/





































































































































































































































































































































































































































Автор: Бен-Ган Ицик
Теги: компьютерные технологии программирование базы данных язык программирования sql
ISBN: 978-5-9775-0220-7
Год: 2009




Текст
Ицик Бен-Ган
Microsoft*
SQL Server 2008
Основы T-SQL
«Русская Редакция»
2009
«БХВ-Петербург»
УДК 681.3.06
ББК
32.973.26-018.2
Б46
Ицик Бен-Ган
Б46 Microsoft® SQL Server® 2008. Основы T-SQL: Пер. с англ. — СПб.:
БХВ-Петербург, 2009. — 432 е.: ил.
ISBN 978-5-9775-0220-7 ("БХВ-Петербург")
ISBN 978-5-7502-0388 -8 ("Русская Редакция")
В книге изложены теоретические основы формирования запросов и программиро-
вания на языке T-SQL: однотабличные запросы, соединения, подзапросы, табличные
выражения, операции над множествами, реорганизация данных и наборы группирова-
ния. Описываются различные аспекты извлечения и модификации данных, обсуждают-
ся параллелизм и транзакции, приводится обзор программируемых объектов. Для до-
полнения теории практическими навыками в книгу включены упражнения, в том числе
и повышенной сложности.
Кинга предназначено для программистов, пишущих на языке T-SOL,
администраторов баз данных, системных архитекторов,
аналитиков и хорошо подготовленных пользователей SOL Sewer
УДК 681.3.06
ББК 32.973.26-018.2
Группа подготовки издания:
Главный редактор
Екатерина Кондукова
Зам. главного редактора
Татьяна Лапина
Зав. редакцией
Григории Добин
Перевод с английского
Татьяны Коротяевой
Редактор
Анна Кузьмина
Компьютерная верстка
Натальи Смирновой
Корректор
Наталия Першакова
Оформление обложки
Елены Беляевой
Зав. производством
Николай Тверских
Подготовлено к изданию по лицензионному договору с Microsoft Corporation, Редмонд, Вашингтон, США.
Microsoft, Microsoft Press. MSDN, SQL Server и Windows являются товарными знаками или охраняемыми товарными
знаками корпорации Microsoft в США и/илн других странах. Все другие товарные знаки являются собственностью соот-
ветствующих фирм.
Все адреса, названия компаний, организаций и продуктов, а таюке имена лиц, используемые в примерах, вымышлены и не
имеют никакого отношения к реальным компаниям, организациям, продуктам и лицам.
Бен-Ган Ицик
Microsoft® SQL Server® 2008. Основы T-SQL
Перевод с английского языка Татьяны Коротяевой
Совместный проект издательства "Русская Редакция" и издательства "БХВ-Петербург"
1
Ш. РУССКАЯ РЕДАКЦИЯ
&У'
Лицензия ИД No 02429 от 24.07.00 . Подписано в печать 30.04.09.
Формат 70x100Vie. Печать офсетная. Усл. печ. л. 34,83.
Тираж 1500 экз. Заказ No 1032
"БХВ-Петербург", 190005, Санкт-Петербург, Измайловский пр., 29.
Санитарно-эпидемиологическое заключение на продукцию Ne 77.99.60 .953.Д.002108.02.07
от 28.02.2007 г. выдано Федеральной службой по надзору
в сфере защиты прав потребителей и благополучия человека.
Отпечатано с готовых диапозитивов
в ГУП "Типография "Наука"
199034, Санкт-Петербург, 9 линия, 12
978-0 -7356 -2601-0 (англ.)
978-5-7502-0388-8 ("Русская Редакция")
,978-5 -9775 -0220-7 ("БХВ-Петербург")
С Оригинальное издание на английском языке, Itzik Ben-Gan, 2009
О Перевод на русский язык, Microsoft Corporation, 2009
О Оформление н подготовка к изданию, издательство "БХВ-Петербург", издательство "Русская Редакция", 2009
Оглавление
ОБ АВТОРЕ
2
БЛАГОДАРНОСТИ
3
ВВЕДЕНИЕ
5
Для кого эта книга
5
О чем эта книга
5
Сопроводительный материал
6
Аппаратные и программные требования
6
Поиск дополнительной интерактивной информации.........
7
Сопровождение книги
7
Вопросы и комментарии
7
ГЛАВА 1. Основы ПОСТРОЕНИЯ ЗАПРОСОВ
и ПРОГРАММИРОВАНИЯ НА ЯЗЫКЕ T-SQL
9
Теоретические основы
9
Язык SQL
10
Теория множеств
11
Логика предикатов
12
Реляционная модель
13
Жизненный цикл данных
18
Архитектура SQL Server
21
Экземпляры SQL Server
21
Базы данных
23
Схемы и объекты
26
Создание таблиц и определение целостности данных
27
Создание таблиц
28
Определение целостности данных
30
Резюме
33
VI
Оглавление
ГЛАВА 2. ОДНОТАБЛИЧНЫЕ ЗАПРОСЫ
34
Элементы инструкции SELECT
34
Элемент FROM
36
Элемент WHERE
38
Элемент GROUP BY
39
Элемент HAVING
44
Элемент SELECT
45
Элемент ORDER BY
51
Дополнительный элемент ТОР
53
Элемент OVER
56
Предикаты и операции
63
Выражение CASE
66
Значение NULL
69
Одновременно выполняемые операции
74
Работа с символьными данными
76
Типы данных
76
Набор параметров символьной обработки
77
Операции и функции
79
Предикат LIKE
86
Работа с датами и временем
88
Типы данных Date и Time
88
Константы
89
Раздельная обработка даты и времени суток
92
Фильтрация диапазонов дат
94
Функции обработки дат и времени суток
94
Запросы метаданных
101
Представления каталогов
101
Представления информационной схемы
102
Системные хранимые процедуры и функции
103
Резюме
104
Упражнения
105
Упражнение 2.1
105
Упражнение 2.2 (дополнительное, повышенной сложности)
105
Упражнение 2.3
106
Упражнение 2.4
106
Упражнение 2.5
107
Упражнение 2.6
107
Упражнение 2.7
107
Упражнение 2.8
108
Оглавление
VII
ГЛАВА 3. СОЕДИНЕНИЯ (JOIN)
109
Перекрестные соединения
110
Синтаксическая запись ANSI SQL-92
110
Синтаксическая запись ANSI SQL-89
111
Перекрестные самосоединения
112
Создание таблиц чисел
113
Внутренние соединения
115
Синтаксическая запись ANSI SQL-92
115
Синтаксическая запись ANSI SQL-89
116
Безопасность внутреннего соединения
117
Дополнительные примеры соединений
117
Составные соединения
118
Соединения при условии неравенства
119
Многотабличные соединения
121
Внешние соединения
122
Основные принципы внешних соединений
122
Дополнения к основным принципам внешних соединений
125
Резюме
134
Упражнения
134
Упражнение 3.1
;
'
135
Упражнение 3.2
135
Упражнение 3.3 (дополнительное, повышенной сложности)
136
Упражнение 3.4
138
Упражнение 3.5
138
Упражнение 3.6
139
Упражнение 3.7
139
Упражнение 3.8 (дополнительное, повышенной сложности)
139
Упражнение 3.9 (дополнительное, повышенной сложности)
140
ГЛАВА 4. ПОДЗАПРОСЫ
142
Независимые подзапросы
142
Примеры независимых скалярных подзапросов
143
Примеры независимых подзапросов с множеством значений
145
Связанные подзапросы
149
Предикат EXISTS
152
Дополнения к основным сведениям о подзапросах
153
Возврат предшествующего или последующего значений
153
Итоги с накоплением
155
Запросы, которые ведут себя плохо
156
VIII
Оглавление
Резюме
161
Упражнения
161
Упражнение 4.1
162
Упражнение 4.2 (дополнительное, повышенной сложности)
162
Упражнение 4.3
!
163
Упражнение 4.4
163
Упражнение 4.5
164
Упражнение 4.6
165
Упражнение 4.7 (дополнительное, повышенной сложности)
165
Упражнение 4.8 (дополнительное, повышенной сложности)
166
ГЛАВА 5. ТАБЛИЧНЫЕ ВЫРАЖЕНИЯ
167
Производные таблицы
167
Присвоение псевдонимов столбцов
169
Применение аргументов
171
Вложение
171
Множественные ссылки
172
Общие табличные выражения
173
Назначение псевдонимов столбцов
174
Применение аргументов
175
Определение множественных ОТВ
175
Множественные ссылки
176
Рекурсивные ОТВ
177
Представления
179
Представления и элемент ORDER BY
181
Необязательные параметры представления
183
Подставляемые табличные функции
187
Операция APPLY
189
Резюме
192
Упражнения
192
Упражнение 5.1
192
Упражнение 5.2
193
Упражнение 5.3
193
Упражнение 5.4
194
Упражнение 5.5
194
Упражнение 5.6
194
Упражнение 5.7 (дополнительное, повышенной сложности)
195
Упражнение 5.8
196
Упражнение 5.9
197
Оглавление
IX
ГЛАВА 6. ОПЕРАЦИИ НАД МНОЖЕСТВАМИ
198
Операция UNION.
199
Операция UNION ALL
200
Операция UNION DISTINCT
201
Операция INTERSECT
202
Операция INTERSECT DISTINCT
202
Операция INTERSECT ALL
203
Операция EXCEPT
205
Операция EXCEPT DISTINCT
206
Операция EXCEPT ALL
207
Приоритет
208
Хитрости для выполнения неподдерживаемых логических стадий
210
Резюме
212
Упражнения
212
Упражнение 6.1
212
Упражнение 6.2
213
Упражнение 6.3
214
Упражнение 6.4
215
Упражнение 6.5 (дополнительное, повышенной сложности)
215
ГЛАВА 7. РЕОРГАНИЗАЦИЯ ДАННЫХ
И НАБОРЫ ГРУППИРОВАНИЯ
217
Разворачивание данных
217
Разворачивание с помощью стандартного SQL
220
Разворачивание с помощью собственной операции T-SQL PIVOT
221
Сворачивание данных
224
Сворачивание данных с помощью стандартного SQL
225
Сворачивание с помощью собственной операции T-SQL UNPIVOT.
227
Наборы группирования
228
Вложенный элемент GROUPING SETS
230
Вложенный элемент CUBE
231
Вложенный элемент ROLLUP
232
Функции GROUPING и GROUPING JD
234
Резюме
237
Упражнения
237
Упражнение 7.1
237
Упражнение 7.2
237
Упражнение 7.3
238
X
Оглавление
ГЛАВА 8. МОДИФИКАЦИЯ ДАННЫХ
240
Добавление данных
240
Инструкция INSERT VALUES
240
Инструкция INSERT SELECT
242
Инструкция INSERT EXEC
243
Инструкция SELECT INTO
244
Инструкция BULK INSERT
245
Свойство IDENTITY
246
Удаление данных
250
Инструкция DELETE
251
Инструкция TRUNCATE
251
DELETE на основе соединения
252
Обновление данных
253
Инструкция UPDATE
254
UPDATE на основе соединения
255
Присваивание в UPDATE
258
Слияние данных
259
Модификация данных с помощью табличных выражений
264
Модификации с помощью элемента ТОР
267
Элемент OUTPUT
268
INSERT с OUTPUT
269
DELETE с OUTPUT
270
UPDATE с OUTPUT
271
MERGE с OUTPUT
272
Компонующий язык DML
273
Резюме
275
Упражнения
275
Упражнение 8.1
275
Упражнение 8.2
276
Упражнение 8.3
276
Упражнение 8.4
276
Упражнение 8.5
276
Упражнение 8.6
277
Упражнение 8.7
277
Упражнение 8.8
278
Упражнение 8.9
279
ГЛАВА 9. ТРАНЗАКЦИИ и ПАРАЛЛЕЛИЗМ
280
Транзакции
280
Блокировки и блокирование
283
Оглавление
XI
Блокировки
283
Поиск и обнаружение блокирования
286
Уровни изоляции
293
Уровень изоляции READ UNCOMMITTED
294
Уровень изоляции READ COMMITTED
295
Уровень изоляции REPEATABLE READ
297
Уровень изоляции SERIALIZABLE
298
Уровни изоляции Snapshot
300
Сводные данные об уровнях изоляции
307
Взаимоблокировки
308
Резюме
311
Упражнения
311
Упражнение 9.1
311
Упражнение 9.2
312
Упражнение 9.3
312
Упражнение 9.4
312
Упражнение 9.5
313
Упражнение 9.6
313
Упражнение 9.7
314
Упражнение 9.8
314
Упражнение 9.9
315
Упражнение 9.10
316
Упражнение 9.11
317
Упражнение 9.12
318
Упражнение 9.13
319
Упражнение 9.14
319
Упражнение 9.15
320
Упражнение 9.16
320
Упражнение 9.17
320
Упражнение 9.18
320
Упражнение 9.19
321
ГЛАВА 10. ПРОГРАММИРУЕМЫЕ ОБЪЕКТЫ
322
Переменные
322
Пакеты
-.
325
Пакет как единица синтаксического анализа
325
Пакеты и переменные
326
Инструкции, которые не могут комбинироваться в одном пакете
326
Пакет как единица разрешения имен
327
Вариант GOn
328
XII
Оглавление
Элементы, управляющие выполнением
328
Управляющий элемент IF... ELSE
328
Управляющий элемент WHILE
330
Пример использования IF и WHILE
332
Курсоры
332
Временные таблицы
337
Локальные временные таблицы
337
Глобальные временные таблицы
339
Табличные переменные
340
Типы Table
341
Динамический SQL
342
Команда EXEC
343
Л
Хранимая процедура spexecutesql
345
Применение PIVOT с динамическим SQL
348
Подпрограммы
350
Функции, определенные пользователем
350
Хранимые процедуры
352
Триггеры
354
Обработка ошибок
358
Резюме
363
ПРИЛОЖЕНИЯ
365
ПРИЛОЖЕНИЕ 1. ПРИСТУПАЯ к РАБОТЕ
367
Установка SQL Server
367
Получение SQL Server
367
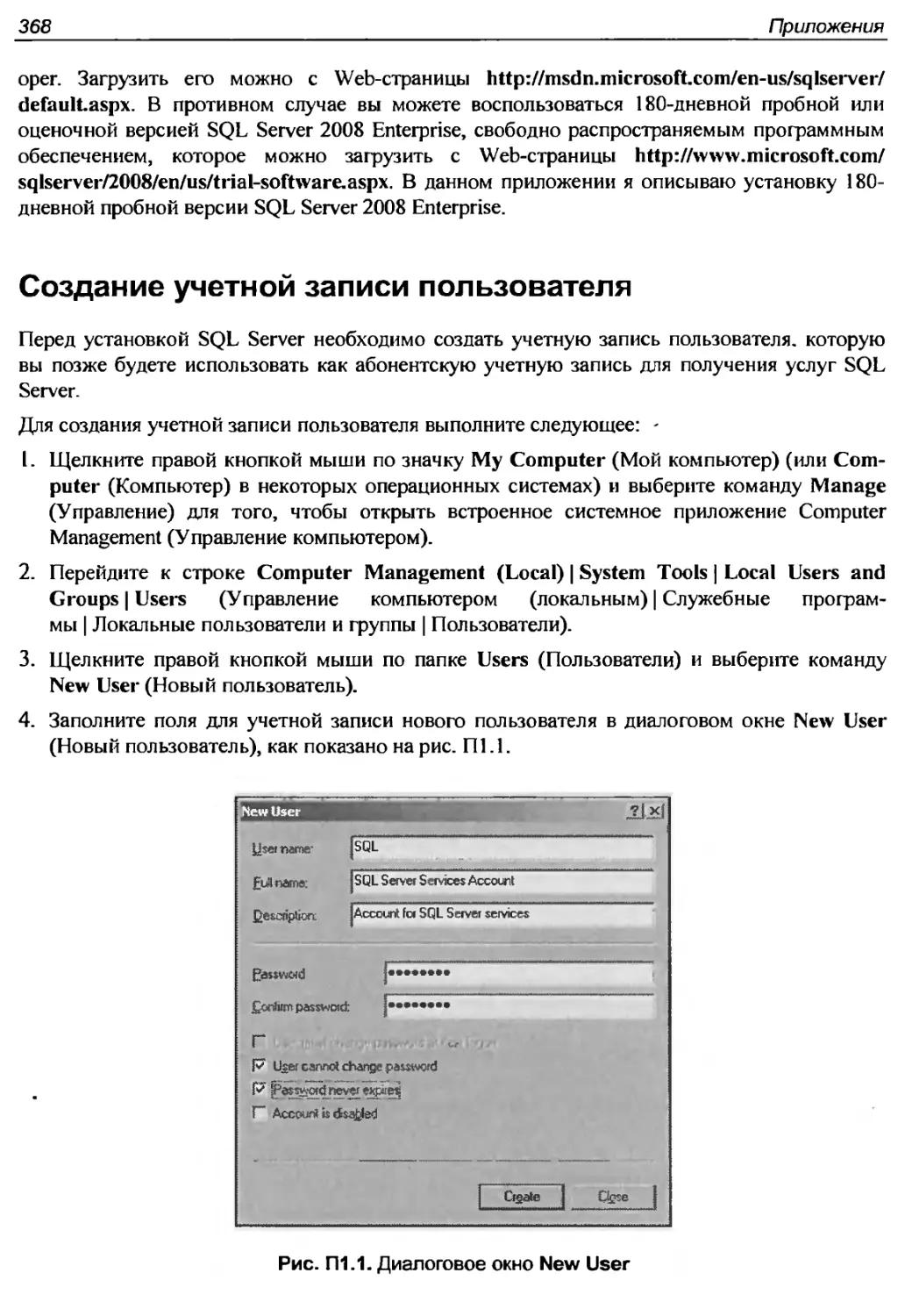
Создание учетной записи пользователя
368
Установка необходимых сопутствующих пакетов программ
369
Установка механизма управления базы данных, документации
и утилит
369
Загрузка исходного программного кода и установка учебной базы
376
Работа с SQL Server Management Studio
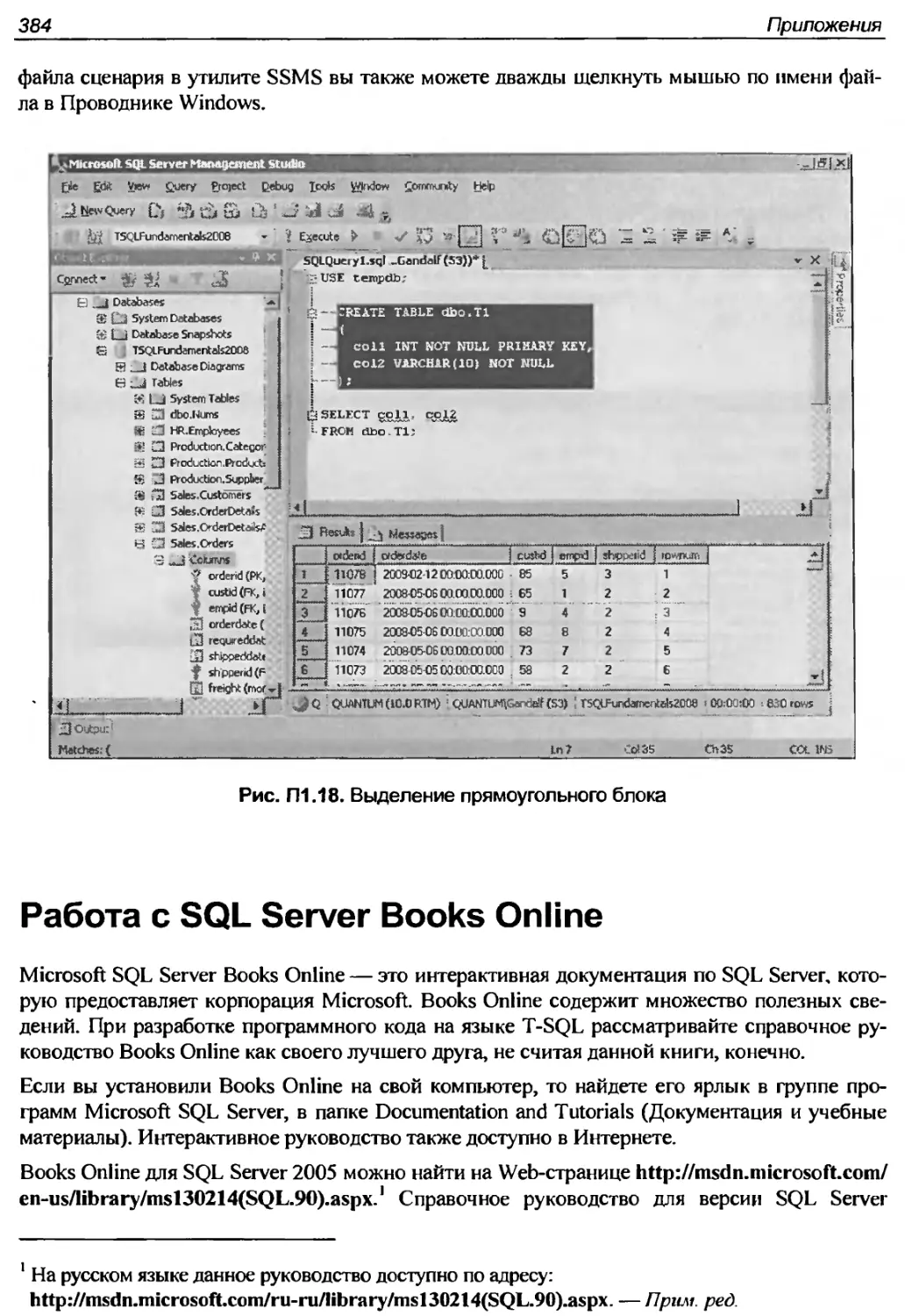
378
Работа с SQL Server Books Online
384
ПРИЛОЖЕНИЕ 2, РЕШЕНИЯ К УПРАЖНЕНИЯМ
388
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
412
To Dato
То live in hearts we leave behind,
Is not to die.
—Thomas Campbell
Об авторе
Ицик Бен-Ган (Itzik Ben-Gan) — преподаватель и соучредитель компании Solid Quality Men-
tors. Обладатель звания SQL Server Microsoft MVP (Most Valuable Professional, наиболее
ценный специалист) с 1999 г. Ицик проводил обучение по всему миру, посвященное форми-
рованию запросов на языке T-SQL, их настройке и программированию. Ицик — автор не-
скольких книг о T-SQL. Им написано множество статей для журнала "SQL Server Magazine",
а также статей и информационных документов для MSDN. Ицик принимает участие в кон-
ференциях "Tech Ed", "DevWeek", "PASS", "SQL Server Magazine Connections", презентаци-
ях для различных групп пользователей в разных странах и различных мероприятиях компа-
нии Solid Quality Mentors.
Благодарности
Многие люди явно или неявно внесли свой вклад в книгу, и я хочу выразить им свою при-
знательность за это.
Рону Тапмейджу (Ron Talmage), научному редактору: я не без оснований просил издатель-
ство "Microsoft Press" о возможности поработать с Вами. Вы добиваетесь истинного пони-
мания вещей; обращаете внимание на тонкости, по достоинству оцениваете SQL и понимае-
те его логику, и все это венчает ваш великолепный английский язык. Вы проделали
замечательную работу!
Дежану Сарка (Dejan Sarka): мне хотелось бы поблагодарить тебя за помощь в работе над
первой главой книги и за твои знания и понимание теории множеств, логики предикатов и
реляционной модели. Мне нравится, что ты всегда задаешь вопросы даже по поводу вещей,
которые большинство людей принимают как данность. Ты один из тех людей, за идеями и
рассуждениями которых я слежу с большим вниманием. Твое понимание реляционной мо-
дели и способность поглощать пиво по истине замечательны, хотя примеры, которые ты
выбираешь для демонстрации своих идей, и не всегда политкорректны.
Сотрудники "Microsoft Press" и "S4Carlisle Publishing Services" также заслуживают благо-
дарности.
Кену Джонсу (Ken Jones), менеджеру проекта: работать с Вами истинное удовольствие.
Я ценю ваше внимание и вашу способность справляться с нами, авторами, и нашими непро-
стыми характерами. Я высоко ценю Ваше дружеское отношение. Спасибо Салли Стикни
(Sally Stickney), выпускающему редактору, за осуществление проекта и Марии Гарджуло
(Maria Gargiulo), техническому редактору, за ежедневное руководство проектом. Работать с
вами было замечательно! Приношу благодарности также Кристиану Холденеру (Christian
Holdener) и Трэси Болл (Tracy Ball), торговым менеджерам проекта, и Бекке МакКей (Веска
McKay), корректору.
Я хотел бы поблагодарить мою компанию Solid Quality Mentors за самую лучшую работу, о
которой я только мог мечтать, в основном состоящую из преподавания и заставляющую
чувствовать себя частью семьи и в кругу друзей. Фернандо Г. Гуэррэро (Fernando G. Guer-
rero), Брайан Моран (Brian Moran) и Дуглас МакДауэлл (Douglas McDowell), руководящие
компанией, вам есть чем гордиться. Компания выросла и добилась больших успехов. Моим
друзьям и коллегам из компании, Рону Талмейджу (Ron Talmage), Эндрю Джей Келли (An-
drew J. Kelly), Эладио Ринкону (Eladio Rincon), Дежану Сарка (Dejan Sarka), Герберту Аль-
берту (Herbert Albert), Фрицу Лехницу (Fritz Lechnitz), Джанлуке Хотцу (Gianluca Hotz),
Эрику Веерману (Erik Veerman), Даниэлю Эй Сеара (Daniel A. Seara), Дэвиде Маури (Davide
Mauri), Андреа Бенедетти (Andrea Benedetti), Мигелю Эгеа (Miguel Egea), Адольфо Вернику
(Adolfo Wiernik), Жавьеру Лориа (Javier Loria), Рушабу Б. Мете (Rushabh В. Mehta) и мно-
гим другим: это честь и удовольствие для меня быть частью команды; я всегда с нетерпени-
ем жду возможности посидеть с вами за кружкой пива, рассуждая об SQL и многом другом!
Мне хочется поблагодарить Жанну Ривз (Jeanne Reeves), сделавшую возможными большин-
ство моих учебных курсов, и всю команду технического персонала за оказанную поддержку.
4
Благодарности
Я глубоко признателен Кати Бломстром (Kathy Blomstrom) за руководство моими писатель-
скими проектами и за отличное их редактирование.
Любору Коллару (Lubor Kollar), члену группы техподдержки Microsoft SQL Server Customer
Advisory Team (SQL CAT): я хочу поблагодарить тебя за столь выдающийся пример для
подражания и дружескую поддержку. Ты всегда был готов помочь или найти нужный ис-
точник информации, чтобы ответить на мой вопрос относительно SQL Server, и это внесло
большой вклад в мое понимание T-SQL. Всегда жду с нетерпением наших встреч в буду-
щем!
Хочу поблагодарить ряд сотрудников из команды разработчиков. Майклу Вангу (Michael
Wang), Майклу Рису (Michael Rys) и всем остальным разработчикам T-SQL: спасибо вам за
замечательный язык T-SQL, невзирая на то, что элемент OVER все еще не до конца реализо-
ван. Умачандару Джаячандрану (Umachandar Jayachandran) (UC): я знаю очень немного лю-
дей, понимающих всю глубину T-SQL, как Вы, и был несказанно рад, когда Вы присоеди-
нились к команде разработчиков средств программирования в языке. Я уверен — T -SQL в
надежных руках!
Сенсею Йехуде Пантановицу (Sensei Yehuda Pantanowitz): Вы мой величайший учитель и
друг; Ваш уход от нас невыносим.
Команде журнала "SQL Server Magazine": Шейле Мольнар (Sheila Molnar), Мэри Ватерлоо
(Mary Waterloo), Карен Форстер (Karen Forster), Мишель Крокетт (Michele Crockett), Майку
Оти (Mike Otey), Лавону Петерсу (Lavon Peters) и Анне Граб (Anne Grubb): мы проработали
вместе уже почти 10 лет, и с вами я чувствую себя как дома. Спасибо за то, что вы предос-
тавили мне возможность писать ежемесячно о предмете, которым я увлечен столь сильно, и
за всю вашу работу по подготовке статей к публикации.
Я хочу выразить признательность моим товарищам, обладателям звания MVP (Most Valu-
able Professional, наиболее ценный специалист), за их вклад в сообщество SQL и мои личные
знания. Отдельные благодарности Стиву Кассу (Steve Kass): когда я рос, я хотел быть таким
же, как Вы! Эрланду Соммарскогу (Erland Sommarskog), Алехандро Меса (Alejandro Mesa),
Аарону Бертранду (Aaron Bertrand) и Тибору Караси (Tibor Karaszi): ваше участие в группе
новостей просто удивительно! Эрланд, Ваши статьи — кладезь информации. Марчелло По-
летти (Marcello Poletti): я уверен, что мы разделяем привязанность к SQL и головоломкам;
Ваши головоломки свирепы, они не раз лишали меня сна.
Мое настоящее призвание — преподавание; я хотел бы поблагодарить моих студентов за то,
что они дали мне возможность реализовать его. Студенческие вопросы и расспросы заста-
вили меня проводить множество исследований, и большей частью накопленных знаний я
обязан им.
Я благодарен моей семье за поддержку. Моим родителям, Габриелю (Gabriel) и Эмилии
(Emilia) Бен-Ган (Ben-Gan) за то, что они поощряли мою увлеченность, несмотря на то, что
она сокращала время наших встреч. Моему брату Майклу Бен-Гану (Michael Ben-Gan) и
моей сестре Ине Авирам (Ina Aviram), которые всегда были готовы помочь мне.
И наконец, Лайлак (Lilach), ты придаешь смысл всему, что я делаю: вопреки расхожему
клише, я, наверное, мог бы закончить книгу без тебя. Но захотел бы я это сделать?
Введение
Эта книга поможет вам сделать первые шаги в освоении языка T-SQL (также называемом
Transact-SQL), диалекте стандартного языка ANSI-SQL в программе Microsoft SQL Server.
Вы познакомитесь с теоретическими основами формирования запросов и программирова-
ния на языке T-SQL, способами извлечения и модификации данных и обзором программи-
руемых объектов.
Несмотря на то, что эта книга предназначена для начинающих, это не просто пошаговое
руководство. Она не ограничивается описанием синтаксических элементов языка T-SQL, а
объясняет скрытую логику языка и его элементов.
Порой в книге затрагиваются темы, достаточно сложные для читателей, впервые знакомя-
щихся с языком T-SQL; подобные разделы не предназначены для обязательного чтения. Ес-
ли вы к тому моменту хорошо освоили материал, обсуждавшийся в книге, можете взяться за
более сложные темы, в противном случае пропускайте такие разделы, чтобы вернуться к
ним по мере приобретения опыта. В книге разделы повышенной сложности, предлагаемые
для необязательного чтения, помечены соответствующим образом.
Многие черты SQL уникальны и отличают его от других языков программирования. Эта книга
поможет вам выработать верный взгляд и по-настоящему понять элементы языка. Вы научи-
тесь думать в терминах множеств и следовать лучшим приемам программирования на SQL.
Книга не привязана к конкретной версии, но в ней описаны элементы, появившиеся в самых
последних версиях SQL Server, включая SQL Server 2008. Когда я пишу о таких элементах,
то указываю версию, в которую они были добавлены.
Для того чтобы дополнить изучение практическими навыками, в книгу включены упражне-
ния, которые помогут опробовать на практике все то, чему вы научились. Иногда в книге
предлагаются упражнения повышенной сложности. Они предназначены для читателей, хо-
рошо освоивших обсуждавшийся материал и желающих проверить себя на более трудных
задачах. Необязательные упражнения повышенной сложности помечены в книге соответст-
вующим образом.
а
Для кого эта книга
Книга предназначена для программистов, пишущих на языке T-SQL, администраторов баз
данных (DBA), системных архитекторов, аналитиков и хорошо подготовленных пользовате-
лей SQL Server, начавших работать с SQL Server и вынужденных писать запросы и разраба-
тывать программы на языке Transact-SQL.
О чем эта книга
Книга начинается с теоретических основ формирования запросов и программирования на
языке T-SQL, закладывая фундамент для всех последующих глав книги, и описания спосо-
б
Введение
бов создания таблиц и обеспечения целостности данных. Далее, в главах 2—8, описываются
различные аспекты извлечения и модификации данных, за которыми следует обсуждение
параллелизма и транзакций в главе 9 и приводится обзор программируемых объектов в гла-
ве 10. Далее приведен перечень глав книги с кратким описанием содержимого этих глав.
П Глава 1 предлагает теоретические основы языка SQL, теории множеств и логики преди-
катов; рассматривает реляционную модель и не только; описывает архитектуру SQL
Server и поясняет, как создавать таблицы и обеспечивать целостность данных.
•
Глава 2 посвящена различным аспектам формирования однотабличных запросов с по-
мощью инструкции SELECT.
П Глава 3 рассказывает о создании многотабличных запросов с помощью соединений,
включая перекрестные соединения, внутренние и внешние соединения.
•
Глава 4 посвящена запросам в запросах, также называемым подзапросами.
•
В главе 5 обсуждаются производные таблицы, ОТВ, представления, подставляемые таб-
личные функции и операция APPLY.
•
Гпава б посвящена операциям над множествами UNION, INTERSECT И EXCEPT.
•
Глава 7 рассказывает о методах реорганизации для представления данных и наборах
группирования.
•
Глава 8 описывает вставку, обновление, удаление и слияние данных.
•
Глава 9 посвящена параллельным подключениям пользователей, одновременно рабо-
тающим с одними и теми же данными; в ней обсуждаются транзакции, блокировки и
блокирование, уровни изоляции и взаимоблокировки.
•
Глава 10 предлагает обзор возможностей программирования в SQL Server на языке
T-SQL.
В книгу также включено приложение 7, призванное помочь вам установить рабочую среду,
загрузить сопроводительный программный код, установить учебную базу TSQLFundamen-
ta1s2008, начать писать Программный код для выполнения в SQL Server и научиться полу-
чать помощь, работая с интерактивным справочным руководством SQL Server Books Online.
В приложении 2 приводятся решения упражнений.
Сопроводительный материал
У книги есть сопутствующий Web-сайт, который делает доступным для вас весь программ-
ный код, использованный в книге, исправленные ошибки и опечатки, дополнительные ре-
сурсы и многое другое. Адрес этого сайта— http://www.sql.co.il/books/. Подробности, ка-
сающиеся программного кода, см. в приложении 1.
Аппаратные и программные требования
В приложении 1 я написал, какие версии SQL Server 2008 вы можете применять для работы
с примерами программного кода, включенными в эту книгу. У каждой версии SQL Server
свои аппаратные и программные требования, которые подробно описаны в разд. "Hardware
Введение
7
and Software Requirements for Installing SQL Server 2008" ("Аппаратные и программные тре-
бования к установке SQL Server 2008") интерактивного справочного руководства SQL Server
Books Online. В приложении I также поясняется, как работать с SQL Server Books Online.
Поиск дополнительной
интерактивной информации
Для получения дополнительной полезной информации от издательства "Microsoft Press"
посетите новые сайты Microsoft Press Online — ваш прямой интерактивный ресурс для дос-
тупа к обновлениям, примерам глав, статьям, сценариям и электронным книгам, связанным
с изданиями "Microsoft Press", нашего лидера в области компьютерной литературы. Загля-
ните на следующие Web-сайты: http://www.microsoft.com/learning/books/online/developer и
http://www.microsoft.com/learning/books/online/serverclient.
Сопровождение книги
Все возможные усилия были предприняты для устранения ошибок в данной книге и на со-
путствующем Web-сайте. Корректировки и изменения собираются и будут включены в ста-
тью базы знаний корпорации Microsoft (Microsoft Knowledge Base). Издательство "Microsoft
Press" предоставляет поддержку и сопровождение своих книг на Web-сайте:
http://www.microsoft.com/learning/support/books/.
Вопросы и комментарии
Если у вас есть замечания и вопросы или идеи, касающиеся книги, или вопросы, на которые
вы не нашли ответы на Web-сайтах, приведенных выше, пожалуйста, отправьте их мне элек-
тронной почтой по адресу itzik@SolidQ.com или обычной почтой по адресу:
Microsoft Press
Attn: Microsoft SQL Server 2008 T-SQL Fundamentals Editor
One Microsoft Way
Redmond, WA 98052-6399
Учтите, что по указанным адресам не оказывается техническая поддержка программных
продуктов корпорации Microsoft.
ГЛАВА 1
Основы построения запросов
и программирования
на языке T-SQL
Вы собираетесь отправиться в путешествие в страну, не похожую ни на какую другую, со
своими законами. Если чтение этой книги — ваш первый шаг на пути изучения языка Trans-
act-SQL (T-SQL), вы должны чувствовать себя как Алиса перед похождениями в Стране чу-
дес. Для меня это путешествие все еще не закончено и продолжающийся путь полон новых
открытий. Я завидую вам — самые волнующие открытия у вас еще впереди!
Я связан с языком T-SQL в течение многих лет— обучаю ему, рассказываю о нем, пишу на
нем и консультирую. Для меня T-SQL больше, чем просто язык— это образ мышления.
Я долго обучал сложным вещам и пространно писал о них, постоянно откладывая обсуждение
основ. Вовсе не потому, что основы языка T-SQL слишком просты. Напротив, кажущаяся про-
стота языка обманчива. Я мог бы бегло объяснить основные синтаксические элементы языка, и
за несколько минут вы смогли бы научиться писать запросы. Но такой подход надолго скрыл
бы суть языка и затруднил бы его понимание.
Быть вашим проводником, когда вы делаете первые шаги в этом царстве, — большая ответ-
ственность. Я хотел убедиться в том, что потратил достаточно времени и усилий на изуче-
ние и постижение языка, прежде чем взяться за описание его основ. T-SQL — глубокий и
мощный язык, и его настоящее освоение включает не только знакомство с синтаксическими
элементами и программирование запросов, возвращающих верный результат. Вы, прежде
всего, должны забыть все, что знаете о других языках программирования, и начать мыслить
в терминах T-SQL.
Теоретические основы
SQL— сокращенное название языка Structured Query Language (язык структурированных
запросов). Это стандартный язык, который был разработан для формирования запросов и
управления данными в системах управления реляционными базами данных (СУРБД).
СУРБД — система управления базой данных, основанная на реляционной модели (семанти-
ческая модель представления данных), которая в свою очередь базируется на двух разделах
10
Глава 1
математики: теории множеств и логике или исчислении предикатов. Другие языки програм-
мирования и различные методы вычислений во многом развивались интуитивно. У языка
SQL в части, основанной на реляционной модели, очень прочная и надежная база— при-
кладная математика. Язык T-SQL покоится на ее крепких и широких плечах. Корпорация
Microsoft представляет язык T-SQL как диалект или расширение стандартного языка SQL,
применяемое в ее СУРБД Microsoft SQL Server.
В этом разделе кратко излагаются терретические основы языка SQL, теория множеств и
логика предикатов, реляционная модель и жизненный цикл данных (data life cycle). По-
скольку это не учебник по математике и не книга, посвященная проектирова-
нию/моделированию данных, теоретические сведения, представленные здесь, не отличаются
строгостью и ни в коей мере не претендуют на полноту. Задача книги — дать вам общее
представление о языке Г-SQL и указать ключевые моменты, важные для правильного пони-
мания языка в дальнейшем.
ЯЗЫКОВАЯ
НЕЗАВИСИМОСТЬ
Реляционная модель не зависит от языка. Это означает, что вы можете реализо-
вать ее с помощью языков программирования, отличных от SQL, например, на
языке С# в модели классов. В наши дни часто можно встретить СУРБД, которые
поддерживают языки, отличающиеся от диалекта SQL, например, интеграция об-
щеязыковой среды выполнения CLR в SQL Server.
Вам следует с самого начала усвоить, что SQL в ряде случаев отступает от реля-
ционной модели и некоторые "пуристы реляционной модели" говорят о том, что
язык SQL следует заменить новым языком, более строго придерживающимся ре-
ляционной модели. Но в наше время SQL — de facto рабочий язык, применяемый
всеми ведущими коммерческими СУРБД.
Язык SQL
SQL — язык, стандартизованный ANSI и ISO, основанный на реляционной модели и разра-
ботанный для формирования запросов и управления данными в СУРБД.
В начале 70-х годов прошлого века корпорация IBM разработала язык SEQUEL (сокращение
от Structured English QUEiy Language) для своей СУРБД System R. Позже название языка
изменили с SEQUEL на SQL из-за споров по поводу торговой марки. Сначала в 1986 г. поя-
вился стандарт ANSI языка SQL, а затем в 1987 г. и стандарт ISO. Начиная с 1986 г. ANSI и
ISO выпускали релизы стандарта языка каждые несколько лет. До настоящего времени были
выпущены следующие стандарты языка: SQL-86 (1986), SQL-89 (1989), SQL-92 (1992),
SQL: 1999 (1999), SQL:2003 (2003), SQL:2006 (2006) и SQL:2008 (2008).
Интересно, что язык SQL напоминает английский и также очень логичен. В отличие от мно-
гих других языков программирования SQL требует от вас точного описания того, что вы
хотите получить, а не того, как получить это. Выбор реального механизма обработки вашего
запроса — задача СУРБД.
У языка SQL есть несколько категорий инструкций, включая Data Definition Language (DDL,
язык описания данных), Data Manipulation Language (DML, язык манипулирования данны-
ми) и Data Control Language (DCL, язык управления данными). DDL имеет дело с определе-
Основы построения запросов и программирования на языке T-SQL
11
ниями и включает такие команды, как CREATE, ALTER и DROP. Язык DML позволяет запра-
шивать и изменять данные и включает такие команды, как SELECT, INSERT, UPDATE, DELETE
и MERGE. Общее заблуждение, что DML содержит только команды модификации данных,
но, как я уже упоминал, он также включает команду SELECT. Язык DCL связан с правами
доступа или полномочиями и включает такие команды, как GRANT и REVOKE. Эта книга по-
священа DML.
Язык T-SQL основан на стандартном SQL и, кроме того, предлагает некоторые нестандарт-
ные собственные расширения. Описывая элемент языка в первый раз, я обычно упоминаю о
том, включен он в стандарт или нет.
Теория множеств
Теория множеств, созданная математиком Георгом Кантором (Georg Cantor),— один из
разделов математики, на которых базируется реляционная модель.
Кантор определил множество следующим образом.
Под "множеством" мы понимаем любое объединение М в одно целое объектов т (ко-
торые называются "элементами" М), хорошо различимых нашим чувственным вос-
приятием или нашей мыслью.
Каждое слово в этом определении имеет глубокий смысл и важное значение. Но чтобы не
потеряться в символах и профессиональной терминологии, давайте рассмотрим не столь
строгое определение:
Множество — это любое объединение определенных объектов, хорошо различимых нашим
чувственным восприятием или нашей мыслью и рассматриваемых как единое целое. Объек-
ты считаются элементами или членами множества.
Определения множества и членства в нем — аксиомы, не требующие доказательств. Все
элементы — часть вселенной (universe) и являются или не являются членами конкретного
множества.
Давайте начнем со слов "единое целое" в определении Кантора. Множество следует рас-
сматривать как единую сущность. Вы должны сделать акцент на объединении объектов в
противоположность отдельным объектам, формирующим множество. Позже, когда вы буде-
те писать на языке T-SQL запросы в отношении таблиц в базе данных (например, таблицы
Employees (Сотрудники)), вы должны будете думать о множестве сотрудников как о еди-
ном целом, а не об отдельных сотрудниках. Такой образ мыслей может показаться триви-
альным и довольно простым, но он явно вызывает затруднение у многих программистов.
Слова "хорошо различимых" означают, что все элементы множества должны быть уникаль-
ны. Забегая вперед, к таблицам базы данных, вы можете добиться уникальности строк таб-
лицы, определив ограничения на основе ключей (key constraints). Без ключа невозможно
однозначно идентифицировать строки, и, следовательно, таблицу нельзя считать множест-
вом. Она будет представлять собой мультимножество (multiset) или неупорядоченную сово-
купность (bag).
Словосочетание "нашим чувственным восприятием или нашей мыслью" подразумевает
субъективность задания множества. Рассмотрим классную комнату. Один человек воспри-
нимает множество людей, находящихся в ней, а другой может различать множество учени-
ков и множество учителей. Следовательно, у вас есть значительная свобода в задании мно-
12
Глава 1
жеств. Когда вы проектируете модель данных для своей базы данных, в процессе разработки
следует тщательно учитывать все субъективные потребности приложения для того, чтобы
задать адекватные определения всех входящих в него объектов.
Что касается слова "объект", определение множества не ограничивается реальными объек-
тами, такими как автомобили или сотрудники, но также относится и к абстрактным объек-
там, например, простым числам или прямым линиям.
То, что осталось за пределами определения множества, данного Кантором, может быть так
же важно, как то, что в него включено. Обратите внимание на то, что в определении не упо-
минается способ упорядочивания элементов множества. Порядок перечисления элементов,
входящих в множество, не важен. В формальной записи, применяемой для перечисления
элементов множества, используются фигурные скобки: {a, Ъ, с}. Поскольку порядок элемен-
тов не имеет значения, одно и то же множество можно задать как {Ъ, я, с} или {6, с, а}.
Элементы множества описываются атрибутами, а не порядком следования элементов. Это
требование (несущественность порядка следования) удовлетворяется благодаря наличию
уникальных имен атрибутов. Многие программисты с трудом привыкают к мысли о том, что
в запросах к таблицам у элементов множества нет определенного порядка следования. Дру-
гими словами, запрос к таблице может возвращать строки таблицы в произвольном порядке
до тех пор, пока вы явно не зададите сортировку данных для удобства их представления.
Логика предикатов
Логика или исчисление предикатов, уходящая корнями в древнегреческую математику,—
еще один раздел математики, на котором базируется реляционная модель. Доктор Эдгар Ф.
Кодд (Edgar F. Codd), создавая реляционную модель, удачно связал логику предикатов с
управлением данными и формированием запросов к ним. Проще говоря, предикат— это
характеристика или выражение, которое соблюдается или не соблюдается, другими слова-
ми, истинно (true) или ложно (false). В реляционных моделях предикаты применяются для
обеспечения логической целостности данных и определения их структуры. Примером пре-
диката, применяемого для обеспечения целостности, может служить ограничение, опреде-
ленное в таблице Employees, которое позволяет включать в таблицу лишь тех сотрудников,
чья заработная плата больше нуля. Предикат формулируется как "заработная плата больше
нуля" (что на языке T-SQL соответствует выражению salary > 0).
Логику предикатов можно также применять при фильтрации данных для создания подмно-
жеств и т. п. Например, если вы хотите запросить таблицу Employees и получить в резуль-
тате только строки с сотрудниками из отдела продаж, вы должны применить в вашем запро-
се-фильтре предикат "department equals sales" (отдел равен отделу продаж). На языке T-SQL
это соответствует выражению department =
1
sales
1
.
В теории множеств можно использовать предикаты для определения множеств. Это полез-
но, т. к. не всегда можно определить множество простым перечислением его элементов (на-
пример, в случае бесконечных множеств) и иногда из соображений краткости удобнее опре-
делить множество, основываясь на его отличительном свойстве. Примером бесконечного
множества, определенного с помощью предиката, может служить множество всех простых
чисел, которое определяется следующим предикатом: "х— положительное целое число,
большее 1, которое делится только на 1 и на само себя". Для любого заданного значения
предикат либо содержит значение true (истина), либо не содержит этого значения. Множе-
ство всех простых чисел — это множество всех элементов, для которых описанный преди-
Основы построения запросов и программирования на языке T-SQL
13
кат равен true. Пример конечного множества, определенного с помощью предиката,—
множество {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}, которое может быть определено как множество всех
элементов, для которых следующий предикат равен true: "х— целое число, не меньшее 0 и
не большее 9".
Реляционная модель
Реляционная модель— это семантическая модель представления данных, основанная на
теории множеств и логике предикатов. Как уже упоминалось, она была создана доктором
Эдгаром Ф. Коддом (Edgar F. Codd) и позже доработана и развита Крисом Дейтом (Chris
Date), Хью Дарвеном (Hugh Darwen) и др. Первая версия реляционной модели была пред-
ложена Коддом в 1969 г. в научно-исследовательском отчете корпорации IBM, названном
"Derivability, Redundancy, and Consistency of Relations Stored in Large Data Banks" ("Выводи-
мость, избыточность и непротиворечивость отношений, хранящихся в больших банках дан-
ных"). Исправленную версию модели Кодд предложил в 1970 г. в статье "A Relational Model
of Data for Large Shared Data Banks" ("Реляционная модель данных для больших совместно
используемых банков данных"), опубликованной в журнале "Communications of the ACM".
Назначение реляционной модели — сделать возможным представление непротиворечивых
данных с минимальной избыточностью или вообще без нее, не жертвуя полнотой этого
представления, и сделать целостность данных (требование непротиворечивости данных)
составной частью модели. Для реализации реляционной модели и предоставления средств
хранения данных, управления ими, обеспечения их целостности и выполнения запросов к
данным создается СУРБД. Строгая математическая основа реляционной модели означает
при наличии варианта модели, построенного на конкретных данных (из которого позже бу-
дет сформирована физическая база данных), возможность с определенностью, а не полага-
ясь только на интуицию, говорить о дефектах проекта.
Реляционная модель включает в себя такие понятия, как высказывания (propositions), доме-
ны, /7-арные отношения, кортежи из п элементов, упорядоченные пары и т. д. Нематемати-
кам они могут показаться очень заумными. В следующих разделах обсуждаются простым
нематематическим языком некоторые ключевые характеристики модели и объясняется их
связь с базами данных.
Высказывания, предикаты и отношения
Общепринятое представление о том, что термин "реляционная" возник из-за взаимосвязи
таблиц, неверно. Определение "реляционная" на самом деле относится к математическому
термину relation (отношение). Отношение— это представление множества в теории мно-
жеств. В реляционной модели отношение — это множество связанных между собой данных,
которые в базе данных реализуются в виде таблицы. Важная особенность реляционной мо-
дели заключается в том, что одно отношение должно представлять одно множество (напри-
мер, Customers (Клиенты)). Следует отметить, что результатом операций над отношениями
(основанными на реляционной алгебре) будет также отношение (например, объединение
двух отношений).
Когда вы разрабатываете модель данных для базы данных, то представляете все данные в
виде отношений (таблиц). Начать следует с определения высказываний, которые необходи-
14
Глава 1
мо представить в вашей базе данных. Высказывание — это суждение или утверждение, ко-
торое может быть истинным или ложным. Например, утверждение "сотрудник Ицик Бен-
Ган родился 12 февраля 1971г. и работает в отделе информационных технологий" —
высказывание. Если оно верно, то появится в виде строки в таблице Employees
(Сотрудники). Ложное высказывание никак не обнаружит себя.
Следующий шаг— формализация высказываний. Делается это с помощью получения ре-
альных данных (тела отношения) и определения структуры (определения заголовков столб-
цов или шапки отношения), например, формированием предикатов из высказываний. Шапка
или заголовок отношения содержит множество атрибутов. Обратите внимание на использо-
вание термина "множество"; в реляционной модели атрибуты неупорядочены. Атрибут
обозначается именем атрибута и именем домена (типа). Например, шапка отношения
Employees (Сотрудники) может состоять из следующих атрибутов (выраженных парами
"имя атрибута" и "имя типа данных"): employeeid integer, firstname character
string, lastname character string, birthdate date, departmentid integer. Домен
или тип— один из базовых блоков, формирующих отношение. Домен— это множество
возможных/допустимых значений атрибута. Например, домен 1NT— множество всех целых
чисел в диапазоне от -2 147 483 648 до 2 147 483 647. Домен— одна из простейших форм
предиката в нашей базе данных, поскольку он ограничивает допустимые значения атрибута.
Например, база данных не примет высказывание, в котором дата рождения сотрудника Feb-
ruary 31, 1971. (Не говоря уже о дате рождения "abc"!) Имейте в виду, что домены не огра-
ничиваются базовыми типами данных, такими как целые числа или символьные строки. До-
мен может быть, к примеру, перечислением допустимых значений, таким как перечисление
возможных должностей сотрудника. Домен может быть сложным. Возможно, лучше всего
считать домен классом, включающим данные и их поведенческую поддержку. Примером
сложного домена может быть геометрический домен, поддерживающий многоугольники.
Пропущенные значения
Один из аспектов реляционной модели служит источником горячих дискуссий: следует ли
ограничить высказывания использованием логики двузначных предикатов? Применение
логики двузначных предикатов означает, что высказывание может быть только истинным
или ложным. Если высказывание не истинно, оно должно быть ложно. Однако, как утвер-
ждают некоторые, в тех случаях, когда что-либо неизвестно, возможно применение троич-
ной (и даже четверичной) логики предикатов. Рассмотрим, к примеру, атрибут номера мо-
бильного телефона в отношении Employees (Сотрудники). Предположим, что номер
мобильного телефона конкретного сотрудника пропущен. Как отразить этот факт в базе
данных? В реализации троичной логики предикатов атрибут мобильного телефона допуска-
ет наличие специального знака для пропущенного значения.
Одни специалисты считают, что троичная логика предикатов не является реляционной, а
другие утверждают, что она остается реляционной. Кода активно отстаивал логику четырех-
значных предикатов, утверждая, что есть два случая пропуска значений: пропущены, но су-
ществуют, и пропущены и не существуют. Примером пропущенного, но существующего
значения может быть номер мобильного телефона сотрудника, который мы просто не знаем.
Примером пропущенного и несуществующего значения может быть номер мобильного те-
лефона сотрудника, у которого вообще нет мобильного телефона. С точки зрения Кодда для
обработки этих двух вариантов пропущенных значений должны использоваться два специ-
альных маркера. В языке SQL реализована троичная логика предикатов благодаря поддерж-
Основы построения запросов и программирования на языке T-SQL
15
ке специального значения NULL, выражающего общую концепцию пропущенного значения.
Применение в языке SQL значений NULL и троичной логики предикатов создает массу пута-
ницы и сложностей, несмотря на то, что можно привести доказательства реальности суще-
ствования пропущенных значений, а использование альтернативного варианта, логики дву-
значных предикатов, порождает не меньше проблем.
Ограничения
Одно из важнейших достоинств реляционной модели — наличие целостности данных, опре-
деленной в самой модели. Целостность достигается правилами или ограничениями, которые
устанавливаются в модели данных и реализуются СУРБД. К простейшим способам дости-
жения целостности относятся тип атрибута и его способность принимать значения NULL,
обеспечивающие целостность домена. Ограничения также устанавливаются самой моделью;
например, отношение Orders (Заказы) (orderid, orderdate, duedate, shipdate)
допускает наличие трех дат в одном заказе, в то время как отношения Employees (Сотруд-
ники) (empid) И EmployeeChildren (Дети сотрудника) (empid, childname) допускают
задание количества детей у сотрудника в пределах от нуля до исчислимой бесконечности.
Другими примерами ограничений могут служить потенциальные ключи, обеспечивающие
целостность объекта, и внешние ключи, поддерживающие ссылочную целостность. Потен-
циальный ключ — это ключ, определенный на одном или нескольких атрибутах, препятст-
вующий появлению в отношении нескольких экземпляров одного и того же кортежа (стро-
ки). Предикат, базирующийся на потенциальном ключе, способен однозначно
идентифицировать строку (например, сотрудника). В отношении можно определить не-
сколько потенциальных ключей. Так, в отношении Employees (Сотрудники) можно в каче-
стве потенциальных ключей задать атрибуты employee id (id сотрудника), ssn (social secu-
rity number, номер социального обеспечения) и др. Один из потенциальных ключей
произвольно выбирается в качестве первичного ключа (скажем атрибут employee id в от-
ношении Employees) и используется как предпочтительный вариант идентификации стро-
ки. Все остальные потенциальные ключи называют также альтернативными ключами.
Внешние ключи применяются для обеспечения ссылочной целостности. Внешний ключ
задается на базе одного или нескольких атрибутов отношения (называемого ссылающим-
ся отношением) и ссылается на потенциальный ключ другого (возможно, того же самого)
отношения. Это ограничение сужает диапазон значений атрибутов внешнего ключа ссы-
лающегося отношения, ограничивая его теми значениями, которые встречаются в атрибу-
тах, являющихся потенциальными ключами справочного отношения или отношения, на
которое ссылаются. Скажем, у отношения Employees в качестве внешнего ключа задан
атрибут departmentid (id отдела), ссылающийся на атрибут departmentid, который
является первичным ключом в отношении Departments (Отделы). Это означает, что зна-
чения атрибута Employees. departmentid ограничены значениями, встречающимися у
атрибута Departments .departmentid.
Нормализация
В реляционной модели также определены правила нормализации (именуемые формами
нормализации). Нормализация—это формальный математический процесс, обеспечиваю-
щий представление одного объекта в единственном отношении. В нормализованной базе
16
Глава 1
данных вы избавлены от аномалий, возникающих при модификации данных, и сводите из-
быточность данных до минимума, не жертвуя полнотой их представления. Если вы выпол-
ните Entity Relationship Modeling (ERM) (построение модели "сущность—отношение") и
представите все объекты и их атрибуты, возможно, нормализация вам и не понадобится;
скорее, вы будете применять ее лишь для того, чтобы усилить модель и убедиться в ее кор-
ректности. В следующих разделах кратко описаны первые три формы нормализации, вве-
денные Коддом.
Первая нормальная форма
Первая нормальная форма (1НФ, 1NF) говорит о том, что строки таблицы должны быть
уникальны, а атрибуты атомарны или неделимы. Это излишнее определение отношения;
другими словами, если таблица корректно представляет отношение, она находится в первой
нормальной форме.
,
Уникальность строк достигается заданием уникальных значений ключа в таблице.
Вы можете применять к атрибутам только те операции, которые определены для типа дан-
ных атрибута. Неделимость или атомарность атрибутов так же субъективна, как и определе-
ние множества. Например, возьмем имя сотрудника в отношении Employees (Сотрудники).
Следует ли его определить одним атрибутом (ФИО), двумя (имя и фамилия) или тремя (имя,
отчество и фамилия)? Это зависит от приложения. Если потребуется обрабатывать отдель-
ные составляющие имени сотрудника (например, для поиска), имеет смысл представить
части имени как отдельные атрибуты, в противном случае в этом нет необходимости.
Точно так же как атрибут может быть, исходя из нужд приложения, недостаточно атомар-
ным (не вполне неделимым), он может быть и сверхатомарным или субатомарным. Напри-
мер, если атрибут адреса считается в данном приложении атомарным, отсутствие города в
составе адреса нарушит первую нормальную форму.
Первую нормальную форму часто понимают неверно. Некоторые люди думают, что попыт-
ка имитировать массив нарушает первую нормальную форму. Примером могло бы быть
определение отношения Yearly Sales (Годовые продажи) с помощью следующих атрибу-
тов: salesperson (продавец), qty2006 (количество в 2006), qty2007 (количество в 2007),
и qty2008 (количество в 2008). На самом деле, в этом примере первая нормальная форма не
нарушена; вы просто накладываете ограничение — разделение данных между тремя задан-
ными годами: 2006, 2007 и 2008.
Вторая нормальная форма
Вторая нормальная форма (2НФ, 2NF) включает два правила. Первое правило: данные
должны удовлетворять первой нормальной форме. Второе правило касается взаимосвязи
неключевых атрибутов и атрибутов потенциальных ключей. Для всех потенциальных клю-
чей каждый неключевой атрибут должен быть полностью функционально зависим от всего
потенциального ключа. Иными словами, неключевой атрибут не может быть полностью
функционально зависимым от части потенциального ключа. Проще говоря, если вам нужно
получить любое значение неключевого атрибута, вы должны задать значения всех атрибутов
потенциального ключа из этой строки. Вы можете найти любые значения любого атрибута в
любой строке, если знаете значения всех атрибутов потенциального ключа.
Основы построения запросов и программирования на языке T-SQL
17
Для демонстрации нарушения второй нормальной формы предположим, что вы определяете
отношение Orders (Заказы), которое представляет данные о заказе и подробную характери-
стику заказа (рис. 1.1). Отношение Orders содержит следующие атрибуты: orderid (id за-
каза), productid (id товара), orderdate (дата заказа), qty (количество), customerid (id
клиента) и companyname (название компании).
Orders
РК
РК
orderid
productid
orderdate
qty
customerid
companyname
Рис. 1 .1 . Модель данных до применения 2НФ
На рис. 1.1 вторая нормальная форма нарушена, поскольку есть неключевые атрибуты, за-
висящие только от части потенциального ключа (в данном примере первичного ключа). На-
пример, вы можете найти дату заказа (orderdate), также как идентификационный номер
клиента (customerid) и название компании (companyname), зная только идентификацион-
ный номер заказа (orderid). Для соответствия второй нормальной форме исходное отно-
шение следует разделить на два: Orders (Заказы) и OrderDetails (Сведения о заказе)
(рис. 1.2). Отношение Orders будет включать атрибуты: orderid, orderdate, customerid
и companyname. Первичный ключ— атрибут orderid. Отношение OrderDetails будет
содержать следующие атрибуты: orderid, productid и qty, с первичным ключом из атри-
бутов orderid, productid.
Orders
OrderDetails
PK orderid
PK,FK1 orderid
orderdate
PK
productid
customerid
qty
companyname
Рис. 1.2 . Модель данных после применения 2НФ,
но до применения ЗНФ
Третья нормальная форма
У третьей нормальной формы (ЗНФ, 3NF) тоже два правила. Данные должны быть во
второй нормальной форме. Кроме того, все неключевые атрибуты должны нетранзитивно
зависеть от потенциальных ключей. Проще говоря, один неключевой атрибут не может
зависеть от другого неключевого атрибута.
Наши отношения Orders (Заказы) и OrderDetails (Сведения о заказе) теперь удовлетво-
ряют второй нормальной форме. Напоминаю, что в данный момент отношение Orders со-
18
Глава 1
держит атрибуты order id, orderdate, customer id и companyname, причем атрибут
orderid определен как первичный ключ. Оба атрибута (cus tome rid и companyname) зави-
сят от всего первичного ключа orderid. Например, для того чтобы найти идентификацион-
ный номер клиента, сделавшего заказ, вам нужен первичный ключ целиком. Но cus tome rid
и companyname также зависят друг от друга. Для соответствия третьей нормальной форме
вам придется добавить отношение Customers (Клиенты) (рис. 1.3) с атрибутами
customerid (первичный ключ) и companyname и удалить атрибут companyname из отно-
шения Orders.
Рис. 1.3 . Модель данных после приведения к ЗНФ
Пользуясь неформальным языком, 2НФ и ЗНФ можно определить следующим предложени-
ем: "Каждый неключевой атрибут зависит от ключа, от целого ключа и ни от чего кроме
ключа — и да поможет мне Кода".
Помимо первых трех нормальных форм Кодда существуют нормальные формы больших
степеней, включающие составные первичные ключи и временные базы данных, но их обсу-
ждение выходит за рамки книги.
Жизненный цикл данных
Часто данные воспринимаются как нечто статичное, единожды введенное в базу данных и
позже запрашиваемое. Но во многих рабочих средах на самом деле данные больше похожи
на изделия на сборочном конвейере, переходящие из одной рабочей среды в другую и под-
вергающиеся изменениям на этом пути следования. В этом разделе описываются разные
рабочие среды, в которых могут находиться данные и характеристики, как данных, так и
рабочей среды на каждом этапе жизненного цикла данных. На рис. 1.4 показан жизненный
цикл данных.
Оперативная обработка транзакций
Сначала данные вводятся в систему оперативной обработки транзакций (OnLine Transac-
tional Processing, OLTP). Главная задача системы OLTP— ввод, причем без составления
отчетов: транзакции в основном вставляют, обновляют и удаляют данные. Реляционная мо-
дель главным образом рассчитана на системы OLTP, в которых нормализованная модель
обеспечивает как высокую производительность ввода данных, так и непротиворечивость
данных. В нормализованной среде каждая таблица представляет один объект, и избыточ-
ность минимальна. Если вам нужно что-то изменить, вы должны изменить это что-то только
в одном месте, в результате оптимизируется производительность изменений и очень мала
вероятность ошибок.
Основы построения запросов и программирования на языке T-SQL
19
Среда OLTP не годится для составления отчетов, т. к. нормализованная модель обычно со-
держит много таблиц (по одной на каждый объект) со сложными взаимосвязями. Даже для
простых отчетов требуется соединение многих таблиц, что приводит к сложным и медленно
выполняющимся запросам.
В SQL Server вы можете реализовать базу данных OLTP, а затем управлять ею и формиро-
вать запросы к ней на языке T-SQL.
OLTP
DW
OLAP
i,
fi
SQL Server
Analysis Services
T-SQL
MDX/DMX
Рис. 1 .4 . Жизненный цикл данных
Хранилище данных
Хранилище данных (data warehouse, DW)— среда, разработанная для извлечения данных и
формирования отчетов. Если обслуживается все учреждение, 317 среду называют хранили-
щем данных; если же она предназначена для обслуживания части учреждения (такой, как
конкретный отдел), ее именуют витриной или киоском данных (data mart). Модель данных
хранилища проектируется и оптимизируется главным образом для поддержки нужд извле-
чения данных. У модели появляется умышленная избыточность, допускающая меньшее ко-
личество таблиц и более простые связи между ними, что, в конечном счете, приводит к
формированию более простых и эффективных запросов по сравнению с рабочей средой
OLTP.
Простейший вариант хранилища данных называется схемой звезды, которая включает не-
сколько таблиц измерений
1
(dimension table) и одну таблицу фактов (fact table). Каждая таб-
лица измерений представляет объект, с помощью которого анализируются данные. Напри-
1
По-моему, точнее было бы назвать такую таблицу таблицей параметров. — Прим. пер.
20
Глава 1
мер, в системе, имеющей дело с заказами и продажами, вы, вероятно, захотите проанализи-
ровать данные в отношении клиентов, товаров, сотрудников, времени и т. д. В схеме звезды
каждое измерение реализовано в виде отдельной таблицы с избыточными данными, напри-
мер, измерение товара можно реализовать единственной таблицей Product Dim вместо трех
нормализованных таблиц: Products, Product Subcategories и ProductCategories. Ес-
ли вы нормализуете таблицу измерения, получив в результате много таблиц для представле-
ния измерения, у вас появится то, что называют измерениями в виде снежинки (snowflake
dimension). Схема, содержащая измерения в виде снежинки, называется схемой снежинки (в
противоположность схеме звезды).
Таблица фактов содержит фактические данные и показатели, скажем, количество для каж-
дой значимой комбинации значений ключей измерения. Например, для каждой значимой
комбинации клиента, товара, сотрудника и дня в таблице фактов будет существовать строка
с количеством и соответствующими значениями ключей. Как правило, данные в хранилище
заранее подытоживаются или агрегируются на определенном уровне детализации (напри-
мер, на каждый день) в отличие от данных в рабочей среде OLTP, которые обычно записы-
ваются на уровне транзакций.
В прежние годы первые версии SQL Server в основном были рассчитаны на рабочие среды
OLTP, но со временем SQL Server начал также ориентироваться на системы хранилищ дан-
ных и нужды аналитической обработки данных. Вы можете реализовать хранилище данных
с помощью базы данных SQL Server, управлять ею и выполнять запросы к ней на языке
T-SQL.
Процесс извлечения данных из исходных систем (OLTP и др.), манипулирования и загрузки
их в хранилище данных называется Extract Transform and Load (ETL, извлечение, передача и
загрузка). Для удовлетворения потребностей ETL SQL Server предоставляет средство, на-
званное Microsoft SQL Server Integration Services (SSIS) (платформа для построения решений
по интеграции и преобразованию данных уровня предприятия, см. http://nisdii.microsoft.com/
ru-ru/library/msl41026.aspx).
Оперативная аналитическая обработка
Системы OnLine Analytical Processing (OLAP, оперативная аналитическая обработка) под-
держивают динамический оперативный анализ сгруппированных данных.
Рассмотрим хранилище данных, которое вы реализовали как реляционную базу данных в
программе SQL Server. Когда пользователь выполняет запрос на получение агрегированных
данных, приложение предъявляет базе данных запрос, обычно сканируя и подытоживая
большие объемы базовых данных. Но даже при этом более эффективно обрабатывать такие
запросы на базе реляционных хранилищ данных по сравнению с рабочей средой OLTP, под-
ход которой к решению этой проблемы может оказаться недостаточно эффективным. Опе-
ративный динамический анализ сгруппированных данных обычно включает в себя частые
запросы на разных уровнях детализации, для которых требуется фигурная нарезка данных.
Любой из таких запросов может оборваться из-за чрезмерных затрат, вызванных необходи-
мостью просмотра и подведения итогов больших объемов данных, и есть вероятность того,
что время отклика будет неудовлетворительным.
Для удовлетворения 1аких потребностей вы можете заранее вычислить итоги, сгруппировав
данные на разных уровнях. Например, можно заранее вычислить годовые, месячные и днев-
ные итоги для измерения time; итоги по категориям, подкатегориям и товарам для измере-
Основы построения запросов и программирования на языке T-SQL
21
ния product (товар) и т. д. Если вы заранее подсчитаете итоги, запросы на сгруппирован-
ные данные могут быть выполнены быстрее.
Один вариант воплощения этой идеи в жизнь — вычисление и хранение разных уровней
группировки в реляционном хранилище данных. Он требует описания сложного процесса
управления начальной обработкой итогов и пошаговым их обновлением. Другой вариант —
применение специального программного продукта, разработанного для систем OLAP,—
Microsoft SQL Server Analysis Services (SSAS или AS). SSAS— это отдельная служ-
ба/подсистема в составе служб SQL Server. Она поддерживает вычисление итогов разных
уровней и хранение их в оптимизированных многомерных структурах, называемых кубами.
Исходные данные для кубов SSAS могут храниться (и обычно хранятся) в реляционном
хранилище данных. Помимо поддержки больших объемов итоговых данных SSAS предос-
тавляет множество мощных и сложных средств анализа данных. Язык, применяемый для
управления кубами SSAS и выполнения запросов к ним, называется Multidimensional Expres-
sions (MDX, многомерные выражения).
Интеллектуальный анализ данных
Системы OLAP предоставляют пользователю ответы на все возможные вопросы, но задача
пользователя — ставить правильные вопросы, которые помогают отсеивать аномалии, трен-
ды и другую полезную информацию из моря данных. В процессе динамического анализа
пользователь переходит от одного представления итоговых данных к другому, снова и снова
получая разные срезы данных для поиска полезной информации.
Интеллектуальный анализ данных или добыча данных (data mining, DM) — следующий этап.
Вместо предоставления пользователю возможности поиска полезной информации в море
данных эту работу для пользователя могут сделать модели интеллектуального анализа. Это
означает, что алгоритмы интеллектуального анализа прочесывают данные и извлекают по-
лезную информацию из них. Добыча данных для организаций имеет огромное практическое
значение, помогая обозначить тренды, установить, какие товары продаются вместе, пред-
сказать предпочтения клиентов, основываясь на заданных параметрах, и т. д.
Система SSAS поддерживает алгоритмы интеллектуального анализа, включая кластериза-
цию, деревья решений и др., направляя энергию на удовлетворение таких потребностей. Для
управления моделями интеллектуального анализа и выполнения запросов к ним применяет-
ся язык Data Mining Extensions (DMX, расширения интеллектуального анализа данных).
Архитектура SQL Server
Этот раздел познакомит вас с архитектурой SQL Server с входящими в его состав объекта-
ми — экземплярами SQL Server, базами данных, схемами и объектами баз данных — и на-
значением каждого из них.
Экземпляры SQL Server
Экземпляр SQL Server (рис. 1.5)— это установка механизма/службы базы данных SQL
Server. На одном компьютере можно установить несколько экземпляров SQL Server. Каж-
2 Зак. 1032
22
Глава 1
дый из них полностью независим от других экземпляров с точки зрения безопасности, дан-
ных, которыми он управляет, и во всех других отношениях. На логическом уровне у двух
экземпляров, размещенных на одном и том же компьютере, общего столько же, сколько у
двух экземпляров, находящихся на разных компьютерах. Конечно же, они совместно ис-
пользуют физические ресурсы сервера, такие как центральный процессор, оперативная па-
мять и диски.
Рис. 1 .5. Экземпляры
Один из экземпляров, установленных на компьютере, может быть задан как экземпляр по
умолчанию, а остальные должны быть именованными экземплярами. Вы задаете экземпляр
как экземпляр по умолчанию или именованный в процессе установки, позже изменить этот
выбор нельзя. Для соединения клиентского приложения с экземпляром по умолчанию необ-
ходимо задать имя компьютера или IP-адрес. Для соединения с именованным экземпляром
клиент должен указать имя компьютера или IP-адрес, за которым следует обратный слэш, и
далее имя экземпляра SQL Server (которое было задано при инсталляции). Например, у вас
есть два экземпляра SQL Server, установленных на компьютере с именем Serverl. Один из
них установлен как экземпляр по умолчанию, а другой — как именованный экземпляр, на-
званный Instl. Для подключения к экземпляру по умолчанию вы должны задать в качестве
имени сервера Serverl, для подключения к именованному экземпляру следует указать
ServerlUnstl.
Для установки нескольких экземпляров SQL Server на одном компьютере есть множество
причин. Я упомяну лишь пару из них. Первая причина — сокращение затрат отдела техни-
ческой поддержки учреждения. Для того чтобы тестировать работу различных функций в
ответ на обращения пользователей, воспроизводить ошибки, с которыми сталкиваются
пользователи в процессе эксплуатации, и т. д., отделу технической поддержки нужны ло-
кальные инсталляции SQL Server, представляющие рабочую среду пользователей с соответ-
ствующими версией, редакцией и пакетом исправлений SQL Server. Если же в учреждении
применяется несколько рабочих сред пользователей, отделу технической поддержки пона-
добится несколько установок SQL Server. Вместо использования нескольких компьютеров,
на каждом из которых установлена отдельная инсталляция SQL Server, требующая техниче-
Основы построения запросов и программирования на языке T-SQL
23
ского сопровождения, отдел технической поддержки может иметь один компьютер с не-
сколькими экземплярами сервера.
Другой пример — люди, подобные мне, обучающие SQL Server и читающие лекции о нем.
Нам очень удобно иметь возможность установки на один ноутбук нескольких экземпляров
SQL Server. Таким образом мы сможем демонстрировать разные редакции программного
продукта, показывая различия в поведении версий и т. д.
И последний пример — разработчики служб баз данных иногда должны гарантировать сво-
им клиентам полное безопасное разделение данных разных клиентов. Поставщик базы дан-
ных может иметь очень мощный информационный центр, размещая множественные экзем-
пляры SQL Server на одном компьютере вместо того, чтобы обслуживать менее мощные
компьютеры, на каждом из которых установлены разные экземпляры сервера.
Базы данных
Вы можете представлять себе базу данных в виде контейнера объектов, таких как таблицы,
представления, хранимые процедуры и т. д. Каждый экземпляр SQL Server может содержать
несколько баз данных (рис. 1.6). Во время установки SQL Server создается несколько сис-
темных баз данных, хранящих системные данные и обслуживающих внутренние задачи.
После установки вы сможете создавать собственные пользовательские базы данных, кото-
рые будут хранить данные приложения.
Экземпляр
Рис. 1 .6. Базы данных
24
Глава 1
К системным базам данных, создаваемым программой установки сервера, относятся сле-
дующие: master, Resource, model, tempdb и msdb.
П master. База данных master хранит метаданные, относящиеся к экземпляру сервера, его
конфигурацию, сведения обо всех базах данных экземпляра и установочную информа-
цию.
П Resource. База данных Resource была добавлена в версию SQL Server 2005 и содержит
все системные объекты. Когда вы запрашиваете сведения о метаданных в базе данных,
они кажутся локальными по отношению к базе данных, но на практике они хранятся в
базе данных Resource.
П model. База данных model используется как шаблон для новых баз данных. Любая соз-
даваемая вами база «данных сначала создается как копия model. Поэтому, если вы хоти-
те, чтобы определенные объекты (например, типы данных) появлялись во всех созда-
ваемых вами новых базах данных, или какие-то свойства базы данных были настроены
определенным образом во всех новых базах данных, то вы должны создать такие объек-
ты и настроить соответствующим образом свойства в базе данных model. Имейте в ви-
ду, что изменения, которые вы внесете в базу данных model, никак не отразятся на уже
существующих базах данных, они коснуться только новых баз данных, которые вы соз-
дадите в дальнейшем.
•
tempdb. В базе данных tempdb SQL Server хранит временные данные, такие как рабочие
таблицы, область сортировки, сведения для контроля версий строк и т. д. SQL Server по-
зволяет вам создавать временные таблицы для собственных нужд, которые, как правило,
хранятся в tempdb. Учтите, что эта база данных уничтожается и создается как копия
model при каждом запуске экземпляра SQL Server. По этой причине, если мне нужно
создать объекты для тестирования и я не хочу, чтобы они оставались в базе данных, я
обычно создаю их в tempdb. Я знаю, что если даже забуду вычистить их, они будут ав-
томатически удалены при следующем запуске сервера.
П msdb. В базе данных msdb хранит свои данные служба, именуемая SQL Server Agent.
SQL Server Agent отвечает за автоматизацию, включающую такие объекты, как задания,
расписания и оповещения. SQL Server Agent — это служба, также отвечающая за репли-
кацию. База данных msdb, кроме того, хранит данные, касающиеся других средств SQL
Server, например, Database Mail и Service Broker.
Вы можете создать столько пользовательских баз данных, сколько вам потребуется в одном
экземпляре сервера. Пользовательская база данных будет хранить объекты и данные для
приложения.
На уровне базы данных можно задать свойство collation (подборка), которое определяет
языковую поддержку, восприимчивость к регистру символов и порядок сортировки сим-
вольных данных в этой базе данных. Если не задавать свойство collation для базы данных во
время ее создания, будет применен вариант подборки, принятый по умолчанию (выбранный
при установке) в данном экземпляре.
Для запуска программного кода на языке T-SQL, относящегося к базе данных, клиентское
приложение должно подключиться к экземпляру SQL Server и установить связь с соответст-
вующей базой данных или использовать ее.
Из соображений безопасности, для того чтобы у вас появилась возможность подключения к
экземпляру SQL Server, администратор баз данных (DBA) должен создать для вас регист-
рацию (login). Регистрацию можно связать с вашими именем пользователя и паролем в ОС
Основы построения запросов и программирования на языке T-SQL
25
Windows, и в этом случае она будет называться аутентифицируемой (проверяемой) Win-
dows. При таком варианте регистрации вам не нужно будет вводить регистрационное имя и
пароль для подключения к SQL Server, поскольку вы уже предоставили их, когда регистри-
ровались в ОС Windows. Регистрация может не зависеть от вашего имени пользователя и
пароля в Windows, в таком случае ее называют аутентифицируемой SQL Server. При под-
ключении к серверу в случае регистрации, аутентифицируемой SQL Server, вам придется
предъявить имя регистрации и пароль.
Для того чтобы вы получили доступ к базе данных, администратор баз данных должен пре-
вратить вашу регистрацию в database user (пользователя базы данных) для каждой базы
данных, техническим обслуживанием которой вы занимаетесь.
До настоящего момента я в основном обсуждал логические аспекты баз данных. На рис. 1.7
показана схема физической структуры базы данных.
Пользовательская
база данных
Рис. 1.7. Физическая схема базы данных
База данных формируется из файла данных и файла журнала транзакций. Когда вы создаете
базу данных, то можете определить разные свойства для каждого файла, включая имя фай-
ла, его местоположение, начальный размер, максимальный размер и размер его автоприра-
щения. У каждой базы данных должен быть хотя бы один файл данных и один файл журна-
ла транзакций (как задано по умолчанию в SQL Server). В файлах данных хранятся данные
объектов, а в файлах журнала транзакций содержится информация, которая необходима
SQL Server для поддержки транзакций.
Несмотря на то, что SQL Server может записывать в несколько файлов данных параллельно,
в каждый момент времени он может писать только в один файл журнала. Следовательно, в
26
Глава 1
отличие от файлов данных наличие нескольких файлов журнала не принесет повышения
производительности. Добавить новый файл журнала вам, возможно, придется, если диск, на
котором хранится файл, будет заполнен.
Файлы данных объединены в логические группы, называемые файловыми группами. Фай-
ловая группа — это место назначения при создании объекта, например, таблицы или индек-
са. Данные объектов распределены между файлами, принадлежащими заданной файловой
группе. Файловые группы — это ваш способ контроля физического местонахождения ваших
объектов. У базы данных должна быть, как минимум, одна файловая группа, называемая
PRIMARY (основная), и, возможно, другие файловые группы. Файловая группа PRIMARY
содержит основной файл данных (с расширением mdf) и системный каталог базы данных.
При необходимости в группу PRIMARY можно вставлять дополнительные файлы данных (с
расширением ndf). Пользовательские файловые группы содержат только дополнительные
файлы данных. Вы можете указать, какую файловую группу пометить как группу по умол-
чанию. Если в операторе создания объекта явно не задана файловая группа, объект создает-
ся в файловой группе, используемой по умолчанию.
РАСШИРЕНИЯ ФАЙЛОВ MDF, LDF И NDF
Расширения файлов баз данных mdf и ldf вполне понятны. Расширение mdf — со-
кращение от Master Data File, т. е. основной файл данных (не путайте с базой
данных master), a ldf— сокращение от Log Data File, т. е. файл журнала. В одной
из легенд говорится о том, что при выборе расширения для дополнительных
файлов данных кто-то из разработчиков, шутя, предложил использовать ndf, как
сокращение от Not Master Data File (неосновной файл данных), и предложение
было принято.
Схемы и объекты
Когда ранее я говорил о том, что базу данных можно представить себе как контейнер объек-
тов, я немного упрощал картину. Как показано на рис. 1.8, база данных включает в себя
схемы, а схемы содержат объекты. Именно схемы служат контейнерами объектов, таких как
таблицы, представления, хранимые процедуры и др.
Вы можете управлять правами доступа на уровне схемы. Например, вы можете предоста-
вить пользователю права на выполнение инструкции SELECT в схеме, разрешив ему запра-
шивать данные их всех объектов схемы. Таким образом, безопасность — один из важных
аспектов при определении способов организации объектов в схемах.
Кроме того, схема — это пространство имен, она используется как префикс в имени объек-
та. Например, у вас в схеме с именем Sales (Продажи) есть таблица Orders (Заказы).
Уточненное имя объекта с включением имени схемы (также называемое составным) —
Sales .Orders. Если при ссылке на объект опустить имя схемы, SQL Server запустит про-
цесс разрешения имени схемы, который включает проверку существования объекта в поль-
зовательской схеме, применяемой по умолчанию, при его отсутствии, дальнейшую проверку
существования объекта в схеме dbo. Рекомендуется в программном коде при ссылке на объ-
екты всегда использовать составные имена. С процессом разрешения имени объекта, если
оно явно не определено, связаны кое-какие незначительные расходы. Они так малы, как мо-
гут быть малы дополнительные расходы, но не лучше ли избежать их? Кроме того, если в
Основы построения запросов и программирования на языке T-SQL
27
разных схемах есть объекты с одним и тем же именем, вы можете в результате получить
совсем не тот объект, который хотели.
Создание таблиц
и определение целостности данных
В этом разделе рассматриваются основы создания таблиц и определения с помощью языка
T-SQL целостности данных. Выполняйте без ограничений предлагаемые примеры про-
граммного кода в вашей рабочей среде. Если вы до сих пор не знаете, как выполнять про-
граммный код в SQL Server, приложение 1 поможет вам.
Как я упоминал ранее, книга в основном посвящена языку DML, а не DDL. Однако важно,
чтобы вы поняли, как создавать таблицы и определять целостность данных. Я не буду уг-
лубляться в детали, а предложу лишь краткое описание самых важных основ.
Прежде чем рассматривать программный код для создания таблицы, вспомните о том, что
таблицы размещаются в схемах, а схемы — в базах данных. В моих примерах используется
база данных testdb и схема dbo. Создать в вашей рабочей среде базу данных testdb можно с
помощью следующего программного кода:
IF DB_ID (1 testdb1) IS NULL
CREATE DATABASE testdb;
Если базы данных с именем testdb не существует, приведенный код создаст новую базу дан-
ных. Функция DB_ID принимает имя базы данных в качестве входного параметра и возвра-
щает внутренний ID базы данных. Если базы данных с именем входного параметра не суще-
ствует, функция возвращает значение NULL. ЭТО простой способ проверить наличие
заданной базы данных. Имейте в виду, что в этой простой инструкции CREATE DATABASE Я
полагался на умолчания в отношении установочных параметров файла, таких как его место-
нахождение и начальный размер. В реальной рабочей среде вы, как правило, будете явно
28
Глава 1
задавать все необходимые установочные параметры базы данных и файлов, но нам установ-
ки по умолчанию вполне подходят.
Я буду пользоваться схемой с именем dbo, которая создается автоматически в каждой базе
данных и, кроме того, используется как схема по умолчанию в тех случаях, когда пользователи
явно не связаны с какой-либо другой схемой.
Создание таблиц
Следующий программный код создает в базе данных testdb таблицу Employees (Сотрудни-
ки).
USE testdb;
IF OBJECT_ID(1dbo.Employees\ ' U •) IS NOT NULL
DROP TABLE dbo.Employees;
CREATE TABLE dbo.Employees
(
empid
INT NOT
NULL,
firstname VARCHAR(30) NOT NULL,
lastname VARCHAR(30) NOT NULL,
hiredate DATE
NOT NULL,
mgrid
INT
NULL,
ssn
VARCHAR (20) NOT NULL,
salary
MONEY
NOT NULL
);
Инструкция USE изменяет текущую связь с базой данных на связь с testdb. Включение инст-
рукции USE в сценарии создания объектов очень важно, т. к. гарантирует создание объектов
в требуемой базе данных.
Инструкция IF запускает функцию OBJECT ID, которая в качестве входных параметров
принимает имя объекта и его тип. Тип 'и
1
представляет таблицу пользователя. Данная
функция возвращает внутренний ID объекта, если объект с заданными именем и типом уже
существует, и значение NULL в противном случае. Если функция возвращает NULL, вы знае-
те, что объекта нет. В нашем случае программный код удаляет существующую таблицу и
затем создает новую. Конечно, можно выбрать и другой алгоритм, например, просто не соз-
давать объект, если он уже существует.
Инструкция CREATE TABLE отвечает за определение того, что раньше я называл телом от-
ношения. В ней вы задаете имя таблицы и в круглых скобках определение ее атрибуты
(столбцы).
Обратите внимание на применение составного имени dbo.Employees в качестве имени
таблицы, как рекомендовалось ранее. Если опустить имя схемы, SQL Server свяжет схему,
используемую по умолчанию для имени пользователя, выполняющего программный код.
Основы построения запросов и программирования на языке T-SQL
29
Для каждого атрибута вы задаете его имя, тип данных и допустимость значений NULL.
В нашей таблице Employees (Сотрудники) атрибуты empid (ID сотрудника) и mgrid (ID
руководителя) определены как INT (четырехбайтовые целые); firstname (имя), last name
(фамилия) и ssn (номер социального обеспечения) — как VARCHAR (символьные строки пе-
ременной длины с указанием максимально возможного количества символов); у атрибута
hiredate (дата приема на работу) тип данных DATE, а у атрибута salary — MONEY. Имейте
в виду, что тип данных DATE был добавлен в версию SQL Server 2008. Если вы работаете с
более ранней версией сервера, используйте вместо него типы данных DATETIME ИЛИ
SMALLDATETIME.
Если вы явно не задаете в столбце допустимость значений NULL, SQL Server будет вынуж-
ден полагаться на установки по умолчанию. Стандарт ANSI требует, чтобы применялось
определение NULL (допустимы значения NULL), если их допустимость в столбце явно не за-
дана, но у SQL Server есть установочные параметры, которые могут изменять это поведение.
Я настоятельно рекомендую применять явные определения и не полагаться на установки по
умолчанию. Я также настоятельно советую определять столбец как NOT NULL, если у вас
нет веской причины разрешить значения NULL. ЕСЛИ атрибут не поддерживает значения
NULL, и вы не подкрепили это с помощью ограничения NOT NULL, можете не сомневаться —
значения NULL В нем появятся. В нашей таблице Employees все столбцы определены как
NOT NULL за исключением столбца mgrid. NULL В столбце mgrid отражает отсутствие у
сотрудника руководителя, как в случае CEO (Chief Executive Officer, главный исполнитель-
ный директор) учреждения.
СТИЛЬ ПРОГРАММНОГО КОДА
Вам следует ознакомиться с несколькими общими замечаниями, касающимися
стиля оформления программного кода, использования пропусков и отступов
(пробелов, табуляций, переходов на новую строку и т. д.) и точек с запятой.
Я не знаю всех формальных правил оформления программного кода. Мой со-
вет— используйте стиль, который удобен вам и вашим коллегам-разработ-
чикам. В конечном счете, важнее всего логичность и читабельность, удобство
сопровождения и корректировки вашего кода. Я постарался отражать эти аспек-
ты в моем программном коде на протяжении всей книги.
Язык T-SQL позволяет свободно обращаться с отступами и пробелами в вашем
программном коде. Этим можно воспользоваться и улучшить читабельность про-
граммы. Например, я мог бы записать программный код из предыдущего раздела
в одну строку. Но он не был бы так нагляден, как текст, разбитый на несколько
строк с применением отступов.
Практика применения точки с запятой для завершения инструкций стандартна и в
некоторых СУРБД является обязательным требованием. В SQL Server от вас
лишь в определенных ситуациях требуется применение точки с запятой, но в тех
случаях, когда точка с запятой не требуется, она не мешает. Я настоятельно ре-
комендую взять за правило завершать все инструкции точкой с запятой. Это
улучшит читабельность вашего программного кода и порой убережет вас от огор-
чений. (Когда точка с запятой требуется, но пропущена, сообщение об ошибке,
выводимое SQL Server, не всегда очень понятно.)
30
Глава 1
Определение целостности данных
Как уже упоминалось ранее, одно из величайших достоинств реляционной модели заключа-
ется в том, что целостность данных— неотъемлемая часть модели. Целостность данных,
реализованная как компонент модели, а именно как компонент определений таблицы счита-
ется декларативной целостностью данных. Целостность данных, воплощаемая в жизнь с
помощью программного кода, такого как хранимые процедуры или триггеры, называется
процедурной целостностью данных.
Тип данных и выбор допустимости или недопустимости значений NULL для атрибутов и да-
же сама по себе модель— примеры ограничений и уточнений, обеспечивающих деклара-
тивную целостность данных. В этом разделе я рассмотрю другие примеры декларативных
ограничений, включая ограничения с помощью первичных ключей, обеспечения уникально-
сти, внешних ключей, условных выражений и значений по умолчанию. Вы можете опреде-
лять такие ограничения при создании таблицы, включив их в инструкцию CREATE TABLE,
или после того, как таблица уже создана с помощью инструкции ALTER TABLE. Ограниче-
ния всех типов за исключением ограничения значением по умолчанию можно определять
как составные, т. е. базирующиеся на нескольких атрибутах.
Ограничения PRIMARY KEY
Ограничение с помощью первичного ключа обеспечивает уникальность строк и, кроме того,
запрещает значения NULL в атрибутах с таким ограничением. Любой уникальный набор зна-
чений в атрибутах с ограничением может появиться в таблице только один раз, другими
словами, только в одной строке. Попытка задать ограничение в виде первичного ключа в
столбце, допускающем значения NULL, будет отвергнута СУРБД. У каждой таблицы может
быть только один первичный ключ.
Далее приведен пример определения ограничения в виде первичного ключа в столбце empid
(id сотрудника) таблицы Employees (Сотрудники), которую вы создали ранее:
ALTER TABLE dbo.Employees
ADD CONSTRAINT PK_Employees
PRIMARY KEY(empid);
С установленным ограничением PRIMARY KEY вы можете быть уверены в том, что все зна-
чения empid будут уникальны и известны. Попытка вставить или обновить строку, в кото-
рой нарушается данное ограничение, будет отвергнута СУРБД и приведет к появлению
ошибки.
Для обеспечения уникальности логического ограничения в виде первичного ключа SQL Server
за кадром создаст уникальный индекс. Уникальный индекс — это средство, применяемое SQL
Server для обеспечения уникальности.
Ограничения UNIQUE
Ограничения типа UNIQUE обеспечивают уникальность строк, давая возможность реализо-
вать концепцию альтернативных ключей, исходя из реляционной модели в вашей базе дан-
ных. В отличие от ограничения в виде первичных ключей можно определить несколько ог-
Основы построения запросов и программирования на языке T-SQL
31
раничений UNIQUE В ОДНОЙ И ТОЙ же таблице. Кроме того, это ограничение подходит не
только для столбцов, определенных как NOT NULL. В языке SQL стандарта ANSI есть два
вида ограничений UNIQUE: ОДНО ИЗ них допускает единственное значение NULL В столбце с
ограничением UNIQUE, а другое допускает наличие множественных значений NULL. В SQL
Server реализован только первый вид ограничения.
В следующем фрагменте программного кода определяется ограничение UNIQUE ДЛЯ столбца
ssn (номер социального обеспечения) таблицы Employees (Сотрудники):
ALTER TABLE dbo.Employees
ADD CONSTRAINT UNQ_Employees_ssn
UNIQUE(ssn);
Как и в случае ограничения в виде первичного ключа, SQL Server создаст за кадром уни-
кальный индекс, обеспечивающий на физическом уровне логическое ограничение типа
UNIQUE.
Ограничения FOREIGN KEY
Внешний ключ обеспечивает ссылочную целостность. Это ограничение определяется для
набора атрибутов в таблице, называемой ссылающейся, и указывает на набор атрибутов
потенциального ключа (первичного ключа или ограничения UNIQUE) В так называемой
справочной таблице. Имейте в виду, что ссылающаяся и справочная таблицы могут быть
одной и той же таблицей. Задача ограничения в виде внешнего ключа— ограничить домен
значений, допустимых в столбцах внешнего ключа, только теми, которые присутствуют в
столбцах справочной таблицы.
В приведенном далее фрагменте программного кода создается таблица Orders (Заказы) со
столбцом orderid (id заказа) в качестве первичного ключа:
IF OB JECT_ID (' dbo. Orders
4
, 'U') IS NOT NULL
DROP TABLE dbo.Orders;
CREATE TABLE dbo.Orders
(
orderid INT NOT
NULL,
empid
INT NOT
NULL,
custid VARCHAR(10) NOT NULL,
orderts DATETIME
NOT NULL,
qty
INT
NOT NULL,
CONSTRAINT PK_Orders
PRIMARY KEY(OrderlD)
);
Допустим, вы хотите реализовать правило целостности, ограничивающее домен значений,
встречающихся в столбце empid (id сотрудника) таблицы Orders (Заказы), только значе-
ниями, имеющимися в столбце empid таблицы Employees (Сотрудники). Добиться этого
32
Глава 1
можно, определив ограничение в виде внешнего ключа для столбца empid в таблице
Orders, указывающее на столбец empid в таблице Employees следующим образом:
ALTER TABLE dbo.Orders
ADD CONSTRAINT FK_Orders_Employees
FOREIGN KEY(empid)
REFERENCES dbo.Employees(empid);
Аналогичным образом, если вы хотите ограничить домен значений, поддерживаемых в
столбце mgrid (id руководителя) таблицы Employees (Сотрудники), только значениями,
встречающимися в столбце empid (id сотрудника) этой же таблицы, сделать это можно, до-
бавив следующий внешний ключ:
ALTER TABLE dbo.Employees
ADD CONSTRAINT FK_Employees_Employees
FOREIGN KEY(mgrid)
REFERENCES Employees(empid);
Обратите внимание на то, что в столбцах внешнего ключа (в последнем примере mgrid)
допускаются значения NULL, даже если таких значений нет в столбцах потенциального клю-
ча справочной таблицы.
Два предыдущих примера— базовые определения внешних ключей, обеспечивающих ссылоч-
ное действие, называемое no action (выполнить откат). Это действие означает, что попыт-
ка удалить строки справочной таблицы или обновить ее атрибуты потенциальных ключей
будет отвергнута, если в ссылающейся таблице есть связанные строки. Например, если вы
попробуете удалить строку сотрудника из таблицы Employees (Сотрудники), когда в табли-
це Orders (Заказы) есть связанные с этим сотрудником заказы, СУРБД отвергнет такую
попытку и выведет сообщение об ошибке.
Вы можете определять внешние ключи с действиями, позволяющими удачно завершить по-
добные попытки (удалить строки из справочной таблицы или обновить справочные атрибу-
ты потенциальных ключей, когда в ссылающейся таблице есть связанные с ними строки).
Можно включить в определение внешнего ключа варианты ON DELETE И ON UPDATE С та-
кими действиями, как CASCADE, SET DEFAULT И SET NULL. Действие CASCADE означает, что
операция (удаление или обновление) будет последовательно применяться к связанным стро-
кам. Например, в случае ON DELETE CASCADE, когда вы удаляете строку из справочной таб-
лицы, СУРБД удалит связанные с ней строки из ссылающейся таблицы. Действия SET
DEFAULT и SET NULL означают, что компенсирующая операция установит атрибуты внеш-
него ключа в связанных строках равными значению столбца, используемому по умолчанию,
или значению NULL соответственно. Учтите, что независимо от выбранного вами действия
ссылающаяся таблица будет иметь только висячие или несвязанные строки (orphaned rows) в
случае исключения значений NULL, О котором я упоминал ранее.
Ограничения CHECK
Ограничение CHECK позволяет определить логическое выражение (предикат), которому
должна удовлетворять строка для того, чтобы быть включенной в таблицу или измененной.
Основы построения запросов и программирования на языке T-SQL
33
Например, следующее ограничение типа CHECK гарантирует наличие только положительных
значений в столбце salary (заработная плата) таблицы Employees (Сотрудники):
ALTER TABLE dbo .Enployees
ADD CONSTRAINT CHK_Employees_salary
CHECK(salary > 0) ;
Попытка вставить или обновить строку с отрицательным или нулевым значением заработ-
ной платы будет отвергнута СУРБД. Имейте в виду, что ограничение средствами проверки
логического выражения отвергает попытку вставить или обновить строку, если вычисляемое
значение выражения равно FALSE. Изменение будет принято, если вычисляемое значение
предиката равно TRUE или UNKNOWN (неизвестное). Например, заработная плата-1000 будет
отвергнута, а зарплаты 50 000 и NULL обе будут приняты.
Вставляя ограничения CHECK и FOREIGN KEY, вы можете задать параметр WITH NOCHECK,
сообщая тем самым СУРБД, что вы хотите обойти проверку ограничения для существую-
щих данных. Этот прием считается неудачным, поскольку вы не можете быть уверены в
непротиворечивости ваших данных. Вы также можете включать или отключать имеющиеся
ограничения CHECK и FOREIGN KEY.
Ограничения DEFAULT
Ограничение типа DEFAULT связано с конкретным атрибутом. Оно представляет собой вы-
ражение, применяемое как значение по умолчанию, когда при вставке строки вы явно не
задаете значение атрибута. Например, в следующем программном коде для атрибута
orderts (представляющего маркер даты и времени заказа) определено ограничение типа
DEFAULT:
ALTER TABLE dbo.Orders
ADD CONSTRAINT DFT_Orders_orderts
DEFAULT(CURRENT_TIMESTAMP) FOR orderts;
Выражение DEFAULT запускает функцию CURRENTJTIMESTAMP, которая возвращает теку-
щие дату и время. После того как ограничение DEFAULT определено, при каждом добавле-
нии строки в таблицу Orders, если значение атрибута orderts явно не задано, SQL Server
будет устанавливать его значение равным CURRENT_TIMESTAMP.
Резюме
В этой главе дан краткий обзор основ формирования запросов и программирования на язы-
ке T-SQL. В ней представлены теоретические основы, приведены строгие основания, на ко-
торых базируется T-SQL. Глава знакомит вас с архитектурой SQL Server и включает разде-
лы, показывающие, как применять язык T-SQL для создания таблиц и определения
целостности данных. Я надеюсь, что теперь вы понимаете, что у языка SQL есть нечто осо-
бое, это не просто еще один язык, который следует выучить для расширения кругозора. Эта
глава познакомила вас с фундаментальными концепциями, а настоящее путешествие нач-
нется только сейчас.
ГЛАВА 2
Однотабличные запросы
В этой главе приводятся основные сведения об инструкции SELECT, пока на примере одно-
табличных запросов. Глава начинается с описания логического процесса выполнения запро-
са, а именно последовательности логических стадий формирования корректного результи-
рующего набора заданного запроса SELECT. Далее обсуждаются другие особенности
однотабличных запросов, включая операции, значение NULL, обработку символьных данных
и данных, представляющих даты и время суток, ранжирование, выражение CASE И запраши-
ваемые метаданные. Во многих примерах программного кода и упражнениях книги исполь-
зуется учебная база данных TSQLFundamentals2008. В приложении ! вы сможете найти ин-
струкции по загрузке и установке этой базы данных.
Элементы инструкции SELECT
Назначение инструкции SELECT — запрос данных из таблицы, некоторая логическая обра-
ботка и возврат результата. В этом разделе я расскажу о стадиях обработки запроса— опи-
шу порядок обработки различных условий, входящих в инструкцию, и события, происходя-
щие на каждой стадии выполнения запроса.
Под "логической обработкой запроса" я понимаю абстрактную процедуру, которая в языке
ANSI SQL определяется как необходимость обработки запроса и получения конечного ре-
зультата. Не беспокойтесь, если некоторые стадии логической обработки, которые будут
описаны здесь, покажутся неэффективными. Процессор или механизм баз данных програм-
мы Microsoft SQL Server не должен строго следовать логической обработке запроса, физи-
чески он может обрабатывать запрос по-другому, изменяя порядок стадий обработки при
условии, что конечный результат будет таким же, как предписано логической обработкой
запроса. SQL Server может (и часто делает это) в ходе физической обработки запроса вы-
полнять много оптимизаций.
Для описания логической обработки запроса и различных элементов, входящих в инструк-
цию SELECT, Я использую как пример запрос из листинга 2.1. Сейчас не старайтесь понять,
что делает этот запрос. Я буду пояснять каждый элемент, применяемый в запросе, и посте-
пенно сформирую этот запрос.
Однотабличные запросы
35
Листинг 2.1. Пример запроса
USE TSQLFundamentals2008;
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
WHERE custid =71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1
SELECT enpid, YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
ORDER BY empid, orderyear4
Программный код начинается с инструкции USE, которая в текущем сеансе работы связыва-
ет вас с учебной базой данных TSQLFundamentals2008. Если в текущем сеансе вы уже уста-
новили связь с нужной вам базой данных, инструкция USE не нужна
Прежде чем перейти к подробному описанию каждой стадии выполнения инструкции
SELECT, отметим порядок, в котором логически обрабатываются отдельные элементы инст-
рукции. В большинстве языков программирования строки программного кода обрабатыва-
ются в порядке их написания. В языке SQL все иначе. Несмотря на то, что элемент (коман-
да) SELECT появляется в запросе первым, логически он обрабатывается почти последним.
Элементы инструкции логически обрабатываются в следующем порядке:
1. FROM.
2. WHERE.
3. GROUP BY.
4. HAVING.
5. SELECT.
6. ORDER BY.
Итак, несмотря на то, что синтаксически наш пример запроса из листинга 2.1 начинается с
элемента SELECT, логические составляющие инструкции обрабатываются в такой последо-
вательности:
FROM Sales.Orders
WHERE custid =71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
ORDER BY empid, orderyear
Или в более понятном виде инструкция выполняет следующие действия:
1. Запрашивает строки из таблицы Sales. Orders.
2. Отбирает только те строки, в которых идентификатор клиента равен 71.
3. Группирует заказы по идентификаторам сотрудников и году заказа.
36
Глава 1
4. Отбирает только группы (ID сотрудника и год заказа), имеющие более одного заказа.
5. Для каждой группы ID сотрудника выбирает (возвращает) год заказа и количество заказов.
6. Упорядочивает (сортирует) строки в выходном наборе no ID сотрудника и году заказа.
К сожалению, мы не можем написать запрос в логически правильной последовательности.
Мы должны начать с команды SELECT, как показано в листинге 2.1.
Теперь, когда вы узнали о порядке, в котором логически обрабатываются элементы запроса,
можно переходить к следующим разделам, подробно поясняющим каждую стадию обработки.
Обсуждая логическую обработку запроса, я ссылаюсь на условия или элементы запроса и на
стадии обработки запроса (например, элемент WHERE И стадия WHERE). Элемент или условие
запроса
1
—
это синтаксический компонент запроса, поэтому, обсуждая синтаксис составной
части запроса я обычно применяю термин "элемент" или "условие" (например, "в элементе
WHERE вы задаете предикат"). Когда же обсуждается логическая манипуляция как часть ло-
гической обработки запроса, я, как правило, использую термин "стадия" (например, "стадия
WHERE возвращает строки, для которых вычисляемое значение предиката равно TRUE").
Напоминаю о своей рекомендации из предыдущей главы, касающейся использования точки
с запятой для завершения инструкций. SQL Server не требует завершения всех инструкций
точкой с запятой. Она необходима только в определенных случаях, там, где без ее примене-
ния смысл программного кода может быть неоднозначным. Но я рекомендую завершать все
инструкции точкой с запятой, потому что это стандартный стиль, он облегчает чтение про-
граммного кода и вполне вероятно, что в будущем SQL Server будет требовать ее примене-
ния в большем количестве случаев. В настоящее время присутствие точки с запятой там, где
она не требуется, не вредит. Поэтому я советую приобрести привычку завершать все инст-
рукции точкой с запятой.
Элемент FROM
Элемент FROM логически обрабатывается самым первым. В нем вы задаете имена таблиц,
которые хотите запросить, и табличные операции, которые хотите применить к этим табли-
цам. В этой главе не обсуждаются табличные операции, я буду обсуждать их в главе 5. Пока
в элементе FROM просто задается имя запрашиваемой таблицы. В примере запроса из лис-
тинга 2.1 запрашивается таблица Orders (Заказы) в схеме Sales (Продажи), в которой най-
дены 830 строк, приведенных далее.
FROM Sales.Orders
Напоминаю о рекомендации, данной в предыдущей главе и касающейся обязательного ис-
пользования составных имен объектов в вашем программном коде. Если вы не зададите имя
схемы явно, SQL Server должен будет неявно разрешать вопрос об имени схемы. Это приво-
дит к незначительным затратам и окончательное решение о том, какой объект использовать
в случае неоднозначности, остается за СУРБД SQL Server. Применяя явное указание имени,
вы гарантируете получение именно того объекта, который и намерены были обработать, и
избавляете себя от ненужных накладных расходов.
1
Часто компоненты инструкции называют предложениями или фразами, и то, и другое не соот-
ветствует значению этих слов в русском языке. По-моему инструкции SQL состоят из команды и
ряда уточняющих условий (где искать, как группировать и т. д.). — Прим. пер.
Однотабличные запросы
37
Для того чтобы вернуть все строки таблицы без какой-либо специальной обработки, вам
нужен запрос с единственным условием FROM, где задана запрашиваемая таблица, и команда
SELECT, где задаются атрибуты, которые вы хотите получить. Например, в следующей ин-
струкции запрашиваются строки из таблицы Orders в схеме Sales с выбранными атрибу-
тами orderid (id заказа), custid (id клиента), empid (id сотрудника), orderdate (дата за-
каза) и freight (стоимость перевозки).
SELECT orderid, custid, empid, orderdate, freight
FROM Sales.Orders;
Далее в сокращенном виде представлен вывод этой инструкции:
orderid
custid
empid
orderdate
freight
10248
85
5
2006-07-04 00:00:00.000
32.38
10249
79
6
2006-07-05 00:00:00.000
11.61
10250
34
4
2006-07-08 00:00:00.000
65.83
10251
84
3
2006-07-08 00:00:00.000
41.34
10252
76
4
2006-07-09 00:00:00.000
51.30
10253
34
3
2006-07-10 00:00:00.000
58.17
10254
14
5
2006-07-11 00:00:00.000
22.98
10255
68
9
2006-07-12 00:00:00.000
148.33
10256
88
3
2006-07-15 00:00:00.000
13.97
10257
35
4
2006-07-16 00:00:00.000
81.91
(830 row(s) affected)
Несмотря на то, что создается впечатление некоторой упорядоченности результата, возвра-
щаемого запросом, это не всегда так. Я подробно остановлюсь на этом вопросе в
разд.
"Элемент SELECT" и "Элемент ORDER BY" далее в этой главе.
ОГРАНИЧЕНИЕ ИМЕН
ИДЕНТИФИКАТОРОВ
До тех пор пока идентификаторы в вашем запросе соответствуют формату обык-
новенных идентификаторов, вам не нужно ограничивать идентификационные
имена схем, таблиц и столбцов. Правила форматирования обыкновенных иден-
тификаторов можно найти в интерактивном справочном руководстве SQL Server
Books Online в разд. "Identifiers" ("Идентификаторы"). Если же идентификатор не
обычный, например, содержит пробелы или специальные символы, начинается с
цифры или совпадает с зарезервированным ключевым словом, его следует огра-
ничить или выделить. Сделать это можно двумя способами. Вариант SQL стан-
дарта ANSI требует применения двойных кавычек, например, "Order Details".
В SQL Server используется собственная форма ограничения — квадратные скоб-
ки, например [Order Details], но поддерживается и стандартный вариант.
В случае идентификаторов, соответствующих формату обыкновенных, ограничи-
тели необязательны. Например, таблицу с именем Order Details, размещенную
В схеме Sales, можно задать как Sales. "Order
Details" или как
"Sales". "Order Details". Мое личное убеждение— не стоит применять огра-
ничители без необходимости, потому что они загромождают программный код.
38
Глава 1
Если присвоение имен входит в вашу компетенцию, я советую всегда использо-
вать обычные имена, например, OrderDetails вместо Order Details.
Элемент WHERE
В условии WHERE вы задаете предикат или логическое выражение для отбора строк, возвра-
щенных стадией FROM. Стадия WHERE передаст в последующую стадию логической обра-
ботки запроса только те строки, для которых вычисляемое логическое выражение равно
TRUE. В примере запроса из листинга 2.1 условие WHERE отбирает только заказы, помещен-
ные клиентом 71.
FROM Sales.Orders
WHERE custid = 71
Из 830 строк, возвращенных стадией FROM, стадия WHERE выбирает 31 строку, в которых
идентификатор клиента равен 71. Для того чтобы увидеть, какие строки вы получите после
применения фильтра custid = 71, выполните следующий запрос:
SELECT orderid, empidj orderdate, freight
fc'ROM Sales.Orders
WHERE custid =71;
Этот запрос вернет следующий набор строк:
orderid
empid
orderdate
freight
10324
9
2006-10-08 00:00:00.000
214.27
10393
1
2006-12-25 00:00:00.000
126.56
10398
2
2006-12-30 00:00:00.000
89.16
10440
4
2007-02-10 00:00:00.000
86.53
10452
8
2007-02-20 00:00:00.000
140.26
10510
6
2007-04-18 00:00:00.000
367.63
10555
6
2007-06 -02 00:00:00.000
252.49
10603
8
2007-07-18 00:00:00.000
48.77
10607
5
2007-07-22 00:00:00.000
200.24
10612
1
2007-07-28 00:00:00.000
544.08
10627
8
2007-08 -11 00:00:00.000
107.46
10657
2
2007-09 -04 00:00:00.000
352.69
10678
7
2007-09-23 00:00:00.000
388.98
10700
3
2007-10-10 00:00:00.000
65.10
10711
5
2007-10-21 00:00:00.000
52.41
10713
1
2007-10-22 00:00:00.000
167.05
10714
5
2007-10-22 00:00:00.000
24.49
10722
8
2007-10-29 00:00:00.000
74.58
10748
3
2007-11-20 00:00:00.000
232.55
Однотабличные запросы
39
10757
6
2007-11 -27 00:00:00.ООО
8.19
10815
2
2008-01-05 00:00:00.000
14.62
10847
4
2008-01-22 00:00:00.000
487.57
10882
4
2008-02-11 00:00:00.000
23.10
10894
1
2008-02-18 00:00:00.000
116.13
10941
7
2008-03-11 00:00:00.ООО
400.81
10983
2
2008-03 -27 00:00:00.000
657.54
10984
1
2008-03 -30 00:00:00.,000
211.22
11002
4
2008-04-06 00:00:00.,000
141.16
11030
7
2008-04-17 00:00:00.,000
830.75
11031
6
2008-04-17 00:00:00..000
227.22
11064
1
2008-05-01 00:00:00.,000
30.09
(31 row(s) affected)
Условие WHERE имеет важное значение, когда дело доходит до выполнения запроса. На ос-
новании содержимого выражения отбора или фильтра SQL Server повышает производитель-
ность за счет применения индексов для доступа к данным. С помощью индексов SQL Server
может иногда получить требуемые данные, затратив гораздо меньше усилий, чем в случае
последовательного просмотра всей таблицы. Кроме того, фильтры запроса снижают сетевой
трафик, создаваемый возвратом всех возможных строк автору запроса и фильтрацией их на
стороне клиента.
Я уже упоминал о том, что стадия WHERE возвращает только те строки, для которых вычис-
ляемое логическое выражение равно TRUE. Всегда помните о том, что в языке T-SQL при-
меняется логика троичных предикатов, в которой логические выражения могут принимать
значения TRUE, FALSE или UNKNOWN. В троичной логике утверждение "возвращает TRUE" —
не то же самое, что утверждение "не возвращает FALSE". Стадия WHERE выбирает строки,
для которых вычисляемое логическое выражение равно TRUE, И не возвращает строки, для
которых это выражение равно FALSE или UNKNOWN. В разд. "Значение NULL" далее в этой
главе я вернусь к обсуждению этого вопроса.
Элемент GROUP BY
Стадия GROUP BY позволяет организовать группы из строк, возвращенных предыдущей ста-
дией логической обработки запроса. Группы определяются элементами, которые задаются в
условии GROUP BY. Например, в запросе из листинга 2.1 элемент GROUP BY содержит empid
(id сотрудника) и YEAR (orderdate).
FROM Sales.Orders
WHERE custid =71
GROUP BY empid, YEAR (orderdate)
Это означает, что условие GROUP BY формирует группу для каждой уникальной комбинации
идентификатора сотрудника и значений года заказа, которые встречаются в данных, воз-
вращенных стадией WHERE. Выражение YEAR (orderdate) вызывает функцию YEAR для
возврата только года из столбца с датой заказа orderdate.
40
Глава 1
Стадия WHERE вернула 31 строку, в которых есть 16 уникальных комбинаций ID сотрудника
и значений года заказа, как показано далее:
empid
YEAR(orderdate)
1
2006
1
2007
1
2008
2
2006
2
2007
2
2008
3
2007
4
2007
4
2008
5
2007
6
2007
6
2008
7
2007
7
2008
8
2007
9
2006
Таким образом, стадия GROUP BY создает 16 групп и связывает с соответствующей группой
каждую из 31 строки, полученных из стадии WHERE.
Если в запрос включена группировка, все стадии, следующие за стадией GROUP BY, включая
HAVING, SELECT и ORDER BY, должны оперировать группами, а не отдельными строками.
В итоге в окончательном результате запроса каждая группа представлена одной строкой.
Это означает, что все выражения, которые задаются в элементах инструкции, обрабатывае-
мых на стадиях, следующих за стадией GROUP BY, должны возвращать скалярную величину
(одно значение) для каждой группы.
Выражения на основе элементов, входящих в список условия GROUP BY, удовлетворяют
этому требованию, т. к. по определению у каждой группы есть только один уникальный ва-
риант всех элементов условия GROUP BY. Например, в группе с идентификатором сотрудни-
ка 8 и годом заказа 2007 существует только одно уникальное значение ID сотрудника и
только одно уникальное значение года заказа. Следовательно, вы можете ссылаться на вы-
ражения empid и YEAR (о rde г date) в элементах инструкции, которые будут обработаны на
стадиях, следующих за стадией GROUP BY, например, в команде SELECT. Приведенный да-
лее запрос возвращает 16 строк для 16 групп, включающих идентификатор сотрудника и год
заказа:
SELECT empid, YEAR(orderdate) AS orderyear
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate);
Однотабличные запросы
41
Далее приведен результат этого запроса:
empid
orderyear
1
2006
1
2007
1
2008
2
2006
2
2007
2
2008
3
2007
4
2007
4
2008
5
2007
6
2007
6
2008
7
2007
7
2008
8
2007
9
2006
(16 row(s) affected)
Поскольку группирующая функция возвращает одно значение на группу, элементы, не
включенные в список условия GROUP BY, разрешены только как входные параметры для
статистических или агрегатных функций, таких как COUNT, SUM, AVG, MIN или MAX. Напри-
мер, следующий запрос вернет общую стоимость перевозки и количество заказов, приходя-
щихся на каждого сотрудника в каждом году:
SELECT
empid,
YEAR(orderdate) AS orderyear,
SUM(freight) AS totalfreight,
COUNT(*) AS numorders
FROM Sales.Orders
WHERE custid =71
GROUP BY empid, YEAR(orderdate);
Данный запрос сгенерирует следующий результат:
empid
orderyear
totalfreight
numorders
1
2006
126.56
1
2
2006
89.16
1
9
2006
214.27
1
1
2007
711.13
2
42
Глава 1
2
2007
352.69
1
3
2007
297.65
2
4
2007
86.53
1
5
2007
277.14
3
6
2007
628.31
3
7
2007
388.98
1
8
2007
371.07
4
1
2008
357.44
3
2
2008
672.16
2
4
2008
651.83
3
6
2008
227.22
1
7
2008
1231.56
2
(16 row(s) affected)
Выражение SUM (freight) вернет сумму всех значений стоимости перевозки в каждой
группе, а функция COUNT (*) вернет количество строк в каждой группе, равное в нашем слу-
чае количеству заказов. Если в любом элементе инструкции, обрабатываемом после элемен-
та GROUP BY, вы попытаетесь сослаться на атрибут, не включенный в список условия GROUP
BY (например, freight (стоимость перевозки)) и не являющийся входным параметром ка-
кой-либо агрегатной функции, то получите ошибку, т. к. в этом случае нет гарантии, что
выражение вернет одно значение для каждой группы. Например, приведенный далее запрос
завершится с ошибкой:
SELECT empid, YEAR(orderdate) AS orderyear, freight
FROM Sales.Orders
WHERE custid =71
GROUP BY empid, YEAR(orderdate);
SQL Server выведет следующую ошибку:
Msg 8120, Level 16, State 1, Line 1
Column 'Sales.Orders.freight1 is invalid in the select list because it is not
contained in either an aggregate function or the GROUP BY clause.
Учтите, что все агрегатные функции, за исключением функции COUNT (*), игнорируют зна-
чения NULL. Например, рассмотрим группу из пяти строк со значениями 30, 10, NULL, 10, 10
в*столбце с именем qty (количество). Выражение COUNT(*) вернуло бы значение 5, по-
скольку в группе пять строк, в то время как COUNT (qty) вернуло бы 4, т. к. есть только
4 известных значения. Если вы хотите обрабатывать только различные известные значения,
встречающиеся в группе, задайте ключевое слово DISTINCT в списке параметров агрегатной
функции. Например, выражение COUNT (DISTINCT qty) вернет 2, т. к. в группе 2 отличаю-
щихся известных значения. Ключевое слово DISTINCT можно применять и в других функ-
циях. Например, выражение SUM (qty) вернет 60, а выражение SUM (DISTINCT qty) — 40.
Выражение AVG(qty) вернет 15, в то время как выражение AVG (DISTINCT qty) вернуло
бы 20. В качестве примера применения ключевого слова DISTINCT с агрегатной функцией в
законченном запросе далее приведен программный код, возвращающий количество отли-
Однотабличные запросы
43
чающихся (разных) клиентов, которых обслужил каждый сотрудник в каждом году, когда
были сделаны заказы:
SELECT
empid,
YEAR(orderdate) AS orderyear,
COUNT(DISTINCT custid) AS numcusts
FROM Sales.Orders
GROUP BY empid, YEAR(orderdate);
Этот запрос сформирует следующий результат:
eiripid
orderyear
numcusts
1
2006
22
2
2006
15
3
2006
16
4
2006
26
5
2006
10
6
2006
15
7
2006
11
8
2006
19
9
2006
5
1
2007
40
2
2007
35
3
. 2007
46
4
2007
57
5
2007
13
6
2007
24
7
2007
30
8
2007
36
9
2007
16
1
2008
32
2
2008
34
3
2008
30
4
2008
33
5
2008
11
6
2008
17
7
2008
21
8
2008
23
9
2008
16
(27 row(s) affected)
44
Глава 1
Элемент HAVING
С помощью условия HAVING вы можете задать предикат (логическое выражение) для выбо-
ра групп, а не отдельных строк, которые были отобраны на стадии WHERE. В следующую
стадию логической обработки запроса стадия HAVING передаст только те группы, для кото-
рых заданное в элементе HAVING логическое выражение равно TRUE. Группы, для которых
вычисляемое логическое выражение равно FALSE ИЛИ UNKNOWN, отбрасываются.
Поскольку условие HAVING обрабатывается после того, как строки сгруппированы, вы мо-
жете в логическом выражении ссылаться на агрегатные функции. Например, в запросе из
листинга2.1 имеющееся у элемента HAVING логическое выражение COUNT (*) > 1 означа-
ет, что на стадии HAVING выбираются только группы (сотрудник и год заказа) с нескольки-
ми строками. В приведенном далее фрагменте запроса из листинга 2.1 показано, какие ста-
дии были обработаны к данному моменту:
FROM Sales.Orders
WHERE custid =71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1
Напоминаю, что на стадии GROUP BY созданы 16 групп с ID сотрудника и годом заказа.
У семи из них по одной строке, после обработки условия HAVING остается девять групп. Для
того чтобы получить эти девять групп, выполните следующий запрос:
SELECT empid, YEAR(orderdate) AS orderyear
FROM Sales.Orders
WHERE custid =71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1;
Этот запрос вернет такой результат:
empid
orderyear
1
2007
3
2007
5
2007
6
2007
8
2007
1
2008
2
2008
4
2008
7
2008
(9 row(s) affected)
Однотабличные запросы
45
Элемент SELECT
В элементе или команде SELECT ВЫ задаете атрибуты (столбцы), которые хотите получить
в результирующей таблице запроса. В список выбора элемента SELECT, состоящий из ат-
рибутов запрашиваемых таблиц с дополнительной обработкой или без нее, вы можете
ввести выражения. Например, список выбора элемента SELECT В листинге 2.1 содержит
следующие выражения: empid, YEAR (orderdate) и COUNT (*). Если выражение ссылает-
ся на атрибут без обработки, например empid, имя результирующего атрибута будет та-
ким же, как имя исходного. При желании вы можете с помощью элемента AS присвоить
собственное имя результирующему атрибуту, например, empid AS employee_id. У вы-
ражений, включающих обработку, таких как YEAR (orderdate), или не использующих
исходный атрибут, например, таких как вызов функции CURRENT TIMESTAMP, В результи-
рующей таблице запроса нет имени, если вы не придумаете им имя. Язык T-SQL допуска-
ет в определенных случаях возврат в результате запроса безымянных столбцов, а реляци-
онная модель не допускает. Настоятельно рекомендуется присваивать подобным
выражениям имена-псевдонимы следующим образом: YEAR (orderdate) AS orderyear,
чтобы у всех атрибутов результирующего набора были имена. В этом случае результи-
рующая таблица, возвращаемая запросом, будет считаться реляционной.
В дополнение к элементу AS язык T-SQL поддерживает еще пару конструкций, с помощью
которых можно именовать выражения, но мне элемент AS кажется наиболее легко воспри-
нимаемой и интуитивно понятной синтаксической конструкцией, и я советую пользоваться
именно ею. Помимо конструкции
<выражение> AS <псевдоним>
T-SQL также поддерживает конструкции
<псевдоним> = <выражение>
(имя-псевдоним равно выражению) и
<выражение> <псевлоним>
(выражение, пробел, псевдоним). Пример конструкции первого вида:
orderyear = YEAR(orderdate)
и пример конструкции второго вида:
YEAR (orderdate) orderyear
Я считаю последнюю конструкцию, в которой задается выражение с последующим пробе-
лом и псевдонимом, особенно непонятной и настойчиво советую избегать ее применения.
Стоит отметить, что, если по ошибке в списке выбора элемента SELECT ВЫ не вставите запя-
тую между именами двух столбцов, ваш программный код не прекратит выполнение с сооб-
щением об ошибке. Вместо этого SQL Server сочтет, что второе имя — псевдоним имени пер-
вого столбца. В качестве примера предположим, что вы хотели написать запрос, выбирающий
столбцы orderid (id заказа) и orderdate (дата заказа) из таблицы Sales .Orders, и по
ошибке не поставили запятую между именами столбцов, как показано далее:
SELECT orderid orderdate
FROM Sales.Orders;
46
Глава 1
Этот запрос, в котором вы как будто намеривались присвоить псевдоним orderdate (дата
заказа) столбцу с именем orderid (id заказа), считается синтаксически корректным. В ре-
зультирующем наборе вы получите только один столбец с псевдонимом orderdate, содер-
жащий идентификаторы заказов:
orderdate
10248
10249
10250
10251
10252
(830 row(s) affected)
Такую ошибку обнаружить очень трудно, поэтому следует быть предельно внимательным
при написании программного кода.
Вместе со стадией SELECT к настоящему моменту уже были обработаны следующие эле-
менты запроса из листинга 2.1:
SELECT eirpid, YEAR (orderdate) AS orderyear, COUNT (*) AS numorders
FROM Sales.Orders
WHERE custid =71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1
Команда SELECT создает результирующую таблицу запроса. В случае запроса из листин-
га 2.1 шапка результирующей таблицы содержит атрибуты empid (id сотрудника),
orderyear (год заказа) и numorders (количество заказов), а тело таблицы состоит из девя-
ти строк (по одной на каждую группу). Для получения этих девяти строк выполните сле-
дующий запрос:
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
WHERE custid =71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1;
Этот запрос формирует следующий результат:
empid
orderyear
numorders
1
2007
2
3
2007
2
5
2007
3
.6
2007
3
8
2007
4
Однотабличные запросы
47
1
2008
2008
2008
2008
3
2
7
4
2
3
2
(9 row(s) affected)
Помните, что элемент SELECT обрабатывается после элементов FROM, WHERE, GROUP BY И
HAVING. Это означает, что псевдонимы, присвоенные выражениям в элементе SELECT, не
существуют, когда рассматриваются элементы инструкции, обрабатываемые до него. Очень
распространенная ошибка программистов, не знающих правильного порядка обработки
элементов запроса, — ссылка на псевдонимы выражений в элементах инструкции, обраба-
тываемых раньше команды SELECT. Далее приведен пример такой некорректной попытки в
элементе WHERE:
SELECT orderid, YEAR(orderdate) AS orderyear
FROM Sales.Orders
WHERE orderyear > 2006;
На первый взгляд этот запрос выглядит корректным, но если вы вспомните, что псевдонимы
столбцов создаются на стадии SELECT, которая наступает после стадии обработки WHERE, то
поймете, что ссылка на псевдоним orderyear в элементе WHERE недопустима. И действи-
тельно SQL Server выдаст следующую ошибку:
Msg 207, Level 16, State 1, Line 3
Invalid column name
1
orderyear
1
.
Один из способов обойти эту проблему— повторить выражение YEAR (orderdate) в эле-
ментах WHERE инструкции SELECT:
SELECT orderid, YEAR(orderdate) AS orderyear
FROM Sales.Orders
WHERE YEAR(orderdate) > 2006;
Интересно отметить, что SQL Server способен опознать повторное использование в запросе
одного и того же выражения YEAR (orderdate). В определении значения или подсчете оно
нуждается только один раз.
Приведенный далее запрос — еще один пример некорректной ссылки на псевдоним столб-
ца. В запросе делается попытка сослаться на псевдоним столбца в элементе HAVING, кото-
рый также обрабатывается раньше, чем элемент SELECT.
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
WHERE custid =71
GROUP BY empid, YEAR(orderdate)
HAVING numorders > 1;
48
Глава 1
Этот запрос завершится аварийно с сообщением об ошибке, в котором говорится о недопус-
тимости имени столбца numorders (количество заказов). Вам снова придется повторить
выражение COUNT (*) в обоих элементах инструкции:
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
WHERE custid =71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1;
В реляционной модели операции над отношениями основаны на реляционной алгебре и их
результат— тоже отношение (множество). В языке SQL дело обстоит несколько иначе в
том смысле, что запрос SELECT не гарантирует возврат истинного множества, а именно уни-
кальных строк, следующих в произвольном порядке. Начнем с того, что язык SQL не требу-
ет определять таблицу как множество. Без ключа уникальность строк не гарантирована и в
этом случае таблица не является множеством; otfa представляет собой мультимножество
или множество с повторяющимися элементами. Но даже если у таблиц, к которым обра-
щены ваши запросы, есть ключи, и таблицы эти определены как множества, запрос SELECT,
обращенный к ним, все же может вернуть результат с повторяющимися строками. Термин
"результирующее множество" часто применяется для описания выходных данных запроса
SELECT, НО при этом результирующее множество необязательно является множеством с ма-
тематической точки зрения. Например, несмотря на то, что таблица Orders (Заказы) —
множество, поскольку уникальность обеспечивается ключом, запрос к таблице Orders воз-
вращает дублирующиеся строки, как показано в листинге 2.2.
j Листинг 2.2. Запрос, возвращающий дублирующиеся строки
SELECT empid, YEAR(orderdate) AS orderyear
FROM Sales.Orders
WHERE custid = 71;
Этот запрос формирует следующий результат:
empid
orderyear
9
2006
1
2006
2
2006
4
2007
8
2007
6
2007
6
2007
8
2007
5
2007
1
2007
8
2007
Однотабличные запросы
49
2
2007
7
2007
3
2007
5
2007
1
2007
5
2007
8
2007
3
2007
6
2007
2
2008
4
2008
4
2008
1
200В
7
2008
2
2008
1
2008
4
2008
7
20U8
6
2008
1
2008
(31 row(s) affected)
Язык SQL предоставляет средства, обеспечивающие уникальность строк в результирующем
наборе инструкции SELECT, С помощью синтаксического элемента DISTINCT, который
удаляет повторяющиеся строки, как показано в листинге 2.3.
I Листинг 2.3. Запрос с элементом DISTINCT
SELECT DISTINCT empid, YEAR(orderdate) AS orderyear
FROM Sales.Orders
WHERE custid = 71;
Этот запрос формирует следующий результат:
empid
orderyear
1
2006
1
2007
1
2008
2
2006
2
2007
2
2008
50
Глава 1
3
4
2007
2007
2008
2007
2007
2008
2007
2008
2007
2006
4
5
6
6
7
7
8
9
(16 row(s) affected)
После удаления дубликатов из 31 строки мультимножества, возвращенного запросом из
листинга 2.2, в множество, возвращенное запросом из листинга 2.3, вошли 16 строк.
Как показано в следующем примере, язык SQL допускает применение звездочки (*) в спи-
ске элемента SELECT для включения в результат всех атрибутов запрашиваемых таблиц
вместо их явного перечисления:
SELECT *
FROM Sales.Shippers;
Подобное применение звездочки — в большинстве случаев, за редким исключением, плохой
стиль программирования. Рекомендуется явно задавать список нужных вам атрибутов, даже
если необходимы все атрибуты из запрашиваемых таблиц. Для подобной рекомендации есть
множество причин. В отличие от реляционной модели язык SQL хранит порядковые номера
столбцов в соответствии с порядком, в котором столбцы были заданы в инструкции CREATE
TABLE. Применение конструкции SELECT * гарантирует возврат столбцов в соответствии с
их порядковыми номерами. Клиентские приложения в результирующем наборе могут ссы-
латься на столбцы по их порядковым номерам (в свою очередь плохой прием), а не по име-
нам. Любые изменения схемы, касающиеся таблицы, такие как вставка или удаление столб-
цов, изменения порядка их следования и т. д., могут в результате привести к сбоям в
клиентском приложении или того хуже к логическим ошибкам, которые останутся незаме-
ченными. Задавая нужные вам атрибуты явно, вы всегда получаете соответствующие столб-
цы, до тех пор пока они присутствуют в таблице. Если столбец, на который ссылается за-
прос, был удален из таблицы, вы получите ошибку и соответствующим образом исправите
программный код.
Некоторых людей интересует, есть ли выигрыш в производительности при использовании
звездочки и явного перечисления имен столбцов. Если применяется звездочка, может по-
требоваться дополнительная работа для разрешения имен столбцов, но обычно она столь
незначительна по сравнению с другими затратами, связанными с выполнением запроса, что
вряд ли будет заметна. Если и существует какой-либо выигрыш в производительности,
пусть и минимально возможный, он, скорее всего, заключается в том, что явное перечисле-
ние имен столбцов предпочтительнее. Поскольку такой подход рекомендован, так или ина-
че, это беспроигрышный вариант.
Однотабличные запросы
51
В элементе SELECT запрещено ссылаться на псевдоним столбца, созданный в этом же син-
таксическом элементе, независимо от того, где появляется выражение, которому присвоен
псевдоним, слева или справа от выражения, пытающегося на него ссылаться. Например,
следующая попытка недопустима:
SELECT 'orderid,
YEAR(orderdate) AS orderyear,
orderyear + 1 AS nextyear
FROM Sales.Orders;
Как уже говорилось ранее в этом разделе, один из способов обойти эту проблему — повто-
рить выражение:
SELECT orderid,
YEAR(orderdate) AS orderyear,
YEAR(orderdate) + 1 AS nextyear
FROM Sales.Orders;
Элемент ORDER BY
Элемент ORDER BY позволяет сортировать строки в выходном наборе для наглядности пред-
ставления данных. С точки зрения логической обработки запроса ORDER BY — последний
обрабатываемый элемент. В примере запроса, приведенном в листинге 2.4, сортируются
строки результата по идентификатору сотрудника и году заказа.
\ Листинг 2.4. Запрос, демонстрирующий применение элемента ORDER BY
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
WHERE custid =71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1
ORDER BY empid, orderyear;
Этот запрос генерирует следующий результат:
empid
orderyear
numorders
1
2007
2
1
2008
3
2
2008
2
3
2007
2
4
2008
3
5
2007
3
6
2007
3
52
Глава 1
1
2008
2
8
2007
4
(9 row(s) affected)
Один из аспектов, наиболее важных для понимания языка SQL, заключается в отсутствии
гарантированного порядка следования строк, т. к. таблица, предназначена для представле-
ния множества (или мультимножества при наличии дубликатов), а в множестве нет заданно-
го порядка следования элементов. Это означает, что когда вы формируете запрос к таблице
без задания элемента ORDER BY, запрос возвращает результат в виде таблицы, и SQL Server
может вернуть строки в выходном наборе в любом порядке. Единственная возможность
сортировки строк в результирующем наборе данных — явное задание элемента ORDER BY.
Но если вы зададите этот элемент, результат не может интерпретироваться как таблица, т. к.
у него гарантированный порядок следования строк. Запрос с элементом ORDER BY возвра-
щает то, что стандарт ANSI называет курсором, т. е. нереляционный результат с гарантиро-
ванным порядком следования строк. Вас, возможно, удивит, почему столь важное значение
придается тому, в каком виде запрос возвращает результат, как таблицу или как курсор. Не-
которые элементы языка и операции в SQL рассчитаны на работу с табличными результата-
ми запроса, а не с курсорами; примерами могут служить табличные выражения и операции
над множествами, которые я буду обсуждать подробно позже в этой книге.
Обратите внимание на то, что элемент ORDER BY ссылается на псевдоним столбца
orderyear, созданный на стадии SELECT. Стадия ORDER BY на самом деле — единственная
стадия, на которой можно ссылаться на псевдонимы столбцов, созданные на стадии SELECT,
поскольку это единственная стадия обработки, которая следует за стадией SELECT.
Если нужно отсортировать значения выражения по возрастанию, вы либо задаете сразу по-
сле выражения сокращение AS с, например orderyear AS с, либо ничего не задаете после
выражения, т. к. вариант сортировки AS с (по возрастанию) выполняется по умолчанию. Ес-
ли же вы хотите отсортировать результат по убыванию, необходимо после выражения за-
дать сокращение DESC, например orderyear desc.
И SQL, и T-SQL разрешают задавать в элементе ORDER BY порядковые номера столбцов,
исходя из порядка следования столбцов в списке элемента SELECT. Например, в запросе из
листинга 2.4 вместо
ORDER BY empid, orderyear
вы могли бы использовать вариант
ORDER BY 1, 2
Но такой прием считается плохим стилем программирования по двум причинам. Во-первых,
в реляционной модели у атрибутов нет порядковых номеров, и на столбцы следует ссылать-
ся по именам. Во-вторых, при корректировке элемента SELECT ВЫ можете забыть внести
соответствующие исправления в элемент ORDER BY. Если вы пользуетесь именами столб-
цов, ваш программный код защищен от ошибок такого рода.
Язык T-SQL допускает задание в элементе ORDER BY атрибутов, которые не включены в
список атрибутов элемента SELECT, подразумевая, что можно сортировать по атрибуту, ко-
торый вы не хотите возвращать в выходных данных запроса. Например, в следующем за-
Однотабличные запросы
53
просе строки со сведениями о сотрудниках сортируются по дате приема на работу, без
включения атрибута hiredate (дата приема) в результирующую таблицу запроса:
SELECT empid, firstname, lastname, country
FROM HR.Employees
ORDER BY hiredate;
Но если задано ключевое слово DISTINCT, список в элементе ORDER BY ограничивается
только теми атрибутами, которые включены в список элемента SELECT. Мотивировка,
кроющаяся за этим ограничением, заключается в том, что при задании ключевого слова
DISTINCT одна результирующая строка может представлять несколько строк исходной таб-
лицы, следовательно, может быть непонятно какое из нескольких возможных значений сле-
дует применять в выражении элемента ORDER BY.
Рассмотрим некорректный запрос, приведенный далее:
SELECT DISTINCT country
FROM HR.Employees
ORDER BY empid;
В таблице Employees (Сотрудники) есть девять сотрудников— пятеро из США и четверо из
Великобритании. Если вы уберете некорректный элемент ORDER BY из этого запроса, то полу-
чите назад две строки — по одной для каждой страны. Поскольку каждая страна в исходной
таблице встречается в нескольких строках и в каждой такой строке разные идентификаторы
сотрудника, значение атрибута empid в элементе ORDER BY на самом деле не определено.
Дополнительный элемент ТОР
Необязательный элемент ТОР— собственный модификатор языка T-SQL, позволяющий
ограничить количество или процентную долю строк, возвращаемых запросом. Если в запро-
се задан элемент ORDER BY, элемент ТОР полагается на него при определении логического
старшинства или приоритета строк. Например, для возврата из таблицы Orders (Заказы)
пяти самых последних заказов можно задать в элементе SELECT вариант ТОР (5) ив эле-
менте ORDER BY выражение orderdate DESC, как показано в листинге 2.5.
1 Листинг 2.S. Демонстрация запроса с использованием элемента ТОР
SELECT TOP (5) orderid, orderdate, custid, empid
FROM Sales.Orders
ORDER BY orderdate DESC;
Этот запрос вернет следующий результат:
orderid
orderdate
custid
empid
11077
2008-05-06 00:00:00.000
65
1
11076
2008-05-06 00:00:00.000
9
4
11075
2008-05-06 00:00:00.000
68
8
3 Зак. 1032
54
Глава 2
11074
2008-05-06 00:00:00.000
73
7
11073
2008-05-05 00:00:00.000
58
2
(5 row(s) affected)
С точки зрения логической обработки запроса элемент ТОР обрабатывается как часть стадии
SELECT сразу после ключевого слова DISTINCT (если оно есть). Имейте в виду, что когда в
запросе задан вариант ТОР, элемент ORDER BY имеет двойное назначение. Как часть стадии
SELECT элемент ТОР полагается на элемент ORDER BY при определении логического при-
оритета строк и, исходя из этого приоритета, отбирает столько строк, сколько требуется.
Позже, на стадии обработки ORDER BY, которая следует за стадией SELECT, тот же самый
элемент ORDER BY используется для сортировки строк в результирующем наборе, обеспечи-
вая наглядность результата. Например, запрос из листинга 2.5 возвращает пять строк с мак-
симальными значениями атрибута orderdate (дата заказа) и для вывода на экран сортирует
строки в выходном наборе по правилу orderdate DESC.
Если вы сомневаетесь по поводу того, что вернет запрос с элементом ТОР, курсор или таб-
личный результат, у вас для этого есть все основания. Когда применяется элемент ТОР, эле-
мент ORDER BY служит двум целям: определению логического старшинства для ТОР и сво-
ему прямому назначению— представлению данных, что изменяет природу результата
запроса, превращая его из таблицы в курсор с гарантируемым порядком следования строк.
Например, вы можете показать в одном и том же запросе, что хотите определить логическое
старшинство строк одним списком элемента ORDER BY, И одновременно отсортировать
строки для вывода результата другим списком или обойтись без него. Для достижения этой
цели придется применить табличное выражение, но обсуждение табличных выражений я
отложу до главы 5. Сейчас же хочу подчеркнуть лишь то, что если конструкция ТОР кажется
непонятной, для этого есть веская причина. Другими словами, дело не в вас, а в замысле
этого синтаксического элемента.
Элемент ТОР можно применять с ключевым словом PERCENT, В этом случае SQL Server вы-
числяет с применением математического округления количество возвращаемых строк, как
процентную долю от числа строк, удовлетворяющих требованиям запроса. Например, в сле-
дующем запросе требуется вернуть один процент самых последних заказов:
SELECT TOP (1) PERCENT orderid, orderdate, custid, empid '
FROM Sales.Orders
ORDER BY orderdate DESC;
Данный запрос формирует следующий результат:
orderid
orderdate
custid
empid
11074
2008-05-06 00:00:00.000
73
7
11075
2008-05-06 00:00:00.000
68
8
11076
2008-05-06 00:00:00.000
9
4
11077
2008-05-06 00:00:00.000
65
1
11070
2008-05-05 00:00:00.000
44
2
11071
2008-05-05 00:00:00.000
46
1
11072
2008-05-05 00:00:00.000
20
4
Однотабличные запросы
55
11073
2008-05-05 00:00:00.000
58
2
11067
2008-05-04 00:00:00.000
17
1
(9 row(s) affected)
Этот запрос возвращает 9 строк, поскольку в таблице Orders (Заказы) 830 строк и 1% с ок-
руглением от 830 равен 9.
Вы, возможно, заметили, что в запросе из листинга 2.5 список ORDER BY не уникален, т. к.
столбец orderdate (дата заказа)— не первичный ключ и для столбца не определены
ограничения, обеспечивающие уникальность отбора. У многих записей может быть одна и
та же дата заказа. Если не задан критерий разрешения конфликтов, старшинство строк при
наличии связанных строк (строк с одной и той же датой заказа) не определено. Этот факт
делает запрос недетерминированным— несколько разных результатов могут считаться
корректными. При наличии связанных строк SQL Server выбирает те строки, к которым
первым произошел физический доступ.
Обратите внимание на то, что в выходных данных запроса из листинга 2.5 минимальная да-
та, вошедшая в число отобранных строк, — May 5, 2008 (5 мая 2008 г.), и в результате есть
одна строка с такой датой. У остальных строк таблицы может быть та же дата заказа и при
имеющемся списке элемента ORDER BY, не обеспечивающем уникальность отбора, неиз-
вестно, какая из этих строк будет возвращена.
Если вы хотите добиться детерминированности запроса, необходимо сделать список ORDER
BY обеспечивающим уникальность отбора; другими словами, добавить дополнительный
критерий отбора связанных строк. Например, можно вставить в список элемента ORDER BY
атрибут orderid DESC, как показано в листинге 2.6, для того чтобы при наличии связанных
записей старшинство определялось убыванием идентификатора заказа.
| Листинг 2.6. Запрос с применением элемента ТОР И СПИСКОМ ORDER BY,
^обеспечивающим уникальность отбора
SELECT TOP (5) orderid, orderdate, custid, empid
FROM Sales.Orders
ORDER BY orderdate DESC, orderid DESC;
Этот запрос вернет следующий результат:
orderid
orderdate
custid
empid
11077
2008--05--06 00:00:00..000
65
11076
2008--05--06 00:00:00..000
9
11075
2008--05--06 00:00:00..000
68
11074
2008--05--06 00:00:00..000
73
11073
2008--05--05 00:00:00..000
58
(5 row(s) affected)
56
Глава 2
Если вы сравните результаты запросов из листингов 2.5 и 2.6, то заметите, что они кажутся
одинаковыми. Важное отличие состоит в том, что результат, приведенный в выходных дан-
ных запроса из листинга 2.5,— это один из нескольких возможных верных результатов
данного запроса, а результат, показанный в выходных данных запроса из листинга 2.6,—
единственно возможный верный результат.
Вместо вставки дополнительного критерия для связанных записей в список ORDER BY вы
можете запросить все связанные записи. Например, помимо пяти строк, полученных из за-
проса листинга 2.5, вы можете попросить вернуть из таблицы все остальные строки с тем же
значением параметра сортировки (в нашем случае датой заказа), что и последняя найденная
строка (в нашем случае May 5, 2008). Этого можно достичь, добавив элемент WITH TIES,
приведенный в следующем запросе:
SELECT ТОР (5) WITH TIES orderid, orderdate, custid, enpid
FROM Sales.Orders
ORDER BY orderdate DESC;
Данный запрос вернет следующий результат:
orderid
orderdate
custid
empid
11077
2008-05-06 00:: 00:00.000
65
1
11076
2008-05-06 00:: 00:00.000
9
4
11075
2008-05-06 00:: 00:00.000
68
8
11074
2008-05-06 00:: 00:00.000
73
7
11073
2008-05-05 00:: 00:00.000
58
2
11072
2008-05-05 00:: 00:00.000
20
4
11071
2008-05-05 00:: 00:00.000
46
1
11070
2008-05-05 00:: 00:00.000
44
2
(8 row(s) affected)
Обратите внимание на то, что в результат включены восемь строк, несмотря на то, что в
запросе вы задали ТОР (5). SQL Server сначала вернул ТОР (5) строк, отобранных на ос-
новании старшинства orderdate DESC, и, кроме того, все оставшиеся строки таблицы, у
которых то же значение orderdate (дата заказа), что и у последней из пяти выбранных
строк.
Элемент OVER
Элемент OVER предоставляет окно или секцию из строк для вычислений определенного ви-
да. Считайте окно просто определенным множеством строк, на которых производится вы-
числение. Примером вида вычислений, поддерживаемых элементом OVER, могут служить
агрегатные или ранжирующие функции. Поскольку элемент OVER предоставляет этим функ-
циям окно строк, функции называют оконными.
Так как основная задача агрегатной функции — объединить множество значений, то обычно
агрегатные функции действуют в контексте запросов с элементом GROUP BY. Вспомним
Однотабличные запросы
57
приведенные в разд. "Элемент GROUP BY" ранее в этой главе рассуждения о том, что по-
сле группировки данных запрос возвращает по одной строке для каждой группы, следова-
тельно, все ваши выражения должны возвращать одно значение на группу.
Агрегатная оконная функция обрабатывает множество значений из окна строк, которое вы
предоставляете функции с помощью элемента OVER, а не в контексте запроса с элементом
GROUP BY. Следовательно, вам не нужно группировать данные, и вы можете вернуть атри-
буты базовой строки и результаты агрегатных функций в одной и той же строке.
Для того чтобы понять элемент OVER, рассмотрим представление Sales -OrderValues.
Я буду рассматривать представления в главе 10, а сейчас считайте, что представление — это
просто таблица. Представление Sales.OrderValues содержит отдельную строку для каж-
дого заказа с идентификатором заказа (orderid), идентификатором клиента (custid),
идентификатором сотрудника (empid), идентификатором поставщика (shipperid), датой
заказа (orderdate) и стоимостью заказа (val).
Элемент OVER С пустыми скобками предоставляет все строки для вычисления. Фраза "все
строки" не обязательно означает все строки из таблицы, указанной в элементе FROM; имеют-
ся в виду все строки, предоставляемые после завершения стадий обработки FROM, WHERE,
GROUP BY И HAVING. Имейте в виду, что элемент OVER разрешается применять только на
стадиях SELECT И ORDER BY. Для того чтобы на этом ознакомительном этапе не перегру-
жать вас лишней информацией, я сосредоточусь на использовании элемента OVER на стадии
SELECT. Итак, если, например, вы задаете выражение SUM (val) OVER () в элементе SELECT
запроса, обращенного к представлению OrderValues, функция вычисляет итоговое значе-
ние для всех строк, обрабатываемых на стадии SELECT. Если в запросе данные не фильтру-
ются, или перед стадией SELECT не применяются другие стадии логической обработки, вы-
ражение вернет итоговое значение для всех строк представления OrderValues.
Если вы хотите ограничить или разделить строки на секции, можно использовать элемент
PARTITION BY. Например, вместо возврата итогового значения для всех строк представле-
ния OrderValues вы хотите вернуть итоговое значение для текущего клиента (для всех
строк с тем же значением атрибута custid, что и в текущей строке), задайте выражение
SUM(val) OVER(PARTITION BY custid).
Приведенный далее запрос, демонстрирующий как секционированные, так и несекциони-
рованные выражения, возвращает все строки представления OrderValues. В каждой стро-
ке в дополнение к базовым атрибутам запрос возвращает общее итоговое значение и итоговое
значение для каждого клиента.
SELECT orderid, custid, val,
SUM(val) OVER() AS totalvalue,
SUM(val) OVER(PARTITION BY custid) AS custtotalvalue
FROM Sales.OrderValues;
Данный запрос вернет следующий результат:
orderid
custid
val
totalvalue
custtotalvalue
10643
1
814.50
1265793.22
4273.00
10692
1
878.00
1265793.22
4273.00
10702
1
330.00
1265793.22
4273.00
10835
1
845.80
1265793.22
4273.00
58
Глава 2
10952
11011
10926
10759
10625
10308
10365
1
2
2
2
2
3
1
471.20
933.50
514.40
320.00
479.75
88.80
403.20
1265793.22
1265793.22
1265793.22
1265793.22
1265793.22
1265793.22
1265793.22
4273.00
4273.00
1402.95
1402.95
1402.95
1402.95
7023.98
(830 row(s) affected)
Столбец totalvalue в каждой строке результирующего набора содержит общую стоимость
заказов, приведенных во всех строках. В столбце custtotalvalue указывается итоговое
значение для всех строк, имеющих то же самое значение атрибута custid, что и текущая
строка.
Одно из преимуществ элемента OVER заключается в том, что, позволяя возвращать базовые
атрибуты и итоговые значения для них в одной и той же строке, он разрешает задавать вы-
ражения, в которых смешаны и те, и другие. Например, в следующем запросе для каждой
строки представления Ordervalues вычисляется процентная доля текущей стоимости зака-
за в общем итоге и процентная доля текущей стоимости заказа в итоговой стоимости зака-
зов для данного клиента.
SELECT orderid, custid, val,
100. * val / SUM(val) OVER() AS pctall,
100. * val / SUM(val) OVER(PARTITION BY custid) AS pctcust
FROM Sales.OrderValues;
Я задал в выражениях десятичное значение 100. (сто с точкой) вместо целого значения 100
для того, чтобы добиться явного преобразования целых значений val и SUM (val) в дейст-
вительные. В противном случае применялось бы деление нацело и дробная часть была бы
отброшена.
Данный запрос вернет следующий результат:
orderid custid val
pctall
pctcust
10643
1
814 .50 0..0643470029014691672941 19 .0615492628130119354083
10692
1
878 .00 0.
.0693636200705830925528 20 .547624 6197051252047741
10702
1
330 .00 0.
.0260706089103558320528 7. 7229113035338169904048
10835
1
845 .80 0.
.0668197606556938265161 19 .7940556985724315469225
10952
1
471 .20 0.. 0372256694501808123130 11 .0273812309852562602387
11011
1
933 .50 0.. 0737482224782338461253 21 .84 64778843903580622513
10926
2
514 .40 0..0406385491620819394181 36 .6655974910011048148544
10759
2
320 .00 0.
.0252805904585268674452 22 .8090808653195053280587
10625
2
479 .75 0..0379011352264945770526 34 .1958017035532271285505
10308
2
88.1ВО 0..0070153638522412057160 6.3295199401261627285362
10365
3
403.20 0.0318535439777438529809 5.7403352515240647040566
Однотабличные запросы
59
(830 row(s) affected)
В элементе OVER также могут применяться четыре ранжирующие функции: ROW_NUMBER,
RANK, DENSE_RANK И NTILE. В следующем запросе показано использование этих функций:
SELECT orderid, custid, val,
ROW_NUMBER() OVER (ORDER BY val) AS rownum,
RANK() OVER(ORDER BY val) AS rank,
DENSE_RANK() OVER(ORDER BY val) AS dense_rank,
NTILE(10) OVER(ORDER BY val) AS ntile
FROM Sales.OrderValues
ORDER BY val;
Данный запрос формирует такой результат:
orderid
custid
val
rownum rank
dense rank ntile
10782
12
12.50
1
1
1
1
10807
27
18.40
2
2
2
1
10586
66
23.80
3
3
3
1
10767
76
28.00
4
4
4
1
10898
54
30.00
5
5
5
1
10900
88
33.75
6
6
6
1
10883
48
36.00
7
7
7
1
11051
41
36.00
8
7
7
1
10815
71
40.00
9
9
8
1
10674
38
45.00
10
10
9
1
10691
63
10164..80 821
821
786
10
10540
63
10191..70 822
822
787
10
10479
65
10495..60 823
823
788
10
10897
37
10835..24 824
824
789
10
10817
39
10952..85 825
825
790
10
10417
73
11188..40 826
826
791
10
10889
65
11380..00 827
827
792
10
11030
71
12615..05 828
828
793
10
10981
34
15810..00 829
829
794
10
10865
63
16387..50 830
830
795
10
(830 row(s) affected)
Функция ROW NUMBER присваивает увеличивающиеся на единицу последовательные целые
номера строкам результирующего набора в соответствии с логическим порядком следова-
ния, заданным в элементе ORDER BY, вложенном в элемент OVER. В нашем примере запроса
60
Глава 2
логический порядок основывается на столбце val (стоимость), следовательно, как видно из
результирующего набора, при увеличении стоимости заказа также увеличивается номер
строки. Но даже если значение, определяющее порядок следования, не растет, номер строки
все равно должен увеличиваться. Таким образом, если список элемента ORDER BY для
функции ROW NUMBER не обеспечивает уникальности отбора, как в предыдущем примере,
запрос оказывается недетерминированным, т. е. возможно несколько корректных результа-
тов. Например, отметим, что две строки со стоимостью 36.00 получили номера 7 и 8. Любой
порядок следования этих строк считался бы корректным. Если вы хотите сделать однознач-
ным определение номера строки, необходимо добавить компоненты в список элемента
ORDER BY, чтобы обеспечить уникальность отбора, т. е. список в элементе ORDER BY дол-
жен однозначно идентифицировать строки. Например, можно добавить в него столбец
orderid (id заказа) как критерий отбора связанных строк (tiebreaker), чтобы сделать опре-
деление номера строки полностью детерминированным.
Как я упоминал ранее, функция ROW_NUMBER должна формировать уникальные значения, даже
когда среди упорядочиваемых значений есть совпадающие. Если вы хотите одинаково тракто-
вать совпадающие значения, встречающиеся среди упорядочиваемых величин, возможно, сле-
дует воспользоваться функциями RANK ИЛИ DENSE RANK. Обе они аналогичны функции
ROW NUMBER, но формируют одно и то же ранжирующее значение во всех строках с совпа-
дающим значением атрибута, применяющегося для логического упорядочивания строк. Разни-
ца заключается в том, что функция RANK показывает, сколько в результирующем наборе строк
с меньшими чем в текущей строке значениями упорядочиваемого атрибута, а функция
DENSE RANK— сколько в наборе строк с меньшими значениями упорядочиваемого атрибута,
отличающимися друг от друга. Например, в нашем примере запроса значение 9 в столбце rank
указывает на наличие 8 строк с меньшими значениями стоимости. Значение 9 в столбце
dense_rank указывает на наличие 8 различных меньших значений.
Функция NTILE позволяет связать строки в результирующем наборе с неперекрывающимися
группами строк (одинакового размера), присвоив каждой строке номер такой группы (ран-
га). В качестве входного параметра функции вы задаете количество групп, которое хотите
получить в результате, а в элементе OVER указываете способ логического упорядочивания
строк. В нашем примере запроса 830 строк и было запрошено 10 групп, следовательно, раз-
мер группы— 83 (830, деленное на 10) строки. Логическое упорядочивание основано на
значениях столбца val (стоимость). Это означает, что 83 строкам с наименьшими стоимо-
стями заказов будет присвоен номер группы 1, следующим 83 строкам— номер группы 2,
следующим далее 83 строкам — номер группы 3 и т. д. Функция NTILE логически связана с
функцией ROW NUMBER. ВЫ как будто присвоили строкам номера, исходя из упорядочивания
значений атрибута val, и затем, на основании вычисленного размера группы, равного 83,
присвоили номер группы 1 строкам с 1-й по 83-ю, номер группы 2 строкам с 84-й по 166-ю
и т. д. Если количество строк в наборе не кратно числу групп, строки из остатка от деле-
ния добавляются по одной к каждой группе, начиная с первой. Например, если у вас всего
102 строки и требуется 5 групп, в первых двух группах будет по 21 строке вместо 20.
Как и агрегатные оконные функции, ранжирующие функции также поддерживают исполь-
зование в элементе OVER уточняющего условия PARTITION BY. Назначение элемента
PARTITION BY в ранжирующих вычислениях возможно легче понять, если считать, что он
обеспечивает независимость вычислений в пределах каждой секции или окна. Например,
выражение ROW_NUMBERO OVER (PARTITION BY custid ORDER BY val) присваивает
номера строкам в каждом подмножестве строк с одинаковым значением атрибута custid
Однотабличные запросы
61
(id клиента), начиная с единицы, в отличие от присвоения последовательных номеров строк
в целом наборе.
Далее приведено это выражение в запросе.
SELECT orderid, custid, val,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY val) AS rownum
FROM Sales.OrderValues
ORDER BY custid, val;
Данный запрос формирует следующий результат:
orderid
custid
val
rownum
10702
1
330.00
1
10952
1
471.20
2
10643
1
814.50
3
10835
1
845.80
4
10692
1
878.00
5
11011
1
933.Ъ0
6
10308
2
88.80
1
10759
2
320.00
2
10625
2
479.75
3
10926
2
514.40
4
10682
3
375.50
1
(830 row(s) affected)
Как видно из результирующего набора, номера строк определяются независимо для каждого
клиента, как будто для каждого клиента счет начинается "с нуля".
Учтите, что элемент ORDER BY, заданный в элементе OVER, не должен ничего делать для
вывода данных и не влияет на получение результата в виде таблицы. Если вы не задали в
запросе предназначенный для вывода данных элемент ORDER BY, как пояснялось ранее, у
вас нет никаких гарантий, касающихся порядка следования строк в результирующем наборе.
Если вы хотите обеспечить определенный порядок вывода данных, следует добавить пред-
назначенный для этого элемент ORDER BY, как я сделал в двух последних запросах, демон-
стрирующих применение ранжирующих функций.
Оконные вычисления, задаваемые на стадии SELECT, обрабатываются до обработки ключе-
вого слова DISTINCT (если таковое имеется).
Приведенный далее перечень, позволяющий собрать все воедино, отображает порядок об-
работки всех синтаксических элементов запроса, которые рассматривались до настоящего
момента:
•
FROM;
•
WHERE;
•
GROUP BY;
62
Гпаев 2
•
HAVING;
•
SELECT:
•
OVER;
•
DISTINCT;
•
TOP;
•
ORDER BY.
Вас не удивляет, почему ключевое слово DISTINCT обрабатывается после выполнения
оконных вычислений, встречающихся в элементе SELECT, а не перед ними? Поясню на при-
мере. В данный момент в представлении содержится 830 строк с 795 различными стоимо-
стями заказов. Рассмотрим следующий запрос и его результат:
SELECT DISTINCT val, ROW_NUMBER() OVER (ORDER BY val) AS rownum
FROM Sales.OrderValues;
val
rownum
12.50
1
18.40
2
23.80
3
28.00
4
30.00
5
33.75
6
36.00
7
36.00
8
40.00
9
45.00
10
12615.05 828
15810.00 829
16387.50 830
(830 row(s) affected)
Функция ROW_NUMBER обрабатывается перед элементом DISTINCT. Сначала 830 строкам из
представления OrderValues присваиваются уникальные номера строк. Затем обрабатыва-
ется ключевое слово DISTINCT— вследствие предыдущей обработки, дублирующиеся
строки, требующие удаления, уже отсутствуют. Возьмите за правило не задавать и ключевое
слово DISTINCT, и функцию ROW_NUMBER в одном и том же элементе SELECT, поскольку в
этом случае элемент DISTINCT никак не влияет на результат запроса. Если вы хотите при-
своить номера 795 строкам с уникальными значениями стоимости заказа, следует выбрать
другое решение. Например, т. к. стадия GROUP BY обрабатывается раньше стадии SELECT,
вы могли бы применить следующий запрос:
SELECT val, ROW_NUMBER() OVER (ORDER BY val) AS rownum
FROM Sales.OrderValues
GROUP BY val;
Однотабличные запросы
63
Данный запрос выводит такой результат:
val
rownum
12.50
1
18.40
2
23.80
3
28.00
4
30.00
5
33.75
6
36.00
7
40.00
8
45.00
48.00
9
10
12615.05 793
15810.00 794
16387.50 795
(795 row(s) affected)
В этом запросе на стадии GROUP BY формируется 795 групп для различных значений и затем
на стадии SELECT формируется строка для каждой группы со стоимостью заказа и номером
строки, основанном на значении атрибута val.
В языке T-SQL есть различные синтаксические элементы, в которых можно задавать логи-
ческие выражения, например, в фильтрах или условиях запросов, таких как WHERE И HAVING,
в ограничениях типа CHECK и др. В логических выражениях могут применяться разные пре-
дикаты (выражения, которые могут принимать значения TRUE (истина), FALSE (ЛОЖЬ) ИЛИ
UNKNOWN (неизвестно)) и операции.
Примеры предикатов, поддерживаемых языком T-SQL, включают в себя предикаты IN,
BETWEEN И LIKE. Предикат IN позволяет проверить, равно ли значение или скалярное выра-
жение одному из элементов заданного множества. Например, следующий запрос вернет за-
казы, у которых идентификатор заказа равен 10 248 или 10 249, или 10 250:
SELECT orderid, empid, orderdate
FROM Sales.Orders
WHERE orderid IN(10248, 10249, 10250);
Предикат BETWEEN позволяет проверить, находится ли значение в заданном диапазоне,
включающем две заданные границы.
Предикаты и операции
64
Глава 2
Например, следующий запрос вернет все заказа с идентификаторами, лежащими в диапазо-
не от 10 300 до 10 310 включительно:
SELECT orderid, empid, orderdate
FROM Sales.Orders
WHERE orderid BETWEEN 10300 AND 10310;
Предикат LIKE позволяет проверить, соответствует ли значение символьной строки задан-
ному образцу или шаблону. Например, следующий запрос вернет всех сотрудников, чья
фамилия начинается с символа D.
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname LIKE N
,
D%1;
Позже в этой главе я подробно остановлюсь на соответствии шаблонам и предикате LIKE.
Если вас заинтересовало применение буквы N как префикса в строке ' D%\ ЭТО сокращение
слова National (национальный), используемое для обозначения типа данных символьной
строки Unicode (NCHAR или NVARCHAR) В противоположность обычному типу символьных
данных (CHAR или VARCHAR). Поскольку тип данных атрибута lastname (фамилия) —
NVARCHAR (40), буква N применяется как префикс строки. В разд. "Работа с символьными
данными" далее в этой главе я опишу обработку символьных строк.
В язык T-SQL включены следующие операции сравнения: =, >, <, >=, <=, о, ! =, ! >, ! <, по-
следние три из которых не являются стандартными. Поскольку у нестандартных операций
есть стандартные альтернативы (например, о вместо ! =), я советую избегать использова-
ния нестандартных операций. Например, приведенный далее запрос вернет все заказы, сде-
ланные 1 января 2008 г. или позднее:
SELECT orderid, empid, orderdate
FROM Sales.Orders
WHERE orderdate >= '20080101';
Если нужно объединить логические выражения, можно применять логические операции OR
и AND. Если вы хотите инвертировать выражение, можно использовать операцию NOT. На-
пример, следующий запрос вернет заказы, сделанные 1 января 2008 г. или позже и принятые
сотрудниками с идентификаторами 1, 3, 5:
SELECT orderid, empid, orderdate
FROM Sales.Orders
WHERE orderdate >=
1
200801011
AND empid IN(1, 3, 5);
Язык T-SQL поддерживает четыре обычные арифметические операции: +,
*, / и, кроме
TOFO, операцию % (остаток целочисленного деления), которая возвращает остаток от деления
нацело. Например, следующий запрос вычисляет чистую стоимость как результат арифме-
тической обработки атрибутов quantity (количество), unitprice (цена единицы) и
discount (скидка):
SELECT orderid, productid, qty, unitprice, discount,
qty * unitprice * (1 - discount) AS val
FROM Sales.OrderDetails;
Однотабличные запросы
65
Обратите внимание на то, что в языке T-SQL тип данных скалярного выражения, включаю-
щего два операнда, определяется в соответствии с тем операндом, тип данных которого
имеет более высокий приоритет или старшинство. Если у обоих операндов один и тот же
тип данных, результат выражения будет иметь тот же самый тип данных. Например, деление
двух целых чисел (INT) даст в результате целое число. Выражение 5/2 вернет целое число 2,
а не десятичное 2.5. Если вы имеете дело с константами, это не проблема, поскольку всегда
можно задать вещественные значения с десятичной точкой. Но если обрабатываются, ска-
жем, два целочисленных столбца, например coll/col2, и вы хотите получить веществен-
ный результат, то необходимо привести операнды к соответствующему типу:
CAST(coll AS NUMERIC(12, 2))/CAST(col2 AS NUMERIC(12, 2))
У гипа NUMERIC (12, 2) разрядность равна 12 и количество разрядов в дробной части — 2, т. е.
всего под число отводится 12 цифр, 2 из которых находятся справа от десятичной точки.
Если у двух операндов разные типы, операнд с типом данных, имеющим более низкий при-
оритет, повышается до типа с более высоким приоритетом. Например, в выражении 5/2.0 у
первого операнда тип INT, а у второго — NUMERIC. Поскольку NUMERIC считается типом с
более высоким приоритетом, чем тип INT, операнд 5 с типом INT перед выполнением
арифметической операции явно преобразуется в 5.0 типа NUMERIC, И ВЫ получаете резуль-
тат 2.5.
Приоритеты или старшинство типов данных можно найти в интерактивном справочном руко-
водстве SQL Server Books Online в разд. "Data Type Precedence" ("Приоритет типов данных").
Если в одном и том же выражении встречается несколько операций, SQL Server оценивает
их, исходя из правил старшинства операций или порядка их выполнения. В приведенном
далее списке показан порядок выполнения операций, начиная с самой старшей операции и
заканчивая самой младшей:
1. ( ) (скобки).
2. * (умножение), / (деление), % (остаток от деления нацело).
3. + (положительный операнд), - (отрицательный), + (сложение), + (сцепление), - (вычита-
ние).
4.
=, >, <, >=, <=, о, !=, ! >, ! < (операции сравнения).
5. NOT.
6. AND.
7. BETWEEN, IN, LIKE, OR.
8.
= (присваивание).
Например, в следующем запросе у операции AND более высокий приоритет по сравнению с
операцией OR:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE
custid = 1
AND empid IN(1, 3, 5)
OR custid = 85
AND empid IN(2, 4, 6);
66
Глава 2
Запрос вернет как заказы, которые были сделаны клиентом 1 и приняты сотрудниками 1, 3
или 5, так и заказы, которые были сделаны клиентом 85 и приняты сотрудниками 2,4 или 6.
У круглых скобок наивысший приоритет, поэтому они предоставляют вам полный контроль.
Ради людей, которым придется просматривать или сопровождать ваш программный код, и
для наглядности хорошо было бы для структурирования кода применять скобки, даже когда
они не требуются. Например, приведенный далее запрос логически эквивалентен предыду-
щему запросу, но его логика гораздо яснее:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE
(custid = 1
AND empid IN(1, 3, 5))
OR
(custid = 85
AND empid IN(2, 4, 6)) ;
Применение скобок для определения порядка выполнения логических операций аналогично
применению скобок в арифметических выражениях. Например, без скобок в следующем вы-
ражении умножение предшествует сложению:
SELECT10+2*3;
I
•
Следовательно, выражение вернет результат 16. Если вы хотите выполнить первым сложе-
ние, можно применить скобки:
SELECT(10+2)*3;
На этот раз выражение будет равно 36.
Выражение CASE
Выражение CASE — это скалярное выражение, которое возвращает значение, зависящее от
условной логики. Учтите, что CASE — это именно выражение, а не инструкция или опера-
тор, т. е. оно не позволяет вам управлять потоком исполнения или выполнять какие-либо
действия, исходя из условной логики. Поскольку CASE — скалярное выражение, его можно
применять там, где допустимы скалярные выражения, в таких элементах, как SELECT,
WHERE, HAVING и ORDER BY, ограничениях типа CHECK и т. д.
У выражения CASE есть две формы: простая и с поиском. В простой форме можно сравнить
одно значение или скалярное выражение со списком возможных значений и вернуть значе-
ние, полученное при первом встреченном совпадении. Если ни одно значение списка не
равно проверяемому значению, выражение CASE возвращает значение, присутствующее в
ветви ELSE (если таковая существует). Если в выражении CASE нет ветви ELSE, по умолча-
нию подставляется ELSE NULL.
Например, в следующем запросе к таблице Production.Products (Товары) применяется
выражение CASE в элементе SELECT ДЛЯ формирования описания значения столбца
categoryid (id категории).
Однотабличные запросы
67
SELECT productid, productname, categoryid,
CASE categoryid
WHEN 1 THEN 1Beverages
1
WHEN 2 THEN 'Condiments'
WHEN 3 THEN 'Confections'
WHEN 4 THEN 'Dairy Products'
WHEN 5 THEN 'Grains/Cereals'
WHEN 6 THEN 'Meat/Poultry'
WHEN 7 THEN 'Produce'
WHEN 8 THEN 'Seafood
1
ELSE 'Unknown Category'
END AS categoryname
FROM Product ion.Products;
Данный запрос формирует следующий результат, приведенный в сокращенном виде:
productid productname
categoryid categoryname
1
Product HHYDP
1
Beverages
2
Product RECZE
1
Beverages
3
Product IMEHJ
2
Condiments
4
Product KSBRM
2
Condiments
5
Product EPEIM
2
Condiments
6
Product VAIIV
2
Condiments
7
Product HMLNI
7
Produce
8
Product WVJFP
2
Condiments
9
Product AOZBW
6
Meat/Poultry
10
Product YHXGE
8
Seafood
(77 row(s) affected)
Приведенный запрос — простой пример использования выражения CASE. ЕСЛИ множество
категорий не слишком маленькое или почти не меняющееся, возможно, лучшее проектное
решение— хранить категории товаров в таблице и соединять эту таблицу с таблицей
Products (Товары), когда нужно получить описания категорий. В базе данных TSQLFun-
damenta]s2008 как раз есть такая таблица— Categories (Категории).
Далее приводится еще один пример простой формы выражения CASE: следующий запрос к
представлению Sales.OrderValues (Стоимости заказов) формирует три группы, основан-
ные на логическом упорядочивании значений атрибута val (стоимость), и преобразует но-
мера групп в описания этих групп (Low (низкая), Medium (средняя) и High (высокая)).
SELECT orderid, custid, val,
CASE NTILE(3) OVER(ORDER BY val)
WHEN 1 THEN 'Low'
WHEN 2 THEN 'Medium'
68
Гпаев 2
WHEN 3 THEN 'High'
ELSE 'Unknown'
END AS titledesc
FROM Sales.OrderValues
ORDER BY val;
Данный запрос вернет следующий результат:
orderid
custid
val
titledesc
10782
12
10807
27
10586
66
10767
76
10898
54
10632
86
11044
91
10584
7
10704
62
10654
5
10813
67
10656
32
10888
30
10300
49
10493
41
10645
34
10667
20
10461
46
10878
63
10553
87
10362
9
10250
34
10799
39
10722
71
11018
48
10417
73
10889
65
11030
71
10981
34
10865
63
12.50
Low
18.40
Low
23.80
Low
28.00
Low
30.00
Low
589.00
Low
591.60
Low
593.75
Low
595.50
Low
601.83
Low
602.40
Medium
604.22
Medium
605.00
Medium
608.00
Medium
608.40
Medium
1535.00 Medium
1536.80 Medium
1538.70 Medium
1539.00 Medium
1546.30 Medium
1549.60 High
1552.60 High
1553.50 High
1570.00 High
1575.00 High
11188.40 High
11380.00 High
12615.05 High
15810.00 High
16387.50 High
(830 row(s) affected)
Однотабличные запросы
69
У простой формы выражения CASE единственное проверяемое значение или выражение,
следующее сразу за ключевым словом CASE И сравниваемое со списком возможных значе-
ний в элементах WHEN. Форма CASE С ПОИСКОМ более гибкая, т. к. позволяет задавать преди-
каты или логические выражения в элементах WHEN, не ограничивая вас проверками на ра-
венство. Выражение с поиском возвращает значение из элемента THEN, связанное с первым
логическим выражением в элементе WHEN, имеющем значение TRUE. ЕСЛИ НИ ОДНО ИЗ выра-
жений в элементах WHEN не равно TRUE, выражение CASE возвращает значение из ветви
ELSE (ИЛИ значение NULL, если ветвь ELSE не задана). Например, в следующем запросе
формируется описание категории, исходя из того, какова величина стоимости: меньше
1000.00, в диапазоне от 1000.00 до 3000.00 или больше 3000.00:
SELECT orderid, custid, val,
%
CASE
WHEN val < 1000.00 THEN 'Less then 10001
WHEN val BETWEEN 1000.00 AND 3000.00 THEN 'Between 1000 and 3000*
WHEN val > 3000.00 THEN 'More than 3000
f
ELSE 'Unknown'
END AS valuecategory
FROM Sales.OrderValues;
Данный запрос формирует следующий результат:
orderid
custid
val
valuecategory
10248
85
440.00 Less then 1000
10249
79
1863.40 Between 1000 and 3000
10250
34
1552.60 Between 1000 and 3000
10251
84
654.06 Less then 1000
10252
76
3597.90 More than 3000
10253
34
1444.80 Between 1000 and 3000
10254
14
556.62 Less then 1000
10255
68
2490.50 Between 1000 and 3000
10256
88
517180 Less then 1000
10257
35
1119.90 Between 1000 and 3000
(830 row(s) affected)
Как видите, любое простое выражение CASE может быть преобразовано в форму CASE С по-
иском, а обратное преобразование необязательно возможно.
Я уже привел несколько примеров, чтобы познакомить вас с выражением CASE. Несмотря на
это, из приведенных примеров может быть не очень понятно, что выражение CASE — край-
не полезный и мощный синтаксический элемент языка.
Значение NULL
Как уже объяснялось в главе 7, язык SQL поддерживает специальное значение NULL ДЛЯ обо-
значения пропущенных или отсутствующих значений и применяет троичную логику, т. е.
70
Глава 2
т. е. предикаты могут принимать одно из трех значений: TRUE (истина), FALSE (ложь) или
UNKNOWN (неизвестно). Язык T-SQL в этом отношении следует стандарту. Трактовка значе-
ний NULL и UNKNOWN в SQL может показаться запутанной, потому что интуитивно людям
привычнее двоичная логика (TRUE, FALSE). Не добавляет ясности и тот факт, что разные
синтаксические элементы языка SQL по-разному интерпретируют значения NULL И
UNKNOWN.
Давайте начнем с троичной логики предикатов. Логическое выражение, включающее только
существующие или имеющиеся в наличии значения, принимает либо значение TRUE (исти-
на), либо значение FALSE (ложь), но если в выражение включено пропущенное значение,
выражение становится равно значению UNKNOWN (неизвестно). Рассмотрим предикат salary
> 0. Если заработная плата равна 1000, выражение принимает значение TRUE. Если зарплата
равна -1000, выражение становится равно FALSE. ЕСЛИ зарплата равна NULL, выражение
принимает значение UNKNOWN.
Язык SQL трактует TRUE И FALSE интуитивно понятным и ожидаемым образом. Например,
если предикат salary > 0 встречается в запросе-фильтре (с элементами WHERE И HAVING),
возвращаются строки или группы, в которых выражение принимает значение TRUE, а те
строки и группы, в которых значение выражения равно FALSE, отбрасываются.
В разных синтаксических элементах языка SQL значение UNKNOWN трактуется по-разному
(и не всегда так, как можно было бы предположить). Корректное определение этой трактов-
ки в SQL для фильтрующих запросов— "принимать TRUE", Т. е. и FALSE, И UNKNOWN отбра-
сываются. С другой стороны, определение трактовки в SQL для ограничений типа CHECK —
"отвергать FALSE", Т. е. значения и TRUE, И UNKNOWN принимаются. Если бы в языке SQL
применялась двоичная логика предикатов, между определениями "принимать TRUE" и "от-
вергать FALSE" не было бы разницы. А в троичной логике предикатов "принимать TRUE"
отвергает значения UNKNOWN (принимать TRUE, следовательно, отвергать и FALSE, И
UNKNOWN), а определение "отвергать FALSE" принимает эти значения (отвергать FALSE —
значит, принимать и TRUE, и UNKNOWN). ЕСЛИ применить предикат salary > 0 из предыду-
щего примера, при заработной плате, равной NULL, значение выражения будет равно
UNKNOWN. Если этот предикат встретится в запросе в элементе WHERE, строка с заработной
платой, равной NULL, будет отброшена. Если же этот предикат встретится в таблице в огра-
ничении CHECK, строка с зарплатой, равной NULL, будет принята.
Одна из коварных особенностей значения UNKNOWN СОСТОИТ в том, что, применив операцию
NOT (не) к этому значению, вы все равно получите значение UNKNOWN. Например, при задан-
ном предикате NOT (salary > 0) и зарплате, равной NULL, выражение salary > 0 будет
равно UNKNOWN и NOT UNKNOWN остается равным UNKNOWN.
Некоторых удивляет то, что выражение, сравнивающее два значения NULL (NULL = NULL),
возвращает значение UNKNOWN. Дело в том, что NULL обозначает пропущенное или неиз-
вестное значение, и вы на самом деле не можете сказать, равно ли одно неизвестное значе-
ние другому. Поэтому язык SQL предлагает вам предикаты is NULL и IS NOT NULL, кото-
рые следует применять вместо сравнений = NULL и О NULL.
Для лучшего усвоения я продемонстрирую вышеупомянутые особенности троичной логики.
В таблице Sales.Customers (Клиенты) есть три атрибута, названные country (страна),
region (регион) и city (город), в которых хранится информация о местонахождении кли-
ента. Все адресные данные включают существующие страны и города. Одни записи содер-
жат реальные регионы (например, страна: USA (США), регион: WA (штат Вашингтон), го-
род: Seattle (Сиэтл)), а в других регион пропущен или не применим (например, страна: UK
Однотабличные запросы
71
(Великобритания), регион: NULL, город: London). Рассмотрим запрос, пытающийся вернуть
всех клиентов, у которых регион равен WA (штат Вашингтон):
SELECT custid, country, region, city
FROM Sales.Customers
WHERE region = N'WA
1
;
Данный запрос формирует следующий результат:
custid
country
region
city
43
USA
WA
Walla Walla
82
USA
WA
Kirkland
89
USA
WA
Seattle
Из 91 строки таблицы Customers (Клиенты) запрос вернет три строки, в которых атрибут
region равен WA. Запрос не вернет строки, в которых значение атрибута region присутст-
вует и отличается от WA (предикат принимает значение FALSE), и строки, в которых атри-
бут region равен NULL (предикат принимает значение UNKNOWN).
Приведенный далее запрос пытается отобрать всех клиентов, у которых регион отличается
от WA:
SELECT custid, country, region, city
FROM Sales.Customers
WHERE region <> N'WA';
Данный запрос вернет следующий результат:
custid
country
region
city
10
Canada
ВС
Tsawassen
15
Brazil
SP
Sao Paulo
21
Brazil
SP
Sao Paulo
31
Brazil
SP
Campinas
32
USA
OR
Eugene
33
Venezuela
DF
Caracas
34
Brazil
RJ
Rio de Janeiro
35
Venezuela
Tachira
San Cristobal
36
USA
OR
Elgin
37
Ireland
Co. Cork
Cork
38
UK
Isle of Wight Cowes
42
Canada
ВС
Vancouver
45
USA
CA
San Francisco
46
Venezuela
Lara
Barquisimeto
47
Venezuela
Nueva Esparta
I. de Margarita
48
USA
OR
Portland
51
Canada
Quebec
Montreal
55
USA
АК
Anchorage
72
Глава 2
61
Brazil
RJ
Rio de Janeiro
62
Brazil
SP
Sao Paulo
65
USA
NM
Albuquerque
67
Brazil
RJ
Rio de Janeiro
71
USA
ID
Boise
75
USA
WY
Lander
77
USA
OR
Portland
78
USA
MT
Butte
81
Brazil
SP
Sao Paulo
88
Brazil
SP
Resende
(28 row(s) affected)
Если вы рассчитывали получить назад 88 строк (в таблице 91 строка минус 3 строки, воз-
вращенные предыдущим запросом), возможно, вас удивит то, что этот запрос вернул
28 строк. Но вспомните: запрос-фильтр "принимает TRUE, И, значит, он отвергает строки со
значением логического выражения, как FALSE, так и UNKNOWN. Таким образом, запрос вер-
нул строки, в которых присутствовало значение атрибута region (регион) и отличалось от
значения WA. Он не вернул ни строки, в которых регион был равен WA, ни строки, в кото-
рых регион был равен NULL. ВЫ получите тот же самый вывод, если примените предикат
NOT (region = N'WA"), поскольку в строках с регионом, равным NULL, выражение
region = N'WA' будет равно UNKNOWN и выражение NOT (region = N'WA') также будет
равно UNKNOWN.
Если вам нужны все строки, в которых region (регион) равен NULL, не применяйте преди-
кат region = NULL, т. к. выражение будет равно UNKNOWN во всех строках, и в тех, где зна-
чение есть, и в тех, где значение пропущено (равно NULL). Приведенный далее запрос вер-
нет пустое множество.
SELECT custid, country, region, city
FROM Sales.Customers
WHERE region = NULL;
custid
country
region
city
(0 row(s) affected)
Вместо этого следует использовать предикат IS NULL:
SELECT custid, country, region, city
FROM Sales.Customers
WHERE region IS NULL;
Данный запрос формирует следующий результат, приведенный в сокращенном виде:
custid
country
region
city
Однотабличные запросы
73
1
Germany
NULL
Berlin
2
Mexico
NULL
Mexico D.F.
3
Mexico
NULL
Mexico D.F.
4
UK
NULL
London
5
Sweden
NULL
Lulea
6
Germany
NULL
Mannheim
7
France
NULL
Strasbourg
8
Spain
NULL
Madrid
9
France
NULL
Marseille
11
UK
NULL
London
(60 row(s) affected)
Если вы хотите получить все строки, в которых атрибут region не равен WA, включая
строки с имеющимся значением, отличным от WA, а также строки с пропущенным значени-
ем, вы должны вставить явную проверку для значений NULL, например, следующую:
SELECT custid, country, region, city
FROM Sales.Customers
WHERE region <> N'WA
1
OR region IS NULL;
Данный запрос формирует такой результат, приведенный в сокращенном виде:
custid
country
region
city
1
Germany
NULL
Berlin
2
Mexico
NULL
Mexico D.F.
3
Mexico
NULL
Mexico D.F.
4
UK
NULL
London
5
Sweden
NULL
Lulea
6
Germany
NULL
Mannheim
7
France
NULL
Strasbourg
8
Spain
NULL
Madrid
9
France
NULL'
Marseille
10
Canada
ВС
Tsawassen
(88 row(s) affected)
Язык SQL противоречиво интерпретирует значения NULL В различных своих синтаксических
элементах, предназначенных для сравнения и сортировки. Некоторые элементы считают два
значения NULL равными друг другу, другие — разными.
Например, при группировке и сортировке два значения NULL считаются равными. Это озна-
чает, что элемент GROUP BY собирает все значения NULL в одной группе, точно так же, как
имеющиеся значения, а элемент ORDER BY отсортировывает все значения NULL вместе. Пра-
во решать, где располагать значения NULL — до имеющихся значений или после них, стан-
74
Глава 2
дарт ANSI языка SQL оставляет за конкретной программной реализацией. Язык T-SQL в
отсортированном наборе помешает значения NULL перед другими имеющимися значениями.
Как уже говорилось, запрос отбирает записи по принципу "принимать TRUE". Выражение,
сравнивающее два значения NULL, в результате дает UNKNOWN, следовательно, такая строка
отвергается.
Стандарт ANSI языка SQL содержит два вида ограничений UNIQUE: ОДИН вид, интерпрети-
рующий значения NULL, как одинаковые (допуская только одно значение NULL), И второй
вид, интерпретирующий значения NULL, как отличающиеся друг от друга (допуская множе-
ственные значения NULL). В языке T-SQL реализован только первый вид.
Помня о противоречивой трактовке в языке SQL значений UNKNOWN и NULL И О возможности
логических ошибок, следует четко прослеживать троичную логику в каждом запросе, кото-
рый вы пишете. Если стандартная трактовка вас не устраивает, необходимо прямое вмеша-
тельство, в противном случае просто убедитесь в том, что поведение, принятое по умолча-
нию, — это именно то, что вам нужно.
Одновременно выполняемые операции
Язык SQL поддерживает идею так называемых одновременно выполняемых операций, означаю-
щую, что все выражения, появляющиеся на одной стадии логической обработки, как будто вы-
числяются в один и тот же момент времени.
Этот принцип объясняет, почему, например, нельзя сослаться в элементе SELECT на псевдо-
нимы столбцов, присвоенные в том же самом элементе SELECT, даже несмотря на то, что
интуитивно кажется, что такая возможность должна быть. Рассмотрим следующий запрос:
SELECT
orderid,
YEAR(orderdate) AS orderyear,
orderyear + 1 AS nextyear
FROM Sales.Orders;
Ссылка в третьем выражении списка элемента SELECT на псевдоним столбца orderyear
(год заказа) недопустима, несмотря на то, что выражение, содержащее эту ссылку, появля-
ется "после" выражения, в котором присваивается псевдоним. Причина кроется в том, что
не существует логического порядка вычисления выражений в списке SELECT— он пред-
ставляет собой множество выражений. На логическом уровне все выражения в списке эле-
мента SELECT вычисляются одновременно. Таким образом, запрос приведет к появлению
следующей ошибки:
Msg 207, Level 16, State 1, Line 4
Invalid column name 'orderyear'.
Далее приводится еще один пример важности концепции одновременно выполняемых опера-
ций: предположим, вы хотите вернуть все строки, в которых col2/coll не меньше 2. По-
скольку в таблице могут быть строки, у которых значение coll равно 0, вы должны убедиться
в том, что в этих строках подобное деление не выполняется — в противном случае запрос за-
вершится аварийно из-за ошибки деления на ноль.
Однотабличные запросы
75
Итак, написав запрос такого формата
SELECT coll, со12
FROM dbo.Tl
WHERE coll <> 0 AND col2/coll > 2;
вы предполагаете, что SQL Server вычисляет выражения слева направо, и если выражение
coll О 0 равно FALSE, SQL Server пойдет в обход, т. е. не будет утруждать себя вычисле-
нием выражения col2/coll > 2, поскольку в этот момент уже известно, что все выраже-
ние равно FALSE. Таким образом, вы, возможно, считаете, что такой запрос никогда не по-
родит ошибки деления на ноль.
SQL Server действительно поддерживает оптимизацию вычислений (short circuits), но в соответ-
ствии с концепцией ANSI SQL SQL Server может обрабатывать выражения из элемента WHERE В
любом понравившемся ему порядке. Подобные решения SQL Server принимает, исходя из оцен-
ки затрат, т. е. выражение, которое можно вычислить с меньшими затратами, вычисляется пер-
вым. Как видите, если SQL Server решит сначала обработать выражение col2/coll > 2, этот
запрос может завершиться аварийно из-за ошибки деления на ноль.
У вас есть несколько способов избежать аварийного завершения этого запроса. Например,
порядок, в котором вычисляются элементы WHEN выражения CASE, гарантирован. Поэтому
можно изменить запрос следующим образом:
SELECT coll, со12
FROM dbo.Tl
WHERE
CASE
WHEN coll = 0 THEN 'no
1
-
or 'yes
1
if row should be returned
WHEN col2/coll > 2 THEN 'yes
1
ELSE ®no
4
^
END =
1
yes';
Для тех строк, в которых значение coll равно нулю, первый элемент WHEN возвращает значе-
ние TRUE, а выражение CASE в этом случае возвращает строку ' по' (если вы хотите возвра-
щать строки, в которых coll равно 0, замените ее на строку 'yes
1
). Второй элемент WHEN
проверяет, равно ли выражение COL2/COLL > 2 значению TRUE, ТОЛЬКО если первый элемент
WHEN не вернет TRUE, т. е. значение coll не равно 0. Если выражение во втором элементе WHEN
равно TRUE, выражение CASE возвращает строку
1
yes'. Во всех остальных случаях выражение
CASE возвращает
1
по
1
. Предикат в элементе WHERE вернет значение TRUE, только если резуль-
тат выражения CASE равен строке 1 yes
1
. Это означает, что никогда не будет предпринята по-
пытка делить на ноль.
Этот прием оказался очень запутанным, и в данном конкретном случае мы можем приме-
нить более простой математический прием, устраняющий всякое деление:
SELECT coll, со12
FROM dbo.Tl
WHERE coll о 0 and col2 > 2*coll;
Я включил этот пример, чтобы показать уникальность и важность концепции одновременно
выполняемых операций и гарантированность порядка обработки в SQL Server элементов
WHEN выражения CASE.
76
Глава 2
Работа с символьными данными
Этот раздел посвящен обработке символьных данных в запросе, включая типы данных, на-
бор параметров символьной обработки (collation), операции и функции и сопоставление с
образцом или шаблоном.
Типы данных
SQL Server поддерживает две разновидности типов символьных данных: обычные и
Unicode. Обычные типы данных включают типы CHAR И VARCHAR, а типы данных Unicode —
NCHAR и NVARCHAR. Разница между ними заключается в том, что обычные типы данных ис-
пользуют один байт для хранения каждого символа, а для каждого символа Unicode требу-
ются два байта. Выбор для столбца символьных данных обычного типа с одним байтом для
хранения каждого символа ограничивает вас всего лишь одним языком в дополнение к анг-
лийскому, т. к. в одном байте можно представить только 256 (28) разных символов. Языко-
вая поддержка столбца определяется действующим набором символьной обработки столбца,
который я опишу вкратце. С помощью типов данных Unicode можно представить 65 536
(216
) разных символов, поскольку на каждый символ отводятся два байта. В одной и той же
кодовой таблице Unicode могут быть представлены все языки, таким образом, применяя в
столбце тип данных, вы сможете смешивать разные языки и не будете ограничены лишь
одним языком в дополнение к английскому.
Разновидности типов символьных данных отличаются и способом отображения символьных
констант или литералов. Для задания символьной константы обычного тира используются
апострофы или одинарные кавычки 'This is a regular character string literal
1
(это строковая константа обычного символьного типа). При задании символьной константы
типа Unicode необходимо указать символ N (сокращение для National (национальный)) в
качестве префикса: N*This is a Unicode character string literal
1
(это строковая
константа символьного типа Unicode).
Любой тип данных без подстроки VAR в собственном имени (CHAR, NCHAR) описывает стро-
ки фиксированной длины, т. е. SQL Server отводит место в строке таблицы, основываясь на
заданном размере столбца, а не на действительном количестве символов в символьной стро-
ке. Например, определение типа столбца CHAR (25) означает, что SQL Server зарезервирует
место в строке таблицы для 25 символов, независимо от длины сохраняемой символьной
строки. Поскольку для более длинной строки требуется увеличение места для всей строки
таблицы, типы данных фиксированной длины больше подходят для систем, ориентирован-
ных на запись. При чтении данных вы будете затрачивать больше места, т. к. потребление
памяти не оптимально.
Тип данных с подстрокой VAR (VARCHAR, NVARCHAR) В собственном имени имеет перемен-
ную длину, т. е. SQL Server использует столько места в строке таблицы, сколько требуется
для хранения символов, заданных в символьной строке, плюс два дополнительных байта для
данных смещения (offset data). Например, определение типа данных столбца VARCHAR (25)
означает, что максимальное количество сохраняемых символов равно 25, но на самом деле
место, занимаемое символьной строкой, определяется реальным количеством символов в
строке. Поскольку потребление памяти меньше, чем в случае типов данных фиксированной
длины, операции чтения выполняются быстрее. Но обновление записей таблицы может при-
вести к удлинению записей, что способно вызвать перемещение данных за пределы текущей
Однотабличные запросы
87
страницы. Следовательно, обновление данных с символьными типами переменной длины
менее эффективно, чем обновление данных, имеющих типы фиксированной длины.
Можно также определять типы данных переменной длины с помощью спецификатора МАХ
вместо указания максимального количества символов. Если столбец определяется с помо-
щью спецификатора МАХ, строка длиной, не превышающей определенного порогового зна-
чения (по умолчанию 8000 байтов), хранится в строке таблицы. Значение, которое больше
пороговой величины, хранится вне строки таблицы как большой объект (LOB).
В разд. "Запросы метаданных" далее в этой главе я объясню, как можно получить метадан-
ные об объектах базы данных, включая типы данных столбцов.
Набор параметров символьной обработки
Набор параметров символьной обработки — это описание символьных данных, включающее в
себя несколько характеристик, таких как языковая поддержка (важна для обычных типов дан-
ных, поскольку типы Unicode поддерживают все языки), порядок сортировки, чувствитель-
ность к состоянию регистра, чувствительность к диакритическим знакам и т. д. Для того чтобы
получить перечень поддерживаемых наборов параметров символьной обработки и их описа-
ния, можно обратиться к табличной функции fn__helpcol 1 ations:
SELECT паше, description
FROM sys.fn_helpcollations();
Например, collation Latinl_General_CI_AS означает следующее:
П Latinl General — поддерживаемый язык — английский;
•
Dictionary sorting — сортироька и сравнение символьных данных базируется на лек-
сикографическом порядке их следования ('А' < 'В' и 'а' < ЧУ).
Вывод о сортировке в лексикографическом порядке, поскольку этот вариант принят по
умолчанию, делается, если явно не задан другой порядок. Точнее, в имени набора пара-
метров символьной обработки не присутствует элемент BIN. ЕСЛИ указанная подстрока
появляется, это означает, что сортировка и сравнение символьных данных выполняются
в соответствии с двоичным представлением символов ('А
1
<'В
1
<'а'<ТУ);
•
CI — данные не чувствительны к состоянию регистра ('а' = 'А');
П AS — данные чувствительны к диакритическим знакам ('а
1
о 'а').
Набор параметров символьной обработки может быть определен на четырех разных уров-
нях: на уровне экземпляра, базы данных, столбца и выражения. Действующим является са-
мый низкий уровень.
Набор параметров символьной обработки экземпляра выбирается на этапе установки про-
граммы. Он определяет наборы параметров символьной обработки всех системных баз дан-
ных и применяется по умолчанию во всех пользовательских базах данных.
Когда создается пользовательская база данных, можно задать для нее набор параметров
символьной обработки с помощью элемента COLLATE. Если этого не сделано, по умолчанию
применяется набор параметров символьной обработки экземпляра.
Набор параметров символьной обработки базы данных определяет набор параметров сим-
вольной обработки метаданных объектов базы данных и используется по умолчанию для
78
Глава 2
столбцов пользовательских таблиц. Важно подчеркнуть, что набор параметров символьной
обработки базы данных определяет набор параметров символьной обработки метаданных,
включая имена объектов и столбцов. Например, если набор параметров символьной обра-
ботки базы данных не чувствителен к состоянию регистра, вы не можете в одной и той же
схеме создать таблицы с именами Т1 и tl, а если набор параметров символьной обработки
базы учитывает состояние регистра, такие имена допустимы.
Набор параметров символьной обработки для столбца можно явно включить в определение
столбца с помощью элемента COLLATE. ЕСЛИ вы этого не сделаете, по умолчанию принима-
ется набор параметров символьной обработки базы данных.
С помощью элемента COLLATE можно преобразовать набор параметров символьной обра-
ботки выражения. Например, в рабочей среде, не чувствительной к состоянию регистра,
следующий запрос применяет не зависящее от состояния регистра сравнение:
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname = N*davis';
Приведенный запрос вернет строку с Сарой Дэвис (Sara Davis) даже несмотря на то, что нет
полного совпадения, потому что состояние регистра в расчет не принимается.
Empid
firstname lastname
1
Sara
Davis
Если вы хотите выполнить отбор с учетом регистра, даже если набор параметров символь-
ной обработки столбца не чувствителен к состоянию регистра, можно преобразовать набор
параметров символьной обработки выражения следующим образом:
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname COLLATE Latinl_General_CS_AS = N'davis';
На этот раз запрос вернет пустой результирующий набор, потому что при сравнении с уче-
том состояния регистра не найдено совпадения.
ИДЕНТИФИКАТОРЫ В КАВЫЧКАХ
В стандартном языке SQL одинарные кавычки применяются для ограничения
символьных констант (например, • literal
1
), а двойные— для ограничения не
соответствующих стандарту идентификаторов, например, имен таблиц или
столбцов, содержащих пробелы или начинающихся с цифры (например,
"irregular
identifier"). В SQL Server есть установочный параметр
QUOTED IDENTIFIER, управляющий назначением двойных кавычек. Этот пара-
метр можно применять на уровне базы данных с помощью команды ALTER
DATABASE или на уровне сеанса с помощью команды SET. Если параметр уста-
новлен, поведение соответствует стандарту языка SQL, т. е. двойные кавычки
применяются для ограничения идентификаторов. Если параметр сброшен, пове-
дение не стандартно и двойные кавычки применяются для ограничения символь-
ных констант. Настоятельно рекомендуется следовать стандартному поведению
(устанавливать параметр). В большинстве интерфейсов баз данных, включая
OLEDB and ODBC, этот параметр установлен по умолчанию.
Однотабличные запросы
79
В качестве альтернативы применению двойных кавычек для ограничения иден-
тификаторов SQL Server поддерживает квадратные скобки (например,
[Irregular Identifier]).
Что касается одинарных кавычек, используемых для ограничения символьных
констант, если вы хотите включить в строку символ апострофа, необходимо за-
дать подряд два символа апострофа. Например, для задания константы abc
1
de
введите • abc
11
de *.
Операции и функции
Этот раздел посвящен конкатенации или сцеплению строк и функциям обработки символь-
ных строк.
'
Сцепление строк (операция "плюс")
В языке T-SQL для сцепления строк применяется операция "плюс" (+). Например, следую-
щий запрос к таблице Employees (Сотрудники) формирует столбец fullname (полное имя),
последовательно соединяя имя, пробел и фамилию сотрудника:
SELECT empid, firstname + N' • + lastname AS fullname
FROM HR.Employees;
Данный запрос вернет следующий результат:
empid
fullname
1
Sara Davis
2
Don Funk
3
Judy Lew
4
Yael Peled
5
Sven Buck
6
Paul Suurs
7
Russell King
8
Maria Cameron
9
Zoya Dolgopyatova
В стандарте ANSI языка SQL предписано, что сцепление со значением NULL ДОЛЖНО в итоге
давать значение NULL. В SQL Server такое поведение принято по умолчанию. Например,
рассмотрим запрос к таблице Customers (Клиенты), приведенный в листинге 2.7.
| Листинг 2.7. Запрос, демонстрирующий сцепление строк
SELECT custid, country, region, city,
country + N', ' + region + N', ' + city AS location
FROM Sales.Customers;
80
Глава 2
В некоторых строках таблицы Customers (Клиенты) в столбце region (регион) встречается
значение NULL. ДЛЯ таких строк SQL Server по умолчанию возвращает в столбце результата
location (полный адрес) значение NULL.
custid
country
region city
location
1
Germany
NULL Berlin
NULL
2
Mexico
NULL Mexico D.F.
NULL
3
Mexico
NULL Mexico D.F.
NULL
4
UK
NULL London
NULL
*
5
Sweden
NULL Lulea
NULL
6
Germany
NULL Mannheim
NULL
7
France
NULL Strasbourg
NULL
8
Spain
NULL Madrid
NULL
9
France
NULL Marseille
NULL
10
Canada
ВС
Tsawassen
Canada,ВС,Tsawassen
11
UK
NULL London
NULL
12
Argentina
NULL Buenos Aires
NULL
13
Mexico
NULL Mexico D.F.
NULL
14
Switzerland
NULL Bern
NULL
15
Brazil
SP
Sao Paulo
Brazil,SP,Sao Paulo
16
UK
NULL London
NULL
17
Germany
NULL Aachen
NULL
18
France
NULL Nantes
NULL
19
UK
NULL London
NULL
20
Austria
NULL Graz
NULL
(91 row(s) affected)
Вы можете изменить способ, которым SQL Server интерпретирует сцепления, задав пара-
метр сеанса CONCAT_NULL_YIELDS_NULL равным OFF. После установки значения параметра
OFF SQL Server в операции сцепления или конкатенации трактует значение NULL как пустую
строку. Для демонстрации этого поведения выполните следующий программный код для
того, чтобы установить значение параметра OFF, и затем повторно выполните запрос из лис-
тинга 2.7.
SET CONCAT_NULL_YIELDS_NULL OFF;
Теперь запрос в операциях сцепления интерпретирует значения NULL как пустые строки, и
вы получите следующий результат, приведенный здесь в сокращенном виде:
custid
country
region city
location
1
Germany
NULL Berlin
Germany,, Berlin
2
Mexico
NULL Mexico D.F.
Mexico,,Mexico D.F.
3
Mexico
NULL Mexico D.F.
Mexico,,Mexico D.F.
Однотабличные запросы
81
4
UK
NULL London
UK,, London
5
Sweden
NULL Lulea
Sweden,,Lulea
6
Germany
NULL Mannheim
Germany,, Mannheim
7
France
NULL Strasbourg
France,,Strasbourg
8
Spain
NULL Madrid
Spain,,Madrid
9
France
NULL Marseille
France,,Marseille
10
Canada
ВС
Tsawassen
Canada,ВС,Tsawassen
11
UK
NULL London
UK,,London
12
Argentina
NULL Buenos Aires
Argentina,,Buenos Aires
13
Mexico
NULL Mexico D.F.
Mexico,,Mexico D.F.
14
Switzerland
NULL Bern
Switzerland,,Bern
15
Brazil
SP
Sao Paulo
Brazil,SP,Sao Paulo
16
UK
NULL London
UK,,London
17
Germany
NULL Aachen
Germany,, Aachen
18
France
NULL Nantes
France,,Nantes
19
UK
NULL
London
UK,, London
20
Austria
NULL Graz
Austria,,Graz
(91 row(s) affected)
Настоятельно рекомендуется избегать изменений стандартного поведения, большинство
программистов ожидают стандартного поведения от программного кода. Если вы хотите
интерпретировать значение NULL как пустую строку, можно сделать это программно. Но
прежде чем я покажу, как это сделать, убедитесь в том, что вы снова установили в вашем
сеансе значение ON ДЛЯ параметра CONCAT_NULL_YIELDS_NULL.
SET CONCAT_NULL_YIELDS_NULL ON;
Для интерпретации значения NULL как пустой строки или, более точно, для замены значения
NULL пустой строкой можно применить функцию COALESCE. Эта функция принимает список
входных значений и возвращает первое значение, отличное от NULL. Далее показано, как
можно изменить запрос из листинга 2.7 для замены в программе значений NULL пустыми
строками.
SELECT custid, country, region, city,
country + N',' + COALESCE(region, N") + N',
1
+ city AS location
FROM Sales.Customers;
В языке T-SQL есть ряд функций, обрабатывающих символьные строки, включая LEFT,
RIGHT, LEN, CHARINDEX, PATINDEX, REPLACE, REPLICATE, STUFF, UPPER, LOWER, RTRIM,
LTRIM И др. В следующих разделах я опишу самые популярные из них.
Функция
SUBSTRING
Функция SUBSTRING извлекает из строки подстроку.
SUBSTRING (string, start, length)
82
Глава 2
Функция обрабатывает входную строку string и извлекает из нее, начиная с позиции
start, подстроку длиной length символов.
Например, следующий программный код вернет строку ' abc
1
:
SELECT SUBSTRING('abcde
1
, 1,3);
Если значение третьего аргумента больше конечной позиции входной строки, функция вер-
нет всю строку до конца и не выведет сообщения об ошибке. Это очень удобно, если нужно
вернуть часть строки, начиная с определенной позиции и до конца— вы просто задаете
очень большое значение или значение, равное полной длине входной строки.
Функции LEFT и RIGHT
Функции LEFT и RIGHT — сокращенные формы функции SUBSTRING, которые возвращают
требуемое количество начальных и конечных символов входной строки.
LEFT (string, n )
RIGHT(string, n)
Первый аргумент string— это обрабатываемая функцией строка. Второй аргумент, п,—
количество начальных или конечных символов, извлекаемых из строки. Например, следую-
щий программный код вернет строку
f
cde':
SELECT RIGHT('abcde', 3);
Функции LEN и DATALENGTH
Функция LEN возвращает количество символов во входной строке.
LEN (string) ;
Имейте в виду, что эта функция возвращает количество символов во входной строке, а не
количество байтов. В случае стандартных символов эти количества совпадают, поскольку
каждому символу требуется один байт. В случае символов Unicode каждый символ занимает
два байта. Следовательно, количество символов равно половине количества требуемых бай-
тов. Для получения количества байтов вместо функции LEN применяйте функцию
DATALENGTH. Например, следующий программный код вернет значение 5:
SELECT LEN(Nт
abcde');
Приведенный далее фрагмент программного кода вернет 10:
SELECT DATALENGTH(Nт
abcde
1
);
Еще одно различие между функциями LEN И DATALENGTH заключается в том, что первая
отбрасывает конечные пробелы, а последняя этого не делает.
Функция
CHARINDEX
Функция CHARINDEX возвращает позицию первого вхождения подстроки в строку.
CHARINDEX(substring, string [, start^pos] )
Однотабличные запросы
83
Функция возвращает позицию первого аргумента (подстроки), найденной во втором аргу-
менте (строке). Вы можете, но необязательно, задать третий аргумент, чтобы указать функ-
ции, с какой позиции следует начать поиск. Если третий аргумент не задан, функция начнет
поиск с первого символа. Если подстрока не найдена, функция вернет 0. Например, сле-
дующий программный код возвращает первую позицию пробела в строке ' itzik Веп-
Gan', равную 6:
SELECT CHARINDEX(' ', *Itzik Веп-Gan');
Функция
PATINDEX
Функция PATINDEX возвращает позицию первого вхождения шаблона или образца в строку.
PATINDEX (pattern,
string)
В аргументе pattern используются шаблоны, аналогичные шаблонам, применяемым в пре-
дикате LIKE языка T-SQL. В разд. "Предикат LIKE" далее в этой главе я кратко опишу
применение шаблонов и сам предикат. Но даже несмотря на то, что я до сих пор не пояснил,
как задаются шаблоны в языке T-SQL, следующий пример продемонстрирует, как найти
первое вхождение цифры в строку:
SELECT PATINDEX('%[0-9]%*, 'abcdl23efgh');
Этот программный код вернет значение 5.
Функция REPLACE
Функция REPLACE заменяет все вхождения подстроки другой подстрокой.
REPLACE(string,
substringl,
substring2)
Функция заменяет подстрокой substring2 все вхождения подстроки substringl в строку
string.
Например, приведенный далее программный код заменяет во входной строке все вхождения
дефиса двоеточиями:
SELECT REPLACE('1-а 2-Ь
1
,
':•);
Данный код вернет следующий результат: ! 1: а 2: b
1
.
Функцию REPLACE можно применять для подсчета количества вхождений символа в строку.
Для этого нужно заменить все вхождения символа пустой строкой (с нулевым количеством
символов) и вычислить разность между исходной длиной строки и новой длиной строки
после замены. Например, следующий запрос вернет для каждого сотрудника количество
символов 'е', встретившихся в атрибуте lastname (фамилия).
SELECT empid, lastname,
LEN (lastname) - LEN (REPLACE (lastname, ' e
1
,
1
') ) AS numoccur
FROM HR.Employees;
Данный запрос сформирует следующий результат:
empid
lastname
numoccur
84
Глава 2
5
Buck
0
8
Cameron
1
1
Davis
0
9
Dolgopyatova
0
2
Funk
0
7
King
0
3
Lew
1
4
Peled
2
6
Suurs
0
Функция
REPLICATE
Функция REPLICATE повторяет строку заданное число раз.
REPLICATE {string,
n)
Например, следующий программный код повторит строку ' abc' три раза, вернув строку
'abcabcabc
1
:
SELECT REPLICATE (1
abc', 3) ;
В следующем примере показано применение функции REPLICATE вместе с функцией RIGHT
и
операцией
сцепления
строк.
Приведенный
далее
запрос
к
таблице
Production.Suppliers (Поставщики) сформирует символьное представление целочис-
ленного идентификатора поставщика, состоящее из 10 цифр с ведущими нулями:
SELECT supplierid,
RIGHT (REPLICATE ('О', 9) + CAST(supplierid AS VARCHAR(10)), 10)
AS strsupplierid
FROM Production.Suppliers;
Выражение, формирующее результирующий столбец strsupplierid (строковый id по-
ставщика), повторяет символ '0' девять раз (создавая строку '000000000') и для получе-
ния результата сцепляет ее со строковым представлением идентификатора поставщика.
Строковое представление целочисленного идентификатора поставщика создается с помо-
щью функции CAST, которая применяется для преобразования типа данных входного значе-
ния. В завершение извлекаются 10 самых правых символов (начиная от конца) результи-
рующей строки для того, чтобы вернуть строковое представление ID поставщика в виде
10 цифр с ведущими нулями. Далее показан результат данного запроса в сокращенном виде:
supplierid strsupplierid
29
0000000029
28
0000000028
4
0000000004
21
0000000021
2
0000000002
22
0000000022
Однотабличные запросы
85
14
0000000014
11
0000000011
25
7
0000000025
0000000007
(29 row(s) affected)
Функция STUFF
Функция STUFF позволяет удалить из строки подстроку и вставить вместо нее другую.
STUFF (s tring, pos, del e te_l ength, insert string)
Функция действует на входной параметр string. Она удаляет количество символов, задан-
ное во входном параметре delete_length, начиная с позиции символа, указанной во вход-
ном параметре pos. Функция вставляет в позицию pos строку, заданную во входном пара-
метре insertstring. Например, следующий программный код обработает строку ' xyz',
удалит один символ, начиная со второй позиции, и вставит вместо него подстроку ' abc'.
SELECT STUFF('xyz
1
, 2, 1, 'abc');
Данный программный код вернет результат:
1
xabcz
1
.
Функции UPPER и LOWER возвращают входную строку, состоящую только из прописных или
строчных символов.
UPPER (string)
LOWER (s tring)
Например, следующий программный код вернет строку
f
ITZIK BEN-GAN ':
SELECT UPPER(1Itzik Ben-Gan');
Приведенный далее программный код вернет строку
1
itzik ben-gan':
SELECT LOWER(1Itzik Ben-Gan
1
);
Функции RTRIM и LTRIM
Функции RTRIM и LTRIM возвращают строку без начальных или конечных пробелов.
RTRIM (string)
LTRIM (s tring)
Если вы хотите удалить и начальные, и конечные пробелы, используйте результат одной
функции как входной параметр для другой. Например, следующий программный код удаля-
ет из входной строки и начальные, и конечные пробелы, возвращая строку
1
abc
1
:
SELECT RTRIM (LTRIM {1
abc ' ));
Функции UPPER и LOWER
4 Зак. 1032
86
Глава 2
Предикат LIKE
В языке T-SQL есть предикат LIKE, позволяющий проверять, соответствует ли символьная
строка заданному шаблону. Аналогичные шаблоны применяются в функции PAT INDEX, опи-
санной ранее. В следующих разделах описаны символы подстановки, используемые в шаб-
лонах, и их применение.
Символ подстановки % (знак процента)
Знак процента представляет строку любого размера, включая пустую строку. Например,
следующий запрос вернет сотрудников, у которых фамилия начинается с буквы D:
SELECT empid, lastname
FROM HR.Employees
WHERE lastname LIKE N'D%';
Данный запрос вернет такой результат:
empid
lastname
1
Davis
9
Dolgopyatova
Символ подстановки _ (знак подчеркивания)
Знак подчеркивания представляет единичный символ. Например, следующий запрос вернет
сотрудников, второй символ фамилии которых — е:
SELECT empid, lastname
FROM HR.Employees
WHERE lastname LIKE N'_e%';
Данный запрос вернет такой результат:
empid
lastname
3
Lew
4
Peled
Шаблон [<список символов*]
Квадратные скобки со списком символов (например,
1
[АБС] ') представляет единичный
символ, который должен быть одним из символов, заданных в списке.
Например, следующий запрос вернет сотрудников, фамилии которых начинаются с буквы
А,ВилиС.
SELECT empid, lastname
FROM HR.Employees
WHERE lastname LIKE N
1
[ABC]% ';
Однотабличные запросы
87
Этот запрос вернет такой результат:
empid
lastname
5
Buck
8
Cameron
Шаблон [<символ>-<символ>]
Квадратные скобки с диапазоном символов (например,
1
[А-Е] ') представляет единичный
символ из заданного диапазона. Например, следующий запрос вернет сотрудников, чьи фами-
лии начинаются с символа из диапазона от А до Е:
SELECT empid, lastname
FROM HR.Employees
WHERE lastname LIKE N'[A-E]%';
Данный запрос вернет такой результат:
empid
lastname
5
Buck
8
Cameron
1
Davis
9
Dolgopyatova
Шаблон [
А
<список или диапазон символов>]
Квадратные скобки со знаком "циркумфлекс"
за которым следует список или диапазон
символов, представляют единичный символ, не вошедший в заданный список или диапазон.
Например, следующий запрос вернет сотрудников, чьи фамилии начинаются с символа, не
входящего в диапазон от А до Е:
SELECT empid, lastname
FROM HR.Employees
WHERE lastname LIKE N
,
[/4
A-E]%f;
Этот запрос вернет такой результат:
empid
lastname
2
Funk
7
King
3
Lew
4
Peled
6
Suurs
88
Глава 2
Символ ESCAPE
Если вы хотите задать символ, который используется и как знак подстановки (например, %, [,
]), можно применить управляющий или экранирующий символ. Задайте в качестве управляюще-
го символ, который наверняка не встретится в данных, и укажите сразу вслед за шаблоном клю-
чевое слово ESCAPE, за которым следует управляющий символ. Например, для проверки наличия
символа подчеркивания в столбце coll напишите coll LIKE '%!_%' ESCAPE '!'.
Для символов %, _ и [ вместо управляющего или экранирующего символа можно использо-
вать квадратные скобки. Вместо coll LIKE '%!_%' ESCAPE 1 !
1
можно написать coll
LIKE '%[_]%'.
Работа с датами и временем
Даты и время суток в SQL Server обрабатываются необычно. Вы столкнетесь с несколькими
особенностями в этой области, такими как запись констант способом, не зависящим от вы-
бранного языка, отдельная обработка даты и времени и т. д.
В этом разделе я сначала опишу типы данных для представления дат и времени суток, под-
держиваемые SQL Server, далее поясню рекомендуемые способы работы с этими типами
данных и в конце познакомлю вас с функциями, связанными с обработкой дат и времени.
Типы данных Date и Time
До появления версии SQL Server 2008 SQL Server поддерживал два типа данных для пред-
ставления времени: DATETIME И SMALLDATETIME. Оба типа включали дату и время суток как
неразделяемые компоненты. Эти типы данных отличались друг от друга требованиями к
объему памяти, поддерживаемыми диапазоном дат и точностью представления данных. SQL
Server 2008 вводит отдельные типы DATE И TIME, ТИП DATETIME2 С большим диапазоном дат
и более высокой точностью представления по сравнению типом DATETIME И ТИП данных
DATETIMEOFFSET с'компонентом для представления данных часового пояса. В табл. 2.1
приведены подробные сведения о типах данных для представления дат и времени суток,
включая требуемый объем памяти, поддерживаемый диапазон дат, точность и рекомендо-
ванный формат ввода.
Таблица 2.1. Типы данных для представления дат и времени суток
Тип данных
Объем па-
мяти (байты)
Диапазон дат
Точность
Рекомендуемый
формат ввода
и пример
DATETIME
8
С 1 января
1753 г. по 31 де-
кабря 9999 г.
3 1/3 мил-
лисекунды
'YYYYMMDD
hh:mm:ss.nnn'
'20090212
12:30:15.123*
SMALLDATETIME
4
С 1 января
1900 г. по 6 июня
2079 г.
1 минута
'YYYYMMDD hh:mrrV
'20090212 12:30'
Однотабличные запросы
89
Таблица 2.1 (окончание)
Тип данных
Объем па-
мяти (байты)
Диапазон дат
Точность
Рекомендуемый
формат ввода
и пример
DATE
3
С 1 января
0001 г. по 31 де-
кабря 9999 г.
1 день
'YYYY-MM-DD'
TIME
ОтЗ
ДО5
100 нано-
секунд
'hh:min:ss.nnnnnnn'
'12:30:15.1234567'
DATЕТIME2
От6
ДО8
С 1 января
0001 г. по 31 де-
кабря 9999 г.
100 нано-
секунд
'YYYY-MM-DD
hh:mm:ss.nnnnnnn'
'2009-02-12
12:30:15.1234567'
DATETIMEOFFSET От 8
ДО 10
С 1 января
0001 г. по 31 де-
кабря 9999 г.
100 нано-
секунд
'YYYY-MM-DD
hh:mm:ss.nnnnnnn [+|-]
hh:mm'
'2009-02-12
12:30:15.1234567
+02:00'
Объем памяти, требуемый для представления данных последних трех типов, приведенных в
табл. 2.1 (TIME, DATETIME2 и DATETIMEOFFSET), зависит от выбранной вами точности. Точ-
ность задается как целое число из диапазона 0—7 и определяет разрядность дробной части
представления секунд. Например, TIME{0) означает 0 разрядов в дробной части, другими
словами точность до секунды, TIME (3) означает с точностью до миллисекунды, A TIME (7)
задает точность до 100 наносекунд. Если разрядность дробной части представления секунд
не задана, SQL Server по умолчанию полагает для трех вышеупомянутых типов данных раз-
рядность дробной части, равную 7.
Константы
Если вам необходимо задать константу для представления даты и времени суток, следует
учесть несколько аспектов. Во-первых, как бы странно это не звучало, SQL Server не пре-
доставляет средств для задания даты и времени суток в виде константы, вместо этого раз-
решается задавать константу другого типа, которую можно преобразовать, явно или неявно,
в тип данных для представления даты и времени суток. Лучше всего использовать для этого
символьные строки, как показано в следующем примере:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE orderdate = * 20070212';
SQL Server распознает константу
1
200702121
как символьную строку, а не как константу для
представления даты и времени суток, но, поскольку выражение включает в себя операнды двух
разных типов, один из них потребуется неявно преобразовать в другой тип. Обычно неявное
преобразование типов основывается на приоритете типов данных. В SQL Server определен
приоритет или старшинство разных типов данных и как правило операнд типа данных с более
низким приоритетом неявно преобразуется в тип данных с более высоким приоритетом. В на-
90
Глава 2
шем примере строковая константа преобразуется в тип данных столбца (DATETIME), Т. К. счи-
тается, что у символьных строк с точки зрения старшинства типов данных более низкий при-
оритет, чем у типа данных для представления дат и времени суток. Правила неявного преобра-
зования типов не всегда просты и на деле в фильтрах и других выражениях применяются
порой разные правила, но в нашем примере мы не будем ничего усложнять. Полный список
приоритетов типов данных см. в разд. "Data Type Precedence" ("Приоритет типов данных") в
интерактивном справочном руководстве SQL Server Books Online.
Я хочу подчеркнуть, что в приведенном примере неявное преобразование происходит за
кадром. Этот запрос логически эквивалентен следующему запросу, явно преобразующему
символьную строку в тип данных DATETIME:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE orderdate = CAST(1200702121 AS DATETIME);
Следует учитывать, что некоторые форматы символьных строк, применяемые для представ-
ления констант дат и времени суток зависят от языка, т. е. при преобразовании их в тип для
представления даты и времени SQL Server может интерпретировать значение по-разному, в
зависимости от установленного в сеансе языка. У каждого регистрационного имени, опре-
деленного администратором базы данных (DBA), есть язык, связанный с этим именем по
умолчанию, и если этот язык не изменен явно, он становится действующим языком сеанса.
В своем сеансе вы можете переопределить язык, принятый по умолчанию, с помощью ко-
манды SET LANGUAGE, но делать это не рекомендуется, т. к. некоторые аспекты программ-
ного кода могут зависеть от принятого по умолчанию языка пользователя.
Действующий в сеансе язык устанавливает за кадром несколько зависящих от него пара-
метров, среди которых есть параметр DATE FORMAT, который определяет, как SQL Server
интерпретирует введенные вами константы, когда преобразует их из символьной строки в
тип данных для представления даты и времени суток. Параметр DATE FORMAT представляет
собой комбинацию символов d (день), ш (месяц) и у (год). Например, при установленном
американском английском (us_english) языке параметр DATEFORMAT равен комбинации
mdy, а если установлен британский английский (British), он равен dmy. Переопределить
значение DATEFORMAT В вашем сеансе можно с помощью команды SET DATEFORMAT, НО
как уже говорилось, обычно делать это не рекомендуется.
Рассмотрим в качестве примера константу
1
02/12/2007'. SQL Server может интерпретиро-
вать дату как 12 февраля 2007 г. или 2 декабря 2007 г., когда вы преобразуете эту константу
в один из следующих типов данных: DATETIME, DATE, DATETIME2 ИЛИ DATETIMEOFFSET.
Определяющим фактором при этом будет установка параметра LANGUAGE/DATEFORMAT. ДЛЯ
демонстрации разных вариантов трактовки символьной строки выполните' приведенный
далее программный код.
SET LANGUAGE British;
SELECT CAST('02/12/2007' AS DATETIME);
SET LANGUAGE us_english;.
SELECT CAST('02/12/2007' AS DATETIME);
Обратите внимание на то, что в результате константа интерпретируется по-разному в разной
языковой среде.
Changed language setting to British.
Однотабличные запросы
91
2007-12-02 00:00:00.000
Changed language setting to us_english.
2007-02-12 00:00:00.000
Учтите, что установка параметра LANGUAGE /DATEFORMAT влияет только на способ интер-
претации введенного вами значения и не оказывает никакого воздействия на формат, при-
меняемый для отображения результата, который определяется интерфейсом базы данных,
применяемым в клиентском приложении (например, OLEDB), а не установочным парамет-
ром LANGUAGE /DATE FORMAT. Например, OLEDB ODBC представляют значения типа
DATETIME в формате 'YYYY-MM-DD hh:mm:ss.nnn\
Поскольку написанный вами программный код в случае его применения пользователями
других национальностей с разными языковыми установками, связанными с регистрацион-
ными именами этих пользователей, может неожиданно прервать выполнение, очень важно
понимать, что некоторые форматы констант зависят от языка, действующего в сеансе. На-
стоятельно рекомендуется задавать константы в независимом от языка виде. Не зависящие
от языка форматы всегда интерпретируются SQL Server одинаково, и на них не влияют ус-
тановленные параметры языковой поддержки. В табл. 2.2 для всех типов данных, представ-
ляющих даты и время суток, приведены форматы констант, считающиеся нейтральными по
отношению к языку.
Таблица 2.2. Форматы типов данных для представления дат и времени суток
Тип данных
He зависящие
от языка форматы
Примеры
DATETIME
'YYYYMMDD hh:mm:ss.nnn'
'YYYY-MM-DDThh:rrirri:ss.nnn'
'YYYYMMDD'
'20090212 12:30:15.123'
'2009-02-12T12:30:15.123'
'20090212'
SMALLDATETIME
'YYYYMMDD hh:mm'
YYYY-MM-DDThh:mm'
YYYYMMDD'
'20090212 12:30'
•2009-02-12Т12:30'
'20090212'
DATE
'YYYYMMDD'
'YYYY-MM-DD'
'20090212'
'2009-02-12'
DATETIME2
'YYYYMMDD hh:mm:ss.nnnnnnn'
'YYYY-MM-DD hh:mm:ss.nnnnnnn'
'YYYY-MM -DDThh:mm:ss.nnnnnnn'
'YYYYMMDD'
'YYYY-MM-DD'
'20090212 12:30:15.1234567'
'2009-02-12 12:30:15.1234567'
'2009-02-12T12:30:15.1234567'
'20090212'
'2009-02-12'
DATETIMEOFFSET 'YYYYMMDD hh:mm:ss.nnnnnnn
[+|-]hh:mm'
'YYYY-MM -DD hh:mm:ss.nnnnnnn
[+|-]hh:mm'
'YYYYMMDD'
'YYYY-MM-DD'
'20090212 12:30:15.1234567 +02:00'
'2009-02-12 12:30:15.1234567 +02:00'
'20090212'
'2009-02-12'
TIME
'hhimrrcss-nnnnnnn'
'12:30:15.1234567'
92
Гпаеа 2
Примите к сведению пару замечаний, касающихся табл. 2.2. Для всех типов данных, вклю-
чающих компоненты даты и времени суток, если не задавать в константе время суток, SQL
Server предполагает полночь. Если вы не укажете часовой пояс, SQL Server предполагает
00:00. Также важно отметить, что форматы 'YYYY-MM -DD' и 'YYYY-MM-DD hh:mm...'
зависят от языка при преобразовании в тип DATETIME ИЛИ SMALLDATETIME И нейтральны по
отношению к языку при преобразовании в типы DATE, DATETIME2 И DATETIMEOFFSET.
Рассмотрим следующий программный код, в котором языковые установки не влияют на то,
как при преобразовании в тип данных DATETIME интерпретируется константа, заданная в
формате 'YYYYMMDD':
SET LANGUAGE British;
SELECT CAST('200702121 AS DATETIME);
SET LANGUAGE us_english;
SELECT CAST('20070212' AS DATETIME);
Полученный результат показывает, что в обоих случаях константа интерпретировалась как
Februai7 12, 2007 (12 февраля 2007 г.):
Changed language setting to British.
20U/-02-12 UL): l)U: 1)1). 000
Changed language setting to us_english.
2007-02-12 00:00:00.000
Я, возможно, не смог особо подчеркнуть, что лучше всего применять нейтральные по отно-
шению к языку форматы, такие как * YYYYMMDD', потому что они трактуются одинаково
независимо от установок параметров LANGUAGE /DATE FORMAT.
Если вы настаиваете на зависящем от языка формате для задания констант, можно исполь-
зовать функцию CONVERT для явного преобразования символьной константы в требуемый
тип данных и в третьем аргументе задать номер используемого стиля. В разд. "The CAST
and CONVERT Functions" ("Функции CAST и CONVERT") интерактивного руководства
SQL Server Books Online есть таблица с номерами всех стилей и соответствующими им
форматами. Например, если вы хотите задать константу
1
02/12/2007* с форматом пред-
ставления mm/dd/yyyy, используйте стиль с номером 101, как показано далее:
SELECT CONVERT(DATETIME,
'02/12/2007f
,
101);
Константа интерпретируется как February 12, 2007 (12 февраля 2007 г.) независимо от дей-
ствующих языковых параметров.
Если вы хотите применить формат dd/mm/yyyy, воспользуйтесь стилем с номером 103:
SELECT CONVERT(DATETIME,
1
02/12/20071
,
103);
На этот раз константа интерпретируется как December 2,2007 (2 декабря 2007 г.).
Раздельная обработка даты и времени суток
В версии SQL Server 2008 введены раздельные типы данных DATE и TIME, НО В предыдущих
версиях программы оба компонента объединены. Если вы хотите работать только с датами
Однотабличные запросы
93
или только со временем суток в версиях SQL Server, предшествующих SQL Server 2008,
можно применить один из типов данных: DATETIME ИЛИ SMALLDATETIME, которые содержат
оба компонента. Также можно использовать целочисленный или строковый типы, в которых
реализована логика представления дат и времени суток, но я не буду сейчас обсуждать этот
вариант. Если вы хотите применить типы DATETIME ИЛИ SMALLDATETIME, ДЛЯ работы только
с датами сохраняйте дату с временем суток, соответствующим полуночи (все нули в компо-
ненте, хранящем время суток). Если вы хотите обрабатывать только время суток, сохраняй-
те времена суток с базовой датой January 1, 1900 (1 января 1900 г.).
Например, у столбца orderdate (дата заказа) таблицы Sales.Orders (Заказы) тип данных
DATETIME, но поскольку важен только компонент, содержащий дату, все даты хранятся со
значением'времени суток, равным полуночи. Когда вам нужно отобрать заказы с опреде-
ленной датой, не приходится использовать диапазон отбора. Вместо этого вы просто приме-
няете операцию равенства, подобную приведенной далее:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE orderdate =
1
20070212';
Если выполняется преобразование строковой константы в тип DATETIME и вы не задали
компонент времени суток, SQL Server полагает, что время суток равно полуночи. Поскольку
все значения в столбце orderdate были сохранены с указанием полуночи в компоненте,
описывающем время суток, вы получаете все заказы, сделанные в требуемый день.
Если в компоненте времени суток хранится не полночь, можно использовать для отбора
диапазон, подобный следующему:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE orderdate >= '20070212?
AND orderdate < '20070213';
Если вы хотите обрабатывать только время суток в версиях программы, предшествующих
версии SQL Server 2008, можете сохранять все значения, используя базовую дату January I,
1900 (1 января 1900 г.). Когда SQL Server преобразует строковую константу, содержащую
только время суток, в тип данных DATETIME ИЛИ SMALLDATETIME, программа считает, что
вы имеете в виду базовую дату. Например, выполните следующий программный код:
SELECT CAST('12:30:15.123' AS DATETIME);
Вы получите результат, приведенный далее:
1900-01-01 12:30:15.123
Предположим, что вы создали таблицу со столбцом tm, имеющим тип данных DATETIME, И
сохранили в нем все значения, используя базовую дату. Для того чтобы отобрать все строки
со значением времени'суток, равным 12:30:15.123, вы применяете фильтр WHERE tm =
' 12:30:15.123'. Поскольку компонент, определяющий дату, не был задан, SQL Server во
время неявного преобразования символьной строки в тип данных DATETIME полагает, что
имеется в виду базовая дата.
Если вы хотите работать только с датами или только с временем суток, а входные значения,
получаемые вами, содержат и дату, и время суток, необходимо применить некоторую обра-
94
Глава 2
ботку входных значений для "обнуления" несущественной части входной величины. Это
означает — приравнять время суток полуночи, если нужны только даты, или задать базовую
дату, если вы хотите работать только с временем суток. В разд. "Функции обработки дат и
времени суток" далее в этой главе я покажу, как быстро добиться этого.
Фильтрация диапазонов дат
Когда необходимо отобрать диапазон дат, например, целый год или месяц целиком, кажется
естественным применение функций, таких как YEAR и MONTH. Например, следующий запрос
вернет заказы, сделанные в 2007 году:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE YEAR(orderdate) = 2007;
Но вам следует знать, что когда вы обрабатываете отбираемый столбец, невозможно эффек-
тивно использовать индексы. Вероятно, это трудно понять без специальных знаний об ин-
дексах и производительности, которые не обсуждаются в этой книге, но пока просто держи-
те в уме это общее замечание. Для того чтобы иметь возможность эффективно применять
индекс, необходимо изменить предикат так, чтобы не было обработки фильтруемого столб-
ца, например, следующим образом:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE orderdate >=
1
200701011 AND orderdate < '20080101';
Аналогичным образом, вместо применения функций для отбора заказов, сделанных в кон-
кретном месяце, как показано в следующем запросе
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE YEAR(orderdate) = 2007 AND MONTH(orderdate) = 2;
используйте для отбора диапазон дат, как показано далее:
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE orderdate >= '20070201' AND orderdate < '20070301';
Функции обработки дат и времени суток
В этом разделе я опишу функции, оперирующие типами данных для представления дат и вре-
мени суток, включая следующие функции: GETDATE, CURRENT_TIMESTAMP, GETUTCDATE,
SYSDATETIME, SYSUTCDATETIME, SYSDATETIMEOFFSET, CAST, CONVERT, SWITCHOFFSET,
TODATETIMEOFFSET, DATEADD, DATED IFF, DATEPART, YEAR, MONTH, DAY И DATENAME. Имейте В
виду, ЧТО функции SYSDATETIME, SYSUTCDATETIME, SYSDATETIMEOFFSET, SWITCHOFFSET И
TODATETIMEOFFSET впервые появились в версии SQL Server 2008, в то время как остальные
доступны и в предыдущих версиях программы. Функции, доступные в версиях, предшествую-
щих SQL Server 2008, были усовершенствованы, в них была включена поддержка новых типов
Однотабличные запросы
95
данных для представления дат и времени суток и новых компонентов, описывающих дату и
время суток.
Текущие дата и время суток
Текущие дату и время суток в системе, где размещен экземпляр SQL Server, возвращают
следующие функции без параметров: GETDATE, CURRENT_TIMESTAMP, GETUTCDATE,
SYSDATETIME, SYSUTCDATETIME и SYSDATETIMEOFFSET. В табл. 2.3 приводится описание
этих функций.
Таблица 2.3. Функции, возвращающие текущие дату и время суток
Функция
Тип результата
Описание
Впервые
в SQL Server 2008?
GETDATE
DATETIME
Текущие дата и время
суток
Нет
CURRENT_TIMESTAMP DATETIME
Такая же, как GETDATE,
но ANSI
Нет
GETUTCDATE
DATETIME
Текущие дата и время
суток в UTC (универсаль-
ное глобальное время)
Нет
SYSDATETIME
DATETIME2
Текущие дата и время
суток
Да
SYSUTCDATETIME
DATETIME2
Текущие дата и время
суток в UTC
Да
SYSDATETIMEOFFSET DATETIMEOFFSET Текущие дата и время
суток, включая часовой
пояс
Да
Учтите, что необходимо указывать пустые скобки во всех функциях, которые не содержат
параметров, за исключением функции стандарта ANSI CURRENT_TIMESTAMP. Кроме того,
т. к. CURRENT_TIMESTAMP и GETDATE возвращают одно и то же, но первая из них включена в
стандарт, рекомендуется применять первую функцию. Я стараюсь в основном следовать
такому правилу: если у меня есть несколько не отличающихся друг от друга с точки зрения
функциональности и производительности вариантов для выполнения одного и того же, и
один из вариантов включен в стандарт, а остальные нет, я предпочитаю использовать стан-
дартный вариант.
В приведенном далее программном коде показано применение функций, возвращающих
текущие дату и время суток.
SELECT
GETDATE()
CURRENT_TIMESTAMP
GETUTCDATE()
SYSDATETIME()
AS [GETDATE],
AS [CURRENT__TIMESTAMP],
AS [GETUTCDATE],
AS [SYSDATETIME],
96
Глава 2
SYSUTCDATETIME ()
AS [ SYSUTCDATETIME] ,
SYSDATETIMEOFFSET()
AS [SYSDATETIMEOFFSET];
Как вы, возможно, заметили, ни одна из функций, впервые появившихся в версии SQL
Server 2008, не возвращает только текущую системную дату или только текущее системное
время. Но вы можете легко получить их, преобразовав результат CURRENT_TIMESTAMP или
SYS DATETIME в тип DATE или TIME следующим образом;
SELECT
CAST(SYSDATETIME() AS DATE) AS [current_date],
CAST(SYSDATETIME() AS TIME) AS [current_time];
Функции CAST и CONVERT
Функции CAST и CONVERT применяются для преобразования типа данных значения.
CAST(value AS datatype)
CONVERT{datatype, value [, style_number])
Обе функции преобразуют входное значение value в заданный тип данных datatype. Ино-
гда у функции CONVERT появляется третий аргумент, с помощью которого можно задать
стиль преобразования. Например, при преобразовании символьной строки в один из типов
данных, представляющих дату и время суток (или наоборот), номер стиля обозначает фор-
мат строки. Стиль 101, например, обозначает формат 'MM/DD/YYYY', а стиль 103 — фор-
мат 'DD/MM/YYYY'. Полный перечень номеров стилей и их значения см. в разд. "CAST and
CONVERT" интерактивного справочного руководства SQL Server Books Online.
Как упоминалось ранее, при преобразовании символьной строки в один из типов данных,
представляющих дату и время суток, применяются некоторые форматы, зависящие от уста-
новленного в системе языка. Я советую либо использовать один из не зависящих от языка
форматов, либо применять функцию CONVERT И ЯВНО задавать номер используемого вами
стиля. В этом случае ваш программный код будет интерпретироваться одинаково независи-
мо от того, какой язык установлен для зарегистрировавшегося пользователя, выполняющего
программный код.
Имейте в виду, что функция CAST включена в стандарт ANSI, а функция CONVERT — нет,
поэтому, до тех пор пока вам не понадобится номер стиля, рекомендуется использовать
функцию CAST, И В ЭТОМ случае ваш программный код будет настолько стандартным, на-
сколько это возможно.
Далее следует несколько примеров применения функций CAST И CONVERT ДЛЯ преобразова-
ния в типы данных, представляющие даты и время суток. Следующий программный код
преобразует символьную константу '20090212' в тип данных DATE:
SELECT CAST('200902121 AS DATE);
Приведенный далее программный код преобразует значение текущих системных даты и
времени суток в тип данных DATE, извлекая только компонент текущей системной даты:
SELECT CAST(SYSDATETIME() AS DATE);
Следующий программный код преобразует значение текущих системных даты и времени
суток в тип данных TIME, извлекая только компонент текущего системного времени суток:
SELECT CAST (SYS DATETIME () AS TIME);
Однотабличные запросы
97
Напоминаю, что типы данных DATE и TIME впервые появились в версии SQL Server 2008.
Как предлагалось ранее, если вы хотите работать только с датами или только с временем
суток в версиях, предшествующих SQL Server 2008, можно "обнулить" неважный для вас
компонент значения типа DATETIME ИЛИ SMALLDATETIME. Другими словами, для работы
только с датами вы задаете во времени суток полночь. Для работы только с временем суток
вы задаете в компоненте даты January 1, 1900 (1 января 1900 г.). Я опишу способ обнуления
ненужного компонента в заданном значении с датой и временем суток, таком как результат
функции CURRENTJTIMESTAMP.
Следующий программный код преобразует значение текущих даты и времени суток в
CHAR(8) с помощью стиля 112 ('YYYYMMDD'):
SELECT CONVERT (CHAR (8) , CURRENTJTIMESTAMP, 112);
Например, если текущая дата 12 февраля 2009 г., этот код вернет строку
1
20090212 На-
поминаю о том, что данный стиль нейтрален в отношении языка, поэтому, когда будет вы-
полнено обратное преобразование в тип DATETIME, ВЫ получите полночь и текущую дату.
SELECT CAST (CONVERT (CHAR (8) , CURRENTJTIMESTAMP, 112) AS DATETIME);
Аналогично для обнуления компонента дат до базовой даты можно сначала преобразовать с
помощью стиля с номером 114 ('hhimmiss.nnn') текущие дату и время суток в значение типа
CHAR(12):
SELECT CONVERT(CHAR(12), CURRENTJTIMESTAMP, 114);
Когда результат будет преобразован обратно в тип данных DATETIME, ВЫ получите текущее
время суток и базовую дату:
SELECT CAST(CONVERT(CHAR(12), CURRENTJTIMESTAMP, 114) AS DATETIME);
Функция
SWITCHOFFSET
Функция SWITCHOFFSET корректирует входное значение типа datetimeoffset в соответ-
ствии с заданным часовым поясом.
SWITCHOFFSET ( da te tlmeoffse t_value, time_zone)
Например, следующий код изменяет текущее системное значение типа datetimeoffset в
соответствии с часовым поясом -05:00.
SELECT SWITCHOFFSET(SYSDATETIMEOFFSET(),
'-05:00');
Таким образом, если текущее системное значение типа datetimeoffset— February 12,
2009 10:00:00.0000000 -08:00, приведенный программный код вернет значение Februaiy 12,
2009 13:00:00.0000000 —05:00.
Следующий программный код исправит текущее значение типа datetimeoffset в соответ-
ствии с универсальным глобальным временем:
SELECT SWITCHOFFSET(SYS DATETIMEOFFSET(),
1
+00:00
1
);
Если использовать вышеупомянутое текущее значение типа datetimeoffset, этот про-
граммный код вернет значение February 12, 2009 18:00:00.0000000 +00:00.
98
Глава 2
Функция
TODATETIMEOFFSET
Функция TODATETIMEOFFSET устанавливает часовой пояс для входного значения даты и
времени суток.
TODATETIMEOFFSET (da te_and_t.i ше_ value, timezone)
в
У этой функции есть два отличия от функции SWITCHOFFSET. Во-первых, она не ограни-
чена значением типа datetimeoffset на входе, входное значение может быть любого
типа, представляющего дату и время суток. Во-вторых, она не пытается изменить время
суток в соответствии с разницей часовых поясов между исходным значением часового
пояса и заданным часовым поясом, а просто возвращает значение даты и времени суток с
заданным часовым поясом в виде значения типа datetimeof fset. Например, если теку-
щее системное значение типа datetimeof fset равно February 12, 2009 10:00:00.0000000
-08:00 и вы выполните следующий фрагмент программного кода:
SELECT TODATETIMEOFFSET (SYSDATETIMEOFFSET () , '-05:00');
то получите значение February 12, 2009 10:00:00.0000000 -05:00. Напоминаю, что функция
SWITCHOFFSET откорректировала время суток в соответствии с разницей между часовым
поясом на входе (-08:00) и заданным часовым поясом (-05:00).
Как я упоминал, вы можете использовать функцию TODATETIMEOFFSET с любым типом
данных для представления дат и времени суток в качестве входного значения. Например,
следующий программный код принимает значение текущих системных даты и времени су-
ток и возвращает его как значение типа datetimeof fset с часовым поясом, равным -05:00.
SELECT TODATETIMEOFFSET(SYSDATETIME() ,
1
-05:00
1
);
Функция
DATE ADD
Функция DATEADD позволяет добавлять заданное число единиц указанного компонента даты
к входному значению даты и времени суток.
DATEADD (part, n, dt_yal)
Корректные значения для входного параметра part (компонент или период времени) вклю-
чают следующие: year (год), quarter (квартал), month (месяц), dayofyear (день в году),
day (день), week (неделя), weekday (день недели), hour (час), minute (минута), second
(секунда), millisecond (миллисекунда), microsecond (микросекунда) и nanosecond (на-
носекунда). Последние два значения впервые введены в версии SQL Server 2008. Компонент
даты можно задавать в сокращенном виде, например уу вместо year. Подробности см. в
интерактивном справочном руководстве SQL Server Books Online.
Тип возвращаемого функцией значения такой же, как тип входного значения даты и време-
ни суток. Если на входе задана строковая константа, у результата тип данных DATETIME.
Например, следующий программный код добавит 1 год к дате Febaiary 12,2009 (12 февраля
2009 г.):
SELECT DATEADD(year, 1,
1
200902121);
Данный программный код вернет следующий результат:
2010-02-12 00:00:00.000
Однотабличные запросы
99
Функция
DATEDIFF
Функция DATEDIFF возвращает разницу между двумя значениями, представляющими дату и
время суток, выраженную в заданных компонентах даты.
DATEDIFF (part, dt_vall, dt_val2)
Например, следующий код вернет разницу в днях (day) между двумя значениями:
SELECT DATEDIFF(day, ' 200802121
, '20090212');
Данный программный код возвращает значение 366.
Готовы к более сложному варианту использования функций DATEADD И DATEDIFF? В верси-
ях программы, предшествующих SQL Server 2008, можно применить приведенный далее
программный код для установки полночи в качестве текущего времени суток в значении
текущих системных даты и времени суток.
SELECT
DATEADD(
day,
DATEDIFF(day,
1
200101011
, CURRENT_TIMESTAMP),
1
200101011);
Достигается это сначала применением функции DATEDIFF ДЛЯ вычисления разницы в днях
между полуночью базовой даты (в данном случае '2001010Г) и текущими датой и временем
суток (назовем эту разницу diff). Далее используется функция DATEADD ДЛЯ добавления
dif f дней к базовой дате. Вы получите полночь текущей системной даты.
Интересно отметить, что, если применить это выражение с периодом продолжительностью
месяц вместо дня и убедиться в том, что используется в качестве базовой даты первый день
месяца (как в нашем примере), вы получите первый день текущего месяца.
SELECT
DATEADD(
month,
DATEDIFF(month, '200101011
, CURRENT_TIMESTAMP), '20010101');
Аналогичным образом, если применить период продолжительностью год и в качестве базо-
вой даты указать первый день года, вы получите в результате первый день текущего года.
Если вам нужен последний день месяца или года, просто примените базовую дату, указы-
вающую на последний день месяца или года. Например, следующее выражение вернет по-
следний день текущего месяца:
SELECT
DATEADD(
month,
DATEDIFF(month,
1
19991231', CURRENTJTIMESTAMP), '19991231');
Функция
DATEPART
Функция DATEPART возвращает целое число, представляющее требуемую часть заданного
значения даты и времени суток.
DATEPART (dt_val, part)
100
Глава 2
Корректные значения артумента part включают year (год), quarter (квартал), month (ме-
сяц), dayofyear (день в году), day (день), week (неделя), weekday (день недели), hour (час),
minute (минута), second (секунда), millisecond (миллисекунда), microsecond (мик-
росекунда), nanosecond (наносекунда), Tzoffset (смещение в минутах со знаком) и
IS0_WEEK (отсчет недель по стандарту ISO 8601). Последние 4 компонента появились впервые
в версии SQL Server 2008. Как я уже упоминал, можно пользоваться сокращениями для частей
даты и времени суток, такими как уу вместо year, mm вместо month, dd вместо day и т. д.
Например, следующий код вернет номер месяца во входном значении:
SELECT DATEPART(month,
1
200902121);
Данный программный код возвращает целое число 2.
Функции YEAR, MONTH и DAY
Функции YEAR, MONTH и DAY— это сокращенные формы функции DATE PART, возвращаю-
щие целочисленное обозначение года, месяца и дня из входного значения, представляющего
дату и время суток.
YEAR <dt_val)
MONTH(dt_val)
DAY (dt_val)
Например, следующий программный код извлекает год, месяц и день из входного значения:
SELECT
DAY(•200902121) AS theday,
MONTH('20090212') AS themonth,
YEAR('20090212 *) AS theyear;
Данный код вернет такой результат:
theday
themonth
theyear
12
2
2009
Функция
DATENAME
Функция DATENAME возвращает символьную строку, содержащую часть заданного значения,
представляющего дату и время суток.
DATENAME (dt__val, part)
Эта функция аналогична функции DATEPART, в ней используются те же параметры, что и для
ввода части даты. Но важно то, что она возвращает вместо номера требуемой части даты ее на-
звание. Например, следующий код вернет название месяца для заданного входного значения:
SELECT DATENAME(month,
1
200902121);
Напоминаю, что функция DATEPART для этого входного значения вернула бы целое число 2.
Функция DATENAME вернет название месяца, зависящее от действующего языка. Если язык
вашего сеанса один из вариантов английского языка (us english, British и т. д.), вы получите
Однотабличные запросы
101
обратно название 'Februaiy' (февраль). Если язык вашего сеанса — итальянский, вы получите
значение 'febbraio*. Если у запрашиваемой части даты нет названия, а есть только числовое
значение (например, у части даты year), функция DATENAME вернет это числовое значение в
виде символьной строки. Например, следующий программный код вернет строку '2009':
SELECT DATENAME(year,
1
200902121);
Функция ISDATE
Функция ISDATE принимает в качестве входного параметра символьную строку и возвраща-
ет 1, если строку можно преобразовать в тип данных, служащий для представления дат и
времени суток, или 0, если такое преобразование невозможно.
ISDATE (string)
Например, следующий программный код вернет 1:
SELECT ISDATE('200902121);
А приведенный далее код вернет 0:
SELECT ISDATE(1200902301);
Запросы метаданных
SQL Server предоставляет средства для получения информации о метаданных объектов, такой
как информация о таблицах в базе данных, столбцах в таблице и т. д. К этим средствам отно-
сятся представления каталогов, представления информационной схемы, системные хранимые
процедуры и функции. Эта область хорошо документирована в разд. "Querying the SQL Server
System Catalog" ("Запросы к системному каталогу SQL Server") интерактивного справочного
руководства SQL Server Books Online, поэтому я не буду подробно обсуждать ее здесь. Я про-
сто приведу по паре примеров для каждой разновидности средств получения метаданных для
того, чтобы вы смогли понять, что возможно, и попытаться начать работать.
Представления каталогов
Представления каталогов содержат очень подробные сведения об объектах базы данных,
включая информацию, специфичную для SQL Server. Например, если вы хотите получить пе-
речень таблиц в базе данных вместе с именами их схем, можно запросить представление
sys. tables следующим образом:
USE TSQLFundamentals2008;
SELECT SCHEMA_NAME (schema_id) AS table_schema_name, name AS table_name
FROM sys.tables;
Функция SCHEMA NAME применяется для преобразования целочисленного идентификатора
схемы в'ее имя. Данный запрос вернет следующий результат:
table schema name table name
HR
Employees
102
Глава 2
Production
Suppliers
Production
Categories
Production
Products
Sales
Customers
Sales
Shippers
Sales
Orders
Sales
OrderDetails
Для получения сведений о столбцах таблицы можно запросить таблицу sys. columns. На-
пример, следующий программный код вернет сведения о столбцах в таблице Sales. Orders
(Заказы), включая имена столбцов, типы данных (ID системного типа, преобразованный в
имя типа с помощью функции TYPE маме), максимальный размер, название набора пара-
метров символьной обработки и допустимость значений NULL.
SELECT
name AS соlumn_name,
»
TYPE_NAME (system_type__id) AS column_type,
max_length,
collation_name,
is_nullable
FROM sys.columns
WHERE object_id = OBJECT_ID(N' Sales.Orders');
Этот запрос вернет такой результат:
column_name
column_type max_length collation_name
is_nullable
orderid
int
4
NULL
0
custid
int
4
NULL
0
empid
int
4
NULL
0
orderdate
datetime
8
NULL
0
requireddate
datetime
8
NULL
0
shippeddate
datetime
8
NULL
1
shipperid
int
4
NULL
0
freight
money
8
NULL
0
shipname
nvarchar
80
Latinl__General_ CI _AI 0
shipaddress
nvarchar
120
Latinl__General_ CI _AI 0
shipcity
nvarchar
30
Latinl__General _CI__AI 0
shipregion
nvarchar
30
Latinl__General _CI__AI 1
shippostalcode nvarchar
20
Latin 1_General^_CI__AI 1
shipcountry
nvarchar
30
Latinl__General CI _AI 0
Представления информационной схемы
Представления информационной схемы — это набор представлений, размещенный в схеме
с именем IN FORMAT ION_SCHEMA И предоставляющий в стандартном виде сведения о мета-
Однотабличные запросы
103
данных. Это означает, что представления определены в соответствии со стандартом ANSI
языка SQL и, естественно, не отражают специфичные для SQL Server свойства.
Например, следующий запрос к представлению INFORMATION_SCHEMA. TABLES формирует
список пользовательских таблиц в текущей базе данных с именами схем.
SELECT TABLE_SCHEMA, TABLE_NAME
FROM INFORMATION_SCHEMA. TABLES
WHERE TABLEJTYPE = N' BASE TABLE';
Приведенный далее запрос к представлению INFORMATION SCHEMA. COLUMNS предоставляет
максимум доступной информации о столбцах в таблице Sales. Orders.
SELECT
COLUMN_NAME, DATA_TYPE, CHARACTER_MAXIMUM_LENGTH,
COLLATION_NAME, IS_NULLABLE
FROM INFORMATION_SCHEMA. COLUMNS
WHERE TABLE_SCHEMA = N'Sales'
AND TABLE_NAME = N
1
Orders';
Системные хранимые процедуры и функции
Системные хранимые процедуры и функции запрашивают системный каталог на внутрен-
нем уровне и возвращают вам более обработанную информацию о метаданных. И как всегда
вы сможете найти полный перечень объектов и их подробные описания в интерактивном
справочном руководстве SQL Server Books Online, здесь же приводится несколько приме-
ров. Хранимая процедура sp_tables возвращает перечень объектов (таких как таблицы и
представления) в текущей базе данных, которые можно запрашивать.
EXEC sys.sp_tables;
Имейте в виду, что схема sys появилась в версии SQL Server 2005. В более ранних версиях
системные хранимые процедуры размещались в схеме dbo.
Процедура sp_help принимает в качестве входного параметра имя объекта и возвращает
множественные результирующие наборы с общей информацией об объекте, а также сведе-
ния о столбцах, индексах, ограничениях и т. д. Например, следующий программный код
вернет подробную информацию о таблице Orders (Заказы):
EXEC sys.sp_help
@objпаше = N'Sales.Orders';
Процедура sp_columns возвращает информацию о столбцах объекта. Например, приведен-
ный далее программный код вернет сведения о столбцах в таблице Orders:
EXEC sys.sp_columns
Gtable_name = N'Orders',
Gtable_owner = N'Sales';
Процедура sp_helpconstraint возвращает информацию об установленных ограничениях
объекта.
104
Глава 2
Например, следующий программный код вернет сведения об ограничениях в таблице
Orders:
EXEC sys.sp_helpconstraint
Gobjname = N
1
Sales.Orders
1
;
Единый набор функций возвращает информацию о свойствах разных элементов, таких как эк-
земпляр SQL Server, база данных, объект, столбец и т. д. Функция SERVERPROPERTY возвращает
запрашиваемое свойство текущего экземпляра сервера. Например, следующий программный код
вернет уровень продукта (product level) (например, RTM, SP1, SP2 и т. д.) текущего экземпляра.
SELECT
SERVERPROPERTY(1ProductLevel
1
);
Функция DATABASE PRO PERT YEX возвращает запрошенное свойство базы данных с заданным
именем. Например, приведенный далее программный код вернет название набора парамет-
ров символьной обработки, применяемого в базе данных TSQLFundamentaIs2008.
SELECT
DATABASEPROPERTYEX(N1TSQLFundamentals20081
,
'Collation
1
)
Функция OBJECTPROPERTY возвращает запрашиваемое свойство объекта с заданным име-
нем. Например, результат следующего запроса показывает, есть ли у таблицы Orders пер-
вичный ключ:
SELECT
OBJECTPROPERTY (OBJECT_ID (N1 Sa^s. Orders'),
1
TableHasPrimaryKey
1
);
Обратите внимание на то, что функция OBJECT ID вложена в функцию OBJECTPROPERTY.
Последняя принимает идентификатор объекта, а не его имя, поэтому функция OBJECT ID
применяется для возврата идентификатора таблицы Orders.
Функция COLUMN PROPERTY возвращает запрашиваемое свойство заданного столбца. Напри-
мер, результат следующего программного кода покажет, допустимы ли значения NULL В
столбце shipcountry (страна доставки) таблицы Orders:
SELECT
COLUMNPROPERTY(OBJECT_ID(N1 Sales.Orders
1
),N
1
shipcountry
1
,
f
AllowsNull
1
);
Резюме
Эта глава познакомила вас с инструкцией SELECT, логической обработкой запроса и други-
ми аспектами однотабличных запросов. Я обсудил здесь лишь несколько тем, содержащих
много новых, уникальных идей и понятий. Если вы только начинаете изучать язык T-SQL,
возможно, сейчас вы чувствуете себя подавленными. Но хочу напомнить, что эта глава вво-
дит ряд наиболее важных аспектов языка SQL, которые, быть может, трудно усвоить на на-
чальном этапе. Если не все понятия и идеи были ясны до конца, вы, вероятно, захотите вер-
нуться к разделам этой главы позже, после небольшого перерыва.
Для того чтобы опробовать на практике то, чему вы научились, и лучше усвоить материал, я
советую выполнить приведенные в конце главы упражнения.
Однотабличные запросы
105
Упражнения
Этот раздел содержит упражнения для практического применения материала, обсуждавше-
гося в этой главе. Решения приведены в приложении 2.
В этот раздел также включены дополнительные более сложные упражнения. Они предна-
значены для тех, кто свободно ориентируется в материале и хочет проверить себя на более
сложных задачах. Дополнительные упражнения помечены соответствующим образом.
Инструкции по загрузке и установке учебной базы данных TSQLFundamentals2008 см. в при-
ложении 1.
Упражнение 2.1
Найдите заказы, сделанные в июне 2007 г.
Используемые таблицы: база данных TSQLFundamentals2008, таблица Sales. Orders.
Предполагаемый результат (в сокращенном виде):
orderid
orderdate
custid
empid
10555
2007-06 -02 00:: 00:
: 00.
,000 71
6
10556
2007-06 -03 00:: 00:
: 00.
,000 73
2
10557
2007-06 -03 00:; 00:: 00.
,000 44
9
10558
2007-06 -04 00:: 00:
: 00.
,000 4
1
10559
2007-06 -05 00:: 00:
: 00.
,000 7
6
10560
2007-06-06 00:: 00:
: 00.
,000 25
8
10561
2007-06-06 00:: 00:
: 00.
.000 24
2
10562
2007-06-09 00:: 00:00.,000
66
1
10563
2007-06-10 00:: 00:
: 00,
.000
67
2
10564
2007-06-10 00:: 00:
: 00.
.000
65
4
(30 row(s) affected)
Упражнение 2.2
(дополнительное, повышенной сложности)
Найдите заказы, сделанные в последний день месяца.
Используемые таблицы: таблица Sales. Orders.
Предполагаемый результат (в сокращенном виде):
orderid
orderdate
custid
empid
10269
2006-07-31 00:00:00.000 89
5
10317
2006-09 -30 00:00:00.000 48
6
10343
2006-10-31 00:00:00.000 44
4
10399
2006-12-31 00:00:00.000 83
8
106
Глава 2
10432
2007-01-31 00:00:00..000 75
3
10460
2007-02-28 00:00:00.,000 24
8
10461
2007-02-28 00:00:00..000 46
1
10490
2007-03 -31 00:00:00..000 35
7
10491
2007-03-31 00:00:00..000 28
8
10522
2007-04-30 00:00:00,.000 44
4
(26 row(s) affected)
Упражнение 2.3
Найдите сотрудников, в фамилиях которых буква 'а' встречается не менее двух раз.
Используемые таблицы: таблица HR. Employees.
Предполагаемый результат:
empid
firstname lastname
9
Zoya
Dolgopyatova
(1 row(s) affected)
Упражнение 2.4
Найдите заказы с общей стоимостью (количество х цена единицы) более 10 ООО, отсорти-
рованные по общей стоимости.
Используемые таблицы: таблица Sales .OrderDetails.
Предполагаемый результат:
orderid
totalvalue
10865
17250.00
11030
16321.90
10981
15810.00
10372
12281.20
10424
11493.20
10817
11490.70
10889
11380.00
10417
11283.20
10897
10835.24
10353
10741.60
10515
10588.50
10479
10495.60
10540
10191.70
10691
10164.80
(14 row(s) affected)
Однотабличные запросы
107
Упражнение 2.5
Найдите страны доставки с наивысшей средней стоимостью перевозки (freight) в 2007 г.
Используемые таблицы: таблица Sales. Orders.
Предполагаемый результат:
shipcountry
avgfreight
Austria
178.3642
Switzerland
117.1775
Sweden
105.16
(3 row(s) affected)
Упражнение 2.6
Отдельно для каждого клиента пронумеруйте строки с заказами в порядке поступления за-
казов (используйте ID заказа для упорядочивания связанных записей).
Используемые таблицы: таблица Sales. Orders.
Предполагаемый результат (в сокращенном виде):
custid
orderdate
orderid
rownum
1
2007-08 -25 00:00:00.000 10643
1
1
2007-10-03 00:00:00.000 10692
2
1
2007-10-13 00:00:00.000 10702
3
1
2008-01-15 00:00:00.000 10835
4
1
2008-03 -16 00:00:00.000 10952
5
1
2008-04-09 00:00:00.000 11011
6
2
2006-09-18 00:00:00.000 10308
1
2
2007-08-08 00:00:00.000 10625
2
2
2007-11 -28 00:00:00.000 10759
3
2
2008-03 -04 00:00:00.000 10926
4
(830 row(s) affected)
Упражнение 2.7
Напишите инструкцию SELECT, которая возвращает пол сотрудника на основании варианта
вежливого обращения: для 'Ms.
1
(мисс) и 'Mrs.' (миссис) верните 'Female
1
(женский); для 'Mr.
1
(мистер) верните 'Male' (мужской) и в остальных случаях (например. 'Dr.' (доктор)) — 'Un-
known' (неизвестно).
Используемые таблицы: таблица HR.Employees.
Предполагаемый результат:
empid
firstname lastname
titleofcourtesy
gender
108
Глава 2
1
2
3
4
5
6
7
Sara
Don
Judy
Yael
Sven
Paul
Davis
Funk
Lew
Ms.
Dr.
Ms.
Mrs
Mr.
Mr.
Mr.
Ms.
Ms.
Female
Unknown
Female
Female
Male
Peled
Buck
Suurs
Male
Male
8
Russell
King
Maria
Cameron
Female
Female
9
Zoya
Dolgopyatova
(9 row{s) affected)
Упражнение 2.8
Выведите для каждого клиента ID клиента и регион. В результирующем наборе отсортируй-
те строки по регионам так, чтобы значения NULL ВЫВОДИЛИСЬ последними (после ненулевых
значений). Учтите, что по умолчанию в языке T-SQL при сортировке значения NULL ВЫВО-
ДЯТСЯ первыми (перед ненулевыми значениями).
Используемые таблицы: таблица Sales. Customers.
Предполагаемый результат (в сокращенном виде):
custid
region
55
АК
10
ВС
42
ВС
45
СА
37
Co. Cork
33
DF
71
ID
38
Isle of Wight
46
Lara
78
MT
1
NULL
2
NULL
3
NULL
4
NULL
5
NULL
6
NULL
7
NULL
8
NULL
9
NULL
11
NULL
(91 row(s) affected)
ГЛАВА 3
u
Соединения (Join)
Элемент запроса FROM логически обрабатывается первым, и в этом элементе к входным таб-
лицам применяются табличные операции. В Microsoft SQL Server 2008 поддерживаются
четыре табличные операции: JOIN, APPLY, PIVOT и UNPIVOT. Табличная операция JOIN —
стандартная, а операции APPLY, PIVOT И UNPIVOT — расширения стандарта в языке T-SQL.
Последние три операции были введены в версии SQL Server 2005. Каждая табличная опера-
ция действует на таблицы, заданные как входные, применяет ряд стадий логической обра-
ботки запроса и возвращает результат в виде таблицы. Эта глава посвящена табличной опе-
рации JOIN. Операция APPLY будет обсуждаться в главе 5, а операции PIVOT и UNPIVOT —
в главе 7.
Табличная операция JOIN (соединение) действует на две входные таблицы. К трем основ-
ным типам соединения относятся перекрестное, внутреннее и внешнее. Все три типа соеди-
нений отличаются друг от друга стадиями логической обработки запроса, у каждого типа
соединения разный набор стадий. Перекрестное соединение применяет только одну стадию
обработки— декартово произведение. Внутреннее соединение применяет две стадии —
декартово произведение и фильтрацию. Внешнее соединение включает три стадии обработ-
ки — декартово произведение, фильтрацию и добавление внешних строк. В этой главе при-
водится подробное описание каждого типа соединений и входящих в их состав стадий обра-
ботки.
Логическая обработка запроса описывает общую последовательность логических шагов,
которые для заданного запроса формируют правильный результат, а физическая обработка
запроса — это способ, которым запрос обрабатывается на практике процессором или управ-
ляющим механизмом СУРБД. Некоторые шаги в логической обработке запроса, исполь-
зующего соединения, могут показаться неэффективными, однако их физическая реализация
может быть оптимизирована. В логической обработке запроса важно подчеркнуть слово
"логическая". На стадиях этого процесса к входным таблицам применяются операции реля-
ционной алгебры. Процессор базы данных не должен следовать стадиям логической обра-
ботки буквально до тех пор, пока он может гарантировать, что сформированный им резуль-
тат будет таким же, как предписывает логическая обработка запроса. Реляционный
процессор SQL Server часто для оптимизации применяет многочисленные сокращения, если
известно, что при этом будет сформирован корректный результат. Несмотря на то, что глав-
ная задача книги— объяснение логических аспектов формирования запросов, я хочу заост-
рить на этом внимание, чтобы избежать непонимания и путаницы.
110
Глава 2
Перекрестные соединения
Логически перекрестное соединение— простейший тип соединения. Оно реализует только
одну стадию логической обработки запроса — декартово произведение. Эта стадия воздей-
ствует на две таблицы, входные для операции соединения, и формирует их декартово произ-
ведение. Таким образом, каждая строка из одной таблицы сопоставляется со всеми строками
другой таблицы. Если у вас т строк в одной таблице и п в другой, вы получите в результи-
рующем наборе тхп строк.
SQL Server поддерживает для перекрестных соединений два варианта синтаксической
записи: синтаксическую запись ANSI SQL-92 и синтаксическую запись ANSI SQL-89.
Я советую пользоваться синтаксической записью ANSI-SQL 92 по причинам, которые
вкратце изложу. Отсюда следует, что синтаксическая запись ANSI-SQL 92 — основной
вариант, применяемый в этой книге. Далее для полноты картины я опишу оба варианта
синтаксической записи.
Синтаксическая запись ANSI SQL-92
В следующем запросе применяется перекрестное соединение таблиц Customers (Клиенты)
и Employees (Сотрудники) (с использованием синтаксической записи ANSI SQL-92) из
учебной базы данных TSQLFundamentals2008 и в результирующем наборе возвращаются
атрибуты custid (id клиента) и empid (id сотрудника).
USE TSQLFundamentals2008;
SELECT С.custid, E.empid
FROM Sales.Customers AS С
CROSS JOIN HR.Employees AS E;
Поскольку в таблице Customers (Клиенты) 91 строка и в таблице Employees (Сотрудники)
9 строк, запрос сформирует результат из 819 строк, показанный далее в сокращенном виде:
custid
empid
1
1
1
2
1
3
1
4
1
5
1
6
1
7
1
8
1
9
2
1
2
2
2
3
Соединения (Join)
111
2
4
2
2
2
5
6
7
2
2
8
9
(819 row(s) affected)
С помощью синтаксической записи вида ANSI SQL-92 вы задаете ключевые слова CROSS
JOIN между двумя таблицами, вовлеченными в соединение.
Обратите внимание на то, что в элементе FROM предыдущего запроса я присвоил псевдони-
мы СИЕ таблицам Customers (Клиенты) и Employees (Сотрудники) соответственно. Ре-
зультирующий набор, формируемый перекрестным соединением, — это виртуальная табли-
ца с атрибутами, взятыми из обеих таблиц, участвующих в соединении. Поскольку я
назначил псевдонимы исходным таблицам, имена столбцов в виртуальной таблице имеют
префиксы в виде назначенных псевдонимов (например, с.custid, Е.empid). Если вы не
присваиваете псевдонимы таблицам в элементе FROM, префиксы имен столбцов в виртуаль-
ной таблице содержат полные имена таблиц (например, Customers, custid,
Employees. empid). Префиксы позволяют однозначно идентифицировать столбцы, если в
обеих таблицах встречаются одинаковые имена столбцов. Таблицам псевдонимы даны для
краткости. Имейте в виду, что префиксы столбцов обязательно задавать только, если имена
столбцов не однозначны (встречаются в обеих таблицах), если же имена определяются од-
нозначно, использование префиксов необязательно. Некоторые программисты всегда при-
меняют префиксы в именах столбцов для большей ясности. Учтите также, что если вы при-
своили таблице псевдоним, использование в качестве префикса полного имени таблицы
считается ошибкой, в неоднозначных ситуациях в качестве префиксов следует применять
назначенные псевдонимы.
SQL Server также поддерживает более старый вариант синтаксической записи для перекре-
стных соединений, введенный в стандарте языка ANSI SQL-89. В этом варианте имена таб-
лиц просто отделяются друг от друга запятой следующим образом:
SELECT С.custid, Е.empid
FROM Sales.Customers AS С, HR.Employees AS E;
Обе синтаксические записи не отличаются ни логикой, ни исполнением. Они включены как
неотъемлемая часть в последний стандарт языка SQL (во время написания книги это ANSI
SQL:2006) и обе полностью поддерживаются последней версией SQL Server (во время напи-
сания этих строк SQL Server 2008). Мне ничего не известно о намерении отказаться от более
старого варианта синтаксиса, и я не вижу никаких причин для этого, поскольку он является
неотъемлемой частью стандарта. Тем не менее, я рекомендую применять синтаксическую
запись ANSI SQL-92 по причинам, которые станут яснее после обсуждения внутренних со-
единений.
Синтаксическая запись ANSI SQL-89
112
Гпаеа 3
Перекрестные самосоединения
Вы можете соединять несколько экземпляров одной и той же таблицы. Эта возможность
называется самосоединением и поддерживается соединениями всех основных типов (пере-
крестным, внутренним и внешним). Например, следующий запрос выполняет перекрестное
самосоединение двух экземпляров таблицы Employees (Сотрудники):
SELECT
El.empid, El.firstname, El.lastname,
E2.empid, E2.firstname, E2.lastname
FROM HR.Employees AS El
CROSS JOIN HR.Employees AS E2;
Этот запрос формирует все возможные комбинации пар сотрудников. Поскольку в таблице
Employees (Сотрудники) 9 строк, запрос вернет 81 строку, которые приведены далее в со-
кращенном виде:
empid firstname lastname
empid firstname lastname
1
Sara
Davis
1
Sara
Davis
2
Don
Funk
1
Sara
Davis
3
Judy
Lew
1
Sara
Davis
4
Yael
Peled
1
Sara
Davis
5
Sven
Buck
1
Sara
Davis
6
Paul
Suurs
1
Sara
Davis
7
Russell
King
1
Sara
Davis
8
Maria
Cameron
1
Sara
Davis
9
Zoya
Dolgopyatova
1
Sara
Davis
1
Sara
Davis
2
Don
Funk
2
Don
Funk
2
Don
Funk
3
Judy
Lew
2
Don
Funk
4
Yael
Peled
2
Don
Funk
5
Sven
Buck
2
Don
Funk
6
Paul
Suurs
2
Don
Funk
7
Russell
King
2
Don
Funk
8
Maria
Cameron
2
Don
Funk
9
Zoya
Dolgopyatova
2
Don
Funk
(81 row(s) affected)
В самосоединении присвоение таблицам псевдонимов обязательно. Без них все имена столб-
цов в результирующем наборе соединения будут неоднозначны.
Соединения (Join)
113
Создание таблиц чисел
Очень удобно применять перекрестные соединения для создания результирующего набора,
содержащего последовательные целые числа (1, 2, 3 и т. д.). Подобная последовательность
чисел — очень мощное средство, которое я применяю для разных задач. С помощью пере-
крестных соединений вы можете формировать числовые последовательности очень эффек-
тивным способом.
Можно начать с создания таблицы с именем Digits (Цифры), содержащей столбец digit
(цифра), и заполнить ее 10 строками, в каждой из которых однозначные числа от 0 до 9. Для
создания таблицы Digits в базе данных tempdb (для проверки) и заполнения ее 10 одно-
значными числами выполните следующий программный код:
USE tempdb;
IF OBJECT_ID(1dbo.Digits ', 'U') IS NOT NULL DROP TABLE dbo.Digits;
CREATE TABLE dbo.Digits(digit INT NOT NULL PRIMARY KEY);
INSERT INTO dbo.Digits(digit)
VALUES(0),(1),(2),(J),(4),(5),(6),(7),(8),(9);
/*
Примечание: приведенная выше запись инструкции INSERT введена
в версии Microsoft SQL Server 2008.
В более ранних версиях используйте следующую запись:
INSERT INTO dbo.Digits(digit) VALUES(0),
INSERT INTO dbo.Digits(digit) VALUES(1)
INSERT INTO dbo.Digits(digit) VALUES(2)
INSERT INTO dbo.Digits(digit) VALUES(3)
INSERT INTO dbo.Digits(digit) VALUES(4)
INSERT INTO dbo.Digits(digit) VALUES(5)
INSERT INTO dbo.Digits(digit) VALUES(6)
INSERT INTO dbo.Digits(digit) VALUES(7)
INSERT INTO dbo.Digits(digit) VALUES(8)
INSERT INTO dbo.Digits(digit) VALUES(9);
*/
SELECT digit FROM dbo.Digits;
В этом программном коде пара синтаксических элементов применяется в этой книге впер-
вые, поэтому я кратко поясню их. Любой текст, помещенный в блок, начинающийся с ком-
бинации символов /* и заканчивающийся комбинацией символов */, интерпретируется как
блок комментариев и игнорируется SQL Server. Кроме того, в приведенном программном
коде используется инструкция INSERT, подробности см. в главе 8. Но учтите, что здесь при-
меняется новый вариант синтаксической записи инструкции INSERT VALUES, который был
введен в SQL Server 2008, он позволяет с помощью одной инструкции вставлять несколько
строк. Вставленный в программный код блок комментариев поясняет, что в более ранних
114
Глава 2
версиях программы необходимо использовать для вставки каждой строки отдельную инст-
рукцию INSERT VALUES.
Далее показано содержимое таблицы Digits (Цифры):
digit
0
1
2
3
4
5
6
7
8
9
Предположим, что вам нужно написать запрос, формирующий последовательность целых чи-
сел в диапазоне от 1 до 1000. Вы можете перекрестно соединить три экземпляра одной и той
же таблицы, каждый из которых представляет разную степень 10 (1, 10, 100)1
.
Перекрестно
соединив три экземпляра одной и той же таблицы, из 10 строк каждый, вы получите результи-
рующий набор из 1000 строк. Для формирования отдельного числа умножьте число из каждо-
го экземпляра на степень 10, представляемую экземпляром, сложите результаты и прибавьте 1.
Далее приведен полный вариант запроса:
SELECT D3.digit * 100 + D2.digit * 10 + Dl.digit + 1 AS n
FROM dbo.Digits AS Dl
CROSS JOIN dbo.Digits AS D2
CROSS JOIN dbo.Digits AS D3
ORDER BY n;
Этот запрос вернет такой результат, приведенный в сокращенном виде:
п
1
2
3
4
5
6
7
8
1
Или разные десятичные разряды числа. — Прим. пер.
Соединения (Join)
115
9
10
998
999
1000
(1000 row(s) affected)
Это был пример формирования последовательности из 1000 целых чисел. Если вам нужно
больше, можно добавить в запрос дополнительные экземпляры таблицы Digits. Например,
если необходимо сформировать 1 000 000 строк, вам понадобится соединить шесть экземп-
ляров таблицы.
Внутренние соединения
Внутреннее соединение включает две стадии логической обработки запроса: оно, как и пе-
рекрестное соединение, определяет декартово произведение двух входных таблиц и затем
отбирает строки на основе заданного вами предиката. У внутренних соединений, как и у
перекрестных, две синтаксические записи: ANSI SQL-92 и ANSI SQL-89.
Синтаксическая запись ANSI SQL-92
В синтаксической записи вида ANSI SQL-92 вы задаете ключевые слова INNER JOIN между
именами таблиц. Слово INNER необязательно, т. к. по умолчанию подразумевается внутрен-
нее соединение, поэтому можно применять единственное ключевое слово JOIN. Предикат,
используемый для фильтрации строк, задается в специальном элементе ON. Этот предикат
также называют условием соединения.
Например, следующий запрос выполняет внутреннее соединение таблиц Employees (Со-
трудники) и Orders (Заказы) в базе данных TSQLFundamentals2008, сопоставляя сотруд-
ников и заказы на основе предиката Е. empid = о. empid:
USE TSQLFundamentals2008;
SELECT E.empid, E.firstname, E.lastname, O.orderid
FROM HR.Employees AS E
JOIN Sales.Orders AS О
ON E.empid = O.empid;
Этот запрос формирует результирующий набор, показанный далее в сокращенном виде:
empid
firstname lastname
orderid
1
Sara
Davis
10258
1
Sara
Davis
10270
116
Глава 2
1
Sara
Davis
10275
1
Sara
Davis
10285
1
Sara
Davis
10292
2
Don
Funk
10265
2
Don
Funk
10277
2
Don
Funk
10280
2
Don
Funk
10295
2
Don
Funk
10300
(830 row(s) affected)
Большинству людей легче всего представлять подобное внутреннее соединение как связы-
вание каждой строки сотрудника со всеми строками заказов, имеющими такой же иденти-
фикатор сотрудника, как ID сотрудника из таблицы Employees (Сотрудники). Это простей-
ший вариант интерпретации внутреннего соединения. Более строгий подход — представить
соединение как операцию реляционной алгебры, которая сначала находит декартово произ-
ведение двух таблиц (9 строк сотрудников х 830 строк заказов = 7470 строк) и затем отбира-
ет строки на основе предиката Е.empid = О.empid, возвращая в итоге 830 строк. Как уже
говорилось, это только логический способ выполнения операции соединения, на практике
физическая обработка запроса процессором базы данных может быть иной.
Вспомните обсуждение из предыдущих глав, касающееся троичной логики предикатов,
применяемой в языке SQL. Как и элементы WHERE И HAVING, элемент ON также возвращает
только те строки, для которых предикат равен значению TRUE И отбрасывает строки, для
которых вычисляемое значение предиката равно FALSE ИЛИ UNKNOWN.
В базе данных TSQLFundainentals2008 у всех сотрудников есть связанные с ними заказы,
поэтому все сотрудники представлены в результирующем наборе. Но если бы были сотруд-
ники без относящихся к ним заказов, они были бы отброшены на стадии фильтрации.
Синтаксическая запись ANSI SQL-89
Как и перекрестные соединения, внутренние соединения могут задаваться с помощью син-
таксической записи вида ANSI SQL-89. Вы вставляете запятую между именами таблиц, как
в перекрестном соединении, и задаете условие соединения в элементе запроса WHERE сле-
дующим образом:
SELECT Е. empid, E.firstname, Е.lastname, О.orderid
FROM HR.Employees AS E, Sales.Orders AS О
WHERE E.empid = O.empid;
Учтите, что в синтаксической записи ANSI SQL-89 нет элемента ON.
И снова повторю, что обе синтаксические записи входят в стандарт, полностью поддержи-
ваются SQL Server и одинаково интерпретируются механизмом баз данных, поэтому не сле-
дует ожидать от них разной производительности. Но одна из синтаксических записей более
безопасна, как поясняется в следующем разделе.
Соединения (Join)
117
Безопасность внутреннего соединения
Я настоятельно рекомендую всегда применять синтаксическую запись вида ANSI SQL-92,
т. к. она более безопасна по ряду причин. Скажем, вы намерены написать запрос с внутрен-
ним соединением и по ошибке забыли задать условие соединения. В случае синтаксической
записи ANSI SQL-92 запрос становится некорректным, и синтаксический анализатор гене-
рирует ошибку. Например, попробуйте выполнить следующий программный код:
SELECT Е.empid, Е.firstname, Е.lastname, О.orderid
FROM HR.Employees AS E
JOIN Sales.Orders AS O;
Вы получите такую ошибку:
Msg 102, Level 15, State 1, Line 3
Incorrect syntax near
Несмотря на то, что, возможно, вы не сразу поймете, что пропущено условие соединения, в
итоге вы разберетесь, в чем дело, и исправите запрос. Но если вы забудете задать условие
соединения в синтаксической записи ANSI SQL-89, то получите корректный запрос, кото-
рый выполнит вместо внутреннего соединения перекрестное:
SELECT Е.empid, Е.firstname, Е.lastname, О.orderid
FROM HR.Employees AS E, Sales.Orders AS 0;
Поскольку запрос не завершается аварийно, логическая ошибка может остаться незамеченной
какое-то время, и пользователи вашего приложения могут получить неверные результаты.
В коротких и простых запросах конечно маловероятно, что программист забудет задать усло-
вие соединения, однако большинство производственных запросов гораздо сложнее и включает
множественные таблицы, условия отбора и другие элементы запросов. В этом случае вероят-
ность того, что вы забудете задать условие соединения, существенно возрастает.
Если я убедил вас в важности применения синтаксической записи ANSI SQL-92 для внут-
ренних соединений, вас может удивить мой совет придерживаться того же стандарта и для
перекрестных соединений. Поскольку в перекрестные соединения не входит условие соеди-
нения, вам может показаться, что для них одинаково хороши оба варианта синтаксических
записей. Но я советую сохранять приверженность синтаксической записи вида ANSI SQL-92
и для перекрестных соединений по двум причинам, первая — согласованность. Кроме того,
допустим, что вы применяете синтаксическую запись вида ANSI SQL-89. Даже если вы на-
меревались написать перекрестное соединение, как разработчикам, вынужденным разбирать
и обслуживать ваш программный код, узнать, что вы собирались включить в него именно
перекрестное соединение, а не внутреннее соединение, для которого просто забыли задать
условие соединения?
Дополнительные примеры соединений
Этот раздел включает несколько примеров соединений, имеющих специальные названия,
такие как составные соединения (composite joins), соединения при условии неравенства и
многотабличные соединения.
5 Зак. 1032
118
Глава 2
Составные соединения
Составное соединение — это соединение, основанное на предикате, включающем несколь-
ко атрибутов из каждой таблицы. Составное соединение обычно требуется, когда нужно
соединить две таблицы на базе отношения "первичный ключ — внешний ключ", и связь эта
составная, т. е. основана на нескольких атрибутах. Например, предположим, что у вас есть
внешний ключ, определенный в таблице dbo.Table2 на столбцах coll, со12 и ссылаю-
щийся на столбцы coll, со12 таблицы dbo.Tablel, и вам нужно написать запрос, выпол-
няющий соединение на основе связи "первичный ключ — внешний ключ". Элемент FROM
запроса будет выглядеть следующим образом:
FROM dbo.Tablel AS Tl
JOIN dbo.Table2 AS T2
ON Tl.coll = T2.coll
AND Tl.col2 = T2.col2
Более наглядный пример: предположим, что вам нужно проверить обновления значений
столбцов
в
таблице OrderDetails (Сведения
о
заказе) базы
данных
TSQLFundamentals2008. Вы
создаете
пользовательскую
контрольную
таблицу
OrderDetailsAudit (Контроль сведений о заказе):
USE TSQLFundamentals2008;
IF OBJECT_ID('Sales.OrderDetailsAudit1
, 'U') IS NOT NULL
DROP TABLE Sales.OrderDetailsAudit;
CREATE TABLE Sales.OrderDetailsAudit
(
lsn
INT NOT NULL IDENTITY,
orderid
INT NOT NULL,
productid INT NOT NULL,
dt
DATETIME NOT NULL,
loginname sysname NOT NULL,
columnname sysname NOT NULL,
oldval
SQL_VARIANT,
newval
SQL_VARIANT,
CONSTRAINT PK_OrderDetailsAudit PRIMARY KEY(lsn),
CONSTRAINT FK_0rderDetailsAudit_OrderDetails
FOREIGN
KEY(orderid, productid)
REFERENCES Sales.OrderDetails(orderid, productid)
);
Каждая строка контрольной таблицы содержит регистрационный порядковый номер (lsn),
ключ измененной строки (orderid, productid), название измененного столбца
(columnname), старое значение (oldval), новое значение (newval), дату сделанного изме-
нения (dt) и автора изменения (loginname). У таблицы есть внешний ключ, составленный
из атрибутов orderid (id заказа), productid (id товара) и ссылающийся на первичный
ключ таблицы Order Detail (Сведения о заказе), определенный на атрибутах orderid (id
заказа) и productid (id товара).
Соединения (Join)
119
Допустим, что вы уже проследили все изменения значений столбцов в таблице Or-
derDetails (Сведения о заказе) и зафиксировали их в таблице OrderDёtailsAudit
(Контроль сведений о заказе).
Вам необходимо написать запрос, который возвращает все изменения значений в столбце
qty (количество), но в каждой строке результирующего набора надо вернуть текущее зна-
чение из таблицы OrderDetails (Сведения о заказе) и все значения до и после изменения
из таблицы Order Details Audit (Контроль сведений о заказе). Для этого требуется выпол-
нить соединение двух таблиц на основе отношения "первичный ключ — внешний ключ"
следующим образом:
SELECT OD.orderid, OD.productid, OD.qty,
ODA.dt, ODA.loginname, ODA.oldval, ODA.newval
FROM Sales.OrderDetails AS OD
JOIN Sales.OrderDetailsAudit AS ODA
ON OD.orderid = ODA.orderid
AND OD.productid = ODA.productid
WHERE ODA. columnname = N'qty';
Поскольку отношение построено на нескольких атрибутах, условие соединения — со-
ставное.
Соединения при условии неравенства
Если условие соединения содержит только операцию равенства, говорят, что это соединение
при условии равенства или эквивалентное соединение. Если же в условии соединения ис-
пользуется любая другая операция сравнения, соединение называют соединением при усло-
вии неравенства.. В качестве примера соединения при условии неравенства следующий за-
прос соединяет два экземпляра таблицы Employees (Сотрудники) для формирования
уникальных пар сотрудников:
SELECT
El.empid, El.firstname, El.lastname,
E2.empid, E2.firstname, E2.lastname
FROM HR. Employees AS El
JOIN HR.Employees AS E2
ON El.empid < E2.empid;
Обратите внимание на предикат, заданный в элементе ON. Задача запроса— сформировать
уникальные пары сотрудников. Если бы вы применили перекрестное соединение, то полу-
чили бы пары из сотрудников с одинаковыми номерами (например, I и 1) и, кроме того,
зеркально отраженные пары (например, I и 2 и 2 и 1). Применение внутреннего соединения
с условием соединения, говорящим о том, что значение ключа слева от операции сравнения
должно быть меньше значения ключа справа, устраняет эти два Неприемлемых варианта.
Пары с одинаковыми номерами отбрасываются, потому что обе части равны. В случае зер-
кально отраженных пар только один их вариант отбирается, поскольку только в одном слу-
чае ключ слева меньше ключа справа. В нашем запросе из 81 возможной пары сотрудников,
120
Глава 2
которые вернуло бы перекрестное соединение, выбираются только 36 уникальных пар, при-
веденных далее:
empid firstname lastname
empid firstname lastname
1
Sara
Davis
2
Don
Funk
1
Sara
Davis
3
Judy
Lew
2
Don
Funk
3
Judy
Lew
1
Sara
Davis
4
Yael
Peled
2
Don
Funk
4
Yael
Peled
3
Judy
Lew
4
Yael
Peled
1
Sara
Davis
5
Sven
Buck
2
Don
Funk
5
Sven
Buck
3
Judy
Lew
5
Sven
Buck
4
Yael
Peled
5
Sven
Buck
1
Sara
Davis
6
Paul
Suurs
2
Don
Funk
6
Paul
Suurs
3
Judy
Lew
6
Paul
Suurs
4
Yael
Peled
6
Paul
Suurs
5
Sven
Buck
6
Paul
Suurs
1
Sara
Davis
7
Russell
King
2
Don
Funk
7
Russell
King
3
Judy
Lew
7
Russell
King
4
Yael
Peled
7
Russell
King
5
Sven
Buck
7
Russell
King
6
Paul
Suurs _
7
Russell
King
1
Sara
Davis
8
Maria
Cameron
2
Don
Funk
8
Maria
Cameron
3
Judy
Lew
8
Maria
Cameron
4
Yael
Peled
8
Maria
Cameron
5
Sven
Buck
8
Maria
Cameron
6
Paul
Suurs
8
Maria
Cameron
7
Russell
King
8
Maria
Cameron
1
Sara
Davis
9
Zoya
Dolgopyatova
2
Don
Funk .
9
Zoya
Dolgopyatova
3
Judy
Lew
9
Zoya
Dolgopyatova
4
Yael
Peled
9
Zoya
Dolgopyatova
5
Sven
Buck
9
Zoya
Dolgopyatova
6
Paul
Suurs
9
Zoya
Dolgopyatova
7
Russell
King
9
Zoya
Dolgopyatova
8
Maria
Cameron
9
Zoya
Dolgopyatova
(36 row(s) affected)
Соединения (Join)
121
Если вам все еще неясно, что делает этот запрос, попробуйте выполнить его по шагам с
меньшим набором сотрудников. Предположим, что таблица Employees (Сотрудники) со-
держит только сотрудников с номерами 1, 2 и 3. Сначала найдите декартово произведение
двух экземпляров таблицы:
El.empid
Е2.empid
1
1
1
2
1
3
2
1
2
2
2
3
3
1
3
2
3
3
Далее выберите строки на основе предиката El. empid < Е2. empid, и вы останетесь всего
с тремя следующими строками:
El.empid
Е2.empid
1
2
1
3
2
3
Многотабличные соединения
Операция соединения выполняется только с двумя таблицами, но в одном запросе может
быть много соединений. Как правило, если в элементе FROM встречается несколько таблич-
ных операций, они логически обрабатываются слева направо. Это означает, что результи-
рующая таблица, полученная в первой табличной операции, служит левой входной таблицей
для второй табличной операции; результат второй табличной операции служит левым вхо-
дом для третьей табличной операции и т. д. Итак, если в элементе FROM есть несколько со-
единений, первое соединение выполняет логическую обработку двух базовых таблиц, а все
остальные соединения получают результат предыдущего соединения как свой левый вход-
ной параметр. В случае перекрестных и внутренних соединений процессор базы данных
может (и часто делает это) для оптимизации изменить порядок выполнения соединений на
внутреннем уровне, т. к. это не повлияет на корректность результата запроса.
Следующий пример запроса соединяет результат первого соединения с таблицей
OrderDetails (Сведения о заказе), чтобы сопоставить заказы и компоненты (товары),
формирующие заказ:
SELECT
С.custid, С.companyname, О.orderid,
OD.productid, OD.qty
122
Глава 2
FROM Sales.Customers AS С
JOIN Sales.Orders AS О
ON C.custid = 0.custid
JOIN Sales.OrderDetails AS OD
ON 0.orderid = OD.orderid;
Этот запрос вернет такой результат, приведенный в сокращенном виде:
custid
companyname
orderid
productid qty
85
Customer ENQZT
10248
11
12
85
Customer ENQZT
10248
42
10
85
Customer ENQZT
10248
72
5
79
Customer FAPSM
10249
14
9
79-
Customer FAPSM
10249
51
40
34
Customer IBVRG
10250
41
10
34
Customer IBVRG
10250
51
35
34
Customer IBVRG
10250
65
15
84
Customer NRCSK
10251
22
6
84
Customer NRCSK
10251
57
15
(2155 row(s) affected)
Внешние соединения
Людям обычно внешние соединения труднее понять, чем другие типы соединений. Сначала я
изложу основы внешних соединений. Если в конце разд. "Основные пртщипы внешних соеди-
нений'
1
вы почувствуете, что свободно ориентируетесь в изложенном материале и готовы пе-
рейти к более сложным вещам, можете прочесть раздел, посвященный дополнениям к основ-
ным принципам внешних соединений. В противном случае пропустите этот раздел и вернитесь
к нему, когда полностью усвоите основные принципы.
«
Основные принципы внешних соединений
Внешние соединения были введены в стандарте языка ANSI SQL-92 и в отличие от внутрен-
них и перекрестных соединений имеют одну синтаксическую запись, в которой ключевое
слово JOIN задается между именами таблиц и условие соединения указывается в элементе
ON. Внешние соединения включают две стадии логической обработки, как и внутренние со-
единения (декартово произведение и выборка с помощью элемента ON) ПЛЮС третью свойст-
венную только этому типу соединения стадию, названную добавлением внешних строк.
Во внешнем соединении одна таблица помечается как "сохраняемая"
2
с помощью ключевых
СЛОВ LEFT OUTER JOIN, RIGHT OUTER JOIN ИЛИ FULL OUTER JOIN, ПОМЕЩАЕМЫХ МЕЖДУ
2
Иногда ее называют главной. — Прим. пер.
Соединения (Join)
123
именами таблиц. Ключевое слово OUTER не обязательно. Ключевое слово LEFT означает, что
сохраняются строки таблицы слева от ключевых слов, а слово RIGHT указывает на сохране-
ние строк таблицы, находящейся справа от ключевых слов. Ключевое слово FULL означает
сохранение строк обеих таблиц. Третья стадия логической обработки запроса во внешнем
соединении определяет строки из сохраняемой таблицы, для которых не найдено совпаде-
ний в другой таблице на основе предиката из элемента ON. На этой стадии в результирую-
щую таблицу, сформированную на первых двух стадиях соединения, добавляются упомяну-
тые строки, и в них заполнителями значений атрибутов из несохраняемой
3
таблицы
соединения служат значения NULL.
Лучше всего понять внешнее соединение на примере. Следующий запрос соединяет табли-
цы Customers (Клиенты) и Orders (Заказы) на основе совпадений идентификаторов клиен-
тов из таблицы клиентов с идентификаторами клиентов из таблицы заказов и возвращает
клиентов и их заказы. Тип соединения — левое внешнее соединение, следовательно, запрос
вернет в результате и тех клиентов, кто не сделал ни одного заказа.
SELECT С.custid, C.companyname, О.orderid
FROM Sales.Customers AS С
LEFT OUTER JOIN Sales.Orders AS О
ON C.custid = 0.custid;
Этот запрос вернет такой результат, приведенный в сокращенном виде:
custid
companyname
orderid
Customer NRZBB 10643
Customer NRZBB 10692
Customer NRZBB 10702
Customer NRZBB 10835
Customer NRZBB 10952
21
Customer KIDPX 10414
21
Customer KIDPX 10512
21
Customer KIDPX 10581
21
Customer KIDPX 10650
21
Customer KIDPX 10725
22
Customer DTDMN NULL
23
Customer WVFAF 10408
23
Customer WVFAF 10480
23
Customer WVFAF 10634
23
Customer WVFAF 10763
23
Customer WVFAF 10789
56
Customer QNIVZ 10684
3
Ее также называют вспомогательной. — Прим. пер.
124
Глава 2
56
56
56
58
58
56
57
58
58
58
Customer QNIVZ 10766
Customer QNIVZ 10833
Customer QNIVZ 10999
Customer QNIVZ 11020
Customer WVAXS NULL
Customer AHXHT 10322
Customer AHXHT 10354
Customer AHXHT 10474
Customer AHXHT 10502
Customer AHXHT 10995
91
91
91
91
91
Customer CCFIZ 10792
Customer CCFIZ 10870
Customer CCFIZ 10906
Customer CCFIZ 10998
Customer CCFIZ 11044
(832 row(s) affected)
Двое клиентов из таблицы Customers (Клиенты) не сделали ни одного заказа. Их иденти-
фикаторы — 22 и 57. Обратите внимание на то, что в результирующем наборе запроса у
обоих клиентов в атрибутах из таблицы Orders (Заказы) возвращены значения NULL. На
второй стадии обработки соединения строки этих двух клиентов были отброшены (на осно-
вании предиката в элементе ON), но на третьей стадии они были добавлены как внешние
строки. Если бы это было внутреннее соединение, указанные строки не попали бы в резуль-
тирующий набор. Эти две строки вставлены для того, чтобы сохранить все строки левой
таблицы.
В результат внешнего соединения, принимая во внимание сохраняемую таблицу, включают-
ся два вида строк— внутренние строки и внешние. Внутренние строки— это строки,
имеющие в другой таблице совпадения, основанные на предикате элемента ON, а у внешних
строк таких совпадений нет. Внутреннее соединение возвращает только внутренние строки,
а внешнее возвращает и те, и другие.
Обычный вопрос в случае применения внешних соединений, являющихся источником вся-
кого рода путаницы, — в каком элементе запроса, ON ИЛИ WHERE, задавать предикат? Из-за
бережного отношения к строкам сохраняемой таблицы внешнего соединения отбор, осно-
ванный на предикате элемента ON, не является окончательным. Другими словами, предикат
ON не определяет появление строки в результирующем наборе только при совпадении со
строками из другой таблицы. Поэтому если нужно задать неокончательный предикат, т. е.
предикат, определяющий, какие строки совпадают со строками несохраняемой таблицы,
задавайте его в элементе ON. ЕСЛИ же вам нужен фильтр, который применяется после того,
как внешние строки добавлены в результирующий набор, и вы хотите, чтобы ваш отбор был
окончательным, задавайте предикат в элементе WHERE. Элемент WHERE обрабатывается по-
сле элемента FROM, а именно после того, как выполнены все табличные операции (в нашем
случае внешние соединения) и все внешние строки уже добавлены. Кроме того, условие
WHERE в отличие от элемента ON является окончательным для исключаемых строк.
Соединения (Join)
125
Предположим, что вам нужно найти клиентов, не сделавших ни одного заказа, или, говоря
более строго, вернуть только внешние строки. Можно использовать предыдущий запрос как
основу и добавить элемент WHERE, который отбирает только внешние строки. Напоминаю,
что внешние строки определяются по значениям NULL В атрибутах из несохраняемой табли-
цы соединения. Таким образом, вы можете отобрать только те строки, в которых один из
атрибутов несохраняемой таблицы, участвовавшей в соединении, равен значению NULL, на-
пример, следующим образом:
SELECT С.custid, С.сотрапупаше
FROM Sales.Customers AS С
LEFT OUTER JOIN Sales.Orders AS О
ON C.custid = O.custid
WHERE 0.orderid IS NULL;
Данный запрос вернет только две строки с клиентами 22 и 57:
custid
companyname
22
Customer DTDMN
57
Customer WVAXS
(2 row(s) affected)
Примите к сведению пару важных замечаний, касающихся этого запроса. Вспомните обсу-
ждение значений NULL В предыдущей главе. При поиске значений NULL следует применять
оператор IS NULL, а не операцию равенства, потому что операция равенства, сравнивая
какое-либо значение с NULL, всегда возвращает значение UNKNOWN, даже когда сравниваются
два значения NULL. Кроме того, в фильтре важен выбор атрибута из несохраняемой табли-
цы, участвовавшей в соединении. Следует выбирать атрибут, который принимает значение
NULL только во внешней строке и ни в каком другом случае (например, значение NULL,
пришедшее из исходной таблицы). Для этой цели подойдут три безопасных варианта: стол-
бец первичного ключа, соединяющий столбец, и столбец, определенный как NOT NULL (зна-
чения NULL не допускаются). Столбец первичного ключа не может иметь значения NULL,
следовательно, NULL В таком столбце может означать только внешнюю строку. Если в стро-
ке есть значение NULL В соединяющем столбце, такая строка отбрасывается во второй ста-
дии соединения, поэтому NULL в таком столбце может означать только то, что это внешняя
строка. И очевидно значение NULL В столбце, определенном как NOT NULL, может означать
только то, что данная строка внешняя.
Для того чтобы применить на практике то, чему вы научились, и лучше разобраться во внеш-
них соединениях, обязательно выполните упражнения, предлагаемые в конце этой главы.
Дополнения к основным принципам
внешних соединений
Этот раздел посвящен более сложным аспектам внешних соединений и предлагается как
дополнительное чтение для тех, кто как следует разобрался в основных принципах внешних
соединений.
126
Глава 2
Включение пропущенных значений
Внешние соединения можно применять в запросе для указания и вставки пропущенных зна-
чений. Предположим, что вам нужно запросить все заказы в таблице orders (Заказы) из
базы данных TSQLFundamentals2008. Вы должны быть уверены, что получите в результи-
рующем наборе как минимум по одной строке для каждой даты из диапазона от January I,
2006 (1 января 2006 г.) до December 31, 2008 (31 декабря 2008 г.). Даты из заданного диапа-
зона не должны подвергаться специальной обработке. Но вы хотите включить в выходной
набор даты без заказов со значениями NULL В атрибутах заказа, применяемыми в качестве
заполнителей.
Для решения этой задачи можно сначала написать запрос, который вернет последователь-
ность всех дат из запрашиваемого диапазона. Затем можно выполнить левое внешнее со-
единение этого набора с таблицей Orders (Заказы). В этом случае результат будет включать
даты без сделанных заказов.
Для формирования последовательности дат из заданного диапазона я обычно использую
дополнительную таблицу чисел. Создадим таблицу с именем Nums, содержащую столбец,
названный п, и заполним ее последовательными целыми числами (1, 2, 3 и т. д.). Я считаю
таблицу чисел очень мощным вспомогательным средством общего назначения, которое по-
могает решить многие проблемы. Вам придется всего один раз создать эту таблицу в базе
данных и заполнить ее последовательностью чисел такой длины, какая вам может понадо-
биться. Для создания таблицы Nums в схеме dbo и заполнения 100 000 строк в ней выполни-
те программный код из листинга 3.1.
Листинг 3.1. Программный код для создания и заполнения вспомогательной
таблицы Nums
SET NOCOUNT ON;
USE TSQLFundamentals2008;
IF OBJECT_ID(1 dbo.Nums
1
, 'U') IS NOT NULL DROP TABLE dbo.Nums;
CREATE TABLE dbo. Nums (n INT NOT NULL PRIMARY KEY);
DECLARE @i AS INT = 1;
/*
Примечание: возможность объявления и инициализации переменной в одном
операторе появилась только в версии Microsoft SQL Server 2008.
В более ранних версиях программы используйте отдельные операторы
DECLARE и SET:
DECLARE 6i AS INT;
SET@i=1;
*/
BEGIN TRAN
WHILE @i <= 100000
BEGIN
INSERT INTO dbo. Nums VALUES (@i);
Соединения (Join)
127
SET@i=@i+1;
END
COMMIT TRAN
SET NOCOUNT OFF;
ПРИМЕЧАНИЕ
He огорчайтесь, если вам непонятны некоторые фрагменты программного кода, та-
кие как использование переменных и циклов, они будут обсуждаться позже в этой
книге. Пока достаточно понять, для чего предназначен этот программный код, а как
он действует в нашем обсуждении — не главное. Но если вы любознательны и хо-
тите удовлетворить свое любопытство, подробности можно найти в главе 10. Я хо-
тел бы обратить внимание на то, что объявление и инициализация переменной в
одном операторе впервые появились в версии SQL Server 2008, что отмечено в
блоке комментариев, вставленных в программный код. Если вы работаете в более
ранней версии программы, вам следует использовать отдельные операторы
DECLARE И SET.
Первый этап решения — формирование всех дат из запрашиваемого диапазона. Их можно
получить, запросив таблицу Nums и выбрав столько чисел, сколько дней в запрашиваемом
диапазоне дат. Для вычисления этого количества можно применить функцию DATEDIFF.
Добавив /7- 1 дней к начальной точке диапазона дат (January1, 2006), вы получите реальную
дату в диапазоне. Далее показано решение запроса.
SELECT DATEADD(day, n-lf
1
20060101') AS orderdate
FROM dbo.Nums
WHERE n <= DATEDIFF (day, '20060101*,
1
20081231») + 1
ORDER BY orderdate;
Этот запрос вернет последовательность из всех дат от January I, 2006 до December 31, 2008,
которая приведена далее в сокращенном виде:
orderdate
2006-01-01
2006-01-02
2006-01-03
2006-01-04
2006-01-05
2008-12 -27
2008-12 -28
2008-12 -29
2008-12 -30
2008-12 -31
(1096 row (:
00:00:00.000
00:00:00.000
00:00:00.000
00:00:00.000
00:00:00.000
00:00:00.000
00:00:00.000
00:00:00.000
00:00:00.000
00:00:00.000
;) affected)
128
Глава 2
Следующий этап — пополнение предыдущего запроса за счет левого внешнего соединения
таблиц Nums и Orders. Условие соединения сравнивает с помощью выражения
DATE ADD (day, Nums.n
-
1,
1
20060101') дату заказа из таблицы Nums и значение атри-
бута orderdate (дата заказа) из таблицы Orders (Заказы) следующим образом:
SELECT DATEADD(day, Nums.n
-
1, "гоОбОЮ!') AS orderdate,
О.orderid, О.custid, О.empid
FROM dbo. Nums
LEFT OUTER JOIN Sales.Orders AS О
ON DATEADD(day, Nums.n
-
1,
1
20060101') = O.orderdate
WHERE Nums.n <= DATEDIFF(day, *20060101*, '20081231') + 1
ORDER BY orderdate;
Этот запрос вернет такой результат, приведенный в сокращенном виде:
orderdate
orderid
custid
empid
2006-01-01 00:00:00.000
2006-01-02 00:00:00.000
2006-01-03 00:00:00.000
2006-01-04 00:00:00.000
2006-01-05 00:00:00.000
2006-06-29 00:00:00.000
2006-06 -30 00:00:00.000
2006-07-01 00:00:00.000
2006-07-02 00:00:00.000
2006-07-03 00:00:00.000
2006-07-04 00:00:00.000
2006-07-05 00:00:00.000
2006-07-06 00:00:00.000
2006-07-07 00:00:00.000
2006-07-08 00:00:00.000
2006-07-08 00:00:00.000
2006-07-09 00:00:00.000
2006-07-10 00:00:00.000
2006-07-11 00:00:00.000
2006-07-12 00:00:00.000
2006-07-13 00:00:00.000
2006-07-14 00:00:00.000
2006-07-15 00:00:00.000
2006-07-16 00:00:00.000
2008-12-27 00:00:00.000
2008-12 -28 00:00:00.000
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
10248
85
5
10249
79
6
NULL
NULL
NULL
NULL
NULL
NULL
10250
34
4
10251
84
3
10252
76
4
10253
34
3
10254
14
5
10255
68
9
NULL
NULL
NULL
NULL
NULL
NULL
10256
88
3
10257
35
4
NULL
NULL
NULL
NULL
NULL
NULL
Соединения (Join)
129
2008-12-29 00:00:00.000
NULL
NULL
NULL
2008-12-30 00:00:00.000
NULL
NULL
NULL
2008-12-31 00:00:00.000
NULL
NULL
NULL
(1446 row(s) affected)
Даты заказов, которых нет в таблице Orders (Заказы), включены в результирующий набор
со значениями NULL в атрибутах заказа.
Фильтрация атрибутов из несохраняемой таблицы
внешнего соединения
Если при поиске логических ошибок нужно просмотреть программный код, содержащий
внешние соединения, обязательно следует проверять элемент WHERE. ЕСЛИ предикат в эле-
менте WHERE ссылается на атрибут из несохраняемой таблицы, участвующей во внешнем
соединении, применяя выражение вида <атрибут> <операция> <значение>, как правило,
это логическая ошибка. Поскольку атрибуты несохраняемой таблицы соединения во внеш-
них строках равны NULL, выражение вида NULL <операция> <значение> дает в результате
UNKNOWN (если для поиска значений NULL не применяется явно оператор is NULL). Напоми-
наю, что элемент WHERE отбрасывает значения UNKNOWN. Подобный предикат в элементе
WHERE приводит к исключению всех внешних строк из результирующего набора, эффектив-
но сводя на нет внешнее соединение. Другими словами, логически соединение становится
внутренним. Таким образом, программист либо ошибся в выборе типа соединения, либо в
предикате. Если все еще не вполне понятно, возможно, поможет приведенный далее при-
мер. Рассмотрим следующий запрос:
SELECT С.custid, С.companyname, О.orderid, О.orderdate
FROM Sales.Customers AS С
LEFT OUTER JOIN Sales.Orders AS О
ON C.custid = 0.custid
WHERE O.orderdate >=
1
20070101';
Запрос выполняет левое внешнее соединение таблиц Customers (Клиенты) и Orders (Зака-
зы). Перед применением фильтра из элемента WHERE операция соединения возвращает внут-
ренние строки, включающие клиентов, сделавших заказы, и внешние строки с атрибутами
заказа, равными NULL, включающие клиентов, не сделавших ни одного заказа. Предикат
о.orderdate >= '20070101' в элементе WHERE равен UNKNOWN для всех внешних строк,
поскольку они содержат значение NULL В атрибуте О.orderdate. Все внешние строки от-
брасываются элементом WHERE, как видно из результата запроса, приведенного далее в со-
кращенном виде:
custid
companyname
orderid
orderdate
19
Customer RFNQC
10400
2007-01-01 00:00:00.000
65
Customer NYUHS
10401
2007-01-01 00:00:00.000
20
Customer THHDP
10402
2007-01-02 00:00:00.000
20
Customer THHDP
10403
2007-01-03 00:00:00.000
130
Глава 2
49
Customer CQRAA
10404
2007-01-03 00:00:00.000
73
68
9
65
58
Customer AHXHT
11073
Customer JMIKW
11074
Customer CCKOT
11075
Customer RTXGC
11076
Customer NYUHS
11077
2008-05-05 00:00:00.000
2008-05-06 00:00:00.000
2008-05-06 00:00:00.000
2008-05-06 00:00:00.000
2008-05-06 00:00:00.000
(678 row(s) affected)
Это означает, что применение внешнего соединения в данном запросе бесполезно. Про-
граммист либо ошибся, применяя внешнее соединение, либо допустил ошибку в предикате
элемента WHERE.
Применение внешних соединений
в многотабличном соединении
Вспомните обсуждение одновременно выполняемых операций из главы 2. Суть заключается
в том, что все выражения, встречающиеся на одной стадии логической обработки запроса,
логически вычисляются одномоментно. Однако это утверждение не применимо к таблич-
ным операциям, выполняемым на стадии FROM. Логически табличные операции выполняют-
ся слева направо. Изменение порядка выполнения внешних соединений может привести к
другому результату, поэтому произвольно изменять этот порядок нельзя.
С порядком выполнения внешних соединений связаны интересные логические ошибки, ко-
торые могут быть допущены. Например, распространенная логическая ошибка, связанная с
внешними соединениями, может рассматриваться как разновидность ошибки из предыдуще-
го раздела. Предположим, что вы пишете запрос с многотабличным соединением, состоя-
щим из внешнего соединения двух таблиц, за которым следует внутреннее соединение с
третьей таблицей. Если предикат внутреннего соединения из элемента ON сравнивает атри-
бут несохраняемой таблицы внешнего соединения и атрибут третьей таблицы, все внешние
строки будут исключены из результирующего набора. Напоминаю, что внешние строки со-
держат значения NULL в атрибутах несохраняемой таблицы, участвующей в соединении, и
сравнение значения NULL С чем-либо еще даст в результате значение UNKNOWN, а это значе-
ние отбрасывается элементом ON. Другими словами, такой предикат сведет на нет внешнее
соединение и логически превратит его во внутреннее соединение. Как пример, рассмотрим
следующий запрос:
SELECT С.custid, О.orderid, OD.productid, OD.qty
FROM Sales.Customers AS С
LEFT OUTER JOIN Sales.Orders AS О
ON C.custid = O.custid
JOIN Sales.OrderDetails AS OD
ON O.orderid = OD.orderid;
Первое соединение — внешнее, возвращающее клиентов и их заказы, а также клиентов, не
сделавших ни одного заказа. Строки, представляющие клиентов без заказов, содержат в ат-
Соединения (Join)
131
рибутах заказа значения NULL. Второе соединение сопоставляет строки компонентов заказов
из таблицы OrderDetails (Сведения о заказе) со строками результирующего набора перво-
го соединения, основываясь на предикате о.orderid = OD.orderid. Однако в строках,
представляющих клиентов без заказов, атрибут о. orderid (id заказа) равен NULL. Следова-
тельно, предикат вернет значение UNKNOWN, И такие строки будут отброшены. Результат,
показанный далее в сокращенном виде, не содержит клиентов 22 и 57, двух клиентов, не
сделавших ни одного заказа.
custid
orderid
productid qty
85
10248
11
12
85
10248
42
10*
85
10248
72
5
79
10249
14
9
79
10249
51
40
65
11077
64
2
65
11077
66
1
65
11077
73
2
65
11077
75
4
65
11077
77
2
(2155 row(s) affected)
Если сформулировать проблему в общем виде, внешние строки аннулируются, если за
внешним соединением любого типа (левым, правым или полным) следует внутреннее или
правое внешнее соединения. При этом, конечно, предполагается, что в условии соединения
сравниваются значения NULL ИЗ левой таблицы с чем-либо из правой таблицы.
У вас есть несколько способов обойти эту проблему, если вы хотите вернуть в результи-
рующем наборе клиентов без заказов. Один из вариантов — применить левое внешнее со-
единение на месте второго соединения:
SELECT С.custid, О.orderid, OD.productid, OD.qty
FROM Sales.Customers AS С
LEFT OUTER JOIN Sales.Orders AS О
ON C.custid = O.custid
LEFT OUTER JOIN Sales.OrderDetails AS OD
ON O.orderid = OD.orderid;
В этом случае внешние строки, полученные в первом соединении, не исключаются из ре-
зультирующего набора, показанного далее в сокращенном виде:
custid
orderid
productid qty
85
10248
11
12
85
10248
42
10
85
10248
72
5
132
Глава 2
79
10249
14
9
79
10249
51
40
65
11077
64
2
65
11077
66
1
65
11077
73
2
65
11077
75
4
65
11077
77
2
22
NULL
NULL
NULL
57
NULL
NULL
NULL
(2157 row(s) affected)
Второй вариант — сначала соединить таблицы Orders (Заказы) и OrderDetails (Сведения
о заказе) с помощью внутреннего соединения и затем соединить с помощью правого внеш-
него соединения результат с таблицей Customers (Клиенты).
SELECT С.custid, О.orderid, OD.productid, OD.qty
FROM Sales.Orders AS О
JOIN Sales.OrderDetails AS OD
ON O.orderid = OD.orderid
RIGHT OUTER JOIN Sales.Customers AS С
ON O.custid = C.custid;
В этом случае внешние строки формируются последним соединением и не отбрасываются.
Третий вариант— применить скобки для того, чтобы превратить внутреннее соединение
таблиц Orders и OrderDetails в независимую логическую стадию. В этом случае вы смо-
жете применить левое внешнее соединение к таблице Customers и результату внутреннего
соединения таблиц Orders и OrderDetails. Такой запрос будет выглядеть следующим
образом:
SELECT С.custid, О.orderid, OD.productid, OD.qty
FROM Sales.Customers AS С
LEFT OUTER JOIN
(Sales.Orders AS О
JOIN Sales.OrderDetails AS OD
ON O.orderid = OD.orderid)
ON C.custid = O.custid;
Применение агрегатной функции COUNT
с внешними соединениями
Другая распространенная ошибка— использование функции COUNT С внешними соединениями.
Когда вы группируете результат внешнего соединения и применяете выражение COUNT (*), оно
Соединения (Join)
133
принимает в расчет как внутренние строки, так и внешние, поскольку считает строки независимо
от их содержимого. Обычно вы не собираетесь учитывать в подсчете внешние строки. Например,
предполагается, что следующий запрос вернет количество заказов у каждого клиента.
SELECT С.custid, COUNT(*) AS numorders
FROM Sales.Customers AS С
LEFT OUTER JOIN Sales.Orders AS О
ON C.custid = O.custid
GROUP BY C.custid;
Однако выражение COUNT (*) подсчитывает строки независимо от их содержимого и у каж-
дого из клиентов с номерами 22 и 57, не сделавших заказов, есть внешняя строка в результа-
те соединения. Как видно из результата, показанного далее в сокращенном виде, для клиен-
тов 22 и 57 приведено количество заказов, равное 1, хотя на самом деле оно равно 0.
custid
numorders
1
6
2
4
3
7
4
13
5
18
22
1
57
1
87
15
88
9
89
14
90
7
91
7
(91 row(s) affected) *
Агрегатная функция COUNT (*) не может определить, действительно ли строка представляет
заказ. Для решения этой проблемы следует применять выражение COUNT (<столбец>) вме-
сто COUNT (*) и указывать столбец из несохраняемой таблицы соединения. В этом случае
функция COUNT () игнорирует внешние строки, поскольку они содержат в этом столбце зна-
чения NULL. Помните о том, что нужно применять столбец, в котором значения NULL появ-
ляются только в случае внешней строки, например, столбец первичного ключа orderid (id
заказа).
SELECT С.custid, COUNT(О.orderid) AS numorders
FROM Sales. Customers AS С
LEFT OUTER JOIN Sales.Orders AS О
134
Глава 2
ON С.custid = О.custid
GROUP BY С.custid;
Обратите внимание на то, что в результате, приведенном далее в сокращенном виде, клиен-
ты 22 и 57 теперь показаны с количеством заказов, равным 0.
custid
numorders
1
6
2
4
3
7
4
13
5
18
22
0
57
0
87
15
88
9
89
14
90
7
91
7
(91 row(s) affected)
Резюме
Эта глава была посвящена операции соединения. В ней описаны стадии логической обра-
ботки запроса, включающие три основных типа соединений: перекрестное, внутреннее и
внешнее. В главе также приведены дополнительные примеры соединений, таких как состав-
ные соединения, соединения при условии неравенства и многотабличные соединения. За-
вершается глава разделом, не предназначенным для обязательного прочтения и описываю-
щим более сложные аспекты внешних соединений. Для того чтобы опробовать на практике
все, чему вы научились, переходите к упражнениям данной главы.
Упражнения
В этом разделе представлены упражнения, которые помогут вам лучше освоить темы, обсу-
ждавшиеся в этой главе. Все упражнения содержат запросы к объектам из базы данных
TSQLFundamentals2008.
Соединения (Join)
135
Упражнение 3.1
Выполните следующий программный код для создания вспомогательной таблицы dbo.Nums
в базе данных TSQLFundamentaIs2008.
SET NOCOUNT QN;
USE TSQLFundamentals2008;
IF OBJECT_ID('dbo.Nums', 'U') IS NOT NULL DROP TABLE dbo.Nums;
CREATE TABLE dbo.Nums (n INT NOT NULL PRIMARY KEY);
DECLARE @i AS INT = 1;
BEGIN TRAN
WHILE @i <= 100000
BEGIN
INSERT INTO dbo.Nums VALUES(@i);
SET@i=@i+1;
END
COMMIT TRAN
SET NOCOUNT OFF;
Упражнение 3.2
Напишите запрос, который формирует пять копий каждой строки с данными о сотруднике.
Используемые таблицы: таблицы HR.Employees и dbo.Nums.
Предполагаемый результат:
empid
firstname lastname
n
1
Sara
Davis
1
2
Don
Funk
1
3
Judy
Lew
1
4
Yael
Peled
1
5
Sven
Buck
1
6
Paul
Suurs
1
7
Russell
King
1
8
Maria
Cameron
1
9
Zoya
Dolgopyatova
1
1
Sara
Davis
2
2
Don
Funk
2
3
Judy
Lew
2
4
Yael
Peled
2
5
Sven
Buck
2
6
Paul
Suurs
2
136
Глава 2
7
Russell
King
2
8
Maria
Cameron
2
9
Zoya
Dolgopyatova
2
1
Sara
Davis
3
2
Don
Funk
3
3
Judy
Lew
3
4
Yael
Peled
3
5
Sven
Buck
3
6
Paul
Suurs
3
7
Russell
King
3
8
Maria
Cameron
3
9
Zoya
Dolgopyatova
3
1
Sara
Davis
4
2
Don
Funk
4
3
Judy
Lew
4
4
Yael
Peled
4
5
Sven
Buck
4
6
Paul
Suurs
4
7
Russell
King
4
8
Maria
Cameron
4
9
Zoya
Dolgopyatova
4
1
Sara
Davis
5
2
Don
Funk
5
3
Judy
Lew
5
4
Yael
Peled
5
5
Sven
Buck
5
6
Paul
Suurs
5
7
Russell
King
5
8
Maria
Cameron
5
9
Zoya
Do1gopyatova
5
(45 row(s) affected)
Упражнение 3.3
(дополнительное, повышенной сложности)
Напишите запрос, который возвращает строку для каждого сотрудника и день из диапазона
June 12,2009 (12 июня 2009 г.),June 16,2009 (16 июня 2009 г.) .
Используемые таблицы: таблицы HR. Employees и dbo .Nums.
Предполагаемый результат:
empid
dt
Соединения (Join)
137
1
2009-06-12 00:00:00.000
1
2009-06 -13 00:00:00.000
1
2009-06 -14 00:00:00.000
1
2009-06 -15 00:00:00.000
1
2009-06-16 00:00:00.000
2
2009-06-12 00:00:00.000
2
2009-06 -13 00:00:00.000
2
2009-06 -14 00:00:00.000
2
2009-06-15 00:00:00.000
2
2009-06 -16 00:00:00.000
3
2009-06-12 00:00:00.000
3
2009-06-13 00:00:00.000
3
2009-06-14 00:00:00.000
3
2009-06 -15 00:00:00.000
3
2009-06-16 00:00:00.000
4
2009-06-12 00:00:00.000
4
2009-06 -13 00:00:00.000
4
2009-06 -14 00:00:00.000
4
2009-06 -15 00:00:00.000
4
2009-06-16 00:00:00.000
5
2009-06 -12 00:00:00.000
5
2009-06 -13 00:00:00.000
5
2009-06 -14 00:00:00.000
5
2009-06-15 00:00:00.000
5
2009-06-16 00:00:00.000
6
2009-06 -12 00:00:00.000
6
2009-06 -13 00:00:00.000
6
2009-06-14 00:00:00.000
6
2009-06-15 00:00:00.000
6
2009-06-16 00:00:00.000
7
2009-06 -12 00:00:00.000
7
2009-06 -13 00:00:00.000
7
2009-06-14 00:00:00.000
7
2009-06 -15 00:00:00.ООО
7
2009-06-16 00:00:00.000
8
2009-06-12 00:00:00.000
8
2009-06 -13 00:00:00.000
8
2009-06-14 00:00:00.000
8
2009-06 -15 00:00:00.000
8
2009-06 -16 00:00:00.000
9
2009-06 -12 00:00:00.000
9
2009-06-13 00:00:00.000
138
Глава 2
9
9
9
2009-06 -14 00:00:00.000
2009-06-15 00:00:00.000
2009-06-16 00:00:00.000
(45 row(s) affected)
Упражнение 3.4
Выберите клиентов из США и для каждого из них найдите общее число заказов и общий
объем заказов.
Используемые
таблицы:
таблицы
Sales. Customers,
Sales. Orders
и
Sales.OrderDetails.
Предполагаемый результат:
custid
numorders
totalqty
32
11
345
36
5
122
43
2
20
45
4
181
48
8
134
55
10
603
65
18
1383
71
31
4958
75
9
327
77
4
46
78
3
59
82
3
89
89
14
1063
(13 row(s) affected)
Упражнение 3.5
Выберите клиентов и их заказы, включая клиентов без заказов.
Используемые таблицы: таблицы Sales. Customers и Sales. Orders.
Предполагаемый результат (в сокращенном виде):
custid
companyname
orderid
orderdate
85
79
34
Customer ENQZT 10248
Customer FAPSM 10249
Customer IBVRG 10250
2006-07-04 00:00:00.000
2006-07-05 00:00:00.000
2006-07-08 00:00:00.000
Соединения (Join)
139
84
Customer NRCSK 10251
2006--07--08 00:00 : 00.000
73
Customer JMIKW 11074
2008--05--06 00:00 : 00.000
68
Customer CCKOT 11075
2008--05--06 00:00 : 00.000
9
Customer RTXGC 11076
2008--05--06 00:00 : 00.000
65
Customer NYUHS 11077
2008--05--06 00:00 : 00.000
22
Customer DTDMN NULL
NULL
57
Customer WVAXS NULL
NULL
(832 row(s) affected)
Упражнение 3.6
Отберите клиентов, не сделавших ни одного заказа.
Используемые таблицы: таблицы Sales. Customers и Sales .Orders.
Предполагаемый результат:
custid
companyname
22
Customer DTDMN
57
Customer WVAXS
(2 row(s) affected)
Упражнение 3.7
Найдите клиентов и их заказы, сделанные Feb 12, 2007 (12 февраля 2007 г.).
Используемые таблицы: таблицы Sales. Customers и Sales. Orders tables.
Предполагаемый результат:
custid
companyname
orderid
orderdate
66
Customer LHANT 10443
2007-02-12 00:00:00.000
5
Customer HGVLZ 10444
2007-02-12 00:00:00.000
(2 row(s) affected)
Упражнение 3.8
(дополнительное, повышенной сложности)
Найдите клиентов и их заказы, сделанные Feb 12, 2007 (12 февраля 2007 г.). Кроме того,
найдите клиентов, не сделавших заказ в этот день.
Используемые таблицы: таблицы Sales.Customers и Sales .Orders.
140
Глава 2
Предполагаемый результат (в сокращенном виде):
custid
companyname
orderid
orderdate
72
Customer AHPOP
NULL
NULL
58
Customer AHXHT
NULL
NULL
25
Customer AZ JED
NULL
NULL
18
Customer BSVAR
NULL
NULL
91
Customer CCFIZ
NULL
NULL
33
Customer FVXPQ
NULL
NULL
53
Customer GCJSG
NULL
NULL
39
Customer GLLAG
NULL
NULL
16
Customer GYBBY
NULL
NULL
4
Customer HFBZG
NULL
NULL
5
Customer HGVLZ
10444
2007-
42
Customer IAIJK
NULL
NULL
34
Customer IBVRG
NULL
NULL
63
Customer IRRVL
NULL
NULL
73
Customer JMIKW
NULL
NULL
15
Customer JUWXK
NULL
NULL
21
Customer KIDPX
NULL
NULL
30
Customer KSLQF
NULL
NULL
55
Customer KZQZT
NULL
NULL
71
Customer LCOUJ
NULL
NULL
77
Customer LCYBZ
NULL
NULL
66
Customer LHANT
10443
2007-
38
Customer LJUCA
NULL
NULL
59
Customer LOLJO
NULL
NULL
36
Customer LVJSO
NULL
NULL
64
Customer LWGMD
NULL
NULL
29
Customer MDLWA
NULL
NULL
(91 row(s) affected)
Упражнение 3.9
(дополнительное, повышенной сложности)
Найдите всех клиентов и для каждого верните значение Yes/No в зависимости от того, сде-
лал ли он заказ Feb 12, 2007 (12 февраля 2007 г.) .
Используемые таблицы: таблицы Sales. Customers и Sales.Orders.
Соединения (Join)
141
Предполагаемый результат (в сокращенном виде):
custid
companyname
Has0rder0n20070212
1
Customer NRZBB
No
2
Customer MLTDN
No
3
Customer KBUDE
No
4
Customer HFBZG
No
5
Customer HGVLZ
Yes
6
Customer XHXJV
No
7
Customer QXVLA
No
8
Customer QUHWH
No
9
Customer RTXGC
No
10
Customer EEALV
No
(91 row(s) affected)
ГЛАВА 4
Подзапросы
Язык SQL позволяет создавать запросы внутри других запросов или вложенные запросы.
Самый внешний запрос — это запрос, именуемый внешним, результирующий набор которо-
го передается инициатору запроса. Внутренний запрос — это запрос, именуемый подзапро-
сом, результирующий набор которого используется внешним запросом. Внутренний запрос
действует как выражение, содержащее константы или переменные и вычисляемое во время
выполнения. В отличие от констант, применяемых в выражениях, результат подзапроса мо-
жет меняться из-за изменений в запрашиваемых таблицах. Благодаря использованию подза-
просов вы можете избавиться в вашем решении от отдельных шагов, требующих сохране-
ния промежуточных результатов запроса в переменных.
Подзапрос может быть как независимым (простым), так и связанным (коррелированным).
Независимый подзапрос не связан с внешним запросом, которому он принадлежит, а у свя-
занного запроса такая зависимость есть. Подзапрос может быть однозначным, многознач-
ным или табличным. Это означает, что вложенный запрос может вернуть одно значение
(скалярный), множество значений или результат в виде целой таблицы.
В этой главе пойдет речь о подзапросах, которые возвращают единственное значение (ска-
лярные подзапросы), и подзапросах, которые возвращают много значений (подзапросы с
множеством значений). О подзапросах, возвращающих целую таблицу (табличных подза-
просах), я расскажу позже в этой книге.
И независимые, и связанные подзапросы могут возвращать скалярные или множественные
значения. Сначала я опишу независимые подзапросы и приведу как скалярные примеры, так
и примеры с множеством значений, которые явно определю как скалярные подзапросы и
подзапросы с множеством значений. Затем я расскажу о связанных подзапросах, но уже не
буду определять их явно как скалярные подзапросы и подзапросы с множественными зна-
чениями, полагая, что вы уже поняли разницу.
И как всегда упражнения в конце главы помогут вам освоить на практике все, чему вы нау-
чились.
Независимые подзапросы
У каждого подзапроса есть внешний запрос, которому он принадлежит. Независимые подза-
просы — это подзапросы, не зависящие от внешнего запроса, которому они принадлежат. Не-
Подзапросы
143
зависимые подзапросы очень удобны для отладки, т. к. вы всегда можете выделить программ-
ный код подзапроса, выполнить его и убедиться в том, что он делает именно то, что и предпо-
лагалось. С логической точки зрения это эквивалентно однократному выполнению программ-
ного кода подзапроса перед выполнением внешнего запроса и последующему использованию
результата подзапроса во внешнем запросе. В следующих разделах рассмотрим конкретные
примеры независимых подзапросов.
Примеры независимых
скалярных подзапросов
Скалярный подзапрос— это подзапрос, возвращающий единственное значение, независимо
от того связанный он или независимый. Такой подзапрос можно включить в те элементы
внешнего запроса, которые могут содержать скалярные выражения (WHERE, SELECT И Т. Д .).
Предположим, что вам нужно обратиться к таблице Orders (Заказы) базы данных
TSQLFundamentals2008 и получить сведения о заказе с максимальным идентификатором
заказа в таблице. Вы можете выполнить эту задачу, применив переменную. Программа мо-
жет извлечь максимальный ID заказа из таблицы Orders и сохранить результат в перемен-
ной. Далее программный код может запросить таблицу Orders и отобрать заказы, у кото-
рых ID заказа равен значению, сохраненному в переменной. Этот способ показан в
приведенном далее программном коде:
USE TSQLFundamentals2008;
DECLARE Gmaxid AS INT = (SELECT MAX(orderid)
FROM Sales.Orders);
SELECT orderid, orderdate, empid, custid
FROM Sales.Orders
WHERE orderid = Gmaxid;
ПРИМЕЧАНИЕ
Помните о том, что объявлять и инициализировать переменные в одном и том же
операторе можно только в Microsoft SQL Server 2008. В более ранних версиях
применяйте отдельные операторы DECLARE И SET.
Этот запрос вернет следующий результат:
orderid
orderdate
empid
custid
11077
2008-05-06 00:00:00.000
1
65
Метод применения переменной можно заменить использованием вложенного подзапроса.
Добиться этого можно, заменив ссылку на переменную независимым скалярным подзапро-
сом, который вернет максимальный идентификатор заказа. На это раз решение будет состо-
ять из одного запроса, вместо приведенного двухшагового варианта.
SELECT orderid, orderdate, empid, custid
FROM Sales.Orders
144
Глава 2
WHERE orderid = (SELECT МАХ (О. orderid)
FROM Sales.Orders AS O);
Для того чтобы скалярный подзапрос был корректным, он всегда должен возвращать един-
ственное значение. Если такой подзапрос способен вернуть несколько значений, он может
во время выполнения завершиться аварийно. Следующий запрос, может быть, выполнится
без ошибки:
SELECT orderid
FROM Sales.Orders
WHERE empid = (SELECT E.empid
FROM HR.Employees AS E
WHERE E.lastname LIKE N'B%');
Цель данного запроса — вернуть ID заказов, помещенных любыми сотрудниками, чьи фа-
милии начинаются с буквы В. Подзапрос возвращает идентификаторы всех сотрудников с
фамилиями, начинающимися с буквы В, а внешний запрос возвращает ID заказов, у которых
ID сотрудника равен результату подзапроса. Поскольку операция равенства предполагает
выражения с одним значением с обеих сторон от знака операции, подзапрос рассматривает-
ся как скалярный. Но так как подзапрос может вернуть несколько значений, применение
операции равенства и скалярного подзапроса в данном случае не корректно. Если подзапрос
вернет несколько значений, запрос завершится аварийно.
Этот запрос, возможно, выполнится без ошибки, потому что в таблице Employees (Сотруд-
ники) содержится только один сотрудник с фамилией, начинающейся с В (Sven Buck с ID
сотрудника 5). Данный запрос вернет следующий результат, приведенный в сокращенном
виде:
orderid
10248
10254
10269
10297
10320
ъ
10874
10899
10922
10954
11043
(42 row(s) affected)
Конечно, если подзапрос возвращает несколько значений, запрос завершается с ошибкой.
Например, попробуйте выполнить запрос с сотрудниками, чьи фамилии начинаются с D.
SELECT orderid
FROM Sales.Orders
Подзапросы
145
WHERE empid = (SELECT E.empid
FROM HR.Employees AS E
WHERE E.lastname LIKE N'D%');
Очевидно, что у двух сотрудников фамилии начинаются с D (Sara Davis и Zoya Dol-
gopyatova).
Следовательно, запрос во время выполнения завершится аварийно со следующей ошибкой:
Msg 512, Level 16, State 1, Line 1
Subquery returned more than 1 value. This is not permitted when the subquery
follows =, !=, <, <= , >, >= or when the subquery is used as an expression.
Если скалярный подзапрос не возвращает ни одного значения, его результат преобразуется в
значение NULL. Напоминаю, что сравнение со значением NULL дает в результате значение
UNKNOWN и фильтр данного запроса не возвращает строку, для которой выражение выбора
равно UNKNOWN. Например, в данный момент таблица Employees (Сотрудники) не содержит
сотрудников с фамилиями, начинающимися с А, следовательно, приведенный далее запрос
вернет пустой результирующий набор:
SELECT orderid
FROM Sales.Orders
WHERE empid = (SELECT E.empid
FROM HR.Employees AS E
WHERE E.lastname LIKE N
,
A%1);
Примеры независимых подзапросов
с множеством значений
Подзапрос с множеством значений — это подзапрос, который возвращает множественные
значения в виде одного столбца независимо от того, связанный это подзапрос, или незави-
симый. В некоторых предикатах, например, IN, могут действовать подзапросы с множест-
венными значениями. Предикат IN применяется в следующем виде.
<скалярное_выражение> IN (<подзапрос_с_множеством _значений>)
Если скалярное_выражение равно одному из значений, возвращенных подзапросом, пре-
дикат принимает значение TRUE. Вспомните последний запрос, обсуждавшийся в предыду-
щем разделе, — вернуть ID заказов, которые были обработаны сотрудниками с фамилиями,
начинающимися с определенной буквы. Поскольку фамилии нескольких сотрудников могут
начинаться с одной и той же буквы, этот запрос следует обрабатывать с помощью предиката
IN и подзапроса с множеством значений, а не с помощью операции равенства и скалярного
подзапроса.
Например, следующий запрос вернет ID заказов, помещенных сотрудниками с фамилиями,
начинающимися с буквы D.
SELECT orderid
FROM Sales.Orders
WHERE empid IN
146
Глава 2
(SELECT Е.empid
FROM HR.Employees AS E
WHERE E.lastname LIKE N
,
D%');
Благодаря предикату IN этот запрос остается корректным при возврате 0, 1, или нескольких
значений. Данный запрос вернет следующий результат, приведенный в сокращенном виде:
orderid
10258
10270
10275
10285
10292
10978
11016
11017
11022
11058
(166 row(s) affected)
У вас может возникнуть вопрос: почему не решить эту задачу с помощью соединения вме-
сто подзапросов, например, следующим образом?
SELECT О.orderid
FROM HR.Employees AS E
JOIN Sales.Orders AS О
ON E.empid = O.enpid
WHERE E.lastname LIKE N'D%';
Вполне вероятно, что при формировании запросов вы столкнетесь с многими задачами, ко-
торые можно решить как с помощью подзапросов, так и с помощью соединений. По моему
мнению, нет надежного практического метода, позволяющего определить, что лучше: под-
запрос или соединение. В одних случаях механизм базы данных интерпретирует оба типа
запросов одинаково. В других случаях соединения предпочтительней, а в третьих справед-
ливо обратное. Я сначала пишу запрос для решения конкретной задачи, полагаясь на интуи-
цию, и если его производительность не удовлетворительна, пытаюсь опробовать разные
редакции запроса. Такие редакции могут содержать соединения, применяемые вместо под-
запросов, или подзапросы, используемые вместо соединений.
Еще в одном примере использования подзапросов с множеством значений предположим,
что вам нужно написать запрос, который возвращает заказы, сделанные клиентами из Со-
единенных Штатов. Вы можете сформировать запрос к таблице Orders (Заказы), возвра-
щающий заказы, у которых соответствующие идентификаторы клиента (множество ID кли-
ентов из USA (США)). Последнюю часть можно реализовать в виде независимого
подзапроса с множеством значений.
Подзапросы
147
Далее запрос приведен полностью:
SELECT custid, orderid, orderdate, empid
FROM Sales.Orders
WHERE custid IN
(SELECT C.custid
FROM Sales.Customers AS С
WHERE C.country = N'USA');
Этот запрос вернет следующий результат, приведенный в сокращенном виде:
custid
orderid
orderdate
empid
65
10262
2006-07-22 00:00:00.000
8
89
10269
2006-07-31 00:00:00.000
5
75
10271
2006-08-01 00:00:00.000
6
65
10272
2006-08-02 00:00:00.000
6
65
10294
2006-08-30 00:00:00.000
4
32
11040
2008-04-22 00:00:00.000
4
32
11061
2008-04-30 00:00:00.000
4
71
11064
2008-05-01 00:00:00.000
1
89
11066
2008-05-01 00:00:00.000
7
65
11077
2008-05-06 00:00:00.000
1
(122 row(s) affected)
Как и в любом другом предикате, вы можете применить отрицание в предикате IN С ПОМО-
ЩЬЮ логической операции NOT (не). Например, следующий запрос вернет список клиентов,
не сделавших ни одного заказа:
SELECT custid, companyname
FROM Sales.Customers
WHERE custid NOT IN
(SELECT O.custid
FROM Sales.Orders AS O);
Учтите, что если следовать хорошему стилю программирования, подзапрос нужно опреде-
лить как исключающий значения NULL. В примере, чтобы сохранить его простоту, я не ис-
ключил значения NULL, НО В разд. "Неполадки, связанные с NULL" далее в этой главе я по-
ясню свою рекомендацию.
Независимый подзапрос с множеством значений возвращает все ID клиентов, встретившие-
ся в таблице Orders (Заказы). Естественно в этой таблице содержатся идентификаторы
только тех клиентов, кто действительно сделал заказ. Внешний запрос вернет клиентов из
таблицы Customers (Клиенты), идентификаторы которых не включены в множество значе-
ний, возвращенных подзапросом, — другими словами, клиентов, не сделавших ни одного
заказа.
148
Глава 2
Данный запрос вернет такой результат:
custid
companyname
22
Customer DTDMN
57
Customer WVAXS
Возможно, вас интересует, не поможет ли повысить производительность задание элемента
DISTINCT в подзапросе, т. к. один и тот же ID клиента может встретиться несколько раз в
таблице Orders (Заказы). Механизм базы данных обладает столь развитой логикой, что
способен принять во внимание необходимость удаления дубликатов без вашей явной прось-
бы об этом, так что не стоит ни о чем беспокоиться.
В последнем примере этого раздела показано применение в одном запросе нескольких незави-
симых подзапросов, как однозначного, так и многозначного. Прежде чем я опишу предложен-
ную задачу, выполните следующий программный код для создания таблицы Orders (Заказы) в
базе данных tempdb (для тестирования) и заполнения ее заказами с четными идентификатора-
ми заказов, взятыми из таблицы Orders базы данных TSQLFundamentals2008.
USE tempdb;
SELECT *
INTO dbo.Orders
FROM TSQLFundamentals2008.Sales.Orders
WHERE orderid % 2 = 0;
Инструкцию SELECT INTO я подробно опишу в главе S, а сейчас достаточно сказать, что она
применяется для создания выходной таблицы и заполнения ее данными результирующего
набора запроса.
Рассматриваемая задача заключается в возврате всех отдельных идентификаторов заказов,
значения которых отсутствуют в таблице и попадают в интервал между максимальным и
минимальным табличными идентификаторами заказа. Решение этой задачи может оказаться
очень сложным, если применить только запрос без вспомогательных таблиц. Очень полез-
ной может быть таблица Nums, использовавшаяся в главе 3. (Если в вашей базе данных нет
таблицы Nums, для ее создания и заполнения можно воспользоваться программным кодом
листинга 3.1.) Таблица Nums содержит возрастающую последовательность целых чисел от 1
и далее без каких-либо пропусков. Для возврата всех пропущенных ID заказов из таблицы
Orders запросите таблицу Nums и отберите только числа, расположенные между минималь-
ным и максимальным значениями таблицы Orders и не включенные в множество иденти-
фикаторов заказа из этой таблицы. Для получения минимального и максимального ID заказа
можно применить скалярные независимые подзапросы, а для возврата множества всех су-
ществующих идентификаторов заказа— независимый подзапрос с множеством значений.
Далее приведено решение полностью:
SELECT П
FROM dbo.Nums
WHERE n BETWEEN (SELECT MIN (O.orderid) FROM dbo.Orders AS O)
AND (SELECT MAX (0. orderid) FROM dbo.Orders AS O)
AND n NOT IN (SELECT O.orderid FROM dbo.Orders AS O);
Подзапросы
149
Поскольку в программном коде, заполнявшем таблицу Orders в базе данных tempdb, отби-
рались только четные идентификаторы заказа, этот запрос вернет все нечетные значения,
расположенные между минимальным и максимальным ID заказа в таблице Orders. Далее в
сокращенном виде показан результат данного запроса:
п
10249
10251
10253
10255
10257
11067
11069
11071
11073
11075
(414 row(s) affected)
После того как вы завершите работу, выполните следующий программный код для очистки
базы данных:
DROP TABLE tempdb.dbo.Orders;
Связанные подзапросы
Связанные (коррелированные) подзапросы — это подзапросы, которые ссылаются на атри-
буты из таблицы, используемой в выходном запросе. Это означает, что подзапрос зависит от
внешнего запроса и не может выполняться независимо. Логически это равносильно выпол-
нению подзапроса отдельно для каждой внешней строки. Например, запрос из листинга 4.1
возвращает для каждого клиента заказы с максимальным ID заказа.
I Листинг 4.1. Связанный подзапрос
USE TSQLFundamentals2008;
SELECT custid, orderid, orderdate, empid
FROM Sales.Orders AS 01
WHERE orderid =
(SELECT MAX(02.orderid)
FROM Sales.Orders AS 02
WHERE 02.custid = 01.custid);
6 Зак. 1032
150
Глава 2
Внешний запрос обращен к экземпляру таблицы Orders (Заказы), названному 01; он отби-
рает заказы, в которых ID заказа равен значению, возвращенному подзапросом. Подзапрос
выбирает из второго экземпляра таблицы Orders, названного 02, заказы, у которых внут-
ренний ID клиента равен внешнему ID клиента, и возвращает максимальный ID заказа среди
отобранных. Проще говоря, для каждой строки из 01 подзапрос должен вернуть максималь-
ный ID заказа для текущего клиента. Если ID заказа в 01 и возвращенный подзапросом ID
заказа совпадают, ID заказа из 01 является максимальным для текущего клиента и в этом
случае строка экземпляра 01 возвращается запросом. Данный запрос вернет следующий
результат, показанный далее в сокращенном виде:
custid
orderid
orderdate
empid
91
11044
2008-04-23 00:00:00. 000
4
90
11005
2008-04-07 00:00:00. 000
2
89
11066
2008-05-01 00:00:00. 000
7
88
10935
2008-03 -09 00:00:00. 000
4
87
11025
2008-04-15 00:00:00. 000
6
5
10924
2008-03-04 00:00:00. 000
3
4
11016
2008-04-10 00:00:00. 000
9
3
10856
2008-01-28 00:00:00. 000
3
2
10926
2008-03-04 00:00:00. 000
4
1
11011
2008-04-09 00:00:00. 000
3
(89 row(s) affected)
Связанные подзапросы, как правило, понять гораздо труднее, чем независимые. Для лучше-
го понимания концепции связанных запросов я считаю полезным сосредоточить внимание
на одной строке внешней таблицы и понять, как она логически обрабатывается.
Например, остановимся на заказе из таблицы Orders с ID заказа, равным 10248.
custid
orderid
orderdate
empid
85
10248
2006-07-04 00:00:00.000
5
С учетом данной выходной строки, когда вычисляется подзапрос, связь или ссылка на
01. custid равна 85. После подстановки значения 85 вы получите следующий запрос:
SELECT МАХ(02.orderid)
FROM Sales.Orders AS 02
WHERE 02.custid =85;
Этот запрос вернет ID заказа, равный 10274. ID заказа из внешней строки (10248) сравнива-
ется с внутренним значением (10274), и, поскольку в данном случае нет совпадения, внеш-
няя строка отбрасывается. Подзапрос возвращает одно и то же значение для всех строк из
01 с одинаковыми ID клиента и совпадение фиксируется только в одном случае — когда ID
заказа во внешней строке равен максимальному идентификатору заказа для текущего клиен-
та. Рассуждая подобным образом, легче уяснить концепцию связанных подзапросов.
Подзапросы
151
Зависимость связанных подзапросов от внешнего запроса делает их отладку более трудной
по сравнению с независимыми подзапросами. Вы можете выделить только порцию подза-
проса и выполнить ее. Например, если вы попытаетесь выделить порцию подзапроса из лис-
тинга 4.1 и выполнить ее, то получите следующую ошибку:
?
Msg 4104, Level 16, State 1, Line 1
The multi-part identifier "01.custid" could not be bound.
Эта ошибка означает, что идентификатор 01. custid невозможно связать с объектом в за-
просе, поскольку экземпляр 01 в запросе не определен. Он определяется только в контексте
внешнего запроса. Для отладки связанных подзапросов вам придется заменить связь кон-
стантой и после проверки правильности программного кода заменить константу настоящей
ссылкой.
В следующем примере связанного подзапроса предположим, что вам нужно запросить
представление Sales.OrderValues (Стоимости заказов) и вернуть процентную долю
стоимости текущего заказа в общей стоимости заказов клиента. В главе 2 я предложил ре-
шение этой задачи с помощью элемента OVER; теперь я объясню, как решить ее с помощью
подзапросов. Всегда полезно попытаться найти разные решения одной задачи, поскольку
различные решения обычно характеризуются разными степенью сложности и производи-
тельностью.
Вы можете написать внешний запрос к одному экземпляру представления OrderValues
(Стоимости заказов), названному 01; в списке инструкции SELECT разделите текущее значе-
ние на результат, возвращенный связанным подзапросом (общая стоимость заказов текуще-
го клиента, полученная из второго экземпляра OrderValues, названного 02). Далее приве-
дено полное решение:
SELECT orderid, custid, val,
CAST(100. * val / (SELECT SUM(02.val)
FROM Sales.OrderValues AS 02
WHERE 02.custid = 01.custid)
AS NUMERIC(5, 2)) AS pet
FROM Sales.OrderValues AS 01
ORDER BY custid, orderid;
Функция CAST применяется для преобразования типа данных выражения в тип NUMERIC с
разрядностью 5 (общее количество цифр) и точностью 2 (количество цифр после десятич-
ной точки).
Данный запрос вернет следующий результат:
orderid
custid
val
pet
10643
1
814.50
19.06
10692
1
878.00
20.55
10702
1
330.00
7.72
10835
1
845.80
19.79
10952
1
471.20
11.03
11011
1
933.50
21.85
10308
2
88.80
6.33
152
Глава 2
10625
10759
10926
2
479.75
34.20
22.81
36.67
2
320.00
514.40
2
Предикат EXISTS
В язык T-SQL включен предикат, названный EXISTS И принимающий на входе подзапрос, а
на выходе возвращающий TRUE, если подзапрос отбирает хотя бы одну строку, и FALSE В
противном случае. Например, следующий запрос возвращает клиентов из Испании, сделав-
ших заказы:
SELECT custid, companyname
FROM Sales.Customers AS С
WHERE country = N'Spain
1
AND EXISTS
(SELECT * FROM Sales.Orders AS О
WHERE O.custid = C.custid);
Внешний запрос к таблице Customers (Клиенты) отбирает только клиентов из Испании, для
которых предикат EXISTS возвращает TRUE. Предикат EXISTS равен значению TRUE, если у
текущего клиента есть связанные с ним заказы в таблице Orders (Заказы).
Одно из достоинств применения предиката EXISTS СОСТОИТ В ТОМ, что он позволяет интуи-
тивно строить запрос как фразу на английском языке. Например, приведенный запрос мож-
но прочесть так, как будто вы произносите его на обычном английском: выберите атрибуты
"идентификатор клиента" и "название компании" из таблицы Customers (Клиенты), если
страна равна Испании и в таблице Orders (Заказы) существует хотя бы один заказ с таким
же идентификатором клиента, как ID клиента из таблицы Customers.
Данный запрос вернет следующий результат:
custid
companyname
8
Customer QUHWH
29
Customer MDLWA
30
Customer KSLQF
69
Customer SIUIH
Как и в других предикатах, в предикате EXISTS МОЖНО задавать отрицание с помощью ло-
гической операции NOT (не). Например, следующий запрос вернет клиентов из Испании, не
сделавших ни одного заказа:
SELECT custid, companyname
FROM Sales.Customers AS С
WHERE country = N'Spain'
AND NOT EXISTS
(SELECT * FROM Sales.Orders AS О
WHERE O.custid = C.custid);
Подзапросы
153
Этот запрос возвращает такой результат:
custid
companyname
22
Customer DTDMN
Несмотря на то, что эта книга в основном посвящена логической обработке запросов, а не
производительности, я думаю, что вам будет интересно узнать, что предикат EXISTS хоро-
шо поддается оптимизации. Это означает, что механизм управления SQL Server знает, что
достаточно определить, вернет ли подзапрос, по крайней мере, одну строку, или не вернет
ни одной и не нужно обрабатывать все полученные строки. Эту способность можно считать
разновидностью сокращенной формы вычислений.
В отличие от большинства других случаев указание звездочки (*) в списке SELECT подзапроса с
применением предиката EXISTS не считается плохим стилем программирования. Предикат
EXISTS следит лишь за наличием совпадающих строк вне зависимости от атрибутов, заданных в
списке SELECT, словно весь элемент SELECT не представляет интереса. Механизм базы данных
SQL Server знает об этом и из соображений оптимизации игнорирует список SELECT В подзапро-
се. Всё из тех же соображений оптимизации задание знака подстановки * для имен столбцов не
оказывает отрицательного воздействия по сравнению с такими альтернативами, как задание кон-
станты. Тем не менее, незначительные накладные расходы возникают в процессе разрешения
имен, заключающемся в замене * полным списком имен столбцов для того, чтобы убедиться в
наличии у вас прав доступа ко всем столбцам. В этом смысле применение константы вместо *
избавляет вас от подобных затрат. Но они так малы, что вы едва ли заметите их. По-моему запро-
сы должны быть естественными и интуитивно понятными, если нет очень серьезной причины для
того, чтобы пожертвовать этими характеристиками. Я нахожу вариант EXISTS (SELECT *
FROM ...) гораздо более понятным, чем EXISTS (SELECT 1 FROM ...). Незначительные до-
полнительные расходы, связанные с подстановкой имен вместо *, не сравнимы с затратами, вы-
званными ухудшением удобочитаемости программного кода.
И наконец, еще один аспект предиката EXISTS, заслуживающий внимания, заключается в
том, что в отличие от большинства предикатов языка T-SQL EXISTS использует двоичную,
а не троичную логику. Если вдуматься, невозможно представить себе ситуацию, в которой
неизвестно, вернет ли запрос какие-нибудь строки.
Дополнения к основным сведениям
о подзапросах
Этот раздел посвящен характеристикам подзапросов, которые, быть может, по вашему мне-
нию не относятся к основополагающим. Я предлагаю его как дополнительное чтение для
тех, кто хорошо усвоил материал, уже изложенный в этой главе.
Возврат предшествующего
или последующего значений
Предположим, что вам нужно запросить таблицу Orders (Заказы) из базы данных
TSQLFundamentals2008 и вернуть для каждого заказа сведения о текущем заказе, а также
154
Глава 2
идентификатор предшествующего заказа. Понятие "предшествующий" подразумевает логи-
ческое упорядочивание, но т. к. вы знаете, что строки в таблице не упорядочены, необходи-
мо найти логический эквивалент понятию "предшествующий", который можно выразить с
помощью выражения на языке T-SQL. Одним из примеров такого эквивалента может слу-
жить "максимальное значение, меньшее текущего". Эту фразу можно выразить на языке Т-
SQL с помошью такого связанного подзапроса:
SELECT orderid, orderdate, empid, custid,
(SELECT MAX(02.orderid)
FROM Sales.Orders AS 02
WHERE 02.orderid < 01.orderid) AS prevorderid
FROM Sales.Orders AS 01;
Данный запрос вернет следующий результат, приведенный в сокращенном виде:
orderid
orderdate
empid
custid
prevorderid
10248
2006-07-04 00:00:00.000
5
85
NULL
10249
2006-07-05 00:00:00.000
6
79
10248
10250
2006-07-08 00:00:00.000
4
34
10249
10251
2006-07-08 00:00:00.000
3
84
10250
10252
2006-07-09 00:00:00.000
4
76
10251
11073
2008-05-05 00:00:00.000
2
58
11072
11074
2008-05-06 00:00:00.000
7
73
11073
11075
2008-05-06 00:00:00.000
8
68
11074
11076
2008-05-06 00:00:00.000
4
9
11075
11077
2008-05-06 00:00:00.000
1
65
11076
(830 row(s) affected)
Обратите внимание на то, что у первого заказа в результирующем наборе нет предшест-
вующего, поэтому подзапрос вернет для него значение NULL.
Точно также последующее значение можно описать фразой: "минимальное значение, пре-
вышающее текущее". Далее приведен запрос на языке T-SQL, который возвращает для каж-
дого заказа следующее значение идентификатора заказа.
SELECT orderid, orderdate, empid, custid,
(SELECT MIN(02.orderid)
FROM Sales.Orders AS 02
WHERE 02.orderid > 01.orderid) AS nextorderid
FROM Sales.Orders AS 01;
Этот запрос формирует следующий результат, приведенный в сокращенном виде:
orderid
orderdate
empid
custid
nextorderid
10248
2006-07-04 00:00:00.000
5
85
10249
Подзапросы
155
10249
10250
10251
10252
2006-07-05 00:00:00.000
6
2006-07-08 00:00:00.000
4
2006-07-08 00:00:00.000
3
2006-07-09 00:00:00.000
4
79
34
84
76
10250
10251
10252
10253
11073
11074
11075
11076
11077
2008-05-05 00:00:00.000
2
2008-05-06 00:00:00.000
7
2008-05-06 00:00:00.000
8
2008-05-06 00:00:00.ООО
4
2008-05-06 00:00:00.000
1
58
73
68
9
65
11074
11075
11076
11077
NULL
(830 row(s) affected)
У последнего заказа нет последующего, поэтому запрос возвращает для него значение NULL.
Итоги с накоплением — это итоги, накапливающие значение со временем. Я воспользуюсь
представлением Sales. OrderTotalsByYear (Стоимость заказа по годам). Создадим запрос
к этому представлению, чтобы просмотреть его содержимое:
SELECT orderyear, qty
FROM Sales.OrderTotalsByYear;
Вы получите следующий результат:
orderyear
qty
2007
25489
2008
16247
2006
9581
Допустим, вам поставили задачу для каждого года вернуть год заказа, объем заказа и общий
объем заказа, накопленный за несколько лет. Это означает возврат общего количества това-
ра, заказанного вплоть до данного года. Таким образом, для самого раннего года, храняще-
гося в представлении (2006 г.), итог с накоплением равен годовому объему заказа. Для вто-
рого года (2007 г.) итог с накоплением — это сумма объемов заказа за первый и второй
годыит.д.
Эту задачу можно решить, если запросить один экземпляр представления (назовем его 01) и
получить для каждого года год заказа и объем и затем вычислить общий объем с помощью
подзапроса ко второму экземпляру представления (назовем его 02). Подзапрос должен ото-
брать в 02 все годы, которые меньше или равны текущему году в 01, и сложить объемы за-
каза из 02.
Далее приведено полное решение:
SELECT orderyear, qty,
(SELECT SUM(02.qty)
Итоги с накоплением
156
Глава 2
FROM Sales.OrderTotalsByYear AS 02
WHERE 02.orderyear <= 01.orderyear) AS runqty
FROM Sales.OrderTotalsByYear AS 01
ORDER BY orderyear;
Этот запрос вернет следующий результат:
orderyear
qty
runqty
2006
9581
9581
2007
25489
35070
2008
16247
51317
Запросы, которые ведут себя плохо
В этом разделе описаны случаи, в которых запросы могут вести себя вопреки вашим ожида-
ниям, и проверенные на практике приемы, которым вы можете следовать для того, чтобы
исключить из ваших программ логические ошибки, возникающие в подобных случаях.
Неполадки, связанные с NULL
Напоминаю о том, что в языке T-SQL применяется троичная логика. В этом разделе я пред-
ставлю проблемы, которые могут возникнуть в подзапросах, если они включают значения
NULL, а вы не принимаете во внимание троичную логику.
Рассмотрим следующий кажущийся естественным запрос, в котором предполагается вер-
нуть клиентов, не сделавших ни одного заказа.
SELECT custid, conipanyname
FROM Sales.Customers AS С
WHERE custid NOT IN(SELECT O.custid
FROM Sales.Orders AS 0);
Кажется, что запрос будет действовать так, как вы рассчитываете, и с учетом текущего со-
держимого таблицы orders (Заказы) из базы данных TSQLFundamentals2008 действительно
вернет две строки с двумя клиентами, не сделавшими ни одного заказа:
custid
companyname
22
Customer DTDMN
57
Customer WVAXS
Далее выполните следующий программный код, вставляющий в таблицу Orders (Заказы)
новый заказ с идентификатором клиента, равным NULL:
INSERT INTO Sales.Orders
(custid, empid, orderdate, requireddate, shippeddate, shipperid,
freight, shipname, shipaddress, shipcity, shipregion,
shippostalcode, shipcountry)
Подзапросы
157
VALUES (NULL, 1,
1
200902121
f
1
20090212 \
'20090212', 1, 123.00, N'abc
1
, N'abc
1
, N'abc',
N'abc', N' abc•, N'abc');
Выполните следующий запрос, который снова должен вернуть клиентов, не сделавших ни
одного заказа:
SELECT custid, companyname
FROM Sales.Customers AS С
WHERE custid NOT IN(SELECT O.custid
FROM Sales.Orders AS O) ;
На этот раз запрос вернет пустой результирующий набор. Помня о том, что вы прочли в
разделе из главы 2, посвященном значениям NULL, попытайтесь объяснить, почему запрос
вернул пустой набор. Подумайте также о способах получения в результирующем наборе
клиентов 22 и 57 и вообще о выработке правил, которым вы сможете следовать для того,
чтобы исключить подобные проблемы, полагая, что проблема существует.
Ясно, что в данной ситуации виновник— клиент с идентификатором NULL, который был
добавлен в таблицу Orders (Заказы) и затем был возвращен подзапросом наряду с извест-
ными идентификаторами клиентов.
Начнем с той части запроса, которая ведет себя, как и ожидалось. Предикат IN возвращает
значение TRUE ДЛЯ клиента, сделавшего заказы (например, клиента 85), поскольку такой
клиент возвращается подзапросом. Операция NOT (не) применяется для отрицания результа-
та предиката IN, следовательно, NOT TRUE превращается в FALSE, И клиент не включается
внешним запросом в результирующий набор. Это означает, что когда ID клиента появляется
в таблице Orders (Заказы) можно утверждать, что клиент сделал заказ и, следовательно, вы
не хотите видеть его в результирующем наборе. Но если в таблице Orders есть идентифи-
катор клиента, равный NULL, нельзя сказать с уверенностью, что определенный клиент не
включен в таблицу Orders, как пояснялось только что.
Предикат IN возвращает значение UNKNOWN (истинностное или логическое значение UNKNOWN,
подобное значениям TRUE И FALSE) для клиента, например, 22, который не вошел в множество
известных ID клиентов в таблице Orders. Предикат IN возвращает для такого клиента значе-
ние UNKNOWN, потому что сравнение его ID со всеми известными идентификаторами клиентов
дает в результате FALSE, а сравнение его со значением NULL, входящим в множество, дает в
результате UNKNOWN. Выражение FALSE OR UNKNOWN равно UNKNOWN. Рассмотрим более кон-
кретный пример— выражение 22 NOT IN (L, 2F NULL) . Его можно перефразировать как
NOT 22 IN (1, 2, NULL) . Далее вы можете раскрыть последнее выражение, записав NOT
(22 = 1 OR 22 = 2 OR 22 = NULL). Вычислив логическое значение каждого отдельного
выражения в круглых скобках, вы получите выражение NOT (FALSE OR FALSE OR
UNKNOWN) , которое преобразуется в выражение NOT UNKNOWN, равное UNKNOWN.
В данном случае логическое значение UNKNOWN до того, как вы примените операцию NOT,
означает, что нельзя с уверенностью сказать о том, что ID клиента входит в множество, по-
скольку значение NULL может представлять как рассматриваемый ID клиента, так и любой
другой идентификатор. Хитрость заключается в том, что применение операции NOT К значе-
нию UNKNOWN в результате дает UNKNOWN, которое отбрасывается в фильтре запроса. Это
означает, что если неизвестно, входит ли ID клиента в множество, также неизвестно и то,
что он в это множество не включен.
158
Глава 2
Короче говоря, если вы применяете в предикате NOT IN подзапрос, который возвращает
хотя бы одно значение NULL, внешний запрос всегда возвращает пустой результирующий
набор. Известные значения из внешней таблицы, входящие в множество, не возвращаются,
потому что предполагается, что внешний запрос возвращает значения, не включенные в
множество. Значения, не вошедшие в множество известных значений, не возвращаются,
поскольку никогда нельзя с уверенностью сказать, что значение не входит в множество, со-
держащее значение NULL.
Итак, каким же правилам нужно следовать, чтобы избежать подобной ошибки?
Во-первых, если предполагается, что в столбце запрещены значения NULL, его нужно опре-
делять, как NOT NULL. Обеспечение целостности гораздо важнее, чем думают многие.
Во-вторых, во всех ваших запросах следует учитывать все три возможные истинностные
значения троичной логики (TRUE, FALSE И UNKNOWN). Особо подумайте о том, может ли ваш
запрос обрабатывать значения NULL И если да, то подходит ли для ваших нужд принятая по
умолчанию трактовка этих значений. Если нет, необходимо ваше вмешательство. Например,
в нашем случае внешний запрос возвращает пустой результирующий набор из-за сравнения
со значением NULL. ЕСЛИ ВЫ хотите проверять, входит ли идентификатор клиента в множе-
ство известных значений и игнорировать значения NULL, следует исключить значения NULL
явно или неявно. Примером явного исключения значений NULL может служить вставка в
подзапрос предиката о. custid is NOT NULL следующим образом:
SELECT custid, companyname
FROM Sales.Customers AS С
WHERE custid NOT IN(SELECT 0.custid
FROM Sales.Orders AS 0
WHERE 0.custid IS NOT NULL);
Пример неявного исключения значений NULL — применение вместо NOT IN предиката NOT
EXISTS следующим образом:
SELECT custid, companyname
FROM Sales.Customers AS С
WHERE NOT EXISTS
(SELECT *
FROM Sales.Orders AS 0
WHERE 0.custid = C.custid);
Напоминаю, что в отличие от предиката IN В предикате EXISTS используется логика двоич-
ных предикатов, EXISTS всегда возвращает TRUE или FALSE И никогда UNKNOWN. Когда под-
запрос сталкивается со значением NULL В атрибуте О.custid, выражение становится равно
UNKNOWN, и строка отбрасывается. Когда применяется предикат EXISTS, варианты NULL ис-
ключаются естественным образом, как будто их не было. Поэтому предикат EXISTS В итоге
обрабатывает только известные ID клиента. Следовательно, применять NOT EXISTS гораздо
безопаснее, чем NOT IN.
После того как поэкспериментируете, выполните следующий программный код для очистки
базы данных:
DELETE FROM Sales.Orders WHERE custid IS NULL;
DBCC CHECKIDENT(1 Sales.Orders
4
, RESEED, 11077);
Подзапросы
159
Ошибка подстановки
в имени столбца подзапроса
Логические ошибки в ваших программах могут быть порой трудноуловимы. В этом разделе
я опишу подобный дефект, связанный с невинной ошибкой подстановки в имени столбца
подзапроса. После пояснения ошибки я приведу практические правила, которые позволят
вам избежать подобных ошибок в дальнейшем.
Примеры в этом разделе запрашивают таблицу MyShippers (Мои перевозчики) в схеме
Sales (Продажи). Выполните следующий программный код для создания и заполнения этой
таблицы:
IF OBJECT_ID(' Sales.MyShippers', '0*) IS NOT NULL
DROP TABLE Sales.MyShippers;
CREATE TABLE Sales.MyShippers
(
shipper_id INT NOT NULL,
companyname NVARCHAR(40) NOT NULL,
phone NVARCHAR(24) NOT NULL,
CONSTRAINT PK_MyShippers PRIMARY KEY(shipper_id)
);
INSERT INTO Sales.MyShippers(shipper_id, companyname, phone)
VALUES(1, N'Shipper GVSUA', N'(503) 555-0137');
INSERT INTO Sales.MyShippers(shipper_id, companyname, phone)
VALUES(2, N'Shipper ETYNR', N'(425) 555-0136');
INSERT INTO Sales.MyShippers(shipper_id, companyname, phone)
VALUES (3, N'Shipper ZHISN', N'(415) 555-0138');
Рассмотрим следующий запрос, который, как предполагается, вернет перевозчиков, доста-
вивших заказы клиенту 43:
SELECT shipper_id, companyname
FROM Sales.MyShippers
WHERE shipper_id IN
(SELECT shipper_id
FROM Sales.Orders
WHERE custid = 43);
Этот запрос сформирует такой результат:
shipper_id companyname
1
Shipper GVSUA
2
Shipper ETYNR
3
Shipper ZHISN
160
Глава 2
Ясно, что только перевозчики 2 и 3 доставили заказы клиенту 43, но по какой-то причине
этот запрос вернул всех перевозчиков из таблицы MyShippers (Мои перевозчики). Проана-
лизируйте внимательно запрос и схемы включенных в запрос таблиц и посмотрите, сможете
ли вы объяснить причину.
Оказывается, что столбец в таблице Orders (Заказы), содержащий идентификатор перевоз-
чика, назван не shipper_id, a shipperid (без знака подчеркивания). Столбец в таблице
MyShippers (Мои перевозчики) назван shipper id со знаком подчеркивания. Разрешение
имен столбцов без уточняющих префиксов выполняется в контексте подзапроса, начиная с
текущей/внутренней области действия и далее с переходом на внешний уровень. В нашем
примере SQL Server сначала ищет столбец shipper id в таблице Orders (Заказы). Такого
столбца в указанной таблице нет, поэтому SQL Server продолжает поиск во внешней табли-
це запроса, MyShippers (Мои перевозчики). Поскольку такой столбец найден, он и исполь-
зуется.
Как видите, подзапрос, который предполагался как независимый, превратился в связанный
подзапрос. До тех пор пока в таблице Orders (Заказы) есть хоть одна строка, для всех строк
из таблицы MyShippers находится совпадение при сравнении внешнего ID перевозчика с
запросом, возвращающим тот же самый внешний ID перевозчика для каждой строки из таб-
лицы Orders.
Кое-кто может сказать, что это недоработка конструкции в стандарте языка SQL. Разработ-
чики такого алгоритма из комитета ANSI SQL не стремились затруднить поиск "ошибки",
подобный внутренний алгоритм разработан для того, чтобы позволить вам ссылаться на
имена столбцов из внешней таблицы без префиксов в виде имени таблицы до тех пор, пока
эти имена столбцов остаются однозначными (встречаются только в одной из таблиц).
Эта проблема гораздо более распространена в рабочих средах, не применяющих согласо-
ванных имен атрибутов в разных таблицах. Иногда имена слегка отличаются, как в нашем
случае— в одной таблице shipperid, а в другой shipper id. Этого вполне достаточно
для того, чтобы ошибка проявилась в полной мере.
Во избежание подобных проблем можно следовать двум практическим правилам — одно
краткосрочное, а другое долгосрочное.
В долгосрочной перспективе вашей организации следует отказаться от недооценки важно-
сти согласованности имен атрибутов в разных таблицах. В краткосрочной перспективе вы,
конечно, не захотите начать корректировку существующих имен столбцов, способную при-
вести к ошибкам в прикладном программном коде.
В краткосрочной перспективе можно применить очень простое правило— сопровождать
имена столбцов в подзапросах префиксами в виде псевдонимов исходных таблиц. В этом
случае в процессе разрешения имен поиск столбца будет выполняться только в заданной
таблице и если столбец не будет найден, вы получите ошибку разрешения имен. Например,
попробуйте выполнить следующий программный код:
SELECT shipper_id, companyname
FROM Sales.MyShippers
WHERE shipper_id IN
(SELECT 0.shipper_id
FROM Sales.Orders AS О
WHERE O.custid = 43);
Подзапросы
161
Вы получите ошибку разрешения имен:
Msg 207, Level 16, State 1, Line 4
Invalid column name 'shipperid1
.
Получив такую ошибку, вы, конечно, сможете установить причину и исправить запрос:
SELECT shipper_id, fcompanyname
FROM Sales.MyShippers
WHERE shipper_id IN
(SELECT 0.shipperid
FROM Sales.Orders AS 0
WHERE 0.custid = 43);
На этот раз запрос вернет предполагаемый результат:
shipper_id companyname
2
Shipper ETYNR
3
Shipper ZHISN
После завершения работы выполните следующий программный код для очистки базы дан-
ных:
IF 0BJECT_ID('Sales.MyShippers
1
, 'U') IS NOT NULL
DROP TABLE Sales.MyShippers;
Резюме
Эта глава посвящена подзапросам. В ней обсуждаются независимые подзапросы, которые
не зависят от внешнего запроса, и связанные подзапросы, зависящие от внешнего запроса.
В зависимости от результата подзапроса я определил скалярные и множественные подза-
просы. Я также предложил в качестве дополнительного чтения раздел с более сложным ма-
териалом, в котором рассказал о возврате предшествующего и последующего значений, ито-
гах с накоплением и нестандартно ведущих себя подзапросах.
Не забывайте всегда учитывать троичную логику и для имен столбцов в подзапросах зада-
вать префиксы в виде псевдонимов исходных таблиц.
Следующая глава посвящена табличным подзапросам, которые также называют табличны-
ми выражениями.
Упражнения
В этом разделе предложены упражнения, которые помогут вам лучше усвоить темы, обсуж-
давшиеся в этой главе. Во всех упражнениях данной главы используется учебная база дан-
ных TSQLFundamentals2008.
162
Глава 2
Упражнение 4.1
Напишите запрос, который возвращает из таблицы Orders (Заказы) все заказы, помещен-
ные в нее в последний день деловой активности.
Используемые таблицы: таблица Sales. Orders.
Предполагаемый результат:
orderid
orderdate
custid
empid
11077
2008-05-06 00:00:00.000
65
1
11076
2008-05-06 00:00:00.000
9
4
11075
2008-05-06 00:00:00.000
68
8
11074
2008-05-06 00:00:00.000
73
7
Упражнение 4.2
(дополнительное, повышенной сложности)
Напишите запрос, который вернет все заказы, сделанные клиентом (клиентами), поместив-
шим максимальное количество заказов. Учтите, что несколько клиентов может иметь оди-
наковое число заказов.
Используемые таблицы: таблица Orders.
Предполагаемый результат (в сокращенном виде):
custid
orderid
orderdate
empid
71
10324
2006-10-08 00:00:00.000
9
71
3,0393
2006-12 -25 00:00:00.000
1
71
10398
2006-12 -30 00:00:00.000
2
71
10440
2007-02-10 00:00:00.000
4
71
10452
2007-02-20 00:00:00.000
8
71
10510
2007-04-18 00:00:00.000
6
71
10555
2007-06 -02 00:00:00.ООО
6
71
10603
2007-07-18 00:00:00.. 000
8
71
10607
2007-07-22 00:00:00.000
5
71
10612
2007-07-28 00:00:00.000
1
71
10627
2007-08 -11 00:00:00.000
8
71
10657
2007-09 -04 00:00:00.000
2
71
10678
2007-09-23 00:00:00.000
7
71
10700
2007-10-10 00:00:00.000
3
71
10711
2007-10-21 00:00:00.000
5
71
10713
2007-10-22 00:00:00.000
1
71
10714
2007-10-22 00:00:00.000
5
71
10722
2007-10-29 00:00:00.000
8
Подзапросы
163
71
10748
2007-11 -20 00:00:00.000
3
71
10757
2007-11-27 00:00:00.000
6
71
10815
2008-01-05 00:00:00.000
2
71
10847
2008-01-22 00:00:00.000
4
71
10882
2008-02-11 00:00:00.000
4
71
10894
2008-02-18 00:00:00.000
1
71
10941
2008-03-11 00:00:00.000
7
71
10983
2008-03 -27 00:00:00.000
2
71
10984
2008-03-30 00:00:00.000
1
71
11002
2008-04-06 00:00:00.000
4
71
11030
2008-04-17 00:00:00.,000
7
71
11031
2008-04-17 00:00:00.000
6
71
11064
2008-05-01 00:00:00.,000
1
(31 row(s) affected)
Упражнение 4.3
Напишите запрос, возвращающий сотрудников, не поместивших ни одного заказа или не
сделавших этого после May 1,2008 (1 мая 2008 г.).
Используемые таблицы: таблицы HR.Employees (Сотрудники) и Sales.Orders (Заказы).
Предполагаемый результат:
empid
FirstName
lastname
3
Judy
Lew
5
Sven
Buck
6
Paul
Suurs
9
Zoya
Dolgopyatova
Упражнение 4.4
Напишите запрос, возвращающий страны, в которых есть клиенты, но нет сотрудников.
Используемые таблицы: таблицы Sales.Customers (Клиенты) и HR.Employees (Сотруд-
ники).
Предполагаемый результат:
country
Argentina
Austria
Belgium
164
Глава 2
Brazil
Canada
Denmark
Finland
France
Germany
Ireland
Italy
Mexico
Norway
Poland
Portugal
Spain
Sweden
Switzerland
Venezuela
(19 row(s) affected)
Упражнение 4.5
Напишите запрос, возвращающий для каждого клиента все заказы, сделанные в последний
день деловой активности клиента.
Используемые таблицы: таблица Sales. Orders (Заказы).
Предполагаемый результат:
custid
orderid
orderdate
empid
1
11011
2008-04-09 00:: 00:00.000 3
2
10926
2008-03 -04 00::00:00.000 4
3
10856
2008-01-28 00:: 00:00.000 3
4
11016
2008-04-10 00:: 00:00.000 9
5
10924
2008-03-04 00:: 00:00.000 3
87
11025
2008-04-15 00:: 00:00.000 6
88
10935
2008-03-09 00:: 00:00.000 4
89
11066
2008-05-01 00:: 00:00.,000 7
90
11005
2008-04-07 00:: 00:00.000 2
91
11044
2008-04-23 00:: 00:00.000 4
(90 row(s) affected)
Подзапросы
165
Упражнение 4.6
Напишите запрос, возвращающий клиентов, сделавших заказы в 2007 г. и не поместивших
ни одного заказа в 2008 г.
Используемые таблицы: таблицы Sales. Customers (Клиенты) и Sales. Orders (Заказы).
Предполагаемый результат:
custid
companyname
21
Customer KIDPX
23
Customer WVFAF
33
Customer FVXPQ
36
Customer LVJSO
43
Customer UISOJ
51
Customer PVDZC
85
Customer ENQZT
(7 row(s) affected)
Упражнение 4.7
(дополнительное, повышенной сложности)
Напишите запрос, возвращающий клиентов, заказавших товар 12.
Используемые таблицы: Sales. Customers (Клиенты), Sales. Orders (Заказы) и
Sales. Order Details (Сведения о заказе).
Предполагаемый результат:
custid
companyname
48
Customer DVFMB
39
, Customer GLLAG
71
Customer LCOCJJ
65
Customer NYCJHS
44
Customer OXFRU
51
Customer PVDZC
86
Customer SNXOJ
20
Customer THHDP
90
Customer XBBVR
46
Customer XPNIK
31
Customer YJCBX
87
Customer ZHYOS
(12 row(s) affected)
166
Глава 2
Упражнение 4.8
(дополнительное, повышенной сложности)
Напишите запрос, который возвращает для каждого клиента общий ежемесячный объем
заказов с накоплением.
Используемые таблицы: представление Sales. CustOrders (Заказы клиентов).
Предполагаемый результат:
custid
ordermonth
qty
runqty
2007-08-01 00:00:00.000
38
38
2007-10-01 00:00:00.000
41
79
2008-01-01 00:00:00.000
17
96
2008-03-01 00:00:00.000
18
114
2008-04-01 00:00:00.000
60
174
2
2006-09-01 00:00:00.000
6
6
2
2007-08-01 00:00:00.000
18
24
2
2007-11 -01 00:00:00.000
10
34
2
2008-03 -01 00:00:00.000
29
63
3
2006-11 -01 00:00:00.000
24
24
3
2007-04-01 00:00:00.000
30
54
3
2007-05-01 00:00:00.000
80
134
3
2007-06 -01 00:00:00.000
83
217
3
2007-09 -01 00:00:00.000
102
319
3
2008-01-01 00:00:00.000
40
359
(636 row(s) affected)
ГЛАВА 5
Табличные выражения
Табличными выражениями называются выражения запросов, представляющие корректную
реляционную таблицу. Вы можете применять их в инструкциях обработки данных так же,
как и другие таблицы. Microsoft SQL Server поддерживает четыре типа табличных выраже-
ний: производные таблицы, общие табличные выражения (common table expression, СТЕ),
представления и подставляемые табличные функции (inline table-valued function, TVF). Все
перечисленные типы выражений я подробно опишу в этой главе. Данная глава посвящена
запросам SELECT, обращенным к табличным выражениям; в главе 8 будет описана модифи-
кация табличных выражений.
Табличные выражения не материализуются где бы то ни было — они виртуальны. Запрос к
табличному выражению на внутреннем уровне преобразуется в запрос к базовому внутрен-
нему объекту такого выражения. Преимущества применения табличных выражений обычно
связаны с логическими аспектами ваших программ, а не с их производительностью. Напри-
мер, табличные выражения помогают упростить решения благодаря модульному подходу.
Табличные выражения также помогают обойти определенные ограничения языка, такие как
невозможность ссылаться на псевдонимы столбцов, присвоенные в элементе SELECT, В дру-
гих, логически обрабатываемых до элемента SELECT синтаксических элементах запроса.
В этой главе также вводится табличная операция APPLY, используемая в сочетании с таб-
личным выражением. Я поясню, как применять эту операцию для объединения табличного
выражения с каждой строкой другой таблицы.
Производные таблицы
Производные таблицы (также называемые табличными подзапросами) определяются в эле-
менте FROM внешнего запроса. Их область действия — внешний запрос. Как только внешний
запрос завершается, производная таблица пропадает.
Вы задаете запрос, описывая производную таблицу в круглых скобках, за которыми следует
ключевое слово AS И имя производной таблицы. Например, в приведенном далее программ-
ном коде описана производная таблица USACusts (Клиенты из США), основанная на запро-
се, который возвращает всех клиентов из Соединенных Штатов, а внешний запрос выбирает
все строки из производной таблицы.
USE TSQLFundamentals2008;
SELECT *
168
Глава 2
FROM (SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA') AS USACusts;
В данном случае, который служит простым примером базового синтаксиса, в производной
таблице нет нужды, потому что внешний запрос не содержит никакой обработки.
Приведенный в этом базовом примере программный код вернет следующий результат:
custid
companyname
32
Customer YSIQX
36
Customer LVJSO
43
Customer UISOJ
45
Customer QXPPT
48
Customer DVFMB *
55
Customer KZQZT
65
Customer NYUHS
71
Customer LCOUJ
75
Customer XOJYP
77
Customer LCYBZ
78
Customer NLTYP
82
Customer EYHKM
89
Customer YBQTI
Определить табличное выражение любого типа можно в запросе, отвечающем трем требо-
ваниям.
1. Порядок следования строк должен быть произвольным. Предполагается, что табличное
выражение представляет собой реляционную таблицу, а у строк реляционной таблицы нет
определенного порядка следования. Напоминаю, что это свойство отношения, пришедшее
из теории множеств. По этой причине стандарт ANSI SQL не разрешает применять элемент
ORDER BY в запросах, определяющих табличные выражения. Язык T-SQL соблюдает это
ограничение в большинстве случаев за исключением элемента ТОР. В запросе с необяза-
тельным элементом ТОР синтаксический элемент ORDER BY служит логической Цели: опре-
деляет для элемента ТОР, какие строки выбирать. Если в запросе с элементами ТОР И ORDER
BY задается табличное выражение, элемент ORDER BY гарантированно применяется только
для логического упорядочивания, необходимого элементу тор, а не как обычно для пред-
ставления данных. Если во внешнем запросе к табличному выражению нет элемента ORDER
BY для представления результата, определенный порядок его вывода не гарантирован.
В разд. "Представления и элемент ORDER BY" далее в этой главе приведена более под-
робная информация.
2. У всех столбцов должны быть имена. Следовательно, вы должны присвоить псевдони-
мы столбцов всем выражениям в списке SELECT запроса, применяемого для задания таб-
личного выражения.
3. Все имена столбцов должны быть уникальны. Следовательно, табличное выражение с
несколькими столбцами, имеющими одно и то же имя, не корректно. Подобное может
Табличные выражения
169
произойти, если в запросе, определяющем табличное выражение, соединяются две таб-
лицы, и в них обеих есть столбец с одним и тем же именем. Если вам нужно включить
оба столбца в ваше табличное выражение, у них должны быть разные имена столбцов.
Эту проблему можно решить, присвоив двум столбцам разные псевдонимы столбцов.
Присвоение псевдонимов столбцов
Одно из преимуществ использования табличных выражений— возможность ссылаться в
любом синтаксическом элементе внешнего запроса на псевдонимы столбцов, присвоенные в
элементе SELECT внутреннего запроса. Это помогает обойти ограничение, запрещающее
ссылаться на присвоенные в элементе SELECT псевдонимы столбцов в элементах запроса,
которые логически обрабатываются до элемента SELECT (таких как WHERE ИЛИ GROUP BY).
Предположим, что вам нужно написать запрос к таблице Sales.Orders (Заказы) и вернуть
за все годы, указанные в датах заказов, количество разных клиентов, делавших заказы в те-
чение каждого года. Следующая попытка не корректна, т. к. элемент GROUP BY ссылается на
псевдоним столбца, который был присвоен в элементе SELECT, а синтаксический элемент
GROUP BY логически обрабатывается до элемента SELECT,
SELECT
YEAR(orderdate) AS orderyear,
COUNT(DISTINCT custid) AS numcusts
FROM Sales.Orders
GROUP BY orderyear;
Эту задачу можно было бы решить, сославшись на выражение YEAR (orderdate) в обоих
элементах: GROUP BY и SELECT, НО хорошо, что в данном примере выражение короткое.
А что если выражение окажется гораздо длиннее? Вставка двух копий одного и того же вы-
ражения может затруднить понимание и техническое сопровождение программного кода, а
также повысить вероятность ошибок. Для того чтобы решить задачу способом, требующим
лишь одной копии выражения, можно применить табличное выражение из листинга 5.1.
I Листинг 5.1* Запрос с производной таблицей» использующей форму
| присвоения псевдонима, встроенного в элемент запроса
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM (SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders) AS D
GROUP BY orderyear;
Этот запрос вернет следующий результат:
orderyear
numcusts
2006
2007
2008
67
86
81
170
Глава 2
В данном программном коде определяется таблица D, получаемая из запроса к таблице
Orders (Заказы), который возвращает год заказа и идентификатор клиента из каждой стро-
ки. В списке SELECT внутреннего запроса для присвоения в элементах GROUP BY И SELECT
псевдонима столбца orderyear (год заказа) выражению YEAR (orderdate) используется
формат внутреннего или встроенного назначения псевдонимов. Внешний запрос может
ссылаться на псевдоним столбца в обоих синтаксических элементах, поскольку в своей об-
ласти действия он обращается к таблице D, имеющей столбцы, названные orderyear (год
заказа) и custid (id клиента).
Как я уже упоминал ранее, SQL Server раскрывает определение табличного выражения и
обращается непосредственно к его базовым объектам. После раскрытия запрос из листин-
га 5.1 выглядит следующим образом:
SELECT YEAR(orderdate) AS orderyear, COUNT(DISTINCT custid) AS numcusts
FROM Sales.Orders
GROUP BY YEAR(orderdate);
Самое время подчеркнуть, что табличные выражения применяются из соображений логики
(а не производительности) обработки. Вообще говоря, табличные выражения не оказывают
ни положительного, ни отрицательного влияния на производительность.
В программном коде из листинга 5.1 используется формат встраиваемого в элемент запроса
назначения выражениям псевдонимов столбцов. Синтаксическая запись для встраиваемого
назначения псевдонимов:
<выражение> [AS] <лсевмоним>
Имейте в виду, что в этой конструкции ключевое слово AS необязательно, но я считаю, что
оно облегчает чтение программного кода, и рекомендую применять его.
В некоторых случаях может оказаться предпочтительнее вторая поддерживаемая форма для
назначения псевдонимов столбцов, которую можно считать внешней формой. В этой форме
не нужно назначать псевдонимы столбцов, следующие за выражениями в списке SELECT, —
все назначаемые имена столбцов указываются в круглых скобках, следующих за именем
табличного выражения.
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM (SELECT YEAR(orderdate), custid
FROM Sales.Orders) AS D(orderyear, custid)
GROUP BY orderyear;
Как правило, рекомендуется применять встраиваемую форму по двум причинам. При отлад-
ке, если используется встроенная форма, выделив запрос, определяющий табличное выра-
жение, и выполнив его, вы получите в результате столбцы с назначенными вами псевдони-
мами. В случае внешней формы назначения невозможно вставить назначенные имена
столбцов при выделении запроса, задающего табличное выражение, поэтому результат в
случае неименованных выражений выводится без имен столбцов. Кроме того, если запрос с
табличным выражением громоздкий, применение внешней формы затрудняет сопоставле-
ние псевдонимов столбцов и относящихся к ним выражений.
Несмотря на то, что использование встраиваемой формы назначения псевдонимов — луч-
ший выбор, в некоторых случаях внешняя форма может оказаться более удобной для рабо-
ты. Например, если не предполагается корректировать в дальнейшем запрос, содержащий
Табличные выражения
171
табличное выражение, и вы хотите использовать его как "черный ящик", т. е. при рассмот-
рении внешнего запроса вы хотите сосредоточить внимание на имени табличного выраже-
ния, за которым следует список назначенных имен столбцов.
Применение аргументов
В запросе, определяющем производную таблицу, можно ссылаться на аргументы. Аргумен-
ты могут быть локальными переменными и входными параметрами подпрограммы, такой
как хранимая процедура или функция. Например, в следующем программном коде объявля-
ется и инициализируется локальная переменная @empid, а запрос, применяемый для опреде-
ления производной таблицы D, ссылается на локальную переменную в элементе WHERE.
DECLARE 0empid AS INT = 3;
/*
—
В версиях более ранних, чем Server 2008, применяйте отдельные
инструкции DECLARE и SET:
DECLARE @empid AS INT;
SET Gempid = 3;
*/
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM (SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
WHERE empid = Gempid) AS D
GROUP BY orderyear;
Запрос возвращает количество разных клиентов, чьи заказы были обработаны за год вход-
ным сотрудником (сотрудником, чей ID хранится в переменной @empid). Далее приведен
результат этого запроса:
orderyear
numcusts
2006
16
2007
46
2008
30
Вложение
Если вам нужно задать производную таблицу, используя запрос, который сам ссылается на
производную таблицу, это приведет к вложению производных таблиц. Вложение производ-
ных таблиц— результат того, что производная таблица определяется в элементе FROM
внешнего запроса, а не отдельно. Вложение порождает проблемы программирования, т. к.
ведет к усложнению программного кода и затрудняет его чтение.
172
Глава 2
Например, программный код в листинге 5.2 возвращает годы, в которые были сделаны зака-
зы, и количество клиентов, заключивших сделки в каждом году, причем выбираются только
те годы, в которые более 70 клиентов сделали заказы.
Листинг 5.2, Запрос с вложенными производными таблицами
SELECT orderyear, numcusts
FROM (SELECT orderyear, COUNT (DISTINCT custid) AS numcusts
FROM (SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders) AS D1
GROUP BY orderyear) AS D2
WHERE numcusts >70;
Этот код вернет следующий результат.
orderyear
numcusts
2007
86
2008
81
Задача самой внутренней производной таблицы, D1,— присвоить псевдоним столбца
orderyear (год заказа) выражению YEAR (orderdate). Запрос к D1 ссылается на
orderyear в элементах GROUP BY и SELECT и присваивает псевдоним столбца numcusts
(количество клиентов) выражению COUNT (DISTINCT custid). Запрос к D1 используется
для задания производной таблицы D2. Запрос к D2 ссылается на numcusts в элементе WHERE
для того, чтобы выбрать годы, в которых более 70 клиентов сделали заказы в течение года.
В этом примере общая цель применения табличных выражений заключается в упрощении
решения за счет повторного использования псевдонимов вместо выражений. Но из-за воз-
росшей сложности, обусловленной применением вложенных производных таблиц, я не уве-
рен, что данное решение проще альтернативного, в котором совсем не используются произ-
водные таблицы, а просто повторяются выражения.
SELECT YEAR(orderdate) AS orderyear, COUNT(DISTINCT custid) AS numcusts
FROM Sales.Orders
GROUP BY YEAR(orderdate)
HAVING COUNT(DISTINCT custid) > 70;
Говоря кратко, вложенность— проблематичный аспект применения производных таблиц.
Множественные ссылки
Другая проблема, связанная с производными таблицами, вызвана тем, что они определяются
в элементе FROM внешнего запроса, а не перед внешним запросом. До тех пор пока не рас-
сматривается синтаксический элемент FROM внешнего запроса, производной таблицы еще не
существует, следовательно, если необходимо сослаться на множественные экземпляры про-
изводной таблицы, вы не можете сделать это. Вместо этого вы вынуждены определять мно-
Табличные выражения
173
жественные производные таблицы, основанные на одном и том же запросе. Запрос в лис-
тинге 5.3 служит тому примером.
! Листинг 5.3. Множественные производные таблицы, базирующиеся на одном
| и том же запросе
SELECT Cur.orderyear,
Cur. numcusts AS cur numcusts, Prv. numcusts AS prvnumcusts,
Cur.numcusts - Prv.numcusts AS growth
FROM (SELECT YEAR(orderdate) AS orderyear,
COUNT(DISTINCT custid) AS numcusts
FROM Sales.Orders
GROUP BY YEAR(orderdate)) AS Cur
LEFT OUTER JOIN
(SELECT YEAR(orderdate) AS orderyear,
COUNT(DISTINCT custid) AS numcusts
FROM Sales.Orders
GROUP BY YEAR(orderdate)) AS Prv
ON Cur.orderyear = Prv.orderyear + 1;
Данный запрос соединяет два экземпляра табличного выражения для создания двух произ-
водных таблиц: первая из них, Cur, представляет текущие годы, а вторая производная таб-
лица Prv,— предыдущие годы. Условие соединения Cur .orderyear = Prv. orderyear +
1 гарантирует, что каждая строка из первой производной таблицы сопоставляется с преды-
дущим годом из второй таблицы. Задав операцию левого внешнего соединения, можно
включить в результирующий набор первый год из таблицы Cur, не имеющий предыдущего
года. В элементе SELECT внешнего запроса вычисляется разница между количеством клиен-
тов, сделавших заказы в текущем и предыдущем годах.
Программный код из листинга 5.3 формирует следующий результат:
orderyear
curnumcusts prvnumcusts growth
2006
67
NULL
NULL
2007
86
67
19
2008
81
86
-5
Невозможность сослаться на множественные экземпляры одной и той же производной таб-
лицы заставляет вас хранить множественные копии определения одного и того же запроса.
Это ведет к удлинению программного кода, который труднее поддерживать в исправном
состоянии, и вероятность появления ошибок в нем также возрастает.
Общие табличные выражения
Общие табличные выражения (ОТВ, Common table expression (СТЕ)) — другой тип таблич-
ных выражений, очень похожих на производные таблицы, но с парой важных дополнитель-
174
Глава 2
ных преимуществ. ОТВ были введены в SQL Server 2005 и являются частью стандарта язы-
ка ANSI SQL: 1999 и более поздних версий стандартов.
ОТВ определяются с помощью инструкции WITH И имеют следующий синтаксис:
WITH <ОТВ__Имя> [ (<Список__столбцов_результата>) ]
AS
(
<внутренний__запрос_за,ца ки[ии_ОТВ>
)
<внешний_запрос__к_ОТВ> ;
Внутренний запрос, задающий ОТВ, должен удовлетворять всем изложенным ранее требо-
ваниям для того, чтобы корректно определить табличное выражение. В приведенном далее
простом примере определяется ОТВ usACusts (Клиенты из США), основанное на запросе,
который возвращает всех клиентов из Соединенных Штатов, а внешний запрос выбирает из
ОТВ все строки.
WITH USACusts AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT * FROM USACusts;
ПРИМЕЧАНИЕ
Синтаксический элемент WITH в языке T-SQL применяется для разных целей. Для
того чтобы исключить неоднозначность, если элемент WITH используется для оп-
ределения ОТВ, предыдущая инструкция в том же фрагменте, если таковая су-
ществует, должна заканчиваться точкой с запятой. Как ни странно, для ОТВ в це-
лом точка с запятой не требуется, но я рекомендую вставлять ее.
Назначение псевдонимов столбцов
ОТВ также поддерживают две формы назначения псевдонимов столбцов: встраиваемую и
внешнюю. Во встраиваемой форме задавайте конструкцию <выражение> AS <псевдо-
ним_столбца>\ во внешней форме указывайте сразу за именем ОТВ список результирую-
щих столбцов в круглых скобках.
Далее приведен пример с встраиваемой формой назначения псевдонимов столбцов:
WITH С AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
)
Табличные выражения
175
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM С
GROUP BY orderyear;
А теперь пример с применением внешней формы:
WITH С(orderyear, custid) AS
(
SELECT YEAR(orderdate), custid
FROM Sales.Orders
)
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM С
GROUP BY orderyear;
Выбор той или иной формы определяется теми же соображениями, что и в случае примене-
ния производных таблиц.
Применение аргументов
В запросе, используемом для определения ОТВ, можно задавать аргументы, как и в запро-
сах с производными таблицами. Далее показан пример:
DECLARE @empid AS INT = 3;
/*
—
До версии SQL Server 2008 используйте отдельные операторы DECLARE
и SET:
DECLARE @empid AS INT;
SET @empid = 3;
*/
WITH С AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
*
WHERE empid = @empid
)
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM С
GROUP BY orderyear;
Определение множественных ОТВ
На первый взгляд разница между производными таблицами и ОТВ может показаться только
семантической. Но тот факт, что вы сначала определяете ОТВ, а затем его применяете, дает
176
Глава 2
ряд преимуществ по сравнению с производными таблицами. Одно из них заключается в том,
что, если нужно сослаться на одно ОТВ из другого, вам нет нужды вкладывать их друг в
друга как производные таблицы. Вместо этого вы просто определяете в одной инструкции
WITH множественные ОТВ, разделенные запятыми. Любое ОТВ может ссылаться на все
ОТВ, определенные прежде, и внешний запрос может ссылаться на все ОТВ. Например,
следующий программный код— альтернатива с применением ОТВ методу вложенных про-
изводных таблиц, представленному в листинге 5.2.
WITH CI AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM CI
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts >70;
Поскольку вы определяете ОТВ до его использования, вам не нужно прибегать к вложен-
ным ОТВ. Каждое ОТВ появляется в программном коде отдельно, в модульном стиле. Мо-
дульный подход делает программный код гораздо понятнее и облегчает его сопровождение
по сравнению с вложенными производными таблицами.
Технически вы не можете ни вкладывать ОТВ друг в друга, ни определять ОТВ в круглых
скобках производной таблицы. Но вложение — прием, создающий проблемы, поэтому счи-
тайте эти ограничения средствами, обеспечивающими ясность программного кода, а не по-
мехами.
Множественные ссылки
Предварительное определение ОТВ, до его использования в запросе, дает и еще одно пре-
имущество. На этапе обработки элемента FROM внешнего запроса ОТВ уже существует, сле-
довательно можно ссылаться на множественные экземпляры одного и того же ОТВ. Напри-
мер, следующий программный код— логический эквивалент показанного ранее в
листинге 5.3 примера, но использующий ОТВ вместо производных таблиц.
WITH YearlyCount AS
(
SELECT YEAR(orderdate) AS orderyear,
COUNT(DISTINCT custid) AS numcusts
Табличные выражения
177
FROM Sales.Orders
GROUP BY YEAR(orderdate)
)
SELECT Cur.orderyear,
Cur.numcusts AS curnumcusts, Prv.numcusts AS prvnumcusts,
Cur.numcusts - Prv.numcusts AS growth
FROM YearlyCount AS Cur
LEFT OUTER JOIN YearlyCount AS Prv
ON Cur.orderyear = Prv.orderyear + 1;
Как видите, OTB YearlyCount (Годовое количество) определено один раз, а используется в
элементе FROM внешнего запроса дважды — один раз как Cur и один раз как Prv. Вам нуж-
но хранить только одну копию запроса с ОТВ, а не множественные копии, как в случае ис-
пользования производных таблиц.
Если вас интересует производительность, то напоминаю еще раз о том, что, как правило,
табличные выражения не влияют на производительность, поскольку они не материализуют-
ся где бы то ни было. В данном случае обе ссылки на ОТВ должны быть раскрыты. На внут-
реннем уровне этот запрос содержит самосоединение двух экземпляров таблицы Orders
(Заказы), в каждом из которых перед соединением данные таблицы просматриваются и по-
дытоживаются — та же физическая обработка, что и в случае использования производных
таблиц.
Рекурсивные ОТВ
Этот раздел дополнительный, т. к. посвящен тонкостям, не относящимся к основным сведе-
ниям.
ОТВ уникальны по сравнению с табличными выражениями других типов, т. к. обладают
рекурсивными возможностями. Рекурсивное ОТВ определяется, как минимум, в двух запро-
сах (возможно и большее количество): как минимум, один из запросов называется фиксиро-
ванным компонентом или якорем и, как минимум, один запрос называют рекурсивным ком-
понентом. Общий вид рекурсивного ОТВ выглядит следующим образом:
WITH <Имя_ОТВ>[ (<розультируюций__список_столбцов>) ]
AS
(
<фикслрованный_компонент>
UNION ALL
<рекурсивныи_компонент>
)
<Щ1ешнлй_запрос_к_ОТВ> ;
Фиксированный компонент — это запрос, возвращающий корректную реляционную резуль-
тирующую таблицу, как запрос, применяемый для определения нерекурсивного табличного
выражения. Фиксированный компонент инициируется только один раз.
178
Глава 2
Рекурсивный компонент — это запрос, у которого есть ссылка на имя ОТВ. Эта ссылка пред-
ставляет собой логически предыдущий результат в серии выполнений. При первом запуске
рекурсивного компонента предыдущий результат — это то, что вернул фиксированный ком-
понент. В каждом последующем запуске рекурсивного компонента ссылка на имя ОТВ пред-
ставляет собой результирующий набор, возвращенный предыдущим запуском рекурсивного
компонента. У рекурсивного компонента нет явного ограничения для прерывания рекурсии —
подобное ограничение неявное. Рекурсивный компонент инициируется многократно до тех
пор, пока не вернет пустой результирующий набор или не превысит некоторый предел.
Оба запроса должны быть совместимы с точки зрения количества возвращаемых столбцов и
типов данных в соответствующих столбцах.
Ссылка на имя ОТВ во внешнем запросе представляет объединенные результирующие на-
боры, полученные в результате запуска фиксированного компонента и всех запусков рекур-
сивного компонента.
Если это ваше первое знакомство с рекурсивными ОТВ, возможно, вы сочтете приведенное
объяснение малопонятным. Лучше всего пояснить их на примере. Следующий программный
код демонстрирует, как применять рекурсивное ОТВ для-получения сведений о сотруднике
(Don Funk, ID сотрудника равно 2) и всех его подчиненных на всех уровнях (прямых и кос-
венных).
WITH EmpsCTE AS
(
SELECT empid, mgrid, firstname, lastname
FROM HR.Employees
WHERE empid = 2
UNION ALL
SELECT C.empid, C.mgrid, C.firstname, C.lastname
FROM EmpsCTE AS P
JOIN HR.Employees AS С
ON C.mgrid = P.empid
)
SELECT empid, mgrid, firstname, lastname
FROM EmpsCTE;
Фиксированный компонент просто запрашивает таблицу HR.Employees (Сотрудники) и
возвращает строку для сотрудника с TD, равным 2.
SELECT empid, mgrid, firstname, lastname
FROM HR.Employees
WHERE empid = 2
Рекурсивный компонент соединяет ОТВ; представляющее предыдущий результирующий
набор, с таблицей Employees для получения прямых подчиненных сотрудников, возвра-
щенных в предыдущем результирующем наборе.
SELECT С.empid, С.mgrid, С.firstname, С.lastname
FROM EmpsCTE AS P
Табличные выражения
179
JOIN HR.Employees AS С
ON C.mgrid = P.empid
Другими словами, рекурсивный компонент запускается многократно и при каждом запуске
возвращает сотрудников на следующем уровне подчинения. В первый раз рекурсивный
компонент запускается и возвращает прямых подчиненных сотрудника 2: сотрудников 3 и 5.
Во второй раз рекурсивный компонент запускается и возвращает прямых подчиненных со-
трудников 3 и 5, это сотрудники с ID 4, 6, 7, 8 и 9. Когда рекурсивный компонент выполня-
ется третий раз, подчиненных сотрудников уже нет, и он возвращает пустой результирую-
щий набор, и, следовательно, рекурсия завершается.
Ссылка на имя ОТВ во внешнем запросе представляет объединенные результирующие наборы,
другими словами, сотрудника с ID 2 и всех его подчиненных.
Далее приведен результат данного программного кода:
empid
mgrid
firstname lastname
2
1
Don
Funk
3
2
Judy
Lew
5
2
Sven
Buck
6
5
Paul
Suurs
7
5
Russell
King
9
5
Zoya
Dolgopyatova
4
3
Yael
Peled
8
3
Maria
Cameron
При наличии логической ошибки в предикате соединения в рекурсивном компоненте или
проблем, связанных с получением данных в циклах, рекурсивный компонент теоретически
может запускаться неограниченное число раз. Из соображений безопасности SQL Server по
умолчанию ограничивает количество возможных запусков рекурсивного компонента чис-
лом 100. Программа завершится аварийно на 101-м запуске рекурсивного компонента. При-
нятый по умолчанию максимальный уровень рекурсии можно изменить, задав в конце
внешнего запроса указание OPTION (MAXRECURSION п), в котором п— целое число в диа-
пазоне от 0 до 32 767, представляющее максимальный уровень рекурсии, который вы хотите
установить. Если вы хотите совсем убрать ограничение, задайте MAXRECURSION 0. Учтите,
что SQL Server хранит промежуточные результирующие наборы, возвращаемые фиксиро-
ванным и рекурсивным компонентами, в рабочей таблице базы данных tempdb. Если вы
удалите ограничение и запустите неуправляемый запрос, рабочая таблица быстро станет
очень большой. Если tempdb больше не может увеличиваться, например, при исчерпании
свободного дискового пространства, запрос завершится аварийно.
Представления
У двух уже рассмотренных типов табличных выражений — производных таблиц и ОТВ —
очень ограниченная область действия, единственная инструкция языка. Как только внешний
запрос к таким табличным выражениям завершается, они исчезают. Это означает, что про-
изводные таблицы и ОТВ не могут использоваться многократно.
180
Глава 2
Представления и подставляемые табличные функции (подставляемые ТФ)— два типа таб-
личных выражений, допускающих многократное использование; их определения хранятся в
объекте базы данных. Созданные один раз эти объекты становятся постоянными компонен-
тами базы данных и исчезают из нее только в случае явного удаления.
Во всем остальном представления и подставляемые ТФ обрабатываются как производные
таблицы и ОТВ. Например, при запросе к представлению или подставляемой ТФ SQL
Server, как и в случае производных таблиц и ОТВ, раскрывает определения табличных вы-
ражений и непосредственно запрашивает лежащие в их основе базовые объекты.
В этом разделе я рассмотрю представления, а следующий раздел посвящу подставляемым
ТФ. Как я уже упоминал, представление — это допускающее многократное использование
табличное выражение, определение которого хранится в базе данных. Например, в следую-
щем программном коде в схеме Sales (Продажи) базы данных TSQLFundamentals2008 соз-
дается представление USACusts (Клиенты из США):
USE TSQLFundamentals2008;
IF OBJECT_ID(1 Sales.USACusts
1
) IS NOT NULL
DROP VIEW Sales.USACusts;
GO
CREATE VIEW Sales.USACusts
AS
SELECT custid, companyname, contactname, contacttitle, address,
city, region, postalcode, country, phone, fax
FROM Sales.Customers
WHERE country = N'USA';
GO
Имейте в виду, что как и в случае производных таблиц и ОТВ, вместо применения встраи-
ваемого в элемент инструкции назначения псевдонимов столбцов, показанного в приведен-
ном только что программном коде, можно использовать внешнее назначение псевдонимов,
указав имена результирующих столбцов в круглых скобках сразу же после имени представ-
ления.
Создав один раз это представление, вы можете запрашивать его из базы данных многократ-
но, как другие таблицы:
SELECT custid, companyname
FROM Sales.USACusts;
Поскольку представление — это объект базы данных, управлять доступом к нему можно с
помощью прав доступа или разрешений так же, как к другим объектам, которые могут за-
прашиваться (например, права на выполнение инструкций SELECT, INSERT, UPDATE и
DELETE). МОЖНО, К примеру, запретить прямой доступ к лежащим в основе базовым объек-
там, предоставив доступ к представлению.
Учтите, что общая рекомендация избегать применения инструкции вида SELECT * имеет
особо важное значение для представлений. В откомпилированной форме представления
столбцы пронумерованы и новые столбцы таблицы не будут автоматически вставляться в
Табличные выражения
181
представление. Предположим, что вы определяете представление на основе запроса SELECT
* FROM dbo.Tl и во время создания представления в таблице T1 есть два столбца: coll и
со12. В метаданных представления SQL Server сохраняет сведения только об этих двух
столбцах. Если вы измените определение таблицы, добавив новые столбцы, эти новые
столбцы не будут включены в представление. Обновить метаданные представления можно с
помощью хранимой процедуры sp_refreshview, но во избежание путаницы лучше всего
явно перечислить в определении представления имена нужных вам столбцов. Если столбцы
вставляются в базовые таблицы и вы хотите включить их в представление, используйте ин-
струкцию ALTER VIEW для соответствующей корректировки определения представления.
Представления и элемент ORDER BY
Запрос, применяемый для определения представления, в отношении табличных выражений
должен удовлетворять всем требованиям, упомянутым ранее при рассмотрении производ-
ных таблиц. Представление не должно обеспечивать определенный порядок следования
строк, у всех столбцов представления должны быть имена и имена всех столбцов представ-
ления должны быть уникальны. В этом разделе я рассмотрю проблему упорядочивания
строк, фундаментальный аспект, который важно понять.
Напоминаю, что присутствие элемента ORDER BY запрещено в запросе, определяющем таб-
личное выражение, потому что в реляционной таблице нет строгого порядка следования
строк. Попытка создания представления с упорядочиванием строк абсурдна, т. к. нарушает
основные свойства отношения, определяемые реляционной моделью. Если вам нужно вер-
нуть строки представления, отсортированные для наглядности, не пытайтесь превратить
представление в то, чем оно не должно быть. Вместо этого следует задать презентационный
элемент ORDER BY ВО внешнем запросе к представлению следующим образом:
SELECT custid, companyname, region
FROM Sales.USACusts
ORDER BY region;
Попробуйте выполнить следующий программный код для создания представления с приме-
нением элемента ORDER BY для вывода данных:
ALTER VIEW Sales.USACusts
AS
SELECT custid, companyname, contactname, contacttitle, address,
city, region, postalcode, country, phone, fax
FROM Sales.Customers
WHERE country = N
1
USA1
ORDER BY region;
GO
Эта попытка завершится неудачно, и вы получите сообщение об ошибке:
Msg 1033, Level 15, State 1, Procedure USACusts, Line 9
The ORDER BY clause is invalid in views, inline functions, derived tables,
subqueries, and common table expressions, unless TOP or FOR XML is also specified.
7 Зак. 1032
182
Глава 2
Сообщение об ошибке означает, что SQL Server допускает присутствие элемента ORDER BY
в двух исключительных случаях: когда применяются необязательные элементы ТОР ИЛИ FOR
XML. Ни один из них не соответствует стандарту SQL и в обоих случаях элемент ORDER BY
предназначен не для вывода результирующего набора.
Поскольку язык T-SQL разрешает применять в представлении элемент ORDER BY, когда за-
дается и элемент ТОР, некоторые программисты считают, что можно создать "упорядочен-
ные" представления, если задать элемент ТОР (100) PERCENT следующим образом:
ALTER VIEW Sales.USACusts
AS
SELECT TOP (100) PERCENT
custid, companyname, contactname, contacttitle, address,
city, region, postalcode, country, phone, fax
FROM Sales.Customers
WHERE country = N'USA'
ORDER BY region;
GO
Несмотря на то, что формально программный код корректен и представление создается, вам
следует знать, что, поскольку запрос используется для определения табличного выражения,
элемент ORDER BY В нем служит только для описания логики выбора строк элементом ТОР.
Если вы запрашиваете представление и не задаете элемент ORDER BY во внешнем запросе,
порядок представления строк не гарантирован.
Например, выполните следующий запрос к представлению:
SELECT custid, companyname, region
FROM Sales.USACusts;
Далее приведен результат одного из моих выполнений запроса, показывающий, что строки
не отсортированы по региону:
custid
companyname
region
32
Customer YSIQX
OR
36
Customer LVJSO
OR
43
Customer UISOJ
WA
45
Customer QXPPT
CA
48
Customer DVFMB
OR
55
Customer KZQZT
AK
65
Customer NYUHS
NM
71
Customer LCOUJ
ID
75
Customer XOJYP
WY
77
Customer LCYBZ
OR
78
Customer NLTYP
MT
82
Customer EYHKM
WA
89
Customer YBQTI
WA
Табличные выражения
183
В некоторых случаях запрос, применяемый для определения табличного выражения, содер-
жит элемент ТОР и элемент ORDER BY, а запрос к табличному выражению (внешний) не со-
держит элемент ORDER BY. В этом случае результат может возвращаться или не возвра-
щаться в заданном порядке следования. Если кажется, что результирующий набор
упорядочен, это может быть следствием оптимизации, особенно если вы задаете что-либо
отличное от ТОР (100) PERCENT. Я хочу особо подчеркнуть тот факт, что любой порядок
следования строк в результирующем наборе считается корректным и никакой определенный
порядок следования не гарантирован, если вы не задали элемент ORDER BY во внешнем за-
просе.
Не путайте поведение запроса, используемого для определения табличного выражения, с
поведением запроса, не предназначенного для этой цели. Запрос с элементами ТОР и ORDER
BY не обеспечивает определенного порядка следования строк только при наличии таблично-
го выражения. Если запрос не используется для определения табличного выражения, эле-
мент ORDER BY служит как для задания критерия выбора строк элементом ТОР, так и для
задания порядка вывода строк.
Необязательные параметры представления
При создании или изменении представления можно задать его атрибуты или дополнитель-
ные параметры как часть определения представления. В заголовке представления после
элемента WITH МОЖНО задать такие атрибуты, как ENCRYPTION И SCHEMABINDING, а в конце
запроса задать конструкцию WITH CHECK OPTION. В следующих разделах описывается на-
значение этих параметров.
Параметр ENCRYPTION
Дополнительный параметр ENCRYPTION МОЖНО применять при создании или изменении
представлений, хранимых процедур, триггеров и определенных пользователем функций
(ОПФ). Параметр ENCRYPTION означает сохранение программой SQL Server на внутреннем
уровне текста с определением объекта в зашифрованном формате. Зашифрованный текст не
виден пользователям в обычных объектах-каталогах, а только привилегированным пользо-
вателям и с помощью специальных средств.
Перед рассмотрением параметра ENCRYPTION выполните следующий программный код для
восстановления исходной версии определения представления USACusts (Клиенты из США):
ALTER VIEW Sales.USACusts
AS
SELECT custid, companyname, contactname, contacttitle, address,
city, region, postalcode, country, phone, fax
FROM Sales.Customers
WHERE country = N'USA1;
GO
Для получения определения представления выполните функцию овJECT_DEFINITI0N:
SELECT OBJECT_DEFINITION(OBJECT_ID(1 Sales.USACusts
1
));
184
Глава 2
Текст, содержащий определение представления, доступен, т. к. представление было создано
без параметра ENCRYPTION. ВЫ получите следующий результат:
CREATE VIEW Sales.USACusts
AS
SELECT custid, companyname, contactname, contacttitle, address,
city, region, postalcode, country, phone, fax
FROM Sales.Customers
WHERE country = N
1
USA';
Далее измените определение представления, только теперь добавьте параметр ENCRYPTION:
ALTER VIEW Sales.USACusts WITH ENCRYPTION
AS
SELECT custid, companyname* contactname, contacttitle, address,
city, region, postalcode, country, phone, fax
FROM Sales.Customers
WHERE country = N
1
USA1;
GO
Снова попробуйте получить текст с определением представления:
SELECT OBJECT_DEFINITION(OBJECT_ID(• Sales.USACusts'));
На сей раз вы получите значение NULL.
Как альтернативу функции OBJECT_DEFINITION ДЛЯ получения определений объектов
можно использовать хранимую процедуру sp_helptext. Функция 0BJECT_DEFINITI0N
была добавлена в SQL Server 2005, хранимая процедура sp helptext есть и в более ранних
версиях. Например, следующий программный код запрашивает определение объекта для
представления USACusts (Клиенты из США):
EXEC sp_helptext 'Sales.USACusts
f
;
Поскольку в нашем случае представление было создано с параметром ENCRYPTION, ВЫ по-
лучите не определение объекта, а следующее сообщение:
The text for object 'Sales.USACusts' is encrypted.
Параметр
SCHEMABINDING
Необязательный параметр SCHEMABINDING применяется в представлениях и ОПФ и связы-
вает схему объектов и столбцы, на которые делается ссылка, со схемой ссылающегося объ-
екта. Это означает, что объекты, на которые приведена ссылка, не могут быть удалены, и
что столбцы, на которые сделана ссылка, не могут удаляться или изменяться.
Например, измените определение представления USACusts с помощью параметра
SCHEMABINDING:
ALTER VIEW Sales.USACusts WITH SCHEMABINDING
AS
Табличные выражения
185
SELECT custid, companyname, contactname, contacttitle, address,
city, region, postalcode, country, phone, fax
FROM Sales.Customers
WHERE country = N'USA';
GO
Теперь попробуйте удалить столбец Address (Адрес) из таблицы Customers (Клиенты):
ALTER TABLE Sales.Customers DROP COLUMN address;
Вы получите такое сообщение:
Msg 5074, Level 16, State 1, Line 1
The object 'USACusts' is dependent on column 'address
1
.
Msg 4922, Level 16, State 9, Line 1
ALTER TABLE DROP COLUMN address failed because one or more objects access this
column.
Без параметра SCHEMABINDING такое изменение схемы было бы допустимым, как и удале-
ние таблицы Customers в целом. Это изменение может привести к ошибкам во время вы-
полнения, когда вы попытаетесь запросить представление или несуществующие объекты
или столбцы, на которые приводится ссылка. Если создать представление с необязательным
параметром SCHEMABINDING, подобных ошибок можно избежать.
Для того чтобы иметь возможность использовать параметр SCHEMABINDING, запрос должен
удовлетворять паре формальных требований. В запросе, в элементе SELECT запрещается
применять *, вместо нее следует явно задавать список столбцов. Кроме того, при ссылке на
объекты следует использовать уточняющие двухчастные имена с указанием имени схемы.
Обычно эти два требования— признаки хорошего стиля программирования. Как вы дога-
дываетесь, создание объектов с необязательным параметром SCHEMABINDING—это хоро-
ший практический прием.
Параметр CHECK OPTION
Назначение параметра CHECK OPTION — помешать внесению через представление измене-
ний, которые противоречат условиям фильтра представления, если таковой существует в
запросе, определяющем представление.
Запрос, определяющий представление USACusts (Клиенты из США), отбирает клиентов, у
которых атрибут country (страна) равен N 'USA1
. В настоящий момент представление опреде-
ляется без параметра CHECK OPTION. Это означает, что вы можете сейчас вставить через пред-
ставление строки с клиентами из других стран и модифицировать через представление записи
клиентов, заменив Соединенные Штаты любой другой страной. Например, в следующем про-
граммном коде успешно вставляется в представление запись о клиенте с названием компании
Customer ABCDE из страны United Kingdom (Великобритания):
INSERT INTO Sales.USACusts(
companyname, contactname, contacttitle, address,
city, region, postalcode, country, phone, fax)
VALUES(
186
Глава 2
N'Customer ABCDE1
, N'Contact ABCDE', N'Title ABCDE', N'Address ABCDE',
N1 London', NULL, N
1
123451
, N'UK', N'012-3456789', N
f
012-34567891);
Строка через представление попадает в таблицу Customers (Клиенты). Однако, поскольку
представление отбирает только клиентов из Соединенных Штатов, если вы запросите пред-
ставление для поиска нового клиента, то получите пустой результирующий набор:
SELECT custid, companyname, country
FROM Sales.USACusts
WHERE companyname = N
T
Customer ABCDE';
Запросите непосредственно таблицу Customers (Клиенты) для поиска нового клиента:
SELECT custid, companyname, country
FROM Sales.Customers
WHERE companyname = N' Customer ABCDE' ;
Вы получите в результирующем наборе информацию о клиенте, потому что новая строка
сохранила ее в таблице Customers:
custid
companyname
country
92
Customer ABCDE
UK
Точно так же, если вы обновите в представлении строку со сведениями о клиенте, изменив в
атрибуте country Соединенные Штаты на любую другую страну, изменение будет сделано
в таблице. Но в представлении клиент больше не появится, потому что не соответствует
фильтру запроса к представлению.
Если вы хотите избежать модификаций, конфликтующих с фильтром представления, до-
бавьте WITH CHECK OPTION в конец запроса, определяющего представление:
ALTER VIEW Sales.USACusts WITH SCHEMABINDING
AS
SELECT custid, companyname, contactname, contacttitle, address,
city, region, postalcode, country, phone, fax
FROM Sales.Customers
WHERE country = N'USA'
WITH CHECK OPTION;
GO
Теперь попробуйте вставить строку, противоречащую условию в фильтре запроса, опреде-
ляющего представление:
INSERT INTO.Sales.USACusts(
companyname, contactname, contacttitle, address,
city, region, postalcode, country, phone, fax)
VALUES (
N'Customer FGHIJ', N'Contact FGHIJ', N'Title FGHIJ', N'Address FGHIJ',
N'London *, NULL, N'12345', N'UK', N'012-3456789', N'012-3456789');
Табличные выражения
187
Вы получите такое сообщение об ошибке:
Msg 550, Level 16, State 1, Line 1
The attempted insert or update failed because the target view either specifies
WITH CHECK OPTION or spans a view that specifies WITH CHECK OPTION and one or
more rows resulting from the operation did not qualify under the CHECK OPTION
constraint.
The statement has been terminated.
Когда закончите работу, выполните следующий программный код для очистки базы данных:
DELETE FROM Sales.Customers
WHERE custid > 91;
DBCC CHECKIDENT(1 Sales.Customers
1
, RESEED, 91);
IF OBJECT ID(' Sales.USACusts') IS NOT NULL DROP VIEW Sales.USACusts;
Подставляемые табличные функции
Подставляемые табличные функции (ТФ) — это допускающие многократное использование
табличные выражения, содержащие входные параметры. Во всех отношениях за исключе-
нием поддержки входных параметров подставляемые ТФ аналогичны представлениям. По
этой причине я предпочитаю рассматривать подставляемые ТФ как параметризованные
представления, хотя формально они так и не называются.
Например, следующий программный код создает в базе данных TSQLFundamentals2008
подставляемую ТФ, названную fn_GetCustOrders:
USE TSQLFundamentals2 008;
IF OBJECT_ID (1 dbo. fn_GetCustOrders') IS NOT NULL
DROP FUNCTION dbo.fn_GetCustOrders;
GO
CREATE FUNCTION dbo.fn_GetCustOrders
(@cid AS INT) RETURNS TABLE
AS
RETURN
SELECT orderid, custid, empid, orderdate, requireddate,
shippeddate, shipperid, freight, shipname, shipaddress, shipcity,
shipregion, shippostalcode, shipcountry
FROM Sales.Orders
WHERE custid = @cid;
GO
Эта подставляемая ТФ принимает входной параметр @cid, содержащий ID клиента, и воз-
вращает все заказы, сделанные клиентом, заданным на входе. Запрашиваются подставляе-
мые ТФ с помощью инструкций языка манипулирования данными, как любые другие таб-
лицы. Если функция принимает входные параметры, вы задаете их в круглых скобках,
следующих за именем функции. Кроме того, убедитесь, что задан псевдоним для табличного
188
Гпаеа 5
выражения. Присвоение табличному выражению псевдонима не всегда обязательное усло-
вие, но это хороший прием, поскольку он делает ваш программный код более понятным и
менее склонным к ошибкам. Например, следующий программный код запрашивает функ-
цию, отбирающую все заказы, сделанные клиентом 1:
SELECT orderid, custid
FROM dbo.fn_GetCustOrders(1) AS CO;
Этот программный код вернет такой результат:
orderid
custid
10643
1
10692
1
10702
1
10835
1
10952
1
11011
1
Как и на другие таблицы, на подставляемую ТФ можно ссылаться в операции соединения.
Например, следующий запрос соединяет подставляемую ТФ, возвращающую заказы клиен-
та 1, с таблицей Sales.OrderDetails (Сведения о заказе), соединяя заказы клиента I со
связанными компонентами заказа:
SELECT CO.orderid, CO.custid, OD.productid, OD.qty
FROM dbof n_GetCustOrders (1) AS CO
JOIN Sales.OrderDetails AS OD
ON CO.orderid = OD.orderid;
Этот программный код вернет такой результат:
orderid
custid
productid qty
10643
1
28
15
10643
1
39
21
10643
1
46
2
10692
1
'63
20
10702
1
3
6
10702
1
76
15
10835
1
59
15
10835
1
77
2
10952
1
6
16
10952
1
28
2
11011
1
58
40
11011
1
71
20
Когда закончите работу, выполните следующий программный код для очистки базы данных:
IF OBJECT_ID(1dbo.fn_GetCustOrders *) IS NOT NULL
DROP FUNCTION dbo.fn GetCustOrders;
Табличные выражения
189
Операция APPLY
Операция APPLY — это нестандартная табличная операция, которая была введена в версии
SQL Server 2005. Эта операция, как и другие табличные операции, применяется в элементе
запроса FROM. Поддерживаются два типа операции APPLY: CROSS APPLY и OUTER APPLY.
Операция CROSS APPLY реализует только одну стадию логической обработки запроса, а
операция OUTER APPLY — две.
Операция APPLY применяется к двум входным таблицам, вторая из которых может быть
табличным выражением; я буду называть их левой и правой таблицами. Обычно правая таб-
лица— это производная таблица или подставляемая ТФ. Операция CROSS APPLY выполня-
ет одну стадию логической обработки запроса— она "прикладывает" правое табличное вы-
ражение к каждой строке из левой таблицы и формирует результирующую таблицу из
объединенных результирующих наборов.
Судя по сказанному, может показаться, что операция CROSS APPLY очень похожа на пере-
крестное соединение, и это правда. Например, следующие два запроса вернут одинаковые
результирующие наборы:
SELECT S.shipperid, Е.empid
FROM Sales.Shippers AS S
CROSS JOIN HR.Employees AS E;
SELECT S.shipperid, E.empid
FROM Sales.Shippers AS S
CROSS APPLY HR.Employees AS E;
Однако в операции CROSS APPLY в отличие от операции соединения правое табличное вы-
ражение может предоставлять разные наборы строк для каждой строки левой таблицы. Это-
го можно добиться, если применить справа производную таблицу и в запросе, определяю-
щем производную таблицу, сослаться на атрибуты из левой таблицы. Или при
использовании подставляемой ТФ можно передать атрибуты левой таблицы как входные
аргументы.
Например, следующий программный код применяет операцию CROSS APPLY ДЛЯ возврата
трех самых последних заказов каждого клиента:
SELECT С.custid, A.orderid, A.orderdate
FROM Sales.Customers AS С
CROSS APPLY
(SELECT TOP(3) orderid, empid, orderdate, requireddate
FROM Sales.Orders AS О
WHERE O.custid = C.custid
ORDER BY orderdate DESC, orderid DESC) AS A;
Табличное выражение А можно рассматривать как связанный табличный подзапрос. С точки
зрения логической обработки запроса правое табличное выражение (в нашем случае произ-
водная таблица) сопоставляется с каждой строкой из таблицы Customers (клиенты). От-
метьте ссылку на атрибут с. custid (id клиента) из левой таблицы в фильтре запроса, опре-
деляющего производную таблицу. Производная таблица возвращает три самые последние
190
Глава 2
заказа для клиента из текущей строки левой таблицы. Поскольку производная таблица при-
меняется к каждой строке левой таблицы, операция CROSS APPLY вернет три самых послед-
них заказа для каждого клиента.
Далее приведен результат этого запроса в сокращенном виде:
custid
orderid
orderdate
1
11011
2008-04-09 00:00:00.000
1
10952
2008-03-16 00:00:00.000
1
10835
2008-01-15 00:00:00.000
2
10926
2008-03-04 00:00:00.000
2
10759
2007-11-28 00:00:00.000
2
10625
2007-08-08 00:00:00.000
3
10856
2008-01-28 00:00:00.000
3
10682
2007-09-25 00:00:00.000
3
10677
2007-09-22 00:00:00.000
(263 row(s) affected)
«
Если правое табличное выражение возвращает пустой набор, операция CROSS APPLY не
возвращает соответствующую строку из левой таблицы. Например, клиенты 22 и 57 не по-
мещали заказы. В обоих случаях производная таблица — пустой набор, следовательно, эти
клиенты не включаются в результат. Если вы хотите отбирать строки левой таблицы, для
которых правое табличное выражение возвращает пустой набор, вместо операции CROSS
APPLY примените операцию OUTER APPLY. Операция OUTER APPLY добавляет вторую логи-
ческую стадию, которая идентифицирует строки из левой таблицы, для которых правое таб-
личное выражение возвращает пустой набор, и включает эти строки в результирующую таб-
лицу как внешние строки со значениями NULL В качестве заполнителей в атрибутах правой
таблицы. По смыслу эта стадия аналогична стадии, вставляющей внешние строки, в опера-
ции левого внешнего соединения.
Например, выполните следующий программный код для выбора трех последних заказов
каждого клиента и также включите в результат клиентов, не сделавших ни одного заказа:
SELECT С.custid, A.orderid, A.orderdate
FROM Sales.Customers AS С
OUTER APPLY
4
(SELECT TOP(3) orderid, empid, orderdate, requireddate
FROM Sales.Orders AS О
WHERE O.custid = C.custid
ORDER BY orderdate DESC, orderid DESC) AS A;
На этот раз в результат, показанный далее в сокращенном виде, включены клиенты 22 и 57,
не сделавшие ни одного заказа:
custid
orderid
orderdate
1
11011
2008-04-09 00:00:00.000
Табличные выражения
191
1
1
2
2
2
3
3
3
10952
10835
10926
10759
10625
10856
10682
10677
2008-03-16 00:00:00.000
2008-01-15 00:00:00.000
2008-03-04 00:00:00.000
2007-11 -28 00:00:00.000
2007-08 -08 00:00:00.000
2008-01-28 00:00:00.000
2007-09-25 00:00:00.000
2007-09-22 00:00:00.000
22
NULL
NULL
57
NULL
NULL
(265 row(s) affected)
Возможно, вы сочтете, что для инкапсуляции удобнее работать с подставляемыми ТФ вме-
сто производных таблиц. В этом случае за вашим программным кодом будет проще следить
и легче его сопровождать. Например, следующий программный код создает подставляемую
ТФ fn TopOrders, которая принимает входные параметры ID клиента (Gcustid) и число
(@п) и возвращает @п самых последних заказов клиента Gcustid:
IF OBJECT_ID('dbo.fn_TopOrders
1
) IS NOT NULL
DROP FUNCTION dbo.fn_TopOrders;
GO
CREATE FUNCTION dbo.fn_TopOrders
(@custid AS INT,
AS INT)
RETURNS TABLE
AS
RETURN
SELECT TOP(@n) orderid, empid, orderdate, requireddate
FROM Sales.Orders
WHERE custid = Gcustid
ORDER BY orderdate DESC, orderid DESC;
GO
Теперь вы можете заменить применение производной таблицы из предыдущих примеров
новой функцией:
SELECT С.custid, С.companyname,
A.orderid, A.empid, A.orderdate, A.requireddate
FROM Sales.Customers AS С
CROSS APPLY dbo. fn_TopOrders (C.custid, 3) AS A;
Этот программный код легче читается и проще обслуживается. С точки зрения физической
обработки реально ничего не изменилось, потому что, как я утверждал ранее, определение
табличных выражений раскрывается, и в итоге SQL Server в любом случае запрашивает не-
посредственно лежащие в основе объекты базы данных.
192
Глава 2
Резюме
Табличные выражения помогают упростить ваш программный код, улучшить его техниче-
ское сопровождение и инкапсулировать логику запросов. Если вам нужно применить таб-
личные выражения и вы не планируете повторное использование их определений, приме-
няйте производные таблицы или ОТВ. У ОТВ по сравнению с производными таблицами
есть пара преимуществ; вам не нужно организовывать вложение ОТВ, как в случае произ-
водных таблиц, что делает применение ОТВ более модульным и облегчает техническое со-
провождение программ. Кроме того, вы можете ссылаться на множественные экземпляры
ОТВ, чего нельзя сделать при работе с производными таблицами.
Если требуются пригодные для повторного использования табличные выражения, приме-
няйте представления и подставляемые ТФ. Если вам не нужны входные параметры, исполь-
зуйте представления, в противном случае — подставляемые ТФ.
Применяйте операцию APPLY, если хотите объединить табличное выражение с каждой стро-
кой исходной таблицы и включить все результирующие наборы в одну результирующую
таблицу.
В этом разделе приводятся упражнения, которые помогут вам лучше освоить темы, обсуж-
давшиеся в данной главе. Все упражнения данной главы требуют подключения в вашем се-
ансе к базе данных TSQLFundamentals2008.
Напишите запрос, возвращающий последнюю дату заказа для каждого клиента.
Используемые таблицы: база данных TSQLFundamentals2008, таблица Sales. orders.
Предполагаемый результат:
Упражнения
Упражнение 5.1
empid
maxorderdate
3
6
9
7
8
1
4
2
5
2008-04-30 00:00:00.000
2008-04-23 00:00:00.000
2008-04-29 00:00:00.000
2008-05-06 00:00:00.000
2008-05-06 00:00:00.000
2008-05-06 00:00:00.000
2008-05-05 00:00:00.000
2008-04-22 00:00:00.000
2008-05-06 00:00:00.000
(9 row(s) affected)
Табличные выражения
193
Упражнение 5.2
Заключите запрос из упражнения 5.1 в производную таблицу. Напишите запрос с соедине-
нием производной таблицы и таблицы Orders (Заказы) для получения заказов с датой зака-
за, максимальной для каждого сотрудника.
Используемые таблицы: таблица Sales .Orders.
Предполагаемый результат:
empid
orderdate
orderid
custid
9
2008-04-29 00:00:00.000 11058
6
8
2008-05-06 00:00:00.000 11075
68
7
2008-05-06 00:00:00.000 11074
73
6
2008-04-23 00:00:00.000 11045
10
5
2008-04-22 00:00:00.000 11043
74
4
2008-05-06 00:00:00.000 11076
9
3
2008-04-30 00:00:00.000 11063
37
2
2008-05-05 00:00:00.000 11073
58
2
2008-05-05 00:00:00.000 11070
44
1
2008-05-06 00:00:00.000 11077
65
(10 row(s) affected)
Упражнение 5.3
Напишите запрос, вычисляющий для каждого заказа номер строки на основании упорядочи-
вания атрибутов orderdate (дата заказа), orderid (id заказа).
Используемые таблицы: Sales . Orders.
Предполагаемый результат (в сокращенном виде):
orderid
orderdate
custid
empid
rownum
10248
2006-07-04 00:00:00.000 85
5
1
10249 / 2006-07-05 00:00:00.000 79
6
2
10250
2006-07-08 00:00:00.000 34
4
3
10251
2006-07-08 00:00:00.000 84
3
4
10252
2006-07-09 00:00:00.000 76
4
5
10253
2006-07-10 00:00:00.000 34
3
6
10254
2006-07-11 00:00:00.000 14
5
7
10255 .
2006-07-12 00:00:00.000 68
9
8
10256
2006-07-15 00:00:00.000 88
3
9
10257
2006-07-16 00:00:00.000 35
4
10
(830 row(s) affected)
Табличные выражения
195
При выполнении следующего программного кода
SELECT * FROM Sales.VEmpOrders ORDER BY empid, orderyear;
предполагается следующий результат:
empid
orderyear
qty
1
2006
1620
1
2007
3877
1
2008
2315
2
2006
1085
2
2007
2604
2
2008
2366
3
2006
940
3
2007
4436
3
2008
2476
4
2006
2212
4
2007
5273
4
2008
2313
5
2006
778
5
2007
1471
5
2008
787
6
2006
963
6
2007
1738
6
2008
826
7
2006
485
7
2007
2292
7
2008
1877
8
2006
923
8
2007
2843
8
2008
2147
9
2006
575
9
2007
955
9
2008
1140
(27 row(s) affected)
Упражнение 5.7
(дополнительное, повышенной сложности)
Напишите запрос к представлению Sales.VEmpOrders, которое возвращает общий объем
заказов с накоплением для каждого сотрудника и для каждого года.
Используемые таблицы: представление Sales.VEmpOrders.
196
Глава 2
Предполагаемый результат:
empid
orderyear
qty
runqty
1
2006
1620
1620
1
2007
3877
5497
1
2008
2315
7812
2
2006
1085
1085
2
2007
2604
3689
2
2008
2366
6055
3
2006
940
940
3
2007
4436
5376
3
2008
2476
7852
4
2006
2212
2212
4
2007
5273
7485
4
2008
2313
9798
5
2006
778
778
5
2007
1471
2249
5
2008
787
3036
6
2006
963
963
6
2007
1738
2701
6
2008
826
3527
7
2006
485
485
7
2007
2292
2777
7
2008
1877
4654
8
2006
923
923
8
2007
2843
3766
8
2008
2147
5913
9
2006
575
575
9
2007
955
1530
9
2008
1140
2670
(27 row(s) affected)
Упражнение 5.8
Создайте подставляемую функцию, которая принимает в качестве входных параметров ID
поставщика (Qsupid AS INT) и требуемое количество товаров (Gn AS INT). Функция
должна возвращать @п товаров с максимальной ценой единицы товара, предоставленных
поставщиком с заданным ID.
Используемые таблицы: Production. Products.
При выполнении следующего запроса
SELECT * FROM Production.fn_TopProducts(5, 2);
Табличные выражения
197
предполагаемый результат будет таким:
productid productname
unitprice
12
Product OSFNS
38.00
11
Product QMVUN
21.00
(2 row(s) affected)
Упражнение 5.9
Используя операцию CROSS APPLY и функцию, созданную в упражнении 5.8, найдите для
каждого поставщика два самых дорогих товара.
Предполагаемый результат:
supplierid companyname
productid productname
unitprice
8
Supplier BWGYE
20
Product QHFFP 81..00
8
Supplier BWGYE
68
Product TBTBL 12..50
20
Supplier CIYNM
43
Product ZZZHR 46..00
20
Supplier CIYNM
44
Product VJIEO 19..45
23
Supplier ELCRN
49
Product FPYPN 20..00
23
Supplier ELCRN
76
Product JYGFE 18..00
5
Supplier EQPNC
12
Product OSFNS 38..00
5
Supplier EQPNC
11
Product QMVUN 21..00
(55 row(s) affected)
ГЛАВА 6
Операции над множествами
Операции над множествами — это операции, применяемые к двум входным множествам,
или, точнее, к двум мультимножествам, результатам двух входных запросов. Напоминаю,
что мультимножество — это ненастоящее множество, поскольку может содержать дублика-
ты. Когда я применяю в этой главе термин "мультимножество", то имею в виду промежу-
точные результирующие наборы двух входных запросов, иногда содержащие дубликаты.
Несмотря на то, что у операции над множествами языка SQL есть два входных мультимно-
жества, ее конечный результат— все же один результирующий набор, который тоже может
быть мультимножеством.
Язык T-SQL поддерживает три операции над множествами: UNION, INTERSECT И EXCEPT.
Операции INTERSECT И EXCEPT были введены в версии Microsoft SQL Server 2005. В этой
главе я сначала приведу общий вид этих операций и требования к ним, а затем подробно
расскажу о каждой операции.
У операции над множествами следующий синтаксис:
Входной запрос1
<операция_над__множествами>
Входной запрос2
[ORDERBY...]
Операция над множествами сравнивает полные строки из двух результирующих наборов
рассматриваемых входных запросов. Будет ли строка возвращена в результирующем наборе
операции над множествами, зависит от результата сравнения и используемой операции. По-
скольку по определению операция над множествами — это операция над двумя множества-
ми (или мультимножествами) и у множества нет гарантированного порядка следования эле-
ментов, два рассматриваемых запроса не могут содержать элементы ORDER BY. Напоминаю,
что запрос с элементом ORDER BY обеспечивает определенный порядок представления и,
таким образом, возвращает не множество, а курсор. Однако, несмотря на то, что участвую-
щие в операции запросы не могут содержать элементы ORDER BY, ВЫ можете при желании
вставить элемент ORDER BY, который применяется к конечному результату операции над
множествами.
С точки зрения логической обработки запроса у каждого отдельного запроса могут быть
все стадии логической обработки за исключением, как я только что объяснил, стадии
ORDER BY ДЛЯ представления данных. Операция над множествами применяется к резуль-
Операции над множествами
199
татам двух запросов и внешний элемент ORDER BY (если он есть) применяется к результа-
ту операции над множествами.
Два запроса, участвующие в операции над множествами, должны формировать результи-
рующие наборы с одинаковым количеством столбцов и у аналогичных столбцов должны
быть совместимые типы данных. Под совместимостью типов данных я понимаю возмож-
ность неявного преобразования типа данных с более низким приоритетом в тип данных с
более высоким приоритетом.
Имена столбцов в результате операции над множествами определяются первым запросом,
поэтому, если результирующим столбцам нужно присвоить псевдонимы, делайте это в пер-
вом входном запросе.
Интересная особенность операций над множествами состоит в том, что при сравнении
строк операция над множествами считает два значения NULL равными. Чуть позже в этой
главе я продемонстрирую важность этой особенности.
Стандарт ANSI SQL поддерживает две "разновидности" каждой операции над множества-
ми — DISTINCT (по умолчанию) и ALL. Элемент DISTINCT логически удаляет дубликаты из
двух входных мультимножеств, превращая их в множества, и операция возвращает резуль-
тат в виде множества. Элемент ALL обрабатывает два мультимножества без удаления дубли-
катов, и операция возвращает также мультимножество, в котором могут быть дубликаты.
SQL Server 2008 поддерживает DISTINCT ДЛЯ всех трех операций над множествами, а
ALL— только с операцией UNION. Синтаксически вы не можете явно задать элемент
DISTINCT. Вместо этого он предполагается, когда явно не задан элемент ALL. Я покажу аль-
тернативы пропущенным операциям INTERSECT ALL И EXCEPT ALL В разд. "Операг{ия
INTERSECT " и "Операция EXCEPT" далее в этой главе.
Операция UNION
В теории множеств объединение двух множеств (назовем их А и В) — это множество, со-
держащее все элементы из обоих множеств А и В. Другими словами, если элемент принад-
лежит любому из входных множеств, он принадлежит и результирующему множеству. На
рис. 6.1 показана диаграмма множеств (также называемая диаграммой Венна) с изображе-
нием объединения множеств. Вся закрашенная область представляет результат операции
над множествами.
Рис. 6.1 . Объединение двух множеств
200
Глава 2
В языке T-SQL операция над множествами UNION объединяет результирующие наборы двух
входных запросов. Если строка присутствует в любом из входных наборов, она появится и в
результате операции UNION. T -SQL поддерживает обе разновидности операции UNION:
UNION ALL и UNION (неявный элемент DISTINCT).
Операция UNION ALL
Операция над множествами UNION ALL возвращает все строки, которые встречаются в лю-
бом из результирующих мультимножеств, полученных во входных запросах операции, без
реального сравнения строк и исключения дубликатов. Предположим, что Запрос 1 возвраща-
ет т строк, а Запрос2 — п строк, тогда Запрос 1 UNION ALL Запрос2 вернет т + n строк.
Например, в следующем программном коде выполняется операция UNION ALL над муль-
тимножеством запроса, выбирающего атрибуты местонахождения (country (страна),
region (регион), city (город)) из таблицы HR.Employees (Сотрудники) в базе данных
TSQLFundamentals2008, и над мультимножеством запроса, выбирающего атрибуты место-
нахождения из таблицы Sales.Customers (Клиенты).
USE TSQLFundamentals2008;
SELECT country, region, city FROM HR.Employees
UNION ALL
SELECT country, region, city FROM Sales.Customers;
Результат содержит 100 строк, девять из таблицы Employees и 91 из таблицы Customers, и
приведен далее в сокращенном виде:
country
region
city
USA
WA
Seattle
USA
WA
Tacoma
USA
WA
Kirkland
USA
WA
Redmond
UK
NULL
London
Finland
NULL
Oulu
Brazil
SP
Resende
USA
WA
Seattle
Finland
NULL
Helsinki
Poland
NULL
Warszawa
(100 row(s) affected)
Поскольку операция UNION ALL не удаляет дубликаты, результат представляет собой муль-
тимножество, а не множество. Одна и та же строка может появиться в результате несколько
раз, как, например (ик, NULL, London) в результате операции над множествами нашего за-
проса.
Операции над множествами
201
Операция UNION DISTINCT
Операция над множествами UNION (С неявным элементом DISTINCT) на логическом уровне
действует как преобразователь входных мультимножеств в настоящие множества за счет
удаления дубликатов и возвращает множество со всеми строками, встречающимися в любом
из входных множеств. Учтите, что если строка появляется в обоих входных множествах, в
результате она появится только один раз; другими словами, результат— также настоящее
множество, а не мультимножество.
С точки зрения физической обработки SQL Server необязательно первым делом удаляет
дубликаты из входных мультимножеств, а затем применяет к ним операцию, вместо этого
он может сначала объединить два мультимножества, а затем убрать дубликаты.
Например, следующий программный код возвращает отличающиеся друг от друга местона-
хождения как сотрудников, так и клиентов:
SELECT country, region, city FROM HR.Employees
UNION
SELECT country, region, city FROM Sales.Customers;
Разница между данным примером и предыдущим с операцией UNION ALL СОСТОИТ В ТОМ, что
в этом примере операция над множествами удаляет дубликаты, а в предыдущем примере
она этого не делает. Следовательно, в результирующем наборе данного примера, приведен-
ного далее в сокращенном виде, содержатся только отличающиеся друг от друга строки:
country
region
city
Argentina
Austria
Austria
Belgium
Belgium
NULL
NULL
NULL
NULL
NULL
Buenos Aires
Graz
Salzburg
Bruxelles
Charleroi
USA
Venezuela
Venezuela
Venezuela
Venezuela
WY
DF
Lara
Nueva Esparta
Tachira
Lander
Caracas
Barquisimeto
I. de Margarita
San Cristobal
(71 row(s) affected)
Итак, когда же следует применять операцию UNION ALL, а когда — UNION? ЕСЛИ дубликаты
возможны после объединения двух множеств операцией объединения, и вам необходимо
вернуть дубликаты, применяйте UNION ALL. ЕСЛИ вероятность наличия дубликатов сущест-
вует, а вы должны вернуть только отличающиеся друг от друга строки, используйте UNION.
Если дубликатов быть не может после объединения двух множеств, операции UNION И
UNION ALL логически равнозначны. Но я в этом случае рекомендую применять UNION ALL,
потому что элемент ALL устраняет дополнительные затраты SQL Server, связанные с про-
веркой на наличие дубликатов.
202
Глава 2
Операция INTERSECT
В теории множеств пересечение двух множеств (назовем их А и В) — это множество всех
элементов, принадлежащих множеству А и множеству В (обратное тоже справедливо). На
рис. 6.2 дано графическое представление пересечения двух множеств.
В языке T-SQL операция над множествами INTERSECT получает пересечение результирую-
щих наборов двух входных запросов и возвращает только те строки, которые встречаются в
обоих входных наборах. После описания операции INTERSECT (с неявно заданным элемен-
том DISTINCT) Я приведу альтернативное решение для выполнения операции INTERSECT
ALL, которая так и не была реализована в версии SQL Server 2008.
Операция INTERSECT DISTINCT
Операция над множествами INTERSECT логически сначала удаляет дублирующиеся строки
из обоих входных мультимножеств, превращая последние в множества, а затем возвращает
только те строки, которые встречаются в обоих множествах. Другими словами, строка воз-
вращается при условии, что она встречается хотя бы один раз в обоих входных мультимно-
жествах.
Например, следующий программный код вернет отличные друг от друга местонахождения,
которые определяют местонахождения как сотрудников, так и клиентов:
SELECT country, region, city FROM HR.Employees
INTERSECT
SELECT country, region, city FROM Sales.Customers;
Этот программный код вернет следующий результат:
country
region
city
UK
NULL
London
USA
WA
Kirkland
USA
WA
Seattle
Операции над множествами
203
Неважно, сколько раз местонахождение клиента или сотрудника встретится во входном на-
боре, если оно появляется, как минимум, один раз в таблице Employees (Сотрудники) и
также, как минимум, один раз в таблице Customers (Клиенты), это местонахождение вой-
дет в результирующий набор. Результат данного запроса показывает, что есть три конкрет-
ных местонахождения, общих для сотрудников и клиентов.
Ранее я уже упоминал о том, что при сравнении строк операция над множествами рассмат-
ривает два значения NULL как равные. Есть как сотрудники, так и клиенты с местонахожде-
нием (ик, NULL, London), но появление этой строки в результате вовсе не тривиально. Ис-
ключив атрибуты country и city, при сравнении атрибута region со значением NULL из
строки сотрудника, с атрибутом region со значением NULL из строки клиента операция над
множествами считает их равными и поэтому возвращает строку. Если такое поведение при
сравнении значений NULL желательно, как в нашем случае, у операций над множествами
есть огромное преимущество по сравнению с альтернативными вариантами. Например, одна
из альтернатив применения операции INTERSECT— использование операции внутреннего
соединения, другая— применение предиката EXISTS. В обоих случаях, когда значение
NULL в атрибуте region из строки сотрудника сравнивается со значением NULL В атрибуте
region из строки клиента, сравнение дает в результате значение UNKNOWN И такая строка
отбрасывается. Это означает, что пока вы не добавите дополнительную логическую обра-
ботку нестандартным образом значений NULL, НИ внутреннее соединение, ни предикат
EXISTS не вернут строку (ик, NULL, London), даже если она встречается в обоих входных
наборах.
Операция INTERSECT ALL
Я предлагаю этот раздел как дополнительное чтение, если вы хорошо усвоили материал, изло-
женный ранее в этой главе. Стандарт ANSI SQL поддерживает ключевое слово ALL В операции
над множествами INTERSECT, но эта разновидность до сих пор не реализована даже в версии
SQL Server 2008. После того как я опишу назначение операции INTERSECT ALL, предусмот-
ренной в стандарте ANSI SQL, я предложу ее альтернативную реализацию на языке T-SQL.
Вспомним назначение ключевого слова ALL в операции над множествами UNION ALL: оно
возвращает все строки-дубликаты. Аналогичным образом ключевое слово ALL в операции
INTERSECT ALL означает, что дублирующиеся пересечения не будут удаляться. Операция
INTERSECT ALL отличается от UNION ALL тем, что она возвращает не все дубликаты, а только
определенное количество дублирующихся строк, равное меньшему числу повторов строк в
каждом из входных мультимножеств. Если иначе взглянуть на операцию INTERSECT ALL, она
не только следит за присутствием строки в обоих входных мультимножествах, но и учитывает
количество экземпляров строки в каждом из них. Если в первом мультимножестве х экземпля-
ров строки R, а во втором — у экземпляров, строка R появится в результате операции
minimum (х, у) раз. Например, местонахождение (ик, NULL, London) встречается четыре раза
в таблице Employees (Сотрудники) и шесть раз в таблице Customers (Клиенты), следователь-
но, операция INTERSECT ALL местонахождений сотрудников и клиентов должна будет вер-
нуть четыре экземпляра (UK, NULL, London), потому что на логическом уровне могут пересечь-
ся четыре экземпляра.
Несмотря на то, что SQL Server не поддерживает встроенную операцию INTERSECT ALL, ВЫ
можете создать решение, формирующее тот же результат. Можно применить функцию
ROW_NUMBER ДЛЯ нумерации экземпляров каждой строки в каждом входном запросе. Для
204
Глава 2
этого укажите все участвующие атрибуты в элементе функции PARTITION BY И (SELECT
<константа>) в элементе функции ORDER BY, для того чтобы показать, что порядок не
имеет значения.
ПРИМЕЧАНИЕ
Применение конструкции ORDER BY (SELECT <константа>) в элементе OVER ран-
жирующей функции — один из нескольких способов сообщить SQL Server о том, что
порядок следования не важен. SQL Server достаточно сообразителен, чтобы по-
нять, что одна и та же константа будет присвоена всем строкам, и, следовательно,
нет нужды реально сортировать данные и тратить на это свои ресурсы.
Затем примените операцию над множествами INTERSECT К двум запросам с функцией
ROW_NUMBER. Поскольку экземпляры каждой строки пронумерованы, пересечение основы-
вается на номерах строк в дополнение к исходным атрибутам. Например, в таблице
Employees, содержащей четыре экземпляра местонахождения (ик, NULL, London), эти эк-
земпляры получат номера с 1-го по 4-й. В таблице Customers, содержащей шесть экземп-
ляров местонахождения (ик, NULL, London), эти экземпляры будут пронумерованы с 1-го по
6-й. Экземпляры с 1-го по 4-й попадут в пересечение двух входных мультимножеств.
Далее приведено решение полностью:
SELECT
ROW_NUMBER()
OVER(PARTITION BY country, region, city
ORDER BY (SELECT 0)) AS rownum,
country, region, city
FROM HR.Employees
INTERSECT
SELECT
ROW_NUMBER()
OVER(PARTITION BY country, region, city
ORDER BY (SELECT 0)),
country, region, city
FROM Sales.Customers;
Этот программный код сформирует следующий результат:
rownum
country
region
city
1
UK
NULL
London
1
USA
WA
Kirkland
1
USA
WA
Seattle
2
UK
NULL
London
3
UK
NULL
London
4
UK
NULL
London
Операции над множествами
205
Конечно, операция INTERSECT ALL не предусматривает возврат каких бы то ни было номеров
строк, они применяются для реализации предложенного решения. Если вы не хотите включать
их в результирующий набор, можно определить табличное выражение (например, ОТВ), осно-
ванное на этом запросе, и выбрать из табличного выражения только исходные атрибуты. Далее
приведен пример того, как можно использовать операцию INTERSECT ALL для возврата эк-
земпляров пересекающихся местонахождений сотрудников и клиентов:
WITH INTERSECT_ALL
AS
(
SELECT
ROW_NUMBER()
OVER(PARTITION BY country, region, city
ORDER BY (SELECT 0)) AS rownum,
country, region, city
FROM HR.Employees
INTERSECT
SELECT
ROW_NUMBER()
OVER(PARTITION BY country, region, city
ORDER BY (SELECT 0)),
country, region, city
FROM Sales.Customers
)
SELECT country, region, city
FROM INTERSECT_ALL;
Далее показан результат этого запроса, который эквивалентен тому, что вернула бы стан-
дартная операция INTERSECT ALL:
country
region
city
ик
NULL
London
USA
WA
Kirkland
USA
WA
Seattle
UK
NULL
London
UK
NULL
London
UK
NULL
London
Операция EXCEPT
В теории множеств разность множеств А и В (А - В) — это множество элементов, принад-
лежащих А и не принадлежащих В. Разность множеств можно рассматривать как множество
206
Глава 2
А без элементов множества Я,'которые также входили и в множество А. На рис. 6.3 показано
графическое представление разности А-В.
Рис. 6.3. Разность множеств
В языке T-SQL разность множеств реализуется с помощью операции EXCEPT. Операция
EXCEPT действует на результирующие наборы двух входных запросов и возвращает строки,
которые встречаются в первом наборе, но не встречаются во втором. После описания опе-
рации EXCEPT (с неявно заданным элементом DISTINCT) Я расскажу об операции EXCEPT
ALL, которая не реализована даже в SQL Server 2008, и о том, как создать альтернативу этой
операции.
Операция EXCEPT DISTINCT
Операция над множествами EXCEPT на логическом уровне в первую очередь исключает
строки-дубликаты из обоих входных мультимножеств, превращая последние в множества, а
затем возвращает только те строки, которые встречаются в первом множестве, но не встре-
чаются во втором. Другими словами, строка возвращается при условии, что она встречается,
как минимум, один раз в первом входном мультимножестве и ноль раз во втором. Обратите
внимание на то, что в отличие от двух других операций EXCEPT асимметрична, т. е. в других
операциях над множествами не важно, какой из входных запросов первый, а какой второй, в
случае операции EXCEPT ЭТО имеет значение.
Например, следующий программный код возвращает разные местонахождения сотрудни-
ков, но не совпадающие с местонахождениями клиентов:
SELECT country, region, city FROM HR.Employees
EXCEPT
SELECT country, region, city FROM Sales.Customers;
Этот запрос вернет такие два местонахождения:
country
region
city
USA
WA
Redmond
USA
WA
Tacoma
Операции над множествами
207
Следующий запрос возвращает разные местонахождения клиентов, но не сотрудников:
SELECT country, region, city FROM Sales.Customers
EXCEPT
SELECT country, region, city FROM HR.Employees;
Этот запрос вернет 66 местонахождений, результат приведен в сокращенном виде:
country
region
city
Argentina
Austria
Austria
Belgium
Belgium
NULL
NULL
NULL
NULL
NULL
Buenos Aires
Graz
Salzburg
Bruxelles
Charleroi
USA
Venezuela
Venezuela
Venezuela
Venezuela
WY
DF
Lara
Nueva Esparta
Tachira
Lander
Caracas
Barquisimeto
I. de Margarita
San Cristobal
(66 row(s) affected)
Вы можете применять и альтернативы операции EXCEPT. Одна из них — операция внешнего
соединения, возвращающая только внешние строки, которые и являются строками, появ-
ляющимися в одном наборе и не встречающимися в другом. Другая альтернатива — исполь-
зование предиката NOT EXISTS. Однако если вы хотите рассматривать два значения NULL,
как одинаковые, операции над множествами демонстрируют такое поведение по умолча-
нию, не требуя специальной обработки, а альтернативные варианты — нет.
Операция EXCEPT ALL
Я предлагаю этот раздел как дополнительное чтение в том случае, если вы хорошо усвоили
уже изложенный в этой главе материал. Операция EXCEPT ALL очень похожа на операцию
EXCEPT, но она также учитывает количество экземпляров каждой строки. При условии, что
строка R встречается х раз в первом мультимножестве и у раз во втором, и х > у, R будет
включена д: - у раз в результат Queryl EXCEPT ALL Query2. Другими словами, на логиче-
ском уровне EXCEPT ALL возвращает только те экземпляры строки из первого мультимно-
жества, для которых нет соответствующих экземпляров во втором.
SQL Server не предоставляет встроенную операцию EXCEPT ALL, НО ВЫ можете использо-
вать альтернативное решение, очень похожее на решение, реализующее операцию
INTERSECT ALL. А именно, добавьте в каждый из входных запросов функцию ROW NUMBER
для нумерации экземпляров каждой строки и примените к результатам этих запросов опера-
цию EXCEPT. Будут возвращены только те экземпляры, которым не нашлось пары.
208
Глава 2
В следующем примере показано, как можно применить операцию EXCEPT ALL ДЛЯ получе-
ния экземпляров местонахождений сотрудников, для которых нет парных экземпляров сре-
ди местонахождений клиентов.
WITH EXCEPT_ALL
AS
(
SELECT
ROW_NUMBER()
OVER(PARTITION BY country, region, city
ORDER BY (SELECT 0)) AS rownum,
country, region, city
FROM HR.Employees
EXCEPT
SELECT
ROW_NUMBER()
OVER(PARTITION BY country, region, city
ORDER BY (SELECT 0)),
country, region, city
FROM Sales.Customers
)
SELECT country, region, city
FROM EXCEPT_ALL;
Этот запрос вернет следующий результат:
country
region
city
USA
WA
Redmond
USA
WA
Tacoma
USA
WA
Seattle
Приоритет
В языке SQL для операций над множествами определен приоритет. У операции INTERSECT
более высокий приоритет, чем у операций UNION и EXCEPT, а у двух последних приоритет
равный. В запросе, содержащем многочисленные операции над множествами, первыми вы-
полняются операции INTERSECT, а затем операции с одинаковым приоритетом в порядке их
следования.
Рассмотрим следующий запрос, показывающий, как операция INTERSECT опережает опера-
цию EXCEPT:
SELECT country, region, city FROM Production.Suppliers
Операции над множествами
209
EXCEPT
SELECT country, region, city FROM HR.Employees
INTERSECT
SELECT country, region, city FROM Sales.Customers;
Поскольку у операции INTERSECT более высокий приоритет, чем'у EXCEPT, она выполняет-
ся первой, хотя и приведена второй. Следовательно, у запроса следующий смысл: "местона-
хождения поставщиков, но не совпадающие местонахождения сотрудников и клиентов".
Этот запрос вернет следующий результат:
country
region
city
Australia
NSW
Sydney
Australia
Victoria
Melbourne
Brazil
NULL
Sao Paulo
Canada
Quebec
Montreal
Canada
Quebec
Ste-Hyacinthe
Denmark
NULL
Lyngby
Finland
NULL
Lappeenranta
France
NULL
Annecy
France
NULL
Montceau
France
NULL
Paris
Germany
NULL
Berlin
Germany
NULL
Cuxhaven
Germany
NULL
Frankfurt
Italy
NULL
Ravenna
Italy
NULL
Salerno
Japan
NULL
Osaka
Japan
NULL
Tokyo
Netherlands
NULL
Zaandam
Norway
NULL
Sandvika
Singapore
NULL
Singapore
Spain
Asturias
Oviedo
Sweden
NULL
Goteborg
Sweden
NULL
Stockholm
UK
NULL
Manchester
USA
LA
New Orleans
USA
MA
Boston
USA
MI
Ann Arbor
USA
OR
Bend
(28 row(s) affected)
210
Глава 2
Для управления порядком выполнения операций над множествами применяйте круглые
скобки, у которых наивысший приоритет. Например, если хотите вернуть "местонахожде-
ния поставщиков, не являющиеся местонахождениями сотрудников, но совпадающие с ме-
стонахождениями клиентов" выполните следующий программный код:
(SELECT country, region, city FROM Production.Suppliers
EXCEPT
SELECT country, region, city FROM HR.Employees)
INTERSECT
SELECT country, region, city FROM Sales.Customers;
Этот запрос вернет следующий результат:
country
region
city
Canada
Quebec
Montreal
France
NULL
Paris
Germany
NULL
Berlin
Хитрости для выполнения неподдерживаемых
логических стадий
Этот раздел рассчитан на читателей с серьезной подготовкой и предлагается как дополни-
тельное чтение. Отдельные запросы, участвующие в операциях над множествами, поддер-
живают все стадии логической обработки запроса (табличные операции, стадии WHERE,
GROUP BY, HAVING и т. д.) за исключением, стадии ORDER BY. С другой стороны, при обра-
ботке результата операции над множествами допустима только стадия ORDER BY. Как быть,
если вам нужно применить помимо ORDER BY другие стадии логической обработки к ре-
зультату операции над множествами? Они не поддерживаются в самом запросе с операцией
над множествами, но с помощью табличных выражений обойти это ограничение очень лег-
ко. Определите табличное выражение, базирующееся на запросе с операцией над множест-
вами, и применяйте любые нужные вам стадии логической обработки во внешнем запросе,
обращенном к табличному выражению. Например, следующий запрос возвращает количест-
во отличающихся друг от друга местонахождений сотрудника или клиента в каждой стране:
SELECT country, COUNT(*) AS numlocations
FROM (SELECT country, region, city FROM HR.Employees
UNION
SELECT country, region, city FROM Sales.Customers) AS U
GROUP BY country;
Данный запрос вернет такой результат:
country
• numlocations
Argentina
1
Austria
2
Операции над множествами
211
Belgium
2
Brazil
4
Canada
3
Denmark
2
Finland
2
France
9
Germany
11
Ireland
1
Italy
3
Mexico
1
Norway
1
Poland
1
Portugal
1
. Spain
3
Sweden
2
Switzerland
2
UK
2
USA
14
Venezuela
4
(21 row(s) affected)
В этом запросе показано, как применить стадию логической обработки запроса GROUP BY К
результату операции над множествами UNION, аналогичным образом можно применить во
внешнем запросе и любую другую стадию обработки.
Невозможность задать элемент ORDER BY в отдельных запросах, участвующих в операции
над множествами, также может вызвать логические проблемы. Что если вам нужно ограни-
чить количество строк в этих запросах с помощью элемента ТОР? И снова табличные выра-
жения помогут решить проблему. Вспомните, что элемент ORDER BY допустим в опреде-
ляющем табличное выражение запросе с элементом ТОР, И в этом случае ORDER BY служит
Для реализации логики элемента ТОР, а не для представления данных.
Итак, если для участия в операции над множествами вам нужен запрос с элементом ТОР И
вспомогательным элементом ORDER BY, просто определите табличное выражение, бази-
рующееся на запросе с элементом ТОР, И используйте внешний запрос к табличному выра-
жению как входной в операции над множествами. Например, следующий программный код
возвращает два самых последних заказа, принятых сотрудниками с ID, равным 3 или 5:
SELECT empid, orderid, orderdate
FROM (SELECT TOP (2) empid, orderid, orderdate
FROM Sales.Orders
WHERE empid = 3
ORDER BY orderdate DESC, orderid DESC) AS Dl
UNION ALL
212
Глава 2
SELECT empid, orderid, orderdate
FROM (SELECT TOP (2) empid, orderid, orderdate
FROM Sales.Orders
WHERE empid = 5
ORDER BY orderdate DESC, orderid DESC) AS D2;
Этот запрос вернет такой результат:
empid
orderid
orderdate
3
11063
2008-04-30 00:00:00.000
3
11057
2008-04-29 00:00:00.000
5
11043
2008-04-22 00:00:00.000
5
10954
2008-03-17 00:00:00.000
Резюме
Эта глава посвящена операциям над множествами, включая общую синтаксическую запись,
ограничения операций и подробное описание каждой поддерживаемой операции над мно-
жествами: UNION, INTERSECT и EXCEPT. Я пояснил, что стандарт ANSI SQL включает две
разновидности каждой операции, определяемые ключевыми словами DISTINCT И ALL, И ЧТО
даже в версии SQL Server 2008 реализована разновидность ALL ТОЛЬКО ДЛЯ операции UNION.
Для отсутствующих операций INTERSECT ALL И EXCEPT ALL Я предложил альтернативные
решения, использующие функцию ROW_NUMBER И табличные выражения. В заключение опи-
сан приоритет операций над множествами и способы выполнения неподдерживаемых ста-
дий логической обработки запроса с помощью табличных выражений.
Упражнения
В этом разделе представлены упражнения, которые помогут вам лучше усвоить темы, обсу-
ждавшиеся в данной главе. Все упражнения кроме первого требуют подключения к учебной
базъ данных TSQLFundamentals2008.
Упражнение 6.1
Напишите запрос, формирующий без применения циклов виртуальную вспомогательную
таблицу, содержащую Ю чисел в диапазоне от I до 10. Порядок следования строк в вашем
результате может быть любым.
Используемые таблицы: нет таблиц.
Предполагаемый результат:
п
Операции над множествами
213
1
2
3
4
5
6
7
8
9
10
(10 row(s) affected)
Упражнение 6.2
Напишите запрос, который возвращает пары, состоящие из клиента и сотрудника, оформ-
лявших заказы в январе 2008 г. (January 2008), но не в феврале 2008 г. (February 2008).
Используемые таблицы: база данных TSQLFundamentals2008, таблица Sales. Orders.
Предполагаемый результат:
custid
empid
5
7
3
9
12
16
1
5
6
1
3
8
9
9
6
1
2
7
17
20
24
1
1
8
25
26
1
3
32
38
39
40
41
42
2
9
3
2
2
4
8 Зак. 1032
214
Глава 2
44
8
47
3
47
4
47
8
49
7
55
2
55
3
56
6
59
8
63
8
64
9
65
3
65
8
66
5
67
5
70
3
71
2
75
1
76
2
76
5
80
1
81
1
81
3
81
4
82
6
84
1
84
3
84
4
88
7
89
4
(50 row(s) affected)
Упражнение 6.3
Напишите запрос, возвращающий пары, состоящие из клиента и сотрудника, оформлявших
заказы в январе 2008 г. (January 2008) и феврале 2008 г. (February 2008).
Используемые таблицы: таблица Sales. Orders.
Предполагаемый результат:
custid
empid
Операции над множествами
215
20
3
39
9
46
5
67
1
71
4
(5 row(s) affected)
Упражнение 6.4
Напишите запрос, возвращающий пары, состоящие из клиента и сотрудника, оформлявших
заказы в январе 2008 г. (January 2008) и феврале 2008 г. (February 2008), но не в 2007 г.
Используемые таблицы: таблица Sales. Orders.
Предполагаемый результат:
custid
empid
67
1
46
5
(2 row(s) affected)
Упражнение 6.5
(дополнительное, повышенной сложности)
Задан следующий запрос:
SELECT country, region, city
FROM HR.Employees
UNION ALL
SELECT country, region, city
FROM Product ion.Suppliers;
Вам нужно вставить в запрос логическую обработку, которая гарантирует, что строки из
таблицы Employees будут включены в результирующий набор перед строками из таблицы
Customers, и в каждом сегменте они будут отсортированы по атрибутам country (страна),
region (регион) и city (город).
Используемые таблицы: таблицы HR. Employees и Production. Suppliers.
Предполагаемый результат:
country
region
city
UK
NULL
London
216
Глава 2
UK
NULL
London
UK
NULL
London
UK
NULL
London
USA
WA
Kirkland
USA
WA
Redmond
USA
WA
Seattle
USA
WA
Seattle
USA
WA
Tacoma
Australia
NSW
Sydney
Australia
Victoria
Melbourne
Brazil
NULL
Sao Paulo
Canada
Quebec
Montreal
Canada
Quebec
Ste-Hyacinthe
Denmark
NULL
Lyngby
Finland
NULL
Lappeenranta
France
NULL
Annecy
France
NULL
Montceau
France
NULL
Paris
Germany
NULL
Berlin
Germany
NULL
Cuxhaven
Germany
NULL
Frankfurt
Italy
NULL
Ravenna
Italy
NULL
Salerno
Japan
NULL
Osaka
Japan
NULL
Tokyo
Netherlands
NULL
Zaandam
Norway
NULL
Sandvika
Singapore
NULL
Singapore
Spain
Asturias
Oviedo
Sweden
NULL
Goteborg
Sweden
NULL
Stockholm
UK
NULL
London
UK
NULL
Manchester
USA
LA
New Orleans
USA
MA
Boston
USA
MI
Ann Arbor
USA
OR
Bend
(38 row(s) affected)
ГЛАВА 7
Реорганизация данных
и наборы группирования
Эта глава посвящена методам реорганизации данных и обработки наборов группирования.
Разворачивание данных означает их поворот для превращения строк в столбцы. Сворачива-
ние — обратный поворот данных для превращения столбцов в строки. Группирующие набо-
ры — это наборы атрибутов, по которым выполняется группирование данных; в этой главе
будут описаны способы задания нескольких группирующих наборов в одном запросе.
Имейте в виду, что читатели, впервые знакомящиеся с языком T-SQL, могут считать все
темы, обсуждаемые в этой главе, предназначенными для изучения в будущем, повышенной
сложности; следовательно, эта глава содержит дополнительный материал. Если вы хорошо
освоили все темы, рассмотренные в книге до настоящего момента, попробуйте взяться за
эту главу, если нет — пропустите ее пока и вернитесь к ней позже, когда наберетесь опыта.
Разворачивание данных
Разворачивание данных включает в себя превращение строк в столбцы вместе с возможным
вычислением сводных данных. Не беспокойтесь, если этого описания недостаточно для
точного представления о том, что означает этот вид реорганизации данных. Лучше всего это
пояснить на примерах.
На протяжении всей главы я буду использовать учебную таблицу Orders (Заказы), которую
вы создадите в базе данных tempdb (для демонстрационных целей) и заполните ее тестовы-
ми данными, выполнив программный код из листинга 7.1.
I Листинг 7.1, Программный код для создания и заполнения таблицы Orders
USE tempdb;
IF OBJECT_ID('dbo.Orders *, 'U') IS NOT NULL DROP TABLE dbo.Orders;
CREATE TABLE dbo.Orders
(
218
Глава 2
orderid INT NOT NULL,
orderdate DATE NOT NULL,
empid INT NOT NULL,
custid VARCHAR(5) NOT NULL,
qty INT NOT NULL,
CONSTRAINT PK_Orders PRIMARY KEY(orderid)
);
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid, qty)
VALUES
(30001,
1
20070802',
3,
'A',
10),
(10001,
'200712241
,
2,
1
A', 12),
(10005,
'20071224',
1,
'B\ 20),
(40001,
'20.080109',
2,
'A',
40),
(10006,
•20080118',
1,
•c\ 14),
(20001,
'20080212',
2,
'B',
12),
(40005,
'20090212',
3,
'A',
10),
(20002,
'20090216', • 1, •c\ 20),
(30003,
'20090418',
2,
'B\ 15),
(30004,
'20070418',
3,
'C', 22),
(30007,
'20090907', -
3,
F
D',
30);
SELECT * FROM dbo.Orders;
ПРИМЕЧАНИЕ
Тип данных DATE и возможность применять один элемент VALUES ДЛЯ вставки
многих строк впервые появились в версии Microsoft SQL Server 2008. Если вы ра-
ботаете в более ранней версии программы, вместо типа данных DATE используй-
те тип DATETIME, а единственную инструкцию INSERT В листинге 7.1 замените от-
дельной инструкцией INSERT для каадой строки. Подробности о типах данных
для представления дат и времени суток см. в главе 2, а дополнительные сведе-
ния об элементе VALUES см. в главе 8.
Запрос, приведенный в конце программного кода в листинге 7.1, формирует следующий
результат, отображающий содержимое таблицы Orders (Заказы):
orderid
orderdate
empid
custid qty
10001
2007-12-24 00:00:00.000
2
A
12
10005
2007-12-24 00:00:00.000
1
В
20
10006
2008-01-18 00:00:00.000
1
С
14
20001
2008-02-12 00:00:00.000
2
В
12
20002
2009-02-16 00:00:00.000
1
С
20
30001
2007-08 -02 00:00:00.000
3
А
10
Реорганизация данных и наборы группирования
219
30003
2009-04-18 00:00:00.000
2
В
15
30004
2007-04-18 00:00:00.000 3
с
22
30007
2009-09 -07 00:00:00.000 3
D
30
40001
2008-01-09 00:00:00.000
2
А
40
40005
2009-02-12 00:00:00.000 3
А
10
Прежде чем я продолжу рассказ о том, что такое разворачивание данных, рассмотрим зада-
ние на создание отчета с общим объемом заказов для каждого сотрудника и клиента. Требо-
вание удовлетворяется следующим очень простым запросом:
SELECT empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY empid, custid;
Этот запрос сформирует такой результат:
empid
custid
sumqty
2
А
52
3
А
20
1
В
20
2
В
27
1
С
34
3
С
22
3
D
30
Допустим, что к вам поступило требование на формирование результата в виде, приведен-
ном в табл. 7.1.
Таблица 7.1. Сводное представление общего объема для каждого сотрудника
(в строках) и каждого клиента (в столбцах)
empid
А
в
С
D
1
NULL
20
34
NULL
2
52
27
NULL
NULL
3
20
NULL
22
30
То, что вы видите в табл. 7.1, — это агрегированное сводное представление данных из таб-
лицы Orders (Заказы), а метод формирования этого представления данных называется раз-
ворачиванием данных.
Каждый запрос на разворачивание включает в себя три стадии логической обработки, у ка-
ждой из которых есть связанные с ней элементы: стадия группирования со связанным груп-
пирующим или построчным элементом, стадия раскрытия со связанным разворачиваемым
или постолбцовым элементом и стадия получения итога со связанным итоговым элементом
и функцией суммирования или накопления.
220
Глава 2
В нашем примере вам необходимо сформировать в результирующем наборе единственную
строку для каждого отдельного ID сотрудника. Это означает, что строки из таблицы Orders
следует сгруппировать по атрибуту empid, и, следовательно, группирующий элемент в на-
шем случае — атрибут empid.
В таблице Orders есть один столбец, содержащий все значения ID клиентов и один столбец,
хранящий заказанные объемы. Процесс разворачивания рассчитан на формирование от-
дельных результирующих столбцов для каждого уникального ID клиента и в каждом из этих
столбцов содержится суммарный объем для данного клиента. Вы можете рассматривать
этот процесс как распределение объемов между ID клиентов. Разворачиваемый элемент в
нашем случае — атрибут custid.
И наконец, поскольку разворачивание включает в себя группирование, вам придется поды-
тожить данные для формирования результирующих значений на "пересечениях" группи-
рующих и разворачиваемых элементов. Для этого нужно задать агрегирующую функцию
(в нашем сдучае SUM) и итоговый элемент (атрибут qty в данном примере).
Резюмируя, разворачивание включает в себя группирование, раскрытие и получение итога.
В данном случае мы группируем по empid, раскрываем или распределяем (объемы) по
custid и получаем итог с помощью SUM (qty). После того как определены элементы, уча-
ствующие в разворачивании, остается только поставить эти элементы в нужные места в об-
щем шаблоне запроса на разворачивание данных.
Я представлю два решения для разворачивания: стандартное решение и решение, исполь-
зующее PIVOT, специальную операцию языка T-SQL.
Разворачивание с помощью стандартного SQL
Стандартное решение для разворачивания данных реализует все три стадии очень простым
способом.
Стадия группирования обеспечивается элементом GROUP BY, В нашем случае GROUP BY
empid.
Стадия раскрытия реализуется элементом SELECT С выражением CASE для каждого резуль-
тирующего столбца. Вы должны знать значения разворачиваемого элемента заранее и за-
дать отдельное выражение для каждого их них. Поскольку в нашем примере мы должны
"распределить" объемы заказов четырех клиентов (А, В, С И D), В нашем запросе будут четы-
ре выражения CASE. Например, далее приведено выражение CASE ДЛЯ клиента А:
CASE WHEN custid = 'A' THEN qty END
Это выражение вернет объем из текущей строки, только если текущая строка представляет
заказ клиента А; В противном случае выражение вернет NULL. Напоминаю, что, если ветвь
ELSE в выражении CASE не задана, по умолчанию вставляется ELSE NULL. Это означает, что
в результирующем столбце для клиента А как значения столбца появляются только объемы
заказов, связанных с клиентом А, ВО всех других случаях значения столбца равны NULL.
Если вы не знаете заранее значений, которые должны раскрыть (конкретные ID клиентов в
нашем случае), и хотите запросить их из данных, вам придется использовать динамический
SQL для построения строки запроса и ее выполнения. Динамическое разворачивание пока-
зано в главе 10.
Реорганизация данных и наборы группирования
221
В заключение выполняется стадия получения сводных данных с помощью применения агре-
гирующей функции (в нашем случае SUM) К результату каждого выражения CASE. Например,
далее приведено выражение, формирующее результирующий столбец для клиента А:
SUM (CASE WHEN custid = 'A
1
THEN qty END) AS A
Конечно, в зависимости от требования может понадобиться какая-либо другая агрегирую-
щая функция (MAX, MIN, COUNT И Т. Д.).
Далее приведено полное решение для разворачивания данных о заказах, возвращающее
полный объем заказов для каждого сотрудника (в строках) и клиента (в столбцах):
SELECT empid,
SUM (CASE WHEN custid = 'A' THEN qty END) AS A,
SUM(CASE WHEN custid = 'B
?
THEN qty END) AS B,
SUM (CASE WHEN custid = 'C' THEN qty END) AS C,
SUM (CASE WHEN custid = 'D
1
THEN qty END) AS D
FROM dbo.Orders
GROUP BY empid;
Этот запрос вернет результат, приведенный ранее в табл. 7.1.
Разворачивание с помощью
собственной операции T-SQL PIVOT
В версию SQL Server 2005 была добавлена собственная табличная операция языка T-SQL,
названная PIVOT. Операция PIVOT применяется в запросе, как и другие табличные операции
(например, JOIN), В элементе FROM. Она воздействует на некоторую исходную таблицу или
табличное выражение, вычисляет сводные данные и возвращает результирующую таблицу.
Операция PIVOT включает в себя стадии логической обработки, описанные ранее (группи-
рование, раскрытие и подведение итогов) с теми же самыми элементами разворачивания, но
применяет другую, собственную синтаксическую запись.
У запроса с операцией PIVOT следующий общий вид:
SELECT ...
FROM <исходная_таблица_или^табличнсю_шьфажение>
PIVOT (<агг_функция> (<итоговый__элемент>)
FOR <развора чива.емыи_элемент>
IN (<список_роз__столбцов>)) AS <псевдоним_рез__таблицы>
В скобках табличной операции PIVOT задается агрегирующая функция (SUM В нашем при-
мере), итоговый элемент (qty), разворачиваемый элемент (custid) и список имен резуль-
тирующих столбцов (А, В, С, D). Следом за круглыми скобками операции PIVOT указывается
псевдоним результирующей таблицы.
Важно отметить, что в табличной операции PIVOT не задаются явно группирующие элемен-
ты, исключая необходимость вставки в запрос элемента GROUP BY. Операция PIVOT опре-
деляет группирующие элементы косвенным образом, как все атрибуты из исходной таблицы
222
Глава 2
(или табличного выражения), не заданные ни как разворачиваемый элемент, ни как итого-
вый. Вы должны быть уверены в том, что исходная таблица для операции PIVOT не содер-
жит никаких атрибутов помимо группирующего, разворачиваемого и итогового элементов.
Таким образом, после задания разворачиваемого и итогового элементов должны остаться
только атрибуты, которые вы намереваетесь использовать как группирующие. Этого можно
добиться, если применять табличную операцию PIVOT не к исходной таблице (в нашем слу-
чае Orders) непосредственно, а к табличному выражению, которое включает только атри-
буты, предоставляемые как элементы разворачивания, и никакие другие. Например, далее
приведено решение для нашего исходного требования, использующее специальную опера-
цию PIVOT.
SELECT empid, А, В, С, D
FROM (SELECT empid, custid, qty
FROM dbo.Orders) AS D
PIVOT (SUM (qty) FOR custid IN (А, В, C, D)) AS P;
Вместо непосредственной обработки таблицы Orders операция PIVOT применяется к про-
изводной таблице D и включающей только элементы разворачивания: empid (id сотрудни-
ка), custid (id клиента) и qty (объем заказа) Помимо разворачиваемого элемента custid и
итогового элемента qty остается атрибут empid, который рассматривается как группирую-
щий элемент.
Этот запрос вернет результат, приведенный ранее в табл. 7.1.
Для того чтобы понять, почему в данном запросе требуется табличное выражение, рассмот-
рим следующий запрос, в котором операция PIVOT применяется непосредственно к таблице
Orders (Заказы).
SELECT empid, А, В, С, D
FROM dbo.Orders
PIVOT (SUM (qty) FOR custid IN (А, В, C, D) ) AS P;
Таблица Orders содержит атрибуты: orderid (id заказа), orderdate (дата заказа), empid
(id сотрудника), custid (id клиента) и qty (объем). Поскольку мы задали custid как разво-
рачиваемый элемент и qty как итоговый, остальные атрибуты (orderid, orderdate и
empid) считаются группирующими элементами. Следовательно, данный запрос вернет сле-
дующий результат:
empid
А
В
С
D
2
12
NULL
NULL
NULL
1
NULL
20
NULL
NULL
1
NULL
NULL
14
NULL
2
NULL
12
NULL
NULL
1
NULL
NULL
20
NULL
3
10
NULL
NULL
NULL
2
NULL
15
NULL
NULL
3
NULL
NULL
22
NULL
Реорганизация данных и наборы группирования
223
3
NULL
NULL
NULL
30
2
40
NULL
NULL
NULL
3
10
NULL
NULL
NULL
(11 row(s) affected)
Поскольку orderid — один из группирующих элементов, вы получите по строке на каждый
заказ, а не по строке на каждого сотрудника. Логический эквивалент этого запроса, исполь-
зуюший стандартное решение для разворачивания данных, включает перечень атрибутов
orderid, orderdate и empid в список элемента GROUP BY следующим образом:
SELECT empid,
SUM(CASE WHEN custid = 'A
1
THEN qty END) AS A,
SUM (CASE WHEN custid = 'B
f
THEN qty END) AS B,
SUM (CASE WHEN custid = •C' THEN qty END) AS c,
SUM (CASE WHEN custid = 'D' THEN qty END) AS D
FROM dbo.Orders
GROUP BY orderid, orderdate, empid;
Я настоятельно рекомендую никогда не обрабатывать непосредственно базовую таблицу,
даже если она содержит только столбцы, применяемые как элементы разворачивания дан-
ных. Вы никогда не знаете наверняка, будут ли в будущем добавлены новые столбцы в таб-
лицу, что сделает ваши запросы некорректными. Я советую считать применение табличного
выражения как входной таблицы для операции PIVOT частью синтаксических требований к
операции.
Рассмотрим еще один пример запроса на разворачивание данных. Предположим, что вместо
возврата сотрудников в строках и клиентов в столбцах вы хотите выполнить обратное дей-
ствие: группирующий элемент— custid (id клиента), разворачиваемый элемент— empid
(id сотрудника), а итоговый элемент и агрегирующая функция остаются SUM (qty). После
того как вы освоите "шаблон" для реализации разворачивания данных (стандартного или
специального), встает вопрос о размещении элементов в нужных местах. В следующем за-
просе применяется собственная операция T-SQL PIVOT:
SELECT custid, [1], [2], [3]
FROM (SELECT empid, custid, qty
FROM dbo.Orders) AS D
PIVOT(SUM(qty) FOR empid IN([1], [2], [3])) AS P;
ID сотрудников 1, 2 и 3 — это значения столбца empid (id сотрудника) в исходной таблице.
Но с точки зрения результата эти значения становятся именами результирующих столбцов.
Следовательно, в элементе IN операции PIVOT ВЫ ДОЛЖНЫ сослаться на них как на иденти-
фикаторы. Если идентификаторы нестандартные (например, начинаются с цифры), необхо-
димо ограничить их, допустим, с помощью квадратных скобок.
Данный запрос вернет следующий результат:
custid
12
3
A
NULL
52
20
224
Глава 2
в
с
D
20
34
NULL
NULL
27
NULL
NULL
22
30
Сворачивание данных
Сворачивание данных— это метод поворота данных, превращающий столбцы в строки.
Обычно он включает в себя запрос к развернутым сводным данным, формирующий из каж-
дой исходной строки множественные результирующие строки, содержащие разные значения
исходного столбца. Другими словами, каждая исходная строка сводной (развернутой) таб-
лицы может превратиться в множество строк, по одной для каждого заданного значения
исходного столбца. Возможно, это определение трудно понять сразу. Для облегчения этого
процесса рассмотрим пример.
Выполните следующий программный код для создания и заполнения таблицы Emp-
custOrders (для демонстрационных целей) в базе данных tempdb:
IF OBJECT_ID(1dbo.EmpCustOrders
1
, 'U') IS NOT NULL DROP TABLE
dbo.EmpCustOrders;
SELECT empid, А, В, C, D
INTO dbo.EmpCustOrders
FROM (SELECT empid, custid, qty
FROM dbo.Orders) AS D
PIVOT (SUM (qty) FOR custid IN (А, В, C, D) ) AS Р;
SELECT * FROM dbo.EmpCustOrders;
Далее приведен результат запроса к таблице EmpCustOrders, отображающий ее содержимое:
empid
А
В
С
D
1
NULL
20
34
NULL
2
52
27
NULL
NULL
3
20
NULL
22
30
В таблице есть строка для каждого сотрудника, столбец для каждого из четырех клиентов А,
в, с и D и объем заказов для каждого сотрудника и каждого клиента в пересечениях "со-
трудник—клиент". Обратите внимание на то, что несущественные пересечения (сочетание
"сотрудник—клиент", у которых нет совместного оформления заказов) представлены значе-
ниями NULL. Вы получили задание на сворачивание данных, возврат строки для каждого
сотрудника и клиента с объемом заказов. Предполагаемый результат должен выглядеть так:
empid
custid
qty
1
В
20
1
С
34
Реорганизация данных и наборы группирования
225
2
2
3
3
3
А
А
С
В
D
52
27
20
22
30
В следующих разделах я приведу два способа решения этой задачи: метод, соответствую-
щий стандарту SQL, и метод, использующий UNPIVOT, собственную операцию языка T-SQL.
Стандартное решение для сворачивания данных включает реализацию трех стадий логиче-
ской обработки: формирование копий, извлечение элементов и исключение несущественных
пересечений.
Первая стадйя решения состоит из формирования множественных копий каждой исходной
строки, по одной на каждый столбец, который вам нужно свернуть. В нашем случае необхо-
димо создать копию для каждого из столбцов А, в, с и D, представляющих ID клиентов.
В реляционной алгебре и в языке SQL для формирования многочисленных копий применяется
декартово произведение (перекрестное соединение). Вам нужно применить перекрестное
соединение к таблице EmpCustOrders и таблице, содержащей строку для каждого клиента.
В SQL Server 2008 можно использовать конструктор значений в виде элемента VALUES ДЛЯ
создания виртуальной таблицы со строкой для каждого клиента. Запрос, реализующий пер-
вую стадию решения, выглядит так:
SELECT *
FROM dbo.EmpCustOrders
CROSS JOIN (VALUES('A
1
) , ('В')/ ('С
1
),(
f
Df)) AS Custs(custid);
В более ранних версиях to SQL Server необходимо заменить элемент VALUES рядом инст-
рукций SELECT, каждая из которых формирует одну строку на основе констант и операций
над множествами UNION ALL.
SELECT *
FROM dbo.EmpCustOrders
CROSS JOIN (SELECT 'A
1
AS custid
UNION ALL SELECT 'B'
UNION ALL SELECT 'C'
UNION ALL SELECT 'D') AS Custs;
Этот вид запроса не является стандартным — стандартный вид требует наличия элемента
FROM в запросе с инструкцией SELECT.
В нашем примере запрос, реализующий первую стадию решения, возвращает следующий
результат:
empid
А
В
С
D
custid
Сворачивание данных
с помощью стандартного SQL
226
Глава 2
1
NULL
20
34
NULL
A
1
NULL
20
34
NULL
В
1
NULL
20
34
NULL
С
1
NULL
20
34
NULL
D
2
52
27
NULL
NULL
A
2
52
27
NULL
NULL
В
2
52
27
NULL
NULL
С
2
52
27
NULL
NULL
D
3
20
NULL
22
30
A
3
20
NULL
22
30
В
3
20
NULL
22
30
С
3
20
NULL
22
30
D
Как видите, для каждой исходной строки сформированы четыре копии — по одной для кли-
ентовА,В,СИD.
Вторая стадия решения — создание столбца (в нашем случае назовем его qty), который
возвращает значение из столбца, соответствующего клиенту, представленному в текущей
копии строки. Более конкретно, в нашем случае: если текущее значение custid равно А, ТО
в столбце qty следует возвращать значение из столбца А; если custid равен в, то qty дол-
жен содержать значение из столбца в, и т. д. Реализовать эту стадию можно с помощью
простого выражения CASE следующим образом:
SELECT empid, custid,
CASE custid
WHEN 'A' THEN A
WHEN 'B' THEN B
WHEN 'C
1
THEN С
WHEN 1D
1
THEN D
END AS qty
FROM dbo.EmpCustOrders
CROSS JOIN (VALUES('А'),('В'),('С
1
),('D')) AS Custs(custid);
Этот запрос вернет такой результат:
empid
custid
qty
1
A
NULL
1
В
20
1
С
34
1
D
NULL
2
A
52
2
В
27
2
С
NULL
2
D
NULL
3
A
20
Реорганизация данных и наборы группирования
237
3
В
NULL
3
С
22
3
D
30
Напоминаю, что в исходной таблице значения NULL представляют несущественные пересе-
чения. Для исключения несущественных пересечений определите табличное выражение на
основе запроса, реализующего вторую стадию решения, и во внешнем запросе отфильтруй-
те значения NULL. Далее приведено решение полностью:
SELECT *
FROM (SELECT empid, custid,
CASE custid
WHEN 'A
1
THEN A
WHEN 'B' THEN В
WHEN ,C' THEN С
WHEN 'D
?
THEN D
END AS qty
FROM dbo.EmpCustOrders
CROSS JOIN (VALUES(fА'),('В
1
),('С'),('D')) AS Custs(custid)) AS D
WHERE qty IS NOT NULL;
Этот запрос вернет следующий результат:
empid
custid
qty
1
в
20
1
с
34
2
А
52
2
В
27
3
А
20
3
С
22
3
D
30
Сворачивание с помощью собственной
операции T-SQL UNPIVOT
Сворачивание данных включает в себя формирование двух результирующих столбцов из
любого количества исходных столбцов, которые вы сворачиваете. В нашем примере необ-
ходимо свернуть исходные столбцы А, в, с и D, создав два результирующих столбца с име-
нами custid (id клиента) и qty (объем). Первый будет содержать имена исходных столбцов
('А
1
,'в
1
,'с'и
1
D1), а последний — значения из исходных столбцов (в нашем случае объ-
емы заказов). В версии SQL Server 2005 появилась очень элегантная минималистическая
собственная табличная операция UNPIVOT. Синтаксис запроса с операцией UNPIVOT таков:
SELECT ...
FROM <&сходная_табтца_Ш1И_табличное__вь1ражвние>
228
Глава 2
UNPIVOT (<рез_столбец__для_хранения_зна чений__исх_стсклбцов>
FOR < рез_столбец_для_хржения^имен_исх_столбцов>
IN(<список__исх^столб11ов>)) AS <псевдоним_рез_таблицы>
•
•
•/
Как и операция PIVOT, UNPIVOT реализована как табличная операция, применяемая в эле-
менте FROM. Она действует на исходную таблицу или табличное выражение (в нашем случае
EmpCustOrders). В круглых скобках операции UNPIVOT задается имя, назначаемое столбцу,
который будет содержать значения исходного столбца (qty), имя, присваиваемое столбцу,
который будет хранить имена исходных столбцов (custid), и список имен исходных столб-
цов (А, в, с и D). Следом за круглыми скобками указывается псевдоним таблицы, которая
получится в результате выполнения табличной операции.
Далее приводится полное решение нашего примера с запросом, использующим операцию
UNPIVOT:
SELECT empid, custid, qty
FROM dbo.EmpCustOrders
UNPIVOT (qty FOR custid IN (А, В, C, D) ) AS U;
Операция UNPIVOT реализует все стадии логической обработки, описанные ранее, формиро-
вание копий, извлечение элементов и удаление, пересечений, равных NULL. Последняя ста-
дия не является необязательной, как в решении на основе стандартного языка SQL.
Также учтите, что сворачивание развернутой сводной таблицы не возвращает первоначаль-
ную таблицу. Сворачивание— это только представление развернутых значений в новом
формате. Но таблицу, которая была свернута, можно развернуть обратно, вернув ее перво-
начальное развернутое состояние. Другими словами, получение сводных данных в процессе
первоначального разворачивания ведет к потере подробной информации. После первона-
чального разворачивания данных все сводные данные можно сохранить при последователь-
ном выполнении операций, конечно, если сворачивание не приводит к потере информации.
Наборы группирования
В этом разделе описывается, что такое наборы группирования и средства SQL Server, под-
держивающие эти наборы.
Набор группирования — это набор атрибутов, по которым вы группируете данные. Тради-
ционно в языке SQL один запрос для получения сводных данных определяет единственный
набор группирования. Например, в следующих четырех запросах определен единственный
набор группирования:
SELECT empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY empid, custid;
SELECT empid, SUM(qty) AS sumqty
FROM dbo.Orders
Реорганизация данных и наборы группирования
229
GROUP BY empid;
SELECT custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY custid;
SELECT SUM(qty) AS sumqty
FROM dbo.Orders;
'
В первом запросе определен набор группирования (empid, custid), во втором —
(empid), в третьем— (custid) и в последнем запросе определен так называемый пустой
набор группирования (). Приведенный программный код возвращает четыре результирую-
щих набора — по одному на каждый из четырех запросов.
Предположим, что вместо четырех отдельных результирующих наборов вы хотели бы полу-
чить один объединенный результирующий набор со сводными данными по всем четырем
наборам группирования. Его можно получить, применив для объединения результирующих
наборов всех четырех запросов операцию над множествами UNION ALL. Поскольку опера-
циям над множествами требуются результирующие наборы с совместимыми схемами, со-
держащие одинаковое количество столбцов, необходимо согласовать запросы, добавив за-
полнители (например, значения NULL) вместо пропущенных столбцов. Далее показано,
каким должен быть программный код:
SELECT empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY empid, custid
UNION ALL
SELECT empid, NULL, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY empid
UNION ALL
SELECT NULL, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY custid
UNION ALL
SELECT NULL, NULL, SUM(qty) AS sumqty
FROM dbo.Orders;
Этот программный код сформирует единственный результирующий набор со сводными
данными по всем четырем объединенным наборам группирования:
empid
custid
sumqty
230
Глава 2
2
A
52
3
A
20
1
В
20
2
В
27
1
С
34
3
С
22
3
D
30
1
NULL
54
2
NULL
79
3
NULL
72
NULL
A
72
NULL
В
47
NULL
С
56
NULL
D
30
NULL
NULL
205
(15 row(s) affected)
Несмотря на то, что вы добились, чего хотели, у этого решения есть две проблемы: объем
программного кода и производительность. Решение требует задания целого запроса с эле-
ментом GROUP BY для каждого набора группирования. При большом количестве наборов
группирования запрос может получиться очень длинным. Кроме того, для обработки запро-
са SQL Server будет просматривать исходную таблицу отдельно для каждого запроса, что
неэффективно.
В версии SQL Server 2008 появился ряд средств, соответствующих стандарту SQL и дающих
возможность определять множественные наборы группирования в одном и том же запросе.
К ним относятся вложенные в элемент GROUP BY элементы GROUPING SETS, CUBE И ROLLUP
И функция GROUPING_ID.
Вложенный элемент GROUPING SETS
Вложенный элемент GROUPING SETS— усовершенствование элемента GROUP BY, обла-
дающее богатыми функциональными возможностями и применяемое главным образом при
создании отчетов и в хранилищах данных. Используя этот вложенный элемент, можно в
одном запросе определять множественные наборы группирования. Просто перечислите в
круглых скобках во вложенном элементе GROUPING SETS нужные вам йаборы группирова-
ния, отделяя их запятыми, и для каждого набора группирования в круглых скобках задайте
его атрибуты, разделенные запятыми. Например, в следующем запросе определены четыре
набора группирования: (empid, custid), (empid), (custid) и ().
SELECT empid, custid, SUM (qty) AS sumqty
FROM dbo.Orders
GROUP BY
GROUPING SETS
Реорганизация данных и наборы группирования
231
(
(empid, custid),
(empid),
(custid),
О
);
Этот запрос логически эквивалентен предыдущему запросу, в котором объединялись ре-
зультирующие наборы четырех запросов со сводными данными, и возвращался тот же са-
мый результат. У данного запроса по сравнению с предыдущим есть два основных преиму-
щества: во-первых, очевидно, что его программный код гораздо короче, и, во-вторых, SQL
Server оптимизирует количество просмотров исходной таблицы и необязательно будет про-
сматривать ее отдельно для каждого набора группирования.
До появления SQL Server 2008 не было логического эквивалента вложенному элементу
GROUPING SETS, не нуждающегося в явном объединении результирующих наборов множе-
ственных запросов со сводными данными. Как уже отмечалось, реализация, предложенная в
версии SQL Server 2008, соответствует стандарту языка SQL.
Вложенный элемент CUBE
Вложенный элемент CUBE элемента GROUP BY предоставляет сокращенный способ опреде-
ления множественных наборов группирования. В круглых скобках вложенного элемента
CUBE указывается список атрибутов, разделенных запятыми, и вы получаете все возможные
наборы группирования, которые можно определить на базе входных атрибутов. Например,
CUBE (а, Ь, с) эквивалентен GROUPING SETS((a, Ъ, с), (а, Ъ) , (а, с), (Ь, с),
(а), (Ь), (с), О).В теории множеств множество всех подмножеств элементов, кото-
рые могут быть сформированы из заданного множества, называется множеством-
степенью. Вложенный элемент CUBE можно рассматривать, как элемент, создающий мно-
жество-степень наборов группирования, которые могут быть сформированы из заданного
множества атрибутов.
Вместо вложенного элемента GROUPING SETS, применявшегося в предыдущем запросе для
определения четырех наборов группирования: (empid, custid), (empid), (custid) и (),
можно просто использовать CUBE (empid, custid). Далее приведен запрос полностью:
SELECT empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY CUBE(empid, custid);
Элемент CUBE, вставляемый в элемент GROUP BY, появился в версии SQL Server 2008 и был
реализован в соответствии со стандартом языка SQL. В более ранних версиях SQL Server
поддерживал нестандартный необязательный элемент CUBE, реализованный не как часть
элемента GROUP BY, а как дополнительный элемент в отдельном синтаксическом элементе
WITH. Далее приведен логический эквивалент предыдущего запроса с более старым вариан-
том элемента CUBE:
SELECT empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
232
Глава 2
GROUP BY empid, custid
WITH CUBE;
Я рекомендую всегда применять средства для определения наборов группирования, соот-
ветствующие стандарту языка SQL, поскольку нестандартные синтаксические элементы
будут исключены в будущей версии SQL Server.
Вложенный элемент ROLLUP
Вложенный элемент ROLLUP, входящий в состав элемента GROUP BY, также предоставляет
сокращенный способ определения множественных наборов группирования. Но в отличие от
вложенного элемента CUBE, ROLLUP создает не все возможные наборы группирования, кото-
рые могут быть определены на базе входных атрибутов, а лишь подмножество этих наборов.
Элемент ROLLUP предполагает наличие иерархии во входных атрибутах и создает все набо-
ры группирования, которые имеют смысл с учетом иерархии. Другими словами, когда
CUBE (а, Ь, с) формирует из трех входных элементов все восемь возможных наборов
группирования, ROLLUP (а, ъ, с) создает только четыре набора группирования, предпола-
гая наличие иерархии а > b > с, и эквивалентен заданию GROUPING SETS((a, b, с), (а,
Ь), (а), ()).
Предположим, что вы хотите получить общие объемы для всех наборов группирования, ко-
торые могут быть определены на основе временной иерархии: год заказа > месяг{ заказа >
день заказа. Можно применить вложенный элемент GROUPING SETS и явно перечислить все
четыре возможных набора группирования:
GROUPING SETS(
(YEAR(orderdate), MONTH(orderdate), DAY(orderdate)),
(YEAR(orderdate), MONTH(orderdate)),
(YEAR(orderdate)) ,
0)
Логический эквивалент с применением вложенного элемента ROLLUP гораздо экономичнее:
ROLLUP(YEAR(orderdate), MONTH(orderdate), DAY(orderdate) )
Далее приведен полный запрос, который следует выполнить в базе данных tempdb:
SELECT
YEAR(orderdate) AS orderyear,
MONTH(orderdate) AS ordermonth,
DAY (orderdate) AS orderday,
SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY ROLLUP(YEAR(orderdate), MONTH(orderdate), DAY(orderdate));
Этот запрос вернет следующий результат:
orderyear
ordermonth
orderday
sumqty
2007
4
18
22
Реорганизация данных и наборы группирования
233
2007
4
NULL
22
2007
8
2
10
2007
8
NULL
10
2007
12
24
32
2007
12
NULL
32
2007
NULL
NULL
64
2008
1
9
40
2008
1
18
14
2008
1
NULL
54
2008
2
12
12
2008
2
NULL
12
2008
NULL
NULL
66
2009
2
12
10
2009
2
16
20
2009
2
NULL
30
2009
4
18
15
2009
4
NULL
15
2009
9
7
30
2009
9
NULL
30
2009
NULL
NULL
75
NULL
NULL
NULL
205
(22 row(s) affected)
Как и у вложенного элемента CUBE, у стандартного вложенного элемента ROLLUP, появив-
шегося в версии SQL Server 2008, в более ранних версиях SQL Server был нестандартный
предшественник в виде необязательного элемента в отдельном синтаксическом элементе
WITH. Далее приведен логический эквивалент предыдущего запроса, использующий нестан-
дартный вариант WITH ROLLUP:
SELECT
YEAR(orderdate) AS orderyear,
MONTH(orderdate) AS ordermonth,
DAY(orderdate) AS orderday,
SUM (qty) AS sumqty
FROM dbo.Orders
GROUP BY YEAR(orderdate), MONTH(orderdate), DAY(orderdate)
WITH ROLLUP;
И снова я советую всегда в новых разработках применять стандартные средства, поскольку
нестандартные элементы будут исключены в будущей версии SQL Server.
Стандартные вложенные элементы GROUPING SETS, CUBE И ROLLUP более гибкие, чем не-
стандартные варианты CUBE и ROLLUP. Вы можете применять несколько стандартных вло-
женных элементов в одном и том же элементе GROUP BY, что позволяет использовать все
234
Глава 2
интересующие вас функциональные возможности. В случае нестандартных вариантов вы
ограничены одним возможным элементом в каждом запросе.
Функции GROUPING и GROUPINGJD
Если у вас есть единственный запрос, определяющий множественные наборы группирова-
ния, вам потребуется возможность связать результирующие строки с наборами группирова-
ния, т. е. определить для каждой результирующей строки, с каким набором группирования
она связана. До тех пор пока атрибуты группирования определены как NOT NULL (не допус-
кающие значений NULL), это легко. Например, рассмотрим следующий запрос:
SELECT empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY CUBE(empid,' custid);
Этот запрос формирует такой результат:
empid
custid
sumqty
2
A
52
3
A
20
NULL
A
72
1
В
20
2
В
27
NULL
В
47
1
С
34
3
С
22
NULL
С
56
3
D
30
NULL
D
30
NULL
NULL
205
1
NULL
54
2
NULL
79
3
NULL
72
(15 row(s) affected)
Поскольку столбцы empid (id сотрудника) и custid (id клиента) определены в таблице
Orders (Заказы), как NOT NULL, значение NULL В этих столбцах может быть только запол-
нителем, указывающим на то, что столбец не участвовал в текущем наборе группирования.
Итак, все строки, в которых empid не равен NULL И custid не равен NULL, связаны с набо-
ром группирования (empid, custid). Все строки, в которых empid не равен NULL, а
custid равен NULL, связаны с набором группирования (empid) и т. д. Некоторые разработ-
чики заменяют значения NULL строкой "ALL" ИЛИ похожим обозначением, если в исходных
столбцах значения NULL не допускаются. Это помогает при выводе результатов.
Реорганизация данных и наборы группирования
235
Но если группируемый столбец определен в таблице как допускающий значения NULL, ВЫ не
можете сказать наверняка, значения NULL в результирующем наборе унаследованы из данных
или просто служат заполнителями для атрибута, не входящего в набор группирования. Один из
способов однозначного определения связи с набором группирования, даже когда в группируе-
мых столбцах допускаются значения NULL, — применение функции GROUPING. Эта функция
принимает имя столбца и возвращает 0, если он член текущего набора группирования, и 1 в
противном случае.
Например, в следующем запросе функция GROUPING выполняется для каждого из атрибутов
группирования:
SELECT
GROUPING(empid) AS grpemp,
GROUPING(custid) AS grpcust,
empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY CUBE(empid, custid);
Этот запрос вернет такой результат:
grpemp
grpcust
empid
custid s umqty
0
0
2
A
52
0
0
3
A
20
1
0
NULL
A
72
0
0
1
В
20
0
0
2
В
27
1
0
NULL
В
47
0
0
1
С
34
0
0
3
С
22
1
0
NULL
с
56
0
0
3
D
30
1
0
NULL
D
30
1
1
NULL
NULL
205
0
1
1
NULL
54
0
1
2
NULL
79
0
1
3
NULL
72
(15 row(s) affected)
Теперь вам больше не надо полагаться на значения NULL для того, чтобы установить связь
между результирующими строками и наборами группирования. Например, все строки, в
которых empid (id сотрудника) равен 0 и custid (id клиента) равен 0, связаны с набором
группирования (empid, custid). Все строки, в которых empid равен 0, a custid равен 1,
связаны с набором группирования (empid) и т. д.
Функция GROUPING была доступна в версиях программы, предшествующих SQL Server 2008, и
могла применяться вместе с нестандартными дополнительными элементами WITH CUBE И
236
Глава 2
WITH ROLLUP. В SQL Server 2008 введена новая функция GROUPING ID, которая еще упроща-
ет процесс связывания результирующих строк и наборов группирования. Вы задаете как вход-
ные параметры функции все элементы, участвующие в любых наборах группирования, — на-
пример, GROUPING_ID (а, b, с, d) — и функция возвращает целочисленное значение
двоичного отображения, в котором каждый бит представляет один из входных элементов —
крайний справа бит представляет крайний справа элемент в списке. Например, набор группи-
рования (а, Ь, с, d) представляется целым числом 0 (0x8 + 0x4 + 0x2 + 0x1). Набор груп-
пирования (а, с) представляется целым числом 5 (0x8 + 1x4 + 0x2 + 1x1) и т. д.
Вместо вызова функции GROUPING ДЛЯ каждого элемента группирования, как вы делали это
в предыдущем запросе, можно вызвать функцию GROUPING_ID один раз и снабдить ее все-
ми элементами группирования как входными параметрами следующим образом:
SELECT
GROUPING_ID(empid, custid) AS groupingset,
empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY CUBE(empid, custid);
Данный запрос сформирует такой результат:
groupingset
empid
custid
sumqty
0
2
A
52
0
3
A
20
2
NULL
A
72
0
1
В
20
0
2
В
27
2
NULL
В
47
0
1
С
34
0
3
С
22
2
NULL
С
56
0
3
D
30
2
NULL
D
30
3
NULL
NULL
205
1
1
NULL
54
1
2
NULL
79
1
3
NULL
72
(15 row(s) affected)
Теперь можно с легкостью определить, с каким набором группирования связана каждая
строка. Целое число 0 (двоичное 00) представляет набор группирования (empid, custid);
целое число 1 (двоичное 01)— (empid); целое 2 (двоичное 10)— (custid); целое 3 (дво-
ичное 11) представляет ().
Реорганизация данных и наборы группирования
237
Резюме
Эта глава посвящена разворачиванию и сворачиванию данных и средствам, относящимся к
наборам группирования.
Я описал стандартные и нестандартные способы разворачивания и сворачивания. В нестан-
дартных методах применяются собственные операции языка T-SQL PIVOT И UNPIVOT, ИХ
основное преимущество— гораздо более компактный программный код по сравнению со
стандартными методами.
В версии SQL Server 2008 появился ряд важных средств, делающих обработку наборов
группирования более гибкой и эффективной: вложенные элементы GROUPING SETS, CUBE И
ROLLUP и функция GROUPING_ID. Избегайте применения нестандартных вариантов WITH
CUBE и WITH ROLLUP, которые будут исключены из будущей версии SQL Server.
Упражнения
В этом разделе предлагаются упражнения, которые помогут вам лучше усвоить темы, обсу-
ждавшиеся в данной главе.
Все упражнения к данной главе содержат запросы к таблице Orders (Заказы) в базе данных
tempdb, которую вы создали и заполнили, выполнив программный код из листинга 7.1.
Упражнение 7.1
Напишите запрос к таблице Orders (Заказы), который возвращает строку для каждого со-
трудника, столбец для каждого года заказа и количество заказов для каждого сотрудника и
года заказа.
Используемые таблицы: база данных tempdb, таблица Orders.
Предполагаемый результат:
empid
cnt2007
cnt2008
cnt2009
1111
2
12
1
3
2
0
2
Упражнение 7.2
Выполните следующий программный код для создания и заполнения таблицы EmpYearOrders:
USE tempdb;
IF OBJECT_ID(•dbo.EmpYearOrders', 'U') IS NOT NULL DROP TABLE
dbo.EmpYearOrders;
238
Глава 2
SELECT empid, [2007] AS cnt2007, [2008] AS cnt2008, [2009] AS cnt2009
INTO dbo.EmpYearOrders
FROM (SELECT empid, YEAR(orderdate) AS orderyear
FROM dbo.Orders) AS D
PIVOT(COUNT(orderyear)
FOR orderyear IN([2007], [2008], [2009])) AS P;
SELECT * FROM dbo.EmpYearOrders;
Результат:
empid
cnt2007
cnt2008
cnt2009
1111
2
12
1
3
2
0
2
Напишите запрос к таблице EmpYearOrders, который сворачивает данные, возвращая стро-
ку для каждого сотрудника и года заказа с количеством заказов. Исключите строки, в кото-
рых количество заказов равно 0 (в нашем примере сотрудник 3 в 2008 г.).
Предполагаемый результат:
empid
orderyear
numorders
1
2007
1
1
2008
1
1
2009
1
2
2007
1
2
2008
2
2
2009
1
3
2007
2
3
2009
2
Упражнение 7.3
Напишите запрос к таблице Orders (Заказы), который вернет общие объемы для каждых:
сотрудника, клиента и года заказа; сотрудника и года заказа; клиента и года заказа. Включи-
те в результат столбец, однозначно определяющий набор группирования, с которым связана
текущая строка.
Используемые таблицы: база данных tempdb, таблица Orders.
Предполагаемый результат:
groupingset
empid
custid
orderyear
sumqty
0
2
A
2007
12
0
ЗА
2007
10
Реорганизация данных и наборы группирования
239
4
NULL
A
2007
22
0
2
A
2008
40
4
NULL
A
2008
40
0
3
A
2009
10
4
NULL
A
2009
10
0
1
В
2007
20
4
NULL
В
2007
20
0
2
В
2008
12
4
NULL
В
2008
12
0
2
В
2009
15
4
NULL
В
2009
15
0
3
С
2007
22
4
NULL
С
2007
22
0
1
С
2008
14
4
NULL
С
2008
14
0
1
С
2009
20
4
NULL
с
2009
20
0
3
D
2009
30
4
NULL
D
2009
30
2
1
NULL
2007
20
2
2
NULL
2007
12
2
3
NULL
2007
32
2
1
NULL
2008
14
2
2
NULL
2008
52
2
1
NULL
2009
20
2
2
NULL
2009
15
2
3
NULL
2009
40
(29 row(s) affected)
ГЛАВА 8
Модификация данных
В языке SQL есть набор инструкций, называемый языком манипулирования данными (Data
Manipulation Language, DML), который связан с полезной манипуляцией данными. Некото-
рые считают, что DML включает в себя только инструкции, изменяющие данные, но на са-
мом деле он затрагивает и извлечение данных. В состав DML входят инструкции SELECT,
INSERT, UPDATE, DELETE и MERGE. До этого момента я уделял основное внимание инструк-
ции SELECT. Данная глава посвящена инструкциям, модифицирующим данные. Помимо
стандартных аспектов модификации данных в этой главе я также коснусь особенностей,
связанных с языком T-SQL.
Для того чтобы не изменять данные в ваших учебных базах данных, в большинстве приме-
ров этой главы для демонстрационных целей будут создаваться, заполняться и обрабаты-
ваться таблицы в базе данных tempdb, использующие схему dbo.
Добавление данных
Язык T-SQL предоставляет несколько инструкций для вставки данных в таблицы: INSERT
VALUES, INSERT SELECT, INSERT EXEC, SELECT INTO и BULK INSERT. Сначала я опишу
эти инструкции, а затем расскажу о свойстве столбца, именуемом IDENTITY И при вставке
автоматически генерирующем числовые значения в результирующем столбце.
Инструкция INSERT VALUES
Инструкция INSERT VALUES применяется для добавления в таблицу строк, формируемых из
заданных значений. Демонстрировать эту инструкцию и другие в действии вы будете с по-
мощью таблицы Orders (Заказы) в схеме dbo базы данных tempdb. Выполните следующий
программный код для создания таблицы Orders:
USE tempdb;
IF OBJECT_ID('dbo.Orders', 'U') IS NOT NULL DROP TABLE dbo.Orders;
CREATE TABLE dbo.Orders
( orderid INT NOT NULL
Модификация данных
241
CONSTRAINT PK_Orders PRIMARY KEY,
orderdate DATE NOT NULL
CONSTRAINT DFT_orderdate DEFAULT(CURRENT_TIMESTAMP),
empid INT NOT NULL,
custid VARCHAR(10) NOT NULL)
В следующем примере показано, как использовать инструкцию INSERT VALUES для добав-
ления одной строки в таблицу Orders (Заказы):
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid)
VALUES(10001, '200902121
, 3, 'A');
Указание имен столбцов сразу после имени таблицы не обязательно, но делая это, вы кон-
тролируете связи "значение—столбец", а не полагаетесь на порядок, в'котором столбцы
появились в инструкции, определяющей таблицу (или корректировавшей ее структуру в по-
следний раз).
Если вы задаете значение в столбце, Microsoft SQL Server использует его. Если нет, SQL
Server проверит, определено ли для столбца значение по умолчанию, и если да, то применит
это значение. Если значение по умолчанию не задано и в столбце допустимы значения NULL,
будет использовано значение NULL. ЕСЛИ ВЫ не задали значение для столбца и он не может
получить его автоматически каким-либо способом, ваша инструкция INSERT завершится
аварийно. В качестве примера использования заданного значения или выражения по умол-
чанию в следующем примере в таблицу Orders (Заказы) вставляется строка без указания
значения в столбце orderdate (дата заказа), но поскольку для этого столбца есть выраже-
ние по умолчанию, определенное как (CURRENT TIMESTAMP) , оно и будет использовано.
INSERT INTO dbo.Orders(orderid, empid, custid)
VALUES(10002, 5,
'B');
В версии SQL Server 2008 элемент VALUES усовершенствован и позволяет задавать множе-
ственные строки, разделенные запятыми. Например, приведенная далее инструкция вставля-
ет в таблицу Orders сразу четыре строки:
INSERT INTO dbo.Orders
(orderid, orderdate, empid, custid)
VALUES
(10003, '20090213', 4, 'B'),
(10004, '20090214', 1, 'A'),
(10005, '20090213', 1, 'C'),
(10006, '20090215', 3, 'C');
Эта инструкция выполняется как атомарная или неделимая операция, т. е. если одна из
строк при вставке в таблицу порождает ошибку, другие строки, включенные в инструкцию,
также не будут добавлены в таблицу.
С этим усовершенствованием связано и еще кое-что, бросающееся в глаза. Была улучшена
не только инструкция INSERT VALUES, НО И сам элемент VALUES — теперь его можно при-
менять для создания виртуальной таблицы. Это средство, названное конструктором значе-
ний строки (Row Value Constructor) или конструктором значений таблгщы (Table Value
Constructor), стандартно. Это означает, что на базе элемента VALUES МОЖНО определять таб-
242
Гпава 8
личное выражение. Далее показан пример запроса к производной таблице, которая опреде-
лена как раз на базе элемента VALUES:
SELECT *
4, 'В')/
1,
'А
1
),
'С'),
FROM (VALUES
(10003, '20090213'
(10004, '20090214'
(10005, '20090213'
(10006, '20090215', 3, 'С'))
AS О(orderid, orderdate, empid, custid);
Следом за круглыми скобками, содержащими конструктор значений таблицы, вы присваи-
ваете псевдоним таблице (в нашем случае о) и следом за ним в круглых скобках задаете
псевдонимы результирующих столбцов. Данный запрос формирует следующий результат:
orderid
orderdate
empid
custid
10003
10004
10005
10006
20090213
20090214
20090213
20090215
В
A
С
С
Инструкция INSERT SELECT
Инструкция INSERT SELECT вставляет в результирующую таблицу набор строк, возвра-
щенных запросом SELECT. Синтаксическая запись инструкции очень похожа на синтаксиче-
скую запись инструкции INSERT VALUES, но вместо элемента VALUES вы задаете запрос
SELECT. Например, в следующем программном коде в таблицу запроса dbo.Orders (Зака-
зы) в базе данных tempdb вставляется результат запроса к таблице Sales.Orders из базы
данных TSQLFundamentals2008, возвращающий заказы, которые следует доставить в Вели-
кобританию (UK).
USE tempdb;
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid)
SELECT orderid, orderdate, empid, custid
FROM TSQLFundamenta1s2 008.Sales.Orders
WHERE shipcountry = 'UK';
В инструкции INSERT SELECT вы также можете при желании задать имена результирующих
столбцов, и мои рекомендации по поводу этих имен остаются прежними. Требование пре-
доставлять значения для всех столбцов, которые не могут получать значения каким-либо
способом автоматически, и явно использовать значения по умолчанию/значения NULL, если
значение не задано, сохраняется таким же, как и в инструкции INSERT VALUES. Инструкция
INSERT SELECT выполняется как атомарная операция, поэтому, если какая-либо строка из-
за ошибок не может быть добавлена в результирующую таблицу, в нее не вставляется ни
одна строка.
Модификация данных
243
\
В версиях программы, предшествующих SQL Server 2008, если вы хотели создать виртуаль-
ную таблицу, основанную на значениях, нужно было применять множественные инструкции
SELECT, каждая из которых возвращала одну строку, основанную на значениях, и затем объ-
единять строки с помощью операций над множествами UNION ALL. В случае инструкции
INSERT SELECT можно применить этот способ вставки множественных строк, основанных
на значениях, в единственной инструкции, которая рассматривается как атомарная или не-
делимая операция.
Например, следующая инструкция вставляет в таблицу Orders (Заказы) четыре строки, ос-
нованные на значениях.
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid)
SELECT 10007, '20090215', 2, 'В* UNION ALL
SELECT 10008, '20090215', 1, 'C' UNION ALL
SELECT 10009, '20090216', 2, 'C' pNION ALL
SELECT 10010, '20090216', 3, 'A';
Как я уже упоминал, версия SQL Server 2008 поддерживает конструкторы таблицы на базе
значений, поэтому этот метод вам больше не понадобится.
До появления версии SQL Server 2008 почти все операции INSERT SELECT регистрировались
полностью (т. е. были полностью описаны в журнале регистрации транзакций) и по сравнению
с операциями с минимальной регистрацией были существенно медленнее. SQL Server 2008
поддерживает минимальную регистрацию в большем количестве сценариев, чем предыдущие
версии программы, включая инструкцию INSERT SELECT. Обсуждения производительности
выходят за рамки книги, но если вы хотите узнать больше, подробности можно найти в
разд. "Operations That Can Be Minimally Logged" ("Операции, допускающие минимальную ре-
гистрацию") интерактивного справочного руководства SQL Server Books Online.
Инструкция INSERT EXEC
Инструкция INSERT EXEC применяется для вставки в результирующую таблицу набора,
возвращенного из хранимой процедуры или пакета динамического SQL. Сведения о храни-
мых процедурах, пакетах и динамическом SQL вы найдете в главе 10. Инструкция INSERT
EXEC синтаксически и логически очень похожа на инструкцию INSERT SELECT, НО вместо
инструкции SELECT задается инструкция EXEC.
Например, в следующем программном коде в базе данных TSQLFundamentals2008 создается
хранимая процедура Sales.usp_getorders, возвращающая заказы, которые доставлены в
страну, заданную как входной параметр процедуры (@country).
USE TSQLFundamentals2008;
IF OBJECT_ID(1 Sales.usp_getorders', 'P') IS NOT NULL
DROP PROC Sales.usp_getorders;
GO
CREATE PROC Sales.usp_getorders
@country AS NVARCHAR(40)
AS
244
Гпава 8
SELECT orderid, orderdate, empid, custid
FROM Sales.Orders
WHERE shipcountry = @country;
GO
Для проверки хранимой процедуры выполните ее с заданной страной France (Франция):
EXEC Sales.usp_getorders ^country = 'France';
Вы получите следующий результат:
orderid
orderdate
empid
custid
10248
2006-07-04 00:00:: 00.
,000 5
85
10251
2006-07-08 00:00:: 00.
,000
3
84
10265
2006-07-25 00:00:: 00.ООО 2
*
7
10274
2006-08-06 00:00:: 00.
,000
6
85
10295
2006-09 -02 00:00:: 00.
,000 2
85
10297
2006-09 -04 00:00:: 00.
,000 5
7
10311
2006-09 -20 00:00:: 00.
,000 1
18
10331
2006-10-16 00:00:: 00.
,000
9
9
10334
2006-10-21 00:00:: 00.000 8
84
10340
2006-10-29 00:00:: 00.ООО 1
9
(77 row(s) affected)
Применяя инструкцию INSERT EXEC, вы можете направить результирующий набор, воз-
вращенный из процедуры, в таблицу dbo. Orders базы данных tempdb:
USE tempdb;
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid)
EXEC TSQLFundamentals2008.Sales.usp__getorders ^country = 'France
1
;
Инструкция SELECT INTO
Инструкция SELECT INTO — нестандартная инструкция языка T-SQL, создающая результи-
рующую таблицу и заполняющая ее результирующим набором запроса. Под "нестандарт-
ной" я подразумеваю не включение ее в стандарт языка ANSI SQL. Эту инструкцию нельзя
применять для добавления данных в существующую таблицу. С точки зрения синтаксиса
просто добавьте конструкцию
INTO <имя_результирукщей_таблицц>
перед элементом FROM запроса с инструкцией SELECT, который используется для формиро-
вания результирующего набора. Например, в следующем программном коде в базе данных
tempdb создается таблица dbo.orders (Заказы) и заполняется всеми строками из таблицы
Sales. Orders базы данных TSQLFundamentals2008:
USE tempdb;
Модификация данных
245
IF OB JECT_ID('dbo. Orders', 'U') IS NOT NULL DROP TABLE dbo.Orders;
SELECT orderid, orderdate, empid, custid
INTO dbo.Orders
FROM TSQLFundamentals2008.Sales.Orders;
Структура результирующей таблицы и данные базируются на исходной таблице. Инструк-
ция SELECT INTO копирует из исходной таблицы базовую структуру (имена столбцов, типы,
допустимость значений NULL, свойство IDENTITY) И данные. Есть три вещи, которые инст-
рукция не копирует из исходной таблицы: ограничения, индексы и триггеры. Если они нуж-
ны вам в результирующей таблице, придется создавать их самостоятельно.
Одно из достоинств инструкции SELECT INTO состоит в том, что до тех пор, пока свойство
Recovery Model (модель восстановления БД) не равно FULL, операция SELECT INTO выпол-
няется в режиме минимальной регистрации. Это означает очень быструю операцию по
сравнению с полной регистрацией.
Если инструкцию SELECT INTO нужно применить вместе с операциями над множествами,
элемент INTO задается непосредственно перед элементом FROM первого запроса. Например,
следующая инструкция SELECT INTO создает таблицу Locations (местонахождения) и за-
полняет ее результатом операции над множествами EXCEPT, которая возвращает местона-
хождения клиентов, не совпадающие с местонахождениями сотрудников:
USE tempdb;
IF OBJECT_ID('dbo.Locations
1
, 'U') IS NOT NULL DROP TABLE dbo.Locations;
SELECT country, region, city
INTO dbo.Locations
FROM TSQLFundamental's2008. Sales. Customers
EXCEPT
SELECT country, region, city
FROM TSQLFundamentals2008.HR.Employees;
Инструкция BULK INSERT
Инструкция BULK INSERT применяется для вставки в существующую таблицу данных, хра-
нящихся в файле. В инструкции задается результирующая таблица, файл-источник и пара-
метры. Вы можете указать много параметров, включая тип файла данных (символьный или
специальный), ограничитель поля, ограничитель строки и др. Все параметры подробно опи-
саны.
Например, в следующем программном коде в таблицу dbo.Orders (Заказы) базы данных
tempdb целиком вставляется содержимое файла c:\temp\orders.txt с указанием типа файла
данных char (символьный), ограничителя поля в виде запятой и ограничителя строки в виде
специального символа новой строки (\п).
USE tempdb;
9 Зак. 1032
246
Гпава 8
BULK INSERT dbo.Orders FROM 1
c:\temp\orders.txt
1
WITH
(DATAFILETYPE = 'char',
FIELDTERMINATOR =
1
,
1
,
ROWTERMINATOR = '\n
f
);
Имейте в виду, что если вы действительно хотите выполнить эту инструкцию, необходимо
поместить в папку c:\temp файл orders.txt, предоставленный вместе программным кодом для
этой книги.
При соблюдении определенных требований инструкцию BULK INSERT В некоторых сцена-
риях можно выполнять в быстром режиме с минимальной регистрацией. Подробности см. в
разд. "Prerequisites for Minimal Logging in Bulk Import" ("Необходимые условия для мини-
мальной регистрации в режиме группового импорта") интерактивного руководства SQL
Server Books Online.
Свойство IDENTITY
SQL Server разрешает определять свойство IDENTITY для столбца с любым числовым ти-
пом, имеющим нулевое количество знаков после десятичной точки (т. е. при отсутствии
дробной части). Это свойство при выполнении инструкции INSERT вызывает автоматиче-
скую генерацию значений, исходя из начального (первого) значения и величины прираще-
ния (шага), которые указываются в определении столбца. Обычно это свойство применяется
при создании суррогатных ключей, формируемых системой, а не взятых из прикладных
данных.
Например, следующий программный код создает таблицу dbo. Т1 в базе данных tempdb:
USE tempdb;
IF OBJECT_ID('dbo. Tl1
, 'U') IS NOT NULL DROP TABLE dbo.Tl;
CREATE TABLE dbo.Tl
(
keycol INT NOT NULL IDENTITY(1, 1)
CONSTRAINT PK_T1 PRIMARY KEY,
datacol VARCHAR(IO) NOT NULL
CONSTRAINT CHK_Tl_datacol CHECK(datacol LIKE '[A-Za-z]%')
);
Таблица содержит столбец keycol, который определен со свойством IDENTITY, исполь-
зующим 1, как начальное значение, и 1, как приращение. Таблица также включает в себя
столбец из символьных строк datacol, для данных которого задано ограничение типа
CHECK, допускаюшее в качестве начального символа строки только алфавитный символ.
В инструкциях INSERT идентификационный столбец следует полностью игнорировать, де-
лая вид, что его нет в таблице.
Модификация данных
247
Например, в следующем программном коде в таблицу вставляются три строки, в которых
заданы значения только для столбца datacol:
INSERT INTO dbo.Tl(datacol) VALUES ('AAAAA');
INSERT INTO dbo.Tl(datacol) VALUES('CCCCC');
INSERT INTO dbo.Tl(datacol) VALUES('BBBBB');
Для столбца keycol SQL Server создаст значения автоматически. Для того чтобы увидеть
их, создайте запрос к таблице:
SELECT * FROM dbo.Tl;
Вы получите такой результат:
keycol
datacol
1
ААААА
2
ССССС
3
ВВВВВ
При формировании запроса к таблице вы, конечно, можете ссылаться на идентификационный
столбец по имени (в нашем случае keycol). Кроме того, SQL Server предоставляет возмож-
ность ссылаться на идентификационный столбец с помощью более общей формы его обозна-
чения $ identity. Этот вариант поддерживается, начиная с версии SQL Server 2005, с заменой
устаревшей формы IDENTITYCOL. Устаревшая форма тоже поддерживается для обеспечения
обратной совместимости, но будет исключена в будущей версии программы.
Например, следующий запрос выбирает идентификационный столбец из Т1, используя обо-
значение общего вида:
SELECT'$identity FROM dbo.Tl;
Этот запрос вернет такой результат:
keycol
1
2
3
Когда в таблицу вставляется новая строка, SQL Server генерирует новое идентификационное
значение, основанное на текущем идентификационном значении и приращении. Если вам
нужно получить только что сгенерированное идентификационное значение, например, для
добавления подчиненных строк в ссылочную таблицу, вы вызываете одну из двух функций:
@@identity и SCOPE_IDENTiTY (). Функция @@identity— унаследованное средство
(появившееся еще до версии SQL Server 2000), возвращающее последнее идентификацион-
ное значение, сгенерированное в текущем сеансе, независимо от области видимости.
SCOPE_iDENTiTY() возвращает последнее идентификационное значение, сгенерированное
сеансом в текущей области видимости (например, в той же процедуре). За исключением
особых случаев, когда вас не интересует текущая область видимости, следует применять
функцию SCOPE_IDENTITY () .
248
Гпава 8
Например, в следующем программном коде в таблицу Т1 с помощью вызова функции
SCOPE_IDENTITY вставляется строка, вновь сгенерированное идентификационное значение
помещается в переменную, и эта переменная запрашивается:
DECLARE @new_key AS INT;
INSERT INTO dbo.Tl(datacol) VALUES('AAAAA
1
);
SET @new_key = SCOPE_IDENTITY();
SELECT @new_key AS new_key
Если вы выполнили программный код всех предыдущих примеров, представленных в дан-
ной главе, этот программный код вернет следующий результат:
new_key
4
Напоминаю, что функции @@identity и SC0PE_IDENTITY() возвращают последнее иден-
тификационное значение, созданное в текущем сеансе. На него не влияют команды вставки,
выполненные в других сеансах. Но если вы хотите узнать текущее идентификационное зна-
чение в таблице (последнее сформированное значение) независимо от сеанса, следует при-
менить функцию IDENT_CURRENT () и задать имя таблицы как входной параметр функции.
Например, выполните следующий программный код в новом сеансе (не в том, где вы вы-
полняли предыдущие инструкции INSERT):
SELECT
SCOPE_IDENTITY() AS [SCOPE_IDENTITY],
@@identity AS [@@identity]f
IDENT_CURRENT('dbo.Tl') AS [IDENT_CURRENT];
Вы получите такой результат:
SCOPE_IDENTITY @@identity IDENT_CURRENT
NULL
NULL
4
И функция @@identity, и функция SC0PE_IDENTITY () вернули значения NULL, поскольку
никаких идентификационных значений не создавалось в сеансе, в котором выполнялся этот
запрос. Функция IDENT_CURRENT () вернула значение 4, т. к. она возвращает текушее иден-
тификационное значение в таблице, независимо от сеанса, в котором это значение было сге-
нерировано.
Обратите внимание на следующие важные детали, относящиеся к свойству идентификации.
Изменение текущего идентификационного значения в таблице не отменяется, если инструк-
ция INSERT, вызвавшая его генерацию, завершилась аварийно или произошел откат тран-
закции, в которой эта инструкция выполняется. Например, выполните следующую инструк-
цию INSERT, противоречащую ограничению типа CHECK, определенному в таблице:
INSERT INTO dbo.Tl(datacol) VALUES(1123451);
Модификация данных
249
Вставка завершится аварийно, и вы получите следующее сообщение об ошибке:
Msg 547, Level 16, State 0, Line 1
The INSERT statement conflicted with the CHECK constraint "CHK_Tl_datacol".
The conflict occurred in database "tempdb", table "dbo.Tl", column
1
datacol
1
.
The statement has been terminated.
Несмотря на то, что вставка завершилась аварийно, текущее идентификационное значение в
таблице изменилось с 4 на 5, и это изменение не было удалено из-за ошибки. Это означает,
что следующая вставка сгенерирует значение 6:
INSERT INTO dbo.Tl(datacol) VALUES(1EEEEE
1
);
Запросите содержимое таблицы:
SELECT * FROM dbo.Tl;
Обратите внимание на пропуск в результате между значениями 4 и 6:
keycol
datacol
1
ААААА
2
ССССС
3
ввввв
4
ААААА
6
ЕЕЕЕЕ
Это означает, что если вас не волнуют пропуски, следует целиком полагаться на свойство
идентификации, автоматически генерирующее значения. В противном случае вам придется
рассмотреть возможность применения альтернативного механизма.
Другая важная особенность свойства идентификации заключается в том, что вы не можете
вставить его в существующий столбец или удалить из имеющегося столбца; вы только мо-
жете определить это свойство вместе со столбцом в инструкциях CREATE TABLE ИЛИ ALTER
TABLE, которые добавляют новый столбец. SQL Server разрешает в инструкциях INSERT
явно задавать собственные значения в идентификационном столбце при условии, что вы
установили по отношению к таблице параметр сеанса IDENTITY_INSERT. Тем не менее, у
вас нет возможности изменять идентификационный столбец.
Например, в следующем программном коде показано, как вставить в таблицу Т1 строку с
явно заданным значением 5 в столбце keycol:
SET IDENTITY_INSERT dbo.Tl ON;
INSERT INTO dbo.Tl(keycol, datacol) VALUES(5,
1
FFFFF1);
SET IDENTITY_INSERT dbo.Tl OFF;
Интересно, что SQL Server изменяет текущее идентификационное значение в таблице, толь-
ко если явно задаваемое значение больше текущего значения в таблице. Поскольку текущее
идентификационное значение в таблице для выполнения приведенного программного кода
равнялось 6, и инструкция INSERT в этом примере использовала меньшее явно задаваемое
значение 5, текущее идентификационное значение в таблице не изменилось. Поэтому если
теперь, после выполнения предыдущего программного кода, вы вызовете функцию
IDENT_CURRENT ДЛЯ этой таблицы, то получите 6, а не 5.
250
Гпава 8
Таким образом, следующая инструкция INSERT, обращенная к таблице, сформирует значе-
ние?.
INSERT INTO dbo.Tl(datacol) VALUES(1GGGGG
1
);
Запросите текущее содержимое таблицы Tl.
SELECT * FROM dbo.Tl;
Вы получите такой результат:
keycol
datacol
1
AAAAA
2
CCCCC
3
BBBBB
4
AAAAA
5
FFFFF
6
EEEEE
7
GGGGG
Важно понять, что свойство идентификации само по себе не обеспечивает уникальности
значений в столбце. Я уже пояснял, что вы можете сами задавать собственные явные значе-
ния, установив параметр IDENTITY INSERT равным ON, и эти значения могут быть равны
значениям, уже имеющимся в строках таблицы. Кроме того, с помощью команды DBCC
CHECKIDENT вы можете переустановить текущее идентификационное значение в таблице.
Подробную информацию о синтаксической записи команды DBCC CHECKIDENT СМ. В
разд. "DBCC CHECKIDENT (Transact-SQL)" интерактивного справочного руководства SQL
Server Books Online. Говоря кратко, свойство идентификации не обеспечивает уникальность.
Если вы хотите гарантировать уникальность значений в идентификационном столбце, опре-
делите для этого столбца ограничение в виде первичного ключа или ограничение, требую-
щее уникальности строк.
Удаление данных
Язык T-SQL предоставляет две инструкции для удаления строк из таблицы: DELETE И
TRUNCATE. В этом разделе я опишу обе. Примеры, предлагаемые в данном разделе, обраще-
ны к созданным в базе данных tempdb копиям таблиц Customers (Клиенты) и Orders (За-
казы) из базы данных TSQLFundamentals2008. Выполните следующий программный код для
создания и заполнения упомянутых таблиц:
USE tempdb;
IF OBJECT_ID(*dbo.Orders
1
, 'U') IS NOT NULL DROP TABLE dbo.Orders;
IF OBJECT_ID(1dbo.Customers',
f
U') IS NOT NULL DROP TABLE dbo.Customers;
SELECT * INTO dbo.Customers FROM TSQLFundamentals2008.Sales.Customers;
SELECT * INTO dbo.Orders FROM TSQLFundamentals2008.Sales.Orders;
Модификация данных
251
ALTER TABLE dbo.Customers ADD
CONSTRAINT PK_Customers PRIMARY KEY(custid);
ALTER TABLE dbo.Orders ADD
CONSTRAINT PK_Orders PRIMARY KEY(orderid),
CONSTRAINT FK_Orders_Customers FOREIGN KEY(custid)
REFERENCES dbo.Customers(custid);
Инструкция DELETE
Инструкция DELETE — это стандартная инструкция для удаления данных из таблицы на ос-
нове предиката. У стандартной инструкции только два синтаксических элемента: элемент
FROM, в котором вы задаете нужную таблицу, и элемент WHERE, в котором задается предикат.
Будет удалено только подмножество строк, для которых предикат равен TRUE.
Например, следующая инструкция удаляет из таблицы dbo.Orders базы данных tempdb все
заказы, сделанные ранее 2007 г.:
USE tempdb;
DELETE FROM dbo.Orders
WHERE orderdate <
1
20070101';
Выполните эту инструкцию, и SQL Server сообщит, что удалено 152 строки:
(152 row(s) affected)
Учтите, что сообщение, указывающее количество обработанных строк, появится, только
если параметр сеанса NOCOUNT равен OFF, вариант, установленный по умолчанию. Если па-
раметр равен ON, SQL Server Management Studio (среда управления базами данных в SQL
Server) только констатирует, что команда завершилась успешно.
Инструкция DELETE регистрируется полностью. Следовательно, при удалении большого
количества строк вам придется подождать какое-то время, пока она выполнится.
Инструкция TRUNCATE
Инструкция TRUNCATE — это нестандартная инструкция, удаляющая все строки из таблицы.
В отличие от инструкции DELETE у TRUNCATE нет фильтра. Например, для удаления всех
строк из таблицы dbo.Tl выполняется следующий программный код:
TRUNCATE TABLE dbo.TL;
Преимущество TRUNCATE ПО сравнению с DELETE состоит в том, что первая выполняется
с минимальной регистрацией в то время, как вторая — с полной регистрацией, что приво-
дит к разнице в производительности. Например, если для удаления всех строк из таблицы
с миллионами строк применяется инструкция TRUNCATE, операция закончится в течение
нескольких секунд. Если же используется инструкция DELETE, операция продлится мину-
ты или даже часы.
252
Гпава 8
У инструкций TRUNCATE и DELETE есть и функциональное отличие, если в таблице присут-
ствует идентификационный столбец. Инструкция TRUNCATE возвращает идентификацион-
ному значению его первоначальную величину, а инструкция DELETE нет.
Инструкция TRUNCATE не допустима, если есть ссылки на результирующую таблицу с по-
мощью внешних ключей, даже когда ссылающаяся таблица пуста и внешний ключ отклю-
чен. Единственный способ сделать инструкцию TRUNCATE допустимой — уничтожить все
внешние ключи, ссылающиеся на таблицу.
Поскольку инструкция TRUNCATE очень быстрая, порой она может оказаться опасной. Мо-
гут возникнуть случайности, такие как отбрасывание или уничтожение данных неправильно
выбранной таблицы. Скажем, у вас есть подключения, открытые для производственной ра-
бочей среды и рабочей среды разработки/и вы предоставляете программный код не тому
подключению. Инструкции TRUNCATE И DROP так быстры, что когда вы осознаете ошибку,
транзакция уже будет зафиксирована. Для того чтобы предотвратить подобные происшест-
вия, можно защитить производственную таблицу, просто создав фиктивную таблицу с
внешним ключом, указывающим на производственную таблицу. Вы даже можете отключить
внешний ключ, чтобы он никак не влиял на производительность. Как я уже упоминал, даже
отключенный, этот внешний ключ не даст опустошить или уничтожить таблицу, на которую
он ссылается.
DELETE на основе соединения
Язык T-SQL поддерживает нестандартную синтаксическую запись инструкции DELETE на
базе соединений. Соединение само по себе служит задаче отбора, поскольку у него есть
фильтр, основанный на предикате (элемент ON). Соединение также дает вам доступ к атри-
бутам связанных строк из другой таблицы, на которые вы можете ссылаться в элементе
WHERE. ЭТО означает, что можно удалить строки из одной таблицы, основываясь на фильтре,
использующем атрибуты из связанных строк другой таблицы.
Например, следующая инструкция удаляет заказы, сделанные клиентами из США:
USE tempdb;
DELETE FROM О
FROM dbo.Orders AS О
JOIN dbo.Customers AS С
ON O.custid = C.custid
WHERE C.country = N'USA';
Во многом так же, как в инструкции SELECT, элемент FROM В инструкции DELETE логически
обрабатывается первым (второй элемент FROM В синтаксической записи инструкции). Далее
обрабатывается элемент WHERE И В заключение— команда DELETE. У этого запроса сле-
дующий способ прочтения или интерпретации: запрос соединяет таблицу Orders (псевдо-
ним о) с таблицей Customers (псевдоним С), основываясь на совпадении ID клиента из таб-
лицы заказов с ID клиента из таблицы клиентов. Затем запрос отбирает только те заказы,
которые были сделаны клиентами из США. В заключение запрос удаляет из таблицы о
(псевдоним таблицы Orders) все отобранные строки.
Модификация данных
253
Два элемента FROM В инструкции DELETE на основе соединения могут создать путаницу.
Разрабатывая эту инструкцию, создавайте ее так, как будто она представляет собой инст-
рукцию SELECT с соединением. Начинайте с элемента FROM с соединениями, далее перехо-
дите к элементу WHERE И В конце вместо команды SELECT задайте команду DELETE с псев-
донимом того участника соединения, который, как предполагается, будет таблицей,
предназначенной для удаления.
Как я уже упоминал, инструкция DELETE на основе соединения— нестандартная. Если вы
хотите сохранить приверженность стандарту, можно применить вложенные запросы вместо
соединений. Например, в следующей инструкции DELETE для решения той же задачи при-
меняется вложенный запрос:
DELETE FROM dbo.Orders
WHERE EXISTS
(SELECT *
FROM dbo.Customers AS С
WHERE Orders.Custid = C.Custid
с
AND C.Country = 'USA');
Этот программный код удаляет все строки из таблицы Orders (Заказы), для которых в таб-
лице клиентов существует связанный клиент из США.
SQL Server, по всей вероятности, обработает эти два запроса одинаково, следовательно
большой разницы в их производительности не должно быть. Тогда почему люди все же
применяют нестандартные варианты инструкций? Одним удобнее применять соединения, а
другие предпочитают подзапросы. Я обычно советую по мере возможности придерживаться
стандарта, пока у вас не появится очень веской причины поступать иначе — например, в
случае большой разницы в производительности.
Обновление данных
Язык T-SQL содержит стандартную инструкцию UPDATE, позволяющую обновлять строки в
таблице. Он также поддерживает нестандартные варианты использования инструкции
UPDATE с соединениями и переменными. В этом разделе рассказывается о различных при-
менениях инструкции UPDATE
В примерах, которые я привожу в данном разделе, используются созданные в базе данных
tempdb копии таблиц Orders (Заказы) и OrderDetails (Сведения о заказе) из базы данных
TSQLFundamentaIs2008.
Выполните следующий программный код для создания и заполнения этих таблиц:
USE tempdb;
IF OBJECT_ID('dbo.OrderDetails
1
, 'U') IS NOT NULL DROP TABLE
dbo.OrderDetails;
IF OBJECT_ID('dbo.Orders
1
,
f
U') IS NOT NULL DROP TABLE dbo.Orders;
254
Гпава 8
SELECT * INTO dbo.Orders FROM TSQLFundamentals2008.Sales.Orders;
SELECT * INTO dbo.OrderDetails FROM
TSQLFundamentals2008.Sales.OrderDetails;
ALTER TABLE-dbo.Orders ADD
CONSTRAINT PK_Orders PRIMARY KEY(orderid);
ALTER TABLE dbo.OrderDetails ADD
CONSTRAINT PK__OrderDetails PRIMARY KEY(orderid, productid),
CONSTRAINT FK_OrderDetails_Orders FOREIGN KEY(orderid)
REFERENCES dbo.Orders(orderid);
Инструкция UPDATE
Инструкция UPDATE — это стандартная инструкция, позволяющая обновлять подмножество
строк в таблице. Для указания подмножества строк, предназначенных для обновления, зада-
ется предикат в элементе WHERE. В элементе SET столбцам, разделенным запятыми, при-
сваиваются значения или выражения.
Например, следующая инструкция UPDATE увеличивает на пять процентов скидку для всех
товаров с идентификатором 51, включенных в заказы:
USE tempdb;
UPDATE dbo.OrderDetails
SET discount = discount + 0.05
WHERE productid = 51;
Конечно, для того чтобы проследить за изменениями, вы можете выполнить инструкцию
SELECT с тем же фильтром до и после обновления. Позже в этой главе я покажу другой спо-
соб отображения изменений с помощью элемента OUTPUT, который вы сможете вставлять в
инструкции, изменяющие данные.
В версии SQL Server 2008 появилась поддержка составных операторов присваивания: +=
(плюс равно), -= (минус равно), *= (умножить равно), /= (делить равно,) и %= (остаток рав-
но), позволяющих сократить выражения присваивания, подобные приведенному в преды-
дущем запросе. Вместо выражения
discount = discount + 0.05
можно использовать сокращенную форму:
discount += 0.05
Полная инструкция UPDATE ВЫГЛЯДИТ следующим образом:
UPDATE dbo.OrderDetails
SET discount += 0.05
WHERE productid = 51;
При написании инструкций UPDATE всегда следует помнить об одновременно выполняемых
операциях, важной особенности языка SQL. Я пояснял ее в главе 2 применительно к инст-
Модификация данных
255
рукции SELECT, но она в той же мере подходит и к инструкциям UPDATE. Суть этой идеи в
том, что все выражения в одной и той же стадии логической обработки как будто вычисля-
ются в один и тот же момент времени. Для уяснения важности этой концепции рассмотрим
следующую инструкцию UPDATE:
UPDATE dbo.Tl
SETcoll=coll+10,col2=coll+10;
Предположим, что в одной строке таблицы до обновления в столбце coll содержится зна-
чение 100, а в столбце со12 — значение 200. Можете вы определить значения в этих столб-
цах после обновления?
Если не принимать во внимание концепцию одновременно выполняемых операций, можно
решить, что столбцу coll будет присвоено значение 110, а столбцу со12 — значение 120,
как будто присваивания выполнялись слева направо. Но присваивания выполняются одно-
временно, т. е. оба присваивания используют одно и то же значение столбца coll, т. е. зна-
чение, существующее до обновления. Результат этого обновления заключается в том, что
столбцы coll и со12 получат значение 110.
С учетом концепции одновременно выполняемых операций можете ли вы догадаться, как
написать инструкцию UPDATE, которая меняет местами значения в столбцах coll и со12?
В большинстве языков программирования, выражения и присваивания в которых выполня-
ются в некотором порядке (как правило, слева направо), вам потребуется временная пере-
менная. Но в языке SQL все присваивания выполняются в один и тот же момент времени,
поэтому решение выглядит очень просто:
UPDATE dbo.Tl
SET coll = col2, col2 = coll;
В обоих присваиваниях используются значения столбцов, существовавшие до обновления,
поэтому вам не нужна временная переменная.
UPDATE на основе соединения
Аналогично инструкции DELETE ЯЗЫК T-SQL поддерживает инструкции UPDATE С нестан-
дартной синтаксической записью, базирующейся на соединениях. Как и в случае инструк-
ции DELETE, соединение служит для отбора строк.
Синтаксическая запись очень похожа на запись инструкции SELECT, основанной на соеди-
нении, т. е. элементы FROM и WHERE такие же, но вместо команды SELECT ВЫ задаете коман-
ду UPDATE. За ключевым словом UPDATE следует псевдоним таблицы, предназначенной для
обновления (в одной и той же инструкции нельзя обновить более одной таблицы), а далее
указывается элемент SET С присваиваниями значений столбцам.
Например, инструкция UPDATE В листинге 8.1 увеличивает на 5% скидку на все товары зака-
зов, сделанных клиентом 1.
I Листинг 8.1. UPDATE на базе JOIN
s
UPDATE OD
SET discount = discount + 0.05
256
Гпава 8
FROM dbo.OrderDetails AS OD
JOIN dbo.Orders AS 0
ON OD.orderid = 0.orderid
WHERE custid = 1;
Для "прочтения" или интерпретации запроса начните с элемента FROM, затем перейдите к
элементу WHERE И заканчивайте элементом UPDATE. Запрос соединяет таблицу
OrderDetails (Сведения о заказе), с псевдонимом 0D, с таблицей Orders (Заказы), с псев-
донимом о, на основе совпадения ID заказа из таблицы со сведениями о заказе с ID заказа из
таблицы заказов. Затем запрос отбирает только те строки, в которых ID клиента равен. 1.
Далее задается запрос на обновление таблицы 0D (псевдоним таблицы OrderDetails), и
скидка увеличивается на 5%.
Если вы хотите решить ту же задачу, используя стандартный программный код, вам потре-
буется вместо соединения применить подзапрос:
UPDATE dbo.OrderDetails
SET discount = discount + 0.05
WHERE EXISTS
(SELECT * FROM dbo.Orders AS О
WHERE 0.orderid = OrderDetails.orderid
AND custid = 1);
Элемент запроса WHERE отбирает компоненты заказов, сделанных клиентом 1. В этой кон-
кретной задаче SQL Server, скорее всего, будет интерпретировать обе версии решения оди-
наково. Следовательно, вас не должна беспокоить разнииа в их производительности. Пред-
почитаемое вами решение зависит от того, что вам больше нравится: соединения или
подзапросы. Как я уже упоминал, при обсуждении инструкции DELETE, мой совет— отда-
вать предпочтение стандартному программному коду, если у вас нет веской причины посту-
пать иначе. В нашей теперешней задаче я такой причины не вижу.
Однако в некоторых случаях версия с соединением будет более производительна, чем вер-
сия с подзапросом. В дополнение к фильтрации соединение предоставляет доступ к атрибу-
там из других таблиц, которые вы сможете использовать в элементе SET ДЛЯ присваивания
значений столбцам. Одно и то же обращение к другой таблице может обеспечивать как от-
бор строк, так и получение значений атрибутов из другой таблицы для последующих при-
сваиваний. Но в методе с подзапросом у каждого подзапроса— самостоятельный доступ к
другой таблице, таков метод обработки подзапросов, реализуемый современными версиями
механизма управления SQL Server.
Например, рассмотрим следующую нестандартную инструкцию UPDATE, основанную на
соединении:
UPDATE Tl
SET coll = T2.coll,
col2 = T2.col2,
col3 = T2.col3
FROM dbo.Tl JOIN dbo.T2
ON T2.keycol = Tl.keycol
WHERE T2.col4 = 'ABC';
Модификация данных
257
Эта инструкция соединяет таблицы Т1 и Т2, основываясь на совпадении Tl. keycol и
т2. keycol. Элемент WHERE отбирает только те строки, в которых значение T2 . col4 рав-
но •ABC'. Инструкция UPDATE помечает таблицу T1 как предназначенную для обновле-
ния, и элемент SET присваивает столбцам coll, со12 и со13 из таблицы T1 значения со-
ответствующих столбцов из таблицы T2.
Попытка описать эту задачу стандартным программным кодом с помощью подзапросов
приведет к следующему громоздкому решению:
UPDATE dbo.Tl
SET coll = (SELECT coll
FROM dbo.T2
WHERE T2.keycol = Tl.keycol),
col2 = (SELECT col2
FROM dbo.T2
WHERE T2.keycol = Tl.keycol),
col3 = (SELECT col3
FROM dbo.T2
WHERE T2.keycol = Tl.keycol)
WHERE EXISTS
(SELECT *
FROM dbo.T2
WHERE T2.keycol = Tl.keycol
AND T2.col4 = 'ABC1);
Эта версия не только извилиста (по сравнению с версией, применяющей соединение), но и у
каждого подзапроса самостоятельное обращение к таблице Т2. Поэтому данная версия ме-
нее эффективна, чем решение с соединением.
В языке ANSI SQL есть поддержка конструкторов строк (также называемых векторными
выражениями), которые, как я уже упоминал, были лишь частично реализованы в версии
SQL Server 2008. До сих пор многие функции конструкторов строк не реализованы в SQL
Server, включая возможность их применения в элементе SET инструкции UPDATE следую-
щим образом:
UPDATE dbo.Tl
SET (coll, col2, col3) =
(SELECT coll, col2, col3
FROM dbo.T2
WHERE T2.keycol = Tl.keycol)
WHERE EXISTS
(SELECT *
258
Гпава 8
FROM dbo.T2
WHERE T2.keycol = Tl.keycol
AND T2.col4 = 'ABC1);
Но как видите, этот вариант все равно сложнее версии с соединением, поскольку требует
отдельных подзапросов для отбора строк и для получения из другой таблицы атрибутов для
присваиваний.
Присваивание в UPDATE
Язык T-SQL поддерживает собственную синтаксическую запись инструкции UPDATE, кото-
рая одновременно и обновляет данные в таблице, и присваивает значения переменным. Эта
запись избавляет вас от необходимости применять отдельные инструкции UPDATE И SELECT
для решения этой задачи.
Один из распространенных случаев применения такой синтаксической записи — поддержка
механизма пользовательской последовательности/автонумерации, когда по какой-либо при-
чине не работает свойство идентификации столбца. Идея заключается в сохранении послед-
него использованного в таблице значения и применения этой специальной синтаксической
записи UPDATE для наращивания значения в таблице и присваивания переменной нового
значения.
Выполните следующий программный код для создания таблицы Sequence (Последователь-
ность) со столбцом val и последующего заполнения ее единственной строкой со значением
О, меньшим первого значения, которое вы хотите использовать:
USE tempdb;
IF OBJECT_ID('dbo.Sequence', 'U') IS NOT NULL DROP TABLE dbo.Sequence;
CREATE TABLE dbo.Sequence(val INT NOT NULL);
INSERT INTO dbo.Sequence VALUES(0);
Теперь, когда вам нужно получить новое значение последовательности, используйте такой
программный код:
DECLARE @nextval AS INT;
UPDATE Sequence SET Gnextval = val = val + 1;
SELECT @nextval;
В программном коде объявляется локальная переменная Qnextval. Затем в нем применяет-
ся специальная синтаксическая запись инструкции UPDATE для увеличения на 1 значения
столбца и присваивания обновленного значения столбца переменной с последующим пред-
ставлением ее значения. Присваивания в элементе SET выполняются справа налево, т. е.
сначала val присваивается val + 1, затем результат (val + 1) присваивается переменной
Gnextval.
Инструкция UPDATE со специальным синтаксисом выполняется как атомарная операция, она
более эффективна, чем применение отдельных инструкций UPDATE И SELECT, Т. к. обраща-
ется к данным всего один раз.
Модификация данных
259
Слияние данных
В версию SQL Server 2008 включена инструкция MERGE, позволяющая изменять данные,
применяя разные действия (INSERT, UPDATE, DELETE), на основании условной логики. Ин-
струкция MERGE — это часть стандарта языка SQL, хотя в версию языка T-SQL добавлено
несколько нестандартных расширений этой инструкции.
Поскольку эта инструкция — нововведение, для решения примеров этого раздела следует
пользоваться версией SQL Server 2008. Задача, решаемая одной инструкцией MERGE, В более
ранних версиях SQL Server обычно преобразуется в комбинацию нескольких других инст-
рукций языка манипулирования данными DML (INSERT, UPDATE, DELETE). Преимущество
применения MERGE заключается в возможности задания запроса с помощью более короткого
и эффективного программного кода, поскольку этой инструкции требуется меньше обраще-
ний к обрабатываемым таблицам.
Для демонстрации инструкции MERGE Я буду использовать таблицы Customers (Клиенты) и
CustomersStage (Часть клиентов). Выполните программный код из листинга 8.2 для соз-
дания этих таблиц в базе данных tempdb и заполнения их тестовыми данными.
j Листинг 8.2. Программа создания и заполнения таблиц Customers
j И CustomersStage
USE tempdb;
IF OBJECT_ID(1 dbo.Customers', 'U') IS NOT NULL DROP TABLE dbo.Customers;
GO
CREATE TABLE dbo.Customers
(
custid INT NOT NULL,
companyname VARCHAR(25) NOT NULL,
phone
VARCHAR(20) NOT NULL,
address
VARCHAR(50) NOT NULL,
CONSTRAINT PK_Customers PRIMARY KEY(custid)
);
INSERT INTO dbo.Customers(custid, companyname, phone, address)
VALUES
(1, 'cust 1\ '(HI) 111-1111', 'address 1'),
(2, 'cust 2', '(222) 222-2222', 'address2'),
(3, 'cust 3\ '(333) 333-3333', 'address 3'),
(4,
1
cust 41
, '(444) 444-4444', 'address 4
f
),
(5, 'cust 5\ '(555) 555-5555', 'address 5');
260
Гпава 8
IF OBJECT_ID(' dbo.CustomersStage
1
, 'U') IS NOT NULL DROP TABLE
dbo.CustomersStage;
GO
CREATE TABLE dbo.CustomersStage
(
custid INT NOT NULL,
companyname VARCHAR(25) NOT NULL,
phone
VARCHAR (20) NOT NULL,
address
VARCHAR(50) NOT NULL,
CONSTRAINT PK_CustomersStage PRIMARY KEY(custid)
);
INSERT INTO dbo.CustomersStage(custid, companyname, phone, address)
VALUES
(2,
f
AAAAA1
,
f
(222) 222-2222
1
, 'address 2'),
(3,
1
cust 3*,
e
(333) 333-3333', 'address 3'),
(5, 'BBBBB', 'CCCCC', 'DDDDD
1
),
-(6, 'cust 6 (new)', '(666) 666-6666', 'address 6'),
(7, 'cust 7 (new)', '(777) 777-7777', 'address 7');
Выполните следующий запрос для просмотра содержимого таблицы Customers (Клиенты):
SELECT * FROM dbo.Customers;
Этот запрос вернет такой результат:
custid
companyname
phone
address
1
cust 1
(111) 111-1111
address 1
2
cust 2
(222) 222-2222
address 2
3
cust 3
(333) 333-3333
address 3
4
cust 4
(444) 444-4444
address 4
5
cust 5
(555) 555-5555
address 5
Выполните следующий запрос для просмотра содержимого таблицы CustomersStage
(Часть клиентов):
SELECT * FROM dbo.CustomersStage;
Этот запрос вернет такой результат:
custid
companyname
phone
address
2
AAAAA
(222) 222-2222
address 2
3
cust 3
(333) 333-3333
address 3
5
BBBBB
CCCCC
DDDDD
6
cust 6 (new)
(666) 666-6666
address 6
7
cust 7 (new)
(777) 777-7777
address 7
Модификация данных
261
Задача первого примера с инструкцией MERGE, который я покажу, включает содержимое
таблицы Customers Stage (исходная таблица) в таблицу Customers (результирующая таб-
лица). Более конкретно, вы предполагаете добавить клиентов, которых нет в таблице, и об-
новить атрибуты клиентов, которые уже есть в таблице.
Если вы вполне освоили материал разделов, посвященных удалению и обновлению на базе
соединений, вы легко разберетесь в инструкции MERGE, семантика которой основывается
также на соединениях. В элементе MERGE задается имя результирующей таблицы, а в эле-
менте USING — имя исходной таблицы. Условие слияния задается предикатом в элементе
ON и очень похоже на то, что вы делаете в случае соединения. Условие слияния определяет,
у каких строк исходной таблицы есть соответствие со строками результирующей таблицы, а
у каких соответствия нет. В элементе WHEN MATCHED THEN определяется действие, пред-
принимаемое, если соответствие найдено, а в элементе WHEN NOT MATCHED THEN — дейст-
вие, выполняемое, если соответствия не найдено.
Далее приведен наш первый пример инструкции MERGE: добавление несуществующих кли-
ентов и обновление данных существующих клиентов:
MERGE INTO dbo.Customers AS TGT
USING dbo.CustomersStage AS SRC
ON TGT.custid = SRC.custid
WHEN MATCHED THEN
UPDATE SET
TGT.companyname = SRC.companyname,
TGT.phone = SRC.phone,
TGT.address = SRC.address
WHEN NOT MATCHED THEN
INSERT (custid, companyname, phone, address)
VALUES (SRC.custid, SRC.companyname, SRC.phone, SRC.address);
ПРИМЕЧАНИЕ
Инструкцию MERGE следует обязательно завершать точкой с запятой, в то время
как в большинстве других инструкций языка T-SQL такое завершение не обяза-
тельно. Но если вы следуете правилам хорошего стиля программирования (о ко-
торых я упоминал ранее в этой книге), рекомендующим завершать все инструкции
точкой с запятой, вас это замечание не касается.
В данной инструкции MERGE таблица Customers (Клиенты) определена как результирующая
таблица (элемент MERGE), а таблица CustomersStage (Часть клиентов)— как исходная
(элемент USING). Имейте в виду, что результирующей и исходной таблицам для краткости
можно присваивать псевдонимы (в нашем случае TGT И SRC). Предикат TGT. custid =
SRC. custid применяется для определения того, что считается соответствием и что считает-
ся несоответствием. В нашем запросе, если ID клиента из исходной таблицы присутствует и
в результирующей, это соответствие. Если ID клиента из исходной таблицы нет в результи-
рующей, это несоответствие.
Инструкция MERGE, когда соответствие найдено, задает операцию UPDATE, устанавливая
значения companyname (название компании), phone (телефон) и address (адрес) результи-
рующей таблицы равными значениям атрибутов соответствующей строки исходной табли-
262
Гпава 8
цы. Обратите внимание на то, что синтаксическая запись операции UPDATE похожа на обыч-
ную инструкцию UPDATE за исключением того,"что вам не нужно задавать имя обновляемой *
таблицы, поскольку оно уже определено в элементе MERGE.
Если соответствие не найдено, инструкция MERGE задает операцию INSERT, вставляя строку
из исходной таблицы в результирующую. И снова синтаксическая запись операции INSERT
похожа на обычную инструкцию INSERT за исключением того, что вам не нужно задавать
имя таблицы, которая служит целью операции, т. к. оно уже определено в элементе MERGE.
Наша инструкция MERGE сообщает о том, что были изменены пять строк:
(5 row(s) affected)
К ним относятся три строки, которые были обновлены (клиенты 2, 3 и 5), и две, которые
были добавлены (клиенты 6 и 7). Запросите таблицу Customers (Клиенты), чтобы увидеть
ее новое содержимое:
SELECT * FROM dbo.Customers;
Этот запрос вернет следующий результат:
custid
companyname
phone
" address
1
cust 1
(111) 111-1111
address 1
2
ААААА
(222) 222-2222
address 2
3
cust 3
(333) 333-3333
address 3
4
cust 4
(444) 444-4444
address 4
5
BBBBB
ССССС
DDDDD
6
cust 6 (new)
(666) 666-6666
address 6
7
cust 7 (new)
(777) 777-7777
address 7
Элемент WHEN MATCHED описывает, какое действие предпринять, когда исходная строка
соответствует результирующей строке. Элемент WHEN NOT MATCHED определяет действие,
предпринимаемое, когда исходная строка не соответствует результирующей строке. Язык Т-
SQL, кроме того, поддерживает третий синтаксический элемент WHEN NOT MATCHED BY
SOURCE. Предположим, к примеру, что вы хотите добавить логическое условие в наш при-
мер с инструкцией MERGE ДЛЯ удаления строк из результирующей таблицы, если они не со-
ответствуют строкам исходной таблицы. Вам всего лишь нужно добавить в элемент WHEN
NOT MATCHED BY SOURCE операцию DELETE следующим образом:
MERGE dbo.Customers AS TGT
USING dbo.CustomersStage AS SRC
ON TGT.custid = SRC.custid
WHEN MATCHED THEN
UPDATE SET
TGT. companyname = SRC. companyname,
TGT.phone = SRC.phone,
TGT.address = SRC.address
WHEN NOT MATCHED THEN
INSERT (custid, companyname, phone, address)
Модификация данных
263
VALUES (SRC.custid, SRC.companyname, SRC.phone, SRC.address)
WHEN NOT MATCHED BY SOURCE THEN
DELETE;
Запросите содержимое таблицы Customers (Клиенты), чтобы увидеть результат выполне-
ния инструкции MERGE:
SELECT * FROM dbo.Customers;
Этот запрос вернет результат, показывающий, что клиенты 1 и 4 были удалены:
custid
companyname
phone
address
2
ААААА
(222) 222-2222
address 2
3
cust 3
(333) 333-3333
address 3
5
BBBBB
CCCCC
DDDDD
6
cust 6 (new)
(666) 666-6666
address 6
7
cust 7 (new)
(777) 777-7777
address 7
Если вернуться назад к нашему первому примеру с инструкцией MERGE, который обновляет
данные имеющихся клиентов и добавляет в таблицу отсутствующих клиентов, можно заме-
тить, что он реализован не самым эффективным способом. Перед обновлением атрибутов
имеющихся клиентов инструкция не проверяет, действительно ли значения столбцов нуж-
даются в изменении. Это означает, что строка с данными клиента обновляется, даже когда
строки исходной и результирующей таблиц идентичны. В элементы, задающие выполняе-
мые операции, можно добавлять предикаты с помощью необязательного ключевого слова
AND; операция будет выполняться, только если помимо первоначального условия добавлен-
ный предикат равен TRUE. В нашем случае необходимо добавить в элемент WHEN MATCHED
AND предикат, который проверяет, изменится ли хотя бы один атрибут, оправдывая тем са-
мым операцию UPDATE. Полная инструкция MERGE выглядит так:
MERGE dbo.Customers AS TGT
USING dbo.CustomersStage AS SRC
ON TGT.custid = SRC.custid
WHEN MATCHED AND
(TGT.companyname <> SRC.companyname
OR TGT.phone <> SRC.phone
OR TGT.address <> SRC.address) THEN
UPDATE SET
TGT.companyname = SRC.companyname,
TGT.phone = SRC.phone,
TGT.address = SRC.address
WHEN NOT MATCHED THEN
INSERT (custid, companyname, phone, address)
VALUES (SRC.cus tid, SRC.companyname, SRC.phone, SRC.addres s);
Как видите, у инструкции MERGE мощные функциональные возможности, позволяющие
описывать логику модификации в более коротком программном коде и с большей эффек-
тивностью, чем у альтернативных вариантов.
264
Гпава 8
Модификация данных
с помощью табличных выражений
SQL Server не ограничивает действия с табличными выражениями (производными таблица-
ми ОТВ, представлениями и подставляемыми табличными функциями, определенными
пользователем) только инструкцией SELECT, НО также допускает их применение и в других
инструкциях DML (INSERT, UPDATE, DELETE И MERGE). Подумайте об этом: табличное вы-
ражение на самом деле не содержит данных, оно — лишь отражение данных, хранящихся в
базовых таблицах. Держа это в уме, представьте себе изменение данных в табличном выра-
жении как модификацию данных во внутренних таблицах через табличное выражение. Как и
в случае инструкции SELECT, обращенной к табличному выражению, в инструкции, изме-
няющей данные, определение табличного выражения раскрывается, поэтому на деле обра-
батываются базовые таблицы, лежащие в основе табличного выражения.
Модификация данных через табличные выражения имеет несколько логических ограниче-
ний.
• Если запрос, определяющий табличное выражение, соединяет таблицы, в одной инст-
рукции модификации данных допустимо воздействовать только на одну из сторон со-
единения, а не на обе.
П Нельзя обновлять столбец, являющийся результатом вычислений; SQL Server не пыта-
ется аннулировать расчетные значения.
П Через табличное выражение нельзя вставить строку, если табличное выражение не со-
держит хотя бы один столбец, не получающий свое значение автоматически (например,
как значение по умолчанию, в нем допустимы значения NULL ИЛИ определено свойство
IDENTITY).
Другие требования см. в интерактивном справочном руководстве SQL Server Books Online.
Они, как видите, не лишены смысла.
Теперь, когда вы знаете, что можете модифицировать данные с помощью табличных выра-
жений, осталось понять, зачем вам это? Одна из причин — облегчение отладки и поиска и
устранения неисправностей. Например, листинг 8.1 содержал следующую инструкцию
UPDATE:
USE tempdb;
UPDATE OD
SET discount = discount +0.05
FROM dbo.OrderDetails AS OD
JOIN dbo.Orders AS О
ON OD.orderid = O.orderid
WHERE custid = 1;
Предположим, что для проверки возможных ошибок вы сначала хотите увидеть, какие стро-
ки будут изменяться этой инструкцией, но не модифицировать их на самом деле. Один из
вариантов — заменить инструкцию в программном коде на SELECT и после проверки кода
снова вернуть инструкцию UPDATE. НО вместо многочисленных переходов от SELECT к
UPDATE И обратно можно просто применить табличное выражение. Это означает, что вы
Модификация данных
265
можете определить табличное выражение на основе запроса, содержащего инструкцию
SELECT с соединением, и задать инструкцию UPDATE по отношению к табличному выраже-
нию. В следующем примере используется ОТВ (поддерживается, начиная с версии SQL
Server 2005):
WITH С AS
(
SELECT custid, OD.orderid,
productid, discount, discount + 0.05 AS newdiscount
FROM dbo.OrderDetails AS OD
JOIN dbo.Orders AS О
ON OD.orderid = O.orderid
WHERE custid = 1
)
UPDATE С
SET discount = newdiscount;
Далее приведен пример с использованием производной таблицы (поддерживается в версиях,
предшествующих SQL Server 2005):
UPDATE D
SET discount = newdiscount
FROM (SELECT custid, OD.orderid,
productid, discount, discount + 0.05 AS newdiscount
FROM dbo.OrderDetails AS OD
JOIN dbo.Orders AS О
ON OD.orderid = O.orderid
WHEREcustid=1)ASD;
С табличным выражением гораздо проще находить изъяны в программах, потому что всегда
можно выделить только инструкцию SELECT, определяющую табличное выражение, и вы-
полнить ее без каких-либо изменений данных. В данном примере табличные выражения
применяются только для удобства. Но в ряде задач использование табличного выражения —
единственно возможный вариант. Для демонстрации подобной задачи я воспользуюсь таб-
лицей Tl, которую можно создать и заполнить, выполнив следующий программный код:
USE tempdb;
IF OBJECT_ID('dbo.Tl', 'U') IS NOT NULL DROP TABLE dbo.Tl;
CREATE TABLE dbo.Tl(coll INT, col2 INT) ;
GO
INSERT INTO dbo.Tl(coll) VALUES(10);
INSERT INTO dbo.Tl(coll) VALUES(20);
INSERT INTO dbo.Tl(coll) VALUES(30);
SELECT * FROM dbo.Tl;
266
Гпава 8
Последний запрос вернет следующий результат, отображающий текущее содержимое таб-
лицы Tl:
coll
со12
10
NULL
20
NULL
30
'NULL
Предположим, что вы хотите обновить таблицу, присвоив col2 результат выражения с
функцией ROW_NUMBER. Проблема состоит в том, что в элементе SET инструкции UPDATE не
допускается применение функции ROW_NUMBER. Попробуйте выполнить следующий про-
граммный код:
UPDATE dbo.Tl
SET со12 = ROW_NUMBER() OVER(ORDER BY coll);
Вы получите сообщение об ошибке:
Msg 4108, Level 15, State 1, Line 2
Windowed functions can only appear in the SELECT or ORDER BY clauses.
Для того чтобы обойти проблему, определите табличное выражение, возвращающее как
столбец, который нужно обновить (col2), так и результирующий столбец, основанный на
выражении с функцией ROW NUMBER (назовите его rownum). Внешней инструкцией, обра-
щающейся к табличному выражению, будет инструкция UPDATE, присваивающая со 12 зна-
чение rownum. Далее показано, как выглядит программный код, использующий ОТВ:
WITH С AS
(
SELECT coll, со12, ROW_NUMBER() OVER(ORDER BY coll) AS rownum
FROM dbo.Tl
)
UPDATE С
SET со12 = rownum;
Создайте запрос к таблице, чтобы увидеть результат обновления:
SELECT * FROM dbo.Tl;
Вы получите следующий результат:
coll
со12
10
1
20
2
30
3
Имейте в виду, для выполнения этих примеров вам понадобится версия SQL Server 2005 или
SQL Server 2008, потому что и ОТВ, и функция ROW_NUMBER появились только в версии
SQL Server 2005.
Модификация данных
267
Модификации с помощью элемента ТОР
В версии SQL Server 2005 появилась возможность применять необязательный элемент ТОР в
инструкциях модификации данных: INSERT, UPDATE И DELETE. Версия SQL Server 2008 рас-
пространяет эту возможность и на инструкцию MERGE. Когда используется элемент ТОР,
SQL Server останавливает обработку инструкции модификации, как только обработана за-
данная процентная доля строк. К сожалению, в отличие от инструкции SELECT в инструкци-
ях, модифицирующих данные, вы не можете задать логический элемент ORDER BY для вари-
анта ТОР. По существу, строки, которые окажутся первыми при обращении SQL Server, и
будут затронуты модификацией.
Я покажу модификацию данных с использованием элемента ТОР на примере таблицы
Orders (Заказы), которую вы создадите в базе данных tempdb и заполните тестовыми дан-
ными, выполнив следующий программный код:
USE tempdb;
IF OBJECT_ID(1dbo.OrderDetails
1
,
f
U') IS NOT NULL DROP TABLE
dbo.OrderDetai1s;
IF OBJECT_ID(1dbo.Orders', 'U') IS NOT NULL DROP TABLE dbo.Orders;
SELECT * INTO dbo.Orders FROM TSQLFundamentals2008.Sales.Orders;
В приведенном далее примере показано применение инструкции DELETE С дополнительным
элементом ТОР для удаления 50 строк из таблицы Orders:
DELETE TOP(50) FROM dbo.Orders;
Поскольку в инструкции, модифицирующей данные, запрещено задавать логический эле-
мент ORDER BY для ТОР, этот запрос создает проблемы, т. к. вы не можете управлять выбо-
ром удаляемых строк. Это будут любые 50 строк из таблицы, к которым SQL Server случай-
но обратится к первым. Описанная проблема демонстрирует ограниченность применения
модификаций с элементом ТОР.
Аналогичным образом вы можете использовать дополнительный элемент ТОР в инструкциях
UPDATE и INSERT, но элемент ORDER BY в них тоже запрещен. Как пример инструкции
UPDATE с элементом ТОР следующий программный код обновляет 50 строк из таблицы
Orders (Заказы), увеличивая значения freight (стоимость перевозки) на 10:
UPDATE ТОР(50) dbo.Orders
SET freight = freight + 10.00;
И снова вы не сможете управлять выбором 50 обновляемых строк; это будут первые
50 строк, к которым случайно обратится SQL Server.
На практике вы, конечно же, следите за тем, какие строки обрабатываются, и не хотели бы,
чтобы они выбирались произвольно. Для того чтобы обойти эту проблему, можно использо-
вать возможность модификации данных через табличные выражения. Можно определить
"табличное выражение на базе запроса SELECT с элементом ТОР, который основан на логиче-
ском элементе ORDER BY, определяющем приоритет строк. Далее вы сможете применить
инструкцию модификации к полученному табличному выражению.
268
Гпава 8
Например, в следующем программном коде удаляются 50 заказов с наименьшими значе-
ниями ID заказа, а не просто любые 50 строк:
WITH С AS
( SELECT TOP(50) *
FROM dbo.Orders
ORDER BY ordered )
DELETE FROM C;
Аналогичным образом в следующем примере обновляются 50 заказов с наибольшими зна-
чениями ID заказа, в которых значения стоимости перевозки увеличиваются на 10.
WITH С AS
( SELECT TOP(50) *
FROM dbo.Orders
ORDER BY orderid DESC )
UPDATE С
SET freight = freight + 10.00;
Для получения того же эффекта в версиях, предшествующих SQL Server 2005, применяйте
вместо ОТВ производные таблицы.
Элемент OUTPUT
Обычно вы не ждете, что инструкция модификации будет делать что-то еще кроме измене-
ния данных. Иными словами, вы не ожидаете, что инструкция модификации вернет какой-
либо вывод. Однако в некоторых сценариях возможность получить данные из модифициро-
ванных строк была бы очень полезна.
Например, представьте себе возможность запросить инструкцию UPDATE О ТОМ, чтобы по-
мимо изменения данных она вернула старые и новые значения обновленных столбцов. Это
пригодилось бы для поиска и устранения неисправностей, проверки и других целей.
В версии SQL Server 2005 появилась такая возможность в виде элемента OUTPUT, который
вставляется в инструкцию, модифицирующую данные. В этом элементе задаются атрибуты
и выражения, которые нужно вернуть из модифицированных строк. SQL Server 2008 также
поддерживает элемент OUTPUT в новой инструкции MERGE.
Элемент OUTPUT во многом похож на элемент SELECT. Вы перечисляете атрибуты и выра-
жения на базе существующих атрибутов, которые хотите вернуть. Особенность синтаксиса
элемента OUTPUT состоит в том, что вам необходимо предварять имена атрибутов ключевы-
ми словами inserted (вставленные) или deleted (удаленные). В инструкции INSERT вы
вставляете inserted, в инструкции DELETE — deleted, а в инструкции UPDATE вы указы-
ваете deleted, если хотите получить представление строки до изменения, и inserted, если
намерены получить представление строки после изменения.
Элемент OUTPUT вернет требуемые атрибуты из модифицированных строк как результи-
рующий набор, во многом подобно инструкции SELECT. Если вы хотите направить резуль-
тирующий набор в таблицу, добавьте элемент INTO с именем результирующей таблицы.
Если же вы хотите вернуть измененные строки инициатору запроса и одновременно напра-
Модификация данных
269
вить копию в таблицу, задайте два элемента OUTPUT: ОДИН С элементом INTO, а другой без
него.
В следующих разделах будут приведены примеры использования элемента OUTPUT В разных
инструкциях, модифицирующих данные.
INSERT с OUTPUT
Примером инструкции INSERT, в которой полезен элемент OUTPUT, может быть ситуация, в
которой нужно вставить в таблицу набор строк с идентификационным столбцом и требуется
получить вывод всех сгенерированных идентификационных значений. Функция
SC0PE_IDENTITY возвращает только самое последнее идентификационное значение, сгене-
рированное в текущем сеансе, она мало поможет в получении всех идентификационных
значений, сгенерированных при вставке набора строк. Элемент OUTPUT существенно упро-
щает решение задачи. Перед демонстрацией этого варианта решения следует с помощью
приведенного далее программного кода создать таблицу Tl с идентификационным столбцом
keycol и еще одним столбцом datacol.
USE tempdb;
IF OBJECT_ID('dbo.Tl', 'U') IS NOT NULL DROP TABLE dbo.Tl;
CREATE TABLE dbo.Tl
о
(
keycol INT NOT NULL IDENTITY(1, 1) CONSTRAINT PK_T1 PRIMARY KEY,
datacol NVARCHAR(40) NOT NULL
);
Предположим, что вы хотите вставить в Tl результат запроса к таблице HR. Employees (Со-
трудники) из базы данных TSQLFundamentals2008. Для получения из инструкции INSERT
всех вновь сгенерированных идентификационных значений просто добавьте элемент
OUTPUT и задайте нужные вам атрибуты.
INSERT INTO dbo.Tl(datacol)
OUTPUT inserted.keycol, inserted.datacol
SELECT lastname
FROM TSQLFundamentals2008.HR.Employees
WHERE country = N'USA1;
Эта инструкция вернет следующий результирующий набор:
keycol
datacol
1
Davis
2
Funk
3
Lew
4
Peled
270
Гпава 8
5
Cameron
(5 row(s) affected)
Как я уже упоминал, вы также можете направить результирующий набор в таблицу. Таблица
может быть реальной таблицей, временной таблицей или табличной переменной. Если ре-
зультирующий набор хранится в результирующей таблице, вы можете манипулировать дан-
ными, запросив таблицу. Например, в следующем программном коде объявляется табличная
переменная @NewRows, один результирующий набор вставляется в таблицу Tl, а другой ре-
зультирующий набор, возвращенный элементом OUTPUT, направляется в табличную пере-
менную. Далее выполняется запрос к табличной переменной, просто чтобы увидеть храня-
щиеся в ней данные:
DECLARE @NewRows TABLE(keycol INT, datacol NVARCHAR(40));
INSERT INTO dbo.Tl(datacol)
OUTPUT inserted.keycol, inserted.datacol
INTO @NewRows
SELECT lastname
FROM TSQLFundamentals2008.HR.Employees
WHERE country = N
1
UK1;
SELECT* * FROM @NewRows;
Этот программный код вернет следующий результат, отображающий содержимое таблич-
ной переменной:
keycol
datacol
6
Buck
7
Suurs
8
King
9
Dolgopyatova
(4 row(s) affected)
DELETE с OUTPUT
Далее в примере показано применение элемента OUTPUT С инструкцией DELETE. Сначала
выполните программный код для создания в базе данных tempdb копии таблицы Orders
(Заказы) из базы данных TSQLFundamentals2008:
USE tempdb;
IF OBJECT_ID(1dbo.Orders
1
, 'U') IS NOT NULL DROP TABLE dbo.Orders;
SELECT * INTO dbo.Orders FROM TSQLFundamentals2008.Sales.Orders;
Модификация данных
271
В следующем программном коде удаляются все заказы, сделанные до 2008 г., и применяется
элемент OUTPUT для вывода атрибутов удаленных строк:
DELETE FROM dbo.Orders
OUTPUT
deleted.orderid,
deleted.orderdate,
deleted.empid,
deleted.custid
WHERE orderdate < •20080101';
Эта инструкция DELETE возвращает такой результирующий набор:
orderid
orderdate
empid
custid
10248
2006--07--04 00:; 00:: 00.
,000 5
85
10249
2006--07--05 00:: 00:
: 00.
.000
6
79
10250
2006--07--08 00:: 00:
: 00.
,000 4
34
10251
2006--07--08 00:: 00:
: 00.
.000
3
84
10252
2006--07--09 00:: 00:
:00-
.000 4
76
10400
2007--01--01 00:: 00:
: 00.
.000 1
19
10401
2007--01--01 00:: 00:
: 00.
.000 1
65
10402
2007--01--02 00:: 00:
: 00.
.000
8
20
10403
2007-
:
01--03 00:: 00:
: 00,
.000 4
20
10404
2007--01--03 00:: 00:
: 00.
.000 2
49
(560 row(s) affected)
Если вы хотите сохранить в архиве удаляемые строки, просто добавьте элемент INTO И за-
дайте имя таблицы-архива как место назначения.
UPDATE с OUTPUT
Применяя элемент OUTPUT С инструкцией UPDATE, МОЖНО ссылаться на отображение мо-
дифицируемой строки до изменения, предваряя имена атрибутов ключевым словом
deleted, и на отображение строки после изменения, задавая имена атрибутов с префик-
сом inserted. Таким образом, вы сможете вернуть как старые, так и новые значения об-
новляемых атрибутов.
Перед демонстрацией применения элемента OUTPUT В инструкции UPDATE выполните сна-
чала следующий программный код, создающий в схеме dbo базы данных tempdb копию
таблицы Sales .OrderDetails (Сведения о заказе) из базы TSQLFundamentals2008:
USE tempdb;
IF OBJECT_ID('dbo.OrderDetails
1
, 'U') IS NOT NULL DROP TABLE dbo.OrderDetails;
SELECT * INTO dbo.OrderDetails FROM TSQLFundamentals2008.Sales.OrderDetails;
272
Гпава 8
Приведенная далее инструкция UPDATE увеличивает на 5% скидку для всех компонентов
заказов с идентификатором товара 51 и, применяя элемент OUTPUT, возвращает ID товара,
старую скидку и новую скидку из модифицированных строк:
UPDATE dbo.OrderDetails
SET discount = discount +0.05
OUTPUT
inserted.productid,
deleted.discount AS olddiscount,
inserted.discount AS newdiscount
WHERE productid = 51;
Эта инструкция вернет следующий результат:
productid olddiscount newdiscount
51
0. ,000
0..050
51
0. ,150
0..200
51
0. ,100
0..150
51
0. ,200
0..250
51
0. ,000
0..050
51
0..150
0..200
51
0..000
0..050
51
0..000
0..050
51
0..000
0..050
51
0..000
0..050
(39 row(s) affected)
MERGE с OUTPUT
Элемент OUTPUT МОЖНО применять и с инструкцией MERGE, НО помните о том, что единст-
венная инструкция MERGE способна выполнять несколько разных операций DML, основан-
ных на логических условиях. Это означает, что одна инструкция MERGE может вернуть бла-
годаря элементу OUTPUT строки, сформированные разными операциями языка DML. Для
того чтобы установить, какая операция DML сформировала выходную строку, можно вы-
полнить в элементе OUTPUT функцию $ act ion, и она вернет строку, представляющую опе-
рацию ('INSERT1
,
1
UPDATE' или
1
DELETE1). Для того чтобы показать использование эле-
мента OUTPUT в инструкции MERGE, я воспользуюсь одним из примеров, приведенных в
разд. "Слияние данных"ранее в этой главе. Для выполнения этого примера сначала повтор-
но выполните листинг 8.2 для создания таблиц Customers (Клиенты) и CustomersStage
(Часть клиентов) в базе данных tempdb и заполнения их тестовыми данными.
В следующем программном коде содержимое таблицы CustomersStage вставляется в таб-
лицу Customers с обновлением атрибутов клиентов, присутствующих в таблице назначе-
ния, и добавлением клиентов, которых не было в таблице.
Модификация данных
273
MERGE INTO dbo.Customers AS TGT
USING dbo.CustomersStage AS SRC
ON TGT.custid = SRC.custid
WHEN MATCHED THEN
UPDATE SET
TGT. companyname = SRC. companyname,
TGT.phone = SRC.phone,
TGT.address = SRC.address
WHEN NOT MATCHED THEN
INSERT (custid, companyname, phone, address)
VALUES (SRC.custid, SRC.companyname, SRC.phone, SRC.address)
OUTPUT $action, inserted.custid,
deleted, companyname AS oldcompanyname,
insert ed. companyname - AS newcompanyname,
deleted.phone AS oldphone,
inserted.phone AS newphone,
deleted.address AS oldaddress,
inserted.address AS newaddress;
В данной инструкции MERGE применяется элемент OUTPUT для возврата старых и новых зна-
чений модифицированных строк. Конечно, в случае операций INSERT старых значений не
существует, поэтому все ссылки на удаленные атрибуты возвращают значения NULL. Функ-
ция $action сообщает о том, какая операция, UPDATE или INSERT, создала результирую-
щую строку. Далее приведен результат этой инструкции MERGE:
§action custid oldcompany newcompany oldphone newphone
oldaddress
newaddress
name
name
UPDATE 2
cust 2
UPDATE 3
cust 3
UPDATE 5
cust 5
INSERT 6
NULL
INSERT 7
NULL
AAAAA
cust 3
BBBBB
(222)
(222)
222-2222 222-2222
(333)
(333)
333-3333 333 -3333
(555)
555-5555
cust 6 (new) NULL
cust 7 (new) NULL
CCCCC
(666)
666-6666
(777)
777-7777
address 2
address 3
address 5
NULL
NULL
address 2
address 3
DDDDD
address 6
address 7
(5 row(s) affected)
Компонующий язык DML
Элемент OUTPUT возвращает результирующую строку для каждой модифицированной стро-
ки. Но если, скажем, для контроля нужно передать в таблицу только подмножество модифи-
274
Гпава 8
цированных строк? В версии SQL Server 2005 вы должны были отправлять все строки в
промежуточную таблицу и затем копировать нужное вам подмножество строк из промежу-
точной таблицы в контрольную. В версии SQL Server 2008 появилось средство, именуемое
компонующим DML и позволяющее пропускать стадию промежуточной таблицы, непо-
средственно вставляя в окончательную таблицу только нужное вам подмножество строк из
полного набора модифицированных строк.
Для демонстрации этой функциональной возможности вам придется сначала с помощью
следующего программного кода создать в схеме dbo базы данных tempdb копию таблицы
Production. Products (Товары) из базы данных TSQLFundamentals2008:
USE tempdb;
IF OBJECT_ID ('dbo. ProductsAudit', 'U') IS NOT NULL DROP TABLE
dbo.ProductsAudit;
IF OBJECT_ID('dbo.Products', 'U') IS NOT NULL DROP TABLE dbo.Products;
SELECT * INTO dbo.Products FROM TSQLFundamentals2008.Production.Products;
CREATE TABLE dbo.ProductsAudit
(
LSN INT NOT NULL IDENTITY PRIMARY KEY,
TS DATETIME NOT NULL DEFAULT (CURRENT_TIMESTAMP) ,
productid INT NOT NULL,
colname SYSNAME NOT NULL,
oldval SQL_VARIANT NOT NULL,
newval SQL_VARIANT NOT NULL
);
Предположим, что сейчас вам необходимо обновить все товары, поставляемые поставщи-
ком 1, увеличив их цену на 15%. Вам также нужно проконтролировать старые и новые зна-
чения обновленных товаров, но только тех, у которых старая цена была меньше 20, а новая
стала больше или равна 20.
Вы сможете получить этот результат, применив компонующий DML. Напишите инструк-
цию UPDATE с элементом OUTPUT И определите на базе инструкции UPDATE производную
таблицу. Затем напишите инструкцию INSERT SELECT, которая запрашивает производную
таблицу, отбирая только подмножество нужных строк. Далее приведено полное решение.
INSERT INTO dbo.ProductsAudit(productid, colname, oldval, newval)
SELECT productid, N
1
unitprice
1
, oldval, newval
FROM (UPDATE dbo.Products
SET unitprice *= 1.15
OUTPUT
inserted.productid,
deleted.unitprice AS oldval,
inserted.unitprice AS newval
WHERE SupplierID =1) AS D
WHERE oldval <20.0 AND newval >= 20.0;
Модификация данных
275
Вспомните прежние рассуждения в книге о логической обработке запросов и табличных
выражениях— результирующее мультимножество одного запроса может использоваться
как входное в последующих инструкциях SQL. В данном случае результат выполнения эле-
мента OUTPUT — это входное мультимножество для инструкции SELECT, а затем результат
инструкции SELECT вставляется в таблицу.
Выполните следующий программный код с запросом к таблице Products Audit (Контроль
товаров):
SELECT * FROM dbo.ProductsAudit;
Вы получите такой результат:
LSN TS
ProductID ColName
OldVal NewVal
1 2008-08-05 18:56:04.793 1
unitprice 18.00
20.70
2 2008-08 -05 18:56:04.793 2
unitprice 19.00
21.85
Обновлены были три товара, но только два из них были отобраны внешним запросом, сле-
довательно, только эти два товара были отслежены.
Резюме
В этой главе рассматривались различные аспекты модификации данных. Я описал вставку, об-
новление, удаление и слияние данных. Я также обсудил модификацию данных с помощью таб-
личных выражений, использование элемента ТОР В инструкциях, модифицирующих данные, и
возврат измененных строк с помощью элемента OUTPUT. В следующем разделе представлены
упражнения, чтобы вы смогли проверить на практике все, чему научились в этой главе.
Упражнения
В данном разделе предлагаются упражнения для практического применения материала, об-
суждавшегося в этой главе. Если явно не указано иначе, в упражнениях предполагается ис-
пользование базы данных tempdb.
Упражнение 8.1
Выполните следующий программный код для создания в базе данных tempdb таблицы
Customers (Клиенты):
USE tempdb;
IF OBJECT ID(1dbo.Customers
1
, 'U') IS NOT NULL DROP TABLE dbo.Customers;
CREATE TABLE dbo.Customers
(
276
Гпава 8
custid INT NOT NULL PRIMARY KEY,
companyname NVARCHAR(40) NOT NULL,
country NVARCHAR(15) NOT NULL,
region NVARCHAR(15) NULL,
city NVARCHAR(15) NOT NULL
);
Упражнение 8.2
Вставьте в таблицу Customers (Клиенты) строку со следующими значениями атрибутов:
•
custid: 100;
•
companyname: Company ABCDE;
•
country: USA;
П region: WA;
П city: Redmond.
Упражнение 8.3
Вставьте в таблицу Customers (Клиенты) в базе данных tempdb всех клиентов из таблицы
TSQLFundamentals2008 .Sales . Customers, сделавших заказы.
Упражнение 8.4
Примените инструкцию SELECT INTO для создания в схеме dbo базы данных tempdb табли-
цы Orders (Заказы) и заполнения ее заказами из таблицы Sales.Orders базы данных
TSQLFundamentals2008, которые были сделаны в 2006—2008 гг.
Упражнение 8.5
Удалите заказы, которые были помещены до августа 2006 г. (August 2006). Для получения
атрибутов orderid (id заказа) и orderdate (дата заказа) удаленных заказов используйте
элемент OUTPUT.
Предполагаемый результат:
orderid
orderdate
10248
2006-07-04 00:00:00.000
10249
2006-07-05 00:00:00.000
10250
2006-07-08 00:00:00.000
10251
2006-07-08 00:00:00.000
10252
2006-07-09 00:00:00.000
Модификация данных
277
10253
2006--07--10 00:00:00.000
10254
2006--07--11 00:00:00..000
10255
2006--07--12 00:00:00.ООО
10256
2006--07--15 00:00:00..000
10257
2006--07--16 00:00:00.,000
10258
2006--07--17 00:00:00.,000
10259
2006--07--18 00:00:00..000
10260
2006--07--19 00:00:00..000
10261
2006--07--19 00:: 00:00..000
10262
2006--07--22 00:00:00..000
10263
2006--07--23 00:: 00:00..000
10264
2006--07--24 00:00:00..000
10265
2006--07--25 00:: 00:00..000
10266
2006--07-26 00:: 00:
: 00.
.000
10267
2006--07--29 00:: 00:
: 00.
.000
10268
2006--07--30 00:: 00:
: 00,
.000
10269
2006--07-31 00:: 00:
: 00.
.000
(22 row(s) affected)
Упражнение 8.6
Удалите заказы, сделанные клиентами из Бразилии (Brazil).
Упражнение 8-7
Выполните следующий запрос к таблице Customers (клиенты) и обратите внимание на то,
что в некоторых строках в столбце region (регион) стоит значение NULL.
SELECT * FROM dbo.Customers;
Результат:
custid
companyname
country
region
city
1
Customer NRZBB Germany
NULL
Berlin
2
Customer MLTDN
Mexico
NULL
Mexico D.F.
3
Customer KBUDE Mexico
NULL
Mexico D.F.
4
Customer HFBZG UK
NULL
London
5
Customer HGVLZ Sweden
NULL
Lulea
6
Customer XHXJV Germany
NULL
Mannheim
7
Customer QXVLA France
NULL
Strasbourg
8
Customer QUHWH Spain
NULL
Madrid
9
Customer RTXGC France
NULL
Marseille
ЮЗак. 1032
278
Гпава 8
10
Customer EEALV Canada
ВС
Tsawassen
(90 row(s) affected)
Упражнение 8.8
Обновите таблицу Customers (Клиенты) и замените все значения NULL в атрибуте region
на значения '<None>\ Для отображения custid (id клиента), oldregion (старое значение
региона) и newregion (новое значение региона) примените элемент OUTPUT.
Предполагаемый результат:
custid
oldregion
newregion
1
NULL
<None>
2
NULL
<None>
3
NULL
<None>
4
NULL
<None>
5
NULL
<None>
6
NULL
<None>
7
NULL
<None>
8
NULL
<None>
9
NULL
<None>
11
NULL
<None>
12
NULL
<None>
13
NULL
<None>
14
NULL
<None>
16
NULL
<None>
17
NULL
<None>
18
NULL
<None>
19
NULL
<None>
20
NULL
<None>
23
NULL
<None>
24
NULL
<None>
25
NULL
<None>
26
NULL
<None>
27
NULL
<None>
28
NULL
<None>
29
NULL
<None>
30
NULL
<None>
39
NULL
<None>
40
NULL
<None>
41
NULL
<None>
44
NULL
<None>
Модификация данных
279
49
NULL
<None>
50
NULL
<None>
52
NULL
<None>
53
NULL
<None>
54
NULL
<None>
56
NULL
<None>
58
NULL
<None>
59
NULL
<None>
60
NULL
<None>
63
NULL
<None>
64
NULL
<None>
66
NULL
<None>
68
NULL
<None>
69
NULL
<None>
70
NULL
<None>
72
NULL
<None>
73
NULL
<None>
74
NULL
<None>
76
NULL
<None>
79
NULL
<None>
80
NULL
<None>
83
NULL
<None>
84
NULL
<None>
85
NULL
<None>
86
NULL
<None>
87
NULL
<None>
90
NULL
<None>
91
NULL
<None>
(58 row(s) affected)
Упражнение 8.9
Обновите все заказы, сделанные клиентами из Великобритании (UK), и присвойте их атри-
бутам shipcountry (страна доставки), shipregion (регион доставки) и shipcity (город
доставки) значения атрибутов country (страна), region (регион) и city (город) соответст-
вующих клиентов.
ГЛАВА 9
Транзакции и параллелизм
Эта глава посвящена транзакциям и их свойствам. В ней описывается, как Microsoft SQL
Server обрабатывает попытки параллельно работающих пользователей получить доступ к
одним и тем же данным. В главе поясняется, как SQL Server применяет блокировки для изо-
ляции противоречивых или несогласованных данных, как находить и устранять ситуации
блокирования и как управлять с помощью уровней изоляции степенью непротиворечивости
данных, которые вы получаете в результате запросов.
В этой главе также обсуждаются взаимоблокировки или тупиковые ситуации и способы сни-
жения их количества. Предлагаемый в этой главе материал — лишь введение в обсуждаемые
темы, многие их которых могут быть достаточно сложными. Более подробную информацию о
них можно найти в интерактивном справочном руководстве SQL Server Books Online.
Транзакции
Транзакция — это единый исполняемый блок, который может включать многочисленные
действия, запрашивающие и модифицирующие данные и возможно изменяющие их опреде-
ление.
Границы транзакции можно задавать явно и неявно. Начало транзакции задается явно с по-
мощью инструкции BEGIN TRAN. Конец транзакции задается явно инструкцией COMMIT
TRAN, если вы хотите подтвердить ее, и инструкцией ROLLBACK TRAN, если не хотите под-
тверждать ее (т. е. хотите отменить все изменения, внесенные транзакцией).
Далее приведен пример установки границ транзакции, состоящей из двух инструкций
INSERT:
BEGIN TRAN;
INSERT INTO dbo.Tl (keycol, coll, col2) VALUES(4, 101,
f
C');
INSERT INTO dbo.T2(keycol, coll, col2) VALUES(4, 201, 'X');
COMMIT TRAN;
Если не обозначить границы транзакции явно, SQL Server по умолчанию трактует каждую
отдельную инструкцию как транзакцию, иными словами, по умолчанию SQL Server авто-
матически фиксирует транзакцию в конце каждой одиночной инструкции. Изменить спо-
Транзакции и параллелизм
281
соб обработки SQL Server неявных транзакций можно с помощью параметра сеанса
IMPLICIT_TRANSACT IONS. По умолчанию этот параметр отключен. Если его включить,
то не нужно обозначать начало транзакции с помощью инструкции BEGIN TRAN, но обя-
зательно следует указать завершение транзакции с помощью инструкции COMMIT TRAN
ИЛИ ROLLBACK TRAN.
У транзакций есть четыре свойства: атомарность (Atomicity), непротиворечивость (Cmsis-
tency), изолированность (Isolation) и устойчивость или долговечность (Durability), обозна-
чаемые аббревиатурой ACID.
П Атомарность. Транзакция— атомарный элемент исполнения. Либо все изменения,
включенные в транзакцию, принимаются, либо не принимается ни одно из них. Если
система выходит из строя до завершения транзакции (до того, как инструкция фиксации
записана в журнал транзакций), при перезагрузке SQL Server аннулирует все внесенные
изменения. Если в процессе выполнения транзакции обнаруживаются ошибки, обычно,
за редким исключением, SQL Server автоматически выполняет откат транзакции. Неко-
торые ошибки не считаются настолько серьезными, чтобы вызвать автоматический от-
кат транзакции, к ним относятся нарушения первичного ключа, превышение времени
ожидания блокировки (которое будет обсуждаться позже в этой главе) и т. д. Для пере-
хвата подобных ошибок и совершения некоторого ряда действий (например, регистра-
ции ошибки и отмены транзакции) можно использовать программный код, предназна-
ченный для обработки ошибок. Обзор методов обработки ошибок приведен в главе 10.
ПРИМЕЧАНИЕ
В любой точке программного кода с помощью вызова функции @@TRANCOUNT можно
программно сообщить, находитесь ли вы в открытой транзакции. Функция вернет О,
если вы не находитесь в открытой транзакции, и значение, большее 0, в противном
случае.
•
Непротиворечивость. Термин "непротиворечивость" определяет состояние данных, к
которым СУРБД предоставляет доступ, когда параллельные транзакции модифицируют
и запрашивают их. Как вы, вероятно, догадываетесь, непротиворечивость— понятие
субъективное, зависящее от нужд вашего приложения. В разд. "Уровни изоляции" далее
в этой главе поясняется, какой уровень непротиворечивости вы получаете в SQL Server
по умолчанию и как контролировать непротиворечивость, если стандартное поведение
не подходит для вашего приложения.
•
Изолированность. Изоляция — это механизм, применяемый для управления доступом к
данным и обеспечения транзакциям доступа к данным, только если уровень непротиворе-
чивости соответствует ожидаемому. Для изоляции от других транзакций данных, модифи-
цируемых или извлекаемых одной транзакцией, SQL Server использует блокировки.
В разд. "Блокировки" далее в этой главе будет более подробно рассказано об изоляции.
П Долговечность или устойчивость. Изменения данных всегда сначала записываются в
журнал транзакций базы данных до того, как будут записаны в область данных базы
данных на диске. После записи инструкции фиксации в журнал транзакций на диске
транзакция считается долговечной или устойчивой, даже если изменение еще не внесе-
но в область данных на диске. Когда система стартует обычным образом или после сис-
темного сбоя, SQL Server проверяет журнал транзакций каждой базы данных и запуска-
ет процесс восстановления, состоящий из двух стадий: повторение сделанного (redo) и
282
Гпава 8
отмена сделанного (undo). Стадия повторения сделанного включает в себя повторное
внесение всех изменений, содержащихся в транзакции, инструкция фиксации которой
записана в журнал, а изменения еще не внесены в область данных. Стадия отмены
включает в себя откат изменений, включенных в транзакции, инструкция фиксации ко-
торых не была записана в журнал.
Например, в следующем программном коде определена транзакция, которая записывает
сведения о заказе в базу данных TSQLFundamentals2008:
USE TSQLFundamentals2008;
—
Начало новой транзакции
BEGIN TRAN;
—
Объявление переменной
DECLARE Gneworderid AS INT;
—
Вставка нового заказа в таблицу Sales.Orders
INSERT INTO Sales.Orders
(custid, empid, orderdate, requireddate, shippeddate,
shipperid, freight, shipname, shipaddress, shipcity,
shippostalcode, shipcountry)
VALUES
(85, 5, '20090212', '200903014 '20090216',
3, 32.38, N' Ship to 85-B', N'6789 rue de l"Abbaye', N'Reims',
N1103451
, N' France');
—
Сохранение ID нового заказа в переменной
SET Gneworderid = SCOPE_IDENTITY();
—
Возврат ID нового заказа
SELECT @neworderid AS neworderid;
—
Вставка строк нового заказа в таблицу Sales.OrderDetails
INSERT INTO Sales.OrderDetails
(orderid, productid, unitprice, qty, discount)
VALUES (@neworderid, 11, 14.00, 12, 0.000);
INSERT INTO Sales.OrderDetails
(orderid, productid, unitprice, qty, discount)
VALUES(@neworderid, 42, 9.80, 10, 0.000);
INSERT INTO Sales.OrderDetails
(orderid, productid, unitprice, qty, discount)
VALUES(@neworderid, 72, 34.80, 5, 0.000);
—
Фиксация транзакции
COMMIT TRAN;
Транзакции и параллелизм
283
Программный код транзакции вставляет строку с общей заголовочной информацией о зака-
зе в таблицу Sales. Orders (Заказы) и несколько строк со сведениями о компонентах, фор-
мирующими заказ, в таблицу Sales.OrderDetails (Сведения о заказе). ID нового заказа
SQL Server формирует автоматически, поскольку у столбца orderid (id заказа) есть свойст-
во идентификации (identity) Сразу после вставки новой строки в таблицу Sales.Orders
ID вновь созданного заказа сохраняется в переменной, и затем эта локальная переменная
используется при вставке строк в таблицу Sales.OrderDetails. Для контроля я добавил
инструкцию SELECT, которая возвращает ID формируемого заказа. Далее приведен резуль-
тат инструкции SELECT, выполненной после исполнения данного программного кода:
neworderid
11078
Учтите, что в данном примере нет обработки ошибок и нет условия для выполнения инст-
рукции ROLLBACK в случае возникновения ошибки. Транзакции можно заключать в конст-
рукцию TRY/CATCH для обработки ошибок. Обзор методов обработки ошибок см. в главе 10.
Когда закончите работать с примером, выполните следующий программный код для очист-
ки базы данных:
DELETE FROM Sales.OrderDetails
WHERE orderid > 11077;
DELETE FROM Sales.Orders
WHERE orderid > 11077;
DBCC CHECKIDENT (1 Sales.Orders
1
, RESEED, 11077);
Блокировки и блокирование
Для изоляции транзакций SQL Server применяет блокировки. В следующих разделах приво-
дятся подробные сведения о блокировках и поясняется, как находить и исправлять ситуации
блокирования, вызванные конфликтующими запросами на блокировку.
Блокировки
Блокировки — это средства управления, получаемые транзакцией для защиты ресурсов дан-
ных и препятствующие конфликтующему и несовместимому доступу к данным из других
транзакций. Сначала я опишу важные режимы блокировок, поддерживаемые SQL Server, и
их совместимость, а затем расскажу о типах блокируемых ресурсов.
Режимы блокировок и совместимость
Начиная изучение транзакций и параллелизма, прежде всего, следует усвоить два основных
режима блокировок: монопольная блокировка (exclusive) и совместная или разделяемая
284
Гпава 8
блокировка (shared). Другие режимы блокировок (обновления, предварительная или плани-
руемая и модификации схемы) сложнее и не будут обсуждаться в этой книге.
Когда вы пытаетесь модифицировать данные, ваша транзакция запрашивает монопольную
блокировку для ресурса данных, и если получает, то удерживает этот режим до завершения
транзакции. Монопольные блокировки называют так, потому что вы не можете получить
монопольную блокировку для ресурса с любым другим режимом блокировки, установлен-
ным другой транзакцией, и не можете установить для ресурса любой режим блокировки,
если другая транзакция поддерживает монопольную блокировку ресурса. Это стандартный
способ выполнения модификаций, и его нельзя изменить ни в отношении режима блокиров-
ки, требуемого для модификации ресурса данных (монопольный), ни в отношении продол-
жительности блокировки (до завершения транзакции).
При попытке чтения данных по умолчанию ваша транзакция запрашивает совместную или
разделяемую блокировку ресурса данных и снимает ее, как только инструкция чтения дан-
ного ресурса выполнена. Этот режим блокировки называют совместным или разделяемым,
т. к. множественные транзакции могут одновременно поддерживать совместные блокировки
одного и того же ресурса данных. Несмотря на то, что нельзя изменять режим блокировки и
время, требуемое для модификации данных, при чтении данных можно управлять способом
обработки блокировки. В разд. "Уровни изоляции" далее в этой главе дается подробное объ-
яснение этой возможности.
Взаимодействие блокировок транзакций называют совместимостью блокировок. В табл. 9.1
показана совместимость монопольных и совместных блокировок. В столбцах приводятся
предоставленные режимы блокировок, а в строках — запрашиваемые режимы блокировок.
Таблица 9,1. Совместимость монопольных и совместных блокировок
Запрашиваемый режим
Предоставлен
монопольный (X)
Предоставлен
совместный (S)
Удовлетворяется запрос на монопольный режим? Нет
Нет
Удовлетворяется запрос на режим совместного
использования?
Нет
Да
"Нет" в ячейке означает, что в запрашиваемом режиме отказано, т. е. запрашиваемый режим
несовместим с предоставленным режимом. "Да" в ячейке означает, что запрашиваемый режим
предоставляется, т. е. запрашиваемый режим совместим с предоставленным режимом. Более
подробную таблицу совместимости блокировок см. в разд. "Lock Compatibility" ("Совмести-
мость блокировок") интерактивного справочного руководства SQL Server Books Online.
Если кратко подытожить взаимосвязь блокировок, данные, модифицируемые одной транзак-
цией, не могут ни изменяться, ни читаться (по крайней мере, по умолчанию) другой транзак-
цией до тех пор, пока первая транзакция не завершится. Данные, читаемые одной транзакцией,
не могут модифицироваться другой транзакцией (по крайней мере, по умолчанию).
Типы блокируемых ресурсов
SQL Server способен блокировать ресурсы разных типов или уровней детализации. Могут
блокироваться ресурсы следующих типов: RID или ключ (строка), страница, объект (напри-
Транзакции и параллелизм
285
мер, таблица), база данных и др. Строки находятся на страницах, а страницы — это физиче-
ские блоки данных, содержащие табличные или индексные данные. Сначала освойте эти
типы ресурсов, а в дальнейшем можете перейти к освоению других типов блокируемых ре-
сурсов, таких как экстенты, области размещения и область динамически распределяемой
памяти или В-дерево.
Для установки блокировки ресурса определенного типа ваша транзакция должна сначала
установить предварительные или планируемые блокировки с тем же режимом на более
крупные порции данных (находящиеся на более высоких уровнях иерархии блокируемых
ресурсов). Например, для монопольной блокировки строки ваша транзакция сначала должна
установить предварительную монопольную блокировку для страницы, на которой находится
строка, и предварительную монопольную блокировку для объекта, владеющего этой стра-
ницей. Точно так же для установки совместной блокировки на определенном уровне иерар-
хии ресурсов вашей транзакции сначала необходимо установить предварительные совмест-
ные блокировки на более высоких уровнях иерархии этих ресурсов. Задача
предварительных блокировок — реальное обнаружение несовместимых запросов на блоки-
ровку на более высоких уровнях иерархии ресурсов и предотвращение предоставления по-
добных режимов. Например, если одна транзакция поддерживает блокировку строки, а дру-
гая запрашивает несовместимый режим блокировки для целой страницы или таблицы,
содержащей эту строку, SQL Server легко определит конфликт благодаря предварительным
блокировкам, которые первая транзакция установила для страницы и таблицы. Предвари-
тельные или планируемые блокировки не мешают запросам на блокировку на более низких
уровнях иерархии ресурсов. Например, предварительная блокировка страницы не помешает
другим транзакциям установить несовместимые режимы блокировок строк, находящихся на
этой странице. Таблица 9.2 расширяет таблицу несовместимых режимов блокировок (см.
табл. 9.1), добавляя предварительную монопольную (intent exclusive) и предварительную
совместную (intent shared) блокировки.
Таблица 9.2. Совместимость блокировок, включая Intent Locks
Запрашиваемый
режим
Предоставлен
монопольный
(X)
Предоставлен
совместный (S)
Предоставлен
предваритель-
ный моно-
польный (IX)
Предоставлен
предваритель-
ный совмест-
ный (IS)
Удовлетворяется
запрос на моно-
польный режим?
Нет
Нет
Нет
Нет
Удовлетворяется
запрос на совме-
стный режим?
Нет
Да
Нет
Да
Удовлетворяется
запрос на предва-
рительный моно-
польный режим?
Нет
Нет
Да
Да
Удовлетворяется
запрос на предва-
рительный совме-
стный режим?
Нет
Да
Да
Да
286
Гпава 8
SQL Server динамически определяет, ресурсы каких типов блокировать. Естественно, для
идеального параллелизма лучше всего блокировать только то, что нужно, а именно только
обрабатываемые строки. Но блокировкам требуются ресурсы оперативной памяти и затраты
на внутреннее управление, поэтому при выборе типов блокируемых ресурсов SQL Server
учитывает и параллелизм, и системные ресурсы.
SQL Server может сначала установить мелкие блокировки (например, строки или страницы) и
затем в определенных обстоятельствах попытаться расширить мелкие блокировки до более
крупных (например, таблицы). Расширение или распространение блокировки происходит, если
одна инструкция устанавливает, как минимум, 5000 блокировок и далее еще по 1250 новых
блокировок, если предыдущие попытки расширения блокировки были неудачны.
До появления SQL Server 2008 нельзя было явно отключить расширение блокировки, всегда
доходившее до уровня таблицы. В SQL Server 2008 для управления расширением блокиро-
вок МОЖНО С ПОМОЩЬЮ инструкции ALTER TABLE установить параметр LOCK_ESCALATION.
При желании вы можете отключить расширение блокировок или задать уровень таблицы
(по умолчанию) или раздела (partition), на котором возникает расширение блокировок. Фи-
зически таблица может быть организована в виде блоков меньшего размера, называемых
разделами.
Поиск и обнаружение блокирования
Если одна транзакция удерживает блокировку ресурса данных, а другая транзакция запра-
шивает несовместимую блокировку для этого же ресурса, запрос блокируется и запраши-
вающая сторона переходит в состояние ожидания. По умолчанию заблокированный запрос
ждет до тех пор, пока блокировщик не снимет конфликтующую блокировку. Позже в этой
главе я поясню, как можно определить в вашем сеансе время ожидания получения блоки-
ровки, если вы хотите ограничить время ожидания для заблокированного запроса.
Блокирование — нормальное явление в системе до тех пор, пока время ожидания приемле-
мо для заблокированных запросов. Но если, в конце концов, некоторые запросы ждут слиш-
ком долго, возможно потребуется найти и устранить блокирование, а также посмотреть,
можно ли что-то сделать для сокращения времени задержки. Например, долго выполняю-
щиеся транзакции в результате будут удерживать блокировки в течение долгого времени.
Можно попытаться сократить такие транзакции, вынося за границы транзакции действия,
которые предположительно не являются неотъемлемой частью блока исполнения. Ошибка в
приложении может привести к тому, что в некоторых обстоятельствах транзакция будет
оставаться открытой. Если такая ошибка обнаружена, ее можно устранить и тем самым
обеспечить завершение транзакции в любых ситуациях.
В этом разделе показана ситуация блокирования и процесс ее обнаружения и устранения.
Откройте три отдельных окна запросов в среде SQL Server Management Studio. (В данном
примере мы будем называть их Connection 1 (подключение), Connection 2 и Connection 3.)
Убедитесь, что вы подключили их все к учебной базе данных TSQLFundamentals2008.
USE TSQLFundamentа1s2 008;
В окне Connection 1 выполните следующий программный код для обновления строки в таб-
лице Production.Products (Товары), которое заключается в добавлении 1.00 к текущей
цене 19.00 единицы товара 2.
BEGIN TRAN;
Транзакции и параллелизм
287
UPDATE Production.Products
SET unitprice = unitprice + 1.00
WHERE productid = 2;
Для обновления строки ваш сеанс должен был установить монопольную блокировку, и если
обновление прошло успешно, значит, SQL Server предоставил вашему сеансу блокировку.
Напоминаю, что монопольные блокировки сохраняются до конца транзакции, а поскольку
транзакция остается открытой, блокировка продолжает удерживаться.
Выполните следующий программный код в окне Connection 2, чтобы попытаться запросить
ту же самую строку:
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
По умолчанию сеансу нужна совместная блокировка для чтения данных, но т. к. строка мо-
нопольно заблокирована другим сеансом и совместная блокировка несовместима с моно-
польной, ваш сеанс блокируется и вынужден ждать.
Предположим, что подобная ситуация произошла в вашей системе и заблокированный сеанс в
результате ждет долго, вероятно, вы захотите найти и устранить причину такого блокирования.
Я предлагаю запросы к объектам динамического управления, включая представления и функ-
ции, которые следует выполнить в окне Connection 3 для обнаружения ситуации блокирова-
ния.
Для получения сведений о блокировках, как тех, которые предоставлены в данный момент
сеансу, так и тех, получения которых сеансы ждут, запросите в окне Connection 3 представ-
ление динамического управления (DMV) sys. dm_tran_locks.
SELECT — примените * для изучения других имеющихся атрибутов
request_session_id
AS spid,
resource_type
AS restype,
resource_database_id
AS dbid,
DB_NAME (resource_database_id) AS dbname,
resource_description
AS res,
resource_associated_entity_id AS resid,
request_mode
AS mode,
request_status
AS status
FROM sys.dm_tran_locks;
Когда я выполнил этот программный код в своей системе (без других открытых окон запро-
сов), то получил следующий результат:
spid restype dbid dbname
res
resid
mode status
53 DATABASE 8
TSQLFundamentals2008
0
S
GRANT
52 DATABASE 8
TSQLFundamentals2008
0
S
GRANT
51 DATABASE 8
TSQLFundamentals2008
0
S
GRANT
54 DATABASE 8
TSQLFundamental s2008
0
S
GRANT
53 PAGE
8
TSQLFundamenta1s2008 1:127
72057594038845440 IS GRANT
288
Гпава 8
52 PAGE
В
TSQLFundainent al s200В 1:127
72057594038845440 IX GRANT
53 OBJECT 8
TSQLFundamentals200В
133575514
IS GRANT
52 OBJECT В
TSQLFundamentals2008
133575514
IX GRANT
52 KEY
8
TSQLFundamentals2008 (020068e8b274) 72057594038845440 X
GRANT
53 KEY
8
TSQLFundamentals2008 (020068e8b274) 72057594038845440 s
WAIT
Каждый сеанс обозначен уникальным ID серверного процесса (SPID). Определить SPID ва-
шего сеанса можно с помощью функции @@SPID. ЕСЛИ ВЫ работаете в графической среде
SQL Server Management Studio, то найдете SPID сеанса в расположенной внизу экрана стро-
ке состояния в круглых скобках справа от регистрационного имени и также в заголовке под-
ключенного окна запроса. Например, на рис. 9.1 показан моментальный снимок окна SQL
Server Management Studio, в котором SPID 53 расположен справа от регистрационного име-
ни QUANTUM\Gandalf.
^Microsoft Server ManagemeritStmlto
Pie fcdit у** £uery ftojert fcebug JooU Wflrxlow Community
:-J*» Query
&^^SjU
-J^lJ ^ £
,,
TSQLFundamentals2008
-
Execute *
s/Jp»j
^.siz^
'
Connect: - 1
SQLQueryl.sql ...Gandalf (53))*
SELECT orderid. orderdate FROH Sales.Orders.
. i Databases
3) -J System Databases
+] ^J Database Snapshots
В Г I TSQLFundamentab2006 i
Ж } Database Diagrams
~3 Tables
35 CJ System TabJes
Ш £3 dbo.Nums
i±} HR.Employees
f+] 13 Production.Categor
!+} £3 Production.Product*
Ш ГЗ Production.5upplter
lil Sales. Customers
•Si tU Sales. OrderDetals
В 'Л Sales.OrderDetaHs*
a £3 Sales.Orders
E- Ll
7 orderid (PK,
у custid (FK, i
f err>pid (FK,»
orderdate (
ti] requireddat
Ш shippeddaU
^ shipperid (F
freight (mot
i<L
{"
|[ ordcj^ j| tudwk'e
j
4
1
10248 | 2006-07-04 00:00:00.000
2 10249 ' 2006-07-05 00:00:00.000
2 10250 2006-07-08 ООШОО.ООО
4
10251 2006-07-08 00:00:00.000
S 10252 2006-07-09 00:00:00.000
6
10253 2006-07-10 00:00:00.000
7|r 10254 2006-07-11 00:00:00.000
di
«
in^
?mfufi7-i 7 nnnrvnn nnn
di
Ready
; QUANTUM (10.ORTM) j QUAMUM\Gandalf (53) : TSQlFundamentals2008
Cdl
00ю0:00 : 830 rows
Рис. 9.1. Окно SQL Server Management Studio
Как видно из результата запроса к представлению sys.dm_tran_locks, в данный момент
четыре сеанса (51—54) удерживают блокировки. Вы можете видеть следующее:
П тип заблокированного ресурса (например, для строки KEY В индексе);
П ID базы данных, в которой заблокирован ресурс; с помощью функции DB ^AME ЭТОТ ID
можно преобразовать в имя базы данных;
П ресурс и его ID;
Транзакции и параллелизм
289
•
режим блокировки;
•
блокировка предоставлена или сеанс ждет ее получения.
Учтите, что это лишь подмножество атрибутов представления. Я советую просмотреть и
другие его атрибуты, чтобы узнать, какая еще информация о блокировках доступна.
В результате моего запроса вы можете увидеть, что процесс 53 ждет получения совместной
блокировки для строки из учебной базы данных TSQLFundamentals2008. (Имя базы данных
получено с помощью функции DB NAME.) Обратите внимание на то, что процесс 52 удержи-
вает монопольную блокировку той же самой строки. Вы можете догадаться об этом, если
обратите внимание на то, что оба процесса блокируют строку с одинаковыми значениями
атрибутов res (ресурс) и resid (id ресурса). Можно выяснить, какая таблица используется,
если подняться наверх в иерархии блокировок для процесса 52 или 53 и просмотреть пред-
варительные блокировки для страницы и объекта (таблицы), содержащих эту строку. Мож-
но применить функцию OBJECT NAME ДЛЯ преобразования ID блокируемого объекта (в на-
шем случае 133575514), появляющегося в столбце resid, в его имя. Вы обнаружите, что в
процесс вовлечена таблица Production. Product (Товары).
Представление sys .dm_tran_locks только дает информацию об ID процессов, вовлечен-
ных в цепочку блокировок, и ничего больше. Для получения сведений о подключениях, свя-
занных с процессами, входящими в цепочку блокировок, запросите представление
sys. dm_exec_connections и отберите SPID этих процессов.
SELECT — используйте * для ознакомления
session_id AS spid,
connect_t ime,
last_read,
last_write,
most_recent_sql_handle
FROM sys.dm_exec_connections
WHERE session_id IN(52, 53);
Имейте в виду, что в моей системе в цепочку блокировок включены процессы 52 и 53. В
зависимости от того, что еще вы делаете в системе, вы можете получить ID разных процес-
сов. Когда вы выполните в своей системе запросы, которые я показал, убедитесь в том, что
вы заменили ID процессов теми, которые включены в ваши цепочки блокировок.
Данный запрос вернет следующий результат (разделенный на несколько частей для нагляд-
ности).
spid
connect_time
last_read
52
2008-06 -25 15:20:03.360 2008-06 -25 15:20:15.750
53
2008-06-25 15:20:07.300 2008-06-25 15:20:20.950
spid last_write
most_recent_sql_handle
52
2008-06-25 15:20:15.817
0x01000800DE2DB7lFB0936F05000000000000000000000000
53
2008-06 -25 15:20:07.327
0x0200000063FC7D052E09844778CDD615CFE7A2DlFB411802
290
Гпава 8
spid
most_recent_sql_handle
52
0x01000800DE2DB71FB0936F05000000000000000000000000
53
0x0200000063FC7D052E09844778CDD615CFE7A2D1FB411802
Предоставляемая вам информация о подключениях содержит следующие характеристики:
П время подключений;
•
время последнего чтения и записи;
П двоичное значение, равное идентификатору или маркеру самого последнего пакета SQL,
выполненного подключением. Вы передаете этот идентификатор как входной параметр
в табличную функцию sys. dm_exec_sql_text, и она возвращает пакет программного
кода, представленный данным идентификатором. Можно запросить табличную функ-
цию, передавая явно двоичный маркер, но, возможно, вы сочтете более удобным при-
менение табличной операции APPLY, описанной в главе 5, для применения табличной
функции к строке в каждом подключении следующим образом (выполняйте в окне
Connection 3).
SELECT session_id, text
FROM sys.dm_exec_connections
CROSS APPLY sys. dm_exec__sql_text (most_recent_sql_handle) AS ST
WHERE session_id IN(52, 53);
Когда я выполнил этот запрос, то получил следующий результат, отображающий последний
пакет или фрагмент программного кода, запускаемый каждым подключением, входящим в
цепочку блокировок:
session id text
52
BEGIN TRAN;
UPDATE Production.Products
SET unitprice = unitprice + 1.00
WHERE productid = 2;
53
(@1 tinyint)
SELECT [productid],[unitprice]
FROM [Production].[Products]
WHERE [productid]=G1
Заблокированный процесс 53 отображает запрос в состоянии ожидания, т. к. это последнее,
что выполнил процесс. Что же касается блокировщика, в нашем примере вы видите инст-
рукцию, вызвавшую проблему, но помните о том, что блокировщик может продолжить ра-
боту и последний выполненный пакет программного кода необязательно совпадет с инст-
рукцией, вызвавшей проблему.
Множество полезной информации о сеансах, участвующих в блокировании, вы найдете в
DMV-представлении sys. dm_exec_sessions.
Транзакции и параллелизм
291
Следующий запрос возвращает только небольшое подмножество доступных атрибутов этих
сеансов:
SELECT — используйте * для ознакомления
session_id AS spid,
login_time,
host_name,
pr ogr am_name,
login_name,
nt_us e r_name,
last_request_start_time,
last_request end_time
FROM sys.dm_exec_sessions
WHERE session_id IN(52, 53);
В данном примере этот запрос вернет результат, разделенный на несколько частей:
spid login_time
host_name
52 2008-06 -25 15:20:03.407 QUANTUM
53 2008-06-25 15:20:07.303 QUANTUM
spid
program_name
login_name
52
Microsoft SQL Server Management Studio - Query QUANTUM\Gandalf
53
Microsoft SQL Server Management Studio - Query QUANTUMXGandalf
spid nt username
last_request_start_time
las t_r e que s t_end_t ime
52
Gandalf
2008-06-25 15:20:15.703 2008-06-25 15:20:15.750
53
Gandalf
2008-06-25 15:20:20.693 2008-06-25 15:20:07.320
Приведенный результат содержит время регистрации сеанса, имя компьютера, имя про-
граммы, регистрационное имя, имя пользователя NT, время начала последнего запроса и
время завершения последнего запроса. Информация такого рода поможет вам понять, чем
занимаются сеансы.
Еще одно DMV-представление, которое вы, возможно, сочтете полезным для обнаружения
ситуации блокирования, — sys. dm exec requests. В этом представлении есть строка для
каждого активного запроса, включая заблокированные. Вы очень легко можете выделить
заблокированные запросы, т. к. значение атрибута blocking_session_id больше нуля.
Например, следующий запрос отбирает только заблокированные запросы:
SELECT — используйте * для изучения
session_id AS spid,
blocking_session_id,
command,
sql_handle,
292
Гпава 8
database_id,
wait_type,
wait_time,
wait_re source
FROM sys.dm_exec_requests
WHERE blocking_session_id > 0;
Этот запрос вернет следующий результат, разделенный на несколько частей:
spid
blocking_session_id
command
53
52
SELECT
spid
sql_handle
database_id
53
0x0200000063FC7D052E09844778CDD615CFE7A2DlFB411802 8
spid
wait_type
wait_time
wait_resource
53
LCK_M_S
1383760
KEY: 8:72057594038845440 (020068e8b274)
Вы легко можете установить сеансы, участвующие в цепочке блокировок, оспариваемый
ресурс, время ожидания заблокированного сеанса в миллисекундах и т. д.
Если нужно завершить блокирующий сеанс, — например, если вы поняли, что из-за ошибки
в приложении транзакция осталась открытой и ничто в приложении не может ее закрыть —
можно сделать это с помощью команды KILL <spid>. (Пока не делайте этого.)
Раньше я упоминал, что по умолчанию у сеанса нет заданного значения времени ожидания
блокировки. Если вы хотите ограничить время, в течение которого сеанс ожидает получения
блокировки, можно задать параметр сеанса LOCK_TIMEOUT. Время задается в миллисекун-
дах — 5000 для задания 5 с, 0 — для немедленного выхода из режима ожидания, -1
— для
неопределенного времени (по умолчанию) и т. д. Для опробования этого параметра сначала
остановите запрос в окне Connection 2, выбрав команду Cancel Executing Query (Отменить
выполняющийся запрос) из меню Query (Запрос) (или с помощью комбинации клавиш
<AIt>+<Break>). После отмены заблокированного запроса в окне Connection 2 выполните
следующий программный код для задания времени ожидания блокировки, равного 5 с, а
потом снова выполните запрос:
SET LOCK_TIMEOUT 5000;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
Запрос все равно блокируется, т. к. подключение Connection 1 все еще не завершило тран-
закцию обновления, но если в течение 5 с заблокированный запрос не будет удовлетворен,
SQL Server завершит его, и вы получите следующее сообщение об ошибке:
Msg 1222, Level 16, State 51, Line 3
Lock request time out period exceeded.
Транзакции и параллелизм
293
Учтите, что превышение допустимого времени ожидания блокировки не приводит к откату
транзакций.
Для удаления значения времени ожидания блокировки, возврата его к значению по умолча-
нию (неопределенному) и повторного запуска запроса выполните в окне Connection 2 сле-
дующий программный код:
SET LOCK__T IMEOUT -1;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
Для завершения транзакции выполните в окне Connection 1 приведенный далее программ-
ный код:
KILL 52;
Эта инструкция вызывает откат транзакции в сеансе Connection 1, т. е. изменение цены то-
вара 2 с 19.00 на 20.00 отменяется, и монопольная блокировка снимается. Перейдите к сеан-
су Connection 2. Обратите внимание на данные, полученные после отмены изменения — а
именно, они будут такими же, как до изменения цены.
productid unitprice
2
19.00
Уровни изоляции
Уровни изолягщи определяют поведение параллельно работающих пользователей, читающих и
записывающих данные. Читающий процесс— это любая инструкция, извлекающая данные и
применяющая по умолчанию совместную блокировку. Пишущий процесс — это любая инструк-
ция, модифицирующая таблицу и запрашивающая монопольную блокировку. Вы не можете
управлять поведением пишущего процесса ни в отношении устанавливаемых блокировок, ни в
отношении их продолжительности, но вы можете управлять читающими процессами. Кроме то-
го, управляя поведением читающей стороны, вы можете неявно влиять на поведение пишущей
стороны. Делается это с помощью установки уровня изоляции, как на уровне сеанса с помощью
параметра сеанса, так и на уровне запроса с помощью табличных рекомендаций или подсказок
(table hint).
Можно установить шесть уровней изоляции: READ UNCOMMITTED, READ COMMITTED (ПО
умолчанию), REPEATABLE READ, SERIALIZABLE, SNAPSHOT И READ COMMITTED SNAPSHOT.
Два последних уровня доступны, только начиная с версии SQL Server 2005. Задать уровень
изоляции всего сеанса можно с помощью следующей команды:
SET TRANSACTION ISOLATION LEVEL <уровень изоляции>;
Для установки уровня изоляции запроса можно применить табличную рекомендацию.
SELECT . . . FROM <таблица> WITH (<уровень_изоляции>) ;
294
Гпава 8
Обратите внимание на то, что в параметре сеанса, если уровень изоляции формируется из
нескольких слов, задается пробел между словами, например, REPEATABLE READ. В реко-
мендации запроса не вставляется
пробел между словами — например, WITH
(RE PEAT ABLE READ) . Кроме того, у некоторых названий уровней изоляции, применяемых
как табличные рекомендации, есть синонимы. Например, NOLOCK эквивалентно заданию
READUNCOMMITTED; HOLDLOCK эквивалентно заданию REPEATABLEREAD.
Стандартный уровень изоляции— READ COMMITTED. Если вы решаете переопределить при-
нимаемый по умолчанию уровень изоляции, ваш выбор повлияет как на параллельную работу
пользователей базы данных, так и на непротиворечивость получаемых ими данных. Для четы-
рех уровней изоляции, доступных в версиях, предшествующих SQL Server 2005, чем выше
уровень изоляции, тем жестче и продолжительней блокировки, запрашиваемые читающей сто-
роной; следовательно, чем выше уровень изоляции, тем выше согласованность или непротиво-
речивость данных и тем ниже степень параллелизма в работе. Обратное также справедливо.
В случае двух уровней изоляции, основанных на моментальных снимках данных, SQL Server
может хранить предыдущие зафиксированные версии строк отдельно в базе данных tempdb.
Если текущая версия строки не согласована в соответствии с ожиданиями читающих процес-
сов, вместо запрашивания совместных блокировок они могут обеспечить предполагаемый
уровень изоляции без ожидания за счет получения предыдущих версий строк.
В следующих разделах описывается каждый из шести поддерживаемых уровней изоляции и
демонстрируется их поведение.
Уровень изоляции READ UNCOMMITTED
READ UNCOMMITTED— низший доступный уровень изоляции. На этом уровне читающий
процесс не запрашивает совместную блокировку. Процесс, не запрашивающий совместную
блокировку, никогда не будет конфликтовать с пишущим процессом, удерживающим моно-
польную блокировку. Это означает, что читающий процесс может прочесть незафиксиро-
ванные изменения (этот вариант называют грязным чтением). Кроме того, это означает, что
читающий процесс не будет сталкиваться с пишущим процессом, который запрашивает мо-
нопольную блокировку. Другим словами, пишущий процесс может изменять данные в то
время, как читающий процесс с уровнем изоляции READ UNCOMMITTED читает данные.
Для того чтобы увидеть незафиксированное чтение (грязное чтение) откройте два окна за-
просов (назовем их Connection 1 и Connection 2). Убедитесь в том; что во всех ваших под-
ключениях используется контекст учебной базы данных TSQLFundamentals2008.
В окне Connection 1 для открытия транзакции, увеличения на 1.00 текущей цены единицы
товара 2 (19.00) и последующего запроса строки товара выполните следующий программ-
ный код:
BEGIN TRAN;
UPDATE Production.Products
SET unitprice = unitprice + 1.00
WHERE productid = 2;
SELECT productid, unitprice
FROM Product ion.Product s
WHERE productid = 2;
Транзакции и параллелизм
295
Обратите внимание на то, что транзакция остается открытой, что означает монопольную
блокировку строки товара в подключении Connection 1. Программный код в окне Connec-
tion 1 возвращает следующий результат, отображающий новую цену товара:
productid unitprice
2
20.00
В окне Connection 2 для установки уровня изоляции READ UNCOMMITTED и запроса строки с
данными о товаре 2 выполните следующий программный код:
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
Поскольку запросу не требовалась совместная блокировка, у него не возникло конфликта с
другой транзакцией. Этот запрос вернул состояние строки после изменения, несмотря на то,
что изменение не было зафиксировано:
productid unitprice
2
20.00
Не забывайте о том, что в сеансе Connection 1 позже в строку могут быть внесены даль-
нейшие изменения и даже в какой-то момент выполнен откат транзакции. Например, для
отката транзакции выполните в окне Connection 1 следующий программный код:
ROLLBACK TRAN;
Приведенный откат отменяет обновление товара 2, возвращая прежнее значение цены това-
ра, равное 19.00. Значение 20.00, полученное считывающим процессом, никогда не было
зафиксировано. Это пример грязного чтения.
Уровень изоляции READ COMMITTED
Если вы хотите помешать чтению незафиксированных изменений, необходимо применять бо-
лее высокий уровень изоляции. Низший уровень изоляции, препятствующий грязному чте-
нию, — READ COMMITTED, служащий уровнем изоляции по умолчанию во всех версиях SQL
Server. Как показывает название, этот уровень изоляции позволяет читать только зафиксиро-
ванные изменения. Он препятствует чтению незафиксированных изменений, требуя от читаю-
щего процесса получения совместной блокировки. Это означает, что если пишущий процесс
удерживает монопольную блокировку, запрос читающего процесса на совместную блокировку
вступит в конфликт с пишущим процессом, и читающий процесс будет вынужден ждать. Как
только пишущая сторона зафиксирует транзакцию, читающая сможет получить совместную
блокировку, но прочтет она неизбежно только зафиксированные изменения.
В следующем примере показано, что на этом уровне изоляции читающий процесс может
прочесть только зафиксированные изменения.
296
Гпава 8
В окне Connection 1 для открытия транзакции, обновления цены товара 2 и запроса строки,
отображающей новую цену, выполните следующий программный код:
BEGIN TRAN;
UPDATE Production.Products
SET unitprice = unitprice + 1.00
WHERE productid = 2;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
Этот программный код вернет такой результат:
productid unitprice
2
20.00
Теперь подключение Connection 1 монопольно блокирует строку с описанием товара 2.
Для задания уровня изоляции сеанса, равного READ COMMITTED, И запроса строки с това-
ром 2 выполните следующий программный код в окне Connection 2:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
He забывайте о том, что данный уровень изоляции устанавливается по умолчанию, поэтому
если вы ранее не меняли уровень изоляции сеанса, вам не нужно устанавливать его явно.
В настоящий момент инструкция SELECT блокируется, поскольку для чтения ей нужна со-
вместная блокировка, а этот запрос на совместную блокировку конфликтует с монопольной
блокировкой, удерживаемой пишущим процессом в Connection 1.
Далее в окне Connection 1 выполните следующий программный код для фиксации транзак-
ции.
COMMIT TRAN;
Теперь перейдите в окно Connection 2 и убедитесь, что вы получили такой результат:
productid unitprice
2
20.00
В отличие от READ UNCOMMITTED на уровне изоляции READ COMMITTED ВЫ не получаете
грязных считываний. Вместо этого вы можете читать только зафиксированные изменения.
Что касается продолжительности блокировок, на уровне изоляции READ COMMITTED чи-
тающий процесс только удерживает совместную блокировку на время работы с ресурсом.
Блокировка не сохраняется до конца транзакции, в действительности она даже не сохраня-
Транзакции и параллелизм
297
ется до завершения инструкции. Это означает, что блокировка ресурса не сохраняется меж-
ду двумя чтениями одного и того же ресурса данных в пределах одной транзакции. Следова-
тельно, другая транзакция может модифицировать ресурс между этими двумя чтениями, и
читающий процесс может получить разные значения в каждом из этих чтений. Подобную
ситуацию называют чтениями без возможности повторения или несогласованной обработ-
кой. Для многих приложений такая ситуация приемлема, а для некоторых нет.
После окончания работы для чистки базы данных выполните следующий программный код
в каждом из открытых подключений:
UPDATE Production.Products
SET unitprice = 19.00
WHERE productid = 2;
Уровень изоляции REPEATABLE READ
Если вы хотите быть уверенными в том, что никто не сможет изменить значения между
двумя чтениями в пределах одной транзакции, необходимо подняться до уровня изоляции
REPEATABLE READ. На этом уровне изоляции читающему процессу для чтения не только
требуется совместная блокировка, но эта блокировка сохраняется до завершения транзак-
ции. Это означает, что как только вы установили совместную блокировку ресурса данных
для его чтения, никто не сможет получить монопольную блокировку для модификации этого
ресурса до тех пор, пока читающий процесс не завершит транзакцию. В этом случае вам
гарантировано чтение с повторяемостью результатов или согласованная обработка.
В приведенном далее примере показано чтение с повторяемостью результатов.
В окне Connection 1 для установки уровня изоляции сеанса REPEATABLE READ, открытия
транзакции и чтения строки с товаром 2 выполните следующий программный код:
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
BEGIN TRAN;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
Этот программный код вернет следующий результат, отображающий текущую цену това-
ра 2:
productid unitprice
2
19.00
Подключение Connection 1 все еще удерживает совместную блокировку строки с товаром 2,
поскольку на уровне изоляции REPEATABLE READ совместные блокировки удерживаются до
конца транзакции. В окне Connection 2 выполните следующий программный код, чтобы
попытаться модифицировать строку с товаром 2:
UPDATE Production.Products
SET unitprice = unitprice + 1.00
WHERE productid = 2;
298
Гпава 8
Попытка будет заблокирована, т. к. запрос обновляющего процесса на монопольную блоки-
ровку конфликтует с совместной блокировкой, предоставленной читающему процессу. Если
бы читающий процесс выполнялся на уровне изоляции READ UNCOMMITTED ИЛИ READ
COMMITTED, в этот момент он не удерживал бы совместную блокировку, и попытка модифи-
кации строки завершилась бы успешно.
Вернитесь в окно Connection 1 и выполните приведенный далее программный код для по-
вторного чтения строки с товаром 2 и фиксации транзакции:
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
COMMIT TRAN;
Этот программный код вернет следующий результат:
productid unitprice
2
19.00
Обратите внимание на то, что повторное чтение возвращает ту же самую цену единицы то-
вара 2, что и первое. Теперь транзакция читающего процесса зафиксирована, и совместная
блокировка снята, модифицирующему процессу в окне Connection 2 предоставлена моно-
польная блокировка, которой он дожидался, и процесс может модифицировать строку.
Еще одна ситуация, возникновению которой препятствует уровень изоляции REPEATABLE
READ, но не более низкие уровни изоляции, называется потерянным обновлением. Потеря
обновления происходит, когда две транзакции читают значение, выполняют вычисления,
основанные на том, что они прочли, а затем обновляют значение. Поскольку на уровнях
изоляции более низких, чем REPEATABLE READ после считывания блокировка ресурса не
сохраняется, обе транзакции могут обновить значение, и "победит" та из них, которая запи-
шет обновление последней, переопределив значение, обновленное другой транзакцией. На
уровне изоляции REPEATABLE READ обе стороны сохраняют свои совместные блокировки
после первого чтения, поэтому позже никто не может установить монопольную блокировку
для обновления. Ситуация приводит к взаимоблокировке или тупику и конфликт обновления
устраняется. Чуть позже в этой главе я расскажу более подробно о взаимоблокировках.
После окончания работы выполните следующий программный код для очистки базы дан-
ных:
UPDATE Production.Products
SET unitprice = 19.00
WHERE productid = 2;
Уровень изоляции SERIALIZABLE
Выполняясь на уровне изоляции REPEATABLE READ, читающие процессы сохраняют совмест-
ные блокировки до конца транзакции. Следовательно, гарантируется повторяемость результа-
тов при считывании строк, которые вы первый раз прочли в транзакции. Однако ваша транзак-
ция блокирует ресурсы (например, строки), которые запрос нашел в процессе выполнения в
Транзакции и параллелизм
299
первый раз, а не строки, которых там не было во время выполнения запроса. Следовательно,
второе чтение в той же самой транзакции может также вернуть и новые строки. Эти новые
строки называют фантомами или призраками, а подобные чтения — фантомными чтениями.
Такая ситуация возникает, если между двумя чтениями другая транзакция добавляет новые
строки, удовлетворяющие условию фильтра читающего запроса.
Для предотвращения фантомных считываний необходимо перейти к более высокому уров-
ню ИЗОЛЯЦИИ SERIALIZABLE.
По большей части уровень изоляции SERIALIZABLE ведет себя так же, как и REPEATABLE
READ, а именно, для чтения он требует от читающего процесса получения совместной
блокировки и сохранения ее до завершения транзакции. Но уровень изоляции
SERIALIZABLE добавляет еще один аспект — логически этот уровень изоляции заставляет
читающий процесс блокировать целый диапазон ключей (строк), которые удовлетворяют
условию фильтрации запроса читающего процесса. Это означает, что процесс блокирует
не только существующие строки, удовлетворяющие условию фильтра запроса, но и буду-
щие строки. Или более точно, он блокирует попытки других транзакций добавить строки,
удовлетворяющие условию фильтра запроса читающей стороны.
В следующем примере показано, как уровень изоляции SERIALIZABLE препятствует фан-
томным считываниям. В окне Connection 1 для установки уровня изоляции транзакции
SERIALIZABLE, открытия транзакции и извлечения всех товаров категории 1 выполните
следующий программный код:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRAN
SELECT productid, productname, categoryid, unitprice
FROM Production.Products
WHERE categoryid = 1;
Вы получите такой результат, отображающий 12 товаров в категории 1:
productid productname
categoryid unitprice
1
Product HHYDP 1
18.00
2
Product RECZE 1
19.00
24
Product QOGNU 1
4.50
34
Product SWNJY 1
14.00
35
Product NEVTJ 1
18.00
38
Product QDOMO 1
263.50
39
Product LSOFL 1
18.00
43
Product ZZZHR 1
46.00
67
Product XLXQF 1
14.00
70
Product TOONT 1
15.00
75
Product BWRLG 1
7.75
76
Product JYGFE 1
18.00
(12 row(s) affected)
300
Гпава 8
В окне Connection 2 выполните следующий программный код, чтобы попытаться вставить
новый товар категории 1:
INSERT INTO Production.Products
(productname, supplierid, categoryid,
unitprice, discontinued)
VALUES('Product ABCDE', 1, 1, 20.00, 0);
На всех уровнях изоляции более низких, чем SERIALIZABLE, такая попытка была бы успеш-
ной. На уровне изоляции SERIALIZABLE она блокируется.
Вернитесь в окно Connection 1, выполните следующий программный код, чтобы извлечь
второй раз товары категории 1 и зафиксировать транзакцию:
SELECT productid, productname, categoryid, unitprice
FROM Production.Products
WHERE categoryid = 1;
COMMIT TRAN;
Вы получите тот же результат, что и раньше, без строк-фантомов. Теперь, когда транзакция
читающего процесса зафиксирована и совместная блокировка с диапазона строк снята, мо-
дифицирующий процесс в окне Connection 2 получит монопольную блокировку, которой он
дожидается, и вставит строку.
Когда закончите работу, выполните следующий программный код для очистки базы данных:
DELETE FROM Production.Products
WHERE productid >77;
DBCC CHECKIDENT (1 Production.Products
1
, RESEED, 77);
Выполните приведенный далее программный код во всех открытых подключениях для воз-
врата уровня изоляции к значению, принятому по умолчанию:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
Уровни изоляции Snapshot
Версия SQL Server 2005 ввела возможность хранения предыдущих версий зафиксированных
строк в базе данных tempdb. Основываясь на технологии хранения версий строк, SQL Server
добавил поддержку двух новых уровней изоляции, названных SNAPSHOT И READ COMMITTED
SNAPSHOT. Уровень изоляции SNAPSHOT логически эквивалентен уровню изоляции
SERIALIZABLE с точки зрения проблем непротиворечивости данных, которые могут возни-
кать или не возникать. Уровень изоляции READ COMMITTED SNAPSHOT аналогичен уровню
изоляции READ COMMITTED. Но читающие процессы, использующие уровни изоляции, ос-
нованные на моментальных снимках данных, не порождают совместных блокировок, по-
этому читающие процессы не ждут, пока запрашиваемые данные монопольно заблокирова-
ны. Тем не менее, у этих процессов сохраняется степень непротиворечивости данных,
аналогичная уровням изоляции SERIALIZABLE И READ COMMITTED. ОНИ получают версию
Транзакции и параллелизм
301
строки, которую рассчитывают увидеть, извлекая ее из хранилища версий в базе данных
tempdb, если текущая версия строки не та, на которую они рассчитывают.
Имейте в виду, что если вы устанавливаете уровни изоляции, основанные на моментальных
снимках данных, инструкции DELETE И UPDATE нуждаются в копировании в базу данных
tempdb версии строки, существующей до внесения изменений. Инструкциям INSERT такое
копирование в tempdb не нужно, поскольку не существует предыдущей версии. Тем не ме-
нее, важно знать, что активизация уровней изоляции, основанных на моментальных снимках
данных, может оказать негативное влияние на производительность обновлений и удалений
данных. Производительность считывания, как правило, повышается, поскольку читающие
процессы не устанавливают совместные блокировки и не должны ждать, пока данные моно-
польно заблокированы или их версия не соответствует ожидаемой. В следующих разделах
описываются уровни изоляции, основанные на моментальных снимках данных, и показано
их поведение.
Уровень изоляции SNAPSHOT
На уровне изоляции SNAPSHOT при чтении читающему процессу гарантируется получение
последней зафиксированной версии строки, которая имеется в наличии в момент запуска
транзакции. Это означает, что обеспечено получение фиксированных и повторяемых считы-
ваний и отсутствие фантомных считываний, точно так же, как и на уровне изоляции
SERIALIZABLE. Но вместо применения совместных блокировок этот уровень изоляции по-
лагается на версии строк. Как упоминалось, уровни изоляции с использованием моменталь-
ных снимков данных вызывают снижение производительности, в основном при обновлени-
ях и удалениях данных, даже если модификация выполняется в сеансе, действующем на
одном из уровней изоляции, основанном на моментальных снимках данных. По этой причи-
не для разрешения работы на уровне изоляции SNAPSHOT сначала необходимо установить
параметр на уровне базы данных, выполнив следующий программный код в любом откры-
том окне запроса:
ALTER DATABASE TSQLFundamentalS2008 SET ALLOW_SNAPSHOT_ISOLATION ON;
В следующем примере показано поведение на уровне изоляции SNAPSHOT. В окне Connec-
tion 1 для открытия транзакции, обновления цены товара 2 добавлением 1.00 к его текущей
цене, равной 19.00, и извлечения строки о товаре, отображающей новое значение цены, вы-
полните следующий программный код:
BEGIN TRAN;
UPDATE Production.Products
SET unitprice = unitprice +1.00
WHERE productid = 2;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
302
Гпава 8
Далее приведен результат выполнения этого программного кода, демонстрирующий, что
цена товара была обновлена и стала равна 20.00:
productid unitprice
2
20.00
Имейте в виду, что несмотря на то, что транзакция в Connection 1 выполнялась на уровне
изоляции READ COMMITTED, принятом по умолчанию, SQL Server должен был перед обнов-
лением скопировать версию строки (с ценой 19.00) в базу данных tempdb. Произошло это
потому, что на уровне базы данных разрешен уровень изоляции SNAPSHOT. ЕСЛИ кто-либо
запустит транзакцию на уровне изоляции SNAPSHOT, может потребоваться версия до обнов-
ления. Например, в окне Connection 2 выполните следующий программный код для того,
чтобы установить уровень изоляции SNAPSHOT, открыть транзакцию и извлечь строку с то-
варом 2:
SET TRANSACTION ISOLATION LEVEL SNAPSHOT;
BEGIN TRAN;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
Если ваша транзакция выполнялась на уровне изоляции SERIALIZABLE, запрос был бы за-
блокирован. Но поскольку она выполняется на уровне SNAPSHOT, ВЫ получаете последнюю
зафиксированную версию строки, которая имелась в момент старта транзакции. Эта версия
(с ценой 19.00) не является текущей версией (с ценой 20.00), поэтому SQL Server достает
подходящую версию из хранилища версий и программный код возвращает следующий ре-
зультат:
productid unitprice
2
19.00
Вернитесь в окно Connection 1 и зафиксируйте транзакцию, модифицировавшую строку:
COMMIT TRAN;
В данный момент текущая версия строки с ценой 20.00 — это зафиксированная версия. Но
если вы снова прочтете данные в окне Connection 2, вы все еще получите версию строки,
которая имелась в момент запуска транзакции (с ценой 19.00). Выполните следующий про-
граммный код в окне Connection 2 для повторного чтения данных и фиксации транзакции:
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
COMMIT TRAN;
Транзакции и параллелизм
303
Как и ожидалось, вы получите такой результат с ценой 19.00:
productid unitprice
2
19.00
В окне Connection 2 выполните следующий программный код для открытия новой транзак-
ции, запроса данных и фиксации транзакции:
BEGIN TRAN
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
COMMIT TRAN;
На этот раз последняя зафиксированная версия строки, доступная в момент запуска тран-
закции, — версия с ценой 20.00.
Следовательно, вы получите такой результат:
productid unitprice
2
20.00
Теперь, когда ни одной транзакции не нужна версия строки с ценой 19.00, поток очистки,
выполняющийся каждую минуту, может удалить ее из базы данных tempdb во время своего
следующего исполнения.
Когда закончите работу, выполните следующий программный код для очистки базы данных:
UPDATE Production.Products
SET unitprice =19.00
WHERE productid = 2;
Обнаружение конфликтов
Уровень изоляции SNAPSHOT предотвращает конфликты обновления, но в отличие от уров-
ней изоляции REPEATABLE READ И SERIALIZABLE, делающих это генерацией взаимоблоки-
ровки, он аварийно завершает транзакцию, указывая, что обнаружен конфликт обновления.
Уровень изоляции SNAPSHOT может находить конфликты обновления, просматривая храни-
лище версий. Он может определить, модифицировала ли другая транзакция данные между
чтением и записью, выполнявшимися в вашей транзакции.
Далее показан сценарий без конфликта обновления, за которым следует пример сценария с
конфликтом обновления.
В окне Connection 1 для установки уровня изоляции SNAPSHOT, открытия транзакции и
чтения строки с товаром 2 выполните следующий программный кот
SET TRANSACTION ISOLATION LEVEL SNAPSHOT;
BEGIN TRAN;
304
Гпава 10
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
Вы получите такой результат:
productid unitprice
2
19.00
Предполагая, что вы выполнили некие вычисления, основанные на чтении, в том же окне
Connection 1 выполните следующий программный код для изменения значения предвари-
тельно извлеченной цены товара на 20.00 и зафиксируйте транзакцию:
UPDATE Production.Products
SET unitprice = 20.00
WHERE productid = 2;
COMMIT TRAN;
Никакая другая транзакция между вашими чтением, вычислениями и записью не модифици-
ровала строку, следовательно, конфликта обновления не было, и SQL Server разрешил вы-
полнение обновления.
Выполните следующий программный код, чтобы изменить значение цены товара 2 на 19.00:
UPDATE Production.Products
SET unitprice = 19.00
WHERE productid = 2;
Далее в окне Connection 1 выполните приведенный далее программный код, чтобы снова
открыть транзакцию и прочитать строку о товаре 2:
BEGIN TRAN;
SELECT productid, unitprice
FROM Production.Products
WHtfRE productid = 2;
Вы получите такой результат, показывающий, что цена товара равна 19.00:
productid unitprice
2
19.00
На этот раз выполните следующий программный код в окне Connection 2, чтобы изменить
цену товара 2 на 25.00:
UPDATE Production.Products
SET unitprice = 25.00
WHERE productid = 2;
Транзакции и параллелизм
305
Полагая, что в Connection 1 вы выполнили вычисления, основанные на считанной вами це-
не, равной 19.00, на основании ваших вычислений попытайтесь в окне Connection I изме-
нить значение цены товара на 20.00:
UPDATE Production.Products
SET unitprice = 20.00
WHERE productid = 2;
SQL Server обнаружил, что на этот раз другая транзакция модифицировала данные между
вашими чтением и записью, следовательно, он аварийно завершит вашу транзакцию с такой
ошибкой:
Msg 3960, Level 16, State 2, Line 1
Snapshot isolation transaction aborted due to update conflict. You cannot use
snapshot isolation to access table
1
Production.Products
1
directly or indi-
rectly in database
,
TSQLFundamentals20081 to update, delete, or insert the row
that has been modified or deleted by another transaction. Retry the transac-
tion or change the isolation level for the update/delete statement.
Конечно, при обнаружении конфликта обновления для повторного выполнения всей тран-
закции можно применить программный код для обработки ошибки.
Когда закончите работу, выполните следующий программный код для очистки базы данных:
UPDATE Production.Products
SET unitprice = 19.00
WHERE productid = 2;
Закройте все подключения. Учтите, что если не все подключения будут закрыты, результаты
могут не соответствовать приведенным в данной главе.
Уровень изоляции READ COMMITTED SNAPSHOT
Уровень изоляции READ COMMITTED SNAPSHOT также основан на версиях строк. Он отлича-
ется от уровня изоляции SNAPSHOT тем, что вместо последней зафиксированной версии
строки, имевшейся в наличии при старте транзакции, читающий процесс получает послед-
нюю зафиксированную версию строки, имевшуюся в момент старта инструкции. Кроме то-
го, уровень изоляции READ COMMITTED SNAPSHOT не обнаруживает конфликты обновления.
В результате его логическое поведение очень похоже на уровень изоляции READ COMMITTED
за исключением того, что читающим процессам не нужно устанавливать совместные блоки-
ровки и ждать, если необходимый ресурс монопольно заблокирован.
Для разрешения применения в базе данных уровня изоляции READ COMMITTED SNAPSHOT не-
обходимо установить флаг базы данных, отличный от того, который требовался для разреше-
ния применения уровня изоляции SNAPSHOT. Выполните следующий программный код, чтобы
разрешить использование уровня изоляции READ COMMITTED SNAPSHOT В базе данных
SQLFundamentals2008:
ALTER DATABASE TSQLFundamentals2008 SET READ_CCMMITTED_SNAPSHOT ON;
Учтите, что для успешного выполнения приведенного программного кода это подключение
должно быть единственным открытым подключением к базе данных TSQLFundamentals2008.
306
Гпава 10
Интересная особенность установки этого флага базы данных заключается в том, что в отличие
от уровня изоляции SNAPSHOT, этот флаг на самом деле изменяет значение уровня изоляции по
умолчанию READ COMMITTED на уровень READ COMMITTED SNAPSHOT. Это означает, что если
данный флаг базы данных установлен, пока вы явно не изменили уровень изоляции сеанса,
READ COMMITTED SNAPSHOT становится уровнем изоляции, принятым по умолчанию.
Для демонстрации применения уровня изоляции READ COMMITTED SNAPSHOT откройте два
подключения. В окне Connection 1 для открытия транзакции, обновления строки с товаром 2 и
чтения строки выполните следующий программный код, оставив транзакцию открытой:
USE TSQLFundamentals2008;
BEGIN TRAN;
UPDATE Production.Products
SET unitprice - unitprice + 1.00
WHERE productid = 2;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
Вы получите результат, показывающий, что цена товара была изменена на 20.00:
productid unitprice
2
20.00
В окне Connection 2 откройте транзакцию и прочтите строку с товаром 2, оставив транзак-
цию открытой:
BEGIN TRAN;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
Вы получите последнюю зафиксированную версию строки, имевшуюся, когда инструкция
стартовала (19.00):
productid unitprice
2
19.00
В окне Connection 1 выполните следующий программный код, чтобы зафиксировать тран-
закцию:
COMMIT TRAN;
Теперь в окне Connection 2 для повторного чтения строки с товаром 2 и фиксации транзак-
ции выполните приведенный далее программный код:
SELECT productid, unitprice
FROM Production.Products
Транзакции и параллелизм
307
WHERE productid = 2;
COMMIT TRAN;
Если бы этот код выполнялся на уровне изоляции SNAPSHOT, вы получили бы цену 19.00, но
т. к. код выполняется на уровне изоляции READ COMMITTED SNAPSHOT, вы получите по-
следнюю зафиксированную версию строки, которая существовала в момент старта инструк-
ции (20.00), а не в момент старта транзакции (19.00).
productid unitprice
2
20.00
Напоминаю, что эта ситуация именуется чтением без повторяемости результатов или несо-
гласованной обработкой.
Когда закончите работу, выполните следующий программный код для очистки базы данных:
UPDATE Production.Products
SET unitprice = 19.00
WHERE productid =2;
Закройте все подключения и затем в окне нового подключения выполните следующий про-
граммный код, запрещающий применение в базе данных TSQLFundamentals2008 уровней
изоляции, основанных на моментальных снимках:
ALTER DATABASE TSQLFundamentals2008 SET ALLOW_SNAPSHOT_ISOLATION OFF;
ALTER DATABASE TSQLFundamenta 1 s2008 SET READ_COMMITTEDJSNAPSHOT OFF;
Сводные данные об уровнях изоляции
В табл. 9.3 приведена сводка проблем логической непротиворечивости или согласованности
данных, которые могут возникнуть на каждом уровне изоляции, и показано, обнаруживает
ли уровень изоляции конфликты обновления и применяет ли версии строк.
Таблица 9.3. Сводные данные об уровнях изоляции
Уровень
изоляции
Незафикси-рованныесчитывания?Повторяе-мостьсчиты-ваний?Потерянныеобновления?ФантомныесчитыванияОбнаружениеконфликтовобновления?Использова-ниеверсийстрок?
READ UNCOMMITTED Да
Да
Да
Да
Нет
Нет
READ COMMITTED
Нет
Да
Да
Да
Нет
Нет
READ COMMITTED
SNAPSHOT
Нет
Да
Да
Да
Нет
Да
REPEATABLE READ
Нет
Нет
Нет
Да
Нет
Нет
308
Гпава 9
Таблица 9.3 (окончание)
Уровень
изоляции
Незафикси-рованныесчитывания?Повторяе-мостьсчиты-ваний?Потерянныеобновления?ФантомныесчитыванияОбнаружениеконфликтовобновления?Использова-ниеверсийстрок?
SERIALIZABLE
Нет
Нет
Нет
Нет
Нет
Нет
SNAPSHOT
Нет
Нет
Нет
Нет
Да
Да
Взаимоблокировки
Взаимоблокировка или тупик — это ситуация, в которой процессы блокируют друг друга.
Во взаимоблокировку могут быть вовлечены два или более процессов. Примером двухпро-
цессной блокировки может служить ситуация, в которой процесс А блокирует процесс В и
процесс В блокирует процесс А. Пример тупика, в котором участвуют несколько процес-
сов — ситуация, в которой процесс А блокирует процесс В, процесс В блокирует процесс С,
процесс С блокирует процесс А. В любом случае SQL Server обнаруживает взаимоблоки-
ровку и вмешивается, завершая одну из транзакций. Если SQL Server не вмешается, вовле-
ченные во взаимоблокировку процессы могут остаться заблокированными навсегда.
Если не задано иное, SQL Server выбирает для завершения транзакцию, которая выполнила
меньше всего работы, поскольку для ее повторного выполнения потребуется меньше всего
затрат. Но начиная с версии SQL Server 2005, при желании вы можете задать значение па-
раметра сеанса DEADLOCK_PRIORITY, выбрав одно из 21 числа в диапазоне от -10 до 10. До
SQL Server 2005 были доступны только два варианта приоритета: LOW (НИЗКИЙ) И NORMAL
(обычный). Процесс с самым низким приоритетом взаимоблокировки выбирается при взаи-
моблокировке в качестве жертвы независимо от того, сколько работы проделано, а в случае
нескольких процессов с одинаковым приоритетом - взаимоблокировки количество работы
используется как дополнительная характеристика для их дифференцирования.
В следующем примере показана простая взаимоблокировка. Далее я поясню, как снизить
количество взаимоблокировок в системе.
Откройте два подключения и убедитесь, что в обоих вы подключены к базе данных
TSQLFundamentals2008. В окне Connection 1 выполните следующий программный код,
чтобы открыть новую транзакцию, обновить в таблице Production.Products (Товары)
строку с товаром 2 и оставить транзакцию открытой:
USE TSQLFundamentals2 008;
BEGIN TRAN;
UPDATE Production.Products
SET unitprice = unitprice + 1.00
WHERE productid = 2;
Транзакции и параллелизм
309
В окне Connection 2 выполните следующий программный код, чтобы открыть новую тран-
закцию, обновить в таблице Sales. OrderDetails (Сведения о заказе) строку с товаром 2 и
оставить транзакцию открытой:
BEGIN TRAN;
UPDATE Sales.OrderDetails
SET unitprice = unitprice +1.00
WHERE productid = 2;
В этот момент транзакция в Connection 1 удерживает монопольную блокировку строки с
товаром 2 в таблице Production. Products, а транзакция в Connection 2 удерживает бло-
кировку строки с товаром 2 в таблице Sales.OrderDetails. Оба запроса выполняются
успешно, и никакое блокирование еше не возникло.
Выполните следующий программный код в окне Connection I, чтобы попытаться извлечь
строку с товаром 2 из таблицы Sales. OrderDetails (Сведения о заказЪ) и завершить тран-
закцию:
SELECT orderid, productid, unitprice
FROM Sales.OrderDetails
WHERE productid = 2;
COMMIT TRAN;
Программный код выполняется на уровне изоляции READ COMMITTED, установленном по
умолчанию, следовательно, транзакции в подключении Connection 1 нужна совместная бло-
кировка для возможности чтения. Поскольку другая транзакция удерживает монопольную
блокировку этого же ресурса, транзакция в подключении Connection 1 блокируется. В этот
момент возникла ситуация блокирования, но пока еще не взаимоблокировка. Конечно, оста-
ется шанс, что подключение Connection 2 завершит транзакцию, снимет все блокировки и
позволит транзакции в подключении Connection 1 получить запрашиваемые блокировки.
Далее в окне Connection 2 выполните следующий программный код, чтобы попытаться из-
влечь строку с товаром 2 из таблицы Product. Production и завершить транзакцию:
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
COMMIT TRAN;
Транзакции в подключении Connection 2 нужна совместная блокировка для чтения строки с
товаром 2 из таблицы product. Production, поэтому этот запрос теперь конфликтует с
монопольной блокировкой того же ресурса, удерживаемой подключением Connection 1.
Процессы блокируют друг друга — вы получили взаимоблокировку, или тупик. SQL Server
опознает взаимоблокировку, обычно в течение нескольких секунд выбирает один из процес-
сов в качестве жертвы взаимоблокировки и завершает его транзакцию со следующим сооб-
щением об ошибке:
Msg 1205, Level 13, State 51, Line 1
Transaction (Process ID 52) was deadlocked on lock resources with another
process and has been chosen as the deadlock victim. Rerun the transaction.
11 Зак. 1032
310
Гпава 10
В этом примере SQL Server выбирает завершение транзакции в подключении Connection 1
(показанной, как процесс с ID 52). Поскольку я не задал приоритет взаимоблокировки и обе
транзакции выполнили примерно одинаковый объем работы, любая из них могла бы быть
завершена.
Взаимоблокировки требуют значительных затрат, т. к. они приводят к отказу от уже сделанной
работы. Для снижения количества взаимоблокировок в системе вам следует придерживаться
нескольких практических рекомендаций.
Очевидно, что, чем длиннее транзакции, тем дольше удерживаются блокировки, повышая
вероятность взаимоблокировок. Следует стараться создавать транзакции настолько корот-
кие, насколько это возможно, вынося за пределы транзакций все действия, которые предпо-
ложительно не являются частью одного и того же блока исполнения.
Взаимоблокировка возникает, когда транзакции обращаются к ресурсам в обратном поряд-
ке. Например, в нашем случае подключение Connection 1 сначала обратилось к строке в
таблице Production. Products, а затем к строке в таблице Sales.OrderDetails, в то
время как подключение Connection 2 сначала обратилось к строке в таблице
Sales.OrderDetails, а затем к строке в таблице Production.Products. Взаимоблоки-
ровка этого типа не возникла бы, если обе транзакции обращались бы к ресурсам в одном и
том же порядке. Поменяв порядок в одной из транзакций, вы сможете предотвратить воз-
никновение взаимоблокировки этого типа, конечно если для вашего приложения в этом нет
логической разницы.
В нашем примере взаимоблокировки есть реальное логическое противоречие, поскольку обе
стороны пытаются обратиться к одним и тем же строкам. Но часто взаимоблокировки воз-
никают и без реальных логических противоречий из-за отсутствия хорошего индексирова-
ния для поддержки фильтров запроса. Например, предположим, что инструкции в подклю-
чении Connection 1 обрабатывают товар 2, а инструкции в Connection 2 — товар 5, здесь не
должно быть никакого противоречия. Однако, если в таблицах нет индексов для столбца
productid (id товара), поддерживающих фильтрацию, SQL Server вынужден просматривать
(и устанавливать блокировки) все строки в таблице. Это конечно может привести к взаимо-
блокировке. Вкратце, хорошо спроектированные индексы могут помочь в предотвращении
взаимоблокировок, за которыми не стоят реальные логические противоречия.
Когда закончите работу, в любом из подключений выполните следующий программный код
для очистки базы данных:
UPDATE Production.Products
SET unitprice = 19.00
WHERE productid = 2;
UPDATE Sales.OrderDetails
SET unitprice = 19.00
WHERE productid = 2
AND orderid >= 10500;
UPDATE Sales.OrderDetails
SET unitprice = 15.20
WHERE productid = 2
AND orderid < 10500;
Транзакции и параллелизм
311
Резюме
Эта глава познакомила вас с транзакциями и параллелизмом. Я описал, что представляют
собой транзакции и как SQL Server управляет ими. Я объяснил, как SQL Server изолирует
данные, к которым обращается одна транзакция, от их несогласованного использования
другими транзакциями и как выявлять и устранять сценарии блокирования. В главе описано,
как можно управлять степенью непротиворечивости получаемых данных с помощью выбора
уровня изоляции и как ваш выбор влияет на параллелизм. Я привел четыре уровня изоляции,
не полагающиеся на версии строк, и два уровня, основанные на этих версиях.
В заключение я рассказал о взаимоблокировках и дал практические советы, которым можно
следовать для того, чтобы снизить частоту их возникновения.
Для того чтобы проверить на практике все, чему вы научились, выполните упражнения.
Упражнения
В этом разделе предлагаются упражнения, чтобы вы могли практически применить знания,
полученные в этой главе. Большинство упражнений в предыдущих главах содержали зада-
ния, для которых вы должны были найти решение в форме запросов или инструкций на язы-
ке T-SQL. Упражнения к этой главе иные. Вам предлагаются инструкции, которым нужно
следовать для выявления и устранения блокирования, ситуаций взаимоблокировок и для
изучения поведения на разных уровнях изоляции. Поэтому для упражнений этой главы не
приводятся ответы.
Во всех упражнениях этой главы с помощью выполнения следующего программного кода
убедитесь в том, что вы подключены к учебной базе данных TSQLFundamentals2008:
USE TSQLFundamentals2008;
Упражнения 9.1—9.6 касаются блокирования, упражнения 9.7—9.12 имеют дело с уровнями
изоляции, упражнения 9.13—19.19 касаются взаимоблокировок.
Упражнение 9.1
Откройте три подключения в среде SQL Server Management Studio (будем называть их Con-
nection 1, Connection 2 и Connection 3). В окне Connection 1 выполните следующий про-
граммный код для обновления строк в таблице Sales. OrderDetails:
BEGIN TRAN;
UPDATE Sales.OrderDetails
SET discount =0.05
WHERE orderid = 10249;
312
Гпава 10
Упражнение 9.2
В окне Connection 2 выполните следующий программный код с запросом к таблице
Sales. OrderDetails; Connection 2 будет заблокировано.
SELECT orderid, productid, unitprice, qty, discount
FROM Sales.OrderDetails
WHERE orderid = 10249;
Упражнение 9.3
В окне Connection 3 выполните следующий программный код для отображения блокировок
и ID процессов, вошедших в цепочку блокирования:
SELECT — используйте * для ознакомления
request_session_id
AS spid,
resource_type
AS restype
resource_database_id
AS dbid,
resource_description
AS res,
resource_associated_entity id AS resid,
request _mode
AS mode,
request_status
AS status
FROM sys.dm tran locks;
Упражнение 9.4
Замените ID процессов 52 и 53 теми, которые, как вы выяснили, включены в цепочку бло-
кирования в предыдущем упражнении. Выполните следующий программный код для полу-
чения информации о подключении, сеансе и блокировании процессов, вовлеченных в це-
почку блокирования:
—
Информация о подключении:
SELECT — используйте * для ознакомления
session_id AS spid,
connect_time,
last_read,
last_write,
mos t_r ecent_sql_handle
FROM sys.dm_exec_connections
WHERE session_id IN(52, 53);
—
Информация о сеансе
SELECT — используйте * для ознакомления
session_id AS spid,
login_tiir\e,
Транзакции и параллелизм
313
hostname,
program__name,
login_name,
nt_user_name,
last_request_start_t ime,
last_request_end_time
FROM sys.dm_exec_sessions
WHERE session_id IN(52f 53);
—
Блокирование
SELECT — используйте * для ознакомления
session_id AS- spid,
blocking_s es s ion_id,
command,
sql_handle,
,
database_id,
wait_type,
wait_time,
wait_resource
FROM sys. dm__exec_requests
WHERE blocking_session_id >0;
Упражнение 9.5
Выполните следующий программный код для получения SQL-текста подключений, вклю-
ченных в цепочку блокирования:
SELECT session_id, text
FROM sys.dm_exec_connections
CROSS APPLY sys. dm_execjsql_text (most_recent_sql_handle) AS ST
WHERE session_id IN (52, 53);
Упражнение 9.6
В окне Connection 1 выполните следующий программный код для отката транзакции:
ROLLBACK TRAN;
Проверьте, что в Connection 2 запрос SELECT вернул две строки сведений о заказах и что
эти строки не были изменены.
Помните о том, что если вам нужно завершить транзакцию блокирующего процесса, вы мо-
жете применить команду KILL.
Закройте все подключения.
314
Гпава 9
Упражнение 9.7
П Откройте два новых подключения (назовем их Connection 1 и Connection 2).
•
В окне Connection 1 выполните следующий программный код для обновления строк в
таблице Sales . OrderDetails (Сведения о заказе) и формирования запроса к ней:
BEGIN TRAN;
UPDATE Sales.OrderDetails
SET discount = discount +0.05
WHERE orderid = 10249;
SELECT orderid, productid, unitprice, qty, discount
EROM Sales.OrderDetails
WHERE orderid = 10249;
•
В окне Connection 2 выполните следующий программный код для установки уровня
изоляции READ UNCOMMITTED и формирования
запроса
к
таблице
Sales.OrderDetails:
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
SELECT orderid, productid, unitprice, qty, discount
EROM Sales.OrderDetails
WHERE orderid = 10249;
Обратите внимание на то, что вы получили модифицированную незафиксированную
версию строк.
П В окне Connection 1 выполните следующий программный код для отката транзакции:
ROLLBACK TRAN;
Упражнение 9.8
П В окне Connection 1 выполните следующий программный код для обновления строк в
таблице Sales. OrderDetails (Сведения о заказе) и формирования запроса к ней:
BEGIN TRAN;
UPDATE Sales.OrderDetails
SET discount = discount +0.05
WHERE orderid = 10249;
SELECT orderid, productid, unitprice, qty, discount
FROM Sales.OrderDetails
WHERE orderid = 10249;
Транзакции и параллелизм
315
П В окне Connection 2 выполните следующий программный код для установки уровня
изоляции READ COMMITTED (устанавливаемый по умолчанию) и формирования запроса
к таблице Sales. OrderDetails:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SELECT orderid, productid, unitprice, qty, discount
FROM Sales.OrderDetails
WHERE orderid = 10249;
Обратите внимание на то, что теперь вы заблокированы.
•
В окне Connection 1 выполните следующий программный код для фиксации транзакции:
COMMIT TRAN;
•
Перейдите в окно Connection 2 и убедитесь, что вы получили измененную зафиксиро-
ванную версию строк.
•
Выполните следующий программный код для очистки базы данных:
UPDATE Sales.OrderDetails
SET discount =0.00
WHERE orderid = 10249;
Упражнение 9.9
•
В окне Connection 1 выполните следующий программный код для установки уровня
изоляции REPEATABLE READ, открытия транзакции и чтения данных из таблицы
Sales. OrderDetails (Сведения о заказе):
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
BEGIN TRAN;
SELECT orderid, productid, unitprice, qty, discount
FROM Sales.OrderDetails
WHERE orderid = 10249;
Вы получите две строки со значением discount (скидка) 0.00.
П В окне Connection 2 выполните следующий программный код и обратите внимание на
то, что вы заблокированы:
UPDATE Sales.OrderDetails
SET discount = discount +0.05
WHERE orderid = 10249;
•
В окне Connection 1 выполните следующий программный код для повторного чтения
данных и фиксации транзакции:
SELECT orderid, productid, unitprice, qty, discount
FROM Sales.OrderDetails
316
Гпава 9
WHERE orderid = 10249;
COMMIT TRAN;
Вы снова получите две строки со значениями discount (скидка), равными 0.00, обеспе-
чивающие повторяемость считываний. Учтите, что если бы ваш программный код выпол-
нялся на более низком уровне изоляции (READ UNCOMMITTED ИЛИ READ COMMITTED), ин-
струкция UPDATE не была бы заблокирована, и вы получили бы считывания без
повторяемости результатов.
П Перейдите в окно Connection 2 и убедитесь, что обновление закончилось.
П Выполните следующий программный код для очистки базы данных:
UPDATE Sales.OrderDetails
SET discount =0.00
WHERE orderid = 10249;
Упражнение 9.10
•
В окне Connection 1 выполните следующий программный код, чтобы установить уро-
вень
изоляции
SERIALIZABLE
и
формирования
запроса
к
таблице
Sales. OrderDetails (Сведения о заказе):
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRAN;
SELECT orderid, productid, unitprice, qty, discount
EROM Sales.OrderDetails
WHERE orderid = 10249;
•
В окне Connection 2 выполните следующий программный код, чтобы попытаться вста-
вить в таблицу Sales.OrderDetails строку с тем же ID заказа, который был отобран
предыдущим запросом, и убедитесь в том, что вы заблокированы:
INSERT INTO Sales.OrderDetails
(orderid, productid, unitprice, qty, discount)
VALUES(10249, 2, 19.00, 10, 0.00);
Имейте в виду, что на более низких уровнях изоляции (READ UNCOMMITTED, READ
COMMITTED, REPEATABLE READ) эта инструкция INSERT не была бы заблокирована.
П В окне Connection 1 выполните следующий программный код для повторного форми-
рования запроса к таблице Sales.OrderDetails (сведения о заказе) и фиксации тран-
закции:
SELECT orderid, productid, unitprice, qty, discount
EROM Sales.OrderDetails
WHERE orderid = 10249;
COMMIT TRAN;
Транзакции и параллелизм
317
Вы получите в той же транзакции такое же результирующее подмножество строк, как и
в предыдущем запросе, и благодаря блокированию инструкции INSERT не получите
фантомных считываний.
П Вернитесь в окно Connection 2 и убедитесь, что инструкция INSERT завершилась.
П Для очистки выполните следующий программный код:
DELETE FROM Sales.OrderDetails
WHERE orderid = 10249
AND productid = 2;
•
В окнах Connection! и Connection2 выполните следующий программный код для
установки уровня изоляции по умолчанию READ COMMITTED:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
Упражнение 9.11
П Выполните следующий программный код, чтобы разрешить применение в базе данных
TSQLFundamentals2008 уровня изоляции SNAPSHOT:
ALTER DATABASE TSQLFundamentals2008 SET ALLOW_SNAPSHOT_ISOLATION ON;
П В окне Connection 1 выполните следующий программный код для открытия транзак-
ции, обновления строк в таблице Sales .OrderDetails (Сведения о заказе) и
формирования запроса к этой таблице:
BEGIN TRAN;
UPDATE Sales.OrderDetails
SET discount = discount + 0.05
WHERE orderid = 10249;
SELECT orderid, productid, unitprice, qty, discount
FROM Sales.OrderDetails
WHERE orderid = 10249;
П В окне Connection 2 выполните следующий программный код для установки уровня
изоляции SNAPSHOT и формирования запроса к таблице Sales .OrderDetails. Обрати-
те внимание на то, что вы не заблокированы — напротив, вы получаете более раннюю
непротиворечивую версию данных, которая была в наличии в момент старта транзакции
(со значениями discount (скидка) равными 0.00).
SET TRANSACTION ISOLATION LEVEL SNAPSHOT;
BEGIN TRAN;
SELECT orderid, productid, unitprice, qty, discount
FROM Sales.OrderDetails
WHERE orderid = 10249;
318
Гпава 9
П Перейдите в окно Connection 1 и зафиксируйте транзакцию:
COMMIT TRAN;
П Перейдите в окно Connection 2 и снова запросите данные, вы все еще получите значе-
ния discount, равные 0.00.
SELECT orderid, productid, unitprice, qty, discount
FROM Sales.OrderDetails
WHERE orderid = 10249;
П В окне Connection 2 зафиксируйте транзакцию и снова запросите данные, обратите
внимание на то, что получаете значения discount (скидка), равные 0.05.
COMMIT TRAN;
SELECT orderid, productid, unitprice, qty, discount
FROM Sales.OrderDetails
WHERE orderid = 10249;
П Для очистки базы данных выполните следующий программный код:
UPDATE Sales.OrderDetails
SET discount =0.00
WHERE orderid = 10249;
Закройте все подключения.
Упражнение 9.12
П Активизируйте уровень изоляции READCOMMITTEDSNAPSHOT В базе данных
TSQLFundamentals2008.
ALTER DATABASE TSQLFundamentals2008 SET READ_COMMITTED_SNAPSHOT ON;
П Откройте два новых подключения (будем называть их Connection 1 и Connection 2).
•
В окне Connection 1 выполните следующий программный код, чтобы открыть транзак-
цию, обновить строки в таблице Sales .OrderDetails (Сведения о заказе) и сформи-
ровать запрос к ней:
BEGIN TRAN;
UPDATE Sales.OrderDetails
SET discount = discount +0.05
WHERE orderid = 10249;
SELECT orderid, productid, unitprice, qty, discount
FROM Sales.OrderDetails
WHERE orderid = 10249;
Транзакции и параллелизм
319
П В окне Connection 2 выполните следующий программный код, который теперь действу-
ет на уровне изоляции READ COMMITTED SNAPSHOT, потому что установлен флаг базы
данных READ_C0MMITTED_SNAPSH0T. Обратите внимание на то, что вы не заблокирова-
ны — вместо этого вы получаете более раннюю непротиворечивую версию данных, ко-
торая имелась в момент старта инструкции (значения discount, равные 0.00).
BEGIN TRAN;
SELECT orderid, productid, unitprice, qty, discount
FROM Sales.OrderDetails
WHERE orderid = 10249;
•
Перейдите в окно Connection 1 и зафиксируйте транзакцию:
COMMIT TRAN;
П Перейдите в окно Connection 2, снова запросите данные и зафиксируйте транзакцию,
обратите внимание на то, что вы получили новые значения discount (скидка), равные
0.05
SELECT orderid, productid, unitprice, qty, discount
FROM Sales.OrderDetails
WHERE orderid = 10249;
COMMIT TRAN;
П Выполните следующий программный код для очистки базы данных:
UPDATE Sales.OrderDetails
SET discount =0.00
WHERE orderid = 10249;
Закройте все подключения.
П Верните флагам базы данных значения, устанавливаемые по умолчанию, отключив уровни
изоляции, основанные на моментальных снимках данных:
ALTER DATABASE TSQLFundamentals2008 SET ALLOW_SNAPSHOT_ISOLATION OFF;
ALTER DATABASE TSQLFundamentals2008 SET READ_COMMITTED_SNAPSHOT' OFF;
Упражнение 9.13
Откройте два новых подключения (будем называть их Connection 1 и Connection 2).
Упражнение 9.14
В окне Connection 1 выполните следующий программный код, чтобы открыть транзакцию и
обновить строку с товаром 2 в таблице Production. Products (Товары):
BEGIN TRAN;
320
Гпава 10
UPDATE Production.Products
SET unitprice = unitprice + 1.00
WHERE productid = 2;
Упражнение 9.15
В окне Connection 2 выполните следующий программный код, чтобы открыть транзакцию и
обновить строку с товаром 3 в таблице Production. Products:
BEGIN TRAN;
UPDATE Production.Products
SET unitprice = unitprice + 1.00
.
WHERE productid = 3;
Упражнение 9.16
В окне Connection 1 выполните следующий программный код, чтобы запросить товар 3. Вы
будете заблокированы.
SELECT productid, unitprice
EROM Product ion.Products
WHERE productid = 3;
COMMIT TRAN;
Упражнение 9.17
В окне Connection 2 выполните следующий программный код, чтобы запросить товар 2. Вы
будете заблокированы, и ошибка взаимоблокировки будет сгенерирована как в окне Con-
nection 1, так и в окне Connection 2.
SELECT productid, unitprice
EROM Product ion.Products
WHERE productid = 2;
COMMIT TRAN;
Упражнение 9.18
Можете ли вы предложить способ предотвращения этой взаимоблокировки?
Подсказка: вернитесь к тому, что вы прочли в разд. "Взаимоблокировки"ранее в этой главе.
Транзакции и параллелизм
321
Упражнение 9.19
Выполните следующий программный код для очистки базы данных:
UPDATE Production.Products
SET unitprice = 19.00
WHERE productid = 2;
UPDATE Production.Products
SET unitprice = 10.00
WHERE productid = 3;
ГЛАВА 10
Программируемые объекты
В этой главе предлагается краткий обзор программируемых объектов, чтобы познакомить
вас с возможностями Microsoft SQL Server в этой сфере и применяемыми концепциями.
В главе описаны переменные, пакеты, элементы, управляющие выполнением программ,
курсоры, временные таблицы, динамический SQL, подпрограммы, такие как функции, опре-
деленные пользователем, хранимые процедуры и триггеры, и способы обработки ошибок.
Цель этой главы — предоставить общий обзор, не вдаваясь в детали. Постарайтесь сосредо-
точиться на логических аспектах и возможностях программируемых объектов, вместо того,
чтобы пытаться понять все элементы программного кода и его технические тонкости.
Переменные
Переменные позволяют хранить значения данных временно, для использования в дальней-
шем в том же пакете, где они были объявлены. Чуть позже в этой главе я опишу пакеты, а
сейчас достаточно сказать, что пакет — эта одна или несколько инструкций на языке T-SQL,
которые посылаются SQL Server для исполнения как единый блок.
Для объявления одной или нескольких переменных используйте инструкцию DECLARE, а для
присвоения значения единственной переменной — инструкцию SET. Например, в следую-
щем программном коде объявляется переменная @ic типом данных INT, И ей присваивается
значение 10:
DECLARE @I AS INT;
SET
= 10;
В версии SQL Server 2008 введена поддержка объявления и инициализации переменных в
одной инструкции следующим образом:
DECLARE @i AS INT = 10;
На протяжении этой главы я применяю отдельные инструкции DECLARE и SET, чтобы вы
могли выполнять программный код в версии SQL Server 2005 и более ранних.
Если значение присваивается скалярной переменной, значение должно быть результатом
скалярного выражения. Выражение может быть скалярным подзапросом. Например, в еле-
Программируемые объекты
323
дующем программном коде объявляется переменная @ empname, и ей присваивается резуль-
тат скалярного подзапроса, возвращающего полное имя сотрудника с ID, равным 3:
USE TSQLFundamentals2008;
DECLARE @empname AS NVARCHAR(61);
SET @empname = (SELECT firstname + N' ' + lastname
FROM HR.Employees
WHERE empid = 3);
SELECT @empname AS empname;
Этот программный код вернет следующий результат:
empname
Judy Lew
Инструкция SET может обрабатывать только одну переменную в каждый момент времени,
поэтому если вам нужно присвоить значения нескольким атрибутам, необходимо применять
множественные инструкции SET. Такой подход может повлечь лишние накладные расходы,
если необходимо выуживать многочисленные атрибуты из одной и той же строки. Напри-
мер, в следующем программном коде применяются две отдельные инструкции SET ДЛЯ при-
своения имени и фамилии сотрудника с ID, равным 3, двум отдельным переменным:
DECLARE @firstname AS NVARCHAR(20), @lastname AS NVARCHAR(40);
SET @firstname = (SELECT firstname
FROM HR.Employees
WHERE empid = 3);
SET @lastname = (SELECT lastname
FROM HR.Employees
WHERE empid = 3);
SELECT @firstname AS firstname, @lastname AS lastname;
Этот программный код вернет такой результат:
firstname lastname
Judy
Lew
SQL Server также поддерживает нестандартную инструкцию SELECT-присваивания, позво-
ляющую в одной инструкции запросить данные и присвоить разным переменным многочис-
ленные значения, полученные из одной и той же строки. Далее приведен пример.
DECLARE @firstname AS NVARCHAR(20), Glastname AS NVARCHAR(40);
SELECT @firstname = firstname,
@ lastname = lastname
324
Гпава 10
FROM HR.Employees
WHERE empid = 3;
SELECT @firstname AS firstname, @lastname AS lastname;
Инструкция SELECT-присваивания ведет себя предсказуемо, если извлечена точно одна
строка. Но учтите, что если запрос извлек несколько строк, программный код не завершает-
ся аварийно. Для каждой выбранной строки выполняются присваивания, и значения из те-
кущей строки перезаписывают существующие значения переменных. Когда инструкция
SELECT-присваивания заканчивается, значения переменных равны значениям строки, к ко-
торой SQL Server обратился последней. Например, у следующей инструкции SELECT-
присваивания есть две отобранные строки:
DECLARE @empname AS NVARCHAR(61);
SELECT @empname = firstname + Nf
' + lastname
FROM HR.Employees
WHERE mgrid = 2;
SELECT @empname AS empname;
Сведения о сотруднике, которые окажутся в переменной после завершения SELECT-
присваивания, зависят от случайно установившегося порядка доступа SQL Server к строкам.
Когда я выполнил этот программный код, то получил такой результат:
empname
Sven Buck
Инструкция SET безопаснее SELECT-присваивания, поскольку она требует применения ска-
лярного подзапроса для извлечения данных из таблицы. Напоминаю, что скалярный запрос
во время выполнения аварийно завершается, если возвращает более одного значения. На-
пример, следующий программный код завершится аварийно:
DECLARE @empname AS NVARCHAR(61);
SET @empname = (SELECT firstname + N' ' + lastname
FROM HR.Employees
WHERE mgrid = 2);
SELECT @empname AS empname;
Поскольку переменной не было присвоено значение, она остается равной значению NULL,
которое используется по умолчанию для всех неинициализированных переменных. Данный
программный код вернет такой результат:
Msg 512, Level 16, State 1, Line 3
Subquery returned more than 1 value. This is not permitted when the subquery
follows =, !=,<, <= , >, >= or when the subquery is used as an expression.
empname
NULL
Программируемые объекты
325
Пакеты
Пакет — это одна или несколько инструкций T-SQL, отправляемых клиентским приложе-
нием SQL Server для выполнения как единого целого. Пакет проходит синтаксический ана-
лиз, разрешение имен (проверку наличия объектов и столбцов, на которые есть ссылки, про-
верку прав доступа) и оптимизацию как единый блок.
Не путайте транзакции и пакеты. Транзакция — это неделимый рабочий блок. Пакет может
содержать несколько транзакций, и транзакция может быть представлена частями в разных
пакетах. Когда транзакция отменяется или откатывается в ходе выполнения, SQL Server
удаляет ту часть действий, которые были выполнены с момента запуска транзакции, незави-
симо от того, где находится начало пакета.
Клиентские прикладные интерфейсы API, например, ADO.NET, снабжают вас методами
предоставления программе SQL Server пакета программного кода для выполнения. Утилиты
SQL Server, такие как SQL Server Management Studio, SQLCMD и OSQL, предоставляют
клиентскую команду GO, обозначающую окончание пакета. Имейте в виду, что команда
GO — это клиентская, а не серверная команда T-SQL.
Пакет как единица синтаксического анализа
Пакет — это набор команд, которые подвергаются синтаксическому анализу и выполняют-
ся как единый блок. Если синтаксическая проверка будет успешна, SQL Server затем попы-
тается выполнить пакет. В случае синтаксической ошибки в пакете весь пакет не передается
SQL Server для выполнения. Например, в следующем программном коде три пакета, во вто-
ром из них есть синтаксическая ошибка (во втором запросе FOM вместо FROM):
—
Корректный пакет
PRINT 1 First batch';
USE TSQLFundamentals2008;
GO
—
Некорректный пакет
PRINT 1 Second batch';
SELECT custid FROM Sales.Customers;
SELECT orderid FOM Sales.Orders;
GO
—
Корректный пакет
PRINT 'Third batch';
SELECT empid FROM HR.Employees;
Поскольку во втором пакете есть синтаксическая ошибка, весь пакет не передается SQL
Server для выполнения. Первый и третий пакеты проходят синтаксическую проверку и, сле-
довательно, передаются для исполнения. Этот программный код формирует следующий
результат, показывающий, что второй пакет целиком не был выполнен:
First batch
Msg 102/ Level 15, State 1, Line 4
Incorrect syntax near
1
Sales
1
.
326
Гпава 10
Third batch
empid
2
7
1
5
6
8
3
9
4
(9 row(s) a ffected)
Пакеты и переменные
Переменные локальны по отношению к пакету, в котором определены. Если вы попробуете
сослаться на переменную, определенную в другом пакете, то получите ошибку, сообщаю-
щую о том, что переменная не определена. Например, в следующем программном коде в
одном пакете переменная объявлена и выведена на печать, а другом пакете делается попыт-
ка напечатать эту переменную.
DECLARE @i AS INT;
SET@i=10;
—
Успешная попытка
PRINT @i;
GO
—
Неудачная попытка
PRINT @I;
Ссылка на переменную в первой инструкции PRINT корректна, т. к. она появляется в том же
пакете, где объявлена переменная, а вторая ссылка не корректна. Таким образом, первая
инструкция PRINT вернет значение переменной (10), а вторая завершится аварийно. Далее
приведен результат, возвращаемый этим программным кодом.
10
Msg 137, Level 15, State 2, Line 3
Must-declare the scalar variable "@i".
Инструкции, которые не могут комбинироваться
в одном пакете
Следующие инструкции не могут комбинироваться с другими инструкциями в одном и том
же пакете: CREATE DEFAULT, CREATE FUNCTION, CREATE PROCEDURE, CREATE RULE,
Программируемые объекты
327
CREATE SCHEMA, CREATE TRIGGER и CREATE VIEW. Например, в следующем программном
коде есть инструкция IF, за которой идет инструкция CREATE VIEW В том же самом пакете,
и, следовательно, она не допустима.
IF OBJECT_ID(1 Sales.MyView
1
, 'V') IS NOT NULL DROP VIEW Sales.MyView;
CREATE VIEW Sales.MyView
AS
SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate);
GO
Попытка выполнить этот программный код приведет к сообщению об ошибке:
Msg 111, Level 15, State 1, Line 3
1
CREATE VIEW1
must be the first statement in a query batch.
Для решения этой проблемы включите инструкции IF и CREATE VIEW В разные пакеты,
добавив команду GO после инструкции IF.
Пакет как единица разрешения имен
Пакет — это блок разрешения имен, т. е. проверка наличия объектов и столбцов выполняет-
ся на уровне пакета. Помните об этом, проектируя границы пакета. Когда вы применяете к
объекту изменения схемы и пытаетесь в том же пакете манипулировать данными объекта,
SQL Server может все еще не знать об изменениях схемы и аварийно завершить инструкцию
обработки данных с ошибкой разрешения имен. Я продемонстрирую эту проблему на при-
мере и затем приведу практические рекомендации.
Выполните следующий программный код для создания в базе данных tempdb таблицы Т1,
содержащей один столбец coll:
USE tempdb;
IF OBJECT_ID(1dbo.Tl1
, 'U') IS NOT NULL DROP TABLE dbo.Tl;
CREATE TABLE dbo.Tl(coll INT);
Затем попытайтесь вставить в Tl столбец со12 и запросить новый столбец в том же пакете:
ALTER TABLE dbo.Tl ADD col2 INT;
SELECT coll, col2 FROM dbo.Tl;
Несмотря на то, что программный код может показаться совершенно корректным, пакет
завершится аварийно на стадии разрешения имен с сообщением об ошибке:
Msg 207, Level 16, State 1, Line 2
Invalid column name
1
col2'.
Во время разрешения имен в инструкции SELECT у таблицы Т1 был только один столбец, и
ссылка на столбец со12 вызвала ошибку. Во избежание подобных проблем лучше всего
328
Гпава 10
включать инструкции языков DDL и DML в разные пакеты, как в приведенном далее при-
мере:
ALTER TABLE dbo.Tl ADD col2 INT;
GO
SELECT coll, col2 FROM dbo.Tl;
Вариант GO n
В клиентских средствах SQL Server 2005 команда GO была усовершенствована, у нее появи-
лась возможность поддержки аргумента, указывающего, сколько раз вы хотите повторить
выполнение пакета. Новый вариант применяется, если вы хотите повторить пакет. Для того
чтобы увидеть действие усовершенствованной команды GO, сначала создайте в базе данных
tempdb таблицу Tl с идентификационным столбцом:
IF OBJECT_ID(1dbo.Tl1
, *U') IS NOT NULL DROP TABLE dbo.Tl;
CREATE TABLE dbo.Tl(coll INT IDENTITY);
Теперь выполните следующий программный код для подавления стандартного вывода,
формируемого инструкциями DML и указывающего количество затронутых обработкой
строк:
SET NOCOUNT ON;
В заключение выполните программный код для определения пакета с инструкцией INSERT
DEFAULT VALUES и его выполнения 100 раз:
INSERT INTO dbo.Tl DEFAULT VALUES;
GO 100
Помните о том, что команда GO — клиентская, а не серверная команда T-SQL. Это означает,
что независимо от версии механизма управления базой данных, к которому вы подключены,
команда GO п поддерживается, только если используемая вами клиентская программа —
SQL Server 2005 или более поздняя версия.
Элементы, управляющие выполнением
Элементы, управляющие выполнением, позволяют контролировать поток исполнения ваше-
го программного кода. Язык T-SQL предоставляет очень простые виды управления с помо-
щью элементов IF. . .ELSE И WHILE.
Управляющий элемент /F... ELSE
Элемент IF.. .ELSE позволяет управлять потоком исполнения вашего программного кода
на основе предиката. Вы задаете инструкцию или блок инструкций, которые выполняются,
если предикат равен TRUE, И необязательно инструкцию или блок инструкций, которые вы-
полняются, если предикат равен FALSE или UNKNOWN.
Программируемые объекты
329
Например, в следующем программном коде проверяется, является ли текущая дата послед-
ним днем года (год текущей даты не равен году завтрашней даты). Если да, печатается со-
общение о том, что сегодня последний день года; если нет, программный код сообщает о
том, что сегодня — не последний день года.
IF YEAR (CURRENT_TIMESTAMP) <> YEAR (DATEADD (day, 1, CURRENT_TIMESTAMP) )
PRINT 1Today is the last day of the year.
1
ELSE
PRINT 'Today is not the last day of the year.
1
В этом примере я использовал инструкции PRINT ДЛЯ ТОГО, чтобы показать, какие части
программного кода были выполнены, а какие— нет, но вы конечно же можете задать лю-
бые другие инструкции.
Помните о том, что в языке T-SQL используется трехзначная или троичная логика и что
блок ELSE активизируется, когда предикат равен FALSE или UNKNOWN. В случаях, когда зна-
чения FALSE и UNKNOWN являются возможными результатами предиката (например, когда
вовлечены значения NULL) И вам нужно дифференцировать обработку для каждого варианта,
убедитесь, что у вас есть явная проверка для значений NULL, выполняемая с помощью пре-
диката IS NULL.
Если управляемый вами поток исполнения включает более двух вариантов обработки, мож-
но вкладывать элементы IF. . .ELSE один в другой. Например, приведенный далее про-
граммный код обрабатывает по-разному следующие три случая.
•
сегодня последний день года;
П сегодня последний день месяца, но не последний день года;
П сегодня не последний день месяца.
IF YEAR (CURRENT__TIMESTAMP) <> YEAR (DATEADD (day, 1, CURRENTJTIMESTAMP) )
PRINT •Today is the last day of the year.
1
ELSE
IF MONTH (CURRENT_TIMESTAMP) <> MONTH (DATEADD (day, 1,
CURRENT_TIMESTAMP) )
PRINT 1Today is the last day of the month but not the last day of the
year.
1
ELSE
PRINT 'Today is'not the last day of the month.';
Если в ветках IF или ELSE вам необходимо выполнить несколько инструкций, применяйте
блок инструкций. Границы блока инструкций помечаются ключевыми словами BEGIN и END.
Например, следующий программный код выполняет полное резервное копирование учебной
базы данных TSQLFundamentals2008, если сегодня первый день месяца, и разностное ре-
зервное копирование (изменения с момента последнего полного копирования), если сегодня
не последний день месяца.
IF DAY (CURRENT_TIMESTAMP) = 1
BEGIN
PRINT 'Today is the first day of the month.';
PRINT 'Starting a full database backup.';
330
Гпава 10
BACKUP DATABASE TSQLFundamentals2008
TO DISK =
1
C: \Temp\TSQLFundamentals2008_Full.BAK
f
WITH INIT;
PRINT ' Finished full database backup.';
END
ELSE
BEGIN
PRINT 'Today is not the first day of the month.'
PRINT 'Starting a differential database backup.';
BACKUP DATABASE TSQLFundamentals2008
TO DISK =
1
C:\Temp\TSQLFundamentals2008_Diff.ВАК
1
WITH INIT;
PRINT 'Finished differential database backup.
1
;
END
Имейте в виду, что в инструкциях BACKUP DATABASE только что приведенного программно-
го кода предполагается, что папка C:\Temp существует.
Управляющий элемент WHILE
Язык T-SQL предоставляет элемент WHILE, чтобы у вас была возможность выполнения про-
граммного кода в цикле. Элемент WHILE многократно выполняет инструкцию или блок ин-
струкций до тех пор, пока предикат, заданный вами после ключевого слова WHILE, равен
TRUE. Когда предикат становится равным FALSE ИЛИ UNKNOWN, цикл завершается.
В T-SQL нет встроенного циклического элемента, выполняемого заданное число раз, но его
очень легко сымитировать с помощью цикла WHILE и переменной. Например, в следующем
программном коде показано, как написать цикл, выполняющийся 10 раз:
DECLARE @i AS INT;
SET@i=1
WHILE @i <= 10
BEGIN
PRINT @i;
SET@i=@i+1;
END;
В приведенном программном коде целочисленная переменная @i, которая служит счетчи-
ком цикла, объявляется и инициализируется значением 1. Далее программный код входит в
цикл, который повторяется, пока переменная не превысит значение 10. При каждом повто-
рении цикла в его теле выводится текущее значение @i, и затем оно увеличивается на 1.
Данный программный код возвращает следующий результат, показывающий, что цикл
повторялся 10 раз:
1
2
3
4
Программируемые объекты
331
5
6
7
8
9
10
Если в какой-то момент, находясь в теле цикла, вы захотите прервать выполнение теку-
щего цикла и перейти к выполнению инструкции, следующей за телом цикла, используйте
команду BREAK. Например, далее в программном коде цикл прерывается, если значение
@i равно 6:
DECLARE @i AS INT;
SET@i=1
WHILE @i <= 10
BEGIN
IF@i=6BREAK;
PRINT @i;
SET@i=@i+1;
END;
Этот программный код формирует результат, показывающий, что цикл повторялся пять раз
и завершился в начале шестого повторения:
1
2
3
4
5
Конечно, приведенный программный код не слишком остроумен; если вы хотите повторить
цикл только пять раз, следует просто задать предикат @i <= 5. В данном случае я просто
хотел показать применение команды BREAK на простом примере.
Если в какой-то момент, находясь в теле цикла, вы хотите пропустить действия, оставшиеся
в текущем проходе цикла, и снова вычислить предикат цикла, используйте команду
CONTINUE. Например, в следующем программном коде показано, как пропустить в шестом
проходе тела цикла все действия, начиная с инструкции IF и заканчивая концом тела цикла:
DECLARE @I AS INT;
SET@i=0;
WHILE @i < 10
BEGIN
SET@i=@i+1;
IF @i - 6 CONTINUE;
PRINT @i;
END;
332
Гпава 10
Результат данного программного кода показывает, что значение @i выводилось во всех по-
вторениях цикла кроме шестого:
1
2
3
4
5
7
8
9
10
Пример использования IF и WHILE
В следующем примере сочетается применение элементов IF И WHILE. Задача программного
кода в этом примере — создание в базе данных tempdb таблицы dbo.Nums и заполнение ее
1000 строк со значениями от 1 до 1000 в столбце п.
SET NOCOUNT ON;
USE tempdb;
IF OBJECT_ID('dbo.Nums
1
, 'U') IS NOT NULL DROP TABLE dbo.Nums;
CREATE TABLE dbo.Nums (n INT NOT NULL PRIMARY KEY);
GO
DECLARE @i AS INT;
SET@i=1;
WHILE @i <= 1000
BEGIN
INSERT INTO dbo.Nums(n) VALUES(@i);
SET@i=@i+1;
END
В приведенном программном коде инструкция IF применяется для проверки наличия таб-
лицы Nums, если таблица уже существует, она удаляется. Цикл WHILE повторяется 1000 раз
и заполняет таблицу Nums значениями от 1 до 1000.
Курсоры
В главе 2 я объяснял, что запрос без синтаксического элемента ORDER BY возвращает мно-
жество (или мультимножество), в то время как запрос с элементом ORDER BY возвращает то,
что стандарт ANSI называет курсором — нереляционный результат с определенным поряд-
ком следования строк. В контексте объяснения в главе 2 применение термина "курсор" было
концептуальным. Язык T-SQL также поддерживает объект, именуемый курсором, который
Программируемые объекты
333
позволяет обрабатывать строки из результирующего набора запроса поочередно в заданном
порядке. Это противоположно применению основанных на множествах запросов — обыч-
ных запросов без курсора, в которых множество или мультимножество обрабатываются це-
ликом и без учета порядка следования.
Я хочу подчеркнуть, что обычно вам следует останавливать выбор на применении основан-
ных на множествах запросов; и только если есть очень веская причина поступать иначе,
следует рассматривать возможность применения курсоров. Эта рекомендация основана на
нескольких факторах.
•
Во-первых, и это главное, когда используются курсоры, вы вступаете в существенное
противоречие с реляционной моделью, которая рассчитана на логику в терминах мно-
жеств.
•
Во-вторых, построчная обработка курсором сопряжена с дополнительными расходами.
Определенные дополнительные затраты связаны с отдельной обработкой каждой записи
курсора по сравнению с обработкой, основанной на множестве. Если сравнить про-
граммный код запроса, базирующегося на множествах, и курсора, которые на внутрен-
нем уровне выполняют похожую физическую обработку, программный код с примене-
нием курсора обычно выполняется в десятки раз медленнее, чем код, основанный на
множествах.
•
В-третьих, в случае курсоров вы тратите много строк программного кода на физические
аспекты решения или, другими словами, на способ обработки данных (объявление кур-
сора, его открытие, организация цикла для обработки записей курсора, закрытие курсо-
ра, освобождение памяти, выделенной курсору). В случае решений, основанных на
множествах, вы главным образом сосредоточены на логических аспектах решения, дру-
гими словами, на том, что нужно получить, а не на том, как это получить. Следователь-
но, решения с применением курсора, как правило, длиннее, менее четкие и их труднее
сопровождать по сравнению с решениями, основанными на множествах.
Большинству людей не просто думать в терминах множеств сразу, на начальном этапе изуче-
ния языка SQL. В отличие от подхода, на который рассчитывает реляционная модель, курсоры
большинству людей интуитивно гораздо понятнее— поочередная обработка записей в опре-
деленном порядке. В результате курсоры широко применяются и в большинстве случаев не-
правильно, т. е. курсоры используются там, где гораздо лучше действуют решения, основан-
ные на множествах. Приложите осознанное усилие для того, чтобы сформировать подход к
решению, основанный на множествах, и по-настоящему научиться думать в терминах мно-
жеств. Для этого потребуется время, в некоторых случаях — годы. Но поскольку вы пишете на
языке, базирующемся на реляционной модели, это единственно верный образ мышления.
Работа с курсорами похожа на рыбную ловлю удочкой, выуживание по одной рыбке. С дру-
гой стороны, работа с множествами напоминает рыбную ловлю сетью, позволяющей пой-
мать сразу много рыбы. Как еще одну аналогию рассмотрим две фабрики по упаковке
апельсинов: одну, работающую по старинке, и другую, современную. Предполагается, что
фабрики упаковывают апельсины в тару трех разных видов в зависимости от размеров пло-
дов: мелкие, средние и крупные. Работающая по старинке фабрика действует в режиме кур-
сора, т. е. двигаются конвейерные ленты, загруженные апельсинами, и человек на конце
каждой ленты осматривает каждый апельсин и помещает его в зависимости от размера в
нужный вид тары. Это очень медленный способ обработки. И здесь порядок следования
имеет значение. Если на лентах конвейера поступают предварительно отсортированные по
размеру апельсины, их обрабатывать легче, поэтому можно установить более высокую ско-
334
Гпава 10
рость движения конвейера. Современная фабрика работает в режиме, основанном на мно-
жествах: все апельсины помещаются в большой контейнер с сеткой из мелких ячеек на дне.
Машина трясет контейнер и только мелкие апельсины проходят через дыры сетки. Затем
машина перемещает апельсины в контейнер с ячейками средней величины и снова трясет
его, давая апельсинам средних размеров пройти через дыры сетки. Крупные апельсины ос-
таются в контейнере.
Предположим, что вы согласились с тем, что основанные на множествах решения — это
ваш выбор, но важно знать исключения, когда следует рассмотреть возможность примене-
ния курсоров. Первый пример — необходимость решать определенную задачу для каждой
строки из некоторой таблицы или представления. Например, вам нужно выполнить некото-
рую административную, задачу для каждой базы вашего экземпляра сервера или для каждой
таблицы вашей базы данных. В любом подобном случае имеет смысл применить курсор для
последовательного задания всех имен баз данных или таблиц и выполнения конкретной за-
дачи в каждой из них. Я приведу примеры подобных задач в разд. "Динамический SQL" да-
лее в этой главе.
Другой пример того, что нужно рассматривать возможность применения курсоров,— ре-
шение, основанное на множествах, работает плохо, и вы исчерпали усилия по его отладке на
базе множеств. Как я уже упоминал, обычно решения на основе множеств гораздо быстрее,
но в некоторых случаях быстрее выполняется решение с использованием курсоров. Как пра-
вило, это вычисления, которые при поочередной обработке строк в определенном порядке
включают обращение к гораздо меньшему объему данных по сравнению с методом, кото-
рым в настоящее время SQL Server (и SQL Server 2008, и предыдущие версии) оптимизиру-
ет соответствующие решения на.базе множеств. Один из таких примеров— итоги с накоп-
лением. В разд. "Итоги с накоплением" главы 4 я предложил для получения итогов с
накоплением решение на основе множеств, использующее подзапросы. Оптимизация не
рассматривается в этой книге, поэтому я не буду вдаваться в детали, объясняющие, почему
для итогов с накоплением решение с применением курсора в настоящее время более эффек-
тивно, чем решение, основанное на множествах. В данный момент я хочу, чтобы вы усвои-
ли, что в большинстве случаев решения, основанные на множествах, получаются более бы-
стрыми, чем решения с курсорами, но иногда из-за оптимизации решения с применением
курсоров действуют быстрее.
В начале данной главы я обещал дать общий обзор. Тем не менее, сейчас, вероятно, уместен
пример программного кода с использованием курсора.
Работа с курсором обычно включает следующие шаги:
1. Объявление курсора, основанного на запросе.
2. Открытие курсора.
3. Считывание в переменные значений атрибутов из первой записи курсора.
4. Пока не достигнут конец курсора (значение функции @@FETCH_ STATUS равно 0), обра-
ботка в цикле записей курсора; в каждом проходе цикла считывание в переменные зна-
чений атрибутов текущей записи курсора и выполнение обработки, необходимой для те-
кущей записи.
5. Закрытие курсора.
6. Освобождение динамической памяти, отведенной курсору.
Программируемые объекты
335
В следующем программном коде с применением курсора по данным представления
Sales.Custorders (Заказы клиентов) вычисляется обший объем заказа с накоплением для
каждого клиента и месяца:
SET NOCOUNT ON;
USE TSQLFundamentals2008;
DECLARE @Result TABLE
( custid INT,
ordemonth DATETIME,
qty INT,
runqty INT,
PRIMARY KEY(custid, ordermonth));
DECLARE @custid AS INT,
Qprvcustid AS INT,
@ordermonth DATETIME,
@qty AS INT,
@runqty AS INT;
DECLARE С CURSOR FAST_FORWARD /* только чтение, только вперед */ FOR
SELECT custid, ordermonth, qty
FROM Sales.CustOrders
ORDER BY custid, ordermonth;
OPEN С
FETCH NEXT FROM С INTO Gcustid, Gordermonth, @qty;
SELECT @prvcustid = Gcustid, @runqty = 0;
WHILE @GFETCH_STATUS = 0
BEGIN
IF @custid <> @prvcustid
SELECT @prvcustid = Qcustid, @runqty = 0;
SET @runqty = @runqty + @qty;
INSERT INTO @Result VALUES(@custid, @ordermonth, @qty, @runqty);
FETCH NEXT FROM С INTO Qcustid, @ordermonth, Gqty;
END
CLOSE C;
336
Гпава 10
DEALLOCATE С;
SELECT
custid,
CONVERT(VARCHAR(7), ordermonth, 121) AS ordermonth,
qty,
runqty
FROM @Result
ORDER BY custid, ordermonth;
В программном коде объявляется курсор на базе запроса, возвращающего из представления
Custorders (Заказы клиентов) строки, упорядоченные по ID клиента и месяцу заказа, и в цик-
ле эти строки последовательно обрабатываются одна за другой. Текущий общий объем с нако-
плением отслеживается и сохраняется в переменной @runqty, которая переустанавливается
каждый раз, когда обнаружен новый клиент. Для каждой строки текущий итог с накоплением
вычисляется добавлением объема текущего месяца (@qty) к значению переменной @runqty и
в табличную переменную @Result вставляется строка с ГО клиента, месяцем заказа, объемом
текущего месяца и объемом заказов с накоплением. Когда обработка всех записей курсора
закончена, выполняется запрос к табличной переменной для вывода итогов с накоплением.
Далее приведен в сокращенном виде результат, возвращаемый данным программным кодом:
custid
ordermonth qty
runqty
2007-08
38
38
2007-10
41
79
2008-01
17
96
2008-03
18
114
2008-04
60
174
2
2006-09
6
6
2
2007-08
18
24
2
2007-11
10
34
2
2008-03
29
63
3
2006-11
24
24
3
2007-04
30
54
3
2007-05
80
134
3
2007-06
83
217
3
2007-09
102
319
3
2008-01
40
359
89
2006-07
80
80
89
2006-11
105
185
'89
2007-03
142
327
89
2007-04
59
386
89
2007-07
59
445
89
2007-10
164
609
Программируемые объекты
337
89
2007-11
94
703
89
2008-01
140
843
89
2008-02
50
893
89
2008-04
90
983
89
2008-05 80
1063
90
2007-07
5
5
90
2007-09
15
20
90
2007-10
34
54
90
2008-02
82
136
90
2008-04
12
148
91
2006-12
45
45
91
2007-07
31
76
91
2007-12
28
104
91
2008-02
20
124
91
2008-04
81
205
(636 row(s) affected)
Временные таблицы
Если вам необходимо временно сохранить данные в таблицах, в определенных ситуациях
работа с временными таблицами может оказаться предпочтительнее. Например, вам нужно,
чтобы данные были видимы только в текущем сеансе или даже в текущем пакете. Или дру-
гой пример, допустим, что вы хотите сделать данные доступными всем пользователям, пре-
доставив им полный доступ с помощью языков DDL и DML, но у вас нет прав на создание
таблиц в какой-либо пользовательской базе данных.
SQL Server поддерживает три вида временных таблиц, работу с которыми в таких ситуациях
вы сочтете более удобной: локальные временные таблицы, глобальные временные таблицы
и табличные переменные. В следующих разделах все эти три вида таблиц описаны и показа-
но их использование на примерах программного кода.
Локальные временные таблицы
Локальная временная таблица создается с помощью задания в ее имени знака решетки в
качестве префикса, например #Т1. Все виды временных таблиц создаются в базе данных
tempdb.
Временная локальная таблица видна только в сеансе, ее создавшем, на уровне ее создания и
на всех внутренних уровнях стека вызова (внутренние процедуры, функции, триггеры и ди-
намические пакеты). SQL Server автоматически уничтожает временную таблицу, когда уро-
вень ее создания в стеке вызовов выходит за пределы области видимости. Например, пред-
положим, что хранимая процедура Prod вызывает процедуру Ргос2, которая в свою
очередь вызывает процедуру РгосЗ, в свою очередь вызывающую процедуру Ргос4. Ргос2
перед вызовом РгосЗ создает временную таблицу #Т1. Таблица #Т1 видима в процедурах
338
Гпава 10
Ргос2, РгосЗ и Ргос4, но не в процедуре Procl и автоматически уничтожается SQL Server,
когда завершается процедура Ргос2. ЕСЛИ временная таблица создается в рассчитанном на
конкретную ситуацию (ad-hoc) пакете на самом внешнем уровне вложенности в сеансе (зна-
чение функции @@NESTLEVEL равно 0), она видна также во всех подчиненных пакетах и ав-
томатически уничтожается SQL Server, только когда сеанс создания таблицы отключается.
Возможно, вас интересует, как SQL Server предотвращает конфликты имен, если два сеанса
создают локальные временные таблицы с одним и тем же именем. SQL Server на внутрен-
нем уровне добавляет к имени таблицы суффикс, делающий имя уникальным в базе данных
tempdb. Вам как разработчику не нужно заботиться об этом — вы ссылаетесь на таблицу с
помощью заданного вами имени, без внутреннего суффикса, и только ваш сеанс получает
доступ к вашей таблице.
Один очевидный сценарий, в котором применение локальных временных таблиц полезно, —
наличие процесса, нуждающегося во временном хранении промежуточных результатов, на-
пример, на время цикла, и последующем запрашивании этих данных.
Другой сценарий— необходимость многократного доступа к результатам какой-либо за-
тратной обработки. Предположим, что вам нужно соединить таблицы Sales.Orders (Зака-
зы) и Sales.OrderDetails (Сведения о заказе) из базы данных TSQLFundamentals2008,
подытожить объемы заказов в пределах года заказа и соединить два экземпляра итоговых
данных для сравнения каждого годового объема заказов с объемом предыдущего года. Таб-
лицы orders и OrderDetails из учебной базы данных очень малы, но подумайте о том,
что на практике у подобных таблиц могут быть миллионы строк. Один вариант — приме-
нить табличные выражения, но вспомните о том, что табличные выражения виртуальны.
Ресурсоемкая работа по просмотру всех данных, соединению таблиц Orders и
OrderDetails и получению итоговых данных выполняется дважды. Вместо этого имеет
смысл выполнить всю ресурсоемкую работу один раз, сохранив результат в локальной вре-
менной таблице, и затем соединить два экземпляра временной таблицы, тем более что ре-
зультат этой работы — крошечный набор, содержащий по одной строке для каждого года
заказа.
В следующем программном коде реализован описанный сценарий с применением локальной
временной таблицы:
USE TSQLFundamentals2008;
IF OBJECT_ID('tempdb.dbo.#MyOrderTotalsByYear
1
) IS NOT NULL
DROP TABLE dbo.#MyOrderTotalsByYear;
GO
SELECT
YEAR(O.orderdate) AS orderyear,
SUM(OD.qty) AS qty
INTO dbo.#MyOrderTotalsByYear
FROM Sales.Orders AS О
JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid
GROUP BY YEAR(orderdate);
Программируемые объекты
339
SELECT Cur.orderyear, Cur.qty AS curyearqty, Prv.qty AS prvyearqty
FROM dbo.#MyOrderTotalsByYear AS Cur
LEFT OUTER JOIN dbo.#MyOrderTotalsByYear AS Prv
ON Cur.orderyear = Prv.orderyear + 1;
Этот программный код формирует следующий результат:
orderyear
curyearqty prvyearqty
2007
25489
9581
2008
16247
25489
2006
9581
NULL
Для того чтобы убедиться в том, что временная таблица видна только в сеансе, ее создав-
шем, попытайтесь обратиться к ней из другого сеанса:
SELECT orderyear, qty FROM dbo.#MyOrderTotalsByYear;
Вы получите такое сообщение об ошибке.
Msg. 208, Level 16, State 0, Line 1
Invalid object name
1
#MyOrderTotalsByYear
1
.
Глобальные временные таблицы
Если создается глобальная временная таблица, она видна во всех других сеансах. Такие
таблицы SQL Server уничтожает автоматически, когда отключается сеанс, создавший табли-
цу, и на нее нет активных ссылок. Глобальная временная таблица создается добавлением к
ее имени двух знаков решетки в качестве префикса, например ##Т1.
Глобальные временные таблицы полезны, если вы хотите обеспечить совместный доступ
всех пользователей к временным данным. Никаких специальных прав доступа не требуется,
и у всех есть полный доступ на языках DDL и DML. Конечно, полный доступ для всех озна-
чает, что любой может даже удалить таблицу, поэтому тщательно рассматривайте возмож-
ность других вариантов.
Например, в следующем программном коде создается глобальная временная таблица
##Globals со столбцами id и val:
CREATE TABLE dbo.##Globals
(. id sysname NOT NULL PRIMARY KEY,
val SQL_VARIANT NOT NULL);
Предполагается, что эта таблица имитирует глобальные переменные, которые не поддержи-
ваются в SQL Server. У столбца id тип данных sysname — тип, который SQL Server приме-
няет на внутреннем уровне для представления идентификаторов, а у столбца val тип дан-
ных SQL VARIANT — общий тип, способный хранить значение почти любого базового типа.
Любой пользователь может вставлять строки в таблицу. Например, выполните следующий
программный код, чтобы вставить строку, представляющую переменную i и инициализи-
рующую 'ее с целочисленным значением 10:
INSERT INTO dbo.##Globals(id, val) VALUES(N1i
1
, CAST(10 AS INT));
340
Гпава 10
Любой пользователь может модифицировать и извлекать данные этой таблицы. Например,
выполните из любого сеанса следующий программный код для того, чтобы запросить теку-
щее значение переменной i:
SELECT val FROM dbo.##Globals WHERE id = N'i';
Этот программный код вернет такой результат:
val
10
ПРИМЕЧАНИЕ
Всегда помните о том, что как только сеанс, создавший глобальную временную
таблицу, завершит подключение и не останется активных ссылок на таблицу, SQL
Server автоматически уничтожит ее.
Если вы хотите, чтобы глобальная временная таблица создавалась при каждом запуске SQL
Server, и не хотите, чтобы SQL Server пытался уничтожить ее автоматически, необходимо
создать таблицу в хранимой процедуре, которая помечена как процедура автозагрузки
(startup). (Подробности см. в разд. "Automatic Execution of Stored Procedures" ("Автоматиче-
ское выполнение хранимых процедур") в интерактивном руководстве SQL Server Books
Online.)
Выполните из любого сеанса следующий программный код для явного уничтожения гло-
бальной временной таблицы:
DROP TABLE dbo.##Globals;
Табличные переменные
Табличные переменные похожи на локальные временные таблицы в одном и не похожи в
другом. Вы объявляете табличные переменные так же, как другие переменные с помощью
инструкции DECLARE.
Как и локальные временные таблицы, табличные, переменные физически присутствуют в
виде таблиц в базе данных tempdb вопреки общему заблуждению об их существовании
только в оперативной памяти. Так же как локальные временные таблицы, табличные пере-
менные видны только в сеансе, их создавшем, но при этом обладают более ограниченной
областью видимости, распространяющейся лишь на текущий пакет. Табличные переменные
не видны ни во внутренних пакетах в стеке вызова, ни в последующих пакетах сеанса.
При откате явно заданной транзакции изменения, внесенные во время этой транзакции во
временные таблицы, отменяются, а для изменений, внесенных в табличные переменные ин-
струкциями, завершившимися в транзакции, откат не выполняется. Отменяются только из-
менения, выполненные активной инструкцией, которая завершилась аварийно или была
преждевременно завершена.
У временных таблиц и табличных переменных есть и оптимизационные отличия, но в этой
книге они не рассматриваются. Сейчас я просто отмечу, что с точки зрения производитель-
ности, как правило, имеет смысл применять табличные переменные с очень малыми объе-
Программируемые объекты
341
мами данных (только несколько строк) и использовать временные таблицы в противном
случае.
Например, в следующем программном коде для сравнения общих объемов заказов за каж-
дый год с объемом заказов предыдущего года вместо локальной временной таблицы приме-
няется табличная переменная:
DECLARE @MyOrderTotalsByYear TABLE
( orderyear INT NOT NULL PRIMARY KEY,
qtyINTNOTNULL );
INSERT INTO @MyOrderTotalsByYear (orderyear, qty)
SELECT
YEAR(O.orderdate) AS orderyear,"
SUM (OD. qty) AS qty
,FRCM Sales.Orders AS О
JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid
GROUP BY YEAR(orderdate);
SELECT Cur.orderyear, Cur.qty AS curyearqty, Prv.qty AS prvyearqty
FROM GMyOrderTotalsByYear AS Cur
LEFT OUTER JOIN GMyOrderTotalsByYear AS Prv
ON Cur.orderyear = Prv.orderyear + 1;
Этот программный код вернет такой результат:
orderyear
curyearqty prvyearqty
2006
9581
NULL
2007
25489
9581
2008
16247
25489
Типы Table
В версию SQL Server 2008 включена поддержка табличных типов данных. Создавая таблич-
ный тип, вы заготавливаете в базе данных определение таблицы, которое позже можете ис-
пользовать для определения табличных переменных и входных параметров хранимых про-
цедур и функций, определенных пользователем.
Например, в следующем программном коде в базе данных TSQLFundamentals2008 создается
табличный тип dbo. OrderTotalsByYear:
USE TSQLFundainent al s2008;
IF TYPE_ID('dbo.OrderTotalsByYear
1
) IS NOT NULL
DROP TYPE dbo.OrderTotalsByYear;
12 Зак. 1032
342
Гпава 10
CREATE TYPE dbo.OrderTotalsByYear AS TABLE
( orderyear INT NOT NULL PRIMARY KEY,
qty INT NOT NULL );
После того как табличный тип данных создан, когда вам понадобится объявить табличную
переменную, базирующуюся на определении табличного типа, вам не придется повторять
программный код— вместо этого вы можете просто задать dbo.OrderTotalsByYear как
тип табличной переменной следующим образом:
DECLARE GMyOrde гТо tа1sBy Yeaг AS dbo.OrderTotalsByYear;
В качестве более законченного примера в следующем программном коде объявляется пере-
менная @MyOrderTotalsByYear нового табличного типа, запрашиваются таблицы Orders
(Заказы) и OrderDetails (Сведения о заказе) для вычисления общих объемов заказов по
годам, результат запроса сохраняется в табличной переменной и из этой переменной запра-
шивается содержимое результатов вычислений.
DECLARE @МуOrderTotalsByYear AS dbo.OrderTotalsByYear;
INSERT INTO @MyOrderTotalsByYear(orderyear, qty)
SELECT
YEAR(O.orderdate) AS orderyear,
SUM(OD.qty) AS qty
FROM Sales.Orders AS О
JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid
GROUP BY YEAR(orderdate);
SELECT orderyear, qty FROM @MyOrderTotalsByYear;
Приведенный программный код вернет такой результат:
orderyear
qty
2006
9581
2007
25489
2008
16247
В случае табличной переменной табличный тип только помогает сократить программный
код, не внося ничего принципиально нового. Но как упоминалось ранее, вы также можете
применять табличный тип в качестве типа входного параметра хранимых процедур и функ-
ций, и это крайне полезная и принципиально новая функциональная возможность.
Динамический SQL
SQL Server позволяет конструировать пакет программного кода на языке T-SQL в виде сим-
вольной строки и затем выполнять этот пакет. Данная функциональная возможность назы-
Программируемые объекты
343
вается динамическим SQL. SQL Server предоставляет два способа выполнения динамическо-
го пакета SQL: с помощью команды EXEC (сокращение от EXECUTE) и с помощью храни-
мой процедуры sp_executesql. Я поясню разницу между этими двумя подходами и приве-
ду примеры использования каждого из них.
Динамический код SQL полезен для решения нескольких задач, включая следующие.
•
Автоматизация административных задач. Например, запрос метаданных, формирова-
ние и выполнение инструкции BACKUP DATABASE для каждой базы данных в экземпляре
сервера.
П Повышение производительности конкретных задач. Например, конструирование пара-
метризованных специализированных (ad-hoc) запросов, которые способны повторно
использовать кэшированные планы выполнения (об этом чуть позже).
П Создание элементов программного кода, основанных на запросах реальных данных.
Например, динамическое формирование запроса PIVOT, если заранее неизвестно, какие
элементы должны включаться в элемент IN операции PIVOT.
ПРИМЕЧАНИЕ
Будьте очень внимательны при сцеплении пользовательского ввода с вашим про-
граммным кодом. Хакеры могут попытаться вставить программный код, который
вы не собирались выполнять. Лучше всего для предотвращения такого внедрения
избегать сцепления пользовательского ввода с вашим программным кодом (на-
пример, с помощью параметров). Но если подобное сцепление необходимо, обя-
зательно тщательно проверьте пользовательский ввод и поищите попытки SQL-
внедрения или SQL-инъекции. Отличную статью, посвященную этой теме, можно
найти в разд. "SQL Injection" ("SQL-внедрение") интерактивного справочного руко-
водства SQL Server Books Online,.
Команда EXEC
Команда EXEC— это оригинальный способ, предлагаемый языком T-SQL для выполнения
динамического кода SQL. EXEC принимает как входной параметр символьную строку в
скобках и выполняет пакет программного кода, содержащийся в этой строке. Команда ЕХЕС
поддерживает в качестве входного параметра обычные символьные строки и символьные
стоки Unicode.
Я начну с очень простого примера использования ЕХЕС для выполнения динамического кода
SQL. В следующем примере в переменной @sql сохраняется символьная строка, содержа-
щая инструкцию PRINT, и затем используется команда ЕХЕС для запуска пакета программ-
ного кода, хранящегося в переменной:
DECLARE @sql AS VARCHAR(IOO);
SET @sql = ' PRINT
1
'This message was printed by a dynamic SQL batch.
,,
;f;
EXEC(@sql) ;
Обратите внимание на применение двух апострофов для представления одного апострофа в
строке, находящейся внутри другой строки. Этот программный код вернет такой результат:
This message was printed by a dynamic SQL batch.
344
Гпава 10
В приведенном далее примере для формирования запроса к представлению
INFORMATION_SCHEMA. TABLES и получения
имен
таблиц
из базы данных
TSQLFundamentals2008 применяется курсор. Для каждой таблицы в примере
конструируется и выполняется пакет программного кода, который вызывает процедуру
sp_spaceused с указанием текущей таблицы для получения данных об использовании
дискового пространства:
USE TSQLFundament а1s2008;
DECLARE @sql AS NVARCHAR(300),
Gschemaname AS sysname,
@tablename AS sysname;
DECLARE С CURSOR FAST_FORWARD FOR
SELECT TABLE_SCHEMA, TABLE_NAME
FROyi IN FORMAT I ON_SCHEMA. TABLES
WHERE TABLE_TYPE
-
'BASE TABLE1;
OPEN С
FETCH NEXT FROM С INTO @schemaname, @tablename;
WHILE @@fetch_status = 0
BEGIN
SET @sql = N'EXEC sp_spaceused N1
''
+ QUOTENAME (@ schemaname) + N' . '
+ QUOTENAME(@tablename) + N'' ';';
EXEC(@sql);
FETCH NEXT FROM С INTO @schemaname, Gtablename;
END
CLOSE C;
DEALLOCATE C;
Функция QUOTENAME, если вам интересно, применяется для ограничения входного значения.
Если второй аргумент с символом, играющим роль кавычек, не задан, функция по умолча-
нию применяет квадратные скобки. Поэтому, если etablename содержит N
f
My Table
1
,
функция QUOTENAME (@mytable) вернет N
1
[My Table] превращая строку в корректный
идентификатор.
Программируемые объекты
345
Этот программный код вернет следующий результат с данными об используемом дисковом
пространстве для всех таблиц, содержащихся в базе данных:
паше
rows reserved data index_size unused
Suppliers
' 29 48KB
8KB 40KB
0KB
name
rows reserved data index_size unused
Categories
8
32 KB
8KB 24KB
0KB
name
rows reserved data index_size unused
Products
77
64 KB
8KB 56KB
0KB
name
rows reserved data index_size unused
Customers
91 104KB 24KB80KB
0KB
name
rows reserved data index__size unused
Shippers
3
16 KB
8KB 8KB
0KB
name
rows reserved data index_size unused
Orders
830 416 KB
152 KB 232 KB
32 KB
name
rows reserved data indexesize unused
OrderDetails 2155 224 KB 72 KB 104 KB
48 KB
name
rows reserved data index_size unused
Employees
9
48 KB
8KB 40KB
0KB
Хранимая процедура spjexecutesql
Хранимая процедура sp_executesql появилась позже команды EXEC. Она более безопас-
ная и гибкая, т. к. у нее есть интерфейс, т. е. она поддерживает входные и выходные пара-
метры. Учтите, что, в отличие от команды EXEC, spjexecutesql поддерживает только сим-
вольные строки Unicode в качестве входного пакета программного кода.
Возможность применения входных и выходных параметров в динамическом коде SQL мо-
жет помочь созданию более безопасного и эффективного программного кода. С точки зре-
346
Гпава 10
ния безопасности параметры, включенные в код, не считаются фрагментом программного
кода, они могут рассматриваться только как операнды в выражениях. Таким образом, при-
меняя параметры, вы можете устранить риск SQL-внедрения.
Хранимая процедура sp_executesql может действовать эффективнее команды ЕХЕС, т. к.
ее параметризация помогает повторному использованию кэшированных планов выполне-
ния. План выполнения — это план физической обработки, который SQL Server создает для
запроса, и в который включен набор инструкций, касающихся задания объектов доступа,
порядка доступа, использования индексов, способов доступа к ним, применяемых алгорит-
мов соединения и т. д. Для простоты одно из условий повторного использования плана,
предварительно помещенного в кэш, — совпадение строки запроса со строкой, для которой
в кэше существует план выполнения. Наилучший способ эффективного повторного исполь-
зования планов выполнения запросов— применение хранимых процедур с параметрами.
В этом случае даже когда значения параметров изменяются, строка запроса остается той же
самой. Но если вы по собственным причинам решили использовать вместо хранимой про-
цедуры пригодный для конкретного случая (ad-hoc) программный код, как минимум, вы все
же сможете работать с параметрами, если будете применять sp_executesql, а значит, по-
высите шансы повторного использования плана.
У процедуры sp_executesql есть два входных параметра и раздел присваиваний. В первом
параметре @stmt задается символьная строка Unicode, содержащая пакет программного
кода, который вы хотите выполнить. Во втором параметре @params указывается символьная
строка Unicode, содержащая объявления входных и выходных параметров. Далее задаются
присваивания значений входных и выходных параметров, разделяемые запятыми.
В следующем примере конструируется пакет программного кода, содержащий запрос к таб-
лице Sales. Orders (Заказы).
В данном примере в фильтре запроса используется входной параметр @orderid:
DECLARE Gsql AS NVARCHAR(100);
SET @sql = N'SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE orderid = Gorderid;1;
EXEC sp_executesql
@stmt = @sql,
Gparams = N'Gorderid AS INT',
Gorderid = 10248;
В приведенном программном коде входному параметру присваивается значение 10248, но
если вы выполните код еще раз с другим значением, строка программного кода останется
прежней. В этом случае вы повышаете шансы повторного использования предварительно
кэшированного плана выполнения.
Для применения выходного параметра просто задайте ключевое слово OUTPUT В объявлении
параметра и в разделе присваиваний значений параметров. В следующем примере показано
применение выходных параметров. В программном коде запрашивается представление
IN FORMAT IONSCHEMA. TABLES для получения списка имен таблиц и представлений, содер-
жащихся в базе данных. Для циклической обработки имен объектов в этом коде использует-
Программируемые объекты
347
ся курсор. В каждом проходе цикла формируется пакет динамического SQL, запрашиваю-
щий подсчет количества строк в текущем объекте и сохраняющий результат в выходном
параметре @п. Значение выходного параметра @п передается в локальную переменную
©numrows, значение которой присваивается выходному параметру. В программном коде в
табличную переменную ©Counts вставляется строка с именем текущего объекта и количе-
ством строк в нем. Когда циклическая обработка записей курсора выполнена, запрашивает-
ся содержимое табличной переменной. Далее приведен весь программный код полностью.
DECLARE ©Counts TABLE
( schemaname sysname NOT NULL,
tablename sysname NOT NULL,
numrows INT NOT NULL,
PRIMARY KEY (schemaname, tablename) );
DECLARE ©sql AS NVARCHAR(350),
©schemaname AS sysname,
©tablename AS sysname,
©numrows AS INT;
DECLARE С CURSOR FAST_FORWARD FOR
SELECT TABLE_SCHEMA, TABLE_NAME
FROM INFORMATION_SCHEMA.TABLES;
OPEN С
FETCH NEXT FROM С INTO ©schemaname, 6tablename;
WHILE @©fetch_status = 0
BEGIN
SET ©sql = N* SET ©n = (SELECT COUNT (*) FROM '
+ QUOTENAME (©schemaname) + N
f
.
f
+ QUOTENAME(©tablename) + N
f
);1;
EXEC sp_executesql
©stmt = ©sql,
©params = N*@n AS INT OUTPUT',
©n = ©numrows OUTPUT;
INSERT INTO ©Counts(schemaname, tablename, numrows)
VALUES (©schemaname, ©tablename, ©numrows);
FETCH NEXT FROM С INTO ©schemaname, ©tablename;
END
CLOSE C;
348
Глава 10
DEALLOCATE С;
SELECT schemaname, tablename, numrows
FROyi ©Counts;
Этот программный код возвращает такой результат:
schemaname tablename
numrows
HR
Employees
9
Production Categories
8
Production Products
77
Production Suppliers
29
Sales
Customers
91
Sales
CustOrders
636
Sales
OrderDetails
2155
Sales
Orders
830
Sales
OrderTotalsByYear 3
Sales
Ordervalues
830
Sales
Shippers
3
(11 row(s) affected)
Применение PIVOT с динамическим SQL
Это раздел повышенной сложности, и читать его следует, если вы хорошо усвоили способы
получения сводных данных и динамический SQL. В главе 7 я пояснял, как применять опера-
цию PIVOT для получения сводных данных. Я писал о том, что в статическом запросе вы
должны знать заранее о том, какие значения задавать в элементе IN операции PIVOT. Далее
приведен пример статического запроса с операцией PIVOT:
SELECT *
FROM (SELECT shipperid, YEAR(orderdate) AS orderyear, freight
FROM Sales.Orders) AS D
PIVOT(SUM(freight) FOR orderyear IN([2006],[2007],[2008])) AS P;
В данном примере запрашивается таблица Sales .Orders (Заказы) и данные реорганизуют-
ся так, что запрос возвращает ID перевозчиков в строках, годы заказов в столбцах и общую
стоимость транспортировки на пересечении каждого перевозчика и года заказа. Этот про-
граммный код возвращает следующий результат:
shipperid 2006
2007
2008
3
4233.78
1
2297.42
2
3748.67
11413.35
4865.38
8681.38
5206.53
12374.04
12122.14
Программируемые объекты
349
В статическом запросе нужно заранее знать, какие значения (в нашем случае годы заказов)
задавать в элементе IN табличной операции PIVOT. Это означает, что необходимо исправ-
лять программный код каждый год. Вместо этого вы можете запросить все встречающиеся
годы заказов из данных, сконструировать пакет динамического кода SQL, базирующийся на
запрошенных вами годах заказов, и выполнить этот пакет следующим образом:
DECLARE
©sql AS NVARCHAR(1000) ,
©orderyear AS INT,
©first AS INT;
DECLARE С CURSOR FAST_FORWARD FOR
SELECT DISTINCT(YEAR(orderdate)) AS orderyear
FROM Sales.Orders
ORDER BY orderyear;
SET @first = 1;
SET ©sql = N'SELECT *
FROM (SELECT shipperid, YEAR(orderdate) AS orderyear, freight
FROM Sales.Orders) AS D
PIVOT(SUM(freight) FOR orderyear IN(';
OPEN С
FETCH NEXT FROM С INTO ©orderyear;
WHILE ©©fetch_status = 0
BEGIN
IF ©first = 0
SET ©sql = ©sql + N',
1
ELSE
SET ©first = 0;
SET ©sql = @sql + QUOTENAME(©orderyear);
FETCH NEXT FROM С INTO ©orderyear;
END
CLOSE C;
DEALLOCATE C;
SET@sql=@sql+N
f
)) AS P;1;
EXEC sp_executesql ©stmt = ©sql;
350
Гпава 10
Подпрограммы
Подпрограммы — это программируемые объекты, включающие в себя программный код
для вычисления или выполнения действий. SQL Server поддерживает три типа подпро-
грамм: функции, определенные пользователем, хранимые процедуры и триггеры.
Начиная с версии SQL Server 2005, вы можете выбирать, разрабатывать вам подпрограмму
на языке T-SQL или с помощью программного кода .NET, основанного на интеграции в
продукт общеязыковой среды выполнения CLR (Common Language Runtime). Поскольку эта
книга посвящена в первую очередь языку T-SQL, примеры в ней даются на этом языке. Во-
обще говоря, если рассматриваемая задача включает в себя в основном манипуляцию дан-
ными, как правило, для ее решения больше подходит T-SQL. Если же задача в основном
связана с итеративной логикой, обработкой строк или интенсивными вычислительными
операциями, .NET, как правило, предпочтительнее.
Функции, определенные пользователем
Задача функции, определенной пользователем (ФОП), — выделить в отдельный логический
блок какие-либо вычисления, возможно, базирующиеся на входных параметрах, и вернуть
результат.
SQL Server поддерживает скалярные и табличные ФОП. Скалярные ФОП возвращают един-
ственное значение, а табличные— таблицу. Одно из достоинств применения ФОП— воз-
можность встраивания их в запросы. Скалярные ФОП могут появиться в тех синтаксических
элементах запроса, где допустимо использование выражения, возвращающего единственное
значение (например, в списке инструкции SELECT). Табличные ФОП могут вставляться в
элемент запроса FROM. Далее приводится пример скалярной ФОП.
В ФОП недопустимы любые побочные эффекты. Это, очевидно, означает, что ФОП запре-
щено вносить в базу данных любые изменения схемы или данных. Другие варианты побоч-
ных эффектов менее очевидны. Например, вызовы функции RAND, возвращающей случайное
значение, или функции NEWID, возвращающей глобально уникальный идентификатор
(GUID), имеют побочные эффекты. Каждый раз, когда функция RAND вызывается без зада-
ния значения, инициирующего генератор случайных чисел, или величины рандомизации,
SQL Server генерирует эту величину, основываясь на предыдущем вызове RAND. ПО ЭТОЙ
причине SQL Server необходимо на внутреннем уровне сохранять информацию при каждом
вызове функции RAND. Аналогично при каждом вызове функции NEWID системе нужно от-
ложить в сторону некоторые данные, чтобы принять их в расчет при следующем вызове
NEWID. Поскольку у функций RAND и NEWID есть побочные эффекты, их запрещено приме-
нять в ваших ФОП.
Например, в следующем программном коде создается ФОП dbo.fn_age, возвращающая
возраст человека с заданной датой рождения (аргумент Gbirthdate) на определенный за-
данный момент времени (аргумент @ event date):
USE TSQLFundamentals2008;
IF OBJECT__ID (1 dbo. fn_age
1
) IS NOT NULL DROP FUNCTION dbo.fn_age;
GO
Программируемые объекты
351
CREATE FUNCTION dbo.fn_age
( ©birthdate AS DATETIME,
©eventdate AS DATETIME )
RETURNS INT
AS
BEGIN
RETURN
DATEDIFF(year, ©birthdate, ©eventdate)
-
CASE WHEN 100 * MONTH(©eventdate) + DAY(©eventdate)
< 100 * MONTH(©birthdate) + DAY(©birthdate)
THEN 1 ELSE 0
END
END
GO
Функция вычисляет возраст как разность в годах между годом рождения и годом заданной
даты минус 1 год в том случае, если в пределах года месяц и день заданной даты меньше
месяца и дня рождения. Выражение 100 * month + day — это просто хитрость для сцеп-
ления месяца и дня. Например, для февраля и числа 12 выражение вернет в результате целое
число 0212.
Имейте в виду, что функция может содержать в своем теле не только элемент RETURN. Она
также может включать программный код с элементами, управляющими ходом выполнения,
вычислениями и т. д. Но функция обязательно должна иметь элемент RETURN, который воз-
вращает значение.
В следующем программном коде для демонстрации применения ФОП в запросе запрашива-
ется таблица HR.Employees (Сотрудники) и в списке SELECT вызывается функция fn age,
вычисляющая возраст сотрудника на сегодня:
SELECT
empid, firstname, lastname, birthdate,
dbo.fn_age(birthdate, CURRENTJTIMESTAMP) AS age
FROM HR.Employees;
Например, если бы вы выполнили этот запрос February 12, 2009 (12 февраля 2009 г.), то по-
лучили бы следующий результат:
empid
firstname lastname
birthdate
age
1
Sara
Davis
1958-12-08 00:00:00.000 50
2
Don
Funk
1962-02-19 00:00:00.000 46
3
Judy
Lew
1973-08 -30 00:00:00.000 35
4
Yael
Peled
1947-09-19 00:00:00.000 61
5
Sven
Buck
1965-03-04 00:00:00.000 43
6
Paul
Suurs
1973-07-02 00:00:00.000 35
7
Russell
King
1970-05-29 00:00:00.000 38
352
Гпава 10
8
9
Maria
Zoya
Cameron
Dolgopyatova
1968-01-09 00:00:00.000 41
1976-01-27 00:00:00.000 33
(9 row(s) affected)
Учтите, что при выполнении этого запроса в вашей системе значения, которые вы получите
в столбце age (возраст), будут зависеть от даты выполнения запроса.
Хранимые прох\едуры — это серверные подпрограммы, содержащие программный код на
языке T-SQL. У хранимых процедур могут быть входные и выходные параметры, они могут
возвращать результирующие наборы запросов и им разрешено выполнять программный
код, обладающий побочными эффектами. С помощью хранимых процедур вы можете не
только модифицировать данные, но и вносить изменения в схемы баз данных.
По сравнению с программным кодом, созданным для конкретной задачи, применение хра-
нимых процедур дает ряд преимуществ.
П В хранимых процедурах сосредотачивается логика решения. Если реализация хранимой
процедуры нуждается в корректировке, вы вносите изменения только в одном месте ба-
зы данных, и все пользователи процедуры начинают использовать ее исправленный ва-
риант.
П Хранимые процедуры облегчают управление безопасностью. Вы можете предоставить
пользователю права на выполнение процедуры, не предоставляя пользователю прямых
прав на совершение действий на внутреннем уровне. Предположим, что вы хотите раз-
решить определенным пользователям удалять клиента из базы данных, но не хотите
предоставлять им право на непосредственное удаление строк из таблицы Customers
(Клиенты). Вы желаете убедиться в том, что требования на удаление клиента коррект-
ны, например, проведена проверка наличия у клиента невыполненных заказов, непога-
шенных задолженностей и т. д. И кроме того, возможно, вы хотите проконтролировать
подобные требования. Не предоставляя прямых прав на удаление строк непосредствен-
но из таблицы Customers, а вместо этого предоставив право на выполнение процедуры,
которая решает поставленную задачу, вы гарантируете, что все требуемые проверки и
контроль будут проводиться всегда. Кроме того, хранимые процедуры могут помешать
SQL-внедрению несанкционированного программного кода, особенно когда они заме-
няют параметрами SQL-код клиента, подготовленный для конкретной задачи.
П Вы можете вставить всю обработку ошибок в хранимую процедуру, незаметно пред-
принимая корректирующее действие, где следует. Я буду обсуждать обработку ошибок
чуть позже в этой главе.
•
Хранимые процедуры дают повышение производительности. Ранее я писал о повторном
использовании предварительно кэшированных планов выполнения. Хранимые процеду-
ры по умолчанию повторно применяют планы выполнения, в то время как SQL Server
более консервативен в отношении повторного использования планов, подготовленных
для конкретного случая. Кроме того, устаревание планов выполнения хранимых проце-
дур происходит медленнее, чем планов, подготовленных для конкретного случая. Еще
один выигрыш в производительности в случае применения хранимых процедур— сни-
Хранимые процедуры
Программируемые объекты
353
жение сетевого трафика. Клиентское приложение должно предоставить SQL Server
только имя процедуры и ее аргументы. Сервер обрабатывает весь программный код
процедуры и возвращает назад клиенту только результат. Промежуточные этапы вы-
полнения процедуры не связаны ни с прямым, ни с обратным сетевым трафиком.
В приведенном
далее
простом
примере
создается
хранимая
процедура
Sales.usp_GetCustomerOrders. Она принимает в качестве входных параметров ID кли-
ента (©custid) и диапазон дат (©fromdate и ©todate). Процедура в качестве результи-
рующего набора возвращает строки из таблицы Sales.Orders (Заказы), представляющие
заказы, сделанные заданным клиентом в заданный промежуток времени, и в качестве вы-
ходного параметра количество извлеченных строк (©numrows):
USE TSQLFundamentа1s2 008;
IF OBJECT_ID('Sales.usp_GetCustomerOrders', *P') IS NOT NULL
DROP PROC Sales.usp_GetCustomerOrders;
GO
CREATE PROC Sales.usp__GetCustomerOrders
©custid AS INT,
©fromdate AS DATETIME = '19000101',
©todate AS DATETIME =
1
99991231*,
©numrows AS INT OUTPUT
AS
SET NOCOUNT ON;
SELECT orderid, custid, empid, orderdate
FROM Sales.Orders
WHERE custid = ©custid
AND orderdate >= ©fromdate
AND orderdate < ©todate;
SET ©numrows = ©©rowcount;
GO
При выполнении процедуры, если не задать значение параметра ©fromdate, процедура вос-
пользуется значением по умолчанию 19000101, и если не задать значение параметра
©todate, процедура применит значение по умолчанию 99991231. Обратите внимание на
использование ключевого слова OUTPUT ДЛЯ обозначения параметра ©numrows как выходно-
го. Команда SET NOCOUNT ON применяется для подавления сообщений о количестве строк,
обработанных в процедуре инструкциями языка DML, такими как инструкция SELECT.
Далее приведен пример выполнения процедуры, запрашивающий сведения о заказах, поме-
щенных клиентом с ID, равным 1, в 2007 г. Программный код помещает значение выходно-
го параметра ©numrows в локальную переменную ©гс и возвращает ее, чтобы показать,
сколько строк было отобрано в запросе.
DECLARE ©re AS INT;
EXEC Sales.usp_GetCustomerOrders
354
Гпава 10
Gcustid = 1,
Gfromdate =
1
20070101 \
Qtodate = '20080101',
@numrows = Qrc OUTPUT;
SELECT @rc AS numrows;
Программный код возвращает результат, отображающий три найденных заказа:
orderid
custid
empid
orderdate
10643
1
6
2007-08 -25 00:00:00.000
10692
1
4
2007-10-03 00:00:00.000
10702
1
4
2007-10-13 00:00:00.000
numrows
3
Выполните программный код снова и задайте ID клиента, не существующий в таблице
Orders (Заказы) (например, ID клиента 100), и вы получите следующий результат, показы-
вающий, что отобрано ноль строк:
orderid
custid
empid
orderdate
numrows
0
Конечно, это очень простой пример. С помощью хранимых процедур можно делать гораздо
больше.
Триггеры
Триггер— это специальная разновидность хранимой процедуры, которая не может выпол-
няться напрямую. Вместо этого он связывается с событием. Когда возникает событие, триг-
гер срабатывает, и выполняется его программный код. SQL Server поддерживает связь триг-
геров с двумя типами событий: события обработки (DML-триггеры), такими как INSERT
(вставка), и событиями определения данных (DDL-триггеры), такими как CREATE TABLE
(создание таблицы).
Триггеры можно применять для разных целей, включая контроль, обеспечение правил цело-
стности, которые не могут задаваться ограничениями, обеспечение политик и т. д.
Триггер считается частью транзакции, которая включает событие, вызывающее срабатыва-
ние триггера. Вызов команды ROLLBACK TRAN В программном коде триггера вызывает откат
всех изменений, произведенных триггером, а также всех изменений, имевших место в тран-
закции, связанной с триггером.
В SQL Server триггеры инициируются инструкцией, а не модифицируемой строкой.
Программируемые объекты
355
DML-триггеры
SQL Server поддерживает два вида DML-триггеров: последующие (after) и замещающие (in-
stead of). Последующий триггер запускается после того, как связанное с ним событие завер-
шилось, и может быть определен только для постоянных таблиц. Замещающий триггер ини-
циируется вместо связанного с ним события и может определяться для постоянных таблиц и
представлений.
В программном коде триггера вы можете обращаться к таблицам inserted (вставленные) и
deleted (удаленные). Эти таблицы содержат строки, подвергшиеся модификации, которая
вызвала срабатывание триггера. Таблица inserted содержит новое представление строк,
обработанных инструкциями INSERT И UPDATE. Таблица deleted содержит старое пред-
ставление строк, обработанных инструкциями DELETE И UPDATE. В случае замещающих
триггеров таблицы inserted и deleted содержат строки, которые предположительно под-
верглись модификации, вызвавшей срабатывание триггера.
Далее приведен простой пример последующего триггера, который контролирует вставки в
таблицу. Выполните приведенный программный код для создания в базе данных tempdb
таблицы dbo.Tl и еще одной таблицы dbo.Tl_Audit, содержащей контрольную информа-
цию о вставках в таблицу Т1.
USE tempdb;
IF OBJECT_ID('dbo.Tl_Audit', 'U') IS NOT NULL DROP TABLE dbo.Tl_Audit;
IF OBJECT_ID('dbo.Tl', 'U') IS NOT NULL DROP TABLE dbo.Tl;
CREATE TABLE dbo.Tl
( keycol INT NOT NULL PRIMARY KEY,
datacol VARCHAR(10) NOT NULL );
CREATE TABLE dbo.Tl_Audit
( audit_lsn INT NOT NULL IDENTITY PRIMARY KEY,
dt DATETIME NOT NULL DEFAULT(CURRENT_TIMESTAMP) ,
login_name sysname NOT NULL DEFAULT (SUSER__SNAME () ) ,
keycol INT NOT NULL,
datacol VARCHAR(10) NOT NULL );
В контрольной таблице у столбца audit lsn есть свойство идентификации, и он представ-
ляет последовательный номер контрольной записи. Столбец dt с помощью выражения по
умолчанию CURRENT_TIMESTAMP предоставляет дату и время вставки. Столбец login name
с помощью выражения SUSERJSNAME () предоставляет регистрационное имя пользователя,
выполнившего вставку.
Далее для создания триггера trg__Tl_insert_audit типа AFTER INSERT, отслеживающего
вставки в таблицу T1, выполните следующий программный код:
CREATE TRIGGER trg_Tl_insert_audit ON dbo.Tl AFTER INSERT
AS
SET NOCOUNT ON;
356
Гпава 10
INSERT INTO dbo.Tl_Audit(keycol, datacol)
SELECT keycol, datacol FROM inserted;
GO
Как видите, триггер просто вставляет в контрольную таблицу результат запроса к таблице
inserted. Значения столбцов контрольной таблицы, которые не заданы явно в инструкции
INSERT, генерируются выражениями по умолчанию, описанными ранее. Для тестирования
триггера выполните следующий программный код:
INSERT INTO dbo.Tl(keycol, datacol) VALUES(10, 'a');
INSERT INTO dbo.Tl(keycol, datacol) VALUES(30, 'x');
INSERT INTO dbo.Tl(keycol, datacol) VALUES(20,
1
g1);
Триггер срабатывает после каждой инструкции. Затем запросите контрольную таблицу:
SELECT audit_lsn, dt, login_name, keycol, datacol
FROM dbo.Tl_Audit;
Вы получите результат, в котором только значения столбцов dt и login_name отражают
дату и время вставки строки и регистрационное имя, использованное вами для подключения
к SQL Server:
audit_lsn
dt
login_name
keycol
datacol
1
2009-02-24 09:04:27.713 QUANTUM\Gandalf 10
a
2
2009-02-24 09:04:27.733 QUANTUM\Ganda1f 30
x
3
2009-02-24 09:04:27.733 QUANTUM\Gandalf 20
g
DDL-триггеры
В версии SQL Server 2005 появилась поддержка DDL-триггеров. Они могут применяться для
аудита, обеспечения политик, изменения управления и других целей.
SQL Server в зависимости от области видимости события поддерживает создание DDL-
триггеров двух уровней, с областью видимости в пределах базы данных и с областью види-
мости в пределах сервера. Триггер базы данных можно создать для событий с областью ви-
димости в пределах базы данных, таких как CREATE TABLE. ДЛЯ событий с областью види-
мости сервера, таких как CREATE DATABASE, ВЫ можете создать триггер для всего сервера.
SQL Server поддерживает только последующие (after) DDL-триггеры и не поддерживает
предшествующие (before) или замещающие (instead of) DDL-триггеры.
В триггере сведения о событии, вызвавшем срабатывание триггера, можно получить, за-
прашивая функцию EVENT DATA, которая возвращает информацию о событии в виде значе-
ния XML (extensible Markup Language, расширяемый язык разметки). Для извлечения из
значения XML атрибутов события, таких как время начала, тип события, регистрационное
имя и других, можно использовать выражения XQueiy.
В данном примере DDL-триггера в базе данных отслеживаются все операции DDL. Сначала
выполните следующий программный код для создания и использования базы данных testdb:
USE master;
IF DB_ID('testdb') IS NOT NULL DROP DATABASE testdb;
Программируемые объекты
357
CREATE DATABASE testdb;
GO
USE testdb;
Далее выполните программный код, создающий таблицу dbo.AuditDDLEvents, которая
содержит контрольную информацию:
'
IF OBJECT_ID(1dbo.AuditDDLEvents'f
1
U1) IS NOT NULL
DROP TABLE dbo.AuditDDLEvents;
CREATE TABLE dbo.AuditDDLEvents
( audit_lsn INT NOT NULL IDENTITY,
posttime DATETIME NOT NULL,
event type sysname NOT NULL,
loginname sysname NOT NULL,
schemaname sysname NOT NULL,
objectname sysname NOT NULL,
targetobjectname sysname NULL,
eventdata XML NOT NULL,
CONSTRAINT PK_AuditDDLEvents PRIMARY KEY(audit_lsn));
Обратите внимание на то, что в таблице есть столбец eventdata с типом данных XML. По-
мимо отдельных атрибутов, которые триггер извлекает из информации о событии и сохра-
няет в отдельных атрибутах, он также сохраняет полную информацию о событии в столбце
eventdata.
Для создания в базе данных контрольного триггера trg audit ddl events с помощью
группы событий D D L_D AT ABAS E_LE VE L_E VENT S, представляющей все события на уровне
базы данных, выполните следующий программный код:
CREATE TRIGGER trg_audit_ddl_events
ON DATABASE FOR DDLJDATABASE_LEVEL_EVENTS
AS
SET NOCOUNT ON;
DECLARE ©eventdata AS XML;
SET ©eventdata = eventdata();
INSERT INTO dbo.AuditDDLEvents(
posttime, eventtype, loginname, schemaname,
objectname, targetobjectname, eventdata)
VALUES (
©eventdata.value (
1
(/EVENT_INSTANCE/PostTime) [1]1
, *VARCHAR(23)1),
©eventdata.value(
1
(/EVENT_INSTANCE/EventType)[1]1
,
1
sysname
1
),
©eventdata.value(
1
(/EVENT_INSTANCE/LoginName)[1]1
,
1
sysname
1
),
©eventdata. value (
1
(/EVENT_INSTANCE/SchemaName) [ 1 ]1
,
1
sysname
1
),
13 Зак. 1032
358
Гпава 10
@eventdata.value(
1
(/EVENT_INSTANCE/Obj ectName) [1]',
1
sysname
1
),
Geventdata.value(
1
(/EVENT_INSTANCE/TargetObj ectName) [ 1]1
, ' sysname
1
),
Geventdata);
GO
В программном коде триггера сначала в переменной Geventdata сохраняется информация о
событии, полученная функцией EVENT DATA. Далее в контрольную таблицу вставляется строка
с атрибутами, извлеченными из информации о событии с помощью выражений XQuery, полу-
ченных методом . value, плюс значение XML с полной информацией о событии.
Для тестирования триггера выполните следующий программный код, содержащий несколь-
ко инструкций DDL:
CREATE TABLE dbo.Tl(coll INT NOT NULL PRIMARY KEY);
ALTER TABLE dbo.Tl ADD col2 INT NULL;
ALTER TABLE dbo.Tl ALTER COLUMN col2 INT NOT NULL;
CREATE NONCLUSTERED INDEX idxl ON dbo.Tl(col2);
Затем выполните программный код с запросом к контрольной таблице:
SELECT * FROM dbo.AuditDDLEvents;
Вы получите результат (разделенный на две части для экономии места), но со значениями в
атрибутах posttime и loginname, отражающими время начала события и регистрационное
имя в вашей рабочей среде:
audit_lsn posttime
eventtype
loginname
1
2009-02-12 09:06:18.293 CREATEJTABLE QUANTUM\Gandalf
2
2009-02-12 09:06:18.413 ALTER_TABLE
QUANTUM\Ganda1f
3
2009-02-12 09:06:18.423 ALTER_TABLE
QUANTUM\GandaIf
4
2009-02-12 09:06:18.423 CREATE_INDEX QUANTUM\Gandalf
audit_lsn
schemaname
objectname
targetobjectname eventdata
1
dbo
Tl
NULL
<EVENT_INSTANCE>.
2
dbo
Tl
NULL
<EVENT_INSTANCE>
3
dbo
Tl
NULL
<EVENT_INSTANCE>
4
dbo
idxl
Tl
<EVENT INSTANCE>
Когда закончите работу, выполните программный код для чистки базы данных:
USE master;
IF DB_ID(1testdb') IS NOT NULL DROP DATABASE testdb;
Обработка ошибок
SQL Server предоставляет средства для обработки ошибок вашего программного кода на
языке T-SQL. Основное средство, применяемое для обработки ошибок,— конструкция
Программируемые объекты
359
TRY.. .CATCH, которая появилась в версии SQL Server 2005. SQL Server также имеет ряд
функций, которые можно вызывать для получения информации об ошибке. Начну с очень
простого примера, демонстрирующего применение конструкции TRY. . .CATCH, за которым
последует более подробный пример, содержащий функции с информацией об ошибках.
Применяя конструкцию TRY. . .CATCH, вы помещаете обычный программный код на языке
T-SQL в блок TRY (между ключевыми словами BEGIN TRY И END TRY), а весь программный
код, обрабатывающий ошибки, в связанный блок CATCH (между ключевыми словами BEGIN
CATCH и END CATCH). ЕСЛИ в блоке TRY нет ошибок, блок CATCH просто пропускается.
Учтите, что если блок TRY. . .CATCH обнаруживает и обрабатывает ошибку, при этом в вы-
зывающем процессе нет ошибки.
Для просмотра случая с блоком TRY без ошибок выполните следующий программный код:
BEGIN TRY
PRINT 10/2;
PRINT 'No error';
END TRY
BEGIN CATCH
PRINT 'Error
1
;
END CATCH
Весь программный код в блоке TRY завершился успешно; следовательно, блок CATCH был
пропущен. Данный код формирует такой результат:
5
No error
Далее выполните похожий программный код, но на этот раз разделите на ноль, и ошибка
появится:
BEGIN TRY
PRINT 10/0;
PRINT fNo error';
END TRY
BEGIN CATCH
PRINT 'Error';
END CATCH
Когда в первой инструкции PRINT блока TRY возникла ошибка деления на ноль, управление
было передано в соответствующий блок CATCH. Вторая инструкция PRINT в блоке TRY не
выполнялась. Таким образом, данный программный код формирует следующий результат:
Error
Обычно обработка ошибки включает в себя некоторую работу в блоке CATCH, выясняющую
причину ошибки и выполняющую определенные действия. SQL Server предоставляет вам
информацию об ошибке с помощью набора функций. Функция ERROR NUMBER возвращает
целочисленный номер ошибки и, возможно, является одной из самых важных функций, воз-
вращающих сведения об ошибках. В блок CATCH обычно включается программный код по-
тока, проверяющего номер ошибки и определяющего план предпринимаемых действий.
Функция ERROR_MESSAGE возвращает текст сообщения об ошибке. Для получения списка
360
Гпава 10
номеров ошибок и соответствующих им сообщений запросите представление каталога
sys.messages. Функции ERRORJSEVERITY и ERRORJSTATE возвращают степень серьезно-
сти ошибки и ее статус. Функция ERROR_LINE возвращает номер строки, в которой возникла
ошибка. И наконец, функция ERROR_PROCEDURE возвращает имя процедуры, в которой про-
изошла ошибка, и значение NULL, если процедура выполнилась без ошибок.
Для выполнения примера с более серьезной обработкой ошибки, использующего функции с
информацией об ошибке, сначала выполните следующий программный код, создающий
таблицу dbo.Employees (Сотрудники) в базе данных tempdb:
USE tempdb;
IF OBJECT_ID('dbo.Employees') IS NOT NULL DROP TABLE dbo.Employees;
CREATE TABLE dbo.Employees
( empid INT NOT NULL,
empname VARCHAR(25) NOT NULL,
mgrid INT NULL,
CONSTRAINT PK_Employees PRIMARY KEY(empid),
CONSTRAINT CHK__Employees_empid CHECK(empid >0),
CONSTRAINT FK_Employees_Employees
FOREIGN KEY(mgrid) REFERENCES dbo.Employees(empid));
В следующем программном коде в блоке TRY В таблицу Employees (Сотрудники) вставля-
ется новая строка, и при возникновении ошибки показано, как определить ошибку, анализи-
руя функцию ERROR NUMBER в блоке CATCH. Программный код также выводит значения
других функций, возвращающих сведения об ошибке, просто для того, чтобы показать, ка-
кая информация об ошибке вам доступна.
BEGIN TRY
INSERT INTO dbo.Employees (empid, empname, mgrid)
VALUES(1,
1
Empl1
, NULL);
—
Также проверьте empid =0, 'A
1
, NULL
END TRY
BEGIN CATCH
IF ERROR_NUMBER () = 2627
BEGIN
PRINT 1
Handling PK violation.;
END
ELSE IF ERROR_NUMBER() = 547
BEGIN
PRINT 1
Handling CHECK/FK constraint violation...
1
;
END
ELSE IF ERROR_NUMBER() = 515
BEGIN
PRINT 1
Handling NULL violation.
END
Программируемые объекты
361
ELSE IF ERROR_NUMBER() = 245
BEGIN
PRINT '
Handling conversion error.. . ';
END
ELSE
BEGIN
PRINT *
Handling unknown error. . . ';
END
PRINT 1
' Error Number
1
+ CAST(ERROR_NUMBER() AS VARCHAR(10));
PRINT 1
' Error Message
1
+ ERROR_MES SAGE();
PRINT 1
' Error Severity
1
+ CAST(ERROR_SEVERITY() AS VARCHAR(10));
PRINT '' Error State
1
+ CAST(ERROR_STATE() AS VARCHAR(10));
PRINT '' Error Line
1
+ CAST(ERROR_LINE() AS VARCHAR(10));
PRINT '' Error Proc :
1
+ COALESCE(ERROR_PROCEDURE(), 'Not within proc
f
END CATCH
Когда вы выполните этот программный код первый раз, новая строка успешно вставится в табли-
цу Employees, и, следовательно, блок CATCH пропускается. Вы получаете следующий результат:
(1 row(s) affected)
Когда вы выполните тот же код второй раз, инструкция INSERT завершится аварийно,
управление передается в блок CATCH и определяется ошибка нарушения первичного ключа.
Вы получите такой результат:
Handling РК violation...
Error Number : 2627
Error Message : Violation of PRIMARY KEY constraint
1
PK_Employees
1
.
Cannot in-
sert duplicate
key in object
1
dbo.Employees
1
.
Error Severity: 14
Error State : 1
Error Line
:3
Error Proc
: Not within proc
Для того чтобы увидеть другие ошибки, выполните программный код со значениями 0, 'А'
и NULL в качестве ID сотрудника.
В данном случае для демонстрации я применил инструкции PRINT как действия, выполняе-
мые при обнаружении ошибки. Конечно, обычно обработка ошибки включает не только
вывод сообщения, информирующего об обнаружении ошибки.
Учтите, что можно создать хранимую процедуру, содержащую пригодный для многократно-
го использования программный код обработки ошибки, например, как показано далее:
IF OBJF.CT_ID(' dbo.usp_err_messagcs ' ,
'P') IS NOT NULL
DROP PROC dbo.usp__err_messages;
GO
362
Гпава 10
CREATE PROC dbo.usp_err_messages
AS
SET NOCOUNT ON;
IF ERROR_NUMBER() = 2627
BEGIN
PRINT 'Handling РК violation... ';
END
ELSE IF ERROR_NUMBER() = 547
BEGIN
PRINT 'Handling CHECK/FK constraint violation...';
END
ELSE IF ERROR_NUMBER() = 515
BEGIN
PRINT 'Handling NULL violation.
END
ELSE IF ERROR_NUMBER() =245
BEGIN
PRINT 'Handling conversion error...';
END
ELSE
BEGIN
PRINT 'Handling unknown error...';
END
PRINT 'Error Number
:
'
+
PRINT 'Error Message :
'
+
PRINT 'Error Severity :
*
+
PRINT 'Error State
:
'
+
PRINT 'Error Line
:
'
+
PRINT 'Error Proc
:
*
+
proc');
GO
В вашем блоке CATCH вы просто выполняете хранимую процедуру:
BEGIN TRY
INSERT INTO dbo.Employees(empid, empname, mgrid)
VALUES(1, 'Empl', NULL);
END TRY
BEGIN CATCH
EXEC dbo. usp_err_messages ;
END CATCH
CAST(ERROR_NUMBER() AS VARCHAR(10));
ERROR_MESSAGE();
CAST(ERROR_SEVERITY() AS VARCHAR(10));
CAST (ERROR_STATE () AS VARCHAR (10));
CAST (ERROR__LINE () AS VARCHAR (10) ) ;
COALESCE(ERROR_PROCEDURE(), 'Not within
Программируемые объекты
363
В этом случае вы можете поддерживать в одном месте пригодный для многократного ис-
пользования программный код обработки ошибок.
Резюме
В этой главе представлен общий обзор программируемых объектов, чтобы вы могли узнать о
возможностях SQL Server в этой сфере и начать формировать свой терминологический сло-
варь. Глава знакомит с переменными, пакетами, элементами управления выполнением про-
грамм, курсорами, временными таблицами, динамическим SQL, функциями, определенными
пользователем, хранимыми процедурами, триггерами и обработкой ошибок— всего лишь
несколько обсуждаемых тем. Я надеюсь, что вы сосредоточились на идеях и функциональных
возможностях и не отвлекались на побитное изучение программного кода примеров.
Поскольку это последняя глава книги, я хотел бы добавить несколько слов о следующих
рекомендуемых шагах. Если чтение этой книги — ваше первое знакомство с языком T-SQL,
нужно с помощью практических занятий добиться того, чтобы вся полученная информация
усвоилась, как следует. Если вы пропустили разделы книги помеченные, как более сложные,
можно попробовать взяться за них, когда начнете свободно ориентироваться в материале.
Когда же степень освоения материала еще возрастет, и вы будете готовы к изучению более
сложных запросов, настройки запросов и программирования, предлагаю прочесть книги
"Inside Microsoft SQL Server 2008: T-SQL Querying" ("Взгляд изнутри на Microsoft SQL
Server 2008: формирование запросов на языке T-SQL") и "Inside Microsoft SQL Server 2008:
T-SQL Programming" ("Взгляд изнутри на Microsoft SQL Server 2008: программирование на
языке T-SQL").
1
1
См. http://www.sql.co.il/books/. — Прим. ред.
П РИЛОЖЕНИЯ
ПРИЛОЖЕНИЕ 1
Приступая к работе
Задача этого приложения — помочь вам начать работу и установить рабочее окружение,
обеспечивающее вас всем необходимым, и извлечь максимум из данной книги.
Разд. "Установка SQL Server" проведет вас через процесс установки в том случае, если у вас
нет еще экземпляра Microsoft SQL Server 2008, к которому можно подключаться для практиче-
ского освоения материалов книги. Если у вас такой экземпляр SQL Server уже есть, вы можете
пропустить данный раздел.
В разд. "Загрузка исходного программного кода и установка учебной базы " поясняется, от-
куда можно загрузить исходный программный код примеров из книги и приводятся инст-
рукции по установке учебной базы данных, используемой в книге.
В разд. "Работа с SQL Server Management Studio" рассказывается о том, как в SQL Server
разрабатывать и выполнять код на языке T-SQL с помощью среды SQL Server Management
Studio (SSMS).
В разд. "Работа с SQL Server Books Online" описывается интерактивное справочное руко-
водство SQL Server Books Online и поясняется его важность для получения сведений о. языке
T-SQL.
Установка SQL Server
Для практического освоения материалов книги и выполнения всех примеров программного
кода вы можете использовать любую редакцию SQL Server 2008 за исключением SQL Server
Compact, которая не обладает полноценной поддержкой языка T-SQL, как все остальные
редакции. Предполагая, что у вас еще нет экземпляра SQL Server для подключения, в сле-
дующих разделах я описываю, где получить версию SQL Server и как ее установить.
Получение SQL Server
Как я уже упоминал, для практического освоения материалов книги вы можете применять
любую редакцию of SQL Server 2008 за исключением редакции SQL Server Compact. Если у
вас есть подписка MSDN, для учебных целей можно использовать SQL Server 2008 Devel-
368
Приложения
орег. Загрузить его можно с Web-страницы http://msdn.microsoft.com/en-us/sqlserver/
default.aspx. В противном случае вы можете воспользоваться 180-дневной пробной или
оценочной версией SQL Server 2008 Enterprise, свободно распространяемым программным
обеспечением, которое можно загрузить с Web-страницы http://www.microsoft.com/
sqlserver/2008/en/us/trial-software.aspx. В данном приложении я описываю установку 180-
дневной пробной версии SQL Server 2008 Enterprise.
Перед установкой SQL Server необходимо создать учетную запись пользователя, которую
вы позже будете использовать как абонентскую учетную запись для получения услуг SQL
Для создания учетной записи пользователя выполните следующее: -
1. Щелкните правой кнопкой мыши по значку My Computer (Мой компьютер) (или Com-
puter (Компьютер) в некоторых операционных системах) и выберите команду Manage
(Управление) для того, чтобы открыть встроенное системное приложение Computer
Management (Управление компьютером).
2. Перейдите к строке Computer Management (Local) | System Tools | Local Users and
Groups | Users
(Управление
компьютером
(локальным) | Служебные
програм-
мы | Локальные пользователи и группы | Пользователи).
3. Щелкните правой кнопкой мыши по папке Users (Пользователи) и выберите команду
New User (Новый пользователь).
4. Заполните поля для учетной записи нового пользователя в диалоговом окне New User
(Новый пользователь), как показано на рис. П1.1.
Создание учетной записи пользователя
Server.
ш
Ц$ег name*
]SQL
Full name:
description.
[Accoun foi SQL Server services
£on1irm password:
•
Г L" v_\ !: '••.' r.or д. p^W*^
|V User cannot change password
P Accoun* is c£ sailed
CREATE | FFI^F 1
Рис. П1.1. Диалоговое окно New User
Приложение 1. Приступая к работе
369
•
Введите User паше (Пользователь) (например, SQL), при желании укажите Full
name (Полное имя) (например, SQL Server Services Account) и Description (Описа-
ние) (например, Учетная запись для получения сервисов SQL Server), а также Pass-
word (Пароль) для защиты и Confirm password (Подтверждение).
•
Сбросьте флажок User must change password at next logon (Потребовать смену па-
роля при следующем входе в систему).
•
Установите флажки User cannot change password (Запретить смену пароля пользо-
вателем) и Never Expires (Срок действия пароля не ограничен).
•
Щелкните мышью по кнопке Create (Создать) для создания учетной записи нового
пользователя.
Установка необходимых
сопутствующих пакетов программ
В этот момент вы можете запустить программу setup.exe с инсталляционного компакт-диска
SQL Server или из инсталляционной папки. Перед инсталляцией SQL Server программа
установки проверяет, все ли необходимые сопутствующие программные компоненты уста-
новлены. К ним относятся платформа Microsoft .NET Framework и обновленная программа
Windows Installer. Если программа установки не находит необходимое программное обеспе-
чение, она сначала установит его, а после установки сопутствующих программ может по-
требовать от вас перезапустить компьютер и снова запустить программу установки.
Установка механизма управления базы данных,
документации и утилит
После того как сопутствующее программное обеспечение установлено, можно переходить к
непосредственной установке основной программы.
Для установки механизма управления базы данных, документации и утилит выполните сле-
дующее:
1. После установки необходимых сопутствующих программ запустите программу установ-
ки. Вы должны увидеть диалоговое окно SQL Server Installation' Center (Центр установ-
ки SQL Server), показанное на рис. П1.2.
2. На левой панели выберите строку Installation (Установка). Проследите за изменениями
экрана.
3. На правой панели выберите New SQL Server Stand-Alone Installation Or Add Features
To An Existing Installation (Установить новый отдельный экземпляр SQL Server или до-
бавить компоненты в существующую установку). Появится диалоговое окно Setup Sup-
port Rules (Правила поддержки установки).
4. Щелкните мышью Show Details (Показать подробности) для того, чтобы вывести на эк-
ран состояние правил поддержки установки (рис. П1.3) и убедиться в том, что не обна-
ружено никаких проблем.
370
Приложения
SQL Server Installation Center
.•JO):*!
Planning
Instjlabcx}
Mantenence
Tools
Resources
Advanced
OpOoos
Hardware and Software Requirements
View the hardware and software requirements.
Security Documentation
View the security documentation.
Onfcne Release Notes
View the latest information about the release.
f
System Configuration Checker
Launch a too) to check for сопсКюги that prevent a successful SQL Server instalation.
Install upgrade Advisor
Upgrade Advisor analyzes any SQL Server 2005 or SQL Server 2000 components that are restated
and Identtffes Issues to fix either before or after you upgrade to SQL Server 2008.
Orkr* Instalation Hefc>
' Launch the online Instalation documentation.
How to Get Started with SQL Server 2008 Fafover Clustering
' Road instructions on how to grw st.*ted SQL Server 2006 falover ckftfwing.
Upgrade Documentation
!
View the document about how to upgrade to SQL Server 2008 from SQL Server 2000 or SQL Server
2005.
Serveraos
Рис. П1.2. Окно SQL Server Installation Center
LHIII II Mill —
Setup SupporL Rules
•НЯ
-JOT*!
1
Setup Support Rub» kJantiy problems that m^ht «о* when you mstal SQL Server Setip support t*es. Fai чл must be
corrected before Setup ten continue.
Setup Support Rule»
Operation completed. Passed: 6. FatodO. WarrrigC &ppedO.
IIKIIIRIIlllRllllllllIIIRRIfllllllllllMilllSIi
Hie detail« ]
ЁР-гип !
RJe
Status
Minimum Operating system version
Passed
Setup adrrinetrat or
Pflsssd
& Restart computer
Passed
© Windows Management Instrumentation (WMI) service
Passed
& Consistency validation for SQL Server regktry keys
Passed
& Long path names to f fes cm SQL Server instalation media
Passed
OK
I Cancel
НФ|
Рис. П1.3. Окно Setup Support Rules
Приложение 1. Приступая к работе
371
SQL Server 20GB Setup
Product Key
Spetrfy tte adtfeft of SQL Server 2008ratal.
ШШШШШ
PrtxJiKt Key
bcen*s Terms
Setup S<jppcrtFfe3
Spec?у a Free edtoon of SQL Setvsf or fwovkk a SQL Server product **y to
thй instance cf SQL
5;rver20CS. trite* tt* 2S<h«ficte'- Vey fromthe Microsoft certificate of ajthentwy Or pfodtxt packaging.
If you jpocfy EfAerpftie Evakiattofv. the nftance be aebvated-wfth <5180-day wtattoft TP
from orvj rdbon to ancthw tdfeto, гш the Mwn Up^a^e VAiard.
<• Specify efreeedwjn:
gntarttw product key:
Г
T
Рис. П1.4. Окно Product Key
5. Когда сделаете это, для продолжения щелкните мышью по кнопке ОК. Появится экран
Product Key (Ключ продукта), показанный на рис. П1.4.
Учтите, что в определенных ситуациях диалоговые окна Setup Support Files (Файлы
поддержки установки) и Setup Support Rules (Правила поддержки установки), описан-
ные в пунктах 7—9, MOIYR появиться раньше диалогового окна Product Key. Если это
произойдет, просто выполните инструкции, приведенные в пунктах 7—9 в этот момент, а
не позже.
6. Убедитесь, что в раскрывающемся списке под переключателем Specify a free edition
(Задать свободно распространяемую версию) выбран вариант Enterprise Evaluation
(Ознакомительная версия), и щелкните мышью по кнопке Next (Далее) для продолжения.
Появится диалоговое окно License Terms (Условия лицензии).
7. Подтвердите, что вы принимаете условия лицензии, и щелкните мышью по кнопке Next
для продолжения. Вы увидите на экране диалоговое окно Setup Support Files (Файлы
поддержки установки).
8. Щелкните мышью по кнопке Install (Установить) для продолжения. Диалоговое окно
Setup Support Rules (Правила поддержки установки) появится снова.
9. Щелкните мышью по кнопке Show details (Показать подробности) для того, чтобы про-
смотреть состояние правил поддержки установки и убедиться в том, что никаких про-
блем не обнаружено. Щелкните мышью по кнопке Next для продолжения. Появится диа-
логовое окно Feature Selection (Выбор компонентов). Выберите компоненты, которые
хотите установить (рис. П1.5).
372
Приложения
Feature Selection
defect the Enterprise Eval'jabon Features to insteP For ck)St«red tostelatons, only Database Engne Services end Analysis
Services iin be clustered.
Setup Support Ro*e?
Feature Selection
Instance Corfigutatton
OtekSpaee Requlremerts
Server Conf Alton
Database Engine Configuration
Error and Usage Reporting
Installation Rules
Ready to IrtstaS
TNRTELFAT
I
ORI PROGRTS*
Comptete
Fpatires:
SekttgS ] UntritctAC |
Scared feature drettcty:
Oescrptcn;
Instance Features
ГпсЫв the Database £ngr>ef the co?e
service fa: «oring, processing and
О SQL
Replication
• Full-Text Search
О Analysis Services
setuilngdata. Tte Datable Engrte
О SQL
Replication
• Full-Text Search
О Analysis Services
provide? controlad access andraptd
О SQL
Replication
• Full-Text Search
О Analysis Services
cramacbon prowsrvj «гк$ <dso pi ovidw
О SQL
Replication
• Full-Text Search
О Analysis Services
•r*h 4upp>3ft for sustaining high
I.J Reporting Services
еуайаЫ**
Shared Features
f..1 Business Intelligence Development Studio
Fi Client Took Connectivity
Integration Services
G Ckent Tools Backwards Compatibility
G Gent Tools SDK
SQL Server Books Online
Щ Management Tools - Basic
Г/j Management Tools - Complete
• SQL client Connectivity SDK
О Microsoft Sync Framework
Redistributable Features
iC:\Program Files\Microsoft SQL Server\
<£ack
J
Рис. П1.5. Диалоговое окно Feature Selection
Выберите следующие компоненты:
•
Database Engine Services (Сервисы ядра СУРБД);
•
Client Tools Connectivity (Клиентские средства связи);
•
SQL Server Books Online (Интерактивное справочное руководство);
•
Management Tools — Complete (Средства управления — полностью).
Для задач этой книги вам не понадобятся другие компоненты.
После этого для продолжения щелкните мышью по кнопке Next. На экране появится
диалоговое окно Instance Configuration (Конфигурация экземпляра), показанное на
рис. П1.6.
Если вы не знаете, что представляют собой экземпляры SQL Server, подробности можно
найти в разд. "Архитектура SQL Server" главы 1.
10. Если на компьютере не установлен экземпляр SQL Server по умолчанию и вы хотите
определить новый экземпляр как экземпляр по умолчанию, просто убедитесь, что уста-
новлен переключатель Default instance (Экземпляр по умолчанию). Если вы хотите
сделать новый экземпляр именованным, убедитесь, что выбран вариант Named instance
(Именованный экземпляр), и задайте имя нового экземпляра (например, SQL08). Когда
позже вы будете подключаться к SQL Server, то для экземпляра по умолчанию зададите
только имя компьютера (например, QUANTUM), а для именованного экземпляра —
имя компьютера\имя экземпляра (например, QUANTUM\SQL08).
Приложение 1. Приступая к работе
373
\ fSQL Server 2006 setuo
Instance Conf Icjuration
Spedty nanw end instance Ю fw the SQL Server retanea.
•aiOLJ
SETUP SYSFWRTRUFCI;
FeatueSetetfian
Invtvmce Configuration
D<& Space
Ser/er Corftgiratlwi
pjUbase Ergfrie Confrg^Mton
EIRW AND REPORT*-G
inAalatiotiftulM
Reads'to Vtftdt
Process
Complete
<*• T^F&JJTIMTARCS
С NJMED INSTANCE:
instance ip-
|
f<t5SQL5ERV$R
V$taaCftt?&<VaCNoy. jciProgram FJ«V<lKrosoft SQL Setver^
SQL Swer^Vottgry: flMM&QSQft SQL ServetV
'
tS5QLlO*tS5QL3eflVEfc
inttafeJ risl^fves.
I EdiUVk
< fca;k [ tgxt> j
|
Рис. П1.6. Диалоговое окно Instance Configuration
1TSQt Server 2000 Setup
Server Configuration
Sptt/y the <onf Kjyrat ton
ШШЯШ
£<FTBF>5i^JpOrtRuia*
Feature Sdectton
Instance Conf^aUpn
Cr^'Jpaca fteqiirefneris
SERVER CENBEURAHON
Datab-jsaEngrrt СогйдиаЫоп
Etta' and Reporting
Ir-rtil abort P.Ue-s
Ready tdtr^-v
Iret^iation Process
Cofuplrte
i Service Accwtft* jj ОЛаЬоп j
fcJocKrt iccor.T<-ndj tbat you use a sepvstt- account by e«ch SQL $et ver service.
Serves
I AcctWtJtNWKt
Ra^word
' Startup Type i
SQL Server Agent
SQL
ihlanuaJ
.4
SQL Server Database Engine
[SQL
: Automatic d
th- сигссоЧ fw (Л SQL Serv$* ;
Jfwst services wfl be tonfjjifrJ «Логика!/ уЛяв to we a tow povfe^ ftuognt On
•some ufcJet Vyndam vcmoos tfijs user vaS need to 5$*сгул few prrvAme account. For iw(
Worm«ioo, tkkHtfc,
S«vtea
Дсес-u* Iteme
Password
5 StarWp T/pa j
SQL Server Browser
NT AUWOftlTYftOCAl...
1 Disabled
Щ
Рис. П1.7. Диалоговое окно Server Configuration
374
Приложения
11. Для продолжения щелкните мышью по кнопке Next. Появится диалоговое окно Disk
Space Requirements (Требования к свободному месту на диске). Убедитесь, что у вас, в
соответствии с требованиями, достаточно дискового пространства для установки.
12. Для продолжения щелкните мышью по кнопке Next. Появится диалоговое окно Server
Configuration (Конфигурация сервера).
13. Как показано на рис. П1.7, в качестве учетной записи службы SQL Server Agent (Агент
SQL Server) и служб SQL Server Database Engine задайте имя пользователя и пароль
учетной записи пользователя, которую вы создали ранее.
Конечно, если вы задали другое имя учетной записи, не SQL, задайте то имя, которое
присвоили учетной записи.
Для работы с данной книгой вам не нужно изменять стандартные настройки на вкладке
Collation (Параметры сортировки), но если вы хотите узнать больше о наборе парамет-
ров символьной обработки, см. разд. "Набор параметров символьной обработки" гла-
вы 2.
14. Для продолжения щелкните мышью по кнопке Next. Появится диалоговое окно Data-
base Engine Configuration (Конфигурация ядра СУБД).
SQL Server 2008 Setup
Database Engine Configuration
Specify Database Engine autbenflcation security mode, administrators and data directories
Setup Support Rjes
Feature Selection
Instance Conbgurdtton
Ddk Space Requirement*
Server Configuration
Database Engine Configuration
Erie* endtls^ge Reporting
Instefctfonftiies
Ready to IrwtaJ
Inst alabon Process
Complete
Account Ргоияоплд |oateOfrectortes j FILESTfcEAM |
Specfy the authentication mode and airtnetreton for the Database Eft^ne.
Authenttcatton Mode
(* Ji£irtdov/s authentication mode
Г tjxed ftode (SQL Server authertxttfon and Wndows authentication)
SQL Server system administrator account
passwoid: j
Cgnfirm password: j
Speofy SQL Server edmrtbtHrtors
mm
NTUMVSandsf (Gancfa
SQL Swver «drruntstratof $
have unrestricted access
to the Database Engine.
Add Current user Add... |
< GPD
Cante}
1
Ж
Рис. П1.8. Диалоговое окно Database Engine Configuration
15. Убедитесь, что на вкладке Account Provisioning (Выделение ресурсов учетной записи)
в области Authentication Mode (Режим проверки подлинности) выбран переключатель
Приложение 1. Приступая к работе
375
Windows authentication mode (Режим проверки подлинности Windows). В области
Specify SQL Server administrators (Задание администраторов SQL Server) нажмите
кнопку Add Current User (Добавить текущего пользователя), чтобы присвоить текуще-
му зарегистрированному пользователю роль System Administrator (sysadmin) (Систем-
ный администратор) сервера (рис. П1.8). У администратора SQL Server есть неограни-
ченный доступ к ядру базы данных SQL Server.
Конечно, у вас вместо QUANTUM\Gandalf появится ваше имя текущего пользователя.
Если хотите изменить стандартные назначения программы установки для каталогов
данных, это можно сделать на вкладке Data Directories (Каталоги данных). Для работы
с книгой не требуется изменение настроек на вкладке FILESTREAM (Потоки файлов).
SQL Server 2008 Setup
Installation Progress
Support R<J«
Feature Seiedton
Instance Configuration
CwkSpace Retfjirefiwrjts
Server Configuration
Oatflbase Engtoc Configuration
trrc* an-j Usage Reporting
InstaJabonRJes
Ready to Inital
Installation Progress
Compete
Setup process compfttfe
feature Name
Status
Database Engine Services
•Success
... j
© Client Took ConnectiYfcy
|Success
9 Management Took - Complete
jSuccess
Management Tods - Bask
iSuccess
SQL Server Books Online
|Success
I
CAFTCRF | НЕ<Р |
Рис. П1.9. Диалоговое окно Installation Progress
16. Для продолжения щелкните мышью по кнопке Next. Появится диалоговое окно Error
And Usage Reporting (Отчет об ошибках и использовании). Выберите варианты, соот-
ветствующие вашим предпочтениям, и щелкните мышью по кнопке Next для продол-
жения. Появится диалоговое окно Installation Rules (Правила установки).
17. Щелкните мышью по кнопке Show Details (Показать подробности) для просмотра со-
стояния правил установки и выявления обнаруженных проблем. Если проблем не най-
дено, щелкните мышью по кнопке Next. Появится диалоговое окно Ready То Install
(Все готово для установки программы) со сводкой параметров установки.
376
Приложения
Complete
Your SQL Server 2008jnstaltatit'fi twnpleted tuctessfu&y.
Setup Support Rufes
Featur e Seiectiort
fiist-ance Ccnfigursttfn
CtokSp-xe Rt(j*reroer*s
Server Configuration
Debase Engine Ctrftfiguritioft
Crror and Usage Repoitlrio
InsWeaHonRuies
Heady to IrtftaS
fnstafl abort Progress
Complete
Summary bg He hw been saved to tht foJowngioceoon:
C:VProa«ftW«WicrQ»ft5QL ScrveriiOttScfajp BootsfrapUooteWSOTZa П2ЭЬ
^Sutrnwry сиаг>0л1.2р09072$ 11^316 bet
^vmation about the Setyp оре-гйчп or posstfe r>e>t steps:
^ Your SQL Server 2008 installation completed successfully.
5uppteit«sr»t-a3 Ifif wrnaboft:
Thefofcwing nctes apptytoths rde«e of SQL Server only
^tcrps-jft Update
For info matton about taw use W^csoft Update t? identify
ft*
SQL
2008, see the
Microsoft update Web sie <http:^oo,mcioJoft.com^vAnK4inkJcWiCei09> at
Mp^Mriicrtteft
.
Reporting Services
ThePeporthg Services nuUlatioo options that you specified m Setup deterrnri-; whether a<3dtfcrwj!
Cbse
Рис. П1.10. Диалоговое окно Complete
18. Убедитесь в том, что сводка корректно отражает выбранные вами параметры, и щелк-
ните мышью по кнопке Install (Установить) для запуска процесса установки. Появится
и останется открытым до завершения установки диалоговое окно Installation Progress
(Выполнение установки). В этом диалоговом окне есть общий индикатор выполнения и
индикация состояния каждого устанавливаемого компонента. Когда установка завер-
шится, над общим индикатором установки появится сообщение Setup process complete
(Процесс установки завершен), как показано на рис. П1.9.
19. Для продолжения щелкните мышью по кнопке Next. Появится диалоговое окно Com-
plete (Завершение), показанное на рис. П1.10.
Это окно должно сообщить об успешном завершении установки.
20. Для завершения щелкните мышью по кнопке Close (Закрыть).
Загрузка исходного программного кода
и установка учебной базы
Вы можете загрузить сопроводительный программный код к книге с Web-сайта
http://www.sql.co.il/books/. Файлы сценариев с исходным программным кодом ко всей кни-
Приложение 1. Приступая к работе
377
ге и файл сценария для создания учебной или тестовой базы данных находятся в одном упа-
кованном файле. Распакуйте файл в локальную папку (например, C:\TSQLFundamentals).
Вы обнаружите до трех файлов сценариев с расширением sql, связанных с каждой главой
книги. Один файл содержит исходный программный код для соответствующей главы и
предлагается для удобства, на случай, если вам не хочется набирать программный код,
встретившийся в книге; имя этого файла соответствует номеру и названию главы. Второй
файл содержит упражнения к данной главе; имя этого файла соответствует номеру и назва-
нию главы, но содержит суффикс "Exercises". Третий файл содержит решения для упражне-
ний данной главы: его имя соответствует номеру и названию главы, но содержит суффикс
"Solutions". Для открытия файлов и выполнения их программного кода используйте среду
SQL Server Management Studio (SSMS). В следующем разделе описана работа в этой среде.
HR.Empfoyees
РК empid
а
lastname
firstname
title
titleofcourtesy
birthdate
hiredate
address
city
region
12 postalcode
country
phone
FK1 mgrid
ProductioaSuppliers
РК supplierid
IX companyname
contactname
contacttitle
address
city
region
12 postalcode
country
phone
fax
ProductioaCategories
PK categoryid
II
categoryname
description
Sales.Orders
PK
orderid
FK2, II custid
FKt 12 empid
13
orderdate
requireddate
И
shippeddate
FK3,15 shipperid
freight
shipname
shipaddress
shipcity
shipregion
16
shippostalcode
shipcountry
Sales.Shippers
PK
shipperid
companyname
phone
Sales.OrdersDetails
PICFK2, II
PK.FK1,12
orderid
productid
unitprice
qty
discount
Production, Products
PK
productid
12
FK2,13
FK1, II
productname
supplierid
categoryid
unitprice
discontinued
Sales.Customers
PK
custid
12
companyname
contactname
contacttitle
address
11
city
14
region
13
postalcode
country
phone
fax
Sales.OrderValues
orderid
custid
empid
shipperid
orderdate
val
Sales.CustOrders
custid
ordermonth
qty
Sales.OrderTotalsSyYear
orderyear
qty
Рис. П1.11. Модель данных базы данных TSQLFundamentals2008
378
Приложения
Вы также найдете текстовый файл orders.txt, предназначенный для практической работы с
материалами из главы 8.
Кроме того, вы обнаружите файл сценария TSQLFundamentals2008.sql, формирующий учеб-
ную базу данных TSQLFundamentals2008 книги. Если вы уже знакомы с выполнением файлов
сценариев в SQL Server, запустите сценарий. Если же нет, выполните следующие действия.
Для выполнения файла сценария, создающего учебную базу данных, выполните следующее:
1. В программе Проводник Windows дважды щелкните кнопкой мыши по имени файла,
чтобы открыть его в графической среде SSMS. Появится диалоговое окно Connect То
Database Engine (Подключиться к компоненту Database Engine).
2. Убедитесь, что в поле Server name (Имя сервера) появилось имя экземпляра, к которому
вы хотите подключиться. Например, введите имя QUANTUM, если ваш экземпляр сер-
вера был установлен как экземпляр по умолчанию на компьютере QUANTUM, и введите
QUANTUM\SQL08, если ваш экземпляр был установлен как именованный экземпляр,
названный SQL08, на компьютере QUANTUM.
3. Убедитесь, что в поле Authentication (Проверка подлинности) выбран вариант Windows
Authentication (Проверка подлинности Windows). Щелкните мышью по кнопке Connect
(Подключиться).
4. Когда подключитесь к SQL Server, нажмите клавишу <F5> для выполнения сценария.
Когда сценарий завершится, на панели Messages (Сообщения) должно появиться сооб-
щение "Command(s) completed successfully" ("Выполнение команд успешно завершено").
В раскрывающемся списке Available Databases (Доступные базы данных) вы должны
увидеть базу данных TSQLFundamentals2008.
5. Когда закончите работу, можно закрыть SSMS.
Для вашего удобства на рис. П1.11 приведена модель данных базы данных TSQLFundamen-
tals2008.
Работа с SQL Server Management Studio
SQL Server Management Studio (SSMS) — это клиентское средство как для разработки про-
граммного кода на языке T-SQL, так и для управления SQL Server. Цель данного раздела —
не полное руководство по работе с SSMS, а только помощь на начальном этапе в написании
и выполнении на SQL Server программного кода T-SQL.
Приступая к работе с SSMS, выполните следующее:
1. Запустите SSMS из группы программ Microsoft SQL Server. Если это ваш первый за-
пуск SSMS, советую настроить стартовые параметры, чтобы утилита была настроена так,
как вы хотите. Если появится диалоговое окно Connect to Server (Соединение с серве-
ром), в этот момент щелкните мышью по кнопке Cancel (Отмена).
2. Выберите команду меню Tools | Options (Сервис | Параметры) для вывода на экран диа-
логового окна Options (Параметры). На странице Environment | General (Сре-
да | Общие) задайте вариант Startup | Open Object Explorer and New Query (При запус-
ке | Открывать обозреватель объектов и новое окно запроса). Этот выбор сообщает
Приложение 1. Приступая к работе
379
SSMS о том, что при запуске следует открыть Object Explorer (Обозреватель объектов) и
окно нового запроса.
Обозреватель объектов — это средство, применяемое для управления SQL Server и про-
смотра в графической среде определений объектов, а окно запроса — это окно, в кото-
ром вы пишете и выполняете в SQL Server программный код на языке T-SQL. Просмот-
рите представленное дерево, чтобы познакомиться с параметрами, которые можно
задать, но пока только некоторые из них кажутся заслуживающими внимания. После то-
го как вы лучше освоите SSMS, многие параметры приобретут дополнительный смысл и
значение, и, возможно, вы захотите изменить некоторые из них.
3. Когда закончите осмотр диалогового окна Options (Параметры), щелкните мышью по
кнопке ОК для подтверждения сделанного выбора.
4. Закройте SSMS и запустите снова, чтобы проверить, действительно ли при запуске от-
крываются Object Explorer (Обозреватель объектов) и окно нового запроса. Вы должны
увидеть диалоговое окно Connect to Server (Соединение с сервером), показанное на
рис. П1.12.
| jj?Connect to server
Н1ИНИНН1
2d
Microsoft*
SQLServer2G08
Server \yptr.
J Debase Engine
£1
\ Server name:
[гйшпта
zl
J Authentication:
j Windows Authentication
d
JO 'ДМК '.J -'i'- . t. jn^lf
d
p ^ vy<vd
Г
Connect
Cancel |
Help
Options »
Рис. П1.12. Диалоговое окно Connect to Server
5. В этом диалоговом окне вы задаете характеристики экземпляра SQL Server, к которому
хотите подключиться.
•
В поле Server name (имя сервера) введите имя сервера, к которому хотите подклю-
читься.
•
Убедитесь, что в поле Authentication (Проверка подлинности) выбран вариант Win-
dows Authentication (Проверка подлинности Windows).
•
Щелкните мышью по кнопке Connect (Подключиться). SSMS запустится и откроет
окно, показанное на рис. П1.13.
Окно обозревателя объектов Object Explorer располагается в левой части стартового
окна, а окно запроса — справа от Object Explorer. Несмотря на то, что эта книга в ос-
380
Приложения
новном посвящена разработке программного кода на языке T-SQL, а не управлению
SQL Server, я настоятельно рекомендую изучить Object Explorer, перемещаясь по дереву
объектов, показанному на рис. П. 14, и щелкая правой кнопкой мыши различные узлы.
Вы увидите, что Object Explorer— очень удобное средство, позволяющее в графиче-
ской среде проверять ваши базы данных и содержащиеся в них объекты.
Microsoft SQL Server Management Studio
£drt View Query groject Rebuff j£ods &indpw Community Help
J EIEWQUERY QI
ОШ
A4
^ , master
Caprert-
®
3
V * EXECUTE *
sgLQueTyl .sql...\Ganda IF (53))
d "QUANTUM (SQL Server 10.0 .1
if Databases
No „_j Security
it. Server Objects
E 3 Replication
!£ Management
>+} SQL Server Agent
jslfiL*^
*>5
—«:TJ
JTF7
1
& Ctofinwted. (1/1)
! QUANTUM (10.0 fcTM) , QUANTLR^Gaoddf (53) master €0:00:00
1
0 rows
fieatfy
Coil
CHI
Рис. П1.13. Стартовое окно SSMS
Имейте в виду, что с помощью мыши можно перемещать элементы из обозревателя
объектов в окно запроса.
ПРИМЕЧАНИЕ
Если вы переместите папку Columns (Столбцы) какой-либо таблицы из обозрева-
теля объектов в окно запроса, SQL Server отобразит список всех столбцов табли-
цы, отделенных друг от друга запятыми.
В окне запроса вы разрабатываете и выполняете код на языке T-SQL. Выполняемый ва-
ми программный код действует в контексте базы данных, к которой вы подключились.
Выбрать базу данных, к которой вы хотите подключиться, можно из раскрывающегося
списка Available Databases (Доступные базы данных), как показано на рис. П1.15.
Приложение 1. Приступая к работе
381
ч* Microsoft SQL Server Man agument Stucfe*
(Чь
View Project
Took wndow £pmn%jnity Hdp
Query
:
£&§JL&-JЫ
Canned - fy &
| SQLQuery l.sql-AGandalf (53)) Щ
E „J Databases
Э L-ii System Databases
S Database Snapshots
F Q T5QLFundamentals20CS
ft! Database Diagrams
3 J3 Tabes
*b LJ System Tables
ft L3 dbo.Nums
ifc p HR.ErrpJoyees
Ж £3 Production. Categories
=S= 3 Production.Products
D Production.5upplier*
t+; 3 Safes.Customers
Ж £3 Sales.OrderDetaits
S? ПЗ Sales-OrderDetafeAudt
3 £3 Sales.Orders
3
Columns
f orderid (PKj int, гк
f custid (FK, Intj nU
f empid (FK, mfc, not
Ш orderdate (datettn
Ш requireddatn (datt
Ш shppeddate(date
I shipperid (FK, mit,
freight (money, nc
1L.
"ИЗ
V-* —F
•'M
...
ЛГ
a^ttfmected,..
j QUANTUM(10.0Й.ТМ) ^ QUWTUM\|Gi*>Jftf (53) master COiOC'.OGI. Ortws *
Ready
Рис. П.14. Окно Object Explorer
Microsoft SQL Serve* Management studio
Fie Edit v«w Quay Project Debug Took Vflmfcw Commur&y Неф
^.NewQuety&?ЪЩ;&2.J?У"
ИT^CUTE*
^ £ *Г31"Г
:3-
' master
FTFFIJ
model
Connect
T
ifMdb
4K
SQLQueryl.*ql „JGandalf (53))*
ВJ
Database Snapshots
TSQLFundamentab2008
^J Database Diagrams
CJ Tables
Ш CJ System Tables
m
dbo.Nums
ffi 3 HR,Employees
Й? • Production.Catogor
Ш Production-Product-
S 3 Production.Suppfcer
5E Sales-Customers
й1 £3 Sdes.OrderDetaJs
£ Z3 5ales.OrdorDetails£
a 3 Sales.Orders
J orderid (PK,
f custid (FK,i
f empid (FKJ
u3 orderdate (
Ш requireddat
23 shippeddatf
f shipperid (F
Ш frejght (mor
4
Tj Output
J
JL.
'JrCprnacted (1/1) r QUANTUM(^.ORTM) j QUA4IUM*(*ndalf ($3) " master [ WjiOOiUO
СоИ
Chi
\ prows
INS
Рис. П1.15. Раскрывающийся список Available Databases
382
Приложения
6. Убедитесь в том, что в данный момент вы подключились к учебной базе данных
TSQLFundamentals2008. Имейте в виду, что в любой момент можно изменить экземпляр,
к которому вы подключились, щелкнув правой кнопкой мыши в пустой области окна за-
проса и выбрав команду Connection | Change Connection (Соединение | Изменить со-
единение).
7. Теперь вы готовы к разработке программного кода на T-SQL. В окне запроса введите
следующий программный код:
SELECT orderid, orderdate FROM Sales.Orders;
8. Для выполнения введенного кода нажмите клавишу <F5>. Или же можно щелкнуть мы-
шью по кнопке Execute (пиктограмма с красным восклицательным знаком; не перепу-
тайте с пиктограммой в виде зеленой стрелки, которая запускает отладчик). Результат
выполнения программного кода вы получите на панели Results (Результаты), показанной
на рис. П1.16.
Можно управлять выводом результатов с помощью элемента меню Query | Results То
(Запрос | Результаты), щелкнув кнопкой мыши по соответствующей пиктограмме на па-
нели инструментов SQL Editor. У вас есть следующие варианты: Results То Grid (В виде
табличной сетки) (по умолчанию), Results То Text (В виде текста) и Results То File
(В файл).
fie
X>evi £u try Project &ebug Tocis
.J
CJew Query Lj *Jj '3 tXJ
TSQLFundamenta1s2008
Cfirmect- $ $j w Г iS
|
Ш
V»indow CwrenurAy Help
i Execute fc- v*
^ [j]
SQLQueryl.sql ...Gandalf (53))* |
SELECT orderid, orderdate FPOH Sales.Orders;
^QBQ-S
*
E' LJ Databases
a! CJ System Databases
Ш jfcj Database Snapshots
S У T5Qt.Fundamentals2008
Ш Ci Database Diagrams
В СЛ Tables
ffl CJ System Tabtes
S
dbo.Nums
Ж 3 HR.Employees
Si ИЗ Production.Categor:
:*! Д Production. Product:
Ш Л Production.Supplier-
Si £3 Sales.Customers
Ж
Sales.OrderDetails
ffi £3 Sales .OrderDeteilsf
В £3 Sales.Orders
В £3 -COKJMFTJ.
$ orderid (PK,
f custid (FK, t
f ernpid (FKj I
3 orderdate (
jjO requueddat
ill shippeddatt
if shipperrffF
21 freight (mor
I"
13 fiesutt j J^ We«age;(
|тог-»|
±T
Otdefid j| oftfefdaie
J
[10248 [ 2006-07-04 00:00 00.000 =
2
10249 "
;
2005-07 -05 00:00:00.000 _
J2 10250 2006-07-08 00:00.00.000 j
4
10251 2006-07-08 00:00:00.000 j
Б
10252 • 2006-07-09 00:00:00.000 \
e
10253 - 2006-07-10 00:00:00.000 :
7
10254 2006-07-11 00:00:00.000 ;
fi 107SS 7ПГК-П7-1 ? nOfWm ОПЛ ;
J
-MM
Г.* !U.
=1
-I
Q ' QUANTUM (10Л RTM) : QUANTUM^Ganda'/ (S3) j TS^LFundamertiilsZOOS { 00:00:00 \ 630 rows j
=i3oapu-
Ready
in2
Cofl
CHI
Рис. П1.16. Выполнение первого запроса
Приложение 1. Приступая к работе
383
Обратите внимание, что, если фрагмент кода выделен (рис. П1.17), во время выполне-
ния программного кода SQL Server выполняет только выделенный фрагмент. SQL
Server выполнит весь программный код в сценарии, только если нет выделенного фраг-
мента кода.
ПРИМЕЧАНИЕ
Если перед выделением фрагмента программного кода нажать и удерживать кла-
вишу <Alt>, можно для копирования или выполнения выделить прямоугольный
блок, который необязательно начинается с начальных символов строк кода
(рис. П1.18).
т
\SDJ9JXJ
EDS EDIT
QUERY
J [^w Query
•«3
£
\t
TSQLFundamentals2009
СцрпЫХ"
groiect fcebug toob yt,tndow Community Hrlp
!
>
ц ^BJR^ ОЁЭСЗ 2
SQLQueryl.sql ...Gandelf (53))*L
' ••a USE TSQLFundamentals2008-
<1.
В DATABASES
if; Cj System Databases
(+•
Database Snapshots
В j T5QLFundamer*aJs2008
Й fJJ Database Diagrams
В
Tables
Ж LJ System TabJes
Ж .'3 dbo.Nums
HR,Employees
Ш u3 ProAjction.Categor
•S C3 ProductioaProduct;
ts 3 Production.Supplier
Ш П Sates.Customers
Й ^ Sates. OrderDetails
В Sales .OrderDetaAsA
iri H Sales.Orders
A _ J CDRV-I?
I' orderid (РК,-
£ custd (FK, i
f errpid (FKj i
orderdate (
Ш requireddat
a) shppeddatt
f shjpperid (F
Й freight (mor
XЦ
II• Л
SELECT
orderid, orderdate, custid, empid, shipperid
ROff_NUHBER(}
OVER(ORDER BY orderdate DESC, orderid DESC) AS romi
FROH Sales.Orders
SELECT *
FROH С
i
- WHEP,E rovnum
• ftemfo j ^ Menajat |
iT
[mor*| ———
1Г:
j| Predate
CUlftd j[ & ) thippewd I lOWrtUfr, !
-J
1 ' 11070 \ 2009-02-12 00:0000.000 85
5
3
1
^
2
11077 , 2008-05-06 00:00 00,000 65
1
2
.2
3 11076 : 2008-05 -0600:00.00.000 ' 9
4
2
;3
4 11075 2008-05-06 00:00:00.000 .:
В2
4
5 '11074 2008-05 -0Б 00:00:00. С 00: 73
7"2
5"
6 11073 : 2008-05 -05 00:00:00.000 • 58
2
2
-
---
_3 0utpu
Ready
;
QUANTUM (IC.O RTM) :
<}UANTUM\Gandaif (53) j TSQLFvndameotalsZOOa ; 00:00:00 ' 830 rows j
tn 10
CO1!
CM
Ш5
Рис. П1.17. Выполнение только выделенного фрагмента
программного кода
В заключение, прежде чем я оставлю вас наедине с вашими изысканиями, хочу напомнить,
что весь сопроводительный программный код к книге можно загрузить с Web-сайта книги
(см. в разд. "Загрузка исходного программного кода и установка учебной базы" ранее в
этом приложении). Предположим, что вы загрузили исходный программный код и извлек-
ли файлы из архива в локальную папку. Открыть файл сценария, с которым вы хотите рабо-
тать, можно с помощью меню File | Open File (Файл | Открыть файл) или с помощью кнопки
Open File (Открыть файл) на панели инструментов Standard (Стандартная). Для открытия
384
Приложения
файла сценария в утилите SSMS вы также можете дважды щелкнуть мышью по имени фай-
ла в Проводнике Windows.
Microsoft SQL Server MarvA^cmeftt studio
••I
ftle Jgdit View Query Project Qebug
TSQLFundamentals2008 » ' 'i Execute »•
logls ^flndow £ommur*ty Help
Г TF*.
О<-=
A;
Canned-
ШК
^
S Databases
Ж Di System Databases
Ss £Li Database Snapshots
В J TSQLFundamentats20D8
В Database Diagrams
в
Tables
tt1 Lj System Tables
ВЗ СПЗ dbo.hums
IS £3 HR.Employees
C3 Production. CateQof
ж £3 Production.Product
85 £3 Production. Supply
tB Ш Sales.Customers
No =3 Sales .OrderDetails
SS Sales.OrderDetails
В S3 Sales.Orders
8 «J COLUMNS
orderid (PK,
Otjtpu: •
Matches: (
SQLQucryl.sql .„Gandalf (53))* [
;>;:U5E tempdb;
CREATE TABLE dbo.Tl
coll INT NOT NULL PRIHARY KEY,
Co 12 VARCHAR (10) NOT NULL
SELECT соД:
FROM dbo.Tl;
Ш RECIA» | ^ MEWAGC* J
custid (FK, i
empid (FK, j
IH1 orderdate (
Ш requtreddat
Ш shippeddat*
f shipperid (F
Щ freight (mor^-j
—
:xi
INo
L
I
FT
JJ
I| orderid j[ otctedafe
cujbd ||empd| j shtppeiid | rownum j
1 1[ 11076 j 2009-02-12 00:00:00.000 • 85 5
3
1
—i
и 11077 2006-05-0600,00.00 .000 •: 65 1
2
2
и [ 11076 ' 2O08-05-OG 00: OO
'
OO!000 "'9 " "4"
"2
;3
4 ] 11075 2008-05-08 00.00:00.000 68 8
2
:
4
5 j 11074 2008-05-06 00:00:00.000
.737
2
5
6 j[ 11073 200S-0"b-05 00:00:00.000 ; 58 2
2
6
« 1i.
:
—
-
j-
-
^Q ! QUANTUM(L&tJRTM) : QUANTUM\Gande!f (53) I TSQLFundarnentattfQOe i 00:00:00 •• 630 rows
Ln7
ColfcS
I
COL 1N5
Рис. П1.18. Выделение прямоугольного блока
Работа с SQL Server Books Online
Microsoft SQL Server Books Online — это интерактивная документация no SQL Server, кото-
рую предоставляет корпорация Microsoft. Books Online содержит множество полезных све-
дений. При разработке программного кода на языке T-SQL рассматривайте справочное ру-
ководство Books Online как своего лучшего друга, не считая данной книги, конечно.
Если вы установили Books Online на свой компьютер, то найдете его ярлык в группе про-
грамм Microsoft SQL Server, в папке Documentation and Tutorials (Документация и учебные
материалы). Интерактивное руководство также доступно в Интернете.
Books Online для SQL Server 2005 можно найти на Web-странице http://msdn.microsoft.com/
en-us/library/mslSOZl^SQL.^.aspx.
1
Справочное руководство для версии SQL Server
1
На русском языке данное руководство доступно по адресу:
http://msdn.microsoft.com/ru-ru/library/msl30214(SQL.90).aspx. — Прим. ред.
Приложение 1. Приступая к работе
385
2008 см. на Web-странице http://insdn.microsoft.com/en-us/library/msl30214.aspx.
2
Приме-
ры, которые я привожу в этом разделе, рассчитаны на локальную установку справочного
руководства Books Online.
© OVER ti*ise tTrafcwct-SQi) - SQL Server 2009 С -tfitfwd «tip Со&чЛЧш -
Ff tared b?'
-Igixl
F*e Edt View
WTx^w Hsip
I
ЛС
^HQw^al - O.&iarch iJjLrriex portents '^Het Favorites $ if ^
Aska Question *J **
(urffltered)
Utokfot:
3
OVER
overflow-field annotate
overflow data [5QLXML]
overflow detections [CLR integration]
overflow errors [SQL Server]
overflow in XML document [5QL Server
overflow row data [SQL Server]
overhead [Database Engine Tuning Ad
overhead [SQL Server]
Overlapping enumeration member
OverUppngDisa3owOutOfPartihonDrn!
OverrideBehavior element
OverrideBehavior enumeration
OverrideBehavior property
overriding backups
overriding collations
overriding connection values
Dvenidng default nuHabibty
overriding default parameterization —
overriding default startup options
overriding degrees of parallelsm
overriding global defaults
overriding isolation levels
overriding parameterization behavior
overriding query optimizer process
overriding report language settings
' overriding report rendering behavior
overriding tuning options
Overwrite enumeration member
•»
OVER Clause (Transact-SQL) I
-гX
| ! UP.L: ms-he(p://M5. SQLCC. v 10/M5.SQLSVR. vlO.en/s 1Ode j6tsql/htm(/ddcef Заб-0Э41 -43eO-ae73-63Q484b7b398.hti -
SQL Server 2008 Socks Online
OVER Clause (Transact-SQL)
^/send Feedback
ID
'£) See Also
• Collapse AH * Language Filt.-г: ли
Determines the partitioning and ordering of the rowsec before the associated window function is
applied.
Applies to:
Ranking window functions
Aggregate windc» functions* For more information, see Aggregate Functions CTransact-SOLi.
ё
[X
в Syntax
TITFE
<m Clause (f/ensact'SQL)
TransatfcSQL Reference
Ctf;i.j.Indexj '^HeipFa..
L^
Рис. П1.19. Окно Index в Books Online
Научиться пользоваться Books Online очень просто, и я не хочу оскорблять ваш интеллект,
пытаясь объяснять очевидное. Раздел, посвященный интерактивному справочному руково-
дству, введен в данное приложение в большей степени не для того, чтобы объяснить вам,
как им пользоваться, а для того чтобы известить вас о существовании такого справочного
руководства и подчеркнуть его важность. Слишком часто люди просят других помочь ре-
шить проблему, связанную с SQL Server, в то время как они легко могут найти ответ, при-
ложив лишь небольшое усилие для поиска его в интерактивном справочном руководстве
Books Online.
Я расскажу о нескольких способах получения информации, доступных в Books Online. Одно
из окон, которым я чаще всего пользуюсь для поиска информации, — окно Index (Указа-
тель), показанное на рис. П1.19.
Введите то, что вы ищете, в поле Look for (Найти). По мере того как вы вводите буквы ин-
тересующей вас темы (например, OVER), руководство Books Online перемещает курсор к
2
На русском языке данное руководство доступно по адресу:
http://msdn.microsoft.com/ru-ru/Iibrary/bb543165.aspx. — Прим. ред.
386
Приложения
первому отобранному элементу в отсортированном списке тем, расположенному под полем
поиска. Вы можете ввести, например, ключевые слова языка T-SQL для получения сведений
об йх синтаксисе или любую другую интересующую вас тему.
I) Transact-SQL Reference (Database Engine) * SQl Server 200Й Combined Неф Colte < .ь - г-ътйИК
£)Je Edrt ye* led* V^ndow Lieip
ОВЭСК
'IF; ЛA* OJHOWTOI
РЦаг eibr
i
[(unfdtered)
В SQL Server 2008 Books Online
• fei Getting Started
\ Б Database Enpne
:
= -Product Evaluation
Getting Started
: •+] Planning end Architecture
Ж-Development
sjr Deployment
I
if Operations
S Security end Protection
I : [+: • Troubleshooting
in- • Technical Reference
Ej3 Errors end Events Reference
pj-Feature Reference
ft-Took Reference
&ШШШШШЯ
Transact-SQL Syntax Conventions
Й5 Tutorial: Writing Transact-SQL Stat
+ (Add) (Transact-SQL)
(Add EQUALS) (Transact-SQL)
+ (Unary Pfus) (Transact-SQL)
-
+ (String Concatenation) (Transact
• - (Negative) (Transact-SQL)
- (Subtract) (Transact-SQL)
. • — (Subtract EQUALS) (Transact-Sc ^
* ANARCH :^LNDE>C ^JCPNTENTS 33HEFE
FFTV(X
*
ES
3~
|Q ^feskaQuestion *J
T
Transact-SQL R. -tabase Engine) , -
_
^-^,
,•
J
X
ms-he)p://MS1SQLCC.vl0/MS.SQLSVR.vl0.en/slCkle_6tsql/htrnl/dbba47d7-e06e--1435-be76-: ^
SQL Server 200E &ooks Online
Transact-SQL Reference (Database Engine)
Feedback
H Collapss
:Л
Transact-SQL is central to using SQL Server, Ail applications that communicate
with an instance of SQL Server do so by sending Transact-SQL statements to the
server, regardless of the user interface of the application.
The fallowing <s a list of the kinds of applications that can generate Transact-SQL^
*.
•
General office productivity applications.
•
Applications that use a graphical user interface (GUI) to let users select the
tables end columns from which they wart to see data.
•
Applications that use general language sentences to determine what data a
user wants to see-
•
Line of business applications that store their data in SQL Server databases.
jJ
<XtR ZiiuX Tran«<ct-SQL)
Ttansact-SQt, Reference
1БЗВ ЯГ шямшшштаяат
' Title
Location
Рис. П1.20. ОКНО Contents в Books Online
На рис. П1.19 видно, что когда вы выбираете тему, ее URL-адрес в руководстве Books
Online появляется в поле URL. Вы можете добавить найденный URL-адрес в Favorites (Из-
бранное) и даже отправить его людям, если вместо объяснения того, как найти нужную те-
му, вы хотите, чтобы они посетили указанный URL.
Когда вы ищете более общую тему, а не ответ на конкретный вопрос, например, "Что ново-
го в SQL Server 2008?" или "Справочник по программированию на T-SQL", возможно, вы
сочтете более удобным окно Contents (Оглавление) — рис. П1.20.
В этом окне вам необходимо перемещаться по дереву тем для поиска интересующей вас
темы. Учтите, что с помощью поля Filtered by (Фильтровать по) можно выбрать SQL Server
2008 Database Engine (Ядро СУБД версии SQL Server 2008) для сужения области поисков и
просмотров.
Еще одно полезное окно — окно Search (Поиск), показанное на рис. П1.21.
Вы можете применить окно Search при поиске статей, содержащих нужные вам слова. Это
более абстрактный вид поиска по сравнению с поиском в окне Index, нечто похожее на ме-
ханизм поиска в Интернете. Интерактивное справочное руководство Books Online может
Приложение 1. Приступая к работе
387
искать информацию в локальной справочной системе, библиотеке MSDN Online и сообще-
стве разработчиков Codezone Community. Если нужно найти конкретное слово в открытой
статье руководства, нажмите комбинацию клавиш <Ctrl>+<F> для вывода диалогового окна
Find (Найти).
Se' rii - SQL Ser>tr 3u-8 Cw^tteipc^lett
- Microsoft Ооездг^
! в® Edt tfew Tools ^ndow
j
«V
WHowQoI - Q^afch JjIndex ( Contents ^Hefe Favorites
"** - AskaQucsbon £}^ _
4Йr
Search * Trans$tt-SQt R..,t-ab&5« Engr*>)
X
4Йr
st
[three-valued logic
Search
J
йa
С .•J Technology:
АЙ
jjj Content Type:
All
5"
11
<
-V
L
Sewchedfor, thrce*vafue4)ogte
Sort: by: Rank
*
'}1
l-2of2iesUb
<
-V
Lps
1
1
5t
«I
St
i
|
Working with Empty Values
operators can potentially return a thrd resiA of EMPTY instead of just TRUE or FALSE. This
need for three-valued logic is a source of many appkation errors. These tables outline the
effect of introducing empty value comparisons, This table ...
i Local Help (2)
Working with Empty Values
Nui Values
Source: MDX and AS5L Reference
*ulf Values
operators can potential return a third result of UNKNOWN instead of just TRUE or FALSE,
This need for three-valued logic к a source of rnany application errors. These tables txAfoe
the effect of introducing null comparisons. The folowtng table ...
MSDN Online <10)
Nil Cofnparis^ns
Handing NJ vafcyes (AD0.NET)
найНДО Virtues
Source: Database Engine Development Concepts
Codwone Community £3)
Fcxr Riias for NULLS - SQL Server Ctrird
Male, Female arrf The Otfw One (NUU,..
JUkAr fW^-frt^FtrfKbrtOT „ тИВвиго». d
Jnttevkcsulis f cs 0>Vfc# tieu** 11 »
1
Чя*з
.ЦA
[Ш
j tocabon
,
OVER Clause <Transact-Sgt)
Trar*ar-SQL Refer, n <
f Ready
Рис. П1.21. Окно Search в Books Online
ПРИМЕЧАНИЕ
В заключение, прежде чем оставить вас наедине с вашими собственными исследо-
ваниями, позвольте дать вам последний совет. Если во время написания программ-
ного кода в SQL Server Management Studio вам нужны сведения о синтаксическом
элементе, убедитесь, что курсор находится в пределах кода с этим элементом, и за-
тем нажмите комбинацию клавиш <Shift>+<F1> Это приведет к загрузке Books
Online и открытию страницы с описанием синтаксиса данного элемента, конечно,
при условии, что такая страница существует в справочной системе.
ПРИЛОЖЕНИЕ 2
Решения к упражнениям
Это приложение содержит решения упражнений всех глав, сопровождающиеся пояснениями
в случае необходимости.
Упражнение 2.1
В качестве решения вы могли бы применить в вашем запросе функции YEAR И MONTH В эле-
менте WHERE следующим образом.
USE TSQLFundamentals2008;
SELECT orderid, orderdate, custid, empid
FROM Sales.Orders
WHERE YEAR(orderdate) = 2007 AND MONTH(orderdate) = 6;
Это корректное решение вернет правильный результат. Но я пояснял, что если обрабатывать
фильтруемый столбец, в большинстве случаев SQL Server не может эффективно использо-
вать индексы. Поэтому я советовал применять вместо этого фильтр диапазона.
SELECT orderid, orderdate, custid, empid
FROM Sales.Orders
WHERE orderdate >=
1
20070601'
AND orderdate < '20070701';
Упражнение 2.2 (дополнительное, повышенной сложности)
На страницах, посвященных обсуждению функций для обработки дат и времени суток, я
предложил для вычисления последнего дня месяца, соответствующего заданной дате, выра-
жение следующего формата:
DATEADD(month, DATEDIFF(month,
1
199912311
, date_val), '199912311)
Это выражение сначала вычисляет разность в месяцах между базовым последним днем не-
которого месяца (в нашем случае December 31, 1999 (31 декабря 1999 г.)) и заданной датой.
Назовите эту разность dif f. Добавляя dif f месяцев к базовой дате, вы получите последний
Приложение 2. Решения к упражнениям
389
день месяца заданной даты. Далее приведен полностью запрос, возвращающий только те
заказы, дата которых равна последнему дню месяца:
SELECT orderid, orderdate, custid, empid
FROM Sales.Orders
WHERE orderdate = DATEADD (month, DATEDIFF(month,
1
19991231', orderdate),
1
199912311);
Упражнение 2.3
Это упражнение включает сопоставление с шаблоном в предикате LIKE. Напоминаю, что
знак процента (%) обозначает символьную строку любой длины, включая пустую строку.
Следовательно, вы можете применить шаблон
1
%а%а%
1
для обозначения появления символа
'а' в любом месте строки, как минимум, дважды. Далее приведено решение полностью:
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname LIKE
,
%a%a%";
Упражнение 2.4
Это довольно сложное упражнение, и если вы сумели решить его правильно, можете собой
гордиться. Хитроумное требование в запросе могло быть не замечено или неверно интерпре-
тировано. Учтите, что в задаче было сказано "вернуть заказы с общей стоимостью, большей
чем 10 000", а не "вернуть заказы со стоимостью, большей чем 10 000". Другими словами,
отдельная строка с частью или отдельным компонентом заказа не должна удовлетворять за-
данному требованию. Ему должна удовлетворять группа всех компонентов заказа. Это означа-
ет, что в элементе WHERE запроса не должно быть фильтра, подобного следующему:
WHERE quantity * unitprice > 10000
В запросе следовало сгруппировать данные по ID заказа и включить фильтр в элемент
HAVING, например, так:
HAVING SUM(quantity*unitprice) > 10000
Далее приведено решение полностью:
SELECT orderid, SUM(qty*unitprice) AS totalvalue
FROM Sales.OrderDetails
GROUP BY orderid
HAVING SUM(qty*unitprice) > 10000
ORDER BY totalvalue DESC;
Упражнение 2.5
Поскольку задание касается деятельности в 2007 г., элемент запроса WHERE должен содержать
фильтр диапазона с подходящими датами (orderdate >=
1
200701011 AND orderdate <
1
20080101*)• Кроме того, задача включает средние стоимости перевозки, приходящиеся на
каждую страну доставки, и таблица может включать много строк для каждой страны доставки,
14 Зак. 1032
390
Приложения
поэтому запрос должен сгруппировать строки по странам и вычислить среднюю стоимость
перевозки. Для выбора трех стран с самыми высокими средними стоимостями перевозок сле-
дует задать в запросе элемент тор (3), основанный на логическом упорядочивании по убыва-
нию средних стоимостей перевозок. Далее приведено решение полностью:
SELECT TOP(3) shipcountry, AVG(freight) AS avgfreight
FROM Sales.Orders
WHERE orderdate >=
1
200701011 AND orderdate <
1
20080101'
GROUP BY shipcountry
ORDER BY avgfreight DESC;
Упражнение 2.6
Поскольку в упражнении требуется пронумеровать строки отдельно для каждого клиента,
выражение должно содержать PARTITION BY custid. Кроме того, требовалось упорядочи-
вание по orderdate (дата заказа) и orderid (id заказа) для связанных записей. Следова-
тельно, элемент OVER должен включать в себя ORDER BY orderdate, orderid. Далее
приведено решение полностью:
SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate, orderid) AS
rownum
FROM Sales.Orders
ORDER BY custid, rownum;
Упражнение 2.7
Вы можете описать условия, заданные в упражнении, с помощью выражения CASE. Приме-
нив простую форму выражения CASE, задайте атрибут titleofcourtesy (форма вежливого
обращения) сразу после ключевого слова CASE; перечислите все возможные варианты веж-
ливого обращения в отдельных элементах WHEN, за которыми следуют элементы THEN С ука-
занием пола; в ветви ELSE задайте 'Unknown' (неизвестен).
SELECT empid, firstname, lastname, titleofcourtesy,
CASE titleofcourtesy
WHEN 'Ms.' THEN 'Female'
WHEN 'Mrs.' THEN 'Female'
WHEN 'Mr.' THEN 'Male'
ELSE 'Unknown'
END AS gender
FROM HR.Employees;
Вы также можете использовать форму с поиском выражения CASE с двумя предикатами:
один обрабатывает все случаи, в которых пол женский (female), и другой — все случаи, в
которых пол мужской (male), и с элементом ELSE СО значением 'Unknown
1
(неизвестен).
SELECT empid, firstname, lastname, titleofcourtesy,
CASE
Приложение 2. Решения к упражнениям
391
WHEN titleofcourtesy IN(1Ms.
1
, 'M:
WHEN titleofcourtesy = 'Mr.
1
THEN
ELSE
'Mrs.') THEN 'Female'
'Male'
'Unknown'
END AS gender
FROM HR.Employees;
Упражнение 2.8
По умолчанию при сортировке SQL Server выводит значения NULL перед ненулевыми зна-
чениями. Для того чтобы выводить значения NULL последними, можно применить выраже-
ние CASE, возвращающее 1, если в столбце region (регион) содержится NULL, И 0 В против-
ном случае. Значения, не равные NULL, получат при выходе из выражения 0 и,
следовательно, при сортировке появятся перед значениями NULL (которые получат 1). Дан-
ное выражение CASE применяется как сортируемый столбец первого уровня. Столбец
region следует задать как сортируемый столбец второго уровня. В этом случае значения,
отличные от NULL, будут корректно отсортированы между собой. Далее приведено решение
полностью:
SELECT custid, region
FROM Sales.Customers
CASE WHEN region IS NULL THEN 1 ELSE 0 END, region;
Упражнение 3.2
Получить пять копий строки можно с помощью базового метода, использующего перекре-
стное соединение. Если вам нужно создать пять копий для каждой строки о сотруднике, не-
обходимо выполнить перекрестное соединение таблицы Employees (Сотрудники) и табли-
цы, в которой пять строк, или же можно выполнить перекрестное соединение таблицы
Employees с таблицей, содержащей более пяти строк, но в элементе WHERE отобрать из этой
таблицы только пять. Для этой цели очень удобна таблица Nums. Просто выполните пере-
крестное соединение Employees и Nums и отберите из таблицы Nums количество строк, рав-
ное числу запрашиваемых копий (в данном случае пять). Далее приведено решение полно-
стью:
•SELECT Е.empid, E.FirstName, E.LastName, Nums.n
FROM HR.Employees AS E
CROSS JOIN dbo.Nums
WHERE Nums.n <= 5
ORDER BY n, empid;
Упражнение 3.3
Это упражнение— расширение предыдущего. Вместо задания сформировать заранее опре-
деленное количество копий каждой строки с данными о сотруднике вас просят создать ко-
пию строки для каждого дня из определенного диапазона дат. Следовательно, вы должны
вместо ссылки на константу вычислить с помощью функции DATEDIFF количество дней в
ORDER BY
392
Приложения
запрашиваемом диапазоне дат и сослаться на результат этого вычисления в элементе запро-
са WHERE. Для формирования дат просто добавьте п- 1 дней к начальной дате заданного
диапазона. Далее приведено решение полностью:
SELECT Е.empid,
DATEADD(day, D.n - 1, '20090612') AS dt
FROM HR.Employees AS E
CROSS JOIN dbo.Nums AS D
WHERE D.n <= DATEDIFF(day, '20090612', '20090616') + 1
ORDER BY empid, dt;
Функция DATEDIFF возвращает 4 дня, потому что между June 12, 2009 (12 июня 2009 г.) и
June 16, 2009 (16 июня 2009 г.) четырехдневная разница. Добавьте к результату 1, и вы по-
лучите 5 для обозначения пяти дней диапазона. Таким образом, элемент WHERE отбирает из
таблицы Nums пять строк, в которых п меньше или равно 5. Добавляя п - 1 день к дате June
12, 2009, вы получите все даты из диапазона June 12, 2009, June 16, 2009.
Упражнение 3.4
В этом упражнении требуется написать запрос, который соединяет три таблицы: Customers
(Клиенты), Orders (Заказы) и OrderDetails (Сведения о заказе). Запрос должен отобрать
в элементе WHERE только те строки, у которых страна клиента — USA (США). Поскольку
вас просят вернуть для каждого клиента итоговые значения, в запросе следует сгруппиро-
вать строки по идентификаторам клиентов. В этом упражнении для того чтобы вернуть вер-
ное количество заказов для каждого клиента, вам нужно решить хитрую задачу. В результа-
те соединения таблиц Orders и OrderDetails вы не получаете одну строку для каждого
заказа — вы получаете по строке на каждый товар из заказа. Поэтому, если использовать
функцию COUNT (*) в списке инструкции SELECT, ВЫ получите количество строк в заказах
каждого клиента, а не количество заказов. Для решения этой проблемы необходимо учиты-
вать каждый заказ лишь один раз. Сделать это можно, применив выражение
COUNT (DISTINCT о. orderid) вместо COUNT (*). Общие объемы не создают особых про-
блем, т. к. объем связан с отдельной строкой заказа, а не с заказом в целом. Далее приведено
решение:
SELECT С.custid, COUNT(DISTINCT О.orderid) AS numorders, SUM(OD.qty)
AS totalqty
FROM Sales.Customers AS С
JOIN Sales.Orders AS О
ON O.custid = C.custid
JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid
WHERE C.country = N'USA'
GROUP BY C.custid;
Упражнение 3.5
Для получения в результирующем наборе клиентов, сделавших заказ, и клиентов, не помес-
тивших ни одного заказа, необходимо применить внешнее соединение следующим образом:
Приложение 2. Решения к упражнениям
393
SELECT С.custid, С.companyname, О.orderid, О.orderdate
FROM Sales.Customers AS С
LEFT JOIN Sales.Orders AS О
ON O.custid = C.custid;
Этот запрос вернет 832 строки (включая клиентов 22 и 57, не сделавших ни одного заказа).
Внутреннее соединение таблиц вернуло бы только 830 строк без упомянутых клиентов.
Упражнение 3.6
Это упражнение расширение предыдущего. Для того чтобы выбрать клиентов, не сделавших
ни одного заказа, вы должны вставить в запрос элемент WHERE, который отбирает только
внешние строки, а именно строки, представляющие клиентов без заказов. У внешних строк
в атрибутах несохраняемой таблицы соединения (Orders) значения NULL. НО ДЛЯ ТОГО что-
бы быть уверенным в том, что значение NULL— это заполнитель во внешней строке, а не
значение NULL, взятое из исходной таблицы, рекомендуется ссылаться на атрибут, служа-
щий первичным ключом или столбцом, по которому выполняется соединение, или являю-
щийся столбцом, в котором не допускаются значения NULL. Далее приведено решение со
ссылкой в элементе WHERE на первичный ключ таблицы Orders:
SELECT С.cus tid, С.companyname
FROM Sales.Customers AS С
LEFT JOIN Sales.Orders AS О
ON O.custid = C.custid
WHERE O.orderid IS NULL;
Этот запрос возвращает только две строки с клиентами 22 и 57, которые не сделали ни од-
ного заказа.
Упражнение 3.7
Решение этого упражнения включает в себя запрос, выполняющий внутреннее соединение
таблиц Customers и Orders и отбирающий только те строки, в которых дата заказа Febru-
ary 12, 2007.
SELECT С.custid, С.companyname, О.orderid, О.orderdate
FROM Sales.Customers AS С
JOIN Sales.Orders AS О
ON O.custid = C.custid
WHERE 0.orderdate =
,
20070212l;
Элемент WHERE отбрасывает клиентов, не сделавших заказ February 12, 2007 (12 февраля
2007 г.), но таково было задание.
Упражнение 3.8 (дополнительное, повышенной сложности)
Это упражнение базируется на предыдущем. В нем есть две хитрости. Во-первых, вам пона-
добится внешнее соединение, т. к. предполагается, что вы выберете клиентов, не удовлетво-
394
Приложения
ряющих определенным критериям. Во-вторых, фильтр для даты заказа нужно вставить в
элемент ON, а не в элемент WHERE. Напоминаю, что фильтр элемента WHERE применяется
после того, как добавлены внешние строки, и определяет окончательный отбор. Ваша задача
сопоставить заказы и клиентов, только если клиент сделал заказ и дата заказа — February 12,
2007. Кроме того, вы хотите включить в результирующий набор клиентов, не сделавших
заказ в указанный день; другими словами, фильтр по дате заказа должен только устанавли-
вать соответствия и не должен рассматриваться как определяющий по отношению к строкам
клиентов. Следовательно, в элементе ON нужно сопоставить клиентов и заказы, основываясь
как на равенстве ID клиента из таблицы Customers и ID клиента из таблицы Orders, так и
на дате заказа, равной February 12,2007. Далее приведено решение:
SELECT С.custid, С.companyname, О.orderid, О.orderdate
FROM Sales.Customers AS С
LEFT JOIN Sales.Orders AS О
ON O.custid = C.custid
AND O.orderdate = '20070212*;
Упражнение 3.9 (дополнительное, повышенной сложности)
Это упражнение — расширение предыдущего. Здесь вместо отбора соответствующих зака-
зов вам нужно вернуть значение Yes/No (Да/Нет), указывающее на соответствие или несоот-
ветствие заказа и клиента. Напоминаю, что во внешнем соединении несоответствие опреде-
ляется как внешняя строка со значениями NULL в атрибутах несохраняемой таблицы.
Поэтому можно применить простую форму выражения CASE, которое проверяет, является
ли текущая строка внешней, и в случае утвердительного ответа возвращает Yes, а в против-
ном случае — No. Поскольку формально у вас на одного клиента приходится несколько со-
ответствий, следует вставить в список инструкции SELECT элемент DISTINCT. В этом слу-
чае вы получите в результирующем наборе только одну строку для каждого клиента. Далее
приведено решение:
SELECT DISTINCT С.custid, С.companyname,
CASE WHEN О.orderid IS NOT NULL THEN 'Yes
1
ELSE 'No* END AS
[HasOrderOn20070212]
FROM Sales.Customers AS С
LEFT JOIN Sales.Orders AS О
ON O.custid = C.custid
AND O.orderdate = '20070212';
Упражнение 4.1
Вы можете написать независимый подзапрос, который возвращает максимальную дату зака-
за из таблицы Orders (Заказы). В элементе WHERE внешнего запроса можно сослаться на
подзапрос для того, чтобы вернуть все заказы, сделанные в последний день деловой актив-
ности. Далее приведено решение:
USE TSQLFundamentals2 008;
SELECT orderid, orderdate, custid, empid
Приложение 2. Решения к упражнениям
395
FROM Sales.Orders
WHERE orderdate =
(SELECT MAX(О.orderdate) FROM Sales.Orders AS O);
Упражнение 4.2
Эту задачу лучше всего решать в несколько этапов. Сначала можно написать запрос, кото-
рый вернет клиента или клиентов, сделавших максимальное количество заказов. Сделать это
можно с помощью группировки заказов по клиентам, упорядочивания клиентов COUNT (*)
по убыванию и применения элемента TOP(l) WITH TIES ДЛЯ получения идентификаторов
клиентов, сделавших максимальное число заказов. Если вы не помните, как применять не-
обязательный элемент ТОР, см. главу 2. Далее приведен запрос для выполнения первого эта-
па решения:
SELECT TOP (1) WITH TIES О.custid
FROM Sales.Orders AS О
GROUP BY O.custid
ORDER BY COUNT(*) DESC;
Этот запрос вернет значение 71. Это ID клиента, сделавшего максимальное количество зака-
зов, которое равно 31. В данных, хранящихся в таблице Orders, есть только один клиент,
поместивший максимальное количество заказов. Но в запросе применяется вариант WITH
TIES для того, чтобы вернуть все ID клиентов, сделавших максимальное количество зака-
зов, на случай, если их несколько.
Следующий этап— написание запроса к таблице Orders, возвращающего все заказы, у ко-
торых ID клиента входит в множество идентификаторов клиента, полученное в результате
выполнения запроса, сформированного на первом этапе.
SELECT custid, orderid, orderdate, empid
FROM Sales.Orders
WHERE custid IN
(SELECT TOP (1) WITH TIES O.custid
FROM Sales.Orders AS О
GROUP BY O.custid
ORDER BY COUNT(*) DESC);
Упражнение 4.3
Вы можете написать независимый подзапрос к таблице orders (Заказы), который отбирает
заказы, помещенные в день May 1, 2008 (1 мая 2008 г.) или после него, и возвращает только
ID сотрудников из строк этих заказов. Напишите внешний запрос к таблице Employees (Со-
трудники), который возвращает сведения о сотрудниках, чьи идентификаторы включены в
множество ID сотрудников, возвращенное подзапросом. Далее приведено решение полно-
стью:
SELECT empid, FirstName, lastname
FROM HR.Employees
396
Приложения
WHERE empid NOT IN
(SELECT O.empid
FROM Sales.Orders AS О
WHERE 0.orderdate >= '20080501');
Упражнение 4.4
Вы можете написать независимый подзапрос к таблице Employees (Сотрудники), возвра-
щающий атрибут country (страна) из каждой строки. Напишите внешний запрос к таблице
Customers (Клиенты), который отбирает только строки клиентов со значением атрибута
country, не вошедшем в множество стран, возвращенное подзапросом. В списке SELECT
внешнего запроса задайте DISTINCT country, чтобы вернуть только названия разных
стран, т. к. у нескольких строк может быть одна и та же страна. Далее приведено решение
полностью:
SELECT DISTINCT country
FROM Sales.Customers
WHERE country NOT IN
(SELECT E.country FROM HR.Employees AS E);
Упражнение 4.5
Это упражнение аналогично упражнению 4.1, за исключением того, что в том упражнении
нужно было вернуть заказы, сделанные в последний день общей деловой активности, а в
этом упражнении вас просят вернуть заказы, помещенные в последний день деловой актив-
ности клиента. Решения у обоих упражнений похожи, но здесь вам нужно связать подза-
прос, сопоставляя внутренний ID клиента с внешним ID клиента следующим образом:
SELECT custid, orderid, orderdate, empid
FROM Sales.Orders AS 01
WHERE orderdate =
(SELECT MAX(02.orderdate)
FROM Sales.Orders AS 02
WHERE 02.custid = 01.custid)
ORDER BY custid;
Вы сравниваете дату заказа из внешней строки не с общей максимальной датой заказа, а с
датой заказа, максимальной для текущего клиента.
Упражнение 4.6
Вы можете решить эту задачу, запросив таблицу Customers (Клиенты) и применив преди-
каты EXISTS и NOT EXISTS вместе со связанными подзапросами для того, чтобы убедиться
в том, что клиент делал заказы в 2007 г., но не в 2008 г. Предикат EXISTS вернет TRUE,
только если в таблице Orders в диапазоне дат, представляющем 2007 г., существует хотя бы
одна строка с таким же ID клиента, как во внешней строке. Предикат NOT EXISTS вернет
Приложение 2. Решения к упражнениям
397
TRUE, только если в таблице Orders в диапазоне дат, представляющем 2008 г., нет ни одной
строки с таким же ID клиента, как и во внешней строке. Далее приведено полное решение:
SELECT custid, companyname
FROM Sales. Customers AS С
WHERE EXISTS
(SELECT *
FROM Sales.Orders AS О
WHERE O.custid = C.custid
AND O.orderdate >= '20070101'
AND O.orderdate < '20080101')
AND NOT EXISTS
(SELECT *
FROM Sales.Orders AS О
WHERE O.custid = C.custid
AND O.orderdate >= '20080101'
AND O.orderdate < '20090101');
Упражнение 4.7
Вы сможете решить это упражнение с помощью вложения предикатов EXISTS СО связанными
подзапросами. Внешний запрос пишется к таблице Customers (Клиенты). В элементе WHERE
внешнего запроса для выбора заказов только текущего клиента можно применить предикат
EXISTS со связанным подзапросом к таблице Orders (заказы). В фильтре подзапроса к таблице
Orders можно использовать вложенный предикат EXISTS С подзапросом к таблице
OrderDetails (Сведения о заказе), выбирающим сведения только о заказах, содержащих товар с
ID, равным 12. В этом случае в результирующий набор попадут только те клиенты, кто сделал
заказы, содержащие в своих сведениях о заказе товар 12. Далее приведено полное решение:
SELECT custid, companyname
FROM Sales.Customers AS С
WHERE EXISTS
(SELECT *
FROM Sales.Orders AS О
WHERE O.custid = C.custid
AND EXISTS
(SELECT *
FROM Sales.OrderDetails AS OD
WHERE OD.orderid = O.orderid
AND OD.ProductID = 12));
Упражнение 4.8
При решении задач, связанных с запросами, мне часто помогает перефразирование задания
в более формальном виде, так чтобы его было удобнее преобразовать в запрос на языке
T-SQL. Для решения данного упражнения можно сначала попытаться выразить иначе, в более
398
Приложения
формальном виде, задание "вернуть для каждого клиента общий ежемесячный объем зака-
зов с накоплением Для каждого клиента вернуть ID клиента, месяц, сумму объемов зака-
зов за данный месяц и сумму объемов за все месяцы, предшествующие или равные текуще-
му. Перефразированный запрос можно перевести на язык T-SQL практически буквально:
SELECT custid, ordermonth, qty,
(SELECT SUM(02.qty)
FROM Sales.CustOrders AS 02
WHERE 02.custid = 01.custid
AND 02.ordermonth <= 01.ordermonth) AS runqty
FROM Sales.CustOrders AS 01
ORDER BY custid, ordermonth;
Упражнение 5.1
Данное упражнение — просто подготовительный этап для решения следующего упражне-
ния. Этот этап включает написание запроса, возвращающего максимальную дату заказа для
каждого сотрудника:
USE TSQLFundamentа1s2008;
SELECT empid, MAX(orderdate) AS maxorderdate
FROM Sales.Orders
GROUP BY empid;
Упражнение 5.2
В этом упражнении требуется использовать запрос из предыдущего упражнения для опреде-
ления производной таблицы и последующего ее соединения с таблицей orders (Заказы),
чтобы найти заказы с максимальной датой заказа для каждого сотрудника.
SELECT О.empid, О.orderdate, О.orderid, О.custid
FROM Sales.Orders AS О
JOIN (SELECT empid, MAX (orderdate) AS maxorderdate
FROM Sales.Orders
GROUP BY empid) AS D
ON O.empid = D.empid
AND O.orderdate = D. maxorderdate;
Упражнение 5.3
Это упражнение — подготовительный этап для следующего упражнения. В нем требуется
запросить таблицу Orders (Заказы) и вычислить номера строк, исходя из упорядочивания
по атрибутам orderdate (дата заказа), orderid (id заказа), следующим образом:
SELECT orderid, orderdate, custid, empid,
ROW_NUMBER() OVER(ORDER BY orderdate, orderid) AS rownum
FROM Sales.Orders;
Приложение 2. Решения к упражнениям
399
Упражнение 5.4
В этом упражнении требуется определить ОТВ, базирующееся на запросе из предыдущего
упражнения, и отобрать из ОТВ только строки с номерами из диапазона 11—20 следующим
образом:
WITH OrdersRN AS
(
SELECT orderid, orderdate, custid, empid,
ROW_NUMBER() OVER(ORDER BY orderdate, orderid) AS rownum
FROM Sales.Orders
)
SELECT * FROM OrdersRN WHERE rownum BETWEEN 11 AND 20;
Вас, возможно, удивит применение табличного выражения в данном упражнении. Напоми-
наю, что вычисления, основанные на элементе OVER (например, функция ROW__NUMBER), раз-
решены только в элементах запроса SELECT И ORDER BY И запрещены непосредственно в
элементе WHERE. Применяя табличное выражение, вы можете выполнить функцию
ROW NUMBER в элементе SELECT, присвоить псевдоним результирующему столбцу и со-
слаться на него в элементе WHERE внешнего запроса.
Упражнение 5.5
Это упражнение можно рассматривать, как задание, обратное требованию вернуть сотруд-
ника и всех его подчиненных на всех уровнях. В данном упражнении фиксированный ком-
понент — это запрос, возвращающий строку с сотрудником 9. Рекурсивный компонент со-
единяет ОТВ (назовем его С), предоставляющее подчиненного/потомка с предыдущего
уровня, с таблицей Employees (назовем ее Р), предоставляющей руководителя/предка на
следующем уровне. В этом случае каждый запуск рекурсивного компонента возвращает
руководителя следующего уровня до тех пор, пока не окажется руководителя на следующем
уровне (в случае руководителя высшего ранга).
Далее приведено полное решение:
WITH EmpsCTE AS
(
SELECT empid, mgrid, firstname, lastname
FROM HR.Employees
WHERE empid = 9
UNION ALL
SELECT P.empid, P.mgrid, P.firstname, P.lastname
FROM EmpsCTE AS С
JOIN HR.Employees AS P
ON C.mgrid = P.empid
)
SELECT empid, mgrid, firstname, lastname
FROM EmpsCTE;
400
Приложения
Упражнение 5.6
Это упражнение— подготовительный этап для решения следующего упражнения. Здесь
требуется определить представление, основанное на запросе, который соединяет таблицы
Orders (Заказы) и OrderDetails (Сведения о заказе), группирует строки по ID сотрудника
и году заказа и возвращает общий объем заказов для каждой группы. Определение пред-
ставления должно выглядеть следующим образом:
USE TSQLFundamentals2008;
IF OBJECT_ID('Sales.VEmpOrders') IS NOT NULL
DROP VIEW Sales.VEmpOrders;
GO
CREATE VIEW Sales.VEmpOrders
AS
SELECT
empid,
YEAR(orderdate) AS orderyear,
SUM(qty) AS qty
FROM Sales.Orders AS О
JOIN Sales.OrderDetails AS OD
ON O.orderid = OD.orderid
GROUP BY
empid,
YEAR(orderdate);
GO
Упражнение 5.7 (дополнительное, повышенной сложности)
В этом упражнении вы запрашиваете представление VEmpOrders и возвращаете общий объ-
ем с накоплением для каждого сотрудника и каждого года заказов. Для получения этого ре-
зультата можно написать запрос к представлению VEmpOrders (назовем его VI), который
вернет из каждой строки ID сотрудника, года заказа и объем. В список SELECT вы можете
вставить подзапрос ко второму экземпляру представления VEmpOrders (назовем его V2),
возвращающий сумму всех объемов из строк, в которых ID сотрудника равен значению это-
го атрибута в VI и год заказа меньше или равен году заказа из VI. Полное решение выглядит
следующим образом:
SELECT empid, orderyear, qty,
(SELECT SUM(qty)
FROM Sales.VEmpOrders AS V2
WHERE V2.empid = Vl.empid
AND V2.orderyear <= VI.orderyear) AS runqty
FROM Sales.VEmpOrders AS Vl
ORDER BY empid, orderyear;
Приложение 2. Решения к упражнениям
401
Упражнение 5.8
В этом упражнении требуется определить функцию fn_TopProducts, которая принимает
ID поставщика (@supid) и число (@п) и должна вернуть @п самых дорогих товаров, предо-
ставленных поставщиком с заданным на входе ID. Далее показано, как должно выглядеть
определение функции:
USE TSQLFundamentals2008;
IF OBJECT_ID(' Production.fn_TopProducts') IS NOT NULL
DROP FUNCTION Production.fn_TopProducts;
GO
CREATE FUNCTION Production.fn_TopProducts
(@supid AS INT, @n AS INT)
RETURNS TABLE
AS
RETURN
SELECT TOP(@n) productid, productname, unitprice
FROM Production.Products
WHERE supplierid = @supid
ORDER BY unitprice DESC;
GO
Упражнение 5.9
В этом упражнении вы пишете запрос к таблице Production.Suppliers (Поставщики) и
используете операцию CROSS APPLY для применения к каждому поставщику функции,
определенной вами в предыдущем упражнении. Предполагается, что ваш запрос вернет два
самых дорогих товара для каждого поставщика. Далее приведено решение:
SELECT S.supplierid, S.companyname, P.productid, P.productname,
P.unitprice
FROM Production.Suppliers AS S
CROSS APPLY Production.fn_TopProducts(S.supplierid, 2) AS P;
Упражнение 6.1
В языке T-SQL применяется инструкция SELECT, основанная на константах и не содержа-
щая элемента FROM. Такая инструкция SELECT возвращает таблицу из одной строки. Напри-
мер, следующая инструкция вернет строку с одним столбцом, названным п и равным I.
SELECT 1 AS n;
Результат выполнения инструкции таков:
П
1
(1 row(s) affected)
402
Приложения
Используя операцию над множествами UNION ALL, можно объединить результирующие
наборы нескольких таких инструкций, каждая из которых возвращает строку с одним чис-
лом из диапазона 1—- 10.
SELECT 1 AS n
UNION ALL SELECT 2
UNION ALL SELECT 3
UNION ALL SELECT 4
UNION ALL SELECT 5
UNION ALL SELECT 6
UNION ALL SELECT 7
UNION ALL SELECT 8
UNION ALL SELECT 9
UNION ALL SELECT 10;
ПРИМЕЧАНИЕ
Между прочим, в SQL Server 2008 усовершенствован элемент VALUES, с которым
вы, возможно, встречались при работе с инструкцией INSERT. Теперь вместо
представления одной строки один элемент VALUES может представлять множест-
венные строки. И, кроме того, вместо применения только в инструкциях INSERT
теперь он может использоваться для определения табличного выражения со
строками, состоящими из констант. Например, для решения этого упражнения вы
можете вместо применения операций над множествами использовать элемент
VALUES следующим образом:
SELECT П
FROM (VALUES(1),(2),(3),(4),(5),(6),(7) ,(8),(9)f (10)) AS Nums(n);
Подробно элемент VALUES и конструкторы строк рассмотрены в главе 8, посвя-
щенной инструкции INSERT.
Упражнение 6.2
Вы можете решить эту задачу, применив операцию над множествами EXCEPT. Слева, на вхо-
де, — запрос, который возвращает пары из клиента и сотрудника, оформлявших заказы в ян-
варе 2008 г. (January 2008). Справа, на входе, — запрос, возвращающий пары из клиента и со-
трудника, оформлявших заказы в феврале 2008 г. (February 2008). Далее приведено решение:
USE TSQLFundamentals2008;
SELECT custid, empid
FROM Sales.Orders
WHERE orderdate >=
1
200801011 AND orderdate <
1
20080201'
EXCEPT
SELECT custid, empid
FROM Sales.Orders
WHERE orderdate >= '20080201' AND orderdate <-'20080301';
Приложение 2. Решения к упражнениям
403
Упражнение 6.3
В упражнении 6.2 требуются пары из клиента и сотрудника, оформлявших заказы в течение
одного периода и не оформлявших их в течение другого периода, а в этом упражнении вы-
бираются пары из клиента и сотрудника, которые оформляли заказы в течение обоих перио-
дов. Поэтому на сей раз вместо операции EXCEPT ВЫ должны применить операцию над
множествами INTERSECT:
SELECT custid, empid
FROM Sales.Orders
WHERE orderdate >=
1
200801011 AND orderdate < '20080201'
INTERSECT
SELECT custid, empid
FROM Sales.Orders
WHERE orderdate >= '20080201' AND orderdate < '20080301';
Упражнение 6.4
В этом упражнении вам придется комбинировать операции над множествами. Для того что-
бы отобрать пары, оформлявшие заказы в январе 2008 г. (January 2008) и феврале 2008 г.
(February 2008), следует применить операцию над множествами INTERSECT, как в упражне-
нии 3. Для исключения из результата пар, состоящих из клиента и сотрудника и оформляв-
ших заказы в 2007 г., нужно применить операцию EXCEPT К результату и третьему запросу.
Решение выглядит следующим образом:
SELECT custid, empid
FROM Sales.Orders
WHERE orderdate >= '20080101' AND orderdate < '20080201'
INTERSECT
SELECT custid, empid
FROM Sales.Orders
WHERE orderdate >= '20080201' AND orderdate < '20080301'
EXCEPT
SELECT custid, empid
FROM Sales.Orders
WHERE orderdate >= '20070101' AND orderdate < '20080101';
He забывайте о том, что у операции INTERSECT более высокий приоритет, чем у операции
EXCEPT. В нашем случае стандартный порядок выполнения операций— именно то, что
нужно, поэтому нет нужды вмешиваться и применять скобки.
404
Приложения
Но вы можете добавить их для большей ясности:
(SELECT custid, empid
FROM Sales.Orders
WHERE orderdate >=
1
200801011 AND orderdate <
1
200802011
INTERSECT
SELECT custid, empid
FROM Sales.Orders
WHERE orderdate >=
1
200802011 AND orderdate <
1
20080301')
EXCEPT
SELECT custid, empid
FROM Sales.Orders
WHERE orderdate >= '20070101' AND orderdate < '20080101';
Упражнение 6.5
(дополнительное, повышенной сложности)
В этом упражнении проблема в том, что входные запросы не могут содержать элемент
ORDER BY и не без оснований. Проблему можно решить, если в каждый запрос, участвую-
щий в операции над множествами, добавить результирующий столбец, содержащий кон-
станту (назовем его sorted). В запросе к таблице Employees (Сотрудники) задайте мень-
шую константу, чем в запросе к таблице Suppliers (Поставщики). Определите табличное
выражение, основанное на запросе с операцией над множествами, и в элементе ORDER BY
внешнего запроса задайте sorted как первый столбец, за которым следуют country,
region и city. Далее приведено полное решение:
SELECT country, region, city
FROM (SELECT 1 AS sorted, country, region, city
FROM HR.Employees
UNION ALL
SELECT 2, country, region, city
FROM Production.Suppliers) AS D
ORDER BY sorted, country, region, city;
Упражнение 7.1
Решение задачи разворачивания данных состоит в задании элементов, участвующих в про-
цессе: группирующего элемента, разворачиваемого элемента, итогового или сводного эле-
мента и агрегирующей функции. После того как все элементы обозначены, вы просто встав-
Приложение 2. Решения к упражнениям
405
ляете их в "шаблон" запроса для разворачивания, будь то стандартное решение или решение
с применением собственной операции языка T-SQL PIVOT.
В этом упражнении группирующий элемент— сотрудник (empid), разворачиваемый эле-
мент— год заказа (YEAR(orderdate)) и агрегирующая функция COUNT; но выбор итогово-
го элемента не очевиден. Вы хотите с помощью функции COUNT сосчитать сопоставимые
строки и заказы, вам неважно, какой атрибут она будет считать. Другими словами, можно
использовать любой понравившийся вам атрибут, если только он не допускает значения
NULL, потому что агрегирующие функции игнорируют значения NULL И подсчет атрибута,
допускающего значения NULL, даст в результате неверное количество заказов.
Если действительно не имеет значения, какой атрибут вы применяете как входной параметр
функции COUNT, почему не использовать тот же атрибут, который вы уже применили как
разворачиваемый элемент? В нашем случае можно использовать год заказа и как разворачи-
ваемый, и как итоговый элемент.
Теперь, когда все элементы разворачивания данных определены, вы готовы к написанию
полного решения. Далее приведено решение без использования операции PIVOT:
USE tempdb;
SELECT empid,
COUNT(CASE WHEN orderyear = 2007 THEN orderyear END) AS cnt2007,
COUNT(CASE WHEN orderyear = 2008 THEN orderyear END) AS cnt2008,
COUNT(CASE WHEN orderyear = 2009 THEN orderyear END) AS cnt2009
FROM (SELECT empid, YEAR(orderdate) AS orderyear
FROM dbo.Orders) AS D
GROUP BY empid;
Напоминаю, что если вы не задаете в выражении CASE ветвь ELSE, неявно предполагается
вариант ELSE NULL. Таким образом, выражение CASE формирует значения, отличные от
NULL, только для соответствующих заказов (заказов, помещенных текущим сотрудником в
текущем году заказа), и только эти заказы учитываются итоговой функцией COUNT.
Учтите, что хотя стандартное решение не требует применения табличного выражения, я ис-
пользовал его в своем решении для того, чтобы присвоить псевдоним выражению
YEAR (orderdate) и избежать повторения этого выражения несколько раз в выходном за-
просе.
Далее приведено решение с применением операции PIVOT:
SELECT empid, [2007] AS cnt2007, [2008] AS cnt2008, [2009] AS cnt2009
FROM (SELECT empid, YEAR(orderdate) AS orderyear
FROM dbo.Orders) AS D
PIVOT(COUNT(orderyear)
FOR orderyear IN([2007], [2008], [2009])) AS P;
Как видите, главное — поместить элементы разворачивания в нужные места.
Если вы предпочитаете использовать свои имена результирующих столбцов, а не имена,
основанные на реальных данных, конечно, можно указать собственные псевдонимы в спи-
ске SELECT. Я присвоил результирующим столбцам [2007], [2008] и [2009] следующие
псевдонимы: cnt2007, cnt2008 и cnt2009 соответственно.
406
Приложения
Упражнение 7.2
Это упражнение содержит запрос на сворачивание исходных столбцов cnt2007, cnt2008 и
cnt2009 в два результирующих столбца: orderyear (год заказа) для хранения года, кото-
рый представлен именем исходного столбца, и numorders (количество заказов) для хране-
ния значения исходного столбца. Для решения этой задачи можно использовать варианты,
уже приведенные мною в данной главе, внеся в них пару незначительных изменений.
В примерах этой главы значения NULL в таблице обозначали несущественные значения в
столбце. В примерах сворачивания данных, которые я предложил, строки со значениями
NULL отбрасывались. В таблице EmpYearOrders нет значений NULL, но иногда встречаются
нули, и запрос должен избавиться от строк с нулевым количеством заказов. В случае стан-
дартного решения просто примените предикат numorders о 0 вместо использования вы-
ражения is NOT NULL. Далее приведена версия с применением элемента VALUES, соответ-
ствующим версии SQL Server 2008:
SELECT *
FROM (SELECT empid, orderyear,
CASE orderyear
WHEN 2007 THEN cnt2007
WHEN 2008 THEN cnt2008
WHEN 2009 THEN cnt2009
END AS numorders
FROM dbo.EmpYearOrders
CROSS JOIN (VALUES(2007), (2008), (2009)) AS Years (orderyear))
ASD
WHERE numorders <> 0;
А это версия на языке T-SQL, не использующая операцию UNPIVOT:
SELECT *
FROM (SELECT empid, orderyear,
CASE orderyear
WHEN 2007 THEN cnt2007
WHEN 2008 THEN cnt2008
WHEN 2009 THEN cnt2009
END AS numorders
FROM dbo.EmpYearOrders
CROSS JOIN (SELECT 2007 AS orderyear
UNION ALL SELECT 2008
UNION ALL SELECT 2009) AS Years) AS D
WHERE numorders <> 0;
Что касается решения с применением собственной операции языка T-SQL UNPIVOT, соот-
ветствующим версии SQL Server 2005, помните о том, что она исключает значения NULL, и
это встроенная часть ее логической реализации.
Приложение 2. Решения к упражнениям
407
Но эта операция не удаляет нули, об их устранении вы должны позаботиться самостоятель-
но, добавив элемент WHERE, подобный следующему:
SELECT ernpid, CAST (RIGHT (orderyear, 4) AS INT) AS orderyear, numorders
FROM dbo.EmpYearOrders
UNPIVOT(numorders FOR orderyear IN(cnt2007, cnt2008, cnt2009)) AS U
WHERE numorders <> 0;
Обратите внимание на выражение, используемое в списке SELECT ДЛЯ формирования ре-
зультирующего столбца orderyear: CAST (RIGHT (orderyear, 4) AS INT). Исходные
имена сворачиваемых в этом запросе столбцов— cnt2007, cnt2008 и cnt2009. Они пре-
вращаются в значения
,
cnt2007l
, 'cnt2008' и
,
cnt2009' соответственно в столбце
orderyear результата операции UNPIVOT. Назначение данного выражения— извлечение
четырех крайних правых символов, представляющих год заказа, и преобразование их в це-
лое число. Стандартному решению не требуется подобное преобразование, т. к. для форми-
рования табличного выражения Years (Годы) применялись константы, с самого начала за-
данные как целые числа.
Упражнение 7.3
Если вы поняли идею наборов группирования, это упражнение вам будет выполнить просто.
Можно применить вложенный элемент GROUPING SETS ДЛЯ перечисления требуемых набо-
ров группирования и функцию GROUPING__ID ДЛЯ создания уникального идентификатора для
набора группирования, связанного с каждой строкой. Далее приведено решение полностью:
SELECT
GROUPING_ID(empid, custid, YEAR(Orderdate)) AS groupingset,
empid, custid, YEAR(Orderdate) AS orderyear, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY
GROUPING SETS
(
(empid, custid, YEAR(orderdate)),
(empid, YEAR(orderdate)),
(custid, YEAR(orderdate))
);
Требуемые наборы группирования не являются ни множеством-степенью, ни сверткой
(rollup) некоторого множества атрибутов. Следовательно, для дальнейшего сокращения про-
граммного кода вы не можете использовать ни вложенный элемент CUBE, НИ вложенный
элемент ROLLUP.
Упражнение 8.2
Убедитесь, что вы подключились к базе данных tempdb.
USE tempdb;
408
Приложения
Для вставки в таблицу Customers (Клиенты) строки со значениями атрибутов, предложен-
ными в упражнении, примените следующую инструкцию INSERT VALUES:
INSERT INTO dbo.Customers(custid, companyname, country, region, city)
VALUES(100, N'Company ABCDE', N'USA', N'WA
1
,N
1
Redmond
1
);
Упражнение 8.3
Один из способов идентификации клиентов, сделавших заказы, — использование предиката
EXISTS, как показано в следующем запросе:
SELECT custid, companyname, country, region, city
FROM TSQLFundamentals2008.Sales.Customers AS С
WHERE EXISTS
(SELECT * FROM TSQLFundamentals2008.Sales.Orders AS О
WHERE O.custid = C.custid);
Для вставки в таблицу Customers (Клиенты) базы данных tempdb строк, возвращенных
этим запросом, можно применить инструкцию INSERT SELECT следующим образом:
INSERT INTO dbo.Customers(custid, companyname, country, region, city)
SELECT custid, companyname, country, region, city
FROM TSQLFundamentals2008.Sales.Customers AS С
WHERE EXISTS
(SELECT * FROM TSQLFundamentals2008.Sales.Orders AS О
WHERE O.custid = C.custid);
Упражнение 8.4
В следующем программном коде сначала проверяется наличие подключения к базе данных
tempdb, затем, если таблица Orders (Заказы) уже существует, она удаляется, и далее для
создания новой таблицы Orders и заполнения ее заказами из базы данных TSQLFundamen-
tals2008, сделанными в течение 2006—2008 гг., применяется инструкция SELECT INTO.
USE tempdb;
IF OBJECT_ID('dbo.Orders',
?
U') IS NOT NULL DROP TABLE dbo.Orders;
SELECT *
INTO dbo.Orders
FROM TSQLFundamentals2008.Sales.Orders
WHERE orderdate >= '20060101'
AND orderdate <
1
20090101';
Упражнение 8.5
Для удаления заказов, помещенных до августа 2006 г., вам понадобится инструкция DELETE
с фильтром на основе предиката orderdate < '200608011
.
Приложение 2. Решения к упражнениям
409
Для получения в соответствии с заданием значений атрибутов удаленных строк используйте
элемент OUTPUT.
DELETE FROM dbo.Orders
OUTPUT deleted.orderid, deleted.orderdate
WHERE orderdate < '20060801';
Упражнение 8.6
В этом упражнении требуется написать инструкцию DELETE, которая удаляет строки из од-
ной таблицы (orders) при наличии соответствующей строки в другой таблице (Customers).
Один из вариантов решения этой задачи— применение приведенной далее стандартной
инструкции DELETE С предикатом EXISTS В элементе WHERE:
DELETE FROM dbo.Orders
WHERE EXISTS
(SELECT *
FROM dbo.Customers AS С
WHERE Orders.custid = C.custid
AND C.country = N
f
Brazil');
Эта инструкция DELETE удаляет строки из таблицы orders (Заказы), если в таблице
Customers (Клиенты) существует связанная строка с тем же самым ID клиента, что и в
строке заказа, и страной клиента, равной Brazil (Бразилия).
Другой способ решения этой задачи — использование следующей инструкции DELETE СО
специальной синтаксической записью языка T-SQL, основанной на соединении:
DELETE FROM О
FROM dbo.Orders AS О
JOIN dbo.Customers AS С
ON O.custid = C.custid
WHERE country = N'Brazil';
Имейте в виду, что, после выполнения предыдущей инструкции DELETE соответствующих
строк не будет найдено.
Соединение таблиц Orders и Customers предназначено для фильтрации строк. Соединение
сопоставляет каждый заказ с клиентом, его сделавшим. Элемент WHERE отбирает строки, в
которых страна клиента равна Бразилии. Конструкция DELETE FROM ссылается на псевдо-
ним о, представляющий таблицу Orders, указывая на то, что операция DELETE применяется
к таблице Orders.
Если вы работаете в версии SQL Server 2008, для решения задачи можно использовать инст-
рукцию MERGE. Несмотря на то, что обычно применение MERGE рассматривается при необ-
ходимости выполнения разных операций, основанных на логических условиях, эту инструк-
цию можно применять и для выполнения одной операции, когда определенный предикат
равен TRUE. Другими словами, инструкцию MERGE МОЖНО использовать с единственным эле-
ментом WHEN MATCHED, при этом наличия элемента WHEN NOT MATCHED не требуется.
410
Приложения
Следующая инструкция MERGE решает задачу, поставленную в упражнении:
MERGE INTO 'dbo.Orders AS О
USING dbo.Customers AS С
ON 0.custid = C.custid
AND country = N'Brazil'
WHEN MATCHED THEN DELETE;
И снова учтите, что если предыдущие инструкции DELETE были выполнены, соответствую-
щих строк не останется. В данной инструкции MERGE таблица orders (Заказы) определена
как таблица назначения, а таблица Customers (Клиенты) как исходная. Заказ будет удален
из таблицы назначения (orders), если в исходной таблице (Customers) найдена соответст-
вующая строка с тем же ID клиента и страной Brazil (Бразилия).
Упражнение 8.8
Решение этого упражнения включает написание инструкции UPDATE, которая отбирает
только те строки, в которых атрибут region (регион) равен NULL. При поиске значений
NULL обязательно применяйте вместо операции равенства предикат is NULL. ДЛЯ вывода
требуемой информации используйте элемент OUTPUT. Далее приведена инструкция UPDATE
полностью:
UPDATE dbo.Customers
SET region =
,
<None>'
OUTPUT
deleted.custid,
deleted.region AS oldregion,
inserted.region AS newregion
WHERE region IS NULL;
Упражнение 8.9
Один из способов решения этого упражнения — применение инструкции UPDATE СО специ-
альным синтаксисом, основанным на соединении. Вы можете соединить таблицы Orders
(Заказы) и Customers (Клиенты), базируясь на совпадении значения ID клиента в строке
заказа с ID клиента в строке с данными о клиенте. В элементе WHERE можно отобрать только
те строки, в которых страна клиента равна UK (Великобритания). В элементе UPDATE задай-
те псевдоним, присвоенный таблице Orders, чтобы обозначить модифицируемую таблицу.
В элементе SET присвойте значениям атрибутов местонахождения перевозчика заказа атри-
буты местонахождения соответствующего клиента. Далее приведена инструкция UPDATE
полностью:
UPDATE О
SET shipcountry - С.country,
shipregion = С.region,
shipcity = С.city
FROM dbo.Orders AS О
Приложение 2. Решения к упражнениям
411
JOIN dbo.Customers AS С
ON 0.custid = С.custid
WHERE С.country = 'UK';
В другом варианте решения используются ОТВ, поддерживаемые программой, начиная с
версии SQL Server 2005. Можно определить ОТВ, основанное на запросе SELECT, который
соединяет таблицы Orders и Customers и возвращает, как результирующие атрибуты ме-
стонахождения из таблицы Orders, так и исходные атрибуты местонахождения из таблицы
Customers. Внешний запрос будет представлять собой инструкцию UPDATE, модифици-
рующую атрибуты таблицы назначения значениями исходных атрибутов. Далее приведено
решение полностью:
WITH CTE_UPD AS
(
SELECT
О.shipcountry AS ocountry, C.country AS ccountry,
O.shipregion AS oregion, C.region AS cregion,
O.shipcity AS ocity, C.city AS ccity
FROM dbo.Orders AS О
JOIN dbo.Customers AS С
ON 0.custid = C.custid
WHERE C.country = 'UK1
)
UPDATE CTE_UPD
SET ocountry = ccountry, oregion = cregion, ocity = ccity;
Начиная с версии SQL Server 2008, вы можете использовать для решения этой задачи инст-
рукцию MERGE. Как уже пояснялось, несмотря на то, что обычно в инструкции MERGE зада-
ются оба элемента (и WHEN MATCHED, И WHEN NOT MATCHED), допустим вариант инструкции
с заданием только одного из этих элементов. При наличии только элемента WHEN MATCHED И
операции UPDATE ВЫ можете написать решение, логически эквивалентное двум предыду-
щим. Далее приведена инструкция, полностью реализующая решение:
MERGE INTO dbo.Orders AS О
USING dbo.Customers AS С
ON O.custid = С.custid
AND C.country = 'UK1
WHEN MATCHED THEN
UPDATE SET shipcountry = C.country,
shipregion = C.region,
shipcity = C.city;
Предметный указатель
D
О
Data Manipulation Language (DML) 240
OLAP 20
Data Mining Extensions (DMX) 21
OLTP 18
M
Multidimensional Expressions
(MDX) 21
s
SQL Server, архитектура 21
SSAS21
А
В
Арифметические операции 64
Взаимоблокировка 308
Атомарность 281
Выражение CASE 66,220
Ат
Риб
Ут14
Высказывание 14
Б
База данных:
master 24
model 24
msdb 24
Resource 24
tempdb 24
пользовательская 24
системная 24
Блок инструкций 329
Блокировка 283
г
Группа, файловая 26
Группирующий набор 217
Д
Долговечность 281
Домен 14
Предметный указатель
413
3
Запрос:
вложенный 142
внешний 142, 172
Значение NULL 15, 69, 125, 156, 203
Значение UNKNOWN 70, 157
И
Изолированность 281
Именованный экземпляр 22
Инструкция:
ALTER TABLE 286
ALTER VIEW 181
BACKUP DATABASE 343
BEGIN TRAN 280
BULK INSERT 245
COMMIT TRAN 280
CREATE TABLE 28
DECLARE 322, 340
DELETE 251
INSERT 113
INSERT EXEC 243
INSERT SELECT 242
INSERT VALUES 240
MERGE 259
ROLLBACK TRAN 280
SELECT 34
SELECT INTO 244
SELECT-присваивание 323
SET 322
TRUNCATE 251
UPDATE 253, 254, 258
USE 28,35
WITH 174
Итог с накоплением 155
первичный 15
потенциальный 15
суррогатный 246
Ключевое слово:
DISTINCT 42, 62
ESCAPE 88
Команда:
BREAK 331
CONTINUE 331
DBCC CHECKIDENT 250
EXEC 343
GO 325, 328
KILL 292
ROLLBACK TRAN 354
SET DATEFORMAT 90
SET LANGUAGE 90
SETNOCOUNT ON 353
Комментарий 113
Константа 89
Конструктор значений строки 241
Конструкция TRY...CATCH 283, 359
Курсор 52, 332
Л
Левое внешнее соединение 123
Логические операции 64
м
Множество 11
Множество-степень 231
Монопольная блокировка 283
Мультимножество 11, 198
к
Н
Ключ:
Набор группирования 228
альтернативный 15
Непротиворечивость 281
внешний 15, 31
Нормализация 15
414
Предметный указатель 414
Нормальная форма:
вторая 16
первая 16
третья 17
О
Обозначение:
Sidentity 247
IDENTITYCOL 247
Общее табличное выражение
(ОТВ) 173
рекурсивное 177
Ограничение 15
CHECK 32
DEFAULT 33
PRIMARY KEY 30
UNIQUE 30
Операция:
CROSS APPLY 189
EXCEPT 206
EXCEPT ALL 207
INTERSECT 202
INTERSECT ALL 203
JOIN 109
OUTER APPLY 190
PIVOT 348
UNION 201
UNION ALL 200
сравнения 64
Отношение 13, 48
п
Пакет 325
Параметр:
CHECK OPTION 185
CONCAT NULL YIELDS NULL 80
DATEFORMAT 90
DEADLOCK PRIORITY 308
ENCRYPTION 183
IDENTITYJNSERT 249
IMPLICIT_TRANS ACTIONS 281
LOCK ESCALATION 286
LOCKTIMEOUT 292
NOCOUNT 251 *
QUOTEDJDENTIF1ER 78
SCHEMABINDING 184
Перекрестное соединение 110
Переменная, табличная 340
План выполнения 346
Подзапрос 142
независимый 142
с множеством значений 145
связанный 149
скалярный 143
табличный 167
Подпрограмма 350
Потерянное обновление 298
Предварительная блокировка 285
Предикат 12
BETWEEN 63
EXISTS 152,158, 203
IN 63, 145, 157
IS NOT NULL 70
IS NULL 70
LIKE 64, 86
NOT EXISTS 207
Представление 180
sys.dm exec connections 289
sys.dmexecrequests 291
sys.dm tran locks 287
информационной схемы 102
каталога 101
sys. messages 360
Приоритет типов данных 65
Р
Разворачивание данных 217
Ранжирующая функция 59
Реляционная модель 13
Предметный указатель
415
С
Самосоединение 112
Свойство IDENTITY 246
Сворачивание данных 224
Связанные строки 55
Совместная блокировка 284
Соединение:
внешнее 122
внутреннее 115
многотабличное 121
перекрестное 117
при условии неравенства 119
при условии равенства 119
составное 118
условия 115
эквивалентное 119
Спецификатор МАХ 77
Ссылки, множественные 172,176
Старшинство операций 65
СУРБД 9
Схема звезды 19
Схема снежинки 20
Сцепление строк 79
т
Таблица:
глобальная временная 339
измерений 19
локальная временная 337
производная 167
фактов 19
Табличная операция:
APPLY 189
PIVOT 221
UNPIVOT 227
Табличная функция,
представляемая 187
Тип 88, 89
Тип данных:
CHAR 76
DATE 89, 92, 96
NCHAR 76
NUMERIC 65
NVARCHAR 76
TIME 89, 92, 96
VARCHAR 76
табличный 342
Транзакция 280
Триггер 354
Троичная логика предикатов 39
У
Уровень изоляции 293
READ COMMITTED 295
READ COMMITTED SNAPSHOT
300, 305
READ UNCOMMITTED 294
REPEATABLE READ 297
SERIALIZABLE 299
SNAPSHOT 300, 301
Устойчивость 281
Ф
Файл, расширение:
mdf 26
ndf 26
Файловая группа 26
Функция:
Saction 272,273
@@FETCH_ STATUS 334
@@identity 247
@@NESTLEVEL 338
@@SPID 288
@@TRANCOUNT 281
CAST 96, 151
CHARINDEX 82
COALESCE 81
COLUMNPROPERTY 104
CONVERT 96
COUNT 132, 133
DATABASEPROPERTYEX 104
DATALENGTH 82
416
Предметный указатель 416
DATEADD 98
DATEDIFF 99, 127
DATENAME 100
DATEPART 99
DAY 100
DBNAME 288
DENSERANK 60
ERROR LINE 360
ERROR MESSAGE 359
ERRORNUMBER 359
ERRORPROCEDURE 360
ERROR SEVER1TY 360
ERROR STATE 360
EVENTDATA 356
fn_helpcollations 77
GROUPING 235
GROUPING JD 236
IDENTCURRENT 248
ISDATE 101
LEFT 82
LEN82
LOWER 85
LTRIM 85
MONTH 100
NEWID 350
NTILE 60
OBJECTDEFINITION 183
OBJECTID 104
OBJECT NAME 289
OBJECTPROPERTY 104
PATINDEX 83
QUOTENAME 344
RAND 350
RANK 60
REPLACE 83
REPLICATE 84
RIGHT 82
ROW NUMBER 59, 203, 207, 266
RTRIM 85
SCHEMA_NAME 101
SCOPEJDENTITY 247
SERVERPROPERTY 104
STUFF 85
SUBSTRING 81
SWITCHOFFSET 97
sys.dmexec_sessions 290
sys.dm_exec_sql_text 290
TOD A TETIM EOFFS ET 98
TYPE_NAME 102
UPPER 85
YEAR 100
оконная 56
определенная пользователем
(ФОП) 350
табличная См. табличная функция
х
Хранилище данных 19
Хранимая процедура 103, 352
sp_executesql 343, 345
sphelptext 184
sprefreshview 181
spspaceused 344
Ц
Целостность 15
Целостность данных:
декларативная 30
процедурная 30
э
Экземпляр по умолчанию 22
Элемент:
ALL 199
AS 45
COLLATE 77
CUBE 231
DISTINCT 199
FROM 36, 221,252
GROUP BY 39, 73, 169, 220, 230
GROUPING SETS 230
HAVING 44
IF...ELSE 328
Предметный указатель
417
INTO 268,271
ON 115, 261
ORDER BY 51, 73, 168, 181, 198,
211,267,332
OUTPUT 268, 270, 271, 272
OVER 56
PARTITION BY 57, 60
RETURN 351
ROLLUP 232
SELECT 45
SET 255
TOP 53, 168,211,267
USING 261
VALUES 225, 241
WHEN MATCHED THEN 261
WHEN NOT MATCHED BY
SOURCE 262
WHEN NOT MATCHED THEN 261
WHERE 38, 124, 129,252
WHILE 330
WITH TIES 56
Я
Язык:
SQL 9
T-SQL 10
манипулирования данными 240