"конец ввода", то он заканчивает работу.
Для того чтобы написать shell, нам необходимо изучить вопросы:
1. Как запустить программу на исполнение.
2. Как создать процесс.
3. Как организовать ожидания, когда будет выполнен exit().
Когда нам станут ясны ответы на эти вопросы, то мы сможем их объединить и на этой
основе написать свой собственный shell.
292
Процессы и программы. Изучение sh
8.4.2. Вопрос 1: Каким образом производится запуск программы?
Ответ: С помощью системного вызова execvp.
На рисунке 8.6 показано, как одна программа запускает другую программу на исполнение.
Например, чтобы запустить на исполнение команду Is -la, программа обращается к вызову
execvp("ls", arglist), где arglist - это массив строковых аргументов командной строки. Ядро
загружает с диска программу в память. Аргументы командной строки Is и -la передаются
программе, и программа запускается на исполнение. В кратком представлении это выглядит так:
1. Программа вызывает execvp.
2. Ядро загружает программу с диска в процесс.
3. Ядро копирует список аргументов arglist в процесс.
4. Ядро вызывает main(argc,argv).
Как в Unix происходит запуск программ:
execvpfprogname, arglist)
1. Копируется поименованная программа!
в вызывающий процесс.
2. Передается указанный список строк
в программу как argv[].
3. Запускается программа.
Программа для запуска
Рисунок 8.6
execvp копирует программу в память и запускает ее на исполнение
Далее представлена программа, которая запускает на исполнение команду Is -1,
/* exed .с - показывает, насколько легко из программы запустить на исполнение другую
программу
7
main()
char*arglist[3];
arglist[0] = "Is";
arglist[1] = "-Г;
arglist[2] = 0;
printff* '* * About to exec Is -l\n"
execvpC'Is", arglist);
printf("* * * Is is done. bye\n");
8.4. Как SHELL запускает программы на исполнение 293
execvp предполагает задание двух аргументов: имя программы, которая будет запускаться,
и массив аргументов командной строки для этой программы. Массив аргументов
командной строки представлен как argv[], когда происходит запуск программы. Заметим, что
в качестве первого строкового аргумента мы устанавливаем имя программы. Заметим
также, что этот массив должен иметь в качестве последнего элемента указатель MULL.
Откомпилируем и запустим программу:
$ссехес1.с-оехес1
$ ./ехес1
*** About to exec Is -I
total 28
drwcr-x— 2 bruce users 1024 Jul 14 21:02 a
drwxr-x— 3 bruce users 1024 Jul 1603:16 c
-rw-r-r- 1 bruce users 0 Jul 14 21:03 у
Куда подевалось второе сообщение из программы? Просмотрите еще раз текст
программы. В программе выдается сообщение о том, что будет выполняться по exec программа Is.
Далее выполняется вызов с помощью exec команды Is. И затем предполагается выдача
сообщения, которое следует в программе за системным вызовом execvp. Но почему тогда нет
на экране второго сообщения?
Программа исполняется в процессе, который представлен участком памяти (chunk)
и структурами данных ядра для поддержки работы процесса. Таким образом, вызов execvp
загружает программу с диска в процесс для того, чтобы процесс смог ее выполнять.
Но в какой процесс происходит загрузка? Здесь происходят довольно странные вещи: ядро
загружает новую программу в текущий процесс, замещая код и данные этого процесса.
execvp действует, как действуют при трансплантации мозга. Кто-то может пожелать:
"Я хотел бы решить эту проблему, используя мозг Альберта Эйнштейна, а после этого
пойти и танцевать твист". Один из вариантов выполнения этого желания - удалить ваш
мозг и поместить в вашу голову на его место мозг Альберта Эйнштейна. Мысли и
аналитические способности, которые стали присущи вашей голове, будут как у Альберта
Эйнштейна. Однако ваш план сходить на танцы1 исчез вместе с вашим собственным мозгом.
Системный вызов exec очищает память текущего процесса от машинно-ориентированного
кода текущей программы, помещает в память код программы, которая была указана в
системном вызове exec, а затем запускает новую программу на исполнение. При выполнении exec
изменяется распределение памяти процесса в соответствии с требованиями новой программы.
Процесс при этом остался тем же самым, а его содержание оказалось новым.
Обобщенная информация о execvpQ
\
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
execvp
Выполнить файл, который ищется с использованием PATH
tinclude < unistd.h >
result = execvp(const char *file, const char *argv[])
file - имя файла, который будет исполняться
argv - строковый массив
-1-при ошибке
1. или сделать что-либо еще по вашему плану действий.
2. execvp - это один из членов семейства функций execv. Все объединение функций обобщенно называют exec.
294
Процессы^ программы. Изучение sh
execvp загружает в текущий процесс программу, которая представлена в системе как файл
file, и пытается выполнить программу. Вызов execvp передает в программу список строк
в виде массива argv с NULL в конце массива, execvp ищет программу file в каталогах,
которые перечислены в переменной среды PATH. '
При успешном окончании execvp не формируется код возврата. Просто текущая программа
удаляется из процесса, а новая программа исполняется в текущем процессе.
Пример 2: Формирование приглашения в shell. Мы достаточно узнали для того, чтобы
написать первую версию shell. Мы знаем, как можно^запустить программу на исполнение
и как передать ей аргументы с уровня командной строки. Сначала shell по приглашению
запросит имя программы и аргументы, а затем запустит программу на исполнение. Наша
версия программы pshl.c будет реализовывать shell, формирующий приглашения:
/*. shell, формирующий приглашения, версия 1
* Приглашения выдаются для ввода имени команды и для ввода ее аргументов.
* Строится вектор аргументов для вызова execvp.
* Используется вызов execvp(), из которого выхода не производится.
7
#include <stdio.h>
#include <signal.h>
#jnciude <string.h>
tdefine MAXARGS 20 /* аргументы с уровня командной строки */
#defineARGLEN 100 Л длина 7
intmainf)
{
char *arglist[MAXARGS+1 ] //* массив указателей 7
int numargs; /* индекс в массиве 7
char argbuf [ARGLEN]; /* сюда будем читать 7
char *makestring(); /* выделение памяти */
numargs = 0;
while (numargs < MAXARGS)
{
printf("Arg[%d]?", numargs);
if (fgets(argbuf, ARGLEN, stdin) && *argbuf != \ri)
arglist[numargs++] = makestring(argbuf);
else
{
if (numargs > 0){ /* есть аргументы? 7
arglist[ngmargs]=NULL;/* закрыть список 7
execute(arglist); /* сделать 7
numargs = 0; Г и сбросить */
}
}
}
return 0;
}
int execute}char *arglist[])
Л
8.4. Как SHEU запускает программы на исполнение
295
использовать execvp
execvp(arglist[0], arglist); /* сделать это 7
perrorfexecvp failed");
exitA);
}
char * makestring(char *buf)
Г
* правильно сформировать новую строку и создать память для строки
7
{
char *cp, *malloc();
but[strlen(buf)-1 ] = '\0'; /* закончить новую строку 7
ср = malloc(strlen(buf)+1); /* получить память 7
if (ср == NULL){ Г или получить отказ 7
fprintf(stderr,"no memory\nM);
exitA);
}
strcpy(cp, buf); Г скопировать символы 7
return cp; /* возвратить указатель 7
}
Программа pshl.c-это наша первая попытка создания Unix shell. Каждый раз программа
pshi выдает приглашения на новой строке. Сначала запрашивается имя программы, а
затем запрашиваются по отдельности аргументы для нее. Программа работает в два этапа.
A) Строится список аргументов, строчка за строчкой. В конец списка добавляется NULL.
B) Системному вызову execvp передается строка arglist[0] и массив arglist (см. рисунок 8.7).
I Is -1 demodir""
arglist
3 execvp(prog, arglist);
1. Чтение командной строки в буфер.
2. Извлечение из буфера списка аргументов.
3. Передача списка аргументов вызову execvp
Рисунок 8.7
Построение однострокового
списка аргументов
Откомпилируем и запустим программу:
$ccpsh1.c-opsh1
$./psh1
Arg[0]? Is
296
Процессы и программы. Изучение sh
Arg[1]?-I
Arg[2]? demodir
Arg[3]?
total 2
drwxr-x— 2 bruce users
drwxr-x— 3 bruce users
-rw-r--r--1 bruce users
$
А как развиваться? Наша программа работает хорошо. Но как мы и предполагали, при
выполнении execvp происходит замена кода shell на код команды. Затем происходит выход,
в результате чего наш shell не может циклически принять на обработку другую команду.
Пользователь вынужден будет повторно запустить shell для того, чтобы можно было бы
запустить на исполнение другую команду
Как сделать так, чтобы shell мог бы запускать команду и далее мог запускать и другую
команду? Решением является создание нового процесса, в котором и будет запускаться на
исполнение программа.
8.4.3. Вопрос 2: Как получить новый процесс?
Ответ: С помощью системного вызова fork процесс производит копирование себя самого.
Использование: fork(); /* выполняется без аргументов */
Изучение системного вызова fork
Давайте продолжим обсуждение проблемы принятия решения с использованием мозга
Эйнштейна. Как мы уже заметили, пересадка мозга Эйнштейна в вашу голову позволит
этой голове мыслить, как голове Эйнштейна. Но при этом ваших мыслей в этой голове уже
больше не будет.
Одно из возможных решений заключается в том, что процесс дублирует самого себя, что
напоминает трехмерное копировальное устройство, которое идентифицирует каждый
атом вашего тела и собирает при этом точную копию, строя ее атом за атомом. После того
как будет создана такая копия, поместите мозг Эйнштейна в голову копии. Теперь эта
копия может решать мудреные проблемы, используя для этого мозг Эйнштейна. А вы будете
продолжать жить по своим планам и останетесь со своими мыслями. Итак, в
определенный момент вашей жизни вы представляли только самого себя. После того как вы нажали
на большую зеленую кнопку на копировальном устройстве, вас уже стало двое. Это ваше
раздвоение выглядит аналогично развилке (fork) дороги. Сначала идет одна дорога, а
потом их становится уже две, причем две дороги будут одинаковыми.
При работе системного вызова fork все происходит так же. На рисунке 8.8 показана
система до и после выполнения системного вызова fork. Процесс содержит программу, которая
исполняется в определенном месте. В какой-то момент в процессе происходит вызов fork.
Управление передается коду fork, который расположен в ядре. Далее в ядре выполняются
такие действия:
(а) Распределяется новый участок памяти и выделяются структуры данных ядра.
(в) С оригинального процесса снимается копия, которая является новым процессом.
(c) Новый процесс добавляется в набор развивающихся процессов.
(d) Управление возвращается назад в оба процесса.
1024 Jul 14 21:02 a
1024 Jul 1603:16с
0 Jul 14 21:03 у
8.4. Как'SHELL запускает программы на исполнение
297
Перед fork:
После fork:
parent process
child process
jlBefore
IfforkO-
After
:^j
Новый процесс содержит тот же код и данные,
что и родительский процесс
Рисунок 8.8
fork() выполняет копирование процесса
После того как вы нажали на кнопку Go на копирующем устройстве, вы раздвоились,
каждый из вас физически идентичен, оба находятся в одной и той же точке своего
мыслительного процесса, но каждый, будучи отдельной сущностью, способен идти своим (или его?)
путем. Аналогичная картина возникает, когда процесс вызвал fork. После его выполнения
процессов становится два. Оба, как цифровые сущности, идентичны, оба находятся в
одной и той же точке программы, и каждый отдельный процесс способен продолжаться
далее своим собственным путем. Давайте рассмотрим ряд простых программ.
Пример: forkdemol .с - Создание нового процесса
В forkdemol.c содержатся два предложения printf. Одно находится перед вызовом fork,
а другое - после.
Г forkdemol .с
* Показывает, как fork создает два процесса. Их можно различить
* с помощью различных кодов возврата, которые получаются после выполнения
fork()
7
#include <stdio.h>
main()
{
int retjromjork, mypid;
mypid = getpid(); /* кто я такой? 7
printff'Before: my pid is %d\n'\ mypid); /* сообщите об этом всем 7
ret_from_fork = fork();
sleepA);
printf("After: my pid is %d, fork() said %d\n",
getpid(), retjromjork);
}
Если бы это была обыкновенная программа, то мы должны были увидеть две строки
вывода. По одной для каждого предложения printf. Однако если мы запустим нашу
программу, то мы увидим:
298
Процессы и программы. Изучениез!)
$ ее forkdemol .с-о forkdemol
$ ./forkdemol
Before: my pld is 4170
After: my pid is 4170, fork() said 4171
$ After: my pid is 4171, fork() said 0
Мы увидим три строки в выводе. Одно сообщение Before: и два сообщения After. Второе
сообщение After: выводится процессом 4171. Заметим, что процесс 4171 не выводит
сообщение Before:. А почему не выводит? На схеме, изображенной на рисунке 8.9, показано,
что происходит в системе до й после выполнения процессом 4171 вызова fork.
Перед fork:
[(Before I
|ffork()-L-|
After I I
После fork:
[(Before
IfforkO-
After-4(
Before
fork()
After-*
>-v?^
i-1:
Один поток управления входит
в ядре в код вызова fork
Рисунок 8.9
Дочерний процесс исполняет код после fork()
Из кода вызова fork в ядре происходит
выход двух потоков управления
Ядро создает процесс 4171с помощью репликации процесса 4170. При этом новый
процесс создается посредством копирования кода и текущего значения счетчика команд в
коде. Место, на которое указывает счетчик в коде, показано на рисунке стрелкой. Новый
процесс 4171 начинает сразу же исполняться, но не с начала программы, а после fork.
Поэтому процесс 4171, возникший в середине процесса 4170, и не выводит сообщение Before:.
Example: forkdemo2.c - Порожденный процесс создает процессы
Дочерний процесс начинает свою жизнь, но он начинает выполнять функцию main не
с начала, а сразу после системного вызова fork.
Предскажите, сколько строк будет выведено при выполнении этой программы:
Г forkdemo2.c - показывает, как дочерние процессы начинают развиваться сразу
* после выхода из fork() и могут далее выполнять код, который они пожелают,
* даже й)гк().Предскажите - сколько будет строк вывода.
7
main()
{
printff'my pid is %d\n", getpid());
fork();
fork();
8.4. Как SHELL запускает программы на исполнение 299
fork();
printff'my pid is %d\n", getpidf));
}
Откомпилируйте и запустите программу для проверки - насколько оправдались ваши
предсказания. Ну и как?
Пример: forkdemo3.c - Различие между отцом и сыном
В программе forkdemol.c мы увидели, что процесс 4170 вызвал fork и создал дочерний
процесс с PID 4171. Оба процесса при развитии выполняют один и тот же код, начиная с
одного и того же места, используя при этом одни и те же данные и атрибуты процесса. Как
процесс может определить, кто он такой -либо процесс-отец, либо процесс-сын?
Эти два процесса не являются полностью идентичными. Вывод, который происходит из
forkdemol.c, показывает, что после выполнения fork значение кода возврата будет разным
для разных процессов. В порожденном процесе системный вызов fork возвращает
значение, равное 0, а в отцовском процессе возвращает значение, равное числу 4171.
Простейшим методом для определения отца или сына может быть проверка значения кода
возврата из вызова fork.
В нашем следующем примере, в программе forkdemo3.c, показывается, как в программе
используется код возврата для формирования и вывода различных сообщений.
Г forkdemo3.c - показывает, как код возврата из fork()
* дает возможность процессу узнать - сын он или отец
7
#include <stdio.h>
main()
{
int fork_rv;
printf("Before: my pid is %d\n", getpid());
forkjv = fork(); /* создание нового процесса 7
J if (fork_rv == -1) /* проверка на правильность выполнения 7
perrorf'fork");
else if (fork_rv == 0)
printfA am the child, my pid=%d\n", getpid());
else
printffl am the parent, my child is %d\n", fork_rv);
}
. Далее показан пример запуска программы на исполнение.
$ ./forkdemo3
Before: my pid is 5931
I am the parent, my child is 5932
I am the child, my pid=5932
300 Процессы и программы. Изучение sh
Обобщенная информация о fork
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
fork
Создать процесс
#include < unistd.h >
pidj result = fork(void)
Нет
•1- при ошибке
О-в дочернем процессе
pid - в отцовском процессе (это pid дочернего процесса)
Системный вызов fork - это то самое средство, с помощью которого мы можем решить
проблему создания процессов в нашем shell при работе в командном режиме. Используя
fork, мы имеем возможность создать новый процесс, а также мы можем с помощью этого
вызова различить, какой из процессов будет новым, а какой порождающим. В новом
процессе далее можно выполнить вызов execvp для запуска на исполнение некоторой
программы по желанию пользователя.
Мы уже разобрали суть двух из трех вопросов, которые необходимо решать при
построении shell. Нам известно, как создавать новый процесс (fork), & также мы знаем, как
запускать программу на исполнение (execvp). Далее рассмотрим, как организовать ожидание
в родительском процессе события, когда дочерний процесс закончит выполнять команды.
А 4.4. Вопрос 3: Как процесс-отец ожидает окончания дочернего процесса?
Ответ: Процесс-отец вызывает wait, чтобы ждать окончания дочернего процесса.
Использование: pid = wait(&status);
Изучение вызова wait()
Системный вызов wait предназначен для решения двух задач. Во-первых, при выполнении
системного вызова wait вызывающий процесс переходит в состояние ожидания до того
момента времени, пока не закончится выполнение дочернего процесса. Во-вторых,
с помощью системного вызова wait процесс-отец может получить значение, которое
дочерний процесс передал ему с помощью системного вызова exit.
На рисунке 8.10 показано, как работает системный вызов wait. Заметим, что ось времени
на рисунке направлена слева направо. В левой части представлено в условном виде, что
процесс-отец начинает работу и вызывает fork. Ядро создает дочерний процесс, который
на рисунке представлен таким же небольшим боксом и который начинает развиваться
параллельно с родительским процессом. Родительский процесс вызывает wait. После
этого ядро задерживает родительский процесс до тех пор, пока не закончится дочерний
процесс. Процесс-отец находится в состоянии ожидания на отрезке времени, который на
рисунке помечен словом wait.
Через некоторое время дочерний процесс заканчивает работу и выполняет exit(n), чтобы
передать родительскому процессу числовой аргумент, значение которого может
находиться в диапазоне от 0 до 255.
8.4. Как SHELL запускает программы на исполнение
301
Когда дочерний процесс вызывает exit, то ядро будит родительский процесс и
предоставляет ему значение аргумента вызова exit> полученное от дочернего процесса. Такая
процедура уведомления и передачи аргумента системного вызова exit изображена на рисунке
с помощью направленной дуги, которая исходит из скобок в вызове exit и идет к процессу-
отцу. Таким образом, системный вызов wait служит для выполнения двух действий:
уведомление и коммуникация.
fork()
wait()
LU»^.^ exit(')
f
Рисунок 8.10
Вызов wait переводит порождающий процесс в ожидание, пока не закончится дочерний
процесс
Пример: waitdemol.c-Уведомление
waitdemol.c показывает, как обращение к exit в дочернем процессе обеспечивает выход из
wait в процессе-отце.
/* waitdemol .с - показывает, как процесс-отец ждет, пока не закончится дочерний процесс
7
<stdio.h>
2
#include
tdefine DELAY
main()
{
intnewpid;
void child_code(), parent_code();
printffbefore: mypid is %d\n", getpidf));
if((newpid = fork())==-t)
perror("fork");
else if (newpid == 0)
child^cOdefDELAY);
else
parent code(newpid);
}
/*
* новый процесс сначала засыпает, а затем выполняет exit
7
void child_code(int delay)
{
printf("child %d here, will sleep for %d seconds\n", getpid(),
sleep(delay);
302
Процессы и программы. Изучение sh
printffchild done, about to exit\n");
exitA7);
}
Г
процесс-отец ждет, пока дочерний процесс напечатает сообщение
Г код возврата из wait() */
7
void parent code(int childpid)
{
int waitjv;
waitjv = wait(NULL);
printff'done waiting for %d. Wait returned: %d\n", childpid,
wait rv);
}
Результат работы программы waitdemol.c будет выглядеть так:
$ ./waitdemol
before: mypid is 10328
child 10329 here, will sleep for 2 seconds
child done, about to exit
done waiting for 10329. Wait returned: 10329
Запустите эту программу йа исполнение. Вы увидите, что родительский процесс всегда
ждет, пока не закончится дочерний процесс. На рисунке 8.11 показан поток управления и
передача данных между двумя процессами. В родительском процессе поток управления
начинается с начала текста программы и затем поток будет блокирован на вызове wait.
В дочернем процессе поток управления начинается от вызова fork в тексте main и далее
проходит через функцию child_code. Поток заканчивается вызовом exit. Вызов exit в дочернем
процессе является сигналом побудки процесса-отца.
| Процесс-отец
Дочерний процесс
Процесс-отец будет
блокирован, а затем
будет продолжен,
когда будет закончен
дочерний процесс
main(}
К| fork(>;
exit(n);
гт—
Рисунок 8.11
Управляющий поток и коммуникация с waitQ
main ()
fork();
jchil decode ()
parent_code()
int status;
wait(bstatus);
FT
8А. Как SHELL запускает программы на исполнение
303
Выводы по результатом работы с программой waitdemol.c. Данная программа
иллюстрирует два важных фактора относительно вызова wait.
1. Вызов wait блокирует выполнение вызывающей программы до окончания дочернего про-
цесса
В этом примере работы программы родительский процесс блокируется до тех пор,
пока в дочернем процессе не будет выполнен вызов exit. Тем самым двум процессам
предоставляется возможность синхронизировать свои действия. Родительский процесс
может с помощью fork породить дочерний процесс, который будет выполнять
некоторую работу. Например, будет производить сортировку содержимого определенного
файла. Родительский процесс будет ждать, пока не будет выполнена такая задача
сортировки, с тем чтобы далее выполнять над файлом уже какие-то другие действия.
Для синхронизации выполнения таких задач обработки файла может быть
использована указанная пара системных вызовов: exit и wait.
2. Вызов wait после своего окончания возвращает PID закончившегося процесса
В этом примере работы программы код возврата системного вызова wait равен
значению PID дочернего процесса, который выполнил вызов exit. Как мы увидим в
программе forkdemo2.c, процесс может создать несколько дочерних процессов. Рассмотрим
программу, которая обрабатывает данные из двух удаленных баз данных. В программе
будет порождено с помощью вызова fork два процесса. Один процесс служит для
установления связи и извлечения данных из одной базы данных, а другой - для извлечения
данных из другой базы данных. Процедура извлечения данных из первой базы данных
может потребовать некоторой последующей обработки этих данных, а при извлечении
данных из второй базы данных не требуется никакой последующей обработки. По коду
возврата из вызова wait родительский процесс будет в состоянии определить - какая из
задач закончилась. Поэтому далее он может подключать или нет последующую
обработку данных.
Пример: waitdemo2.c-Коммуникация у
Одна из целей системного вызова wait - уведомить родительский процесс о том, что
дочерний процесс закончился. Другая цель системного вызова wait - сообщить
родительскому процессу, как закончился дочерний процесс.
Успех, неудача и гибель^ Процесс может закончиться по одному из трех вариантов. Во-
первых, процесс может успешно выполнить решаемую им задачу. По соглашению,
принятому в Unix, при успешном выполнении программа выполняет вызов exit(O) или
возвращает 0 при выходе из main.
Во-вторых, программа может не справиться с выполнением своей задачи. Например,
программа может закончиться раньше положенного, если при своем исполнении у нее не
хватит памяти. По соглашению, принятому в Unix, в программах, где обнаруживаются
ошибки при выполнении, будет выполняться системный вызов exit с ненулевым аргументом.
Программист для каждого из возможных видов ошибок устанавливает значения таких
кодов возврата. В электронном справочнике приводятся значения таких кодов.
Наконец, программа может быть закончена по сигналу (см. главы 6 и 7). Сигнал может
быть послан с клавиатуры, от внутреннего таймера, из ядра, прийти от других процессов.
Обычно если сигнал не игнорируется и не перехватывается в процессе, то при
поступлении он убивает процесс.
После выполнения wait полученное значение кода возврата равно PID дочернего процесса,
который закончил работу. А как процесс-отец узнает о результативности окончания
дочернего процесса - закончился ли он успешно, неудачно или был убит?
304
Процессы и программы. Изучение^
Получить ответ можно с помощью аргумента системного вызова wait. Процесс-отец
вызывает wait, указывая в аргументе адрес целочисленной переменной. Ядро сохраняет в этой
переменной статусную информацию об окончании дочернего процесса. Если дочерний
процесс вызывает exit, то ядро поместит аргумент вызова exit в эту целочисленную
переменную. Если дочерний процесс будет убит, то ядро в эту целочисленную переменную
поместит номер сигнала. Поле для представления целочисленной переменной состоит
функционально из трех частей: поле в восемь разрядов для хранения аргумента вызова exit,
поле из семи разрядов для размещения в нем значения номера сигнала, и один разряд служит
для индикации того, что был получен дамп образа процесса. На рисунке 8.12 показаны три
поля, в которых размещается статусная информация о дочернем процессе.
Значение кода возврата из exit-
Щ
Номер сигнала
Флаг наличия дампа образа процесса
Процесс-отец-
Дочерний процесс
¦if;lW
Рисунок 8.12
Представление статусной информации о дочернем процессе в трех полях
Наш следующий пример, waitdemo2.c, построен на основе программы waitdemolx.
Программа производит отображение статусной информации о закончившемся дочернем процессе.
Г waitdemo2.c - показывает, как процесс-отец получает статусную информацию о дочернем
* процессе
7
#include <stdio.h>
#define DELAY 5
main()
{
intnewpid;
void child_code(), parent_code();
printff'before: mypid is %d\n", getpid());
if((newpjd = fork())==-1)
perrorf'fork");
else if (newpid == 0)
child_code(DELAY);
else
parentjxxle(newpid);
8.4. Как SHELL запускает программы на исполнение
305
Г
* новый процесс засыпает, а затем выполняет exit
7
void child codefint delay)
{
printf("child %d here, will sleep for %d seconds\n", getpid(),
delay);
sleep(delay);
printff'child done, about to exit\nM);
exitA7);
}
V* - <
* процесс-отец ждет, когда дочерний процесс отпечатает сообщение
7
void parent code(int chiidpid)
{ ¦>
int wait_rv; /* код возврата из wait() */
int child_status;
int high_8, low_7, bit_7;
wait^rv = wait(&child_status);
printf("done waiting for %d. Wait returned: %d\n", chiidpid,
waitjv);
highT 8 = child.status » 8; Г 1111 1111 0000 0000 7
low J = child_status & 0x7F; /* 0000 0000 0111 1111 7
bitj = child.status & 0x80; /* 0000 0000 1000 0000 */.
printf("status: exit=%d, sig=%d, core=%d\n"l high_8, low_7,
bit 7);
}
Сначала позволим программе waitdemo2 закончиться нормально. Статусная информация
дочернего процесса из системного вызова exit будет скопирована и передана процессу-
отцу:
$ /waitdemo2
before: mypid is 10855
child 10856 here, will sleep for 5 seconds
child done, about to exit
done waiting for 10856. Wait returned: 10856
status: exit=17, sig=0, core=0
$
Далее мы запустим программу waitdemo2 в фоновом режиме и с помощью команды kill
4 (см. главу 7) пошлем дочернему процессу сигнал SIGTERM:
$/waitdemo2 &
$ before: mypid is 10857
child 10858 here, will sleep for 5 seconds
kill 10858
$ done waiting for 10858. Wait returned: 10858
status: exit=0. sia=15. core=0
306
Процессы и программы. ИзучениевЬ
Обобщенная информация о waitQ
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
См. также
wait
Ожидать окончания процесса
#include <sys/types.h>
#include <sysAvait.h>
pidj result = wait(int *statusptr)
Указатель на статусную информацию дочернего процесса
-1 -при ошибке,
pid - закончившегося процесса
waitpidB), wait3B)
Системный вызов wait приостанавливает вызывающий процесс, пока не станет доступной
статусная информация об одном из его дочерних процессов. В качестве такой информации будет
или код возврата, или номер сигнала. Если один из дочерних процессов уже был закончен или
был^бит сигналом, то происходит немедленный выход из вызова wait. Системный вызов wait
возвращает PID закончившегося процесса. Если в системном вызове wait значение аргумента
не было равно NULL, то производится копирование статуса из exit или номера сигнала в
переменную, на которую направлен указ;атель в wait. Значения полей статусной информации можно
проверить с помощью макросов, которые находятся в <sys/wait.h>.
Системный вызов wait возвращает -1, если у вызывающего процесса не было дочерних
процессов или нет статусной информации об окончании.
8.4.5. Итог: Как Shell запускает программы на исполнение
Этот раздел начинался с вопроса: "Как shell запускает программы на исполнение?" Теперь
мы получили ответ, shell использует системный вызов fork для создания нового процесса.
Затем shell применяет системный вызов exec для того, чтобы запустить в новом процессе
программу, которую требует исполнить пользователь. Наконец, shell использует системный
вызов wait, чтобы ждать, пока в новом процессе закончится исполнение программы. Кроме
того, системный вызов wait получает из ядра статусную информацию из exit или номер
сигнала. На основе этой информации можно оценить, как закончился дочерний процесс.
Время
1. Выдача
приглашения
2. Прием
команды
3. Создание 4. Ожидание окончания 5. Принять статусную
нового процесса дочернего процесса информацию дочернего процесса
write Ь-
read
1 Tfon4 L Г
Н
exec U-4 main
exit #
4. Запуск на исполнение 5. Исполнение 6. Новая программа
новой программы новой программы закончила исполнение
Рисунок 8.13
Последовательность шагов в цикле shell с выполнением fork(), exec(), wait()
8.5. Созданиеshell:psh2:c
307
Любой shell в Unix использует модель, которая представлена на рисунке 8.13. Далее мы
объединим все три рассмотренных системных вызова и напишем реальный shell.
8.5. Создание shell: psh2.c
На рисунке 8.14 представлена упрощенная блок-схема выполнения действий в составе
shell в Unix. Наш shell, который реализован в составе программы psh2.c, использует логику,
которая представлена указанной блок-схемой.
«—»_.)»».. Получить команду
г
i
wait
I
execvp
t
exit
Рисунок 8.14
Логика shell в Unix
/** shell версия 2
Решается "проблема однократности", которая была присуща версии 1
Используется системный вызов execvp(), но предварительно используется
fork(), с тем чтобы shell мог бы ожидать возможности выполнения следующей команды.
Новая проблема: shell перехватывает сигналы. Запустите vi, нажмите лс.
•*/
#include
#include
#defineMAXARGS
#define ARGLEN
main()
{
char
int
char
char
numargs = 0;
while (numargs < MAXARGS)
{
printf(MArg[%d]?". numargs);
if (fgets(argbuf, ARGLEN, stdin) && *argbuf != '\n')
arglist[numargs++] = makestring(argbuf);
else
<stdio.h>
<signal.h>
20
100
*argiist[MAXARGS+1];
numargs;
argbuf [ARGLEN];
*makestring();
/* аргументы командной строки */
/* длина аргументов */
/* массив указателей */
/* индекс в массиве 7
Л сюда будет происходить чтение */
/* выделение памяти */
{
if (numargs > 0){ /* есть аргументы? */
arglist[numargs]=NULL; /* завершить список */
308
Процессы и программы. Изучение sh
execute(arglist); /* выполнить это */
numargs = 0; /* и выполнить reset */
}
}
return 0;
}
execute(char *arglist[])
Л
* использование fork и execvp, ожидание, пока это будет сделано
7
{
int pid,exitstatus;
pid = fork();
switch(pid){
case-1:
caseO:
default:
Г PID и статус дочернего процесса */
/* образовать новый процесс 7
perrorffork failed");
exitA);
execvp(arglist[0], arglist); /* do it 7
perrorfexecvp failed");
exitA);
while(wait(&exitstatus) != pid)
printf("child exited with status %d,%d\n",
exitstatus»8, exitstatus&0377);
}
}
char *makestring(char *buf)
Г
* оформить правильно новую строку и отвести память для строки
7
{
char *cp, *maHoc();
but[strlen(buf)-1 ] = '\0'; /* сформировать новую строку 7
ср = malloc(strlen(buf)+1); /* получить память*/
if (ср — NULL){ /* или умереть 7
fprintf(stderr,"no memory\nH);
exitA);
}
strcpy(cp, but); Г копирование символов 7
return cp; /* возвратить указатель ptr 7
}
Проверим работу psh2 и убедимся, решается ли "однократная проблема" после внесения
изменения в execute.
8.5. Создание shell: psh2.c
309
$/psh2
Arg[0]? Is
Arg[1]?-I
Arg[2]? demodir
Arg[3]?
total 2
drwxr-x~ 2 bruce users 1024 Jul 1421:02 a
drwxr-x— 3 bruce users 1024 Jul 1603:16 c
-rw-r-r-1 bruce users 0 Jul 14 21:03 у
child exited with status 0,0 '
Arg[0]?ps
Arg[1]?
PIDTTYTIMECMD
11616pts/4 00:00:00 bash
11648pts/4 00:00:00 psh2
11664pts/4 00:00:00 ps
child exited with status 0,0
Arg[0J?pshl Посмотрите! Мы смогли запустить pshl
Arg[1]?
Arg[0]?ps Это приглашение для pshl!
Arg[1]?
PIDTTY TIMECMD
116l6pts/4 00:00:00 bash
11648pts/4 00:00:00 psh2
11683pts/4 00:00:00 ps
child exited with status 0,0
Arg[0]? grep
Arg[1]?fred
Arg[2]? /etc/passwd
Arg[3)?
child exited with status 1,0
Arg[0]? Нажмите здесь несколько раз на "D ¦
Arg[0]? Arg[0]? Arg[0]? exit
Arg[1]?
execvp failed: No such file or directory
child exited with status 1,0
Arg[0]? Нажмите здесь на "С
$
Что нужно еще сделать?
Программа psh2.c работает хорошо. Этот новый shell воспринимает с уровня командной
строки имя программы и список аргументов, запускает программу на исполнение,
выводит сообщения о полученных результатах и опять циклически возвращается к месту
приема и последующего исполнения очередной программы. Программе psh2.c недостает
совершенства обычных shell, но она представляет собой исходную точку в создании таких
shell.
310
Процессы и программы. HsyneHnesh
Для последующих версий необходимо сделать следующие улучшения:
(a) Обеспечить пользователю возможность выхода из shell при нажатии на Ctrl-D или
с помощью выполнения команды "exit".
(b) Позволить пользователю набирать сразу все аргументы на одной строке.
Эти свойства будут нами добавлены при работе с материалом следующей главы. В этой
версии мы добавим переменные и средства управления ходом выполнения в составе shell,
что сделает реализацию shell еще более похожей на программу, написанную на языке
программирования. Однако прежде всего нам требуется справиться с серьезной проблемой
в psh2.c.
8.5.1. Сигналы и psh2. с
Как мы увидели при тестировании программы, есть только одна возможность закончить
ее исполнение - нажать на Ctrl-C. Что произойдет, если мы нажмем на Ctrl-C в то время,
когда программа psh2 будет ожидать момента окончания дочернего процесса? Например:
Arg[0]?tr
Arg[1]?[a-z]
Arg[2]?[A-Z]
Arg[3]?
hello
HELLO
nowto press
NOWTO PRESS
Ctrl-C Нажать здесь на V
$
В данном случае закончится дочерний процесс, а также будет закончен й наш shell. Сигнал
SIGINT, который вырабатывается при нажатии на Ctrl-C, убивает процесс выполнения
команды tr, а также процесс, в котором выполняется программа psh2. Почему так происходит?
Сигналы, которые вырабатываются с помощью клавиатуры, поступают на ВСЕ
присоединенные процессы.
Обе программы, psh2 и tr, присоединены к терминалу (см. рисунок 8.15). При нажатии на
ключ прерывания, драйвер терминала требует от ядра послать сигнал SIGINT всем
процессам, которые связаны с этим терминалом. Процесс tr умирает. Наша программа psh2
также заканчивается.
Рисунок 8.15
Сигналы от клавиатуры поступают
на все присоединенные процессы
8.6. Защита: программирование процессов
311
Как можно предотвратить убийство нашего shell, что может произойти при нажатии
пользователем на ключи прерывания или выхода? Эти модификации мы оставим для
выполнения в упражнениях.
8.6. Защита: программирование процессов
Мы хотели понять особенности работы с процессами в Unix. Поэтому мы "поиграли " с
командой ps и изучили особенности использования в shell системных вызовов fork, exec, exit,
wait с целью управления процессами и запуска программ.
Рассмотрим, в чем заключается сходство между функциями и процессами.
execvp/exit и call/return
call/return
В программе, написанной на языке С, активно используются функции. Одна функция
может вызывать другую и передавать ей при этом список аргументов. Вызываемая функция
выполняет некоторые действия и возвращает после выполнения некий результат. В
каждой функции имеются свои собственные локальные переменные. Различные функции
взаимодействуют между собой с помощью механизма call/return.
Основой структурного программирования является модель функций с приватными
данными, которые взаимодействуют между собой с помощью передачи списков аргументов
и получения в ответ результатов работы функций. В Unix предоставляется возможность
распространить эту модель с уровня функций на уровень самих программ. Модель может
быть изображена в виде, который представлен на рисунке 8.16.
exec/exit
В программе на языке С можно выполнить fork/exec в отношении другой программы и при
этом передать новому процессу список аргументов. Вызываемая программа выполняет
некоторые действия и может возвратить результат с помощью вызова exit(n).
В вызывающем процессе можно принять значение аргумента exit с помощью вызова
wait(&result). Значение из вызова exit передается из подпрограммы и оказывается в
разрядах 8-15 слова result в вызывающей программе.
Стек вызовов практически не имеет ограничений. Вызываемая функция может вызывать
другие функции, а программа, которая стала выполняться в процессе после выполнения
fork/exec, может вызвать на выполнение другие программы с помощью этого же
механизма fork/exec. Система Unix разработана так, чтобы имелась возможность быстро и просто
создавать новые процессы.
Механизм fork/exec и exit/wait, который используется для вызова программ и получения
результатов после выполнения, применяется не только при работе в shell. Приложения
часто разрабатывают как набор программ, запускающих при исполнении подпрограммы,
^ вместо создания одной большой программы, содержащих большое количество функций.
Аргументы, которые передаются с помощью exec, должны быть строковыми
переменными. Это одновременно накладывает ограничения и на все коммуникации между
подпрограммами. В свою очередь, требование на поддержание текстового интерфейса между
программами почти автоматически приводит к такому же требованию в отношении
взаимодействий между платформами. Последствия от реализации этого требования могут
быть драматическими.
312
Процессы и программы. Изучение sh
Рисунок 8.16
Вызов функций и вызов программ
Глобальные переменные и fork/exec
Использование глобальных переменных принято считать плохим стилем. Использование
таких переменных приводит к нарушению принципов инкапсуляции, глобальные
переменные приводят к возникновению сторонних эффектов3, к появлению кодов, неудобных
при эксплуатации. Но некоторые альтернативы могут быть еще хуже по своим
проявлениям. Возникает вопрос: каким образом можно будет управлять связкой значений, которые
всем нужны, и не загромождать список аргументов, особенно в случае, когда эти значения
нужно передавать по иерархическим уровням?
В Unix есть метод, который позволяет создавать глобальные значения. Текстовые
переменные, которые передаются по значению дочерним процессам, образуют среду. Являясь
устойчивой к возникновению сторонних эффектов, среда оказывается полезным
дополнением для механизма fork/exec, exit/wait. В следующей главе мы рассмотрим, как работает
это средство и как его можно использовать.
8.7. Дополнение относительно EXIT и EXEC
Основными темами этой главы были процессы, системные вызовы fork, execvp, wait.
Но нам понадобилось рассмотреть несколько деталей, касающихся системных вызовов
exit и exec.
8.7.1. Окончание процесса: exit и _exit
Процесс может быть закончен с помощью вызова exit, который является по смыслу
противоположным вызову fork. Системный вызов fork создает процесс, а вызов exit удаляет
процесс из системы. Все выглядят вполне логичным.
Вызов exit сбрасывает все потоки,. вызывает функции, которые были зарегистрированы
с atexit и on_exit, и выполняет те функции, которые были ассоциированы exit в конкретной
системе. Далее происходит обращение к системному вызову _exit. Системный вызов _exit
является функцией ядра, при выполнении которого производится освобождение всей
памяти, выделенной процессу, закрытие всех файлов, открытых процессом. Кроме того,
происходит освобождение всех структур данных, которые были задействованы ядром для
управления процессом.
3. Некоторые утверждают, что глобальные переменные вызывают появление бородавок.
8.7. Дополнение относительно EXIT и EXEC
313
Что происходит с аргументом, который передается дочернему процессу с помощью exit?
Это значение, которое является последним сообщением процесса, сохраняется в ядре до
тех пор, пока процесс-отец не воспримет это значение с помощью системного вызова wait.
Если процесс-отец в текущий момент не выполнил wait, то значение аргумента в вызове
exit остается в ядре до тех пор, пока процесс-отец не выдаст wait. Это событие будет
расценено как окончание дочернего процесса и прием его последнего сообщения.
Процесс, который "умер", но о котором сохраняется все еще не востребованное значение
аргумента exit, называется зомби. В протоколах современных версий команды ps такие
процессы помечаются меткой defunct.
Обобщенная информация о _exit()
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
См. также
„exit
Закончить текущий процесс
#include <unistd.h>
«include <stdlib.h>
void _exft(iitt status)
status - возвращаемое значение
Нет
atexitC), exitC), on_exitC)
Системный вызов exit заканчивает текущий Процесс и выполняет все необходимые
действия по очистке от пребывания процесса в системе. Эти действия варьируются от одной
версии Unix к другой, но во всех этих версиях всегда есть следующие операции:
(a) Закрыть все файловые дескрипторы и дескрипторы каталогов. ( '
(b) Изменить у всех дочерних процессов (для заканчивающегося процесса) значения
родительского идентификатора процесса (parent PID) на значение, равное PID процесса init.
(c) Уведомить порождающий процесс об окончании дочернего, если он выполняет wait
или waitpid.
(d) Послать процессу-отцу сигнал SIGCHLD.
Если процесс заканчивается раньше, чем порожденные им процессы, то эти дочерние
процессы продолжают развиваться в системе. Они не остаются сиротами, а становятся
"детьми" процесса init, который будет выполнять роль опекуна. Заметим также, что даже если
процесс-отец не вызовет wait, ядро все равно оповестит порождающий процесс о том, что
закончен дочерний процесс, путем посылки сигнала SIGCHLD. Однако по умолчанию
сигнал SIGCHLD в процессе игнорируется. Поэтому если вы желаете, чтобы программа
реагировала на поступление этого сигнала, то в программе необходимо установить
обработчик этого сигнала.
8.7.2. Семейство вызовов exec
В нашем shell и в наших программах мы использовали вызов execvp, чтобы показать, каким
образом процерс может запускать программы на исполнение. Следует заметить, что execvp не
является системным вызовом. Это библиотечная функция, которая использует системный
вызов execve, который и обеспечивает доступ к сервисам ядра. Символ е в execve соответствует
термину environment. На эту тему мы поговорим в следующей главе.
Есть еще ряд полезных функций, которые вызывают execve. Далее приведен еще ряд
представителей семейства exec:
314 Процессы и программы. Изучение sh
execlp(filefargv0,argv1,..,
execlp не использует массив аргументов, как это было в execvp. Вместо этого аргументы
передаются в функцию main с помощью механизма argv[], когда аргументы просто
включены & список аргументов для execlp. Например:
execlp("ls", "Is", "-a", "demodir", NULL);
Здесь показан пример запуска программы Is с установленными для этой команды
аргументами, execlp полезна в тех случаях, когда вы заранее знаете команду, которую хотели бы
выполнить, и аргументы для этой команды. Использовать execlp в shell не представляется
возможным, поскольку вы не знаете, сколько аргументов будет набирать пользователь при
вводе командной строки.
execl(fullpath, argvO, argvl,.., NULL)
Символ р в execlp и execvp соответствует термину path. Эти две функции при выполнении
организуют поиск программы, имя которой задано значением первого аргумента при
обращении к функции. Они ищут программу во всех каталогах, которые перечислены в
списке, хранящемся переменной окружения PATH. Если вам известно точное место
расположения программы, то его можно задать в качестве первого аргумента при обращении к
execl. Например:
execlGbin/ls", "Is", "-a", "demodir", NULL);
При таком обращении будет запущена на исполнение программа /bin/Is с указанными
для нее аргументами. При указании места расположения программа вызывается
быстрее, чем в случае использования execlp. В последнем случае поиск требуемой
программы может происходить в нескольких каталогах. При использовании точного указания
места расположения программы достигается большая защищенность, чем в случае
использования execlp. Если в переменной PATH содержится неправильный список
каталогов, то таким способом вы можете запустить не ту версию программы.
execv(fullpath, arglist)
Функция execv выполняет то же, что и функция execvp. Но в функции execv не производится
поиск файла, используя для этого переменную PATH. Первый аргумент функции должен
точно указывать место расположения программы, которая будет запускаться на
исполнение. При использовании функций execv и execl с указанием точного пути к программе
достигается больший уровень секретности, чем при использовании списка каталогов в
переменной PATH, который может быть легко изменен злоумышленниками.
Заключение
Основные идеи
• В Unix исполнение программы - это загрузка исполнимого кода в процесс и последующее
исполнение этого кода. Процесс - это пространство памяти и другие системные ресурсы,
которые необходимы программы для ее исполнения.
• Каждая программа при своем исполнении находится в составе своего собственного
процесса. Процесс имеет: уникальный идентификатор процесса (PID), собственника
процесса, размер, а также другие свойства.
• Системный вызов fork создает новый процесс путем построения почти точной копии
вызывающего процесса. Новый процесс называют дочерним процессом.
• Программа может загрузить в текущий процесс посредством вызова требуемой
функции из семейства функций exec.
Заключение
315
• Программа может ожидать, когда закончится дочерний процесс. Это достигается
с помощью выполнения вызова wait.
• Вызывающая программа может передавать список строковых аргументов для
функции main в новой программе. Новая программа может возвратить вызывающей
программе небольшое числовое значение, которое передается с помощью вызова exit.
• В Unix shell управление исполнением программ выполняется с помощью fork, exec и wait
Что дальше?
Shell производит запуск программ на исполнение. Но shell - это также и язык
программирования. Далее мы рассмотрим скрипты (процедуры) shell и то, каким образом следует
модифицировать нашу версию shell, обеспечить обработку скриптов, управление
порядком выполнения команд и как использовать переменные.
Исследования
8.1 Родительские и дочерние процессы. По коду возврата из fork процесс может
определить, является ли он процессом-отцом или дочерним процессом. Какие другие
средства может использовать процесс?
8.2 Предскажите, каким будет вывод при работе такой программы:
main()
{
intn;
for(n = 0;n<10;n++)
{
printff'my pid = %d, n = %d\n", getpidQ, n);
sleepA);
if (fork() != 0) /* что будет, если эти две 7
exit@); /* строки будут удалены?*/
}
}
Каким будет вывод программы, если две строки, содержащие комментарий, будут
удалены?
8.3 В программе psh2.c используется массив фиксированной длины, где содержится список
аргументов. Каким образом следует модифицировать программу, чтобы устранить
ограничение на количество аргументов, которые пользователь может задавать при
обращении к команде? Необходима ли такая модификация? Как воспримет Unix
установление пределов на число и на длину аргументов для exec?
8.4 fork и файловые дескрипторы. Изучите такой код:
main()
{
intfd;
int pid;
char msg! [] = 'Testing 1 2 3. .\n";
char msg2[] = "Hello, hello\n";
if ((fd = creatC'testfile", 0644)) == -1)
return 0;
316
Процессы и программы. Изучение sh
if (write(fd, msgl, strlen(msg1)) == -1)
return 0;
if {(pid = fork())
return 0;
if (write(fd, msg2, strlen(msg2)) ==-1)
return 0;
close(fd);
return 1;
}
Проверьте, как будет работать эта программа. После вызова fork в обоих процесса
файловый дескриптор будет установлен в одну и ту же позицию в выходном файле.
Сколько сообщений попадет в этот файл? С помощью каких строк вы будете судить о
файловых дескрипторах и связях с файлами?
8.5 fork u стандартный ввод/вывод. Изучите такой код:
#indude <stdio.h>
main()
{
FILE*fp;
intpid;
char msgl [] = 'Testing 1 2 3..\n";
char msg2Q = "Hello, heHo\n";
if ((fp = fopenC'testfileZ', V')) == NULL)
return 0;
fprintf(fp>"%s,\msg1);
if((pid = fork())==-1)
return 0;
fprintf(fp, ,,%s", msg2);
fclose(fp);
return 1;
}
Проверьте, как работает эта программа. Сколько сообщений окажется в файле?
Объясните полученный результат. Сравните результаты вывода этой программы с
результатами работы программы forkdemol.c.
8.6 Фоновая обработка. Откомпилируйте и запустите на исполнение программу:
main()
{
inti;
iff (forkf) != 0)
exit@);
for(i=1;i<=10;i++){ - ¦ '.
printf("still here..\n");
sleep(i);
}
return 0;
Заключение
317
Разберитесь, что делает эта программа и как она работает. В Unix пользователи могут
запускать программы на исполнение в фоновом режиме. Насколько эта программа
подходит для исполнения в фоновом режиме?
8.7 Ошибки при выполнении ехес. Если выполнение функции ехес заканчивается в дочернем
процессе аварийно, то программа вызывает exit. Обращение к exit - это экстремальное
проявление действий. Почему не используется возврат из функции с выдачей
сообщения о коде ошибки?
Программные упражнения
8.8 Оэюидание окончания двух дочерних процессов. Расширьте код программы waitdemol.c
с тем, чтобы процесс-отец создавал бы два дочерних процесса и далее ожидал, когда
каждый из них выдаст exit.
Модифицируйте ваше решение дальше так, чтобы программа могла бы воспринимать
некоторое целое число, которое должно задаваться в качестве аргумента в командной
строке. Далее программа должна создавать дочерние процессы, количество которых
задается значением переданного числа. Для каждого процесса должна задаваться
случайная длина временного интервала (в секундах), на котором процесс спит.
Наконец, процесс-отец после каждого выполнения exit в дочернем процессе должен быть
оповещен о таком событии.
8.9 Использование сигнала SIGCHLD. Напишите программу, с помощью которой поможет
изучить действие сигнала SIGCHLD. Модифицируйте программу waitdemo2.c, где
нужно установить обработчик сигнала SIGCHLD, а затем построить цикл, где будет
каждую секунду выводиться сообщение "waiting".
После того, как дочерний процесс выполнит exit, процесс-отец должен вывести
сообщение, в котором должно находиться статусное сообщение дочернего процесса. После
чего процесс-отец должен завершить работу.
8.10 Множественность сигналов SIGCHLD. Напишите программу, которой передается
при вызове в качестве аргумента целое число. В соответствии со значением этого
числа программа создает указанное число дочерних процессов. Все дочерние процессы
засыпают на пять секунд, а затем выполняют exit. Процесс-отец устанавливает
обработчик для сигнала SIGCHLD, после чего входит в цикл, где выводит сообщение раз
в секунду. Обработчик сигнала вызывает wait. Он выводит сообщение о PID дочернего
процесса и увеличивает счетчик. Когда счетчик достигнет значения аргумента,
который был передан в программу, то программа должна быть завершена. Проверьте
работу этой программы, задавая различное число порождаемых дочерних процессов.
Программа может пропустить факт окончания некоторых дочерних процессов, когда
задается требование на порождение слишком большого числа дочерних процессов.
Сможете ли вы объяснить, почему могут возникнуть потери сигналов? Каким может
быть решение этой проблемы?
8.11 Модифицируйте программу psh2.c с тем, чтобы программа заканчивала исполнение,
если пользователь наберет на терминале команду "exit3' или когда программа
обнаружит конец файла.
8.12. Сигналы и shells. Стандартные Unix shells не заканчивают свою работу, если
пользователь посылает сигнал прерывания или сигнала выхода при работе дочернего
процесса. Как стандартный Unix shell реагирует на эти сигналы, когда производится чтение
командной строки? Модифицируйте программу psh2.c с тем, чтобы достигнуть такого
же поведения, которое свойственно обычному shell.
Глава 9
Программируемый shell.
Переменные и среда shell
Цели
Идеи и средства
• В Unix shell является языком программирования.
• Что такое shell скрипт? Каким образом shell обрабатывает скрипт?
• Как в shell работают управляющие структуры? exit(O) = успех.
• Shell переменные: зачем и как?
• Что такое среда? Как она устроена?
Системные вызовы и функции
• exit
• getenv
Команды
• env
9.1. Программирование в среде SHELL
Командный интерпретатор shell запускает программы на исполнение и одновременно сам
рассматривается как язык программирования. (Более точно - командный интерпретатор
не является языком программирования. Но он поддерживает язык программирования с
одноименным названием. -Примеч. пер.) Неотъемлемой частью Unix являются программы,
написаные на языке shell, которые называют shelUcKpunmaMu. Например, процедура
начальной загрузки Unix, а также многие административные программы используют
shell-скрипты. В этой главе мы начнем изучение программных возможностей shell, а затем
мы добавим некоторые из этих возможностей к тому shell, который мы написали в
последней главе. В частности, мы добавим управляющую структуру if.then, локальные
переменные и глобальные переменные.
9.2. SHELL-скрипты: что это такое и зачем?
319
9.2. SHELL-скрипты: что это такое й зачем?
Unix shell - это интерпретатор языка программирования. Shell интерпретирует команды,
которые поступают от пользователя при наборе на клавиатуре, а также интерпретирует
последовательности команд, которые хранятся в составе shell-скриптов.
9.2.1. Shell скрипт - это пакет команд
Shell-скрипт представляет собой файл, в котором находится последовательность (пакет)
команд. Запуск скрипта означает выполнение каждой команды из такого файла. Вы
можете использовать скрипт, который будет выполнять несколько команд по мере выдачи
одного требования. Вот пример:
# Это скрипт scriptO
# Он запускает определенные команды
Is
echo the current dateAime is
date
echo my name is
whoami
Первые две строки - это комментарии. В shell строки, которые начинаются с символа #,
игнорируются. Оставшаяся часть скрипта содержит команды. Shell выполняет команды из
скрипта одну за другой, пока не будет достигнут конец файла или пока shell не обнаружит
команду exit.
Исполнение shell-скрипта. Вы можете запустить shell-скрипт на исполнение, передавая
командному интерпретатору имя скрипта в качестве аргумента:
$sh scriptO
scriptO scrip» script2 script3
the current dateAime is
Sun Jul 29 23:29:49 EDT 2001
my name is
bruce
$ • , ¦
Или вы можете установить право на исполнение для файла и просто набрать имя скрипта
(Здесь предполагается, что имя файла и имя скрипта одно и то же. - Примеч. пер.).
$ chmod +x scriptO
$ scriptO
scriptO scriptl script2 script3
the current dateAime is
Sun Jul 29 23:31:23 EDT 2001
my name is
bruce
$
320
Программируемый shell. Переменные и среда shell
При этом вам понадобится выполнить команду chmod в отношении скрипта только один раз.
Бит исполнения остается установленным до тех пор, пока вы его не измените. Второр метод,
который основан на представлении файла как исполнимого и который предполагает
обращение к скрипту по имени, является более простым методом. Использование скрипта, как
исполнимого файла дает возможность рассматривать скрипт как команду, аналогично тому, как
мы используем системные команды или программы, которые мы написали.
Какой shell мы используем? Мы изучали и писали скрипты, которые использовали
синтаксис sh. Это изначальный (оригинальный) shell в Unix. Его называют также и Bourne
Shell - по имени автора, который его разработал. После появления sh были разработаны
еще много различных shell. Каждый имеет определенные отличия по отношению к другим
как по синтаксису, так и по свойствам. То небольшое синтаксическое подмножество,
которо.е мы будем изучать, будет общим для нескольких shell, в том числе для sh, bash и ksh.
Программные свойства sh: переменные, ввод/вывод и оператор if..then
Shell-скрипты представляют собой реальные программы. Отметим, какими свойствами
обладает скрипт script2.
#!/bin/sh
# script2: реальная программа с переменными, вводом,
# потоком управления
BOOK=$HOME/phonebook.data
echo find what name in phonebook
read NAME
if grep $NAME $BOOK > Дтр/pb.tmp
then
echo Entries for $NAME
cat Дтр/pb.tmp
else
echo No entries for $NAME
fi
rm Дтр/pb.tmp
Запуск и исполнение script2:
$./script2
find what name in phonebook
dave
Entries for dave
dave 432-6546
$./script2
find what name in phonebook
f ran
No entries for fran
$ cat $HOME/phonebook.data
ann 222-3456
bob 323-2222
carta 123-4567
dave 432-6546
eloise 567-9876
9.3. smshl-Разбор текста командной строки
321
В скрипте помимо последовательности команд используются:
Переменные
Shell имеет переменные. В script2 мы установили значения переменных BOOK и NAME.
Эти переменные были далее использованы в скрипте. Для извлечения значения, которое
хранится в переменной, используется префикс $. Имена переменных не должны
содержать прописных букв, хотя я только что сделал наоборот. (Автор слишком категоричен
в отношении именования переменных. Большие буквы возможно использовать в именах
переменных с учетом некоторых ограничений. - Примеч. пер.).
Пользовательский ввод
Команда read дает возможность для shell читать строки со стандартного ввода. Вы можете
использовать команду read, чтобы сделать скрипты интерактивными, а также чтобы
получать данные из файлов или из программных каналов.
Управление
В этом примере показано, каким образом в shell используется управляющая структура
if..then..else..fi. В shell используются и другие управляющие структуры, в том числ while,
case, for.
Среда
В данном скрипте используется переменная НОМЕ. Значением этой переменной является
путь к вашему домашнему каталогу. Значение переменной НОМЕ устанавливается
программой login. Это значение доступно для всех потомков вашего входного shell (log-in
shell). HOME-это одна из нескольких переменных окружения. В такие переменные
пользователи могут записывать собственные установки (значения), которые действуют на
поведение различных программ. Например, в переменную TZ записывается текущее время
данного часового пояса (зоны). Если переменной TZ было присвоено значение EST5EDT,
то с помощью этого значения сообщается всем програмам, которые используют ctime
(такие программы, как date и ls-l), о необходимости отображать время для восточного
временного пояса U.S. Мы рассмотрим роль и структуру среды далее в этой главе.
Улучшение нашего shell
В последней главе мы написали shell, в котором для создания и запуска процессов были
использованы системные вызовы:
fork, execvp и wait.
В этой главе мы сделаем несколько улучшений в нашем shell. Во-первых, добавим
средство для разбора текста командной строки. После введения такого средства пользователь
может написать команду и все аргументы для нее в одной строке. Далее добавим в shell
управляющую структуру if..then. И наконец, мы добавим локальные и глобальные
переменные.
9.3. smshl -Разбор текста командной строки
Первое улучшение нашего shell будет заключаться в добавлении возможности разбора
текста командной строки. Эта версия будет называться smshl.c. Пользователь может
теперь набирать текст команды в одной строке:
find /home -name core -mtime +3 -print
Программа будет разбивать эту командную строку на массив строк, который может быть
передан через вызов execvp. Логика программы smshl.c представлена на рисунке 9.1.
Улучшения программы psh2.c заключаются: в разбиении командной строки на аргументы;
322
Программируемый shell. Переменные и среда shell
в игнорировании сигналов SIGINT и SIGQUIT в shell и в восстановлении их диспозиции по
умолчанию в дочернем процессе; в обеспечении пользователей возможностью выхода
посредством нажатия на Ctrl-D (ключ конца файла).
Игнорировать сигналы
—ш, ч^ Получить команду —- #*¦ exit
I Разбор строки
! !
J * fork — —ц
I wait Разрешить сигналы
t I execvp
и.
^ Рисунок 9.1
exit Shell с сигналами, exit и разбором
командной строки
Функция main для shell будет такой:
int main()
{
char *cmdline, *prompt, **arglist;
int result;
void setup();
prompt = DFL_PROMPT;
setup();
while ((cmdline = next_cmd( prompt, stdin)) != NULL){
if ((arglist = splitline(cmdline)) != NULL){
result = execute(arglist);
freelist(arglist);
}
free(cmdline);
}
return 0;
}
Назначение трех функций:
next_cmd
next_cmd читает следующую команду из входного потока. В ней выполняется вызов malloc,
чтобы иметь возможность принимать командные строки произвольной длины. Функция
возвращает NULL при достижении конца файла.
splitline
splitline разбивает текст командной строки на массив слов и возвращает этот массив. Она
использует malloc для того, чтобы можно было строить командные строки с произвольным
количеством аргументов. Массив заканчивается указателем NULL.
execute
execute использует для запуска команды fork, execvp и wait, execute возвращает код окончания
команды.
9.3. smshi-Разбор текста командной строки
323
Программа smshi состоит из трех файлов: smshl.c, splitline.c и execute.c. Откомпилируем
программы и проверим работу:
$ ее smshi .с splitline.c execute.c -о smshi
$ ./smshi
>ps-f
UID PID PPID С STIME TTY TIME CMD
bruce 23203 23199 0 Jul29 pts/4 00:00:00 bash
bruce 25383 23203 0 08:23 pts/4 00:00:00 ./smshi
bruce25385 25383 0 08:23 ts/4 00:00:00ps-f
> нажмите здесь Ctrl-D
$
Заметьте, что ps-f является дочерним процессом ./smshi, который в свою очередь является
дочерним процессом bash. Далее представлен код smshl.c:
Г* smshi .с small - shell версия 1
** Первая реально полезная версия после shell, который использовал
** приглашения. Здесь производится разбор текста командной строки.
** Используется fork, exec, wait; игнорируются сигналы
**/
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
#include "smsh.h"
#defineDFL,PROMPT,,>H
intmain()
{
char *cmdtine, *prompt, **arglist;
int result;
void setup();
prompt = DFL_PROMPT;
setup();
while ((cmdline = next_cmd(prompt, stdin)) != NULL){
if ((arglist = splitline(cmdline)) != NULL){
result = execute(arglist);
freelist(arglist);
}
free(cmdline);
}
return 0;
}
voidsetup()
Г
* назначение: инициализация shell
* возврат: отсутствует. При возникновении проблемы вызывается fatal()
7
324
Программируемый shell. Переме
signal(SIGINT, SIG IGN);
signal(SIGQUIT, SIG IGN);
}
void fatal(char *s1, char *s2, int n)
{
fprintf(stderr,"Error: %s,%s\n", s1, s2);
exit(n);
}
Далее представлен программный код execute.c:
Г execute.c - код, который использует small shell для выполнения команд */
#include <stdio.h>
#include <stdlib.h>
#include <unlstd.h>
#include <signal.h>
#include <sys/wait.h>
int execute( char *argv[])
/*
* назначение: запуск программы разборки аргументов
* возврат: статусная информация, передаваемая с помощью wait или -1 при
* ошибке
* ошибки: -1 - при ошибках в fork() или wait() */
{
int pid;
int childJnfo = -1;
if(argv[6]==NULL)rHeT*/
return 0;
if((pid = fork())==-1)
perror("fork");
else if (pid == 0){
signal(SIGINT, SIG_DFL);
signai(SIGQUIT, SIG.DFL);
execvp(argv[0],argv);
perror("cannot execute command");
exitA);
}
else {
if(wait(&childjnfo)==-1)
perrorf'wait");
}
return childjnfo;
}
Далее представлен код splitline.c:
Г splitline.c - функции чтения команды и синтаксического разбора для smsh
•
* char *next_cmd(char *prompt, FILE *fp) - получить следующую команду
I smshl-Разбор текста командной строки
* char **splitline(char *str); - синтаксический разбор строки
7
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "smsh.h"
char * next_cmd(char ^prompt, FILE *fp)
Г
* назначение: чтение следующей командной строки из fp
* возврат: строка с динамическим распределением памяти, где содержится
* командная строка
* ошибки: NULL при EOF (в действительности это не ошибка)
* вызовы fatal из emallocQ
* замечания: пространство выделяется участками длиной BUFSIZ.
7
{
char *buf; /* буфер 7
int bufspace = 0; /* общий размер 7
int pos = 0; /* текущая позиция 7
int с; /* для ввода символа 7
printf("%s", prompt); /* приглашение для пользователя */
while((c = getc(fp)) != EOF) {
/* необходима память? */
if(pos+1 >= bufspace){ /* 1 для \0 7
if (bufspace == 0) /* у: сначала 7
buf = emalloc(BUFSIZ);
else /* или расширить 7
buf = erealloc(buf,bufspace+BUFSIZ);
bufspace += BUFSIZ; /* модифицировать размер 7
}
/* конец команды? 7
if(c=='\n')
break;
Г нет, добавить в буфер 7
buf[pos++] = с;
}
if (с == EOF && pos == 0) Г EOF и нет ввода 7
return NULL; /* скажем так */
buf [pos] = '\0';
return buf;
}
/•*
** splitline (преобразование командной строки в массив)
#define is_delim(x) ((x) == ' '|| (х) == '\Г)
char ** splitline(char *!ine)
5
Программируемый shell. Переменные и ц
Г
* назначение: представление текста строки в качестве
* массива из токенов (* подстрок), разделяемых пробелами
* возврат: массив указателей на копии токенов ( массив заканчивается NULL)
* или NULL, если в строке нет токенов
* действие: обозначить массив, локализовать подстроки, сделать копии
* замечание: будет работать strtokf)
7
{
char
char
int
int
int
char
char
int
if (line ==
*newstr();
**args;
spots = 0;
bufspace = 0;
argnum = 0;
*cp = line;
*start;
len;
NULL)
return NULL;
args = emalloc(BUFSIZ);
bufspace:
= BUFSIZ;
spots = BUFSIZ/sizeof(char *);
while(*cp
!= '\0')
/* индекс свободного элемента таблицы 7
Г байты в таблице */
/* используемые слоты */
/* позиция в строке */
/* отработка специальной ситуации */
/* инициализация массива */
while (is_delim(*cp)) /* пропуск лидирующих пробелов */
ср++;
if (*ср == '\0') /* выход по признаку конца строки */
break;
/* выделить место для массива (+1 для NULL) */
if (argnum+1 >=spots){
args = erealloc(args,bufspace+BUFSIZ);
bufspace += BUFSIZ;
spots += (BUFSIZ/sizeof(char *));
}
Г отметить точку start, для последующего нахождения конца слова"
start = ср;
1еп = 1;
while (*++Ср != '\0' && !(is_delim(*cp)))
len++;
args[argnum++] = newstrfstart, len);
}
args[argnum] = NULL;
return args;
}
Л
* назначение: создание строк
9.3. smshi-Разбор текста командной строки
* возврат: строка, никогда не NULL
7
char *newstr(char *s, int I)
{
char*rv = emalloc(l+1);
rv[l] = '\0';
stmcpy(rv, s, I);
return rv;
}
void
freelist(char **list)
Г
* назначение: освобождение списка, который возвращается от splitline
* возврат: ничего
* действие: освобождение всех строк в списке и затем освобождение ci
7
{
char **cp = list;
while(*cp)
free(*cp++);
free(list);
}
void * emalloc(size t n)
{
void *rv;
if((rv = malloc(n))==NULL)
fatalf'out of тетогуи,,,и,1);
return rv;
}
void * erealloc(void *p, size t n)
{
void *rv;
if ((rv = realloc(p.n)) == NULL)
fatal("realloc() failed","",!);
return rv;
}
Далее представлен код smsh.h:
#defineYES1
#define NO 0
char *next_cmd();
char **splitline(char *);
void freelist(char **);
void *emalloc(size_t);
void *erealloc(void *, size J);
int execute(char **);
void fatal(char *, char *, int);
328
Программируемый shell. Переменные порода shell
9.3.1. Замечания относительно smsh 1
smshl много проще в использовании, чем psh2. Дополнительные удобства такие:
Несколько команд в одной командной строке
Обычный shell предоставляет пользователю возможность в тексте командной строки
отделять одну команду от другой знаком "точка с запятой". В таком случае пользователь
может писать несколько команд в одной строке:
Is demodir; ps -f; date
Фоновая обработка
Обычный shell предоставляет пользователю возможность запускать процесс в фоновом
режиме. Это требование отмечается знаком амперсанда (&) в конце текста команды:
find /"home - name core - print &
Работа процесса в фоновом режиме означает, что вы его запускаете, а затем опять получаете
приглашение от shell. Фоновый процесс продолжает работать, а вы можете использовать shell
для запуска других программ. Хотя это довольно мудрено звучит, но при этом реализуется
чрезвычайно простой принцип. Изучите блок-схему, чтобы понять, как вам можно получить
опять приглашение от shell без ожидания, когда закончится запущенная команда. Идея простая
и элегантная. Но вам необходимо спланировать, как вы собираетесь управлять сигналами,
и решить, как избежать появления зомби. Все это напоминает авантюрное кино.
Команда exit
Обычный shell предоставляет пользователю возможность набрать команду exit с тем,
чтобы выйти из shell. Команда exit допускает использование целочисленного аргумента, как,
например, exit3. В таком случае целочисленное значение аргумента будет передаваться как
аргумент в функцию exit.
9.4. Поток управления в SHELL: почему и как?
Второе усовершенствование в нашем shell - это добавление управляющей структуры
if. then.
9.4.1. Что делает if?
В shell поддерживается управляющая структура if. Пусть вы планируете копировать
(выполнять back up) свой диск каждую пятницу (Friday). Для этого рассмотрим такой пример:
if date | grep Fri
then
echo time for backup. Insert tape and press enter
read x
tar cvf /dev/tape /home
fi
Управляющая структура if в shell работает аналогично тому, как работает оператор if в других
языках: проверяется некое условие, и если результат такой проверки положительный, то
выполняется некий блок программного кода. В shell под условием понимается команда, а под
позитивным результатом - успешное выполнение команды.
В примере команда - это date | grep Fri. При ее выполнении ищется подстрока "Fri" в выводе
команды date. Команда grep либо успешно закончит поиск указанной подстроки, либо
подстрока не будет найдена. А как программа может сказать о своем успешном окончании?
9.4. Поток управления в SHELL: почему и как?
329
Выполнение exit(O) при успехе. Программа grep вызывает exit(O) для того, чтобы
оповестить об успешной работе. Все Unix-программы следуют принятому соглашению: код
возврата, равный 0, при выходе из программы будет означать успешное выполнение
программы. Пусть, например, команда diff сравнивает два текстовых файла. Тогда команда diff
возвратит 0, если она не обнаружила отличий в файлах. Это будет означать успешное
выполнение. Программы для управления файлами и каталогами, такие, как mv, ср и rm, будут
возвращать 0, если они успешно справились с переименованием, копированием и
удалением файлов соответственно. Алгоритм управляющей структуры rf..then в скриптах shell
основан на предположении, что нулевой код возврата команды будет означать успех.
Использование else в структуре if. В управляющей структуре //может быть
использована альтернативная ветвь else:
Is
who
if diff fiiel filel
then
echo no differences found, removing backup
rm filel .bak
else
echo backup differs, making it read-only
chmod-w filel .bak
fi
date
В блоке else, как и в блоке then, содержится некоторое число команд, в числе которых могут
быть и управляющие структуры if..then.
Управляющая структура if характеризуется еще одним свойством. В этой структуре между
ключевыми словами if и then располагается блок команд. Успешность выполнения условия
будет определяться кодом возврата последней выполненной команды из этого блока.
9.4.2. Как работает if
Управляющая структура //работает так:
(a) Shell запускает команду, которая следует за словом //
(b) Shell проверяет код возврата выполненной команды.
(c) Код возврата, равный 0, означает успех, а ненулевое значение означает неудачу
(d) Shell выполняет команды, которые следуют за словом then, если был зафиксирован
успех.
(e) Shell выполняет команды после слова else, если был зафиксирована неудача.
(О С помощью ключевого слова//отмечается конец блока //
330
Программируемый shell. Переменные и среда shell
9.4.3. Добавление if к smsh
Мы знаем, что делает управляющая структура // Каким образом можно добавить структуру
if к нашему shell? Знаем, как запускать команду. Для этого нужно вызвать execute. Знаем, как
проверить код возврата после выполнения exit в программе. Он становится доступен нам
после выполнения wait. Мы можем сохранять результат, полученный из команды после if,
в некоторой переменной. Затем нам необходимо решить откуда читать команды: из блока
then или из блока else. Нам также нужно быть уверенными в том, что мы обнаружим then на
строке, которая следует за строкой блока //
Добавление нового уровня: process
Наша исходная модель слишком проста. Блок-схема г smshl содержит путь, идущий
непосредственно от splitline к fork. Каждая команда проходит через exec. В новой версии некоторые
строки не будут проходить через exec: это строки, которые начинаются с if, then или fi, а также
блок команд then, когда обнаружено невыполнение условия. С добавлением синтаксиса if
командная обработка делается более сложной. Поэтому мы напишем оберточную функцию
process, которая и должна спрятать всю эту сложность.
Модифицированная версия блок-схемы показана на рисунке 9.2.
smshl
Игнорировать сигналы
> ^Получить команду —- #*• exit
Разбор строки
fork
wait
u*
Разрешить сигналы
execvp
I
t
_ exit
smsh2
Игнорировать сигналы
i— —•>Получить команду —
| Разбор строки
control command?
h
— fork -v
• •#*- exit
г
wait
1
I
Разрешить сигналы
execvp
I
t
exit
Этот блок
является
функцией,
которая
называется
process
Рисунок 9.2
Добавление потока управления командами в smsh
Что делает process?
Функция process управляет передачами управления в скрипте по мере проверки значений
ключевых слов: //, then и ft. Она будет вызывать fork и exec, только когда будет в этом
необходимость, process должна записывать код возврата команд, которые работают в блоке ус-
ловие. По этому коду будет приниматься решение о передаче управления на блок then или
на блок else.
9.4. Поток управления в SHELL: почему и как?
331
Как работает process? Область кода и область состояния развития
Функция process рассматривает текст скрипта как текст, состоящий из нескольких
областей. Одна область - это блок then, другая область - это блок else, а третья область - это
часть, которая вся находится вне структуры // Shell будет трактовать команды в
различных областях по-разному, как это изображено на рисунке 9.3.
Рассмотрим область, которая находится вне структуры ?? Будем называть эту область
нейтральной (neutral). Здесь производится чтение, синтаксический разбор и выполнение
команд.
Область Вхождение в shell
Рисунок 9,3
Скрипт, состоящий из
различных областей
Следующая область - это область, которая находится между строкой ifn then. В этой
области shell выполняет команду, от которой shell будет записывать ее код возврата. Другая
область находится между then l и else или//. Последняя область находится между else wfi.
После/? опять продолжается нейтральная область.
Shell должен отслеживать, в какой текущей области он находится. Он должен также
отслеживать, каков результат выполнения команды в блоке условие, когда он переходит в
область wantjhen. В различных областях необходимо вести различную обработку. В
программе вводится понятие состояния, которое зависит от места проведения обработки. Функция
process вызывает три функции, которые управляют переменными состояния.
is_controLcommand
is_control_command - логическая функция, с помощью которой process узнает, является ли
команда некоторым языковым элементом, или это команда, которую нужно выполнить.
do_control_command
do^controLcommand обрабатывает ключевые слова if, then wfi. Каждое слово - это граница
между двумя состояниями. Эта функция модифицирует переменную состояния и
выполняет необходимые для нее действия.
ok_to_execute
ok_to_execute проверяет текущее состояние и результат условной команды. Возвращает
булево значение, которое идентифицирует успешность выполнения текущей команды.
9.4.4. smsh2.c: Модифицированный код
smsh2.c построена на основе программы smshl.c. В функции было сделано только одно
изменение - вызов execute был заменен на вызов process:
/** smsh2.c - small-shell версия 2
** Этот shell поддерживает синтаксически разбор командной строки
** и логику if..then..else.fi (с помощью process())
neutral
want_then
then__block
else_block
neutral
Is
who
if diff filel filel.bak
then
else
rm filel.bak
echo removing backup
a
chmod -w filel.bak
date
332
Программируемый shell. Переменные и среда sh
#include <stdio.h>
#include <stdlib.h>
#include <unlstd.h>
finclude <signal.h>
#include <sys/wait.h>
#include "smsh.h"
#define DFLPROMPT ">"
intmain()
{
char *cmdline, *prompt **arglist;
int result, process(char **);
voidsetup();
prompt = DFL_PROMPT;
setup));
while ((cmdline = next_cmd(prompt, stdin)) != NULL){
if ((arglist = sptitline(cmdline)) != NULL){
result = process(arglist);
freelist(arglist);
}
free(cmdline);
}
return 0;
}
voidsetup()
Л
* назначение: инициализация shell
x возврат: ничего. Вызов fatal() в случае возникновения проблем
7
{
signal(SIG!NT, SIGJGN);
signal(SIGQU!T, SIGJGN);
}
void fatal(char *s1, char *s2, int n)
{
fprintf(stderr,"Error: %s,%s\nM, s1, s2);
exit(n);
}
Изменения в двух новых файлах process.c и controlflow.c:
Г process.c
* уровень командной обработки
* Функция process)char **arglist) вызывается в основном цикле
'* Она установлена перед функцией execute)). Этот слой управляет двумя видами * обработки:
* а) встроенными функциями (например, exit)), set, =, read,..)
b) управляющими структурами (например, if, while, for)
t. Поток управления в SHELL: почему и как?
31
7
#include <stdio.h>
#include "smsh.h"
int is_control_command(char *);
int do_control_command(char **);
intokJo_execute();
int process(char **args)
Г
* назначение: обработка пользовательской команды
* возврат: результат выполненной команды
* особенности: если встроенная команда, то вызов соответствующей
* функции,если это не execute()
* ошибки: возникают при выполнении подпрограмм, которые здесь используются
7
{
int rv = 0;
if (args[0] == NULL)
rv = 0;
else if (is_control_command(args[0]))
rv = doj)ontroLcommand(args);
else if (okto_executeO)
rv = execute(args);
return rv;
}
Г controlflow.c
* "if" обработка. Производится с двумя переменными состояния:
* if_state и if result
*/"
#include <stdio.h>
#include "smsh.h"
enum states { NEUTRAL, WANTJHEN, THEN_BLOCK};
enum results {SUCCESS, FAIL};
static int instate = NEUTRAL;
static int ifjesult = SUCCESS;
static int last_stat = 0;
int syn_err(char *);
int okjo execute()
Г
* назначение: определение команды, которую должен выполнить shell
* возврат: 1 для yes, 0 для по
* особенности: если зафиксирован УСПЕХ в THEN_BLOCK и в ifjesult, тогда yes
* если зафиксирована НЕУДАЧА в THEN_BLOCK и в ifjesult, тогда по
* если зафиксирована НЕУДАЧА в WANT THEN, тогда это синтаксическая ошибка * (не тот sh)
7
4
Программируемый shell. Переменные и
int rv = 1; /* по умолчанию */
if (instate == WANTJHEN){
syn_err("then expected");
rv = 0;
}
else if (if state == THEN BLOCK && if result == SUCCESS)
rv=1;
else if (instate == THEN_BLOCK && «result == FAIL)
rv = 0;
return rv;
}
int is_control command(char *s)
Л
* назначение: ответить на вопрос - является ли команда управляющей для
* shell?
* возврат: 0 или 1
7
{
return (strcmp(s,"if')==01| strcmp(s,"then")==01| strcmp(s,"fiM)==0);
}
int do control command(char **args)
Л
* назначение: обработка "if, "then", "fi" - изменение состояния или
* обнаружение ошибки
* возврат: 0, если ok, -1 - при обнаружении синтаксической ошибки
7
{
char*cmd = args[0];
int rv = -1;
if(strcmp(cmd,"if)==0){
if (instate != NEUTRAL)
rv = syn_err("if unexpected");
eise{
last_stat = process(args+1);
if .result = (last.stat == 0? SUCCESS: FAIL);
instate = WANfjHEN;
rv = 0;
}
}
else if (strcmp(cmd,"then")==0){
if (instate != WANTJHEN)
rv = syn_err("then unexpected");
else {
instate = THEN_BLOCK;
rv = 0;
9.4. Поток управления в SHELL: почему и как?
335
}
else if (strcmp(cmd,nfin)==0){
if(if_state!=THEN_BLOCK)
rv = syn_err("fi unexpected");
else {
«state = NEUTRAL;
rv = 0;
}
}
else
fatalfinternal error processing:", cmd, 2);
return rv;
}
int syn_err(char *msg)
Г назначение: управление синтаксическими ошибками в управляющих структурах
* особенности: переустановить состояние на НЕЙТРАЛЬНОЕ
* возврат: -1 - в интерактивном режиме. В скриптах должен быть вызов fatal
7
{
instate = NEUTRAL;
fprintf(stderr,"syntax error: %s\n", msg);
return-1;
}
Код в controlflow.c не выполняет обработку части else в составе управляющей структуры //.
Выполнение такой обработки остается в качестве упражнения. Откомпилируем и
протестируем эту версию:
$ ее -о smsh2 smsh2.c splitline.c execute.с process.c controlflow.c
$ ./smsh2
> grep Ip /etc/passwd
lp:x:4:7:lp:/var/spool/lpd:
> if grep Ip /etc/passwd
lp:x:4:7:lp:/var/spool/lpd:
> then
> echo ok
ok
>fi
> if grep pati /etc/passwd
> then
> echo ok
>fi
> echo ok
ok
>then
syntax error: then unexpected
336
Программируемый shell. Переменные и среда shell
Что мы еще должны сделать?
Все выглядит хорошо. Насколько полученные результаты сравнимы с результатами
работы обычного shell?
$ if grep lp /etc/passwd
>then
> echo ok
>fi
lp:x:4:7:lp:/var/spool/lpd:
ok
$
Этот shell управляет обработкой структуры //не так, как это делается в нашем shell.
Стандартный shell задерживает выполнение всей структуры, пока не будет обнаружено
ключевое слово/?. Как это работает? Почему это так делается? В обычном shell также
поддерживается обработка вложенных структур // Можно ли изменить нашу программу так, чтобы
она обрабатывала вложенные структуры if?
9.5. SHELL-переменные: локальные и глобальные
В Unix shell, как в любом языке программирования, используются переменные. Вы имеете
возможность устанавливать значения переменных, извлекать значения переменных и
просматривать списки переменных, как это представлено в следующем коде:
$ аде=7
$ echo $age
7
$ echo age
аде
$ echo $age+$age
7+7
$ read name
fido
$ echo hello, $name, how are you
hello, fido, how are you
$ Is > $name.$age
$ food = muffins
food: not found
# присвоение значения
# извлечение значения
# требуется использовать символ $
# выполнение строковых операций
# ввод значения из stdin
# будет интерпретировано как:
# используется как часть команды
& в операторе присваивания нет пробелов
$
В shell используют два типа переменных: локальные переменные и переменные среды
(переменные окружения). (Более точно нужно говорить не о типе переменных, а о некой
их разновидности. Тип переменных задается допустимыми значениями и допустимыми
действиями. Если говорить о разновидностях переменных, то есть еще одна
разновидность - специальные переменные. Это переменные, для имен которых используют один
определенный метасимвол или целое число. - Примеч. пер.) Мы уже упоминали ранее
в этой главе, что такие переменные, как НОМЕ и TZ, позволяют пользователям передавать
собственные установки для программ. Такие переменные среды ведут себя отчасти так,
как глобальные переменные. Их значения доступны для всех дочерних процессов в shell.
Далее в этой главе мы изучим особенности построения и использования среды. А теперь
нам нужно лишь запомнить, что есть два сорта переменных.
9.5. SHELL-переменные: локальные и глобальные
337
9.5,1. Использование переменных shell
Предшествующий пример проиллюстрировал нам большинство операций над
переменными. Возможные операции над переменными:
Операция Синтаксис Замечания
Пробелы отсутствуют
Также: read varl var2..
Присваивание
Ссылка
Удаление
Получение значения
из input
Получение списка
переменных
Сделать переменную
глобальной
var=value
$var
unset var
read var
set
export var
Имена переменных формируются как комбинация из символов: A-Z, a-z, 0-9 и _. Первый
символ не может быть цифрой. (Это не так. См. предшествующее замечание о
специальной разновидности переменных. -Примеч. пер.). При наборе символов в именах
переменных регистр (верхний или нижний) является значимым.
Значениями переменных являются строки. Значения не являются целочисленными. Все
действия над переменными - строчные. (В Korn shell, POSIX shell и других shell допускается
использование и целочисленных типов переменных. Их можно объявить с помощью typeset и
далее выполнять над ними целочисленную обработку. - Примеч. ред.)
Получение листинга переменных. Список переменных, которые в текущий момент
определены в shell, можно получить так (В этот список не выводятся значения специальных
переменных, которые составляют третью разновидность. - Примеч. пер.):
$ set
BASH=/bin/bash
BASH_VERSION=1.14.7A)
DlSPLAY=:0.0
EUID=500
HOME=/home2/bruce
HOSTIYPE=i386
IFS=
LANG=en
LANGUAGE=en
LD_LIBRARY_PATH=/usr/lib:/usr/local/lib
LOGNAME=bruce
OPTERR=1
0PT1ND=1
OSTYPE=Linux
PATH=/bin:/usr/bin:/usr/X11 R6/bin:/usr/local/bin:/home2/bruce/bin
PPID=30928
PS4=+
PWD=/home2/bruce/projs/ubook/src/ch09
SHELL==/bin/bash
338
Программируемый shell. Переменные и среда shell
SHLVL=2
TERM=xterm-color
UID=500
USER=bruce
_=/bin/vl
age=7
name=fido
В этот список включены переменные окружения, которые были установлены на момент
моего входа в систему, плюс две локальные переменные, которые были добавлены мною
в последующей работе.
9.5.2. Система памяти для переменных
Для добавления переменных к нашему shell нам необходимо место для хранения имен
и значений этих переменных. Эта система памяти должна отличать локальные
переменные от глобальных. Вот какой будет выглядеть абстрактная модель системы памяти:
Модель
Переменная
data
НОМЕ
TERM
Значение
"phonebookdat"
7home2Aido"
41061'
Глобальная?
Нет
Дэ
дэ
Интерфейс (неполный)
VLstore(char *var, char *val) добавление/модификация var-val
VUookup(char *var) извлечение значения из vaT
VUist выдать список в виде таблицы на stdout
Реализация
Мы будем реализовывать эту таблицу, где shell хранит все свои переменные, в формате
либо связанного списка, либо хеш-таблицы, либо дерева. В первом приближении мы
используем массив структур. Каждая переменная - это:
struct var {
char *str; /* строка: name=val 7
int global; /* логическая переменная */
};
static struct vartab[MAXVARS];
Структура представлена на рисунке 9.4.
vartab
1 I -Ч H TERM=vtlQO |
Рисунок 9.4
>[city=:Boston | Система памяти для переменных shell
9.5. SHELL-переменные: локальные и глобальные
339
9.5.3. Команды для добавления переменных: встроенные команды
Мы умеем резервировать память для хранения переменных. Теперь нам требуется
добавить для нашего shell команды: по присвоению значений переменным, по получению
списка переменных, по извлечению значений переменных. Другими словами, пользователи
нашего shell должны иметь возможность исполнять такие команды:
> TERM=xterm
>set
>echo$TERM
set- это команда нашего shell, а не программа, которую должен запустить shell. Это
аналогично той ситуации, когда if и then рассматривают как ключевые слова, которые shell
обрабатывает сам. Чтобы различать set от команд, которые shell запускает с помощью exec,
мы будем называть set встроенной командой.
Команду, представленную в форме vamame=value, shell обрабатывает так: добавляет запись
в свою таблицу переменных. Операторы присваивания также относятся к встроенным
командам.
Введение в наш shell встроенных команд требует дополнительного изменения
блок-схемы. До того как будут вызваны fork и exec, требуется определить, не является ли команда
встроенной (см. рисунок 9.5).
Рисунок 9.5
Добавление к smsh встроенных
команд
Модифицируем функцию process, с тем чтобы проверять команды на принадлежность
к встроенным командам до вызова fork/exec:
if (args[0] == NULL)
rv = 0;
else if (is_controLcommand(args[0]))
rv = do_controLcommand(args);
else if (okJo_execute()){
if(!builtinjx)mmand(args, &rv))
rv = execute(args);
smsh3
Игнорировать сигналы
-. шшш _ —>Получить команду —— «>exit
• Разбор строки
i У '
I**. —» ~— Управляющая команда?
I У ' п
i •—- Встроенная? —-• —
I Выполнить встроенную Г"""" fork — —•
Г« 1 командУ wait Разрешить сигналы
J I execvp
I
I
exit
340
Программируемый she/1. Переменные и среда shell
Новая функция builtin_command объединяет в своем составе вызов операций по проверке на
встроенность и исполнение встроенных команд. После выполнения builtin_command
возвращает логическое значение и модифицирует статус по ссылке.
Новый код программы builtin.C:
/* builtin.C
* содержит переключатель и функции для встроенных команд
7
#include <stdio.h>
#include <strlng.h>
#include <ctype.h>
#include "smsh.h"
#include "varlib.h"
int assign(char *);
int. okname(char *);
int builtin command(char **args, int *resultp)
Г
* назначение: запуск на исполнение встроенной команды
* возврат: 1, если в args[0] встроенная команда, 0, если нет
* особенности: проверка значения args[0] на принадлежность ко всем
* встроенным командам. Вызов функции.
7
{
int rv = 0;
if (strcmp(args[0] ."set") == 0){ /* Это команда 'set'? */
VLIist();
*resultp = 0;
rv=1;
}
else if (strchr(args[0], '=') != NULL){ /* оператор присваивания */
*resultp = assign(args[0]);
if (*resultp != -1) Г x-y=123 - так нельзя! */
rv=1; }
else if (strcmp(args[Q], "export") == 0){
if (args[1] != NULL && okname(args[1]))
*resultp = VLexport(args[1]);
else
*resultp = 1;
rv=1;
}
return rv;
> ¦
int assign(char *str)
Г
* назначение: выполнить name=val и гарантировать допустимость имени
* возврат: -1 для недопустимого Ival, или результат VLstore
9.5. SHELL-переменные: локальные и глобальные
* предостережение: строка модифицируется, но потом восстанавливается ее
* исходное значение
{
char *cp;
int rv;
ср = strchr(str,,=1);
*cp = '\0';
rv = (okname(str)? VLstore(str,cp+1): -1);
cp = '=';
return rv;
}
int okname(char *str)
Г
* назначение: оценка допустимости имени переменной в строке
* возврат: 0, если нет, 1, если да
7
{
char*cp;
for(cp = str; *cp; cp++){
if ((isdigit(*cp) && cp==str) |j !(isalnum(*cp) || *cp==V))
return 0;
}
return (cp != str); /* нет пустых строк */
}
9.5.4. Как все работает?
Откомпилируем и запустим на исполнение нашу модернизированную программу:
$ се -о smsh3 smsh2.c splitline.e exeeute.e process2.c \
controlflow.c builtin.c varlib.c
$./smsh3
>set
> day=monday
> temp=75
> TZ=CST6CDT
> x.y=z
cannot execute command: No such file or directory
> set
day=monday
temp=75
TZ=CST6CDT
> date
TueJul31 11:56:59EDT2001
> echo $temp, $day
$temp, $day
342
Программируемый shell. Переменные и среда shell
Работа проходит нормально. Теперь наш shell поддерживает переменные. Мы можем
присваивать значения переменным, можем получать список переменных. Программа не
принимает на обработку недопустимые имена переменных, рассматривая при этом
выражения с именами переменных как имена программ, которые необходимо выполнить.
Значение переменной TZ не передается в команду date. В нашем примере запуска
программы обнаруживаются два момента, которые предполагают последующую доработку.
Во-первых, в переменной TZ установлен код центрального временного пояса U.S.,
а команда date выводит дату, которая соответствует восточному временному поясу U.S.
Мы ранее уже установили, что переменная TZ является частью среды и эта переменная
передается от процесса-отца к дочернему процессу. Как это работает? Как shell может
поместить переменные в среду, с тем чтобы дочерние процессы могли бы получать значения
этих переменных? Наша следующая тема для рассмотрения будет посвящена среде.
Не была произведена выборка значений в операциях подстановки переменных Stemp, $day.
При запуске нашего теста также было обнаружено, что наш shell не выбирает значения
переменных. Это означает, что когда наш shell производит обработку команды echo $temp, $day, то
он не делает подстановку - вместо имени переменной не подставляется ее значение. Данные
переменные являются локальными в shell. Команда echo не знает значений этих переменных.
До запуска внешних программ shell должен производить подстановку переменных. Этот
вопрос будет изучен в конце данной главы.
9.6. Среда: персонализированные установки
Пользователи любят персонализировать свой компьютер. Некоторым нравится выводить
на свои экраны живописные изображения, а другие предпочитают использовать
ограниченную палитру цветов. Некоторые пользователи предпочитают проводить
редактирование с помощью emacs, а другие предпочитают редактор vi. В Unix пользователям
предоставлена возможность указывать на свои предпочтения с помощью набора переменных,
который называют средой (окружением). Каждый пользователь имеет собственный
уникальный домашний каталог, пользовательское имя, файл для размещения в нем входящей
почты, тип терминала и наиболее предпочтительный редактор. С помощью переменных
среды можно описать многие настраиваемые установки.
Поведение многих программ будет зависеть от таких установок. Например, при запуске
скрипта script3 будет видно, что команда date использует значение, которое хранится
в переменной TZ:
#!/bin/sh
# scripft - показывает, как переменная среды передается команде
# TZ - это временная зона, значение влияет на дату и на результат работы
# команды Is -I
#
echo 'The time in Boston is"
TZ=EST5EDT
export TZ # добавить TZ к окружению
date # date использует значение переменной TZ
echo "The time in Chicago is"
TZ=CST6CDT
date
echo "The time in LA is"
TZ=PST8PDT
date
9.6. Cpwa: персонализированные установки
343
Среда-это не часть shell. Но в shell есть команды, с помощью которых можно читать и
изменять среду shelh Как обычно, сначала мы посмотрим, что делает среда. Затем рассмотрим, как
она работает. И наконец, добавим в наш код возможность работать со средой.
9.6.1. Использование среды
Получение листинга среды
С помощью команды env можно получить список всех установок в вашей среде:
$ env
LOGNAME=bruce
m_UBRARY_PATH=r/usr/lib:Aisr/locaiyiib
TERM=xterm-color
HOSTTYPE=i386
PATH=/bin:/usr/bin:/usr/X11 R6/bin:/usr/local/bin:/home2/bruce/bin
HOME=/home2/bruce
SHELL=/bin/bash
USER=bruce
LANGUAGE=en
D!SPLAY=:0.0
LANG=en
=/usr/bin/env
SHLVL=2
env - это обычная программа, а не встроенная команда shell. В списке переменных,
который был представлен, содержатся переменные, которые полезны для использования
во многих программах. Например, переменная LANG используется программами, которые
отображают информацию или выводят сообщения. В Web-броузере переменная LANG.
может быть использована для кодировки вывода текста о назначении кнопок или для
кодировки текстов пунктов меню. С помощью переменной DISPLAY вы сообщаете
системе X Windows, где вы хотели бы открыть окна. С помощью значения переменной TERM
передается информация для curses об использовании конкретного кода для управления
экраном.
Модификация среды
var=value
Изменение установок переменных в вашей среде выполняется посредством присвоения
новой строки в качестве значения для переменной среды. Например, если ваш
Web-броузер поддерживает выдачу сообщений на французском языке, а также выводит тексты
меню на этом языке, то вы должны будете обратиться к нему с установленным значением
LANG=fr.
export var
При использовании встроенной команды export в shell производится добавление новой
переменной в среду. Если переменная var существовала, как локальная переменная, то
теперь эта переменная будет переведена в состав переменных среды. Если переменная var не
существовала, то shell создает ее. В bash допускается объединение действий по
присвоению значения и экспортированию: export var=value
344 Программируемый shell. Переменные и среда shell
Чтение среды в программах С
В стандартной библиотеке С есть функция getenv:
«include <stdlib.h>
majn()
{
char *cp = getenv("LANG");
if (cp != NULL && strcmp(cp, "fr") == 0)
printf("Bonjour\n");
else
printf(HHello\nM);
}
9.6.2, Что собой представляет среда? Как она работает?
Среда- это просто массив строк, который доступен для каждой программы (см. рисунок 9.6).
Каждая строка в массиве представлена в такой форме: var=value. Адрес массива хранится
в глобальной переменной environ. Вот и все, что нужно для работы со средой. Среда-это
просто массив строк, на который "смотрит" указатель из переменной environ. Для прочтения среды
необходимо прочитать этот массив строк. Для изменения среды следует изменить строки,
либо изменить указатели в массиве, либо установить глобальную переменную так, чтобы она
указывала на другой массив.
-fr["TERM=vtlOO |
•>|TZ=EST5EDT I
>| PATH=/bin:/usr/bin |
¦>|HOME=/users/bub~|
Рисунок 9.6
Среда - это массив указателей
на строки
Примеры программ
showenv.c работает аналогично команде env:
Г showenv.c - показывает, как читать и выводить содержимое среды
7
extern char **environ; /* указатель на массив строк */
main()
{
inti;
for(i = 0;environ[i];i++)
printf(,,%s\n", environ [i]);
}
changeenv.c изменяет среду, а затем запускает на исполнение команду env:
/* changeenv.c - показывает, как изменять среду
* замечание: "env" вызывается для отображения новых установок
environ
Ч
NULL
9.6. Среда: персонализированные установки
345
7
#include
extern char **
main()
<stdio.h>
environ;
char*table[3];
table[0] = 'TERM=vt100";
table[1] = "HOME^onAhe/range'
table[2] = 0;
environ = table;
execlpfenv", "env", NULL);
/* установка значений массива 7
Г указатель на массив 7
/* выполнить программу 7
}
Далее приведена демонстрация работы:
$ /changeenv
TERM=vt100
HOME=/on/the/range
$
Проанализируйте внимательно эту программу. Мы создали массив строк в одной
программе changeenv, а затем вызвали execlp для запуска другой программы env. Эта новая программа
может читать массив строк. Почему-то оказалось, что этот массив был скопирован из
пространства данных первой программы в пространство данных второй программы.
Но exec уничтожает все данные!
Когда мы обсуждали системный вызов exec, то отметили, что он работает как трансплантат
мозга. Происходит замещение кода и данных вызывающей программы на коды и данные
новой программы. Массив, на который указывает переменная environ, представляет собой
единственное исключение из этого правила. Когда ядро выполняет системный вызов execve,
то оно копирует массив и строки в область данных новой программы (см. рисунок 9.7).
environ Родительский процесс
wait()
тш=
code
data
fork()
Дочерний процесс
имеет тот же код, данные и
environ, что и родительский
процесс
щШ
exec копирует среду из вызывающего
процесса
«&э
exec загружает новый код
и данные в процесс
Рисунок 9.7
Строки из среды копируются при выполнении ехес()
346
Программируемый shell. Переменные и среда shell
Давайте отследим, как происходит передача массива от родительского процесса в новую
программу. Вызов fork копирует весь родительский процесс, кодовую часть и данные,
включая и среду. При выполнении exec удаляется кодовая часть и данные из процесса
и вместо них в процесс помещаются код и данные новой программы. Из старой
программы копируются лишь аргументы, передаваемые в execvp, и строки, которые хранятся в
составе среды.
Дочерний процесс не может изменить среду родительского процесса
Установки среды дочернего процесса - это копии строк родительского процесса.
Дочерний процесс не может модифицировать среду родительского процесса. Передача
значений в среду является простой и удобной, поскольку весь массив автоматически
копируется, когда процесс вызывает fork и exec.
9.6.3. Добавления средств по управлению средой в smsh
Изменим наш shell теперь так, чтобы обеспечить доступ к среде. Во-первых, наш shell
будет включать переменные среды в свой список переменных. Во-вторых, пользователи
нашего shell будут в состоянии модифицировать значения переменных среды, а также
добавлять в среду новые переменные.
Доступ к переменным среды
Мы знаем структуру среды и можем использовать набор функций для добавления
переменных в состав списка переменных. Когда стартует наш shell, то будет произведено
копирование значений среды в наш массив среды (см. рисунок 9.8). После проведения
копирования мы можем использовать команду set и оператор присваивания для просмотра
и модификации имеющихся установок в среде.
environ
VLenviron2table
копирует строки
из массива среды
-HTERM=vtlOO |
->| TZ=EST5EDT |
->| PATH=/bin: /usr/bin |
Рисунок 9.8
Копирование значений из среды в vartab
9.6. Среда: персонализированные установки
347
Изменения в среде
При проверке работы smsh36b^o видно, что при изменении значения TZsto никак не
отражается на команде date. Мы знаем, как изменять значения переменных среды. Простейший
вариант изменения среды - создать совершенно новый массив, в котором будут
находиться установки из нашей предыдущей среды, и установить указатель на этот новый массив
в переменной environ (см. рисунок 9.9). После того как вызывается exec, ядро копирует эти
установки для новой программы. Заметим, что в начальном массиве среды, на который те-'
перь нет ссылки, все еще остаются исходные значения.
NULL
-Ц PATH=/bin:/usr/bin |
NULL'
->|LANG=fr
vartab
->| TERM=xterm |
->| TZ=PST8PDT |
X
->| PATH=/bin: /sbin~~|
->| LANG=fr]
VLtable2environ
создает новый массив строк
при копировании всех shell-
переменных, которые
отмечены как экспортируемые
-И day=mon
Рисунок 9.9
Копирование значений из vartab в новую среду
Изменения в smsh
Добавим теперь два шага в программный поток, как это показано на рисунке 9.10. Эти
шаги будут реализованы с помощью добавления двух строк кода:
Установка в smsh4.c
void setup()
Л
* назначение: инициализация shell
* возврат: ничего. Вызов fatal() при возникновении проблемы
7
{
extern char **environ;
VLenviron2table(environ);
signal(SIGINT, SIG IGN);
signal(SIGQUIT, SIG IGN);
}
Исполнить в execute2.c
348
Программируемый shell. Переменные и среда shell
Hh«
if ((pid = fork()) == -1)
perrorffork");
else if (pid == 0){
environ = VLtable2environ(); /* new line 7
sighal(SIGINT, SIG DFL);
signal(SiGQUIT, SIG.DFL);
execvp(argv[0],argv);
perrorfcannot execute command");
exitA);
smsh4
Игнорировать сигналы
env2tab
. тшшт ш*тт> H>~ ПОЛуЧИТЬ КОМЭНДУ —«"» 4*~ вХК
Разбор строки
I
—— Управляющая команда?
I I"
I У Встроенная п^ ^^
j I команда? $
| Выполнить встроенную f ™"* *ork "^
|^_ 1 команду wajt tab^env
J I Разрешить сигналы
• execvp
¦I I Рисунок 9.10
I ' * Добавление средств управле-
L _ _<_ — —«— т "* ' " " exit ния средой в smsh
Проверка работоспособности выполненных изменений
$ make smsh4
ее -о smsh4 smsh4.c splitline.c execute2.c process2.c controlflow.c \
buittin.c varlib.c
$ ./smsh4
> date
Tue Jul 31 09:51:03EDT 2001
> TZ=PST8PDT
> export TZ
> date
Tue Jul 31 06:51:30PDT 2001
>
Пользователь может модифицировать значения переменных среды и добавлять новые
переменные среды к массиву переменных среды. Shell обеспечивает доступность этих
новых значений для любой программы, которую он запускает.
9.6. Среда: персонализированные установки
9.6.4. Код var lib. с
/* varlib.c
* система для хранения пары name=value
* с возможностью маркировки элементов как относящиеся к среде
* интерфейс:
VLstore(name, value) возвращает 1 при успехе, 0 в неудаче
* VUookup(name) возвращает строку или NULL, если ничего нет
* VUist() выводит текущий массив среды
* функции для работы со средой
* VLexport(name) добавляет имя в список переменных среды
* VLtable2envlron() копирование из массива в environ
VLenviron2table() копирование из environ в массив
* особенности:
* массив представляет собой массив структур, где
* содержится флаг глобальной переменной и строка
* в форме name=value. Тем самым разрешается добавление EZ к
среде. При этом гарантируется простой поиск, поскольку
* будет происходить поиск "name="
7
#include
#include
#include
#include
<stdio.h>
<stdlib.h>
"variib.h"
<string.h>
tdefine MAXVARS 200
struct var {
char *str;
int global;
/* связанный список б
Г строка name=val 7
/* boolean 7
};
static struct var tab[MAXVARS]; /* таблица (или массив) */
static char *new_string(char *, char *); /* приватные методы 7
static struct var *find_item(char *, int);
int VLstore(char *name, char *val)
Г
* проход по списку; если найден, то заменить; иначе добавить в конец,
* так как ничего не удаляется: пробел означает свободную позицию
* при возникновении проблем возвращается 1. При успешной работе - 0.
7
{
struct var *itemp;
char *s;
int rv = 1;
/* найти место для размещения и образовать новую строку */
if ((itemp=findjtem(name,1 ))!=NULL&&
(s=new_string(name,val))!=NULL)
о
Программируемый shell. Переменные
{
if (itemp->str) /* есть значение? 7
free(itemp->str); /* у: удалить его */
itemp- >str = s;
rv = 0; Г все хорошо! */
}
return rv;
}
char * new string(char *name, char *val)
Г
* возвращается новая строка в форме name=value или NULL при ошибке
7
{
char *retval;
retval = malloc(strlen(name) + strlen(val) + 2);
if (retvaJ != NULL)
sprintf(retval, "%s=%s", name, val);
return retval;
}
char * VUookup(char *name)
Г
* возврат значения переменной или пустая строка, если нет значения
7
{
struct var *itemp;
if ((itemp = findjtem(name,0)) != NULL)
return itemp->str + 1 + strlen(name);
return"";
}
int VLexport(char *name)
Г
* Пометка переменной для экспортирования; добавление переменной, если ее нет
ж Возвращается 0 при нормальном выполнении, 1 - неуспех
7
{
struct var *itemp;
int rv = 1;
if ((itemp = findjtem(name,0)) != NULL){
itemp->global= 1;
rv = 0;
}
else if (VLstore(name,"") == 1)
rv = VLexport(name);
return rv;
}
static struct var * find jtem(char *name, int firstj)lank)
I Среда: персонализированные установки
351
Г
* Поиск элемента в таблице
* Возвращается указатель ptr на структуру или NULL, если элемент не найден
* ИЛИ, если (first_blank), тогда возвращается указатель на первую пустую
* позицию
7
{
int i;
int len = strien(name);
char *s;
for(i = 0; KMAXVARS && tab[i].str != NULL; i++)
{
s = tab[i].str;
if (strncmp(s,name,len) == 0 && s[len] == '='){
return &tab[i];
}
}
if (i < MAXVARS && first_blank)
return &tab[i];
return NULL;
}
void VUist()
Г
* Выполняется команда set
* Выводится список содержимого переменной table, в котором каждая
* экспортируемая переменная будет помечена символом '*'
7
{
int i;
for(i = 0; KMAXVARS &&tab[i].str != NULL; i++)
{
if (tab[i]. global)
printf(" * %s\n", tab[i].str);
else
printf("%s\n",tab[i].str);
}
}
int VLenviron2table(char *env[])
Г
* Инициализировать переменную table посредством загрузки массива строк
* Возврат: 1, когда ok; 0, когда not ok (Здесь обычная функция С,, которая может возвращать то,
что ей удобно. В данном случае возвращается ИСТИНА.с точки зрения С, а не UNIX, если успех,
и ЛОЖЬ, если неуспех. - Примеч. ред.)
7
{
int i;
?
Программируемый shell. Переменные и q
char *newstring;
for(i = 0; env[i] != NULL; i++)
{
if (i == MAXVARS)
return 0;
newstring = mallocf 1 +strlen(env[i]));
if (newstring == NULL)
return 0;
strcpy( newstring, env[i]);
tab[i].str = newstring;
tab[i].global = 1;
}
while(i < MAXVARS){ /* Я знаю, что нам не надо это делать */
tabpj.str = NULL; /* статические глобальные переменные имеют */
tab[i++].global = 0; /* нулевое значение по умолчанию */
}
return 1;
}
char ** VLtable2environ()
Г
* Создание массива указателей, предназначенного для построения новой среды
* Заметьте, что вам необходимо выполнить 1гее(),чтобы избежать потери памяти
7
{
int i, /* индекс */
j, /* другой индекс */
п = 0; /* счетчик */
char **envtab; /* массив указателей */
Г
* сначала нужно определить число глобальных переменных
7
for(i = 0; KMAXVARS && tab[i].str != NULL; i++)
if (tab[i].global ==1)
n++;
/* затем выделить память для этих переменных */
envtab = (char **) malloc((n+1) * sizeof(char *));
if (envtab == NULL)
return NULL;
/* далее загрузить массив указателей */
for(i = 0, j = 0; KMAXVARS &&tab[i].str != NULL; i++)
if (tab[i].global ==1)
envtab[j++] = tab[i].str;
envtabO] = NULL;
return envtab;
9.7. Общие замечания о SHELL
353
9.7. Общие замечания о SHELL
В этой главе мы изучили shell с позиций языка программирования. Мы добавили в shell
три существенных свойства: разбор командной строки, средства для отработки логики
if..then\\ переменные. Наш маленький shell быстро вырос по размеру. Его основные
свойства сведены в таблицу.
Свойство
Команды
Переменные
if
Среда
exit
cd
>.<¦!
Поддержка
Запуск программ
=, set
if.then
Вся
Нет
Необходимо дополнительно
read, подстановка $var
else
exit
cd
Все перечисленное
Подстановка переменных. Для добавления возможности вести подстановку значений
переменных потребуется дополнительное изучение. Где в блок-схеме shell должен делать
подстановку переменной - вместо $Х подставлять значение переменной X?
Проанализируйте вот такую последовательность действий:
$ read х
who am i
$$x
mori.xyz.com!nobodytty1 Dec 31 13:56
$ grep $x/etc/passwd
grep: am: No such file or directory
grep: i: No such file or directory
$
Какой вывод можно сделать по приведенным выше результатам относительно связи
между шагом разбора командной строки в shell и той частью в shell, где производится
подстановка переменных? Каковы преимущества такого решения? Как это можно добавить в
нашу программу?
Перенаправление ввода/вывода. Shell предоставляет пользователям возможность
перенаправлять ввод и вывод процесса в файлы или другие процессы. Каким образом работает
этот механизм? Можем ли мы ввести его в наш shell? Вопросы перенаправления
ввода/вывода будут изучены в следующей главе.
Заключение
Основные идеи
• Unix shell запускает программы, которые называют скриптами shell. Скрипт shell
может запускать программы, воспринимать ввод от пользователя, использовать
переменные и исполняться по сложной логике.
• Логика управляющей структуры ff..then в shell построена на соглашении, что
программа при успешном окончании возвращает значение 0. Для получения кода
возврата из программы shell использует wait.
354
Программируемый shell. Переменные и среда shell
• В язык программирования shell включен механизм переменных. Значениями этих
переменных являются строки, которые могут быть использованы произвольной
командой. Переменные shell локальны в скрипте.
• Каждая программа наследует список строк из родительского процесса, из которого
данная программа вызывается. Список строк называют средой. Среда используется
для поддержания глобальных установок в сессии и для установки параметров для
определенных программ. Shell предоставляет возможность просмотра и модификации
среды.
Что дальше?
Мы будем изучать перенаправление ввода/вывода.
Исследования
9.1 Опасность при работе со встроенными командами. Напишите С-программу (или
shell-скрипт) и назовите ее set. Далее попытайтесь выполнить программу из shell. Что
произошло? Напишите С-программу (или shell-скрипт) и назовите ее no=dice. Далее
попытайтесь выполнить программу. Что произошло? Попытайтесь выполнить
программу test. Как можно добиться запуска перечисленных программ?
9.2 Вложенные структуры if. Проект, использующий process.c и controlflow.c, можно
расширить, чтобы имелась возможность использовать вложенные if. Можно ли тогда
будет задавать управляющие структуры в формате:
if cmd 1
then
if cmd2
then
cmd3
else
cmd4
fi
else
cmd5
fi
с произвольной степенью вложенности? Понадобится ли при этом большее число
переменных состояния? Если вы думаете строить решение на основе стека, то оцените
возможность решить ту же проблему на основе использования рекурсии.
9.3 varlib.c при модификации среды создает полностью новый массив среды. Почему нельзя
использовать realloc для установки размера оригинала?
Программные упражнения
9.4 Множественность команд в командной строке. Модифицируйте snfishl.c, чтобы иметь
возможность задавать несколько команд в одной строке. Самый простой вариант
выполнить это - нужно модифицировать next_cmd. Сократите частоту выдачи
приглашений.
9.5 exit3. Модифицируйте smshl.c, чтобы была возможность выполнять команду exit, для
которой задается аргумент. Рассмотрите возможность отказа выполнения этой команды,
если в качестве аргумента будет задаваться нечисловое значение (например, exit left).
Куда следует разместить обработку этой команды в блок-схеме обработки команд?
Будет ли нам необходимо добавлять новый шаг в алгоритм обработки?
Заключение 355
9.6 else. Модифицируйте программу process.c для поддержки части else в управляющей
структуре if.
9.7 Функция okjo^execute использует две переменные для идентификации текущей области
и текущего состояния. Вы можете заменить две переменные одной, которая может
принимать несколько значений. Рассмотрите такой набор состояний:
NEUTRAL, IF_SUCCEEDED, IF_FAILED, SKIPPING_THEN, DOINGJTHEN, SKIPPING_ELSE, DOING_ELSE
Модифицируйте controlflow.c, чтобы можно было использовать такую систему.
9.8 Фоновые процессы. Модифицируйте smshl.c, чтобы при наличии в конце команды
символа & эта команда запускалась на исполнение в фоновом режиме. Вам потребуется
сделать некоторые изменения в next^cmd.
9.9 Обычный shell задерживает исполнение управляющей структуры, пока не будет
прочитано оконечное ключевое слово/?. (Заметим, что fi - это не сокращения слова final. Это
слово if, написанное наоборот.) Полностью другое решение заключается в том, что
читаются все строки в структуре // в структуру данных, состоящую из трех частей.
Первая часть содержит команду проверки условия. Следующая часть - список команд
для области then. Последняя часть - список команд для области else.
После прочтения строк из структуры вы можете далее выполнять команду проверки
условия, а потом на основе полученного предыдущего результата исполнять список
команд then или список команд else. Напишите версию smsh, которая обрабатывает
структуру if, используя рассмотренный метод. В вашем решении должна быть
предусмотрена возможность использования вложенных структур if.
9.10 Добавьте в нашем shell обработку цикла while. Для этого вам понадобится прочитать
список команд, составляющий тело цикла. Остерегайтесь потери памяти.
9.11 Процесс имеет много атрибутов. Один из атрибутов процесса - текущий каталог.
Разработчики Unix написали программу chdir, которая относится к ряду программ
работы с каталогами (такими, как pwd, Is, mv и т. д.). Эта программа была отвергнута, а
возможность смены каталога была включена непосредственно в shell. Что плохого могло
происходить при использовании утилиты chdir? Добавьте команду cd в ваш shell.
9.12 В shell поддерживаются специальные переменные, для представления с их помощью
системных установок. Например, в переменной $$ содержится PID для shell. В
переменной $? содержится код возврата последней команды. Добавьте эти переменные
в вашу программу. (Автор не точен в трактовке специальных переменных. Как уже
указывалось в замечании - это переменные с одно-символьными именами.
Конструкция вида $$ означает подстановку переменной с односимвольными именем $. Другими
словами - $$ это не имя специальной переменной, а операция "взять значение от
переменной с именем $". - Примеч. пер.)
9.13 В стандартных Unix shells допустимо использование "'экранирования" аргументов
командной строки. Команда вида vi "MyBook Report" содержит два аргумента. Добавьте
возможность экранирования в ваш shell. Где в составе алгоритма shell будут
обрабатываться экранированные аргументы? Рассмотрите команду rm "file1.c;2". Если ваш shell
распознает символ ";" в качестве разделителя команд, то это выражение будет
воспринято при грамматическом разборе как одна команда с двумя аргументами.
9.14 Приглашение, составленное пользователем. В большинстве shell пользователи имеют
возможность устанавливать собственный текст в приглашении, что выполняется присвоением
специальной переменной текстовой строки в качестве значения. Добавьте это свойство
в ваш shell. Предварительно решите, какую переменную вы будете использовать для
установки приглашения. В sh и bash используется переменная PS1, а в csh используется prompt.
Глава 10
Перенаправление ввода/вывода
и программные каналы
п~=---=*рз=г'--г-]
рж| ^ДЦааий >Р"~—[ -Iff ~Й)
^*HL
Цели
/{??// я средства
• Перенаправление ввода/вывода: что это такое и зачем?
• Определение стандартного ввода, вывода и вывода ошибочных сообщений.
• Перенаправление стандартного ввода/вывода для файлов.
• Использование fork для. перенаправления ввода/вывода для других программ.
• Программные каналы (pipes).
• Использование fork при работе с программными каналами.
Системные вызовы и функции
• dup, dup2
pipe
10.1. SHELL-программирование
Как работают команды:
Is > my .files
who | sort > userlist
Каким образом shell сообщает программе о том, что необходимо передавать ее выходные
данные в файл, а не выводить на экран? Каким образом shell соединяет выходной поток одного
процесса с входным потоком другого процесса? Что подразумевается под термином
стандартный ввод? В этой главе мы сосредоточим наше внимание на конкретной форме
межпроцессного взаимодействия - на механизме перенаправления ввода/вывода (I/O) и на
программных каналах (pipes). Начнем с рассмотрения того, как могут помочь механизмы
перенаправления ввода/вывода и программные каналы при написании shell-скриптов. Далее мы
рассмотрим основополагающие свойства операционной системы, которые позволяют
реализовать работу по перенаправлению ввода/вывода. Наконец, мы напишем программы, где будут
изменены входные и выходные потоки для процессов.
10.2. Приложение SHELL: наблюдение за пользователями
357
10.2. Приложение SHELL: наблюдение за пользователями
Рассмотрим такую проблему. Вы располагаете списком друзей, которые работают на той
же Unix-машине, на которой работаете и вы. Необходимо создать программу, которая
будет сообщать вам о входе пользователей в систему и о выходе из нее. По таким
результатам вы сможете вести наблюдение за своими друзьями.
Вы можете написать С-программу, которая будет использовать файл utmp и
интервальные таймеры. Программа будет открывать файл utmp, помещать туда список
пользователей, а затем засыпать до тех пор, пока не появится необходимость опять обращаться
к файлу utmp и вносить в него определенные изменения. Сколько времени пойдет на такую
разработку и какой код необходим для выполнения таких действий?
Более простым решением будет написать shell-скрипт. В Unix уже есть программы,
которая формирует список текущих пользователей в системе. Это команда who. Кроме
того, в Unix есть программа, которые позволяют переходить в состояние сна и в состояние
обработки списков строк. Далее приведен скрипт, который ведет отчетность обо всех
входах в систему и обо всех выходах из нее:
Алгоритм
shell-код
get list of users (call it prev)
while true
sleep
get list of users (call it curr)
compare lists
in prev, not in curr -> logout
echo "logged in:*'
in curr, not in prev-> login
make prev = curr
repeat
who | sort > prev
while true; do
sleep 60
who | sort > curr
echo "logged out:"
comm-23 prev curr
comm-13 prev curr
mv curr prev
done
В этом скрипте в составе тела цикла while использованы совместно семь средств Unix,
а также показана полезность механизма перенаправления ввода/вывода при решении
проблемы в данной программе. Давайте рассмотрим детали программ и связи между
программами. В первой строке скрипта производится построение списка пользователей,
отсортированного по именам пользователей. Это список тех пользователей, которые уже вошли в
систему на момент, когда начал работу скрипт. Команда who выводит список пользователей,
а команда sort читает список со стандартного входа и выводит отсортированную версию
этого списка.
who
sort
> file
о
Рисунок 10.1
Соединение вывода команды
who со входом команды sort
358
Перенаправление ввода/вывода и программные каналы
Строка who | sort > prev требует от shell одновременного запуска команд who и sort. Кроме
того, сообщается о необходимости послать вывод команды who непосредственно на вход
команды sort (см. рисунок 10.1). Два процесса запланированы для параллельного
исполнения. Они будут разделять время центрального процессора с другими процессами в
системе. Часть текста строки вида:
sort > prev
воспринимается для shell как требование записать вывод команды sort в файл prev. При
этом файл будет создан, если он до выполнения этого перенаправления не существовал.
Если же файл существовал, то его старое содержимое будет заменено на новое.
После того как процесс проснется через минуту, в скрипте будет создан новый список
пользователей в файле с именем сип*. Каким образом можно сравнить два отсортированных
списка, состоящих из записей о входе в систему? В Unix есть средство comm, действие которого
представлено на рисунке 10.2. С помощью comm можно найти общие строки в составе двух
отсортированных файлов. В рассматриваемых двух файлах есть три подмножества:
множество из строк файла 1, множество из строк файла 2, множество строк, которые содержатся
одновременно в одном и другом файлах. Команда comm сравнивает два отсортированных
списка и выводит результат в три колонки, для каждого из этих подмножеств. С помощью
опций команды можно подавить вывод любой из колонок. Например, с помощью двух
команд:
comm -23 prev curr # запрет вывода колонок 2 и 3 => показать строки только в prev
и
comm -13 prev curr # запрет вывода колонк 1 и 3 => показать строки только в curr
будут получены те два множества, которые мы хотели. Записи о logouts: строки о тех
вхождениях в систему, которые есть в предшествующем списке (prev), но которых нет в
текущем списке (cur). Записи о новых logins: строки о вхождениях систему, которых нет в
предшествующем списке, но которые есть в текущем списке.
I 1 ( 3 ) 2 J Рисунок 10.2
\^^ \У у Команда comm сравнивает два списка и выводит
"^ч */ три набора строк
Наконец, с помощью команды mv curr prev происходит замена списка prev на список curr.
Выводы
Скрипт watch.sh продемонстрировал нам три важные идеи:
(a) Мощность shell-скриптов ~ решение достигнуто более простым образом и быстрее,
чем при использовании языка С.
(b) Гибкость программных средств - каждое средство выполняет свою конкретную
роль при решении общей задачи
(c) Возможность использования средств перенаправления ввода/вывода и
программных каналов.
10.3. Сущность стандартного ввода/вывода и перенаправления
359
В скрипте watch.sh показано, каким образом можно использовать оператор >, который
позволяет рассматривать файлы как переменные произвольного размера и произвольной
структуры.
Результат выполнения оператора присваивания вида ( на языке С):
х = func_a(func_b(y)); /* сохранить вывод функции func_a от функции func_b в х */
будет аналогичен результату выполненя командной строки в shell:
prog_b | prog_a > x #сохранить вывод от комбинации двух команд в х
Вопросы
А как это все работает? Какова роль shell в установлении связей между процессами?
Какую роль при этом играет ядро? Какова роль конкретных программ?
10.3. Сущность стандартного ввода/вывода и перенаправления
Механизм перенаправления ввода/вывода в Unix основан на использовании принципа
стандартных потоков данных. Рассмотрим команду sort. Эта команда читает данные из
одного потока, записывает отсортированные результаты в другой поток и выдает сообщения
об ошибках при работе в третий поток. Проигнорируем сейчас рассмотрение вопроса
о месте, где существуют эти стандартные потоки. Тогда утилиту sort можно представить
так, как это показано на рисунке 10.3. На рисунке изображены три потока данных:
standard input - стандартный ввод, т. е. поток данных, который входит в процесс.
standard output - стандартный вывод, т. е. поток результирующих данных процесса.
standard error - стандартный поток ошибок, т. е. поток сообщений об ошибках.
Входные данные
^ Q -— Сообщения об ошибках
Выходные данные
Рисунок 10.3
Программное средство читает входные
данные и записывает результаты
и сообщения об ошибках
10.3.1. Фактор 1: Три стандартных файловых дескриптора
Во всех средствах Unix используется трехпоточная модель, которая изображена на
рисунке 10.3. Модель построена на основе простого соглашения. Каждый из трех
потоков представлен собственным файловым дескриптором. На рисунке 10.4 показаны
детали такого соглашения.
360
Перенаправление ввода/вывода и программные каналы
Стандартные файловые дескрипторы
0: stdin
1: stdout
2: stderr
Рисунок 10.4
Три специальных файловых дескриптора
Утверждение: Все средства Unix используют файловые дескрипторы 0,1,2.
Файловый дескриптор 0 означает стандартный ввод, файловый дескриптор 1 - стандартный
вывод, файловый дескриптор 2 - стандартный вывод сообщений об ошибках. Во всех
средствах Unix предполагается в начале их работы, что файловые дескрипторы 0, 1,2 уже являются
для них открытыми на чтение, запись и запись, соответственно.
10.3.2. Соединения по умолчанию: терминал
Когда вы запускаете на исполнение некоторую программу с уровня командной строки
shell, то обычно stdin, stdout и stderr присоединены к вашему терминалу. Поэтому
программа читает с клавиатуры и записывает результаты и сообщения об ошибках на экран.
Например, если вы наберете sort и нажмете на ключ Enter, то ваш терминал будет
подсоединен к программе sort. Далее вы можете набирать на клавиатуре столько строк, сколько
вам необходимо. Когда вы обозначите конец интерактивного файла нажатием на ключ
Ctrl-D на отдельной строке, то программа sort отсортирует полученные входные данные
и запишет результат на stdout.
Большинство средств в Unix обрабатывают данные, которые читаются из файлов или со
стандартного ввода. Если для некоторого средства задается в командной строке имя
файла, то программа будет читать данные из файла. Если имя файла не указано, то программа
читает данные из стандартного ввода.
10.3.3. Вывод происходит только на stdout
С другой стороны, в большинстве программ не указываются имена выходных файлов.
Предполагается, что они записывают результаты своей работы через дескриптор I и
ошибочные сообщения - через дескриптор 2 . Если вам потребовалось послать выходные
результаты процесса в файл или на вход другого процесса, вы должны изменить путь, по
которому можно пройти от файлового дескриптора при передаче данных.
10.3.4. Shell, отсутствие программы, перенаправление ввода/вывода
Вы обращаетесь к shell с просьбой присоединить файловый дескриптор I к файлу с
помощью нотации по перенаправлению вывода: cmd > filename. Shell связывает этот файловый
дескриптор с указанным файлом.
1. В командах sort и dd допускается подавление stdout. Для этого есть достаточные аргументы.
10.3. Сущность стандартного ввода/вывода и перенаправления 361
Программа продолжает писать через файловый дескриптор 1, не предполагая о смене
места назначения данных. В листинге listargs.c показано, что программу никак не
затрагивает, когда будут сделаны перенаправления на уровне командной строки.
Г listargs.c
вывод числа аргументов в командной строке, списка аргументов, а затем
* вывод сообщения на stderr
7
#include <stdio.h>
main(int ac, char*av[])
{
int i;
printf("Number of args: %d, Args are:\n", ac);"
for(i=0;i<ac;i++)
printf("args[%d] %s\n", i, av[i]);
fprintf(stderr,This message is sent to stderr.\n");
}
Программа listargs выводит на стандартный вывод список аргументов в командной строке.
Заметим, что программа listargs не выводит символ перенаправления и имя файла.
$ ее listargs.c -о listargs
$ /listargs testing one two
args[0] ./listargs
args[1] testing
args[2]one
args[3] two
This message is sent to stderr.
$ ./listargs testing one two > xyz
This message is sent to stderr.
$ cat xyz
args[0] ./listargs
args[1] testing
args[2] one
args[3]two
$ /listargs testing >xyz one two 2> oops
$ cat xyz
args[0] ./listargs
args[1] testing
args[2) one
args[3] two
$ cat oops
This message is sent to stderr.
Эти примеры демонстрируют важность использования средства перенаправления в shell.
Особо важным является то обстоятельство, что shell не передает в команду символ
перенаправления и имя файла.
Вторым важным фактором является то, что требование по перенаправлению может
оказаться в произвольном месте в команде и знак перенаправления при этом не требуется
выделять пробелами. Даже команда, подобная такой: > listing Is, будет допустимой. Таким
образом, знак > не заканчивает команду и аргументы. Он рассматривается только как
средство для установления требования на перенаправление.
362
Перенаправление ввода/вывода и программные каналы
И наконец, еще одно свойство. Во многих shell нотация перенаправления поддерживается
и в отношении других файловых дескрипторов. Например, в нотации 2>filename указано на
необходимость перенаправления файлового дескриптора 2, т. е. стандартного вывода
сообщений об ошибках, в поименованный файл.
10.3.5. Соглашения по перенаправлению ввода/вывода
Мы убедились на примере программы watch.sh, что перенаправление ввода/вывода
является составной частью программирования в Unix. В программе listargs.c было показано, что
перенаправляет ввод и вывод shell, а не программа.
Но как shell производит перенаправление ввода/вывода? Как можно написать программу,
в которой происходит перенаправление ввода/вывода? Наша задача в этой главе -
написать ряд программ, в которых выполнялись бы три базовые операции перенаправления:
who > userlist присоединение stdout к файлу
sort < data присоединение stdin к файлу
who | sort присоединение stdout к stdin
10.3.6. Фактор 2: Принцип "Первый доступный, самый малый по значению
дескриптор"
А что же все-таки представляет собой файловый дескриптор? Файловый дескриптор - это
реализация в высшей степени простой концепции. Это просто индекс в массиве. У
каждого процесса в любой момент может быть несколько открытых файлов. Для учета таких
открытых файлов составляется массив. Файловый дескриптор - это просто индекс элемента
в этом массиве. На рисунке Ю.5 представлена иллюстрация принципа "Первый
доступный, самый малый по значению дескриптор".
В Unix всегда новое соединение устанавливается через файловый дескриптор с наименьшим значением
Рисунок 10.5
Принцип "Первый доступный, самый малый по значению дескриптор"
Утверждение: Когда вы отрываете файл, то вы всегда получите первый доступный,
самый меньший по значению индекс в массиве.
Когда происходит установка нового соединения с файловыми дескрипторами, то
возникает ситуация, аналогичная соединению с многоканальным телефоном. Абоненты звонят по
основному номеру, а внутренняя телефонная система назначает для каждого нового
соединения внутреннюю линию. При реализации большинства таких систем каждому
очередному звонку назначается доступная линия с наименьшим номером.
10.4. Каким образом можно подключить stdin к файлу
363
10.3.7. Синтез
Итак, нами было установлено два базовых фактора. Во-первых, мы имеем соглашение,
согласно которому все процессы в Unix используют файловые дескрипторы 0,1,2 для стандартного
ввода, стандартного вывода и стандартного вывода ошибочных сообщений. Во-вторых, нами
установлен факт, что в ситуации, когда процессу требуется получить новый файловый
дескриптор, ядро назначает файловый дескриптор, наименьший по значению среди
доступных. При объединении этих факторов становится понятным, как работает механизм
перенаправления ввода/вывода. Мы теперь сможем писать программы, которые выполняют
перенаправление ввода/вывода.
10.4. Каким образом можно подключить stdin к файлу
Мы детально обсудим вопрос, как программа перенаправляет стандартный ввод для того,
чтобы данные поступали в программу из файла. Если быть точными, то процессы не
читают непосредственно из файлов. Процессы читают из файловых дескрипторов. Если мы
присоединили файловый дескриптор 0 к файлу, то этот файл становится источником
данных для стандартного ввода.
Мы поэкспериментируем с тремя методами присоединения стандартного ввода к файлу.
Некоторые из этих методов касаются не файлов, а используются в отношении
программных каналов.
10.4.1. Метод 1: Закрыть, а затем открыть
В первом методе используется техника закрыть-затем-открыть. Эта техника
воспроизводит действия, когда при разговоре по телефону разрывают соединение и получают
свободную телефонную линию. Затем на нее "навешивают" телефон. В результате вы
используете эту линию для разговора по указанному номеру. В данном случае выполняются
такие шаги:
В начале работы мы имеем типичную конфигурацию. К драйверу терминала
присоединены три стандартных потока. Данные проходят через файловый дескриптор 0 и выходят
через дескриптор 1 (см. рисунок 10.6).
"\
. /
Файловые
дескрипторы
О
1
213
1
1 \ \
Терминал
1 Драйвер терминала
Файл на диске
Рисунок 10.6
Типичная начальная
конфигурация
Затем, после выполнения close(O) (это первый шаг), происходит отсоединение
стандартного ввода. Мы вызвали close(O), чтобы разорвать соединение стандартного ввода с
драйвером терминала. На рисунке 10.7 показана ситуация, когда перестал использоваться
первый элемент в массиве файловых дескрипторов.
364
Перенаправление ввода/вывода и программные каналы
V—-j, ТА
[о| 1 |2J3i I f|
} {
11 f f 11
После вызова close(O)
^
Рисунок 10.1
Теперь stdin закрыт
Наконец, выполняется open(ftlename,0_RDONLY) (это последний шаг). В результате
открывается файл, который вы желаете подсоединить к stdin. Минимальный номер
доступного файлового дескриптора равен 0. Поэтому файл, который вы открываете, будет
подсоединен к стандартному вводу (см. рисунок 10.8). Любая функция, которая будет читать
из стандартного ввода в программе, будет читать из этого файла.
Гч
/
Указательна
соединение
v A
о|1|а|з| | | 1
^—1—1— ¦
шЫш^]
"S-LI
РЩ
Новое соединение
После вызова ореп()
open создает соединение с
файлом и помещает указатель
на это соединение в доступную запись
с наименьшим номером
Рисунок 10.2
Теперь stdin присоединен к файлу
В программе, которая представлена ниже, используется метод закрыть-затем-открыть:
/*stdjnredjr1.c
* цель: показать, как перенаправляется стандартный ввод путем настройки
* файлового дескриптора 0 на соединение с файлом.
* действие: производится чтение трех строк со стандартного ввода, а затем
* закрывается файловый дескриптор 0 и открывается файл на диске. Затем еще
* производится чтение трех строк из стандартного ввода.
7
#include
#lnclude
main()
<std!o.h>
<fcntl.h>
int
fd;
10.4. Каким образом можно подключить stdin к файлу
365
Г чтение и вывод трех строк */
fgets(line, 100, stdin); printf(M%s", line);
fgets(line, 100, stdin); printf(M%s", line);
fgets(iine, 100, stdin); printf("%s", line);
Г перенаправление ввода 7
close(O);
fd = openCyetc/passwd", О RDONLY);
if (fd !== 0){
fprintffstderr/'Could not open data as fd 0\n");
exitA);
}
/* прочитать и вывести три строки */
fgets(line, 100, stdin); printf("%s", line);
fgets(line, 100, stdin); printf("%s", line);
fgets(line, 100, stdin); printf("%sM, line);
}
Программа stdinreaderl читает и выводит три строки из стандартного ввода,
перенаправляет стандартный ввод, а затем еще раз читает и выводит три строки из стандартного ввода.
Программа stdinreaderl в результате читает три строки, которые набираются на клавиатуре,
и выводит их, а затем читает следующие три строки из файла passwd и выводит их:
$ ./stdinredirl
linel
linel
testing Iine2
testing Iine2
line 3 here
line 3 here
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:
daemon:x:2:2:daemon:/sbin:
$
Ничего особого не произошло. По сути освобождается линия, и вы можете звонить по ней
по новому номеру. Когда будет установлено соединение, вы получаете возможность
слушать нового абонента через стандартный ввод (тот же телефон).
10.4.2. Метод2: open..close..dup..close
Рассмотрим такую ситуацию. Зазвонил телефон. Вы отвечаете, но далее захотели перевести
разговор на другой телефон. Вы сообщаете кому-то на другом телефоне, что на этот телефон
будет переведен полученный звонок, тем самым предоставляя звонящему два соединения.
Затем, после перевода линии на другой телефон, разрываете связь со своим телефоном.
Действуюей остается только соединение с другим телефоном. Знакомая ситуация при
переключении телефона? Идея этого метода заключается в дублировании соединения между
телефонами для того, чтобы вы могли разорвать связь с одним из них без потери соединения
с абонентом.
Системный вызов dup в Unix, действие которого изображено на рисунке 10.9, позволяет
установить второе соединение с существующим файловым дескриптором. Этот метод
требует выполнения четырех шагов:
366
Перенаправление ввода/вывода и программные каналы
open(file). Первый шаг заключается в открытии файла, к которому будет присоединен
stdin.
В результате выполнения этого вызова будет получен файловый дескриптор, значение
которого не равно 0, поскольку дескриптор 0 в текущий момент открыт.
close(O). Следующий шаг заключается в закрытии файлового дескриптора 0. После
этого файловый дескриптор считается свободным.
dupffd). Системный вызов dup(fd) выполняет дублирование файлового дескриптора fd.
В качестве дубля дескриптора будет использован свободный файловый дескриптор
с наименьшим номером. Именно поэтому дублирующим файловым дескриптором для
дескриптора отрытого файла оказывается дескриптор в позиции 0 в массиве
дескрипторов открытых файлов. В результате мы подсоединили дисковый файл к файловому
дескриптору 0.
close(fd). Наконец, мы выполняем close(fd). После выполнения этого вызова начальное
соединение с файлом закрывается и остается соединение только с файловым
дескриптором 0. Сравните этот метод с технологией переключения разговора по телефону с
одного телефона на другой.
fd = open("f", 0_RDONLY);
close@) ;
i k
L PI
0|1|2|3|4|
ITv
1 sAilnY^S^'j
1 ° I
dup(fd) ;
close(fd) ;
nl 1
10Ц
m r
OD
Ы О 1 A 1
1 JL3141 I
Рисунок 10.9
Использование dup для
перенаправления
В программе stdinredir2.c использован метод 2:
/* stdinredir2.c
* показывает использование второго метода перенаправления стандартного ввода
* используется #define для установки того или другого способа
7
#include
#include
Г #define
1* «define
<stdio.h>
<fcntl.h>
CLOSE DUP
USE DUP2
Г open, close, dup, close */
Г open, dup2, close 7
10.4. Каким образом можно подключить stdin к файлу
367
intfd; -
int newfd;
char line[100];
I* чтение и вывод трех строк */
fgets(line, 100, stdin); printf("%sf,( line);
fgets(line, 100, stdin); printf("%s", line);
fgets(line, 100, stdin); printf("%s", line);
/* перенаправление ввода */
fd = openf'data", 0_RDONLY); /* открытие дискового файла */
#ifdefCLOSE_DUP
close@~);
newfd = dup(fd); /* присвоение файловому дескриптору fd значения 0 */
#else
newfd = dup2(fd,0); /* закрыть 0, присвоить для fd значение 0 */
#endif
if (newfd != 0){
fprintf(stderr,"Could not duplicate fd to 0\nM);
exitA);
}
close(fd); /* закрытие оригинального файлового дескриптора fd */
/* чтение и вывод трех строк */
fgets(line, 100, stdin); printf("%s", line);
fgetsjline, 100, stdin); printfp/os", line);
fgetsjline, 100, stdin); printfp/os", line);
Данный четырехшаговый метод мы рассмотрели исходя из познавательных целей: были
показаны возможности системного вызова dup. Метод существенно важен при работе
с программными каналами. Более простой в использовании метод объединяет шаги, где
выполняются системные вызовы close(O) и dup(fd), в один шаг. В методе выполняется
системный вызов dup2.
10.4.3. Обобщенная информация о системном вызове dup
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
dup,dup2
Копирование файлового дескриптора
#include <unistd.h>
newfd = dup(oldfd);
newfd = dup2(oldfd, newfd); ч
oldfd - копируемый файловый дескриптор
newfd - копия файлового дескриптора oldfd
-1 - при обнаружении ошибки
newfd - новый файловый дескриптор
Системный вызов dup создает копию файлового дескриптора oldfd. С помощью
системного вызова dup2 файловый дескриптор newfd становится дублем файлового дескриптора
oldfd. Два файловых дескриптора ссылаются на один и тот же открытый файл. Оба
системных вызова возвращают в качестве результата новый файловый дескриптор или значение
-1 при ошибке.
368
Перенаправление ввода/вывода и программные каналы
10.4.4. Метод 3: open.. dup2.. close
В коде программы stdinredir2.c есть оператор #ifdef, с помощью которого происходит
замещение системных вызовов close(O) и dup(fd) на системный вызов dup2(fd,0). Системный
вызов dup2(orig,new) заводит файловый дескриптор new в качестве дубликата старого
файлового дескриптора orig.
Это действие будет выполнено, даже если придется закрыть существующее соединение
с файловым дескриптором new.
10.4.5. Shell перенаправляет stdin не для себя, а для других программ
Рассмотренные примеры показывают, как программа может присоединить свой
стандартный ввод к файлу. Естественно, на практике, если в программе возникает необходимость
читать из файла, то она может просто открыть этот файл, а не изменять стандартный ввод.
Смысл этих примеров заключался в том, чтобы показать, как одна программа может
изменять стандартный ввод для другой программы.
10.5. Перенаправление ввода/вывода для других программ:
who > userlist
Когда пользователь набирает команду вида who > userlist, то shell в ответ запускает на
исполнение команду who, для которой ее стандартный вывод он перенаправит на файл user-
list. А как это все происходит?
Секрет заключается во втором разрыве при использовании fork и exec. После выполнения fork
дочерний процесс работает все еще в соответствии с программным кодом shell. Но дочерний
процесс намерен вызвать exec. Системный вызов exec производит замену программы
в дочернем процессе, но остаются неизменными атрибуты и соединения процесса. Другими
словами, после выполнения exec у процесса остается то же значение пользовательского
идентификатора (UID), остается то же значение приоритета, что и было, а также остаются в его
распоряжении те же файловые дескрипторы, которые были за ним закреплены до
выполнения exec. Итак, еще раз - программа получает в свое распоряжение открытые файлы процесса,
куда она загружается. На рисунке 10.10 иллюстрируется, каким образом происходит
перенаправление вывода для дочернего процесса.
Дочерний процесс
наследует от процесса-отца
указатели на открытые файлы.
Дочерний процесс
перенаправляет стандартный
вывод:
closeA);
creat{" f');
exec();
| ?7 II \ Открытый файл, унаследованный дочерним процессом
В —-" Файл, открытый дочерним процессом
Рисунок 10.10
Shell перенаправляет вывод у дочернего процесса
Дочерний процесс
Процесс-отец
10.5. Перенаправление ввода/вывода для других программ: who > useriist
369
Давайте в пошаговом режиме рассмотрим, как процесс использует этот принцип для
перенаправления стандартного вывода.
/. Начало действий
На рисунке 10.11 представлен процесс, который был запущен в пользовательском
пространстве. Как показано на рисунке, файловый дескриптор 1 был присоединен к файлу/
Для облегчения восприятия ситуации на рисунке другие файлы не показаны.
Рисунок 10.11
Процесс имеет стандартный
вывод и готов выполнить fork
2. После выполнения системного вызова fork
Рисунок 10.12
Стандартный вывод дочернего процесса был скопирован от процесса-отца
На рисунке 10.12 видно, что появился новый процесс. Этот процесс выполняет тот же код,
что и оригинальный процесс. Но он знает, что является дочерним процессом. Дочерний
процесс имеет тот же программный код, те же данные, тот же самый набор открытых
файлов, как у его процесса-отца. Поэтому, естественно, в элементе 1 в массиве дескрипторов
открытых файлов у дочернего процесса будет также ссылка на файл f. Далее дочерний
процесс вызывает close(l).
fork();
. 0 11 | 2 I 3 | 4 |
^\.
1 \ 1
. Дочерний
процесс
370
Перенаправление ввода/вывода и программные каналы
3. После того, как дочерний процесс выполнил close A)
Процесс-отец
Ш^ШШШ^Шшё
0
1
2
3
4
<
creat("g");
0
1
2
3
4
\
"v^t Доступный элемент
У процесса-отца остается В
соединение с этим файлом -^ §
Дочерний процесс
Рисунок 10.13
Дочерний процесс может закрыть свой стандартный вывод
На рисунке 10.13 видно, что процесс-отец не выполнял вызов close(l). Поэтому в
процессе-отце файловый дескриптор 1 остается соединенным с файлом f. В дочернем
процессе в текущий момент файловый дескриптор 1 - это свободный дескриптор с самым
минимальным номером. Далее дочерний процесс открывает файл g.
4. После выполнения в дочернем процессе системного вызова creat("g\ m)
''Vr" [ C -"'' / '
0 11 I 2 | 3 | 4 |
^\»
- •, exec ("p") ;
0 11 |2|3|4|
>
r
1 t * 1
Рисунок 10.14
Дочерний процесс открывает новый файл и получает в результате fd = 1
Как показано на рисунке 10.14, теперь файловый дескриптор 1 будет присоединен к файлу
g. Стандартный вывод дочернего процесса оказался перенаправлен на файл g. Далее
дочерний процесс вызывает exec, чтобы запустить на исполнение команду who.
10.5. Перенаправление ввода/вывода для других программ: who > userlist
371
5. После запуска в дочернем процессе новой программы с помощью вызова exec
Процесс-отецц
0|1|2|з|4
Шс
lin<> : ,
0|1 |2 | 3|4|
Ў
\ 1 \
Дочерний процесс
Новая программа
Массив указателей
на открытые файлы
является частью
процесса. Массив -
это не данные,
которые обрабатывает
программа
Рисунок 10.15
Дочерний процесс запускает на исполнение программу с новым стандартным выводом
На рисунке 10.1-5 изображено, как дочерний процесс начинает выполнять команду who.
Программный код и данные shell удаляются из дочернего процесса и замещаются на код и данные
программы who. После выполнения exec файловые дескрипторы остаются теми же. Открытые
файлы (Более точно - дескрипторы открытых файлов. - Примеч. пер.) не являются частью
кода или данных программы. Это атрибуты процесса. Команда who записывает список
пользователей в дескриптор 1. Команда who направляет результаты свой работы в файл g, даже не
догадываясь об этом.
В программе whotofile.c проиллюстрировано использование рассмотренного метода:
Г whotofile.c
* назначение: показать, как происходит перенаправление вывода для другой
* программы
* принцип: fork, затем перенаправление вывода в дочернем процессе, затем
* exec
7
#include
main()
{
<stdio.h>
int pid;
intfd;
printff About to run who into a file\nM);
Г создание нового процесс или quit */
if((pid = fork())==-1){
perror("fork");exitA);
Ь
/* работает дочерний процесс 7
if(pid==0){
closeA);
fd = creatCuserlisf, 0644);
execlp("whoM, "who"
perrorfexeclp");
exitA);
NULL);
/* закрытие, *
Г затем открытие 7
Г и запуск 7
372
Перенаправление ввода/вывода и программные каналы
Г процесс-отец ждет окончания дочернего процесса, затем выводит сообщение */
if(pid!=0){
wait(NULL);
printff'Done running who. results in userlist\n");
}
}
10.5./. Итоговые замечания по перенаправлению стандартных потоков
в файлы
Итак, в Unix поддерживаются три базовых принципа, которые позволяют легко
присоединять стандартный ввод, стандартный вывод и стандартный вывод ошибок к файлам:
(a) В качестве файловых дескрипторов для стандартного ввода, вывода и вывода
сообщений об ошибках используются, соответственно, файловые дескрипторы О, I и 2.
(b) Ядро всегда использует при назначении файловый дескриптор с наименьшим
номером, из числа пронумерованных и неиспользуемых дескрипторов.
(c) Набор файловых дескрипторов не изменяется после выполнения вызова exec.
Shell использует наличие интервала между выполнением системного вызова fork и exec для
того, чтобы присоединить потоки данных к файлам.
Shell также поддерживает такие нотации для перенаправления:
who»userlog
sort < data
Разработка программы, где используются эти две операции, остается в качестве
упражнения.
10.6. Программирование программных каналов
Мы рассмотрели, каким образом можно написать программу, которая присоединяет
стандартный вывод к файлу. Теперь разберемся с тем, как можно использовать программные
каналы для соединения стандартного вывода одного процесса со стандартным вводом
другого процесса. На рисунке 10.16 показано, как работает программный канал.
Программный канал представляет собой однонаправленный канал в составе ядра.
Г\
who
HI 1
i
ЧЦишаив
!„L
k°l
пшГ-Гп.п-г •¦»
sort
Mill
1
Рисунок 10.16
Два процесса соединены с
помощью программного канала
10.6. Программирование программных каналов
373
В программном канале происходит чтение с одного конца канала, а запись производится
в другой конец канала. Для реализации конструкции вида who \ sort, нам необходимо знать
две вещи. Нам нужно знать, как можно создать программный канал и как можно
присоединить стандартный ввод и вывод к программному каналу.
10.6.1. Создание программного канала
Структура программного канала (довольно часто этот термин не переводится и
используется в тексте в первоначальном виде- pipe. -Примеч. пер.) показана на рисунке 10.17. Для
создания программного канала используется системный вызов pipe:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
pipe
Создание программного канала
«include <unistd.h>
result = pipe(intarray[2])
array - целочисленный массив из двух элементов
-1 - при обнаружении ошибки
0 - при успешном завершении
pipe[1] pipe[0]
Отсюда происходит
чтение данных
Рисунок 10.17
Программный канал
Системный вызов pipe создает программный канал и присоединяет к двум концам канала
два файловых дескриптора. Файловый дескриптор аггау[0] используется на том конце
канала, откуда производится чтение, а файловый дескриптор аггау[1] присоединяется к концу
канала, куда производится запись данных. Внутреннее устройство канала, как и
внутреннее устройство структур у открытого файла, скрывается ядром. Процесс видит только два
файловых дескриптора.
На рисунке 10.18 изображены два шага создания программного канала процессом. На
изображении слева показан стандартный набор файловых дескрипторов перед выдачей
системного вызова pipe. На изображении, где представлена ситуация после вызова pipe, видно,
что был создан новый программный канал в ядре и для процесса были построены два
соединения с этим программным каналом.
Заметим, что при выполнении системного вызова pipe, как и при выполнении open, при
назначении дескрипторов используется метод поиска файловых дескрипторов с
наименьшим номером среди доступных в текущий момент.
Сюда производится
запись данных
374
Перенаправление ввода/вывода и программные каналы
Перед выполнением pipe
После выполнения pipe
\хЕ-
1EZZIZH
j ; ' Р
\
Процесс имеет открытыми обычные файлы Ядро создает программный канал и два файловых дескриптора
Рисунок 10.18
Процесс создает программный канал
Программа pipedemo.c создает программный канал, а затем использует канал для посылки
данных самой себе:
Г pipedemo.c *
Цель: продемонстрировать, как создается и используется программный канал.
Действие: создается программный канал, производится запись данных
* через один из концов канала, а затем после определенной работы происходит
* чтение данных с другого конца программного канала. На самом деле все это
* происходит несколько иначе, но смысл идеи демонстрируется точно.
7
#include
#include
main()
{
<stdio.h>
<unistd.h>
7
int len, i, apipe[2]; /* два файловых дескриптора */
char buf[BUFSIZ]; /* буфер для чтения */
Г построить программный канал */
Iff (pipe (apipe) == -1){
perrorfcould not make pipe");
exitA);
}
printf("Got a pipe! It is file descriptors: {%d %d }\n",
apipe[0],apipe[1]);
/* чтение из stdin, запись в программный канал, чтение из программного
* канала, печать
while (fgets(buf, BUFSIZ, stdin)){
len = strlen(buf);
if (write(apipe[1], buf, len) != Ien){ /* запись данных 7
perror("writing to pipe"); /* выход 7
break; /* pipe 7
10.6. Программирование программных каналов
375
}
}
}
for (j = 0; Klen; i++) /* зачистка 7
buffi] = X;
ten = read(apipe[0], buf, BUFSIZ); /* чтение 7
if (ten ==-1){/* from 7
perrorf'reading from pipe"); /* pipe 7
break;
}
if (writeA, buf, ten) != Ien){ /* запись 7
perror("writing to stdouf); /* to 7
break; /* stdout 7
}
На рисунке 10.19 изображен поток данных, который проходит от клавиатуры к процессу,
от процесса к программному каналу, и от процесса возвращается опять к терминалу.
Теперь мы знаем, как создается программный канал, как можно писать данные в канал и
читать данные из канала. На практике, конечно, вряд ли программа будет посылать
данные сама себе. Но мы можем связать вместе два процесса, используя для этого вызовы pipe
и fork.
Рисунок 10.19
Поток данных в программе
pipedemo.c
10.6.2. Использование fork для разделения программного канала
После создания процессом программного канала, процесс соединен с обоими концами
канала. После того, как процесс создаст дочерний процесс, который является копий
порождающего процесса, порожденный процесс получит по наследству все эти соединения
с ппогпаммным каналом. Это показано на рисунке 10.20. Процесс-отец и дочерний про-
376
Перенаправление ввода/вывода и программные каналы
цесс имеют возможность записывать данные в канал на конце, где можно записывать.
Процесс-отец и дочерний процесс имеют возможность читать данные на конце,
предназначенном для чтения, (см. рисунок 10.21). Оба процесса имеют возможность писать и
читать. Но программный канал будет использоваться более эффективно тогда, когда один
процесс записывает данные в канал, а другой процесс читает данные из канала.
Разделение программного канала:
Процесс вызывает pipe.
Ядро создает программный канал и
добавляет к массиву дескрипторов
открытых файлов указатели на два
конца программного канала
Затем процесс вызывает fork.
Ядро создает новый процесс и
копирует в этот процесс массив
дескрипторов открытых файлов
процесса-отца
Оба процесса имеют доступ
к обоим концам одного
и того же программного канала
Рисунок 10.20
Разделение программного канала
Процесс-отец
|0|1|2|з|4|
Iх-
X
I < . ч> - вЦр^"^ ' -^"^Шй 1
[-,>;: _^ifiiFi:_\-, •:[
Процесс-отец
I 0 11|2|з|4|
!>
<,
I " ¦p-v, ' ,jm
Щ^0
. Дочерний процесс
0|1|2|3|4|
^
Ж I
1
Рисунок 10.21
Поток данных между
процессами
В программе pipedemo2.c показывается, как можно совместно использовать вызовы pipe
и fork для создания двух процессов, которые взаимодействуют между собой через
программный канал:
Г pipedemo2.c
* Демонстрируется, каким образом с помощью fork() можно
* разделять программный канал
10.6. Программирование программных каналов 377
* Процесс-отец может писать в канал и читать из него, а дочерний
* процесс может только писать в канал
7
#include <stdio.h>
#define CHILD^MESS "I want a cookie\n"
#define PARJWESS "testing..\n"
#define oops(m.x) {perror(m); exit(x);}
main()
{
int pipefd[2]; Л pipe 7
int len; /* для записи 7
char buf[BUFSIZ]; /* для чтения */
int read Jen;
if (pipe(pipefd) == -1)
oopsf'cannot get a pipe", 1);
switch(fork()){
case-1:
oopsfcannotfork", 2);
Г дочерний процесс пишет в канал каждые 5 секунд 7
case 0:
len = strlen(CHILD MESS);
while A){
if (write(pipefd[1], CHILD.MESS, len) != len)
oopsC'write", 3);
sleepE);
}
/* процесс-отец читает из канала, а также пишет в канал 7
default:
len = strlen(PAR_MESS);
while A){
if (write(pipefd[1], PAR_MESS, ien)!=len)
oopsCwrite", 4);
sleepA);
read^len = read(pipefd[0], but, BUFSIZ);
if (readJen <= 0)
break;
write( 1, buf, read Jen);
}
}
}
10.6.3. Финал: Использование pipe, fork и exec
Мы познакомились со всеми идеями и последовательностью действий, которые нужны
для написания программы, соединяющей вывод команды who со вводом команды sort. Мы
знаем, как создавать программный канал, мы знаем, как можно разделять программный
378
Перенаправление ввода/вывода и программные каналы
канал между двумя процессами, мы знаем, как изменить стандартный вывод процесса, мы
знаем, как изменить стандартный ввод процесса.
А теперь объединим все, перечисленное выше, с тем, чтобы можно было бы написать
программу общего назначения. Программа будет называться pipe. При ее вызове необходимо
будет указывать два аргумента, которые являются именами двух программ. На примерах:
pipe who sort
pipe Is head
показаны варианты обращения к программе pipe. Алгоритм программы такой:
pipe(p)
fork()
I
child parent
I I
close(p[0]) close(p[1])
dup2(p[1],1) dup2(p[0],0)
close(p[1]) close(p[0])
exec "who" exec "sort"
Далее представлен код программы:
/* pipe.c
* * Демонстрируется, как можно создать конвейер из двух процессов.
* * Берутся два аргумента, задаваемые при обращении к программе. Каждый
* аргумент - это имя команды. Производится соединение вывода команды,
* заданной значением av[1], с вводом команды, заданной значением 3v[2]
* * Использование: pipe command 1 command2
* Действие: command 11 command2
* * Ограничения: команды в конвейере не должны иметь аргументов
* • * используется execlpO, т.к. известно число аргументов
* * Замечание: поменяйте ролями дочерний процесс и отцовский и посмотрите, * что получится */
#include . <stdio.h>
#include <unistd.h>
#define oops(m,x) {perror(m); exit(x);}
main(int ac, char **av)
{
nt thepipe[2], /* два файловых дескриптора, */
newfd, /* необходимые для программного канала */
pid; /* идентификатор процесса pid */
if (ас != 3){
exitA);
fprintf(stderr, "usage: pipecmdl cmd2\n");
}
if (pipe(thepipe) == -1) /* get a pipe */
oopsfCannot get a pipe", 1);
/* _ */
/* теперь, когда мы имеем канал, давайте образуем два процесса */
10.6. Программирование программных каналов
379
if ((pid = fork()) == -1) /* образовать процесс 7
oopsf'Cannotfork", 2);
/* „ */
/* Все хорошо. Теперь процессов стало два */'
Г Процесс-отец будет читать из канала */
if (pid > 0){ # /* Процесс-отец будет выполнять exec av[2] */
close(thepipe[1 ]); /* Процесс-отец не будет писать в канал */
if(dup2(thepipe[0],0)==-1)
oops("could not redirect stdin",3);
close(thepipe[0]); /* stdin будет дублирован, закрываем pipe */
execlp(av[2],av[2],NULL);
oops(av[2],4);
}
Г дочерний процесс выполняет exec av[1 ] и производит запись в программный канал
7
close(thepipe[0]); /* дочерний процесс не будет читать из канала */
if (dup2(thepipe[1],1)==-1)
oops("could not redirect stdout", 4);
close(thepipe[ 1 ]); /* stdout будет дублирован, закрываем pipe 7
execlp(av[l],av[1],NULL);
oops(av[1], 5);
' >
Программа pipe.c использует те же идеи и средства, которые использует shell при создании
конвейеров. Однако shell не запускает внешнюю программу, аналогично pipe.c. Shell
создает канал, затем с помощью fork создает два процесса, затем производит перенаправление
стандартного ввода и вывода на канал, и, наконец, запускаются по exec две программы.
10.6.4. Технические детали: Программные каналы не являются файлами
Программные каналы во многом выглядят так, будто это обычные файлы. Процесс
использует системный вызов write для помещения данных в канал и использует системный
вызов read для извлечения данных из канала/ Программный канал, как и файл, выглядит
как последовательность байтов, в которой не различаются какие-то блоки или записи.
Но с другой стороны, программные каналы и файлы имеют отличия. Например, как для
программного канала следует трактовать конец файла? Следующие технические детали
разъясняют некоторые сходство и различия.
Чтение из программных каналов
1. Системный вызов read может быть блокирован на канале
При попытке процесса выполнять системный вызов read в отношении программного
канала, такой вызов будет блокирован до тех пор, пока в программный канал не будет
записано некоторое количество данных. А что гарантирует от попадания процесса
в состояние бесконечного ожидания при блокирований?
2. Чтение признака конца файла EOF из программного канала
Когда все процессы-писатели закроют канал на стороне, где происходит запись в
канал, то попытка выполнить вызов read в отношении такого состояния канала приведет
к тому, что системный вызов получит в качестве результата 0. Что расценивается, как
признак конца файла.
380
Перенаправление ввода/вывода и программные каналы
3. Наличие многих процессов-читателей может вызвать проблемы
Структурно программный канал представляет собой очередь. После того, как процесс
прочитал из канала какое-то число байтов, эти данные больше не остаются в канале.
Если два процесса пытаются читать из одного программного канала, то один процесс
получит в результате один набор байтов, а другой процесс получит уже другой набор
байтов. Если два процесса не используют некоторый метод, который мог бы
координировать их доступ к каналу, то данные, которые они прочитают, вероятно, будут
неопределенными (Здесь данные не определены в том смысле, что процессы не могут
знать, в каком порядке они могут произвести чтение данных из канала. -Пргшеч. пер.)
Запись в программные каналы
4. Запись в программный канал по системному вызову write блокируется, пока в канале
не появится свободное место.
Каналы имеют конечный размер, который по значению значительно меньше типовых
размеров дисковых файлов. Когда процесс пытается выполнить вызов write в
отношении канала, то такой вызов будет блокирован до тех пор, пока в канале не появится
достаточно места для проведения такой записи. Если процессу необходимо записать,
скажем, 1000 байтов, а свободное пространство в канале в этот момент имеет размер
только 500 байтов, то процесс будет ждать, пока в канале появится свободное
пространство не менее 1000 байтов. А что произойдет, если процесс пожелает записать
в канал сообщение размером в миллион байтов? Не будет ли процесс бесконечно долго
ждать выполнения такого вызова?
5. При выполнении write гарантируется минимальный размер участка памяти
В соответствии со стандартом POSIX установлено, что ядро не разбивает участки
памяти под данные на блоки, меньшие по размеру 512 байтов. В Linux гарантирован
размер нерасщепляемого буфера для программного канала в 4096 байтов. Если два
различных процесса будут пытаться писать в канал, и каждый процесс передает
сообщения не более 512 байтов, то для процессов будет гарантировано, что их сообщения в
канале не будут расщеплены.
6. write заканчивается аварийно, если в текущий момент при работе с каналом
обнаруживается отсутствие процессов-читателей
Если все процессы-читатели произведут закрытие канала на том конце, где
производится чтение, то тогда попытка выполнить вызов write в отношении канала может
привести к проблеме.(Новые данные из канала не будут, конечно, читаться, когда будут
убиты все процессы-читатели - Примеч. пер.). Если данные не были востребованы из
канала, то куда девать новые данные? Для того чтобы избежать потери данных, ядро
использует два метода, чтобы уведомить процесс о том, что попытка выполнить write
будет бесполезной. Ядро посылает процессу сигнал SIGPIPE. Если при этом процесс
убивается, то каких-то дальнейших действий и не требуется. В другом варианте после
выполнения write в указанной ситуации в качестве кода возврата устанавливается -1,
а значение переменной errno становится равным EPIPE.
Заключение
Основные идеи
• Перенаправление ввода/вывода дает возможность отдельным программам работать по
своему назначению. Каждая программа выполняет свои функции.
• По соглашениям, принятым в Unix, программы производят чтение входных данных
чепез Файловый лескпиптоп 0. запись данных — чеоез пескоиптоо 1. и выдачу
Заключение
381
сообщений об ошибках - через дескриптор 2. Эти три файловых дескриптора
называют стандартным вводом, стандартным выводом, стандартным выводом
сообщений об ошибках.
• Когда вы входите в систему, то процедура входа устанавливает файловые
дескрипторы 0,1 и 2. Эти соединения и все дескрипторы открытых файлов передаются
от процесса-отца к дочернему процессу. Они остаются у дочернего процесса и после
. выполнения системного вызова exec.
• Системные вызовы, которые создают файловые дескрипторы, всегда используют при
назначении нового дескриптора значение дескриптора с наименьшим номером среди
доступных дескрипторов.
• Перенаправление стандартного ввода, вывода и сообщений об ошибках изменяет
место, к которому будут прикреплены файловые дескрипторы 0,1,2. Существуют
несколько методов перенаправления стандартного ввода/вывода.
• Программный канал -это очередь данных в ядре, в отношении которой к каждому
концу присоединен файловый дескриптор. Программа создает программный канал
с помощью системного вызова pipe.
• При выполнении процессом-отцом системного вызова fork дескрипторы на обоих
концах канала копируются для дочернего процесса.
Программные каналы могут связывать процессы, у которых общий процесс-отец.
Что дальше?
В традиционных программных каналах Unix происходит передача данных между
процессами только в одном направлении. А что произойдет, если два процесса попытаются
передавать данные через канал в прямом и обратном направлениях? Что, если два процесса не
будут являться родственниками или если два процесса развиваются на разных
компьютерах? В последующих главах мы рассмотрим работу программных каналов более
детально, а затем начнем изучение вопросов сетевого программирования. Идея, которая
была реализована в программных каналах, была обобщена при реализации идеи сокетов.
Исследования
10.1 Значение символов >>. Нотация » говорит, что shell должен произвести
присоединение (по append) вывода к файлу. Как будет поступать shell - будет ли он использовать
метод auto-append (см. главу 5)? Или будет производить установку указателя записи на
конец файла, и начинать потом запись с этого места? Проведите эксперимент с
использованием скриптов, чтобы ответить на эти вопросы.
10.2 В программе pipe.c процесс-отец запускал программу, которая принимала данные,
а дочерний процесс запускал программу, которая вырабатывала данные. Какие будут
отличия, если эти процессы поменять ролями в части обработки данных? Для изменения
ролей достаточно сделать такие изменения: if (pid > 0) нужно заменить на if (pid == 0). Что
при этом произошло? Почему?
10.3 Какие необходимо сделать изменения в вашем shell, чтобы иметь возможность
работать с программными каналами? Во-первых, как вам следует модифицировать поток
управления для того, чтобы идентифицировать и управлять командами, которые
заканчиваются знаком для программного канала? Во-вторых, что будет, если несколько
команд будут разделены знаком для программного канала?
382
Перенаправление ввода/вывода и программные каналы
10.4 В программе pipe.c читающий процесс sort закрывает свой файловый дескриптор на
чтение из канала. Измените код таким образом, чтобы читающий процесс не закрывал бы
дескриптор на запись в канал. После чего запустите программу на исполнение и
понаблюдайте за ее поведением.
10.5 Добавление средств обработки символовв > и < к вашему shell. Мы ранее, в этой главе
изучили смысл нотации для присоединения стандартного ввода или стандартного вывода
к файлу. Мы увидели, что символ перенаправления и имя файла могут оказаться в
произвольном месте командной строки. Мы также отметили, что символ перенаправления и
имя файла не являются частью списка аргументов, которые передаются в программу.
В каком месте алгоритма нашего небольшого shell необходимо будет
идентифицировать требования на изменение ввода или вывода на дисковый файл?
Где в алгоритме нашего небольшого shell должно производиться перенаправление?
Что произойдет, если пользователь наберет: set > varlist? Допустит ли shell выполнить
перенаправление вывода для встроенных команд? Каким образом можно добавить эту
возможность в наш shell?
10.6 Защита от пользователей. Что произойдет, если пользователь наберет: sort <data >data. .
В чем заключается проблема с таким требованием на перенаправление? Что в данной
ситуации будут делать стандартные shells в Unix? Как может ваш shell справиться
с этой проблемой?
10.7 Мы изучили и проверили методы для присоединения стандартного ввода или
стандартного вывода процесса к файлу. Во всех наших примерах предполагалось
использование обычных дисковых файлов. Может ли механизм перенаправления ввода/вывода
работать с файлами устройств? Другими словами, что будет, если вы выполните close @)
и open ('7dev/ttyn,0)? Что будет делать shell с командой who > /dev/tty?
10.8 В программе pipe.c мы вызывали fork и exec. Но мы не вызывали wait. А почему?
10.9 В чем dup похож на link?
Программные упражнения
10.10 Модифицируйте скрипт watch.sh так, чтобы он получил бы в результате ряд
усовершенствований.
а) В данной версии должны выводятся записи о всех входах пользователей в систему и
о всех выходах. Может быть полезным вариант, где можно будет передавать в качестве
аргумента имя файла, хранящего список тех пользователей, за которыми следует вести
наблюдение.
(b) В данной версии производится некий вывод при каждой итерации цикла, даже если
ничего не изменяется. Модифицируйте эту программу так, чтобы она выводила бы
сообщения о новых входах и новых выходах только в случае, если появляется нечто, что
необходимо показать.
(c) В команде who выводится список пользователей, с указанием для каждого
пользователя времени входа в систему и названия терминала. Это может быть излишней
информацией для вас. Если пользователь соединяется с системой, используя для этого
второе окно, то это тоже может быть вам не интересно. Напишите версию программы,
которая сообщала бы когда для пользователя изменяется состояние "вышедший из
системы" на "не вышедший из системы", независимо от терминала.
(d) В данной версии данные хранятся в файлах prev и сшт в текущем каталоге. Эти
файлы остаются в каталоге, когда программа заканчивает работу. Такое решение не-
Заключение
383
удовлетворительно по нескольким причинам. Каковы эти причины? Проверьте свой
скрипт и используйте в нем временные файлы. Удаляйте эти файлы при выходе из
программы. Прочитайте документацию о команде trap, которую можно использовать в shell.
Проверьте, как используется команда mktemp.
10.11 Модифицируйте программу whotofile.c так, чтобы она присоединяла бы вывод
команды who к файлу. Обеспечьте гарантию, чтобы программа продолжала работать в
ситуации, когда обнаруживается, что файла не существует.
10.12 Напишите программу sortfromfile.c, которая перенаправляет вывод команды sort таким
образом, чтобы команда читала бы из файла. Имя файла должно задаваться в качестве
аргумента при обращении к программе
10.13 Расширьте возможности программы pipe.c так, чтобы она могла бы управлять трехт
ступенчатыми конвейерами. В этой новой версии программа должна принимать через
список аргументов имена трех программ, которые она будет запускать на исполнение
в составе конвейера. Команда
pipe3 who sort head
должна в результате привести к построению и запуску конвейера вида:
who | sort | head.
10.14 Расширьте возможности программы pipe3 в предшествующем пункте так, чтобы она
могла бы строить конвейеры с произвольным количеством ступеней.
10.15 Развилка для процесса. Утилита tee предоставляет вам возможность перенаправлять
данные в файл, а также передавать эти же данные команде, которая работает на
следующей ступени конвейера. Например, при работе конвейера:
who | tee userlist | sort > Iist2
будет получен файл без сортировки и отсортированный файл: userlist и Iist2. В качестве
аргумента для команды tee используется имя файла. Прочитайте документацию о этой
команды, чтобы ознакомиться с деталями. Напишите программу progtee, которая
перенаправляла бы данные некоторой программе, а также передавала бы данные на
следующую ступень конвейера. Например, в конвейере:
who | progtee mall smith | sort | progtee mail -s "hello" root > Iist2
будет производиться передача по почте Смиту списка пользователи (без сортировки),
передача отсортированного списка будет произведена для root, и копия
отсортированного списка будет передана в файл Iist2
10.16 Программа isatty. Программам, которые производят запись на стандартный вывод,
обычно нет дела до того, что файловый дескриптор может быть присоединен к
терминалу или к дисковому файлу. Из текста следует, что процесс не может узнать, куда
сейчас прикреплен дескриптор. Это не так. Библиотечная функция isatty(fd) возвращает
значение true, если файловый дескриптор fd присоединен к терминалу. В функции isatty
используется системный вызов fstat. Прочитайте документацию об этом вызове и
используйте эту информацию для написания функции isaregfile, которая должна
возвращать true, если ее аргумент оказывается на самом деле файловым дескриптором,
присоединенным к обычному файлу.
Глава 11
Соединение между локальными
и удаленными процессами.
Серверы и сокеты
УШ?..
7]
\шЫ—I
1 '"^ж!
а?5!
..j
Цели
Идеи и средства
• Модель клиент/сервер.
• Использование программных каналов для двусторонних связей.
• Сопрограммы.
• Сходство между файлами и процессами.
• Сокеты: зачем, что это такое, как устроены?
• Сетевые службы (сервисы).
• Использование сокетов для клиент/серверных программ.
Системные вызовы и функции
fdopen
рореп
socket
bind
listen
accept
connect
//./. Продуктыисервисы 385
11.1. Продукты и сервисы
Программисты в Unix используют программные каналы для создания своеобразных
линий цифровой сборки, родственные лентам заводских конвейеров, которые передают
собираемые узлы от одного работающего к другому.
В ряде учреждений не достаточна модель конвейера. В ряде случаев нужны
двунаправленные связи. Рассмотрим химчистки, юридические и ветеринарые службы.
Вы сдаете одежду в приемник химчистки, ведете свое домашнее животное к ветеринару,
пересылаете по почте документы юристу. Здесь, в отличие от рабочего на автомобильном
заводе, который лередает автомобиль на конвейере следующему рабочему, вы
предполагаете после выполнения сдачи получить что-то назад. В этих примерах мы рассмотрели
работу, выполняющуюся неким другим человеком, которая рассматривается как услуга
(сервис), а сами мы в таких примерах выступаем в роли клиентов по отношению к этому
сервису (службе). .
Какое отношение все это имеет к Unix? Программные каналы в Unix передают данные от
одного процесса к другому. Процессы и программные каналы могут не только
воспроизводить работу сборочного конвейера, на выходе которого получают некие продукты, но
также и воспроизводят службу сервиса. В этой главе мы сфокусируем внимание на
потоках данных между процессами, что является базисом для программирования модели
клиент/сервер.
11.2. Вводная метафора: интерфейс автомата для получения
напитка
Программы поглощают информацию. Большинство людей поглащают напитки.
Представьте себе автомат по продаже газированного напитка, как это показано на
рисунке 11.1. Вы бросаете монетку, нажимаете на кнопку и получаете чашку некого напитка. А что
происходит при этом внутри автомата?
Внутри может находиться емкость с газированной водой и отдельная емкость для
питьевого концентрата. При нажатии на кнопку начнется процесс смешивания исходных
материалов. Далее только что полученный напиток будет налит в чашку покупателя.
Но возможен и другой вариант. Внутри автомата может находиться просто бутыль с
предварительно приготовленным напитком, к которой присоединен насос. При нажатии на
кнопку напиток просто наливается в чашку.
Миксер / Кнопка
Г/
Напиток, полученный по требованию Напиток, приготовленный заранее,
и извлекается из емкости
Рисунок 11.1
Напиток, который готовится сейчас или заранее?
f
386 Соединение между локальными и удаленными процессами. Серверы и сокеты
Unix, как и автомат для продажи содовой, представляет один интерфейс, даже когда
данные приходят от источников разных типов (см. рисунок 11.2).
\ к
а
/ НШРИ' * ' - 1 _
Четыре типа источников
данных:
1. Дисковые файлы.
2. Устройства.
3. Программные каналы.
4. Сокеты.
Один интерфейс ввода/вывода
Рисунок 11.2.
Один интерфейс и разные источники
A, 2) Дисковые файлы и файлы устройств
Используется open для соединения, используется read и write для передачи данных.
C) Программные каналы
Используется pipe для создания, используется fork для разделения канала,-используется
read и write для передачи данных.
D) Сокеты
Используется socket, listen, connect для соединения, используется read и writq для
передачи данных.
В абстракции файла Unix инкапсулирует как источник, так и средства для "производства
данных". В главе 2 мы рассматривали особенности чтения данных из файла. В главе 5 идея
файла была расширена и распространена на устройства. Там мы рассмотрели, что чтение
из процессов происходит аналогично чтению данных из файлов. *
11.3. be: калькулятор в UNIX
В любой версии Unix есть калькулятор be. В программе be есть переменные, циклы
и функции. Калькулятор be может обрабатывать очень большие числа, как мы убедились в
главе 1:
$ be
17Л123
22142024630120207359320573764236957523345603216987331732240497016947\
29282299663749675090635587202539117092799463206393818799003722068558\
0536286573569713
Символ обратного слеша в конце строки указывает на последующее продолжение строки.
Но be не является калькулятором.
Программа-калькулятор производит грамматический разбор входных данных, выполняет
требуемые действия, а затем выводит результат.
/ /. 3. be: калькулятор в UNIX
387
В большинстве версий be происходит грамматический разбор входных данных, но дейст
вий по вычислению не производится1. Вместо этого программа be запускает на
исполнение программу-калькулятор dc и соединяется с ней через программные каналы.
Программа dc является программой, где используется работа со стеком. Это предполагает, что
пользователь должен вводить оба вычисляемых значения перед знаком операции.
Например, пользователь должен вводить данные так:
22+
чтобы сложить 2 и 2.
2 + 2
Г====1 шшшшчшЛл
\ 1 , ....?
? -Г-Н
Шк
2 2 + р г
4 L
^М% -:><
Рисунок 11.3
be и dc, работающие
как сопрограммы
На рисунке 11.3 показано, как программа be производит обработку выражения 2+2.
Пользователь набирает текст 2+2, затем нажимает на клавишу Enter. Программа be читает это
выражение со стандартного входа, делает его разбор - выделяет значения и действие,
затем посылает программе dc такую последовательность команд:
ИЛИ НОМ И|И «_^И
С. , с. , ' , р .
Программа dc помещает в стек два значения, применяет в отношении этих значений
операцию сложения, затем выводит на свой стандартный вывод значение, которое будут
получено в результате вычисления выражения на вершине стека.
Программа be читает результат из программного канала, к которому присоединен
стандартный вывод программы dc. После чего полученный результат передается
пользователю. В составе be нет переменных. Если пользователь ^наберет при вводе: х = 2 + 2, тогда
программа be обратится к dc с тем, чтобы было выполнено арифметическое действие и
результат был помещен в регистр х в программе dc. При выполнении команды be -с видно,
что после разбора происходит посылка данных калькулятору. Даже при использовании
версии GNU команды be происходит преобразование пользовательского ввода в
выражение, ориентированное на стековое выполнение.
Идеи, реализованные в be
/. Модель клиент/сервер
Пара программ bc/dc представляет собой пример программной реализации модели клиент/
сервер. В программе dc реализован сервис: вычисление выражения. У программы dc есть
хорошо определенный язык, который использует обратную польскую запись. Два
процесса взаимодействуют взаимосвязи через stdin и stdout. В программе be реализован
пользовательский интерфейс. Эта программа пользуется тем сервисом, который реализован в
программе dc. Программу be называют клиентом программы dc.
2. Двунаправленные коммуникации
В отличие от модели сборочной (поточной) линии при обработке данных, модель клиент/
сервер часто требует, чтобы один процесс имел связь как со стандартным вводом, так и со
стандартным выводом другого процесса. Традиционно программные каналы в Unix
1. В версии GNU программа be производит и счетные действия.
388
Соединение между локальными и удаленными процессами. Серверы и сокеты
используют для передачи данных только в одном направлении . На рисунке 11.3 показаны
два программных канала между be и dc. По верхнему каналу передаются команды для
калькулятора, которые подаются на стандартный ввод dc. По нижнему каналу передаются
данные от dc к be, со стандартного вывода dc.
3. Постоянный сервис
При исполнении программы be будет запущен только один процесс dc. В shell, который мы
< написали, для исполнения каждой команды создавался новый процесс. Программа be
будет использовать один и тот же интерфейс при каждом новом получении задания (одной
строки текста) от пользователя. Такое взаимодействие отличается от стандартного
механизма типа "вызов-возврат" (call-return), который мы используем при функциональных
вызовах.
Пару bc/dc называют сопрограммами (coroutines), чтобы отличить их от другой пары -
подпрограммы (subroutines). В данном случае оба процесса продолжают работать, но
управление передается от одного процесса к другому по мере того, как каждый из них
заканчивает выполнение своей части задания. Для процесса be заданием является разбор входного
текста и вывод результата, а для процесса dc заданием является выполнение
арифметических действий.
/1.3.1. Кодирование be: pipe, fork, dup, exec
be dc
Рисунок 11.4
be, dc и ядро
На рисунке 11.4 показано, каким образом построена информационная связь в ядре, через
которое производится соединение пользователя с процессом be, а процесса be с процессом dc.
Возьмем этот рисунок в качестве основы для построения такого кода:
(a) Создать два программных каналов.
(b) Создать процесс для исполнения программы dc.
(c) В новом процессе перенаправить stdin и stdout на программные каналы, а затем
выполнить exec dc.
2. Некоторые программные каналы используют для передачи данных в прямом и обратном направлениях
(см. упражнение 11.11)
иШ
11.3. be: калькулятор в UNIX 389
(d) В родительском процессе считать данные от пользователя и произвести их
разборку. Далее выдать через канал команды для dc. Потом прочитать из канала ответ от
dc выдать результат пользователю.
Далее следует код программы tinybc.c. В этой версии be используется sscanf для проведения
разбора входного текста пользователя. Взаимодействие с dc производится через два
канала:
/** tinybc.c * Небольшой калькулятор, где используется dc для вычислений
** * Демонстрируется работа с двунаправленными каналами
** . . * Ввод выглядит так: число операция число
** * tinybc преобразует ввод в строку: число \п число \п операция \n p
** * и передает полученный результат на stdout
** + + +
** stdin >0 >— pipetodc ====>
** | tinybc | | dc-
** stdout < 1 <— pipefromdc ==<
*•
** * схема программы
** а. Построить два канала
** b. fork (породить другой процесс)
** с. В цепочке dc-to-be между процессами:
** Перенаправить стандартные ввод и вывод на каналы.
** Затем выполнить exed dc
** d. В процессе tinybc образовать:
** Работу с пользователем через ввод/вывод
** Посылку команд и результатов через каналы
** е. После закрытия каналов dc заканчивается
** * замечание: многострочные ответы не обрабатываются
**/
#include <stdio.h>
#define oops(m,x) {perror(m); exit(x);}
main()
{
int pid, todc[2], fromdc[2]; /* оборудование */
Г образовать два канала */
if (pipe(todc) == -11| pipe(fromdc) == -1)
oopsfpipe failed", 1);
Г создать процесс для поддержки интерфейса пользователя 7
if((pid = fork())==-1)
oopsfcannot fork", 2);
if (pid == 0) /* дочерним процессом будет dc 7
else {
be_dc(todc, fromdc);
be_bc(todc, fromdc); /* родительским процессом будет ui */
wait(NULL); /* ожидание окончания дочернего процесса */
О Соединение между локальными и удаленными процессами. Серверы и соке
}
}
be_dc(intin[2],intout[2])
Г
* установка stdin и stdout, затем: execl dc
7
{
Г установка stdin из pipein 7
if (dup2(in[0],0) == -1) /* дублирование дескриптора 0 на конце для чтения */
oopsfdc: cannot redirect stdin",3);
close(in[0]); /* пересылка через fd 0 7
close(in[1 ]); /* писать через этот конец нельзя 7
/* установка stdout для pipeout 7
if (dup2(out[1 ], 1) == -1) Г дублировать fd 1 для конца на запись 7
oopsfdc: cannot redirect stdout" ,4);
close(out[1 ]); /* пересылка через fd 1 7
close(out[0]); /* нельзя читать через этот конец 7
/* теперь выполнить execl dc с опцией - */ ¦
execlpC'dc", "dc","-", NULL);
oopsfCannot run dc", 5);
}
be„bc(inttodc[2], intfromdo[2])
Г
ж Читать из stdin и преобразовать в обратную польскую запись, выдать
в канал, затем читать из другого канала. Выдать результат пользователю
* Используется fdopen() для преобразования файлового дескриптора в поток
7
{
int num1,num2;
char operation[BUFSIZJ, message[BUFSIZ], *fgets();
FILE *fpout, *fpin, *fdopen();
/* установка 7
close(todc[0]); /* не производить чтение из канала к dc 7
close(fromdc[1]); Г не писать в канал из dc 7
fpout = fdopen(todc[1 ], "w"); /* преобразовать файловые дескрипторы 7
fpin = fdopen(fromdc[0], "r"); /* в потоки */
if (fpout == NULL || fpin NULL)
fatalf'Error converting pipes to streams");
/* основной цикл 7
while (printfftinybc:"), fgets(message,BUFSIZ,stdin) != NULL){
/* ввод для разборки 7
if (sscanf(message,"%d%[-+7A]%d",&num1 .operation,
&num2)!=3){
printf("syntax error\n");
continue;
/1.3. be: калькулятор в UNIX
391
if (fprintf(fpout, ,,%d\n%d\n%c\np\n,,l num1, num2,
operation) == EOF)
fatalfError writing");
fflush(fpout);
if (fgets(message, BUFSIZ, fpin) == NULL)
break;
printf(M%d %c %d = %s", numl, ^operation, num2, message);
}
fclose(fpout); /* закрыть канал */
fclose(fpin); /* dc увидит EOF */
}
fatal(charmess[])
{
fprintf(stderr, "Error: %s\n", mess);
exitA);
}
Далее представлены результаты выполнения tinybc:
$ ее tinybc.c -о tinybc ;./tinybc
tinybc: 2+2
2 + 2 = 4
tinybc:- 55
55Л 5 = 503284375
tinybc:
Внимательно изучите результаты работы и определите, что делает каждая часть
программы. Программа tinybc выдает приглашение и вводит текст арифметического выражения.
Результат вычисления - это строка, которая была выработана в dc. Программа tinybc только
читает строку результатов из канала и включает ее в вывод.
/ /. 3.2. Замечания, касающиеся сопрограмм
Какие еще средства в Unix могут быть использованы в качестве сопрограмм? Можно ли
использовать утилиту sort как сопрограмму для некоторой программы? Нет. Утилита sort
читает сразу все данные до конца файла, а потом выдает результаты на вывод.
Единственный вариант - послать признак конца файла через канал, чтобы закрыть записывающий
конец. Но после закрытия записывающего конца вы не сможете послать следующую
порцию данных на сортировку.
dc обрабатывает данные и команды построчно. Взаимодействие с dc простое и
предсказуемое. Когда вы обращаетесь к dc, чтобы напечатать значение, то в ответ вы получаете одну
текстовую строку. Когда же вы обращаетесь к dc и передаете значение, вы не получите
никакого ответа.
Для программы, которая представлена как часть клиент/серверной сопрограммной
системы, необходимо использование ясного способа для обозначения конца сообщения.
Программа должна использовать простые, предсказуемые запросы и ответы.
392 Соединение между локальными и удаленными процессами. Серверы и сокеты
11.3.3. fdopen: файловые дескрипторы становятся похожими на файлы
В программе tinybc.c мы ввели в использование библиотечную функцию fdopen. Эта
функция работает аналогично функции fopen, возвращая FILE *. Но при работе с функцией
передается в качестве аргумента файловый дескриптор, а не имя файла.
При использовании fopen открывается нечто обозначенное через имя файла. Функция fopen
открывает файлы устройств, а также обычные дисковые файлы. Использование fdopen
предполагается в случаях^ когда вы располагаете не именем файла, а файловым дескриптором.
Например, это необходимо в случае работы с программным каналом. Возможно вы захотите
преобразовать соединение в тип FILE * с тем, чтобы можно было использовать далее
стандартные, буферируемые операции ввода/вывода. Посмотрите, как в программе tinybc.c
используются операции fprintf и fgets для передачи данных через каналы к dc.
При использовании fdopen удаленный процесс становится более похожим на файл. В
следующей секции мы поработаем с рореп. Это функция, в которой инкапсулированы вызовы
pipe, fork, dup и exec. Эта функция полностью воссоздает иллюзию, что программы и файлы
выполняют одно и то же.
11.4. рореп: делает процессы похожими на файлы
Далее мы продолжим обсуждение вопроса, как программа может получить некие сервисы
посредством присоединения к другому процессу. Кроме того обсудим возможности
библиотечной функции рореп. Мы рассмотрим, что делает рореп и как она работает. Затем мы
напишем нашу собственную версию.
11\4.1\ Чтоделаетфункциярореп
Функция fopen открывает буферируемое соединение с файлом:
FILE *fp; Г указатель на структуру */
fp = fopen(Hfile1", "r"); /* аргументы: имя файла, тип соединения 7
с = getc(fp); /* пхимвольное чтение 7
fgets(buf, ten, fp); /* построчное чтение */'
fscanf(fp,,,%d%d%s,,>&x,&y,x.); /* чтение токенов 7
fclose(fp); /* закрытие после окончания работы 7
При обращении к fopen задаются два строковых аргумента: имя файла и тип соединения
(т. е. "г", "w", "а",...). Функция рореп во многом выглядит и работает аналогично,
функции fopen. Функция рореп открывает буферируемое соединение с процессом:
FILE *fp; /* используется такой же тип стурктуры 7
fp = popen("ls", "r"); /* аргументы: имя программы, тип соединения 7
fgets(buf, len, fp); /* точно такое же назначение 7
pclose(fp); Г закрытие после окончания работы 7
На рисунке 11.5 иллюстрируется сходство между функциями рореп и fopen. Обе функции
используют один и тот же синтаксис, и возвращают значение одного и того же типа.
Первый аргумент при обращении к рореп-это имя команды, которая должна быть
"открыта". Это может быть любая команда shell. Второй аргумент - это символ, которым может
/1.4. рореп: делает процессы похожими на файлы
393
Is
Рисунок 11.5
fopen и рореп
Примеры рореп
В следующей программе, где рассматривается конвейер who|sort, используется функция
рореп для получения отсортированного списка текущих пользователей:
Г popendemo.c
* Демонстрируется, как открыть программу для стандартного ввода/вывода
* Важные моменты:
* 1. рореп() возврзщает FILE *, аналогично функции fppen()
* 2. Указатель FILE * можно использовать при записи/чтении со
* всеми стандартными функциями
* 3. Вам необходимо выполнить pclose() при окончании
7
#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE *fp;
char buf[1Q0];
int i = 0;
fp = popenC'wholsort", Y); /* открытие команды 7
while (fgets(buf, 100, fp) != NULL) /* читать из команды */
printf("%3d %sn, i++, buf); /* вывод данных 7
pclose(fp); Л ВАЖНО! 7
return 0;
}
Второй. пример использует рореп для соединения программы mail с пользователями,
которым выдается сообщение о системной проблеме:
Г рореп_ех3.с
* Показывается, как использовать рореп для записи в процесс данных,
* считано из stdin. Эта программа посылает email двум
* пользователям. Заметим, как легко можно использовать fprintf
* для форматирования данных для посылки сообщения.
7
#include <stdio.h>
main()
{
FILE *fp;
I Г~Т~
popen("Is", "r")
fopen("file", "r")
394
Соединение между локальными и удаленными процессами. Серверы и сокеты
fp = popenf'mail admin backup", "w");
fprintf(fp, "Error with backup!!\n");
pclose(fp);
}
Обязательное выполнение pclose
Когда вы закончите чтение или запись из соединения, созданного с помощью рореп,
необходимо выполнить pclose, а не fclose. Окончание запущенного процесса должно ожидаться
в порождающем процессе. Иначе процесс становится зомби. При выполнении pclose
выполняется wait.
/1.4.2. Разработка функции рореп: использование fdopen
Как работает рореп и как мы ее будем разрабатывать? Функция рореп запускает программу
на исполнение и строит свя*зь со стандартным вводом или выводом этой программы.
Нам потребуется новый процесс, чтобы запустить в нем программу. Поэтому мы
используем fork. Нам потребуется соединение с этим процессом. Поэтому мы используем pipe.
Нам потребуется файловый дескриптор для буферируемого потока. Поэтому мы
используем fdopen. Наконец, нам потребуется запускать любую команду shell в новом процессе.
Поэтому мы используем exec. Но что мы будем исполнять? Единственной программой,
которая может запускать на исполнение любую команду shell, будет программа самого
shell: /bin/sh. Удобно запускать sh с опцией - с. Тем самым мы обращаемся к shell, чтобы он
запустил команду, а потом сделал бы exit. Например:
sh -с "who|sort"
Мы обращаемся к sh, чтобы он запустил командную строку who|sort (см. также рисунок
П.6).
Скомбинируем вызовы pipe, fork, dup2 и exec, как это показано на диаграмме.
pipe(p)
fork()
close(p[1]);
fp = fdopen(p[0],
return fp;
Y")
close(p[0]);
dup(p[1],1);
close(p[1]);
execl("/bin/sh","sh"l,,-c"lcmd,NULL);
sh -c "Is"
Файловые ^^
дескрипторы jp
Mimmiw 'ii
Рисунок 11.6
Чтение из команды
11.4. рореп: делает процессы похожими на файлы
395
В программе рореп.с представлена реализация этой диаграммы:
Г рореп.с - версия библиотечной функции рореп()
* FILE *popen(char ^command, char *mode)
* command - обычная команда shell
* mode - символ "г" или "w"
* В качестве результата возвращается поток, присоединенный к
* команде, или NULL
* execls "sh" "-с" command
* подумать: можно ли управлять дочерним процессом с помощью сигналов?
7
#include <stdio.h>
#include <signal.h>
#define READ 0
#define WRITE 1
FILE *popen(const char ^command, const char *mode)
{
int pfp[2], pid; /* программный канал и процесс 7
FILE *fdopen(), *fp; /* fdopen строит fd для потока канала */
int parent_end, chlld_end;
if (*mode == 'r'){ /* направление передачи */
parent_end = READ;
child_end = WRITE;
} else if (*mode == 'w'){
parent_end - WRITE;
child.end = READ;
} else return NULL;
if (pipe(pfp) == -1) /* построить канал */
return NULL;
if ((pid = fork()) == -1){ /* и процесс */
close(pfp[0]); /* или завершить дела с каналом */
close(pfp[1]);
return NULL;
}
/* -— код процесса-отца - 7
Г необходимо закрыть один конец и выполнить fdopen на другом конце */
if (pid > 0){
if (close(pfp[child_end]) == • 1)
return NULL;
return fdopen(pfp[parent end], mode); /* тот же режим */
>
}
Г". код дочернего процесса 7
/* необходимо перенаправить stdin или stdout, затем выполнить exec для команды */
if (close( pfp[parent_end]) == -1) /* закрыть другой конец */
exit( 1); /* сделать возврат с кодом 1 7
if (dup2(pfp[child_end], child_end) == -1)
396
Соединение между локальными и удаленными процессами. Серверы и сокеты
exitA);
if (close(pfp[child_end]) == -1) /* закрыть на этом конце 7
exitA); .
Г все готово для запуска команды 7
execlC/bin/sh", "sh", "-с", command, NULL);
exitA);
}
В этой версии рореп не используется механизм сигналов. А в чем проблема?
/ /. 4.3. Доступ к данным: файлы, программный интерфейс API и сервера
Счпомощью fopen можно получать данные из файла, а с помощью рореп данные можно
получать от процесса. Давайте сосредоточимся на основном вопросе получения данных
и сравним при этом три метода. В качестве примера мы сравним три метода получения
списка пользователей, которые вошли в систему.
Метод 1: получение данных из файлов. Данные можно получить, читая их из файла.
В главе 2 мы написали версию программы who, которая читает список текущих
пользователей из файла utmp. .
Сервис, основанный на работе с файлами, нельзя признать отличным. Клиентские
программы зависят от конкретного формата файла и специфических имен членов в
структурах. Строки вида:
Г Backwards compatibility hacks. */
#define ut_name ut_user
в заголовочном файле Linux для структуры utmp иллюстрируют, как это реально выглядит.
Метод 2: получение данных от функций. Вы можете получить данные, обращаясь для
этого к функции. Библиотечная функция скрывает форматы данных и расположение
файлов за стандартным функциональным интерфейсом. В Unix есть функциональный
интерфейс для файла utmp. Страничка электронного справочника getutent описывает
функции, с помощью которых можно читать базу данных utmp. Структура памяти может
меняться, но программы, которые будут использовать данный интерфейс, будут продолжать
работу.
Однако сервисы, основанные на API (Applicationprogramming interface- программный
интерфейс), не всегда обеспечивают удовлетворительное решение. Есть два метода
использования функций из системных библиотек. Программа может использовать статическое
связывание, когда код функции включается в текст. Такие функции допускают
использование имен файлов или форматов файлов, которые в текущий момент не являются
правильными. С другой стороны программа может обращаться к функциям, которые
находятся в разделяемых библиотеках. Но эти библиотеки не всегда инсталлированы в системе.
Или версия, которая находится в системе, не может быть сопряжена с той версией, которая
нужна программе.
Метод 3: получение данных от процессов. Третий метод основан на получении данных
при чтении из процесса. Примеры bc/dc и рореп показали, как можно создавать соединения
с другими процессами. Программа, которая хотела получить список пользователей, может
обратиться к рореп, чтобы связаться с программой who. Программа who не является вашей
программой. Она проверяет правильность файловых имен и форматов файлов, а также
использует необходимые библиотеки. Методу получения данных посредством обращения к
конкретным программам присущи еще ряд преимуществ. Серверные программы могут
быть написаны на любом языке: это могут быть скрипты, написанные на shell, или отком-
/1.5. Сокеты: соединения с удаленными процессами 397
пилированные С-коды. Это могут быть программы на Java или Perl. Наиболее
выразительное преимущество при реализации сервисных систем в виде отдельных программ
заключается в том, что клиентская программа может работать на одной машине, а серверная
программа может работать на другой машине. Все, что необходимо при этом:
использовать некоторый вариант соединения процессов на различных машинах.
11.5. Сокеты: соединения с удаленными процессами
С помощью программных каналов процесс может передавать данные другим процессам так
же легко, как он посылает данные в файлы. Но каналы имеют два существенных ограничения.
Канал создается одним процессом и разделяется с другим после выполнения fork. Поэтому
программные каналы могут соединять только родственные процессы. Кроме того,
программные каналы соединяют процессы, которые развиваются на одной и той же машине. В Unix
есть еще и другой метод для межпроцессных взаимодействий - сокеты:
Рисунок 11.7
Соединение с удаленным процессом
Сокеты предоставляют процессам возможность создавать соединения, которые похожи на
каналы. Но ими могут пользовать не обязательно родственные процессы, а даже
процессы, которые развиваются на разных машинах (см. рисунок 11.7). Далее мы изучим
основные идеи построения и использования сокетов. Посмотрим, как можно использовать
сокеты для связывания клиентов и серверов, которые работают на разных машинах. Идея
взаимодействия проста и аналогична телефонному звонку, чтобы узнать текущее время.
/1.5.1. Аналогия: "....времяравно..."
Многие клиенты пользуются таким сервисом - определяют время по определенному
телефонному номеру. Вы набираете этот номер. Автомат, с которым вы свяжетесь, сообщает
текщее время в конкретном городе. Как это все работает? Что, если вам придет в голову
мысль установить собственную службу времени? Вы можете использовать простейшее
решение, изображенное на рисунке И.8.
На этом рисунке вы изображены на правой стороне и находитесь в офисе. Вы выступаете
в роли сервера, который отвечает на запрос о текущем времени. В офисе на стене
находятся часы.
Последовательность действий, которые вы будете следовать при работе в качестве
временного сервера, в точности соответствует тем шагам, которые необходимо будет сделать
в составе службы, использующей сокеты. Поэтому начнем детально описывать эти шаги.
398 Соединение между локальными и удаленными процессами. Серверы и сокеты
яг
• Линия связи
Линия связи
Телефонный номер на
этой лини
Клиент:
набрать телефонный номер
службы времени
принять данные
отключиться ^ ¦
установка сервиса
ожидать звонка Щт
шшттшшттшттттшш+»~ ПрИНЯТЬ ВЫЗОВ |
шяшшшттшшттттштшмм^^ сообщить, сколько |
времени, отключиться 1
Рисунок 11.8
Служба времени
Установка и работа сервиса
Что нужно установить и как начать работу в вашей службе времени сразу после того, как
вы купили и установили часы?
Установка сервиса. Установка вашего сервиса состоит из трех шагов.
1. Следует получить телефонную линию
Прежде всего, вам необходимо заполучить телефонную линию, к которой вы можете
присоединить телефон с помощью розетки на стене. Телефонный провод и розетка
позволят вам подсоединиться к телефонной сети так, чтобы звонки приходили бы на
телефон на вашем столе. Выражаясь более формально, можно сказать, что розетка будет
являться оконечной точкой соединения. Когда у вас возникнет необходимость
установить дома телефон, то обратитесь к телефонной компании или к монтеру с просьбой
установить оконечную точку соединения (Это не очередной шаг в установке сервиса.
Так автор шутит. -Примеч. пер.).
2. Следует получить телефонный номер для телефонного аппарата на установленной
линии
Клиентам необходим.номер, чтобы с его помощью подсоединиться к вашей оконечной
точке соединения. В телефонной сети идентифицируется каждая настенная
телефонная розетка с телефонным номером. Чтобы продолжить наши аналогии, представим
себе, что вы заняты большим бизнесом и в дополнение к службе времени намерены
открыть еще ряд служб. Поэтому ваша телефонная розетка будет идентифицироваться
телефонным номером и дополнительным номером. Например, вашим номером может
быть 617-999-1234. А расширением номера может быть 8080. Телефонный номер
будет идентифицировать здание, где находится ваш офис, а расширение номера (8080)
будет идентифицировать ваш конкретный телефон в этом здании. Итак, в чем смысл
этого дополнения? Один номер предназначен для здания, а второй номер - для вашей
службы. Это важно.
11.5. Сокеты: соединения с удаленными процессами 399
3. Распределение входящих запросов
Вы можете использовать платные телефоны, на которых будет отметка по incoming
calls. Но вашей службе не подходит такой тип телефона. Вы договариваетесь с
телефонной компанией/чтобы по вашей линии было бы можно принимать входящие
запросы. Вам также необходим механизм формирования очереди из входящих запросов. Вам
необходим механизм, которое будет сообщать каждому позвонившему, как важен его
запрос для вас. А затем включить музыку. Идея использовать очереди имеет прямое
отношение к сокетам, а включение музыки - не имеет никакого отношения.
Работа службы. Работа службы времени заключается в выполнении в цикле
следующих трех шагов:
4. Ожидание звонка (запроса)
Следует просто сидеть и ничего не делать до тех пор, пока не поступит вызов (зазвонит
телефон). Используя техническую терминологию, вы должны быть заблокированы на
звонке. Когда зазвонит телефон, то вы разблокируетесь и принимаете запрос.
5. Обслуживание
В нашем случае вы смотрите на часы, а затем сообщаете по телефону позвонившему -
сколько сейчас времени.
6. Отключение
Ваша работа по данному запросу окончена, поэтому вы отключаетесь.
Эти шесть шагов, три из которых являются установочными, а три связаны с
обслуживанием запроса, представляют в деталях, как должна работать служба времени через
телефонную сеть.
Использование сервиса
В каком порядке клиент может воспользоваться вашим сервисом? Клиент должен
выполнить следующие четыре шага:
1. Следует получить телефонную линию
Клиенту также необходима оконечная точка соединения. Клиент заказывает и
получает телефонную линию в телефонной сети.
2. Соединение с вашим номером
Далее клиент использует линию, чтобы связаться через телефонную сеть с вашей
линией. Клиент соединяется по бизнес-номеру и расширению, которые
идентифицируют вашу службу. Комбинация бизнес-номера и расширения называется
сетевым адресом вашей службы. Используя техническую терминологию, телефонный
номер вашего учреждения - это адрес хоста, а номер вашего расширения - это
номер порта или просто порт. Относительно рассматриваемого ранее примера
адресом хоста будет 617-999-1234, а портом будет 8080.
3. Использование сервиса
Теперь связь между двумя оконечными точками соединения (точка клиента и точка
сервера) установлена. Поэтому можно через установленное соединение с любой
стороны передавать данные для другой стороны. В случае со службой времени данные
через установленное соединение посылает сервер, а клиент принимает эту
информацию. В более развитых сервисах потребуются более сложные взаимодействия между
клиентом и сервером. Более сложные сервисы мы рассмотрим позже.
4. Отсоединение
Взаимодействие закончено. Клиент отсоединяется.
400 Соединение между локальными иудаленными процессами. Серверы и сокеты
Важные концепции
Пример со службой времени проиллюстрировал четыре концепции, которые мы будем
использовать при программировании сокетов.
Клиент и сервер
Эти идеи мы обсуждали уже несколько раз. Сервер - это программа, которая при своей
работе обеспечивает некоторый сервис. В терминах Unix под сервером подразумевают
программу, а не компьютер. Когда говорят о компьютере, то обычно употребляют термины:
компьютер, хост, система, машина и бокс. Серверный процесс работает в цикле: ожидает
запрос, обрабатывает его, затем опять возвращается к шагу приема нового запроса.
Клиентский процесс не является циклическим. Клиент устанавливает соединение,
обменивается данными с сервером и далее продолжает свою работу.
Имя хоста и порт
С позиций Internet сервер рассматривается как процесс, развивающийся на некотором
компьютере. Компьютер называют хостом. Для машин назначают имена, как, например:
sales.xyzcorp.com. Такое имя называют hostname (именем хоста). На этом хосте сервер
имеет номер порта. Комбинация из имени хоста и порта идентифицирует сервер.
Семейство адресов
Ваша служба времени имеет телефонный номер. Но эта служба также имеет и адрес
улицы и почтовый индекс (zip code). Ваша служба еще определяется и по определенным
координатам: по долготе и по широте. Можно придумать еще и другие числовые способы
идентификации. Каждый из таких наборов номеров представляет собой адрес вашей
службы. Хотя вы вряд ли будете работать с долготой и широтой, которые будут выступать
в роли номера телефона и расширения номера.
Каждый из таких адресов принадлежит к семейству адресов. Телефонный номер и
расширение номера имеют смысл в семействе адресов телефонной сети, что мы будем
обозначать символически как AF_PHONE. Аналогично долгота и широта будут иметь смысл
для семейства адресов в системе глобальных координат, что мы будем обозначать
символически как AFJ3LOBAL.
Протокол
Протокол - это правила взаимодействия между клиентом и сервером. Для службы
времени протокол простой: клиент звонит, сервер отвечает, сервер сообщает точное время,
сервер отсоединяется.
Что получится, если мы начнем работать со службой DAS (directory-assistance
service-справочная служба)? В таком случае протокол будет уже более сложным. Вы, выполняя функции
сервера, должны будете отвечать определенным образом. Вначале вы поприветствуете
клиента ^Телефонная справочная служба. Какой город вас интересует*}"}. Клиент в ответ
должен назвать имя города. Сервер задает клиенту следующий вопрос, касающийся имени
("Что необходимо найти?"). Клиен;г в ответ называет имя персоны или название
учреждения. После этого сервер сообщает клиенту искомый телефонный номер или сообщает о том,
что искомого объекта в этом городе нет. В некоторых справочных службах могут соединить
вас с найденым по запросу телефонным номером (за отдельную плату). Такой обмен
сообщениями и составляет протокол справочной службы DAP (directory-assistanceprotocol), речь
о котором пойдет далее .
В каждой клиент/серверной системе должен быть определен свой протокол.
11,5. Сокеты: соединения судаленнымипроцессами 401
11.5.2. Время Internet, DAP и метеорологические серверы
Телефонная служба времени и телефонная справочная служба - это примеры серверов.
Но эти примеры носят учебный характер. В Internet дело обстоит несколько не так.
Давайте выполним:
$ telnet mit.edu 13
Trying 18.7.21.69...
Connectedtomit.edu.
Escape character is ,Л]\
Mon Aug 13 22:36:44 2001
Connection closed by foreign host.
$
Где-то на машине MIT располагается сервер времени, который ожидает поступления
запросов через порт 13. Когда мы обращаемся к этому серверу с помощью программы telnet,
то сервер воспринимает запрос, определяет показание часов в системе, посылает ответ
о текущем времени в линию, затем отсоединяется. Все в точности соответствует
действиям, которые мы наблюдали при работе со службой времени. Даже используется тот же
протокол. Теперь попытаемся соединиться через порт 13 с другими хостами. В результате
вы можете определить, каково текущее время на машинах по всему миру.
Программа telnet аналогична телефону. Она устанавливает соединение с портом на
удаленном хосте, а затем пересылает данные с вашей клавиатуры через установленное
соединение. Далее выводит на ваш экран результирующие данные через это же соединение.
А что можно сказать относительно телефонной справочной службы? Сервер DAS обычно
прослушивает запросы через порт 79. Например, мы можем выполнить:
$ telnet princeton.edu 79
Trying 128.112.128.81...
Connected to princeton.edu.
Escape character is "У-
smith
alias:000012345
name.Waldo Smith
department: Special Student
email:waldos@Princeton.EDU
emailbox: waldos@mail. Princeton. EDU
netid:waldos
alias: 000333333
name: IgnatzE Smith
department: Undergraduate Class of 1997
email: ismith@Princeton.EDU
emailbox: .ismith@mail.Princeton.EDU
netid: ismith
Сервер принимает запрос, когда он поступит от клиента. В протоколе определено, что
клиент должен набрать искомое имя и затем нажать на клавишу return. Сервер посылает
клиенту все записи, которые удалось обнаружить, а затем разрывает соединение.
402 Соединение между локальными и удаленными процессами. Серверы и сокеты
А как можно узнать сводку погоды? Попытаемся выполнить:
telnet rainmaker.wunderground.com 3000
Протокол для этого метеосервера будет более сложным, но и более дружественным.
/ /. 5.«?. Списки сервисов: широко известные порты
Каким образом я узнаю, что для доступа к серверу времени необходимо использовать
порт 13 , а порт 79 используется для доступа к справочному серверу? Просто нужно
з^ать широко известные порты. Это аналогично ситуации, когда в Соединенных
Штатах знают, что в аварийных ситуациях нужно звонить по номеру 911, а для
получения справки звонят по номеру 411. В файле /etc/services находится список
широко известных сервисов и номера их портов.
$ more /etc/services
# $NetBSD: services.v 1.181996/03/26 00:07:58 mrg Exp $
#
#. Network services, Internet style
#
# Note that it is presently the policy of IANA to assign a single well-known
# port number for both TCP and UDP; hence, most entries here have two entries
# even if the protocol doesn't support UDP operations.
# Updated from RFC 1340, "Assigned Numbers" (July 1992). Not all ports
# are included, only the more common ones.
#
# from: @(#)services 5.8 (Berkeley) 5/9/91
#
tcpmux 1Дср
echo 7Дср
echo 7/udp
discard 9Дср
discard 9/udp
systat 11 Дер
daytime 13Дср
daytime 13/udp
--More--A3%)
По этому листингу можно найти и убедиться, что сервис daytime имеет порт 13. Изучите
содержимое этого файла с целью ознакомления со стандартными службами на машинах
Internet. Обратите внимание на записи ftp, telnet, finger и http.
Все эти службы, которые работают на хостах Internet, базируются на идеях и технологии,
которые были нами рассмотрены на примере службы времени. Теперь преобразуем эти
идеи в вызовы Unix с тем, чтобы можно было написать нашу собственную версию
сервера времени и клиента времени.
# TCP port service multiplexer
sink null
sink null
users
/ 1.5.k Сокеты: соединения с удаленными процессами
403
11.5.4. Разработка timeserv.c: сервер времени
Работа нашей телефонной службы описывалась последовательностью действий из шести
шагов. Каждый шаг соответствует системному вызову. В таблице, которая следует ниже,
показано такое соответствие:
Вот таким будет
/* timeserv.c -
7
#include
«include
«include
#include
«include
«include
«include
«include
действие
1. Получение телефонной линии
2. Связывание линии с номером
3. Готовность к приему запросов
4. Ожидание запроса
5. Передача данных
6. Отсоединение
код:
системный вызов
socket
bind
listen
accept
read/write
close
сервер времени дня, использующий механизм сокетов
<stdio.h>
<unistd.h>
<sys/types.h>
<sys/socket.h>
<netinet/in.h>
<netdb.h>
<time.h>
<strings.h>
«define PORTNUM 13000 /* телефонный номер нашего сервера времени 7
«define HOSTLEN 256
«define oops(msg) {perror(msg); exitA);}
int main(int ac, char *av[])
{
struct sockaddrjn saddr; /* здесь строится наш адрес 7
struct hostent *hp; /* это часть нашего */
char hostname[HOSTLEhl]; /* адреса 7
int sockjd.sockjd; /* идентификатор линии, дескриптор файла 7
FILE *sock_fp; /* использовать сокет как поток 7
char *ctime(); Л преобразование значения времени в секундах в строковое
представление 7
time t thetime; /* результирующее время 7
/* " ¦
* Шаг 1: обратиться к ядру для построения сокета
7
sockjd = socket(PFJNET, SOCK.STREAM, 0); /* создание сокета 7
if (sockJd==-1)
oopsCsockef);
/*
* Шаг 2: связывание адреса с сокетом. Адрес - это: хост, порт
7
404
Соединение между локальными и удаленными процессами. Серверы и сокеты
bzero((void *)&saddr, sizeof(saddr)); /* очистить нашу структуру */
gethostname(hostname, HOSTLEN); /* Где я нахожусь?*/
hp = gethostbyname(hostname); /* получить информацию о хосте 7
/* заполнить поле хоста 7
bcopy((void *)hp->h_addr, (void *)&saddr.sin_addr, hp->hjength);
saddr.sin_port = htons(PORTNUM); /* заполнить поле порта сокета 7
saddr.sin Jamily = AFJNET; /* заполнить поле семейства адресов 7
if (bind(sock_id, (struct sockaddr *)&saddr, sizeof(saddr)) != 0)
oopsf'bind");
Г
* Шаг З: готовность принимать запросы на сокете в очереди с Qsize=1
7
if (listen($ockjd, 1) != 0)
oopsf'listen");
Л
*#основной цикл: accept(), write(), close()
7
while A){
sockjd = accept(sockjd, NULL, NULL); /* ожидание запроса 7
printfCWowlgotacall^n");
if (sockjd ==-1)
oopsC'accept"); /*¦ ошибка при получении запроса 7 \
sockjp = fdopen(sockJdrw"); /* сюда мы будем писать 7
if (sockJp == NULL) /* Сокет как поток 7
oopsffdopen"); /* если нельзя 7
thetime = time(NULL); /* получить время 7
Л и преобразовать в строчное представление 7
fprintf(sock_fp, "The time here is..");
fprintf(sockJp, "%s", ctime(&thetime));
fclose(sock fp); /* release connection 7
}
}
Далее представлено пояснение, как работает эта программа.
Шаг 1: обращение к ядру для создания сокета
Сокет - это оконечная точка соединения. Сокет, аналогично телефонной розетке на стене,
представляет собой место, из которого можно сделать запрос, и место, к которому могут
быть направлены запросы. Системный вызов socket служит для создания сокета.
socket
. НАЗНАЧЕНИЕ Создание сокета '' '
INCLUDE #include <sys/types.h>
#include <sys/socket.h>
ИСПОЛЬЗОВАНИЕ spckid = socket(int domain, int type, int protocol)
/1.5. Сокеты: соединения с удаленными процессами
405
socket
АРГУМЕНТЫ domain - коммуникационный домен
PFJNET - для lnternet-сокетов
type - тип сокета
SOCK_SfTREAM - выглядит как канал
protocol - используемый протокол для сокета
О - по умолчанию
КОДЫ ВОЗВРАТА . -1 - при обнаружении ошибки
sockid - идентификатор сокета, если успех
Системный вызов socket создает оконечную точку для коммуникации. После выполнения
возвращает идентификатор сокета. Существуют различные виды коммуникационных
систем, каждая из которых называется коммуникационным доменом. Internet - это один
домен. Позже мы увидим, что ядро Unix представляет собой другой домен. В Linux
поддерживаются коммуникации с несколькими другими доменами. Тип сокета определяет
тип потока данных, который программа планирует использовать. Тип SOCKJSTREAM
работает аналогично двунаправленному программному каналу. Данные, которые
записываются с одного конца, можно читать с другого конца. Данные при этом рассматриваются
как непрерывная последовательность байтов. В следующей главе мы рассмотрим тип
SOCK_DGRAM.
Последний аргумент, protocol, обозначает протокол, который используется в сетевом коде
ядра. Но это не протокол между клиентом и сервером. Значение 0 указывает на
использование стандартного протокола.
Шаг 2: связывание адреса с сонетом. Адрес: хост, порт
Следующий шаг заключается в установлении сетевого адреса для нашего сокета. В
Internet домене адрес состоит из имени хоста и номера порта. "Мы не можем использовать порт
13. Он зарезервирован для сервера реального времени. Будем использовать вместо этого
порт 13000. Вы вправе выбрать любой номер порта для вашего сервера. Только он не
должен быть слишком малым по значению и не должен уже использоваться. Порты с
минимальными номерами могут быть использованы только для системных сервисов, а не
обычными пользователями. Проверьте в вашей системе, каков диапазон номеров. Для
представления номера порта отводится поле в 16 разрядов. Поэтому можно сказать, что
портов много. Свойства системного вызова bind::
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
bind
Связывание адреса с сокетом
«include <sys/types.h>
«include <sys/socket.h>
result = bind(int sockid, struct sockaddr *addrp,
socklenj addrlen)
sockid - идентификатор сокета
addrp - указатель на структуру, содержащую адрес
addrlen - длина структуры
-1 - при обнаружении ошибки
0-, если успех
Системный вызов bind назначает адрес для сокета. Адрес назначается для такой же цели. Он
подобен телефонному номеру, по которому распознается телефонная розетка на стене вашего
офиса. Процессы будут использовать адрес сокета, когда они пожелают связаться с вашим
сервером. В каждом семействе адресов есть свой формат. Семейство Internet-адресов
406 Соединение между локальными и удаленными процессами. Серверы и соты
(AFJNET) использует в качестве адреса имя хоста и номер порта. Адрес - это структура,
в которой в качестве членов указаны имя хоста и номер порта. Наша программа сначала
обнуляет структуру, затем заполняет поле хоста и поле порта. Наконец, заполняется поле
семейства адресов. Обратитесь к справочнику, чтобы получить информацию о функциях, которые
были использованы для формирования каждого из членов структуры. После того, как были
заполнены все требуемые части адреса, полученный адрес присоединяется к сокету. В других
типах сокетов используются адреса с другими членами.
Шаг 3: готовность принимать запросы на сонете в очереди размером size = 1
Сервер принимает входящие запросы. Поэтому наша программа должна выполнить
системный вызов listen:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
listen
Установить готовность соединения на сокете принимать
запросы
tinclude <sys/socket.h>
result = listen(int sockld, int qsize)
sockid - идентификатор сокета, который будет принимать
запросы
qsize - максимальное число запросов на установление связи
-1 - при обнаружении ошибки
0 - если успех
Системный вызов listen сообщает ядру о готовности определенного сокета принимать
входящие запросы. Не все типы сокетов могут принимать входящие запросы. Тип
SOCKSTREAM может. Второй аргумент в системном вызове определяет размер очереди
входящих запросов. В нашем коде мы затребовали очередь, которая вмещает только один
запрос. Максимальный размер очереди зависит от реализации сокета.
Шаг 4: ожидание поступления и прием запроса
После того как сокет был создан, ему приписан адрес, подготовлен для приема входящих
запросов, программа готова к работе. Далее сервер ждет, пока поступит запрос. Для этого
используется системный вызов accept:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
accept
Получить соединение на сокете
#include <sys/types.h>
#include <sys/socket.h>
fd = accept(int sockid, struct sockaddr *callerid, socklenj
*addrlenp}
sockid - принять запрос н§ этом сокете
callerid - указатель на структуру с адресом вызывателя
addrlenp - указатель на ячейку, где находится длина адреса
вызывателя
-1 - при обнаружении ошибки
fd - файловый дескриптор, открытый на чтение и запись
Системный вызов accept задерживает текущий процесс до тех пор, пока не появится
входящее соединение на указанном сокете. accept возвращает файловый дескриптор, который
открыт на чтение и запись. Этот файловый дескриптор является соединением с файловым
дескриптором вызывающего процесса. Системный вызов accept поддерживает формат иденти-
/1.5. Сокеты: соединения с удаленными процессами
407
фикатор вызывателя {caller ID). Сокет в вызывателе имеет адрес. Для Internet-соединений
в качестве адреса используется имя хоста и номер порта. Если calleridn addrlenp ненулевые,
то ядро помещает адрес вызывателя в структуру, на которую указывает callerid, а длину этой
структуры помещает в ячейку, на которую указывает addrlenp.
Подобно человеку, который по звонку абонента может принять некое решение
о дальнейшем разговоре, сетевая программа может использовать адрес запрашивающего
процесса для принятия какого-либо решения при управлении входящим запросом.
Шаг 5: передача данных
Файловый дескриптор, который возвращается после выполнения accept, является
обычным файловым дескриптором. К нему применимо все то, что мы узнали при
рассмотрении open в главе 2. В программе timeserv.c мы используем fdopen, чтобы
преобразовать этот файловый дескриптор в поток. Поэтому мы можем использовать fprintf. Мы
могли бы также использовать и вызов write.
Шаг 6: закрытие соединения
Файловый дескриптор, который был получен после выполнения accept, может быть закрыт
с помощью стандартного системного вызова close. Когда один процесс закроет свой конец
на сокете, то процесс на другом конце увидит признак конца файла, если он попытается
прочитать данные. Программные каналы работают аналогично.
/ /. 5.5. Проверка работы программы timeserv. с
Откомпилируем и запустим программу нашего сервера времени:
$ ее timeserv.c-о timeserv
$ timeserv &
29362
$
Мы стартовали наш сервер, указав после команды знак амперсанта. Поэтому shell
запустит сервер, но не выполнит вызова wait. Сервер будет заблокирован на системном вызове
accept. Мы можем соединиться с ним с помощью telnet:
$ telnet 'hostname' 13000
Trying 123.123.123.123
Connected to somesite.net
Escape character is ,A]\
Wow! got a call!
The time here is. .Tue Aug 1411:36:30 2001
Connection closed by foreign host.
$
$ telnet hostname* 13000
Trying 123.123.123.123
Connected to somesite.net
Escape character is]'.
Wow! got a call!
The time here is„Tue Aug 14 11:36:53 2001
Connection closed by foreign host.
408
Соединение между локальными и удаленными процессами. Серверы и сокет
Мы установили два соединения, и сервер в ответ выдал каждый раз по запросу точное
время. Сервер будет работать до тех пор, пока мы не убьем его:
Skill 29362
telnet работает в данном случае как клиент для этого сервера. Но это не всегда приемлемый
вариант для связи с сервером. Далее мы напишем специального клиента для этого сервера.
11.5.6 Разработка программы timeclnt. с: клиент времени
В нашем клиенте для телефонной службы времени были представлены четыре Шага его
деятельности. Причем каждому соответствует свой системный вызов:
Действие
1. Получить телефонную линию
2. Вызвать сервер
3. Передать данные
4. Отсоединиться
Системный вызов
socket
1 connect
readytorite
close
Вот каким будет код:
/* timeclnt.c - клиент для timeserv.c
* обращение: timeclnt имя хоста номер порта
7
#include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <netdb.h>
#define oops(msg) {perror(msg);exitA);}
main(intac, char*av[|)
{
struct sockaddrjn servadd; Л номер запроса 7
struct hostent *hp; /* используется для получения номера 7
ints ockjd.sockjd; /* сокет и файловый дескриптор fd 7
char message[BUFSIZ]; /* место для приема сообщения 7
int messlen; /* длина сообщения 7
• /*
* Шаг 1: получить сокет
7
sockjd = socket(AFJNET, SOCK.STREAM, 0); /* получить линию 7
if (sockjd==-1)
oopsf'socket"); /* или неудача 7
, Г
* Шаг 2: связь с сервером
4 * потребуется сначала создать адрес сервера {хост, порт)
7
bzero(&servadd, sizeof(servadd)); /* обнулить адрес 7
hp = gethostbyname(av[1 ]); /* поиск ip # хоста 7
^ if (hp == NULL) .
/1.5. Сокеты: соединения с удаленными процессами
409
oops(av[1 ]); /* или закончить */
bcopy(hp->h_addr, (struct sockaddr *)&servadd.sin_addr, hp->hjength);
servadd.sinjort = htons(atoi(av[2]));/* занести номер порта 7
servadd.sinjamily = AFJNET ;/* занести тип сокета */
Г теперь вызов¦*/
if (connect(sockjd,(struct sockaddr *)&servadd, sizeof(servadd)) !=0)
oopsfconnecf);
Г
* Шаг З: передача данных от сервера, затем отсоединиться
7
messlen = read(sockjd, message, BUFSIZ); /* чтение 7
if (messlen — -1)
oopsfread"); v
if (write( 1, message, messlen) != messlen) /* и запись */
oopsfwrite"); /* на stdout 7
close(sock id);
} *
Далее следует пояснение, как работает программа.
ШЬг 1: обращение к ядру для создания сокета
Для соединения с сетью клиенту необходим сокет. Точно так же, как клиенту нашей
телефонной службе времени была нужна телефонная линия для соединения с телефонной
сетью. Сокет дЛя клиента должен быть в качестве Internet-сокета (AFJNET) и быть
потоковым сокетом (SOCK_STREAM).
Шаг 2: соединение с сервером
Клиент соединяется с сервером времени. Есть системный вызов connect, который является
сетевым эквивалентом телефонного вызова.
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
connect
Соединение с сокетом
#include <sys/types.h>
#include <sys/socket.h>'
result = connect(int sockid, struct sockaddr *serv_addrp,
socklenj addrlen);
sockid - сокет, используемый для соединения
serv_addrp - указатель на структуру, где находится адрес сервера
addften - длина этой структуры
-1 - при обнаружении ошибки
0, если успех
При выполнении connect предпринимается попытка связать сокет; заданный
идентификатором sockid, с сокетом по адресу, на который указывает servjaddrp. Если попытка была
успешной, то вызов connect возвращает О, В этом случае sockid будет рассматриваться как
действующий файловый дескриптор, который открыт на чтение и запись. При записи
в этот файловый дескриптор данные передаются сокету на противоположный конец
соединения. Данные, которые будут записываться на одном конце, могут быть считаны
с помощью файлового дескриптора н& другом конце.
410 Соединение между локальными и удаленными процессами. Серверы и сокеты
Шаги 3 и 4: передача данных, а затем отсоединение
После успешного выполнения connect процесс может читать и писать данные через
файловый дескриптор, как в случае, если бы он был соединен с обычным файлом или
программным каналом. В клиент/серверной службе времени программа timeclnt просто читает одну
строку, поступившую от сервера. Клиент, после прочтения значения времени, выполняет
close в отношении файлового дескриптора и заканчивается. Если клиент неожиданно
закончится, то тогда ядро закроет открытый им файловый дескриптор.
11.5.7. Проверка работы программы timeclnt с
Далее мы не увидим картинок на нескольких страницах. Достаточно посмотреть на простой
рисунок 11.9 и вспомнить о чем идет речь. Серверный процесс развивается на одном
компьютере. Клиентский процесс на другом компьютере связывается через сеть с сервером.
Сервер посылает данные клиенту с помощью вызова write. Клиент принимает это сообщение
с помощью вызова read.
Рисунок 11.9
Процессы на различных машинах
Для полной проверки созданной нами программной системы необходимо запустить две
программы на разных машинах. Я не уверен, что это будет наглядно выглядеть в книге,
но все же проверка может быть проведена так:
$ hostname # определить имя текущей машины
computer1.mysite.net # первая машина
$ ее timeserv.c -о timeserv # создание сервера
$ ./timeserv & # и запуск его
[1] 10739
$
$ scp timeclnt.с bruce@computer2: # передать куда-либо код код клиента
bruce@computers2's password:
timeclnt.c 11 KB 11.8 kB/s | ETA: 00:00:001100%
$ ssh bruce@computer2
bruce@computer2's password:
No mail.
computer2:bruce$ cc timeclnt.c -o timeclnt
/ /. 5. Сокеты: соединения с удаленными процессами
411
computer2:bruce$ ./timeclnt computerl 13000Wow! got a call!
The time here is ..Tue Aug 14 02:44:31 2001
computer2:bruce$
Сервер был откомпилирован и запущен на computerl. Затем я скопировал программный код
клиента на компьютер computer2 и открыл сессию на компьютере computer2. На компьютере
computer2 я откомпилировал программу клиента и обратился к программе с запросом на
соединение с сервером, который работает на computerl, для подсоединения к порту 13000.
Сообщение, которое я увидел, было послано через сеть от сервера на computerl к клиенту
на computed. А клиент уже посылает сообщение на стандартней вывод.
Действительно ли я получил вывод от computed? Я подсоединен к сотри1ег2,чработая на
computerl. Поэтому терминал, на котором появилось сообщение, реально подсоединен
к computerl. Обратитесь к упражнению, где вам предлагается подумать о том, что реально
происходит?
Программы timeserv/timeclnt дают нам возможность узнать значение времени, которое
опрашивается на другом компьютере. Проверка значения времени на другом компьютере
также позволяет проводить синхронизацию часов компьютера. Одна из машин в сети
может отвечать за измерение времени. Другие машины могут использовать этот вид клиент/
серверной системы для периодической переустановки их часов.
/1.5.8. Другие серверы: удаленный Is
Нашим следующим проектом будет разработка программы, которая выводила бы списки
файлов на удаленном компьютере. Вы должны быть зарегистрированы на двух системах.
Что нужно сделать, если вам понадобится получить список файлов на другой машине?
Вы должны открыть сессию на другой машине и запустить на исполнение команду Is.
Более быстрым, более удобным методом будет использование программы "удаленная Is",
которая будет названа rls. При обращении к ней вы должны будете задать имя хоста и имя
каталога:
$ rls computer2.site.net /home/me/code
Естественно, для работы rls нужен серверный процесс, который должен развиваться на
другой машине и принимать запросы. После отработки запроса сервер возвращает ответ
на запрос. В данном случае система будет выглядеть так, как показано на рисунке НЛО.
На одном компьютере работает сервер. Клиент на другом компьютере связывается
с сервером и посылает ему имя каталога. В ответ сервер передает клиенту список файлов
в этом каталоге. Клиент отображает этот список, выдавая его на стандартный вывод. Такая
система, состоящая из двух процессов, обеспечивает доступ к каталогам на другом
компьютере.
-*~* li Система remote Is
Сеть
412 Соединение между локальными и удаленными процессами. Серверы и сокеты
Планирование работы системы remote Is (удаленная Is)
Для реализации системы rls нам потребуется три составляющих:
(a) протокол
(b) клиентская программа
(c) серверная программа
Протокол
Протокол состоит из запроса и ответа. Сначала клиент посылает одну строку, в которой
указано имя каталога. Сервер читает эту строку. Далее сервер открывает и читает
указанный каталог. После чего посылает клиенту список файлов. Клиент построчно читает
список файлов до тех пор, пока сервер не закроет соединение, что вызовет выработку
признака конца файла.
Клиент: rls
Г rls.c - клиент службы "remote Is"
¦ * ¦¦ использование: rls имя_хоста каталог
7
#include
#include
#include
#include
#include
#define
#define
<stdioJi>
<sys/types.h>
<sys/socket.h>
<netinet/in.h>
<netdb.h>
oops(msg)
PORTNUM
{perror(msg);exitA);}
15000
/* номер вызова */
/* структура для получения номера */
/* сркет и файловый дескриптор fd */
/* буфер для приема сообщения */
/* длина сообщения */
main(int ас, char*av[])
{
struct sockaddrjn servadd;
struct hostent *hp;
int sock id, sock fd;
charbuffer[BUFSIZ];
int njead;
if(acN3)exitA);
/** Шаг 1: получить сокет **/
sockjd = socket(AFJNET, SOCK.STREAM, 0); /* получить линию */
if (sockjd == -1)
oops("sockef);
/** Шаг 2: соединение с сервером *7
bzero(&servadd, sizeof(servadd));
hp = gethostbyname(av[1]);
if(hp==NULL)
oops(av[1]); /* или окончание */
bcopy(hp->h_addr, (struct sockaddr *)&servadd.sin_addr, hp->hjength);
servadd.sin_port = htons(PORTNUM); /* занести в данное поле номер порта 7
servadd.sin Jamily =¦ AFJNET; /* занести в данное поле тип сркета */
if (connect(sockjd,(struct sockaddr *)&servadd, sizeof(servadd)) !=0)
oops("connect");
/** Шаг З: послать имя каталога, затем поочитать пoлvчeнный оезмьтат **/
/* или неудача 7
Г обнулить адрес 7
/* поиск ip # хоста 7
/1.5. Сокеты: соединения с удаленными процессами
413
if (write(sockjd, av[2], strlen(av[2])) == -1)
oops("write");
if(write(sockjd>,,\n,M)==-1)
oops("write");
while((njead = read(sock_id, buffer, BUFSIZ)) > 0)
if (writeA, buffer, njead) == -1)
oops("write");
close(sockjd);
}
Обратите внимание на разницу между этим клиентом и клиентом службы времени.
Клиент rls сначала записывает имя каталога в сокет. В соответствии с протоколом, клиент
должен посылать строку. Поэтому клиентом использован при посылке символ newline.
Далее клиент входит в цикл, производя копирование данных от сокета на стандартный
вывод, пока не будет обнаружен признак конца файла. Программа rls.c использует
низкоуровневые вызовы write и read для передачи данных между клиентом и сервером. В цикле
используется стандартный буфер, который должен иметь подходящий размер. Далее мы
напишем сервер.
Сервер: rlsd
Сервер получает сокет, выполняет bind, listen, а затем accept, чтобы воспринять запрос.
После приема запроса сервер читает имя каталога из сокета. Потом он формирует список
файлов из указанного каталога. Как сервер получает список файлов из каталога? Мы
могли бы скопировать нашу версию команды Is из главы 3. Но мы можем также использовать
более простой метод - просто используем рореп, чтобы прочитать вывод, который будет
получен при работе обычной команды Is (см. рисунок 11.11).
Клиент
ШШШШШ#ШШ&ё№%№1ШЯШ
Запрос от клиента
?шше&&шттшт8шшс* i»i
ывод результатов команды Is
Рисунок 11.11
Использование рореп ("Is") для получения списка файлов из удаленных каталогов
В последующем коде используется рореп по отношению к этому концу:
Г rlsd.c - сервер "remote Is"- без паранойи
7
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
4 Соединение между локальными и удаленными процессами. Серверы и сокеты
#include <sys/socket.h>
#include <netinet/in.h>
#include <netdb.h>
#include <time.h>
#include <strings.h>
#define PORTNUM15000
#define HOSTLEN256
#define oops(msg) {perror(msg); exit( 1)
int main(intac, char *av[])
i
struct sockaddrjn saddr;
struct hostent *hp;
char hostname[HOSTLEN];
int sockjd.sockjd;
FILE *sockJpi, *sock_fpo;
FILE *pipe_fp;
char dirname[BUFSIZ];
char command[BUFSIZ];
int dirlen, c;
/* порт нашего сервера "remote ls
;}
/* сюда будет помещен адрес */
/* это часть нашего */
Г адреса 7
/* идентификатор линии, файловый дескриптор */
Г потоки для ввода и вывода */
/* использовать рореп для запуска Is */
Г из клиента */
Лдлярореп(O
/** Шаг 1: обратиться к ядру для образов&ния сокета **/
sock id = socket(PF INET, SOCK STREAM, 0); /* получить сокет */
if(sock_id==-1)
oops(Msocket");
/** Шаг 2: связать адрес с сокетом. Адрес: имя_хоста, порт **/
bzero((void *)&saddr, sizeof(saddr));
gethostname(hostname, HOSTLEN);
hp = gethostbyname(hostname);
bcopy((void *)hp->h_addr, (void
saddr.sin.port = htons(PORTNUM);
saddr.sinjamily = AFJNET;
if (bind(sockjd, (struct sockaddr
oopsfbind");
/* очистить структуру 7
/* где я нахожусь? 7
/* получить информацию о хосте 7
*)&saddr.sin_addr, hp->hjength);
/* установить номер порта сокета */
/* установить семейство адресов */
*)&saddr, sizeof(saddr)) != 0)
/** Шаг З: готовность принимать входящие запросы на сокете в очереди с размером Qsize=1 **/
if (listen(sockjd, 1)!=0)
oops("listen");
Г
* основной цикл: accept(), write(), close()
7
while A){
sockjd = accept(sock_id, NULL, NULL); /* ожидать запрос 7
if (sockJd==-1)
oops("acceptM);
/* открыть конец на чтение, как буферируемый поток 7
if((sock_fpi = fdopen(sockJd,"rM)) ==
= NULL)
""* ~ oops("fdopen reading");
if (fgets(dirname, BUFSIZ-5, sockjpi) == NULL)
/ /. 5. Сокеты: соединения с удаленными процессами
415
oopsf'reading dirname'");
sanitize(dimame);
Г открыть записывающий конец, как буферируемый поток */
if ((sockfpo = fdopenlsockJd/W)) == NULL)
oopsffdopen writing");
sprintficommand/'ls %s", dirname);
if ((pipejp = popen(command, Y)) == NULL)
oops("popenM);
/* передача данных от Is к сокету */
while((c = getc(pipejp)) != EOF)
putc(c, sockjpo);
pclose(pipejp);
fclose(sockjpo);
fclose(sock fpi);
}
у
sanitizefchar *str)
Л
* Будет очень плохо, если кто-либо передаст имя каталога в формате:
¦ *"; rm *", а мы наивно сочтем этот текст как команду "Is; rm *"
* Поэтому... это приведет к удалению всех файлов
* Более надежное решение следует реализовать в качестве упражнения
7
{
char *src, *dest;
for (src = dest = str; *src; src++)
if (*src == 7 || isalnum(*src))
*dest++ = *src;
*dest='\0';
}
Следует заметить, что наш сервер использует стандартные буферируемые потоки для-чте-
ния и для записи. Сервер использует fgets для чтения имени каталога от клиента. После
вызова рореп сервер передает данные, используя для этого getc и putc, что аналогично рабо^
те по копированию файла. На самом же деле сервер копирует данные от одного процесса
к другому, который находится на другом компьютере.
Обратите внимание на функцию sanitize. Любой сервер, который запускает команды
с использованием аргументов и данных, которые он принимает через Internet, должен
быть написан очень аккуратно. Наш сервер ожидает приема от клиента имени каталога
.Далее сервер присоединяет этот принятый текст к команде Is. Например, если клиент
посылает строку "/bin", то наш сервер создаст и выполнит строку "Is /bin", которая является
правильной. Однако если кто-либо пошлет серверу строку вида"; rm *", то наш сервер
создаст и выполнит строку "Is; rm *".
Для уменьшения риска появления ошибок наша программа преполагает, что строка,
которую она принимает, не выйдет за пределы буфера; не будет переполнения буфера для
команды; не будут использованы специальные символы в имени каталога. Конечно,
последнее ограничение, которое требует использования в имени только алфавитно-цифро-
416
Соединение между локальными и удаленными процессами. Серверы и сокеты
вых символов, слишком сильное. Использование функции рореп при построении сетевого
сервиса слишком рискованно, поскольку она передает строку для shell. Идею передачи
строк для shell при создании сетевых служб следует считать устаревшей идеей. Я включил
этот пример по двум соображениям. Во-первых, чтобы показать еще один вариант
использования рореп. И во-вторых, чтобы предупредить вас об опасности такого использования.
Это представляется важным.
11.6. Программные демоны
Серверные программы, как большая часть программ, имеют короткие, выразительные
имена, Многие серверные программы имеют в конце имени символ d. Например, httpd, inetd,
syslogd, atd. С помощью символа dуказывается, что данная программа является демоном. Таким
образом, syslogd идентифицирует программу которая является демоном системного журнала
{system log daemon). Термин "демон" обозначает спиритического слугу, который в любой
момент выступает для вас в роли некого паранормального помощника. Он постоянно витает,
ожидая возможности прийти вам на помощь. В вашей системе нужно набрать для
исполнения команду ps -el или ps -ax, чтобы посмотреть процессы, в которых исполняются
программы с именами, которые заканчиваются символом d. В справочнике помещена информация
об этих командах. Кроме того, вы можете узнать дополнительную информацию о вариантах
использования в Unix базовых операций при программировании клиент/серверных
приложений.
Большая часть демонов стартует, когда начинает работать система. Скрипты shell в
каталоге с именем вида /etc/red3 стартуют в фоновом режиме. Они работают с отсоединенными
терминалами, готовые производить обработку данных или поддерживать какой-то сервис.
Заключение
Основные идеи
• Некоторые программы при исполнении представляют отдельные процессы, которые
выдают и принимают данные. В системе клиент/сервер серверный процесс
производит обработку данных или поставляет некоторые данные для клиентских процессов.
• В системе клиент/сервер имеются средства связи и протокол. Клиенты и серверы могут
взаимодействовать через программные каналы или сокеты. Протокол представляет собой
набор правил для организации общения между клиентом и сервером.
• Библиотечная функция рореп может выполнить произвольную команду shell в серверной
программе. В результате доступ к серверу представляется таким, будто это буферируемый
доступ к файлу.
• Программный канал доступен для использования через пару связанных файловых
дескрипторов. Клиентский процесс создает коммуникационную линию посредством
соединения своего сокета с сокетом сервера.
• Соединения между сокетами могут быть установлены, когда они находятся на разных
машинах. Каждый сокет идентифицируется номером машины и номером порта.1
• При установлении соединений с помощью программных каналов и сокетов
используются файловые дескрипторы. Файловое дескрипторы дают программе простой
интерфейс для связи с файлами, устройствами и другими процессами.
3. Конкретное имя каталога зависит от версии Unix.
Заключение
417
Что дальше?
В этой главе мы рассмотрели программный проект, где была реализована модель клиент/
сервер. Мы рассмотрели два метода для связывания процессов: программные каналы и со-
кеты. В следующей главе мы сфокусируем внимание на принципах проектирования,
которые используются в клиент/серверном программировании. Мы напишем при этом
более сложные приложения. В частности, мы объединим программирование сокетов с
нашим знанием файловых систем и средств управления процессами и напишем Web-сервер
Исследования
11.1 Протокол доставки пиццы. Что произойдет, если вы решили вместо службы времени
или справочной службы заняться бизнесом по доставке пиццы? В данной службе
протокол будет более сложным. Опишите последовательность сообщений, которые
передаются между клиентом, и сервером в службе по доставке пиццы. Заметьте, что этот
протокол содержит цикл, который дает возможность клиенту добавить несколько
пунктов к порядку доставки.
11.2 Сигналы и функция рореп. Версия рореп, которая была представлена в тексте, не
ориентирована на сигналы. Правильно ли это? Дочерний процесс наследует диспозиции
по управлению сигналами от процесса-отца: убить процесс, проигнорировать сигнал,
вызвать функцию по обработке сигнала.
11.3 Поток данных при проверке работы программы timeserv. Пример запуска сервера и
клиента службы времени показал, что я использовал ssh для получения доступа
к computer2 с компьютера computerl. С помощью этого shell я откомпилировал и запустил
на исполнение клиента.
Мой терминал на самом деле присоединен к компьютеру computerl. Перерисуйте
рисунок 11.11 так, чтобы на нем был показан мой shell на компьютере computerl, мой shell на
компьютере computed, мой терминал и корректный поток данных от клиента timeclnt
к моему терминалу. Получится достаточно сложный поток , не так ли?
11.4 Сокеты не являются файлами. Мы уже предварительно убедились, что дисковые
файлы и файлы устройств поддерживают один и тот же стандартный файловый
интерфейс. Но соединения с дисковыми файлами имеют один набдр свойств, а
соединения с файлами устройств имеют другой набор. А какие специальные свойства будут
характерны для сокетов? Обратитесь за деталями к справочнику на странице setsockopt.
11.5 Серверы и stderr. Сервер "remote Is" при работе запускает команду Is. Что произойдет,
если при выполнении команды Is будет обнаружена ошибка? Рассмотрите две
особенности управления сообщениями об ошибках. Во-первых, следует решить вопрос - как
вы будете посылать клиенту сообщения об ошибках? Во-вторых, как вы будете
записывать ошибочные сообщения в журнал и сообщать пользователю о возникшей
проблеме?
Программные упражнения
11.6 Добавьте опцию -с в программу tinybc. После добавления этой опции должен работать
вот такой конвейер:
printf + 2\п4 * 4\пи | tinybc -с i dc
11.7 Добавьте опцию -с для вашего shell. Какие для этого потребуются изменения?
418 Соединение между локальными и удаленными процессами. Серверы и сокеты
11.8 Напишите функцию pclose. При обращении к данной функции задается аргумент RLE*,
что является результатом работы рореп. Функция выделяет память для буфера и для
учетных деталей. Функция fclose освобождает эту память и закрывает
соответствующий файловый дескриптор. Что должна делать по аналогии функция pclose? Что
случится, если дочерний процесс погибнет между вызовом рореп и вызовом pclose?
11.9 Идентификатор вызывателя. Наш сервер службы времени не использовал
возможность работы с идентификатором вызывателя, которая поддерживается в системном
вызове accept. Модифицируйте программу timeserv.c так, чтобы она по мере
поступления запроса выдавала бы сообщение в виде:
Got a call from 123.123.123.123 (computer2.mysite.net).
Обратитесь к справочнику и соответствующим заголовочным файлам для изучения тех
функций и структур, которые вам понадобятся при выполнении этого проекта.
11.10 Напишите программу, которая использует sort в качестве подпрограммы. Ваша
программа должна читать строки данных в массив строк. Затем программа должна создать
два программных канала и процесс для запуска sort. Пошлите последовательность
строк на вход sort через один канал. Затем закройте этот канал. Прочитайте результаты,
полученные в результате работы sort, через другой канал. Перешлите результаты в
массив. Выведите содержимое массива на экран.
11.11 Двунаправленные программные каналы. В версиях Unix, которые поддерживают
концепции System V, используются двунаправленные программные каналы. Вы можете
проверить, поддерживаются ли в вашей версии Unix такие каналы, с помощью запуска
такой программы:
/*
* testbpd.c - проверка наличия двунаправленных каналов
7
main()
{
intp[2];
if (pipe(p) == -1) exitA);
if(write(p[0],,,hello,,,5)==-1)
perrorf'write into pipe[0] failed");
else
printf("write into pipe[0] worked\nM);
}
I
Внутренняя структура такого канала такова, что поддерживаются две очереди. Одна
строится от pipe[0] к pipe[l], а другая - в противоположном направлении. Запись
данных через один конец канала добавляет данные к очереди, которая направлена к
другому концу канала. А чтение данных с одного конца канала.приводит к извлечению
данных из очереди, которая направлена к другому концу канала.
Если ваша система не поддерживает двунаправленные каналы, то вы можете создать
такую пару:
#include <sys/types.h>
#include <sys/socket.h>
intapipe[2];/* канал */
socketpair(AFUNIX, S0CK_STREAM, PF_UNSPEC5 apipe); {
Перепишите программу tinybc.c так, чтобы она использовала один двунаправленный
программный канал, а не два однонаправленных канала.
Заключение
419
11.12 Блокировка IP. Модифицируйте программу timeserv.c так, чтобы она отвечала на
клиентские запросы только по определенному IP хоста. Сервер должен принимать запрос
и проверять адрес клиента. Если клиент указывает недопустимый адрес, то сервер
разрывает соединение. В противном случае сервер посылает клиенту сообщение о
текущем времени.
Расширьте это блокирующее свойство так, чтобы сервер мог читать список доступных
номеров IP из файла. Опишите, какие вы знаете практические приложения, которые
используют такую технику.
11.13 Увеличение безопасности. Использование рореп в сервере является весьма
рискованным. Есть два способа уменьшить степень риска. Во-первых, можно написать более
гибкую, более безопасную версию функции sanitize. Например, не возникает проблем
с именами каталогов, в составе которых содержатся символы точки, тире, пробела,
многие другие символы. Но в именах каталогов могут содержаться символы звездочки
и точки с запятой. А для этих символов установлен особый смысл в shell. Напишите
более приемлемую функцию, которая увеличивает безопасность.
Другой метод - не использовать рореп, а вместо нее использовать fork, exec, dup и т. д.
Перепишите программу risd.c на основе данного предложения. Понадобится ли вам при
этом использовать wait? Почему да или почему нет?
11.14 Finger-сервер. Напишите версию сервера для телефонной справочной службы, к
которой мы обращались через порт 79. Сервер должен принимать в одной строке
пользовательское имя, а посылать в ответ клиенту список записей, которые были найдены по
его запросу.
11.15 Прокси сервера слуэюбы времени. Прокси - это программа, которая принимает ваше
требование, передает его на другой сервер, а затем пересылает вам ответ от этого
сервера. Все происходит аналогично как работает приемный пункт химчистки. Здесь
одежду только принимают, но не чистят. Одежда пересылается на предприятие для
чистки, а потом забирается оттуда и выдается клиенту.
Напишите прокси для сервера службы времени. Ваша программа должна принимать
запросы на соединения через стандартный порт. Для выполнения соединения ваша
программа должна открыть соединение с сервером "реального" времени, должна
получить значение времени от сервера и послать полученное значение обратно вашему
клиенту.
11.16 Прокси и кеши. Прочтите об использовании прокси-серверов в предшествующем
пункте. Время изменяется с дискретностью один раз в секунду. Поэтому, если ваш
прокси-сервер получает много запросов, поступающих через миллисекундные отрезки
времени, то нет резона на каждый запрос от клиента обращаться к серверу. Напишите
кеш-прокси-сервер для службы времени, сохраняющий значение времени, которое он
считал от сервера. Он обращается к серверу, только если предварительно считанная
строка от этого сервера хранится у него более одной секунды (см. gettimeofday).
11.17 Еще о кешировани и прокси. Кеширование для сервера службы времени, которое
было рассмотрено в предшествующем упражнении, довольно простая идея.
Объясните, почему можно использовать кеширования для finger-сервера. Напишите finger-
сервер, который поддерживает кеш с пользовательской информацией.
Сервер службы времени имеет вполне очевидный срок хранения отдельного элемента
информации в кеше. А сколько времени следует хранить пользовательскую
информацию в кеше для finger-сервера?
420 , Соединение между локальными и удаленными процессами. Серверы и сокеты
HAS Сервер для "выпечки" номеров. В некоторых булочных-пекарнях есть автомат,
который выдает номера покупателей. Обозначение на счетчике, означающее "сейчас
обслуживается", будет отображать номер следующего покупателя, который будет
обслужен. Разработайте клиент/серверную систему для "выпечки " номеров. Сервер
вырабатывает последовательные номера. Пользователь запускает клиентскую программу для
получения номера от сервера.
11.19 Использование рореп Каждый С-программист знает, что в argv [0] обычно содержится
имя программы, которая запущена. Есть и другой, достаточно экзотический способ,
с помощью которого процесс может получить имя своей исполняемой программы.
Программа может использовать рореп ив выводе ps отыскать программу с собственным
идентификатором процесса. Напишите программу, которая использует этот метод.
Глава 12
Соединения и протоколы.
Разработка Web-сервера
Цели
Идеи и средства
• Сокеты на сервере: цель и устройство.
• Сокеты на клиенте: цель и устройство.
• Протокол системы клиент/сервер.
• Проект сервера: использование fork для множества запросов.
• Проблема зомби.
• HTTP.
12.1. В центре внимания - сервер
Использовать World Wide Web (глобальную паутину) достаточно просто. Следует набрать
Web-адрес в броузере или кликнуть на ссылке. И с удаленного компьютера будет доставлена
Web-страница. А как работает Web? Передача страницы от Web-сайта производится таким же
образом, как проходила передача текущего времени от сервера службы времени?
Большая часть клиент/серверных систем, использующих механизм сокетов, достаточно
похожи. Электронная почта, файловый сервер, средство удаленного доступа,
распределенные базы данных и многие другие Internet-сервисы выглядят по-разному при
представлении на экране, но работают они одинаково.
После освоения какой-либо клиент/серверной системы, использующей механизм сокетов
потока, нам будет достаточно просто понять, как работает большинство других таких
систем. В этой главе мы рассмотрим базовые операции и принципы проектирования, которые
являются общими для сетевых программ. Далее эти абстракции будут применены при
написании Web-сервера.
422
Соединения и протоколы. Разработка Web-сервера
12.2. Три основные операции
В главе 11 мы убедились в том, что клиент/серверные системы, использующие сокеты
потока, имеют структуры, которые аналогичны структуре на рисунке 12.1. Клиенты
и серверы являются процессами. На сервере устанавливается некий сервис, затем сервер
входит в цикл получения и обслуживания запросов.
Клиент
\
У
Сервер
^-^
__JU \1
ц— i,,,,,.-™.
Ч N
1 Л i ¦
1 1 1
1 f
^BrL-J
_ли_г
?=т^
/
г
1 1 1 1
1
¦-¦'¦¦¦:-r---\xm
,х*]
щ
Клиент:
соединение с сервером .
получение сервиса
отсоединение
Сервер:
установка сервера
•¦>- прием-запрос -¦—i
•«>¦обеспечениесервиса I
отсоединение — «J
Рисунок 12.1
Основные компоненты схемы клиент/серверного взаимодействия
Клиент соединяется с сервером, посылает запросы серверу, принимает данные от сервера,
рассчитывается с сервером и заканчивается. В таком взаимодействии задействованы три
основные операции:
1. Сервер устанавливает сервис.
2. Клиент соединяется с сервером.
3. Сервер и клиент выполняют необходимые финансовые действия.
Рассмотрим сначала каждую из этих операций.
12.3. Операции 1 и 2: установление соединения
Для работы поточных систем необходима установка соединения. Рассмотрим
последовательность шагов по установке соединения и затем сопоставим этим шагам необходимые
библиотечные функции.
12.3.1. Операция 1: установка сокета на сервере
Сначала, как это показано на рисунке 12.2, сервер устанавливает сервис. Заметим, что
каждый поточный сервер при установке сервиса выполняет три таких шага:
(a) Создать сокет.
sock = socket(PF_INET, SOCK.STREAM, 0)
(b) Связать сокет с адресом.
bind(sock, &addr, sizeof(addr))
12.3. Операции 1 и 2:установление соединения
423
mm
Шаг1:
Создание сокета на сервере
Рисунок 12.2
Создание сокета на сервере.
(с) Перейти в состояние приема (режим прослушивания) входящих запросов.
listen(sock, queue_size)
Чтобы каждый раз не раскрывать эти шаги для каждого сервера, которые мы будем
разрабатывать, объединим эту процедуру из трех шагов в простую функцию: makeserversocket.
Код этой функции будет находиться в файле socklib.c, текст которого будет приведен далее
в этой главе. Когда мы будем писать различные сервера, то мы будем обращаться к
указанной функции. При этом будем учитывать такие особенности:
sock = make_server_socket(int portnum)
возвращается -1 - при ошибке
при успешном выполнении будет создан сокет на сервере, который прослушивает порт "portnum"
12.3.2. Операция 2: соединение с сервером
Далее клиент соединяется с сервером (см. рисунок 12.3). Поточные сетевые клиенты
соединяются с серверами по мере выполнения таких двух шагов:
(а) Создать сокет.
sock = socket(PFJNET, SOCK.STREAM, 0)
(b) Использовать сокет для установления соединения с сервером.
connect(sock, &sery_addr, sizeof(serv_addr))
Сведем эти два шага в одну функцию connect_to_server, код которой будет приведен позже
в составе программы socklib.c. Когда мы будем писать коды для различных клиентов, то мы
будем обращаться к этой функции.
При этом будем учитывать такие особенности:
fd = connectJo_server(hostname, portnum)
возвращается -1 - при ошибке
Шаг 2:
Создание
и соединение
с сокетом на клиенте
Рисунок 12.3
Соединение с сервером
I I I I, i j
рр
¦
При успешном выполнении будет открыт дескриптор на чтение и запись. Он будет
соединен с сокетом "portnum" на хосте "hostname".
424 Соединения и протоколы. Разработка Wei
12.3.3. socklib.c
Далее представлен программный код программы socklib.c:
Г socklib.c
*
* В этом файле содержатся функции, которые часто используются при написании
* клиент/серверных программ для Интернет.
* Здесь представлены основные функции:
* int make_server_socket(portnum)
* Возвращает сокет на сервере при успехе
* или-1 -при ошибке
* int make_server_socket_q(portnum,backlog)
* int connecUo_server(char *hostname, int portnum)
* Возвращает присоединенный сокет при успехе
* или-1 -при ошибке
7
#inciude
#include
#include
#!nclude
#include
#include
#include
#include
#define
#define
<stdio.h>
<unistd.h>
<sys/types.h>
<sys/socket.h>
<netinet/in.h>
<netdb.h>
<time.h>
<strings.h>
HOSTLEN 256
BACKLOG 1
int make server socket(int portnum)
{
return make server_socket q(portnum, BACKLOG);
}
int make server socket q(int portnum, int backlog)
{
struct sockaddrjn saddr; /* здесь будет наш адрес */
struct hostent *hp; /* это часть нашего */
charhostname[HOSTLEN]; ./* адреса 7
intsockjd; /* сокет */
sockjd = socket(PF_INET, SOCK_STREAM, 0); Л получить сокет */
if (sockjd == -1)
return -1;
/** построить адрес и связать его с сокетом **/
bzero((void *)&saddr, sizeof(saddr)); /* очистить нашу структуру */
gethostname(hostname, HOSTLEN); /* где я нахожусь? */
hp = gethostbyname(hostname); Г получить информацию о хосте */
Г заполнить поле хоста 7
bcopy((void *)hp->h_addr, (void *)&saddr.sin_addr, hp->h_length);
saddr.sin^port = htons(portnum); /* ycfaHOBHTb номер порта для сокета */
saddr.sin Jamily = AFJNET; /* установить семейство адресов */
if (bind(sock_id, (struct sockaddr *)&saddr, sizeof(saddr)) != 0)
return -1;
12.4. Операция 3: взаимодействие между клиентом и сервером
425
Г* переход в режим приема входящих запросов **/
if (listen(sockJd, backlog) != 0)
return-1;
return sock id;
}
int connectjo server(char *host, intportnum)
{
int sock;
struct sockaddrjn servadd; /* номер запроса */
struct hostent *hp; /* используется для получения номера */
/** Шаг 1: получить сокет **/
sock = socket(AFJNET, SOCKSTREAM, 0);/* получить линию */
if (sock ==-1)
return-1;
/** Шаг 2: соединение с сервером **/
bzero(&servadd, sizeof(servadd)); /* обнулить адрес */
hp = gethostbyname(host); Г получить ip # хоста */
if (hp== NULL)
return -1;
bcopy(hp- >h_addr, (struct sockaddr *)&servadd.sin_addr, hp->
hjength);
servadd.sin^port = htons(portnum); /* установить номер порта */
servadd.sinjamiiy = AFJNET; /* установить тип сокета */
if (connect(sock, (struct sockaddr *)&servadd, sizeof (servadd))
!=0)
return-1;
return sock;
}
12.4. Операция З: взаимодействие между клиентом и сервером
У нас есть функция для создания сокета на сервере и функция для соединения с сокетом
на сервере. Как можно будет использовать на практике эти новые функции? Как отнесутся
клиент и сервер к каждой из них? В этой секции мы рассмотрим обобщенное
представление клиентской программы, обобщенную форму серверной программы, а также
некоторые проектные решения по созданию сервера.
Типичный клиент
Сетевой клиент вызывает сервер и получает в ответ некий сервис. Типичный клиент будет
выглядеть так:
main()
{
int fd;
fd = connect to server(host, port); /* вызов сервера 7
if(fd==-lf "
exit( 1); /* или окончание работы */
talk_with_server(fd); /* диалог с сервером */
close(fd); Г отсоединение, когда все сделано 7
}
Функция talk_with_server управляет диалогом с сервером. Детали функции зависят от
приложения. Например, клиент электронной почты будет "вести разговор" с почтовым
сервером относительно почты, а клиента службы прогноза погоды будет интересовать
погода.
426
Соединения и протоколы. Разработка Web-сервера
Типичный сервер
Типичный сервер будет выглядеть так:
main()
{
int sock, fd;
sock = make_server_socket(port);
if (sock =.= -1)
exitA);
/* сокет и соединение 7
whlleA){
fd = accept(sock, NULL, NULL);
if (fd == -1)
break;
processjequest(fd);
close(fd);
/* получить очередной запрос 7
Г или закончиться 7
/* диалог с клиентом 7
Г отсоединение, когда все сделано 7
}
}
Функция processjequest управляет диалогом с клиентом. Детали этой функции зависят от
приложения. Например, почтовый сервер сообщает клиенту о письмах, а сервер службы
прогноза погоды сообщает клиенту, какой будет погода.
12.4.1. timeserv/timeclnt, использующие socklib.c
Как можно использовать эти два типовых прототипа для построения клиент/серверных
систем? Например, что нужно сделать с нашей клиент/серверной службой времени, чтобы
она удовлетворяла бы этой модели? На рисунке 12.4 проиллюстрировано, как достигнуть
данного соответствия. Для того, чтобы написать клиентские и серверные программы для
службы времени с использованием socklib.c, мы напишем функции, которые поддерживают
диалог: функцию talk_with_server для клиента и функцию processjequest для сервера службы
времени:
Ш
Рисунок 12.4
Сервер и клиент для службы времени (версия 1)
talk with_server(fd)
{
charbuf[LEN];
intn;
n=read(fd,buf,LEN);
process request(fd)
{
timej now;
char *cp;
time(&now);
12.4. Операция 3: взаимодействие между клиентом и сервером 427
writeA,buf,n);
ср = ctime(&now);
writeffd, cp, strlen(cp));
Сервер с помощью вызова time получает от ядра текущее время. Далее он выполняет ctime,
чтобы преобразовать полученное числовое значение времени в печатный формат. Сервер
записывает эту строку в сокет, что приводит к пересылке этой строки на сокет клиента.
Клиент читает строку из сокета и записывает ее на стандартный вывод. В этой новой
версии поддерживается та же логика, как и в предшествующей версии. Но мы получили
более модульный проект, а код стал понятнее.
12.4.2. Вторая версия сервера: использование fork
Рассмотрим теперь вторую версию сервера службы времени. Здесь вместо получения
текущего времени будет использована команда Unix date. На рисунке 12.5 показаны
введенные элементы. Код будет такой:
processjequest(fd)
Г
* послать дату клиенту через fd
7
{
intpid = fork();
switch(pid){
date 7
case -1: return; /* сервис не предоставлен7
caseO: dup2(fd, 1);
/* дочерний процесс запускает
close(fd); /* перенаправление stdout 7
execl( /bin/date","date",NULL);
oopsfexeclp"
default: wait(NULL);
/* или заканчивается 7
/* родительский процесс ждет дочерний * процесс 7
timed
date
Рисунок 12.5
Сервер выполняет fork для запуска программы date
Как показано на рисунке, сервер с помощью fork создает новый процесс. Дочерний
процесс перенаправляет стандартный вывод на сокет, а затем выполняет команду date.
Команда date вычисляет дату и записывает полученный результат на стандартный вывод, что
в результате приводит к посылке этого результата клиенту. В этой программе мы
использовали вызов wait. Обычно shell вызывает wait после вызова fork. А какой смысл вызова wait
в данном случае? Далее мы рассмотрим этот вопрос .
428
Соединения и протоколы. Разработка Web-сервера
12.4.3. Вопрос по ходу проектирования: делать самому и делегировать
работу другому?
Служба времени иллюстрирует нам возможность использования двух типов серверов:
Делаю все сам - сервер выбирает запрос и выполняет сам работы по данному запросу.
Делегирую - сервер выбирает запрос, а затем с помощью fork порождает процесс,
который выполняет работы по полученному запросу.
Какие преимущества и недостатки у этих методов?
Делаю сам, когда выполняются быстрые, простые задачи. Для определения текущей
даты и времени требуется всего один системный вызов time и библиотечная функция ctime.
При использовании fork и exec для запуска команды date потребуется не менее трех
системных вызовов и в системе появится новый процесс. Для некоторых серверов наиболее
эффективным методом будет выполнение работы самим сервером и управление очередью
запросов через listen. При обращении к функции make_server_socket_q в программе socklib.c
размер очереди задается через аргумент функции.
Делегирую, когда выполняются более медленные, более сложные задачи. Серверы,
которые выполняют продолжительные по времени задачи или задачи, которые
предполагают ожидание распределения ресурсов, делегируют свою работу. Происходит то, что
делает работник в приемной офиса, который принимает входящие звонки. Он может
переключать абонента на службу продаж в вашем офисе или на конкретную персону. После
чего он опять переходит к приему новых входящих звонков. Работая по такой схеме,
сервер может управлять одновременно многими запросами. Для одновременного
обслуживания нескольких клиентов сервер не должен выдавать wait чтобы ждать окончания
дочернего процесса, который управляет запросом. Но если родительский процесс не
выдает wait, то его дочерний процесс при окончании становится зомби. Каким образом сервер
может предотвратить появление зомби?
Использование сигнала SIGCHLD для предотвращения зомби. Вместо того чтобы
ждать, когда умрет дочерний процесс, родительский процесс может настроиться на прием
сигнала, который возникает при окончании дочернего процесса. В главе 8 было
рассмотрено, что ядро посылает процессу-отцу сигнал SIGCHLD, когда дочерний процесс
выполняет вызов exit или когда дочерний процесс будет кем-то убит. Но в отличие от
других сигналов, сигнал SIGCHLD игнорируется по умолчанию. Процесс-отец может
установить обработчик сигнала SIGCHLD. В этом обработчике можно вызвать wait. Самое простое
решение будет выглядеть так:
Г Самое простое использование обработчика сигнала SIGCHLD, в котором вызывается
* wait() 7
main()
{
int sock, fd;
void child_waiter(int), process request(int);
signal(SIGCHLD, child_waiter);
if ((sock = make_server_socket(PORTNUM)) ==-1)
oops("make_server_sockef);
whileA){
fd = accept(sock,NULL,NULL);
if (fd ===== -1)
break;
processjequest(fd);
close(fd);
\
12.4. Операция 3: взаимодействие между клиентом и сервером
429
}
void child_waiter(int signum)
{
wait(NULL);
} '
void process request(int fd)
{
if (fork() == 0){ Г дочерний процесс 7
dup2(fd, 1); /* перенаправить сокет на fd 1 */
close(fd); /* закрыть сокет 7
execlp("date,,,,,date",NULL); Г выполнить по exec команду date 7
oopsfexeclp date");
}
}
Рассмотрим поток управления в этой программе. Поступает запрос. Процесс-отец
вызывает fork. Затем процесс-отец возвращается на прием следующего запроса. Дочерний
процесс при этом должен выполнить работу по запросу. Когда дочерний процесс закончится,
процесс-отец получит сигнал SIGCHLD. Управление передается на функцию обработки
сигнала, и выполняется вызов wait. Дочерний процесс удаляется из таблицы процессов,
а в процессе-отце управление передается от обработчика в функцию main. Звучат
фанфары! Но остались две проблемы - одна простая, а другая более тонкая. Простая проблема
заключается в том, что при передаче управления на обработчик сигнала прерывается
системный вызов accept. Будучи прерванным по сигналу, системный вызов accept возвращает-
1, а в переменной ептю-значение EINTR. В нашем коде анализируется значение -1,
возвращаемое accept. В данной ситуации будет зафиксирована ошибка и произойдет окончание
работы основного цикла. Нам понадобится модифицировать функцию main, чтобы
различать ошибочную ситуацию и ситуацию, которая возникает при прерывании системного
вызова. Такую модификацию следует сделать в качестве упражнения.
Решение более тонкой проблемы будет зависеть от того, как в данной версии Unix
производится управление множеством сигналов. Что произойдет, если несколько дочерних
процессов выполнят одновременно вызов exit? Пусть процессу-отцу в некоторой ситуации
сразу было послано три сигнала SIGCHLD. Первый сигнал был воспринят процессом-отцом,
и управление было передано обработчику сигналов. Процесс-отец затем вызывает wait,
чтобы удалить дочерний процесс из таблицы процессов. Пока все нормально?
Когда процесс-отец занят выполнением обработчика сигнала, ему поступил второй
сигнал. В Unix поддерживается механизм блокировки сигналов, но не поддерживается
накопление поступающих сигналов в очереди. Поэтому второй сигнал будет блокирован,
а третий сигнал будет потерян. Если на интервале времени, когда работает обработчик
сигнала, поступят еще сигналы от дочерних процессов (после выполнения в них exit), то они
также будут потеряны.
Обработчик сигнала вызывает wait только один раз. Поэтому каждый потерянный сигнал
означает уменьшение обращений к wait на единицу. А это в свою очередь означает
увеличение на единицу числа зомби. Для решения проблемы обработчик сигналов должен
вызывать необходимое число раз wait, чтобы удалить все зомби. Проблему можно решить
с помощью системного вызова waitpid:
void child_waiter(int signum)
{
while(waitpid(-1, NULL, WNOHANG) > 0)
430
Соединения и протоколы. Разработка Web-сервера
Вызов waitpid воспроизводит развернутое множество функций wait. При обращении к
вызову с помощью первого аргумента задается идентификатор процесса, окончания которого
необходимо дождаться. Если в качестве первого элемента задается -1, то это означает
требование ожидать окончания всех дочерних процессов. Второй аргумент - это указатель
на целое число, которое будет определять статус при возврате. В данном случае сервер
не интересуется, что случается с его дочерними процессами при их окончании. В более
развитых вариантах сервер может использовать статусную информацию для определения
причин окончания процессов. Через последний аргумент задаются опции для waitpid.
Опция WNOHANG указывает, что нет необходимости ждать, если зомби отсутствует.
Этот цикл повторяется до тех пор, пока не будут закончены все ожидаемые процессы.
Даже если закончатся сразу все дочерние процессы и при этом каждый выработает сигнал
SIGCHLD, то все эти дочерние процессы будут обнаружены.
12.5. Написание Web-сервера
Мы теперь располагаем вполне достаточной информацией для того, чтобы написать Web-
сервер. Web-сервер ~ это, по сути, расширенный вариант сервера просмотра каталогов,
который мы уже написали. Дополнительными частями будут сервер cat и сервер exec.
12.5.1. Что делает Web-сервер
Web-сервер реализует простую концепцию. Web-сервер - это программа, в которой
выполняются три наиболее значимых для пользователя действия:
(a) получение списка каталогов
(b) выполнение команды cat в отношении файлов
(c) запуск программ
Web-сервер
a) запуск программ,
b) отображение файлов,
c) получение списка каталогов
Ответ
Рисунок 12.6
Web-сервер обеспечивает удаленное выполнение Is, cat, exec
Логика Web-сервера и клиента
Web-сервер предоставляет пользователям возможность выполнять эти три действия на
удаленных машинах, используя при этом соединения с помощью сокетов потока
(см. рисунок 12.6). Пользователи запускают клиентские программы на своих машинах
и устанавливают соединение с нашим сервером, чтобы послать запрос на сервер. А Web-
сервер посылает клиентам в ответ затребованную информацию. Последующий перечень
действий иллюстрирует, каким образом будет протекать работа:
12.5. Написание Web-сервера
/ 431
клиент сервер
пользователь выбирает ссылку
выполнить connect в отношении сервера —> вызов accept
выдать запрос с помощью write —> прочитать запрос с помощью read
Удовлетворение запроса:
каталог: список файлов в каталоге
обычный файл: выдать cat для файла
файл.сдк запустить файл на исполнение
не существует: сообщение об ошибке
читать ответ с помощью read <— выдать ответ с помощью write
отсоединиться
Отобразить ответ:
html: визуализировать
картинка: нарисовать
звук: воспроизвести
повторить
12.5.2. Планирование работы нашего Web-сервера
Какие действия нам необходимо запрограммировать?
(а) Установка сервера
Мы можем использовать make_server_socket из программы socklib.c.
(b) Получить запрос
Использовать accept для получения файлового дескриптора клиента. Мы можем
использовать fdopen для того, чтобы преобразовать этот файловый дескриптор
в буферируемый поток.
(с) Прочитать запрос
Как должен выглядеть запрос? Каким образом клиент формулирует запрос на
что-либо? Нам следует разобраться с этими вопросами.
(d) Отработка запроса
Мы знаем, как получить список каталогов, получить содержимое файла с помощью
cat и как запустить программу на исполнение. Мы можем использовать opendir и readdir,
open и read, dup2 и exec.
(e) Поспать ответ
Как должен выглядеть ответ? Что, предполагается, должен увидеть клиент?
С этими вопросами нам также следует разобраться.
Это все выглядит обнадеживающе. Мы знаем уже почти все идеи и подходы, которые
необходимы для написания Web-сервера. Единственное, что нам осталось сделать, -
ознакомиться с протоколом Web-сервера.
12.5.3. Протокол Web-сервера
Взаимодействие между Web-клиентом (обычно это броузер) и Web-сервером строится на
запросе от клиента и ответе от сервера. Формат запроса и формат ответа определены
протоколом HTTP - (hypertext transfer protocol - протокол передачи гипертекста/ Протокол HTTP похож на
протокол для временных серверов и finger серверов, которые были рассмотрены в последней
главе. Для протокола используют простой текст. Как и в случаях работы с временными
серверами и finger серверами, мы можем использовать telnet для взаимодействия с Web-
серверами. Web-сервера прослушивают порт 80. Вот реальная копия взаимодействия:
432
Соединения и протоколы. Разработка Web-сервера
$ telnet www.prenhall.com 80
Trying 165.193.123.253...
Connected to www.prenhall.com.
Escape character is ,A]\
GET /index.html HTTP/1.0
HTTP/1.1200 OK
Server: Netscape-Enterprise/3.6 SP3
Date: Tue, 22 Jan 2002 16:11:14 GMT
Content-type: text/html
Last-modified: Fri, 08 Sep 2000 20:20:06 GMT
Content-length: 327
Accept-ranges: bytes
Connection: close
<HTMLXHEAD>
<META НПР-EQUIV^'Refresh'' CONTENT=; URL=http://vig.prenhall.com/n>
</HEADXBODYX/BODYX/HTML>
<! —- - --— >
<!-- Caught you peeking! -->
<!— - >
Connection closed by foreign host.
$ .
Тепрь здесь я посылаю одну строку запроса и принимаю многострочный ответ. Несколько
слов о деталях.
Запрос HTTP: GET
Я использовал telnet для установления связи с Web-сервером на конкретном хосте.
telnet создал сокет, и после этого был вызов connect. Сервер воспринимает запрос на
соединение и создает канал данных, который соединяет мою клавиатуру с процессом сервера,
проходя при этом через сокеты.
Затем я набрал такой запрос:
GET /index.html HTTP/1
Запрос HTTP представляет собой одну строку, состоящую из трех полей. В первом поле
размещается текст команды, во втором поле - аргумент, в третьем поле указывается
версия протокола, который поддерживает взаимодействие клиента. В случае, который
иллюстрируется здесь, я выбрал команду GET с аргументом /index.html. При этом я указал, что
будет выбран протокол HTTP version l .0.
HTTP использует и другие команды. В большинстве случаев для Web-запросов
используют GET, поскольку в большинстве случаев пользователи "кликают" на ссылки для
получения страниц. Команда GET может сопровождаться несколькими строками
дополнительных аргументов. Мы рассматриваем здесь простой запрос и будем обозначать конец
. списка аргументов с помощцю пустой строки. Мы будем использовать те же соглашения
относительно выдачи приглашений, которые были использованы нами при написании
shell. Фактически Web-сервер выступает в роли shell, у которого есть встроенные команды
cat и Is.
12.5. Написание Web-сервера / 433
Ответ HTTP: OK
Сервер читает запрос, проверяет его и посылает обратно ответ. Текст ответа состоит из
двух частей: заголовка и содержимого. Заголовок начинается со статусной строки:
HTTP/1.1 200OK
Статусная строка состоит из двух или более подстрок. В первой подстроке указывается
версия используемого протокола взаимодействия для сервера. Во второй подстроке
находится номер кода ответа. В данном примере код ответа равен 200. Текстовое
сопровождение для этого кода — "ОК". Мы затребовали файл /info.html (Здесь, вероятно, следует
считать, что в командной строке рассматривается команда GET /info.html /HTTP 1.0 и
использован аргумент /info.html. - Примеч. пер.), и сервер сообщает, что такой файл есть. Если
бы файла с указанным именем не было , то код ответабыл бы равен 404 и мы получили бы
сообщение типа: "Not found".
Остаток заголовка состоит из нескольких строк, в которых содержится дополнительная
информация, составляющая ответ. В этом примере в состав дополнительной информации
входит: имя сервера; время выдачи ответа; тип данных, посылаемых сервером; тип
соединения, используемый для ответа. Заголовок ответа может содержать также и
дополнительные строки информации, кроме указанных. Сервер обозначает конец заголовка выдачей
пустой строки. Эта пустая строка в нашем случае следует сразу за строкой текста:
Connection: close.
Оставшаяся часть текста ответа составляет, собственно, содержание ответа. В нашем
случае сервер посылает назад содержимое файла /index.html.
Итоговые замечания по HTTP
Базовая структура взаимодействия между Web-клиентом и Web-сервером такова:
Клиент посылает запрос
GET filename HTTP/version
Опдаальные аргументы
Пустая строка
Сервер посылает ответ
HTTP/version status- code status- message
Дополнительная информация
Пустая строка
Содержимое
Полное описание протокола находится в документе, который называется RFC1945 для
версии 1.0 и RFC2068 для версии 1.1.
В нашем Web-сервере воспринимаются запросы HTTP от клиентов и затем передаются
обратно HTTP ответы. Простой текстовый формат таких запросов и ответов легко читать
и обрабатывать с помощью стандартных функций ввода/вывода и текстовых функций
языка С.
12.5.4. Написание Web-сервера
Наш Web-сервер будет поддерживать только команду GET. Сервер будет читать строку
запроса и пропускать дополнительные аргументы. Затем он будет обрабатывать запрос и
посылать обратно ответ. Главный цикл нашего Web-сервера будет выглядеть так:
434
Соединения и протоколы. Разработка Web-сервера
while) 1){
fd = accept(sock, NULL, NULL);
fpin = fdopen(fd, Y);
fgetsffpin, request, LEN);
read_untiLcrnl(fpin);
process_rq(request, fd);
fclose(fpin);
/* получить запрос */
/* сделать преобразование: FILE * */
Г прочитать клиентское требование 7
/* пропустить аргументы 7
/* ответить клиенту */
Г разорвать соединение 7
Для простоты здесь опущены действия по проверке ошибок для каждого системного
вызова и каждой функции.
Обработка запроса. Обработка запроса заключается в идентификации команды и затем
выполнении действий над аргументами.
process_rq(char *rq, intfd)
{
phar cmd[11], arg[513];
if (fork() !=0)
return;
sscanf(rq, "%10s %512s", cmd, arg);
if (strcmp(cmd, "GET") != 0)
cannotjto(fd);
else if (not_exist(arg))
do_404(arg, fd);
else if (isadir(arg))
doJs(arg, fd);
else if (endsjn_cgi(arg))
do_exec(arg, fd);
else /* в противном случае */
do cat(arg, fd);
}
Г если дочерний процесс, то работать */
Г если родительский процесс, то return */
Г проверка команды */
Г проверка наличия аргумента 7
/* п: обратиться к пользователю */
Г каталог? 7
Г у: список содержимого 7
/* имя X.cgi? 7
/* у: выполнить файл */
Г отобразить содержимое */
В сервере создается новый дочерний процесс для управления каждым запросом
пользователя. Дочерний процесс разделяет текст запроса на две части: команда и аргументы. Если
получили команду, отличную от GET, то сервер посылает назад HTTP код о
нереализованной команде. Если же принята команда GET, то сервер делает предположение, что он
должен выбрать из запроса: или имя каталога, или имя исполняемой программы с расшире-
нием-cgi или имя обычного файла. Если нет такого каталога или файла с указанным
именем, то сервер извещает об ошибке.
Если имя каталога или файла найдено, то сервер решает, какую из трех операций следует
выполнить:
Is, exec или cat.
Функция получения листинга каталога. Функция dojs обеспечивает отработку
запросов на получение списка каталогов:
dojsfchar *dir, int fd)
{
FILE *fp;
fp = fdopen(fd,Mw"); /* преобразование сокета в FILE * */
12.5. Написание Web-сервера
435
header(fp, "text/plain"); /* послать ответный заголовок HTTP 7
fprintf(fp,"\r\n"); Г и пометить конец заголовка */
fflush(fp); /* воздействовать на сокет 7
dup2(fd,1) Г сделать сокет stdout 7
dup2(fd,2); /* сделать сокет stderr 7
close(fd); /* закрыть сокет 7
execl("/bin/ls,,,,,lsn,,,-r,,dir,NULL); /* выполнение Is -17
perror(dir); /* или ошибка7
exit( 1); /* окончание дочернего процесса */
\
Мы в этой функции не использовали рореп, как это было сделано при обработке каталога
в предшествующей главе. С помощью непосредственного исполнения команды Is мы
сняли все проблемы, которые возникают при передаче от пользователя к рореп произвольной
строки при запуске через shell.
Другие функции. Оставшаяся часть кода будет представлена далее в этой главе.
Программа уже работает, но она не полна и не удовлетворяет требованиям безопасности.
Необходимо учесть еще ряд моментов:
(a) устранить зомби
(b) обеспечить защиту от переполнения буфера
(c) программы CGI должны иметь доступ к некоторым переменным окружения
(d) в заголовке HTTP должно содержаться больше информации.
Но, тем не менее, программа представляет собой завершенный Web-сервер. Программа
содержит 230 строк программного кода на С, включая комментарии и пустые строки.
12.5.5. Запуск Web-сервера
Откомпилируем программу и затем запустим ее с указанием определенного порта:
$ ее webserv.c socklib.c -о webserv
$ /webserv 12345
Теперь вы можете посетить наш Web-сервер по адресу: http://yourhostname: 12345/. Можно
поместить html-файл в каталог и открыть его с помощью:
http://yourhostname: 12345Д ilename. html.
Создайте такой скрипт:
#!/bin/sh
# hello.cgi - a cheery cgi page
printf "Content-type: text/plain\n\nhello\nM;
Назовите скрипт hello.cgi и измените для скрипта права доступа с помощью chmod на 755.
Затем используйте ваш броузер для обращения к скрипту:
http://yourhostname: 12345/hello.cgi.
436
Соединения и протоколы. Разработка Web
12.5.6. Исходный код webserv
Далее приведен программный код данного простого Web-сервера:
Г webserv.c - минимальный по возможносям web-сервер (версия 0.2)
Использование: ws номер_порта
Свойства: поддерживает только одну команду GET
* исполняется в текущем каталоге
* создает новый дочерний процесс для выполнения каждого запроса
* есть дыры в обеспечении безопасности работы
* используется только для демонстрационных целей
есть еще ряд недоделок
* является хорошей начальной точкой для дальнейших проектов
* Трансляция: ее webserv.c sockiib.c -о webserv
7
#include <stdio.h>
#jnclude <sys/types.h>
#include <sys/stat.h>
#include <string.h>
main(intac,char*av[])
{
int sock, fd;
FILE *fpin;
charrequest[BUFSIZ];
if(ac==1){
fprintf(stderr,"usage: ws portnum\n");
exitA);
}
sock = make_server_socket(atoi(av[1 ]));
if(sock==-1)exitB);
/* основной цикл */
while(t){
/* получение и буферирование запроса */
fd = accept(sock, NULL, NULL);
fpin = fdopen(fd, "r");
j* чтение запроса*/
fgets(requestlBUFSIZ,fpJn);
printf("got a call: request = %s", request);
read_til_cml(fpin);
Г выполнить то, что хочет клиент */
process jq(request, fd);
fclose(fpin);
}
}
/* _ m •
read_til_crnl(FILE*)
пропустить всю информационную часть в запросе до признака
CRNL
- 7
read_tii.cml(FILE *fp)
,5. Написание Web-сервера
charbuf[BUFSIZ];
while(fgets(buf,BUFSIZ,fp) != NUU&&strcmp(buf,"\r\ri") != 0)
}
r
process_rq(char *rq, int fd)
Выполнение того, что затребовано в запросе, и запись ответа через fd
Обработка запроса в новом процессе
rq - это команда HTTP: GET Доо/bar.htm! HTTP/1.0
process_rq(char *rq, intfd)
{
charcmd[BUFSIZ],arg[BUFSIZ];
/* создание нового процесса и возврат при неудаче */
if (fork() != 0)
return;
strcpy(arg,"./");
if (sscanf(rq, "%s%s", cmd, arg+2) !== 2)
return;
if (strcmp(cmd,MGEr) != 0)
cannot_do(fd);
else if (not_exist(arg))
do_404(arg, fd);
else if (isadir(arg))
do_ls(arg, fd);
else if (endsjn_cgi(arg))
do_exec(arg, fd);
else
do cat(arg, fd);
}
Л
Заголовок ответа: нужен только один
Если contentjype равен NULL, тогда не посылать тип содержимого
header(FILE *fp, char *contenUype)
{
fprintf(fp, "НПР/1.0 200 OK\r\n");
if (content_type)
fprintf(fp, "Content-type: %s\r\n", content_type);
}
Л
Первые простые функции:
cannot_do(fd) не реализована команда HTTP
do_404(item,fd) нет такого объекта
3
Соединения и протоколы. Разработка WeL
cannot_do(int fd)
{
FILE*fp = fdopen(fd,"wM);
fprintf(fp, "HTTP/1.0 501 Not lmplemented\r\n");
fprintf(fp, "Content-type: text/plain\r\n");
fprintf(fp, "\r\n");
fprintf(fp, 'That command is not yet implemented\r\n");
fclose(fp);
}
do_404(char *item, int fd)
{
FILE*fp = fdopen(fd,"w");
fprintf(fp, "HTTP/1.0 404 Not Found\r\n");
fprintf(fp, "Content-type: text/plain\r\n");
fprintf(fp, "\r\n");
fprintf(fp, 'The item you requested: %s\r\nis not found\r\n",
item);
fclose(fp);
}
Г
Секция для получения листинга каталога
isadir() использует stat, not_exist() использует stat
do_ls запускает Is.
isadir(char *f)
{
struct stat info;
return (stat(f, &info) != -1 &&S_ISDIR(info.st mode));
}
not_exist(char *f)
{
struct stat info;
return(stat(f,&info)==-1);
}
do ls(char *dir, int fd)
{
FILE *fp;
fp = fdopen(fd,"w");
header(fp, "text/plain");
fprintf(fp,"\r\n");
fflush(fp);
dup2(fd,1);
dup2(fd,2);
close(fd);
ехес1р(8","Ь","-Г^1Г^иЩ;
perror(dir);
\5. Написание Web-сервера
exitA);
}
Не _ _. •
Обработка cgi. Функция для проверки расширения и для запуска
программы
7
char * file_type(char *f)
Г получить расширение имени файла */
{
char *ср;
if ((ср = strrchr(f,'.')) != ЫиЩ
return ср+1;
return"";
}
ends in cgi(char *f)
{
return (strcmp(file type(f), "cgi") == 0);
}
do exec(char *prog, int fd)
{
FILE*fp;
fp = fdopen(fd,"w");
header(fp, NULL);
fflush(fp);
dup2(fd, 1);
dup2(fd,2);
close(fd);
execl(prog,prog,NULL);
perror(prog);
}
Л ¦¦'- *
do_cat(filename,fd)
Послать обратно содержимое ответа, следующего за заголовком
7
do cat(char *f, int fd)
{
char *extension = file_type(f);
char *content = "text/plain";
FILE*fpsock,*fpfile;
int c;
if (strcmp(extension,"htmr) ==0)
content = "text/html";
else if (strcmp(extension, "gif") == 0)
content = "image/gif;
else if (strcmp(extension, "jpg") == 0)
content = "image/jpeg";
440
Соединения и протоколы. Разработка Web-сервера
else if (strcmp(extension, "jpeg") == 0)
content = "image/jpeg";
fpsock = fdopen(fd, V);
fpfile = fopen(f, "r");
if (fpsock != NULL && fpfile != NULL)
{
header(fpsock, content);
fprintf(fpsock, "\r\n");
while((c = getc(fpfile)) != EOF)
putc(c, fpsock);
fclose(fpfile);
fclose(fpsock);
}
exit@);
}
12.5.7. Сравнение Web-серверов
Web-сервер - это программа, которая дает пользователям возможность получать на
других компьютерах листинг каталогов, читать содержимого файлов, запускать программы.
Все Web-серверы выполняют одни и те же базовые операции и все должны удовлетворять
правилам ядра HTTP.
В чем заключается различие между серверами? Некоторые серверы легче
конфигурировать, ими легче управлять, чем другими. У некоторых серверов более развиты средства по
поддержанию безопасной работы. На некоторых серверах процессы развиваются быстрее,
чем на других, или могут использовать для своих нужд меньше памяти. Наиболее важное
свойство для Web-сайтов - эффективность сервера, что предполагает ответы на такие
вопросы. Сколько запросов сразу может отрабатывать сервер? Сколько системных
ресурсов необходимо серверу при обслуживании каждого запроса?
Web-сервер в этой главе создавал новый запрос для обслуживания каждого запроса. Будет
ли такой подход наиболее эффективным? Требования на чтение файлов и получение
листингов каталогов могут выполняться долго. Поэтому сервер не должен ждать завершения
таких действий. Но нужен ли нам для этого новый процесс?
Существует третий метод для одновременного запуска нескольких операций. Программа
может запустить на исполнение в одном процессе сразу несколько задач на основе
механизма, который называют механизм нитей. Этот механизм мы изучим в одной из последующих
глав.
Заключение
Основные идеи
• Клиент/серверные программы, использующие механизм сокетов, удовлетворяют
требованиям общей структуры (framework). Сервер воспринимает и обрабатывает запросы
(требования). Запросы вырабатывают клиенты.
• На серверах устанавливаются сокеты. Серверные сокеты имеют конкретные адреса
и настраиваются на прием запросов.
Заключение
441
• Клиенты создают и используют клиентские сокеты. Клиент не осведомлен об адресе
своего сокета. (Здесь, вероятно, подразумевается, что клиент не выполняет bind -
связывание сокета. -Примеч. ред.)
• Сервер может обрабатывать запросы по одному из двух вариантов. Он может
обрабатывать запросы сам или может породить процесс с помощью fork, который и будет
управлять запросом.
• Web-сервер - это популярное приложение, использующее механизм сокетов. Web-
сервер обрабатывает три основных типа запросов: послать клиенту содержимое
файла, послать клиенту листинг каталога, запустить программу. Протокол по передаче
запросов (требований) и ответов называется протоколом HTTP.
Что дальше?
Телефонная модель реализуется не только в сетевых системах клиентов/серверов.
Некоторые люди делают покупки по почтовым каталогам, посылая заказы на товары, а в ответ
получают выбранные товары. Используя коммуникационную запросную систему, каждый
покупатель может связываться с несколькими магазинами. А каждый магазин может
одновременно обслуживать много покупателей. В следующей главе мы рассмотрим сетевое
программирование, где используется модель почтовых карточек: сокеты дейтаграмм.
Исследования
12.1 В примере кода клиента для time клиента происходит однократный вызов read и write.
Что произойдет, если общий объем данных, поставляемых сервером, превысит
допустимую нагрузку или будет переполнен буфер? Каким образом следует модифицировать
клиента, чтобы иметь возможность управлять данными, для которых требуется
многократная выдача read? А теперь о сервере. Что будет происходить, если после выполнения
вызова write возвращаемое значение оказывается меньше, чем длина строки?
12.2 Сравнение wait и waitpid. Модифицированная версия обработчика сигнала SIGCHLD
использует waitpid и цикл. Можно ли использовать в таком цикле wait для решения
проблемы управления множеством сигналов?
Программные упражнения
12.3 Модифицируйте типовой сервер так, чтобы он производил рестарт вызова accept если
его исполнение было прервано сигналом.
12.4 Модифицируйте Web-сервер так, чтобы он вел учет всех поступивших запросов и
записывал статус ответов.
12.5 Когда Web принимает запрос на выполнение CGI-программы, то сервер передает ряд
переменных в среду CGI программы. Определите, какие это переменные, и добавьте
некоторые из них к Web-серверу, В главе, посвященной вопросам программирования
в shell, рассмотрено, каким образом можно добавлять переменные в среду.
12.6 Web-сервера cgi-bin используют две основные системы для идентификации
требований, по которым запускаются программы. Сервер, который был представлен в этой
главе, идентифицировал программы по расширению.сдк Другой метод использует
маршрутное имя.
442
Соединения и протоколы. Разработка Web-сервера
Если файл имеет в составе маршрутного имени каталог с именем cgi-bin, то такой будет
файл запускаться на исполнение. Например, если поступит запрос на файл /cgi-bin/counter,
то этот файл будет запущен сервером на исполнение. Модифицируйте сервер, в котором
должна будет поддерживаться такая система идентификации.
12.7 Заголовки ответов. Модифицируйте Web-сервер так, чтобы он посылал клиентам
больше информации в заголовке. Пример соединения в тексте показывает типичный набор
полей в заголовке. Добавьте в сервер возможность добавлять эти поля в заголовок Web-
сервера. /
12.8 Метод HEAD. Модифицируйте Web-сервер так, чтобы он мог поддерживать
обработку запроса HEAD. Ознакомьтесь с деталями в спецификациях HTTP.
12.9 Метод POST. Модифицируйте Web-сервер так, чтобы он мог поддерживать обработку
запроса POST. Ознакомьтесь с деталями в спецификациях HTTP.
Проекты
На основе материала, изученного в этой главе, вы можете написать версии следующих
программ Unix:
httpd, telnetd, fingerd, ftpd
Глава 13
Программирование с использованием
дейтаграмм.
Лицензионный сервер1
Л^
pj^HL,
Цели
Идеи и средства
• Программирование с использованием дейтаграмм, сокеты дейтаграмм.
• ТСРиШР.
• Лицензионный сервер.
• Программные билеты (tickets).
• Проектирование устойчивых систем.
• Проектирование распределенных систем.
• Unix-сокеты доменов.
Системные вызовы
• socket
• sendto, recvfrom
1. Эта глава основана на материале лекций, которые были написаны и представлены Лоуренсом Де-Люка, когда
он преподавал в Harvard Extension School в качестве ассистента. Лекции основаны на практическом материале.
444 Программирование с использованием дейтаграмм. Лицензионный сервер
13.1. Программный контроль
Для выполнения программы необходима память, процесс, время центрального
процессора и ряд системных ресурсов. Всем этим управляет операционная система. Кроме того,
для некоторых программ требуется еще иметь и разрешение от собственника программы
на исполнение.
Используя обычную терминологию, вам необходима лицензия на использование ряда
программ, а в ряде лицензий указываются определенные ограничения в отношении
программ. Например, лицензией может быть установлен предел на допустимое число
пользователей, которым можно одновременно запускать программу. Лицензия, приобретенная
на возможность работы десяти пользователей, может иметь одну стоимость, а лицензия
для работы пятидесяти пользователей будет иметь совсем другую стоимость. Некоторые
производители программного обеспечения устанавливают арендную плату на
программные лицензии. Предполагается, что программы по такой лицензии не будут работать,
когда истечет срок аренды. На использование программного обеспечения могут
накладываться также ограничения, которые уже никак не связаны с юридическими отношениями.
В школьной компьютерной лаборатории может быть установлено ограничение на время
в течение дня, когда на компьютерах лаборатории нельзя запускать игровые программы.
Некоторые собственники программного обеспечения используют систему "суда чести"
(honor system) для того, чтобы установить правила на использование их программ. Они
печатают условия лицензии на экране или бумаге и обращаются к пользователям с
просьбой выполнять условия контракта. Другие собственники программного обеспечения
соблюдают лицензионные правила на технологическом уровне. Один из технологических
методов соблюдения программных лицензий - писать программы, которые соблюдают их
собственные лицензии. Популярной технологией является проектирование прикладных
программ, которые запрашивают разрешение на работу у лицензионного сервера. Такой
сервер представляет собой процесс, которые сообщает прикладной программе может она
выполняться или нет. Лицензионный сервер знает и соблюдает лицензионные правила,
/(см. рисунок 13.1).
Рисунок 13.1
Лицензионный сервер дает
разрешение
Для выдачи запроса на разрешение и для получения гарантии на выполнение требуется
установление коммуникаций между лицензированной программой и лицензионным
сервером.
Как работает лицензионный сервер? В этой главе мы рассмотрим модель клиент/сервер,
которая будет использована при лицензионном управлении. При изучении этого
материала мы изучим еще один вид сокетов - сокеты дейтаграмм. Кроме того, изучим другой
адресный домен - Unix домен, сетевой протокол, в котором поддерживается состояние
системы, а также некоторые подходы для установления средств по обеспечению
безопасности и надежности работы в системе клиент/сервер.
13.2. Краткая история лицензионного контроля 445
13.2. Краткая история лицензионного контроля
Техника контроля за использованием программного обеспечения развивалась в течение
многих лет. В эру автономных персональных компьютеров программное обеспечение с
ограничениями на использование поставлялось на специальных дисках или поступало с ключевыми
дисками, на треках которых был скрытый закодированный шифр. Секретный код было
трудно копировать. Программа могла работать только тогда, когда такой диск был вставлен в
дисковод. Если вы потеряли специальный диск или пролили на него кофе, то вы уже не сможете
запустить программу на исполнение. Но народ скоро раскрыл тайну копирования
специальных дисков. Поэтому производителям программного обеспечения пришлось изобрести
аппаратные ключи. Аппаратные ключи представляют собой адаптеры, которые вставляются
в параллельный порт, последовательный порт или в порт USB.
Лицензированная программа запускается на исполнение, только если она обнаруживает,
что адаптер вставлен в компьютер. Если вы потеряли аппаратный ключ или забыли ключ
на работе, когда принесли компьютер домой, то вы не сможете запустить программу.
Использование компьютеров в составе сетей, работа в многопользовательских системах
привнесли новые проблемы. Если десять пользователей хотят одновременно исполнять
одну и ту же программу на одной машине или в сети, то должен ли каждый из таких
пользователей вставлять аппаратный ключ в порт сервера? Производители программного
обеспечения для серверов предложили метод соблюдения лицензий, который является
гибким и не обременяет законных пользователей дополнительными неудобствами.
В сетевых и многопользовательских системах предлагается новое решение, а именно
лицензионный сервер. Лицензионная программа проверяет не наличие ключевого диска или
ключа, а получает разрешение на исполнение от серверного процесса. Лицензионному
серверу не грозит быть залитым кофе, его нельзя оставить в портфеле, но его могут
разделять на одном компьютере многие пользователи. Серверные процессы могут также
работать по таким алгоритмам, которые обеспечивают контроль за допустимым количеством
пользователей программы, за тем, когда будет использоваться программа, где будет
использоваться программа и даже за тем, как будет использоваться программа. Поскольку
большинство компьютеров работают в составе Internet, то метод контролируемого
доступа (с помощью сервера) к программному обеспечению и данным становится все более
популярным.
Наш проект
Наш лицензионный сервер будет отслеживать выполнение лицензионного ограничения
по допустимому количеству пользователей, то есть сервер должен разрешать
одновременное обращение к программе для одновременной работы с ней только определенному
количеству пользователей и не более.
13.3. Пример, не связанный с компьютерами: управление
использованием автомобилей в компании
Компания приобрела лицензию, в которой установлен предел на число одновременно
работающих пользователей с программой. В компании может работать больше служащих, чем
установленный в лицензии предел на число пользователей программы. Но не всем служащим
необходимо сразу, одновременно работать с программой. Как обеспечить возможность
использования программы с учетом выполнения таких ограничений и требований?
446
Программирование с использованием дейтаграмм. Лицензионный сервер
В нашей повседневной жизни очень большое количество систем разделяют
фиксированное число каких-то предметов среди большего числа их пользователей. Рассмотрим здесь
некую модель такого использования. Обратимся к примеру решения проблемы
разделения среди водителей автомобилей компании. Пусть автомобильная компания имеет некое
количество автомобилей в своем парке. Водителей в составе компании больше, чем число
автомобилей в этой компании. Как можно управлять доступом водителей к автомобилям?
13.3.Л Описание системы управления ключами от автомобилей
Можно управлять доступом к автомобилям с помощью системы выдачи ключей от
машин. Если нет ключа от определенной машины в гнезде для его хранения, то вы не
сможете использовать данный автомобиль. Если ключ на месте, то вы можете вынуть его из
гнезда, отметить в журнале, что вы забрали ключ, и использовать автомобиль. Когда вы
попользовались машиной, то вы возвращаете ключ в гнездо для хранения и вычеркиваете
ваше имя в списке пользователей, которым были выданы ключи. Такая процедура
управления ключами изображена на рисунке 13.2.
Менеджер службы Ячейки хранения
Группа водителей выдачи ключей ключей Фиксированное число машин
Рисунок 13.2
Управление доступом
к автомобилям
Каково назначение журнала учета выдачи ключей? Целью системы управления ключами
является лимитирование доступа к машинам. Значимым является наличие доступных
ключей. Люди не всегда дисциплинированны. Водитель может забыть и не вернуть ключ,
даже если он поставил машину в парк. Менеджер службы выдачи ключей может обнаружить
и позвонить тому водителю, кто забыл вернуть ключ. Обратившись к учетному журналу,
можно узнать, использует ли водитель сейчас автомобиль или забыл сдать ключ?
Система выдачи ключей может быть использована в качестве полезной модели для
управления доступом к программному обеспечению. Прежде чем заняться переводом этой
модели в программный эквивалент, нам нужно более подробно описать систему ключей.
Компоненты системы управления ключами
(a) Центральное место хранения ключей - место, где можно хранить ключи.
(b) Менеджер ключей - некто, отвечающий за выдачу и возврат ключей.
(c) Ключи - некоторая сущность, которую вам нужно получить.
(d) Учетный список - место для хранения записей о взятии и возврате ключей.
13.3.2. Управление автомобилями в терминах модели клиент/сервер
После рассмотрения состава системы выдачи ключей от автомобилей мы теперь опишем
эту систему в терминах языка программирования клиент/серверных систем.
Клиенты и сервер
Сначала установим, кто является клиентом, а кто - сервером? Менеджер ключей имеет
ресурс, который необходим водителям. В терминах сетевого программирования
менеджера ключей мы будем называть сервером, а водителей - клиентами.
13.4. Управление лицензией
447
Протокол
Далее. Что является протоколом? Что считать транзакцией? Протокол управления
ключами СКМР (car-key-management protocol) имеет две транзакции:
Получить ключ
Клиент: Привет, я хотел бы получить ключ.
Сервер: Пожалуйста, вот вам ключ 5. Или: Извините, ключей сейчас нет.
Вернуть ключ назад
Клиент: Я возвращаю ключ 5.
Сервер: Благодарю.
Коммуникационная система
Далее. Как будет взаимодействовать клиент и сервер? В системе выдачи ключей от
автомобилей люди просто будут обмениваться фразами в диалоге друг с другом.
Структуры данных
Наконец, какие необходимы структуры данных для организации работы водителей
и менеджера ключей? У менеджера ключей находится учетный журнал, где на каждый
ключ заведена отдельная запись. Когда водитель берет ключ, то менеджер заносит в
соответствующую запись имя водителя. Когда водитель возвращает ключ, то менеджер
вычеркивает имя водителя из этой записи. В следующей таблице иллюстрируется
учетный лист журнала:
Журнал учета ключей
Номер ключа Водитель
1 adam(g>sales
2
3 * carol@support
4
Если в учетном листе нет имени водителя в учетной записи для какого-то ключа,
то ключ еще не выдан. Ключ распределен (выдан), если в учетной записи для данного
ключа есть имя водителя.
13.4. Управление лицензией
Теперь мы преобразуем систему управления ключами в лицензионную систему
управления.
13.4. 1. Система лицензионного сервера: что делает сервер?
На рисунке 13.3 изображена некая группа людей, у которых может возникнуть желание
запустить на исполнение лицензионную программу. Наша система работает так:
(a) Пользователь U стартует лицензионную программу Р.
(b) Программа Р обращается к серверу S за разрешением на запуск.
(c) Сервер S проверяет текущее число пользователей, которые уже работают с
программой Р.
(d) Если допустимый предел по количеству пользователей еще не достигнут,
то сервер S разрешает доступ и программа Р начинает исполняться.
448
Программирование с использованием дейтаграмм. Лицензионный сервер
(е) Если же предел по количеству пользователей был достигнут, то сервер 5 не дает
разрешения на запуск. Программа Р сообщает пользователю U, что нужно попытаться
выполнить ее запуск позже.
Множество пользователей Лицензионная программа Лицензионный сервер
у / I Управление доступом к
\/ программному обеспечению
Сокеты
Лицензионный сервер мало чем отличается от серверной системы выдачи ключей от
автомобилей. В автомобильном варианте водители обращались к менеджеру ключей за
разрешением пользоваться автомобилем. В программном варианте программа также
обращается к серверу за разрешением на свое исполнение.
Это выглядит в отношении автомобильного варианта так, как если бы водитель обращался
к автомобилю, а автомобиль запрашивал ключ у менеджера ключей2.
Разработчик лицензионной программы пишет обе программы: приложение и сервер. Эти
две программы составляют систему. Сервер предоставляет разрешение прикладной
программе на ее запуск, а также отслеживает выполнение лицензионных требований. Если
лицензионный сервер не работает, то прикладная программа не сможет получить
разрешение на запуск и откажет пользователю в запуске.
Мы использовали в качестве модели систему выдачи ключей от автомобиля. Как можно
преобразовать детали этой системы в программную модель? Как лицензионная
программа будет обращаться к серверу за разрешением на запуск? Как сервер будет гарантировать
возможность запуска? Что можно считать программным эквивалентом ключа для
автомобиля?
13.4.2. Система лицензионного сервера: как работает сервер?
Ticket-модель
Менеджер ключей выдает ключи. А что выдает лицензионный сервер? Рассмотрим
примеры работы кинотеатров и стадионов. Вы платите деньги за право входа в
кинотеатр. Вам для этого выдают билет (ticket). Наш лицензионный сервер будет в ответ на
запросы выдавать электронные билеты {tickets). На что должен быть похож цифровой
билет? Клиенты и серверы при взаимодействии обмениваются текстовыми
сообщениями. Поэтому электронный билет должен быть строкой текста. Для его
представления мы будем использовать следующий формат:
р1а\номер_билета. Например: 6589.3
2. Эту идею нельзя отбрасывать.. Механизмы и приборы становятся все более интеллектуальными и более
взаимосвязанными между собой. Поэтому вскоре ваш радиоприемник будет запрашивать сервер, можно ли сейчас
проиграть вашу любимую мелодию?
13.4. Управление лицензией
449
Каждый билет состоит из идентификатора процесса (PID), которому выдается билет,
а также из номера билета. Мы включили в состав билета PID, руководствуясь теми же
соображениями, какие есть у авиакомпаний, которые печатают на авиабилете вашу
фамилию при покупке вами авиабилета. Наличие вашей фамилии на авиабилете
гарантирует, что только вы можете использовать этот билет, а также, что это может помочь
в ситуации, когда вы потеряли билет. А могут ли процессы потерять выделенные им
билеты?
Сервер и клиенты
Прежде всего разберемся, кто есть клиент, а кто есть сервер. Лицензионный сервер
содержит ресурс, который необходим программам: билеты. В терминах сетевого
программирования сервер - это сервер, а приложение - это клиент.
Протокол
Во-вторых, что следует считать протоколом? Какие будут транзакции? Наш протокол
управления билетами содержит две основные транзакции:
Получение ключа
Клиент: HELO мой_р1сНгакой-то
Сервер: TICK выдается_билет ИЛИ FAIL, если нет билетов
Сдать билет обратно
Клиент: GBYE идентификатор_ключа
Сервер: THNX сообщение
Мы определили текстовый протокол, состоящий из простых четырех символьных
команд с аргументами. Команды похожи на команды, которые используют Web-клиенты
и серверы.
Коммуникационная система
Далее следует решить, как будут передаваться эти короткие текстовые сообщения
между клиентом и сервером? Далее мы рассмотрим этот вопрос.
Структура данных
Наконец, нужно решить, какие структуры данных необходимы клиентам и серверу?
Мы будем использовать целочисленный массив, который будет выполнять роль
учетной страницы в журнале. Каждая запись в этом массиве будет соответствовать одному
билету. Когда клиент получает билет, то менеджер записывает PID клиента в эту
запись. Когда клиент возвращает билет, то менеджер стирает PID клиента из записи
в учетном списке. Все это представлено в качестве иллюстрации в таблице.
Учетная страница по выдаче билетов
Номер билета Процесс
1 УЖ
2 О
3 6589
4 О
Если элемент массива содержит 0 в поле для PID, то билет свободен. Если же в таком поле
записан PID, то билет находится в использовании.
450
Программирование с использованием дейтаграмм. Лицензионный сервер
13.4.3. Коммуникационная система
Как будет клиент выдавать запрос на билет и как сервер будет выдавать билеты? Намнуж-
но будет использовать какой-либо вид межпроцессного взаимодействия. Клиенты
и серверы обмениваются короткими сообщениями. Лицензионный сервер принимает
запросы на билеты, обрабатывает их и отвечает на запросы, которые поступают от многих
пользователей. Какую технику межпроцессных взаимодействия следует выбрать?
Сигналы - это короткие сообщения, но слишком уж короткие. Неименованные программные
каналы соединяют только родственные процессы. Наиболее подходящим решением будет
использование сокетов. Но и среди сокетов мы должны сделать выбор. Мы знаем о
существовании сокетов потоков, которые похожи на программные каналы, но поддерживают
соединения между не родственными процессами. Другой тип сокетов называется сокета-
ми дейтаграмм. Сокеты дейтаграмм (или сокеты UDP) будут наилучшим выбором в
нашем проекте.
13.5.Сокеты дейтаграмм
С »помощью сокетов потока данные передаются от одного процесса к другому таким же
образом, как в телефонной сети обеспечивается связь между абонентами. Вы
устанавливаете соединение, а затем используете соединение для поддержания байтового потока
данных, непрерывного, двунаправленного, работающего по принципу программного
канала.
Сокеты потока используют сетевой протокол TCP {transmission control protocol). Сокеты
дейтаграмм используют протокол UDP (user datagram protocol). Чем отличаются эти
протоколы? Когда более целесообразно выбрать сокеты потока, а когда следует выбирать
сокеты дейтаграмм? Как мы будем использовать сокеты дейтаграмм в программе?
13.5.1 Потоки (streams) и дейтаграммы
Как происходит работа сокетов? Как происходит фактическая передача данных по
Internet? Что делает ядро, когда мы записываем данные в сокет потока? В чем при этом будет
отличие от варианта, когда данные записывают в сокет дейтаграмм?
Существование непрерывного, наполненного потока данных между двумя сокетами
потока является иллюзией. Средства установления коммуникаций Internet разбивают ваш
поток данных на отдельные пакеты. Передача данных по сети будет выглядеть
приблизительно так, как это изображено на рисунке 13.4.
Рисунок 13.4
Передача данных с помощью пакетов в Internet
13.5. Сокеты дейтаграмм
451
Разбиение больших "кусков" информации на небольшие пакеты также имеет свою
аналогию в нашем быту. Представьте себе, что вам нужно послать документ, размером
в 100 страниц, используя для этого службу срочной доставки. Что нужно будет сделать,
если компания по срочным доставкам потребует от вас использовать для пересылки
только их конверты, которые вмещают только 20 страниц бумаги? Вы будете вынуждены
разложить все страницы вашего документа в пять пакетов и каждый отдельный пакет
заклеить и написать на нем адрес. Далее вы положите эти пять пакетов в почтовый ящик,
а служба доставки сообщений доставит их (на что вы надеетесь) к месту назначения.
У адресата кто-либо вскроет эти пять пакетов и составит из них одну стопку страниц,
располагая их в правильном порядке в соответствии с содержанием вашего документа.
Интернет работает аналогично службе срочной доставки сообщений. Данные, которые
передаются через Internet, помещаются в контейнеры ограниченного размера. Большие
"куски" данных разбиваются на более мелкие фрагменты, которые будут посылаться через
сеть. Если вам нужно принять весь большой "кусок" данных сразу, то кто-либо на
принимающей стороне должен будет сложить принятые фрагменты в правильном порядке.
Port 48842
132.44.55
Internet,
¦
66
USA
Port
103.
23
123.45
Internet,
1ШШ2Щ§3
н
Wm
.67 |
USA
Рисунок 13.5
Коммуникации можно устанавливать либо с помошью соединения, либо без соединения.
Сокеты потока выполняют для вас всю работу по разбиению, упорядочению и реассемб-
лированию. Сокеты дейтаграмм такую работу не делают. В следующей таблице
представлен список отличий между этими двумя средствами:
TCP
UDP
Потоки
Дейтаграммы
Фрагментация /
Реассемблирование
Упорядочение
Надежность
Нет
Нет
Могут быть потери
Только при соединении Множество отправителей
При работе сокета потока ядро разбивает "куски" данных на пронумерованные
фрагменты. Ядро на принимающей машине размещает принятые фрагменты в необходимом
порядке, воссоздавая точную последовательность байт, которую переслал отправитель.
При работе сокета дейтаграмм ядро не устанавливает меток на данные, которые
необходимы для упорядочения или реассемблирования после приема.
При использовании сокетов потока доставка гарантируется, при использовании сокетов
дейтаграмм - нет. На принимающей стороне сокета потоков ведется проверка номеров
фрагментов в последовательности их приема, чтобы определить - все ли фрагменты были
452
Программирование с использованием дейтаграмм. Лицензионный сервер
приняты. Принимающая сторона извещает отправителя о потерянных фрагментах и
предлагает передать повторно копии потерянных частей. При работе сокетов дейтаграмм
проверка на потерю пакетов не проводится и не выдаются требования на повторную передачу
пропавших пакетов. Если пакет потерялся в Internet, то он уже не придет по назначению.
При использовании TCP выполняет гораздо больше работы, чем при использовании UDP.
Но UDP быстрее, проще и меньше загружает сеть.
При использовании UDP сокетов происходит то же, что и при пересылке сообщений через
почтовые ящики: отправители пишут на почтовой карточке адрес получателя; почтовая
служба в конечном итоге доставляет эту карточку в ваш почтовый ящик; вы вынимаете карточку из
почтового ящика. При работе с TCP для чтения одного сообщения от удаленного процесса,
требуется выполнить следующую последовательность вызовов: accept, read, close.
Для нашего приложения UDP будет вполне подходящим вариантом. Клиенты посылают
короткие сообщения, запрашивая разрешение на исполнение. Сервер посылает в ответ
короткие сообщения о разрешении или, наоборот, об отказе. Клиенты и сервер
обмениваются этими сообщениями без проблем по установке соединений. Эти короткие
сообщения не нуждаются в фрагментации и реассемблировании. Надежность передачи тоже не
столь существенна. Если потерялся запрос на билет или сам билет, то пользователь может
попытаться еще раз запустить свою программу. В любом случае, сервер и клиенты либо
будут работать на одной машине, либо в одной и той же секции сети. Поэтому риск
потерять пакеты будет небольшим.
Если выбрать UDP для построения Web-серверов или почтовых Ъерверов, то это будет
плохое решение. Web-страницы и почтовые сообщения.могут быть большими по объему
документами. Эти потоки данных должны приниматься полностью и в правильном
порядке. Использование UDP будет вполне оправданным при передаче музыкальных или
видео данных, когда потеря ноты или фрейма не будет значима по отношению к
конечному результату.
13.5.2. Программирование дейтаграмм
Дейтаграмма - это сетевой эквивалент почтовой карточки. Дейтаграмма состоит из трех
основных частей: адрес назначения, обратный адрес и сообщение (см. рисунок 13.6).
Port 48842
132.44.55
Internet,
66
USA
Port
103.
23
123.
Internet
j
mm
Hi
45.67
, USA
Отправитель
Место назначения
Данные
Рисунок 13.6
Три составные части дейтаграммы
Сокет дейтаграмм - это бокс для поставки дейтаграмм. Отправитель указывает адрес
сокета назначения. Сеть передает дейтаграмму от отправителя к указанному сокету.
Принимающий процесс изымает дейтаграммы из сокета. Программы используют вызов sendto
при отправлении дейтаграммы через сокет и вызов recvfrom при изъятии дейтаграммы из
сокета (см. рисунок 13.7).
13.5. Сокеты дейтаграмм
453
•^г- ¦ ¦ - х
.
recvfrom
h>i \Ц
•-^|||у>--^|
Сокетьк
| ILsendto , A
gr—p
h<r
ш
i
Xoct1
Xoct2
На одном хосте может быть много активных сокетов.
Каждому сокету назначается номер порта.
Номер порта для пакета будет использоваться как адрес.
Рисунок 13.7
Использование sendto и recvfrom
Прием дейтаграмм. Программа dgrecv.c представляет собой пример сервера,
использующего дейтаграммы. Программа dgrecv.c назначает порт для сокета. Номер порта
задается в командной строке. Далее программа входит в цикл, принимая и печатая дейтаграммы,
которые будут посылать клиенты:
tk-k
* dgrecv.c -
Получатель дейтаграмм
Использование: dgrecv номер_порта
Действие: прослушивание указанного порта и вывод сообщений
7
#include
«include
«include
«include
«include
«define oops(m,x)
<stdio.h>
<stdlib.h>
<sys/types.h>
<sys/socket.h>
<netinet/in.h>
{perror(m);exit(x);}
int makejJgram_server_socket(int);
int getjnternet_address(char *, int, int *
void say_who_called(struct sockaddrjn *);
int main(int ac, char *av[])
{
int port;
int sock;
charbuf[BUFSIZ];
sizej msglen; /* длина данных */
struct sockaddrjn saddr; /* сюда помещается адрес отправителя */
socklenj saddrlen; /* и длина адреса */
if (ас == 11| (port = atoi(av[1])) <= 0){
fprintf(stderr,"usage: dgrecv portnumber\nH);
exitA);
, struct sockaddrjn*);
/* использовать этот порт */
/* для данного сокета */
/* для передачи сюда данных */
454
Программирование с использованием дейтаграмм. Лицензионный сервер
I* получить сокет и назначить ему номер порта 7
if((sock = make_dgram_server_socket(port)) == -1}
oopsfcannot make socket",2);
Г прием сообщений от этого порта */
saddrlen = sizeof(saddr);
while((msglen = recvfrom(sock,buf,BUFSIZlOl&saddr,&saddrlen))>0) {
buf[msglen] = '\0*;
printf(Mdgrecv: got a message: %s\n", buf);
say who called(&saddr);
}
return 0;
}
void say_who called(struct sockaddr In *addrp)
{
charhost[BUFSIZ];
int port;
getjntemet^addresslhost.BUFSIZ.&port.addrp);
printf(" from: %s:%d\n", host, port);
}
Функции make^dgram^server.socket и getjntemet_address определены в файле dgram.c и будут
представлены позже. Прием сообщения от сокета дейтаграмм происходит проще, чем
прием сообщения через сокет потоков. Вызов recvfrom будет блокирован, пока не будет
принята дейтаграмма. Когда прием закончится, то содержимое сообщения, обратный
адрес и длина сообщения будут скопированы в буферы.
Посылка дейтаграмм. Программа dgsend.c посылает дейтаграммы. Программа dgsend.c
создает сокет, а затем этот сокет будет использован для посылки сообщения .сокету,
который находится на машине с указанным именем и имеет указанный номер порта
(что задается в командной строке):
* dgsend.c- отправитель дейтаграмм
* Использование: dgsend имя_хоста номер_порта "сообщение"
* Действие: посылка сообщения по адресу имя хоста:номер порта
7
#include <stdio.h>
#include <stdlib.h>
#jnclude <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#define oops(m.x) {perror(m);exit(x);}
Int make_dgram_client_socket();
Int makejnternet_address(char *,int, struct sockaddrjn *);
int main(int ac, char *av[])
{
int. sock; /* использовать этот сокет для посылки */
char *msg; /* послать это сообщение */
13.5. Сокеты дейтаграмм
455
struct sockaddrjn saddr; /* поместить сюда адрес отправителя*/
If (ас !=
fprintf(stderr,"usage: dgsend host port 'message'VO; .
exitA);
}
msg = av[3];
/* получить сокет дейтаграмм ¦*/
if((sock = makejJgram_clieht_socket()) == -1)
oopsf'cannot make socket",2);
Г объединение имениjcocra и номера_порта для получения адреса назначения */
makejnternet_address(av[1], atoi(av[2]), Ssaddr);
Г послать строку через сокет по этому адресу */
if (sendto(sock, msg, strlen(msg), 0, &saddr, sizeof(saddr)) == -1)
oopsfsendto failed", 3);
return 0; *
}
При разовом вызове sendto произойдет передача содержимого буфера на сокет по указан-,
ному адресу.
Функции поддержки. Детали обработки сокета и адресов сокетов реализованы в
функциях, которые находятся в программе dgram.c:
А***********
•
7
«include
«include
«include
«include
«include
«include
«include
«include
«define
r****************************^
dgram.c
Функции поддержки обрабртки дейтаграмм
<stdio.h>
<unistd.h>
<sys/types.h>
<sys/socket.h>
<netinet/in.h>
<arpa/inet.h>
<:netdb.h>
<string.h>
HOSTLEN 256 ~
int makejnternet_address();
int make_dgram_server_socket(int portnum)
struct sockaddr jn saddr; /* здесь строится наш */
charhostname[HOSTLEN]; /* адрес 7
int sockJd; /* сокет 7
sockjd = socket(PFJNET, SOCK.DGRAM, 0); /* получить сокет */
if (sockJd==-1) return -1;
¦/** построить адрес и связывание его с сокетом *7
gethostname(hostname, HOSTLEN); /* где я нахожусь? 7
makejnternet_address(hostname, portnum, &saddr);
if (bind(sock_id, (struct sockaddr *)&saddr, sizeof(saddr)) != 0)
return-1;
456
Программирование с использованием дейтаграмм. Лицензионный сервер
return sockjd;
}
int make dgram client socket()
{
return socket(PF INET, SOCK DGRAM, 0);
}
int makejnternet_address(char *hostname, int port, struct sockaddrjn
*addrp)
Г
* конструктор адреса Internet-сокета, использует имя_хоста и номер_порта
* (host,port)->*addrp
7
struct hostent *hp;
! bzero((void *)addrp, sizeof(struct sockaddrjn));
hp = gethostbyname(hostname);
if (hp==NUIl) return-1;
bcopy((void *)hp->h,addr, (void *)&addrp->sin_addr, hp->hjength);
addrp->sin_port = htons(port);
addrp- >sin Jamily = AFJNET;
return 0;
} ,
int
getjnternet_address(char *host, int len, int *portp, struct sockaddrjn
*addrp)
Г
* извлечь имя_хоста и номер_порта из адреса сокета
* *addrp->(host,port)
7
{
strncpy(host, inet_ntoa(addrp->sin_addr), len);
*portp = ntohs(addrp->sinjx>rt);
return 0;
}
Создание сокета дейтаграмм аналогично созданию сокета потоков. Есть два отличия.
Нужно установить в качестве типа сокета SOCK_DGRAM и не нужно вызывать listen.
(Кроме того сервер сокета дейтаграмм не делает accept, а его клиент не должен
соединяться с сервером - не делает connect, г- Примеч. ред.)
Компиляция и проверка работы.
$ ее dgrecv.c dgram .с -о dgrecv
$ /dgrecv 4444 &
[1] 19383
$ се dgsend.c dgram.c-о dgsend
$ /dgsend host2 4444 "testing 123"
dgrecv: got a message: testing 123
from: 10.200.75.200:1041
13.5. Сокеты дейтаграмм
457
$ps
PIDTTYTIMECMD
14599 pts/3 00:00:00 bash
19383 pts/3 00:00:00 dgrecv
19393 pts/3 00:00:00 ps
$
Мы откомпилировали и стартовали сервер, который будет прослушивать порт 4444. Затем
был откомпилирован и запущен на исполнение клиент, который будет посылать текстовую
строку в порт с номером 4444. Сервер принимает сообщение, а затем выводит сообщение
и выводит адрес отправителя, который прислал сообщение. Сокет клиента адресуется
именем хоста и номером порта. Ядро установило для клиента произвольный номер порта
1041. Из протокола команды ps видно, что сервер продолжает свою работу.
13.5.3. Обобщение информации о sendto и recvfгот
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
sendto
Послать сообщение от сокета
tinclude <sys/types.h>
«include <sys/socket.h>
nchars = sendto(int socket, const void *msg, size t ten,
int flags,
const struct sockaddr *dest,
socklenj destjen);
АРГУМЕНТЫ socket- идентификатор сокета
msg - символьный массив, который нужно передать
ten - число передаваемых символов
flags - битовый набор, с помощью которого устанавливаются свойства
передачи
обычно используют 0
dest - указатель на адрес удаленного сокета
destjen - длина адреса .
КОДЫ ВОЗВРАТА -1 - при обнаружении ошибки
nchars - число посланных символов
sendto выполняет передачу данных от сокета к сокету назначения. Первые три аргумента
аналогичны аргументам в системном вызове write: идентификатор сокета, на который
посылается сообщение; символьный массив, который должен быть передан; число символов
для передачи. После выполнения sendto возвращает, как и вызов write, количество реально
переданных символов. С помощью аргумента flags можно задавать различные свойства
процедуры передачи. За деталями следует обратиться к документации. Последние два
аргумента определяют адрес сокета по месту назначения. Адрес сокета представляется в форме
структуры. Как Internet-адрес он содержит IP-адрес хоста и номер порта. Другие типы
адресов будут содержать другие компоненты.
recvfrom
НАЗНАЧЕНИЕ Принять сообщение от сокета
INCLUDE «include <sys/types.h>
tinclude <sys/socket.h>
458
Программирование с использованием дейтаграмм. Лицензионный сервер
recvfrom
ИСПОЛЬЗОВАНИЕ nchars = recvfrom(int socket, const void *msg, sizej len,
int flags,
const struct sockaddr *sender,
socklenj *senderjen);
АРГУМЕНТЫ socket - идентификатор сокета
msg - символьный массив
len - число символов для приема
flags - битовый набор, с помощью которого устанавливаются свойства прием
обычно используют О
sender -указатель на адрес удаленного сокета
sender Jen - указатель на место, где содержится размер адреса удаленного сокета
КОДЫ ВОЗВРАТА -1 - при обнаружении ошибки
nchars - число принятых символов
recvfrom читает дейтаграмму из сокета. Первые три аргумента recvfrom аналогичны
аргументам в системном вызове read: идентификатор, сокета, из которого читается сообщение;
символьный массив, в который будут помещаться принятые данные; число символов для
чтения. После выполнения sendto возвращает, как и вызов read, количество реально принятых
символов. С помощью аргумента flags можно задавать различные свойства процедуры
приема. За деталями следует обратиться к документации. Последние два аргумента используются
для определения адреса отправителя. Адрес сокета отправителя будет храниться в структуре,
на которую указывает первый аргумент. Длина адреса должна быть определена в recvfrom. Это
значение будет модифицировано, если действительный адрес имеет отличный размер. Если
эти указатели нулевые, то адрес отправителя не был записан.
13.5.4. Ответ на принятые дейтаграммы
Примеры программ dgsend.c и dgrecv.c показали, как можно посылать данные от клиента
к серверу. А как сервер может послать обратно свой ответ клиенту? В реальной жизни
может быть так, что кто-то прислал вам почтовую карточку с приглашением на обед. Как вы
узнаете - куда послать вам свой ответ? Все очень просто: вы пошлете ответ по обратному
адресу, который был указан в приглашении.
Программа dgrecv2.c принимает сообщения от клиентов и отвечает на них, посылая
благодарственное сообщение по адресу клиента:
/••••••••••••••••••••••••••••***^
*dgrecv2.c- приемник дейтаграмм
* Использование: dgrecv номер_порта
*' Действие: принять сообщение, отпечатать его и выдать ответ */•
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#define oops(m,x) {perror(m);exit(x);}
int make_dgram_serverjocket(int);
int getjnternet_address(char *, int, int *, struct sockaddrjn *);
void say_who_called(struct sockaddrjn *);
void reply_to_sender(int,char *,struct sockaddrjn *, socklenj);
int main(int ac, char *av[])
13.5. Сокетыдейтаграмм
459
{
int port; /* использовать этот порт 7
int sock; /* для этого сокета 7
char buf[BUFSIZ]; /* для приема сюда данных 7
sizej msglen; /* длина данных 7
struct sockaddrjn saddr; /* поместить сюда адрес отправителя 7
socklenj saddrlen; '/* и длину адреса 7
if (ас == 11| (port = atoi(av[1 ])) <= 0){
fprintf(stderr,"usage: dgrecv portnumber\n");
exitA);
}
Г получить сокет и назначить ему номер порта 7
if((sock = make_dgram_server_socket(port)) == -1)
oopsfcannot make socket",2);
/* принимать сообщения от этого сокета 7
saddrlen = sizeof (saddr);
while((msglen = recvfrom(sockJbuflBUFSIZ,0,&saddr,&saddrlen))>0) {
buf[msglen] = '\0';
printffdgrecv: got a message: %s\n", but);
say_who_called(&saddr);
reply to.sendertsock.buf.&saddr.saddrlen);
}
return 0;
}
void
reply to sender(int sock.char *msg,struct sockaddr in *addrp, socklen t len)
{
char reply[BUFSIZ+BUFSIZ];
sprintf(reply, "Thanks for your %d char message\n"f strlen(msg));
sendto(sock, reply, strlen(reply), 0, addrp, len);
}
void say who called(struct sockaddr in *addrp)
{
char hostfBUFSIZ];
int port;
getJnternetaddress(host,BUFSIZ,&port,addrp);
printf(" from: %s:%d\n", host, port);
}
Программа-отправитель, естественно, должна быть модифицирована, с тем чтобы она
могла принимать ответы. Это нужно сделать в качестве упражнения.
13.5.5. Итог по теме дейтаграмм
Дейтаграммы - это короткие сообщения, которые передаются от одного сокета к другому.
Отправитель использует системный вызов sendto, с помощью которого задается само
сообщение, его длина и место назначения, куда сообщение нужно передать. Принимающий
процесс использует вызов recvfrom для приема сообщения через сокет. Дейтаграммы непо-
460
Программирование с использованием дейтаграмм. Лицензионный сервер
средственно используют многоуровневую структуру адресации пакетов, которые
перемещаются через Internet. Поэтому дейтаграммы менее нагружают сетевой код ядра и меньше
загружают сетевой трафик. Дейтаграммы могут быть потеряны при передаче. Кроме того,
они могут поступать в произвольном порядке. По этим двум причинам сокеты дейтаграмм
лучше всего использовать для приложений, в которых простота, эффективность и скорость
являются более важными характеристиками, чем целостность и согласованность.
Сообщения, которые необходимы для протокола лицензионного сервера, являются
простыми. Приемлемым решением будет просто иметь один сервер, который будет ^дрини-
мать короткие сообщения, обрабатывать их и посылать обратно ответы, используя для
этого технику дейтаграмм.
13.6. Лицензионный сервер. Версия 1.0
Давайте вернемся к проекту лицензионного сервера. Наш сервер должен лимитировать
число попыток одновременного использования программы. Когда-пользователь пытается
запустить программу с ограничением на запуск, то процесс будет обращаться к серверу
за разрешением на запуск программы.
Если количество лиц, использующих программу в текущий момент, не превышает
предела, то лицензионный сервер разрешает запуск, о чем оповещается с помощью посылки
процессу билета (ticket). Если же фиксируется, что в текущий момент с программой
работает максимально возможное число пользователей, то программа вежливо сообщает
пользователю, чтобы он попытался бы запустить ее позже. Или требуется приобрести
лицензию на программу, по которой допускается большее число одновременно работающих
пользователей. Лицензионная программа и сервер взаимодействуют между собой
посредством двусторонних пересылок дейтаграмм.
Алгоритм работы двух программ их взаимодействие будут выглядеть так:
clnt
get tick
do your
work
ret tick
exit
- HELO pid -
-TICK pid.t-
-GBYE pid.t-
THNXr
srv
wait for RQ
recv RQ
proc RQ
reply to RQ
Клиентская и серверная программы состоят из двух файлов: небольшой файл, где
содержится функция main, и большой файл, где содержатся функции по управления
билетами. Сначала мы рассмотрим работу клиента, а затем сервера.
13.6. Лицензионный сервер. Версия 1.0
461
13.6.1. Клиент. Версия 1
/••••••••••••••••••••••••***^
xlclnt1.c
* Лицензионный сервер, клиент, версия 1
* Компонуется с объектными модулями Iclnt funcsl .о dgram.o
7
#include <stdio.h>
int main(int ac, char *av[])
{
setup();
if (getjicket() !=0)
exit(O);
dojegular_work();
release_ticket();
shut down();
}
* dojegular.work. Здесь выполнятся основная работа приложения */
do regular work()
{
printff'SuperSleep version 1*0 Running - Licensed Software\n");
sleep( 10); /* наш патентованный алгоритм sleep 7
}
Обобщенное представление кода для клиента позволяет нам сделать такой вывод. Клиент
получает билет, выполняет свою работу, освобождает (сдает) билет и затем заканчивается.
В качестве лицензионной программы в данном обобщенном представлении использована
специальная версия утилиты steep. Те, кто не удовлетворен работой стандартной версии
sleep, может приобрести лицензию на использование этой версий. Естественно, кто это
сделает, должен будет запустить наш специальный лицензионный сервер. В противном
случае наша программа sleep откажется запускаться. Функции поддержки в IclntJuncsl .с:
* Iclnt funcsl .с: функции для клиента лицензионного сервера
7
#include <stdio.h>
#include <sys/typea.h>
«include <sys/socket.h>
tinciude <netinet/in.h>
tinclude <netdb.h>
/* Важные переменные
7
static int pid = -1; /*НашРЮ7
static int sd = -1; /* Наш сокет 7
static struct sockaddr serv_addr; /* Адрес сервера 7
static socklen X servalee; /* длина адреса 7
static char ticket_buff 1Я); * Г буфер для хранения нашего билета 7
static havejicket = 0; /* Флаг, который устанавливается при наличии билета 7
?
Программирование с использованием дейтаграмм. Лицензий
#define MS6LEN 128 /* Размер наших дейтаграмм */
#define SERVER.PORTNUM 2020 /* Наш номер порта */
#define HOSTLEN 512
#define oops(p) {perror(p); exit( 1);}
char *do transaction();
Г
* setup : получить pid, сокет и адрес лицензионного сервера
* IN - без аргументов
* RET пусто, при ошибках заканчивается
* замечение: предполагается, что сервер находится на том же хосте, на
* котором находится клиент
7
setup()
{
char hostname[BUFSIZ];
pid = getpid(); /* для билетов и сообщений 7
sd = make_dgram_client_socket(); /* для общения с сервером 7
if(sd==-1)
oopsfCannot create socket");
gethostname(hostname, HOSTLEN); /* сервер находится на том же хосте 7
makeJnternet_address(hostname, SERVER_PORTNUM, &serv.addr);
serv alen = sizeof(serv addr);
}
shut down()
{
close(sd);
}
/••••••••••••••••••••••••••••••••••••••^
*geUicket
* получает от лицензионного сервера билет
х Результат: 0 при успехе, -1 - при неудаче
7
intget_ticket()
{
char Response;
charbuffMSGLEN];
if(havejicket) /* не быть жадным 7
return(O);
sprintf(buf, "HELO %d", pid); /* составить запрос 7
if ((response = doJransaction(buf)) == NUH)
return(-1); y
Г Произвести разборку отвага и посмотреть, получен ли билет?
* Если да, то сообщение будет таким: TICK ticket-string.
* Если неудача, то сообщение будет таким: FAIL failure-msg
7
if (strncmp(response, "TICK", 4) == 0){
,6. Лицензионный сервер. Версия 1.0
strcpy(ticket_buf, response + 5); /* получить идентификатор билете
havejicket = 1; /* установить этот флаг */
narratefgot ticket", ticket_buf);
return(O);
}
if (strncmp(response,"FAIL",4) ==0)
narrateC'Could not get ticket",response);
else
narratefUnknown message:", response);
return(-1);
}/*getticket7
^••••••••••••••••••••••••••••••••••••••••••^
* release^ticket
* Возврат билета серверу
* Результаты : 0 при успехе, -1 - при неудаче
7 *
int release ticket()
{
charbuf[MSGLEN];
char Response;
if(lhavejicket) /* билета нет 7
return(O); /* возвращать нечего */
sprintf(buf, "GBYE %s", ticket_buf); Г составить сообщение 7
if ((response = dojransaction(buf)) == NULL)
retum(-1);
/* проверка ответа
* успех: THNX info-string
* неудача: FAIL error-string
if (strncmp(response, "THNX", 4) == 0){
narrate("released ticket OK","");
return 0;
}
if (strncmp(response, "FAIL", 4) == 0)
narrate("release failed", response+5);
else
narratefUnknown message:", response);
return)-1);
} Г releasejicket 7
/**•••••**•*••••••••••••••••*••••*•••
* dojransaction
* Посылает запрос на сервер и получает ответ от сервера
* IN msg_p - сообщение для посылки
* Результаты: указатель на строку сообщения или NULL - при ошибке
* ЗАМЕЧАНИЕ: возвращается указатель на статическую память, которая
* перезаписывается при каждом успешном вызове
464 Программирование с использованием дейтаграмм. Лицензионный сервер
* Для дхтижения сверх секретности сравнивается retaddr с serv addr * (зачем?)
7
char *do transaction(char *msg)
{
static char buf[MSGLEN];
struct sockaddr retaddr;
socklenj addrlen=sizeof( retaddr);
int ret;
ret = sendto(sd, msg, strlen(msg), 0, Sserv addr, serv alen);
if(ret==-1){
syserrf'sendto");
return(NULL);
}
Г Получение ответа */
ret = recvfrom(sd, but, MSGLEN, 0, &retaddr, &addrlen);
if(ret==-1){
syserrfrecvfrom");
return(NULL);
}
Г теперь возвращается собственно сообщение */
return(buf);
} Г dojransaction */
* narrate: выводит сообщения на stderr для отладки и для демонстрационных
* целей
* IN msgl, msg2: строки для вывода с pid и заголовком
* RET пусто, заканчивается при ошибке
7
narrate(char *msg1, char *msg2)
{
fprintffstderr/'CLIENT [%d]: %s %s\n", pid, msgl, msg2);
}
syserr(char*msg1)
{
char but [MSGLEN];
sprintf(buf,nCUENT [%d]: %s", pid, msgl);
perror(buf);
}
getjicket и releasejicket являются основными функциями в файле. Обе выполняют одну и ту
же последовательность действий: составляют короткий запрос, посылают сообщение на
сервер, ожидают ответа от сервера, а затем проверяют и действуют в зависимости от
полученного ответа.
getjicket обращается с запросом на билет, посылая команду HELO, за которой следует ее PIP.
Сервер удовлетворяет запрос, посылая назад сообщение в форме ТЮК ticket-id. Если сердар
отвергает запрос, то он посылает назад сообщение в форме FAIL explanation.
13.6. Лицензионный сервер. Версия1.0
465
releasejicket возвращает билет, что делается с помощью посылки команды GBYE ticket-id. Если
билет был принят, то сервер оправляет сообщение в форме THNX greeting. Если же билет был
признан недействительным, то сервер отправляет сообщение в форме FAIL explanation.
Почему билет может оказаться недействительным? Мы рассмотрим эту проблему и
способы ее разрешения позже.
13.6.2. Сервер. Версия 1
^••••••••••••••••••••••••••***********
* Iservl .с
* Программа лицензионного сервера. Версия 17
#include <stdio.h>
«include <sys/types.h>
«include <sys/socket.h>
#include <netinet/in.h>
«include <signal.h>
«include <sys/ermo.h>
«define MSGLEN 128 /* Размер наших дейтаграмм 7
int main(int ас, char *av[])
{
struct sockaddrjn client_addr;
socklenj addrlen=sizeof(client_addr);
charbuf[MSGLEN];
int ret;
int sock;
sock = setup();
whileA){
addrlen = sizeof (client_addr);
ret = recvfromlsock.buf.MSGLEN.O.&client^addr.&addrlen);
if (ret !=-!){
buf[ret] = '\0';
narrateCGOT:", but, &client_addr);
handle request(buf,&client addr.addrlen);
}
elseif(errno!=EINTR)
perror(Mrecvfrom");
}
}
В самом общем представлении лицензионный сервер - это цикл, в котором принимается
дейтаграммный запрос, обрабатывается запрос и далее посылается ответ на запрос. Код
для управления запросами представлен в программе Iservjuncsl .с:
* Isrvjuncsl .с
* Функции лицензионного сервера
7
«include <stdio.h>
«include <svs/tvDes.h>
466
Программирование с использованием дейтаграмм. Лицензионный серь
#include <sys/socket.h>
#include <netinet/in.h>
#include <netdb.h>
#include <signal.h>
#include <sys/ermo.h>
#deflne SERVER_PORTNUM 2020 /* Номер порта нашего сервера */
#define MSGLEN 128 /* Размер наших дейтаграмм 7
#define TICKET_AVAIL 0 /* Слот, доступный для использования 7
#deflne MAXUSERS 3 /* Для нас могут работать только 3 пользователя 7
#define oops(x) {perror(x); exit(-1);}
^•••••••••••••••••••••••••••••**^
* Важные переменные
7
int ticket_array[MAXUSERS]; ./* наш массив билетов 7
intsd = -1; /*Нашсокет7
int numjicketsj)ut = 0; /* Число выданных и невозвращенных билетов 7
char *doJiello();
char*do_goodbye()
^•••••••••••••••••••••••••••••••••^
* setup() - инициализация лицензионного сервера
7
setup()
{
sd = make dgram server socket(SERVER PORTNUM);
if(sd==-1)
oopsfmake socket");
free_alljickets();
return sd;
}
free_all tickets!}
{
int i;
for(i=0; i<MAXUSERS; i++)
ticket array[i]= TICKET AVAIL;
}
/••••••••••••••••••••••••••••••••ж**
* shut down() - закрыть лицензионный сервер
7
shut down()
{
close(sd);
}
^••••••••••••••••••••••••••••••••*
* handle_request(request, clientaddr, addrlen)
* ветвление по коду запроса
7
.6. Лицензионный сервер. Версия 1.0
handle request(char *req.struct sockaddrjn *client, socklenj addlen)
{
char Response;
int ret;
/* выполнить действие и составить ответ */
if (strncmp(req, "HELO", 4) == 0)
response = do_hello(req);
else if (strncmp(req, "GBYE", 4) ==0)
response = do_goodbye(req);
else
response = TAIL invalid request";
/* послать ответ клиенту */
narratefSAID:", response, client);
ret = sendtofsd, response, strlen(response),0, client, addlen);
if (ret ==-1)
perrorfSERVER sendto failed");
}
*doJiello
* Выдает билет, если имеется в наличии
* IN msg_p сообщение, принятое от клиента
* Результаты: указатель на ответ
* ЗАМЕЧАНИЕ: результат помещается в статический буфер, который
* переписывается при каждом вызове
7
char *dd hello(char *msg p)
{
intx;
static char replybuf [MSGLEN];
if(num_tickets_out >= MAXUSERS)
returnfFAIL no tickets available");
/* иначе найти свободный билет и отдать его клиенту 7
for(x = 0; x<MAXUSERS && ticket_array[x] != TICKET.AVAIL; х++)
»
Г Закономерная проверка */
if(x == MAXUSERS) {
narratefdatabase corrupt'V'.NULL);
return("FAIL database corrupt");
}
/* Найти свободный билет. Записать "имя" пользователя, т. е. PID, в массив
* Представить билет в форме: pid.slot
7
ticket.array[x] = atoi(msg_p + 5); /* получить PID из сообщения 7
sprintf(replybuf, 'TICK %d.%d", tickeUrrayfx], x);
numJickets_out++;
retum(replybuf);
468
Программирование с использованием дейтаграмм. Лицензионный сервер
} Г do.hello */
* do_goodbye
* Возврат билета клиенту
* IN msgj) сообщение, принятое от клиента
* Ответ: указатель на ответ
ЗАМЕЧАНИЕ: результат помещается в статический буфер, который
* переписывается при каждом вызове
7
char *do goodbye(char *msg_p)
{
int pid, slot; /* компоненты билета */
/* Пользователь возвращает билет. Нужно выдать сообщение в ответ на принятый
* обратно билет. Это сообщение будет таким:
й> GBYEpid.slot
• Р/
Ф: if((sscanf((msgj) + 5), "%d.%d", &pid, &slot) != 2) ||
^ (ticketjmy[slot] !=pid)){
narratef'Bogus ticket", msg^p+5, NUll);
returnf'FAIL invalid ticket");
}
Г Билет действителен. Все в порядке. 7
ticket^array[s!ot] = TICKET_AVAIL;
num_tickets_out--;
/* Ответить 7
return('THNXSeeya!");
} Г dojjoodbye 7
/•••••••••••••••••************^
* narrate() - дополнительная информация для отладки и для учетных целей
7
narrate(char *msg1, char *msg2, struct sockaddr in *clientp)
{
fprintf(stderr,"\t\tSERVER: %s %s", msgl, msg2);
if(clientp)
fprintf(stderr,"(%s:%d)", inet_ntoa(clientp->sin_addr),
ntohs(clientp- >sin j>ort));
putc('\n', stderr);
}
Здесь были представлены три основных функции:
handlejequest
Запросы состоят из четырех-символьных команд, за которыми следуют аргумент.
Сервер проверяет команду и вызывает далее соответствующую функцию. Даже если
команда ошибочная, сервер должен послать клиенту некий ответ, иначе клиент
останется блокированным, ожидая поступления ответа.
13.6. Лицензионный сервер. Версия 1.0
469
do_hello
Команда HELO служит для выдачи запроса на билет. Сервер ищет в массиве ключей
свободный элемент. Запись, в которой в поле PID находится 0, обозначает свободный
ключ. Сервер использует специальную переменную numjicketsjxit, где будет храниться
значение числа выданных и еще не возвращенных билетов. Сервер будет
осуществлять поиск в таблице при поступлении каждого запроса, а эта переменная будет
показывать, есть ли еще билеты.
dp_goodbye
С помощью команды GBYE выдается запрос на возврат билета. Билет - это строка, в
которой содержится PID клиента и номер билета. Сервер сравнивает PID и номер билета
с данными, которые представлены в учетном списке ticket_array. Если обнаруживается
совпадение, то сервер вычеркивает имя клиента из списка и благодарит клиента. Если
обнаруживается несовпадение, то где-то произошла ошибка.
Если бы вы работали в службе регистрации в авиакомпании и пассажир предоставил вам
билет на самолет, в котором указаны номер и фамилия, не представленные в базе данных
авиакомпании, то вы задали бы пассажиру такой вопрос: "Где вы приобрели этот билет?
И, наконец, кто вы сами такой?" Проблему подделки билетов мы обсудим позже. А теперь
проверим работу нашей программы.
13.6.3. Тестирование Версии 1
Откомпилируем программу сервера и запустим ее на исполнение в фоновом режиме:
$ сс Iservl .с Iservjuncsl .с dgram.c-о Iservl
$ ./Iservl &
[1] 25738
Откомпилируем программу клиента и выполним четыре запуска этой программы:
$ сс Iclntl .с Iclnt funcsl .с dgram.c -о Iclntl
$ /Iclntl Mclntl &./lclnt1 & ./Iclntl *
SERVER: GOT: HELO 25912 A0.200.75.200:1053)
SERVER: SAID: TICK 25912.0 A0.200.75.200:1053)
CLIENT [25912]: got ticket 25912.0
SuperSleep version 1.0 Running - Licensed Software
SERVER: GOT: HELO 25913 A0.200.75.200:1054)
SERVER: SAID: TICK 25913.1 A0.200.75.200:1054)
CUENT [25913]: got ticket 25913.1
SuperSleep version 1.0 Running - Licensed Software
SERVER: GOT: HELO 25915 A0.200.75.200:1055)
SERVER: SAID: TICK 25915.2 A0.200.75.200:1055)
CUENT [25915]: got ticket 25915.2
SuperSleep version 1.0 Running - Licensed Software
SERVER: GOT: HELO 25914 A0.200.75.200:1059)
SERVER: SAID: FAIL no tickets available A0.200.75.200:1059)
CUENT [25914]: Could not get ticket FAIL no tickets available
SERVER: GOT: GBYE 25912.0 A0.200.75.200:1053)
SERVER: SAID: THNX See ya! A0.200.75.200:1053)
CUENT [25912]: released ticket OK
SERVER: GOT: GBYE 25913.1 A0.200.75.200:1054)
SERVER: SAID: THNX See ya! A0.200.75.200:1054)
470
Программирование с использованием дейтаграмм. Лицензионный сервер
CLIENT [25913]: released ticket OK
SERVER: GOT: GBYE 25915.2 A0.200.75.200:1055)
SERVER: SAID: THNX See ya! A0.200.75.200:1055) .
CUENT [25915]: released ticket OK
Результаты выглядят не совсем такими, что можно были бы получить в реальной системе.
Тем не менее, вы видите, что сервер принимает запросы и выдает по ним билеты. Клиенты по
запросу получают билеты и начинают свою работу. Вы видите по полученным результатам,
что процессу 25914 не повезло и он не получил билета. К тому моменту, когда этот процесс
выдал запрос, все билеты были выданы. А вот процесс 25915 получил билет. Если вы будете
запускать этот тест несколько раз, то получите различные результаты.
13.6.4. Что еще нужно сделать?
Лицензионный сервер версии I работает хорошо. Сервер управляет запросами и
поддерживает список процессов, которые получили от него билеты. Клиенты получают
билеты от сервера, выполняют свою работу и возвращают билеты после того, как все сделали.
Все выглядит идеально. Но окружающий нас мир не является идеальным. Программное
обеспечение и пользователи не всегда делают то, что должны делать или хотели бы
делать. Как могут возникнуть неправильные действия? Как мы должны реагировать в ответ
на возникновение ошибочных ситуаций?
13.7. Программирование с учетом существующих реалий
Наша система лицензионного обслуживания работает корректно до тех пор, пока
сотрудничают два процесса. В ряде случаев при работе программ возникают проблемы. Что
произойдет, если исполнение приложения SuperSleep будет закончено по инициативе
пользователя, или если при исполнении возникнет ситуация, связанная с нарушением адресации
и приложение было убито ядром? Что тогда случится с выделенным билетом для
приложения? Что произойдет, если аварийно закончит работу лицензионный сервер? Что
произойдет, если после всего этого лицензионный сервер опять будет перезапущен?
Программы, которые должны работать в обычных условиях реального мира, должны быть
подготовлены к возникновению различных разрушительных ситуаций. Мы рассмотрим
два возможных случая: случай, когда клиент аварийно заканчивается, и случай, когда
аварийно заканчивается сервер.
13.7.1. Управление авариями в клиенте
Если клиент аварийно заканчивается, то не будет возвращен билет, который он взял
у сервера (см. рисунок 13.8).
Если процесс
аварийно
заканчивается
то он не возвращает
свой билет
hz3| I
Запись в списке
выдачи для
умершего
процесса
Рисунок 13.8
Клиент уносит билет с собой
в могилу
13.7. Программирование с учетом существующих реалий 471
В примере с автомобилями может случиться, что водитель не вернул ключ от автомобиля
потому что его уволили, или он погиб, или ушел домой, или просто пропал. Как такие
события отразятся на системе? Учетный лист показывает, что билет или ключ от
автомобиля находится все еще в использовании. Другие процессы или водители не смогут
получить этот ключ. В программной модели, если достаточное число процессов попадут
в аварию, то весь учетный список будет заполнен пометками о выдаче ключей. И уже
никто не сможет запустить программу, в которой нужно подтвердить разрешение на запуск.
Менеджер службы выдачи ключей может повлиять на ситуацию, когда не были
возвращены ключи. Он просто может позвонить тем людям, у которых остались ключи. Через
регулярный промежуток времени менеджер будет пролистывать весь список учета и
звонить каждому водителю, задавая ему один и тот же вопрос: " Вы все еще используете
взятый ключ? " Если мейеджер получает ответ, то он вычеркивает имя этого водителя из
списка. Чем более часто менеджер будет проверять людей, у которых находятся ключи,
тем более точным будет список.
Лицензионный сервер может использовать такую же технику. Через определенный
регулярный интервал лицензионный сервер будет обращаться к массиву билетов и проверять,
существуют ли те процессы,. которые представлены в этом массиве? Если
обнаруживается, процесс больше не существует, то лицензионный сервер может вычеркнуть его
имя из списка, освобождая ( восстанавливая) тем самым выданный процессу билет.
Чем более часто лицензионный сервер будет выполнять такую функцию, тем более точен
будет список.
Восстановление потерянных билетов: планирование
Куда следует поместить код для восстановления потерянных билетов? Как мы будем
вызывать его? В нашем сервере выполняются две независимые операции: ожидание
входящих запросов от клиентов и через регулярные промежутки времени операция по
восстановлению потерянных билетов. Планирование таких действий по восстановлению
будет достаточно простым. Необходимо использовать вызовы alarm и signal для
регулярного вызова процедуры восстановления. Мы ранее использовали эту технику в главе, где
была рассмотрена программа с перемещением сообщения.
Наш новый поток управления в программе будет выглядеть так, как показано на
рисунке 13.9.
Запрос
Ответ
Рисунок 13.9
main()
set alarm
loop
wait for req
recv req
cancel alarm
process req
reply to req
restore alarm
ticket_reclaim()
check all tickets
set alarm
Использование alarm для планирования процедуры восстановления билетов
472
Программирование с использованием дейтаграмм. Лицензионный сервер
Когда мы разрабатывали программу, которая сразу выполняла две работы, то мы должны
были позаботиться о взаимовлиянии функций. Возникнет ли проблема, если нашему
серверу, когда он занят обработкой клиентского запроса, будет послан сигнал SIGALRM,
по которому нужно будет заниматься восстановлением билетов? Разделяют ли эти две
операции некие переменные или структуры данных? Да, разделяют. При выдаче и возврате
билетов модифицируется учетный список. И при выполнении функции восстановления
билетов учетный список может также быть модифицирован. Может ли из-за этой зависимости
между двумя функциями возникнуть опасность нарушения целостности такой структуры
данных? Ответ на этот вопрос остается в качестве упражнения. Чтобы быть застрахованным от
проблем, мы будем выключать службу alarm на время обработки запросов.
Восстановление потерянных билетов: кодирование
Мы хотим восстановить билеты процессов, которые умерли. Как можно определить,
не умер ли тот или иной процесс? Можно использовать рореп, а затем в выводе команды ps
искать PID процессов, которым были выданы билеты. Есть более быстрое, более простое
решение. Оно основано на использовании специального свойства системного вызова kill.
Определить, существует ли в текущий момент некий процесс, можно с помощью посылки
проверяемому процессу сигнала с номером 0. Если процесс не существует, то ядро не
будет передавать сигнал, а возвратит ошибочный код и установит в переменной еггпо
значение ESRCH. Мы используем это свойство в новой версии функции ticketjeclaim, которая
находится в программе Iservjuncs2.c:
#define RECLAIM JNTERVAL 60 /* работа по восстановлению будет производиться
* через каждые 60 секунд*/
* ticket jeclaim
* Просматривает список выданных билетов и восстанавливает билеты мертвых
* процессов
* Результаты: нет
7
void ticket reclaim!)
{
inti;
char tick[BUFSIZJ;
for(i = 0; i < MAXUSERS; i++) {
if((ticket array[i] != TICKET AVAIL) &&
(kill(tickeUrray[i], 0~) == -1) && (errno == ESRCH)) {
Г нет процесса 7
sprintf(tick, "%d.%dH, ticket_array[i],i);
narrateC'freeing", tick, NULL);
ticket_array[i] = TICKET AVAIL;
num tickets out--;
}
}
alarm(RECLAIMJNTERVAL); /* сброс службы alarm */
\
13.7. Программирование с учетом существующих реалий 473
Далее мы добавим этот код в main, чтобы можно было планировать выполнение функции
восстановления билетов и можно было бы выключать alarm при проведении обычной
обработки запроса. Эта модифицированная версия находится в программе IservZc:
int main(int ас, char *av[])
{
struct sockaddr clientjtddr;
socklenJaddrlen=sizeof(clientjtddr);
charbuffMSGLEN];
int ret, sock;
void ticketjeclaim(); /* дополнение к версии 2 */
unsigned timejeft;
sock = setup();
signal(S!GALRM, ticketjeclaim); /* запуск восстановителя билетов */
alarm(RECLAIMJNTERVAL); /* после этого задержка */
whileA){
addrlen = sizeof (client_addr);
ret = recvfromlsock.buf.MSGLEN.O.&dient^addr.&addrlen);
if(ret!=-1){
buffret] = "\0';
narratefGOT:", buf, &client_addr);
timejeft = alarm(O);
handlejequest(buf,&client_addr,addrlen);
alarm(time left);
}
else if (errno != EINTR)
perrorf'recvfrom");
}
}
После таких минимальных дополнений наш лицензионный сервер будет восстанавливать
невозвращенные билеты по схеме периодического планирования. А почему бы не
заниматься восстановлением потерянных билетов, лишь когда у сервера нет билетов и клиент
может получить отказ на его запрос? Не будет ли такое решение лучше, чем предыдущее?
13.7.2. Управление при возникновении аварийных ситуаций на сервере
Крах сервера имеет два серьезных последствия. Во-первых, теряется учетный список.
Не остается информации о том, каким процессам были выданы билеты. Во-вторых,
клиенты далее не смогут работать, поскольку программы, которая разрешает работу, не
существует. Очевидным решением будет повторный запуск сервера (см. рисунок 13.10).
474
Программирование с использованием дейтаграмм. Лицензионный сервер
Билеты, выданные предыдущим сервером
Этот новый клиент
может получить
билет
Этот новый сервер
стартует с таблицей,
в которой нет билетов
Рисунок 13.10
Сервер повторно стартует после своего краха
При повторном запуске сервера могут запускаться и новые клиенты, но возникают две
новые проблемы.
Первая новая проблема заключается в том, что массив выданных билетов во вновь
стартовавшем сервере сначала будет пустым. Сервер имеет "свежий" набор не выданных
билетов. Но до возникновения аварийной ситуации массив выданных билетов мог быть
полностью заполненным. А новый сервер готов с охотой выдавать разрешение на работу
новым клиентам. Уничтожение и повторный старт сервера аналогичен процедуре
печатанья денег. Другая новая проблема заключается в том, что могут быть клиенты, которые
имеют билеты, которые были получены от предыдущего сервера. Они должны быть
оповещены о том, что теперь эти билеты объявлены фиктивными.
Легализация билетов
Решение этих двух проблем заключается в использовании механизма легализации
билетов. Механизм легализации предполагает, что каждый клиент посылает серверу через
регулярные интервалы времени копию своего билета. Клиент при обращении к серверу
посылает ему дейтаграмму, которая по смыслу является вопросом: " Вот мой билет. Он все
еще пригоден? " (см. рисунок 13.11).
^^сётш
Рисунок 13.11
Клиент проверяет легальность билета
В билете должен содержаться индекс массива и PID. Сервер обращается к таблице. Если
слот пустой, то сервер должен предположить, что он выдал билет клиенту в своей
"прежней жизни". Сервер должен будет добавить запись в таблицу. Постепенно, по мере того
как клиенты будут представлять свои билеты на признание их Легальности, таблица будет
повторно заполнена.
Перестроение таблицы в сервере при проведении процедуры легализации билетов решает
проблему потери таблицы, но приводит к другим проблемам. Если новый клиент
обратится с запросом на билет до того, как произойдет полное восстановление таблицы, то сервер
может выдать билет под йомером, который уже был выдан другому клиенту.
13.7. Программирование с учетом существующих реалий
475
Когда клиент, у которого уже был билет с таким же номером, представит свой билет для
проверки его на легальность, то сервер не подтвердит легальность этого билета.
Можно предложить решение, когда сервер признает сразу нелегальными все билеты,
которых нет в таблице. Клиенты, которые владеют такими отвергнутыми билетами,
просто должны будут запросить новый билет. Будет ли такое решение лучше?
Добавление проверки легальности в протокол
Проверка легальности билета - это новая транзакция в протоколе:
Клиент: VALD tickid
Сервер: GOOD или FAIL, если билет нелегален
Сделаем изменения в клиенте и сервере с целью добавления средства проверки
легальности билетов.
Добавление к клиенту средства проверки легальности билетов
Добавим средство для проверки легальности билета клиента путем добавления функции
проверки легальности и путем вызова этой функции из функции main в программе. Поток
управления в клиенте теперь будет иметь вид, показанный на рисунке 13.12.
е2л№
main()
get ticket
until done
do some work
(-—validate .щ..птч
I return ticket \
I exit i
LvalidateO
ask server
if valid
return •—-
take action
HELO pid »
< TICK tickid
GBYS tickid—
< THNX
VALD ticki,d —
< GOOD
main()
set alarm
loop
wait for
-recv req
req
cancel alarm
process req
reply to
req
restore alarm
Рисунок 13.12
Клиент проверяет легальность вначале и далее
Клиент может планировать проведение проверок на легальность билета, используя для
этого любую, наиболее подходящую схему. Клиент может установить таймер и проводить
проверку на легальность по схеме периодического планирования. Если клиентская
программа представляет собой электронную таблицу, то проверка на легальность может
проходить после выполнения определенного объема вычислений. Лицензионная версия игры
в пинг-понг может проводить проверку легальности после каждого удара по шарику.
В клиентской программе SuperSleep интервал в 10 секунд может быть разбит на два
интервала по 5 секунд. Между этими интервалами можно проводить проверку на
легальность билета программы. Это изменение нужно сделать в качестве упражнения.
Проверка легальности билетов на сервере
Для добавления проверки легальности билетов на сервере нужно сделать два изменения.
Прежде всего, необходимо добавить функцию для проверки легальности:
476 Программирование с использованием дейтаграмм. Лицензионный сервер
* do_validate
* Проверяет легальность билета клиента
* IN msg_p сообщение, принятое от клиента
* Результат: указатель на ответ
* ЗАМЕЧАНИЕ: результат записывается в статический буфер, который переписывается
* при каждом вызове.
7
static char *do validate(char *msg)
{
int pid, slot; /* компоненты билета 7
Г сообщение будет в формате: VALD pid.slot - разобрать его и проверить на легальность 7
if (sscanf(msg+5,,,%d.%d,,,&pid,&slot)==2 && ticket_array[slot]==pid)
return("GOOD Valid ticket");
/* плохой билет 7
narratef Bogus ticket", msg+5, NULL);
retum("FAIL invalid ticket");
}
Сделаем еще добавления в handle_request:
handle request(char *req,struct sockaddr in *client, socklen t addlen)
{ ¦ " ¦ ¦
char *response;
int ret;
Г обработка и подготовка ответа 7
if (stmcmp(req, "HELO", 4) == 0)
response = doJiello(req);
else if (stmcmp(req, "GBYE", 4) == 0)
response = do_goodbye(req);
else if (strncmp(req, "VALD", 4) == 0)
response = do_validate(req);
else
response = "FAIL invalid request";
/* послать ответ клиенту 7
narrate("SAID:", response, client);
ret = sendto(sd, response, strlen(response),0, client, addlen);
if (ret—.-1)"
perrorfSERVER sendto failed");
}
13.7.3. Тестирование версии 2
Теперь откомпилируем и протестируем эти новые версии нашего клиента и сервера. Тест
предполагает, что будут убиваться клиенты и сервера и будут повторно стартовать новые
клиенты и новые сервера. Обратите внимание на PID и сообщения от программ. Для
достижения целей тестирования клиент будет "спать" на двух интервалах по 15 секунд
каждый, а сервер будет проводить проверку легальности билетов каждые 5 рекунд.
Результаты тестирования будут такими:
\7. Программирование с учетом существующих реалий
$ ее Iserv2.c Iserv_funcs2.c dgram.c -о Iserv2
$ се Iclnt2.c Iclnt_funcs2.c dgram.c -о Iclnt2
$ ./Iserv2& # стартовать сервер
[1] 30804
$ /Iclnt2 &./lclnt2 &./lclnt2 & # запуск на исполнение трех кли
[2] 30805
[3] 30806
[4] 30807
$ SERVER: GOT: HELO 30805 A0.200.75.200:1085)
SERVER: SAID: TICK 30805.0 A0.200.75.200:1085)
CLIENT [30805]: got ticket 30805.0
SuperSleep version 1.0 Running - Licensed Software
SERVER: GOT: HELO 30806 A0.200.75.200:1086)
SERVER: SAID: TICK 30806.1 A0.200.75.200:1086)
CLIENT [30806]:got ticket 30806.1
SuperSleep version 1.0 Running - Licensed Software
SERVER: GOT: HELO 30807 A0.200.75.200:1087)
SERVER: SAID: TICK 30807.2 A0.200.75.200:1087)
CUENT [30807]: got ticket 30807.2
SuperSleep version 1.0 Running - Licensed Software
$ kill 30806 # убить клиента
[3]-Terminated./lclnt2
SERVER: freeing 30806.1
SERVER: GOT: VALD 30805.0 A0.200.75.200:1085) '
SERVER: SAID: GOOD Valid ticket A0.200.75.200:1085)
CUENT [30805]: Validated ticket: GOOD Valid ticket
SERVER: GOT: VALD 308Q7.2 A0.200.75.200:1087)
SERVER: SAID: GOOD Valid ticket A0.200.75.200:1087)
CUENT [30807]: Validated ticket: GOOD Valid ticket
$ kill 30804 # убить сервер
[1] Terminated ./Iserv2
$ ./Iserv2 & # стартовать новый сервер
[5] 30808
$
SERVER: GOT: GBYE 30805.0 A0.200.75.200:1085)
SERVER: Bogus ticket 30805.0
SERVER: SAID: FAIL invalid ticket A0.200.75.200:1085)
CLIENT [30805]: release failed invalid ticket
SERVER: GOT: GBYE 30807.2 A0.200.75.200:1087)
SERVER: Bogus ticket 30807.2
SERVER: SAID: FAIL invalid ticket A0.200.75.200:1087)
CLIENT [30807]: release failed invalid ticket
$ /clnt2 # начать исполнение нового клиента
SERVER: GOT: HELO 30809 A0.200.75.200:1087)
SERVER: SAID: TICK 30809.0 A0.200.75.200:1087)
CUENT [30809]: got ticket 30809.0
478
Программирование с использованием дейтаграмм. Лицензионный сервер
SuperSleep version 1.0 Running - Licensed Software
SERVER: GOT: VALD 30809.0 A0.200.75.200:1087)
SERVER: SAID: GOOD Valid ticket A0.200.75.200:1087)
CLIENT [30809]: Validated ticket: GOOD Valid ticket
SERVER: GOT: GBYE 30809.0 A0.200.75.200:1087)
SERVER: SAID: THNXSeeya! A0.200.75.200:1087)
CLIENT [30809]: released ticket OK
[2] Done
[4]- Done
$
$ps
PIDTTY
23509 pts/3
30808 pts/3
30810 pts/3
$
./Iclnt2
./Iclnt2
TIMECMD
00:00:00 bash
00:00:00 Iserv2
00:00:00 ps
Фу! Тест закончился успешно. Поработайте сами с этими программами и посмотрите, как
они взаимодействуют.
13.8. Распределенные лицензионные сервера
Лицензионная программа и лицензионный сервер связаны между собой через сокеты,
а сокеты могут соединять процессы, которые развиваются на разных хостах.
Теоретически клиент может работать на одной машине, а сервер может работать на другой, что
и происходит в Internet, когда Web броузеры и Web сервера работает на различных
машинах. А есть ли проблемы при запуске клиентов и серверов на разных машинах? Да, есть.
Проблема 1: Дублирование идентификаторов процессов (PID)
На одной машине все PID являются уникальными. Но это не относится к сети. Нет ничего
ошибочного или необычного в том, что изображено на рисунке 13.13:
Лензионный сервер
mrrT\ L
J
| 200 |
НИ
J.-6
1
Хост1
щ\
п
Т1ТГ
1
1
4 В
II
! Хост2
[й2йо;,?
J
v v-Ч
й
У;?;?ms-::;m?*fi€? ¦¦ [- -¦¦"-: * ;; ':'• Ш-1 - ' >¦'
ХостЗ
Рисунок 13.13
Идентификаторы процессов (PIDs) не являются уникальными в сети
В билетах и в таблице билетов содержится номер билета и P1D. В ситуации, которая
показана на рисунке 13.13, лицензионный сервер будет считать, что он выдал три билета
одному и тому же процессу. Это будет расценено, как ошибка. Процесс нуждается только в
одном билете для своей работы. Запрос дополнительных билетов от клиента может быть
расценен, как наличие не выявленной программной ошибки у клиента.
13.8. Распределенные лицензионные сервера
479
Мы можем решить проблемы дублирования PID за счет расширения формата у билетов,
а также за счет того, что содержимое таблицы билетов будет включать нечто, что могло
бы идентифицировать хост, на котором работает сервер.
Проблема 2: Восстановление потерянных билетов
Сервер посылает сигнал 0 всем процессам, которые имеют билет. При использовании
модернизированной таблицы билетов сервер будет знать, на каком хосте работает клиент.
J
200 |
ни
l
[XocTl
Ли1
200 }
1
денз
¦
ионнь
1
щ
II
Хост2
и сервер
Гэоо
1
Г
ХостЗ
Рисунок 13.14
Процесс не может послать сигнал на другой хост
Однако, сервер не может посылать сигналы процессам на другие машины
(см, рисунок 13.14). Если лицензионный сервер захочет послать сигнал процессу, который
находится на host3, то для выполнения этого действия лицензионный сервер должен будет
послать требование на host3.
А почему бы не запустить лицензионный сервер на каждом хосте сети? Каждый такой
локальный сервер будет тогда поддерживать свою службу восстановления потерянных
билетов (см. рисунок 13.15).
Лицензионный сервер
юга
Лицензионный сервер
Лицензионный сервер
Чг
Хост1
V
I
Хост 2
ХостЗ
Рисунок 13.15
Работают локальные копии lserv
При использовании локальных серверов решается проблема получения сигналов от
других хостов, но опять возникают такие вопросы: Какой сервер выдавал билет? Как сделать,
чтобы основной сервер имел бы коммуникации с локальными серверами? Кому клиент
должен посылать билет для определения его легализации?
480 Программирование с использованием дейтаграмм. Лицензионный сервер
Проблема 3: Крах хостов
Что произойдет, если перестает работать одна из машин, а не программа ? Как сможет
главный сервер, если он все еще работает, восстанавливать билеты? Как смогут
клиентские программы, если они все еще работают, проверять легальность своих билетов? Если
произойдет крах главного сервера, то кто будет выдавать билеты?
Модели распределенной лицензионной системы
Каким образом можно построить лицензионную систему, в которой одновременно в
составе обслуживающей системы задействованы несколько машин? Есть три метода.
Рассмотрим детали проекта, сильные и слабые стороны различных вариантов. Нужно также
представлять себе, как в.каждом из вариантов будет работать система, если случится
авария или неисправность с клиентом, сервером, компьютером или с сетью.
Решение 1: С центральным сервером общаются локальные сервера
На каждой машине есть локальный сервер, аналогичный тому, что мы написали. Каждый
клиент общается со своим локальным сервером. Локальный сервер передает запрос
центральному серверу. Центральный сервер передает назад билет или отказ на выдачу
билета. Локальный сервер записывает и передает ответ клиенту. Локальный сервер также
должен пресекать попытки нарушить установленные пределы. Например, попытку нарушить
предел на максимальное число запусков программы, установленный для этой машины,
или попытку запуска программы вне установленного времени дня.
Решение 2: С центральным сервером общаются все
Клиенты посылают запросы непосредственно серверу на конкретном хосте. Локальные
сервера работают на каждом хосте, но эти сервера не общаются с локальными клиентами.
Вместо этого локальные сервера выступают в роли агентов центрального сервера по
восстановлению билетов.
Решение 3: Локальные сервера общаются с локальными серверами
На каждой машине есть локальный сервер, подобный тому, что мы написали. Каждый
клиент общается со своим локальным сервером. Все локальные сервера общаются друг
с другом. Каждый раз, когда клиент запрашивает билет, то локальный сервер обращается
ко всем другим серверам с вопросом, сколько билетов они выдали. Если общее число
выданных билетов меньше установленного лицензий предела, то локальный сервер выдает
билет клиенту.
13.9. UNIX-сокеты доменов
Наш лицензионный сервер использует стандартный способ адресации сокетов на основе
указания идентификатора хоста и номера порта. При использовании Internet адресов
сервер на одной машине может принимать запросы от клиентов другой машины как в
локальной, так и в глобальных сетях.
А что, если клиенту нужно поддерживать связь только сервером своей собственной
машины? Это происходит в двух моделях распределенной лицензионной системы. Может ли
сокет быть использован для внутренних коммуникаций?
13.9.1. Имена файлов, как адреса сокетов
Есть два вида соединений - потоки и дейтаграммы. И есть также два типа адресации
сокетов - Internet-адреса и локальные адреса. Internet-адрес состоит из идентификатора хоста
и номера порта. Локальный адрес - это имя файла. Его обычно называют адресом Unix-do-
мена.
13.9. UNIX-сокетыдоменов
481
Не имя хоста, не номер порта, а именно имя файла (такое как, например, /dev/log, /dev/printer
или /tmp/lserversock).
Два имени сокета /dev/log и /dev/printer используются во многих системах Unix. Имя /dev/log
используется сервером (syslogd), который ведет журнал системы. Программы, которые
желают записать сообщение в системный журнал, посылают дейтаграммы в сокет с адресом
/dev/log. В некоторых системах печати в Unix используется сокет по адресу /dev/printer.
13.9.2. Программирование с использование сокетов доменов
Для того, чтобы ознакомиться, как строятся клиент/серверные системы, которые
используют сокеты доменов, мы напишем систему журналирования. Примером системы
журналирования является файл wtmp. В файл wtmp записывает информация о всех входах и
выходах пользователей в/из системы, а также информация о других коммуникациях.
Системы журналирования используются системными программами поддержки
работоспособности и программами по поддержанию безопасности, которые ведут записи по мере
появления подозрительной активности. Сервер-журнал (log server) является "писцом".
Клиенты посылают сообщения серверу, а сервер добавляет эти сообщения к файлу, который
может модифицировать только он. Сервер-журнал может поддерживать этот файл
в любом месте, где он захочет, в любом формате, который он захочет. Никому из клиентов
не нужно знать об этих деталях.
Мы будем использовать Unix доменный адрес для сокета дейтаграмм для нашего сервера-
журнала. На этот сокет могут посылать дейтаграммы только клиенты, которые находятся
на той же машине, на которой находится сокет. Далее представлен код клиента и сервера
для системы журналирования, где используются сокеты доменов. Сервер создает сокет
и связывает (binds) с ним адрес:
^••••••••••••••••••••••••••*************^
* logfiled.c - простой сервер ведения журнала, использующий дейтаграммные
* сокеты доменов
ж Использование: logfiled »имя_журнала
- 7
#include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/un.h>
#include <time.h>
#defineMSGLEN512
#define oops(m,x) {perror(m); exit(x);}
#define SOCKNAME 7tmp/logfilesockn
int main(int ac, char*av[])
{
int sock; /* сюда будут читаться сообщения 7
struct sockaddrjm addr; /* это адрес 7
socklenjaddrlen;
charmsg[MSGLEN];
int I; ч
char socknamef] = SOCKNAME;
time J now; „
int msgnum = 0;
482 Программирование с использованием дейтаграмм. Лицензионный сервер
char *timestr;
Г построение адреса 7
addr.sunjamily = AF_UNIX; /* семейство адресов AF_UNIX 7
strcpy(addr.sun_path, sockname); /* адресом является имя файла 7
addrlen = strlen(sockname) + sizeof(addr.sun_family);
sock = socket(PF_UNIX, SOCK.DGRAM, 0); /*заметьте: семейство протоколов PFUNIX */
if (sock ==-1)
oops("sockef,2);
Г связывание адреса 7
if (bindfsock, (struct sockaddr *) &addr, addrlen) == -1)
oopsfbind", ,3);
/* чтение и запись 7
whileA)
{
I = readfsock, msg, MSGLEN); /* прочитать задание на работу для DGRAM 7
msg[l] = '\0'; /* это будет строка 7
time(&now);
timestr = ctime(&now);
timestrfstrlen(timestr)-1 ] = '\0'; Л отметка newline 7
printf( [%5d] %s %s\nM, msgnum++, timestr, msg);
fflush(stdout);
}
}
Мы все также используем socket и bind для создания сокета для сервера. Тип сокета ¦
SOCK_DGRAM, а семейство протоколов - PFJJNIX3. Адресом сокета является имя файла.
Код клиента будет короче:
У**********************************
* logfilec.c - клиент системы журналирования.
* Посылает сообщения серверу-журналу
* Использование: logfilec "здесь_находится сообщение"
7
#include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/un.h>
#define SOCKET ¦ytmp/logfilesock"
#define oops(m.x) { perror(m); exit(x);}
mainfintac, char*av[])
{
int sock;
struct sockaddr_un addr;
socklenj addrlen;
char sockname[] = SOCKET;
char *msg = av[1];
if (ac != 2){
3. Вместо PF_UNIX может быть использован PF_LOCAL
13.10. Итог: сокеты и сервера
483
fprintf(stderr,"usage: logfilec ,message,\nn);
exitA);
}
sock = socket(PFUNIX, SOCK.DGRAM, 0);
if (sock ==-1)
oopsfsockef^);
addr.sunjamily = AF_UNIX;
strcpy(addr.sun_path, sockname);
addrlen = strlen(sockname) + sizeof(addr.sunjamily);
if (sendto(sock,msg, strlen(msg), 0, &addr, addrlen) == -1)
! oopsC'sendto"^);
}
Мы используем socket для создания сокета и sendto для посылки сообщения. Сервер
принимает сообщение и затем печатает сообщение, предваряя его номером сообщения и
временной отметкой.
Вот пример работы:
$ ее logfiled.c-о logfiled
$ ./logfiled » visitorlog&
1500
$ ее logfilec.с-о logfilec
$ ./logfilec 'Nice system. Swell software!'
$ ./logfilec "Testing this log thing."
$ ./logfilec "Can you read this?"
$ cat vistorlog
[ 0] Mon Aug 20 18:25:34 2001 Nice system. Swell software!
[ 1 ] Mon Aug 20 18:25:44 2001 Testing this log thing.
[ 2] Mon Aug 20 18:25:48 2001 Can you read this?
Эти две короткие программы показывают, как можно использовать сокеты доменов и
демонстрируют концепцию построения сервера-журнала. Еще одним свойством этой
системы является то, что она реализует режим autoappend без использования флага 0_APPEND.
Сервер выбирает по одному сообщению и присоединяет это сообщение к тексту файла.
Даже если несколько клиентов одновременно пошлют сообщения серверу, то механизм
управления сокетом обеспечивает последовательную обращение к сокету.
13.10. Итог: сокеты и сервера
Сокеты представляют собой мощное, многоцелевое средство для передачи данных между
процессами. Мы рассмотрели два типа сокетов и два типа адресов сокетов:
домен
сокет PFJNET PFJJNIX
SOCK_STREAM Связность, межмашинная связь Связность, локальная связь
SOCKJDGRAM Дейтаграммы, межмашинная связь Дейтаграммы, локальная связь
В последних нескольких главах мы имели дело с проектами, где использовались три из
этих четырех комбинаций. Помните об этой диаграмме, когда у вас возникнет потребность
работать с Unix программами и когда вы будете разрабатывать собственные проекты. Какого
сорта сообщения вы посылаете? Насколько часто вы хотели бы, чтобы они приходили?
484
Программирование с использованием дейтаграмм. Лицензионный сервер
Заключение
Основные Идеи
• Дейтаграммы представляют собой короткие сообщения, которые передаются от
одного сокета к другому. Сокеты дейтаграмм не требуют установления соединения.
Каждое сообщение содержит адрес назначения. Сокеты дейтаграмм (ГОР) проще, быстрее
и меньше загружают систему, чем сокеты потоков (TCP).
• Лицензионный сервер - это программа, которая отслеживает выполнение правил
использования лицензионных программ. Лицензионный сервер выдает право на
исполнение программ. Реализация этого права представлена в форме коротких
билетов.
• Лицензионный сервер ведет учет - какие билеты и каким процессам были выделены.
Эта информация хранится во внутренней базе данных. Этим лицензионный сервер
отличается от Web сервера.
• Сервера, которые имеют дело с записями о состоянии системы, должны быть
спроектированы так, чтобы реагировать на возникновение аварий у клиентов и серверов.
• Для работы системы лицензирования могут быть использованы несколько машин
сети. Возможны несколько вариантов построения таких систем. У каждого варианта
есть сильные и слабые стороны.
• Сокеты могут использовать два вида адресов: сетевой и локальный. Сокеты с
локальными адресами называют сокеты доменов Unix или именованными сокетами. Эти
сокеты используют имена файлов в качестве адресов и могут обмениваться данными
с сокетами, которые находятся на одной и той же машине.
Что дальше?
Нами было рассмотрено два метода, которые используют сервера по управлению
множеством запросов. Лицензионный сервер принимает запросы в форме дейтаграмм и выдает
ответы по одному во времени. Web сервер принимает запросы как поток данных и
использует fork для того, чтобы выдавать параллельно ответы на несколько запросов. При
построении серверов может быть использован еще и третий вариант. Процесс может
использовать технику нитей (threads), что позволяет запускать на исполнение одновременно
несколько функций. Концепция и техника использования нитей будет рассмотрена далее.
Исследования
13.1 В примерах, где используются сокеты потоков, сервер не использует адрес клиента,
когда он отвечает ему на запрос. Как сервер узнает, куда послать сообщение для клиента?
13.2 Как процесс 25915 победил процесс 25914 в борьбе за билет? ( Речь идет о работе клиент/
серверной модели в параграфе 13.6.3 - Примеч. переев) Рассмотрите последовательность
операций от момента созданий каждого из клиентских процессов и моментом прибытия
запроса на сервер. В мультизадачных системах процессы мультиплексируют процессор. Где
должны прерываться процессы, чтобы получить результаты, которые были показаны по
мере тестирования?
13.3 Как вы будете использовать один лицензионный сервер, для управления доступом
к двум или большему числу программ? Опишите изменения в протоколе, структурах
данных и программной логике, чтобы можно было поддерживать лицензирование
нескольких программ.
Заключение 485
13.4 Существует ли потенциальная угроза для списка билетов, если функция ticketreclaim
была вызвана во время обычной обработки клиентского запроса? Не будут ли
противоречивыми состояние массива и значение счетчика в этой точке кода? Как обработчик
модифицирует массив и счетчик? Как могут сказаться неожиданные изменения этих
величин на работу обычных функций управления?
13.5 Многократное использование PID. Идентификаторы присваиваются процессам при
их создании. Рассмотрим такую последовательность событий. Клиентский процесс,
у которого PID равен 7777, получил билет, а затем неожиданно "умирает". Вскоре
после смерти клиента другой пользователь запускает программу и порождается новый
процесс, которому был также присвоен PID, равный 7777. Когда начинает работать
функция ticket_reclaim, то она обнаружит, что процесс 7777 существует. Билет,
который был выдан ранее процессу 7777, не был возвращен. В текущем процессе 7777
работает совсем другая программа и ему не был выделен билет. Как разрешить
проблему в такой ситуации? Что нужно модифицировать в системе, чтобы избежать
возникновения таких ситуаций?
13.6 Один из методов предотвращения потери массива ticket_array на сервере - писать данные
в таблицу, которая будет содержаться дисковом файле. Как нужно изменить сервер,
чтобы реализовать эту схему (схема backup)? Предположим, что клиент (customer)
преднамеренно убил сервер с тем, чтобы вызвать появление новых билетов. Как будет работать
схема backup в такой ситуации?
13.7 У клиента есть билет, который он получил от предшествующей версии сервера.
Сервер, который слишком долго ждет проверки на легальность билетов, может
обнаружить, что доступных билетов больше нет, когда к нему клиент вновь обратится за
билетом. ( Вероятно, имеется в виду ситуация, когда клиент, уже имеющий билет,
обращается к серверу для легализации своего билета, а у сервера нет свободных позиций -
Примеч. перев.). Найдите решение в такой ситуации. Клиент не должен получить
разрешение на продолжение, поскольку это приведет к нарушению установленного
лицензионного максимума. Но клиента также нельзя внезапно закончить.
13.8 Сравните три модели распределенного лицензионного контроля. Насколько они
отвечают тому набору вопросов, которые были приведены в тексте?
13.9 Написание сокетов. Мы использовали write и sendto для передачи данных от одного
сокета к другому. Изучите справочный материал относительно send и sendmsg. Какие
есть отличия между этими методами?
13.10 Аналогия между службой выдачи ключей для автомобилей и дейтаграммами -
больше, чем метафора. Представьте себе, что в каждой автомобильной компании есть
некоторый GPS прибор, с помощью которого автомобиль может определить свое место
нахождения. В автомобиле есть также компьютер и спутниковый модем, который
соединяет компьютер с Internet. Представьте также, что в автомобилях также можно
управлять зажиганием, но не с помощью автомобильного ключа, а с помощью магнитной
карты, которая должна вставляться в считыватель на приборной панели. Разработайте
систему, которая дает возможность водителям заказывать и использовать автомобили
компании, а также позволяет менеджеру автомобильного парка следить за водителями
и за местом расположения каждого автомобиля.
486 Программирование с использованием дейтаграмм. Лицензионный сервер
Программные Упражнения
13.11 Модифицируйте программу dgrecv.c с тем, чтобы она выводила бы помимо адреса
отправителя время, когда было принято сообщение, а также номер сообщения.
Нумерацию сообщений следует вести с нуля. Вывод должен иметь такой формат:
dgrecv: got a message: testing 123
from: 10.200.75.200:1041
at: Sun Aug 19 10:22:27 EDT 2001
msg#:23
13.12 Написать клиентскую программу dgrecv2.c, как добавление к программе dgsend.c.
13.13 Печать статуса сервера. Лицензионный сервер хранит таблицу, в которой содержится
информация о клиентах, которым были выделены билеты. Что нужно сделать, чтобы
сервер по вашему желанию распечатал бы содержание этой таблицы? Возможность
просмотра этой таблицы может помочь вам при отладке и тестировании сервера. Можно для
этого использовать сигналы - стандартный механизм для связи с процессами сервера.
Модифицируйте программу Iservl так, чтобы она в ответ на сигнал SIGHUP выводила бы
содержимое таблицы на стандартный вывод. Можете проверить работоспособность
этой модификации с помощью команды kill -HUP serverpid.
13.14 "Сбормусора", метод 2. Модифицируйте лицензионный сервер так, чтобы он
вызывал ticketjeclaim только в случае, когда клиенту отказано в праве на запуск программы.
Каковы преимущества и недостатки такого решения?
13.15 Модифицируйте программу Iclnt2.c так, чтобы она засыпала бы на пять секунд, а затем
проверяла бы легальность своего билета. Если билет легален, то клиент засыпает еще на
пять секунд, а затем циклически повторяет действия. Если билет признан не легальным,
то клиент должен попытаться получить другой билет. Если этот запрос будет
удовлетворен, то процесс продолжает нормально работать. Если же нет, то процесс сообщает
пользователю о возникшей проблеме при общении с лицензионным сервером и
заканчивает свою работу.
13.16 Модифицируйте наш shell или программу с перемещением текста из предыдущих
глав так, чтобы они использовали бы лицензионный сервер. Где следует добавить код
для подтверждения легальности билета? Что вы будете сообщать пользователю, если
билет стал не легальный, поскольку произошла авария на сервере?
13.17 Модифицируйте клиентский и серверный коды, где обеспечивается поддержка
билетов, так, чтобы можно было указывать IP адрес хоста. Будете ли вы изменять таблицу
билетов? Не забудьте при внесении изменений включить в код функции
подтверждения легальности билетов.
13.18 Реализуйте одну из трех моделей распределенного лицензионного контроля.
13.19 Одна из проблем при построении системы журналирования заключается в том, что
сообщения являются анонимными. Модифицируйте систему так, чтобы сообщения,
которые будут записываться в журнал, содержали бы имя того, кто прислал сообщение.
13.20 Чтение из сокета. При построении сервера-журнала мы использовали вызов read.
Напишите две новых версии сервера. В одной нужно использовать recvfrom, а в другой -
recv. В чем отличие этих методов при получении данных? С деталями следует
познакомиться в документации.
13.21 Какие изменения необходимо сделать в кодах лицензионного сервера и клиента
с тем, чтобы можно было бы использовать сокеты доменов? Объясните, почему клиент
должен использовать bind?
Заключение 487
13.22 Сетевой агент для раздачи игральных карт . В первой главе мы рассматривали
Internet вариант игры в бридж. В любой распределенной карточной игре программное
обеспечение должно моделировать одну колоду карт, гарантируя при этом, что два клиента
не смогут иметь на руках одинаковые карты.
Напишите две программы cardd и cardc, которые будут использовать сокеты
дейтаграмм для управления колодой карт. В начале работы серверная программа должна
перемешать карты. Клиентская программа запускается с командной строки с тем,
чтобы получить карты от дилера. Пример запуска:
$ cardc get 5
4DAH2DTDKC
показывает, что пользователь запросил пять карт и получил четверку бубен, туз червей,
двойку бубен, десятку бубен и короля треф.
Убедитесь, что ваша программа не выдает дважды одну и ту же карту и что в протоколе
отмечается, что агент кончает раздавать карты. Какие другие транзакции было бы
полезно добавить в протокол?
Проекты
Используя материал этой главы, как базовый, следует изучить и написать версии таких
программ Unix:
talk, rwho, streaming video servers
Глава 14
Нити.
Параллельные функции
ЕЖЛ
Цели
Идеи и средства
• Нить исполнения.
• Мультинитьевые программы.
• Создание и уничтожение нитей.
• Разделение данных между нитями становится безопасным при использовании
средства mutex.
• Синхронизация передачи данных с помощью условных переменных.
• Передача аргументов нитям.
Системные вызовы и функции
• pthread_create, pthreadjoin
• pthreadjriutexjock, pthread_mutex_unlock
• pthread_cond_wait, pthread_cond_signal
14.1. Одновременное выполнение нескольких нитей
Не знаю как вы, а меня на самом деле приводят в состояние, близкое к помешательству,
Web-страницы, которые заполнены чем-то мигающим, танцующим, кружащимся, ани-
мированными изображениями и рекламами. Хотя такие страницы и вызывают
раздражение, но при их рассмотрении возникает чисто технический вопрос: как одна программа
может выполнять одновременно несколько различных дел?
Web-программы, где одновременно выполняется несколько действий, не только ани-
мируют изображения. Ваш Web-броузер может выгружать и раскомпрессировать такие
изображения, которые находятся на различных серверах по всему миру. Web-броузер
выгружает эти изображения параллельно. Как может Web броузер одновременно выгружать
и раскомпрессировать несколько изображений?
14.2. Нить исполнения 489
Но не только броузер может выполнять несколько дел одновременно. Web-сервер может
читать изображения с диска и может одновременно посылать их броузерам, поскольку он
связан , возможно, с сотнями Web-броузерами. Как сервер может одновременно
осуществлять такого рода пересылки данных?
Не нужно думать, что мы не догадываемся! Мы уже знаем о многозадачности!
Нами уже был изучен такого рода вопрос. В главе, посвященной видеоиграм, мы
рассматривали, как можно использовать один интервальный таймер и два счетчика для того,
что управлять сразу перемещением по двум измерениям. В других главах мы
рассматривали, как shell и Web-сервер используют fork и exec для создания новых процессов, чтобы
запустить на исполнение несколько параллельных программ. Почему бы ни использовать
эти идеи?
При использовании fork и exec мы одновременно запускали на исполнение несколько
программ. А что произойдет, если мы попытаемся одновременно запустить на исполнение
несколько функций или сделать несколько одновременных обращений к одной и той же
функции?
В этой главе мы будем изучать нити (threads). Нити связаны с исполнением функций.
Нить рассматривается по отношению к функции в том же качестве, как процесс по
отношению к программе, т. е. нить - это среда, в которой будет исполняться функция. Мы
будем писать программы, в которых будут одновременно исполняться несколько функций,
причем все функции будут находиться в составе одного и того же процесса.
Нашей основной целью будет создание программы, которая будет заполнять текстовый
экран анимированными сообщениями. Мы создадим эту программу на основе
модификации программы Web-сервера, который управлял одновременно требованиями для
получения листингов каталогов и получения содержимого файлов. Причем нужно будет все
выполнить без создания новых процессов.
14.2. Нить исполнения
Что же все-таки представляет собой нить! Что она делает? Как можно создать нить?
Начнем с изучения обычной программы, которая исполняет код последовательно -
команду за командой. Затем, после внесения двух небольших изменений, мы включим их в
программу и запустим две функции для параллельного выполнения.
14.2.1. Однонитьевая программа
Рассмотрим такую программу:
/* hello_sing!e.c - программа из одной нити, которая выдает hello world */
#include <stdio.h>
#defineNUM 5
main()
{
void printjnsg(char *);
prirrt_msg("hello");
print_msg("world\n");
}
void print_msg(char *m)
{
inti;
490
Нити. Параллельные функции
for(i=0; KNUM;
printf("%s", m);
fflush(stdout);
sleep( 1);
}
>
В программе hello_single.c функция main делает два функциональных вызова/один за другим.
При каждом выполнении функции выполняется цикл. Результат отображает внутренний
поток управления:
$ сс hello_single.c -о hello_single
$ ./hello_single
hellohellohellohellohelloworld
world
world
world
world
$
Каждое сообщение будет выдаваться с задержкой в 1 секунду. Программа при этом
потратит 10 секунд на свое выполнение. На рисунке 14.1 показан поток управления при
исполнении программы.
. Нить исполнения
Один процесс,
две функции,
одна нить
Рисунок 14.1
Единственная нить исполнения
Сначала поток управления входит в функцию main. Затем происходит обращение к
функции printjnsg, далее поток управления проходит к следующей команде в функции main.
После этого управление передается снова к функции printjnsg для вторичного ее
исполнения. После исполнения функции управление передается в функцию main, в которой больше
нет команд. Поэтому происходит выход из этой функции.
Такой путь, полученный при трассировке команд по мере их исполнения в профамме,
и будет называться нитью исполнения. Традиционные программы имеют одну-единствен-
ную нить исполнения. Даже программы, где используются операторы goto и где
используются рекурсивные подпрограммы, имеют одну, хотя и достаточно запутанную нить
исполнения.
main()
V
1
L
1-
Н
—1—
1
Г'
print_msg{)
,. „J
71
14.2. Нить исполнения
491
14.2.2. Мультинитьевая программа
А что произойдет, если мы попробуем одновременно обратиться к функции printjnsg,
чтобы параллельно исполнить эту функцию, что будет аналогично тому, когда с помощью fork
запускались одновременно два процесса? Модифицированная предшествующая картинка
представлена на рисунке 14.2.
Единственная нить исполнения входит в функцию main. Эта нить создает затем новую
main ()
pririt_msg
print_msg
Начаи
У
~ш
И п „--,- п
ънаянить
print_msg()
> — 1
1 1
™_Хс\
л
V,
Новые нити
Рисунок 14.2
Несколько нитей исполнения
нить, в составе которой запускается на исполнение функция printjnsg. Начальная нить
доходит до следующей команды, где она стартует еще одну нить, в составе которой
запускается второй раз на исполнение функция printjrisg. Наконец, начальная нить переходит в
состояние ожидания - ждет, когда две нити объединятся, а далее функция main моежт быть
завершаена. Первая нить выходит из функции main.
Деятельность людей - это постоянная мультинитьевая задача управления. Родитель,
которому требуется выполнить несколько дел, может выполнять их последовательно. Но можно
поступить и так. Родитель ловит на улице двух своих детям и поручает одному из них купить
молоко в бакалейном магазине, а другому поручает вернуть книги в библиотеку. Родитель
остается ждать, когда они возвратятся после выполнения своих поручений. После чего он
может идти домой.
Нить подобна ребенку, которому вы поручили выполнить для вас некоторое дело. Если вы
захотите запустить на исполнение сразу несколько заданий, то вам необходимо иметь несколько
детей. Если в программе есть требуется запустить на исполнение одновременно несколько'
функций, то программа создаст для этого несколько нитей. Такой программой является
hellojnulti.c, где поток управления соответствует потоку, изображенному на рисунке 14.2:
Г hello_multi.c - мультинитьевая программа для вывода hello world 7
#include <stdio.h>
#lnclude <pthread.h>
#defineNUM 5
main()
{
pthreadj t1, t2; /* две нити 7
void *print_msg(void *);
pthread_create(&t1, NULL, print_msg, (void *)"heHo");
pthread_create(&t2, NULL, print_msg, (void *)"world\n");
pthreadjoin(t1,NULL);
pthreadJoin(t2, NULL);
}
void *orint msa(void *m)
492
Нити. Параллельные функции
{
char *cp = (char *) m;
int i;
for(i=0; 1<NUM ; i++){
printf("%s", m);
fflush(stdout);
sleep( 1);
}
return NULL;
> ' , '
Обратите внимание на изменения, которые произошли по отношению к первоначальной
программе. Во-первых, мы включили новый заголовочный файл. Файл pthread.h содержит
определения типов данных и прототипы функций. Во-вторых, мы определили две
переменные t1 и t2 типа pthreadj. Они представляют две нити, что аналогично двум детям,
которых родитель сажает в автомобиль, и которые будут у него на побегушках.
Каждой точке в потоке управления на диаграмме соответствует строка кода. Давайте
рассмотрим детально каждую инструкцию кода:
pthread_create(&t1, NULL, print_msg, (void *)"helloM)
Это функциональный вызов, с помощью которого выдается требование типа: "Сын мой,
пожалуйста, запусти на исполнение функцию printjnsg и передай ей аргумент hello".
Первый аргумент в функциональном вызове - это адрес нити. Второй аргумент - это
указатель на атрибуты нити. Указатель NULL обозначает атрибуты по умолчанию. Третий
аргумент - это функция, которая должна быть выполнена в составе нити. Последний
аргумент- указатель на аргумент, который вы хотели бы передать выполняемой
функции.
С помощью такой одной команды создается новая нить с определенными атрибутами.
Эта новая нить запускает на исполнение функцию print_msg с аргументом "hello".
pthread_create(&t2, NULL, print_msg, (void *)"world\n")
Это функциональный вызов, с помощью которого создается новая нить с атрибутами
по умолчанию. Эта новая нить выполнения,запускает на исполнение функцию printjnsg
с аргументом " worid\n "•.
pthreadjoin(tl.NULL)
Аналогично отцу, который ждет, когда его два сына возвратятся после выполнения
своих заданий, функция main будет в этом месте кода ждать возвращения с маршрутов
своих двух нитей. Функция pthreadjoin имеет два аргумента. Первый аргумент
указывает на нить, возвращение из которой ожидается. Второй аргумент указывает на ячейку,
куда будет помещено значение при выходе из нити. Если в качестве указателя записан
NULL, то возвращаемое значение не воспринимается.
pthreadJoin(t2, NULL)
Функция main ожидает окончания работы другой нити.
Теперь откомпилируем и запустим программу на исполнение:
$ ее hellojnulti.c -Ipthread -о hellojnulti
$ ./hellojnulti
helioworld
helloworld
14.2. Нить исполнения
493
helloworld
helloworld
helloworld
' $
Эта программа будет исполняться в течение только пяти секунд, поскольку два цикла будут
работать параллельно. Существующие различия в алгоритмах управления нитями могут
привести к тому, что вы получите вывод на экран, который будет отличен от приведенного выше.
Заметьте, насколько оказался гибким механизм нитей. В данном случае мы одновременно
запустили на исполнение одну и ту же функцию, задавая при запуске разные аргументы.
Мы можем также легко выполнить запуск различных функций, которые будут исполняться
параллельно.
14.2.3. Обобщенная информация о функцииpthread_create
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
pthread_create
Создание новой нити
#include<pthread.h>
int pthread_create( pthread J *thread,
pthread_attr_t *attr,
void *(*funcHvoid *),
void *arg);
thread - указатель на переменную типа pthreadj
attr - указатель на переменную типа ptheadjrttft
или NULL
tunc - функция, которая будет запущена в составе нити
arg - аргумент для передачи в функцию
Код ошибки - при обнаружении ошибки
0 - при успешном окончании
Функция pthread_create создает новую нить выполнения и вызывает функцию func(arg) для
исполнения в составе этой нити. Для новой нити можно задавать атрибуты с помощью
аргумента attr. Аргумент func определяет функцию, для которой задан один указатель на
аргумент и указатель на значение, которое будет выработано при выходе из функции.
Аргумент функции и возвращаемое значение определены как указатели типа void *, что
позволяет передавать упомянутые выше значения произвольного типа.
Если в качестве attr задан NULL, то используются атрибуты по умолчанию. Далее будет
проведено обсуждение атрибутов. Функция pthread_create возвращает 0 при успешном
выполнении и ненулевой код ошибки в противном случае.
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
pthreadjoin
Ожидание окончания нити
#include <pthread.h>
int pthread join(pthread_t thread, void **retval)
thread - ожидаемая нить, retval - указатель на
переменяю с кодом возврата.
КОДЫ ВОЗВРАТА Код ошибки - при обнаружении ошибки
О - при успешном окончании нити
494
Нити. Параллельные функции
Функция pthreadjoin блокирует вызывающую нить до тех пор, пока не закончится нить
thread. Если аргумент mv#/ не равен нулю, то код возврата из нити будет помещен в
переменную, на которую указывает retval.
Функция pthreadjoin возвращает 0, когда произойдет возврат из нити. Функция pthreadjoin
возвращает ненулевой код ошибки в случае возникновения ошибки. Ошибкой для нити
будет ожидание завершения нити, которая не существовала. Будет ошибкой ждать нить,
если ее ждет кто-то еще. Ошибкой для нити будет ожидание собственного окончания.
Программирование с использованием нитей подобно установлению соглашений между
несколькими людьми при необходимости выполнить ими ряд задач. Если вы будете
'корректно управлять проектом, вы можете достичь более быстрого выполнения работы.
Но вы должны быть уверены, что ваши исполнители не станут выполнять работы
по-своему и что они будут выполнять необходимые задачи в правильной последовательности.
Рассмотрим теперь средства для взаимодействия и координации нитей.
14.3. Взаимодействие нитей
Процессы взаимодействуют между собой, используя для этого программные каналы,
сокеты, сигналы, механизм exit^vait и среду. При работе с нитями все обстоит гораздо
проще. Нити исполняют функции в составе одного процесса. Так что, подобно любым
функциям в том же процессе, нити разделяют глобальные переменные. Они могут
взаимодействовать между собой путем установления значений глобальных переменных и путем
чтения этих переменных. Одновременный доступ к памяти - это мощное, но одновременно
и опасное свойство нитей.
14.3.1. Пример 1: incrprintc
/* incprint.c - одна нить производит инкремент, а другая печатает
7
#include <stdio.h>
#include <pthread.h> ,
#defineNUM 5 !
int counter = 0; \
main() !
{
pthread J t1; /* одна нить 7
void *print_count(void *); /* ее функция 7
int i;
pthread create(&t1, NULL, print count, NULL);
for(i = 6";i<NUM;i++){
counter++;
sleepA);
}
pthreadjoin(t1, NULL);
}
void *print_count(void *m)
{
int i;
for(i=0; KNUM ; i++){
printf("count = %d\n", counter);
sleep( 1);
}
return NULL;
14.3. Взаимодействие нитей
495
В программе incprint.c используется две нити. Начальная нить выполняет цикл, в котором
раз в секунду производится инкремент счетчика counter. До входа в цикл начальная нить
создает новую нить. Эта новая нить запускает на исполнение функцию, которая печатает
значение счетчика counter. Обе функции, main и print_count, выполняются в одном и том же
процессе. Поэтому каждая из них имеет доступ к переменной counter. На рисунке 14.3
показаны две функции и глобальная переменная.
main()
Счетчик
print_count
for
counter++
sleep
join
print_coupt()
I for
jf—| print
ILj sleep
3
Рисунок 14.3
Две нити разделяют глобальную переменную
Когда функция main изменяет значение счетчика counter, то функция printcounter видит сразу
это изменение. В данном случае отпадает необходимость посылать новое значение
счетчика через программный канал или счетчик. Теперь откомпилируем и запустим
программу:
$ сс incprint.c -Ipthread -о incprint
$ ./incprint
count = 1
count = 2
count = 3
count = 4
count = 5
Кажется, что программа работает правильно. Одна функция модифицирует переменную,
а другая функция читает значение этой переменной и отображает это значение на экране.
Этот пример показывает, что функции, которые работают в составе отдельных нитей,
разделяют глобальные переменные. Наш следующий пример более интересный.
14.3.2. Пример 2: twordcount. с
До появления компьютеров студенты, чтобы быть уверенными, что их курсовая работа
имеет требуемый объем, считали вручную количество слов в тексте курсовой работы.
Представьте себе студента, у которого на руках курсовая работа на Ю страницах. Этот
студент будет сам считать количество слов в тексте из 10 страниц. Или он может найти 10
студентов и дать каждому из них отдельную страницу, в которой требуется подсчитать
количество слов. Такой подсчет слов, который будет производиться параллельно на 10
страницах, пройдет гораздо быстрее.
Программ wc в Unix позволяет найти количество строк, количество слов, количество
символов в тексте одного или более файлов. Обычно эта программа реализована как одна
нить. Как можно создать мультинитьевую программу, которая могла бы подсчитывать
и печатать общее число слов в двух файлах?
496
Нити. Параллельные функции
Версия 1: Две нити, один счетчик
В нашей первой версии будет создаваться отдельная нить для подсчета слов в каждом
файле. Эта идея проиллюстрирована на рисунке 14.4.
Один процесс
Один счетчик
Две нити
Рисунок 14.4
Общий счетчик для двух нитей
Далее представлен код данной версии - twordcounti .с:
Г twordcounti .с - вариант с нитями для счетчика слов для двух файлов. Версия 1 */
#include <stdio.h>
#include <pthread.h>
#include <ctype.h>
int total_words;
main(intac, char*av[])
{
pthreadj t1, t2; /* две нити 7
void *count_words(void *);
If (ac != 3){
printffusage: %s filel file2\n", av[0]);
exitA);
}
total_words = 0;
pthread_create(&t1, NULL, countjvords, (void *) av[1]);
pthread~create(&t2, NULL, count words,, (void *) av[2]);
pthreadJoin(t1, NULL);
pthreadjoin(t2, NULL);
printf("%5d: total words\n*', total_words);
}
void *count_words(void *f)
{
char *filename = (char *) f;
FILE *fp;
intc, prevc = '\0';
if ((fp = fopen(filename, T)) != NULL»
while((c = getc(fp))!=EOF){
if (!isalnum(c) && isalnum(prevc))
total_words++;
prevc = c;
}
fclose(fp);
} else
perror(filename);
return NULL;
14.3. Взаимодействие нитей
497
В функции count_words отслеживаются отдельные слова по признаку: в конце слова должен
был быть алфавитно-цифровой символ, за которым следует символ, не являющийся
алфавитно-цифровым. По этому алгоритму пропускается последнее слово в файле, а строка
вида "U.S.A" рассматривается как состоящая из трех слов. Откомпилируем и
протестируем программу:
$ ее twordcountl .с -Ipthread -о twd
$ ./twd /etc/group/usr/dict/words
45614: total words
$ wc -w /etc/group /usr/dict/words
58/etc/group
45402 /usr/dict/words
45460 total
При работе twordcountl будут получены результаты, которые отличаются от результатов
при работе обычной версии команды wc. Причиной тому является использование
различных правил обнаружения конца слова.
Последовательность действий. В программе есть более тонкая проблема, чем правило
определения конца слова. Обе нити инкрементируют один и тот же счетчик и могут делать
это потенциально одновременно. Какие неприятности это может вызвать? В языке С не
специфицировано, каким образом будет выполняться на компьютере операция вида
total_words++. Может быть, что выполнение этой операции будет происходить так:
total_words = total_words +1.
То есть программа заносит текущее значение переменной в регистр, добавляет к
содержимому регистра 1, затем полученный результат в регистре заносится обратно в память. Что
произойдет, если обе нити попытаются одновременно выполнить инкремент счетчика,
используя последовательность выборка - суммирование - запоминание?
Время
Нить1
Нить 2
»¦ Получить значение переменной
Добавить к значению 1
Сохранить значение в переменной
total words
Получить значение переменной
Сохранить значение в переменной
т..
Рисунок 14.5
Две нити инкрементируют один и тот же счетчик
На рисунке 14.5 показано, что обе нити выбирают одно и то же значение, инкрементируют
значение регистра, а затем сохраняют в ячейке новое значение. Выполняется два
инкремента, но значение счетчика увеличится только на единицу. Как можно предотвратить
влияние нитей друг на друга? Рассмотрим два решения.
498 Нити. Параллельные функции
Версия 2: Две нити, один счетчик, один mutex
Общественный шкафчик для хранения, типа тех, что используются в аэропортах и на
терминалах автобуса, открыт до тех пор, пока он кому-либо не понадобится. Когда некоторый
человек бросает в приемник несколько монет и получает взамен ключ, то уже никто, кроме
него, не будет иметь доступа к этому шкафчику. Позже, когда этот человек возвратится и
откроет ключом шкафчик (деблокирует пространство хранения), то любой человек может
опять использовать его для хранения. Если наши две нити разделяют общий счетчик как
средство хранения данных, то им понадобится некий способ "повесить замок" на эту
переменную.
В системах, где используются нити, допустимо использовать переменные, которые называют
mutual exclusion locks (замки взаимного исключения). С помощью этого механизма достигается
возможность строить систему нитей, в которой будет предотвращаться одновременный доступ
к некоторой переменной, функции или к другим ресурсам. В модифицированной версии
программы twordcount2.c показано, как создавать и использовать средство mutex.
(В русскоязычной литературе вместо перевода названия mutual exclusion lock часто
используют аббревиатуру mutex. Далее в тексте используется это сокращение. - Примеч. пер.)
Г twordcount2.c - Работа со счетчиком слов с помощью нитей для двух файлов */
/* Версия 2: использование mutex для блокировки счетчика */
#lnclude <stdio.h>
#include <pthread.h>
#lnclude <ctype.h>
int total words; /* счетчик и замок к нему */
pthread_mutex_t counter jock = PTHREAD.MUTEXJNITIAUZER;
main(intac, char*av[])
{
pthreadj t1, t2; /* две нити */
void *count_words(void *);
if (ac !=3){
printffusage: %sfile1 file2\n", av[0]);
exltA);
}
totah/vords = 0;
pthread_create(&t1, NULL, countj/vords, (void *) av[1]);
pthread_create(&t2, NULL, count_words, (void *) av[2]);
pthreadJoin(t1, NULL);
pthreadjoin(t2, NULL);
printf(n%5d: total words\n", total words);
}
void *count_words(void *f)
{
char ^filename = (char *) f;
FILe*fp;
intc, prevc = '\0';
if ((fp = fopen(filename, T)) != NULL){
while((c = getc(fp))!=EOF){
if (lisalnum(c) && isalnum(prevc)){
pthread_mutexJock(&counterJock);
14.3. Взаимодействие нитей
499
total_words++;
pthread_mutex unlock(&counter_lock);
}
prevc = с;
}
fclose(fp);
} else
perror(filename);
return NULL;
}
Программа теперь выглядит аналогично тому, что изображено на рисунке 14.6:
Один процесс
Один счетчик
Один замок
Две нити
Рисунок 14.6
Две нити используют mutex для
разделения счетчика
Мы добавили в программе только три строки. Сначала мы определили глобальную
переменную counter Jock типа pthread_mutex_t. Переменной было присвоено начальное значение.
Затем мы изменили count^words так, чтобы обеспечить чередование шагов по инкременту
счетчика между вызовом pthread_mutexJock и вызовом pthreadjmrtex_unlock.
Теперь двум нитям гарантируется безопасное разделение одного счетчика. Если одна нить
вызовет pthread_mutex_lock после того, как другая нить закрыла mutex, то первая нить будет
блокирована до тех пор, пока не будет деблокирован mutex. После того как mutex будет
разблокирован, будет также разблокирован вызов pthread_mutex_lock. Теперь нить может проводить
инкремент счетчика. На mutex может находиться произвольное число нитей, которые будут
ждать, когда будет разблокирован mutex. Когда некая нить разблокирует mutex, то система
управления нитями передаст управление на развитие только какой-то одной нити среди
других ожидающих. Но следует учитывать, что средство mutex будет полезно тогда, когда все
нити взаимодействуют с его помощью. Если некая нить захочет инкрементировать счетчик,
не используя при этом mutex, то ничто не может ее остановить.
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
pthreadjnutexjock
Ожидание и блокировка mutex
#include <pthread.h>
int pthread^mutexJock(pthread_mutex_t *mutex)
mutex - указатель на объект взаимного исключения
КОДЫ ВОЗВРАТА 0 - при успешном окончании
Код ошибки - при обнаружении ошибки
500
Нити. Параллельные функции
С помощью pthreadjnutexjock производится блокировка заданного mutex. Если mutex не
заблокирован, то он закрывается и становится собственностью нити, которая выполнила
этот вызов. Код возврата при этом из pthread_mutex_lock будет равен 0. Если при обращении
оказывается, что mutex уже заблокирован другой нитью, то вызывающая нить будет
приостановлена до тех пока, mutex не будет разблокирован. Если при выполнении вызова
возникла ошибка, то pthreadjnutexjock возвращает код ошибки.
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
pthread_mutex_unlock
Разблокировка mutex
#include <pthread.h>
int pthread jrmtexjmlock(pthread jriutexJ *mutex)
mutex - указатель на объект взаимного исключения
0 - при успешном окончании
Код ошибки - при обнаружении ошибки
При выполнении pthread_mutex_unlock снимается блокировка указанного mutex. Если в
данный момент на этом mutex были блокированы нити, то одной из них разрешается
блокировать mutex. pthread_mutex_unlxk возвращает 0 при нормальном окончании. И возвращает
ненулевой код ошибки при возникновении каких-то проблем.
Мы рассмотрели случай, когда все работает хорошо. А что произойдет, если нить
попытается заблокировать mutex, который она уже заблокировала? Что произойдет, если нить
заканчивается и не выполнила до этого момента разблокирования mutex? В разных
системах управления нитями управление такими ситуациями происходит по-разному.
Обратитесь к вашей документации за деталями.
Нужен ли нам mutex? Если обе нити должны одновременно модифицировать одну и ту
же переменную, то они могут использовать mutex, чтобы обеспечить правильный доступ
к переменной. При использовании mutex программа работает более медленно. На
проверку замка, на установку замка, на освобождение замка в отношении каждого слова из
обоих файлов суммарно будет выполнено много действий. Более эффективное решение
будет основано на том, что каждая нить получает в свое распоряжение собственный
счетчик.
Версия 3: Две нити, два счетчика, несколько аргументов для нитей
В следующей версии программы, которая занята подсчетом слов, мы откажемся от mutex
и вместо этого предоставим каждой нити собственный счетчик. После окончания работы
нитей значения двух счетчиков будут суммированы.
Как мы установим эти счетчики для нитей и как нити возвратят обратно полученные
значения в счетчиках? В обычном варианте в однонитьевой программе функция подсчета
слов возвращает число слов в вызывающую функцию. Нить может возвратить значение
при обращении к pthread_exit. Это значение далее можно получить с помощью pthreadjoin.
В справочнике приведены детали. Мы будем использовать другой, более простой метод.
Вместо метода, когда нить передает назад значение счетчика, вызывающая нить может
передать для функции указатель на переменную. И далее функция будет в состоянии ин-
крементировать эту переменную. Но при передаче этого указателя возникает проблема.
Мы уже передаем нити имя файла, А при обращении к pthread_create можно передавать
только один аргумент. Как можно передать при обращении к нити имя файла и имя
счетчика? Легко. Мы создадим структуру с двумя элементами и передадим адрес ^той
структуры. Вот каким станет код:
\3. Взаимодействие нитей
Г twordcount3.c - Работа со счетчиком слов с помощью нитей для двух файлов
* - Версия 3: по одному счетчику на файл
7
#include <stdio.h>
#inelude <pthread.h>
#include <ctype.h>
struct arg_set { Л Два значения в одном аргументе */
char *fname; /* файл для обработки */
int count; /* число слов */
};
main(intac, char*av[])
{
pthreadj t1, t2; /* две нити */
struct arg_set argsl, args2; /* два набора аргументов */
void *count words(void *); •
if(ac!=3)f
printf("usage: %s file 1 file2\n", av[0]);
exit(l);
} .
argsl .fname = av[1];
argsl .count = 0;
pthread_create(&t1, NULL, count_words, (void *) &args1);
args2.fname~av[2];
args2.count = 0;
pthread^createf^.-NULL, countj/vords, (void *) &args2);
pthreadjoin(t1,NULL);
pthreadjoin(t2, NULL);
printf("%5d: %s\n,,l argsl .count, av[1 ]);
printf("%5d: %s\nM, args2.count, av[2]);
printf( %5d: total words\n", argsl .count+args2.count);
}
void *count words(void *a)
{
struct arg_set *args = a; /* сбрх аргумента правильного типа 7
FILE *fp; ~
intclprevc = ,\0';
if ((fp = fopen(args->fname, T)) != NULL){
while((c = getc(fp))!=EOF){
if (lisalnum(c) && isalnum(prevc))
args->count++;
prevc = c;
}
fclose(fp);
} else
perror(args->fname);
return NULL;
502
Нити. Параллельные функции
Мы решили проблему передачи двух аргументов с помощью определения структуры,
в которой будет содержаться имя фащт и число слов в этом файле. В функции main мы
определили две такие структуры как локальные переменные, инициализировали
структуры и передали адреса структур нитям (см. рисунок 14.7). При передаче указателей на
локальные структуры не только отпадает необходимость в mutex, но мы также
отказываемся от использования и глобальных переменных.
Один процесс
Замок!
Нет замков!
Две нити
Рисунок 14.7
Каждая нить имеет указатель на
собственную структуру
При каждом обращении к countj/vords будет использован указатель на разные структуры,
так что нити будут читать различные файлы и инкрементировать значения через разные
указатели. Структуры являются локальными переменными в функции main. Поэтому
память, которая выделяется для счетчиков, сохраняется до тех пор, пока не кончится
исполнение main.
14.3.3. Взаимодействие между нитями: итог
Процесс содержит все свои переменные в пространстве данных. Все нити, которые были
запущены в процессе, имеют доступ к таким переменным. Если эти переменные никто не
изменял, то нити могут их читать и использовать их значения без каких-либо аномалий.
Если некие нити в процессе будут намерены модифицировать переменную, то все другие
нити, которые используют значение переменной, должны использовать некоторый метод
по установлению правильного взаимодействия, чтобы предотвратить искажение данных.
В каждый момент времени только одна нить должна использовать переменную.
Выше были представлены три версии программы для подсчета слов, три метода,
позволяющие разделять данные между процессами. Первый метод, который был использован
в программе twordcountl .с, использовал метод, который предоставляет нитям возможность
модифицировать одну и ту же переменную напрямую, без установления каких-либо форм
взаимодействия. Такая программа работает, но работает неправильно.
Второй метод, который использован в программе twordcount2.c, был основан на применении
mutex. Метод гарантировал, что только одна из нитей сможет в любой момент
инкрементировать значение разделяемого счетчика. Эт*а программа работает, но требует
многократного вызова функций по проверке, установке и снятию "замка" (блокировки).
Третий метод, который использован в программе twordcountS.C, был основан на применении
не одного разделяемого счетчика, а на создании отдельного счетчика для каждой нити.
Нити в программе больше не разделяют переменную, поэтому нет необходимости
использовать некоторое средство для организации взаимодействия нитей друг с другом. Но нити
по-прежнему взаимодействуют с начальной нитью. В частности, начальная нить не
должна читать значение счетчика до тех пор, пока не завершатся две другие нити. Для этого
14.4. Сравнение нитей с процессами
503
начальная нить использует pthreadjoin, чтобы блокироваться до тех пор, пока не закончатся
другие нити. Когда эти нити закончат работу, то вызов pthreadjoin будет разблокирован, что
обеспечит эффективный неблокированный доступ к счетчику. Функции main будет
предоставлена возможность прочитать значение.
В третьей версии также показано, каким образом можно передавать нити несколько
аргументов при вызове функции. Для этого мы создали одну структуру, в которой содержались
все необходимые аргументы, а затем был передан адрес этой структуры. Нить может
читать и модифицировать любой член данной структуры. Другие функции, если они имеют
доступ к этой структуре, увидят в структуре новые значения. Естественно, если более чем
одна нить захочет изменять эти значения, то должен быть использован механизм mutex,
чтобы предотвратить искажение данных.
14.4. Сравнение нитей с процессами
Процессы, как сущности, были введены в Unix с самого начала. Нити появились позже.
Модель процесса ясна и универсальна. Концепция нитей появилась по многим причинам.
В настоящее время используются несколько типов нитей, с различными атрибутами. Мы
рассмотрим примеры таких нитей на примере использования интерфейса, названного
POSIX threads. Мы не рассматриваем вопросы эффективности и планирования. Ответы на
эти вопросы зависят от версии Unix и от версий нитей, которые вы используете.
Процессы отличаются от нитей рядом фундаментальных свойств. Каждый процесс имеет:
собственное пространство данных, файловые дескрипторы и идентификатор процесса PID.
Нити же разделяют: одно пространство данных, набор файловых дескрипторов и PID.
Механизм реализации нитей является значимым для программистов.
Разделяемое пространство данных. Рассмотрим систему управления базой данных,
которая управляет большой, сложной трехуровневой базой данных. Один процесс может
быть занят обслуживанием множества запросов от клиентов. Переменные не изменяются.
При разделении такого набора данных не возникает каких-либо проблем.
Теперь рассмотрим программу, где для управления памятью используются вызовы таНоси
free. Для одной нити выделяется участок памяти,, в которой нить намерена хранить одну
строку. Когда эта нить не заблокирована, то другие нити могут обратиться к free и
освободить этот участок памяти. В начальной нити может быть использован указатель на уже
освобожденную память или, еще хуже, освобожденный участок памяти будет
перераспределен для хранения новых данных.
Использование механизма нитей может привести к накоплению памяти. Программист,
испуганный возможностью потерять память, которая происходит при работе нитей с
указателями на память, может перестраховаться и никогда не возвращать память.
Функции, которые в однонитьевой модели возвращают указатели на статические
локальные переменные, на смогут работать в мультинитьевой модели. В такой модели
несколькими нитями одновременно может быть активизирована одна и та же функция.
Короче говоря, если количество разделяемых переменных будет большим, а переменные
не будут хорошо определены, то отладка приложения, которое использует мультинитье-
вую модель, превратится в кошмар.
Разделяемые файловые дескрипторы. Файловые дескрипторы автоматически
дублируются при выполнении fork. Поэтому дочерний процесс сразу получает набор
файловых дескрипторов. Если дочерний процесс закрывает файловый дескриптор, который он
унаследовал от процесса-отца, то файловый дескриптор у процесса-отца остается
открытым. В мультинитьевой программе возможна передача одного и того же файлового
504
Нити. Параллельные функции
дескриптора двум разным нитям. Но при этом речь идет именно об одном и том же
файловом дескрипторе. Если некая функция в одной нити закроет файл, то этот файловый
дескриптор будет закрыт для всех нитей процесса. А для других нитей может еще
требоваться связь с файлом.
fork, exec, exit, сигналы. Все нити разделяют один и тот же процесс. Если нить вызвала exec,
то ядро произведет смену программы - текущая программа будет заменена на новую. Все
работающие нити будут потеряны, что для них будет неприятным сюрпризом. Если одна из
нитей вызовет exit, то это приведет к окончанию процесса. Что будет, если по вине нити про-
зошла ошибка, связанная с нарушением адресации (segmentation violation) или произошли
какие-то еще системные ошибки и нить по этой причине должна быть аварийно закончена?
В такой ситуации будет закончен весь процесс, а не только такая аварийная нить.
Вызов fork создает новый процесс, который содержит точную копию кода и данных
вызывающего процесса. Если функция в одной нити вызывает fork, то будут ли дублированы
другие нити в новом процессе? Нет. В новом процессе будет запущена только одна нить -
та, которая вызвала fork. Что произойдет, если нить была занята модификацией неких
данных и в это время другая нить вызвала fork? Будут ли в этой ситуации сохранены данные
в новом процессе?
При работе с нитями с сигналами дело обстоит еще сложнее. Процессы могут принимать
все виды сигналов. А кто принимает сигнал? Каждая из нитей или нет? Как быть с
сигналами, которые возникают по причине нарушения адресации памяти или при
возникновении ошибок при передаче по шине? Кто должен получить такие сигналы? Обратитесь
к документации за разъяснениями об особенностях обработки сигналов нитями.
Эксперимент над вами. В этой главе было сделано введение в базовые идеи, касающиеся
нитей, были рассмотрены основные проблемы и проекты, что дает вам возможность
подумать о том, что вы получите при использовании нитей. Хорошим упражнением будет
программирование двух решений одной и той же проблемы: одно программируется с
использованием механизма нитей, а другое программируется с использованием процессов. Какое
из программных решений будет более ясным на этапах проектирования, кодирования
и отладки?
Какой из вариантов выполняется более быстро? Какой вариант в большей степени
переносим на разные версии Unix?
14.5. Уведомление для нитей
Обратимся еще раз к мультинитьевой программе подсчета слов. Представьте себе, что вы
председатель комиссии по выборам в большом городе. Когда закончатся выборы, то
небольшие избирательные участки закончат считать голоса раньше. У них на участке
зарегистрировано меньше избирателей, и поэтому требуется меньше времени на подсчет
голосов. Вы, как председатель, не объявляете общий итог голосования до тех пор, пока не
поступят сведения от всех избирательных участков. Но вы хотели бы ознакомиться с
каждым отчетом, когда он поступит из участка.
Подсчет слов в файле происходит аналогично подсчету голосов на участках. Некоторые
файлы будут длиннее других, и поэтому потребуется больше времени для их обработки.
Интересно посмотреть, что случится при обращении вида:
twordcount большой_файл неболыиой_файл
Начальная нить использует pthreach/vait для того, чтобы ждать, пока не финишируют две
другие нити. В нашем примере вторая нить получит свой результат задолго до того, как
получит результат первая нить. Как может более быстрая нить уведомить начальную нить
о том. -что она выполнила свою оаботу?
14.5. Уведомление для нитей
505
Как может одна нить уведомить другую нить? Когда нить закончит подсчет слов, то
она кончает свою работу. Как эта нить может оповестить начальную нить о том, что у нее
уже готовы результаты? При использовании механизма процессов системный вызов wait
заканчивался (заканчивалось ожидание), когда заканчивался произвольный дочерний
процесс. Можно ли использовать подобный механизм в отношении нитей? Может ли некая
нить ждать окончания работы произвольной нити? Нет. Нити не могут работать по такому
сценарию. Нити не имеют родителя, поэтому не очевидно - кого следует уведомлять при
окончании работы нити.
14.5./. Уведомление для центральной комиссии о результатах выборов
Когда избирательные комиссии закончат подсчет голосов, то они должны будут отправить
полученные результаты в центральную комиссию. Рассмотрим следующую систему,
которая работает в центральной комиссии и собирает результаты от участковых комиссий
(как это ни странно звучит, но в данной ситуации все происходит точно так, как
происходит передача уведомлений между нитями об определенных событиях).
(a) В центральной избирательной комиссии устанавливается почтовый ящик для прие*
ма сообщений о проведенном голосовании. Этот почтовый ящик может хранить только
одно сообщение о голосовании от какой-либо комиссии. Такой почтовый ящик имеет
"флажок, который может взводиться.
(b) В центральной комиссии ждут поднятия флажка на почтовом ящике.
(c) Председатель участковой комиссии посылает сообщение о своих результатах
выборов в почтовый ящик.
(d) Председатель участковой комиссии взводит флажок на почтовом ящике (это будет
называться сигнализацией).
* (е) В центральной комиссии видят, что флажок на почтовом ящике поднялся. Тогда
в ответ в центральной комиссии выполняются следующие шаги:
из почтового ящика выбирается сообщение от участковой комиссии;
производится обработка данных, которые поступили в сообщении;
переход обратно в состояние ожидания (переход на пункт (Ь).
На первый взгляд такая схема выглядит достаточно мудреной. Отправитель передает
данные в контейнер для сообщений, а затем устанавливает флаг, который оповещает
получателя данных, что информация поступила в почтовый ящик.
Индикатор состояния
Почтовый ящик для отчета о голосовании
Замок почтового ящика
Отчеты
Центральная избирательная
комиссия
Участок 1
Участок 2
Рисунок 14.8
Использование почтового ящика
с замком для передачи данных
506 Нити. Параллельные функции
На рисунке 14.8 изображена центральная избирательная комиссия и две участковых.
Каждая участковая комиссия отправляет отчет о голосовании в почтовый ящик и оповещает об
этом центральную комиссию. В центральной комиссии после этого вынимают отчет из
почтового ящика. Техническим термином, который используется для описания действия
по подъему флажка на почтовом ящике, будет термин сигнализация с помощью флага.
Мы можем сказать, что получатель ждет, когда с помощью флага будет
просигнализировано о поступлении отчета о голосовании. Действия в отношении этого флажка не имеют
ничего общего с действиями над обычными сигналами в Unix. Лишь сам термин и общая
идея будут действительно совпадать.
На рисунке показана еще одна важная деталь: замок на почтовом ящике для отчетов о
голосовании. Почтовый ящик может одновременно хранить только один отчет. Тем самым
подчеркивается, что он является критическим ресурсом. Лишь только одна персона
в любой момент времени может иметь доступ к ящику. Использование замка немного
усложняет процедуру, но замок обеспечивает надежность хранения. Вся процедура с
использованием замка будет такой:
(a) В центральной комиссии устанавливается почтовый ящик для приема отчетов о
голосовании.
В этом ящике можно хранить только один отчет.
Почтовый ящик оборудован флажком, который можно взвести и потом, после сброса,
опять взвести.
Почтовый ящик имеет mutex, который может быть заблокированным или нет.
(b) В центральной комиссии разблокируют ящик ичначинают ждать, когда с помощью
флага комиссию оповестят о поступлении отчета.
(c) Председатель участковой комиссии ждет, когда он сможет блокировать почтовый
ящик. Если почтовый ящик в текущий момент не пустой, то председатель участковой
комиссии разблокирует ящик и опять ждет, наблюдая за флагом, когда нужно будет
повторно блокировать ящик.
Председатель посылает отчет в почтовый ящик.
(d) Председатель участковой комисси с помощью флага сигнализирует о поступлении
отчета в почтовый ящик и снимает блокиррвку с почтового ящика.
(e) В центральной комиссии выходят из состояния ожидания, поскольку обнаружили
подъм флажка на ящике.
Председетатель центральной комиссии блокирует почтовый ящик.
Далее он вынимает из почтового ящика отчет о голосовании.
Потом производится обработка поступивших данных.
Председатель центральной комиссии сигнализирует с помощью флага, если этого
ждут в участковой комиссии .
Передается управление на шаг (Ь).
14.5.2. Программирование с использованием условных переменных
Теперь мы перенесем принцип избирательной системы в программу для подсчета слов.
В избирательной системе были использованы три объекта: контейнер, флаг и замок. Эти
элементы соответствуют трем элементам в мире программирования: переменная,
условный объект и mutex. На рисунке 14.9 изображены три нити и три переменные. В одной
переменной находится указатель на счетчик слов. Другая переменная выступает в роли
условной переменной. Третья переменная будет хранить mutex.
14.5. Уведомление для нитей
507
А теперь обратимся к алгоритму программы. Начальная нить запускает две нити, которые
будут заниматься счетом. Далее начальная нить переходит в состояние ожиданий
поступления результатов от счетных нитей. Для этого начальная нить обращается к pthread_cond_wait и
ждет, когда с помощью флага будет просигнализировано об ожидаемом событии. Этот вызов
блокирует начальную нить.
Когда счетная нить закончит подсчет, она готова передать результат, помещая указатель на
глобальную переменную в почтовый ящик mailbox. В начале нить должна приобрести
замок для почтового ящика, затем нить должна проверить почтовый ящик. Если почтовый
ящик не пустой, то нить разблокирует его и будет ждать уведомления с помощью флага
о возможности вновь заблокировать почтовый ящик. Далее нить помещает результат
в почтовый ящик. Наконец, счетная нить с помощью условной переменной flag и вызова
pthread_cond_signal уведомляет о данном событии. Такое уведомление с помощью флага
приводит к побудке начальной нити, которая была блокирована на этом флаге, когда она
вызвала pthread_COnd-wait. Разбуженная начальная нить поспешит открыть почтовый ящик. Она
попытается заблокировать этот почтовый ящик, но блокировка все еще поддерживается
счетной нитью.
Условная переменная для Переменная для
уведомления читателя хранения данных
X
pthread_cond_t flag
struct arg_set *mb
pthreadjnutexj lock
pthread_cond_wait
Начальная нить
Замок для исключительного
эксклюзивного) доступа
Две нити
Рисунок 14.9
Использование блокируемой переменной для передачи данных
Когда счетная нить снимет блокировку с помощью pthread_mutex_unlock, то начальная нить
сумеет, наконец, ее установить на почтовый ящик. Теперь за этой нитью закреплена
блокировка. Оригинальная нить выбирает сообщение из ящика, сообщение выводится на
экран, добавляется полученное значение счетчика слов к общей сумме, производится
сигнализация с помощью флага, если счетная нить находится в состоянии ожидания. Затем
управление вновь передается на pthread_cond_wait,<HTo приводит к атомарному
разблокированию mutex и блокировке нити до момента, когда вновь будет установлен флаг.
Последовательность шагов, описанная в предшествующих параграфах, в точности
соответствует тому, что было представлено в описании работы избирательных участков. Эти
шаги были реализованы в коде программы twordcount4.c:
[* twordcount4.c - Программа подсчета слов в двух файлов, использующая
* механизм нитей.
* - Версия 4: использование условной переменной предоставляет счетным
508
Нити. Параллельные функцн
* нитям легкую возможность оповещать о готовности
результатов.
7
#include <stdio.h>
«include <pthread.h>
«include <ctype.h>
struct arg_set { /* два значения в одном арп/менте*/
char*fname; /* файл для обработки */
w int count; /* счетчик слов */
};
struct arg_set *mailbox;
pthread„mutexj lock = PTHREAD_MUTEXJNITIAUZER;
pthread.cond J flag = PTHREAD^CONDJNITIALfZER;
main(intac, char*av[])
{
pthreadj t1, t2; /* две нити */
struct arg_set argsl, args2; /* два набора аргументов */
void *count_words(void *);
int reportsjn = 0;
int totaLwords = 0;
if (ac != 3){
printffusage: %s filel file2\n", av[0]);
exitA);
}
pthread_mutexJock(&lock); /* теперь блокировка ящика для сообщений 7
argsl .fname = av[1];
argsl .count = 0;
ptfiread_create(&t1, NULL, count_words, (void *) &args1);
args2.fname = av[2];
args2.count = 0;
pthread_create(&t2, NULL, countjvords, (void *) &args2);
while( reports jn < 2){
printf("MAIN: waiting for flag to go up\n");
pthread_cond_wait(&flag, &lock); /* wait for notify */
printf("MAIN: Wow! flag was raised, I have the lock\n");
printf("%7d: %s\n", mailbox->count, mailbox->f name);
totaLwords += mailbox- >count;
if (mailbox ==&args1)
pthread join(t1,NULL);
if (mailbox == &args2)
pthread join(t2,NULL);
mailbox = NULL;
pthread_cond_signal(&flag);
reports in++;
}
printff%7d: total words\nH, totaLwords);
14.5. Уведомление для нитей
509
void *count_words(void *a)
{
struct arg_set *args = a; /* скопировать аргументы 7
FILE *fp;
intclprevc = ,\0*;
if ((fp = fopen(args->fname, Tj) != NULL){
while((c = getc(fp))!=EOF){
if (!isalnum(c) && isalnum(prevc))
args->count++;
prevc = c;
}
fclose(fp);
}else
perror(args->fname);
printf("COUNT: waiting to get lock\n");
pthread_mutex_lock(&lock); /* получить почтовый ящик 7
printff'COUNT: have lock, storing data\n");
if (mailbox != NULL)
pthread_cond_wait (&flag, &lock);
mailbox = args; /* здесь поместить указатель на наши аргументы 7
- printff'COUNT: raising flag\nu);
pthread_cond_signal(&flag); /* установить флаг 7
printf("COUNT: unlocking box\n");
pthread_mutex_unlock(&lock); /* освободить почтовый ящик 7
return NULL; " f\
}. ;. ... J>, A . ;.
Tie результатам работы можно отследить последовате'льность возникновения различных
событий: / ,
$ ее twordcount4.c -Ipthread -о twc4 I
$ /twc4 /etc/group /usr/dict/words
COUNT: waiting to get lock
MAIN: waiting fof'flag to go up /
COUNT: have lock, storing data * \
COUNT: raising flag |
COUNT: unlocking box ¦ ' ' !
MAIN: Wow! flag was raised, I have the lock
195:/etc/group
MAIN: waiting for flag to go up
COUNT: waiting to get lock
COUNT: have lock, storing data
COUNT: raising flag
COUNT: unlocking box *
MAIN: Wow! flag was raised, I have the lock /
45419:/usr/dict/Words \
45614: total words
510
Нити. Параллельные функции
По выведенной странице результатов нет возможности ощутить возбуждения при ночном
подсчете голосов, но первый результат пришел быстро, а второму сообщению
предшествовала ощутимая задержка.
14.5.3. Функции для работы с условными переменными
Флаг на почтовом ящике, который одна нить использовала для уведомления другой нити о
полученном результате, является условной переменной. Нити могут использовать следующие
обращения к функциям для установления связей с помощью условных переменных:
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
pthread_cond_wait
Блокировка нити на условной переменной
#include <pthread.h>
int pthread_cond_wait(pthread_condJ *cond,
pthreadjnutexj *mutex);
cond - указатель на условную переменную
mutex - указатель на mutex
0 - при успешном окончании
Код ошибки - при обнаружении ошибки
При обращении к pthread_cond_wait вызывающая нить будет блокирована до тех пор, пока
другая нить не оповестит через условную переменную cond о неком событии.
pthread_cond_wait всегда используется с mutex. При своей работе pthread_cond_wait атомарно
освобождает mutex, а затем переходит к ожиданию на условной переменной. Результат
будет не определен, если вы не произвели блокировку mutex до вызова данной функции.
Прежде чем передать управление в вызывающую нить, функция pthread_cond_wait атомарно
выполняет relock в отношении указанного mutex.
НАЗНАЧЕНИЕ
INCLUDE
ИСПОЛЬЗОВАНИЕ
АРГУМЕНТЫ
КОДЫ ВОЗВРАТА
pthread_cond_signal N
Разблокировка нити, ожидающей на условной переменной
#include <pthread.h>
int pthread_cond_signal(pthread_cond_t *cond);
cond - указатель на условную переменную
0 - при успешном окончании
Код ошибки - при обнаружении ошибки
С помощью функции pthread_cond_signal производится отметка о событии, которое
ассоциировано с условной переменной cond. Тем самым производится разблокирование одной
из ожидающих нитей на этой условной переменной. Если на условной переменной ждут
несколько нитей, то только одна из них будет разблокирована.
14.5.4. Обратимся опять к Web
Мы рассмотрели базовые принципы и возможности, касающиеся нитей POSIX. Мы знаем
теперь, как создавать нити, как организовать ожидание, когда нити будут закончены, как
организовать корректное разделение данных нитями. Мы также знаем, как нити могут
оповещать другие нити о произошедших событиях. Мы знаем вполне достаточно, чтобы
можно было использовать нити для разработки Web-сервера и для разработки
приложения, которое управляет усложненной анимацией.
14.6. Web-сервер, который использует механизм нитей
511
14.6. Web-сервер, который использует механизм нитей
В предыдущей главе нами уже был разработан Web-сервер. В этом сервере был
использован вызов fork для создания новых процессов, которые управляют запросами от клиентов.
Web-сервер выполнял три операции: посылал по запросу листинги каталогов, посылал по
запросу содержимое файлов и посылал по запросу вывод программ CGI. В сервере
понабился новый процесс, чтобы запустить программу CGI. Но в сервере не было
необходимости создавать новый процесс для получения листинга каталога или для чтения файла.
14.6.1. Изменения в нашем Web-сервере
Мы модифицируем наш исходный Web-сервер в нескольких направлениях. Наиболее важной
модификацией будет замена вызова fork на pthread_create. Теперь процессы не будут управлять
клиентскими запросами. Запросы будут управляться с помощью отдельных нитей.
Сделаем еще два таких изменения. Прежде всего мы удалим возможность обработки
программ CGI. Эту возможность можно будет добавить позже. Далее, мы напишем еще одну
собственную версию функции для получения листинга каталогов. В начальной версии
был использован вызов exec для запуска на исполнение стандартной команды Is.
14.6.2. При использовании нитей появляются новые возможности
Использование нитей вместо процессов предоставляет нам добавить новые свойства
серверу: возможность вести внутреннюю статистику. Персонал, который запускает
серверы, всегда заинтересован в получении информации - как долго работал сервер, какое
количество требований было принято сервером, общий объем данных, который был выдан
сервером в окружающий мир.
Все требования к серверу разделяют одно и то же пространство памяти. Поэтому мы
будем использовать разделяемые переменные, чтобы хранить там такую статистику. Как
пользователь может получить доступ к этим статистическим данным? Мы добавим
специальный URL для сервера: status. Когда удаленный пользователь затребует этот URL,
то сервер пошлет ему в ответ внутренние статистические данные.
14.6.3. Предотвращение появления зомби для нитей: отсоединение нитей
Рассмотрим теперь еще одну деталь, которая носит технический характер. Во всех
программах в этой главе в отношении каждой нити было обращение вида: pthreadjoin. Нити
используют системные ресурсы. Если бы мы не вызывали pthreadjoin, то эти ресурсы не были
бы возвращены системе после окончания нити. Это было бы аналогично случаю, когда
после вызова malloc не выдается free.
В программе для подсчета слов начальная нить ждет окончания счетных нитей, поскольку
она должна получить общий результат. В Web-сервере нет необходимости ждать нити,
которые управляют запросами клиентов. Эти нити не возвращают какой-либо полезной
информации.
Мы можем создавать нити, окончания которых можно не ожидать (с помощью операции
join). В таких отсоединенных нитях автоматически производится освобождение их
ресурсов по мере окончания работы нитей. В отношении таких нитей не разрешается
выполнять действие join. Для создания отсоединенных нитей необходимо передать специальный
атрибут для функции pthread_create:
512
Нити. Параллельные функции
/* создание отсоединенной нити 7
pthreadj t;
pthread jrttrJ attr_detached;
pthread_attr_init(&attr_detached);
pthread^attr_setdetached(&attLdetached, PTHREAD^CREATE^DETACHED);
pthread_create(&t, &attrjtetached, tunc, arg);
14.6.4. Код
Полный код для мультинитьевого Web-сервера:
/* twebserv.c - минимальный web-сервер с использованием механизма нитей
* (версия 0.2)
* Использование: tws номер_порта
* Свойства: поддержка только команды GET
* запуск в текущем каталоге
* создание нити для управления каждым запросом
* поддержка URL специального назначения для выдачи информации о внутреннем состоянии
* Трансляция : ее twebserv.c socklib.c -Ipthread -о twebserv
7
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
«include <pthread.h>
«include <stdlib.h>
«include <unistd.h>
«include <dirent.h>
«include <time.h>
Г сервер находится здесь 7
time J server_started;
int server_bytes_sent;
int serverjequests;
main(intac, char*av[])
{
int . sock,fd;
int *fdptr;
pthreadj worker;
pthread_attrj attr;
void *handle_call(void *);
if (ac == 1 ){"
fprintf(stderr,"usage: tws portnum\n");
exitA);
}
sock = make_server_socket(atoi(av[1]));
if (sock == -I) {pefrorfmaking socket"); exitB);}
setup(&attr);
Г здесь находится основной цикл: получить запрос, управление запросом в
* новой нити */
whileA){
fd = accept(sock, NULL, NULL);
serverjequests++;
fdptr = malloc(sizeof(int));
*fdptr = fd;
pthread-create(&worker,&attr,handle^call,fdptr);
6. Web-сервер, который использует механизм нитей
}
}
Л
* инициализация статусных переменных и
ж установка атрибута нити для отсоединения
7
setupfpthread attrj *attrp)
{
pthread attrjnit(attrp);
pthread_attr_setdetachstate(attrp,PTHREAD_CREATE.DETACHED);
time(&server_started);
serverjequests = 0;
server bytes_sent = 0;
}
void *handie_caII(void *fdptr)
{
FILE *fpin;
char request[BUFSIZ];
int fd ;
fd = *(int*)fdptr;
free(fdptr); /* получить fd из аргумента 7
fpin = fdopen(fd, V); /* буфер ввода 7 :
fgets(request,BUFSIZ,fpin); /* чтение требования от клиента 7 «
printffgot a call on %d: request = %sH, fd, request);
skip jest_of_header(f pin);
processjrq(request, fd); Г rq процесса клиента */
fclose(fpin);
}
He ^ _ *
skipjest_of_header(FILE *)
пропуск всех требований на информацию пока не будет обнаружен CRNL
skip rest of_header(FILE *fp)
{
char buf[BUFSIZ];
while(fgets(buf,BUFSIZ,fp) != NULL && strcmpfbuf/V^") != 0)
}
Г
process_rq(char *rq, int fd}
выполнение действия по требованию и запись ответа в fd
управление требованием в новом процессе
rq - это команда HTTP : GET Доо/bar.html HTTP/1.0
process_rq(char *rq, intfd)
{
char cmd[BUFSIZ], arg[BUFSIZ];
if (sscanf(rq, ,,%s%s"l cmd, arg) != 2)
return;
sanitize(arg);
printf("sanitized version is %s\n", arg);
if (strcmp(cmd,"GEr) != 0)
not imolementedO:
4 Нити. Параллельные фут
else if (built_in(arg, fd))
else if (not exist(arg))
do_404(arg, fd);
else if (isadir(arg))
do_ls(arg, fd);
else
do_cat(arg, fd);
}
/*
* убедиться, что все маршруты - ниже текущего каталога
7
sanitize(char *str)
{
char *src, *dest;
src = dest = str;
while(*src){
if(strncmp(src,"/../",4) == 0)
src += 3;
else if (stmcmp(src,7A2) == 0)
src++;
else
*dest++ = *src++;
}
*dest='\0';
if(*str*=7)
strcpy(str,str+1);
if (str[0]=='\0' || strcmp(strJ,,./,,)==01| strcmp(str,M./..n)==0)
strcpy(str,".");
}
/* Здесь управление встроенными URL */
built_in(char *arg, intfd)
{
FILE *fp;
if (strcmp(arg,"status") != 0)
return 0;
httpjeply(fd, &fp, 200, "OK", Mtext/plain",NULL);
fprintf(fp,"Server started: %sM, ctime(&server_started));
fprintf(fp,"Total requests: %d\nn, server_requests);
fprintf(fp,"Bytes sent out: %d\n", server_bytes_sent);
fclose(fp);
return 1;
}
http_reply(int fd, FILE **fpp, int code, char *msg, char *type, char ^content)
{
FILE*fp = fdopen(fd,,,wM);
int bytes = 0;
if (fp != NULL){
bytes = fprintf(fp,"HTTP/1.0 %d %s\r\n", code, msg);
bytes += fprintf(fp,"Content-type: yosV^^n", type);
if (content)
bytes += fprintf(fp,"%s\r\n", content);
}
ffiush(fp);
if(fpp)
.6. Web-сервер, который использует механизм нитей
*fpp = fp;
else
fclose(fp);
return bytes;
}
/• ....... *
первые простые функции:
notjmplemented(fd) незадействованная НИР-команда
и do_404(item,fd) нет такого объекта
7 7
not implemented(int fd)
http_reply(fdJNULL,501 ,"Not Implemented", "text/plain",
'That command is not implemented");
}
do_404(char *item, int fd)
{ "
http_reply(fdlNULL,4041"NotFound">"text/plainn,
'The item you seek is not here");
}
/• mm mmmm m mm m e m m •
секция листинга каталога
isadirf) использует stat, not exist() использует stat
77
isadir(char *f)
{
struct stat info;
return (stat(f, &info) != -1 &&S ISDIRfinfo.st mode));
}
not exist(char *f)
{ "
struct stat info;
return(stat(f,&info)==-1);
}
do_ls(char *dir, int fd)
{ "
DIR *dirptr;
struct dirent *direntp;
FILE *fp;
int bytes = 0;
bytes = http_reply(fd,&fp,200rOK","text/plain"lNULL);
bytes += fprintf(fp,"Listing of Directory %s\n", dir);
if ((dirptr = opendir(dir)) != NULL){
while(direntp = readdir(dirptr)){
bytes += fprintf(fp, "%s\n", direntp->d_name);
}
closedir(dirptr);
}
fclose(fp);
server_bytes_sent += bytes;
}
Г
функции для выполнения cat для файлов.
file_type(filename) использует 'расширение': что используется в cat
7
516
Нити. Параллельные функции
char * file type(char *f)
{
char*cp;
if ((cp = strrchr(f, ¦;))!= NULL)
return cp+1;
return,,и;
}
Г do_cat(filename,fd): послать заголовок, а затем и содержание 7
do_cat(char *f, int fd)
{ "
char *extension = filejype(f);
char *type = "text/plain";
FILE *fpsock, *fpfile;
int c;
int bytes = 0;
if (strcmp(extension,"htmr) == 0)
type = "text/html";
else if (strcmp(extension, "gif') == 0)
type = "image/gif;
else if (strcmp(extension, "jpg") == 0)
type = "image/jpeg";
else if (strcmp(extension, "jpeg") == 0)
type = "image/jpeg";
fpsock = fdopen(fd, "w");
fpfile = fopen(f, "r");
\\ (fpsock != NULL && fpfile != NULL)
{
bytes = http_reply(fd,&fpsock,200l,,OK,,Jtype,NULL);
while((c = getc(fpfile)) != EOF){
putc(c, fpsock);
bytes++;
}
fclose(fpfile);
fclose(fpsock);
}
server_bytes_sent += bytes;
}
Заметим, что мы получили работающую программу. Но есть одна проблема: для хранения
статистики были использованы разделяемые переменные. Эти разделяемые переменные
в данном решении не защищены средствами блокировки. В качестве упражнения
добавьте механизм mutex.
14.7. Нити и анимация
При реализации Web-сервера не было необходимости в использовании нитей. Для
управления параллельными запросами вполне достаточно было использовать fork. С другой
стороны, в работе Web-броузера будет трудно обойтись без использования нитей, с
помощью которых можно достаточно просто анимировать изображения и различные рекламы.
Еще один пример использования нитей - управление анимацией. Таймер посылает через
регулярные отрезки времени сигнал SIGALRM. В обработчике сигнала используют счетчики.
Они определяют моменты времени, когда следует перемещать изображение.
14.7. Нити и анимация
517
14.7.1. Преимущества нитей
Программа, которая использует механизмы обработчика сигнала и интервальный таймер,
работает. Однако использование в программе вместо этих механизмов нитей привнесет
улучшение во внутренней и внешней структуре. Итак, внутри программы будут
использованы два независимых потока управления: поток управления анимацией и поток
управления данными с клавиатуры (см. рисунок 14.10).
Установки для анимации используются
анимационной нитью
\ row | \ I
t directioni ; ;
\ speed II i
Анимационные установки
модифицируются нитью,
которая управляет данными
с клавиатуры
Рисунок 14.10
Анимируемое изображение и управление с помощью клавиатуры
Нити при непосредственной реализации представляются нам анимационным кодом,
который будет отличен от кода для работы с данными, поступающими от клавиатуры. Нити
разделяют переменные, которые определяют позицию и скорость анимации, как показано
на рисунке 14.11.
main()
animate
J until done
П~| getch
!4~-~J handle char
row
direction
speed
\
Нить клавиатуры
Рисунок 14.11
Нить анимации и нить клавиатуры
animate()
=5
j 1°оР
I sleep
| move
bounce?
\
Анимационные
установки
Нить анимации
Естественно, анимацией управляет интервальный таймер, который не показан. В данном
случае решение на основе использования нитей позволяет нам сконцентрировать
внимание на программных компонентах.
При использовании нитей становится очевидным второе преимущество относительно
подхода, где были использованы обработчики сигналов и таймеры. Современные
библиотеки нитей таковы, что допускают запуск различных нитей на различных процессорах,
обеспечивая при этом правильное решение при одновременном исполнении нитей. При
рассмотрении задачи анимации таким результатом будет формирование законченных
траекторий перемещения, скоростей, распределение текстур. При этом происходит
выполнение каждой нити на своем собственном процессоре, что приводит к более быстрой работе.
518
Нити. Параллельные функции
14.7.2. Программа bounceld.c, построенная с использованием нитей
Сравните начальную версию программы bounceld.c с новой, двухнитьевой версией
bounceld.c:
Г tbouncel d.c: управление анимацией с использованием двух нитей .
* Замечание: одна нить управляет анимацией,
* другая управляет вводом от клавиатуры
Компиляция: ее tbouncel d.c -leurses -Ipthread -o tbouncel d
7
#include <stdio.h>
#include <curses.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
/* Разделяемые переменные, которые используют две нити. Здесь необходим
* mutex.
7
•define MESSAGE "hello"
int row; /* текущая строка */
int col; /* текущая колонка 7
int dir; /* направление перемещения */
int delay; /* задержка между перемещениями */
main()
{
int ndelay; /* новая задержка */
int с; /* пользовательские входные данные7
pthreadj msgjhread; Г нить */
void *moving_msg();
initscr(); /* инициализация curses и терминала 7
crmode();
noecho();
clear();
row =10; Г здесь начало */
col = 0;
dir = 1; /* добавить 1 к счетчику строк */
delay = 200; /* 200ms = 0.2 секунд 7
if (pthread_create(&msgJhread,NULL,moving_msg,MESSAGE)){
fprintf(stderr,"error creating thread");
endwin();
exit@);
}
whileA){
ndelay = 0;
c = getch();
if (c == 'Q') break;
if (c == " •) dir
if (c == T && delay > 2) ndelay = delay/2;
if (c == 's') ndelay = delay * 2;
14.7. Нити и анимация
519
if (ndelay > 0)
delay = ndelay;
}
pthread_cancel( msg Jhread);
endwin();
}
void *moving_msg(char *msg)
{
whileA){
usleep(delay*1000); /* спать */
move(row, col); /* установить курсор в требуемую позицию */
addstr(msg); /* перестроить (redo) сообщение 7
refresh(); /* и показать его */
/* переместиться на следующую позицию и проверить необходимость
* выполнения */
col += dir; f переместиться в новую колонку */
if (col <=0&&dir== -1)
dir = 1;
else if (col+strlen(msg) >= COLS && dir == 1)
dir = -1;
}
}
В чем отличие этой новой версии от начальной, построенной на основе модели
управления сигналами? Основное отличие в том, что функция main создает новую нить для
выполнения в ней функции movingjnsg. Функция movingjnsg выполняет простой цикл: sleep, move,
проверка на необходимость смены направления, повтор. Тем временем в другой части
этого же процесса в main выполняется такой простой цикл: getch, обработка, повторение.
В полученном варианте программы используются глобальные переменные, с помощью
которых фиксируется состояние шарика. Нам необходимы глобальные переменные
в версии, где использована модель управления сигналами, поскольку мы не могли
передать аргументы обработчику сигнала. Но нити могут принимать аргументы. Мы можем
улучшить эту программу, создав структуру для помещения в нее установок, как мы уже
делали в версиях 3 и 4 при реализации программы для счета слов на основе использования
модели нитей.
14.7.3. Множественная анимация: tanimate.c
Как можно одновременно анимировать несколько изображений? В мультинитьевой
программе для подсчета слов были запущены параллельные нити для выполнения подсчета
слов. Каждая работа со своим файлом и со своим счетчиком слов. Давайте используем тот
же принцип для запуска нескольких одновременно развивающихся анимаций.
Такая анимационная программа tanimate.c, где использованы нити, является развитием
программы tbOuncel.c. При обращении к tanimate.c задается до десяти текстовых строк в качестве
аргументов. В программе организуется анимация каждого аргумента, который будет
отображаться на отдельной строке. Каждое текстовое сообщение будет передвигаться на своей
строке с собственной скоростью и в собственном направлении. Это немного напоминает
картинку, которую мы видим на Web-странице. Например, при выполнении команды:
tanimate 'Buy this' 'Drive this car' 'Spend Money here' Consume 'Buy!'
520
Нити. Параллельные функции
на экране будет несколько анимированных строк, которые перемещаются со сменой
направления, как показано на рисунке 14.12.
''-гу^Чй
Buy this!
Drive this car!
Spend money here!
Buy!
rf 'Q* to quit, 'O'..^' to bounce
Л
Рисунок 14.12
Множество сообщений с изменением
направления
Пользователь может изменить направление любого из сообщений, нажимая для этого на
клавиши","Г,...
С помощью программы можно анимировать любой список из текстовых строк, даже если
эти текстовые строки являются командами Unix. Попробуйте выполнить:
tanimate'Is'
tanimate 'users'
tanimate 'date'
В программе tanimate запускается анимационная функция в нескольких нитях. При каждом
запуске в функцию передается разный набор аргументов. Через аргументы задается
текстовое сообщение, строка, направление перемещения и скорость:
Г tanimate.c: анимация нескольких строк на основе использования
* нитей,curses, usleep()
* Основная идея: одна нить на одну анимируемую строку
* одна нить для работы с терминалом
* разделяемые переменные для взаимодействия
* Компиляция: compile cc tanimate.c -leurses -Ipthread -о tanimate
* Необходимо: блокировать разделяемые переменные
* управление экраном возложить на отдельную нить
7
«include
#include
#include
#include
#include
<stdio.h>
<curses.h>
<pthread.h>
<stdlib.h>
<unistd.h>
#defmeMAXMSG10
«define TUNIT 20000
struct propset {
char *str;
int row;
int delay;
int dir;
};
/* предельное количество строк */
Г время в микросекундах */
Г сообщение */
Г строка */
Г задержка в микросекундах */
Г +1 или -17
pthreadjnutexj mx = PTHREAD_MUTEXJNITIAUZER;
, 7. Нити и анимация
int main(lnt ас, char*av[])
{
int с; /* входные данные от пользователя 7
pttireadt thrdsfMAXMSG]; /* нити */
struct propset props[MAXMSG]; Г свойства строки */
void *animate(); Л Функция 7
int num_msg ; Л число строк 7
int i;
if (ас ==1){
printffusage: tanimate string. Дп");
exitA);
}
numjnsg = setup(ac-1 ,av+1 ,props);
/* создать все нити */
for(i=0; Knumjnsg; i++)
if (pthread^createt&thrdsfi], NULL, animate, &props[i])){
fprintf(stderr,Merror creating thread");
endwin();
exit(O);
}
Л обработка данных от пользователя 7
whileA){
c = getch();
if (с =='Q') break;
И (с — ¦')
for(i=0;i<num_msg;i++)
props[i].dir = -props[i].dir;
if(c>=,0'&&c<=,9'){
i = с - '0*;
if (i < numjnsg)
props[i].dir = -props[i].dir;
}
}
Г закончить исполнение всех нитей */
pthread_mutexJock(&mx);
for (i=0; i<num^msg; i++)
pthread_cancel(thrds[i]);
endwinf);
return 0;
}
int setup(int nstrings, char *strings[], struct propset propsQ)
{
int num_msg = (nstrings > MAXMSG? MAXMSG : nstrings);
int i;
Г установить значение номеров строк и скоростей для каждой текстовой строк!
* задаваемого сообщения */
9
Нити. Параллельные ф
#srand(getpid());
for(i=0; i<num_msg; i++){
props[i].str = strings[i];
props[i].row = i;
propsfi]. delay = 1+(rand()%15);
props[i].dir = ((rand()%2)?1:-1);
}
/* установить curses */
initscr();
crmode();
noecho();
clear();
mvprintw(UNES-1,0,,MQ' to quit, '0'.
return num_msg;
/* сообщение 7
Г строка */
Г скорость 7
Л+1 или -17
'%d' to bounce",num_msg-1);
}
/* код, который запускается в каждой нити 7
void *animate(void *arg)
{
struct propset *info = arg;
int len = strlen(info->str)+2;
intcol = rand()%(COLS-len-3);
whileA)
{
usleep(info- >delay*TUNIT);
pthread_mutexJock(&mx);
/* указатель на блок info 7
/* +2 для заполнения */
Г пространство для заполнения */
/* только одна нить */
move(info->row, col); /* может вызвать curses */
Г при одновременном обращении */
Г Поскольку я сомневаюсь в */
/* реентерабельности, */
Г в парковке курсора 7
/* и его показе, */
Г то действие с curses будет таким */
Г перемещение элемента в следующую колонку и проверка на необходимость смены
* направления
7
col += info- >dir;
if (col <= 0 && info- >dir == -1)
info->dir=1;
else if (col+len >= COLS && info- >dir == 1)
info- >dir
addchC');
addstr(info->str);
addchC');
move(UNES-1,COLS-1);
refresh();
pthread_mutex_unlock(&mx);
14.7. Нити и анимация 523
14.7.4. Mutexes и tanimate. с
Откомпилируем программу tanimate.c и запустим ее на исполнение. В коде представлены
три основные секции: секция инициализации, секция с функцией для анимации
сообщения, секция, содержащая цикл для ввода данных от пользователя и для обработки этих
данных. В цикле работы с пользователем запускается начальная нить. Функция animate
запускается в нескольких нитях. В программе tanimate возможно запускать сразу до
двенадцати нитей. При одновременной работе двенадцати нитей требуется синхронизация. Что
в данной программе является разделяемыми ресурсами и как можно предотвратить их
неправильное использование?
Искажение данных: динамическая инициализация mutex. Анимационная функция
использует и модифицирует значения, которые в информационной структуре представляют
позицию, скорость и направление перемещения. Когда пользователь хочет изменить
направление перемещения для некоторого сообщения, то нить, которая управляет работой
с терминалом, изменяет член dire этой структуре. Поскольку структура является
разделяемой, то для проведения в ней изменений значений необходимо использовать mutex, чтобы
предотвратить искажение данных. Как теперь поступить - ввести один mutex для всех
переменных направления или создать для каждой переменной dir свой. Лучшим вариантом
все же будет создание для каждой структуры свой mutex. Нить анимации и нить
терминала будут использовать этот mutex, когда они будут читать и модифицировать
данные в структуре. Модифицированная структура тогда будет такой:
struct propset {
char *str; /* сообщение 7
int row;/* строка 7
int delay; /* задержка в микросекундах 7
intdir;/*+1 или-1 7
pthread_mutex_t lock; /* mutex для dir 7
};
Тогда инициализация в setup будет выглядеть так:
for(i=0; Knumjnsg; i++){
props[i] .str = strings[i]; 4 /* сообщение 7
props[i].row = I; Г строка 7
propsfi].delay = 1 +(rand()%15); /* скорость 7
props[i].dir = ((rand()%2)?1 :-1); /* +1 или -1 7
pthread mutex init(&props[i].lock,NULL);
}
Другие измененийя в коде следует выполнить в качестве упражнения.
Искажения при выводе на экран: критические секции. Разделяемыми ресурсами в
программе являются не только переменные направления. Всеми нитями анимации будут
разделяться также экранные функции и функции curses, которые модифицируют экран.
Поэтому будем использовать mutex mx, чтобы предотвратить одновременный доступ
к curses-функциям.
Чтобы убедиться в необходимости такой блокировки, рассмотрим такие вызовы средств
управления экраном в animate: move, addch, addstr.. refresh. Что произойдет, если две нити
попытаются одновременно выполнить эту последовательность? Или, например, что будет,
если две нити будут обращаться к curses в таком порядке: move, addch, addch, addstr, addstr...
524
Нити. Параллельные функции
Первая нить будет смещать курсор в одну позицию экрана, а другая будет смещать этот же
курсор в другую позицию. Первая нить будет выводить свой текст на экран, предполагая
при этом, что курсор расположен в позиции, куда она его передвинула. Но выводимый
текст будет выведен, начиная с позиции, которую определила вторая нить.
Библиотека curses ничего не знает о нитях. При использовании таких функций они не
должны прерываться другими нитями. Такие функции не являются реентерабельными.
Чтобы гарантировать использование в каждый момент времени только одной функции
curses, воспользуемся механизмом mutex.
В библиотеке curses содержатся внутренние структуры данных. Мы будем использовать
mutex для предотвращения искажений структур данных, которые управляются
системными библиотеками. Это делается точно так, когда мы использовали mutex для
предотвращения искажений данных при работе с собственными структурами данных.
14.7.5. Нить для curses
Не только механизм mutex позволяет предотвратить для curses возможность искажения
данных. Есть еще один метод - нужно создать новую нить для управления всеми
вызовами к функциям управления экраном (см. рисунок 14.13).
Вы можете воспринимать эту нить по управлению выводом на экране аналогично
департаменту общественных отношений для большого бизнеса. Любой департамент,
который хочет опубликовать информацию, посылает запрос в департамент общественных
отношений. Сотрудники департамента позаботятся о получении сообщения.
Нить по управлению экраном работает аналогично департаменту общественных
отношений. Любая нить, которая хочет вывести на экран сообщение, должна послать запрос для
SMT (screen-management thread - нить управления экраном).
Один процесс
со многими N
нитями
Одна нить читает
и обрабатывает
данные
от пользователя
Каждый анимируемый образ управляется
отдельной нитью. Эти нити передают запросы
на модификацию экрана в почтовый ящик
Одна нить принимает
запросы на
модификацию
экрана и вызывает
к curses-функциям
Вывод на экран
Рисунок 14.13
Отдельная нить взаимодействует с curses
В нашем случае нити будут посылать запросы для вывода своих текстов на экран.
Поэтому каждый запрос может быть представлен как структура, в которой содержатся значения
строки, колонки и сама строка. Анимационные нити являются поставщиками таких
сообщений, a SMT будет принимать и обрабатывать сообщения.
Заключение
525
Такая система с несколькими производителями запросов и одним потребителем
аналогична системе, которая была запрограммирована в программе счета слов, где были
использованы нити. Нам потребуется переменная, в которой будут сохраняться
поступившие сообщения. Потребуется mutex, чтобы предотвратить искажения текстов сообщений.
Также потребуется условная переменная для того, чтобы уведомить SMT о том, что
анимационная нить послала сообщение.
Централизация и абстрагирование при управлении экраном придают программе большую
гибкость. Если заменить curses на какую-то другую систему для управления дисплеем, то
потребуется изменить только функции, которые будут использованы в SMT. SMT может
даже взаимодействовать с удаленным графическим сервером через программный канал
или сокет, без анимационных нитей. Данный проект остается для выполнения в качестве
упражнения.
Заключение
Основные идо и
• Нить исполнения - это поток управления при исполнении программы. С помощью
библиотеки pthreads программа может запускать одновременно на исполнение
несколько функций.
• Функции, которые исполняются одновременно, имеют свои локальные переменные,
но могут также разделять все глобальные переменные и динамически распределяемые
данные.
• Когда нити разделяют переменную, то нужны гарантии, что нити не получат доступ
к этой переменной каким-то другим способом. Чтобы гарантировать, что в любой
момент времени с разделяемой переменной будет работать только одна нить, нити
должны использовать mutex для блокировки одновременного доступа.
• Когда у нитей появляется необходимость в координации или синхронизации своих
действий, то они могут использовать для этого условную переменную. Одна нить
может ожидать на условной переменной наступления некоторого события, а другая
нить будет сигнализировать через эту переменную о наступлении такого события.
• Нитям требуется использовать блокировку mutex для предотвращения
одновременного доступа к функциям, которые работают с разделяемыми ресурсами. Таким же
образом должны быть защищены и функции, которые не являются реентерабельными.
Что дальше?
Программа может использовать несколько процессов, которые взаимодействуют через
программные каналы, файлы, сокеты, используют сигналы. В программе могут быть
также использованы и несколько нитей, которые могут взаимодействовать и координировать
свои действия через разделяемые переменные, файлы, блокировки (замки) и сигналы.
В последней главе наше внимание будет сфокусировано на межпроцессных
взаимодействиях. Сколько методов взаимодействий есть в Unix? Какой из них может быть выбран как
лучший для конкретного приложения?
526
Нити. Параллельные функции
Исследования
14.1 Поэкспериментируйте с основными операциями над нитями посредством внесения
некоторых изменений в программу hellojriulti.c. Прежде всего добавьте еще одно или два
сообщения, чтобы убедиться, насколько легко добавлять в программу новые нити для
исполнения.
Далее, измените printjnsg так, чтобы число повторений было бы равно длине текста
строки. Выводите текст сообщения после каждого обращения к pthreadjoin, чтобы
отслеживать происходящее в программе. Предугадайте результат.
14.2 Использование программного канала в tanimate. Будет забавным результат, если
позволить программе tanimate читать список текстовых строк для нее со стандартного ввода.
Читать по одному сообщению в строке. Тогда должна будет работать такая команда:
who | tanimate
Добавление такой возможности в программу не является тривиальным делом. Для
добавления такой возможности вам понадобится читать строки со стандартного ввода и
затем перенаправлять стандартный ввод на терминал с тем, чтобы curses смог бы
читать символы в неканоническом режиме. Подсказка: откройте /dev/tty и выполните dup
для стандартного ввода.
14.3 В главе, посвященной видеоиграм, мы блокировались с помощью сигнальных масок,
с помощью которых предотвращались прерывания во время выполнения критических
секций кода. Сравните метод использования сигнальных масок и обработчиков
сигналов с методом нитей и методом блокировок mutex, а также с методом условных
переменных.
Программные упражнения
14.4 Humu создают нити. В программе hellojriulti.c начальная нить создает две нити для
печати. Напишите новую версию, в которой нить, которая выводит сообщение "hello",
образует новую нить для печати "world\n". Какая из нитей будет ждать окончания нити
для- вывода uworld\n"? Почему?
14.5 В программе twordcountl .с используются три нити: начальная нить и две нити для
подсчета слов. Но начальной нити нечего делать. Напишите версию программы, в которой
начальная нить сначала подсчитывает число слов в первом файле и создает вторую
нить, которая должна подсчитывать число слов во втором файле. Результат получим
быстрее, чем раньше? Это решение лучше?
14.6 Обработка ошибок. Функция COunt_words сообщает о возникновении ошибки, если ей
не удается открыть заданный для нее файл. Другая нить тем не менее продолжает
работать. Хорошо ли это? Модифицируйте программу так, чтобы count_words вызывала exit,
если не удается открыть файл.
14.7 Масштабирование числа обрабатываемых файлов. Как можно расширить
использование методов, которые были использованы в программе twordcount2.c и twordcountS.c так,
чтобы программы могли бы обрабатывать столько файлов, сколько будет задано при
обращении к этим программам в командной строке? Модифицируйте обе эти
программы так, чтобы они могли бы принимать на обработку произвольное число файлов,
имена которых задаются как аргументы в командной строке. Какую версию будет проще
модернизировать с тем, чтобы она управляла произвольным количеством файлов?
Какое решение будет более эффективным?
Заключение 527
14.8 Процессы или нити.
(a) Напишите версию программы для подсчета слов. Она использует fork, чтобы
создать новые процессы для работы над отдельными файлами. Вам необходимо
разработать систему для дочерних процессов, которые могли бы посылать их результаты
обратно процессу-отцу для проведения над ними дальнейшей обработки. Не
используйте при этом значение аргумента в вызове exit, поскольку это число не может быть
более 255. Используйте одно из преимуществ от использования fork, которое
заключается в возможности запускать обычную команду wc -w для подсчета слов в файле.
(b) Напишите версию программы для подсчета слов, которая состоит из единственной
нити.
(c) Сравните эти три версии (процессы, мультинитьевую версию, однонитьевую
версию) по легкости проектирования, простоте кодирования, скорости выполнения и
мобильности возможностей. Встретились ли неожиданности при сравнении?
14.9 Управление несколькими файлами. Расширьте возможности программы twordcount4.c
так, чтобы она могла бы управлять более чем двумя файлами, имена которых задаются
как аргументы командной строки.
14.10 Программа twordcount4.c использует глобальные переменные. Удалите глобальные
переменные и сделайте их локальными для функции main. Передайте указатели на эти
переменные как члены структуры, которая используется для передачи аргументов при
обращении к нитям.
14.11 Добавьте блокировку с помощью mutex в программу twebserv.c для защиты программы,
где содержатся статистические данные.
14.12 Удалите все глобальные данные из программы tbounceld.c, используя вместо них
структуру, где содержатся все свойства перемещаемых сообщений.
14.13 Для работы с переменными разделяемого состояния в программе tbounceld.c
необходимо использовать mutex. Какие условия гонок могут возникнуть в этой программе? Какие
могут возникнуть эффекты в программе, если две нити начнут мешать друг другу?.
14.14 В варианте программы с однострочной анимацией был использован контроль за
скоростью. Пользователь мог нажать клавиши us" и "Г, чтобы увеличить или
уменьшить задержки между перемещениями. Добавьте механизм управления скоростью для
версии с многими сообщениями.
14.15 Все сообщения в программе tanimate.c перемещаются по горизонтали. Измените
программу так, чтобы некоторые строки могли бы перемещаться вверх и вниз, а другие
строки перемещались бы влево и вправо. Как вы будете управлять коллизиями?
14.16 Модифицируйте программу tanimate так, чтобы для управления экраном
использовалась бы отдельная нить. Нити, которые представляют сообщения, должны посылать
сообщения нити, управляющей экраном. Разработайте систему для взаимодействий
между нитями.
14.17 MyibmuHumbeebiufinger-cepeep. Напишите finger-сервер, где использовалась бы мно-
гонитьевая модель. Сервер принимает на входе одну строку. Затем он блокирует эту
строку в базе данных пользователей и посылает назад информацию о том, что запись
о сопоставлениях в данной строке была выполнена. Сервер должен выполнять такие
действия:
(a) Загружает базу данных пользователя в память.
(b) Запускает новую, отсоединенную нить для каждого запроса.
528
Нити. Параллельные функции
(c) Сервер записывает число попаданий (вхождений) для каждой записи.
(d) С помощью специального запроса STATUS возвращается статистика.
(e) Сервер обновляет свою внутреннюю базу данных, если он принял SIGHUP.
14.18 Curses-сервер. В последней секции о программе tanimate дискутировался вопрос
о разделении функций по отображению, функций для работы со временем и функций
по обработке данных. Напишите клиент/серверную версию программы tanimate, где
необходимо использовать дейтаграммные сокеты для посылки простых запросов из
программы tanimate к curses-серверу общего назначения.
Curses-сервер поддерживает простой протокол, состоящий из двух команд:
CLEAR очистить дисплей
DRAW R С Any string передать текст "Any string" в строку R, начиная с колонки С
В модифицированной версии tanimate не должно быть обращений к функциям curses.
Вместо этого передаются сообщения для curses-сервера. Curses-сервер принимает
такие сообщения и выводит строки. Когда вы получите работающую версию, то
перейдите к изучению идей и проекта оконной системы XII для Unix.
Глава 15
Средства межпроцессного
взаимодействия (IPC).
Как можно пообщаться?
Цели
Идеи и средства
• Блокирование на вводе от нескольких источников: select и poll.
Именованные программные каналы.
• Разделяемая память.
• Файлы блокираторы.
• Семафоры.
• Обзор средств IPC.
Системные вызовы и функции
• select, poll
• mkfifo
• shmget, shmat, shmctl, shmdt
• semget, semctl, semop
Команды
• talk
530
Средства межпроцессного взаимодействия (IPC). Как можно пообщаться?
15.1. Выбор при программировании
В давние времена, когда два человека хотели каким-то образом пообщаться, их выбор был
невелик: либо поговорить, либо запустить камнем. (Последнее можно воспринимать либо
как юмор автора, либо как описание известного для школьников способа вызова подружек
на прогулку. -Примеч. пер.). У современных людей выбор для общения значительно
больший: телефон, электронная почта, обычная почта, экспресс новости, курьерская связь,
голосовая почта, пейджерная связь, выдача сообщений на монитор, приватный разговор или
бросание камнями. У каждого метода есть свои сильные и слабые стороны. Какой из
вариантов выбрать? Почему так много таких вариантов общения?
Программисты в Unix также могут выбрать подходящий для них вариант для
установления коммуникаций между процессами. Но опять же каждый метод имеет свои
преимущества и свои недостатки. На основании чего можно сделать выбор? Мы начнем изучения
механизма talk. Это команда в Unix, с помощью которой пользователи могут интерактивно
общаться - посылать текстовых сообщений друг другу. Мы проведем сравнение и
обсудим других возможных методов, которые существуют в Unix для организации передачи
информации между процессами.
15.2. Команда talk: Чтение многих входов
Команда talk в Unix представляет собой один из вариантов для организации
межпроцессных взаимодействий. С помощью команды talk пользователи получают возможность
передавать набираемые на клавиатуре сообщения между двумя терминалами. Команда talk
работает даже в варианте, когда терминалы различных компьютеров соединены между
собой через Интернет (см. рисунок 15.1).
Хост1
Хост 2
Процесс talk
Процесс talk
Рисунок 15.1
Команда talk при работе в сети
При выполнении команды talk экран разделяется на две области: верхнюю и нижнюю.
Работа терминала происходит в посимвольном режиме (character-by-character). При наборе
пользователями текста этот текст одновременно отображается на обоих экранах. Символы,
которые набирает пользователь, отображаются в верхней области его экрана. А на экране его
собеседника эти символы будут отображаться в нижней области экрана. При своей работе
команда talk использует сокеты, как это показано на рисунке 15.2.
Программа talk считывает символы и записывает их по месту назначения. Но в отличие от
других программ, которые мы изучали, команда talk ждет поступления ввода сразу от двух
файловых дескрипторов.
15.2. Команда talk: Чтение многих входов
531
Рисунок 15.2
Команда talk
15.2.1. Чтение из двух файловых дескрипторов
Команда talk принимает данные от клавиатуры и сокета. Символы, которые поступают от
клавиатуры, копируются в верхнюю область экрана и передаются через сокет другому
пользователю. Символы, которые читаются из сокета, добавляются в нижнюю область
экрана.
Пользователи при работе с командой talk могут производить набор текстов с произвольной
скоростью и в произвольном порядке во времени. Команда talk должна быть готова читать
данные из какого-то источника в любой момент времени. Программы ориентированы на
очевидные, простые протоколы.
Сервер ждет поступления требования на выполнение read или recvfrom, а затем посылает
ответ с write или sendto. Но пользователи не всегда выдерживают очередность в разговоре.
Что делает команда talk? Совершенно определенно, что команда talk не будет работать так:
while( 1){
read(fd_kbd, &с, 1); /* читать $ клавиатуры 7
waddch(topwin, с); /* добавить на экран 7
write(fd_sock, &c, 1); /* послать другому пользователю*/
read(fd_sock, &с, 1); /* прочитать сообщение от другого пользователя */
waddch(botwin, с); /* добавить на экран 7
}
Что произойдет, если второй пользователь на другой стороне будет чем-либо занят,
а первый пользователь ничего не набирает на клавиатуре и ждет сообщения? Тогда
программа будет заблокирована на первом системном вызове read, и данные другим
пользователем получены не будут. Метод, код которого представлен выше, будет работать только
в случае, если пользователи будут соблюдать строгую очередность во времени при наборе
сообщений.
А почему бы не установить для файлового дескриптора режим не блокируемый'? Для этого
мы можем вызывать fcntl и установить флаг OJMONBLOCK. При установленном не
блокируемом режиме при работе вызова read сразу происходит выход из вызова. При этом
результат значения вызова будет равен 0, если при попытке чтения на входе нет данных.
Не блокируемый режим будет работать, но при таком подходе слишком
непроизводительно тратится время центрального процессора. При каждом чтении выполняется системный
вызов. Программа может сотни и тысячи раз выполнять код, который проверяет наличие
данных на входе и который находится в ядре. Проверки будут продолжаться до того
момента, когда появится на входе хотя бы один символ.
532 Средства межпроцессного взаимодействия (IPC). Как можно пообщаться?
15.2.2. Системный вызов select
В Unix есть системный вызов select, который специально разработан для программ,
которые хотели бы быть заблокированы на вводе от нескольких файловых дескрипторов.
Принцип работы достаточно простой:
(a) Создается список файловых дескрипторов, за которыми необходимо наблюдать.
(b) Этот список передается вызову select.
(c) Системный вызов select блокирует процесс, пока не поступят данные от любого
файлового дескриптора из списка.
(d) Системный вызов select устанавливает определенные разряды в значении
переменной для оповещения, по какому из дескрипторов поступили входные данные.
Программа selectdemo.c ждет ввода от двух устройств:
Л selectdemo.c: контролирует ввод от двух устройств И использует timeout
* Использование: selectdemo devl dev2 timeout
* Действие: оповещение о вводе из каждого файла и
* сообщение об окончании таймаута
7
#include <stdio.h>
#include <sysAime.h>
#include <sys/types.h>
#include <unistd.h>
#include <fcntl.h>
#define oops(m,x) {perror(m); exit(x);}
main(intac,char*av[])
{
int fd 1, fd2; /* контролируемые файловые дескрипторы */
struct timeval timeout; /* интервал ожидания */
fd_set readfds; /* те дескрипторы, за которыми будет наблюдение при вводе*/
int retval; /* возврат из select */
if (ас != 4){
fprintf(stderr,Musage: %s file file timeout", *av);
exitA);
}
/** открытие файлов **/
if ((fd1 = open(av[1],0_RDONLY)) — -1)
oops(av[1],2);
if ((W2 = open(av[2] ,0_RDONLY)) == -1)
oops(av[2], 3);
maxfd=1+(fd1>fd2?fd1:fd2);
whileA )¦{
Г* образовать список дескрипторов, за которым будет наблюдение **/
FD_ZERO(&readfds); /* очистка всех разрядов 7
FDJ>ET(fd1, &readfds); /* установить бит для fd1 */
FD_SET(fd2, &readfds); /* установить бит для fd2 */
/** установить величину таймаута **/
timeout.tv_sec = atoi(av[3]); Г установить значение в секундах */
15.2. Команда talk: Чтение многих входов
533
timeout.tv_usec = 0; /* нет useconds */
/** ожидание ввода **/
retval = select(maxfdJ&readfdslNULL,NULL,&timeout);
if(retval==-1)
oopsf'select''^);
if (retval > 0){
/** проверка разрядов для каждого наблюдаемого файлового дескриптора **/
if(FDJSSET(fd1,&readfds))
showdata(av[1],fd1);
if(FDJSSET(fd2, &readfds))
showdata(av[2],fd2);
}
else
printffno input after %d seconds\n", atoi(av[3]));
}
}
showdata(char *fname, int fd)
{
charbuf[BUFSIZ];
intn;
printff%s:", fname, n);
fflush(stdout);
n = read(fd, but, BUFSIZ);
if(n = -1)
oops(fname,5);
writeA,buf, n);
writeA,M\nM);
}
Приведенный программный код представляет собой реализацию четырех шагов,
рассмотренных выше. Список файловых дескрипторов хранится в форме битового набора
в переменной типа fd_set С помощью макросов FDZERO, FD_SET и FDJSSET производится
очистка всех разрядов, установка конкретного разряда и проверка значения требуемого
разряда в битовом наборе fd_set. Нам хотелось бы контролировать сразу два источника данных.
Поэтому мы вызываем макрос FDJ5ET для обоих дескрипторов.
При обращении к select также задается значение таймаута. Если данные не поступили
в течение установленного времени, то происходит выход из select. В программе selectdemo.c
длительность интервала ожидания задается в секундах через аргумент при обращении
к программе. Мною был проверен такой код:
$ ее selectdemo.c -о selectdemo
$ ./selectdemo /dev/tty /dev/mouse 10
hello
/dev/tty: hello
no input after 4 seconds
no input after 4 seconds
testing
/dev/tty: testing
534
Средства межпроцессного взаимодействия (IPC). Как можно пообщаться?
Я переместил мышь
/dev/mouse: (
/dev/mouse:
/dev/mouse: я
В этой программе иллюстрируется возможность программы ожидать, пока на входе не
появятся данные либо с клавиатуры, либо от мыши. Более интересной была бы
программа, которая вместо вывода сообщения производила бы некую обработку входных данных.
Обобщенная информация о системном вызове select
select
НАЗНАЧЕНИЕ Синхронизация при мультиплексировании ввода/вывода
INCLUDE #include <sysAime.h>
ИСПОЛЬЗОВАНИЕ int = selectfint numfds,
fd_set *read_set
fd_set xwrite_set
fd,set *error_set,
stfuct timeval *timeout);
void FD ZERO(fd set *fdset)
void FDSETfintfd.fd set *fdset)
void FD_CLR(intfd, fd_set *fdset)
void FDJSSET(int fd, fd.set *fdset)
АРГУМЕНТЫ numfds - максимальное число fd для наблюдения + 1
read_set - ждать входных данных на этих дескрипторах
writelset - ждать подтверждения успешности записи на этих fd
error" set - ждать возникновения ситуации исключения на этих fd
timeout - выход после истечения данного интервала времени
КОДЫ ВОЗВРАТА -1 - при обнаружении ошибки
О - при окончании таймаута
пит - число дескрипторов файла, удовлетворяющих критерию
select одновременно ведет наблюдение за несколькими файловыми дескрипторами. Выход
из вызова происходит по мере того, как на одном из контролируемых дескрипторов что-
либо произойдет. Более точно, вызов select контролирует события на трех наборах
файловых дескрипторов. С помощью одного набора select определяет - нет ли данных, готовых
для чтения. С помощью другого набора select определяет - нет ли данных, готовых для
записи. С помощью третьего набора select определяет - не возникла ли ситуация
исключения. Каждый набор файловых дескрипторов представлен двоичным массивом. Значение
аргумента numfds на единицу больше, чем число дескрипторов, за которыми будет вестись
наблюдение.
Выход из select происходит, когда возникнет любое событие, которое было определено
с помощью аргументов при обращении к вызову. Или выход происходит, когда закончится
интервал таймаута. Результатом выполнения select будет целое число, которое указывает -
сколько дескрипторов удовлетворили случившимся событиям.
Нулевой указатель, который может быть задан при обращении к select, говорит о
необходимости игнорирования соответствующего условия.
15.3. Выбор соединения
535
15.2.3. selectиtalk
В этой главе мы не будет писать программу talk. Локализация другого пользователя и
установка соединения требует выполнения нескольких шагов. Например, для локализации
другого пользователя необходимо выполнить поиск в файле utmp. Мы изучали все эти идеи
и средства, которые требуется применить для выполнения последующих шагов. Каковы
эти шаги? Какие требуется при этом выполнить системные вызовы?
15.2.4. select или poll
Если вам не нравится использовать вызов select, то вы можете использовать вместо него
вызов poll. Вызов select был разработан в Berkeley, а вызов poll был разработан в Bell Labs.
Оба вызова выполняют аналогичные действия. В большинстве версий Unix до сих пор
поддерживаются эти две версии вызова.
15.3. Выбор соединения
Команда talk является хорошим примером системных программ в Unix: это синтез
кооперации и соединения процессов. При работе talk два процесса read и write будет работать с
информацией точно так же как если бы данные находились в обычных дисковых файлах.^
Файловый дескриптор
для записи
Файловый дескриптор
для чтения
Файловый дескриптор
для чтения и для записи рисунок 153
Три файловых дескриптора
Файловые дескрипторы в talk присоединены к клавиатуре, экрану и сокету (см. рисунок 15.3).
Но они могут быть присоединены и к другим процессам или к другим устройствам. Пересылка
данных между процессами - это важнейшая часть работы talk.
Это одна из операций при работе с процессами. Выбор метода соединения является
важным потому, что выбор предопределяет правильный алгоритм или структуру данных.
15.3.1. Одна проблема и три ее решения
Проблема: передача данных от сервера клиенту. Каким же образом выбрать
коммуникационный метод, который можно было бы использовать? Рассмотрим time/date-сервер,
который мы написали, используя технику потоковых сокетов.
Один процесс может определить, сколько сейчас времени, а другой процесс хочет узнать -
сколько сейчас времени (см. рисунок 15.4). Каким образом можно передать информацию
о времени от одного процесса другому процессу?
536
Средства межпроцессного взаимодействия (IPC). Как можно пообщаться?
Клиент. ¦« .^Сервер
Рисунок 15.4
У одного процесса есть информация,
которая необходима другому
процессу
Три решения: файл, программный канал, разделяемая память. На рисунке 15.5
изображены три метода: один метод нам знаком, а два других являются новыми. Знакомым
является метод использования файла. Двумя новыми являются такие методы: именованные
программные каналы и разделяемые сегменты памяти, В каждом из этих методов
осуществляется передача данных соответственно через диск, через ядро, через пространство
пользовательской памяти. Каковы детали, слабые и сильные стороны каждого из этих
методов?
Передача данных
через программный
канал
Рисунок 15.5
Три пути для передачи данных
У двух процессов установлены
указатели на разделяемый
сегмент памяти
Разделение данных
при записи и чтении из файла
15.3.2. Механизм IPC на основе использования файлов
Процессы могут взаимодействовать, передавая информацию через файлы. Один процесс
пишет в файл, а другие процессы будут читать данные из этого файла.
Time/Date-cepeep использует файл. Не будем писать программу на С. Достаточно
написать простой скрипт:
#!/bin/sh
# time-сервер, файловая версия
while true; do
date >/tmp/current_date
sleep 1
done
Сервер каждую секунду записывает в файл текущие дату и время. При выполнении
операции перенаправления (символ >) происходит уничтожение содержимого файла, а потом
происходит запись даты и времени.
15.3. Выбор соединения 537
Time/Date-клиент использует файл. Клиент читает содержимое файла:
#!/bin/sh
# time-клиент, файловая версия
cat Amp/current_date
Замечания относительно решения с использованием файлов для IPC
Доступ: Клиенты должны иметь возможность читать содержимое файла. Используя
механизм стандартных прав доступа к файлам, мы даем серверу право на запись в файл, а
клиенты будут обладать только правами на чтение из файла.
Множественность клиентов: Сразу несколько клиентов могут попытаться одновременно
читать данные из файла. В Unix не устанавливается ограничений на количество
процессов, которые могут открыть один и тот же файл.
Условия гонок: Сервер модифицирует содержимое файла. Он уничтожает старое
содержимое файла и заносит в файл новые значения даты и времени. Если клиент попытается
читать данные на промежутке времени между уничтожением данных в файле сервером
и записью в файл новых данных, то клиент получит либо пустые данные, либо частично
правильный результат.
Предотвращение условия гонок: Сервер и клиенты должны использовать определенный
вариант мехнизма mutex. Далее мы рассмотрим методы файл-блокировок. Кроме того,
если использовать Iseek и write вместо creat, то файл никогда не будет пустым. Системный
вызов write является атомарной операцией.
15.3.3. Именованные программные каналы
Обычные программные каналы можно использовать только для соединения родственных
процессов. Обычный программный канал создается процессом и уничтожается после
того, как последний ni процессов закроет его.
г г г г
"^U , |
pipe О mkfifoO
Рисунок 15.6
Каналы FIFO являются независимыми от процессов
Именованный программный канал, который также называют каналом FIFO, может быть
использован для соединения неродственных процессов. Он может существовать независимо
от существования процессов (Может существовать после его создания до своего явного
уничтожения. - Примеч. пер.)-см. рисунок 15.6. Канал FIFO аналогичен неприсоединенно-
му к водопроводу садовому шлангу, который лежит на газоне. Можно один конец этого
шланга поднести к уху одного из экспериментаторов, а другой экспериментатор может что-
либо крикнуть на другом конце (Автор предлагает еще один необычный механизм общения
между людьми: садовый шланг. - Примеч. пер.). Наши экспериментаторы, не являясь
родственниками, могут таким образом общаться через садовый шланг. При этом шланг будет
существовать и в случае, когда никто не будет его таким образом использовать. Канал FIFO -
это программный канал, к которому можно обращаться по имени канала.
538
Средства межпроцессного взаимодействия (IPC). Как можно пообщаться?
Использование каналов FIFO
1. Как я могу создать канал FIFO?
mkfifo(char *name, modej mode) С помощью библиотечной функции mkfifo будет создан
канал FIFO, для которого будут установлены затребованные права доступа. Есть еще
и команда mkfifo, которая при своем выполнении вызывает эту же функцию.
2. Как я могу удалить канал FIFO?
При использовании unlink (fifoname) происходит удаление канала FIFO. Это делается
точно так же, как происходит удаление обычного файла.
3. Как. я могу настроить канал FIFO, чтобы использовать его для приема сообщений,
когда канал будет использован для соединения процессов?
open (fifoname, 0_RDONLY). Выполнение системного вызова open будет блокировано до тех
пор, пока какой-либо процесс не откроет его на запись.
4. Как я могут настроить канал FIFO, чтобы иметь возможность посылать через него
сообщения?
open (fifoname, CMWRONLY). Выполнение системного вызова open будет блокировано до тех
пор, пока какой-либо процесс не откроет канал FIFO на чтение.
5. Как два процесса будут общаться через канал FIFO?
Процесс-отправитель должен будет использовать системный вызов write, а
процесс-получатель должен будет использовать системный вызов read. Когда процесс-отправитель
выполнит close, то процесс-получатель обнаружит признак конца файла (При попытке
процесса-получателя читать из канала FIFO. -Примеч. пер.).
Time/Date сервер и клиент, использующие канал FIFO. Ниже приведены два скрипта.
Первый - это сервер, а второй - клиент. Они взаимодействуют при передаче информации
о времени с помощью канала FIFO.
#!/bin/sh
# time-сервер
while true; do
rm -f Дтр/timejifo
mkfifo Amp/timeJifo
date > /tmpAime_fifo
done
#!/bin/sh
# time- клиент
cat /tmp/time_fifo
Замечания относительно решения с использованием каналов FIFO для IPC
Доступ: Каналы FIFO используют механизм прав доступа точно так же, как это делается
в отношении обычных файлов. Сервер должен иметь право на запись в канал. Клиенты
должны иметь только права на чтение из канала.
Множественность читателей: Поименованный программный канал по сути работает как
очередь, а не как обычный файл. Процесс-писатель добавляет данные в очередь, а
процессы-читатели удаляют данные из очереди. Каждый клиент при обращении к каналу FIFO
извлекает оттуда строку с датой и временем. Поэтому сервер всякий раз должен повторно
посылать в канал информацию о времени и дате.
15.3. Выбор соединения
539
Условие гонок'. При построении сервера на основе использования канала не возникает
проблемы состязаний (проблемы гонок). Системные вызовы read и write являются
атомарными, если размер сообщения не превышает размер канала. При чтении сообщения
изымаются из канала FIFO, а при записи информация заносится в канал. Ядро блокирует
процессы до тех пор, пока процесс-писатель и процесс-читатель связаны через канал..
(При попытке чтения из пустого канала или при попытке записи в полный канал. -
Примеч. пер.) Нет необходимости использовать какие-либо дополнительные средства
синхронизации.
Серверы, которые читают из каналов FIFO. Time/date-сервер написан с
использованием канала FIF,0, где происходит блокировка до тех пор, пока клиент не откроет канал FIFO
на чтение. В приложениях, где сервер читает из канала FIFO, происходит ожидание, пока
клиент не запишет данные в канал. Что можно привести в качестве примера, где сервер
ожидал бы клиентского ввода?
15.3.4. Разделяемая память
По какому маршруту "путешествуют" данные, когда их передают между процессами
через файл или канал FIFO? Системный вызов write копирует данные из памяти процесса
в буфер ядра. Системный вызов read копирует данные из буфера ядра в память процесса.
При использовании разделяемой
памяти одному процессу
предоставляется возможность
передавать данные
непосредственно в
пространство памяти
другого процесса
Использование канала предполагает двойное копирование данных
Рисунок 15.7
Два процесса разделяют блок памяти
Зачем процессам приходится копировать данные в/из ядра, если оба процесса
развиваются на одной машине, развиваются в различных частях пользовательского пространства
памяти? Два процесса на одной машине могут обменяться данными (или разделять данные),
используя для этого механизм разделяемого сегмента памяти. Это часть
пользовательского пространства памяти, на которую два процесса имеют указатели (см. рисунок 15.7).
В зависимости от установленных прав доступа оба процесса могут писать данные в это
место памяти и читать оттуда. Информация разделяется, а не копируется, между
процессами. Разделяемую память можно рассматривать как глобальные переменные в
отношении нитей.
Свойства разделяемых сегментов памяти
• Разделяемый сегмент памяти существует независимо от процесса.
• Разделяемый сегмент памяти имеет имя, в качестве которого выступает ключ.
• Ключ - это целое число.
• Разделяемый сегмент памяти имеет собственника и права доступа к сегменту.
• Процессы могут присоединить сегмент, после чего они получают указатель на сегмент.
540
Сродства межпроцессного взаимодействия (IPC). Как можно пообщаться?
Использование разделяемого сегмента памяти
1. Как я могу получить разделяемый сегмент?
int segjd = shmget(key, size-of-segment, flags)
Если сегмент уже существует, то системный вызов shmget определяет его
месторасположение. Если сегмент не существует, то вы можете с помощью аргумента flags задать
требование на создание сегмента, указав при этом желаемые права доступа к сегменту.
Это в некоторой степени напоминает работу системного вызова open.
2. Как я могу присоединить разделяемый сегмент памяти?
void ptr = *shmat(segjd, NULL, flags)
С помощью shmat разделяемый сегмент памяти становится частью адресного
пространства процесса. В результате получаем указатель на сегмент. При обращении можно
использовать флаги, если необходимо определить, чтобы сегмент был бы только читаемым.
3. Как я могу сделать разделяемый сегмент доступным на чтение и на запись данных?
strcpy(ptr, "hello");
memcpyO, ptr[i] - это обычные операции с указателями.
Time/Date-cepeep, использующий механизм разделяемой памяти
/* shmjs.c: time-сервер, в котором используется разделяемая память.
* Будет выглядеть несколько эксцентричным приложением
7
#include <stdio.h>
#include <sys/shm.h>
#include <time.h>
#define TIME MEM KEY 99 Г это используется как имя для файла 7
#define SEG_SKE ({sizeJ) 100) /* размер сегмента 7
#define oops~(m,x) {perfor(m); exit(x);}
main()
{
int segjd;
char *mem_ptr, *ctime();
long now;
int n;
/* создание разделяемого сегмента памяти 7
segjd = shmget(TtME_MEM_KEY, SEG_SIZE, IPC_CREAT|0777);
if (segjd ==-1)
oopsfshmget", 1);
Г присоединить сегмент и получить указатель на место, к которому сегмент был присоединен
7
mem_ptr = shmat(segjd, NULL, 0);
if (mem_ptr ==. (void *j -1)
oops("shmat", 2);
Г запуск на исполнение в течение минуты 7
for(n=0; n<60; п++){
time(&now); /*• получить значение текущего времени 7
strcpy(mem_ptr, ctime(&now)); /* записать в mem */
sleep( 1); /* подождать 1 секунду 7
}
/* теперь удалить сегмент */
shmctl(seg id, IPC RMID, NULL);
15.3. Выбор соединения
541
Time/Date-клиент, использующий разделяемую память
Г shmjc.c: time-клиент, в котором используется разделяемая память.
* Будет выглядеть несколько эксцентричным приложением
7
#include <stdlo.h>
#include <sys/shm.h>
#include <time.h>
#define TIME MEM KEY 99 /* это напоминает номер порта 7
#define SEGJSIZE ((sizej) 100) /* размер сегмента 7
#define oops(m,x) {perFor(m); exit(x);}
main()
{
int segjd;
char *mem_ptr, *ctime();
long now;
Г создать разделяемый сегмент памяти 7
segjd = shmget(TIME_MEM_KEY, SEG.SIZE, 0777);
if (segjd ==-1)
oopsfshmgefj);
/* присоединить сегмент и получить указатель на сегмент 7
mem_ptr = shmat(seg_id, NULL, 0);
if (mem_ptr == (void *) -1)
oops("shmaf,2);
printf('The time, direct from memory:..%s", mem_ptr);
shmdt(mem_ptr); /* отсоединить сегмент, если он уже не нужен 7
}
Замечания по средству IPC на основе использования разделяемой памяти
Доступ: Клиенты при работе с сервером должны иметь возможность читать из разделяемого
сегмента памяти. Разделяемые сегменты памяти используют механизм прав доступа,
который работает аналогично механизму прав доступа в файловой системе. Разделяемый
сегмент имеет собственника и имеет разряды доступа для пользователя, группы и всех
остальных. Механизм разделяемой памяти можно контролировать для обеспечения защиты
данных. Поэтому сервер имеет право на запись, а клиенты имеют только права на чтение.
Множественность клиентов: из разделяемого сегмента могут одновременно читать
данные сразу несколько клиентов.
Условия гонок: Сервер модифицирует данные в разделяемом сегменте при вызове strcpy.
Это библиотечная функция, которая исполняется в пользовательском пространстве. Если
клиент читает данные из сегмента памяти в момент, когда сервер производит записи в
сегмент новой строки, то клиент может прочитать комбинацию из новой и старой строк.
Предотвращение условий гонок: Сервер и клиенты должны использовать некоторые
системные средства синхронизации при доступе к разделяемым ресурсам. В ядре есть механизм
синхронизации, который называется семафоры. Мы рассмотрим позже.
15.3.5. Сравнение методов коммуникации
Исходной задачей была проблема передачи строки от одного процесса к другому. Все три
метода могут быть использованы для решения этой задачи. Клиенты получают данные от
сервера, когда они этого пожелают. Мы рассмотрели уже четыре версии клиент-серверных
систем. Мы может даже написать версии, где использовался бы механизм дейтаграмм или
механизм доменных адресов в Unix. Какой из методов кажется вам более
предпочтительным? Какой критерий использовать при выборе?
542
Средства межпроцессного взаимодействия (IPC). Как можно пообщаться?
Скорость
При передаче данных через файлы и именованные каналы выполняется много действий.
Ядро копирует данные в свое пространство, а затем передает эти данные обратно в
пользовательское пространство. При работе с файлами ядро копирует данные на диск, а затем
копирует данные обратно в пользовательское пространство. На практике хранение данных
в памяти оказывается более сложным, чем это может показаться. Система виртуальной
памяти производит свопирование страниц пользовательской памяти на диск. Поэтому
разделяемый сегмент памяти может также записываться на диск и читаться с диска.
Наличие или отсутствие соединения
Файлы и разделяемые сегменты памяти выступают в роли доски объявлений. Кто-либо
вывешивает свое объявление на доску и уходит. Те, кто читает объявления, могут читать
объявление в любое время. Причем объявление можно читать одновременно. Механизм
программных каналов FIFO требует установления соединения между процессами.
Процесс-писатель и процесс-читатель должны оба открыть канал FIFO до того, как ядро будет
пересылать по каналу данные. При этом клиент может лишь только читать данные. В
механизме потоковых сокетов также требуется устанавливать соединение. А при
использовании дейтаграммных сокетов устанавливать соединение не требуется. Для некоторых
приложений наличие или отсутствие соединения имеет достаточно важное значение.
Область передачи
Насколько далеко могут "путешествовать" ваши сообщения? Механизм разделяемой памяти
и именованных программных каналов можно использовать для взаимодействия процессов,
которые развиваются на одной и той же машине. Файл может храниться на файловом сервере
и может быть использован для связи процессов, которые развиваются на различных машинах.
Сокеты с Internet адресами могут соединять процессы на различных машинах, сокеты с Unix
адресами не могут быть использованы для установления такой связи. Какую область
передачи вы хотели бы использовать? Расширенную или ограниченную?
Ограничения на доступ
Вы желаете, чтобы каждый имел возможность работать с вашим сервером, или желаете
установить ограничения на доступ к серверу и предоставить доступ только определенным
пользователям? В механизмах, где используются файлы, каналы FIFO, разделяемая
память, сокеты с Unix адресами, используются стандартные средства прав доступа, которые
используются в файловой системе. В Internet-сокетах этого нет.
Условия гонок
Использование в программах механизма разделяемой памяти и разделяемых файлов
делает программы более сложными, чем при использовании программных каналов и сокетов.
Каналы и сокеты - это очереди, управление которыми производит ядро. Процесс-писатель
помещает данные в один конец очереди, а процесс-читатель выбирает данные с другого
конца очереди. Процессы при этом не заботятся о внутренней структуре очереди.
Доступ к разделяемым файлам и разделяемой памяти ядром не контролируется. Если
процесс читает файл в тот момент, когда другой процесс пытается записать информацию
в файл, то читающий процесс может получить либо неполные, либо искаженные данные.
Далее мы рассмотрим блокировки (замки) файлов и семафоры.
15.4. Взаимодействие и координация процессов
543
15.4. Взаимодействие и координация процессов
Что еще можно сказать об уже надоевших условиях гонок? Клиенты и серверы могут
разделять одни и те же файлы или одну и ту же памятьГКак мы можем предотвратить
процессы от получения данных каким-либо Другим путем? Как процессы могут координировать
свои действия? Теперь мы рассмотрим средства, с помощью которых процессы могут
правильно разделять ресурсы: блокировки файлов и семафоры.
15.4.1. Блокировки файлов
Два вида блокировок
Рассмотрим две проблемы. Во-первых, возникает вопрос - что случится, если сервер в
текущий момент занят переписыванием содержимого файла, а клиент попытается
обратиться к файлу на чтение? Клиент при обращении к файлу найдет его пустым или не
полностью сформированным. В нашем date/time-сервере мы не сталкивались с такой
проблемой, но в серверах, которые обрабатывают метеорологические данные, где используются
более длинные сообщения, такая проблема, вероятно, возникнет. Поэтому, пока сервер
занят переписыванием содержимого файла, клиенты должны ждать окончания этой
процедуры на сервере.
Рассмотрим теперь противоположную ситуацию. Что произойдет, если клиент читает
файл строку за строкой и неожиданно сервер отбирает у клиента файл, сбрасывает (тран-
катенирует) содержимое файла и начинает записывать в файл новые данные. Клиент
убедится, что файл изменился, увидев это собственными глазами. Поэтому, когда клиент
читает файл, сервер должен ждать, когда клиент закончит процедуру чтения. Другим
клиентам нет необходимости ждать окончания чтения. Но если несколько процессов будут
одновременно читать один и тот же файл, то в этом нет никакого риска.
Для предотвращения указанных проблем нам нужно иметь два типа блокировок файла.
Первый тип, блокировка по записи, означает: "Я пишу в файл, и все остальные должны
ждать, пока я не закончу это делать". Второй тип, блокировка по чтению, означает: "Я
читаю из файла. Процессы-писатели должны ждать, пока я не закончу это делать. Но другим
процессом можно читать этот файл".
Программирование с использованием блокировок файлов
В Unix есть три способа, которые позволяют блокировать открытые файлы: flock, lockf и fcntl.
Наиболее гибким и переносимым из трех является метод с использованием fcntl.
Использование fcntl для блокирования файлов
1. Как я могу установить блокировку по чтению для открытого файла?
Для этого следует использовать fcntl (fd, FJ5ETLKW, &locklnfo)
Здесь первый аргумент-это файловый дескриптор, который должен быть блокирован по
чтению. Второй аргумент, FJJETLKW, сообщает о вашем желании переводить текущий
процесс в состояние ожидания процесса, если блокировка была уже установлена. Нужно
ждать, пока блокировка будет сброшена, если в этом есть необходимость. Третий
аргумент указывает на переменную типа struct flock. В следующем ниже коде устанавливается
блокировка на чтение на файловый дескриптор:
set read lockfint fd)
{
struct flock lockinfo;
lockinfo.ljype =F_RDLCK; /* блокировка на чтение раздела 7
544 Средства межпроцессного взаимодействия (IPC). Как можно пообщаться?
lockinfo.Lpid =getpid(); /*для МЕНЯ*/
lockinfo.l_start =0; /* начинается со смещением 0 байт.. */
lockinfo.h/vhence = SEEK_SET; /* от начало файла 7
lockinfo.ljen =0; /* до конца 7
fcntl(fd, F SETLKW, &Iockinfo);
}
2. Как я могу установить блокировку на запись для открытого файла?
Для этого следует использовать fcntl (fd, FJJETLW/V, &Iockinfo)
при установленном значении поля lockinfo.ljype = F_WRLCK;
3. Как я могу снять блокировку?
Для этого следует использовать fcntl (fd, FJSETUQW, &lockinfo)
при установленном значении поля lockinfo.ljype = FJJNLCK;
4. Как я могут блокировать только часть файла?
Для этого следует использовать fcntl (fd, F_SETLKWf &lockinfo)
при установленном значении поля lockinfo.l_start, равном значению смещения от начала,
и при установленном значении поля lockinfo.ljen, равном длине области в файле.
Код time-сервера, использующего технику блокирования файлов:
/* filejs.c - запись текущей date/time в файл
* Использование: filejs имя_файла
* Действие: записать текущие time/date в файл имя _файла
* Замечание: используется метод блокировки на базе fcntl()
7
tinclude <stdio.h>
«include <sys/file.h>
#include <fcntl.h>
#include <time.h>
#define oops(m,x) {perror(m); exit(x);}
main(intac, char*av[])
{
int fd;
timej now;
char ^message;
if (ac != 2){
fprintf(stderr,Musage: filejs filename\nM);
exitA);
}
if ((fd = open(av[1 ]lO„CREAT|O_TRUNC|O-WRONLY,0644)) == -1)
oops(av[1],2);
{
time(&now);
message = ctime(&now); /* получить значение времени */
lock_operation(fd, F_WRLCK); /* заблокировать файл по записи */
if (ls"eek(fd, 0L, SEEK_SET) == -1)
oopsC'Iseek"^);
15.4. Взаимодействие и координация процессов
if (writetfd, message, strlen(message)) == -1)
oopsC'write", 4);
lock_operation(fd, FJJNLCK); /* разблокировать файл */
sleep( 1); /* ожидание нового момента времени
}
}
lock operation(int fd, int op)
{
struct flock lock;
lock,l_whence = SEEK.SET;
lock.lstart = lock.Men = 0;
lock.lj)id = getpid();
lock.Mype = op;
if (fcntl(fd, F.SETLKW, &lock) == -1)
oopsAock operation", 6);
}
Код для time-клиента, использующего технику блокирования файлов:
/* fileje.c - чтение текущего значения dateAime из файла
* Использование:filejcимяфайла
* Замечание: на основе применения fcntl()
*/
tinclude <stdio.h>
#include <sys/file.h>
#include <fcntl.h>
#define oops(m,x) {perror(m); exit(x);}
#defineBUFLEN10
main(intac,char*av[])
{
int fd, nread;
char buf[BUFLEN];
if(ac!=2){
fprintf(stderr,"usage: filejc filename\n");
exitA);
}
if ((fd=open(av[1],OJTOONLY)) == -1)
oops(av[1],3);
lock operation(fd, FJTOLCK);
while((nread = read(fd, buf, BUFLEN)) > 0)
writeA,buf, nread);
lock_pperation(fd, FJJNLCK);
close(fd);
}
lock_operation(intfd, int op)
{
struct flock lock;
546 Средства межпроцессного взаимодействия (IPC). Как можно пообщаться?
lock.l_whence = SEEK_SET;
lock.l_start = lock.ljen = 0;
lock.l_pid = getpid();
lock.l type = op;
if (fcntlffd, FSETLKW, &lock) = -1)
oops("lock operation", 6);
}
Блокирование файлов: итог
При вызове fcntl с установленным F_SETLKV\^po устанавливает для процессу определенный
вид блокировки. Клиенты могут установить блокировку на чтение перед тем, как читать
данные. Если сервер установил блокировку на запись, то клиенты будут задерживаться
в моменты, когда с файлом работает сервер. Сервер должен установить блокировку на
запись до того, как он будет пытаться модифицировать содержимое файла. Если клиент
установил блокировку на чтение, то сервер будет задерживаться до тех пор, пока все
клиенты не сбросят свои блокировки на чтение.
Важное замечание: процессы могут игнорировать блокировку
В нашем обсуждении блокировок файлов мы предполагали, что программы сервера и
клиента будут при исполнении ждать установки и освобождения блокировок, когда они хотят
читать или модифицировать разделяемые данные. Может ли процесс проигнорировать
наличие блокировок и читать или изменять файл тогда, когда другой процесс пользуется
блокировкой? Да. Unix предоставляет процессам возможность использовать блокировки
при взаимодействии, но Unix не запрещает и другие формы взаимодействия.
15.4.2. Семафоры
В версии tirne/date-клиента и сервера, которые были построены на основе использования
метода разделяемой памяти, сегмент разделяемой памяти играл ту же роль, что и файл,
в версии, где используется файла в качестве средства для передачи данных. Как при этом
можно предотвратить взаимовлияние процессов? Устанавливаются ли блокировки при
чтении и при записи в сегменты памяти? Нет, но процессы могут использовать весьма
гибкий механизм по обеспечению синхронизации: семафоры.
Семафор - это переменная ядра, которая доступна для всех процессов в системе. Процесс
может использовать такие переменные ядра для синхронизации доступа к разделяемой
памяти и другим ресурсам. В главе, где рассматривались нити, было объяснено, как нити
могут использовать условные переменные для того, чтоб оповестить другие нити, когда
случается нечто интересное. Условные объекты являются глобальными в составе
процесса. Семафоры же являются глобальными в составе системы. Каким образом можно
использовать такие глобальные переменные для наших time-сервера и time-клиента?
Счетчики процессов и операции над процессами и счетчиками
Сервер производит запись в сегмент. Он должен ждать момента, когда ни один из
клиентов не читает из сегмента. Клиенты читают из сегмента. Они должны ждать, пока сервер
не закончит запись в сегмент. Мы можем выразить эти правила работы с сегментами с
помощью значений переменных:
• Клиент ждет, пока установится значение number_of_writers ==0
• Сервер ждет, пока установится значение numberjrfjeaders == 0
15.4. Взаимодействие и координация процессов
547
Семафоры представляют собой глобальные переменные в масштабе системы. Мы можем
использовать один семафор для всех процессов-читателей, а другой семафор - для всех
процессов-писателей. Для управления этими переменными необходимы две операции.
Процесс-читатель, например, должен ждать, пока счетчик процессов-писателей не станет
равным нулю, а затем немедленно инкрементировать счетчик процессов-читателей. Когда
процесс-читатель закончит работу по чтению данных, то он должен будет декрементиро-
вать счетчик процессов-читателей.
Процесс-писатель, аналогично, должен ждать, пока счетчик процессов-читателей не
достигнет нуля, а затем инкрементировать счетчик процессов-писателей. Две операции -
ожидание, когда счетчик процессов-читателей достигнет нуля, и увеличение счетчика
процессов-писателей, рассматриваются как единая неделимая операция. Другими
словами, эта пара действий рассматривается как одна атомарная операция. Процесс, который
использует семафоры для синхронизации своих действий, может использовать несколько
переменных и выполнять в отношении них несколько атомарных операций.
г~"Тг^Г
X
0 I
Семафорный набор
num_rd
num_wrt
Рисунок 15.8
Семафорный набор: numreaders
Это еще не вся информация о семафорах. Процесс может выполять набор действий над
семафорами, выполнять все сразу. >
Наборы семафоров, наборы действий
Птегсервер использует два семафора (см. рисунок 15.8). Процессы-читатели и процессы-
писатели выполняют два набора действий.
Прежде чем модифицировать разделяемую память, сервер должен выполнить такой набор
действий:
[0] ждать, пока numjeaders станет равным 0.
[1] прибавить 1 к numj/vriters.
Когда сервер закончит работу с разделяемой памятью, то он должен выполнить такой
набор действий:
[0] вычесть 1 из num_writers.
Прежде чем читать из разделяемой-памяти, клиент должен выполнить такие действия:
[0] ждать, пока значение num_writers достигнет 0.
[1] прибавить 1 к numjeaders.
Когда клиент закончит работу с памятью, то он должен выполнить такой набор действий:
[0] вычесть 1 из numjeaders.
548 Средства межпроцессного взаимодействия (IPC). Как можно пообщаться?
Сервер shm_ts2.c
К нашей предыдущей программе shmjs.c добавим механизм семафоров и получим в
результате программу shmjs2.c:
Г shm_ts2.c - time-сервер, который разделяет память, версия 2:
* использование семафоров для реализации блокировки
* Программа использует разделяемую память по ключу 99
* Программа использует семафорный набор по ключу 9900
7
#include <stdio.h>
#include <sys/shm.h>
#jnclude <time.h>
#include <sys/types.h>
#include <sys/sem.h>
#include <signal.h>
«define Т1МЕ.МЕМКЕГ 99
«define TIME SEM KEY 9900
«define SEG SIZE ("(size tI00)
»
Г аналогично имени файла */
Г размер сегмента 7
«define oops(m.x) {perror(m); exit(x);}
union semun {int val; struct semid_ds *buf; ushort *array;};
int segJd, semsetJd; /* глобальные переменные для cleanup() 7
void cleanup(int);
main()
{
char *mem_ptr, *ctime();
timej now;
intn;
/* создание разделяемого сегмента памяти */
segjd = shmget(TIME.MEM.KEY, SEG_SIZE, IPC.CREAT|0777);
if(segjd==-1)
oopsfshmget", 1);
Г присоединение сегмента и получение указателя на сегмент 7
mem_ptr = shmat(segjd, NULL, 0);
if (mem_ptr == (void *) -1)
oopsC'shmaf, 2);
Г создание набора семафоров semset: ключ 9900,2 семафора и права доступа:
* rw-rw-rw
7
semset jd = semget(TIME_SEM_KEY, 2, @666|IPC_CREAT|IPC.EXCL));
if (semsetJd==-1)
oopsfsemgef, 3);
set_sem_value(semset_id, 0,0); /* установить счетчики 7
set_sem_value(semsetjd, 1,0); Л в 0 7
signal(SIGINT, cleanup);
/* запустить на исполнение в течение минуты */
for(n=0; n<60; п++){
time(8diow); /* поручить значение текущего времени */
4. Взаимодействие и координация процессов
549
cleanup(O);
printf("\tshmjs2 waiting for lock\n");
wait_and jock(semsetjd); /* блокировка памяти */
printf(H\tshmJs2 updating memory\nH);
strcpy(mem_ptr, ctime(&now)); /* запись в память */
sleepE);
releasejock(semset_id); /* снятие блокировки */
printf("\tshmjs2 released lock\nM);
sleep( 1); /* ожидать 1 секунду */
}
}
void cleanup(int n)
{
shmctl(segjd, IPC.RMID, NULL); /* удалить разделяемую память 7
semctl(semset id, 0, IPC.RMID, NULL); /* удалить семафорный набор 7
}
/*
* инициализация семафора
7
set sem value(int semset id, intsemnum, intval)
{
union semun initval;
initval.val = val;
if (semctl(semsetjd, semnum, SETVAL, initval) == -1)
oopsC'semctr', 4);
}
/*
* построение и выполнение набора действий над элементами:
* ожидать достижение 0 на n readers и инкремент счетчика n writers
7
wait and lock(int semset id)
{
struct sembuf actions[2];
actions[0].sem_num = 0;
actions[0].semjg = SEM_UNDO;
actions[0].sem_op = 0;
actions! 1].sem^num = 1;
actions[1].sem_flg = SEM^UNDO;
actions[1].sem-op = +1 ;
if (semop(semsetjd, actions, 2) == -1)
oopsf semop: locking", 10);
}
Г
/* набор действий 7
T sem[0] - это счетчик njeaders 7
/* автоматическое восстановление 7
Г ожидать.когда, счетчик читателей достигнет нуля 7
Г sem[1 ] - это счетчик n_writers 7
/* автоматическое восстановление 7
/* инкремент счетчика писателей 7
* пхтроение и выполнение набора действий из одного элемента:
декремент счетчика num_writers
550
Средства межпроцессного взаимодействия (IPC). Как можно пообщаться?
releaseJock(int semsetjd)
{
struct sembuf actions[1]; /* набор действий */
actions[0] .sem_num = 1; /* sem[0] - это счетчик n_writers 7
actlons[0].senrrflg = SEM_UNDO; /* автоматическое восстановление */
actions[0] .sem_op = -1 ; /* декремент счетчика писателей */
if (semop(semsetJd, actions, 1 )==-1)
oopsf'semop: unlocking", 10);
}
Сервер выполняет пять действий в отношении семафорного набора:
1. Создает семафорный набор:
semsetjd = semget (key_t key, int numsems, int flags)
С помощью semget создается семафорный набор, в котором будет находиться numsems
семафоров. В программе shm_ts2 создается набор из двух семафоров. Набор имеет права
доступа 0666. После выполнения semget в качестве результата возвращается
идентификатор (ID) семафорного набора.
2. Устанавливает значения двух семафоров в 0:
semctl (int semsetjd, int semnum, int cmd, union semun arg)
Мы используем semctl, чтобы управлять семафорным набором. Первый аргумент - это
идентификатор набора. Второй аргумент - это количество составных семафоров в
наборе. Третий аргумент - это команда управления. Если для команды управления также
необходим аргумент, то для этого при обращении к semctl будет использован четвертый
аргумент. В программе shmjs2 мы использовали команду управления SETVAL, с
помощью которой была произведена инициализация каждого составного семафора -
значение каждого семафора было установлено в 0.
3. Ждет, когда счетчик читателей станет равным нулю, затем инкрементирует
счетчик писателей num_writers:
semop (int semid, struct sembuf *actions, sizej numactions)
С помощью semop выполняется набор действий над семафорным набором. Первый
аргумент идентифицирует семафорный набор. Второй аргумент - это массив
действий. С помощью последнего аргумента задается размер массива действий. Каждое
действие в наборе действий - это структура, с помощью которой задается такое требова-
ние:"Выполнить операцию sem_op над семафором под номером semjium с
использованием опций semjlg". Весь набор действий выполняется как групповое действие. Это
главная особенность. Функция wait_andJock предназначена для выполнения двух
действий: ожидание, когда счетчик читателей достигнет нуля, и потом инкрементирование
счетчика писателей. Мы создали массив из двух действий. Нулевое действие выражает
такое требование: "Ожидать, когда значение семафора станет равным 0". Первое
действие выражает такое требование: "Прибавить 1 к семафору 1". Процесс
будет.блокирован до тех пор, пока не будут успешно выполнены оба этих действия. Когда
счетчик читателей достигнет 0, будет увеличен на 1 счетчик писателей. После этого
производится выход из semop.
С помощью флага SEMJJND0 для ядра устанавливается требование на выполнение
действия отката (undo), если процесс будет закончен (Имеется в виду аномальное
окончание процесса. -Примеч. пер.). В данном приложении посредством инкремента
счетчика писателей достигается эффективная блокировка сегмента памяти. Если процесс
15.4. Взаимодействие и координация процессов 551
"погибнет" до момента выполнения декремента счетчика, то другие процессы уже не
смогут использовать разделяемый сегмент памяти (Тем самым автор onHCbmaet
потенциальную опасность возникновения тупиковой ситуации, если не будет использована
возможность отката. -Примеч. пер.).
4. Декремент счетчика писателей num_writers:
В release Jock мы выполняем только одно действие: декремент счетчика писателей.
Мы обращаемся к semop, подготовив предварительно массив действий, где будет
содержаться одно действие. Если клиент ждет, когда счетчик писателей достигнет нуля,
то такому клиенту будет предоставлена возможность возобновить свое исполнение.
5. Удаление семафора:
semctl(semsetjd, О, IPC.RMID, 0)
Когда сервер сделает все необходимое, то он вызывает опять semctl с тем, чтобы
удалить семафор.
Клиент: shm_tc2.c
Программа клиента проще - shmJcZ В программе shm_tc2 нет действий по инициализации
семафоров, а также нет и удаления семафоров.
Г shm_tc2.c - time-клиент, разделяющий память Версия2:
* использование семафоров для блокировки процессов
* Программа использует разделяемую память по ключу 99
* Программа использует семафорный набор по ключу 9900
7
#include
«include
«include
#include
#include
#include
<stdio.h>
<sys/shm.h>
<time.h>
<sys/types.h>
<sys/ipc.h>
<sys/sem.h>
#define TIME_MEM_KEY 99 /* ключ напоминает номер порта */
#define TIME_SEM_KEY 9900 /* ключ напоминает имя файла */
#define SEG_SIZE ((sizeJ) 100) /* размер сегмента */
#define oops(m,x) {perror(m); exit(x);}
union semun {int val; struct semid_ds *buf; ushort *array;};
main()
{
int segjd;
char *mem_ptr, *ctime();
long now;
int semsetjd; /* id для семафорного набора */
Г создание разделяемого сегмента памяти */
segjd = shmget(TIME_MEM_KEY, SEG_SIZE, 0777);
if(segjd==-1)
oopsC'shmgef.l);
/* присоединение сегмента и получение указателя на сегмент */
mem_ptr = shmat(segjd, NULL, 0);
if (mem^ptr == (void
oops(Hshmat",2); . »
Г установление связи с семафорным набором 9900 с двумя составными
* семабооами
2
Средства межпроцессного взаимодействия (IPC). Как можно пообща:
7
semsetjd = semget(TIME_SEM_KEY, 2,0);
wait_and_lock(semsetjd);
printf('The time, direct from memory:..%s", memjrtr);
releasejock(semsetjd);
shmdt(mem ptr); /* отсоединение сегмента */
}
Г
* построение и использование набора действий, состоящего из двух элементов:
*' ожидание, когда счетчик писателей станет равным 0 И инкремент счетчика
*• читателей
7
wait and lock(int semset id)
{
union semun semjnfo; /* свойства */
struct sembuf actions[2]; /* набор действий */
actions[0] .sem_num = 1; /* sem[1 ] - это счетчик писателей n_writers *J
actions[0].senrfflg = SEMJJNDO; /* автоматическое восстановление 7
actions[0].semj)p==0; Л ожидать, когда достигнет 0 7
actions! 1].semjium = 0; /* sem[0] - это счетчик читателей njeaders 7
actions[1].semJlg = SEM_UNDO; /* автоматическое восстановление7
actions[1 ] .senf op = +1 f /* инкремент счетчика читателей ncr njeaders */
if (semop(semsetjd, actions, 2) == -1)
oopsfsemop: locking", 10);
}
Г
* построение и использование одноэлементного набора действий:
* декремент счетчика читателей num readers
7 .."..-
release lock(int semset id)
{
union semun semjnfo; /* свойства 7
struct sembuf actions[1 ]; Г набор действий */
actions[0] .sem_num = 0; /* sem[0] ~ это счетчик читателей njeaders 7
actions[0] .sem Jig = 3EM_UNDO; /* автоматическое восстановление7
• actions[0] .sem~op = -1; Г декремент счетчика читателей 7
if (semop(semsetJd, actions, 1) == -1)
oopsfsemop: unlocking", 10);
}
Компиляция и проверка работы данных программ:
$ ее shmjs2x -о shmserv
$ ее shm Jc2.c -о shmclnt
$ /shmierv&
[1] 15533
shmjs2 waiting for lock
shm"ts2 updating memory
$ shm_ts2 released lock
shmjs2 waiting for lock
shm_ts2 updating memory
$ /shmclnt
shm ts2 released lock
The time, direct from memory:. Sat Oct 27 17:36:34 2001
$ shmjs2 waiting for lock
shm"ts2 updating memory
15.4. Взаимодействие и координация процессов
553
owner
bruce
perms
777
perms
666
bytes
100
nsems
2
nattch
1
status
owner perms used-bytes messages
$ /shmclnt
shm ts2 released lock
The time, direct from memory:..Sat Oct 27 17:36:40 2001
$ shm_ts2 waiting for lock
ipcs
Shared Memory Segments —¦
key shmid owner perms bytes nattch status
0x00000063 30670854 bruce
Semaphore Arrays - *
key semid
0x000026ac 262146
Message Queues -
key msqid
$ shmjs2 released lock
shm_ts2 waiting for lock
Skill -INT 15533
$ semop: unlocking: Invalid argument
Тестовый запуск программ на исполнение показывает, что клиент ждет, когда сервер
снимет блокировку. Одновременно могут работать несколько клиентов. Каждый клиент будет
ждать, когда счетчик сервера достигнет 0, и затем клиент инкрементирует счетчик
клиентов. Если одновременно три клиента читают из разделяемой памяти, то счетчик читателей
будет равен трем. Сервер будет ждать, когда эти три клиента декрементируют счетчик
читателей.
Конечно, программа не претендует на отработку всех возможных ситуаций. Например,
как предотвратить одновременное исполнение сразу двух серверов? Ведь сервер ждет,
только когда счетчик читателей достигнет 0, и не проверяет значение счетчика писателей.
Ожидание на семафоре - положительное решение проблемы
Наш клиент ждет, когда значение семафора "число_писателей" станет равным нулю.
А сервер ждет, когда значение семафора "число_читателей" станет равным нулю. В нашей
программе у нас можем возникнуть желание ждать на семафоре до того момента, когда его
значение станет равным некоторому положительному ч(ислу. Например, нам может
понадоиться дождаться, когда значение семафора станет равным 2. Как это можно
выполнить в программе?
Используем для этого не совсем очевидный метод: обратимся к ядру с требованием
вычесть 2 из значения семафора. Семафоры не могут принимать отрицательных значений.
Поэтому ядро блокирует вызов до момента, когда значение семафора станет равным 2 или
большим. Заметим, как все просто. Когда значение семафора станет равным 2, наш
процесс вычтет свою 2. При этом любой другой процесс, который хотел бы вычесть 2 из
значения семафора, будет блокирован.
Член semop в операции работает следующим образом:
semj)p - положительное число
Действие: Инкремент значения семафора на величину semop.
8ет_ор-нуль
Действие: Блокировка процесса до момента, когда значение семафора станет равным нулю.
sem_op - отрицательное число
Действие: Блокировка процесса до момента, когда после прибавления величины sem_op
к значению семафора полученное значение не будет отрицательным.
554
Средства межпроцессного взаимодействия (IPC). Как можно пообщаться?
15.4.3. Сравнение сокетов и каналов FIFO с разделяемой памятью
Мы написали четыре версии time/date-сервера и клиента. Версии с использованием
сокетов и каналов FIFO были весьма простыми. Клиент соединялся с сервером, сервер
посылал некоторые данные, и процессы разъединялись. Версии с разделяемой памятью и
разделяемыми файлами на первый взгляд выглядят просто. Но они требуют использования
средств блокировки или семафоров для защиты данных от неправильного использования.
При добавлении средств блокировки или семафоров такие версии будут более
предпочтительны в работе.
При использовании файлов и разделяемой памяти сразу несколько клиентов могут читать
информацию от одного сервера. При этом клиенты и серверы с данными работают не
одновременно. Данные будут сохранены, если произойдет аварийное окончание процессов.
Но даже при использовании программных каналов и сокетов могут возникнуть некоторые
виды блокировок. Каналы и сокеты при реализации э свою очередь представляют собой
сегменты памяти, через которые данные передаются от источника данных к потребителю
данных. Но уже ядро, а не сам процесс будет управлять блокировками и семафорами,
с тем чтобы защитить данные в таких сегментах от искажений.
15.5. Спулер печати
Один time/date-сервер посылает данные нескольким клиентам. В некоторых приложениях
работа происходит в обратном порядке: несколько клиентов посылают данные одному
серверу. Так, например, организована работа с спулером печати. Какие вопросы
проектирования могут здесь возникнуть?
15.5.1. Несколько писателей, один читатель
Несколько пользователей разделяют один принтер (см. рисунок 15.9). Как можно
использовать модель клиент/сервер при разработке программы, которая позволяла бы разделять
принтер? Одновременно сразу несколько пользователей могут послать требование на
печать, но принтер в каждый момент времени может печатать только один файл.
Программа организации печати должна воспринимать множественный ввод данных и
вырабатывать один поток на вывод, предназначенный для выдачи на принтер. Что должен делать
сервер? Что должны выполнять клиенты? Как они должны взаимодействовать?
Один принтер
й
А*#*»$
Рисунок 15.9
Очередь заданий на печать Несколько одновременных запросов
?
ы ?
Несколько источников данных, один принтер.
15.5. Спулер печати
555
Какие должны быть использованы функциональные устройства? Какие данные и
сообщения необходимо использовать для взаимодействия этих компонентов?
Принтер
Шш^ш
Ipl
timtbA*mmm
1
sh
1
Щ " '
- " \ '. '.
щ
г
Файл| |
1^
Рисунок 15.10
Получение файла для принтера
Наиболее простой способ напечатать файл в системе-Unix - выполнить команду:
cat filename > /dev/lp1 или ср filename /dev/lp1
Здесь /dev/lp1 - это имя файла устройства для принтера. В вашей системе файл устройства
для принтера может иметь другое имя. Но при этом все равно будет возможность
использовать метод посылки данных на принтер или другое устройство, если открыть файл
устройства с помощью open, а потом выполнить write.
Можем ли мы использовать блокировки по записи?
Мы знаем о наличии блокировок по записи и о семафорах. А почему нельзя написать
специальную версию программ cat или ср, которые были бы ориентированы на печать и которые
использовали бы при своей работе блокировки по записи на устройстве для предотвращения
одновременного доступа со стороны процессов? Пусть имеется работающая программа
копирования, которая использует механизм блокировок файла. Если одна программа установит
блокировку на принтер, то другие источники информации для программы копирования будут
блокированы до тех пор, пока первое из заданий не сбросит блокировку. Какой процесс будет
далее обслужен принтером? Ядро может разблокировать один из процессов, но при этом не
будет учтена очередность поступления запросов на печать. Решить проблему выбора среди
запросов совсем не просто. Вторая проблема, связанная с управлением печати на принтере,
заключается в. том, что некоторые пользователи могут попытаться схитрить и поэтому не
будут использовать для доступа к принтеру специальную программу. Третья проблема
заключается в том, что некоторые файлы требуют специальной обработки.
Например, файл с изображением нужно будет конвертировать в графические команды,
которые будут понятны принтеру.
Многие пользователи не знают, какие программы следует использовать для
конвертирования данных в печатный формат. Поэтому без использования этих программ их ждет
разочарование, когда они увият результат распечатки. Решение этих проблем достигается за
счет централизации.
556
Средства межпроцессного взаимодействия (IPC). Как можно пообщаться?
15.5.2. Модель клиент/сервер
Использование в программе модели клиент/сервер решает те проблемы печати, которые
мы рассмотрели. Программа сервер, которая будет называться демоном печати, имеет
возможность выполнять печать на принтере, а другие пользователи лишены такой
возможности (см. рисунок 15.11). Каждый пользователь должен запустить клиентскую
программу Ipr тогда, когда появится необходимость напечатать файл. Программа Ipr копирует
файл и затем помещает эту копию в очередь заданий на печать. Пользователь может
удалить или отредактировать файл по мере того, как будет печататься копия. Демон печати
может использовать программы преобразования для правильной печати изображений
и шрифтов.
Ipr sh
ш
Ipr ?
Ж
shell
Рисунок 15.11
Клиент/серверная система печати.
Как взаимодействуют клиент и сервер? Какими данными они обмениваются? Передает ли
клиент серверу весь файл или клиент только посылает серверу имя файла? Что будет, если
клиент развивается на одной машине, а сервер - на другой? Как выбрать метод связи
между процессами? Для Unix было разработано много различных систем печати. В некоторых
используются сокеты, в других используются программные каналы. В некоторых
используют только fork и файлы.
А как обстоят дела в части обеспечения кооперации, использования блокирования файлов,
взаимного исключения? Разработайте компонентную модель, коммуникационную модель
и модель кооперации для поддержки печати так, чтобы все это работало на одной машине.
Затем выполните проект таким образом, чтобы все это работало под управлением Internet.
Сравните идеи, которые будут использованы вами, с идеями, принятыми в различных
системах печати Unix.
15.6. Обзор средств IPC
557
15.6. Обзор средств IPC
Нами были изучены различные формы для организации межпроцессного взаимодействия.
В обобщенном виде эти результаты можно представить в виде таблицы.
Метод
exec/Wait
environ
pipe
kill-signal
inet сокет
inet сокет
Unix сокет
Unix сокет
Именованный
канал
Разделяемая
память
Очередь сооб-
| щений
| Файлы
| Переменные
I Блокировки
(файлов
| Семафоры
| mutexes
(link
Тип
М
м
S
м
S
м
S
м
S
R
М
R
м
с
с
с
с
Различные
машины
*
•
•
N
N
Р/С j
*
•
*
•
?
9
9
9
?
•
*
•
*
•
*
Sib
*
•
?
9
9
9
?
•
*
*
*
•
*
Unrel
*
9
9
•
•
•
*
*
•
*
*
*
Различные I
нити |
• |
• I
?
?
?
?
?
?
* I
?
•
*
?
•
?
Сокращения:
Р/С - отношение типа клиент/сервер (parent/child)
Sib - отношения на уровне братьев (sibling)
Unrel ~ неродственные (unrelated) процессы
М - посылака сообщений среднего размера (messages)
S - поток (stream) данных с использованием read и write
R - случайный (random) доступ к данным
С - используется для задач синхронизации/координации
* - соответствующее приложение
? - несоответствующее приложение
N - соответствующее с сетевой файловой системой
В таблицу не включены ТЫ и их производные - сетевые средства Bell Labs.
558
Средства межпроцессного взаимодействия (IPC). Как можно пообщаться?
Пояснения
fork-execv-argv, exit-wait
Эти системные вызовы используются для обращения к программе с передачей ей при
вызове списка аргументов, а также для того, чтобы передать вызывающей программе целое
число при окончании вызываемой программы. Процесс-отец использует fork для создания
нового процесса. Программа в новом процессе вызывает execv для запуска на исполнение
новой программы и для передачи ей списка параметров. Дочерний процесс с помощью exit
перадает процессу-отцу целое значение, которое отец принимает с помощью wait.
Метод ориентирован на сообщения, предполагает только родственные процессы,
процессы развиваются только на одной машине.
environ
Системный вызов exec автоматически копирует в новую программу массив строк,
на который выставлен указатель через глобальную переменную environ. С помощью
этого метода программа может передавать требуемые значения дочернему процессу
и последующим потомкам, которые будут потом запускать программы. Среда
копируется. Поэтому дочерний процесс не может изменить среду процесса-отца.
Свойства метода: ориентирован на сообщения, передача информации в одном
направлении, только для родственных процессов, процессы только на одной машине.
pipe
Программный канал (pipe) - это однонаправленный поток данных, который создается
процессом. С ним связаны два файловых дескриптора, которые содержатся в ядре.
Данные, записанные через один файловый дескриптор, могут быть считаны через
другой файловый дескриптор. Если после создания программного канала процесс
вызывает fork, то новый процесс может писать или читать из этого же самого канала, что
обеспечивает передачу данных от одного процесса к другому.
Свойства метода: потоковая ориентация, передача данных обычно в одном
направлении, процессы только на одной машине.
kill-signal
Сигнал - это одно целочисленное сообщение, которое передается от одного процесса
(с использованием системного вызова kill) к другому. Принимающий процесс может
установить функцию обработки сигнала, используя для этого системный вызов signal.
Сигнал, когда поступит процессу, будет перехвачен.
Свойства метода: ориентирован на сообщения, однократная передача в одном
направлении, передача только между процессами с одним UID, процессы только на одной машине.
Internet-сокеты
Internet-сокеты являются соединением между конечными точками, установленными на
машине с определенным номером порта. Данные передаются от одного процесса
к другому посредством побайтной передачи данных через один сокет и приема их на
другом сокете. Это аналогично тому, как если бы один человек говорил бы по телефону
в Бостоне, а другой человек слушал бы его в Токио. Internet-сокеты разделяются на два
типа: потоковые сокеты и дейтаграммные сокеты. Оба типа - двунаправленные.
Потоковые сокеты работают аналогично файловым дескрипторам. Программист
использует вызовы write и read для передачи и приема данных. Дейтаграммные сокеты работают
по принципу пересылки почтовых открыток. Процесс-писатель посылает процессу-
читателю небольшой буфер с данными. Все транзакции производятся с буферами
данных, а не с потоками данных.
15.6. Обзор средств IPC
559
Свойства метода: есть поточные версии и есть версии, ориентированные на
сообщения, двунаправленная передача данных, процессы не должны быть родственными,
процессы могут быть разнесены по разным машинам.
Именованные сокеты
Именованные сокеты, которые также называют Unix-доменные сокеты, используют
в качестве адреса имя файла, а не адресную пару: имя_хоста-номер_порта.
Именованные сокеты используют в потоковых и дейтаграммных версиях. Поскольку в качестве
адреса используются имена файлов, а не "хост-порт", то они могут соединять
процессы только на одной машине.
Свойства метода: есть поточные версии и версии, ориентированные на сообщения,
двунаправленная передача данных, процессы не должны быт*> родственными,
процессы могут развиваться только на одной машине.
Именованные программные каналы (FIFO)
Именованный программный канал работает аналогично обычному (неименованному)
программному каналу. Но он может связывать не родственные процессы.
Именованные каналы идентифицируются с помощью имен файлов. Процесс-писатель открывает
файл для записи, используя вызов open. Процесс-читатель открывает файл на чтение,
используя вызов Open. Такие каналы используются аналогично именованным сокетам,
но они позволяют передавать данные только в одном направлении.
Свойства метода: потоковая ориентация, передача данных в одном направлении,
передача между произвольными (не родственными) процессами, процессы расположены
на одной машине.
Блокировки файлов
Unix предоставляет возможность процессам устанавливать блокировки на секции
файлов. Один процесс может блокировать секцию файла. После чего он может потом
модифицировать эту секцию. Другой процесс, который попытается обратиться к
блокированной секции, будет приостановлен или будет извещен о блокировке секции
файла. Такие блокировки позволяют одному процессу взаимодействовать с другим
процессом, независимо от того, кто из них будет писать, а кто читать из файла. Для
установки и проверки совещательной (advisory) блокировки могут быть использованы
системные вызовы flock, lockf и fcntl. На некоторых системах доступны для
использования принудительные (compulsory) блокировки.
Свойства метода: ориентированный на сообщения, произвольные направления
передачи, передача между произвольными (не родственными) процессами, процессы
расположены на одной машине.
Разделяемая память
% Каждый процесс имеет собственное пространство данных. Любые переменные, которые
определены в программе или появляются при работе программы, будут доступны только
этому процессу. Процесс может с помощью вызовов shmget и shmat создать участок памяти,
который может разделяться с другими процессами. Данные, которые один процесс
записывает в такой разделяемый участок памяти, могут быть прочитаны любым другим
процессом, который имеет доступ к этому участку памяти. Это наиболее эффективная форма
для IPC, поскольку для ее реализации не требуется пересылки данных.
Свойства метода: асинхронный доступ, произвольные направления передачи,
передача между произвольными (не родственными) процессами, процессы расположены
на одной машине.
560
Средства межпроцессного взаимодействия (IPC). Как можно пообщаться?
Семафоры '
Семафоры - переменные с системным масштабом использования, которые программы
могут использовать для координации своей работы. Процесс может инкрементировать
и декрементировать значение семафора, может ожидать на семафоре, когда его
значение достигнет требуемой величины. Семафоры работают как билеты (tickets) при
работе с лицензионным сервером. Когда процесс ждет использования ресурса, то он декре-
.» мёнтирует значение семафора. Если в текущий момент нет ни одного билета , то
процесс будет заблокирован до тех пор, пока другой процесс не инкрементирует значение
семафора. Семафоры могут быть использованы самым разным образом.
Свойства метода: доступ, ориентированный на сообщения, произвольные направления
передачи, передача между произвольными (не родственными) процессами, процессы
расположены на одной машине.
Очереди сообщений
Очереди сообщений напоминают программные каналы FIFO. Но они не используют
имена файлов. Процессы могут добавлять сообщения в очередь, а также могут выбирать
сообщения из очереди. Множество процессов могут разделять множество очередей.
Свойства метода: доступ, ориентированный на сообщения, передача данных, только
водном направлении, передача между произвольными (не родственными)
процессами, процессы расположены на одной машине.
Файлы
Файл одновременно может быть открыт более чем одним процессом. Если один
процесс записывает данные в файл, то другой процесс может прочитать эти данные.
Важно, что один и тот же файл могут открыть одновременно несколько процессов. При
правильно спланированном протоколе можно реализовать сложные коммуникации
между процессами на основе использования обыкновенных файлов.
Свойства метода: случайный доступ, произвольные направления передачи, передача
между произвольными (не родственными) процессами, при использовании NFS можно
устанавливать межмашинные соединения.
15.7. Соединения и игры
В этой главе были рассмотрены варианты передачи данных между процессами. Ядро в Unix
управляет процессами, файлами, устройствами. Оно выполняет определенные действия
с программными каналами, сокетами, файлами, разделяемой памятью и сигналами при ора-
низации передачи данных с одного места в другое. Для некоторых программ создание
системы передачи данных и организация передачи данных^является основной целью.
Кен Томпсон, один из авторов Unix, писал в 1978 году:
Ядро UNIX представляет собой скорее мультиплексор ввода/вывода, нежели
собственно операционную систему. Но ведь так и должно быть. В соответствии с такой
точкой зрения, в большинстве других операционных систем можно обнаружить ряд
свойств, которые были удалены из ядра UNIX. ...Многие из возможностей
реализуются в прикладном ПО, которое использует ядро в качестве инструментального
средства1.
В первой главе мы рассматривали утилиту be, Web-сервер и игру в бридж через Internet.
Далее мы написали версию be и два Web-сервера. А почему бы не написать сетевой
вариант игры в бридж? Вы можете использовать curses для разработки пользовательского ин-
1. "Unix Implementation," Bell System TechnicalJournal, vol. 56, no. 6, 1978.
Заключение
561
терфейса, а также механизм сокетов для установления связей. Кто будет выступать в
качестве серверов? Кто будет в качестве клиентов? Какое средство может быть использовано
для организации блокирования? Все необходимые средства, которые могут вам
понадобиться при разработке так или иначе были рассмотрены в предшествующих главах.
Программирование в Unix не такое трудное, как это представляется с первого взгляда. Но оно
и не так просто, как это может показаться вначале.
При упоминании об играх и сетях следует обратиться к высказыванию Денниса Ричи,
который так описывал игру Космическое путешествие (SpaceTravel), которая привела
в результате к Unix:
Написанная вначале для Multics, игра не была средством моделирования перемещения
крупных тел в Солнечной системе. Это была игра с игроком, управляющим в космосе
космическим кораблем, который наблюдал пейзаж и пытался посадить корабль на
различных планетах и лунах.
Управление космическим кораблем, наблюдение за пейзажем и попытка посадить корабль
на неких планетах и лунах - это своего рода Web-серфинг. Может быть, упоминание
о серфинге не является хорошей метафорой. Но пользователи действительно с помощью
своего Web броузера перемещаются куда угодно. Web-серверы передают по запросам
"пейзажи" удаленных мест. Люди используют telnet, ssh и ftp, чтобы "высадиться" на других
машинах.
Возможно, что Internet оказался непреднамеренной реализацией экспансивного
пространства Ричи и Томпсона, которое они смоделировали еще в 1969 году?
Заключение
Основные идеи
• Многие программы при своем исполнении состоят из двух или более процессов,
которые при работе составляют систему, где производится разделение данных или
происходит передача данных между процессами. Два человека, которые используют,
например, команду talk, запускают два процесса. Эти процессы передают данные от
клавиатур и сокетов на экраны и сокеты.
• Для некоторых процессов необходимо принимать данные от множества источников и
посылать данные, опять же, множеству потребителей. Использование системных
вызовов select и poll предоставляет процессу возможность ожидать ввода от множества
файловых дескрипторов.
• В Unix поддерживается несколько методов для организации передачи данных между
процессами. Именованные программные каналы и разделяемая память - это два
механизма которые могут быть использованы для передачи данных между процессами на
одной машине. Коммуникационные методы сравниваются по разным
характеристикам: скорость передачи данных, тип передаваемых сообщений, диапазон передачи,
поддержка ограничений на доступ, защита от возможных искажений данных.
• Блокировки файлов - это средство, которое процессы могут использовать для
предотвращения искажений данных в файлах.
• Семафоры - это переменные системного масштаба доступа, которые процессы могут
использовать для синхронизации своих действий. Один процесс может ожидать
возможности изменить семафор, а другой процесс может в этот момент его изменять.
562 Средства межпроцессного взаимодействия (IPC). Как можно пообщаться?
Что дальше?
Хороший Способ еще более узнать о возможностях программирования в Unix - это
продолжить изучать имеющиеся программы и писать собственные программы. Очень много
информации можно получить через Интернет, во многих книгах можно найти материал,
который поможет изучить детали внутренней структуры Unix и детали программного
интерфейса. Рассматривайте программы, которые вы используете ежедневно, обращайтесь
к новым программам, которые вызывают у вас интерес. В процессе использования
и изучения программ, в процессе написания ваших собственных версий программ вы
обогатите и расширите ваше понимание Unix.
Исследования
15.1 Humu вместо select. А почему бы не использовать нити для чтения из двух файловых
дескрипторов в программе talk? Одна нить будет читать данные с клавиатуры, а другая
нить будет читать данные от сокета. Какие новые трудности добавятся в программе,
где будет реализовано многонитьевое решение?
15.2 TCP или UDP? Программа talk читает и записывает в большей части отдельные
символы, но при этом использует для передачи данных потоковые (stream) сокеты. Каковы
могут быть преимущества и каковы недостатки, если для программы использовать
дейтаграммные сокеты?
15.3 Time-сервер, построенный на основе использования каналов FIFO, блокируется при
выполнении date >ytmp/Hme_fifo до тех пор, пока клиент не откроет канал FIFO на чтение. Если
сервер будет блокирован надолго, то клиент получит значение времени, когда сервер был
блокирован или когда сервер был разблокирован? Почему?
15.4 Разделяемая память и файлы. Ознакомьтесь с документацией по вызову mmap. Вызов
mmap дает возможность представить секцию файла в виде массива в памяти. Тем самым
программе предоставляется возможность произвольного доступа к данным в файле, не
используя для этого вызов lseek. Насколько сравнима возможность работы с данными
с помощью mmap с возможностью работы с данными с помощью средств на основе
использования файлов или разделяемой памяти при решении задачи передачи данных
между процессами? Какие преимущества и какие недостатки можно отметить у метода
mmap по сравнению с другими методами?
15.5 Сервер talk. Объясните работу talk который визуализирует сообщения у двух
связанных процессов. Поэкспериментируйте с talk, чтобы понять, как реализовано
соединение между процессами. Какие еще программы могут быть подключены для
проведения исследования?
Программные упражнения
15.6 Обратитесь к справочнику и проверьте - поддерживаются ли на вашей системе
системные вызовы select и pQll? На некоторых системах может быть один системный вызов, а
другой эмулируется с помощью другого. Перепишите программу selectdemo.c и используйте
в ней вызов poll.
15.7 Напишите версию time/date-сервера и клиента, в которых используются :
(a) Дейтаграммные сокеты с Inernet-адресами.
(b) Потоковые сокеты с Unix-доменовыми адресами.
15.8 Напишите С-версию date/time-сервера и клиента, где используются каналы FIFO.
Заключение
563
15.9 Множество серверов с механизмом разделения памяти
(a) Можно ли запустить одновременно два сервера, которые используют механизм
разделения памяти? Почему да или почему нет? Попытайтесь это сделать.
(b) Модифицируете в сервере текст wait_andJock, чтобы сервер ждал, пока счетчик
серверов не стал бы равным нулю.
15.10 Семафоры выполняют функции блокировок файлов. Мы использовали механизм
блокирования файлов, чтобы в файловой версии сервера правильно разделять файл.
Перепишите эту программу и используйте вместо механизма блокировок файлов
механизм семафоров.
15.11 Механизм файловых блокировок выполняет функции семафоров. Мы использовали
семафоры в версии сервера для защиты данных в разделяемой памяти. Перепишите
эту программу, где вместо семафоров нужно использовать механизм блокировок
файлов. Вам понадобится для этого файл.
15.12 Слишком много читателей. Решение на основе использования семафоров в сервере,
где использован механизм разделяемой памяти, не будет обеспечивать правильный
показ времени, если такое решение будет использованы достаточно большим
количеством клиентов. Рассмотрим ситуацию: читатель А инкрементировал на 1 счетчик
читателей. Далее читатель В инкрементировал счетчик читателей до 2. После чего
закончил работу читатель А и уменьшил счетчик читателей на 1, но читатель С опять
увеличил его до 2. Затем закончил работу читатель В, но опять стартовал читатель А,
а читатель С закончился. После чего опять стартовал читатель В и т. д. Все время к
разделяемой памяти обращались на чтение. Объясните, почему это не даст возможность
писателю записывать в память новое значение времени. Модифицируйте систему так,
чтобы писатель мог бы предотвратить блокирование новыми читателями сегмента
разделяемой памяти.
15.13 Напишите специальную версию команды ср для печати, которая использовала бы
блокировку, чтобы предотвратить одновременный доступ к выходному файлу.
Используйте ее на вашей машине, чтобы распечатать два файла при таком обращении:
printcp file1/dev/lp1 & printcp file2 /dev/lp1 &
Предметный указатель
$$281
$?355
$НОМЕ 320
.135
.. 135
/32
/dev 166
/dev/nulll95
/dev/tty 45-46,91,130, 382,526,533
/dev/zero 195
/etc/group 114
/etc/passwd 112-113
/etc/services 402
_exit системный вызов 312-313
<еггпо.Ь>,заголовочный файл 88
<signal.h> заголовочный файл 217
<sys/stat.h> заголовочный файл 116,121
>357-358
»381
А
accept системный вызов 404,406
AFJNET409,414
AF_UNIX418
aio_read системный вызов 275-276
aio_return системный вызов 275
aiocb структура 275
alarm системный вызов 238-243,471
Algol 60 31
API 396
AT&T 50
atexit библиотечная функция 312
atm.sh программа 204
В
be команда 38-41, 386
be команда, разработка 388
Bell Laboratories 50
biff команда 193
bind системный вызов 403-405,413-414,422
bounce_aio.c программа 275
bounce_async.c программа 272
bounce ld.c программа 262
bounce2d.c программа, 2D анимация 266
Bourne Shell 320
BRKINT 188
BSD 50
builtin.c программа 340
С
c_ ее 184,213
cjflag, c_oflag, c_cflag, cjflag 184
cat команда 34
cat команда в отношении /dev/mouse 193
cat команда для мыши 193
cd команда 33, 134, 152
cfgetospeed библиотечная функция 188
changeenv.c программа 344
chdir системный вызов 152, 355
chmod команда 123,136,319
chmod системный вызов 124
chown системный вызов 123
close и сокеты 407
close системный вызов 64
closedir библиотечная функция 100,101
close-then-open (закрыть, а затем открыть) 363
стр команда 76
сотт команда 358
connect системный вызов 386,408-410,
412,423
connect_to_server функция 423,425
cooked режим 203
ср команда 35,73-76
cpl.c программа 75
creat системный вызов 73,177
crmode режим 203
ctime библиотечная функция 69,427
Ctrl-C200,214,250,310
curses 231-238,278
curses и нити 520-533
D
dc команда 40-41 г 3 87
dc команда, как сопрограмма 391
defunct, метка окончания процесса 313
dgram.c программа 455
dgrecv.c программа 453
dgrecv2.c программа 458
Предметный указатель
565
dgsend.c программа 454
diffKOMaHAal59,329
dirent структура 100,101
du команда 136
dup системный вызов 366-369
dup2 системный вызов 367, 379, 395
Е
EACCESS 89
ECHO 186-187, 189,209
echo команда 339
echo, опция stty 181
ЕСНОЕ189
ЕСНОК 189
echostate.c программа 186
EINTR 88,240
ENOENT 88
env команда 344
environ, глобальная переменная 346-349,557
EPERM 143
EPIPE 380
erase, ключ стирания 182, 189, 203,224, 235
errno, переменная 88,89, 90
exec и файловые дескрипторы 368
exec и pipe, системные вызовы 378
exec и нити 504
execl.с программа292
execl библиотечная функция 315, 396
execlp библиотечная функция 314
execute.c программа 324
execv библиотечная функция 314, 558
execve системный вызов 345
execvp библиотечная функция 292-296,
300,308
exit библиотечная функция 303, 304, 308,
309,315,550
exit и нити 504
exit команда 329
export команда 348
export функция 350
F
FJ3ETFL 174
F SETLKW 544
FJJNLCK, FJtDLCK, F_WRLCK 544, 545
fcntl и блокировки файлов 543-546
fcntl системный вызов 174,210,212,274
fdopen библиотечная функция 390,392,
394-396,414,434
FIFO и системный вызов open 538
FIFO и системный вызов read 538
FIFO и системный вызов unlink 538
FIFO и системный вызов write 538
FIFO, именованные программные
каналы 537-539, 560
FIFO, создание 538
file_ts.c программа 544
fileinfo.c программа 107
filesize.c программа 106
find команда 137, 328
flock структура 545
fork и pipe 375-378
fork и нити 504
fork и серверы 427
fork и файловые дескрипторы 316,369
fork системный вызов 297-301, 308,309,
311,314,330,376,389,397,556
fork, возвращаемое значение 300
forkdemo 1 .с программа 297
forkdemo2.c программа 298
forkdemo3 .с программа 299
fstat системный вызов 383
G
get_ticket функция 463
getdents системный вызов 101, 129
getenv библиотечная функция 344
getgrgid библиотечная функция 114,118
gethostbyname библиотечная функция 405
gethostname системный вызов 404,408
getitimer системный вызов 243,246
getpid системный вызов 297, 545, 546
getpwuid библиотечная функция 113,114
GID114
GNU/Linux51
grep команда 61, 68, 100, 105,199,210,290,
309, 319, 328, 329,334, 335,352
566
Предметный указателе
Н
hello_multi.c программа 491
hello__single.c программа 489
hello 1.с программа 232
hello2.c программа 233
ЬеИоЗ.с программ[а 235
hello4.c программа 235
hello5.c программа 236
НОМЕ переменная 321
HTTP, протокол 41,433-436
I
ICANON 187-188, 207
icanon, опция stty 202
icrnl, опция stty 181
if-then-else команда 321, 328-331
IGNBRK 188
IGNCR188
IGNPAR 188
incprint.c программа 494
init программа 313
INLCR188
inode, файл устройства 170
INPCK188
Internet адрес 453
intr, опция stty 181
ioctl системный вызов 190
IPC 29
IPC, доступ 543
IPC, именованные каналы FIFO 536-538
IPC, именованный программный канал
536-538
IPC, область передачи 543
IPC, программный канал 375-378
IPC, разделяемая память 539-541, 546-553
IPC, сигналы 261
IPC, файлы 535-536
IPC: сравнение методов 535-542
IPC_CREAT 540, 548
isatty библиотечная функция 383
ISIG 188,215
ISTRIP188
ITIMERJPROF 242, 245-246
ITIMERJREAL 242, 245-246
ITIMERJVIRTUAL 242, 245-246
itimerval структура 243,244,246
IXOFF 188
IXON 188
К
Kernighan, Brian 229
kill команда 261, 305, 408,477, 486, 553
kill системный вызов 261-262,472, 557
L
lclnt_funcsl .с программа 461
lclntl.c программа 461
less команда 34
link системный вызов 150
listargs.c программа 361
listchars.c программа 179
listen системный вызов 386,403,406,406,
414,415,423
In команда 135, 150, 159-160
logfilec.c программа 482
logfiled.c программа 481
login команда 30, 130
login, наблюдение за пользователями 357
logout 86-87
logout команда 30
logout, запись 87
logout_tty.c программа 87
lpd программа 554
lpr команда 35, 120, 556
Is команда 33, 97-99, 137
Is команда, удаленная 413-417
Is удаленная команда 411-415
lsl.c программа 102
ls2.c программа 115
lseek системный вызов 88,90
lseek системный вызов, присоединение •
данных 176
lservl .с программа 465
lsrvjimcsl.c программа 465
lstat системный вызов 160
М
main, аргументы функции 294
make__server_socket функция 424,425
Предметный указатель
567
man команда 56
mkdir команда 35, 137, 149, 164
mkdir системный вызов 133
mkfifo библиотечная функция 538
mkfifo команда 537, 538
mmap системный вызов 562
more команда 34
moreO 1 х программа 42
more02.c программа 46
mount команда 158
mutex ~ mutual exclusion lock (замок
взаимного исключения) 498-501, 507, 508
mutex, динамическая инициализация 523
mv команда.35, 135, 150, 152
N
newline, символ 179-180
noecho режим, установка 209
О
0_APPEND 176, 177,483
O^ASYNC 272, 274
0_CREAT177
0_EXCL 177
O_NDELAY210,212,214
O_NONBLOCK210
OJtDONLY 365, 366, 367
OJIDONLY, 0_WRONLY, OJIDWR 63
0_SYNC 174, 177
OJTRUNC 177
on_exit библиотечная функция 313
onlcr, опция stty 181
open .. dup2 .. close 369
open системный вызов 62, 63, 171, 173, 177,
178,192,374,383
open., close., dup.. close 365
opendir библиотечная функция 62, 101
P
PARMRK 188
passwd команда 12Р
passwd структура 113
passwd файл 112-113
pause системный вызов 238-241
pclose библиотечная функция 393, 394
perror библиотечная функция 90
PFJLOCAL482
PFJJNIX482
pg команда 34
PID 299, 300,479
pipe и exec 379
pipe и fork 377-380
pipe системный вызов 374,375,388,389,557
pipe.c программа 378
pipedemo.c программа 374
pipedemo2.c программа 376
play_again0.c программа 205
play_againl.c программа 206
play__again3 .с программа 210
poll системный вызов 535, 561
рореп библиотечная функция 394-395
рореп библиотечная функция, риск
использования 417,418
рореп.с программа 395
popendemo.c программа 393
PPID286
ps команда 285-287
pshl .с программа 294
psh2.c программа 307
pthread_attr_init библиотечная функция 512
pthread_attr_setdetached библиотечная
функция 512
PTHREADj:ONDJNITIALIZER 508
pthread_cond_signal библиотечная функция
508,510
pthread_cond_t тип данных 508
pthread_cond_wait библиотечная функция 507,
508-510
pthread_create библиотечная функция 492,
493,495,497,500,501,508
PTHREAD_CREATEJDETACHED 512
pthread Join библиотечная функция 491,492,493
pthreadjmrtexJnit библиотечная функция 523
PTHREADJvWTEXJMTIALIZER 499,509
pthread_mutex_Jock библиотечная функция
499, 500, 509
pthreadjmitexj: тип данных 498
pthreadjnutex_unlock библиотечная функция
499,500,507
pwd команда 33, 1343
pwd команда, алгоритм 153-154
pwd команда, создание 152-156
568
Предметный указать
Q
quit сигнал 216
quit, опция stty 181
R
raw режим 203
read и программные каналы 379
read команда 321, 328, 336
read системный вызов 61, 64, 375, 386
readdir библиотечная функция 100,101,102
readlink системный вызов 160
recvfrom системный вызов 452,453,457
release Jicket функция 461,463,464,465
rename системный вызов 127, 150-152
Ritchie, Dennis 228, 561
rls.c программа 412
rlsd.c программа 413
rm команда 35, 149
rmdir команда 33, 133, 149
rmdir системный вызов 149
rotate.c программа 200
RPN41
S
S JSDIR макрос 111
SA_NODEFER256
SAJtESETHAND 256
SAJtESTART 256
SA_SIGINFO 256
sanitize функция 415-416
script2 программа 320
SEEK_CUR86
SEEKJEND 86
SEEK_SET86
select системный вызов 213, 532-534
selectdemo.c программа 532
sem_op 552
sembuf структура 549
semctl системный вызов 549, 550
semget системный вызов 548, 550
semop системный вызов 550
send системный вызов 485
sendmsg системный вызов 485
sendto системный вызов 457,483,485
set group id бит 121
set user id бит 120-121
set команда 337
setecho.c программа 186
setitimer системный вызов 243,246
SGID 121
shell 31, 229
shell скрипт, исполнение 319
shell, встроенные команды 339-342
shell, исполнение программ 306
shell, основной цикл 290 ,323
shell, основные функции 289-290
shell, переменные 289-290,337-340
shell, поток управления 328-331
shell, пример small-shell 323-328
shell, программирование 289-290
shell, простой пример 294
shell, разработка 307
shell, скрипт 137,204, 319-321, 331, 343,
355,354-355,536,538
shell, цикл while 355,357
shmj;c.c программа 541
shm_tc2.c программа 551
shm_ts.c программа 540
shm_ts2.c программа 548
shmat системный вызов 540
shmget системный вызов 540
showenv.c программа 344
showtty.с программа 187
SIG_BLOCK259
SIG_DFL 217-218
SIGJGN217-218
SIG_SET259
SIGJUNBLOCK259
sigactdemo.c программа 256
sigaction системный вызов 255-58
sigaction структура 256 l.
sigaddset библиотечная функция 259
SIGALRM 238-239,472
SIGCHLD 313, 317,428-430
sigdelset библиотечная функция 260
sigdemo 1 .с программа 218
srgdemo2.c программа 220
sigemptyset библиотечная функция 259
sigfillset библиотечная функция 259
Предметный указатель
561
SIGINT 214, 216, 217,218
SIGIO 272, 273-277
SIGKILL216,281
signal системный вызов 217-218,248, 323,
548, 557
SIGPIPE380
sigprocmask системный вызов 259
SIGQUIT216
SIGSEGV216
SIGUSR1 262
SIGUSR2 262
SIG WINCH 227
sleep библиотечная функция 218,219,220,
235-238
sleep 1 .с программа 239
smshl.c программа 321
smsh2.c программа 331
SOCK__STREAM 403, 405,408, 412
sockaddr_jn структура 453
socket системный вызов 3 86,403-405,412,
422,423
socketpair системный вызов 418
socklen_t тип данных 459
socklib.c программа 424
sort команда, как сопрограмма 391
space travel 229
splitline.c 325
spwd.c program 154
st_mode, файл устройства 171
stat системный вызов 106
stat структура 105, 106, 107
stdinredirl.c программа 364
stdinredir2.c программа 366
sticky bit, разряд 108,121
stty команда 165, 166, 181-182, 202
stty, разработка 187
SUID 120, 121
symlink системный вызов 160
System V 50
T
talk команда 529
tanimate.c программа 520
tbounceld.c, программа 518
tcgetattr системный вызов 183
TCP 451
TCSANOW, TCSADRAIN, TCSAFLUSH 183,184
tcsetattr системный вызов 184
tee команда 383
termios структура 183
test программа 354
Thompson, Ken 228, 560
time системный вызов 404
time J; тип данных 69
timeclnt.c программа 408
timeserv.c программа 403
timeval структура 245,246
tinybc.c программа 389
TIOCGWINSZ 190
touch команда 127
tty драйвер 181-190
tty команда 168
twebserv.c программа 512
twordcountl .с программа 496
twordcount2.c программа 498
U
UCB 50
UDP 451
UID 112,113
umask системный вызов 124
Unix сокеты доменов 480-483
Unix, история 50
unlink системный вызов 150, 193
usleep библиотечная функция 241
utime системный вызов 126
utmp структура 58
utmp файл 57-60, 84, 357
utmp функции буферизации 79
utmplib.c программа 81
V
varlib.c программа 348
VERASE 185, 188
VINTR215-216
VKILL 188
VMIN207
VTIME213,225
5717
Предметный указатель
W
wait системный вызов 301-309, 312,321,
322,324,557
waitdemol.c программа 301
waitdemo2.c программа 303
waitpid системный вызов 313, 429
watch.sh программа 359
Web броузер 41
Web сервер 41
Web сервер, алгоритм 434
Web сервер, нити 510-516
Web сервер, протокол 431-432
Web сервер, разработка 430-440
webserv.c программа 436
while цикл 357
who команда 52-56
who 1 .с программа 65
who2.c программа 67
whotofile.c программа 371
winsize структура 190
WNOHANG429
write и программные каналы 379-380
write и сокеты 407
write команда 169
write системный вызов 74, 377, 386, 485
writeO.c программа 170
wtmp файл 175
Z
zero, устройство 195
А
аварии, на стороне клиента 470
аварии, на стороне сервера 473
автомат состояний 330,331
адрес 400
адрес Unix 481-484
адрес вызывателя 407
адрес вызывателя 407.
адрес для сокета 405
адрес, Интернет 454
анимация и нити 516-526
анимация на основе использования нитей 517
анимация, 2D 268-273
анимация, множественная 519
анимация, управляемая 263-277
аргументы для main 291
асинхронные сигналы 215
асинхронный ввод 271-277
атомарная операция 176, 190, 547
Б
билет 448
билеты, восстановление 470-472
билеты, легализация 474-476
блок двойной косвенной адресации 144
блокирование сигналов 252,255,258
блокировка по записи 543
блокировка по чтению 543
блокировки файлов 543-546, 559
блокировки файлов 543-546, 559
блокировки файлов, запись 543
блокировки файлов, использование fcntl 544
блокировки файлов, использование link. 195
блокировки файлов, использование
ссылок 195
блокировки файлов, чтение 543
блокируемый ввод 209
буфер экрана 234
буферирование 77-85, 93
буферирование в ядре 82, 171
буферирование в ядре, управление 172
буферирование, терминал 199-201, 213
буферирование, ядро 83
В
ввод/вывод 28
взаимодействие нитей 494-503
взаимодействие нитей 494-503
возврат каретки, символ 179
восстановление билетов 471-473
время доступа к файлу 106, 126
время модификации файла 36, 96, 126-127,
197,280
время последней модификации
файла 96, 196,280
время, представление 69
встроенные команды 339-342
вывод значений установок драйвера 185
выполнение программы 292
Предметный указатель
57)
группа пользователей при управлении
доступом к файлам 105
группа цилиндров 145
групповой идентификатор GID 107, 113
групповой идентификатор, имя группы 115
групповой идентификатор, назначение
GID114
групповой идентификатор, эффективный 120
группы 115
дамп образа процесса 304
данные, блоки данных 139, 140
данные, искажение данных 257
данные, область данных 138
данные, реассемблирование данных 452
данные, фрагментация данных 451
двунаправленные коммуникации 387
двунаправленный программный канал 418
дейтаграммы, ответ 458
дейтаграммы, посылка 454
дейтаграммы, прием 453
демон 416
дисковые блоки 138
дисковые соединения, атрибуты 172-177
дисковый блок 138
длина имени файла 34
доступ 88
дочерний процесс 296-306, 322, 336, 341,
346, 394, 427, 433-434
дочерний процесс и программный канал 375,377
дочерний процесс и файловые
дескрипторы 368-371
дочерний процесс, ожидание окончания 300-306
драйвер терминала 180-190
драйвер устройства 170
драйвер устройства, изменение установок 172-173
драйвер, tty 181-190
драйвер, терминал 180-190
3
задержка, программирование 237
записи о входах в сессии 56-60, 175
запись на терминалы 170
запуск программ на исполнение 289-296
значение кода возврата, передаваемое
родительскому процессу 305
зомби 313,427-429
И
игнорирование сигнала 217,220,249,250,
254,258,278,323,324
идентификатор пользователя 108, 112
идентификатор пользователя и
пользовательское имя 112-113
идентификатор пользователя,
эффективный 121
имена файлов 149
имена файлов с начальной точкой 96
имена файлов, длина 34
именованный программный
канал 537-539, 559
имя "точка" 98
имя хоста 400
имя"точка_точка" 98
индексные дескрипторы 139-142
инструментальное средство,
программное 199
инструментальные программные
средства 198, 359
интервальный таймер 241-248, 304 . «
интерфейс автомата для получения
напитка 385, 386
интерфейс, данные 386
информация о файле, отображение
информации 115
искажение данных 257
исполнимый файл 320
исполняемая программа 283
история, Unix 50
канонический режим 202
каталоги 32
каталоги, действия над каталогами,
устройство 145-149
каталоги, дерево каталогов 32, 97, 134
каталоги, закрытие 101
каталоги, объединение деревьев
каталогов 156
572
Предметный указатель
каталоги, определение 98
каталоги, открытие 100
каталоги, переименование 135
каталоги, перемещение по дереву 134
каталоги, проверка свойств 110
каталоги, путь к каталогу 134
каталоги, смена каталога 33
каталоги, создание 33, 134
каталоги, стандартная система 53
каталоги, структура 141
каталоги, удаление 33, 135
каталоги, чтение 97-100
каталоги, чтение записей 101,129
клавиши инициализации функций
редактирования 224
клиент 385, 387
клиент, аварии на стороне клиента 470
клиент, использование разделяемой
памяти 548
клиент, типичный 425
клиент, установка 399-400
клиент/сервер 384-386,400
клиент/сервер, взаимодействие 425
клиент/сервер, установка 424
ключ kill 200,203,226
ключи для удаления символов 200,225
ключи управления процессом 224
ключи, для редактирования 224
ключи, для управления процессом 224
код возврата в скриптах 303, 304
коды символов 179
копирование файла 73, 75
корневая файловая система 157
корневой каталог 32, 135
косвенный блок 144
критическая секция 258
Л
легализация, билеты 474-476
лицензионный клиент, версия 1 461
лицензионный сервер 444,447
М
маска 122, 123,124, 185, 186
маска на создание файлов 123
маскирование 108-110
медленные устройства 279
межпроцессные коммуникации 29
метеорологический сервер 402
младший номер 169
множество процессов 299
мультинитьевая программа 491
Н
надежность коммуникаций 451
наименьший по значению доступный
файловый дескриптор 362,364,365,373,375
неблокируемый ввод 210
неканонический режим 202-203
неканонический режим, установка 207
ненадежные коммуникации 451
несколько аргументов для нитей 500
нити и curses 523-534
нити и exit 504
нити и fork 504
нити и exec 504
нити и память 504
нити и процессы 503-505
нити и сигналы 504
нити исполнения 489-490
нити отсоединенные 511
нити, аргументы 500
О
обработка символов 48, 179-181,277
обработчик сигналов 218, 261,282
обработчик сигналов 217-219, 281, 317
опции командной строки 36, 55
открытие файла на запись 63
открытие файла на чтение 63
открытие файла на чтение и запись 63
отсоединенные нити 511
отсутствие ожидания 210
. очереди сообщений 560
ошибки системных вызовов 88
П
память 288-289
память ядра 287-288
память ядра 288-289
Предметный указатель
573
переменные состояния 262, 331
переменные, shell 337-340
переменные, разделение между нитями 494
перенаправление ввода 363- 370
перенаправление ввода 363- 368
перенаправление ввода/вывода 289-290,355,
356,372
перенаправление ввода/вывода, принцип 362-363
перенаправление вывода 357-358» 369-372
перенаправление вывода 357-358, 368-371
перенаправление, ввод/вывод 372
платы 137-138, 170*
повторно входная функция 260
подкаталоги, структура 148
подстановка переменных 341, 354
поле листинга для указания режима работы
с файлом 104, 108-111,
получение листинга содержимого каталога
102
пользователи, регистрация входов 357
пользователи, список текущих
пользователей 65, 67
пользовательская программа 199
пользовательские имена 112
пользовательский режим 78, 79
пользовательское имя и UID 112
пользовательское пространство 27,49, 284
помывка автомобиля 191
поправка к приоритету 285
порт 400
порты, широко известные 402
порция спагетти 159
потоки 190
права доступа, файл устройства 166, 169
права доступа к файлу 36-37, 73, 106-108,
123, 136, 143, 149, 192
права доступа, файлы 105
прерываемый системный вызов 241
приглашение 31
программа 285
программные лицензии 444
программный канал 374, 373-381,
385-387, 558
программный канал двунаправленный 418
программный канал, запись данных 375,379
программный канал, разделение 375-378
программный канал, создание 373
программный канал, средство IPC 376-379
программный канал, чтение данных 375,379
программы, запуск на исполнение 289-295
прокси сервер 419
протокол 400, 412,449,450
протокол лицензионного сервера 460
протокол, лицензионный сервер 460
процесс 284-288
процесс дочерний 296-305,322,337,341,346,
369-372,428
процесс родительский 296-305, 313, 314,
346,369-372,389,428,557
процесс фоновый 316, 328
процесс, идентификатор 285
процесс, окончание 312
процесс, определение существования 472-473
процесс,.приоритет 285
процесс, размер 285
процесс, создание 296-300
процесс, уничтожение 312
процесс, управление 28
процесс, управление через терминал 310
процессор 28,285
процессы в системе 286-287
процессы и аргументы 311
процессы и нити 503-504
процессы и файлы 392
процессы и функции 311
процессы, чтение данных 392, 396
путь, каталоги 134 i , <
Р
рабочий каталог 32-33
раздел диска 138
разделы диска 138
разделяемая память 559
разделяемая память и семафоры 548
разделяемая память, IPC 539-541, 546-554
разделяемая память, time сервер 548
разделяемая память, клиент 551
разделяемые переменные для нитей 494
размер окна 191, 226
574
Предметный указатель
размер файла 105
размер файла 105
размер файла, файл устройства 168
разряды прав доступа, декодирование 111
распределение дисковой памяти 142
распределенные сервера 478-480
реассемблирование, данные 451
регистрация окончания сессии 87
редактирование при работе драйвера
терминала 200-^202
режим auto-append 174-176,381
режим эхоотображения 172
режим ядра 90
режим, raw 203
режим, й отношении файла 73, 104
режим, канонический 202
режим, неканонический 202
режимы работы драйвера терминала 200-201
режимы работы терминала 202-205
рекурсивные сигналы 252,255
родительский каталог 135
родительский каталог, структура 148
родительский процесс 285, 295-305, 312,
313, 345, 388, 394, 427,428, 557
родительский процесс и файловые
дескрипторы 369-372
родительский процесс и программный
канал 374, 378
С
свойства файла, отображение свойств 106
свойства файла, установка свойств 123-126
свойства файла, чтение свойств 105-107
свопинг 121
связи между устройствами 157
связи между устройствами 158
сектор диска 138
сектор диска 138
семафоры 545-553, 560
семафоры и разделяемая память 548
семафоры, действия над семаформами 546
семафоры, операции 553
семафоры, установки 547
семейство адресов 400
сервер Web, протокол 431,432
сервер, Web 41,430-432
сервер, аварийные ситуации 473
сервер, использующий разделяемую
память 548
сервер, общий 426
сервер, прокси 419
сервер, разработка 426-43 0
сервер, установка 397-398
сервер, установка сокета 422-423
сервера, распределенные 478-480
сервис 385
сети 29
сигнал прерывания 217
сигнал, игнорирование 217,220,248,251,322,323
сигналы 215-223, 304, 310
сигналы и нити 504
сигналы, IPC 262
сигналы, блокирование 252, 256,259
сигналы, имена 216
сигналы, множество 249-252,429
сигналы, надежные 254-257
сигналы, ненадежные 249-252
сигналы, посылка 261
сигналы, потеря 429
сигналы, при вводе 271-277
сигналы, реакция 217
сигналы, рекурсии 252, 256
сигналы, терминал 215, 310
сигнальные наборы 260
символическая ссылка 159-161
синхронные сигналы 215
системное пространство 25, 49
системные вызовы, ошибки 88
системные вызовы, прерываемые 241
системные вызовы, сокращение 78
системные сервисы 26-27
скорость передачи данных 171
скрипт, shell 137, 204, 319-321, 354,
357-358, 536
скрытый файл 97
служба времени 397
собственник файла 105,106, 121-123,125—
126,143,169
создание процесса 296-300
создание файла 73, 177
Предметный указатель
575
сокет, установка сокета на сервере 422-423
сокеты 386, 397-410, 559
сокеты дейтаграмм 450-456
сокеты потока 405, 450
сокеты, Unix сокеты доменов 481-484
сопрограмма 388, 391
список текущих пользователей 65, 70
список файлов и информация 116
справочник, поиск 57
спулер печати 554-556
среда 318, 322, 343-354
среда и дочерние процессы 346
среда и системный вызов exec 347-349
среда, изменения среды 346, 348-349
ссылки 106, 124, 141-142
ссылки, использование для блокировок 195
ссылки, символические 159, 160
ссылки, твердые 150, 160
стандартные файловые дескрипторы 359
стандартный ввод 45, 199, 356, 359
стандартный вывод 198, 199, 359
стандартный вывод сообщений
об ошибках 198,359
старший номер 169, 171
статус файла 105
статус, файл 104
страница документации 55
страницы памяти 122, 288-289
страницы, память 288-289
суперблок 139, 145, 160
супервизорный режим 79
Супермен 7у
счетчик ссылок 104, 148
Т
таблица inode 139, 141
таймаут 198,200,207,213,225,281,532-534
таймаут на входе 200, 209,213, 225,281,
532-534
таймаут, без задержек 210
таймер, интервальный 241-248, 304
таймер, программирование 243-248
таймеры 28
твердая ссылка 148, 160, 161
текущий каталог 152
текущий указатель в файле 86-87
терминал, буферирование 200-202,213
терминал, получение атрибутов 182
терминал, редактирование 200-202
терминал, установка атрибутов 182
терминал, эхоотображение 200-202
терминалы, как файлы 166-}68
терминалы, разработка программы write 169
терминалы, режимы 200-203,224
терминалы, сигналы 214,310
терминальные соединения, атрибуты 178-190
тип файла 106, 108
тип файла, установка 123
тип, файл 106
точка монтирования 157, 163
транкатенация файла 73
трансплантация мозга 293
трансплантация, мозг 293, 345
трек диска 138
трек диска 138
тройной косвенный блок 145
У
уведомление для нитей 505-510
уведомление для нитей 505-510
удаление мозга 293
управление ненадежными сигналами 249
управление процессами через терминал 310
управление событиями 263
управляющие символы 181-185
условие гонок 174-177,497, 542
условная переменная 507
успех 329
установка текущей позиции в файле 86-87
установки драйвера терминала,
изменения 187
установки драйвера терминала,
просмотр 186
устройства 28,49
устройства, отличия от файлов 171-172
устройства, права доступа к устройствам 168
устройства, схожесть с файлами 166-171
устройства, управление 187,198,221
устройство/dev/null 195
устройство для сропинга 121
576
Предметный указатель
файл устройства 166, 386
файл устройства, stjnode 171
файл устройства, индексный дескриптор inode 170
файл устройства, права доступа 168
файл устройства, размер файла 168
файл, блочное использование дисковой памяти 140
файл, буферирование при чтении 77
файл, время последнего доступа 106, 126
файл, время последней модификации 36,126-127
файл, группа 125-126
файл, запись в файл 63, 73
файл, копирование 73, 75
файл, перезапись 85
файл, переименование 35, 135, 150-152
файл, перемещение 135
файл, печать содержимого 35
файл, поблочное чтение 143
файл, просмотр 34
файл, режим присоединения данных 174-176
файл, скрытый 97
файл, собственник 105,106,121, 122,123,
125, 126., 143, 169
файл, создание 73, 140, 177
файл, текущий указатель 85-86, 316
файл, транкатенация 73, 177
файл, удаление 35
файл, устройство 167,386
файл, чтение и запись 64
файл, чтение содержимого 62, 63, 64
файловая система 161
файловая система, варианты 145
файловая система, корневая файловая
система 157
файловая система, представления с позиций
пользователя 134-137
файловая система, структура 137-141
файловые дескрипторы и программные
каналы 374
файловые дескрипторы и системный
вызов exec 370
файловые дескрипторы и системный вызов
fork 316,369
файловые дескрипторы, множественное
чтение 530-534
файловые дескрипторы, стандартное
использование 360
файловый дескриптор 61, 62, 63, 363
файловый дескриптор и системный
вызов socket 409
файлы, IPC 536-537
файлы, получение листингов со свойствами 32,96
файлы, сравнение 76
фоновый процесс 328
фрагментация, данные 451
фрагментация, файл 121, 145
Ч
чтение каталогов 98-101
чтение многих входов 530-534
Ш
широко известные порты 402
Э
экран, буфер экрана 234
экран, виртуальный 234
экран, размер 190
экран, управление 231-238
эпоха 69
эффективный идентификатор группы
(EGID) 121
эффективный идентификатор пользователя
(EUID) 120,125
Я
ядро 28